Область техники к которой относится изобретение
Настоящее изобретение относится, в целом, к протоколам связи в одноранговой инфраструктуре и, в частности, структурам данных формата сообщения, обеспечивающим структурированную связь в одноранговом графе.
Предшествующий уровень техники
Различные технологии связи в Интернете позволяют пользователям с общими интересами сотрудничать, совместно использовать файлы, осуществлять интерактивную переписку, передавать в многоадресном режиме аудио- и видеоинформацию для презентаций и групповых встреч и участвовать в играх для множества игроков. Однако в настоящее время связь в Интернете осуществляется, в основном, в централизованной среде с серверами, где весь трафик идет на большие центральные серверы или через них, с которыми индивидуумы могут соединяться для участия в этой связи.
С повторным появлением технологии равноправных устройств современная модель связи в Интернете на основе серверов быстро вытесняется. Действительно, технологии равноправных устройств позволяют пользователям связываться друг с другом в бессерверной среде, свободной от ограничений связи в Интернете на основе серверов. В системе на основе равноправных устройств можно обеспечивать анонимность и приватность пользователей, поскольку связь осуществляется непосредственно между равноправными устройствами в сети. Однако, хотя индивидуальная связь и совместное использование файлов относительно хорошо развиты в одноранговых сетях, установление, обнаружение, подключение, поддержание и совместное использование информации в среде равноправных устройств не столь хорошо развиты.
Связь между равноправными устройствами и, фактически, все типы связи зависят от возможности установления правильных соединений между избранными объектами или узлами. Эти объекты или узлы могут представлять собой равноправные устройства (т.е. пользователи или машины) или группы, сформированные в сети равноправных устройств. Соединения между узлами образуют одноранговый граф, который позволяет осуществлять связь и передавать информацию на узлы и между ними. Однако объекты могут иметь один или несколько адресов, которые, могут изменяться по причине перемещения этих объектов в сети, изменения топологии, отсутствия возможности возобновления пользования адресом, изменения функции или цели группы и т.д. Классическое архитектурное решение для решения этой проблемы состоит в том, что каждому объекту присваивают неизменяемое имя и «разрешают» это имя относительно текущего адреса, когда необходимо соединение. Это преобразование имени в адрес может быть очень устойчивым и также должно допускать простые и быстрые обновления.
Для повышения вероятности нахождения адреса объекта теми, кто стремится связаться с ним, многие протоколы соединения равноправных устройств позволяют объектам объявлять свой(и) индивидуальный(е) или групповой(ые) адрес(а) с помощью различных механизмов. Некоторые протоколы могут позволять клиенту узнавать адреса других объектов посредством обработки запросов от других присутствующих в сети. Действительно, именно это получение адреса обеспечивает успешную работу одноранговых сетей за счет поддержания устойчивого графа. То есть, чем лучше информация о других равноправных устройствах и группах в сети (т.е. чем более устойчив граф), тем выше вероятность того, что поиск конкретного ресурса или записи увенчается успехом.
Как и в централизованной среде с серверами, одноранговые графы могут быть полностью открытыми, что допускает поиск файлов в Интернете и совместное использование их в графе. Однако, поскольку одноранговые сети сформированы в виде графа распределенных пользователей или равноправных узлов, необходимо, чтобы связь и данные (записи) передавались от одного равноправного устройства к другому до того, как все равноправные устройства в сети смогут получить совместно используемую информацию. Системы, которые обеспечивают такую маршрутизацию, включают в себя Usenet и OSPF. Однако такие современные системы подвержены ограничениям, которые, на сегодняшний день, сдерживают развитие технологии связи между равноправными устройствами. Кроме того, для одноранговых сетей в настоящее время характерно недостаточно адекватное управление графом, которое временами допускает «разрыв» или расщепление графов, когда один из членов покидает группу. В таком случае информация от одной части графа может уже не передаваться равноправным членам по другую сторону раздела, созданного выбытием одного из равноправных устройств. Еще один недостаток состоит в отсутствии адекватного механизма обнаружения такого раздела.
Помимо функциональных проблем, присущих уровню техники, объем сетевого трафика может легко перегружать равноправные устройства, участвующие в облаке. Размер и структура сообщения уменьшают способность равноправных устройств к быстрой обработке сообщений и приводит к задержкам или обрывам связи с ростом облака.
Поэтому уровень техники испытывает необходимость в протоколе обмена сообщениями между равноправными устройствами и в структуре данных, которые решают вышеописанные и другие проблемы, существующие в технике.
Сущность изобретения
Концепции изобретения, раскрытые в данной заявке, предусматривают расширяемую структуру данных для сообщений, пригодную для использования в протоколе разрешения имен для соединения равноправных устройств. Эта структура данных сообщения использует поля данных сообщения для построения различных сообщений, используемых в PNRP. Каждое поле данных сообщения содержит элемент сообщения. Предпочтительно первое поле является элементом заголовка сообщения, который содержит информацию протокола и идентифицирует тип сообщения.
Как и сами сообщения, каждый элемент сообщения содержит ряд полей данных элемента сообщения. Эти поля элемента сообщения включают в себя поле типа, поле длины и содержимое или полезную нагрузку элемента сообщения. Поле типа включает в себя идентификатор, который обозначает тип элемента сообщения. Поле длины определяет длину элемента сообщения, включая поля типа поля и длины.
В одном варианте осуществления для правильной работы протокола разрешения имен для соединения равноправных устройств (PNRP) формируются по меньшей мере десять сообщений. Эти десять сообщений включают в себя сообщение RESOLVE («разрешение»), сообщение RESPONSE («ответ»), сообщение SOLICIT («ходатайство»), сообщение ADVERTISE («объявление»), сообщение REQUEST («запрос»), сообщение FLOOD («распространение»), сообщение INQUIRE («вопрос»), сообщение AUTHORITY («полномочие»), сообщение ACK («квитирование») и сообщение REPAIR («исправление»). Эти сообщения построены из двадцати двух разных элементов сообщения, существующих в предпочтительном варианте осуществления.
Перечень чертежей
Прилагаемые чертежи, включенные в описание изобретения и составляющие его часть, иллюстрируют некоторые аспекты настоящего изобретения и, совместно с описанием, служат для объяснения принципов изобретения.
На чертежах:
фиг.1 - обобщенная блок-схема иллюстративной компьютерной системы, на которой базируется настоящее изобретение;
фиг.2 - упрощенная блок-схема функциональных элементов протокола разрешения имен для соединения равноправных устройств (PNRP);
фиг.3 - схема обмена сообщениями протокола, иллюстрирующая один аспект настоящего изобретения;
фиг.4 - схема обмена сообщениями протокола, иллюстрирующая другой аспект настоящего изобретения;
фиг.5 - схема структуры данных, иллюстрирующая модель расширяемой структуры данных, отвечающей настоящему изобретению, которая позволяет строить сообщения, согласно настоящему изобретению;
фиг.6 - упрощенная схема структуры данных, иллюстрирующая конструкцию иллюстративного сообщения, отвечающего настоящему изобретению.
Хотя изобретение описано применительно к определенным предпочтительным вариантам осуществления, эти варианты осуществления не следует рассматривать в порядке ограничения. Напротив, предполагается охват всех альтернатив, модификаций и эквивалентов, отвечающих сущности и объему изобретения, заданным прилагаемой формулой изобретения.
Подробное описание изобретения
На чертежах, где одинаковые элементы обозначены одинаковыми ссылочными позициями, проиллюстрирована реализация изобретения в подходящей вычислительной среде. Хотя это и не требуется, изобретение описано в общем контексте машиноисполняемых команд, например программных модулей, выполняемых персональным компьютером. В целом, программные модули включают в себя процедуры, программы, объекты, компоненты, структуры данных и т.п., которые выполняют конкретные задания или реализуют определенные абстрактные типы данных. Кроме того, специалистам в данной области очевидно, что изобретение можно применять на практике к другим конфигурациям компьютерных систем, в том числе к портативным устройствам, многопроцессорным системам, программируемой бытовой электронике, в том числе на основе микропроцессора, сетевым ПК, миникомпьютерам, универсальным компьютерам и т.п. Изобретение также можно применять на практике в распределенных вычислительных средах, где задания выполняются удаленными обрабатывающими устройствами, связанными посредством сети связи. В распределенной вычислительной среде программные модули могут размещаться как в локальных, так и в удаленных устройствах хранения.
На фиг.1 показан пример подходящей среды 100 вычислительной системы, в которой можно реализовать изобретение. Среда 100 вычислительной системы является всего лишь примером подходящего вычислительного устройства и не призвана как-либо ограничивать объем использования или функциональные возможности изобретения. Также, среду 100 вычислительной системы не следует рассматривать как имеющую какую-либо зависимость или требование в отношении к какому-либо одному компоненту, проиллюстрированному в иллюстративной операционной среде 100, или их комбинации.
Изобретение применимо ко многим другим средам или конфигурациям вычислительной системы общего или специального назначения. Примеры общеизвестных вычислительных систем, сред и/или конфигураций, которые могут быть пригодны для использования в соответствии с изобретением, включают в себя, но не в ограничительном смысле, персональные компьютеры, компьютеры-серверы, карманные или портативные устройства, многопроцессорные системы, системы на основе микропроцессора, телевизионные приставки, программируемую бытовую электронику, сетевые ПК, универсальные компьютеры, распределенные вычислительные среды, которые включают в себя любые из вышеперечисленных систем или устройств, и т.п.
Изобретение можно описать в общем контексте машиноисполняемых команд, например программных модулей, выполняемых компьютером. В целом, программные модули включают в себя процедуры, программы, объекты, компоненты, структуры данных и т.п., которые выполняют конкретные задания или реализуют определенные абстрактные типы данных. Изобретение также можно применять на практике в распределенных вычислительных средах, где задания выполняются удаленными обрабатывающими устройствами, связанными посредством сети связи. В распределенной вычислительной среде программные модули могут размещаться как на локальных, так и на удаленных компьютерных носителях данных, включая запоминающие устройства.
Согласно фиг.1 иллюстративная система для реализации изобретения включает в себя вычислительное устройство общего назначения в виде компьютера 110. Компоненты компьютера 110 могут включать в себя, но не в ограничительном смысле, процессор 120, системную память 130 и системную шину 121, которая подключает различные компоненты системы, включая системную память, к процессору 120. Системная шина 121 может относиться к любому из нескольких типов шинных структур, включая шину памяти или контроллер памяти, периферийную шину и локальную шину, с использованием разнообразных шинных архитектур. В порядке примера, но не ограничения, такие архитектуры включают в себя шину архитектуры промышленного стандарта (ISA), шину микроканальной архитектуры (MCA), шину расширенного стандарта ISA (EISA), локальную шину Ассоциации по стандартам в области видеоэлектроники (VESA) и шину подключений периферийных компонентов (PCI), также именуемую шиной расширения.
Компьютер 110 обычно содержит разнообразные машиночитаемые носители. Машиночитаемые носители могут представлять собой любые имеющиеся носители, к которым может осуществлять доступ компьютер 110, и включают в себя энергозависимые и энергонезависимые носители, сменные и стационарные носители. В порядке примера, но не ограничения, машиночитаемый носитель может представлять собой компьютерный носитель данных или среду передачи данных. Компьютерные носители данных включают в себя энергозависимые и энергонезависимые, сменные и стационарные носители, реализованные посредством любого способа или технологии для хранения информации, например машиночитаемых команд, структур данных, программных модулей или других данных. Компьютерные носители данных включают в себя, но не в ограничительном смысле, ОЗУ, ПЗУ, электрически стираемые программируемые ПЗУ, флэш-память или память другой технологии, CD-ROM, цифровые универсальные диски (DVD) или иные оптические дисковые носители данных, магнитные кассеты, магнитную ленту, магнитные дисковые носители данных или иные магнитные запоминающие устройства или любой другой носитель, который можно использовать для хранения полезной информации и к которому компьютер 110 может осуществлять доступ. Среды передачи данных обычно воплощают машиночитаемые команды, структуры данных, программные модули или другие данные в виде сигнала, модулированного данными, такими как несущая волна или иной транспортный механизм. Среды передачи данных также включают в себя любые среды доставки информации. Термин «сигнал, модулированный данными» означает сигнал, одна или несколько характеристик которого изменены так, чтобы кодировать информацию в этом сигнале. В порядке примера, но не ограничения, среды передачи данных содержат проводные среды, например проводную сеть или прямое проводное соединение, и беспроводные среды, например акустические, радиочастотные, инфракрасные и другие беспроводные среды. В число машиночитаемых носителей также включены комбинации любых из вышеперечисленных позиций.
Системная память 130 содержит компьютерные носители данных в виде энергозависимой и/или энергонезависимой памяти, например постоянной памяти (ПЗУ) 131 и оперативной памяти (ОЗУ) 132. Базовая система ввода/вывода (BIOS) 133, содержащая основные процедуры, которые помогают переносить информацию между элементами компьютера 110, например при запуске, хранится в ПЗУ 131. ОЗУ 132 обычно содержит данные и/или программные модули, которые оперативно доступны процессору 120 и/или в данный момент обрабатываются им. В порядке примера, но не ограничения, на фиг.1 показаны операционная система 134, прикладные программы 135, другие программные модули 136 и данные 137 программ.
Компьютер 110 может также включать в себя другие сменные/стационарные, энергозависимые/энергонезависимые компьютерные носители данных. В порядке примера, на фиг.1 показан носитель 141 на жестких дисках, который производит считывание со стационарного энергонезависимого магнитного носителя и запись на него, дисковод 151 для магнитного диска, который производит считывание со сменного энергонезависимого магнитного диска 152 и запись на него, и дисковод 155 для оптического диска, который производит считывание со сменного энергонезависимого оптического диска 156, например CD-ROM или другого оптического носителя, и запись на него. Другие сменные/стационарные, энергозависимые/энергонезависимые компьютерные носители данных, которые можно использовать в иллюстративной операционной среде, включают в себя, но не в ограничительном смысле, кассеты с магнитной лентой, карты флэш-памяти, цифровые универсальные диски, ленту для цифрового видео, твердотельные ОЗУ, твердотельное ПЗУ и т.д. Накопитель 141 на жестких дисках обычно подключен к системной шине 121 посредством интерфейса стационарной памяти, например интерфейса 140, а дисковод 151 для магнитного диска и дисковод 155 для оптического диска обычно подключены к системной шине 121 посредством интерфейса сменной памяти, например, интерфейса 150.
Накопители и дисководы и соответствующие компьютерные носители данных, описанные выше и показанные на фиг.1, обеспечивают хранение машиночитаемых команд, структур данных, программных модулей и других данных для компьютера 110. Например, на фиг.1 показано, что в накопителе 141 на жестких магнитных дисках хранятся операционная система 144, прикладные программы 145, другие программные модули 146 и данные 147 программ. Заметим, что эти компоненты могут быть идентичны операционной системе 134, прикладным программам 135, другим программным модулям 136 и данным 137 программ или отличны от них. Операционная система 144, прикладные программы 145, другие программные модули 146 и данные 147 программ обозначены здесь иными позициями, чтобы показать, что они, как минимум, представляют собой другие копии. Пользователь может вводить команды и информацию в компьютер 110 через устройства ввода, например клавиатуру 162 и указательное устройство 161, под которым обычно понимают мышь, шаровой манипулятор или сенсорную панель. Другие устройства ввода (не показаны) могут включать в себя микрофон, джойстик, игровую панель, спутниковую антенну, сканер и т.п. Эти и другие устройства ввода часто подключают к процессору 120 через интерфейс 160 пользовательского ввода, который подключен к системной шине, но можно подключать посредством других структур интерфейса и шины, например параллельного порта, игрового порта или универсальной последовательной шины (USB). Монитор 191 или устройство отображения другого типа может также быть подключен к системной шине 121 через интерфейс, например видеоинтерфейс 190. Помимо монитора, компьютеры могут содержать другие периферийные устройства вывода, например громкоговорители 197 и принтер 196, которые могут быть подключены через периферийный интерфейс 195 вывода.
Компьютер 110 может работать в сетевой среде с использованием логических соединений с одним или несколькими удаленными компьютерами, например удаленным компьютером 180. В качестве удаленного компьютера 180 может выступать другой персональный компьютер, сервер, маршрутизатор, сетевой ПК, равноправное устройство или другой общий сетевой узел, который обычно содержит многие или все элементы, описанные выше применительно к персональному компьютеру 110, хотя на фиг.1 показано только запоминающее устройство 181. Логические соединения, указанные на фиг.1, включают в себя локальную сеть (ЛС, LAN) 171 и глобальную сеть (ГС, WAN) 173, но также могут включать в себя другие сети. Такие сетевые среды обычно используются в офисах, компьютерных сетях масштаба предприятия, интрасетях и в Интернете.
При использовании в сетевой среде ЛС персональный компьютер 110 подключен к локальной сети 171 через сетевой интерфейс или адаптер 170. При использовании в сетевой среде ГС компьютер 110 обычно содержит модем 172 или другие средства установления соединения через ГС 173, такие как Интернет. Модем 172, который может быть внутренним или внешним, может быть подключен к системной шине 121 через интерфейс 160 пользовательского ввода или другой соответствующий механизм. В сетевой среде программные модули, указанные в отношении персонального компьютера 110, или часть из них могут храниться в удаленном запоминающем устройстве. В порядке примера, но не ограничения, на фиг.1 показано, что удаленные прикладные программы 185 размещены в запоминающем устройстве 181. Очевидно, что показанные сетевые соединения являются иллюстративными и что можно использовать другие средства установления линии(й) связи между компьютерами.
Ниже изобретение будет описано со ссылкой на действия и символические представления операций, которые выполняются одним или несколькими вычислительными устройствами, если не указано обратное. При этом следует понимать, что такие действия и операции, которые иногда называют машиноисполняемыми, включают в себя манипуляции, выполняемые процессором компьютера в отношении электрических сигналов, представляющих данные в структурированной форме. Эти манипуляции сводятся к преобразованию данных или поддержанию их в ячейках системы памяти компьютера, в результате чего происходит переконфигурирование или иное изменение работы компьютера путем, хорошо известным специалистам в данной области. Структуры данных, где поддерживаются данные, являются физическими ячейками памяти, которые имеют конкретные свойства, заданные форматом данных. Однако, хотя изобретение описано в вышеприведенном контексте, это не означает, и это очевидно специалистам в данной области, что некоторые из описанных ниже действий и операций не могут также быть реализованы в аппаратных средствах.
Согласно вышесказанному успех протокола связи между равноправными устройствами (Р2Р) зависит от способности протокола устанавливать правильные соединения между выбранными объектами. Аналогично, формирование групп в такой сети Р2Р опирается на эту способность. Поскольку конкретный пользователь может подключаться к сети различными способами в разных местах, имеющих разные адреса, предпочтительный подход состоит в присвоении пользователю или группе уникального идентификатора с последующим разрешением этого идентификатора относительно конкретного адреса или адресов посредством протокола. Такой протокол разрешения имен для соединения равноправных устройств (PNRP), в частности применяемый в системе и способе управления идентификацией, описан в совместно рассматриваемой заявке №09/942,164, озаглавленной «Peer-To-Peer Name Resolution Protocol (PNRP) And Multilevel Cache For Use Therewith», поданной 29 августа 2001 г., в совместно рассматриваемой заявке №10/122,863, озаглавленной «Multilevel Cache Architecture and Cache Management Method for Peer-To-Peer Name Resolution Protocol», поданной 15 апреля 2002 г., и в совместно рассматриваемой заявке №09/955,923, озаглавленной «Peer-To-Peer Group Management and Method for Maintaining Peer-To-Peer Graphs», поданной 19 сентября 2001 г., идеи и содержание которых включены в данное описание во всей полноте посредством ссылки.
Аналогично, в совместно рассматриваемой заявке №09/956,260, озаглавленной «Peer-To-Peer Name Resolution Protocol (PNRP) Security Infrastructure And Method», поданной 19 сентября 2001 г., описана лежащая в основе инфраструктура защиты, которая позволяет гарантировать действительность идентификаторов различных сетевых объектов, не обременяя без необходимости сеть избыточным трафиком. В групповой среде Р2Р совместно рассматриваемая заявка №09/955,924, озаглавленная «Peer-To-Peer Name Resolution Protocol (PNRP) Group Security Infrastructure And Method», поданная 19 сентября 2001 г., описывает лежащую в основе инфраструктуру защиты, используемую для таких групп. Идеи и содержание этих заявок также включены в данное описание во всей полноте посредством ссылки. Однако, хотя интерфейсы и способы, отвечающие настоящему изобретению, находят конкретное применение в таком PNRP и взаимодействуют с ним, специалистам в данной области очевидно, что настоящее изобретение не ограничивается этим, но применимо к любой системе Р2Р или протоколу, который желает обеспечить функции управления графом Р2Р.
Согласно рассмотренному во включенной выше совместно рассматриваемой заявке, описывающей PNRP, и чтобы обеспечить некоторые полезные исходные сведения протокол разрешения имен для соединения равноправных объектов (PNRP) является протоколом разрешения имени относительно адреса на основе равноправных устройств. Ресурсы равноправного устройства могут быть представлены «именем равноправного устройства» (Peer Name). Приложение может регистрировать «имя равноправного устройства» с помощью PNRP, чтобы другие равноправные устройства могли обнаружить его. Другие приложения могут использовать PNRP для разрешения «имени равноправного устройства», чтобы получить соответствующий IP-адрес и порт регистрирующего приложения. PNRP не обеспечивает никакого механизма отыскания или просмотра «имен равноправных устройств». Механизм распространения «имен равноправных устройств» должен осуществляться другими средствами. Разрешение «имен равноправных устройств» относительно адресов осуществляется за счет того, что участвующие равноправные устройства кооперируются в пересылке сообщений друг другу, и за счет поддержания распределенного кэша отображений «имени равноправного устройства» в адрес. Механизм регистрации и разрешения не опирается на существование серверов, за исключением инициализации. При первом появлении экземпляра PNRP ему нужно найти адрес каких-либо других экземпляров PNRP для обмена данными с ними. В отсутствие других средств, для получения списка других экземпляров PNRP, используются общеизвестные серверы.
Другими словами, PNRP позволяют приложениям равноправных устройств регистрировать отображение «имени равноправного устройства» в конечную точку и разрешать «имя равноправного устройства» для получения конечной точки. Теперь будут уместны некоторые определения. «Имя равноправного устройства» (Peer Name) - это строка, идентифицирующая ресурс равноправного устройства. Для регистрации «имени равноправного устройства» приложение должно иметь доступ к паре открытого/секретного ключей. Пара ключей используется для подписания некоторых сообщений во избежание фальсификации. «Имя равноправного устройства» можно также извлечь из открытого ключа, чтобы обеспечить проверку принадлежности идентификатора. Конечная точка представляет собой один адрес, порт и протокол IPv6/IPv4. В действительности список конечных точек можно зарегистрировать с одним «именем равноправного устройства», и этот список возвращается при разрешении «имени равноправного устройства». Узел является экземпляром службы протокола PNRP. Обычно на компьютер приходится один узел. Облако представляет собой сеть узлов, доступных друг для друга. Один узел может быть подключен к более чем одному облаку. Облако имеет свойство области действия, которое эквивалентно областям действия, заданным в IPv6 - «глобальная» (Global), «пространственно-локальная» (Site Local) и «канально-локальная» (Link Local). Узел может иметь несколько пространственно-локальных облаков и несколько канально-локальных облаков. Связь между узлами никогда не должна проходить от одного облака к другому. Для различения облаков используются имена облаков. «Имя равноправного устройства» можно регистрировать на более чем одном узле. PNRP различает каждую регистрацию. С каждым экземпляром «имени равноправного устройства» будет связан отдельный список конечных точек. Узел также может регистрировать «имя равноправного устройства» на более чем одном облаке, к которому подключен узел. Все эти регистрации отличаются друг от друга. Обычно списки конечных точек также различаются во всех этих экземплярах. Пытаясь разрешить «имя равноправного устройства», узел делает это на выбранном облаке. Разрешение будет успешным, только если «имя равноправного устройства» зарегистрировано в том же облаке. Можно одновременно разрешать «имя равноправного устройства» на более чем одном облаке, но эти разрешения обрабатываются как независимые запросы разрешения.
Служба PNRP состоит из нескольких модулей, действующих совместно, как показано на фиг.2. Компонент 200 «управление службой» имеет дело с простыми служебными действиями, как то: запуском и остановкой службы PNRP. Сервер RPC (удаленный вызов процедуры) и суррогаты 202 обеспечивают интерфейс между клиентскими процессами и службой PNRP. Это позволяет управлять открытым интерфейсом, обеспечивая точки ввода для запросов и извещения о событиях и выполнении запроса. Они также имеют дело с восстановлением из прекращения клиентского процесса. «Средство управления (Менеджер) облаков» 204 поддерживает состояние конкретных клиентских запросов и поддерживает список имеющихся облаков PNRP. Он отвечает за создание облаков и информирование клиентов об изменениях в состояниях облаков.
«Менеджер кэша» 206 поддерживает локальный кэш PNRP и список локально зарегистрированных имен PNRP для каждого облака. Он является частью распределенного кэша PNRP. Он обеспечивает поиск и выбор следующего скачка для запросов разрешения, поступающих от других компьютеров. Он осуществляет поддержку на уровне своего собственного кэша, периодически инициируя запросы разрешения, чтобы обеспечить хорошо структурированный кэш. Он осуществляет обнаружение разрывов облаков и пытается исправить их. Он обеспечивает возможность иметь несколько зарегистрированных «идентификаторов (ИД) равноправного устройства» (Peer ID) и структурирует кэш, чтобы поддерживать каждый из них. «Менеджер протокола» 208 имеет дело с созданием и отправкой действительных сообщений PNRP и с обработкой принятых сообщений PNRP. Он действует совместно с «кэш-менеджером» 206, реализуя протокол PNRP. Наконец, «транспорт сообщений» 210 имеет дело с фактическими отправкой и приемом сообщений. Он оперирует множеством сетевых интерфейсов и адресами и обнаруживает изменения в наборе локальных адресов. Если требуется множество протоколов (IPv4 и IPv6), то этот компонент будет работать с обоими протоколами.
Каждый узел PNRP поддерживает кэш отображений «имени равноправного устройства» в конечную точку для некоторых других узлов в облаке. Осуществляется обмен сообщениями, построенными в соответствии с настоящим изобретением, между узлами для распространения информации об «именах равноправных узлов» по узлам в облаке. Каждый узел отвечает за надлежащее поддержание своего кэша. Согласно описанному в вышеупомянутых заявках, протокол PNRP задает числовое пространство имен. Каждое «имя равноправного узла» преобразуется в число, и эти числа можно сравнивать, чтобы определить степень близости в пространстве имен. При поступлении на узел запроса разрешения «имени равноправного устройства» узел может сравнить число с числами в своем кэше, чтобы найти узел, который численно ближе к нужному узлу. Таким образом, запрос разрешения переходит от узла к узлу, с каждым скачком приближаясь к своей цели.
«Имена равноправных узлов» преобразуются в 128-битовые числа, именуемые идентификаторами (ИД) Р2Р (P2P ID), с использованием хэш-функций, описанных во включенных выше заявках. Одно и то же «имя равноправного устройства» всегда порождает один и тот же ИД Р2Р. Конкретный экземпляр регистрации «имени равноправного устройства» также имеет 128-битовое число, именуемое «местоположением службы» (Service Location). Оба вместе они образуют 256-битовое число, именуемое ИД PNRP. Участок ИД PNRP, связанный с «местоположением службы», обеспечивает уникальность конкретного экземпляра регистрации «имени равноправного устройства» в сети.
Приложение может регистрировать «имя равноправного устройства» с помощью PNRP. На основе имени создается ИД PNRP, и отправляются сообщения, информирующие другие узлы о регистрации. Одно и то же «имя равноправного устройства» можно регистрировать на более чем одном узле. ИД Р2Р будет одинаковым на каждом узле, но ИД PNRP будет уникальным для каждого узла. Приложение может запрашивать разрешение «имени равноправного устройства» относительно адреса. Из «имени равноправного устройства» извлекается ИД Р2Р, и на другие узлы отправляются сообщения для определения местоположения узла, зарегистрировавшего этот ИД Р2Р. При разрешении ИД Р2Р относительно адреса возвращается сертифицированный адрес равноправного устройства (CPA). CPA включает в себя участок ИД PNRP, связанный со «местоположением службы» целевого устройства, текущий IP-адрес, открытый ключ и многие другие поля. Для предотвращения фальсификации CPA снабжается подписью.
Заданный ИД Р2Р может регистрироваться многими разными узлами. PNRP использует суффикс «местоположение службы» (Service Location), гарантирующий, что каждый зарегистрированный экземпляр имеет уникальный ИД PNRP. «Местоположение службы» - это 128-битное число, соответствующее уникальной конечной точке сетевой службы. Значение создается путем объединения адреса, порта, протокола IPv6 и части открытого ключа. «Местоположения службы» следует считать непрозрачными для клиентов PNRP. «Местоположение службы» имеет два важных свойства. В любой момент «местоположение службы» идентифицирует уникальный экземпляр «имени равноправного устройства». При сравнении двух «местоположений служб» длина их общего префикса является адекватной мерой сетевой близости. Два «местоположения служб», начинающихся с четырех одинаковых битов, обычно отстоят друг от друга не дальше, чем начинающиеся с трех одинаковых битов. Эти преимущества могут применяться только для собственных глобальных адресов IPv6 для однонаправленной передачи.
Создание и регистрация идентификаторов PNRP является только одной частью службы PNRP. Действие службы PNRP можно разделить на четыре фазы. Первая состоит в обнаружении облака PNRP. Новый узел должен найти существующий узел в облаке, к которому он желает присоединиться. Облако может быть глобальным облаком PNRP, пространственно-локальным облаком (в масштабе предприятия) или канально-локальным облаком. Вторая фаза - это присоединение к облаку PNRP. Обнаружив существующий узел, новый узел осуществляет процедуру SYNCHRONIZE («синхронизация»), чтобы получить часть верхнего уровня кэша существующих узлов. Подмножество отдельного уровня кэша предоставляет новому узлу достаточно информации, чтобы он мог начать участвовать в облаке. Третья фаза предусматривает активное участие в облаке. По завершении инициализации узел может участвовать в регистрации и разрешении ИД PNRP. На этой фазе равноправное устройство также осуществляет регулярную поддержку кэша. Конечная фаза относится к выходу равноправного устройства из облака. Узел отменяет регистрацию любых локально зарегистрированных ИД PNRP, после чего заканчивает работу.
Протокол PNRP, отвечающий настоящему изобретению, содержит десять разных типов сообщений, позволяющих выполнять различные функции PNRP. На высоком уровне эти сообщения включают в себя сообщение RESOLVE («разрешение»), которое используется для запрашивания разрешения целевого ИД PNRP относительно CPA. Сообщение RESPONSE («ответ») используется как результат выполнения запроса разрешения. Сообщение FLOOD («распространение») содержит CPA, предназначенный для кэша PNRP получателя. Сообщение SOLICIT («ходатайство») используется, чтобы просить узел PNRP «объявить» свой верхний уровень кэша. Сообщение ADVERTISE («объявление») содержит список идентификаторов (ИД) PNRP для адресов CPA в верхнем уровне кэша. Сообщение REQUEST («запрос») используется, чтобы просить узел распространить подмножество «объявленных» CPA. Сообщение INQUIRE («вопрос») используется, чтобы спрашивать узел, зарегистрирован ли на этом узле конкретный ИД PNRP. Сообщение AUTHORITY («полномочие») используется для подтверждения локальной регистрации ИД PNRP и, в необязательном порядке, для обеспечения цепи сертификатов, помогающей подтверждать действительность CPA для этого ИД. Сообщение ACK («квитирование») используется для подтверждения приема и/или успешной обработки тех или иных сообщений. Наконец, сообщение REPAIR («исправление») используется при попытках слияния облаков, которые могут быть расщеплены.
Узел может инициировать шесть основных типов транзакций в PNRP, при выполнении которых используются сообщения, отвечающие настоящему изобретению. Эти транзакции включают в себя обнаружение облака, синхронизацию, разрешение, распространение, подтверждение действительности идентификации и исправление. Чтобы дать возможность понять сущность этих транзакций, подробности которых объяснены в вышеуказанных заявках, кратко опишем эти транзакции в отношении сообщений и структур сообщений настоящего изобретения.
Транзакция обнаружения облака позволяет равноправному устройству обнаружить облако равноправных устройств. Согласно предпочтительному варианту осуществления каждый узел может присоединиться к нескольким облакам. Множество облаков, к которым можно присоединиться, зависит от способности узла к соединению в сети. Если компьютер узла имеет несколько адаптеров интерфейса, он может присоединяться к нескольким канально-локальным облакам. Если узел является частью локальной сети, поддерживающей IPv6, он может осуществлять доступ к пространственно-локальному облаку. Если узел имеет соединения с несколькими такими локальными сетями (возможно, через VPN (виртуальную частную сеть), он может осуществлять доступ к нескольким пространственно-локальным облакам. Если узел подключен к Интернету, он может осуществлять доступ к глобальному облаку.
Узел может по собственному выбору присоединяться или не присоединяться к облаку, к которому он осуществил доступ. Когда приложение впервые запрашивает регистрацию имени равноправного устройства на облаке либо разрешение имени равноправного устройства на облаке, узел должен присоединиться к облаку, если он еще не сделал этого. Чтобы присоединиться к облаку, он должен попытаться определить местоположение по меньшей мере одного другого узла в том же облаке. Если он не может найти другой узел, он может предположить, что он является первым узлом в облаке и будет ожидать другие узлы, которые присоединятся позднее.
Всякий раз когда узел PNRP присоединяется к облаку, он должен осуществить обнаружение облака, чтобы найти другой узел. Обнаружение облака может также произойти позже, если реализация PNRP определяет нарушение его кэша и необходимость получения дополнительных элементов кэша. Если первоначальная попытка «обнаружения кэша» не дает результатов, позже можно производить другие попытки. Обнаружение облака осуществляется с использованием следующих процедур. Во-первых, равноправное устройство может провести обнаружение из существующего кэша. В такой процедуре равноправное устройство сначала проверяет существующий кэш. Если в кэше не существует ни каких элементов, то равноправное устройство должно сделать попытку обнаружения посредством поданного адреса узла, рассмотренного ниже. Если имеются элементы кэша, то для всех элементов кэша равноправное устройство вычисляет приоритет, отдавая предпочтение CPA, время существования которых не истекло, затем - CPA, имеющим длительное время существования, а затем - CPA, время существования которых истекло совсем недавно. Затем равноправное устройство делает попытки синхронизации с выбранными узлами по очереди, пока один из них не предоставит некоторые элементы кэша.
Как указано выше, в отсутствие существующего кэша равноправное устройство пытается осуществить обнаружение посредством поданного адреса узла. В этой процедуре равноправное устройство проверяет, указано ли в административной конфигурации множество равноправных устройств, с которыми нужно соединиться. Если нет, равноправное устройство пытается осуществить рассмотренное ниже обнаружение в многоадресном режиме. В противном случае, для каждой указанной конечной точки, равноправное устройство делает попытки синхронизации по очереди, пока одна из них не предоставит некоторые элементы кэша.
Что касается обнаружения в широковещательном режиме, при наличии «простого протокола обнаружения услуги» (SSDP), равноправное устройство создает MSEARCH SSDP для экземпляра службы PNRP в нужном облаке. Строка «цель поиска» (Search Target) для использования в сообщении «поиск SSDP» (SSDP Search) выглядит как “urn:Microsoft Windows Peer Name Resolution Protocol:<major>:<Protocol>:<Scope>”, где<major> - число, выражающее версию, Protocol - «IPv6», и Scope принимает одно из трех значений: Global, SiteLocal и LinkLocal. Поиск можно выполнять заранее, чтобы ответы поступали своевременно. В отсутствие SSDP равноправное устройство может попытаться использовать другие протоколы обнаружения. Если ничего не найдено, равноправному устройству придется попробовать использовать описанное ниже обнаружение посредством сервера каталожных имен (DNS). В случае поступления ответов их помещают в список узлов, подлежащих испытанию. Если ответы не поступают в короткий период времени, то узел может пожелать попытаться использовать другие протоколы обнаружения. Период времени может определяться реализацией. Равноправное устройство может совершать попытки синхронизации с выбранными узлами по очереди, пока один из них не предоставит некоторые элементы кэша.
Для обнаружения посредством DNS равноправное устройство создает запрос DNS на предмет общеизвестного имени исходного сервера. Это имя для глобального облака может быть, например, SEED.PNRP.NET. В случае успеха равноправное устройство может провести описанную ниже синхронизацию. Если же обнаружение облака в данный момент не дало результата, PNRP задает состояние облака, в соответствии с которым нельзя обнаружить других членов облака, и предполагает, что является первым узлом в облаке. Позже можно повторить попытку синхронизации.
Синхронизация позволяет узлу получить множество CPA из кэша другого узла. Синхронизация осуществляется после обнаружения облака. Она осуществляется с отдельным узлом, произвольным образом выбранным из множества узлов, возвращенного в результате обнаружения облака. Синхронизацию защищают для подавления определенных атак. Синхронизацию также можно осуществлять, если кэш для облака становится пустым вследствие устаревания, но это случается весьма редко. Перед началом синхронизации узел должен убедиться, что имеет по меньшей мере один локально зарегистрированный CPA. Если «имя равноправного устройства» еще не зарегистрировано, то узел может генерировать ИД узла для самого себя в облаке. В процессе синхронизации используется пять типов сообщений, отвечающих настоящему изобретению, а именно: SOLICIT, ADVERTISE, REQUEST, FLOOD и ACK.
На фиг.3 показан простой обмен сообщениями для синхронизации. Согласно фиг.3 предположим, что узел А 212 инициирует синхронизацию с узлом В 214. В такой ситуации обмен сообщениями между узлами выглядит, как показано на фиг.3. В частности, сообщение 216 SOLICIT запрашивает список ИД PNRP у узла 214, выбранного при обнаружения облака. Структура этого сообщения 216 SOLICIT представлена в Таблице 1.
Узел отслеживает значение «одноразового номера» (Nonce), используемое для создания хэшированного «одноразового номера». С этим состоянием связаны таймеры, а также счет повторных попыток. Если в ответ на отправленное SOLICIT 216 сообщение 218 ADVERTISE не поступает, то SOLICIT 216 будет отправлено повторно. В случае превышения счета повторных попыток состояние освобождается и транзакция прекращается.
Узел 214, приняв SOLICIT 216, отвечает сообщением 218 ADVERTISE. ADVERTISE 218 содержит массив идентификаторов (ИД) PNRP. Узел 214 сначала применяет эвристику дросселирования, чтобы определить, желает ли он участвовать в транзакции синхронизации. Если он занят, он отвечает сообщением 218 ADVERTISE без ИД PNRP в массиве. В противном случае он выбирает хорошо распределенное множество ИД PNRP из своего кэша. Это можно делать с использованием элементов верхнего уровня кэша или путем произвольного выбора. В отсутствие достаточного количества элементов кэша узел 214 должен также включить свои собственные локально зарегистрированные ИД. Сообщение 218 ADVERTISE включает в себя хэшированный «одноразовый номер» из сообщения 216 SOLICIT. ADVERTISE 218 рассматривается как подтверждение приема SOLICIT 216.
Если массив ИД PNRP не пуст, то узел 214 также сохраняет состояние, в соответствии с которым было отправлено ADVERTISE 218 с хэшированным значением «одноразового номера». Это состояние может выражаться битом в битовой карте. С этим состоянием связан таймер, в связи с чем, если в течение заданного им промежутка времени, например 15 секунд, не поступает сообщение о совпадении, то транзакция прерывается и состояние освобождается. Узел 214 также может добавлять в свой кэш «CPA источника» (Source CPA) из сообщения 216 SOLICIT. Структура сообщения 218 ADVERTISE представлена в Таблице 2.
Приняв ADVERTISE 218, узел 212 сначала убеждается, что отправил соответствующее SOLICIT 216. Если нет, он игнорирует сообщение. ADVERTISE 218 обрабатывается как подтверждение приема SOLICIT 216. Если массив ИД PNRP в ADVERTISE 218 пуст, то транзакция завершается. В противном случае узел 212 перебирает массив ИД PNRP в ADVERTISE 218 и выбирает те из них, которые он хочет включить в свой кэш. Он отправляет сообщение 220 REQUEST, включающее в себя массив выбранных ИД PNRP. Он помещает в сообщение 220 REQUEST исходное значение «одноразового номера», используемое для создания хэшированного «одноразового номера», входящего в состав сообщения 216 SOLICIT. Структура сообщения 220 REQUEST представлена в Таблице 3.
Сообщение 220 REQUEST поступает на узел В 214, который отвечает сообщением 222 ACK, подтверждая его прием во избежание повторных передач. Если ACK 222 своевременно не поступает, узел А 212 будет повторно передавать REQUEST. Если все повторные передачи REQUEST исчерпаны, а ACK не принято, то транзакция считается неудачной и прекращается.
Если транзакция завершилась успешно, т.е. узел 212 принял ACK 222 от узла 214, то узел 212 проверяет действительность «одноразового номера». Для этого он хэширует принятый «одноразовый номер» и проверяет, совпадает ли он с ранее сохраненным состоянием. В отсутствие совпадения, никакой дальнейшей обработки не происходит. Если же он действительный, то для каждого ИД PNRP в массиве, который все еще имеется в его кэше, он посылает сообщение FLOOD 2241, 2242, …, 224N. Сообщение 224 FLOOD включает в себя CPA для ИД PNRP. Заметим, что сообщения 224 FLOOD не являются синхронными. То есть подтверждение приема FLOOD(ID=1) 2241 не обязательно должно приходить до отправки FLOOD(ID=2) 224. Приняв FLOOD 224, равноправное устройство 212 производит нормальную обработку сообщения 224 FLOOD. Она включает в себя отправку ACK 226 и проверку действительности CPA.
Ходатайствующий узел 212 может принять решение повторить эту процедуру, если количество выбранных ИД не слишком велико. В этом случае ему следует использовать для синхронизации другой узел, чтобы получить другой список ИД.
Узел инициирует процесс «разрешения», отправляя сообщение RESOLVE. Причиной инициирования «разрешения» может быть запрос приложения на разрешение «имени равноправного объекта» относительно адреса, регистрация ИД PNRP, поддержка кэша или обнаружение расщепления облака. Сообщение RESOLVE содержит некоторые флаги и коды для настройки обработки разрешения, для установления предельного количества узлов, посещаемых в попытках разрешения, и для регулировки точности совпадения ИД. Оно задает нужный целевой ИД PNRP. При каждом скачке вставляется ИД следующего скачка, а также CPA наилучшего совпадения, найденный до сих пор. Кроме того, включается массив конечных точек посещенных узлов, чтобы трассировать путь сообщения RESOLVE от скачка к скачку. Инициатор RESOLVE добавляет себя в качестве первого элемента пути. Транзакция разрешения разрешает ИД PNRP относительно «сертифицированного адреса равноправного устройства». Только обладатель CPA уполномочен удовлетворить запрос разрешения для своего CPA. Кэшированные CPA можно использовать только как подсказки для маршрутизации запросов «разрешения». Их нельзя использовать для задания поля “best match” («наилучшее совпадение») в RESOLVE или RESPONSE.
Сообщение RESOLVE заканчивается по достижении узла, обладающего целевым ИД PNRP, или когда количество посещенных узлов достигает «максимального количества скачков» (MaxHops), заданного в RESOLVE, или когда ни для какого узла на пути больше нет возможности переслать RESOLVE на лучший узел. По завершении выбранное содержимое из RESOLVE переносится в новое сообщение RESPONSE, которое пересылается обратно инициатору RESOLVE. RESPONSE содержит CPA «наилучшего совпадения» из RESOLVE, а также список посещенных узлов. Приняв RESPONSE, инициатор RESOLVE может легко проверить, найден ли целевой CPA, сравнив ИД PNRP для CPA «наилучшего совпадения» с целью.
На фиг.4 показан пример транзакции RESOLVE/RESPONSE между тремя узлами. В этом упрощенном примере узел А 228 пытается осуществить разрешение узла Т 232 через узел В 230. В транзакции «разрешения» помимо ACK используются 3 сообщения, а именно RESOLVE, RESPONSE и AUTHORITY. По завершении разрешения узел А 228 может отправить сообщение INQUIRE непосредственно на узел Т 232, что будет рассмотрено ниже.
Для сообщений RESOLVE следует рассмотреть три случая, первые два из которых проиллюстрированы на фиг.4. Три случая представляют собой инициирование RESOLVE 234 на узле А 228, пересылку RESOLVE 236 с узла А 228 на другой узел В 230 и отправку RESOLVE обратно с узла (на фиг.4 не показана). Рассмотрим по очереди каждый из трех сценариев.
Сначала рассмотрим инициирование RESOLVE на узле А 228. Согласно фиг.4 узел А 228 по некоторой причине инициирует RESOLVE. Эти причины включают в себя запрос приложения на разрешение, объявление регистрации, поддержку ширины кэша или обнаружение расщепления облака. Инициатор 228 также задает код операции, указывающий, может ли RESOLVE быть удовлетворено локально зарегистрированным ИД. Если может, то узел А 228 сканирует множество локально зарегистрированных ИД на предмет совпадения. Если таковое найдено, то RESOLVE завершается на самом узле А 228 с совпадающим ИД. Если локально зарегистрированный ИД неприемлем или если ни один из локальных ИД не совпадает, то создается сообщение RESOLVE, поля которого указаны в Таблице 4. Это сообщение 234 RESOLVE затем пересылается какому-либо другому узлу 230 для обработки, описанной ниже.
Когда узлу А 228 желательно или необходимо переслать RESOLVE 234 на другой узел В 230, сначала нужно выбрать этот следующий узел. Чтобы выбрать следующий скачок, узел А 228 создает список L из трех кэшированных CPA, ИД PNRP которых ближе всего к Target ID (узлу Т 232), исключая любой худший адрес, уже указанный в Path, и те, которые не ближе к ИД цели (Target ID), чем ближайший к А локально зарегистрированный ИД. Если ИД цели присутствует в списке L, то этот элемент выбирается в качестве следующего скачка. В противном случае, если список L не пуст, то один элемент выбирается произвольным образом. Другими словами, узел А 228 находит некоторые новые узлы, которые ближе к цели, чем он сам, и выбирает, на какой из них переслать сообщение 234 RESOLVE.
Если узел А 228 способен выбрать следующий скачок, то узел А 228 вставляет соответствующий элемент в «принятую битовую карту» (“received bitmap”). Узел А 228 добавляет себя в Path («путь»), выбирая свой наилучший адрес для выбранного следующего скачка и помечая элемент как «принятый» (Accepted). Узел А 228 устанавливает NextHop («следующий скачок») на ожидаемый ИД PNRP выбранного адресата и пересылает сообщение 234 RESOLVE на узел В 230. В случае успешной отправки сообщения 234 RESOLVE узел-отправитель 228 предполагает получение подтверждения приема в виде сообщения 238 AUTHORITY. В случае приема AUTHORITY 238 узел 228 поддерживает контекст для RESOLVE 234 и выжидает в течение времени ожидания возвращения сообщения 240 RESPONSE. Если AUTHORITY 238 не принято по истечении некоторого времени, вновь отправляется RESOLVE 234. Допустимо всего N повторных попыток, после чего будет признано, что NextHop недействителен. В предпочтительном варианте осуществления N=3. В случае превышения счета повторных попыток CPA «следующего скачка» удаляется из локального кэша и элемент добавляется в «путь» как неудачный скачок. Если счет скачков не превышен, то из локального кэша выбирается другой «следующий скачок», и процесс повторяется. Если количество элементов в «пути» больше или равно MaxHops («максимального количества скачков»), то генерируется сообщение RESPONSE, «код ответа» (Response Code) которого равен RESULT_MAX_HOP_LIMIT_HIT, которое отправляется на наиболее недавний элемент в Path, помеченный как «принятый».
Если узел не способен найти следующий скачок, он проверяет, должен ли «ИД цели» находиться на нижнем уровне кэша. Если должен быть, то узел подозревает, что «ИД цели» не существует.Узел проверяет существующие элементы «пути» и отсчитывает те, которые помечены как «подозрительные» (Suspicious). Если счет превышает порог, то генерируется сообщение RESPONSE, «код ответа» которого равен RESULT_TOO_MANY_MISSES, которое отправляется на наиболее недавний элемент в «пути», помеченный как «принятый». Если узлу не удалось найти следующий скачок, но счет «подозрительных» не превышен, то узел отправляет RESOLVE обратно на последний узел в «пути», помеченный как «принятый». Сначала узел добавляет себя в «путь», выбирая наилучший адрес для узла-адресата и помечая элемент как «отвергнутый». Он присваивает NextHop значение 0 и устанавливает флаг RF_IGNORE_NEXTHOP для указания обратной трассировки. Если «ИД цели» должен находиться на нижнем уровне кэша узла, то он подозревает, что «ИД цели» не существует. В этом случае узел также помечает элемент своего «пути» как «подозрительный». Если узлу не удалось найти следующий скачок и в «пути» нет узлов (за исключением его самого), значит он является инициатором сообщения RESOLVE. В этом случае он возвращает вызывающей стороне результат, указывающий неудачное разрешение, с «кодом ответа» RESULT_NO_BETTER_PATH_FOUND. Вызывающей стороне предоставляется CPA «наилучшего совпадения».
Узел В 230 получает сообщение 234 RESOLVE, содержащее целевой ИД PNRP, CPA «наилучшего совпадения», ИД PNRP «следующего скачка» и «путь», в котором перечислены адреса всех узлов, обработавших RESOLVE. Если в поле флагов не установлен RF_IGNORE_NEXTHOP, и в поле “BestMatch CPA” может быть CPA или может ничего не быть, то узел В 230 проверяет свою локальную нагрузку обработки. Если нагрузка слишком высока для обработки новых запросов RESOLVE, он отвечает посредством AUTHORITY 238, где в поле флагов установлен флаг «AF_REJECT_TOO_BUSY», и обработка завершается. Получатель AUTHORITY обязан добавить конечную точку отвергающего узла в массив пути и перемаршрутизировать запрос «разрешения» в другое место.
Принимающий узел 230 проверяет, что массив Path содержит по меньшей мере 1 адрес, помеченный как «принятый», и что последний такой адрес совпадает с источником сообщения. Если нет, никакой обработки больше не производится. Принимающий узел также проверяет параметры в принятом запросе. Если какие-либо параметры не находятся в действительном диапазоне, то он отвечает сообщениями AUTHORITY, где в поле флагов задано «AF_INVALID_REQUEST», и обработка завершается. Примером недействительного параметра является слишком большое значение MaxHops. Получатель AUTHORITY обязан добавить конечную точку отвергающего узла в массив пути и перемаршрутизировать запрос RESOLVE в другое место.
Принимающий узел (например, узел В 230) проверяет факт локальной регистрации ИД «следующего скачка». Исходный сервер может пропустить этот тест. В случае неудачи он отвечает посредством AUTHORITY, где в поле флагов установлено «AF_UNKNOWN_ID», и обработка завершается. Получатель AUTHORITY обязан перемаршрутизировать запрос RESOLVE в другое место. Приняв AF_UNKNOWN_ID, получатель AUTHORITY также должен удалить ИД PNRP отправителя AUTHORITY из своего кэша. Если в сообщение включен CPA «наилучшего совпадения», то узел проверяет BestMatch, насколько это возможно. Если CPA «наилучшего совпадения» действительный, то узел следует обычным правилам принятия решения относительно добавления CPA в свой кэш.
Узел также проверяет наличие в «пути» соответствующего элемента. В случае наличия имеет место цикл, поскольку это не обратно трассированное RESOLVE. Тогда узел отвечает посредством AUTHORITY, где в поле флагов установлено «AF_REJECT_LOOP», и обработка завершается. Получатель AUTHORITY обязан добавить конечную точку отвергающего узла в массив Path и перемаршрутизировать запрос RESOLVE в другое место.
Если все предыдущие проверки пройдены, то узел В 230 отправляет AUTHORITY 238, подтверждающее прием сообщения 234 RESOLVE. Если в RESOLVE установлен флаг RF_SEND_CHAIN, то в AUTHORITY включается цепь сертификатов для «следующего скачка». В сообщение AUTHORITY включается участок, соответствующий строке «классификатор» (Classifier) для «имени равноправного устройства», соответствующего ИД PNRP следующего скачка.
Узел В 230 проверяет, имеет ли он локально зарегистрированный CPA, который имеет лучше совпадение, чем текущее BestMatch. Если это так, то он заменяет им BestMatch. Узел также проверяет, имеет ли он локально зарегистрированный CPA, который удовлетворяет критериям RESOLVE, на основании OpCode, Precision и TargetID. При наличии совпадения или если количество элементов в «пути»>=«максимального количества скачков», то узел создает сообщение RESPONSE с текущим BestMatch. Путь сообщения RESOLVE копируется в путь сообщения RESPONSE. Узел задает ResponseCode («код ответа»), указывающий RESULT_FOUND_MATCH или RESULT_MAX_HOP_LIMIT_HIT. Затем узел удаляет свой адрес из «пути», а также последующие элементы, помеченные как «отвергнутые», и отправляет RESPONSE на наиболее недавний элемент в пути, который помечен как «принятый».
Если узел В 230 не отправил RESPONSE (как показано на фиг.4), то он пытается переслать сообщение 236 RESOLVE на следующий узел Т 232. Эта пересылка следует вышеописанной процедуре. Это значит, что узел Т 232 отвечает первоначально посредством сообщения 242 AUTHORITY. Затем он осуществляет рассмотренные выше проверки и, определив, что он совпадает с целью, отвечает узлу В 230 сообщением 244 RESPONSE, идентифицируя себя как BestMatch. В ответ на сообщение 244 RESPONSE узел В 230 отправляет обратно сообщение 246 ACK. Затем узел В 230 проверяет путь и пересылает сообщение 240 RESPONSE на узел А 228, который отвечает сообщением 248 ACK.
Как указано выше, узлу может также понадобиться обработать обратно трассированное RESOLVE. Когда узел принимает сообщение R RESOLVE, оно содержит целевой ИД PNRP, CPA «наилучшего совпадения», ИД PNRP «следующего скачка» и «путь», где перечислены адреса всех узлов, обработавших RESOLVE. Для обратно трассированного RESOLVE в поле флагов установлено RF_IGNORE_NEXTHOP. Сначала узел проверяет свою «принятую битовую карту», чтобы удостовериться в том, что он раньше пересылал это RESOLVE. Если бит не отправлен, сообщение игнорируется. Затем узел проверяет «путь», чтобы убедиться в том, что его адрес указан в «пути» и что он является последним элементом, помеченным в «пути» как «принятый». В противном случае сообщение игнорируется. Если сообщение не игнорируется, то узел отправляет AUTHORITY обратно отправителю для квитирования сообщения. Оно не включает в себя цепь сертификатов.
Если количество элементов в «пути»>=«максимального количества скачков», то узел создает сообщение S RESPONSE с текущим BestMatch. «Путь» сообщения R RESOLVE копируется в «путь» S. Узел задает «код ответа» для указания превышения MaxHops. Затем узел удаляет свой адрес из «пути» и отправляет RESPONSE обратно на наиболее недавний элемент в «пути», который помечен как «принятый». Если узел не отправил RESPONSE, то он пытается переслать RESOLVE на следующий скачок. Это происходит в соответствии с вышеописанной процедурой за некоторыми исключениями: а) «Узел В 230 проверяет, имеет ли он локально зарегистрированный CPA, который имеет лучшее совпадение, чем текущее BestMatch. Если да, то он заменяет им BestMatch.» НЕ ПРИМЕНЯЕТСЯ; и b) если текущий узел является инициатором транзакции «разрешения» И причиной является REASON_REPAIR_DETECTION, то обработка завершается.
Согласно кратко рассмотренному выше, когда узел принимает сообщение 244, 240 RESPONSE, оно содержит целевой ИД PNRP, CPA «наилучшего совпадения» и «путь», в котором перечислены адреса всех узлов, обработавших RESOLVE. Принимающий узел также проверяет свою «принятую битовую карту», чтобы удостовериться в том, что он раньше отправил RESOLVE 234, 236, которое соответствует этому RESPONSE 240, 244. Если бит не отправлен, то сообщение игнорируется. Принимающий узел также проверяет «путь», чтобы убедиться в том, что его адрес является последним (наиболее недавним) в «пути» и что он помечен как «принятый». В противном случае сообщение игнорируется. Если сообщение не игнорируется, то этот принимающий узел отправляет ACK 246, 248 для подтверждения приема. Узел проверяет действительность CPA «наилучшего совпадения», насколько это возможно, и добавляет его в свой кэш. Добавление CPA в кэш подчиняется набору правил, согласно которому может потребоваться обмен дополнительными сообщениями, чтобы Р мог проверять действительность CPA «наилучшего совпадения». Это описано в вышеуказанных заявках.
Затем узел удаляет себя из «пути». Узел также удаляет предыдущие элементы, помеченные как «отвергнутые», пока не доходит до элемента, помеченного как «принятый», или пока не кончится список. В случае нахождения элемента, помеченного как «принятый», узел пересылает RESPONSE на этот узел. Если узел, на который переслано RESPONSE, не отвечает посредством ACK, то узел повторно передает RESPONSE до N раз. Если время повторных передач истекло, то узел удаляет неудачный узел-адресат из пути и предпринимает повторную попытку обработки RESPONSE, описанную в этом абзаце. Если в «пути» нет других элементов, значит узел является инициатором исходного RESOLVE 234. Узел 228 удостоверяется в том, что он выдал запрос. Если это не так, то RESPONSE игнорируется. Если «код ответа» указывает успех, то узел 228 осуществляет проверку действительности идентификации в отношении источника CPA «наилучшего совпадения». При этом предусмотрена отправка сообщения 250 INQUIRE на узел назначения 232 и проверку возвращенного сообщения 252 AUTHORITY. В случае неудачной проверки действительности идентификации он меняет код ответа на IDENTITY_FAILURE. Он возвращает результаты обратно вызывающей стороне.
Сообщение AUTHORITY может быть фрагментировано отправителем. Получатель должен убедиться в том, что он принял все фрагменты, прежде чем обрабатывать сообщение AUTHORITY. Если какой-либо фрагмент не принят в течение разумного периода времени, то исходное сообщение (INQUIRE или RESOLVE) нужно повторно отправлять, пока не будет превышен счет повторных попыток. Если в сообщении AUTHORITY установлен флаг AF_SERT_CHAIN, то узел должен выполнить операцию проверки действительности цепи в отношении кэшированного CPA для ИД PNRP, указанного в ValidateID. Цепь нужно проверять, чтобы гарантировать, что все сертификаты действительны, и взаимосвязь между корнем и листом цепи действительна. Хэш открытого ключа для корня цепи нужно сравнивать с полномочием в «имени равноправного устройства» CPA, чтобы гарантировать их совпадение. Открытый ключ для листа цепи нужно сравнивать с ключом, используемым для подписания CPA, чтобы гарантировать их совпадение. Наконец, ИД Р2Р нужно проверять, чтобы видеть, что это хэш «полномочия» и «классификатора», согласно правилам создания ИД Р2Р. Если какая-либо из вышеупомянутых проверок дает отрицательный результат, то CPA следует удалить из кэша, и сообщение RESOLVE следует изменить, добавив адрес узла, отправившего сообщение AUTHORITY, в «путь» сообщения RESOLVE и пометив элемент как «отвергнутый».
Если установлен AF_UNKNOWN_ID, то CPA следует удалить из кэша. Если AF_CERT_CHAIN не установлен, то CPA, соответствующий ИД PNRP ValidateIP требует проверки достоверности цепи сертификатов, CPA следует удалить из кэша, и сообщение RESOLVE следует изменить, добавив адрес узла, отправившего сообщение AUTHORITY, в «путь» сообщения RESOLVE и пометив элемент как «отвергнутый».
После проверки действительности CPA, соответствующего ИД PNRP ValidateID, его следует пометить как полностью действительный. Строка «классификатор» извлекается из сообщения AUTHORITY и присоединяется к CPA. Если флаги AF_REJECT_TOO_BUSY, AF_UNKNOWN_ID, AF_REJECT_LOOP и AF_INVALID_REQUEST не установлены, значит RESOLVE принято для обработки, и обработка AUTHORITY проведена.
В некоторых случаях, узел, принимающий сообщение RESOLVE, может, по своему выбору, не принимать его для пересылки, но все же предлагать узлу-отправителю следующий скачок. В этом случае узел возвращает предложенные «переводную конечную точку» (Referral Endpoint) и «переводной ИД PNRP» (Referral PNRP ID) в сообщении AUTHORITY. В этом случае поле «флаги» сообщения AUTHORITY должно содержать AF_REDIRECT. Узел, который принимает AUTHORITY с AF_REDIRECT, может, по своему выбору, использовать или не использовать «переводную конечную точку» для отправки сообщения RESOLVE. В любом случае, узел, ответивший посредством AUTHORITY, добавляется в «путь». Единственный раз, когда узел обязан использовать «переводную конечную точку», это случай, когда узел, инициирующий RESOLVE, делает это для обнаружения расщепления облака и отправляет на исходный сервер PNRP сообщение RESOLVE с «причиной» REASON_REPAIR. В других случаях узел должен игнорировать «переводную конечную точку».
PNRP использует направленное распространение для рассылки элементов кэша CPA между узлами. Распространение используется в нескольких случаях. В ходе синхронизации, в ответ на сообщение REQUEST, запрашиваемые CPA распространяются на равноправное устройство, отправившее REQUEST. Сообщение REQUEST принимается только после принятия сообщения SOLICIT и отправки сообщения ADVERTISE. Всякий раз при добавлении CPA на нижний уровень кэша добавленный CPA распространяется на n равноправных устройств, ближайших к локально зарегистрированному ИД. Значение n можно регулировать, но значение 4 предпочтительно. Если причиной добавления CPA является прием FLOOD, то CPA не следует распространять на узлы, чьи адреса указаны в «списке распространения» (Flooded List) принятого FLOOD. При наличии достаточного места адреса в принятом «списке распространения» следует копировать в новый «список распространения» сообщения FLOOD. Всякий раз при удалении CPA из нижнего уровня кэша по получении FLOOD, содержащего отмену CPA, отмененный CPA распространяется на n равноправных устройств, ближайших к локально зарегистрированному ИД. Опять же, значение n можно регулировать, но значение 4 предпочтительно. CPA не следует распространять на узлы, чьи адреса указаны в «списке распространения» принятого FLOOD. При наличии достаточного места адреса в принятом «списке распространения» следует копировать в новый «список распространения» сообщения FLOOD. Наконец, в случае приема FLOOD для нового равноправного устройства и добавления CPA на нижний уровень кэша сообщение FLOOD отправляется на новое равноправное устройство с локальным ИД узла. Исключение делается, если источником FLOOD является новое равноправное устройство.
PNRP не создает постоянных взаимосвязей между соседями. В самом широком смысле каждый узел, представленный посредством CPA в кэше CPA, можно рассматривать как соседа. Однако при добавлении и удалении CPA из кэша не обязательно извещать источник CPA. Наличие CPA равноправного устройства в кэше узла не гарантирует, что этот сосед имеет CPA этого узла в своем кэше. Взаимосвязь является асимметричной. Однако вышеописанное конечное состояние FLOOD пытается создать симметрию для близких друг к другу ИД.
Каждое сообщение FLOOD пользователя протокола дейтаграмм (UDP) квитируется посредством ACK прежде, чем над этим FLOOD будет предпринято какое-либо другое действие. Отправитель FLOOD поддерживает состояние в течение некоторого времени после отправки FLOOD. В случае приема ACK состояние освобождается. Если ACK не поступает в течение некоторого периода времени, то FLOOD повторно отправляется, и таймер перезапускается. Повторные попытки отправки FLOOD предпринимаются до заданного количества раз, предпочтительно до 3. Если ACK не поступает после последней попытки, то состояние освобождается. Кроме того, если пункт назначения FLOOD имеется в кэше отправителя, то элемент кэша удаляется во избежание дальнейших попыток отправки сообщения на неотвечающий узел.
Когда узел принимает сообщение FLOOD, его обработка начинается с квитирования сообщения FLOOD путем отправки ACK. В поле флагов устанавливается «KF_NACK», если ValidateID присутствует и не имеет локальной регистрации. Затем осуществляется проверка действительности сообщения FLOOD. Она включает в себя локальную верификацию подписи и содержимого CPA. Если CPA признан действительным, производится определение того, следует ли добавлять CPA в кэш. Если CPA соответствует ИД PNRP, который локально зарегистрирован на том же узле, то добавлять его в кэш нет необходимости. Если идентификатор, используемый для подписи CPA нельзя проверить с помощью одного лишь CPA и если бы CPA был добавлен на один из двух нижних уровней просмотра кэша, то проверку действительности идентификации следует осуществлять согласно рассмотренному ниже. Если проверка действительности дает отрицательный результат, то узел игнорирует сообщение FLOOD. Если она проходит успешно, то узел продолжает обработку FLOOD. Если время существования CPA истекло, то узел удаляет соответствующий CPA из кэша, если он там имеется. Если он найден, то узел пересылает отмену другим соседям, отправляя сообщения FLOOD.
Если CPA не является CPA отмены, то узел обновляет кэш. Если совпадающий CPA уже в кэше, то узел обновляет элемент кэша новыми данными CPA. Если это новый элемент, то узел создает новый элемент и пытается добавить его в кэш. Элемент может не быть добавлен, если для освобождения места под него нужно удалить другой элемент, но существующие элементы предпочтительнее новых элементов по причине более высоких уровней доверительности или лучшей метрики близости. Если элемент принадлежит самому низкому уровню кэша, то его следует добавить. Если CPA принадлежит самому низкому уровню кэша, то его следует переслать некоторым соседям, даже если не удается добавить его в кэш. Если FLOOD принято в ходе синхронизации, то пересылка FLOOD подавляется, поскольку предполагается, что все обнаруженные CPA уже известны другим узлам. Если FLOOD необходимо переслать, то выбирается множество ИД PNRP, ближайших к локально зарегистрированному ИД. На каждый из них отправляется сообщение FLOOD с новым CPA и «списком распространения» (Flooded List), который включает в себя n соседей, плюс содержимое «списка распространения», полученного в сообщении FLOOD, которое было получено.
«Проверка действительности идентификации» - это средство ослабления угрозы, используемое для проверки действительности CPA. Эта проверка имеет две цели. Во первых, проверка действительности идентификации гарантирует, что узел PNRP, указанный в CPA, имеет локально зарегистрированный ИД PNRP из этого CPA. Во-вторых, для безопасных ИД PNRP проверка действительности идентификации гарантирует, что CPA подписан с использованием ключа с криптографически доказуемой взаимосвязью с полномочием в ИД PNRP. Подробности относительно того, как проверка действительности идентификации достигает этих двух целей, можно найти в вышеуказанных совместно рассматриваемых заявках.
Проверка действительности идентификации производится в два разных момента времени. Во-первых, проверка действительности идентификации производится при добавлении CPA на два нижних уровня кэша. Действительность CPA на двух нижних уровнях кэша существенна для способности PNRP к разрешению ИД PNRP. Осуществление проверки действительности идентификации перед добавлением CPA на любой из этих двух уровней ослабляет некоторые атаки. В этом случае CPA будет удерживаться в списке до, например, 30 секунд в ожидании сообщения AUTHORITY. Во-вторых, проверка действительности идентификации производится конъюнктурно в процессе «разрешения». Кэши PNRP имеют высокую скорость обновляемости. Поэтому большинство элементов кэша перезаписывается в кэш до того, как когда-нибудь используются. PNRP не проверяет действительность большинства CPA, пока они не будут реально использоваться. Когда CPA используется для маршрутизации пути RESOLVE, PNRP размещает результат проверки действительности идентификации на вершине сообщения RESOLVE. RESOLVE содержит ИД «следующего скачка», который обрабатывается так же, как «ИД цели» в сообщении INQUIRE. Квитирование RESOLVE осуществляется с помощью сообщения AUTHORITY, такого же, как предполагается для INQUIRE. Если конъюнктурная проверка действительности идентификации дает отрицательный результат, значит получатель RESOLVE не тот, кого предполагает отправитель. Поэтому RESOLVE маршрутизируется в другое место, и недействительный CPA удаляется из кэша.
Чтобы проиллюстрировать эту проверку действительности, предположим, что «Р» - это узел, запрашивающий проверку действительности идентификации на предмет ИД PNRP «Т». «N» это узел, принимающий запрос на проверку действительности идентификации. Р генерирует либо сообщение INQUIRE с TargetID=Т, либо сообщение RESOLVE с NextHop=Е (и не установленным RF_IGNORE_NEXTHOP). N проверяет свой список локально зарегистрированных ИД PNRP. Если Т нет в этом списке, то N отвечает сообщением AUTHORITY, где указано, что ИД «Т» не является локально зарегистрированным. Если принятым сообщением является RESOLVE, то RESOLVE игнорируется, поскольку Р позаботится о пересылке его в другое место. Когда Т находится в списке ИД PNRP на N, N строит сообщение AUTHORITY и задает ИД цели равным Т. Если флаг установлен RF_SEND_CHAIN, то N извлекает цепь сертификатов (если имеется), связывающую ключ, используемый для подписания CPA, с полномочием для ИД PNRP «Т». Цепь сертификатов вставляется в сообщение AUTHORITY. В сообщение AUTHORITY также добавляется участок «имени равноправного устройства», относящийся к «классификатору».
N отправляет сообщение AUTHORITY на Р. Если сообщение AUTHORITY длиннее 1216 байт, то сообщение разбивается на несколько фрагментов по 1216 байт или меньше, и отправляется каждый фрагмент. Если Т является незащищенным ИД или если действительность CPA уже подтверждена (отправлено RESOLVE с неустановленным RF_SEND_CHAIN), то обработка завершается. Р удостоверяет взаимосвязь между ключом подписания CPA и полномочием, используемым для генерации ИД PNRP «Т». Если проверка действительности дает отрицательный результат, то CPA отвергается. Если проверка действительности дает отрицательный результат и инициирующим сообщением является RESOLVE, то Р пересылает RESOLVE в другое место.
Как объясняется в вышеуказанных заявках и кратко рассмотрено выше, облака PNRP могут быть расщеплены. Это может происходить в двух случаях. Во-первых, облака могут образовываться независимо и нуждаться в слиянии. Во-вторых облака могут образовываться едиными, но какой-то фрагмент облака может отделяться от остального облака. Для связывания любых возможных разрывов предполагается, что облака имеют особые исходные серверы. Это те же серверы, что используются для начальной загрузки через DNS. При наличии в облаке нескольких исходных серверов они могут периодически связываться друг с другом для обеспечения обмена идентификаторами ИД в своих кэшах. Для этого можно использовать процесс синхронизации. Так можно избегать образования островов.
Узлы в облаке периодически опрашивают исходные серверы, чтобы проверить, не отделился ли узел от главного облака, и, при необходимости, попытаться влиться обратно. Частота, с которой узел осуществляет проверку на расщепление, обратно пропорциональна его оценке размера облака. Это позволяет избегать слишком частых проверок на расщепление. Узел, недавно присоединившийся к облаку, должен выждать некоторый период времени, пока его кэш не заполнится, прежде чем предположить, что он способен оценить размер облака.
Для обеспечения слияния облаков используется сообщение REPAIR протокола PNRP. REPAIR имеет ИД PNRP, IP-адрес узла и номер «уровня исправления» (Repair Level). Уровни кэша нумеруются, начиная с 0 для верхнего уровня (широчайший диапазон номеров), и каждый последующий уровень (меньший диапазон) имеет номер на 1 больше. При первом обнаружении расщепления устанавливают начальное значение «уровня исправления», равное 0. Когда узел решает, что он должен выполнить проверку на код расщепления, узел внутренним образом генерирует REPAIR, используя адрес известного исходного сервера, например IP-адрес, локально зарегистрированный ИД PNRP и уровень 0. Он сам обрабатывает это REPAIR.
После обработки REPAIR узел проводит проверку на расщепление. Сначала он находит локально зарегистрированный ИД, ближайший к ИД в сообщении REPAIR. Затем он отправляет RESOLVE для этого ИД+1 по IP-адресу, указанному в сообщении REPAIR. Это RESOLVE должно иметь «код причины», указывающий «исправление». Если осуществляется разрешение относительно известного узла, то никакого расщепления нет. Если осуществляется разрешение относительно нового узла, то возможно расщепление. Если обнаруженный новый узел попадает на нижний уровень кэша (наибольший номер), то распространение производится как обычно. В сообщении FLOOD устанавливается «код причины», указывающий «исправление». Кроме того, если узел, принимающий RESOLVE, помещает ИД источника на свой нижний уровень кэша, то этот узел будет распространять элементы на источник. Все это распространение приведет к обмену несколькими ИД с новым облаком. Все новые узлы, обнаруженные посредством распространения, трассируются таким образом.
Если обнаруженный новый узел оказывается ближе ранее известных узлов и на принятом «уровне исправления» имеются элементы кэша, то узел отправляет сообщение REPAIR на элементы в кэше на «уровне исправления». Для каждого отправленного REPAIR узел выбирает ИД или IP-адрес вновь обнаруженного узла и переходит на «уровень исправления»+1. Если вновь обнаруженный узел оказывается дальше ранее известных узлов, то узел отправляет REPAIR на новый узел, переходя к некоторому ИД и адресу из локального кэша, и принятый «уровень исправления». Каждый узел, который принимает сообщение REPAIR, обрабатывает их одинаково.
Ниже будет показано, что протокол PNRP состоит из десяти типов сообщений. Каждое сообщение начинается с заголовка PNRP, за которым следуют поля, специфические для этого типа сообщения. Служебная информация (например, описание полей) вычисляется отдельно в столбце «длина» каждой таблицы поля сообщения. Ниже описана общая структура данных сообщения, совместно используемая всеми сообщениями, после чего следует описание структуры данных сообщения для каждого из десяти типов сообщений, включенных в протокол, отвечающий настоящему изобретению. Далее приведено описание всех структур данных поля, которые используются для построения сообщений, отвечающих настоящему изобретению.
На фиг.5 показана схема иллюстративной структуры данных, которая иллюстрирует основную структуру данных 260 сообщения, используемую для построения десяти сообщений PNRP, отвечающих настоящему изобретению. Можно видеть, что структура данных 260 сообщения содержит ряд полей 2621-N. Согласно предпочтительному варианту осуществления первое поле 2621 зарезервировано для «заголовка PNRP» (PNRP Header). Структура данных 264 поля для каждого из отдельных полей 2621-N, которые используются для построения сообщения 260, включает в себя компонент 266 «тип», компонент 268 «длина» и фактическое содержимое или полезную нагрузку 270 структуры данных 264 поля. Компонент 268 «длина» вычисляется как длина 272 всего поля 264. Таким образом, обеспечивается полная расширяемость протокола.
Сообщение RESOLVE строится в соответствии со структурой данных, отвечающей настоящему изобретению. Из упрощенной схемы структуры данных, показанной на фиг.6, можно видеть, что сообщение 280 RESOLVE построено из ряда полей 282-292. Кроме того, различные поля строятся в соответствии со структурой данных поля, отвечающей настоящему изобретению. Например, поле 282 PNRP_HEADER («заголовок PNRP») содержит структуру данных 294 поля. Компоненты этой структуры данных 294 включают в себя «тип» («ИД поля» (Field ID) 296) и «длину» (Length) 298. Содержимое этой структуры данных 294 PNRP_HEADER включает в себя компонент 300 «протокол» (Protocol), компонент 302 «старшее число версии» (Version Major), компонент 304 «младшее число версии» (Version Minor), компонент 306 «тип сообщения» (Message Type) и компонент 308 «ИД сообщения» (Message ID). Аналогично, поле 288 VALIDATE_PNRP_ID содержит структуру данных 310 поля. Как и структуры данных всех остальных полей, структура данных 310 VALIDATE_PNRP_ID начинается с компонента «тип» («ИД поля» (Field ID) 312) и компонента 314 «длина» (Length). Содержимое этой структуры данных поля включает в себя компонент 316 «ИД Р2Р» (P2P ID) и компонент 318 «местоположение службы» (Service Location). Все эти разные поля построены аналогичным образом, в соответствии с фиг.5, и их описания приведены ниже.
Очевидно, и это будет проиллюстрировано ниже, данное сообщение RESOLVE содержит целевой ИД PNRP, подлежащий разрешению, CPA инициатора RESOLVE, CPA «наилучшего совпадения» и список узлов, обработавших RESOLVE. RESOLVE включает в себя поле «флаги» (Flags). Для подполя «флаги» поля Resolve_Controls («управление разрешением») заданы два флага: RF_SEND_CHAIN - 0x0001, которое требует, чтобы получатель отправил цепь сертификатов (если таковая существует) в ответе AUTHORITY; и RF_IGNORE_NEXTHOP - 0x0004, который используется на пути обратной трассировки RESOLVE. Если узел принимает RESOLVE в порядке обратной трассировки, то отправитель не знает ИД PNRP этого узла. Поле «следующий скачок» устанавливается равным нулю, и устанавливается RF_IGNORE_NEXTHOP, указывающее, что AUTHORITY будет использоваться только для квитирования RESOLVE. Согласно рассмотренному выше прием RESOLVE подтверждается сообщением AUTHORITY. Согласно предпочтительному варианту осуществления настоящего изобретения «тип сообщения» в «заголовке» устанавливается равным 5. Детали структуры данных сообщения RESOLVE, построенного в соответствии с принципами настоящего изобретения, представлены в Таблице 5.
В этой Таблице 5, «Р» - это длина кодированного CPA в байтах, округленная в большую сторону до ближайшей границы двойного слова (DWORD). «А» - это количество элементов в массиве, обеспеченном флагами. Оно не должно превышать значение «максимального количества скачков» (MaxHops).
RESPONSE генерируется, когда RESOLVE достигает узла, имеющего целевой ИД PNRP, или когда размер обеспеченного флагами пути достигает MaxHops сообщения RESOLVE. Когда генерируется RESPONSE, все элементы из соответствующего обеспеченного флагами пути RESOLVE копируются в путь RESPONSE. Сообщения RESPONSE маршрутизируются через все адреса, помеченные в «пути» как «принятые», снизу вверх, пока каждая соответствующая конечная точка сети не обработает RESPONSE и оно не вернется к инициатору RESOLVE. Как описано выше, прием RESPONSE подтверждается сообщением ACK. Согласно предпочтительному варианту осуществления «тип сообщения» в «заголовке» задается равным 6. Детали структуры данных сообщения RESPONSE, построенного в соответствии с принципами настоящего изобретения, представлены в Таблице 6.
В этой Таблице 6, «Р» - это длина кодированного CPA источника в байтах, округленная в большую сторону до ближайшей границы двойного слова. «В» - это количество элементов в массиве конечных точек.
Сообщение SOLICIT требует у получателя объявить некоторые элементы из его кэша отправителю. Отправитель включает CPA, который получатель может добавить в свой кэш. В сообщении ADVERTISE должно быть возвращено «хэшированный одноразовый номер» (HashedNonce). Прием SOLICIT подтверждается сообщением ADVERTISE. Согласно предпочтительному варианту осуществления «тип сообщения» в «заголовке» устанавливается равным 1. Детали структуры данных сообщения SOLICIT, построенного в соответствии с принципами настоящего изобретения, представлены в Таблице 7. В этой таблице «Р» - это длина кодированного CPA источника в байтах, округленная в большую сторону до ближайшей границы двойного слова.
«одноразовый
номер»
Сообщение ADVERTISE генерируется в ответ на SOLICIT. В ADVERTISE перечислены некоторые ИД PNRP из кэша объявляющей стороны. Это позволяет получателю ADVERTISE избирательно запрашивать CPA для заполнения своего кэша. Прием ADVERTISE играет роль подтверждения приема SOLICIT. Никакое подтверждение приема ADVERTISE не генерируется. Любое ADVERTISE, которое не играет роль подтверждения приема SOLICIT, должно быть проигнорировано. Значение «хэшированного одноразового номера» должно быть идентично принятому в сообщении SOLICIT. Узел, принимающий ADVERTISE, должен быть способен удостовериться в действительности «хэшированного одноразового номера». Согласно предпочтительному варианту осуществления «тип сообщения» в «заголовке» устанавливается равным 2. Детали структуры данных сообщения ADVERTISE, построенного в соответствии с принципами настоящего изобретения, представлены в Таблице 8. В этой таблице «А» - это количество элементов массива ИД.
Сообщение REQUEST используется для того, чтобы потребовать у объявляющей стороны распространить подмножество объявленных CPA. «Одноразовый номер» нужно хэшировать и сравнить с «хэшированным одноразовым номером», полученным из исходного SOLICIT. «Массив ИД» содержит ИД PNRP, в отношении которых отправитель желает, чтобы они были распространены обратно отправителю, чтобы он мог получить соответствующие CPA. Прием REQUEST подтверждается сообщением ACK. Согласно предпочтительному варианту осуществления настоящего изобретения «тип сообщения» в «заголовке» устанавливается равным 3. Детали структуры данных сообщения REQUEST, построенного в соответствии с принципами настоящего изобретения, представлены в Таблице 9. В этой таблице «А» - это количество элементов массива ИД.
Сообщение FLOOD используется PNRP для распространения кэшированных CPA на выбранные равноправные устройства. Сообщения FLOOD инициируются в ответ на сообщение REQUEST при добавлении нового CPA на нижний уровень кэша или при обработке отмененного CPA с более ранней версией на нижнем уровне кэша. Сообщения FLOOD содержат список адресов, помогающий предотвратить избыточные FLOOD, так называемый «список распространения» (FloodedList). «Список распространения» содержит адрес отправителя, каждого пункта назначения, на который отправитель намеревается непосредственно передать FLOOD, и адреса любых других узлов PNRP, про которые отправитель знает, что они уже приняли FLOOD. «Список распространения» имеет максимальное количество элементов. По заполнении списка элементы заменяются по принципу «первым вошел - первым вышел» (FIFO). При этом предполагается, что получатели FLOOD с большей вероятностью будут распространять FLOOD «ближним» соседям, чем более удаленным. Прием FLOOD подтверждается сообщением ACK. Поле ValidateID является необязательным. В случае его наличия требуется, чтобы получатель ответил посредством ACK, если CPA с указанным ИД PNRP локально кэширован, а в противном случае - посредством NACK. Согласно предпочтительному варианту осуществления, «тип сообщения» в «заголовке» устанавливается равным 4. Детали структуры данных сообщения FLOOD, построенного в соответствии с принципами настоящего изобретения, представлены в Таблице 10. В этой таблице «Р» - это длина кодированного CPA в байтах, округленная в большую сторону до ближайшей границы двойного слова, а «А» - это количество элементов массива.
Сообщение INQUIRE используется узлами PNRP для осуществления проверки действительности идентификации в отношении выбранных CPA до ввода их в локальный кэш. Проверка действительности идентификации подтверждает, что CPA все еще действителен на своем инициирующем узле, и запрашивает информацию, позволяющую удостоверить полномочие инициирующего узла на регистрацию этого CPA. Для поля «флаги» (Flags) задан один флаг RF_SEND_CHAIN, который требует, чтобы получатель отправил цепь сертификатов (если таковая существует) в сообщении AUTHORITY. Прием INQUIRE подтверждается сообщением AUTHORITY, если ИД PNRP локально зарегистрирован. В противном случае сообщение INQUIRE игнорируется. Согласно предпочтительному варианту осуществления, «тип сообщения» в «заголовке» устанавливается равным 7. Детали структуры данных сообщения INQUIRE, построенного в соответствии с принципами настоящего изобретения, представлены в Таблице 11. Из этой таблицы явствует, что после FLAGS_FIELD имеются дополнительные 2 байта, позволяющие поместить следующее поле на границу двойного слова.
Сообщение AUTHORITY используется для подтверждения или отрицания того факта, что ИД PNRP все еще зарегистрирован на локальном узле, и, в необязательном порядке, обеспечивает цепь сертификатов, позволяющую получателю AUTHORITY удостовериться в том, что узел имеет право зарегистрировать CPA, соответствующий ИД цели. Для поля «флаги» заданы следующие флаги: AF_UNKNOWN_ID - 0x0001, указывающий, что заданный «проверяемый» ИД PNRP не зарегистрирован на этом хосте; AF_INVALID_SOURCE - 0х0002, который не используется; AF_INVALID_BEST_MATCH - 0x0004, который также не используется; AF_REJECT_TOO_BUSY - 0x0008, который действителен только в ответе на RESOLVE и указывает, что хост слишком занят, чтобы принять RESOLVE, и отправителю следует переслать его в другое место для обработки; AF_REJECT_DEADEND - 0x0010, который не используется; AF_REJECT_LOOP - 0x0020, указывающий, что узел уже обработал сообщение RESOLVE и его сюда больше не нужно посылать; AF_TRACIN_ON - 0x0040, используемый только для отладки; AF_REDIRECT - 0x0080, указывающий, что узел не пересылает сообщение RESOLVE, но включил «переводной адрес» в сообщение AUTHORITY; AF_INVALID_REQUEST - 0x0100, указывающий отрицательный результат проверки действительности сообщения RESOLVE, что может произойти, если MaxsHops чрезмерно велико; и AF_CERT_CHAIN - 0x8000, указывающий включение цепи сертификатов, что позволяет удостоверять взаимосвязь между «проверяемым» ИД PNRP и открытым ключом, используемым для подписания CPA.
В поле «проверяемого ИД PNRP» (Validate PNRP ID) содержится ИД, для которого отправлено AUTHORITY. Поле «цепь сертификатов» (Cert Chain) является необязательным. Флаг AF_CERT_CHAIN указывает его наличие или отсутствие. Поле «переводная конечная точка» (Referral Endpoint) также является необязательным. Это поле используется узлом, который не может переслать сообщение RESOLVE, но знает другой узел, на который можно отправить RESOLVE. Поле конечной точки содержит адрес и порт IPv6 для равноправного узла, на который нужно отправить RESOLVE. В настоящее время это поле игнорируется, за исключением того случая, когда узел пытается обнаружить расщепление облака через исходный сервер. Поле «классификатор» (Classifier) содержит строку фактического классификатора, которая является частью «имени равноправного устройства», используемого для создания ИД PNRP. Прием AUTHORITY не подтверждается явным образом. Само AUTHORITY отправляют в качестве подтверждения приема/ответа на сообщения INQUIRE или RESOLVE. При приеме AUTHORITY вне данного контекста его нужно игнорировать. Согласно предпочтительному варианту осуществления «тип сообщения» в «заголовке» устанавливается равным 8. Детали структуры данных сообщения AUTHORITY, построенного в соответствии с принципами настоящего изобретения, представлены в Таблице 12. В этой таблице «С» - это длина кодированной цепи сертификатов в байтах, округленная в большую сторону до ближайшей границы двойного слова, а «S» - это длина строки «классификатор» в байтах.

Сообщение AUTHORITY может быть слишком длинным, поскольку оно содержит «цепь сертификатов» и строку «классификатор». Для облегчения его передачи по сети, его можно в явном виде разбить на несколько фрагментов при отправке. Получатель должен иметь возможность соединить фрагменты до обработки сообщения. В случае разбиения сообщения поля Header и ACKed Header повторяются в каждом фрагменте. Каждый фрагмент также содержит поле Split Control. Значение смещения для поля Split Control изменяется от фрагмента к фрагменту, отражая смещение фрагмента. Значение «размер» (Size) для Split Control - это размер всего сообщения за минусом размеров полей Header, ACKed Header и Split Control. Все фрагменты кроме последнего должны иметь одинаковый размер. В отсутствие разбиения сообщения поле Split Control является необязательным.
Сообщение ACK используется в PNRP, поскольку он является протоколом запроса/ответа. В некоторых случаях использование ACK вместо ответа упрощает протокол. ACK всегда передается по получении сообщений REQUEST, RESPONSE и FLOOD. Другие сообщения квитируются соответствующим типом ответного сообщения. ACK может действовать как ACK или, в случае FLOOD с установленным Validate ID, как NACK, за счет установления в поле «флаги» KF_NACK=1. Согласно предпочтительному варианту осуществления, «тип сообщения» в «заголовке» устанавливают равным 9. Детали структуры данных сообщения ACK, построенного в соответствии с принципами настоящего изобретения, представлены в Таблице 13.

Сообщение REPAIR используется потому, что в некоторых случаях облака PNRP могут испытывать разрыв. Это сообщение используется для проверки на разрыв и инициирования исправления в случае необходимости. REPAIR требует от других узлов, чтобы они распространили REPAIR на другие уровни кэша. Согласно предпочтительному варианту осуществления «тип сообщения» в «заголовке» устанавливают равным 10. Детали структуры данных сообщения REPAIR, построенного в соответствии с принципами настоящего изобретения, представлены в Таблице 14. Из этой таблицы явствует, что после CASHE_LEVEL имеются 2 дополнительных байта, позволяющие поместить следующее поле на границу двойного слова.
Рассмотрев сообщения и их структуры данных, обратимся к элементам сообщения, используемым для построения этих сообщений. Ниже приведено подробное описание байтовых кодов структур, передаваемых в сообщениях PNRP. Передача всех чисел осуществляется в сетевом порядке байтов, и весь текст кодируется до передачи в формате UTF-8, если не указано обратное. Эти элементы сообщения являются строительными блоками для рассмотренных выше сообщений. Основным элементом сообщения является описание поля. Каждый элемент поля должен начинаться на 4-байтовой границе в сообщении. Это значит, что между полями могут быть зазоры.
Элемент MESSAGE_FIELD является описанием поля, которое используется, чтобы гарантировать легкую расширяемость PRNP в будущем. Для каждого набора данных в сообщении он обеспечивает 16-битовый «ИД поля» (Field ID), идентифицирующий тип поля, и 16-битовый счетчик байтов для поля. Детали структуры данных элемента MESSAGE_FIELD, построенного согласно принципам настоящего изобретения, представлены в Таблице 15.
PNRP_HEADER - тип 0х0010, используется в начале всех сообщений PNRP. «Протокол»+«версия» образует 4-байтовый идентификатор, полезный для определения того, действительно ли принятое сообщение предназначено для PNRP. Детали структуры данных элемента PNRP_HEADER, построенного согласно принципам настоящего изобретения, представлены в Таблице 16.
«ИД сообщения» используется в PNRP_HEADER, чтобы узел мог гарантировать, что принятое сообщение, предназначенное быть ответом на сообщение, отправленное узлом, действительно является таким сообщением. Например, пусть узел отправляет сообщение RESOLVE на другой узел. Этот первый узел ожидает приема в ответ сообщения AUTHORITY, как показано на фиг.4. Однако, без какой-либо трассировки или отслеживания ответа на исходное RESOLVE, нет никакой гарантии, что полученное сообщение AUTHORITY является законным, а не подделанным злонамеренным узлом в облаке. Благодаря включению «ИД сообщения» в сообщение RESOLVE узел, генерирующий сообщение AUTHORITY, может включать этот «ИД сообщения» в свой ответ в поле PNRP_HEADER_ACKED, рассмотренное ниже.
PNRP_HEADER_ACKED - тип 0х0018, есть весь заголовок сообщения PNRP, используемый для идентификации квитированного сообщения. Детали структуры данных элемента PNRP_HEADER_ACKED, построенного согласно принципам настоящего изобретения, представлены в Таблице 17.
Элемент IPV6_ENDPOINT - тип 0х0021, используется, поскольку PNRP предназначен для работы в облаках IPv6. Эта структура задает конечную точку сети IPv6. Также имеется флаг, который можно использовать для указания полезности узла в пересылке RESOLVE. «Флаг пути» (Path Flag) используется для указания того, было ли RESOLVE, отправленное по «адресу» (Address), «принято» (Accepted) или «отвергнуто» (Rejected). Кроме того, если «адрес» относится к ближнему соседу, может быть установлен флаг «подозрение» (Suspect), поскольку узел должен знать всех своих ближних соседей. Указатель «адрес удален» (AddressRemoved) используют в процессе отладки, чтобы помечать элемент как удаленный, в действительности не удаляя его. Эти указатели таковы:
PNRP_FLAGGED_ADDRESS_ACCEPTED - 0х01;
PNRP_FLAGGED_ADDRESS_REJECTED - 0х02;
PNRP_FLAGGED_ADDRESS_UNREACHABLE - 0х04;
PNRP_FLAGGED_ADDRESS_LOOP - 0х08;
PNRP_FLAGGED_ADDRESS_TOO_BUSY - 0х10;
PNRP_FLAGGED_ADDRESS_BAD_VALIDATE_ID - 0х20;
PNRP_FLAGGED_ADDRESS_REMOVED - 0х80; и
PNRP_FLAGGED_SUSPECT_UNREGISTERED_ID - 0х40.
Детали структуры данных элемента IPV6_ENDPOINT, построенного согласно принципам настоящего изобретения, представлены в Таблице 18.
Элемент PNRP_ID - тип 0х0030, есть сцепка 128-битового ИД Р2Р (P2P ID) и 128-битового «местоположения службы» (Service Location). Детали структуры данных элемента PNRP_ID, построенного согласно принципам настоящего изобретения, представлены в Таблице 19.
TARGET_PNRP_ID - тип 0х0038, есть ИД цели запроса разрешения или соответствующего ответа. Детали структуры данных элемента TARGET_PNRP_ID, построенного согласно принципам настоящего изобретения, представлены в Таблице 20.
VALIDATE_PNRP_ID - тип 0х0039, есть ИД PNRP, для которого запрашиваются проверка действительности и полномочие. Детали структуры данных элемента VALIDATE_PNRP_ID, построенного согласно принципам настоящего изобретения, представлены в Таблице 21.
FLAGS_FIELD - тип 0х0040 идентифицирует флаги, которые являются битовыми полями, используемыми в зависимости от контекста. Детали структуры данных элемента FLAGS_FIELD, построенного согласно принципам настоящего изобретения, представлены в Таблице 22.
Поле RESOLVE_CONTROLS - тип 0х0041, содержит информацию, подлежащую использованию при обработке RESOLVE или RESPONSE. Флаги используются для указания наличия обратной трассировки RESOLVE или запроса на сообщение AUTHORITY. Флаги включают в себя RF_IGNORE_NEXT_HOP - 0x0001; RF_SEND_CHAIN - 0x0004; RF_DONT_REMOVE_PATH_ENTRIES - 0x0008, который используется только для отладки; и RF_TRACING_ON - 0х0010, который используется только для отладки. Значение Max Hops ограничивает количество скачков до завершения RESOLVE. Значение «код операции» (Operation Code) описывает порядок установления совпадения. Определять наличие совпадения можно только на 128 старших битах (P2P ID) для ЛЮБЫХ (ANY) кодов или с учетом «местоположения службы» (Service Location), а также БЛИЖАЙШИХ (NEAREST) кодов. Коды операции также определяют, следует ли при определении совпадения рассматривать ИД, зарегистрированные в одном и том же узле как инициатор RESOLVE. Коды операций включают в себя:
SEARCH_OPCODE_NONE - 0;
SEARCH_OPCODE_ANY_PEERNAME - 1;
SEARCH_OPCODE_NEAREST_PEERNAME - 2;
SEARCH_OPCODE_NEAREST64_PEERNAME - 4;
SEARCH_OPCODE_UPPER_BITS - 8.
Значение «точность» (Precision) задает точность совпадения ИД равной фактическому количеству битов. Это значение используется, если код операции равен SEARCH_OPCODE_UPPER_BITS.
Значение Reason («причина») используется для указания, отправлено ли RESOLVE в процессе исправления, для поддержания кэша, в процессе регистрации или по запросу приложения. «Причина» принимает следующие значения:
REASON_APP_REQUEST - 0;
REASON_REGISTRATION - 1;
REASON_CACHE_MAINTENANCE - 2;
REASON_REPAIR_DETECTION - 3;
REASON_SYNC_REQUEST - 4;
REASON_CPA_VIA_RESOLVE - 5;
REASON_CPA_VIA_FLOOD - 6;
REASON_REPAIR - 7;
REASON_CPA_VIA_BACK_FLOOD - 8.
Значение «код результата» (Result Code) указывает, почему RESOLVE было завершено и преобразовано в RESPONSE. Оно может указывать успех или неудачу по причине того, что превышен счет скачков, не найден лучший путь или слишком многим соседям не удалось определить местоположение пункта назначения. Эти коды результата включают в себя:
RESULT_NONE - 0;
RESULT_FOUND_MATCH - 1;
RESULT_MAX_HOP_LIMIT_HIT - 2;
RESULT_NO_BETTER_PATH_FOUND - 3;
RESULT_TOO_MANY_MISSES - 4.
Значение «ИД транзакции» (TransID) используется инициатором запроса для корреляции RESPONSE. Инициатор RESOLVE задает значение «ИД транзакции», и узел, инициирующий RESPONSE, дублирует это значение в сообщении RESPONSE. Промежуточные узлы не должны изменять это значение. Детали структуры данных элемента RESOLVE_CONTROLS, построенного согласно принципам настоящего изобретения, представлены в Таблице 23.
Элемент CACHE_LEVEL - тип 0х0042, описывает, какой уровень кэша следует использовать при выполнении REPAIR. Он используется при выполнении исправления расщепленного кэша. Детали структуры данных элемента CACHE_LEVEL, построенного согласно принципам настоящего изобретения, представлены в Таблице 24.
Элемент FLOOD_CONTROLS - тип 0х0043, содержит информацию, подлежащую использованию при обработке FLOOD. Единственный используемый код - это код причины (reason code) отправки FLOOD. Детали структуры данных элемента FLOOD_CONTROLS, построенного согласно принципам настоящего изобретения, представлены в Таблице 25.
CPA_SOURCE - тип 0х0058, есть CPA, используемый в качестве CPA источника в сообщении SOLICIT. CPA кодируется для передачи по сети. Детали структуры данных элемента CPA_SOURCE, построенного согласно принципам настоящего изобретения, представлены в Таблице 26.
Элемент CPA_BEST_MATCH - тип 0х0059, есть CPA, используемый в качестве «наилучшего совпадения» в RESOLVE или RESPONSE. CPA кодируется для передачи по сети. Детали структуры данных элемента CPA_BEST_MATCH, построенного согласно принципам настоящего изобретения, представлены в Таблице 27.
Элемент PNRP_ID_ARRAY - тип 0х0060, содержит идентификаторы ИД PNRP для сообщений ADVERTISE и REQUEST, хранящиеся в массиве. Ниже описаны данные, включая размеры массивов. Детали структуры данных элемента PNRP_ID_ARRAY, построенного согласно принципам настоящего изобретения, представлены в Таблице 28.
IPV6_ENDPOINT_ARRAY - тип 0х0071, есть массив всех посещенных узлов. Распространяемые сообщения посещают различные узлы. В этот массив заносится каждый посещенный узел или узел, на который было передано сообщение. Ниже описаны данные, включая размеры массивов. Детали структуры данных элемента IPV6_ENDPOINT_ARRAY, построенного согласно принципам настоящего изобретения, представлены в Таблице 29.
Элемент IPV6_REFERRAL_ADDRESS - тип 0х0072, есть «конечная точка IPv6», используемая конкретно для обеспечения альтернативного адреса для отправки RESOLVE. Это поле используется в сообщении AUTHORITY, когда узел не хочет пересылать RESOLVE, но желает предоставить адрес, который может попробовать какой-то другой узел. Детали структуры данных элемента IPV6_REFERRAL_ADDRESS, построенного согласно принципам настоящего изобретения, представлены в Таблице 30.
Элемент IPV6_REFERRAL_ID - тип 0х0073, используется совместно с IPV6_REFERRAL_ADDRESS для указания ИД PNRP, используемого для перевода. Детали структуры данных элемента IPV6_REFERRAL_ID, построенного согласно принципам настоящего изобретения, представлены в Таблице 31.
Элемент «цепь сертификатов» (CERT_CHAIN) - тип 0х0080, строится с использованием интерфейса прикладного программирования (API) «Windows CAPI». Сначала, сертификаты, образующие цепь, помещаются в хранилище «сертификатов в памяти» CAPI, а затем экспортируются как хранилище кодированных сертификатов PKCS7. Это экспортированное хранилище отправляют без изменения.
Элемент WCHAR - тип 0х0084 определен для поддержки одного символа UNICODE. Он используется только как часть поля массива UNICODE, например, Classifier («классификатор»).
Элемент CLASSIFIER - тип 0х0085, есть строка «классификатор» UNICODE, которая используется как основа для «имени равноправного устройства» (Peer Name). Он кодируется как массив элементов WCHAR. Детали структуры данных элемента CLASSIFIER, построенного согласно принципам настоящего изобретения, представлены в Таблице 32.
Элемент HASHED_NONCE - тип 0х0092, есть зашифрованное значение Nonce («одноразового номера»), включенное в сообщение ADVERTISE. Предполагается, что получатель имеет ключ для дешифровки «одноразового номера». Детали структуры данных элемента HASHED_NONCE, построенного согласно принципам настоящего изобретения, представлены в Таблице 33.
Элемент NONCE - тип 0х0093, есть дешифрованное значение «одноразового номера», включенное в сообщение REQUEST. Предполагается, что получатель удостоверяется в том, что значение дешифрованного «одноразового номера» совпадает со значением, отправленным до того, как оно было зашифровано. Детали структуры данных элемента NONCE, построенного согласно принципам настоящего изобретения, представлены в Таблице 34.
Элемент SPLIT_CONTROLS - тип 0х0098, используется при отправке длинного сообщения в виде последовательности фрагментов, а не в виде единого сообщения. Каждый фрагмент включает в себя поле Split Controls («управление разбиением»), что позволяет получателю строить сообщение. Детали структуры данных элемента SPLIT_CONTROLS, построенного согласно принципам настоящего изобретения, представлены в Таблице 35.
Элемент PNRP_TRACE - тип 0х0099, используется при отладке, чтобы поддерживать данные, которые можно переносить от скачка к скачку между сообщениями RESOLVE и RESPONSE. Он используется для сохранения данных трассировки. Может не поддерживаться в окончательной версии протокола.
Вышеизложенное описание различных вариантов осуществления изобретения было представлено в целях иллюстрации и описания. Оно не притязает на исчерпывающий характер или ограничение изобретения раскрытыми вариантами осуществления. В свете вышеизложенных принципов возможны многочисленные модификации или вариации. Рассмотренные варианты осуществления были выбраны и описаны, чтобы наилучшим образом проиллюстрировать принципы изобретения и его практические применения, чтобы, таким образом, специалисты в данной области могли использовать изобретение в различных вариантах осуществления и с различными модификациями, которые считаются подходящими для конкретного использования. Все эти модификации и вариации находятся в пределах объема изобретения, определенного прилагаемой формулой изобретения, будучи интерпретированы в соответствии с объемом их явных, законных и справедливых полномочий.
| название | год | авторы | номер документа |
|---|---|---|---|
| ЗАЩИТНАЯ ИНФРАСТРУКТУРА И СПОСОБ ДЛЯ ПРОТОКОЛА РАЗРЕШЕНИЯ РАВНОПРАВНЫХ ИМЕН (PNRP) | 2003 |
|
RU2320008C2 |
| СПОСОБ, СИСТЕМА И УСТРОЙСТВО ДЛЯ ПОДДЕРЖКИ УСЛУГИ HIERARCHICAL MOBILE IP | 2004 |
|
RU2368086C2 |
| ОБНАРУЖЕНИЕ СЕТЕВЫХ УЗЛОВ И МАРШРУТИЗИРУЕМЫХ АДРЕСОВ | 2006 |
|
RU2427894C2 |
| ЭФФЕКТИВНАЯ СВЯЗЬ ДЛЯ УСТРОЙСТВ ДОМАШНЕЙ СЕТИ | 2014 |
|
RU2619694C1 |
| УПРАВЛЕНИЕ РАЗРЫВОМ УСЛУГИ ДЛЯ БЕСПРОВОДНОГО УСТРОЙСТВА | 2018 |
|
RU2749750C1 |
| ЭФФЕКТИВНАЯ СВЯЗЬ ДЛЯ УСТРОЙСТВ ДОМАШНЕЙ СЕТИ | 2020 |
|
RU2721938C1 |
| СПОСОБ РАБОТЫ УЗЛА ИНТЕРФЕЙСА ПОЛЬЗОВАТЕЛЯ В СООТВЕТСТВИИ С РАСПРЕДЕЛЕННОЙ МНОГОВЫХОДОВОЙ СИСТЕМОЙ ПОИСКОВОГО ВЫЗОВА, СПОСОБ РАБОТЫ РАСПРЕДЕЛЕННОЙ МНОГОВЫХОДОВОЙ СИСТЕМЫ ПОИСКОВОГО ВЫЗОВА | 1994 |
|
RU2157596C2 |
| ЭФФЕКТИВНАЯ СВЯЗЬ ДЛЯ УСТРОЙСТВ ДОМАШНЕЙ СЕТИ | 2020 |
|
RU2735238C1 |
| СПОСОБ И СИСТЕМА, ПОЗВОЛЯЮЩИЕ ИЗБЕЖАТЬ ЗАВИСАНИЯ PDP КОНТЕКСТА | 2008 |
|
RU2470483C2 |
| ЭФФЕКТИВНАЯ СВЯЗЬ ДЛЯ УСТРОЙСТВ ДОМАШНЕЙ СЕТИ | 2014 |
|
RU2640728C1 |


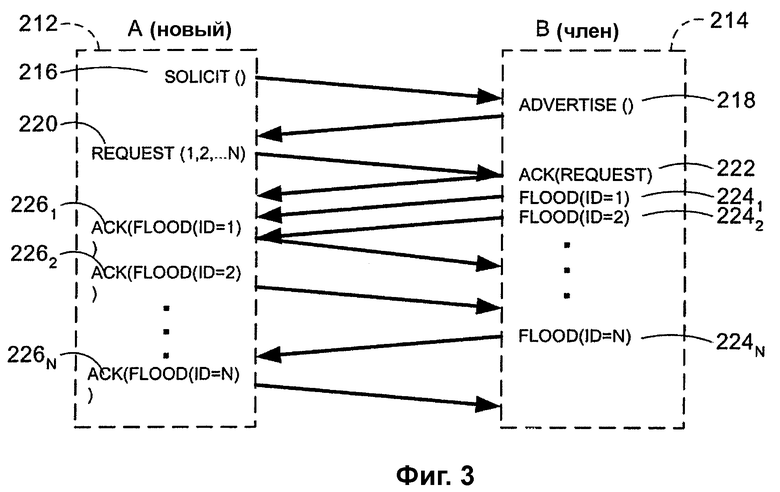

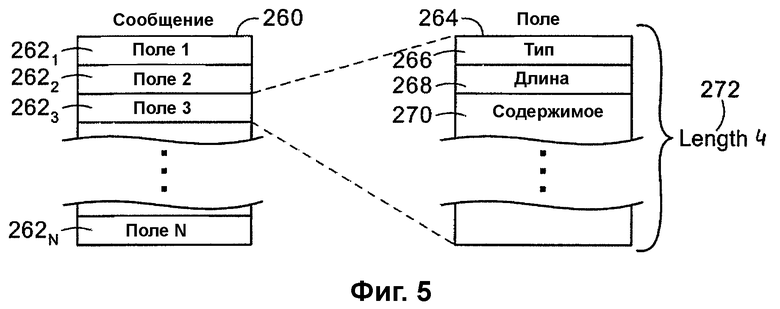
Изобретение относится к протоколам связи в одноранговой инфраструктуре, в частности к расширяемой структуре данных для сообщений в протоколе разрешения имен для соединения равноправных устройств. Техническим результатом является повышение надежности обработки сообщений. В структуре данных сообщений используется ряд полей, каждое из которых содержит элемент сообщения. Предпочтительно первое поле является заголовком сообщения, который включает в себя информацию протокола и идентифицирует тип сообщения. Каждый элемент сообщения содержит ряд полей. Эти поля элемента сообщения включают в себя поле типа, поле длины и содержимое или полезную нагрузку элемента сообщения. Для правильной работы протокола разрешения имен для соединения равноправных устройств (PNRP) формируется, по меньшей мере, десять сообщений, а именно: RESOLVE («разрешение»), RESPONSE («ответ»), SOLICIT («ходатайство»), ADVERTISE («объявление»), REQUEST («запрос»), FLOOD («распространение»), INQUIRE («вопрос»), AUTHORITY («полномочие»), АСК («квитирование»), и REPAIR («исправление»). 5 н. и 42 з.п. ф-лы, 6 ил., 35 табл.
1. Способ предоставления идентификационных данных одноравноправных узлов первому узлу в одноранговой сети, содержащий этапы, на которых:
принимают на втором узле сообщение SOLICIT от первого узла, запрашивающего идентификаторы протокола разрешения имен для соединения равноправных устройств (PNRP), причем сообщение SOLICIT включает в себя по меньшей мере элемент сообщения, относящийся к заголовку, и элемент сообщения, относящийся к хэшированному одноразовому номеру,
генерируют на втором узле сообщение ADVERTISE, причем сообщение ADVERTISE включает в себя по меньшей мере элемент сообщения, относящийся к заголовку из квитированного сообщения, упомянутый элемент сообщения, относящийся к хэшированному одноразовому номеру, и элемент сообщения, относящийся к массиву идентификаторов PNRP, причем элемент сообщения, относящийся к массиву идентификаторов PNRP, включает в себя выбор для распространения из списка идентификаторов PNRP в кэше второго узла, и
посылают сообщение ADVERTISE на первый узел.
2. Способ по п.1, в котором каждый элемент каждого из сообщений SOLICIT и ADVERTISE содержит структуру данных элемента сообщения, содержащую поле идентификации поля, поле длины и полезную нагрузку.
3. Способ по п.2, в котором сообщение SOLICIT дополнительно включает в себя элемент сообщения, относящийся к источнику с сертифицированным адресом равноправного устройства (СРА).
4. Способ по п.3, в котором полезная нагрузка элемента сообщения SOLICIT, относящегося к источнику с СРА, содержит кодированный СРА источника.
5. Способ по п.2, в котором полезная нагрузка элемента сообщения, относящегося к хэшированному одноразовому номеру, содержит зашифрованное значение одноразового номера.
6. Способ по п.2, в котором полезная нагрузка элемента сообщения ADVERTISE, относящегося к заголовку из квитированного сообщения, содержит идентификацию сообщения для квитированного сообщения.
7. Способ по п.2, в котором полезная нагрузка элемента сообщения ADVERTISE, относящегося к массиву идентификаторов PNRP, содержит некоторое количество элементов в массиве идентификаторов PNRP, полную длину массива, идентификатор типа каждого элемента массива, длину каждого элемента массива и массив идентификаторов PNRP.
8. Способ распространения набора сертифицированных адресов равноправных устройств (СРА) на первый узел в одноранговой сети, содержащий этапы, на которых:
принимают на втором узле сообщение REQUEST от первого узла, запрашивающего распространение набора адресов СРА, при этом сообщение REQUEST включает в себя по меньшей мере первый элемент сообщения, относящийся к заголовку, элемент сообщения, относящийся к одноразовому номеру, и элемент сообщения, относящийся к массиву идентификаторов протокола разрешения имен для соединения равноправных устройств (PNRP), причем элемент сообщения, относящийся к массиву идентификаторов PNRP, включает в себя список идентификаторов PNRP, соответствующий упомянутому набору адресов СРА,
генерируют на втором узле сообщение FLOOD для каждого известного идентификатора PNRP из элемента сообщения, относящегося к массиву идентификаторов PNRP, при этом каждый известный идентификатор PNRP соответствует идентификатору PNRP в кэше второго узла, причем сообщение FLOOD включает в себя по меньшей мере второй элемент, относящийся к заголовку, элемент сообщения, относящийся к управлению распространением, соответствующий каждому известному идентификатору PNRP элемент сообщения, относящийся к СРА наилучшего совпадения, и содержащий список распространения элемент сообщения, относящийся к массиву конечных точек IPv6,
посылают сообщение FLOOD на первый узел.
9. Способ по п.8, дополнительно содержащий этапы, на которых
освобождают на втором узле состояние, соответствующее сообщению FLOOD, если от первого узла принято сообщение АСК, причем сообщение АСК включает в себя по меньшей мере третий элемент сообщения, относящийся к заголовку, и элемент сообщения, относящийся к заголовку из квитированного сообщения,
повторно посылают сообщение FLOOD от второго узла на первый узел и переустанавливают период лимита времени ожидания, если период лимита времени ожидания истекает до того, как от первого узла будет принято сообщение АСК, и
освобождают на втором узле упомянутое состояние и удаляют СРА, соответствующий первому узлу, из кэша второго узла, если истекает максимальное количество периодов лимита времени ожидания.
10. Способ по п.8, в котором каждый элемент сообщения каждого из сообщений REQUEST и FLOOD содержит структуру данных элемента сообщения, содержащую поле идентификации поля, поле длины и полезную нагрузку.
11. Способ по п.10, в котором полезная нагрузка элемента сообщения REQUEST, относящегося к одноразовому номеру, содержит дешифрованное значение одноразового номера.
12. Способ по п.10, в котором полезная нагрузка элемента сообщения REQUEST, относящегося к массиву идентификаторов PNRP, содержит некоторое количество элементов в массиве идентификаторов PNRP, полную длину массива, идентификатор типа каждого элемента массива, длину каждого элемента массива и массив идентификаторов PNRP.
13. Способ по п.10, в котором полезная нагрузка элемента сообщения FLOOD, относящегося к управлению распространением, содержит битовое поле для контекстно-зависимых флагов и код причины, описывающий причину инициирования сообщения FLOOD.
14. Способ по п.10, в котором полезная нагрузка элемента сообщения FLOOD, относящегося к СРА наилучшего совпадения, содержит кодированный СРА.
15. Способ по п.10, в котором полезная нагрузка элемента сообщения FLOOD, относящегося к массиву конечных точек IPv6, содержит некоторое количество элементов в массиве, полную длину массива, идентификатор типа каждого элемента массива, длину каждого элемента массива и массив адресов для каждого узла, который был уже посещен или на который было передано сообщение RESPONSE.
16. Способ по п.9, в котором каждый элемент сообщения АСК содержит структуру данных элемента сообщения, содержащую поле идентификации поля, поле длины и полезную нагрузку.
17. Способ по п.16, в котором полезная нагрузка элемента сообщения АСК, относящегося к заголовку из квитированного сообщения, содержит идентификацию сообщения для квитированного сообщения.
18. Способ разрешения целевого идентификатора протокола разрешения имен для соединения равноправных устройств (PNRP) для первого узла в одноранговой сети в сертифицированный адрес равноправного устройства (СРА), содержащий этапы, на которых:
принимают на втором узле сообщение RESOLVE от первого узла, запрашивающего разрешение целевого идентификатора PNRP, при этом сообщение RESOLVE включает в себя по меньшей мере первый элемент сообщения, относящийся к заголовку, элемент сообщения, относящийся к управлению разрешением, соответствующий упомянутому целевому идентификатору PNRP элемент сообщения, относящийся к целевому идентификатору PNRP, первый элемент сообщения, относящийся к проверке действительности идентификации PNRP, элемент сообщения, относящийся к текущему СРА наилучшего совпадения, и элемент сообщения, относящийся к массиву конечных точек IPv6,
генерируют на втором узле сообщение AUTHORITY, при этом сообщение AUTHORITY включает в себя по меньшей мере второй элемент сообщения, относящийся к заголовку, элемент сообщения, относящийся к заголовку из квитированного сообщения, элемент сообщения, относящийся к управлению разбиением, элемент сообщения, относящийся к полю флагов, второй элемент сообщения, относящийся к проверке действительности идентификации PNRP, элемент сообщения, относящийся к цепочке сертификатов, элемент сообщения, относящийся к переводной идентификации IPv6, и элемент сообщения, относящийся к классификатору, и
посылают сообщение AUTHORITY на первый узел.
19. Способ по п.18, в котором каждый элемент каждого из сообщений RESOLVE и AUTHORITY содержит структуру данных элемента сообщения, содержащую поле идентификации поля, поле длины и полезную нагрузку.
20. Способ по п.19, в котором полезная нагрузка элемента сообщения RESOLVE, относящегося к управлению разрешением, содержит битовое поле для контекстно-зависимых флагов, максимальное количество узлов, которые может посетить сообщение RESOLVE, коды операции для управления операцией разрешения, точное число значащих битов, которые должны совпадать, код причины, описывающий причину инициирования RESOLVE, код результата, описывающий причину возвращения ответа, и значение идентификации транзакции.
21. Способ по п.19, в котором полезная нагрузка элемента сообщения RESOLVE, относящегося к целевому идентификатору PNRP, содержит хэш имени равноправного устройства для целевого равноправного устройства и местоположение службы, полученное из объявленного адреса службы.
22. Способ по п.19, в котором полезная нагрузка элемента сообщения RESOLVE, относящегося к проверке действительности идентификации PNRP, содержит хэш имени равноправного устройства для узла, для которого запрошены проверка действительности и полномочие, и местоположение службы, полученное из объявленного адреса службы узла, для которого запрошены проверка действительности и полномочие.
23. Способ по п.19, в котором полезная нагрузка элемента сообщения RESOLVE, относящегося к СРА наилучшего совпадения, содержит кодированный СРА.
24. Способ по п.19, в котором полезная нагрузка элемента сообщения RESOLVE, относящегося к массиву конечных точек IPv6, содержит некоторое количество элементов в массиве, полную длину массива, идентификатор типа каждого элемента массива, длину каждого элемента массива и массив адресов для каждого узла, посещенного сообщением RESPONSE, или на который оно было передано.
25. Способ по п.18, в котором при генерировании на втором узле сообщения AUTHORITY сообщение AUTHORITY разбивают на два или более фрагментированных сообщения, если длина сообщения AUTHORITY превышает максимальную длину.
26. Способ по п.19, в котором полезная нагрузка элемента сообщения AUTHORITY, относящегося к заголовку из квитированного сообщения, содержит идентификацию сообщения для квитированного сообщения.
27. Способ по п.19, в котором полезная нагрузка элемента сообщения AUTHORITY, относящегося к управлению разбиением, содержит информацию о размере фрагментации и смещении фрагментации.
28. Способ по п.19, в котором полезная нагрузка элемента сообщения AUTHORITY, относящегося к полю флагов, содержит битовое поле для контекстно-зависимых флагов.
29. Способ по п.19, в котором полезная нагрузка элемента сообщения AUTHORITY, относящегося к проверке действительности идентификации PNRP, содержит хэш имени равноправного устройства для узла, для которого запрошены проверка действительности и полномочие, и местоположение службы, полученное из объявленного адреса службы узла, для которого запрошены проверка действительности и полномочие.
30. Способ по п.19, в котором полезная нагрузка элемента сообщения AUTHORITY, относящегося к цепочке сертификатов, содержит хранилище кодированных сертификатов PKCS7.
31. Способ по п.19, в котором сообщение AUTHORITY дополнительно включает в себя элемент сообщения, относящийся к переводному адресу IPv6, при этом полезная нагрузка данного элемента сообщения содержит флаг пути для конечной точки узла, номер протокола IP, порт IPv6 и адрес IPv6 в качестве адреса альтернативного узла.
32. Способ по п.19, в котором полезная нагрузка элемента сообщения AUTHORITY, относящегося к переводной идентификации IPv6, содержит хэш имени равноправного устройства и местоположение службы для узла, на который осуществляется перевод.
33. Способ по п.19, в котором полезная нагрузка элемента сообщения AUTHORITY, относящегося к классификатору, содержит строку классификатора Unicode, которая использовалась как основа для имени равноправного устройства, закодированную как массив элементов WCHAR, содержащий некоторое количество элементов в массиве адресов, полную длину массива, идентификатор типа каждого элемента массива, длину каждого элемента массива и массив символов Unicode.
34. Способ по п.18, в котором, если второй узел имеет локально зарегистрированный СРА, соответствующий элементам сообщения RESOLVE,
генерируют на втором узле первое сообщение RESPONSE, содержащее по меньшей мере третий элемент сообщения, относящийся к заголовку, упомянутый элемент сообщения, относящийся к управлению разрешением, упомянутый элемент сообщения, относящийся к целевому идентификатору PNRP, соответствующий локально зарегистрированному СРА элемент сообщения, относящийся к обновленному СРА наилучшего совпадения, и элемент сообщения, относящийся к массиву конечных точек IPv6, и посылают первое сообщение RESPONSE на первый узел.
35. Способ по п.34, в котором каждый элемент сообщения RESPONSE содержит структуру данных элемента сообщения, содержащую поле идентификации поля, поле длины и полезную нагрузку.
36. Способ по п.35, в котором полезная нагрузка элемента сообщения RESPONSE, относящегося к СРА наилучшего совпадения, содержит кодированный СРА.
37. Способ по п.35, в котором полезная нагрузка элемента сообщения RESPONSE, относящегося к массиву конечных точек IPv6, содержит некоторое количество элементов в массиве, полную длину массива, идентификатор типа каждого элемента массива, длину каждого элемента массива и массив адресов для каждого узла, посещенного сообщением RESPONSE, или на который оно было передано.
38. Способ по п.34, в котором, если второй узел не генерирует сообщение RESPONSE,
пересылают сообщение RESOLVE от второго узла на третий узел,
принимают второе сообщение RESPONSE от третьего узла, причем второе сообщение RESPONSE включает в себя соответствующий третьему узлу второй элемент сообщения, относящийся к СРА наилучшего совпадения, и
пересылают второе сообщение RESPONSE на первый узел.
39. Способ проверки действительности идентификации протокола разрешения имен для соединения равноправных устройств (PNRP) для первого узла в одноранговой сети, содержащий этапы, на которых:
принимают на втором узле сообщение INQUIRE от первого узла запрашивающего проверку действительности идентификации PNRP, при этом сообщение INQUIRE включает в себя по меньшей мере первый элемент сообщения, относящийся к заголовку, первый элемент сообщения, относящийся к полю флагов, и соответствующий упомянутому идентификатору PNRP элемент сообщения, относящийся к проверке действительности идентификации PNRP, и
если идентификатор PNRP локально зарегистрирован на втором узле, генерируют на втором узле сообщение AUTHORITY, при этом сообщение AUTHORITY включает в себя по меньшей мере второй элемент сообщения, относящийся к заголовку, элемент сообщения, относящийся к заголовку из квитированного сообщения, элемент сообщения, относящийся к управлению разбиением, второй элемент сообщения, относящийся к полю флагов, упомянутый элемент сообщения, относящийся к проверке действительности идентификации PNRP, элемент сообщения, относящийся к цепочке сертификатов, элемент сообщения, относящийся к переводной идентификации IPv6, и элемент сообщения, относящийся к классификатору, и посылают сообщение AUTHORITY на первый узел.
40. Способ по п.39, в котором каждый элемент сообщения INQUIRE содержит структуру данных элемента сообщения, содержащую поле идентификации поля, поле длины и полезную нагрузку.
41. Способ по п.40, в котором полезная нагрузка элемента сообщения INQUIRE, относящегося к полю флагов, содержит битовое поле для контекстно-зависимых флагов.
42. Способ по п.40, в котором полезная нагрузка элемента сообщения INQUIRE, относящегося к проверке действительности идентификации PNRP, содержит хэш имени равноправного устройства для узла, для которого запрошены проверка действительности и полномочие, и местоположение службы, полученное из объявленного адреса службы узла, для которого запрошены проверка действительности и полномочие.
43. Способ слияния расщепленного облака в одноранговой сети, причем облако представляет собой группу сетевых узлов, которые доступны друг для друга, содержащий этапы, на которых:
принимают на первом узле сообщение REPAIR, причем сообщение REPAIR включает в себя по меньшей мере первый элемент сообщения, относящийся к заголовку, первый элемент сообщения, относящийся к целевому идентификатору протокола разрешения имен для соединения равноправных устройств (PNRP), элемент сообщения, относящийся к уровню кэша, подлежащему использованию для исправления, и первый элемент сообщения, относящийся к конечной точке IPv6,
находят на первом узле ближайший локально зарегистрированный идентификатор PNRP, причем этот ближайший локально зарегистрированный идентификатор PNRP является локально зарегистрированным идентификатором PNRP, который наиболее близок численно к первому целевому идентификатору PNRP, соответствующему первому элементу сообщения, относящемуся к целевому идентификатору PNRP,
увеличивают упомянутый ближайший локально зарегистрированный идентификатор PNRP на единицу и
посылают сообщение RESOLVE по IP-адресу сообщения REPAIR, при этом сообщение RESOLVE включает в себя по меньшей мере второй элемент сообщения, относящийся к заголовку, элемент сообщения, относящийся к управлению разрешением, соответствующий увеличенному ближайшему локально зарегистрированному идентификатору PNRP элемент сообщения, относящийся к обновленному целевому идентификатору PNRP, элемент сообщения, относящийся к проверке действительности идентификации PNRP, первый элемент сообщения, относящийся к текущему сертифицированному адресу равноправного устройства (СРА) наилучшего совпадения, и второй элемент сообщения, относящийся к массиву конечных точек IPv6.
44. Способ по п.43, дополнительно содержащий этапы, на которых
принимают на первом узле сообщение RESPONSE, включающее в себя по меньшей мере третий элемент сообщения, относящийся к заголовку, упомянутый элемент сообщения, относящийся к управлению разрешением, упомянутый элемент сообщения, относящийся к обновленному целевому идентификатору PNRP, элемент сообщения, относящийся к обновленному СРА наилучшего совпадения, и элемент сообщения, относящийся к обновленному массиву конечных точек IPv6,
посылают сообщение FLOOD на одно или более выбранных равноправных устройств, если новый узел, соответствующий упомянутому элементу сообщения, относящемуся к обновленному СРА наилучшего совпадения, находится на самом нижнем уровне кэша первого узла, при этом сообщение FLOOD включает в себя по меньшей мере четвертый элемент сообщения, относящийся к заголовку, элемент сообщения, относящийся к управлению распространением, упомянутый элемент сообщения, относящийся к обновленному СРА наилучшего совпадения, и третий элемент сообщения, относящийся к массиву конечных точек IPv6,
посылают сообщение REPAIR на все объекты с уровня кэша, подлежащего использованию при исправлении, первого узла, соответствующего упомянутому элементу сообщения, относящемуся к уровню кэша, подлежащему использованию при исправлении, если упомянутый новый узел численно ближе к первому целевому идентификатору PNRP, чем другие узлы, известные первому узлу, и
посылают сообщение REPAIR на упомянутый новый узел, если этот новый узел численно дальше от первого целевого идентификатора PNRP, чем другие узлы, известные первому узлу.
45. Способ по п.43, в котором каждый элемент сообщения REPAIR содержит структуру данных элемента сообщения, содержащую поле идентификации поля, поле длины и полезную нагрузку.
46. Способ по п.45, в котором полезная нагрузка элемента сообщения REPAIR, относящегося к целевому идентификатору PNRP, содержит хэш имени равноправного устройства для целевого равноправного устройства и местоположение службы, полученное из объявленного адреса службы.
47. Способ по п.45, в котором полезная нагрузка элемента сообщения REPAIR, относящегося к уровню кэша, содержит номер уровня кэша, идентифицирующий уровень кэша, подлежащий использованию при выполнении исправления.
| СПОСОБ ОБНАРУЖЕНИЯ УДАЛЕННЫХ АТАК В КОМПЬЮТЕРНОЙ СЕТИ | 2000 |
|
RU2179738C2 |
| СПОСОБ ПРЕДОСТАВЛЕНИЯ ПОЛЬЗОВАТЕЛЯМ ТЕЛЕКОММУНИКАЦИОННОЙ СЕТИ ДОСТУПА К ОБЪЕКТАМ | 1998 |
|
RU2169437C1 |
| НОСИТЕЛЬ ЗАПИСИ, СПОСОБ И УСТРОЙСТВО ДЛЯ ЗАПИСИ ИНФОРМАЦИОННЫХ ФАЙЛОВ И УСТРОЙСТВО ДЛЯ ВОСПРОИЗВЕДЕНИЯ ИНФОРМАЦИИ С ТАКОГО НОСИТЕЛЯ ЗАПИСИ | 1991 |
|
RU2073913C1 |
| US 5633933 A, 27.05.1997 | |||
| US 6249873 A, 19.06.2001. | |||

