[0001] Настоящая заявка испрашивает приоритет предварительной заявки США 61/557325, поданной 8 ноября 2011 г., и предварительной заявки США 61/561911, поданной 20 ноября 2011 г., обе из которых включены в настоящий документ в качестве ссылки во всей их полноте.
Область техники
[0002] Настоящее изобретение относится к кодированию видео и, в частности, контекстно-адаптивному бинарному арифметическому кодированию (CABAC), используемому в кодировании видео.
Предшествующий уровень техники
[0003] Возможности цифрового видео могут быть включены в широкий диапазон устройств, включая цифровые телевизоры, системы цифрового прямого вещания, беспроводные системы вещания, персональные цифровые помощники (PDA), портативные или настольные компьютеры, планшетные компьютеры, электронные книги, цифровые камеры, цифровые записывающие устройства, цифровые медиаплееры, игровые видеоустройства, игровые приставки, сотовые или спутниковые радиотелефоны, так называемые «смартфоны», устройства видеотелеконференций, устройства потокового видео и тому подобное. Цифровые видеоустройства реализуют технологии сжатия видео, такие как те, что описаны в стандартах, определенных MPEG-2, MPEG-4, ITU-T H.263, ITU-Т H.264/MPEG-4, часть 10, Расширенное кодирование видео (AVC), стандарт Высокоэффективного кодирования видео (HEVC), находящийся в настоящее время в стадии разработки, и расширения таких стандартов. Видеоустройства могут передавать, принимать, кодировать, декодировать и/или хранить цифровую видеоинформацию более эффективно путем реализации таких методов сжатия видео.
[0004] Методы сжатия видео выполняют пространственное (внутри изображения, интра-) предсказание и/или временное (между изображениями, интер-) предсказание для сокращения или устранения избыточности, присущей видеопоследовательностям. Для блочного кодирования видео видеослайс (то есть видеоизображение или часть видеоизображения) может быть разделен на блоки видео, которые также могут упоминаться как блоки дерева, единицы кодирования (CU) и/или узлы кодирования. Блоки видео в интра-кодированном (I) слайсе (сегменте) изображения кодируются с использованием пространственного предсказания относительно опорных выборок в соседних блоках в том же изображении. Блоки видео в интер-кодированном (Р или В) сегменте изображения могут использовать пространственное предсказание относительно опорных выборок в соседних блоках в том же изображении или временное предсказание относительно опорных выборок в других опорных изображениях. Изображения могут упоминаться как кадры, и опорные изображения могут упоминаться как опорные кадры.
[0005] Пространственное или временное предсказание приводит в результате к блоку предсказания для блока, подлежащего кодированию. Остаточные данные представляет пиксельные разницы между исходным блоком, подлежащим кодированию, и блоком предсказания. Интер-кодируемый блок кодируется в соответствии с вектором движения, который указывает на блок опорных выборок, образующих блок предсказания, и остаточными данными, указывающими разницу между кодированным блоком и блоком предсказания. Интра-кодируемый блок кодируется в соответствии с режимом интра-кодирования и остаточными данными. Для дальнейшего сжатия остаточные данные могут быть преобразованы из пиксельной области в область преобразования, приводя в результате к остаточным коэффициентам преобразования, которые затем могут быть квантованы. Квантованные коэффициенты преобразования, первоначально упорядоченные в двумерный массив, могут сканироваться, чтобы сформировать одномерный вектор коэффициентов преобразования, и энтропийное кодирование может быть применено для достижения еще большего сжатия.
Сущность изобретения
[0006] В общем, это раскрытие описывает методы для контекстно-адаптивного бинарного арифметического кодирования (CABAC) в процессе видеокодирования. В частности, это раскрытие предлагает сокращение числа контекстов CABAC, используемых для одного или нескольких синтаксических элементов, неограничительные примеры которых включают pred_typ, merge_idx, inert_pred_flag, ref_idx_lx, cbf_cb, cbf_cr, coeff_abs_level_greater1_flag и coeff_abs_level_greater2_flag. Модификации могут сократить до 56 контекстов с пренебрежимо малыми изменениями эффективности кодирования. Предлагаемые сокращения контекста для синтаксических элементов могут быть использованы отдельно или в любой комбинации.
[0007] В одном примере осуществления раскрытия способ кодирования видео может включать в себя определение первого типа предсказания для блока видеоданных в Р слайсе (сегменте), представление первого типа предсказания как синтаксический элемент типа предсказания P сегмента, определение второго типа предсказания для блока видеоданных в B сегменте, представление второго типа предсказания как синтаксический элемент типа предсказания B сегмента, определение бинаризации Р сегмента для синтаксического элемента типа предсказания P сегмента, определение бинаризации В сегмента для синтаксического элемента типа предсказания В сегмента, при этом синтаксический элемент типа предсказания P сегмента и синтаксический элемент типа предсказания В сегмента определяются с использованием той же самой логики бинаризации, и кодирование видеоданных на основе бинаризации синтаксического элемента типа предсказания Р сегмента и синтаксического элемента типа предсказания В сегмента.
[0008] В другом примере настоящего раскрытия способ декодирования видео может включать в себя отображение бинаризованного синтаксического элемента типа предсказания P сегмента на тип предсказания, используя отображение бинаризации для блока видеоданных в Р сегменте, отображение бинаризованного синтаксического элемента типа предсказания В сегмента на тип предсказания, используя отображение бинаризации для блока видеоданных в В сегменте, и декодирование видеоданных, основываясь на отображенных типах предсказания.
[0009] В другом примере настоящего раскрытия способ кодирования видеоданных включает в себя определение типа разделения для режима предсказания для блока видеоданных, кодирование структурного элемента типа разделения синтаксического элемента типа предсказания для блока видеоданных с использованием CABAC с одним контекстом, причем этот один контекст является тем же самым для любого типа разделения, и кодирование структурного элемента размера разделения синтаксического элемента типа предсказания для блока видеоданных с использованием CABAC в режиме обхода.
[0010] В другом примере настоящего раскрытия способ декодирования видеоданных содержит прием синтаксического элемента типа предсказания для блока видеоданных, которые были кодированы с использованием CABAC, причем синтаксический элемент типа предсказания включает в себя структурный элемент типа разделения, представляющий тип разделения, и структурный элемент размера разделения, представляющий размер разделения, декодирование структурного элемента типа разделения синтаксического элемента типа предсказания с использованием контекстно-адаптивного бинарного арифметического кодирования с одним контекстом, причем этот один контекст является тем же самым для любого типа разделения, и декодирование структурного элемента типа разделения синтаксического элемента типа предсказания с использованием CABAC в режиме обхода.
[0011] В другом примере настоящего раскрытия способ кодирования видеоданных включает в себя кодирование флага кодированного блока цветности Cb для блока видеоданных с использованием CABAC, причем кодирование флага кодированного блока цветности Cb включает в себя использование набора контекстов, включающего в себя один или более контекстов как часть CABAC, и кодирование флага кодированного блока цветности Cr с использованием CABAC, причем кодирование флага кодированного блока цветности Cr содержит использование того же самого набора контекстов, что и для флага кодированного блока цветности Cb, как часть CABAC.
[0012] Настоящее раскрытие также описывает вышеуказанные способы в терминах устройств, сконфигурированных для выполнения этих способов, а также в терминах считываемого компьютером носителя для хранения инструкций, которые, при их выполнении, побуждают один или более процессоров выполнять эти способы.
[0013] Детали одного или нескольких примеров приведены на прилагаемых чертежах и в описании ниже. Другие признаки, цели и преимущества будут очевидны из описания и чертежей и из формулы изобретения.
Краткое описание чертежей
[0014] На фиг. 1 представлена блок-схема, иллюстрирующая примерную систему кодирования и декодирования видео, которая может использовать методы, описанные в настоящем раскрытии.
[0015] На фиг. 2 представлена блок-схема, иллюстрирующая примерный видеокодер, который может реализовать способы, описанные в настоящем раскрытии.
[0016] На фиг. 3 представлена блок-схема, иллюстрирующая примерный видеодекодер, который может реализовать способы, описанные в настоящем раскрытии.
[0017] На фиг. 4 показан концептуальный чертеж, демонстрирующий как квадратные, так и неквадратные типы разделения.
[0018] На фиг. 5 показан концептуальный чертеж, демонстрирующий асимметричные типы разделения.
[0019] На фиг. 6 представлена блок-схема последовательности операций, иллюстрирующая пример способа кодирования видео согласно настоящему раскрытию.
[0020] На фиг. 7 представлена блок-схема последовательности операций, иллюстрирующая пример способа декодирования видео согласно настоящему раскрытию.
[0021] На фиг. 8 представлена блок-схема последовательности операций, иллюстрирующая пример способа кодирования видео согласно настоящему раскрытию.
[0022] На фиг. 9 представлена блок-схема последовательности операций, иллюстрирующая пример способа декодирования видео согласно настоящему раскрытию.
[0023] На фиг. 10 представлена блок-схема последовательности операций, иллюстрирующая пример способа кодирования видео согласно настоящему раскрытию.
Подробное описание
[0024] Настоящее раскрытие описывает способы кодирования данных, таких как видеоданные. В частности, в настоящем раскрытии описываются способы, которые могут способствовать эффективному кодированию видеоданных с использованием процессов контекстно-адаптивного энтропийного кодирования. В частности, в настоящем раскрытии предлагается сокращение количества контекстов CABAC, используемых для кодирования синтаксических элементов, таких как pred_typ, merge_idx, inert_pred_flag, ref_idx_lx, cbf_cb, cbf_cr, coeff_abs_level_greater1_flag и coeff_abs_level_greater2_flag. Модификации сокращают до 56 контекстов с пренебрежимо малыми изменениями эффективности кодирования. Настоящее раскрытие описывает кодирование видео для целей иллюстрации. Однако способы, описанные в данном описании, также могут быть применимы к кодированию других типов данных.
[0025] На фиг. 1 представлена блок-схема, иллюстрирующая пример системы 10 кодирования и декодирования видео, которая может быть сконфигурирована, чтобы использовать методы контекстно-адаптивного бинарного арифметического кодирования (CABAC) в соответствии с примерами настоящего раскрытия. Как показано на фиг. 1, система 10 включает в себя устройство-источник 12, которое передает кодированное видео к устройству-получателю 14 через канал 16 связи. Кодированные видеоданные могут также храниться на носителе 34 хранения данных или файловом сервере 36, и устройство-получатель 14 может обращаться к ним по желанию. При хранении на носителе хранения данных или файловом сервере видеокодер 20 может предоставить кодированные видеоданные другому устройству, такому как сетевой интерфейс, компакт-диск (CD), программатор или устройство оборудования штамповки Blu-Ray или цифрового видеодиска (DVD) или другие устройства, для хранения кодированных видеоданных на носителе хранения данных. Кроме того, устройство, отдельное от видеодекодера 30, такое как сетевой интерфейс, CD или DVD считыватель или тому подобное, может извлекать кодированные видеоданные с носителя хранения данных и предоставлять извлеченные данные на видеодекодер 30.
[0026] Устройство-источник 12 и устройство-получатель 14 могут включать в себя любое из широкого спектра устройств, включая настольные компьютеры, ноутбуки (т. е. портативные компьютеры), планшетные компьютеры, телевизионные приставки, телефонные аппараты, такие как так называемые смартфоны, телевизоры, камеры, устройства отображения, цифровые медиаплееры, игровые консоли или тому подобное. Во многих случаях такие устройства могут быть оснащены для беспроводной связи. Таким образом, канал 16 связи может содержать беспроводной канал, проводной канал или комбинацию проводных и беспроводных каналов, пригодных для передачи кодированных видеоданных. Аналогично файловый сервер 36 может быть доступен для устройства-получателя 14 через любое стандартное соединение передачи данных, в том числе Интернет-соединение. Это может включать в себя беспроводной канал (например, соединение Wi-Fi), проводное соединение (например, DSL, кабельный модем и т. д.) или сочетание того и другого, которое подходит для доступа к кодированным видеоданным, хранящимся на файловом сервере.
[0027] Методы САВАС, в соответствии с примерами настоящего раскрытия, могут быть применены к кодированию видео для поддержки любого из множества мультимедийных приложений, таких как эфирное телевизионное вещание, передачи кабельного телевидения, передачи спутникового телевидения, передачи потокового видео, например, через Интернет, кодирование цифрового видео для хранения на носителе данных, декодирование цифрового видео, сохраненного на носителе данных, или других приложений. В некоторых примерах система 10 может быть сконфигурирована для поддержки односторонних или двусторонних передач видео для поддержки таких приложений, как потоковое видео, воспроизведение видео, видеовещание и/или видеотелефония.
[0028] В примере по фиг. 1 устройство-источник 12 включает в себя источник 18 видео, видеокодер 20, модулятор/демодулятор 22 и передатчик 24. В устройстве-источнике 12 источник 18 видео может включать в себя источник, такой как устройство захвата видео, например, видеокамеру, видеоархив, содержащий ранее захваченное видео, интерфейс видеоканала для приема видео от поставщика видеоконтента и/или систему компьютерной графики для генерации данных компьютерной графики в качестве исходного видео или комбинацию таких источников. В качестве одного примера, если источник 18 видео представляет собой видеокамеру, устройство-источник 12 и устройство-получатель 14 могут образовывать так называемые камеры-телефоны или видеотелефоны. Однако способы, описанные в настоящем раскрытии, могут применяться к кодированию видео в общем и могут быть применены к беспроводным и/или проводным приложениям или приложению, в котором кодированные видеоданные сохранены на локальном диске.
[0029] Захваченное, предварительно захваченное или генерируемое компьютером видео может кодироваться с помощью видеокодера 20. Кодированная информация видео может модулироваться с помощью модема 22 в соответствии со стандартом связи, например, протоколом беспроводной связи, и передаваться к устройству-получателю 14 посредством передатчика 24. Модем 22 может включать в себя различные смесители, фильтры, усилители и другие компоненты, предназначенные для модуляции сигнала. Передатчик 24 может включать в себя схемы, предназначенные для передачи данных, в том числе усилители, фильтры и одну или более антенн.
[0030] Захваченное, предварительно захваченное или генерируемое компьютером видео, которое кодируется с помощью видеокодера 20, также может храниться на носителе 34 хранения данных или файловом сервере 36 для последующего потребления. Носитель 34 хранения данных может включать Blu-Ray диски, DVD-диски, CD-ROM, флэш-память или любой другой подходящий цифровой носитель хранения данных для хранения кодированного видео. Кодированное видео, сохраненное на носителе 34 хранения данных, может затем быть доступным для устройства-получателя 14 для декодирования и воспроизведения. Хотя это не показано на фиг. 1, в некоторых примерах носитель 34 хранения данных и/или файловый сервер 36 может хранить выходной сигнал передатчика 24.
[0031] Файловый сервер 36 может быть любым типом сервера, способным хранить кодированное видео и передавать это кодированное видео к устройству-получателю 14. Примерные файловые серверы включают в себя веб-сервер (например, для веб-сайта), FTP-сервер, устройства хранения, связанные с сетью (NAS), локальный диск или любой другой тип устройства, способного хранить кодированные видеоданные и передавать его к устройству-получателю. Передача кодированных видеоданных с файлового сервера 36 может быть потоковой передачей, передачей загрузки или сочетанием того и другого. Файловый сервер 36 может быть доступным для устройства-получателя 14 через любое стандартное соединение передачи данных, в том числе Интернет-соединение. Это может включать в себя беспроводной канал (например, соединение Wi-Fi), проводное соединение (например, DSL, кабельный модем, Ethernet, USB и т. д.) или сочетание того и другого, которое подходит для доступа к кодированным видеоданным, хранящимся на файловом сервере.
[0032] Устройство-получатель 14 в примере по фиг. 1 включает в себя приемник 26, модем 28, видеодекодер 30 и устройство 32 отображения. Приемник 26 устройства-получателя 14 принимает информацию по каналу 16, и модем 28 демодулирует информацию для получения демодулированного потока битов для видеодекодера 30. Информация, передаваемая через канал 16, может включать в себя различную синтаксическую информацию, генерируемую видеокодером 20, для использования видеодекодером 30 при декодировании видеоданных. Такой синтаксис также может быть включен в кодированные видеоданные, сохраненные на носителе 34 хранения данных или файловом сервере 36. Каждый из видеокодера 20 и видеодекодера 30 может являться частью соответствующего кодера-декодера (кодека), который способен кодировать или декодировать видеоданные.
[0033] Устройство 32 отображения может быть встроенным или внешним по отношению к устройству-получателю 14. В некоторых примерах устройство-получатель 14 может включать в себя встроенное устройство отображения, а также может быть сконфигурировано для взаимодействия с внешним устройством отображения. В других примерах устройство-получатель 14 может быть устройством отображения. В общем, устройство 32 отображения отображает декодированные видеоданные пользователю и может содержать любое из множества устройств отображения, таких как жидкокристаллический дисплей (LCD), плазменный дисплей, дисплей на органических светоизлучающих диодах (OLED) или другой тип устройства отображения.
[0034] В примере на фиг. 1 канал 16 связи может содержать любую проводную или беспроводную среду связи, например, радиочастотный (РЧ) спектр или одну или нескольких физических линий передачи, или любую комбинацию беспроводных и проводных сред передачи. Канал 16 связи может являться частью пакетной сети, например, локальной сети, сети широкого охвата или глобальной сети, такой как Интернет. Канал 16 связи обычно представляет собой любую подходящую среду связи или набор различных сред связи для передачи видеоданных от устройства-источника 12 к устройству-получателю 14, включая любую подходящую комбинацию проводных или беспроводных сред передачи. Канал 16 связи может включать в себя маршрутизаторы, коммутаторы, базовые станции или любое другое оборудование, которое может быть полезным для обеспечения связи от устройства-источника 12 к устройству-получателю 14.
[0035] Видеокодер 20 и видеодекодер 30 могут работать в соответствии со стандартом сжатия видео, таким как стандарт Высокоэффективного кодирования видео (HEVC), находящийся в настоящее время на стадии разработки Объединенной совместной группы по кодированию видео (JCT-VC) ITU-Т Группы экспертов по кодированию видео (VCEG) и ISO/IEC Группы экспертов по движущемуся изображению (MPEG). Недавний проект стандарта HEVC, называемый "HEVC рабочий проект 6" или "WD6", описывается в документе JCTVC-H1003, Bross et al., "High efficiency video coding (HEVC) text specification draft 6", Объединенной совместной группы по кодированию видео (JCT-VC) ITU-T SGI 6 WP3 и ISO/IEC JTC1/SC29/WG11, 8-е заседание: Сан-Хосе, Калифорния, США, февраль 2012 г., который по состоянию на 1 июня 2012 года можно скачать с http://phenix.int-evry.fr/jct/doc_end_user/documents/8_San%20Jose/wg11/JCTVC-1003-v22.zip.
[0036] Кроме того, видеокодер 20 и видеодекодер 30 могут действовать в соответствии с другими проприетарными или промышленными стандартами, такими как стандарт ITU-T H.264, альтернативно называемый MPEG-4, часть 10, Расширенное кодирование видео (AVC), или расширения таких стандартов. Методы настоящего раскрытия, однако, не ограничиваются каким-либо конкретным стандартом кодирования. Другие примеры включают MPEG-2 и ITU-T H.263.
[0037] Хотя это не показано на фиг. 1, в некоторых аспектах видеокодер 20 и видеодекодер 30 могут, каждый, быть интегрирован с аудиокодером и декодером и могут включать в себя соответствующие блоки MUX-DEMUX или другие аппаратные средства и программное обеспечение для обработки кодирования аудио и видео в общем потоке данных или отдельных потоках данных. Если применимо, в некоторых примерах блоки MUX-DEMUX могут соответствовать протоколу мультиплексора ITU H.223 или другим протоколам, таким как протокол пользовательских дейтаграмм (UDP).
[0038] Видеокодер 20 и видеодекодер 30, каждый, может быть реализован как любой из множества подходящих схем кодера, таких как один или более микропроцессоров, цифровые сигнальные процессоры (DSP), специализированные интегральные схемы (ASIC), программируемые вентильные матрицы (FPGA), дискретная логика, программное обеспечение, аппаратные средства, программно-аппаратные средства или любые их комбинации. Когда технологии реализованы частично в программном обеспечении, устройство может хранить инструкции для программного обеспечения на подходящем постоянном считываем компьютером носителе и выполнять инструкции в аппаратных средствах с использованием одного или более процессоров для выполнения методов настоящего раскрытия. Каждый из видеокодера 20 и видеодекодера 30 может быть включен в один или более кодеров или декодеров, каждый из которых может быть интегрирован как часть комбинированного кодера/декодера (кодека) в соответствующем устройстве.
[0039] Видеокодер 20 может реализовывать любой или все методы настоящего раскрытия для CABAC в процессе кодирования видео. Кроме того, видеодекодер 30 может осуществлять некоторые или все из этих методов для CABAC в процессе кодирования видео. Устройство кодирования видео, как описано в данном раскрытии, может относиться к видеокодеру или видеодекодеру. Аналогичным образом блок кодирования видео может относиться к видеокодеру или видеодекодеру. Кроме того, кодирование видео может относиться к кодированию видео или декодированию видео.
[0040] В одном примере настоящего раскрытия видеокодер 20 может быть сконфигурирован, чтобы определять первый тип предсказания для блока видеоданных в Р сегменте, представлять первый тип предсказания как синтаксический элемент типа предсказания P сегмента, определять второй тип предсказания для блока видеоданных в B сегменте, представлять второй тип предсказания как синтаксический элемент типа предсказания B сегмента, определять бинаризацию Р сегмента для синтаксического элемента типа предсказания P сегмента, определять бинаризацию В сегмента для синтаксического элемента типа предсказания В сегмента, при этом синтаксический элемент типа предсказания P сегмента и синтаксический элемент типа предсказания В сегмента определяются с использованием той же самой логики бинаризации, и кодировать видеоданные на основе бинаризации синтаксического элемента типа предсказания Р сегмента и синтаксического элемента типа предсказания В сегмента.
[0041] В другом примере настоящего раскрытия видеодекодер 30 может быть сконфигурирован, чтобы отображать бинаризованный синтаксический элемент типа предсказания P сегмента на тип предсказания, используя отображение бинаризации для блока видеоданных в Р сегменте, отображать бинаризованный синтаксический элемент типа предсказания В сегмента на тип предсказания, используя то же самое отображение бинаризации для блока видеоданных в В сегменте, и декодировать видеоданные, основываясь на отображенных типах предсказания.
[0042] В другом примере настоящего раскрытия видеокодер 20 может быть сконфигурирован, чтобы определять тип разделения для режима предсказания для блока видеоданных, кодировать структурный элемент типа разделения синтаксического элемента типа предсказания для блока видеоданных с использованием CABAC с одним контекстом, причем этот один контекст является тем же самым для любого типа разделения, и кодировать структурный элемент размера разделения синтаксического элемента типа предсказания для блока видеоданных с использованием CABAC в режиме обхода.
[0043] В другом примере настоящего раскрытия видеодекодер 30 может быть сконфигурирован, чтобы принимать синтаксический элемент типа предсказания для блока видеоданных, которые были кодированы с использованием CABAC, причем синтаксический элемент типа предсказания включает в себя структурный элемент типа разделения, представляющий тип разделения, и структурный элемент размера разделения, представляющий размер разделения, декодировать структурный элемент типа разделения синтаксического элемента типа предсказания с использованием САВАС с одним контекстом, причем этот один контекст является тем же самым для любого типа разделения, и декодировать структурный элемент размера разделения синтаксического элемента типа предсказания с использованием CABAC в режиме обхода.
[0044] В другом примере настоящего раскрытия, как видеокодер 20, так и видеодекодер 30 могут быть сконфигурированы, чтобы кодировать флаг кодированного блока цветности Cb для блока видеоданных с использованием CABAC, причем кодирование флага кодированного блока цветности Cb включает в себя использование набора контекстов, включающего в себя один или более контекстов как часть CABAC, и кодировать флаг кодированного блока цветности Cr с использованием CABAC, причем кодирование флага кодированного блока цветности Cr содержит использование того же самого набора контекстов, что и для флага кодированного блока цветности Cb, как часть CABAC.
[0045] JCT-VC работает над развитием стандарта HEVC. Усилия HEVC стандартизации базируются на развивающейся модели устройства кодирования видео, называемой тестовой моделью HEVC (HM). HM предполагает несколько дополнительных возможностей устройств кодирования видео относительно существующих устройств в соответствии, например, с ITU-Т H.264/AVC. Например, в то время как H.264 обеспечивает девять режимов кодирования с интра-предсказанием, HM может обеспечить тридцать три режима кодирования с интра-предсказанием. В следующем разделе будут более подробно описаны некоторые аспекты HM.
[0046] В общем, рабочая модель HM описывает, что видеокадр или изображение может быть разделено на последовательность блоков дерева или наибольших единиц кодирования (LCU), которые включают в себя выборки как яркости, так и цветности. Блок дерева имеет цель, подобную таковой макроблока стандарта H.264. Сегмент (слайс) включает в себя ряд последовательных блоков дерева в порядке кодирования. Видеокадр или изображение может быть разделено на один или более сегментов. Каждый блок дерева может быть разделен на единицы кодирования (CU) в соответствии с квадродеревом. Например, блок дерева, в качестве корневого узла квадродерева, может быть разделен на четыре дочерних узла, а каждый дочерний узел, в свою очередь, может быть родительским узлом и может быть разделен на следующие четыре дочерних узла. Окончательный, неразделимый дочерний узел, как узел листа квадродерева, включает в себя узел кодирования, то есть блок кодированного видео. Данные синтаксиса, связанные с кодированным битовым потоком, могут определять максимальное количество раз разбиения блока дерева, а также могут определять минимальный размер узлов кодирования.
[0047] CU включает в себя узел кодирования и единицы предсказания (PU) и единицы преобразования (TU), связанные с узлом кодирования. Размер CU обычно соответствует размеру узла кодирования и обычно должен быть квадратной формы. Размер CU может находиться в диапазоне от 8×8 пикселей до размера блока дерева максимально с 64×64 пикселей или более. Каждая CU может содержать одну или более PU и одну или более TU. Данные синтаксиса, ассоциированные с CU, могут описывать, например, разделение CU на одну или более PU. Режимы разделения могут отличаться в зависимости от того, пропускается ли CU, или кодирована в прямом режиме, кодирована в режиме интра-предсказания или кодирована в режиме интер-предсказания. PU могут быть разделены, чтобы быть в неквадратной форме. Данные синтаксиса, ассоциированные с CU, также могут описывать, например, разделение CU на одну или более TU в соответствии с квадродеревом. TU может быть квадратной или неквадратной формы.
[0048] Новый стандарт HEVC допускает преобразования в соответствии с TU, которые могут быть различными для различных CU. TU обычно имеют размер в зависимости от размера PU в пределах данной CU, определенной для разделенной LCU, хотя это может не всегда иметь место. TU, как правило, такого же размера или меньше, чем PU. В некоторых примерах остаточные выборки, соответствующие СU, могут быть разделены на более мелкие единицы, используя структуру квадродерева, известную как "остаточное квадродерево" (RQT). Листовые узлы RQT могут упоминаться как единицы преобразования (TU). Пиксельные разностные значения, связанные с TU, могут быть преобразованы для получения коэффициентов преобразования, которые могут быть квантованы.
[0049] В общем, PU относится к данным, относящимся к процессу предсказания. Например, когда PU является кодированной в интра-режиме, PU может включать данные, описывающие режим интра-предсказания для PU. В качестве другого примера, когда PU кодирована в интер-режиме, PU может включать данные, определяющие вектор движения для PU. Данные, определяющие вектор движения для PU, могут описывать, например, горизонтальную составляющую вектора движения, вертикальную составляющую вектора движения, разрешение для вектора движения (например, точность в одну четверть пикселя или точность в одну восьмую пикселя), опорное изображение, на которое указывает вектор движения, и/или список опорных изображений (например, список 0, список 1 или список С) для вектора движения.
[0050] В общем, TU используется для процессов преобразования и квантования. Данная CU, имеющая одну или более PU, может также включать в себя одну или более единиц преобразования (TU). После предсказания видеокодер 20 может вычислить остаточные значения из блока видео, идентифицированного узлом кодирования, в соответствии с PU. Узел кодирования затем обновляется для ссылки на остаточные значения вместо исходного блока видео. Остаточные значения содержат пиксельные разностные значения, которые могут преобразовываться в коэффициенты преобразования, квантоваться и сканироваться с использованием преобразований и другой информации преобразования, определенной в TU, чтобы создать преобразованные в последовательную форму коэффициенты преобразования для энтропийного кодирования. Узел кодирования может быть в очередной раз обновлен, чтобы ссылаться на эти преобразованные в последовательную форму коэффициенты преобразования. Настоящее раскрытие обычно использует термин "блок видео", чтобы ссылаться на узел кодирования CU. В некоторых конкретных случаях настоящее раскрытие может также использовать термин "блок видео", чтобы ссылаться на блок дерева, т. е. LCU или СU, которая включает в себя узел кодирования и PU и TU.
[0051] Видеопоследовательность обычно включает в себя ряд видеокадров или изображений. Группа изображений (GOP) обычно включает в себя последовательность из одного или более видеоизображений. GOP может включать синтаксические данные в заголовке GOP, заголовке одного или более изображений или в другом месте, которое описывает ряд изображений, включенных в GOP. Каждый сегмент изображения может включать синтаксические данные сегмента, которые описывают режим кодирования для соответствующего сегмента. Видеокодер 20 обычно работает на блоках видео в отдельных сегментах видео для кодирования видеоданных. Блок видео может соответствовать узлу кодирования внутри CU. Блоки видео могут иметь фиксированные или переменные размеры и могут отличаться по размеру в соответствии с заданным стандартом кодирования.
[0052] В качестве примера HM поддерживает предсказание в различных размерах PU. В предположении, что размер определенной CU равен 2N×2N, HM поддерживает интра-предсказание в PU размеров 2N×2N или N×N и интер-предсказание в симметричных PU размеров 2N×2N, 2N×N, Nx2N или N×N. HM также поддерживает асимметричное разделение для интер-предсказания в PU размеров 2N×nU, 2N×nD, nL×2N и nR×2N. В асимметричном разделении одно направление СU не разделяется, а другое направление разделяется на 25% и 75%. Часть СU, соответствующая 25% разделению, обозначается посредством "n" с последующим указанием "вверх", "вниз", "влево" или "вправо". Так, например, "2N×nU" относится к 2N×2N CU, которая разделена горизонтально с 2N×0,5N PU сверху и 2N×1,5N PU снизу.
[0053] На фиг. 4 показана концептуальная диаграмма, демонстрирующая как квадратные, так и неквадратные типы разделения для интра-предсказания и интер-предсказания. Разделение 102 является разделением 2N×2N и может быть использовано как для интра-предсказания, так и для интер-предсказания. Разделение 104 является разделением N×N и может быть использовано как для интра-предсказания, так и для интер-предсказания. Разделение 106 является разделением 2N×N и в настоящее время используется в HEVC для интер-предсказания. Разделение 108 является разделением N×2N и в настоящее время используется в HEVC для интер-предсказания.
[0054] На фиг. 5 представлена концептуальная диаграмма, показывающая асимметричные типы разделения. Разделение 110 является разделением 2N×nU и в настоящее время используется в HEVC для интер-предсказания. Разделение 112 является разделением 2N×nD и в настоящее время используется в HEVC для интер-предсказания. Разделение 114 является разделением nL×2N и в настоящее время используется в HEVC для интер-предсказания. Разделение 116 является разделением nR×2N и в настоящее время используется в HEVC для интер-предсказания.
[0055] В этом описании «N×N» и «N на N» могут использоваться взаимозаменяемым образом для обозначения размеров в пикселях блока видео по вертикали и горизонтали, например, 16×16 пикселей или 16 на 16 пикселей. В общем, 16×16 блок будет иметь 16 пикселей в вертикальном направлении (y=16) и 16 пикселей в горизонтальном направлении (х=16). Аналогично блок N×N, в общем виде, имеет N пикселей в вертикальном направлении и N пикселей в горизонтальном направлении, где N представляет собой неотрицательное целое число. Пиксели в блоке могут быть упорядочены в строки и столбцы. Кроме того, блоки не обязательно должны иметь одинаковое число пикселей в горизонтальном направлении и в вертикальном направлении. Например, блоки могут содержать N×M пикселей, где М не обязательно равно N.
[0056] После кодирования с интра-предсказанием или интер-предсказанием с использованием PU для CU видеокодер 20 может вычислить остаточные данные, к которым применяются преобразования, указанные посредством TU в PU. Остаточные данные могут соответствовать разнице в пикселях между пикселями некодированного изображения и значениями предсказания, соответствующими CU. Видеокодер 20 может формировать остаточные данные для СU, а затем преобразовывать остаточные данные для получения коэффициентов преобразования.
[0057] После любых преобразований, чтобы сформировать коэффициенты преобразования, видеокодер 20 может выполнять квантование коэффициентов преобразования. Квантование, в общем, относится к процессу, в котором коэффициенты преобразования квантуются, чтобы по возможности уменьшить объем данных, используемых для представления коэффициентов, обеспечивая дальнейшее сжатие. Процесс квантования может уменьшить битовую глубину, ассоциированную с некоторыми или всеми коэффициентами. Например, n-битное значение можно округлить вниз до m-битного значения во время квантования, где n больше, чем m.
[0058] В некоторых примерах видеокодер 20 может использовать предопределенный порядок сканирования для сканирования квантованных коэффициентов преобразования для получения преобразованного в последовательную форму вектора, который может энтропийно кодироваться. В других примерах видеокодер 20 может выполнять адаптивное сканирование. После сканирования квантованных коэффициентов преобразования, чтобы сформировать одномерный вектор, видеокодер 20 может энтропийно кодировать одномерный вектор, например, в соответствии с контекстно-адаптивным кодированием переменной длины (CAVLC), контекстно-адаптивным бинарным арифметическим кодированием (CABAC), основанным на синтаксисе контекстно-адаптивным бинарным арифметическим кодированием (SBAC), энтропийным кодированием с разделением интервала вероятности (PIPE) или другим методом энтропийного кодирования. Видеокодер 20 может также энтропийно кодировать синтаксические элементы, ассоциированные с кодированными видеоданными для использования видеодекодером 30 в декодировании видеоданных.
[0059] Для выполнения CABAC видеокодер 20 может назначить контекст в контекстной модели для символа, подлежащего передаче. Контекст может относиться, например, к тому, являются ли соседние значения символа ненулевыми, или нет. Для выполнения CAVLC видеокодер 20 может выбрать код переменной длины для символа, подлежащего передаче. Кодовые слова в VLC могут быть сконструированы так, что относительно более короткие коды соответствуют более вероятным символам, в то время как более длинные коды соответствуют менее вероятным символам. Таким образом, использование VLC может достигать экономии в битах по сравнению, например, с использованием кодовых слов одинаковой длины для каждого символа, подлежащего передаче. Определение вероятности может быть основано на контексте, назначенном символу.
[0060] Настоящее раскрытие относится к способам для энтропийных кодеров контекстно-адаптивного бинарного арифметического кодирования (CABAC) или другим энтропийным кодерам, таким как энтропийное кодирование с разделением интервала вероятности (PIPE) или связанным кодерам. Арифметическое кодирование является формой энтропийного кодирования, используемого во многих алгоритмах сжатия, которые имеют высокую эффективность кодирования, поскольку оно способно отображать символы на кодовые слова нецелочисленной длины. Примером алгоритма арифметического кодирования является основанное на контексте бинарное арифметическое кодирование (CABAC), используемое в H.264/AVC.
[0061] В общем, кодирование символов данных с помощью CABAC включает в себя один или более из следующих этапов:
(1) Бинаризация: Если символ, подлежащий кодированию, не является бинарным значением, он отображается на последовательности так называемых "структурных элементов". Каждый структурный элемент может иметь значение "0" или "1".
(2) Назначение контекста: Каждому структурному элементу (в обычном режиме) назначается контекст. Контекстная модель определяет, как рассчитывается контекст для данного структурного элемента на основе информации, доступной для структурного элемента, такой как значения ранее кодированных символов или число структурных элементов.
(3) Кодирование структурных элементов: Структурные элементы кодируются арифметическим кодером. Для кодирования структурного элемента арифметический кодер требует в качестве входа вероятность значения структурного элемента, то есть вероятность того, что значение структурного элемента равно "0", и вероятность того, что значение структурного элемента равно "1". (Оцененная) вероятность каждого контекста представлена целым числом, называемым «состоянием контекста». Каждый контекст имеет состояние, и, таким образом, состояние (т. е. оцененная вероятность) является тем же самым для структурных элементов, назначенных одному контексту, и отличается между контекстами.
(4) Обновление состояния: Вероятность (состояние) для выбранного контекста обновляется на основе фактического кодированного значения структурного элемента (например, если значение структурного элемента было "1", вероятность "1" увеличивается).
[0062] Следует отметить, что энтропийное кодирование с разделением интервала вероятности (PIPE) использует принципы, аналогичные принципам арифметического кодирования, и, таким образом, может также использовать метод настоящего раскрытия.
[0063] CABAC в H.264/AVC и HEVC использует состояния, и каждое состояние неявно связано с вероятностью. Существуют варианты CABAC, в которых вероятность символа ("0" или "1") используется непосредственно, то есть вероятность (или ее целочисленная версия) является состоянием. Например, такие варианты САВАС описаны в "Description of video coding technology proposal by France Telecom, NTT, NTT DOCOMO, Panasonic and Technicolor", JCTVC-A114, 1st JCT-VC Meeting, Dresden, DE, апрель 2010 г., далее упоминается как "JCTVC-A114", и A. Alshin and E. Alshina, "Multi-parameter probability update for САВАС", JCTVC-F254, 6th JCT-VC Meeting, Torino, IT, июль 2011 г., далее упоминается как "JCTVC-F254".
[0064] В настоящем раскрытии предложено сокращение количества бинаризаций и/или контекстов, используемых в CABAC. В частности, настоящее раскрытие предлагает методы, которые могут снизить количество контекстов, используемых в CABAC, на величину до 56. С числом на 56 меньше контекстов экспериментальные результаты показывают, 0,00%, 0,01% и -0,13% изменения частоты искажения битов (BD) в высокоэффективном интра-режиме только, произвольном доступе и тестовых условиях малой задержки соответственно. Таким образом, сокращение в количестве требуемых контекстов снижает потребности в хранении как в кодере, так и декодере без существенного влияния на эффективность кодирования.
[0065] В настоящем раскрытии предложено сокращение числа контекстов CABAC, используемых для синтаксических элементов pred_typ, merge_idx, inert_pred_flag, ref_idx_lx, cbf_cb, cbf_cr, coeff_abs_level_greater1_flag и coeff_abs_level_greater2_flag. Модификации сокращают до 56 контекстов с пренебрежимо малыми изменениями в эффективности кодирования. Предлагаемые сокращения контекста для синтаксических элементов, приведенных выше, могут быть использованы по отдельности или в любой комбинации.
[0066] Синтаксический элемент pred_type включает в себя режим предсказания (pred_mode_flag) и тип разделения (part_mode) для каждой единицы кодирования. Синтаксический элемент pred_mode_flag, равный 0, определяет, что текущая единица кодирования кодирована в режиме интер-предсказания. Синтаксический элемент pred_mode_flag, равный 1, указывает, что текущая единица кодирования кодирована в режиме интра-предсказания. Синтаксический элемент part_mode определяет режим разделения текущей единицы кодирования.
[0067] Синтаксический элемент merge_jdx[х0][y0] определяет индексы кандидатов слияния списка кандидатов слияния, где х0, у0 определяют местоположение (х0, у0) верхней левой выборки яркости рассматриваемого блока предсказания относительно верхней левой выборки яркости изображения. Когда merge_jdx[х0][y0] отсутствует, то делается вывод, что он равен 0. Список кандидатов слияния является списком соседних единиц кодирования с текущими единицами, из которых информация о движении может быть скопирована.
[0068] Синтаксический элемент inter_pred_flag[х0][y0] определяет, используется ли моно-предсказание или би-предсказание для текущей единицы предсказания. Индексы массива х0, у0 определяют местоположение (х0, у0) верхней-левой выборки яркости рассматриваемого блока предсказания относительно верхней-левой выборки яркости изображения.
[0069] Синтаксический элемент ref_idx_lx относится к конкретному опорному изображению внутри списка опорных изображений.
[0070] Синтаксические элементы cbf_cb, cbf_cr указывают, содержат ли блоки преобразования цветности (Cb и Cr, соответственно) ненулевые коэффициенты преобразования. Синтаксический элемент cbf_cb[х0][y0][trafoDepth], равный 1, определяет, что блок преобразования Cb содержит один или более уровней коэффициентов преобразования, не равных 0. Индексы массива х0, у0 указывают местоположение (х0, у0) верхней-левой выборки яркости рассматриваемого блока преобразования относительно верхней-левой выборки яркости изображения. Индекс массива trafoDepth указывает текущий уровень подразделения единицы кодирования на блоки с целью кодирования преобразования. Индекс массива trafoDepth равен 0 для блоков, которые соответствуют единицам кодирования. Когда cbf_cb[х0][y0][trafoDepth] не присутствует, и режимом предсказания является не интра-предсказание, значение cbf_cb[х0][y0][trafoDepth] выводится как равное 0.
[0071] Синтаксический элемент cbf_cr[х0][y0][trafoDepth], равный 1, указывает, что блок преобразования Cr содержит один или более уровней коэффициентов преобразования, не равных 0. Индексы массива х0, у0 указывают местоположение (х0, у0) верхней-левой выборки яркости рассматриваемого блока преобразования относительно верхней-левой выборки яркости изображения. Индекс массива trafoDepth указывает текущий уровень подразделения единицы кодирования на блоки с целью кодирования преобразования. Индекс массива trafoDepth равен 0 для блоков, которые соответствуют единицам кодирования. Когда cbf_cr[х0][y0][trafoDepth] не присутствует, и режимом предсказания не является интра-предсказание, значение cbf_cr[х0][y0][trafoDepth] выводится равным 0.
[0072] Синтаксический элемент coeff_abs_level_greater1_flag[n] указывает для позиции n сканирования, имеются ли уровни коэффициентов преобразования больше, чем 1. Когда coeff_abs_level_greater1_flag[n] не присутствует, то делается вывод, что он равен 0.
[0073] Синтаксический элемент coeff_abs_level_greater2_flag [n] указывает для позиции n сканирования, имеются ли уровни коэффициентов преобразования больше, чем 2. Когда coeff_abs_level_greater2_flag[n] не присутствует, делается вывод, что он равен 0.
[0074] В одном предложении для HEVC различные бинаризации по синтаксическому элементу pred_type используются в P и B сегментах, как показано в таблице 1. Настоящее раскрытие предлагает использовать те же самые бинаризации для P и B сегментов. Примеры приведены в таблицах 2-4. Таблица 5 показывает влияние эффективности кодирования на P сегмент в стандартных условиях тестирования (см., например, F. Bossen, "Common test conditions and software reference configurations”, JCTVC-F900).
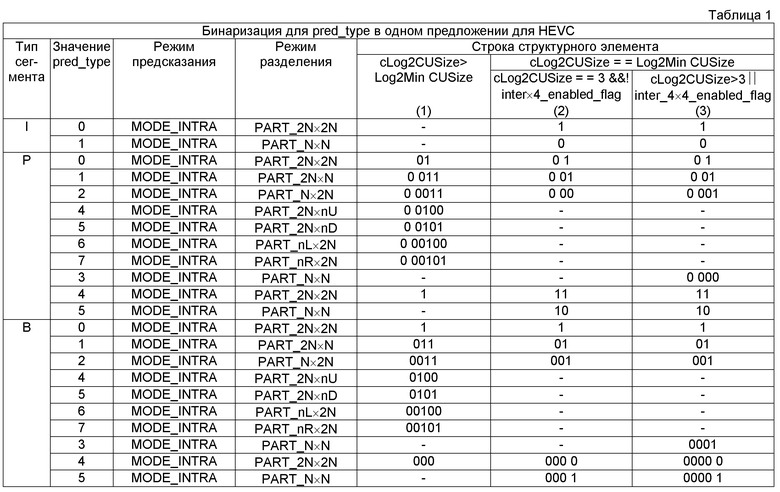
[0075] Как видно из таблицы 1, I сегменты (например, сегменты, которые включают только блоки интра-предсказания) включают в себя два различных типа предсказания (pred_type). Одна строка структурного элемента (бинаризация) используется для блока интра-предсказания с типом разделения 2N×2N, а другая строка структурного элемента используется для блока интра-предсказания с типом разделения N×N. Как показано в таблице 1, строка структурного элемента, используемая для I сегментов, не зависит от размера CU.
[0076] Для Р и В сегментов, в таблице 1, различные строки структурного элемента используются для каждого значения pred_type. Вновь значение pred_type зависит как от режима предсказания (интер-предсказания или интра-предсказания), так и используемого типа разделения. Для Р и В сегментов фактическая используемая строка структурного элемента дополнительно зависит от размера кодируемой CU и от того, поддерживается ли интер-предсказание для размера 4×4 блока.
[0077] Первый столбец под строкой структурного элемента применяется для ситуации, когда логарифмическая функция размера CU кодируемой СU превышает логарифмическую функцию минимально допустимого размера CU. Согласно одному примеру в HEVC, первый столбец строк структурного элемента используется, если cLog2CUSize > Log2MinCUsize. Логарифмическая функция используется для создания меньшего числа, так что может быть использован меньший последовательный индекс.
[0078] Если логарифмическая функция от размера CU кодируемой CU эквивалентна логарифмической функции минимально допустимого размера CU (т. е. cLog2CUSize = = Log2MinCUSize), то один из столбцов 2 и 3 под строкой структурного элемента в таблице 1 используется для выбора бинаризации. Столбец 2 используется, когда логарифмическая функция от размера CU кодируемой CU эквивалентна 3, и интер-предсказание для 4×4 СU не поддерживается (т.е. cLog2CUSize = = 3 &&! inter_4×4_enabled_flag). Столбец 3 используется, когда логарифмическая функция от размера CU для кодируемой СU больше, чем 3, или когда интер-предсказание для 4×4 CU поддерживается (то есть cLog2CUSize > 3 || inter_4×4_enabled_flag).
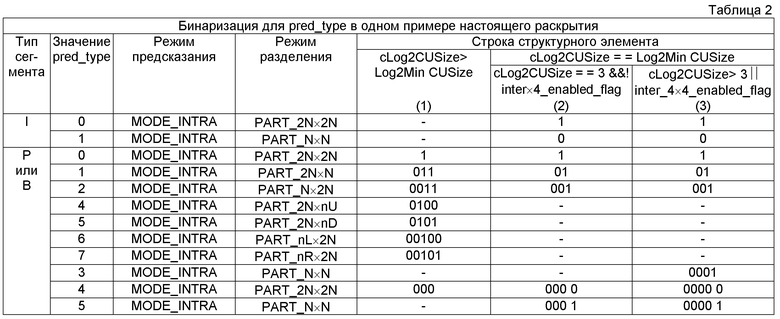
[0079] В таблице 2 ниже показаны примеры бинаризации, где P и B сегменты используют те же строки структурного элемента, в соответствии с одним или более примерами, описанными в настоящем раскрытии. Как показано в таблице 2, P сегменты используют те же бинаризации, используемые для B сегментов в таблице 1. Таким образом, нет необходимости хранить и использовать отдельный набор контекстов для Р и В сегментов. Таким образом, общее количество контекстов, необходимых для кодирования синтаксического элемента pred_type, снижается. Кроме того, только одно отображение (вместо двух) между логикой строки структурного элемента (показано в столбцах (1)-(3)) и фактической строкой структурного элемента должно быть сохранено.
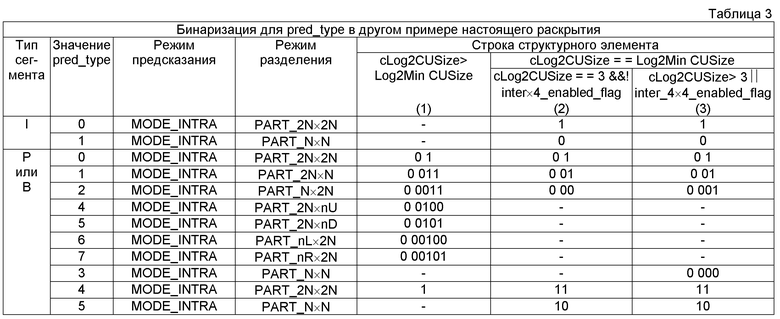
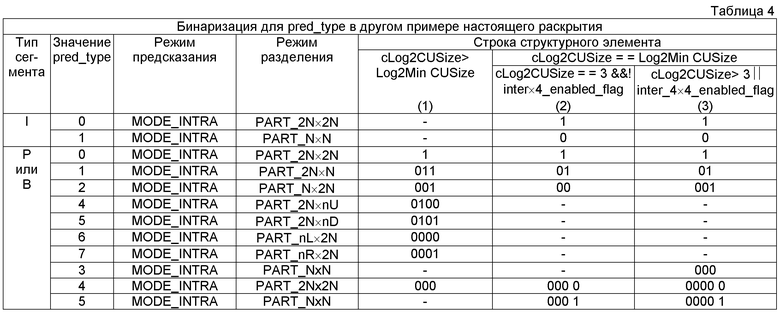
[0080] В таблице 3 ниже показан другой пример бинаризации для pred_type. В этом примере B сегменты используют те же бинаризации, что и P сегменты из таблицы 1. Таблица 4 ниже показывает дополнительный пример, где Р сегменты и В сегменты используют те же бинаризации. Таблицы 2-4 предназначены только для того, чтобы показать примеры общих бинаризаций между Р и В сегментами. Любые бинаризации или правила бинаризации могут быть использованы так, что синтаксические элементы pred_type для P и B сегментов совместно используют те же бинаризации.
[0081] Видеокодер 20 и видеодекодер 30 могут хранить те же правила отображения и таблицы отображения (например, как показано в таблицах 2-4) для использования с P и B сегментами. Кодирование и декодирование CABAC могут быть применены к синтаксическому элементу pred_type с использованием этих отображений.
[0082] Таким образом, видеокодер 20 может быть сконфигурирован, чтобы определять первый тип предсказания для блока видеоданных в Р сегменте, представлять первый тип предсказания как синтаксический элемент типа предсказания P сегмента, определять второй тип предсказания для блока видеоданных в B сегменте, представлять второй тип предсказания как синтаксический элемент типа предсказания B сегмента, определять бинаризацию Р сегмента для синтаксического элемента типа предсказания P сегмента, определять бинаризацию B сегмента для синтаксического элемента типа предсказания В сегмента, причем синтаксический элемент типа предсказания Р сегмента и синтаксический элемент типа предсказания В сегмента определяются с использованием той же логики бинаризации, и кодировать видеоданные на основе бинаризаций синтаксического элемента типа предсказания Р сегмента и синтаксического элемента типа предсказания В сегмента.
[0083] Видеокодер 20 может быть дополнительно сконфигурирован для бинаризации синтаксического элемента типа предсказания P сегмента с определенной бинаризацией Р сегмента, бинаризации синтаксического элемента типа предсказания В сегмента с определенной бинаризацией В сегмента, применения контекстно-адаптивного бинарного арифметического кодирования (CABAC) к бинаризованному синтаксическому элементу типа прогнозирования Р сегмента и применения контекстно-адаптивного бинарного арифметического кодирования (CABAC) к бинаризованному синтаксическому элементу типа прогнозирования В сегмента.
[0084] Аналогичным образом видеодекодер 30 может быть сконфигурирован для отображения бинаризованного синтаксического элемента типа предсказания Р сегмента на тип предсказания с использованием отображения бинаризации для блока видеоданных в Р сегменте, отображения бинаризованного синтаксического элемента типа предсказания В сегмента на тип предсказания с использованием того же самого отображения бинаризации для блока видеоданных в В сегменте и декодирования видеоданных на основе отображенных типов предсказания.
[0085] Видеодекодер 30 может быть дополнительно сконфигурирован, чтобы принимать подвергнутый контекстно-адаптивному бинарному арифметическому кодированию синтаксический элемент типа предсказания Р сегмента, который указывает тип предсказания для блока видеоданных в Р сегменте, принимать подвергнутый контекстно-адаптивному бинарному арифметическому кодированию синтаксический элемент типа предсказания В сегмента, который указывает тип предсказания для блока видеоданных в В сегменте, декодировать синтаксический элемент типа предсказания Р сегмента, чтобы сформировать бинаризованный синтаксический элемент типа предсказания Р сегмента, и декодировать синтаксический элемент типа предсказания В сегмента, чтобы сформировать бинаризованный синтаксический элемент типа предсказания В сегмента.
[0086] Таблица 5 ниже показывает производительность кодирования с использованием общей бинаризации для P и B сегментов, показанных в таблице 2. Как можно видеть из таблицы 5, незначительная эффективность кодирования теряется (или не теряется вообще) при использовании общих бинаризаций. HE (высокая эффективность) низкой задержки P является общим тестовым условием для бинаризаций однонаправленно предсказанных (Р) сегментов. Классы A-E представляют различные разрешения кадров. Класс А соответствует разрешению 2k×4k. Класс B соответствует разрешению 1920×1080. Класс C соответствует разрешению WVGA. Класс D соответствует разрешению WQVGA. Класс E соответствует разрешению 720P. Изменение от 0,1 до 0,2 процента при тестовом условии НЕ низкой задержки Р, как правило, считается незначительным.
[0087] Опционально те же бинаризации (не ограничиваясь таблицами 2-4) для типа предсказания (включает размер предсказания и/или режим предсказания) могут быть совместно использованы в двух и более различных типах сегментов интер- предсказания. Сегменты интер-предсказания могут включать в себя, без ограничения указанным:
a. P сегмент: сегмент поддерживает только однонаправленное предсказание движения;
b. В сегмент: сегмент поддерживает однонаправленное и двунаправленное предсказание движения;
c. В масштабируемом кодировании видео: улучшенный слой может совместно использовать те же самые бинаризации с базовым слоем;
d. В многовидовом кодировании: разные виды (представления) могут совместно использовать те же самые бинаризации.
[0088] Когда поддерживается асимметричное разделение, четыре контекста, поровну разделенные на два набора контекстов, используются для CABAC на последних двух структурных элементах для сигнализации синтаксического элемента pred_type для асимметричных разделений (т. е. PART_2N×nU, PART_2N×nD, PAPT_nL×2N, PART_nR×2N). В зависимости от того, выполнено ли разделение в горизонтальном направлении или вертикальном направлении, применяется один набор контекстов. Предпоследний структурный элемент (т. е. структурный элемент типа разделения; part_mode) определяет, имеет ли текущая CU симметричные разделения или асимметричные разделения. Последний структурный элемент (т. е. структурный элемент размера разделения; part_mode) определяет, является ли размером первого разделения одна четверть или три четверти от размера CU. Таблица 6 показывает пример контекстов предпоследнего (тип разделения) и последнего (размер разделения) для синтаксического элемента pred_type.
[0089] Настоящее раскрытие предлагает использовать один контекст для предпоследнего структурного элемента (т. е. структурного элемента типа разделения) и использовать режим обхода на последнем структурном элементе (т.е. структурном элементе размера разделения). В результате, число контекстов уменьшается с 4 до 1. Таблица 7 показывает пример контекста, используемого согласно данному примеру настоящего раскрытия. Таблица 8 показывает производительность кодирования, связанную с предлагаемыми изменениями. Высокая эффективность (НЕ) произвольного доступа является тестовым условием с кадрами произвольного доступа. НЕ низкой задержки B является тестовым условием, которое допускает двунаправленное предсказание.
[0090] Таким образом, согласно этому примеру, видеокодер 20 может быть сконфигурирован, чтобы определять тип разделения для режима предсказания для блока видеоданных, кодировать структурный элемент типа разделения синтаксического элемента типа предсказания для блока видеоданных с использованием контекстно-адаптивного бинарного арифметического кодирования с одним контекстом, причем один контекст является одинаковым для любого типа разделения, и кодировать структурный элемент размера разделения синтаксиса типа предсказания для блока видеоданных с использованием контекстно-адаптивного бинарного арифметического кодирования в режиме обхода.
[0091] Кроме того, согласно этому примеру, видеодекодер 30 может быть сконфигурирован, чтобы принимать синтаксический элемента типа предсказания для блока видеоданных, который был кодирован с использованием контекстно-адаптивного бинарного арифметического кодирования (CABAC), причем синтаксический элемент типа предсказания включает в себя структурный элемент типа разделения, представляющий тип разделения, и структурный элемент размера разделения, представляющий размер разделения, декодировать структурный элемент типа разделения синтаксического элемента типа предсказания с использованием контекстно-адаптивного бинарного арифметического кодирования с одним контекстом, причем один контекст является одинаковым для любого типа разделения, и декодировать структурный элемент размера разделения синтаксиса типа предсказания для блока видеоданных с использованием контекстно-адаптивного бинарного арифметического кодирования в режиме обхода.
[0092] В другом примере при кодировании прямоугольного типа разделения режим обхода или один контекст может быть использован для структурного элемента, который указывает, является ли режимом разделения PART_nL×2N или PART_nR×2N, или же режимом является PART_2N×nU, PART_2N×nD. Использование режима обхода или одного контекста применимо, потому что вероятность любого используемого режима разделения близка к 50%. Также опционально режим обхода или один контекст может быть использован для структурного элемента, который указывает, является ли режим симметричным разделением или асимметричным разделением.
[0093] Следующий пример настоящего раскрытия относится к сигнализации в режиме «слияния» интер-предсказания. В режиме слияния кодер инструктирует декодер, через сигнализацию битового потока синтаксиса предсказания, копировать вектор движения, опорный индекс (идентифицирующий опорное изображение, в данном списке опорных изображений, на которое указывает вектор движения) и направление предсказания движения (которое идентифицирует список опорных изображений (Список 0 или Список 1), т. е. с точки зрения того, предшествует ли во времени опорный кадр или следует за текущим кадром) от выбранного вектора движения-кандидата для текущей части изображения, которое должно кодироваться. Это выполняется посредством сигнализации в битовом потоке индекса в список векторов движения-кандидатов, идентифицирующего выбранный вектор движения-кандидат (то есть конкретный кандидат пространственного предсказателя вектора движения (MVP) или кандидат временного MVP).
[0094] Таким образом, в режиме слияния синтаксис предсказания может включать в себя флаг, идентифицирующий режим (в данном случае режим слияния) и индекс (merge_idx), идентифицирующий выбранный вектор движения-кандидат. В некоторых случаях вектор движения-кандидат будет в причинной части по отношению к текущей части. То есть вектор движения-кандидат будет уже декодирован декодером. Таким образом, декодер уже принял и/или определил вектор движения, опорный индекс и направление движения предсказания для причинной части. Таким образом, декодер может просто извлечь вектор движения, опорный индекс и направление предсказания движения, ассоциированные с причинной частью, из памяти и скопировать эти значения в качестве информации движения для текущей части. Для восстановления блока в режиме слияния декодер получает блок предсказания, используя полученную информацию движения для текущей части, и добавляет остаточные данные к блоку предсказания для восстановления кодированного блока.
[0095] В HM4.0 один из пяти кандидатов слияния сигнализируется, когда текущая PU находится в режиме слияния. Усеченный унарный код используется для представления синтаксического элемента merge_idx. В одном предложении для HEVC, для CABAC, каждый структурный элемент использует один контекст. Настоящее раскрытие предлагает использовать один контекст повторно во всех четырех структурных элементах, как показано в таблице 9.
синтаксического элемента pred_type
[0096] Таблица 10 показывает производительность кодирования, связанную с этим примером.
[0097] Опционально более чем один контекст может быть использован в кодировании индекса слияния, при этом некоторые структурные элементы совместно используют тот же самый контекст, и некоторые структурные элементы используют различные контексты. В качестве одного примера только последовательные структурные элементы (bin) совместно используют тот же контекст. Например, bin2 и bin3 могут совместно использовать один контекст; bin2 и bin4 не могут совместно использовать один и тот же контекст, если только bin3 также не использует этот контекст.
[0098] В качестве другого примера предположим, что общее количество структурных элементов индекса слияния равно N (первый структурный элемент есть bin0, последний структурный элемент есть bin N-1). Y порогов, thresi, i=1, …, y, используются для определения контекста, совместно использующегося в кодировании индекса слияния. В этом примере следующие правила указывают, как контексты совместно используются между структурными элементами:
1. 0<Y<N (имеется меньше порогов, чем структурных элементов)
2. thresi < thresi+1
3. 0 < thres1
4. thresY=N
5. binj будет совместно использовать один контекст, где i={ thresY, …, thresi+1 -1}
[0099] На основании этих правил предыдущий способ, в котором один контекст многократно использоваться во всех четырех структурных элементах, можно рассматривать как один случай, где N=4, Y=1, thres1=4. Поэтому структурные элементы от 0 до 3 совместно используют тот же контекст.
[0100] Другой пример включает в себя установку N=4, Y=2, thres1=2, thres2=4. В этом примере bin0 и bin1 совместно используют одни и те же контексты, и bin2 и bin3 совместно используют одни и те же контексты.
[0101] Флаг интер-предсказания (inter_pred_flag) определяет, используется ли моно-предсказание или би-предсказание для текущей PU. В некоторых примерах индекс контекста для флага интер-предсказания равен текущей глубине CU. Так как имеется четыре возможных глубины CU (0 - 3), то существует четыре возможных контекста для кодирования inter_pred_flag.
[0102] Настоящее раскрытие предполагает, что индекс контекста, используемый для выбора контекста для кодирования inter_pred_flag, равен текущей глубине CU (например, уровень декомпозиции квадродерева для CU), но ограничен выбранным порогом (то есть меньшим из текущей глубины CU или порога). Порог может быть выбран равным 2 в одном примере. Альтернативно индекс контекста может быть равным максимальной глубине CU минус текущую глубину CU и ограничен сверху выбранным порогом. Альтернативно предопределенная таблица отображения может быть спроектирована для выбора индекса контекста по заданной глубине CU. Таблица отображения может быть реализована в виде набора логики. В результате три контекста используются для кодирования синтаксического элемента между inter_pred_flag.
[0103] Таблица 11 показывает производительность кодирования, когда таблица инициализации изменяется, но количество контекстов не изменяется. Таблица 12 показывает производительность кодирования предлагаемого способа, который уменьшает количество контекстов с 4 до 3.
CABAC по inter_pred_flag
[0104] Индекс опорного кадра (ref_idx_lx) сигнализируется с помощью усеченного унарного кода по отношению к активному опорному кадру в ассоциированном списке (например, Список0 или Список1). Три контекста используются для кодирования индекса опорного кадра. Один контекст - для структурного элемента 0, один контекст - для структурного элемента 1 и один контекст используется для остальной части структурных элементов. Таблица 13 показывает пример назначений контекста для структурных элементов унарного кода для ref_idx_lx.
структурных элементов)
[0105] Настоящее раскрытие предлагает использование двух контекстов для кодирования унарного кода для ref_idx_lx: один контекст для структурного элемента 0 и другой контекст для остальных структурных элементов. Таблица 14 показывает пример назначения контекста для структурных элементов унарного кода для ref_idx_lx согласно этому примеру настоящего раскрытия. Таблица 15 показывает производительность кодирования, ассоциированную с предложенными модификациями.
[0106] Для синтаксических элементов флага кодированного блока цветности (cbf_cb и cbf_cr) два различных набора контекстов (5 контекстов в каждом наборе контекстов) используются для CABAC. Индекс фактического контекста, используемого в каждом наборе, равен текущей глубине преобразования, ассоциированной с флагом кодированного блока цветности, который кодируется. Таблица 16 показывает наборы контекстов для флагов кодированного блока цветности cbf_cb и cbf_cr.
[0107] Настоящее раскрытие предлагает, что cbf_cb и cbf_cr совместно используют один набор контекстов. Индекс действительного контекста, используемого в каждом наборе, может все еще быть равным текущей глубине преобразования, ассоциированной с флагом кодированного блока цветности, который кодируется. Таблица 17 показывает наборы контекстов для флагов кодированного блока цветности cbf_cb и cbf_cr согласно примерам настоящего раскрытия. Таблица 18 показывает производительность кодирования, ассоциированную с предложенными модификациями.
[0108] Таким образом, согласно этому примеру, как видеокодер 20, так и видеодекодер 30 могут быть сконфигурированы, чтобы кодировать флаг кодированного блока цветности Cb для блока видеоданных с использованием контекстно-адаптивного бинарного арифметического кодирования (CABAC), причем CABAC использует набор контекстов, включающий в себя один или более контекстов, и кодировать флаг кодированного блока цветности Cr с использованием CABAC, причем CABAC использует тот же набор контекстов, как и для флага кодированного блока цветности Cb. Видеокодер 20 и видеодекодер 30 могут быть дополнительно сконфигурированы для выбора контекста из одного или более контекстов на основе глубины преобразования блока преобразования блока, ассоциированного с блоком видеоданных.
[0109] В одном предложении для HEVC имеется двенадцать наборов контекстов как для coeff_abs_level_greater1_flag, так и coeff_abs_level_greater2_flag. coeff_abs_level_greater1_flag указывает, имеет ли коэффициент преобразования абсолютное значение больше, чем 1. coeff_abs_level_greater2_flag указывает, имеет ли коэффициент преобразования абсолютное значение больше, чем 2. Наборы контекстов одинаково назначаются для компонента яркости и цветности, т. е. 6 наборов контекстов для яркости и 6 контекстов для цветности. Каждый набор контекстов состоит из 5 контекстов. Индекс набора контекстов, ctxSet, выбран на основе предыдущего уровня coeff_abs_level_greater1_flag. Для coeff_abs_level_greater1_flag индекс контекста в наборе контекстов, greater1Ctx, определяется на основе концевых единиц до максимум 4. Индекс контекста может быть представлен в виде:
сtxIdx_level_greater1 = (ctxSet * 5) + Min(4, greater 1Ctx) (1)
[0110] Для coeff_abs_level_greater2_flag индекс контекста в наборе контекстов, greater2Ctx, основывается на числе coeff_abs_level_greater1_flag, составляющем от 1 до максимум 4. Индекс контекста может быть представлен в виде:
ctxIdx_level_greater2 = (ctxSet * 5) + Min(4, greater2Ctx) (2)
greater1Ctx основан на числе для значимых коэффициентов и числе коэффициентов, которые больше 1. С другой стороны, greater2Ctx основан на числе коэффициентов, которые больше, чем 1.
[0111] В некоторых примерах различное число контекстов может быть использовано в различных наборах контекстов, в том числе, например:
1. Наборы контекстов для уровня большего, чем 1, или уровня большего, чем 2, могут иметь разное число контекстов. Например, наборы контекстов 0 и 3 могут иметь 5 контекстов, а остальные наборы контекстов могли бы иметь 2 контекста.
2. Наборы контекстов для коэффициента яркости могут иметь разное число контекстов по сравнению с наборами контекстов для компонента цветности. Например, набор контекстов 0 для яркости может иметь 5 контекстов, а набор контекстов 0 для цветности может иметь 4 контекста.
3. Набор контекстов для уровня большего, чем 1, может иметь отличающееся число контекстов, по сравнению с набором контекстов для уровня большего, чем 2. Например, набор контекстов 0 для уровня большего, чем 1, может иметь 5 контекстов, и набор контекстов 0 для уровня большего, чем 2, мог бы иметь только 3 контекста.
[0112] В других примерах может быть использовано другое число для наборов контекстов для кодирования больше 1 или больше 2, в том числе, например:
1. Наборы контекстов для коэффициента яркости могут иметь отличающееся число наборов контекстов по отношению к наборам контекстов, используемых для компонента цветности. Например, яркость могла бы использовать 6 контекстов, а цветность могла бы использовать 4 контекста.
2. Наборы контекстов для больше 1 могут иметь другое число контекстов по отношению к используемым наборам контекстов больше 2. Например, в случае больше 1 могло бы использоваться 6 контекстов, а в случае больше 2 могло бы использоваться 4 контекста.
[0113] Опционально используется метрика для определения того, какой контекст используется в наборе контекстов, и диапазон значения метрики больше, чем число контекстов в наборе контекстов. В одном таком аспекте один контекст мог бы быть ассоциирован с одним или более значений метрики. Совместное использование контекста предпочтительно ограничено непрерывными значениями. Например, пусть значение метрики равно у. у=2 ассоциировано с контекстом 3, и у=1 и у=4 также могут быть ассоциированы с контекстом 3. Однако если у=3 ассоциировано с контекстом 4, у=4 не может быть ассоциировано с контекстом 3.
[0114] Например, для coeff_abs_level_greater1_flag наборы контекстов 0 и 3 имеют 5 контекстов, а наборы контекстов 1, 2, 4 и 5 имеют 2 контекста. Для coeff_abs_level_greater2_flag наборы контекстов 0, 1 и 2 имеют 5 контекстов, а наборы контекстов 3, 4 и 5 имеют 2 контекста. Это может быть представлено в виде:
ctxIdx_level_greater1 = (ctxSet * 5) + Min(Thres_greater1, greater1Ctx)(3)
если ctxSet = 0 или ctxSet = 3, Thres_greater1 = 4;
в противном случае, Thres_greater1 = 1
ctxIdx_level_greater2 = (ctxSet * 5) + Min(Thres_greater2, greater2Ctx)(4)
если ctxSet <3, Thres_greater2 = 4;
в противном случае, Thres_greater2 = 1
Thres_greater1 и Thres_greater2 можно выбрать различным образом в зависимости от следующих ситуаций:
1. Компонент яркости или цветности,
2. Наборы контекстов.
[0115] В качестве другого примера для coeff_abs_level_greater1_flag наборы контекстов 0 и 3 имеют 5 контекстов, и наборы контекстов 1, 2, 4 и 5 имеют 3 контекста. Для coeff_abs_level_greater2_flag наборы контекстов 0, 1 и 2 имеют 5 контекстов, и наборы контекстов 3, 4 и 5 имеют 2 контекста. Это может быть представлено в виде:
ctxIdx_level_greater1 = (ctxSet * 5) + greater1Ctx_mapped(3) ctxIdx_level_greater2 = (ctxSet * 5) + greater2Ctx_mapped(4)
[0116] В таких примерах отображение может быть таким, как показано в таблицах 19 и 20:
[0117] Таблицы инициализации CABAC для coeff_abs_level_greater1_flag и coeff_abs_level_greater2_flag также модифицированы для наборов контекстов для Thres_greater1 или Thres_greater2, равного 1. Модификации перемещают инициализацию пятого контекста вперед, чтобы стать инициализацией второго контекста. Этот предложенный способ уменьшает количество контекстов от 120 до 78.
[0118] Таблица 21 перечисляет число контекстов для всех синтаксических элементов, упомянутых в предыдущих разделах. Общее снижение составляет 56 контекстов.
[0119] На фиг. 2 представлена блок-схема, иллюстрирующая примерный видеокодер 20, который может реализовать способы, описанные в настоящем раскрытии. Видеокодер 20 может выполнять интра- и интер-кодирование блоков видео в сегментах видео. Интра-кодирование опирается на пространственное предсказание для уменьшения или устранения пространственной избыточности в видео в течение определенного видеокадра или изображения. Интер-кодирование основывается на временном предсказании для уменьшения или устранения временной избыточности в видео в смежных кадрах или изображениях видеопоследовательности. Интра-режим (режим I) может относиться к любому из нескольких режимов пространственного сжатия. Интер-режимы, такие как однонаправленное предсказание (режим P) или двунаправленное предсказание (режим B), могут относиться к любому из различных режимов временного сжатия.
[0120] В примере на фиг. 2 видеокодер 20 включает в себя модуль 35 разделения, модуль 41 предсказания, память 64 опорных изображений, сумматор 50, модуль 52 преобразования, модуль 54 квантования и модуль 56 энтропийного кодирования. Модуль 41 предсказания включает в себя модуль 42 оценки движения, модуль 44 компенсации движения и модуль 46 интра-предсказания. Для восстановления блоков видео видеокодер 20 также включает в себя модуль 58 обратного квантования, модуль 60 обратного преобразования и сумматор 62. Фильтр устранения блочности (не показан на фиг. 2) также может быть включен, чтобы фильтровать границы блоков для устранения артефактов блочности из восстановленного видео. При желании фильтр устранения блочности, как правило, фильтрует выходной сигнал сумматора 62. Дополнительные фильтры контура (в контуре или после контура) также могут быть использованы в дополнение к фильтру устранения блочности.
[0121] Как показано на фиг. 2, видеокодер 20 принимает видеоданные, и модуль 35 разделения разделяет данные на блоки видео. Такое разделение может также включать разделение на сегменты (слайсы), мозаичные элементы (плитки) или другие крупные единицы, а также разделение блока видео, например, в соответствии со структурой квадродерева LCU и CU. Видеокодер 20 обычно иллюстрирует компоненты, которые кодируют блоки видео в сегменте видео, подлежащем кодированию. Сегмент может быть разделен на несколько блоков видео (и, возможно, в наборы блоков видео, называемых плитками). Модуль 41 предсказания может выбрать один из множества возможных режимов кодирования, таких как один из множества режимов интра-кодирования или один из множества режимов интер-кодирования для текущего блока видео на основе результатов по ошибкам (например, скорость кодирования и уровень искажений). Модуль 41 предсказания может предоставить в результате интра- или интер-кодированный блок на сумматор 50 для формирования остаточных данных блока и на сумматор 62 для восстановления кодированного блока для использования в качестве опорного изображения.
[0122] Модуль 46 интра-предсказания в модуле 41 предсказания может выполнять кодирование с интра-предсказанием текущего блока видео по отношению к одному или более соседних блоков в том же кадре или сегменте в качестве текущего блока, подлежащего кодированию, чтобы обеспечить пространственное сжатие. Модуль 42 оценки движения и модуль 44 компенсации движения в модуле 41 предсказания выполняют кодирование с интер-предсказанием текущего блока видео по отношению к одному или более блоков предсказания в одном или более опорных изображений, чтобы обеспечить временное сжатие.
[0123] Модуль 42 оценки движения может быть выполнен с возможностью определения режима интер-предсказания для сегмента видео в соответствии с предопределенным шаблоном для видеопоследовательности. Предопределенный шаблон может обозначить сегменты видео в последовательности как Р сегменты, B сегменты или GPB (обобщенные P/B) сегменты. Модуль 42 оценки движения и модуль 44 компенсации движения могут быть с высокой степенью интеграции, но проиллюстрированы отдельно для концептуальных целей. Оценка движения, осуществляемая модулем 42 оценки движения, является процессом генерации векторов движения, который оценивает движение для блоков видео. Вектор движения, например, может указывать смещение PU блока видео внутри текущего видеокадра или изображения по отношению к блоку прогнозирования в опорном изображении.
[0124] Блок предсказания представляет собой блок, который находится в точном соответствии с PU кодируемого блока видео в смысле пиксельной разности, который может быть определен суммой абсолютных разностей (SAD), суммой квадратичных разностей (SSD) или другими разностными метриками. В некоторых примерах видеокодер 20 может вычислять значения для субцелых пиксельных позиций опорных изображений, хранящихся в памяти 64 опорных изображений. Например, видеокодер 20 может интерполировать значения в одну четверть пиксельных позиций, одну восьмую пиксельных позиций или других дробных пиксельных позиций опорного изображения. Таким образом, модуль 42 оценки движения может выполнять поиск движения относительно полных пиксельных позиций и дробных пиксельных позиций и выводить вектор движения с дробной пиксельной точностью.
[0125] Модуль 42 оценки движения вычисляет вектор движения для PU блока видео в интер-кодированном сегменте путем сравнения положения PU с положением блока прогнозирования опорного изображения. Опорное изображение может быть выбрано из первого списка опорных изображений (список 0) или второго списка опорных изображений (Список 1), каждый из которых идентифицирует одно или более опорных изображений, сохраненных в памяти 64 опорных изображений. Модуль 42 оценки движения передает вычисленный вектор движения на модуль 56 энтропийного кодирования и модуль 44 компенсации движения.
[0126] Компенсация движения, осуществляемая модулем 44 компенсации движения, может включать в себя извлечение или генерацию блока предсказания на основе вектора движения, определяемого оценкой движения, возможно выполняя интерполяцию с субпиксельной точностью. После приема вектора движения для PU текущего блока видео, модуль 44 компенсации движения может определить положение блока предсказания, на который указывает вектор движения в одном из списков опорных изображений. Видеокодер 20 формирует остаточный блок видео путем вычитания пиксельных значений блока предсказания из пиксельных значений текущего кодируемого блока видео, образуя пиксельные разностные значения. Пиксельные разностные значения образуют остаточные данные для блока и могут включать разностные компоненты как яркости, так и цветности. Сумматор 50 представляет собой компонент или компоненты, которые выполняют эту операцию вычитания. Модуль 44 компенсации движения также может генерировать синтаксические элементы, ассоциированные с блоками видео и сегментами видео, для использования видеодекодером 30 при декодировании блоков видеосегмента видео.
[0127] Модуль 46 интра-предсказания может интра-предсказывать текущий блок, в качестве альтернативы интер-предсказанию, выполняемому модулем 42 оценки движения и модулем 44 компенсации движения, как описано выше. В частности, модуль 46 интра-предсказания может определить режим интра-предсказания, используемый для кодирования текущего блока. В некоторых примерах модуль 46 интра-предсказания может кодировать текущий блок, используя различные режимы интра-предсказания, например, во время отдельных проходов кодирования, и модуль 46 интра-предсказания 46 (или модуль 40 выбора режима в некоторых примерах) может выбрать соответствующий режим интра-предсказания для использования из протестированных режимов. Например, модуль 46 интра-предсказания может вычислять значения соотношения скорость-искажение путем анализа соотношения скорость-искажение для различных протестированных режимов интра-предсказания и выбрать режим интра-предсказания, имеющий лучшие характеристики соотношения скорость-искажение среди протестированных режимов. Анализ скорость-искажение обычно определяет величину искажения (или ошибку) между кодированным блоком и исходным, некодированным блоком, который был закодирован для получения кодированного блока, а также скорость передачи битов (то есть число битов), используемую для генерации кодированного блока. Модуль 46 интра-предсказания может вычислять отношения искажений и скоростей для различных кодированных блоков, чтобы определять, какой режим интра-предсказания демонстрирует лучшее значение соотношения скорости-искажения для блока.
[0128] В любом случае, после выбора режима интра-предсказания для блока, модуль 46 интра-предсказания может предоставлять информацию, указывающую на выбранный режим интра-предсказания, на модуль 56 энтропийного кодирования. Модуль 56 энтропийного кодирования может кодировать информацию, указывающую выбранный режим интра-предсказания, в соответствии с методами настоящего изобретения. Видеокодер 20 может включать в передаваемый битовый поток данные конфигурации, которые могут включать в себя множество таблиц индексов режима интра-предсказания и множество таблиц индексов модифицированного режима интра-предсказания (также называемых таблицами отображения кодовых слов), определения контекстов кодирования для различных блоков и указания наиболее вероятного режима интра-предсказания, таблицы индексов режима интра-предсказания и таблицы индексов модифицированного интра-предсказания, чтобы использовать для каждого из контекстов.
[0129] После того как модуль 41 предсказания генерирует блок предсказания для текущего блока видео посредством интер-предсказания или интра-предсказания, видеокодер 20 формирует остаточный блок видео путем вычитания блока предсказания из текущего блока видео. Остаточные видеоданные в остаточном блоке могут включаться в одну или более TU и подаваться на модуль 52 преобразования. Модуль 52 преобразования преобразует остаточные видеоданные в остаточные коэффициенты преобразования, используя преобразование, такое как дискретное косинусное преобразование (DCT) или концептуально подобное преобразование. Модуль 52 преобразования может преобразовывать остаточные видеоданные из пиксельной области в область преобразования, например частотную область.
[0130] Модуль 52 преобразования может отправить полученные в результате коэффициенты преобразования на модуль 54 квантования. Модуль 54 квантования квантует коэффициенты преобразования для дальнейшего снижения битовой скорости. Процесс квантования может уменьшить битовую глубину, ассоциированную с некоторыми или всеми коэффициентами. Степень квантования может быть модифицирована путем настройки параметра квантования. В некоторых примерах модуль 54 квантования может затем выполнять сканирование матрицы, включающей в себя квантованные коэффициенты преобразования. В качестве альтернативы, модуль 56 энтропийного кодирования может выполнять сканирование. В качестве одного примера методы кодирования, описанные в настоящем раскрытии, могут быть выполнены полностью или частично модулем 56 энтропийного кодирования. Однако аспекты настоящего описания не ограничены этим. Например, методы кодирования, описанные в настоящем раскрытии, могут быть выполнены компонентом видеокодера 20, не показанным на фиг. 2, таким как процессор или любой другой компонент. В некоторых примерах методы кодирования настоящего раскрытия могут быть выполнены одним из других блоков или модулей, показанных на фиг. 2. В некоторых других примерах методы кодирования настоящего раскрытия могут быть выполнены с помощью комбинации блоков и модулей видеокодера 20. Таким образом, видеокодер 20 может быть сконфигурирован для выполнения примерных методов, описанных в настоящем раскрытии.
[0131] После квантования модуль 56 энтропийного кодирования кодирует квантованные коэффициенты преобразования. Например, модуль 56 энтропийного кодирования может выполнять контекстно-адаптивное кодирование переменной длины (CAVLC), контекстно-адаптивное бинарное арифметическое кодирование (CABAC), основанное на синтаксисе контекстно-адаптивное бинарное арифметическое кодирование (SBAC), энтропийное кодирование с разделением интервала вероятности (PIPE) или другую технологию энтропийного кодирования или метод. После энтропийного кодирования модулем 56 энтропийного кодирования кодированный битовый поток может передаваться на видеодекодер 30 или архивироваться для последующей передачи или извлечения видеодекодером 30. Блок 56 энтропийного кодирования также может энтропийно кодировать вектора движения и другие синтаксические элементы для текущего кодируемого сегмента видео.
[0132] В одном примере настоящего раскрытия модуль 56 энтропийного кодирования может быть сконфигурирован, чтобы определять первый тип предсказания для блока видеоданных в Р сегменте, представлять первый тип предсказания как синтаксический элемент типа предсказания P сегмента, определять второй тип предсказания для блока видеоданных в B сегменте, представлять второй тип предсказания как синтаксический элемент типа предсказания B сегмента, определять бинаризацию Р сегмента для синтаксического элемента типа предсказания P сегмента, определять бинаризацию B сегмента для синтаксического элемента типа предсказания В сегмента, причем синтаксический элемент типа предсказания P сегмента и синтаксический элемент типа предсказания В сегмента определяются с использованием той же самой логики бинаризации, и кодировать видеоданные на основе бинаризации синтаксического элемента типа предсказания P сегмента и синтаксического элемента типа предсказания В сегмента.
[0133] В другом примере настоящего раскрытия модуль 56 энтропийного кодирования может быть сконфигурирован, чтобы определять тип разделения для режима предсказания для блока видеоданных, кодировать структурный элемент типа разделения синтаксического элемента типа предсказания для блока видеоданных с использованием контекстно-адаптивного бинарного арифметического кодирования с одним контекстом, причем один контекст является одинаковым для любого типа разделения, и кодировать структурный элемент типа разделения синтаксиса типа предсказания для блока видеоданных с использованием контекстно-адаптивного бинарного арифметического кодирования в режиме обхода.
[0134] В другом примере настоящего раскрытия модуль 56 энтропийного кодирования может быть сконфигурирован, чтобы кодировать флаг кодированного блока цветности Cb для блока видеоданных с использованием контекстно-адаптивного бинарного арифметического кодирования (CABAC), причем CABAC использует набор контекстов, включающий в себя один или более контекстов, и кодировать флаг кодированного блока цветности Cr с использованием CABAC, причем СААВС использует тот же самый набор контекстов, что и для флага кодированного блока цветности Cb. Видеокодер 20 и видеодекодер 30 могут быть дополнительно сконфигурированы, чтобы выбирать контекст из одного или более контекстов на основе глубины преобразования модуля преобразования, ассоциированного с блоком видеоданных.
[0135] Модуль 58 обратного квантования и модуль 60 обратного преобразования применяют обратное квантование и обратное преобразование, соответственно, для восстановления остаточного блока в пиксельной области для последующего использования в качестве опорного блока опорного изображения. Модуль 44 компенсации движения может вычислять опорный блок путем суммирования остаточного блока с блоком предсказания одного из опорных изображений в одном из списков опорных изображений. Модуль 44 компенсации движения может также применять один или более интерполяционных фильтров к восстановленному остаточному блоку для вычисления суб-целых пиксельных значений для использования в оценке движения. Сумматор 62 суммирует восстановленный остаточный блок со скомпенсированным по движению блоком предсказания, сформированным посредством модуля 44 компенсации движения, чтобы получить опорный блок для сохранения в памяти 64 опорных изображений. Опорный блок может быть использован модулем 42 оценки движения и модулем 44 компенсации движения в качестве опорного блока для интер-предсказания блока в последующем видеокадре или изображении.
[0136] На фиг. 3 представлена блок-схема, иллюстрирующая примерный видеодекодер 30, который может реализовать способы, описанные в настоящем раскрытии. В примере на фиг. 3 видеодекодер 30 включает в себя модуль 80 энтропийного декодирования, модуль 81 предсказания, модуль 86 обратного квантования, модуль 88 обратного преобразования, сумматор 90 и память 92 опорных изображений. Модуль 81 предсказания включает в себя модуль 82 компенсации движения и модуль 84 интра-предсказания 84. Видеодекодер 30 может в некоторых примерах выполнять проход декодирования, в общем, обратным образом к проходу кодирования, описанному со ссылкой на видеокодер 20 по фиг. 2.
[0137] Во время процесса декодирования видеодекодер 30 принимает битовый поток кодированного видео, который представляет блоки видеосегмента кодированного видео и ассоциированные синтаксические элементы, из видеокодера 20. Модуль 80 энтропийного декодирования видеодекодера 30 энтропийно декодирует битовый поток для генерации квантованных коэффициентов, векторов движения, а также других синтаксических элементов. Модуль 80 энтропийного декодирования направляет векторы движения и другие синтаксические элементы в модуль 81 предсказания. Видеодекодер 30 может получать синтаксические элементы на уровне сегмента видео и/или на уровне блока видео.
[0138] В качестве одного примера методы кодирования, описанные в настоящем раскрытии, могут быть выполнены полностью или частично посредством модуля 80 энтропийного декодирования. Однако аспекты настоящего раскрытия не ограничены этим. Например, методы кодирования, описанные в настоящем раскрытии, могут быть выполнены компонентом видеодекодера 30, не показанным на фиг. 3, таким, как процессор или любой другой компонент. В некоторых примерах методы кодирования настоящего раскрытия могут быть выполнены одним из других блоков или модулей, показанных на фиг. 3. В еще некоторых других примерах методы кодирования настоящего раскрытия могут быть выполнены с помощью комбинации блоков и модулей видеодекодера 30. Таким образом, видеодекодер 30 может быть сконфигурирован для выполнения примерных методов, описанных в настоящем раскрытии.
[0139] В одном примере настоящего раскрытия модуль 80 энтропийного декодирования может быть сконфигурирован, чтобы отображать бинаризованный синтаксический элемент типа предсказания P сегмента на тип предсказания с использованием отображения бинаризации для блока видеоданных в Р сегменте, отображать бинаризованный синтаксический элемент типа предсказания В сегмента на тип предсказания с использованием того же отображения бинаризации для блока видеоданных в В сегменте и декодировать видеоданные на основе отображенных типов предсказания.
[0140] В одном примере настоящего раскрытия модуль 80 энтропийного декодирования может быть сконфигурирован, чтобы принимать синтаксический элемент типа предсказания для блока видеоданных, который был закодирован с использованием контекстно-адаптивного бинарного арифметического кодирования (CABAC), причем синтаксический элемент типа предсказания включает в себя структурный элемент типа разделения, представляющий тип разделения, и структурный элемент размера разделения, представляющий размер разделения, декодировать структурный элемент типа разделения синтаксического элемента типа предсказания с использованием контекстно-адаптивного бинарного арифметического кодирования с одним контекстом, причем один контекст является одинаковым для любого типа разделения, и декодировать структурный элемент размера разделения синтаксического элемента типа предсказания для блока видеоданных с использованием контекстно-адаптивного бинарного арифметического кодирования в режиме обхода.
[0141] В другом примере настоящего раскрытия модуль 80 энтропийного декодирования может быть сконфигурирован, чтобы кодировать флаг кодированного блока цветности Cb для блока видеоданных с использованием контекстно-адаптивного бинарного арифметического кодирования (CABAC), причем САВАС использует набор контекстов, включающий в себя один или более контекстов, и кодировать флаг кодированного блока цветности Cr с использованием CABAC, причем САВАС использует тот же самый набор контекстов, что и для флага кодированного блока цветности Cb. Видеокодер 20 и видеодекодер 30 могут быть дополнительно сконфигурированы, чтобы выбирать контекст из одного или более контекстов на основе глубины преобразования модуля преобразования, ассоциированного с блоком видеоданных.
[0142] Когда сегмент видео кодирован как интра-кодированный (I) сегмент, модуль 84 интра-предсказания модуля 81 предсказания может генерировать данные предсказания для блока видео текущего сегмента видео на основе сигнализированного режима интра-предсказания и данных из ранее декодированных блоков текущего кадра или изображения. Когда видеокадр кодирован как интер-кодированный (т.е. B, P или GPB) сегмент, модуль 82 компенсации движения модуля 81 предсказания формирует блоки предсказания для блока видео текущего сегмента видео на основе векторов движения и других синтаксических элементов, полученных из модуля 80 энтропийного декодирования. Блоки предсказания могут быть сформированы из одного из опорных изображений в одном из списков опорных изображений. Видеодекодер 30 может построить списки опорных кадров, список 0 и список 1, используя методы построения по умолчанию на основе опорных изображений, хранящихся в памяти 92 опорных изображений.
[0143] Модуль 82 компенсации движения определяет информацию предсказания для блока видео текущего сегмента видео путем анализа векторов движения и других синтаксических элементов и использует информацию предсказания для получения блоков предсказания для текущего декодируемого блока видео. Например, модуль 82 компенсации движения использует некоторые из полученных синтаксических элементов для определения режима предсказания (например, интра- или интер-предсказания), используемого для кодирования блоков видеосегмента видео, типа сегмента интер-предсказания (например, B сегмента, P сегмента или GPB сегмента), структурной информации для одного или более списков опорных изображений для сегмента, векторов движения для каждого интер-кодированного блока видеосегмента, состояния интер-предсказания для каждого интер-кодированного блока видеосегмента и другой информации для декодирования блоков видео в текущем сегменте видео.
[0144] Модуль 82 компенсации движения также может выполнять интерполяцию на основе интерполяционных фильтров. Модуль 82 компенсации движения может использовать интерполяционные фильтры, как используется видеокодером 20 во время кодирования блоков видео, для вычисления интерполированных значений для суб-целых пикселей опорных блоков. В этом случае модуль 82 компенсации движения может определить интерполяционные фильтры, использованные видеокодером 20, из принятых синтаксических элементов и использовать интерполяционные фильтры для получения блоков предсказания.
[0145] Модуль 86 обратного квантования обратно квантует, то есть деквантует, квантованные коэффициенты преобразования, предоставленные в потоке битов и декодированные модулем 80 энтропийного декодирования. Процесс обратного квантования может включать использование параметра квантования, вычисленного видеокодером 20 для каждого блока видео в сегменте видео, чтобы определить степень квантования и аналогично степень обратного квантования, которые должны применяться. Модуль 88 обратного преобразования применяет обратное преобразование, например обратное DCT, обратное целочисленное преобразование или концептуально подобный процесс обратного преобразования к коэффициентам преобразования для получения остаточных блоков в пиксельной области.
[0146] После того, как модуль 82 компенсации движения генерирует блок предсказания для текущего блока видео на основе векторов движения и других синтаксических элементов, видеодекодер 30 формирует декодированный блок видео путем суммирования остаточных блоков из модуля 88 обратного преобразования с соответствующими блоками предсказания, сгенерированными модулем 82 компенсации движения. Сумматор 90 представляет собой компонент или компоненты, которые выполняют эту операцию суммирования. При желании фильтр устранения блочности может также применяться для фильтрации декодированных блоков, чтобы удалить артефакты блочности. Другие фильтры контура (в контуре кодирования или после контура кодирования) также могут быть использованы для сглаживания пиксельных переходов или улучшения иным образом качества видео. Декодированные блоки видео в данном кадре или изображении затем сохраняются в памяти 92 опорных изображений, в которой хранятся опорные кадры, используемые для последующей компенсации движения. Память 92 опорных изображений также сохраняет декодированные видео для последующего представления на устройстве отображения, таком как устройство 32 отображения на фиг. 1.
[0147] На фиг. 6 представлена блок-схема, иллюстрирующая пример способа кодирования видео согласно настоящему раскрытию. Способ по фиг. 6 может быть реализован видеокодером 20. Видеокодер 20 может быть сконфигурирован, чтобы определять первый тип предсказания для блока видеоданных в Р сегменте (602) и представлять первый тип предсказания как синтаксический элемент типа предсказания P сегмента (604). Видеокодер 20 может быть дополнительно сконфигурирован, чтобы определять второй тип предсказания для блока видеоданных в B сегменте (606) и представлять второй тип предсказания в качестве синтаксического элемента типа предсказания В сегмента (608). Синтаксический элемент типа предсказания Р сегмента и синтаксический элемент типа предсказания B сегмента определяют режим предсказания и тип разделения. Режим предсказания может включать в себя одно из интер-предсказания и интра-предсказания. Тип разделения может включать в себя одно из симметричных разделений и асимметричных разделений.
[0148] Видеокодер 20 может быть дополнительно сконфигурирован, чтобы определять бинаризацию Р сегмента для синтаксического элемента типа предсказания Р сегмента (610) и определять бинаризацию B сегмента для синтаксического элемента типа предсказания В сегмента, причем синтаксический элемент типа предсказания Р сегмента и синтаксический элемент типа предсказания В сегмента определяются с использованием той же самой логики бинаризации (612). Видеокодер 20 может затем кодировать видеоданные на основе бинаризаций синтаксического элемента типа предсказания Р сегмента и синтаксического элемента типа предсказания В сегмента (614).
[0149] Кодирование видеоданных может содержать бинаризацию синтаксического элемента типа предсказания Р сегмента с определенными бинаризациями Р сегмента, бинаризацию синтаксического элемента типа предсказания В сегмента с определенными бинаризациями В сегмента, применение контекстно-адаптивного бинарного арифметического кодирования (CABAC) к бинаризованному синтаксическому элементу типа предсказания Р сегмента и применение контекстно-адаптивного бинарного арифметического кодирования (CABAC) к бинаризованному синтаксическому элементу типа предсказания B сегмента.
[0150] На фиг. 7 представлена блок-схема, иллюстрирующая пример способа декодирования видео согласно настоящему раскрытию. Способ по фиг. 7 может быть реализован с помощью видеодекодера 30. Видеодекодер 30 может быть сконфигурирован для приема подвергнутого контекстно-адаптивному бинарному арифметическому кодированию синтаксического элемента типа предсказания P сегмента, который указывает тип предсказания для блока видеоданных в Р сегменте (702), и приема подвергнутого контекстно-адаптивному бинарному арифметическому кодированию синтаксического элемента типа предсказания B сегмента, который указывает тип предсказания для блока видеоданных в B сегменте (704). Синтаксический элемент типа предсказания P сегмента и синтаксический элемент типа предсказания B сегмента определяют режим предсказания и тип разделения. Режим предсказания может включать в себя одно из интер-предсказания и интра-предсказания. Тип разделения может включать в себя одно из симметричных разделений и асимметричных разделений.
[0151] Видеодекодер 30 может быть дополнительно сконфигурирован, чтобы декодировать синтаксический элемент типа предсказания P сегмента для получения бинаризованного синтаксического элемента типа предсказания P сегмента (706) и декодировать синтаксический элемент типа предсказания В сегмента для получения бинаризованного синтаксического элемента типа предсказания В сегмента (708). Видеодекодер 30 может быть дополнительно сконфигурирован, чтобы отображать бинаризованный синтаксический элемент типа предсказания P сегмента на тип предсказания с использованием отображения бинаризации для блока видеоданных в Р сегменте (710), и чтобы отображать бинаризованный синтаксический элемент типа предсказания В сегмента на тип предсказания с использованием того же самого отображения бинаризации для блока видеоданных в B сегменте (712). Видеодекодер 30 может затем декодировать видеоданные на основе отображенных типов предсказания (714).
[0152] На фиг. 8 представлена блок-схема последовательности операций, иллюстрирующая пример способа кодирования видео согласно настоящему раскрытию. Способ по фиг. 8 может быть реализован видеокодером 20. Видеокодер 20 может быть сконфигурирован, чтобы определять тип разделения для режима предсказания для блока видеоданных (802) и кодировать структурный элемент типа разделения синтаксического элемента типа предсказания для блока видеоданных с использованием контекстно-адаптивного бинарного арифметического кодирования (CABAC) с одним контекстом (804). Один контекст является одинаковым для любого типа разделения. В одном примере тип разделения является асимметричным разделением, и структурный элемент типа разделения указывает, является ли асимметричное разделение вертикально разделенным или горизонтально разделенным. Например, структурный элемент размера разделения указывает, является ли первое разделение равным одной четверти размера блока видеоданных или первое разделение равно трем четвертям размера блока видеоданных.
[0153] Видеокодер 20 может быть дополнительно сконфигурирован, чтобы кодировать структурный элемент размера разделения синтаксического элемента типа предсказания для блока видеоданных с использованием CABAC в режиме обхода (806).
[0154] На фиг. 9 представлена блок-схема последовательности операций, иллюстрирующая пример способа декодирования видео согласно настоящему раскрытию. Способ по фиг. 9 может быть реализован с помощью видеодекодера 30. Видеодекодер 30 может быть сконфигурирован, чтобы принимать синтаксический элемент типа предсказания для блока видеоданных, которые были закодированы с использованием контекстно-адаптивного бинарного арифметического кодирования (CABAC), причем синтаксический элемент типа предсказания включает в себя структурный элемент типа разделения, представляющий тип разделения, и структурный элемент размера разделения, представляющий размер разделения (902). В одном примере тип разделения является асимметричным разделением, и структурный элемент типа разделения указывает, является ли асимметричное разделение вертикально разделенным или горизонтально разделенным. Например, структурный элемент размера разделения указывает, является ли первое разделение равным одной четверти размера блока видеоданных или первое разделение равно трем четвертям размера блока видеоданных.
[0155] Видеодекодер 30 может быть дополнительно сконфигурирован, чтобы декодировать структурный элемент типа разделения синтаксического элемента типа предсказания с использованием CABAC с одним контекстом, причем один контекст является тем же самым для любого типа разделения (904), и декодировать структурный элемент размера разделения синтаксического элемента типа предсказания с использованием CABAC в режиме обхода (906).
[0156] На фиг. 10 представлена блок-схема последовательности операций, иллюстрирующая пример способа кодирования видео согласно настоящему раскрытию. Способ по фиг. 10 может быть реализован видеокодером 20 или видеодекодером. Для целей фиг. 10 видеокодер 20 и видеодекодер 30 будут упоминаться в совокупности как устройства кодирования видео. В соответствии с методами по фиг. 10 устройство кодирования видео может быть сконфигурировано, чтобы кодировать флаг кодированного блока цветности Cb для блока видеоданных с использованием контекстно-адаптивного бинарного арифметического кодирования (CABAC), причем кодирование флага кодированного блока цветности Cb включает в себя использование набора контекстов, включающего в себя один или более контекстов как часть CABAC (1002), а также кодировать флаг кодированного блока цветности Cr с использованием CABAC, причем кодирование флага кодированного блока цветности Cr включает в себя использование того же набора контекстов, что и для флага кодированного блока цветности Cb, как часть CABAC (1004). В одном примере набор контекстов включает в себя 5 контекстов.
[0157] В одном опциональном примере настоящего раскрытия устройство кодирования видео может быть дополнительно сконфигурировано, чтобы выбирать контекст из одного или более контекстов на основе глубины преобразования единицы преобразования, ассоциированной с блоком видеоданных (1006).
[0158] При работе в качестве видеокодера устройство кодирования видео может быть дополнительно сконфигурировано, чтобы сигнализировать кодированный флаг кодированного блока цветности Cb в кодированном битовом потоке видео и сигнализировать кодированный флаг кодированного блока цветности Cr в кодированном битовом потоке видео. При работе в качестве видеодекодера устройство кодирования видео может быть дополнительно сконфигурировано, чтобы принимать кодированный флаг кодированного блока цветности Cb в кодированном битовом потоке видео, а также принимать кодированный флаг кодированного блока цветности Cr в кодированном битовом потоке видео.
[0159] В одном или более примерах описанные функции могут быть реализованы в аппаратных средствах, программном обеспечении, микропрограммном обеспечении или любой их комбинации. При реализации в программном обеспечении функции могут храниться или передаваться как одна или более инструкций или код на считываемом компьютером носителе и выполняться блоком обработки на основе аппаратных средств. Считываемые компьютером носители могут включать в себя считываемые компьютером носители информации, что соответствует материальному носителю, такому как носители хранения данных, или среды связи, включая любую среду, которая способствует передаче компьютерной программы из одного места в другое, например, в соответствии с протоколом связи. Таким образом, считываемые компьютером носители обычно могут соответствовать (1) материальному считываемому компьютером носителю хранения данных, который является невременным (нетранзитивным), или (2) коммуникационной среде, такой как сигнал или несущая волна. Носители хранения данных могут быть любыми доступными носителями, к которым могут получать доступ один или более компьютеров или один или более процессоров для извлечения инструкций, кода и/или структур данных для реализации методов, описанных в настоящем раскрытии. Компьютерный программный продукт может включать в себя считываемый компьютером носитель.
[0160] В качестве примера, а не ограничения, такие считываемые компьютером носители хранения данных могут включать в себя RAM, ROM, EEPROM, CD-ROM или другой оптический диск, накопитель на магнитных дисках или другие магнитные запоминающие устройства, флэш-память или любой другой носитель, который может использоваться для хранения желаемого программного кода в форме инструкций или структур данных и к которому может обращаться компьютер. Кроме того, любое соединение корректно называть считываемым компьютером носителем. Например, если инструкции передаются от веб-сайта, сервера или другого удаленного источника с помощью коаксиального кабеля, волоконно-оптического кабеля, витой пары, цифровой абонентской линии (DSL) или беспроводных технологий, таких как инфракрасная, радио и микроволновая, то коаксиальный кабель, волоконно-оптический кабель, витая пара, DSL или беспроводные технологии, такие как инфракрасная, радиочастотная и микроволновая, включаются в определение носителя. Следует понимать, однако, что считываемые компьютером носители данных и средства хранения данных не включают соединения, несущие волны, сигналы или другие транзитивные среды хранения, а вместо этого направлены на нетранзитивные, материальные носители. Диски (disk и disc), как используется здесь, включают в себя компакт-диск (CD), лазерный диск, оптический диск, цифровой универсальный диск (DVD), гибкий диск и Blu-Ray Disc, где магнитные диски (disk) обычно воспроизводят данные магнитным способом, в то время как оптические диски (disc) воспроизводят данные оптически с помощью лазеров. Комбинации вышеперечисленного также должны быть включены в объем считываемых компьютером носителей.
[0161] Инструкции могут выполняться одним или более процессорами, такими как один или более цифровых сигнальных процессоров (DSP), микропроцессоров общего назначения, специализированными интегральными схемами (ASIC), программируемыми логическими матрицами (FPGA) или другими эквивалентными интегрированными или дискретными логическими схемами. Соответственно термин "процессор", как он использован здесь, может относиться к любой из указанных выше структур или любой другой структуре, пригодной для реализации описанных здесь методов. Кроме того, в некоторых аспектах функциональность, описанная здесь, может быть представлена в специализированных аппаратных средствах и/или программных модулях, сконфигурированных для кодирования и декодирования или включена в комбинированный кодек. Кроме того, эти методы могут быть полностью реализованы в одной или более схем или логических элементов.
[0162] Методы настоящего раскрытия могут быть реализованы в широком спектре устройств или аппаратов, включая беспроводной телефон, интегральную схему (IC) или набор микросхем (например, чипсет). Различные компоненты, модули или блоки описаны в настоящем раскрытии, чтобы подчеркнуть функциональные аспекты устройств, сконфигурированных для выполнения раскрытых методов, но не обязательно требует реализации различными модулями аппаратных средств. Скорее, как описано выше, различные модули могут быть объединены в блоке аппаратных средств кодека или обеспечиваются совокупностью взаимодействующих модулей аппаратных средств, в том числе одного или более процессоров, как описано выше, в сочетании с соответствующим программным обеспечением и/или программно-аппаратными средствами.
[0163] Различные примеры были описаны. Эти и другие примеры входят в объем прилагаемой формулы изобретения.
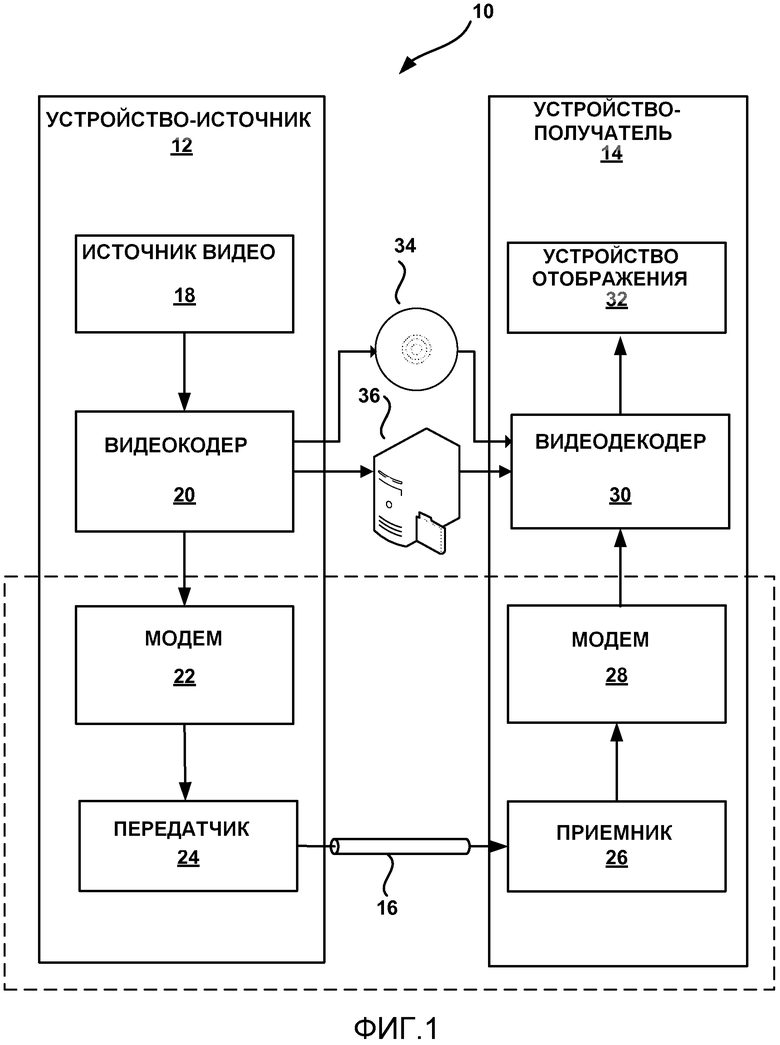
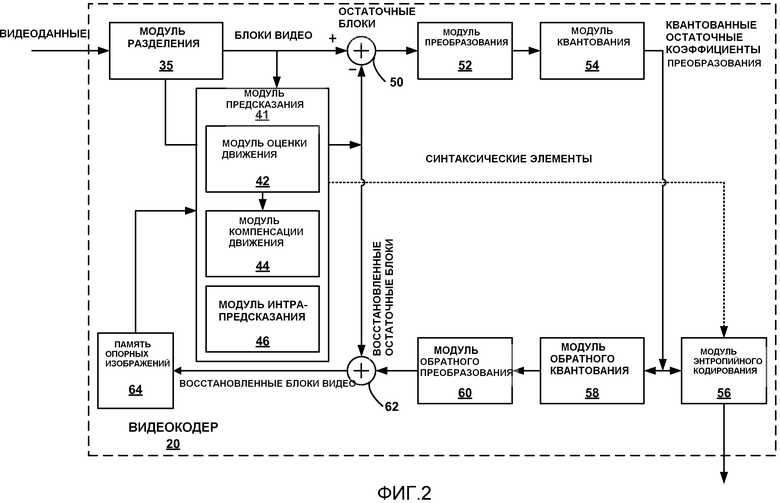
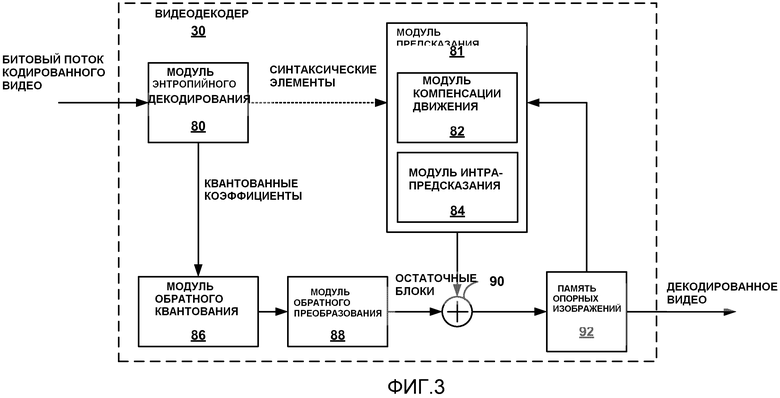
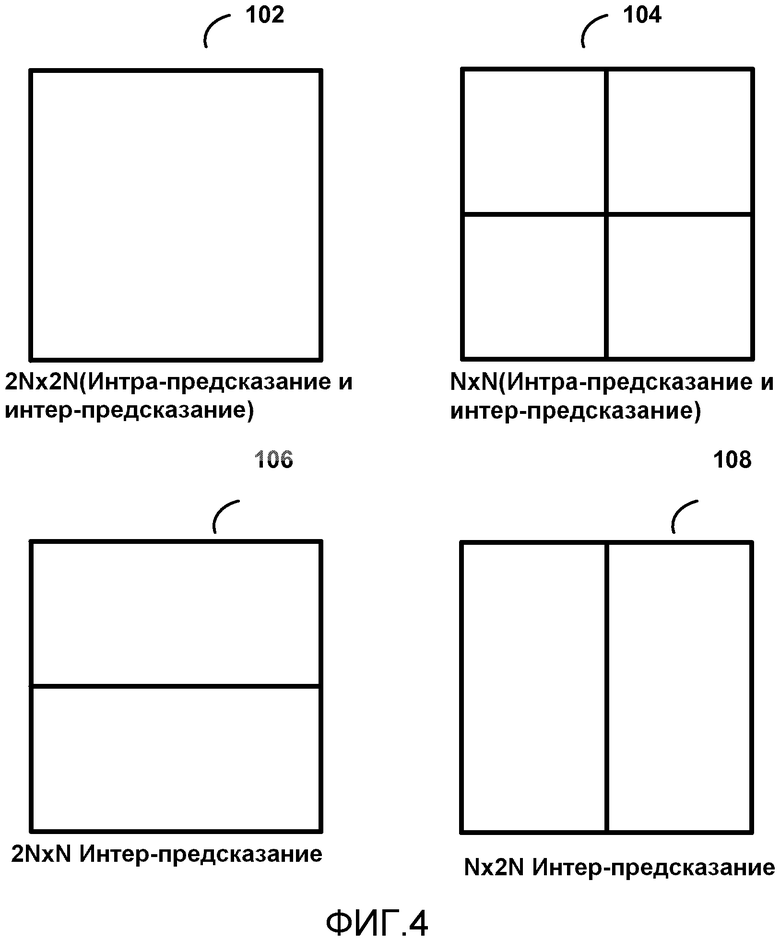
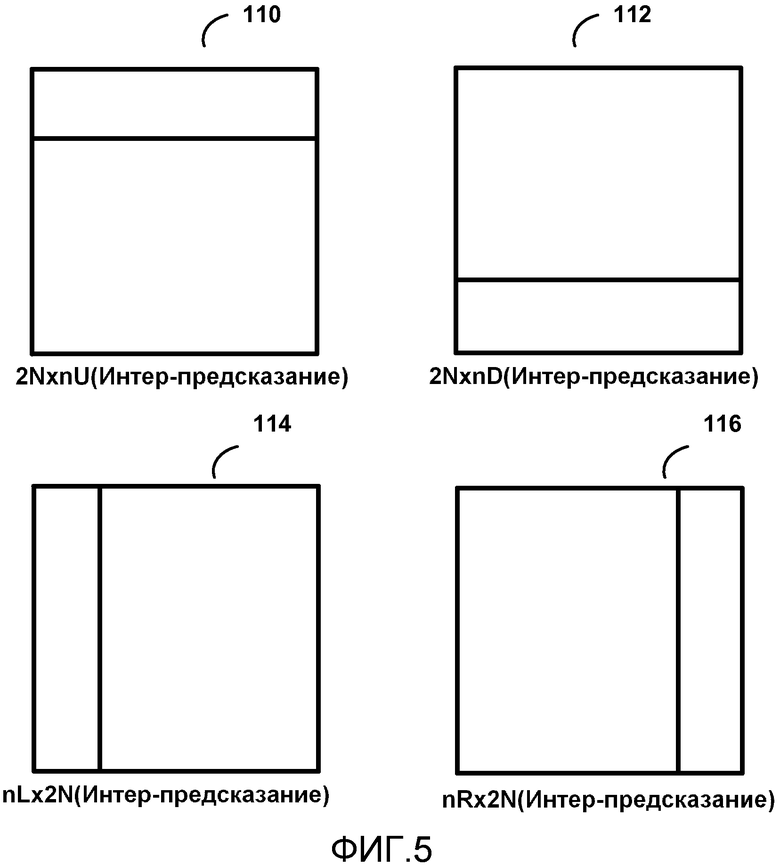
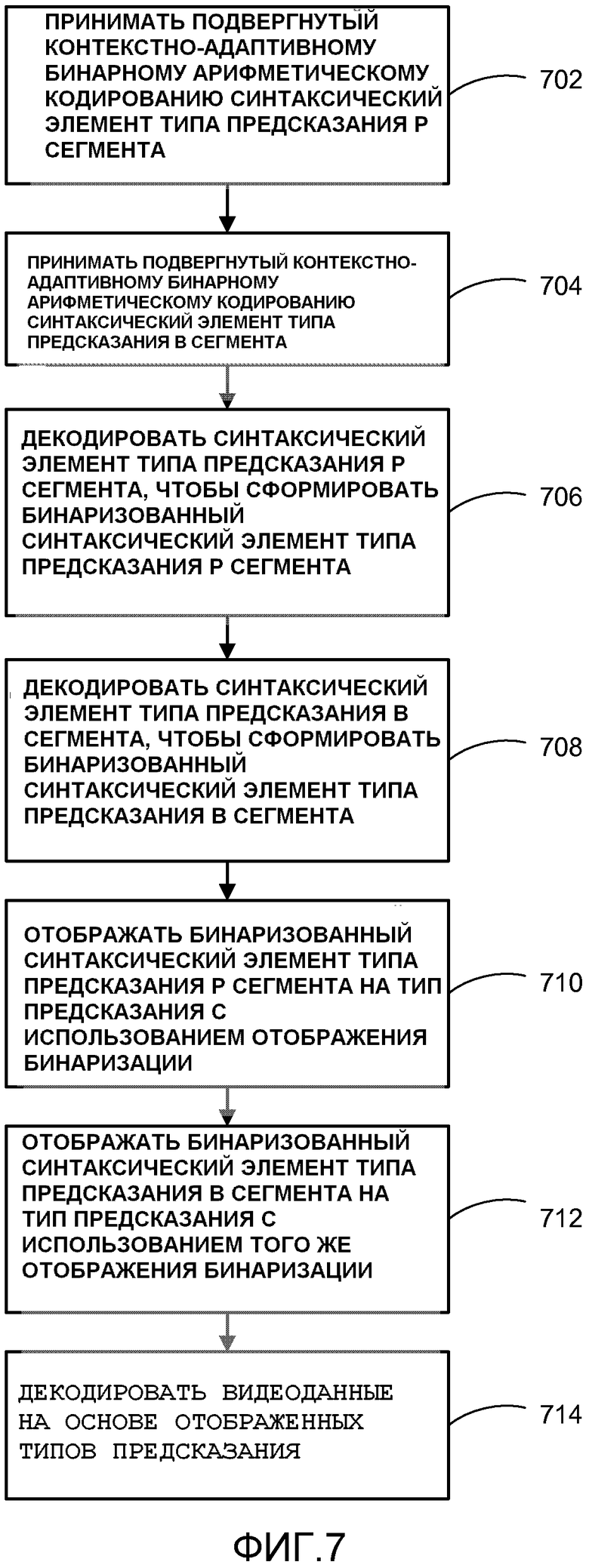
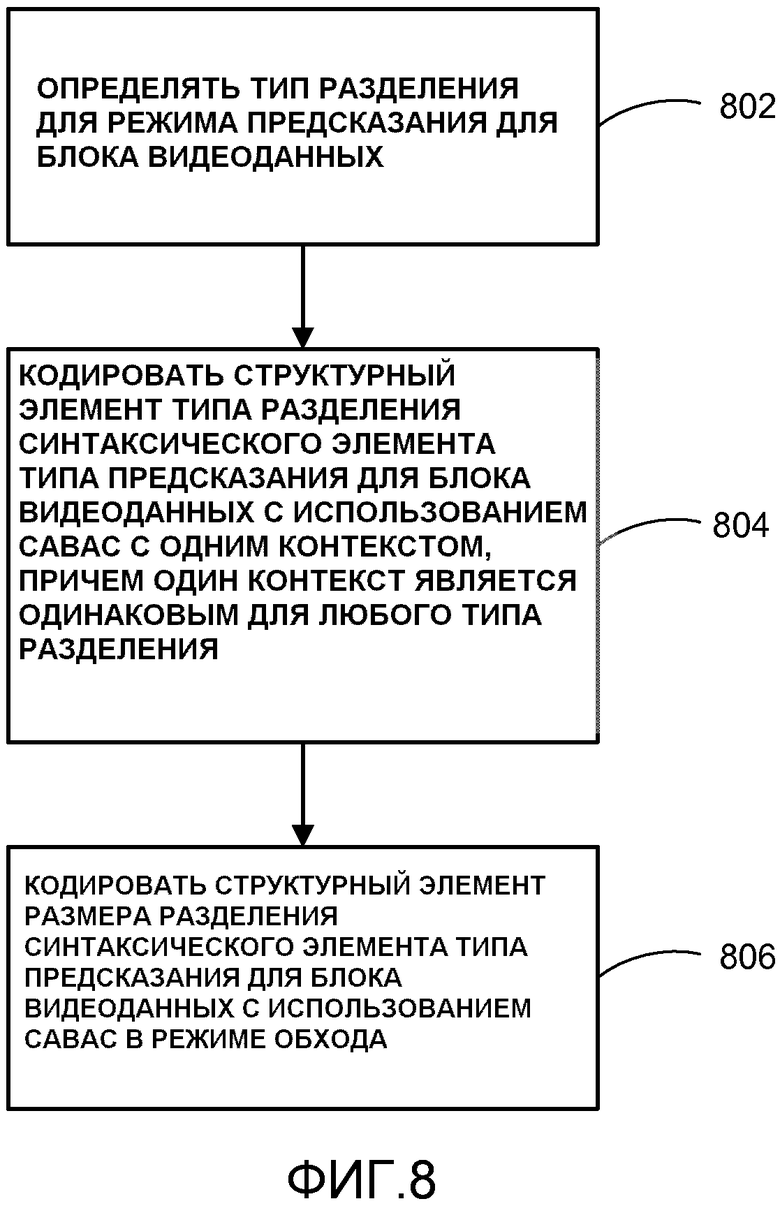
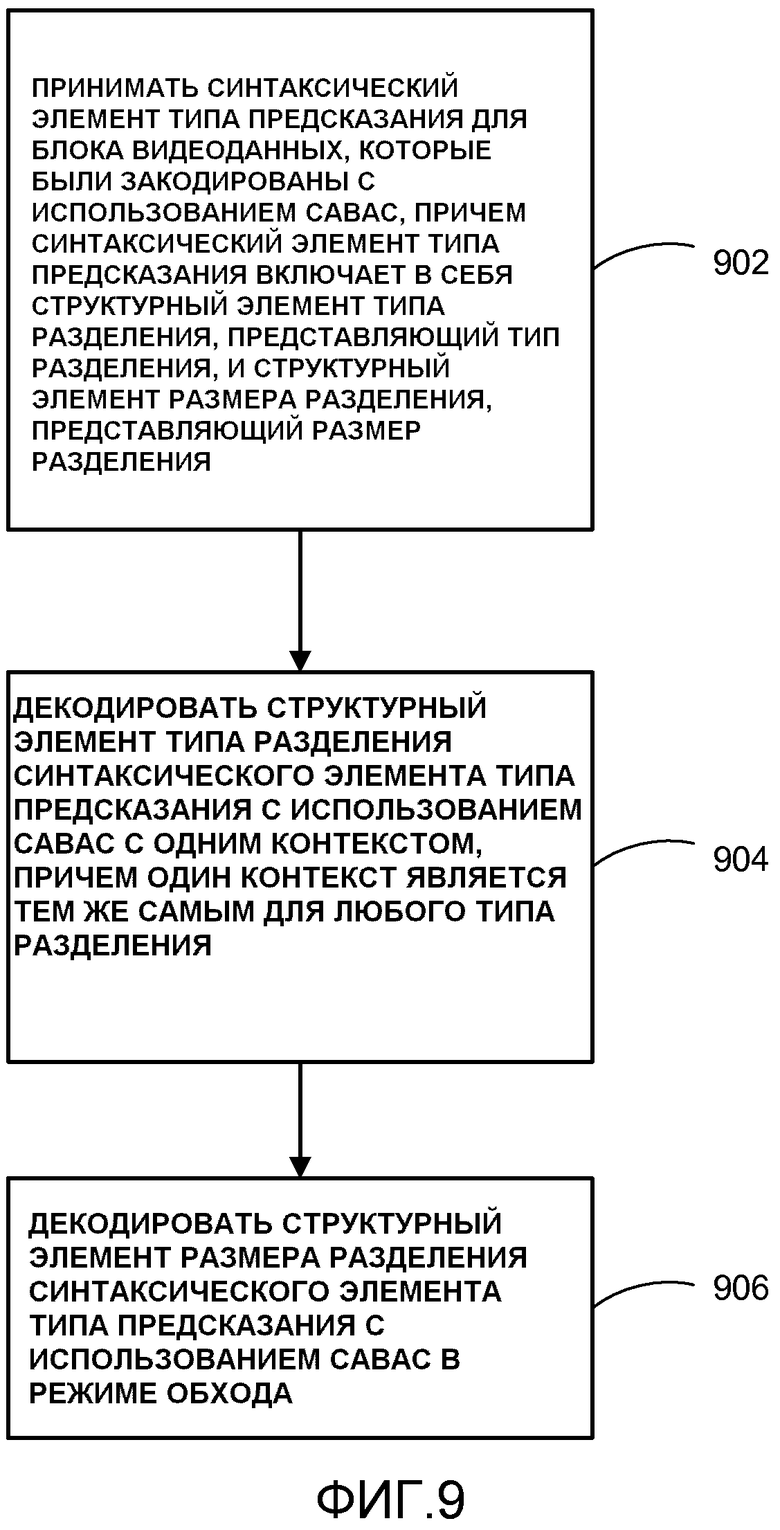
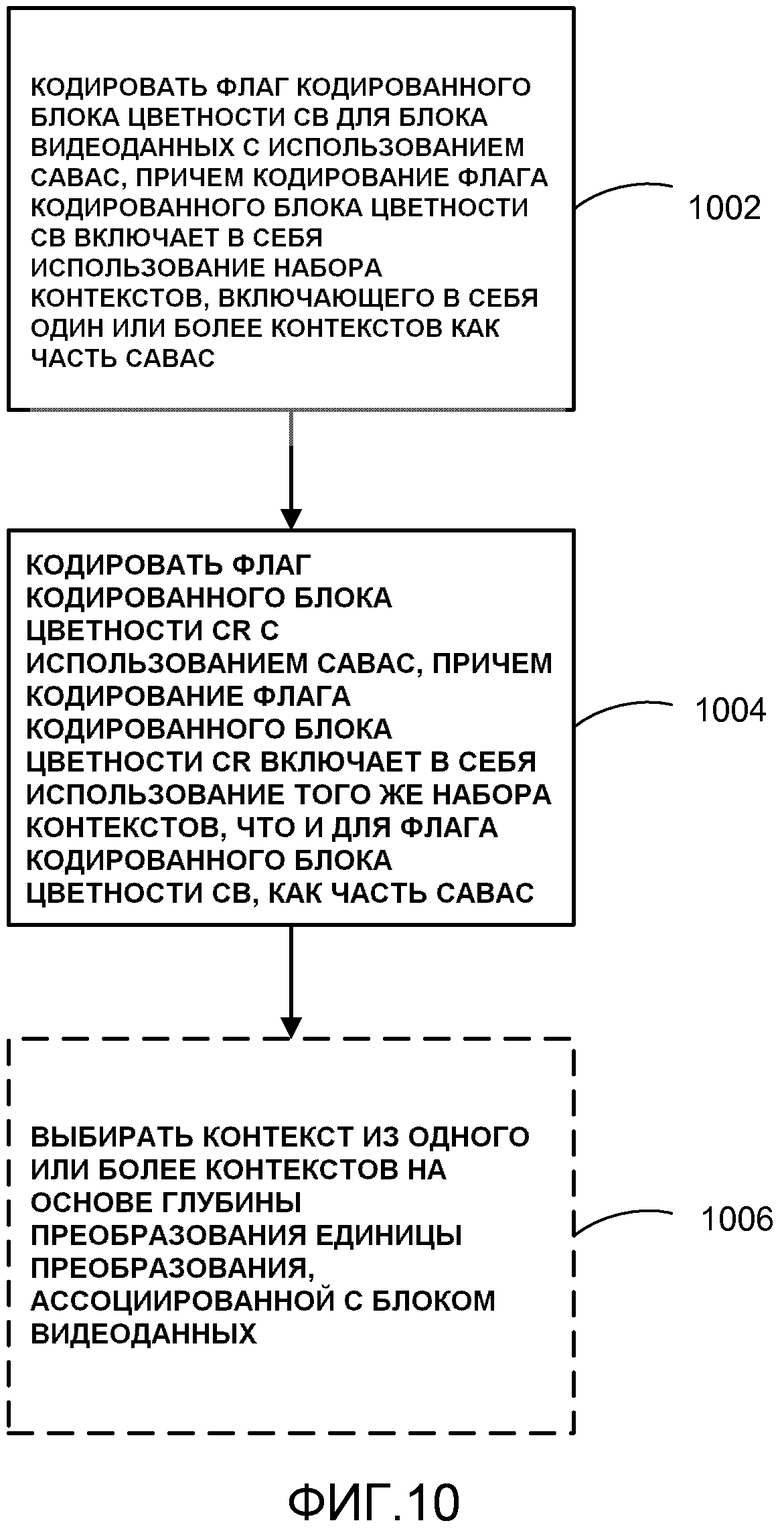
Изобретение относится к технологиям кодирования и декодирования видео. Техническим результатом является повышение эффективности кодирования или декодирования за счет сокращения числа контекстов контекстно-адаптированного бинарного арифметического кодирования (CABAC), которое используется для одного или нескольких синтаксических элементов. Предложен способ кодирования видеоданных. Способ включает в себя этап, на котором определяют первый тип предсказания для блока видеоданных в Р сегменте и представляют первый тип предсказания как синтаксический элемент типа предсказания Р сегмента. Далее, согласно способу определяют второй тип предсказания для блока видеоданных в B сегменте и представляют второй тип предсказания как синтаксический элемент типа предсказания В сегмента, а также, осуществляют определение бинаризации Р сегмента для синтаксического элемента типа предсказания Р сегмента и осуществляют определение бинаризации В сегмента для синтаксического элемента типа предсказания B сегмента. 8 н. и 32 з.п. ф-лы, 10 ил., 22 табл.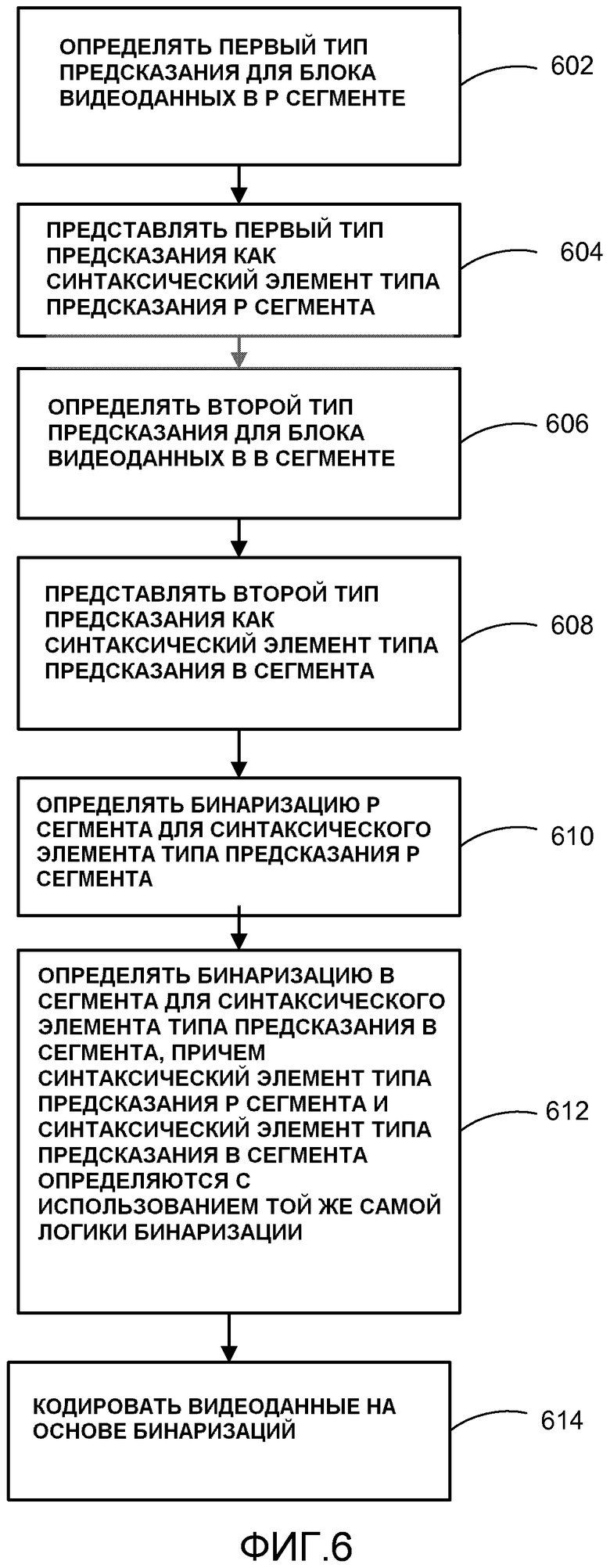
1. Способ кодирования видеоданных, содержащий:
определение первого типа предсказания для блока видеоданных в Р сегменте;
представление первого типа предсказания как синтаксический элемент типа предсказания Р сегмента;
определение второго типа предсказания для блока видеоданных в B сегменте;
представление второго типа предсказания как синтаксического элемента типа предсказания В сегмента;
определение бинаризации Р сегмента для синтаксического элемента типа предсказания Р сегмента;
определение бинаризации В сегмента для синтаксического элемента типа предсказания B сегмента, причем синтаксический элемент типа предсказания P сегмента и синтаксический элемент типа предсказания B сегмента определяются с использованием той же самой логики бинаризации; и
кодирование видеоданных на основе бинаризаций синтаксического элемента типа предсказания Р сегмента и синтаксического элемента типа предсказания B сегмента.
2. Способ по п. 1, в котором кодирование видеоданных включает в себя:
бинаризацию синтаксического элемента типа предсказания Р сегмента с определенной бинаризацией P сегмента;
бинаризацию синтаксического элемента типа предсказания В сегмента с определенной бинаризацией В сегмента;
применение контекстно-адаптивного бинарного арифметического
кодирования (CABAC) к бинаризованному синтаксическому элементу типа предсказания Р сегмента; и
применение контекстно-адаптивного бинарного арифметического кодирования (CABAC) к бинаризованному синтаксическому элементу типа предсказания В сегмента.
3. Способ по п. 1, в котором синтаксический элемент типа предсказания P сегмента и синтаксический элемент типа предсказания B сегмента определяют режим предсказания и тип разделения.
4. Способ по п. 3, в котором режим предсказания включает в себя одно из интер-предсказания и интра-предсказания.
5. Способ по п. 3, в котором тип разделения включает в себя одно из симметричных разделений и асимметричных разделений.
6. Способ декодирования видеоданных, включающий в себя:
отображение бинаризованного синтаксического элемента типа предсказания P сегмента на тип предсказания с использованием отображения бинаризации для блока видеоданных в Р сегменте;
отображение бинаризованного синтаксического элемента типа предсказания В сегмента на тип предсказания с использованием того же отображения бинаризации для блока видеоданных в В сегменте; и
декодирование видеоданных на основе отображенных типов предсказания.
7. Способ по п. 6, дополнительно содержащий:
прием подвергнутого контекстно-адаптивному бинарному арифметическому кодированию синтаксического элемента типа предсказания Р сегмента, который указывает тип предсказания для
блока видеоданных в Р сегменте; и
прием подвергнутого контекстно-адаптивному бинарному арифметическому кодированию синтаксического элемента типа предсказания В сегмента, который указывает тип предсказания для блока видеоданных в В сегменте;
причем декодирование видеоданных дополнительно содержит:
декодирование синтаксического элемента типа предсказания P сегмента, чтобы сформировать бинаризованный синтаксический элемент типа предсказания Р сегмента; и
декодирование синтаксического элемента типа предсказания В сегмента, чтобы сформировать бинаризованный синтаксический элемент типа предсказания В сегмента.
8. Способ по п. 6, в котором синтаксический элемент типа предсказания Р сегмента и синтаксический элемент типа предсказания B сегмента определяют режим предсказания и тип разделения.
9. Способ по п. 8, в котором режим предсказания включает в себя одно из интер-предсказания и интра-предсказания.
10. Способ по п. 8, в котором тип разделения включает в себя одно из симметричных разделений и асимметричных разделений.
11. Устройство, сконфигурированное для кодирования видеоданных, содержащее:
средство для определения первого типа предсказания для блока видеоданных в Р сегменте;
средство для представления первого типа предсказания как синтаксический элемент типа предсказания Р сегмента;
средство для определения второго типа предсказания для блока видеоданных в B сегменте;
средство для представления второго типа предсказания как синтаксический элемент типа предсказания В сегмента;
средство для определения бинаризации Р сегмента для синтаксического элемента типа предсказания Р сегмента;
средство для определения бинаризации В сегмента для синтаксического элемента типа предсказания B сегмента, причем синтаксический элемент типа предсказания P сегмента и синтаксический элемент типа предсказания B сегмента определяются с использованием той же самой логики бинаризации; и
средство для кодирования видеоданных на основе бинаризаций синтаксического элемента типа предсказания Р сегмента и синтаксического элемента типа предсказания B сегмента.
12. Устройство по п. 11, в котором средство для кодирования видеоданных включает в себя:
средство для бинаризации синтаксического элемента типа предсказания Р сегмента с определенной бинаризацией P сегмента;
средство для бинаризации синтаксического элемента типа предсказания В сегмента с определенной бинаризацией В сегмента;
средство для применения контекстно-адаптивного бинарного арифметического кодирования (CABAC) к бинаризованному синтаксическому элементу типа предсказания Р сегмента; и
средство для применения контекстно-адаптивного бинарного арифметического кодирования (CABAC) к бинаризованному синтаксическому элементу типа предсказания В сегмента.
13. Устройство по п. 11, в котором синтаксический элемент типа предсказания P сегмента и синтаксический элемент типа предсказания B сегмента определяют режим предсказания и тип разделения.
14. Устройство по п. 13, в котором режим предсказания включает в себя одно из интер-предсказания и интра-предсказания.
15. Устройство по п. 13, в котором тип разделения включает в себя одно из симметричных разделений и асимметричных разделений.
16. Устройство, сконфигурированное для декодирования видеоданных, включающее в себя:
средство для отображения бинаризованного синтаксического элемента типа предсказания P сегмента на тип предсказания с использованием того же отображения бинаризации для блока видеоданных в Р сегменте;
средство для отображения бинаризованного синтаксического элемента типа предсказания В сегмента на тип предсказания с использованием того же отображения бинаризации для блока видеоданных в В сегменте; и
средство для декодирования видеоданных на основе отображенных типов предсказания.
17. Устройство по п. 16, дополнительно содержащее:
средство для приема подвергнутого контекстно-адаптивному бинарному арифметическому кодированию синтаксического элемента типа предсказания Р сегмента, который указывает тип предсказания для блока видеоданных в Р сегменте; и
средство для приема подвергнутого контекстно-адаптивному бинарному арифметическому кодированию синтаксического элемента типа предсказания В сегмента, который указывает тип предсказания для блока видеоданных в В сегменте;
причем средство для декодирования видеоданных дополнительно содержит:
средство для декодирования синтаксического элемента типа предсказания P сегмента, чтобы сформировать бинаризованный синтаксический элемент типа предсказания Р сегмента; и
средство для декодирования синтаксического элемента типа предсказания В сегмента, чтобы сформировать бинаризованный синтаксический элемент типа предсказания В сегмента.
18. Устройство по п. 16, в котором синтаксический элемент типа предсказания Р сегмента и синтаксический элемент типа предсказания B сегмента определяют режим предсказания и тип разделения.
19. Устройство по п. 18, в котором режим предсказания включает в себя одно из интер-предсказания и интра-предсказания.
20. Устройство по п. 18, в котором тип разделения включает в себя одно из симметричных разделений и асимметричных разделений.
21. Устройство, сконфигурированное для кодирования видеоданных, содержащее:
видеокодер, сконфигурированный для:
определения первого типа предсказания для блока видеоданных в Р сегменте;
представления первого типа предсказания как синтаксический элемент типа предсказания Р сегмента;
определения второго типа предсказания для блока видеоданных в B сегменте;
представления второго типа предсказания как синтаксического элемента типа предсказания В сегмента;
определения бинаризации Р сегмента для синтаксического элемента типа предсказания Р сегмента;
определения бинаризации В сегмента для синтаксического элемента типа предсказания B сегмента, причем синтаксический элемент типа предсказания P сегмента и синтаксический элемент типа предсказания B сегмента определяются с использованием той же самой логики бинаризации; и
кодирования видеоданных на основе бинаризаций синтаксического элемента типа предсказания Р сегмента и синтаксического элемента типа предсказания B сегмента.
22. Устройство по п. 21, в котором видеокодер дополнительно сконфигурирован для:
бинаризации синтаксического элемента типа предсказания Р сегмента с определенной бинаризацией P сегмента;
бинаризации синтаксического элемента типа предсказания В сегмента с определенной бинаризацией В сегмента;
применения контекстно-адаптивного бинарного арифметического кодирования (CABAC) к бинаризованному синтаксическому элементу типа предсказания Р сегмента; и
применения контекстно-адаптивного бинарного арифметического кодирования (CABAC) к бинаризованному синтаксическому элементу типа предсказания В сегмента.
23. Устройство по п. 21, в котором синтаксический элемент типа предсказания P сегмента и синтаксический элемент типа предсказания B сегмента определяют режим предсказания и тип разделения.
24. Устройство по п. 23, в котором режим предсказания включает в себя одно из интер-предсказания и интра-предсказания.
25. Устройство по п. 23, в котором тип разделения включает в себя одно из симметричных разделений и асимметричных разделений.
26. Устройство, сконфигурированное для декодирования видеоданных, включающее в себя:
видеодекодер, сконфигурированный для:
отображения бинаризованного синтаксического элемента типа предсказания P сегмента на тип предсказания с использованием отображения бинаризации для блока видеоданных в Р сегменте;
отображения бинаризованного синтаксического элемента типа предсказания В сегмента на тип предсказания с использованием того же отображения бинаризации для блока видеоданных в В сегменте; и
декодирования видеоданных на основе отображенных типов предсказания.
27. Устройство по п. 26, в котором видеодекодер дополнительно сконфигурирован для:
приема подвергнутого контекстно-адаптивному бинарному арифметическому кодированию синтаксического элемента типа предсказания Р сегмента, который указывает тип предсказания для блока видеоданных в Р сегменте; и
приема подвергнутого контекстно-адаптивному бинарному арифметическому кодированию синтаксического элемента типа предсказания В сегмента, который указывает тип предсказания для блока видеоданных в В сегменте;
декодирования синтаксического элемента типа предсказания P сегмента, чтобы сформировать бинаризованный синтаксический элемент типа предсказания Р сегмента; и
декодирования синтаксического элемента типа предсказания В сегмента, чтобы сформировать бинаризованный синтаксический элемент типа предсказания В сегмента.
28. Устройство по п. 26, в котором синтаксический элемент типа предсказания Р сегмента и синтаксический элемент типа предсказания B сегмента определяют режим предсказания и тип разделения.
29. Устройство по п. 28, в котором режим предсказания включает в себя одно из интер-предсказания и интра-предсказания.
30. Устройство по п. 28, в котором тип разделения включает в себя одно из симметричных разделений и асимметричных разделений.
31. Считываемый компьютером носитель хранения данных, хранящий инструкции, которые при исполнении побуждают один или более процессоров кодировать видеоданные, чтобы:
определять первый тип предсказания для блока видеоданных в Р сегменте;
представлять первый тип предсказания как синтаксический элемент типа предсказания Р сегмента;
определять второй тип предсказания для блока видеоданных в B сегменте;
представлять второй тип предсказания как синтаксический элемент типа предсказания В сегмента;
определять бинаризацию Р сегмента для синтаксического элемента типа предсказания Р сегмента;
определять бинаризацию В сегмента для синтаксического элемента типа предсказания B сегмента, причем синтаксический
элемент типа предсказания P сегмента и синтаксический элемент типа предсказания B сегмента определяются с использованием той же самой логики бинаризации; и
кодировать видеоданные на основе бинаризаций синтаксического элемента типа предсказания Р сегмента и синтаксического элемента типа предсказания B сегмента.
32. Считываемый компьютером носитель хранения данных по п. 31, причем инструкции дополнительно побуждают один или более процессоров:
бинаризовать синтаксический элемент типа предсказания Р сегмента с определенной бинаризацией P сегмента;
бинаризовать синтаксический элемент типа предсказания В сегмента с определенной бинаризацией В сегмента;
применять контекстно-адаптивное бинарное арифметическое кодирование (CABAC) к бинаризованному синтаксическому элементу типа предсказания Р сегмента; и
применять контекстно-адаптивное бинарное арифметическое кодирование (CABAC) к бинаризованному синтаксическому элементу типа предсказания В сегмента.
33. Считываемый компьютером носитель хранения данных по п. 31, причем синтаксический элемент типа предсказания P сегмента и синтаксический элемент типа предсказания B сегмента определяют режим предсказания и тип разделения.
34. Считываемый компьютером носитель хранения данных по п. 33, причем режим предсказания включает в себя одно из интер-предсказания и интра-предсказания.
35. Считываемый компьютером носитель хранения данных по п.33, причем тип разделения включает в себя одно из симметричных разделений и асимметричных разделений.
36. Считываемый компьютером носитель хранения данных, хранящий инструкции, которые при исполнении побуждают один или более процессоров декодировать видеоданные, чтобы:
отображать бинаризованный синтаксический элемент типа предсказания P сегмента на тип предсказания с использованием отображения бинаризации для блока видеоданных в Р сегменте;
отображать бинаризованный синтаксический элемент типа предсказания В сегмента на тип предсказания с использованием того же отображения бинаризации для блока видеоданных в В сегменте; и
декодировать видеоданные на основе отображенных типов предсказания.
37. Считываемый компьютером носитель хранения данных по п. 36, причем инструкции дополнительно побуждают один или более процессоров:
принимать подвергнутый контекстно-адаптивному бинарному арифметическому кодированию синтаксический элемент типа предсказания Р сегмента, который указывает тип предсказания для блока видеоданных в Р сегменте;
принимать подвергнутый контекстно-адаптивному бинарному арифметическому кодированию синтаксический элемент типа предсказания В сегмента, который указывает тип предсказания для блока видеоданных в В сегменте;
декодировать синтаксический элемент типа предсказания P сегмента, чтобы сформировать бинаризованный синтаксический элемент типа предсказания Р сегмента; и
декодировать синтаксический элемент типа предсказания В сегмента, чтобы сформировать бинаризованный синтаксический элемент типа предсказания В сегмента.
38. Считываемый компьютером носитель хранения данных по п. 36, причем синтаксический элемент типа предсказания Р сегмента и синтаксический элемент типа предсказания B сегмента определяют режим предсказания и тип разделения.
39. Считываемый компьютером носитель хранения данных по п. 38, причем режим предсказания включает в себя одно из интер-предсказания и интра-предсказания.
40. Считываемый компьютером носитель хранения данных по п. 38, причем тип разделения включает в себя одно из симметричных разделений и асимметричных разделений.
| US 5917943 A, 29.06.1999 | |||
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| US 7796065 B2, 14.09.2010 | |||
| US 7982641 B1, 19.07.2011 | |||
| УСТРОЙСТВО И СПОСОБ КОДИРОВАНИЯ ИНФОРМАЦИИ ИЗОБРАЖЕНИЯ, А ТАКЖЕ УСТРОЙСТВО И СПОСОБ ДЕКОРИРОВАНИЯ ИНФОРМАЦИИ ИЗОБРАЖЕНИЯ | 2004 |
|
RU2350041C2 |
| ОСНОВАННОЕ НА КОНТЕКСТЕ АДАПТИВНОЕ НЕРАВНОМЕРНОЕ КОДИРОВАНИЕ ДЛЯ АДАПТИВНЫХ ПРЕОБРАЗОВАНИЙ БЛОКОВ | 2003 |
|
RU2330325C2 |

