ПРЕДПОСЫЛКИ ИЗОБРЕТЕНИЯ
1. Область техники
Настоящее изобретение, в общем, относится к устройствам для редактирования и способам редактирования. Более конкретно, настоящее изобретение относится к устройству для редактирования, предназначенному для разделения файла данных, включающего основные данные, сформированные с помощью взаимного соединения одного или множества блоков записываемых данных фиксированной длины и управляющих данных, которые управляют положением записи и местоположением недостоверных данных, которые не подлежат воспроизведению. Настоящее изобретение также относится к способу редактирования, предназначенному для использования в устройствах для редактирования вышеприведенного типа, и к носителю записи.
2. Предшествующий уровень техники
В настоящее время разрабатывается следующий тип систем накопления информации. Носитель памяти малых размеров, который имеет встроенное твердотельное запоминающее устройство, такое как флэш память, формируется и устанавливается в управляющую систему, специально используемую для вышеприведенного типа носителя памяти. В качестве альтернативы, вышеописанный носитель памяти устанавливается в управляющую систему, интегрированную в устройство аудио/видеоотображения или в информационное устройство. Таким образом, компьютерные данные, данные, относящиеся к изображению, и звуковые данные могут быть записаны в запоминающей среде.
В вышеуказанной системе накопления информации, в которой используется твердотельное запоминающее устройство, требуется проведение операции редактирования в отношении файла, хранящегося в системе накопления информации. Кроме того, требуется чтобы количество эффективных операций редактирования, таких как перемещение, копирование и перезапись информации, которые требуется проводить в отношении редактирования файла, размещенного в запоминающей среде, было минимальным, а время обработки и потребление энергии, требуемой для выполнения операции по редактированию, было уменьшено до минимального уровня.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
В соответствии с этим, настоящее изобретение направлено на устройство для редактирования, предназначенное для более эффективного выполнения операции редактирования.
Для достижения вышеуказанной цели в соответствии с одним аспектом настоящего изобретения предлагается устройство для редактирования, предназначенное для разделения файла данных, включающего основные данные и первые управляющие данные, которые добавлены к основным данным, причем основные данные формируются с помощью взаимосвязи одного или большего количества блоков записи данных фиксированной длины, первых управляющих данных, предназначенных для управления положением записи основных данных и положением недействительных данных, которые не должны быть воспроизведены. Устройство для редактирования включает операционное средство, предназначенное для определения точки разделения в блоке данных фиксированной длины, включающем основные данные, и для разделения основных данных на первый файл данных и второй файл данных в соответствии с точкой разделения. Средство редактирования редактирует первые управляющие данные с целью сделать недействительной первую часть блока записываемых данных заранее заданной фиксированной длины, включающую основные данные. Блок генерирования генерирует вторые управляющие данные с целью сделать вторую часть блока записываемых данных заранее заданной фиксированной длины, включающую основные данные, недействительной и добавляет вторые управляющие данные ко второму файлу данных.
В соответствии с другим аспектом настоящее изобретение направлено на способ редактирования, предназначенный для разделения файла данных, включающего основные данные и первые управляющие данные, относящееся к основным данным, причем основные данные формируются путем взаимного соединения одного или множества блоков записываемых данных фиксированной длины, причем эти первые управляющие данные предназначены для управления положением записи основных данных и положением недействительных данных, которые не должны быть воспроизведены. Способ редактирования включает: этап определения, предназначенный для определения точки разделения в заранее заданном блоке записываемых данных фиксированной длины, включающем основные данные, и для раздела основных данных на первый и второй файлы данных в соответствии с точкой разделения; этап редактирования, состоящий в редактировании первых управляющих данных с целью сделать первую часть блока записываемых данных заранее заданной фиксированной длины, включающую основные данные, недействительной; и этап генерирования, состоящий из генерирования вторых управляющих данных с целью сделать вторую часть заранее заданного блока записываемых данных фиксированной длины, включающую основные данные, недействительной, и для добавления вторых управляющих данных ко второму файлу данных.
В соответствии с еще одним аспектом настоящее изобретение направлено на носитель записи, предназначенный для управления, по меньшей мере, одним файлом и для считывания и записи файла поблочно с определенной длиной данных. Носитель записи включает область записи данных, предназначенную для записи, по меньшей мере, одного файла данных, который формируется, по меньшей мере, из одного элемента основных данных, по меньшей мере, одного элемента промежуточных данных, предназначенных для резервирования области записи, и первых управляющих данных, предназначенных для управления положениями записи основных данных и промежуточных данных в запоминающей среде. В области записи управляющих данных записываются вторые управляющие данные, которые управляют файлом данных, записанным в области записи данных.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг.1А изображает вид спереди запоминающего устройства стержневого типа в соответствии с одним из вариантов воплощения настоящего изобретения;
фиг.1В - вид сбоку запоминающего устройства стержневого типа в соответствии с одним из вариантов воплощения настоящего изобретения;
фиг.1С - вид сверху запоминающего устройства стержневого типа в соответствии с одним из вариантов воплощения настоящего изобретения;
фиг.1D - вид снизу запоминающего устройства стержневого типа в соответствии с одним из вариантов воплощения настоящего изобретения;
фиг.2 - иерархию файловой системы, используемую в одном из вариантов воплощения настоящего изобретения;
фиг.3 - физическую структуру данных запоминающего устройства стержневого типа в соответствии с одним из вариантов воплощения настоящего изобретения;
фиг.4 - содержание управляющих флагов запоминающего устройства стержневого типа в соответствии с одним из вариантов воплощения настоящего изобретения;
фиг.5 - концепцию физических адресов и логических адресов до и после обновления данных запоминающего устройства стержневого типа в соответствии с одним из вариантов воплощения настоящего изобретения;
фиг.6 - формат управления таблицы перевода логического-в-физический (логического/физического) адреса, используемый в одном из вариантов воплощения настоящего изобретения;
фиг.7 - структуру таблицы перевода логического/физического адреса, используемой в одном из вариантов воплощения настоящего изобретения;
фиг.8 - взаимозависимость между объемом флэш памяти, количеством блоков, объемом памяти, выделяемой на каждый из блоков, объемом памяти, выделяемой на каждую из страниц и размером таблицы перевода логического/физического адреса запоминающего устройства стержневого типа в соответствии с одним из вариантов воплощения настоящего изобретения;
фиг.9 - блок-схему, иллюстрирующую управляющую систему в соответствии с одним из вариантов воплощения настоящего изобретения;
фиг.10 - структуру таблицы размещения файлов (FAT);
фиг.11 - структуру кластеров, соединенных в FAT;
Фиг.12 - структуру директории;
Фиг.13 - поддиректории и содержание хранения файлов;
Фиг.14 - структуру директорий запоминающего устройства стержневого типа в соответствии с одним из вариантов воплощения настоящего изобретения;
фиг.15 - файл списка сообщений в соответствии с одним из вариантов воплощения настоящего изобретения;
фиг.16 - заголовок файла списка сообщений в соответствии с одним из вариантов воплощения настоящего изобретения;
фиг.17 - вход папки файла списка сообщений в соответствии с одним из вариантов воплощения настоящего изобретения;
фиг.18 - вход сообщения файла списка сообщений в соответствии с одним из вариантов воплощения настоящего изобретения;
фиг.19 - структуру данных файла данных сообщения в соответствии с одним из вариантов воплощения настоящего изобретения;
фиг.20 - фрейм формата файла данных сообщения в соответствии с одним из вариантов воплощения настоящего изобретения;
фиг.21А - пример фреймовой структуры файла данных сообщения в соответствии с одним из вариантов воплощения настоящего изобретения;
фиг.21В - содержимое фрейма заголовка файла данных сообщения, изображенного на фиг.21А;
фиг.22А - другой пример фреймовой структуры файла данных сообщения в соответствии с одним из вариантов воплощения настоящего изобретения;
фиг.22В изображает содержимое фрейма заголовка файла данных сообщения, изображенного на фиг.22А;
фиг.23 - промежуточный фрейм во вновь созданном файле данных сообщения;
фиг.24 - область, защищенную от воспроизведения, замещенную промежуточным фреймом;
фиг.25 - алгоритм, иллюстрирующий операцию разделения в соответствии с одним из вариантов воплощения настоящего изобретения;
фиг.26А - файл F1 перед выполнением операции разделения;
фиг.26В - первый файл F1-1 после выполнения операции разделения;
фиг.26С - второй файл F1-2 после выполнения операции разделения;
фиг.27 - FAT перед выполнением операции разделения;
фиг.28 - FAT после выполнения операции разделения;
фиг.29 - структуру FAT перед выполнением операции разделения;
фиг.30 - структуру FAT после выполнения операции разделения;
фиг.31 - структуру данных фрейма оглавления в соответствии с одним из вариантов воплощения настоящего изобретения;
фиг.32 - пример блока накопления данных и содержания накопления данных в соответствии с одним из вариантов воплощения настоящего изобретения;
фиг.33 - другой пример блока накопления данных и содержания сохраненных данных в соответствии с одним из вариантов воплощения настоящего изобретения; и
фиг.34 - еще один пример блока накопления данных и содержания сохраненных данных в соответствии с одним из вариантов воплощения настоящего изобретения.
ОПИСАНИЕ НАИЛУЧШИХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Варианты воплощения настоящего изобретения описаны ниже со ссылкой на приведенные чертежи. В этом варианте воплощения запоминающее устройство стержневого типа, имеющее внешнюю конфигурацию в виде стержня, служит в качестве носителя записи в соответствии с настоящим изобретением. Устройство для редактирования в соответствии с настоящим изобретением описано в контексте управляющей системы, предназначенной для записи/воспроизведения файла из в/из запоминающего устройства стержневого типа, и способ редактирования в соответствии с настоящим изобретением выполняется с помощью способа редактирования, применяемого в управляющей системе вышеприведенного типа.
1. Внешняя конфигурация запоминающего устройства стержневого типа
Описание конфигурации запоминающего устройства 1 стержневого типа, которое служит в качестве носителя записи в соответствии с настоящем изобретением, приводится со ссылками на фиг.1А-1D.
Запоминающее устройство 1 стержневого типа содержит, например, запоминающее устройство, имеющее заранее определенную емкость, в корпусе стержневого типа, такого как изображен на фиг.1А-1D. В этом варианте воплощения в качестве запоминающего устройства используется флэш память.
Корпус, изображенный на фиг.1А-1D, выполнен, например, из литого пластика и имеет размеры 60 мм (W11), 20 мм (W12) и 2,8 мм (W13), как изображено на фиг.1А-1C.
Контактный разъем 2, имеющий девять электродов, сформирован так, что он проходит от нижней части передней стороны к донной поверхности корпуса, как изображено на фиг.1А и 1D. Операции считывания/записи выполняются во встроенном запоминающем устройстве через контактный разъем 2.
Срез 3 выполнен в верхней левой части корпуса, как видно на фиг.1С. Благодаря наличию среза 3, запоминающее устройство 1 стержневого типа защищено от неправильной установки, например, механизм монтажа/демонтажа управляющей системы. Предотвращающие скольжение выемки 4 выполнены на донной поверхности корпуса для улучшения удобства использования. Ползунковый переключатель 5, предназначенный для защиты от случайного стирания данных, также размещен на донной поверхности устройства.
2. Формат запоминающего устройства стержневого типа
2.1. Иерархия файловой системы запоминающего устройства
Формат системы запоминающего устройства 1 стержневого типа, которое служит в качестве носителя записи выполнен следующим образом.
На фиг.2 изображена иерархия процесса обработки файловой системы запоминающего устройства 1 стержневого типа. Иерархия процесса обработки файловой системы состоит, как показано на фиг.2, из слоя работы приложений, слоя управления файлами, слоя логических адресов, слоя физических адресов и слоя доступа к флэш памяти, в порядке убывания. В этой иерархии слой управления файлами служит в качестве так называемой "таблицы размещения файлов (FAT)". На фиг.2 изображено, что файловая система в этом варианте воплощения использует концепцию логического адреса и физического адреса, которые будут более подробно описаны ниже.
2.2. Физическая структура данных
На фиг.3 изображена физическая структура данных флэш памяти, которая служит в качестве запоминающего устройства, размещенного в запоминающем устройстве 1 стержневого типа.
В блоке данных первоначально определены области накопления флэш памяти, которые обозначены как "сегменты", имеющие фиксированную длину. Каждый сегмент имеет размер четыре мегабайта (МБ) или восемь МБ, и количество сегментов в отдельном запоминающем устройстве типа флэш может меняться в зависимости от емкости флэш памяти.
Каждый сегмент разделен на блоки данных фиксированного размера, которые обозначены как "блоки", имеющие размер 8 килобайт (КБ) или 16 КБ, как обозначено в позиции А на фиг.3. В основном, один сегмент разделен на 512 блоков, и, таким образом, количество блоков n, обозначенных в позиции А на фиг.3, равно 511. Однако, так как во флэш памяти может быть некоторое количество поврежденных областей, запись в которые невозможна, на практике количество блоков, в которые разрешена запись, может быть меньше, чем 511.
Среди блоков от 0 до n, размещенных таким образом, как изображено в позиции А на фиг.3, два ведущих блока, то есть блок 0 и блок 1 обозначены как "загрузочные блоки". Однако на практике в качестве загрузочных блоков определяются два блока от начала исправных блоков, и поэтому блок 0 и блок 1 не всегда являются загрузочными блоками. Остальные блоки используются как блоки пользователя, предназначенные для хранения данных пользователя.
Каждый блок разделен на страницы от 0 до m, как показано в позиции D на фиг.3, и каждая из страниц сформирована из области данных размером 512 байт и резервной области размером 16 байт, как показано в позиции Е на фиг.3, и которая, таким образом, имеет общую емкость 528 байт, которые представляют собой фиксированную длину. Структура блока резервирования будет описана подробно со ссылкой на позицию F на фиг.3. Так количество страниц в каждом блоке равно 16, когда емкость блока составляет 8 КБ, и 32, когда емкость блока составляет 16 КБ.
Одинаковая структура страниц, обозначенная на позициях D и Е на фиг.3, используется для загрузочных блоков и блоков пользователя. В флэш памяти операция воспроизведения/записи данных выполняется постранично, в то время как стирание данных выполняется поблочно. Однако, так как данные записываются только в свободные страницы, данные в которых были стерты, перезапись/запись данных на практике выполняется поблочно.
В ведущем загрузочном блоке (блок 0), как показано на позиции В на фиг.3, заголовок записывается в страницу 0, информация адреса, указывающая на положение изначально поврежденных данных хранится в странице 1, и информация CIS/IDI хранится в странице 2. Второй загрузочный блок (блок 1) используется, как резервная копия загрузочного блока, как показано в позиции С на фиг.3.
Структура резервной области, обозначенной в позиции Е на фиг.3, показана в позиции F на фиг.3. В резервной области первые три байта, то есть от байта 0 до байта 2, используются как область перезаписи, которая может перезаписываться в соответствии с обновлением содержимого данных области данных. В области перезаписи статус блока хранится в байте номер 0, данные флага блока хранятся в байте номер 1, как статус данных, и статус данных страницы хранится в заранее заданном верхнем бите байта 2, как флаг таблицы перевода.
В принципе, байты от байта 3 до байта 15 хранят фиксированные данные в соответствии с содержимым текущей страницы, то есть они хранят информацию, которая не может быть перезаписана. Управляющие флаги (информация блока) хранятся в байте номер 3, и логический адрес (Логический Адрес), который будет описан ниже, хранится в последующих двух байтах, то есть в байтах номер 4 и 5. Последующие пять байтов, то есть байты номер 6-10, используются как область резерва формата, и в последующих двух байтах, то есть, в байте номер 11 и в байте номер 12 хранится код исправления ошибок (КИО) с распределенной информацией, предназначенный для исправления ошибок в области резерва формата. Остальные три байта, то есть байт номер 13 - байт номер 15, хранят данные КИО для исправления ошибок в данных, записанных в области данных, обозначенной в позиции Е на фиг.3.
Содержимое флагов управления, записанных в байте номер 3 резервной области, обозначенной в позиции F на фиг.3, определены в битах номер 7 - номер 0, как показано на фиг.4.
Биты номер 7, 6, 1 и 0 являются зарезервированными (неопределенными) областями. В бите номер 5 записывается флаг, указывающий, когда доступ к текущему блоку разрешен ("1", свободен) или запрещен ("0", считывание запрещено). В бите номер 4 хранится флаг, указывающий, когда включена защита от копирования ("1", разрешено) или ("0", запрещено).
В бите номер 3 хранится флаг таблицы перевода, который представляет собой идентификатор, предназначенный для указания, когда текущий блок содержит таблицу перевода логического-в-физический (логического/физического) адреса, которая будет подробно описана ниже. Если значение в бите номер 3 равно "0", текущий блок использован для таблицы перевода логического/физического адреса. Если значение бита номер 3 равно "1", то текущей блок не содержит таблицу перевода логического/физического адреса.
В бите номер 2 хранится флаг системы. Если флаг системы равен "1", текущий блок определяется, как блок пользователя. Если флаг системы равен "0", текущий блок определяется, как загрузочный блок.
Взаимосвязь сегментов и блоков с емкостью флэш памяти описана ниже со ссылкой на фиг.8. Емкость флэш памяти запоминающего устройства 1 стержневого типа определяется как одна из 4 МБ, 8 МБ, 16 МБ, 32 МБ, 64 МБ и 128 МБ.
Когда флэш память имеет наименьшую емкость 4 МБ, емкость одного блока определяется как 8 КБ, и количество блоков составляет 512, при этом емкость флэш памяти, то есть 4 МБ, эквивалентна емкости одного сегмента. Когда емкость флэш памяти равна 8 МБ, емкость одного блока равна 8 КБ, и количество блоков в двух сегментах составляет 1024 (512 на каждый сегмент). Как указано выше, когда один блок имеет размер 8 КБ, количество страниц в одном блоке равно 16.
Что касается флэш памяти, имеющей емкость 16 МБ, емкость одного блока может быть либо 8 КБ, либо 16 КБ. В соответствии с этим флэш память разделена на два типа, то есть один тип, имеющий 4 сегмента и 2048 блоков (один блок равен 8 КБ), и другой тип, имеющий 2 сегмента и 1024 блока (один блок равен 16 КБ). Когда один блок равен 16 КБ, число страниц в одном блоке равно 32.
Что касается флэш памяти, имеющей емкость 32 МБ, 64 МБ или 128 МБ, емкость одного блока определена только равной 16 КБ. В соответствии с этим, число сегментов/блоков флэш памяти, имеющей емкость 32 МБ, 64 МБ и 128 МБ, равно 4/2048, 8/4096 и 16/8192 соответственно.
2.3. Концепция физического адреса и логического адреса
В отношении описанной выше физической структуры данных флэш памяти концепция физического адреса и логического адреса в файловой системе в соответствии с настоящим вариантом воплощения описана ниже в контексте операции перезаписи данных, изображенных в позициях А и В на фиг.5.
Каждый блок имеет физический адрес. Физический адрес определен в соответствии с порядком физического расположения блоков во флэш памяти, и взаимосвязь между блоками и соответствующими физическими адресами не изменяется. В примере, изображенном в позиции А на фиг. четыре блока имеют физические адреса, такие как 105, 106, 107 и 108. Каждый из действительных физических адресов представлен двумя байтами.
Теперь предположим, как обозначено в позиции А на фиг.5, что блоки, имеющие физические адреса 105 и 106, представляют собой записанные области, в которых хранятся данные, и блоки с физическими адресами 107 и 108 являются свободными областями, в которых информация была стерта.
В противоположность этому, логический адрес представляет собой адрес, присвоенный данным, записанным в блоках, и используемый файловой системой FAT, которая будет описана ниже.
В примере, обозначенном позицией А на фиг.5, четыре блока имеют логические адреса, такие, как 102, 103, 104 и 105. Логический адрес также, как и физический адрес, представлен двумя байтами.
Предположим теперь, что данные, хранящиеся по физическому адресу 105, как показано в позиции А на фиг.5, необходимо перезаписать или частично стереть. При выполнении такого типа операции в файловой системе флэш памяти обновленные данные записываются в неиспользованные блоки, а не тот же блок: (в данном случае в блок с физическим адресом 105). То есть данные, хранящиеся по физическому адресу 105, стираются, как изображено в позиции В на фиг.5, и обновленные данные записываются в блок с физическим адресом 107, который представлял собой свободный блок, в соответствии с операцией 1.
Затем, в соответствии с операцией 2 блок данных с логическим адресом 102, соответствующим физическому адресу 105 перед обновлением данных, как показано в позиции А на фиг.5, перемещается таким образом, что он будет соответствовать физическому адресу 107, который теперь назначается блоку, в который были записаны обновленные данные. В соответствии с этим логический адрес 104, связанный с физическим адресом 107 перед обновлением данных, перемещается так, что он будет связан с физическим адресом 105.
То есть физический адрес представляет собой адрес, однозначно связанный с соответствующим блоком, в то время как логический адрес представляет собой адрес, однозначно связанный с данными, которые были записаны в этот блок.
С помощью перестановки блоков, как описано выше, становится возможным избежать необходимости производить интенсивный доступ к одной и той же области хранения информации (блоку), таким образом удлиняя срок службы флэш памяти, которая имеет ограниченное количество доступов (перезаписей).
Благодаря перемещению логического адреса, как представлено операцией 2, даже если блоки будут переставлены и перемещены после обновления данных, FAT идентифицирует те же адреса, позволяя, таким образом, впоследствии осуществлять правильный доступ к данным.
Для упрощения управления обновлением данных в таблице перевода логического/физического адреса, которая будет подробно описана ниже, перестановка блоков ограничена одним сегментом, другими словами, запрещено переставлять блоки между сегментами.
2.4. Таблица перевода логического/физического адреса
В соответствии с описанием со ссылкой на фиг.5, связь между физическим адресом и логическим адресом изменяется при выполнении перестановки блока. В соответствии с этим при доступе к флэш памяти для воспроизведения/считывания данных из/в флэш память необходимо обратиться к таблице перевода логического/физического адреса, которая указывает связь между физическим адресом и логическим адресом. Более конкретно, FAT связана с таблицей перевода логического/физического адреса таким образом, что определяется физический адрес, соответствующий логическому адресу, определенному в FAT, позволяя, таким образом, осуществлять доступ к блоку, представленному определенным физическим адресом. Другими словами, без таблицы перевода логического/физического адреса невозможно осуществить доступ к флэш памяти с помощью FAT.
Обычно, когда запоминающее устройство 1 стержневого типа устанавливается, например, в управляющую систему, микрокомпьютер управляющей системы проверяет содержимое информации, записанной в запоминающем устройстве 1 стержневого типа, таким образом, чтобы сформировать таблицу перевода логического/физического адреса и затем записывает сформированную таблицу в ОЗУ управляющей системы. То есть информация таблицы перевода логического/физического адреса не хранится в запоминающем устройстве 1 стержневого типа.
В противоположность этому, в соответствии с данным вариантом воплощения настоящего изобретения таблица перевода логического/физического адреса записывается в запоминающем устройстве 1 стержневого типа.
На фиг.6 изображен формат сформированной таблицы перевода логического/физического адреса, которая должна быть записана в запоминающее устройство 1 стержневого типа в соответствии с настоящим вариантом воплощения. В настоящем варианте воплощения информация таблицы, в которой физические адреса размером в два байта записаны в соответствии со связанными с ними логическими адресами, которые размещены в порядке возрастания, сформирована как таблица перевода логического/физического адреса.
Как указано выше, как физические адреса, так и логические адреса представлены двумя байтами. Это основывается на том факте, что одинаковое количество битов требуется для охвата всех 8192 блоков запоминающего устройства типа флэш, имеющего максимальную емкость 128 МБ.
Таким образом, физические адреса и логические адреса, изображенные на фиг.6 в качестве примера, представлены двумя байтами. В этом примере физические адреса и логические адреса обозначены в шестнадцатеричной системе счисления, а именно величины после 0х, являются шестнадцатеричными. Такое же обозначение относится к нижеприведенному описанию настоящего изобретения. Для простоты представления, однако, на некоторых фигурах часть 0х опущена.
Пример структуры таблицы перевода логического/физического адреса, основанной по принципу, изображенному на фиг.6, изображена на фиг.7. Таблица перевода логического/физического адреса хранится в блоке, расположенном в конечном сегменте флэш памяти, как изображено в позиции А на фиг.7.
Как показано в позиции А на фиг.7, среди страниц, разделяющих блок, которые были описаны со ссылкой на позиции А и D на фиг.3, область для двух страниц, то есть страницы 0 и страницы 1, предназначена для таблицы перевода логического/физического адреса для сегмента 0. Например, так как флэш память, имеющая емкость 4 МБ, имеет только один сегмент, как описано со ссылкой на фиг.8, только страница 0 и страница 1 служат в качестве области для записи таблицы перевода логического/физического адреса.
Флэш память, имеющая емкость 8 МБ, имеет два сегмента. В соответствии с этим, страница 0 и страница 1 предназначены для таблицы перевода логического/физического адреса для сегмента 0, и последующая страница 2 и страница 3 выделены для таблицы перевода логического/физического адреса для сегмента 1.
В соответствии с этим, при увеличенной емкости флэш памяти область каждой из двух страниц предназначена для таблицы перевода логического/физического адреса для каждого сегмента. Так как имеются 16 сегментов флэш памяти, имеющей максимальную емкость 128 МБ, 32 страницы предназначены для таблиц перевода логического/физического адреса для сегментов 0-15. В соответствии с этим, максимальный номер N страницы, указанный в позиции А на фиг.7, равен 31. Как видно из вышеприведенного описания, таблицы перевода логического/физического адреса управляются посегментно.
Как представлено в позиции В на фиг.7, область данных из двух страниц указывает на структуру таблицы перевода логического/физического адреса для одного сегмента. То есть, поскольку область данных для одной страницы составляет 512 байтов, как показано в позиции Е на фиг.3, 1024 (= 512×2) байт подробно изображены в позиции В на фиг.7.
Область данных из двух страниц, имеющая 1024 байта, разделена на поля из двух байтов, как показано в позиции В на фиг.7, в которых разделенные поля размером в два байта предназначены для записи логического адреса 0, логического адреса 1 и так далее, и последние два байта, то есть 991-й байт и 992-й байт от начала определены как поля для логического адреса 495. Затем связанные с ними физические адреса записываются в соответствующие поля размером в два байта. Затем в таблице перевода логического/физического адреса, используемой в настоящем варианте воплощения, при обновлении взаимосвязи между физическим адресом и логическим адресом, благодаря перестановке блоков для обновления данных, компоновка записи физического адреса обновляется на основе логического адреса, вследствие чего перезаписывается информация таблицы.
Остальные 32 байта, то есть с 993-го байта до последнего 1024-го байта, связываются с полем для хранения физических адресов для дополнительных блоков. То есть будут управляться физические адреса для дополнительных 16 блоков. Дополнительные блоки представляют собой так называемые "рабочие блоки", которые предназначены для временного хранения, например, данных, которые должны быть обновлены в поблочно.
Хотя один сегмент разделен на 512 блоков, количество управляемых блоков устанавливается равным 496 блокам, соответствующим логическим адресам от 0 до логического адреса 495 в структуре таблицы, изображенной в позиции В на фиг.7. Это происходит потому, что выделены вышеописанные дополнительные блоки, и определенное количество блоков в флэш памяти может быть занято неисправными областями (неиспользуемыми областями). В соответствии с этим, на практике в флэш памяти может содержаться значительное количество неисправных блоков. Таким образом, достаточно установить таблицу перевода логического/физического адреса так, что могут управляться только 496 блоков (блоки, в которых разрешена запись/стирание).
В блоке, в котором хранится таблица перевода логического/физического адреса, записывается "0" в бит номер 3 управляющих флагов области резервирования каждой страницы, как изображено на фиг.4. Таким образом, становится возможным идентифицировать, что в соответствующем блоке записана таблица перевода логического/физического адреса.
В блоке, в котором записана таблица перевода логического/физического адреса, при перезаписи содержимого таблицы перевода логического/физического адреса всегда выполняется обработка по переставлению, как показано в позициях А и В на фиг.5. В соответствии с этим, блок, в котором записана таблица перевода логического/физического адреса, не является фиксированным, то есть невозможно записать таблицу перевода логического/физического адреса в какой-то конкретный блок.
Таким образом, посредством FAT осуществляют доступ к флэш памяти для поиска блока, в котором в бит номер 3 управляющих А флагов записан "0", определяя, таким образом, блок, в котором хранится таблица перевода логического/физического адреса. Для облегчения поиска блока, в котором хранится таблица перевода логического/физического адреса, в настоящем варианте воплощения определено, что блок, в котором записана таблица перевода логического/физического адреса, располагается в пределах конечного сегмента. Это определяет FAT, так что поиск проводят только в конечном сегменте блока, в котором записана таблица перевода логического/физического адреса. Другими словами, нет необходимости производить поиск таблицы перевода логического/физического адреса по всем сегментам флэш памяти.
Таблица перевода логического/физического адреса, изображенная на фиг.7, записывается, например, при производстве запоминающего устройства 1 стержневого типа.
Рассмотрим снова фиг.8, на которой изображена взаимосвязь между емкостью флэш памяти и размером таблицы перевода логического/физического адреса.
Как было указано со ссылкой на фиг.7, размер таблицы перевода логического/физического адреса для управления одним сегментом равен 1024 байта для двух страниц, то есть 1 КБ. В соответствии с этим, когда флэш памяти имеет емкость 4 МБ (только один сегмент), размер таблицы перевода логического/физического адреса равен 1 КБ, как показано в позиции Е на фиг.8. Когда флэш памяти имеет емкость 8 МБ (2 сегмента), размер таблицы перевода логического/физического адреса составляет 2 КБ (4 страницы).
Когда емкость флэш памяти составляет 16 МБ, размер таблицы перевода логического/физического адреса составляет 4 КБ (8 страниц) для флэш памяти, имеющей 2048 блоков (4 сегмента), и равна 2 КБ (4 страницы) для флэш памяти, имеющей 1024 блока (2 сегмента).
В отношении блоков флэш памяти, имеющих емкость 32 МБ (4 сегмента), 64 МБ (8 сегментов) и 128 МБ (16 сегментов), размер таблицы перевода логического/физического адреса равен 4 КБ (8 страниц), 8 КБ (16 страниц) и 16 КБ (32 страницы) соответственно.
3. Конфигурация управляющей системы
В соответствии с настоящим вариантом воплощения изобретения принята следующая конфигурация управляющей системы. На фиг.9 изображена конфигурация основного блока управляющей системы, предназначенной для воспроизведения, записи и редактирования данных в соответствии с вышеописанным запоминающим устройством 1 стержневого типа. Основной блок 100 управляющей системы и запоминающее устройство 1 стержневого типа формируют систему хранения файлов.
Различные типы основных данных могут быть воспроизведены из запоминающего устройства 1 стержневого типа и записаны в него с помощью основного блока 100 управляющей системы, такие как данные подвижных изображений, данные неподвижных изображений, сообщения, записанные через микрофон, высококачественные аудиоданные (обозначаемые в дальнейшем как "музыкальные данные"), записанные с носителей записи, таких как компакт-диски (CD, товарный знак) и мини диски (MD, товарный знак) и управляющие данные.
В настоящем варианте воплощения для простоты представления предполагается, что основной блок 100 управляющей системы представляет собой систему для записи и воспроизведения данных сообщений, которые служат в качестве основных данных. Однако система ввода-вывода и система обработки данных, таких как подвижные изображения и неподвижные изображения или музыка, может быть выполнена в основном блоке 100 управляющей системы, так, что основной блок 100 управляющей системы будет служить в качестве системы для файлов соответствующих данных.
Механизм 120 монтажа/демонтажа предназначен для загрузки запоминающего устройства 1 стержневого типа в основной блок 100 управляющей системы с возможностью отсоединения. Передача данных между запоминающим устройством 1 стержневого типа, загруженным в механизм 120 монтажа/демонтажа и микропроцессор 109 выполняется через микросхему 101 интерфейса (И/Ф (I/F)) процессора.
Микрофон 103 также установлен в основном блоке 100 управляющей системы, и звук, улавливаемый микрофоном 103, подается на цифровой сигнальный процессор 102 (ЦПС (DSP)) через усилитель 104 микрофона в качестве звукового сигнала. ЦПС 102 преобразует входящий звуковой сигнал в цифровые аудиоданные и выполняет заранее определенную обработку сигнала, такую как кодирование цифрового звукового сигнала, который затем подается в управляющий микропроцессор 109 как данные записи. Микропроцессор 109 способен выполнить обработку, необходимую для записи данных в запоминающее устройство 1 стержневого типа через микросхему 101 интерфейса процессора.
Микропроцессор 109 также считывает аудиоданные или файл данных сообщения, записанные в запоминающем устройстве 1 стержневого типа через микросхему 101 интерфейса процессора и выводит воспроизводимые аудиоданные/данные сообщения на ЦПС 102. ЦПС 102 затем выполняет заранее заданную обработку сигнала, такую как декодирование подаваемых данных, и выводит данные в конечной форме в виде аналогового звукового сигнала на усилитель 105 громкоговорителя. Усилитель 105 громкоговорителя усиливает входные аудио данные и выводит их на громкоговоритель 106, и, таким образом, воспроизводится звук.
Микропроцессор 109 также управляет драйвером 107 дисплея, который предназначен для отображения заранее заданного изображения, например меню, и указаний для действий пользователя или для отображения содержания файла, хранящегося в запоминающем устройстве 1 стержневого типа, на блоке 108 дисплея. Данные изображения, такие как движущиеся или неподвижные изображения, хранящиеся в запоминающем устройстве 1 стержневого типа, могут считываться и отображаться в блоке 108 дисплея.
Операционный блок 112 имеет различные клавиши, используемые для выполнения пользователем операций на главном блоке 100 являющей системы. Микропроцессор 109 принимает команду в ответ на операцию, выполняемую в операционном блоке 112, и в соответствии с этой командой выполняет заранее заданный управляющий процесс. Содержимое операций может представлять собой инструкцию для записи файла, выбора файла, воспроизведения файла, разделения файла, что будет описано ниже, или редактирования файла.
Конфигурация основного блока 100 управляющей системы, изображенная на фиг.9, представляет собой всего лишь пример и не ограничивает конфигурацию по настоящему изобретению. То есть может использоваться электронное устройство любого типа в качестве основного блока 100 управляющей системы, если оно обеспечивает обмен данных с запоминающим устройством 1 стержневого типа.
4. Структура FAT
Как описано в иерархии файловой системы, изображенной на фиг.2, обработка, связанная с управлением файлами, выполняется с помощью FAT. Более конкретно, для того чтобы считать/записать (воспроизвести/записать) данные с/в запоминающее устройство 1 стержневого типа с помощью управляющей системы, изображенной на фиг.9, посредством FAT связываются с местами хранения файлов в соответствии с запросом, поступающим от приложения обработки иерархии файловой системы, и при этом выполняется вышеописанный перевод логического/физического адреса, позволяя, таким образом, обеспечить доступ к запоминающему устройству стержневого типа.
Структура управления FAT описана ниже со ссылкой на фиг.10. В данном варианте воплощения настоящего изобретения FAT и таблица перевода логического/физического адреса хранятся в поминающем устройстве 1 стержневого типа. В соответствии с этим, структура FAT, изображенная на фиг.10, управляется в запоминающем устройстве 1 стержневого типа.
Структура управления FAT сформирована в виде, как показано на фиг.10, из таблицы разделов, свободного пространства, загрузочного сектора, FAT, копии FAT, корневой директории и области данных.
В области данных используются блоки данных, такие как кластер 2, кластер 3 и так далее. Кластер представляет собой блок данных, то есть управляемый блок, который обрабатывается с помощью FAT. В общем случае, в FAT стандартный размер кластера равен 4 КБ и может представлять собой любую степень двух между 512 байтами и 32 КБ.
В настоящем варианте воплощения, как указано выше, один блок равен 8 КБ или 16 КБ. В запоминающем устройстве 1 стержневого типа, в котором каждый блок равен 8 КБ, размер кластера FAT равен 8 КБ. В запоминающем устройстве 1 стержневого типа, в котором каждый блок равен 16 КБ, размер кластера FAT равен 16 КБ. То есть 8 КБ или 16 КБ используется, как для размера блока данных, который используется под управлением FAT, а также как размер блока данных в запоминающем устройстве 1 стержневого типа, а именно размер кластера, обрабатываемого в FAT, равен размеру блока соответствующего запоминающего устройства 1 стержневого типа. В соответствии с этим, для краткости изложения, сделаем предположение, что один блок равен одному кластеру.
Номера блоков обозначены величинами от х до (х+m-1), (х+m), (х+m+1), (х+m+2) и так далее, с левой стороны на фиг.10, и различные данные, формирующие структуру FAT, хранятся, таким образом, в соответствующих блоках. На практике, однако, данные не обязательно хранятся в физически последовательных блоках, как указано на схеме, изображенной на фиг.10.
Рассматривая структуру FAT, можно видеть, что в таблице разделов хранится адрес заголовка и адрес конца раздела FAT, имеющего максимальную емкость 2 GB. Загрузочный сектор указывает на вид FAT - 12-битовый или 16-битовый FAT, а также указывает на структуру FAT. Структура FAT включает в себя данные о размере FAT, размере кластера и размере каждой области.
FAT представляет собой таблицу, представляющую структуру связи кластеров, формирующих соответствующий файл, которая будет описана ниже. В области, следующей за FAT, хранится копия FAT.
В корневой директории хранятся имена файлов, номер начального кластера и различные атрибуты. Для описания каждого файла используются 32 байта.
В FAT взаимосвязь между входом в FAT и кластером представляет собой взаимно однозначное соответствие. Во входе в каждый кластер описывается связанным кластер, то есть номер последующего кластера. То есть в отношении файла, сформированного из множества кластеров (блоков), номер начального кластера указывается в директории, а номер второго кластера представлен во входе в начальный кластер в FAT. Номер третьего кластера представлен во входе во второй кластер. Таким образом, описываются связи между кластерами в FAT.
Концепция связанной структуры кластеров схематически изображена на фиг.11, причем числа, изображенные на фиг.11, представлены в шестнадцатеричной системе. Если записаны два файла, такие как MAIN.С и FUNC.C, номера начальных кластеров, например, 002 и 004 этих двух файлов описаны в директории.
При рассмотрении файла MAIN.С последующей номер кластера 003 указан во входе в ведущий кластер номер 002, и следующий номер 006 последующего кластера описан во входе кластера номер 003. Если кластер номер 006 будет последним кластером этого файла MAIN.С, во входе кластера номер 006 будет записан код FFF, который указывает на последний кластер.
В соответствии с этим, файл MAIN.С хранится по порядку в кластерах 002, 003 и 006. То есть, предполагая, что номер кластера соответствует номеру блока запоминающего устройства 1 стержневого типа, файл MAIN.С будет храниться в блоках 002, 003 и 006 запоминающего устройства 1 стержневого типа. Однако, как указано выше, так как кластер, управляемый FAT, равен логическому адресу, он не обязательно должен соответствовать физическому адресу.
Аналогично, FAT показывает, что файл FUNC.C хранится по порядку в кластерах 004 и 005, как указано позициями В и С на фиг.11.
Во входах кластеров, соответствующих неиспользуемым блокам, указан код 000.
В оглавлении каждого файла, хранящегося в корневой директории, описан не только номер ведущего кластера, обозначенного в позициях А и В на фиг.11, но также и различные данные, такие, как данные, изображенные на фиг.12. То есть записываются имя файла, расширение, атрибут, зарезервированная область, информация о времени последнего обновления и информация о дате последнего обновления, номер начального кластера и размер файла, при этом они занимают количество байт, указанное в круглых скобках.
Поддиректория, которая соответствует более низшему слою, чем директория, хранится в области данных, а не в области корневой директории, изображенной на фиг.10, а именно поддиректория обрабатывается как файл, имеющий структуру директории. Размер поддиректории неограничен, и требуются вход в поддиректорию и вход в корневую директорию.
На фиг.13 изображен пример структуры, в которой файл, DIR1, атрибут которого представляет собой директорию, хранится в корневой директории, файл DIR2, атрибут которого означает директорию, хранится в файле DIR1, и, наконец, файл "FILE" располагается в файле DIR2.
Номер начального кластера файла DIR1, который служит в качестве поддиректории, указан в корневой директории, а именно кластеры X, Y и Z связаны с вышеописанным FAT. На фиг.13 видно, что поддиректории DIR1 и DIR2 обрабатываются как файлы и связи интегрированы в FAT.
Вышеприведенное описание структуры FAT сведено, в общем, на фиг.29. Способ управления FAT описан ниже со ссылкой на схематическую диаграмму карты памяти, представленную на фиг.29.
На карте памяти, изображенной на фиг.29, представлены таблица разделов, свободное пространство, загрузочный сектор, FAT, область резервной копии FAT, корневая директория, поддиректория и область данных, сформированные, начиная от верхней части карты памяти.
Карта памяти, изображенная на фиг.29, представляет собой карту, полученную после выполнения перевода логического/физического адреса, на основе таблицы перевода логического/физического адреса.
Вышеуказанный загрузочный сектор FAT, область резервной копии FAT, корневая директория, поддиректория и область данных в общем обозначены как "область разделов FAT". В вышеуказанной таблице разделов записан адрес заголовка и адрес конца области разделов FAT. В общем, для FAT, используемой в гибком диске, таблица разделов не предусмотрена.
Свободное пространство формируется, поскольку на первой дорожке не хранятся никакие другие данные, кроме таблицы разделов.
Последующий загрузочный сектор показывает, является ли FAT 12-битовым FAT или 16-битовым FAT, и размер структуры FAT, размер кластера и размер каждой из областей записываются в соответствии с типом FAT.
С помощью FAT управляют размещением файлов, хранящихся в областях данных. Область резервных копий файлов представляет собой область, в которую копируется FAT.
Часть корневой директории хранит имя файла, адрес начального кластера и различные атрибуты, причем для каждого файла используются 32 байта.
Часть поддиректории служит как файл, атрибут которого представляет собой директорию, и в примере, изображенном на фиг.29, в поддиректории хранятся четыре файла, таких как PBLIST.MSV, CAT.MSV, DOG.MSV и MAN.MSV. Часть поддиректории управляет именами файлов и местоположением записи файлов в FAT. Более конкретно, в поддиректории, изображенной на фиг.29, адрес "5" FAT записан в сегменте, в котором выписано имя файла CAT.MSV, и адрес FAT "10" хранится в сегменте, в котором записано имя файла DOG.MSV. Адрес FAT "110" хранится в сегменте, в котором записано имя файла MAN.MSV.
Кластер 2 и последующие кластеры используются как собственно область данных, и голосовые данные, сжатые с помощью способа адаптивной дифференциальной импульсно-кодовой модуляции (АДИКМ (ADPCM)), записываются в область данных.
В данном варианте воплощения голосовые данные, сжатые способом АДИКМ, записываются в файле под именем CAT.MSV в кластеры с 5 по 8. Аудиоданные, сжатые способом АДИКМ, то есть DOG-1, которые представляют собой первую часть имени файла DOG.MSV, записаны в кластеры 10-12, в то время как аудиоданные, сжатые способом АДИКМ, т.е. DOG-2, которые представляют собой вторую часть файла с названием DOG.MSV, записываются в кластеры 100 и 101. Аудиоданные, сжатые способом АДИКМ в файле с названием MAN.MSV, записаны в кластеры 110 и 111.
На фиг.29 изображен пример, в котором один файл разделен и записан в разные кластеры. Кластеры области данных, обозначенные как "пустые", представляют собой свободные участки пространства для записи данных.
Кластер 200 и последующие кластеры используются для управления названиями файла. Файл CAT.MSV записан в кластер 200, файл DOG.MSV записан в кластер 201, и файл MAN.MSV записан в кластер 202.
Порядок файлов может быть перегруппирован в кластер 200 и в последующие кластеры.
Когда запоминающее устройство 1 стержневого типа, выполненное в соответствии с вышеприведенным описанием, устанавливается в первый раз, производится ссылка на заголовок памяти, то есть на таблицу разделов, определяя, таким образом, адрес заголовка и конечный адрес области раздела FAT. После считывания части данных из загрузочного сектора воспроизводятся данные, хранящиеся в корневой директории и поддиректории. Затем при поиске сегмента, в котором записана информация, управляющая воспроизведением, в отношении поддиректории, то есть в котором записан PBLIST-MSV, проверяется конечный адрес сегмента, в который записан PBLIST.MSV. В этом варианте воплощения, в связи с тем что адрес "200" указан в конце сегмента, в котором записан PBLIST.MSV, будет сделана ссылка на кластер 200.
Кластер 200 и последующие кластера содержат имена файлов, а также порядок воспроизведения файлов. В этом варианте воплощения файл CAT.MSV представляет собой первую воспроизводимую фонограмму. Файл DOG.MSV представляет собой вторую фонограмму, и файл MAN.MSV представляет собой третью фонограмму.
После выполнения ссылок на все кластеры, следующие после кластера 200, опять делается ссылка на поддиректорию, производя, таким образом, поиск сегмента, соответствующего именам файлов CAT.MSV, DOG.MSV и MAN.MSV. В таблице карты, изображенной на фиг.29, адрес "5" указан в конце сегмента, в котором записано имя файла CAT.MSV. Адрес "10" хранится в конце сегмента, в котором записано имя файла DOG.MSV. Адрес "110" указан в конце сегмента, в котором записано имя файла MAN.MSV.
Затем, после того как будет выполнен поиск начальных адресов FAT на основании адреса "5", адрес "6" кластера будет найден как вход. При обращении к адресу "6" входа будет найден адрес "7" кластера как вход, и при обращении к адресу "7" входа будет найден адрес "8" кластера как вход. При дальнейшем обращении к адресу "8" входа, будет определен код "FFF", который указывает на конец файла.
В соответствии с этим, файл CAT.MSV занимает кластеры 5, 6, 7 и 8, и, выполняя обращения к кластерам 5, 6, 7 и 8 из области данных, становится возможным выполнить доступ в область, в которой в действительности записаны данные, сжатые способом АДИКМ, под названием CAT.MSV.
Способ поиска файла DOG.MSV, записанного в различных местах, выглядит следующим образом.
Адрес "10" указан в конце сегмента, в котором записан файл DOG.MSV. После поиска адреса входа в FAT на основании адреса "10" будет найден адрес "11" кластера как вход. При обращении к адресу "11" входа будет найден адрес "12" кластера как вход. При обращении к адресу "12" входа будет найден адрес "100" кластера как вход. При дальнейшем обращении к адресу "110" входа будет найден адрес "101" кластера как вход. И, наконец, при обращении к адресу "101" входа будет найден код FFF, указывающий конец файла.
В соответствии с этим, файл DOG.MSV занимает кластеры 10, 11, 12, 100 и 101, и при обращении к кластерам 10, 11 и 12 области данных может быть обеспечен доступ к области, в которой записаны данные, сжатые способом АДИКМ, соответствующие первой части файла DOG.MSV. При дальнейшем обращении к кластерам 100 и 101 в области данных может быть обеспечен доступ к области, в которую записаны данные АДИКМ, соответствующие второй части файла DOG.MSV.
В отношении файла под именем MAN.MSV, при поиске адреса входа в FAT на основе адреса "110" будет найден адрес "111" кластера как вход. При обращении к адресу "111" входа будет найден код "FFF", представляющий конец файла. Таким образом, файл MAN.MSV занимает кластеры 110 и 111.
В соответствии с вышеприведенным описанием части данных файла, которые записаны в разных местах флэш памяти могут быть взаимосвязаны и могут быть последовательно воспроизведены.
Приведем теперь описание разделения файла CAT.MSV на три файла, изображенного на фиг.29. На фиг.30 изображена карта памяти, когда файл CAT.MSV разделен. Процесс редактирования FAT при выполнении операции разделения выполняется следующим образом.
Предположим, что пользователь выполняет операцию разделения на границе между кластером 6 и кластером 7, в результате которой будут созданы два файла, то есть CAT1.MSV и CAT2.MSV.
Файлы DOG.MSV м MAN.MSV, которые были предварительно записаны соответственно в кластерах 201 и 202, будут сначала сдвинуты соответственно в кластера 202 и 203. Затем имя файла в кластере 200 будет изменено на CAT1.MSV, что представляет собой комбинацию названия САТ1, введенного пользователем и идентификатора MSV, и имя CAT2.MSV, которое представляет собой комбинацию названия САТ2, введенного пользователем и идентификатора MSV, будет записано в кластер 201.
Затем имя CAT.MSV, записанное в поддиректорию, будет переписано в виде CAT1.MSV, и имя CAT2.MSV будет записано в неиспользованный сегмент.
Номер "7" кластера, в котором хранится CAT2.MSV, будет записан в конце сегмента, в котором записан CAT2.MSV. Затем вместо адреса "6" входа FAT будет записан код "FFF", чтобы конец файла, обозначенный сегментом CAT1.MSV поддиректории, был записан в кластер 6.
5. Структура файлов запоминающего устройства стержневого типа
5.1. Конфигурация директории
Структура файлов, хранящихся в запоминающем устройстве 1 стержневого типа, организована в следующем виде. Приведем сначала описание конфигурации директории со ссылкой на фиг.14.
Как указано выше, основные данные, которые могут управляться запоминающим устройством 1 стержневого типа, включают данные подвижного изображения, данные неподвижного изображения, данные, записанные через микрофон, высококачественные аудиоданные, записанные с носителя записи, такого как CD и MD, управляющие данные, данные телефонного справочника и т.д. В соответствии с этим, в конфигурации директории, изображенной на фиг.14, после корневой директории располагаются директория сообщений (VOICE), директория неподвижного изображения (DCIM), директория подвижного изображения (MOXXXXNN), директория управления (CONTROL), директория музыкальных данных (HIFI), и директория телефонного справочника (TEL).
В данном варианте воплощения конфигурация директории описана подробно ниже в контексте файлов данных сообщений. Файл списка сообщений (MSGLIST.MSF), файл В списка сообщений (MSGLISTB.MSF), который представляет собой копию файла списка сообщений, папки (FOLDER1 и FOLDER2) и т.д. формируются как поддиректории директории VOICE, как изображено на фиг.14. Собственно файлы данных сообщений, например файл под именем 98120100.MSV, формируются в папках.
Вышеописанная конфигурация директории представляет собой, всего лишь, пример, и внутри папки, такой как FOLDER1, может быть сформирована другая папка.
Структура директории VOICE зарегистрирована в файле списка сообщений и создается произвольно соответствующей управляющей системой. Файл списка сообщения служит в качестве управляющего файла для структуры директории, и имеет резервную копию в запоминающем устройстве 1 стержневого типа, благодаря чему предотвращается непреднамеренное стирание данных.
5.2. Файл списка сообщений
Структура файла списка сообщений описана ниже со ссылкой на фиг.15-18. Цифры, изображенные в строках и колонках на чертежах, представляют собой количество байт в шестнадцатеричной системе счисления.
На фиг.15 изображена конфигурация данных файла списка сообщений. Первые 32 байта файла списка сообщение используются как заголовок, после чего следует вход в папку размером 64 байта и множество входов сообщений размером 32 байта каждый. В файле списка сообщений располагается, таким образом, заранее заданное количество комбинаций входов в папку и входов сообщения.
В файле списка сообщений, который построен, как описано выше, порядок расположения папок, определяемый входом в папку, указывает переключение папок и порядок отображения папок. Порядок расположения данных сообщения с помощью входа в сообщение указывает на переключение и на отображение данных сообщения и на порядок воспроизведения данных сообщения.
Структура заголовка размером 32 байта файла списка сообщений изображена на фиг.16. В заголовке, как изображено на фиг.16, описаны идентификатор (MSG-ID) файла списка сообщений, занимающий четыре байта, номер (FMT-VER) версии формата, занимающий два байта, код (MCode) изготовителя, занимающий два байта, дата и время (YMDHMSW) редактирования, занимающие восемь байт, номер (FILE-NO), файла, занимающей четыре байта, размер (FSIZE) входа в папку, занимающей два байта, размер (MSIZE) входа сообщения, занимающий два байта, смещение (OFFSET) входа в папку, занимающее два байта, код (CCODE) знака, занимающий два байта, и номер (REV) изменения, занимающий два байта. Знаком (R) в заголовке обозначено зарезервированное пространство, и такое же сокращение относится к фиг.17, 18 и 20.
Идентификатор (MSG-ID) ведущего файла списка сообщений представляет собой фиксированную величину, такую как Ox4D53474C (="MSGL"), что указывает на то, что соответствующий файл представляет собой файл списка сообщений.
Номер (FMT-VER) формата версии указывает на номер версии формата, который определен в системе, предназначенной для записи файлов голосовых данных в запоминающем устройстве 1 стержневого типа, с помощью чего становится возможным идентифицировать номер используемой в настоящее время версии. Верхний байт номера представляет собой большее число, и нижние два байта обозначают меньшее число, так что 0×0100, например, представляет версию 1.0.
Код (MCode) изготовителя представляет собой код изготовителя и модель системы, которая в последний раз была использована для редактирования файла списка сообщений. Дата и время (YMDHMSW) редактирования указывает год, месяц, дату, час, минуту, секунду и день недели, в которые файл списка сообщений был отредактирован в последний раз. Используются двоичные величины, на которые всего выделено восемь байт: два байта на год и один байт на каждый из параметров другой информации. Конкретная величина устанавливается в информации, указывающей день недели (с понедельника по воскресенье).
Номер файла (FILE-NO) представляет собой номер файла сообщения, которое было в создано в последний раз. Номер файла указывается как порядковый номер, используемый для создания имен файла сообщения, и увеличивается каждый раз при создании нового файла, благодаря чему резервируется величина для создаваемого в последующем имени файла. Номер файла сбрасывается в ноль при изменении даты.
Размер (FSIZE) входа в папку указывает размер входа (ВХОД В ПАПКУ) в папку, который изображен на фиг.15, и представляет собой фиксированную величину, например 64 (байта).
Размер (MSIZE) входа сообщения представляет размер входа (ВХОД В СООБЩЕНИЕ) в сообщения, изображенного на фиг.15, и представляет собой фиксированную величину, например 32 (байта).
Смещение (OFFSET) входа в папку представляет собой место, с которого начинается вход в первую папку, выраженное посредством величины смещения от начала файла. Например, для начального положения папки, размещенной по адресам от 0×0020 до 0×005F, как изображено на фиг.15, в качестве величины смещения задана величина 32 от точки начала файла.
Структура входа в папку изображена на фиг.17. Во входе в папку описаны идентификатор (FLD-ID) папки размером в два байта, код (MCode) изготовителя размером в два байта название (FLD-NAME) папки размером 12 байт, код (C-CODE) символа размером в два байта и название 4(DISP-NAME) дисплея размером в 4 байта.
Идентификатор папки представляет собой фиксированную величину, например 0×4644 (="FD"), предназначенную для идентификации заголовка данных входа в папку. Код (MCode) изготовителя представляет собой код изготовителя и модель системы, в которой была создана соответствующая папка.
В качестве названия (FLD-NAME) папки записывается название папки FAT в виде строки символов, такое как название директории, представленной в коде, определенном, например, JIS Х 0201. Название папки в основном формируется из названия директории, имеющего максимум восемь байт, точки (".") и расширения, имеющего максимум три байта. Если расширение не является необходимым, может быть указано только название директории без расширения и точки. Символ окончания 0х00 помещается в конце строки символов, хотя его можно опустить при нехватке места, если строка символов будет занимать всю область записи названия папки.
Код (C-CODE) символа представляет собой код, предназначенный для идентификации кодировки символов, которые описывают следующее далее название дисплея, и представляет собой, например, 0×90 для JIS X 0208-1997 (так называемый "смещенный JIS код") или 0×03 для ISO8859-1.
Название (DISP-NAME) дисплея указывает на название папки, изображаемое в системе, и записывается в строке знаков, то есть в кодировке знаков, описанной в вышеприведенном С-CODE. По меньшей мере, один байт символа 0×00 окончания записывается в конце строки символов, и значения после кода 0×00 выбираются произвольно. Запись символа окончания не является необходимой, если из-за нехватки места название папки занимает всю область записи названия дисплея. Если система автоматически создает название дисплея, название папки записывается в FAT.
Структура входа в сообщение изображена на фиг.18. Вход сообщения формируется из идентификатора (MID) сообщения, который занимает один байт, приоритета (PRI), который занимает один байт, режима (AL-M) включения сигнала сигнализации, который занимает один байт, даты (AL-DATE) сигнала сигнализации, которая занимает 5 байт, имени (FILE-NAME) файла, которое занимает 8 байт, и времени и даты (REG-DATE) записи, которые занимают 6 байт.
Идентификатор сообщения представляет собой фиксированную величину, например 0×4D (="M"), которая предназначена для идентификации заголовка данных входа в сообщение. Приоритет (PRI) представляет собой значимость (или приоритет) сообщения и обозначается четырьмя уровнями приоритета, например от 0×00 до 0×03, причем большая величина указывает более высокий приоритет. Когда приоритет (PRI) не указан, устанавливается величина 0×00.
Режим (AL-M) включения сигнала тревоги указывает на режим сигнала сигнализации. Отдельные биты определены следующим образом.
бит 1, бит 0 ... установка времени и даты
бит 1=0, бит 0=0 работа в назначенное время
бит 1=0, бит 0=1 работа в назначенный день недели
бит 1=1, бит 0=0 работа в назначенное время, день и месяц
бит 1=1, бит 0=1 зарезервировано
бит 2 ... резерв (установлен в 0)
бит 3 ... флаг остатка
0 бит 7 устанавливается в 0 (стирается) после срабатывания сигнала сигнализации
1 бит 7 не устанавливается в 0 (не стирается) после срабатывания сигнала сигнализации
бит 4 ... резерв (установлен в 0)
бит 5 ... флаг воспроизведения сообщения
0 сообщение не воспроизводится во время сигнала сигнализации
1 сообщение воспроизводится во время сигнала сигнализации
бит 6 ... флаг звучания сигнала сигнализации
0 звук сигнализации не воспроизводится во время сигнала сигнализации
1 звук сигнализации воспроизводится во время сигнала сигнализации
бит 7... флаг установки сигнала сигнализации
0 сигнал сигнализации не установлен
1 сигнал сигнализации установлен
Если функция сигнал сигнализации не используется, режим (AL-M) тревоги устанавливается в значение 0×00. Когда в оба бита 5 и 6 записана 1, работа выполняется таким образом, что воспроизводится звуковой сигнал сигнализации, воспроизводится сообщение, и сообщение стирается.
Дата (AL-DATE) сигнала сигнализации представляет собой время и дату, в которые включается сигнал сигнализации, как указано двоичным числом в порядке год, месяц, дата, час, минута и день недели, причем каждая часть информации занимает один байт. Год указан как величина смещения от 1980 года. Величины 0 до 127 представляют год от 1980 до 2107. Если год не будет установлен, устанавливается величина 0×РР. Использование других величин, кроме 0-127 и 0×РР запрещено.
В имени (FILE-NAME) файла записывается имя файла сообщения в FAT, и имя файла без расширения записывается в кодировке, определенной, например, JIS Х 0201. Символ 0×00 окончания записывается в конце строки символов, хотя он может быть опущен из-за нехватки пространства, если строка символов занимает всю область записи имени файла.
В дате (REC-DATE) записи записываются время и дата, при которых была произведена запись сообщения в виде однобайтовых двоичных величин в порядке год, месяц, дата, час, минута и секунда. Год представлен как величина смещения от 1980 года. Величины от 0 до 127 представляют годы от 1980 до 2107. Если год не установлен, записывается величина 0×FF. Использование других величин, кроме 0-127 и 0×FF запрещено.
Файл списка сообщений, выполненный, как описано выше, помещается непосредственно после директории VOICE и используется совместно отдельными системами.
Когда система вначале идентифицирует запоминающее устройство 1 стержневого типа, например, когда система перезагружается, или когда запоминающее устройство 1 стержневого типа вставляется в систему, выполняются следующие операции с (1) по (7).
(1) Сначала проверяется, соответствуют ли входы поддиректории в директории VOICE содержимому файла списка сообщений.
(2) Вновь созданная поддиректория добавляется к файлу списка сообщений.
(3) Нестертая поддиректория стирается из файла списка сообщений. (Операции (2) и (3) необходимы потому, что поддиректория может быть добавлена или стерта без выполнения операции редактирования файла списка сообщений на персональном компьютере (ПК)).
(4) Проверяется, соответствуют ли входы файла в поддиректории в директории VOICE содержимому файла списка сообщений.
(5) Вновь созданный файл добавляется в файл списка сообщений.
(6) Стертый файл удаляется из файла списка сообщений. (Операции (5) и (6) необходимы, поскольку файл может быть добавлен или стерт без выполнения операции редактирования в файле списка сообщений на ПК).
(7) Если в системе не используется директория, создается новая директория.
Размер файла списка сообщений имеет фиксированную величину 32736 байт (32×1024-32). В область величиной 32 байта, следующую после входа в последнее сообщение, записывается код 0×00. Максимальное количество сообщений (файлов FAT), которые могут быть введены, равно 1020, когда количество поддиректорий в директории VOICE равно единице. В файле списка сообщений, вход в папку (поддиректорию) требует отвода области, равной двум областям входов сообщения, и при этом, поскольку количество входов в папку увеличится на единицу, количество сообщений, которое может быть введено, уменьшается на два.
5.3. Файл данных сообщения
Файл данных сообщения предназначен для записи собственно данных сообщения в следующем виде. Имя файла данных сообщения регистрируется в файле списка сообщений и произвольно создается системой.
На фиг.19 изображена структура данных файла данных сообщения. Файл данных сообщения формируется из фрейма (FORMAT FRAME) формата, фрейма (ТОС FRAME) оглавления, фрейма (TITLE FRAME) названия, фрейма (MAKER FRAME) изготовителя, фрейма (AUTHOR FRAME) автора, информационного фрейма (INFORMATION FRAME), промежуточного фрейма (SPACE FRAME) и фрейма (DATA FRAME) данных.
Однако фреймы TITLE FRAME, MAKER FRAME, AUTHOR FRAME и INFORMATION FRAME являются необязательными и файл данных сообщения, в основном, формируется из фрейма (FORMAT FRAME) формата и фрейма (ТОС FRAME) оглавления, промежуточного фрейма (SRACE FRAME) и фрейма (DATA FRAME) данных, которые обозначены на фиг.19 сплошными линиями.
Фрейм формата является основной управляющей информацией, предназначенной для соответствующего файла данных сообщения, и указывает на тип кодирования-декодирования и т.д., что будет пояснено более подробно далее.
Фрейм оглавления служит в качестве управляющей информации, указывающей на расположение отдельных фреймов в файле данных сообщения, другими словами, структура фреймов файла данных сообщения может быть идентифицирована фреймом оглавления.
В фрейме данных хранятся собственно данные сообщения. Промежуточный фрейм, который будет описан более подробно ниже, представляет собой область, не предназначенную для воспроизведения (неиспользуемую область), которая служит как зарезервированная область для расширения фрейма оглавления или используется для установки области, не используемой при воспроизведении в файле.
В одном и том же файле могут быть помещены множество фреймов данных и множество промежуточных фреймов, хотя другие фреймы представлены в одном и том же файле только один раз. Фрейм формата всегда располагается в заголовке файла, непосредственно после него следует фрейм оглавления.
Фрейм названия, фрейм изготовителя, фрейм автора и информационный фрейм, которые являются необязательными, все вместе располагаются после фрейма оглавления в порядке убывания идентификатора фрейма (описано ниже). После вышеуказанных необязательных фреймов всегда следует промежуточный фрейм.
Структура фрейма формата изображена на фиг.20. Фрейм формата представляет собой важный фрейм, в котором описаны тип кодирования и т.д., и который должен быть помещен в заголовке фрейма.
Фрейм формата формируется, как показано на фиг.20, из идентификатора (FILE-ID) файла размером восемь байт, фрейма (SIZE-FMT) размера фрейма формата, занимающего четыре байта, номера (FMT-VER) версии формата размером два байта и названия (C-NAME) компании размером 16 байт, установленного названия (S-NAME) размером 16 байт, номером (SET-VER) версии программно-аппаратных средств размером в два байта, времени и даты (DATE-TIME) записи размером восемь байт, идентификатора (FMT-ID) формата размером два байта, количества каналов (CHAN) размером в два байта, частоты выборок (количество выборок в секунду) (SAMP) размером четыре байта, среднего количества байт в секунду (BYTE) размером четыре байта, величины выравнивания (ALIGN) блока размером в два байта, количества бит в выборке (BIT) размером в два байта и размера дополнительный области (ЕХТ) размером в два байта. Также может быть выделено дополнительное пространство.
Идентификатор (FILE-ID) файла указывает, что соответствующий файл представляет собой файл голосового формата (файл звуковых данных в данном варианте воплощения), с использованием, например, кодировки знаков IS08859-1. Идентификатор Файла представляет собой фиксированную величину, например "MS-VOICE".
Фрейм (SIZE-FMT) размера фрейма формата представляет размер фрейма формата в байтах. Как описано более подробно ниже, благодаря этому описанию размера фрейма формата может быть осуществлен доступ к фрейму оглавления.
Номер (FMT-VER) версии формата представляет версию голосового формата. Один верхний байт указывает на большее число версии, и один нижний байт представляет меньшее число версии. Например, 0×0100 представляет собой версию 1.0, и 0×0203 представляет собой версию 2.3.
Название (C-NAME) компании обозначает название компании, которая создала файл, в форме строки символов с использованием, например, кодировки символов ISO859-1. Код 0×00 окончания устанавливается в конце строки символов, хотя он может быть опущен из-за недостатка места, если строка символов занимает все пространство, выделенное для названия компании.
Установленное название (S-NAME) указывает на название системы, в которой был создан файл в форме строки символов, с использованием, например, кодирования символов ISO8859-1. Код 0×00 устанавливается в конце строки символов, хотя он может быть опущен из-за недостатка места, если строка символов занимает всю область, выделенную для установленного названия.
Номер (SET-VER) версии программно-аппаратных средств указывает на версию программно-аппаратных средств системы. Один верхний байт указывает большее число номера версии, и один нижний байт указывает на меньшее число номера версии. Например, 0×0100 представляет версию 1.0, и 0×0203 представляет версию 2.3.
Время и дата (DATA-TIME) записи представлены двоичной величиной, в которой два байта выделены для года и по одному байту выделено на каждый из других участков информации, таких как месяц, день, час, минута, секунда и день недели.
Тип кодирования-декодирования устанавливается в формате идентификатора (FMT-ID) в следующем виде.
0×0002 G726 АДИКМ 22 кГц/3 бита
0×0005 G726 АДИКМ 11 кГц/3 бита
0×0007 G726 АДИКМ 8 кГц/4 бита
0×0009 G726 АДИКМ 8 кГц/2 бита
Количество (CHAN) каналов указывает количество каналов в следующем виде.
0×0001 монофоническое
0×0002 стерео
Количество (SAMP) выборок в секунду указывает частоту выборок в следующем виде.
0×00001F40 8 кГц
0×00002В11 11,025 кГц
Среднее количество (BYTE) байт в секунду представляют количество байт в секунду, которое используется для вычисления времени воспроизведения по размеру данных.
Величина (ALIGN) выравнивания блока указывает в единицах байт группу данных, которая не может быть разделена, что используется для расположения начала данных. Например, 0×0030 представляет собой 46 байт, и 0×0010 представляет собой 16 байт.
Количество (BIT) бит в выборке указывает количество бит на выборку в следующем виде.
0×0004 4 бита
0×0003 3 бита
0×0002 2 бита
Размер дополнительной области (ЕХТ) представляет собой размер области, предназначенной для описания информации, являющейся уникальной для типа кодировки (область дополнительных данных), как указано в байтовых блоках. То есть, если создается дополнительная область данных, указывается размер данной области. Дополнительная область данных создается в блоках по 16 байт. Если дополнительная область данных не является необходимой, устанавливается код 0×0000 в размере дополнительной области (ЕХТ).
После фрейма формата располагается фрейм оглавления, изображенный на фиг.31. В фрейме оглавления описывается расположение отдельных фреймов в файле. Так как для каждого фрейма используется восемь байт, размер фрейма оглавления равен величине, которая представляет собой произведение 8 байт на общее количество фреймов. В соответствии с этим, размер фрейма оглавления меняется при добавлении или удалении фреймов. Если общее количество фреймов будет нечетным числом, в неиспользуемой области размером в восемь байт в конце фрейма оглавления устанавливается код 0×00. На фиг.31 код 0×00 устанавливается по адресам от 0×0028 до 0×002F. Конфигурация из восьми байт, используемая для одного фрейма, выглядит следующим образом.
Идентификатор (FRAME ID) фрейма 1 байт
зарезервировано (RESERVED) 3 байта (фиксированная величина 0×00)
размер (FRAME SIZE) фрейма 4 байта
Тип фрейма определяется идентификатором фрейма следующим образом.
фрейм формата 0×01
фрейм оглавления 0×02
промежуточный фрейм 0×03
фрейм данных 0×04
фрейм названия 0×05
фрейм изготовителя 0×06
фрейм автора 0×07
информационный фрейм 0×08
Размер фрейма представляет размер фрейма, описанного идентификатором фрейма в байтах.
В фрейме оглавления группа вышеописанных данных по восемь байт описана в порядке расположения фреймов. Конкретный пример фрейма оглавления будет описан ниже.
В соответствии с содержимым фрейма оглавления может быть идентифицирована структура фреймов соответствующего файла звуковых данных. При доступе к файлу звуковых данных сначала идентифицируется фрейм формата и затем проверяется содержимое фрейма оглавления. Как указано выше, доступ к фрейму оглавления может быть осуществлен благодаря описанному размеру фрейма формата в фрейме (SIZE-FMT) размера формата. То есть адрес заголовка в фрейме оглавления представляет собой адрес, который смещен от заголовка файла на величину размера фрейма формата.
Как указано выше, после фрейма оглавления могут быть помещены фрейм названия, фрейм изготовителя, фрейм автора и информационный фрейм.
Фрейм названия представляет собой фрейм, предназначенный для записи названия, и он индицирует два ведущих байта, например тип кодировки символов записанного названия в следующем виде.
0×0000 JIS × 0208-1997 (SJIS)
0×0001 ISO8859-1
Размер фрейма названия представляет собой произведение целого числа на 16 байт, и код 0×00 окончания устанавливается в конце строки символов названия.
Фрейм изготовителя представляет собой название компании, название машины и номер версии программно-аппаратных средств машины, в которой был создан файл. В фрейме изготовителя, также как и в фрейме названия, два ведущих байта обозначают тип кодировки символов, после чего идет строка символов. Размер фрейма изготовителя представляет собой произведение целого числа на 16 байт, и код 0×00 устанавливается в конце строки символов.
Фрейм автора представляет собой имя автора (держателя авторских прав) в виде строки символов. Два ведущих байта описывают тип кодировки символов, после чего следует строка символов. Размер кадра автора представляет собой произведение целого числа на 16 байт, и код 0×00 устанавливается в конце строки символов.
Информационный фрейм представляет собой фрейм, предназначенный для записи дополнительной информации. Дополнительная информации включает название альбома, имя исполнителя и имя дирижера. Дополнительная информация может, кроме того, включать количество воспроизведений, когда выполняется средний объем обучения. Первый байт указывает на идентификатор категории информации и третий и четвертый байты представляют тип кодировки символов, с помощью которых записана строка информационных символов. Строка символов хранится начиная с девятого байта от заголовка фрейма. Размер информационного фрейма представляет собой целое число, кратное 16 байтам, и код 0×00 устанавливается в неиспользуемой области.
После вышеуказанных необязательных фреймов или фрейма оглавления следует промежуточный фрейм. Необходимость промежуточного фрейма, который служит как не подлежащая воспроизведению область, является существенной. Таким образом, промежуточную область необходимо оставлять при создании данных. Промежуточная область используется как зарезервированная область для расширения фрейма оглавления или используется, когда создается область, неиспользуемая при воспроизведении в одном кластере, при выполнении операции разделения (описана ниже). Любой тип данных может храниться в промежуточном фрейме и могут быть записаны некоторые фиктивные данные. Размер промежуточного фрейма представляет собой целое число, кратное 16 байтам. Обработка промежуточного фрейма подробно описана ниже.
В фрейме данных хранятся собственно данные сообщения. Данные сообщения хранятся без промежутка как определенное количество бит, начинающихся от самого старшего бита (ССБ) байта заголовка фрейма данных. Для границы хранения данных используется байтовая граница. Например, для данных размером четыре бита и данных размером два бита на выборку, таких как данные, изображенные на фиг.32 и 33 соответственно, граница хранения данных представляет собой один байт. Для данных размером три бита на выборку, таких как данные, изображенные на фиг.34, граница хранения данных представляет собой три байта. Когда голосовые данные разделяются, вышеупомянутые блоки хранения используются как блоки данных.
Файл данных сообщения формируется с помощью вышеописанных различных фреймов. Пример фрейма формата файла данных сообщения изображен на фиг.21А-22В. В нижеследующем описании предполагается, что отсутствуют фрейм названия, фрейм изготовителя, фрейм автора и фрейм информации, которые являются необязательными.
Фреймовая структура создается, когда производится обычная запись звуковых данных, в виде, изображенном на фиг.21А. Фрейм формата, фрейм оглавления, промежуточный фрейм и фрейм данных формируются начиная с заголовка файла, как изображено на фиг.21А. Множество блоков (кластеров), формирующих отдельный файл, соединены поблочно с помощью FAT, и не обязательно представляют собой физически последовательные блоки, как указывалось выше.
Информация в вышеописанной фреймовой структуре указана в фрейме оглавления так, как информация, изображенная на фиг.21В.
Как описано выше, множество участков информации, каждый из которых имеет длину восемь байт, располагаются в порядке расположения фреймов. В первой области размером восемь байт устанавливается идентификатор фрейма, то есть 0×01, и за ней следует размер фрейма формата. Во второй области размером восемь байт устанавливается код 0×02 в идентификаторе фрейма, и за ней следует размер фрейма оглавления. Так как количество фреймов равно четырем, размер фрейма оглавления равен 4×8 байт = 32 байта (=0×00000020). В третьей области размером восемь байт устанавливается код 0×03 в идентификаторе фрейма, и за этим следует размер промежуточного фрейма. В последней области размером восемь байт устанавливается код 0×04 в идентификаторе фрейма, после чего следует размер фрейма данных.
В файле данных сообщения часть данных может быть стерта и установлена как область, защищенная от воспроизведения с использованием промежуточного фрейма. Например, если предположить, что имеется часть сообщения в фрейме данных, которая должна быть стерта и не должна воспроизводиться, как изображено на фиг.22А, такая часть сообщения заменяется промежуточным фреймом. Так как промежуточный фрейм игнорируется при воспроизведении данных, это приводит к тому, что как будто часть сообщения была стерта во время воспроизведения данных.
Когда фреймовая структура изменяется от структуры, изображенной на фиг.21А, на структуру, изображенную на фиг.22А, содержимое фрейма оглавления обновляется, как изображено на фиг.22В.
Размер первого фрейма формата восемь байт остается таким же. Идентификатор фрейма второй области размером восемь байт представляет собой 0×02. Поскольку количество фреймов увеличилось с двух до шести, размер фрейма оглавления изменился и стал равен 6×8 байтов = 48 байтов (=0×00000030). В третьей области размером восемь байт код 0×03 устанавливается в идентификатор фрейма, и после этого следует размер промежуточного фрейма. Когда фрейм оглавления расширяется на 16 байт, размер промежуточного фрейма уменьшается на 16 байт, что приводит к величине 0×00000180.
В следующей области размером восемь байт указывается размер первой части фрейма данных, которая содержит часть сообщения, которое не должно быть воспроизведено, и которое было разделено новым промежуточным фреймом. В пятой области размером восемь байт, описывается размер нового промежуточного фрейма, содержащего вышеуказанную часть сообщения. В последней области размером восемь байт показан размер второй части фрейма данных, разделенной новым промежуточным фреймом.
Фреймовая структура файла данных сообщения управляется фреймом оглавления, как описано выше. Содержимое фрейма оглавления обновляется в соответствии с изменениями в фреймовой структуре при добавлении промежуточного фрейма или фрейма данных или в результате выполнения операции редактирования, такой как операция разделения файла или операция комбинирования файла, которые будут подробно описаны ниже.
Промежуточный фрейм обрабатывается следующим образом. Когда файл данных сообщения вновь создается, промежуточный фрейм, имеющий размер от 128 байт до 640 байт (=128+512) байт, располагается после фрейма оглавления, как изображено на фиг.23. В этом случае размер промежуточного фрейма определяется таким образом, что начальное положение фрейма данных помещается на границе сектора.
Хотя это будет описано более подробно ниже, когда файл данных сообщения разделяется, устанавливается область защиты от воспроизведения в виде промежуточного фрейма в кластере, включающем точку разделения.
Более конкретно, если точка разделения устанавливается в кластере, как изображено на фиг.24, заголовок данных сообщения, то есть вторая часть файла, помещается в точке разделения. Минимальный блок файла представляет собой кластер. Таким образом, первая часть файла перед точкой разделения в кластере содержит часть данных, которая не должна воспроизводиться (заштрихованная часть на фиг.24), причем эта часть данных заменяется промежуточным фреймом так, что он может быть защищен от воспроизведения.
После выполнения операции разделения или операции комбинирования файла данных сообщения два промежуточных фрейма могут быть размещены рядом друг с другом. В этом случае два промежуточных фрейма комбинируются в один промежуточный фрейм, другими словами, они управляются фреймом оглавления как один промежуточный фрейм.
Как описано выше, файл данных сообщения имеет не только фрейм данных, но также и фрейм формата, фрейм оглавления, фрейм названия, фрейм изготовителя, фрейм автора, информационный фрейм и промежуточный фрейм. По сравнению с другими фрейм формата, фрейм оглавления и промежуточный фрейм являются существенными по следующим причинам.
Запоминающее устройство 1 стержневого типа используется не только в управляющей системе, такой как система, изображенная на фиг.9, но также и в устройстве, использующем систему FAT, таком как персональный компьютер (ПК).
Более конкретно, запоминающее устройство 1 стержневого типа, содержащее файл данных сообщения, который записывается и управляется управляющей системой, такой как система, изображенная на фиг.9, загружается в ПК так, что файлы могут быть перемещены или имя файла может быть изменено с использованием системы FAT. Однако это нарушает соответствие информации получаемого в результате файла с содержимым файла данных сообщения, управляемого файлом списка сообщения. Чтобы преодолеть этот недостаток, когда запоминающее устройство 1 стержневого типа сначала идентифицируется управляющей системой, такой как система, изображенная на фиг.9, входы поддиректории в директории VOICE управляются в соответствии с содержимым файла списка сообщений. Это позволяет использовать запоминающее устройство 1 стержневого типа в управляющей системе, даже если, например, пользователь изменяет название файла на ПК. В этом случае, если файл данных сообщения вводится непосредственно в фрейм данных, а также, косвенно, в другие фреймы, информация, требуемая для воспроизведения фрейма данных, также передается в управляющую систему, изображенную на фиг.9. Таким образом, даже если файл, хранящийся в запоминающем устройстве 1 стержневого типа, будет перемещен с помощью ПК, данные могут быть без серьезных проблем воспроизведены в управляющей системе.
При воспроизведении сообщения с использованием вышеописанной информации требуется отображать время записи и остающееся время сообщения. В этом случае они могут отображаться модулем 108 дисплея управляющей системы, изображенной на фиг.9.
Обычно размер файла, управляемый файловой системой FAT, указывается в модуле дисплея. В файле данных сообщения, однако, размер файла скорее вычисляется в виде времени, а не в том виде, который обычно используется в файловой системе, управляемой системой FAT.
Вначале вычисляется полный размер фрейма данных в файле сообщения с использованием фрейма оглавления, и затем преобразуется в общее время воспроизведения с использованием среднего количества байт в секунду, записанного в фрейме формата. Остающееся время можно вычислить, вычитая время воспроизведения воспроизведенного сообщения от общего времени воспроизведения. В соответствии с этой технологией подсчета могут быть предотвращены ошибки вычисления, вызванные количеством данных в промежуточных фреймах и других фреймах.
6. Операция редактирования с разделением
Операция редактирования с разделением, которая представляет собой часть системы в соответствии с настоящим вариантом воплощения, описана ниже.
В соответствии с операцией редактирования с разделением определенная точка разделения указывается командой пользователя с тем, чтобы разделить отдельный файл звуковых данных на два файла звуковых данных в точке разделения. Эта операция описана ниже со ссылкой на фиг.9, 25-28.
Фиг.25 представляет собой алгоритм, поясняющий операцию редактирования с разделением, выполняемую под управлением микропроцессора 109. Фиг.26А, 26В и 26С поясняют концепцию разделения файла данных сообщения запоминающего устройства 1 стержневого типа. Фиг.27 и 28 изображают содержимое FAT до и после выполнения операции разделения.
Когда запоминающее устройство 1 стержневого типа загружено в управляющую систему, пользователь может идентифицировать файлы данных сообщения, которые записаны в запоминающем устройстве 1 стержневого типа, на модуле 108 дисплея. Если пользователю требуется, чтобы определенный файл данных сообщения был разделен на два файла, пользователь выбирает файл данных сообщения, который следует разделить с использованием модуля 112, проверяя при этом имя файла, отображаемое модулем 108 дисплея.
После того как файл будет выбран пользователем, на этапе F101, изображенном на фиг.25, микропроцессор 109 устанавливает файл звуковых данных, который следует разделить. Затем пользователь указывает точку разделения выбранного файла. Для определения точки разделения могут быть рассмотрены различные операции, например микропроцессор 109 может воспроизводить выбранный файл данных сообщения, и пользователь может выполнить операцию ввода в точке, в которой файл следует разделить, при прослушивании воспроизводимого сообщения. Однако эта операция может привести к незначительному смещению от требуемой точки разделения, и таким образом, предпочтительно, может быть предусмотрена функция точного регулирования точки разделения пользователем.
После определения точки разделения пользователем микропроцессор 109 определяет точку разделения на этапе F102 и далее следует следующая операция разделения. На этапе F103, если определенная точка разделения будет находиться внутри кластера (блока), данные, записанные в кластер, копируются в неиспользованный кластер, при этом дублируя данные кластера, содержащего точку разделения. Однако, если установленная точка разделения будет помещена на границе кластера (блока), не будет необходимости дублировать данные кластера, что будет более подробно описано ниже. Кроме того, данные, записанные в кластере в заголовке файла, включающем управляющий заголовок, копируются в неиспользованный кластер, благодаря чему производится дубликат данных кластера, содержащего управляющий заголовок. Управляющий заголовок представляет собой часть данных, включающих фрейм формата, фрейм оглавления и промежуточный фрейм.
На этапе F104 связь кластера в FAT изменяется, и на этапе F105 изменяется вход в директорию FAT. В соответствии с этим формируется новая связь кластеров так, что один исходный файл может быть разделен на два файла с использованием кластера, включающего точку разделения, который был вновь скопирован на этапе F103, и кластера, включающего управляющий заголовок. Это будет описано более подробно ниже.
Затем на этапе F106 будет обновлен фрейм оглавления управляющего заголовка, который размещен в заголовке исходного файла, вследствие этого формируется первый файл, соответствующий первой части исходного файла, следующей до точки разделения.
На этапе F107 будет обновлен управляющий заголовок кластера, который был скопирован и связан с заголовком файла, таким образом, формируется второй файл, соответствующий второй части исходного файла после точки разделения.
Операция разделения выполняется в соответствии с вышеописанной обработкой. Пример выполнения операции разделения изображен на фиг.26А-28.
Предположим теперь, что файл F1, изображенный на фиг.26А, представляет собой файл данных сообщения, выбранный пользователем и который записан в кластеры CL (2) - CL (9).
FAT, указывающий на связи кластеров файла F1, изображен на фиг.27. Кластер заголовка файла F1 представляет собой кластер CL2, соответствующий входу директории (не показан). В кластере CL (2) FAT записан код 003, что указывает на то, что кластер CL (2) связан с кластером CL (3). Во входе в кластер CL (3) записано 004, что указывает на то, что кластер CL (3) связан с кластером CL (4). Затем связи записываются аналогично, и в последнем кластере CL (9) установлена величина FFF, что указывает на то, что кластер CL (9) представляет собой последний кластер.
В соответствии с FAT, сформированным как описано выше, управляется запись файла F1, изображенного на фиг.26А в кластерах CL (2) - CL (9). В кластере CL (А) и последующих кластерах записывается величина 000, то есть эти кластеры не используются.
Теперь предположим, что пользователь дает команду разделить файл F1 в точке разделения ТР (DP), изображенной на фиг.26А. Точка разделения ТР помещена в кластере CL (5). В соответствии с этим выполняется обработка на этапе F103, показанном на фиг.25, то есть кластер CL (5) копируется в неиспользуемый кластер CL (А), и кластер CL (2), включающий управляющий заголовок, копируется в неиспользуемый кластер CL (В).
Затем на этапах F104 и F105 связь кластеров и связь директории FAT обновляются так, что формируется связь кластера, изображенного на Фиг.26В и 26С. Если два разделенных файла обозначены именами F1-1 и F1-2, сначала формируется вход директории файла F1-1, и кластер заголовка устанавливается в кластере CL (2).
Во входе в FAT, как изображено на фиг.28, в кластере CL (2) устанавливается код 003, в кластере CL (3) устанавливается код 004, в кластере CL (4) устанавливается код 00А, и в кластере CL (А) устанавливается код FFF. Таким образом, с помощью FAT управляют файлом F1-1 так, что файл F1-1 записан последовательно в кластерах CL (2), CL (3), CL (4) и CL (А), как изображено на фиг.26В.
Тем временем формируется вход в директорию файла F1-2, и кластер заголовка устанавливается в кластере CL (В). Во входе в FAT, как изображено на фиг.28, записывается 005 в кластер CL (В), 006 записывается в кластер CL (5), 007 устанавливается в кластер CL (6), 008 устанавливается в кластер CL (7), 009 записывается в кластер CL (8), и FFF записывается в кластер CL (9). В соответствии с этим, с помощью FAT управляют файлом F1-2 так, что файл F1-2 записывается по порядку в кластеры CL (В), CL (5), CL (6), CL (7), CL (8) и CL (9), как изображено на фиг.26С.
В соответствии с этим, на этапе F106, изображенном на фиг.25, обновляется управляющий заголовок файла F1-1, то есть содержимое кластера CL (2). Более конкретно, обновляется размер фрейма данных, указанный в фрейме оглавления.
На фиг.26В изображено, что последний кластер CL (А) представляет собой кластер, включающий точку разделения ТР, и вторая часть данных сообщения после точки разделения ТР представляет собой ненужные данные. Таким образом, размер фрейма данных изменяется до части, определенной стрелкой, представленной штрихпунктирной линией на фиг.26В, то есть заштрихованная часть удаляется из фрейма данных. Это делает заштрихованную часть кластера CL (А) недействительной, и, таким образом, в файле F1-1 будет воспроизводиться часть данных исходного файла F1 до точки разделения ТР.
На этапе F107, изображенном на фиг.25, обновляется управляющий заголовок файла F1-2, то есть содержимое кластера CL (В). Более конкретно, обновляется размер фрейма данных, описанный в фрейме оглавления, и изменяется установка промежуточного фрейма.
На фиг.26С видно, что второй кластер CL (5) представляет собой кластер, включающий точку разделения ТР, и данные сообщения кластера CL (5) перед точкой разделения ТР, представляют собой несущественные данные. Кроме того, кластер CL (В) представляет собой копию кластера CL (2), и данные сообщения фрейма данных, помещенные после промежуточного фрейма в кластере CL (2), также представляет собой несущественные данные для файла F1-2.
Таким образом, размер промежуточного фрейма в фрейме оглавления изменяется так, что промежуточный фрейм, установленный в исходном кластере CL (2) и скопированный в кластер CL (В), расширяется до точки разделения ТР кластера (5). Размер фрейма данных в фрейме оглавления также изменяется.
Промежуточный фрейм расширяется на кластеры CL (В) и CL (5) в файле F1-2, и служит в качестве области, защищенной от воспроизведения. В результате, в файле F1-2 будет воспроизводиться часть данных исходного файла F1 после точки разделения ТР.
Дальнейшее описание операции разделения приведено ниже со ссылкой на фиг.29 и 30. Как видно из вышеприведенного описания настоящего варианта воплощения, для выполнения операции разделения требуется только следующая простая процедура. Кластер, включающей точку разделения, и кластер, включающий управляющий заголовок, копируются. Затем управляющие заголовки (фреймы оглавления) разделенных файлов частично обновляются, и размеры фреймов данных и промежуточных фреймов изменяются. В результате, исходный файл разделяется на два файла звуковых данных - до и после точки разделения. Благодаря этой процедуре, количество копирований и перезаписи данных, которые требуются для выполнения операции редактирования, такой как операция разделения файла данных сообщения, может быть минимизировано. Это позволяет улучшить эффективность операции редактирования и минимизировать количество доступов, требуемых для операции редактирования, уменьшая, таким образом, время обработки и потребление энергии до минимального уровня.
Если точка разделения ТР будет помещена на границе кластера, копирование кластера, включающего точку разделения, не потребуется. Например, если граница между кластером CL (5) и кластером CL (6) файла F1 будет находиться в точке разделения, разделенный файл F1-1 будет формироваться из кластеров CL (2) - CL (5), и разделенный файл F1-2 будет формироваться из кластера CL (X), который является дубликатом CL (2), и кластеров CL (6) - CL (9). В этом случае для выполнения операции разделения требуется только копирование кластера, включающего управляющий заголовок, что делает операцию еще более простой и короткой.
В примере, приведенном на фиг.26А, 26В и 26С, кластер CL (5) интегрирован в файл F1-1, в то время как кластер CL (А) интегрирован в файл F1-2. Однако кластер CL (А) может быть интегрирован в файл F1-1, в то время как кластер (5) может быть интегрирован в файл F1-2. То же самое касается кластеров, содержащих управляющий заголовок.
В области, в которую первоначально записывался исходный кластер CL (5) и которая теперь используется как часть промежуточного фрейма, то есть в первой части кластера CL (5) файла F1-2, звуковые данные могут быть зарезервированы или представлять собой фиктивные данные, т.е. могут быть заполнены нулевыми данными. В качестве альтернативы она может использоваться как область хранения для хранения любого типа дополнительных данных. То же самое касается области, которая стала недействительной, вместо того чтобы использоваться как часть промежуточного фрейма, то есть заштрихованная часть, изображенная на фиг.26В во второй части кластера CL (А) файла F1-1.
Различные типы данных могут храниться в промежуточном фрейме, как описано выше. Вместо того чтобы это пространство было заменено промежуточным фреймом, в нем могут оставаться те же данные сообщения. В этом случае, когда два разделенных файла комбинируются в исходный фрейм, все кластеры могут использоваться в том виде, в каком они есть, делая при этом обработку более эффективной. Если после выполнения операции разделения два промежуточных фрейма расположены рядом друг с другом, они могут комбинироваться в единый промежуточный фрейм.
Процедура и содержание операции разделения не ограничиваются вышеописанными примерами, и могут быть сделаны различные изменения.
В вышеприведенном варианте воплощения, после того как будет сделан дубликат кластера, содержащего точку разделения, часть разделенных файлов формируется как промежуточный фрейм или недействительная часть с помощью обновления фрейм оглавления. В качестве альтернативы, однако, к данным сообщения перед точкой разделения могут добавляться фиктивные данные с тем, чтобы сформировать общие данные кластера, которые могут затем быть записаны в неиспользованный кластер. Фиктивные данные могут также добавляться к данным сообщения после точки разделения так, чтобы сформировать полные данные кластера, которые могут затем записываться в неиспользуемый кластер. Два кластера могут быть объединены с помощью связи кластеров, формируя разделенные файлы. В этом случае фиктивные данные отдельных кластеров могут управляться как промежуточный фрейм или как недействительные части, как в данном варианте воплощения.
Хотя настоящее изобретение было описано на примере этих вариантов воплощения в контексте конфигурации системы и операции редактирования разделением, оно не ограничивается вышеприведенной конфигурацией и операцией.
В частности, в данном варианте воплощения была описана операция разделения файла данных сообщения в системе, использующей запоминающее устройство стержневого типа.
Однако другие типы файлов, такие как музыкальные файлы данных и файлы данных подвижного изображения, могут быть обработаны в системе, использующей запоминающее устройство стержневого типа. Затем операция разделения может выполняться аналогично на музыкальных файлах данных или на файлах данных подвижных изображений, при этом операция редактирования с разделением является также эффективной.
Носитель записи в соответствии с настоящим изобретением не ограничивается запоминающим устройством стержневого типа, таким как изображено на фиг.1A-1D. Может использоваться носитель на основе твердотельного запоминающего устройства, имеющий другую конфигурацию, такую как запоминающее устройство в виде микросхемы, запоминающее устройство в виде карточки, запоминающее устройство в виде модуля и т.д.
Кроме того, могут быть выполнены различные модификации в деталях в отношении формата файловой системы, используемой в данном варианте воплощения, в соответствии с ее практическим использованием.
Изменения емкости флэш памяти не ограничиваются изображенными на фиг.8. Запоминающее устройство в носителе записи в соответствии с настоящим изобретением может представлять собой запоминающее устройство, не являющееся флэш памятью.
Как видно из вышеприведенного описания, настоящее изобретение предлагает следующие преимущества. Управляющая информация для каждого файла, записываемого на носителе записи, также записывается на носитель записи. Благодаря этой управляющей информации могут управляться положение основных данных и области, защищенной от воспроизведения. При выполнении операции редактирования с разделением файла копируются данные отдельного блока, например вышеописанный кластер или блок, включающий точку разделения, и обновляется управляющая информация файла, который должен быть разделен, формируя, таким образом, первый файл, соответствующий первой части исходного файла. Создается управляющая информация второй части файла и добавляется к заголовку второго файла, и формируется первая часть исходного файла перед точкой разделения во втором файле как область, защищенная от воспроизведения, формируя, таким образом, второй файл. При таком расположении перемещение, копирование и перезапись данных, которые требуются для разделения файла, могут быть минимизированы, и время обработки и потребление энергии для операции редактирования могут быть также уменьшены до минимального уровня.


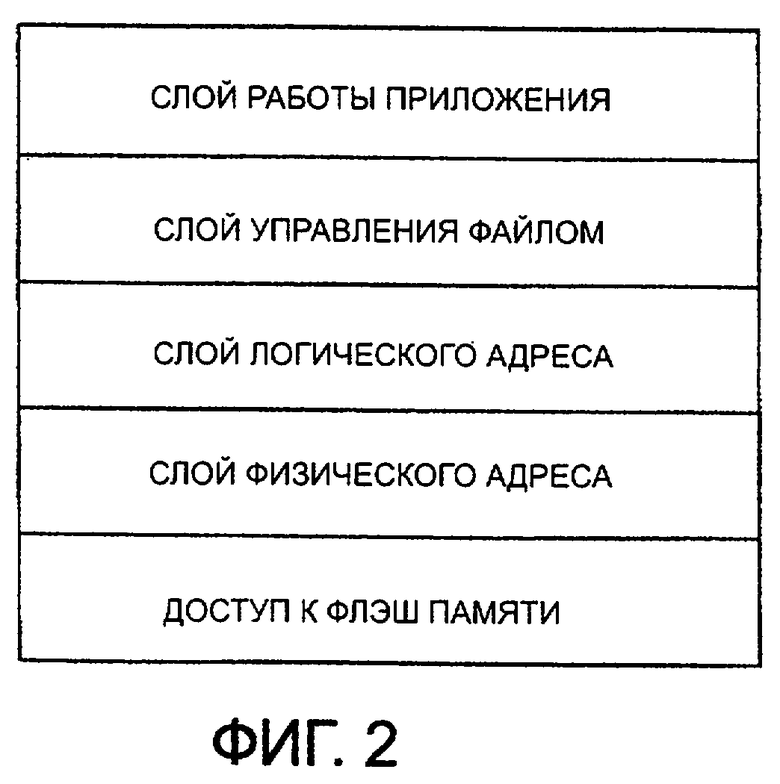
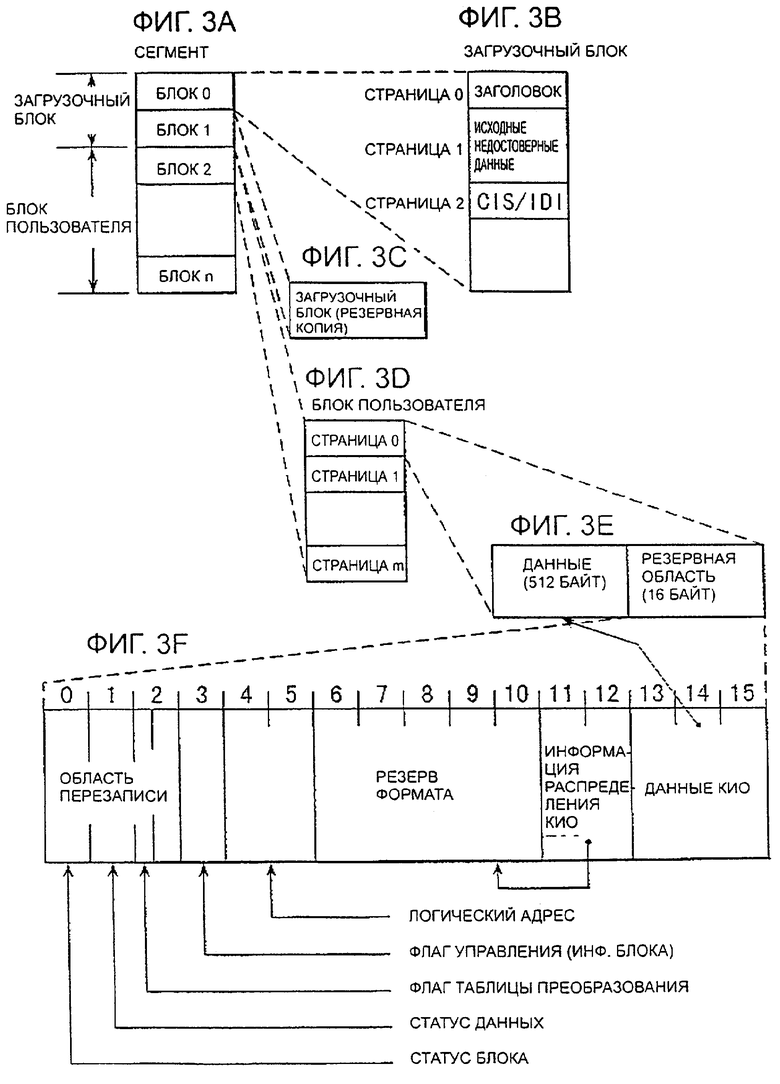


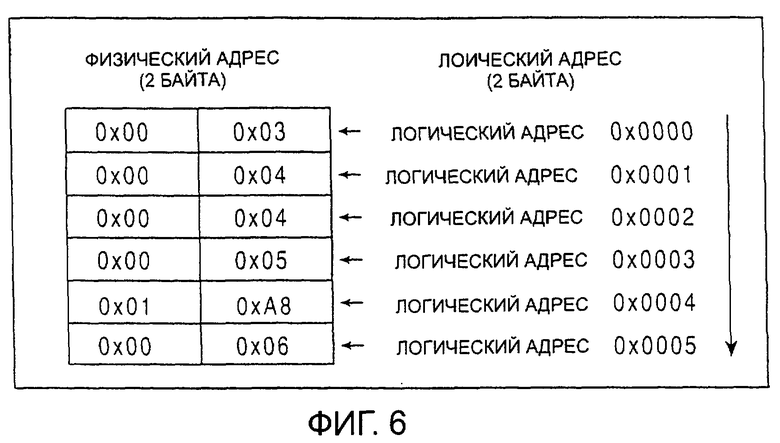
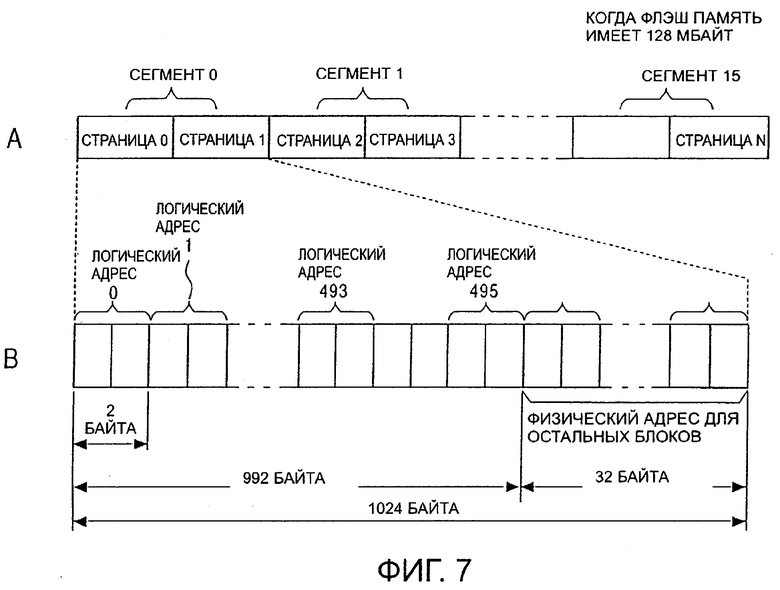

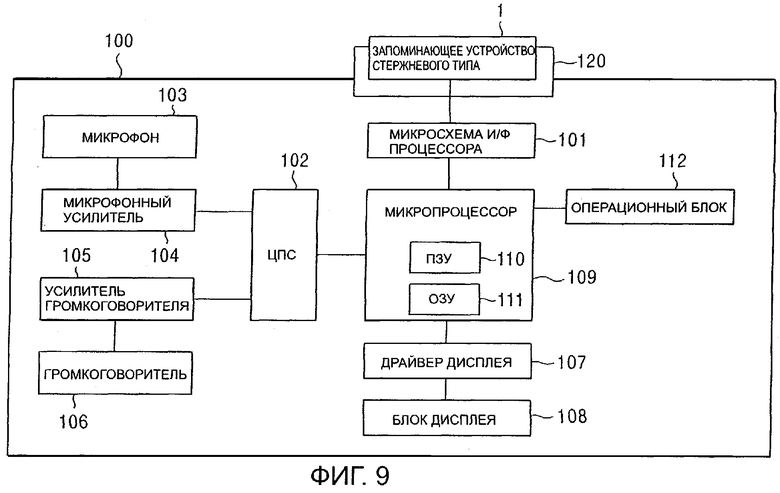
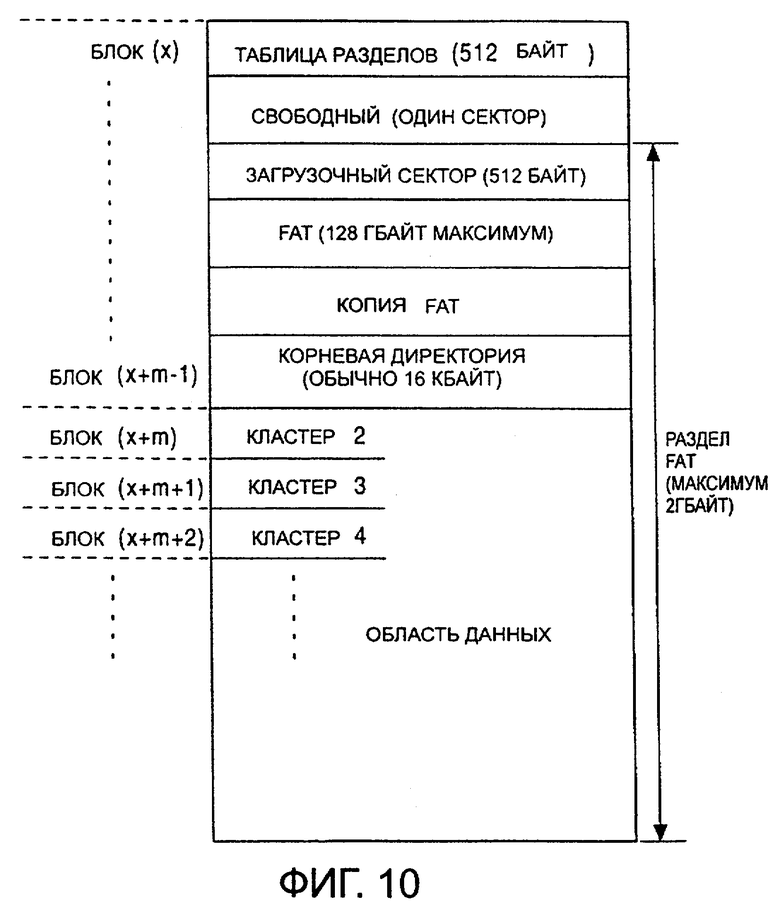



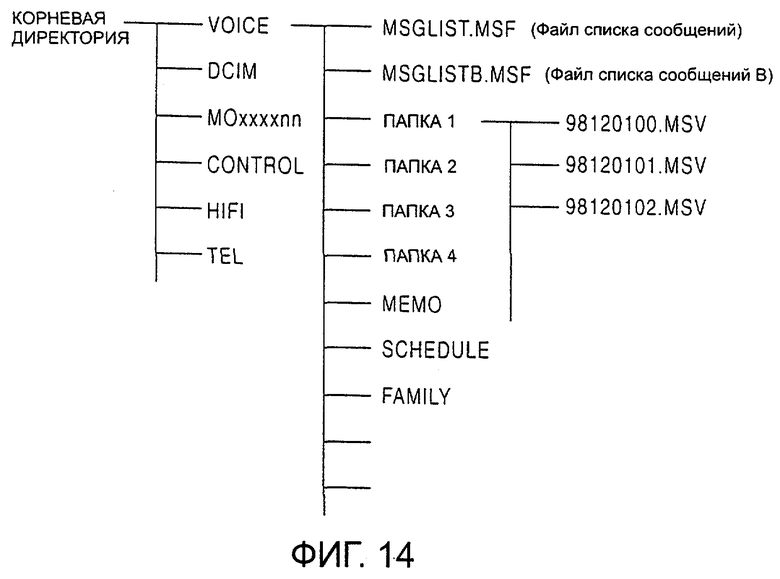


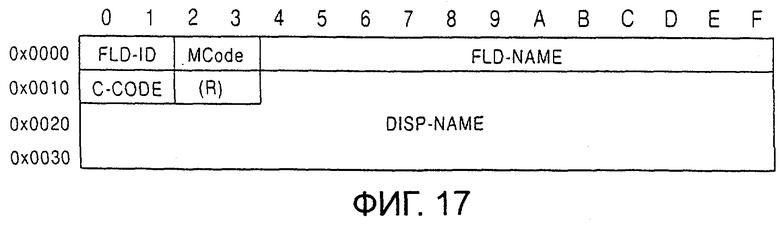
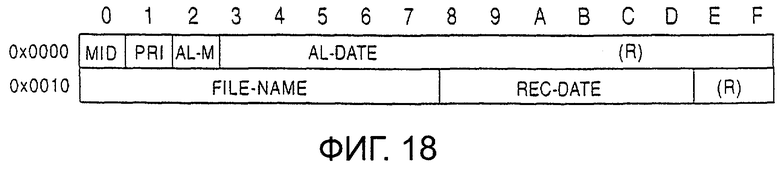



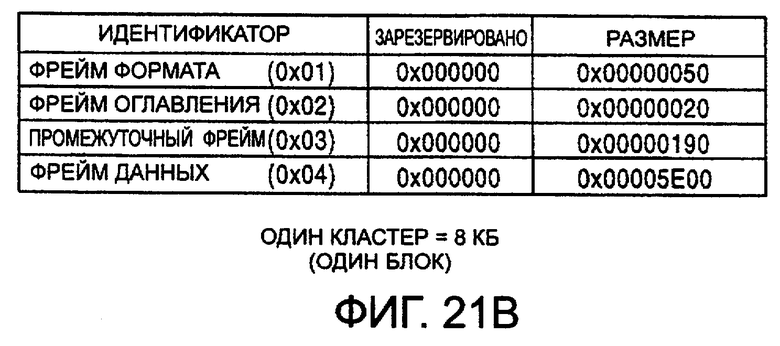
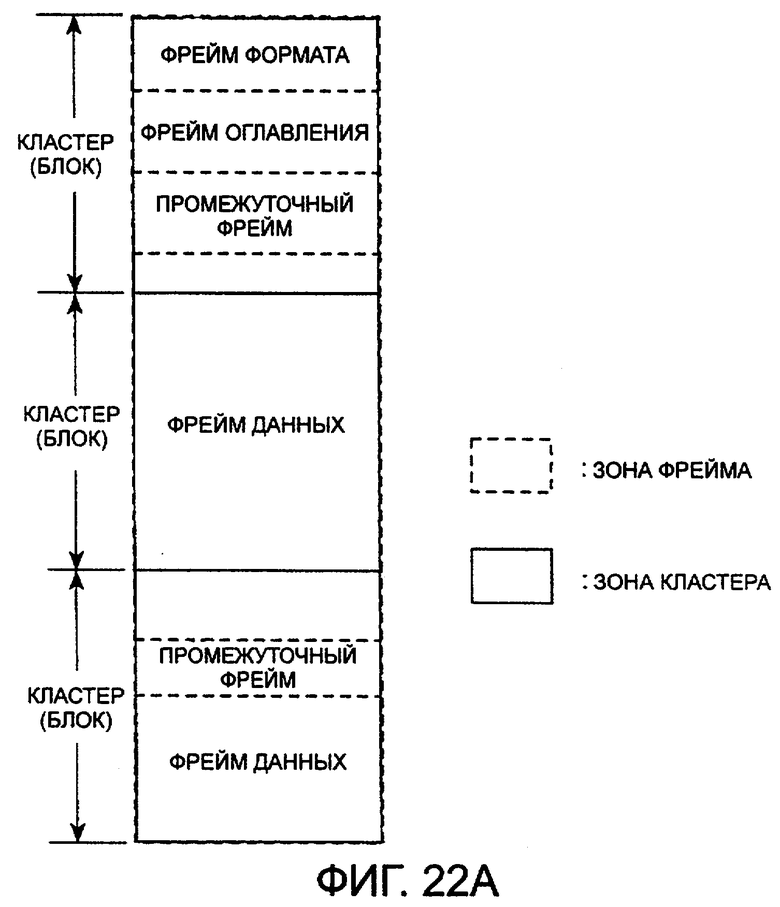
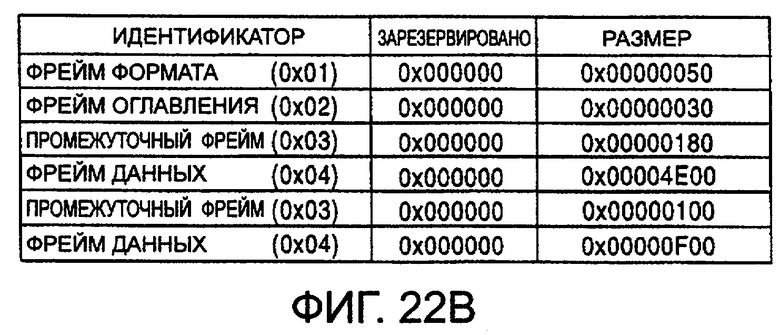
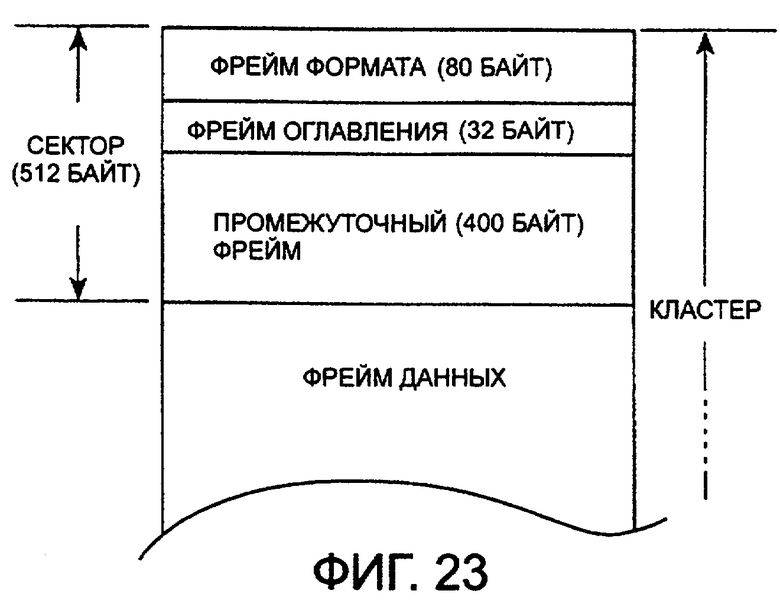
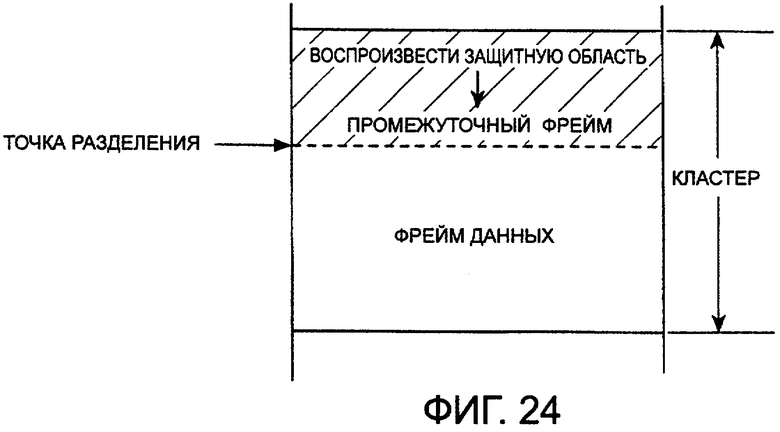
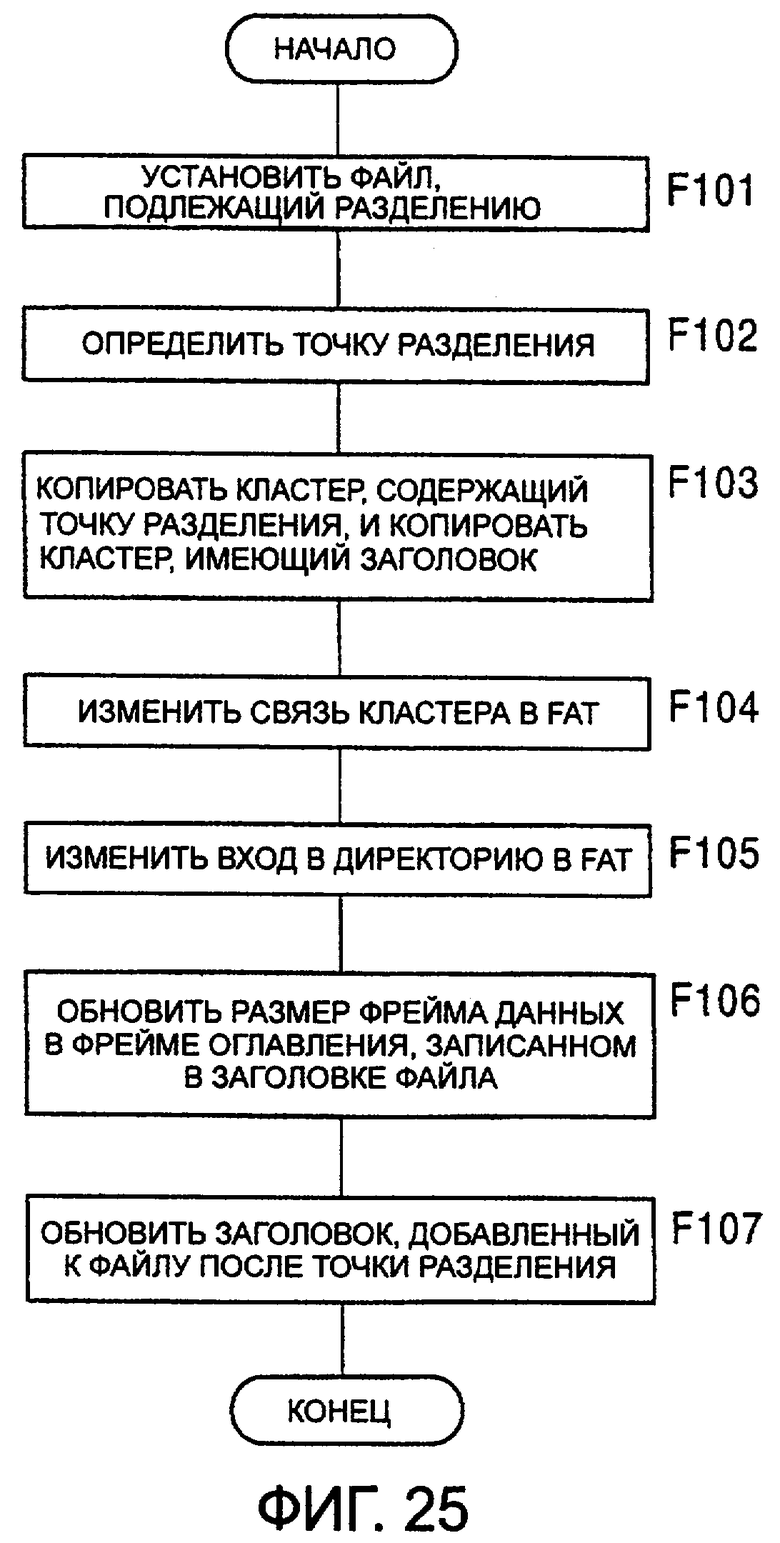

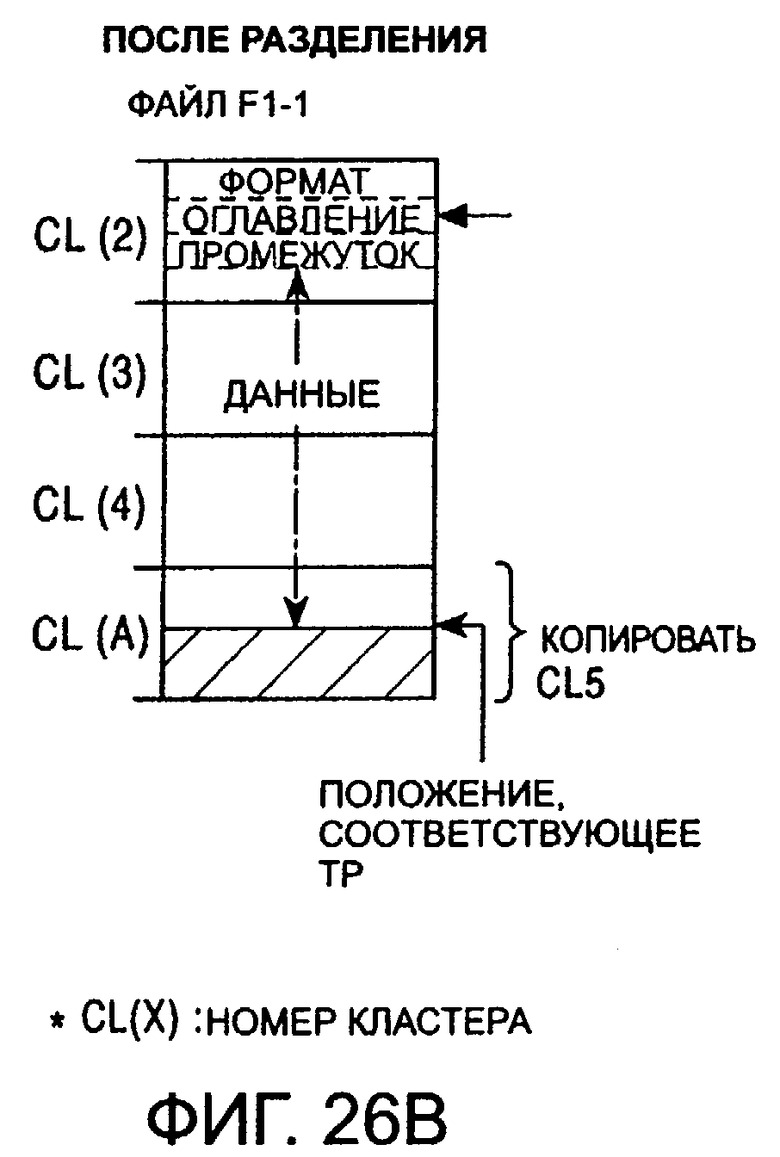
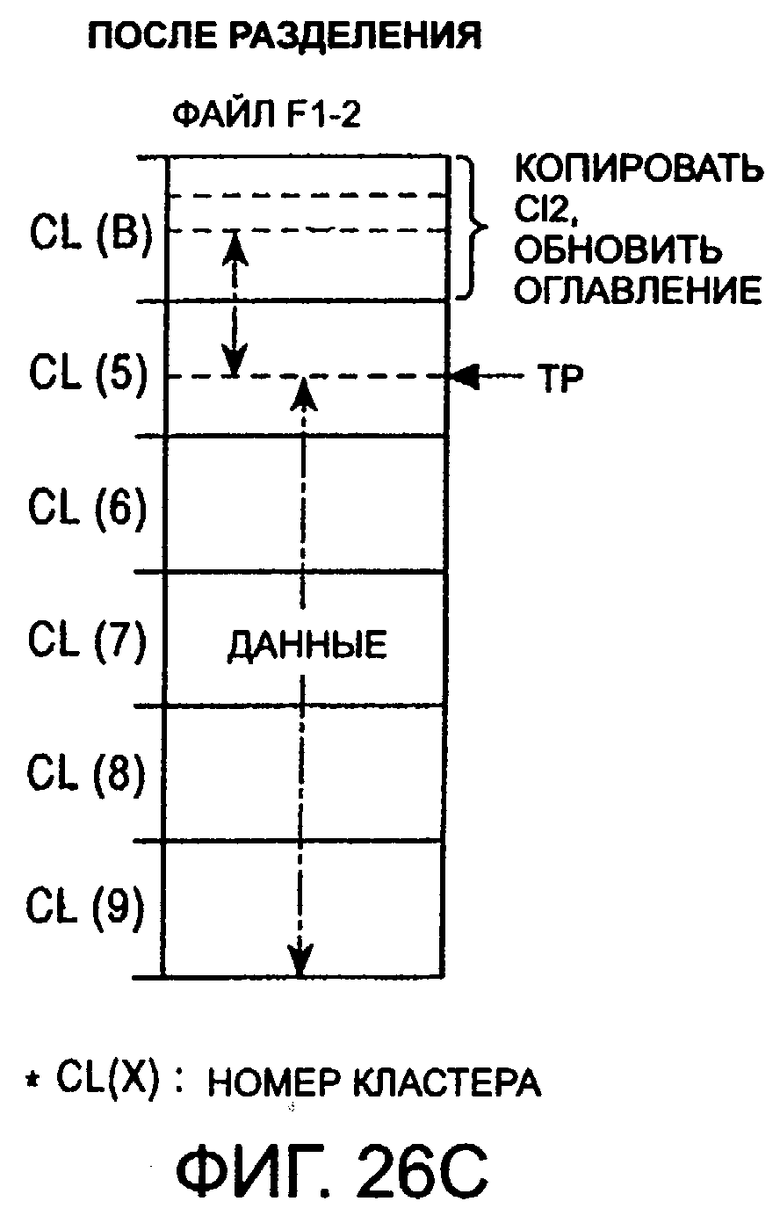
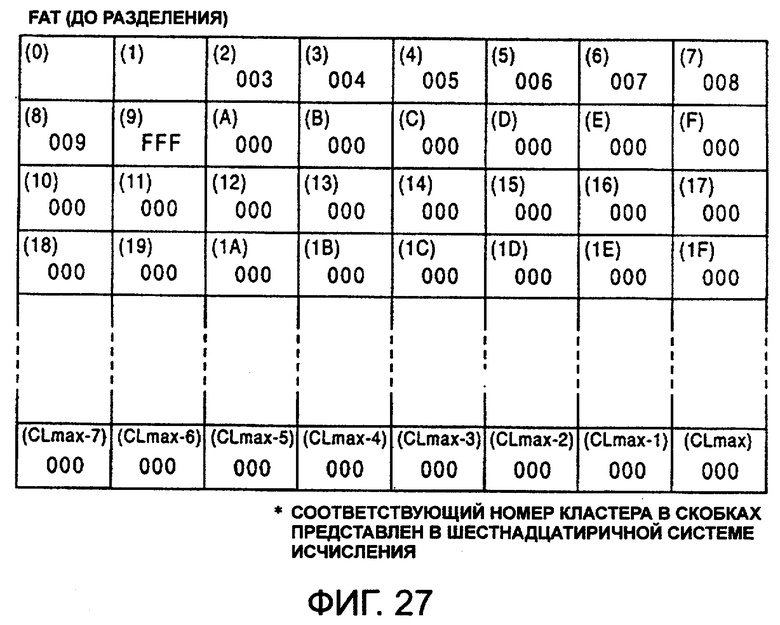



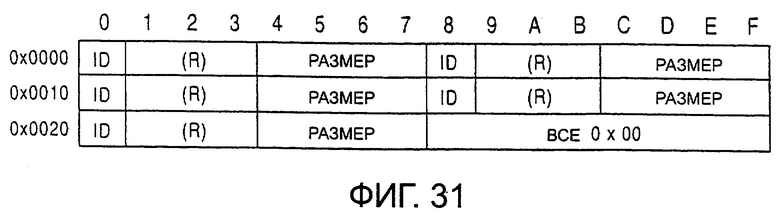



Изобретение относится к редактированию записей. Его использование в носителях записи малых размеров позволяет обеспечить более эффективное редактирование. Устройство предназначено для разделения файла данных с основными и управляющими данными на первый файл и второй файл. Технический результат достигается благодаря тому, что устройство содержит: операционное средство для определения точки разделения на первый и второй файлы; средство редактирования для редактирования первых управляющих данных, чтобы сделать недействительной первую часть блока записываемых данных фиксированной длины с основными данными; и средство генерирования для генерирования вторых управляющих данных, чтобы сделать недействительной вторую часть блока записываемых данных фиксированной длины с основными данными, и для добавления вторых управляющих данных ко второму файлу данных. 3 н. и 26 з.п.ф-лы, 46 ил.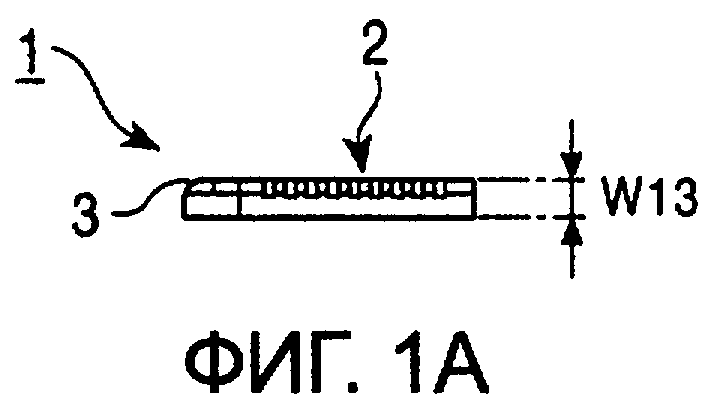
| СПОСОБ ЗАПИСИ ЦИФРОВОЙ ИНФОРМАЦИИ НА НОСИТЕЛЕ И УСТРОЙСТВО ДЛЯ ВОСПРОИЗВЕДЕНИЯ ЦИФРОВОЙ ИНФОРМАЦИИ С НОСИТЕЛЯ ЗАПИСИ | 1991 |
|
RU2037888C1 |

