ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Способы и устройства, совместимые с настоящим изобретением, относятся к кодированию и декодированию видеосигнала с использованием взвешенного предсказания, а более конкретно, к кодированию и декодированию видеосигнала с использованием взвешенного предсказания, которые могут уменьшать величину разностного сигнала посредством формирования образа взвешенного предсказания умножением предсказываемого изображения текущего блока на заданный масштабный коэффициент и кодирования разностного сигнала, полученного вычитанием изображения взвешенного предсказания из текущего блока.
УРОВЕНЬ ТЕХНИКИ
С развитием информационных и коммуникационных технологий, мультимедийная связь продолжает расширяться в дополнение к текстовой и речевой связи. Существующие ориентированные на текст системы связи не удовлетворяют различным желаниям потребителей, и, соответственно, продолжают расширяться мультимедийные услуги, которые могут предоставлять разнообразные виды информации, такие как текст, изображения, музыка и прочие. Поскольку мультимедийные данные велики, требуются запоминающие носители данных большой емкости и широкие полосы пропускания, соответственно, для хранения и передачи мультимедийных данных. Соответственно, технологии кодирования со сжатием требуются для передачи мультимедийных данных, которые включают в себя текст, изображения и звуковые данные.
Основной принцип сжатия данных состоит в том, чтобы удалять избыточность данных. Данные могут сжиматься посредством удаления пространственной избыточности, такой как повторение одного и того же цвета или объекта в изображении, временной избыточности, такой как небольшое изменение соседних кадров в кадрах киноизображения или непрерывное повторение звуков в звуковом сигнале, и визуальной/перцепционной избыточности, которое учитывает невосприимчивость человека к высоким частотам. В общепринятом способе кодирования видеосигнала, временная избыточность удаляется временной фильтрацией, основанной на компенсации движения, а пространственная избыточность удаляется пространственным преобразованием.
Фиг.1 - схема, иллюстрирующая предсказание при традиционном способе кодирования видеосигнала.
Существующие видео кодеки, такие как кодеки MPEG-4 и H.264, повышают эффективность сжатия удалением подобия между соседними кадрами на основе компенсации движения. Обычно, предсказание подобного изображения в опорном кадре, предшествующем по времени текущему кадру 110, назван прямым предсказанием 120, а предсказание подобного изображения в опорном кадре, следующем за текущим кадром по времени, назван обратным предсказанием 130. Временное предсказание, использующее опережающий опорный кадр и отстающий опорный кадр, названо двунаправленным предсказанием 140.
Существующие однослойные видео кодеки могут улучшать свою эффективность посредством выбора и кодирования с использованием оптимального режима из числа различных режимов, которые описаны выше. С другой стороны, многослойные видеокодеки, такие как масштабируемое расширение H.264 (или масштабируемое кодирование видеосигнала MPEG), используют другой способ предсказания, то есть способ предсказания базового слоя, для того чтобы удалять подобие между слоями. То есть видеокодеки выполняют предсказание изображения с использованием изображения в кадре, который находится в том же временном положении, что и блок, который должен декодироваться в настоящий момент, в изображении базового слоя. В этом случае, если соответственные слои имеют разные разрешения, видеокодек выполняет временное предсказание после повышающей дискретизации изображения базового слоя и приведения разрешения изображения базового слоя в соответствии разрешению текущего слоя.
Хотя может существовать несколько причин для выбора режима предсказания, непосредственное кодирование может выполняться по отношению к соответственным способам предсказания, чтобы выбирать способ, который обладает более низкой стоимостью. Стоимость С может определяться различными путями, и типичная стоимость рассчитывается в качестве равенства (1) на основе искажения в зависимости от скорости передачи. Здесь E обозначает разность между исходным сигналом и сигналом, восстановленным посредством декодирования кодированных битов, а В обозначает количество битов, требуемых для выполнения соответствующих способов. К тому же, λ обозначает коэффициент Лагранжа, который может выравнивать скорость отражения E и B.
С=Е+λB (1)
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Традиционные способы кодирования видеосигнала с использованием временного предсказания раскрыты во многих патентных документах. Например, публикация № 2004-047977 нерассмотренной заявки на выдачу патента Кореи раскрывает пространственно масштабируемое сжатие и, в частности, способ кодирования видеосигнала, который включает в себя расчет векторов движения для соответственных кадров, основанный на сумме крупномасштабного базового слоя и слоя апертурной коррекции.
Однако, за исключением предсказания базового слоя, традиционные способы кодирования видеосигнала испытывают проблему, что они никогда не используют большой объем информации базового слоя.
Настоящее изобретение предлагает способ кодирования и декодирования видеосигнала с использованием взвешенного предсказания, и устройство для его осуществления, которые могут повысить эффективность кодирования видеосигнала посредством снижения ошибки текущего блока, который должен сжиматься, и предсказанного изображения.
Настоящее изобретение также предлагает способ кодирования и декодирования видеосигнала с использованием взвешенного предсказания и устройство для его осуществления, которые могут повышать эффективность кодирования видеосигнала посредством информации базового слоя при формировании предсказанного изображения.
Согласно одному аспекту настоящего изобретения предложен способ кодирования видеосигнала, который включает в себя этапы: формирование предсказанного изображения для текущего блока; формирование коэффициента взвешенного предсказания, который является масштабным коэффициентом предсказанного изображения, который минимизирует разность между текущим блоком и предсказанным изображением; формирование изображения взвешенного предсказания умножением предсказанного изображения на коэффициент взвешенного предсказания; и кодирование разностного сигнала, сформированного вычитанием изображения взвешенного предсказания из текущего блока.
Согласно еще одному аспекту настоящего изобретения предложен способ кодирования многослойного видеосигнала, который включает в себя этапы: формирование предсказанного изображения для текущего блока; формирование коэффициента взвешенного предсказания, который является масштабным коэффициентом предсказанного изображения, который минимизирует разность между текущим блоком и предсказанным изображением; формирование изображения взвешенного предсказания умножением предсказанного изображения на коэффициент взвешенного предсказания; выбор изображения, которое повышает эксплуатационные показатели сжатия текущего блока, между предсказанным изображением и изображением взвешенного предсказания; кодирование разностного сигнала, сформированного вычитанием выбранного изображения из текущего блока; и вставку информации, которая указывает, следует ли использовать изображение взвешенного предсказания в отношении текущего блока согласно результату выбора.
Согласно еще одному другому аспекту настоящего изобретения предложен способ декодирования многослойного видеосигнала, который включает в себя этапы: восстановления разностного сигнала текущего блока, который должен быть восстановлен, из битового потока; восстановления предсказанного изображения текущего блока из битового потока; формирования изображения взвешенного предсказания умножением предсказанного изображения на коэффициент взвешенного предсказания; и восстановления текущего блока добавлением разностного сигнала к изображению взвешенного предсказания; при этом коэффициент взвешенного предсказания является масштабным коэффициентом предсказанного изображения, который минимизирует разность между текущим блоком и предсказанным изображением.
Согласно еще одному другому аспекту настоящего изобретения предложен кодировщик мультимедийного видеосигнала, который включает в себя: средство для формирования предсказанного изображения для текущего блока; средство для формирования коэффициента взвешенного предсказания, который является масштабным коэффициентом предсказанного изображения, который минимизирует разность между текущим блоком и предсказанным изображением; средство для формирования изображения взвешенного предсказания умножением предсказанного изображения на коэффициент взвешенного предсказания; и средство для кодирования разностного сигнала, сформированного вычитанием изображения взвешенного предсказания из текущего блока.
Согласно еще одному другому аспекту настоящего изобретения предложен кодировщик многослойного сигнала, который включает в себя: средство для формирования предсказанного изображения для текущего блока; средство для формирования коэффициента взвешенного предсказания, который является масштабным коэффициентом предсказанного изображения, который минимизирует разность между текущим блоком и предсказанным изображением; средство для формирования изображения взвешенного предсказания умножением предсказанного изображения на коэффициент взвешенного предсказания; средство для выбора изображения, которое повышает эксплуатационные показатели сжатия текущего блока, между предсказанным изображением и изображением взвешенного предсказания; и средство для кодирования разностного сигнала, сформированного вычитанием выбранного изображения из текущего блока, и вставки информации, которая указывает, следует ли использовать изображение взвешенного предсказания в отношении текущего блока согласно результату выбора.
Согласно еще одному другому аспекту настоящего изобретения предложен декодер многослойного сигнала, который включает в себя: средство для восстановления разностного сигнала текущего блока, который должен быть восстановлен, из битового потока; средство для восстановления предсказанного изображения текущего блока из битового потока; средство для формирования изображения взвешенного предсказания умножением предсказанного изображения на коэффициент взвешенного предсказания; и средство для восстановления текущего блока добавлением разностного сигнала к изображению взвешенного предсказания; при этом коэффициент взвешенного предсказания является масштабным коэффициентом предсказанного изображения, который минимизирует разность между текущим блоком и предсказанным изображением.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Вышеприведенные и другие аспекты настоящего изобретения будут более очевидны из последующего подробного описания примерных вариантов осуществления, взятых в сочетании с прилагаемыми чертежами, на которых:
фиг.1 - схема, иллюстрирующая предсказание при традиционном способе кодирования видеосигнала;
фиг.2 - схема, иллюстрирующая идею взвешенного предсказания согласно примерному варианту осуществления настоящего изобретения;
фиг.3 - схема, иллюстрирующая идею еще одного взвешенного предсказания согласно примерному варианту осуществления настоящего изобретения;
фиг.4 - блок-схема последовательности операций способа, иллюстрирующая последовательность операций кодирования видеосигнала с использованием взвешенного предсказания согласно примерному варианту осуществления настоящего изобретения;
фиг.5 - блок-схема последовательности операций способа, иллюстрирующая последовательность операций кодирования видеосигнала с использованием взвешенного предсказания согласно другому примерному варианту осуществления настоящего изобретения;
фиг.6 - блок-схема последовательности операций способа, иллюстрирующая последовательность операций кодирования видеосигнала с использованием взвешенного предсказания согласно еще одному другому примерному варианту осуществления настоящего изобретения;
фиг.7 - блок-схема последовательности операций способа, иллюстрирующая последовательность операций декодирования видеосигнала согласно примерному варианту осуществления настоящего изобретения;
фиг.8 - блок-схема последовательности операций способа, иллюстрирующая последовательность операций декодирования, которая соответствует последовательности операций кодирования по фиг.5;
фиг.9 - блок-схема последовательности операций способа, иллюстрирующая последовательность операций декодирования, которая соответствует последовательности операций кодирования по фиг.6;
фиг.10 - представление, иллюстрирующее структуру данных для избирательного выполнения традиционного предсказания и взвешенного предсказания согласно примерному варианту осуществления настоящего изобретения;
фиг.11 - структурная схема, иллюстрирующая конструкцию кодировщика согласно примерному варианту осуществления настоящего изобретения;
фиг.12 - структурная схема, иллюстрирующая конструкцию декодера, который соответствует кодировщику по фиг.11;
фиг.13 - структурная схема, иллюстрирующая конструкцию кодировщика согласно еще одному примерному варианту осуществления настоящего изобретения;
фиг.14 - структурная схема, иллюстрирующая конструкцию декодера, который соответствует кодировщику по фиг.13;
фиг.15 - структурная схема, иллюстрирующая конструкцию кодировщика видеосигнала, использующего взвешенное предсказание согласно еще одному другому примерному варианту осуществления настоящего изобретения; и
фиг.16 - структурная схема, иллюстрирующая конструкцию декодера, который соответствует кодировщику по фиг.15.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
В дальнейшем, примерные варианты осуществления настоящего изобретения будут подробно описаны со ссылкой на прилагаемые чертежи. Аспекты и признаки настоящего изобретения, и способы для достижения аспектов и признаков будут становиться очевидными при обращении к примерным вариантам осуществления, которые далее будут описаны подробно со ссылкой на прилагаемые чертежи. Однако настоящее изобретение не ограничено примерными вариантами осуществления, раскрытыми ниже, и может быть реализовано в различных вариантах. Объекты, определенные в описании, такие как конструкция и элементы, предусмотрены для содействия исчерпывающему пониманию изобретения специалистами в данной области техники, и настоящее изобретение определено только в пределах объема прилагаемой формулы изобретения. Во всем описании настоящего изобретения одинаковые номера ссылок чертежей используются для идентичных элементов на различных фигурах.
В последующем описании предполагается, что блок включает в себя макроблок и подразделенные структурные элементы макроблока, и все операции выполняются в структурном элементе блока. К тому же, изображение, формируемое традиционным способом временного предсказания, которое описано выше со ссылкой на фиг.1, представлено в качестве предсказанного изображения. Эти определения приведены, чтобы помочь пониманию изобретения, но настоящее изобретение не ограничено такими определениями.
При кодировании видеосигнала согласно примерным вариантам осуществления настоящего изобретения, предсказанное изображение не используется как есть, а текущий блок предсказывается посредством умножения предсказанного изображения на масштабный коэффициент после того, как рассчитан масштабный коэффициент, который используется для оптимального предсказания текущего блока, который должен быть сжат. В последующем описании, для удобства разъяснения, предсказание текущего блока посредством умножения предсказанного изображения на масштабный коэффициент обозначено как взвешенное предсказание, а значение, полученное умножением предсказанного изображения на масштабный коэффициент, обозначено как изображение взвешенного предсказания. К тому же, масштабный коэффициент обозначен как коэффициент взвешенного предсказания. Эти определения даны, чтобы помочь пониманию изобретения, но настоящее изобретение не ограничено такими определениями.
Далее будет описан способ расчета коэффициента взвешенного предсказания согласно примерному варианту осуществления настоящего изобретения.
Предполагается, что значения пикселей текущего блока представлены как x(i, j), а значения пикселей предсказанного изображения представлены как y(i, j). В случае выполнения предсказания посредством традиционного способа, как проиллюстрировано на фиг.1, среднеквадратическая ошибка E между текущим блоком и предсказанным изображением выражается как изложено ниже в равенстве (2).

В случае способа предсказания согласно примерному варианту осуществления настоящего изобретения, значения пикселей изображения α×y(i, j) взвешенного предсказания, которые получены умножением значений пикселей предсказанного изображения y(i, j) на коэффициент α взвешенного предсказания, используются вместо значений пикселей предсказанного изображения y(i, j), и, таким образом, среднеквадратическая ошибка E между текущим блоком и предсказанным изображением выражается как изложено ниже в равенстве (3).

Для того чтобы минимизировать среднеквадратическую ошибку E в равенстве (3), равенство 4 получают посредством выполнения нахождения частной производной равенства (3) по α и установления результата нахождения частной производной равным нулю.

Из равенства (4), получают α, как изложено ниже в равенстве (5).

В равенстве (5), x(i, j) и y(i, j) представлены в виде взаимной корреляции. В примерном варианте осуществления настоящего изобретения кодировщик рассчитывает α для каждого блока в текущем кадре, согласно равенству (5), и передает рассчитанное α на сторону декодера. Декодер восстанавливает изображение взвешенного предсказания умножением восстановленного предсказанного изображения на α, принятое из кодировщика, и восстанавливает соответствующий блок добавлением разностного сигнала к изображению взвешенного предсказания.
В еще одном примерном варианте осуществления настоящего изобретения, для того чтобы рассчитывать коэффициент α взвешенного предсказания, значения пикселей изображения z(i, j) базового слоя, которое находится в том же временном положении, что и текущий блок, используется вместо значений пикселей блока x(i, j) исходного кадра, и, поэтому, отдельная передача α не требуется. В этом случае, α рассчитывается с использованием равенства (6).

Если α рассчитывается с использованием равенства (6), декодер может узнавать и значения пикселей изображения z(i, j) базового слоя, и значения пикселей предсказанного изображения y(i, j), и, таким образом, может перерассчитывать α без отдельного приема α из кодировщика. Фиг.2 иллюстрирует идею взвешенного предсказания согласно примерному варианту осуществления настоящего изобретения.
Кодировщик формирует предсказанное изображение 250 по текущему блоку 210 текущего кадра, который должен сжиматься, используя, по меньшей мере, одно из изображений 220 опережающего опорного кадра, который существует в том же самом слое текущего кадра, изображения 230 отстающего опорного кадра и изображения 240 кадра базового слоя. Кодировщик рассчитывает α согласно примерному варианту осуществления настоящего изобретения по равенству (6) (260) и формирует изображение взвешенного предсказания умножением предсказанного изображения 250 на α (270). Затем кодировщик получает разностный сигнал вычитанием изображения взвешенного предсказания из текущего блока 210 и кодирует разностный сигнал перед передачей кодированного разностного сигнала на сторону декодера.
В случае видео кодека, который формирует значения пикселей предсказанного изображения y(i, j) из значений, уже восстановленных посредством квантования, то есть видео кодека, который использует замкнутый цикл, кодирование и декодирование видеосигнала может выполняться в достаточной мере только с использованием способа, который описан выше со ссылкой на фиг.2. Однако, в случае видео кодека, который формирует значения пикселей предсказанного изображения y(i, j), соответствующие значениям исходного кадра, которые не были квантованы, то есть видео кодека, который использует разомкнутый цикл, значения предсказанного сигнала y(i, j) на стороне кодировщика могут быть отличными от таковых на стороне декодера, а это может служить причиной того, что α, рассчитанное кодировщиком, будет совершенно отличным от α, рассчитанного декодером. В этом случае, кодировщик и декодер могут выполнять кодирование и декодирование видеосигнала с одним и тем же α, используя информацию базового слоя вместо предсказанного сигнала y(i, j) в равенстве (6).
Фиг.3 схематично иллюстрирует последовательность операций расчета коэффициента α взвешенного предсказания с использованием информации базового слоя вместо предсказанного сигнала y(i, j).
Кодировщик формирует предсказанное изображение 350 по текущему блоку 310 текущего кадра, который должен сжиматься, используя, по меньшей мере, одно из изображений 320 опережающего опорного кадра, который существует в том же самом слое в качестве текущего кадра, изображения 330 отстающего опорного кадра и изображения 340 кадра базового слоя. Кодировщик рассчитывает коэффициент α взвешенного предсказания способом, подобным таковому по равенству (6) (390). Здесь значения y(i, j) пикселей предсказанного изображения 350 текущего блока замещаются значениями u(i, j) пикселей изображения предсказания базового слоя, сформированными согласно информации базового слоя. Значения u(i, j) пикселей изображения предсказания базового слоя получают как изложено ниже.
Если предсказанное изображение 350 формируется из, по меньшей мере, одного из опережающего опорного кадра 320 или отстающего опорного кадра 330 текущего слоя, кодировщик отыскивает опорные изображения 360 и 370 базового слоя, которые указаны такими же векторами 365 и 375 движения, как вектора 325 и 335 движения текущего блока, из опережающего кадра или отстающего кадра изображения 340 базового слоя, которые находятся в таком же временном положении, как текущий блок. В это же время, если предсказанное изображение 350 формируется из изображения 340 базового слоя, кодировщик использует значения пикселей изображения 340 базового слоя в качестве значений y(i, j) пикселей предсказанного изображения 350 и выполняет повышающую дискретизацию изображения базового слоя, когда разрешение базового слоя ниже, чем разрешение текущего слоя. Если используются значения u(i, j) вновь сформированного изображения 380 предсказания базового слоя, коэффициент α взвешенного предсказания согласно примерному варианту осуществления настоящего изобретения, рассчитывается как в равенстве (7).

Кодировщик формирует изображение взвешенного предсказания умножением предсказанного изображения 350 на α (395). Затем кодировщик получает разностный сигнал вычитанием изображения взвешенного предсказания из текущего блока 310, кодирует разностный сигнал и передает кодированный разностный сигнал на сторону декодера.
Примерные варианты осуществления, которые описаны выше со ссылкой на фиг.2 и 3, полезны, если исходный кадр текущего слоя подобен кадру базового слоя, и если качество кадра базового слоя выше предопределенного уровня, но они непригодны, если качество кадра базового слоя значительно снижено, и, таким образом, велика разница между исходным кадром и кадром базового слоя. В этом случае, традиционный способ предсказания может выполняться избирательно, без использования коэффициента взвешенного предсказания. Частности такого выбора будут пояснены позже, со ссылкой на фиг.10.
Фиг.4 - блок-схема последовательности операций способа, иллюстрирующая последовательность операций кодирования видеосигнала с использованием взвешенного предсказания согласно примерному варианту осуществления настоящего изобретения.
Ссылаясь на фиг.4, кодировщик формирует предсказанное изображение текущего блока согласно традиционному способу предсказания, как описано выше со ссылкой на фиг.1 (S410). Затем кодировщик рассчитывает коэффициент взвешенного предсказания, который является масштабирующим коэффициентом, который минимизирует разницу между текущим блоком и предсказанным изображением (S420), как в примерных вариантах осуществления, представленных равенствами с (5) по (7). Кодировщик формирует изображение взвешенного предсказания для выполнения более точного предсказания посредством умножения предсказанного изображения на коэффициент взвешенного предсказания (S430), формирует разностный сигнал вычитанием изображения взвешенного предсказания из текущего блока (S440), а затем кодирует разностный сигнал (S450).
Фиг.5 - блок-схема последовательности операций способа, иллюстрирующая последовательность операций кодирования видеосигнала с использованием взвешенного предсказания согласно другому примерному варианту осуществления настоящего изобретения.
Ссылаясь на фиг.5, для того чтобы рассчитывать коэффициент α взвешенного предсказания, как описано выше со ссылкой на фиг.2, значения z(i, j) пикселей изображения базового слоя, которое находится в таком же временном положении, как текущий блок, используются вместо значений x(i, j) пикселей текущего блока текущего кадра, и, таким образом, отдельная передача коэффициента α взвешенного предсказания не требуется. Для этого кодировщик согласно примерному варианту осуществления настоящего изобретения формирует предсказанное изображение текущего блока, который должен сжиматься, согласно традиционному способу предсказания, как описано со ссылкой на фиг.1 (S510), и рассчитывает коэффициент α взвешенного предсказания с использованием значений z(i, j) пикселей соответствующего изображения кадра базового слоя, который находится в таком же временном положении, как текущий кадр, и значений y(i, j) пикселей предсказанного изображения (S520). В примерном варианте осуществления настоящего изобретения пример способа для расчета коэффициента α взвешенного предсказания представлен в равенстве (6). Кодировщик формирует изображение взвешенного предсказания для более точного предсказания посредством умножения предсказанного изображения на коэффициент взвешенного предсказания (S530), формирует разностный сигнал вычитанием изображения взвешенного предсказания из текущего блока (S540), а затем кодирует разностный сигнал (S550).
Фиг.6 - блок-схема последовательности операций способа, иллюстрирующая последовательность операций кодирования видеосигнала с использованием взвешенного предсказания согласно еще одному другому примерному варианту осуществления настоящего изобретения.
Как описано выше со ссылкой на фиг.3, в видеокодеке, значение предсказанного сигнала y(i, j) на стороне кодировщика становится отличным от такового на стороне декодера вследствие ошибки из-за дрейфа, и, таким образом, если способ кодирования видеосигнала, который проиллюстрирован на фиг.5, используется как есть, коэффициент α взвешенного предсказания, рассчитанный в декодере, становится отличным от такового, рассчитанного в кодировщике. Соответственно возникает погрешность в значении блока видеосигнала, восстановленного стороной декодера. Способ кодирования видеосигнала согласно примерному варианту осуществления настоящего изобретения выполняет расчет коэффициента α взвешенного предсказания как изложено ниже.
Кодировщик формирует предсказанное изображение текущего блока согласно традиционному способу предсказания, как описано выше со ссылкой на фиг.1 (S610). Если предсказанное изображение текущего блока, который должен сжиматься, формируется с использованием по меньшей мере одного из опережающего кадра или отстающего кадра текущего слоя ('да' на S620), кодировщик отыскивает область, которая указана вектором движения, который является таким же, как вектор движения текущего блока, из опережающего кадра или отстающего кадра изображения базового слоя, которое находится в таком же временном положении, как текущий блок, и формирует изображение предсказания базового слоя с использованием такого же способа, как способ, который формировал предсказанное изображение (S630). Затем кодировщик рассчитывает коэффициент α взвешенного предсказания согласно равенству (7) с использованием изображения базового слоя, соответствующего текущему блоку, и изображения предсказания базового слоя (S640). В противоположность, если предсказанное изображение текущего блока формируется из изображения базового слоя ('нет' на S620), изображение базового слоя, соответствующее текущему блоку, становится изображением предсказания базового слоя, а значение z(i, j) используется вместо u(i, j) в равенстве (7) (S635).
Кодировщик формирует изображение взвешенного предсказания для выполнения более точного предсказания посредством умножения предсказанного изображения на коэффициент взвешенного предсказания (S650), а затем кодирует разностный сигнал, полученный вычитанием изображения взвешенного предсказания из текущего блока (S660).
фиг.7 - блок-схема последовательности операций способа, иллюстрирующая последовательность операций декодирования видеосигнала согласно примерному варианту осуществления настоящего изобретения.
Ссылаясь на фиг.7, декодер согласно этому примерному варианту осуществления настоящего изобретения восстанавливает разностный сигнал текущего блока, который должен быть восстановлен, из битового потока, передаваемого из кодировщика, и предсказанного изображения текущего блока (S710), и извлекает коэффициент взвешенного предсказания, сформированный и переданный кодировщиком, из битового потока (S720). В представленном примерном варианте осуществления настоящего изобретения декодер может использоваться в случае, где кодировщик рассчитывает коэффициент взвешенного предсказания и вставляет коэффициент взвешенного предсказания в битовый поток, который должен передаваться. Декодер формирует изображение взвешенного предсказания умножением восстановленного предсказанного изображения на извлеченный коэффициент взвешенного предсказания (S730), а затем восстанавливает текущий блок добавлением разностного сигнала к изображению взвешенного предсказания (S740).
Фиг.8 - блок-схема последовательности операций способа, иллюстрирующая последовательность операций декодирования, которая соответствует последовательности операций кодирования по фиг.5.
Ссылаясь на фиг.8, декодер согласно этому примерному варианту осуществления настоящего изобретения восстанавливает разностный сигнал текущего блока, который должен быть восстановлен, из битового потока и предсказанного изображения текущего блока (S810). Декодер формирует коэффициент взвешенного предсказания, который минимизирует разницу между соответствующим изображением кадра базового слоя, который находится в таком же временном положении, как текущий кадр, где расположен текущий блок, и восстановленным изображением предсказания (S820). В это время, коэффициент взвешенного предсказания может рассчитываться согласно равенству (6). Декодер формирует изображение взвешенного предсказания умножением восстановленного изображения предсказания на коэффициент взвешенного предсказания (S830) и восстанавливает текущий блок добавлением восстановленного разностного сигнала к изображению взвешенного предсказания (S840).
Фиг.9 - блок-схема последовательности операций способа, иллюстрирующая последовательность операций декодирования, которая соответствует последовательности операций кодирования по фиг.6.
Ссылаясь на фиг.9, декодер согласно этому примерному варианту осуществления настоящего изобретения восстанавливает разностный сигнал текущего блока, который должен восстанавливаться, из битового потока и предсказанного изображения текущего блока (S910). Если предсказанное изображение формируется из опорного кадра текущего слоя ('да' на этапе S920), декодер отыскивает опорное изображение базового слоя из опережающего кадра или отстающего кадра изображения базового слоя, которое соответствует текущему блоку, посредством использования векторов движения текущего блока как они есть, и формирует изображение предсказания базового слоя таким же образом, как способ формирования предсказанного изображения текущего блока, используя опорное изображение базового слоя (S930). С другой стороны, если предсказанное изображение не формируется из кадра базового слоя ('нет' на этапе S920), декодер формирует изображение предсказания базового слоя посредством использования изображения базового слоя текущего блока как он есть или посредством повышающей дискретизации изображения базового слоя (S935). Затем кодировщик формирует коэффициент взвешенного предсказания, который минимизирует разность между текущим блоком и предсказанным изображением, используя изображение базового слоя, соответствующее текущему блоку, и изображение предсказания базового слоя (S940). То есть декодер рассчитывает коэффициент взвешенного предсказания посредством использования значения пикселя изображения z(i, j) базового слоя и значений пикселей изображения u(i, j) предсказания базового слоя согласно равенству (7), как описано выше. Декодер формирует изображение взвешенного предсказания умножением восстановленного изображения предсказания на коэффициент взвешенного предсказания (S950) и восстанавливает текущий блок добавлением восстановленного разностного сигнала к изображению взвешенного предсказания (S960).
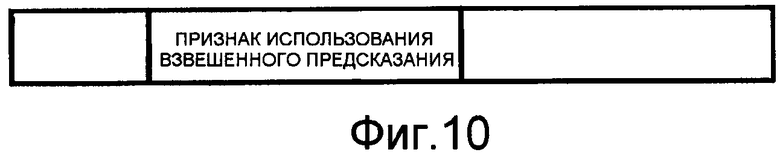
Фиг.10 - схема, иллюстрирующая структуру данных для избирательного выполнения традиционного предсказания и взвешенного предсказания согласно примерному варианту осуществления настоящего изобретения.
Вышеописанный способ эффективен в случае, когда нет значительного различия между кадром базового слоя и текущим кадром, а предсказание не выполняется в достаточной мере посредством существующего способа. Соответственно, также возможно избирательно использовать существующий способ предсказания и способ взвешенного предсказания согласно настоящему изобретению. Для того чтобы избирательно использовать существующий способ предсказания и способ взвешенного предсказания, бит признака для указания, следует ли использовать способ взвешенного предсказания, может вставляться в битовый поток.
Как проиллюстрировано на фиг.10, если битом признака использования взвешенного предсказания, вставленным в битовый поток, является '1', декодер использует способ взвешенного предсказания, тогда как, если битом является '0', декодер использует существующий способ предсказания. В этом случае, является достаточным, что бит признака взвешенного предсказания является значением, посредством которого может различаться использование и отсутствие использования способа взвешенного предсказания. Бит признака взвешенного предсказания может вставляться в структурный элемент кадра или серии последовательных макроблоков, либо в структурный элемент макроблока. С другой стороны, бит признака может вставляться и в заголовок кадра или серии последовательных макроблоков, и заголовок макроблока, а предсказание выполняется посредством использования комбинации этих двух битов. Например, если значением признака заголовка серии последовательных макроблоков является '0', существующий способ предсказания может использоваться по всем кадрам, а если значением флага является '1', способ взвешенного предсказания может использоваться по всем кадрам. К тому же, если значением флага заголовка серии последовательных макроблоков является '2', существующий способ предсказания и способ взвешенного предсказания могут использоваться избирательно согласно значению флага макроблока.
С другой стороны, существующий способ предсказания и способ взвешенного предсказания могут избирательно использоваться составляющими сигнала цветности YUV. В этом случае, признак использования взвешенного предсказания может быть состоящим из трех битов, и соответствующие биты указывают, следует ли использовать взвешенное предсказание по отношению к соответствующим составляющим цветового пространства.
Идея кодирования видеосигнала с использованием взвешенного предсказания, как описано выше, также может применяться к разностному предсказанию. Разностным предсказанием является технология, использующая то, что разностные сигналы, сформированные в двух слоях, подобны друг другу, если векторы движения между двумя слоями подобны друг другу в многослойной структуре. Если предполагается, что исходным сигналом для текущего слоя является O2, предсказанным сигналом текущего слоя является P2, разностным сигналом текущего слоя является R2, исходным сигналом базового слоя является O1, предсказанным сигналом базового слоя является P1, а разностным сигналом базового слоя является R1, разностные сигналы соответственных слоев выражаются как изложено ниже.
R2=O2-P2
R1=O1-P1
В этом случае, R1 является сигналом, квантованным и кодированным в базовом слое, и на текущем слое эффективность сжатия улучшается квантизацией R2-R1 вместо R2. Эта последовательность операций может использоваться приемлемым образом посредством определения, следует ли применять эту последовательность операций в структурном элементе макроблока или подблока.
В отношении кодирования видеосигнала с использованием взвешенного предсказания, разностное значение получается вычитанием изображения взвешенного предсказания из исходного сигнала, вместо P1 и P2. Соответственно разностные сигналы соответственных слоев могут быть выражены как изложено ниже в равенстве (8) и равенстве (9).
R2=O2-P2 (8)
R1=O1-β P1 (9)
Здесь α и β - коэффициенты взвешенного предсказания блоков соответственных слоев.
В этом случае, поскольку подобие между R1 и R2 понижено, эксплуатационные показатели разностного предсказания могут ухудшаться. Соответственно сигнал, который подобен R2, вместо R2-R1, формируется с использованием O1, P1, α и β, и значение, полученное вычитанием R2 из сигнала, кодируется. То есть, если сигналом, подобным R2, является R1', он может быть выражен, как изложено ниже в равенстве (10).
R1'=O1-αP1 (10)
Затем получается равенство (11) компоновкой равенства (9) для P1 и подстановкой результата компоновки в равенство (10).
R1'=O1-α(O1-R1)/β=(1-α/β)O1+α/β R1 (11)
То есть вместо кодирования R2-R1 может кодироваться.
R2-R1'=R2-((1-α/β)O1+α/β R1).
В этом случае, существующий способ предсказания используется вместо способа взвешенного предсказания, если все коэффициенты взвешенного предсказания соответственных слоев равны '1'.
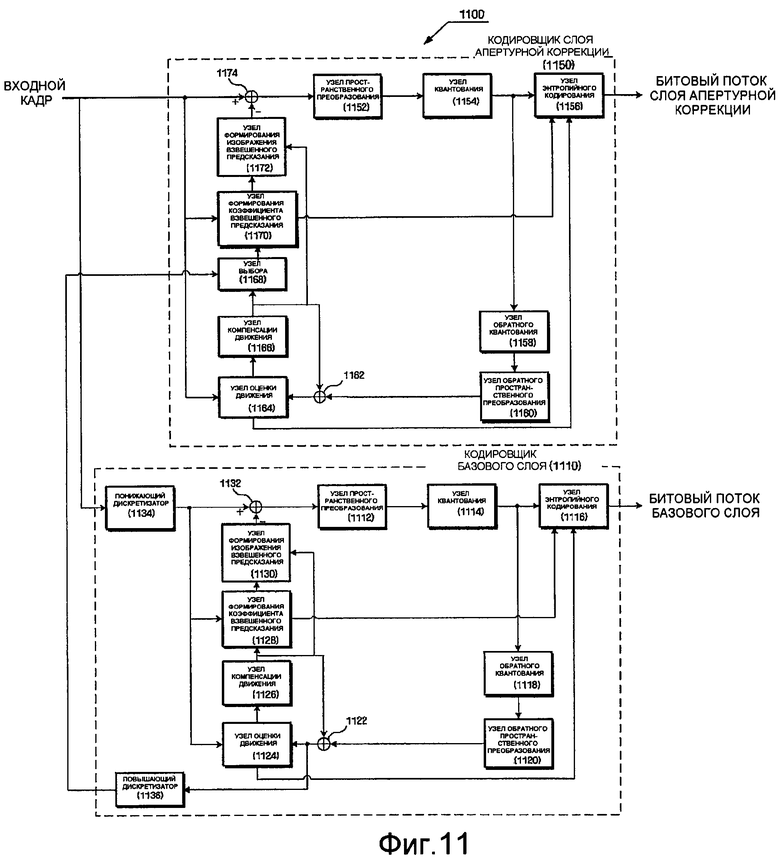
Фиг.11 - структурная схема, иллюстрирующая конструкцию кодировщика видеосигнала согласно примерному варианту осуществления настоящего изобретения.
Ссылаясь на фиг.11, хотя кодировщик 1100 видеосигнала согласно этому примерному варианту осуществления настоящего изобретения сконструирован как однослойный кодировщик, он также может включать в себя кодировщик 1110 базового слоя и кодировщик 1150 слоя апертурной коррекции.
Кодировщик 1150 апертурной коррекции может включать в себя узел 1152 пространственного преобразования, узел 1154 квантования, узел 1156 энтропийного кодирования, узел 1164 оценки движения, узел 1166 компенсации движения, узел 1168 выбора, узел 1170 формирования коэффициента взвешенного предсказания, узел 1172 формирования изображения взвешенного предсказания, узел 1158 обратного квантования и узел 1160 обратного пространственного преобразования.
Узел 1168 выбора выбирает благоприятный способ предсказания среди способов для предсказания базового слоя, прямого предсказания, обратного предсказания и двунаправленного предсказания. Хотя может быть предпочтительным, чтобы такой выбор выполнялся в структурном элементе макроблока, он также может выполняться в структурном элементе кадра или серии последовательных макроблоков. Для этого, узел 1168 выбора принимает соответствующий кадр базового слоя из повышающего дискретизатора 1136 кодировщика 1110 базового слоя, и принимает восстановленный кадр из сумматора 1162.
Узел 1170 формирования коэффициента взвешенного предсказания принимает исходный кадр и предсказанный кадр из узла выбора, формирует коэффициент взвешенного предсказания согласно равенству (5) и выдает сформированный коэффициент взвешенного предсказания в узел 1172 формирования изображения взвешенного предсказания и узел 1156 энтропийного кодирования.
Узел 1172 формирования изображения взвешенного предсказания формирует изображение взвешенного предсказания умножением предсказанного изображения текущего блока, предоставленного узлом 1166 компенсации движения, на коэффициент взвешенного предсказания, переданный из узла 1170 формирования коэффициента взвешенного предсказания.
Узел 1164 оценки движения выполняет оценку движения текущего кадра из числа входных видеокадров, опираясь на опорный кадр, и получает векторы движения. Узел 1164 оценки движения отправляет данные о движении, такие как векторы движения, полученные в результате оценки движения, размер блока движения, номер опорного кадра и другие, в узел 1156 энтропийного кодирования.
Узел компенсации движения снижает временную избыточность входного видеокадра. В этом случае, узел 1166 компенсации движения формирует предсказанный по времени кадр для текущего кадра посредством выполнения компенсации движения для опорного кадра с использованием векторов движения, рассчитанных в узле 1164 оценки движения.
Вычитатель 1174 удаляет временную избыточность видеосигнала вычитанием предсказанного по времени кадра из текущего кадра.
Узел 1152 пространственного преобразования удаляет пространственную избыточность из кадра, из которого была удалена временная избыточность вычитателем 1174, с использованием способа пространственного преобразования, который поддерживает пространственную масштабируемость. Дискретное косинусное преобразование (ДКП, DCT), вейвлет-преобразование или другие могут использоваться в качестве способа пространственного преобразования.
Узел 1154 квантования квантует коэффициенты преобразования, полученные узлом 1152 пространственного преобразования. Квантование означает представление коэффициентов преобразования, которые выражены в виде вещественных значений, в качестве дискретных значений посредством разделения коэффициентов преобразования по заданным отрезкам, а затем отображения дискретных значений в заданные индексы.
Узел 1156 энтропийного преобразования выполняет кодирование без потерь коэффициентов преобразования, квантованных узлом 1154 квантования, данных о движении, предоставленных из узла 1164 оценки движения и коэффициента взвешенного предсказания, предоставленного из узла 1170 формирования коэффициента взвешенного предсказания, и формирует выходной битовый поток. Арифметическое кодирование или кодирование переменной длины могут использоваться в качестве способа кодирования без потерь.
В случае, где кодировщик 1100 видеосигнала поддерживает кодирование видеосигнала замкнутого цикла, для того чтобы снизить ошибку из-за дрейфа, возникающую между стороной кодировщика и стороной декодера, он дополнительно включает в себя узел 1158 обратного квантования и узел 1160 обратного пространственного преобразования.
Узел 1158 обратного квантования выполняет обратное квантование над коэффициентами, квантованными узлом 1154 квантования. Эта последовательность операций обратного квантования соответствует обратной последовательности операций от последовательности операций квантования.
Узел 1160 обратного пространственного преобразования выполняет обратное пространственное преобразование над результатами обратного квантования и выдает результаты в сумматор 1162 обратного пространственного преобразования.
Сумматор 1162 восстанавливает видеокадр добавлением разностного кадра, предоставленного узлом 1160 обратного пространственного преобразования, к предыдущему кадру, предоставленному узлом 1166 компенсации движения и сохраненному в буфере кадра (не проиллюстрирован), и выдает восстановленный видеокадр в узел 1164 оценки движения в качестве опорного кадра.
С другой стороны, кодировщик 1110 базового слоя может включать в себя узел 1112 пространственного преобразования, узел 1114 квантования, узел 1116 энтропийного кодирования, узел 1124 оценки движения, узел 1126 компенсации движения, узел 1128 формирования коэффициента взвешенного предсказания, узел 1130 формирования изображения взвешенного предсказания, узел 1118 обратного квантования, узел 1120 обратного пространственного преобразования, понижающий дискретизатор 1134 и повышающий дискретизатор 1136. Хотя, в примерном варианте осуществления настоящего изобретения, повышающий дискретизатор 1136 включен в кодировщик 1110 базового слоя, он может существовать в любом месте в кодировщике 1100 видеосигнала.
Понижающий дискретизатор 1134 осуществляет понижающую дискретизацию исходного видеокадра до разрешения базового слоя. Эта понижающая дискретизация выполняется при допущении, что разрешение слоя апертурной коррекции является отличным от разрешения базового слоя. Если разрешения этих двух слоев одинаковы, последовательность операций понижающей дискретизации может быть опущена.
Повышающий дискретизатор 1136 выполняет повышающую дискретизацию сигнала, выданного из сумматора 1122, то есть восстановленного видеокадра, если необходимо, и выдает подвергнутый повышающей дискретизации видеокадр в узел 1168 выбора кодировщика 1150 слоя апертурной коррекции. Конечно, если разрешение слоя апертурной коррекции является таким же, как разрешение базового слоя, последовательность операций повышающей дискретизации может быть опущена.
Операции узла 1112 пространственной обработки, узла 1114 квантования, узла 1116 энтропийного кодирования, узла 1164 оценки движения, узла 1166 компенсации движения, узла 1168 формирования коэффициента взвешенного предсказания, узла 1170 формирования изображения взвешенного предсказания, узла 1118 обратного квантования и узла 1120 обратного пространственного преобразования являются такими же, как таковые, существующие в слое апертурной коррекции, а потому, из разъяснение опущено.
фиг.12 - структурная схема, иллюстрирующая конструкцию декодера, который соответствует кодировщику по фиг.11.
Ссылаясь на фиг.12, хотя декодер 1200 видеосигнала согласно этому примерному варианту осуществления настоящего изобретения может быть сконструирован в виде однослойного декодера, он также может включать в себя декодер 1210 базового слоя и декодер 1250 слоя апертурной коррекции.
Декодер 1250 слоя апертурной коррекции включает в себя узел 1255 энтропийного декодирования, узел 1260 обратного квантования, узел 1265 обратного пространственного преобразования, узел 1270 компенсации движения и узел 1275 формирования изображения взвешенного предсказания.
Узел 1255 энтропийного декодирования извлекает коэффициент взвешенного предсказания, данные о движении и данные о текстуре посредством выполнения декодирования без потерь, которое является обратным кодированию без потерь. Узел 1255 энтропийного декодирования выдает извлеченные данные о текстуре в узел 1260 обратного квантования, извлеченные данные о движении в узел 1270 компенсации движения, а коэффициент взвешенного предсказания в узел 1275 формирования изображения взвешенного предсказания.
Узел 1260 обратного квантования выполняет обратное квантование данных о текстуре, переданных из узла 1255 энтропийного декодирования. Эта последовательность операций обратного квантования состоит в том, чтобы отыскивать коэффициенты квантования, которые соответствуют значениям, выраженным заданными индексами и переданными со стороны 1100 кодировщика. Таблица, которая представляет отображения между индексами и коэффициентами квантования, может передаваться со стороны 1100 кодировщика, или она может заранее устанавливаться кодировщиком и декодером.
Узел 1265 обратного пространственного преобразования выполняет обратное пространственное преобразование и восстанавливает коэффициенты, сформированные обратным квантованием над разностным изображением в пространственной области. Например, если коэффициенты были пространственно преобразованы способом вейвлет-преобразования на стороне кодировщика видеосигнала, узел 1265 обратного пространственного преобразования будет выполнять обратное вейвлет-преобразование, тогда как, если коэффициенты были преобразованы согласно способу преобразования ДКП на стороне кодировщика видеосигнала, узел 1265 обратного пространственного преобразования будет выполнять обратное преобразование ДКП.
Узел 1270 компенсации движения выполняет компенсацию движения восстановленных видеокадров и формирует подвергнутые компенсации движения кадры с использованием данных о движении, предоставленных из узла 1255 энтропийного декодирования. Конечно, эта последовательность операций компенсации движения может выполняться, только когда текущий кадр закодирован посредством последовательности операций временного предсказания на стороне кодировщика.
Узел 1275 формирования изображения взвешенного предсказания принимает коэффициент взвешенного предсказания из узла 1255 энтропийного декодирования, а восстановленный кадр предсказания из узла 1270 компенсации движения или повышающего дискретизатора 1245 базового слоя, соответственно, и формирует изображение взвешенного предсказания умножением предсказанного кадра на коэффициент взвешенного предсказания.
Сумматор 1280 восстанавливает видеокадры добавлением разностного изображения к подвергнутым компенсации движения кадрам, предоставленным из узла 1275 формирования изображения взвешенного предсказания, когда разностное изображение, восстанавливаемое узлом обратного пространственного преобразования, сформировано посредством временного предсказания.
С другой стороны, декодер 1210 базового слоя может включать в себя узел 1215 энтропийного декодирования, узел 1220 обратного квантования, узел 1225 обратного пространственного преобразования, узел 1230 компенсации движения, узел 1235 формирования изображения взвешенного предсказания и повышающий дискретизатор 1245.
Повышающий дискретизатор 1245 выполняет повышающую дискретизацию изображения базового слоя, восстановленного декодером 1210 базового слоя до разрешения слоя апертурной коррекции. Если разрешение базового слоя является таким же, как разрешение слоя апертурной коррекции, последовательность операций повышающей дискретизации может быть опущена.
Операции узла 1215 энтропийного декодирования, узла 1220 обратного квантования, узла 1225 обратного пространственного преобразования, узла 1230 компенсации движения и узла 1235 формирования изображения предсказания являются такими же, как таковые в слое апертурной коррекции, и идентичное их разъяснение будет опущено.
Фиг.13 - структурная схема, иллюстрирующая конструкцию кодировщика согласно еще одному примерному варианту осуществления настоящего изобретения.
Со ссылкой на фиг.13, кодировщик видеосигнала согласно этому примерному варианту осуществления настоящего изобретения выполняет способ кодирования, который проиллюстрирован на фиг.5, и может включать в себя кодировщик 1310 базового слоя и кодировщик 1350 слоя апертурной коррекции.
Кодировщик 1350 апертурной коррекции может включать в себя узел 1352 пространственного преобразования, узел 1354 квантования, узел 1356 энтропийного кодирования, узел 1364 оценки движения, узел 1366 компенсации движения, узел 1368 выбора, узел 1370 формирования коэффициента взвешенного предсказания, узел 1372 формирования изображения взвешенного предсказания, узел 1358 обратного квантования и узел 1360 обратного пространственного преобразования.
Узел 1370 формирования коэффициента взвешенного предсказания принимает предсказанное изображение текущего блока из узла 1368 выбора, и изображение базового слоя, соответствующее текущему блоку, из повышающего дискретизатора 1332 кодировщика 1310 базового слоя и рассчитывает коэффициент α взвешенного предсказания согласно равенству (6). Узел 1372 формирования изображения взвешенного предсказания формирует изображение взвешенного предсказания умножением предсказанного изображения текущего блока, предоставленного из узла 1366 компенсации движения, на коэффициент взвешенного предсказания, переданный из узла 1370 формирования коэффициента взвешенного предсказания.
С другой стороны, кодировщик 1310 базового слоя может включать в себя узел 1312 пространственного преобразования, узел 1314 квантования, узел 1316 энтропийного кодирования, узел 1324 оценки движения, узел 1326 компенсации движения, узел 1318 обратного квантования, узел 1320 обратного пространственного преобразования, понижающий дискретизатор 1330 и повышающий дискретизатор 1332.
Повышающий дискретизатор 1136 выполняет повышающую дискретизацию сигнала, выданного из сумматора 1322, то есть восстановленного видеокадра, если необходимо, и выдает подвергнутый повышающей дискретизации видеокадр в узел 1368 выбора кодировщика 1350 слоя апертурной коррекции и узел 1370 формирования коэффициента взвешенного предсказания. Конечно, если разрешение слоя апертурной коррекции является таким же, как разрешение базового слоя, последовательность операций повышающей дискретизации может быть опущена.
Операции узлов 1312 и 1352 пространственной обработки, узлов 1314 и 1354 квантования, узлов 1316 и 1356 энтропийного кодирования, узлов 1324 и 1364 оценки движения, узлов 1326 и 1366 компенсации движения, узла 1170 формирования изображения взвешенного предсказания, узлов 1318 и 1358 обратного квантования и узлов 1320 и 1360 обратного пространственного преобразования являются такими же, как таковые, имеющие место в кодировщике, который проиллюстрирован на фиг.11, и идентичное их разъяснение будет опущено.
Фиг.14 - структурная схема, иллюстрирующая конструкцию декодера, который соответствует кодировщику по фиг.13.
Ссылаясь на фиг.14, декодер 1440 видеосигнала согласно этому примерному варианту осуществления настоящего изобретения может включать в себя декодер 1410 базового слоя и декодер 1450 слоя апертурной коррекции.
Декодер 1450 слоя апертурной коррекции включает в себя узел 1455 энтропийного декодирования, узел 1460 обратного квантования, узел 1465 обратного пространственного преобразования, узел 1470 компенсации движения, узел 1475 формирования коэффициента взвешенного предсказания и узел 1480 формирования изображения взвешенного предсказания.
Узел 1475 формирования коэффициента взвешенного предсказания рассчитывает коэффициент взвешенного предсказания таким же образом, как узел 1370 формирования коэффициента взвешенного предсказания кодировщика, который проиллюстрирован на фиг.13. То есть узел 1475 формирования коэффициента взвешенного предсказания принимает восстановленное изображение предсказания из узла 1470 компенсации движения и изображение базового слоя, соответствующее текущему блоку, из повышающего дискретизатора 1440 кодировщика 1410 базового слоя и рассчитывает коэффициент α взвешенного предсказания согласно равенству (6). Узел 1480 формирования изображения взвешенного предсказания формирует изображение взвешенного предсказания умножением предсказанного изображения текущего блока, предоставленного из узла 1470 компенсации движения через узел 1475 формирования коэффициента взвешенного предсказания, на коэффициент взвешенного предсказания, переданный из узла 1475 формирования коэффициента взвешенного предсказания.
Сумматор 1485 восстанавливает видеокадры добавлением разностного изображения к изображению взвешенного предсказания, предоставленному узлом 1480 формирования изображения взвешенного предсказания, когда разностное изображение, восстанавливаемое узлом 1465 обратного пространственного преобразования, сформировано посредством временного предсказания.
С другой стороны, декодер 1410 базового слоя может включать в себя узел 1415 энтропийного декодирования, узел 1420 обратного квантования, узел 1425 обратного пространственного преобразования, узел 1430 компенсации движения и повышающий дискретизатор 1440.
Операции узлов 1415 и 1455 энтропийного декодирования, узлов 1420 и 1460 обратного квантования, узлов 1425 и 1465 обратного пространственного преобразования, узлов 1430 и 1470 компенсации движения и повышающего дискретизатора 1440 являются такими же, как таковые, имеющие место в декодере видеосигнала, который проиллюстрирован на фиг.12, и идентичное их разъяснение будет опущено.
Фиг.15 - структурная схема, иллюстрирующая конструкцию кодировщика видеосигнала, использующего взвешенное предсказание согласно еще одному другому примерному варианту осуществления настоящего изобретения.
Ссылаясь на фиг.15, кодировщик 1500 видеосигнала согласно этому примерному варианту осуществления настоящего изобретения выполняет способ кодирования, который проиллюстрирован на фиг.6. Вкратце, кодировщик 1500 видеосигнала включает в себя кодировщик 1510 базового слоя и кодировщик 1550 слоя апертурной коррекции.
Кодировщик 1550 слоя апертурной коррекции может включать в себя узел 1552 пространственного преобразования, узел 1554 квантования, узел 1556 энтропийного кодирования, узел 1560 оценки движения, узел 1562 компенсации движения, узел 1564 выбора и узел 1566 формирования изображения взвешенного предсказания.
Узел 1566 формирования изображения взвешенного предсказания формирует изображение взвешенного предсказания умножением предсказанного изображения текущего блока, предоставленного из узла 1564 выбора, на коэффициент взвешенного предсказания, переданный из узла 1520 формирования коэффициента взвешенного предсказания кодировщика 1510 базового слоя.
С другой стороны, кодировщик 1510 базового слоя может включать в себя узел 1522 пространственного преобразования, узел 1524 квантования, узел 1526 энтропийного кодирования, узел 1514 оценки движения, узел 1516 компенсации движения, узел 1520 формирования коэффициента взвешенного предсказания, понижающий дискретизатор 1512 и повышающий дискретизатор 1528. Хотя, в примерном варианте осуществления настоящего изобретения, узел 1520 формирования коэффициента взвешенного предсказания и повышающий дискретизатор 1528 включены в кодировщик 1510 базового уровня, они могут существовать где угодно в кодировщике 1500 видеосигнала.
Узел 1520 формирования коэффициента взвешенного предсказания принимает векторы движения из узла 1560 оценки движения кодировщика 1550 слоя апертурной коррекции, отыскивает опорное изображение базового слоя из кадра базового слоя, предоставленного из понижающего дискретизатора 1512, и формирует изображение предсказания базового слоя с использованием опорного изображения базового слоя таким же образом, как предсказанное изображение, сформированное в слое апертурной коррекции. Узел 1520 формирования коэффициента взвешенного предсказания рассчитывает коэффициент α взвешенного предсказания согласно равенству (7) с использованием изображения базового слоя и изображения предсказания базового слоя и выдает коэффициент α взвешенного предсказания в узел 1566 формирования изображения взвешенного предсказания кодировщика 1550 слоя апертурной коррекции.
Операции узлов 1522 и 1552 пространственного преобразования, узлов 1524 и 1554 квантования, узлов 1526 и 1556 энтропийного кодирования, узлов 1514 и 1560 оценки движения, узлов 1516 и 1562 компенсации движения, узла 1564 выбора, понижающего дискретизатора 1512 и повышающего дискретизатора 1528 являются такими же, как таковые у кодировщика, показанного на фиг.11, а потому, их разъяснение опущено.
Фиг.16 - структурная схема, иллюстрирующая конструкцию декодера, который соответствует кодировщику по фиг.15.
Ссылаясь на фиг.16, декодер 1600 видеосигнала согласно этому примерному варианту осуществления настоящего изобретения может включать в себя декодер 1610 базового слоя и декодер 1650 слоя апертурной коррекции.
Декодер 1650 слоя апертурной коррекции включает в себя узел 1655 энтропийного декодирования, узел 1660 обратного квантования, узел 1665 обратного пространственного преобразования, узел 1670 компенсации движения и узел 1675 формирования изображения взвешенного предсказания.
Узел 1675 формирования изображения взвешенного предсказания формирует изображение взвешенного предсказания умножением восстановленного изображения предсказания текущего блока, предоставленного из узла 1670 компенсации движения, на коэффициент взвешенного предсказания, переданный из узла 1640 формирования коэффициента взвешенного предсказания кодировщика 1610 базового слоя.
Сумматор 1680 восстанавливает видеокадры добавлением разностного изображения к изображению взвешенного предсказания, предоставленному из узла 1675 формирования изображения взвешенного предсказания, когда разностное изображение, восстанавливаемое узлом обратного пространственного преобразования, сформировано посредством временного предсказания.
С другой стороны, декодер 1610 базового слоя может включать в себя узел 1615 энтропийного декодирования, узел 1620 обратного квантования, узел 1625 обратного пространственного преобразования, узел 1635 компенсации движения, узел 1640 формирования коэффициента взвешенного предсказания и повышающий дискретизатор 1645.
Узел 1640 формирования коэффициента взвешенного предсказания рассчитывает коэффициент взвешенного предсказания таким же образом, как узел 1520 формирования коэффициента взвешенного предсказания кодировщика, который проиллюстрирован на фиг.15. То есть узел формирования коэффициента взвешенного предсказания принимает векторы движения из узла 1655 энтропийного декодирования декодера 1650 слоя апертурной коррекции, отыскивает опорное изображение базового слоя из восстановленного кадра базового слоя, предоставленного из сумматора 1630, и формирует изображение предсказания базового слоя с использованием опорного изображения базового слоя таким же образом, как предсказанное изображение, сформированное в слое апертурной коррекции. Узел 1640 формирования коэффициента взвешенного предсказания рассчитывает коэффициент α взвешенного предсказания согласно равенству (7) с использованием изображения базового слоя и изображения предсказания базового слоя, и выдает рассчитанный коэффициент α взвешенного предсказания в узел 1675 формирования изображения взвешенного предсказания кодировщика 1650 слоя апертурной коррекции.
Операции узлов 1615 и 1655 энтропийного декодирования, узлов 1620 и 1660 обратного квантования, узлов 1625 и 1665 обратного пространственного преобразования, узлов 1635 и 1670 компенсации движения и повышающего дискретизатора 1645 являются такими же, как таковые, имеющие место в декодере видеосигнала, который проиллюстрирован на фиг.12, а потому, их разъяснение опущено.
Хотя показано, что на фиг.с 11 по 16 существует множество составляющих элементов, имеющих одинаковые наименования, но с разными идентификационными номерами, специалистам в данной области техники будет очевидно, что одиночный составляющий элемент может работать как в базовом слое, так и в слое апертурной коррекции.
Соответственные составляющие элементы, которые проиллюстрированы на фиг.с 11 по 16, могут быть воплощены в качестве программного обеспечения или аппаратных средств, таких как программируемая пользователем вентильная матрица (FPGA) и специализированная интегральная схема (ASIC). Кроме того, составляющие элементы могут быть сконструированы так, что находятся в адресуемом запоминающем носителе, или приводят в исполнение один или более процессоров. Функции, предусмотренные в составляющих элементах, могут быть реализованы подразделенными составляющими элементами, а составляющие элементы и функции, предусмотренные в составляющих элементах, могут комбинироваться для выполнения заданных функций. В дополнение составляющие элементы могут быть реализованы так, что приводят в исполнение один или более компьютеров в системе.
ПРОМЫШЛЕННАЯ ПРИМЕНИМОСТЬ
Как описано выше, способ кодирования и декодирования видеосигнала согласно настоящему изобретению может давать по меньшей мере один из следующих результатов.
Во-первых, эффективность кодирования видеосигнала может быть повышена посредством снижения ошибки между текущим блоком, который должен сжиматься, и предсказанным изображением.
Во-вторых, эффективность кодирования видеосигнала может быть повышена посредством использования информации базового слоя при формировании предсказанного изображения.
Примерные варианты осуществления настоящего изобретения были описаны в иллюстративных целях, и специалисты в данной области техники будут принимать во внимание, что различные модификации, дополнения и замещения возможны, не выходя из объема и сущности изобретения, которое раскрыто в прилагаемой формуле изобретения.













Изобретение относится к системам кодирования и декодирования видеосигнала с использованием взвешенного предсказания. Техническим результатом является повышение эффективности кодирования/декодирования видеосигнала посредством снижения ошибки текущего блока, который должен сжиматься, и предсказанного изображения. Предложен способ декодирования видеосигнала, содержащий этапы: принимают битовый поток кодированного видеосигнала и декодируют кодированный видеосигнал, при этом битовый поток содержит: первый участок, который содержит информацию, используемую для формирования опорного блока, для того чтобы восстанавливать текущий блок в слое апертурной коррекции и второй участок, который содержит информацию, указывающую, формируется ли коэффициент взвешенного предсказания, который должен применяться к опорному блоку, с использованием информации о базовом слое, который соответствует слою апертурной коррекции. 2 н. и 10 з.п. ф-лы, 16 ил.
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| WO 03075578 A1, 12.09.2003 | |||
| US 6081551 A, 27.06.2000 | |||
| US6141379 A, 31.10.2000 | |||
| УСТРОЙСТВО КОМПРЕССИИ С ДИФФЕРЕНЦИАЛЬНОЙ ИМПУЛЬСНО-КОДОВОЙ МОДУЛЯЦИЕЙ | 1994 |
|
RU2162280C2 |
| US 2004086043 A1, 06.05.2004 | |||
| ЯН РИЧАРДСОН | |||
| Железнодорожный снегоочиститель | 1920 |
|
SU264A1 |

