УРОВЕНЬ ТЕХНИКИ
В типичных документальных информационных системах к документам есть доступ на всем уровне документа, вследствие чего весь документ поступает на клиентский компьютер с сервера для редактирования. Это требует наличия низкоуровневых данных, ассоциированных с базовым форматом документа, передаваемым с сервера на клиентский компьютер. Кроме того, инкрементные форматы документа приходится подвергать операции очистки памяти и дефрагментации через сетевое соединение. Более того, блокировками необходимо управлять через сеть. Управление блокировками может представлять собой сложную и недолговечную задачу, которая требует значительного объема изменяемого информационного наполнения. Передача низкоуровневых данных, включая информацию по очистке памяти и дефрагментации, а также по механизму блокировки, чрезмерно привязывает приложение к его низкоуровневому формату файла и может быть негибкой и приводить к неэффективности.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Примерные системы и способы, описанные в настоящем документе, относятся к синхронизации файла (например, документа) и/или загрузке по протоколу, не использующему информацию о состоянии.
Согласно одному аспекту, структура данных для хранения документа в первом вычислительном устройстве не зависит от формата документа, причем структура данных включает в себя: множество ячеек и множество объектов данных, задающих содержание документа. Каждая из ячеек имеет идентификатор ячейки, который однозначно идентифицирует конкретную ячейку в рамках документа и ассоциирован, по меньшей мере, с одной версией. Каждый объект данных ассоциирован с одной из ячеек и имеет один идентификатор объекта, который однозначно идентифицирует объект данных в рамках соответствующей ячейки, и сконфигурирован для обеспечения связи с другими ячейками и с объектами в пределах соответствующей ячейки. В дополнение, каждая из ячеек задана таким образом, чтобы каждая другая ячейка оставалась незатронутой изменениями, относящимися к объектам данных этой ячейки.
Согласно другой особенности, манифест версии хранится на машиночитаемом носителе первого вычислительного устройства. Манифест версии задает версию, представляющую состояние ячейки в момент времени. Манифест версии включает в себя: множество объектных групп, где каждая объектная группа содержит, по меньшей мере, один объект данных; и блок совместимых данных, содержащий, по меньшей мере, один объект данных, где каждый блок совместимых данных задан так, чтобы редактирование одного из блоков совместимых данных не оказывало воздействия ни на один другой блок совместимых данных.
Согласно еще одному аспекту, способу синхронизации документа на первом вычислительном устройстве, документ разбивается на ячейки, каждая ячейка задается, по меньшей мере, одним манифестом версии, причем способ включает в себя: получение первой версии и, по меньшей мере, одной ячейки, ассоциированной с документом; получение обновления первым вычислительным устройством, где обновление указывает на идентификатор обновленной версии, ассоциированный с каждой ячейкой, ассоциированной с документом; сохранение первой версии каждой ячейки, когда идентификатор первой версии ячейки соответствует идентификатору обновленной версии ячейки; генерирование новой версии каждой ячейки, причем генерирование новой версии включает в себя назначение новой версии нового идентификатора версии, когда идентификатор первой версии ячейки не соответствует идентификатору обновленной версии ячейки; стирание любой ячейки, на которую не ссылаются корневые объекты; и синхронизацию документа путем замены ячеек на новую версию каждой ячейки. Идентификатор ячейки включает в себя пару глобально уникального идентификатора (globally unique identifier, GUID) и целого числа (integer, INT), причем GUID представляет собой глобально уникальную область действия, определяющую совокупность ячеек и версий, включает в себя корневые объекты, причем к ячейкам в пределах области имеется доступ через корневые объекты. Идентификатор ячейки ассоциирован с первой версией, обладающей, по меньшей мере, с одним идентификатором первой версии. Каждый, по меньшей мере, из одного идентификатора версии представляет состояние ячеек в каждый момент времени. Ячейка включает в себя область действия, определяющая совокупность ячеек и версий, и область действия включает в себя, по меньшей мере, один корневой объект. Ячейки в пределах области определения доступны через корневой объект.
Данное описание сущности изобретения обеспечено для предложения выбора в упрощенной форме концепций, которые дополнительно описаны ниже в Подробном описании. Данное описание сущности изобретения не следует рассматривать как идентифицирующее ключевые признаки или основные признаки заявленного объекта изобретения. Также данное описание сущности изобретения не должно использоваться для ограничения заявленного объема объекта изобретения.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
Не ограничивающие и не исчерпывающие варианты воплощения описаны со ссылкой на следующие фигуры, на которых одинаковые номера ссылок относятся к одинаковым деталям на всех различных изображениях, если не указано иное.
Фиг.1 представляет собой схематическую блок-схему, иллюстрирующую примерную авторскую систему.
Фиг.2 представляет собой блок-схему, иллюстрирующую авторскую систему согласно фиг.1, в которой документ, хранящийся в первом вычислительном устройстве, может включать в себя блоки согласованного информационного наполнения.
Фиг.3 представляет собой схематическую блок-схему блока совместимых данных.
Фиг. 4 представляет собой схематическую блок-схему области определения.
Фиг.5 представляет собой схематическую блок-схему примерной клиентской вычислительной системы, сконфигурированной для внедрения среды авторских разработок; и
фиг.6 представляет собой блок-схему, иллюстрирующую примерную технологию синхронизации, осуществляемую авторским приложением.
ПОДРОБНОЕ ОПИСАНИЕ
В следующем подробном описании приведены ссылки на прилагаемые чертежи, которые составляют его часть и на которых в виде иллюстрации показаны конкретные варианты воплощения или примеры. Тогда как раскрытие будет описано в общем контексте программных модулей, которые функционируют совместно с прикладной программой, работающей на операционной системе, установленной на системе ЭВМ, специалистам в данной области техники должно быть понятно, что раскрытие также может быть внедрено в сочетании с другими программными модулями. Варианты воплощения, описанные в настоящем документе, могут сочетаться между собой, а другие варианты воплощения могут быть использованы без отступлений от сущности или объема настоящего раскрытия. Поэтому следующее подробное описание не должно рассматриваться в ограничительном смысле, а объем раскрытия задан прилагаемыми пунктами формулы изобретения и их эквивалентами.
Варианты воплощения настоящего раскрытия обеспечивают среду, в которой одиночный клиент может создавать документ, или несколько клиентов могут совместно создавать документ при потреблении минимальных серверных и обменных ресурсов. В примерных вариантах воплощения, когда возможное совместное использование приложения состоит в редактировании документа, приложение воздействует только на определенные элементы документа. Прежде чем клиент получил доступ к элементам документа, модель данных приложения была разбита на заданные блоки совместимых данных.
В примерных вариантах воплощения, описанных в настоящем раскрытии, документ разбивают на последовательность частей, называемых блоками совместимых данных. По умолчанию, документ можно преобразовать в один-единственный блок совместимых данных, который охватывает весь документ. Когда конкретные сведения о структуре документа известны, документ можно разбивать на более чем один блок совместимых данных. Например, презентационную программу, например, программу, созданную с использованием презентационной графической программы POWERPOINT®, состоящей более чем из одного слайда, можно разделить на несколько блоков совместимых данных, где каждый блок совместимых данных включает в себя один слайд. Например, презентацию, состоящую из десяти слайдов, можно разбивать на десять блоков совместимых данных.
В примере, описанном выше, возможны больше или меньше чем десять блоков совместимых данных. Например, каждый слайд может включать себя нижний колонтитул, а каждый нижний колонтитул может представлять собой блок совместимых данных. Поэтому презентация, состоящая из десяти слайдов, может иметь 20 блоков совместимых данных. Также, по умолчанию, весь документ может представлять собой один блок совместимых данных.
Существуют два основных подхода к внедрению допустимых ошибок. Первый состоит в том, что допустимые ошибки могут быть точно вычислены с помощью алгоритма «diff». Например, используемый алгоритм может представлять собой библиотеку «Удаленная дифференциальная компрессия» (Remote Differential Compression, RDC), библиотека обнаружена в платформе WINDOWS. Алгоритмический подход обладает преимуществом, состоящим в том, что данные можно считать неявными, и тогда никакой структуры или структурных сведений может не потребоваться. Это является идеальным для сценариев, когда формат документа фиксирован, неизвестен или не может быть изменен. Не ограничивающие примеры форматов файла, которые является фиксированными, неизвестными или которые нельзя изменить, включают в себя текстовые форматы, растровые изображения и аудиофайлы.
Однако ценой за эту приспособляемость является высокая себестоимость вычислений и неэффективность передачи данных, вызванной изменениями, которые невозможно хорошо отследить с помощью алгоритма. Это может произойти, если не была разработана эффективная синхронизация данных. То есть данные не обладают «явно заданными» допустимыми ошибками или хорошей локальностью изменений.
Второй подход состоит в том, что допустимые ошибки можно подразделить на меньшие блоки изменений, называемые «гранулами», которые можно относительно близко выровнять с ожидаемыми изменениями. Относительная ошибка в таком случае представляет собой набор гранул, которые могут различаться по двум состояниям. Эта схема является менее дорогостоящей для вычислений и потенциально более эффективна, когда данные можно удачно разделить на небольшие блоки изменений, которые близко выровнены с ожидаемыми корректировками.
Два подхода можно использовать независимо или в сочетании друг с другом. Например, при использовании двух подходов в сочетании друг с другом модель доступа к документу может обеспечить произвольный уровень крупности разбиения на модули в блоках совместимых данных. Через схему явно заданной допустимой ошибки механизмы синхронизации могут повысить произвольный уровень крупности разбиения, что приводит к повышению эффективности.
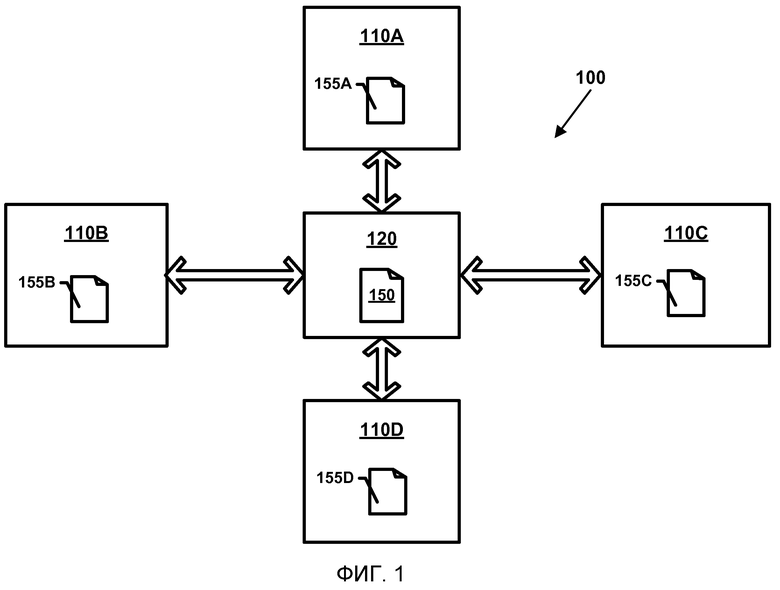
Обратимся теперь к фигурам: фиг.1 иллюстрирует примерную авторскую систему 100, обладающую признаками, которые иллюстрируют примерные особенности раскрытия. Авторская система 100 включает в себя устройство хранения данных 120, на котором хранится главная копия документа 150. В одном варианте воплощения устройство хранения 120 может включать в себя (но не ограничено) сервер, клиентский компьютер или другое вычислительное устройство. В другом варианте воплощения устройство хранения 120 может включать в себя одно или несколько устройств хранения (например, сеть вычислительных устройств).
Авторская система 100 также включает в себя одно или несколько клиентских вычислительных устройств 110A, 110B, 110C, 110D, связанные с возможностью обмена данными с устройством хранения данных 120. Каждое из клиентских вычислительных устройств может редактировать документ 150 путем получения обновления на один или несколько блоков совместимых данных 155 и редактирования объектов данных в блоке совместимых данных 155. Блоки совместимых данных 155 синхронизируют, когда клиентские вычислительные устройства периодически посылают на устройство хранения данных 120 обновления, которые оно разделяет с другими клиентскими вычислительными устройствами.
Как вытекает из термина, используемого в настоящем документе, клиентское вычислительное устройство включает в себя любое вычислительное устройство, которое достигает блока совместимых данных, создаваемого из главной копии документа. Клиентское вычислительное устройство может быть отличным от устройства хранения данных 120 или может включать в себя другую клиентскую учетную запись, реализуемую на устройстве хранения данных 120. В одном варианте воплощения вычислительное устройство, которое действует как устройство хранения данных 120 для одного документа, может действовать как клиентское вычислительное устройство для другого документа и наоборот.
В показанном примере четыре клиентских вычислительных устройства 110A, 110B, 110C и 110D соединены, с возможностью обмена данными, с устройством хранения данных 120. Однако в других вариантах воплощения с устройством хранения данных 120 может быть соединено любое количество вычислительных устройств. В показанном примере каждое клиентское вычислительное устройство 110A, 110B, 110C, 110D может посылать на устройство хранения данных 120 обновления, созданные клиентом клиентского вычислительного устройства, и может запрашивать с устройства хранения данных 120 другие блоки совместимых данных для редактирования/авторинга. В одном варианте воплощения устройство хранения данных 120 может представлять собой серверное вычислительное устройство, а клиентские вычислительные устройства могут представлять собой клиентские вычислительные устройства 110A, 110B, 110C, 110D. Возможны и другие конфигурации системы. Например, в альтернативном варианте воплощения можно использовать несколько серверных вычислительных устройств.
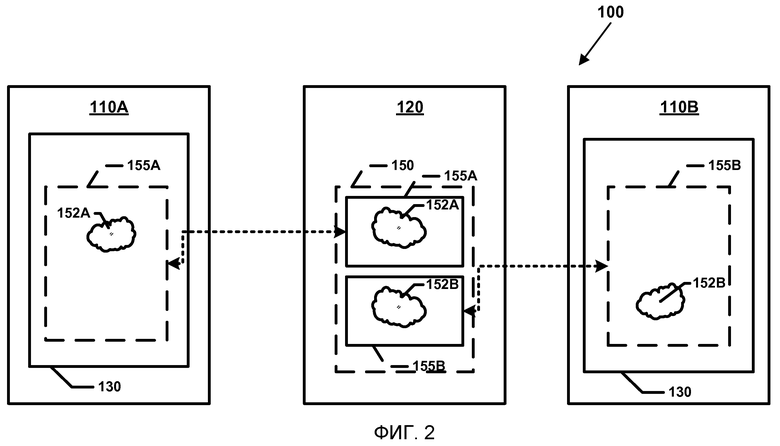
Как показано на фиг.2, документ 150, хранимый на устройстве хранения данных 120, может включать в себя контент 152A и 152B, разбитый на блоки совместимых данных 155A, 155B. Авторские приложения 130 на клиентских вычислительных устройствах 110 обрабатывают и управляют контентом блоков совместимых данных 155A, 155B документа 150. Вообще говоря, клиентское вычислительное устройство 11 OA может синхронизировать обновления для контента 152A отдельно от обновлений, обеспечиваемых клиентским вычислительным устройством 110B. Поскольку обновления делаются для различных блоков совместимых данных, между блоками совместимых данных конфликт слияния не возникнет.
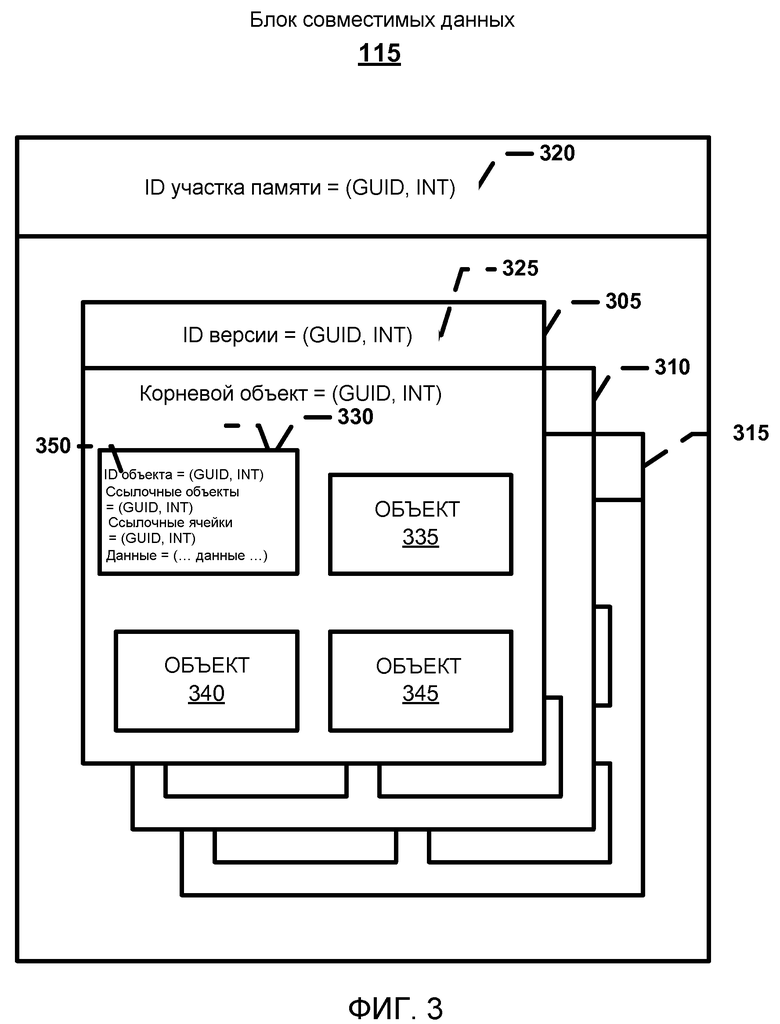
Обратимся к фиг.3. Показан блок совместимых данных 155A (то есть структура данных), включающий в себя множество версий программы для блока совместимых данных 155A 305, 310 и 315. Ячейки представляют собой группы объектов данных со сходными свойствами. Например, ячейка может содержать группу текстов, группу рисунков и т.д. Каждая из ячеек 305, 310 и 315 включает в себя идентификатор ячейки 320 (показанный лишь для ячейки 305), который однозначно идентифицирует конкретную ячейку в документе 150. Каждая из ячеек 305, 310 и 315 может сообщаться, по меньшей мере, с одной другой ячейкой внутри документа 150, с использованием идентификаторов ячеек. Также каждая из ячеек 305, 310 и 315 ассоциирована, по меньшей мере, с одной версией программы 325 (показанной лишь для ячейки 305). Следует отметить, что состояние ячейки описывается версией, которая содержит состояние группы объектов данных.
Каждая ячейка может включать в себя идентификатор ячейки, включающий в себя пару глобально уникального идентификатора (globally unique identifier, GUID) и целого числа (integer, INT). Каждая ячейка также может быть включена в файл, задающий совокупность ячеек и версий. Область действия также может включать в себя, по меньшей мере, один корневой объект. Ячейки в области определения могут быть доступны через корневые объекты. Идентификатор ячейки может быть ассоциирован с первой версией, включающей в себя, по меньшей мере, один первый идентификатор версии. Каждый, по меньшей мере, из одного идентификатора версии может представлять состояние ячеек в момент времени. Под термином «файл» понимается не то, что он используется для представления поименованного сохраняемого «логического объекта», и он не должен представлять собой физический файл, такой как текстовой файл или изображение jpeg.
Блок совместимых данных 155A включает в себя множество объектов данных 330, 335, 340 и 345, задающих содержание документа 150. Как правило, объекты данных могут представлять собой произвольные двоичные данные. Неисключительные примеры объектов данных включают в себя текст, рисунок, таблицу, гиперссылку, файл кинофрагмента, аудиофайл и т.д. Каждый объект данных 330, 335, 340 и 345 ассоциирован с одной из ячеек 305, 310 и 315 и имеет идентификатор объекта, который однозначно идентифицирует объект данных в ассоциированной ячейке. Например, идентификатор объекта 350 однозначно идентифицирует объект данных 330 в ячейке 305. Идентификаторы ячеек, идентификаторы объектов и идентификаторы версий могут включать в себя пару GUID и INT. Кроме того, GUID может быть глобально уникальной внутри ячейки.
Каждый объект данных 330, 335, 340 и 345 сконфигурирован таким образом, чтобы он сообщался с другими ячейками и с объектами внутри ассоциированной ячейки. Например, объект данных 330 может сообщаться с опорными ячейками 310 и 315, причем в опорных ячейках 310 и 315 не содержатся объекты. Это помогает обеспечивать согласованность, даже если одна ячейка изменяется независимо от другой. Обычно объект может адресоваться к любому другому объекту в пределах той же ячейки и к другим ячейкам, но не к объектам в других ячейках. В дополнение, каждая из ячеек 305, 310 и 315 задана таким образом, чтобы каждая другая ячейка оставалась неподверженной изменениям объектов данных ячейки. Также, каждая ячейка 305, 310 и 315 может быть способна адресоваться, по меньшей мере, к одной ячейке в пределах области действия. Область действия может задавать совокупность ячеек и версий. См. фиг.4, где схематически изображена область действия.
В ходе разбиения каждый из объектов данных 330, 335, 340 и 345 можно сгруппировать, по меньшей мере, в одну группу объектов. Использование групп объектов минимизирует служебные сигналы сопровождаемых объектов каждого по отдельности. В сценарии, когда все объекты относительно крупные, наличие групп объектов может быть необязательным, поскольку служебные сигналы малы. Однако в сценарии, когда объекты могут быть произвольно малы, группы объектов используют для контроля служебных сигналов. Группы объектов также учитывают отбор объектов (то есть блоков изменений) и их группирование в более крупные блоки. В ходе разделения на части возникает необходимость в тестировании и поддержании характеристик «блока изменений» как раз созданных групп.
Устройство хранения данных 120 может сортировать объекты данных 330, 335, 340 и 345 по группам объектов, исходя из различных факторов, таких как вероятность (то есть эвристика, основанная на применении), с которой каждый объект данных будет обновлен клиентским компьютером 110. Например, объекты могут быть сгруппированы по нескольким категориям. Не ограничивающие примеры этих категорий включают в себя: 1) типы объектов, про которые известно, что они часто изменяются (например, свойства метаданных документа, такие как подсчет слов и последний момент изменений); ii) типы объектов, про которые известно, что они изменяются очень часто (например, рисунки); iii) объекты, частота изменений который неизвестна; и iv) объекты, которые часто изменялись (например, списковая структура для списка, который пользователь непрерывно изменял).
В дополнение, устройство хранения данных 120 может сортировать объекты данных 330, 335, 340 и 345 по группам объектов, исходя из размера каждого объекта данных. Например, в алгоритм сортировки можно вводить размер. Если объект считается крупным, то служебный сигнал отслеживания объекта как одиночный объект становится незначительным. Это особенно верно, когда выгода просчитывалась (то есть это способствует предотвращению выборки или синхронизации объекта, которая не обязательна). Если объект очень мал по отношению к служебному сигналу группы объектов, то объект может быть включен в группу независимо от того, как часто объект изменяется.
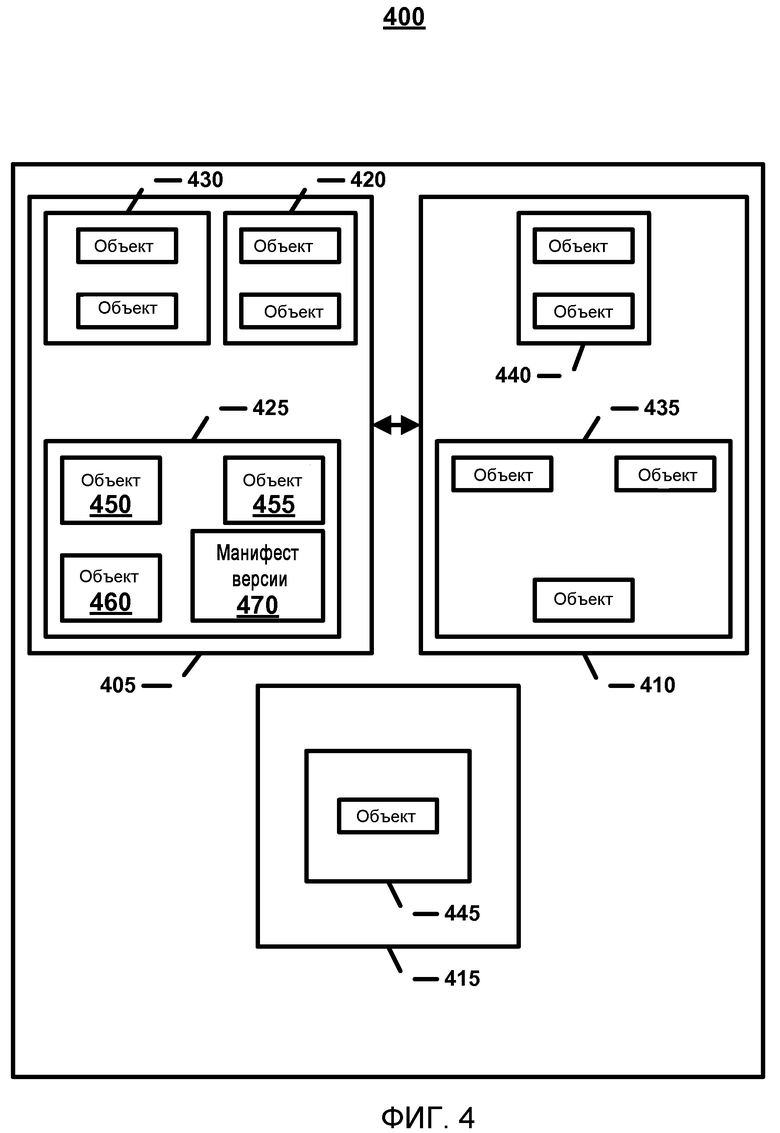
Как указывалось выше, каждая ячейка 305, 310 и 315 может быть пригодной для адресации, по меньшей мере, к одной ячейке в области действия, и область действия может определять совокупность ячеек и версий. Фиг.4 показывает схематическую блок-схему области действия 400. Область действия 400 включает в себя корневую ячейку 405, ячейку 410 и ячейку «мусорных» данных 415. Например, корневая ячейка 405 включает в себя версии 420, 425 и 430. Пример версии может включать в себя последний автосохраненный экземпляр блока сохраненных данных 155A, то есть состояние файла перед последним изменением. Например, версия может включать в себя состояние текстового поля перед тем, как текст был добавлен (версия один). Если текст добавляют к текстовому полю, может быть создана новая версия (версия два). Поэтому, операция «отмена выполненного действия» может приводить к возвращению от версии два к версии один. Также, каждая ячейка может включать в себя различное количество версий. Например, ячейка 405 включает в себя две версии (версии 435 и 440), а ячейка ненужной информации включает в себя одну версию (версию 445).
Версии ячеек достигаются за счет разбиения документа на блоки совместимых данных, которые позволяют блоку репликации (или обновления) быть значительно меньше, чем весь документ. Использование версий ячеек позволяет повысить быстродействие изменений. В случае частичной синхронизации (то есть наличия синхронизирующих блоков совместимых данных в противовес синхронизации всего документа) разбиение позволяет замечать обновления, которые в противном случае не были бы заметны. Эффективное разбиение позволяет также осуществлять слияние приложений, чтобы запускать меньшее их количество. Например, конфликты, по определению, могут возникать, только когда возникают изменения в самом блоке совместимых данных, а любые другие изменения в других блоках совместимых данных не могут породить конфликты, и синхронизационное приложение можно запускать без обязательного слияния. В дополнение, блоки совместимых данных могут образовывать эффективный базис для операций пошаговой загрузки/сохранения. Сценарии загрузки и синхронизации, когда они полностью интегрированы с приложением, являются более быстродействующими, и, таким образом, могут быть получены новые свойства раздельного/совместного использования данных.
Для поддержания совместимости в пределах блока совместимых данных необходимо гарантировать, чтобы все обновления были совместимыми. Это влечет за собой то, что потенциально несовместимые обновления должны быть укомплектованы друг с другом, с образованием совместимого обновления и транзакции. Прикладной программный интерфейс (access application programming interface, API) субфайла может производить обновления через транзакции, без неконтролируемого уровня диапазона побайтового доступа.
Для контроля эффективной синхронизации и репликации может быть использован субфайл репликации, который может быть создан на уровне блока совместимых данных (то есть разбиение на разделы). В такой простейшей форме это может вызвать не что иное, как назначение GUID каждому разделу, который изменяется всякий раз, когда создается обновление для этого раздела.
Обновления могут быть сделаны на уровне блока совместимых данных за счет новых версий в форме переходов. Синхронизации могут повлечь за собой пересылку новой версии (то есть состояний) между клиентом и сервером. Однако обновления обычно бывают небольшими и основываются на некотором предыдущем состоянии, которое может быть в наличии как у клиента, так и у сервера. Это может быть выгодно использовано при передаче приращений или дельт, что делает синхронизацию более эффективной.
Каждая версия может включать в себя любое количество объектов данных. Например, версия 425 имеет три объекта данных (объекты данных 450, 455 и 460). Для каждой версии ячейки можно создать манифест версии 470. Манифест версии 470 может указывать на корневую совокупность объектов, содержащихся в версии, любую зависимость/ссылки для манифестов других версий и группы объектов (то есть каким образом объекты расположены в группе объектов). Каждый манифест версии 470 может указывать на другие группы объектов, заданные в манифесте предыдущей версии.
Манифест версии 470 может задавать версию, представляющую состояние документа 150 в момент времени. Манифест версии 470 включает в себя, по меньшей мере, одну группу объектов, а каждая группа объектов включает в себя, по меньшей мере, один объект данных. Манифест версии 470 также описывает одиночную версию, которую, по определению, можно использовать лишь для описания состояния объектов в одиночной ячейке (которая представляет собой блок совместимых данных).
Второе вычислительное устройство (например, устройство хранения данных 120) может частично или полностью определять, какие объекты данных в какую группу объектов помещены. Второе вычислительное устройство также может задавать каждую группу объектов, исходя из того, как часто каждый объект обновляется. В дополнение, второе вычислительное устройство может задавать каждую группу объектов, исходя из размера объекта. Также, первое вычислительное устройство (например, клиентский компьютер 110) может влиять на то, какие объекты данных в какие группы объектов помещены.
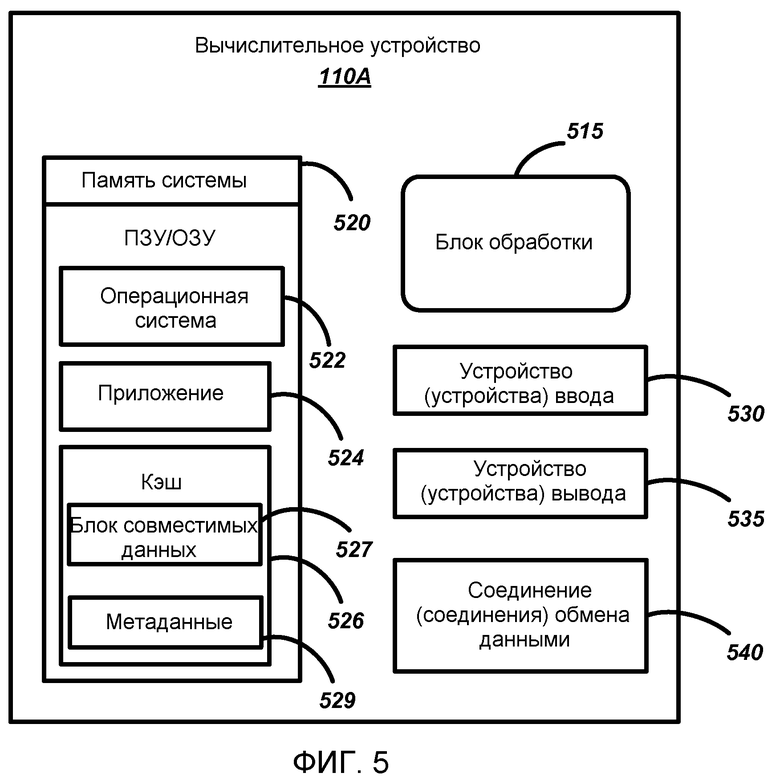
Обратимся теперь к фиг.5, где клиентское устройство 110A показано более подробно. Клиентское устройство 110A может представлять собой персональный компьютер, серверный компьютер, компьютер-ноутбук, персональный цифровой секретарь, смартфон или любое другое подобное вычислительное устройство.
На фиг.5 примерное клиентское вычислительное устройство 11 OA обычно включает в себя, по меньшей мере, один блок обработки данных 515 для исполнения программных приложений и программ, хранящихся в системной памяти 520. В зависимости от конкретной конфигурации и типа вычислительного устройства 110A системная память 520 может включать в себя (но не ограничена) RAM (random access memory, оперативное запоминающее устройство, ОЗУ), ROM (read-only memory, постоянное запоминающее устройство, ПЗУ), EEPROM (Electrically Erasable Programmable Read-Only Memory, электрически стираемое программируемое постоянное запоминающее устройство, ЭСППЗУ), флэш-память, CD-ROM, digital versatile disks (цифровой универсальный диск, DVD) или другие оптические устройства хранения данных, магнитные кассеты, магнитные ленты, запоминающее устройство на магнитных дисках или другие магнитные запоминающие устройства, или другие запоминающие технологии.
В памяти системы 520 обычно хранится операционная система 522, такая как операционная система WINDOWS® от Корпорации Майкрософт, Редмонд, Вашингтон, пригодная для регулирования работы вычислительного устройства 110A. Память системы 520 также может включать в себя кэш документа 526, в котором может храниться блок совместимых данных 527 документа. В кэше клиента 526 также могут храниться метаданные 529 документа.
В памяти системы 520 также может храниться одно или несколько прикладных программ, таких как приложения для создания авторских разработок 130, которые используют для создания и редактирования документов. Один не ограничивающий пример авторских приложений 130, пригодных для создания документов в соответствии с принципами настоящего раскрытия, - это программное средство обработки текстов WORD® от корпорации Майкрософт. Другие неограничивающие примеры приложений для создания авторских разработок включают в себя презентационное программное обеспечение POWERPOINT®, программное обеспечение VISIO® для черчения и составления графиков и Интернет-браузер INTERNET EXPLORER®, - все от корпорации Майкрософт. Также можно использовать и другие прикладные программы.
Вычислительное устройство 110A также может иметь устройство (устройства) ввода 530, такие как клавиатура, мышь, «перо», устройство для речевого ввода, сенсорное устройство ввода и т.д., для ввода и управления данными. Также может быть включено устройство (устройства) вывода 535, такое как экран дисплея, динамик ПК, принтер и т.д. Эти устройства вывода 535 хорошо известны в данной области техники и не нуждаются здесь в подробном обсуждении.
Вычислительное устройство 110A также может содержать средства связи 540, которые позволяют устройству 110A иметь связь с другими вычислительными устройствами, например, устройством хранения 120 из фиг.1, по сети в распределенной вычислительной среде (например, интрасеть или Интернет). В качестве примера и без ограничений, среда устройств связи 540 включает в себя проводную среду, такую как проводная сеть или однопроводное соединение, и беспроводную среду, такую как акустическая, радиочастотная, инфракрасная и другие беспроводные среды.
Фиг.6 представляет собой блок-схему, излагающую основные стадии, включенные в способ 600, соответствующий варианту воплощения раскрытия для синхронизации документа после изменений, сделанных для создания блока совместимых данных. Способ 600 может быть внедрен с использованием вычислительного устройства 110A, как было описано выше применительно к фиг.5. Пути внедрения стадий способа 600 будут подробнее описаны ниже.
Способ 600 начинается с запуска блока 605 и перехода к стадии 610, где вычислительное устройство 110A может принимать версию и любые ячейки, к которым эта версия приложена. Например, совокупность версий может быть получена вместе с соответствующими командами относительно того, какие ячейки должны обладать состоянием, настроенным на определенную версию. Иными словами, при синхронизации происходит прием следующего: i) {версии} - совокупности версий; ii) {(ячейки, версии)} - совокупности идентификаторов ячеек, кортежи идентификаторов версии, которые описывают ячейки, которые «модифицируются», и каково их новое состояние с точки зрения полученных версий. Термин «модифицируется» означает, что некоторая часть информации в версии изменяется. Например, клиент, используя вычислительное устройство 110A (например, клиентский компьютер) может принимать слайд из презентации или информацию из заголовка/сноски документа обработки текста. Как только изменения были применены, средство хранения документов может обходиться без каких-либо ячеек и/или версий, которые не могут быть «раскрыты» путем запуска в корневых ячейках и прослеживания ссылок на объект/ячейку. Термин «раскрытие» относится к оптимизации, которую средства хранения могут осуществлять, чтобы избавиться от посторонней информации, которая больше не используется клиентами, поскольку у клиентов нет никакой возможности получить доступ к этим данным. Например, как только изменения были применены, средство хранения данных может освободиться от любых ячеек и/или версий, к которым они больше не адресуются прямо или косвенно в корневых ячейках.
После стадии 610, где вычислительное устройство 110A принимает версию и соответствующие ячейки, к которым эти версии прилагаются, способ 600 может перейти к стадии 620, на которой вычислительное устройство 110A может принимать обновления к блоку совместимых данных 527. Обновления могут указывать на идентификатор обновленной версии, ассоциированный с каждой ячейкой, ассоциированной с блоком совместимых данных 527 или документом 150. Например, на вычислительном устройстве 110A можно запускать презентационную графическую программу POWERPOINT®, а блок совместимых данных 527 может представлять собой слайд. Обновления к слайду могут быть получены, когда пользователь редактирует слайд.
Как только вычислительное устройство 11 OA принимает обновления на блок совместимости 527 на стадии 620, способ 600 может перейти к стадии 680, где вычислительное устройство 110A определяет, надо ли сохранять первую версию, или следует генерировать новую версию. Когда вычислительное устройство 110A определяет, что первую версию следует сохранить, способ 600 переходит к стадии 630, где вычислительное устройство 110A может сохранять первую версию. Первую версию можно сохранять, когда идентификатор первой версии ячейки соответствует идентификатору обновленной версии ячейки. Пример, когда идентификатор первой версии может соответствовать идентификатору обновленной версии, - это когда версия создается, а затем версия отменяется. Например, пользователь может печатать слово на слайде, а затем стирать вновь напечатанное слово. Поскольку слайд не изменялся, нет необходимости в генерировании новой версии.
Когда вычислительное устройство 110A определяет, что новая версия создана, способ 600 переходит от стадии 680 к стадии 640, где вычислительное устройство 110A генерирует новую версию. Генерирование новой версии может включать в себя назначение новой версии нового идентификатора версии, когда идентификатор первой версии ячейки не соответствует идентификатору обновленной версии ячейки. Генерирование новой версии также может включать в себя определение для каждой ячейки, соответствует ли идентификатор каждого объекта в ячейке идентификатору обновленной версии. Идентификатор обновленного объекта может определять манифест версии. Манифест версии может определять версию блока совместимых данных 527 или документа и может включать в себя, по меньшей мере, первую группу объектов, которая содержит, по меньшей мере, первый объект данных. Манифест версии также может указывать на манифест предыдущей версии. Например, в ходе редактирования пользователем приложение отслеживает совокупность объектов, которые модифицируются в виде части пользовательской редакторской правки. Затем создают идентификатор новой версии с использованием стандартного алгоритма генерирования GUID. Совокупность объектов затем упаковывают в группы объектов (как обсуждалось выше), а затем группы объектов и манифест предыдущей версии извлекают из манифеста новой версии, который представляет новую версию.
Сразу после генерирования новой версии на стадии 640 вычислительным устройством 110A способ 600 может переходить к стадии 650, где вычислительное устройство 110A может очищать память любой ячейки, на которую не ссылаются корневые объекты. Очистка памяти включает в себя определение объектов, которые невозможно «раскрыть» путем отслеживания ссылок на объект/ячейку, возникающих в корневых ячейках. Поскольку ячейки с очищенной памятью не могут быть доступны, в них никогда не возникнет необходимость, и дисковое пространство/ресурс можно очищать, стирая их.
Как только вычислительное устройство 110A стирает любую ячейку, на которую корневые объекты не ссылаются на стадии 650, способ 600 может переходить к стадии 660, где вычислительное устройство 110A может синхронизировать документ 150 или блок совместимых данных 527. Например, вычислительное устройство 110A может синхронизировать документ путем замены существующих ячеек на новую версию каждой ячейки. Как только вычислительное устройство 110A синхронизировало документ 150 или блок совместимых данных 527 на стадии 660, способ 600 может затем завершиться на стадии 670.
На всем протяжении данного описания могли упоминаться выражения «один вариант воплощения», «вариант воплощения», «варианты воплощения», «особенность» или «особенности», означающие, что конкретный описанный признак, структура или характеристика может быть включена, по меньшей мере, в один вариант воплощения настоящего раскрытия. Таким образом, использование таких фраз может относиться более чем только к одному варианту воплощения или особенности. В дополнение, описанные признаки, структуры или характеристики могут сочетаться между собой любым подходящим образом в одном или более вариантах воплощения или особенностях. Кроме того, ссылка на одиночный предмет может означать одиночный предмет или множество предметов, точно так же как ссылка на множество предметов может означать одиночный предмет. Более того, использование термина «и», встроенного в перечень, должно подразумевать, что были рассмотрены все элементы перечня, одиночный пункт перечня или любое сочетание пунктов в перечне.
Варианты воплощения раскрытия могут быть внедрены в виде компьютерного процесса (способа), вычислительной системы или в виде готового изделия, такого как компьютерный программный продукт или машиночитаемый носитель. Процессы (программы) можно внедрять любым числом способов, включая структуры, описанные в данном документе. Один такой способ состоит в машинных операциях, и устройства этого типа описаны в данном документе. Другой способ (не обязательный) предназначен для одной или нескольких отдельных операций согласно способам, выполняемым на вычислительном устройстве совместно с одним или несколькими операторами-людьми, выполняющими некоторые из этих операций. Эти люди-операторы не нуждаются в том, чтобы находиться рядом друг с другом, и каждый из них может находиться лишь рядом с машиной, которая выполняет свою часть программы.
Компьютерный программный продукт может представлять собой среду для хранения информации компьютера, считываемую компьютерной системой и кодирующую компьютерную программу в виде команд для исполнения компьютерного процесса. Компьютерный программный продукт также может представлять собой сигнал, распространяющийся на носителе, считываемом вычислительной системой, и кодирующий компьютерную программу в виде команд для исполнения компьютерного процесса. Термин «среда для хранения информации компьютера», используемый в настоящем документе, включает в себя как среду хранения данных, так и среду передачи данных.
Специалистам в данной области техники должно быть понятно, что раскрытие можно применять с использованием компьютеров с другими конфигурациями системы, включая портативные устройства, многопроцессорные системы, электронику на основе микропроцессоров или программируемую бытовую электронику, миникомпьютеры, мэйнфреймы и т.п. Раскрытие также можно применять в распределенной вычислительной среде, где задачи выполняются с использованием устройств дистанционной обработки, связанных через сети передачи данных. В распределенной вычислительной среде программные модули могут быть расположены как в локальных, так и в удаленных устройствах памяти. Обычно программные модули включают в себя подпрограммы, программы, компоненты, структуры данных и другие типы структур, которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ УПРАВЛЕНИЯ И ПЕРЕДАЧИ ОБНОВЛЕНИЙ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ | 2004 |
|
RU2357279C2 |
| ИНТЕРФЕЙСЫ ДЛЯ ПРИКЛАДНОГО ПРОГРАММИРОВАНИЯ ДЛЯ КУРИРОВАНИЯ КОНТЕНТА | 2014 |
|
RU2666302C2 |
| ОБНОВЛЕНИЕ ФАЙЛА МАНИФЕСТА ДЛЯ СЕТЕВОЙ ПОТОКОВОЙ ПЕРЕДАЧИ КОДИРОВАННЫХ ВИДЕОДАННЫХ | 2011 |
|
RU2558615C2 |
| СОВМЕСТНАЯ РАБОТА МНОЖЕСТВЕННЫХ КЛИЕНТОВ ДЛЯ ОСУЩЕСТВЛЕНИЯ ДОСТУПА И ОБНОВЛЕНИЯ СТРУКТУРИРОВАННЫХ ЭЛЕМЕНТОВ ДАННЫХ | 2008 |
|
RU2504001C2 |
| СИСТЕМА И СПОСОБ ДЛЯ ОБНОВЛЕНИЯ ФАЙЛОВ С ИСПОЛЬЗОВАНИЕМ КОРРЕКТИРОВАНИЯ СЖАТЫМИ ИЗМЕНЕНИЯМИ | 2004 |
|
RU2367005C2 |
| ПЕРСОНАЛИЗИРОВАННЫЙ РЕПОЗИТОРИЙ ОБЪЕКТОВ | 2016 |
|
RU2696225C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ТРАНЗАКЦИОННЫХ ФАЙЛОВЫХ ОПЕРАЦИЙ ПО СЕТИ | 2004 |
|
RU2380749C2 |
| МОДУЛЬ ВИЗУАЛЬНОГО ПРОСМОТРА ЦЕПОЧКИ БЛОКОВ | 2018 |
|
RU2746584C2 |
| ПРОГРАММИРУЕМАЯ ОБЪЕКТНАЯ МОДЕЛЬ ДЛЯ ПОДДЕРЖКИ БИБЛИОТЕКИ ПРОСТРАНСТВ ИМЕН ИЛИ СХЕМ В ПРОГРАММНОМ ПРИЛОЖЕНИИ | 2004 |
|
RU2371759C2 |
| СПОСОБЫ, УСТРОЙСТВА И СИСТЕМЫ ДЛЯ СИГНАЛИЗАЦИИ ПРЕДВАРИТЕЛЬНЫХ ВЫБОРОВ | 2022 |
|
RU2830976C2 |
Изобретение относится к средствам синхронизации документов. Технический результат заключается в уменьшении объема изменяемой информации. Принимают первую версию и, по меньшей мере, одну ячейку, ассоциированную с документом, причем, по меньшей мере, одна ячейка содержит идентификатор ячейки, а идентификатор ячейки ассоциирован с первой версией, содержащей, по меньшей мере, один идентификатор первой версии, причем каждый из, по меньшей мере, одного идентификатора первой версии представляет состояние ячеек в момент времени, а область действия задает совокупность ячеек и версий, причем область действий включает в себя, по меньшей мере, один корневой объект. Принимают обновления для первого вычислительного устройства, причем обновление указывает на идентификатор обновленной версии, ассоциированный с каждой ячейкой, ассоциированной с документом. Сохраняют первую версию каждой ячейки, когда идентификатор первой версии ячейки соответствует идентификатору обновленной версии ячейки. Генерируют новую версию каждой ячейки, причем генерирование новой версии включает в себя назначение новой версии идентификатора новой версии, когда идентификатор первой версии ячейки не соответствует идентификатору обновленной версии ячейки. Стирают любую ячейку, на которую не было ссылки в корневых объектах, и синхронизируют документ путем замены ячеек на новую версию каждой ячейки. 3 н. и 9 з.п. ф-лы, 6 ил.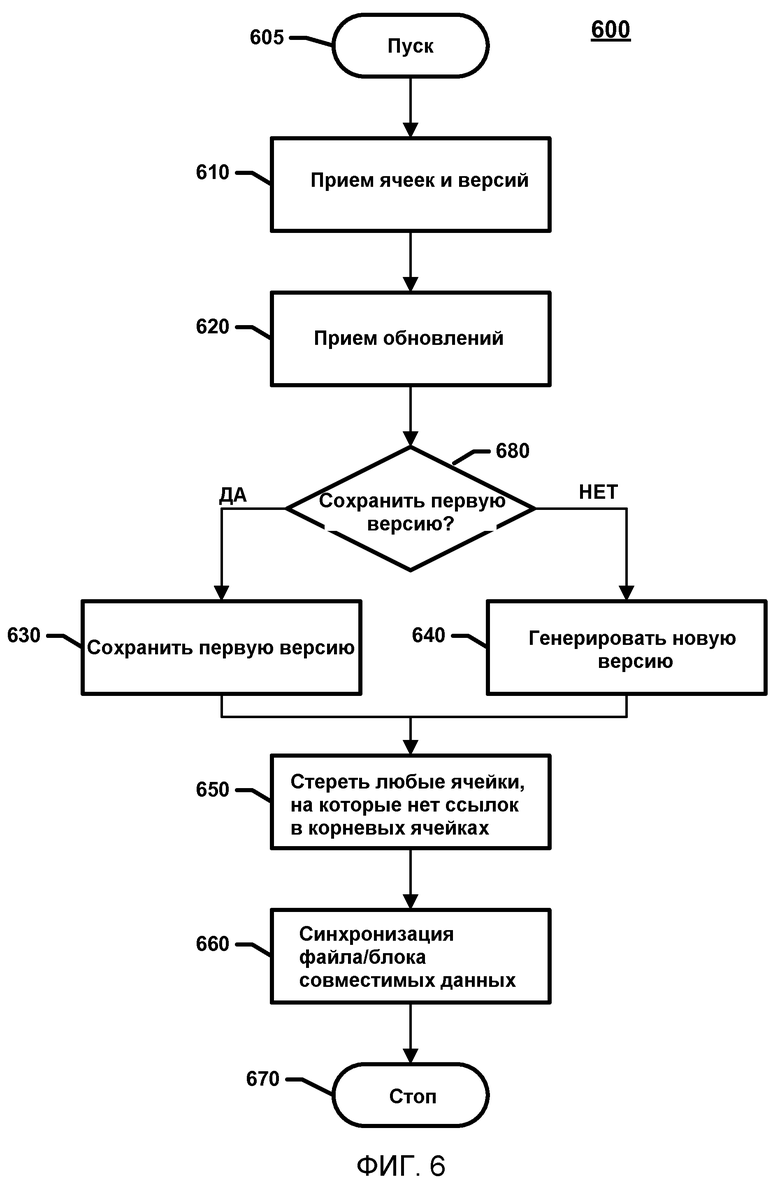
1. Способ синхронизации документа на первом вычислительном устройстве, причем документ разбивают на ячейки, а каждая ячейка задается, по меньшей мере, одним манифестом версии, причем способ включает в себя:
прием первой версии и, по меньшей мере, одной ячейки, ассоциированной с документом, причем, по меньшей мере, одна ячейка содержит идентификатор ячейки, содержащий пару глобально уникального идентификатора и целого числа, причем глобально уникальный идентификатор является глобально уникальным, а идентификатор ячейки ассоциирован с первой версией, содержащей, по меньшей мере, один идентификатор первой версии, причем каждый из, по меньшей мере, одного идентификатора первой версии представляет состояние ячеек в момент времени, а область действия задает совокупность ячеек и версий, и причем область действий включает в себя, по меньшей мере, один корневой объект, причем ячейки в пределах области действия доступны, по меньшей мере, через один корневой объект;
прием обновления для первого вычислительного устройства, причем обновление указывает на идентификатор обновленной версии, ассоциированный с каждой ячейкой, ассоциированной с документом;
сохранение первой версии каждой ячейки, когда идентификатор первой версии ячейки соответствует идентификатору обновленной версии ячейки;
генерирование новой версии каждой ячейки, причем генерирование новой версии включает в себя назначение новой версии идентификатора новой версии, когда идентификатор первой версии ячейки не соответствует идентификатору обновленной версии ячейки;
стирание любой ячейки, на которую не было ссылки в корневых объектах;
и
синхронизацию документа путем замены ячеек на новую версию каждой ячейки.
2. Способ по п.1, в котором генерирование новой версии включает в себя определение для каждой ячейки, соответствует ли идентификатор объекта каждого объекта в ячейке идентификатору обновленного объекта.
3. Способ по п.2, в котором идентификатор обновленного объекта задает манифест версии, задающий версию документа и включающий в себя, по меньшей мере, первую группу объектов, которая содержит, по меньшей мере, первый объект данных.
4. Способ по п.3, в котором манифест версии указывает на группу объектов, заданную в предыдущем манифесте версии.
5. Машиночитаемый запоминающий носитель, содержащий сохраненные на нем машиноисполняемые команды, которые при исполнении выполняют способ синхронизации документа на первом вычислительном устройстве, причем документ разбивается на ячейки, а каждая ячейка задается, по меньшей мере, одним манифестом версии, причем способ включает в себя:
прием первой версии и, по меньшей мере, одной ячейки, ассоциированной с документом, причем, по меньшей мере, одна ячейка содержит идентификатор ячейки, содержащий пару глобально уникального идентификатора и целого числа, причем глобально уникальный идентификатор является глобально уникальным, а идентификатор ячейки ассоциирован с первой версией, содержащей, по меньшей мере, один идентификатор первой версии, причем каждый из, по меньшей мере, одного идентификатора первой версии представляет состояние ячеек в момент времени, а область действия задает совокупность ячеек и версий, и причем область действий включает в себя, по меньшей мере, один корневой объект, причем ячейки в пределах области действия доступны, по меньшей мере, через один корневой объект;
прием обновления для первого вычислительного устройства, причем обновление указывает на идентификатор обновленной версии, ассоциированный с каждой ячейкой, ассоциированной с документом;
сохранение первой версии каждой ячейки, когда идентификатор первой версии ячейки соответствует идентификатору обновленной версии ячейки;
генерирование новой версии каждой ячейки, причем генерирование новой версии включает в себя назначение новой версии идентификатора новой версии, когда идентификатор первой версии ячейки не соответствует идентификатору обновленной версии ячейки;
стирание любой ячейки, на которую не было ссылки в корневых объектах; и
синхронизацию документа путем замены ячеек на новую версию каждой ячейки.
6. Машиночитаемый запоминающий носитель по п.5, в котором генерирование новой версии включает в себя определение для каждой ячейки, соответствует ли идентификатор объекта каждого объекта в ячейке идентификатору обновленного объекта.
7. Машиночитаемый запоминающий носитель по п.5, в котором идентификатор обновленного объекта задает манифест версии, задающий версию документа и включающий в себя, по меньшей мере, первую группу объектов, которая содержит, по меньшей мере, первый объект данных.
8. Машиночитаемый запоминающий носитель по п.5, в котором манифест версии указывает на группу объектов, заданную в предыдущем манифесте версии.
9. Компьютерная система для обновления множества имеющихся публикаций с использованием одного запроса на комплектование публикации, причем компьютерная система содержит:
по меньшей мере, один процессор; и
по меньшей мере, одно запоминающее устройство, соединенное с возможностью связи с, по меньшей мере, одним процессором и содержащее машиночитаемые команды, которые, при исполнении по меньшей мере одним процессором, выполняют способ синхронизации документа на первом вычислительном устройстве, причем документ разбивается на ячейки, а каждая ячейка задается, по меньшей мере, одним манифестом версии, причем способ включает в себя:
прием первой версии и, по меньшей мере, одной ячейки, ассоциированной с документом, причем, по меньшей мере, одна ячейка содержит идентификатор ячейки, содержащий пару глобально уникального идентификатора и целого числа, причем глобально уникальный идентификатор является глобально уникальным, а идентификатор ячейки ассоциирован с первой версией, содержащей, по меньшей мере, один идентификатор первой версии, причем каждый из, по меньшей мере, одного идентификатора первой версии
представляет состояние ячеек в момент времени, а область действия задает совокупность ячеек и версий, и причем область действий включает в себя, по меньшей мере, один корневой объект, причем ячейки в пределах области действия доступны, по меньшей мере, через один корневой объект;
прием обновления для первого вычислительного устройства, причем обновление указывает на идентификатор обновленной версии, ассоциированный с каждой ячейкой, ассоциированной с документом;
сохранение первой версии каждой ячейки, когда идентификатор первой версии ячейки соответствует идентификатору обновленной версии ячейки;
генерирование новой версии каждой ячейки, причем генерирование новой версии включает в себя назначение новой версии идентификатора новой версии, когда идентификатор первой версии ячейки не соответствует идентификатору обновленной версии ячейки;
стирание любой ячейки, на которую не было ссылки в корневых объектах; и
синхронизацию документа путем замены ячеек на новую версию каждой ячейки.
10. Компьютерная система по п.9, в которой генерирование новой версии включает в себя определение для каждой ячейки, соответствует ли идентификатор объекта каждого объекта в ячейке идентификатору обновленного объекта.
11. Компьютерная система по п.9, в которой идентификатор обновленного объекта задает манифест версии, задающий версию документа и включающий в себя, по меньшей мере, первую группу объектов, которая содержит, по меньшей мере, первый объект данных.
12. Компьютерная система по п.9, в которой манифест версии указывает на группу объектов, заданную в предыдущем манифесте версии.
| US 7325202 В2, 29.01.2008 | |||
| US 7322012 В2, 22.01.2008 | |||
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| US 5774868, 30.06.1998 | |||
| СПОСОБ И УСТРОЙСТВО, ПРЕДНАЗНАЧЕННЫЕ ДЛЯ ДВУХЭТАПНОГО ФИКСИРОВАНИЯ ИЗМЕНЕНИЙ ПРИ РАСПРЕДЕЛЕНИИ ДАННЫХ В WEB-ФЕРМЕ | 2003 |
|
RU2314547C2 |

