Предшествующий уровень техники
Создание заметок с использованием голосового потока является процессом сбора информации из аудиозаписи и ассоциирования этой информации со сгенерированным пользователем контентом. В некоторых ситуациях это может быть полезным пользователю для обеспечения дополнительной информации, когда пользователь пересматривает созданные заметки. Например, пользователь может печатать заметки во время презентации, такой как лекции или совещания, но не может вспомнить дополнительные детали, связанные с этими заметками во время последующего пересмотра. Попытки создателя заметки включать все эти детали во время прослушивания презентации могут привести к упущению последних деталей создателем заметки в том виде, как их следует соблюдать. Обычные системы, такие как сокращенные слова, стенография и быстрый ввод, часто трудны для обучения и могут быть непрактичными для случайных переговоров.
Краткое описание существа изобретения
Может быть обеспечено создание заметок с использованием голосового потока. Краткое описание существа изобретения обеспечивается для введения подборки концепций в упрощенной форме, которые дополнительно описаны ниже в подробном описании. Краткое описание существа изобретения не предназначено для идентификации ключевых признаков или существенных признаков заявленного изобретения. Также краткое описание существа изобретения не предназначено для использования в качестве ограничения объема заявленного изобретения.
Может быть обеспечено создание заметок с использованием голосового потока. Аудиопоток, ассоциированный с по меньшей мере одним говорящим, может быть записан и преобразован в текстовые блоки. Ввод текста может быть принят от пользователя, например, в электронном документе. Ввод текста может быть сравнен с текстовыми блоками для идентификации совпадений, и совпадающие текстовые блоки могут быть отображены для пользователя для выбора.
Как вышеупомянутое общее описание, так и последующее подробное описание обеспечивают примеры и являются только пояснением. Соответственно, вышеупомянутое общее описание и последующее подробное описание не должно рассматриваться как ограничение. Дополнительно, признаки или вариации могут быть предоставлены в дополнение к изложенным в настоящем документе. Например, варианты воплощения могут быть направлены на различные комбинации и подкомбинации признаков, описанные в подробном описании.
Краткое описание чертежей
Прилагаемые чертежи, которые включены в состав и составляют часть этого описания, иллюстрируют различные варианты воплощения настоящего изобретения. На чертежах:
Фиг.1 является структурной схемой операционной среды;
Фиг.2 является структурной схемой приложения создания заметок;
Фиг.3 является логической блок-схемой способа обеспечения идентификации по образцу голоса; и
Фиг.4 является структурной схемой системы, включающей в себя вычислительное устройство.
Подробное описание
Следующее подробное описание ссылается на сопровождающие чертежи. Везде, где это возможно, на чертежах в последующем описании используются одни и те же ссылочные позиции для указания на идентичные или аналогичные элементы. В то время как могут быть описаны некоторые варианты воплощения изобретения, возможны модификации, адаптации и другие воплощения. Например, замены, дополнения или модификации могут быть выполнены в отношении элементов, проиллюстрированных на чертежах, и способы, описанные здесь, могут быть модифицированы путем замены, переупорядочивания или добавления этапов для описанных способов. Соответственно, последующее подробное описание не ограничивает изобретение. Вместо этого надлежащий объем изобретения определяется прилагаемой формулой изобретения.
В соответствии с вариантами воплощения изобретения голосовой поток вокруг создателя заметки может быть записан. Голос(а) может быть распознан, например, с помощью алгоритма преобразования речи в текст и разбит на предложения и/или фразы, чтобы обеспечить буфер последних текстовых блоков. По мере того как создатель заметки печатает заметки, их напечатанный текст может сопоставляться с последними предложениями и позициями фраз из голосового потока. Рекомендации по автозавершению могут быть предложены создателю заметки. Эти рекомендации могут быть выбраны и добавлены к напечатанным заметкам на основе небольшого количества текста, введенного создателем заметки.
По мере того как пользователь печатает заметки, например, на ноутбуке или планшетном компьютере, микрофон в компьютере может записывать все, что говорится вокруг. Компьютер может преобразовывать входящую речь в текстовый поток на основе совпадений при распознавании речи. Алгоритмы распознавания речи, такие как на основе скрытых моделей Маркова (HMM), известны в данной области техники как статистические модели, которые выдают последовательность символов или чисел. При распознавании речи HMM может выдавать последовательность из n-мерных векторов действительных значений, где n является малым целым числом, например 10, на регулярной основе, например каждые 10 миллисекунд. Векторы могут содержать коэффициенты косинусного преобразования Фурье, которые могут быть получены посредством преобразования Фурье в отношении короткого временного промежутка речи, деколлеряции спектра с использованием косинусного преобразования и затем взятия первого (самого старшего) коэффициента. HMM может иметь статистическое распределение, которое представляет собой смесь диагональных ковариационных гауссианов, которые могут дать вероятность для каждого наблюдаемого вектора. Каждое слово или (для более общих систем распознавания речи) каждая фонема может иметь разное выходное распределение. Скрытая модель Маркова для последовательности слов или фонем может быть составлена путем объединения отдельных обученных HMM для отдельных слов и фонем.
Системы распознавания речи могут использовать различные комбинации из нескольких стандартных методов для улучшения результатов на основе подхода, описанного выше. Типичная система с большим словарным запасом может потребовать зависимость контекста для фонем (так фонемы с различными левым и правым контекстами имеют разные реализации в качестве состояний HMM). Средство распознания речи может использовать нормализацию косинусного преобразования Фурье для нормализации в отношении различных говорящих и условий записи и/или он может использовать нормализацию длины вокального тракта (VTLN) для нормализации в отношении мужчин и женщин и линейную регрессию максимальной вероятности (MLLR) для более общей адаптации говорящих.
Поскольку речь распознается и преобразуется в текст, каждому слову и/или фразе может быть назначена взвешенная вероятность, например, путем оценки контекста и/или грамматических правил. По мере того как преобразуется все больше речи, вероятности могут быть отрегулированы на основе последних идентифицированных слов и/или фраз. Кроме того, пользовательские собственные заметки могут быть использованы для присвоения и/или изменения вероятностей. Например, голосовой поток может быть преобразован в текстовый поток, содержащий фразу "four times eight is thirty-two» («четырежды восемь равно тридцать два»). Преобразование может присвоить более высокую вероятность тому, что первое слово есть "four", а не "for", на основе контекста других чисел во фразе, или пользователь может, в непосредственной временной близости, ввести текст "four times".
Записанный голосовой поток и/или текстовый поток, полученный посредством преобразования, могут быть сохранены в буфере на конфигурируемое количество времени. Например, буфер может сохранять предыдущую минуту записи, прежде чем сбросить голосовой поток и/или текстовый поток. Это время, например, может быть увеличено или уменьшено в зависимости от предпочтений пользователя и/или возможностей устройства. Кроме того, текст в буфере может быть разбит на блоки на основе пауз, разрывов в предложениях, разрывов во фразе и/или сочетания слов. Например, переходные слова, такие как "переход к", "следующая точка", "иначе" и т.д., могут представлять собой записи в списке границ фраз, которые могут быть использованы для разделения текста.
По мере того как пользователь вводит текст, в отношении этих блоков может выполняться поиск на предмет возможных совпадений, которые могут отображаться для пользователя. Например, текстовый буфер может содержать слова “Audio recording is easy, but audio searching is hard" («Запись аудио легка, но поиск аудио труден»). Если пользователь затем напечатает буквы "a-u-d", фразы "audio recording is easy" и "audio searching is hard" могут быть идентифицированы как потенциально совпадающие блоки. Эти блоки могут отображаться для выбора, например, в выпадающем списке, и пользователь может выбрать один из них с помощью известных взаимодействий, таких как кликанье кнопкой мыши на выбранном блоке, нажатие клавиши, такой как пробел или символ табуляции для выбора отображаемого блока, нажатие ее стилусом и т.д. Блоки могут отображаться в соответствии с заметкой времени, ассоциированной с каждой фразой и/или словом, например с расположением их в хронологическом порядке (сначала старые) или обратном хронологическом порядке (сначала новые).
Блоки также могут быть отсортированы по релевантности. Например, текстовый поток может содержать блоки «forewarned is forearmed» («информирован - значит вооружен») и «try for a high score» («попытка не пытка»). Если пользователь напечатает "f-o-r", расположение в порядке релевантности может привести к фразе "forewarned is forearmed", которая расположена первой в списке на основе напечатанных букв, являющихся частью более длинного слова, появляется более часто в блоке или ассоциирована с более важным словом (поскольку здесь предлогам, таким как «for», дана меньшая значимость).
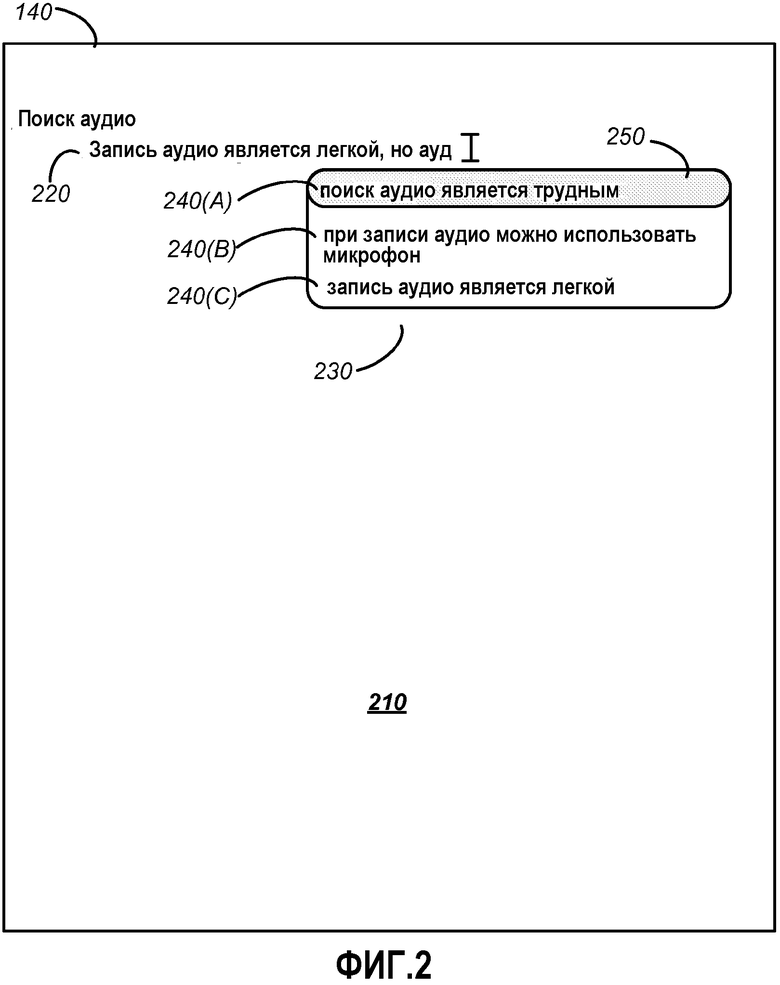
Фиг.1 является структурной схемой операционной среды 100 для обеспечения идентификации по образцу голоса. Операционная среда 100 может содержать пользовательское устройство 105, содержащее 110 микрофон, соединенный с преобразователем 120 речи в текст (STT). STT преобразователь 120 может быть соединен с буфером 130 памяти, выполненным с возможностью хранения текста, полученного посредством преобразования. Пользовательское устройство 105 может дополнительно содержать приложение 140 создания заметок, такое как приложение для работы с текстом, которое может быть связано с возможностью обмена данными с STT преобразователем 120 и/или буфером 130. Приложение 140 создания заметок может быть выполнено с возможностью создавать, открывать, редактировать и/или сохранять электронные документы в виде файлов.
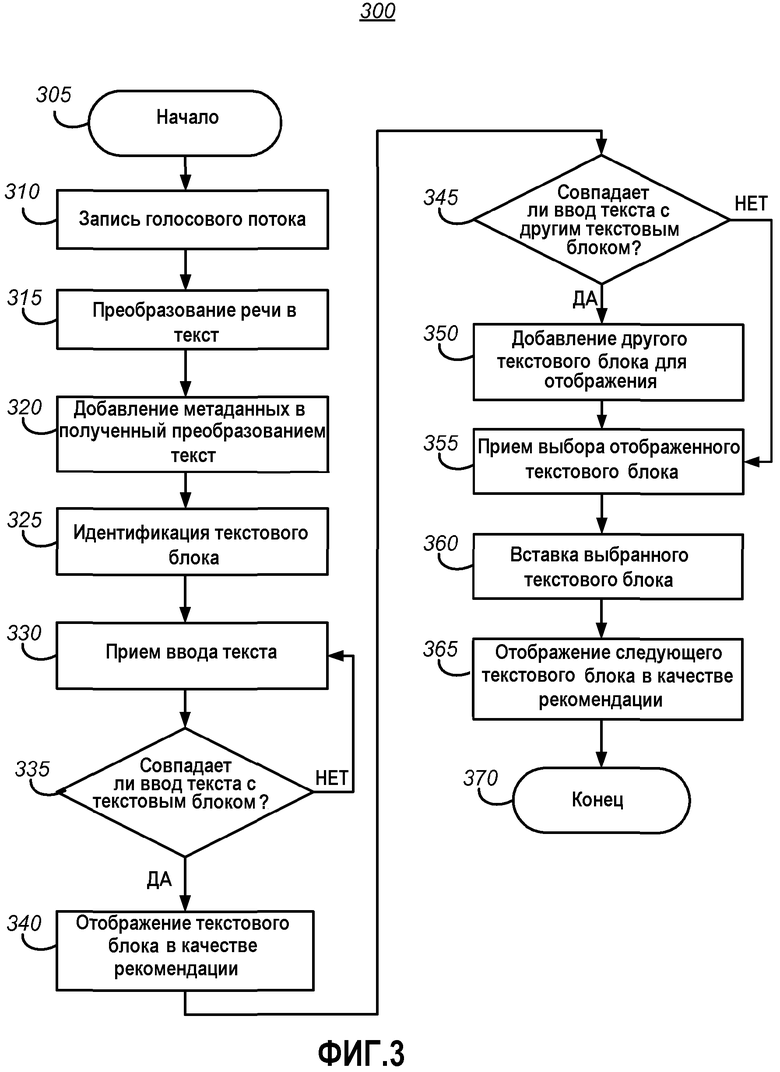
Фиг.2 более подробно иллюстрирует приложение 140 создания заметок. Приложение 140 создания заметок может содержать область 210 пользовательского интерфейса, выполненную с возможностью принимать пользовательский ввод 220 текста. В ответ на прием пользовательского ввода 220 текста, приложение 140 создания заметок может определить, какие сегменты текста, преобразованные из записанной речи и сохраненные в буфере 130, совпадают с текстом в пользовательском вводе 220 текста. В соответствии с вариантами воплощения изобретения совпадение может содержать, например, фонетическое (например, "for" совпадает с "four") и/или побуквенное совпадение. Приложение 140 создания заметок может отображать совпадающие сегменты текста, например, в элементе 230 всплывающей подсказки, содержащем множество совпадающих текстовых сегментов 240(A)-(C). Наиболее релевантное совпадение, такое как текстовый сегмент, следующий за последним введенным текстом, может содержать выбор идентификации 250 совпадающих текстовых сегментов 240(A)-(C), такой как выделение (подсвечивание). Идентификация выбора может перемещаться пользователем, например, с помощью клавиш со стрелками, и выделенный один из совпадающих текстовых сегментов 240(A)-(C) может быть выбран для вставки в область 210 пользовательского интерфейса, например, нажатием пользователем клавиш ввода и/или табуляции на клавиатуре или выбором опции с помощью мыши и/или стилуса.
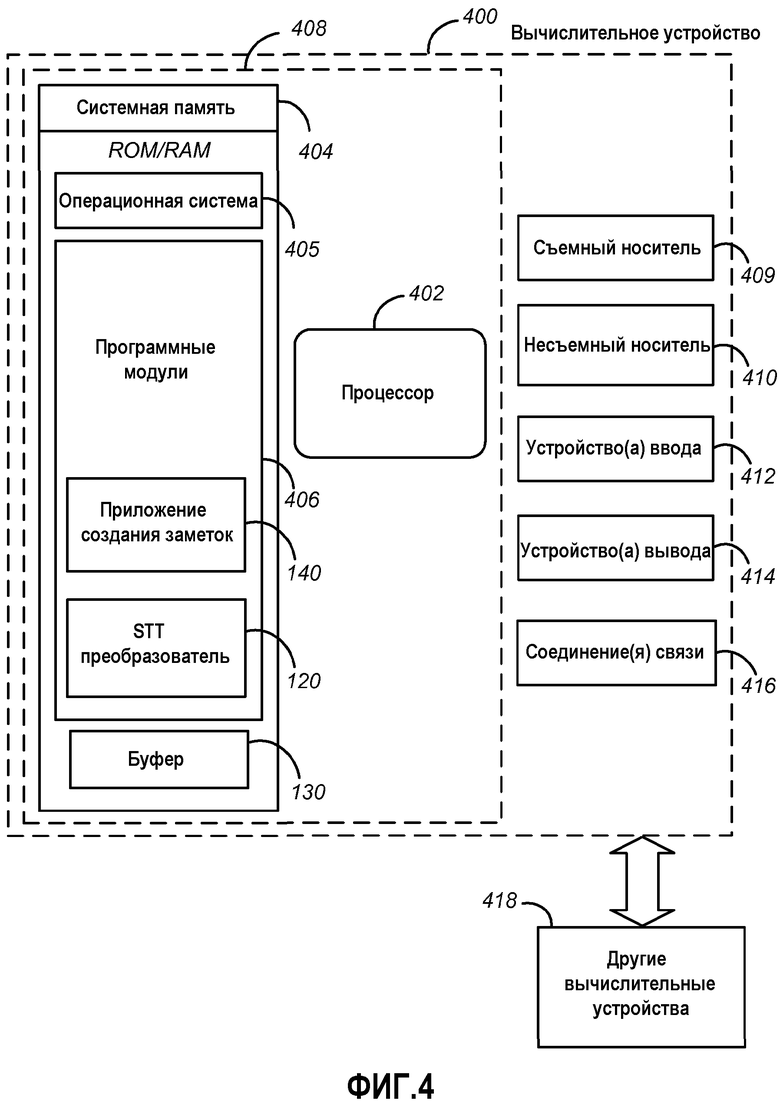
Фиг.3 является логической блок-схемой, показывающей основные этапы, включенные в способ 300 в соответствии с вариантом воплощения изобретения для обеспечения идентификации по образцу голоса. Способ 300 может быть осуществлен с использованием вычислительного устройства 400, как описано более подробно ниже со ссылкой на фиг.4. Пути осуществления этапов способа 300 будут описаны более подробно ниже. Способ 300 может начаться с начального этапа 305 и продолжаться до этапа 310, где вычислительное устройство 400 может записывать голосовой поток в буфер. Например, пользовательское устройство 105 может записать голосовой/речевой поток через микрофон 110.
На этапе 310 способ 300 может перейти к этапу 315, где вычислительное устройство 400 может преобразовывать записанный речевой поток в текстовый поток. Так, например, STT преобразователь 120 может выполнять алгоритм скрытой модели Маркова для преобразования записанного голоса в буквы и слова. В соответствии с вариантами воплощения изобретения, STT преобразователь 120 может идентифицировать и вставлять пунктуацию в соответствии с программными и/или грамматическими правилами. Например, текстовый поток может иметь точки, вставленные во время пауз, и/или может иметь запятые, вставленные перед союзами.
От этапа 315 способ 300 может перейти к этапу 320, где вычислительное устройство 400 может добавлять метаданные в текстовый поток, полученный посредством преобразования. Например, пользовательское устройство 105 может добавлять временные заметки к каждому слову, фразе и/или предложению в текстовом потоке. Метаданные могут также включать в себя данные для содействия в сопоставлении полученного посредством преобразования текста, с текстовыми вводами от пользователя, такими как общепринятые сокращения, опечатки и/или фонетические альтернативы.
От этапа 320 способ 300 может перейти к этапу 325, где вычислительное устройство 400 может идентифицировать, по меньшей мере, один текстовый блок в полученном преобразованием текстовом потоке. STT преобразователь 120 и/или приложение 140 создания заметок может идентифицировать логические разрывы между словами, например, посредством идентификации перечислений, предлогов и/или союзов в текстовом потоке и/или пауз, которые могут идентифицировать фразу и/или границы предложений. Например, текстовый поток может содержать перечисления, такие как "первая точка", "второй элемент", "следующая тема", "последняя вещь" и т.д. Эти перечисления могут быть использованы для идентификации фразы и/или границ предложений. В соответствии с вариантами воплощения изобретения такие вводные фразы и/или союзы могут классифицироваться как менее релевантные для создания заметок, чем содержательные текстовые блоки, которые они окружают. Эти менее релевантные части текстового потока могут быть разбиты на свои блоки так, чтобы исключить ненужные слова из предложений, представляемых для пользователя, как описано ниже.
От этапа 325 способ 300 может перейти к этапу 330, где вычислительное устройство 400 может принимать ввод текста. Например, пользователь пользовательского устройства 105 может вводить, по меньшей мере, один символ и/или слова в приложение 140 создания заметок.
От этапа 330 способ 300 может перейти к этапу 335, где вычислительное устройство 400 может определить, совпадает ли ввод текста с чем-либо из текстового потока, полученного посредством преобразования. Например, текстовый поток может содержать "We should set up a meeting for next Tuesday. How does two o'clock work?" («Нам следует назначить встречу на следующий вторник. Как насчет 14:00?). Поток может быть разбит на два (и/или более) блоков, таких как "set up a meeting for next Tuesday" и "how does two o'clock work". Если пользователь напечатает буквы "m-e-e-t", вычислительное устройство 400 может идентифицировать "set up a meeting for next Tuesday", как совпадающий текстовый блок. Если никакой текстовый блок не совпадает, по меньшей мере, с частью полученного преобразованием текстового потока, тогда способ 300 может вернуться к этапу 330 и далее принимать текстовые вводы.
В противном случае способ 300 может перейти к этапу 340, где вычислительное устройство 400 может отображать совпавший текстовый блок в качестве рекомендации. Например, приложение 140 создания заметок может отображать совпавший текстовый блок в элементе 230 всплывающей подсказки. Отображение может быть приближено к текущей точке ввода текста в электронном документе, отображаемом в приложении 140 создания заметок.
От этапа 340 способ 300 может перейти к этапу 345, где вычислительное устройство 400 может определить, совпадает ли ввод текста, по меньшей мере частично, с по меньшей мере одним вторым идентифицированным текстовым блоком. Например, приложение 140 создания заметок может сканировать буфер 130 на предмет каких-либо текстовых блоков, которые совпадают с вводом текста.
Если дополнительные текстовые блоки совпадают, способ 300 может перейти к этапу 350, где вычислительное устройство 400 может отображать по меньшей мере один второй текстовый блок в качестве второго рекомендуемого текстового блока для пользователя системы. Например, приложение 140 создания заметок может отображать множество текстовых блоков 240(A)-(C) в порядке, ассоциированном со взвешенной вероятностью, связанной с возможной релевантностью текстового блока совпадающему вводу текста. Совпадающим текстовым блокам могут быть присвоены взвешенные вероятности релевантности, например, по временной близости к вводу текста, по контенту и/или по контексту. Некоторые примеры назначения весов релевантности могут содержать ситуацию, когда совпадающему слову, сказанному десять секунд назад, назначается вес как более релевантному, чем тому же слову, произнесенному 30 секунд назад, и/или ситуацию, когда совпадающему слову в предложной группе назначается вес как менее релевантному, чем тому же слову за пределами такой группы.
От этапа 350 или если нет дополнительных совпадающих текстовых блоков, идентифицированных на этапе 345, способ 300 может перейти к этапу 355, где вычислительное устройство 400 может принимать выбор одного из отображаемых текстовых блоков. Например, один из текстовых блоков 240(A)-(C) может быть нажат пользователем с помощью мыши и/или стилуса.
От этапа 355 способ 300 может перейти к этапу 360, где вычислительное устройство 400 может вставлять выбранный текстовый блок в электронный документ в приложении 140 создания заметок. Например, если пользователь ввел буквы "m-e-e-t" и выбрал текстовый блок "Meeting with Sandy on Tuesday" («Встреча с Сэнди во вторник»), слова "Meeting with Sandy on Tuesday" могут быть вставлены на место введенных букв "m-e-e-t". В соответствии с вариантами воплощения изобретения, метаданные, назначенные для каждого текстового блока, могут быть использованы для предоставления дополнительной информации, такой как ассоциирование "Sandy" с контактом в адресной книге пользователя и/или добавление даты следующего вторника в соответствии с пользовательским календарем.
От этапа 360 способ 300 может перейти к этапу 365, где вычислительное устройство 400 может отображать последовательно последний текстовый блок за выбранным текстовым блоком. Например, после вставки выбранного текстового блока приложение 140 создания заметок может использовать метаданные в виде временных отметок, ассоциированные со вставленным текстовым блоком, чтобы идентифицировать следующий текстовый блок в последовательном порядке, и может отображать такой текстовый блок как рекомендацию для пользователя. Например, после вставки «Meeting with Sandy on Tuesday" приложение 140 создания заметок может отображать последующую фразу "about marketing efforts" («об усилиях по маркетингу») в качестве выбираемой рекомендации для вставки в электронный документ. Эта рекомендация может быть выбрана для вставки пользователем, как описано со ссылкой на этап 355. Способ 300 может завершиться на этапе 370.
Вариант воплощения в соответствии с изобретением может содержать систему для обеспечения создания заметок с использованием голосового потока. Система может содержать запоминающее устройство и процессор, соединенный с запоминающим устройством. Процессор может быть выполнен с возможностью записывать аудиопоток, ассоциированный с говорящим, преобразовывать аудиопоток в текстовые блоки, принимать ввод текста от пользователя, определять, является ли ввод текста ассоциированным с одним из текстовых блоков, если да, то отображать по меньшей мере один текстовый блок для пользователя в качестве рекомендации в выбираемом элементе интерфейса. Преобразование аудиопотока в текстовые блоки может содержать выполнение преобразования речи в текст в аудиопотоке и идентификацию по меньшей мере одной границы текстового блока. Граница текстового блока может содержать, например, границу фразы, границу предложения и границу по времени, и каждый блок может быть ассоциирован с временной отметкой, приспособленной для поддержания порядка следования текстовых блоков. Процессор может быть дополнительно выполнен с возможностью принимать выбор отображаемого текстового блока от пользователя и вставлять отображаемый по меньшей мере один текстовый блок в электронный документ. Процессор может быть дополнительно выполнен с возможностью отображать дополнительные текстовые блоки, такие как текстовые блоки, следующие за текстовым блоком, выбранным пользователем. В соответствии с вариантами воплощения изобретения процессор может быть выполнен с возможностью идентифицировать множество текстовых блоков, которые совпадают с вводом текста, и отображать по меньшей мере некоторые из этих блоков. Отображаемые блоки могут быть упорядочены, например, в соответствии с релевантностью вводу текста пользователем или хронологически в соответствии с временной отметкой, ассоциированной с текстом, полученным посредством преобразования. Другой вариант воплощения в соответствии с изобретением может содержать систему для обеспечения создания заметок с использованием голосового потока. Система может содержать запоминающее устройство и процессор, соединенный с запоминающим устройством. Процессор может быть выполнен с возможностью записывать голосовой поток в буфер, преобразовывать голосовой поток в текстовый поток, идентифицировать по меньшей мере один текстовый блок, ассоциированный с текстовым потоком, принимать ввод текста в электронный документ от пользователя и определять, является ли ввод текста по меньшей мере частично совпадающим с этим по меньшей мере одним текстовым блоком. Если ввод текста совпадает с текстовым блоком, процессор может быть выполнен с возможностью отображать этот по меньшей мере один текстовый блок для пользователя в качестве выбираемого элемента, принимать выбор отображаемого по меньшей мере одного текстового блока от пользователя и вставлять по меньшей мере один текстовый блок в электронный документ. Процессор может быть дополнительно выполнен с возможностью идентифицировать множество текстовых блоков, ассоциированных с текстовым потоком, например, по паузе в записанном голосовом потоке, границе предложения, связующему слову в текстовом потоке и/или границе фразы. Процессор может быть дополнительно выполнен с возможностью отображать каждый из множества текстовых блоков, которые по меньшей мере частично совпадают с вводом текста, пользователю в виде списка выбираемых элементов, принимать второй ввод текста от пользователя и удалять любые из отображаемого множества текстовых блоков, которые даже по меньшей мере частично не совпадают со вторым вводом текста, из списка выбираемых элементов. Процессор может быть дополнительно выполнен с возможностью сохранять конфигурируемый период времени записанного голосового потока. Например, предыдущие пять, десять или пятнадцать минут преобразованной записи могут быть сохранены. Процессор может быть также выполнен с возможностью определять, когда конкретный голосовой поток является законченным, например, посредством идентификации затянутой паузы или обнаружения того, что пользователь отключил соответствующее устройство записи, и сохранять соответствующие текстовые блоки, полученные посредством преобразования, в электронном документе.
Еще один вариант воплощения в соответствии с изобретением может содержать систему для обеспечения создания заметок с использованием голосового потока. Система может содержать запоминающее устройство и процессор, соединенный с запоминающим устройством. Процессор может быть выполнен с возможностью записывать речевой поток в буфер, причем буфер содержит объем памяти в запоминающем устройстве, достаточный для хранения конфигурируемого периода времени записанного речевого потока, преобразовывать записанный речевой поток, сохраненный в буфере, в соответствующий текстовый поток, содержащий множество слов, ассоциировать метаданные, содержащие временную отметку, с каждым из этого множества слов, идентифицировать по меньшей мере один текстовый блок в соответствующем текстовом потоке, принимать ввод текста в электронный документ от пользователя системы, определять, является ли ввод текста по меньшей мере частично совпадающим с этим по меньшей мере одним текстовым блоком, при этом данный по меньшей мере один текстовый блок содержит самый последний (наиболее недавно) идентифицированный текстовый блок в соответствующем текстовом потоке, в ответ на определение того, что ввод текста по меньшей мере частично совпадает с упомянутым по меньшей мере одним текстовым блоком, и отображать упомянутый по меньшей мере один текстовый блок в качестве рекомендуемого текстового блока для пользователя системы. Процессор может быть дополнительно выполнен с возможностью определять, является ли ввод текста по меньшей мере частично совпадающим с по меньшей мере одним вторым идентифицированным текстовым блоком, отображать по меньшей мере один второй текстовый блок в качестве второго рекомендуемого текстового блока для пользователя системы, принимать выбор по меньшей мере одного из упомянутого по меньшей мере одного текстового блока и этого по меньшей мере одного второго текстового блока от пользователя системы, вставлять выбранный по меньшей мере один из упомянутого по меньшей мере одного текстового блока и по меньшей мере одного второго текстового блока в электронный документ и отображать по меньшей мере один третий текстовый блок в качестве третьего рекомендуемого текстового блока, причем этот по меньшей мере третий текстовый блок представляет собой последовательно более поздний текстовый блок по отношению к выбранному по меньшей мере одному из упомянутого по меньшей мере одного текстового блока и по меньшей мере одного второго текстового блока.
Фиг.4 является структурной схемой системы, включающей в себя вычислительное устройство. В соответствии с вариантом воплощения изобретения вышеупомянутое запоминающее устройство и процессор могут быть реализованы в вычислительном устройстве, таком как вычислительное устройство 400 на фиг.4. Любая подходящая комбинация аппаратных средств программного обеспечения или программно-аппаратных средств (firmware) может быть использована для реализации запоминающего устройства и процессора. Например, запоминающее устройство и процессор могут быть реализованы с вычислительным устройством 400 или любым из других вычислительных устройств 418 в сочетании с вычислительным устройством 400. Вышеупомянутые система, устройство и процессоры являются примерами, и другие системы, устройства и процессоры могут содержать вышеупомянутые запоминающее устройство и процессор в соответствии с вариантами воплощения изобретения. Кроме того, вычислительное устройство 400 может содержать операционную среду для системы, как описано выше. Система может работать в других условиях и не ограничивается вычислительным устройством 400.
Ссылаясь на фиг.4, система в соответствии с вариантом воплощения изобретения может включать в себя вычислительное устройство, такое как вычислительное устройство 400. В базовой конфигурации вычислительное устройство 400 может включать в себя, по меньшей мере, один процессор 402 и системную память 404. В зависимости от конфигурации и типа вычислительного устройства системная память 404 может содержать, но не ограничиваться этим, энергозависимую (например, оперативное запоминающее устройство (RAM)), энергонезависимую (например, постоянное запоминающее устройство (ROM)), флэш-память или любую их комбинацию. Системная память 404 может содержать операционную систему 405, буфер 130 и один или более программных модулей 406, содержащих приложение 140 создания заметок и/или STT преобразователь 120. Операционная система 405, например, может быть пригодна для управления работой вычислительного устройства 400. В одном из вариантов программные модули 406 могут включать в себя генератор 407 образца голоса, который может быть выполнен с возможностью анализировать записанные голоса и создавать сигнатуру образца голоса. Кроме того, варианты воплощения изобретения могут быть осуществлены в сочетании с графической библиотекой, другими операционными системами или любой другой прикладной программой и не ограничиваются каким-либо конкретным приложением или системой. Такая базовая конфигурация иллюстрирована на фиг.4 посредством компонентов в пределах пунктирной линии 408.
Вычислительное устройство 400 может иметь дополнительные свойства или функции. Например, вычислительное устройство 400 может также включать в себя дополнительные устройства хранения данных (съемные и/или несъемные), такие как, например, магнитные диски, оптические диски или лента. Такой дополнительный носитель проиллюстрирован на фиг.4 с помощью съемного носителя 409 и несъемного носителя 410. Вычислительное устройство 400 может также содержать соединение 416 связи, которое может обеспечить возможность устройству 400 осуществлять связь с другими вычислительными устройствами 418, например, по сети в распределенной вычислительной среде, например, по локальной сети или через Интернет. Соединение 416 связи является одним из примеров сред связи.
Термин «машиночитаемый носитель», используемый здесь, может включать в себя компьютерные носители данных. Компьютерные носители данных могут включать в себя энергозависимые и энергонезависимые, съемные и несъемные носители, реализованные любым способом или технологией для хранения информации, такой как машиночитаемые команды, структуры данных, программные модули или другие данные. Системная память 404, съемный носитель 409 и несъемный носитель 410 - все являются примерами компьютерных носителей данных (т.е. запоминающих устройств). Компьютерные носители данных могут включать в себя, но не в ограничительном смысле, RAM, ROM, электрически стираемое программируемое постоянное запоминающее устройство (EEPROM), флэш-память или другую технологию памяти, CD-ROM, цифровые универсальные диски (DVD) или другие оптические запоминающие устройства, магнитные кассеты, магнитные ленты, магнитные диски или другие магнитные запоминающие устройства либо любой другой носитель, который может быть использован для хранения информации и к которому может быть осуществлен доступ вычислительным устройством 400. Любые такие компьютерные носители данных могут быть частью устройства 400. Вычислительное устройство 400 может также иметь устройство(а) 412 ввода, такие как клавиатура, мышь, перо, устройство ввода звука, устройство тактильного ввода и т.д. Устройство(а) 414 вывода, такие как дисплей, динамики, принтер и т.д., также могут быть включены в состав. Указанные устройства являются примерами, и могут быть использованы другие.
Термин «машиночитаемый носитель», используемый здесь, может также включать в себя среды связи. Среды связи могут быть воплощены посредством машиночитаемых команд, структур данных, программных модулей или других данных в модулированном сигнале данных, таком как несущая волна или другой механизм передачи, и включают в себя любые среды доставки информации. Термин «модулированный сигнал данных» может описывать сигнал, который имеет одну или несколько характеристик, устанавливаемых или изменяемых таким образом, чтобы кодировать информацию в сигнал. В качестве примера, но не ограничения, среды связи могут включать в себя проводные среды, такие как проводная сеть или прямое проводное соединение, и беспроводные среды, такие как акустическая, радиочастотная (RF), инфракрасная и другие беспроводные среды.
Как отмечалось выше, некоторое количество программных модулей и файлов данных может быть сохранено в системной памяти 404, включая операционную систему 405. При исполнении в процессоре 402 программные модули 406 (например, приложение 140 создания заметок и/или STT преобразователь 120) могут выполнять процессы, включающие в себя, например, один или более этапов способа 300, как описано выше. Вышеупомянутый процесс является примером, и процессорный блок 402 может выполнять другие процессы. Другие программные модули, которые могут быть использованы в соответствии с вариантами воплощения настоящего изобретения, могут включать в себя электронную почту и приложения контактов, приложения обработки текстов, приложения электронных таблиц, приложения баз данных, приложения слайд-презентации, чертежи или автоматизированные прикладные программы и т.д.
В основном в соответствии с вариантами воплощения изобретения программные модули могут включать в себя процедуры, программы, компоненты, структуры данных и другие типы структур, которые могут выполнять определенные задачи или которые могут реализовывать определенные абстрактные типы данных.
Более того, варианты воплощения изобретения могут быть осуществлены с другими конфигурациями компьютерных систем, включая наладонные устройства, многопроцессорные системы, микропроцессорную или программируемую бытовую электронику, миникомпьютеры, универсальные компьютеры и тому подобное. Варианты воплощения изобретения также могут быть осуществлены в распределенных вычислительных средах, где задачи выполняются удаленными устройствами обработки данных, которые связаны через сеть связи. В распределенной вычислительной среде программные модули могут быть расположены как на локальных, так и на удаленных устройствах хранения данных.
Дополнительно, варианты воплощения изобретения могут быть осуществлены в электрической схеме, содержащей дискретные электронные элементы, упакованные или интегрированные электронные микросхемы, содержащие логические элементы, схеме с использованием микропроцессора или на одной микросхеме, содержащей электронные элементы или микропроцессоры. Варианты воплощения изобретения также могут быть осуществлены с использованием других технологий, способных выполнять логические операции, такие как, например, И, ИЛИ, НЕ, включая, но не в ограничительном смысле, механические, оптические, жидкостные и квантовые технологии. Кроме того, варианты воплощения изобретения могут быть осуществлены в пределах компьютера общего назначения или в любых других схемах или системах.
Варианты воплощения изобретения, например, могут быть осуществлены в виде компьютерного процесса (способа), вычислительной системы или как промышленное изделие, такое как компьютерный программный продукт или машиночитаемый носитель. Компьютерный программный продукт может быть компьютерным носителем данных, который считывается компьютерной системой и на котором кодирована компьютерная программа, состоящая из инструкций для выполнения компьютерного процесса. Компьютерный программный продукт может также быть распространяемым сигналом на несущей, который считывается вычислительной системой и в котором закодирована компьютерная программа, состоящая из инструкций для выполнения компьютерного процесса. Соответственно, настоящее изобретение может быть воплощено в аппаратных и/или программных средствах (включая программно-аппаратные средства, резидентные программные средства, микро-код и т.д.). Иными словами, варианты воплощения настоящего изобретения могут принимать форму компьютерного программного продукта в машиноиспользуемом или машиночитаемом носителе данных, на котором имеется машиноиспользуемый или машиночитаемый код программы, воплощенный в этом носителе для использования посредством или в сочетании с системой выполнения команд. Машиноиспользуемый или машиночитаемый носитель может быть любым носителем, который может содержать, хранить, передавать, распространять или перемещать программу для использования посредством или в сочетании с системой, аппаратурой или устройством выполнения команд.
Машиноиспользуемый или машиночитаемый носитель может быть, например, но не в ограничительном смысле, электронной, магнитной, оптической, электромагнитной, инфракрасной или полупроводниковой системой, аппаратурой, устройством или средой распространения. Согласно более конкретным примерам машиночитаемого носителя (неполный список) машиночитаемый носитель может включать в себя следующее: электрическое соединение, имеющее один или более проводов, портативную компьютерную дискету, оперативное запоминающее устройство (RAM), постоянное запоминающее устройство (ROM), стираемую программируемую постоянную память (EPROM или флэш-память), оптическое волокно и портативное постоянное запоминающее устройство на компакт-диске (CD-ROM). Отметим, что машиноиспользуемый или машиночитаемый носитель может быть даже бумагой или другой подходящей средой, на которой напечатана программа, при этом программа может быть захвачена в электронном виде с помощью, например, оптического сканирования бумаги или другой среды, затем скомпилирована, интерпретирована или иным образом обработана соответствующим образом, если это необходимо, и затем сохранена в компьютерной памяти.
Варианты воплощения настоящего изобретения, например, описаны выше со ссылками на блок-схемы и/или оперативные иллюстрации способов, систем и компьютерных программных продуктов в соответствии с вариантами воплощения изобретения.
Функции/действия, отмеченные в блоках, могут происходить не в том порядке, что показан в блок-схеме. Например, два блока, показанные последовательно, на самом деле, могут выполняться по существу одновременно или блоки могут иногда выполняться в обратном порядке, в зависимости от задействуемых функций действий.
В то время как были описаны некоторые варианты воплощения изобретения, могут существовать другие варианты. Кроме того, хотя варианты воплощения настоящего изобретения были описаны как связанные с данными, хранящимися в памяти и других носителях информации, данные могут быть сохранены на или считаны с других видов машиночитаемых носителей, таких как вторичные устройства хранения данных, такие как жесткие диски, дискеты или CD-ROM, несущая волна из Интернета, либо другие формы RAM или ROM. Дополнительно, раскрытые этапы способа могут быть изменены в любой форме, в том числе путем изменения порядка этапов и/или вставки или удаления этапов, не отклоняясь от изобретения.
Все права, включая авторские права на код, включенный в настоящий документ, принадлежат и находятся в собственности заявителя. Заявитель сохраняет и оставляет за собой все права на код, включенный в настоящий документ, и дает разрешение на воспроизведение материала только в связи с воспроизведением выданного патента и ни для каких других целей.
Хотя описание включает в себя примеры, объем изобретения определяется нижеследующей формулой изобретения. Кроме того, в то время как описание приведено на языке, характерном для структурных признаков и/или методологических действий, формула изобретения не ограничивается признаками или действиями, описанными выше. Скорее, конкретные признаки и действия, описанные выше, раскрываются как пример для вариантов воплощения изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И УСТРОЙСТВО УПРАВЛЕНИЯ РАСПИСАНИЯМИ В ПОРТАТИВНОМ ТЕРМИНАЛЕ | 2012 |
|
RU2630233C2 |
| СИСТЕМЫ И СПОСОБЫ ДЛЯ ОБРАБОТКИ ВХОДНЫХ ПОТОКОВ КАЛЕНДАРНЫХ ПРИЛОЖЕНИЙ | 2013 |
|
RU2636691C2 |
| АССОЦИИРОВАНИЕ ИНФОРМАЦИИ С ЭЛЕКТРОННЫМ ДОКУМЕНТОМ | 2006 |
|
RU2406129C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ УПРАВЛЕНИЯ ПРИЛОЖЕНИЕМ ПОСРЕДСТВОМ РАСПОЗНАВАНИЯ НАРИСОВАННОГО ОТ РУКИ ИЗОБРАЖЕНИЯ | 2013 |
|
RU2650029C2 |
| ВЫВЕДЕНИЕ НАМЕРЕНИЯ ПОЛЬЗОВАТЕЛЯ НА ОСНОВЕ ПРЕДЫДУЩИХ ВЗАИМОДЕЙСТВИЙ С ГОЛОСОВЫМ ПОМОЩНИКОМ | 2011 |
|
RU2544787C2 |
| ОПРЕДЕЛЕНИЕ НАМЕРЕНИЯ ПОЛЬЗОВАТЕЛЯ НА ОСНОВЕ ОНТОЛОГИЙ ПРЕДМЕТНЫХ ОБЛАСТЕЙ | 2011 |
|
RU2541221C2 |
| ПЕРСОНАЛИЗИРОВАННЫЙ СЛОВАРЬ ДЛЯ ЦИФРОВОГО ПОМОЩНИКА | 2011 |
|
RU2541219C2 |
| ПОДДЕРЖАНИЕ КОНТЕКСТНОЙ ИНФОРМАЦИИ МЕЖДУ ПОЛЬЗОВАТЕЛЬСКИМИ ВЗАИМОДЕЙСТВИЯМИ С ГОЛОСОВЫМ ПОМОЩНИКОМ | 2018 |
|
RU2785950C2 |
| ПОДДЕРЖАНИЕ КОНТЕКСТНОЙ ИНФОРМАЦИИ МЕЖДУ ПОЛЬЗОВАТЕЛЬСКИМИ ВЗАИМОДЕЙСТВИЯМИ С ГОЛОСОВЫМ ПОМОЩНИКОМ | 2015 |
|
RU2653250C2 |
| ОРКЕСТРОВКА СЛУЖБ ДЛЯ ИНТЕЛЛЕКТУАЛЬНОГО АВТОМАТИЗИРОВАННОГО ПОМОЩНИКА | 2011 |
|
RU2556416C2 |
Изобретение относится к аудиозаписи и предназначено для сбора информации из аудиозаписи. Технический результат - обеспечено создание заметок с использованием голосового потока. Для этого аудиопоток, ассоциированный с по меньшей мере одним говорящим, может записываться и преобразовываться в текстовые блоки. Ввод текста может приниматься от пользователя, например, в электронном документе. Ввод текста может сравниваться с текстовыми блоками для идентификации совпадений, и совпадающие текстовые блоки могут отображаться пользователю для выбора. 3 н. и 7 з.п. ф-лы, 4 ил.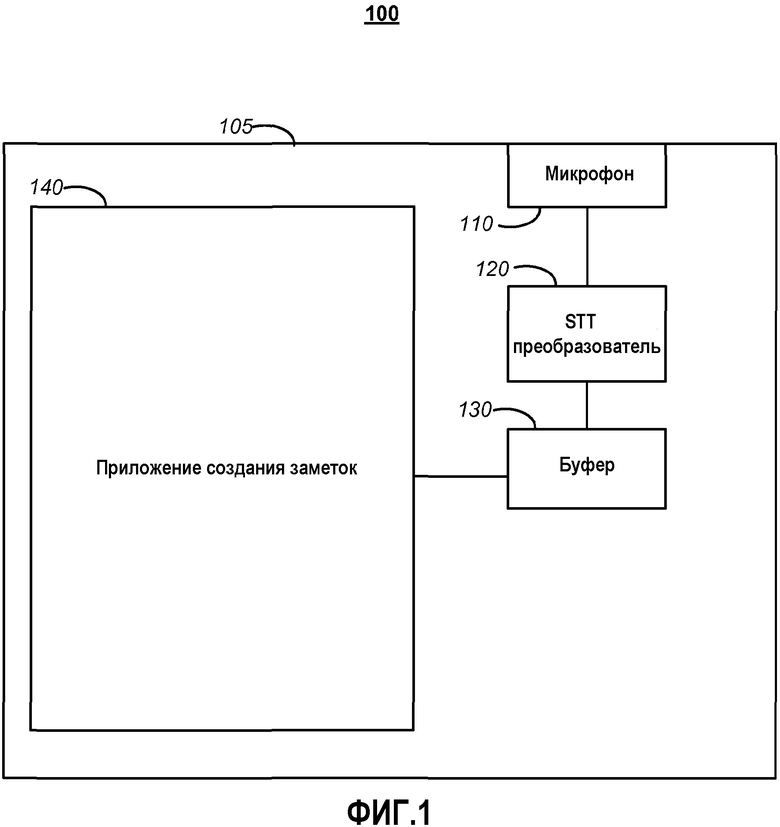
1. Способ обеспечения создания заметок с использованием голосового потока, содержащий этапы, на которых:
записывают аудиопоток, ассоциированный с по меньшей мере одним говорящим;
преобразуют аудиопоток в по меньшей мере один текстовый блок;
принимают по меньшей мере один ввод текста от пользователя;
определяют, ассоциирован ли этот по меньшей мере один ввод текста от пользователя с упомянутым по меньшей мере одним текстовым блоком, и
в ответ на определение того, что по меньшей мере один ввод текста от пользователя ассоциирован с по меньшей мере одним текстовым блоком, отображают упомянутый по меньшей мере один текстовый блок для пользователя в качестве рекомендуемого.
2. Способ по п.1, в котором при преобразовании аудиопотока в по меньшей мере один текстовый блок:
выполняют преобразование речи в текст в отношении аудиопотока и
идентифицируют по меньшей мере одну границу текстового блока согласно по меньшей мере одному из следующего: граница фразы, граница предложения и граница по времени.
3. Способ по п.1, дополнительно содержащий этапы, на которых:
принимают выбор отображенного по меньшей мере одного текстового блока от пользователя; и
вставляют отображенный по меньшей мере один текстовый блок в электронный документ.
4. Способ по п.1, дополнительно содержащий этапы, на которых:
идентифицируют множество текстовых блоков, полученных посредством преобразования, которые по меньшей мере частично совпадают с упомянутым по меньшей мере одним вводом текста, и
отображают упомянутое множество текстовых блоков, полученных посредством преобразования, для пользователя в качестве выбираемого списка.
5. Способ по п.4, в котором каждый из множества текстовых блоков, полученных посредством преобразования, отображается в выбираемом списке в хронологическом порядке.
6. Способ по п.5, в котором каждый из множества текстовых блоков, полученных посредством преобразования, отображается в выбираемом списке в обратном хронологическом порядке.
7. Машиночитаемый носитель, который хранит набор инструкций, которыми при их исполнении выполняется способ обеспечения создания заметок с использованием голосового потока, причем способ, осуществляемый посредством данного набора инструкций, содержит этапы, на которых:
записывают голосовой поток в буфер;
преобразуют голосовой поток в текстовый поток;
идентифицируют по меньшей мере один текстовый блок, ассоциированный с текстовым потоком;
принимают ввод текста в электронный документ от пользователя;
определяют, является ли ввод текста по меньшей мере частично совпадающим с этим по меньшей мере одним текстовым блоком;
в ответ на определение того, что ввод текста по меньшей мере частично совпадает с по меньшей мере одним текстовым блоком, отображают данный по меньшей мере один текстовый блок для пользователя в качестве выбираемого элемента;
принимают выбор отображенного по меньшей мере одного текстового блока от пользователя; и
вставляют упомянутый по меньшей мере один текстовый блок в электронный документ.
8. Машиночитаемый носитель по п.7, в котором способ дополнительно содержит этап, на котором:
идентифицируют множество текстовых блоков, ассоциированных с текстовым потоком, причем каждый из множества текстовых блоков идентифицируется согласно по меньшей мере одной границе, причем эта по меньшей мере одна граница содержит по меньшей мере одно из следующего: пауза в записанном голосовом потоке, граница предложения, связующее слово в текстовом потоке и граница фразы.
9. Машиночитаемый носитель по п.8, в котором способ дополнительно содержит этапы, на которых:
отображают каждый из множества текстовых блоков, которые по меньшей мере частично совпадают с вводом текста, для пользователя в виде списка выбираемых элементов;
принимают второй ввод текста от пользователя; и
удаляют из списка выбираемых элементов любые из отображаемого множества текстовых блоков, которые даже по меньшей мере частично не совпадают со вторым вводом текста.
10. Система для обеспечения создания заметок с использованием голосового потока, содержащая:
запоминающее устройство; и
процессор, соединенный с запоминающим устройством, причем процессор выполнен с возможностью:
записывать речевой поток в буфер, причем буфер содержит объем памяти в запоминающем устройстве, достаточный для хранения конфигурируемого периода времени записанного речевого потока,
преобразовывать записанный речевой поток, сохраненный в буфере, в соответствующий текстовый поток, содержащий множество слов,
ассоциировать метаданные, содержащие временную отметку, с каждым из этого множества слов,
идентифицировать по меньшей мере один текстовый блок в соответствующем текстовом потоке, причем этот по меньшей мере один текстовый блок содержит по меньшей мере одно из следующего: пауза, граница предложения, связующее слово и граница фразы,
принимать ввод текста в электронный документ от пользователя системы,
определять, является ли ввод текста по меньшей мере частично совпадающим с упомянутым по меньшей мере одним текстовым блоком, причем этот по меньшей мере один текстовый блок представляет собой наиболее недавно идентифицированный текстовый блок в соответствующем текстовом потоке,
в ответ на определение того, что ввод текста по меньшей мере частично совпадает с упомянутым по меньшей мере одним текстовым блоком, отображать этот по меньшей мере один текстовый блок в качестве рекомендуемого текстового блока для пользователя системы,
определять, является ли ввод текста по меньшей мере частично совпадающим с по меньшей мере одним вторым идентифицированным текстовым блоком,
в ответ на определение того, что ввод текста по меньшей мере частично совпадает с по меньшей мере одним вторым идентифицированным текстовым блоком, отображать по меньшей мере один второй текстовый блок в качестве второго рекомендуемого текстового блока для пользователя системы,
принимать выбор по меньшей мере одного из упомянутого по меньшей мере одного текстового блока и по меньшей мере одного второго текстового блока от пользователя системы,
вставлять выбранный по меньшей мере один из упомянутого по меньшей мере одного текстового блока и по меньшей мере одного второго текстового блока в электронный документ и
отображать по меньшей мере один третий текстовый блок в качестве третьего рекомендуемого текстового блока, причем по меньшей мере один третий текстовый блок представляет собой последовательно более поздний текстовый блок по отношению к выбранному по меньшей мере одному из упомянутого по меньшей мере одного текстового блока и по меньшей мере одного второго текстового блока.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| СТЕРЕОФОНИЧЕСКИ СОВМЕСТИМОЕ КОДИРОВАНИЕ МНОГОКАНАЛЬНОГО ЗВУКА | 2005 |
|
RU2381570C2 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Печь-кухня, могущая работать, как самостоятельно, так и в комбинации с разного рода нагревательными приборами | 1921 |
|
SU10A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |

