Область техники, к которой относится изобретение
Изобретение относится к устройству и способу, предназначенным для кодирования многоканального звукового сигнала, и в частности, но не исключительно, к сведению фонограмм стереофонического речевого сигнала к монофоническому сигналу для кодирования с помощью монофонического кодера, такого как кодер линейного предсказания с кодированием.
Уровень техники
Эффективное кодирование звуковых сигналов является критическим для увеличивающегося количества прикладных программ и систем. Например, в мобильной связи для снижения количества данных, которые необходимо передавать через радиоинтерфейс, используются эффективные кодеры речевых сигналов.
Например, Международный союз по телекоммуникациям (ITU) стандартизирует кодер речевых сигналов, известный как встраиваемый кодек переменного потока данных (EV-VBR), который может кодировать речевой сигнал высокого качества со скоростями передачи данных, находящимися в пределах от 8 до 64 кбит/с. Этот кодер, так же как множество других эффективных кодеров речевых сигналов, использует методы линейного предсказания с кодированием (CELP), чтобы достигать высокой степени сжатия процесса кодирования при работе на более низких скоростях передачи данных.
В некоторых применениях может захватываться больше чем один звуковой сигнал, и, в частности, в звуковых системах может записываться стереофонический сигнал с использованием двух микрофонов. Например, стереофоническая запись обычно может использоваться в аудио- и видеоконференцсвязи, а также в прикладных программах широковещательной передачи.
Во многих многоканальных системах кодирования и, в частности, во многих многоканальных системах кодирования речи, кодирование низкого уровня основано на кодировании единственного канала. В таких системах многоканальный сигнал может быть преобразован в монофонический сигнал для нижних уровней кодера, чтобы выполнять кодирование. Генерирование такого монофонического сигнала упоминается как сведение фонограмм. Такое сведение фонограмм может быть связано с параметрами, которые описывают аспекты стереофонического сигнала относительно монофонического сигнала. В частности, сведение фонограмм может генерировать информацию о межканальной разности времени прихода сигналов (ITD), которая характеризует разницу согласования во времени между левым и правым каналами. Например, если два микрофона расположены на расстоянии друг от друга, сигнал от динамика, расположенного ближе к одному микрофону, чем к другому, будет достигать последнего микрофона с задержкой относительно первого микрофона. Эта ITD может быть определена и может использоваться в декодере, чтобы восстанавливать стереофонический сигнал из монофонического сигнала. ITD может значительно улучшать качество перспективы восстанавливаемого стереофонического сигнала, поскольку было найдено, что ITD имеет доминантное перцепционное влияние на определение местонахождения стереофонического сигнала для частот ниже приблизительно 1 кГц. Таким образом, важно также оценивать ITD.
Традиционно, монофонический сигнал генерируется посредством суммирования стереофонических сигналов вместе. Затем монофонический сигнал кодируется и передается в декодер вместе с ITD.
Например, Европейский институт стандартизации электросвязи в своем ETSI TS126290 технического описания "Extended Adaptive Multi-Rate - Wideband (AMR-WB+) Codec; Transcoding Functions" определяет сведение фонограмм стереофонического сигнала, где монофонический сигнал определяется просто как средняя величина от левого и правого каналов следующим образом.
xML(n)=0,5(xLL(n)+xRL(n)),
где xML(n) представляет n выборку монофонического сигнала, xLL(n) представляет n выборку сигнала левого канала, а xRL(n) представляет n выборку сигнала правого канала.
Другой пример сведения фонограмм обеспечен в работе H. Purnhagen, "Low Complexity Parametric Stereo Coding in MPEG-4", Proceedings 7th International Conference on Digital Audio Effects (DAFx'04), Naples, Italy, October 5-8, 2004, pp 163-168. В этом документе описан способ сведения фонограмм, который получает выходной монофонический сигнал в виде взвешенной суммы поступающих каналов на основе частот по диапазонам, используя информацию, полученную относительно межканальной разности интенсивности (IID). В частности:
М[k,i]=gl L[k,i]+gr R[k,i],
где М[k,i] представляет i выборку k элемента разрешения по частоте монофонического сигнала, L[k,i] представляет i выборку k элемента разрешения по частоте сигнала левого канала и R[k,i] представляет i выборку k элемента разрешения по частоте сигнала правого канала, gl - весовой коэффициент левого канала, а gr - весовой коэффициент правого канала.
Характерная особенность таких подходов заключается в том, что они либо приводят к монофоническим сигналам, имеющим высокое время реверберации, либо имеют большую сложность и/или задержку. Например, способ AMR-WB+ сведения фонограмм обеспечивает выходной сигнал, время реверберации которого является приблизительно таким, как время полета по помещению плюс время полета между этими двумя микрофонами. Сведение фонограмм, обеспечиваемое в работе Purnhagen, имеет большую сложность и накладывает задержки из-за анализа и восстановления частот.
Однако множество монофонических кодеров обеспечивают лучшие результаты для сигналов с низким временем реверберации. Например, кодеры речевых сигналов CELP (линейное предсказание с кодированием) низкой скорости передачи битов и другие кодеры, которые используют возбуждение на основе импульса, чтобы представлять речевые сигналы и звуковые сигналы, работают лучше всего, когда присутствуют сигналы, имеющие короткое время реверберации. Соответственно функционирование кодера и качество получаемого в результате кодированного сигнала имеет тенденцию быть близкими к оптимальным.
Следовательно, может быть выгодна улучшенная система, и, в частности, может быть выгодна система, обеспечивающая возможность повышенной гибкости, облегченной реализации, улучшенного качества кодирования, улучшенной эффективности кодирования, уменьшенной задержки и/или улучшенных функциональных характеристик.
Сущность изобретения
Соответственно изобретение стремится предпочтительно смягчить, улучшить или устранить один или больше из вышеупомянутых недостатков в отдельности или в любом сочетании.
В соответствии с аспектом изобретения обеспечено устройство для кодирования многоканального звукового сигнала, причем устройство содержит: приемник для приема многоканального звукового сигнала, содержащего по меньшей мере первый звуковой сигнал от первого микрофона и второй звуковой сигнал от второго микрофона; модуль разности времени для определения межвременной разности первого звукового сигнала и второго звукового сигнала; модуль задержек для генерирования компенсированного многоканального звукового сигнала из многоканального звукового сигнала посредством задерживания по меньшей мере одного из первого звукового сигнала и второго звукового сигнала в ответ на сигнал межвременной разности; монофонический модуль для генерирования монофонического сигнала посредством объединения каналов компенсированного многоканального звукового сигнала; и кодер монофонического сигнала для кодирования монофонического сигнала.
Изобретение может обеспечивать улучшенное кодирование многоканального звукового сигнала. В частности, улучшенное качество для заданной скорости передачи данных может быть достигнуто во многих вариантах осуществления. Изобретение может обеспечивать улучшенное монофоническое кодирование монофонического сигнала сведения фонограмм из стереофонического сигнала посредством снижения времен реверберации монофонического сигнала сведения фонограмм. Модуль задержек может задерживать либо первый звуковой сигнал, либо второй звуковой сигнал, в зависимости от того, который микрофон является ближайшим к (основному) источнику звуковых сигналов. Межвременная разность может быть индикацией межвременной разности между соответствующими компонентами звуковых сигналов от первого и второго звуковых сигналов, исходящих из одного и того же источника звуковых сигналов. Модуль для генерирования монофонического сигнала может быть выполнен с возможностью суммировать два канала объединенного многоканального звукового сигнала, которые соответствуют первому и второму звуковым сигналам. В некоторых вариантах осуществления суммирование может быть взвешенным суммированием.
В соответствии с дополнительным признаком изобретения модуль разности времени выполнен с возможностью определять взаимные корреляции между первым звуковым сигналом и вторым звуковым сигналом для множества сдвигов по времени, и определять межвременную разность в ответ на взаимные корреляции.
Признак может обеспечивать возможность улучшенного определения межвременной разности. Признак может улучшать качество закодированного звукового сигнала и/или может облегчать реализацию и/или снижать сложность. В частности, признак может обеспечивать улучшенное стереофоническое восприятие стереофонического сигнала, сформированного из монофонического сигнала и межвременной разности. Взаимные корреляции могут указывать вероятность того, что межвременная разность равна сдвигу по времени индивидуальных взаимных корреляций.
В соответствии с другим аспектом изобретения обеспечен способ кодирования многоканального звукового сигнала, причем способ содержит: прием многоканального звукового сигнала, содержащего по меньшей мере первый звуковой сигнал от первого микрофона и второй звуковой сигнал от второго микрофона; определение межвременной разности между первым звуковым сигналом и вторым звуковым сигналом; генерирование компенсированного многоканального звукового сигнала из многоканального звукового сигнала посредством задерживания по меньшей мере одного из первого звукового сигнала и второго звукового сигнала в ответ на сигнал межвременной разности; генерирование монофонического сигнала посредством объединения каналов компенсированного многоканального звукового сигнала; и кодирование монофонического сигнала в кодере монофонического сигнала.
Эти и другие аспекты, признаки и преимущества изобретения будут очевидны и объяснены со ссылкой на вариант (варианты) осуществления, описанные в дальнейшем.
Краткое описание чертежей
Ниже будут описаны варианты осуществления изобретения, только посредством примера, со ссылкой на чертежи, на которых
фиг. 1 иллюстрирует пример устройства для кодирования многоканального звукового сигнала в соответствии с некоторыми вариантами осуществления изобретения;
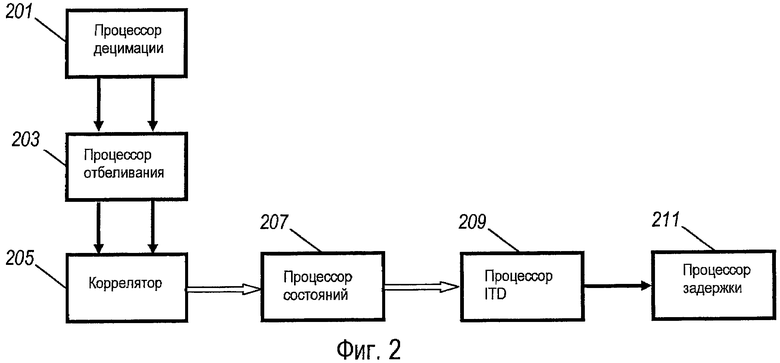
фиг. 2 иллюстрирует пример модуля обработки данных, предназначенного для оценивания межвременной разности в соответствии с некоторыми вариантами осуществления изобретения;
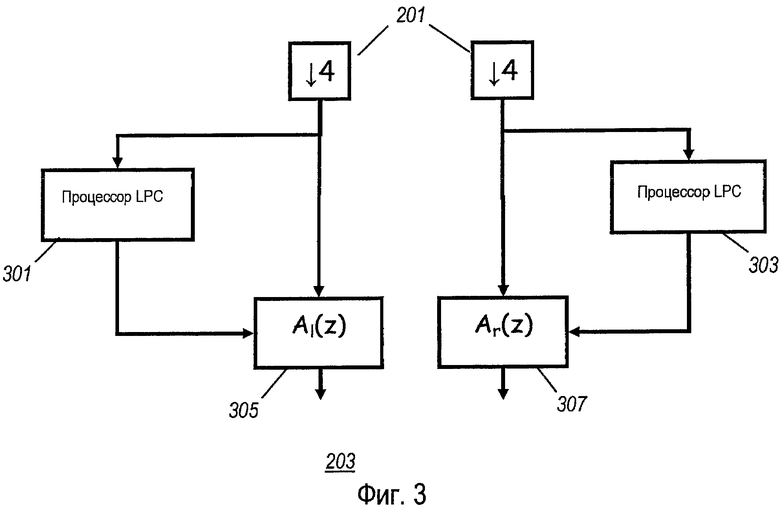
фиг. 3 иллюстрирует пример процессора отбеливания в соответствии с некоторыми вариантами осуществления изобретения;
фиг. 4 иллюстрирует пример обновления состояния для конечного автомата матрицы в соответствии с некоторыми вариантами осуществления изобретения; и
фиг. 5 иллюстрирует пример способа кодирования многоканального звукового сигнала в соответствии с некоторыми вариантами осуществления изобретения.
Подробное описание некоторых вариантов осуществления изобретения
Последующее описание сфокусировано на вариантах осуществления изобретения, применимых к кодированию многоканального звукового сигнала с использованием монофонического кодера и, в частности, к кодированию стереофонического речевого сигнала с использованием монофонического кодера CELP.
Фиг. 1 иллюстрирует устройство для кодирования многоканального звукового сигнала в соответствии с некоторыми вариантами осуществления изобретения. В конкретном примере стереофонический речевой сигнал подвергается сведению фонограмм к монофоническому сигналу и кодируется с использованием монофонического кодера.
Устройство содержит два микрофона 101, 103, захватывающие звуковые сигналы из аудиосреды, в которой расположены эти два микрофона. В примере два микрофона используются для записи речевых сигналов в помещении и расположены с внутренним расстоянием до 3 метров. В конкретном применении, микрофоны 101, 103 могут, например, записывать речевые сигналы от множества людей в помещении, и использование двух микрофонов может обеспечивать лучшую зону уверенного приема звуковых сигналов для этого помещения.
Микрофоны 101, 103 связаны с процессором 105 обработки кадров, который принимает первый и второй сигналы от первого и второго микрофонов 101, 103, соответственно. Процессор обработки кадров делит сигналы на последовательные кадры. В конкретном примере частота дискретизации сигналов составляет 16 киловыборок в секунду, а продолжительность кадра составляет 20 мс, приводя к тому, что каждый кадр содержит 320 выборок. Следует отметить, что обработка кадров не обязательно приводит к дополнительной задержке в речевом тракте, поскольку этот кадр может быть тем же кадром, что используется для речевого кодирования, или обработка кадра может выполняться, например, на старых выборках речевых сигналов.
Процессор 105 обработки кадров подсоединен к процессору 107 ITD, который выполнен с возможностью определять межвременную разность между первым звуковым сигналом и вторым звуковым сигналом. Межвременная разность представляет собой индикацию задержки сигнала в одном канале относительно сигнала в другом канале. В этом примере межвременная разность может быть положительной или отрицательной, в зависимости от того, который из каналов является запаздывающим относительно другого. Задержка обычно будет происходить из-за разницы в задержках между доминирующим источником речи (то есть человеком, говорящим в настоящее время) и микрофонами 101, 103.
Процессор 107 ITD помимо этого подсоединен к двум элементам 109, 111 задержки. Первый элемент 109 задержки выполнен с возможностью вводить задержку в первый звуковой канал, а второй элемент 109 задержки выполнен с возможностью вводить задержку во второй звуковой канал. Величина вводимой задержки зависит от оцененной межвременной разности. Кроме того, в конкретном примере в любое данное время используется только один из элементов задержки. Таким образом, в зависимости от знака оцененной межвременной разности задержка вводится либо в первый, либо во второй звуковой сигнал. В частности, величина задержки устанавливается так, чтобы быть настолько близкой к оцененной межвременной разности, насколько возможно. В результате этого звуковые сигналы на выходе элементов 109, 111 задержки являются близко выровненными по времени и, в частности, будут иметь межвременную разность, которая обычно может быть близка к нулю.
Элементы 109, 111 задержки подсоединены к блоку 113 объединения, который генерирует монофонический сигнал посредством объединения каналов компенсированного многоканального звукового сигнала и, в частности, посредством объединения двух выходных сигналов от элементов 109, 111 задержки. В примере блок 113 объединения представляет собой простой модуль суммирования, который складывает два сигнала вместе. Кроме того, сигналы масштабируются с помощью коэффициента 0,5, чтобы поддерживать амплитуду монофонического сигнала, подобную амплитуде индивидуальных сигналов до объединения.
Таким образом, выходной сигнал блока 113 объединения представляет собой монофонический сигнал, который является сведением фонограмм двух захваченных сигналов. Кроме того, из-за задержки и снижения межвременной разности, сгенерированный монофонический сигнал имеет значительно уменьшенную реверберацию.
Блок 113 объединения подсоединен к монофоническому кодеру 115, который выполняет монофоническое кодирование монофонического сигнала для генерирования закодированных данных. В конкретном примере монофонический кодер представляет собой кодер линейного предсказания с кодированием (CELP) в соответствии со встраиваемым кодеком переменного потока данных (EV-VBR), стандартизируемым Международным союзом по телекоммуникациям (ITU).
Кодеры CELP, как известно, обеспечивают чрезвычайно эффективное кодирование и, в частности, обеспечивают хорошее качество речи даже для низких скоростей передачи данных. Однако кодеры CELP имеют тенденцию не выполнять операции также хорошо для сигналов с большим временем реверберации, и поэтому не являются подходящими для кодирования традиционно производимых монофонических сведений фонограмм. Однако, из-за компенсации задержки и образующейся в результате уменьшенной реверберации, монофонические кодеры CELP могут использоваться в устройстве фиг. 1, чтобы обеспечивать весьма эффективное кодирование речевого монофонического сигнала сведения фонограмм. Следует оценить, что эти преимущества являются особенно подходящими для монофонических кодеров CELP, но не ограничены этим, и могут применяться ко многим другим кодерам.
Монофонический кодер 115 подсоединен к мультиплексору 117 вывода, который помимо этого подсоединен к процессору 107 ITD. В примере мультиплексор 117 вывода мультиплексирует данные кодирования от монофонического кодера 115 и данные, представляющие межвременную разность, от процессора 107 ITD в единый выходной битовый поток. Включение межвременной разности в битовый поток может помогать декодеру в восстановлении стереофонического сигнала из монофонического сигнала, декодированного из данных кодирования.
Таким образом, описанная система обеспечивает улучшенную функциональную характеристику и, в частности, может обеспечивать улучшенное качество звучания для данной скорости передачи данных. В частности, улучшенное использование монофонического кодера, такого как кодер CELP, может приводить к значительно улучшенному качеству. Кроме того, описанные функциональные возможности являются простыми в реализации и имеют относительно низкие требуемые ресурсы.
В дальнейшем со ссылкой на фиг. 2 будет описана оценка межвременной разности, выполняемая процессором 107 ITD.
Алгоритм, используемый процессором 107 ITD, определяет оценку межвременной разности посредством объединения последовательных результатов наблюдения взаимных корреляций между первым и вторым звуковыми сигналами для различных возможных сдвигов по времени между каналами. Корреляции выполняются в децимированной остаточной области LPC, чтобы обеспечивать более хорошо определенные корреляции, облегчать реализацию и снижать потребности в вычислениях. В примере взаимные корреляции обрабатываются так, чтобы вывести вероятность, связанную с каждой потенциальной задержкой между -12 мс и +12 мс (±~4 метра), а затем вероятности накапливаются, используя модифицированный алгоритм, подобный алгоритму Витерби. Результат представляет собой оценку межвременной разности со встроенным гистерезисом.
Процессор 107 ITD содержит процессор 201 децимации, который принимает кадры выборок для двух каналов от процессора 105 обработки кадров. Процессор 201 децимации сначала выполняет фильтрацию фильтром нижних частот, за которой следует децимация. В конкретном примере, фильтр нижних частот имеет ширину полосы пропускания, равную приблизительно 2 кГц, и коэффициент децимации, равный четырем, используется для сигнала 16 киловыборок в секунду, что приводит к децимированной частоте дискретизации сигналов, составляющей 4 киловыборки в секунду. Воздействие фильтрования и децимации в некоторой степени снижает количество обрабатываемых выборок, таким образом уменьшая потребности в вычислениях. Однако, кроме того, этот подход позволяет фокусировать оценку межвременной разности на более низких частотах, где перцепционная значимость межвременной разности является наиболее существенной. Таким образом, фильтрование и децимация не только уменьшают затраты вычислительных ресурсов, но также обеспечивают синергетический эффект, гарантирующий, что оценка межвременной разности является релевантной для наиболее воспринимаемых частот.
Процессор 201 децимации подсоединен к процессору 203 отбеливания, который выполнен с возможностью применять алгоритм спектрального отбеливания к первому и второму звуковым сигналам до корреляции. Спектральное отбеливание приводит к сигналам временной области двух сигналов, имеющим наибольшее сходство с совокупностью импульсов, в случае вокализованной или тональной речи, таким образом обеспечивая возможность при последовательной корреляции приводить к лучше определенным значениям взаимной корреляции и, в частности, приводить к более узким максимумам корреляции (частотная характеристика импульса соответствует равномерному или белому спектру, и наоборот, представление временной области белого спектра является импульсом).
В конкретном примере, спектральное отбеливание содержит вычислительные коэффициенты линейного предсказания для первого и второго звуковых сигналов и для фильтрования первого и второго звуковых сигналов в ответ на коэффициенты линейного предсказания.
Элементы процессора 203 отбеливания показаны на фиг. 3. В частности, сигналы от процессора 201 децимации подаются в процессоры 301, 303 LPC, которые определяют коэффициенты линейного предсказания (LPC) для фильтров линейного предсказания для двух сигналов. Следует оценить, что специалистам в данной области техники известны различные алгоритмы для определения LPC, и что можно использовать любой соответствующий алгоритм, не приуменьшая изобретение.
В примере два звуковых сигнала подаются в два фильтра 305, 307, которые подсоединены к процессорам 301, 303 LPC. Два фильтра определены так, что они являются обратными фильтрами для фильтров линейного предсказания, определяемых процессорами 301, 303 LPC. В частности, процессоры 301, 303 LPC определяют коэффициенты для обратных фильтров для фильтров линейного предсказания, и коэффициенты двух фильтров устанавливаются на эти значения.
Выходной сигнал двух обратных фильтров 305, 307 в случае вокализованной речи напоминает совокупности последовательностей импульсов, и таким образом позволяет выполнять значительно более точную взаимную корреляцию, чем это возможно в речевой области.
Процессор 203 отбеливания подсоединен к коррелятору 205, который выполнен с возможностью определять взаимные корреляции между выходными сигналами двух фильтров 305, 307 для множества сдвигов по времени.
В частности, коррелятор может определять значения:
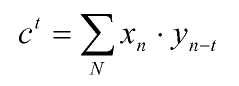
где t - сдвиг по времени, x и y - выборки из двух сигналов, а N представляет выборки в определенном кадре.
Корреляция выполняется для совокупности возможных сдвигов по времени. В конкретном примере корреляция выполняется для суммы 97 сдвигов по времени, соответствующей максимальному сдвигу по времени ±12 мс. Однако следует оценить, что в других вариантах осуществления могут использоваться другие совокупности сдвигов по времени.
Таким образом, коррелятор генерирует 97 значений взаимной корреляции с каждой взаимной корреляцией, соответствующей конкретному сдвигу по времени между двумя каналами, и таким образом, возможной межвременной разности. Значение взаимной корреляции соответствует индикации относительно того, насколько близко согласовываются два сигнала для конкретного сдвига по времени. Таким образом, для высокого значения взаимной корреляции, сигналы точно согласовываются, и имеется, соответственно, высокая вероятность того, что сдвиг по времени является точной оценкой межвременной разности. И наоборот, для низкого значения взаимной корреляции сигналы точно не согласовываются, и имеется, соответственно, низкая вероятность того, что сдвиг по времени является точной оценкой межвременной разности. Таким образом, для каждого кадра коррелятор 205 генерирует 97 значений взаимной корреляции с каждым значением, являющимся индикацией вероятности того, что соответствующий сдвиг по времени является правильной межвременной разностью.
В примере коррелятор 205 выполнен с возможностью выполнять организацию окон на первом и втором звуковых сигналах до взаимной корреляции. В частности, каждый блок выборок кадров из двух сигналов подвергается организации окон с 20 мс окном, содержащим прямоугольную центральную секцию, составляющую 14 мс, и два участка Hann по 3 мс на каждом конце. Эта организация окон может улучшать точность и снижать воздействие краевых эффектов на краю окна корреляции.
Также, в примере, взаимная корреляция нормализуется. Нормализация, в частности, должна гарантировать, что максимальное значение взаимной корреляции, которое может быть достигнуто (то есть когда два сигнала идентичны), имеет значение единицы. Нормализация обеспечивается для значений взаимной корреляции, которые являются относительно независимыми от уровней сигналов для входных сигналов и проверенных коррелированных сдвигов по времени, таким образом обеспечивая более точную индикацию вероятности. В частности, это обеспечивает возможность улучшенного сравнивания и обработки для последовательности кадров.
В простом варианте осуществления выходной сигнал коррелятора 205 можно оценивать прямо, и межвременную разность для текущего кадра можно устанавливать на значение, которое имеет самую высокую вероятность, как показано значением взаимной корреляции. Однако такой способ может иметь тенденцию обеспечивать менее достоверный выходной сигнал, поскольку речевой сигнал колеблется от вокализованного до невокализованного при молчании, и в описанном примере, сигнал коррелятора подается в процессор 207 состояний, который обрабатывает значения корреляции для множества состояний, чтобы обеспечивать более точную оценку межвременной разности.
В примере значения корреляции используются как обновляемые этапы в накапливающем сумматоре показателей алгоритма Витерби, реализованном в процессоре 207 состояний.
Таким образом, процессор 207 состояний, в частности, реализует накапливающий сумматор показателей, который имеет ряд состояний, соответствующих сдвигам по времени. Таким образом, каждое состояние представляет сдвиг по времени и имеет связанное накопленное значение показателей.
Соответственно конечный автомат основанной на алгоритме Витерби матрицы в форме накапливающего сумматора показателей сохраняет значение показателя для каждого из сдвигов по времени, для которых было рассчитано значение корреляции (то есть в конкретном примере для 97 состояний/сдвигов по времени). Каждое состояние/сдвиг по времени, в частности, связано с вероятностным показателем, который является показательным для вероятности того, какая межвременная разность соответствует сдвигу по времени этого состояния.
Вероятностные показатели для всех сдвигов по времени пересчитываются в каждом кадре, чтобы принять во внимание значения корреляции, которые были определены для текущего кадра. В частности, показатели маршрутов рассчитываются для состояний/сдвигов по времени в зависимости от взаимных корреляций. В конкретном примере взаимные корреляции преобразуются в логарифмическую область с помощью применения формулы log(0,5+pi) где pi - i значение корреляции (которое находится между 0 и 1 из-за процесса нормализации и соответствует вероятности того, какая межвременная разность соответствует связанному сдвигу по времени).
В примере вклад в данный вероятностный показатель определяется из предыдущего вероятностного показателя того сдвига по времени и значения корреляции для сдвигов, которые были рассчитаны для текущего кадра. Кроме того, делается вклад от значений корреляции, связанных с соседними сдвигами, соответствующими ситуации, где межвременная разность изменяется от одного значения к другому (то есть так, что наиболее вероятное состояние изменяется от такого, которое соответствует одному сдвигу по времени, к такому, которое соответствует другому сдвигу по времени).
Показатели маршрутов для маршрутов от соседних состояний, соответствующих примыкающим значениям межвременной разности, взвешиваются значительно ниже, чем показатель маршрута для маршрута от одного и того же состояния. В частности, эксперименты показали, что конкретная выгодная функциональная характеристика была найдена для значений соседних корреляций, которым присваиваются весовые коэффициенты по меньшей мере в пять раз выше, чем для взаимных корреляций одного и того же состояния. В конкретном примере показатели маршрутов примыкающих состояний взвешивались с помощью коэффициента 0,009, а показатель маршрута того же самого состояния взвешивался с помощью коэффициента 0,982.
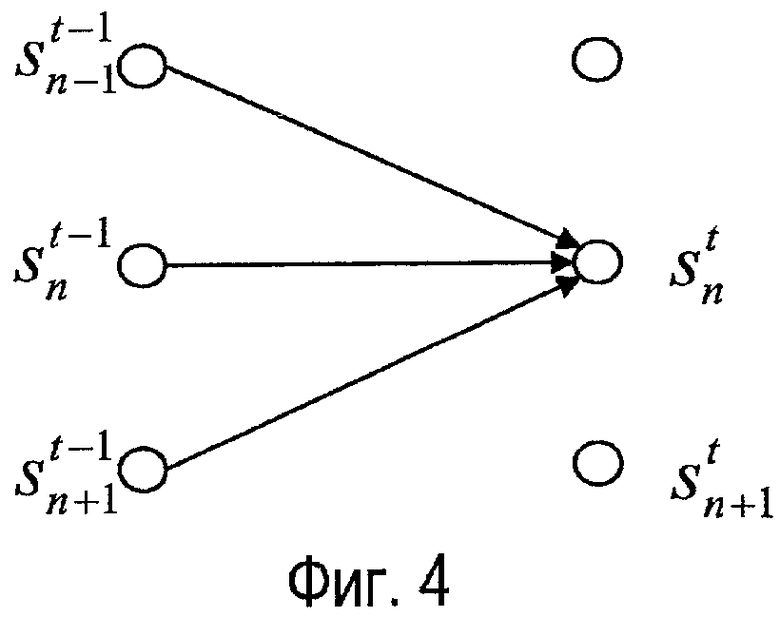
Фиг. 4 иллюстрирует пример обновления показателей для кадра t для конечного автомата матрицы. В конкретном примере показатель вероятности состояния для состояния sn в момент времени t рассчитывается из показателя маршрутов для маршрутов из подмножества предыдущих состояний, содержащих состояние sn в момент времени t-1, и примыкающие состояния sn-1 и sn+1 в момент времени t-1. В частности, показатель вероятности состояния для состояния sn имеет вид:
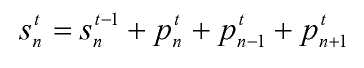
где ptx - рассчитанный взвешенный показатель маршрута от состояния x к состоянию n в кадре t.
В примере вероятностные показатели модифицируются в каждом кадре посредством вычитания самого низкого показателя вероятности состояния из всех показателей вероятности состояний. Это уменьшает проблемы переполнения от непрерывно увеличивающихся показателей вероятности состояний.
В примере вклады в данный показатель сдвига по времени включены только для подмножества сдвигов, содержащих сам сдвиг и примыкающие сдвиги. Однако следует оценить, что в других вариантах осуществления могут рассматриваться другие подмножества сдвигов по времени.
В примере показатели состояний для конечного автомата матрицы обновляются в каждом кадре. Однако, в отличие от общепринятых алгоритмов Витерби, процессор 207 состояний не выбирает предпочтительный маршрут для каждого состояния, а вычисляет показатель вероятности состояния для данного состояния в виде объединенного вклада от всех маршрутов, входящих в это состояние. Также процессор 207 состояний не осуществляет обратное прослеживание через матрицу, чтобы определять сохраняющие работоспособность маршруты. Скорее, в примере, текущая оценка межвременной разности может быть просто выбрана, как сдвиг по времени, соответствующий состоянию, в настоящее время имеющему самый высокий показатель вероятности состояния. Таким образом, в конечном автомате не вводится никакой задержки. Кроме того, поскольку вероятностный показатель состояний зависит от предыдущих значений (и других состояний), по существу достигнут гистерезис.
В частности, процессор 207 состояний подсоединен к процессору 209 ITD, который определяет межвременную разность из сдвига по времени, связанного с состоянием, имеющим самый высокий показатель вероятности состояния. В частности, он может прямо устанавливать межвременную разность равной сдвигу по времени состояния, имеющего самый высокий показатель вероятности состояния.
Процессор 209 ITD подсоединен к процессору 211 задержки, определяющему задержку, которую нужно применять к элементам 109, 111 задержки. Во-первых, процессор 211 задержки компенсирует межвременную разность с помощью коэффициента децимации, применяемого в процессоре 201 децимации. В простом варианте осуществления оцениваемая межвременная разность может быть задана как ряд децимированных выборок (например, при 4 кГц, соответствующих дискретности 250 мкс), и она может быть преобразована в ряд недецимированных выборок посредством ее умножения на коэффициент децимации (например, в 16 кГц выборки, умножая их на коэффициент 4).
В примере процессор 211 задержки устанавливает значения для обоих элементов 109, 111 задержки. В частности, в зависимости от знака межвременной разности, один из элементов задержки устанавливается на нуль, а другой элемент задержки устанавливается на рассчитанное количество недецимированных выборок.
Описанный подход для вычисления межвременной разности обеспечивает улучшенное качество кодированного сигнала и, в частности, обеспечивает уменьшенную реверберацию монофонического сигнала до кодирования, таким образом улучшая работу и функциональную характеристику монофонического кодера 115 CELP.
Были выполнены особые испытания, где три стереофонических испытательных сигнала записывались в конференц-зале с помощью пары микрофонов в различных конфигурациях. В первой конфигурации микрофоны были размещены на расстоянии 1 м друг от друга, и двое говорящих мужчин находились на оси за каждым из этих двух микрофонов, и был записан тестовый разговор. Во второй конфигурации два микрофона были размещены на расстоянии 3 м друг от друга, и говорящие мужчины снова были на оси за каждым из этих двух микрофонов. В заключительной конфигурации микрофоны были на расстоянии 2 м друг от друга, а два говорящих человека были сбоку от оси микрофонов, но на противоположных сторонах от оси, повернувшись к каждому из двух микрофонов. Во всех этих сценариях алгоритм хорошо отслеживал задержки, и когда результирующий монофонический сигнал был закодирован с помощью базового алгоритма для кодека ITU-T EV-VBR, в каждом сценарии наблюдалось усиление, составляющее приблизительно 0,3 дБ в SEGSNR и WSEGSNR.
В некоторых вариантах осуществления переход от одной задержки к другой достигается с помощью простого изменения количества выборок, где соответствующий сигнал задерживается элементами 109, 111 задержки. Однако, в некоторых вариантах осуществления, могут быть включены функциональные возможности для выполнения плавного перехода от одной задержки к другой.
В частности, устройство может быть выполнено с возможностью перехода от первой задержки ко второй задержке, генерируя первый сигнал, который задерживается элементом задержки до перехода, и второй сигнал, который задерживается элементом задержки вслед за переходом. Затем первый и второй сигналы объединяются для генерирования комбинированного сигнала, который включает в себя вклад и от сигнала до перехода, и от сигнала после перехода. Вклад от двух сигналов постепенно изменяется так, что первоначально вклад преобладающе или исключительно поступает от первого сигнала, а в конце перехода вклад преобладающе или исключительно поступает от второго сигнала.
Таким образом, во время перехода задержки аппарат может синтезировать два сигнала, соответствующие начальной и заключительной задержке. Два сигнала могут быть объединены посредством взвешенного суммирования, такого как:
s=a·s1+b·s2,
где s1 и s2 представляют первый и второй сигналы, а a и b - весовые коэффициенты, которые модифицируются во время переходного интервала (который, в частности, может быть равен одному кадру). В частности, первоначально значения могут быть установлены на a=1 и b=0, а заключительные значения могут быть установлены на a=0 и b=1. Переход между этими значениями может быть выполнен в соответствии с любой соответствующей функцией и, в частности, во время перехода может поддерживать соотношение a+b=1.
Таким образом, в таких вариантах осуществления плавный переход между различными задержками достигается посредством синтезирования сигналов для обеих задержек и постепенного перехода от одного к другому во временной области.
В конкретном примере, применяется присоединенное с наложением 20 мс окно half-Hann (половины Hann), чтобы гарантировать, что переход от одной задержки к следующей выполняется настолько незаметно, насколько возможно.
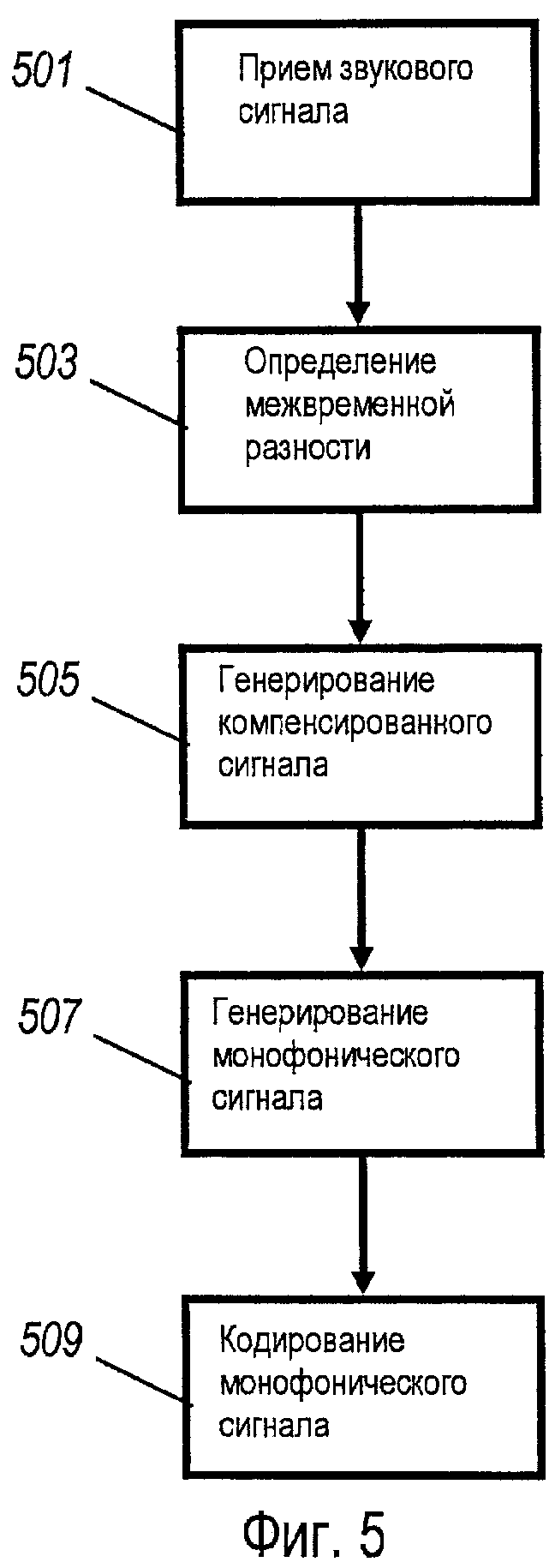
Фиг. 5 иллюстрирует способ кодирования многоканального звукового сигнала в соответствии с некоторыми вариантами осуществления изобретения.
Способ инициируется на этапе 501, на котором принимается многоканальный звуковой сигнал, содержащий по меньшей мере первый звуковой сигнал от первого микрофона и второй звуковой сигнал от второго микрофона.
Этап 501 сопровождается этапом 503, на котором определяется межвременная разность между первым звуковым сигналом и вторым звуковым сигналом.
Этап 503 сопровождается этапом 505, на котором генерируется компенсированный многоканальный звуковой сигнал из многоканального звукового сигнала посредством задерживания по меньшей мере одного из первого и второго стереофонических сигналов в ответ на сигнал межвременной разности.
Этап 505 сопровождается этапом 507, на котором генерируется монофонический сигнал посредством объединения каналов компенсированного многоканального звукового сигнала.
Этап 507 сопровождается этапом 509, на котором монофонический сигнал кодируется кодером монофонического сигнала.
Следует оценить, что в приведенном выше описании для ясности описаны варианты осуществления изобретения со ссылкой на различные функциональные модули и процессоры. Однако должно быть очевидно, что может использоваться любое подходящее распределение функциональных возможностей между различными функциональными модулями или процессорами без приуменьшения изобретения. Например, функциональные возможности, иллюстрируемые как выполняемые отдельными процессорами или контроллерами, могут выполняться одним и тем же процессором или контроллерами. Следовательно, ссылки на конкретные функциональные модули сделаны только для того, чтобы их можно было рассматривать скорее как ссылки на подходящее средство для обеспечения описанных функциональных возможностей, чем указывающие на строгую логическую или физическую структуру или организацию.
Изобретение может быть реализовано в любой соответствующей форме, включая аппаратное обеспечение, программное обеспечение, встроенное программное обеспечение или любую их комбинацию. Если требуется, изобретение может быть реализовано, по меньшей мере частично, как компьютерное программное обеспечение, выполняемое на одном или больше процессорах для обработки данных и/или процессорах цифровых сигналов. Элементы и компоненты варианта осуществления изобретения могут быть физически, функционально и логически реализованы любым соответствующим способом. Действительно, функциональные возможности могут быть реализованы в единственном модуле, во множестве модулей или как часть других функциональных модулей. Также изобретение может быть реализовано в единственном модуле или может быть физически и функционально распределено между различными модулями и процессорами.
Хотя настоящее изобретение было описано в связи с некоторыми вариантами осуществления, оно не предназначено для того, чтобы быть ограниченным конкретной формой, сформулированной в данном описании. Скорее, объем настоящего изобретения ограничен только прилагаемой формулой изобретения. Дополнительно, хотя признак может фигурировать как описанный в связи с конкретными вариантами осуществления, специалистам в данной области техники должно быть понятно, что в соответствии с изобретением различные признаки описанных вариантов осуществления могут быть объединены. В формуле изобретения термин "содержащий" не исключает присутствие других элементов или этапов.
Кроме того, хотя они перечислены индивидуально, множество модулей, средств, элементов или этапов способа могут быть реализованы, например, с помощью единственного модуля или процессора. Дополнительно, хотя отдельные признаки могут быть включены в различные пункты формулы изобретения, возможно, их можно выгодно объединять, и включение в различные пункты формулы изобретения не подразумевает, что комбинация признаков не является выполнимой и/или выгодной. Также включение признаков в одну категорию формулы изобретения не подразумевает ограничение этой категорией, а скорее указывает, что этот признак является в равной степени подходящим для других категорий, соответственно. Кроме того, порядок признаков в пунктах формулы изобретения не подразумевает какой-либо конкретный порядок, в котором должны действовать признаки, и, в частности, порядок отдельных этапов в заявляемом способе не подразумевает, что этапы должны выполняться в этом порядке. Скорее, этапы могут выполняться в любом подходящем порядке.
Изобретение относится к кодированию многоканального звукового сигнала, в частности к сведению фонограмм стереофонического речевого сигнала к монофоническому сигналу для кодирования с помощью монофонического кодера, такого как кодер линейного предсказания. Техническим результатом является повышение качества и эффективности кодирования. Указанный результат достигается тем, что устройство для кодирования многоканального звукового сигнала содержит приемник многоканального звукового сигнала, содержащего первый и второй звуковые сигналы от первого и второго микрофонов, модуль разности времени для определения межвременной разности между первым и вторым звуковыми сигналами посредством объединения последовательных наблюдений взаимных корреляций между первым и вторым звуковыми сигналами, при этом взаимные корреляции нормализуются для вывода вероятностей состояния, накапливаемых с использованием алгоритма Витерби, для достижения межвременной разности со встроенным гистерезисом, и алгоритм Витерби вычисляет показатель вероятности состояния для каждого заданного состояния в виде объединенного вклада от всех маршрутов, входящих в это состояние, модуль задержек для компенсации многоканального звукового сигнала посредством задержки первого или второго звукового сигнала в ответ на сигнал межвременной разности, монофонический модуль для генерирования монофонического сигнала посредством объединения каналов компенсированного многоканального звукового сигнала, и кодер монофонического сигнала. 2 н. и 8 з.п. ф-лы, 5 ил.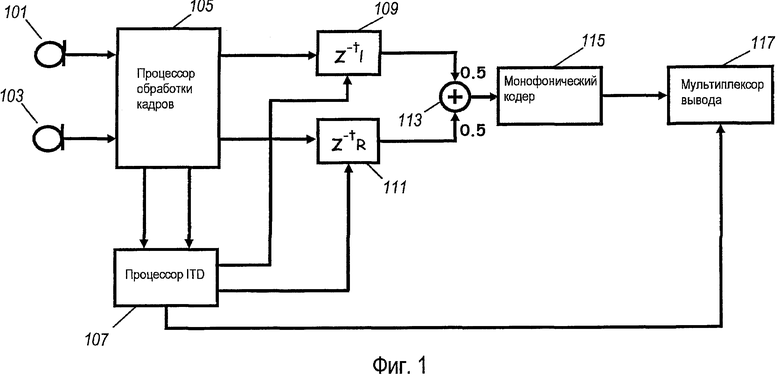
1. Устройство для кодирования многоканального звукового сигнала, причем устройство содержит
приемник для приема многоканального звукового сигнала, содержащего по меньшей мере первый звуковой сигнал от первого микрофона и второй звуковой сигнал от второго микрофона,
модуль разности времени для определения межвременной разности между первым звуковым сигналом и вторым звуковым сигналом посредством объединения последовательных наблюдений взаимных корреляций между первым звуковым сигналом и вторым звуковым сигналом, и при этом взаимные корреляции нормализуются так, чтобы выводить вероятности состояния, которые накапливаются с использованием алгоритма, подобного Витерби, для достижения межвременной разности со встроенным гистерезисом, и алгоритм, подобный Витерби, вычисляет показатель вероятности состояния для каждого заданного состояния в виде объединенного вклада от всех маршрутов, входящих в это состояние;
модуль задержек для генерирования компенсированного многоканального звукового сигнала из многоканального звукового сигнала посредством задержки по меньшей мере одного из первого звукового сигнала и второго звукового сигнала в ответ на сигнал межвременной разности,
монофонический модуль для генерирования монофонического сигнала посредством объединения каналов компенсированного многоканального звукового сигнала и
кодер монофонического сигнала для кодирования монофонического сигнала.
2. Устройство по п.1, в котором модуль разности времени выполнен с возможностью определять взаимные корреляции между первым звуковым сигналом и вторым звуковым сигналом для множества сдвигов по времени и определять межвременную разность в ответ на взаимные корреляции.
3. Устройство по п.2, в котором модуль разности времени выполнен с возможностью выполнять фильтрацию нижних частот первого звукового сигнала и второго звукового сигнала до взаимной корреляции.
4. Устройство по п.2, в котором модуль разности времени выполнен с возможностью децимировать первый звуковой сигнал и второй звуковой сигнал до взаимной корреляции.
5. Устройство по п.2, в котором модуль задержек выполнен с возможностью компенсировать межвременную разность для коэффициента децимации для выполнения децимации, чтобы определять задержку по меньшей мере для одного из первого звукового сигнала и второго звукового сигнала.
6. Устройство по п.2, в котором модуль разности времени выполнен с возможностью применять спектральное отбеливание к первому звуковому сигналу и второму звуковому сигналу до корреляции.
7. Устройство по п.2, в котором модуль разности времени выполнен с возможностью выполнять организацию окон первого звукового сигнала и второго звукового сигнала до взаимной корреляции.
8. Устройство по п.2, в котором модуль разности времени содержит
конечный автомат матрицы, имеющий множество состояний, причем каждое из множества состояний соответствует сдвигу по времени из множества сдвигов по времени,
модуль маршрутов для определения показателей маршрутов для состояний конечного автомата матрицы в ответ на взаимные корреляции,
вычислительный модуль для определения показателей состояний для состояний в ответ на показатели маршрутов, связанные с маршрутами от предыдущих состояний к текущим состояниям, и
модуль для определения межвременной разности в ответ на показатели состояний.
9. Устройство по п.1, в котором модуль задержек выполнен с возможностью переходить от первой задержки ко второй задержке, генерируя первый компенсированный многоканальный звуковой сигнал в ответ на первую задержку и второй компенсированный многоканальный звуковой сигнал в ответ на вторую задержку, и объединять первый компенсированный многоканальный звуковой сигнал и второй компенсированный многоканальный звуковой сигнал для генерирования компенсированного многоканального звукового сигнала.
10. Способ кодирования многоканального звукового сигнала, причем способ содержит
прием многоканального звукового сигнала, содержащего по меньшей мере первый звуковой сигнал от первого микрофона и второй звуковой сигнал от второго микрофона,
определение межвременной разности между первым звуковым сигналом и вторым звуковым сигналом посредством объединения последовательных наблюдений взаимных корреляций между первым звуковым сигналом и вторым звуковым сигналом и при этом взаимные корреляции обрабатывают так, чтобы выводить вероятности, которые накапливают с использованием алгоритма, подобного Витерби, который вычисляет показатель вероятности состояния для каждого заданного состояния в виде объединенного вклада от всех маршрутов, входящих в это состояние;
генерирование компенсированного многоканального звукового сигнала из многоканального звукового сигнала посредством задержки по меньшей мере одного из первого звукового сигнала и второго звукового сигнала в ответ на сигнал межвременной разности,
генерирование монофонического сигнала посредством объединения каналов компенсированного многоканального звукового сигнала и
кодирование монофонического сигнала в кодере монофонического сигнала.
| WO 03090206 A1, 30.10.2003 | |||
| US 2007127729 A1, 07.06.2007 | |||
| US 2005177360 A1, 11.08.2005 | |||
| WO 2005083679 A1, 09.09.2005 | |||
| EP 1565036 A2, 17.08.2005 | |||
| WO 2004093495 A1, 28.10.2004 | |||
| RU 2005135648 A, 20.03.2006 | |||
| RU 2005104123 A, 10.07.2005. |

