ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение относится к системам и способам, облегчающим проведение спектрального анализа ДНК и, более конкретно, к системам и способам, использующим технологию обработки изображений и/или технологию обработки сигналов, чтобы полностью или частично автоматизировать и/или ускорить обработку данных, относящихся к последовательностям ДНК. Согласно иллюстративным вариантам осуществления настоящего изобретения предоставлены системы и способы, поддерживающие одну или несколько из следующих технологий проведения спектрального анализа ДНК: (i) способ сравнительного анализа гистограмм; (ii) выбор/классификация с использованием метода опорных векторов и генетических алгоритмов; и (iii) способы создания видео из спектрограмм (спектрограммного видео), основанные на извлечении спектрограмм из данных, относящихся к последовательностям ДНК.
УРОВЕНЬ ТЕХНИКИ
В биоинформатике осуществляется поиск возможности организации огромных объемов биологических данных в легко воспринимаемую информацию, которая может быть использована для получения полезного знания. В области биоинформатики были разработаны способы спектрального анализа последовательностей ДНК. Как правило, способы спектрального анализа более совершенны по сравнению с ручными способами анализа образцов ДНК, целью которых является идентификация образцов ДНК, служащих биологическими маркерами, связанными с важными жизненными процессами. Обычно автоматический анализ выполняют, используя непосредственно цепочки последовательностей ДНК, состоящие из четырех символов A, T, C и G, которые представляют четыре нуклеотидных основания. Однако из-за огромной длины последовательностей ДНК (например, длина самой короткой человеческой хромосомы составляет 46,9 Мб), широкого спектра паттернов, связанных с ограниченным набором символов, и статистической природы проблемы, такой интуитивный/ручной подход является неэффективным, если вообще возможным, для достижения требуемой цели.
Спектральный анализ ДНК предлагает подход методичного решения проблемы получения полезной информации из данных, относящихся к последовательностям ДНК. Как правило, спектральный анализ ДНК включает идентификацию вхождения каждого из нуклеотидных оснований в последовательности ДНК в виде отдельного цифрового сигнала и преобразование каждого из четырех нуклеотидных сигналов в частотный домен. Затем величина частотного компонента может использоваться для выявления, насколько часто повторяется паттерн нуклеотидного основания с такой частотой. Большая величина/значение обычно указывает на более частое повторение. Чтобы улучшить читаемость результатов, в предшествующем уровне техники описаны системы, в которых каждое из нуклеотидных оснований представлено цветом, и частотные спектры четырех оснований объединены и представлены в виде цветовой спектрограммы. Эти способы описаны в следующих документах:
D. Anastassiou, "Frequency-Domain Analysis of Biomolecular Sequences," Bioinformatics, Vol. 16, No. 12, December 2000, pp. 1073-1081; and
D. Sussillo, A. Kundaje and D. Anastassiou, "Spectrogram Analysis of Genomes," EURASIP Journal on Applied Signal Processing, Special Issue on Genomic Signal Processing, Vol. 2004, No. 1, January 2004, pp. 29-42.
Перевод величин/значений для нуклеотидных оснований в визуальное изображение, т.е. спектрограмму, представляет собой мощный инструмент визуализации анализа ДНК. Полученный цвет в пикселях указывает на относительную интенсивность четырех оснований с конкретной частотой, а представление последовательностей ДНК в виде цветных изображений предоставляет возможность для более легкой идентификации паттернов путем визуального осмотра. Обычно цветовой тон в каком-либо районе спектрограммы отражает ее общий нуклеотидный состав, а четкие линии и пятна в спектрограмме указывают на наличие особых повторяющихся паттернов.
Алгоритм или способ генерации спектрограмм ДНК может быть кратко представлен в виде следующих пяти этапов:
(i) Формирование бинарных индикаторных последовательностей (BIS) u A [n], u T [n], u C [n] u G [n] для четырех нуклеотидных оснований. BIS для конкретного основания принимает значение "1" в позициях, в которых основание присутствует, и "0" в иных случаях. Таким образом, иллюстративную последовательность ДНК, имеющую нуклеотидную последовательность: "AACTGGCATCCGGGAATAAGGTCT", BIS преобразует следующим образом:
AACTGGCATCCGGGAATAAGGTCT …
Вышеприведенный иллюстративный BIS паттерн приведен на Фиг.1. Основанные на вышеприведенной последовательности ДНК, BIS значения могут быть представлены графически следующим образом (показано на Фиг.2):

(ii) Дискретное Преобразование Фурье (DFT), выполняемое над BIS. Затем получают частотный спектр каждого основания, вычисляя DFT из соответствующего ему BIS, используя уравнение (1):
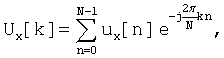 k=0, 1,...,
k=0, 1,...,  X=А, T, C или G (1)
X=А, T, C или G (1)
Последовательность U[k] обеспечивает меру частотного контента на частоте k, которая эквивалентна основному периоду N/k образцов (показано на Фиг.3).

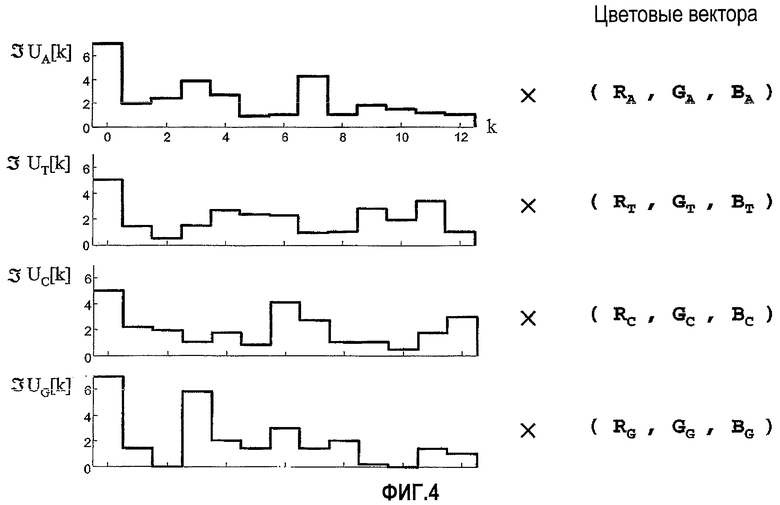
(iii) Отображение значений DFT на цвета RGB. Четыре последовательности DFT уменьшают до трех последовательностей в пространстве RGB, используя следующий набор линейных уравнений, которые все вместе определены как Уравнение (2):

где (a r , a g , a b ), (t r , t g , t b ), (c r , c g , c b ) и (g r , g g , g b ) представляют собой цветовые векторы отображения для нуклеотидных оснований A, T, C и G, соответственно. Полученный цвет пикселя (Xr[k], X g [k], X b [k]) представляет собой, таким образом, суперпозицию цветовых векторов отображения, взвешенных по величине частотной компоненты соответствующего ей основания в виде приведенного ниже набора и показанных на Фиг.4.
На Фиг. 5 и 6 дополнительно показано отображение значений DFT на цвета согласно иллюстративным вариантам осуществления настоящего изобретения. Таким образом, обращаясь к Фиг.5, для соответствующих нуклеотидных оснований A, T, C и G, соответственно, выбраны цветовые вектора. При выборе цветовых векторов обычно является желательным улучшить и/или увеличить цветовой контраст признаков, присущих ДНК. Основанные на иллюстративных цветовых векторах, значения DFT объединяют в цветовом пространстве, как показано на Фиг.6. Можно использовать альтернативные способы и/или протоколы отображения, например, значения DFT могут быть отображены на значения Тон-Насыщенность-Яркость (пространство HSV), пространство YCrCb и т.д.
(iv) Нормализация значений пикселей. Перед рендерингом цветовых спектрограмм значения RGB каждого пикселя обычно нормализуют таким образом, чтобы они попадали в интервал от 0 до 1. Существует множество способов выполнения функции нормализации. В самом простом способе все значения делят на глобальный максимум. Однако такой одноэтапный подход может ухудшить общий цветовой контраст изображения. Более подходящим способом является выполнение нормализации на двух уровнях: на первом уровне все значения пикселей делят на статистический максимум, например, равный общему значению плюс одно стандартное отклонение так, что после исходной операции, у большинства пикселей значения RGB будут находиться в интервале от 0 до 1; затем, на втором уровне, для оставшихся пикселей с любым значением RGB, превышающим единицу, отдельно выполняют второй уровень нормализации путем деления каждого из таких значений в пикселях на их локальный максимум max(xr, xg, xt). Этот двухуровневый подход препятствует слишком сильному уменьшению общей интенсивности изображения в связи с наличием пикселей, имеющих предельные значения, и в результате цветовой контраст изображения спектрограммы может быть лучше сохранен. На фиг.7 представлены иллюстративные нормализованные графики объединенных значений DFT по Фиг.6.
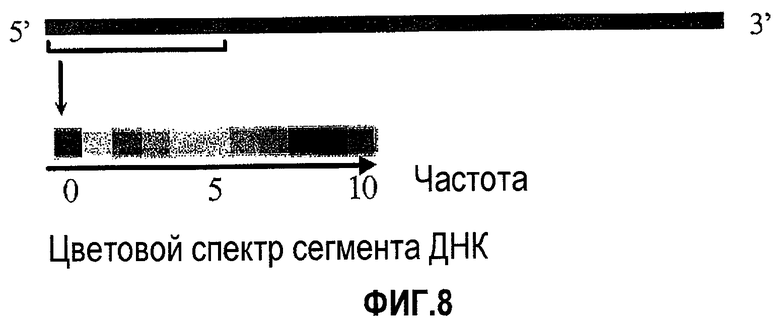
(v) Краткосрочное преобразование Фурье (STFT). До настоящего времени рассматривалось только одно окно дискретного преобразования Фурье (DFT). Однако для длинных последовательностей ДНК может возникнуть необходимость в повторении этапов (i)-(iv) для окон DFT, которые перемещаются вдоль последовательности. В результате это дает последовательные полосы цветных пикселей, при этом каждая из полос изображает частотный спектр локального сегмента ДНК. Затем путем последовательного соединения этих полос формируют спектрограмму ДНК. Приведенные ниже изображения представлены на Фиг. 8 и 9.

Следует отметить, что набор уравнений, определенный как уравнения (8) в публикации D. Anastassiou ("Frequency-Domain Analysis of Biomolecular Sequences," Bioinformatics, Vol. 16, No. 12, December 2000, pp. 1073-1081) предполагает, что порядок этапов (ii) и (iii) является обратимым, т.е. можно сначала уменьшить четыре бинарные индикаторные последовательности до трех числовых последовательностей (xr, xg, xt), а затем выполнить дискретное преобразование Фурье (DFT). Однако это нуждается в дополнительном доказательстве, потому что бинарные индикаторные последовательности не являются независимыми функциями.
Внешний вид спектрограммы очень сильно зависит от выбора размера окна краткосрочного преобразования Фурье (STFT), длины перекрывающейся последовательности между смежными окнами и цветовых векторов отображения. Как правило, размер окна определяет эффективный диапазон значения пикселей в спектрограмме. Большее окно дает в результате спектрограмму, которая выявляет статистические данные, собранные от более длинных локальных сегментов ДНК, и может быть полезным при идентификации паттернов более широкого круга. Вообще, размер окна должен в несколько раз превышать длину представляющего интерес повторяющегося паттерна и должен быть в несколько раз меньше размера области, содержащей этот паттерн. Перекрытие окон определяет длину сегмента ДНК, общего для двух смежных STFT окон. Следовательно, чем больше перекрытие, тем более плавно происходит переход частотного спектра от одного STFT окна к следующему. Более короткие интервалы между окнами дают более высокое разрешение изображения, тем самым облегчая обнаружение признаков путем обработки изображения или визуального осмотра. Однако для более коротких интервалов обычно также требуется большее количество вычислительных ресурсов.
В патенте США №6 6,287,773, Newell, раскрыт способ детектирования известных блоков функционально выровненной последовательности белка в тестируемой последовательности нуклеиновой кислоты, например, в неохарактеризованной EST. Способ Newell'773 включает этапы, на которых: (a) выполняют обратную трансляцию набора белковых последовательностей в набор функционально выровненных последовательностей нуклеиновых кислот, используя кодон-содержащие таблицы, и создают профиль из набора функционально выровненных последовательностей нуклеиновых кислот; (b) конструируют первую индикаторную функцию (аденин) для профиля; (c) конструируют вторую индикаторную функцию (аденин) для тестируемой последовательности нуклеиновой кислоты; (d) вычисляют преобразование Фурье для каждой из индикаторной функций; (e) выполняют комплексное сопряжение преобразования Фурье второй индикаторной функции; (f) умножают преобразование Фурье первой индикаторной функции на комплексно сопряженное преобразование Фурье второй индикаторной функции для получения преобразования Фурье для количества совпадений адениновых оснований; (g) повторяют этапы (b)-(f) для гуанина, тимина, и цитозина; (h) суммируют результаты преобразования Фурье для количества совпадений для каждого основания, соответственно, для получения полного преобразования Фурье; (i) вычисляют обратное преобразование Фурье для полного преобразования Фурье с целью получения комплексного ряда; и (j) берут реальную часть ряда для определения общего количества совпадений оснований для множества возможных лагов профиля относительно тестируемой последовательности. Первая индикаторная функция позволяет получать непрерывное значение в области от 0 до 1 в виде функции процентного присутствия аденина в конкретной позиции. Далее, способ может детектировать присутствие известных блоков функционально выровненных белковых последовательностей в тестируемой последовательности нуклеиновой кислоты, исходя из общего количества совпадений для множества возможных лагов, т.е. облегчить процесс сопоставления последовательностей.
Несмотря на прилагаемые в настоящее время усилия, остается потребность в системах и способах, облегчающих быструю визуализацию геномной информации. Кроме того, остается потребность в системах и способах, облегчающих идентификацию повторяющихся паттернов ДНК, например, CpG-островков, Alu-повторов, некодирующих РНК, тандемных повторов и различного типа сателлитных повторов. Остается потребность в инструментах, которые могут идентифицировать структурно или композиционно аналогичные образцы, демонстрирующие аналогичные спектральные свойства. Такие инструменты отличаются от инструментов выравнивания последовательностей, которые предназначены для линейного выравнивания последовательности или представления в виде нуклеотидов. Все еще остается потребность в системах и способах, облегчающих быстрый, полномасштабный анализ спектральных изображений, использующих способы контролируемого и/или неконтролируемого обучения. Кроме того, остается потребность в системах и способах увеличения разрешения спектральных изображений последовательностей, например, для предоставления возможности быстрой визуализации всего генома с требуемым разрешением. Эти и другие потребности удовлетворяют раскрытые в данном описании системы и способы.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение предоставляет имеющие преимущества системы и способы, облегчающие спектральный анализ ДНК и, более конкретно, системы и способы, использующие технологии обработки изображений и/или технологии обработки сигналов, чтобы полностью или частично автоматизировать и/или ускорить обработку данных, относящихся к последовательностям ДНК. Как более подробно раскрыто ниже в настоящем описании, иллюстративные системы и способы по настоящему изобретению поддерживают один или несколько из следующих способов спектрального анализа ДНК: (i) способ сравнительного анализа гистограмм; (ii) выбор/классификацию с использованием метода опорных векторов и генетических алгоритмов; и (iii) неконтролируемую классификацию и обнаружение структурно новых сегментов ДНК; и (iv) способы создания спектрограммного видео, основанные на извлечении спектрограмм из данных, относящихся к последовательностям ДНК. Раскрытые системы и способы предоставляют многочисленные преимущества, включая (i) облегчение визуализации геномной информации, (ii) идентификацию повторяющихся паттернов ДНК, например, CpG-островков, Alu-повторов, тандемных повторов, сателлитных повторов и т.д., (iii) быстрый, полномасштабный анализ спектральных изображений, используя способы контролируемого и/или неконтролируемого обучения, и (iv) увеличение разрешения спектральных изображений последовательностей, например, для предоставления возможности быстрой визуализации всего генома при изменяющемся и требуемом разрешении.
Согласно первому аспекту настоящего изобретения генерируют спектрограмму ДНК, применяя преобразование Фурье, чтобы преобразовать выраженную в символах последовательность ДНК, состоящую из букв A, T, C, G, в визуальное представление, которое выделяет периодичность совместной встречаемости паттернов ДНК. Раскрытые системы и способы облегчают идентификацию и/или определение положения повторяющихся паттернов ДНК путем применения операторов обработки изображения для нахождения заметных признаков в вертикальном и горизонтальном направлении спектрограммы ДНК. Быстрый, полномасштабный анализ полученных спектральных изображений выполняется путем использования способов контролируемого и неконтролируемого обучения. В контролируемом режиме два иллюстративных способа детектирования и классификации повторяющихся паттернов ДНК по настоящему изобретению включают (a) способ сравнительного анализа гистограмм; и (b) технологию, которая включает выбор и классификацию признаков путем использования алгоритмов опорных векторов и генетических алгоритмов.
Раскрытые операторы обработки изображения являются эффективными для идентификации и/или определения положения паттернов ДНК, таких как CpG-островки, Alu-повторы, некодирующие РНК (например, микро-РНК и небольшие ядерные РНК), тандемные повторы, различного типа сателлитные повторы и т.п. Операторы обработки изображения могут быть использованы для идентификации и/или определения положения повторяющихся элементов во множестве биологических систем, например, в пределах хромосомы, в пределах генома, или в геномах различных видов. Раскрытые система и способ преодолевают ограничения существующих технологий, в которых последовательность ДНК или геном обрабатывают с целью генерации огромного количества изображений спектрограмм, но используя такие изображения нельзя эффективно и надежно определить или объяснить положение повторяющихся паттернов и/или определить связь между биологическим или клиническим значением и такими повторяющимися паттернами.
Согласно второму аспекту настоящего изобретения генерируют спектрограмму ДНК путем преобразования последовательности ДНК в бинарную индикаторную последовательность, и затем путем применения краткосрочного преобразования Фурье и отображения выходных данных на цветовое пространство для визуализации. Спектрограмму ДНК продвигают вдоль последовательностей ДНК для получения видеоизображения. Видеоизображение, называемое "спектрограммное видео", может быть сгенерировано из очень длинных последовательностей ДНК для облегчения их визуализации, например, длинных последовательностей ДНК, таких как хромосомы или полные геномы. В отличие от обычной спектрограммы ДНК той же самой последовательности, раскрытое спектрограммное видео обеспечивает улучшенное разрешение. Кроме того, раскрытое спектрограммное видео облегчает визуализацию генома за короткий промежуток времени и с требуемым разрешением. Анализ спектрограммного видео можно использовать для обеспечения или облегчения полного анализа генома и/или детектирования изменений в образцах ДНК полной длины (или требуемых ее частях).
Способы детектирования изменений сцены могут использоваться относительно спектрограммного видео для обнаружения прерываний в линейных визуальных признаков. Кроме того, для каждой сцены в спектрограммном видео из спектрального домена могут быть извлечены статистические признаки. Более того, отдельные сцены из полного (или по существу полного) спектрограммного видео могут быть кластеризованы при помощи способов неконтролируемой кластеризации. Действительно, способы неконтролируемого детектирования видеопризнаки по настоящему изобретению можно использовать для идентификации и/или выявления различного рода геномного сходства на уровне спектральной ДНК. Таким образом, такие аналитические способы можно использовать для автоматического анализа ДНК, например, нахождения генных сетей, важных мотивов, повторяющихся элементов ДНК и других заметных паттернов ДНК.
Дополнительные обеспечивающие преимущества особенности и функции раскрытых систем и способов будут очевидны из подробного нижеприведенного описания совместно с прилагаемыми чертежами.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
С целью облегчить специалисту в данной области техники изготовление и применение раскрытых систем и способов приводятся ссылки на прилагаемые чертежи, на которых:
На Фиг.1 приведены иллюстративные бинарные индикаторные последовательности (BIS) для последовательности ДНК согласно способам спектральных отображений, используемым по настоящему изобретению;
На Фиг.2 приведены графики иллюстративных BIS, показанных на Фиг.1;
На Фиг.3 приведены дискретные преобразования Фурье (DFT) для иллюстративных BIS по Фиг. 1 и 2;
На Фиг.4 показано отображение значений иллюстративных DFT по Фиг.3 на цветовое пространство;
На Фиг.5 показано отображение значений иллюстративных DFT по Фиг.3 на цветовое пространство, основанное на иллюстративных цветовых векторах;
На Фиг.6 приведено суммирование значений DFT в цветовом пространстве по настоящему изобретению;
На Фиг.7 приведены нормализованные графики суммирования значений DFT в цветовом пространстве;
Фиг.8 представляет собой иллюстративный цветовой спектр для последовательности ДНК (воспроизведенная в серых тонах);
Фиг.9 представляет собой иллюстративное последовательное соединение множества полос цветовых спектров для иллюстративных сегментов ДНК по настоящему изобретению;
Фиг.10 представляет собой изображения спектрограмм иллюстративных CpG-островков;
Фиг.11 представляет собой изображение спектрограммы CpG-островков по Фиг.10, ограниченное красными и зелеными цветами;
На Фиг.12 приведен ряд спектрограмм с удаленным шумом по настоящему изобретению;
Фиг.13 представляет собой спектральные изображения и краевые измерения для спектрограмм, основанных на зеленом и красном цветах, по настоящему изобретению;
На Фиг.14 приведены края, извлеченные из иллюстративной спектрограммы RGB, и родственная классификация CpG-островков, связанная с ними;
На Фиг.15 приведена блок-схема для иллюстративного способа/технологии сравнительного анализа гистограмм по настоящему изобретению;
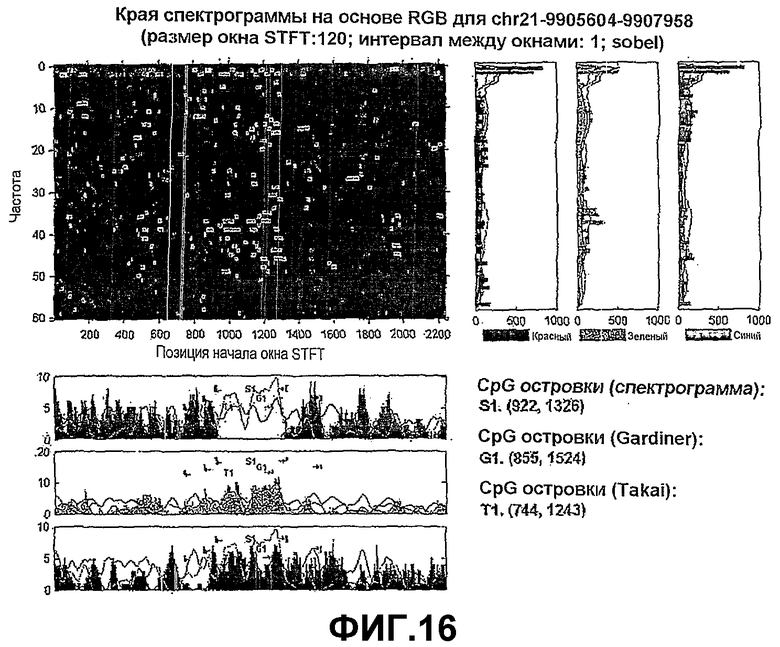
Фиг.16 и 17 представляют собой иллюстративные графики, показывающие обнаружение CpG-островков при помощи краевых гистограмм на спектрограммах, полученных путем цветового отображения;
На Фиг.18 приведена блок-схема для иллюстративного метода/технологии генетический алгоритм-опорные вектора, (GA-SVM) по настоящему изобретению;
На Фиг.19 приведена блок-схема для иллюстративного способа/технологии для генерации спектрограммного видео по настоящему изобретению; и
Фиг.20 представляет собой изображение из иллюстративного спектрограммного видео по настоящему изобретению.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Системы и способы по настоящему изобретению облегчают спектральный анализ ДНК. Как раскрыто в настоящем описании, иллюстративные системы и способы поддерживают и/или используют один или несколько из следующих способов спектрального анализа ДНК: (i) способ сравнительного анализа гистограмм; (ii) выбор/классификацию с использованием метода опорных векторов и генетических алгоритмов; и (iii) способы создания спектрограммного видео, основанные на извлечении спектрограмм из данных, относящихся к последовательностям ДНК. Настоящее изобретение может обеспечить множество преимуществ, например, (i) улучшенную визуализацию геномной информации, (ii) идентификацию повторяющихся паттернов ДНК, например, CpG-островков, Alu-повторов, некодирующих РНК, тандемных повторов, сателлитных повторов и т.д., (iii) неконтролируемую классификацию и обнаружение структурно новых сегментов ДНК; (iv) быстрый, полномасштабный анализ спектральных изображений при помощи способов контролируемого и/или неконтролируемого обучения и (v) увеличенное разрешение спектральных изображений последовательностей, например, для получения возможности быстрой визуализации всего генома при требуемом разрешении.
Согласно раскрытым системам и способам, спектрограммы ДНК генерируют обычным способом, как более подробно раскрыто в настоящем описании выше со ссылкой на Фиг. 1-9. Например, можно использовать обычный алгоритм или способ генерации спектрограмм ДНК, который содержит следующие пять этапов:
(i) Формирование бинарных индикаторных последовательностей (BIS) u A [n], u T [n], u C [n] u G [n] для четырех нуклеотидных оснований. Как указано выше, BIS паттерн показан на Фиг.1, а график значений BIS представлен на Фиг.2.
(ii) Дискретное Преобразование Фурье (DFT), выполняемое над BIS. Получают частотный спектр для каждого основания, вычисляя DFT из соответствующего ему BIS, используя уравнение (1):
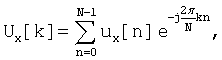 k=0, 1, …,
X=А, T, C или G (1)
k=0, 1, …,
X=А, T, C или G (1)
Как показано на Фиг.3, последовательность U[k] обеспечивает меру частотного контента на частоте k, которая эквивалентна основному периоду N/k образцов.
(iii) Отображение значений DFT на цвета RGB. Четыре последовательности DFT уменьшают до трех последовательностей в пространстве RGB, используя набор линейных уравнений, которые приведены ниже:
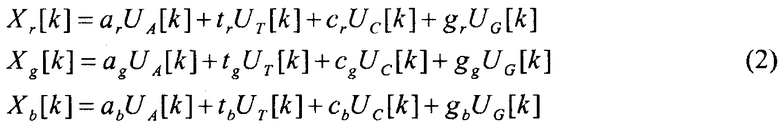
где (a r , a g , a b ), (t r , t g , t b ), (c r , c g , c b ) и (g r , g g , g b ) представляют собой цветовые векторы отображения для нуклеотидных оснований A, T, C и G, соответственно. Полученный цвет пикселя (Xr[k], X g [k], X b [k]) представляет собой, таким образом, суперпозицию цветовых векторов отображения, взвешенных по величине частотной компоненты соответствующего ей основания (см. Фиг.4). Отображение значений DFT на цвета показано на Фиг.5 и 6.
(iv) Нормализация значений пикселей. Перед рендерингом изображений цветовых спектрограмм, значения RGB каждого пикселя обычно нормализуют таким образом, чтобы они попадали в интервал от 0 до 1. На фиг.7 представлены иллюстративные нормализованные графики объединенных значений DFT по Фиг.6.
(v) Краткосрочное преобразование Фурье (STFT). Спектрограммы ДНК, сформированные путем последовательного соединения отдельных полос последовательности ДНК, где каждая полоса обычно изображает спектральную частоту локального сегмента ДНК (см. Фиг.8 и 9).
Согласно настоящему изобретению, CpG-островки могут быть преимущественно выделены из сгенерированных таким образом спектральных изображений ДНК. CpG-островки представляют собой важные биологические маркеры для промоторных участков генов в организмах, содержащих в своих геномах 5-метилцитозин, и CpG-островки играют важную роль в дифференцировке клеток и в регуляции генной экспрессии у позвоночных животных. CpG-островки были определены Гардинер-Гарденом и Фроммером (Gardiner-Garden и Frommer) как участки с по меньшей мере 200 парами оснований (п.о.) с C+G содержанием, превышающим 50%, и наблюдаемым/ожидаемым CpG соотношением, превышающим 0,6. CpG-островки были также определены Такай и Джонсом (Takai и Jones) как участки, содержащие более 500 п.о., с содержанием C+G нуклеотидов, равным по меньшей мере 55%, и наблюдаемым/ожидаемым CpG соотношением, равным 0,65. Следует отметить, что определение Такай и Джонса направлено на возврат идеи о том, что, по всей вероятности, CpG-островки имеют связь с 5'-участками генов, и исключение большинства элементов с Alu-повторами. В обоих определениях наблюдаемое/ожидаемое CpG соотношение получают из уравнения: (количество C x количество G/длина сегмента).
На Фиг.10 представлены две иллюстративные спектрограммы, показывающие CpG-островок в центре. Размер окна STFT выбран таким образом, чтобы он включал 120 пар оснований (п.о.), с перекрытием 119 п.о. между смежными окнами. Следует отметить, что при выделении CpG из спектрального изображения обычно отсутствует необходимость различения А от T и C от G. Следовательно, вместо использования четырех цветовых векторов соответственно для четырех нуклеотидных оснований, можно использовать два цветовых вектора, например, красный (1, 0, 0) для A и T и зеленый (0, 1, 0) для C и G. Соответствующие спектрограммы показаны на Фиг.11, и в обоих изображениях CpG-островки лучше контрастируют с фоном. Этот выбор цветовых векторов также позволяет рассматривать только красные и зеленые цветовые компоненты, в то время как синий компонент может быть игнорирован. Таким образом, раскрытая технология выбора цвета позволяет и/или облегчает генерацию изображений, в которых признаки лучше различимы, т.е. улучшенное выполнение извлечения достигается путем выбора оптимальной цветовой схемы(схем).
Вообще, способы детектирования признаков изображения могут включать три этапа, на которых: (i) удаляют шумы из изображения, (ii) выделяют классификационные признаки, и (iii) принимают решение путем оценки классификационных признаков. С точки зрения раскрытых систем и способов, не требуется удаление шумов в спектральных изображениях, хотя путем включения соответствующего этапа удаления шума, как правило, можно достичь лучших результатов.
УДАЛЕНИЕ ШУМОВ ИЗ ИЗОБРАЖЕНИЙ
Необработанное изображение спектрограммы содержит шумы, удаление которых может улучшить или увеличить надежность детектирования, эффективность и/или производительность. Удаление шумов из изображения спектрограммы может быть достигнуто при помощи одной или нескольких морфологических операций. Например, путем выполнения морфологического открытия с последующим морфологическим закрытием, могут быть удалены небольшие участки “слабых” пикселей. После этого участки, содержащие “сильные” пиксели, которые расположены в непосредственной близости друг от друга, могут быть слиты. Удаление шума обычно выполняют отдельно в зеленом и красном цветовых пространствах. Форму и размер структурных элементов для морфологических операций тщательно выбирают таким образом, чтобы отфильтровать шум, в то же время сохранить полезные детали в спектрограмме. Было установлено, что прямоугольные структурирующие элементы с высотой один и длиной пятьдесят пикселей обеспечивают эффективные параметры для операций по удалению шума совместно с детектированием CpG-островков. Иллюстративные спектрограммы с удаленным шумом показаны на Фиг.12, на котором изображения, представленные слева, включают только изображения с зеленым и красным каналами, а соответствующие изображения, представленные справа, включают изображения после использования фильтра морфологического "закрытия" с последующим морфологическим "раскрытием".
ВЫДЕЛЕНИЕ КЛАССИФИКАЦИОННЫХ ПРИЗНАКОВ
Путем визуального осмотра было отмечено, что в CpG островках интенсивность зеленого цвета обычно более сильна (наличие C и G), чем красного цвета (наличие A и T). Кроме того, интенсивность красного цвета обычно равномерно низка, т.е. по существу однородна, на участке, тогда как в интенсивности зеленого пространства имеется большее колебание, которое является очевидным вследствие наличия одного или нескольких кластеров ярких пятен. Для решения указанных ранее проблем однородности/неоднородности, системы и способы по настоящему изобретению преимущественно облегчат улучшенное выделение классификационных признаков. Таким образом, согласно иллюстративным вариантам осуществления по настоящему изобретению, на спектрограмме с удаленным шумом в зеленом и красном пространствах соответственно выполняют детектирование края 'Sobel'. Как известно в данной области техники, оператор Sobel представляет собой дискретный дифференциальный оператор, который вычисляет аппроксимацию градиента функции интенсивности изображения. В каждой точке изображения результат оператора Sobel представляет собой либо соответствующий вектор градиента, либо норму этого вектора. Можно использовать альтернативные способы детектирования края, например, детектор края Canny, без отступления от сути и объема настоящего изобретения.
Применение детектирования края при помощи Sobel к спектрограмме с удаленным шумом дает бинарные изображения краев, которые соответствуют пикселям, которые сильнее отличаются от своих соседей по интенсивности. Было обнаружено, что в зеленом пространстве имеется большее количество краевых пикселей для CpG-островков, чем в красном пространстве. Бинарные изображения, генерируемые путем детектирования края, затем обрабатывают, вычисляя количество краевых пикселей по оси X (позиция окна STFT) и оси Y (спектральная частота), соответственно. В результате получают четыре гистограммы: x- и y-гистограммы для зеленого и красного пространств. Наконец, вышеуказанные гистограммы сглаживают, вычисляя значение скользящего среднего для каждой из них.
Иллюстративные спектральные изображения, отражающие результаты считывания краев для зеленого и красного пространств, приведены на Фиг.13. В левой колонке на Фиг.13 показано исходное изображение, тогда как в правой колонке показано соответствующее изображение после применения детектирования края при помощи Sobel с использованием квадратной маски 2x2. На изображениях справа показаны горизонтальные и вертикальные краевые гистограммы.
Таким образом, на выделение классификационных признаков влияет ряд параметров, что может быть учтено согласно системам и способам по настоящему изобретению. Среди параметров, которые влияют на выделение классификационных признаков и которые являются контролируемыми согласно настоящему изобретению, присутствуют следующие: (i) способ детектирования края, (ii) пороговое значение для детектирования края, и (iii) размер окна для определения скользящего среднего.
ПРИНЯТИЕ РЕШЕНИЯ ПУТЕМ ОЦЕНКИ КЛАССИФИКАЦИОННЫХ ПРИЗНАКОВ
После идентификации классификационных признаков спектрального изображения, согласно раскрытым системам/способам предполагается, что может быть предоставлен классификатор для CpG-островков. Имеются два иллюстративных подхода для создания классификатора: (i) подход фиксированного порогового значения, и (ii) подход с использованием метода опорных векторов/генетического алгоритма (GA-SVM).
В раскрытом подходе фиксированного порогового значения CpG-островки преимущественно выделяют следующим образом:
(i) (x_гистограмма_зеленый-x_гистограмма_красный) > пороговое значение (в этом примере, равное 2),
(ii) участки, удовлетворяющие (1) и имеющие длину < 200 п.о., отклоняются,
(iii) участки, удовлетворяющие как (1), так и (2) и разделенные менее чем 100 п.о., сливаются.
Как показано на Фиг.14, края выделяют из цветовой спектрограммы, которая отображает основания 'A', 'T' на красный цвет, и 'C', 'G' на зеленый цвет. Краевые пиксели, которые могут быть отображены на красный и зеленый цвета, выделяют из соответствующих цветовых пространств независимо. Дополнительный цвет, например желтый цвет, может использоваться для отображения результатов, связанных с совместным существованием как красных, так и зеленых краев. Как это очевидно из проиллюстрированного на Фиг.13, сумма зеленых пикселей в гистограммах по оси X явно превышает сумму красных пикселей для CpG-островка. Основываясь на вышеприведенных критериях идентификации CpG-островков, CpG-островок идентифицирован как расположенный с 1102 до 1322 нуклеотид сегмента ДНК. Для сравнения, CpG-островки, на основании определения CpG по Гардинеру и Такаю, также показаны на Фиг.14, т.е. по Гардинеру (855, 1524) и Такаю (744, 1243). Следует отметить, что приведенные в настоящем описании критерии идентификации CpG-островков являются более строгими по сравнению с определениями/критериями по Гардинеру и Такаю, по меньшей мере, для иллюстративной спектрограммы, представленной на Фиг.14. Как очевидно специалистам в данной области техники, существует возможность подгонки критериев идентификации CpG-островков путем изменения значений применяемых параметров.
Таким образом, в более широком смысле, иллюстративные система и способ сравнительного анализа гистограмм по настоящему раскрытию включают в себя следующие этапы, последовательность операций которых представлена на Фиг.15. Хотя порядок, в котором этапы приведены в настоящем описании, представлен для раскрытой системы/способа, необходимо иметь в виду, что раскрытая система и способ не ограничены приведенным в настоящем описании порядком. Кроме того, раскрытые система и способ не исключают введения одного или нескольких дополнительных этапов, которые могут дополнительно улучшить или облегчить процесс идентификации, как раскрытая система, так и способ не ограничены в своем объеме при реализации любого этапа, раскрытого в настоящем описании, что очевидно из подробного раскрытия, приведенного в настоящем описании.
Иллюстративные система и способ сравнительного анализа гистограмм/обработки фиксированного порогового значения
1. Ввести последовательность ДНК длины М в раскрытую систему/способ:
Параметры:
N - размер окна STFT,
q - перекрытие,
p - визуальное разрешения (где М >>p> N)
2. Преобразовать введенную последовательность ДНК размера N в бинарную индикаторную последовательность;
3. Применить краткосрочное преобразование Фурье (STFM) к бинарной индикаторной последовательности и создать вектор частотного домена;
4. Отобразить вектора частотного домена для A, T, C и G в цветовое пространство, например, цветовое пространство RGB ("красное-зеленое-синее") или HSV (Тон-Насыщенность-Яркость);
5. Применить детектирование спектрального изображения ДНК, используя способ детектирования края (например, детектор края Sobel или Canny);
6. Вычислить горизонтальные и вертикальные гистограммы для красных, зеленых, синих компонентов из RGB (или компонентов HSV, если используется цветовое пространство HSV) отдельно, используя проекцию на край. Гистограммы также могут представлять объединенные цвета. Например, C и G могут быть объединены и представлены зеленым компонентом, а A и T могут быть объединены для представления красного компонента;
7. Оценить данные гистограммы. Например, для CpG-островков, можно использовать следующие критерии выделения:
(1) (x_гистограмма_зеленый - x_гистограмма_красный)>пороговое_значение (например, равное 2)
(2) участки, удовлетворяющие (1) и имеющие длину <200 п.о. отклоняются.
(3) Участки, удовлетворяющие как (1), так и (2) и разделенные менее чем 100 п.о., сливаются.
8. Сегменты ДНК, которые удовлетворяют критериям оценки, отмечают как повторяющийся элемент(элементы), и отмечают/записывают позиции начала и конца (например, CpG-островка). Имеются и другие типы последовательностей ДНК, которые могут демонстрировать повторяющиеся характеристики на структурном уровне для полных геномов и/или для нескольких геномов. Недавно было установлено, что некодирующие РНК могут выполнять и/или быть связаны с важными функциональными ролями. Последовательности ДНК, которые приводят к структурам “шпилька”, представляют класс таких некодирующих РНК. Например, микроРНК (miРНК) представляют собой небольшие РНК, которые регулируют посттрансляционную экспрессию генов. Дэвид Бартел (David Bartel), профессор биологии института Whitehead при Массачусетском Технологическом Институте, предположил, что miРНК могли бы регулировать одну треть всех человеческих генов (Cell, Cell press, January 14,2005).
Раскрытые способы обработки обычно реализуют при помощи соответствующего программного обеспечения/программных средств, которое загружено/исполняется в соответствующем блоке обработки. Система обработки может быть автономной, например, персональным компьютером, или связанной с сетью (интранет, экстранет, распределенная сеть, которая связывается через Интернет и т.д.). Блок/система обработки обычно связана с соответствующей памятью/устройством хранения, например, для получения доступа к программному обеспечению/программным средствам, базам данных, которые содержат параметры и значения, связанные с раскрытыми системами/способами, и для хранения (как краткосрочного, так и долгосрочного) значений/данных/изображений, сгенерированных посредством раскрытых систем/способов. Раскрытый блок/система обработки также обычно связана с одной или несколькими системами вывода данных для отображения и/или записи значений/данных/изображений, сгенерированных согласно настоящему изобретению, например, с принтером(принтерами), монитором(мониторами) и т.п. Таким образом, как известно специалистам в данной области техники, раскрытые системы и способы сильно зависят от способов реализации на компьютере и/или процессоре.
Обращаясь к иллюстративным GA-SVM подходам/способам по настоящему изобретению, метод опорных векторов с генетическим алгоритмом используется для оценки и ранжирования качества набора признаков, например, набора признаков на основе изображения. В иллюстративных вариантах осуществления раскрытые функциональные возможности оценки/ранжирования являются эффективными для идентификации, например, CpG-островков. Кроме того, для обнаружения заметных признаков можно использовать рекурсивный способ(способы) последовательного исключения признаков и/или метод анализа главных компонент. Следует отметить, что имеющиеся определения CpG-островков, аналогичные определениям по Гардинеру и Такаю, обеспечивают реализацию раскрытых систем и способов, хотя могут быть использованы альтернативные определения, как это очевидно специалистам в данной области техники. Обычной целью раскрытого GA-SVM подхода/способа является обнаружение признаков, которые полезны для классификации CpG-островков.
Раскрытый GA-SVM подход/способ обычно подразумевает использование метода опорных векторов с генетическим алгоритмом для оценки и ранжирования качества набора признаков, например, для идентификации CpG-островков. Таким образом, например, раскрытый GA-SVM подход/способ можно использовать для выделения заданного количества признаков, например, 127 признаков, из каждого сегмента ДНК, имеющего заданную длину, например, сегмента ДНК, который представляет собой 200 оснований в длину. Согласно иллюстративным вариантам осуществления настоящего изобретения композиция набора признаков представляет собой следующее (общее количество признаков = 127):
• Количество зеленых пикселей (1)
• Количество красных пикселей (1)
• Количество краевых зеленых пикселей (1)
• Количество краевых красных пикселей (1)
• Количество краевых зеленых пикселей минус количество краевых красных пикселей (1)
• Сумма краевых красных пикселей в гистограмме по оси частоты (61)
• Сумма краевых зеленых пикселей в гистограмме по оси частоты (61)
Могут использоваться различные определения CpG-островков, например, определение CpG-островков по Гардинеру и/или Такаю. Обычно на основе на выбранного определения генерируется большое количество признаков согласно раскрытому GA-SVM подходу/способу, например, 127 признаков каждого изображения спектрограммы. Всего, согласно иллюстративному варианту осуществления настоящего изобретения, было использовано 3206 сегментов ДНК, эти сегменты были преобразованы в спектрограммы. Наборы признаков выделяют из спектрограмм, представляющих CpG или не-CpG классы.
Согласно настоящему раскрытию, для "обучения" в методе опорных векторов используется заданный процент входных данных, например, две трети входных данных могут использоваться для обучения в SVM (см. таблицу ниже). Оставшиеся данные (например, одна треть от общего количества) используются с целью проверки согласно раскрытому GA-SVM подходу/способу. Предварительные результаты показали, что из 127 признаков, указанных выше, наилучший набор признаков состоит из 57 элементов, и была достигнута оптимальная точность, равная 67%.
Иллюстративный GA-SVM подход/способ по настоящему изобретению включает в себя следующие операционные параметры:
• Общее количество последовательностей:
• Количество испытаний: 100000
Как раскрыто в настоящем описании, иллюстративные реализации основаны на схеме отображения цветов, в которой 'А', 'T' и 'C', 'G' основания группируют в красные и зеленые цвета, соответственно. В таких реализациях необходимо учитывать красные и зеленые цветовые компоненты в алгоритмах выделения для идентификации CpG островков. Однако согласно настоящему изобретению может быть использована другая схема отображения цветов, если имеется необходимость в учете всех трех цветовых слоев R, G и B (или HSV). Набор признаков и критериев выбора может быть подобран таким образом, чтобы он соответствовал альтернативной схеме отображения цветов, как, исходя из подробного приведенного здесь описания, очевидно специалистам в данной области техники. На Фиг.16 и 17 представлены результаты обнаружения CpG-островка, в котором краевые гистограммы используют n спектрограммам, полученных с использованием цветового отображения.
Иллюстративные GA-SVM система и способ для выбора и классификации признаков
1. Ввести: последовательность ДНК длины М в раскрытую систему/способ:
Параметры:
N - размер окна STFT,
q - перекрытие,
p - визуальное разрешения (где М>>p>N)
2. Преобразовать введенную последовательность ДНК размера N в бинарную индикаторную последовательность;
3. Применить краткосрочное преобразование Фурье (STFM) к бинарной индикаторной последовательности и создать вектор частотного домена
4. Отобразить векторы частотных доменов для A, T, C и G в цветовое пространство, например, RGB или HSV;
5. Применить детектирования края к спектральному изображению ДНК, используя обычный способ детектирования края (например, детектор края Sobel или Canny);
6. Вычислить горизонтальные и вертикальные гистограммы для красного, зеленого и синего компонентов (или компонентов HSV) отдельно, используя проекцию на край. Гистограммы также могут представлять объединенные цвета. Например, C и G могут быть объединены и представлены зеленым компонентом, а A и T могут быть объединены для представления красного компонента;
7. Оценить и ранжировать набор заметных спектральных признаков, используя способ выбора признаков при помощи метода опорных векторов с генетическим алгоритмом. В качестве альтернативы можно использовать рекурсивный способ последовательного исключения признаков и/или метод анализа главных компонент для обнаружения заметных признаков. Например, могут быть использованы следующие признаки: 127 признаков (выделенные из сегмента ДНК, который имеет длину N оснований, где N может изменяться; в иллюстративном варианте осуществления N равно 200 п.о.)
• Количество зеленых пикселей (1)
• Количество красных пикселей (1)
• Количество краевых зеленых пикселей (1)
• Количество краевых красных пикселей (1)
• Количество краевых зеленых пикселей минус количество краевых красных пикселей (1)
• Сумма краевых красных пикселей в гистограмме по оси частоты (61)
• Сумма краевых зеленых пикселей в гистограмме по оси частоты (61)
8. Разработать/реализовать классификатор, используя подмножество главных признаков ранжирования из предыдущего этапа. В иллюстративном варианте осуществления настоящего изобретения используется классификатор, полученный методом опорных векторов; однако, могут быть использованы альтернативные классификаторы без отступления от сути или объема настоящего раскрытия, например, нейронная сеть(сети), способы/системы самоорганизующегося отображения (SOM) и другие классификаторы, известные в используемой литературе по машинному обучению. Классификатор детектирует и классифицирует неизвестные введенные последовательности ДНК в подсегменты, которые имеют повторяющуюся структуру(структуры) ДНК (например, CpG-островки);
9. Отмечают сегменты ДНК, которые удовлетворяют критериям оценки как повторяющийся элемент(элементы), и отмечают/записывают позиции начала и конца (например, CpG-островков).
Последовательность операций для иллюстративной GA-SVM системы/способа выбора и классификации признаков, как раскрыто в настоящем описании выше, представлена на Фиг.18. Как описано выше при помощи сравнительного анализа гистограмм/систем и способов обработки фиксированного порогового значения, раскрытые GA-SVM системы/способы обычно реализуют посредством соответствующего программного обеспечения/программных средств, которые загружены/исполняются в соответствующем блоке обработки. Система обработки может быть автономной, например, персональным компьютером или связанной с сетью (интранет, экстранет, распределенная сеть, которая связывается через Интернет и т.д.). Блок/система обработки обычно связана с соответствующей памятью/устройством хранения, например, для получения доступа к программному обеспечению/программным средствам, базам данных, которые содержат параметры и значения, связанные с раскрытыми системами/способами, и для хранения (как краткосрочного, так и долгосрочного) значений/данных/изображений, сгенерированных посредством раскрытых систем/способов. Раскрытый блок/система обработки также обычно связана с одной или несколькими системами вывода данных для отображения и/или записи значений/данных/изображений, сгенерированных согласно настоящему изобретению, например, с принтером(принтерами), монитором(мониторами) и т.п. Таким образом, раскрытые системы и способы сильно зависят от реализаций на компьютере и/или процессоре, как известно специалистам в данной области техники.
Раскрытый сравнительный анализ гистограмм/GA-SVM системы/способы обработки фиксированного порогового значения имеют широкий спектр применений и полезных свойств. Например, спектральный анализ повторяющихся ДНК можно использовать для быстрого анализа всего генома и для идентификации/обнаружения значимых паттернов для длинных последовательностей ДНК. Действительно, идентификация таких паттернов может быть использована для эпигеномного анализа последовательностей ДНК, который является важным и/или полезным для изучения и диагностирования рака, нарушений, связанных с развитием и старением.
Важно отметить, что можно выполнять и контролируемые и неконтролируемые классификации без отображения FFT результата в цветовое пространство. Признаки могут быть выделены непосредственно из 4 преобразованных бинарных индикаторных последовательностей. В этом случае, вместо изображения спектрограммы RGB, входные данные представляют собой FFT преобразованные бинарные индикаторные последовательности. Нормализация может быть необязательным этапом. Остальную часть анализа выполняют в отношении векторов признаков, состоящих из 4 преобразованных индикаторных последовательностей, объединенных для представления полного вектора - что представляет каждый сегмент ДНК.
СИСТЕМЫ/СПОСОБЫ СОЗДАНИЯ СПЕКТРОГРАММНОГО ВИДЕО ИЗ СПЕКТРОГРАММ
Согласно другому аспекту настоящего изобретения раскрыты системы и способы создания спектрограммного видео из спектрограмм, связанных с последовательностью ДНК. Частотный спектр очень длинной последовательности ДНК (например, хромосомы, которая может состоять из 150 миллионов оснований в длину) не может быть вписан в один кадр спектрограммы ни с каким подходящим разрешением. Вместо просмотра отдельных изображений, иллюстративные системы и способы настоящего изобретения облегчают создание непрерывного видео из спектрограмм. Раскрытое спектрограммное видео по существу соответствует "панорамированию" генома или другой представляющей интерес последовательности ДНК. При помощи спектрограммного видео возможна визуализация генома за короткий промежуток времени и с требуемом разрешением. Кроме того, анализ спектрограммного видео обеспечивает анализ всего генома и позволяет детектировать изменения в паттернах ДНК полной длины. В отличие от спектрограммы той же самой последовательности, раскрытое спектрограммное видео обеспечивает большее разрешение той же самой последовательности.
Как раскрыто в настоящем описании, создание и использование спектрограммного видео предлагает многочисленные преимущества и/или функциональные возможности, включая:
• Непрерывный просмотр всего генома, в отличие от сохранения и просмотра отдельных спектрограмм;
• Экономию времени: спектрограммное видео, созданное путем стыковки спектрограмм ДНК, тогда как просмотр спектрограмм по отдельности является очень трудоемким;
• Анализ непрерывных линейных геномных паттернов. При низком разрешении эти паттерны могут выходить за пределы одной спектрограммы.
• Визуализацию длинных последовательностей с требуемым разрешением и очень хорошим уровнем детализации.
• Возможность изменять разрешение в процессе выполнения просмотра спектрограммного видео. Например, при появлении интересного паттерна раскрытая система/способ облегчает моментальное "углубление" в большее количество деталей для конкретной подпоследовательности.
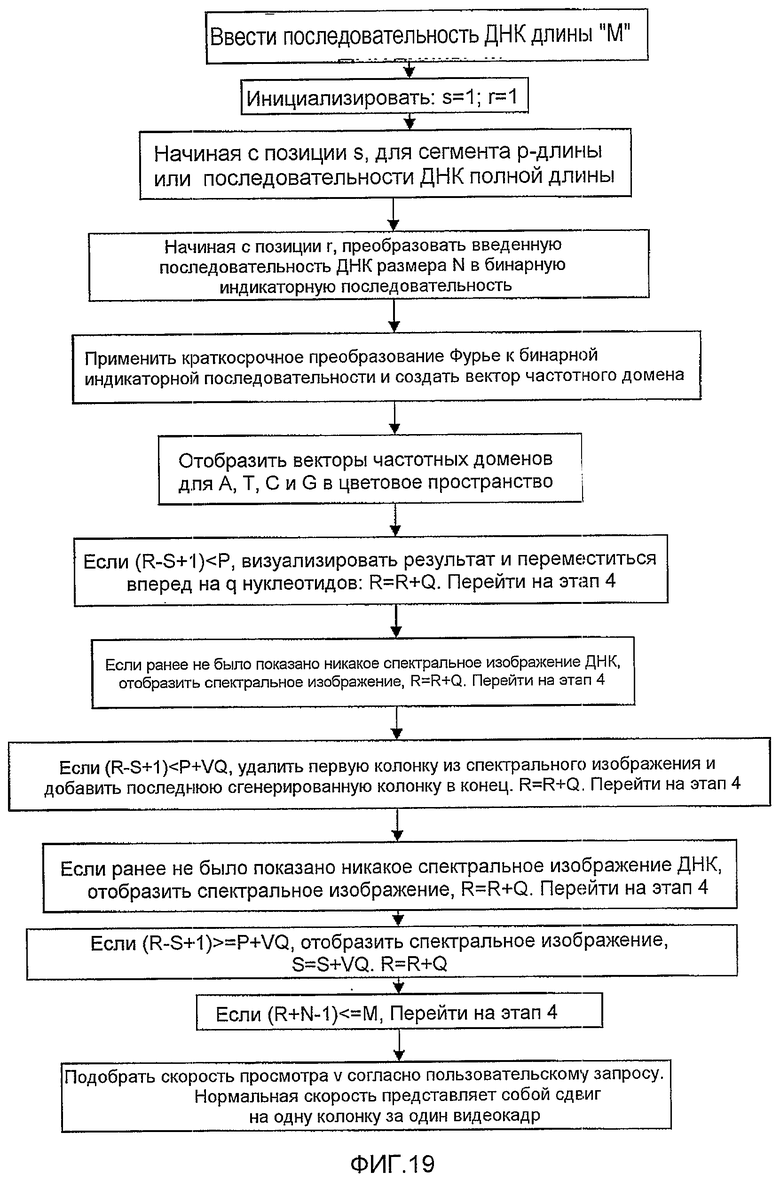
Раскрытая система/способ для перевода спектрограммы в спектрограммное видео может быть осуществлен при помощи программного обеспечения/программных средств. Согласно иллюстративному варианту осуществления настоящего изобретения программное обеспечение/программные средства предоставлены для работы в блоке обработки/компьютере, причем такое программное обеспечение приспособлено для отображения частотного спектра всей последовательности ДНК (или требуемой ее части) путем последовательного панорамирования окна спектрограммы вдоль последовательности ДНК, например, от 5' к 3'-концу. В настоящем описании раскрыта иллюстративная программа/алгоритм для реализации раскрытого спектрограммного видео. Также приведена ссылка на последовательность операций, показанную на Фиг.19.
ИЛЛЮСТРАТИВНЫЙ АЛГОРИТМ/ПРОГРАММА ДЛЯ СОЗДАНИЯ СПЕКТРОГРАММНОГО ВИДЕО
(1) Ввести: последовательность ДНК длины М в раскрытую систему/способ
Параметры:
N - размер окна STFT,
q - интервал окна (N - перекрытие окон),
p - визуальное разрешение (ширина видеоизображения), и
v - скорость просмотра, т.е. количество колонок спектральных изображений, сдвигаемых за один видеокадр (где М>>p>N).
(2) Инициализировать: s=1; r=1.
(3) Начиная с позиции s, для сегмента p-длины или подпоследовательности последовательности ДНК полной длины;
(4) Начиная с позиции r, преобразовать входную последовательность ДНК размера N в бинарную индикаторную последовательность;
(5) Применить краткосрочное преобразование Фурье к бинарной индикаторной последовательности и создать вектор частотного домена;
(6) Отобразить векторы частотных доменов для A, T, C и G в цветовое пространство, например, цветовое пространство RGB или HSV;
(7) Если (r-s+1)<p, визуализировать результат и переместиться вперед на q нуклеотидов: r=r+q. Перейти на этап 4.
(8) Если ранее не было показано никакое спектральное изображение ДНК, отобразить спектральное изображение. r=r+q. Перейти на этап 4.
(9) Если (r-s+1)<p+vq, удалить первую колонку из спектрального изображения и добавить последнюю сгенерированную колонку в конец. r=r+q. Перейти на этап 4.
(10) Если (r-s+1)>=p+vq, отобразить спектральное изображение. s=s+vq. r=r+q.
(11) Если (r+N-1)<=М, перейти на этап 4.
(12) Подобрать скорость просмотра v согласно пользовательскому запросу. Нормальная скорость представляет собой сдвиг на одну колонку за один видеокадр.
На Фиг.20 показано иллюстративное изображение из спектрограммного видео. Как очевидно из изображения на Фиг.20 (которое является фиксированным, а не движущимся изображением), раскрытые система и способ, относящиеся к созданию спектрограммного видео, предлагают существенные преимущества для просмотра и анализа последовательностей ДНК, например, для обнаружения как известного, так и неизвестного биомаркера. Кроме того, для обнаружения прерываний в линейных визуальных признаках могут использоваться способы обнаружения изменения сцен относительно спектрограммного видео. Для каждой сцены в спектрограммном видео из спектрального домена могут быть выделены статистические признаки. Кроме того, отдельные сцены из полного (или по существу полного) спектрограммного видео могут быть кластеризованы при помощи способов неконтролируемой кластеризации. Действительно, способы неконтролируемого детектирования видеопризнаков, как более подробно описано ниже, могут быть использованы для идентификации и/или выявления гомологий по всему геному на уровне спектральной ДНК. Таким образом, такие аналитические способы могут быть использованы для автоматического анализа ДНК, например, для обнаружения генных сетей, важных мотивов, спектрально и структурно повторяющихся элементов ДНК и других заметных паттернов ДНК.
НЕКОНТРОЛИРУЕМЫЙ АНАЛИЗ СПЕКТРОГРАММ И СПЕКТРОГРАММНОГО ВИДЕО
Согласно иллюстративным вариантам осуществления настоящего изобретения спектрограммы можно использовать для неконтролируемого исследования элементов и сетей генной регуляции. Действительно, согласно настоящему изобретению рассмотрен крупномасштабный анализ спектрограмм для обнаружения важных элементов регуляции. Для определения групп большинства распространенных паттернов можно использовать неконтролируемые способы, такие как иерархическая кластеризация.
Наиболее часто встречаемые в геноме паттерны, как правило, могут быть идентифицированы/может быть определено их положение без учета линейной зависимости встречаемости нуклеотидов (т.е. простых статистических измерений). В обычных способах в биоинформатике используется выравнивание множества последовательностей с тем, чтобы найти ультразаконсервированные сегменты. Однако системы и способы настоящего изобретения могут использоваться совместно со спектральным анализом для идентификации эволюционно и/или медленно меняющихся изменений, не ультра-, а в основном законсервированных элементов, которые встречаются в геноме.
Используя крупномасштабные способы анализа спектрограмм, системы и способы настоящего изобретения облегчают сканирование генома и сосредоточены на спектрально-законсервированных последовательностях с точки зрения подобных частот встречаемости паттернов. Вместо того чтобы смотреть на расположение нуклеотидов в линейном порядке, раскрытые системы/способы преимущественно исследуют структурные характеристики, которые могут быть очевидными только из спектрального представления и практически неразличимыми при выравнивании последовательностей. Преимущество раскрытого способа/подхода состоит в том, что распределение каждого повторяющегося спектрального паттерна в пределах одной хромосомы может быть визуализировано, например, по всем хромосомам и геномам. Действительно, раскрытые аналитические методы могут быть применены для геномов с целью идентификации как известных, так и новых паттернов. Длинные повторяющиеся элементы, например, начиная от нескольких сотен пар оснований до нескольких сотен тысяч пар оснований, такие как Alu, короткие структуры типа “шпилька” (например, микроРНК), SINE, LINE, и CpG-островки, могут быть эффективно охарактеризованы таким способом. Кроме того, можно показать паттерны с различным разрешением: в пределах окна, равного 200 п.о., и в пределах длинных окон, равных 100 т.п.о. Это облегчает обнаружение новых классов повторяющихся элементов. Перед применением используемого алгоритма(алгоритмов) некоторые повторяющиеся элементы могут быть маскированы, например, элементы, которые не представляют интереса для пользователя.
Ниже приведен иллюстративный способ/алгоритм:
Этап 1. Для введенной последовательности ДНК (например, хромосомы), сгенерировать спектрограмму S1 длиной L (L -количество нуклеотидов), используя STFT окно W (где W<L) и перекрытие окон V, где V<W.
Этап 2. Переместить на R нуклеотидов вправо и генерировать спектрограмму Si до тех пор, пока не будет достигнут конец последовательности ДНК.
Этап 3. Со всеми спектрограммами, сгенерированными на этапах 1 и 2, выполнить неконтролируемую кластеризацию изображений (например, кластеризацию k-средних, иерархическую кластеризацию). Иллюстративные метрики подобия для использования согласно раскрытому способу/алгоритму включают любую метрику подобия изображений, например, L1 метрику, которая генерирует C кластеры. Признаки для кластеризации могут включать: цвет, структуру, специфические объекты, которые проявляются на изображениях: линии, квадраты, диагонали и т.д.
Этап 4. Найти наибольший кластер, взять центр кластера и выполнить поиск по ресурсу известных геномов, чтобы увидеть класс меток элементов этого кластера. Это может выявить большинство повторяющихся элементов на конкретной хромосоме.
Этап 5. Выбрать одно из (a) или (b):
(a) Случайным образом выбрать P спектрограмм, которые являются самыми дальними от центра кластера, и выполнить поиск класса меток. Проверить, что они также принадлежат тому же самому классу.
(b) Визуализировать для пользователя спектрограммы и типы классов меток всех элементов в наборе спектрограмм. Если спектрограмма находится в кластере, в котором известен центр, но спектрограмма, которая находится дальше от центра кластера, неизвестна, то определить новый элемент в качестве метки класса центра кластера и визуализировать различие.
Этап 6. Продолжить со вторым по величине кластером, и выполнить/повторить этапы (5) и (6). Продолжать со следующим по величине кластером до тех пор, пока метка центра кластера-класса остается неизвестной. Обозначить, что для кластеров K метки известны, а для кластеров U метки неизвестны.
Этап 7. Для всех кластеров U с неизвестными метками, с существенным размером кластеров (обычно, по меньшей мере половина максимального количества элементов в наибольшем кластере): найти наиболее часто встречаемый паттерн, статистическое распределение внутри той же самой хромосомы. Найти статистическое распределение по хромосомам.
Этап 8. Увеличивать V и выполнять переход на этап (1) с данным размером шага (например, размером шага =1) до тех пор, пока V не достигнет половины W, затем перейти на этап (9).
Этап 9. Увеличивать W и выполнять переход на этап (1) с данным размером шага до тех пор, пока W не достигнет половины L, затем перейти на этап (10).
Этап 10. Увеличить L и перейти на этап (1).
Этап 11. Суммировать результаты на каждом уровне V, W, и L.
Как очевидно специалистам в данной области техники, раскрытый способ/алгоритм может быть адаптирован для работы/реализации на компьютере, таким образом облегчая автоматизированную операцию этого способа. Действительно, раскрытый способ/алгоритм может преимущественно выполняться неконтролируемым способом, таким образом генерируя V, W и L значения для последовательностей ДНК без контроля и/или вмешательства со стороны пользователя.
Согласно настоящему изобретению, новые элементы могут быть идентифицированы аналогичным способом с использованием этапа 5, т.е. раскрытый способ/алгоритм облегчает идентификацию последовательностей, имеющих потенциально значимое подобие, которое ранее было нераспознано и/или недооценено. Действительно, последовательности, полученные от первого вида, могут быть эффективно сравнены с упорядоченными геномами, полученными от различных видов, для определения и/или идентификации потенциально новых элементов внутри последовательности ДНК для таких видов. Кроме того, новые классы элементов могут быть идентифицированы из последовательностей ДНК при помощи способов, описанных на этапе 7 вышеприведенного способа/алгоритма. Эти классы могут быть эффективно исследованы относительно других геномов согласно настоящему раскрытию. Дополнительные применения раскрытого способа/алгоритма включают:
• внутригеномное сравнение: алгоритм для крупномасштабного анализа может быть применен к каждой хромосоме изучаемого генома. Затем, все центры кластеров могут быть использованы для выполнения полной кластеризации, чтобы увидеть функционально важные элементы (по хромосомам) для этого генома.
• Сравнительный анализ геномов: алгоритм для крупномасштабного анализа может быть применен к каждому геному известных 200+ упорядоченных геномов. Затем, все центры кластеров можно использовать для выполнения полной кластеризации, чтобы увидеть функционально законсервированные элементы в процесее эволюции.
АНАЛИЗ СПЕКТРОГРАММНОГО ВИДЕО ДЛЯ ОБНАРУЖЕНИЯ ПАТТЕРНОВ В ПРЕДЕЛАХ ГЕНОМА
В приведенных ниже иллюстративных вариантах осуществления и реализации настоящего изобретения способы обнаружения сцен изменения могут быть применены к спектрограммному видео, сгенерированного согласно вышеописанному способу для обнаружения прерываний в важных линейных визуальных признаках. Для каждой сцены могут быть выявлены статистические признаки из спектрального домена. Кроме того, отдельные сцены из полного спектрограммного видео могут быть кластеризованы при помощи способа неконтролируемой кластеризации. Затем можно использовать способы неконтролируемого детектирования видеопризнаков для выявления общих черт по всему геному на уровне спектральной ДНК. Затем результаты таких способов неконтролируемого детектирования можно использовать для автоматического анализа ДНК с тем, чтобы обнаружить генные сети, важные мотивы, повторяющиеся элементы ДНК и другие заметные паттерны ДНК. Иллюстративный способ/алгоритм для проведения такого неконтролируемого детектирования приведен ниже:
Этап 1. Создать спектрограммное видео для данной последовательности ДНК (например, части или полной хромосомы);
Этап 2. Выявить признаки, например, горизонтальные и вертикальные краевые гистограммы для данного окна, цвет, длину краев, количества одинаковых цветов в конкретном столбце и т.д.
Этап 3. Найти перебивку спектра, например, найти непрерывные паттерны, используя выявленные признаки - этот способ аналогичен обнаружению "перебивок (быстрая смена кадра, плана)" на пленке.
Этап 4. Кластеризовать сцены, например, сохранить признаки каждой перебивки спектра. Действительно, перебивки спектра могут быть кластеризованы при помощи этих признаков, как если бы кластеризовали сцены на видео.
Этап 5. Найти кластеры с самыми длинными элементами, например, порядок сортировки и визуализации "сцен" с конкретной длиной.
Этап 6. Проверить спектральные элементы, имеющие одинаковую длину, например, те, которые принадлежат к одной сцене. Каждый сегмент, соответствующий перебивке спектра, может быть преимущественно проверен в отношении известного геномного ресурса (например, NCBI) для определения любой известной функциональной роли.
Таким образом, раскрытые в настоящем описании системы, способы и технологии предусматривают ряд полезных инструментов для оценки, определения и/или идентификации повторяющихся паттернов в последовательностях ДНК, и для связи этих паттернов с биологическим и/или клиническим значением. Хотя системы, способы и технологии были описаны в отношении иллюстративных вариантов осуществления, необходимо учитывать, что настоящее изобретение не ограничено такими иллюстративными вариантами осуществления. Скорее, как это очевидно специалисту в данной области техники, раскрытые системы, способы и технологии чувствительны к широкому спектру изменений, модификаций и/или усовершенствований без отступления от сути или объема настоящего изобретения. Настоящее изобретение охватывает такие изменения, модификации и/или усовершенствования в пределах своего объема.
| название | год | авторы | номер документа |
|---|---|---|---|
| ОБНАРУЖЕНИЕ СИГНАЛА С УМЕНЬШЕННЫМ ИСКАЖЕНИЕМ | 2012 |
|
RU2620571C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ИДЕНТИФИКАЦИИ ТИПА ИЗОБРАЖЕНИЯ | 2016 |
|
RU2669511C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБНАРУЖЕНИЯ ИГРОВЫХ ЭПИЗОДОВ В ПОЛЕВЫХ ВИДАХ СПОРТА В ВИДЕОПОСЛЕДОВАТЕЛЬНОСТЯХ | 2012 |
|
RU2526049C2 |
| СПОСОБ И СИСТЕМА ИДЕНТИФИКАЦИИ НОВООБРАЗОВАНИЙ НА РЕНТГЕНОВСКИХ ИЗОБРАЖЕНИЯХ | 2020 |
|
RU2734575C1 |
| ВЫДЕЛЕНИЕ ДОМИНИРУЮЩЕГО ЦВЕТА С ИСПОЛЬЗОВАНИЕМ ЗАКОНОВ ВОСПРИЯТИЯ ДЛЯ СОЗДАНИЯ ОКРУЖАЮЩЕГО ОСВЕЩЕНИЯ, ПОЛУЧАЕМОГО ИЗ ВИДЕОКОНТЕНТА | 2005 |
|
RU2352081C2 |
| УСТРОЙСТВО И СПОСОБ ОПРЕДЕЛЕНИЯ ОПТИМАЛЬНОЙ ЗАДНЕЙ ПОДСВЕТКИ | 2007 |
|
RU2450476C2 |
| БЛОК ЦВЕТОВОГО ПРЕОБРАЗОВАНИЯ ДЛЯ УМЕНЬШЕНИЯ ОКАНТОВКИ | 2006 |
|
RU2413383C2 |
| СИСТЕМА И СПОСОБ ДЛЯ СЖАТИЯ СИГНАЛА ЦИФРОВОГО ИЗОБРАЖЕНИЯ С ИСПОЛЬЗОВАНИЕМ ИСТИННЫХ ИЗОБРАЖЕНИЙ | 2012 |
|
RU2581567C2 |
| СПОСОБ ИДЕНТИФИКАЦИИ КАДРОВ ПОТОКА МУЛЬТИМЕДИЙНЫХ ДАННЫХ НА ОСНОВЕ КОРРЕЛЯЦИОННОГО АНАЛИЗА ГИСТОГРАММ ИЗОБРАЖЕНИЙ КАДРОВ | 2015 |
|
RU2607415C2 |
| ОДНО- И МНОГОМОДУЛЯТОРНЫЕ ПРОЕКЦИОННЫЕ СИСТЕМЫ С ГЛОБАЛЬНЫМ РЕГУЛИРОВАНИЕМ ЯРКОСТИ | 2014 |
|
RU2767328C2 |















Изобретение относится к средствам проведения спектрального анализа ДНК. Технический результат заключается в ускорении проведения анализа спектральных изображений. Предоставляют последовательность ДНК. Создают множество спектрограмм, основанных на последовательности ДНК. Выполняют по меньшей мере одну из следующих функций в отношении множества спектрограмм: неконтролируемая классификация и обнаружение структурно новых элементов ДНК. Выполняют неконтролируемое исследование последовательности ДНК, в котором контролируемые и/или неконтролируемые классификации выполняют без отражения результатов преобразования Фурье в цветовое пространство и в котором один или несколько признаков извлекают непосредственно из бинарных индикаторных последовательностей, подвергнутых преобразованию Фурье. 2 н. и 17 з.п. ф-лы, 1 табл., 20 ил.
1. Способ оценки наличия заметного паттерна в последовательности ДНК, содержащий этапы, на которых:
предоставляют последовательность ДНК;
создают множество спектрограмм, основанных на последовательности ДНК;
выполняют по меньшей мере одну из следующих функций в отношении множества спектрограмм: неконтролируемая классификация и неконтролируемая классификация и обнаружение структурно новых элементов ДНК; и
выполняют неконтролируемое исследование последовательности ДНК,
в котором контролируемые и/или неконтролируемые классификации выполняют без отображения результатов преобразования Фурье в цветовое пространство, и
в котором один или несколько признаков извлекают непосредственно из бинарных индикаторных последовательностей, подвергнутых преобразованию Фурье.
2. Способ по п.1, в котором последовательность ДНК представляет геном, хромосому или их часть.
3. Способ по п.1 или 2, в котором этап создания множества спектрограмм включает в себя один или несколько из следующих этапов: (i) ввода последовательности ДНК, (ii) преобразования последовательности ДНК в бинарную индикаторную последовательность, (iii) применения краткосрочного преобразования Фурье к бинарной индикаторной последовательности для создания вектора частотной области, (iv) отображения векторов частотной области в цветовое пространство, (v) применения детектирования края к спектральному изображению ДНК; и (vi) вычисления горизонтальной и вертикальной гистограмм.
4. Способ по п.1, дополнительно содержащий создание спектрограммного видео, при этом создание спектрограммного видео включает алгоритм, который адаптирован для исполнения в блоке обработки.
5. Способ по п.4, в котором алгоритм включает в себя:
(a) использование вводов, включающих в себя последовательность ДНК длины М; параметры включают в себя N - размер окна STFT, q - интервал окна, включающий в себя N - перекрытие окна, р - разрешение просмотра, и v - скорость просмотра, включающая в себя количество колонок спектрального изображения, перемещаемых на один видеокадр, где М>>р>N;
(b) инициализирование переменной, включающее в себя установку s=1, r=1;
(c) начиная с позиции s, для сегмента длины р или подпоследовательности полной последовательности ДНК;
(d) начиная с позиции r, преобразование введенной последовательности ДНК размера N в бинарную индикаторную последовательность;
(e) применение краткосрочного преобразования Фурье к бинарной индикаторной последовательности и создание вектора частотной области;
(f) отображение векторов частотной области для А, Т, С и G в цветовое пространство;
(g) если (r-s+1)<p, то визуализацию результата и перемещение вперед на q нуклеотидов, включая в себя установку: r=r+q и переход на этап (d);
(h) если ранее не было показано спектральное изображение ДНК, то отображение спектрального изображения, установку r=r+q и переход на этап (d);
(i) если (r-s+1)<p+vq, удаление первой колонки из спектрального изображения и добавление последней сгенерированной колонки в конец, установку r=r+q и переход на этап (d);
(j) если (r-s+1)>=p+vq, то отображение спектрального изображения и установку s=s+vq, и r=r+q;
(k) если (r+N-1)<=M, то переход на этап (d);
(l) подбор скорости просмотра v согласно пользовательскому запросу.
6. Способ по п.1, дополнительно содержащий выполнение сравнительного анализа гистограмм множества спектрограмм, в котором сравнительный анализ гистограмм включает в себя:
(a) использование ввода, включающего в себя последовательность ДНК длины М; параметры включают в себя N - размер окна STFT, q - перекрытие, р - разрешение просмотра, где M>>p>N;
(b) преобразование введенной последовательности ДНК размера N в бинарную индикаторную последовательность;
(c) применение краткосрочного преобразования Фурье (STFM) к бинарной индикаторной последовательности и создание вектора частотной области;
(d) отображение векторов частотной области для А, Т, С и G в цветовое пространство;
(e) применение детектирования края к спектральному изображению ДНК, используя способ детектирования края;
(f) вычисление горизонтальной и вертикальной гистограмм для красных, зеленых, синих компонентов отдельно путем использования проекции на край;
(g) оценку данных гистограмм, в которой для CpG островков применяются следующие критерии извлечения:
(i)(х_гистограмма_зеленая-х_гистограмма_красная)>пороговое значение;
(ii) отклонение областей, удовлетворяющих (1) при длине<200 п.о.;
(iii) объединение областей, удовлетворяющих как (1), так и (2), разделенных менее чем 100 п.о.;
(h) отметку сегментов ДНК, которые удовлетворяют критериям оценки, как повторяющийся элемент, и запись позиций начала и конца повторяющегося элемента.
7. Способ по п.1, дополнительно содержащий выполнение выбора и классификации признаков, в котором выбор и классификация признаков включает в себя:
(a) использование вводов, включающих в себя последовательность ДНК длины М; параметры N - размер окна STFT, q - перекрытие, р - разрешение просмотра, где M>>p>N;
(b) преобразование введенной последовательности ДНК размера N в бинарную индикаторную последовательность;
(c) применение краткосрочного преобразования Фурье (STFM) к бинарной индикаторной последовательности и создание вектора частотной области;
(d) отображение векторов частотной области для А, Т, С и G в цветовое пространство;
(e) применение детектирования края к спектральному изображению ДНК, используя способ детектирования края;
(f) вычисление горизонтальной и вертикальной гистограмм для красных, зеленых, синих компонентов;
(g) оценку и ранжирование набора заметных спектральных признаков, используя способ выбора признаков, используя метод опорных векторов с генетическим алгоритмом;
(h) формирование классификатора, использующего поднабор главных признаков ранжирования из предыдущего этапа;
(i) отметку сегментов ДНК, которые удовлетворяют критериям оценки, как повторяющийся элемент, и запись позиций начала и конца повторяющегося элемента.
8. Способ по п.1, в котором неконтролируемое исследование включает в себя способ кластеризации.
9. Способ по п.1, в котором неконтролируемое исследование включает в себя:
этап (1): для введенной последовательности ДНК генерируют спектрограмму S1 длиной L, причем L - количество нуклеотидов, используя STFT окно W, где W<L, и перекрытие окна составляет V, где V<W;
этап (2): выполняют перемещение на R нуклеотидов вправо и генерируют спектрограмму S1 до тех пор, пока не будет достигнут конец последовательности ДНК;
этап (3): со всеми спектрограммами, сгенерированными на этапах (1) и (2), выполняют неконтролируемую кластеризацию на основе изображений;
этап (4): находят наибольший кластер, берут центр кластера и выполняют поиск по ресурсу известных геномов, чтобы увидеть класс меток элементов этого кластера;
этап (5): выбирают один из подэтапов (а) или (b):
(a) случайным образом выбирают Р спектрограмм, которые являются самыми дальними от центра кластера, и выполняют поиск меток класса, выделяют Р спектрограмм, которые находятся в одном и том же классе, и проверяют то, что выделенные Р спектрограммы принадлежат одному и тому же классу;
(b) визуализируют для пользователя спектрограммы и типы меток класса всех элементов в наборе спектрограмм, причем если спектрограмма находится в кластере, в котором известен центр, но спектрограмма, которая находится дальше от центра кластера, неизвестна, то обозначают новый элемент в качестве метки класса центра кластера и визуализируют различие;
этап (6): продолжают со вторым наибольшим кластером и повторяют этапы (5) и (6), и продолжают со следующим наибольшим кластером до тех пор, пока центра кластера и метка класса остаются неизвестными, и отмечают то, что К кластеров имеют известные метки, a U кластеров имеют неизвестные метки;
этап (7): для всех U кластеров с неизвестными метками, с существенным размером кластеров находят наиболее часто встречаемый паттерн, статистическое распределение внутри одной и той же хромосомы и находят статистическое распределение по хромосомам;
этап (8): увеличивают V и переходят на этап (1) с заданным размером шага до тех пор, пока V не достигнет половины W, затем переходят на этап (9);
этап (9): увеличивают W и переходят на этап (1) с упомянутым заданным размером шага до тех пор, пока W не достигнет половины L, затем переходят на этап (10);
этап (10): увеличивают L и переходят на этап (1); и этап (11): суммируют результаты на каждом из уровней V, W, и L.
10. Способ по п.1, в котором один или несколько паттернов ДНК идентифицированы.
11. Способ по п.10, в котором один или несколько паттернов ДНК включают в себя по меньшей мере одно из следующего: CpG островок, один или несколько Alu-повторов, одну или несколько некодирующих РНК, один или несколько тандемных повторов и один или несколько сателлитных повторов.
12. Способ по п.1, дополнительно содержащий выполнение сравнительного анализа гистограмм, в котором сравнительный анализ гистограмм выполняют на векторах признаков, состоящих из индикаторных последовательностей, подвергнутых Фурье преобразованию, которые объединены для представления полного вектора.
13. Способ по н.12, в котором полный вектор представляет каждый сегмент ДНК.
14. Способ по п.1, в котором нормализация представляет собой необязательный этап.
15. Система для оценки наличия заметного паттерна в последовательности ДНК, содержащая средства для выполнения этапов способа по любому из предшествующих пунктов.
16. Система по п.15, содержащая по меньшей мере один процессор и программное средство, выполненные с возможностью реализации полностью или частично этапов упомянутого способа, приведенного в одном или нескольких предшествующих пунктах.
17. Система по п.1, в которой упомянутый анализ выполняют на векторах признаков, состоящих из объединенных индикаторных последовательностей, которые объединены для представления полного вектора.
18. Система по п.17, в которой полный вектор представляет каждый сегмент ДНК.
19. Система п.15, в которой нормализация представляет собой необязательный этап.
| R.HALL et al., A rapid method for illustrating features in both coding and non-coding regions of a genome, Bioinformatics Applications Note, vol 20, №6, 2004 | |||
| D.SUSSILLO et al., Spectrogram analysis ofgenomes, Eurasip Journal On Applied Signal Processing Hindawi USA, vol.2004, №1, 01.01.2004 | |||
| MICHAEL В | |||
| EISEN et al | |||
| Cluster analysis and |

