[0001] Настоящая заявка испрашивает приоритет предварительной заявки на патент США № 61/450,555, поданной 8 марта 2011, предварительной заявки на патент США № 61/451,485, поданной 10 марта 2011, предварительной заявки на патент США № 61/451,496, поданной 10 марта 2011, предварительной заявки на патент США № 61/452,384, поданной 14 марта 2011, предварительной заявки на патент США № 61/494,855, поданной 8 июня 2011, и предварительной заявки на патент США № 61/497,345, поданной 15 июня 2011, каждая из которых полностью включена в настоящее описание посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[0002] Настоящее описание относится к кодированию видео и, более конкретно, к способам для сканирования и кодирования коэффициентов преобразования, сгенерированных процессами кодирования видео.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
[0003] Возможности цифрового видео могут быть встроены в широкий диапазон устройств, включающих в себя цифровые телевизоры, цифровые системы прямого вещания, системы беспроводного вещания, персональные цифровые ассистенты (PDA), ноутбуки или настольные компьютеры, цифровые камеры, цифровые устройства записи, цифровые медиа плееры, игровые видео устройства, игровые видео приставки, сотовые или спутниковые радиотелефоны, устройства видео телеконференций и т.п. Цифровые видео устройства реализуют способы сжатия видео, такие как способы, описанные в стандартах, определенных в MPEG-2, MPEG-4, ITU-T H.263, ITU-T H.264/MPEG-4, Часть 10, расширенное кодирование видео (AVC), в настоящее время разрабатываемый стандарт высокоэффективного кодирования видео (HEVC), и расширения таких стандартов для передачи, приема и хранения цифровой видеоинформации более эффективно.
[0004] Способы сжатия видео включают в себя пространственное предсказание и/или временное предсказание для уменьшения или удаления избыточности, свойственной видео последовательностям. Для кодирования видео, основанного на блоке, видеокадр или вырезка могут быть фрагментированы на блоки. Каждый блок может быть дополнительно фрагментирован. Блоки в интра- (внутренне) кодированных (I) кадре или вырезке кодируются, используя пространственное предсказание относительно опорных выборок в соседних блоках в том же кадре или вырезке. Блоки в интер- (внешне) кодированном (P или B) кадре или вырезке могут использовать пространственное предсказание относительно опорных выборок в соседних блоках в том же кадре или вырезке или временное предсказание относительно опорных выборок в других опорных кадрах. Пространственное или временное предсказание приводит к предсказывающему блоку для блока, который должен быть закодирован. Остаточные данные представляют пиксельные разности между оригинальным блоком, который должен быть закодирован, и предсказывающим блоком.
[0005] Внешне кодированный блок кодируется в соответствии с вектором движения, который указывает на блок опорных выборок, формирующих предсказывающий блок, и остаточными данными, указывающими разность между закодированным блоком и предсказывающим блоком. Внутренне кодированный блок кодируется в соответствии с режимом внутреннего кодирования и остаточными данными. Для дополнительного сжатия остаточные данные могут быть преобразованы из пиксельной области в область преобразования, приводя к остаточным коэффициентам преобразования, которые затем могут быть квантованы. Квантованные коэффициенты преобразования, первоначально скомпонованные в двумерном массиве, могут сканироваться в конкретном порядке, чтобы сформировать одномерный вектор коэффициентов преобразования для статистического кодирования.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0006] В целом, настоящее раскрытие описывает устройства и способы для кодирования коэффициентов преобразования, ассоциированных с блоком остаточных видеоданных, в процессе кодирования видео. Способы, структуры и методы, описанные в настоящем раскрытии, применимы для процессов кодирования видео, которые используют статистическое кодирование (например, контекстное адаптивное двоичное арифметическое кодирование (CABAC)) для кодирования коэффициентов преобразования. Аспекты настоящего раскрытия включают в себя выбор порядка сканирования как для кодирования отображения значимости, так и для кодирования уровня и знака, а также выбор контекстов для статистического кодирования, совместимого с выбранным порядком сканирования. Способы, структуры и методы настоящего раскрытия применимы для использования как в кодере видео, так и в декодере видео.
[0007] Настоящее раскрытие предлагает согласованность (гармонизацию) порядка сканирования для кодирования как отображения значимости коэффициентов преобразования, так и для кодирования уровней коэффициентов преобразования. То есть, скажем, в некоторых примерах порядок сканирования для кодирования отображения значимости и уровня должен иметь один и тот же шаблон и направление. В другом примере предполагается, что порядок сканирования для отображения значимости должен быть в обратном направлении (то есть от коэффициентов для более высоких частот к коэффициентам для более низких частот). В еще одном примере предполагается, что порядок сканирования для кодирования отображения значимости и уровня должен быть согласован таким образом, чтобы каждый осуществлялся в обратном направлении.
[0008] Настоящее раскрытие также предлагает, чтобы в некоторых примерах коэффициенты преобразования были сканированы в поднаборах. В частности, коэффициенты преобразования сканируются в поднаборе, состоящем из ряда последовательных коэффициентов, в соответствии с порядком сканирования. Такие поднаборы могут быть применимы как для сканирования отображения значимости, так и для сканирования уровня коэффициентов.
[0009] Дополнительно, настоящее раскрытие предлагает, чтобы в некоторых примерах сканирование отображения значимости и сканирование уровня коэффициентов были выполнены в последовательных сканированиях и в соответствии с одним и тем же порядком сканирования. В одном аспекте порядком сканирования является обратный порядок сканирования. Последовательные сканирования могут состоять из нескольких проходов сканирования. Каждый проход сканирования может состоять из прохода сканирования элементов синтаксиса. Например, первым сканированием является сканирование отображения значимости (также называемое контейнером (накопителем) 0 уровня коэффициентов преобразования), второе сканирование имеет контейнер один уровней коэффициентов преобразования в каждом поднаборе, третье сканирование может иметь контейнер два уровней коэффициентов преобразования в каждом поднаборе, четвертое сканирование имеет оставшиеся контейнеры уровней коэффициентов преобразования, и пятое сканирование выполняется для знака уровней коэффициентов преобразования. Проход для знака может иметь место в любой момент после прохода отображения значимости. Дополнительно, количество проходов сканирования может быть уменьшено посредством кодирования более чем одного элемента синтаксиса для каждого прохода. Например, один проход сканирования для элементов синтаксиса использует закодированные контейнеры, и второй проход сканирования для элементов синтаксиса использует контейнеры обхода (например, оставшиеся уровни и знак). В этом контексте контейнером является часть строки контейнера, которая статистически кодируется. Заданный элемент синтаксиса с недвоичным значением отображается в двоичную последовательность (так называемую строку контейнеров).
[0010] Настоящее раскрытие также предлагает, чтобы в некоторых примерах коэффициенты преобразования были закодированы, используя CABAC, в двух различных областях контекста. Выведение контекста для первой области контекста зависит от позиции коэффициентов преобразования, в то время как выведение контекста для второй области зависит от казуальных (случайных) соседних коэффициентов преобразования. В другом примере вторая область контекста может использовать две различные модели контекста в зависимости от местоположения коэффициентов преобразования.
[0011] В одном примере настоящего раскрытия предложен способ кодирования коэффициентов преобразования, ассоциированных с остаточными данными видео в процессе кодирования видео. Способ содержит кодирование информации, указывающей значимые коэффициенты преобразования в блоке коэффициентов преобразования со сканированием, осуществляющимся в обратном направлении сканирования от коэффициентов более высокой частоты в блоке коэффициентов преобразования к коэффициентам более низкой частоты в блоке коэффициентов преобразования.
[0012] В другом примере настоящего раскрытия предложена система для кодирования коэффициентов преобразования, ассоциированных с остаточными данными видео в процессе кодирования видео. Система содержит модуль кодирования видео, сконфигурированный для кодирования информации, указывающей значимые коэффициенты преобразования в блоке коэффициентов преобразования, со сканированием, осуществляющемся в обратном направлении сканирования от коэффициентов более высокой частоты в блоке коэффициентов преобразования к коэффициентам более низкой частоты в блоке коэффициентов преобразования.
[0013] В другом примере настоящего раскрытия предложена система для кодирования коэффициентов преобразования, ассоциированных с остаточными данными видео в процессе кодирования видео. Система содержит средство для кодирования информации, указывающей значимые коэффициенты преобразования в блоке коэффициентов преобразования, со сканированием, осуществляющемся в обратном направлении сканирования от коэффициентов более высокой частоты в блоке коэффициентов преобразования к коэффициентам более низкой частоты в блоке коэффициентов преобразования, и средство для формирования отображения значимости для блока, на основании кодированной информации, указывающей значимые коэффициенты преобразования.
[0014] В другом примере настоящего раскрытия компьютерный программный продукт содержит считываемый компьютером запоминающий носитель, хранящий сохраненные на нем команды, которые при выполнении вынуждают процессор устройства для кодирования коэффициентов преобразования, ассоциированных с остаточными данными видео в процессе кодирования видео, кодировать информацию, указывающую значимые коэффициенты преобразования в блоке коэффициентов преобразования, со сканированием, осуществляющимся в обратном направлении сканирования от коэффициентов более высокой частоты в блоке коэффициентов преобразования к коэффициентам более низкой частоты в блоке коэффициентов преобразования.
[0015] Подробности одного или более примеров приводятся в сопроводительных чертежах и описании, представленных ниже. Другие признаки, задачи и преимущества будут очевидны из описания и чертежей и из формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0016] Фиг. 1 является концептуальной диаграммой, иллюстрирующей процесс кодирования отображения значимости.
[0017] Фиг. 2 является концептуальной диаграммой, иллюстрирующей шаблоны и направления сканирования для кодирования отображения значимости.
[0018] Фиг. 3 является концептуальной диаграммой, иллюстрирующей способ сканирования для кодирования уровня блока преобразования.
[0019] Фиг. 4 является блок-схемой, иллюстрирующей примерную систему кодирования видео.
[0020] Фиг. 5 является блок-схемой, иллюстрирующей примерный кодер видео.
[0021] Фиг. 6 является концептуальной диаграммой, иллюстрирующей обратные порядки сканирования для кодирования отображения значимости и уровня коэффициентов.
[0022] Фиг. 7 является концептуальной диаграммой, иллюстрирующей первый поднабор коэффициентов преобразования в соответствии с обратным диагональным порядком сканирования.
[0023] Фиг. 8 является концептуальной диаграммой, иллюстрирующей первый поднабор коэффициентов преобразования в соответствии с обратным порядком горизонтального сканирования.
[0024] Фиг. 9 является концептуальной диаграммой, иллюстрирующей первый поднабор коэффициентов преобразования в соответствии с обратным порядком вертикального сканирования.
[0025] Фиг. 10 является концептуальной диаграммой, иллюстрирующей области контекста для кодирования отображения значимости.
[0026] Фиг. 11 является концептуальной диаграммой, иллюстрирующей примерные области контекста для кодирования отображения значимости, использующего обратный порядок сканирования.
[0027] Фиг. 12 является концептуальной диаграммой, иллюстрирующей примерных казуальных соседей для статистического кодирования, использующего прямой порядок сканирования.
[0028] Фиг. 13 является концептуальной диаграммой, иллюстрирующей примерных казуальных соседей для статистического кодирования, использующего обратный порядок сканирования.
[0029] Фиг. 14 является концептуальной диаграммой, иллюстрирующей примерные области контекста для статистического кодирования, использующего обратный порядок сканирования.
[0030] Фиг. 15 является концептуальной диаграммой, иллюстрирующей примерных казуальных соседей для статистического кодирования, использующего обратный порядок сканирования.
[0031] Фиг. 16 является концептуальной диаграммой, иллюстрирующей другой пример областей контекста для CABAC, использующего обратный порядок сканирования.
[0032] Фиг. 17 является концептуальной диаграммой, иллюстрирующей другой пример областей контекста для CABAC, использующего обратный порядок сканирования.
[0033] Фиг. 18 является концептуальной диаграммой, иллюстрирующей другой пример областей контекста для CABAC, использующего обратный порядок сканирования.
[0034] Фиг. 19 является блок-схемой, иллюстрирующей примерный блок статистического кодирования.
[0035] Фиг. 20 является блок-схемой, иллюстрирующей примерный декодер видео.
[0036] Фиг. 21 является блок-схемой, иллюстрирующей примерный блок статистического декодирования.
[0037] Фиг. 22 является блок-схемой, иллюстрирующей примерный процесс для сканирования отображения значимости и уровня коэффициентов с согласованным порядком сканирования.
[0038] Фиг. 23 является блок-схемой, иллюстрирующей примерный процесс для сканирования отображения значимости и уровня коэффициентов и выведения контекста статистического кодирования.
[0039] Фиг. 24 является блок-схемой, иллюстрирующей другой примерный процесс для сканирования отображения значимости и уровня коэффициентов и выведения контекста статистического кодирования.
[0040] Фиг. 25 является блок-схемой, иллюстрирующей другой примерный процесс для сканирования отображения значимости и уровня коэффициентов и выведения контекста статистического кодирования.
[0041] Фиг. 26 является блок-схемой, иллюстрирующей примерный процесс для кодирования отображения значимости, использующего обратное направление сканирования.
[0042] Фиг. 27 является блок-схемой, иллюстрирующей примерный процесс для сканирования отображения значимости и уровня коэффициентов в соответствии с поднабором коэффициентов преобразования.
[0043] Фиг. 28 является блок-схемой, иллюстрирующей другой примерный процесс для сканирования отображения значимости и уровня коэффициентов, в соответствии с поднабором коэффициентов преобразования.
[0044] Фиг. 29 является блок-схемой, иллюстрирующей другой примерный процесс для сканирования отображения значимости и уровня коэффициентов в соответствии с поднабором коэффициентов преобразования.
[0045] Фиг. 30 является блок-схемой, иллюстрирующей примерный процесс для статистического кодирования, использующего множественные области.
ПОДРОБНОЕ ОПИСАНИЕ
[0046] Цифровые видео устройства реализуют способы сжатия видео, чтобы более эффективно передавать и принимать цифровую видеоинформацию. Сжатие видео может применять способы пространственного (внутрикадрового) предсказания и/или временного (межкадрового) предсказания, чтобы уменьшить или удалить избыточность, свойственную последовательностям видео.
[0047] Для кодирования видео в соответствии со стандартом высокоэффективного кодирования видео (HEVC), в настоящее время разрабатываемым совместной объединенной командой для кодирования видео (JCT-VC), в качестве одного примера, видеокадр может быть фрагментирован на блоки кодирования. Блок кодирования в целом относится к области изображения, которая служит базовым блоком, к которому применяются различные инструменты кодирования для сжатия видео. Блок кодирования обычно является квадратным (хотя не обязательно), и может быть рассмотрен как аналогичный так называемому макроблоку, например, в соответствии с другими стандартами кодирования видео, такими как ITU-T H.264. Кодирование, в соответствии с некоторыми из в настоящее время предложенных аспектов развития стандарта HEVC, описано ниже в настоящей заявке в целях иллюстрации. Однако способы, описанные в настоящем раскрытии, могут быть полезны для других процессов кодирования видео, таких как процессы, определенные в соответствии с H.264 или другим стандартом, или составляющие собственность процессы кодирования видео.
[0048] Чтобы достигнуть желаемой эффективности кодирования, блок кодирования (CU) может иметь переменные размеры в зависимости от видео контента. В дополнение, блок кодирования может быть разбит на меньшие блоки для предсказания или преобразования. В частности, каждый блок кодирования может быть дополнительно фрагментирован на блоки предсказания (блоки PU) и блоки преобразования (блоки TU). Блоки предсказания могут быть рассмотрены как аналогичные так называемым фрагментам (разделениям) в соответствии с другими стандартами кодирования видео, такими как стандарт H.264. Блок преобразования (TU) в целом относится к блоку остаточных данных, к которым применяется преобразование, чтобы сформировать коэффициенты преобразования.
[0049] Блок кодирования обычно имеет компоненту яркости, обозначенную как Y, и две компоненты цветности, обозначенные как U и V. В зависимости от формата дискретизации видео, размер компонент U и V, в терминах количества выборок, может быть одинаковым или отличаться от размера компоненты Y.
[0050] Чтобы закодировать блок (например, блок предсказания данных видео), сначала выводится предсказатель для блока. Предсказатель, также называемый предсказывающим блоком, может быть выведен или с помощью интра-предсказания (I) (то есть, пространственного предсказания) или интер-предсказания (P или B) (то есть, временного предсказания). Следовательно, некоторые блоки предсказания могут быть интра-кодированы (I), используя пространственное предсказание относительно опорных выборок в соседних опорных блоках в одном и том же кадре (или вырезке), и другие блоки предсказания могут быть однонаправлено внешне кодированы (P) или двунаправлено внешне кодированы (B) относительно блоков опорных выборок в других ранее закодированных кадрах (или вырезках). В каждом случае опорные выборки могут быть использованы для формирования предсказывающего блока для блока, который должен быть закодирован.
[0051] После идентификации предсказывающего блока, определяется разность между оригинальным блоком данных видео и его предсказывающим блоком. Эта разность может называться остаточными данными предсказания, и указывает пиксельные разности между пиксельными значениями в блоке, который должен быть закодирован, и пиксельными значениями в предсказывающем блоке, выбранном для представления закодированного блока. Чтобы достигнуть лучшего сжатия, остаточные данные предсказания могут быть преобразованы, например, используя дискретное косинусное преобразование (DCT), целочисленное преобразование, преобразование Карунена-Лева (Karhunen-Loeve) (K-L) или другое преобразование.
[0052] Остаточные данные в блоке преобразования, таком как TU, могут быть скомпонованы в двумерном (2D) массиве значений пиксельной разности, находящихся в пространственной, пиксельной области. Преобразование преобразовывает остаточные пиксельные значения в двумерный массив коэффициентов преобразования в области преобразования, такой как частотная область. Для дополнительного сжатия коэффициенты преобразования могут быть квантованы прежде статистического кодирования. Статистический кодер затем применяет статистическое кодирование, такое как контекстное адаптивное кодирование с переменной длиной кода (CAVLC), контекстное адаптивное двоичное арифметическое кодирование (CABAC), статистическое кодирование с фрагментированием интервала вероятности (PIPE) и т.п., к квантованным коэффициентам преобразования.
[0053] Для выполнения статистического кодирования блока квантованных коэффициентов преобразования обычно выполняется процесс сканирования таким образом, чтобы двумерный (2D) массив квантованных коэффициентов преобразования в блоке был обработан в соответствии с конкретным порядком сканирования в упорядоченный одномерный (1D) массив, то есть, вектор, коэффициентов преобразования. Статистическое кодирование применяется в одномерном (1-D) порядке коэффициентов преобразования. Сканирование квантованных коэффициентов преобразования в блоке преобразования преобразует в последовательную форму 2D массив коэффициентов преобразования для статистического кодера. Отображение значимости может быть сгенерировано для указания позиций значимых (то есть, ненулевых) коэффициентов. Сканирование может быть применено для сканирования уровней значимых (то есть, ненулевых) коэффициентов и/или для кодирования знаков значимых коэффициентов.
[0054] Для DCT, в качестве примера, часто имеется более высокая вероятность ненулевых коэффициентов по направлению к левому верхнему углу (то есть, низкочастотной области) 2D блока преобразования. Может быть желательно сканировать коэффициенты способом, который увеличивает вероятность группирования ненулевых коэффициентов вместе в одном конце преобразованной в последовательную форму серии коэффициентов, разрешая нулевым коэффициентам группироваться вместе по направлению к другому концу преобразованного в последовательную форму вектора и более эффективно кодироваться как серии нулей. Поэтому порядок сканирования может быть важен для эффективного статистического кодирования.
[0055] В качестве одного примера, так называемый диагональный (или волнового фронта) порядок сканирования был принят для использования при сканировании квантованных коэффициентов преобразования в стандарте HEVC. Альтернативно, могут быть использованы зигзагообразный, горизонтальный, вертикальный или другие порядки сканирования. Посредством преобразования и квантования, как упомянуто выше, ненулевые коэффициенты преобразования в целом располагаются в низкочастотной области по направлению к верхней левой области блока, например, где преобразованием является DCT. В результате после процесса диагонального сканирования, который может сначала пересечь верхнюю левую область, ненулевые коэффициенты преобразования обычно более вероятно должны быть расположены во фронтальной части сканирования. Для процесса диагонального сканирования, который сначала пересекает из более нижней правой области, ненулевые коэффициенты преобразования обычно более вероятно должны быть расположены в задней части сканирования.
[0056] Ряд нулевых коэффициентов обычно будет сгруппирован в одном конце сканирования, в зависимости от направления сканирования, из-за уменьшенной энергии на более высоких частотах и из-за эффектов квантования, которые могут вынуждать некоторые ненулевые коэффициенты становиться нулевыми коэффициентами после уменьшения глубины в битах. Эти характеристики распределения коэффициентов в преобразованном в последовательную форму 1D массиве могут быть использованы в структуре статистического кодера для повышения эффективности кодирования. Другими словами, если ненулевые коэффициенты могут быть эффективно скомпонованы в одной части 1D массива с помощью некоторого соответствующего порядка сканирования, может ожидаться улучшенная эффективность кодирования из-за структуры многих статистических кодеров.
[0057] Чтобы достигнуть этой задачи размещения большего количества ненулевых коэффициентов в одном конце 1D массива, различные порядки сканирования могут быть использованы в видео кодере-декодере (кодеке), чтобы закодировать коэффициенты преобразования. В некоторых случаях диагональное сканирование может быть эффективным. В других случаях различные типы сканирования, такие как зигзагообразное, вертикальное или горизонтальное сканирование может быть более эффективным.
[0058] Различные порядки сканирования могут быть произведены разными способами. Один пример заключается в том, что для каждого блока коэффициентов преобразования "наилучший" порядок сканирования может быть выбран из ряда доступных порядков сканирования. Устройство кодирования видео затем может обеспечить декодеру индикацию, для каждого блока, индекса наилучшего порядка сканирования среди набора порядков сканирования, обозначенных соответствующими индексами. Выбор наилучшего порядка сканирования может быть определен посредством применения нескольких порядков сканирования и выбора одного, который является наиболее эффективным при размещении ненулевых коэффициентов около начала или конца 1D вектора, таким образом способствуя эффективному статистическому кодированию.
[0059] В другом примере порядок сканирования для текущего блока может быть определен на основании различных факторов, относящихся к кодированию подходящего блока предсказания, таких как режим предсказания (I, B, P), размер блока, преобразование или других факторов. В некоторых случаях, так как одна и та же информация, например, режим предсказания, может быть выведена как на стороне кодера, так и на стороне декодера, может не быть необходимости обеспечивать индикацию индекса порядка сканирования декодеру. Вместо этого декодер видео может сохранить данные конфигурации, которые указывают заданное знание подходящего порядка сканирования режима предсказания для блока и один или более критериев, которые отображают режим предсказания в конкретный порядок сканирования.
[0060] Чтобы дополнительно повысить эффективность кодирования, доступные порядки сканирования могут не быть постоянными все время. Вместо этого некоторая адаптация может быть разрешена таким образом, чтобы порядок сканирования адаптивно регулировался, например, на основании коэффициентов, которые уже закодированы. Обычно адаптация порядка сканирования может быть сделана таким образом, чтобы в соответствии с выбранным порядком сканирования более вероятно были сгруппированы нулевые и ненулевые коэффициенты.
[0061] В некоторых кодеках видео первоначальные доступные порядки сканирования могут быть в очень регулярной форме, такой как только горизонтальное, вертикальное, диагональное или зигзагообразное сканирование. Альтернативно, порядки сканирования могут быть выведены посредством процесса обучения и поэтому могут показаться несколько случайными. Процесс обучения может вовлекать применение различных порядков сканирования к блоку или последовательностям блоков для идентификации порядка сканирования, который приводит к желаемым результатам, например, с точки зрения эффективного размещения ненулевых коэффициентов и нулевых коэффициентов, как упомянуто выше.
[0062] Если порядок сканирования выведен (получен) из процесса обучения, или если множество различных порядков сканирования может быть выбрано, может быть выгодно сохранить конкретные порядки сканирования как на стороне кодера, так и на стороне декодера. Объем данных, задающих такие порядки сканирования, может быть существенным. Например, для блока преобразования 32x32 один порядок сканирования может содержать 1024 позиций коэффициентов преобразования. Так как могут существовать блоки разных размеров, и для каждого размера блока преобразования может существовать ряд различных порядков сканирования, общий объем данных, которые должны быть сохранены, не является пренебрежимым. Обычные порядки сканирования, такие как диагональный, горизонтальный, вертикальный или зигзагообразный порядок, могут не требовать области хранения или могут требовать минимальной области хранения. Однако диагональный, горизонтальный, вертикальный или зигзагообразный порядки могут не обеспечить достаточного разнообразия, чтобы обеспечить производительность кодирования, которая находится наравне с обученными порядками сканирования.
[0063] В одном обычном примере для стандарта H.264 и HEVC, в настоящее время разрабатываемого, когда используется статистический кодер CABAC, позиции значимых коэффициентов (то есть, ненулевых коэффициентов преобразования) в блоке преобразования (то есть, блоке преобразования в HEVC) являются кодированными прежде уровней коэффициентов. Процесс кодирования местоположений значимых коэффициентов называется кодированием отображения значимости. Значимость коэффициента является такой же, что и контейнер нуль уровня коэффициентов. Как показано на ФИГ. 1, кодирование отображения значимости квантованных коэффициентов 11 преобразования производит отображение 13 значимости. Отображение 13 значимости является отображением (картой) единиц и нулей, где единицы указывают местоположения значимых коэффициентов. Отображение значимости обычно требует высокого процентного содержания скорости передачи видео. Способы настоящего раскрытия могут также применяться для использования с другими статистическими кодерами (например, PIPE).
[0064] Примерный процесс для кодирования отображения значимости описан в D. Marpe, H. Schwarz, и T. Wiegand "Context-Based Adaptive Binary Arithmetic Coding in the H.264/AVC Video Compression Standard", IEEE Trans. Circuits and Systems for Video Technology, Vol. 13, № 7, July 2003. В этом процессе кодируется отображение значимости, если есть по меньшей мере один значимый коэффициент в блоке, как указано флагом закодированного блока (CBF), который определен как:
Флаг закодированного блока: coded_block_flag является однобитным символом, который указывает, есть ли значимые, то есть, ненулевые, коэффициенты в единственном блоке коэффициентов преобразования, для которого шаблон закодированного блока указывает ненулевые записи. Если coded_block_flag является нулем, никакая дополнительная информация не передается для связанного блока.
[0065] Если есть значимые коэффициенты в блоке, отображение значимости кодируется следующим порядком сканирования коэффициентов преобразования в блоке следующим образом:
Сканирование коэффициентов преобразования: двумерные массивы уровней коэффициентов преобразования субблоков, для которых coded_block_flag указывает ненулевые записи, сначала отображаются в одномерный список, используя заданный шаблон сканирования. Другими словами, субблоки со значимыми коэффициентами сканируются в соответствии с шаблоном сканирования.
[0066] При заданном шаблоне сканирования отображение значимости сканируется следующим образом.
Отображение значимости: Если coded_block_flag указывает, что блок имеет значимые коэффициенты, кодируется отображение значимости с двоичными значениями. Для каждого коэффициента преобразования в порядке сканирования передается однобитный символ significant_coeff_flag. Если символ significant_coeff_flag равен единице, то есть, если ненулевой коэффициент существует в этой позиции сканирования, посылается дополнительный однобитный last_significant_coeff_flag. Этот символ указывает, является ли текущий значимый коэффициент последним в блоке, или следуют ли дополнительные значимые коэффициенты. Если достигнута последняя позиция сканирования, и кодирование отображения значимости не было еще закончено посредством last_significant_coeff_flag со значением единица, очевидно, что последний коэффициент должен быть значимым.
[0067] Последние предложения для HEVC удалили last_significant_coeff_flag. В этих предложениях перед посылкой отображения значимости посылается индикация позиции X и Y последнего значимого коэффициента.
[0068] В настоящее время в HEVC предложено, чтобы три шаблона сканирования использовались для отображения значимости: диагональный, вертикальный и горизонтальный. ФИГ. 2 показывает пример зигзагообразного сканирования 17, вертикального сканирования 19, горизонтального сканирования 21 и диагонального сканирования 15. Как показано на ФИГ. 2, каждое из этих сканирований осуществляется в прямом направлении, то есть, от коэффициентов преобразования более низкой частоты в верхнем левом углу блока преобразования к коэффициентам преобразования более высокой частоты в правом нижнем углу блока преобразования. После кодирования отображения значимости кодируется оставшаяся информация об уровне (контейнеры 1-N, где N является общим количеством контейнеров) для каждого значимого коэффициента преобразования (то есть, значения коэффициента).
[0069] В процессе CABAC, ранее определенном в стандарте H.264, после обработки субблоков 4x4 каждый из уровней коэффициентов преобразования преобразовывается в двоичную форму, например, в соответствии с унарным кодом, чтобы сформировать последовательность контейнеров. В H.264 модель контекста CABAC, установленная для каждого субблока, состоит из моделей контекста два на пять с пятью моделями как для первого контейнера, так и для всех оставшихся контейнеров (вплоть до и включая 14-ый контейнер) элемента синтаксиса coeff_abs_level_minus_one, который кодирует абсолютное значение коэффициента преобразования. В частности, в одной предложенной версии HEVC оставшиеся контейнеры включают в себя только контейнер 1 и контейнер 2. Остаток от уровней коэффициентов кодируется кодированием Голомба-Райса и экспоненциальными кодами Голомба.
[0070] В HEVC выбор моделей контекста может быть выполнен так, как в оригинальном процессе CABAC, предложенном для стандарта H.264. Однако различные наборы моделей контекста могут быть выбраны для различных субблоков. В частности, выбор модели контекста, установленной для данного субблока, зависит от некоторой статистической информации о ранее закодированных субблоках.
[0071] ФИГ. 3 показывает порядок сканирования, следующий одной предложенной версии процесса HEVC, чтобы закодировать уровни коэффициентов преобразования (абсолютное значение уровня и знак уровня) в блоке 25 преобразования. Должно быть отмечено, что имеется прямой зигзагообразный шаблон 27 для сканирования субблоков 4x4 большего блока и обратный зигзагообразный шаблон 23 для сканирования уровней коэффициентов преобразования в каждом субблоке. Другими словами, последовательность из субблоков 4x4 сканируется в прямом зигзагообразном шаблоне таким образом, чтобы субблоки сканировались в последовательности. Затем в каждом субблоке обратное зигзагообразное сканирование выполняется для сканирования уровней коэффициентов преобразования в субблоке. Следовательно, коэффициенты преобразования в двумерном массиве, сформированном блоком преобразования, преобразуются в последовательную форму в одномерный массив таким образом, чтобы за коэффициентами, которые обратно сканируются в данном субблоке, затем следовали коэффициенты, которые обратно сканируются в последующем субблоке.
[0072] В одном примере CABAC-кодирование коэффициентов, сканированных в соответствии с подходом сканирования субблока, показанном на ФИГ. 3, может использовать 60 контекстов, то есть, 6 наборов из 10 контекстов, распределенных. как описано ниже. Для блока 4x4 может быть использовано 10 моделей контекста (5 моделей для контейнера 1 и 5 моделей для контейнеров 2-14), как показано в Таблице 1.
1
2
3
4
Первоначальный - нет хвостовых единиц в субблоке
1 хвостовая единица в субблоке
2 хвостовые единицы в субблоке
3 или более хвостовых единиц в субблоке
1
2
3
4
1 коэффициент больший чем единица
2 коэффициента, больших чем единица
3 коэффициента, больших чем единица
4 или более коэффициентов, больших чем единица
[0073] Для Таблицы 1 одна из моделей 0-4 контекста в наборе контекстов используется для контейнера 1, если, соответственно, в настоящее время закодированный коэффициент, который сканируется в субблоке, закодирован после того, как коэффициент больше чем 1, был закодирован в субблоке, этот в настоящее время закодированный коэффициент является первоначальным коэффициентом, сканированным в субблоке, или нет никаких хвостовых единиц (никаких ранее закодированных коэффициентов) в субблоке, есть одна хвостовая единица в субблоке (то есть, единица была закодирована, но никакие коэффициенты большие чем единица, не были закодированы), есть две хвостовых единицы в субблоке, или в субблоке есть три или более хвостовых единиц. Для каждого из контейнеров 2-14 (хотя в настоящее время предложенная версия HEVC кодирует только контейнер 2, используя CABAC, с последующими контейнерами уровня коэффициентов, кодируемых экспоненциальным кодом Голомба), одна из моделей 0-4 контекста может быть использована, соответственно, если коэффициент является первоначальным коэффициентом, сканированным в субблоке, или имеются нулевые ранее закодированные коэффициенты, большие чем единица, имеется один ранее закодированный коэффициент больший чем единица, имеются два ранее закодированных коэффициента большие чем единица, имеются три ранее закодированных коэффициента большие чем единица, или имеются четыре ранее закодированных коэффициента большие чем единица.
[0074] Существуют 6 различных наборов этих 10 моделей, в зависимости от количества коэффициентов, больших чем 1, в ранее закодированном субблоке 4x4 в прямом сканировании субблоков:
2
3
4
4-7 больших чем 1 в предыдущем субблоке
8-11 больших чем 1 в предыдущем субблоке
12-15 больших чем 1 в предыдущем субблоке
16 больших чем 1 в предыдущем субблоке
[0075] Для Таблицы 2 наборы 0-5 моделей контекста используются для заданного субблока, если, соответственно, размер субблока составляет 4x4, имеются 0-3 коэффициентов больше чем 1, в ранее закодированном субблоке, имеются 4-7 коэффициентов больших чем 1, в ранее закодированном субблоке, имеются 8-11 коэффициентов больших чем 1, в ранее закодированном субблоке, имеются 12-15 коэффициентов больших чем 1, в ранее закодированном субблоке, или данный субблок является первым субблоком 4x4 (верхний левый субблок), или имеются 16 коэффициентов больших чем 1, в ранее закодированном субблоке.
[0076] Вышеописанный процесс кодирования для H.264 и процесс, в настоящее время предложенный для HEVC, имеют несколько недостатков. Как показано на ФИГ. 3, один недостаток состоит в том, что сканирование уровней коэффициентов осуществляется вперед для сканирования субблоков (то есть, начиная с верхнего левого субблока), а затем обратно для сканирования уровней коэффициентов в каждом субблоке (то есть, начиная с нижнего правого коэффициента в каждом субблоке). Этот подход подразумевает движение назад и вперед в пределах блока, что может сделать выборку данных более сложным.
[0077] Другой недостаток обусловлен тем фактом, что порядок сканирования уровня коэффициентов отличается от порядка сканирования отображения значимости. В HEVC имеются три разных предложенных порядка сканирования для отображения значимости: прямой диагональный, прямой горизонтальный и прямой вертикальный, как показано на ФИГ. 2. Все сканирования значимых коэффициентов отличаются от сканирования уровней коэффициентов, в настоящее время предложенных для HEVC, так как сканирования уровня осуществляются в обратном направлении. Так как направление и шаблон сканирования уровня коэффициентов не совпадают с направлением и шаблоном сканирования значимости, должно быть проверено больше уровней коэффициентов. Например, предположим, что горизонтальное сканирование используется для отображения значимости, и последний коэффициент значимости найден в конце первой строки коэффициентов. Сканирование уровня коэффициентов в HEVC будет требовать диагонального сканирования через множественные строки для сканирования уровня, когда только первая строка фактически содержит уровни коэффициентов, отличные от 0. Такой процесс сканирования может ввести нежелательную неэффективность.
[0078] В текущем предложении по HEVC сканирование отображения значимости осуществляется вперед в блоке от коэффициента DC, найденного в левом верхнем углу блока, к коэффициенту самой высокой частоты, обычно найденному в правом нижнем углу блока, в то время как сканирование уровней коэффициентов является в обратном направлении в каждом субблоке 4x4. Это также может привести к более сложной и более неэффективной выборке данных.
[0079] Другой недостаток для текущих предложений HEVC обусловлен наборами контекстов. Набор контекстов (см. Таблицу 2 выше) для CABAC отличается для размера блока 4x4, чем для других размеров блока. В соответствии с этим раскрытием, было бы желательно согласовать (гармонизировать) контексты для всех размеров блока таким образом, чтобы меньше памяти было выделено на хранение различных наборов контекстов.
[0080] Кроме того, как описано более подробно ниже, в настоящее время предложенные контексты CABAC для отображения значимости для HEVC действительны только, если порядок сканирования является прямым (вперед). Также, это может не учитывать обратные сканирования отображения значимости.
[0081] Кроме того, контексты, описанные выше для кодирования уровня квантованного коэффициента, пытаются использовать локальную корреляцию уровней коэффициентов. Эти контексты зависят от корреляции среди субблоков 4x4 (см. набор контекстов в Таблице 2) и корреляции в каждом субблоке (см. модели контекста в Таблице 1). Недостаток этих контекстов состоит в том, что зависимость может быть слишком отдаленной (то есть, имеется низкая зависимость между коэффициентами, которые отделены друг от друга несколькими другими коэффициентами, от одного субблока до другого). Кроме того, в каждом субблоке зависимость может быть слабой.
[0082] Настоящее раскрытие предлагает несколько различных особенностей, которые могут уменьшить или устранить некоторые из недостатков, описанных выше. В некоторых примерах эти особенности могут обеспечить более эффективный и согласованный порядок сканирования коэффициентов преобразования при кодировании видео. В других примерах настоящего раскрытия эти особенности обеспечивают более эффективный набор контекстов, которые должны быть использованы в основанном на CABAC статистическом кодировании коэффициентов преобразования, совместимым с предложенным порядком сканирования. Должно быть отмечено, что все способы, описанные в настоящем раскрытии, могут быть использованы независимо или могут быть использованы вместе в любой комбинации.
[0083] ФИГ. 4 является блок-схемой, иллюстрирующей примерную систему 10 кодирования и декодирования видео, которая может быть сконфигурирована для использования способов для кодирования коэффициентов преобразования в соответствии с примерами настоящего раскрытия. Как показано на ФИГ. 4, система 10 включает в себя устройство-источник 12, которое передает закодированное видео на устройство 14 назначения с помощью канала 16 связи. Закодированное видео может быть также сохранено на запоминающем носителе 34 или файловом сервере 36 и может быть доступно посредством устройства 14 назначения, если необходимо. Устройство-источник 12 и устройство 14 назначения могут содержать любое большое разнообразие устройств, включающих в себя настольные компьютеры, портативные компьютеры (то есть, ноутбук), планшетные компьютеры, телевизионные приставки, телефонные трубки, такие как так называемые смартфоны, телевизоры, камеры, устройства отображения, цифровые медиа плееры, консоли для видео игр и т.п. Во многих случаях такие устройства могут быть оборудованы для беспроводной связи. Следовательно, канал 16 связи может содержать беспроводной канал, проводной канал или комбинацию беспроводных и проводных каналов, подходящих для передачи закодированных видеоданных. Аналогично, файловый сервер 36 может быть доступен посредством устройства 14 назначения через любое стандартное соединение передачи данных, включающее в себя Интернет-соединение. Оно может включать в себя беспроводной канал (например, соединение Wi-Fi), проводное соединение (например, DSL, кабельный модем и т.д.) или их комбинацию, которая подходит для того, чтобы получить доступ к закодированным видеоданным, сохраненным на файловом сервере.
[0084] Способы для кодирования коэффициентов преобразования в соответствии с примерами настоящего раскрытия могут применяться к кодированию видео в поддержку любого из множества мультимедийных приложений, таких как телевизионные вещания по воздуху, передачи кабельного телевидения, передачи спутникового телевидения, текущие видео передачи, например, с помощью Интернета, кодирование цифрового видео для хранения на запоминающем носителе данных, декодирование цифрового видео, сохраненного на запоминающем носителе данных или других приложений. В некоторых примерах система 10 может быть сконфигурирована для поддержания односторонней или двухсторонней передачи видео, чтобы поддержать приложения, такие как потоковая передача видео, воспроизведение видео, вещание видео и/или видео телефония.
[0085] В примере согласно ФИГ. 4 устройство-источник 12 включает в себя источник 18 видео, кодер 20 видео, модулятор/демодулятор 22 и передатчик 24. В устройстве-источнике 12 источник 18 видео может включать в себя источник, такой как устройство захвата видео, например, видеокамеру, видео архив, содержащий ранее захваченное видео, интерфейс подачи видео для приема видео от поставщика видео контента, и/или систему компьютерной графики для генерирования данных компьютерной графики в качестве исходного видео, или комбинацию таких источников. В качестве одного примера, если источником 18 видео является видеокамера, устройство-источник 12 и устройство 14 назначения могут формировать так называемые камерофоны или видеотелефоны. Однако способы, описанные в настоящем раскрытии, могут применяться к кодированию видео в целом и могут применяться к беспроводным и/или проводным приложениям.
[0086] Захваченное, предварительно захваченное или сгенерированное компьютером видео может быть закодировано кодером 20 видео. Закодированная информация видео может быть модулирована модемом 22 в соответствии со стандартом связи, таким как протокол беспроводной связи, и передаваться на устройство 14 назначения с помощью передатчика 24. Модем 22 может включать в себя различные смесители, фильтры, усилители или другие компоненты, сконструированные для модуляции сигнала. Передатчик 24 может включать в себя схемы, сконструированные для передачи данных, включающие в себя усилители, фильтры и одну или более антенн.
[0087] Захваченное, предварительно захваченное или сгенерированное компьютером видео, которое кодируется кодером 20 видео, может также быть сохранено на запоминающем носителе 34 или файловом сервере 36 для более позднего использования. Запоминающий носитель 34 может включать в себя диски Blu-ray, диски DVD, диски CD-ROM, флэш-память или любые другие подходящие цифровые запоминающие носители для хранения закодированного видео. Закодированное видео, сохраненное на запоминающем носителе 34, затем может быть доступно посредством устройства 14 назначения для декодирования и воспроизведения.
[0088] Файловый сервер 36 может быть любым типом сервера, способного хранить закодированное видео и передавать это закодированное видео на устройство 14 назначения. Примерные файловые серверы включают в себя web-сервер (например, для web-сайта), сервер FTP, сетевые устройства хранения данных (NAS), локальный дисковой накопитель или любой другой тип устройства, способного хранить закодированные видеоданные и передавать их на приемное устройство. Передача закодированных видеоданных от файлового сервера 36 может быть потоковой передачей, передачей загрузки или их комбинацией. Файловый сервер 36 может быть доступен посредством устройства 14 назначения через любое стандартное соединение передачи данных, включающее в себя Интернет-соединение. Оно может включать в себя беспроводной канал (например, соединение Wi-Fi), проводное соединение (например, DSL, кабельный модем, Ethernet, USB и т.д.) или их комбинацию, которая подходит для того, чтобы получить доступ к закодированным видеоданным, сохраненным на файловом сервере.
[0089] Устройство 14 назначения в примере на ФИГ. 4 включает в себя приемник 26, модем 28, декодер 30 видео и устройство 32 отображения. Приемник 26 устройства 14 назначения принимает информацию по каналу 16, и модем 28 демодулирует информацию, чтобы сформировать демодулированный битовый поток для декодера 30 видео. Информация, переданная по каналу 16, может включать в себя разную информацию синтаксиса, сгенерированную кодером 20 видео, для использования посредством декодера 30 видео при декодировании видеоданных. Такой синтаксис может быть также включен с закодированными видеоданными, сохраненными на запоминающем носителе 34 или файловом сервере 36. Каждый из кодера 20 видео и декодера 30 видео могут быть частью соответствующего кодека (CODEC), который способен кодировать или декодировать видеоданные.
[0090] Устройство 32 отображения может быть объединено с, или быть внешним по отношению к, устройством 14 назначения. В некоторых примерах устройство 14 назначения может включать в себя интегрированное устройство отображения и также быть сконфигурировано для того, чтобы взаимодействовать с внешним устройством отображения. В других примерах устройство 14 назначения может быть устройством отображения. В целом, устройство 32 отображения отображает декодированные видеоданные пользователю и может содержать любое из множества устройств отображения, таких как жидкокристаллический дисплей (LCD), плазменный дисплей, дисплей на органических светодиодах (OLED) или другой тип устройства отображения.
[0091] В примере на ФИГ. 4 канал 16 связи может содержать любой беспроводной или проводной коммуникационный носитель, такой как радиочастотный (RF) (РЧ) спектр или одна или более физических линий передачи, или любую комбинацию беспроводных и проводных носителей. Канал 16 связи может быть частью основанной на пакетной передаче сети, такой как локальная сеть, широкомасштабная сеть или глобальная сеть, такая как Интернет. Канал 16 связи в целом представляет любой подходящий коммуникационный носитель или коллекцию различных коммуникационных носителей для передачи данных видео от устройства-источника 12 на устройство 14 назначения, включая любую подходящую комбинацию проводных или беспроводных носителей. Канал 16 связи может включать в себя маршрутизаторы, коммутаторы, базовые станции или любое другое оборудование, которое может быть полезным, чтобы облегчить передачу данных от устройства-источника 12 на устройство 14 назначения.
[0092] Кодер 20 видео и декодер 30 видео могут работать в соответствии со стандартом сжатия видео, таким как в настоящее время разрабатываемый стандарт высокоэффективного кодирования видео (HEVC), и могут соответствовать тестовой модели HEVC (HM). Альтернативно, кодер 20 видео и декодер 30 видео могут работать в соответствии с другими составляющими собственность или промышленными стандартами, такими как стандарт ITU-T H.264, альтернативно называемый MPEG-4, Часть 10, усовершенствованное кодирование видео (AVC), или расширениями таких стандартов. Способы настоящего раскрытия, однако, не ограничиваются никаким особым стандартом кодирования. Другие примеры включают в себя MPEG-2 и ITU-T H.263.
[0093] Хотя не показано на ФИГ. 4, в некоторых аспектах кодер 20 видео и декодер 30 видео могут быть объединены с кодером и декодером аудио, и могут включать в себя соответствующие блоки MUX-DEMUX или другое аппаратное и программное обеспечение, чтобы выполнять кодирование как аудио, так и видео в общем потоке данных или отдельных потоках данных. Если применимо, в некоторых примерах блоки MUX-DEMUX могут соответствовать протоколу мультиплексора ITU H.223 или другим протоколам, таким как протокол пользовательских дейтаграмм (UDP).
[0094] Кодер 20 видео и декодер 30 видео могут быть реализованы как любая из множества подходящих схем кодера, например, один или более микропроцессоров, цифровые сигнальные процессоры (процессоры DSP), специализированные интегральные схемы (схемы ASIC), программируемые пользователем вентильные матрицы (матрицы FPGA), дискретная логика, программное обеспечение, аппаратное обеспечение, программно-аппаратное обеспечение или любые их комбинации. Когда способы реализованы частично в программном обеспечении, устройство может сохранить команды для программного обеспечения в подходящем невременном считываемом компьютере носителе и выполнять команды в аппаратном обеспечении, используя один или более процессоров для выполнения способов настоящего раскрытия. Каждый из кодера 20 видео и декодера 30 видео могут быть включены в один или более кодеров или декодеров, любой из которых может быть интегрирован как часть объединенного кодера/декодера (CODEC) в соответствующем устройстве.
[0095] Кодер 20 видео может реализовать любые или все из способов настоящего раскрытия, чтобы улучшить кодирование коэффициентов преобразования в процессе кодирования видео. Аналогично, декодер 30 видео может реализовать любые или все из этих способов, чтобы улучшить декодирование коэффициентов преобразования в процессе кодирования видео. Видео кодер, как описано в настоящем раскрытии, может относиться к кодеру видео или декодеру видео. Аналогично, блок кодирования видео может относиться к кодеру видео или декодеру видео. Аналогично, кодирование видео может относиться к кодированию видео или декодированию видео.
[0096] В одном примере раскрытия кодер видео (такой, как кодер 20 видео или декодер 30 видео) может быть сконфигурирован для кодирования множества коэффициентов преобразования, ассоциированных с остаточными данными видео в процессе кодирования видео. Кодер видео может быть сконфигурирован для кодирования информации, указывающей значимые коэффициенты для множества коэффициентов преобразования в соответствии с порядком сканирования, и кодирования информации, указывающей уровни множества коэффициентов преобразования в соответствии с порядком сканирования.
[0097] В другом примере раскрытия кодер видео (такой, как кодер 20 видео или декодер 30 видео) может быть сконфигурирован для кодирования множества коэффициентов преобразования, ассоциированных с остаточными видеоданными в процессе кодирования видео. Кодер видео может быть сконфигурирован для кодирования информации, указывающей значимые коэффициенты преобразования в блоке коэффициентов преобразования, со сканированием, осуществляющемся в обратном направлении сканирования от коэффициентов более высокой частоты в блоке коэффициентов преобразования, к коэффициентам более низкой частоты в блоке коэффициентов преобразования.
[0098] В другом примере раскрытия кодер видео (такой, как кодер 20 видео или декодер 30 видео) может быть сконфигурирован для кодирования множества коэффициентов преобразования, ассоциированных с остаточными данными видео в процессе кодирования видео. Кодер видео может быть сконфигурирован для компоновки блока коэффициентов преобразования в один или более поднаборов коэффициентов преобразования на основании порядка сканирования, кодирования первой части уровней коэффициентов преобразования в каждом поднаборе, причем первая часть уровней включает в себя по меньшей мере значимость коэффициентов преобразования в каждом поднаборе, и кодирования второй части уровней коэффициентов преобразования в каждом поднаборе.
[0099] В другом примере раскрытия кодер видео (такой, как кодер 20 видео или декодер 30 видео) может быть сконфигурирован для кодирования информации, указывающей значимые коэффициенты для множества коэффициентов преобразования в соответствии с порядком сканирования, разделения закодированной информации на по меньшей мере первую область и вторую область, статистического кодирования закодированной информации в первой области в соответствии с первым набором контекстов, используя критерии выведения контекста, и статистического кодирования закодированной информации во второй области в соответствии со вторым набором контекстов, используя те же критерии выведения контекста, что и в первой области.
[0100] ФИГ. 5 является блок-схемой, иллюстрирующей пример кодера 20 видео, который может использовать способы для кодирования коэффициентов преобразования, как описано в настоящем раскрытии. Кодер 20 видео будет описан в контексте кодирования HEVC в целях иллюстрации, а не ограничения, настоящего раскрытия относительно других стандартов или способов кодирования, которые могут требовать сканирования коэффициентов преобразования. Кодер 20 видео может выполнять внутреннее (интра-) и внешнее (интер-) кодирование блоков CU в видеокадрах. Внутреннее кодирование основано на пространственном предсказании, чтобы уменьшить или удалить пространственную избыточность в видео в заданном кадре видео. Внешнее кодирование основано на временном предсказании, чтобы уменьшить или удалить временную избыточность между текущим кадром и ранее закодированными кадрами видео последовательности. Внутренний режим (I - режим) может относиться к любому из нескольких режимов, основанных на пространственном сжатии видео. Внешние режимы, такие как однонаправленное предсказание (P-режим) или двунаправленное предсказание (B-режим), могут относиться к любому из нескольких режимов, основанных на временном сжатии видео.
[0101] Как показано на ФИГ. 5, кодер 20 видео принимает текущий блок видео в кадре видео, который должен быть закодирован. В примере согласно ФИГ. 5 кодер 20 видео включает в себя модуль 44 компенсации движения, модуль 42 оценки движения, модуль 46 внутреннего предсказания, буфер 64 опорных кадров, сумматор 50, модуль 52 преобразования, модуль 54 квантования и модуль 56 статистического кодирования. Модуль 52 преобразования, иллюстрированный на ФИГ. 5, является модулем, который применяет фактическое преобразование к блоку остаточных данных, и не должен быть перепутан с блоком коэффициентов преобразования, который также может называться блоком преобразования (TU) CU. Для восстановления блока видео кодер 20 видео также включает в себя модуль 58 обратного квантования, модуль 60 обратного преобразования и сумматор 62. Фильтр удаления блочности (не показан на ФИГ. 5) также может быть включен, чтобы фильтровать границы блока для удаления артефактов блочности из восстановленного видео. При желании фильтр удаления блочности обычно будет фильтровать выходной сигнал сумматора 62.
[0102] Во время процесса кодирования кодер 20 видео принимает кадр или вырезку видео, которые должны быть закодированы. Кадр или вырезка могут быть разделены на множественные блоки видео, например, наибольшие блоки кодирования (блоки LCU). Модуль 42 оценки движения и модуль 44 компенсации движения выполняют кодирование с внешним предсказанием принятого блока видео относительно одного или более блоков в одном или более опорных кадрах, чтобы обеспечить временное сжатие. Модуль 46 внутреннего предсказания может выполнить кодирование с внутреннем предсказанием принятого блока видео относительно одного или более соседних блоков в одних и тех же кадре или вырезке в качестве блока, который должен быть закодирован, чтобы обеспечить пространственное сжатие.
[0103] Модуль 40 выбора режима может выбрать один из режимов кодирования, внутренний или внешний, например, на основании результатов ошибки (то есть, искажения) для каждого режима, и выдать получившийся в результате внутренне - или внешне кодированный блок к сумматору 50 для генерирования остаточных данных блока и сумматору 62 для восстановления закодированного блока, чтобы использовать в опорном кадре. Некоторые кадры видео могут быть обозначены как I-кадры, где все блоки в I-кадре закодированы в режиме внутреннего предсказания. В некоторых случаях модуль 46 внутреннего предсказания может выполнять кодирование с внутренним предсказанием блока в P- или B-кадре, например, когда поиск движения, выполненный модулем 42 оценки движения, не приводит к достаточному предсказанию блока.
[0104] Модуль 42 оценки движения и модуль 44 компенсации движения могут быть высоко интегрированы, но иллюстрируются отдельно в концептуальных целях. Оценка движения является процессом генерирования векторов движения, которые оценивают движение для блоков видео. Вектор движения, например, может указать смещение блока предсказания в текущем кадре относительно опорной выборки опорного кадра. Опорная выборка может быть блоком, который, как считается, точно соответствует части CU, включающего в себя PU, кодируемого в терминах пиксельной разности, которая может быть определена суммой абсолютной разности (SAD), суммой квадратичной разности (SSD) или другими метриками разности. Компенсация движения, выполненная модулем 44 компенсации движения, может включать выборку или генерирование значений для блока предсказания на основании вектора движения, определенного посредством оценки движения. Снова, модуль 42 оценки движения и модуль 44 компенсации движения могут быть функционально объединены в некоторых примерах.
[0105] Модуль 42 оценки движения вычисляет вектор движения для блока предсказания внешне кодированного кадра посредством сравнения блока предсказания с опорными выборками опорного кадра, сохраненного в буфере 64 опорных кадров. В некоторых примерах кодер 20 видео может вычислять значения для суб-целочисленных пиксельных позиций опорных кадров, сохраненных в буфере 64 опорных кадров. Например, кодер 20 видео может вычислять значения одночетвертных пиксельных позиций, одной восьмой от пиксельных позиций или других фракционных пиксельных позиций опорного кадра. Поэтому, модуль 42 оценки движения может выполнять поиск движения относительно полных пиксельных позиций и фракционных пиксельных позиций и сформировать вектор движения с фракционной пиксельной точностью. Модуль 42 оценки движения посылает вычисленный вектор движения на модуль 56 статистического кодирования и модуль 44 компенсации движения. Часть опорного кадра, идентифицированная вектором движения, может называться опорной выборкой. Модуль 44 компенсации движения может вычислять значение предсказания для блока предсказания текущего CU, например, посредством извлечения опорной выборки, идентифицированной вектором движения для PU.
[0106] Модуль 46 внутреннего предсказания может кодировать с внутренним предсказанием принятый блок, в качестве альтернативы внешнему предсказанию, выполняемому модулем 42 оценки движения и модулем 44 компенсации движения. Модуль 46 внутреннего предсказания может кодировать принятый блок относительно соседних ранее закодированных блоков, например, блоков выше, выше и справа, выше и слева или слева от текущего блока, принимая порядок кодирования слева направо, снизу вверх для блоков. Модуль 46 внутреннего предсказания может быть сконфигурирован со множеством различных режимов внутреннего предсказания. Например, модуль 46 внутреннего предсказания может быть сконфигурирован с некоторым количеством направленных режимов предсказания, например, 33 направленными режимами предсказания, на основании размера кодируемого CU.
[0107] Модуль 46 внутреннего предсказания может выбрать режим внутреннего предсказания, например, посредством вычисления значения ошибки для различных режимов внутреннего предсказания и выбора режима, который обеспечивает самое низкое значение ошибки. Направленные режимы предсказания могут включать в себя функции для комбинирования значений пространственно соседних пикселей и применения комбинированных значений к одной или более пиксельным позициям в PU. Как только значения для всех пиксельных позиций в PU будут вычислены, модуль 46 внутреннего предсказания может вычислять значение ошибки для режима предсказания на основании пиксельных разностей между PU и принятым блоком, который должен быть закодирован. Модуль 46 внутреннего предсказания может продолжить проверять режимы внутреннего предсказания до тех пор, пока не будет обнаружен режим внутреннего предсказания, который обеспечивает приемлемое значение ошибки. Модуль 46 внутреннего предсказания может затем послать PU в сумматор 50.
[0108] Кодер 20 видео формирует остаточный блок посредством вычитания данных предсказания, вычисленных модулем 44 компенсации движения или модулем 46 внутреннего предсказания, из закодированного оригинального блока видео. Сумматор 50 представляет компонент или компоненты, которые выполняют эту операцию вычитания. Остаточный блок может соответствовать двумерной матрице значений пиксельной разности, где количество значений в остаточном блоке является тем же, что и количество пикселей в PU, соответствующем остаточному блоку. Значения в остаточном блоке могут соответствовать разностям, то есть, ошибке, между значениями совместно расположенных пикселей в PU и в оригинальном блоке, который должен быть закодирован. Разности могут быть разностями в цветности или яркости в зависимости от типа блока, который кодируется.
[0109] Модуль 52 преобразования может формировать один или более блоков преобразования (блоков TU) из остаточного блока. Модуль 52 преобразования применяет преобразование, такое как дискретное косинусное преобразование (DCT), направленное преобразование или концептуально аналогичное преобразование, к TU, формируя блок видео, содержащий коэффициенты преобразования. Модуль 52 преобразования может послать получившиеся в результате коэффициенты преобразования на модуль 54 квантования. Модуль 54 квантования может затем квантовать коэффициенты преобразования. Модуль 56 статистического кодирования может затем выполнить сканирование квантованных коэффициентов преобразования в матрице в соответствии с заданным порядком сканирования. Настоящее раскрытие описывает модуль 56 статистического кодирования как выполняющий сканирование. Однако, должно быть понятно, что в других примерах другие блоки обработки, такие как модуль 54 квантования, могут выполнять сканирование.
[0110] Как упомянуто выше, сканирование коэффициентов преобразования может включать в себя два сканирования. Одно сканирование идентифицирует, какие от коэффициентов являются значимыми (то есть, ненулевыми), чтобы сформировать отображение значимости, и другое сканирование кодирует уровни коэффициентов преобразования. В одном примере настоящее раскрытие предлагает, чтобы порядок сканирования, используемый для кодирования уровней коэффициентов в блоке, был таким же, что и порядок сканирования для кодирования значимых коэффициентов в отображении значимости для этого блока. В HEVC блок может быть блоком преобразования. Используемый в настоящем описании термин «порядок сканирования» может относиться к любому направлению сканирования и/или шаблону сканирования. Как таковые, сканирования для отображения значимости и уровней коэффициентов могут быть одними и теми же в шаблоне сканирования и/или направлении сканирования. Таким образом, в качестве одного примера, если порядок сканирования, используемый для формирования отображения значимости, является шаблоном горизонтального сканирования в прямом направлении, то порядок сканирования для уровней коэффициентов также должен быть шаблоном горизонтального сканирования в прямом направлении. Аналогично, в качестве другого примера, если порядок сканирования для отображения значимости является шаблоном вертикального сканирования в обратном направлении, то порядок сканирования для уровней коэффициентов также должен быть шаблоном вертикального сканирования в обратном направлении. То же самое можно применять для диагонального, зигзагообразного или других шаблонов сканирования.
[0111] ФИГ. 6 показывает примеры обратных порядков сканирования для блока коэффициентов преобразования, то есть, блока преобразования. Блок преобразования может быть сформирован, используя преобразование, такое как, например, дискретное косинусное преобразование (DCT). Должно быть отмечено, что каждый из обратного диагонального шаблона 9, обратного зигзагообразного шаблона 29, обратного вертикального шаблона 31 и обратного горизонтального шаблона 33 осуществляется от коэффициентов более высокой частоты в правом нижнем углу блока преобразования к коэффициентам более низкой частоты в левом верхнем углу блока преобразования. Следовательно, один аспект раскрытия представляет унифицированный порядок сканирования для кодирования отображения значимости и кодирования уровней коэффициентов. Предложенный способ применяет порядок сканирования, используемый для отображения значимости, к порядку сканирования, используемому для кодирования уровня коэффициентов. В целом, горизонтальный, вертикальный и диагональный шаблоны сканирования были показаны, чтобы эффективно работать, таким образом, уменьшая потребность в дополнительных шаблонах сканирования. Однако, общие способы настоящего раскрытия применяются для использования с любым шаблоном сканирования.
[0112] В соответствии с другим аспектом, настоящее раскрытие предлагает, чтобы сканирование значимости было выполнено как обратное сканирование, от последнего значимого коэффициента в блоке преобразования к первому коэффициенту (то есть, коэффициенту DC) в блоке преобразования. Примеры обратных порядков сканирования показаны на ФИГ. 6. В частности, сканирование значимости осуществляется от последнего значимого коэффициента в позиции более высокой частоты к значимым коэффициентам в позициях более низкой частоты, и в конечном счете, к позиции коэффициента DC.
[0113] Чтобы облегчить обратное сканирование, могут быть использованы способы для идентификации последнего значимого коэффициента. Процесс для идентификации последнего значимого коэффициента описан в J. Sole, R. Joshi, I-S. Chong, M. Coban, M. Karczewicz, "Parallel Context Processing for the significance map in high coding efficiency" JCTVC-D262, 4th Meeting JCT-VC, Тэгу, KR, January 2011, и в американской предварительной заявке на патент № 61/419,740, поданной 3 декабря 2010, в Joel Sole Rojals и др., названной "Encoding of the position of the last significant transform coefficient in video coding". Как только идентифицирован последний значимый коэффициент в блоке, затем может быть применен обратный порядок сканирования как для отображения значимости, так и для уровня коэффициентов.
[0114] Настоящее раскрытие также предлагает, чтобы сканирование значимости и сканирование уровня коэффициентов не были обратными и прямыми, соответственно, но, вместо этого, имели одно и то же направление сканирования и, более подробно, только одно направление в блоке. В частности, предложено, чтобы сканирование значимости и сканирование уровня коэффициентов использовали обратный порядок сканирования от последнего значимого коэффициента в блоке преобразования к первому коэффициенту. Следовательно, сканирование значимости осуществляется в обратном направлении (обратное сканирование относительно в настоящее время предлагаемого сканирования для HEVC) от последнего значимого коэффициента к первому коэффициенту (коэффициенту DC). Этот аспект раскрытия представляет унифицированный однонаправленный порядок сканирования для кодирования отображения значимости и кодирования уровней коэффициентов. В частности, этот унифицированный однонаправленный порядок сканирования может быть унифицированным обратным порядком сканирования. Порядки сканирования для сканирований значимости и уровня коэффициентов в соответствии с унифицированным шаблоном обратного сканирования могут быть обратным диагональным, обратным зигзагообразным, обратным горизонтальным или обратным вертикальным, как показано на ФИГ. 6. Однако, может быть использован любой шаблон сканирования.
[0115] Вместо того, чтобы определить наборы коэффициентов в двумерных субблоках, как показано на ФИГ. 3, для цели выведения контекста CABAC, настоящее раскрытие предлагает определить наборы коэффициентов как несколько коэффициентов, которые последовательно сканируются в соответствии с порядком сканирования. В частности, каждый набор коэффициентов может содержать последовательные коэффициенты в порядке сканирования по всему блоку. Любой размер набора может быть рассмотрен, хотя было обнаружено, что размер из 16 коэффициентов в наборе сканирования работал эффективно. Размер набора может быть фиксированным или адаптивным. Это определение обеспечивает наборы, которые должны быть 2-D блоками (если используется способ сканирования субблока), прямоугольниками (если используются горизонтальное или вертикальное сканирования) или диагональными формами (если используются зигзагообразное или диагональное сканирования). Наборы диагонально сформированных коэффициентов могут быть частью диагональной формы, последовательных диагональных форм или частей последовательных диагональных форм.
[0116] ФИГ. 7-9 показывают примеры коэффициентов, скомпонованных в поднаборах из 16 коэффициентов, в соответствии с конкретными порядками сканирования вне компоновки в фиксированных блоках 4x4. ФИГ. 7 изображает поднабор 51 из 16 коэффициентов, которые состоят из первых 16 коэффициентов в обратном диагональном порядке сканирования. Следующий поднабор в этом примере будет просто состоять из следующих 16 последовательных коэффициентов вдоль обратного диагонального порядка сканирования. Аналогично, ФИГ. 8 изображает поднабор 53 из 16 коэффициентов для первых 16 коэффициентов в обратном горизонтальном порядке сканирования. ФИГ. 9 изображает поднабор 55 из 16 коэффициентов для первых 16 коэффициентов в обратном вертикальном порядке сканирования.
[0117] Этот способ совместим с порядком сканирования уровней коэффициентов, который является тем же, что и порядок сканирования для отображения значимости. В этом случае нет необходимости в отличающемся (и иногда трудоемком) порядке сканирования уровней коэффициентов, таких как показаны на ФИГ. 3. Сканирование уровней коэффициентов может быть сформировано, подобно сканированию отображения значимости, в настоящее время предложенному для HEVC, как прямое сканирование, которое осуществляется от положения последнего значимого коэффициента в блоке преобразования к позиции коэффициента DC.
[0118] Как в настоящее время предложено в HEVC, для статистического кодирования, использующего CABAC, коэффициенты преобразования кодируются следующим образом. Во-первых, имеется один проход (в порядке сканирования отображения значимости) в полном блоке преобразования для кодирования отображения значимости. Затем, имеются три прохода (в порядке сканирования уровней коэффициентов) для кодирования контейнера 1 уровня (1-ый проход), остальной части уровня коэффициентов (2-ой проход) и знака уровня коэффициентов (3-ий проход). Эти три прохода для кодирования уровней коэффициентов не делаются для полного блока преобразования. Вместо этого каждый проход выполняется в субблоках 4x4, как показано на ФИГ. 3. Когда три прохода были закончены в одном субблоке, следующий субблок обрабатывается посредством последовательного выполнения тех же трех проходов кодирования. Этот подход облегчает параллелизацию кодирования.
[0119] Как описано выше, настоящее раскрытие предлагает сканирование коэффициентов преобразования более согласованным образом так, чтобы порядок сканирования для уровней коэффициентов был тем же, что и порядок сканирования значимых коэффициентов, чтобы сформировать отображение значимости. В дополнение предложено, чтобы сканирования уровня коэффициентов и значимых коэффициентов были выполнены в обратном направлении, которое осуществляется от последнего значимого коэффициента в блоке к первому коэффициенту (компоненту DC) в блоке. Это обратное сканирование является противоположным сканированию, используемому для значимых коэффициентов в соответствии с HEVC, как предложено в настоящее время.
[0120] Как описано ранее со ссылками на ФИГ. 7-9, настоящее раскрытие дополнительно предлагает, чтобы контексты для уровней коэффициентов (включая отображение значимости) были разделены на поднаборы. Таким образом, контекст определен для каждого поднабора коэффициентов. Следовательно, в этом примере один и тот же контекст не обязательно используется для всего сканирования коэффициентов. Вместо этого различные поднаборы коэффициентов в блоке преобразования могут иметь различные контексты, которые индивидуально определены для каждого поднабора. Каждый поднабор может содержать одномерный массив последовательно сканированных коэффициентов в порядке сканирования. Поэтому, сканирование уровня коэффициентов идет от последнего значимого коэффициента к первому коэффициенту (компоненту DC), где сканирование концептуально фрагментируется на различные поднаборы последовательно сканированных коэффициентов в соответствии с порядком сканирования. Например, каждый поднабор может включать в себя n последовательно сканированных коэффициентов для конкретного порядка сканирования. Группирование коэффициентов в поднаборах в соответствии с их порядком сканирования может обеспечить лучшую корреляцию между коэффициентами и, таким образом, более эффективное статистическое кодирование.
[0121] Настоящее раскрытие дополнительно предлагает увеличить распараллеливание основанного на CABAC статистического кодирования коэффициентов преобразования посредством расширения концепции нескольких проходов уровня коэффициентов для включения дополнительного прохода для отображения значимости. Таким образом, пример с четырьмя проходами может включать в себя: (1) кодирование значений флага значимых коэффициентов для коэффициентов преобразования, например, чтобы сформировать отображение значимости, (2) кодирование контейнера 1 значений уровня для коэффициентов преобразования, (3) кодирование оставшихся контейнеров значений уровня коэффициентов и (4) кодирование знаков уровней коэффициентов, всех в одном и том же порядке сканирования. Используя способы, описанные в настоящем раскрытии, может быть облегчено кодирование с четырьмя проходами, изложенное выше. Таким образом, сканирование значимых коэффициентов и уровней для коэффициентов преобразования в одном и том же порядке сканирования, где порядок сканирования осуществляется в обратном направлении от высокочастотного коэффициента к низкочастотному коэффициенту, поддерживает работу способа кодирования с несколькими проходами, описанного выше.
[0122] В другом примере пять способов сканирования прохода могут включать в себя: (1) кодирование значений флага значимого коэффициента для коэффициентов преобразования, например, чтобы сформировать отображение значимости, (2) кодирование контейнера 1 значений уровня для коэффициентов преобразования, (3) кодирование контейнера 2 значений уровня для коэффициентов преобразования, (4) кодирование знаков уровней коэффициентов (например, в режиме обхода), и (5) кодирование оставшихся контейнеров значений уровня коэффициентов (например, в режиме обхода), причем все проходы используют один и тот же порядок сканирования.
[0123] Пример с меньшим количеством проходов может быть также использован. Например, двухпроходное сканирование, где уровень и информация о знаке обрабатываются параллельно, может включать в себя: (1) кодирование регулярных контейнеров прохода в проходе (например, значимость, уровень контейнера 1 и уровень контейнера 2), и (2) кодирование контейнеров обхода в другом (например, оставшиеся уровни и знак), причем каждый проход использует один и тот же порядок сканирования. Регулярные контейнеры являются контейнерами, закодированными с помощью CABAC, используя обновленный контекст, определенный критериями выведения контекста. Например, как будет объяснено более подробно ниже, критерии выведения контекста могут включать в себя закодированную информацию об уровне казуального (случайного) соседнего коэффициента относительно текущего коэффициента преобразования. Контейнеры обхода являются контейнерами, закодированными с помощью CABAC, имеющим фиксированный контекст.
[0124] Примеры нескольких проходов сканирования, описанных выше, могут быть обобщены как включающие в себя первый проход сканирования первой части уровней коэффициентов, причем первая часть включает в себя проход значимости, и второй проход сканирования второй части уровней коэффициентов.
[0125] В каждом из примеров, представленных выше, проходы могут быть выполнены последовательно в каждом поднаборе. Хотя использование одномерных поднаборов, содержащих последовательно сканированные коэффициенты, может быть желательным, несколько способов прохода также могут применяться к субблокам, таким как субблоки 4x4. Пример процессов с двумя проходами и с четырьмя проходами для последовательно сканированных поднаборов изложен более подробно ниже.
[0126] В упрощенном процессе с двумя проходами для каждого поднабора блока преобразования первый проход кодирует значимость коэффициентов в поднаборе, следуя порядку сканирования, и второй проход кодирует уровень коэффициентов от коэффициентов в поднаборе, следуя тому же порядку сканирования. Порядок сканирования может быть охарактеризован направлением сканирования (прямым или обратным) и шаблоном сканирования (например, горизонтальным, вертикальным или диагональным). Алгоритм может быть более поддающимся для параллельной обработки, если оба прохода в каждом поднаборе следуют одному и тому же порядку сканирования, как описано выше.
[0127] В более усовершенствованном процессе с четырьмя проходами для каждого поднабора блока преобразования первый проход кодирует значимость коэффициентов в поднаборе, второй проход кодирует контейнер 1 уровня коэффициентов от коэффициентов в поднаборе, третий проход кодирует оставшиеся контейнеры уровня коэффициентов от коэффициентов в поднаборе, и четвертый проход кодирует знак уровня коэффициентов от коэффициентов в поднаборе. Снова, чтобы быть более поддающимися для параллельной обработки, все проходы в каждом поднаборе должны иметь один и тот же порядок сканирования. Как описано выше, порядок сканирования с обратным направлением был показан как эффективно работающий. Должно быть отмечено, что четвертый проход (то есть, кодирование знака уровней коэффициентов) может быть сделан непосредственно после первого прохода (то есть, кодирования отображения значимости) или непосредственно перед оставшимися значениями прохода уровня коэффициентов.
[0128] Для некоторых размеров преобразования поднабор может быть целым блоком преобразования. В этом случае имеется единственный поднабор, соответствующий всем значимым коэффициентам для всего блока преобразования, и сканирование значимости и сканирование уровня осуществляются в одном и том же порядке сканирования. В этом случае вместо ограниченного числа n (например, n=16) коэффициентов в поднаборе, поднабор может быть единственным поднабором для блока преобразования, причем единственный поднабор включает в себя все значимые коэффициенты.
[0129] Ссылаясь на ФИГ. 5, как только коэффициенты преобразования сканированы, модуль 56 статистического кодирования может применить статистическое кодирование, такое как CAVLC или CABAC, к этим коэффициентам. В дополнение, модуль 56 статистического кодирования может кодировать информацию о векторе движения (MV) и любой из множества элементов синтаксиса, полезных при декодировании видеоданных в декодере 30 видео. Элементы синтаксиса могут включать в себя отображение значимости с флагами значимых коэффициентов, которые указывают, являются ли значимыми конкретные коэффициенты (например, ненулевые), и флаг последнего значимого коэффициента, который указывает, является ли конкретный коэффициент последним значимым коэффициентом. Декодер 30 видео может использовать эти элементы синтаксиса, чтобы восстановить закодированные видеоданные. После статистического кодирования посредством модуля 56 статистического кодирования получившееся в результате закодированное видео может быть передано на другое устройство, такое как декодер 30 видео, или заархивировано для более поздней передачи или поиска.
[0130] Для статистического кодирования элементов синтаксиса модуль 56 статистического кодирования может выполнять CABAC и выбрать модели контекста на основании, например, количества значимых коэффициентов в ранее сканированных N коэффициентах, где N является целочисленным значением, которое может быть связано с размером сканируемого блока. Модуль 56 статистического кодирования может также выбрать модель контекста на основании режима предсказания, используемого для вычисления остаточных данных, которые были преобразованы в блок коэффициентов преобразования, и типа преобразования, используемого для преобразования остаточных данных в блок коэффициентов преобразования. Когда соответствующие данные предсказания были предсказаны, используя режим внутреннего предсказания, модуль 56 статистического кодирования может дополнительно основывать выбор модели контекста на направлении режима внутреннего предсказания.
[0131] Дополнительно, в соответствии с другим аспектом настоящего раскрытия, предложено, чтобы контексты для CABAC были разделены на поднаборы коэффициентов (например, поднаборы, показанные на ФИГ. 7-9). Предложено, чтобы каждый поднабор состоял из последовательных коэффициентов в порядке сканирования по всему блоку. Любой размер поднаборов может быть рассмотрен, хотя размер 16 коэффициентов в поднаборе сканирования считался работающим эффективно. В этом примере поднабор может быть 16 последовательными коэффициентами в порядке сканирования, который может быть в любом шаблоне сканирования, включая субблочный, диагональный, зигзагообразный, горизонтальный и вертикальный шаблоны сканирования. В соответствии с этим предложением сканирование уровня коэффициентов осуществляется от последнего значимого коэффициента в блоке. Поэтому сканирование уровня коэффициентов идет от последнего значимого коэффициента к первому коэффициенту (компоненту DC) в блоке, где сканирование концептуально фрагментировано в различных поднаборах коэффициентов, чтобы получить контексты для применения. Например, сканирование организовано в поднаборах из n последовательных коэффициентов в порядке сканирования. Последним значимым коэффициентом является первый значимый коэффициент, встречающийся в обратном сканировании от коэффициента самой высокой частоты блока (обычно считающегося близким к правому нижнему углу блока) к коэффициенту DC блока (левый верхний угол блока).
[0132] В другом аспекте раскрытия предложено, чтобы критерии выведения контекста CABAC были согласованы (гармонизированы) для всех размеров блока. Другими словами, вместо того, чтобы иметь различные выведения контекста на основании размера блока, как рассмотрено выше, каждый размер блока будет полагаться на одно и то же выведение контекстов CABAC. Таким образом, нет необходимости принимать во внимание конкретный размер блока, чтобы получить контекст CABAC для блока. Выведение контекста является одним и тем же как для кодирования значимости, так и для кодирования уровня коэффициентов.
[0133] Также предложено, чтобы наборы контекста CABAC зависели от того, является ли поднабор поднабором 0 (определенным как поднабор с коэффициентами для самых низких частот, то есть, содержащий коэффициент DC и смежные низкочастотные коэффициенты) или нет (то есть, критерии выведения контекста). См. Таблицы 3a и 3b, представленные ниже.
1
2
Самая низкая частота
Самая низкая частота
1 больший чем 1 в предыдущем поднаборе
>1 больших чем 1 в предыдущем поднаборе
4
5
Самая высокая частота
Самая высокая частота
1 больший чем 1 в предыдущем поднаборе
>1 больших чем 1 в предыдущем поднаборе
Для сравнения с Таблицей 2. Имеется зависимость от поднабора, является ли он поднабором 0 (самые низкие частоты) или нет.
[0134] Для Таблицы 3a, представленной выше, наборы 0-2 моделей контекста используются для поднаборов сканирования самой низкой частоты (то есть, набор n последовательных коэффициентов) если, соответственно, имеется нуль коэффициентов больших чем единица в ранее закодированном поднаборе, имеется один коэффициент, больший чем единица, в ранее закодированном поднаборе, или имеются более чем один коэффициент, больших чем единица, в ранее закодированном поднаборе. Наборы 3-5 моделей контекста используются для всех поднаборов, более высоких, чем поднабор самой низкой частоты, если, соответственно, имеются нуль коэффициентов, больших чем единица, в ранее закодированном поднаборе, имеется один коэффициент, больший чем единица, в ранее закодированном поднаборе, или имеются более чем один коэффициент, больший чем единица, в ранее закодированном поднаборе.
1
2
Самая низкая частота
Самая низкая частота
1-3 больших чем 1 в предыдущем поднаборе
>3 больших чем 1 в предыдущем поднаборе
4
5
Самая высокая частота
Самая высокая частота
1-3 больших чем 1 в предыдущем поднаборе
>3 больших чем 1 в предыдущем поднаборе
[0135] Таблица 3b показывает таблицу набора контекстов, которая показала хорошую производительность, так как она учитывает более точное количество числа больших чем единица, коэффициентов в предыдущем поднаборе. Таблица 3b может быть использована в качестве альтернативы Таблице 3a, представленной выше.
[0136] Таблица 3c показывает упрощенную таблицу набора контекстов с критериями выведения контекста, которая также может быть альтернативно использована.
1
Самая низкая частота
1 больших чем 1 в предыдущем поднаборе
3
Самая высокая частота
1 больших чем 1 в предыдущем поднаборе
[0137] В дополнение поднабор, содержащий последний значимый коэффициент в блоке преобразования, может использовать уникальный набор контекстов.
[0138] Настоящее раскрытие также предлагает, чтобы контекст для поднаборов все еще зависел от количества коэффициентов больших чем 1, в предшествующих поднаборах. Например, если количество коэффициентов в предшествующих поднаборах является скользящим окном, пусть это количество будет uiNumOne. Как только это значение будет проверено, чтобы решить контекст для текущего набора субсканирования, тогда это значение не устанавливается в нуль. Вместо этого это значение нормализуется (например, используется uiNumOne=uiNumOne/4, что эквивалентно uiNumOne >>=2 или uiNumOne=uiNumOne/2, что эквивалентно uiNumOne >>=1). Выполняя это, значения поднаборов прежде непосредственно предшествующих поднаборов могут быть все еще рассмотрены, но принимая во внимание меньший вес в решении контекста CABAC для в настоящее время закодированного поднабора. В частности, решение контекста CABAC для заданного поднабора принимает во внимание не только количество коэффициентов, большее чем единица, в непосредственно предыдущем поднаборе, но также и взвешенное количество коэффициентов, большее чем единица, в ранее закодированных поднаборах.
[0139] Дополнительно, набор контекстов может зависеть от следующего: (1) количества значимых коэффициентов во в настоящее время сканируемом поднаборе, (2) является ли текущий поднабор последним поднабором со значимым коэффициентом (то есть, используя обратный порядок сканирования, это относится к тому, является ли поднабор первым сканированным для уровней коэффициентов или нет). Дополнительно, модель контекста для уровня коэффициентов может зависеть от того, является ли текущий коэффициент последним коэффициентом.
[0140] Подход высоко адаптивного выбора контекста был ранее предложен для кодирования отображения значимости блоков 16x16 и 32x32 коэффициентов преобразования в HEVC. Должно быть отмечено, что этот подход выбора контекста может быть расширен до всех размеров блока. Как показано на ФИГ. 10, этот подход делит блок 16x16 на четыре области, где каждый коэффициент в области 41 более низкой частоты (эти четыре коэффициента в верхнем левом углу в координатных позициях x, y [0,0], [0,1], [1,0], [1,1] в примере блока 16x16, где [0,0] указывает левый верхний угол, коэффициент DC) имеет свой собственный контекст, коэффициенты в верхней области 37 (коэффициенты в верхней строке из координатных позиций x, y [2,0]-[15,0] в примере блока 16x16) совместно используют 3 контекста, коэффициенты в левой области 35 (коэффициенты в левом столбце из координатных позиций x, y [0,2]-[0,15] в примере блока 16x16) совместно используют еще 3 контекста, и коэффициенты в оставшейся области 39 (оставшиеся коэффициенты в блоке 16x16) совместно используют 5 контекстов. Выбор контекста для коэффициента X преобразования в области 39, в качестве примера, основан на сумме значимости максимум этих 5 коэффициентов преобразования B, E, F, H и I. Так как X не зависит от других позиций в одной и той же диагональной линии X вдоль направления сканирования (в этом примере зигзагообразный или диагональный шаблон сканирования), контекст значимости коэффициентов преобразования вдоль диагональной линии в порядке сканирования может быть вычислен параллельно от предшествующих диагональных линий в порядке сканирования.
[0141] Предложенные контексты для отображения значимости, как показано на ФИГ. 10, действительны только, если порядок сканирования является прямым, так как контекст становится неказуальным в декодере, если используется обратное сканирование. То есть, декодер еще не декодировал коэффициенты B, E, F, H и I, как показано на ФИГ. 10, если используется обратное сканирование. В результате битовый поток не является декодируемым.
[0142] Однако, настоящее раскрытие предлагает использование сканирования в обратном направлении. Таким образом, отображение значимости имеет соответствующую корреляцию среди коэффициентов, когда порядок сканирования находится в обратном направлении, как показано на ФИГ. 6. Поэтому, использование обратного сканирования для отображения значимости, как описано выше, предлагает желаемую эффективность кодирования. Кроме того, использование обратного сканирования для отображения значимости служит для согласования сканирования, используемого для кодирования уровня коэффициентов и отображения значимости. Чтобы поддержать обратное сканирование значимых коэффициентов, контексты должны быть изменены таким образом, чтобы они были совместимы с обратным сканированием. Предложено, чтобы кодирование значимых коэффициентов использовало контексты, которые являются казуальными относительно обратного сканирования.
[0143] Настоящее раскрытие дополнительно предлагает, в одном примере, способ для кодирования отображения значимости, который использует контексты, изображенные на ФИГ. 11. Каждый коэффициент в области 43 более низкой частоты (эти три коэффициента в верхнем левом углу в координатных позициях x, y [0,0], [0,1], [1,0] в примере блока 16x16, где [0,0] указывает левый верхний угол, коэффициент DC) имеет свое собственное выведение контекста. Коэффициенты в верхней области 45 (коэффициенты в верхней строке из координатных позиций x, y [2,0] - [15,0] в примере блока 16x16) имеют контекст, зависящий от значимости двух предшествующих коэффициентов в верхней области 45 (например, два коэффициента непосредственно справа от коэффициента, который должен быть закодирован, где такие коэффициенты являются казуальными (случайными) соседями в целях декодирования, принимая во внимание обратное сканирование). Коэффициенты в левой области 47 (коэффициенты в левом столбце из координатных позиций x, y [0,2]-[0,15] в примере блока 16x16) имеют контекст, зависящий от значимости двух предшествующих коэффициентов (например, два коэффициента непосредственно ниже коэффициента, который должен быть закодирован, где такие коэффициенты являются казуальными соседями в целях декодирования, принимая во внимание обратную ориентацию сканирования). Должно быть отмечено, что эти контексты в верхней области 45 и левой области 47 на ФИГ. 11 являются инверсией контекстов, показанных на ФИГ. 10 (например, где коэффициенты в верхней области 37 имеют контекст, зависящий от коэффициентов слева, и коэффициенты в левой области 35 имеют контекст, зависящий от коэффициентов, представленных выше). Ссылаясь на ФИГ. 11, контексты для коэффициентов в оставшейся области 49 (то есть, оставшиеся коэффициенты вне области 43 более низкой частоты, верхней области 45 и левой области 47), зависят от суммы (или любой другой функции) значимости коэффициентов в позициях, отмеченных посредством I, H, F, E и B.
[0144] В другом примере коэффициенты в верхней области 45 и левой области 47 могут использовать точно одно и то же выведение контекста в качестве коэффициентов в области 49. В обратном сканировании такое возможно, так как соседние позиции, отмеченные посредством I, H, F, E и B, доступны для коэффициентов в верхней области 45 и левой области 47. В конце строк/столбцов позиции для казуальных коэффициентов I, H, F, E и B могут находиться вне блока. В этом случае предполагается, что значение таких коэффициентов равно нулю (то есть, является не значимым).
[0145] Имеются много вариантов при выборе контекстов. Основная идея состоит в том, чтобы использовать значимость коэффициентов, которые были уже закодированы, в соответствии с порядком сканирования. В примере, показанном на ФИГ. 10, контекст коэффициента в позиции X выводится на основании суммы значимости коэффициентов в позициях B, E, F, H и I. Эти коэффициенты контекста появляются до текущего коэффициента в порядке обратного сканирования, предложенного в настоящем раскрытии для отображения значимости. Контексты, которые были казуальными в прямом сканировании, становятся неказуальными (не доступными) в порядке обратного сканирования. Способ для решения этой проблемы состоит в том, чтобы зеркально отразить контексты обычного случая на ФИГ. 10 к показанным на ФИГ. 11 для обратного сканирования. Для сканирования значимости, которое осуществляется в обратном направлении от последнего значимого коэффициента к позиции коэффициента DC, соседство контекста для коэффициента X состоит от коэффициентов B, E, F, H, I, которые ассоциированы с позициями более высокой частоты относительно позиции коэффициента X, и которые были уже обработаны кодером или декодером в обратном сканировании до кодирования коэффициента X.
[0146] Как рассмотрено выше, контексты и модели контекста, иллюстрированные в Таблицах 1 и 2, пытаются использовать локальную корреляцию уровней коэффициентов среди субблоков 4x4. Однако зависимость может быть слишком отдаленной. То есть, может быть низкая зависимость между коэффициентами, которые отделены друг от друга несколькими коэффициентами, например, от одного субблока до другого. Кроме того, в каждом субблоке зависимость между коэффициентами может быть слабой. Настоящее раскрытие описывает способы для решения этих проблем путем создания набора контекстов для уровней коэффициентов, которые используют более локальное соседство контекста.
[0147] Настоящее раскрытие предлагает использовать локальное соседство для выведения контекста уровней коэффициентов преобразования, например, при кодировании видео в соответствии с HEVC или другими стандартами. Это соседство состоит из коэффициентов, уже закодированных (или декодированных), которые имеют высокую корреляцию с уровнем текущего коэффициента. Коэффициенты могут пространственно граничить с коэффициентом, который должен быть закодирован, и могут включать в себя как коэффициенты, которые служат границей коэффициенту, который должен кодироваться, так и другие соседние коэффициенты, такие как показаны на ФИГ. 11 или ФИГ. 13. В частности, коэффициенты, используемые для выведения контекста, не ограничиваются субблоком или предыдущим субблоком. Вместо этого локальное соседство может содержать коэффициенты, которые пространственно расположены близко к коэффициенту, который должен быть закодирован, но могут не обязательно находиться в том же субблоке, что и коэффициент, который должен быть закодирован, или в том же субблоке, что один другой, если коэффициенты были скомпонованы в субблоках. Вместо того, чтобы полагаться на коэффициенты, расположенные в фиксированном субблоке, настоящее раскрытие предлагает использовать соседние коэффициенты, которые доступны (то есть, были уже закодированы), принимая во внимание заданный используемый порядок сканирования.
[0148] Различные наборы контекста CABAC могут быть заданы для различных поднаборов коэффициентов, например, на основании ранее закодированных поднаборов коэффициентов. В заданных поднаборах коэффициентов контексты выводятся на основании локального соседства коэффициентов, иногда называемого соседством контекста. В соответствии с настоящим раскрытием, пример соседства контекста показан на ФИГ. 12. Коэффициенты в соседстве контекста могут быть пространственно расположены около коэффициента, который должен быть закодирован.
[0149] Как показано на ФИГ. 12, для прямого сканирования контекст уровня для коэффициента X преобразования зависит от значений коэффициентов B, E, F, H и I. В прямом сканировании коэффициенты B, E, F, H и I ассоциированы с позициями более низкой частоты относительно позиции и коэффициента X, и которые уже были обработаны кодером или декодером до кодирования коэффициента X.
[0150] Для кодирования контейнера 1 для CABAC контекст зависит от суммы количества значимых коэффициентов в этом соседстве контекста (то есть, в этом примере, коэффициентов B, E, F, H и I). Если коэффициент в соседстве контекста выпадает из блока, то есть, из-за потери данных, можно считать, что это значение равно 0 в целях определения контекста коэффициента X. Для кодирования остальных контейнеров для CABAC, контекст зависит от суммы количества коэффициентов в соседстве, которые равны 1, а также от суммы количества коэффициентов в соседстве, которые больше чем 1. В другом примере контекст для контейнера 1 может зависеть от суммы значений контейнера 1 коэффициентов в локальном соседстве контекста. В другом примере контекст для контейнера 1 может зависеть от комбинации суммы коэффициентов значимости и значений контейнера 1 в этом соседстве контекста.
[0151] Имеется много возможностей для выбора соседства контекста. Однако соседство контекста должно состоять от коэффициентов таким образом, чтобы кодер и декодер имели доступ к одной и той же информации. В частности, коэффициенты B, F, E, I и H в соседстве должны быть казуальными соседями в том смысле, что они были ранее закодированы или декодированы, и доступны для ссылки при определении контекста для коэффициента X.
[0152] Контексты, описанные выше со ссылками на ФИГ. 12, являются одной из многих возможностей. Такие контексты могут применяться к любому из трех сканирований, в настоящее время предложенных для использования в HEVC: диагонального, горизонтального и вертикального. Настоящее раскрытие предлагает, чтобы соседство контекста, используемое для выведения контекста для уровня коэффициентов, могло быть тем же самым, что и соседство контекста, используемое для выведения контекстов для отображения значимости. Например, соседство контекста, используемое для выведения контекста для уровня коэффициентов, может быть локальным соседством, как в случае кодирования отображения значимости.
[0153] Как описано более подробно выше, настоящее раскрытие предлагает использование обратного порядка сканирования для сканирования значимых коэффициентов, чтобы сформировать отображение значимости. Обратный порядок сканирования может быть обратным зигзагообразным шаблоном, вертикальным шаблоном или горизонтальным шаблоном, как показано на ФИГ. 6. Если порядок сканирования для сканирования уровня коэффициентов также находится в обратном шаблоне, то соседство контекста, показанное на ФИГ. 12, будет неказуальным. Настоящее раскрытие предлагает инвертировать позицию соседства контекста таким образом, чтобы оно было казуальным в отношении обратного порядка сканирования. ФИГ. 13 показывает пример соседства контекста для обратного порядка сканирования.
[0154] Как показано на ФИГ. 13, для сканирования уровня, которое выполняется в обратном направлении от последнего значимого коэффициента к позиции коэффициента DC, соседство контекста для коэффициента X состоит от коэффициентов B, E, F, H и I, которые ассоциированы с позициями более высокой частоты относительно позиции коэффициента X. Учитывая обратное сканирование, коэффициенты B, E, F, H и I были уже обработаны кодером или декодером до кодирования коэффициента X, и поэтому являются казуальными в том смысле, что они являются доступными. Аналогично, это соседство контекста может быть применено к уровням коэффициентов.
[0155] Настоящее раскрытие дополнительно предлагает в одном примере другой способ для кодирования отображения значимости, который использует контексты, выбранные для поддержания обратного сканирования. Как рассмотрено выше, высоко адаптивный подход выбора контекста был предложен для HEVC для кодирования отображения значимости блоков 16x16 и 32x32 коэффициентов преобразования. Например, как было описано относительно ФИГ. 10 выше, этот подход делит блок 16x16 на четыре области, где каждая позиция в области 41 имеет свой собственный набор контекстов, область 37 имеет контексты, область 35 имеет другие 3 контекста, и область 39 имеет 5 контекстов. Выбор контекста для коэффициента преобразования X, в качестве примера, основан на сумме значимости максимум этих 5 позиций B, E, F, H, I. Так как X является независимым от других позиций на одной и той же диагональной линии X вдоль направления сканирования, контекст значимости коэффициентов преобразования вдоль диагональной линии в порядке сканирования может быть вычислен параллельно от предшествующих диагональных линий в порядке сканирования.
[0156] Текущий подход HEVC для выведений контекста имеет несколько недостатков. Одной проблемой является количество контекстов для каждого блока. Наличие большего количества контекстов подразумевает больше памяти и больше обработки каждый раз, когда контексты обновляются. Поэтому, может быть выгодно иметь алгоритм, который имеет немного контекстов и также немного способов для генерирования контекстов (например, меньше, чем эти четыре способа, то есть, четыре шаблона, в предыдущем примере).
[0157] Одним способом разрешения таких недостатков является кодирование отображения значимости в обратном порядке, то есть, от последнего значимого коэффициента (более высокой частоты) к компоненту DC (самой низкой частоты). Последствие этого процесса в обратном порядке заключается в том, что контексты для прямого сканирования больше не являются достоверными. Способы, описанные выше, включают в себя способ для определения контекстов для адаптивного двоичного арифметического кодирования, основанного на контексте (CABAC) для информации, указывающей текущий один из значимых коэффициентов на основании ранее закодированных значимых коэффициентов в обратном направлении сканирования. В примере обратного зигзагообразного сканирования ранее закодированные значимые коэффициенты находятся в позициях справа от линии сканирования, на которой находится текущий из значимых коэффициентов.
[0158] Генерирование контекста может отличаться для различных позиций блоков преобразования на основании по меньшей мере расстояния от границ и расстояния от компонента DC. В примерном способе, описанном выше, было предложено, чтобы кодирование отображения значимости использовало наборы контекстов, изображенных на ФИГ. 11.
[0159] Настоящее раскрытие предлагает набор контекстов для обратного сканирования отображения значимости, которое может привести к более высокой производительности через уменьшение количества контекстов для каждого блока. Снова ссылаясь на ФИГ. 11, уменьшение количества контекста для каждого блока может быть достигнуто, разрешая левой области 47 и верхней области 45 использовать то же выведение контекста, что и для оставшейся области 49. В обратном сканировании это возможно, так как соседние позиции, отмеченные I, H, F, E и B, являются доступными для коэффициентов в областях 47 и 45.
[0160] ФИГ. 14 показывает пример выведения контекста в соответствии с этим примером. В этом примере имеются только две области контекста: низкочастотная область 57 для коэффициента DC и оставшаяся область 59 для всех других коэффициентов. Также, этот пример предлагает всего два способа для выведения контекста. В низкочастотной области 57 (коэффициент DC в позиции x, y [0,0]) контекст выводят на основании позиции, то есть, коэффициент DC имеет контекст его самого. В оставшейся области 57 контекст выводят на основании значимости соседних коэффициентов в локальном соседстве для каждого коэффициента, который должен быть закодирован. В этом примере он выводится в зависимости от суммы значимости 5 соседей, обозначенных I, H, F, E и B на ФИГ. 14.
[0161] Поэтому, количество способов для выведения контекста в блоке уменьшено с 4 до 2. Кроме того, количество контекстов уменьшено на 8 относительно предыдущего примера на ФИГ. 11 (2 для области 43 более низких частот и 3 для каждой из верхней области 45 и левой области 47). В другом примере коэффициент DC может использовать тот же способ, что и для остальной части блока, таким образом, количество способов для выведения контекста в блоке уменьшается до 1.
[0162] ФИГ. 15 показывает пример, в котором текущая позиция коэффициента X вынуждает некоторые из соседних коэффициентов (в этом случае H и B) находиться вне текущего блока. Если любые из соседей текущего коэффициента находятся вне этого блока, можно предположить, что такие соседние коэффициенты имеют значимость 0 (то есть, они являются нулевыми значениями и, поэтому, не значимыми). Альтернативно, один или несколько специальных контекстов могут быть заданы для одного или более коэффициентов ниже справа. Таким образом, коэффициенты более высокой частоты могут иметь контексты в зависимости от позиции, аналогично коэффициенту DC. Однако предположение, что соседи должны быть нулевыми, может обеспечить достаточные результаты, в частности, потому, что нижние правые коэффициенты обычно будут иметь низкую вероятность наличия значимых коэффициентов или по меньшей мере значимых коэффициентов с большими значениями.
[0163] Уменьшение количества контекстов в примере на ФИГ. 14 хорошо для реализации. Однако это может привести к небольшому снижению производительности. Настоящее раскрытие предлагает дополнительный способ, чтобы повысить производительность, в то же время все еще уменьшая количество контекстов. В частности, предлагается иметь второй набор контекстов, который также основан на соседних коэффициентах. Алгоритм выведения контекста является точно таким же, но используются два набора контекстов с различными моделями вероятности. Набор контекстов, которые используются, зависит от позиции коэффициента, который должен быть закодирован в блоке преобразования.
[0164] Более определенно, увеличенная производительность была показана при использовании модели контекста для коэффициентов более высокой частоты (например, нижние правые координатные позиции x, y коэффициентов), которая отличается от модели контекста для коэффициентов в более низких частотах (например, верхние левые координаты x, y коэффициентов). Один способ для отделения коэффициентов более низкой частоты от коэффициентов более высокой частоты, и, таким образом, модели контекста, используемой для каждых коэффициентов, состоит в том, чтобы вычислить значение x+y для коэффициента, где x является горизонтальной позицией, и y является вертикальной позицией коэффициента. Если это значение меньше, чем некоторый порог (например, 4 был показан как работающий эффективно), то используется набор контекстов 1. Если значение равно или больше, чем этот порог, то используется набор контекстов 2. Снова, наборы контекстов 1 и 2 имеют разные модели вероятности.
[0165] ФИГ. 16 показывает пример областей контекста для этого примера. Снова, коэффициент DC в позиции (0,0) имеет свою собственную область 61 контекста. Область 63 контекста более низкой частоты состоит от коэффициентов преобразования в позиции x+y, равной или меньше, чем порог 4 (не включая коэффициент DC). Область 65 контекста более высокой частоты состоит от коэффициентов преобразования в позиции x+y большей, чем порог 4. Порог 4 используется в качестве примера и может быть приспособлен к любому количеству, которое предусматривает лучшую производительность. В другом примере порог может зависеть от размера TU.
[0166] Выведение контекста для области 63 контекста более низкой частоты и области 65 контекста более высокой частоты является точно таким же в терминах способа, которым используются соседи для выбора контекста, но используемые вероятности (то есть, контексты) отличаются. В частности, могут быть использованы одни и те же критерии для выбора контекста на основании соседей, но применение таких критериев приводит к выбору отличающегося контекста для различных позиций коэффициента, так как различные позиции коэффициента могут быть ассоциированы с различными наборами контекстов. Таким образом, знание, что коэффициенты более низкой и высокой частоты имеют различную статистику, включено в алгоритм таким образом, чтобы могли быть использованы различные наборы контекстов для отличного коэффициента.
[0167] В других примерах функция x+y может быть изменена на другие функции в зависимости от позиции коэффициента. Например, опция должна предоставить один и тот же набор контекстов для всех коэффициентов с x<T && y<T, T является порогом. ФИГ. 17 показывает пример блока коэффициентов преобразования с этими областями контекста. Снова, коэффициент DC в позиции (0,0) может иметь свою собственную область 61 контекста. Область 73 контекста более низкой частоты состоит из всех коэффициентов преобразования, чья позиция X или Y меньше или равна порогу 4 (не включая коэффициент DC). Область контекста более высокой частоты состоит из всех коэффициентов преобразования, чья позиция X или Y больше, чем порог 4. Снова, порог 4 используется в качестве примера и может быть приспособлен к любому количеству, которое предусматривает лучшую производительность. В одном примере порог может зависеть от размера TU.
[0168] Вышеупомянутые описанные способы, показанные на ФИГ. 16 и 17, имеют два набора из 5 контекстов, что все еще является меньшим количеством контекстов, чем количество контекстов, показанных на ФИГ. 10, и показывает более высокую производительность. Это достигается посредством разделения блоков на различные области и определения различных наборов контекста для коэффициентов в различных областях, но все еще посредством применения одних и тех же критериев выведения контекста к каждой области.
[0169] ФИГ. 18 показывает другой пример блока коэффициентов преобразования с областями контекста. В этом примере коэффициент DC в области 81 и коэффициенты в позициях x, y (1, 0) и (0, 1) в областях 83 и 85 имеют свой собственный контекст. Оставшаяся область 87 уже имеет другой контекст. В вариации примера, показанного на ФИГ. 18, области 83 и 85 совместно используют контекст.
[0170] В целом, вышеописанные способы могут включать в себя сканирование значимых коэффициентов в блоке коэффициентов преобразования в обратном направлении от коэффициентов более высокой частоты в блоке коэффициентов преобразования к коэффициентам более низкой частоты в этом блоке коэффициентов преобразования, чтобы сформировать отображение значимости, и определение контекстов для контекстного адаптивного двоичного арифметического кодирования (CABAC), значимых коэффициентов отображения значимости на основании локального соседства ранее сканированных коэффициентов в блоке. Контексты могут быть определены для каждого из значимых коэффициентов на основании ранее сканированных коэффициентов преобразования в локальном соседстве, имеющем более высокие частоты, чем соответствующий коэффициент преобразования. В некоторых примерах контексты могут быть определены на основании суммы количества значимых коэффициентов в ранее сканированных коэффициентах соседства контекста. Локальное соседство для каждого из значимых коэффициентов, которые должны быть закодированы, может содержать множество коэффициентов преобразования, которые пространственно соседствуют с соответствующим коэффициентом в блоке.
[0171] Контекст для значимого коэффициента в позиции DC (например, верхней крайней левой) блока коэффициентов преобразования может быть определен на основании индивидуального контекста, заданного для значимого коэффициента в позиции DC. Кроме того, контекст может быть определен для коэффициентов на левом крае и верхнем крае блока, используя критерии, по существу аналогичные или идентичные критериям, используемым для определения контекста для коэффициентов, которые не находятся на левом крае и верхнем крае блока. В некоторых примерах контекст для коэффициента в более низкой самой правой позиции блока может быть определен, используя критерии, которые предполагают, что соседние коэффициенты вне блока являются коэффициентами с нулевым значением. Кроме того, в некоторых примерах определение контекста может содержать определение контекста для коэффициентов, используя по существу аналогичные или идентичные критерии для выбора контекстов в наборе контекстов, но различных наборах контекстов, на основании позиций коэффициентов в блоке коэффициентов преобразования.
[0172] Ссылка на верх, низ, право, лево и т.п. в настоящем раскрытии используется в целом для удобства ссылки на относительные позиции коэффициентов более высокой частоты и более низкой частоты в блоке коэффициентов преобразования, который скомпонован обычно так, чтобы иметь коэффициенты более низкой частоты по направлению вверх налево и коэффициенты более высокой частоты по направлению к вниз вправо блока, и не должна быть рассмотрена как ограничивающая для случаев, в которых коэффициенты более высокой и более низкой частоты могут быть скомпонованы другим нетрадиционным способом.
[0173] Снова ссылаясь на ФИГ. 5, в некоторых примерах модуль 52 преобразования может быть сконфигурирован для обнуления некоторых коэффициентов преобразования (то есть, коэффициентов преобразования в некоторых местоположениях). Например, модуль 52 преобразования может быть сконфигурирован для обнуления всех коэффициентов преобразования вне верхнего левого квадранта в TU после преобразования. В качестве другого примера, модуль 56 статистического кодирования может быть сконфигурирован для обнуления коэффициентов преобразования в массиве после некоторой позиции в массиве. В любом случае кодер 20 видео может быть сконфигурирован для обнуления некоторый части коэффициентов преобразования, например, до или после сканирования. Фраза "обнуление" используется, чтобы обозначать установление значения коэффициента равным нулю, но не обязательно пропуск или отклонение коэффициента. В некоторых примерах это установление коэффициентов в нуль может быть в дополнение к обнулению, которое может следовать из квантования.
[0174] Модуль 58 обратного квантования и модуль 60 обратного преобразования применяют обратное квантование и обратное преобразование, соответственно, чтобы восстановить остаточный блок в пиксельной области, например, для более позднего использования в качестве опорного блока. Модуль 44 компенсации движения может вычислять опорный блок посредством добавления (суммирования) остаточного блока к предсказывающему блоку одного из кадров буфера 64 опорных кадров. Модуль 44 компенсации движения может также применять один или более интерполяционных фильтров к восстановленному остаточному блоку, чтобы вычислить субцелочисленные пиксельные значения для использования при оценке движения. Сумматор 62 суммирует восстановленный остаточный блок с блоком предсказания с компенсацией движения, сформированным модулем 44 компенсации движения, чтобы сформировать восстановленный видео блок для сохранения в буфере 64 опорных кадров. Восстановленный видео блок может быть использован модулем 42 оценки движения и модулем 44 компенсации движения как опорный блок для внешнего кодирования блока в последующем видеокадре.
[0175] ФИГ. 19 является блок-схемой, иллюстрирующей пример модуля 56 статистического кодирования для использования в кодере видео согласно ФИГ. 5. ФИГ. 19 иллюстрирует различные функциональные аспекты модуля 56 статистического кодирования для выбора порядка сканирования и соответствующего набора контекстов, используемых при статистическом кодировании CABAC. Модуль 56 статистического кодирования может включать в себя модуль 90 выбора порядка сканирования и контекста, модуль 92 сканирования 2D-в-1D, механизм 94 статистического кодирования и память 96 порядка сканирования.
[0176] Модуль 90 выбора порядка сканирования и контекста выбирает порядок сканирования, который должен быть использован модулем 92 сканирования 2D-в-1D для сканирования отображения значимости и сканирования уровня коэффициентов. Как рассмотрено выше, порядок сканирования состоит как из шаблона сканирования, так и из направления сканирования. Память 96 сканирования может сохранять команды и/или данные, которые определяют, какой порядок сканирования использовать для конкретных ситуаций. В качестве примеров, режим предсказания кадра или вырезки, размер блока, преобразование или другие характеристики используемых данных видео могут быть использованы для выбора порядка сканирования. В одном предложении для HEVC каждый из режимов внутреннего предсказания назначается на конкретный порядок сканирования (субблочный диагональный, горизонтальный или вертикальный). Декодер проводит синтаксический анализ режима внутреннего предсказания и определяет порядок сканирования для применения, используя таблицу поиска. Адаптивные способы могут быть использованы, чтобы отследить статистику самых частых значимых коэффициентов. В другом примере сканирование может быть основано на наиболее часто используемых коэффициентах первыми в порядке сканирования. В качестве другого примера, модуль 90 выбора порядка сканирования и контекста может использовать предварительно определенный порядок сканирования для всех ситуаций. Как описано выше, модуль 90 выбора порядка сканирования и контекста может выбрать порядок сканирования для сканирования как отображения значимости, так и уровня коэффициентов. В соответствии со способами настоящего раскрытия, два сканирования могут иметь один и тот же порядок сканирования, и в частности оба могут быть в обратном направлении.
[0177] На основании выбранного порядка сканирования, модуль 90 выбора порядка сканирования и контекста также выбирает контексты, которые должны быть использованы для CABAC в механизме 94 статистического кодирования, например, контексты, описанные выше со ссылками на ФИГ. 11 и ФИГ. 13-18.
[0178] Модуль 92 сканирования 2D-в-1D применяет выбранные сканирования к двумерному массиву коэффициентов преобразования. В частности, модуль 92 сканирования 2D-в-1D может сканировать коэффициенты преобразования в поднаборах, как описано выше со ссылками на ФИГ. 7-9. В частности, коэффициенты преобразования сканируются в поднаборе, состоящем из ряда последовательных коэффициентов, в соответствии с порядком сканирования. Такие поднаборы применяются как для сканирования отображения значимости, так и для сканирования уровня коэффициентов. Дополнительно, модуль 92 сканирования 2D-в-1D может выполнять сканирование отображения значимости и уровня коэффициентов как последовательные сканирования в соответствии с одним и тем же порядком сканирования. Последовательные сканирования могут состоять из нескольких сканирований, как описано выше. В одном примере первым сканированием является сканирование отображения значимости, второе сканирование имеет контейнер один уровней коэффициентов преобразования в каждом поднаборе, третье сканирование имеет оставшиеся контейнеры уровней коэффициентов преобразования, и четвертое сканирование имеет знак уровней коэффициентов преобразования.
[0179] Механизм 94 статистического кодирования применяет процесс статистического кодирования к сканированным коэффициентам, используя выбранный контекст из модуля 90 выбора контекста и порядка сканирования. В некоторых примерах контекст, используемый для CABAC, может быть предварительно определен для всех случаев, и, таким образом, может не быть необходимости в процессе или блоке для выбора контекстов. Процесс статистического кодирования может быть применен к коэффициентам после того, как они полностью были сканированы в вектор 1D, или когда каждый коэффициент добавляется к вектору 1D. В других примерах коэффициенты обрабатываются непосредственно в массиве 2D, используя порядок сканирования. В некоторых случаях механизм 94 статистического кодирования может быть сконфигурирован для кодирования различных секций вектора 1D параллельно, чтобы способствовать распараллеливанию процесса статистического кодирования для повышенной скорости и эффективности. Механизм 94 статистического кодирования формирует битовый поток, переносящий закодированное видео. Битовый поток может быть передан на другое устройство или сохранен в архиве хранения данных для более позднего извлечения. В дополнение к остаточным данным коэффициента преобразования битовый поток может переносить данные вектора движения и различные элементы синтаксиса, полезные при декодировании закодированного видео в битовом потоке.
[0180] В дополнение, модуль 56 статистического кодирования может обеспечить сигнализацию в закодированном видео битовом потоке, чтобы указать порядок сканирования и/или контексты, используемые в процессе CABAC. Порядок сканирования и/или контексты могут быть сигнализированы, например, как элементы синтаксиса на различных уровнях, таких как кадр, вырезка, LCU, уровень CU или уровень TU. Если установлен предварительно определенный порядок сканирования и/или контекст, может не быть необходимости обеспечить сигнализацию в закодированном битовом потоке. Кроме того, в некоторых примерах для декодера 30 видео может быть возможно вывести некоторые значения параметра без сигнализации. Чтобы разрешить определение различных порядков сканирования для различных блоков TU, может быть желательно сигнализировать такие элементы синтаксиса на уровне TU, например, в заголовке квадродерева (дерева квадрантов) TU. Хотя сигнализация в закодированном видео битовом потоке описана в целях иллюстрации, информация, указывающая значения параметра или функцию, может быть сигнализирована вне диапазона в побочной информации.
[0181] В этом контексте сигнализация порядка сканирования и/или контекстов в закодированном битовом потоке не требует передачи в реальном времени таких элементов от кодера на декодер, а вместо этого обозначает, что такие элементы синтаксиса кодируются в битовый поток и сделаны доступными для декодера любым способом. Это может включать в себя передачу в реальном времени (например, в видеоконференц-связи), а также сохранение закодированного битового потока на считываемом компьютером носителе для будущего использования посредством декодера (например, в потоковой передаче, загрузке, доступе к диску, доступе к карточке, DVD, Blu-ray и т.д.).
[0182] Должно быть отмечено, что хотя показано как отдельные функциональные блоки, для простоты иллюстрации структура и функциональные возможности порядка сканирования и модуля 90 выбора контекста, модуля 92 сканирования 2D-в-1D, механизма 94 статистического кодирования и памяти 96 порядка сканирования могут быть высоко интегрированы друг с другом.
[0183] ФИГ. 20 является блок-схемой, иллюстрирующей пример декодера 30 видео, который декодирует закодированную последовательность видео. В примере на ФИГ. 20 декодер 30 видео включает в себя модуль 70 статистического декодирования, модуль 72 компенсации движения, модуль 74 внутреннего предсказания, модуль 76 обратного квантования, модуль 78 обратного преобразования, буфер 82 опорных кадров и сумматор 80. Декодер 30 видео в некоторых примерах может выполнять проход декодирования, в целом обратный проходу кодирования, описанному относительно кодера 20 видео (ФИГ. 5).
[0184] Модуль 70 статистического декодирования выполняет статистическое декодирование закодированного видео в процессе, который является обратным процессу, используемому модулем 56 статистического кодирования ФИГ. 5. Модуль 72 компенсации движения может генерировать данные предсказания на основании векторов движения, принятых от модуля 70 статистического декодирования. Модуль 74 внутреннего предсказания может генерировать данные предсказания для текущего блока текущего кадра на основании сигнализированного режима внутреннего предсказания и данных от ранее декодированных блоков текущего кадра.
[0185] В некоторых примерах модуль 70 статистического декодирования (или модуль 76 обратного квантования) могут сканировать принятые значения, используя сканирование, зеркально отражающее порядок сканирования, используемый модулем 56 статистического кодирования (или модулем 54 квантования) кодера 20 видео. Хотя сканирование коэффициентов может быть выполнено в модуле 76 обратного квантования, сканирование будет описано в целях иллюстрации, как выполняемое модулем 70 статистического декодирования. В дополнение, хотя показаны как отдельные функциональные блоки для простоты иллюстрации, структура и функциональные возможности модуля 70 статистического декодирования, модуля 76 обратного квантования и других модулей декодера 30 видео могут быть высоко интегрированы друг с другом.
[0186] В соответствии со способами настоящего раскрытия декодер 30 видео может сканировать как отображение значимости коэффициентов преобразования, так и уровни коэффициентов преобразования в соответствии с одним и тем же порядком сканирования. То есть, порядок сканирования для кодирования отображения значимости и уровня должен иметь одни и те же шаблон и направление. В дополнение декодер 30 видео может использовать порядок сканирования для отображения значимости, которое находится в обратном направлении. В качестве другого примера, декодер 30 видео может использовать порядок сканирования для кодирования отображения значимости и уровня, которое согласовано в обратном направлении.
[0187] В другом аспекте настоящего раскрытия декодер 30 видео может сканировать коэффициенты преобразования в поднаборах. В частности, коэффициенты преобразования сканируются в поднаборе, состоящем из ряда последовательных коэффициентов, в соответствии с порядком сканирования. Такие поднаборы применимы как для сканирования отображения значимости, так и для сканирования уровня коэффициентов. Дополнительно, декодер 30 видео может выполнять сканирование отображения значимости и сканирование уровня коэффициентов как последовательные сканирования в соответствии с одним и тем же порядком сканирования. В одном аспекте порядком сканирования является обратный порядок сканирования. Последовательные сканирования могут состоять из нескольких сканирований. В одном примере первым сканированием является сканирование отображения значимости, второе сканирование имеет контейнер один уровней коэффициентов преобразования в каждом поднаборе, третье сканирование имеет оставшиеся контейнеры уровней коэффициентов преобразования, и четвертое сканирование имеет знак уровней коэффициентов преобразования.
[0188] Декодер 30 видео может принять от закодированного битового потока сигнализацию, что он идентифицирует порядок сканирования и/или контексты, используемые для CABAC, посредством кодера 20 видео. Дополнительно или альтернативно, порядок сканирования и контексты могут быть выведены декодером 30 видео на основании характеристик закодированного видео, таких как режим предсказания, размер блока или других характеристик. В качестве другого примера, кодер 20 видео и декодер 30 видео могут использовать предварительно определенные порядки сканирования и контексты для всех случаев использования, и, таким образом, не потребуется сигнализация в закодированном битовом потоке.
[0189] Независимо от того, как определен порядок сканирования, модуль 70 статистического декодирования использует обратный порядок сканирования для сканирования вектора 1D в массив 2D. Массив 2D коэффициентов преобразования, сформированных модулем 70 статистического декодирования, может квантоваться и может в целом соответствовать массиву 2D коэффициентов преобразования, сканированных модулем 56 статистического кодирования кодера 20 видео, чтобы сформировать вектор 1D коэффициентов преобразования.
[0190] Модуль 76 обратного квантования обратно квантует, то есть, деквантует, квантованные коэффициенты преобразования, обеспеченные в битовом потоке и декодированные модулем 70 статистического декодирования. Процесс обратного квантования может включать в себя обычный процесс, например, аналогичный процессам, предложенным для HEVC или определенным стандартом декодирования H.264. Процесс обратного квантования может включать в себя использование параметра квантования QP, вычисленного кодером 20 видео для CU, чтобы определить степень квантования и, аналогично, степень обратного квантования, которое должно быть применено. Модуль 76 обратного квантования может обратно квантовать коэффициенты преобразования или до, или после того, как коэффициенты будут преобразованы из вектора 1D в массив 2D.
[0191] Модуль 78 обратного преобразования применяет обратное преобразование, например, обратное DCT, обратное целочисленное преобразование, обратное KLT, обратное вращательное преобразование, обратное направленное преобразование или другое обратное преобразование. В некоторых примерах модуль 78 обратного преобразования может определить обратное преобразование на основании сигнализации от кодера 20 видео или посредством выведения преобразования из одной или более характеристик кодирования, таких как размер блока, режим кодирования и т.п. В некоторых примерах модуль 78 обратного преобразования может определить преобразование, чтобы применить к текущему блоку на основании сигнализированного преобразования в корневом узле квадродерева для LCU, включающего в себя текущий блок. В некоторых примерах модуль 78 обратного преобразования может применить каскадное обратное преобразование.
[0192] Модуль 72 компенсации движения формирует блоки с компенсацией движения, возможно выполняя интерполяцию на основании интерполяционных фильтров. Идентификаторы для интерполяционных фильтров, которые должны быть использованы для оценки движения с субпиксельной точностью, могу быть включены в элементы синтаксиса. Модуль 72 компенсации движения может использовать интерполяционные фильтры, которые используются кодером 20 видео во время кодирования блока видео, чтобы вычислить интерполированные значения для субцелочисленных пикселей опорного блока. Модуль 72 компенсации движения может определить интерполяционные фильтры, используемые кодером 20 видео, в соответствии с принятой информацией синтаксиса и использовать интерполяционные фильтры, чтобы сформировать предсказывающие блоки.
[0193] Модуль 72 компенсации движения и модуль 74 внутреннего предсказания в примере HEVC могут использовать некоторую из информации синтаксиса (например, обеспеченную посредством квадродерева), чтобы определить размеры блоков LCU, используемых для кодирования кадра(ов) закодированной последовательности видео. Модуль 72 компенсации движения и модуль 74 внутреннего предсказания могут также использовать информацию синтаксиса, чтобы определить информацию разделения, которая описывает, как разделен каждый CU кадра закодированной последовательности видео (и аналогично, как разбиты субблоки CU). Информация синтаксиса может также включать в себя режимы, указывающие, как кодируется каждое разделение (например, внутреннее или внешнее предсказание, и для внутреннего предсказания режим кодирования с внутренним предсказанием), один или более опорных кадров (и/или опорных списков, содержащих идентификаторы для опорных кадров) для каждого внешне кодированного PU и другую информацию для декодирования закодированной последовательности видео.
[0194] Сумматор 80 объединяет остаточные блоки с соответствующими блоками предсказания, сгенерированными модулем 72 компенсации движения или модулем 74 внутреннего предсказания, чтобы сформировать декодированные блоки. При желании фильтр удаления блочности может быть также применен, чтобы фильтровать декодированные блоки для удаления артефактов блочности. Декодированные блоки видео затем сохраняются в буфере 82 опорных кадров, который обеспечивает опорные блоки для последующей компенсации движения и также формирует декодированное видео для представления на устройстве отображения (таком, как устройство 32 отображения согласно ФИГ. 4).
[0195] Как упомянуто выше, способы для сканирования коэффициентов преобразования, представленных в настоящем раскрытии, применяются как для кодера, так и для декодера. Кодер видео может применять порядок сканирования для сканирования коэффициентов преобразования из двумерного массива в одномерный массив, тогда как декодер видео может применять порядок сканирования, например, обратным образом к кодеру, чтобы сканировать коэффициенты преобразования из одномерного массива в двумерный массив. Альтернативно, декодер видео может применять порядок сканирования для сканирования коэффициентов преобразования из одномерного массива в двумерный массив, и кодер видео может применять порядок сканирования обратным образом к декодеру, чтобы сканировать коэффициенты преобразования из двумерного массива в одномерный массив. Следовательно, сканирование посредством кодера может относиться к сканированию 2D-в-1D посредством кодера или сканированию 1D-в-2D посредством декодера. В дополнение, сканирование в соответствии с порядком сканирования может относиться к сканированию в порядке сканирования для сканирования 2D-в-1D, сканированию в порядке сканирования для сканирования 1D-в-2D, сканированию в обратном порядке сканирования для сканирования 1D-в-2D или сканированию в обратном порядке сканирования для сканирования 2D-в-1D. Следовательно, порядок сканирования может быть установлен для сканирования посредством кодера или сканирования посредством декодера.
[0196] Декодер 30 видео может работать способом, по существу симметричным способу кодера 20 видео. Например, декодер 30 видео может принимать статистически закодированные данные, представляющие закодированный CU, включающий в себя закодированные данные PU и TU. Декодер 30 видео может обратным образом выполнять статистическое кодирование принятых данных, формируя закодированные коэффициенты квантования. Когда кодер 20 видео статистически кодирует данные, используя алгоритм арифметического кодирования (например, CABAC), декодер 30 видео может использовать модель контекста для декодирования данных, которые соответствуют той же модели контекста, используемой кодером 20 видео для кодирования данных.
[0197] Декодер 30 видео может также обратно сканировать декодированные коэффициенты, используя обратное сканирование, которое зеркально отражает сканирование, используемое кодером 20 видео. Для обратного сканирования коэффициентов декодер 30 видео выбирает тот же порядок сканирования, используемый кодером 20 видео, который может быть сохранен в декодере или сигнализирован посредством кодера в закодированном битовом потоке. Используя этот порядок сканирования, декодер 30 видео, таким образом, формирует двумерную матрицу из одномерного вектора квантованных коэффициентов преобразования, получившихся в результате процесса статистического декодирования. В частности, декодер 30 видео обратно сканирует коэффициенты из одномерного массива в двумерный массив в соответствии с порядком сканирования, используемым кодером 20 видео.
[0198] Затем декодер 30 видео может обратно квантовать коэффициенты в двумерной матрице, сформированной обратным сканированием, выполненным в соответствии с порядком сканирования. Декодер 30 видео может затем применять одно или более обратных преобразований к двумерной матрице. Обратное преобразование может соответствовать преобразованиям, примененным кодером 20 видео. Декодер 30 видео может определить обратные преобразования, чтобы применить на основании, например, информации, сигнализированной в корне квадродерева, в соответствии с в настоящее время декодируемым CU, или посредством ссылки на другую информацию, указывающую соответствующие обратные преобразования. После применения обратного преобразования (преобразований), декодер 30 видео восстанавливает остаточные видеоданные в пиксельной области и применяет декодирование с внутренним предсказанием или внешним предсказанием, если применимо, чтобы восстановить оригинальные видеоданные.
[0199] ФИГ. 21 является блок-схемой, иллюстрирующей пример модуля 70 статистического декодирования для использования в декодере видео согласно ФИГ. 20. ФИГ. 21 иллюстрирует различные функциональные аспекты модуля 70 статистического декодирования для выбора порядка сканирования и контекстов, используемых для декодирования CABAC в процессе декодирования видео. Как показано на ФИГ. 21, модуль 70 статистического кодирования может включать в себя модуль 100 выбора порядка сканирования и контекста, модуль 102 сканирования 1D-в-2D, механизм 104 статистического декодирования и память 106 порядка сканирования.
[0200] Механизм 104 статистического декодирования статистически декодирует закодированное видео, переданное на декодер 30 видео или извлеченное декодером 30 видео из устройства хранения данных. Например, механизм 104 статистического декодирования может применять процесс статистического декодирования, например, CAVLC, CABAC или другой процесс, к битовому потоку, переносящему закодированное видео, чтобы восстановить 1D-вектор коэффициентов преобразования. В дополнение к остаточным данным коэффициента преобразовании механизм 104 статистического декодирования может применять статистическое декодирование, чтобы воспроизвести данные вектора движения и различные элементы синтаксиса, полезные при декодировании закодированного видео в битовом потоке. Механизм 104 статистического декодирования может определить, какой процесс статистического декодирования, например, CAVLC, CABAC или другой процесс, выбрать на основании сигнализации в закодированном видео битовом потоке или посредством выведения соответствующего процесса из другой информации в битовом потоке.
[0201] В соответствии со способами настоящего раскрытия, механизм 104 статистического декодирования может выполнять статистическое декодирование закодированного видео, используя CABAC, в соответствии с двумя различными областями контекста. Модуль 100 выбора порядка сканирования и контекста может выдать выведение контекста механизму 104 статистического декодирования. В соответствии с примерами настоящего раскрытия, выведение контекста для первой области контекста зависит от позиции коэффициентов преобразования, в то время как выведение контекста для второй области зависит от казуальных соседей коэффициентов преобразования. В другом примере вторая область контекста может использовать две различные модели контекста в зависимости от местоположения коэффициентов преобразования.
[0202] Модуль 100 выбора порядка сканирования и контекста может также определить порядок сканирования и/или индикацию порядка сканирования на основании сигнализации в закодированном видео битовом потоке. Например, модуль 70 статистического декодирования может принимать элементы синтаксиса, которые явно сигнализируют порядок сканирования. Снова, хотя сигнализация в закодированном видео битовом потоке описана в целях иллюстрации, порядок сканирования может быть принят модулем 70 статистического декодирования как внеполосный в побочной информации. Кроме того, в некоторых примерах для модуля 100 выбора порядка сканирования и контекста может быть возможно вывести порядок сканирования без сигнализации. Порядок сканирования может быть основан на режиме предсказания, размере блока, преобразовании или других характеристиках закодированного видео. Подобно памяти 96 на ФИГ. 19, память 106 согласно ФИГ. 21 может хранить команды и/или данные, определяющие порядок сканирования.
[0203] Модуль 102 сканирования 1D-в-2D принимает порядок сканирования от модуля 100 выбора порядка сканирования и контекста и применяет порядок сканирования или непосредственно, или обратным способом, чтобы управлять сканированием коэффициентов. В соответствии со способами настоящего раскрытия, один и тот же порядок сканирования может быть использован как для сканирования отображения значимости, так и для уровня коэффициентов. В другом аспекте раскрытия сканирование отображения значимости может быть в обратном направлении. В другом аспекте раскрытия как сканирование отображения значимости, так и сканирование уровня коэффициентов могут быть в обратном направлении.
[0204] В соответствии с другим аспектом раскрытия, модуль 102 сканирования 1D-в-2D может сканировать одномерный массив коэффициентов преобразования в один или более поднаборов коэффициентов преобразования, кодируя значимость коэффициентов преобразования в каждом поднаборе и кодируя уровни коэффициентов преобразования в каждом поднаборе. В другом аспекте раскрытия сканирование отображения значимости и уровня коэффициентов выполняется в последовательных сканированиях в соответствии с одним и тем же порядком сканирования. В одном аспекте порядком сканирования является обратный порядок сканирования. Последовательные сканирования могут состоять из нескольких сканирований, где первым сканированием является сканирование отображения значимости, второе сканирование имеет контейнер один уровней коэффициентов преобразования в каждом поднаборе, третье сканирование имеет оставшиеся контейнеры уровней коэффициентов преобразования, и четвертое сканирование имеет знак уровней коэффициентов преобразования.
[0205] На стороне кодера кодирование коэффициентов преобразования может содержать кодирование коэффициентов преобразования в соответствии с порядком сканирования, чтобы сформировать одномерный массив коэффициентов преобразования. На стороне декодера кодирование коэффициента преобразования может содержать декодирование коэффициентов преобразования в соответствии с порядком сканирования, чтобы восстановить двумерный массив коэффициентов преобразования в блоке преобразования.
[0206] Должно быть отмечено, что хотя показаны как отдельные функциональные блоки для простоты иллюстрации, структура и функциональные возможности модуля 100 выбора порядка сканирования и контекста, модуля 102 сканирования 1D-в-2D, механизма 104 статистического декодирования и памяти 106 порядка сканирования могут быть высоко интегрированы друг с другом.
[0207] ФИГ. 22 является блок-схемой, иллюстрирующей примерный процесс для сканирования отображения значимости и уровня коэффициентов с согласованным порядком сканирования. Предложен способ кодирования множества коэффициентов преобразования, ассоциированных с остаточными видеоданными в процессе кодирования видео. Способ может быть выполнен кодером видео, таким как кодер 20 видео или декодер 30 видео на ФИГ. 4. Кодер видео может быть сконфигурирован для выбора порядка (120) сканирования. Порядок сканирования может быть выбран на основании режима предсказания, размера блока, преобразования или других характеристик видео. В дополнение, порядок сканирования может быть порядком сканирования по умолчанию. Порядок сканирования определяет как шаблон сканирования, так и направление сканирования. В одном примере направлением сканирования является обратное направление сканирования, осуществляющееся от коэффициентов более высокой частоты во множестве коэффициентов преобразования к коэффициентам более низкой частоты во множестве коэффициентов преобразования. Шаблон сканирования может включать в себя один из: зигзагообразного шаблона, диагонального шаблона, горизонтального шаблона или вертикального шаблона.
[0208] Кодер видео может быть дополнительно сконфигурирован для кодирования информации, указывающей значимые коэффициенты для множества коэффициентов преобразования в соответствии с порядком (122) сканирования, и определения контекстов для кодирования уровней значимых коэффициентов для множества поднаборов значимых коэффициентов, причем каждый из множества поднаборов содержит один или более значимых коэффициентов, сканированных в соответствии с порядком (124) сканирования. Кодер видео также кодирует информацию, указывающую уровни множества коэффициентов преобразования, в соответствии с порядком (126) сканирования. Поднаборы могут иметь различные размеры. Должно быть отмечено, что этапы 122, 124 и 126 могут чередоваться, так как определение контекстов для информации уровня зависит от ранее закодированных соседних коэффициентов.
[0209] ФИГ. 23 является блок-схемой, иллюстрирующей другой примерный процесс для сканирования отображения значимости и уровня коэффициентов и выведение контекста CABAC. Способ согласно ФИГ. 23 немного отличается от способа, показанного на ФИГ. 22, так как контексты блоков различных размеров могут использовать одни и те же критерии выведения контекста. В качестве примера, кодер видео может получить первый контекст для первого блока коэффициентов преобразования, причем первый блок имеет первый размер в соответствии с критериями выведения контекста, и получить второй контекст для второго блока коэффициентов преобразования, причем второй блок имеет второй отличный размер в соответствии с теми же критериями выведения контекста, что и первый блок (123). Подобно ФИГ. 22, этапы 122, 123 и 126 могут чередоваться, так как определение контекстов для информации уровня зависит от ранее закодированных соседних коэффициентов.
[0210] ФИГ. 24 является блок-схемой, иллюстрирующей другой примерный процесс для сканирования отображения значимости и уровня коэффициентов и выведение контекста CABAC. Способ согласно ФИГ. 24 немного отличается от способа, показанного на ФИГ. 22, так как контексты для поднаборов определяются на основании наличия коэффициента DC в поднаборах. В качестве одного примера, кодер видео может определить различные наборы контекстов для различных поднаборов коэффициентов на основании того, содержат ли соответствующие поднаборы коэффициент DC от коэффициентов преобразования (125). Подобно ФИГ. 22, этапы 122, 125 и 126 могут чередоваться, так как определение контекстов для информации уровня зависит от ранее закодированных соседних коэффициентов.
[0211] ФИГ. 25 является блок-схемой, иллюстрирующей другой примерный процесс для сканирования отображения значимости и уровня коэффициентов и выведение контекста CABAC. Способ согласно ФИГ. 25 немного отличается от способа, показанного на ФИГ. 22, так как контексты определены на основании взвешенного количества значимых коэффициентов в других предшествующих поднаборах. В качестве одного примера, кодер видео может определить различные наборы контекстов для различных поднаборов коэффициентов на основании ряда значимых коэффициентов в непосредственно предыдущем поднаборе коэффициентов и взвешенного количества значимых коэффициентов в других предшествующих поднаборах коэффициентов (127). Подобно ФИГ. 22, этапы 122, 127 и 126 могут чередоваться, так как определение контекстов для информации уровня зависит от ранее закодированных соседних коэффициентов.
[0212] ФИГ. 26 является блок-схемой, иллюстрирующей примерный процесс для кодирования отображения значимости, используя обратное направление сканирования. Предложен способ кодирования коэффициентов преобразования, ассоциированных с остаточными видеоданными, в процессе кодирования видео. Способ может быть выполнен видео кодером, таким как кодер 20 видео или декодер 30 видео на ФИГ. 4. Кодер видео может быть сконфигурирован для выбора порядка сканирования с обратным направлением (140) и определения контекстов для адаптивного двоичного арифметического кодирования, основанного на контексте (CABAC), информации, указывающей текущий один из значимых коэффициентов на основании ранее закодированных значимых коэффициентов в обратном направлении (142) сканирования. Кодер видео может быть дополнительно сконфигурирован для кодирования информации, указывающей значимые коэффициенты преобразования вдоль обратного направления сканирования, чтобы сформировать отображение (146) значимости.
[0213] В одном примере сканирование имеет диагональный шаблон, и ранее закодированные значимые коэффициенты находятся в позициях справа от линии сканирования, на которой находится текущий один из значимых коэффициентов. В другом примере сканирование имеет горизонтальный шаблон, и ранее закодированные значимые коэффициенты находятся в позициях ниже линии сканирования, на которой находится текущий один из значимых коэффициентов. В другом примере сканирование имеет вертикальный шаблон, и ранее закодированные значимые коэффициенты находятся в позициях справа от линии сканирования, на которой находится текущий один из значимых коэффициентов.
[0214] Кодер видео может быть дополнительно сконфигурирован для кодирования информации, указывающей уровни значимых коэффициентов преобразования (148). Этап кодирования информации, указывающей уровни значимых коэффициентов преобразования, может выполняться в обратном направлении сканирования от коэффициентов более высокой частоты в блоке коэффициентов преобразования к коэффициентам более низкой частоты в блоке коэффициентов преобразования. Подобно ФИГ. 22, этапы 142, 146 и 148 могут чередоваться, так как определение контекстов для информации уровня зависит от ранее закодированных соседних коэффициентов.
[0215] ФИГ. 27 является блок-схемой, иллюстрирующей примерный процесс для сканирования отображения значимости и уровня коэффициентов, в соответствии с поднаборами коэффициентов преобразования. Предложен способ кодирования коэффициентов преобразования, ассоциированных с остаточными видеоданными, в процессе кодирования видео. Способ может быть выполнен кодером видео, таким как кодер 20 видео или декодер 30 видео на ФИГ. 4. Кодер видео может быть сконфигурирован для компоновки блока коэффициентов преобразования в одном или более поднаборах коэффициентов преобразования (160), кодирования значимости коэффициентов преобразования в каждом поднаборе (162) и кодирования уровней коэффициентов преобразования в каждом поднаборе (164). В одном примере компоновка блока коэффициентов преобразования может включать в себя компоновку блока коэффициентов преобразования в единственный набор коэффициентов преобразования, соответствующих всему блоку преобразования. В другом примере компоновка блока коэффициентов преобразования может включать в себя компоновку блока коэффициентов преобразования в один или более поднаборов коэффициентов преобразования на основании порядка сканирования.
[0216] Кодер видео может быть сконфигурирован для кодирования значимости коэффициентов преобразования в каждом поднаборе в соответствии с порядком сканирования и кодирования уровней коэффициентов преобразования в соответствии с порядком сканирования. Кодирование отображения значимости (162) и уровней (164) может быть выполнено вместе в двух или более последовательных проходах сканированиях в поднаборе (165).
[0217] ФИГ. 28 является блок-схемой, иллюстрирующей другой примерный процесс для сканирования отображения значимости и уровня коэффициентов в соответствии с поднаборами коэффициентов преобразования. Кодер видео может выполнять последовательные сканирования (165) посредством первого кодирования значимости коэффициентов преобразования в поднаборе в первом сканировании коэффициентов преобразования в соответствующем поднаборе (170).
[0218] Кодирование уровней коэффициентов (164) в каждом поднаборе включает в себя по меньшей мере второе сканирование коэффициентов преобразования в соответствующем поднаборе. Второе сканирование может включать в себя кодирование контейнера один уровней коэффициентов преобразования в поднаборе во втором сканировании коэффициентов преобразования в соответствующем поднаборе (172), кодирование оставшихся контейнеров уровней коэффициентов преобразования в поднаборе в третьем сканировании коэффициентов преобразования в соответствующем поднаборе (174) и кодирование знака уровней коэффициентов преобразования в поднаборе в четвертом сканировании коэффициентов преобразования в соответствующем поднаборе (176).
[0219] ФИГ. 29 является блок-схемой, иллюстрирующей другой примерный процесс для сканирования отображения значимости и уровня коэффициентов в соответствии с поднаборами коэффициентов преобразования. В этом примере кодирование знака уровней коэффициентов преобразования (176) выполняется до кодирования уровней (172, 174).
[0220] ФИГ. 30 является блок-схемой, иллюстрирующей примерный процесс для статистического кодирования, использующего множественные области. Предложен способ кодирования множества коэффициентов преобразования, ассоциированных с остаточными видеоданными, в процессе кодирования видео. Способ может быть выполнен кодером видео, таким как кодер 20 видео или декодер 30 видео на ФИГ. 4. Кодер видео может быть сконфигурирован для кодирования информации, указывающей значимые коэффициенты для множества коэффициентов преобразования, в соответствии с порядком сканирования (180), разделения закодированной информации на первую область и вторую область (182), статистического кодирования закодированной информации в первой области в соответствии с первым набором контекстов, используя адаптивное двоичное арифметическое кодирование, основанное на контексте (184), и статистического кодирования закодированной информации во второй области в соответствии со вторым набором контекстов, используя контекстное адаптивное двоичное арифметическое кодирование (186). В одном примере порядок сканирования имеет обратное направление и шаблон диагонального сканирования. Этот способ может также применяться более чем к двум областям, причем каждая область имеет набор контекстов.
[0221] Первая и вторая области могут быть разделены несколькими способами. В одном примере первая область содержит по меньшей мере компонент DC множества коэффициентов преобразования, и вторая область содержит оставшееся множество коэффициентов преобразования не в первой области.
[0222] В другом примере первая область содержит все коэффициенты преобразования в области, определенной посредством x+y<T, где x является горизонтальной позицией коэффициента преобразования, y является вертикальной позицией коэффициента преобразования, и T является порогом. Первая область может содержать коэффициент DC. Вторая область содержит оставшееся множество коэффициентов преобразования не в первой области.
[0223] В другом примере первая область содержит все коэффициенты преобразования в области, определенной посредством x<T и y<T, где x является горизонтальной позицией коэффициента преобразования, y является вертикальной позицией коэффициента преобразования, и T является порогом. Вторая область содержит оставшееся множество коэффициентов преобразования не в первой области.
[0224] В другом примере первая область содержит коэффициент DC, вторая область содержит все коэффициенты преобразования (кроме коэффициента DC) в области, определенной посредством x<T и y<T, где x является горизонтальной позицией коэффициента преобразования, y является вертикальной позицией коэффициента преобразования и T является порогом, и третья область содержит оставшееся множество коэффициентов преобразования не в первой области или второй области. В другом примере вторая и третья области, описанные выше, могут использовать один и тот же способ для получения контекстов, но используются различные наборы контекста для каждой области.
[0225] В другом примере первая область включает в себя компонент DC и коэффициенты преобразования в позициях (1,0) и (0,1). Вторая область содержит оставшееся множество коэффициентов преобразования не в первой области.
[0226] В другом примере первая область содержит только компонент DC множества коэффициентов преобразования, и вторая область содержит оставшееся множество коэффициентов преобразования.
[0227] В целом, первый контекст для каждого коэффициента преобразования в первой области основан на позиции каждого коэффициента преобразования в первой области, в то время как второй контекст для каждого коэффициента преобразования во второй области основан на закодированной информации казуальных соседей каждого коэффициента преобразования. В некоторых примерах второй контекст дополнительно основан на позиции каждого коэффициента преобразования во второй области. В другом примере второй контекст для каждого коэффициента преобразования во второй области основан на закодированной информации пяти казуальных соседей каждого коэффициента преобразования.
[0228] В одном или более примерах функции, описанные в настоящем раскрытии, могут быть реализованы в аппаратном обеспечении, программном обеспечении, программно-аппаратном обеспечении или любой их комбинации. Если реализованы в программном обеспечении, функции могут быть выполнены основанным на аппаратном обеспечении блоком обработки, таким как один или более процессоров, которые выполняют программное обеспечение в форме считываемых компьютером команд или кода. Такие команды или код могут быть сохранены на или переданы по считываемому компьютером носителю и выполнены основанным на аппаратном обеспечении блоком обработки. Считываемые компьютером носители могут включать в себя считываемые компьютером запоминающие носители, которые соответствуют материальному невременному носителю, такому как запоминающие носители данных или коммуникационные носители, включающие в себя любой носитель, который облегчает передачу компьютерной программы от одного места к другому, например, в соответствии с протоколом связи. Таким образом, считываемые компьютером носители в целом могут соответствовать (1) материальным считываемым компьютером запоминающим носителям, которые являются невременными, или (2) коммуникационному носителю, такому как сигнал или несущая. Запоминающие носители данных могут быть любыми доступными носителями, которые могут быть доступны посредством одного или более компьютеров, или одного или более процессоров, чтобы восстановить команды, код и/или структуры данных для реализации способов, описанных в настоящем раскрытии. Компьютерный программный продукт может включать в себя считываемый компьютером носитель.
[0229] Посредством примера, а не ограничения, такие считываемые компьютером запоминающие носители могут содержать RAM, ROM, EEPROM, флэш-память, CD-ROM или любую другую твердотельную память, оптические или магнитные запоминающие носители, включающие в себя запоминающее устройство на оптических дисках, или запоминающее устройство на магнитных дисках или другие магнитные запоминающие устройства, или любой другой носитель, который может быть использован, чтобы сохранять желаемый программный код в форме команд или структур данных, и который может быть доступным посредством компьютера. Кроме того, любое соединение должным образом называется считываемым компьютером носителем. Например, если команды передаются от вебсайта, сервера или другого удаленного источника, используя коаксиальный кабель, волоконно-оптический кабель, витую пару, абонентскую цифровую линию (DSL) или беспроводные технологии, такие как инфракрасное излучение, радио и микроволны, то эти коаксиальный кабель, волоконно-оптический кабель, витая пара, DSL или беспроводные технологии, такие как инфракрасное излучение, радио и микроволны, включены в определение носителя. Однако должно быть понятно, что материальные считываемые компьютером запоминающие носители и запоминающие носители данных не включают в себя соединения, несущие, сигналы или другие временные носители, но вместо этого относятся к невременным, материальным запоминающим носителям. Диск (disk) и диск (disc), как используются в настоящем описании, включают в себя компакт-диск (CD), лазерный диск, оптический диск, универсальный цифровой диск (DVD), дискету и диск blue-ray, где диски (disks) обычно воспроизводят данные магнитным способом, в то время как диски (discs) воспроизводят данные оптическим образом посредством лазеров. Комбинации вышеупомянутого должны быть также включены в понятие считываемых компьютером носителей.
[0230] Команды могут быть выполнены одним или более процессорами, такими как один или более цифровых сигнальных процессоров (процессоров DSP), микропроцессоры общего назначения, специализированные интегральные схемы (схемы ASIC), программируемые пользователем вентильные матрицы (матрицы FPGA) или другие эквивалентные интегральные или дискретные логические схемы. Соответственно, термин "процессор", который используется в настоящем описании, может относиться к любой вышеупомянутой структуре или любой другой структуре, подходящей для реализации способов, описанных в настоящем описании. В дополнение, в некоторых аспектах функциональные возможности, описанные в настоящем описании, могут быть обеспечены в специализированных модулях аппаратного обеспечения и/или программного обеспечения, сконфигурированных для кодирования и декодирования, или встроены в комбинированный кодек. Кроме того, способы могут быть полностью реализованы в одной или более схемах или логических элементах.
[0231] Способы настоящего раскрытия могут быть выполнены большим разнообразием устройств или аппаратур, включающих в себя настольные компьютеры, портативные компьютеры (то есть, ноутбук), планшетные компьютеры, телевизионные приставки, телефонные трубки, такие как так называемые смартфоны, телевизоры, камеры, устройства отображения, цифровые медиа плееры, консоли для видео игр и т.п. Во многих случаях такие устройства могут быть оборудованы для беспроводной связи. В дополнение такие способы могут быть реализованы интегральной схемой (IC) или набором схем IC (например, чипсетом). Устройство, сконфигурированное для выполнения способов настоящего раскрытия, может включать в себя любое из упомянутых выше устройств и, в некоторых случаях, может быть кодером видео или декодером видео, или комбинированным видео кодеком, то есть, CODEC видео, который может быть сформирован комбинацией аппаратного обеспечения, программного обеспечения и программно-аппаратного обеспечения. Различные компоненты, модули или блоки могут быть описаны в настоящем раскрытии, чтобы подчеркнуть функциональные аспекты устройств, сконфигурированных для выполнения раскрытых способов, но не обязательно требуют реализации различными блоками аппаратного обеспечения. Вместо этого, как описано выше, различные блоки могут быть скомбинированы в блоке аппаратного обеспечения кодека или обеспечены коллекцией взаимодействующих блоков аппаратного обеспечения, включающих в себя один или более процессоров, как описано выше, вместе с подходящим программным обеспечением и/или программно-аппаратным обеспечением.
[0232] Были описаны различные примеры. Эти и другие примеры попадают в объем следующей формулы изобретения.
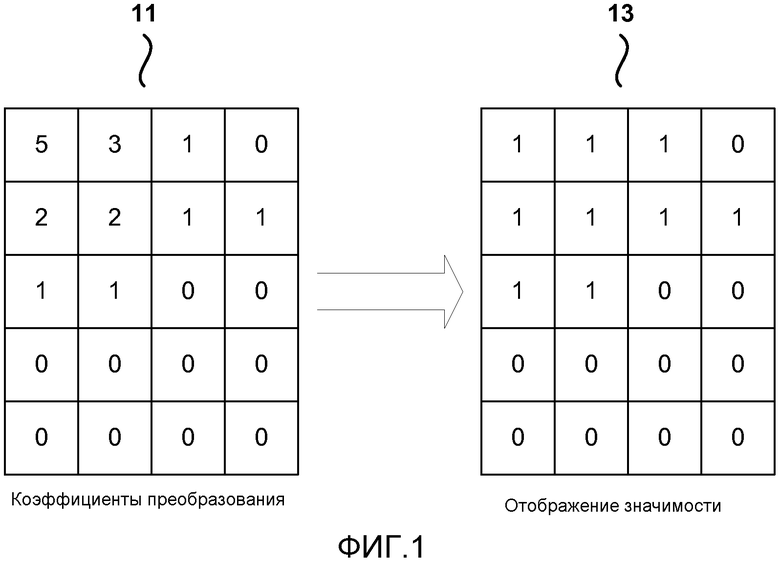

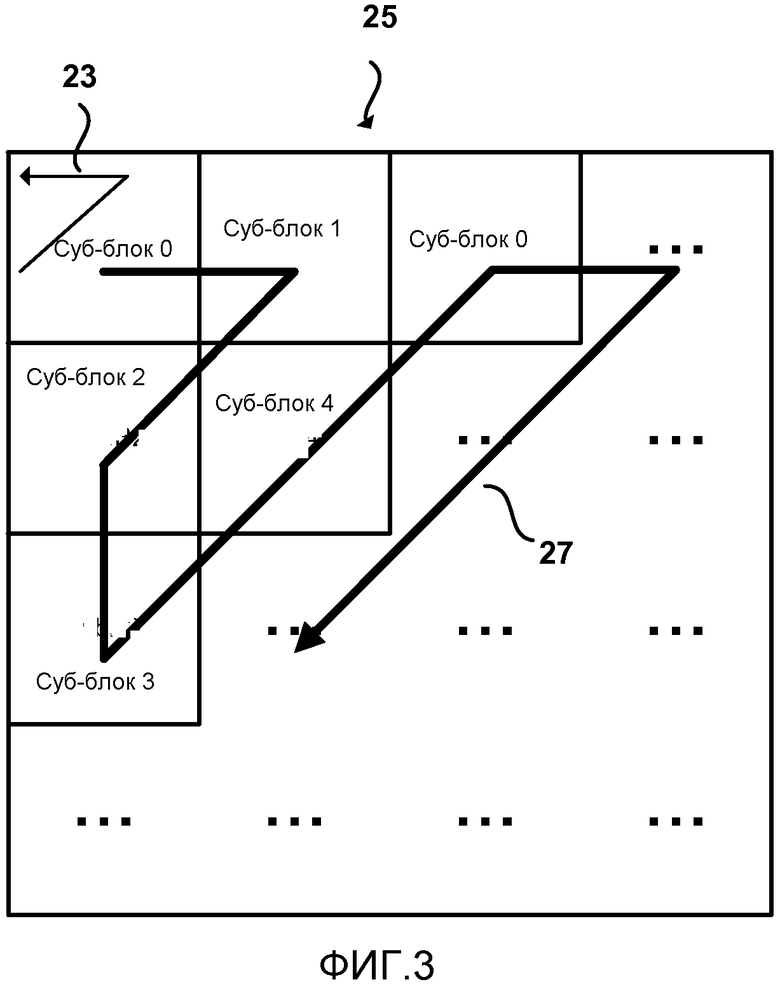

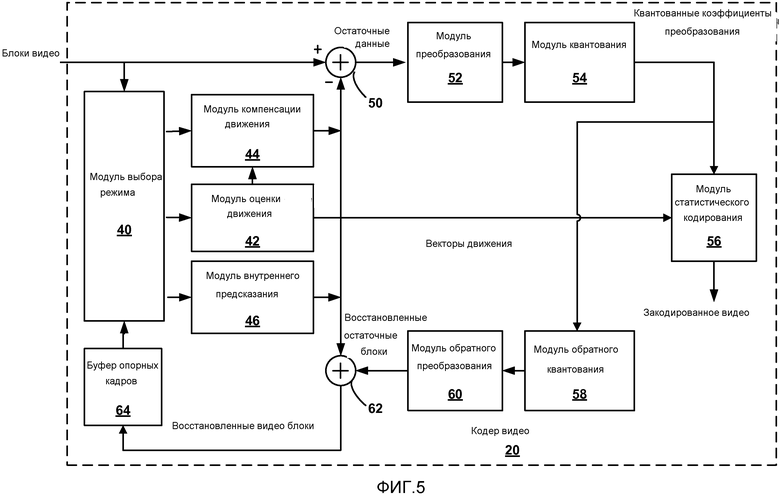

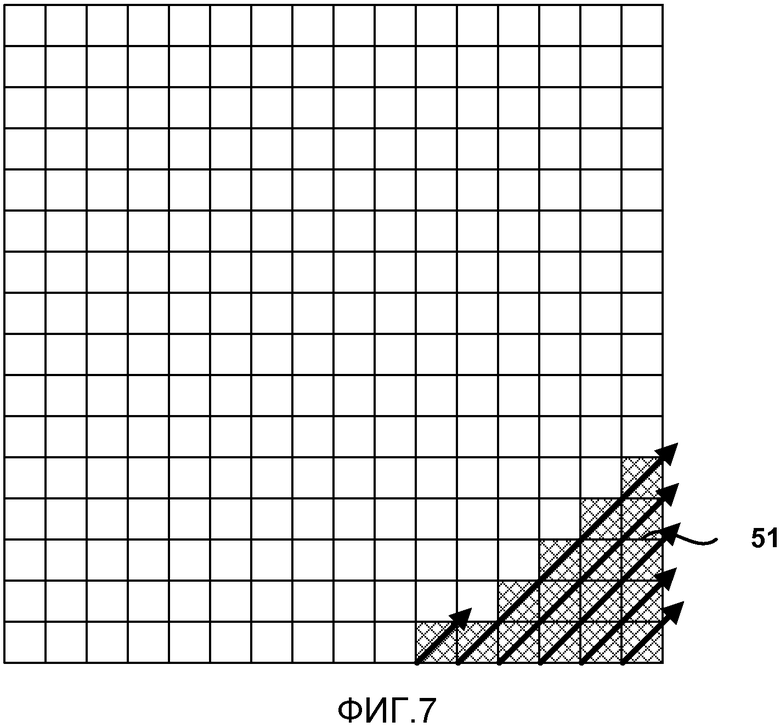
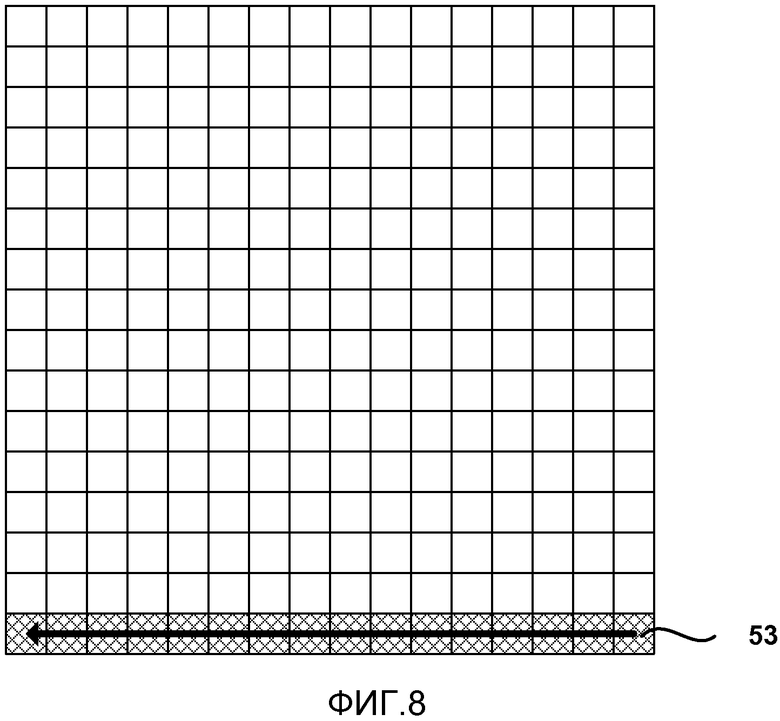







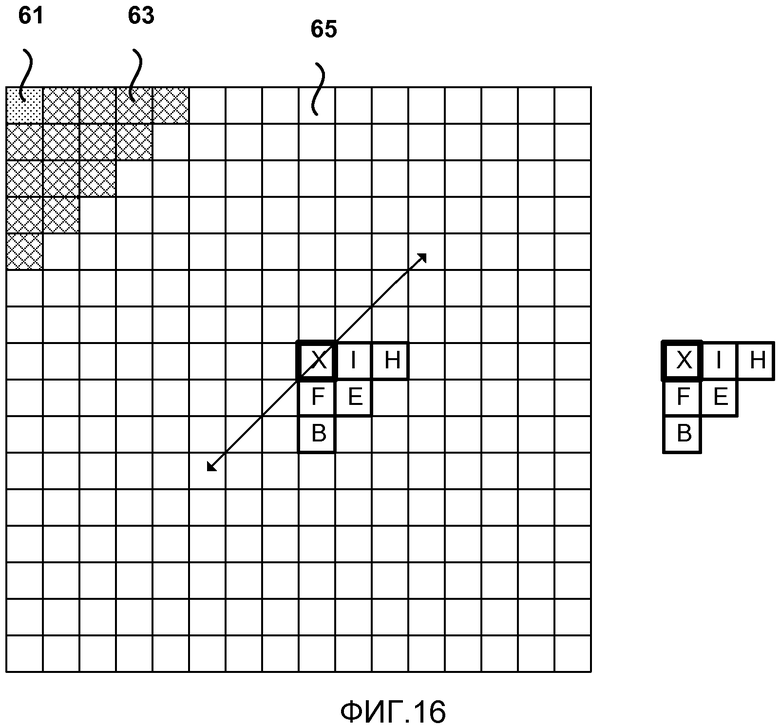

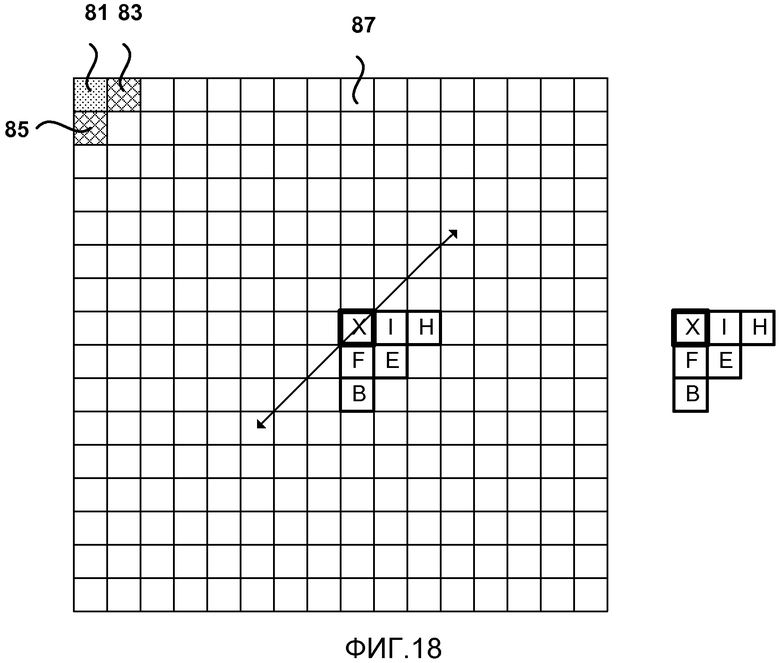

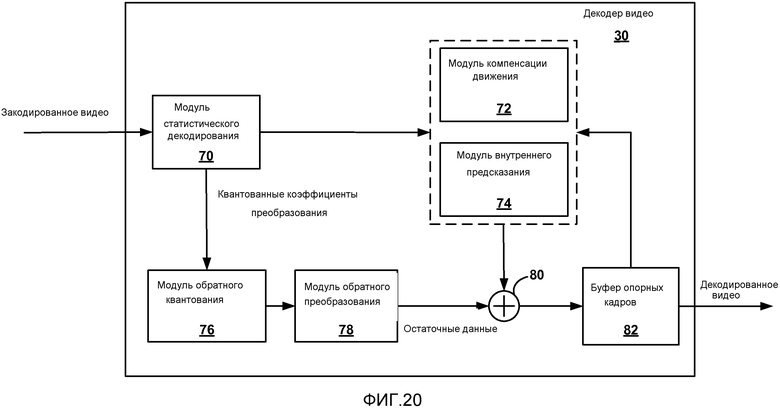

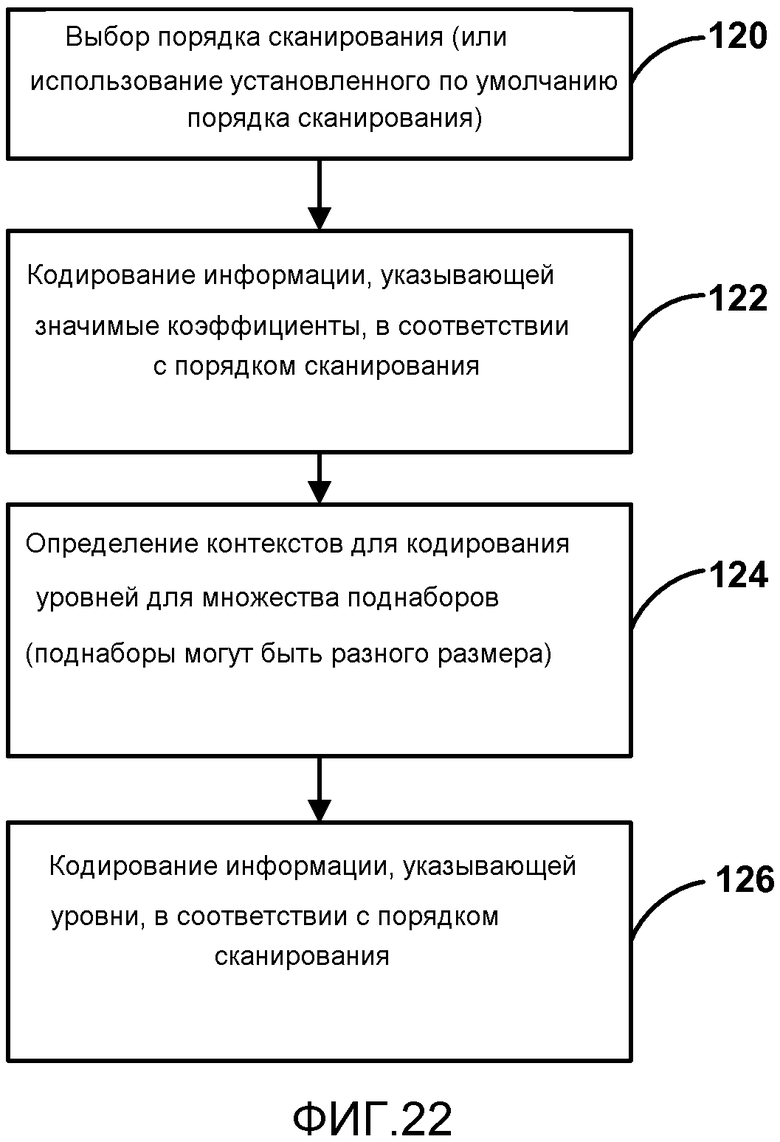


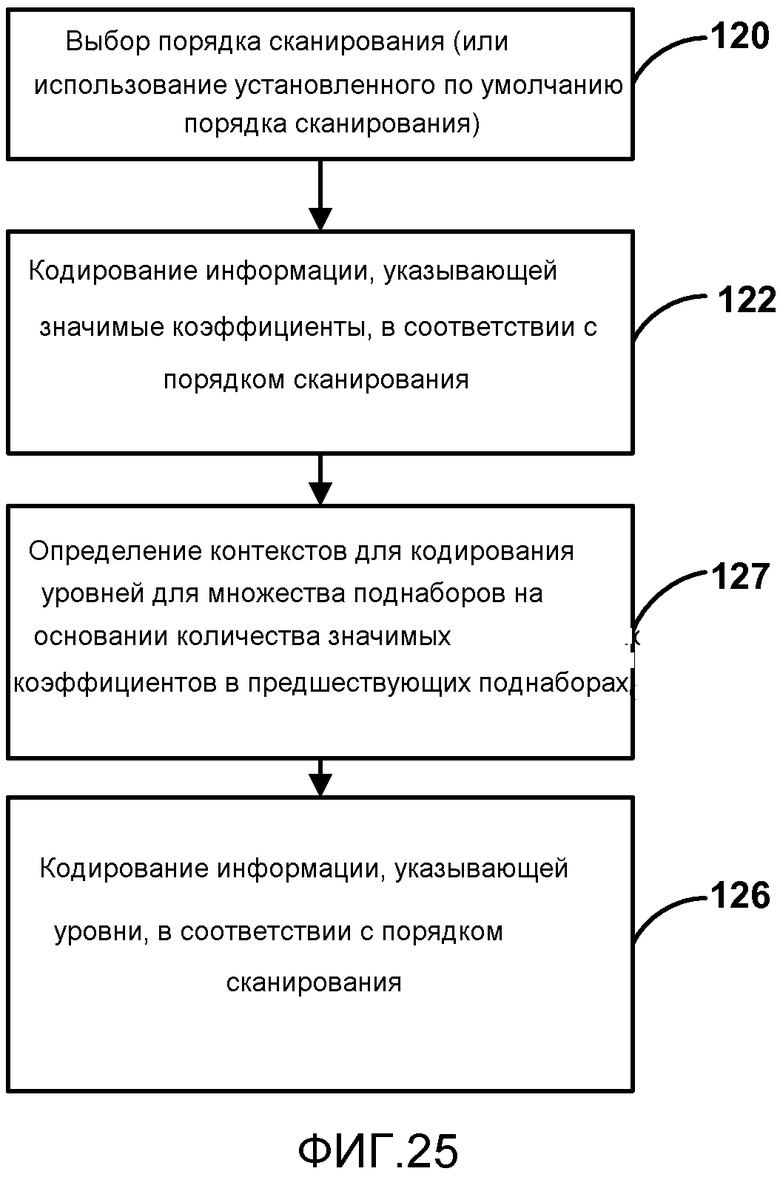



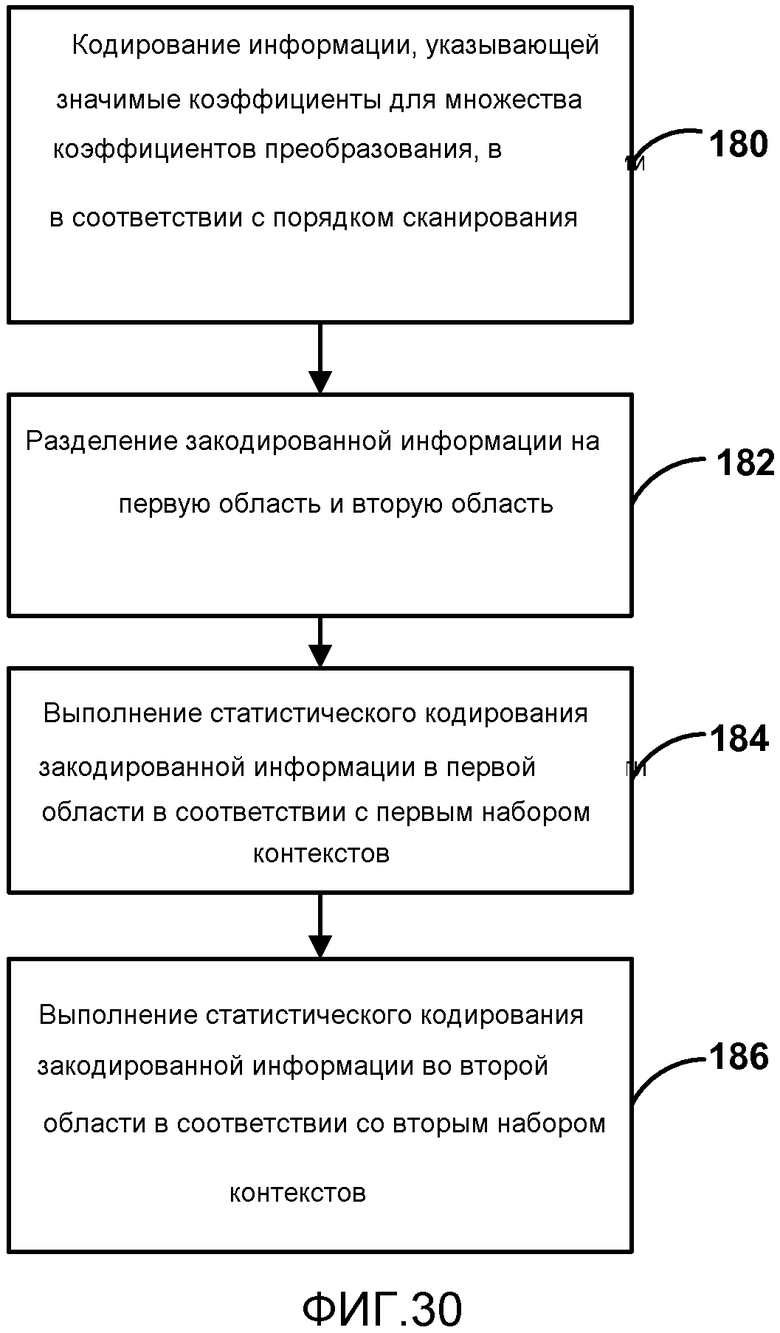
Изобретение относится к вычислительной технике. Технический результат заключается в согласованности порядка сканирования для кодирования как отображения значимости коэффициентов преобразования, так и для кодирования уровней коэффициентов преобразования. Способ кодирования коэффициентов преобразования, ассоциированных с остаточными данными видео в процессе кодирования видео, содержит кодирование информации, указывающей значимые коэффициенты преобразования в блоке коэффициентов преобразования со сканированием, осуществляющемся в обратном направлении сканирования от коэффициентов более высокой частоты в блоке коэффициентов преобразования к коэффициентам более низкой частоты в блоке коэффициентов преобразования, формирование отображения значимости для блока на основании кодированной информации, указывающей значимые коэффициенты преобразования, и кодирование информации, указывающей уровни значимых коэффициентов преобразования, в обратном направлении сканирования от коэффициентов более высокой частоты в блоке коэффициентов преобразования к коэффициентам более низкой частоты в блоке коэффициентов преобразования. 4 н. и 18 з.п. ф-лы, 30 ил., 5 табл.
1. Способ кодирования коэффициентов преобразования, ассоциированных с остаточными данными видео в процессе кодирования видео, причем способ содержит:
кодирование информации, указывающей значимые коэффициенты преобразования в блоке коэффициентов преобразования со сканированием, осуществляющемся в обратном направлении сканирования от коэффициентов более высокой частоты в блоке коэффициентов преобразования к коэффициентам более низкой частоты в блоке коэффициентов преобразования,
формирование отображения значимости для блока на основании кодированной информации, указывающей значимые коэффициенты преобразования, и
кодирование информации, указывающей уровни значимых коэффициентов преобразования, в обратном направлении сканирования от коэффициентов более высокой частоты в блоке коэффициентов преобразования к коэффициентам более низкой частоты в блоке коэффициентов преобразования.
2. Способ по п. 1, дополнительно содержащий определение контекстов для контекстного адаптивного двоичного арифметического кодирования (САВАС) информации, указывающей текущий один из значимых коэффициентов, на основании ранее закодированных значимых коэффициентов в обратном направлении сканирования.
3. Способ по п. 2, в котором, если ранее закодированный значимый коэффициент расположен вне блока преобразования, закодированная информация уровня для ранее закодированного значимого коэффициента предполагается равной нулю.
4. Способ по п. 2, в котором сканирование имеет диагональный шаблон, и ранее кодированные значимые коэффициенты находятся в позициях справа от линии сканирования, на которой находится текущий один из значимых коэффициентов.
5. Способ по п. 2, в котором сканирование имеет горизонтальный шаблон, и ранее кодированные значимые коэффициенты находятся в позициях ниже линии сканирования, на которой находится текущий один из значимых коэффициентов.
6. Способ по п. 2, в котором сканирование имеет вертикальный шаблон, и ранее кодированные значимые коэффициенты находятся в позициях справа от линии сканирования, на которой находится текущий один из значимых коэффициентов.
7. Система для кодирования коэффициентов преобразования, ассоциированных с остаточными данными видео в процессе кодирования видео, причем система содержит:
память, выполненную с возможностью хранить блок коэффициентов преобразования, и
процессор кодирования видео, сконфигурированный для:
кодирования информации, указывающей значимые коэффициенты преобразования в упомянутом блоке коэффициентов преобразования со сканированием, осуществляющемся в обратном направлении сканирования от коэффициентов более высокой частоты в блоке коэффициентов преобразования к коэффициентам более низкой частоты в блоке коэффициентов преобразования,
формирования отображения значимости для блока на основании кодированной информации, указывающей значимые коэффициенты преобразования, и
кодирования информации, указывающей уровни значимых коэффициентов преобразования, в обратном направлении сканирования от коэффициентов более высокой частоты в упомянутом блоке коэффициентов преобразования к коэффициентам более низкой частоты в блоке коэффициентов преобразования.
8. Система по п. 7, в которой процессор кодирования видео дополнительно сконфигурирован, чтобы определить контексты для контекстного адаптивного двоичного арифметического кодирования (САВАС) информации, указывающей текущий один из значимых коэффициентов, на основании ранее закодированных значимых коэффициентов в обратном направлении сканирования.
9. Система по п. 8, в которой, если ранее закодированный значимый коэффициент расположен вне блока преобразования, закодированная информация уровня для этого ранее кодированного значимого коэффициента предполагается равной нулю.
10. Система по п. 8, в которой сканирование имеет диагональный шаблон, и ранее закодированные значимые коэффициенты находятся в позициях справа от линии сканирования, на которой находится текущий один из значимых коэффициентов.
11. Система по п. 8, в которой сканирование имеет горизонтальный шаблон, и ранее закодированные значимые коэффициенты находятся в позициях ниже линии сканирования, на которой находится текущий один из значимых коэффициентов.
12. Система по п. 8, в которой сканирование имеет вертикальный шаблон, и ранее закодированные значимые коэффициенты находятся в позициях справа от линии сканирования, на которой находится текущий один из значимых коэффициентов.
13. Система для кодирования коэффициентов преобразования, ассоциированных с остаточными данными видео в процессе кодирования видео, причем система содержит:
средство для кодирования информации, указывающей значимые коэффициенты преобразования в блоке коэффициентов преобразования со сканированием, осуществляющемся в обратном направлении сканирования от коэффициентов более высокой частоты в блоке коэффициентов преобразования к коэффициентам более низкой частоты в блоке коэффициентов преобразования;
средство для формирования отображения значимости для блока на основании закодированной информации, указывающей значимые коэффициенты преобразования, и
средство для кодирования информации, указывающей уровни значимых коэффициентов преобразования, в обратном направлении сканирования от коэффициентов более высокой частоты в блоке коэффициентов преобразования к коэффициентам более низкой частоты в блоке коэффициентов преобразования.
14. Система по п. 13, дополнительно содержащая средство для определения контекстов для контекстного адаптивного двоичного арифметического кодирования (САВАС) информации, указывающей текущий один из значимых коэффициентов, на основании ранее закодированных значимых коэффициентов в обратном направлении сканирования.
15. Система по п. 14, в которой сканирование имеет диагональный шаблон, и ранее закодированные значимые коэффициенты находятся в позициях справа от линии сканирования, на которой находится текущий один из значимых коэффициентов.
16. Система по п. 14, в которой сканирование имеет горизонтальный шаблон, и ранее закодированные значимые коэффициенты находятся в позициях ниже линии сканирования, на которой находится текущий один из значимых коэффициентов.
17. Система по п. 14, в которой сканирование имеет вертикальный шаблон, и ранее закодированные значимые коэффициенты находятся в позициях справа от линии сканирования, на которой находится текущий один из значимых коэффициентов.
18. Считываемый компьютером носитель данных, хранящий на нем инструкции, которые, когда выполняются, вынуждают один или более процессоров устройства для кодирования коэффициентов преобразования, ассоциированных с остаточными данными видео в процессе кодирования видео:
кодировать информацию, указывающую значимые коэффициенты преобразования в блоке коэффициентов преобразования со сканированием, осуществляющемся в обратном направлении сканирования от коэффициентов более высокой частоты в блоке коэффициентов преобразования к коэффициентам более низкой частоты в блоке коэффициентов преобразования,
формировать отображение значимости для блока на основании закодированной информации, указывающей значимые коэффициенты преобразования, и
кодировать информацию, указывающую уровни значимых коэффициентов преобразования, в обратном направлении сканирования от коэффициентов более высокой частоты в блоке коэффициентов преобразования к коэффициентам более низкой частоты в блоке коэффициентов преобразования.
19. Считываемый компьютером носитель по п. 18, дополнительно вынуждающий один или более процессоров определять контексты для контекстного адаптивного двоичного арифметического кодирования (САВАС) информации, указывающей текущий один из значимых коэффициентов, на основании ранее закодированных значимых коэффициентов в обратном направлении сканирования.
20. Считываемый компьютером носитель по п. 19, в котором сканирование имеет диагональный шаблон, и ранее закодированные значимые коэффициенты находятся в позициях справа от линии сканирования, на которой находится текущий один из значимых коэффициентов.
21. Считываемый компьютером носитель по п. 19, в котором сканирование имеет горизонтальный шаблон, и ранее закодированные значимые коэффициенты находятся в позициях ниже линии сканирования, на которой находится текущий один из значимых коэффициентов.
22. Считываемый компьютером носитель по п. 19, в котором сканирование имеет вертикальный шаблон, и ранее закодированные значимые коэффициенты находятся в позициях справа от линии сканирования, на которой находится текущий один из значимых коэффициентов.
| US 7379608 B2, 27.05.2008 | |||
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| ЭЛЕКТРИЧЕСКИ АДРЕСУЕМОЕ УСТРОЙСТВО, СПОСОБ ЭЛЕКТРИЧЕСКОЙ АДРЕСАЦИИ И ИСПОЛЬЗОВАНИЕ ЭТОГО УСТРОЙСТВА И ЭТОГО СПОСОБА | 1998 |
|
RU2182732C2 |
| US 7535387 B1, 19.05.2009 | |||
| АДАПТИВНЫЙ ПОРЯДОК СКАНИРОВАНИЯ КОЭФФИЦИЕНТОВ | 2005 |
|
RU2404534C2 |

