Предшествующий уровень техники
Настоящее изобретение относится к доступу и воспроизведению информации в компьютерной системе. Более конкретно, настоящее изобретение относится к представлению данных на основе голосового ввода, осуществляемого пользователем.
Многие компьютерные интерфейсы основываются на взаимодействиях, управляемых компьютером, при которых пользователю необходимо придерживаться последовательности выполнения, установленной компьютером, или знать одну или более команд, предоставленных компьютером. Другими словами, большинство компьютерных интерфейсов не адаптированы для способа, которым пользователь желает взаимодействовать с компьютером, а вместо этого принуждают пользователя взаимодействовать с компьютером посредством специфического набора интерфейсов.
Прогресс в области интерфейсов "компьютер/пользователь" позволил пользователям взаимодействовать с компьютером с помощью голосовых команд. Были обеспечены голосовые порталы, такие как использующие голосовой XML (голосовой расширяемый язык разметки), чтобы позволить осуществлять доступ к контенту (информационно значимому содержимому) сети Интернет с использованием голосового ввода. При такой архитектуре сервер документов (например, web-сервер) обрабатывает запросы от клиента посредством интерпретатора голосового XML. Web-сервер может вырабатывать документы и ответы, которые обрабатываются интерпретатором голосового XML и воспроизводятся в слышимой форме пользователю. Используя специальные голосовые команды в сочетании с распознаванием речи, пользователь может передвигаться (осуществлять навигацию) по всемирной паутине (web) и прослушивать данные, воспроизводимые в слышимой форме.
Однако большинство приложений, представляющих данные пользователю, например данные о направлениях движения, информацию об уличном движении, сообщения о погоде или расписания сеансов кино, не являются особо дружественными для пользователя. В частности, приложения имеют сложности при воспроизведении частей информации, которые были ранее воспроизведены, или частей структурированной информации, хранящейся в таблице. Например, различные службы предлагают направления движения, но делают это посредством однократного длительного прочтения пользователю или в виде заранее определенных этапов. В результате пользователям возможно придется записывать все направления движения или заново проигрывать все направления движения или заранее определенные этапы, чтобы запомнить необходимую информацию. Во многих случаях обе такие ситуации не желательны.
Соответственно, существует необходимость в более гибком доступе к частям данных и их воспроизведении. Такие система и способ воспроизведения были бы проще в использовании, если бы были более естественными для пользователя.
Сущность изобретения
Настоящее изобретение обеспечивает улучшенный интерфейс для воспроизведения данных пользователю на основе голосового ввода. В одном аспекте настоящего изобретения способ воспроизведения информации пользователю включает в себя этапы, на которых идентифицируют первый объект и второй объект из фрагмента речи. Первый объект и второй объект связывают с тэгами (неотображаемыми элементами разметки), соответствующими хранящейся информации. Хранящуюся информацию выборочно воспроизводят на основе первого объекта и второго объекта. В одном варианте воплощения идентифицируемые объекты могут быть объектами запроса, объектами навигации и/или объектами команд для выборочного воспроизведения информации. В одном конкретном аспекте хранящаяся информация организована в таблицу с множеством строк и множеством столбцов. Первый объект включает в себя информацию, имеющую отношение к конкретной строке, а второй объект включает в себя информацию, имеющую отношение к конкретному столбцу.
Согласно другому аспекту настоящего изобретения предложен способ, который включает в себя воспроизведение сегмента информации пользователю. Сегмент информации включает в себя тэги, соответствующие частям сегмента. Способ дополнительно включает в себя этап, на котором идентифицируют по меньшей мере один объект из фрагмента речи и связывают объект с тэгом, соответствующим частям сегмента. Затем часть сегмента, соответствующую тэгу, воспроизводят. В дополнительном варианте воплощения для воспроизведения частей сегмента можно использовать нормализатор/анализатор текста для идентификации релевантных частей внутри сегмента.
В результате настоящее изобретение обеспечивает удобный способ представления многомерных данных и воспроизведения частей информации, хранящейся в базе данных. Пользователям предоставляется более естественный интерфейс для получения данных на основе голосового ввода. Например, пользователь может запросить отдельные ячейки в таблице или создать двустороннюю диалоговую связь на основе хранящейся информации.
Перечень фигур
Фиг.1 - блок-схема системы представления данных.
Фиг.2 - вид операционной среды вычислительного устройства в плане.
Фиг.3 - блок-схема вычислительного устройства по фиг.2.
Фиг.4 - вид телефона в плане.
Фиг.5 - блок-схема компьютера общего назначения.
Фиг.6 - блок-схема архитектуры системы "клиент/сервер".
Фиг.7 - блок-схема модуля распознавания и восприятия речи.
Фиг.8 - блок-схема модуля воспроизведения данных.
Фиг.9 - схема таблицы курса акций и объектов для воспроизведения данных в таблице.
Фиг.10А-10С - иллюстративный код, используемый для воспроизведения таблицы по фиг.9.
Фиг.11 - схема таблицы направлений движения и объектов для воспроизведения данных в таблице.
Фиг.12 - схема таблицы данных о продажах и объекты для воспроизведения данных в таблице.
Фиг.13 - абзац текста и объекты для воспроизведения данных в абзаце текста.
Фиг.14А-14D - иллюстративный код, используемый для воспроизведения данных в абзаце по фиг.13.
Фиг.15 - сообщение голосовой почты и объекты, используемые для воспроизведения данных в сообщении голосовой почты.
Подробное описание иллюстративных вариантов воплощения изобретения
Фиг.1 представляет собой блок-схему системы 10 представления данных для воспроизведения данных на основе голосового ввода. Система 10 включает в себя модуль 12 речевого интерфейса, модуль 14 распознавания и восприятия речи и модуль 16 воспроизведения данных. Пользователь подает входные данные в форме голосового запроса в модуль 12 речевого интерфейса. Модуль 12 речевого интерфейса собирает речевую информацию от пользователя и выдает сигнал, служащий индикатором выполнения сбора речевой информации. После того как вводимая речь собрана модулем 12 речевого интерфейса, модуль 14 распознавания и восприятия речи распознает речь, используя средство распознавания (распознаватель) речи, и идентифицирует объекты, такие как ключевые слова или ключевые фразы, которые имеют отношение к информации, выбранной пользователем для воспроизведения системой 10. Объекты используются модулем 16 воспроизведения данных для извлечения данных из базы данных 18. Как только релевантная информация идентифицирована в базе данных 18, используя упомянутые объекты, релевантная информация может быть воспроизведена пользователю. Выходные данные модуля 16 воспроизведения данных могут быть различными по форме, включая звуковые и/или визуальные выходные данные.
Предоставив общее описание воспроизведения данных на основе голосового запроса, было бы полезно описать основные вычислительные устройства, которые могут функционировать в системе 10, описанной выше. Как будет понятно специалисту в данной области техники, компоненты системы 10 могут располагаться внутри отдельного компьютера или могут быть распределены в распределенной вычислительной среде, использующей сетевые соединения и протоколы.
Со ссылкой на фиг.2 позицией 30 показана иллюстративная форма мобильного устройства, такого как устройство управления данными (электронная записная книжка (PIM), персональное цифровое информационное устройство (PDA) и т.п.). Однако предполагается, что настоящее изобретение может быть реализовано на практике с использованием других вычислительных устройств, как будет описано ниже. Например, телефоны и/или устройства управления данными также подходят для настоящего изобретения. Такие устройства будут выгодным образом усовершенствованы по сравнению с существующими портативными персональными устройствами управления информацией и другими портативными электронными устройствами.
Иллюстративная форма мобильного устройства 30 управления данными показана на фиг.2. Мобильное устройство 30 включает в себя корпус 32 и имеет интерфейс пользователя, включающий в себя дисплей 34, который использует экран сенсорного дисплея в сочетании с пером 33. Перо 33 используется для нажатия или контактирования с дисплеем 34 по назначенным координатам для выбора поля, для выборочного движения начального положения курсора или предоставления командной информации другим способом, таким как жесты или рукописный ввод. В качестве альтернативы или дополнения для навигации устройство 30 может включать в себя одну или более кнопок 35. Кроме того, могут быть обеспечены другие средства ввода, такие как вращающиеся колесики, ролики и т.п. Однако следует отметить, что изобретение не ограничивается только такими формами средств ввода. Например, другая форма ввода может включать визуальный ввод, например посредством машинного зрения.
Теперь со ссылкой на фиг.3 показана блок-схема функциональных компонентов, составляющих мобильное устройство 30. Центральный процессор (ЦП) 50 выполняет функции управления программным обеспечением. ЦП 50 соединен с дисплеем 34, так что текст и графические иконки, созданные в соответствии с управляющим программным обеспечением, появляются на дисплее 34. Громкоговоритель 43 может быть соединен с ЦП 50 обычно через цифроаналоговый преобразователь (ЦАП) 59 для обеспечения выходных данных в слышимой форме. Данные, которые загружаются или вводятся пользователем в мобильное устройство 30, хранятся в энергозависимом оперативном запоминающем устройстве 54 для считывания/записи, двунаправленно соединенном с ЦП 50. Оперативное запоминающее устройство (ОЗУ) 54 обеспечивает энергозависимое хранение команд, исполняемых ЦП 50, и хранение временных данных, таких как значение регистров. Значения, установленные по умолчанию, для опций конфигурации и другие переменные хранятся в постоянном запоминающем устройстве (ПЗУ) 58. ПЗУ 58 может быть также использовано для хранения программного обеспечения операционной системы для устройства, которое управляет основными функциями мобильного устройства 30 и другими основными функциями ядра операционной системы (например, загрузкой компонентов программного обеспечения в ОЗУ 54).
ОЗУ 54 также служит как хранилище для кода в соответствии со способом, аналогичным функционированию жесткого диска на ПК, который используется для хранения прикладных программ. Следует отметить, что хотя энергонезависимая память используется для хранения кода, в качестве альтернативы код хранится в энергозависимой памяти, которая не используется для исполнения кода.
Сигналы могут быть переданы/приняты мобильным устройством беспроводным способом через беспроводной приемопередатчик 52, который соединен с ЦП 50. Кроме того, при желании можно также обеспечить, в необязательном порядке, интерфейс 60 связи для загрузки данных напрямую с компьютера (например, с настольного компьютера) или из проводной сети. Соответственно, интерфейс 60 может включать в себя различные формы устройств связи, например инфракрасную линию связи, модем, сетевую карту и т.п.
Мобильное устройство 30 включает в себя микрофон 29, аналогово-цифровой (А/Ц) преобразователь (АЦП) 37 и, в необязательном порядке, программу распознавания (речи, двухтонального многочастотного набора (DTMF), почерка, жестов или программу машинного зрения), хранящуюся в памяти 54. Например, в ответ на звуковую информацию, инструкции или команды от пользователя устройства 30 микрофон 29 выдает речевые сигналы, которые оцифровываются А/Ц преобразователем 37. Программа распознавания речи может осуществлять функции нормализации и/или извлечения признаков в отношении оцифрованных речевых сигналов для получения промежуточных результатов распознавания речи. Используя беспроводной приемопередатчик 52 или интерфейс 60 связи, речевые данные могут быть переданы к удаленному серверу 204 распознавания, описанному ниже и показанному на фиг.6. Результаты распознавания затем возвращаются на мобильное устройство 30 для их воспроизведения (например, зрительного и/или звукового) и окончательной передачи к web-серверу 202 (фиг.6), причем web-сервер 202 и мобильное устройство 30 функционируют в отношении клиент/сервер. Похожая обработка может использоваться и для других форм ввода. Например, рукописный ввод может быть оцифрован с предварительной обработкой на устройстве 30 или без нее. Как и речевые данные, такая форма ввода может быть передана к серверу 204 распознавания для распознавания, причем результаты распознавания возвращаются либо устройству 30, либо к web-серверу 202, либо им обоим. Более того, данные DTMF, данные жестов и визуальные данные могут обрабатываться аналогично. В зависимости от формы ввода устройство 30 (и другие формы клиентов, описанные далее) будут включать в себя необходимые устройства, такие как камера для визуальных входных данных.
Фиг.4 показывает вид в плане иллюстративного варианта воплощения портативного телефона 80. Телефон 80 включает в себя дисплей 82 и клавиатуру 84. В основном, блок-схема по фиг.3 применима к телефону по фиг.4, хотя для выполнения других функций могут потребоваться дополнительные схемы. Например, для варианта воплощения по фиг.3 приемопередатчику необходимо работать как телефону, однако такая схема не имеет отношения к настоящему изобретению.
В добавление к портативным или мобильным вычислительным устройствам, описанным выше, следует также понимать, что настоящее изобретение может быть использовано с другими различными вычислительными устройствами, такими как обычный настольный компьютер. Например, настоящее изобретение позволит пользователю с ограниченными физическими возможностями вводить или вносить текст в компьютер или другое вычислительное устройство, если работать с другими обычными устройствами ввода, такими как цифробуквенная клавиатура, ему слишком сложно.
Изобретение также применимо для многочисленных других вычислительных систем, сред и конфигураций общего или специального назначения. Примеры широко известных вычислительных систем, сред и/или конфигураций, которые могут подходить для использования с изобретением, включают в себя, но не в ограничительном смысле, обычные телефоны (не содержащие никакого экрана), персональные компьютеры, серверные компьютеры, карманные или портативные устройства, планшетные компьютеры, многопроцессорные системы, системы, основанные на микропроцессоре, телевизионные приставки, программируемую бытовую электронику, сетевые ПК, микрокомпьютеры, главные компьютеры вычислительных центров, распределенные вычислительные среды, включающие в себя любые из вышеперечисленных систем или устройств, и т.п.
Далее следует краткое описание компьютера 120 общего назначения, показанного на фиг.5. Однако компьютер 120 опять-таки является всего лишь одним из примеров подходящей вычислительной среды и не предполагает какого-либо ограничения по объему использования или функциональности изобретения. Компьютер 120 не следует интерпретировать как имеющий какую-либо зависимость или требования, относящиеся к одному или к комбинации компонентов, показанных в нем.
Изобретение может быть раскрыто в общем контексте машино-исполняемых команд, таких как программные модули, исполняемые компьютером. В общем случае, программные модули включают в себя процедуры, программы, объекты, компоненты, структуры данных и т.д., выполняющие конкретные задания или реализующие определенные абстрактные типы данных. Изобретение может также быть применено на практике в распределенных вычислительных средах, где задания выполняются удаленными обрабатывающими устройствами, соединенными через сеть связи. В распределенных вычислительных средах программные модули могут располагаться как на локальных, так и на удаленных компьютерных носителях данных, включая запоминающие устройства. Задания, выполняемые программами и модулями, описаны ниже со ссылками на чертежи. Специалист в данной области техники может использовать описание и чертежи как машино-исполняемые, которые могут быть записаны на любой форме машиночитаемого носителя.
Со ссылкой на фиг.5 компоненты компьютера 120 могут включать в себя, но не в ограничительном смысле, блок 140 обработки, системную память 150 и системную шину 141, соединяющую различные системные компоненты, включая системную память, с блоком 140 обработки. Системная шина 141 может быть шиной любой структуры, включая шину памяти или контроллер памяти, периферийную шину и локальную шину, использующей любую из разновидностей архитектур шин. В качестве примера, но не ограничения, такие архитектуры включают шину архитектуры промышленного стандарта (ISA), универсальную последовательную шину (USB), шину микроканальной архитектуры (MCA), усовершенствованную шину ISA (EISA), локальную шину стандарта ассоциации по стандартам видеоэлектроники (VESA) и шину межсоединения периферийных компонентов (PCI), также известную как шину Mezzanine. Компьютер 120 обычно включает в себя различные машиночитаемые носители. Машиночитаемый носитель может быть любым доступным носителем, к которому компьютер 120 может осуществить доступ, и включает в себя как энергозависимый, так и энергонезависимый носитель, как съемный, так и несъемный носитель. В качестве примера, но не ограничения, машиночитаемые носители могут содержать компьютерные носители данных и среды передачи. Компьютерные носители данных включают в себя как энергозависимые, так и энергонезависимые носители, как съемные, так и несъемные носители, реализованные любым способом или технологией для хранения информации, такой как машиночитаемые команды, структуры данных, программные модули или другие данные. Компьютерный носитель данных включает в себя, но не в ограничительном смысле, ОЗУ, ПЗУ, электрически стираемое перепрограммируемое ПЗУ (EEPROM), флеш-память или другой тип памяти, CD-ROM, цифровые универсальные диски (DVD) или другие оптические дисковые носители, магнитные кассеты, магнитную ленту, магнитные дисковые носители, или другие магнитные запоминающие устройства, или любые другие носители, которые могут быть использованы для хранения необходимой информации и к которым компьютер 120 может осуществить доступ.
Среда передачи обычно воплощает машиночитаемые команды, структуры данных, модули программ или другие данные в сигнале, модулированном данными, таком как сигнал несущей или другой транспортный механизм, и включает в себя любую среду доставки информации. Термин “сигнал, модулированный данными” обозначает сигнал, имеющий одну или более его характеристик, заданных или измененных таким способом, чтобы обеспечить кодирование информации в сигнале. В качестве примера, но не ограничения, среда передачи включает в себя проводную среду, такую как проводная сеть или прямое проводное соединение и беспроводную среду, такую как акустическая, радиочастотная, инфракрасная и другая беспроводная среда. Сочетания любых из вышеперечисленных носителей также включены в спектр машиночитаемых носителей.
Системная память 150 включает в себя компьютерные носители данных в форме энергозависимой и/или энергонезависимой памяти, такой как постоянное запоминающее устройство (ПЗУ) 151 и оперативное запоминающее устройство (ОЗУ) 152. Базовая система 153 ввода/вывода (BIOS), содержащая базовые процедуры, помогающие передавать информацию между элементами внутри компьютера 120, например, при включении, обычно хранится в ПЗУ 151. ОЗУ 152 обычно содержит данные и/или программные модули, являющиеся оперативно доступными для блока 140 обработки и/или уже обрабатываются им. В качестве примера, но не ограничения, на фиг.5 показаны операционная система 154, прикладные программы 155, другие программные модули 156 и данные 157 программ.
Компьютер 120 может также включать в себя другие съемные/несъемные энергозависимые/энергонезависимые компьютерные носители данных. Только для примера на фиг.5 показан накопитель 161 на жестких магнитных дисках, считывающий с несъемного энергонезависимого магнитного носителя или записывающий на него, привод 171 магнитного диска, считывающий со съемного энергонезависимого магнитного диска 172 или записывающий на него, и привод 175 оптического диска, считывающий со съемного энергонезависимого оптического диска 176, такого как CD-ROM или другой оптический носитель, или записывающий на него. Другие съемные/несъемные энергозависимые/энергонезависимые компьютерные носители данных, которые могут быть использованы в иллюстративной операционной среде, включают в себя, но не в ограничительном смысле, кассеты с магнитной пленкой, платы флеш-памяти, цифровые универсальные диски, цифровую видеоленту, твердотельное ОЗУ, твердотельное ПЗУ и т.п. Накопитель 161 на жестких магнитных дисках обычно присоединяют к системной шине 141 через интерфейс несъемной памяти, такой как интерфейс 160, а привод 171 магнитного диска и привод 175 оптического диска обычно соединяют с системной шиной 141 интерфейсом съемной памяти, таким как интерфейс 170.
Приводы и связанные с ними компьютерные носители данных, описанные выше со ссылкой на фиг.5, обеспечивают хранение машиночитаемых команд, структур данных, программных модулей и других данных для компьютера 120. На фиг.5, например, накопитель 161 на жестких магнитных дисках показан как хранящий операционную систему 164, прикладные программы 165, другие программные модули 166 и данные 167 программ. Следует отметить, что эти компоненты могут как совпадать, так и отличаться от операционной системы 154, прикладных программ 155, других программных модулей 156 и данных 157 программ. Операционной системе 164, прикладным программам 165, другим программным модулям 166 и данным 167 программ присвоены здесь другие ссылочные позиции, чтобы показать, что они как минимум являются другими копиями.
Пользователь может вводить команды или информацию в компьютер 120 через устройства ввода, такие как клавиатура 182, микрофон 183 и указывающее устройство, такое как мышь, трекбол или сенсорная панель. Другие устройства ввода (не показаны) могут включать в себя джойстик, игровую клавиатуру, спутниковую параболическую антенну, сканер и т.п. Эти и другие устройства ввода, как правило, соединяются с блоком 140 обработки через интерфейс 180 пользовательского ввода, соединенный с системной шиной, но могут быть соединены и посредством других интерфейсов и структур шин, таких как параллельный порт, игровой порт или универсальная последовательная шина (USB). Монитор 184 или устройство отображения другого типа также соединены с системной шиной 141 через интерфейс, такой как видеоинтерфейс 185. Кроме монитора, компьютер может также включать в себя другие периферийные устройства вывода, такие как громкоговорители 187 и принтер 186, которые могут быть соединены через выходной периферийный интерфейс 188.
Компьютер 120 может функционировать в сетевой среде, используя логические соединения с одним или более удаленными компьютерами, такими как удаленный компьютер 194. Удаленный компьютер 194 может быть персональным компьютером, карманным компьютером, сервером, маршрутизатором, сетевым ПК, одноранговым устройством или другим обычным сетевым узлом и обычно включает многие или все элементы, описанные выше в связи с компьютером 120. Логические соединения, обозначенные на фиг.5, включают в себя локальную сеть (LAN) 191 и глобальную сеть (WAN) 193, но могут также включать и другие сети. Такие сетевые среды обычно характерны для офисов, компьютерных сетей масштаба предприятия, интрасетей и сети Интернет.
При использовании в сетевой среде LAN компьютер 120 соединен с LAN 191 через сетевой интерфейс или адаптер 190. При использовании в сетевой среде WAN компьютер 120 обычно включает в себя модем 192 или другие средства для установления связи через WAN 193, такую как Интернет. Модем 192, который может быть или внешним или внутренним, может быть соединен с системной шиной 141 через интерфейс 180 пользовательского ввода или через другие подходящие средства. В сетевой среде программные модули, изображенные в соотношении компьютера 120 или его частей, могут храниться в удаленном запоминающем устройстве. В качестве примера, но не ограничения, фиг.5 показывает удаленные прикладные программы 195, как находящиеся на удаленном компьютере 194. Следует понимать, что показанные сетевые соединения, являются иллюстративными и можно использовать другие средства установления линии связи между компьютерами.
Фиг.6 показывает архитектуру 200 для распознавания, основанного на web, и воспроизведения данных, которая является одной иллюстративной средой настоящего изобретения. В общем случае, к информации, хранящейся на web-сервере 202, может быть осуществлен доступ через клиента 100, такого как мобильное устройство 30 или компьютер 120 (которые представляют здесь другие формы вычислительных устройств, имеющих экран дисплея, микрофон, камеру, сенсорную панель и т.п., как того требует форма ввода данных) или через телефон 80, в котором информация запрашивается в слышимой форме или через тоны, вырабатываемые телефоном 80 в соответствии с нажатием клавиш, и в котором информация от web-сервера 202 возвращается к пользователю только в слышимом виде.
В этом варианте воплощения архитектура 200 унифицирована в том плане, что при получении информации через клиента 100 или через телефон 80 с использованием распознавания один сервер 204 распознавания может поддерживать любой режим функционирования. Кроме того, архитектура 200 функционирует с использованием расширения широко известных языков разметки (например, HTML, XHTML, cHTML, XML, WML и т.п.). Таким образом, к информации, хранящейся на web-сервере 202, может быть также осуществлен доступ с использованием широко известных способов на основе графического интерфейса пользователя (GUI), включенных в эти языки разметки. Путем использования расширения широко известных языков разметки облегчается авторская разработка на web-сервере 202 и текущие приложения могут быть также легко модифицированы для включения распознавания голоса.
В общем случае клиент 100 выполняет HTML страницы, программы на макроязыке и т.п., в общем показанные позицией 206, предоставляемые web-сервером 202, используя браузер. Если требуется распознавание голоса, например речевых данных, которые могут быть оцифрованными звуковыми сигналами или признаками речи, в которой звуковые сигналы, предварительно обработанные клиентом 100, как описано выше, подаются на сервер 204 распознавания с указанием грамматической и языковой модели 220 для использования при распознавании речи, которая может быть обеспечена клиентом 100. Как вариант, речевой сервер 204 может включать в себя языковую модель 220. Реализация сервера 204 распознавания может быть различной по форме, одна из которых показана, но в общем случае он включает в себя средство распознавания 211. Результаты распознавания передаются назад клиенту 100 для локального воспроизведения при желании или необходимости. При желании модуль 222 преобразования "текст-в-речь" может быть использован для предоставления озвученного текста клиенту 100. После компиляции информации путем распознавания и любого графического интерфейса пользователя, если используется, клиент 100 при необходимости посылает информацию на web-сервер 202 для дальнейшей обработки и получения дополнительных HTML страниц/программ на макроязыке.
Как показано на фиг.6, клиент 100, web-сервер 202 и сервер 204 распознавания обычно соединены между собой при раздельной адресации через сеть 205, которой в рассматриваемом случае является глобальная сеть, такая как Интернет. Следовательно, нет необходимости, чтобы эти устройства физически были расположены в непосредственной близости друг от друга. В частности, нет необходимости в том, чтобы web-сервер 202 включал в себя сервер 204 распознавания. Таким образом, авторская разработка на web-сервере 202 может быть сосредоточена на приложении, для которого он предназначен, без необходимости для авторов знать о сложностях сервера 204 распознавания. Напротив, сервер 204 распознавания может быть независимо сконструирован и соединен с сетью 205 и, таким образом, может обновляться и усовершенствоваться без дополнительных изменений, требующихся на web-сервере 202. Web-сервер 202 может также включать в себя средство авторской разработки, которое может динамически генерировать разметку и программы на макроязыке на стороне клиента. В еще одном варианте воплощения web-сервер 202, сервер 204 распознавания и клиент 100 могут быть объединены в зависимости от вычислительных возможностей реализующих их машин. Например, если клиент 100 включает в себя компьютер общего назначения, например персональный компьютер, то клиент может включать в себя сервер 204 распознавания. Точно так же при желании web-сервер 202 и сервер 204 распознавания могут быть объединены на одной машине.
Доступ к web-серверу 202 по телефону 80 включает в себя соединение телефона 80 с проводной или беспроводной телефонной сетью 208, которая в свою очередь соединяет телефон 80 со шлюзом 210 третьей стороны. Шлюз 210 соединяет телефон 80 с телефонным голосовым браузером 212. Телефонный голосовой браузер 212 включает в себя мультимедийный сервер 214, который обеспечивает телефонный интерфейс и голосовой браузер 216. Так же как и клиент 100, телефонный голосовой браузер 212 принимает HTML страницы/программы на макроязыке и т.п. с web-сервера 202. В одном варианте воплощения HTML страницы/программы на макроязыке используются в форме, похожей на HTML страницы/программы на макроязыке, используемые клиентом 100. Таким образом, web-серверу 202 не требуется поддерживать клиента 100 и телефон 80 по отдельности или даже отдельно поддерживать стандартных клиентов GUI. Напротив, можно было использовать обычный язык разметки. Кроме того, как и в случае клиента 100, для распознавания голоса из звуковых сигналов, передаваемых телефоном 80, эти сигналы передаются от голосового браузера 216 на сервер 204 распознавания либо через сеть 205, либо по выделенной линии 207, например, используя протокол TCP/IP (управления передачей/межсетевой протокол). Web-сервер 202, сервер 204 распознавания и телефонный голосовой браузер 212 могут быть осуществлены в любой подходящей вычислительной среде, такой как настольный компьютер общего назначения, показанный на фиг.5.
Описав различные среды и архитектуры, функционирующие в системе 10, приводим более подробное описание различных компонентов и функций системы 10. Фиг.7 показывает блок-схему модуля 14 распознавания и восприятия речи. Входные речевые данные, принятые от модуля 12 речевого интерфейса, посылаются на модуль 14 распознавания и восприятия речи. Модуль 14 распознавания и восприятия речи включает в себя средство 306 распознавания, которое имеет связанную с ним языковую модель 310. Средство 306 распознавания использует языковую модель 310 для идентификации возможных поверхностно-семантических структур для представления соответствующих входных данных. Средство 306 распознавания обеспечивает, по меньшей мере, один поверхностно-семантический объект, основанный на вводимых речевых данных. В некоторых вариантах воплощения средство 306 распознавания может обеспечить более чем один альтернативный поверхностно-семантический объект для каждой альтернативной структуры.
Хотя на фиг.7 представлен ввод речевых данных, настоящее изобретение может быть использовано с распознаванием почерка, распознаванием жестов или с графическим интерфейсом пользователя (где пользователь взаимодействует с клавиатурой или другим устройством ввода). В этих отличных от предыдущих вариантах воплощения средство 306 распознавания речи заменяется подходящим средством распознавания, что известно из данного уровня техники. Для графических интерфейсов пользователя грамматика (имеющая языковую модель) связывается с пользовательским вводом данных, например, осуществляемым через окно ввода. Соответственно, вводимые пользователем данные обрабатываются согласованным путем без значительного изменения, основанного на способе ввода.
Для пользовательского ввода данных, основывающегося на языке, таких как речь и рукописный текст, языковая модель 310, используемая средством 306 распознавания, может быть любой из набора известных стохастических моделей. Например, языковая модель может быть N-граммной моделью, которая моделирует вероятность нахождения слова в языке при заданной группе из N предшествующих слов во входных данных. Языковая модель может также быть бесконтекстной грамматикой, которая связывает семантическую и/или синтаксическую информацию с конкретными словами и фразами. В еще одном варианте воплощения настоящего изобретения используется унифицированная языковая модель, которая объединяет N-граммную языковую модель с бесконтекстной грамматикой. В этой унифицированной модели семантические и/или синтаксические лексемы обрабатываются как веса разряда для слов и N-граммная вероятность вычисляется для каждой гипотетической комбинации слов и лексем.
Языковая модель 310 может генерировать иерархическую поверхностно-семантическую структуру на основе информации, необходимой для модуля 16 воспроизведения данных для воспроизведения релевантной информации как функции предоставляемых объектов. В одном варианте воплощения вводимая речь анализируется на предмет идентификации различных семантических лексем или объектов внутри вводимого текста. Объекты идентифицируются на основе набора объектов, найденных в языковой модели 310. В общем случае объекты представляют информацию, используемую модулем 16 воспроизведения данных для воспроизведения информации. Как описано ниже, объекты могут включать в себя объекты запроса, объекты навигации и/или объекты команд. Объекты запроса содержат информацию, относящуюся к данным, хранящимся в базе данных 18. Объекты навигации содержат информацию, используемую при перемещении (навигации) по хранящейся информации, в то время как объекты команд могут осуществлять различные команды на основе хранящейся информации.
Модуль 14 распознания и восприятия речи может также использовать контроль 312 стиля для распознавания альтернативных фраз для идентификации объектов во вводимой речи. Контроль 312 стиля связан с языковой моделью 310 для помощи в предоставлении релевантных объектов для модуля 16 воспроизведения данных. В среде, показанной на фиг.6, информация, относящаяся к контролю 312 стиля, может быть воплощена автором приложения на web-сервере 202, используя средства авторской разработки, такие как ASP.NET, разработанные Microsoft Corporation, Redmond, Washington. Как вариант, могут использоваться и другие средства авторской разработки, такие как JSP, J2EE, J2SE, J2ME и т.п. Например, фраза "Каково расстояние до моего следующего поворота?" может быть "стилизована" во фразу "Как далеко до моего следующего поворота?". Кроме того, "Каково направление моего следующего поворота?" может быть перефразировано как "В какую сторону мой следующий поворот?" или "В каком направлении мой следующий поворот?". Таким образом, контроль 312 стиля может быть использован для идентификации релевантных данных в базе данных 18 и также для идентификации подходящих ответов для предоставления пользователю.
В случае, если пользователь вводит речь, которую не может распознать языковая модель, система может предложить пользователю повторить ввод. Однако, если система не имеет информации, относящейся к входным данным на основе семантической информации во входных данных или отсутствия ввода, система может исполнять подходящую процедуру помощи, выдающую инструкции пользователю в отношении доступных опций.
Фиг.8 подробно показывает блок-схему модуля 16 воспроизведения данных. Модуль 16 воспроизведения данных включает в себя модуль 602 командного оператора, модуль 604 анализатора/нормализатора текста, модуль 606 интерфейса базы данных, модуль 607 генератора ответов, модуль 608 звукового интерфейса, модуль 610 видеоинтерфейса и модуль 612 преобразования "текст-в-речь". Модуль 16 воспроизведения данных принимает объекты от модуля 14 распознавания и восприятия речи и обеспечивает вывод (звуковой и/или визуальный) релевантной информации для пользователя. Как упоминалось ранее, ключевые слова или фразы идентифицируются модулем 14 распознавания и восприятия речи, который предоставляет объект как их функцию. Модуль 16 воспроизведения данных интерпретирует объекты, принятые от модуля 14 распознавания и восприятия речи, для поиска и/или извлечения данных из базы данных 18, используя интерфейс 606 базы данных. Интерфейс 606 базы данных включает в себя информацию, относящуюся к структуре или схеме данных, хранящихся в базе данных 18. Следует отметить, что интерфейс 606 базы данных может быть модулем общего назначения, который может осуществлять доступ к данным многочисленных различных источников, например локального компьютера или web-сервера, расположенного в глобальной сети. Для извлечения релевантной информации модуль 16 воспроизведения данных связывает объекты, принятые от модуля 14 распознавания и восприятия речи, с тэгами или идентификаторами, соответствующими хранящейся информации в базе данных 18.
В некоторых примерах данные, хранящиеся в базе данных 18, уже включают в себя различные тэги или идентификаторы, соответствующие типу информации или структуре информации в базе данных 18. В других примерах анализатор/нормализатор 604 текста может быть использован для генерирования тэгов или для идентификации релевантной информации в данных иным способом. Дополнительная обработка данных может осуществляться до воспроизведения релевантной информации пользователю. Например, командный оператор 602 может быть использован для обработки различных комбинаций данных, полученных из базы данных 18, на основе принятых объектов.
Как только релевантная информация обработана в соответствии с запросом пользователя, данные направляются в генератор 607 ответа. Генератор 607 ответа может вырабатывать подходящий ответ в ответ на вводимые пользователем данные. Генератор 607 ответа затем посылает данные в звуковой интерфейс 608 и/или видеоинтерфейс 610 для воспроизведения пользователю. Модуль преобразования 612 "текст-в-речь" в звуковом интерфейсе 608 может быть использован для воспроизведения данных в слышимой форме.
Фиг.9 схематично показывает таблицу 650 в базе данных 18, которая может быть выборочно воспроизведена по запросу пользователя. Таблица 650 показывает курсы акций различных компаний на конец каждого квартала 2002 года. Таблица 650 включает названия компаний, хранящиеся в строках 652, столбцы 654 для каждого квартала 2002 года и курсы 656 акций для столбцов и строк. Тэги, связанные с таблицей 650, соответствуют столбцам и строкам. Объекты 660 запроса и объекты 662 навигации определяются языковой моделью 310 для воспроизведения данных в таблице 650.
Для того чтобы выборочно воспроизводить данные в таблице 650, пользователь посылает запрос, включающий в себя объекты 660 запроса и/или объекты 662 навигации. Запрос интерпретируется модулем 14 распознавания и восприятия для идентификации релевантных объектов запроса и навигации. Затем объекты связывают тэгами, соответствующими столбцам и строкам.
Объекты 660 запроса могут быть использованы для воспроизведения информации из конкретной ячейки в таблице 650. Например, голосовым запросом может быть "Какой был курс акций Microsoft на конец второго квартала?". В этом случае модуль 14 восприятия речи предоставляет объекты запроса "Microsoft" и "квартал 2" для модуля 16 воспроизведения данных. Используя эти объекты, модуль 16 воспроизведения данных связывает эти объекты с тэгами базы данных 18 для определения соответствующей ячейки (показана как заштрихованная ячейка в таблице 650), которую и следует воспроизвести. В этом случае "Microsoft" является объектом запроса, содержащим информацию, относящуюся к объекту <название компании> (<company name>), а "квартал 2" является объектом запроса, содержащим информацию, относящуюся к объекту <квартал> (<quarters>).
"Microsoft" связывают с тэгом, соответствующим строке, обозначенной "MSFT", а "квартал 2" связывают с тэгом, соответствующим столбцу, обозначенному "Q2". После связывания объектов с подходящими тэгами курс акций "54,12" передается на генератор 607 ответа. Ответ может быть сгенерирован с использованием релевантной информации и воспроизведен пользователю, используя звуковой интерфейс 608 и/или видеоинтерфейс 610. Например, воспроизводимый ответ может быть "курс акций Microsoft на конец второго квартала был пятьдесят четыре доллара двенадцать центов".
В этом примере генератор 607 ответа принимает значение "54,12" и использует это значение в сочетании с хранящимся контекстом для воспроизведения извлеченных данных. В этом примере хранящимся контекстом является "Курс акций <название компании> на конец <квартала> был <результат>", где <квартал> и <результат> (<results>) были также нормализованы. Контекст, используемый для воспроизведения извлеченных данных, может быть на индивидуальной основе связан с тэгами или идентификаторами для данных, как это необходимо и/или как функция объектов. Если используются визуальные выходные данные, то генератор 607 ответа может обеспечивать указания того, как следует визуально отобразить извлеченные данные.
Кроме того, объекты 660 запроса могут включать в себя объекты, которые будут воспроизводить целиком строки или целиком столбцы. Например, пользователь может спросить "Каков курс акций Microsoft на конец каждого квартала 2002 года?". В этом примере модуль 16 воспроизведения данных будет воспроизводить пользователю каждое из значений курса акций Microsoft в 2002 году.
Объекты 662 навигации могут быть использованы для того, чтобы пользователь выполнял навигацию по таблице 650 в нужную позицию в таблице. Например, пользователь после запроса курса акций Microsoft на конец второго квартала может спросить "Каков курс акций Microsoft на конец следующего квартала?". В этом случае модуль 14 распознавания и восприятия речи будет идентифицировать объекты "Microsoft" и "следующий квартал". Эти объекты будут связаны с тэгом для строки "Microsoft" и с тэгом следующего столбца, например столбца "Q3". В результате будут переданы данные для следующего квартала в строке Microsoft.
Различные интерфейсы прикладного программирования для речи могут быть использованы для реализации настоящего изобретения. Одним из таких интерфейсов может быть, например, Интерфейс Программирования Речевых Приложений (SAPI), разработанный Microsoft Corporation, Redmond, Washington. Кроме того, настоящее изобретение может быть воплощено с использованием расширения языка разметки, такого как спецификация языковых тэгов для речевых приложений (SALT). SALT является разрабатываемым стандартом, позволяющим осуществлять доступ к информации, приложениям и web-службам, например, с персональных компьютеров, телефонов, планшетных персональных компьютеров и беспроводных мобильных устройств. SALT расширяет языки разметки, такие как HTML, XHTML и XML. Спецификацию SALT 1.0 можно посмотреть в интерактивном режиме по адресу http://www.SALTforum.org. Следует отметить, что SALT может обеспечивать семантическую информацию на основе вводимых пользователем данных, например, от речевого сервера 204, причем такая информация формирует объекты, передаваемые в модуль 16 воспроизведения данных. Как будет раскрыто далее, использование расширений SALT или подобных расширений обеспечивает поддержку для взаимодействия пользователя, управляемого на основе событий, для выборочного воспроизведения данных.
Фиг.10А-10С показывают иллюстративный код XML (расширяемого языка разметки), использующий SALT для воспроизведения данных в таблице 650, как описано выше. Как показано на фиг.10А, код включает в себя часть 670 заголовка, часть 672 данных и часть 674 ввода данных. Часть 670 заголовка включает в себя различную информацию для инициализации и установления элементов web-страницы или приложения. Часть 672 данных представляет данные таблицы 650 с различными тэгами. Например, часть 672 данных включает тэг 676 для <компании> (<company>), который указывает строку, тэг 677 для <названия> (<name>) и тэг 678 для <Q2>, где <name>, <Q1>, <Q2> и т.д. обозначают столбцы. Хотя здесь показано, что часть 672 данных включает в себя информацию для воспроизведения, часть 672 данных может включать в себя связи с другими местоположениями, где имеется информация, например, с использованием Унифицированного Указателя Ресурсов (URL). Часть 674 ввода данных определяет различные виды ввода данных, ожидаемые от пользователя.
Фиг.10В продолжает код для воспроизведения данных в таблице 650. На фиг.10В различные тэги речевых приложений обозначены тэгом "SALT". Например, тэги включают в себя тэг 680 "прослушивания" (listen), тэг 682 “грамматики” (grammar) и тэги 684 и 686 “приглашения” (prompt). Тэг 680 прослушивания используется при вводе речи. Тэг прослушивания конфигурирует средство распознавания речи, выполняет распознавание и обрабатывает события при вводе речи. Тэг 682 грамматики используется для задания грамматики, используемой при распознавании. Таким образом, грамматика 682 идентифицирует языковую модель. В этом примере часть 688, относящаяся к правилу грамматики (rule), была определена для различных названий компаний в таблице 650, а часть 690 правил была определена для каждого квартала в таблице 650. Тэги 684 и 686 приглашения используются для задания выходных данных системы, например контекста, как описано выше. Тэгами приглашения могут быть простой текст, разметка речевых выходных данных, переменные величины, связи со звуковыми файлами или комбинации вышеперечисленного. Функции и/или способы программирования на макроязыке могут также быть использованы для форматирования извлеченных данных, как описано далее. Приглашение 684 генерирует ответ на основе запроса пользователя и функционирует как генератор 607 ответа, показанный на фиг.8. Приглашение 686 запрашивает пользователя о вводе запроса.
Фиг.10C продолжает код с фиг.10В и включает в себя программу 692 на макроязыке для воспроизведения релевантной информации на основе голосового запроса пользователя. Программа 692 на макроязыке идентифицирует релевантную ячейку, которая подлежит воспроизведению, и вызывает приглашение 684 для воспроизведения на основе идентифицированных объектов и связи между объектами и тэгами, соответствующими данным в части 672 данных. Этот пример также показывает поддержку событий и размещение вложенной программы на макроязыке, причем после активации распознавания и идентификации объектов функция вызывается или выполняется в части 692 программы на макроязыке для выборочного воспроизведения данных.
Модуль 16 воспроизведения данных также исключительно полезен при создании диалога между компьютером и пользователем. Диалог, в частности, применим при сценарии, в котором пользователь хочет извлечь части информации, хранящейся в базе данных, по запросу. Одним из таких сценариев является воспроизведение направлений движения. Фиг.11 показывает таблицу 700, которая включает примеры направлений движения. Таблица 700 состоит из множества строк 702 и множества столбцов 704. Каждая строка 702 представляет поворот в направлениях движения, в то время как каждый из столбцов 704 представляет конкретную информацию о каждом повороте. Дополнительная информация, обозначенная позицией 706, может также быть связана с таблицей 700. Дополнительная информация 706 показана как общие значения по маршруту, но может включать в себя и другую информацию или связи с другой информацией. В одном варианте воплощения обеспечивается информация о расположенных поблизости предприятиях, таких как банки и рестораны. Множество объектов 708 запроса и множество объектов 710 навигации также связаны с таблицей 700.
При воспроизведении направлений движения пользователю модуль 16 воспроизведения данных может по умолчанию отображать первую строку (поворот) информации. Модуль 16 воспроизведения данных может быть запрограммирован для воспроизведения всей совокупности или части данных пользователю о первом повороте. Например, при наличии информации в первой строке направлений генератор 607 ответа может воспроизвести пользователю в слышимой форме "Сверните налево на Конкорд Авеню через 0,5 мили". Далее пользователь может запросить дополнительную информацию о повороте, такую как "Какой столб с указателем мне следует искать?". Как вариант, пользователь может попросить повторить воспроизведение части информации о повороте. Например, пользователь может спросить "В каком направлении мне следует повернуть?". В этом случае объект направления связывают с тэгом текущего направления, а именно "лево" (lett). Модуль 16 воспроизведения данных извлекает релевантную информацию из таблицы 700 и воспроизводит подходящий ответ, такой как "Поверните налево", где "лево" было получено из первой строки и первого столбца. Если пользователь хочет услышать о следующем повороте, то пользователь может послать запрос, такой как "Где следующий поворот?".
Используя объекты 710 навигации, модуль 16 воспроизведения данных может воспроизводить релевантную информацию о поворотах относительно текущего местоположения. Например, пользователь может спросить "Как называется улица, на которую я должен повернуть в следующий раз?". Объект навигации "следующая" (next) будет связан с тэгом для следующего поворота (то есть строкой) при заданном его текущем положении в таблице 700, и объект запроса, относящийся к названию улицы, будет связан с соответствующим столбцом, и релевантная информация будет воспроизведена.
В любой момент времени пользователь может осуществить доступ к любой части таблицы 700, используя соответствующий запрос, обеспечивающий соответствующие объекты. Кроме того, пользователь может осуществить доступ к общему расстоянию и приблизительному времени 706 пути при соответствующем запросе, связанном с объектом <общий> (total). Как вариант, запрос может затребовать новый набор направлений движения на основе текущего местоположения и вводимых пользователем данных. Например, пользователь может произнести "Пожалуйста, проведите меня к ближайшему мексиканскому ресторану". Эта вводимая информация будет интерпретирована для генерирования нового набора направлений движения, основанного на текущем положении, и данных, обеспечивающих адрес ближайшего мексиканского ресторана. Соответственно, языковая модель, связанная с направлениями движения, может быть расширена для распознавания различных объектов запроса, навигации или команд, основанных на этой информации, и, при необходимости, исполнения кода, например, программ на макроязыке, которые собирали бы новые данные, содержащиеся в удаленных базах данных, которые будут использоваться для доступа к удаленной информации. Система может также получать новые языковые модели для выборочного отображения новых данных. В одном варианте воплощения ранее воспроизведенные данные (например, таблица 700) из, например, страницы на языке разметки или другого кода могут быть сохранены с отмеченным текущим положением, так что при завершении воспроизведения новой информации система может вернуться к воспроизведению предыдущей информации (например, таблицы 700) с ее текущего положения.
Модуль 16 воспроизведения данных может быть также использован для выполнения специальных команд. Фиг.12 схематично показывает данные как таблицы 750 и 752, которые включают в себя данные о продажах товаров соответственно в 2001 и 2002 годах. В добавлении к запрашиванию отдельных ячеек и навигации по таблице, как описано выше, пользователь может запросить информацию, используя команды, обрабатывающие данные в таблицах 750 и 752, для воспроизведения описанной информации. Все объекты 760 запроса, объекты 762 навигации и объекты 764 команд используются при воспроизведении данных из таблицы 750 и 752. Используя объекты 764 команд, пользователь может выборочно воспроизводить релевантную информацию на основе информации в таблицах 750 и 752 и выполнять команду, основанную на такой информации.
Например, при использовании объекта <сравнить> (<compare>) пользователь может запросить "Пожалуйста, предоставьте мне данные о продажах в отношении детали 1001 в первом квартале 2001 года и в первом квартале 2002 года". При таком запросе модуль 16 воспроизведения данных выборочно воспроизведет величины "$3048,26" и "$4125,06" с дополнительным контекстом или без него. В одном варианте воплощения величины могут быть отображены рядом для простого сравнения пользователем либо могут быть воспроизведены в слышимой форме.
Командный оператор 602, используя объекты 764 команд, может также вычислять данные на основе запроса пользователя. Например, пользователь может спросить "Пожалуйста, сложите продажи детали 1001 в первом квартале 2002 года и во втором квартале 2002 года". Эта команда использует объект <сложить> (<add>), который был также идентифицирован на основе вводимой пользователем информации. В этом случае интерфейс 606 базы данных извлечет значения информации в отношении детали 1001 в релевантных кварталах 2002 года и пошлет релевантные данные к командному оператору 602. Затем командный оператор 602 складывает значения друг с другом и посылает результаты генератору 607 ответа, который воспроизводит данные, используя звуковой интерфейс 608 и/или видеоинтерфейс 610. Командный оператор 602 может также складывать более двух величин, например целую строку информации. Также можно использовать и другие команды, в зависимости от конкретных приложений. Например, <вычесть> (<subtract>) и <взять процент> (<percent>) могут воспроизводить величины, основанные на двух или более значениях данных.
Модуль 16 воспроизведения данных может также выборочно воспроизводить неструктурированные данные, например абзацы текста, которые могут в исходном виде находиться в базе данных 18 в качестве звукового файла, или рукописно вводимую информацию с соответствующим преобразованием. Фиг.13 показывает абзац 800 текста, относящегося к отчету об уровне цен на бирже. Объекты 802 запроса и объекты 804 навигации определяют для выборочного воспроизведения абзаца 800 на основе голосового ввода пользователя. Для выборочного воспроизведения абзаца 800 различные тэги должны соответствовать релевантной информации внутри абзаца 800. В одном варианте воплощения нормализатор/анализатор 604 текста используется для идентификации релевантных частей абзаца 800 и генерирования различных тэгов на основе релевантных частей. Например, нормализатор/анализатор 604 может идентифицировать предложения (аналогично строкам таблицы, как это пояснено выше), числа, названия компаний и т.п. Обработка может включать в себя индивидуализированную семантическую информацию для частей данных.
Как только абзац 800 предварительно обработан для идентификации релевантных тэгов, абзац 800 может быть воспроизведен. Первоначально модуль 16 воспроизведения данных начинает воспроизводить первое предложение текста. При молчании пользователя или распознавании "следующего" объекта навигации модуль воспроизведения данных начнет воспроизведение следующего предложения.
Пользователь может также запросить воспроизведение определенных частей абзаца 800. Например, пользователь может запросить повторить последний биржевой индекс, используя запрос, такой как "Каким был последний биржевой индекс?". Как только объект <биржевой индекс> (<stock index>) идентифицируется модулем 14 распознавания и восприятия речи, модуль 16 воспроизведения данных свяжет этот объект с тэгом в абзаце 800. Например, после воспроизведения первого предложения абзаца 800 модуль 16 воспроизведения данных свяжет объект биржевого индекса с тэгом, соответствующим "Стандартному и Низкому пятисотенному Биржевому индексу". Таким образом, после воспроизведения сегмента информации (то есть предложения), может быть воспроизведена часть этого сегмента на основе голосового ввода пользователя. Следует понимать, что любая часть абзаца может быть извлечена, используя подходящий запрос, обеспечивающий соответствующие объекты для доступа к необходимой информации. Эта методика обработки неструктурированных данных с последующим разрешением пользователю посылать запросы, осуществлять навигацию и обеспечивать команды может быть легко расширена для воспроизведения целой газеты, журнала или других источников информации. Такая методика может быть дополнена определенной иерархической структурой (например, такими газетными разделами, как спортивный раздел, деловой раздел, раздел метро и т.п.) для воспроизведения информации. Тем не менее, методика включает в себя идентификацию объектов, обеспечиваемых пользователем, и использование таких объектов для выборочного воспроизведения информации.
Фиг.14А-14D показывает иллюстративный код XML с SALT для воспроизведения абзаца 800. Со ссылкой на фиг.14А показаны часть 810 заголовка и часть 812 данных. Часть 810 заголовка включает данные для инициализации документа. Часть 812 данных показывает абзац 800 после его анализа и нормализации нормализатором/анализатором 604 текста. Как показано, различные тэги, такие как <предложение> (<sentence>), <название объекта = “биржевой индекс”> (<entity name = "stock index">) и <название объекта = “число”> (<entity name = "number">), связаны с частями абзаца 800.
Код продолжается на фиг.14В, где показаны различные языковые тэги речевого приложения. Например, код включает тэг 814 прослушивания, тэг 816 грамматики и ярлыки 818 и 820 приглашения. Тэг 814 прослушивания инициализирует средство распознавания речи и начинает идентифицировать объекты из голосовых входных данных пользователя. Тэг 816 грамматики инициализирует модель языка, которая в этом случае определяет правила 820 навигации и правила 822 запроса.
Фиг.14С показывает продолжение кода с фиг.14В. Тэг 826 программы на макроязыке идентифицирует начало части кода, соответствующей программе на макроязыке. Часть, соответствующая программе на макроязыке, включает различные функции для работы модуля 16 воспроизведения данных. Функция 828 исполнения команды распознает команды навигации или запроса и вызывает необходимые функции на основе распознанных объектов. Функция 830 инициализации начинает проигрывать абзац 800 с самого начала. Функция 832 перехода назад и функция 834 перехода вперед обеспечены соответственно для перехода назад на одно предложение или перехода к следующему предложению. На фиг.14D функция 836 извлечения элемента извлекает релевантную информацию из абзаца 800 на основе голосовых данных, вводимых пользователем. Средство 836 отображения отображает абзац 800, например, на экране.
Как определено выше, модуль 16 воспроизведения данных может также быть использован для воспроизведения других форм неструктурированного текста. Например, фиг.15 показывает сообщение 840 голосовой почты. Объекты 842 используются для воспроизведения частей сообщения. Для воспроизведения частей сообщения 840 голосовой почты интерфейс 606 базы данных (фиг.8) включает в себя средство распознавания речи для преобразования сообщения 840 голосовой почты в текст. После преобразования сообщения в текст используется нормализатор/анализатор 604 текста для идентификации релевантных частей сообщения голосовой почты. Например, нормализатор/анализатор 604 текста может идентифицировать человека, тему сообщения и/или числа, такие как телефонные номера. На основе этой идентификации генерируются тэги, подобные тэгам, описанным выше для абзаца 800. После воспроизведения сообщения голосовой почты или части сообщения голосовой почты пользователь может запросить повторение релевантных частей. Например, в сообщении голосовой почты по фиг.15 пользователь может запросить повтор телефонного номера или темы сообщения. Используя объекты 842, модуль 16 воспроизведения данных связывает объекты с тэгами, соответствующими данным в сообщении 840 голосовой почты. Запрошенные данные затем воспроизводятся.
В еще одном варианте воплощения множество сообщений голосовой почты могут обрабатываться для обеспечения выборочного доступа к каждому сообщению, используя объекты навигации. Объекты команд могут быть использованы для идентификации обратных вызовов и т.д., используя информацию в сообщении (например, номера телефонов) или путем доступа к другой информации, такой как список лиц, имеющих телефонные номера. В другом примере, со ссылкой на пример с направлениями движения по фиг.11, к информации, относящейся к ближайшим предприятиям, можно осуществить доступ в удаленных хранилищах информации и/или в удаленных приложениях.
Хотя настоящее изобретение описано со ссылкой на конкретные варианты воплощения, специалисту в данной области техники будет очевидно, что изменения могут быть выполнены в форме и деталях, не выходя за рамки сущности и объема настоящего изобретения.
Изобретение относится к доступу и воспроизведению информации в компьютерной системе, а более конкретно к представлению данных на основе голосового ввода, осуществляемого пользователем. Техническим результатом является расширение функциональных возможностей. Способ воспроизведения информации из документа пользователю на основе запроса заключается в выполнении этапов: воспроизводят данные в документе для пользователя, идентифицируют первый и второй объекты из запроса, осуществляют доступ к документу для идентификации семантических тэгов, связанных с текстом в документе, связывают первый объект с первым семантическим тэгом, соответствующим первой порции хранящегося текста в документе, и второй объект со вторым семантическим тэгом, соответствующим второй порции хранящегося текста в документе, при этом, по меньшей мере, одна из этих первой и второй порций хранящегося текста связана с данными в документе, которые были воспроизведены, идентифицируют третью порцию хранящегося текста, которая связана как с первой порцией, так и со второй порцией, и выборочно воспроизводят в слышимой форме третью порцию хранящегося текста. 3 н. и 30 з.п. ф-лы, 20 ил.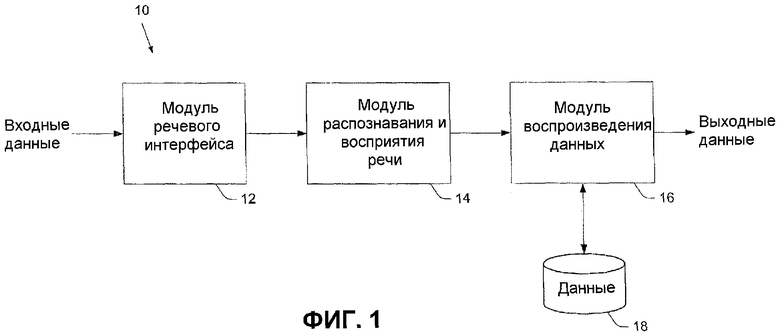
1. Способ воспроизведения информации из документа пользователю на основе запроса, включающий в себя этапы, на которых
воспроизводят данные в документе для пользователя,
идентифицируют первый объект и второй объект из запроса,
осуществляют доступ к документу для идентификации семантических тэгов, связанных с текстом в документе,
связывают первый объект с первым семантическим тэгом, соответствующим первой порции хранящегося текста в документе, и второй объект со вторым семантическим тэгом, соответствующим второй порции хранящегося текста в документе, при этом по меньшей мере одна из этих первой порции и второй порции хранящегося текста связана с данными в документе, которые были воспроизведены,
идентифицируют третью порцию хранящегося текста, которая связана как с первой порцией, так и со второй порцией, и
выборочно воспроизводят в слышимой форме третью порцию хранящегося текста.
2. Способ по п.1, дополнительно содержащий этапы, на которых
принимают второй запрос и
идентифицируют из второго запроса объект навигации, содержащий информацию для навигации по хранящемуся тексту.
3. Способ по п.1, в котором запрос дополнительно включает в себя объект команд, содержащий информацию для выполнения выбранной команды в отношении хранящегося текста.
4. Способ по п.1, в котором при идентификации первого объекта и второго объекта из запроса используют языковую модель для идентификации первого объекта и второго объекта.
5. Способ по п.4, в котором при идентификации первого объекта и второго объекта из запроса используют контроль стиля для распознавания альтернативных фраз для первого объекта и второго объекта.
6. Способ по п.1, в котором хранящийся текст организован в многомерную структуру, причем по меньшей мере один из первого объекта и второго объекта соответствует по меньшей мере одной размерности в этой многомерной структуре.
7. Способ по п.6, в котором многомерная структура является таблицей, включающей в себя множество строк и множество столбцов, при этом первый объект включает в себя информацию, относящуюся к конкретной строке, а второй объект включает в себя информацию, относящуюся к конкретному столбцу.
8. Способ по п.1, в котором выборочное воспроизведение в слышимой форме третьей порции хранящегося текста основывается на по меньшей мере одном из первого объекта и второго объекта.
9. Способ по п.8, в котором при выборочном воспроизведении в слышимой форме третьей порции хранящегося текста воспроизводят в слышимой форме третью порцию хранящегося текста в сочетании с хранящимся контекстом на основе первого объекта и второго объекта.
10. Способ по п.1, в котором запрос является речевым фрагментом.
11. Способ по п.1, в котором запрос включает в себя рукописные входные данные.
12. Способ по п.1, в котором при выборочном воспроизведении в слышимой форме третьей порции хранящегося текста исполняют программу на макроязыке для воспроизведения этой порции.
13. Способ воспроизведения информации пользователю на основе голосового запроса, включающий в себя этапы, на которых:
воспроизводят в слышимой форме сегмент текста пользователю, причем этот сегмент включает в себя семантические тэги, соответствующие частям данного сегмента,
принимают голосовой запрос от пользователя и идентифицируют по меньшей мере один семантический объект из этого запроса при воспроизведении сегмента текста в слышимой форме,
связывают упомянутый по меньшей мере один семантический объект с семантическим тэгом, соответствующим порции текста в сегменте, который воспроизведен в слышимой форме, и
воспроизводят в слышимой форме порцию текста в сегменте, соответствующую семантическому тэгу.
14. Способ по п.13, дополнительно включающий в себя этап, на котором выполняют анализ сегмента для идентификации семантических тэгов релевантной информации внутри сегмента.
15. Способ по п.14, в котором сегмент текста является речевыми данными.
16. Способ по п.13, в котором сегмент текста является предложением и семантические тэги соответствуют данным внутри этого предложения.
17. Способ по п.13, в котором сегмент текста является строкой и семантические тэги соответствуют столбцам в этой строке.
18. Способ по п.13, в котором по меньшей мере один семантический тэг соответствует имени собственному.
19. Способ по п.13, в котором по меньшей мере один семантический тэг соответствует числу.
20. Способ по п.19, в котором упомянутый по меньшей мере один семантический тэг соответствует телефонному номеру.
21. Способ по п.13, в котором по меньшей мере один семантический тэг соответствует части, относящейся к направлениям движения.
22. Способ по п.13, в котором при воспроизведении в слышимой форме порции текста в сегменте воспроизводят в слышимой форме порцию текста в сегменте в сочетании с хранящимся контекстом на основе первого объекта и второго объекта.
23. Способ по п.13, в котором запрос является речевым фрагментом.
24. Способ по п.13, в котором запрос включает в себя рукописные входные данные.
25. Способ по п.13, в котором при выборочном воспроизведении в слышимой форме порции текста в сегменте исполняют программу на макроязыке.
26. Способ предоставления информации пользователю, включающий в себя этапы, на которых:
идентифицируют первый объект, второй объект и объект команд из голосового запроса пользователя,
осуществляют доступ к хранящейся информации и связывают первый объект и второй объект с тэгами, соответствующими первой порции хранящейся информации и второй порции хранящейся информации,
формируют выходные данные в зависимости от значений, относящихся к первой и второй порциям хранящейся информации, на основе операции над данными, связанной с объектом команд, идентифицированным из голосового запроса пользователя, причем эти выходные данные не являются непосредственно находимыми в хранящейся информации, и
воспроизводят в слышимой форме сформированные выходные данные.
27. Способ по п.26, в котором операция над данными содержит сложение первой порции и второй порции.
28. Способ по п.26, в котором операция над данными содержит вычитание первой порции из второй порции.
29. Способ по п.26, в котором операция над данными содержит вычисление процентной доли на основе первой порции и второй порции.
30. Способ по п.26, в котором при связывании осуществляют доступ к базе данных, содержащей совокупность хранящейся информации, включая первую и вторую порции хранящейся информации, причем эта совокупность хранящейся информации включает в себя значения, хранящиеся в реляционной таблице в этой базе данных, причем упомянутые тэги соответствуют столбцам и строкам этой таблицы.
31. Способ по п.30, в котором первая и вторая порции хранящейся информации содержат первое и второе числовые значения, хранящиеся в упомянутой таблице, при этом операция над данными представляет собой математическую операцию, выполняемую в отношении первого и второго числовых значений для формирования результирующего числового значения.
32. Способ по п.31, в котором при воспроизведении сформированных выходных данных в слышимой форме воспроизводят в слышимой форме результирующее числовое значение.
33. Способ по п.30, дополнительно содержащий этапы, на которых идентифицируют объект навигации из голосового запроса пользователя и
идентифицируют тэг, соответствующий информации, хранящейся в упомянутой таблице, на основе объекта навигации и, в ответ на это, воспроизводят в слышимой форме данную информацию, хранящуюся в упомянутой таблице.
| US 6519562 B1, 11.02.2003 | |||
| СИСТЕМА ДВУСТОРОННЕЙ/ШИРОКОВЕЩАТЕЛЬНОЙ МОБИЛЬНОЙ И ПОРТАТИВНОЙ СПУТНИКОВОЙ СВЯЗИ | 1999 |
|
RU2192095C2 |
| Бетонная смесь | 1979 |
|
SU817002A1 |
| US 5666438 A, 09.09.1997 | |||
| US 6292833 В1, 18.09.2001 | |||
| Перекатываемый затвор для водоемов | 1922 |
|
SU2001A1 |
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |

