Область техники
[0001] Настоящее изобретение относится к поиску в базе данных и, в частности, к поиску записи в базе данных, которая обеспечивает наилучшее совпадение с данным запросом, связанным с идентичностью личности, которая может включать в себя ожидаемые и не ожидаемые атрибуты данных, и к извлечению записи, которая обеспечивает наилучшее совпадение с запросом совместно с применимой на практике обратной связью, которая объясняет событие и результат совпадения.
Уровень техники
[0002] Подходы, описанные в этом разделе, - это подходы, которым можно следовать, но не обязательно подходы, которые были ранее рассмотрены или использованы. Поэтому, если не указано обратное, подходы, описанные в этом разделе, могут не соответствовать предшествующему уровню техники, от которого отталкивается данная заявка, и не признаются предшествующим уровнем техники путем включения в этот раздел.
[0003] Возможности эффективного обращения к базе данных и поиска в ней важны для эффективного использования данных, которые поддерживаются в базах справочных данных в целях отыскания совпадения. Для решения этой задачи критическую роль играет способность обеспечивать эффективное извлечение результата установления совпадения, т.е. результата установления совпадения справочных данных с запросом, который включает в себя персональные указатели, которые предполагаются частью запроса, а также ранее неизвестные указатели, для идентификации и выбора результатов установления совпадения эффективным и экономичным образом, и для обеспечения применимой на практике обратной связи, которую можно использовать для принятия деловых решений, касающихся использования результатов установления совпадения, например, для эффективного текущего контроля данных.
[0004] В отношении идентификации личности существующая технология рассматривает конкретное и конечное количество полей данных, например данные имена, фамилии, физические и электронные адреса, должности и псевдонимы, или набор неопределенных компонентов данных, которые могут включать или не включать в себя информацию, связанную с личностью. Эта существующая технология в целом основана на посимвольном или математическом эвристическом сравнении, которое дает оценку точности на основании количества совпадающих символов или другой базовой корреляционной информации, с учетом допустимых орфографических вариаций, например различных вариантов написания конкретного слова, а также использования переносов, заглавных букв, дефисов, пунктуации, известных сокращений и синонимов. Кроме того, существующая технология предполагает конкретную структуру данных запроса и не позволяет использовать конечное, но временно неограниченное множество ценных предсказательных элементов данных или других выведенных указателей, связанных с личностью, которые были удостоверены и синтезированы или объединены в базу данных личностей для использования в процессе установления совпадения.
Сущность изобретения
[0005] Предусмотрен способ, который включает в себя этапы, на которых (a) принимают запрос на инициирование поиска данных для конкретной личности, (b) определяют на основании запроса стратегию поиска в базе справочных данных, (c) производят поиск в базе справочных данных в соответствии со стратегией совпадения с запросом и (d) выводят результат установления совпадения. Способ также может обеспечивать обратную связь, связанную с совпадением, которая выражает оценочное качество совпадения, которую конечный пользователь может использовать для определения степени, в которой совпадающий объект отвечает критериям качества этого конечного пользователя. Предусмотрены также система, которая выполняет способ, и носитель данных, который содержит инструкции, которые управляют процессором для выполнения способа.
[0006] Запросы обрабатываются для распознавания и синтеза указателей запроса, включающих в себя как ожидаемые, так и не ожидаемые компоненты данных для оценивания и выбора кандидатов. Справочные данные, касающиеся личностей, поддерживаются в базе данных, к ним осуществляется доступ, их оценивают и используют для идентификации совпадений с запросом. Запрашивающей стороне или запрашивающей системе предоставляются результат установления совпадения и применимые на практике данные, включающие в себя указатели достоверности, которые описывают относительную силу результата установления совпадения, и атрибуты для указания обратной связи по данным и альтернативным указателям, которые использовались для распространения совпадения.
Краткое описание чертежей
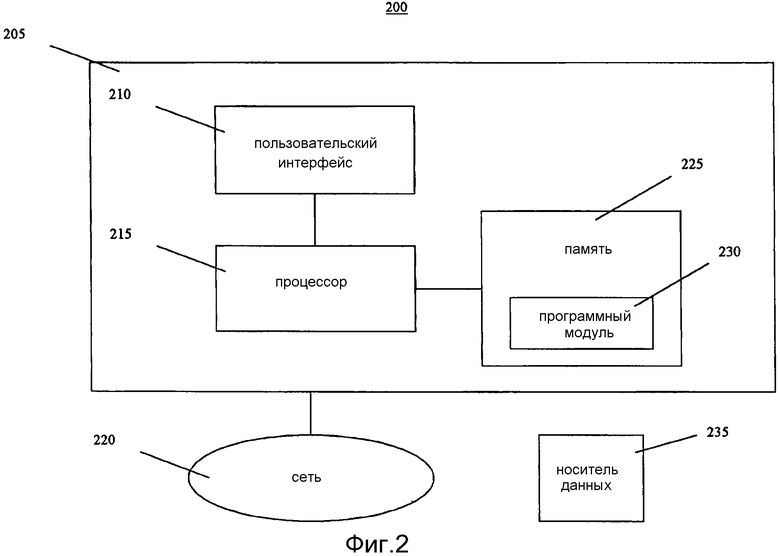
[0007] Фиг.1 - функциональная блок-схема способа, который присваивает данным идентичности личности применимые на практике атрибуты.
[0008] Фиг.2 - блок-схема системы для применения настоящего изобретения.
Описание изобретения
[0009] Указатели представляют собой информацию, связанную с идентичностью личности. Указатели включают в себя распознаваемые атрибуты запроса, то есть компоненты данных, которые являются ожидаемыми компонентами запроса, например имя, адрес и дата рождения личности, или которые особо указаны в запросе, например в качестве метаданных через заголовки столбцов в файле или конкретных полях ввода данных в онлайновом приложении, которые можно использовать с другими данными для уникальной идентификации личности. Указатели также могут включать в себя атрибуты, которые раньше не встречались, и альтернативные способы выражения или оценивания значений данных, например альтернативные варианты написания имен.
[0010] Обратная связь - это информация о совпадении, которая выражает оценочное качество события совпадения в отношении достоверности, выражаемой степенью совпадения между запросом и кандидатом на совпадение, сравнительный рейтинг каждого поля данных, используемого в событии совпадения, и указание источника данных, который использовался для совпадения с запросом. Конечный пользователь может использовать обратную связь для определения степени, в которой совпадающий объект отвечает критериям качества этого конечного пользователя, и для инициирования различных действий и контрольного вмешательства на основании этой обратной связи.
[0011] На фиг.1 показана функциональная блок-схема способа 100, который присваивает данным идентичности личности применимые на практике атрибуты. Короче говоря, способ 100 принимает запрос 103 и выполняет процессы 115, 120, 125, 130 и 135 для установления совпадения данных из запроса 103 с данными в базе 110 справочных данных и, таким образом, выдачи результата 160.
[0012] Способ 100 использует правила 104 обработки, таблицу 105 атрибутов и частотную таблицу 109 и на промежуточных этапах создает данные 140, атрибуты 145, функцию 150 и наилучшего кандидата 155.
[0013] Каждый из процессов 115, 120, 125, 130 и 135 описан здесь в отношении их соответствующих общих операций. Каждый из процессов 115, 120, 125, 130 и 135 может быть сконфигурирован как самостоятельный процесс или как иерархия подчиненных процессов.
[0014] Запрос 103 является запросом, который инициирует поиск информации о конкретной личности. Поиск производится на основании указателей, которые включены в запрос 103, и в связи с этим запрос 103 включает в себя множество элементов данных, которые, в свою очередь, включают в себя конкретную информацию, касающуюся личности в отношении полей данных, которые представляют собой полное множество или подмножество ранее определенных распознаваемых атрибутов, которое определено в правилах 104 обработки и таблице 105 атрибутов, и также могут потенциально включать в себя дополнительные и практически неограниченные указатели, касающиеся личности. Запрос 103 может предоставляться способу 100 пользователем-человеком или автоматизированным процессом. Например, запрос 103 может выводиться из индивидуального запроса, обрабатываемого с использованием экранов онлайнового ввода данных, или из файлов, передаваемых с использованием возможностей пакетной обработки. Запрос 103 включает в себя данные, которые способ 100 переформатирует как данные 140 и которые этот способ 100 будет использовать для уникальной идентификации личности. Данные 140 могут включать в себя, например, такие данные как имя, адрес, дата рождения, номер социального страхования и другие формы идентификации.
[0015] База 110 справочных данных - это база данных информации о личности с максимальной степенью персональной и профессиональной информации, т.е. известных атрибутов, касающихся каждой личности. Процессы (не показаны) используются для оценивания данных, которые затем заносятся в базу 110 справочных данных, которую затем можно использовать в целях отыскания совпадения. Посредством набора дополнительных процессов (не показаны) базу 110 справочных данных можно обновлять для включения дополнительной информации о личности, которая уже представлена в базе 110 справочных данных, и для включения информации о дополнительных личностях.
[0016] Правила 104 обработки включают в себя автоматизированные и воспроизводимые правила делового регламента и метаданных (далее именуемые «правилами») на основании процессов стандартизации и нормализации, которые включают в себя семантическую и численную логику устранения неоднозначности для интерпретации значений запроса, например различные комбинации слов (имя/второе имя/фамилия или фамилия/имя/второе имя, а также различные манипуляции, например, другие перестановки атрибутов, в том числе полного множества или подмножества атрибутов имени), адресацию (компоненты отдельного адреса или смешанного адреса) и различные форматы даты. Правила для метаданных определяют информацию о каждом элементе данных, например, (a) является ли он буквенным, т.е. состоящим из букв алфавита, цифровым или буквенно-цифровым, т.е. состоящим из букв и цифр, (b) допустимый размер и (c) форматирование. Правила обработки делового регламента определяют действия, осуществляемые на основании значения одного или более элементов данных, например условие, которое должно выполняться, прежде чем можно будет осуществить последующую операцию или вычисление.
[0017] Пример процессов стандартизации в правилах 104 обработки включает в себя замену разных версий сокращенного написания слова «улица» в адресе, например «St.» и «Strt» общим и согласованным значением, например «street». Пример процессов нормализации в правилах 104 обработки включает в себя замену общеупотребительных слов или сокращений, например «manufacturing» и «mnfctring», аббревиатурой «mnf» в качестве согласованного термина для облегчения установления совпадения. Пример семантической логики и логики устранения неоднозначности включает в себя разделение уличного адреса на отдельные поля для номера дома и названия улицы.
[0018] Таблица 105 атрибутов - это таблица распознаваемых атрибутов, т.е. полей данных, которые могут быть связаны с данными, которые могут идентифицировать личность. Таблица 105 атрибутов также включает в себя метаданные, которые определяют характеристики распознаваемых атрибутов. Метаданные являются информацией о данных, то есть описывают характеристики данных. Например, в таблице 105 атрибутов может быть указан атрибут «имя», и она может включать в себя метаданные, касающиеся имени, которые указывают, что имя должно быть строкой буквенных символов. Таблица 105 атрибутов также может обновляться данными из данных 140 для включения атрибутов, которые не были распознаны ранее, для которых можно определить предсказательное взвешивание или другую информацию. Значения в таблице 105 атрибутов будут контролироваться и регулироваться при осуществлении обновлений базы 110 справочных данных.
[0019] В частотной таблице 109 указаны количества записей в базе 110 справочных данных, которые имеют конкретные значения для конкретных атрибутов. Таким образом, частотная таблица 109 генерируется из базы 110 справочных данных для идентификации частоты (F) вхождения конкретных значений данных в базе 110 справочных данных. Например, база 110 справочных данных может иметь 5647 вхождений «Jon» в качестве имени, 893 вхождений «Smythe» в качестве фамилии и 197 вхождений «Jon Smythe» в качестве комбинации имени/фамилии. Соответственно, частотная таблица 109 будет указывать, что (a) имя «Jon» имеет частоту 5647, (b) фамилия «Smythe» имеет частоту 893 и (c) комбинация имя/фамилия «Jon Smythe» имеет частоту 197. Частотная таблица 109 обновляется при обновлении записей в базе 110 справочных данных.
[0020] Способ 100 начинается с процесса 115.
[0021] Процесс 115 принимает запрос 103 и структурирует указатели из запроса 103 в общий формат, т.е. данные 140. В нижеприведенной таблице 1 показано примерное представление данных 140. В таблице 1 данные 140 показаны в виде примерного набора элементов данных, представленного в примерном общем формате ожидаемых значений запроса, например имени, адреса, города, штата, почтового индекса и номера телефона.
Примерное представление данных 140
350 Sixth Ave Suite 7712
Manhattan, NY 10118A
(917) 555-5555
01271960
123-456-7890
mailto:jsmith@abc.com
http://www.abcllc.com
[0022] От процесса 115 способ 100 переходит к процессу 120.
[0023] Процесс 120 анализирует данные 140 для идентификации конкретных полей данных, которые связаны с атрибутами в таблице 105 атрибутов для расширения возможности идентификации совпадений из базы 110 справочных данных с использованием одного или более из этих полей данных. В связи с этим процесс 120 выделяет из данных 140 атрибуты, которые относятся к поиску совпадения, таким образом выдавая атрибуты 145.
[0024] Процесс 120 осуществляется в соответствии с правилами 104 обработки для очистки, анализа и стандартизации всех компонентов введенных значений данных запроса, выраженных в данных 140.
[0025] Очистка предусматривает удаление посторонних значений, например пунктуации и других форм бесполезных символов, например черточек в номере телефона знаков дроби, разделяющих компоненты даты. Например, очистка значения даты, представленного в формате 01/27/60, приводит к значению 012760.
[0026] Анализ включает в себя разбиение данных 140 для повышения возможности идентификации совпадений с запросом 103. Он может включать в себя разложение индивидуальных указателей запроса на множественные элементы данных, например разделение даты рождения 012760, представленной в формате MMDDYY, на отдельные элементы, которые включают в себя месяц (MM (01)), число (DD (27)) и год (YY (60)). Анализ также может включать в себя слияние отдельных элементов, например имени (John), второго имени или инициала (Q) и фамилии (Public) в один элемент, например имя (JohnQPublic).
[0027] Стандартизация включает в себя связывание альтернативных значений с данными 140 для повышения возможности идентификации совпадений. Она может включать в себя связывание двухсимвольного значения (NJ) для ряда значений запроса, которые представляют название штата (New Jersey; N Jersey; New Jrsy).
[0028] Процесс 120 также использует правила 104 обработки для анализа и сохранения информации из данных 140, которые прежде не встречались, для генерации новых правил, которые будут сохранены в правилах 104 обработки для использования при дальнейшем выполнении процесса 120. Новые правила могут определяться автоматически на основании аналогий с существующими правилами. Таким образом, указатели, которые включены в данные 140, но не определены в таблице 105 атрибутов, т.е. дополнительные указатели, будут сохраняться для последующего использования процессами 120 и 125 и, возможно, использования процессами 130 и 135 для обработки кандидатов, идентифицированных из базы 110 справочных данных. Способ 100 включает в себя возможность автоматизированного сохранения этих дополнительных указателей для разработки и определения атрибутов, которые будут занесены в таблицу 105 атрибутов, и разработки соответствующих правил, которые будут внесены в правила 104 обработки.
[0029] Таким образом, процесс 120 анализирует данные 140, и если процесс 120 выявляет отсутствие правила в правилах 104 обработки для тех или иных конкретных данных, эти конкретные данные сохраняются в правилах 104 обработки и помечаются для анализа. Например, если запрос 103 содержит адрес электронной почты и если адрес электронной почты является ранее нераспознанным значением и поэтому не имеет соответствующего правила в правилах 104 обработки, правила 104 обработки могут обновляться посредством процесса обновления (не показан) для сохранения адресов электронной почты в качестве новых указателей, которые могут становиться распознанным атрибутом.
[0030] В нижеприведенной таблице 2 показано примерное представление правил 104 обработки, и в таблице 3 показано примерное представление атрибутов 145. Примеры правил обработки включают в себя (i) разделение поля имени данных 140 на отдельные поля имени и фамилии, (ii) разделение поля адреса данных 140 на отдельные поля номера дома и названия улицы, и (iii) разделение поля даты рождения данных 140 на отдельные поля месяца, числа и года. Гибкие указатели включают в себя данные из данных 140, которые ранее не были идентифицированы как данные, считающиеся частью запроса, но которые должны сохраняться правилами 104 обработки для будущих событий совпадения. Они включают в себя как данные, которые можно классифицировать на основании шаблонов, так и данные в произвольной форме.
Примерное представление правил 104 обработки
Фамилия: Smythe
Название улицы адреса: Sixth Ave
Альтернативное название улицы адреса: 6th
(определенное на основании альтернативной логики в правилах 104 обработки)
Адрес2: Suite 7712
Альтернативный адрес2: 7th floor (определенное на основании альтернативной логики в правилах 104 обработки)
Город: New York (вместо «Manhattan», который не является городом)
Штат: NY
Почтовый индекс: 10118 (удалить «A» как посторонние данные)
DOB/DD: 27
DOB/YY: 60
Примерное представление атрибутов 145
ресурса (URL) компании
[0031] Например, согласно таблице 2, правила 104 обработки указывают, что имя нужно разложить на отдельные значения имени и фамилии. Таким образом, «Jon Smythe» разлагается на имя «Jon» и фамилию «Smythe» и сохраняется, как показано в таблице 3.
[0032] Способ 100 переходит от процесса 120 к процессу 125.
[0033] Процесс 125 обращается к таблице 105 атрибутов для дополнительного уточнения атрибутов 145 для разработки функции 150. Для каждого атрибута из атрибутов 145 процесс 125 назначает вес на основании относительного значения влияния атрибута при идентификации личности, таким образом обеспечивая взвешенный атрибут, где вес указывает полезность атрибута при нахождении совпадения с данными 140. Например, это определение будет включать в себя взвешивание, определенное в таблице 105 атрибутов, которая обеспечивает статическое взвешивание, например имя имеет более высокий вес, чем адрес, и взвешивание относительно других заполненных полей, определенных в таблице 105 атрибутов, например дата начала трудовой деятельности более ценна, когда она, по меньшей мере, на 18 лет превышает дату рождения, а также взвешивание на основании фактического значения данных поля, определенного в таблице 105 атрибутов, например необычное имя, такое как Erasmus, имеет более высокий вес, чем более распространенное имя, например John. Этот анализ также рассматривает альтернативные значения полей данных в атрибутах 145, например акронимы и альтернативные варианты написания (например, Jon и Jonathan в качестве имени). Помимо статического взвешивания по атрибуту таблица 105 атрибутов назначает отрегулированные весовые коэффициенты на основании отсутствия или присутствия значений данных для других атрибутов и оценочной предсказательности. Например, вес имени имеет меньшее значение в отсутствие данных для фамилии, и комбинация номера дома и названия улицы имеет больший вес, чем эти два поля по отдельности.
[0034] Процесс 125 определяет оптимальную стратегию поиска в базе 110 справочных данных и представляет эту стратегию в виде функции 150, представленной здесь как f(x). В частности, процесс 125 получает вес (W) из таблицы 105 атрибутов и частоту (F) из частотной таблицы 109, вычисляет предсказательное взвешивание (K), где K=W×F, для каждого атрибута (x), таким образом обеспечивая K(x), где K(x) - предсказательное взвешивание атрибута x. Функция 150 может вычислять множественные значения f(x) на основании разных комбинаций атрибутов, например фамилии и DOB или имени/фамилии и DOB, и результаты вычисления используются процессом 125 для определения оптимальной стратегии поиска. Функция 150 имеет следующий общий формат:
f(x)=K1<поле1>+K2<поле2>+K3<поле3>+...+KN<полеN>,
где K вычисляется для каждого компонента атрибутов 145.
[0035] В нижеприведенной таблице 4 показано примерное представление таблицы 105 атрибутов, и в таблице 5 показано примерное представление частотной таблицы 109.
Примерное представление таблицы 105 атрибутов
[0036] В примере, приведенном в таблице 4, таблица 105 атрибутов включает в себя атрибут «имя», метаданные, указывающие, что имя должно быть строкой буквенных символов, и для имени - вес (W)=0,25. Значения веса (W) указывают относительное влияние атрибутов в запросе 103, выраженное в данных 140, идентифицирующих совпадение из базы 110 справочных данных. В примере, представленном в таблице 4, когда атрибут имеет значение W=1, этот атрибут считается лучшим предсказателем совпадения, чем атрибут со значением W, меньшим 1. Например, если запрос 103 включает в себя персональный номер мобильного телефона, который является атрибутом, значение которого можно считать уникальным, персональный номер мобильного телефона будет в большей степени влиять на событие совпадения, чем фамилия, которая, вероятно, будет иметь более распространенное значение.
Примерное представление частотной таблицы 109
[0037] В процессе 125 определение предсказательного взвешивания может рассматривать соотношение между атрибутами и вычислять измененный вес на основании такого соотношения. Например, хотя имя и фамилия будут иметь собственные предсказательные весовые коэффициенты, комбинация этих имени и фамилии может быть более предсказательной или менее предсказательной при идентификации надлежащего совпадения в базе 110 справочных данных. Например, могут наблюдаться более частые вхождения комбинированного значения имени и фамилии «Jon Smith» в базе 110 справочных данных, что отражено в частотной таблице 109, чем «Erasmus Hoffert». Комбинированное значение имени/фамилии может иметь частоту (F), согласно частотной таблице 109, для указания более предсказательного взвешивания или менее предсказательного взвешивания.
[0038] Как отмечено выше, для каждого атрибута (x) процесс 125 получает вес (W) из таблицы 105 атрибутов и частоту (F) из частотной таблицы 109 и вычисляет предсказательное взвешивание (K), где K=W×F. На основании разных комбинаций атрибутов можно вычислить множественные значения предсказательного взвешивания. Например, с использованием примерных данных, приведенных в таблице 4 и таблице 5 для одного вычисления f(x):
[0039] для имени=Jon, K1=0,25×5647=1411,75
[0040] для фамилии=Smythe, K2=0,5×893=446,5
[0041] соответственно f(x), т.е. функция 150, для имени и фамилии будет выражаться как:
[0042] f(x)=1411,75 <имя «Jon»>+446,5 <фамилия «Smythe»>
[0043] С использованием примерных данных, приведенных в таблице 4 и таблице 5 для второго вычисления f(x):
[0044] для имени/фамилия=Jon Smyth, K1=0,9×197=177,3
[0045] для DOB/MMDDYY= 012760, K2=0,7×211=147,7
[0046] соответственно f(x), т.е. функция 150, для имени/фамилии и DOB/MMDDYY будет выражаться как:
[0047] f(x)=177,3 <имя/фамилия «Jon Smythe»>+147,7<DOB/MMDDYY «012760»>
[0048] В общем случае для данного атрибута вес (W) увеличивается, если атрибут является хорошим предсказателем совпадения, но увеличение частоты (F) говорит о том, что атрибут не является хорошим предсказателем совпадения. Рассмотрим пример поиска личности, носящей распространенное имя, например «John», но уникальный номер мобильного телефона, например «1234567890», и соответственно в частотной таблице 109, для имени «John», (F)=10000, и для номера мобильного телефона «1234567890», (F)=1. Предсказательное взвешивание (K), где K=W×F, для этих атрибутов, на основании таблицы 4, представляет собой K<имя «John»>=0,25×10000=2500, и K<номер мобильного телефона «1234567890»>=1×1=1. Таким образом, создается впечатление, что в f(x) имя «John» имеет более высокое предсказательное взвешивание, чем номер мобильного телефона «1234567890». Однако на основании выполняемой фактической логики более низкая f(x) может быть более предсказательной, чем более высокая f(x).
[0049] Хотя в настоящем примере функция 150 представлена в виде суммы произведений, функция 150 не обязательно является суммой или арифметическим уравнением. В общем случае функция 150 является списком взвешенных атрибутов, где вес конкретного атрибута или комбинаций атрибутов указывает предсказательность и, следовательно, важность этого атрибута или комбинаций атрибутов при идентификации надлежащего совпадения с записью в базе 110 справочных данных.
[0050] Способ 100 переходит от процесса 125 к процессу 130.
[0051] Процесс 130 осуществляет поиск по базе 110 справочных данных в соответствии с функцией 150, т.е. стратегией, которая была определена процессом 125, и создает наилучшего кандидата 155. В частности, процесс 130 извлекает записи из базы 110 справочных данных в соответствии с функцией 150. Затем процесс 130 сравнивает атрибуты из этих записей с данными 140 и на основании сравнения выбирает из базы 110 справочных данных набор кандидатов, которые с наибольшей вероятностью обеспечивают совпадение с данными 140. После этого процесс 130 оценивает набор кандидатов, сравнивая значение каждого атрибута из извлеченных записей в базе 110 справочных данных со значением того же атрибута из данных 140 для окончательного определения наилучшего кандидата на совпадение, т.е. наилучшего кандидата 155.
[0052] В нижеприведенной таблице 6 показано примерное представление набора кандидатов из базы 110 справочных данных.
Примерный набор кандидатов из базы 110 справочных данных
[0053] Наилучшим кандидатом 155 является запись из набора кандидатов, которая имеет наибольшее подобие с данными 140, полученная методами просеивания набора кандидатов в процессе 130. Такие методы включают в себя рассмотрение источника данных, откуда происходит наполнение базы 110 справочных данных, и оценок качества, касающихся этих данных (если некоторые источники признаны более актуальными и более качественными, чем другие источники).
[0054] Например, для записи 1 в таблице 6 процесс 130 сравнивает значения данных для атрибута «фамилия» из данных 140 («Smythe») и базы 110 справочных данных («Smith») и определяет высокую степень подобия, а также для атрибута «название улицы адреса», имеющего значение «Sixth Ave» в данных 140 и «6th Ave» в базе 110 справочных данных. Для записи 2 в таблице 6 процесс 130 сравнивает значения данных для атрибута «фамилия» из данных 140 («Smithe») и базы 110 справочных данных («Smarth») и определяет меньшую степень подобия, и для атрибута «название улицы адреса» процесс 130 определяет отсутствие подобия между «Sixth Ave» в данных 140 и «5th Ave» в базе 110 справочных данных.
[0055] В нижеприведенной таблице 7 показано примерное представление наилучшего кандидата 155.
Примерное представление наилучшего кандидата 155
[0056] Способ 100 переходит от процесса 130 к процессу 135.
[0057] Процесс 135 выводит результат 160, который включает в себя наилучшего кандидата 155A и обратную связь 165. Наилучший кандидат 155A является копией наилучшего кандидата 155. Обратная связь 165 - это информация, касающаяся степени подобия между данными 140 и наилучшим кандидатом 155A, который применим на практике, т.е. может использоваться конечным пользователем для принятия деловых решений.
[0058] Обратная связь 165 включена с результатом 160 для указания качества наилучшего кандидата 155A, например уровень достоверности того, что наилучший кандидат 155A дает адекватное совпадение с запросом 103. Обратная связь 165 также может включать в себя относительную степень подобия, выраженную относительной корреляцией между каждым полем в данных 140 и каждым компонентом наилучшего кандидата 155A. Эта обратная связь выражается в трех компонентах: (1) коде достоверности, который указывает относительную степень достоверности в подобии между данными 140 и кандидатами в базе 110 справочных данных; (2) строке класса совпадения, которая указывает степень подобия между атрибутами данных 140 и кандидатами в базе 110 справочных данных; и (3) профиле данных совпадения, который указывает тип данных в базе 110 справочных данных, которые использовались в событии совпадения. Эти компоненты обратной связи конечный пользователь может использовать для определения деловых правил, предписывающих использование и потребление совпадений идентичности личности, чтобы этот конечный пользователь мог принимать деловые решения, касающиеся события совпадения, на основании степени, в которой совпадающий объект отвечает критериям качества этого конечного пользователя, и для текущих контрольных вмешательств. Эти структуры обратной связи могут быть гибкими, отражая охват и начало гибких указателей в запросе 103. Пользователю могут предоставляться дополнительные возможности просмотра и обозрения данных для запросов, которые могут не давать совпадения.
[0059] В нижеприведенной таблице 8 показано примерное представление обратной связи 165.
Примерное представление обратной связи 165
Строка класса совпадения:
Имя: A
Номер дома адреса: B
Название улицы адреса: A
Адрес2: Z
Город: A
Почтовый индекс: B
Штат: A
Номер телефона: Z
DOB: F
Номер мобильного телефона: A
Профиль данных совпадения:
Имя: 03
Фамилия: 03
Номер дома адреса: 00
Название улицы адреса: 00
Адрес2: 99
Город: 00
Почтовый индекс: 00
Штат: 00
Номер телефона: 98
DOB: 98
Номер мобильного телефона: 00
[0060] Обратную связь по строке класса совпадения можно определить с использованием структуры кодирования следующим образом: «A» означает, что данные для кандидата на совпадение из базы 110 справочных данных и данные в данных 140 считаются одинаковыми (например, Jon и John); «B» означает наличие некоторого подобия между данными 140 и записью из базы 110 справочных данных (например, Jon и Jhonny); «F» означает, что данные для кандидата на совпадение в базе 110 справочных данных и данные в данных 140 считаются неодинаковыми (например, Jon и Jim); «Z» означает отсутствие значения для поля данных в данных 140 или в базе 110 справочных данных для конкретного поля данных.
[0061] Обратная связь по профилю данных совпадения указывает тип данных в базе 110 справочных данных, которые использовались процессом 130 для установления совпадения записи из базы 110 справочных данных с данными 140, и ее можно определить с использованием структуры кодирования, например, «00» означает основное название или адрес предприятия, «03» означает альтернативные значения, например генеральный директор (CEO) или прежние названия или адреса, «98» указывает атрибут из данных 140, который не был использован процессом 130, или «99» указывает, что атрибут не включен в данные 140.
[0062] Таким образом, способ 100 включает в себя 1) прием запроса на инициирование поиска конкретной личности, 2) обработку запроса для максимального использования каждого поля данных запроса по отдельности и совместно с другими полями данных запроса, включающую в себя процессы для очистки, анализа и стандартизации запроса, 3) определение оптимальных способов для поиска по базе справочных данных на основании единичного или множественных очищенных, проанализированных и стандартизированных значений запроса, 4) извлечение кандидатов для выбора объектов базы справочных данных, которые дают совпадение с запросом, и 5) возвращение наилучшего кандидата и обеспечение обратной связи, включающей в себя результаты установления совпадения с применимыми на практике атрибутами.
[0063] Способ 100 включает в себя этапы 1) приема входных данных, содержащих множество элементов, 2) преобразования подмножества множества элементов в набор терминов, 3) оценивания предсказательности способности к идентификации кандидата на совпадение с использованием гибких указателей на основании запроса конечного пользователя, включающего в себя как данные, которые предполагаются частью запроса, так и альтернативные данные, которые могут предоставляться конечным пользователем, 4) извлечения сохраненных справочных данных на основании терминов для идентификации наиболее вероятных кандидатов на совпадение с входными данными, 5) выбора наилучшего совпадения из множества кандидатов на совпадение на основании оценочной предсказательности и 6) обеспечения результатов установления совпадения с применимыми на практике атрибутами, определенными уникальными аспектами каждого инициирования запроса и получения кандидата, которые позволяют конечному пользователю принимать деловые решения, касающиеся использования кандидата на совпадение.
[0064] Способ 100 включает в себя функциональные возможности для идентификации личности с использованием конечного, но временно неограниченного набора указателей, которые можно использовать для формирования оценки подобия между запросом и кандидатами на совпадение. Способ 100 решает определенные проблемы, связанные с уникальной идентификацией личности, включающие в себя 1) распространенность персональных имен, относящихся к разным отдельным личностям, что менее характерно для предприятий, 2) конкретное имя без дополнительных указателей, которые могут быть связаны с личностью, а также с предприятием или с более чем одной личностью или предприятием, и 3) личности, которые часто связаны с множественными адресами и физическими местоположениями или другими указателями. Расширяя гибкий и переменный набор атрибутов идентификации и совпадения на личность, можно решить эти вопросы. Гибкость метода включает в себя значения как метаданных, так и фактических данных и будет использоваться при 1) наполнении базы данных информацией, связанной с личностями, а также 2) выборе личности из базы данных на основании запроса и правил, определяющих порог одобрения для данных целей.
[0065] Согласно способу 100, набор указателей сначала определяется так, что X1, X2, …, Xn представляют атрибуты, подлежащие использованию для установления совпадения (например, имя, второе имя, фамилия, известные элементы адреса, другая описательная информация). Этот набор указателей является расширяемым без ограничения по размеру, и все справочные данные будут использоваться в процессе установления совпадения, выбора и оценивания. Справочные данные строятся таким образом, чтобы содержать максимально большой набор данных для включения всех ожидаемых значений X и дополнительных оценочных или выведенных данных на основании уравнений и предсказательных алгоритмов.
[0066] На каждой итерации установления совпадения опрашивается набор запросов для определения S, подмножества набора X. На основании набора коэффициентов корреляции, определенных в более обширном наборе X на момент совпадения или в течение другого предварительно определенного предсказательного интервала, осуществляется установление совпадения, и обратная связь возвращается в виде (1) интервала достоверности, описывающего степень совпадения в случае модификации коэффициентами корреляции в X и наблюдаемом подмножестве S при использовании для набора запросов, (2) строки класса совпадения, указывающей родственные элементы S и качество совпадения в этих конкретных элементах, и (3) строки профиля совпадения, указывающей, какие справочные данные использовались для формирования оценки, касающейся качества совпадения, т.е. оценки, касающейся уровня достоверности того, что наилучший кандидат является адекватным совпадением с запросом. Строка класса совпадения и строка профиля совпадения могут быть гибкими по длине и формату, которые определяются компонентами данных, которые используются в процессе установления совпадения.
[0067] На фиг.2 показана блок-схема системы 200 для применения настоящего изобретения. Система 200 включает в себя компьютер 205, подключенный к сети передачи данных, т.е. сети 220, например Интернету.
[0068] Компьютер 205 включает в себя пользовательский интерфейс 210, процессор 215 и память 225. Хотя компьютер 205 представлен здесь как автономное устройство, это не является ограничением, напротив, он может подключаться к другим устройствам (не показано) в распределенной системе обработки.
[0069] Пользовательский интерфейс 210 включает в себя устройство ввода, например клавиатуру или подсистему распознавания речи, позволяющее пользователю передавать информацию и выборы команд на процессор 215. Пользовательский интерфейс 210 также включает в себя устройство вывода, например дисплей или принтер. Устройство управления курсором, например мышь, шаровой манипулятор, джойстик или материал, чувствительный к прикосновению, расположенный на дисплее, позволяет пользователю воздействовать на курсор на дисплее для передачи дополнительной информации и выборов команд на процессор 215.
[0070] Процессор 215 представляет собой электронное устройство, сконфигурированное на основе логических схем, которое реагирует на инструкции и выполняет их.
[0071] Память 225 представляет собой энергонезависимый машиночитаемый носитель, на котором записана компьютерная программа. В связи с этим в памяти 225 хранятся данные и инструкции, считываемые и выполняемые процессором 215 для управления работой процессора 215. Память 225 можно реализовать в виде оперативной памяти (ОЗУ), жесткого диска, постоянной памяти (ПЗУ) или их комбинации. Одним из компонентов памяти 225 является программный модуль 230.
[0072] Программный модуль 230 содержит инструкции, предписывающие процессору 215 выполнять описанные здесь способы. Например, под управлением программного модуля 230 процессор 215 выполняет процессы способа 100. Термин "модуль" используется здесь для обозначения функциональной операции, которая может быть реализована либо как автономный компонент, либо как объединенная конфигурация множества подчиненных компонентов. Таким образом, программный модуль 230 можно реализовать как единичный модуль или как множество модулей, которые действуют совместно друг с другом. Кроме того, хотя программный модуль 230 описан здесь как установленный в памяти 225 и, таким образом, реализованный в виде программного обеспечения, его можно реализовать в виде оборудования (например, электронной схемы), программно-аппаратного обеспечения, программного обеспечения или их комбинации.
[0073] Процессор 215 принимает запрос 103, по сети 220 или через пользовательский интерфейс 210 и обращается к правилам 104 обработки, таблице 105 атрибутов и базе 110 справочных данных. Правила 104 обработки, таблица 105 атрибутов и база 110 справочных данных могут быть компонентами компьютера 205, например, храниться в памяти 225 или могут располагаться на устройствах, внешних по отношению к компьютеру 205, при этом компьютер 205 обращается к ним через сеть 220. Процессор 215 выводит результат 160 на пользовательский интерфейс 210 или на удаленное устройство (не показано) через сеть 220.
[0074] Хотя указано, что программный модуль 230 уже загружен в память 225, он может быть сконфигурирован на носителе 235 данных для последующей загрузки в память 225. Носитель 235 данных также является энергонезависимым машиночитаемым носителем, на котором записана компьютерная программа, и может представлять собой любой традиционный носитель данных для хранения программного модуля 230 в вещественной форме. Примеры носителя 235 данных включают в себя гибкий диск, компакт-диск, магнитную ленту, постоянную память, оптический носитель данных, флэш-носитель, подключаемый к универсальной последовательной шине (USB), цифровой универсальный диск или зип-диск. Носителем данных 235 также может быть оперативная память или электронное запоминающее устройство другого типа, установленное в системе дистанционного хранения и подключенное к компьютеру 205 по сети 220.
[0075] Описанные здесь методы являются примерными и не призваны налагать никаких конкретных ограничений на настоящее раскрытие. Следует понимать, что специалисты в данной области техники могут предложить различные альтернативы, комбинации и модификации. Например, этапы, связанные с описанными здесь процессами, могут осуществляться в любом порядке, если особо не указано обратное и не определяется самими этапами. Настоящее раскрытие призвано охватывать все подобные альтернативы, модификации и вариации, входящие в объем нижеследующей формулы изобретения.
[0076] Термины "содержит" или "содержащий" следует интерпретировать как указывающие наличие упомянутых признаков, целых чисел, этапов или компонентов, но не исключающие наличия одного или более других признаков, целых чисел, этапов или компонентов или их групп.
| название | год | авторы | номер документа |
|---|---|---|---|
| АВТОМАТИЗИРОВАННАЯ СИСТЕМА ВЕДЕНИЯ ИМУЩЕСТВЕННЫХ ДАННЫХ КАНДИДАТОВ И ДЕПУТАТОВ В БАЗЕ ДАННЫХ ИЗБИРАТЕЛЬНОЙ СИСТЕМЫ | 2006 |
|
RU2315356C1 |
| НЕДЕТЕРМИНИРОВАННОЕ РАЗРЕШЕНИЕ НЕОДНОЗНАЧНОСТИ И СОПОСТАВЛЕНИЕ ДАННЫХ МЕСТА КОММЕРЧЕСКОГО ПРЕДПРИЯТИЯ | 2014 |
|
RU2598165C1 |
| АВТОМАТИЗИРОВАННАЯ СИСТЕМА ВЕДЕНИЯ ПЕРСОНАЛЬНЫХ ДАННЫХ В БАЗЕ ДАННЫХ ИЗБИРАТЕЛЬНОЙ СИСТЕМЫ | 2006 |
|
RU2314566C1 |
| СИСТЕМА И СПОСОБ ДЛЯ ОБЛЕГЧЕНИЯ РАЗВИТИЯ МОБИЛЬНОГО СООБЩЕСТВА | 2009 |
|
RU2469500C2 |
| РАСШИРЕНИЕ СТРУКТУРЫ АУТЕНТИФИКАЦИИ ДЛЯ ВЕРИФИКАЦИИ ИДЕНТИФИКАЦИОННОЙ ИНФОРМАЦИИ | 2011 |
|
RU2577472C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПОДДЕРЖКИ ОТПЕЧАТКА БЕСПРОВОДНОЙ СЕТИ | 2010 |
|
RU2439852C1 |
| СИСТЕМА И СПОСОБ ДЛЯ АГРЕГИРОВАНИЯ И АССОЦИАТИВНОГО СВЯЗЫВАНИЯ ДАННЫХ ПРОФЕССИОНАЛЬНОЙ ПРИНАДЛЕЖНОСТИ С СОДЕРЖАНИЕМ КОММЕРЧЕСКИХ ДАННЫХ | 2011 |
|
RU2546317C2 |
| АВТОМАТИЗИРОВАННАЯ СИСТЕМА РЕГИСТРАЦИИ ПЕРСОНАЛЬНЫХ БИОМЕТРИЧЕСКИХ ДАННЫХ ЗАЯВИТЕЛЕЙ НА ПОЛУЧЕНИЕ ПАСПОРТНО-ВИЗОВЫХ ДОКУМЕНТОВ | 2008 |
|
RU2395838C1 |
| ИНФОРМАЦИОННО-СПРАВОЧНАЯ СИСТЕМА ГОСУДАРСТВЕННОГО РЕГИСТРА НАСЕЛЕНИЯ | 2003 |
|
RU2246756C1 |
| СИСТЕМА И СПОСОБ ДЛЯ ГЛОБАЛЬНОЙ СЛУЖБЫ КАТАЛОГОВ | 2010 |
|
RU2576495C2 |
Изобретение относится к средствам поиска в базе данных. Технический результат заключается в повышении совпадения результата с данными запроса. Принимают запрос на инициирование поиска данных, касающихся конкретной личности. Определяют на основании запроса стратегию поиска в базе справочных данных. В соответствии со стратегией производят в базе справочных данных поиск совпадения с запросом и выводят совпадение. Выделяют из запроса атрибут, который имеет отношение к поиску. Назначают вес атрибуту, таким образом обеспечивая взвешенный атрибут, причем вес указывает полезность атрибута при нахождении совпадения с запросом. Устанавливают функцию на основании взвешенного атрибута. Извлекают из базы справочных данных кандидатов, значения атрибутов которых указывают вероятные совпадения с запросом, на основании функции. Определяют наилучшего кандидата из кандидатов и возвращают наилучшего кандидата в качестве совпадения, причем запрос включает в себя значение запроса для атрибута. Изменяют упомянутый вес в зависимости от количества записей в базе справочных данных, которые имеют значение запроса для атрибута. 3 н. и 6 з.п. ф-лы, 2 ил., 8 табл.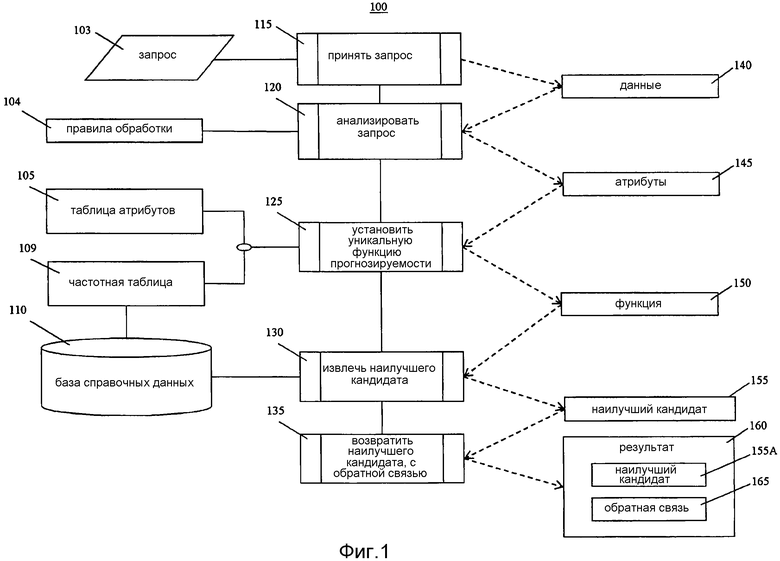
1. Способ поиска в базе данных, содержащий этапы, на которых
принимают запрос на инициирование поиска данных, касающихся конкретной личности,
определяют на основании упомянутого запроса стратегию поиска в базе справочных данных,
в соответствии с упомянутой стратегией производят в упомянутой базе справочных данных поиск совпадения с упомянутым запросом и
выводят упомянутое совпадение,
причем упомянутое определение упомянутой стратегии содержит этапы, на которых:
выделяют из упомянутого запроса атрибут, который имеет отношение к упомянутому поиску,
назначают вес упомянутому атрибуту, таким образом обеспечивая взвешенный атрибут,
причем упомянутый вес указывает полезность упомянутого атрибута при нахождении совпадения с упомянутым запросом, и
устанавливают функцию на основании упомянутого взвешенного атрибута, и
при этом упомянутый поиск содержит этапы, на которых: извлекают из упомянутой базы справочных данных кандидатов, значения атрибутов которых указывают вероятные совпадения с упомянутым запросом, на основании упомянутой функции,
определяют наилучшего кандидата из упомянутых кандидатов и возвращают упомянутого наилучшего кандидата в качестве упомянутого совпадения,
причем упомянутый запрос включает в себя значение запроса для упомянутого атрибута, и
при этом упомянутое установление содержит этап, на котором: изменяют упомянутый вес в зависимости от количества записей в упомянутой базе справочных данных, которые имеют упомянутое значение запроса для упомянутого атрибута.
2. Способ по п. 1, дополнительно содержащий этап, на котором выводят указатель уровня достоверности того, что упомянутое совпадение является адекватным совпадением с упомянутым запросом.
3. Способ по п. 2, в котором упомянутый указатель указывает, какие справочные данные использовались для формирования оценки, касающейся упомянутого уровня достоверности.
4. Система для поиска в базе данных, содержащая процессор и
память, которая содержит инструкции, которые, будучи считаны упомянутым процессором, предписывают упомянутому процессору:
принимать запрос на инициирование поиска данных, касающихся конкретной личности,
определять на основании упомянутого запроса стратегию поиска в базе справочных данных,
в соответствии с упомянутой стратегией производить в упомянутой базе справочных данных поиск совпадения с упомянутым запросом и
выводить упомянутое совпадение,
причем для определения упомянутой стратегии упомянутые инструкции предписывают упомянутому процессору:
выделять из упомянутого запроса атрибут, который имеет отношение к упомянутому поиску,
назначать вес упомянутому атрибуту, таким образом обеспечивая взвешенный атрибут,
причем упомянутый вес указывает полезность упомянутого атрибута при нахождении совпадения с упомянутым запросом, и
устанавливать функцию на основании упомянутого взвешенного атрибута, и
при этом для осуществления поиска в упомянутой базе справочных данных упомянутые инструкции предписывают упомянутому процессору:
извлекать из упомянутой базы справочных данных кандидатов, значения атрибутов которых указывают вероятные совпадения с упомянутым запросом, на основании упомянутой функции,
определять наилучшего кандидата из упомянутых кандидатов и
возвращать упомянутого наилучшего кандидата в качестве упомянутого совпадения,
причем упомянутый запрос включает в себя значение запроса для упомянутого атрибута, и
при этом для установления упомянутой функции упомянутые инструкции предписывают упомянутому процессору
изменять упомянутый вес в зависимости от количества записей в упомянутой базе справочных данных, которые имеют упомянутое значение запроса для упомянутого атрибута.
5. Система по п. 4, в которой упомянутые инструкции также предписывают упомянутому процессору выводить указатель уровня достоверности того, что упомянутое совпадение является адекватным совпадением с упомянутым запросом.
6. Система по п. 5, в которой упомянутый указатель указывает, какие справочные данные использовались для формирования оценки, касающейся упомянутого уровня достоверности.
7. Носитель данных, содержащий инструкции, которые, будучи считаны упомянутым процессором, предписывают упомянутому процессору:
принимать запрос на инициирование поиска данных, касающихся конкретной личности,
определять на основании упомянутого запроса стратегию поиска в базе справочных данных,
в соответствии с упомянутой стратегией производить в упомянутой базе справочных данных поиск совпадения с упомянутым запросом и
выводить упомянутое совпадение,
причем для определения упомянутой оптимальной стратегии упомянутые инструкции предписывают упомянутому процессору
выделять из упомянутого запроса атрибут, который имеет отношение к упомянутому поиску, и
назначать вес упомянутому атрибуту, таким образом обеспечивая взвешенный атрибут,
причем упомянутый вес указывает полезность упомянутого атрибута при нахождении совпадения с упомянутым запросом, и
устанавливать функцию на основании упомянутого взвешенного атрибута, и
при этом для осуществления поиска в упомянутой базе справочных данных упомянутые инструкции предписывают упомянутому процессору:
извлекать из упомянутой базы справочных данных кандидатов, значения атрибутов которых указывают вероятные совпадения с упомянутым запросом, на основании упомянутой функции,
определять наилучшего кандидата из упомянутых кандидатов и
возвращать упомянутого наилучшего кандидата в качестве упомянутого совпадения,
причем упомянутый запрос включает в себя значение запроса для упомянутого атрибута, и
при этом для установления упомянутой функции упомянутые инструкции предписывают упомянутому процессору:
изменять упомянутый вес в зависимости от количества записей в упомянутой базе справочных данных, которые имеют упомянутое значение запроса для упомянутого атрибута.
8. Носитель данных по п. 7, в котором упомянутые инструкции также предписывают упомянутому процессору выводить указатель уровня достоверности того, что упомянутое совпадение является адекватным совпадением с упомянутым запросом.
9. Носитель данных по п. 8, в котором упомянутый указатель указывает, какие справочные данные использовались для формирования оценки, касающейся упомянутого уровня достоверности.
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| СПОСОБ ПОИСКА И ВЫБОРКИ ИНФОРМАЦИИ С ПОВЫШЕННОЙ РЕЛЕВАНТНОСТЬЮ | 2003 |
|
RU2236699C1 |

