Область техники
Настоящее изобретение относится к системам обеспечения отказоустойчивой работы и, более конкретно, к построению высоконадежных кластеров.
Уровень техники
В настоящее время для осуществления отказоустойчивой работы компьютерной системы, а также для решения сложных вычислительных задач используют технологии кластеризации. В первую очередь, популярность кластеров обусловлена постоянно увеличивающимся количеством задач, а также возрастающей необходимостью их выполнения в режиме 24/7 (двадцать четыре часа в сутки, семь дней в неделю). Для целей данного описания под кластером подразумевается группа компьютеров, в том числе и серверов, объединенных физически и/или логически, представляющая собой с точки зрения пользователя единый ресурс.
Для обеспечения отказоустойчивости в кластерах существуют системы перераспределения задач, в которых учитывается работоспособность узлов - компьютеров, входящих в состав кластера. В большинстве современных систем для перераспределения задач между работоспособными узлами кластера используются менеджеры задач. В частности, в патенте US 7661015B2 рассматривается система исполнения заданий по расписанию в кластере из нескольких серверов. В предлагаемом решении существует центральный менеджер, а также агенты, сообщающие о состоянии серверов центральному менеджеру. Каждая задача назначается на определенный узел, в случае невыполнения задачи менеджер переназначает ее на другого представителя кластера. В патенте US 5987621A описывается механизм отказоустойчивой работы файловых серверов, в котором ведущий сервер периодически опрашивает другие узлы кластера с целью получения информации об их работоспособности, а в случае обнаружения неработоспособного сервера определяется набор задач, которые должны быть переданы на выполнение работоспособному узлу кластера. Схожие идеи описаны и в заявке WO 2007112245A2. В патенте US 4980857A рассматривается система работы в распределенной среде вычислений. Здесь предлагается система, включающая несколько вычислительных узлов с контроллерами, устройства обеспечения отказоустойчивости и менеджер задач. Каждому узлу в предлагаемом решении назначается список задач, которые он должен выполнить. Состояние каждого узла периодически проверяется, также узел может посылать сообщения об ошибках всем членам кластера, на основании которых определяются параметры для рассматриваемого сервера. В случае выхода из строя какого-либо сервера менеджер задач перераспределяет задачи между оставшимися узлами кластера.
Несмотря на существующие технологии перераспределения задач при обнаружении неработоспособного узла кластера возникает проблема обеспечения отказоустойчивости при неработоспособности менеджера распределения задач, а также при отсутствии активного менеджера распределения задач в кластере, узлы которого содержат функции менеджера. Например, в патенте US 7661015B2 предлагается отслеживать состояние менеджера, а в случае его неработоспособности выбирать нового менеджера из работоспособных узлов кластера. При этом стоит отметить, что процесс замены менеджера может занять некоторое время, что является критичным при работе с большим количеством задач, которые нужно выполнять в точно указанное время.
Также при построении кластеров большое внимание уделяется технологиям оповещения о неработоспособности узлов. В существующих системах, например в публикациях US 20100211829A1 и US 7451359B1, для определения статуса работоспособности серверы периодически обновляют свой статус с указанием временной метки данного обновления. Однако для использования данного подхода при работе с периодическими задачами, время выполнения которых относительно невелико, необходимо повышать точность синхронизации часов внутри кластера, что требует дополнительных ресурсов и затрат. Для решения подобной проблемы в патентах US 5987621A и US 4980857A описывается способ, в котором с течением времени каждый узел кластера посылает сигналы другим узлам для демонстрации того, что он находится в работоспособном состоянии. При этом стоит отметить, что при использовании данного решения существенно возрастает частота коммуникаций между узлами кластера даже при незначительном увеличении частоты обновления статуса и возрастании количества узлов кластера, что может привести к задержке распространения сигнала и, следовательно, к неправильной интерпретации статуса узла кластера.
Таким образом, требуется получить отказоустойчивую систему выполнения задач по расписанию в распределенных средах, не зависящую от работоспособности центрального менеджера распределения задач, а также легко масштабируемую без потерь точности и производительности.
Анализ предшествующего уровня техники и возможностей, позволяет получить новый результат, а именно способ и систему отказоустойчивого выполнения задач по расписанию в распределенных средах.
Сущность изобретения
Настоящее изобретение предназначено для отказоустойчивого выполнения задач по расписанию в распределенных средах.
Техническим результатом является повышение отказоустойчивости при выполнении задач в распределенных средах, который достигается путем использования меток работоспособности и выбора задач с учетом параметров предполагаемого исполнителя. Для целей данного описания под распределенной средой будем понимать систему, включающую, по крайней мере, два компьютера, объединенных физически и/или логически.
В рамках одного из вариантов реализации предлагается способ отказоустойчивого выполнения задач в системах, состоящих, по крайней мере, из двух компьютеров, в котором: по крайней мере, для одного компьютера обновляют метку работоспособности, для этого
i) находят максимум для значений меток работоспособности среди всех компьютеров системы;
ii) увеличивают значение текущей метки работоспособности, по крайней мере, одного компьютера;
iii) выбирают максимум из значений, полученных на этапах a) i и a) ii;
обнаруживают, по крайней мере, один компьютер, находящийся в неработоспособном состоянии, путем сравнения с заранее заданным пороговым значением разницы между величиной, полученной на первом шаге, и меткой работоспособности, по крайней мере, одного другого компьютера системы; по крайней мере для одного обнаруженного неработоспособного узла формируют список задач, исполнителем которых являлся упомянутый неработоспособный узел; выбирают, по крайней мере, одну задачу из сформированного списка задач путем сопоставления параметров, по крайней мере, одного работоспособного компьютера и, по крайней мере, одной задачи из списка задач, назначенных на неработоспособные компьютеры; выполняют, по крайней мере, одну выбранную задачу с целью обеспечения отказоустойчивого выполнения задач в системах, состоящих, по крайней мере, из двух компьютеров.
В одном из частных вариантов реализации значение метки работоспособности не зависит напрямую от текущего времени.
В еще одном из частных вариантов реализации значение метки работоспособности принадлежит упорядоченному множеству, на котором определена операция сложения.
В другом частном варианте реализации шаги а)-е) выполняют с заранее заданной периодичностью.
В одном из частных вариантов реализации период зависит от частоты и длительности выполнения задач для рассматриваемой системы, состоящей, по крайней мере, из двух компьютеров.
В еще одном из частных вариантов реализации компьютер считается неработоспособным, если разница между величиной, полученной на шаге а), и меткой работоспособности упомянутого компьютера системы превышает заранее заданное пороговое значение.
В другом частном варианте реализации дополнительно при обнаружении неработоспособных компьютеров определяют множество компьютеров с повышенным приоритетом проверки работоспособности при следующей итерации способа путем сравнения с заранее заданным вторым пороговым значением разницы между величиной, полученной на шаге а), и меткой работоспособности, по крайней мере, одного другого компьютера системы.
В одном из частных вариантов реализации при обнаружении неработоспособных компьютеров учитываются только компьютеры с повышенным приоритетом проверки работоспособности.
В еще одном из частных вариантов реализации сопоставление параметров компьютера и задачи осуществляется с использованием правил нечеткой логики.
В одном из вариантов реализации предлагается система отказоустойчивого выполнения задач, содержащая по крайней мере два компьютера, каждый из которых связан со следующими объектами: средство обновления метки работоспособности, которое связано с базой данных для сохранения обновленной метки работоспособности, и со средством обнаружения неработоспособных компьютеров, а также предназначенное для обновления метки работоспособности путем:
i) нахождения максимума для значений меток работоспособности среди всех компьютеров системы;
ii) увеличения значения текущей метки работоспособности, по крайней мере, одного компьютера;
iii) выбора максимума из значений, полученных на этапах i и ii; упомянутое средство обнаружения неработоспособных компьютеров путем сравнения разницы между значением, полученным от средства обновления метки работоспособности, и меткой работоспособности, по крайней мере, одного другого компьютера системы с заранее заданным пороговым значением, которое также связано со средством формирования списка задач и с упомянутой базой данных; упомянутое средство формирования списка задач, предназначенное для выбора, по крайней мере, одной задачи, исполнителем которой назначен неработоспособный компьютер, которое также связано со средством выбора задач и с упомянутой базой данных; упомянутое средство выбора задач, предназначенное для выбора для дальнейшего выполнения, по крайней мере, одной задачи из сформированного списка задач путем сопоставления параметров, по крайней мере, одного компьютера и, по крайней мере, одной задачи из сформированного списка задач, которое также связано со средством выполнения задач и с упомянутой базой данных; упомянутая база данных, предназначенная для сохранения информации о параметрах, метках и статусах работоспособности, по крайней мере, одного компьютера системы, а также информации, по крайней мере, об одной задаче, выполняющейся в системе, включающей, по крайней мере, два компьютера; упомянутое средство выполнения задач, выбранных с помощью средства выбора задач, с целью обеспечения отказоустойчивого выполнения задач.
В одном из частных вариантов реализации значение метки работоспособности не зависит напрямую от текущего времени.
В еще одном из частных вариантов реализации значение метки работоспособности принадлежит упорядоченному множеству, на котором определена операция сложения.
В другом частном варианте реализации компьютер считается неработоспособным, если разница между его текущей меткой работоспособности и максимальной меткой работоспособности для кластера превышает заранее заданное пороговое значение
В одном из частных вариантов реализации средство обнаружения неработоспособных компьютеров дополнительно определяет множество компьютеров с повышенным приоритетом проверки работоспособности при следующей итерации путем сравнения системы с заранее заданным вторым пороговым значением разницы между максимальной меткой работоспособности для кластера и меткой работоспособности, по крайней мере, одного компьютера.
В еще одном из частных вариантов реализации при обнаружении неработоспособных компьютеров учитываются только компьютеры с повышенным приоритетом проверки работоспособности.
В другом частном варианте реализации сопоставление параметров компьютера и задачи осуществляется с использованием правил нечеткой логики.
Дополнительные преимущества изобретения будут раскрыты далее в ходе описания вариантов реализации изобретения. Также отметим, что все материалы данного описания направлены на детальное понимание того технического предложения, которое изложено в формуле изобретения.
Краткое описание чертежей
Дополнительные цели, признаки и преимущества настоящего изобретения будут раскрыты дальше в описании со ссылками на прилагаемые чертежи.
Фиг.1 представляет собой предлагаемую систему отказоустойчивого выполнения задач по расписанию в распределенных средах.
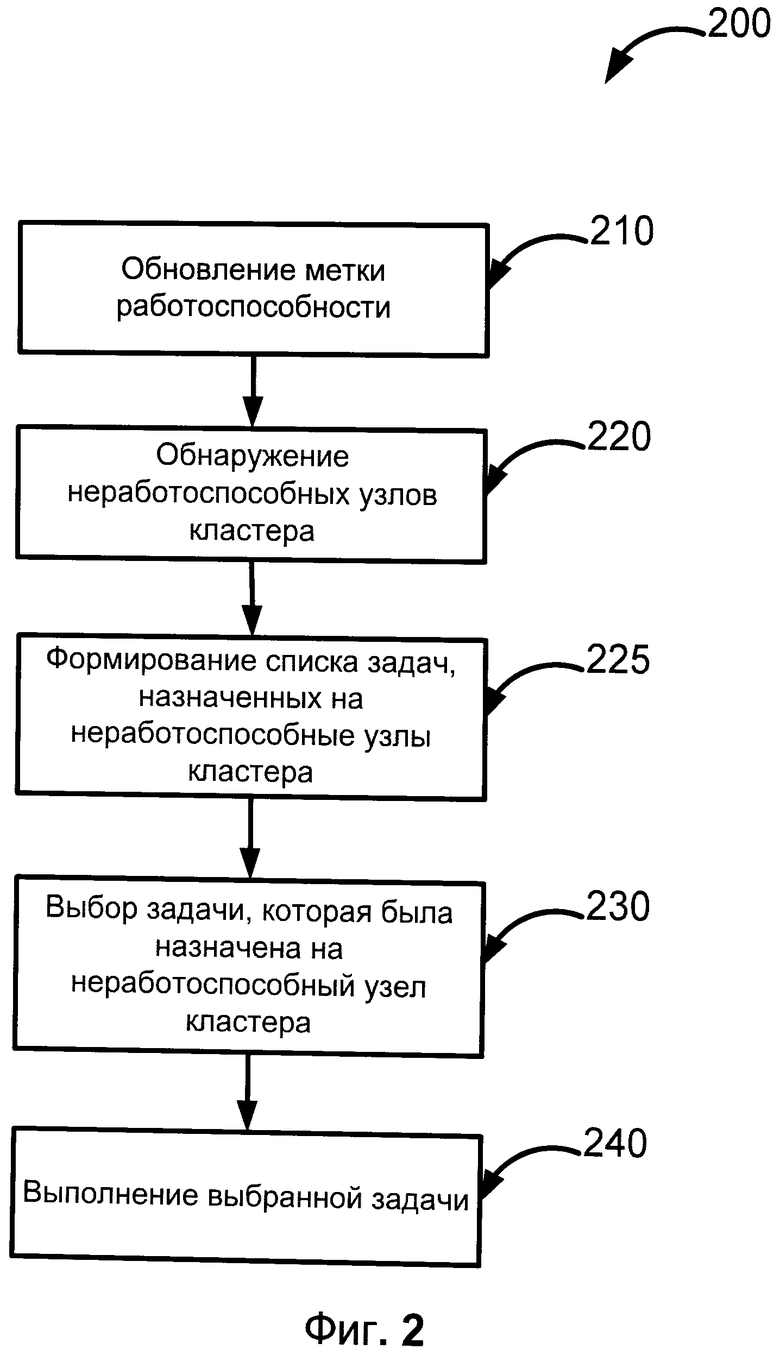
Фиг.2 иллюстрирует предлагаемый способ отказоустойчивого выполнения задач по расписанию в распределенных средах, реализованный с помощью системы, изображенной на Фиг.1.
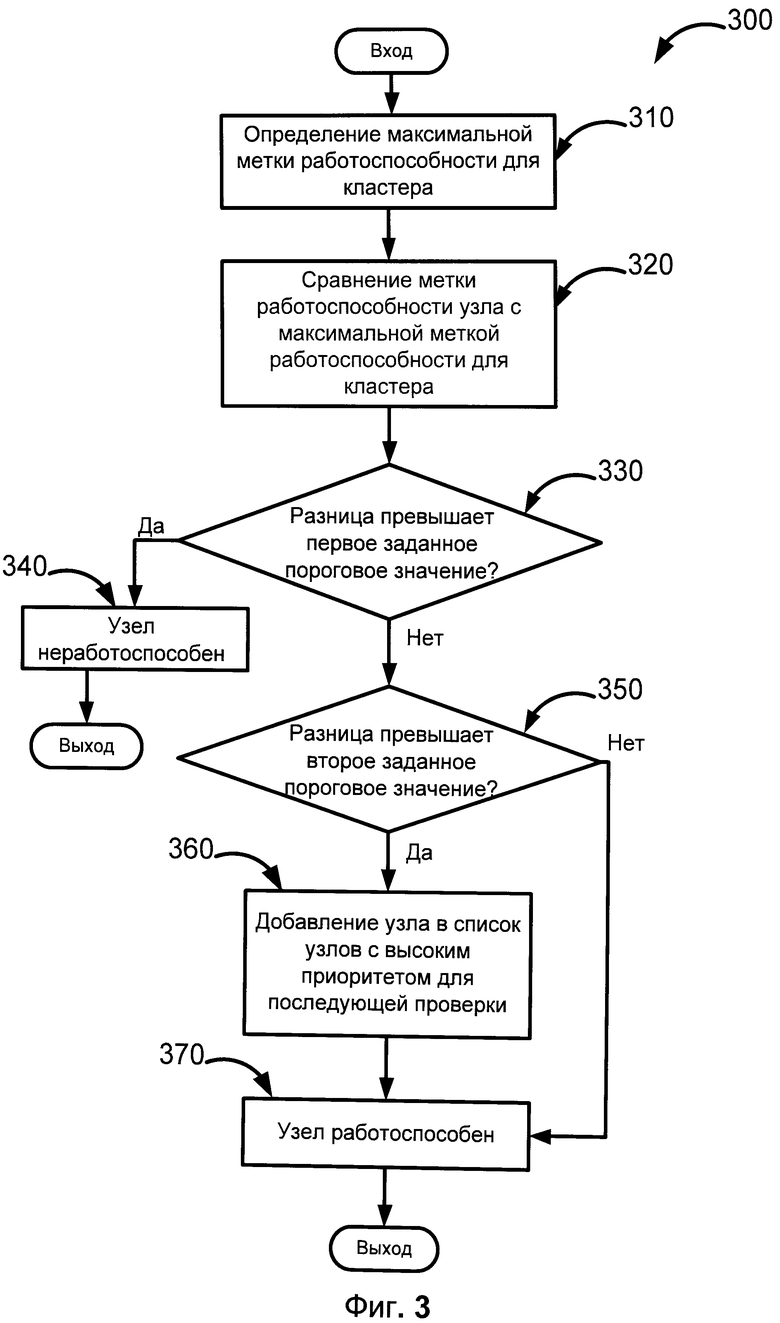
Фиг.3 демонстрирует один из вариантов обнаружения неработоспособных узлов кластера.
Фиг.4 представляет пример выбора задачи для выполнения.
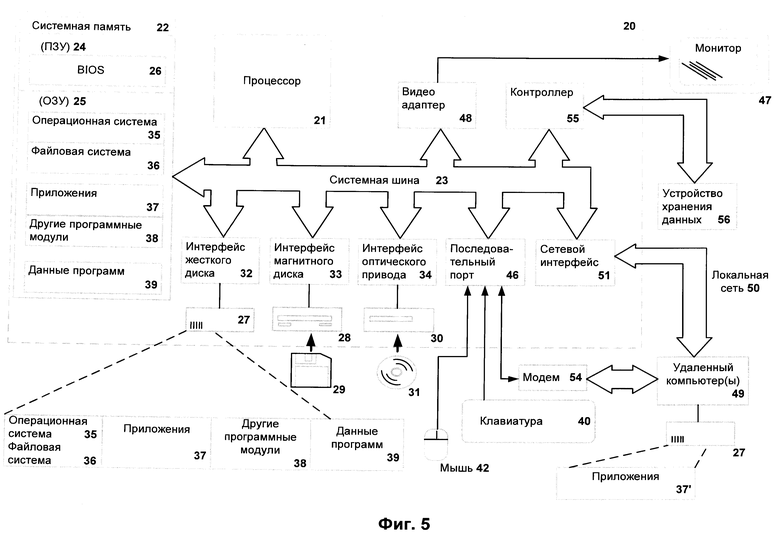
Фиг.5 является примером компьютерной системы общего назначения.
Подробное описание предпочтительных вариантов осуществления
Объекты и признаки настоящего изобретения, способы для достижения этих признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Сущность, приведенная в описании, является ничем иным, как конкретными деталями, обеспеченными для помощи специалисту в области техники в исчерпывающем понимании изобретения, и настоящее изобретение определяется только в объеме приложенной формулы.
В область решаемых задач входит обеспечение отказоустойчивого выполнения задач по расписанию в распределенных средах.
Основные преимущества настоящего решения вытекают из применения меток работоспособности для определения статуса узлов кластера, а также из децентрализованного механизма назначения задач, текущий исполнитель которых на данный момент является неработоспособным.
Фиг.1 иллюстрирует предлагаемую систему 100 отказоустойчивого выполнения задач по расписанию в распределенных средах, включающую средство обновления метки работоспособности 110, соединенное с базой данных 105 и средством обнаружения неработоспособных узлов 120, которое также взаимодействует с упомянутой базой данных 105, а также со средством формирования списка задач 125, которое передает данные о задачах средству выбора задач 130, после чего выбранные задачи поступают на вход средству выполнения задач 140. Стоит отметить, что в некоторых вариантах реализации средство выполнения задач 140 также может получать описатель задач из базы данных 105 для корректного исполнения каждой задачи.
Стоит отметить, что все вышеуказанные средства могут быть воплощены в жизнь различными способами, в том числе в виде отдельно стоящего устройства или группы устройств, в виде программного обеспечения, установленного на одном или нескольких устройствах, а также в виде программно-аппаратного комплекса. В предпочтительных вариантах реализации предлагаемого изобретения база данных 105 является общей для всех узлов кластера, а средство обновления метки работоспособности 110, средство обнаружения неработоспособных узлов 120, средство формирования списка задач 125, средство выбора задач 130 и средство выполнения задач 140 установлены на каждом из узлов кластера.
Также в некоторых вариантах воплощения предлагаемого решения копии базы данных 105 распределены по узлам кластера для обеспечения отказоустойчивой работы в случае возникновения неисправностей в самой базе данных 105, то есть данные из базы 105 могут быть восстановлены в любой момент времени при наличии хотя бы одного работоспособного узла кластера. Обеспечение синхронизации между хранилищами осуществляется с использованием любых из известных способов, например, описанными в публикациях US 8055613 B1, US 7366859 B2, US 7958199 B2.
Предварительно средство обновления метки работоспособности 110 обновляет метку работоспособности (для краткости метку) для узла кластера, который обратился к средству обновления метки работоспособности 110. Обновление метки осуществляется следующим образом:
1) к текущей метке работоспособности упомянутого узла кластера прибавляют единицу;
2) с использованием значений меток работоспособности для всех узлов кластера, сохраненных в базе данных 105, определяют максимум метки работоспособности по всем узлам кластера;
3) выбирают максимальное из значений, полученных на этапах 1) и 2). Далее будем считать это значение максимальной меткой работоспособности для кластера.
Новое значение метки работоспособности для данного узла сохраняется в базе данных 105. Здесь и далее под меткой работоспособности понимается значение, напрямую независящее от текущего времени, смысл которого заключается в демонстрации относительной величины отставания узла кластера от остальных узлов кластера при обновлении метки работоспособности. Указанная величина отставания при обновлении метки работоспособности в некоторых случаях может интерпретироваться как неработоспособность узла кластера. В частности, в качестве указанной метки работоспособности может рассматриваться элемент любого упорядоченного множества, в том числе конечного, на котором задана операция сложения. В одном из вариантов реализации может быть использовано множество целых чисел. Аналогичным образом все работоспособные узлы кластера периодически обновляют соответствующую метку путем обращения к средству обновления метки работоспособности 110. В предпочтительном варианте реализации периодичность обновления метки работоспособности одинакова для всех узлов кластера.
Стоит отметить, что средство обновления метки работоспособности 110 может быть реализовано различными способами. В некоторых вариантах исполнения изобретения средство обновления метки работоспособности 110 представляет собой программное обеспечение, установленное на каждом из узлов кластера и которое периодически обновляет соответствующую метку работоспособности. В других вариантах работы рассматриваемого изобретения средство обновления метки работоспособности 110 представляет собой отдельно стоящее устройство или группу устройств, к которому работоспособные узлы кластера обращаются с заданной периодичностью для обновления метки работоспособности.
Периодичность обновления метки работоспособности в некоторых вариантах реализации зависит от длительности и частоты выполнения задач, характерных для рассматриваемого кластера в целом или его отдельных узлов. Например, для адаптивной настройки может рассматриваться среднее время, а также средняя частота выполнения задач для данного кластера. То есть если по некоторым причинам указанное время увеличивается или уменьшается, тогда частота обновления метки работоспособности либо уменьшается, либо увеличивается соответственно. Для оценки времени выполнения той или иной задачи могут быть использованы различные методики, например, учитывающие статистику времени выполнения задачи на различных узлах кластера. Также время выполнения задачи может определяться с использованием информации о среднем времени выполнения аналогичных задач на аналогичном оборудовании. Данные о частоте выполнения задач для кластера могут быть получены из базы данных 105, в которой сохраняется информация о выполняемых задачах и о расписании их выполнения.
Далее информацию о максимальной метке работоспособности передается средству обнаружения неработоспособных узлов 120. Обнаружение неработоспособных узлов осуществляется путем сравнения максимальной метки работоспособности для кластера с текущими метками работоспособности всех узлов кластера. Если разница между текущей меткой работоспособности узла и максимальной меткой работоспособности для кластера превышает заранее заданное (первое) пороговое значение, тогда данный узел считается неработоспособным. В базе данных 105 может сохраняться информация о статусе работоспособности узла кластера для использования на последующих этапах. Более подробно способ обнаружения неработоспособных узлов кластера рассмотрен на Фиг.3.
Также в некоторых вариантах исполнения изобретения средство обнаружения неработоспособных узлов 120 при определении неработоспособных узлов может учитывать информацию с предыдущего шага. Таким образом, если ранее было выяснено, что разница между текущей меткой работоспособности узла и максимальной меткой работоспособности для кластера не превышает заданное первое пороговое значение, однако близко к нему, то есть превышает заранее заданное второе пороговое значение, тогда работоспособность этих узлов может быть определена в первую очередь. Стоит отметить, что режим определения неработоспособных узлов может изменяться в зависимости от целей конкретной реализации предлагаемого изобретения. В некоторых случаях, когда не имеет значения, какую из задач нужно выполнить в первую очередь, целесообразно прекращать поиск неработоспособных узлов при нахождении первого неработоспособного узла. В других вариантах реализации требуется находить все неработоспособные узлы кластера каждый раз.
Также возможны комбинации, в которых, например, первоначально определяются все неработоспособные узлы, а также близкие к данному состоянию. Затем в следующий раз статус работоспособности проверяется только для тех узлов, которые в последний раз были близки к неработоспособному состоянию. Перепроверка состояния всех узлов кластера может осуществляется периодически с периодом, например, кратным периоду обновления метки работоспособности и разнице между первым и вторым пороговым значением.
Стоит отметить, что при наличии нескольких копий базы данных 105, распределенных по узлам кластера, для которых периодически запускается процесс синхронизации копий между собой и с центральной базой данных 105, для корректного определения первого и второго пороговых значений необходимо учитывать периодичность синхронизации. В предпочтительном варианте реализации период синхронизации копий базы данных 105 с центральной базой данных 105 и пороговые значения для определения неработоспособных узлов являются взаимно зависимыми. Например, если известно, что максимально допустимая задержка при внесении изменений в копию базы данных 105 на одном из узлов кластера и их обнаружением на другом узле кластера составляет N единиц времени, тогда первое пороговое значение, используемое для определения работоспособности узлов кластера, должно, по крайней мере, превышать N+1. Аналогично и наоборот - если первое пороговое значение равно М, тогда синхронизация копий базы данных 105 должна осуществляться, по крайней мере, каждые М-1 единицы времени либо чаще. Здесь под единицей времени подразумевается периодичность обновления метки работоспособности.
После обнаружения неработоспособных узлов средство формирования списка задач 125 выбирает те задачи из базы данных 105, которые были назначены на неработоспособные узлы кластера, либо для которых не указан исполнитель. Полный список задач для рассматриваемого кластера с информацией об исполнителях и периодичности выполнения хранится в базе данных 105. Далее средство выбора задач 130 осуществляет выбор, по крайней мере, одной задачи из сформированного списка, которую требуется выполнить. Выбор задачи может быть реализован различными способами. В частности, может учитываться ряд факторов, например, приоритет задачи, ресурсы, необходимые для выполнения задачи, примерное время выполнения задачи на компьютере с аналогичной конфигурацией и так далее. Более подробно механизм выбора задачи описан на Фиг.4. Стоит отметить, что выбранная задача необязательно должна начать выполняться сразу, в общем случае запуск задачи на выполнение осуществляется в соответствии с заранее заданным расписанием для данной задачи.
Далее с помощью средства выполнения задач 140 осуществляется выполнение выбранных задач. Для определения порядка действий при выполнении некоторой задачи в базе данных 105 сохраняется описатель, с помощью которого средство выполнения задач 140 распознает, каким образом выполнять то или иное действие. Описатель, в частности, может быть представлен в виде сценария, описанного, в том числе с использованием технологий псевдокода, объектно-ориентированных либо декларативных языков программирования. Здесь под псевдокодом подразумевается набор инструкций в определенном порядке, которые должны быть выполнены для достижения результата, под декларативным языком программирования понимается указание того, какой результат должен быть достигнут без упоминания требуемой последовательности действий. В одном из частных вариантов реализации описатель представляет собой инструкцию или набор инструкций, одинаково трактуемых всеми узлами кластера, например, вида «Создать отчет о работе системы».
В предпочтительных вариантах работы предлагаемой системы 100 каждый узел кластера периодически обновляет свою метку работоспособности с помощью средства обновления метки работоспособности 110 и сохраняет ее в базу данных 105, к которой имеют доступ все узлы кластера, затем определяет неработоспособные узлы при использовании средства обнаружения неработоспособных узлов 120 на основании значений меток работоспособности узлов кластера и собственной метки работоспособности, после находит задачи, которые должны быть выполнены неработоспособными узлами кластера, а также с помощью средства выбора задач 130 выбирает те из них, которые будут переназначены на него, а в дальнейшем, воспользовавшись средством выполнения задач 140, приступает к выполнению выбранных задач в соответствии с сохраненными в базе данных 105 инструкциями выполнения задачи.
Стоит отметить, что в некоторых вариантах реализации работоспособный узел 1 кластера может назначить часть своих задач другому работоспособному узлу 2 кластера. Данное действие необходимо в том случае, если узел 1 является работоспособным, однако ресурсы, которыми он располагает, недостаточны для корректного выполнения заданной задачи. Переназначение задачи может осуществляться с использованием описанных ранее механизмов, а также с учетом описания к Фиг.4. Также в других вариантах реализации узел 2 может выбираться произвольно из списка работоспособных узлов кластера. Для исключения возможного циклического переназначения задачи в случае отсутствия в кластере узла, который способен выполнить данную задачу, с задачей ассоциируется список узлов, которые не смогли ее выполнить. При этом указанный список обнуляется в случае успешного выполнения рассматриваемой задачи.
В частных вариантах реализации рассматриваемого изобретения узел 1 также может отказаться от выполнения некоторой задачи при отсутствии необходимых ресурсов для ее выполнения без непосредственного переназначения задачи. В таком случае узел 1 обнуляет поле в базе данных 105, соответствующее информации об исполнителе данной задачи. Исполнитель такой задачи будет определен на последующих итерациях с помощью средства формирования списка задач 125.
Таким образом, предлагаемое решение позволяет выполнять задачи в отказоустойчивом режиме, а также сокращает количество и частоту сетевых взаимодействий при определении статуса работоспособности узла кластера.
Фиг.2 представляет собой способ 200 отказоустойчивого выполнения задач по расписанию в распределенных средах, реализованный с помощью системы 100. Стоит отметить, что существуют различные варианты выполнения рассматриваемого способа, в частности, нижеописанные шаги могут быть выполнены на отдельно стоящем устройстве или группе устройств, с помощью соответствующего программного обеспечения, а также при использовании программно-аппаратного комплекса.
Предварительно на шаге 210 осуществляется обновление метки работоспособности (для краткости метки) с помощью средства обновления метки работоспособности 110. Процесс обновления метки работоспособности более детально описан выше при рассмотрении режимов работы средства обновления метки работоспособности 110.
Стоит отметить, что в предпочтительных вариантах реализации все шаги рассматриваемого способа выполняются на соответствующем узле кластера.
Далее на шаге 220 происходит определение неработоспособных узлов при помощи средства обнаружения неработоспособных узлов 120. Данное действие осуществляется путем сравнения максимальной метки работоспособности для кластера с метками работоспособности, по крайней мере, одного узла кластера. Если разница между текущей меткой работоспособности узла и максимальной меткой работоспособности для кластера превышает заранее заданное (первое) пороговое значение, тогда данный узел считается неработоспособным. В базе данных 105 может сохраняться информация о статусе работоспособности узла кластера для использования на последующих этапах. Более подробно способ обнаружения неработоспособных узлов кластера рассмотрен на Фиг.3. Стоит отметить, что в некоторых вариантах реализации в качестве максимальной метки работоспособности может рассматриваться обновленная метка рассматриваемого узла кластера. Различные варианты исполнения указанного шага аналогичны описанным выше в ходе рассмотрения вариантов работы средства обнаружения неработоспособных улов 120.
После определения неработоспособных узлов на этапе 225 с помощью средства 125 формируется список задач, назначенных на неработоспособные узлы кластера. Полный список задач для рассматриваемого кластера с информацией об исполнителях и периодичности выполнения хранится в базе данных 105. Указанный список, например, формируется с использованием стандартных механизмов для современных систем управления базами данных, таких как, Oracle 11g, Microsoft SQL Server 2008 и так далее.
Стоит отметить, что для хранения информации о метках работоспособности узлов кластера достаточно обеспечить возможность записи в некоторое поле базы данных одновременно с операцией чтения из этого поля, при этом допустимо не оговаривать результат одновременной записи в одно поле. В то же время для хранения информации о задачах, параметрах узлов кластера, а также других вспомогательных данных необходимо использовать реляционные системы управления базами данных. Таким образом, в некоторых частных вариантах реализации информацию о метках работоспособности целесообразно хранить в базе данных, отличной от той, в которой содержатся данные о задачах и параметрах узлов кластера.
Затем на шаге 230 с помощью средства выбора задач 130 осуществляется выбор, по крайней мере, одной задачи из сформированного списка. Выбор задачи может быть реализован различными способами. В частности, может учитываться целый ряд факторов, например приоритет задачи, ресурсы, необходимые для выполнения задачи, примерное время выполнения задачи на компьютере с аналогичной конфигурацией и так далее. Более подробно механизм выбора задачи описан на Фиг.4.
Далее на шаге 240 с помощью средства выполнения задач 140 осуществляется выполнение выбранных задач. Для определения порядка действий при выполнении задачи в базе данных 105 сохраняется описатель, с помощью которого средство выполнения задач 140 распознает каким образом осуществлять то или иное действие. Более подробно указанное действие описано выше со ссылкой на средство выполнения задач 140.
В предпочтительном варианте работы предлагаемого способа 200 каждый узел кластера периодически обновляется свою метку работоспособности с помощью средства обновления метки работоспособности 110 и сохраняет ее в базе данных 105, к которой имеют доступ все участники кластера, затем определяет неработоспособные узлы при использовании средства обнаружения неработоспособных узлов 120 на основании значений меток работоспособности узлов кластера и максимальной метки работоспособности для кластера, после находит задачи, которые должны быть выполнены неработоспособными узлами кластера с помощью средства формирования списка задач 125, а также с помощью средства выбора задач 130 выбирает те из них, которые будут переназначены на него, а в дальнейшем, воспользовавшись средством выполнения задач 140, приступает к выполнению выбранных задач в соответствии с сохраненными в базе данных 105 инструкциями выполнения задачи.
Фиг.3 представляет собой способ 300 определения неработоспособных узлов кластера с использованием меток работоспособности. На первом этапе 310 осуществляется определение максимальной метки работоспособности для кластера. Далее на шаге 320 происходит сравнение найденной максимальной метки с аналогичной меткой для каждого узла кластера. На этапе 330 осуществляется оценка разницы между максимальной меткой работоспособности для кластера и меткой работоспособности некоторого узла кластера. В случае, если разница между рассматриваемыми метками превышает заранее заданное первое пороговое значение, тогда узел считается неработоспособным 340. Иначе, если разница не превышает первое пороговое значение, но превышает второе пороговое значение 350, тогда считаем, что узел находится в пограничном состоянии и его целесообразно добавить на этапе 360 в список узлов с повышенным приоритетом при последующем обнаружении неработоспособных узлов. Таким образом, при следующей итерации проверки будут рассматриваться метки узлов с более высоким приоритетом.
Полная проверка работоспособности всех узлов кластера осуществляется периодически, при этом период должен быть кратен разнице между первым и втором пороговыми значениями, а также периоду обновления метки работоспособности. После добавления узла в список узлов с повышенным приоритетом для последующей проверки, данный узел считается работоспособным на этапе 370. Также узел считается работоспособным на шаге 370 в случае, если разница не превышает ни первое пороговое значение, ни второе пороговое значение. При повторной проверке состояния работоспособности узлов кластера проверяется состояние узлов, которые предварительно были добавлены в список с повышенным приоритетом. Таким образом, если среди указанного списка нет неработоспособных узлов, то остальные узлы находятся в работоспособном состоянии, либо их неработоспособность некритична на данном этапе.
Стоит отметить, что в некоторых вариантах реализации отсутствуют шаги 350 и 360, то есть разница сравнивается только с первым пороговым значением, а решение о работоспособности выносится, если разница не превышает заданное первое пороговое значение.
Фиг.4 иллюстрирует пример выбора задачи либо группы задач, назначенных на неработоспособные на данный момент узлы кластера и которые нужно перераспределить между работоспособными узлами. При выборе задачи или группы задач могут быть использованы различные подходы. В некоторых вариантах реализации все задачи одного из неработоспособных узлов переназначаются на работоспособный узел, который первым обнаружил неработоспособное состояние данного узла. В других вариантах реализации задачи выбираются по одной в произвольном порядке. В иных частных воплощениях изобретения задачи выбираются в соответствии с различными параметрами, как изображено на Фиг.4, например, учитывая степень использования ресурсов компьютера и каналов связи при выполнении задачи, предполагаемое время выполнения, приоритет и так далее.
Для выбора задачи с учетом множества параметров информация о задачах сохраняется в базе данных в виде, изображенном на Фиг.4. Значение параметров для задачи может быть получено с использование экспертных оценок, а также путем анализа статистических данных. В частном варианте реализации значения параметров представляют собой лингвистические переменные, а для более качественного выбора задачи может использоваться система нечеткой логики.
Также оцениваются характеристики самого узла сети, для того чтобы определить, какие именно задачи могут быть выполнены данным элементом кластера. Стоит отметить, что в связи с относительным постоянством конфигурации элементов кластера, данные о характеристиках компьютеров могут также быть сохранены в базе данных для обеспечения быстроты выбора задачи. В частности, для узлов кластера оцениваются параметры, аналогичные показателям для задачи. Например, в соответствии с Фиг.4, в качестве параметров для узлов кластера могут быть рассмотрены: пропускная способность канала связи, степень загруженности ресурсов компьютера и так далее. Предлагаемая система нечеткой логики предполагает три этапа:
1. Фаззификация - введение нечеткости. Для выполнения этой операции для всех входных величин определяются лингвистические переменные, для каждой лингвистической переменной формируются терм-множества, для каждого терма строятся функции принадлежности. Например, лингвистическая переменная «степень использования ресурсов компьютера», для нее терм-множество будет иметь вид {«низкая», «ниже средней», «средняя», «выше средней», «высокая»}, что позволяет отойти от большого количества чисел и различных размерностей для разных типов параметров. Стоит отметить, что при введении нечеткости для аналогичных параметров, например степени использования канала связи (для задачи) и пропускной способности канала связи (для узла кластера), функция принадлежности должна учитывать однородность рассматриваемых величин.
2. Создание и использование нечеткой базы знаний. Нечеткая база знаний состоит из продукционных правил вида ЕСЛИ <посылка правила> ТО <заключение правила>. Например, можно использовать следующее правило: «ЕСЛИ степень использования ресурсов компьютера превышает степень загруженности ресурсов компьютера, ТО данная задача не может быть выполнена на данном узле кластера». Построение таких правил обычно не вызывает затруднения, так как они понятны и являются своего рода «вербальным кодированием». Аналогичные правила формируются для всех параметров задачи.
3. Дефаззификация - получение на выходе четкого результата, отражающего в данном случае информацию о том, какие задачи из списка будут выполнены на рассматриваемом узле кластера.
Фиг.5 представляет пример компьютерной системы общего назначения, персональный компьютер или сервер 20, содержащий центральный процессор 21, системную память 22 и системную шину 23, которая содержит разные системные компоненты, в том числе память, связанную с центральным процессором 21. Системная шина 23 реализована, как любая известная из уровня техники шинная структура, содержащая, в свою очередь, память шины или контроллер памяти шины, периферийную шину и локальную шину, которая способна взаимодействовать с любой другой шинной архитектурой. Системная память содержит постоянное запоминающее устройство (ПЗУ) 24, память с произвольным доступом (ОЗУ) 25. Основная система ввода/вывода (BIOS) 26 содержит основные процедуры, которые обеспечивают передачу информации между элементами персонального компьютера 20, например, в момент загрузки операционной системы с использованием ПЗУ 24.
Персональный компьютер 20, в свою очередь, содержит жесткий диск 27 для чтения и записи данных, привод магнитных дисков 28 для чтения и записи на сменные магнитные диски 29 и оптический привод 30 для чтения и записи на сменные оптические диски 31, такие как CD-ROM, DVD-ROM и иные оптические носители информации. Жесткий диск 27, привод магнитных дисков 28, оптический привод 30 соединены с системной шиной 23 через интерфейс жесткого диска 32, интерфейс магнитных дисков 33 и интерфейс оптического привода 34 соответственно. Приводы и соответствующие компьютерные носители информации представляют собой энергонезависимые средства хранения компьютерных инструкций, структур данных, программных модулей и прочих данных персонального компьютера 20.
Настоящее описание раскрывает реализацию системы, которая использует жесткий диск 27, сменный магнитный диск 29 и сменный оптический диск 31, но следует понимать, что возможно применение иных типов компьютерных носителей информации 56, которые способны хранить данные в доступной для чтения компьютером форме (твердотельные накопители, флешкарты памяти, цифровые диски, память с произвольным доступом (ОЗУ) и т.п.), которые подключены к системной шине 23 через контроллер 55.
Компьютер 20 имеет файловую систему 36, где хранится записанная операционная система 35, а также дополнительные программные приложения 37, другие программные модули 38 и данные программ 39. Пользователь имеет возможность вводить команды и информацию в персональный компьютер 20 посредством устройств ввода (клавиатуры 40, манипулятора «мышь» 42). Могут использоваться другие устройства ввода (не отображены): микрофон, джойстик, игровая консоль, сканнер и т.п.
Подобные устройства ввода по своему обычаю подключают к компьютерной системе 20 через последовательный порт 46, который, в свою очередь, подсоединен к системной шине, но могут быть подключены иным способом, например, при помощи параллельного порта, игрового порта или универсальной последовательной шины (USB). Монитор 47 или иной тип устройства отображения также подсоединен к системной шине 23 через интерфейс, такой как видеоадаптер 48. В дополнение к монитору 47, персональный компьютер может быть оснащен другими периферийными устройствами вывода (не отображены), например колонками, принтером и т.п.
Персональный компьютер 20 способен работать в сетевом окружении, при этом используется сетевое соединение с другим или несколькими удаленными компьютерами 49. Удаленный компьютер (или компьютеры) 49 являются такими же персональными компьютерами или серверами, которые имеют большинство или все упомянутые элементы, отмеченные ранее при описании существа персонального компьютера 20, представленного на Фиг.5. В вычислительной сети могут присутствовать также и другие устройства, например маршрутизаторы, сетевые станции, пиринговые устройства или иные сетевые узлы.
Сетевые соединения могут образовывать локальную вычислительную сеть (LAN) 50 и глобальную вычислительную сеть (WAN). Такие сети применяются в корпоративных компьютерных сетях, внутренних сетях компаний и, как правило, имеют доступ к сети Интернет. B LAN- или WAN-сетях персональный компьютер 20 подключен к локальной сети 50 через сетевой адаптер или сетевой интерфейс 51. При использовании сетей персональный компьютер 20 может использовать модем 54 или иные средства обеспечения связи с глобальной вычислительной сетью, такой как Интернет. Модем 54, который является внутренним или внешним устройством, подключен к системной шине 23 посредством последовательного порта 46.
Следует уточнить, что сетевые соединения являются лишь примерными и не обязаны отображать точную конфигурацию сети, т.е. в действительности существуют иные способы установления соединения техническими средствами связи одного компьютера с другим.
В заключение следует отметить, что приведенные в описании сведения являются только примерами, которые не ограничивают объем настоящего изобретения, определенный формулой. Специалисту в данной области становится понятным, что могут существовать и другие варианты осуществления настоящего изобретения, согласующиеся с сущностью и объемом настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ ОБЕСПЕЧЕНИЯ ОТКАЗОУСТОЙЧИВОСТИ АНТИВИРУСНОЙ ЗАЩИТЫ, РЕАЛИЗУЕМОЙ В ВИРТУАЛЬНОЙ СРЕДЕ | 2014 |
|
RU2568282C2 |
| Способ ограничения области автоматического выбора виртуальной машины защиты | 2019 |
|
RU2710860C1 |
| Способ балансировки нагрузки на виртуальных машинах защиты при условии ограничении области выбора виртуальных машин защиты | 2019 |
|
RU2724801C1 |
| СПОСОБ УПРАВЛЕНИЯ АВТОМАТИЗИРОВАННОЙ СИСТЕМОЙ ПРАВОВЫХ КОНСУЛЬТАЦИЙ | 2019 |
|
RU2718978C1 |
| СИСТЕМА И СПОСОБ ИЗМЕНЕНИЯ ФУНКЦИОНАЛА ПРИЛОЖЕНИЯ | 2014 |
|
RU2573783C1 |
| АППАРАТНО-ВЫЧИСЛИТЕЛЬНЫЙ КОМПЛЕКС С ПОВЫШЕННЫМИ НАДЕЖНОСТЬЮ И БЕЗОПАСНОСТЬЮ В СРЕДЕ ОБЛАЧНЫХ ВЫЧИСЛЕНИЙ | 2013 |
|
RU2557476C2 |
| Система и способ балансировки подключений между клиентами и серверами | 2021 |
|
RU2771444C1 |
| СПОСОБ ФУНКЦИОНИРОВАНИЯ ОПЕРАЦИОННОЙ СИСТЕМЫ ВЫЧИСЛИТЕЛЬНОГО УСТРОЙСТВА ПРОГРАММНО-АППАРАТНОГО КОМПЛЕКСА | 2016 |
|
RU2626350C1 |
| СПОСОБ РАСПРЕДЕЛЕННОГО ВЫПОЛНЕНИЯ ЗАДАЧ КОМПЬЮТЕРНОЙ БЕЗОПАСНОСТИ | 2011 |
|
RU2494453C2 |
| СИСТЕМА УПРАВЛЕНИЯ И ДИСПЕТЧЕРИЗАЦИИ КОНТЕЙНЕРОВ | 2015 |
|
RU2704734C2 |

Группа изобретений относится к отказоустойчивым системам и может быть использована для построения высоконадежных кластеров. Техническим результатом является повышение отказоустойчивости при выполнении задач в распределенных средах. Ключевой особенностью данного технического решения является использование меток работоспособности и выбор задач с учетом параметров как самой задачи, так и ее предполагаемого исполнителя. Система содержит средство обновления метки работоспособности, средство обнаружения неработоспособных узлов, средство формирования списка задач, средство выбора задач, средство выполнения задач, базу данных. 2 н. и 12 з.п. ф-лы, 5 ил. 
1. Способ отказоустойчивого выполнения задач в системах, состоящих, по крайней мере, из двух компьютеров, в котором:
a) по крайней мере для одного компьютера обновляют метку работоспособности, для этого:
i. находят максимум для значений меток работоспособности среди всех компьютеров системы;
ii. увеличивают значение текущей метки работоспособности, по крайней мере, одного компьютера;
iii. выбирают максимум из значений, полученных на этапах i и ii;
b) обнаруживают, по крайней мере, один компьютер, находящийся в неработоспособном состоянии, путем сравнения с заранее заданным пороговым значением разницы между величиной, полученной на шаге а), и меткой работоспособности, по крайней мере, одного другого компьютера системы, при этом компьютер считается неработоспособным, если разница между величиной, полученной на шаге а), и меткой работоспособности упомянутого компьютера системы превышает заранее заданное пороговое значение;
c) по крайней мере для одного обнаруженного неработоспособного компьютера формируют список задач, исполнителем которых являлся упомянутый неработоспособный компьютер;
d) выбирают, по крайней мере, одну задачу из сформированного списка задач путем сопоставления параметров, по крайней мере, одного работоспособного компьютера и, по крайней мере, одной задачи из списка задач, назначенных на неработоспособные компьютеры;
е) выполняют, по крайней мере, одну выбранную задачу с целью обеспечения отказоустойчивого выполнения задач в системах, состоящих, по крайней мере, из двух компьютеров.
2. Способ по п.1, в котором значение метки работоспособности не зависит напрямую от текущего времени.
3. Способ по п.2, в котором значение метки работоспособности принадлежит упорядоченному множеству, на котором определена операция сложения.
4. Способ по п.1, в котором шаги а) - е) выполняют с заранее заданной периодичностью.
5. Способ по п.4, в котором период зависит от частоты и длительности выполнения задач для рассматриваемой системы, состоящей, по крайней мере, из двух компьютеров.
6. Способ по п.1, в котором дополнительно при обнаружении неработоспособных компьютеров определяют множество компьютеров с повышенным приоритетом проверки работоспособности при следующей итерации способа путем сравнения с заранее заданным вторым пороговым значением разницы между величиной, полученной на шаге а), и меткой работоспособности, по крайней мере, одного другого компьютера системы.
7. Способ по п.6, в котором при обнаружении неработоспособных компьютеров учитываются только компьютеры с повышенным приоритетом проверки работоспособности.
8. Способ по п.1, в котором сопоставление параметров компьютера и задачи осуществляется с использованием правил нечеткой логики.
9. Система отказоустойчивого выполнения задач, содержащая, по крайней мере, два компьютера, каждый из которых связан со следующими объектами:
- средство обновления метки работоспособности, которое связано с базой данных для сохранения обновленной метки работоспособности и со средством обнаружения неработоспособных компьютеров, а также предназначенное для обновления метки работоспособности путем:
i) нахождения максимума для значений меток работоспособности среди всех компьютеров системы;
ii) увеличения значения текущей метки работоспособности, по крайней мере, одного компьютера;
iii) выбора максимума из значений, полученных на этапах i и ii;
- упомянутое средство обнаружения неработоспособных компьютеров путем сравнения разницы между значением, полученным от средства обновления метки работоспособности, и меткой работоспособности, по крайней мере, одного другого компьютера системы с заранее заданным пороговым значением, которое также связано со средством формирования списка задач и с упомянутой базой данных, при этом компьютер считается неработоспособным, если разница между его текущей меткой работоспособности и максимальной меткой работоспособности для кластера превышает заранее заданное пороговое значение;
- упомянутое средство формирования списка задач, предназначенное для выбора, по крайней мере, одной задачи, исполнителем которой назначен неработоспособный компьютер, которое также связано со средством выбора задач и с упомянутой базой данных;
- упомянутое средство выбора задач, предназначенное для выбора для дальнейшего выполнения, по крайней мере, одной задачи из сформированного списка задач путем сопоставления параметров, по крайней мере, одного компьютера и, по крайней мере, одной задачи из сформированного списка задач, которое также связано со средством выполнения задач и с упомянутой базой данных;
- упомянутая база данных, предназначенная для сохранения информации о параметрах, метках и статусах работоспособности, по крайней мере, одного компьютера системы, а также информации, по крайней мере, об одной задаче, выполняющейся в системе, включающей, по крайней мере, два компьютера;
- упомянутое средство выполнения задач, выбранных с помощью средства выбора задач, с целью обеспечения отказоустойчивого выполнения задач.
10. Система по п.9, в которой значение метки работоспособности не зависит напрямую от текущего времени.
11. Система по п.10, в которой значение метки работоспособности принадлежит упорядоченному множеству, на котором определена операция сложения.
12. Система по п.9, в которой средство обнаружения неработоспособных компьютеров дополнительно определяет множество компьютеров с повышенным приоритетом проверки работоспособности при следующей итерации путем сравнения системы с заранее заданным вторым пороговым значением разницы между максимальной меткой работоспособности для кластера и меткой работоспособности, по крайней мере, одного компьютера.
13. Система по п.12, в которой при обнаружении неработоспособных компьютеров учитываются только компьютеры с повышенным приоритетом проверки работоспособности.
14. Система по п.9, в которой сопоставление параметров компьютера и задачи осуществляется с использованием правил нечеткой логики.
| US 7228453 B2, 05.06.2007 | |||
| US 6718486 B1, 06.04.2004 | |||
| US 7451359 B1, 11.11.2008 | |||
| US 2009177914 A1, 09.07.2009 | |||
| ОТКАЗОУСТОЙЧИВОЕ ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО И СПОСОБ ФУНКЦИОНИРОВАНИЯ ПОДОБНОГО УСТРОЙСТВА | 2002 |
|
RU2279707C2 |
| СПОСОБ ДЕЦЕНТРАЛИЗОВАННОГО УПРАВЛЕНИЯ ПРОЦЕССОМ РАСПРЕДЕЛЕННОГО МОДЕЛИРОВАНИЯ И ОБРАБОТКИ ДАННЫХ | 2006 |
|
RU2365977C2 |

