[0001] Эта заявка испрашивает приоритет предварительной заявки на патент США № 61/454862, поданной 21 марта 2011 года, и предварительной заявки на патент США № 61/502703, поданной 29 июня 2011 года, полное содержимое каждой из которых включено в данный документ посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ
[0002] Это раскрытие относится к методикам кодирования видео, используемым для сжатия данных видео, и, конкретнее, к режимам кодирования видео, используемым при сжатии видео.
УРОВЕНЬ ТЕХНИКИ
[0003] Возможности цифрового видео могут быть включены в широкий диапазон видеоустройств, в том числе средства цифрового телевидения, системы цифрового прямого вещания, устройства беспроводной связи, такие как беспроводные телефонные трубки, системы беспроводного вещания, персональные цифровые помощники (PDA), переносные или настольные компьютеры, планшетные компьютеры, цифровые камеры, устройства цифровой записи, игровые видеоустройства, консоли видеоигр, персональные мультимедийные проигрыватели и подобное. Такие видеоустройства могут реализовать методики сжатия видео, например, такие, которые описаны в MPEG-2, MPEG-4 или ITU-T H.264/MPEG-4, Часть 10, Усовершенствованное Кодирование Видео (AVC) для того, чтобы сжимать данные видео. Методики сжатия видео выполняют пространственное и/или временное предсказание (предсказание во времени), чтобы сократить или удалить избыточность, присущую последовательностям видео. Новые стандарты видео, например стандарт Высокоэффективного Кодирования Видео (HEVC), разрабатываемый «Объединенной командой по кодированию видео», которая представляет собой сотрудничество между MPEG и ITU-T, продолжают появляться и развиваться. Новый стандарт HEVC иногда называется H.265.
[0004] Эти и другие стандарты кодирования видео и методики используют основанное на блоках кодирование видео. Методики основанного на блоках кодирования видео делят данные видео кадра видео (или его части) на блоки видео и затем кодируют блоки видео с использованием методик предсказывающего основанного на блоках сжатия. Блоки видео могут быть дополнительно разделены на разделы блока видео. Блоки видео (или его разделы) могут быть названы единицами (CU) кодирования и могут быть кодированы с использованием одной или более специфичных для видео методик кодирования, а также обычных методик сжатия данных. Разные режимы могут быть выбраны и использованы для кодирования блоков видео.
[0005] С новым стандартом HEVC наибольшие единицы (LCU) кодирования могут быть разделены на все меньшие и меньшие CU согласно схеме разделения квадродерева. CU могут быть предсказаны на основе так называемых единиц (PU) предсказания, которые могут иметь размеры раздела, соответствующие размеру CU или меньшие, чем размер CU так, что множественные PU могут быть использованы для предсказания данной CU.
[0006] Разные режимы могут быть использованы для кодирования CU. Например, разные режимы внутреннего (intra) кодирования могут быть использованы для кодирования CU на основе предсказывающих данных в пределах одного и того же кадра или среза (сегмента) для того, чтобы использовать пространственную избыточность в пределах кадра видео. В качестве альтернативы режимы внешнего (inter) кодирования могут быть использованы для кодирования CU на основе предсказывающих данных от другого кадра или среза для того, чтобы использовать временную избыточность по кадрам последовательности видео. После того как предсказывающее кодирование выполнено согласно выбранному режиму, затем может быть выполнено кодирование с преобразованием, например дискретные косинусные преобразования (DCT), целочисленные преобразования или подобное. С HEVC кодирование с преобразованием может происходить относительно единиц (TU) преобразования, которые также могут иметь варьирующиеся размеры преобразования в стандарте HEVC. Квантование коэффициентов преобразования, сканирование квантованных коэффициентов преобразования и энтропийное кодирование также могут быть выполнены. Информация синтаксиса сигнализируется с кодированными данными видео, например, в заголовке среза видео или заголовке блока видео для того, чтобы информировать декодер как декодировать данные видео. Из других вещей, информация синтаксиса может идентифицировать режим, который был использован при кодировании видео разных блоков видео.
[0007] Режим слияния представляет собой специфичный режим внешнего кодирования, используемый при сжатии видео. В режиме слияния вектор движения соседнего блока видео перенимается (наследуется) для кодируемого текущего блока видео. В некоторых случаях режим слияния побуждает текущий блок кодирования перенимать вектор движения предварительно заданного соседа, и в других случаях индексное значение может быть использовано для идентификации конкретного соседа, из которого текущий блок видео перенимает свой вектор движения (например, сверху, сверху справа, слева, слева снизу или совместно размещенного из временно-смежного кадра).
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0008] Это раскрытие описывает двойной предсказывающий режим слияния, в котором блок видео, кодируемый в двойном предсказывающем режиме слияния, перенимает свою информацию движения из двух разных соседних блоков, при этом каждый из упомянутых двух разных соседних блоков кодированы в одинарном предсказывающем режиме. Двойное предсказывающее кодирование может улучшить возможность достижения сжатия или улучшить качество на данном уровне сжатия. Однако в некоторых случаях может не иметься (или иметься несколько) соседей, которые были кодированы в двойном предсказывающем режиме, тем самым делая двойное предсказание недоступным (или ограниченным) относительно кодирования (в режиме) режима слияния. Описанный двойной предсказывающий режим слияния может увеличить число двойных предсказывающих кандидатов, которые могут быть использованы в контексте кодирования режима слияния, позволяя двум отдельным одинарно предсказывающим соседям использоваться для задания двойной предсказывающей информации движения для блока видео.
[0009] В одном примере, это раскрытие описывает способ декодирования данных видео. Способ содержит прием одного или более элементов синтаксиса для текущего блока видео, при этом текущий блок видео кодируется согласно двойному предсказывающему режиму слияния и основываясь на упомянутом одном или более элементах синтаксиса, идентификацию двух разных соседних блоков видео, кодированных в одинарных предсказывающих режимах. Способ также содержит использование информации движения упомянутых двух разных соседних блоков видео, чтобы декодировать текущий блок видео согласно двойному предсказывающему режиму слияния.
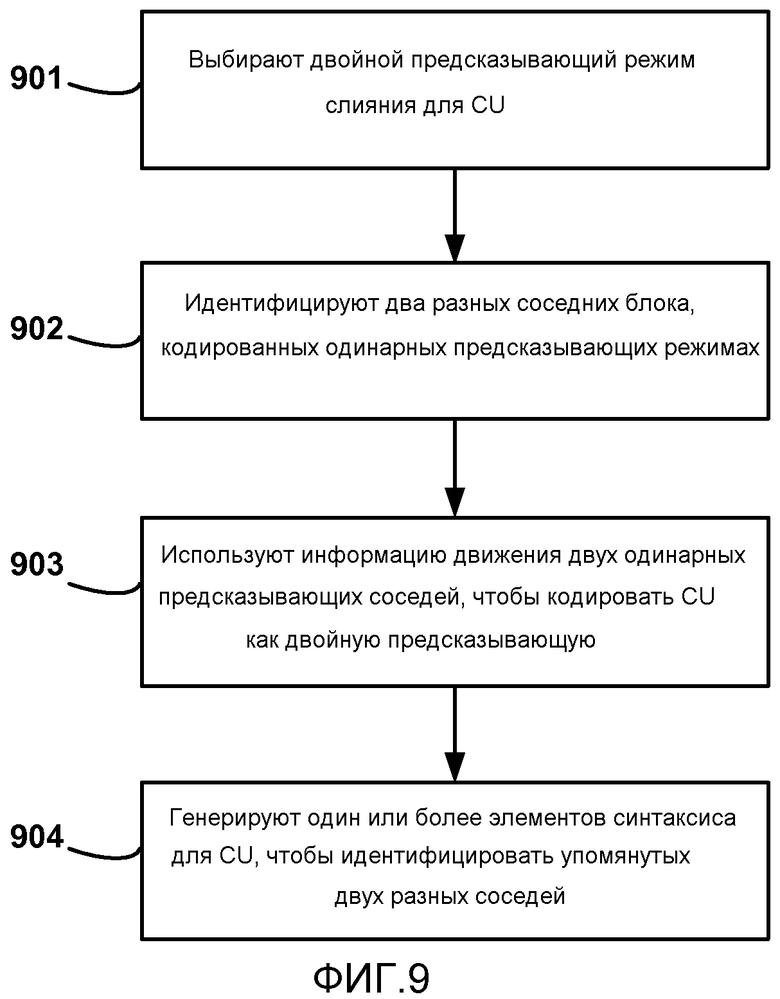
[0010] В другом примере, это раскрытие описывает способ кодирования данных видео. Способ содержит выбор двойного предсказывающего режима слияния для кодирования текущего блока видео, идентификацию двух разных соседних блоков видео, кодированных в одинарных предсказывающих режимах, использование информации движения упомянутых двух разных соседних блоков видео, чтобы кодировать текущий блок видео согласно двойному предсказывающему режиму слияния, и генерирование одного или более элементов синтаксиса, чтобы идентифицировать упомянутые два разных соседних блока видео для декодера видео.
[0011] В другом примере, это раскрытие описывает устройство декодирования видео, которое декодирует данные видео. Устройство декодирования видео содержит декодер видео, сконфигурированный для приема одного или более элементов синтаксиса для текущего блока видео, при этом текущий блок видео кодируется согласно двойному предсказывающему режиму слияния и основываясь на упомянутом одном или более элементах синтаксиса, идентификации двух разных соседних блоков видео, кодированных в одинарных предсказывающих режимах. Декодер видео сконфигурирован для использования информации движения упомянутых двух разных соседних блоков видео, чтобы декодировать текущий блок видео согласно двойному предсказывающему режиму слияния.
[0012] В другом примере это раскрытие описывает устройство кодирования видео, содержащее кодер видео, сконфигурированный для выбора двойного предсказывающего режима слияния для кодирования текущего блока видео, идентификации двух разных соседних блоков видео, кодированных в одинарных предсказывающих режимах, использования информации движения упомянутых двух разных соседних блоков видео, чтобы кодировать текущий блок видео согласно двойному предсказывающему режиму слияния, и генерирования одного или более элементов синтаксиса, чтобы идентифицировать упомянутые два разных соседних блока видео для декодера видео.
[0013] В другом примере это раскрытие описывает устройство для декодирования данных видео, причем устройство содержит средство для приема одного или более элементов синтаксиса для текущего блока видео, при этом текущий блок видео кодируется согласно двойному предсказывающему режиму слияния, средство для идентификации двух разных соседних блоков видео, кодированных в одинарных предсказывающих режимах, на основе упомянутого одного или более элементов синтаксиса и средство для использования информации движения упомянутых двух разных соседних блоков видео, чтобы декодировать текущий блок видео согласно двойному предсказывающему режиму слияния.
[0014] В другом примере это раскрытие описывает устройство для кодирования данных видео, причем устройство содержит средство для выбора двойного предсказывающего режима слияния для кодирования текущего блока видео, средство для идентификации двух разных соседних блоков видео, кодированных в одинарных предсказывающих режимах, средство для использования информации движения упомянутых двух разных соседних блоков видео, чтобы кодировать текущий блок видео согласно двойному предсказывающему режиму слияния и средство для генерирования одного или более элементов синтаксиса, чтобы идентифицировать упомянутые два разных соседних блока видео для декодера видео.
[0015] Методики, описанные в этом раскрытии, могут быть реализованы в аппаратном обеспечении, программном обеспечении, аппаратно-программном обеспечении или любой их комбинации. Например, различные методики могут быть реализованы или исполнены одним или более процессорами. Как используется в данном документе, процессор может относится к микропроцессору, специализированной интегральной схеме (ASIC), программируемой пользователем вентильной матрице (FPGA), цифровому сигнальному процессору (DSP) или другой эквивалентной интегральной схеме или схеме дискретной логики. Программное обеспечение может быть исполнено одним или более процессорами. Программное обеспечение, содержащее инструкции, чтобы исполнять методики, может быть исходно сохранено в считываемом компьютером носителе и загружено и исполнено процессором.
[0016] Соответственно, это раскрытие также предполагает считываемый компьютером носитель хранения, содержащий инструкции, чтобы побуждать процессор выполнять любые методики, описанные в этом раскрытии. В некоторых случая считываемый компьютером носитель может формировать часть продукта хранения компьютерной программы, который может быть продан производителям и/или использован в устройстве. Компьютерный программный продукт может включать в себя считываемый компьютером носитель и в некоторых случаях также может включать в себя материалы упаковки.
[0017] В частности, это раскрытие также описывает считываемый компьютером носитель, содержащий инструкции, которые при исполнении побуждают процессор декодировать данные видео, при этом инструкции побуждают процессор принять один или более элементов синтаксиса для текущего блока видео, при этом текущий блок видео кодирован согласно двойному предсказывающему режиму слияния, идентифицировать два разных соседних блока видео, кодированных в одинарных предсказывающих режимах, на основе упомянутого одного или более элементов синтаксиса, использовать информацию движения упомянутых двух разных соседних блоков видео, чтобы декодировать текущий блок видео согласно двойному предсказывающему режиму слияния.
[0018] В другом примере, раскрытие описывает считываемый компьютером носитель, содержащий инструкции, которые при исполнении побуждают процессор кодировать данные видео, при этом инструкции побуждают процессор выбирать двойной предсказывающий режим слияния для кодирования текущего блока видео, идентифицировать два разных соседних блока видео, кодированных в одинарных предсказывающих режимах, использовать информацию движения упомянутых двух разных соседних блоков видео, чтобы кодировать текущий блок видео согласно двойному предсказывающему режиму слияния и генерировать один или более элементов синтаксиса, чтобы идентифицировать упомянутые два разных соседних блока видео для декодера видео.
[0019] Подробности одного или более аспектов раскрытия изложены в описании ниже по тексту и (проиллюстрированы) на сопроводительных чертежах. Другие признаки, цели и преимущества методик, описанных в этом раскрытии, станут очевидными из описания и чертежей и из формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
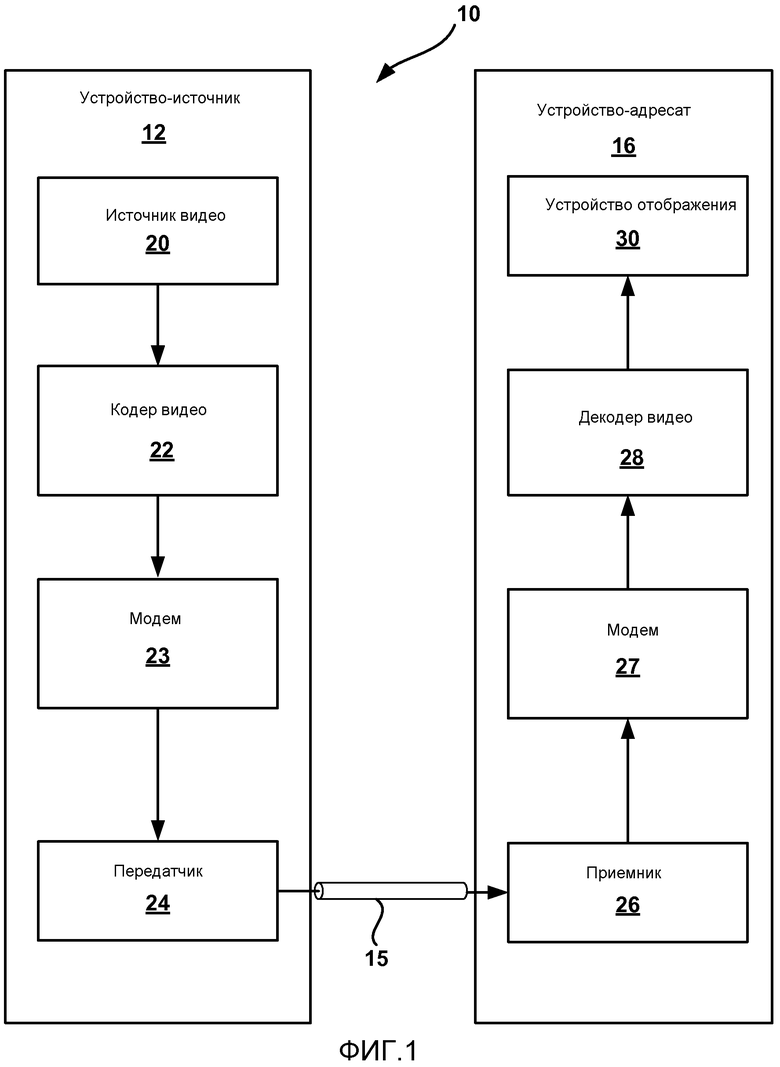
[0020] Фиг.1 представляет собой блок-схему, иллюстрирующую одну примерную систему кодирования и декодирования видео, которая может реализовывать одну или более методик этого раскрытия.
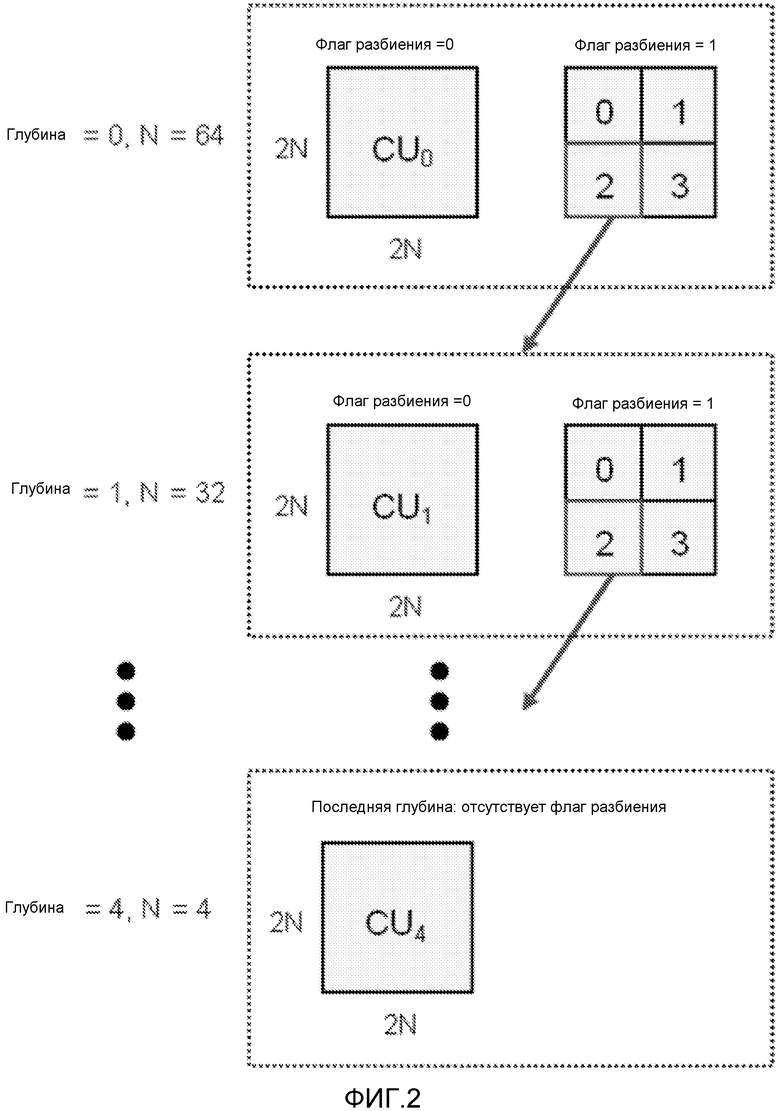
[0021] Фиг.2 представляет собой схему, иллюстрирующую разделение квадродерева единиц (CU) кодирования в соответствии с методиками этого раскрытия.
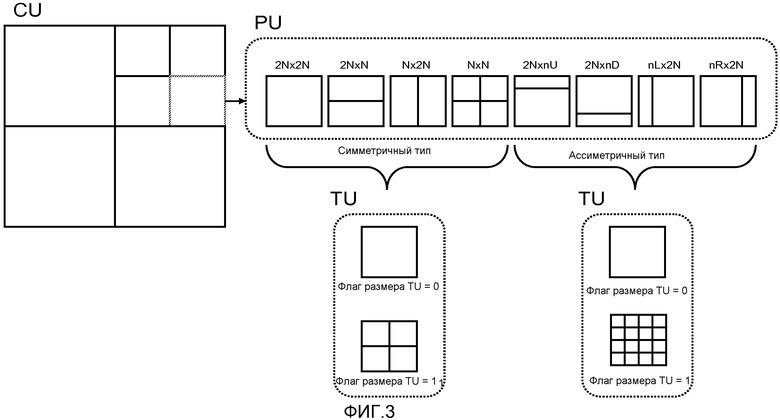
[0022] Фиг.3 представляет собой концептуальную схему, иллюстрирующую некоторые возможные соотношения между CU, единицами (PU) предсказания и единицами (TU) преобразования, в соответствии с методиками этого раскрытия.
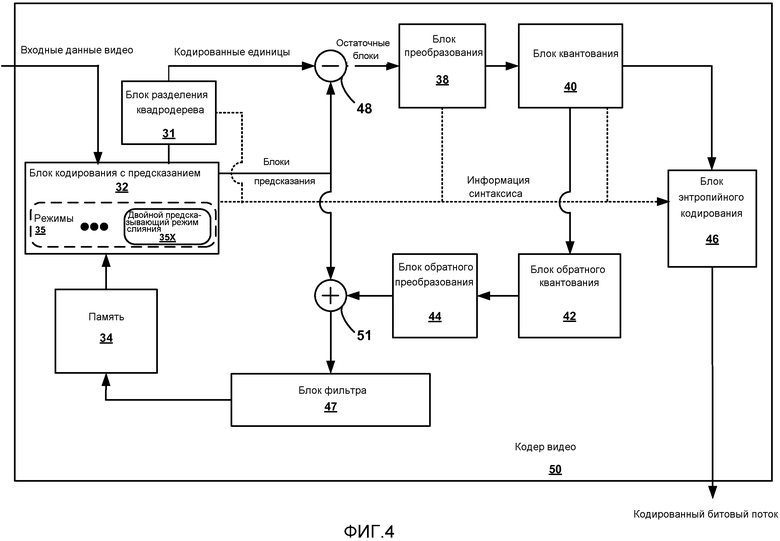
[0023] Фиг.4 представляет собой блок-схему, иллюстрирующую кодер видео, который может реализовать методики этого раскрытия.
[0024] Фиг.5 представляет собой блок-схему, иллюстрирующую примерную единицу предсказания кодера, совместимую с одним или более примерами этого раскрытия.
[0025] Фиг.6 представляет собой блок-схему, иллюстрирующую декодер видео, который может реализовать методики этого раскрытия.
[0026] Фиг.7 представляет собой схему, иллюстрирующую местоположение разных соседних блоков видео относительно текущего блока видео так, что текущий блок видео может использовать информацию одного или более разных соседних блоков видео в двойном предсказывающем режиме слияния, совместимую с этим раскрытием.
[0027] Фиг.8 и 9 представляют собой блок-схемы последовательностей операций, иллюстрирующие методики, совместимые с этим раскрытием.
ПОДРОБНОЕ ОПИСАНИЕ
[0028] В большинстве систем кодирования видео оценка движения и компенсация движения используются для сокращения временной избыточности в последовательности видео для того, чтобы достичь сжатия данных. В этом случае вектор движения может быть сгенерирован для того, чтобы идентифицировать предсказывающий блок данных видео, например, из другого среза или кадра видео, который может быть использован для предсказания значений кодируемого текущего блока видео. Значения предсказывающего блока видео вычитаются из значений текущего блока видео для выработки блока остаточных данных. Вектор движения передается от кодера к декодеру вместе с остаточными данными. Декодер может определить местоположение того же самого предсказывающего блока (на основании вектора движения) и восстановить кодированный блок видео, объединяя остаточные данные с данными предсказывающего блока. Многие другие методики сжатия также могут быть использованы, например преобразования и энтропийное кодирование, чтобы дополнительно улучшить сжатие видео.
[0029] Процесс оценки движения обычно выполняется в кодере. Информация движения (например, векторы движения, индексы векторов движения, направления предсказания или другая информация) может быть кодирована и передана от кодера к декодеру так, что декодер может идентифицировать тот же самый предсказывающий блок, который был использован, чтобы кодировать данный блок видео. Многие другие режимы кодирования могут быть использованы, чтобы сделать возможными различные типы временного предсказания между двумя разными кадрами или различные типы пространственного предсказания в пределах данного кадра.
[0030] В так называемом режиме слияния информация движения соседнего блока видео перенимается для кодируемого текущего блока видео. В этом случае сам вектор движения не передается для блока видео, кодируемого в режиме слияния. Вместо этого, индексное значение может быть использовано, чтобы идентифицировать соседа, от которого текущий блок видео перенимает свой вектор движения (и возможно другую информацию движения). Например, информация движения может быть перенята от соседа сверху, соседа сверху справа, соседа слева, соседа снизу слева или совместно размещенного временного соседа из смежного во времени кадра.
[0031] В большинстве режимов слияния, если сосед кодируется в одинарном предсказывающем режиме, то текущий блок видео перенимает один вектор движения. Если сосед кодируется в двойном предсказывающем режиме, то текущий блок видео перенимает два вектора движения. В таких примерах блок, кодируемый в режиме слияния, ограничен информацией движения своих соседей. Одинарное предсказание и двойное предсказание иногда называют однонаправленным (P) предсказанием и двунаправленным (B) предсказанием, однако термин «направленное» обычно неуместен, поскольку с современными стандартами кодирования видео двойное предсказание просто основано на двух разных списках предсказывающих данных и направление не является обязательным. Другими словами, данные в двух разных списках для двойного предсказания могут происходить из предшествующего или последующего кадров и им нет необходимости быть двунаправленными из обоих предшествующего и последующего кадров соответственно. По этой причине это раскрытие использует термины одинарное предсказание и двойное предсказание вместо терминов однонаправленное предсказание и двунаправленное предсказание.
[0032] Двойное предсказывающее кодирование может улучшать способность достигать сжатия или улучшать качество видео на данном уровне сжатия. Однако в некоторых случаях может не иметься (или иметься несколько) соседей, которые были кодированы в двойном предсказывающем режиме, тем самым делая двойное предсказание недоступным (или ограниченным) при кодировании режима слияния. Например, с традиционным режимом слияния, если отсутствует двойной предсказывающий режим в каком-либо из соседних блоков, текущий блок может терять возможность использовать преимущества, которые могут возникать из двойного предсказания.
[0033] Это раскрытие описывает двойной предсказывающий режим слияния как расширение или дополнение к приемам режима слияния. Более конкретно это раскрытие описывает двойной предсказывающий режим слияния, который перенимает информацию движения от двух разных соседних блоков, при этом каждый из упомянутых двух разных соседних блоков был кодирован в одинарном предсказывающем режиме. Описанный двойной предсказывающий режим слияния может увеличить количество двойных предсказывающих кандидатов, которые могут быть использованы в контексте кодирования режима слияния.
[0034] Фиг.1 представляет собой блок-схему, иллюстрирующую примерную систему 10 кодирования и декодирования видео, которая может реализовать методики этого раскрытия. Как показано на Фиг.1, система 10 включает в себя устройство-источник 12, которое передает кодированное видео устройству-адресату 16 через канал 15 связи. Устройство-источник 12 и устройство-адресат 16 могут содержать любое из широкого диапазона устройств. В некоторых случаях, устройство-источник 12 и устройство-адресат 16 могут содержать телефонные трубки-устройства беспроводной связи, так называемые сотовые или спутниковые радиотелефоны. Методики этого раскрытия, однако, которые применяются в основном к кодированию и декодированию блоков видео в двойном предсказывающем режиме слияния могут быть применены к не являющимся проводными устройствам, включающим в себя возможности кодирования и/или декодирования видео. Устройство-источник 12 и устройство-адресат 16 представляют собой лишь примеры устройств кодирования, которые могут поддерживать методики, описанные в данном документе.
[0035] В примере по Фиг.1, устройство-источник 12 может включать в себя источник 20 видео, кодер 22 видео, модулятор/демодулятор (модем) 23 и передатчик 24. Устройство-адресат 16 может включать в себя приемник 26, модем 27, декодер 28 видео и устройство 30 отображения. В соответствии с этим раскрытием, кодер 22 видео устройства-источника 12 может быть сконфигурирован, чтобы кодировать один или более блоков видео, согласно двойному предсказывающему режиму слияния. В двойном предсказывающем режиме слияния блок видео перенимает свою информацию движения от двух разных соседних блоков, при этом каждый из упомянутых двух разных соседних блоков был кодирован в одинарном предсказывающем режиме. Элементы синтаксиса могут быть сгенерированы в кодере 22 видео для того, чтобы идентифицировать упомянутые два разных соседних блока видео, кодируемые в одинарных предсказывающих режимах. Таким образом, декодер видео может восстановить двойной предсказывающий блок видео, основываясь на информации движения упомянутых двух разных соседних блоков видео, идентифицированных элементами синтаксиса.
[0036] Более конкретно, кодер 22 видео может выбирать двойной предсказывающий режим слияния для кодирования текущего блока видео и идентифицировать два разных соседних блока видео, кодированных в одинарных предсказывающих режимах. Кодер 22 видео может использовать информацию движения двух разных соседних блоков видео, чтобы кодировать текущий блок видео согласно двойному предсказывающему режиму слияния, и генерировать один или более элементов синтаксиса, чтобы идентифицировать два разных соседних блока видео для декодера видео.
[0037] Источник 20 видео может содержать устройство захвата видео, например видеокамеру, видеоархив, содержащий ранее захваченное видео, трансляцию видео от поставщика контента видео или другого источника видео. В качестве дополнительной альтернативы, источник 20 видео может генерировать основанные на компьютерной графике данные в качестве видеоисточника или комбинацию видео в реальном времени, архивированного видео и сгенерированного компьютером видео. В некоторых случаях, если источник 20 видео представляет собой видеокамеру, устройство-источник 12 и устройство-адресат 16 могут формировать так называемые телефоны-камеры или видеотелефоны. В каждом случае, захваченное, предварительно захваченное или сгенерированное компьютером видео может быть кодировано кодером 22 видео.
[0038] Как только данные видео кодированы кодером 22 видео, информация кодированного видео затем может быть модулирована модемом 23 согласно стандарту связи, например множественный доступ с кодовым разделением (CDMA), мультиплексирование с ортогональным частотным разделением (OFDM) или любой другой стандарт связи или методика. Кодированные и модулированные данные затем могут быть переданы к устройству-адресату 16 через передатчик 24. Модем 23 может включать в себя различные смесители, фильтры, усилители или другие компоненты, выполненные для модуляции сигналов. Передатчик 24 может включать в себя схемы, выполненные для передачи данных, в том числе усилители, фильтры и одну или более антенн. Приемник 26 устройства-адресата 16 принимает информацию по каналу 15 и модем 27 демодулирует информацию.
[0039] Процесс декодирования видео, выполняемый декодером 28 видео, может включать в себя методики, обратные методикам кодирования, выполняемым кодером 22 видео. В частности, декодер 28 видео может принимать один или более элементов синтаксиса для текущего блока видео, при этом текущий блок видео кодируется согласно двойному предсказывающему режиму слияния и на основании упомянутого одного или более элементов синтаксиса, идентифицировать два разных соседних блока видео, кодируемых в одинарных предсказывающих режимах. Декодер видео может использовать информацию движения упомянутых двух разных соседних блоков видео, чтобы декодировать текущий блок видео согласно двойному предсказывающему режиму слияния.
[0040] Канал 15 связи может содержать любой беспроводной или проводной носитель связи, например радиочастотный (РЧ) спектр или одну или более физических линий передачи, или любую комбинацию беспроводного или проводного носителей. Канал 15 связи может формировать часть пакетной сети, например, локальной сети, широкомасштабной сети или глобальной сети, такой как Интернет. Канал 15 связи, в общем, представляет любой подходящий носитель связи или совокупность разных носителей связи для передачи данных видео от устройства-источника 12 устройству-адресату 16. Кроме того, Фиг.1 является лишь примерной и методики этого раскрытия могут применяться к любым настройкам кодирования видео (например, кодирования видео или декодирования видео), которые необязательно включают в себя передачу каких-либо данных между устройствами кодирования и декодирования. В других примерах данные могут быть извлечены из локальной памяти, переданы потоком по сети и т.п.
[0041] В некоторых случаях кодер 22 видео и декодер 28 видео могут работать по существу согласно стандарту сжатия видео, такому как развивающийся стандарт HEVC. Однако методики этого раскрытия также могут быть применены в контексте ряда других стандартов кодирования видео, в том числе некоторых старых стандартов или новых или развивающихся стандартов. Хотя не показано на Фиг.1, в некоторых случаях, каждый из кодера 22 видео и декодера 28 видео может быть объединен с кодером и декодером аудио и может включать в себя надлежащие блоки MUX-DEMUX или другое аппаратное обеспечение и программное обеспечение, чтобы обрабатывать как аудио, так и видео в общем потоке данных или раздельных потоках данных. Если применимо, блоки MUX-DEMUX могут соответствовать протоколу мультиплексора ITU H.223 или другим протоколам, таким как протокол пользовательских дейтаграмм (UDP).
[0042] Каждый из кодера 22 видео и декодера 28 видео может быть реализован как один или более микропроцессоров, цифровых сигнальных процессоров (DSP), интегральных схем специального назначения (ASIC), программируемых пользователем вентильных матриц (FPGA), дискретной логики, программного обеспечения, аппаратного обеспечения, программно-аппаратного обеспечения или их комбинаций. Каждый из кодера 22 видео и декодера 28 видео может быть включен в один или более кодеров и декодеров, любой из которых может быть объединен как часть комбинированного кодера/декодера (CODEC) в соответствующем мобильном устройстве, устройстве абонента, устройстве вещания, сервере или подобном. В этом раскрытии термин средство кодирования относится к кодеру, декодеру или CODEC, и термины средство кодирования, кодер, декодер и CODEC все относятся к конкретным машинам, выполненным для кодирования (кодирования и/или декодирования) данных видео в соответствии с этим раскрытием.
[0043] В некоторых случаях, устройства 12, 16 могут работать по существу симметричным образом. Например, каждое из устройств 12, 16 может включать в себя компоненты декодирования и кодирования видео. Следовательно, система 10 может поддерживать одностороннюю или двустороннюю передачу видео между устройствами 12, 16 видео, например, для потоковой передачи видео, воспроизведения видео, вещания видео или видеотелефонии.
[0044] Во время процесса кодирования кодер 22 видео может исполнить некоторое число методик или операций кодирования. В общем, кодер 22 видео работает в отношении блоков данных видео в соответствии со стандартом HEVC. В соответствии с HEVC блоки видео называются единицами (CU) кодирования и множество CU существуют в пределах отдельных кадров видео (или других независимо заданных единицах видео, таких как срезы). Кадры, срезы, участки кадров, группы графических изображений или другие структуры данных могут быть заданы как единицы информации видео, которая включает в себя множество CU. CU могут иметь варьирующиеся размеры в соответствии со стандартом HEVC и битовый поток может задавать наибольшие единицы (LCU) кодирования в качестве наибольшего размера CU. Двойной предсказывающий режим слияния может быть использован, чтобы кодировать LCU, CU или возможно другие типы блоков видео. Со стандартом HEVC, LCU могут быть разделены на меньшие и меньшие CU согласно схеме разделения квадродерева и разные CU, которые заданы в схеме могут быть дополнительно разделены на так называемые единицы (PU) предсказания. LCU, CU и PU все являются блоками видео в рамках этого раскрытия.
[0045] Кодер 22 видео может выполнять предсказывающее кодирование, при котором кодируемый блок видео (например, PU единицы (CU) кодирования в пределах LCU) сравнивается с одним или более предсказывающими кандидатами для того, чтобы идентифицировать предсказывающий блок. Этот процесс предсказывающего кодирования может быть intra (внутренним) (в случае с которым предсказывающие данные генерируются на основе соседних intra-данных в пределах одного и того же кадра или среза) или inter (внешним) (в случае с которым предсказывающие данные генерируются на основании данных видео в предшествующих или последующих кадрах или срезах). Многие другие режимы кодирования могут поддерживаться, и кодер 22 видео может выбирать желаемый режим кодирования видео. Согласно этому раскрытию по меньшей мере некоторые блоки видео могут быть кодированы с использованием двойного предсказывающего режима слияния, описанного в данном документе.
[0046] После генерирования предсказывающего блока разности между кодируемым текущим блоком видео и предсказывающим блоком кодируются как остаточный блок, и синтаксис предсказания (такой как вектор движения в случае внешнего кодирования или предсказывающий режим в случае внутреннего кодирования) используется, чтобы идентифицировать предсказывающий блок. Более того, в двойном предсказывающем режиме слияния, описанном в данном документе, синтаксис предсказания (например, элементы синтаксиса) может идентифицировать два разных соседних блока видео для декодера видео. Соответственно, декодер может идентифицировать два разных соседних блока видео, кодируемых в одинарных предсказывающих режимах, основываясь на элементах синтаксиса, и использовать информацию движения упомянутых двух разных соседних блоков видео, чтобы декодировать текущий блок видео согласно двойному предсказывающему режиму слияния.
[0047] Остаточный блок может быть преобразован и квантован. Методики преобразования могут содержать процесс DCT или концептуально аналогичный процесс, целочисленные преобразования, вейвлетные преобразования или другие типы преобразований. В процессе DCT в качестве примера процесс преобразования конвертирует набор пиксельных значений (например, остаточные пиксельные значения) в коэффициенты преобразования, которые могут представлять энергию пиксельных значений в частотной области. Стандарт HEVC делает возможными преобразования согласно единицам (TU) преобразования, которые могут быть разными для разных CU. TU типично устанавливают размеры, основываясь на размере PU в пределах данной CU, заданной для разделенной LCU, несмотря на то, что это может не всегда иметь место. TU типично имеют такой же размер или меньший, чем PU.
[0048] Квантование может быть применено к коэффициентам преобразования и, в общем, влечет за собой процесс, который ограничивает число бит, связанных с каким-либо заданным коэффициентом преобразования. Более конкретно, квантование может быть применено согласно параметру (QP) квантования, заданному на уровне LCU. Соответственно тот же самый уровень квантования может быть применен ко всем коэффициентам преобразования в единицах (TU) преобразования, связанных с разными PU единиц (CU) кодирования в пределах LCU. Однако вместо того, чтобы сигнализировать сам QP, изменение (т.е. дельта) в QP может быть сигнализировано с LCU, чтобы указать изменение в QP относительно такового у предшествующего LCU.
[0049] Следом за преобразованием и квантованием энтропийное кодирование может быть выполнено в отношении квантованных и преобразованных остаточных блоков видео. Элементы синтаксиса также могут быть включены в энтропийно кодируемый битовый поток. В общем, энтропийное кодирование содержит один или более процессов, которые совместно сжимают последовательность квантованных коэффициентов преобразования и/или другую информацию синтаксиса. Методики сканирования могут быть выполнены в отношении квантованных коэффициентов преобразования для того, чтобы задать один или более упорядоченных одномерных векторов коэффициентов из двумерных блоков видео. Сканируемые коэффициенты затем энтропийно кодируются вместе с какой-либо информацией синтаксиса, например, через контекстно-зависимое адаптивное кодирование с переменной длиной кодового слова (CAVLC), контекстно-зависимое адаптивное двоичное арифметическое кодирование (CABAC) или другой процесс энтропийного кодирования.
[0050] Как часть процесса кодирования, кодированные блоки видео могут быть декодированы для того, чтобы сгенерировать данные видео, которые используются для последующего основанного на предсказании кодирования последующих блоков видео. Это часто называют циклом декодирования процесса кодирования и, в общем, имитирует декодирование, которое выполняется устройством-декодером. В цикле декодирования кодера или декодера методики фильтрации могут быть использованы, чтобы улучшить качество видео и, например, сгладить пиксельные границы и возможно удалить артефакты из декодированного видео. Эта фильтрация может проходить в цикле или после цикла. С фильтрацией в цикле, фильтрация восстановленных данных видео возникает в цикле кодирования, что означает, что фильтрованные данные сохраняются кодером или декодером для последующего использования в предсказании данных последующего изображения. Напротив, с фильтрацией после цикла, фильтрация восстановленных данных видео возникает вне цикла кодирования, что означает, что нефильтрованные версии данных сохраняются кодером или декодером для последующего использования в предсказании данных последующего изображения. Фильтрация цикла часто следует за отельным процессом фильтрации по удалению блочности, который типично применяет фильтрацию к пикселям, которые находятся на или вблизи границ смежных блоков видео для того, чтобы удалить артефакты блочности, которые проявляются на границах блока видео.
[0051] Относительно предшествующих стандартов кодирования, развивающийся стандарт HEVC вводит новые элементы и размеры блока для блоков видео. В частности, HEVC ссылается на единицы (CU) кодирования, которые могут быть разделены согласно схеме разделения квадродерева. “LCU” относится к единице кодирования наибольшего размера (например, “наибольшей единице кодирования”) поддерживаемой в данной ситуации. Сам размер LCU может быть сигнализирован как часть битового потока, например, как синтаксис уровня последовательности. LCU может быть разделена на меньшие CU. CU могут быть разделены на единицы (PU) предсказания для целей предсказания. PU могут иметь квадратные или прямоугольные формы. Преобразования не фиксируются в развивающемся стандарте HEVC, но задаются согласно размерам единицы (TU) преобразования, которые могут быть такого же размера, что и данная CU, или возможно меньше. Остаточные данные для данной CU могут быть переданы в TU. Элементы синтаксиса могут быть заданы на уровне LCU, уровне CU, уровне PU и уровне TU.
[0052] Чтобы проиллюстрировать блоки видео согласно стандарту HEVC, Фиг.2 концептуально показывает LCU глубины 64 на 64, которая затем разделяется на меньшие CU согласно схеме разделения квадродерева. Элементы называемые “флагами разбиения” могут быть включены в синтаксис уровня CU, чтобы указать, является ли какая-либо данная CU сама подразделенной на еще четыре CU. На Фиг.2, CU0 может содержать LCU, CU1-CU4 могут содержать суб-CU наибольшей единицы (LCU) кодирования. Элементы синтаксиса двойного предсказывающего режима слияния, как описано в этом раскрытии, могут быть заданы на уровне CU (или возможно уровне LCU, если LCU не разбита на меньшие CU). Двойной предсказывающий режим слияния также может поддерживаться для PU единиц (CU) кодирования в некоторых примерах.
[0053] Фиг.3 дополнительно иллюстрирует одно возможное соотношение между CU, PU и TU, которое может соответствовать развивающемуся стандарту HEVC или другим стандартам. Однако другие соотношения также возможны, и Фиг.3 лишь показана в качестве одного возможного примера. В этом случае любая данная CU наибольшей единицы (LCU) кодирования сама может быть разделена на PU, такие как показаны на Фиг.3. Тип PU для данной CU может быть сигнализирован как синтаксис уровня CU. Как показано на Фиг.3, PU симметричного типа и PU ассиметричного типа могут быть заданы для данной CU. Более того, две разных структуры TU могут быть заданы для каждой из четырех PU симметричного типа и PU ассиметричного типа. Таким образом, однобитовый элемент синтаксиса (флаг размера TU) может быть использован, чтобы сигнализировать размер TU, который также может зависеть от типа PU (симметричная или несимметричная). Кодируемые шаблоны (CBP) блока могут быть заданы для LCU для того, чтобы указать, включает ли в себя какая-либо данная CU ненулевые коэффициенты преобразования (например, имеются ли какие-либо TU).
[0054] В других примерах, TU может быть задана не так, как показано на Фиг.3. Например, остаточные выборки соответствующие CU могут быть подразделены на меньшие единицы с использованием структуры квадродерева, известной как “остаточное квадродерево” (RQT). Листовой узел RQT может быть назван единицами (TU) преобразования. В некоторых случаях, TU могут быть заданы для CU согласно структуре квадродерева, но TU могут необязательно зависеть от PU, заданных для какой-либо данной CU. PU используемые для предсказания могут быть заданы отдельно от TU какой-либо CU. Некоторое число разных типов схем разделения для CU, TU и PU возможны.
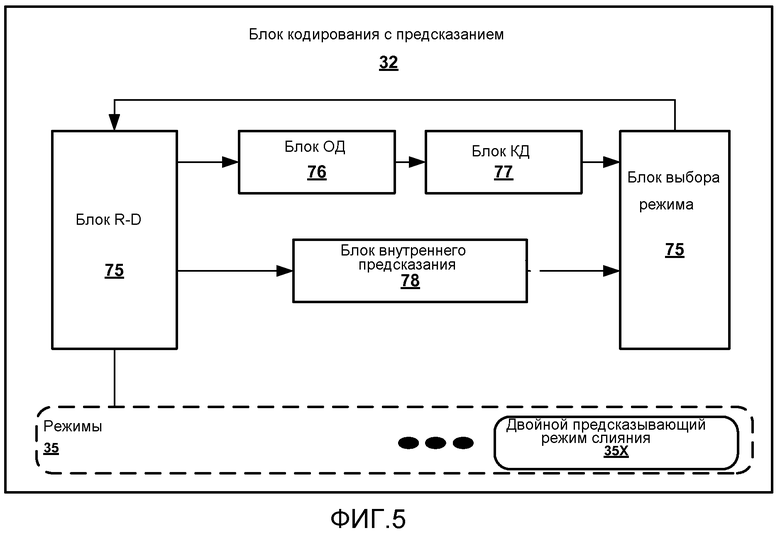
[0055] Фиг.4 представляет собой блок-схему, иллюстрирующую кодер 50 видео в соответствии с этим раскрытием. Кодер 50 видео может соответствовать кодеру 22 видео устройства 20 или кодеру видео другого устройства. Как показано на Фиг.4, кодер 50 видео включает в себя блок 32 кодирования с предсказанием, блок 31 разделения квадродерева, сумматоры 48 и 51 и память 34. Кодер 50 видео также включает в себя блок 38 преобразования и блок 40 квантования, а также блок 42 обратного квантования и блок 44 обратного преобразования. Кодер 50 видео также включает в себя блок 46 энтропийного кодирования и блок 47 фильтра, который может включать в себя фильтры устранения блочности и фильтры в цикле и/или после цикла. Данные кодируемого видео и информация синтаксиса, которая задает образ кодирования, могут быть переданы к блоку 46 энтропийного кодирования, который выполняет энтропийное кодирование в отношении битового потока.
[0056] Как показано на Фиг.4, блок 32 кодирования с предсказанием может поддерживать множество разных режимов 35 кодирования при кодировании блоков видео. Режимы 35 могут включать в себя режимы внешнего кодирования, которые задают предсказывающие данные из разных кадров (или срезов) видео. Режимы внешнего кодирования могут быть двойными предсказывающими, что означает, что два разных списка (например, Список 0 и Список 1) предсказывающих данных (и типично два разных вектора движения) используются, чтобы идентифицировать предсказывающие данные. Режимы внутреннего кодирования могут в качестве альтернативы быть одинарными предсказывающими, что означает, что один список (например, Список 0) предсказывающих данных (и типично один вектор движения) используется, чтобы идентифицировать предсказывающие данные. Интерполяции, смещения или другие методики могут быть выполнены вместе с генерированием предсказывающих данных. Также могут поддерживаться так называемые режимы SKIP и режимы DIRECT, которые перенимают информацию движения, связанную с совместно размещенным блоком другого кадра (или среза). Блоки режима SKIP не включают в себя какой-либо остаточной информации, тогда как блоки режима DIRECT включают в себя остаточную информацию.
[0057] В дополнение режимы 35 могут включать в себя режимы внешнего кодирования, которые задают предсказывающие данные на основании данных в пределах того же кадра (или среза) видео, что и кодируемый. Режимы внутреннего кодирования могут включать направленные режимы, которые задают предсказывающие данные на основании данных в конкретном направлении в пределах одного и того же кадра, а также DC и/или планарные режимы, которые задают предсказывающие данные, основываясь на среднем или взвешенном среднем соседних данных. Блок 32 кодирования с предсказанием может выбирать режим для данного блока на основании некоторых критериев, например на основании анализа искажение-скорость передачи или некоторых характеристик блока, таких как размер блока, текстура или другие характеристики.
[0058] В соответствии с этим раскрытием блок 32 кодирования с предсказанием поддерживает двойной предсказывающий режим 35X слияния. В двойном предсказывающем режиме 35X слияния кодируемый блок видео перенимает информацию движения от двух разных соседних блоков, при этом каждый из двух разных соседних блоков был кодирован в одинарном предсказывающем режиме. Таким образом, блок видео кодируется с двумя разными векторами движения, которые исходят от двух разных соседних блоков видео. В этом случае блок 32 кодирования с предсказанием выводит указание, что двойной предсказывающий режим слияния был использован для данного блока, и выводит элементы синтаксиса, которые идентифицируют упомянутые два разных одинарных предсказывающих соседа, которые совместно задают информацию движения для текущего двойного предсказывающего блока. Предсказывающие блоки, связанные с двойным предсказывающим режимом слияния могут быть объединены в один двойной предсказывающий блок (возможно с использованием весовых коэффициентов), и двойной предсказывающий блок может быть вычтен из кодируемого блока (посредством сумматора 48), чтобы задать остаточные данные, связанные с блоком, кодируемым в двойном предсказывающем режиме слияния.
[0059] Информация движения может содержать два разных одинарных предсказывающих вектора движения, связанных с упомянутыми двумя разными соседними блоками видео. Эти два разных одинарных предсказывающих вектора движения могут быть использованы как упомянутые два двойных предсказывающих вектора движения текущего блока видео. Информация движения может дополнительно содержать два опорных индексных значения, связанных с упомянутыми двумя разными одинарными предсказывающими векторами движения, при этом опорные индексные значения идентифицируют один или более списков предсказывающих данных, связанных с упомянутыми двумя разными одинарными предсказывающими векторами движения. Снова, остаточные данные могут быть генерированы как разность между кодируемым блоком и предсказывающими данными, заданными упомянутыми двумя разными одинарными предсказывающими векторами движения, которые совместно задают двойной предсказывающий блок слияния, используемый в предсказании.
[0060] В случае HEVC текущий кодируемый блок видео может содержать так называемую CU, заданную относительно LCU согласно схеме разделения квадродерева. В этом случае блок 31 разделения квадродерева может генерировать данные синтаксиса LCU, которые задают схему разделения квадродерева, и блок 32 кодирования с предсказанием может генерировать информацию режима для CU, которая задает двойной предсказывающий режим слияния, при этом упомянутый один или более элементов синтаксиса (которые идентифицируют упомянутые два одинарных предсказывающих соседа) включаются в информацию режима для CU.
[0061] Описанный двойной предсказывающий режим слияния может увеличить число двойных предсказывающих кандидатов, которые могут быть использованы в контексте кодирования режима слияния. Например, если никакие из соседей не кодируются в двойном предсказывающем режиме, описанный двойной предсказывающий режим слияния может сделать возможным двойное предсказание, которое должно быть использовано посредством объединения информации движения двух соседей при предсказании текущего блока видео. Также, даже если один или более соседей кодируются в двойном предсказывающем режиме, объединяя два однонаправленных соседа согласно описанному двойном предсказывающему режиму слияния, можно все еще обеспечивать улучшения кодирования в некоторых ситуациях.
[0062] Обычно во время процесса кодирования кодер 50 видео принимает входные данные видео. Блок 32 кодирования с предсказанием выполняет методики предсказывающего кодирования в отношении блоков видео (например, CU и PU). Блок 31 разделения квадродерева может разбивать LCU на меньшие CU и PU согласно разделению HEVC, поясненному выше по тексту со ссылкой на Фиг.2 и 3. Для внешнего кодирования блок 32 кодирования с предсказанием сравнивает CU и PU с различными предсказывающими кандидатами в одном или более опорных кадрах или срезах видео (например, одном или более “списке” опорных данных) для того, чтобы задать предсказывающий блок. Для внутреннего кодирования блок 32 кодирования с предсказанием генерирует предсказывающий блок, основываясь на соседних данных в пределах одного кадра или среза видео. Блок 32 кодирования с предсказанием выводит блок предсказания и сумматор 48 вычитает блок предсказания из кодируемой CU или PU для того, чтобы генерировать остаточный блок. Снова, по меньшей мере, некоторые блоки видео могут быть кодированы с использованием двойного предсказывающего режима слияния, описанного в данном документе.
[0063] Фиг.5 иллюстрирует один пример блока 32 кодирования с предсказанием кодера 50 видео более подробно. Блок 32 кодирования с предсказанием может включать в себя блок 75 выбора режима, который выбирает желаемый режим из режимов 35, которые включают в себя двойной предсказывающий режим 35X слияния в качестве возможности. Для внешнего кодирования блок 32 кодирования с предсказанием может содержать блок 76 оценки движения (ОД) и блок 77 компенсации движения (КД), который идентифицирует один или более векторов движения, которые указывают на предсказывающие данные, и генерирует блок предсказания, основываясь на векторе движения. Типично оценка движения учитывает процесс по генерированию упомянутого одного или более векторов движения, которые оценивают движение. Например, вектор движения может указывать сдвиг предикивного блока в пределах предсказывающего кадра относительно текущего кодируемого блока в пределах текущего кадра. В случае двойного предсказывающего режима 35X слияния, два однонаправленных вектора движения двух соседей объединяются, чтобы создать двунаправленное предсказание.
[0064] Компенсация движения типично учитывает процесс выборки или генерирования предсказывающего блока (или блоков) основываясь на векторе движения, определенном оценкой движения. В некоторых случаях, компенсация движения для внешнего кодирования может включать в себя интерполяции до субпиксельного разрешения, которые позволяют процессу оценки движения оценивать движение блоков видео до такого субпиксельного разрешения. Взвешенные комбинации двух блоков (в случае двойного предсказания) также могут быть использованы.
[0065] Для внутреннего кодирования блок 32 кодирования с предсказанием может содержать блок 78 внутреннего предсказания. В этом случае предсказывающие данные могут быть сгенерированы на основе данных в пределах текущего блока видео (например, смежного с кодируемым блоком видео). Кроме того, режимы внутреннего кодирования могут включать в себя направленные режим, которые задают предсказывающие данные, основываясь на данных в конкретном направлении в пределах одного и того же кадра, а также DC и/или планарный режимы, которые задают предсказывающие данные, основываясь на среднем или взвешенном среднем данных соседей.
[0066] Блок 79 искажение-скорость передачи (R-D) может сравнивать результаты кодирования блоков видео (например, CU или PU) в разных режимах. В дополнение блок 79 R-D может делать возможными другие типы корректировок параметра, например корректировок интерполяций, сдвигов, параметров квантования или других коэффициентов, которые могут негативно воздействовать на скорость кодирования. Блок 75 выбора режима может анализировать результаты кодирования исходя из скорости кодирования (т.е. битов кодирования, требуемых для блока) и искажения (например, представляющего качество видео кодируемого блока относительно исходного блока) для того, чтобы выполнять выборы режима для блоков видео. Таким образом, блок 79 R-D обеспечивает анализ результатов разных режимов, чтобы позволить блоку 75 выбора режима выбирать желаемый режим для разных блоков видео. В соответствии с этим раскрытием двойной предсказывающий режим 35X слияния может быть выбран когда блок 79 R-D идентифицирует его как желаемый режим для данного блока видео, например, вследствие усилений кодирования или эффективности кодирования.
[0067] Ссылаясь вновь на Фиг.4, после того как блок 32 кодирования с предсказанием выводит блок предсказания и после того как сумматор 48 вычитает блок предсказания из кодируемого блока видео для того, чтобы сгенерировать остаточный блок остаточных пиксельных значений, блок 38 преобразования применяет преобразование к остаточному блоку. Преобразование может содержать остаточный блок. Преобразование может содержать дискретное косинусное преобразование (DCT) или концептуально аналогичное преобразование, такое как задано стандартом ITU H.264 или стандартом HEVC. Так называемые структуры “бабочка” могут быть заданы, чтобы выполнить преобразования или также может быть использовано основанное на матрице умножение. В некоторых примерах в соответствии со стандартом HEVC, размер преобразования может меняться для разных CU, например, в зависимости от уровня разделения, который возникает по отношению к данной LCU. Единицы (TU) преобразования могут быть заданы для того, чтобы установить размер преобразования, применяемый блоком 38 преобразования. Вейвлетные преобразования, целочисленные преобразования, преобразования поддиапазона или другие типы преобразований также могут быть использованы. В любом случае, блок преобразования применяет преобразование к остаточному блоку, вырабатывая блок остаточных коэффициентов преобразования. Преобразование, в общем, может конвертировать остаточную информацию из пиксельной области в частотную область.
[0068] Блок 40 квантования затем квантует остаточные коэффициенты преобразования, чтобы дополнительно снизить битрейт. Блок 40 квантования, например, может ограничивать число битов, используемых для кодирования каждого из коэффициентов. В частности, блок 40 квантования может применять дельта QP, заданный для LCU для того, чтобы задать уровень квантования для применения (например, посредством объединения дельта QP с QP предшествующей LCU или некоторым другим известным QP). После того как квантование выполнено в отношении остаточных выборок, блок 46 энтропийного кодирования может сканировать и энтропийно кодировать данные.
[0069] CAVLC представляет собой методику энтропийного кодирования, поддерживаемую стандартом ITU H.264 и развивающимся стандартом HEVC, который может быть применен на векторизованной основе блоком 46 энтропийного кодирования. CAVLC использует таблицы кодирования с переменной длиной кодового слова (VLC) образом, который эффективно сжимает упорядоченные “серии” коэффициентов и/или элементов синтаксиса. CABAC представляет собой другой тип методики энтропийного кодирования, поддерживаемой стандартом ITU H.264 или стандартом HEVC, который может быть применен на векторизованной основе блоком 46 энтропийного кодирования. CABAC может влечь за собой несколько стадий, в том числе бинаризацию, выбор модели контекста и бинарное арифметическое кодирование. В этом случае, блок 46 энтропийного кодирования кодирует коэффициенты и элементы синтаксиса согласно CABAC. Многие другие типы методик энтропийного кодирования также существуют, и новые методики энтропийного кодирования вероятно будут появляться в будущем. Это раскрытие не ограничено какой-либо конкретной методикой энтропийного кодирования.
[0070] Следом за энтропийным кодированием блоком 46 энтропийного кодирования кодированное видео может быть передано другому устройству или заархивировано для более поздней передачи или извлечения. Кодированное видео может содержать энтропийно кодированные векторы и различную информацию синтаксиса (в том числе информацию синтаксиса, которая задает двух соседей в случае двойного предсказывающего режима слияния). Такая информация может быть использована декодером, чтобы надлежащим образом сконфигурировать процесс декодирования. Блок 42 обратного квантования и блок 44 обратного преобразования применяют обратное квантование и обратное преобразование, соответственно, чтобы восстановить остаточный блок в пиксельной области. Сумматор 51 добавляет восстановленный остаточный блок к блоку предсказания, выработанному блоком 32 кодирования с предсказанием, чтобы выработать восстановленный блок видео для сохранения в памяти 34. До упомянутого сохранения, однако, блок 47 фильтра может применить фильтрацию к блоку видео, чтобы улучшить качество видео. Фильтрация, применяемая блоком 47 фильтра, может сокращать артефакты и сглаживать пиксельные границы. Более того, фильтрация может улучшить сжатие посредством генерирования предсказывающих блоков видео, которые содержат близкие соответствия кодируемым блокам видео.
[0071] В соответствии с этим раскрытием, поддерживается двойной предсказывающий режим 35X слияния, который перенимает информацию движения из двух разных соседних блоков, при этом каждый из упомянутых двух разных соседних блоков был кодирован в одинарном предсказывающем режиме. Описанный двойной предсказывающий режим 35X слияния может увеличить число двойных предсказывающих кандидатов, которое может быть использовано в контексте кодирования в режиме слияния. Соответственно блок 79 R-D (Фиг.5) может идентифицировать двойной предсказывающий режим 35X слияния как наиболее желаемый режим кодирования вследствие усилений кодирования, достигаемых этим режимом относительно других режимов. В таких случаях, блок 75 выбора режима может выбирать двойной предсказывающий режим 35X слияния для кодирования одного из блоков видео.
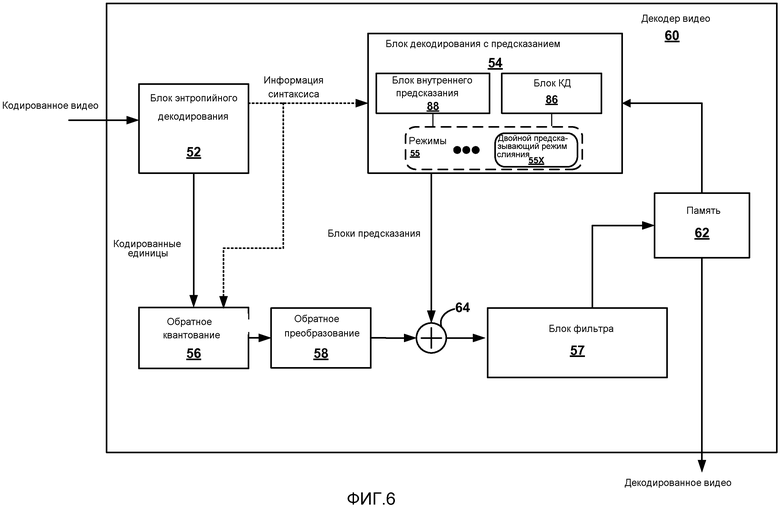
[0072] Фиг.6 представляет собой блок-схему, иллюстрирующую пример кодера 60 видео, который декодирует последовательность видео, которая кодирована вышеописанным образом. Методики этого раскрытия могут быть выполнены декодером 60 видео в некоторых примерах. В частности, декодер 60 видео принимает один или более элементов синтаксиса для текущего блока видео, при этом текущий блок видео кодируется согласно двойному предсказывающему режиму слияния и основываясь на упомянутом одном или более элементах синтаксиса, идентифицирует два разных соседних блока видео, кодируемых в одинарных предсказывающих режимах. Декодер 60 видео затем использует информацию движения упомянутых двух разных соседних блоков видео, чтобы декодировать текущий блок видео согласно двойному предсказывающему режиму слияния.
[0073] Последовательность видео, принимаемая на декодере 60 видео, может содержать кодированный набор кадров изображения, набор кадровых срезов, обычно кодированную группу графических изображений (GOP) или широкое многообразие единиц информации видео, которая включает в себя кодированную LCU (или другие блоки видео) и информацию синтаксиса, чтобы задать то, как декодировать такие LCU. Процесс декодирования LCU может включать в себя декодирование указания режима кодирования, который может быть двойным предсказывающим режимом слияния, описанным в данном документе.
[0074] Декодер 60 видео включает в себя блок 52 энтропийного декодирования, который выполняет обратную функцию декодирования кодирования, выполняемого блоком 46 энтропийного кодирования по Фиг.2. В частности, блок 52 энтропийного декодирования может выполнять декодирование CAVLC или CABAC или любой другой тип энтропийного декодирования, используемого кодером 50 видео. Декодер 60 видео также включает в себя блок 54 декодирования с предсказанием, блок 56 обратного квантования, блок 58 обратного преобразования, память 62 и сумматор 64. В частности, как и кодер 50 видео, декодер 60 видео включает в себя блок 54 декодирования с предсказанием и блок 57 фильтра. Блок 54 декодирования с предсказанием декодера 60 видео может включать в себя блок 86 компенсации движения, который декодирует внешне кодированные блоки и возможно включает в себя один или более фильтров интерполяции для субпиксельной интерполяции в процессе компенсации движения. Блок 54 декодирования с предсказанием также может включать в себя блок внутреннего предсказания для декодирования внутренних режимов. Блок 54 декодирования с предсказанием может поддерживать множество режимов 35, в том числе двойной предсказывающий режим 55X слияния. Блок 57 фильтра может фильтровать вывод сумматора 64 и может принимать энтропийно декодированную информацию фильтра для того, чтобы задать коэффициенты фильтра, применяемые для фильтрации цикла.
[0075] После приема кодированных данных видео блок 52 энтропийного декодирования выполняет декодирование обратное кодированию, выполняемому блоком 46 энтропийного кодирования (кодера 50 на Фиг.4). В декодере блок 52 энтропийного декодирования синтаксически анализирует битовый поток, чтобы определить LCU и соответствующее разделение, связанное с LCU. В некоторых примерах LCU или единицы (CU) кодирования LCU могут задавать режимы кодирования, которые были использованы, и эти режимы кодирования могут включать в себя двойной предсказывающий режим слияния. Соответственно блок 52 энтропийного декодирования может перенаправлять информацию синтаксиса блоку предсказания, который идентифицирует двойной предсказывающий режим слияния. В этом случае, информация синтаксиса может включать в себя один или более элементов синтаксиса, которые идентифицируют два разных соседних блока видео, кодированных в одинарных предсказывающих режимах. В этом случае, блок 86 КД блока 54 декодирования с предсказанием может использовать информацию движения упомянутых двух разных соседних блоков видео, чтобы декодировать текущий блок видео согласно двойному предсказывающему режиму слияния. То есть блок 86 КД может осуществлять выборку предсказывающих данных, идентифицированных информацией движения упомянутых двух разных соседних блоков видео, и использовать некоторую комбинацию этих предсказывающих данных при декодировании текущего блока видео в двойном предсказывающем режиме слияния.
[0076] Фиг.7 представляет собой концептуальную иллюстрацию, показывающую один пример пяти разных соседей, которые могут быть учтены для целей двойного предсказывающего режима слияния. В этом примере, сосед сверху (T), сосед сверху справа (TR), сосед слева (L), сосед снизу слева (BL) и совместно размещенный временный (Temp) сосед из другого кадра видео может быть учтен для целей двойного предсказывающего режима слияния. Конечно, другие соседи (пространственные или временные) также могут быть использованы для наследования любого режима слияния информации движения.
[0077] Снова, с режимом слияния, текущий блок видео может перенимать всю информацию движения соседнего блока-кандидата. Это означает, что текущий блок будет иметь тот же самый вектор движения, тот же самый опорный кадр и тот же самый режим предсказания (одинарное предсказание или двойное предсказание), что и выбранный соседний блок. Выбранный соседний блок может быть сигнализирован как часть кодированного битового потока, но информации движения нет необходимости быть сигнализированной, поскольку декодер может получить информацию движения из выбранного соседнего блока.
[0078] Согласно данному раскрытию поддерживается двойной предсказывающий режим слияния, который перенимает информацию движения из двух разных соседних блоков, при этом каждый из упомянутых двух разных соседних блоков был кодирован в одинарном предсказывающем режиме. Описанный двойной предсказывающий режим слияния может увеличивать число двойных предсказывающих кандидатов, которые могут быть использованы в контексте режима слияния. Вместо того, чтобы сигнализировать одного соседа, двойной предсказывающий режим слияния может сигнализировать двух разных соседей, двойной предсказывающий режим слияния может быть расширением к традиционному режиму слияния посредством простого увеличения соседних блоков-кандидатов для включения в состав их комбинаций или может быть полностью отдельным режимом относительно традиционного режима слияния.
[0079] Предполагая пространственные и временные соседние блоки-кандидаты, показанные на Фиг.1, двойной предсказывающий режим слияния может работать в по меньшей мере двух сценариях. В первом сценарии все соседние блоки-кандидаты кодируются в одинарных предсказывающих режимах. В этом случае, любые два из блоков-кандидатов могут быть выбраны, и информация движения из обоих выбранных кандидатов может быть объединена, чтобы достичь двойного предсказания. Например, предположим, что соседние блоки, показанные на Фиг.1, кодируются согласно следующей информации:
L: uni-pred, L0, refIdx = 0
T: uni-pred, L1, refIdx = 0
TR: uni-pred, L0, refIdx = 1
BL: uni-pred, L0, refIdx = 0
Temp: uni-pred, L1, refIdx = 1
В этом случае имеются 10 комбинаций любых двух из пяти кандидатов. L0 опирается на первый список предсказывающих данных и L1 опирается на второй список предсказывающих данных. RefIdx может содержать индекс к конкретному графическому изображению в соответствующем списке. Кодер видео может выбирать лучшую комбинацию (например, исходя из искажения и скорости передачи) и может отправлять информацию синтаксиса, которая идентифицирует упомянутые два выбранных соседних блока. Декодер может декодировать информацию синтаксиса и получить информацию движения из выбранных соседних блоков.
[0080] Во втором сценарии по меньшей мере один из соседних блоков-кандидатов может быть кодирован в двойном предсказывающем режиме. В этом случае любые два из одинарных предсказывающих соседних блоков могут быть учтены (в комбинации), чтобы получить кандидата двойного предсказывающего режима слияния. Однако любые двойные предсказывающие блоки также могут быть использованы по отдельности для рассмотрения в качестве кандидата двойного предсказывающего слияния. Например, предположим, что соседние блоки, показанные на Фиг.1, кодируются согласно следующей информации:
L: bi-pred, L0, refIdx = 0, L1, rexIdx = 0
T: uni-pred, L1, refIdx = 0
TR: uni-pred, L0, refIdx = 1
BL: uni-pred, L0, refIdx = 0
Temp: bi-pred, L0, refIdx = 0, L1, refIdx = 1
Таким образом, L0 может содержать значение, которое опирается на первый список предсказывающих данных, L1 может содержать значение, которое опирается на второй список предсказывающих данных, и refIdx может представлять собой значения, которые задают индексы к конкретному графическому изображению в соответствующем списке. В этом втором примере два из пяти кандидатов уже представляют собой двойной предсказывающий режим, таким образом, они могут быть рассмотрены по отдельности для целей двойных предсказывающих режимов слияния. В дополнение разные комбинации трех оставшихся одинарных предсказывающих кандидатов могут быть учтены. Таким образом, в этом случае, будет 5 возможных вариантов двойного предсказывающего режима:
1. L
2. Temp
3. T+TR
4. T+BL
5. TR+BL
[0081] В этом втором примере кодер может выбирать лучшего соседа (или комбинацию соседей) из этих пяти возможных вариантов (например, исходя из искажения и скорости передачи кодирования) и может отправлять информацию синтаксиса, которая идентифицирует, какой отдельный сосед или комбинация соседей была использована в режиме слияния. Декодер может декодировать информацию синтаксиса и получить информацию движения из выбранного соседнего блока(-ов).
[0082] В примере по Фиг.7 показаны пять кандидатов. Однако дополнительные кандидаты также могут быть учтены либо в тех же самых областях, что и кандидаты по Фиг.7, или в других областях. В некоторых случаях, может быть несколько кандидатов сверху (T), несколько кандидатов сверху слева (TL), несколько кандидатов слева (L), несколько кандидатов снизу слева (BL) и несколько временных (T) кандидатов. В некоторых случаях размер текущего блока может отличаться от такового у кандидатов, в случае с которыми край сверху, край слева текущего блока может быть смежным с несколькими кандидатами. В других случаях, кандидаты даже на больших расстояниях от текущего блока видео могут быть учтены для целей двойного предсказывающего режима слияния, описанного в этом раскрытии. Многие другие сценарии, использующие многих других кандидатов, возможны в соответствии с этим раскрытием. Таким образом, Фиг.7 является лишь одним примером, иллюстрирующим пять соседних кандидатов относительно текущего блока видео.
[0083] Фиг.8 представляет собой блок-схему последовательности операций, иллюстрирующую методику декодирования в соответствии с этим раскрытием. Фиг.8 будет описана с перспективы декодера 60 видео по Фиг.6, несмотря на то, что другие устройства могут выполнять аналогичные методики. Как показано на Фиг.8, декодер 60 видео принимает LCU, включающую в себя элементы синтаксиса для LCU и для CU в пределах LCU (801). В частности, блок 52 энтропийного декодирования может принимать битовый поток, который включает в себя LCU, и синтаксически анализировать битовый поток, чтобы идентифицировать элементы синтаксиса, которые могут быть перенаправлены блоку 54 декодирования с предсказанием. Соответственно блок 54 декодирования с предсказанием может (задавать) режимы CU, основываясь на элементах синтаксиса. В других примерах, режимы могут быть заданы на уровне PU, а не на уровне CU.
[0084] При определении режимов блок 54 декодирования с предсказанием идентифицирует любые CU, кодированные в двойном предсказывающем режиме слияния (803). Если какая-либо CU не кодирована в двойном предсказывающем режиме слияния (“нет” 803), то эта CU декодируется согласно своему режиму (804). Например, могут поддерживаться многие другие внутренние режимы и многие другие внешние режимы. Если какая-либо CU кодирована в двойном предсказывающем режиме слияния (“да” 803), то эта CU является двойной предсказывающей. Однако ее векторы движения для двойного предсказания исходят из двух однонаправленных соседей, как описано в данном документе. В этом случае блок 86 КД блока 54 декодирования с предсказанием идентифицирует два разных одинарных предсказывающих соседа CU, основываясь на элементе синтаксиса CU (805), и использует информацию движения одинарных предсказывающих соседей, чтобы декодировать двойную предсказывающую CU.
[0085] Фиг.9 представляет собой блок-схему, иллюстрирующую методику кодирования в соответствии с этим раскрытием. Фиг.9 будет описана с перспективы кодера 50 видео по Фиг.4, хотя другие устройства могут выполнять аналогичные методики. Как показано на Фиг.9 блок 32 кодирования с предсказанием выбирает двойной предсказывающий режим слияния для CU. Например, блок 32 кодирования с предсказанием (см. Фиг.5) может включать в себя блок 75 выбора режима, который выбирает бипредикивный режим 35X слияния для CU, основываясь на множестве возможных режимов 35. Блок 75 R-D может идентифицировать скорость кодирования и уровень качества или искажения, связанные с разными режимами посредством анализа результатов кодирования блоком 76 ОД и блоком 77 КД для разных внешних режимов и посредством анализа результатов кодирования блоком 78 внутреннего предсказания для внутренних режимов. Таким образом, блок 75 выбора режима может идентифицировать лучший режим для любой данной ситуации.
[0086] Как только блок 32 кодирования с предсказанием выбирает двойной предсказывающий режим 35X слияния для CU, блок предсказания идентифицирует два разных соседних блока, кодированных в одинарных предсказывающих режимах (902). Этот процесс идентификации упомянутых двух разных соседних блоков, кодированных в одинарных предсказывающих режимах, может быть выполнен блоком 76 ОД образом аналогичным таковому, описанному выше по тексту. Например, блок 76 ОД и блок 77 КД могут генерировать результаты кодирования разных комбинаций информации движения из разных однонаправленных соседей, и эти результаты могут быть проанализированы блоком 75 R-D, чтобы определить скорость кодирования и качество или искажение, связанные с такими разными комбинациями. В конечном счете, блок 75 R-D может определять, какая комбинация двойного предсказывающего режима слияния одинарных предсказывающих соседей дает лучшие результаты кодирования.
[0087] Соответственно блок 32 кодирования с предсказанием использует информацию движения лучшей комбинации двух одинарных предсказывающих соседей, чтобы кодировать CU в качестве двойной предсказывающей (903). Конечно, любые двойные предсказывающие соседи также могут быть учтены, и возможно использованы для кодирования в режиме слияния, если результаты искажения-скорости передачи лучше, чем использование двух одинарных предсказывающих соседей. Блок 32 предсказания (например, блок 76 ОД или блок 77 КД) генерирует один или более элементов синтаксиса для CU, чтобы идентифицировать упомянутых двух разных одинарных предсказывающих соседей, используемых для кодирования CU в двойном предсказывающем режиме слияния. Элементы синтаксиса, например, могут содержать индексные значения, которые идентифицируют двух соседей CU, таких как сосед (L) слева, сосед (BL) снизу слева, сосед сверху (T), сосед сверху справа (TR) или совместно размещенный во времени (T) сосед как концептуально проиллюстрировано на Фиг.7. Однако многие другие схемы сигнализации для элементов синтаксиса также могут быть использованы.
[0088] Методики этого раскрытия могут быть реализованы в широком многообразии устройств или аппаратов, в том числе беспроводная телефонная трубка и интегральная схема (ИС) или набор ИС (т.е. комплект ИС). Любые компоненты, модули или блоки были описаны с обеспечением выделения функциональных аспектов и необязательно требуют реализации посредством разных блоков аппаратного обеспечения.
[0089] Соответственно методики, описанные в данном документе, могут быть реализованы в аппаратном обеспечении, программном обеспечении, аппаратно-программном обеспечении или в любой их комбинации. Любые признаки, описанные как модули или компоненты, могут быть реализованы вместе в интегральном логическом устройстве или отдельно как дискретные, но взаимодействующие логические устройства. Если реализовано в программном обеспечении, методики могут быть реализованы по меньшей мере частично посредством считываемого компьютером носителя, содержащего инструкции, которые при исполнении выполняют один или более вышеописанных способов. Считываемые компьютером носители хранения данных могут формировать часть компьютерного программного продукта, который может включать в себя материалы упаковки.
[0090] Считываемые компьютером носители могут содержать материальный считываемый компьютером носитель хранения, такой как оперативная память (RAM), такая как синхронная динамическая оперативная память (SDRAM), постоянная память (ROM), энергонезависимая оперативная память (NVRAM), электрически стираемая программируемая постоянная (EEPROM), Flash память, магнитные или оптические носители хранения данных и т.п. Методики дополнительно или в качестве альтернативы могут быть реализованы по меньшей мере частично считываемой компьютером средой связи, которая переносит или передает код в форме инструкций или структур данных и которая может быть доступна, считана и/или исполнена компьютером.
[0091] Инструкции могут быть исполнены одним или более процессорами, такими как один или более цифровых сигнальных процессоров (DSP), микропроцессоры общего назначения, специализированные интегральные микросхемы (ASIC), программируемые пользователем вентильные матрицы (FPGA) или другие эквивалентные интегральные или дискретные логические схемы. Термин “процессор”, как используется в данном документе, может относиться к любой вышеперечисленной структуре или любой другой структуре, подходящей для реализации методик, описанных в данном документе. В дополнение, в некоторых аспектах, функциональность, описанная в данном документе, может быть обеспечена в пределах специализированных модулей программного обеспечения или модулей аппаратного обеспечения или встроена в объединенный кодер-декодер видео (CODEC). Также методики могут быть полностью реализованы в одной или более схемах или логических элементах.
[0092] Были описаны различные аспекты раскрытия. Эти и другие аспекты находятся в пределах объема нижеследующей формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ВНУТРЕННЕЕ ПРЕДСКАЗАНИЕ ИЗ ПРЕДСКАЗЫВАЮЩЕГО БЛОКА | 2014 |
|
RU2679190C2 |
| ВЫПОЛНЕНИЕ ПРЕДСКАЗАНИЯ ВЕКТОРА ДВИЖЕНИЯ ДЛЯ КОДИРОВАНИЯ ВИДЕО | 2012 |
|
RU2573227C1 |
| ВЫБОР ЕДИНЫХ КАНДИДАТОВ РЕЖИМА СЛИЯНИЯ И АДАПТИВНОГО РЕЖИМА ПРЕДСКАЗАНИЯ ВЕКТОРА ДВИЖЕНИЯ | 2012 |
|
RU2574280C2 |
| Построение списка слияний в треугольном предсказании | 2020 |
|
RU2781275C1 |
| ИЕРАРХИЯ ВИДЕОБЛОКОВ С ПРЕДСКАЗАНИЕМ ДВИЖЕНИЯ | 2012 |
|
RU2562379C2 |
| КОДИРОВАНИЕ ВЕКТОРА ДВИЖЕНИЯ И БИ-ПРЕДСКАЗАНИЕ В HEVC И ЕГО РАСШИРЕНИЯХ | 2013 |
|
RU2624560C2 |
| УНИФИЦИРОВАННЫЙ ВЫБОР КАНДИДАТОВ ДЛЯ РЕЖИМА СЛИЯНИЯ И АДАПТИВНОГО РЕЖИМА ПРЕДСКАЗАНИЯ ВЕКТОРА ДВИЖЕНИЯ | 2012 |
|
RU2574831C2 |
| СПОСОБ СИГНАЛИЗАЦИИ ТИПА СМЕЩЕНИЯ И КОЭФФИЦИЕНТОВ ДЛЯ АДАПТИВНОГО СМЕЩЕНИЯ ВЫБОРОК | 2012 |
|
RU2580102C2 |
| БУФЕРИЗАЦИЯ ДАННЫХ ПРЕДСКАЗАНИЯ ПРИ КОДИРОВАНИИ ВИДЕО | 2012 |
|
RU2573744C2 |
| УЧИТЫВАЮЩИЕ ПАРАЛЛЕЛИЗАЦИЮ КАНДИДАТЫ СЛИЯНИЯ ДЛЯ КОДИРОВАНИЯ ВИДЕО | 2012 |
|
RU2582062C2 |

Изобретение относится к средствам кодирования и декодирования видео с предсказанием. Техническим результатом является повышение качества при сжатии видео. В способе принимают элементы синтаксиса для текущего блока видео, задающие кандидатов режима слияния из набора кандидатов, которые должны быть использованы для кодирования текущего блока видео согласно режиму слияния. В способе первый кандидат в наборе является кандидатом слева, второй кандидат в наборе является временным кандидатом, третий кандидат в наборе является кандидатом двойного предсказывающего режима слияния, заданным согласно двум разным соседним блокам видео, которые кодированы в одинарных предсказывающих режимах. 8 н. и 19 з.п. ф-лы, 9 ил.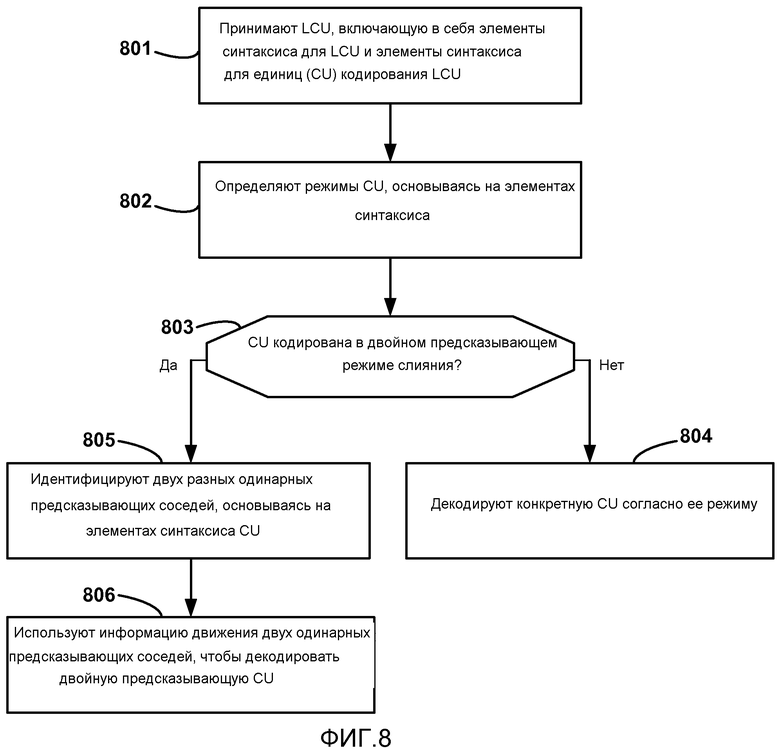
1. Способ декодирования данных видео, причем способ содержит этапы, на которых:
принимают один или более элементов синтаксиса для текущего блока видео, при этом упомянутый один или более элементов синтаксиса задают одного или более кандидатов режима слияния из набора кандидатов, которые должны быть использованы, чтобы кодировать текущий блок видео согласно режиму слияния, при этом первый кандидат в наборе кандидатов является кандидатом слева, второй кандидат в наборе кандидатов является временным кандидатом и третий кандидат в наборе кандидатов является кандидатом двойного предсказывающего режима слияния, заданным согласно двум разным соседним блокам видео, которые кодированы в одинарных предсказывающих режимах; и
когда упомянутый один или более элементов синтаксиса задают третьего кандидата:
идентифицируют упомянутые два разных соседних блока видео, кодированных в одинарных предсказывающих режимах, на основе упомянутого одного или более элементов синтаксиса; и
используют информацию движения упомянутых двух разных соседних блоков видео, чтобы декодировать текущий блок видео.
2. Способ по п. 1, в котором информация движения содержит два разных одинарных предсказывающих вектора движения, связанных с упомянутыми двумя разными соседними блоками видео.
3. Способ по п. 2, в котором информация движения дополнительно содержит по меньшей мере два значения, связанные с упомянутыми двумя разными одинарными предсказывающими векторами движения, при этом значения идентифицируют один или более списков предсказывающих данных, связанных с упомянутыми двумя разными одинарными предсказывающими векторами движения.
4. Способ по п. 1, в котором текущий блок видео содержит единицу (CU) кодирования, заданную согласно стандарту (HEVC) высокоэффективного кодирования видео, при этом CU задают относительно наибольшей единицы (LCU) кодирования согласно схеме разделения квадродерева, причем способ дополнительно содержит:
прием данных синтаксиса LCU, которые задают схему разделения квадродерева; и
прием информации режима для CU, которая задает кандидата двойного предсказывающего режима слияния, при этом упомянутый один или более элементов синтаксиса включены в информацию режима для CU.
5. Способ по п. 1, в котором текущий блок видео содержит единицу (PU) предсказания единицы (CU) кодирования, которая задана согласно стандарту (HEVC) высокоэффективного кодирования видео.
6. Способ кодирования данных видео, причем способ содержит этапы, на которых:
выбирают кандидата из набора кандидатов для кодирования текущего блока видео согласно режиму слияния, при этом первый кандидат в наборе кандидатов является кандидатом слева, второй кандидат в наборе кандидатов является временным кандидатом и третий кандидат в наборе кандидатов является кандидатом двойного предсказывающего режима слияния, заданным согласно двум разным соседним блокам видео, которые кодированы в одинарных предсказывающих режимах; и
при выборе третьего кандидата:
идентифицируют упомянутые два разных соседних блока видео, кодированных в одинарных предсказывающих режимах;
используют информацию движения упомянутых двух разных соседних блоков видео, чтобы кодировать текущий блок видео; и
генерируют один или более элементов синтаксиса, которые идентифицируют упомянутые два разных соседних блока видео, которые кодированы в одинарных предсказывающих режимах, для декодера видео.
7. Способ по п. 6, в котором информация движения содержит два разных одинарных предсказывающих вектора движения, связанных с упомянутыми двумя разными соседними блоками видео.
8. Способ по п. 7, в котором информация движения дополнительно содержит по меньшей мере два значения, связанные с упомянутыми двумя разными одинарными предсказывающими векторами движения, при этом значения идентифицируют один или более списков предсказывающих данных, связанных с упомянутыми двумя разными одинарными предсказывающими векторами движения.
9. Способ по п. 6, в котором текущий блок видео содержит единицу (CU) кодирования, заданную согласно стандарту (HEVC) высокоэффективного кодирования видео, причем способ дополнительно содержит:
задание CU относительно наибольшей единицы (LCU) кодирования согласно схеме разделения квадродерева;
генерирование данных синтаксиса LCU, которые задают схему разделения квадродерева; и
генерирование информации режима для CU, которая задает кандидата двойного предсказывающего режима слияния, при этом упомянутый один или более элементов синтаксиса включены в информацию режима для CU.
10. Способ по п. 6, в котором текущий блок видео содержит единицу (PU) предсказания единицы (CU) кодирования, которая задана согласно стандарту (HEVC) высокоэффективного кодирования видео.
11. Устройство декодирования видео, которое декодирует данные видео, причем устройство декодирования видео содержит декодер видео, сконфигурированный для:
приема одного или более элементов синтаксиса для текущего блока видео, при этом упомянутый один или более элементов синтаксиса, задают одного или более кандидатов режима слияния из набора кандидатов, которые должны быть использованы, чтобы кодировать текущий блок видео согласно режиму слияния, при этом первый кандидат в наборе кандидатов является кандидатом слева, второй кандидат в наборе кандидатов является временным кандидатом и третий кандидат в наборе кандидатов является кандидатом двойного предсказывающего режима слияния, заданным согласно двум разным соседним блокам видео, которые кодированы в одинарных предсказывающих режимах; и
когда упомянутый один или более элементов синтаксиса задают третьего кандидата:
идентификации упомянутых двух разных соседних блоков видео, кодированных в одинарных предсказывающих режимах, на основе упомянутого одного или более элементов синтаксиса; и
использования информации движения упомянутых двух разных соседних блоков видео, чтобы декодировать текущий блок видео.
12. Устройство декодирования видео по п. 11, в котором декодер видео включает в себя:
блок энтропийного декодирования, сконфигурированный для приема и декодирования упомянутого одного или более элементов синтаксиса; и
блок предсказания, сконфигурированный для идентификации упомянутых двух разных соседних блоков видео и использования информации движения упомянутых двух разных соседних блоков видео, чтобы декодировать текущий блок видео.
13. Устройство декодирования видео по п. 11, в котором информация движения содержит два разных одинарных предсказывающих вектора движения, связанных с упомянутыми двумя разными соседними блоками видео.
14. Устройство декодирования видео по п. 13, в котором информация движения дополнительно содержит по меньшей мере два значения, связанные с упомянутыми двумя разными одинарными предсказывающими векторами движения, при этом значения идентифицируют один или более списков предсказывающих данных, связанных с упомянутыми двумя разными одинарными предсказывающими векторами движения.
15. Устройство декодирования видео по п. 11, в котором текущий блок видео содержит единицу (CU) кодирования, заданную согласно стандарту (HEVC) высокоэффективного кодирования видео, при этом CU задана относительно наибольшей единицы (LCU) кодирования согласно схеме разделения квадродерева, при этом декодер:
принимает данные синтаксиса LCU, которые задают схему разделения квадродерева; и
принимает информацию режима для CU, которая задает кандидата двойного предсказывающего режима слияния, при этом упомянутый один или более элементов синтаксиса включены в информацию режима для CU.
16. Устройство декодирования видео по п. 11, в котором текущий блок видео содержит единицу (PU) предсказания единицы (CU) кодирования, которая задана согласно стандарту (HEVC) высокоэффективного кодирования видео.
17. Устройство декодирования видео по п. 11, в котором устройство декодирования видео содержит одно или более из:
интегральной схемы;
микропроцессора; и
устройства беспроводной связи, которое включает в себя кодер видео.
18. Устройство кодирования видео, содержащее кодер видео, сконфигурированный для:
выбора кандидата из набора кандидатов для кодирования текущего блока видео согласно режиму слияния, при этом первый кандидат в наборе кандидатов является кандидатом слева, второй кандидат в наборе кандидатов является временным кандидатом и третий кандидат в наборе кандидатов является кандидатом двойного предсказывающего режима слияния, заданным согласно двум разным соседним блокам видео, которые кодированы в одинарных предсказывающих режимах;
при выборе третьего кандидата:
идентификации упомянутых двух разных соседних блоков видео, кодированных в одинарных предсказывающих режимах;
использования информации движения упомянутых двух разных соседних блоков видео, чтобы кодировать текущий блок видео; и
генерирования одного или более элементов синтаксиса, чтобы идентифицировать упомянутые два разных соседних блока видео, которые кодированы в одинарных предсказывающих режимах, для декодера видео.
19. Устройство кодирования видео по п. 18, в котором информация движения содержит два разных одинарных предсказывающих вектора движения, связанных с упомянутыми двумя разными соседними блоками видео.
20. Устройство кодирования видео по п. 19, в котором информация движения дополнительно содержит по меньшей мере два значения, связанные с упомянутыми двумя разными одинарными предсказывающими векторами движения, при этом значения идентифицируют один или более списков предсказывающих данных, связанных с упомянутыми двумя разными одинарными предсказывающими векторами движения.
21. Устройство кодирования видео по п. 18, в котором текущий блок видео содержит единицу (CU) кодирования, заданную согласно стандарту (HEVC) высокоэффективного кодирования видео, при этом кодер видео включает в себя:
блок разделения квадродерева, сконфигурированный для задания CU относительно наибольшей единицы (LCU) кодирования согласно схеме разделения квадродерева и генерирования данных синтаксиса LCU, которые задают схему разделения квадродерева; и
блок предсказания, сконфигурированный для генерирования информации режима для CU, которая задает кандидата двойного предсказывающего режима слияния, при этом упомянутый один или более элементов синтаксиса включены в информацию режима для CU.
22. Устройство кодирования видео по п. 18, в котором текущий блок видео содержит единицу (PU) предсказания единицы (CU) кодирования, которая задана согласно стандарту (HEVC) высокоэффективного кодирования видео.
23. Устройство кодирования видео по п. 18, в котором устройство кодирования видео содержит одно или более из:
интегральной схемы;
микропроцессора; и
устройства беспроводной связи, которое включает в себя кодер видео.
24. Устройство для декодирования данных видео, причем устройство содержит:
средство для приема одного или более элементов синтаксиса для текущего блока видео, при этом упомянутый один или более элементов синтаксиса задают одного или более кандидатов режима слияния из набора кандидатов, которые должны быть использованы, чтобы кодировать текущий блок видео согласно режиму слияния, при этом первый кандидат в наборе кандидатов является кандидатом слева, второй кандидат в наборе кандидатов является временным кандидатом и третий кандидат в наборе кандидатов является кандидатом двойного предсказывающего режима слияния, заданным согласно двум разным соседним блокам видео, которые кодированы в одинарных предсказывающих режимах; и
когда упомянутый один или более элементов синтаксиса задают третьего кандидата:
средство для идентификации двух разных соседних блоков видео, кодированных в одинарных предсказывающих режимах, на основе упомянутого одного или более элементов синтаксиса; и
средство для использования информации движения упомянутых двух разных соседних блоков видео, чтобы декодировать текущий блок видео.
25. Устройство для кодирования данных видео, причем устройство содержит:
средство для выбора кандидата из набора кандидатов для кодирования текущего блока видео согласно режиму слияния, при этом первый кандидат в наборе кандидатов является кандидатом слева, второй кандидат в наборе кандидатов является временным кандидатом и третий кандидат в наборе кандидатов является кандидатом двойного предсказывающего режима слияния, заданным согласно двум разным соседним блокам видео, которые кодированы в одинарных предсказывающих режимах; и
при выборе третьего кандидата:
средство для идентификации упомянутых двух разных соседних блоков видео, кодированных в одинарных предсказывающих режимах;
средство для использования информации движения упомянутых двух разных соседних блоков видео, чтобы кодировать текущий блок видео; и
средство для генерирования одного или более элементов синтаксиса, чтобы идентифицировать упомянутые два разных соседних блока видео, которые кодированы в одинарных предсказывающих режимах, для декодера видео.
26. Считываемый компьютером носитель, содержащий инструкции, которые при исполнении побуждают процессор декодировать данные видео, при этом инструкции побуждают процессор:
принять один или более элементов синтаксиса для текущего блока видео, при этом упомянутый один или более элементов синтаксиса задают одного или более кандидатов режима слияния из набора кандидатов, которые должны быть использованы, чтобы кодировать текущий блок видео согласно режиму слияния, при этом первый кандидат в наборе кандидатов является кандидатом слева, второй кандидат в наборе кандидатов является временным кандидатом и третий кандидат в наборе кандидатов является кандидатом двойного предсказывающего режима слияния, заданным согласно двум разным соседним блокам видео, которые кодированы в одинарных предсказывающих режимах;
когда упомянутый один или более элементов синтаксиса задают третьего кандидата:
идентифицировать упомянутые два разных соседних блока видео, кодированных в одинарных предсказывающих режимах, на основе упомянутого одного или более элементов синтаксиса; и
использовать информацию движения упомянутых двух разных соседних блоков видео, чтобы декодировать текущий блок видео.
27. Считываемый компьютером носитель, содержащий инструкции, которые при исполнении побуждают процессор
кодировать данные видео, при этом инструкции побуждают процессор:
выбирать кандидата из набора кандидатов для кодирования текущего блока видео согласно режиму слияния, при этом первый кандидат в наборе кандидатов является кандидатом слева, второй кандидат в наборе кандидатов является временным кандидатом и третий кандидат в наборе кандидатов является кандидатом двойного предсказывающего режима слияния, заданным согласно двум разным соседним блокам видео, которые кодированы в одинарных предсказывающих режимах; и
при выборе третьего кандидата:
идентифицировать упомянутые два разных соседних блока видео, кодированных в одинарных предсказывающих режимах;
использовать информацию движения упомянутых двух разных соседних блоков видео, чтобы кодировать текущий блок видео; и
генерировать один или более элементов синтаксиса, чтобы идентифицировать упомянутые два разных соседних блока видео, которые кодированы в одинарных предсказывающих режимах, для декодера видео.
| СПОСОБ ВИДЕОКОДИРОВАНИЯ И СПОСОБ ДЕКОДИРОВАНИЯ, УСТРОЙСТВА ДЛЯ ПРОГРАММЫ ДЛЯ ИХ РЕАЛИЗАЦИИ И ЗАПОМИНАЮЩИЕ НОСИТЕЛИ ДЛЯ ХРАНЕНИЯ ТАКИХ ПРОГРАММ | 2007 |
|
RU2384971C1 |
| УСТРОЙСТВО ВИДЕОКОДИРОВАНИЯ, СПОСОБ ВИДЕОКОДИРОВАНИЯ, ПРОГРАММА ВИДЕОКОДИРОВАНИЯ, УСТРОЙСТВО ВИДЕОДЕКОДИРОВАНИЯ, СПОСОБ ВИДЕОДЕКОДИРОВАНИЯ И ПРОГРАММА ВИДЕОДЕКОДИРОВАНИЯ | 2006 |
|
RU2391794C2 |
| СПОСОБ КОДИРОВАНИЯ И СПОСОБ ДЕКОДИРОВАНИЯ ИЗОБРАЖЕНИЙ, УСТРОЙСТВА ДЛЯ НИХ, ПРОГРАММА ДЛЯ НИХ И НОСИТЕЛЬ ИНФОРМАЦИИ ДЛЯ ХРАНЕНИЯ ПРОГРАММ | 2007 |
|
RU2407220C2 |
| WO 9713374 A1, 10.04.1997 | |||
| WO 2010086018 A1, 05.08.2010 | |||

