Область изобретения
Настоящее изобретение, в целом, относится к области воспроизведения данных и, более конкретно, к новому представлению данных в независимом от воспроизведения постоянном формате данных, который является более легко используемым множеством взаимодействующих вычислительных приложений и вычислительных сред.
Предшествующий уровень техники
Хранение и формат данных являются повсеместными при управлении данными и обработке данных. В контексте вычислительных приложений данные являются жизненно важным средством коммуникации. От простых данных, основанных на содержании, до сложных внедренных наборов инструкций данные выступают как входная информация для большинства вычислительных приложений и являются результирующей выходной информацией для этих вычислительных приложений. Не удивительно, что создатели и разработчики вычислительных приложений разработали ошеломляющее количество вычислительных приложений, чтобы создавать, управлять, запоминать и обрабатывать данные, которые касаются каждого из нас почти в каждом аспекте нашей жизни. От простых приложений обработки текстов до сложных способов шифрования для использования при передаче уязвимых данных вычислительные приложения обработки данных интегрируются в ежедневные дела и деятельность. Разработка огромного количества вычислительных приложений, оперирующих с данными, выявила ожидаемый побочный продукт - просто ряд переменных и несравнимых форматов и типов данных.
При наличии несравнимых форматов данных становится чрезвычайно трудно совместно использовать данные между взаимодействующими вычислительными приложениями и вычислительными средами, которые имеют свои собственные, присущие им, форматы и описания (определения) данных. Для решения этой проблемы разработчики вычислительных приложений разработали и реализовали различные фильтры и трансляторы данных, которые дают возможность вычислительным приложениям принимать несобственные форматы данных. Однако интеграция и реализация таких механизмов преобразования данных происходит за счет другого, а именно повышенных требований к обработке и потери целостности данных. Кроме того, преобразование данных может быть недоступно для всех и каждого вычислительного приложения, пытающегося обработать несобственные данные. Как таковое совместное использование необходимых данных между взаимодействующими вычислительными приложениями, в лучшем случае, осуществляется с трудом.
Данные могут быть охарактеризованы с помощью расширения (для) воспроизведения (интерпретации), которое представляет лежащий в основе формат и/или расположение. Расширение (для) воспроизведения подсказывает взаимодействующим приложениям формат и/или расположение данных и, если подходит, запустит преобразование данных с помощью взаимодействующего вычислительного приложения в собственный формат, присущий запрашивающему взаимодействующему вычислительному приложению. Обычно расширение воспроизведения также предоставляет указание о том, какое вычислительное приложение или вычислительная среда сгенерировала часть или множество данных. Например, если конкретное вычислительное приложение текстового процессора сгенерировало данные (например, документ), расширение (для) воспроизведения может быть, например, ".doc". Для сравнения, если вычислительное приложение электронной таблицы сгенерировало некоторые данные (например, электронную таблицу, график и т. д.), тогда расширение воспроизведения может быть ".xls".
В настоящее время вычислительные приложения обычно генерируют данные (например, отчеты), имеющие одно описание (определение) расширения воспроизведения (например, ".html", ".doc", ".xls", ".xml"), которое обычно является присущим вычислительному приложению, которое генерирует данные. Как таковым взаимодействующим приложениям при обработке отчетов необходимо выполнить преобразование расширения воспроизведения внешним приложением в собственное расширение воспроизведения. Этот этап преобразования в некоторых случаях может вносить ошибки, то есть ошибки расположения/форматирования данных и, более важно, ошибки данных. Кроме того, данные в таком виде имеют ограниченное использование для взаимодействующих приложений, так как сгенерированный отчет является трудно запрашиваемым. В большинстве случаев участвующие пользователи будут использовать вычислительные приложения для того, чтобы генерировать новые данные, имеющие новые описания отчета, вместо попытки повторно использовать уже сгенерированный отчет.
Другим недостатком существующей практики является невозможность выполнять связанный со временем анализ уже сгенерированных данных. Как описано, вычислительные приложения могут работать с одним или более совместными хранилищами данных. Эти хранилища данных имеют различные таблицы, имеющие различные описания полей. Со временем значения полей будут изменяться таким образом, чтобы отражать одно или более изменений в хранилище данных работы организации и/или предприятия. Например, автомобильное агентство может использовать вычислительное приложение, взаимодействующее с хранилищем данных, чтобы регистрировать продажи. Величины продаж могут изменяться в зависимости от того, насколько больше автомобилей продано. В этом же примере вычислительное приложение может работать таким образом, чтобы генерировать отчет, чтобы показать все продажи, осуществленные каждым сотрудником из персонала продаж автомобильного агентства. Опять при увеличении продаж изменяются значения в отчете. Вычислительные приложения, генерирующие текущие данные (например, отчет), работают таким образом, чтобы собирать необходимые данные в соответствии с описанием (определением) и генерировать рабочий продукт данных в соответствии с определением отчета. Однако рабочий продукт данных выступает в качестве моментального "снимка" значений полей данных, найденных в совместном хранилище данных в момент генерирования рабочего продукта данных.
Кроме того, современные вычислительные приложения могут показывать сгенерированный рабочий продукт данных как логическую структуру данных, которая, вероятно, не схематизирована, не сохранена в не постоянном формате данных и, следовательно, является трудно запрашиваемой. Как таковые эти приложения не смогут поддерживать запрос во временном измерении относительно рабочих продуктов накопленных данных, чтобы обеспечить связанный со временем анализ одного или более значений данных. При сохранении данных в зависимом от воспроизведения не постоянном формате современные приложения не могут выполнять временной анализ, который может использоваться для того, чтобы определять тенденции.
Независимые от воспроизведения постоянные форматы данных имеют много приложений вне контекста генерирования и управления отчетами. Например, независимые от воспроизведения постоянные форматы данных могут быть включены, чтобы передавать множество данных, таких как Web-информация, через несравнимые вычислительные приложения, имеющие свои собственные, присущие им требования и стандарты.
Из вышеприведенного понятно, что существует потребность в системах и способах, которые предоставляют данные в независимом от воспроизведения постоянном формате для использования в множестве обработок, который не реализован в современной практике. При наличии этих систем и способов преодолеваются недостатки предшествующего уровня техники.
Краткое изложение изобретения
Настоящее изобретение предоставляет системы и способы, предназначенные для того, чтобы обеспечивать сохранность данных, независимо от воспроизведения (интерпретации). В иллюстративной реализации обеспечивают данные, имеющие заранее определенную структуру. Данные обрабатывают таким образом, чтобы создавалось представление данных, в котором представление включает в себя информацию о данных и структуру данных. При работе данные анализируются и преобразуются в заранее определенный формат, который является постоянным.
В рассмотренной реализации набор сгенерированных данных обеспечивают с помощью вычислительного приложения в независимом от воспроизведения в постоянном формате данных. Независимый от воспроизведения (интерпретации) постоянный формат данных, помимо прочего, дает возможность приложению выполнять запросы о прошедшем времени и о времени появления относительно отчета, представленного как источник схематизированных запрашиваемых данных, и, что более важно, дает возможность воспринимать (понимать) как любой другой источник данных посредством других взаимодействующих вычислительных приложений.
Другие признаки и аспекты описанных в настоящей заявке систем и способов описаны более подробно ниже.
Краткое описание чертежей
Фиг. 1 и фиг. 2 являются схематическими иллюстрациями примерных вычислительных сред, подходящих для настоящего изобретения, причем фиг. 2 изображает примерную сетевую вычислительную среду;
фиг. 3 - блок-схема изображения примерной реализации отчета как источника данных в соответствии с описанными в настоящей заявке системой и способами;
фиг. 4 - блок-схема, изображающая последовательность операций обработки отчета в соответствии с описанными в настоящей заявке системами и способами;
фиг. 5 - блок-схема, изображающая последовательность операций использования отчета в соответствии с описанными в настоящей заявке системой и способами;
фиг. 6 - подробная блок-схема примерных компонентов, предназначенных для того, чтобы обрабатывать схематизированные структуры данных в соответствии с описанными в настоящей заявке системой и способами;
фиг. 7 - блок-схема обработки, выполняемой для того, чтобы показать отчет как источник схематизированных запрашиваемых данных в соответствии с описанными в настоящей заявке системой и способами;
фиг. 8А - блок-схема последовательности операций обработки, выполняемой для того, чтобы показать источник данных как независимое от воспроизведения постоянство информации;
фиг. 8В - блок-схема последовательности операций обработки, выполняемой при преобразовании независимого от воспроизведения постоянства информации как отчета, показываемого как источник схематизированных запрашиваемых данных; и
фиг. 9 - блок-схема этапов обработки, выполняемой при обработке данных, показываемых как источник схематизированных запрашиваемых данных, чтобы сгенерировать желаемый моментальный "снимок".
Подробное описание иллюстративных вариантов реализации
Обзор
Сохранение данных равносильно эффективному хранилищу данных и обработке данных. В настоящее время вычислительные приложения и вычислительные среды работают с данными таким образом, чтобы генерировать один или более рабочих продуктов данных, которые могут быть описаны с помощью одного или более расширений для воспроизведения (интерпретации). Обычно расширение для воспроизведения может использоваться для того, чтобы характеризовать формат и описание данных, найденных в рабочих продуктах данных. Обычно вычислительное приложение будет работать с набором данных в режиме обработки данных, чтобы генерировать рабочие продукты данных, имеющие конкретное расширение для их воспроизведения (интерпретации). Например, вычислительное приложение обработки текстов может работать с текстовым типом данных, чтобы генерировать отформатированные документы. Такие отформатированные документы затем могут быть сохранены как данные, имеющие тип ".doc" для воспроизведения.
Однако возникает проблема, когда взаимодействующие вычислительные приложения и вычислительные среды конкурируют относительно данных, которые имеют несобственный формат или описание данных (т.е. запоминаемые и показываемые как имеющие разные и изменяющиеся расширения воспроизведения (интерпретации)). Обычно вычислительные приложения, если оснащены, будут обращаться к одной или более операциям преобразования данных, чтобы преобразовать требуемый рабочий продукт данных в собственное расширение воспроизведения. Однако такое преобразование может быть интенсивной обработкой и может вносить существенные ошибки в конечный рабочий продукт данных.
Настоящее изобретение имеет целью исключить недостатки существующей практики с помощью предоставления системы и способов, которые показывают данные, имеющие независимый от рендеринга (воспроизведения, интерпретации) постоянный формат данных. Конкретно предоставлено примерное вычислительное приложение, которое работает с данными в соответствии с заранее определенным описанием (определением). Описание данных содержит, помимо прочего, информацию, относящуюся к требуемым предоставляемым данным, информацию о расположении данных и информацию о форматировании данных. Примерное вычислительное приложение извлекает требуемые данные и описание данных из совместного хранилища данных. После сбора данных примерное вычислительное приложение определяет схему для данных и запоминает данные в промежуточном формате данных. Промежуточный формат данных является независимым от рендеринга (воспроизведения) постоянным форматом данных. Как таковые извлеченные данные, имеющие связанную схему, показываются как источник данных со всеми выгодами, которые источник данных предоставляет взаимодействующим приложениям. Кроме того, при запоминании в качестве независимого от воспроизведения постоянного формата данных решаются современные вопросы возможности повторного использования (т.е. возможности использования между несравнимыми вычислительными приложениями и вычислительными средами, имеющими изменяющиеся требования к расширению воспроизведения (интерпретации) данных), а также с помощью настоящей системы и способов связанные со временем запросы являются более легко выполняемыми относительно набора сгенерированных отчетов.
Понятно, что несмотря на то, что раскрытые в настоящей заявке системы и способы описаны в контексте генерирования одного или более рабочих продуктов данных, независимое от интерпретации постоянство информации может быть использовано различными способами, которые выходят за рамки предоставленных примеров.
А. Примерная вычислительная среда
Фиг. 1 иллюстрирует пример подходящей среды 100 вычислительной системы, в которой может быть реализовано изобретение. Среда 100 вычислительной системы является только одним примером подходящей вычислительной среды и не предназначена для того, чтобы предложить какие-либо ограничения относительно объема использования функциональных возможностей изобретения. Также вычислительная среда 100 не должна интерпретироваться как имеющая какую-либо зависимость или требование, относящиеся к любому компоненту или комбинации компонентов, проиллюстрированных в примерной рабочей среде 100.
Изобретение работает с другими многочисленными вычислительными средами или конфигурациями вычислительных систем общего назначения или специализированных вычислительных систем. Примеры известных вычислительных систем, сред и/или конфигураций, которые могут быть подходящими для использования с изобретением, включают в себя, но не ограничены, персональные компьютеры, серверные компьютеры, карманные или портативные устройства, мультипроцессорные системы, системы, основанные на микропроцессорах, телевизионные приставки, программируемую бытовую электронику, сетевые ПК, миникомпьютеры, универсальные компьютеры, распределенные вычислительные среды, которые включают в себя любые из упомянутых выше систем или устройств, или тому подобные.
Изобретение может быть описано в общем контексте доступных для выполнения с помощью компьютера инструкций, таких как программные модули, выполняемые компьютером. Обычно программные модули включают в себя подпрограммы, программы, объекты, компоненты, структуры данных и т.д., которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных. Изобретение также может быть применено в распределенных вычислительных средах, где задачи выполняют с помощью удаленных обрабатывающих устройств, которые связаны через коммуникационную сеть или другой носитель передачи данных. В распределенной вычислительной среде программные модули и другие данные могут быть расположены на запоминающем носителе как местного, так и удаленного компьютера, включая запоминающие устройства памяти.
Со ссылкой на фиг. 1 примерная система, предназначенная для реализации изобретения, включает в себя вычислительное устройство общего назначения в виде компьютера 110. Компоненты компьютера 110 могут включать в себя, но не ограниченными, процессор 120, системную память 130 и системную шину 121, которая соединяет различные компоненты системы, включая системную память, с процессором 120. Системная шина может относиться к любому из нескольких типов шинных структур, включая шину памяти или контроллер памяти, периферийную шину и локальную шину, использующие любую из множества шинных архитектур. В качестве примера, а не ограничения, такие архитектуры включают в себя шину промышленной стандартной архитектуры (ISA, ПСА), шину микроканальной архитектуры (МСА, МКА), шину расширенной промышленной стандартной архитектуры (EISA, РПСА), локальную шину Ассоциации по стандартам видеооборудования (VESA) и шину межсоединения периферийных компонентов (PCI, МПК) (также известную как шина mezzanine).
Компьютер 110 обычно включает в себя множество доступных для чтения с помощью компьютера носителей. Доступные для чтения с помощью компьютера носители включают в себя любые имеющиеся носители, к которым можно осуществлять доступ с помощью компьютера 110, и включают в себя как энергозависимые носители, так и энергонезависимые носители, сменные и постоянные носители. В качестве примера, а не ограничения, доступный для чтения с помощью компьютера носитель может содержать запоминающую среду компьютера и коммуникационную среду. Запоминающая среда компьютера включает в себя как энергозависимые носители, так и энергонезависимые носители, сменные и постоянные носители, реализованные с помощью любого способа или технологии, для запоминания информации, такой как доступные для чтения с помощью компьютера инструкции, структуры данных, программные модули или другие данные. Запоминающая среда компьютера включает в себя, но не ограничена, RAM, ОЗУ, ROM, ПЗУ, EEPROM, ЭСППЗУ (электрически стираемое программируемое ПЗУ), флэш-память или другую технологию памяти, CD-ROM (ПЗУ на компакт-диске, универсальные цифровые диски (DVD, УЦД) или другие запоминающие устройства на оптическом диске, магнитных кассетах, магнитной ленте, запоминающее устройство на магнитном диске или другие магнитные запоминающие устройства или любые другие носители, которые могут быть использованы для того, чтобы запоминать необходимую информацию, и к которым можно осуществлять доступ с помощью компьютера 110. Коммуникационная среда обычно содержит доступные для чтения с помощью компьютера инструкции, структуры данных, программные модули или другие данные в модулированном сигнале данных, таком как несущий сигнал или другой механизм переноса, и включает любой носитель доставки информации. Понятие "модулированный сигнал данных" означает сигнал, который имеет один или более из множества его параметров измененными таким образом, чтобы кодировать информацию в сигнале. В качестве примера, а не ограничения, коммуникационная среда включает в себя проводную среду, такой как проводная сеть или непосредственное проводное соединение и беспроводную среду, такую как акустическую, РЧ, инфракрасное излучение или другую беспроводную среду. Комбинации любых из перечисленных выше носителей также должны быть включены в рамки доступных для чтения с помощью компьютера носителей.
Системная память 130 включает в себя запоминающую среду компьютера в виде энергозависимой и/или энергонезависимой памяти, такую как память, предназначенную только для чтения (ROM, ПЗУ) 131 и память с произвольным доступом (RAM, ОЗУ) 132. Базовая система ввода/вывода 133 (BIOS), содержащая базовые подпрограммы, которые помогают передавать информацию между элементами внутри компьютера 110, такую как во время запуска, обычно хранится в ПЗУ 131. ОЗУ 132 обычно содержит данные и/или программные модули, которые являются оперативно доступными с помощью процессора 120 и/или являются выполняемыми в текущий момент в процессоре 120. В качестве примера, а не ограничения, фиг. 1 иллюстрирует операционную систему 134, прикладные программы 135, другие программные модули и программные данные 137.
Компьютер также может включать в себя другие сменные/постоянные энергозависимые/энергонезависимые компьютерные запоминающие носители. Только в качестве примера фиг. 1 иллюстрирует накопитель 141 на жестком диске, который считывает из постоянного энергонезависимого магнитного носителя и записывает на него, накопитель 151 на магнитом диске, который считывает из сменного энергонезависимого магнитного диска 152 или записывает на него, и накопитель 155 на оптическом диске, который считывает из сменного энергонезависимого оптического диска 156, такого как ПЗУ на компакт-диске или другой оптический носитель, или записывает на него. Другие сменные/постоянные, энергозависимые/энергонезависимые компьютерные запоминающие носители, которые могут использоваться в примерной операционной среде, включают в себя, но не ограничены, кассеты на магнитных лентах, платы флэш-памяти, цифровые универсальные диски, цифровую видеоленту, твердотельное ОЗУ, твердотельное ПЗУ и тому подобные. Накопитель 141 на жестком диске обычно соединен с системной шиной 121 через интерфейс постоянной памяти, такой как интерфейс 140, а накопитель 151 на магнитном диске и накопитель 155 на оптическом диске обычно соединены с системной шиной 121 с помощью интерфейса сменной памяти, такого как интерфейс 150.
Накопители и связанные с ними компьютерные запоминающие носители, обсужденные выше и проиллюстрированные на фиг. 1, обеспечивают запоминание доступных для чтения с помощью компьютера инструкций, структур данных, программных модулей и других данных для компьютера 110. Например, на фиг. 1 накопитель 141 на жестком диске изображен как хранящий операционную систему 144, прикладные программы 145, другие программные модули 146 и программные данные 147. Заметим, что эти компоненты могут быть либо теми же самыми, что и операционная система 134, прикладные программы 135, другие программные модули 136 и программные данные, или отличными от них. Операционной системе 144, прикладным программам 145, другим программным модулям 146 и программным данным 147 на чертеже даны разные номера для того, чтобы проиллюстрировать, что они, как минимум, являются разными экземплярами. Пользователь может вводить команды и информацию в компьютер 110 через устройства ввода, такие как клавиатура 162 и указывающее устройство 161, обычно упоминаемое как "мышь", шаровой манипулятор или сенсорная панель. Другие устройства ввода (не изображены) могут включать в себя джойстик, игровую панель, антенну спутниковой связи, сканер или тому подобные. Эти и другие устройства ввода часто соединены с процессором 120 через пользовательский входной интерфейс 160, который соединен с системной шиной, но могут быть соединены с помощью других конструкций интерфейса и системной шины, таких как параллельный порт, игровой порт или универсальная последовательная шина (USB, УПШ). Монитор 191 или другой тип устройства отображения также соединен с системной шиной 121 через интерфейс, такой как видеоинтерфейс 190. Кроме монитора компьютеры также могут включать в себя другие периферийные устройства вывода, такие как громкоговорители 197 и принтер 196, которые могут быть соединены через выходной периферийный интерфейс 190.
Компьютер 110 может работать в сетевой среде с использованием логических соединений с одним или более удаленных компьютеров, таких как удаленный компьютер 180. Удаленный компьютер 180 может быть персональным компьютером, сервером, маршрутизатором, сетевым ПК, одноранговым устройством в сети или другим обычным узлом сети, и обычно включает в себя многие или все элементы, описанные выше относительно компьютера 110, несмотря на то, что на фиг. 1 проиллюстрировано только запоминающее устройство 181 памяти. Логические соединения, изображенные на фиг. 1, включают в себя локальную сеть (LAN, ЛС) 171 и глобальную сеть (WAN, ГС) 173, но также могут включать в себя другие сети. Такие сетевые среды являются обыкновенными в учреждениях, в компьютерных сетях предприятий, в интрасетях и в Internet.
При использовании в сетевой среде ЛС компьютер 110 соединен с ЛС 171 через сетевой интерфейс или адаптер 170. При использовании в сетевой среде ГС компьютер 110 обычно включает в себя модем 172 или другое средство для установления связи через ГС 173, такую как Internet. Модем 172, который может быть внутренним или внешним, может быть соединен с системной шиной 121 через пользовательский интерфейс 160 ввода или другой подходящий механизм. В сетевой среде программные модули, изображенные относительно компьютера 110, или их части могут запоминаться в запоминающем устройстве удаленной памяти. В качестве примера, а не ограничения, фиг. 1 изображает удаленные прикладные программы 185, как находящиеся в запоминающем устройстве 181. Понятно, что изображенные сетевые соединения являются примерными, и могут использоваться любые другие средства установления линии связи между компьютерами.
В. Примерная сетевая вычислительная среда
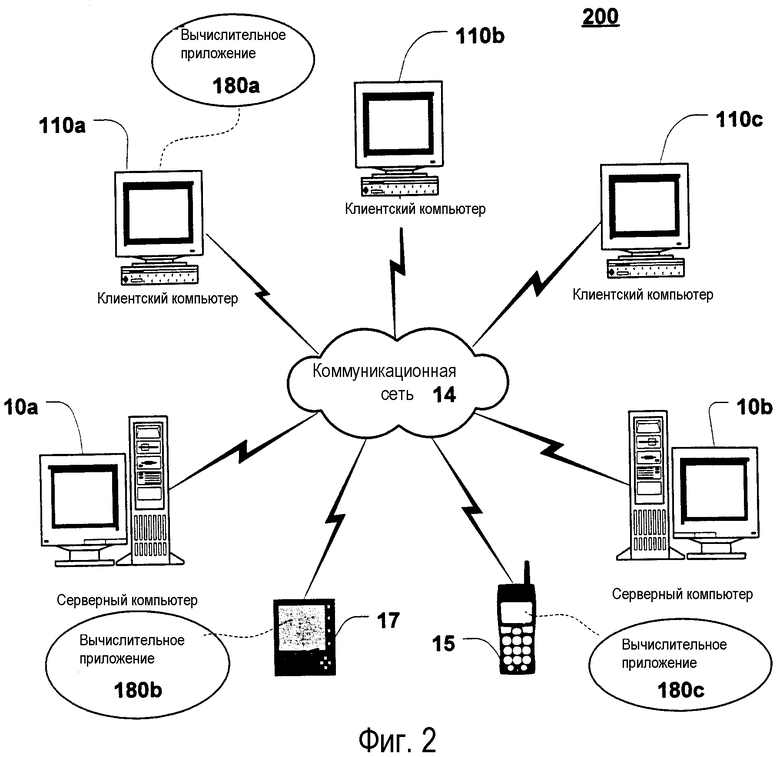
Компьютер 20а, описанный выше, может быть использован как часть компьютерной сети. В целом вышеприведенное описание для компьютеров применяется как для серверных компьютеров, так и для клиентских компьютеров, используемых в сетевой среде. Фиг.2 иллюстрирует примерную сетевую среду с сервером, находящимся в связи с клиентскими компьютерами посредством сети, в которой может быть использовано настоящее изобретение. Как изображено на фиг.2, несколько серверов 10а, 10b и т.д. соединены через коммуникационную сеть 160 (которая может быть ЛВС, ГВС, интрасетью, Internet или другой компьютерной сетью) с несколькими клиентскими компьютерами 20а, 20b, 20с или вычислительными устройствами, таким как мобильный телефон 15, телефон 16 наземной линии связи и персональный цифровой ассистент 17. В сетевой среде, в которой коммуникационная сеть 160, например, является Internet, серверы могут быть Web-серверами, с которыми клиенты 20 взаимодействуют через любое число известных протоколов, таких как протокол передачи гипертекста (HTTP, ППГТ) или беспроводной протокол приложений (WAP, БПП). Каждый клиентский компьютер 20 может быть оборудован браузером 180а для того, чтобы получать доступ к серверам 10. Аналогично персональный цифровой ассистент 17 может быть оборудован браузером 180b, а мобильный телефон 15 может быть оборудован браузером 180с для того, чтобы отображать и принимать различные данные.
При работе пользователь (не изображен) может взаимодействовать с вычислительным приложением, выполняющимся на клиентском вычислительном устройстве, чтобы показывать отчет, как источник схематизированных запрашиваемых данных. Отчеты могут быть запомнены в серверных компьютерах и переданы взаимодействующим пользователям через клиентские вычислительные устройства через коммуникационную сеть 160. Пользователь может генерировать, управлять и взаимодействовать с такими отчетами с помощью взаимодействия с вычислительными приложениями в клиентских вычислительных устройствах. Эти входные сообщения могут передаваться с помощью клиентских вычислительных устройств в серверные компьютеры для обработки и запоминания. Серверные компьютеры могут иметь (хостировать) главные вычислительные приложения, чтобы показывать отчеты как источники запрашиваемых схематизированных данных.
Следовательно, настоящее изобретение может быть использовано в сетевой компьютерной среде, имеющей клиентские вычислительные устройства для доступа к сети и взаимодействия с сетью, и серверный компьютер для взаимодействия с клиентскими компьютерами. Однако системы и способы, описанные в настоящем описании, могут быть реализованы с помощью множества сетевых архитектур и, следовательно, не должны ограничиваться изображенным примером. Системы и способы, описанные в настоящей заявке, теперь будут описаны более подробно со ссылкой на настоящие иллюстративные реализации.
С. Отчеты как источники данных
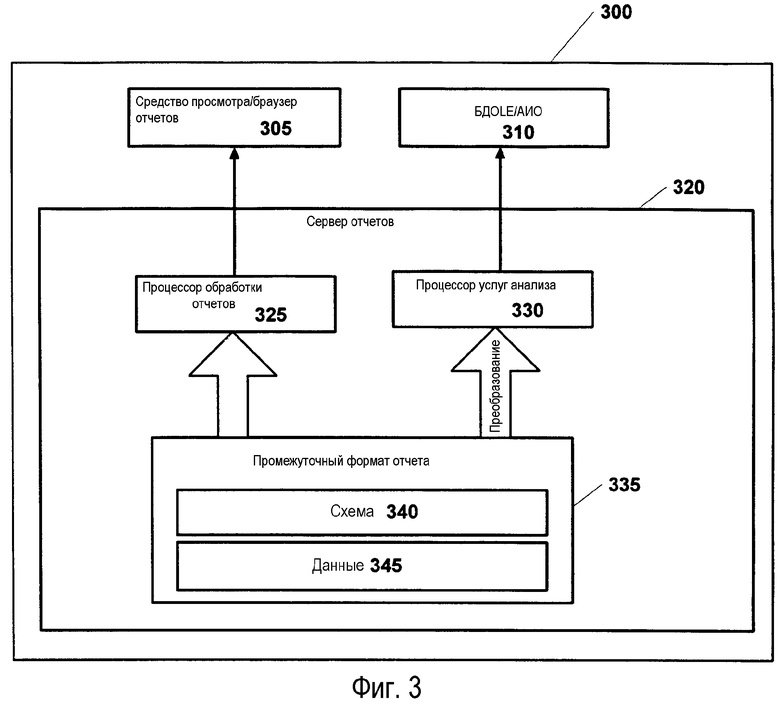
Фиг.3 изображает блок-схему примерной иллюстративной архитектуры примерной системы генерирования и управления отчетами, которая показывает отчет. Как изображено, примерная архитектура 200 содержит сервер 320 отчетов. Сервер 320 отчетов дополнительно содержит средство 325 обработки отчетов, средство 330 обеспечения услуг анализа и промежуточный формат 335 отчета. Промежуточный формат 335 отчета дополнительно содержит данные 345 и схему 340. Наконец, примерная архитектура 400 содержит средство 305 просмотра/браузер и OLEDB, БДOLE (база данных OLE (связывание и внедрение объекта)/ADO, объекты данных (абстрактный Active X) 310. При работе сервер 320 отчетов генерирует схему 340, которая работает c данными 325 отчета. Сервер 320 отчетов генерирует промежуточный формат отчета, который является источником схематизированных запрашиваемых данных, имеющим независимый от воспроизведения (интерпретации) постоянный формат данных. Затем промежуточный формат данных может быть использован сервером 320 отчетов, чтобы отобразить сгенерированный отчет через 305. В этом контексте промежуточный формат 335 обрабатывают с помощью средства 325 обработки отчетов сервера 320 отчетов, чтобы отобразить отчет на средстве 305 просмотра отчетов/браузере. Промежуточный формат также может использоваться сервером 320 отчетов для того, чтобы передавать сгенерированный отчет во взаимодействующие среды через средство 330 обеспечения услуг анализа с использованием модуля 210 БДOLE.
При наличии отчета в промежуточном формате, который схематизирован, отчет выглядит и действует как источник данных для взаимодействующих сред и взаимодействующих вычислительных приложений.
D. Показ рабочих продуктов данных в качестве источников схематизированных данных
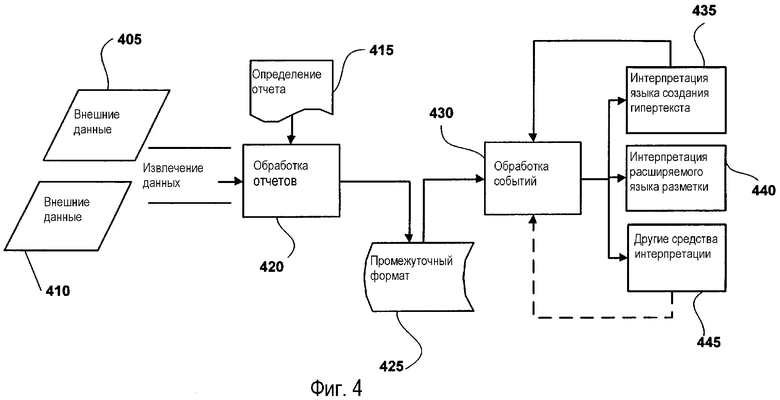
Фиг.4 изображает примерный поток данных между примерными компонентами системы генерирования и управления рабочими продуктами данных (например, отчетом), которая показывает отчеты как источники схематизированных запрашиваемых данных. Как изображено, система 400 генерирования и управления отчетами содержит различные компоненты, предназначенные для использования при показе отчетов как источников схематизированных запрашиваемых данных. Конкретно система 400 генерирования и управления отчетами содержит модуль 420 обработки отчетов. Как изображено, модуль 420 обработки отчетов взаимодействует с определением 415 отчета и принимает данные из внешних источников 405 и 410 данных для того, чтобы генерировать отчеты, которые запоминают в промежуточном формате 425.
При работе сгенерированный отчет может быть запрошен одной или более взаимодействующими средами. В этом контексте отчет, запомненный в промежуточном формате данных, передают в модуль 430 обработки событий, который координирует передачу сгенерированных отчетов, полностью или частично, в запрашивающие среды. Модуль 430 обработки событий определяет воспроизведение (интерпретацию) запрашивающей среды и обеспечивает отчет, полностью или частично, в запрашивающую среду в расширении воспроизведения, присущем запрашивающей среде. Например, если запрашивается воспроизведение html, используются расширения 440 для воспроизведения html. Подобным образом, если запрашивается воспроизведение XML, используют расширения 440 для воспроизведения XML. И так далее, таким образом, что другие типы воспроизведения (интерпретации) были бы представлены с помощью других расширений 445 воспроизведения.
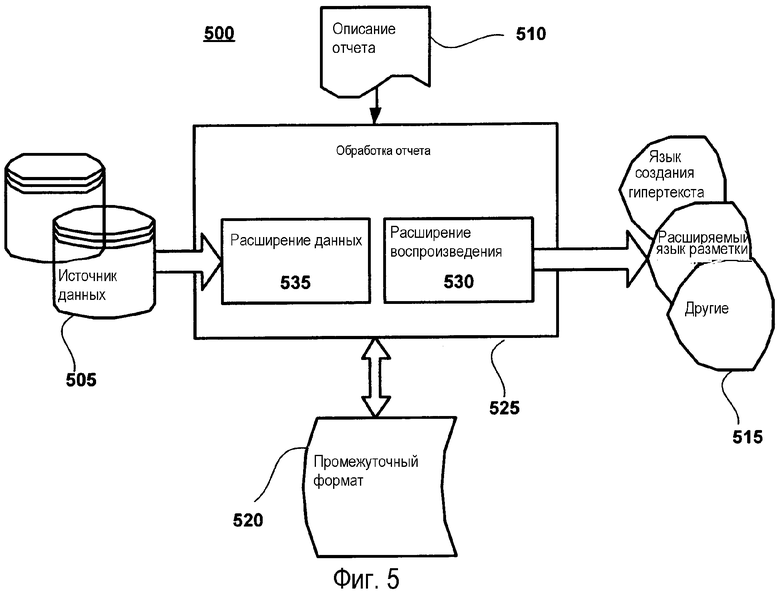
Фиг.5 укрупненно изображает примерное использование примерной системы 500 генерирования и управления отчетами. Как изображено, система 500 генерирования и управления отчетами содержит модуль 525 обработки отчетов. Модуль 525 обработки отчетов содержит расширения 525 данных и расширения 530 воспроизведения. Кроме того, модуль обработки отчетов взаимодействует с описанием (определением) 510 отчета и источником 505 данных. При работе запрос отчета передают в модуль 525 обработки отчетов. Модуль 525 обработки отчетов получает надлежащее описание (определение) отчета из организованных в файл описаний 510 отчетов для применения к данным, найденным в источнике 505 данных. Затем данные обрабатывают с помощью модуля 525 обработки отчетов с использованием расширения 535 данных, чтобы идентифицировать элементы данных из источника 505 данных. Затем модуль 525 обработки отчетов обрабатывает данные в соответствии с соответствующим описанием (определением) отчета, чтобы сгенерировать отчет, который показывают как источник схематизированных запрашиваемых данных. Затем отчет запоминают с помощью модуля 525 обработки отчетов в промежуточном формате 520 данных для будущего использования.
Дополнительно к генерированию отчетов система 500 генерирования и управления отчетами может передавать сгенерированные отчеты во взаимодействующие среды независимо от воспроизведения (интерпретации), требуемого запрашивающими средами. Например, система 500 генерирования и управления отчетами может быть использована для того, чтобы передавать сгенерированный отчет во взаимодействующую среду. В этом контексте сгенерированный отчет, сохраненный в промежуточном формате 520, извлекают с помощью модуля 525 обработки отчетов и обрабатывают с использованием расширений 530 воспроизведения, чтобы сгенерировать отчет в формате воспроизведения, воспринимаемом запрашивающей средой.
Фиг.6 изображает более подробное использование примерной системы генерирования и управления отчетами, которая может показывать отчет как источник схематизированных запрашиваемых данных, имеющий независимый от воспроизведения постоянный формат данных. Как изображено, система 600 генерирования и управления отчетами содержит сервер 605 отчетов. Сервер 605 отчетов, в свою очередь, содержит модуль 610 преобразования, модуль 615 обработки отчетов и средство 625 оптимизации/выполнения обработки запросов. Сервер 605 отчетов взаимодействует с различными взаимодействующими компонентами, включающими в себя, но не ограниченными, пользовательский интерфейс (UI, ПИ) 630 отчета, описания (определения) 650 отчетов, второй сервер 635 отчетов, поставщик 640 данных услуг анализа (AS, УА) и основной компонент 645 управления.
При генерировании отчета сервер 605 отчетов взаимодействует с описаниями 650 отчетов, чтобы получить соответствующее описание отчета для желаемого отчета. Затем описание отчета обрабатывают с помощью модуля 615 обработки отчетов сервера 605 отчетов. Сервер 605 отчетов, используя соответствующее описание отчета, собирает соответствующие данные и генерирует источник схематизированных запрашиваемых данных, представляющий желаемый отчет. Затем отчет может быть отображен на ПИ 630 отчета с помощью сервера 605 отчетов. В этой рассмотренной операции модуль 615 обработки отчетов сервера 605 отчетов взаимодействует с модулем 610 преобразования, чтобы преобразовать желаемый отчет для просмотра и отображения в ПИ 630 отчета.
При работе система 600 генерирования и управления отчетами может поддерживать несколько операций и функций. Например, отчет, выполняемый на множестве уже сгенерированных отчетов. Как изображено на фиг. 6 с помощью стрелки, запрос отчета относительно отчета подают в сервер 635 отчетов. Сервер 635 отчетов обрабатывает отчет по запросу отчета и взаимодействует с модулем поставщика данных УА для того, чтобы выполнить запрос. В свою очередь, поставщик 640 данных УА взаимодействует со средством 625 оптимизации/выполнения обработки запросов. Это средство взаимодействует с модулем 615 обработки отчетов, чтобы получить/сгенерировать необходимые данные, чтобы удовлетворить отчет по запросу отчета. Аналогично запрос OWC, ОРС (односторонний режим связи) относительно отчета может быть подан в основной модуль 645 управления, который, в свою очередь, взаимодействует с поставщиком 640 данных УА, чтобы выполнить запрос ОРС относительно отчета.
Другим использованием системы 600 генерирования и управления отчетами является предоставление возможности участвующим пользователям просматривать отчеты на ИП 630 отчетов, исходящем от дистанционных взаимодействующих сред. В этом контексте ИП 630 отчетов взаимодействует с модулем 615 обработки отчетов. Модуль 615 обработки отчетов взаимодействует с модулем 610 преобразования. Модуль 610 преобразования работает таким образом, чтобы преобразовывать данные из одного формата данных в другой. Как таковой он может быть использован для того, чтобы преобразовывать данные в независимом от воспроизведения (интерпретации) формате данных в зависимый от воспроизведения формат данных для воспроизведения в запрашивающей среде. Затем модуль 610 преобразования взаимодействует со средством 625 оптимизации/выполнения обработки запросов для связи с одним или более взаимодействующими модулями.
Понятно, что сервер 605 отчетов в рассмотренных реализациях может содержать любое из следующего: вычислительное аппаратное обеспечение, вычислительное программное обеспечение и комбинация вычислительного аппаратного обеспечения и вычислительного программного обеспечения.
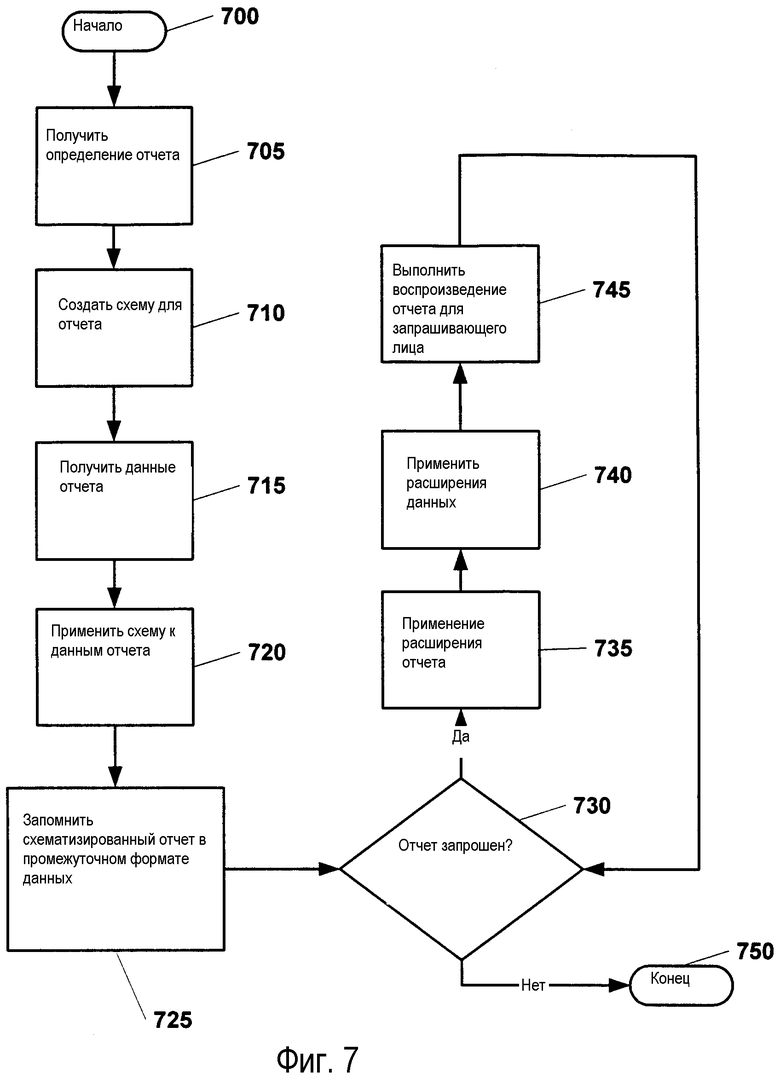
Фиг.7 изображает блок-схему этапов примерной обработки, выполняемой для того, чтобы показывать отчет как источник схематизированных запрашиваемых данных, и последующей обработки, выполняемой при использовании такого показанного отчета. Как изображено, обработка начинается на этапе 700 и переходит к этапу 705, где получают описание (определение) отчета. На этапе 710 создают схему для отчета в соответствии с полученным описанием отчета. Затем данные отчета получают на этапе 715, и созданную схему, созданную на этапе 710, применяют к данным отчета на этапе 720. Затем схематизированный отчет запоминают в промежуточном формате на этапе 725 (в соответствии с обработкой, описанной на фиг.8А и фиг.8В). После этого этапа обработка переходит к этапу 730, где выполняют проверку, чтобы определить, запрошен ли отчет (например, запрошен собственной средой или взаимодействующей средой). В контексте предоставленных примеров среда содержит любое из следующего: вычислительная среда и частичная вычислительная среда. Если отчет запрошен, обработка переходит к этапу 735, где расширения данных применяют к отчету и расширения данных подают на этап 740. В рассмотренной иллюстративной реализации расширения данных применяют к данным отчета, чтобы помочь идентифицировать описание полей данных. Расширения воспроизведения, как описано выше, используют для того, чтобы преобразовать отчет для использования в формате воспроизведения среды, использующей отчет. Затем выполняют воспроизведение (интерпретацию) отчета на этапе 745 для отображения в среде, запрашивающей отчет. Затем обработку заканчивают на этапе 750. Однако, если на этапе 730 отчет не запрошен, обработка переходит к этапу 750 и заканчивается.
Е. Постоянство информации, независимое от воспроизведения
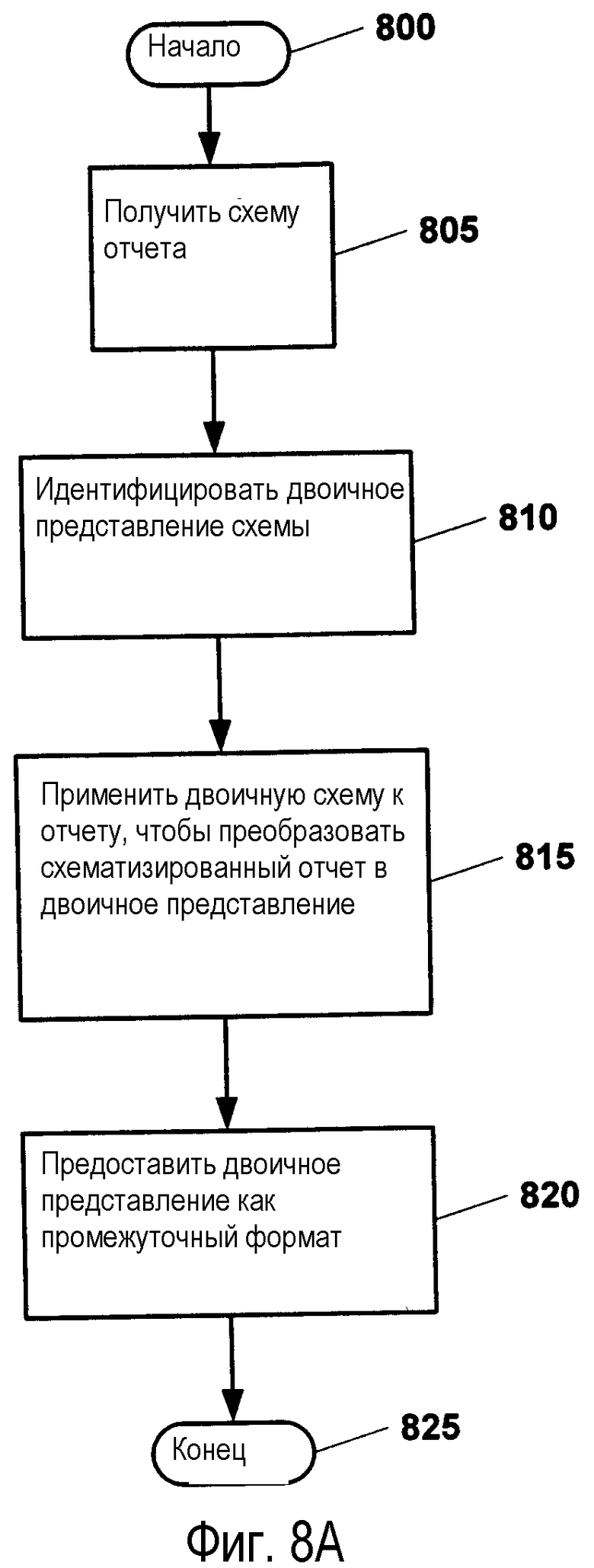
Фиг.8А изображает блок-схему примерной обработки, выполняемой для того, чтобы обеспечить показанный отчет в независимом от воспроизведения (интерпретации) постоянном формате данных. Как изображено, обработка начинается на этапе 800 и переходит к этапу 805, где получают схему показанного схематизированного запрашиваемого отчета. Затем обработка переходит к этапу 810, где идентифицируют независимый от воспроизведения постоянный формат данных. В иллюстративной реализации независимый от воспроизведения постоянный формат данных содержит двоичный формат данных. В контексте для этапа 810 обработка описанных в настоящей заявке способов в соответствии с предоставленным примером подразумевает идентификацию двоичного представления схемы. Дополнительно к предоставленному примеру обработка переходит к этапу 815, где идентифицированную двоичную схему применяют к требуемому отчету, чтобы преобразовать схематизированный отчет в двоичный формат данных. В этап преобразования включено выполнение процесса анализа данных, который определен, по меньшей мере, одним правилом анализа, которое действует таким образом, чтобы разделить данные отчета для обработки. Затем обработка переходит к этапу 820, где сгенерированное двоичное представление предоставляют как промежуточный формат данных, в котором может находиться показанный отчет. Затем обработку заканчивают на этапе 825.
Понятно, что несмотря на то, что примерная реализация рассматривает использование двоичного представления независимого от воспроизведения постоянного формата данных, изобретательские концепции, раскрытые в настоящем описании, распространяются за предоставленные иллюстративные реализации таким образом, чтобы включать в себя, но не ограничиваться, шестнадцатеричные представления, представления на языке ассемблера и представления на языке программирования высокого уровня.
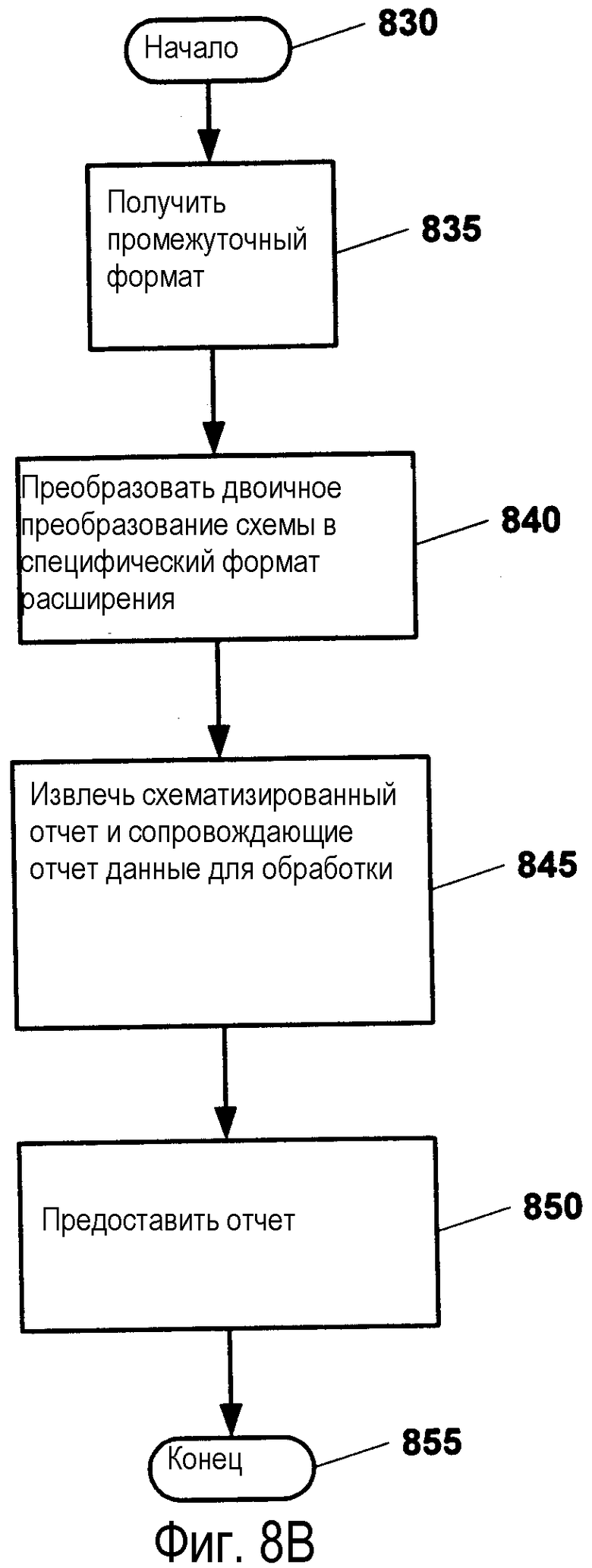
Фиг.8В изображает блок-схему этапов примерной обработки, выполняемой при обработке запросов с помощью взаимодействующих сред, чтобы извлечь показанный отчет, полностью или частично, для использования в запрашивающей среде. Как изображено, обработка начинается на этапе 830 и переходит к этапу 835, где запрашивают требуемый отчет (полностью или частично) и предоставляют его в промежуточном формате (например, независимом от воспроизведения постоянном формате данных). После этого этапа обработку выполняют на этапе 840, где промежуточный формат, независимый от воспроизведения формат, преобразуют в зависимый от воспроизведения формат, а именно формат воспроизведения (интерпретации) запрашивающей среды. В иллюстративной реализации этап преобразования предполагает двоичное преобразование схемы отчета в специфический формат расширения запрашивающей среды. На этапе 845 схематизированный отчет и сопровождающие данные извлекают для представления в расширении воспроизведения запрашивающей среды. Затем окончательный отчет подают на этапе 850. Затем обработку заканчивают на этапе 850.
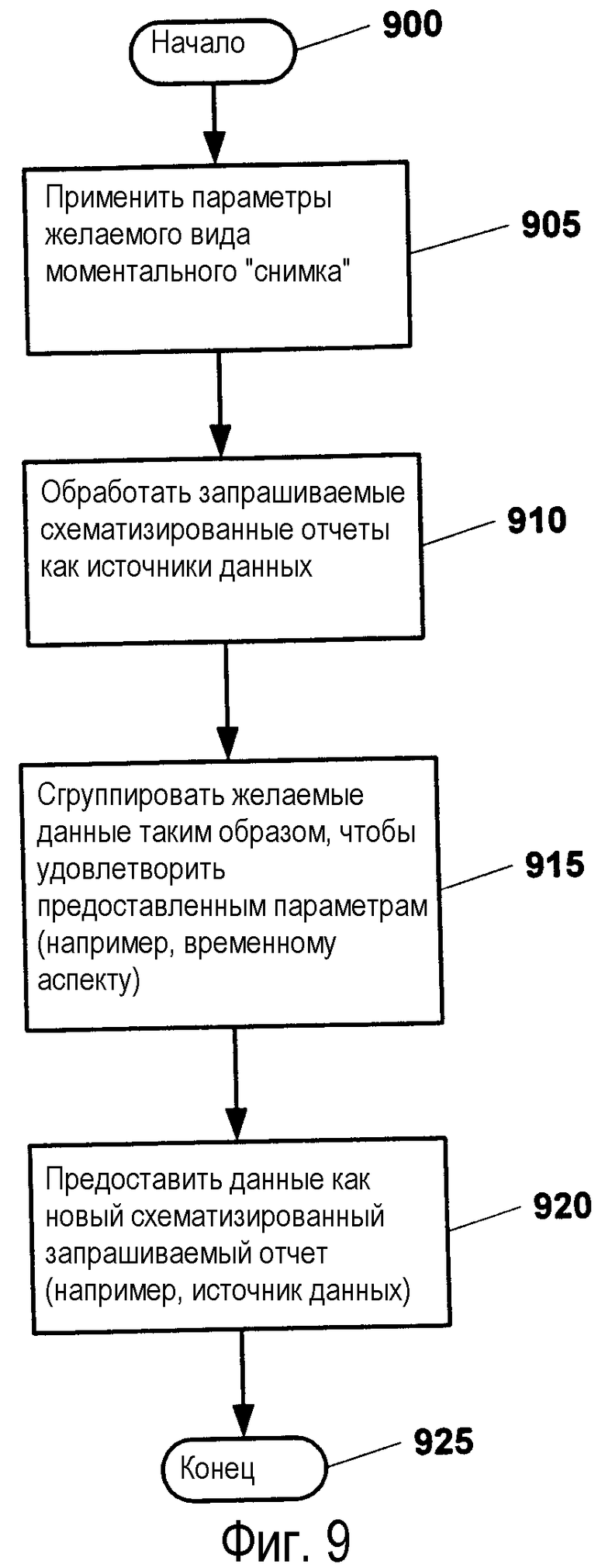
Фиг.9 изображает блок-схему этапов примерной обработки, выполняемой при выполнении запроса, основанного на времени, относительно набора сгенерированных отчетов. Как изображено, обработка начинается на этапе 900 и переходит к этапу 905, где обеспечивают параметры желаемого вида моментального "снимка". После этого этапа обработка переходит к этапу 910, где схематизированные запрашиваемые отчеты обрабатывают в качестве источников данных. Затем на этапе 915 данные группируют из набора сгенерированных отчетов в соответствии с полученными параметрами (например, все величины продаж от года 1 до года 2 в географической области Мидвест по всем отчетам продаж от года 1 до года 2). Затем сгруппированные данные собирают и обрабатывают на этапе 920, чтобы обеспечить новый схематизированный запрашиваемый отчет, имеющий желаемые данные моментального "снимка". Обработка переходит к этапу 925, где она заканчивается.
Обработка, описанная на фиг.9, использует один или более признаков описанных в настоящем описании систем и способов. Конкретно описанные в настоящей заявке системы и способы предлагают механизм, который показывает отчет как источник схематизированных запрашиваемых данных, имеющий независимый от воспроизведения постоянный формат данных. При наличии схематизированных, запрашиваемых и постоянных отчетов относящийся ко времени запрос (например, моментальный "снимок" тенденции) легко обрабатывают на наборе таких отчетов, так как данные собирают по значению времени, идентифицированному из схемы отчета. Значения являются надежными, так как отчет сохранен как постоянный формат данных.
F. Заключение
Как упомянуто выше, несмотря на то, что примерные варианты осуществления настоящего изобретения описаны в связи с различными вычислительными устройствами и сетевыми архитектурами, лежащие в основе принципы могут быть применены к любому вычислительному устройству или системе, в которых желательно осуществлять и/или выполнять другие связанные функции. Следовательно, процессы и системы, описанные выше, могут быть применены к множеству приложений и устройств. Несмотря на то, что примерные структуры данных, языки программирования, названия и примеры выбраны в настоящем описании как представляющие различные выборы, они не предполагаются ограничивающими.
Различные способы, описанные в настоящем описании, могут быть реализованы в связи с аппаратным обеспечением или программным обеспечением или в соответствующих случаях с помощью их комбинации. Следовательно, способы и устройства настоящего изобретения или его некоторые аспекты или части могут принимать вид программного кода (т.е. инструкций), осуществленных на материальном носителе, таком как гибкие дискеты, ПЗУ на компакт-дисках, жесткие диски или любые другие запоминающие носители, доступные для чтения с помощью компьютера, в которых, когда программный код загружен и выполняется с помощью машины, такой как компьютер, машина становится устройством, предназначенным для применения изобретения. В случае выполнения программного кода в программируемых компьютерах вычислительное устройство обычно будет включать в себя процессор, запоминающий носитель, доступный для чтения с помощью процессора (включая энергозависимую и энергонезависимую память и/или запоминающие элементы), по меньшей мере, одно устройство ввода и, по меньшей мере, одно устройство вывода. Одна или более программ, которые могут использовать аспекты интерфейса отладки настоящего изобретения, например, посредством использования API, ИПП (интерфейс прикладных программ) обработки данных, предпочтительно реализованы на процедурном или объектно-ориентированном языке программирования высокого уровня, чтобы взаимодействовать с компьютерной системой. Однако, если необходимо, программа (программы) могут быть реализованы на языке ассемблера или машинном языке. В любом случае язык может быть компилируемым или интерпретируемым языком и может быть объединен с реализациями аппаратного обеспечения.
Способы и устройства согласно настоящему изобретению также могут быть применены посредством коммуникаций, осуществленных в виде программного кода, который передают через некоторый носитель передачи, например через систему электрических проводов или кабельную систему, через оптико-волоконные кабели или посредством любых других видов передачи, в которых, когда программный код принят и загружен в машину и выполняется с помощью машины, такой как EPROM, ППЗУ (программируемое ПЗУ), вентильная матрица, программируемое логическое устройство (PLD, ПЛУ), клиентский компьютер, устройство видеозаписи или тому подобные, или принимающая машина, имеющая возможности отладки, как описано выше в примерных вариантах осуществления, становится устройством, подходящим для применения изобретения. При реализации в процессоре общего назначения программный код объединяется с процессором таким образом, чтобы обеспечить уникальное устройство, которое работает таким образом, чтобы вызывать функциональные средства настоящего изобретения. Кроме того, любые способы запоминания, используемые в связи с настоящим изобретением, могут постоянно быть комбинацией аппаратного обеспечения и программного обеспечения.
Несмотря на то, что изобретение описано в связи с настоящими предпочтительными вариантами осуществления, следует понимать, что могут быть использованы другие подобные варианты осуществления, или могут быть сделаны изменения в описанном варианте осуществления для выполнения той же самой функции настоящего изобретения, без отклонения от него. Например, специалист в данной области техники поймет, что настоящее изобретение, как описанное в настоящей заявке, может применяться к любому вычислительному устройству или среде, проводным или беспроводным, и может быть применено к любому числу таких вычислительных устройств, соединенных посредством коммуникационной сети и взаимодействующих через сеть. Кроме того, следует подчеркнуть, что подразумевается множество компьютерных платформ, включая операционные системы карманных устройств и другие операционные системы специфических приложений, особенно, так как ряд беспроводных сетевых устройств продолжает распространяться. Кроме того, настоящее изобретение может быть реализовано в множестве или посредством множества обрабатывающих микросхем или устройств, и память также может быть осуществлена посредством множества устройств. Следовательно, настоящее изобретение не должно быть ограничено любым одним вариантом осуществления, а вместо этого должно быть понято в рамках объема и сущности в соответствии с прилагаемой формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ВИД ОТЧЕТА ЭЛЕКТРОННЫХ ДАННЫХ С ПОИМЕНОВАННЫМИ ОБЪЕКТАМИ | 2006 |
|
RU2419853C2 |
| СОВМЕСТНОЕ ИСПОЛЬЗОВАНИЕ ПОШАГОВОГО ЯЗЫКА РАЗМЕТКИ И ОБЪЕКТНО ОРИЕНТИРОВАННОГО ИНСТРУМЕНТАЛЬНОГО СРЕДСТВА РАЗРАБОТКИ | 2004 |
|
RU2379745C2 |
| ВИРТУАЛИЗАЦИЯ ВЗАИМОДЕЙСТВИЯ С ПОЛЬЗОВАТЕЛЕМ МОБИЛЬНОГО УСТРОЙСТВА | 2007 |
|
RU2439681C2 |
| ПОСЛЕДОВАТЕЛЬНЫЙ МУЛЬТИМОДАЛЬНЫЙ ВВОД | 2004 |
|
RU2355045C2 |
| УКАЗАНИЕ, ЗАДАНИЕ И ОБНАРУЖЕНИЕ ПАРАМЕТРОВ ДОКУМЕНТОВ ЭЛЕКТРОННЫХ ТАБЛИЦ | 2006 |
|
RU2421797C2 |
| ИДЕНТИФИКАЦИЯ ЗАГРУЖАЕМЫХ ПРИЛОЖЕНИЙ, СОВМЕСТИМЫХ С ОСНОВОЙ | 2013 |
|
RU2637880C2 |
| УСТРОЙСТВО СЕРВЕРА, УСТРОЙСТВО КЛИЕНТ, СПОСОБ РАСПРЕДЕЛЕНИЯ СОДЕРЖАНИЯ И КОМПЬЮТЕРНАЯ ПРОГРАММА | 2014 |
|
RU2668549C2 |
| СПОСОБЫ И СИСТЕМЫ ДЛЯ АУТЕНТИФИКАЦИИ КОМПОНЕНТОВ В ГРАФИЧЕСКОЙ СИСТЕМЕ | 2003 |
|
RU2310227C2 |
| ХРАНЕНИЕ ИНФОРМАЦИИ О ПРАВАХ НА ЦИФРОВОЕ МУЛЬТИМЕДИА В ПРЕОБРАЗОВАННОМ ЦИФРОВОМ МУЛЬТИМЕДИЙНОМ СОДЕРЖИМОМ | 2006 |
|
RU2418359C2 |
| ПУБЛИКАЦИЯ ЦИФРОВОГО СОДЕРЖАНИЯ В ОПРЕДЕЛЕННОМ ПРОСТРАНСТВЕ, ТАКОМ, КАК ОРГАНИЗАЦИЯ, В СООТВЕТСТВИИ С СИСТЕМОЙ ЦИФРОВОГО УПРАВЛЕНИЯ ПРАВАМИ (ЦУП) | 2004 |
|
RU2344469C2 |

Изобретение относится к вычислительной технике. Техническим результатом является обеспечение сохранности данных независимо от воспроизведения. Данные имеют некоторую заранее определенную структуру. При работе данные обрабатывают таким образом, что данные и связанную с ними структуру представляют в формате данных, который является постоянным. При работе данные анализируют в соответствии с одним или более ограничений и преобразуют в постоянный формат данных, после чего эти данные группируют согласно основанному на времени параметру. 3 н. и 6 з.п. ф-лы, 10 ил.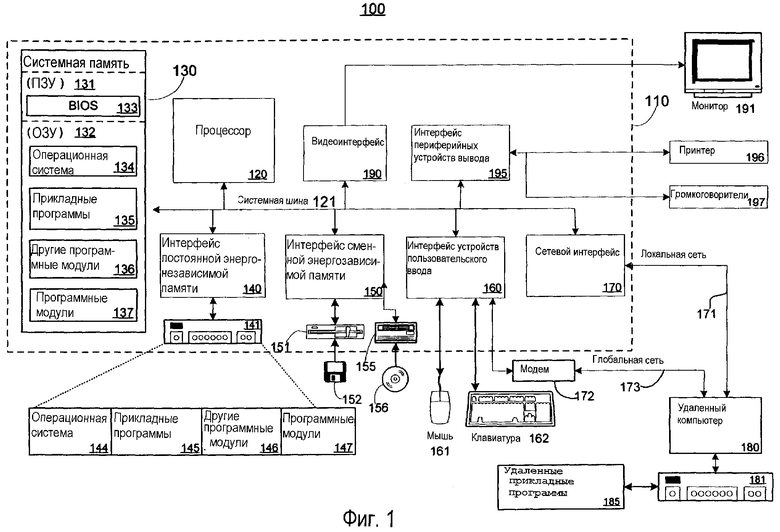
группируют независимые от воспроизведения постоянные данные согласно основанному на времени параметру.
| Способ получения 2-метил-5-ацетилпиридина | 1983 |
|
SU1122652A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| US 5864870 А, 26.01.1999 | |||
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| СИСТЕМА И СПОСОБ ДЛЯ ИНТЕГРАЦИИ СООБЩЕНИЯ В ГРАФИЧЕСКУЮ СРЕДУ | 1998 |
|
RU2192040C2 |

