Описание
Область техники, к которой относится изобретение
Настоящее изобретение в целом относится к связи, а более конкретно, к методикам разбора (или демультиплексирования) данных на множество потоков в системе связи.
Уровень техники
Система связи со многими входами и выходами (MIMO) применяет множество (T) передающих антенн на передающем объекте и множество (R) приемных антенн на принимающем объекте для передачи данных. Канал MIMO, образованный T передающими антеннами и R приемными антеннами, может быть разложен на S пространственных каналов, где S≤min {T, R}. S пространственных каналов могут быть использованы для передачи данных таким способом, чтобы достигать более высокую общую пропускную способность и/или большую надежность.
S пространственных каналов могут испытывать разные канальные условия (например, разное замирание, многолучевое распространение и влияния помех) и могут обеспечивать разные отношения уровня сигнала к совокупному уровню взаимных помех и шумов (SNR). SNR каждого пространственного канала определяет его пропускную способность передачи, которая обычно измеряется определенной скоростью передачи данных, которые могут быть надежно переданы по пространственному каналу. Если SNR меняется от пространственного канала к пространственному каналу, то поддерживаемая скорость передачи данных также меняется от канала к каналу. Кроме того, если канальные условия меняются со временем, то скорости передачи данных, поддерживаемые пространственными каналами, также меняются со временем.
Главной проблемой в кодированной системе MIMO является разбор данных на множество потоков таким образом, чтобы для всех потоков могла достигаться хорошая производительность. Этот разбор усложняется, если могут использоваться разные скорости передачи данных для разных потоков, и эти потоки могут переносить различное количество бит в заданный временной интервал. Разбор дополнительно усложняется, если разные скорости передачи данных ассоциативно связываются с разными шаблонами исключения, как описано ниже.
Следовательно, имеется потребность в данной области техники в методиках для разбора данных на множество потоков с разными скоростями передачи данных.
Сущность изобретения
Далее описываются методики для разбора данных на множество потоков с индивидуально выбираемыми скоростями передачи данных. Разные скорости передачи данных могут достигаться с разными сочетаниями схемы модуляции и кодовой скорости. Разные кодовые скорости могут быть получены путем использования базового кода для формирования фиксированного количества кодовых бит и затем исключения (или удаления) стольких кодовых бит, сколько необходимо для достижения нужных кодовых скоростей. Каждая кодовая скорость затем ассоциативно связывается с определенным шаблоном исключения, используемым для исключения кодовых бит.
На передающем объекте кодирующее устройство кодирует данные трафика в соответствии с базовым кодом (например, двоичным сверточным кодом скорости 1/2) и формирует кодовые биты. Анализатор затем разбирает кодовые биты на множество (М) потоков исходя из последовательности разбора, которая указывает порядок для разбора кодовых бит на М потоков. Последовательность разбора формируется для (1) достижения кратчайших возможных серий кодовых бит для каждого потока и (2) распределения серий кодовых бит равномерно или почти равномерно по M потокам. Кратчайшие возможные серии для каждого потока диктуются производительностью кодирования и часто определяются шаблоном исключения, используемым для того потока.
В варианте осуществления для разбора данных схема модуляции и кодовая скорость для каждого потока изначально определяются исходя из скорости передачи данных, выбранной для такого потока. Схемы модуляции и кодовые скорости для всех M потоков используются для определения цикла разбора и количества циклов исключения для каждого потока в цикле разбора. Цикл разбора является интервалом, в котором выполняется разбор, а цикл исключения является одним моментом времени шаблона исключения. Последовательность циклов исключения формируется для М потоков из условия, чтобы для каждого потока с множеством циклов исключения множество циклов исключения для этого потока распределялись по последовательности равномерно или почти равномерно. Ниже описываются несколько схем для распределения циклов исключения для каждого потока по последовательности. Кодовые биты от кодирующего устройства затем разбираются на М потоков исходя из последовательности циклов исключения, один цикл исключения за раз и в порядке, указанном последовательностью. Кодовые биты в каждом потоке дополнительно исключаются на основе шаблона исключения для такого потока. Затем М потоков обрабатываются (например, перемежаются, посимвольно преобразуются и т.д.) для передачи через множество каналов передачи (например, множество пространственных каналов).
Принимающий объект выполняет обратное восстановление множества потоков способом, дополнительным к разбору, выполненному передающим объектом. Различные аспекты и варианты осуществления изобретения описываются более подробно далее.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг.1 иллюстрирует блок-схему передающего объекта и принимающего объекта.
Фиг.2 иллюстрирует процессор передаваемых (TX) данных в передающем объекте.
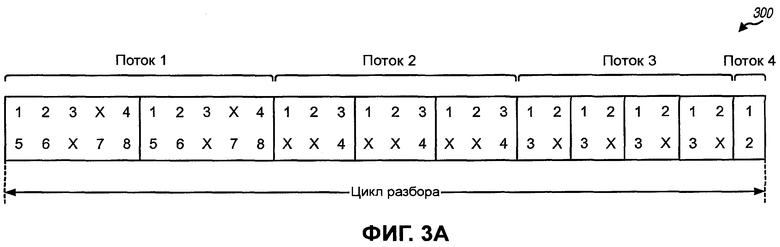
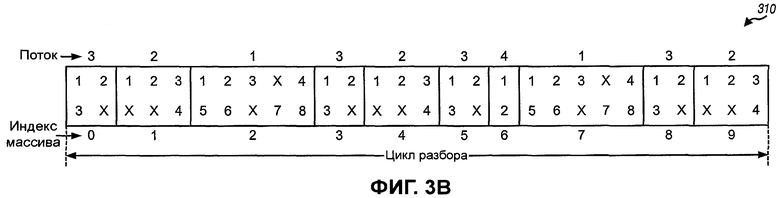
Фиг.3A и 3B иллюстрируют две последовательности циклов исключения, сформированные на основе двух разных схем разбора.
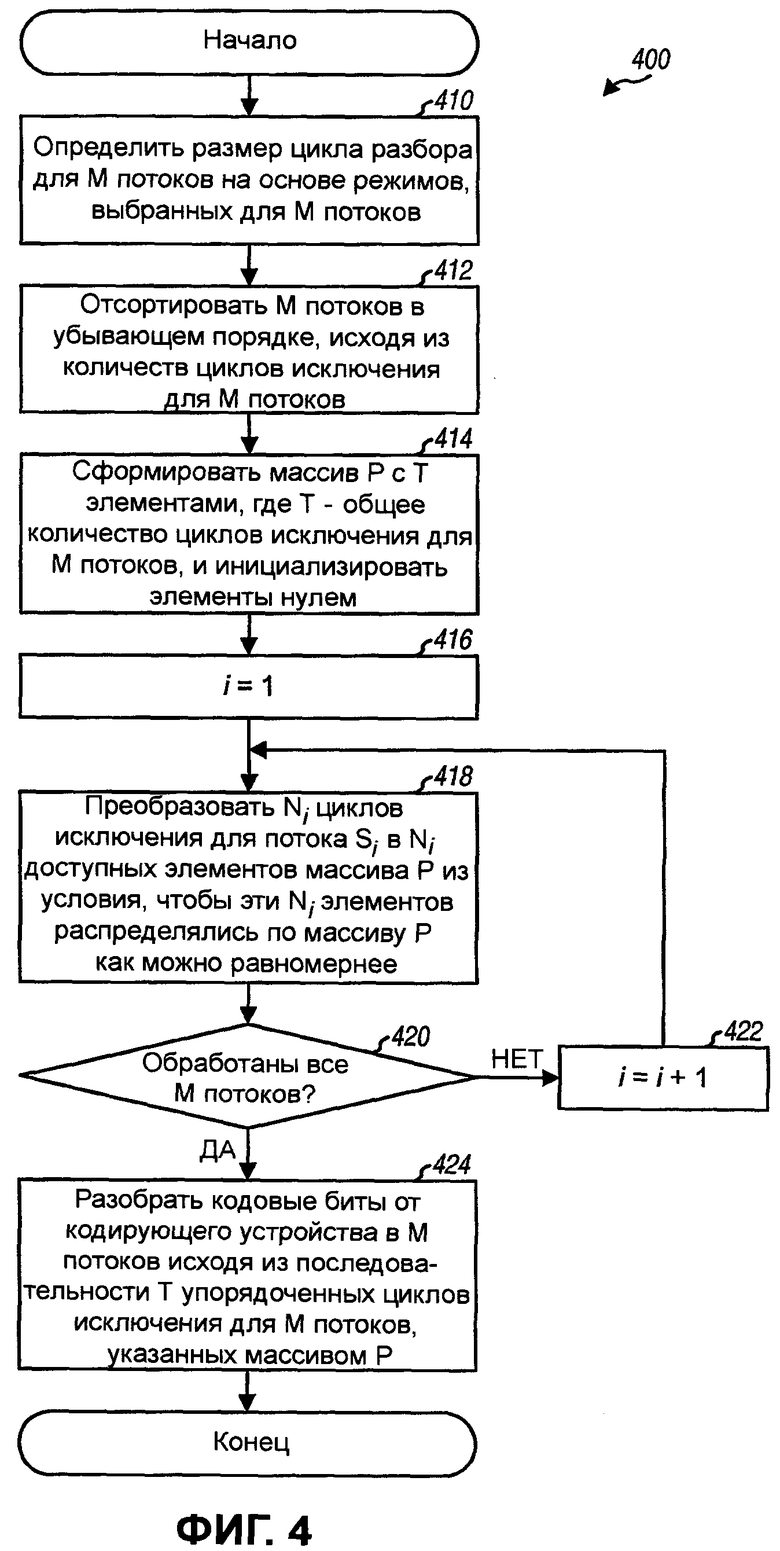
Фиг.4 иллюстрирует процесс для выполнения разбора с циклами исключения для каждого потока, распределенными равномерно по циклу разбора.
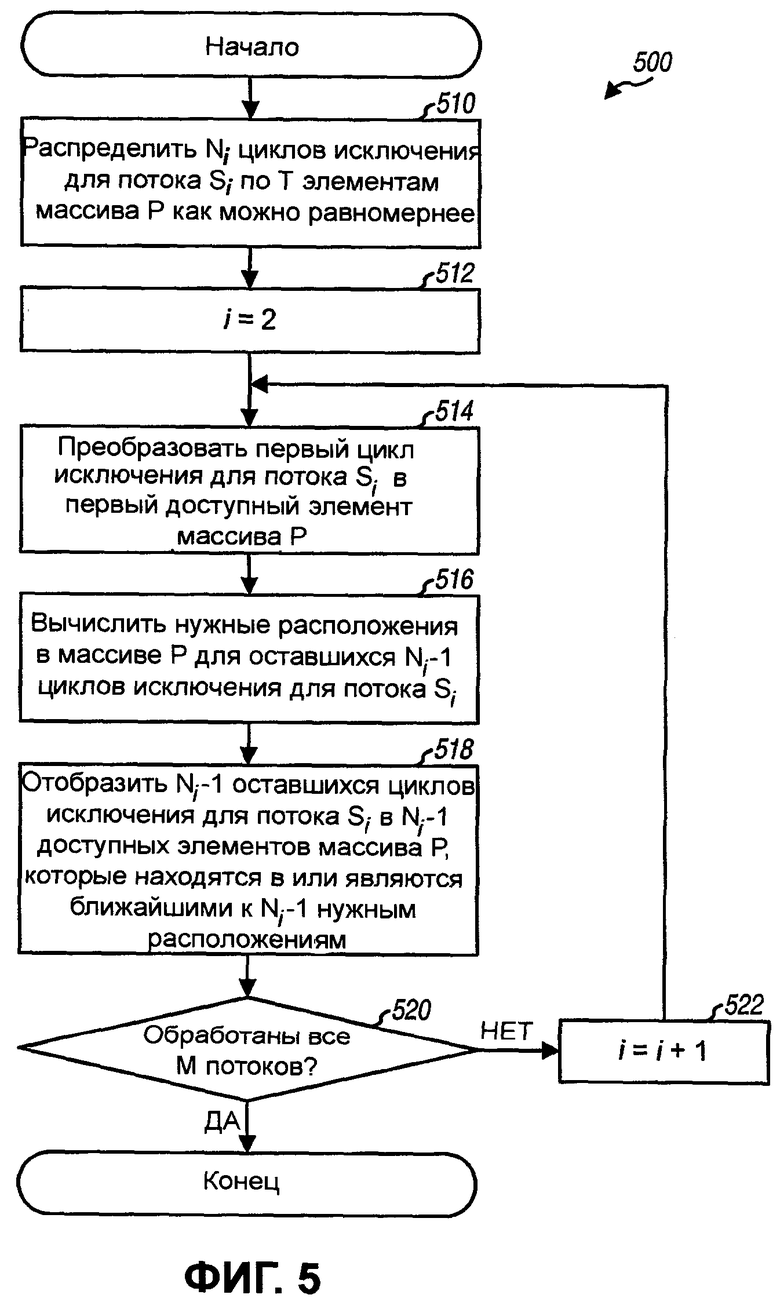
Фиг.5 иллюстрирует вариант осуществления для формирования последовательности циклов исключения.
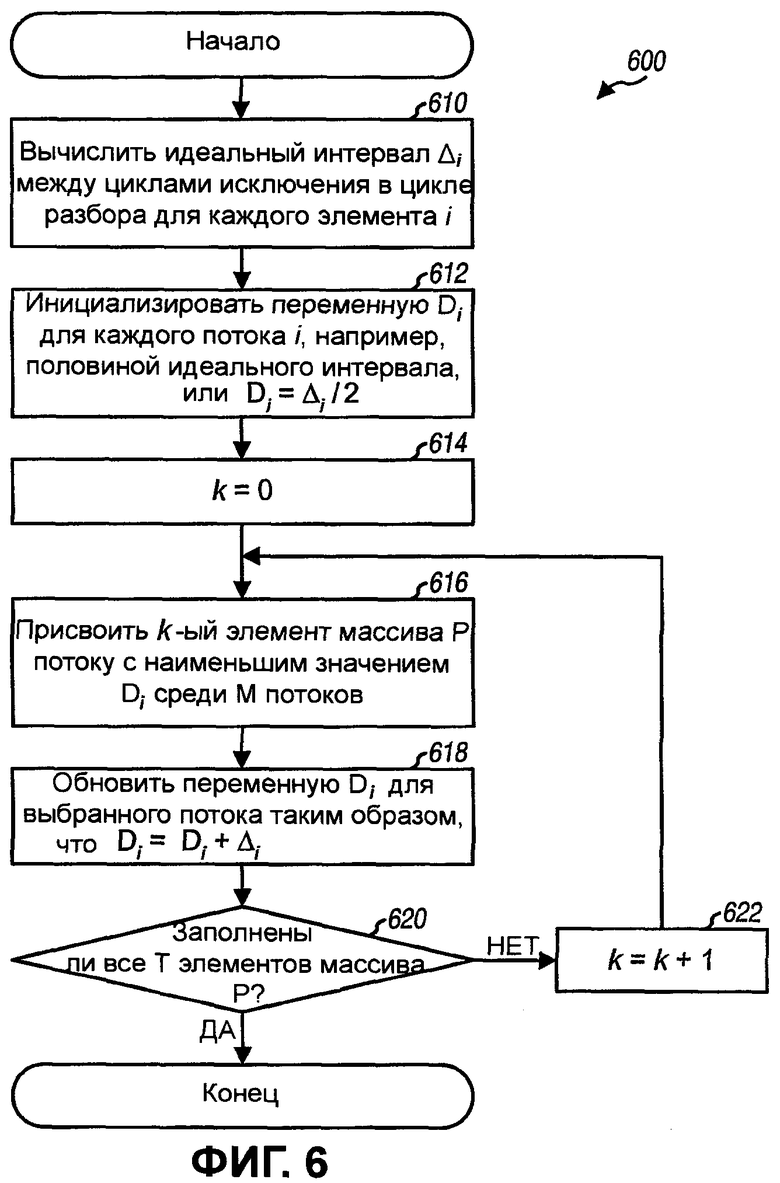
Фиг.6 иллюстрирует другой вариант осуществления для формирования последовательности циклов исключения.
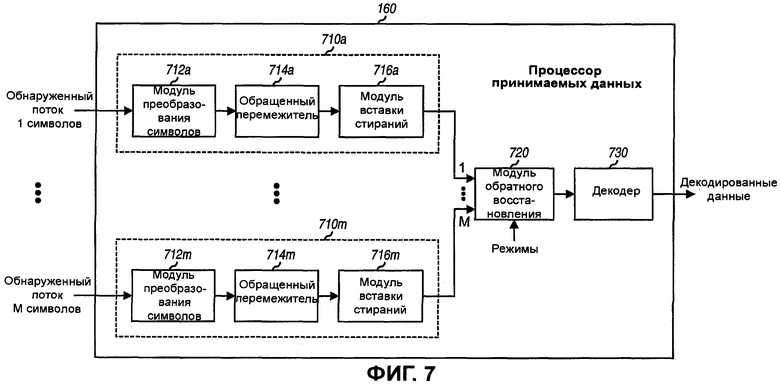
Фиг.7 иллюстрирует процессор принимаемых (RX) данных в принимающем объекте.
Осуществление изобретения
Термин «типовой» используется в данном документе, чтобы обозначать «служащий в качестве примера, отдельного случая или иллюстрации». Любой вариант осуществления, описанный в этом документе как «типовой», не должен быть обязательно истолкован как предпочтительный или преимущественный перед другими вариантами осуществления.
Методики разбора, описанные в этом документе, могут использоваться для различных беспроводных и проводных систем связи, допускающих передачу множества потоков данных одновременно. Например, эти методики могут использоваться для системы MIMO, системы мультиплексирования с ортогональным частотным разделением каналов (OFDM), системы MIMO, которая использует OFDM (т.е. системы MIMO-OFDM) и т.д. OFDM является методикой модуляции с множеством несущих, которая эффективно разделяет общую полосу пропускания системы на множество ортогональных поддиапазонов частот, которые также называются тонами, поднесущими, элементами дискретизации и частотными каналами. С помощью OFDM каждый поддиапазон ассоциативно связывается с соответствующей поднесущей, которая может модулироваться с данными. Для ясности, методики разбора описываются ниже для типовой системы MIMO.
Фиг.1 иллюстрирует блок-схему передающего объекта 110 и принимающего объекта 150 в системе 100 MIMO. Передающий объект 110 может быть точкой доступа или терминалом пользователя. Принимающий объект 150 также может быть точкой доступа или терминалом пользователя.
На передающем объекте 110 процессор 120 передаваемых данных принимает данные трафика от источника данных 112, кодирует данные трафика для формирования кодовых бит и разбирает кодовые биты на множество (М) потоков. Процессор 120 передаваемых данных дополнительно обрабатывает (например, исключает, перемежает и посимвольно преобразует) каждый поток кодовых бит для формирования соответствующего потока символов модуляции. Пространственный процессор 122 передачи принимает М потоков символов модуляции от процессора 120 передаваемых данных, мультиплексирует в контрольные символы, выполняет пространственную обработку в случае необходимости и предоставляет Т потоков символов передачи Т модулям 124a-124t передатчика (TMTR). Каждый модуль 124 передатчика выполняет модуляцию OFDM (если возможно) для формирования символов данных и дополнительно обрабатывает (например, преобразует в аналоговую форму, усиливает, фильтрует и преобразует с повышением частоты) свои символы данных для формирования модулированного сигнала. Модули 124a-124t передатчика предоставляют Т модулированных сигналов для передачи от Т антенн 126a-126t соответственно.
На принимающем объекте 150 R антенн 152a-152r принимают Т переданных сигналов, и каждая антенна 152 предоставляет принятый сигнал соответствующему модулю 154 приемника (RCVR). Каждый модуль 154 приемника обрабатывает свой принятый сигнал и предоставляет поток принятых символов пространственному процессору 156 приема. Пространственный процессор 156 приема выполняет пространственную обработку приемника (или пространственную согласованную фильтрацию) принятых символов от всех R модулей 154 приемника и предоставляет М потоков обнаруженных символов, которые являются оценками символов модуляции, отправленных передающим объектом 110. Процессор 160 принимаемых данных затем обрабатывает М потоков обнаруженных символов и предоставляет декодированные данные приемнику 162 данных.
Контроллеры 130 и 170 управляют работой блоков обработки на передающем объекте 110 и принимающем объекте 150 соответственно. Запоминающие устройства 132 и 172 хранят данные и/или программные коды, используемые контроллерами 130 и 170 соответственно.
Фиг.2 иллюстрирует блок-схему варианта осуществления процессора 120 передаваемых данных на передающем объекте 110. Внутри процессора 120 передаваемых данных кодирующее устройство 210 кодирует данные трафика в соответствии со схемой кодирования и формирует кодовые биты. Схема кодирования может включать в себя сверточный код, турбо-код, код с разреженным контролем четности (LDPC), код контроля циклическим избыточным кодом (CRC), блочный код и т.д., либо их сочетание. В одном варианте осуществления кодирующее устройство 210 реализует устройство двоичного сверточного кодирования скорости 1/2, которое формирует два кодовых бита для каждого бита данных. Анализатор 220 принимает кодовые биты от кодирующего устройства 210 и разбирает кодовые биты на М потоков, как описано далее.
М процессоров 230a-230m потоков принимают М потоков кодовых бит от анализатора 220. Каждый процессор 230 потоков включает в себя модуль 232 исключения, перемежитель 234 и модуль 236 символьного преобразования. Модуль 232 исключения исключает (или удаляет) столько кодовых бит в его потоке, сколько необходимо для достижения требуемой кодовой скорости для потока. Например, если кодирующее устройство 210 является устройством сверточного кодирования скорости 1/2, то кодовые скорости выше, чем 1/2, могут быть получены путем удаления некоторых кодовых бит от кодирующего устройства 210. Перемежитель 234 перемежает (или переупорядочивает) кодовые биты от модуля 232 исключения на основе схемы перемежения. Перемежение обеспечивает временное, частотное и/или пространственное разнесение для кодовых бит. Модуль 236 символьного преобразования преобразует перемеженные биты в соответствии со схемой модуляции и предоставляет символы модуляции. Преобразование символов может достигаться посредством (1) группирования множеств из B бит для образования В-разрядных значений, где B ≥ 1, и (2) преобразования каждого В-разрядного значения в точку на сигнальной группе, соответствующей схеме модуляции. Каждая преобразованная сигнальная точка является комплексной величиной и соответствует символу модуляции. М процессоров 230a-230m потоков предоставляют М потоков символов модуляции пространственному процессору 122 передачи. Кодирование, разбор, исключение, перемежение и преобразование символов могут выполняться на основе управляющих сигналов, предоставленных контроллером 130.
Система 100 может поддерживать множество режимов для передачи данных. В таблице 1 перечислено типовое множество из 14 режимов, которые обозначены индексами режимов с 1 по 14. Каждый режим связан с конкретной скоростью передачи данных или спектральной эффективностью (Spec Eff), конкретной кодовой скоростью и конкретной схемой модуляции (Mod). В Таблице 1 BPSK обозначает двухпозиционную фазовую манипуляцию, QPSK обозначает квадратурную фазовую манипуляцию и QAM обозначает квадратурную амплитудную модуляцию. Скорость передачи данных для каждого режима определяется кодовой скоростью и схемой модуляции для этого режима, и может задаваться в единицах информационных бит на символ модуляции. Число кодовых бит на символ модуляции (bits/sym) также задается для каждого режима в Таблице 1. Кодовая скорость и схема модуляции для каждого режима в Таблице 1 предназначены для определенной конструкции.
модуляции
Как показано в Таблице 1, семь разных кодовых скоростей используются для 14 поддерживаемых режимов. Каждая кодовая скорость выше, чем скорость 1/2, может достигаться путем исключения некоторых из кодовых бит скорости 1/2 от кодирующего устройства 210 исходя из определенного шаблона исключения. Таблица 2 перечисляет типовые шаблоны исключения для семи разных кодовых скоростей, заданных в Таблице 1, для конкретного сверточного кода с длиной кодового ограничения k=7. Эти шаблоны исключения обеспечивают хорошую производительность для этого сверточного кода и идентифицируются на основе компьютерного моделирования. Другие шаблоны исключения также могут использоваться для поддерживаемых кодовых скоростей для этого сверточного кода, а также для других сверточных кодов такой же или иной длиной кодового ограничения.
Для кодовой скорости m/n имеются n кодовых бит для каждых m бит данных. Устройство 210 сверточного кодирования скорости 1/2 формирует 2m кодовых бит для каждых m бит данных. Для получения кодовой скорости m/n модуль 232 исключения выводит n кодовых бит для каждого множества из 2m кодовых бит от кодирующего устройства 210. Соответственно, модуль 232 исключения удаляет 2m-n кодовых бит из каждого множества из 2m кодовых бит от кодирующего устройства 210 для получения n кодовых бит для кодовой скорости m/n. Кодовые биты, которые необходимо удалить из каждого множества, обозначаются нулями («0») в шаблоне исключения. Например, для получения кодовой скорости 7/12 два кодовых бита удаляются из каждого множества из 14 кодовых бит от кодирующего устройства 210, причем удаленные биты являются 8-ым и 14-ым битами во множестве, что обозначается шаблоном исключения «11111110111110». Если требуемая кодовая скорость равна 1/2, никакого исключения не выполняется.
Режим, выбранный для каждого потока, определяет кодовую скорость для этого потока, которая, в свою очередь, определяет шаблон исключения для потока. Если для разных потоков могут выбираться разные режимы, то могут использоваться вплоть до М разных шаблонов исключения для М потоков.
Анализатор 220 разбирает кодовые биты от кодирующего устройства 210 на М потоков таким образом, чтобы достичь следующих целей.
• Смешивать кодовые биты от кодирующего устройства 210 по М потокам как можно больше, для того чтобы наименьшая возможная серия (или кластер) кодовых бит отправлялась каждому потоку.
• Поддерживать разные режимы для М потоков.
Анализатор 220 выполняет разбор на группе кодовых бит от кодирующего устройства 210. Цикл разбора является наименьшим интервалом, на котором выполняется разбор, и соответствует одной группе кодовых бит от кодирующего устройства 210. Размер цикла разбора (или количество кодовых бит в каждой группе) определяется режимами, использованными для М потоков, и выбирается из условия, чтобы для каждого из М потоков формировалось одинаковое количество символов модуляции. Как показано на фиг.2, исключение выполняется после разбора для того, чтобы полностью поддерживать использование разного режима для каждого потока. Размер цикла разбора, таким образом, дополнительно выбирается, чтобы включать в себя целое число циклов исключения для каждого из М потоков для того, чтобы исключение могло правильно выполняться для каждого потока. Цикл разбора включает в себя, по меньшей мере, один цикл исключения для каждого из М потоков.
Для ясности далее описывается разбор для конкретного примера. Для этого примера M=4 и четыре потока передаются с режимами, заданными в Таблице 3. В этом примере цикл разбора включает в себя достаточное количество кодовых бит от кодирующего устройства 210 для формирования двух символов модуляции для каждого из четырех потоков. Для потока 1 используются два цикла исключения для шаблона исключения «1110111011» скорости 5/8, чтобы получать 16 кодовых бит для двух символов модуляции 256-QAM. Для потока 2 используются три цикла исключения для шаблона исключения «111001» скорости 3/4, чтобы получать 12 кодовых бит для двух символов модуляции 64-QAM. Для потока 3 используются четыре цикла исключения для шаблона исключения «1110» скорости 2/3, чтобы получать 12 кодовых бит для двух символов модуляции 64-QAM. Для потока 4 используется один цикл исключения для шаблона исключения «11» скорости 1/2, чтобы получать 2 кодовых бита для двух символов модуляции BPSK. Цикл разбора включает в себя 56 кодовых бит от кодирующего устройства 210.
Фиг.3А иллюстрирует последовательность 300 циклов исключения, сформированную на основе индекса потока. Для последовательности 300 анализатор 220 предоставляет потоку 1 первые 20 кодовых бит в цикле разбора, затем следующие 18 кодовых бит потоку 2, затем следующие 16 кодовых бит потоку 3, затем последние 2 кодовых бита в цикле разбора потоку 4. Последовательность 300 легко сформировать, но она не обеспечивает хорошего смешивания кодовых бит по четырем потокам, так как циклы исключения, а отсюда и кодовые биты, для каждого потока следуют друг за другом в цикле разбора.
Улучшенное смешивание может достигаться путем распределения циклов исключения для каждого потока как можно равномернее по циклу разбора. Распределение циклов исключения по циклу разбора может достигаться различными способами. В последующем описании различные процессы сначала описываются, в общем, для М потоков с индивидуально выбираемыми режимами, а затем описываются конкретно для примера с четырьмя потоками, заданными в Таблице 3.
Фиг.4 показывает процесс 400 для выполнения разбора с циклами исключения для каждого потока, распределенными равномерно по циклу разбора. В начале размер цикла разбора для М потоков определяется на основе режимов, выбранных для М потоков (этап 410). Режим, выбранный для каждого потока, указывает (1) кодовую скорость для потока, которая определяет шаблон исключения для потока, и (2) схему модуляции для потока, которая определяет количество кодовых бит на символ модуляции (bits/sym). Размер цикла разбора может определяться следующим образом. Сначала определяется количество выходных кодовых бит на шаблон исключения (bits/pc) для каждого потока путем подсчета числа единиц («1») в шаблоне исключения для этого потока, как показано в Таблице 2. Количество циклов исключения на символ модуляции (pc/sym) определяется затем для каждого потока как целочисленное отношение bits/sym к bits/pc. Отношение pc/sym для каждого потока затем уменьшается, с тем чтобы знаменатель был как можно меньшим целым. Затем определяется наименьший общий знаменатель для уменьшенных отношений pc/sym для всех М потоков. Отношение pc/sym для каждого потока затем представляется с использованием наименьшего общего знаменателя. Числители для M отношений тогда указывают количество циклов исключения для М потоков для одного цикла разбора. Ниже описывается пример для определения цикла разбора.
М потоков затем сортируются на основе количества циклов исключения для каждого потока, например, в убывающем порядке от потока с наибольшим количеством циклов исключения к потоку с наименьшим количеством циклов исключения (этап 412). М отсортированных потоков обозначаются как S1, S2, …, SM и имеют N1, N2, …, NM циклов исключения на цикл разбора соответственно, где N1≥N2≥…≥NM после сортировки.
Образуется массив Р с Т элементами (этап 414), где Т - общее количество циклов исключения для всех М потоков в цикле разбора. Т может вычисляться следующим образом:
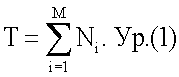
Т элементов из массива Р инициализируются путем установки каждого элемента в ноль (также этап 414). Индекс i инициализируется в 1 для первого потока (этап 416).
Ni циклов исключения для потока Si затем преобразуются в Ni доступных элементов массива Р из условия, чтобы эти Ni элементов распределялись как можно равномернее по массиву Р (этап 418). Это преобразование может достигаться различными способами, как описано ниже. Каждый из Ni преобразованных элементов соответствует одному циклу исключения для потока Si. Затем выполняет определение, обработаны ли все М потоков (этап 420). Если ответ «Нет», то индекс i увеличивается (этап 422), и процесс возвращается к этапу 418 для обработки следующего потока. В противном случае, если все М потоков обработаны, то массив Р представляет последовательность с окончательным упорядочением Т циклов исключения для М потоков, где Ni циклов исключения для каждого потока Si распределяются как можно равномернее по циклу разбора/последовательности. Кодовые биты от кодирующего устройства 210 затем разбираются на М потоков исходя из последовательности Т упорядоченных циклов исключения для М потоков, как описано ниже (этап 424). Затем процесс 400 завершается.
Фиг.5 показывает процесс 500 для формирования последовательности циклов исключения для М потоков. Процесс 500 является одним вариантом осуществления этапов 416-422 на фиг.4.
N1 циклов исключения для потока S1 (который имеет наибольшее количество циклов исключения) сначала распределяются по Т элементам массива Р как можно равномернее (этап 510). Это может быть достигнуто путем сохранения S1 в N1 элементов массива, имеющих индексы, вычисленные следующим образом:
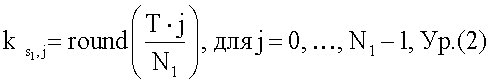
где 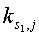 - индекс элемента массива для j-го цикла исключения потока Si. Значения точно на 1/2 могут округляться в большую сторону в уравнении (2).
- индекс элемента массива для j-го цикла исключения потока Si. Значения точно на 1/2 могут округляться в большую сторону в уравнении (2).
Ni циклов исключения для каждого из М-1 оставшихся потоков затем распределяются по Т элементам массива Р как можно равномернее, один поток за раз и в убывающем порядке от потоков S2-SM. Индекс i устанавливается в два для следующего потока, который нужно обработать (этап 512). Первый цикл исключения для потока Si преобразуется в первый доступный (или ненулевой) элемент массива Р (этап 514). Доступным элементом является элемент массива, который содержит ноль и уже не хранит цикл исключения для потока. «Нужные» расположения в массиве Р для оставшихся Ni-1 циклов исключения для потока Si могут быть вычислены (этап 516) следующим образом:
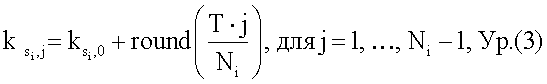
где 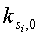 - индекс элемента массива для первого цикла исключения потока Si; и
- индекс элемента массива для первого цикла исключения потока Si; и

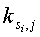 - нужное расположение в массиве Р для j-го цикла исключения потока Si.
- нужное расположение в массиве Р для j-го цикла исключения потока Si.
Ni-1 циклов исключения для потока Si затем преобразуются в Ni-1 доступных элементов массива Р, которые находятся в или являются ближайшими к Ni-1 нужным расположениям (этап 518). Для каждого значения индекса j, где j=1, …, Ni-1, j-ый цикл исключения для потока Si сохраняется в -ом элементе массива Р, если этот элемент доступен. Если этот элемент недоступен, то проверяются следующие элементы по обеим сторонам этого недоступного элемента до тех пор, пока не найдется какой-нибудь доступный элемент, и j-ый цикл исключения для потока Si сохраняется в этом доступном элементе. Следующие элементы идентифицируются путем попеременного увеличения и уменьшения по модулю Т. Например, элементы с индексами 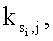
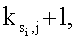
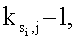
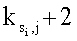 и так далее последовательно проверяются, чтобы понимать, доступны ли они.
и так далее последовательно проверяются, чтобы понимать, доступны ли они.
Окончательное расположение для j-ого цикла исключения может определяться без неопределенности в целочисленной арифметике путем выполнения целого деления на Ni и затем добавления единицы, если остаток больше либо равен 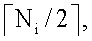 где
где 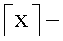 преобразование к верхнему значению, которое дает следующее большее целое значение для x. Например, если T=10 и Ni=3, то
преобразование к верхнему значению, которое дает следующее большее целое значение для x. Например, если T=10 и Ni=3, то 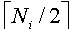 =2. Для j=1 целое деление T/Ni=10/3 дает частное 3 и остаток 1, который меньше, чем =2, поэтому частное 3 предоставляется в качестве нужного расположения. Для j=2 целое деление 2·T/Ni=20/3 дает частное 6 и остаток 12, который равен
=2. Для j=1 целое деление T/Ni=10/3 дает частное 3 и остаток 1, который меньше, чем =2, поэтому частное 3 предоставляется в качестве нужного расположения. Для j=2 целое деление 2·T/Ni=20/3 дает частное 6 и остаток 12, который равен 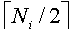 =2, поэтому частное 6 плюс единица предоставляется в качестве нужного расположения.
=2, поэтому частное 6 плюс единица предоставляется в качестве нужного расположения.
После этапа 518 выполняется определение, обработаны ли все М потоков (этап 520). Если ответ «Нет», то индекс i увеличивается (этап 522), и процесс возвращается к этапу 514 для обработки следующего потока. В противном случае процесс 500 завершается.
Процесс 500 описывается ниже для примера с четырьмя потоками, заданными в Таблице 3. Цикл разбора для четырех потоков определяется следующим образом. Схемы модуляции для потоков 1, 2, 3 и 4 имеют 8, 6, 6 и 1 bits/sym соответственно. Кодовые скорости для потоков 1, 2, 3 и 4 связаны с шаблонами исключения, которые обеспечивают 8, 4, 3 и 2 bits/pc соответственно. Потоки 1, 2, 3 и 4, таким образом, имеют отношения pc/sym 1, 3/2, 2 и 1/2 соответственно. Наименьший общий знаменатель равен 2 для четырех отношений pc/sym. Потоки 1, 2, 3 и 4 тогда имеют отношения pc/sym 2/2, 3/2, 4/2 и 1/2 соответственно, используя наименьший общий знаменатель, и таким образом имеют 2, 3, 4 и 1 циклов исключения на цикл разбора соответственно.
Четыре потока сортируются в убывающем порядке на основе количества циклов исключения для получения следующего отсортированного порядка: потоки 3, 2, 1 и 4. Поток 3 обозначается как S1 (или S1=3) и имеет N1=4 циклов исключения. Поток 2 обозначается как S2 (или S2=2) и имеет N2=3 циклов исключения. Поток 1 обозначается как S3 (или S3=1) и имеет N3=2 циклов исключения. Поток 4 обозначается как S4 (или S4=4) и имеет N4=1 циклов исключения. Если два потока имеют одинаковое количество циклов исключения, то поток с меньшим индексом может выбираться путем сортировки. Сортировка обеспечивает перестановку или преобразование из условия, чтобы N1≥N2≥N3≥N4, или Ni≥Nℓ для i<ℓ,
 Сортировка затем такая, что Si<Sℓ, если Ni=Nℓ. Общее количество циклов исключения для всех четырех потоков вычисляется как T=4+3+2+1=10. Массив Р содержит 10 элементов, которые инициализируются в нули.
Сортировка затем такая, что Si<Sℓ, если Ni=Nℓ. Общее количество циклов исключения для всех четырех потоков вычисляется как T=4+3+2+1=10. Массив Р содержит 10 элементов, которые инициализируются в нули.
N1=4 циклов исключения для потока S1 сначала распределяются по 10 элементам массива Р как можно равномернее. Индексы четырех элементов массива Р для четырех циклов исключения потока S1 вычисляются, как показано в уравнении (2), и дают в результате k=0, 3, 5 и 8. Четыре элемента с этими индексами устанавливаются в S1.
N2=3 циклов исключения для потока S2 затем распределяются по 10 элементам массива Р как можно равномернее. Это достигается путем сохранения S2 в первом доступном элементе массива Р, которым является элемент с индексом k=1. Нужные расположения для оставшихся двух циклов исключения для потока S2 вычисляются, как показано в уравнении (3) и находятся на k=4 и 8. S2 сохраняется в элементе с индексом k=4, так как этот элемент доступен. Поскольку элемент с индексом k=8 недоступен, S2 сохраняется в элементе с индексом k=9, так как это ближайший доступный элемент к k=8.
N3=2 циклов исключения для потока S3 затем распределяются по 10 элементам массива Р как можно равномернее. Это достигается путем сохранения S3 в первом доступном элементе массива Р, которым является элемент с индексом k=2. Нужное расположение для оставшегося цикла исключения для потока S2 вычисляется, как показано в уравнении (3) и находится на k=7. Элемент с индексом k=7 устанавливается в S3, так как этот элемент доступен.
N4=1 цикл исключения для потока S4 затем сохраняется в массиве Р на единственном доступном элементе, оставшемся в массиве Р, которым является элемент с индексом k=6.
Фиг.3В иллюстрирует последовательность циклов 310 исключения, сформированную на основе процесса 500 на фиг.5 для примера с четырьмя потоками, заданными в Таблице 3. Процесс 500 преобразует (1) четыре цикла исключения для потока S1 в четыре элемента с индексами k=0, 3, 5 и 8 в массиве Р, (2) три цикла исключения для потока S2 в три элемента с индексами k=1, 4 и 9, (3) два цикла исключения для потока S3 в два элемента с индексами k=2 и 7, и (4) один цикл исключения для потока S4 в один элемент с индексом k=6.
Для последовательности 310 анализатор 220 предоставляет потоку 3 первые 4 кодовых бита в цикле разбора, затем следующие 6 кодовых бит потоку 2, затем следующие 10 кодовых бит потоку 1, затем следующие 4 кодовых бита потоку 3, и так далее, и последние 4 кодовых бита в цикле разбора потоку 2. Последовательность 310 обеспечивает хорошее смешивание кодовых бит от кодирующего устройства 210 по четырем потокам, так как циклы исключения для каждого потока распределяются почти равномерно по циклу разбора.
Фиг.6 иллюстрирует процесс 600 для формирования последовательности циклов исключения для М потоков. Процесс 600 является другим вариантом осуществления этапов 412-422 по фиг.4. Для процесса 600 идеальный интервал между циклами исключения внутри цикла разбора для каждого потока i вычисляется сначала как Δi=T/Ni для i=1, …, M (этап 610). Переменная Di для каждого потока i инициализируется, например, в половину идеального интервала для потока, или Di=Δi/2 для i=1, …, M (этап 612). Индекс k для Т элементов массива Р инициализируется в ноль (этап 614).
Для каждого значения индекса k, k-ый элемент массива Р присваивается потоку с наименьшим значением D i среди М потоков (этап 616). Переменная Di для выбранного потока затем обновляется путем добавления Δi к переменной, или Di=Di+Δi (этап 618). Затем выполняется определение, все ли Т элементов массива Р заполнены (этап 620). Если ответ «Нет», то индекс k увеличивается (этап 622), и процесс возвращается к этапу 616 для заполнения следующего элемента массива Р. В противном случае процесс 600 завершается.
Процесс 600 описывается ниже для примера с четырьмя потоками, заданными в Таблице 3. Идеальный интервал между циклами исключения для каждого потока i вычисляется как: Δ1=5, Δ2=10/3, Δ3=10/4 и Δ4=10. Переменные Di для четырех потоков могут инициализироваться как: D1=5/2, D2=5/3, D3=5/4 и D4=5.
Таблица 4 показывает результат обработки для каждого значения индекса k. Для k=0 поток 3 имеет наименьшее значение Di среди четырех потоков, которое равно D3=5/4, элемент с индексом 0 присваивается потоку 3, или P(0)=3, и D3 обновляется как D3=5/4+5/2=15/4. Для k=1 поток 2 имеет наименьшее значение Di среди четырех потоков, которое равно D2=5/3, элемент с индексом 1 присваивается потоку 2, или P(1)=2, и D2 обновляется как D2=5/3+10/3=5. Для k=2 поток 1 имеет наименьшее значение Di среди четырех потоков, которое равно D1=5/2, элемент с индексом 2 присваивается потоку 1, или P(2)=1, и D1 обновляется как D1=5/2+5=15/2. Обработка для каждого оставшегося значения индекса k выполняется подобным образом. Для каждого значения индекса k поток с наименьшим значением Di выделяется серым затенением в Таблице 4 и также выбирается для k-го элемента массива Р. Если два элемента имеют одинаковое значение Di, что является случаем для k=4 в Таблице 4, то поток с меньшим индексом i может выбираться первым.
Разные последовательности циклов исключения с разными упорядочениями циклов исключения могут достигаться путем инициализации переменной Di разными способами. Например, переменная Di для потока с наибольшим количеством циклов исключения, и поэтому с наименьшим идеальным интервалом, может инициализироваться нулем, чтобы дать этому потоку больший вес в распределении его циклов исключения равномерно по циклу разбора.
Если переменная D3 для потока 3 инициализируется в нуль в Таблице 4, то процесс 600 сформировал бы следующую последовательность циклов исключения: 3, 2, 1, 3, 2, 3, 4, 1, 3, 2.
Фиг.5 и 6 иллюстрируют два варианта осуществления для формирования последовательностей циклов исключения из условия, чтобы циклы исключения для каждого из М потоков распределялись как можно равномернее по циклу разбора. Циклы исключения также могут распределяться равномерно или почти равномерно другими способами, и это находится в рамках объема изобретения. Анализатор 220 распределяет кодовые биты от кодирующего устройства 210 на М потоков, один цикл исключения за раз, исходя из упорядочения Т циклов исключения в цикле разбора, например, как показано на фиг.3В. Этот разбор на цикл исключения обычно обеспечивает хорошую производительность, поскольку исключение обычно предназначается для последовательных кодовых бит от кодирующего устройства 210.
Анализатор 220 может также распределять кодовые биты от кодирующего устройства 210 на М потоков, один кодовый бит за раз, исходя из определенного упорядочения кодовых бит в цикле разбора. Например, процесс 600 на фиг.1 может реализовываться с Ni, представляющим количество кодовых бит для потока i перед исключением, вместо количества циклов исключения для потока i. Массив Р тогда включал бы в себя Tbit элементов для Tbit входных кодовых бит в Т циклах исключения для М потоков. Каждый элемент массива Р заполняется одним из М потоков с помощью процесса 600. Анализатор 220 затем распределяет кодовые биты от кодирующего устройства 210 на М потоков на основе упорядочения, заданного в массиве Р.
Для примера с четырьмя потоками, показанными в Таблице 3, количество кодовых бит перед исключением для каждого потока задается в четвертом столбце, которое равно Nbit,1=20, Nbit,2=18, Nbit,3=16 и Nbit,4=2. Общее количество кодовых бит на цикл разбора равно Tbit=56. Идеальный интервал между кодовыми битами для каждого потока i вычисляется как Δbit,i=Tbit/Nbit,i. Переменная Dbit,i для каждого потока i может быть инициализирована в половину идеального интервала, или Dbit,i=Δbit,i/2. Каждый из Tbit элементов массива Р затем заполняется одним из М потоков, например, аналогично обработке, показанной в Таблице 4. Массив Р тогда представляет последовательность Tbit упорядоченных кодовых бит для цикла разбора. Анализатор 220 затем предоставляет первый кодовый бит в цикле разбора потоку, указанному первым элементом массива Р, второй кодовый бит потоку, указанному вторым элементом массива Р, и т.д. Разбор на основе кодового бита (вместо разбора на основе цикла исключения) может обеспечивать хорошую производительность при определенных обстоятельствах (например, если для всех потоков используется одинаковая кодовая скорость).
Принимающий объект 150 выполняет обратное восстановление M принятых потоков способом, дополнительным к разбору, выполненному передающим объектом 110. Обработка с помощью принимающего объекта 150 также зависит от и является дополнительной к обработке, выполненной передающим объектом 110.
Фиг.7 иллюстрирует блок-схему варианта осуществления процессора 160 принимаемых данных на принимающем объекте 150. В процессоре 160 принимаемых данных М процессоров 710a-710m потоков обеспечиваются М обнаруженными потоками символов от пространственного процессора 156 приема. Каждый процессор 710 потока включает в себя модуль 712 преобразования символов, обращенный перемежитель 714 и модуль 716 вставки стираний. Модуль 712 преобразования символов формирует логарифмические отношения правдоподобия (LLR) или какие-нибудь другие представления для кодовых бит у обнаруженных символов. LLR для каждого кодового бита указывает правдоподобие того, что кодовый бит является единицей («1») или нулем («0»). Обращенный перемежитель 714 обратно перемежает LLR для кодовых бит способом, дополнительным к перемежению, выполненному перемежителем 234 на передающем объекте 110. Модуль 716 вставки стираний вставляет стирания для кодовых бит, исключенных модулем 232 исключения на передающем объекте 110. Стирание является значением LLR нуля (0) и указывает равное правдоподобие того, что исключенный кодовый бит является нулем («0») или единицей («1»), так как неизвестна никакая информация для исключенного кодового бита, который не передается.
Модуль 720 обратного восстановления принимает выходные сигналы от М процессоров 710a-710m потоков для М потоков, обратно восстанавливает или мультиплексирует эти выходные сигналы в комбинированный поток способом, дополнительным к обработке, выполненной анализатором 220 на передающем объекте 110, и предоставляет комбинированный поток декодеру 730. Декодер 730 декодирует LLR в комбинированном потоке способом, дополнительным к кодированию, выполненному кодирующим устройством 210 на передающем объекте 110, и предоставляет декодированные данные. Декодер 730 может реализовывать декодер Витерби, если кодирующее устройство 210 является устройством сверточного кодирования.
Для ясности, методики разбора описаны для двоичного сверточного кода скорости 1/2. Эти методики также могут использоваться для различных других кодов, таких как турбо-код, код LDPC, блочный код и т.д.
Методики разбора также описаны для системы MIMO. Эти методики могут также использоваться в других системах связи, допускающих передачу множества потоков через множество каналов передачи. Канал передачи может быть пространственным каналом в системе MIMO, множеством поддиапазонов в системе OFDM, пространственным каналом для множества поддиапазонов в системе MIMO-OFDM, кодовым каналом и т.д.
Методики разбора могут быть реализованы различными средствами. Например, эти методики могут реализовываться в аппаратном обеспечении, программном обеспечении либо их сочетании. Для аппаратной реализации модули обработки, используемые для выполнения разбора на передающем объекте, могут реализовываться в одной или нескольких специализированных интегральных схемах (ASIC), цифровых процессорах сигналов (DSP), устройствах цифровой обработки сигналов (DSPD), программируемых логических устройствах (PLD), программируемых пользователем вентильных матрицах (FPGA), процессорах, контроллерах, микроконтроллерах, микропроцессорах, других электронных блоках, спроектированных для выполнения описанных здесь функций, или их сочетаниях. Модули обработки, используемые для выполнения дополнительного обратного восстановления на принимающем объекте, также могут реализовываться в одной или нескольких ASIC, DSP и так далее.
Для программной реализации методики разбора могут реализовываться с помощью модулей (например, процедур, функций и так далее), которые выполняют описанные здесь функции. Программные коды могут храниться в запоминающем устройстве (например, запоминающем устройстве 132 или 172 на фиг.1) и исполняться процессором (например, контроллером 130 или 170). Запоминающее устройство может реализовываться внутри процессора или внешним по отношению к процессору, в этом случае оно может быть коммуникационно соединено с процессором через различные средства, которые известны в данной области техники.
Предшествующее описание раскрытых вариантов осуществления предоставляется, чтобы дать возможность любому специалисту в данной области техники создавать или использовать настоящее изобретение. Различные модификации к этим вариантам осуществления будут полностью очевидны специалистам в данной области техники, а общие принципы, определенные в этом документе, могут быть применены к другим вариантам осуществления без отклонения от сущности или объема изобретения. Таким образом, настоящее изобретение не предназначено, чтобы ограничиваться вариантами осуществления, показанными в этом документе, а должно соответствовать самому широкому объему, согласующемуся с принципами и новейшими признаками, раскрытыми в этом документе.
Изобретение относится к области сетей передачи данных. Технический результат заключается в повышении производительности. Сущность изобретения заключается в том, что схема модуляции и кодовая скорость для каждого потока определяются исходя из скорости передачи данных, выбранной для этого потока. Схемы модуляции и кодовые скорости для всех М потоков используются для определения цикла разбора и количества циклов исключения для каждого потока в цикле разбора. Последовательность циклов исключения формируется для М потоков из условия, чтобы цикл(ы) исключения для каждого потока распределялись по последовательности как можно равномернее. Кодирующее устройство кодирует данные графика в соответствии с базовым кодом (например, двоичным сверточным кодом скорости 1/2) и формирует кодовые биты. Анализатор затем разбирает кодовые биты на М потоков исходя из последовательности циклов исключения, один цикл исключения за раз и в порядке, указанном последовательностью. 7 н. и 28 з.п. ф-лы, 8 ил., 4 табл.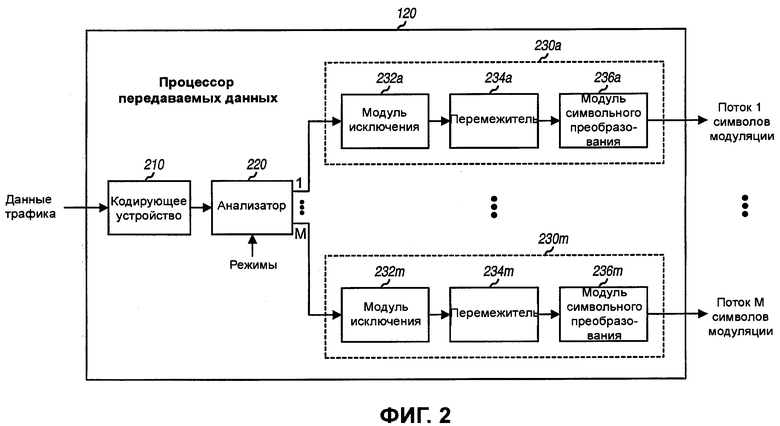
1. Способ синтаксического разбора данных в системе связи, содержащий этапы, на которых:
формируют последовательность циклов прокалывания для множества потоков из условия, чтобы для каждого потока с множеством циклов прокалывания множество циклов прокалывания для потока распределялись по последовательности циклов прокалывания почти равномерно; и
разбирают кодовые биты на множество потоков, исходя из последовательности циклов прокалывания.
2. Способ по п.1, дополнительно содержащий этап, на котором:
определяют количество циклов прокалывания в цикле разбора для каждого из множества потоков, исходя из схем модуляции и шаблонов прокалывания, использованных для множества потоков.
3. Способ по п.1, в котором этап, на котором формируют последовательность циклов прокалывания, содержит этапы, на которых:
упорядочивают множество потоков в убывающем порядке, исходя из количества циклов прокалывания для каждого из множества потоков, и
распределяют один или несколько циклов прокалывания для каждого из множества упорядоченных потоков почти равномерно по последовательности циклов прокалывания.
4. Способ по п.3, в котором этап, на котором распределяют один или несколько циклов прокалывания для каждого из множества упорядоченных потоков, содержит этапы, на которых:
распределяют циклы прокалывания для потока с наибольшим количеством циклов прокалывания почти равномерно по последовательности циклов прокалывания, и
для каждого оставшегося потока во множестве потоков,
преобразуют первый цикл прокалывания для потока в первое доступное расположение внутри последовательности,
определяют нужные расположения для оставшихся циклов прокалывания, при их наличии, для потока, и
преобразуют оставшиеся циклы прокалывания, при их наличии, в доступные расположения в последовательности, которые находятся в нужных положениях, либо являются ближайшими к нужным положениям.
5. Способ по п.1, в котором этап, на котором формируют последовательность циклов прокалывания, содержит этапы, на которых:
определяют интервал между циклами прокалывания для каждого из множества потоков, и
распределяют множество циклов прокалывания для множества потоков, исходя из интервала между циклами прокалывания для каждого потока.
6. Способ по п.5, в котором этап, на котором распределяют множество циклов прокалывания для множества потоков, содержит этапы, на которых:
инициализируют переменную для каждого потока, исходя из интервала для потока, и
для каждого расположения в последовательности циклов прокалывания,
идентифицируют поток с наименьшим значением для переменной среди множества потоков,
заполняют расположение в последовательности циклом прокалывания для идентифицированного потока, и
обновляют переменную для идентифицированного потока, исходя из интервала для идентифицированного потока.
7. Способ по п.1, дополнительно содержащий этап, на котором:
кодируют данные графика в соответствии со сверточным кодом скорости 1/2 для формирования кодовых бит.
8. Способ по п.1, дополнительно содержащий этап, на котором:
выбирают режим для каждого из множества потоков, причем режим для каждого потока указывает кодовую скорость и схему модуляции для использования для потока, где разные режимы выбираются для множества потоков.
9. Способ по п.1, дополнительно содержащий этап, на котором:
исключают кодовые биты в каждом потоке на основе шаблона прокалывания для потока.
10. Способ по п.1, дополнительно содержащий этап, на котором:
обрабатывают множество потоков для передачи через множество пространственных каналов.
11. Устройство в системе связи, содержащее:
контроллер, функционирующий для формирования последовательности циклов прокалывания для множества потоков из условия, чтобы для каждого потока с множеством циклов прокалывания множество циклов прокалывания для потока распределялись по последовательности циклов прокалывания почти равномерно; и
анализатор, функционирующий для разбора кодовых бит на множество потоков, исходя из последовательности циклов прокалывания.
12. Устройство по п.11, в котором контроллер дополнительно функционирует для упорядочения множества потоков в убывающем порядке, исходя из количества циклов прокалывания для каждого потока, и для распределения одного или нескольких циклов прокалывания для каждого потока почти равномерно по последовательности циклов прокалывания.
13. Устройство по п.11, в котором контроллер дополнительно функционирует для определения интервала между циклами прокалывания для каждого из множества потоков, и для распределения множества циклов прокалывания для множества потоков исходя из интервала между циклами прокалывания для каждого потока.
14. Устройство по п.11, дополнительно содержащее:
кодирующее устройство, функционирующее для кодирования данных графика, чтобы формировать кодовые биты.
15. Устройство по п.11, в котором контроллер функционирует для выбора режима для каждого из множества потоков, причем режим для каждого потока указывает кодовую скорость и схему модуляции для использования для потока, где разные режимы выбираются для множества потоков.
16. Устройство в системе связи, содержащее:
средство для формирования последовательности циклов прокалывания для множества потоков из условия, чтобы для каждого потока с множеством циклов прокалывания множество циклов прокалывания для потока распределялись по последовательности циклов прокалывания почти равномерно; и
средство для разбора кодовых бит на множество потоков, исходя из последовательности циклов прокалывания.
17. Устройство по п.16, в котором средство для формирования последовательности циклов прокалывания содержит:
средство для упорядочения множества потоков в убывающем порядке, исходя из количества циклов прокалывания для каждого из множества потоков, и
средство для распределения одного или нескольких циклов прокалывания для каждого из множества упорядоченных потоков почти равномерно по последовательности циклов прокалывания.
18. Устройство по п.16, в котором средство для формирования последовательности циклов прокалывания содержит:
средство для определения интервала между циклами прокалывания для каждого из множества потоков, и
средство для распределения множества циклов прокалывания для множества потоков, исходя из интервала между циклами прокалывания для каждого потока.
19. Устройство по п.16, дополнительно содержащее:
средство для кодирования данных графика для формирования кодовых бит.
20. Устройство по п.16, дополнительно содержащее:
средство для выбора режима для каждого из множества потоков, причем режим для каждого потока указывает кодовую скорость и схему модуляции для использования для потока, где разные режимы выбираются для множества потоков.
21. Способ синтаксического разбора данных в системе связи, содержащий этапы, на которых:
формируют последовательность разбора, указывающую порядок для разбора кодовых бит на множество потоков, причем последовательность разбора образуется для достижения кратчайших возможных серий кодовых бит для каждого потока, исходя из производительности кодирования, и дополнительно для распределения кратчайших возможных серий кодовых бит для каждого потока почти равномерно по множеству потоков; и
разбирают кодовые биты на множество потоков, исходя из последовательности разбора.
22. Способ по п.21, дополнительно содержащий этапы, на которых:
определяют шаблон прокалывания для каждого потока; и
определяют кратчайшие возможные серии кодовых бит для каждого
потока, исходя из количества выходных кодовых бит в шаблоне прокалывания для потока.
23. Способ по п.21, в котором кратчайшие возможные серии кодовых бит для каждого потока предназначаются для одного кодового бита.
24. Способ обратного восстановления данных в системе связи, содержащий этапы, на которых:
формируют последовательность циклов прокалывания для множества потоков из условия, чтобы для каждого потока с множеством циклов прокалывания множество циклов прокалывания для потока распределялись по последовательности циклов прокалывания почти равномерно; и
обратно восстанавливают символы во множестве входных потоков, исходя из последовательности циклов прокалывания, для формирования выходного потока символов.
25. Способ по п.24, в котором этап, на котором формируют последовательность циклов прокалывания, содержит этапы, на которых:
упорядочивают множество потоков в убывающем порядке, исходя из количества циклов прокалывания для каждого из множества потоков, и
распределяют один или несколько циклов прокалывания для каждого из множества упорядоченных потоков почти равномерно по последовательности циклов прокалывания.
26. Способ по п.24, в котором этап, на котором формируют последовательность циклов прокалывания, содержит этапы, на которых:
определяют интервал между циклами прокалывания для каждого из множества потоков, и
распределяют множество циклов прокалывания для множества потоков, исходя из интервала между циклами прокалывания для каждого потока.
27. Способ по п.24, дополнительно содержащий этап, на котором:
вставляют стирания в каждый входной поток на основе шаблона прокалывания для входного потока.
28. Способ по п.24, дополнительно содержащий этап, на котором:
декодируют выходной поток символов в соответствии со сверточным кодом для получения декодированных данных.
29. Устройство в системе связи, содержащее:
контроллер, функционирующий для формирования последовательности циклов прокалывания для множества потоков из условия, чтобы для каждого потока с множеством циклов прокалывания множество циклов прокалывания для потока распределялись по последовательности циклов прокалывания почти равномерно; и
модуль обратного восстановления, функционирующий для обратного восстановления символов во множестве входных потоков, исходя из последовательности циклов прокалывания, для формирования выходного потока символов.
30. Устройство по п.29, в котором контроллер функционирует для упорядочения множества потоков в убывающем порядке, исхода из количества циклов прокалывания для каждого потока, и для распределения одного или нескольких циклов прокалывания для каждого потока почти равномерно по последовательности циклов прокалывания.
31. Устройство по п.29, в котором контроллер функционирует для определения интервала между циклами прокалывания для каждого из множества потоков, и для распределения множества циклов прокалывания для множества потоков исходя из интервала между циклами прокалывания для каждого потока.
32. Устройство по п.29, дополнительно содержащее:
по меньшей мере один модуль вставки стираний, функционирующий для вставки стираний в каждый входной поток на основе шаблона прокалывания для входного потока.
33. Устройство в системе связи, содержащее:
средство для формирования последовательности циклов прокалывания для множества потоков из условия, чтобы для каждого потока с множеством циклов прокалывания множество циклов прокалывания для потока распределялись по последовательности циклов прокалывания почти равномерно; и
средство для обратного восстановления символов во множестве входных потоков, исходя из последовательности циклов прокалывания, для формирования выходного потока символов.
34. Устройство по п.33, дополнительно содержащее:
средство для вставки стираний в каждый входной поток на основе шаблона прокалывания для входного потока.
35. Устройство по п.33, дополнительно содержащее:
средство для декодирования выходного потока символов в соответствии со сверточным кодом скорости 1/2 для получения декодированных данных.
| US 2001034872 A1, 25.10.2001 | |||
| СПОСОБ АНАЛИЗА ГРАММАТИЧЕСКИХ КОНСТРУКЦИЙ | 1994 |
|
RU2104583C1 |
| WO 9623360 A1, 01.08.1996 | |||
| US 2002101915 A1, 01.08.2002 | |||
| EP 1231737 A1, 13.08.2002 | |||
| US 2004097215 A1, 20.05.2004. | |||

