Изобретение относится к способу идентификации границы элемента контента в потоке контента, к устройству для идентификации границы элемента контента в потоке контента и компьютерному программному продукту, позволяющему выполнение способа или выполнение конфигурирования устройства.
WO 02/100098 описывает способ обнаружения времени начала и окончания ТВ-программы. EPG-данные (электронный путеводитель по программе) указывает время начала и окончания программы. Характеристические данные собираются из видеосегмента (видеокадров) программы в момент начала и в момент окончания. Первое значение (сигнатура), представляющее характеристические данные, включено в EPG-данные.
Когда пользователь выбирает программу из EPG каталога, наблюдается сигнал вещания ТВ-канала, и второе значение (сигнатура), представляющее характеристические данные, определяется из видеоданных ТВ-канала. Когда первое значение совпадает со вторым значением, приемник обнаруживает время начала или время окончания программы.
Первое значение формируется из кодированных титров между кадрами одного или более кадров в начале/конце программы (слова запуска) или низкоуровневых характеристик кадра, например блока DCT-данных или цветовой гистограммы начального/конечного кадра.
Способ, известный из WO 02/100098, требует, чтобы сигнатуры были дополнительно включены в EPG-данные. По традиции EPG не включает в себя такие данные, возможно, потому что радио- и телевизионные вещательные компании предпочитают не включать такую информацию в трансляцию EPG-данных. Следовательно, традиционные EPG-данные не разрешат способу, известному из WO 02/100098, работать. Более того, способ ненадежен, потому что он не работает, если наблюдение сигнала вещания запущено в середине программы, и он пытается найти соответствие от этой точки с сигнатурой, представляющей начало ТВ-программы.
Желательно предоставить способ идентификации границы элемента контента, который более надежен и прост, чем способ из WO 02/100098.
Способ настоящего изобретения содержит этапы:
- приема предварительно определенных дополнительных данных, относящихся к элементу контента, дополнительных данных, содержащих атрибутные данные, описывающих, по существу, весь элемент контента,
- использования процессора анализа контента для анализа потока контента так, чтобы обнаружить, соответствует ли поток контента атрибутным данным, и
- идентификации границы элемента контента в потоке контента, когда соответствие изменяется с правильного на неправильное или наоборот.
Дополнительные данные, содержащие атрибутные данные, могут быть включены в поток контента телевизионной вещательной компанией или получены приемником независимо от потока контента. Атрибутные данные могут указывать жанр (например, комедия, драма), тему (например, Олимпийские игры), формат (например, кинофильм, новости) элемента контента или любую другую информацию, которая отличительно характеризует, по существу, весь элемент контента от других элементов контента, возможно присутствующих в потоке контента.
WO 02/100098 требует, чтобы две сигнатуры были предоставлены так, чтобы определить границы элемента контента. Наоборот, только одни данные требуются в настоящем изобретении так, чтобы сохранить пропускную способность канала передачи и отменить необходимость данных в потоке контента. Более того, такие сигнатуры должны быть вычислены на стороне телевизионной вещательной компании, что требует дополнительного оборудования обработки данных, тогда как дополнительные данные в качестве используемых в настоящем изобретении могут просто быть текстовыми данными, включенными в поток контента.
Поток контента анализируется так, что атрибутные данные обнаруживаются или не обнаруживаются. Например, характерные аудио/видео данные, ассоциативно связанные с конкретными атрибутными данными, наблюдаются в потоке контента. Например, элементы контента отдельного жанра часто имеют общие аудио/видео характеристики. Если конкретные аудио/видео характеристики идентифицированы в потоке контента, то соответствующая часть потока контента принадлежит элементу контента.
Когда существует переход между соответствием потока контента атрибутным данным и несоответствием, или наоборот, граница элемента контента, как предполагается, является обнаруженной.
Устройство настоящего изобретения содержит процессор анализа контента для:
- приема предварительно определенных дополнительных данных, относящихся к элементу контента, дополнительных данных, содержащих атрибутные данные, описывающих, по существу, весь элемент контента,
- анализа потока контента так, чтобы обнаружить, соответствует ли поток контента атрибутным данным, и
- идентификации границы элемента контента в потоке контента, когда соответствие изменяется с правильного на неправильное или наоборот.
Устройство функционирует в соответствии со способом настоящего изобретения.
Эти и другие аспекты изобретения будут дополнительно объяснены и описаны путем примера со ссылкой к следующим чертежам:
фиг.1 показывает вариант осуществления способа настоящего изобретения;
фиг.2 является временной диаграммой, где показано обнаружение границы элемента контента в потоке контента с использованием алгоритма анализа контента и, например, EPG-данных (или других служебных данных), указывающих жанр элемента контента; и
фиг.3 является функциональной блок-схемой варианта осуществления устройства согласно настоящему изобретению.
Радиовещательные или телевизионные вещательные компании медиа-контента дополняют элементы транслируемого контента, например ТВ-программы, дополнительными данными, такими как EPG-данные, которые часто содержат жанр программы, имя телевизионного ведущего или корреспондента. Как другой пример, киностудии производят кинофильмы, которые дополняются списком актеров, играющих роли в соответствующем кинофильме.
Поток контента может быть сигналом телевизионного вещания или восстановленным видеосигналом с DVD-диска и т.д., но не указаны границы элемента контента, в которых пользователь заинтересован, или которые важно идентифицировать так, чтобы запомнить или найти элемент контента. Альтернативно, границы элемента контента могут быть недоступны, например, ввиду формата или средства, которым границы обозначены в потоке контента (например, нечитаемые зашифрованные граничные данные).
В настоящем изобретении дополнительная информация об элементе контента используется для того, чтобы идентифицировать границу начала и/или границу окончания элемента контента. Дополнительные данные, например EPG-данные или другие служебные данные, содержат атрибутные данные, описывающие, по существу, весь элемент контента. Например, общей практикой является включение в состав EPG-данных типа жанра ТВ-программы. Однако тип жанра необязательно должен быть предварительно включен в поток контента, однако тип жанра конкретного элемента контента может быть определен, например, с помощью заголовка конкретного элемента контента, предварительно включенного в поток контента, например, посредством поиска в Интернете.
Полезно использовать такие атрибутные данные, так как эти данные описывают любую часть или большую часть элемента контента. Поэтому процесс анализа контента может быть начат, по существу, с любой части элемента контента, например внутри элемента контента или вне элемента контента в потоке контента.
Фиг.1 показывает вариант осуществления способа настоящего изобретения. На этапе 110 дополнительные данные, как включенные радио- или телевизионной вещательной компанией, автором или другим поставщиком услуг в поток контента, принимаются на принимающей стороне. Дополнительные данные содержат атрибутные данные, которые описывают элемент контента так, что, по существу, любая часть элемента контента соответствует этому описанию. Например, если атрибутные данные указывают, что элемент контента классифицирован как драма, большая часть элемента контента будет согласована с таким описанием.
Возможно, что элемент контента имеет части разных жанров. В этом случае содержимое элемента будет трудно описать посредством одного колонтитула (ключевого слова). Например, кинофильм может начинаться с мрачных сцен, но постепенно развиваться к веселой концовке. Другими словами, разные шаблоны изменяющихся жанров могут встречаться в элементе контента. В одном варианте осуществления шаблон жанра отдельного элемента контента включен в атрибутные данные или доступен с помощью атрибутных данных. Например, в соответствии с последовательностью жанров в элементе контента телевизионная вещательная компания включает список ключевых слов, ассоциативно связанных с этой последовательностью жанров, в атрибутные данные. Вместо одного ключевого слова жанра, как обычно включено в известные EPG-данные телевизионными вещательными компаниями, может быть включена последовательность ключевых слов. Таким образом, элемент контента описан более точно и надежно посредством атрибутных данных в случае элемента контента с многочисленными жанрами. Конечно, вышеописанный вариант осуществления может быть распространен на атрибутные данные, описывающие не только жанры, но также и другие типы классификации, например музыкальные стили.
Атрибутные данные могут быть в любом формате и необязательно как текстовые ключевые слова. Например, телевизионная вещательная компания включает цифровые коды, например номера жанров, для элемента контента в потоке контента. Коды могут быть не многозначительными, как таковые, а просто служат как указатели в схеме классификации телевизионной вещательной компании для элементов контента.
Жанр или другое значение классификации, указанное в атрибутных данных, могут не быть полезными, как таковые, чтобы определить, соответствует ли поток контента этому описанию, например, когда атрибутные данные являются просто текстовыми данными типа спорт, новости, прогноз погоды и т.д. Существуют различные способы обнаружения соответствия потока контента атрибутным данным. Например, два возможных подхода объяснены со ссылкой на этапы 121 и 122.
В одном примере делается попытка использовать атрибутные данные для того, чтобы получить информацию о текстовых/аудио/видео характеристиках контента, которые будут согласовываться с конкретным описанием (например, типом жанра), указанным в атрибутных данных. На этапе 121 процессор анализа контента выполнен с возможностью получать характеристические данные контента, ассоциативно связанные с конкретным типом атрибутных данных. Характеристические данные контента должны быть такими, чтобы позволить процессору определить, соответствует ли поток контента конкретному типу/значению атрибутных данных. Например, в случае атрибутных данных, указывающих имя актера, доминирующего в (конкретной части) элементе контента, процессор получает, например, речевые характеристики или биометрические данные (изображения) лица актера. Такая информация может быть загружена из специализированных баз данных или из Интернета.
Во втором примере могут быть один или более процессоров анализа контента, конкретно приспособленных обнаруживать соответствие потока контента с (соответствующим) конкретным типом атрибутных данных. На этапе 122 определяется, существует ли какой-либо процессор анализа контента, который подходит, чтобы обнаружить соответствие потока контента конкретному типу атрибутных данных. Один из процессоров, который определен как подходящий, автоматически выбирается, и начинается анализ потока контента. Например, ряд детекторов жанра (процессоров анализа контента) может быть установлен в соответствии с соответствующими жанрами. Для конкретного жанра, как указано в атрибутных данных, соответствующий детектор жанра инициируется для анализа контента из потока контента. Например, способ обнаружения мультипликации известен из WO 03010715, а способ обнаружения коммерческого блока известен из WO 02093929.
На этапе 130 поток контента анализируется процессором анализа контента так, чтобы обнаружить, соответствует ли поток контента атрибутным данным. Например, детектор конкретного жанра используется, чтобы обнаружить соответствие или несоответствие.
Когда процессор анализа контента обнаруживает переход от совпадения к несоответствию (или наоборот) с атрибутными данными на этапе 140, предполагается, что идентифицируется граница элемента контента в соответствующей части потока контента.
В одном варианте осуществления способа процессор анализа контента сначала используется, чтобы автономно определить текущий жанр потока контента независимо от предварительно определенного жанра, указанного в атрибутных данных. Текущий жанр может быть сравнен с предварительно определенным жанром, и может быть определено совпадение или несоответствие. В этом варианте осуществления процессор анализа контента не инструктируется заранее о типе жанра элемента контента, который должен быть найден в потоке контента. Поэтому может потребоваться проверить последовательно, присутствует ли отдельный один из возможных жанров в потоке контента. Таким образом, этот вариант осуществления может быть медленнее, чем когда процессор анализа контента инструктирован заранее о конкретном, разыскиваемом жанре.
Фиг.2 является временной диаграммой, указывающей первую границу 211 и вторую границу 212 элемента контента в потоке 201 контента. В этом варианте осуществления процессор анализа сконструирован так, чтобы отличать поток контента в соответствии с атрибутными данными. Процессор непрерывно выводит значение доверия или вероятности, указывающее степень соответствия потока контента предварительно определенным атрибутным данным. Например, значение вероятности относится к проценту видеокадров в потоке видео с характеристиками видео в соответствии с конкретным типом жанра. Когда значение вероятности падает ниже предварительно определенного порогового значения, идентифицируется граница элемента контента.
Процесс анализа контента эффективно формирует значение доверия для каждого последующего кадра элемента контента (видеокадра). Например, значение доверия может находиться в диапазоне между 0 и 1, где 1 указывает достоверность того, что кадр принадлежит идентифицируемому жанру видео. Система, предоставляющая такую идентификацию контента, раскрыта, например, в WO 2004019527. Используются сигнатуры, которые содержат средние величины множественных аудиовизуальных признаков, взятых из каждого кадра элемента контента.
Любое число последовательных значений доверия, содержащихся во временном окне конкретной продолжительности, может быть изучено относительно их согласованности в превышении порогового значения для положительной идентификации конкретного жанра. Например, если, скажем, по меньшей мере, 80% всех значений доверия в окне в 20 секунд превышает значение 0,5, все окно определяется, как принадлежащее одному и тому же жанру. Иначе сигнализируется об изменении жанра, начинающемся с этого окна. Все эти параметры - продолжительность окна и пороговое значение обнаружения, и процентное соотношение для значений доверия являются только примерами; они могут быть установлены по-разному относительно особенностей данного жанра (также включая в себя возможности процессора анализа в идентификации этого жанра). Кроме того, результаты идентификации жанра, полученные для ряда последующих окон, могут быть взяты, чтобы создать грубый шаблон идентификации, который может быть изучен на предмет его согласованности подобным образом.
Множественные значения доверия могут также быть сформированы в одно и то же время, каждое указывает вероятность другого жанра. В этом случае изменение с жанра A на жанр B может быть просто установлено как местоположение, где положительная идентификация жанра B совпадает с отрицательной идентификацией жанра B, с обеими идентификациями в соответствии с процедурой, описанной выше.
Необязательно, перед тем как процессор анализа контента используется для того, чтобы проверить соответствие потока контента атрибутным данным, поток контента предварительно обрабатывается так, чтобы проверить, встречаются ли коммерческие блоки. Известные способы обнаружения коммерческих блоков могут быть использованы, чтобы обнаружить рекламные перерывы. Например, рекламная вставка 240 обнаружена в потоке контента между начальной и конечной позициями. Часть потока контента, где найдена рекламная вставка, может быть неинтересна для дальнейшего анализа контента. Следовательно, часть рекламной вставки может быть исключена из дальнейшего анализа контента (дополнительно, определенные области вокруг рекламной вставки могут быть помечены как "запрещенные области" для дальнейшего анализа контента). Например, один из подходящих способов обнаружения рекламных блоков описан в WO 02093929.
Если процессор анализа контента обнаруживает соответствие потока контента атрибутным данным, процессор анализа контента может начать кластеризацию блоков контента потока контента. Блок контента может быть видеосъемкой или видеосценой. Видеосъемка обычно составлена из последовательных видеокадров, производящих впечатление как выполненные за одно движение камеры. Границы между видеосъемками в потоке контента могут быть определены, например, как места (видеокадры), где визуальные параметры, например векторы движения, изменяются от неподвижности к более рассеянному поведению. Способ обнаружения "нарезки" известен из WO 2004075537. Технология кластеризации видеосъемок известна, например, из статьи Дирка Фарина, Вольфганга Эффелсберга, Питера Х.Н. де Виз "Robust Clustering-Based Video-Summarization with Integration of Domain-Knowledge", Международная конференция IEEE по мультимедиа и фотосъемке, 1, стр. 89-92, Лозанна, Швейцария, август 2002 года. Видеосцена может соответствовать последовательности (кластеру) смежных видеосъемок, возможно коррелирующих через звук. Граница сцены может быть обнаружена как одновременное присутствие границы съемки и паузы тишины в звуке (тишина звука определенной продолжительности) или любым другим переходом звука. Кластеризация видеосцен может быть более подробно изучена в статье Я. Несвадбы, Н. Луиса, Я. Бенойс-Пенью, М. Десайнте-Катерине и М. Клейна Мидделинк "Low-level cross-media statistical approach for semantic partitioning of audio-visual content in a home multimedia environment", Proc. IEEE IWSSIP'04 (Международный семинар по системам, сигналам и обработке изображений), стр. 235-238, Познань, Польша, сентябрь 13-15, 2004 год.
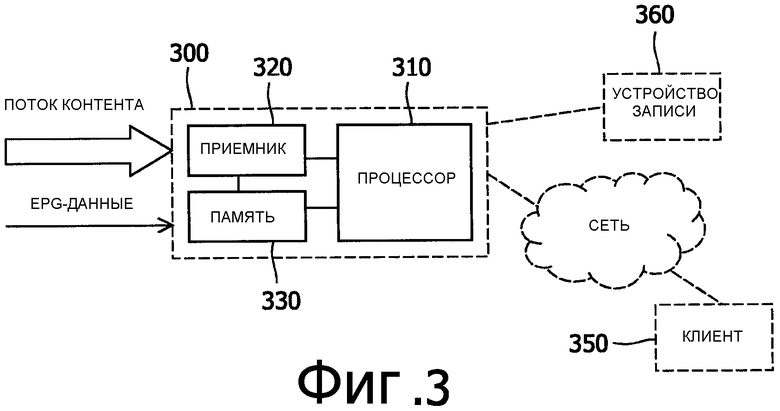
Фиг.3 показывает вариант осуществления устройства 300 настоящего изобретения. Устройство 300 содержит процессор 310 (цифровых данных) для анализа потока контента (т.е. процессор анализа контента) и, необязательно, приемник 320 и модуль 330 памяти.
Приемник 320 выполнен с возможностью принимать поток контента, например цифровые телевизионные сигналы или цифровые видеосигналы, из Интернета, как известно в системах видео по запросу, Интернет радиосетях и т.д. Приемник 320 может также быть размещен, чтобы получать дополнительные данные, например EPG-данные, содержащие атрибутные данные. Модуль 330 памяти выполнен с возможностью хранить поток контента и/или атрибутные данные, которые доступны процессору 310. Модуль памяти может быть известным модулем памяти RAM (оперативное запоминающее устройство), приводом жесткого диска компьютера или другим устройством хранения.
Процессор 310 выполнен с возможностью получать предварительно определенные атрибутные данные, описывающие, по существу, весь элемент контента. Как было объяснено со ссылкой на способ, атрибутные данные могут указывать жанр кинофильма, музыкальный стиль песни и т.д. или последовательность жанров/музыкальных стилей. Процессор 310 использует атрибутные данные, чтобы обнаруживать, принадлежит ли поток контента элементу контента, анализируя поток контента так, чтобы обнаружить соответствие потока контента атрибутным данным. Поток контента, который должен быть анализирован, может быть доступен процессору 310 из модуля 330 памяти, служащего в качестве буфера.
Процессор 310 может быть центральным процессором (CPU), подходящим образом выполненным с возможностью осуществлять настоящее изобретение и разрешить работу устройства, как объяснено выше со ссылкой на способ. Процессор 310 может быть выполнен с возможностью читать, по меньшей мере, одну инструкцию из блока 330 памяти так, чтобы разрешить работу устройства.
Устройство 300 может быть выполнено с возможностью включать в себя признаки границ элемента контента в потоке контента и, например, повторно передавать поток контента удаленному клиентскому устройству 350, например, через сеть передачи данных к ТВ-приемнику или портативному ПК. Следовательно, устройство может быть встроено в оборудование поставщика услуг (сервер обработки контента), например поставщика кабельного телевидения.
Альтернативно, поток контента с признаками может быть передан устройству 360 записи, соединенному с устройством 300. Другими словами, устройство может быть осуществлено в любом потребительском электронном устройстве (или многоцелевой платформе/устройстве), таком как телевизионный приемник (ТВ-приемник) с кабельной, спутниковой или другой линией приема; видеокассетное или HDD-устройство записи или проигрыватель, аудиопроигрыватель, система домашнего кинотеатра, устройство удаленного управления, такое как устройство удаленного управления iPronto, и т.д.
Вариации и модификации описанного варианта осуществления возможны в рамках изобретенной концепции. Например, поток контента может быть потоком аудиоконтента, и подходящие способы анализа аудиоконтента могут быть применены для целей настоящего изобретения. В другом примере телевизионная вещательная компания поддерживает базу данных типов атрибутных данных и соответствующих кодов. Только коды могут быть включены в дополнительные данные, объединенные в поток контента. Устройство может обращаться к базе данных, чтобы получить атрибутные данные (и даже более детальную информацию), соответствующие коду или кодам.
Элемент контента может содержать, по меньшей мере, одну или любую комбинацию из визуальной информации (например, видеоизображения, фотографии, графику) и аудиоинформации. Выражение "аудиоинформация" или "аудиоконтент" далее в данном документе используется как данные, имеющие отношение к звуку, содержащие звуковые тоны, тишину, речь, музыку, спокойствие, внешний шум или подобное. Аудиоинформация может быть в форматах типа MPEG-1 layer II (mp3) стандарт (Экспертная группа по кинематографии), формате AVI (чередовании аудио и видео), формате WMA (звуковой медиа-формат Windows) и т.д. Выражение "видеоинформация" или "видеоконтент" используется как данные, которые являются видимыми, такими как движущаяся картинка, "неподвижные изображения", видеотекст и т.д. Видеоданные могут быть в форматах типа GIF (формат обмена графическими данными), JPEG (названным после Объединенной группы экспертов по машинной обработке фотографических изображений), MPEG-4 и т.д.
Поток контента может быть получен любым путем, например, в форме цифрового видеосигнала (например, в одном из форматов цифрового видеовещания), принятого через спутниковую, наземную, кабельную, Интернет (потоковое, видео по требованию, точка-точка) или другую линию связи.
Процессор может выполнять программу системы программного обеспечения, чтобы разрешить выполнение этапов способа настоящего изобретения. Программное обеспечение может активировать устройство по настоящему изобретению независимо от того, где оно находится. Чтобы активировать устройство, процессор может передать программу системы программного обеспечения другим (внешним) устройствам, например. Независимые пункты способа и пункты компьютерного программного продукта могут использоваться для того, чтобы защитить изобретение, когда программное обеспечение изготовлено или эксплуатируется на потребительских электронных продуктах. Внешнее устройство может быть соединено с процессором с помощью существующих технологий, таких как Bluetooth, IEEE 802.11 [a-g] и т.д. Процессор может взаимодействовать с внешним устройством в соответствии со стандартом UPnP (универсальный стандарт "включи и работай").
"Компьютерная программа" должна пониматься так, чтобы означать любой продукт программного обеспечения, сохраненный на машиночитаемом носителе, таком как гибкий диск, загружаемый через сеть, такую как Интернет, или реализуемый любым другим образом.
Различные программные продукты могут выполнять функции системы и способа настоящего изобретения и могут быть объединены несколькими способами с аппаратными средствами или размещены на других устройствах. Изобретение может быть осуществлено посредством аппаратных средств, содержащих несколько отдельных элементов, и посредством соответствующего запрограммированного компьютера.

Изобретение относится к способу идентификации границы элемента контента в потоке контента. Технический результат заключается в увеличении точности нахождения границ контента. Принимают предварительно определенные дополнительные данные, относящиеся к элементу контента, дополнительные данные содержат атрибутные данные, описывающие, по существу, весь элемент контента, используют процессор анализа контента для анализа потока контента для того, чтобы обнаруживать, соответствует ли поток контента атрибутным данным, и идентифицируют границу элемента контента в потоке контента, когда соответствие изменяется на несоответствие с заранее определенными атрибутами, или наоборот, Атрибутные данные могут указывать жанр кинофильма, музыкальный стиль песни или последовательность жанров/музыкальных стилей. Процессор анализа контента использует атрибутные данные, чтобы обнаружить, принадлежит ли поток контента элементу контента, анализируя поток контента так, чтобы обнаружить соответствие потока контента атрибутным данным. 2 н. и 10 з.п. ф-лы, 3 ил.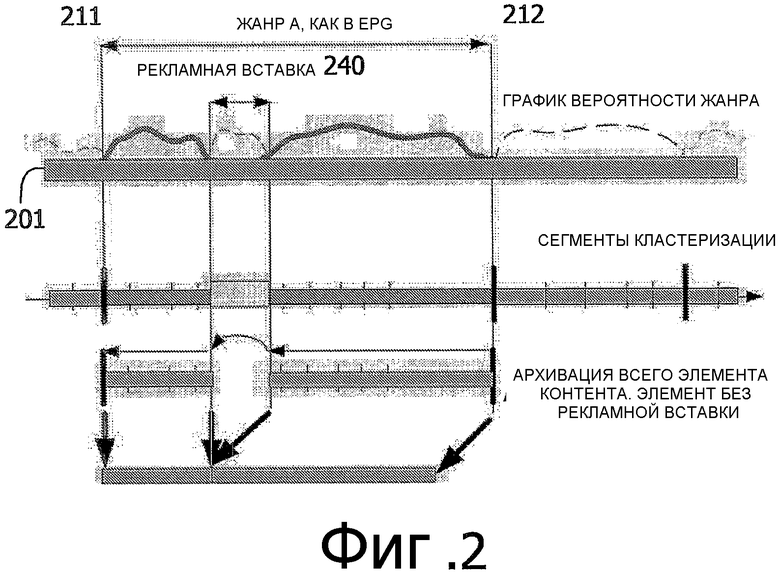
1. Способ идентификации границы (211, 212) элемента контента в потоке контента (201), причем способ содержит этапы, на которых:
(110) принимают заранее определенные дополнительные данные, относящиеся к элементу контента, при этом дополнительные данные содержат атрибутные данные, описывающие, по существу, элемент всего контента;
(130) используют процессор (310) анализа контента для анализа потока контента так, чтобы обнаружить, соответствует ли поток контента атрибутным данным; и
(140) идентифицируют границу элемента контента в потоке контента, когда соответствие изменяется на несоответствие с заранее определенными атрибутами или наоборот.
2. Способ по п.1, в котором дополнительные данные являются EPG-данными.
3. Способ по п.1 или 2, в котором атрибутные данные указывают последовательность жанров элемента контента.
4. Способ по п.1 или 2, в котором процессор анализа контента специально выполнен с возможностью обнаруживать соответствие потока контента только конкретному типу атрибутных данных.
5. Способ по п.1 или 2, в котором процессор анализа контента выполнен с возможностью получать характеристические данные контента, связанные с конкретным типом атрибутных данных, причем характеристические данные контента позволяют процессору анализа контента определять, соответствует ли поток контента конкретному типу атрибутных данных, во время анализа потока контента.
6. Способ по п.1 или 2, дополнительно содержащий этап, на котором группируют блоки контента в потоке контента, если блоки контента соответствуют атрибутным данным.
7. Устройство (300) для идентификации границы (211, 212) элемента контента в потоке (201) контента, причем устройство содержит процессор (310) анализа контента для:
приема заранее определенных дополнительных данных, относящихся к элементу контента, при этом дополнительные данные содержат атрибутные данные, описывающие, по существу, элемент всего контента, анализа потока контента для того, чтобы обнаружить, соответствует ли поток контента атрибутным данным, и
идентификации границы элемента контента в потоке контента, когда соответствие изменяется на несоответствие с заранее определенными атрибутными данными или наоборот.
8. Устройство по п.7, в котором процессор анализа контента специально выполнен с возможностью обнаруживать соответствие потока контента только конкретному типу атрибутных данных.
9. Устройство по п.7, в котором процессор анализа контента выполнен с обеспечением возможности получать характеристические данные контента, связанные с конкретным типом атрибутных данных, и использовать характеристические данные контента так, чтобы определять, соответствует ли поток контента конкретному типу атрибутных данных во время анализа потока контента.
10. Устройство по п.8, в котором процессор анализа контента выполнен с возможностью группировать блоки контента в потоке контента, если блоки контента соответствуют атрибутным данным.
11. Устройство по п.9, в котором процессор анализа контента выполнен с возможностью группировать блоки контента в потоке контента, если блоки контента соответствуют атрибутным данным.
12. Устройство по любому из пп.7-11, выполненное с возможностью быть встроенным в устройство записи видео или аудио, видео- или аудиопроигрывателя и сервера обработки контента.
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| МНОГОКАНАЛЬНАЯ СИСТЕМА ЦИФРОВОГО ТЕЛЕВИДЕНИЯ | 1998 |
|
RU2225076C2 |
| DIMITROVA N | |||
| et al | |||
| Color super histograms for video representation, Image Processing, 1999, ICIP 99, Proceedings | |||
| Металлический водоудерживающий щит висячей системы | 1922 |
|
SU1999A1 |
| Металлический водоудерживающий щит висячей системы | 1922 |
|
SU1999A1 |
| FARIN D | |||
| et al | |||
| Robust clustering-based | |||

