Перекрестная ссылка на родственные заявки
Данная заявка является частичным продолжением находящейся одновременно на рассмотрении заявки на патент США серийный номер 10/902325 (Заявки '325), зарегистрированной 29 июля 2004 года и озаглавленной "Strategies for Processing Image Information Using a Color Information Data Structure", авторов изобретения Glenn F. Evans и Stephen J. Estrop. Заявка '325, в свою очередь, притязает на приоритет Предварительной заявки на патент США номер 60/492029 (Заявки '029), поданной 1 августа 2003 года. Заявки '325 и '029 полностью включены в настоящий документ по ссылке.
Область техники, к которой относится изобретение
Предмет данной заявки связан со стратегиями обработки информации изображений, а в более конкретной реализации со стратегиями обработки информации видеоизображений с помощью конвейера видеообработки.
Уровень техники
Примерные проблемы, связанные с обработкой видео
Используемую сегодня технологию обработки видео можно пояснить посредством отслеживания эволюции этой технологии с течением времени. Отдельные признаки добавлялись на различных стадиях эволюции, чтобы разрешать проблемы, с которыми отрасль сталкивалась в тот момент. Чтобы поддерживать совместимость и согласованность, новые технологии, возможно, сохранили часть этих признаков, даже если проблемы, для разрешения которых разрабатывались признаки, с тех пор отпали. Как результат современная технология может рассматриваться как накопление подобных появлявшихся последовательно признаков, отражающих систему предшествующих проблем, с которыми сталкивалась в различное время отрасль, соглашения между группами стандартизации, изменения технологических ограничений и возможности и т.д.
Одно следствие вышеописанной природы технологии обработки видео заключается в том, что специалисты в данной области техники создали укоренившиеся стереотипы мышления, касающиеся определенных аспектов технологии обработки видео. Существуют устоявшиеся представления, касающиеся того, как следует интерпретировать видеоинформацию, и устоявшиеся представления, касающиеся того, как "корректно" обрабатывать эту видеоинформацию. Авторы данного изобретения считают, что многие из этих установившихся норм не являются обоснованными и должны быть пересмотрены.
Главным из этих устоявшихся представлений является то, что видеоинформация, как правило, должна обрабатываться в форме, в которой она принимается из источника широковещательной передачи, носителя хранения (к примеру, DVD-диска) или другого носителя. Тем не менее, многие видеостандарты разрабатывались без учета того, что видеоинформация должна обрабатываться до отображения. Например, традиционные телевизионные приемники до сих пор не применяют функциональность сложной обработки; эти устройства просто принимают и отображают видеоинформацию. По сути, форма, в которой принимается видеоинформация, может не предоставлять возможности простой и эффективной обработки этой информации.
Как результат прямое применение стандартных алгоритмов обработки ко многим общепринятым формам видеоинформации создает различные искажения изображения. Специалисты в данной области техники в некоторых случаях обращали внимание на эти искажения. Тем не менее, вместо исследования основных предпосылок используемых методик профессионалы зачастую прибегали к локальным исправлениям, чтобы устранять проблемы. Эти решения могут скрывать проблемы в определенных конкретных для варианта применения ситуациях, но не решают проблемы в общем.
Например, видеоинформация часто принимается посредством конвейера видеообработки в форме, которая является нелинейной, чересстрочной, субдискретизированной по цветности, и выражается в определенном варианте связанного с яркостью цветового пространства (к примеру, информация Y'U'V). (Термин "нелинейная" означает здесь, что существует нелинейное отношение между входящим сигналом и результирующей выходной яркостью, генерируемой из этого сигнала; другие термины в предыдущем предложении полностью истолковываются ниже). Специалисты могут попытаться применить различные алгоритмы обработки линейного типа к этой информации, чтобы модифицировать ее заранее заданным способом, например посредством изменения размера видеоинформации, объединения видеоинформации с другой информацией (к примеру, создания составных изображений) и т.д. Авторы данного изобретения считают, что многие из этих алгоритмов не предоставляют оптимальные и даже корректные результаты при обработке видеоинформации такого характера. Работа только с чересстрочной, субдискретизированной по цветности информацией 4:2:2 или 4:2:0 (которая описана ниже) приводит к негативным результатам. Например, обработка информации в 4:2:2 или 4:2:0 может привести к распространению ошибок через различные стадии конвейера видеообработки.
Изъяны обработанных результатов выражаются в различных помехах, которые могут быть очевидны (или нет) невооруженному глазу. Кроме того, специалисты в данной области техники, вероятно, замечали некачественные результаты, но не идентифицировали причины. В некоторых случаях это может быть обусловлено неспособностью специалистов полностью понимать сложную природу многих стандартов кодирования видео. В других случаях специалисты могут не знать о том, что они используют линейные алгоритмы для того, чтобы обрабатывать нелинейную информацию; фактически в некоторых случаях специалисты могут ошибочно полагать, что они имеют дело с линейной информацией. Помимо этого общий базис области техники видеообработки нацелен на генерирование информации изображений, а не обязательно промежуточную обработку и корректировку этой информации.
Применение линейных алгоритмов к нелинейной информации - это только один пример вышеописанного укоренившегося стереотипа мышления в области техники обработки видео. Как описано ниже, стали стандартными многие другие методики, которые не генерируют оптимальных результатов, как, например, в случае сглаживания.
Например, специалисты могут попытаться устранить помехи, вызываемые некоторыми алгоритмами квантования со сглаживанием, посредством добавления небольшой величины случайного шума в информацию входного изображения и последующего квантования результирующего изображения с шумами. Эти методики оценивают ошибку квантования посредством последующего вычисления разности между изображением с шумами и квантованным результатом. Это может иметь эффект устранения помех сглаживания, но ценой того, что выходное изображение имеет большее содержание шумов относительно величины случайного шума, добавленного в информацию исходного изображения.
Существует множество других примеров устоявшихся понятий в области техники обработки видео, которые продолжают применяться благодаря привычке и знакомству без признания их существенных, но неочевидных недостатков. Общая идея усовершенствований, описанных в данном документе, включает в себя пересмотр этих негибких идей наряду с исполнением альтернативных решений.
Область техники обработки видео обладает богатой терминологией. И излагается краткое введение в определенные разделы области техники обработки видео для помощи читателям. Например, некоторые термины, уже использованные выше (линейный, чересстрочный, яркость, субдискретизированный по цветности и т.д.), определяются ниже. В качестве общего предмета терминологии термин "информация изображения" используется в данном документе, чтобы представлять широкий класс информации, которая может подготавливаться к просмотру в качестве любого типа визуального вывода, в том числе, но не только, информации видеоизображений.
Понятие текущего уровня техники
- Цветовое пространство и связанные вопросы
Цвета могут быть задаваемы с помощью трех компонентов. Поток изображений, который основан на передаче цветового содержимого с помощью дискретных цветовых компонент, упоминается как компонентный видеосигнал. Одна стандартная спецификация задает цвет с помощью красной, зеленой и голубой (RGB) компонент. Более формально, RGB-компоненты описывают пропорциональную интенсивность эталонных ламп, которые создают воспринимаемо эквивалентный цвет для данного спектра. В общем, цветовое пространство RGB может быть задано посредством цветовых значений, ассоциативно связанных с составными цвета и белой точкой. Белая точка означает цветность, ассоциативно связанную с опорным белым цветом.
Электронные устройства, которые воспроизводят цветные изображения, дополняют трехцветный характер человеческого зрения посредством предоставления трех типов источников света. Три типа источников света генерируют различные спектральные характеристики, которые воспринимаются как различные цвета человеком. Например, электронно-лучевая трубка (ЭЛТ) предоставляет красный, зеленый и голубой люминофоры, чтобы создавать различные цвета, таким образом составляя определенный вариант цветового пространства RGB, описанного выше. Другие технологии не используют люминофоры, а иным способом воспроизводят цвет с помощью источников света, которые излучают, по меньшей мере, три вида света.
Тем не менее, модель кодирования RGB не является эффективным вариантом для передачи информации изображений и не полностью соответствует некоторым устаревшим стандартам. Следовательно, информация изображений, как правило, передается целевому устройству с помощью какой-либо модели кодирования, отличной от RGB. После приема информация изображений может быть внутренне преобразована дисплейным устройством в RGB-связанное цветовое пространство для представления. Как описывается далее в разделе "Вопросы, связанные с показателем гамма", данные каждой компоненты R, G и В могут быть выражены в отношении пре-гамма-скорректированной формы, упоминаемой как значения R', G' и В'.
(В общем, в соответствии с условными обозначениями апостроф означает нелинейную информацию в данном изобретении.)
Общей тактикой в этом отношении является задание цвета посредством ссылки на связанную с яркостью компоненту (Y) и связанные с цветностью компоненты. Яркость, в общем, означает воспринимаемую интенсивность (освещенность) света. Яркость может быть выражена в пре-гамма-скорректированной форме (способом, описанным в разделе "Вопросы, связанные с показателем гамма"), чтобы получить ее нелинейный эквивалент, упоминаемый как "сигнал яркости" (Y'). Компоненты цветности задают цветовое содержимое информации изображений относительно сигнала яркости. Например, в цифровой области символ Cb соответствует n-битному целому масштабированному представлению разности B'-Y' (типично в диапазоне - 127…128 в 8-битных значениях), а символ Сr соответствует n-битному целому масштабированному представлению разности R'-Y'. Символ Рb означает аналоговый эквивалент Cb, a символ Рr означает аналоговый эквивалент Сr. Символы Рb и Рr также могут означать цифровую нормализованную форму Сb и Сr в номинальном диапазоне [-0,5…0,5]. Информация изображений компонент, задаваемая посредством СbСr и РbРr, может быть формально снабжена апострофом (к примеру, Cb'Cr' и Pb'Pr'), если они представляют нелинейную информацию. Тем не менее, поскольку Рb, Рr, Сb и Сr всегда означают нелинейные данные, обозначение с апострофом частот опускается для удобства и единообразия (к примеру, используется обозначение Y'PbPr вместо Y'Pb'Pr').
Цветовое содержимое также может передаваться как композитный видеосигнал (вместо вышеописанного компонентного видеосигнала). Композитные сигналы объединяют информацию яркости и цветности в одном сигнале. Например, в системе кодирования Y'UV U представляет масштабированную версию B-Y, а V представляет масштабированную версию R-Y. Эти компоненты сигнала яркости и цветности затем обрабатываются, чтобы предоставить один сигнал. Система кодирования Y'IQ задает другую систему композитного кодирования, сформированную посредством преобразования компонент U и V вышеописанным способом. Одна причина того, что в отрасли исторически продвигалось применение Y-связанных цветовых пространств (Y'CbCr, Y'PbPr, YUV, YIQ и т.д.), состоит в том, что уменьшение информации цветных изображений в этих цветовых пространствах может осуществляться проще в сравнении с информацией изображений, выражаемой в цветовом пространстве RGB. Эти цветовые пространства также являются обратно совместимыми с более старыми стандартами, разработанными для информации черно-белых изображений. Термин "связанная с сигналом яркости информация", в общем, означает любое цветовое пространство, которое имеет связанную с яркостью компоненту и связанные с цветностью компоненты, и включает в себя, по меньшей мере, все вышеупомянутые цветовые пространства.
В общем, можно преобразовывать цветовое содержимое из одного цветового пространства в другое цветовое пространство с помощью одного или более матричных аффинных преобразований. Более формально, свойство метамерии дает возможность выражать один набор коэффициентов цветового пространства в отношении другого набора функций соответствия (при этом "метамерные возбуждения" означают два спектра, которые соответствуют одному набору коэффициентов цветового пространства, и, следовательно, считаются воспринимаемо идентичными, т.е. выглядят как один цвет).
- Вопросы, связанные с показателем гамма
Электронно-лучевые трубки (ЭЛТ) не имеют функции преобразования линейной характеристики. Другими словами, отношение напряжения, применяемого к ЭЛТ, и результирующая яркость, генерируемая ЭЛТ, не задают линейной функции. Более конкретно, прогнозируемая теоретическая характеристика ЭЛТ имеет характеристику, пропорциональную степенному закону 5/2; т.е. для данного входного напряжения V результирующая яркость ЭЛТ L может быть вычислена как L=V2,5. Функция преобразования также упоминается как "функция гамма-характеристики", а экспонента сигнала напряжения упоминается как "гамма".
С другой стороны, когда информация видеоизображений захватывается камерой или генерируется системой трехмерной подготовки к просмотру, информация изображений выражается в линейном цветовом пространстве RGB, что означает, что существует линейное отношение между входящим сигналом и выходной яркостью. Чтобы разрешить несоответствие между линейностью камеры и нелинейностью дисплея, камеры традиционно выполняют предварительную корректировку сигнала, который они сгенерировали, посредством применения инверсии гаммы. Другими словами, функция преобразования камеры (иногда упоминаемая как кодирующая функция преобразования) - это приблизительно обратная функция характеристики яркости ЭЛТ. Результат применения кодирующей функции преобразования (или обратной гаммы) заключается в том, чтобы сгенерировать "гамма-скорректированную" информацию изображений, которая имеет нелинейную форму. Когда нелинейный сигнал передается посредством дисплейного устройства, генерируется близкая к линейной яркость. Кроме того, согласно вышеописанному обозначению, нелинейная (или предварительно скорректированная) информация изображений обозначается посредством добавления апострофа к компонентам, к примеру, R'G'B' или Y'CbCr (где апострофы для компонент Сb и Сr подразумеваются).
Таким образом, стало общераспространенной и стандартной практикой сохранять информацию изображений в нелинейной (скорректированной) форме яркость-цветность. Чтобы сохранить совместимость, любой источник, генерирующий сигнал, который должен отображаться на ЭЛТ, также должен сначала применить обратную функцию к сигналу.
Особо отметим, что кодирование информации изображений с помощью функции преобразования, как правило, применяет специальную функцию аппроксимации к части низкого напряжения функции. Т.е. методики кодирования, как правило, предоставляют линейный сегмент в этой части, чтобы ослабить эффект шума в датчике формирования изображений. Этот сегмент упоминается как "линейный хвост", имеющий заданный "закругленный наклон". Этот сегмент повышает качество информации изображений, представляемых на фактических ЭЛТ, поскольку эти устройства имеют линейные характеристики яркости-напряжения около 0 вследствие физической структуры этих устройств.
- Дискретизация и синхронизация информации цветности относительно информации яркости
Человеческое зрение больше реагирует на изменения интенсивности света, чем на хроматические компоненты света. Системы кодирования используют преимущество этого, чтобы уменьшать объем информации цветности (СbСr), которая кодируется относительно объема информации яркости (Y'). Эта методика упоминается как субдискретизация цветности. Числовое обозначение, представляемое, как правило, как L:M:N, может быть использовано для того, чтобы выразить эту стратегию дискретизации, где L представляет опорный коэффициент дискретизации компонента яркости (V), а М и N означают дискретизацию цветности (к примеру, Сb и Сr соответственно) относительно дискретизации яркости (V). Например, обозначение 4:4:4 может обозначать данные Y'CbCr, в которых предусмотрена одна выборка цветности для каждой выборки яркости. Обозначение 4:2:2 может обозначать данные Y'CbCr, в которых предусмотрена одна выборка цветности для каждых двух выборок яркости (горизонтально). Обозначение 4:2:0 может обозначать данные Y'CbCr, в которых предусмотрена одна выборка цветности для каждого кластера "два-на-два" выборок яркости. Обозначение 4:1:1 может обозначать данные Y'CbCr, в которых предусмотрена одна выборка цветности для четырех выборок яркости (горизонтально).
В тех случаях, когда стратегия кодирования предусматривает больше информации яркости, чем информации цветности, декодер может восстановить "отсутствующую" информацию цветности посредством выполнения интерполяции на основе информации цветности, которая предоставляется. Обобщая, понижающая дискретизация означает любую методику, которая генерирует меньшее число выборок изображений в сравнении с первоначальным набором выборок изображений. Повышающая дискретизация означает любую методику, которая генерирует большее число выборок изображений в сравнении с первоначальным набором выборок изображений. Таким образом, вышеописанная интерполяция задает тип повышающей дискретизации.
Стратегии кодирования также задают способ, которым выборки цветности пространственно синхронизируются с выборками яркости. Стратегии кодирования различаются в этом отношении. Выборки цветности синхронизируются с выборками яркости таким образом, чтобы выборки цветности размещались непосредственно "над" выборками яркости. Это упоминается как пространственное совмещение. Другие стратегии размещают выборки цветности в пустотах между выборками в двухмерной решетке выборок цветности.
- Вопросы, связанные с квантованием
Квантование относится к методологии, посредством которой дискретные числовые значения назначаются амплитудам сигнала цветовых компонент (или черно-белой информации). В цифровой области числовые значения охватывают заранее заданный диапазон (гамму цветов) значений цветового пространства за заранее заданное число этапов. Часто используют, например, 255 этапов для описания каждого значения компоненты, так чтобы каждая компонента могла допускать значение от 0 до 255. Часто выражают каждое цветовое значения с помощью 8 бит.
Преобразование из числа высокой точности к числу меньшей точности иногда может генерировать различные искажения изображения. Разработаны различные алгоритмы дисперсии ошибок, чтобы разрешать эту проблему, такие как алгоритм Флойда-Стайнберга. Алгоритмы дисперсии ошибок позволяют распределять ошибки, генерированные округлением при квантовании, на соседние пиксельные точки. Дополнительная исходная информация, касающаяся алгоритма Флойда-Стайнберга, представлена в подробном описании далее.
- Вопросы, связанные со сравнением чересстрочного и построчного представления
Первоначально телевизионные приемники отображали только информацию черно-белых изображений в построчной развертке сверху вниз. Сегодня традиционные телевизионные сигналы развертываются в чересстрочном режиме. При чересстрочной развертке захватывается первое поле видеокадра, а затем через короткий промежуток времени - второе поле видеокадра (к примеру, через 1/50 или 1/60 секунды). Второе поле вертикально немного смещено относительно первого поля, так чтобы второе поле захватывало информацию в пустотах между строками развертки первого поля. Видеоинформация представляется посредством быстрого отображения первого и второго полей друг за другом, так чтобы видеоинформация в большинстве случаев воспринималась человеком как один непрерывный поток информации.
Тем не менее, мониторы вычислительных машин и другое оборудование представления отображают информацию изображений построчно, а не чересстрочно. Таким образом, для того чтобы устройство представляло чересстрочную информацию на мониторе вычислительной машины, оно должно отображать прогрессивные кадры на скорости нечетного поля посредством интерполирования данных для противоположного поля (процесс упоминается как "расперемежение"). Например, чтобы отобразить нечетное поле, необходимо интерполировать "отсутствующие" данные для пространственной позиции между строками посредством анализа полей на другой стороне. Термин "построчный формат", в общем, относится ко всем форматам изображений с прогрессивной разверткой.
Информация изображений (к примеру, от видеокамеры) типично сохраняется в чересстрочной форме, к примеру, когда первое поле сохранено отдельно (семантически) от второго поля. Если информация изображений должна быть просто отображена на телевизионном дисплее с чересстрочной разверткой, его чересстрочная информация Y'UV может передаваться непосредственно в ЭЛТ. ЭЛТ внутренне преобразует информацию в информацию R'G'B' и управляет выходными пушками с помощью этого сигнала.
Чересстрочная развертка является более выгодной, поскольку она удваивает фактическое вертикальное разрешение информации изображений. Тем не менее, чересстрочная развертка также приводит к искажениям изображения. Это обусловлено тем, что объекты могут перемещаться при 60 Гц, но при чересстрочном представлении только половина изображения показывается каждые 30 Гц. Результирующее искажение, генерируемое вследствие этого явления, иногда упоминается как "растяжка". Искажение изображения обнаруживается в значительной степени при отображении быстроменяющихся видеоизображений, когда кажется, что объекты распадаются на четные и нечетные строки.
Дополнительную информацию, касающуюся каждой из вышеуказанных тем, можно найти во многих вступительных публикациях, к примеру, в широко известном материале "Digital Video and HDTV (Morgan Kaufmann Publishers, 2003)" автора Charles Poyton.
Сущность изобретения
Описываются стратегии обработки информации изображений в линейной форме, чтобы уменьшить количество искажений изображения (по сравнению с обработкой данных в нелинейной форме). Примерные типы операций обработки могут включать в себя масштабирование, создание композитных изображений, альфа-сопряжение, выделение краев и т.д. В более конкретной реализации описываются стратегии для обработки информации изображений, которая: а) является линейной; b) находится в цветовом пространстве RGB; с) имеет высокую точность (к примеру, обеспечиваемую посредством представления с плавающей запятой); d) является построчной и е) является полноканальной. Другие усовершенствования предоставляют стратегии для: а) обработки информации изображений в псевдолинейном пространстве, чтобы повысить скорость обработки; b) реализации улучшенной методики дисперсии ошибок; с) динамического вычисления и применения ядер фильтра; d) оптимизации генерирования конвейерного кода и е) реализации различных задач обработки с помощью новых методик пиксельного шейдера.
Краткое описание чертежей
Фиг.1 показывает примерный конвейер обработки изображений, включающий в себя обработку информации изображений в линейном формате.
Фиг.2 показывает примерную процедуру обработки информации изображений в линейном формате с помощью конвейера обработки изображений по фиг.1.
Фиг.3 показывает выборку информации изображений 4:2:0 в качестве предмета обсуждения некоторых трудностей при обработке этой информации без внесения искажений в изображения.
Фиг.4 показывает примерный модуль конвейера обработки изображений, который касается обработки информации изображений в псевдолинейном формате.
Фиг.5 показывает примерную процедуру обработки информации изображений в псевдолинейном формате с помощью модуля конвейера обработки изображений, показанного фиг.4.
Фиг.6 и 7 совместно поясняют известные подходы к выполнению сглаживания и дисперсии ошибок.
Фиг.8 показывает примерную систему для предоставления сглаживания и дисперсии ошибок, которая дает отличные результаты для моделей, описанных в связи в фиг.6 и 7.
Фиг.9 показывает примерную процедуру осуществления сглаживания и дисперсии ошибок с помощью системы на фиг.8.
Фиг.10 показывает примерную систему предоставления фильтрации при выполнении масштабирования, включающего в себя динамическое вычисление ядер фильтра.
Фиг.11 показывает примерную процедуру осуществления фильтрации с помощью системы на фиг.10.
Фиг.12 показывает примерный конвейер обработки изображений, который может содержать все описанные в данном документе усовершенствования.
Фиг.13 показывает примерную систему генерирования эффективного кода, используемого для того, чтобы реализовать конвейер обработки изображений по фиг.12, к примеру, посредством исключения модулей кода, которые не требуются для конкретного приложения обработки изображений.
Фиг.14 показывает примерную процедуру применения системы оптимизации кода, показанной на фиг.13.
Фиг.15 показывает примерную систему для реализации конвейера обработки изображений по фиг.12 посредством использования графического процессора (GPU), содержащего функциональность пиксельного шейдера.
Фиг.16 показывает известную структуру пиксельного шейдера.
Фиг.17 показывает общие принципы, связанные с применением информации текстуры к полигонам в контексте типичных графических вариантов применения.
Фиг.18 показывает примерную реализацию 4-отводного фильтра, использующего пиксельный шейдер.
Фиг.19 показывает примерную процедуру, которая описывает работу фильтра по фиг.19.
Фиг.20 показывает более общую реализацию аспектов конвейера обработки изображений по фиг.1 с помощью пиксельного шейдера.
Фиг.21 показывает примерное вычислительное окружение для реализации аспектов различных признаков, показанных на вышеописанных чертежах.
Одинаковые номера используются в данном описании и на чертежах, чтобы ссылаться на аналогичные компоненты или признаки. Номера последовательности 100 означают признаки, первоначально заложенные на фиг.1, номера последовательности 200 означают признаки, первоначально заложенные на фиг.2, номера последовательности 300 означают признаки, первоначально заложенные на фиг.3, и т.д.
Подробное описание предпочтительного варианта осуществления
Последующее описание излагает различные стратегии усовершенствования конвейера обработки изображений. Стратегии предлагают новые способы обработки информации изображений на основе пересмотра укоренившихся представлений в данной области техники. Первый класс усовершенствований (описанный в разделе А) может абстрактно применяться ко всем конвейерам обработки изображений. Второй класс усовершенствований (описанный в разделе В) применяется в большей степени к определенным конкретным для технологии или конкретным для реализации вариантам применения конвейеров обработки изображений.
Согласно одной примерной стратегии информация изображений, принимаемая посредством конвейера обработки изображений, преобразуется в линейную форму и затем обрабатывается в этой форме. В одной примерной реализации, например, принимаемая связанная с яркостью информация изображений (к примеру, Y'CbCr) преобразуется в линейную форму RGB и обрабатывается в этой форме. Примерные задачи обработки могут включать в себя расперемежение, изменение размера (масштабирование), составление композитных изображений, альфа-сопряжение, выделение краев, увеличение резкости и т.п. Обработка информации изображений в линейном пространстве (в отличие от нелинейного пространства) имеет явные преимущества, поскольку она, как правило, генерирует выходные результаты, имеющие меньше искажений изображения.
Согласно другой примерной стратегии информация изображений преобразуется в полноканальный (4:4:4) формат высокой точности и обрабатывается в этом формате, после чего выполняется квантование информации до меньшей точности. Информация более высокой точности может быть выражена в формате с плавающей запятой. Обработка полноканальной информации высокой точности является выгодной, поскольку она генерирует выходные результаты, имеющие меньше искажений изображений, и позволяет снижать падение разрешения цветности по мере того, как информация обрабатывается в конвейере.
Согласно другой примерной стратегии специальные меры предусмотрены для обработки информации чересстрочных изображений 4:2:0. Эти специальные меры обеспечивают способы интегрирования операции повышающей дискретизации с операцией расперемежения. Эта стратегия обладает преимуществами по ряду причин. Например, эта стратегия обеспечивает, что информация 4:2:0 будет обработана корректно, к примеру, без генерирования так называемого искажения обработки "дефект цветности".
Согласно другой примерной стратегии специальные функции преобразования могут быть применены для преобразования информации в псевдолинейное пространство вместо теоретической корректировки линейного пространства. После этого следует выполнение обработки информации изображений в этом псевдолинейном пространстве с помощью алгоритмов линейного типа (без необходимости модифицировать эти алгоритмы, чтобы учитывать их применение к нелинейным сигналам). Эта стратегия обладает преимуществами, поскольку она влечет за собой математические операции, которые могут выполняться быстрее с помощью доступных аппаратных средств обработки. Эта стратегия также устраняет необходимость изменять алгоритмы обработки посредством включения механизмов коррекции ошибок в эти алгоритмы. Целью алгоритмов коррекции ошибок являлась минимизация негативных эффектов при использовании линейных алгоритмов для того, чтобы работать с нелинейными данными. Тем не менее, исполнение и применение этих механизмов коррекции ошибок зачастую становилось более сложным, чем исходные алгоритмы обработки.
Согласно другой примерной стратегии применяется уникальный алгоритм дисперсии ошибок. Для каждого пиксела в информации исходных изображений алгоритм квантует сумму, задаваемую посредством исходного изображения, информации о шуме и вектора ошибок. Это имеет результатом квантованное значение для этого конкретного пиксела. После этого алгоритм вычисляет вектор ошибок для последующего пиксела, который должен быть обработан, посредством вычисления разности между квантованным значением и исходным значением. Эта стратегия превосходит известные в данной области техники стратегии, которые, по сути, добавляют шум в информацию исходных изображений и затем квантуют информацию изображений с шумами. Эти известные методики далее вычисляют вектор ошибок со ссылкой на информацию изображений с шумами вместо информации исходных изображений. Таким образом, в отличие от стратегии, раскрытой в данном документе, известные методики ухудшают информацию исходных изображений пропорционально информации о шумах, добавляемых в нее. В качестве дополнительного усовершенствования стратегии, описанные в данном документе, используют генератор шумов, имеющий относительный период повторения и достаточно похожие на шумы псевдослучайные характеристики, так чтобы сам генератор шумов не создавал искажений в информации целевых изображений.
Согласно другой стратегии вариант фильтра Катмулла-Рома используется для того, чтобы выполнять операции масштабирования. Стратегия включает в себя вычисление числа ядер фильтра, требуемых для того, чтобы изменить размер информации изображений, и числа отводов, требуемых каждым ядром, и последующее предварительное вычисление ядер фильтра. Далее эти ядра фильтра применяются к информации изображений. Более конкретно, ядра могут быть циклически применены к строкам и столбцам информации изображений. Эта стратегия обладает преимуществами по ряду причин. Например, применение динамически рассчитываемых ядер фильтра уменьшает некоторые искажения изображений, известные в используемых вариантах применения. Предварительное вычисление ядер фильтра имеет преимущества, поскольку оно ускоряет фактическое применение фильтра. Разумное использование минимального набора циклически применяемых ядер имеет дополнительные преимущества в плане эффективности.
Согласно другой стратегии описана функциональность генерирования кода для реализации конвейера обработки изображений. Функциональность принимает требования, которые задают то, какие типы операций предположительно должен выполнять конвейер, а затем выборочно ассемблирует модули кода из библиотеки таких модулей, чтобы реализовать эти функции. Функциональность не содержит модулей из библиотеки, которые не требуются. Эта стратегия обладает преимуществами по многим причинам. Например, она помогает генерировать код, который является более эффективным и, таким образом, потенциально выполняется быстрее.
Наконец, другая стратегия использует графический процессор (GPU) для того, чтобы реализовывать определенные аспекты конвейера обработки изображений или все функции в конвейере обработки изображений. Конкретные реализации применяют пиксельный шейдер (процессор цифровых сигналов (DSP) в GPU), чтобы осуществлять фильтрацию изображений. В одном случае одна или более единиц текстуры пиксельного шейдера могут быть назначены весам ядер фильтра, и одна или более других единиц текстуры пиксельного шейдера могут быть назначены другим дельта-смещенным версиям той же информации входных изображений (ассоциативно связанной с отводами ядра). Эта стратегия обладает преимуществами, поскольку она потенциально предоставляет большую скорость обработки и пропускную способность обработки в сравнении с реализацией в ЦП благодаря возможностям векторной обработки пиксельных шейдеров.
Дополнительные признаки и сопутствующие преимущества стратегий излагаются в этом описании.
Что касается терминологии, термин "информация изображения" служит для того, чтобы содержать в себя все типы информации, которые могут быть потребляемы пользователем в любой визуальной форме. Информация изображений, может представлять информацию, выраженную в любом формате, например аналоговом формате, цифровом формате или любом сочетании аналогового и цифрового форматов. Информация изображений может представлять информацию статических изображений (к примеру, цифровые фотографии) и/или информацию движущихся изображений (к примеру, информацию видеоизображений). Дополнительные вариации допускаются при использовании термина "информация изображений".
Термин "конвейер обработки изображений" относится к любой функциональности для обработки информации изображений. Конвейер включает в себя, по меньшей мере, два функциональных компонента, которые работают с информацией изображений последовательным методом, т.е. один за другим.
Термин "линеаризация" означает преобразование информации изображений из нелинейной предварительно скорректированной формы в линейную форму. Термин "нелинеаризация" означает операцию, обратную линеаризации.
Термин "связанная с яркостью информация изображений" означает информацию изображений, имеющую связанную с яркостью компоненту (к примеру, Y') и компоненты цветности. Термин "связанное с яркостью цветовое пространство" означает любой из нескольких стандартов для формирования связанной с яркостью информации изображений (к примеру, Y'CbCr и т.д.).
В целом, в отношении структурных аспектов описанной сущности любые из функций, изложенных в данном документе, могут быть реализованы с помощью программного обеспечения, микропрограммного обеспечения (к примеру, схемы с фиксированной логикой), ручной обработки или комбинации этих реализации. Термины "модуль", "функциональность" и "логика" при использовании в данном документе обычно представляют программное обеспечение, микропрограммное обеспечение или сочетание программного обеспечения и микропрограммного обеспечения. В случае реализации в программном обеспечении термины модуль, функциональность или логика представляют программный код, который выполняет заданные задачи при приведении в исполнение в процессорном устройстве или устройствах (к примеру, ЦП или множестве ЦП). Программный код может быть сохранен на одном или более стационарных или съемных машиночитаемых запоминающих устройств.
Что касается процедурных аспектов данной сущности, определенные операции описаны как составляющие отдельные этапы, выполняемые в определенном порядке. Эти реализации являются примерными и неограничивающими. Определенные этапы, описанные в данном документе, могут быть сгруппированы вместе и выполняться в одной операции, а определенные этапы могут выполняться в порядке, который отличается от порядка, используемого в примерах, изложенных в данном описании.
Данное описание включает в себя следующее содержимое:
А. Примерные общие усовершенствования конвейера видеообработки
A1. Обработка информации изображений в цветовом (линейном) пространстве RGB
А2. Использование полноканальной информации изображений с плавающей запятой в конвейере
A3. Специальные меры для информации изображений 4:2:0
А4. Обработка информации изображений в псевдолинейном пространстве
А5. Усовершенствования алгоритмов дисперсии ошибок
А6. Динамическое вычисление ядер фильтра
В. Примерные связанные с реализацией усовершенствования в конвейере видеообработки
B1. Оптимальное генерирование кода конвейерной обработки
B2. Общие принципы использования GPU для выполнения обработки изображений
B3. Усовершенствования пиксельного шейдера
С. Примерное вычислительное окружение
А. Примерные общие усовершенствования конвейера видеообработки
A1. Обработка информации изображений в цветовом пространстве RGB (линейном)
Фиг.1 показывает примерный конвейер 100 обработки изображений для обработки информации изображений (к примеру, видеоинформации). В качестве общего представления самая верхняя строка модулей принимает информацию изображений от любого из различных источников (камеры, сканера, диска, носителя хранения, цифровой сети и т.д.) и затем преобразует информацию изображений в форму для обработки. Крупный модуль в середине чертежа представляет эту обработку, которая приводит к обработанной информации изображений. Самая нижняя строка модулей преобразует обработанную информацию изображений в ту форму, которая подходит для вывода узлу назначения (к примеру, телевизионному приемнику, монитору вычислительной машины, носителю хранения, цифровой сети и т.д.).
Предусмотрено несколько уникальных и преимущественных аспектов для конвейера 100 обработки изображений, идентифицированных в отдельных подразделах данного изобретения. Этот подраздел останавливается на обработке информации изображений в линейной форме. Другие усовершенствования вытекают из дополнительной обработки информации изображений в чересстрочной (расперемеженной) форме в рамках цветового пространства RGB. В отличие от этого типичный подход в данной области техники заключается в том, чтобы выполнять обработку чересстрочной Y'UV-информации 4:4:4 или 4:2:2. Как признается авторами данного изобретения, обработка информации изображений в нелинейном пространстве приводит к различным искажениям изображения. Подход, осуществляемый в конвейере 100 по фиг.1, разрешает эти проблемы.
Каждый из модулей, показанных на фиг.1, описывается по очереди.
Что касается верхней строки модулей, модуль 102 отмены сглаживания преобразует принимаемую информацию изображений Y'CbCr, имеющую первую точность, в информацию изображений, имеющую вторую точность, при этом вторая точность выше первой точности. Модуль 102 выполняет эту задачу посредством выполнения обработки отмены сглаживания. Т.е. операция сглаживания (не показана) могла использоваться для того, чтобы квантовать информацию входных изображений, которая поступает в конвейер 100, до первой точности. Модуль 102 эффективно применяет инверсию этих операций квантования, чтобы получить вторую, более высокую, точность.
Модуль 104 повышающей дискретизации преобразует информацию входных изображений, имеющих первое число выборок, в информацию выходных изображений, имеющую второе число выборок, при этом второе число выборок больше первого числа выборок. В типичном варианте применения информация изображений принималась конвейером в форме, в которой больше выборок информации яркости (Y') в сравнении с информацией цветности (Сb или Сr); это обусловлено тем, что глаз более чувствителен к информации яркости, что дает возможным уменьшать объем информации цветности относительно информации яркости без заметного ухудшения качества. Модуль 104 повышающей дискретизации типично работает, чтобы увеличивать число выборок цветности, так чтобы выборки цветности были в равенстве с выборками яркости. Например, модуль 104 повышающей дискретизации может преобразовать информацию изображений Y'CbCr 4:2:0 или 4:2:2 в информацию изображений Y'PbPr 4:4:4. Операция повышающей дискретизации, выполняемая модулем 104, увеличивает число выборок посредством интерполяции существующих выборок (тем самым эффективно выполняя операцию масштабирования). Эти методики интерполяции зачастую конкретно учитывают то, как различные стандарты размещают информацию цветности относительно информации яркости, чтобы предоставлять точные результаты.
Модуль 106 применяет матричное преобразование к информации изображений Y'CbCr 4:4:4, чтобы преобразовать ее в другое цветовое пространство, т.е. цветовое пространство R'G'B'.
Затем модуль 108 преобразует нелинейную информацию R'G'B' в линейную форму посредством применения к ней функции преобразования. Это налагает повторение того, что символы апострофа ('), ассоциативно связанные с информацией изображений R'G'B', указывают то, что она в нелинейной форме. Отсутствие апострофов (к примеру, RGB) обычно означает линейные данные (за исключением того, что также распространено удалять апострофы, если традиционно понятно, что упоминаемые сигналы представляют нелинейную информацию, как описано выше). Модельная функция преобразования, показанная на фиг.1 под модулем 108 на фиг.1, иллюстрирует общую форму функции преобразования, которая используется, которая также является общей формой собственной функции преобразования ЭЛТ (не показана). Эта модельная функция преобразования также указывает, что она может использовать линейный хвост рядом с частью V=0 своей кривой, чтобы учитывать специальные соображения, которые применяются в этой "закругленной" области.
Модуль 110 необязательно выполняет операцию расперемежения для информации изображений, чтобы преобразовывать их из чересстрочной формы в построчный формат. При выполнении этой задачи модуль 110 может управляться с помощью либо информации изображений RGB, либо исходной информации изображений Y'CbCr (например, для специального случая информации 4:2:0). Тем не менее, операции расперемежения предпочтительно должны выполняться в линейном пространстве RGB. Это обусловлено тем, что расперемежение обычно является формой обработки изображений (включающей в себя, например, интерполяцию существующих выборок). Следовательно, выполнение этой обработки в линейном пространстве дает более точные результаты.
Модуль 112 необязательно преобразует составные цвета линейной информации RGB, чтобы выразить информацию в другом цветовом пространстве. Это преобразование может содержать применение матричного преобразования к информации RGB, чтобы изменять ее составные цвета, чтобы соответствовать тем составным цветам, которые необходимы для обработки, выполняемой в компонентах нисходящего потока конвейера видеообработки. В одном примере модуль 112 может преобразовывать различные типы информации изображений в общее цветовое пространство, что облегчает смешение информации в последующей операции.
Модуль 114, в общем, представляет любой тип обработки информации изображений, имеющих преобразованное цветовое пространство. В этом аспекте обработка осуществляется для информации изображений, т.е. в этом конкретном примере: а) в линейной форме; b) в цветовом пространстве RGB; с) в форме 4:4:4 (полноканальной) и d) в построчном формате. Хотя предпочтительно, чтобы обработка осуществлялась в линейном цветовом пространстве, чтобы уменьшить искажения изображений, все аспекты, перечисленные в этом списке, не должны присутствовать в конвейере обработки изображений, чтобы давать преимущества.
В любом случае модуль 114 может выполнять любой вид обработки информации изображений. По сути, обработка содержит любое преобразование информации изображений, к примеру, выходное изображение = некоторая функция (входное изображение), в том числе любой тип операции фильтра изображений. Репрезентативный и неограничивающий список этих операций обработки включает в себя: а) создание композитных изображений; b) альфа-сопряжение (к примеру, различные затухания и плавные исчезновения); с) выделение краев; d) увеличение резкости; е) изменение размера (масштабирование до больших или меньших размеров изображений); f) расперемежение (если оно еще не выполнено) и т.д. Создание композитных изображений влечет за собой смешение одного типа информации изображений с другим типом информации изображений. Например, модуль 114 может быть использован для того, чтобы объединять графику (к примеру, текстовую информацию) поверх информации видеоизображений, снимаемой с DVD-диска. Альфа-сопряжение влечет за собой плавное сопряжение цветов на основе альфа-коэффициента (который определяет степень, в которой один цвет сопрягается с другим). Например, операция сопряжения определяется следующим уравнением: Окончательный цвет = цвет источника × коэффициент сопряжения источника + цвет назначения × коэффициент сопряжения назначения. В этом уравнении цвет пиксела назначения представляет цвет пиксела в заранее существующей сцене, а цвет пиксела источника представляет новый цвет пиксела, который механизм сопряжения намеревается добавить в пиксел назначения. Коэффициенты сопряжения могут варьироваться от 0 до 1 и используются для того, чтобы управлять тем, какую долю цвета пикселов источника и назначения имеют в значении конечного цвета. Повторимся, что предоставлены просто репрезентативные примеры большого числа потенциальных вариантов применения обработки. В общем, многие из вышеописанных вариантов применения видеообработки могут применять аффинное взвешивание к переходу между информацией изображений источника и назначения. В этих видах вариантов применения использование нелинейного взвешивания может приводить к тому, что общая яркость информации изображений уменьшается слишком быстро. Это всего один пример искажения изображения, который настоящее решение позволяет устранить или смягчить посредством обработки нелинейной информации изображений.
Нижняя строка модулей на фиг.1, в общем, выполняет операции, обратные вышеописанным операциям в верхней строке. Т.е. после обработки в модуле 114 модуль 116 необязательно преобразует информацию изображений в другое цветовое пространство, например обратно в цветовое пространство RGB. Модуль 118 применяет необязательное повторное перемежение информации изображений, если оно должно быть сохранено или отображено в чересстрочной форме. Модуль 120 применяет функцию преобразования, чтобы снова преобразовать информацию изображений RGB в нелинейную форму (R'G'B') (если требуется). Модуль 122 изменяет цветовое пространство информации изображений R'G'B' обратно в форме, который отделяет компоненту яркости (Y') от компонентов цветности (к примеру, PbPr). Модуль 124 необязательно субдискретизирует информацию изображений Y'PbPr, чтобы уменьшить объем выборок цветности (PbPr) относительно объема выборок яркости (Y'). Т.е. этот модуль 124 может преобразовать информацию изображений Y'PbPr 4:4:4 (где предусмотрена выборка цветности на каждую выборку яркости) в информацию изображений Y'PbPr 4:2:2 или 4:2:0 (где предусмотрено меньше выборок цветности относительно выборок яркости). Наконец, модуль 126 применяет операцию квантования к информации изображений. Информация квантования имеет эффект преобразования информации изображений к меньшей точности, чтобы упростить эффективную передачу посредством сети, запоминающего устройства, дисплея и т.п. Операция квантования может быть объединена с операцией сглаживания, чтобы снизить искажения, которые в противном случае могли возникать вследствие ошибок округления, генерируемых посредством квантования. Как подробнее описано в следующем подразделе, операция сглаживания имеет эффект распространения этих ошибок на соседние пикселы по мере того, как обрабатывается информация изображений, тем самым смягчая эффекты искажений изображений.
Фиг.2 показывает процедуру 200, которая обобщает вышеописанные операции в форме блок-схемы последовательности операций способа. Этап 202 включает в себя преобразование информации изображений в линейное цветовое пространство, такое как RGB. Информация также предпочтительно расперемежается в построчную форму и подвергается повышающей дискретизации до формата 4:4:4 (полноканального). Таким образом, этап 202 соответствует верхней строке модулей на фиг.1.
Этап 204 влечет за собой осуществление любого вида (и комбинации) задач обработки информации изображений в линейной форме.
Этап 206 представляет преобразование линейной информации изображений в любой выходной формат, затребованный конкретным приложением. Это может повлечь за собой преобразование обработанной линейной информации изображений в нелинейное цветовое пространство, ее повторное перемежение, понижающую дискретизацию, квантование и т.д. Этап 206 соответствует нижней строке модулей на фиг.1.
А2. Использование полноканальной информации изображений с плавающей запятой в конвейере
Возвращаясь к фиг.1, конвейер 100 также предоставляет превосходные результаты для известных стратегий, поскольку он использует (а) полноканальную информацию изображений (т.е. 4:4:4), имеющую (b) относительно высокую эффективность обработки с (с) необязательно линейной семантикой. Более конкретно, как описано выше, конвейер 100 преобразует информацию изображений, которую он принимает, до большей точности, чем исходная форма. Конвейер 100 также преобразует информацию изображений в полноканальную форму (4:4:4) посредством увеличения объема выборок цветности в информации относительно выборок яркости. Затем выполняются различные задачи обработки с более точной полноканальной информацией изображений. После того как обработка выполнена, конвейер 100 может снова необязательно преобразовать обработанную информацию изображений в субдискретизированную форму меньшей точности.
В общем, преобразование информации изображений в более точную и полноканальную форму эффективно усиливает компоненту сигнала относительно компоненты шумов информации, тем самым давая возможность обработке, которая выполняется с этой информацией, получать более точные результаты. В отличие от этого известные стратегии, которые не используют высокоточную или полноканальную информацию изображений в различных промежуточных соединениях конвейера, могут распространять ошибки по конвейеру и могут уменьшать разрешение информации изображений (посредством существенной утраты цветового содержимого). Фиг.1, в общем, иллюстрирует обработку высокоточной полноканальной информации изображений посредством информационного блока, обозначенного 128, который передает данные в модуль обработки 128 (хотя другие модули на этом чертеже также могут использовать преимущества обработки информации в высокоточной и полноканальной форме, например модуль 110 перемежения).
Далее приводится более конкретный поясняющий пример. Рассмотрим преимущество работы с высокоточной линейной информацией изображений RGB в сравнении с информацией изображений Y'UV 4:2:0 или 4:2:2 обычной точности. Вспомним, что информация изображений 4:2:0 и 4:2:2 предоставляет половину и одну четвертую (соответственно) объема информации цветности относительно объема информации яркости. Типично информация изображений высокой четкости (HD) (в частности, 1920×1080i, 2,07 мегапикселов) масштабируется с понижением разрешения до 1280×720р (0,92 мегапикселов) или 720×480р (0,35 мегапикселов). Если конвейер выполняет операцию понижения масштаба в этом контексте к формату субдискретизации 4:2:0 (к примеру с 1920×1080 до 1280×720), то конвейер масштабирует с понижением 2,07 мегапикселов информации яркости и 0,52 мегапиксела информации цветности до 0,92 мегапикселов информации яркости и 0,23 мегапикселов информации цветности. Тем не менее, если конвейер выполняет повышающую дискретизацию до 4:4:4, затем преобразует в высокоточную RGB (к примеру, с плавающей запятой), после чего масштабирует с понижением и далее преобразует в YUV 4:4:4, то конвейер эффективно сохраняет 0,92 мегапиксела информации яркости и 0,52 мегапиксела информации цветности. Другими словами, использование высокоточной обработки в этом контексте дает возможность конвейеру сохранять практически всю исходную информацию цветности.
Один способ, чтобы достичь высокоточной промежуточной информации изображений, заключается в том, чтобы использовать формат плавающей запятой для того, чтобы представлять информацию. Числа с плавающей запятой имеют компоненты мантиссы и компоненты экспоненты. Компонента экспоненты задает то, как должна быть смещена компонента мантиссы. С помощью этого формата информация с плавающей запятой может выражать значения от очень малых до очень высоких посредством соответствующего смещения представления информации (к примеру, посредством изменения компоненты экспоненты). Может быть использован любой тип представления с плавающей запятой, имеющий любое число бит, в том числе 16-битное представление с плавающей запятой, 32-битное представление с плавающей запятой и т.д. Особенно подходящей формой плавающей запятой для использования в конвейере 100 обработки изображений является так называемый формат плавающей запятой FP16, хотя могут быть использованы другие представления плавающей запятой.
A3. Специальные меры для информации изображений 4:2:0
В качестве обзора, как описано в разделе "Уровень техники", информация изображений 4:4:4 включает в себя четыре выборки Сb и Сr для каждых четырех выборок Y'. Информация изображений 4:2:2 включает в себя две выборки Сb и две выборки Сr для каждых четырех выборок Y'. Информация 4:2:0 включает в себя в два раза меньше выборок Сb и Сr на каждую строку развертки и в два раза меньше строк развертки Сb и Сr в сравнении с Y'. Другими словами, разрешение информации цветности составляет половину разрешения информации яркости в горизонтальном и вертикальном направлениях. Например, если полное разрешение изображения составляет 720×480, то информация цветности сохраняется только при 360×240. При 4:2:0 не только отсутствующие выборки должны быть интерполированы в каждой строке развертки, но и все строки развертки информации цветности должны быть интерполированы из строк развертки выше и ниже. Фиг.3 показывает пример чересстрочной информации изображений 4:2:0 MPEG2. Дополнительная информация, касающаяся обработки информации изображений 4:2:0, может быть получена в документе авторов Don Munsil и Stacey Spears, "The Chroma Up-sampling Error and the 4:2:0 Interlaced Chroma Problem", DVD Benchmark, апрель 2001 года (декабрь 2002 года, обновлено в январе 2003 года).
Недостаточный объем и позиционное выравнивание информации цветности в информации изображений 4:2:0 создают ряд сложностей при обработке этой информации. Вообще говоря, могут возникать проблемы, потому что одна стадия в конвейере 100 обработки требует анализа другой стадии в конвейере 100 обработки, чтобы корректно интерпретировать информацию изображений 4:2:0. Рассмотрим пример модуля 104 повышающей дискретизации и модуля 106 преобразования по фиг.1. Чтобы корректно интерпретировать информацию изображений 4:2:0, модуль 104 повышающей дискретизации оптимально требует знаний о том, как цветовая информация выражается в информации изображений, которая является информацией, которая предоставляется модулем 110 расперемежения. Но, поскольку модуль 110 расперемежения расположен ниже относительно модуля 104 повышающей дискретизации, это знание недоступно модулю 104 повышающей дискретизации. Если модули 104 и 106 обрабатывают информацию 4:2:0 без преимуществ анализа расперемежения, они могут генерировать ошибки в информации изображений, которые может быть трудно или невозможно исправить. Эта трудность, в конечном счете, вытекает из того факта, что строки развертки 4:2:0 не могут обрабатываться независимо друг от друга в анализе расперемежения (в отличие, например, от информации изображений 4:2:2).
Чтобы разрешить эту сложность, конвейер 100 по фиг.1 может включать специальные меры для обработки информации изображений 4:2:0. В качестве общей меры конвейер 100 может быть модифицирован таким образом, чтобы анализ, выполняемый на различных стадиях (и информация, доступная на различных стадиях), в большей степени совместно использовался с другими стадиями в конвейере вместо необходимости каждой стадии автоматически анализировать только ту информацию, которая предоставлена ей посредством предыдущей стадии.
Что касается конкретно проблемы, вызываемой позицией модуля 110 расперемежения в конвейере 100, конвейер 100 может быть модифицирован таким образом, чтобы анализ расперемежения (выполняемый модулем 110) выполнялся ранее, к примеру, вместе с анализом повышающей дискретизации (выполняемый модулем 104). Фиг.1 иллюстрирует эту тактику посредством пунктирной линии 130. Альтернативно модуль 110 расперемежения может выполнять анализ расперемежения посредством также изучения исходной информации входных изображений, которая предоставлена в модуль 104 повышающей дискретизации. Т.е. модуль 110 расперемежения может выполнять анализ для вывода модуля 108 в сочетании с информацией исходных изображений, чтобы получить лучшее понимание того, как должно выполняться расперемежение информации изображений.
Помимо этого могут быть разработаны меры по интеграции модулей, чтобы совместно использовать анализ, выполняемый отдельно различными модулями в конвейере 100, чтобы тем самым более эффективно разрешать недостаток информации цветности в информации изображений 4:2:0.
А4. Обработка информации изображений в псевдолинейном пространстве
Предыдущие разделы разрешали цель разработки конвейера обработки изображений, который устраняет некоторые искажения изображения. Тем не менее, конвейеры обработки изображений также должны предоставлять выходные результаты эффективным способом. Конвейер обработки изображений генерирует результаты эффективным способом, когда он осуществляет ее с достаточной скоростью и с допустимым объемом ресурсов обработки. С этой целью данный раздел предлагает различные аппроксимации, которые могут быть применены к конвейеру 100, показанному на фиг.1, для того чтобы уменьшить сложность конвейера 100.
Т.е. данный подраздел предлагает модификации в конвейер 100, показанный на фиг.1, так чтобы он предоставлял информацию изображений, которая является практически линейной, но не полностью линейной. Как результат эти модификации, считается, должны преобразовывать информацию изображений в псевдолинейном пространстве вместо теоретической корректировки линейного пространства. Преимущество заключается в том, что аппаратная реализация математических операций, требуемых функциями преобразования (в модулях 108 и 120), может быть значительно упрощена, приводя к более быстрой и более эффективной обработке информации изображений. Более конкретно, выбранные операции типично исполняют порядок величины быстрее, чем исходные сопутствующие функции (которые являются математически более точными). Негативное влияние обработки изображений в псевдолинейном пространстве минимально, поскольку информация псевдолинейных изображений является практически линейной. Таким образом, любой алгоритм линейного характера может быть применен к этой информации без модификации, чтобы предоставлять удовлетворительные выходные результаты для большинства приложений.
Фиг.4 предоставляет дополнительную информацию, касающуюся вышеописанной аппроксимации. Более конкретно, фиг.4 представляет модификацию только определенных модулей конвейера 100 обработки фиг.1 и, следовательно, содержит только сокращенное обозначение полного конвейера 100 обработки, показанного на фиг.1.
Выдержка 400 конвейера, показанная на фиг.4, включает в себя модуль 402 функции преобразования, который заменяет модуль 108 функции преобразования, фиг.8. Вместо применения математически точного преобразования информации изображений, чтобы преобразовать ее в линейное пространство (как делает модуль 108), модуль 402 применяет функцию преобразования аппроксимации (g_approx(x)), которая преобразует информацию изображений в вышеописанное псевдолинейное пространство. Этот модуль прибегает к функции преобразования g_approx(х), поскольку она "проще", чем более точная функция преобразования, требуемая модулем 108, фиг.1.
Модуль 404 представляет эквивалент модуля 114 обработки по фиг.1. Модуль 404 выполняет любое число задач обработки с псевдолинейной информацией изображений в псевдолинейном пространстве обработки.
Модули 406, 408 и 410 затем выполняют задачу преобразования информации обработанных изображений в формат, подходящий для вывода (к примеру, на дисплей, запоминающее устройство, сетевой целевой узел и т.д.). Модулю 406 назначается конкретная задача отвечать за устранение эффектов модуля 402 посредством применения инверсии его операции, т.е. g_approx'(x). Затем модуль 408 линеаризирует вывод модуля 406 посредством применения функции преобразования g_in(x); эта операция выполняется, поскольку следующая стадия 410 предназначена для того, чтобы принимать линейный ввод. Затем модуль 410 применяет обратную функцию преобразования (g_out'(x)), чтобы получить окончательную гамма-скорректированную информацию выходных изображений, чтобы подходить тому формату, который требуется. При фактической реализации модули 406, 408 и 410 могут быть интегрированы в одно преобразование, представляемое посредством F(x), выполняемое модулем 412.
Что важно, алгоритмы, которые применяются к псевдолинейному цветовому пространству модулем 404, являются такими же, как алгоритмы, которые применяются к корректному линейному цветовому пространству в модуле 114, фиг.1. Другими словами, стратегия обработки, представленная посредством фиг.4, не требует специальной подгонки самих алгоритмов обработки изображений. В отличие от этого подход, применяемый известными предыдущими стратегиями, заключается в том, чтобы выполнять обработку в том нелинейном пространстве, в котором принята информация изображений, и затем применять различные специальные или подходящие для данного варианта применения коэффициенты корректировки для алгоритмов, чтобы исправлять все искажения изображений. Тем не менее, эти корректировки зачастую были неточными и в любом случае типично сложными. Обобщая, предшествующие методики не применяют всеобъемлющего и общеприменимого подхода к преобразованию информации в псевдолинейную форму, после чего эта псевдолинейная форма удаляется вышеописанным способом.
Оставшаяся часть описания в данном подразделе посвящена примерным аппроксимациям, которые могут быть использованы для того, чтобы реализовать вышеописанные модули на фиг.4. Для начала заметим, что функции преобразования, используемые для того, чтобы выполнять гамма-обработку, типично являются степенными функциями (к примеру, х0,45 или инверсия х1/0,45 ≈ х2,222) либо сочетанием нескольких функций. Степенные функции типично очень ресурсоемки при вычислениях на основе пикселов с использованием традиционных аппаратных средств.
Тем не менее, заметим, что х0,45 примерно равно квадратному корню х или, другими словами, х0,45 ≈ х0,50. Кроме того, х1/0,45 примерно равно х2 или, другими словами, х1/0,45 ≈ x·x. Существуют оптимизированные аппаратные средства для вычисления х, которые быстрее, чем операции, требуемые общей степенной функцией (зачастую на порядок величины). Эти аппаратные средства позволяют возводить х в квадрат очень быстро, и это просто операция умножения. Следовательно, эти аппроксимации могут существенно сократить вычислительные ресурсы, ассоциативно связанные с реализацией функций преобразования.
Более формально, функция g_approx(х), выполняемая посредством модуля 402, может принимать форму x2·sign(x), a обратная функция преобразования, выполняемая посредством модуля 406, может принимать форму (abs(x))·sign(x). (Особо отметим, что функции преобразования и обратные функции преобразования могут применять сегмент линейного хвоста, примерно равный нулю.)
Вышеуказанный подход может быть обобщен для различных входных и выходных гамм, представляемых посредством функций g_in(x) и g_out(x) с помощью следующей примерной последовательности операций:
1) Применение обратной линейной аппроксимации g_approx (x)=x2=x·x к информации изображений. Модуль 402 может выполнить этот этап.
2) Обработка данных в псевдолинейном пространстве. Модуль 404 может выполнить этот этап.
3) Применение линейной аппроксимации g_approx'(x). Модуль 406 может выполнить эту операцию.
4) Применение функции преобразования g_in(x), чтобы линеаризовать вывод модуля 406. Модуль 408 может выполнить эту операцию.
5) Применение функции преобразования g_out'(x) к выводу модуля 408, чтобы сгенерировать информацию в требуемом пространстве g_out.
Этапы (3)-(5) могут быть объединены в одну функцию F(x), т.е.: F(x)=g_out'(g_in(g_approx'(x))).
Если конвейер преобразует из гаммы 2,222 в гамму 2,4, то функция F(x) может быть выражена как:
F(x)-(((x0,5)l/0,45)l/2,6)=x0,426.
Ресурсы в вышеуказанном алгоритме включают только очень "несложный" диалог, требуемый функцией g_approx(х), после чего осуществляется обработка информации в псевдолинейном пространстве, затем следует потенциально ресурсоемкий диалог, требуемый функцией F(x). Но, поскольку уравнение F(x) просто требует умножения экспонент, затраты на эту функцию не больше, чем на исходную обратную функцию. Следовательно, решение, показанное на фиг.4, имеет эффект потенциального уменьшения затрат полного цикла линеаризации/нелинеаризации примерно наполовину. Как указано выше, это решение обладает преимуществами в том, что он требует специальной настройки алгоритмов, выполняемых модулем 404.
Фиг.5 показывает процедуру 500, которая обобщает вышеописанные операции, и является эквивалентом процедуры 200 линеаризации, показанной на фиг.2. Этап 502 влечет за собой преобразование информации входных изображений в псевдолинейное пространство. Этап 504 влечет за собой выполнение обработки информации изображений в псевдолинейном пространстве с помощью модуля 404. Также этап 506 влечет за собой преобразование обработанной информации в соответствующее нелинейное цветовое пространство для вывода.
А5. Усовершенствования алгоритмов дисперсии ошибок
Квантование высокоточной информации изображений в формат более низкой точности может приводить к ошибкам, поскольку аппроксимации, требуемые квантованием, могут приводить к искажениям изображения, если не обрабатываются корректно. Различные алгоритмы дисперсии ошибок служат для того, чтобы рассеять ошибки, вызываемые квантованием, и тем самым минимизировать искажения изображений. Эта дисперсия ошибок является формой сглаживания.
Фиг.6 показывает известный вариант применения алгоритма Флойда-Стайнберга, чтобы рассеивать ошибки, вызываемые квантованием. Рассмотрим точку Х в изображении, которая представляет пиксел (или обобщая, элемент изображения) в изображении. Квантование этого элемента изображения Х генерирует разность ошибок, вычисляемую как разность между высокоточным представлением элемента изображения и значением, в которое оно квантуется. Алгоритм Флойда-Стайнберга делит разность на различные компоненты и затем распределяет эти компоненты по элементам изображения, которые располагаются рядом с элементом Х (и которые еще не обработаны посредством алгоритма). Когда обработка переходит к этому соседнему элементу изображения, компоненты ошибок, ранее рассеянные на этот элемент изображения, добавляются к нему, и затем этот элемент обрабатывается вышеописанным способом, к примеру, посредством его квантования, вычисления еще одной разности ошибок и рассеяния этой ошибки на соседние элементы изображения. Обработка всего изображения может продолжаться различными способами, например, слева направо и снизу вверх.
Алгоритм Флойда-Стайнберга назначает различные веса компонентам ошибок, которые он рассеивает на соседние элементы изображения. Фиг.6 показывает веса 7, 1, 5 и 3, назначенные элементам изображения, которые размещаются рядом с элементом Х (по часовой стрелке). Более точно, коэффициенты взвешивания, примененные к компонентам ошибок, - это 7/16, 1/16, 5/15 и 3/16, где знаменатель 16 отражает сумму весов, назначенных соседним элементам изображения.
Тем не менее, алгоритмы дисперсии ошибок, такие как Флойд-Стайнберг, иногда генерируют изображения назначения, имеющие различные искажения изображения. Эти искажения изображения могут проявляться в визуально различимых орнаментах, которые особенно заметны при определенном содержимом изображения. Известные стратегии разрешают эту проблемы посредством добавления случайного шума к исходному изображению, чтобы затемнять орнаменты, вызываемые алгоритмами дисперсии ошибок. Но это устранение само по себе может иметь различные недостатки. Во-первых, известные стратегии добавляют шум к исходному изображению и затем квантуют исходное изображение с шумами в качестве базиса (способом, более подробно описываемым ниже). Хотя эта методика имеет эффект скрытия искажений изображения, вызываемых алгоритмом дисперсии ошибок, она также ухудшает качество окончательного изображения назначения. Т.е. шум в изображении назначения увеличивается в пропорции к шуму, добавляемому в исходное изображение. Во-вторых, известные стратегии могут добавлять шум с помощью генераторов шумов, имеющих относительно короткий период повтора. Следовательно, генераторы шумов могут генерировать собственные искажения изображений орнаментов, которые могут быть визуально отличимыми в изображении назначения (возможно, наряду с некоторыми признаками искажений дисперсии ошибок, которые генератор шумов предназначен скрывать).
Фиг.7 показывает процедуру 700, которая более точно поясняет первую из вышеуказанных проблем. Цель процедуры 700 состоит в том, чтобы квантовать информацию исходных изображений ("Исходную"), чтобы сгенерировать информацию изображений назначения ("Конечную") с помощью алгоритма распределения ошибок. Этап 702 влечет за собой генерирование информации изображений "Временная" посредством добавления информации шумов к информации исходных изображений для элемента изображения i (к примеру, пиксела). Этап 704 влечет за собой генерирование информации конечных изображений посредством квантования суммы, заданной информацией временных изображений и информацией изображений Error_Term(i). Error_Term представляет компонент ошибок, добавленный к элементу изображения i на основе предыдущего квантования ранее обработанного элемента или элементов изображения. Этап 706 влечет за собой задание следующего компонента Error_Term (который должен быть применен к будущему элементу изображения, который должен быть обработан) как таким образом рассчитанную информацию конечных изображений минус информацию временных изображений. Применение алгоритма, по сути, имеет чистый эффект квантования изображения с шумами с вытекающими вышеизложенными отрицательными сторонами.
Фиг.8 показывает систему 800, которая разрешает вышеотмеченные проблемы предшествующего уровня техники. Модуль 802 сглаживания преобразует информацию 804 исходных изображений в информацию 806 изображений назначения с помощью алгоритма дисперсии ошибок. Алгоритм дисперсии ошибок содержит вышеописанный алгоритм Флойда-Стайнберга, но не ограничен этим алгоритмом. Генератор 808 шумов вставляет произвольный шум в процесс квантования, чтобы помочь скрыть некоторые из искажений изображения, генерируемых алгоритмом дисперсии ошибок.
Система 800 отличается от известных стратегий, по меньшей мере, в двух отношениях. Во-первых, система 800, по сути, добавляет информацию шумов в процесс квантования, а не информацию 804 исходных изображений. Другими словами, информация 804 исходных изображений сохраняет базис, из которого измеряются векторы ошибок, вместо (в предшествующих методиках) исходного изображения плюс информации шумов. Таким образом, увеличение объема шума в системе 800 не обязательно имеет эффект постепенного добавления шумов в информацию 806 изображений назначения для глаза. Это обусловлено тем, что векторы ошибок, которые распространяются на соседние элементы изображений, сохраняют показатель отклонения информации 806 изображений назначения относительно информации исходных изображений 804, и, таким образом, алгоритм дисперсии ошибок постоянно пытается скорректировать эффекты случайных шумов, добавляемых в процесс квантования.
Фиг.9 показывает процедуру 900, которая поясняет вышеупомянутую обработку. Этап 902 влечет за собой генерирование информации конечных изображений для элемента изображения i посредством квантования суммы информации исходных изображений, информации шумов и вектора ошибок для элемента изображения i. Этап 904 влечет за собой вычисление вектора ошибок, который должен быть рассеян на соседний элемент (или элементы) изображения, посредством вычисления разности между информацией конечных изображений и информацией исходных изображений для элемента изображения i.
Далее приводится более конкретный поясняющий пример. Допустим, что задача состоит в том, чтобы квантовать элемент изображения, имеющий значение 23,3, до ближайшего целого. Допустим (в известной стратегии, показанной на фиг.7), что +0,4 объема информации шумов добавлено к значению, делая его равным 23,7. Значение конечного изображения для этого элемента изображения должно быть 24, и вектор ошибок, который распространяется, должен быть -0,3 (разность между значением конечного выходного изображения и значением изображения с шумами 23,7). В усовершенствованной стратегии, фиг.9, наоборот, вектор ошибок, который распространяется, должен быть равен -0,7 (разность между значением конечного выходного изображения и значением исходного изображения).
Более формальное описание вышеуказанной методики излагается ниже на основе применения алгоритма дисперсии ошибок Флойда-Стайнберга. Для каждого пиксела в изображении задача алгоритма заключается в том, чтобы квантовать высокоточное значение V и сохранить его в пиксельную позицию Р(х, у) матрицы пикселов Р, где Р(х, у) имеет меньшую точность, чем V. Векторы ошибок, генерируемые алгоритмом, сохраняются в высокоточной матрице пикселов Е, имеющей такой же размер, что и матрица пикселов Р. Вектор ошибок для пиксела Р(х, у) сохраняется в соответствующем размещении в Е(х, у). Функция round() в алгоритме округляет высокоточное число до ближайшего низкоточного числа. Функция random() в алгоритме возвращает случайное высокоточное число в диапазоне {-0,5…0,5}. Временные значения Desired и Error являются высокоточными значениями. Фактические коэффициенты распространения ошибок берутся из алгоритма распространения ошибок Флойда-Стайнберга.
Алгоритм 1: Усовершенствованная дисперсия ошибок
For each pixel х, у:
Desired=V+E(x, у)
Р(х, y)=round (Desired+random())
Error=Desired-P(x, у)
E(x+1, y)=Error·7/16
E(x-1, y+1)=Error·l/16
E(x, y+1)=Error·5/16
E(x+1, y+1)=Error·3/16
End
В качестве второго усовершенствования генератор 808 шумов использует шаблон относительно долгого повтора в отличие от известных подходов. Фраза "относительно долгий" может быть интерпретирована в относительных сроках посредством подтверждения того, что генератор 808 шумов не повторяет свои числа обработки всего кадра информации изображений или, по меньшей мере, не повторяет себя до степени, которая приводит к заметным искажениям в информации 806 изображений назначения. Один конкретный генератор случайных чисел, который соответствует этому требованию, - это так называемый генератор случайных шумов R250.
А6. Динамическое вычисление ядер фильтра
Фильтры масштабирования могут быть использованы в различных соединениях конвейера 100, показанного на фиг.1, когда размер информации изображения изменяется с исходного размера до размера назначения. Например, обработка, выполняемая в модуле 114, может повлечь за собой масштабирование информации изображений вверх или вниз в зависимости от варианта применения и/или в зависимости от управляющих сигналов, вводимых пользователем. Масштабирование также может выполняться в других соединениях конвейера 100, например в модулях 104 и 124 дискретизации.
Ряд алгоритмов фильтрации может быть использован совместно с алгоритмами масштабирования. Один конкретный известный тип фильтра - это так называемый фильтр Катмулла-Рома. Применение этого типа фильтра к задаче изменения размера информации изображений приводит к некоторому увеличению резкости краев информации изображений.
Данный подраздел описывает фильтр, используемый для масштабирования (такой как фильтр типа Катмулла-Рома, но не только этот тип фильтра), который может быть вычислен и применен на попиксельной основе к информации изображений. Это может быть концептуализировано как динамическое вычисление и применение отдельного фильтра для каждого пиксела и информации изображений. Каждый фильтр может включать в себя одно или более ядер, и каждое ядро может иметь один или более отводов. Ядро задает веса, которые применяются пикселам в информации изображений. Отводы задают выборки информации изображений, для которых выполняется ядро. Невозможность вычислять и применять ядра фильтра, таким образом, может приводить к различным искажениям в изображении назначения, таким как картины биений.
Тем не менее, вычисление отдельных ядер фильтра для каждого пиксела может быть чрезмерно затратным в отношении времени, требуемого для того, чтобы вычислять ядра. Это может препятствовать представлению информации изображений в реальном времени на некоторых аппаратных средствах. Чтобы разрешить эту проблему, данный подраздел задает различные стратегии динамического вычисления фазовых ядер фильтра ко всем строкам или столбцам информации входных изображений и последующего применения этих ядер. В качестве обзора стратегии влекут за собой вычисление числа ядер, требуемых строке (или столбцу) информации исходных изображений, вычисление числа отводов, требуемых ядрами, и вычисление и сохранение требуемого числа ядер в матрице. После этих этапов следует применение ядер фильтра, сохраненных в матрице, к информации изображений.
Алгоритм является эффективным, поскольку ядра вычисляются до применения. Кроме того, достигается экономия вычислительных ресурсов, поскольку в определенных случаях относительно небольшое число вычисленных ядер может быть циклически применено к строке или столбцу гораздо большего размера в информации изображений. Помимо этого те же ядра, примененные к конкретной строке или столбцу, могут быть применены к другим строкам или столбцам (соответственно) в информации изображений. Другими словами, в зависимости от требований по изменению размера конкретного варианта применения необязательно вычислять отдельный фильтр для каждого отдельного пиксела в информации изображений.
Фиг.10 показывает общее представление системы 1000 для реализации модуля 1002 фильтрации вышеописанного исполнения. Модуль 1002 фильтрации включает в себя модуль 1004 динамического предварительного вычисления ядер. Назначение этого модуля 1004 заключается в том, чтобы сначала вычислять число ядер, требуемых для конкретной операции масштабирования, и число отводов, требуемых для ядер. Число ядер и отводов зависит от способа, которым изменяется размер информации изображений (нижеописанным методом). Затем модуль 1004 предварительного вычисления осуществляет предварительное вычисление требуемого числа ядер и сохраняет ядра в модуле 1006 хранения. Далее модуль 1008 применения ядер применяет ядра в модуле 1006 хранения ядер к информации изображений, чтобы добиться требуемого режима фильтрации. Как упоминалось выше, вычисление ядер до их применения помогает выполнять процесс фильтрации быстрее. Более того, сложность вычисления фильтров существенно снижается для тех операций масштабирования, которые требуют предварительного вычисления только нескольких ядер.
Правая часть фиг.10 показывает то, как ядра 1010 могут быть итеративно применены к конкретной строке 1012 информации 1014 изображений. Ядра 1010 применяются последовательно и циклично (где в одном примерном случае каждое ядро применяется к одному выходному пикселу). Например, если имеется небольшое число ядер для относительно длинной строки информации изображений, то эти ядра применяются один за другим и повторяются многократно, пока строка изображения обрабатывается. Т.е. предварительно сохраненные ядра формируют список; они применяются одно за другим к строке, и, когда последнее ядро встречается в списке, обработка продолжается посредством циклического возврата и повторного извлечения с начала списка. Итеративный характер методики варианта применений представлен посредством цикла 1016, показанного на фиг.10. Ядра 1010 могут быть применены к другим строкам аналогичным образом. Кроме того, аналогичная обработка может быть повторена в отношении ядер, которые применяются к столбцам информации 1014 изображений.
Примерный алгоритм, который может быть использован модулем 1004 для того, чтобы вычислять число ядер и отводов, прилагается ниже. Модуль 1004 применяет алгоритм отдельно к масштабированию в размерностях х и у информации 1014 изображений. Таким образом, хотя алгоритм задан, чтобы масштабировать в размерности х, алгоритм также применяем к размерности у, к примеру, посредством изменения ссылок с ширины на высоту и т.д. В размерности х ScaleRatio, используемый в алгоритме, задает соотношение ширины исходного изображения с шириной требуемого конечного (целевого) изображения. Функция ceiling, используемая в алгоритме, округляет действительное число до следующего большего целого. Функция gcd в алгоритме вычисляет наибольший общий знаменатель двух целых чисел.
Алгоритм 2: Вычисление числа ядер и отводов
ScaleRatio=SourceWidth/DestinationWidth
if ScaleRatio<1,0
ScaleRatio=1,0
Taps=ceiling(ScaleRatio·4)
if Taps is odd
Taps=Taps+1
Kernels=DestinationWidth/gcd(SourceWidth, DestinationWidth)
В качестве примера рассмотрим вертикальное масштабирование информации исходных изображений, имеющей вес в 720 пикселов, до информации изображений назначения, имеющей вес в 480 пикселов. Применение вышеуказанного алгоритма к этому сценарию дает:
ScaleRatio=720/480=1,5
Taps=ceiling(ScaleRatio·4)=6
Kernels=480/gcd(720, 480)=480/240=2
Таким образом, модуль 1004 должен предварительно вычислять и предварительно выделять 2 ядра по 6 отводов каждое. Операция изменения масштаба выполняется в чередующемся попеременном режиме между двумя ядрами по мере того, как перемещается по строке пикселов.
В качестве еще одного примера рассмотрим вертикальное масштабирование информации исходных изображений, имеющей вес в 721 пикселов, до информации изображений назначения, имеющей вес в 480 пикселов. Применение вышеуказанного алгоритма к этому сценарию дает:
ScaleRatio=721/480=1,5021
Taps=ceiling(ScaleRatio·4)=7
Число отводов четное, поэтому добавляем один и получаем 8
Kernels=480/gcd(721, 480)=480/1=480
Таким образом, модуль 1004 должен предварительно вычислять и предварительно выделять 480 ядер по 8 отводов каждое. Операция изменения размера использует уникальное ядро для каждого из 480 выходных пикселов. Тем не менее, по-прежнему достигается существенная экономия, поскольку один набор из 480 ядер может быть использован в каждом вертикальном столбце пикселов. Кроме того, в реальных случаях на практике соотношение размеров назначения и источника стремится к тому, чтобы быть достаточно простым соотношением, что делает результирующее число необходимых ядер регулируемым. Также могут налагаться специальные ограничения, которые не позволяют пользователям вводить запросы на изменение размера, которые требуют особенно большого числа ядер фильтра (к примеру, при превышении заранее заданного порога).
Фиг.11 показывает процедуру 1100, которая обобщает вышеописанные операции. Этап 1102 влечет за собой определение числа ядер (и отводов на ядро), требуемых для того, чтобы добиться необходимого изменения размера изображения в горизонтальной и вертикальной размерностях. Модуль 1004 предварительного вычисления может выполнить эту задачу с помощью алгоритма, предоставленного выше. Этап 1104 влечет за собой выделение пространства в модуле 1006 хранения ядер, чтобы сохранять число ядер, вычисленное на этапе 1004. Этап 1106 влечет за собой фактическое предварительное вычисление и сохранение ядер. Далее, этап 1108 влечет за собой применение предварительно вычисленных ядер, сохраненных в модуле 1006 хранения, к информации изображений. Вариант применения продолжается посредством циклического последовательного прохождения через ядра при обработке всех данных строк или столбцов.
В. Примерные связанные с реализацией усовершенствования в конвейере видеообработки
B1. Оптимальное генерирование кода конвейерной обработки
Следующий раздел предоставляет ряд реализации конвейера 100 видеообработки по фиг.1 более специфичного для технологии характера в сравнении с разделом А. Начнем с того, что фиг.12 показывает высокоуровневое общее представление конвейера 1200 обработки изображений, который выступит в качестве основы для пояснения усовершенствований данного раздела.
Конвейер 1200, показанный на фиг.12, включает в себя стадии обработки, заданные посредством входной стадии 1202, стадии 1204 обработки и выходной стадии 1206. Что касается входной стадии 1202, входной источник 1208 представляет любой источник информации изображений. Источник 1208 в целом может содержать новую захваченную информацию изображений (к примеру, созданную посредством камеры или сканера) или ранее захваченную информацию изображения, которая представляется входной стадии 1202 посредством определенного канала (к примеру, принимается с диска, по IP-сети и т.д.). В первом случае функциональность 1210 обработки захвата может выполнять любой вид предварительной обработки информации изображений, принимаемой из источника 1208. Во втором случае функциональность 1212 декодера выполняет любой вид потокового извлечения и распаковки изображений, чтобы сгенерировать данные изображений. В общем, эта обработка может включать в себя отделение информации изображений от аудиоинформации в принимаемой информации, распаковку информации и т.д. Что касается стадии 1204 обработки, функциональность 1214 обработки выполняет любой вид обработки с результирующей информацией изображений, например смешивание нескольких потоков информации изображений вместе в композитный сигнал. Что касается выходной стадии, функциональность 1216 выходной обработки представляет любой вид обработки, выполняемой с информацией обработанных изображений при подготовке к выводу на выходное устройство 1218. Выходное устройство 1218 может представлять телевизионный приемник, монитор вычислительной машины и т.д. Выходные устройства также могут представлять устройства хранения. Дополнительно выходное устройство (или выходная функциональность 1216) может предоставлять функциональность сжатия и форматирования (например, мультиплексоры), которые подготавливают информацию для сохранения на устройстве, распространения по сети.
В общем, операции обработки, изложенные на фиг.1, могут быть распространены по стадиям (1202, 1204, 1206) любым методом. Например, стадия 1204 обработки, как правило, реализует модуль 114 обработки, показанный на фиг.1. Каждая из стадий (1202, 1204, 1206) физически может быть реализована как отдельное устройство для выполнения назначенных задач или несколько устройств, соединенных последовательным или параллельным способом. Функции могут быть реализованы посредством любого сочетания программного обеспечения и аппаратных средств.
Фиг.13 показывает примерную систему 1300 для конфигурирования конвейера 1200 обработки изображений, показанного на фиг.12. Более конкретно, примерная система 1300 может содержать функциональность для автоматического генерирования вычислительного кода, чтобы реализовать конвейер 1200 таким образом, чтобы он выполнял любую комбинацию операций обработки изображений, показанных на фиг.1.
Чтобы функционировать вышеописанным образом, система 1300 включает в себя конфигурационный модуль 1302. Конфигурационный модуль 1302 принимает информацию 1304 требований к конвейеру, которая задает требования, которым должен удовлетворять сконфигурированный конвейер. Информация 1304 требований может иметь несколько компонентов. Компонент 1306 входных требований задает характеристики информации изображений, которую, как ожидается, должен принимать конвейер. Компонент 1306 входных требований может задавать один тип информации изображений, который может быть обработан, или может задавать набор из нескольких разрешенных типов информации изображений, которая может быть обработана. Один способ удобного задания нескольких характеристик разрешенной входной информации заключается в том, чтобы задать используемые стандарты видеокодирования, которые могут подразумевать полную совокупность признаков, которыми обладает информация изображений, такие как разрешенные цветовые пространства, схемы субдискретизации цветности, функции гамма-преобразования и т.д. Например, ITU-R Recommendation ВТ.601 - это международный стандарт, который задает студийное цифровое кодирование информации изображений. Этот стандарт использует кодирование Y'CbCr информации изображений. ITU-R Recommendation ВТ.709 - это международный стандарт, который задает студийное кодирование видеоинформации высокой четкости. Содержимое высокой четкости (HD) представляет видеосодержимое, которое выше, чем стандартная четкость (SD), типично 1920×1080, 1280×720 и т.п. Это всего два из множества стандартов видеокодирования, которые может обрабатывать конвейер обработки изображений.
Компонент 1308 выходных требований задает характеристики информации изображений, которую, как ожидается, должен выводить конвейер. Т.е. компонент 1308 выходных требований может задавать один вид информации изображений, который может быть сгенерирован, чтобы соответствовать конкретному выходному устройству, или может задавать набор из нескольких разрешенных видов информации изображений, которая может быть сгенерирована, чтобы соответствовать различным типам выходных устройств. Помимо этого один способ удобного задания нескольких характеристик разрешенной выходной информации заключается в том, чтобы задать используемые стандарты видеокодирования.
Промежуточный компонент 1310 требований обработки задает характер задач обработки, которые должен выполнять конвейер для информации выходных изображений. Может быть задано любое число задач обработки, в том числе, но не только, изменение размера (масштабирование), составление композитных изображений, альфа-сопряжение, выделение краев и т.д.
В общем, оператор может вручную выбирать требования 1304 к конвейеру. Альтернативно одно или более требований 1304 могут быть автоматически выведены из среды, в которой должен использоваться конвейер.
Учитывая входные требования 1304 к конвейеру, конфигурационный модуль 1302 выполняет задачу использования статического анализа для того, чтобы взаимодействовать с библиотекой модулей 1312 кода, чтобы компоновать собственную совокупность модулей кода, которая соответствует требованиям 1304 к конвейеру. Один способ осуществления этого заключается в том, чтобы сгенерировать основное уравнение, которое преобразует любой тип входной информации к любому типу выходной информации, включая любой тип промежуточной обработки. Это основное уравнение включает в себя ряд компонентов. Компоненты ассоциативно связаны с соответствующими модулями кода, сохраненными в библиотеке 1312. В этой реализации конфигурационный модуль 1302 выполняет задачу компилирования собственной совокупности модулей кода посредством исключения всех компонентов, которые не требуются с точки зрения входных требований 1304 к конвейеру. Это имеет результатом выбор конкретных модулей кода из библиотеки 1312 и пропускание остальных модулей.
Результатом обработки, выполняемой конфигурационным модулем 1302, является оптимизированный конвейерный код 1314, который затем может быть применен для того, чтобы обрабатывать информацию изображений. Этот код 1314 модернизирован, чтобы выполнять только те функции, которые требуются от него. Как результат конвейерная сборка на основе этого кода имеет потенциал более быстрого выполнения своих операций, чем, скажем, объемная универсальная программа, которая имеет различные связанные подпрограммы для обработки множества отдельных задач, которые могут никогда не быть использованными в конкретном приложении.
В качестве одного примера допустим, что задача видеоконвейера в конкретном варианте применения заключается в том, чтобы преобразовать чересстрочную информацию изображений Y'CbCr 4:2:2 в промежуточное линейное построчное цветовое пространство RGB 4:4:4, выполняя создание составных изображений в цветовом пространстве RGB и затем выводя результирующую обработанную информацию телевизионному приемнику. Эта последовательность операций включает в себя определенные операции (к примеру, повышающую дискретизацию, преобразование трансфер-матрицы, применение функции преобразования, создание составных изображений и т.п.), но не другие операции. Следовательно, конфигурационный модуль 1302 должен генерировать только код, необходимый для того, чтобы выполнять вычисления, которые требуются, и ничего более.
Выше описана конфигурационная операция в контексте включения или исключения модулей. Тем не менее, расширенная конфигурационная функциональность может выполнять другие операции оптимизации, такие как объединение выбранных модулей кода конкретным эффективным методом, удаление избыточного кода, который является общим для выбранных модулей кода, и т.д.
Предусмотрен ряд способов для того, чтобы реализовать конфигурационный модуль 1302. Один способ реализации этой функциональности заключается в том, чтобы использовать ресурсы существующих конфигурационных средств (например, традиционного компилятора C++), которые уже обладают определенной возможностью анализировать исходный код и удалять избыточный код, и применять эту функциональность к текущей задаче оптимизации конвейерного кода посредством указания и выбора соответствующих модулей.
Фиг.14 показывает процедуру 1400, которая обобщает вышеописанное описание в форме блок-схемы последовательности операций способа. Этап 1402 влечет за собой ввод требований к конвейеру видео. Этап 1404 влечет за собой определение оптимального кода, который удовлетворяет входным требованиям. Этап 1406 влечет за собой вывод и выполнение оптимального кода.
В2. Общие принципы использования GPU для выполнения обработки изображений
Фиг.15 показывает общее представление системы 1500, которая может быть использована для того, чтобы реализовать аспекты конвейера изображений, показанного на фиг.12 (и, более абстрактно, операций видеообработки 100, проиллюстрированных на фиг.1). Система 1500 может представлять вычислительную машину (например, персональную вычислительную машину), содержащую один или более ЦП. Система 1500 назначает определенные задачи обработки изображений (или все задачи обработки изображений), показанные на фиг.1, функциональности графического модуля. Функциональность графической обработки может содержать один или более графических процессоров (упоминаемых в данной области техники как GPU). В общем, фиг.15 включает в себя пунктирную линию, чтобы разграничивать функции, выполняемые ЦП системы 1500, от функций, которые могут выполняться графическим модулем системы 1500 (хотя это разделение является просто примерным, другие назначения ЦП/GPU возможны).
В качестве исходных данных, GPU - это, в общем, устройство обработки, аналогичное ЦП, но, как правило, с меньшими возможностями выполнять решения на ветвлении. Системы типично используют GPU для того, чтобы выполнять информационно насыщенные задачи подготовки к просмотру, которые выполняются периодически, например подготовку к просмотру информации с помощью трехмерного конвейера обработки (включающего в себя вертексные шейдеры, пиксельные шейдеры и т.д.). Таким образом, главной сферой использования GPU является технология проведения игр и имитационное моделирование, которая использует GPU для того, чтобы подготавливать к просмотру различные сцены, символы, спецэффекты и т.д. Назначение периодических или информационно насыщенных задач GPU освобождает системный ЦП для того, чтобы выполнять другие высокоуровневые задачи управления, и тем самым повышает производительность такой системы. В этом случае вместо генерирования информации для проведения игр система 1500 использует функциональность графического модуля для того, чтобы изменять принимаемую информацию изображений (к примеру, видеоинформацию) до вывода на любой вид выходного устройства. Например, один вариант применения системы 1500 заключается в том, чтобы принимать видеоинформацию с DVD, создавать составные изображений из видеоинформации в графической функциональности (к примеру, посредством объединения текстовых надписей на видеоинформации) и затем выводить результирующий сигнал телевизионному приемнику.
С помощью вышеуказанного общего представления каждый из примерных компонентов описывается ниже поочередно. Следующий раздел (В3) предоставляет более конкретную информацию, касающуюся того, как функциональность графического модуля может быть использована для того, чтобы реализовывать аспекты конвейера 100, показанного на фиг.1.
Начнем с того, что система 1500 получает видеоинформацию из любого из ряда источников. Например, система 1500 может получать видеоинформацию из сети 1502 (такой как удаленный источник, подключенный к Интернету), любого типа базы данных 1504, любого типа машиночитаемого дискового носителя 1506 (такого как оптический диск, DVD и т.д.) или какого-либо другого источника 1508. В любом случае принимаемая информация может содержать сочетание информации изображений и аудиоинформации. Блок 1510 демультиплексора отделяет аудиоинформацию от информации изображений. Функциональность 1512 аудиообработки обрабатывает аудиоинформацию.
Декодер 1514 изображений обрабатывает информацию изображений. Декодер 1514 изображений может преобразовывать сжатую информацию изображений из принимаемого формата в какой-либо другой формат и т.п. Вывод декодера 1514 изображений может включать в себя так называемую информацию идеальных изображений, а также информацию субпотоков изображений. Информация идеальных изображений составляет основной поток изображений, который должен быть подготовлен к просмотру на дисплейном устройстве. Информация субпотоков изображений может составлять любую дополнительную информацию, ассоциативно связанную с информацией идеальных изображений, например информацию кодированных титров между кадрами, все виды информации наложения графических элементов (например, различные элементы управления графического редактирования), различные виды субизображений, представляемых DVD-проигрывателями, и т.д. (В другой реализации определенные аспекты видеодекодера могут назначаться функциональности графического модуля.)
В одной примерной реализации модуль 1516 рендерера видеомикширования (VMR) играет центральную роль в обработке полученной таким образом информации изображений. В качестве обзора, VMR-модуль 1516 взаимодействует с графическим интерфейсом 1518 и драйвером 1520 дисплея, который, в свою очередь, управляет графическим модулем 1522. Это взаимодействие может повлечь за собой исследование возможностей графического модуля 1522. Это взаимодействие также влечет за собой координирование обработки информации изображений посредством графического интерфейса 1518, драйвера 1520 дисплея и графического модуля 1522. В одной реализации графический интерфейс 1318 может быть реализован с помощью функциональности DirectDraw, предоставляемой посредством Microsoft® Corporation DirectX. DirectDraw выступает в этом контексте в качестве средства обмена сообщения для информационного соединения VMR-модуля 1516 с графическим модулем 1522. Графический модуль 1522 сам может составлять фиксированный модуль в вычислительной машине или аналогичном устройстве или может составлять съемный блок, такой как графическая плата. (В общем, в большинстве случаев назначаемые приложения, упомянутые в первом разделе данной заявки, предоставляют сведения, касающиеся примерных структур данных, которые VMR-модуль 1516 может использовать для того, чтобы взаимодействовать с графическим модулем 1522. Поскольку это взаимодействие не является важным для настоящей заявки, сведения об этом взаимодействии не повторяются в этом документе.)
Графический модуль 1522 включает в себя один или более графических процессоров (GPU) 1524. Как упоминалось выше, система может назначать любую комбинацию операций обработки, показанных на фиг.1, GPU 1524. GPU 1524 выполняет эти задачи с помощью пиксельного шейдера 1526. Пиксельный шейдер означает функциональность, которая позволяет выполнять различные типы операций с информацией изображений на попиксельной основе. Подраздел В3 предоставляет дополнительную информацию, касающуюся архитектуры типичного пиксельного шейдера, а также то, как эта технология может быть использована для того, чтобы выполнять операции, показанные на фиг.1.
GPU 1524 может взаимодействовать с локальным запоминающим устройством 1528, ассоциативно связанным с графическим модулем 1522. Это локальное запоминающее устройство 1528 может обслуживать любое число связанных с хранением задач. Например, это запоминающее устройство 1528 может сохранять конечную поверхность изображения, которая затем переадресуется выходному устройству 1530 (такому как дисплейный монитор, телевизионный приемник, устройство хранения, сетевое назначение и т.д.).
В3. Усовершенствования пиксельного шейдера
В качестве исходных данных, фиг.16 показывает архитектуру пиксельного шейдера 1600, который, как правило, используется в конвейерах трехмерной обработки. Каждый пиксел в типичном варианте применения пиксельного шейдера может быть представлен посредством вектора из четырех значений с плавающей запятой, к примеру, RGBA (красное, зеленое, голубое, альфа), где каждое значение соответствует отдельному каналу. Архитектура пиксельного шейдера 1600 включает в себя последовательность регистров ввода/вывода (1602, 1604, 1606, 1608) и арифметическое логическое устройство (АЛУ) 1610 для выполнения операций с входными данными. Более конкретно, эти регистры включают в себя цветовые регистры 1602. Эти регистры 1602 направляют итеративные вертексные цветовые данные от вертексного шейдера (не показан) к пиксельному шейдеру 1600. Постоянные регистры 1604 предоставляют заданные пользователями константы пиксельному шейдеру 1600. Выходные/временные регистры 1606 предоставляют временное хранение промежуточных вычислений. В этом наборе регистров регистр r0 также принимает вывод пиксельного шейдера 1600. Текстурные регистры 1608 предоставляют текстурные данные АЛУ 1610 пиксельного шейдера. АЛУ 1610 пиксельного шейдера выполняют инструкции арифметической и текстурной адресации на основе программы. Программа включает в себя совокупность инструкций, выбранных из набора разрешенных команд пиксельного шейдера.
Последующее описание специально посвящено использованию текстурных регистров 1608 (далее упоминаемых в общем как "блоки"), чтобы предоставлять информацию изображений и веса фильтров АЛУ 1610 пиксельного шейдера. Следовательно, предоставляется дополнительная вводная информация, касающаяся понятия текстур, в контексте фиг.17.
Говоря примерно, в игровых приложениях текстура задает изображение, которое вставляется на полигональные поверхности, задающие символы, сцены и т.д. Фиг.17 показывает работу 1700 приложения текстурирования, в котором текстура 1702 применяется к полигону 1704. Полигон 1704 состоит из двух треугольных непроизводных элементов, скомпонованных так, чтобы формировать прямоугольник. Полигон 1704 включает в себя четыре вершины V1, V2, V3 и V4. Каждая вершина включает в себя координаты текстуры. Координаты текстуры задаются относительно традиционной системы координат U и V. В этой системе координат координата U, в общем, соответствует оси X, а координата V, в общем, соответствует оси Y. Значения по оси U зафиксированы, чтобы варьироваться в диапазоне от 0,0 до 1,0, и значения по оси V зафиксированы, чтобы варьироваться в диапазоне от 0,0 до 1,0.
Координаты текстуры, ассоциативно связанные с вершинами, задают то, как текстура 1702 должна быть помещена на полигон 1704. В примерном случае, фиг.17, вершина V1 имеет координаты текстуры 0,0, 0,0, что соответствует верхнему левому углу текстуры 1702. Вершина V2 имеет координаты текстуры 1,0, 0,0, что соответствует верхнему правому углу поверхности 1702. Вершина V3 имеет координаты текстуры 0,0, 0,5, что соответствует центру левого края текстуры 1702. А вершина V4 имеет координаты текстуры 1,0, 0,5, что соответствует центру правого края текстуры 1702. Следовательно, когда текстура 1702 отображается на полигоне 1704 в соответствии с координатами текстуры, только верхняя половина текстуры 1702 применяется к полигону 1704. Результат применения текстуры 1702 к полигону 1704 показан в текстурированной поверхности 1706.
Конвейеры трехмерной обработки типично обеспечивают возможность ряда специальных операций обработки текстуры, разработанных в контексте генерирования информации для проведения игр. Одна специальная операция упоминается как режим завертывания. В режиме завертывания конвейер трехмерной обработки повторяет текстуры несколько раз, к примеру, в одном случае для того, чтобы сгенерировать строку или матрицу текстур, которые имеют одно содержимое. Режим зеркального отображения также дублирует соседнюю структуру, но транспонирует (отражает) текстуру как зеркало.
Дополнительная информация, касающаяся общих вопросов, связанных с любыми пиксельными шейдерами, может быть найдена в ряде платных публикаций, таких как Wolfgang F. Engel, "Direct3D ShaderX: Vertex and Pixel Shader Tips and Tricks", Wordware Publishing, Inc., 2002 г.
Используя вышеприведенное введение, оставшееся описание излагает примерные новые методики использования пиксельного шейдера для того, чтобы реализовывать аспекты конвейера обработки изображений, показанного на фиг.1.
Начнем с того, что фиг.18 показывает примерный вариант применения 1800 пиксельного шейдера 1526 (фиг.15), чтобы реализовать фильтр обработки изображений, имеющий ядро с четырьмя отводами. Поскольку тип обработки, показанный на фиг.18, также является основополагающим для многих других операций, выполняемых конвейером 100, фиг.1, принципы, изложенные в отношении фиг.18, применяются к другим типам обработки, которые могут выполняться пиксельным шейдером 1526. Случай с ядром фильтра с четырьмя отводами, разумеется, является просто иллюстративным. Последующие примеры поясняют, как эта модель может быть распространена на другие структуры фильтров.
В общем, ЦП 1524 может быть сконфигурирован, чтобы сканировать одно или более входных изображений, извлекать пиксельные значения из каждого, применять вычисление на основе ввода и выводить один пиксел. Эта операция может быть выражена следующим образом: вывод(x, у)=функция(ввод1 (x, у), ввод2(x, у),…, вводр(х, у), константы матрицы[m]). Другими словами, это общее выражение означает, что результат (вывод(х, у)) математически зависит от некоторой функции входных сигналов (ввод1(х, у), ввод2(х, у),…, вводр(х, у)) и, необязательно, различных заданных констант (матричные константы[m]).
В конкретном контексте обработки изображений с помощью фильтров пиксельный шейдер 1526 требует ввода одного или более входных изображений вместе с ассоциативно связанными весами фильтров, которые должны быть применены к изображениям. Более формально, фильтр, который генерирует вывод (Out[x]), ассоциативно связанный с выходным пикселом, может быть задан следующим образом:
Out[x]=sum(in[x-taps/2+i]·kernel[i], i=0… taps-1).
Другими словами, вывод для пиксела (Out[x]) представляет взвешенное суммирование различных входных членов. Ядро представляет информацию взвешивания, которое должно быть применено к входным членам. Различные входные члены, в свою очередь, могут представлять смещенные версии той же выборки информации входных изображений.
Фиг.18 показывает то, как пиксельный шейдер 1526 может реализовывать вышеприведенное уравнение. Проиллюстрированный пример 1800 с четырьмя отводами показывает последовательность текстурных блоков 1802, которые предоставляют ввод в АЛУ 1804 пиксельного шейдера. Показанный подход должен назначить веса фильтрации первому текстурному блоку и назначить четыре различные дельта-смещенные версии одной информации изображений следующим четырем текстурным блокам (представляющим четыре отвода ядра). АЛУ 1804 пиксельного шейдера считывает информацию, сохраненную в текстурных блоках (в одной операции считывания) и предоставляет один вывод для конкретного пиксела (в одной операции записи). Эта процедура повторяется много раз, чтобы сгенерировать полное изображение. Данный подход задает одномерный сверточный фильтр с базовым окном отводов фильтра, равным taps.
Работа примера 1800, показанного на фиг.18, более формально может быть выражена следующим образом. Примерное используемое одномерное ядро имеет пикселы шириной w и веса ядра w[-1], w[0], w[2] и w[3]. Текстура весов вычисляется посредством расчета четырех весов ядра фильтра для каждого пиксела. Одномерное ядро также включает в себя четыре ввода, заданных как in[-1], in[0], in[1] и in[2]. Символ Δ задается как 1/w. С учетом вышеизложенного следующая информация назначается текстурным блокам 1-5:
Текстура 1: "текстура весов" с координатами 0,…, 1;
Текстура 2: in[-1], входное изображение с координатами (0,…, 1)+(-1)·Δ (т.е. от 0-Δ до 1-Δ);
Текстура 3: in[0], входное изображение с координатами (0,…, 1)+(0)·Δ;
Текстура 4: in[1], входное изображение с координатами (0,…, 1)+(1)·Δ;
Текстура 5: in[2], входное изображение с координатами (0,…, 1)+(2)·Δ дельта (т.е. 0+2·Δ до 1+2·Δ).
Если tn представляет пиксел, извлеченный из текстурного блока n, то вычисления, выполняемые АЛУ 1804 пиксельного шейдера, могут быть выражены посредством следующей программы:
Алгоритм 3: Реализация фильтра с помощью пиксельного шейдера
Let w[0]=t1.red
Let w[l]=t1.green
Let w[2]=t1.blue
Let w[3]=t1.alpha
Out.rgba=t2.rgba·w[0]+t3.rgba·w[1]+t4.rgba·w[2]+t5.rgba·w[3]
Другими словами, матрице w сначала назначаются значения информации взвешивания, которые сохранены в первом текстурном блоке (t1). Затем выходной результат (Out.rgba) формируется посредством модификации информации смещенных изображений в текстурных блоках t2-t5 на веса w. Суффиксы, присоединенные к информации регистров, задают канальную информацию. Следовательно, вывод Out.rgba представляет вектор из четырех значений с плавающей запятой, сохраненных в каналах зеленого, красного, синего и альфа. Можно видеть, что вышеприведенный алгоритм требует, к примеру, taps+1 входных текстурных блоков, поскольку один блок назначается для хранения информации взвешивания.
В общем, если информация входных изображений выражена в RGB-формате, то текстурные блоки могут хранить одинаковые величины компонент красного, зеленого и голубого. Тем не менее, если пиксельный шейдер применяется для обработки связанной с яркостью информации изображений (такой как YUV), то текстурные блоки могут хранить больше информации яркости относительно информации цветности (U, V). Эта мера использует преимущество того факта, что человеческий глаз более чувствителен к информации яркости, чем к информации цветности, поэтому необязательно сохранять и обрабатывать столько же информации цветности, сколько и информации яркости, чтобы добиться приемлемых выходных результатов.
Допускается ряд вариаций и оптимизаций вышеописанного подхода.
Согласно одному варианту вышеописанный режим завертывания может быть использован для того, чтобы обрабатывать любую текстуру как бесконечный элемент информации изображений. В этом режиме один подход заключается в том, чтобы задать координаты входной текстуры взвешивания от 0 до 1,0/gcd(ширина источника, ширина назначения) вместо 0,…, 1. При применении этой текстуры блок предварительной выборки текстур автоматически "завернется" к следующей копии информации взвешивания, сохраненной в текстуре. Эта мера дает возможность проектировщику уменьшить требования по хранению ядра и при этом обеспечивать, чтобы информация применялась с дублированием при необходимости.
Согласно другому варианту ядро может иметь более четырех отводов.
Чтобы разрешить эту ситуацию, реализация может разбить наборы информации взвешивания ядра на группы по четыре значения и назначить каждое дополнительной входной текстуре взвешивания.
Рассмотрим случай, когда предусмотрено шесть отводов. В этом случае реализация может использовать две текстуры взвешивания (первая текстура с четырьмя значениями, и вторая текстура с оставшимися двумя значениями, оставляя два сегмента неиспользуемыми). Эта реализация также требует шести текстур входных изображений. Таким образом, чтобы реализовать эту структуру, GPU из восьми текстур может быть использован для того, чтобы выполнять фильтрацию с помощью шести отводов за один проход.
Согласно другому варианту число отводов может превышать число текстурных блоков. Отметим, что вычисление информации выходных изображений представляет суммирование членов taps. Следовательно, большее число отводов может быть вычислено посредством разбиения вычисления суммирования на несколько проходов обработки. Например, если ядро фильтра имеет 12 отводов, то одна реализация может вычислить Out[x]=sum(in[x+i]·w [i], i=0…11) как:
Sum1[x]=sum(in[x+i]·w [i], i=0…3)
Sum2 [x]=sum(in[x+i]·w [i], i=4…8)
Sum3[x]=sum(in[x+i]·w [i], i=9…11)
Эта реализация затем может объединить результаты с помощью конечного прохода:
Out[x]=sum1[x]+sum2[x]+sum3[x] (три считывания, одна запись)
Другая возможная реализация может сформировать агрегированный результат Out[x] посредством следующего ряда операций:
Out[x]=sum1[x] (запись)
Out[x]=out[x]+sum2[x] (считывание, считывание, запись)
Out [x]=out [x]+sum3[x] (считывание, считывание, запись)
Второй подход требует значительно меньше памяти, чем первый подход, но также требует в два раза больше обращений к памяти по сравнению с первым подходом (к примеру, четырех считываний и трех записей). Этот признак второй стратегии может делать ее неприемлемой, поскольку циклы считывания-изменения-записи в GPU очень затратны или даже запрещены.
Согласно другому варианту реализация может предоставлять специальный режим ("критический пиксел"), который интерпретирует все пикселы вне заданной информации изображений как черные (или какое-либо другое значение по умолчанию). Эта мера может быть применена для того, чтобы автоматически скрыть краевые условия в информации, которая должна быть отображена.
Согласно другому варианту реализация может применить вышеупомянутый режим зеркального отображения при обработке информации изображений. Этот режим отражает информацию изображений горизонтально или вертикально при обращении к информации изображений вне границ информации изображений.
Фиг.19 показывает процедуру 1900, которая обобщает многие из вышеописанных признаков. Этап 1902 влечет за собой назначение различной входной информации различным входным блокам пиксельного шейдера. Эта информация может содержать информацию изображений и информацию взвешивания, применяемую к различным текстурным блокам, константы, применяемые к различным блокам констант, и т.п. Этап 1904 влечет за собой вычисление выходной информации изображений на попиксельной основе, базируясь на программных инструкциях, предоставляемых в АЛУ 1804 пиксельного шейдера. Этап 1906 определяет, требуются ли дополнительные проходы. Если да, процедура 1900 повторяет одну или более из операций, показанных на фиг.19, один или несколько раз. Этап 1908 дает окончательный выходной результат.
Напоследок, фиг.20 показывает вариант применения пиксельного шейдера 1526, который выполняет некоторые из операций, представленных в контексте фиг.1. Фиг.20 конкретно посвящена одному примерному варианту осуществления, в котором конвейер принимает информацию изображений YUV 4:2:2, выполняет ее повышающую дискретизацию, преобразует в линейную RGB-форму и выполняет масштабирование результирующей линейной информации. Обработка, показанная на фиг.20, основана на понятиях, разработанных выше относительно фиг.18 и 19.
Отметим, что информация изображений 4:2:0, выраженная в гибридном плоском формате (таком как NV12), может интерпретироваться как содержащая плоскость яркости и плоскость цветности. Следовательно, можно параллельно выполнять определенные операции с этой информацией.
Один подход заключается в том, чтобы разделить текстурные блоки на две группы, одну группу для использования при интерполяции компоненты цветности. Операция повышающей дискретизации активирует операцию масштабирующего укрупнения, которая может быть использована для того, чтобы генерировать информацию цветности 4:4:4. Затем пиксельный шейдер 1526 может использовать компоненту яркости и интерполированную компоненту цветности для того, чтобы вычислять на попиксельной основе соответствующую информацию R'G'B' с помощью трансфер-матрицы. Далее пиксельный шейдер 1526 может применять функцию преобразования для того, чтобы линеаризовать информацию изображений. После этого пиксельный шейдер 1526 может быть использован для того, чтобы выполнять дополнительное масштабирование в RGB-пространстве с помощью второй группы текстурных блоков.
Более формально, далее приводится примерная последовательность этапов, которая может быть использована для того, чтобы преобразовать информацию изображений вышеописанным способом.
1) Установка текстур 1-5 вышеописанным методом (показанным на фиг.18), чтобы выполнять первую операцию масштабирования.
2) Использование вышеописанной операции масштабирования для того, чтобы вычислить информацию СbСr при скорости дискретизации, в два раза большей, чем для информации яркости.
3) Загрузка матрицы преобразования цветового пространства из Y'CbCr в R'G'B' в массив из 16 ограничений в качестве матрицы М.
4) Вычисление информации R'G'B' следующим образом:
Вычисление R'=dotProd4(М[0], aY'CbCr)
Вычисление G'=dotProd4(М[1], aY'CbCr)
Вычисление В'=dotProd4(М[2], aY'CbCr)
Вычисление A=dotProd4(М[3], aY'CbCr)
5) Вычисление RGB из R'G'B' с помощью функции преобразования.
6) Выполнение второй операции масштабирования посредством вычисления масштабированных линейных RGB-данных с помощью вышеизложенных алгоритмов (со ссылкой на фиг.18), но для текстур 6-12.
7) После того как выполнено горизонтальное масштабирование, применение вертикального масштабирования к RGB-информации.
Фиг.20 показывает процедуру 2000, которая описывает вышеописанный алгоритм в форме блок-схемы последовательности операций способа. Этап 2002 влечет за собой назначение информации соответствующим текстурным блокам (к примеру, первому набору текстурных блоков). Этап 2004 влечет за собой использование первого набора текстурных блоков, чтобы выполнить повышающую дискретизацию информации цветности. Этап 2006 влечет за собой загрузку ограничений для использования при выполнении преобразования цветового пространства в пиксельном шейдере 1526. Этап 2008 влечет за собой использование ограничений для того, чтобы преобразовать информацию изображений в нелинейную форму R'G'B'. Этап 2010 влечет за собой преобразование информации R'G'B' в линейную форму RGB. Помимо этого этап 2012 влечет за собой масштабирование RGB-информации.
С. Примерное вычислительное окружение
В одной примерной реализации различные аспекты обработки, показанные на предыдущих чертежах, могут выполняться посредством вычислительного оборудования. В этом случае фиг.21 предоставляет информацию, касающуюся примерного вычислительного окружения 2100, которое может быть использовано для того, чтобы реализовывать аспекты обработки, показанные на предшествующих чертежах. Например, вычислительная машина может быть использована для того, чтобы реализовать часть или весь конвейер 100 обработки изображений, показанный на фиг.1.
Вычислительное окружение 2100 включает в себя вычислительную машину 2102 общего назначения и дисплейное устройство 2104. Тем не менее, вычислительное окружение 2100 может включать в себя другие виды вычислительного оборудования. Например, хотя не показано, вычислительное окружение 2100 может включать в себя карманные или дорожные устройства, телевизионные абонентские приставки, игровые консоли, функциональность обработки, интегрированную в устройства обработки/представления видео (к примеру, телевизионные приемники, цифровые видеомагнитофоны и т.д.), мейнфреймы и т.д. Дополнительно фиг.21 показывает элементы вычислительного окружения 2100, сгруппированные так, чтобы упростить пояснение. Тем не менее, вычислительное окружение 2100 может использовать конфигурацию распределенной обработки. В распределенном вычислительном окружении вычислительные ресурсы могут быть физически распределены по окружению.
Примерная вычислительная машина 2102 включает в себя один или более процессоров 2106, системное запоминающее устройство 2108 и шину 2110. Шина 2110 соединяет различные системные компоненты. Например, шина 2110 соединяет процессор 2106 с системным запоминающим устройством 2108. Шина 2110 может быть реализована с помощью любого типа структуры шины или сочетания структур шины, включая шину памяти или контроллер памяти, периферийную шину, ускоренный графический порт и процессорную или локальную шину, использующую любую из множества архитектур шины. Вычислительная машина 2102 также может соединяться с одним или более устройств GPU (не показаны) вышеописанным способом.
Вычислительная машина 2102 также может включать в себя множество машиночитаемых носителей, в том числе множество типов энергозависимых и энергонезависимых носителей, каждый из которых может быть съемным или стационарным. Например, системное запоминающее устройство 2108 включает в себя машиночитаемый носитель в форме энергозависимого запоминающего устройства, такого как оперативное запоминающее устройство (ОЗУ) 2112, и энергонезависимого запоминающего устройства, такого как постоянное запоминающее устройство (ПЗУ) 2114. ПЗУ 2114 включает в себя систему ввода-вывода (BIOS) 2116, которая содержит базовые процедуры, которые помогают передавать информацию между элементами вычислительной машины 2102, например, в ходе загрузки. ОЗУ 2112 типично содержит модули данных и/или программ в форме, к которой может быть быстро осуществлен доступ процессором 2106.
Другие виды вычислительных носителей хранения включают в себя накопитель 2118 на жестких дисках для считывания и записи на стационарный энергозависимый магнитный носитель, накопитель 2120 на магнитных дисках для считывания или записи на съемный энергонезависимый магнитный диск 2122 (к примеру, гибкий диск) и накопитель 2124 на оптических дисках для считывания или записи на съемный энергонезависимый оптический диск 2126, такой как CD-ROM, DVD-ROM или другой оптический носитель. Накопитель 2118 на жестких дисках, накопитель 2120 на магнитных дисках и накопитель 2124 на оптических дисках соединены с системной шиной 2110 посредством одного или более интерфейсов 2128 носителей данных. Альтернативно накопитель 2118 на жестких дисках, накопитель 2120 на магнитных дисках и накопитель 2124 на оптических дисках могут быть соединены с системной шиной 2110 посредством SCSI-интерфейса (не показан) или другого механизма соединения. Хотя не показано, вычислительная машина 2102 может включать в себя другие типы машиночитаемых носителей, такие как кассеты магнитной ленты или другие магнитные устройства хранения, карты флэш-памяти, CD-ROM, универсальные цифровые диски (DVD) или другие оптические устройства хранения, электрически стираемое программируемое постоянное запоминающее устройство (ЭСППЗУ) и т.д.
В общем, вышеуказанные машиночитаемые носители предоставляют энергонезависимое хранение машиночитаемых инструкций, программных модулей и других данных для использования вычислительной машиной 2102. Например, читаемые носители могут сохранять операционную систему 2130, прикладные модули 2132, другие программные модули 2134 и программные данные 2136.
Вычислительное окружение 2100 может включать в себя множество устройств ввода. Например, вычислительное окружение 2100 включает в себя клавиатуру 2138 и указательное устройство 2140 (к примеру, мышь) для ввода команд и информации в вычислительную машину 2102. Вычислительное окружение 2100 может включать в себя другие устройства ввода (не проиллюстрированы), такие как микрофон, джойстик, игровой планшет, спутниковая антенна, последовательный порт, сканер, устройства считывания карт, цифровые или видеокамеры и т.д. Интерфейсы 2142 ввода/вывода соединяют устройства ввода с процессором 2106. Обобщая, устройства ввода могут быть соединены с вычислительной машиной 2102 посредством любого вида интерфейса и структур шины, такого как параллельный порт, последовательный порт, игровой порт, порт универсальной последовательной шины (USB) и т.д.
Вычислительное окружение 2100 также включает в себя дисплейное устройство 2104. Видеоадаптер 2144 соединяет дисплейное устройство 2104 с шиной 2110. Помимо дисплейного устройства 2104 вычислительное окружение 2100 может включать в себя другие периферийные устройства вывода, такие как динамики (не показан), принтер (не показан) и т.д.
Вычислительная машина 2102 работает в сетевом окружении, используя логические соединения с одной или более удаленными вычислительными машинами, такими как удаленное вычислительное устройство 2146. Удаленное вычислительное устройство 2146 может содержать любой тип вычислительного оборудования, в том числе персональную вычислительную машину общего назначения, портативную вычислительную машину, сервер, игровую консоль, сетевое устройство расширения и т.п. Удаленное вычислительное устройство 2146 может включать в себя все из признаков, описанных выше относительно персональной вычислительной машины 2102, или какой-либо их поднабор.
Любой тип сети 2148 может быть использован для того, чтобы соединять вычислительную машину 2102 с удаленным вычислительным устройством 2146, например, ГВС, ЛВС и т.д. Вычислительная машина 2102 соединяется с сетью 2148 посредством сетевого интерфейса 2150, который может использовать широкополосное подключение, модемное подключение, DSL-подключение или другую стратегию подключения. Хотя не проиллюстрировано, вычислительное окружение 2100 может предоставлять функциональность беспроводной связи для соединения вычислительной машины 2102 с удаленным вычислительным устройством 2146 (к примеру, посредством модулированных радиосигналов, модулированных инфракрасных сигналов и т.д.).
В заключение, в данной заявке ряд примеров представлен в альтернативе (к примеру, случай А или случай В). Помимо этого данная заявка содержит в себе случаи, которые объединяют альтернативы в одной реализации (к примеру, случай А и случай В), даже если эта заявка может не упоминать эти объединенные случаи в явном виде в каждом примере.
Более того, ряд признаков описан в данном документе посредством первоначальной идентификации примерных проблем, которые эти признаки могут разрешать. Эта манера пояснения не является принятием того, чтобы другие признавали или формулировали проблемы способом, заданным в данном документе. Признание и формулирование проблем, имеющихся в области техники видеообработки, должно пониматься как часть настоящего изобретения.
Хотя изобретение было описано на языке, характерном для структурных признаков и/или методологических действий, необходимо понимать, что изобретение, определенное в прилагаемой формуле изобретения, не обязательно ограничено описанными характерными признаками или действиями. Точнее, характерные признаки и действия раскрываются как примерные формы реализации заявленного изобретения.
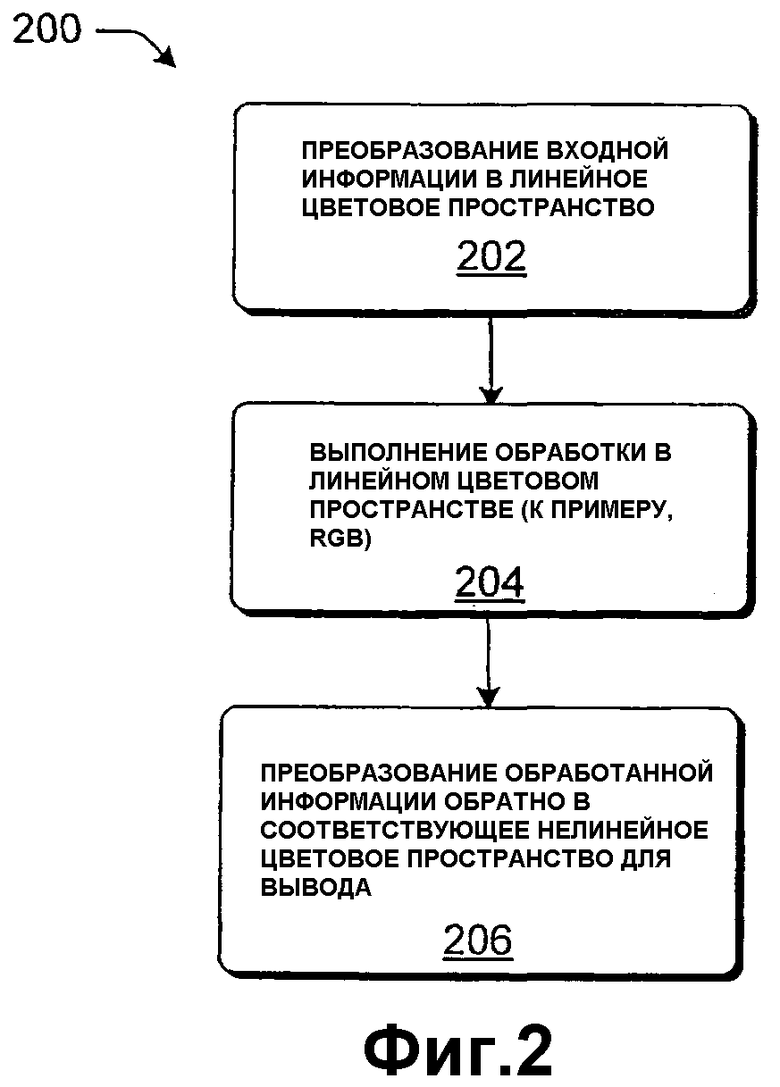
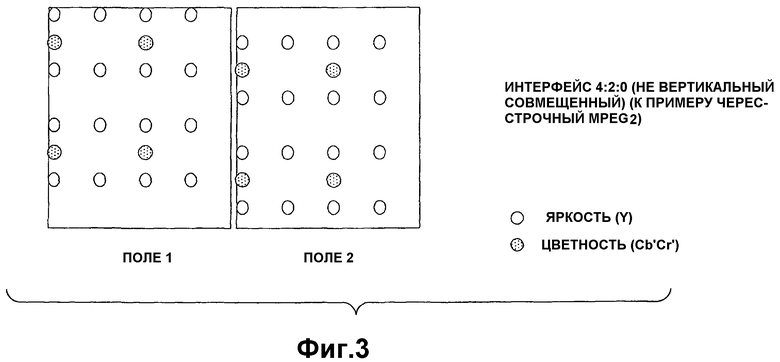
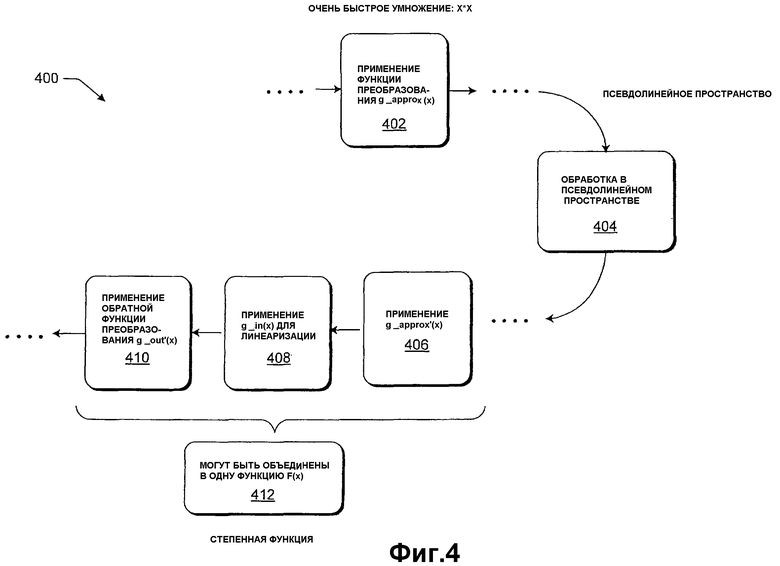
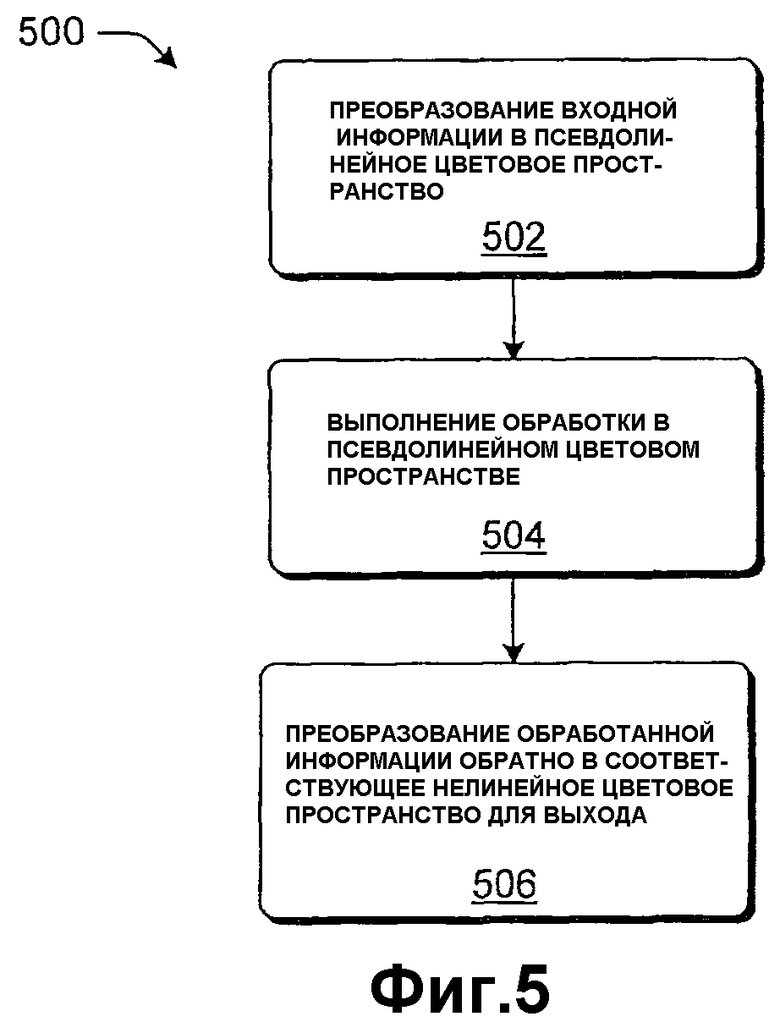
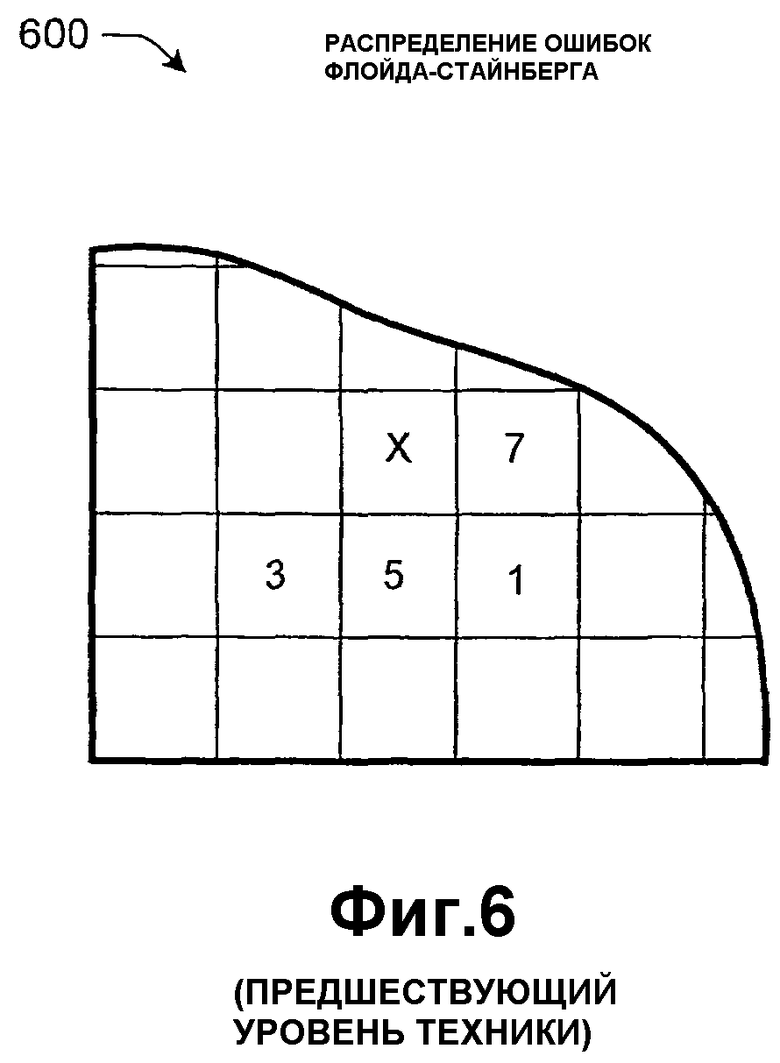
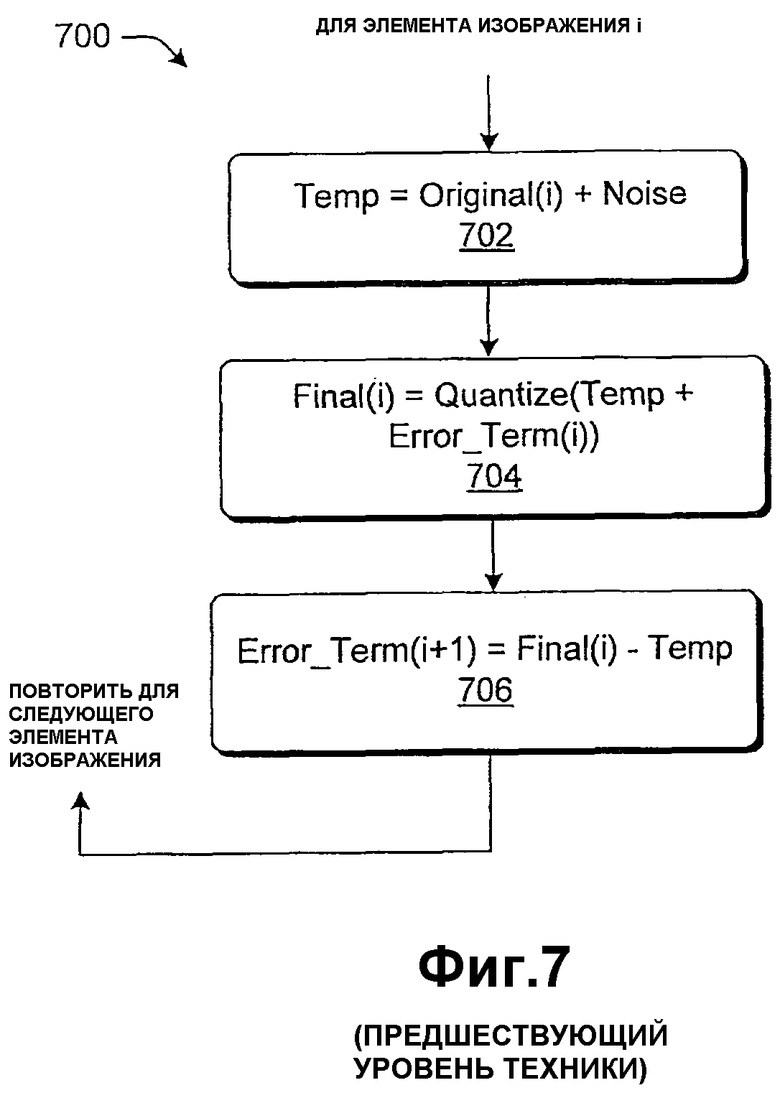
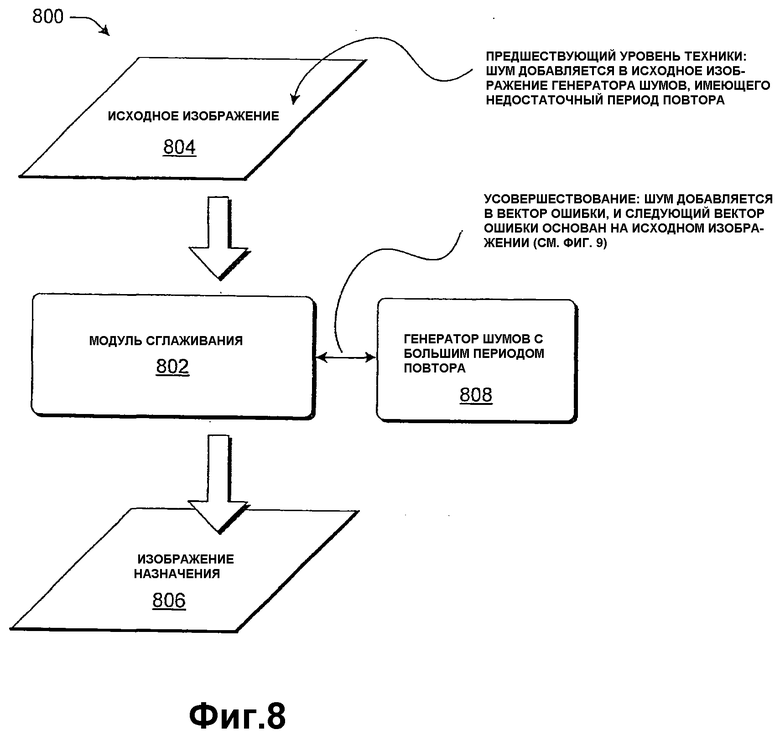
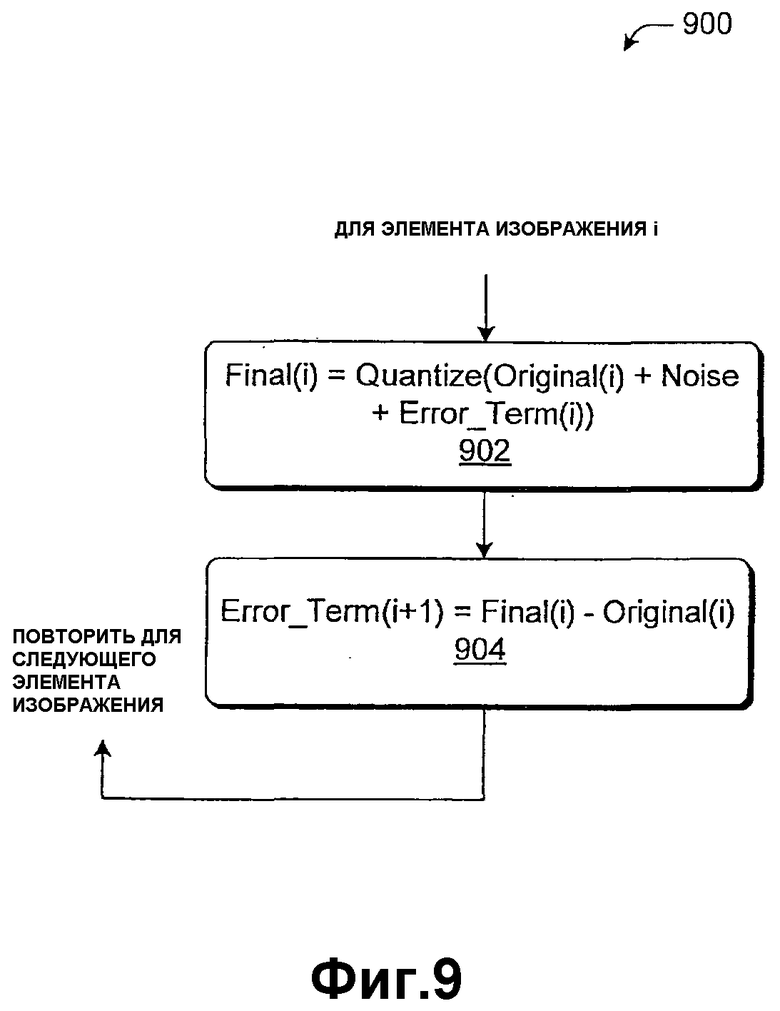
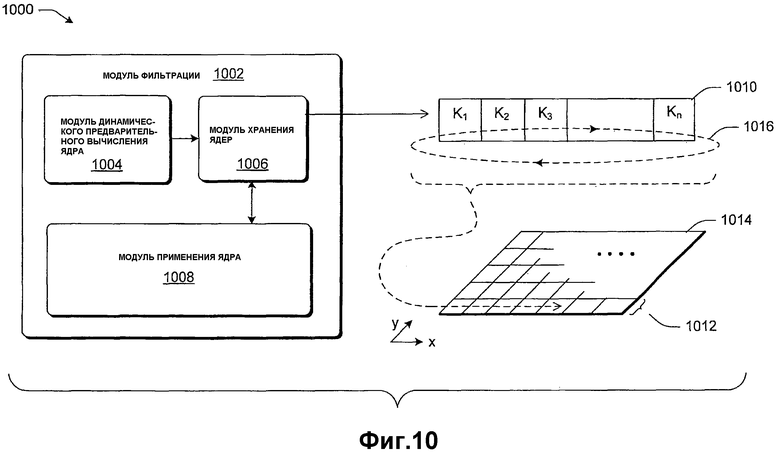
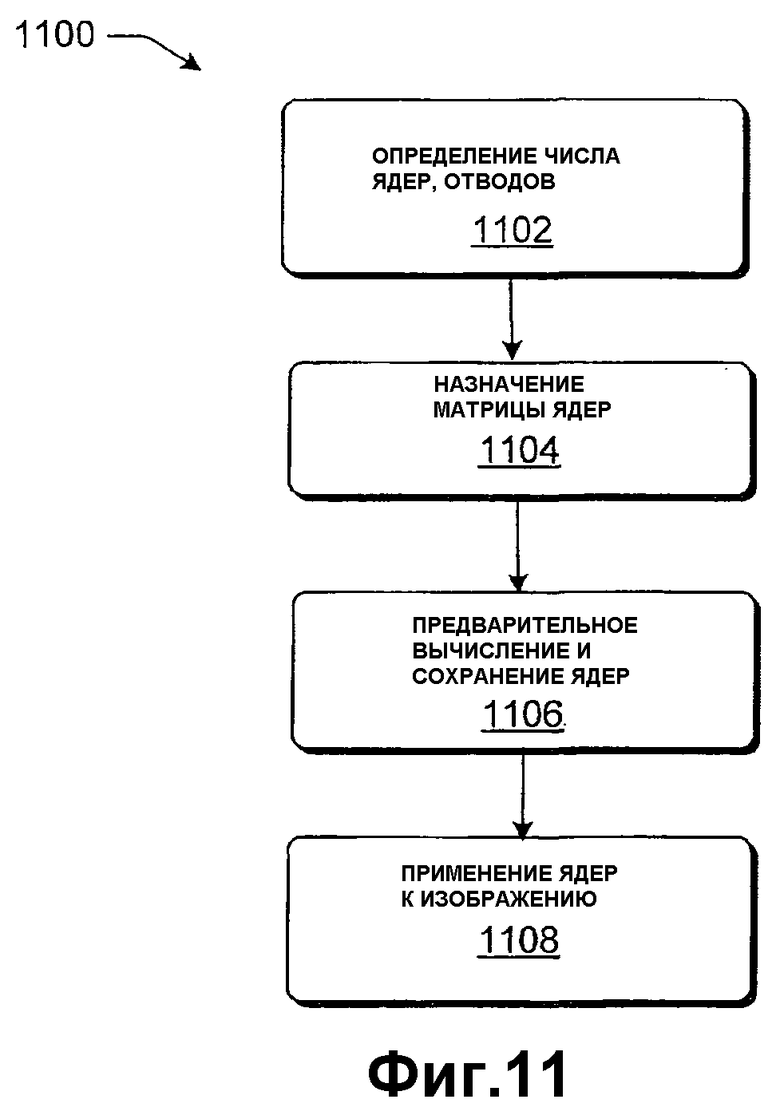
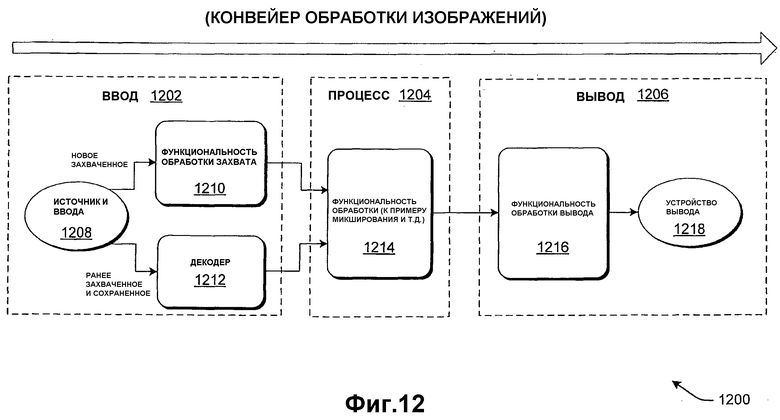
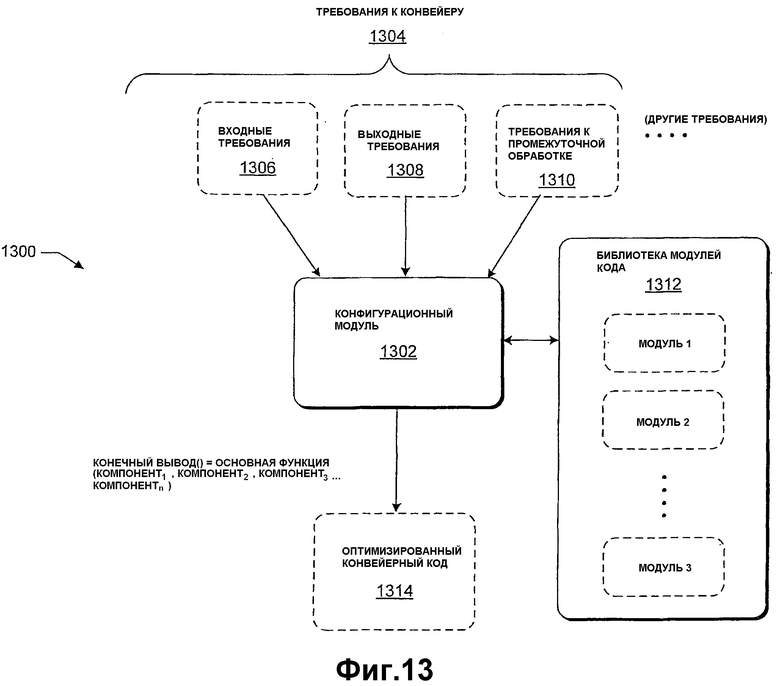
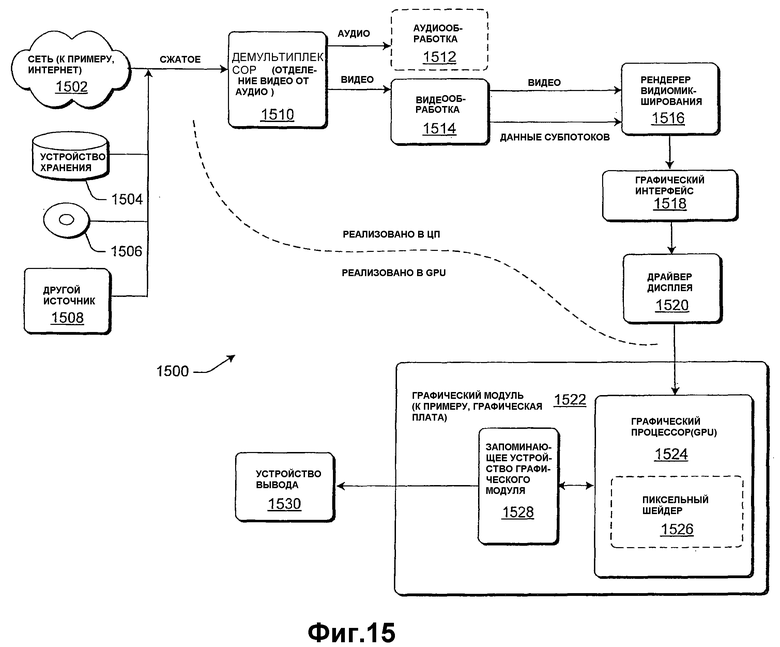
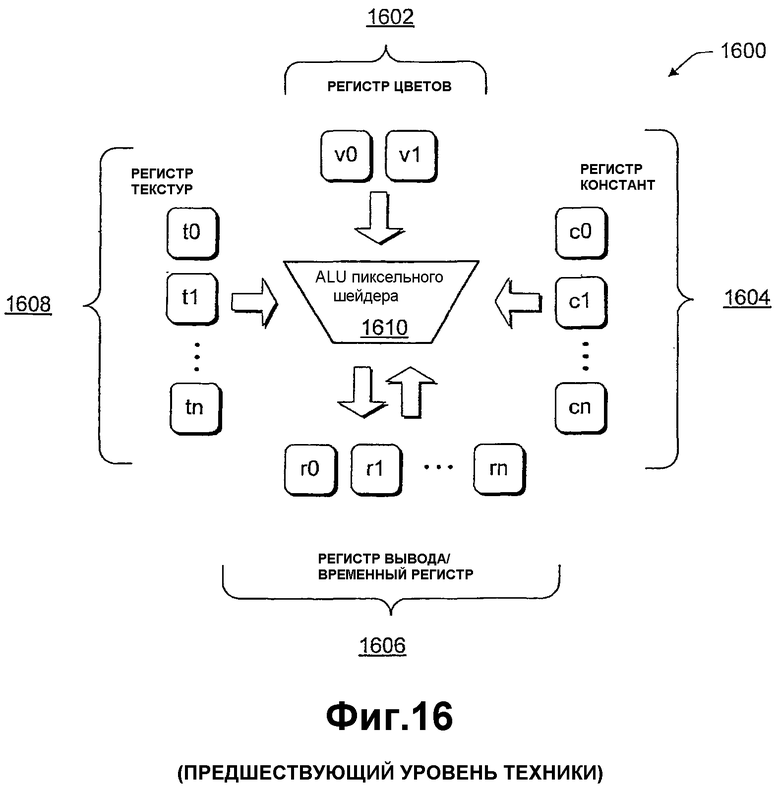
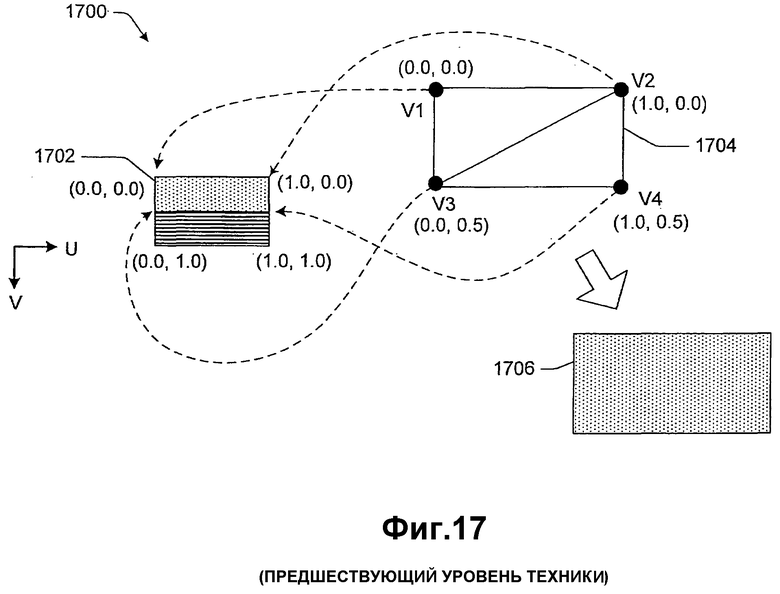
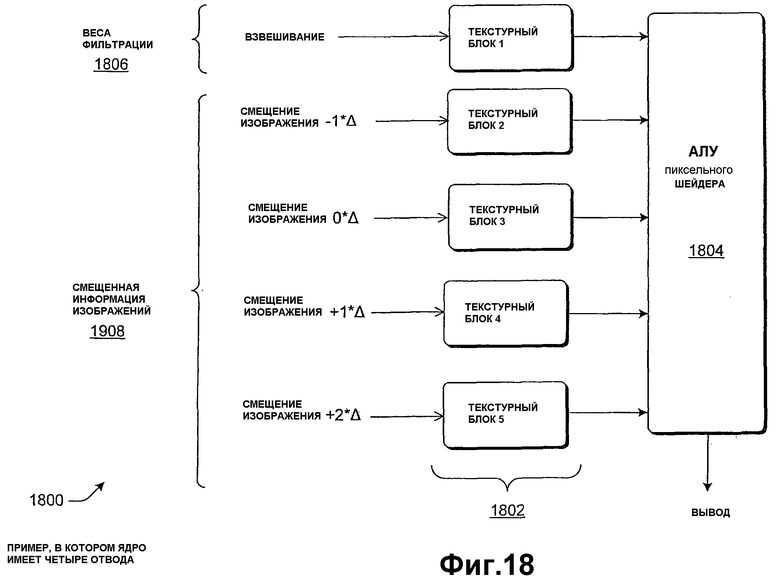
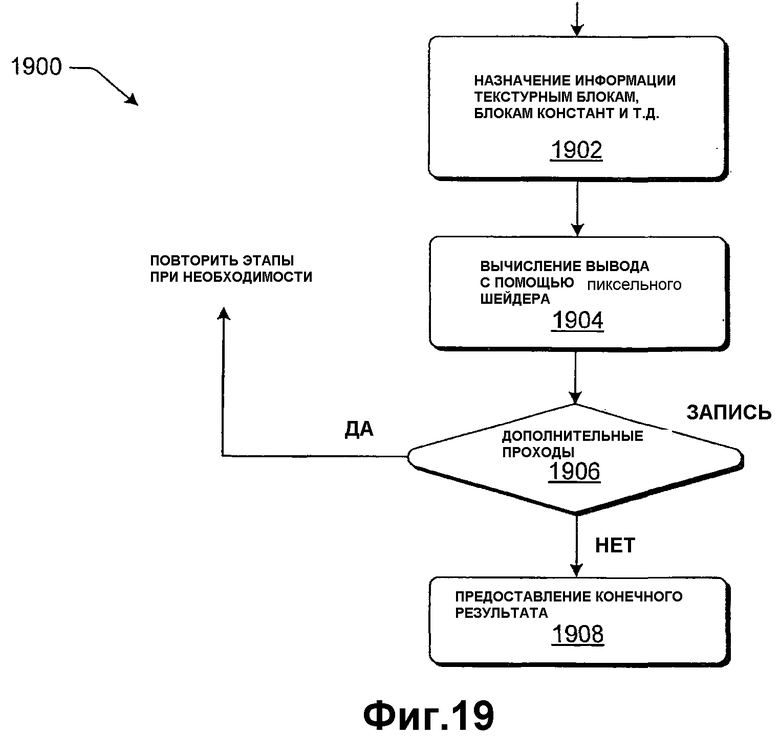
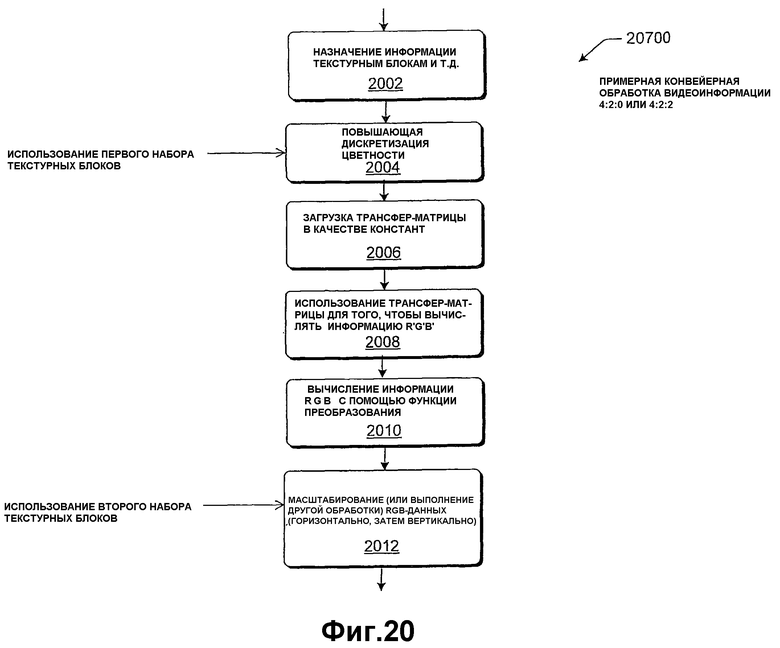
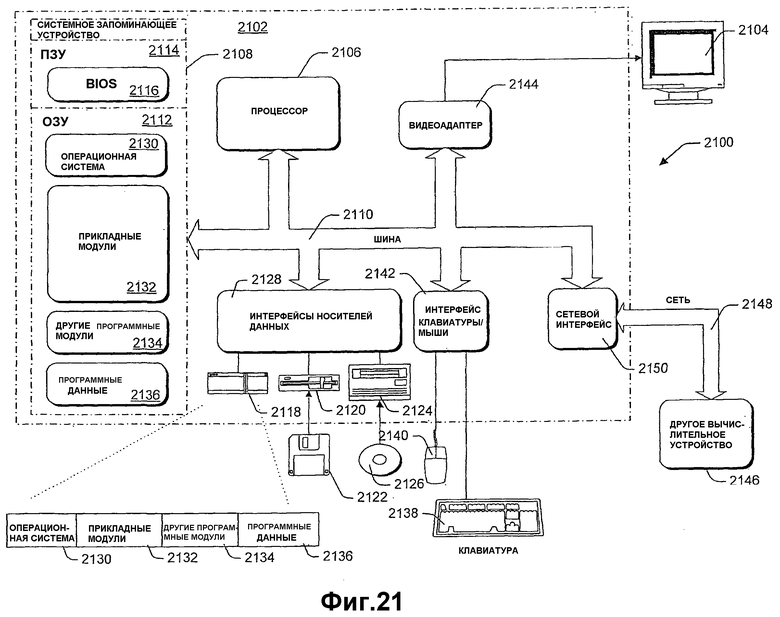
Изобретение относится к обработке информации изображений. Техническим результатом является уменьшение искажений изображения. Операции обработки включают в себя масштабирование, создание композитных изображений, альфа-сопряжение, выделение краев и т.д. В более конкретной реализации описываются стратегии для обработки информации изображений, которая: а) является линейной; b) находится в цветовом пространстве RGB; с) имеет высокую точность (к примеру, обеспечиваемую посредством представления с плавающей запятой); d) является построчной и е) является полноканальной. Другие усовершенствования предоставляют стратегии для: а) обработки информации изображений в псевдолинейном пространстве, чтобы повысить скорость обработки; b) реализации улучшенной методики дисперсии ошибок; с) динамического вычисления и применения ядер фильтрации; d) оптимизации генерирования конвейерного кода и е) реализации различных задач обработки с помощью новых методик пиксельного шейдера. 3 н. и 17 з.п. ф-лы, 21 ил.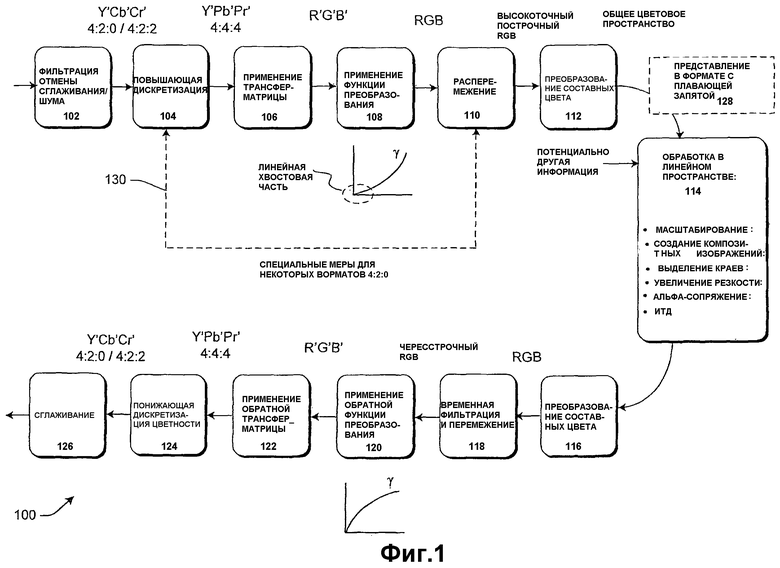
1. Способ обработки информации изображений в линейной форме, при этом способ содержит этапы, на которых:
принимают информацию изображений в чересстрочной нелинейной форме;
преобразуют информацию изображений в линейную форму посредством применения функции преобразования к информации изображений;
преобразуют информацию изображений в построчную форму посредством расперемежения информации изображений;
выполняют обработку информации изображений в построчной линейной форме и выполняют по меньшей мере одну операцию масштабирования, при этом
операция масштабирования влечет за собой предварительное вычисление ряда ядер фильтра и последующее применение заранее вычисленных ядер фильтра для того, чтобы обработать информацию изображений.
2. Способ по п.1, в котором предварительное вычисление также влечет за собой вычисление ряда ядер фильтра, которые необходимы, и определение того, сколько отводов должно иметь каждое ядро.
3. Способ по п.2, в котором применение ядер фильтра влечет за собой циклическое повторение последовательности предварительно вычисленных ядер фильтра при обработке строки или столбца информации изображений.
4. Способ по любому из предыдущих пунктов, в котором принимаемая информация изображений находится в связанном с яркостью цветовом пространстве.
5. Способ по п.4, при этом способ дополнительно содержит этапы, на которых до преобразования информации изображений в линейную форму преобразуют информацию изображений в нелинейное цветовое пространство R'G'B' посредством применения матрицы преобразования к информации изображений.
6. Способ по п.1, в котором обработка содержит этап, на котором изменяют размер информации изображений.
7. Способ по п.1, в котором обработка содержит этап, на котором выполняют операцию создания композитных изображений с информацией изображений.
8. Способ по п.1, в котором обработка содержит этап, на котором выполняют альфа-сопряжение информации изображений.
9. Способ по п.1, в котором обработка содержит этап, на котором выполняют выделение краев информации изображений.
10. Способ по п.1, в котором принимаемая информация изображений находится в связанном с яркостью цветовом пространстве, и в котором принимаемая информация изображений имеет меньшее число выборок цветности в сравнении с выборками яркости.
11. Способ по п.10, при этом способ дополнительно содержит этап, на котором выполняют повышающую дискретизацию информации изображений, чтобы увеличить число выборок цветности в сравнении с числом выборок яркости.
12. Способ по п.1, при этом способ дополнительно содержит этап, на котором квантуют и сглаживают информацию изображений после того, как она обработана, чтобы снизить ее точность, чтобы тем самым предоставить информацию квантованных изображений.
13. Способ по п.12, в котором квантование и сглаживание применяют алгоритм дисперсии ошибок, чтобы уменьшить количество искажений в информации квантованных изображений, при этом алгоритм дисперсии ошибок распределяет вектор ошибок на соседние элементы изображений относительно элемента изображения, который подвергается обработке.
14. Способ по п.1, в котором линейная форма содержит псевдолинейную форму.
15. Способ по п.14, при этом способ дополнительно содержит этап, на котором выполняют операцию, чтобы удалить псевдолинейную форму информации изображений после обработки.
16. Способ по п.1, при этом способ содержит, по меньшей мере, одну операцию масштабирования.
17. Способ по п.1, при этом способ задает конвейер обработки изображений, и в котором программа оптимизированного кода используется для того, чтобы реализовать конвейер обработки изображений.
18. Способ по п.17, в котором оптимизированный код генерируется посредством этапов, на которых:
вводят требования шаблона обработки изображений и
ассемблируют модули кода из библиотеки модулей кода, которые могут быть использованы для того, чтобы реализовать требования, при этом модули кода, которые не требуются, не используются в оптимизированном коде.
19. Конвейер обработки изображений, содержащий:
средства для приема информации изображений в чересстрочной нелинейной форме;
средства для преобразования информации изображений в линейную форму посредством применения функции преобразования к информации изображений;
средства для преобразования информации изображений в построчную форму посредством расперемежения информации изображений;
средства выполнения обработки информации изображений в построчной линейной форме и
средства выполнения по меньшей мере одной операции масштабирования, при этом
операция масштабирования влечет за собой предварительное вычисление ряда ядер фильтра и последующее применение заранее вычисленных ядер фильтра для того, чтобы обработать информацию изображений.
20. Машиночитаемый носитель, сохраняющий машиночитаемые инструкции, сконфигурированные, чтобы реализовывать способ по п.1.
| ЕР 0651577 А2, 03.05.1995 | |||
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| US 6370198 B1, 09.04.2002 | |||
| US 6304733 A, 07.03.2000 | |||
| US 4463372 A, 31.07.1994 | |||
| US 5235432 A, 10.08.1993 | |||
| Устройство для кодирования видеосигнала | 1987 |
|
SU1474701A2 |

