Заявление о преимуществе 35 U.S.C. §119
Настоящая Патентная заявка притязает на приоритет (a) Предварительной патентной заявки номер 60/721416, озаглавленной "A VIDEO TRANSCODER FOR REAL-TIME STREAMING AND MOBILE BROADCAST APPLICATIONS", зарегистрированной 27 сентября 2005 года, (b) Предварительной патентной заявки номер 60/789377, озаглавленной "A VIDEO TRANSCODER FOR REAL-TIME STREAMING AND MOBILE BROADCAST APPLICATIONS", зарегистрированной 4 апреля 2006 года, (c) Предварительной заявки номер 60/727643, озаглавленной "METHOD AND APPARATUS FOR SPATIO-TEMPORAL DEINTERLACING AIDED BY MOTION COMPENSATION FOR FIELD-BASED VIDEO", зарегистрированной 17 октября 2005 года, (d) Предварительной заявки номер 60/727644, озаглавленной "METHOD AND APPARATUS FOR SHOT DETECTION IN VIDEO STREAMING", зарегистрированной 17 октября 2005 года, (e) Предварительной заявки номер 60/727640, озаглавленной "A METHOD AND APPARATUS FOR USING AN ADAPTIVE GOP STRUCTURE IN VIDEO STREAMING", зарегистрированной 17 октября 2005 года, (f) Предварительной заявки номер 60/730145, озаглавленной "INVERSE TELECINE ALGORITHM BASED ON STATE MACHINE", зарегистрированной 24 октября 2005 года, и (g) Предварительной заявки номер 60/789048, озаглавленной "SPATIO-TEMPORAL DEINTERLACING AIDED BY MOTION COMPENSATION FOR FIELD-BASED MULTIMEDIA DATA", зарегистрированной 3 апреля 2006 года. Все семь этих предварительных патентных заявок назначены ее правопреемнику и тем самым полностью содержатся в данном документе по ссылке.
Ссылка на находящиеся одновременно на рассмотрении Заявки на патент
Настоящая заявка на патент связана с патентной заявкой (США) № 11/373577, озаглавленной "CONTENT CLASSIFICATION FOR MULTIMEDIA PROCESSING", зарегистрированной 10 марта 2006 года, назначенной правопреемнику этой заявки и таким образом явно содержащейся в данном документе по ссылке.
Уровень техники
Область техники, к которой относится изобретение
Настоящая заявка направлена на устройства и способы перекодирования видеоданных для потоковой передачи в реальном времени, а более конкретно к перекодированию видеоданных для потоковой передачи в реальном времени в мобильном широковещательном приложении.
Уровень техники
Эффективное видеосжатие используется во множестве мультимедийных приложений, таких как потоковая передача видео и видеотелефония, вследствие ограниченных ресурсов полосы пропускания и непостоянства доступной полосы пропускания. Конкретные стандарты кодирования видео, такие как MPEG-4 (ISO/IEC), H.264 (ITU) или аналогичное кодирование видео, предоставляют высокоэффективное кодирование, оптимально подходящее для таких приложений, как беспроводная широковещательная передача. Некоторые мультимедийные данные, например, цифровые телевизионные представления, как правило, кодируются согласно другим стандартам, таким как MPEG-2. Соответственно, транскодеры используются для того, чтобы перекодировать или преобразовывать мультимедийные данные, кодированные согласно одному стандарту (к примеру, MPEG-2), в другой стандарт (к примеру, H.264) до беспроводной широковещательной передачи.
Усовершенствованные оптимизированные по скорости кодеки могут предоставлять преимущества по устойчивости к ошибкам, восстановлению после ошибок и масштабируемости. Более того, применение информации, определенной из самих мультимедийных данных, также может предоставлять дополнительные усовершенствования по кодированию, в том числе устойчивость к ошибкам, восстановление после ошибок и масштабируемость. Соответственно, существует потребность в транскодере, который предоставляет высокоэффективную обработку и сжатие мультимедийных данных, который использует информацию, определенную из самих мультимедийных данных, и является масштабируемым и устойчивым к ошибкам для применения во множестве приложений мультимедийных данных, в том числе мобильной широковещательной передаче потоковой мультимедийной информации.
Сущность изобретения
Каждое из изобретаемых устройств и способов, основанных на содержимом перекодирования, описанных и проиллюстрированных, имеет несколько аспектов, ни один из которых не отвечает исключительно за требуемые атрибуты. Не ограничивая объем этого изобретения, далее будут кратко обсуждены его наиболее заметные признаки. После рассмотрения этого обсуждения, а более точно, после прочтения раздела, озаглавленного "Подробное описание изобретения", станет понятно, как признаки данного управляемого содержимым перекодирования предоставляют усовершенствования в устройства и способы обработки мультимедийных данных.
Изобретаемые аспекты, описанные в данном документе, относятся к использованию информации содержимого для различных способов кодирования мультимедийных данных и в различных модулях и компонентах кодера, например, кодера, используемого в транскодере. Транскодер может управлять перекодированием мультимедийных данных с помощью информации содержимого. Информация содержимого может приниматься из другого источника, например, метаданных, которые принимаются вместе с видео. Транскодер может быть сконфигурирован для того, чтобы формировать информацию содержимого с помощью множества различных операций обработки. В некоторых аспектах транскодер формирует классификацию содержимого мультимедийных данных, которая затем используется в одном или более процессов кодирования. В некоторых аспектах управляемый содержимым транскодер может определять пространственную и временную информацию содержимого мультимедийных данных и использовать информацию содержимого для кодирования с одинаковым качеством с учетом содержимого по каналам и основанного на классификации сжатия/назначения битов.
В некоторых аспектах информация содержимого (к примеру, метаданные, показатели содержимого и/или классификация содержимого) мультимедийных данных получается и вычисляется, а затем предоставляется компонентам транскодера для использования в обработке мультимедийных данных для кодирования. Например, препроцессор может использовать определенную информацию содержимого для обнаружения смены сцен, преобразования из видеоформата в фильм (IVTC), устранения чересстрочной развертки, компенсации движения и подавления шумов (к примеру, двумерного вейвлет-преобразования) и пространственно-временного ослабления шумов, к примеру, удаления дефектов изображения, подавления ревербераций, разблокирования и/или снижения шумности. В некоторых аспектах препроцессор также может использовать информацию содержимого для понижающей дискретизации пространственного разрешения, к примеру, определения соответствующих "защищенных" зон и зон "управления движущимися объектами" при понижающей дискретизации со стандартного разрешения (SD) до четверти логической матрицы видеографики (QVGA).
В некоторых аспектах кодер включает в себя модуль классификации содержимого, который сконфигурирован так, чтобы вычислять информацию содержимого. Кодер может использовать классификацию содержимого для управления скоростью передачи в битах (к примеру, назначения битов) при определении параметров квантования для каждого MB, для оценки движения, например, выполнения цветовой оценки движения (ME), выполнения предсказания векторов движения (MV), масштабируемости при предоставлении базового уровня и уровня улучшения, а также для устойчивости к ошибкам посредством использования классификации содержимого так, чтобы влиять на схемы иерархии предсказания и устойчивости к ошибкам, в том числе, к примеру, процессы адаптивного внутреннего обновления, выравнивания границ и предоставление избыточных данных I-кадра в уровне улучшения. В некоторых аспектах транскодер использует классификацию содержимого во взаимодействии с мультиплексором данных для поддержания оптимального качества мультимедийных данных в каналах. В некоторых аспектах кодер может использовать информацию классификации содержимого для принудительного периодического появления I-кадров в кодированных данных, чтобы обеспечить быстрое переключение каналов. Эти реализации также могут применять I-блоки, которые могут требоваться в кодированных данных для устойчивости к ошибкам, с тем чтобы переключение с произвольным доступом и устойчивость к ошибкам (на основе, к примеру, классификации содержимого) могли эффективно комбинироваться посредством иерархии предсказания, чтобы повысить эффективность кодирования с увеличением запаса устойчивости по ошибкам.
В одном аспекте способ обработки мультимедийных данных содержит классификацию содержимого мультимедийных данных и кодирование мультимедийных данных в первой группе данных и во второй группе данных на основе классификации содержимого, причем первая группа данных содержит коэффициент, а вторая группа данных содержит первое дифференциальное уточнение, ассоциативно связанное с коэффициентом первой группы данных. Кодирование может включать в себя определение скорости передачи битов на основе классификации содержимого мультимедийных данных и кодирование мультимедийных данных на основе скорости передачи битов. Классификация содержимого может содержать определение сложности мультимедийных данных, и при этом выбранные мультимедийные данные кодируются на основе сложности мультимедийных данных. Сложность может содержать временную сложность или пространственную сложность либо временную сложность и пространственную сложность. Кодирование может включать в себя кодирование мультимедийных данных так, чтобы обеспечить декодирование только первой группы данных или первой группы данных и второй группы данных в одну комбинированную группу данных. Первое дифференциальное уточнение может указывать разность между выбранным видеокадром и данными кадра, вытекающими из декодирования первой группы данных. Первая группа данных может быть базовым уровнем, а вторая группа данных может быть уровнем улучшения. Помимо этого, способ может включать в себя выбор коэффициента из одного из коэффициента остаточной ошибки исходного базового уровня и коэффициента остаточной ошибки исходного уровня улучшения и вычисления первого дифференциального уточнения на основе коэффициента и коэффициента остаточной ошибки исходного уровня улучшения. Кодирование дополнительно может содержать кодирование информации заголовков макроблоков и информации вектора движения в первой группе данных. Кодирование дополнительно может содержать квантование первой группы данных с первым размером шага и квантование второй группы данных со вторым размером шага, при этом первый размер шага и второй размер шага соотносятся посредством коэффициента масштабирования. Кодирование дополнительно может включать в себя определение первого параметра квантования, имеющего первый размер шага квантования, для использования при кодировании первой группы данных и определение второго параметра квантования, имеющего второй размер шага квантования, для использования при кодировании второй группы данных, при этом первый и второй параметры квантования определяются на основе информации содержимого выбранных данных кадра и при этом упомянутый первый размер шага квантования более грубый, чем упомянутый второй размер шага квантования. В другом аспекте кодирование включает в себя кодирование первой группы данных с помощью I-кадров и P-кадров либо любой их комбинации и кодирование второй группы данных с помощью I-кадров, P-кадров и B-кадров либо любой их комбинации.
В другом аспекте устройство кодирования мультимедийных данных включает в себя средство классификации содержимого мультимедийных данных, средство кодирования мультимедийных данных в первой группе данных и во второй группе данных на основе классификации содержимого, причем первая группа данных содержит коэффициент, а вторая группа данных содержит первое дифференциальное уточнение, ассоциативно связанное с коэффициентом первой группы данных. Средство кодирования может содержать средство для определения скорости передачи битов на основе классификации содержимого мультимедийных данных и кодирования мультимедийных данных на основе скорости передачи битов. Средство классификации содержимого может включать в себя средство определения сложности мультимедийных данных, и при этом выбранные мультимедийные данные кодируются на основе сложности мультимедийных данных, причем сложность содержит временную сложность или пространственную сложность либо временную сложность и пространственную сложность. Средство кодирования может содержать средство для того, чтобы обеспечить декодирование только первой группы данных или первой группы данных и второй группы данных в одну комбинированную группу данных.
В другом аспекте устройство включает в себя модуль классификации содержимого мультимедийных данных, сконфигурированный так, чтобы классифицировать содержимое мультимедийных данных и предоставлять данные классификации содержимого, и кодер, сконфигурированный так, чтобы кодировать мультимедийные данные в первой группе данных и во второй группе данных на основе классификации содержимого, причем первая группа данных содержит коэффициент, а вторая группа данных содержит первое дифференциальное уточнение, ассоциативно связанное с коэффициентом первой группы данных. Кодер может включать в себя компонент скорости передачи битов, сконфигурированный так, чтобы определять назначение битов на основе классификации содержимого, при этом компонент кодирования дополнительно сконфигурирован так, чтобы кодировать выбранные мультимедийные данные с помощью назначения битов.
В другом аспекте машиночитаемый носитель содержит инструкции, которые при исполнении инструктируют машине классифицировать содержимое мультимедийных данных и кодировать мультимедийные данные в первой группе данных и во второй группе данных на основе классификации содержимого, причем первая группа данных содержит коэффициент, а вторая группа данных содержит первое дифференциальное уточнение, ассоциативно связанное с коэффициентом первой группы данных.
В другом аспекте процессор сконфигурирован так, чтобы классифицировать содержимое мультимедийных данных и кодировать мультимедийные данные в первой группе данных и во второй группе данных на основе классификации содержимого, причем первая группа данных содержит коэффициент, а вторая группа данных содержит первое дифференциальное уточнение, ассоциативно связанное с коэффициентом первой группы данных.
Краткое описание чертежей
Фиг.1A - это блок-схема мультимедийной широковещательной системы, включающей в себя транскодер для перекодирования между различными видеоформатами.
Фиг.1B - это блок-схема кодера, сконфигурированного так, чтобы кодировать мультимедийные данные и предоставлять кодированную первую группу данных и кодированную вторую группу данных.
Фиг.1C - это блок-схема процессора, сконфигурированного так, чтобы кодировать мультимедийные данные.
Фиг.2 - это блок-схема примера транскодера системы по фиг.1.
Фиг.3 - это блок-схема последовательности операций способа, иллюстрирующая работу анализатора, используемого в транскодере по фиг.2.
Фиг.4 - это блок-схема последовательности операций способа, иллюстрирующая работу декодера, используемого в транскодере по фиг.2.
Фиг.5 - это системная временная схема, иллюстрирующая последовательность операций, выполняемых посредством транскодера по фиг.2.
Фиг.6 - это блок-схема, иллюстрирующая последовательность операций и функций препроцессора, которые могут быть использованы в транскодере по фиг.2.
Фиг.7 - это блок-схема примерного двухпроходного кодера, который может быть использован в транскодере по фиг.2.
Фиг.8 иллюстрирует пример классификационной диаграммы, которая иллюстрирует один аспект того, как ассоциативно связывать значения текстуры и движения с классификацией содержимого.
Фиг.9 - это блок-схема последовательности операций способа, иллюстрирующая примерную операцию классификации содержимого, например, для использования в кодере по фиг.7.
Фиг.10 - это блок-схема последовательности операций способа, иллюстрирующая операцию управления скоростью, например, для использования в кодере по фиг.7.
Фиг.11 - это блок-схема последовательности операций способа, иллюстрирующая работу примерного блока оценки движения, например, для использования в кодере по фиг.7.
Фиг.12 - это блок-схема последовательности операций способа, иллюстрирующая работу примерной функции кодера для определения режима, например, для использования в кодере по фиг.7.
Фиг.13 - это блок-схема последовательности операций способа, иллюстрирующая примерную операцию осуществления масштабируемости для использования в кодере по фиг.7.
Фиг.14 - это блок-схема последовательности операций способа, иллюстрирующая примерную операцию осуществления потока данных с искажением в зависимости от скорости, как происходит, к примеру, в кодере по фиг.7.
Фиг.15 - это график, иллюстрирующий взаимосвязь между сложностью кодирования, назначенными битами и визуальным качеством человека.
Фиг.16 - это график, иллюстрирующий нелинейную схему обнаружения сцен.
Фиг.17A - это блок-схема последовательности операций способа, иллюстрирующая обработку мультимедийных данных, которые получены, приняты или иным образом доступны.
Фиг.17B - это блок-схема системы кодирования мультимедиа.
Фиг.18 - это схема, иллюстрирующая процесс устранения чересстрочной развертки с помощью оценки/компенсации движения.
Фиг.19 - это блок-схема мультимедийной системы связи.
Фиг.20 - это схема, иллюстрирующая организацию видеопотока битов в уровне улучшения и базовом уровне.
Фиг.21 - это схема, иллюстрирующая совмещение серий макроблоков с границами видеокадров.
Фиг.22 - это блок-схема, иллюстрирующая иерархию предсказания.
Фиг.23 - это блок-схема последовательности операций, иллюстрирующая способ кодирования мультимедийных данных на основе информации содержимого.
Фиг.24 - это блок-схема последовательности операций, иллюстрирующая способ кодирования мультимедийных данных, так чтобы совмещать границы данных на основе уровня информации содержимого.
Фиг.25 - это график, иллюстрирующий защищенную область движущихся объектов и защищенную область тайтлов кадра данных.
Фиг.26 - это график, иллюстрирующий защищенную область движущихся объектов кадра данных.
Фиг.27 - это блок-схема последовательности операций, иллюстрирующая процесс кодирования мультимедийных данных с помощью адаптивного внутреннего обновления на основе информации мультимедийного содержимого.
Фиг.28 - это блок-схема последовательности операций, иллюстрирующая процесс кодирования мультимедийных данных с помощью избыточных I-кадров на основе информации мультимедийного содержимого.
Фиг.29 иллюстрирует векторы компенсации движения между текущим кадром и предыдущим кадром MVP и текущим кадром и следующим кадром MVN.
Фиг.30 - это блок-схема последовательности операций способа, иллюстрирующая обнаружение кадров.
Фиг.31 - это блок-схема последовательности операций способа, иллюстрирующая кодирование базового уровня и уровня улучшения.
Фиг.32 - это схематичное представление, иллюстрирующее кодирование макроблока.
Фиг.33 - это схематичное представление, иллюстрирующее модули для кодирования базового уровня и уровня улучшения.
Фиг.34 иллюстрирует пример процесса в блоке выбора коэффициентов базового уровня и уровня улучшения.
Фиг.35 иллюстрирует еще один пример процесса в блоке выбора коэффициентов базового уровня и уровня улучшения.
Фиг.36 иллюстрирует еще один пример процесса в блоке выбора коэффициентов базового уровня и уровня улучшения.
Фиг.37 - это блок-схема последовательности операций способа, иллюстрирующая кодирование мультимедийных данных на основе информации содержимого.
Фиг.38 - это схема, иллюстрирующая возможные системные решения в процессе преобразования из видеоформата в фильм.
Фиг.39 иллюстрирует границы в макроблоке, которые должны быть отфильтрованы посредством процесса разблокирования.
Фиг.40 - это схема, иллюстрирующая процесс пространственно-временного устранения чересстрочной развертки (деинтерлейсинга).
Фиг.41 иллюстрирует пример одномерной монофазной повторной дискретизации.
Фиг.42 - это блок-схема последовательности операций способа, иллюстрирующая пример адаптивной GOP-структуры в потоковой передаче видео.
Следует отметить, что аналогичные номера ссылок означают аналогичные детали по всем представлениям на чертежах соответствующим образом.
Подробное описание изобретения
Последующее подробное описание направлено на определенные аспекты, описываемые в данной заявке. Тем не менее, изобретение может быть осуществлено большим количеством различных способов. Ссылка в этом подробном описании на "один аспект" или "аспект" означает, что конкретный признак, конструкция или характеристика, описываемые в связи с аспектом, включены, по меньшей мере, в один аспект. Вхождение фразы "в одном аспекте", "согласно одному аспекту" или "в некоторых аспектах" в разных местах данного подробного описания не обязательно все указывают на тот же аспект, а также не являются отдельными или альтернативными аспектами, взаимоисключающими другие аспекты. Более того, описаны различные признаки, которые могут быть продемонстрированы посредством некоторых аспектов, но не посредством других. Аналогично, описаны различные требования, которые могут быть требованиями для некоторых аспектов, но не для других аспектов.
Последующее описание включает в себя подробные сведения для того, чтобы предоставить полное понимание примеров. Тем не менее, специалистам в данной области техники следует понимать, что примеры могут быть использованы на практике, даже если все подробности процесса или устройства в примере или аспекте не пояснены или проиллюстрированы в данном документе. Например, на блок-схемах могут быть показаны электрические компоненты, которые не иллюстрируют все электрические соединения или все электрические элементы компонента, чтобы не отвлекать от понимания примеров ненужными подробностями. В других случаях такие компоненты, другие структуры и методики могут быть подробно показаны, чтобы дополнительно пояснить примеры.
Настоящее устройство относится к устройствам и способам управления кодированием и перекодированием с помощью информации содержимого кодируемых мультимедийных данных. "Информация содержимого" или "содержимое" (мультимедийных данных) - это обширные термины, означающие информацию, связанную с содержимым мультимедийных данных, и могут включать в себя, например, метаданные, показатели, вычисленные из мультимедийных данных, и относящуюся к содержимому информацию, ассоциативно связанную с одним или более показателями, например, классификацию содержимого. Информация содержимого может быть предоставлена в кодер или определена посредством кодера в зависимости от конкретного варианта применения. Информация содержимого может быть использована для многих аспектов кодирования мультимедийных данных, в том числе обнаружения смены сцен, временной обработки, пространственно-временного понижения шумов, понижающей дискретизации, определения скоростей передачи битов для квантования, масштабирование устойчивости к ошибкам, сохранения оптимального качества мультимедиа в широковещательных каналах и быстрого переключения каналов. С помощью одного или более этих аспектов транскодер может управлять обработкой мультимедийных данных и формировать связанные с содержимым кодированные мультимедийные данные. Описания и чертежи в данном документе, которые описывают аспекты перекодирования, также могут быть применены к аспектам кодирования и аспектам декодирования.
Устройства и способы транскодера связаны с перекодированием из одного формата в другой и подробно описываются в данном документе как связанные с перекодированием видео MPEG-2 в улучшенный масштабируемый формат H.264 для передачи по беспроводным каналам в мобильные устройства, иллюстрирующие некоторые аспекты. Тем не менее, описание перекодирования видео MPEG-2 в формат H.264 не выступает в качестве ограничения области применения изобретения, а является просто примером некоторых аспектов изобретения. Раскрытые устройства и способы предоставляют высокоэффективную архитектуру, которая поддерживает устойчивое к ошибкам кодирование с помощью возможностей произвольного доступа и разбиения на уровне и также может быть применена к перекодированию и/или кодированию видеоформатов, отличных от MPEG-2 и H.264.
"Мультимедийные данные" или просто "мультимедиа" при использовании в данном документе являются обширным термином, который включает в себя видеоданные (которые могут включать в себя аудиоданные), аудиоданные или и видеоданные, и аудиоданные. "Видеоданные" или "видео" при использовании в данном документе является широким термином, относящимся к основанным на кадрах или основанным на полях данным, которые включают в себя одно или более изображений или связанных последовательностей изображений, содержащих текст, информацию изображений и/или аудиоданных, и могут быть использованы для того, чтобы означать мультимедийные данные (к примеру, термины могут быть использованы взаимозаменяемо), если не указано иное.
Ниже описываются примеры различных компонентов транскодера и примеры процессов, которые могут использовать информацию содержимого для кодирования мультимедийных данных.
Фиг.1A - это блок-схема, иллюстрирующая поток данных некоторых аспектов системы 100 широковещательной передачи мультимедийных данных. В системе 100 поставщик 106 мультимедийных данных передает кодированные мультимедийные данные 104 в транскодер 200. Кодированные мультимедийные данные 104 принимаются посредством транскодера 200, который обрабатывает мультимедийные данные 104 в "сырые" необработанные мультимедийные данные на этапе 110. Обработка на блоке 110 декодирует и разбирает кодированные мультимедийные данные 104 и дополнительно обрабатывает мультимедийные данные, чтобы подготовить их к кодированию в другой формат. Декодированные мультимедийные данные предоставляются на этап 112, где мультимедийные данные кодируются в предварительно определенный мультимедийный формат или стандарт. После того как мультимедийные данные кодированы, на этапе 114 они подготавливаются для передачи, например, посредством беспроводной широковещательной системы (к примеру, сотовой телефонной широковещательной сети или посредством другой сети связи). В некоторых аспектах принятые мультимедийные данные 104 кодированы согласно стандарту MPEG-2. После того как перекодированные мультимедийные данные 104 декодированы, транскодер 200 кодирует мультимедийные данные в стандарт H.264.
Фиг.1B - это блок-схема транскодера 130, который может быть сконфигурирован так, чтобы выполнять обработку на этапах 110 и 112 фиг.1A. Транскодер 130 может быть сконфигурирован так, чтобы принимать мультимедийные данные, декодировать и разбирать мультимедийные данные на пакетированные элементарные потоки (к примеру, субтитры, аудио, метаданные, "необработанное" видео, CC-данные и временные метки представления), кодировать их в требуемый формат и предоставлять кодированные данные для дополнительной обработки или передачи. Транскодер 130 может быть сконфигурирован так, чтобы предоставлять кодированные данные в две или более группы данных, например, кодированную первую группу данных и кодированную вторую группу данных, что упоминается как многоуровневое кодирование. В некоторых примерах аспектов различные группы данных (или уровни) в схеме многоуровневого кодирования могут кодироваться на различных уровнях качества и форматироваться так, что данные, кодированные в первой группе данных, имеют худшее качество (к примеру, предоставляют меньший уровень визуального качества при отображении), чем данные, кодированные во второй группе данных.
Фиг.1C - это блок-схема процессора 140, который может быть сконфигурирован так, чтобы перекодировать мультимедийные данные, и может быть сконфигурирован так, чтобы выполнять часть или всю обработку, проиллюстрированную на этапах 110 и 112 по фиг.1A. Процессор 140 может включать в себя модули 124a...n, выполнять один или более процессов перекодирования, описанных в данном документе, в том числе декодирование, разбор, предварительную обработку и кодирование, и использовать информацию содержимого для обработки. Процессор 140 также включает в себя внутреннее запоминающее устройство 122 и может быть сконфигурирован так, чтобы обмениваться данными с внешним запоминающим устройством 120 напрямую или косвенно посредством другого устройства. Процессор 140 также включает в себя модуль 126 связи, сконфигурированный так, чтобы обмениваться данными с одним или более устройствами, внешними для процессора 140, в том числе принимать мультимедийные данные и предоставлять кодированные данные, такие как данные, кодированные в первой группе данных, и данные, кодированные во второй группе данных. В некоторых примерах аспектов различные группы данных (или уровни) в схеме многоуровневого кодирования могут кодироваться на различных уровнях качества и форматироваться так, что данные, кодированные в первой группе данных, имеют худшее качество (к примеру, предоставляют меньший уровень визуального качества при отображении), чем данные, кодированные во второй группе данных.
Транскодер 130 или его компоненты препроцессора 140 (сконфигурированные для перекодирования), а также процессы, содержащиеся в нем, могут быть реализованы посредством аппаратных средств, программного обеспечения, микропрограммного обеспечения, промежуточного программного обеспечения, микрокода или комбинации вышеозначенного. Например, анализатор, декодер, препроцессор или кодер могут быть автономными компонентами, включенными как аппаратные средства, микропрограммное обеспечение, промежуточное программное обеспечение в компонент другого устройства, или могут быть реализованы в микрокоде либо программном обеспечении, которое приводится в исполнение в процессоре, либо как комбинация вышеозначенного. Когда реализован в программном обеспечении, микропрограммном обеспечении, промежуточном программном обеспечении или микрокоде, программный код или сегменты кода, которые выполняют процессы компенсации движения, классификации кадров и кодирования, могут быть сохранены на машиночитаемом носителе, таком как носитель хранения. Сегмент кода может представлять процедуру, функцию, подпрограмму, программу, стандартную процедуру, вложенную процедуру, модуль, комплект программного обеспечения, класс или любое сочетание инструкций, структур данных или операторов программы. Сегмент кода может быть связан с другим сегментом кода или аппаратной схемой посредством передачи и/или приема информации, данных, аргументов, параметров или содержимого памяти.
Иллюстративный пример архитектуры транскодера
Фиг.2 иллюстрирует блок-схему примера транскодера, который может быть использован для транскодера 200, проиллюстрированного в мультимедийной широковещательной системе 100 по фиг.1. Транскодер 200 содержит анализатор/декодер 202, препроцессор 226, кодер 228 и синхронизирующий уровень 240, дополнительно описанные ниже. Транскодер 200 сконфигурирован так, чтобы использовать информацию содержимого мультимедийных данных 104 для одного или более аспектов процесса перекодирования, как описано в данном документе. Информация содержимого может быть получена из источника, внешнего для транскодера 200, через мультимедийные метаданные или вычислена посредством транскодера, например, посредством препроцессора 226 или кодера 228. Компоненты, показанные на фиг.2, иллюстрируют компоненты, которые могут быть включены в транскодер, который использует информацию содержимого для одного или более процессов перекодирования. В конкретной реализации один или более компонентов транскодера 200 могут быть исключены либо могут быть включены дополнительные компоненты. Дополнительно, части транскодера и процессов перекодирования описаны для того, чтобы предоставить возможность специалистам в данной области техники использовать на практике изобретение, даже если все подробности процесса или устройства могут не описываться в данном документе.
Фиг.5 иллюстрирует временную схему в качестве графической иллюстрации временной взаимосвязи работы различных компонентов и/или процессов транскодера 200. Как показано на фиг.5, кодированное потоковое видео 104 (кодированные мультимедийные данные), например, видео MPEG-2 сначала принимается в произвольный нулевой момент времени (0) посредством анализатора 205 (фиг.2). Далее видеопоток разбирается 501, демультиплексируется 502 и декодируется 503, например, посредством анализатора 205 в комбинации с декодером 214. Как проиллюстрировано, эти процессы могут выполняться параллельно с небольшим смещением по времени, чтобы предоставить потоковый вывод данных обработки в препроцессор 226 (фиг.2). В момент времени T1 504, после того как препроцессор 226 принял достаточно данных от декодера 214 для того, чтобы начать вывод результатов обработки, оставшиеся этапы обработки становятся последовательными по характеру, при этом кодирование 505 первого прохода, кодирование 506 второго прохода и повторное кодирование 507 выполняется последовательно после предварительной обработки до завершения повторного кодирования в момент времени Tf 508.
Транскодер 200, описанный в данном документе, может быть сконфигурирован так, чтобы перекодировать различные мультимедийные данные, и многие из процессов применяются к тому типу мультимедийных данных, который перекодируется. Хотя некоторые из примеров, предоставляемых в данном документе, относятся к перекодированию данных MPEG-2 в данные H.264, эти примеры не предназначены для того, чтобы ограничивать изобретение этими данными. Аспекты кодирования, описываемые ниже, могут быть применены к перекодированию любого соответствующего стандарта мультимедийных данных в другой соответствующий стандарт мультимедийных данных.
Анализатор/декодер
Снова ссылаясь на фиг.2, анализатор/декодер 202 принимает мультимедийные данные 104. Анализатор/декодер 202 включает в себя анализатор транспортных потоков ("анализатор") 205, который принимает мультимедийные данные 104 и разбирает данные на элементарный поток (ES) видео 206, ES 208 аудио, временные метки представления (PTS) 210 и другие данные, такие как субтитры 212. ES переносит один тип данных (видео или аудио) из одного видео- или аудиокодера. Например, ES видео содержит видеоданные для последовательности данных, включающие в себя заголовок последовательности и все подчасти последовательности. Пакетированный элементарный поток, или PES, состоит из одного ES, который составлен в пакеты, каждый из которых в типичном варианте начинается с добавленного заголовка пакета. PES-поток содержит только один тип данных из одного источника, к примеру, из одного видео- или аудиокодера. PES-пакеты имеют переменную длину, не соответствующую фиксированной длине транспортных пакетов, и могут быть гораздо длиннее, чем транспортный пакет. Когда транспортные пакеты сформированы из PES-потока, PES-заголовок может быть помещен в начало рабочих данных транспортного пакета, сразу после заголовка транспортного пакета. Оставшееся содержимое PES-пакета заполняет рабочие данные последовательных транспортных пакетов, пока PES-пакет не будет полностью использован. Конечный транспортный пакет может быть заполнен до фиксированной длины, к примеру, посредством дополнения байтами, к примеру, байтами = 0xFF (все единицы).
Анализатор 205 передает ES 206 видео в декодер 214, который является частью анализатора/декодера 202, показанной здесь. В других конфигурациях анализатор 205 и декодер 214 являются отдельными компонентами. PTS 210 отправляются в PTS-формирователь 215 транскодера, который может формировать отдельные временные метки представления, конкретные для транскодера 200, для использования при компоновке данных, которые должны быть отправлены из транскодера 200 в широковещательную систему. PTS-формирователь 215 транскодера может быть сконфигурирован так, чтобы предоставлять данные в синхронизирующий уровень 240 транскодера 200, чтобы координировать синхронизацию широковещательной передачи данных.
Фиг.3 иллюстрирует блок-схему последовательности операций одного примера процесса 300, которому анализатор 205 может следовать при разборе различных пакетированных элементарных потоков, описанных выше. Процесс 300 начинается на этапе 302, когда мультимедийные данные 104 принимаются от поставщика 106 содержимого (фиг.1). Процесс 300 переходит к этапу 304, на котором выполняется инициализация анализатора 205. Инициализация может активироваться посредством независимо сформированной команды 306 сбора данных. Например, процесс, который независим от анализатора 205 и основан на внешне принимаемом ТВ-расписании и информации настройки каналов, может формировать команду 306 сбора данных. Дополнительно, могут быть введены дескрипторы 308 буфера транспортного потока (TS) реального времени, чтобы помогать в инициализации и для основной обработки.
Как проиллюстрировано на этапе 304, инициализация может включать в себя запрос проверки синтаксиса команд, выполнение обработки PSI/PSIP/SI первого прохода (конкретная для программы информация/программа и протокол системной информации/системная информация), выполнение обработки, конкретно связанной либо с командой сбора данных, либо с проверкой согласованности PSI/PSIP/SI, назначение PES-буферов для каждого PES и задание распределения по времени (к примеру, для совмещения с требуемым моментом начала сбора данных). PES-буферы содержат разобранные ES-данные и передают все разобранные ES-данные в соответствующие аудиодекодер 216, тестовый декодер 220, декодер 214 или PTS-формирователь 215 транскодера.
После инициализации процесс 300 переходит к этапу 310 для основной обработки принимаемых мультимедийных данных 104. Обработка на этапе 310 может включать в себя фильтрацию целевых идентификаторов пакетов (PID), непрерывный мониторинг и обработку PSI/PSIP/SI и процесс распределения по времени (к примеру, для достижения требуемой продолжительности сбора данных), с тем чтобы поступающие мультимедийные данные передавались в соответствующие PES-буферы. Как результат обработки мультимедийных данных на этапе 310 формируются программный дескриптор и индикатор PES-буфера "read", которые взаимодействуют с декодером 214 (фиг.2) так, как описано ниже.
После этапа 310 процесс 300 переходит к этапу 314, на котором выполняется завершение операций разбора, формирование прерывания таймера и освобождение PES-буферов после их использования. Следует отметить, что PES-буферы имеются для всех релевантных элементарных потоков программы, упомянутых в дескрипторе, например, потоков аудио, видео и субтитров.
Снова ссылаясь на фиг.2, анализатор 205 отправляет ES 208 аудио в аудиодекодер 216 для соответствия реализации транскодера и предоставляет кодированный текст 216 в синхронизирующий уровень 240 и декодирует аудиоинформацию. Информация 212 субтитров доставляется в текстовый декодер 220. Данные 218 кодированных субтитров между кадрами (CC) из декодера 214 также предоставляются в текстовый кодер 220, который кодирует информацию 212 субтитров и CC-данные 218 в формате, осуществляемом посредством транскодера 200.
Анализатор/декодер 202 также включает в себя декодер 214, который принимает ES 206 видео. Декодер 214 может формировать метаданные, ассоциативно связанные с видеоданными, декодирует кодированный пакетированный элементарный видеопоток в необработанное видео 224 (например, в формате стандартного разрешения) и обрабатывает видеоданные кодированных субтитров между кадрами в ES-поток видео.
Фиг.4 иллюстрирует блок-схему последовательности операций, показывающую один пример процесса 400 декодирования, который может быть выполнен посредством декодера 214. Процесс 400 начинается с ввода данных 206 элементарного видеопотока на этапе 402. Процесс 400 переходит к этапу 404, на котором декодер инициализируется. Инициализация может включать в себя ряд задач, в том числе обнаружение заголовка видеопоследовательности (VSH), выполнение VSH первого прохода, обработку видеопоследовательности (VS) и дисплейного расширения VS (включая видеоформат, составные цвета и матричные коэффициенты) и назначение буферов данных так, чтобы надлежащим образом буферизовать декодированное изображение, ассоциативно связанные метаданные и данные кодированных субтитров между кадрами (CC). Дополнительно, информация 406 "read" PES-буфера видео, предоставляемая посредством анализатора 205, вводится (к примеру, которая может быть сформирована посредством процесса 300 на этапе 310 по фиг.3).
После инициализации на этапе 404 процесс 400 переходит к этапу 408, на котором основная обработка ES видео выполняется посредством декодера 214. Основная обработка включает в себя запрашивание информации "read" PES-буфера видео или "интерфейса" для доступности новых данных, декодирование ES видео, восстановление и сохранение пиксельных данных при синхронизации границ изображений, метаданных формирования видео и аудио-видео и сохранение на границах изображений и сохранение CC-данных на границах изображений. Этап 410 результатов основной обработки 408 включает в себя формирование дескрипторов последовательности, дескрипторов буфера декодированных изображений, дескрипторов буферов метаданных и дескрипторов буферов CC-данных.
После основной обработки 408 процесс 400 переходит к этапу 412, на котором он выполняет процесс завершения. Процесс завершения может включать в себя определение условий завершения, в том числе отсутствие новых данных, появляющихся в течение конкретного времени выше предварительно определенного порога, обнаружение конечного кода последовательности и/или обнаружение явного сигнала завершения. Процесс завершения дополнительно может включать в себя освобождение декодированного изображения, ассоциативно связанных метаданных и буферов CC-данных после их использования посредством препроцессора, который описывается ниже. Процесс 400 завершается на этапе 414, где он может перейти в состояние ожидания ES видео, который должен быть принят в качестве ввода.
Препроцессор
Фиг.2 и подробнее фиг.6 иллюстрируют примерный аспект препроцессора 226, который может использовать информацию содержимого для одной или более операций предварительной обработки. Препроцессор 226 принимает метаданные 222 и декодированные "необработанные" видеоданные 224 от анализатора/декодера 202. Препроцессор 226 сконфигурирован так, чтобы выполнять определенные типы обработки для видеоданных 224 и метаданных 222 и предоставлять обработанное мультимедиа (к примеру, опорные кадры базового уровня, опорные кадры уровня улучшения, информацию полосы пропускания, информацию содержимого) и видео в кодер 228. Такая предварительная обработка мультимедийных данных позволяет повышать визуальную четкость, подавление наложения спектра и эффективность сжатия данных. В общем, препроцессор 226 принимает видеопоследовательности, предоставляемые посредством декодера 214 в анализаторе/декодере 202, и преобразует видеопоследовательности в прогрессивные видеопоследовательности для дополнительной обработки (к примеру, кодирования) посредством кодера 228. В некоторых аспектах препроцессор 226 может быть сконфигурирован для множества операций, в том числе операций преобразования из видеоформата в фильм, устранения чересстрочной развертки, фильтрации (к примеру, удаления дефектов изображения, подавления ревербераций, разблокирования и снижения шумности), изменения размера (к примеру, понижающей дискретизации пространственного разрешения со стандартного разрешения до четверти логической матрицы видеографики (QVGA)) и формирования GOP-структуры (к примеру, вычисления формирования таблицы сложности, обнаружения смены сцен и обнаружения затенения/вспышки).
Препроцессор 226 может использовать метаданные от декодера для того, чтобы затрагивать одну или более операций предварительной обработки. Метаданные могут включать в себя информацию, связанную, описывающую или классифицирующую содержимое мультимедийных данных ("информацию содержимого"); в частности, метаданные могут включать в себя классификацию содержимого. В некоторых аспектах метаданные не включают в себя информацию содержимого, требуемую для операций кодирования. В этих случаях препроцессор 226 может быть сконфигурирован так, чтобы определять информацию содержимого и использовать информацию содержимого для операций предварительной обработки и/или предоставлять информацию содержимого в другие компоненты транскодера 200, к примеру, декодер 228. В некоторых аспектах препроцессор 226 может использовать эту информацию содержимого для того, чтобы воздействовать на секционирование GOP, определять соответствующий тип фильтрации и/или определять параметры кодирования, которые передаются в кодер.
Фиг.6 показывает иллюстративный пример различных этапов обработки, которые могут быть включены в препроцессор 226, и иллюстрирует обработку, которая может быть выполнена посредством препроцессора 226. В этом примере препроцессор 226 принимает метаданные и видео 222, 224 и предоставляет выходные данные 614, содержащие (обработанные) метаданные и видео, в кодер 228. В типичном варианте предусмотрено три типа видео, которое может приниматься. Во-первых, принимаемое видео может быть прогрессивным видео, где не требуется устранение чересстрочной развертки. Во-вторых, видеоданные могут быть видео, преобразованным из фильма в видеоформат, чересстрочным видео, преобразованным из кинопоследовательностей в 24 кадра в секунду, в данном случае видео. В-третьих, видео может быть чересстрочным видео, не преобразованным из фильма в видеоформат. Препроцессор 226 может обрабатывать эти типы видео так, как описано ниже.
На этапе 601 препроцессор 226 определяет то, являются ли принятые видеоданные 222, 224 прогрессивным видео. В некоторых случаях это может быть определено из метаданных, если метаданные содержат эту информацию, либо посредством обработки самих видеоданных. Например, процесс преобразования из видеоформата в фильм, описанный ниже, позволяет определять то, является ли принимаемое видео 222 прогрессивным видео. Если является, процесс переходит к этапу 607, на котором операции фильтрации (к примеру, снижения шумности) выполняются для видео, чтобы уменьшить шум, такой как белый гауссовый шум. Если видеоданные 222, 224 не являются прогрессивным видео, на этапе 601 процесс переходит к этапу 604 к модулю 604 обнаружения фаз.
Модуль 604 обнаружения фаз различает видео, которое изначально преобразовано из фильма в видеоформат и которое начиналось в стандартном широковещательном формате. Если принято решение о том, что видео преобразовано из фильма в видеоформат (путь решения "ДА", выходящий из модуля 604 обнаружения фаз), преобразованное из фильма в видеоформат видео возвращается в исходный формат при обратном преобразовании 606 из видеоформата в фильм. Избыточные кадры идентифицируются и устраняются, а поля, извлеченные из того же видеокадра, переплетаются в полное изображение. Поскольку последовательность восстановленных киноизображений фотографически записана с регулярными интервалами в 1/24 секунды, процесс оценки движения, выполняемый в модуле 612 секционирования GOP или декодере 228, является более точным при использовании преобразованных из видеоформата в фильм изображений, чем преобразованных из фильма в видеоформат данных, которые имеют нерегулярную временную базу.
В одном аспекте модуль 604 обнаружения фаз принимает конкретные решения после приема видеокадра. Эти решения включают в себя: (i) является текущее видео из вывода преобразования из фильма в видеоформат, а фаза продвижения на шаг кадра 3:2 является одной из пяти фаз P0, P1, P2, P3 и P4, показанных на фиг.38, или нет; и (ii) видео сформировано как традиционное NTSC. Это решение обозначается как фаза P5. Данные решения отображаются как выводы модуля 604 обнаружения фаз, показанного на фиг.2. Путь из модуля 604 обнаружения фаз, помеченный "ДА", активирует преобразование 606 из видеоформата в фильм, указывая то, что оно предоставлено с корректной фазой продвижения на шаг кадра, с тем чтобы оно могло отсортировать поля, которые сформированы из одного фотографического изображения, и комбинировать их. Путь из модуля 604 обнаружения фаз, помеченный "НЕТ", аналогично активирует модуль 605 устранения чересстрочной развертки, чтобы разделить видимый NTSC-кадр на поля для оптимальной обработки. Модуль 604 обнаружения фаз может непрерывно анализировать видеокадры, поскольку различные типы видео могут приниматься в любое время. В качестве примера, видео, соответствующее NTSC-стандарту, может быть вставлено в видео в качестве рекламы. После преобразования из видеоформата в фильм результирующее прогрессивное видео отправляется в модуль снижения шумности (фильтр) 607, который может быть использован для того, чтобы понижать белый гауссов шум.
Когда традиционное NTSC-видео распознается (путь "НЕТ" из модуля 601 обнаружения фаз), оно передается в модуль 605 устранения чересстрочной развертки для сжатия. Модуль 605 устранения чересстрочной развертки преобразует чересстрочные поля в прогрессивное видео, и операции понижения шумности затем могут быть выполнены для прогрессивного видео. Один иллюстративный пример обработки устранения чересстрочной развертки описан ниже.
Традиционные аналоговые видеоустройства, такие как телевизоры, выполняют рендеринг видео чересстрочным способом, т.е. эти устройства передают строки развертки с четными номерами (четное поле) и строки развертки с нечетными номерами (нечетное поле). С точки зрения дискретизации сигналов, это эквивалентно пространственно-временной субдискретизации в шаблоне, описанном посредством:

где Θ означает изображение исходного кадра, F означает чересстрочное поле, а (x,y,n) представляет горизонтальную, вертикальную и временную позицию пиксела, соответственно.
Без потери общности можно предположить, что n=0 - это четное поле в данном описании, так что вышеприведенное уравнение 1 упрощается следующим образом:
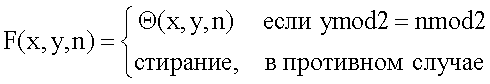
Поскольку прореживание не выполняется в горизонтальном направлении, шаблон субдискретизации может быть проиллюстрирован в следующей n-y координате.
Цель модуля устранения чересстрочной развертки заключается в том, чтобы преобразовывать чересстрочное видео (последовательность полей) в нечересстрочные прогрессивные кадры (последовательность кадров). Другими словами, интерполировать четные и нечетные поля так, чтобы "восстановить" или сформировать полнокадровые изображения. Это может быть представлено посредством уравнения 3:
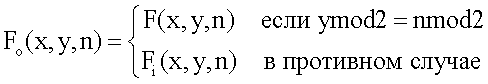
где F i представляет результаты устранения чересстрочной развертки для отсутствующих пикселов.
Фиг.40 - это блок-схема, иллюстрирующая определенные аспекты модуля 605 устранения чересстрочной развертки, который использует Wmed-фильтрацию и оценку движения для того, чтобы формировать прогрессивный кадр из чересстрочных мультимедийных данных. Верхняя часть фиг.40 показывает таблицу 4002 интенсивности движения, которая может быть сформирована с помощью информации из текущего поля, двух предыдущих полей (поля PP и поля P) и двух последующих полей (поля Next и поля Next Next). Таблица 4002 интенсивности движения категоризирует или секционирует текущий кадр на два или более различных уровня движения и может быть сформирована посредством пространственно-временной фильтрации, описанной подробнее ниже. В некоторых аспектах таблица 4002 интенсивности движения сформирована так, чтобы идентифицировать статичные области, области медленного движения и области быстрого движения, как описано в ссылках к уравнениям 4-8 ниже. Пространственно-временной фильтр, к примеру, Wmed-фильтр 4004 фильтрует чересстрочные мультимедийные данные с помощью критериев на основе таблицы интенсивности движения и формирует пространственно-временной подготовленный кадр с устраненной чересстрочной разверткой. В некоторых аспектах процесс Wmed-фильтрация влечет за собой горизонтальное соседство в [-1, 1], вертикальное соседство в [-3, 3] и временное соседство в пять последующих полей, которые представлены посредством пяти полей (поле PP, поле P, поле Current, поле Next, поле Next Next), проиллюстрированных на фиг.40, где Z -1 представляет задержку одного поля. Относительно поля Current поле Next и поле P являются полями без четности, а поле PP и поле Next Next являются полями с четностью. "Соседство", используемое для пространственно-временной фильтрации, означает пространственное и временное размещение полей и пикселов, фактически используемых в ходе операции фильтрации, и может быть проиллюстрировано как "апертура", как показано, например, на фиг.6 и 7.
Модуль 605 устранения чересстрочной развертки также может включать в себя модуль 4006 понижения шумности (фильтр понижения шумности), сконфигурированный так, чтобы отфильтровывать пространственно-временной подготовленный кадр с устраненной чересстрочной разверткой, сформированный посредством Wmed-фильтра 4004. Понижение шумности пространственно-временного подготовленного кадра с устраненной чересстрочной разверткой делает последующий процесс поиска движения более точным, особенно если исходная последовательность чересстрочных мультимедийных данных загрязнена белым шумом. Он также может удалять, по меньшей мере, частично помехи дискретизации между четными и нечетными строками в Wmed-изображении. Модуль 4006 понижения шумности может быть реализован как множество фильтров, включая модуль понижения шумности на основе вейвлет-сжатия и вейвлет-фильтра Винера. Модуль понижения шумности может быть использован для того, чтобы удалять шум из варианта Wmed-кадра, прежде чем он дополнительно обрабатывается с помощью информации компенсации движения, и может удалять шум, который присутствует в Wmed-кадре, и сохранять наличие сигнала вне зависимости от частотного содержимого сигнала. Различные типы фильтров понижения шумности могут быть использованы, в том числе вейвлет-фильтры. Вейвлеты - это класс функций, используемых для того, чтобы локализовать данный сигнал как в пространственной области, так и в области масштабирования. Фундаментальная идея относительно вейвлетов заключается в том, чтобы анализировать сигнал при различных масштабах или разрешениях, с тем чтобы незначительные изменения в вейвлет-представлении формировали соответствующие небольшие изменения в исходном сигнале.
Вейвлет-сжатие или вейвлет-фильтр Винера также может быть применен как модуль понижения шумности. Вейвлет-сжатие состоит из вейвлет-преобразования сигнала шума, за которым следует сжатие небольших вейвлет-коэффициентов до нуля (или меньшего значения) при оставлении неизмененными больших коэффициентов. В завершение обратное преобразование выполняется для того, чтобы получить оцененный сигнал.
Фильтрация с понижением шумности повышает точность компенсации движения в шумных окружениях. Понижение шумности с вейвлет-сжатием может влечь за собой сжатие в области вейвлет-преобразования и в типичном варианте содержит три этапа: линейное прямое вейвлет-преобразование, нелинейное понижение шумности со сжатием и линейное обратное вейвлет-преобразование. Фильтр Винера - это MSE-оптимальный линейный фильтр, который может быть использован для того, чтобы улучшать изображения, ухудшенные посредством аддитивного шума и размывания. Эти фильтры, в общем, известны в данной области техники и описываются, например, в работе "Ideal spatial adaptation by wavelet shrinkage", указанной выше, и в работе авторов S. P. Ghael, A. M. Sayeed и R. G. Baraniuk, "Improvement Wavelet denoising via empirical Wiener filtering", Proceedings of SPIE, том 3169, стр. 389-399, Сан-Диего, июль 1997 года, которые явно полностью содержатся в данном документе по ссылке.
В некоторых аспектах фильтр понижения шумности основан на аспекте биортогонального кубического B-сплайнового вейвлет-фильтра (4, 2). Один такой фильтр может быть задан посредством выполнения прямого и обратного преобразования:
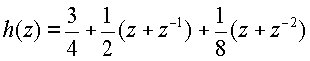 (прямое преобразование)
(прямое преобразование)
и
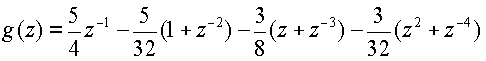
(обратное преобразование)
Применение фильтра понижения шумности позволяет повысить точность компенсации движения в шумном окружении. Реализации таких фильтров дополнительно описаны в работе "Ideal spatial adaptation by wavelet shrinkage", авторы D.L. Donoho и I.M. Johnstone, Biometrika, том 8, стр.425-455, 1994 год, которые явно полностью содержатся в данном документе по ссылке.
Нижняя часть фиг.40 иллюстрирует аспект для определения информации движения (к примеру, вариантов векторов движения, оценки движения, компенсации движения) чересстрочных мультимедийных данных. В частности, фиг.40 иллюстрирует схему оценки движения и компенсации движения, которая используется для того, чтобы сформировать предварительный прогрессивный кадр после компенсации движения из выбранного кадра, и затем комбинируется с предварительным Wmed-кадром, чтобы сформировать "конечный" прогрессивный кадр, показанный как текущий кадр 4014 с устраненной чересстрочной разверткой. В некоторых аспектах варианты (или оценки) векторов движения (MV) чересстрочных мультимедийных данных предоставляются в модуль устранения чересстрочной развертки из внешних модулей оценки движения и используются для того, чтобы предоставлять начальную точку для двунаправленного модуля оценки и компенсации движения (ME/MC) 4018. В некоторых аспектах модуль 4022 выбора MV-вариантов использует ранее определенные MV для соседних блоков для MV-вариантов обрабатываемых блоков, например, MV предыдущих обработанных блоков, к примеру, блоков в предыдущем кадре 4020 с устраненной чересстрочной разверткой. Компенсация движения может осуществляться двунаправленно на основе предыдущего кадра 70 с устраненной чересстрочной разверткой и следующего (к примеру, будущего) Wmed-кадра 4008. Текущий Wmed-кадр 4010 и текущий кадр 4016 после компенсации движения (MC) объединяются или комбинируются посредством модуля 4012 комбинирования. Результирующий текущий кадр 4014 с устраненной чересстрочной разверткой, теперь прогрессивный кадр, предоставляется обратно в ME/MC 4018, чтобы быть использованным как предыдущий кадр 4020 с устраненной чересстрочной разверткой, а также передается за пределы модуля 605 устранения чересстрочной развертки для последующей обработки.
Можно выделить схемы предсказания устранения чересстрочной развертки, содержащие межполевую интерполяцию, из внутриполевой интерполяции с помощью схемы устранения чересстрочной развертки Wmed+MC. Другими словами, пространственно-временная Wmed-фильтрация может быть использована, в первую очередь, для целей внутриполевой интерполяции, тогда как межполевая интерполяция может выполняться в ходе компенсации движения. Это снижает пиковое соотношение "сигнал-шум" результата Wmed, но визуальное качество после того, как применена компенсация движения, является более удовлетворительным, поскольку дефектные пикселы из неточных решений режима внутриполевого предсказания удаляются из процесса Wmed-фильтрации.
После соответствующей обработки преобразования из видеоформата в фильм или устранения чересстрочной развертки на этапе 608 прогрессивное видео обрабатывается для подавления помех дискретизации и повторной дискретизации (к примеру, изменения размера). В некоторых аспектах повторной дискретизации модуль повторной дискретизации фазы реализован для изменения размера изображений. В одном примере понижающей дискретизации соотношение между исходным и измененным изображением может быть p/q, где p и q - это относительно простые числа. Общее число фаз равно p. Частота отсечки полифазного фильтра в некоторых аспектах равна 0,6 для коэффициентов изменения размера примерно в 0,5. Частота отсечки не совпадает точно с коэффициентом изменения размера, чтобы повысить высокочастотную характеристику последовательности измененного размера. Это неизбежно предоставляет определенные помехи дискретизации. Тем не менее, хорошо известно, что человеческий глаз предпочитает резкие, но с небольшими помехами изображения размытым и не содержащим помех изображениям.
Фиг.41 иллюстрирует пример полифазной повторной дискретизации, показывающий фазы, если соотношение изменения размера составляет 3/4. Частота отсечки, проиллюстрированная на фиг.41, также составляет 3/4. Исходные пикселы проиллюстрированы на вышеуказанном чертеже с вертикальными осями. Синусоидальная функция также нарисована центрированной вокруг осей, чтобы представлять форму сигнала фильтра. Поскольку частота отсечки выбрана так, чтобы быть такой же, что и соотношение повторной дискретизации, нули синусоидальной функции перекрывают позицию пикселов после изменения размера, проиллюстрированного на фиг.41 с помощью пересечений. Чтобы найти значение пиксела после изменения размера, доля может быть просуммирована из исходных пикселов, как показано в следующем уравнении:
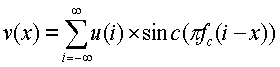
где f c - это частота отсечки. Вышеуказанный одномерный полифазный фильтр может быть применен к горизонтальному направлению и вертикальному направлению.
Другой аспект повторной дискретизации (изменения размера) учитывает развертку за пределами экрана. В телевизионном сигнале NTSC изображение имеет 486 строк развертки, а в цифровом видео может иметь 720 пикселов для каждой строки развертки. Тем не менее, не все полное изображение видно на телевизоре вследствие несовпадений между размером и форматом экрана. Часть изображения, которая не видна, называется разверткой за пределами экрана.
Чтобы помочь широковещательным станциям помещать полезную информацию в область, видимую как можно большим числом телевизоров. Общество инженеров кино и телевидения (SMPTE) задало конкретные размеры кадра движущихся объектов, называемые защищенной областью движущихся объектов и защищенной областью тайтлов. См. руководящие указания SMPTE RP 27.3-1989 "Specifications for Safe Action and Safe Title Areas Test Pattern for Television Systems". Защищенная область движущихся объектов задается посредством SMPTE как область, в которой должны находиться все существенные движущиеся объекты. Защищенная область тайтлов задается как область, в которой вся полезная информация может быть заключена, чтобы обеспечить видимость на большинстве домашних телевизионных приемников.
Например, ссылаясь на фиг.25, защищенная область 2510 движущихся объектов занимает по центру 90% экрана, давая 5% границу вокруг. Защищенная область 2505 тайтлов занимает по центру 80% экрана, давая 10% границы. Ссылаясь теперь на фиг.26, поскольку защищенная область тайтлов слишком мала, чтобы добавить дополнительное содержимое в изображение, некоторые станции помещают текст в защищенную область движущихся объектов, которая находится внутри белого прямоугольного окна 2615.
Обычно черные границы могут быть видны в развертке за пределами экрана. Например, на фиг.26 черные границы отображаются в верхней стороне 2620 и нижней стороне 2625 изображения. Эти черные границы могут быть удалены в развертке за пределами экрана, поскольку видео H.264 применяет расширение границ при оценке движения. Расширенные черные границы позволяют увеличивать остаток. Консервативно, граница может быть обрезана на 2% и затем выполнено изменение размера. Фильтры для изменения размера могут быть сформированы соответствующим образом. Отсечение выполняется для того, чтобы удалить развертку за пределами экрана до полифазной понижающей дискретизации.
Снова ссылаясь на фиг.6, прогрессивное видео затем переходит к этапу 610, где выполняются операции разблокирования и подавления ревербераций. Два типа помех, "блокировка" и "реверберации", как правило, возникают в приложениях видеосжатия. Помехи изображения возникают, поскольку алгоритмы сжатия делят каждый кадр на блоки (к примеру, блоки 8x8). Каждый блок восстанавливается с некоторыми небольшими ошибками, и ошибки по краям блока зачастую контрастируют с ошибками по краям соседних блоков, делая границы блоков видимыми. В отличие от этого помехи ревербераций появляются как искажения по краям элементов изображений. Помехи реверберации возникают, поскольку кодер отбрасывает слишком много информации при квантовании высокочастотных DCT-коэффициентов. В некоторых иллюстративных примерах деблокирование и подавление ревербераций может использовать фильтры нижних частот с FIR (конечной импульсной характеристикой), чтобы скрывать эти видимые помехи.
В одном примере обработки деблокирования фильтр деблокирования может быть применен ко всем краям блоков 4x4 кадра, за исключением краев на границе кадра и всех краев, для которых процесс фильтра деблокирования отключен. Этот процесс фильтрации должен выполняться на основе макроблоков после завершения процесса составления кадров, причем все макроблоки в кадре обрабатываются в порядке увеличения адресов макроблоков. Для каждого макроблока вертикальные края фильтруются первыми, слева направо, а затем горизонтальные края фильтруются сверху вниз. Процесс фильтра деблокирования компоненты яркости выполняется по четырем краям из 16 выборок, и процесс фильтра деблокирования для каждой компоненты цветности выполняется по двум краям из 8 выборок для горизонтального направления и для вертикального направления, как показано на фиг.39. Значения выборки выше и слева от текущего макроблока, которые, возможно, уже модифицированы посредством операции процесса деблокирования для предыдущих макроблоков, должны быть использованы в качестве входных данных процесса фильтра деблокирования для текущего макроблока и могут быть дополнительно модифицированы в ходе фильтрации текущего макроблока. Значения выборки, модифицированные в ходе фильтрации вертикальных краев, могут быть использованы в качестве входных данных для фильтрации горизонтальных краев для того же макроблока. Процесс деблокирования может быть активирован для компонент яркости и цветности отдельно.
В примере обработки подавления ревербераций двумерный фильтр может быть адаптивно применен так, чтобы сглаживать области около краев. Краевые пикселы подвергаются небольшой фильтрации или не подвергаются фильтрации, чтобы избежать размывания.
Модуль секционирования GOP
После деблокирования и подавления ревербераций прогрессивное видео обрабатывается посредством модуля 612 секционирования GOP. Размещение GOP может включать в себя обнаружение смены кадров, формирование таблиц сложности (к примеру, временных, пространственных таблиц полосы пропускания) и адаптивное секционирование GOP. Все вышеозначенное описывается далее.
A. Обнаружение смены сцен
Обнаружение кадров относится к определению того, когда кадр в группе изображений (GOP) предоставляет данные, которые указывают то, что произошла смена сцены. В общем, в GOP кадры могут не иметь существенной смены для любых двух или трех (или большего числа) соседних кадров либо могут быть медленные смены либо быстрые смены. Разумеется, эти классификации смены сцен при необходимости могут быть дополнительно разбиты до большего уровня смены в зависимости от варианта применения.
Обнаружение смены кадров или сцен важно для эффективного кодирования видео. В типичном варианте, когда GOP не изменяется значительно, за I-кадром в начале GOP следует ряд предиктивных кадров, позволяет в значительной степени кодировать видео так, чтобы последующее декодирование и отображение видео было визуально приемлемым. Тем не менее, когда сцена сменяется, резко или медленно, дополнительные I-кадры и меньшее кодирование с предсказанием (P-кадры и B-кадры) может требоваться, чтобы предоставить впоследствии декодированные визуально приемлемые результаты.
Системы и способы обнаружения кадров и кодирования, которые повышают производительность существующих систем кодирования, описываются ниже. Эти аспекты могут быть реализованы в модуле 612 секционирования GOP препроцессора 226 (фиг.7) либо включены в устройство кодера, которое может работать с или без препроцессора. Данные аспекты используют статистику (или показатели), которые включают в себя статистические сравнения между соседними кадрами видеоданных, чтобы определять то, если возникла резкая смена сцен, сцена медленно сменяется или имеются вспышки камеры в сцене, которые могут особенно усложнять кодирование видео. Статистика может быть получена от препроцессора и затем отправлена в устройство кодирования, либо она может быть сформирована в устройстве кодирования (к примеру, посредством процессора, сконфигурированного так, чтобы выполнять компенсацию движения). Результирующая статистика помогает в принятии решения по обнаружению смены сцен. В системе, которая осуществляет перекодирование, зачастую имеется надлежащий препроцессор или конфигурируемый процессор. Если препроцессор выполняет устранение чересстрочной развертки с помощью компенсации движения, статистика компенсации движения доступна и готова к применению. В таких системах алгоритм обнаружения кадров может немного повысить сложность системы.
Иллюстративный пример модуля обнаружения кадров, описанный в данном документе, должен использовать только статистику из предыдущего кадра, текущего кадра и следующего кадра, а следовательно, имеет очень небольшую задержку. Модуль обнаружения кадров различает несколько различных типов событий кадров, в том числе резкую смену сцен, монтажный переход и другую медленную смену сцен, а также вспышку камеры. Посредством определения различных типов событий кадров с различными стратегиями в кодере эффективность кодирования и визуальное качество улучшается.
Обнаружение смены сцен может быть использовано для любой системы кодирования видео, чтобы она интеллектуально сохраняла биты посредством вставки I-кадра с фиксированным интервалом. В некоторых аспектах информация содержимого, полученная посредством препроцессора (к примеру, либо содержащаяся в метаданных, либо вычисленная посредством препроцессора 226), может быть использована для обнаружения смены сцен. Например, в зависимости от информации содержимого, пороговые значения и другие критерии, описанные ниже, могут динамически корректироваться для различных типов видеосодержимого.
Кодирование видео обычно выполняется для структурированной группы изображений (GOP). GOP обычно начинается с внутренне кодированного кадра (I-кадра), за которым следует последовательность из P (прогнозирующих) или B (двунаправленных) кадров. В типичном варианте I-кадр может сохранять все данные, требуемые для того, чтобы отображать кадр, B-кадр базируется на данных в предшествующих и последующих кадрах (к примеру, содержащих только данные, измененные из предыдущего кадра или отличающиеся от данных в следующем кадре), а P-кадр содержит данные, которые изменены с предыдущего кадра. В большинстве случаев между I-кадрами вставляются P-кадры и B-кадры в кодированном видео. В отношении размера (к примеру, числа битов, используемых для того, чтобы кодировать кадр) I-кадры в типичном варианте гораздо больше P-кадров, которые, в свою очередь, больше B-кадров. Для эффективной обработки кодирования, передачи и декодирования длина GOP должна быть достаточно большой для того, чтобы снижать фактические потери из больших I-кадров, и достаточно маленькой для того, чтобы противостоять несовпадению между кодером и декодером или ухудшению качества канала. Помимо этого, макроблоки (MB) в P-кадрах могут быть внутренне кодированными по той же причине.
Обнаружение смены сцен может быть использовано видеокодером для того, чтобы определять соответствующую длину GOP и вставлять I-кадры на основе длины GOP вместо вставки зачастую ненужного I-кадра с фиксированным интервалом. В практической системе потоковой передачи видео качество канала связи обычно ухудшается посредством битовых ошибок или потерь пакетов. То, где размещаются I-кадры или I-MB, может существенно влиять на качество декодированного видео и удобство просмотра. Одна схема кодирования заключается в том, чтобы использовать внутренне кодированные кадры для изображений или частей изображений, которые имеют существенное отличие в сравнении с совместно размещенными предыдущими изображениями или частями изображений. Обычно эти зоны не могут эффективно и рационально предсказываться при оценке движения, и кодирование может выполняться более эффективно, если эти зоны исключены из методик межкадрового кодирования (к примеру, кодирования с помощью B-кадров и P-кадров). В контексте ухудшения качества канала эти зоны, вероятно, испытывают распространение ошибок, которое может быть уменьшено или исключено (либо практически исключено) посредством внутрикадрового кодирования.
Части видео GOP могут быть классифицированы на две или более категорий, при этом каждая зона может иметь различные критерии внутрикадрового кодирования, которые могут зависеть от конкретной реализации. В качестве примера, видео может быть классифицировано на три категории: резкая смена сцен, монтажный переход и другие медленные смены сцен, а также вспышки камеры.
Резкие смены сцен включают в себя кадры, которые значительно отличаются от предыдущего кадра, обычно вызываемые работой камеры. Поскольку содержимое этих кадров отличается от содержимого предыдущего кадра, кадры резкой смены сцен должны быть кодированы как I-кадры.
Монтажный переход и другие медленные изменения сцен включают в себя медленное переключение сцен, обычно вызываемое посредством вычислительной обработки съемки камерой. Постепенное смешивание двух различных сцен может выглядеть более приятным для человеческих глаз, но налагает сложную задачу на кодирование видео. Компенсация движения не может эффективно уменьшить скорость передачи битов этих кадров, и большее число внутренних MB может быть обновлено для этих кадров.
Вспышки камеры, или события вспышки камеры, возникают, когда содержимое кадра включает в себя вспышки камеры. Эти вспышки имеют относительно небольшую длительность (к примеру, один кадр) и являются очень яркими, так что пикселы в кадре, визуализирующем вспышки, демонстрируют очень высокую яркость относительно соответствующей области в соседнем кадре. Вспышки камеры сдвигают яркость изображения внезапно и быстро. Обычно продолжительность вспышки камеры меньше продолжительности временного маскирования зрительной системы человека (HVS), которая в типичном варианте задается равной 44 мс. Человеческие глаза не чувствительны к качеству этих коротких всплесков яркости, и поэтому они могут быть кодированы более грубо. Поскольку кадры вспышке не могут эффективно обрабатываться с помощью компенсации движения и они являются плохим вариантом предсказания для будущих кадров, грубое кодирование этих кадров не снижает эффективность кодирования будущих кадров. Сцены, классифицированные как вспышки, не должны быть использованы для того, чтобы предсказывать другие кадры вследствие "искусственной" высокой яркости, и другие кадры не могут быть эффективно использованы для того, чтобы предсказывать эти кадры, по той же причине. После идентификации эти кадры могут быть извлечены, поскольку они могут потребовать относительно высокого объема обработки. Один вариант состоит в том, чтобы удалять вспышки камеры и кодировать коэффициент DC на их месте; это решение является простым, вычислительно быстрым и экономит много битов.
Когда любые из вышеприведенных категорий кадров обнаружены, объявляется событие кадра. Обнаружение кадров полезно не только для того, чтобы повышать эффективность кодирования, оно также может помочь в идентификации поиска и индексации видеосодержимого. Один иллюстративный аспект процесса обнаружения сцен описан ниже. В этом примере, процесс обнаружения кадров сначала вычисляет информацию, или показатели, для выбранного кадра, обрабатываемого для обнаружения кадров. Показатели могут включать в себя информацию из двумерной обработки оценки и компенсации движения для видео и других основанных на яркости показателей.
Чтобы выполнять двумерную оценку/компенсацию движения, видеопоследовательность должна быть предварительно обработана с помощью модуля двунаправленной компенсации движения, который сопоставляет каждый блок 8x8 текущего кадра с блоками в двух кадрах, наиболее близких к соседним кадрам, один в прошлом и один в будущем. Блок компенсации движения формирует векторы движения и разностные показатели для каждого блока. Фиг.29 - это иллюстрация, которая демонстрирует пример сопоставления пикселов текущего кадра C с прошлым кадром P и будущим (или следующим) кадром N и показывает векторы движения для сопоставленных пикселов (прошлый вектор движения MVP и будущий вектор движения MVN). Общее описание формирования двунаправленных векторов движения и связанного кодирования, в общем, приводится ниже со ссылкой на фиг.32.
После определения информации двунаправленного движения (к примеру, информации движения, которая идентифицирует MB (наиболее совпадающие) в соответствующих соседних кадрах, дополнительные показатели могут быть сформированы (к примеру, посредством модуля компенсации движения в модуле 612 секционирования GOP или другом соответствующем компоненте) посредством различных сравнений текущего кадра со следующим кадром и предыдущим кадром. Модуль компенсации движения может формировать разностный показатель для каждого блока. Разностным показателем может быть сумма квадратов разностей (SSD) или сумма абсолютной разности (SAD). Без потери общности здесь в качестве примера используется SAD.
Для каждого кадра соотношение SAD, также упоминаемое как "коэффициент контрастности", вычисляется следующим образом:
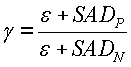
где SAD P и SAD N - это сумма абсолютных разностей прямого и обратного разностного показателя соответственно. Следует отметить, что знаменатель содержит небольшое положительное число ε, чтобы не допустить ошибки деления на нуль. Числитель также содержит ε, чтобы компенсировать влияние единицы в знаменателе. Например, если предыдущий кадр, текущий кадр и следующий кадр идентичны, поиск движения должен давать SADP=SADN=0. В этом случае вышеуказанные формирователи вычисления γ=1 вместо 0 или бесконечности.
Гистограмма яркости может быть вычислена для каждого кадра. В типичном варианте мультимедийные изображения имеют глубину яркости (к примеру, число "элементов разрешения") в восемь битов. Глубина яркости, используемая для вычисления гистограммы яркости согласно некоторым аспектам, может быть задана равной 16, чтобы получить гистограмму. В других аспектах глубина яркости может быть задана равной соответствующему числу, которое может зависеть от типа обрабатываемых данных, доступной вычислительной мощности или других предварительно определенных критериев. В некоторых аспектах глубина яркости может задаваться динамически на основе вычисленного или принятого показателя, например, содержимого данных.
Нижеприведенное уравнение иллюстрирует один пример вычисления разности гистограмм яркости (лямбды):
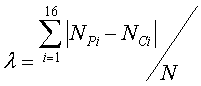
где NPi - это число блоков в i-том элементе разрешения для предыдущего кадра, NCi - это число блоков в i-том элементе разрешения для текущего кадра, а N - это общее число блоков в кадре. Если разность гистограмм яркости предыдущего и текущего кадра полностью непохожа (или непересекающаяся), то λ=2.
Используя эта информацию, показатель разности кадров (D) вычисляется следующим образом:
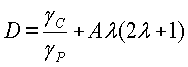
где A - это константа, выбранная посредством варианта применения, 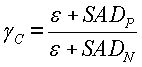 и
и 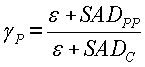
Выбранный (текущий кадр) классифицируется как кадр резкой смены сцен, если разностный показатель кадров удовлетворяет критерию, показанному в уравнении 9:
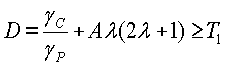
где A - это константа, выбранная посредством варианта применения, а T 1 - это порог.
В одном примере, который показывает моделирование, задание A=1 и T1=5 предоставляет хорошую производительность обнаружения. Если текущий кадр является кадром резкой смены сцен, то γc должно быть большим, а γp должно быть маленьким. Соотношение γc/γp может быть использовано вместо только γc, с тем чтобы показатель был нормализован к уровню активности.
Следует отметить, что вышеприведенный критерий использует разность гистограмм яркости лямбду (λ) нелинейным способом. Фиг.16 иллюстрирует, что λ·(2λ+1) является выпуклой функцией. Когда λ небольшая (к примеру, около нуля), это просто предыскажение. Чем больше становится λ, тем больше предыскажение предоставляется посредством функции. С помощью этого предыскажения для любого λ больше 1,4, резкая смена сцен обнаруживается, если порог T1 задан равным 5.
Текущий кадр определяется как монтажный переход или медленная смена сцен, если показатель интенсивности сцены D удовлетворяет критерию, показанному в уравнении 5:
для определенного числа непрерывных кадров, где T 1 - это такой же порог, что и используемый выше, а T 2 - это другое значение порога.
Событие вспышки обычно заставляет гистограмму яркости смещаться к более яркой стороне. В камере этого иллюстративного аспекта статистика гистограммы яркости используется для того, чтобы определять то, содержит ли текущий кадр вспышки камеры. Процесс обнаружения кадров может определять то, больше ли яркость текущего кадра, чем яркость предыдущего кадра, на определенный порог T 3 и больше яркость текущего кадра, чем яркость следующего кадра, на порог T 3, как показано в уравнениях 11 и 12:
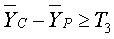
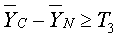
Если вышеуказанный критерий не удовлетворяется, текущий кадр не классифицируется как содержащий вспышки камеры. Если критерий удовлетворяется, процесс обнаружения кадров определяет то, больше ли обратный разностный показатель SAD P и прямой разностный показатель SAD N определенного порога T4, как проиллюстрировано в уравнениях ниже:
где 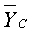 - это средняя яркость текущего кадра,
- это средняя яркость текущего кадра, 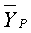 - это средняя яркость предыдущего кадра,
- это средняя яркость предыдущего кадра, 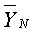 - это средняя яркость следующего кадра, а SADP и SADN - это прямой и обратный разностные показатели, ассоциативно связанные с текущим кадром.
- это средняя яркость следующего кадра, а SADP и SADN - это прямой и обратный разностные показатели, ассоциативно связанные с текущим кадром.
Процесс обнаружения кадров определяет события вспышки камеры посредством определения сначала того, больше ли яркость текущего кадра яркости предыдущего кадра и яркости следующего кадра. Если нет, кадр не является событием вспышки камеры; но если да, то это может быть. Процесс обнаружения кадров в таком случае может определить то, больше ли обратный разностный показатель порога T3 и больше ли прямой разностный показатель порога T4; если оба этих условия удовлетворены, процесс обнаружения кадров классифицирует текущий кадр как имеющий вспышки камеры. Если критерий не удовлетворяется, кадр не классифицируется даже как любой тип кадра либо ему может быть присвоена классификация по умолчанию, которая идентифицирует кодирование, которое должно быть выполнено для кадра (к примеру, удалить кадр, кодировать как I-кадр).
Некоторые примерные значения T1, T2, T3 и T4 показаны выше. В типичном варианте эти пороговые значения выбираются посредством тестирования конкретной реализации обнаружения кадров. В некоторых аспектах одно или более пороговых значений T1, T2, T3 и T4 являются предварительно определенными, и эти значения включаются в классификатор кадров в устройстве кодирования. В некоторых аспектах одно или более пороговых значений T1, T2, T3 и T4 могут быть заданы в ходе обработки (к примеру, динамически) на основе использования информации (к примеру, метаданных), предоставляемой в классификатор кадров, или на основе информации, вычисленной самим классификатором кадров.
Кодирование видео с помощью информации обнаружения кадров в типичном варианте выполняется в кодере, но описано здесь для полноты раскрытия обнаружения кадров. Ссылаясь на фиг.30, процесс 301 кодирования может использовать информацию обнаружения кадров для того, чтобы кодировать видео на основе обнаруженных кадров в последовательности кадров. Процесс 301 переходит к этапу 303 и проверяет, классифицирован ли текущий кадр как резкая смена сцены. Если да, на этапе 305 текущий кадр может быть кодирован как I-кадр, и граница GOP может быть определена. Если нет, процесс 301 переходит к этапу 307; если текущий кадр классифицирован как часть медленно изменяющейся сцены, на этапе 309 текущий кадр и другие кадры в медленно изменяющейся сцене могут быть кодированы как кадры с предсказанием (к примеру, P-кадр или B-кадр). Процесс 301 далее переходит к этапу 311, на котором он проверяет, классифицирован ли текущий кадр как сцена вспышки, содержащая вспышки камеры. Если да, на этапе 313 кадр может быть идентифицирован для специальной обработки, например, дл удаления или кодирования коэффициента DC для кадра; если нет, классификация текущего кадра не выполнена, и текущий кадр может быть кодирован в соответствии с другими критериями, кодирован как I-кадр или удален.
В вышеописанном аспекте величина разности между кадром, который должен быть сжат, и двумя соседними кадрами указывается посредством разностного показателя кадров D. Если значительная величина одностороннего изменения яркости обнаружена, это указывает эффект монтажного перехода в кадре. Чем более кратковременным является монтажный переход, тем большее усиление может быть достигнуто посредством использования B-кадров. В некоторых аспектах модифицированный разностный показатель кадров используется так, как показано в уравнении ниже:
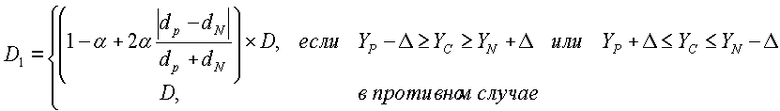
где d P=|YC-YP| и d N=|YC-YP| - это разность компоненты яркости между текущим кадром и предыдущим кадром и разность компоненты яркости между текущим кадром и следующим кадром соответственно, Δ представляет константу, которая может быть определена обычным опытным путем, поскольку она может зависеть от реализации, а α - это переменная взвешивания, имеющая значение от 0 до 1.
B. Формирование таблицы полосы пропускания
Препроцессор 226 (фиг.6) также может быть сконфигурирован так, чтобы формировать таблицу полосы пропускания, которая может быть использована для кодирования мультимедийных данных. В некоторых аспектах модуль 712 классификации содержимого в кодере 228 (фиг.7) вместо него формирует таблицу полосы пропускания.
Визуальное качество человека V может быть функцией от сложности кодирования C и назначенных битов B (также упоминаемых как полоса пропускания). Фиг.15 - это график, иллюстрирующий данную взаимосвязь. Следует отметить, что показатель сложности кодирования C рассматривает пространственные и временные частоты с точки зрения видения пользователя. Для искажений, более чувствительных к человеческим глазам, значение сложности соответственно выше. В типичном варианте можно допустить, что V монотонно уменьшается в C и монотонно увеличивается в B.
Чтобы достичь постоянного зрительного качества, полоса пропускания (Bi) назначается i-тому объекту (кадру или MB), который должен быть кодирован, который удовлетворяет критериям, выраженным в нижеследующих двух уравнениях:
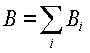
В двух вышеприведенных уравнениях Ci - это сложность кодирования i-го объекта, B - это общая доступная полоса пропускания, а V - это достигнутое зрительное качество для объекта. Визуальное качество человека трудно сформулировать как уравнение. Следовательно, вышеуказанный набор уравнений не является точно заданным. Тем не менее, если предполагается, что трехмерная модель является непрерывной во всех переменных, соотношение полосы пропускания (B i /B) может трактоваться как неизменное с соседством пары (C, V). Соотношение полосы пропускания βi задается в уравнении, показанном ниже:
Назначение битов в таком случае может быть задано так, как выражено в следующих уравнениях:
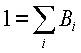
для (C
i
,V)
 δ(C
0
,V
0
)
δ(C
0
,V
0
)
где δ указывает "соседство".
На сложность кодирования влияет чувствительность зрительной системы человека, как пространственная, так и временная. Зрительная модель человека по Гироду является примером модели, которая может быть использована для того, чтобы задавать пространственную сложность. Эта модель учитывает локальную пространственную частоту и окружающее освещение. Результирующий показатель называется Dcsat. В точке предварительной обработки в процессе то, должно изображение быть внутренне кодированным или внешне кодированным, неизвестно, и соотношения полосы пропускания для обоих случаев формируются. Биты назначаются согласно соотношению между βINTRA различных видеообъектов. Для внутренне кодированных изображений соотношение полосы пропускания выражается в следующем уравнении:
В вышеприведенном уравнении Y - это компонента средней яркости макроблока,
αINTRA - это весовой коэффициент для квадрата яркости и члена D csat, идущего за ним,
βINTRA - это коэффициент нормализации, чтобы гарантировать то, что . Например, значение αINTRA=4 достигает хорошего зрительного качества. Информация содержимого (к примеру, классификация содержимого) может быть использована для того, чтобы присваивать αINTRA значение, которое соответствует требуемому уровню хорошего зрительного качества для конкретного содержимого видео. В одном примере, если видеосодержимое содержит широковещательную передачу новостей с "говорящей головой", уровень зрительного качества может быть задан ниже, поскольку изображение информации или отображаемая часть экрана может считаться меньшей важности, чем аудиочасть, и меньше бит может быть выделено для того, чтобы кодировать данные. В другом примере, если видеосодержимое содержит спортивный сюжет, информация содержимого может быть использована так, чтобы присваивать α1NTRA значение, которое соответствует более высокому уровню зрительного качества, поскольку отображаемые изображения могут быть более важны зрителю, и, соответственно, большее число битов выделяется для того, чтобы кодировать данные.
Чтобы понять это взаимоотношение, следует отметить то, что полоса пропускания назначается логарифмическим образом в соответствии со сложностью кодирования. Член квадрата яркости Y отражает тот факт, что коэффициенты с большим модулем используют больше битов для того, чтобы кодировать. Чтобы представить логарифм из получения отрицательных значений, единица добавляется к члену в скобках. Логарифмы с другими основаниями также могут быть использованы.
Временная сложность определяется посредством измерения разностного показателя кадров, который измеряет разность между двумя последовательными кадрами с учетом величины движения (к примеру, векторов движения) наряду с разностным показателем кадров, таким как сумма абсолютных разностей (SAD).
Назначение битов для внутренне кодированных изображений может учитывать как пространственную, так и временную сложность. Это выражено ниже:
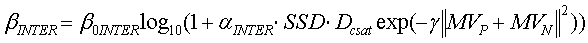
В вышеприведенном уравнении MVP и MVN - это прямой и обратный векторы движения для текущего MB (см. фиг.29). Следует отметить, что Y2 в формуле внутренне кодированной полосы пропускания заменено суммой квадратов разностей (SSD). Чтобы понять роль ||MV P +MV N || 2 в вышеприведенном уравнении, отметим следующие характеристики зрительной системы человека: области, подвергающиеся плавному предсказуемому движению (небольшое ||MV P +MV N || 2), привлекают внимание и могут быть отслежены глазом и в типичном варианте не могут допускать больше искажений, чем стационарные области. Тем не менее, области, подвергающиеся быстрому или непредсказуемому движению (большое ||MV P +MV N || 2), не могут отслеживать и могут допускать существенное квантование. Опыты показали, что αINTER=1, γ=0,001 достигает хорошего зрительного качества.
C. Адаптивное секционирование GOP
В другом иллюстративном примере обработки, которая может быть выполнена посредством препроцессора 226, модуль 612 секционирования GOP по фиг.6 также может адаптивно изменять структуру группы изображений, кодированных вместе, и описывается со ссылкой на пример, использующий MPEG2. Некоторые более старые стандарты сжатия видео (к примеру, MPEG2) не требуют того, чтобы GOP имела регулярную структуру, хотя она может налагаться. Последовательность MPEG2 всегда начинается с I-кадра, т.е. кадра, закодированного без ссылки на предыдущие изображения. Формат MPEG2 GOP обычно заранее устанавливается в кодере посредством фиксирования разнесения в GOP P- или прогнозных изображений, которые следуют после I-кадра. P-кадры - это изображения, которые частично предсказаны из предыдущих I- или P-изображений. Кадры между начальным I-кадром и последующими P-кадрами кодируются как B-кадры. B-кадр (B означает двунаправленный) может использовать предыдущие и следующие I- или P-изображения отдельно или одновременно как ссылку. Число битов, требуемых для того, чтобы кодировать I-кадр, в среднем превышает число битов, требуемых для того, чтобы кодировать P-кадр; аналогично, число битов, требуемых для того, чтобы кодировать P-кадр, в среднем превышает число битов, требуемых для B-кадра. Пропущенный кадр, если он используется, не должен требовать битов для своего представления.
Концепция, лежащая в основе использования P- и B-кадров, и в более новых алгоритмах сжатия пропуск кадров для того, чтобы снизить скорость передачи данных, требуемых для того, чтобы представлять видео, является устранением временной избыточности. Когда временная избыточность высокая, т.е. есть незначительное изменение от изображения к изображению, использование P-, B- или пропущенных изображений эффективно представляет видеопоток, поскольку I- или P-изображения, декодированные ранее, используются в дальнейшем как ссылки для того, чтобы декодировать другие P- или B-изображения.
Адаптивное секционирование GOP основано на адаптивном использовании этой концепции. Разности между кадрами квантуются, и решение, чтобы представлять изображение посредством I, P, B или пропущенного кадра, автоматически принимается после того, как выполняются соответствующие тесты для квантованных разниц. Адаптивная структура имеет преимущества, недоступные в фиксированной GOP-структуре. Фиксированная структура должна игнорировать возможность того, что произошли небольшие изменения в содержимом; адаптивная процедура должна представлять гораздо больше B-кадров, которые должны быть вставлены между каждым I- и P- или двумя P-кадрами, тем самым уменьшая число битов, требуемых для того, чтобы адаптивно представлять последовательность кадров. Наоборот, когда изменение видеосодержимого существенно, эффективность P-кадров значительно снижается, поскольку разница между предсказанными и опорными кадрами слишком большая. При этих условиях совпадающие объекты могут выпадать из зон поиска движения или похожесть между совпадающими объектами снижается вследствие искажения, вызываемого за счет изменений угла камеры. В этой точке P-кадры или I- и ее соседний P-кадр должны быть выбраны так, чтобы быть ближе друг к другу, и должно быть вставлено меньшее число B-кадров. Фиксированная GOP может не выполнять эту корректировку.
В системе, раскрытой здесь, эти условия автоматически измеряются. GOP-структура является гибкой и сделана так, чтобы приспосабливаться к этим изменениям в содержимом. Система оценивает разностный показатель кадров, который может рассматривать как меру расстояния между кадрами, с одинаковыми аддитивными способами расстояния. В концепции при условии кадров F1, F2 и F3, имеющих межкадровое расстояние d12 и d23, расстояние между F1 и F3 берется равным, по меньшей мере, d12+d23. Назначения кадров делаются на основе этого аналогичного расстоянию показателя.
Модуль секционирования GOP работает посредством назначения типов изображений кадрам по мере того, как они принимаются. Тип изображения указывает способ предсказания, который может требоваться при кодировании каждого блока.
I-изображения кодируются без ссылки на другие изображения. Поскольку они автономны, они предоставляют точки доступа в потоке данных, где декодирование может начинаться. Тип кодирования I назначается кадру, если расстояние до предшествующего кадра превышает порог смены сцен.
P-изображения могут использовать предыдущие I- или P-изображения для предсказания с компенсацией движения. Они используют блоки в предыдущих полях или кадрах, которые могут быть смещены от предсказываемого блока как основа для кодирования. После того как опорный кадр вычитается из рассматриваемого блока, остаточный блок кодируется, в типичном варианте с помощью дискретного косинусного преобразования, для устранения пространственной избыточности. Типы кодирования P назначаются кадру, если расстояние между ним и последним кадром, назначенным так, чтобы быть P-кадром, превышает второй порог, который в типичном варианте меньше первого.
Изображения B-кадров могут использовать предыдущие и следующие P- или I-изображения для компенсации движения, как описано ниже. Блок в B-изображении может быть спрогнозированным прямо, обратно или двунаправленно; либо он может быть внутренне кодирован без ссылки на другие кадры. В H.264 опорный блок может быть линейной комбинацией максимум 32 блоков из максимум стольких кадров. Если кадр не может быть назначен так, чтобы быть I- или P-типа, он назначается так, чтобы быть B-типа, если расстояние от него до промежуточного предшественника больше третьего порога, который в типичном варианте меньше второго порога.
Если кадр не может быть назначен так, чтобы стать кодированным B-кадром, ему назначается состояние "пропуск кадра". Этот кадр может быть пропущен, поскольку он практически является копией предыдущего кадра.
Оценка показателя, которая количественно представляет расстояние между соседними кадрами в порядке отображения, является первой частью этой обработки, которая выполняется. Данный показатель является расстоянием, ссылающимся на вышеуказанное; с его помощью каждый кадр может быть оценен для надлежащего типа. Таким образом, разнесение между I- и соседним P- или двумя последовательными P-кадрами может быть переменным. Вычисление расстояния начинается посредством обработки видеокадров с основанным на блоках модулем компенсации движения, причем блок является базовой единицей видеосжатия, состоящей обычно из 16х16 пикселов, хотя возможны другие размеры блоков, например, 8х8, 4х4 и 8х16. Для кадров, составляющих два поля с устраненной чересстрочной разверткой, компенсация движения может быть выполнена на основе поля, при этом поиск опорных блоков выполняется скорее в полях, а не в кадрах. Для блока в первом поле текущего кадра прямой опорный блок обнаруживается в полях кадра, который следует за ним; аналогично, обратный опорный кадр обнаруживается в полях, которые непосредственно предшествуют текущему полю. Текущие блоки собираются в сжатое поле. Процесс продолжается со вторым полем кадра. Два компенсированных поля комбинируются так, чтобы формировать прямой и обратный компенсированный кадр.
Для кадров, созданных при преобразовании 606 из видеоформата в фильм, поиск опорных блоков выполняется только на основе кадров, поскольку присутствуют только восстановленные кинокадры. Два опорных блока и две разности, прямая и обратная, находятся, приводя также к прямому и обратному компенсированному кадру. Итак, модуль компенсации движения формирует векторы движения и показатели разности для каждого блока; но блок является частью NTSC-поля в случае вывода обрабатываемого модуля 605 устранения чересстрочной разверткой и является частью кинокадра, если вывод преобразования из видеоформата в фильм обрабатывается. Отметим, что разности в показателе оцениваются между блоком в рассматриваемом поле или кадре и блоком, который совпадает с ним, либо в предшествующем поле или кадре, либо в поле или кадре, который следует сразу за ним, в зависимости от того, оценивается прямая или обратная разность. Только значения яркости попадают в это вычисление.
Таким образом, этап компенсации движения формирует два набора разностей.
Они находятся между блоками текущих значений яркости и значений яркости, взятых из кадров, которые находятся непосредственно впереди и непосредственно позади текущего кадра во времени. Абсолютное значение каждой прямой и каждой обратной разности определяется для каждого пиксела, и каждое отдельно суммируется по всему кадру. Оба поля включаются в два суммирования, когда обрабатываются NTSC-поля с устраненной чересстрочной разверткой, которые содержат кадр. Таким образом, SADP и SADN, суммированные абсолютные значения прямой и обратной разности, находятся.
Для каждого кадра соотношение SAD вычисляется с помощью взаимосвязи:
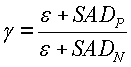
где SADP и SADN - это суммированные абсолютные значения прямых и обратных разностей соответственно. Небольшое положительное число добавляется в числитель ε, чтобы не допустить ошибки деления на нуль. Аналогичный член ε добавляется в знаменатель, уменьшая чувствительность γ, когда SADP или SADN близко к нулю.
В альтернативном аспекте разностью может быть SSD, сумма квадратов разностей, и SAD, сумма абсолютных разностей, или SATD, в которой блоки значений пикселов преобразуются посредством применения дискретного косинусного преобразования к ним до того, как берутся разности в элементах блоков. Суммы оцениваются в области активного видео, хотя меньшая область может быть использована в других аспектах.
Гистограмма яркости каждого кадра, как принимается (без компенсации движения), также вычисляется. Гистограмма работает для коэффициента DC, т.е. коэффициента (0,0) в матрице 16x16 коэффициентов, которая является результатом применения двумерного дискретного косинусного преобразования к блоку значений яркости, если доступны. Эквивалентно среднее значение из 256 значений яркости в блоке 16x16 может быть использовано на гистограмме. Для изображений, глубина яркости которых равна восьми битам, число элементов изображения задается равным 16. Следующий показатель оценивает разность гистограмм:
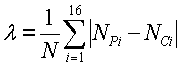
В вышеприведенном NPi - это число блоков из предыдущего кадра в i-том элементе разрешения, NCi - это число блоков из текущего кадра, который принадлежит i-тому элементу разрешения, а N - это общее число блоков в кадре.
Эти промежуточные результаты собираются с тем, чтобы сформировать разностный показатель текущего кадра как:
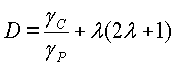
где γC - это соотношение SAD на основе текущего кадра, а γP - это соотношение SAD на основе предыдущего кадра. Если сцена имеет плавное движение и ее гистограмма компоненты яркости практически не изменяется, то D~1. Если текущий кадр отображает резкую смену сцен, то γC должно иметь большое значение, а γP должно иметь небольшое значение. Соотношение γc/γp используется вместо только γc, с тем чтобы показатель был нормализован к уровню активности контекста.
Фиг.42 иллюстрирует процесс назначения типов сжатия кадрам. D, текущая разность кадров, заданная в уравнении 19, является основой для решений, принимаемых в отношении назначений кадров. Как указывает этап 4202 принятия решений, если рассматриваемый кадр является первым в последовательности, путь решения, помеченный "ДА", идет к этапу 4206, тем самым объявляя то, что кадр является I-кадром. Накопленные разности кадров задаются равными нулю на этапе 4208, и процесс возвращается (на этапе 4210) к начальному этапу. Если рассматриваемый кадр не является первым кадром в последовательности, путь, помеченный "НЕТ", идет из этапа 4202, где принято решение, и на тестовом этапе 4204 текущая разность кадров тестируется относительно порога смены сцен. Если текущая разность кадров превышает этот порог, путь решения, помеченный "ДА", идет из этапа 4206, снова приводя к назначению I-кадра.
Если текущая разность кадров меньше порога смены сцен, путь "НЕТ" идет к этапу 4212, где текущая разность кадров прибавляется к накопленной разности кадров. Продолжая проходить блок-схему последовательности операций способа на этапе 4214 принятия решения, накопленная разность кадров сравнивается с порогом t, который, в общем, меньше порога смены сцен. Если накопленная разность кадров превышает t, управление переходит к этапу 4216, и кадр назначается так, чтобы быть P-кадром; накопленная разность кадров затем сбрасывается до нуля на этапе 4218. Если накопленная разность кадров меньше t, управление переходит от этапа 4214 к этапу 4220. Здесь накопленная разность кадров сравнивается с x, которое меньше t. Если текущая разность кадров меньше t, кадр назначается как пропущенный на этапе 4222, и затем процесс возвращается; если текущая разность кадров больше t, кадр назначается так, чтобы быть B-кадром, на этапе 4226.
Кодер
Ссылаясь снова на фиг.2, транскодер 200 включает в себя кодер 228, который принимает обработанные метаданные и необработанное видео из препроцессора 226. Метаданные могут включать в себя любую информацию, изначально принятую в исходном видео 104, и любую информацию, вычисленную посредством препроцессора 226. Кодер 228 включает в себя кодер 230 первого прохода, кодер 232 второго прохода и повторный кодер 234. Кодер 228 также принимает входные данные из управления 231 транскодером, которое может предоставлять информацию (к примеру, метаданные, информацию устойчивости к ошибкам, информацию содержимого, информацию кодированной скорости передачи битов, информацию баланса базового уровня и уровня улучшения и информацию квантования) из кодера 232 второго прохода в кодер 230 первого прохода, повторный кодер 234, а также препроцессор 226. Кодер 228 кодирует принимаемое видео с помощью информации содержимого, принятой от препроцессора 226, и/или информации содержимого, которая формируется посредством самого кодера 228, например, посредством модуля 712 классификации содержимого (фиг.7).
Фиг.7 иллюстрирует блок-схему функциональных модулей, которые могут быть включены в примерный двухпроходный кодер, который может быть использован для кодера 228, проиллюстрированного на фиг.7, хотя фиг.7 и описание в данном документе не обязательно разрешает всю функциональность, которая может быть включена в кодер. Соответственно, определенные аспекты функциональных модулей описываются далее после нижеприведенного описания кодирования базового уровня и уровня улучшения.
Кодирование базового уровня и уровня улучшения
Кодером 228 может быть масштабируемый SNR-кодер, который может кодировать необработанное видео и метаданные из препроцессора 226 в первую группу кодированных данных, также упоминаемую в данном документе как базовый уровень, и одну или более дополнительных групп кодированных данных, также упоминаемых в данном документе как уровни улучшения. Алгоритм кодирования формирует коэффициенты базового уровня и уровня улучшения, которые, когда декодированы, могут быть комбинированы в декодере, когда оба уровня доступны для декодирования. Когда оба уровня недоступны, кодирование базового уровня позволяет их декодировать как один уровень.
Один аспект такого процесса многоуровневого кодирования описан в ссылке к фиг.31. На этапе 321 I-кадр кодируется с полностью внутренне кодированными макроблоками (внутренне кодированными MB). В H.264 внутренне кодированные MB в I-кадрах кодируются с полностью используемым пространственным предсказанием, которое предоставляет значительную величину улучшения кодирования. Предусмотрено два подрежима: внутренний 4x4 и внутренний 16x16. Если базовый уровень должен использовать преимущество улучшения кодирования, предоставляемое посредством пространственного предсказания, то базовый уровень должен быть кодирован и декодирован перед кодированием и декодированием уровня улучшения. Используется двухпроходное кодирование и декодирование I-кадров. В базовом уровне параметр квантования базового уровня QPb предоставляет коэффициентам преобразования грубый размер шага квантования. Попиксельная разность между исходным кадром и восстановленным кадром базового уровня кодируется на уровне улучшения. Уровень улучшения использует параметр квантования QPe, который предоставляет более точный размер шага квантования. Средство кодирования, такое как кодер 228 по фиг.2, может выполнять кодирование на этапе 321.
На этапе 323 кодер кодирует данные базового уровня и данные уровня улучшения для P- и/или B-кадров в обрабатываемой GOP. Средство кодирование, такое как кодер 228, может выполнять кодирование на этапе 323. На этапе 325 процесс кодирования проверяет, есть ли еще P- или B-кадры, чтобы кодировать. Средство кодирования, такое как масштабируемый SNR-кодер 228, может выполнять этап 325. Если еще P- или B-кадры остаются, этап 323 повторяется до тех пор, пока не будет закончено кодирование всех кадров в GOP. P- и B-кадры состоят из внешне кодированных макроблоков (внешне кодированных MB), хотя могут быть внутренне кодированные MB в P- и B-кадрах, как описано ниже.
Чтобы декодер различал между данными базового уровня и уровня улучшения, кодер 228 кодирует служебную информацию, этап 327. Типы служебной информации включают в себя, например, данные, идентифицирующие число уровней, данные, идентифицирующие уровень как базовый уровень, данные, идентифицирующие уровень как уровень улучшения, данные, идентифицирующие взаимосвязи между уровнями (например, уровень 2 является уровнем улучшения для базового уровня 1 или уровень 3 является уровнем улучшения для уровня улучшения 2), или данные, идентифицирующие уровень как конечный уровень улучшения в строке уровней улучшения. Служебная информация может содержаться в заголовках, связанных с данными базового и/или уровня улучшения, к которым она относится, либо содержаться в отдельных сообщениях данных. Средство кодирования, такое как кодер 228 по фиг.2, может выполнять процесс на этапе 327.
Чтобы иметь одноуровневое кодирование, коэффициенты двух уровней могут быть комбинированы до обратного квантования. Следовательно, коэффициенты двух уровней должны быть сформированы интерактивно, в противном случае это может вводить значительный объем служебной информации. Одна причина увеличения служебной информации заключается в том, что кодирование базового уровня и кодирование уровня улучшения может использовать различные временные ссылки. Требуется алгоритм для того, чтобы формировать коэффициенты базового уровня и уровня улучшения, которые могут быть комбинированы в декодере до деквантования, когда оба уровня доступны. В то же время алгоритм должен предоставлять приемлемое видео базового уровня, когда уровень улучшения недоступен, или декодер принимает решение декодировать уровень улучшения по таким причинам, как, например, экономия энергии. Подробности иллюстративного примера такого процесса дополнительно описаны ниже в контексте краткого пояснения стандартного кодирования с предсказанием непосредственно далее.
P-кадры (или внешне кодированные секции) могут использовать временную избыточность между зоной в текущем изображении и наиболее совпадающей зоной прогнозирования в опорном изображении. Местоположение наиболее совпадающей зоны прогнозирования в опорном изображении может быть кодировано в векторе движения. Разность между текущей зоной и наиболее совпадающей опорной зоной прогнозирования известна как остаточная ошибка (или ошибка предсказания).
Фиг.32 - это иллюстрация примера процесса составления P-кадров, например, в MPEG-4. Процесс 331 является более подробной иллюстрацией примерного процесса, который может выполняться на этапе 323 по фиг.31. Процесс 331 включает в себя текущее изображение 333, составленное из 5x5 макроблоков, при этом число макроблоков в данном примере является произвольным. Макроблок составлен максимум из 16x16 пикселов. Пикселы могут быть заданы как 8-битовое значение компоненты яркости (Y) и два 8-битовых значения компоненты цветности (Cr и Cb). В MPEG компоненты Y, Cr и Cb могут быть сохранены в формате 4:2:0, при этом компоненты Cr и Cb подвергнуты понижающей дискретизации на 2 в направлениях X и Y. Следовательно, каждый макроблок должен состоять из 256 компонент Y, 64 компонент Cr и 64 компонент Cb. Макроблок 335 текущего изображения 333 предсказывается из опорного изображения 337 в точке времени, отличной от текущего изображения 333. В опорном изображении 337 выполняется поиск, чтобы найти наилучшим образом совпадающий макроблок 339, который является ближайшим в отношении значений Y, Cr и Cb к текущему кодируемому макроблоку 335. Размещение наилучшим образом совпадающего макроблока 339 в опорном изображении 337 кодируется в векторе 341 движения. Опорным изображением 337 может быть I-кадр или P-кадр, который декодер должен иметь восстановленным до составления текущего изображения 333. Наилучшим образом совпадающий макроблок 339 вычитается из текущего макроблока 335 (разность для каждой из компонент Y, Cr и Cb вычисляется), приводя к остаточной ошибке 343. Остаточная ошибка 343 кодируется с помощью двухмерного дискретного косинусного преобразования (DCT) 345 и затем квантуется 347. Квантование 347 может выполняться для того, чтобы предоставлять пространственное сжатие, например, посредством назначения меньшего числа битов высокочастотным компонентам, при этом назначая больше битов низкочастотным компонентам. Квантованные коэффициенты остаточной ошибки 343 наряду с идентифицирующей информацией вектора 341 движения и опорного изображения 333 являются кодированной информацией, представляющей текущий макроблок 335. Кодированная информация может быть сохранена в запоминающем устройстве для будущего использования или обработана, например, для целей коррекции ошибок либо улучшения изображения, или передана по сети 349.
Кодированные квантованные коэффициенты остаточной ошибки 343 наряду с кодированным вектором 341 движения могут быть использованы для того, чтобы восстанавливать текущий макроблок 335 в кодере для использования как части опорного кадра для последующей оценки и компенсации движения. Кодер может моделировать процедуры декодера для данного восстановления P-кадров. Моделирование в декодере приводит к тому, что кодер и декодер работают с одним опорным изображением. Процесс восстановления, выполняемый либо в кодере для последующего внешнего кодирования, либо в декодере, представлен здесь. Восстановление P-кадра может быть начато после того, как опорный кадр (или часть изображения либо кадра, который указывается ссылкой) восстановлен. Кодированные квантованные коэффициенты деквантуются 351, а затем выполняется двумерное обратное DCT, или IDCT, 353, приводя к декодированной или восстановленной остаточной ошибке 355. Кодированный вектор 341 движения декодируется и используется для того, чтобы находить уже восстановленный наиболее совпадающий макроблок 357 в уже восстановленном опорном изображении 337. Восстановленная остаточная ошибка 355 затем прибавляется к восстановленному наиболее совпадающему макроблоку 357, чтобы сформировать восстановленный макроблок 359. Восстановленный макроблок 359 может быть сохранен в запоминающем устройстве, отображен независимо или в изображении с другими восстановленными макроблоками либо обработан дополнительно для улучшения изображений.
B-кадры (или любая секция, кодированная с двунаправленным предсказанием) могут использовать временную избыточность между зоной в текущем изображении и наиболее совпадающей зоной прогнозирования в предыдущей зоне наиболее совпадающей зоной прогнозирования в последующей зоне. Последующая наиболее совпадающая зона прогнозирования и предыдущая наиболее совпадающая зона прогнозирования комбинируются, чтобы сформировать двунаправленную прогнозную зону. Разность между зоной текущего изображения и наиболее совпадающей опорной зоной прогнозирования известна как остаточная ошибка (или ошибка предсказания). Размещения наиболее совпадающей зоны прогнозирования в последующем опорном изображении наиболее совпадающей зоны прогнозирования в предыдущем опорном изображении может быть кодировано в двух векторах движения.
Фиг.33 иллюстрирует пример процесса кодера для кодирования коэффициентов базового уровня и уровня улучшения, которое может быть выполнено посредством кодера 228. Базовый уровень и уровень улучшения кодируются, чтобы предоставить масштабированный поток битов SNR. Фиг.33 иллюстрирует пример для кодирования коэффициентов остаточной ошибки между MB, как, например, должно быть выполнено на этапе 323 по фиг.31. Тем не менее, аналогичные способы могут быть использованы для того, чтобы также кодировать коэффициенты внутри MB. Средство кодирования, такое как компонент 228 кодера по фиг.2, может выполнять процесс, проиллюстрированный на фиг.33 и этапе 323 на фиг.32. Исходные (которые должны быть кодированы) видеоданные 406 (видеоданные содержат информацию компонентов яркости и цветности в этом примере) вводятся в контур 302 наиболее совпадающего макроблока базового уровня и контур 365 наиболее совпадающего макроблока уровня улучшения. Назначение обоих контуров 363 и 365 заключается в том, чтобы минимизировать остаточную ошибку, которая вычисляется в сумматорах 367 и 369 соответственно. Контуры 363 и 365 могут осуществляться параллельно, как показано, или последовательно. Контуры 363 и 365 включают в себя логику для выполнения поиска в буферах 371 и 373 соответственно, которые содержат опорные кадры, чтобы идентифицировать наиболее совпадающий макроблок, который минимизирует остаточную ошибку между наиболее совпадающим макроблоком и исходными данными 361 (буферы 371 и 373 могут быть одним и тем же буфером). Остаточные ошибки контура 363 и контура 365 отличаются, поскольку контур 363 базового уровня, в общем, использует более грубый размер шага квантования (более высокое значение QP), чем контур 365 уровня улучшения. Блоки 375 и 377 преобразования преобразуют остаточные ошибки каждого контура.
Преобразованные коэффициенты затем разбираются на коэффициенты базового уровня и уровня улучшения в модуле 379 выбора. Разбор модуля 379 выбора может выполняться в нескольких формах, как описано ниже. Один общий признак методик разбора заключается в том, что коэффициент уровня улучшения, C' enh, вычисляется так, что он является дифференциальным уточнением к коэффициенту базового уровня C' base . Вычисление уровня улучшения, чтобы быть уточнением к базовому уровню, дает возможность декодеру декодировать коэффициент базового уровня самостоятельно и иметь приемлемое представление изображения либо комбинировать коэффициенты базового уровня и уровня улучшения и иметь уточненное представление изображения. Коэффициенты, выбранные посредством модуля 379 выбора, затем квантуются посредством квантователей 381 и 383. Квантованные коэффициенты C' base и C' enh (вычисленные с помощью квантователей 381 и 383 соответственно) могут быть сохранены в запоминающем устройстве или переданы по сети в декодер.
Чтобы сопоставить восстановление макроблока в декодере, деквантователь 385 деквантует коэффициенты остаточной ошибки базового уровня. Деквантованные коэффициенты остаточной ошибки обратно преобразуются 387 и прибавляются 389 к наиболее совпадающему макроблоку, найденному в буфере 371, приводя к восстановленному макроблоку, который совпадает с тем, что должно быть восстановлено в декодере. Квантователь 383, деквантователь 391, обратный преобразователь 393, сумматор 397 и буфер 373 выполняют аналогичные вычисления в контуре 365 уровня улучшения тем, которые выполнялись в контуре 363 базового уровня. Кроме того, сумматор 393 используется для того, чтобы комбинировать обратно квантованные коэффициенты уровня улучшения и базового уровня, используемые при восстановлении уровня улучшения. Квантователь и деквантователь уровня улучшения, в общем, используют более точный размер шага квантователя (меньшее QP), чем базовый уровень.
Фиг.34, 35 и 36 иллюстрируют примеры процессов модуля выбора коэффициентов базового уровня и уровня улучшения, которые могут использоваться в модуле 379 выбора по фиг.33. Средство выбора, такое как кодер 228 по фиг.2, может выполнять процессы, проиллюстрированные на фиг.34, 35 и 35. Используя фиг.34 в качестве примера, преобразованные коэффициенты разбираются на коэффициенты базового и уровня улучшения, как показано в следующих уравнениях:

где функция min может быть либо математическим минимумом, либо минимальной величиной из двух аргументов. Уравнение 25 проиллюстрировано как этап 401, а уравнение 26 проиллюстрировано как сумматор 510 на фиг.34. В уравнении 26 Qb означает квантователь 381 базового уровня, а Qb-1 означает деквантователь 385 базового уровня. Уравнение 26 преобразует коэффициент уровня улучшения в дифференциальное уточнение коэффициента базового уровня, вычисленного с помощью уравнения 25.
Фиг.35 - это иллюстрация еще одного примера модуля 379 выбора коэффициентов базового уровня и уровня улучшения. В этом примере уравнение (.), содержащееся на этапе 405, представляет следующее:
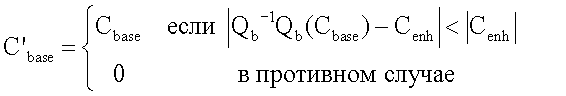
Сумматор 407 вычисляет коэффициент уровня улучшения, как показано в следующих двух уравнениях:
где C base задается посредством уравнения 27.
Фиг.36 - это иллюстрация еще одного примера модуля 379 выбора коэффициентов базового уровня и уровня улучшения. В этом примере коэффициент базового уровня остается неизменным, и уровень улучшения равен разности между квантованным/деквантованным коэффициентом базового уровня и исходным коэффициентом уровня улучшения.
Помимо коэффициентов остаточной ошибки базового уровня и уровня улучшения, декодеру требуется информация, идентифицирующая то, как кодированы MB. Средство кодирования, такое как компонент 228 кодера по фиг.2, может кодировать служебную информацию, которая может включать в себя таблицу внутренне кодированных и внешне кодированных частей, такую как, к примеру, таблица MB, в которой макроблоки (или субмакроблоки) идентифицируются как внутренне кодированные или внешне кодированные (также идентифицируя то, каков тип внешнего кодирования, в том числе, к примеру, прямое, обратное или двунаправленное), и на какие внешне кодированные части кадра(ов) содержатся ссылки. В примерном аспекте таблица MB и коэффициенты базового уровня кодируются а базовом уровне, а коэффициенты уровня улучшения кодируются в уровне улучшения.
P-кадры и B-кадры могут содержать внутренне кодированные MB, а также меж-MB. Общераспространено для гибридных видеокодеров использовать оптимизацию соотношения "скорость передачи-искажение" (RD), чтобы принимать решение кодировать конкретные макроблоки в P- или B-кадрах как внутренне кодированные MB. Чтобы иметь одноуровневое кодирование, при котором внутренне кодированные MB не зависят от меж-MB уровня улучшения, все соседние меж-MB не используются для пространственного предсказания внутренне кодированных MB базового уровня. Чтобы сохранять вычислительную сложность неизменной для декодирования уровня улучшения, для внутренне кодированных MB в P- или B-кадре базового уровня уточнение на уровне улучшения может быть пропущено.
Внутренне кодированные MB в P- или B-кадрах требуют гораздо больше битов, чем между MB. По этой причине внутренне кодированные MB в P- или B-кадрах могут кодироваться только с качеством базового уровня при более высоком QP. Это приводит к определенному ухудшению качества видео, но данное ухудшение должно быть незаметным, если оно устраняется в последующем кадре с помощью коэффициентов меж-MB в базовом уровне и уровне улучшения, как описано выше. Две причины делают это ухудшение незаметным. Первая - это признак зрительной системы человека (HVS), а вторая - это то, что меж-MB улучшают внутренние MB. С объектами, которые изменяют позицию с первого кадра на второй кадр, некоторые пикселы в первом кадре не видны во втором кадре (информация, которая должна быть скрыта), а некоторые пикселы во втором кадре видны для первого раза (нескрытая информация). Глаза человека нечувствительны к нескрытой и должной быть скрытой визуальной информации. Таким образом, для нескрытой информации, даже если она кодирована с более низким качеством, глаза могут не сообщить различие. Если та же информация остается в следующем P-кадре, имеется высокая вероятность того, что следующий P-кадр на уровне улучшения может улучшить ее, поскольку уровень улучшения имеет меньшее QP.
Другая стандартная методика, которая вводит внутренне кодированные MB в P- или B-кадры, известна как внутреннее обновление. В этом случае некоторые MB кодируются как внутренне кодированные MB, даже если стандартная оптимизация R-D
должна диктовать то, что они должны быть внешне кодированными MB. Эти внутренне кодированные MB, содержащиеся в базовом уровне, могут быть кодированы с помощью QPb или QPe. Если QPe используется для базового уровня, то уточнения не требуется на уровне улучшения. Если QPb используется для базового уровня, то уточнение может потребоваться, иначе на уровне улучшения будет заметным ухудшение качества. Поскольку внешнее кодирование более эффективно, чем внутреннее кодирование, в отношении эффективности кодирования, эти уточнения на уровне улучшения внутренне кодируются. Таким образом, коэффициенты базового уровня не используются для уровня улучшения. Следовательно, качество повышается на уровне улучшения без введения новых операций.
B-кадры, как правило, используются на уровне улучшения вследствие высокого качества сжатия, которое они предлагают. Тем не менее, B-кадры могут не иметь опорных внутренне кодированных MB P-кадра. Если пикселы B-кадра должны быть кодированы с качеством уровня улучшения, это может потребовать слишком большого числа битов вследствие более низкого качества внутренне кодированных MB P-кадра, как описано выше. Посредством использования преимущества качества HVS, как описано выше, MB B-кадра могут быть кодированы с более низким качеством при ссылке на внутренне кодированные MB P-кадров более низкого качества.
Другой предельный случай внутренне кодированных MB в P- или B-кадрах - это когда все MB в P- или B-кадре кодированы во внутреннем режиме вследствие наличия смены сцен в кодируемом видео. В этом случае весь кадр может быть кодирован с качеством базового уровня и без уточнения на уровне улучшения. Если смена сцен происходит в B-кадре и при условии, что B-кадры кодируются только на уровне улучшения, то B-кадр может кодирован с качеством базового уровня или просто отброшен. Если смена сцен происходит в P-кадре, изменений может не потребоваться, но P-кадр может быть отброшен или кодирован с качеством базового уровня. Масштабированное уровневое кодирование дополнительно описано в находящейся одновременно на рассмотрении Патентной заявке (США) номер [Адвокатская выписка номер 050078], озаглавленной "Scalable Video Coding With Two Layer Encoding And Single Layer Decoding" и принадлежащей ее правопреемнику, которая полностью содержится по ссылке в данном документе.
Часть первого прохода кодера
Фиг.7 показывает иллюстративный пример кодера 228 по фиг.2. Показанные этапы иллюстрируют различную обработку в кодере, которая может быть включена в кодер 228. В этом примере кодер 228 включает в себя часть 706 первого прохода выше разделительной линии 704 и часть 706 второго прохода (включая функциональность кодера 232 второго прохода и повторного кодера 234 на фиг.2) под линией 704.
Кодер 228 принимает метаданные и необработанное видео от препроцессора 226. Метаданные могут включать в себя любые метаданные, принятые или вычисленные посредством препроцессора 226, в том числе метаданные, связанные с информацией содержимого видео. Часть 702 первого прохода кодера 228 иллюстрирует примерные процессы, которые могут быть включены в кодирование 702 первого прохода, которое описывается ниже относительно функциональности. Специалисты в данной области техники должны знать, что эта функциональность может быть осуществлена в различных формах (к примеру, аппаратные средства, программное обеспечение, микропрограммное обеспечение или комбинация вышеуказанного).
Фиг.7 иллюстрирует модуль адаптивного внутреннего обновления (AIR). AIR-модуль 710 предоставляет входные данные в модуль 708 создания экземпляров I-кадров, который создает экземпляр I-кадра на основе метаданных. Часть 702 первого прохода также может включать в себя модуль 712 классификации содержимого, сконфигурированный так, чтобы принимать метаданные и видео и определять информацию содержимого, связанную с видео. Информация содержимого может быть предоставлена в модуль 714 назначения битов управления скоростью передачи, который также принимает метаданные и видео. Модуль 714 назначения битов управления определяет информацию управления назначением битов и предоставляет ее в модуль 715 определения режима. Информация содержимого и видео может предоставляться в модуль 716 внутренней модели (искажений), который предоставляет информацию искажений внутреннего кодирования в модуль 715 определения режима и модуль 718 масштабируемости соотношения "скорость передачи-искажение" для базового и уровня улучшения. Видео и метаданные предоставляются в модуль 720 оценки движения (искажений), который предоставляет информацию искажений внешнего кодирования в модуль 718 масштабируемости соотношения "скорость передачи-искажение" для базового уровня и уровня улучшения. Модуль 718 масштабируемости соотношения "скорость передачи-искажение" для базового уровня и уровня улучшения определяет информацию масштабируемости соотношения "скорость передачи-искажение" с помощью оценок искажения из модуля 720 оценки движения и модуля 716 искажений внутренней модели, которая предоставляется в модуль 715 определения режима. Модуль 715 определения режима также принимает входные данные из модуля 722 упорядочения серий макроблоков/MB. Модуль 722 упорядочения серий макроблоков/MB принимает входные данные из модуля 740 устойчивости к ошибкам (показанного в части 706 второго прохода) и предоставляет информацию по совмещению независимо кодируемых частей видео (серий макроблоков) с границами единиц доступа для устойчивости к ошибкам в модуль 715 определения режима. Модуль 715 определения режима определяет информацию режима кодирования на основе входных данных и предоставляет "оптимальный" режим кодирования в часть 706 второго прохода. Дополнительное иллюстративное пояснение некоторых примеров такого кодирования в части 702 первого прохода приводится далее.
Как указано выше, модуль 712 классификации содержимого принимает метаданные и необработанное видео, предоставляемое посредством препроцессора 226. В некоторых примерах препроцессор 226 вычисляет информацию содержимого из мультимедийных данных и предоставляет информацию содержимого в модуль 712 классификации содержимого (к примеру, в метаданных), который может использовать информацию содержимого для того, чтобы определять классификацию содержимого для мультимедийных данных. В некоторых других аспектах модуль 712 классификации содержимого сконфигурирован так, чтобы определять различную информацию содержимого из мультимедийных данных, и также может быть сконфигурирован так, чтобы определять классификацию содержимого.
Модуль 712 классификации содержимого может быть сконфигурирован так, чтобы определять различную классификацию содержимого для видео, имеющего различные типы содержимого. Различная классификация содержимого может приводить к различным параметрам, используемым в аспектах кодирования мультимедийных данных, например, определение скорости передачи битов (к примеру, назначения битов) для определения параметров квантования, оценка движения, масштабируемость, устойчивость к ошибкам, поддержание оптимального качества мультимедийных данных в каналах, а также для схем быстрого переключения каналов (к примеру, периодическая активация I-кадров, чтобы обеспечить быстрое переключение каналов). Согласно одному примеру кодер 228 сконфигурирован так, чтобы определять оптимизацию соотношения "скорость передачи-искажение" (R-D) и назначения скорости передачи битов на основе классификации содержимого. Определение классификации содержимого дает возможность мультимедийным данным быть сжимаемыми для заданного уровня качества согласно требуемой скорости передачи битов на основе классификации содержимого. Кроме того, посредством классификации содержимого мультимедийных данных (к примеру, определения классификации содержимого на основе зрительной системы человека) результирующее перцепционное качество передаваемых мультимедийных данных на дисплее приемного устройства зависит от видеосодержимого.
В качестве примера процедуры, которую проходит модуль 712 классификации содержимого для того, чтобы классифицировать содержимое, фиг.9 иллюстрирует процесс 900, иллюстрирующий примерный процесс, посредством которого может работать модуль 712 классификации содержимого. Как показано, процесс 900 начинается на этапе 902 ввода, где модуль 712 классификации содержимого принимает необработанные мультимедийные данные и метаданные. Далее процесс 900 переходит к этапу 904, на котором модуль 712 классификации содержимого определяет пространственную информацию и временную информацию мультимедийных данных. В некоторых аспектах пространственная и временная информация определяется посредством пространственного и временного маскирования (к примеру, фильтрации). Пространственная и временная информация может быть определена на основе метаданных, которые включают в себя данные смены сцен и сглаживание векторов движения (MV). Процесс 900 далее переходит к этапу 912, который выполняет оценки пространственной сложности, временной сложности и чувствительности. Процесс 900 затем переходит к этапу 916, на котором содержимое мультимедийных данных классифицируется на основе результатов определенных пространственных, временных данных и данных чувствительности, на этапах 904 и 912. Кроме того, на этапе 916 конкретная кривая соотношения "скорость передачи-искажение" (R-D) может быть выбрана и/или данные кривой R-D могут быть обновлены. Процесс 900 далее переходит к этапу 918 вывода, при этом вывод может включать в себя таблицу сложности-искажения или значение, указывающее пространственную или временную деятельность (к примеру, классификацию содержимого) и/или выбранные кривые R-D. Ссылаясь снова на фиг.7, модуль 712 классификации содержимого предоставляет вывод в модуль 714 назначения битов управления скоростью передачи, модуль внутренней модели 716 (искажений), а также в модуль 708 создания экземпляров I-кадров, описанный выше.
Информация содержимого
Модуль 712 классификации содержимого может быть сконфигурирован так, чтобы вычислять разнообразие информации содержимого из мультимедийных данных, в том числе разнообразие связанных с содержимым показателей, включая пространственную сложность, временную сложность, значения коэффициента контрастности, стандартные отклонения и разностные показатели кадров, дополнительно описанные ниже.
Модуль 712 классификации содержимого может быть сконфигурирован так, чтобы определять пространственную сложность и временную сложность мультимедийных данных, а также ассоциативно связывать значение текстуры с пространственной сложностью и значение движения с временной сложностью. Модуль 712 классификации содержимого принимает заранее обработанную информацию содержимого, связанную с содержимым мультимедийных данных, кодируемых из препроцессора 226, либо альтернативно, препроцессор 226 может быть сконфигурирован так, чтобы вычислять информацию содержимого. Как описано выше, информация содержимого может включать в себя, например, одно или более значений Dcsat, значений коэффициента контрастности, векторы движения (MV) и сумму абсолютных разностей (SAD).
В общем, мультимедийные данные включают в себя одну или более последовательностей изображений, или кадров. Каждый кадр может быть разбит на блоки пикселов для обработки. Пространственная сложность - это обширный термин, который, в общем, описывает меру уровня пространственных деталей в кадре. Сцены с преимущественно плоскими, или неизменяющимися, или мало изменяющимися областями компонента яркости и цветности имеют низкую пространственную сложность. Пространственная сложность ассоциативно связана с текстурой видеоданных. Пространственная сложность, в данном аспекте, основана на показателе зрительной чувствительности человека, называемом Dcsat, который вычисляется для каждого блока как функция от локальной пространственной частоты и окружающего освещения. Специалисты в данной области техники знают методики использования шаблонов пространственной частоты и характеристик освещения и контрастности визуальных изображений, чтобы использовать преимущество зрительной системы человека. Ряд показателей чувствительности известен для использования преимуществ перспективных ограничений зрительной системы человека и может быть использован со способом, описанным в данном документе.
Временная сложность - это обширный термин, который используется для того, чтобы, в общем, описывать меру уровня движения в мультимедийных данных, указываемых ссылкой между кадрами в последовательности кадров. Сцены (к примеру, последовательности кадров видеоданных) с незначительным движением или без движения имеют низкую временную сложность. Временная сложность может быть вычислена для каждого макроблока и может быть основана на значении Dcsat, векторах движения и сумме абсолютных пикселных разностей между одним кадром и другим кадром (к примеру, опорным кадром).
Разностный показатель кадров предоставляет меру разности между двумя последовательными кадрами с учетом движения (например, вектора движения или MV)
наряду с остаточной энергией, представленной как сумма абсолютной разности (SAD) между прогнозным параметром и текущим макроблоком. Разность кадров также предоставляет меру двунаправленной и однонаправленной эффективности предсказания.
Один пример разностного показателя кадров, основанного на информации движения, принимаемой от препроцессора, потенциально выполняющего устранение чересстрочной развертки с компенсацией движения, следующий. Модуль устранения чересстрочной развертки выполняет двунаправленную оценку движения, и тем самым двунаправленный вектор движения, и информация SAD доступна. Разность кадров, представляемая посредством SAD_MV для каждого макроблока, может быть извлечена следующим образом:
где MV=Square_root(MVx 2+MVy 2), SAD=min(SADN, SADP), где SADN - это SAD, вычисленная из обратного опорного кадра, а SADP - это SAD, вычисленная из прямого опорного кадра.
Другой подход оценки разности кадров описан выше со ссылкой на уравнения 6-8. Соотношение SAD (или коэффициент контрастности) γ может быть вычислено так, как описано выше в уравнении 6. Гистограмма яркости каждого кадра также может быть определена, при этом разность гистограммы λ вычисляется с помощью уравнения 7. Разностный показатель кадров D может быть вычислен так, как показано в уравнении 8.
В одном иллюстративном примере коэффициент контрастности и разностный показатель кадров используются следующим образом для того, чтобы получить классификацию видеосодержимого, которая позволяет надежно предсказывать признаки в данной видеопоследовательности. Хотя описывается в данном документе как выполняющееся в кодере 228, препроцессор 226 также может быть сконфигурирован для того, чтобы определять классификацию содержимого (или другую информацию содержимого) и передавать классификацию содержимого в кодер 228 посредством метаданных. Процесс, описанный в примере ниже, классифицирует содержимое на восемь возможных классов, аналогично классификации, полученной из анализа на основе кривых R-D. Процесс классификации выводит значение в диапазоне от 0 до 1 для каждого суперкадра на основе сложности сцены и числа событий смены сцен в этом суперкадре. Модуль классификации содержимого в препроцессоре может выполнять следующие этапы (1)-(5) для каждого суперкадра, чтобы получить показатель классификации содержимого из значений контрастности кадров и разности кадров.
1. Вычисление средней контрастности кадров и отклонения контрастности кадров из значений контрастности макроблоков.
2. Нормализация значений контрастности кадров и разности кадров с помощью значений, полученных из моделирования, т.е. 40 и 5 соответственно.
3. Вычисление показателя классификации содержимого с помощью, к примеру, обобщенного уравнения:
где CCW1, CCW2, CCW3 и CCW4 - это весовые коэффициенты. В этом примере значения выбираются равными 0,2 для CCW1, 0,9 для CCW2, 0,1 для CCW3 и -0,00009 для CCW4.
4. Определение числа смены сцен в суперкадре. В общем, суперкадр означает группу изображений или кадров, которая может быть отображена в конкретном периоде времени. В типичном варианте период времени составляет одну секунду. В некоторых аспектах суперкадр содержит 30 кадров (для видео 30 кадров в секунду). В других аспектах суперкадр содержит 24 кадра (для видео 24 кадра в секунду). В зависимости от числа смен сцен один из следующих случаев приводится в исполнение.
(a) Нет смены сцен. Когда нет смены сцен в суперкадре, показатель полностью зависит только от значений разности кадров, как показано в следующем уравнении:
(b) Одна смена сцен. Когда имеется кадр с одной сменой сцен, наблюдаемый в суперкадре, уравнение по умолчанию должно быть использовано для того, чтобы вычислять показатель, как показано ниже:
exp(CCW4*Frame_Difference_Deviation^2)
(a) Две смены сцен. Когда наблюдается, что имеется самое большее 2 смены сцен в данном суперкадре, последнему суперкадру назначается больший весовой коэффициент, чем первому, поскольку первый в любом случае должен быть обновлен посредством второго быстро, как показано в следующем уравнении:
*Frame_Difference Mean-CCW3* I_Contrast_Deviationl^2*I_Contrast_Deviation2 2* exp(CCW4*Frame_Difference_Deviation^2)
(d) Три или более смен сцен. Если в данном суперкадре наблюдается более 3 I-кадров (скажем, N), последнему I-кадру присваивается больший весовой коэффициент, а всем остальным I-кадрам присваивается весовой коэффициент 0,05, как показано в следующем уравнении:
5. Корректировка может быть использована для показателя в случае сцен с незначительным движением, когда средняя разность кадров меньше 0,05. Сдвиг (CCOFFSET) 0,33 должен быть добавлен в CCMetric.
Модуль 712 классификации содержимого использует значение Dcsat, векторы движения и сумму абсолютных разностей, чтобы определять значение, указывающее пространственную сложность для макроблока (или указанный объем видеоданных). Временная сложность определяется посредством измерения показателя разности кадров (разности между двумя последовательными кадрами с учетом объема движения, с векторами движения и суммой абсолютных разностей между кадрами).
В некоторых аспектах модуль 712 классификации содержимого может быть сконфигурирован так, чтобы формировать таблицу полосы пропускания. Например, формирование таблицы полосы пропускания может выполняться посредством модуля 712 классификации содержимого, если препроцессор 226 не формирует таблицу полосы пропускания.
Определение значений текстуры и движения
Для каждого макроблока в мультимедийных данных модуль 712 классификации содержимого ассоциативно связывает значение текстуры с пространственной сложностью и значение движения с временной сложностью. Значение текстуры относится к значениям свечения мультимедийных данных, при этом низкое значение текстуры указывает небольшие изменения в значениях свечения соседних пикселов данных, а высокое значение текстуры указывает значительные изменения в значениях свечения соседних пикселов данных. После того как значения текстуры и движения вычислены, модуль 712 классификации содержимого определяет классификацию содержимого посредством рассмотрения информации движения и текстуры. Модуль 712 классификации содержимого ассоциативно связывает текстуру для классифицируемых видеоданных с относительным значением текстуры, например, "низкая" текстура, "средняя" текстура или "высокая" текстура, которое, в общем, указывает сложность значений яркости макроблоков. Кроме того, модуль 712 классификации содержимого ассоциативно связывает значение движения, вычисленное для классифицируемых видеоданных, с относительным значением движения, например, "низкое" движение, "среднее" движение или "высокое" движение, которое, в общем, указывает объем движения макроблоков. В альтернативных аспектах большее или меньшее число категорий для движения и текстуры может быть использовано. Далее показатель классификации содержимого определяется с учетом ассоциативно связанных значений текстуры и движения.
Фиг.8 иллюстрирует пример классификационной диаграммы, которая иллюстрирует то, как значения текстуры и движения ассоциативно связываются с классификацией содержимого. Специалисты в данной области техники знакомы с множеством способов реализовывать такую классификационную диаграмму, например, таблицей поиска или базой данных. Классификационная диаграмма формируется на основе предварительно определенных оценок содержимого видеоданных. Чтобы определить классификацию видеоданных, значение текстуры "низкая", "средняя" или "высокая" (на оси x) перекрестно ссылается со значением движения "низкое", "среднее" или "высокое" (на оси y). Классификация содержимого, указанная в пересекающемся прямоугольнике, назначается видеоданным. Например, значение текстуры "высокая" и значение движения "среднее" приводит к классификации семь (7). Фиг.8 иллюстрирует различные комбинации относительных значений текстуры и движения, которые ассоциативно связаны с восемью различными классификациями содержимого в данном примере. В некоторых других аспектах большее или меньшее число классификаций может быть использовано. Дополнительное описание иллюстративного аспекта классификации содержимого раскрыто в находящейся одновременно на рассмотрении Патентной заявке (США) номер 11/373577, озаглавленной "Content Classification For Multimedia Processing", зарегистрированной 10 марта 2006 года, назначенной правопреемнику этой заявки и таким образом явно содержащейся в данном документе по ссылке.
Назначение битов управления скоростью передачи
Как описано в данном документе, классификация содержимого мультимедийных данных может быть использована в алгоритмах кодирования для того, чтобы эффективно улучшать битовое управление при сохранении постоянным воспринимаемого качества видео. Например, показатель классификации может быть использован в алгоритмах для обнаружения смены сцен, управления назначением скорости передачи битов при кодировании и повышающего преобразования скорости передачи кадров (FRUC). Системы компрессора/декомпрессора (кодек) и алгоритмы обработки цифровых сигналов, как правило, используются при обмене видеоданными и могут быть сконфигурированы так, чтобы экономить полосу пропускания, но имеется компромисс между качеством и экономией полосы пропускания. Наилучшие кодеки предоставляют наибольшую экономию полосы пропускания при создании наименьшего ухудшения качества видео.
В одном иллюстративном примере модуль 714 назначения битов управления скоростью передачи использует классификацию содержимого для того, чтобы определять скорость передачи битов (к примеру, число битов, назначаемых для кодирования мультимедийных данных), и сохраняет скорость передачи битов в запоминающем устройстве для использования посредством других процессов и компонентов кодера 228. Скорость передачи битов, определенная из классификации видеоданных, помогает экономить полосу пропускная при предоставлении мультимедийных данных с согласованным уровнем качества. В одном аспекте различная скорость передачи битов может быть ассоциативно связана с каждой из восьми различных классификаций содержимого, и затем эта скорость передачи битов используется для того, чтобы кодировать мультимедийные данные. Результирующий эффект заключается в том, что хотя различным классификациям мультимедийных данных назначается различное число битов для кодирования, воспринимаемое качество аналогично или согласованно при просмотре на дисплее.
В общем, мультимедийные данные с более высокой классификацией содержимого указывают более высокий уровень движения и/или текстуры, и им назначается больше битов при кодировании. Мультимедийным данным с более низкой классификацией (указывающее меньше текстуры и движения) назначается меньшее число битов. Для мультимедийных данных конкретной классификации битов скорость передачи битов может быть определена на основе выбранного целевого воспринимаемого уровня качества для просмотра мультимедийных данных. Определение качества мультимедийных данных может быть определено посредством просмотра и упорядочения людьми мультимедийных данных. В некоторых альтернативных аспектах оценки качества мультимедийных данных могут выполняться посредством автоматических тестовых систем с помощью, например, алгоритмов соотношения сигнал-шум. В одном аспекте набор стандартных уровней качества (к примеру, пять) и соответствующая скорость передачи битов, требуемая для того, чтобы достичь каждого конкретного уровня качества, заранее определяется для мультимедийных данных каждой классификации содержимого. Чтобы определить набор уровней качества, мультимедийные данные конкретной классификации содержимого могут быть оценены посредством формирования средней экспертной оценки (MOS), которая предоставляет числовой индикатор визуально воспринимаемого качества мультимедийных данных, когда они кодируются с помощью конкретной скорости передачи битов. MOS может быть выражена как одно число в диапазоне от 1 до 5, где 1 - это наименьшее воспринимаемое качество, а 5 - это наибольшее воспринимаемое качество. В других аспектах MOS может иметь более пяти или менее пяти уровней качества, и различные описания каждого уровня качества могут быть использованы.
Определение качества мультимедийных данных может быть определено посредством просмотра и упорядочения людьми мультимедийных данных. В некоторых альтернативных аспектах оценки качества мультимедийных данных могут выполняться посредством автоматических тестовых систем с помощью, например, алгоритмов соотношения сигнал-шум. В одном аспекте набор стандартных уровней качества (к примеру, пять) и соответствующая скорость передачи битов, требуемая для того, чтобы достичь каждого конкретного уровня качества, заранее определяется для мультимедийных данных каждой классификации содержимого.
Знание взаимосвязи между уровнем визуально воспринимаемого качества и скоростью передачи в битах мультимедийных данных определенной классификации содержимого может быть определено посредством вызова целевого (к примеру, требуемого) уровня качества. Целевой уровень качества, используемый для того, чтобы определять скорость передачи битов, может быть заранее выбран, выбран посредством пользователя, выбран посредством автоматического процесса или полуавтоматического процесса, требующего ввода от пользователя или из другого процесса, или выбран динамически посредством устройства или системы кодирования на основе предварительно определенных критериев. Целевой уровень качества может быть выбран, например, на основе типа приложений кодирования или типа клиентского устройства, которое принимает мультимедийные данные.
В проиллюстрированном примере на фиг.7 модуль 714 назначения битов управления скоростью передачи принимает и данные из модуля 712 классификации содержимого, и метаданные непосредственно из препроцессора 226. Модуль 714 назначения битов управления скоростью передачи размещается в части первого прохода кодера 228, а модуль 738 точной настройки управления скоростью передачи размещается в части 706 второго прохода. Этот аспект двухпроходного управления скоростью передачи сконфигурирован так, что первый проход (модуль 714 назначения битов управления скоростью передачи) выполняет контекстно-адаптивное назначение битов с упреждающим просмотром на один суперкадр (к примеру, при цели долгосрочной средней скорости передачи битов в 256 кбит/с) и ограничивает пиковую скорость, а второй проход (модуль 738 точной настройки управления скоростью передачи) уточняет результаты первого прохода для двухуровневой масштабируемости и выполняет адаптацию скорости. Управление скоростью работает на четырех уровнях: (1) уровень GOP - управляет распределением битов I-, P-, B- и F-кадров так, чтобы сделать их неоднородными в рамках GOP; (2) уровень суперкадров - управляет жесткими пределами на максимальный размер суперкадра; (3) уровень кадров - управляет требованиями по битам согласно пространственной и временной сложности кадров мультимедийных данных, которая основана на информации содержимого (к примеру, классификации содержимого); и (4) уровень макроблоков - управляет назначением битов макроблоков на основе таблиц пространственной и временной сложности, которые основаны на информации содержимого (к примеру, классификации содержимого).
Примерная блок-схема последовательности операций работы модуля 714 управления скоростью передачи проиллюстрирована на фиг.10. Как показано на фиг.10, процесс 1000 начинается на этапе 1002 ввода. Модуль 714 управления скоростью передачи принимает различные входные данные, не все из которых обязательно проиллюстрированы на фиг.7. Например, входная информация может включать в себя метаданные из препроцессора 226, целевую скорость передачи битов, размер буфера кодера (или, в качестве эквивалента, максимальное время задержки для управления скоростью передачи), начальную задержку управления скоростью передачи и информацию частоты кадров. Дополнительная входная информация может включать в себя входные данные на уровне группы изображений (GOP), в том числе, например, максимальный размер суперкадра, длину и распределение P/B-кадров в GOP (включая информацию смены сцен), требуемая компоновка базового уровня и уровня улучшения, показатель искажения в зависимости от сложности для изображений в GOP для следующих 30 кадров. Другая входная информация включает в себя входные данные на уровне изображений, в том числе таблицу искажения в зависимости от сложности для текущего изображения (принятого из модуля 712 классификации содержимого), параметры квантования (QP) и разрыв битов за последние 30 кадров (попадание в окно передачи переменной длительности). Наконец, входная информация на уровне макроблоков (MB) включает в себя, например, среднюю абсолютную разность (MAD) совместно размещенных макроблоков (MB) в опорном изображении и шаблон кодированных блоков (CBP) макроблоков после квантования (независимо от того, пропущены или нет).
После ввода данных на этапе 1002 процесс 1000 переходит к этапу 1004 для инициализации кодирования потока битов. Параллельно выполняется инициализация 1006 буфера. Затем инициализируется GOP, как показано на этапе 1008, при этом назначение 1010 битов GOP принимается как часть инициализации. После инициализации GOP последовательность операций переходит к этапу 1012, где инициализируется серия макроблоков. Эта инициализация включает в себя обновление битов заголовков, как показано посредством этапа 1014. После того, как инициализация на этапах 1004, 1008 и 1012 выполнена, управление скоростью (RC) для базовой единицы или макроблока (MB) выполняется так, как показано посредством этапа 1016. Как часть определения при управлении скоростью макроблока на этапе 1016 принимаются входные данные посредством интерфейсов в кодере 228. Эти входные данные могут включать в себя назначение 1018 битов макроблока (MB), обновление параметров 1020 квадратической модели и обновление параметров 1022 медианного абсолютного отклонения от медианы (MAD, устойчивая оценка дисперсии). Затем процесс 1000 переходит к этапу 1024 для приведения в исполнение операций после кодирования одного изображения 1024. Эта процедура включает в себя прием обновления параметров буфера, как показано посредством этапа 1026. После этого процесс 1000 переходит к этапу 1028 вывода, где модуль 714 управления скоростью передачи выводит параметры квантования QP для каждого макроблока MB, которые должны быть использованы посредством модуля 715 определения режима, как показано на фиг.7.
Оценка движения
Модуль 720 оценки движения принимает входные данные из метаданных и необработанного видео из препроцессора 226 и предоставляет выходные данные, которые могут включать в себя размер блока, показатели искажения векторов движения и идентификаторы опорных кадров, в модуль 715 определения режима. Фиг.11 иллюстрирует примерную работу модуля 720 оценки движения. Как показано, процесс 1100 начинается с ввода 1102. На уровне кадров модуль 720 принимает ввод идентификатора опорного кадра и векторов движения. На уровне макроблоков ввод 1102 включает в себя входные пикселы и пикселы опорных кадров. Процесс 1100 переходит к этапу 1104, на котором выполняется цветовая оценка движения (ME) и предсказание векторов движения. Чтобы выполнить этот процесс, принимаются различные входные данные, в том числе векторы движения MPEG-2 и векторы движения компоненты яркости MV 1106, сглаживание 1108 векторов движения и непричинные векторы 1110 движения. Затем процесс 1100 переходит к этапу 1112, на котором выполняется алгоритм или методология поиска векторов движения, например, способы шестиугольного или ромбовидного поиска. Входные данные в процесс на этапе 1112 могут включать в себя сумму абсолютных разностей (SAD), сумму квадратов разностей (SSD) и/или другие показатели, как показано посредством этапа 1114. После того как поиск векторов движения выполнен, процесс 1100 переходит к этапу 1116 завершения, на котором выполняется обработка завершения. После этого процесс 100 завершается на этапе 1118 вывода, который предоставляет вывод размера блока, вектора движения (MV), показателей искажения и идентификаторов опорных кадров.
Масштабируемость R-D для базового уровня и уровня улучшения
Фиг.13 иллюстрирует примерную блок-схему последовательности операций процесса 1300 масштабируемости, который может быть выполнен посредством модуля 718 масштабируемости R-D. Процесс 1300 начинается на начальном этапе 1302 и переходит к этапу 1304, на котором модуль 718 масштабируемости R-D принимает входные данные из модуля 720 оценки движения и выполняет оценку движения. Оценка движения базируется на вводе опорных кадров базового уровня, опорных кадров уровня улучшения и исходного кадра, который должен быть кодирован, как указано, посредством этапа 1306. Эта информация может быть вычислена посредством модуля 612 секционирования GOP и передана в модуль 718 масштабируемости R-D посредством, к примеру, метаданных. Процесс 1300 переходит к этапу 1308, чтобы определить информацию масштабируемости данных базового уровня и уровня улучшения. Кодирование базового уровня затем выполняется, как показано на этапе 1310, за которым следует кодирование уровня улучшения на этапе 1312. Кодирование уровня улучшения может использовать результаты кодирования базового уровня для межуровневого предсказания в качестве входных данных, как проиллюстрировано посредством этапа l314, таким образом, по времени оно выполняется после кодирования базового уровня. Это дополнительно описано в находящейся одновременно на рассмотрении Патентной заявке (США) номер [Адвокатская выписка номер 050078], озаглавленной "Scalable Video Coding With Two Layer Encoding And Single Layer Decoding". После того как кодирование завершено, процесс 1300 завершается на этапе 1316.
Упорядочение серий макроблоков/макроблоков
Часть 702 первого прохода также включает в себя модуль 722 упорядочения серий макроблоков/макроблоков, который принимает входные данные из модуля 740 устойчивости к ошибкам в части второго прохода и предоставляет информацию совмещения серий макроблоков в модуль 715 определения режима. Серии макроблоков - это участки независимо декодируемых (декодируемых по энтропии) кодированных видеоданных. Единицы доступа (AU) - это кодированные видеокадры, каждый из которых содержит набор NAL-единиц, всегда содержащих ровно одно первично кодированное изображение. Помимо первично кодированного изображения единица доступа также может содержать одну или более избыточно кодированных изображений или других NAL-единиц, не содержащих серии макроблоков или сегменты данных серий макроблоков в кодированном изображении. Декодирование единицы доступа всегда приводит к декодированному изображению.
Кадры могут быть мультиплексированными с временным разделением каналов блоками пакетов физического уровня (называемыми TDM-капсулой), которые предоставляют наибольшее временное разнесение. Суперкадр соответствует одной единице времени (к примеру, 1 секунде) и содержит четыре кадра. Совмещение границ серий макроблоков и AU с границами кадров во временной области приводит к наиболее эффективному разделению и локализации поврежденных данных. В ходе глубокого затухания большая часть смежных данных в TDM-капсуле затрагивается посредством ошибок. Вследствие временного разнесения оставшиеся TDM-капсулы имеют высокую вероятность быть неповрежденными. Неповрежденные данные могут быть использованы для того, чтобы восстанавливать и скрывать потерянные данные от затронутой TDM-капсулы. Аналогичная логика применяется к мультиплексированию в частотной области (FDM), где частотное разнесение достигается посредством разделения в частотных поднесущих, которые модулируют символы данных. Кроме того, аналогичная логика применяется к пространственному (посредством разделения в антеннах передающих и приемных устройств) и другим формам разнесения, часто применяемым в беспроводных сетях.
Чтобы совмещать серии макроблоков и AU с кадрами, создание кодовых блоков внешнего кода (FEC) и инкапсуляция MAC-уровня должны также совмещаться. Фиг.20 иллюстрирует организацию кодированных видеоданных или потока битов видео в серии макроблоков и AU. Кодированное видео может составляться в одном или более потоков битов, к примеру, в потоке битов базового уровня и потоке битов уровня улучшения, где применяется многоуровневое видеокодирование.
Поток битов видео содержит AU, как проиллюстрировано на фиг.20 посредством кадра 1' 2005, кадра 3' 2010 и кадра M' 2015. AU содержат серии макроблоков данных, как проиллюстрировано посредством серии макроблоков 1 2020, серии макроблоков 2 2025 и серии макроблоков N 2030. Каждое начало серии макроблоков идентифицируется посредством начального кода и предоставляется в сетевую адаптацию. В общем, I-кадры или внутренне кодированные AU являются крупными, а за ними следуют P-кадры или кадры с прямым предсказанием, за которыми следует B-кадры. Кодирование AU на несколько серий макроблоков налагает существенные дополнительные расходы в отношении кодированной скорости передачи битов, поскольку пространственное предсказание в сериях макроблоков ограничено, и заголовки макроблоков также способствуют дополнительным расходам. Поскольку границы серий макроблоков являются точками повторной синхронизации, ограничение смежных пакетов физического уровня сериями макроблоков управляет ошибками, поскольку когда PLP поврежден, ошибка ограничивается серией макроблоков в PLP, тогда как если PLP содержал несколько серий макроблоков или части нескольких серий макроблоков, ошибка должна повлиять на все серии макроблоков или части серий макроблоков в PLP.
Поскольку I-кадры в типичном варианте являются крупными, например, порядка десятков кбит/с, дополнительная служебная информация, обусловленная несколькими сериями макроблоков, не является значительной частью общего размера I-кадра или общей скорости передачи битов. Кроме того, наличие большего числа серий макроблоков во внутренне кодированном AU обеспечивает более оптимальную и более частую повторную синхронизацию и более эффективное маскирование пространственных ошибок. Помимо этого, I-кадры переносят наиболее важную информацию в потоке битов видео, поскольку P- и B-кадры предсказываются из I-кадров. I-кадры также выступают в качестве точек произвольного доступа для обнаружения канала.
Ссылаясь теперь на фиг.21, тщательное совмещение I-кадров с границами кадров и также серий макроблоков с I AU с границами кадров предоставляет наиболее эффективное управление ошибками, защиту от ошибок (поскольку если одна серия макроблоков, которая принадлежала кадру 1 2105, потеряна, серии макроблоков, которые принадлежат кадру 2 2110, имеют высокую вероятность быть неповрежденными, поскольку кадр 2 2110 имеет значительное временное разделение от кадра 1 2105, восстановление после ошибок может выполняться посредством повторной синхронизации и маскирования ошибок.
Поскольку P-кадры в типичном варианте имеют размер порядка нескольких кбит/с, совмещение серий макроблоков P-кадра и целого числа P-кадров с границами кадров предоставляет устойчивость к ошибкам без нежелательной потери эффективности (по аналогичным причинам, что и для I-кадров). Временное маскирование ошибок может использоваться в таких аспектах. Альтернативно, рассредоточение последовательных P-кадров так, чтобы они поступали в различных кадрах, предоставляет добавленное временное разнесение в P-кадрах, которое может быть обусловлено тем, что временное маскирование основано на векторах движения и данных из ранее восстановленных I- или P-кадров. B-кадры могут быть от чрезвычайно малых (сотни битов) до умеренно крупных (несколько тысяч битов). Следовательно, совмещение целого числа B-кадров с границами кадров требуется для того, чтобы достигать устойчивости к ошибкам без нежелательной потери эффективности.
Модуль определения режима
Фиг.12 иллюстрирует некоторые примеры работы модуля 715 определения режима. Как показано, процесс 1200 начинается на этапе 1202 ввода. В одном иллюстративном примере различная информация, вводимая в модуль 715 определения режима, включает в себя тип серии макроблоков, режим Intra 4x4cost, режим Intra 16xl6cost, режим IntraUV 8x8cost, режим IntraY 16x16, режим IntraUV, данные векторов движения (MVD), параметры квантования (QP), SpPredMB4x4Y, SpPredMB16xl6Y, SpPredMB8x8U, SpPredMB8x8V, флаг "скорость передачи-искажение", необработанные YMB-пикселы, необработанные UMB-пикселы и необработанные VMB-пикселы. Далее процесс 1200 переходит к этапу 1204 инициализации кодирования, которая может быть инициирована посредством входного сигнала или интерфейса, направляющего инициализацию кодера, как указано, посредством этапа 1206. Инициализация может включать в себя задание разрешенных режимов (включая пропуск, направление), задание весовых коэффициентов режима (при необходимости по умолчанию все весовые коэффициенты равны для всех режимов) и задание буферов. После инициализации процесс 1200 переходит к этапу 1208, где выполняется основная обработка для определения режима, включающая в себя: вычисление затрат режима макроблоков (MB) для каждого разрешенного режима, взвешивание затрат каждого режима макроблоков MB
с помощью весового коэффициента и выбор режима минимальных затрат режима MB. Входные данные, вовлеченные в эти операции, включают в себя оценку движения (к примеру, MVD и предсказания) и пространственное предсказание (к примеру, внутренние затраты и предсказания), как показано, посредством этапов 1210 и 1212. С модулем 715 определения режима взаимодействует кодирование по энтропии на этапе 1214, которое, помимо прочего, повышает степень сжатия. Процесс 1200 переходит к этапу 1216, где буферы обновляются так, чтобы передавать информацию в часть 706 второго прохода кодера. В завершение процесс 1200 переходит к этапу 1218, на котором "оптимальный" режим кодирования может быть сообщен в часть 706 второго прохода кодера.
Часть второго прохода кодера
Ссылаясь снова на фиг.7, часть 706 второго прохода кодера 228 включает в себя модуль 232 кодера второго прохода для выполнения второго прохода кодирования. Кодер 232 второго прохода принимает вывод из модуля 715 определения режима. Кодер 232 второго прохода включает в себя модуль 726 MC/квантования с преобразованием и зигзагообразный кодер (ZZ)/кодер 728 по энтропии. Результаты кодера 232 второго прохода выводятся в модуль 730 масштабирования и модуль 731 упаковки пакета битов, который выводит кодированный базовый и уровень улучшения для передачи посредством транскодера 200 посредством синхронизирующего уровня 240 (проиллюстрированного на фиг.2). Как показано на фиг.2, следует отметить, что базовый и уровень улучшения из кодера 232 второго прохода и повторного кодера 234 ассемблируются посредством синхронизирующего уровня 240 в пакетированные PES 242, включающие в себя базовый уровень и уровни улучшения, PES 244 данных (к примеру, CC и других текстовых данных) и PES 246 аудио. Следует отметить, что аудиодекодер 236 принимает декодированную аудиоинформацию 218 и, в свою очередь, кодирует информацию и выводит информацию 238 в синхронизирующий уровень 240.
Повторный кодер
Ссылаясь снова на фиг.7, часть 706 второго прохода кодера также включает в себя повторный кодер 234, который соответствует повторному кодеру 234 на фиг.2. Повторный кодер 234 также принимает вывод части 702 первого прохода и включает в себя части MC/квантования 726 с преобразованием и ZZ/кодирования 728 по энтропии. Дополнительно, модуль 730 масштабируемости выполняет вывод в повторный кодер 234. Повторный кодер 234 выводит результирующий базовый и уровень улучшения из повторного кодирования в модуль 731 упаковки пакета битов для передачи в модуль синхронизации (к примеру, синхронизирующий уровень 240, показанный на фиг.2). Пример кодера 228 на фиг.7 также включает в себя модуль 738 точной настройки управления скоростью передачи, который предоставляет обратную связь по упаковке потока битов в модуль 234 MC/квантования с преобразованием в кодере 232 второго прохода и модуль 736 ZZ/кодирования по энтропии в повторном кодере 234, чтобы помочь точно настроить кодирование второго прохода (к примеру, повысить эффективность сжатия).
Модуль устойчивости к ошибкам
Пример кодера 228, проиллюстрированный на фиг.7, также включает в себя модуль 740 устойчивости к ошибкам в части 706 второго прохода. Модуль 740 устойчивости к ошибкам обменивается данными с модулем 731 упаковки потока битов и модулем 722 упорядочивания серий макроблоков/MB. Модуль 740 устойчивости к ошибкам принимает метаданные от препроцессора 228 и выбирает схему устойчивости к ошибкам, например, совмещение серий макроблоков и единиц доступа с границами кадров, иерархия с предсказанием и адаптивное внутреннее обновление. Выбор схемы устойчивости к ошибкам может быть основан на информации, принимаемой в метаданных, или из информации, передаваемой в модуль устойчивости к ошибкам, из модуля 731 упаковки потока битов и модуля 722 упорядочивания серий макроблоков/MB. Модуль 740 устойчивости к ошибкам предоставляет информацию в модуль упорядочивания серий макроблоков/макроблоков (MB) в части 702 первого прохода, чтобы реализовать выбранные процессы устойчивости к ошибкам. Передача видео в отказоустойчивых окружениях может использовать устойчивые к ошибкам стратегии и алгоритмы, которые могут приводить к представлению более четких и менее наполненных ошибками данных зрителю. Нижеприведенное описание устойчивости к ошибкам может применяться к любым отдельным или комбинации существующего или будущего варианта применения, транспортного и физического уровня и другим технологиям. Эффективные алгоритмы устойчивости к ошибкам интегрируют понимание свойств восприимчивости к ошибкам и возможностей защиты от ошибок для OSI-уровней в сочетании с требуемыми свойствами системы связи, такой как низкая задержка и высокая пропускная способность. Обработка устойчивости к ошибкам может быть основана на информации содержимого мультимедийных данных, например, классификации содержимого мультимедийных данных. Одно из основных преимуществ - это восстанавливаемость после ошибок затухания и многолучевого канала. Подходы устойчивости к ошибкам, описанные ниже, относятся, в частности, к процессам, которые могут содержаться в кодере 228 (к примеру, в частности, в модуле 740 устойчивости к ошибкам и модуле 722 упорядочивания серий макроблоков/MB), и могут быть расширены, в общем, до обмена данными в отказоустойчивых окружениях.
Устойчивость к ошибкам
Для основанной на предсказании гибридной системы сжатия внутренне кодируемые кадры независимо кодируются без какого-либо временного предсказания. Внешне кодированные кадры могут быть предсказаны во времени из предшествующих кадров (P-кадров) и будущих кадров (B-кадров). Оптимальный предиктор может быть идентифицирован посредством процесса поиска в опорном кадре (одном или более), и измерение искажений, например, SAD, используется для того, чтобы определить наилучшее совпадение. Кодированная с предсказанием зона текущего кадра может быть блоком переменной длины и формы (16×16, 32×32, 8×4 и т.д.) или группой пикселов, идентифицированных как объект посредством, к примеру, сегментации.
Временное предсказание в типичном варианте растягивается на множество кадров (к примеру, десять или десятки кадров) и завершается, когда кадр кодирован как I-кадр, причем GOP в типичном варианте задается посредством частоты I-кадров. Для максимальной эффективности кодирования GOP - это сцена, например, границы GOP совмещены с границами сцены, и кадры смены сцен кодируются как I-кадры. При небольшом движении последовательности содержат относительно статичный фон, и движение, в общем, ограничено объектом на переднем плане. Примеры содержимого таких последовательностей с небольшим движением включают в себя программы новостей и прогноза погоды, где более 30% самого просматриваемого содержимого имеет такой характер. В последовательностях с небольшим движением большинство зон являются внешне кодированными, и спрогнозированные кадры ссылаются обратно на I-кадр посредством промежуточных спрогнозированных кадров.
Ссылаясь на фиг.22, внутренне кодированный блок 2205 в I-кадре является предиктором для внешне кодированного блока 2210 в кодированном кадре (или AU) PI. В этом примере зона данных блоков является стационарной частью фона. Посредством последовательного временного предсказания чувствительность внутренне кодированного блока 2205 к ошибкам возрастает, поскольку это "хороший" предиктор, что также подразумевает, что его "важность" выше. Дополнительно, внутренне кодированный блок 2205 в силу этой цепочки временного предсказания, называемой цепочкой предсказания, остается дольше на дисплее (в течение сцены в примере на чертеже).
Иерархия предсказания задается как дерево блоков, создаваемое на основе этого уровня важности, или измерение сохраняемости с родителем наверху (внутренне кодированный блок 2205) и дочерними элементами внизу. Отметим, что внешне кодированный блок 2215 на P1 находится на втором уровне иерархии и т.д. Листья - это блоки, которые завершают цепочку предсказания.
Иерархия предсказания может быть создана для видеопоследовательностей независимо от типа содержимого (например, также музыки и спорта, а не только новостей) и применима к сжатию основанного на предсказании видео (и данных) в общем (это применяется ко всем изобретениям, описанным в этой заявке). После того как иерархия предсказания установлена, алгоритмы устойчивости к ошибкам, такие как адаптивное внутреннее обновление, описанное ниже, могут быть применены более эффективно. Измерение важности может быть основано на восстанавливаемости данного блока после ошибок, например, посредством операций маскировки и применения адаптивного внутреннего обновления для того, чтобы повышать устойчивость кодированного потока битов к ошибкам. Оценка измерения важности может быть основана на количестве раз, когда блок используется в качестве прогнозного параметра, также упоминаемого как показатель сохраняемости. Показатель сохраняемости также используется для того, чтобы повышать эффективность кодирования за счет приостановки распространения ошибок предсказания. Показатель сохраняемости также увеличивает назначение битов для блоков с более высокой важностью.
Адаптивное внутреннее обновление
Адаптивное внутреннее обновление используется в методике устойчивости к ошибкам, которая может быть основана на информации содержимого мультимедийных данных. В процессе внутреннего обновления некоторые MB кодируются внутренне, даже если стандартная оптимизация R-D должна диктовать то, что они должны быть внешне кодированными MB. AIR использует внутреннее обновление с взвешиванием движения для того, чтобы ввести внутренне кодированные MB в P- или B-кадры. Эти внутренне кодированные MB, содержащиеся в базовом уровне, могут быть кодированы с помощью QPb или QPe. Если QPe используется для базового уровня, не требуется выполнять уточнение на уровне улучшения. Если QPb используется для базового уровня, то уточнение может потребоваться, иначе на уровне улучшения ухудшение качества будет заметным. Поскольку внешнее кодирование более эффективно, чем внутреннее кодирование, в отношении эффективности кодирования, эти уточнения на уровне улучшения внутренне кодируются. Таким образом, коэффициенты базового уровня не используются для уровня улучшения, и качество повышается на уровне улучшения без введения новых операций.
В некоторых аспектах адаптивное внутреннее обновление может быть основано на информации содержимого мультимедийных данных (к примеру, классификации содержимого) вместо или помимо основы взвешенного движения. Например, если классификация содержимого относительно высокая (к примеру, сцены, имеющие высокую пространственную и временную сложность), адаптивное внутреннее обновление может вводить относительно большее число внутренне кодированных MB в P- или B-кадры. Альтернативно, если классификация содержимого относительно низкая (указывая менее динамичную сцену с низкой пространственной и/или временной сложностью), то адаптивное внутреннее обновление может вводить меньшее число внутренне кодированных MB в P- и B-кадры. Эти показатели и способы повышения устойчивости к ошибкам могут быть применены не только в контексте беспроводной мультимедийной связи, но также к сжатию данных и мультимедийной обработке, в общем (к примеру, при рендеринге графики).
Кадр переключения каналов
Кадр переключения каналов (CSF), задаваемый в данном документе, является обширным термином, описывающим кадр произвольного доступа, вставляемый в соответствующее место широковещательного потока для быстрого обнаружения канала и тем самым быстрой смены каналов между потоками при широковещательной мультиплексной передаче. Кадры переключения каналов также повышают устойчивость к ошибкам, поскольку они предоставляют избыточные данные, которые могут быть использованы в том случае, если первичный кадр передан с ошибкой. I-кадры или прогрессивный I-кадр, такой как прогрессивный кадр обновления декодера, в H.264 в типичном варианте выступает в качестве точки произвольного доступа. Тем не менее, частые I-кадры (или короткие GOP, короче длительности сцен) приводят к значительному снижению эффективности сжатия. Поскольку внутренне кодированные блоки могут быть использованы для устойчивости к ошибкам, произвольный доступ и устойчивость к ошибкам может быть эффективно комбинирована посредством эффективности предсказания, чтобы повышать эффективность кодирования при увеличении устойчивости к ошибкам.
Усовершенствование переключения с произвольным доступом и устойчивости к ошибкам может быть достигнуто во взаимодействии и может быть основано на информации содержимого, такой как классификация содержимого. Для последовательностей с небольшим движением цепочки прогнозирования являются длинными, и значительная часть информации, требуемой для того, чтобы восстанавливать суперкадр или сцену, содержится в I-кадре, который был в начале сцены. Ошибки каналов зачастую являются пульсирующими, и когда затухание возникает, и FEC и канальное кодирование завершается сбоем, имеется серьезная остаточная ошибка того, что маскирование сбоит. Это особенно серьезно для последовательностей с небольшим движением (и, следовательно, низкой скоростью передачи битов), поскольку объем кодированных данных недостаточной большой для того, чтобы предоставлять хорошее временное разнесение в потоке битов видео, и поскольку это последовательности с высокой степенью сжатия, что делает каждый бит пригодным для восстановления. Последовательности с большим движением более устойчивы к ошибкам вследствие характера содержимого - больше новой информации в каждом кадре увеличивает число внутренне кодированных блоков, которые являются независимо декодируемыми и более устойчивыми к ошибкам по природе. Адаптивное внутреннее обновление на основе иерархии предсказания предоставляет высокую производительность для последовательностей с большим движением, и повышение производительности незначительно для последовательностей с небольшим движением. Следовательно, кадр переключения каналов, содержащий большую часть I-кадра, является хорошим источником разнесения для последовательностей с небольшим движением. Когда ошибка возникает в суперкадре, декодирование в последовательном кадре начинается с CSF, который восстанавливает потерянную информацию благодаря предсказанию, и достигается устойчивость к ошибкам.
В случае последовательностей с большим движением, таких как последовательности, имеющие относительно высокую классификацию содержимого (к примеру, 6-8), CSF может состоять из блоков, которые содержатся в SF, т.е. тех, которые являются хорошими предикторами. Все остальные зоны CSF не должны кодироваться, поскольку они являются блоками, которые имеют короткие цепочки предсказания, что подразумевает то, что они завершаются внутренними блоками. Следовательно, CSF по-прежнему служит для того, чтобы выполнять восстановление потерянной информации благодаря предсказанию, когда возникает ошибка. CSF для последовательностей с небольшим движением совпадают с размером I-кадров, и они могут кодироваться при меньшей скорости передачи битов за счет более сильного квантования, тогда как CSF для последовательностей с большим движением гораздо меньше соответствующих I-кадров.
Устойчивость к ошибкам на основе иерархии предсказания может хорошо работать с масштабируемостью и позволяет достигать высокоэффективного многоуровневого кодирования. Масштабируемость для того, чтобы поддерживать иерархическую модуляцию в технологиях физического уровня может требовать секционирования данных потока битов видео с конкретными коэффициентами полосы пропускания. Это не всегда могут быть идеальные коэффициенты для оптимальной масштабируемости (например, с небольшой дополнительной служебной информацией). В некоторых аспектах используется двухуровневая масштабируемость с коэффициентом полосы пропускания 1:1. Секционирование потока битов видео на два уровня одинакового размера может быть не так эффективно для последовательностей с небольшим движением. Для последовательностей с небольшим движением базовый уровень, содержащий всю информацию заголовков и метаданных, больше уровня улучшения. Тем не менее, поскольку CSF для последовательностей с небольшим движением больше, они точно вписываются в оставшуюся полосу пропускания уровня улучшения.
Последовательности с большим движением имеют достаточно остаточной информации для того, чтобы секционирование данных 1:1 могло быть выполнено с наименьшей служебной информацией. Дополнительно, кадр переключения каналов для таких последовательностей гораздо меньше для последовательностей с большим движением. Следовательно, устойчивость к ошибкам на основе иерархии предсказания также может хорошо работать с масштабируемостью для последовательностей с большим движением. Расширение концепций, описанных выше, до клипов с умеренным движением возможно на основе описаний этих алгоритмов, и предлагаемые концепции применяются к кодированию видео в целом.
Мультиплексор
В некоторых аспектах кодера мультиплексор может быть использован для кодирования нескольких мультимедийных потоков, сформированных посредством кодера, и использован для того, чтобы подготавливать кодированные биты для широковещательной передачи. Например, в иллюстративном аспекте кодера 228, показанном на фиг.2, синхронизирующий уровень 240 содержит мультиплексор. Мультиплексор может быть реализован так, чтобы предоставлять управление назначением скорости передачи битов. Оцененная сложность может предоставляться в мультиплексор, который затем может назначать доступную полосу пропускания для набора мультиплексированных видеоканалов согласно сложности кодирования, предполагаемой для этих видеоканалов, что в таком случае дает возможность качеству конкретного канала оставаться относительно постоянным, даже если полоса пропускания для набора мультиплексированных видеопотоков относительно постоянна. Это дает возможность каналу в рамках набора каналов иметь переменную скорость передачи битов и относительно постоянное визуальное качество вместо относительно постоянной скорости передачи битов и переменного визуального качества.
Фиг.18 - это блок-схема, иллюстрирующая систему кодирования нескольких мультимедийных потоков или каналов 1802. Мультимедийные потоки 1802 кодируются посредством соответствующих кодеров 1804, которые поддерживают обмен данными с мультиплексором (MUX) 1806, который, в свою очередь, поддерживает обмен данными со средой 1808 передачи. Например, мультимедийные потоки 1802 могут соответствовать различным каналам содержимого, таким как новостные каналы, спортивные каналы, каналы с фильмами и т.п. Кодеры 1804 кодируют мультимедийные потоки 1802 в формат кодирования, указанный для системы. Хотя описываются в контексте кодирования видеопотоков, принципы и преимущества раскрытых методик, в общем, применимы к мультимедийным потокам, включающим в себя, например, аудиопотоки. Кодированные мультимедийные потоки предоставляются в мультиплексор 1806, который комбинирует различные кодированные мультимедийные потоки и отправляет комбинированный поток в среду 1808 передачи для передачи.
Среда 1808 передачи может соответствовать множеству сред, таких как, но не только, цифровые спутниковые каналы связи, к примеру, DirecTV®, цифровые кабельные, проводные и беспроводные Интернет-каналы связи, оптические сети, сотовые телефонные сети и т.п. Среда 1808 передачи может включать в себя, например, модуляцию до радиочастоты (RF). В типичном варианте вследствие спектральных ограничений и т.п. среда передачи имеет ограниченную полосу пропускания, и данные из мультиплексора 1806 в среду передачи поддерживаются с относительно постоянной скоростью передачи битов (CBR).
В традиционных системах применение постоянной скорости передачи битов (CBR) при выводе из мультиплексора 1806 может требовать того, чтобы кодированное мультимедиа или видеопотоки, которые поступают в мультиплексор 1806, также были CBR. Как описано в уровне техники, применение CBR при кодировании видеосодержимого может приводить к переменному визуальному качеству, что в типичном варианте нежелательно.
В проиллюстрированной системе два или более кодера 1804 передают предполагаемую сложность кодирования входных данных. Один или более кодеров 1804 может принимать адаптивное управление скоростью передачи битов от мультиплексора 1806 в ответ. Это позволяет кодеру 1804, который, как ожидается, кодирует относительно сложное видео, принимать более высокую скорость передачи битов или более высокую полосу пропускания (больше битов на кадр) для этих кадров видеоспособом квазипеременной скорости передачи битов. Это дает возможность мультимедийному потоку 1802 быть кодированным при согласованном визуальном качестве. Дополнительная полоса пропускания, которая используется посредством конкретного кодера 1804, кодирующего относительно сложное видео, поступает от битов, которые в противном случае были бы использованы для кодирования других видеопотоков 1804, если бы кодеры были реализованы так, чтобы работать при постоянных скоростях передачи битов. Это поддерживает вывод мультиплексора 1806 на постоянной скорости передачи битов (CBR).
Хотя отдельный мультимедийный поток 1802 может быть относительно "пульсирующим", т.е. варьировать используемую полосу пропускания, кумулятивная сумма из нескольких мультимедийных потоков может быть менее пульсирующей. Скорость передачи битов от каналов, которые кодируют менее сложное видео, может быть заново выделена, например, посредством мультиплексора 1806, каналам, которые кодируют относительно сложное видео, и это позволяет повышать визуальное качество комбинированных видеопотоков в целом.
Кодеры 1804 предоставляют в мультиплексор 1806 индикатор сложности набора видеокадров, которые должны быть кодированы и мультиплексированы вместе. Вывод мультиплексора 1806 должен предоставлять вывод, который не выше скорости передачи битов, заданной для среды 1808 передачи. Индикаторы сложности могут быть основаны на классификации содержимого, как описано выше, чтобы предоставлять выбранный уровень качества. Мультиплексор 1006 анализирует индикаторы сложности и предоставляет в различные кодеры 1004 назначенное число битов полосы пропускания, и кодеры 1804 используют эту информацию для того, чтобы кодировать видеокадры в наборе. Это дает возможность набору видеокадров индивидуально иметь переменную скорость передачи битов и при этом достигать постоянной скорости передачи битов как группе.
Классификация содержимого также может быть использована для обеспечения основанного на качестве сжатия мультимедиа, в общем, для любого обобщенного модуля сжатия. Классификация содержимого и способы и устройства, описанные в данном документе, могут быть использованы в основанной на качестве и/или основанной на содержимом мультимедийной обработке любых мультимедийных данных. Один пример - это ее использование при сжатии мультимедиа, в общем, для любого обобщенного модуля сжатия. Другой пример состоит в распаковке или декодировании в любом модуле распаковки или декодере либо постпроцессоре, например, операции интерполяции, повторной дискретизации, улучшения, восстановления и представления.
Ссылаясь теперь на фиг.19, типичная система видеосвязи включает в себя систему видеосжатия, состоящую из видеокодера и видеодекодера, соединенных посредством сети связи. Беспроводные сети являются одним классом отказоустойчивых сетей, где канал связи предоставляет логарифмически-нормальное затухание или коррекцию и многолучевое затухание в мобильных сценариях помимо потерь в каналах. Чтобы противостоять канальным ошибкам и предоставлять надежную связь для данных прикладного уровня, RF-модулятор включает в себя прямую коррекцию ошибок, включающую в себя модули перемежения, и канальное кодирование, такое как сверточное или турбокодирование.
Видеокодирование снижает избыточность в исходном видео и увеличивает объем информации, переносимой в каждом бите кодированных видеоданных. Это повышает влияние на качество, когда даже небольшая часть кодированного видео потеряна. Пространственное и временное кодирование, присущее системам сжатия видео, усугубляет потери и заставляет ошибки распространяться, приводя к видимым помехам в восстановленном видео. Алгоритмы устойчивости к ошибкам в видеокодере и алгоритмы восстановления после ошибок в видеодекодере повышают отказоустойчивость системы сжатия видео.
В типичном варианте система сжатия видео знает о базовой сети. Тем не менее, в отказоустойчивых сетях интеграция или совмещение алгоритмов защиты от ошибок в прикладном уровне с FEC и канальным кодированием в канальном/физическом уровне очень желательно и предоставляет наибольшую эффективность для повышения производительности по ошибкам системы.
Фиг.14 иллюстрирует один пример потока данных искажений в зависимости от скорости передачи, который возникает в кодере 228, чтобы кодировать кадры. Процесс начинается 1400 с начала 1402 и переходит к этапу 1404 принятия решения, где он принимает ввод 1410 модуля обнаружения смены сцен из препроцессора 226 (к примеру, посредством метаданных), и устойчивый к ошибкам ввод 1406 получается. Если информация указывает, что выбранный кадр является I-кадром, процесс внутренне кодирует кадр. Если информация указывает то, что выбранный кадр - это P-
или B-кадр, процесс использует внутреннее кодирование и (внутреннее) кодирование с оценкой движения для того, чтобы кодировать кадр.
После того как утвердительный режим возникает для режимов этапа 1404, процесс 1400 переходит к этапу 1414 подготовки, на котором скорость R задается равной значению R=Rqual, требуемому целевому качеству на основе кривых R-D. Эта настройка принимается из этапа 1416 данных, содержащего кривые R-D. Процесс 1400 далее переходит к этапу 1418, на котором выполняется назначение битов управления скоростью передачи (Qpi) на основе информации действий изображений/видео (к примеру, классификации содержимого) из процесса классификации содержимого на этапе 1420.
Этап 1418 назначения битов управления скоростью передачи используется, в свою очередь, для оценки движения на этапе 1422. Оценка 1422 движения также может принимать ввод метаданных из препроцессора 1412, сглаживания векторов движения (MPEG-2+предыстория) из этапа 1424 и нескольких опорных кадров (причинные + непричинные макроблоки MB) из этапа 1426. Процесс 1400 далее переходит к этапу 1428, на котором вычисление внутренне кодированных режимов определяется для назначения битов управления скоростью передачи (Qpi). Затем процесс 1400 переходит к этапу 1430, на котором определяются параметры режима и квантования. Определение режима на этапе 1430 выполняется на основе оценки ввода этапа 1422, ввода устойчивости 1406 к ошибкам и масштабируемости R-D, которая определяется на этапе 1432. После того как режим определен, последовательность операций переходит к этапу 1432. Следует отметить, что последовательность операций из этапа 1430 к этапу 1432 осуществляется, когда данные передаются из первого прохода в часть второго прохода кодера.
На этапе 1432 преобразование и квантование выполняется посредством второго прохода кодера 228. Процесс преобразования/квантования корректируется или точно настраивается так, как указано с помощью этапа 1444. На этот процесс преобразования/квантования может оказывать влияние модуль точной настройки управления скоростью передачи (фиг.7). Процесс 1400 далее переходит к этапу 1434 для зигзагообразной сортировки и кодирования по энтропии, чтобы предоставить кодированный базовый уровень. Зигзагообразная сортировка подготавливает данные в эффективном формате для кодирования. Кодирование по энтропии - это методика сжатия, которая использует последовательности битовых кодов для того, чтобы представлять наборы возможных символов. Результат этапа 1432 преобразования/квантования уровня улучшения также отправляется в сумматор 1436, который вычитает базовый уровень и отправляет результат в кодер 1438 ZZ/по энтропии для уровня улучшения, как ранее описано со ссылкой на фиг.31-36. Дополнительно заметим, что уровень улучшения отправляется обратно (см. строку 1440 обновление истинной скорости) для обновления классификации 1420 содержимого истинной скорости и операции определения долгосрочной и краткосрочной предыстории скоростей передачи битов, используемых посредством управления скоростью передачи.
Фиг.17A - это блок-схема последовательности операций способа, иллюстрирующая обработку мультимедийных данных, которые получены, приняты или иным образом доступны. Процесс 1700 начинается на этапе 1702, где он классифицирует содержимое мультимедийных данных. В одном иллюстративном аспекте классификация содержимого может быть выполнена посредством средства классификации, например, модуля 712 классификации содержимого на фиг.7. Процесс 1700 переходит к этапу 1704, где он кодирует мультимедийные данные в первой группе данных и второй группе данных на основе классификации содержимого. Это кодирование выполняется так, что первая группа данных содержит коэффициент, а вторая группа данных содержит первое дифференциальное уточнение, ассоциативно связанное с коэффициентом первой группы данных. Это может быть выполнено посредством средства кодирования, описанного в данном документе, например, кодера 228 на фиг.7.
Фиг.17B - это блок-схема системы 1710 кодирования мультимедиа, которая может выполнять процесс, проиллюстрированный на фиг.17A. В некоторых аспектах системой 1710 кодирования мультимедиа может быть транскодер, к примеру, транскодер 200. В других аспектах система 1710 кодирования может содержать часть транскодера. Система 1710 кодирования мультимедиа включает в себя средство классификации содержимого мультимедийных данных, модуль классификации содержимого мультимедийных данных 1712. Средством классификации содержимого может быть, к примеру, модуль классификации в препроцессоре (к примеру, препроцессоре 226) или кодере (к примеру, кодере 228). Система 1710 кодирования также включает в себя средство кодирования мультимедийных данных, модуль кодирования мультимедийных данных 1714, который может быть сконфигурирован так, чтобы кодировать мультимедийные данные в первой группе данных и во второй группе данных на основе классификации содержимого, причем это кодирование выполняется таким образом, что первая группа данных содержит коэффициент, а вторая группа данных содержит первое дифференциальное уточнение, ассоциативно связанное с коэффициентом первой группы данных. Другие компоненты транскодера, такие как описанные в данном документе, также могут быть включены в систему 1710 кодирования.
Фиг.23, 24, 27 и 28 - это блок-схемы последовательности операций, иллюстрирующие примеры кодирования мультимедийных данных, которые осуществляют аспекты, описанные в данном документе. Фиг.23 - это блок-схема последовательности операций, иллюстрирующая процесс 2300 кодирования мультимедийных данных на основе информации содержимого. На этапе 2305 процесс 2300 принимает кодированные мультимедийные данные, а на этапе 2310 процесс 2300 декодирует мультимедийные данные. На этапе 2315 процесс 2300 определяет информацию содержимого, ассоциативно связанную с декодированными мультимедийными данными. На этапе 2320 процесс 2300 кодирует мультимедийные данные на основе информации содержимого.
Фиг.24 - это блок-схема последовательности операций способа, иллюстрирующая процесс 2400 способ кодирования мультимедийных данных, так чтобы совмещать границы данных на основе уровня информации содержимого. На этапе 2405 процесс 2400 получает информацию содержимого, ассоциативно связанную с мультимедийными данными, что может быть выполнено, к примеру, посредством препроцессора 226 или модуля 712 классификации содержимого, показанного на фиг.7. На этапе 2410 процесс 2400 кодирует мультимедийные данные, так чтобы совмещать границы данных на основе информации содержимого. Например, границы серий макроблоков и границы единиц доступа совмещаются с границами кадров на основе классификации содержимого кодируемых мультимедийных данных. Кодированные данные затем доступны для последующей обработки и/или передачи в мобильное устройство, и процесс 2400 завершается.
Фиг.27 - это блок-схема последовательности операций способа, иллюстрирующая процесс 2700 кодирования данных с помощью адаптивного внутреннего обновления на основе информации содержимого. Когда процесс 2700 начинается, мультимедийные данные были получены. На этапе 2705 процесс 2700 получает информацию содержимого мультимедийных данных. Получение информации содержимого может быть выполнено, например, посредством препроцессора 226 или модуля 712 классификации содержимого, как описано выше. Процесс 2700 переходит к этапу 2710, на котором он кодирует мультимедийные данные с помощью схемы устойчивости к ошибкам на основе адаптивного внутреннего обновления, причем схема устойчивости к ошибкам на основе адаптивного внутреннего обновления основана на информации содержимого. Функциональность этапа 2710 может быть осуществлена посредством кодера 228. Кодированные данные становятся доступными для последующей обработки и передачи, и процесс 2700 затем завершается.
Фиг.28 - это блок-схема последовательности операций способа, иллюстрирующая процесс кодирования мультимедийных данных с помощью избыточных I-кадров на основе информации мультимедийного содержимого. Когда процесс 2800 начинается, мультимедийные данные доступны для обработки. На этапе 2805 процесс 2800 получает информацию содержимого мультимедийных данных. Как описано выше, это может быть выполнено, например, посредством препроцессора 226 и/или кодера 228. На этапе 2810 процесс 2800 кодирует мультимедийные данные, так чтобы вставить один или более дополнительных I-кадров в кодированные данные на основе информации содержимого. Это может быть сделано посредством кодера 228, как описано выше в связи со схемой устойчивости к ошибкам, вставки I-кадров в базовый уровень или уровень улучшения в зависимости от используемой схемы устойчивости к ошибкам. После этапа 2810 кодированные данные доступны для последующей обработки и/или передачи в мобильное устройство.
Следует отметить, что способы, описанные в данном документе, могут быть реализованы для множества аппаратных средств, процессоров и систем связи, известных специалистам в данной области техники. Например, общее требование к клиенту работать так, как описано в данном документе, заключается в том, что клиент имеет дисплей для того, чтобы отображать содержимое и информацию, процессор, чтобы управлять работой клиента, и запоминающее устройство для сохранения данных и программ, связанных с работой клиента. В одном аспекте клиентом является сотовый телефон. В другом аспекте клиентом является карманный компьютер, имеющий средства связи. В еще одном другом аспекте клиентом является персональный компьютер, имеющий средства связи. Помимо этого, такие аппаратные средства, как приемное GPS-устройство, могут содержаться в клиенте для того, чтобы реализовывать различные аспекты. Различные иллюстративные логические узлы, логические блоки, модули и схемы, описанные в связи с раскрытыми в данном документе вариантами осуществления, могут быть реализованы или выполнены с помощью процессора общего назначения, процессора цифровых сигналов (DSP), специализированной интегральной схемы (ASIC), программируемой пользователем матричной БИС (FPGA) или другого программируемого логического устройства, дискретного логического элемента или транзисторной логики, дискретных компонентов аппаратных средств либо любой их комбинации, предназначенной для того, чтобы выполнять описанные в данном документе функции. Процессором общего назначения может быть микропроцессор, но в альтернативном варианте, процессором может быть любой традиционный процессор, контроллер, микроконтроллер или конечный автомат. Процессор также может быть реализован как сочетание вычислительных устройств, к примеру, сочетание DSP и микропроцессора, множество микропроцессоров, один или более микропроцессоров вместе с ядром DSP либо любая другая подобная конфигурация.
Различные иллюстративные логические узлы, логические блоки, модули и схемы, описанные в связи с раскрытыми в данном документе вариантами осуществления, могут быть реализованы или выполнены с помощью процессора общего назначения, процессора цифровых сигналов (DSP), специализированной интегральной схемы (ASIC), программируемой пользователем матричной БИС (FPGA) или другого программируемого логического устройства, дискретного логического элемента или транзисторной логики, дискретных компонентов аппаратных средств либо любой их комбинации, предназначенной для того, чтобы выполнять описанные в данном документе функции. Процессором общего назначения может быть микропроцессор, но в альтернативном варианте процессором может быть любой традиционный процессор, контроллер, микроконтроллер или конечный автомат. Процессор также может быть реализован как сочетание вычислительных устройств, к примеру, сочетание DSP и микропроцессора, множество микропроцессоров, один или более микропроцессоров вместе с ядром DSP либо любая другая подобная конфигурация.
Раскрытые способы и устройства предоставляют перекодирование видеоданных, кодированных в одном формате, в видеоданные, кодированные в другом формате, причем кодирование основано на содержимом видеоданных и кодирование является устойчивым к ошибкам. Способы или алгоритмы, описанные в связи с раскрытыми в данном документе примерами, могут быть реализованы непосредственно в аппаратных средствах, в программном модуле, приводимом в исполнение процессором, микропрограммном обеспечении или в сочетании двух или более из этих элементов. Программный модуль может постоянно размещаться в памяти типа RAM, флэш-памяти, памяти типа ROM, памяти типа EEPROM, регистрах, на жестком диске, сменном диске, компакт-диске или любой другой форме носителя хранения данных, известной в данной области техники. Примерный носитель хранения данных подключен к процессору таким образом, чтобы процессор мог считывать информацию и записывать информацию на носитель хранения данных. В альтернативном варианте носитель хранения может быть встроен в процессор. Процессор и носитель хранения данных могут постоянно размещаться в ASIC. ASIC может постоянно размещаться в пользовательском терминале. В альтернативном варианте процессор и носитель хранения данных могут постоянно размещаться как дискретные компоненты в пользовательском терминале.
Примеры, описанные выше, являются просто иллюстративными, и специалисты в данной области техники теперь могут выполнять различные применения и отступления от вышеописанных примеров без отклонения от раскрытых в данном документе понятий изобретения. Различные модификации в этих примерах могут быть очевидными для специалистов в данной области техники, а описанные в данном документе общие принципы могут быть применены к другим примерам, к примеру, к службе обмена мгновенными сообщениями или любым общим приложениям обмена беспроводными данными, без отступления от духа и области применения описываемых в этом документе новых аспектов. Таким образом, область применения изобретения не предназначена, чтобы быть ограниченной показанными в данном документе примерами, а должна удовлетворять самой широкой области применения, согласованной с принципами и новыми признаками, раскрытыми в данном документе. Слово "примерный" используется в данном документе исключительно для того, чтобы обозначать "служащий в качестве примера, отдельного случая или иллюстрации". Любой пример, описанный в данном документе как "примерный", не обязательно должен быть истолкован как предпочтительный или выгодный по сравнению с другими примерами. Соответственно, новые признаки, описываемые в данном документе, должны задаваться исключительно посредством области применения нижеприведенной формулы изобретения.
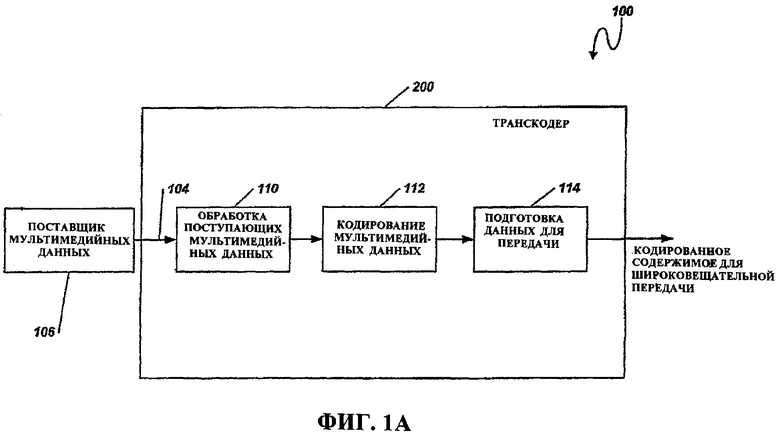
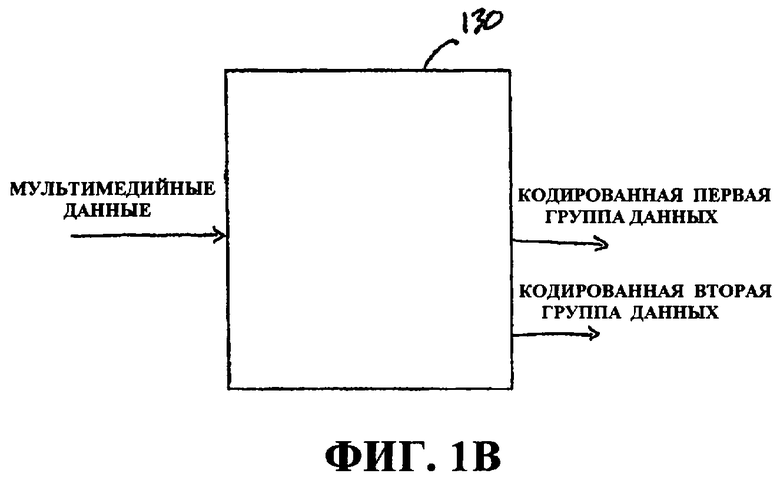
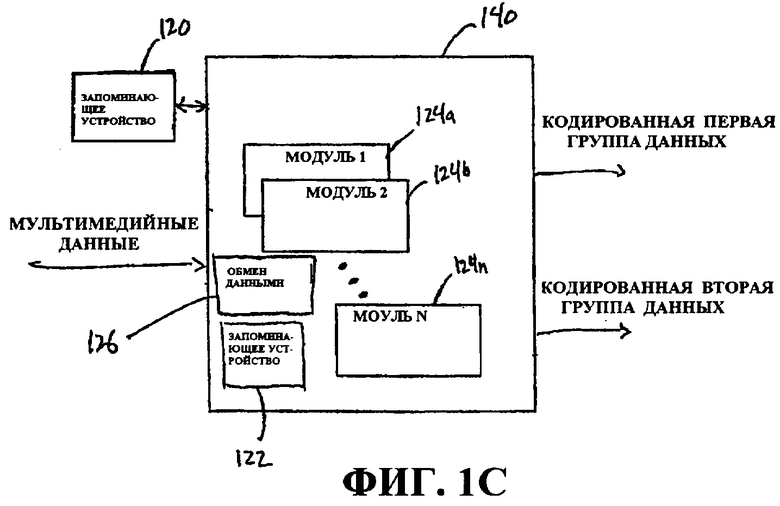
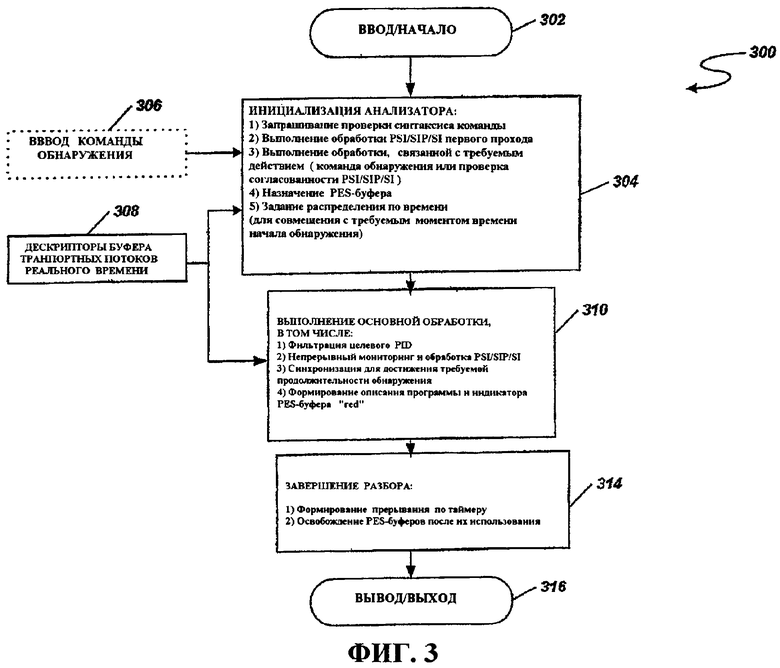
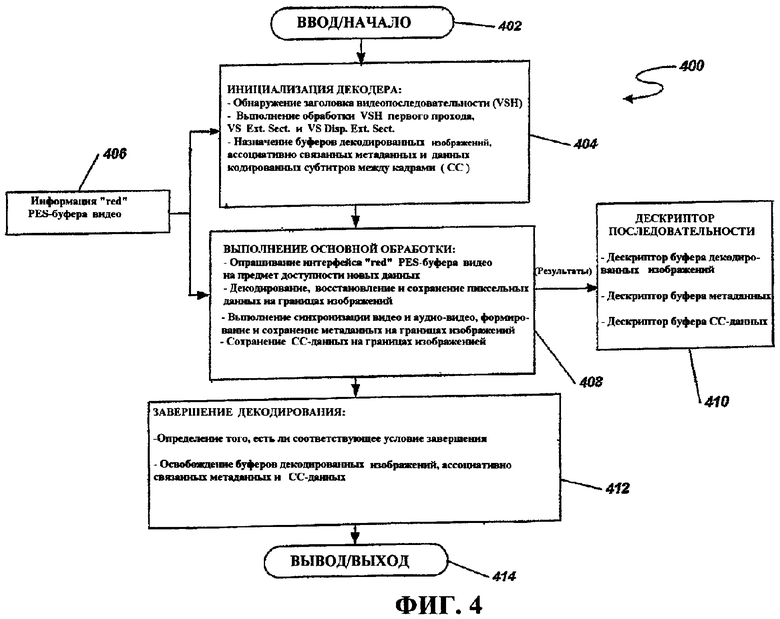
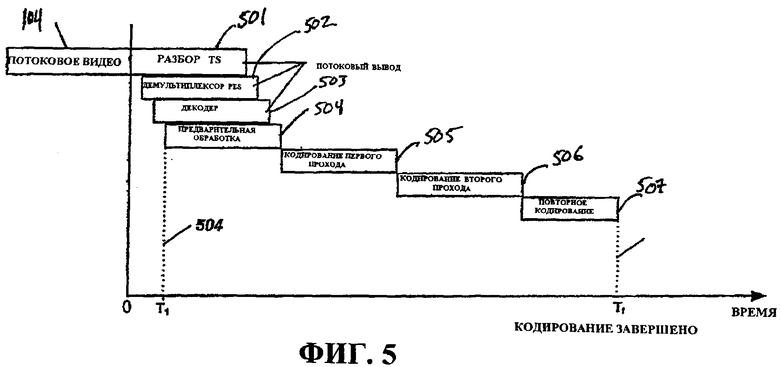
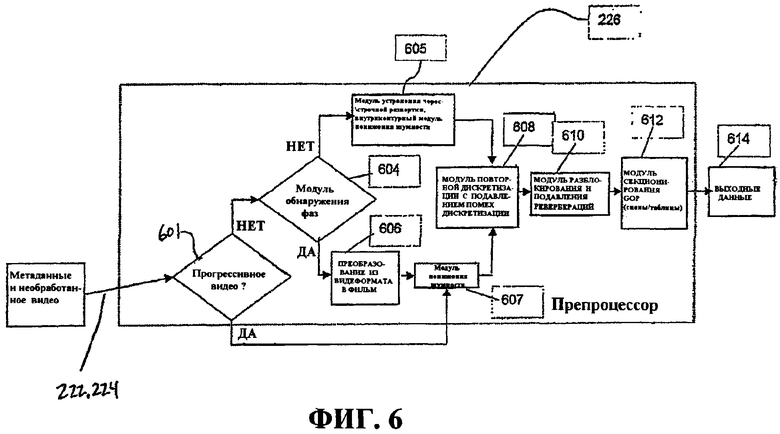
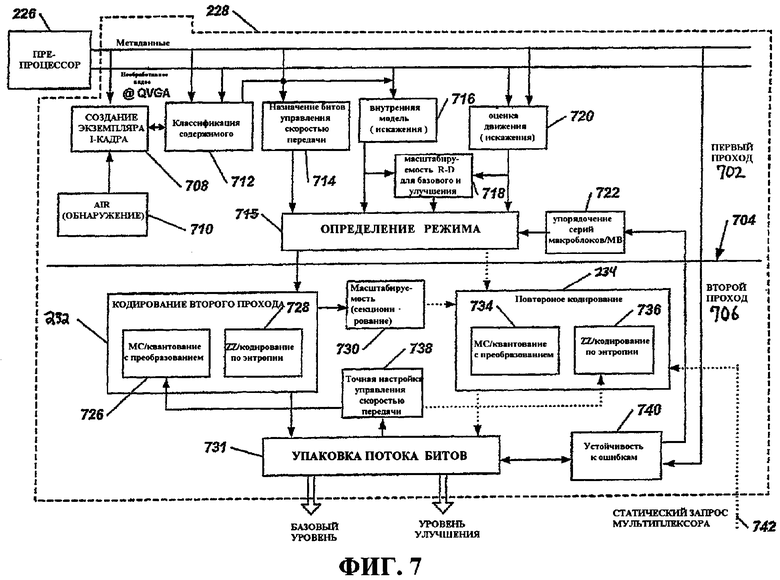
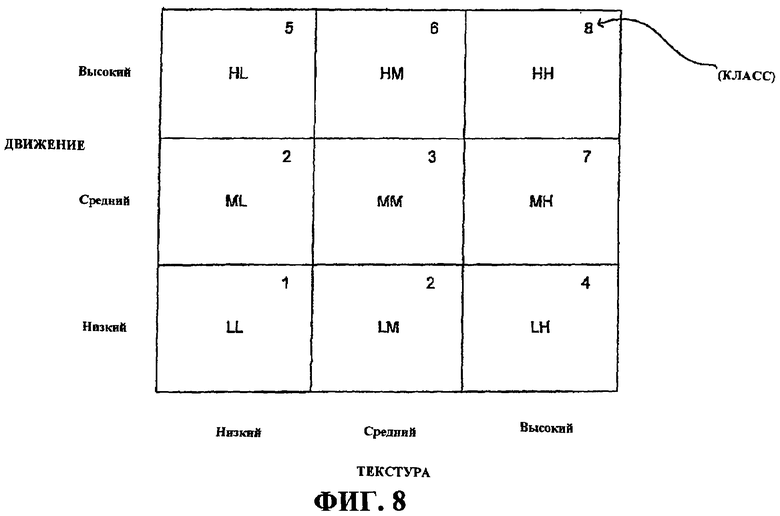
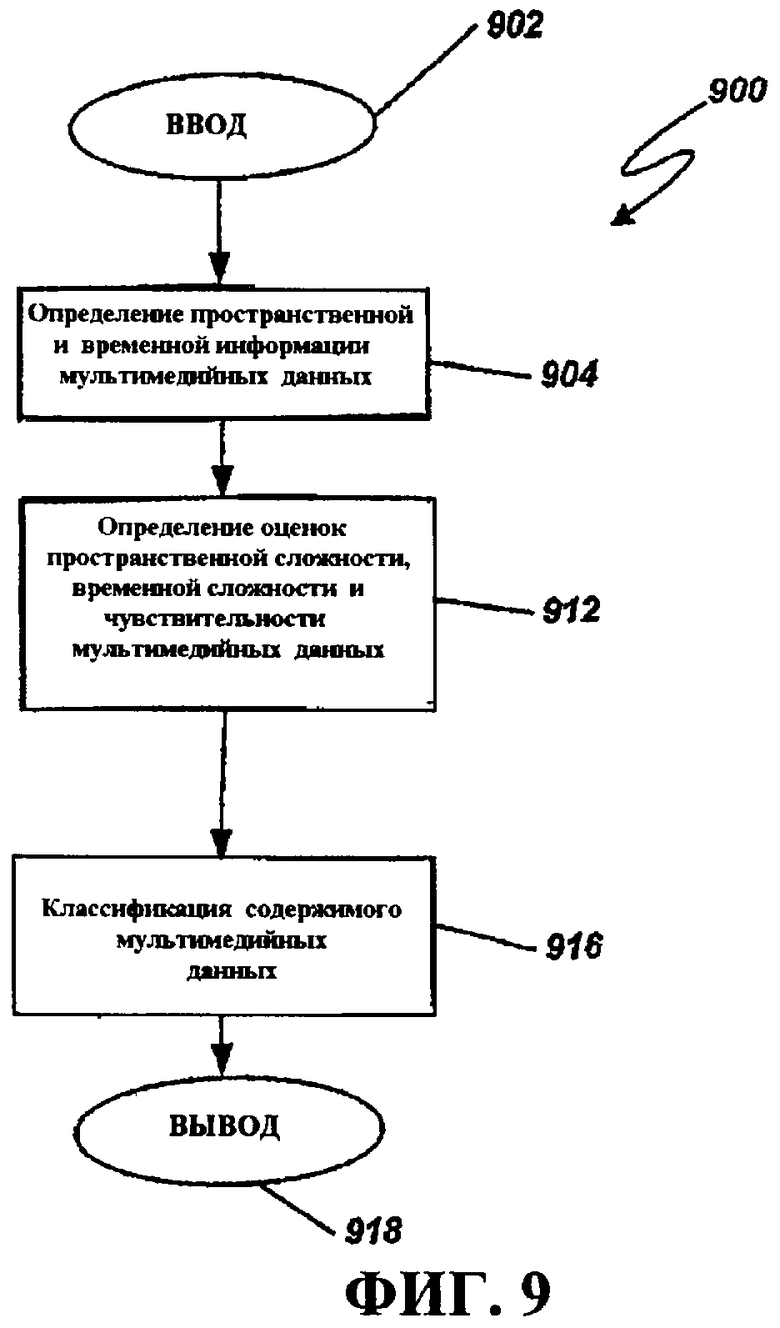
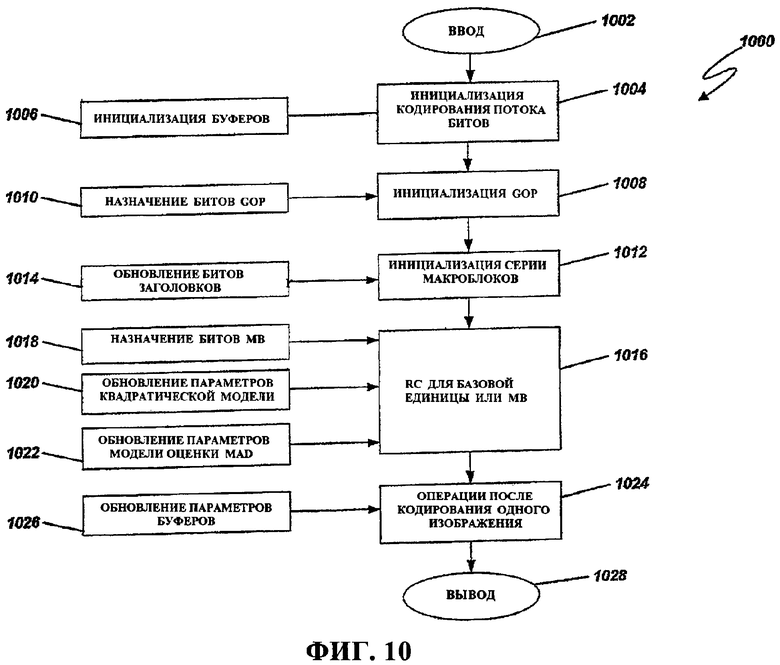
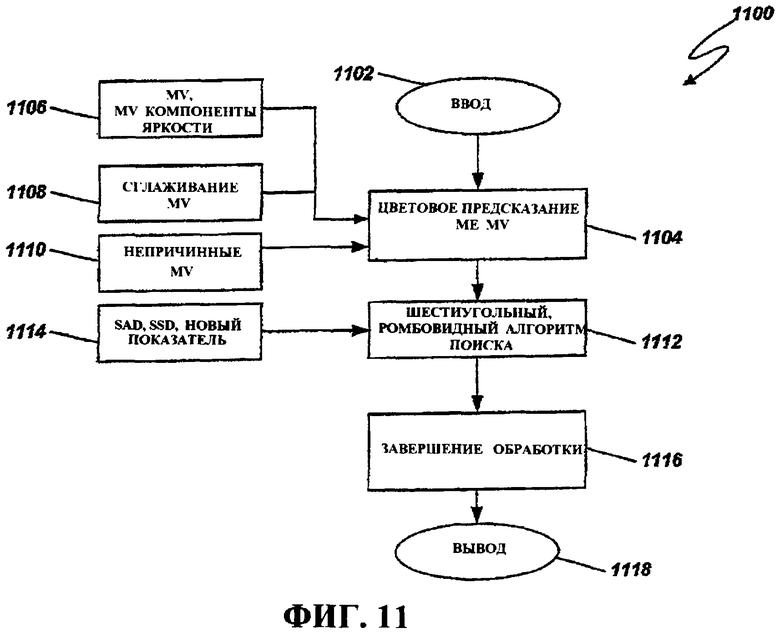
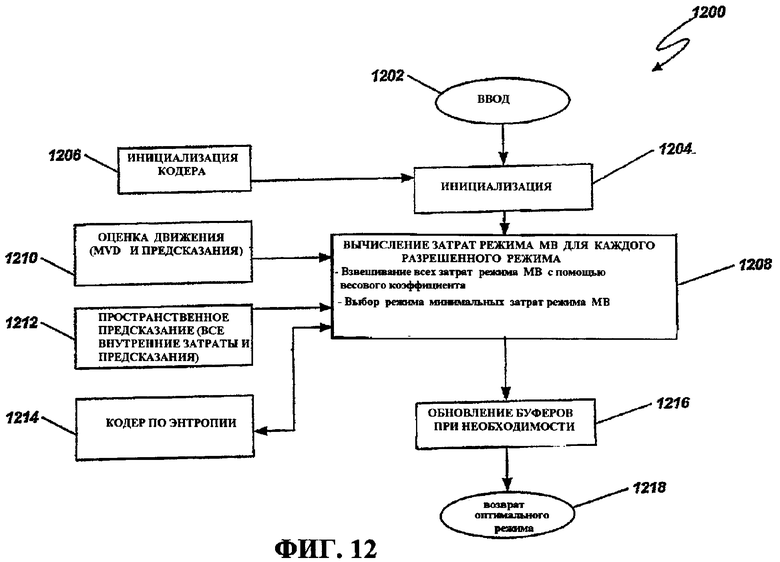
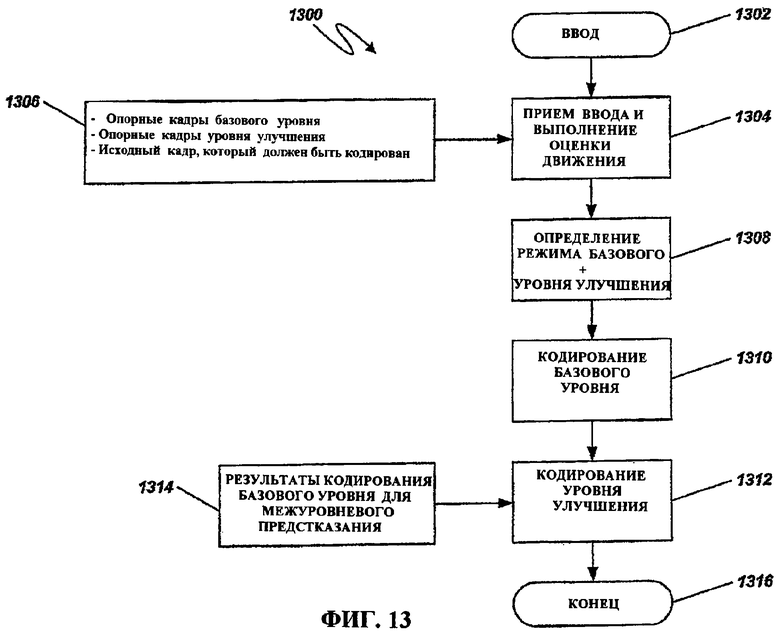
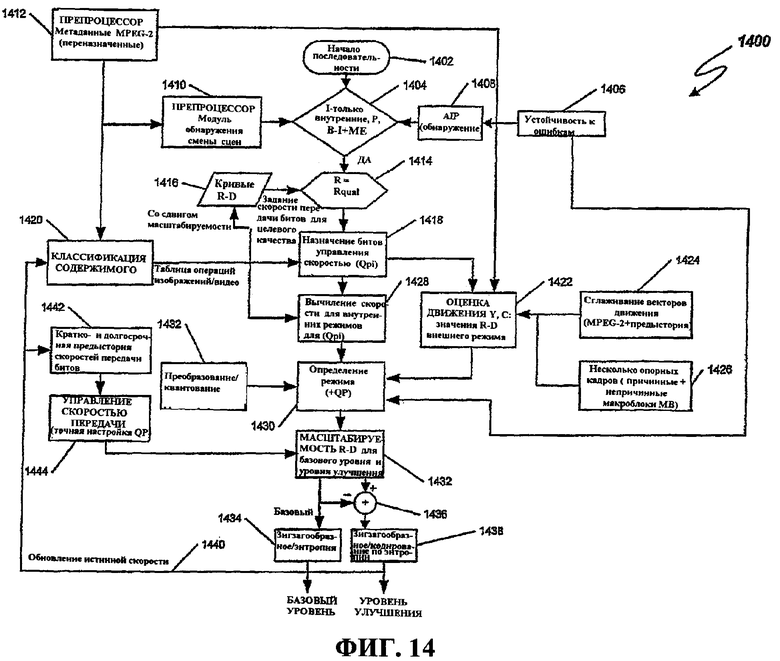
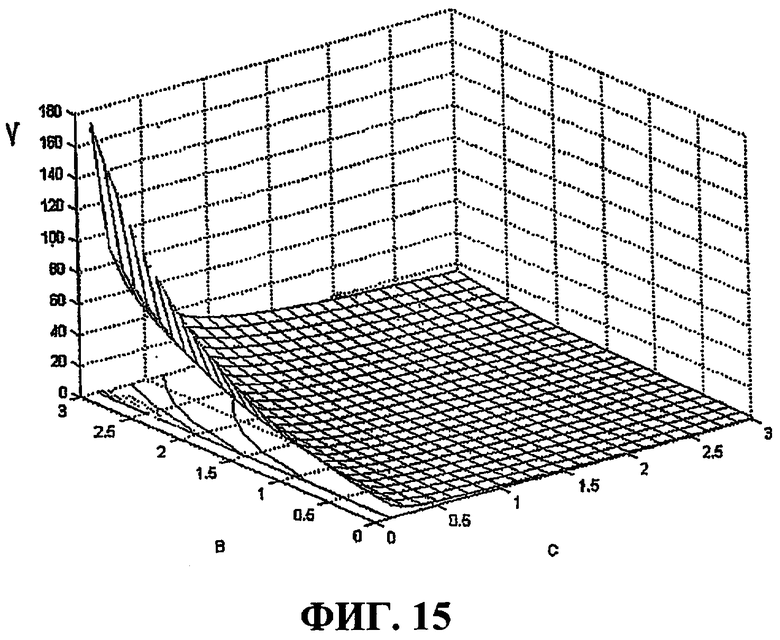
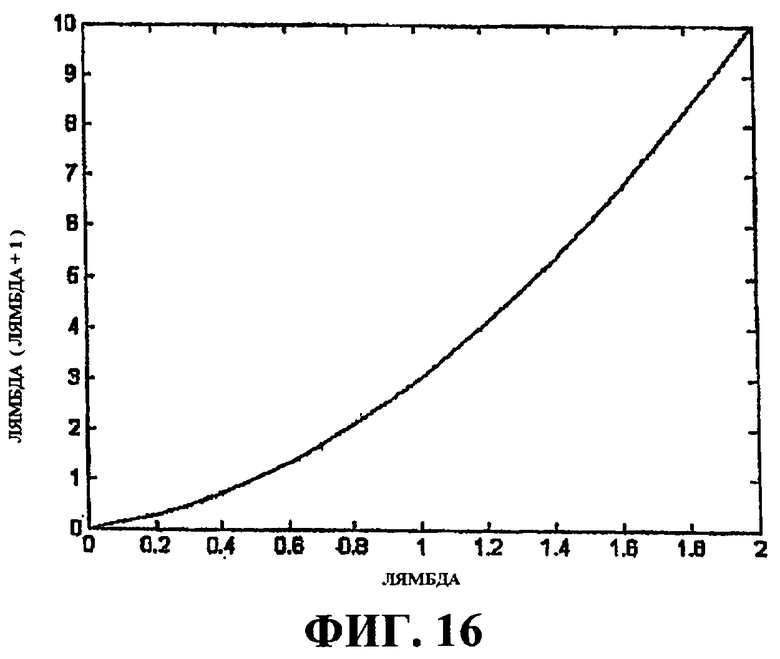
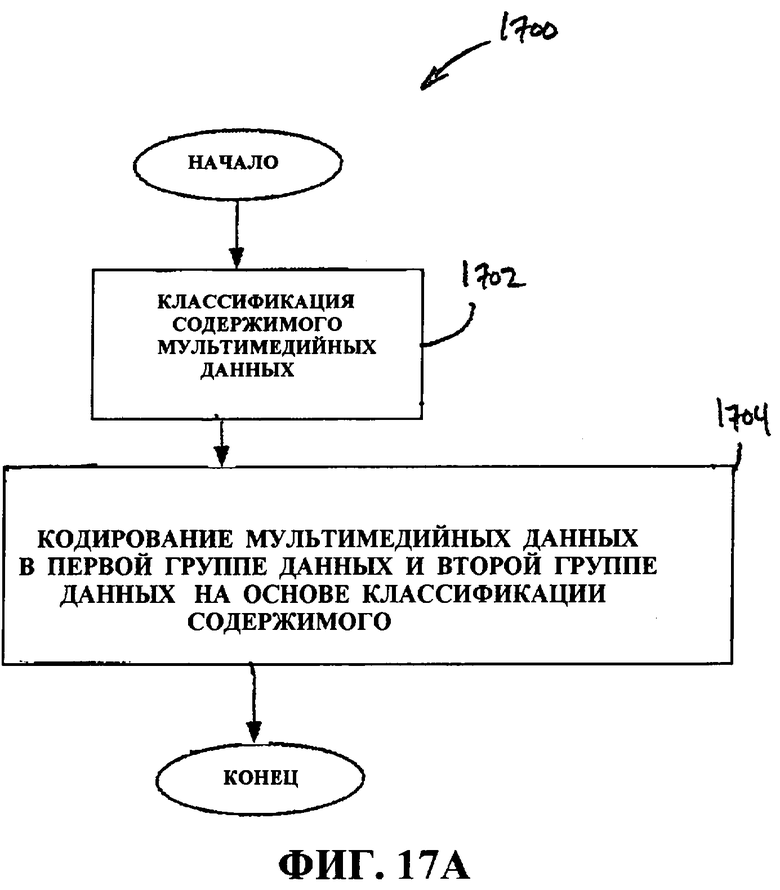
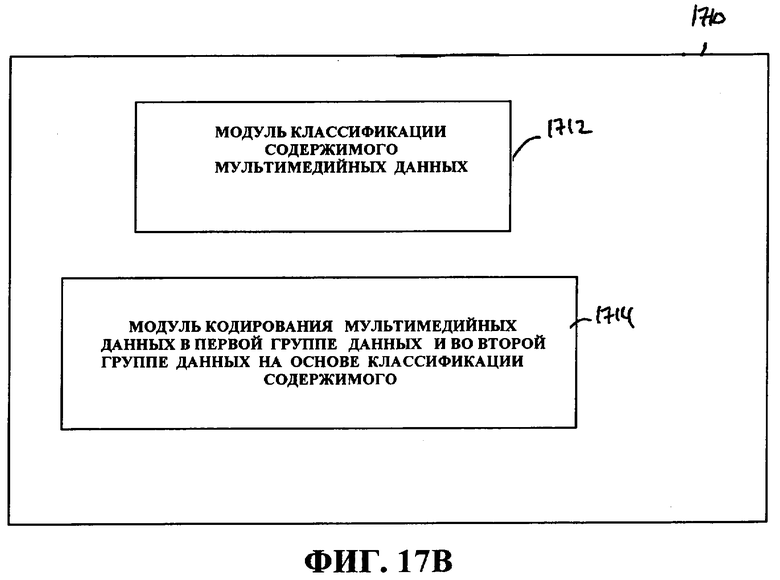
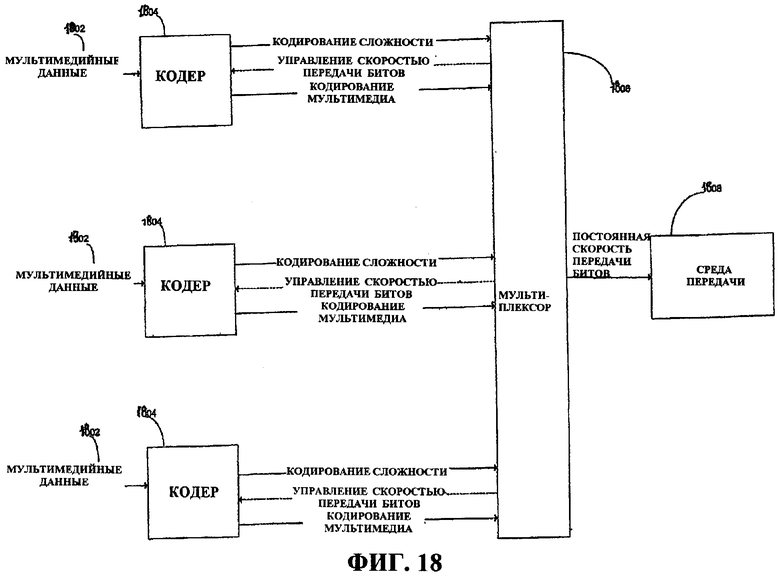
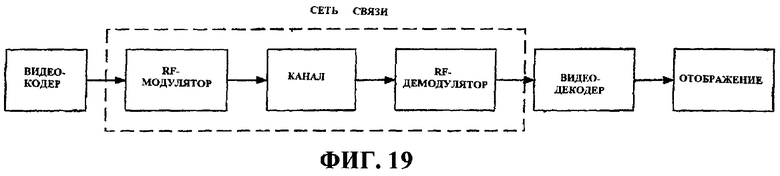
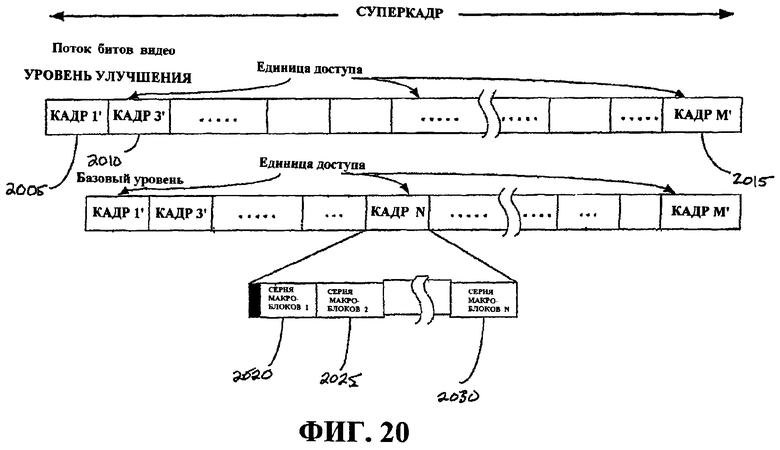
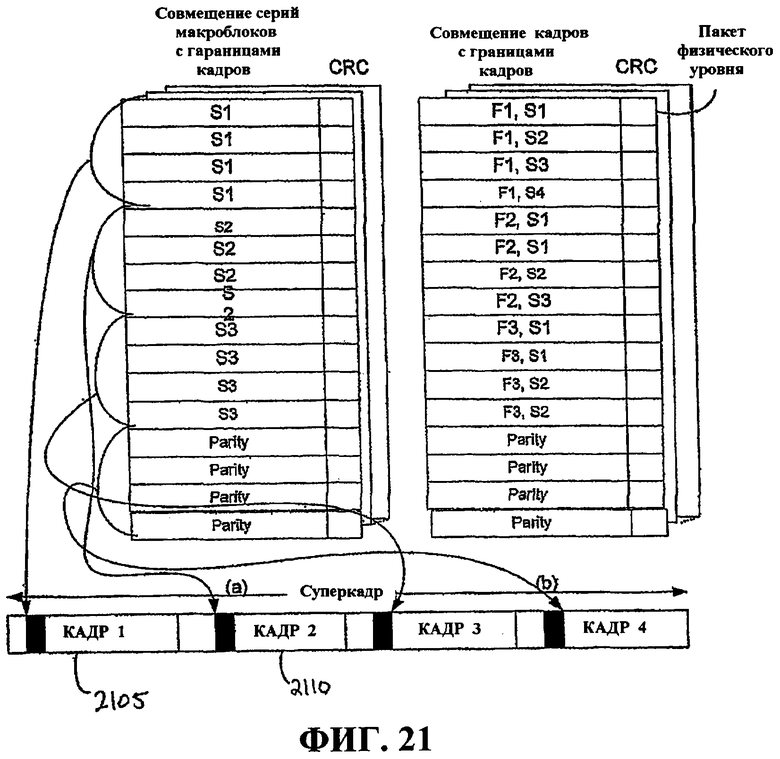
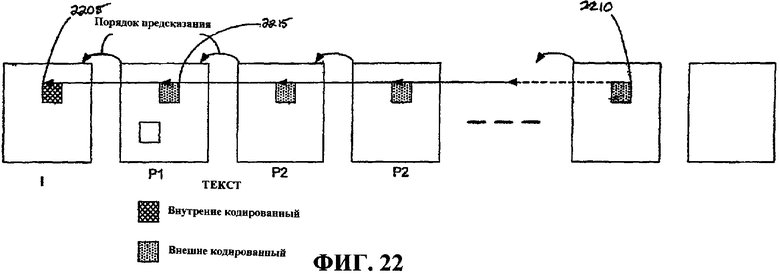
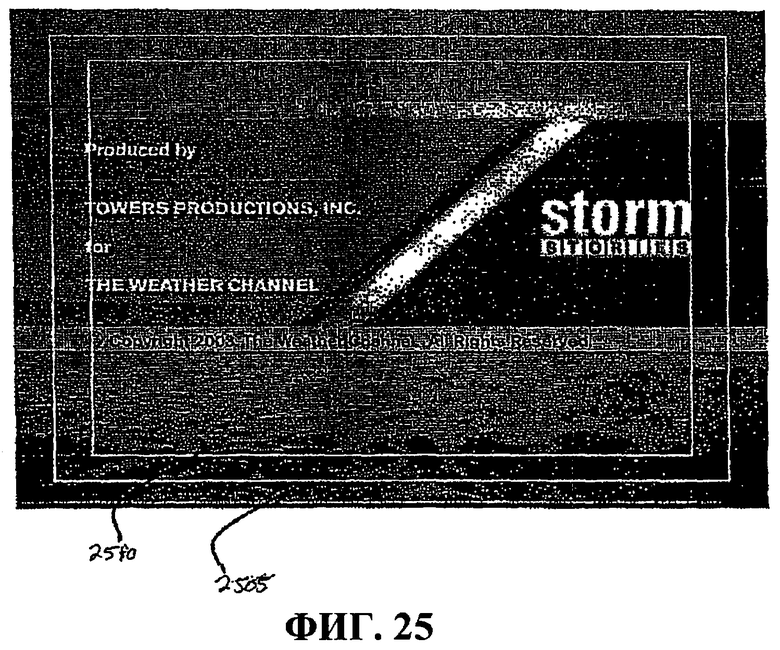

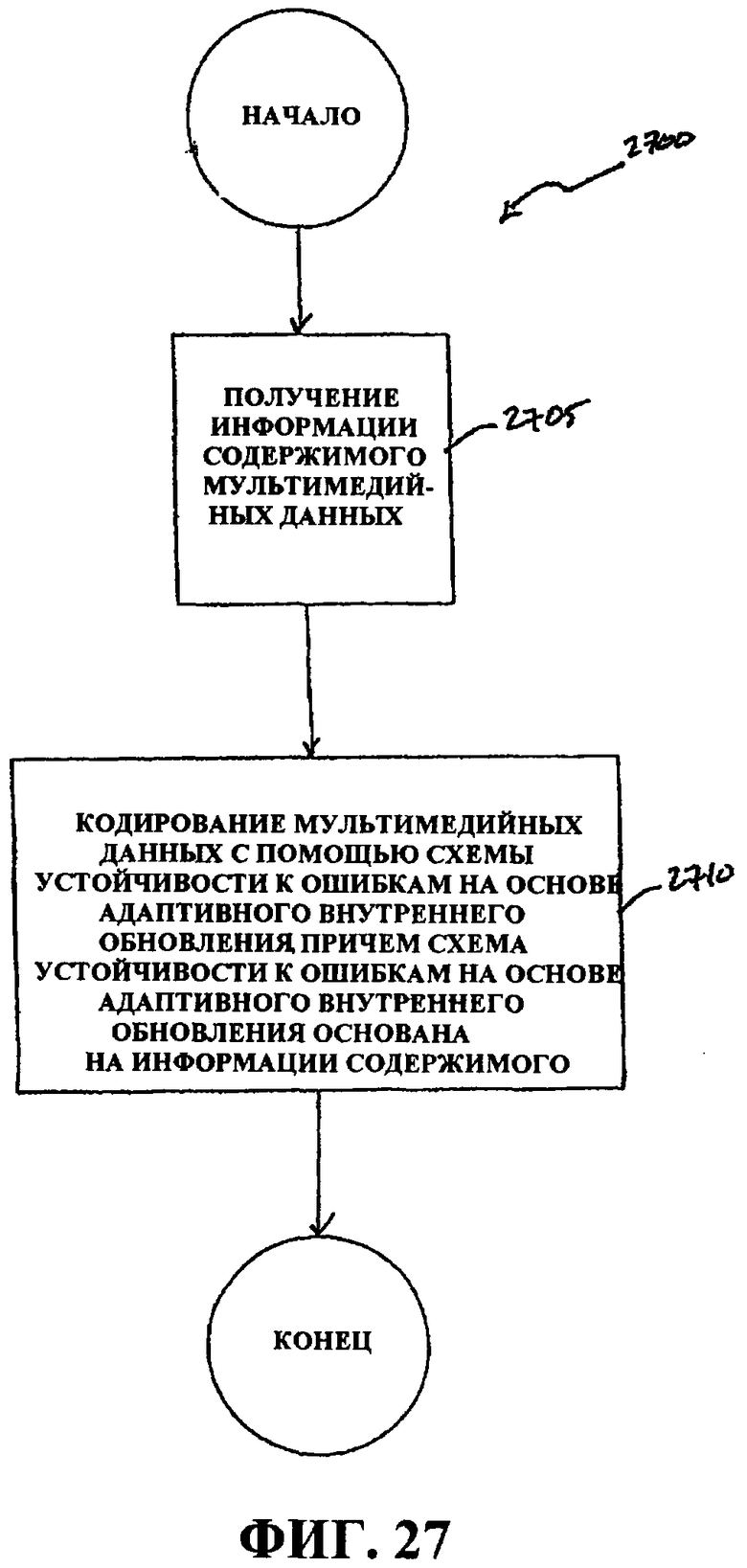
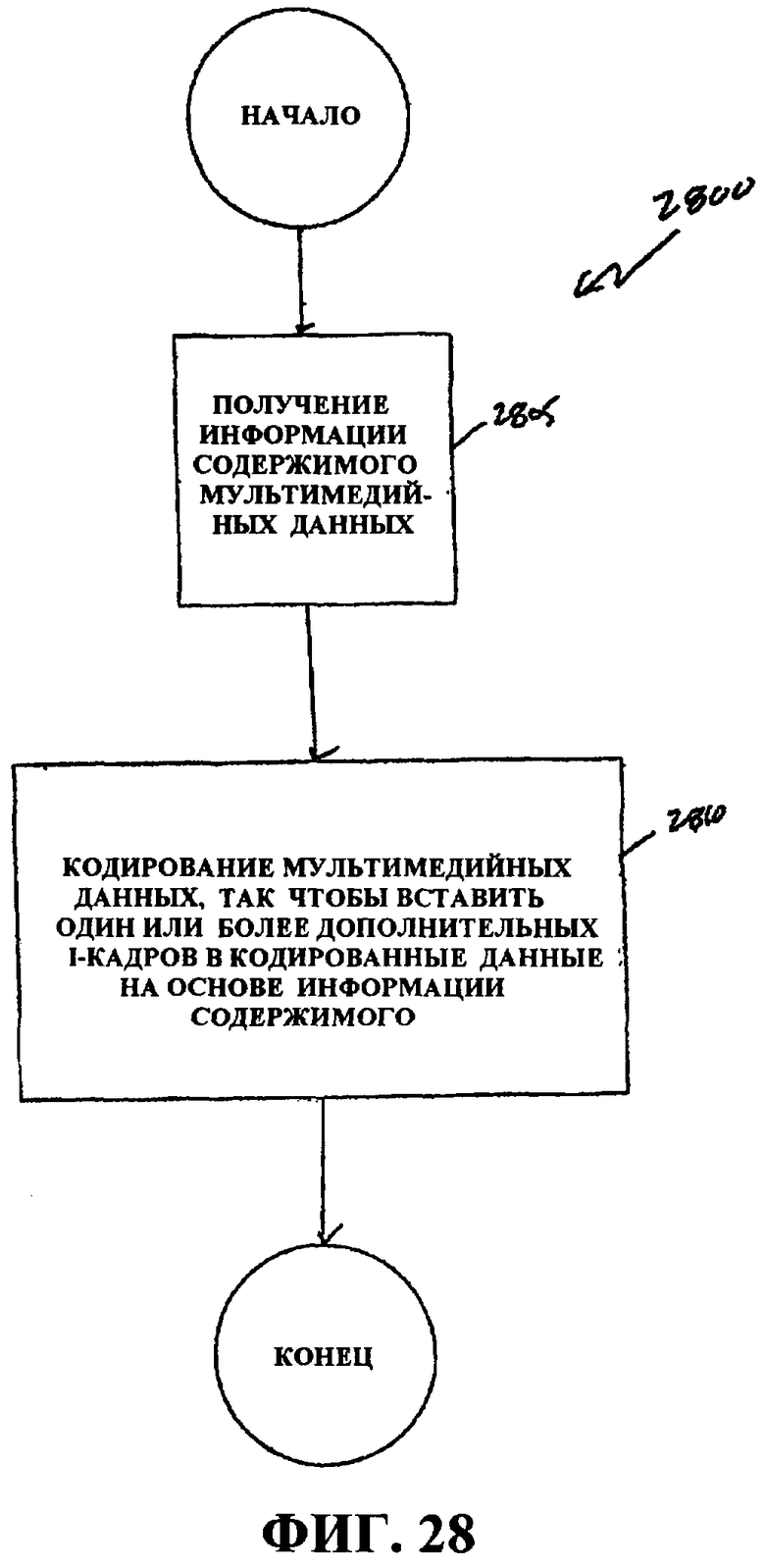
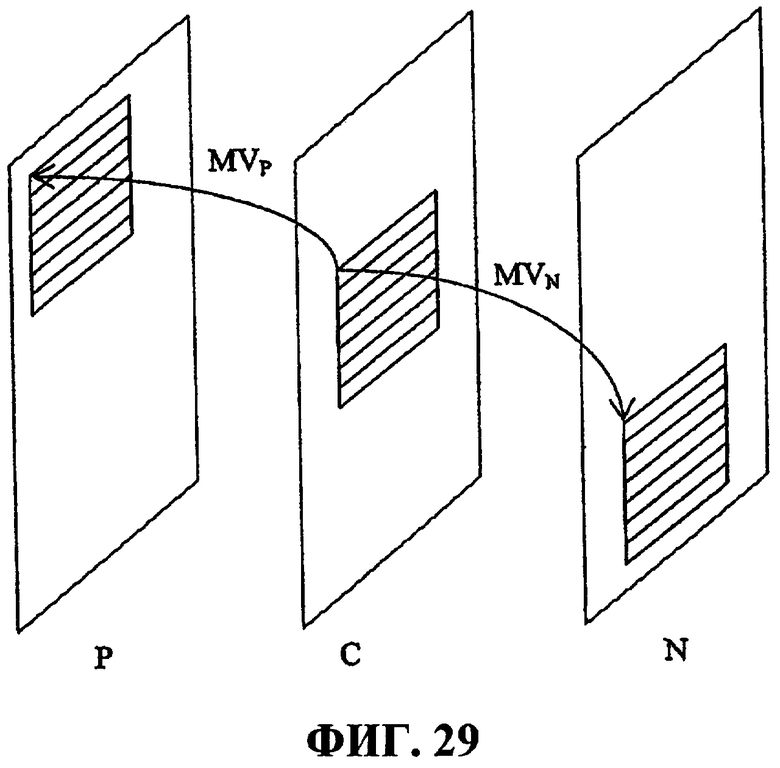
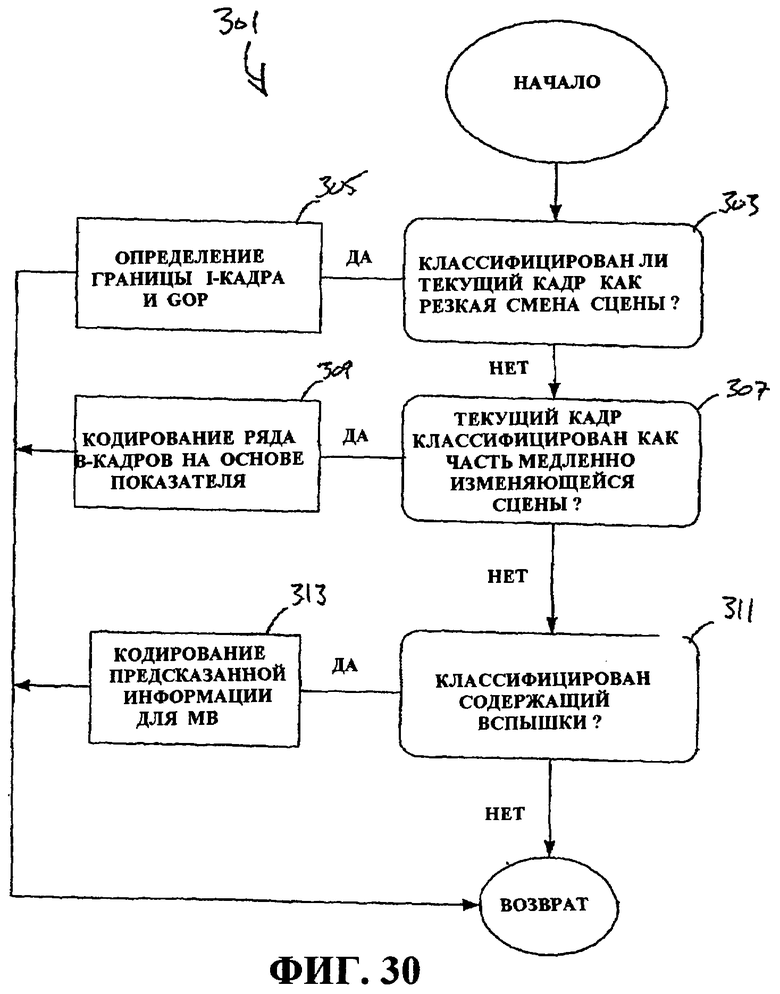
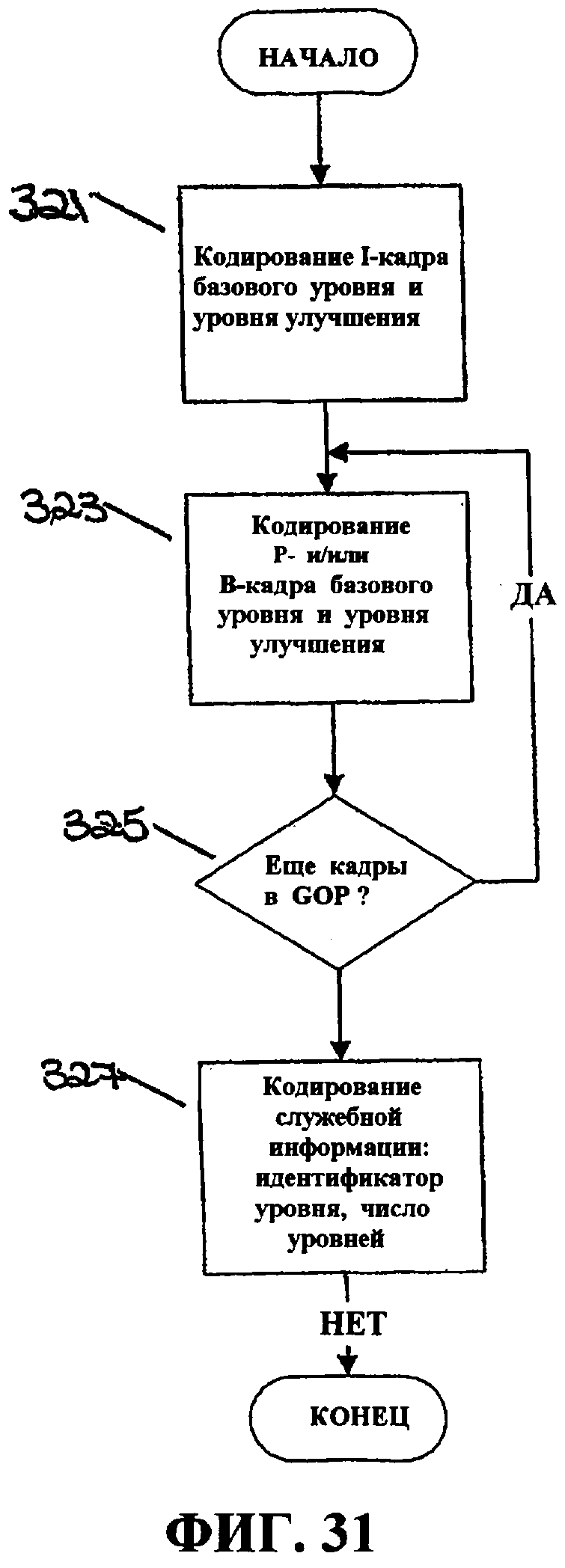
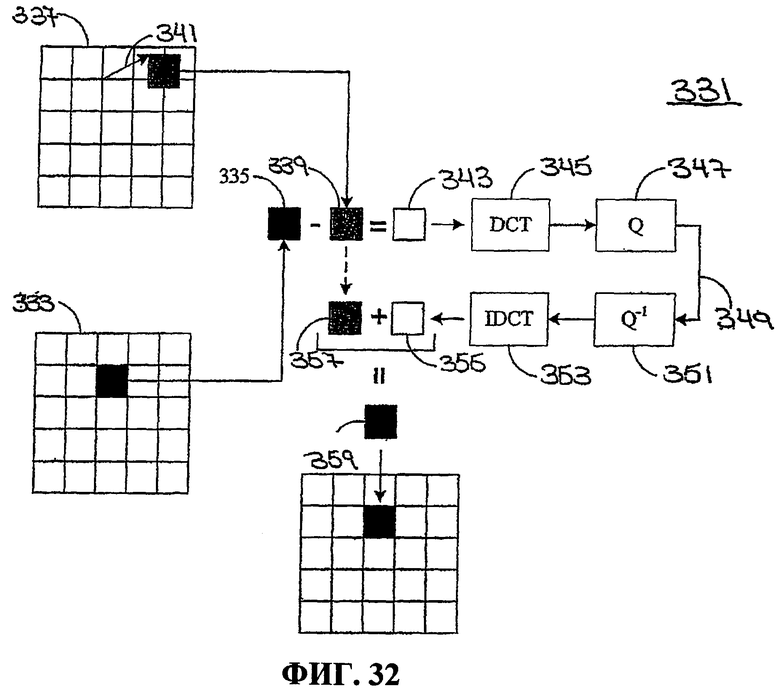
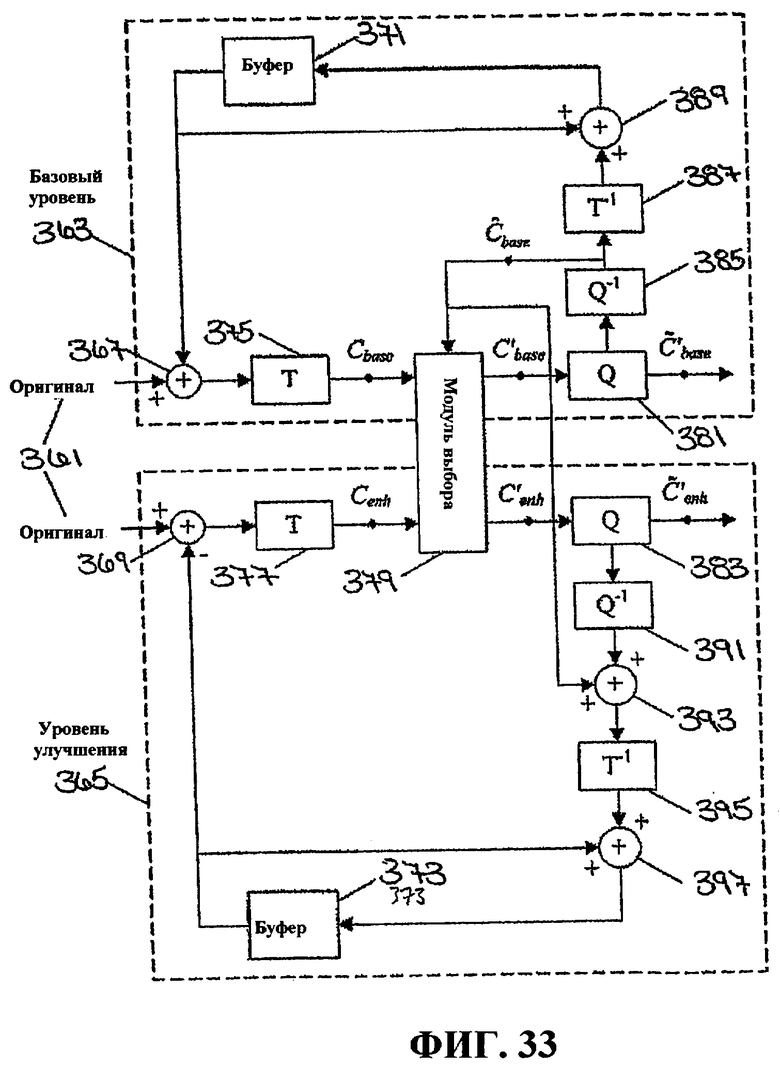
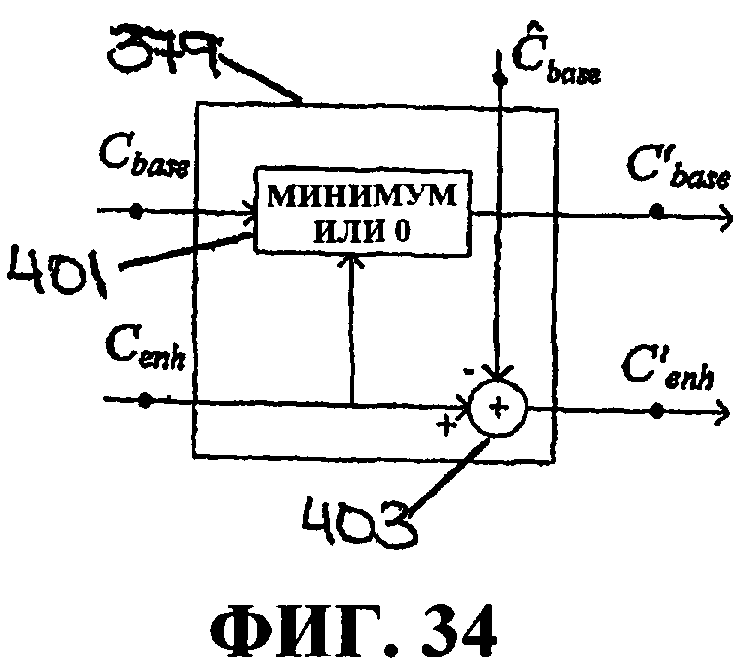
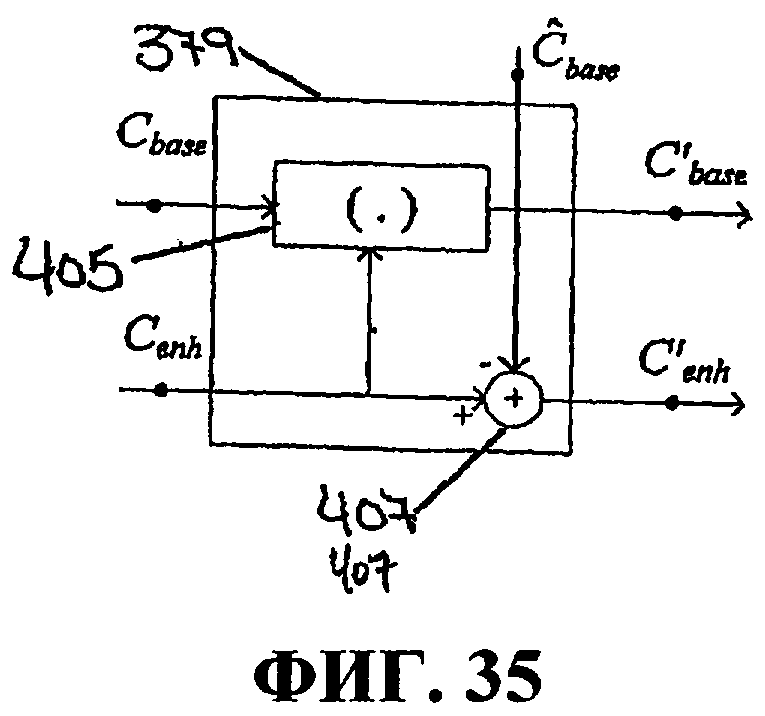
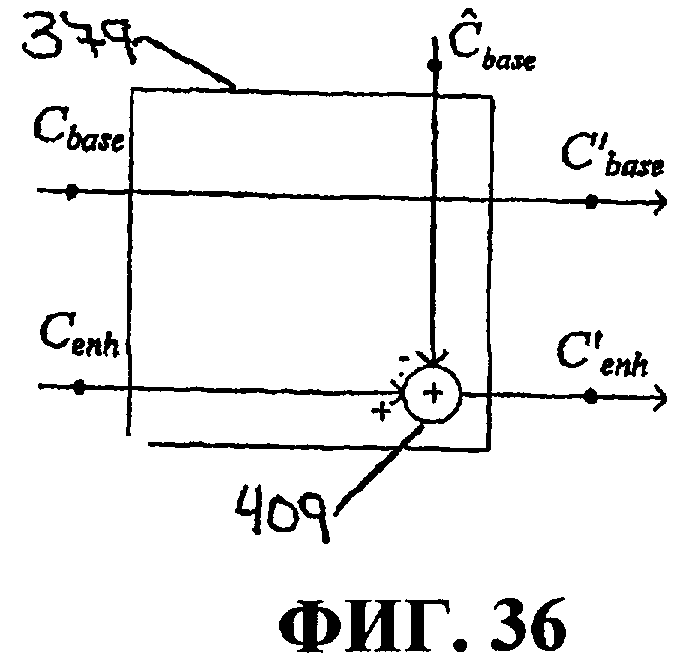
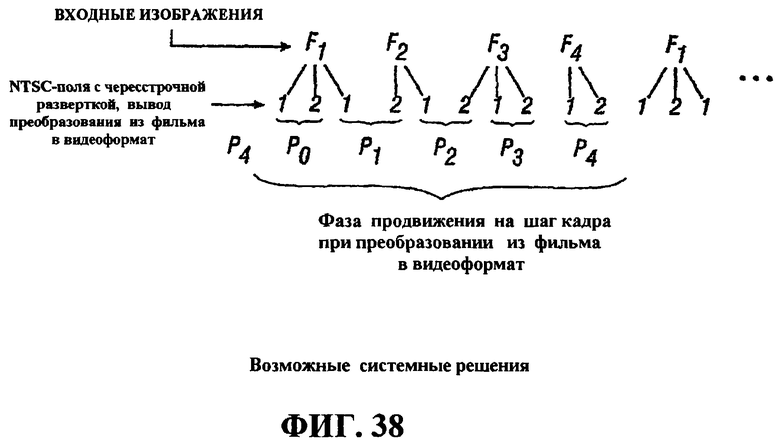
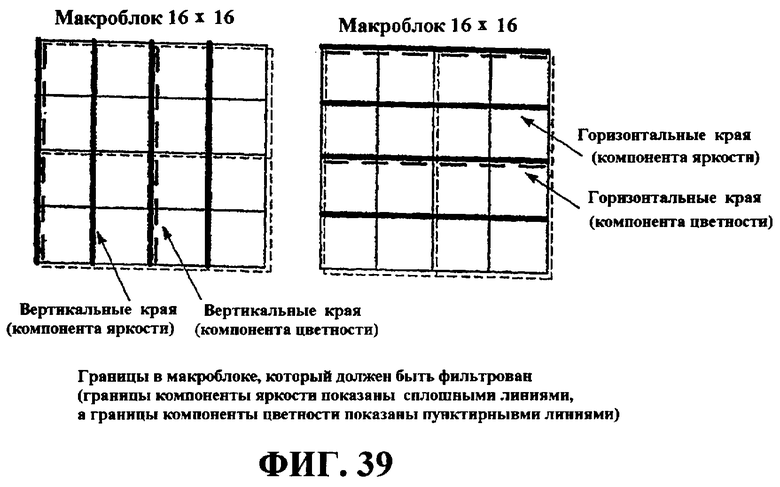
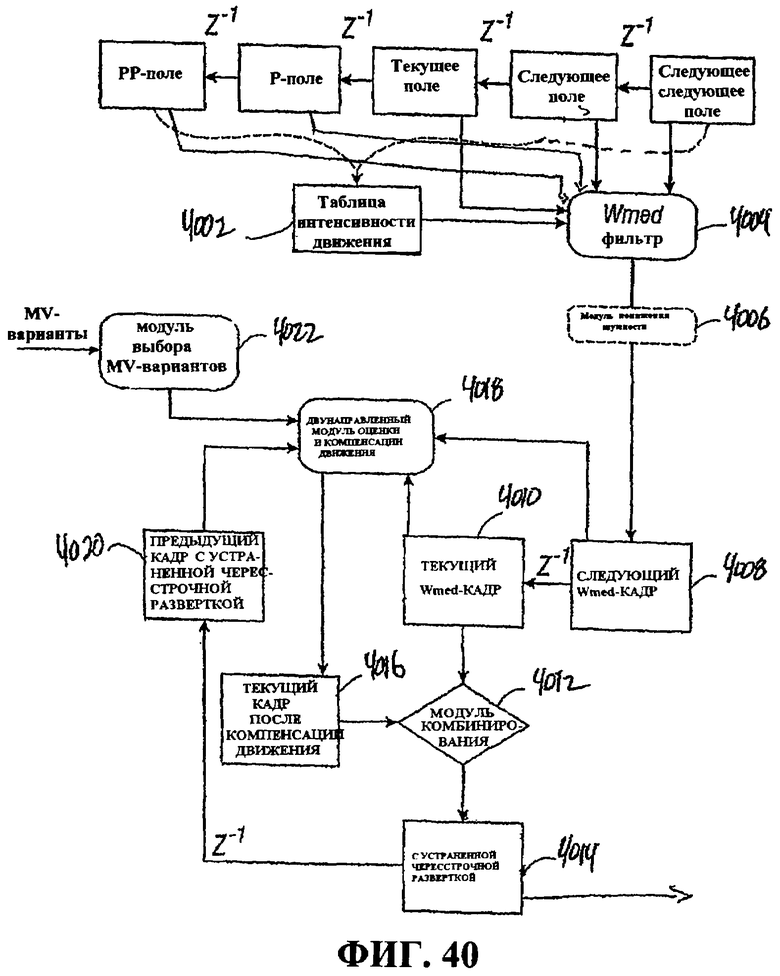
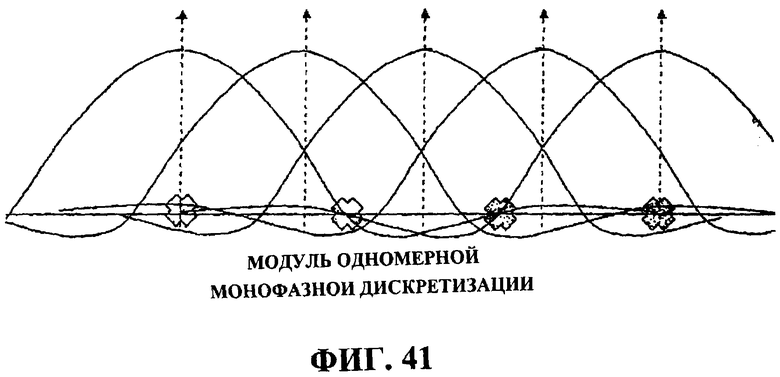
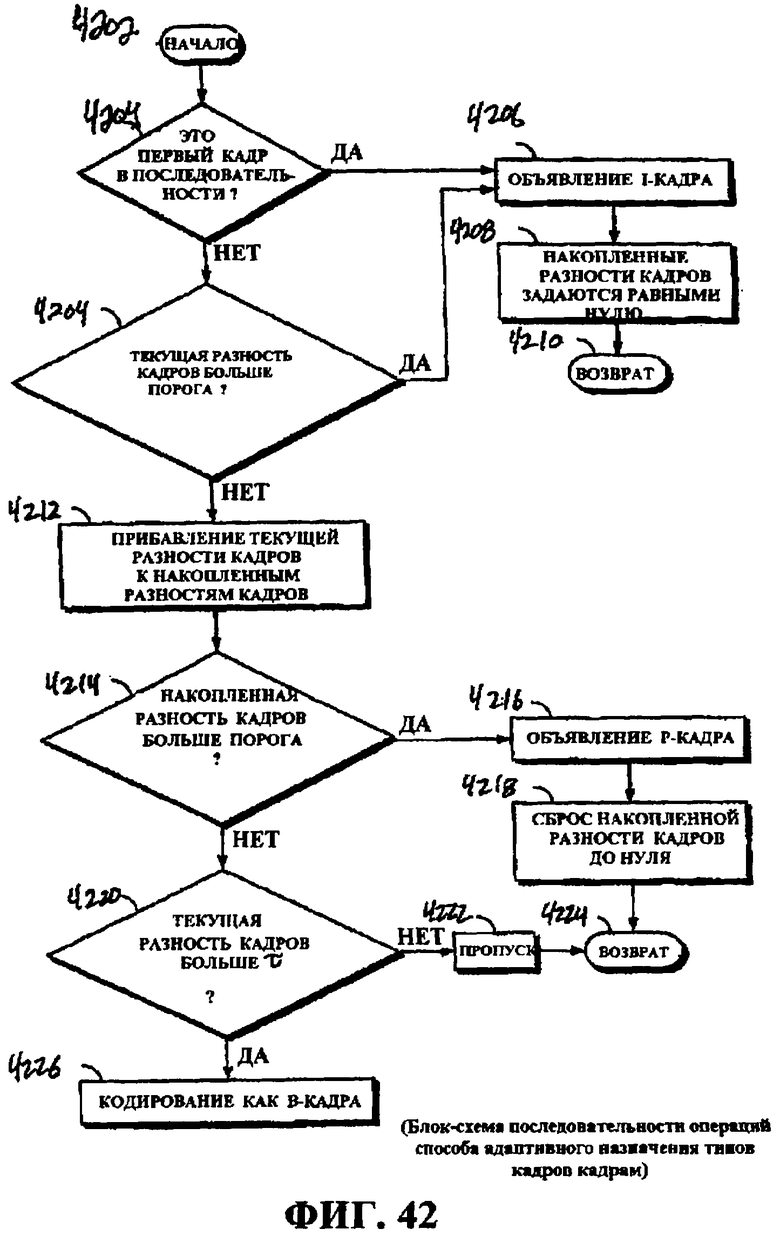
Изобретение относится к устройствам перекодирования видеоданных для потоковой передачи в реальном времени, и в частности, к перекодированию видеоданных для потоковой передачи в реальном времени в мобильном широковещательном приложении. Техническим результатом является создание транскодера, который предоставляет высокоэффективную обработку и сжатие мультимедийных данных, который использует информацию, определенную из самих мультимедийных данных, и является масштабируемым и устойчивым к ошибкам для применения во множестве приложений мультимедийных данных. Предложенное устройство использования информации содержимого для кодирования мультимедийных данных включает в себя модуль классификации содержимого, сконфигурированный так, чтобы классифицировать содержимое мультимедийных данных и предоставлять данные классификации содержимого, и кодер, сконфигурированный так, чтобы кодировать мультимедийные данные в первой группе данных и во второй группе данных на основе классификации содержимого, причем первая группа данных содержит коэффициент, а вторая группа данных содержит первое дифференциальное уточнение, ассоциативно связанное с коэффициентом первой группы данных. 5 н. и 44 з.п. ф-лы, 42 ил.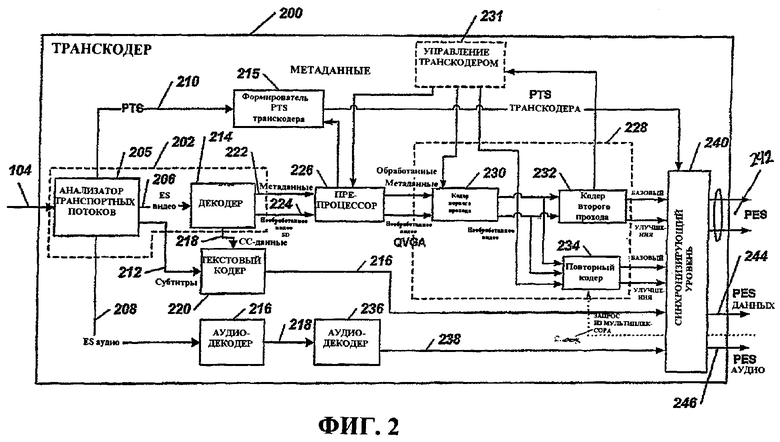
1. Способ кодирования мультимедийных данных, содержащий этапы, на которых: классифицируют содержимое мультимедийных данных; секционируют мультимедийные данные на первую группу данных и вторую группу данных, основываясь на классификации содержимого, при этом секционирование определяется в соответствии с коэффициентом полосы пропускания; и кодируют мультимедийные данные в первой группе данных и во второй группе данных на основе секционирования, причем количество информации в первой группе данных по отношению к количеству информации во второй группе данных соответствует коэффициенту полосы пропускания.
2. Способ по п.1, в котором первая группа данных содержит коэффициент, а вторая группа данных содержит первое дифференциальное уточнение, ассоциативно связанное с коэффициентом первой группы данных.
3. Способ по п.1, в котором упомянутое кодирование содержит этап, на котором определяют скорость передачи битов на основе классификации содержимого мультимедийных данных и кодируют мультимедийные данные на основе скорости передачи битов.
4. Способ по п.1, в котором классификация содержимого содержит этап, на котором определяют сложность мультимедийных данных.
5. Способ по п.4, в котором сложность содержит временную сложность или пространственную сложность.
6. Способ по п.4, в котором сложность содержит временную сложность и пространственную сложность.
7. Способ по п.1, в котором кодирование содержит этап, на котором кодируют мультимедийные данные так, чтобы обеспечить декодирование только первой группы данных или первой группы данных и второй группы данных в одну комбинированную группу данных.
8. Способ по п.1, в котором первое дифференциальное уточнение указывает разницу между выбранным видеокадром и данными кадра, вытекающими из декодирования первой группы данных.
9. Способ по п.1, в котором первая группа данных - это базовый уровень, а вторая группа данных - это уровень улучшения.
10. Способ по п.9, дополнительно содержащий этапы, на которых: выбирают коэффициент из одного из коэффициента остаточной ошибки исходного базового уровня и коэффициента остаточной ошибки исходного уровня улучшения; и вычисляют первое дифференциальное уточнение на основе упомянутого коэффициента и коэффициента остаточной ошибки исходного уровня улучшения.
11. Способ по п.1, в котором кодирование дополнительно содержит этап, на котором кодируют информацию заголовков макроблоков и информацию вектора движения в первой группе данных.
12. Способ по п.1, в котором кодирование дополнительно содержит этап, на котором квантуют первую группу данных с первым размером шага и квантуют вторую группу данных со вторым размером шага, при этом первый размер шага и второй размер шага соотносятся посредством коэффициента масштабирования.
13. Способ по п.1, в котором кодирование дополнительно содержит этап, на котором определяют первый параметр квантования, имеющий первый размер шага квантования, для использования при кодировании первой группы данных и определяют второй параметр квантования, имеющий второй размер шага квантования, для использования при кодировании второй группы данных, при этом первый и второй параметры квантования определяются на основе информации содержимого выбранных данных кадра и при этом упомянутый первый размер шага квантования более грубый, чем упомянутый второй размер шага квантования.
14. Способ по п.1, в котором кодирование содержит этап, на котором кодируют первую группу данных с помощью I-кадров и P-кадров либо любой их комбинации и кодируют вторую группу данных с помощью I-кадров, P-кадров и В-кадров либо любой их комбинации.
15. Устройство для кодирования мультимедийных данных, содержащее: средство классификации содержимого мультимедийных данных; средство секционирования мультимедийных данных на первую группу данных и вторую группу данных, основываясь на классификации содержимого, при этом секционирование определяется в соответствии с коэффициентом полосы пропускания; средство кодирования мультимедийных данных в первой группе данных и во второй группе данных на основе секционирования, причем количество информации в первой группе данных по отношению к количеству информации во второй группе данных соответствует коэффициенту полосы пропускания.
16. Устройство по п.15, в котором первая группа данных содержит коэффициент, а вторая группа данных содержит первое дифференциальное уточнение, ассоциативно связанное с коэффициентом первой группы данных.
17. Устройство по п.15, в котором упомянутое средство для кодирования содержит средство определения скорости передачи битов на основе классификации содержимого мультимедийных данных и кодирования мультимедийных данных на основе скорости передачи битов.
18. Устройство по п.15, в котором упомянутое средство классификации содержимого содержит средство определения сложности мультимедийных данных, при этом выбранные мультимедийные данные кодируются на основе сложности мультимедийных данных.
19. Устройство по п.18, в котором сложность содержит временную сложность или пространственную сложность.
20. Устройство по п.18, в котором сложность содержит временную сложность и пространственную сложность.
21. Устройство по п.15, в котором упомянутое средство кодирования содержит средство кодирования мультимедийных данных так, чтобы обеспечить декодирование только первой группы данных или первой группы данных и второй группы данных в одну комбинированную группу данных.
22. Устройство по п.16, в котором первое дифференциальное уточнение указывает разность между выбранным видеокадром и данными кадра, вытекающими из декодирования первой группы данных.
23. Устройство по п.16, в котором первая группа данных - это базовый уровень, а вторая группа данных - это уровень улучшения.
24. Устройство по п.15, в котором средство кодирования содержит средство кодирования информации заголовков макроблоков и информации вектора движения в первой группе данных.
25. Устройство по п.15, в котором упомянутое средство кодирования дополнительно содержит средство квантования первой группы данных с первым размером шага и квантования второй группы данных со вторым размером шага, при этом первый размер шага и второй размер шага соотносятся посредством коэффициента масштабирования.
26. Устройство по п.15, в котором упомянутое средство кодирования содержит средство определения первого параметра квантования, имеющего первый размер шага квантования, для использования при кодировании первой группы данных и определения второго параметра квантования, имеющего второй размер шага квантования, для использования при кодировании второй группы данных, при этом первый и второй параметры квантования определяются на основе информации содержимого выбранных данных кадра и при этом упомянутый первый размер шага квантования более грубый, чем упомянутый второй размер шага квантования.
27. Устройство по п.15, в котором упомянутое средство кодирования содержит: средство кодирования первой группы данных с помощью I-кадров и P-кадров; и средство кодирования второй группы данных с помощью I-кадров, P-кадров и В-кадров.
28. Устройство по п.23, в котором упомянутое средство кодирования содержит: средство выбора коэффициента из одного из коэффициента остаточной ошибки исходного базового уровня и коэффициента остаточной ошибки исходного уровня улучшения; и средство вычисления первого дифференциального уточнения на основе упомянутого коэффициента и коэффициента остаточной ошибки исходного уровня улучшения.
29. Устройство для кодирования мультимедийных данных, содержащее: модуль классификации содержимого, сконфигурированный так, чтобы классифицировать содержимое мультимедийных данных и предоставлять данные классификации содержимого; модуль секционирования, который секционирует мультимедийные данные на первую группу данных и вторую группу данных, основываясь на классификации содержимого, при этом секционирование определяется в соответствии с коэффициентом полосы пропускания; и кодер, сконфигурированный для кодирования мультимедийных данных в первой группе данных и во второй группе данных на основе секционирования, причем количество информации в первой группе данных по отношению к количеству информации во второй группе данных соответствует коэффициенту полосы пропускания.
30. Устройство по п.29, в котором первая группа данных содержит коэффициент, а вторая группа данных содержит первое дифференциальное уточнение, ассоциативно связанное с коэффициентом первой группы данных.
31. Устройство по п.29, в котором кодер содержит компонент скорости передачи битов, сконфигурированный так, чтобы определять назначение битов на основе классификации содержимого, при этом компонент кодирования дополнительно сконфигурирован так, чтобы кодировать выбранные мультимедийные данные с помощью назначения битов.
32. Устройство по п.29, в котором классификация содержимого содержит определение сложности мультимедийных данных, при этом выбранные мультимедийные данные кодируются на основе сложности мультимедийных данных.
33. Устройство по п.32, в котором сложность содержит временную сложность или пространственную сложность.
34. Устройство по п.32, в котором сложность содержит временную сложность и пространственную сложность.
35. Устройство по п.29, в котором кодирование содержит кодирование мультимедийных данных так, чтобы обеспечить декодирование только первой группы данных или первой группы данных и второй группы данных в одну комбинированную группу данных.
36. Устройство по п.30, в котором первое дифференциальное уточнение указывает разность между выбранным видеокадром и данными кадра, вытекающими из декодирования первой группы данных.
37. Устройство по п.29, в котором первая группа данных - это базовый уровень, а вторая группа данных - это уровень улучшения.
38. Машиночитаемый носитель, содержащий инструкции, которые при исполнении инструктируют машине: классифицировать содержимое мультимедийных данных; секционировать мультимедийные данные на первую группу данных и вторую группу данных, основываясь на классификации содержимого, при этом секционирование определяется в соответствии с коэффициентом полосы пропускания; и кодировать мультимедийные данные в первой группе данных и во второй группе данных на основе секционирования, причем количество информации в первой группе данных по отношению к количеству информации во второй группе данных соответствует коэффициенту полосы пропускания.
39. Машиночитаемый носитель по п.38, в котором первая группа данных содержит коэффициент, а вторая группа данных содержит первое дифференциальное уточнение, ассоциативно связанное с коэффициентом первой группы данных.
40. Машиночитаемый носитель по п.38, в котором инструкции, чтобы кодировать, содержат инструкции, чтобы определять назначение битов на основе классификации содержимого, при этом компонент кодирования дополнительно сконфигурирован так, чтобы кодировать выбранные мультимедийные данные с помощью назначения битов.
41. Машиночитаемый носитель по п.38, в котором классификация содержимого содержит определение сложности мультимедийных данных, при этом выбранные мультимедийные данные кодируются на основе сложности мультимедийных данных.
42. Машиночитаемые инструкции по п.41, в которых сложность содержит временную сложность или пространственную сложность.
43. Машиночитаемые инструкции по п.41, в которых сложность содержит временную сложность и пространственную сложность.
44. Процессор, сконфигурированный так, чтобы: классифицировать содержимое мультимедийных данных; секционировать мультимедийные данные на первую группу данных и вторую группу данных, основываясь на классификации содержимого, при этом секционирование определяется в соответствии с коэффициентом полосы пропускания; и кодировать мультимедийные данные в первой группе данных и во второй группе данных на основе секционирования, причем количество информации в первой группе данных по отношению к количеству информации во второй группе данных соответствует коэффициенту полосы пропускания.
45. Процессор по п.44 в котором первая группа данных содержит коэффициент, а вторая группа данных содержит первое дифференциальное уточнение, ассоциативно связанное с коэффициентом первой группы данных.
46. Процессор по п.44, при этом процессор дополнительно сконфигурирован так, чтобы определять назначение битов на основе классификации содержимого, при этом компонент кодирования дополнительно сконфигурирован так, чтобы кодировать выбранные мультимедийные данные с помощью назначения битов.
47. Процессор по п.44, при этом процессор дополнительно сконфигурирован так, чтобы определять сложность мультимедийных данных, и при этом классификация содержимого основана на сложности мультимедийных данных.
48. Процессор по п.47, в котором сложность содержит временную сложность или пространственную сложность.
49. Процессор по п.47, в котором сложность содержит временную сложность и пространственную сложность.
| MIHAELA VAN DER SCHAAR et al | |||
| A Hybrid Temporal-SNR Fine-Granular Scalability for Internet Video, IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, IEEE SERVICE CENTER, PISCATAWAY, vol.11, no.3, March 2001, c.318-331 | |||
| US 2005013500 A1, 20.01.2005 | |||
| WO 03105070, 18.12.2003 | |||
| СПОСОБ И УСТРОЙСТВО СЖАТИЯ ВИДЕОИНФОРМАЦИИ | 1997 |
|
RU2209527C2 |
| RUSERT T | |||
| et al | |||
| Enhanced interframe | |||

