Настоящее изобретение относится к аудиообработке, в частности к многоканальной аудиообработке многоканального сигнала, содержащего сигналы двух или более каналов.
В области многоканальной или стереофонической обработки известно, что следует применять так называемое стереофоническое кодирование средним/боковым сигналами. В этой концепции комбинация сигнала левого или первого аудиоканала и сигнала правого или второго аудиоканала формируется для получения среднего или монофонического сигнала M. Дополнительно, разность между сигналом левого или первого канала и сигналом правого или второго канала формируется для получения бокового сигнала S. Этот способ кодирования средним/боковым сигналами дает в результате значительный выигрыш от кодирования, когда левый сигнал и правый сигнал до некоторой степени подобны друг другу, поскольку боковой сигнал будет становиться довольно небольшим. Типично, выигрыш от кодирования каскада квантователя/энтропийного кодера будет становиться более высоким, когда становится меньшим диапазон значений, которые должны подвергаться квантованию/энтропийному кодированию. Отсюда, что касается PCM или основанного на кодах Хаффмана, либо арифметического энтропийного кодера, выигрыш от кодирования возрастает, когда становится меньшим боковой сигнал. Однако существуют определенные ситуации, в которых кодирование средним/боковым сигналами не будет давать в результате выигрыш от кодирования. Ситуация может возникать, когда сигналы в обоих каналах сдвинуты по фазе по отношению друг к другу, например, на 90°. В таком случае средний сигнал и боковой сигнал могут быть до некоторой степени в подобном диапазоне, а потому кодирование среднего сигнала и бокового сигнала с использованием энтропийного кодера не будет давать в результате выигрыша от кодирования и даже может иметь следствием повышенную скорость передачи битов. Поэтому избирательное по частоте кодирование средним/боковым сигналами может применяться, для того чтобы деактивировать кодирование средним/боковым сигналами в полосах, например, где боковой сигнал не становится меньшим до определенной степени по отношению к исходному левому сигналу.
Хотя боковой сигнал будет становиться нулевым, когда левый и правый сигналы идентичны, давая в результате максимальный выигрыш от кодирования вследствие устранения бокового сигнала, ситуация снова становится иной, когда средний сигнал и боковой сигнал идентичны в отношении профиля или формы сигнала, но единственной разницей между обоими сигналами являются их полные амплитуды. В этом случае, когда дополнительно предполагается, что боковой сигнал не имеет фазового сдвига по отношению к среднему сигналу, боковой сигнал значительно увеличивается, хотя, с другой стороны, средний сигнал не увеличивается настолько сильно в отношении своего диапазона значений. Когда возникает такая ситуация в определенной полосе частот, то вновь следовало бы деактивировать кодирование средним/боковым сигналами вследствие потери выигрыша от кодирования. Кодирование средним/боковым сигналами может применяться избирательно по частоте или, в качестве альтернативы, может применяться во временной области.
Существуют альтернативные технологии многоканального кодирования, которые не полагаются на разновидность подхода к форме сигнала в качестве кодирования средним/боковым сигналами, но которые полагаются на параметрическую обработку, основанную на определенных бинауральных контрольных сигналах. Такие технологии известны под названием «кодирование бинауральными контрольными сигналами», «параметрическое стереофоническое кодирование» или «кодирование объемного звучания MPEG». Здесь определенное число контрольных сигналов рассчитывается для множества полос частот. Эти контрольные сигналы включают в себя межканальные разности уровней, показатели межканальной когерентности, межканальные разновременности и/или межканальные разности фаз. Эти подходы начинаются с предположения, что многоканальное впечатление, ощущаемое слушателем, не обязательно полагается на детализированные формы сигналов двух каналов, но полагается на точную избирательность по частоте при условии контрольных сигналов или межканальной информации. Это означает, что в машине воспроизведения должно быть уделено внимание воспроизведению многоканальных сигналов, которые точно отражают контрольные сигналы, но формы сигналов не имеют решающего значения.
Этот подход может быть особенно сложным в случае, когда декодер должен применять обработку декорреляцией, для того чтобы искусственно создавать стереофонические сигналы, которые декоррелированы друг от друга, хотя все эти каналы выводятся из одного и того же канала понижающего микширования. Декорреляторы для этой цели, в зависимости от своей реализации, сложны и могут привносить артефакты, особенно в случае переходных участков сигнала. Дополнительно, в противоположность кодированию формы сигнала, подход с параметрическим кодированием является вносящим потери подходом к кодированию, который неизбежно приводит к потере информации, вызванной не только типичным квантованием, но также привнесенной из-за наблюдения главным образом за бинауральными контрольными сигналами, нежели за конкретными формами сигналов. Этот подход дает в результате очень низкие скорости передачи битов, но может включать в себя ухудшения качества.
Существуют последние разработки для унифицированного кодирования речи и аудиосигналов (USAC), проиллюстрированного на фиг.7a. Основной декодер 700 выполняет операцию декодирования кодированного стереофонического сигнала на входе 701, который может быть кодирован средним/боковым сигналами. Основной декодер выдает средний сигнал на линии 702 и боковой сигнал или остаточный сигнал на линии 703. Оба сигнала преобразуются в область QMF гребенками 704 и 705 фильтров QMF. Затем декодер 706 объемного звучания MPEG применяется для формирования сигнала 707 левого канала и сигнала 708 левого канала. Эти низкополосные сигналы впоследствии вводятся в декодер 709 повторения спектральной полосы (SBR), который создает широкополосные левый и правый сигналы на линиях 710 и 711, которые затем преобразуются во временную область посредством гребенок 712, 713 фильтров синтеза QMF, так чтобы получались широкополосные левый и правый сигналы L, R.
Фиг.7b иллюстрирует ситуацию, когда декодер 706 объемного звучания MPEG выполнял бы декодирование среднего/бокового сигналов. В качестве альтернативы, блок 706 декодера объемного звучания MPEG мог бы выполнять основанное на бинауральных контрольных сигналах параметрическое декодирование для формирования стереофонических сигналов из одиночного монофонического сигнала основного декодера. Естественно, декодер 706 объемного звучания MPEG также мог бы формировать множество низкополосных выходных сигналов, которые должны вводиться в блок 709 декодера SBR, с использованием параметрической информации, такой как межканальная разность уровней, показатели межканальной когерентности или другие межканальные информационные параметры.
Когда блок 706 декодера объемного звучания MPEG выполняет декодирование среднего/бокового сигналов, проиллюстрированное на фиг.7b, может применяться вещественный коэффициент g усиления, а DMX/RES и L/R являются сигналом понижающего микширования/остаточным сигналом и левым/правым сигналами, соответственно, представленными в области комплексного гибридного QMF.
Использование комбинации блока 706 и блока 709 вызывает лишь небольшое увеличение вычислительной сложности по сравнению со стереофоническим декодером, используемым в качестве основы, так как комплексное представление QMF сигнала уже имеется в распоряжении в качестве части декодера SBR. В конфигурации без SBR, однако, основанное на QMF стереофоническое кодирование, как предложенное в контексте USAC, давало бы в результате значительное увеличение вычислительной сложности вследствие необходимых гребенок QMF, которые в этом примере потребовали бы 64-полосных гребенок анализа и 64-полосных гребенок синтеза. Эти гребенки фильтров должны были бы добавляться только с целью стереофонического кодирования.
В находящейся на стадии разработки системе USAC MPEG, однако, также существуют режимы кодирования на высоких скоростях передачи битов, где SBR типично не используется.
Цель настоящего изобретения состоит в том, чтобы предложить улучшенную концепцию обработки аудиосигналов, которая, с одной стороны, дает высокий выигрыш от кодирования, а, с другой стороны, дает в результате хорошее качество аудиосигнала и/или уменьшенную вычислительную сложность.
Эта цель достигается аудиодекодером в соответствии с пунктом 1 формулы изобретения, аудиокодером в соответствии с пунктом 15 формулы изобретения, способом декодирования аудиосигнала в соответствии с пунктом 21 формулы изобретения, способом кодирования аудиосигнала в соответствии с пунктом 22 формулы изобретения, компьютерной программой в соответствии с пунктом 23 формулы изобретения или кодированным многоканальным аудиосигналом в соответствии с пунктом 24 формулы изобретения.
Настоящее изобретение полагается на полученные сведения, что выигрыш от кодирования подхода к высококачественному кодированию формы сигнала может быть значительно увеличен за счет предсказания второго комбинированного сигнала с использованием первого комбинированного сигнала, где оба комбинированных сигнала выводятся из исходных сигналов канала с использованием правила комбинирования, такого как правило комбинирования среднего/бокового сигналов. Было обнаружено, что эта информация о предсказании, которая вычисляется предсказателем в аудиокодере так, чтобы была удовлетворена цель оптимизации, вызывает лишь небольшие издержки, но дает в результате значительное увеличение скорости передачи битов, требуемой для разностного сигнала, без потери какого бы то ни было качества аудиосигнала, поскольку предсказание согласно настоящему изобретению, тем не менее, является основанным на форме сигнала кодированием, а не основанным на параметрах подходом к стереофоническому или многоканальному кодированию. Для того чтобы снизить вычислительную сложность, предпочтительно выполнять кодирование в частотной области, причем информация о предсказании выводится из входных данных частотной области избирательным по полосе образом. Алгоритм преобразования для преобразования представления во временной области в спектральное представление предпочтительно является критически дискретизированным процессом, таким как модифицированное дискретное косинусное преобразование (MDCT) или модифицированное дискретное синусное преобразование (MDST), которое отлично от комплексного преобразования по той причине, что рассчитываются только вещественные значения или только мнимые значения, в то время как в комплексном преобразовании рассчитываются вещественные и комплексные значения спектра, давая в результате 2-кратную избыточную дискретизацию.
Предпочтительно, используется преобразование, основанное на привнесении и подавлении наложения спектров. MDCT, в частности, является таким преобразованием и предоставляет возможность перекрестного затухания между последующими блоками без каких бы то ни было издержек, обусловленных широко известным свойством подавления наложения спектров во временной области (TDAC), которое получается обработкой наложения-сложения на стороне декодера.
Предпочтительно, информация о предсказании, рассчитанная в кодере, передаваемая в декодер и используемая в декодере, содержит мнимую часть, которая преимущественно может отражать разности фаз между двумя аудиоканалами в произвольно выбранных величинах между 0° и 360°. Вычислительная сложность значительно уменьшается, только когда применяется вещественнозначное преобразование или, в общем, преобразование, которое дает только вещественный спектр или дает только мнимый спектр. Для того чтобы воспользоваться мнимой информацией о предсказании, которая указывает фазовый сдвиг между определенной полосой левого сигнала и соответствующей полосой правого сигнала, вещественно мнимый преобразователь или, в зависимости от реализации преобразования, мнимо-вещественный преобразователь предусмотрен в декодере, для того чтобы рассчитывать остаточный сигнал предсказания по первому комбинированному сигналу, который повернут по фазе относительно исходного комбинированного сигнала. Этот повернутый по фазе остаточный сигнал предсказания затем может комбинироваться с остаточным сигналом предсказания, переданным в битовом потоке, для восстановления бокового сигнала, который может комбинироваться со средним сигналом, чтобы получать декодированный левый канал в определенной полосе и декодированный правый канал в этой полосе.
Для повышения качества аудиосигнала, такой же вещественно-мнимый или мнимо-вещественный преобразователь, который применяется на стороне декодера, также реализован на стороне кодера, когда остаточный сигнал предсказания рассчитывается в кодере.
Настоящее изобретение является полезным по той причине, что оно дает улучшенное качество аудиосигнала и сниженную скорость передачи битов по сравнению с системами, имеющими такую же скорость передачи битов или имеющими такое же качество аудиосигнала.
Дополнительно, получаются преимущества в отношении вычислительной эффективности унифицированного стереофонического кодирования в системе USAC MPEG на высоких скоростях передачи битов, где типично не используется SBR. Вместо обработки сигнала в области комплексных гибридных QMF, эти подходы реализуют основанное на остаточном сигнале стереофоническое кодирование с предсказанием в унаследованной области MDCT лежащего в основе кодера стереофонического преобразования.
В соответствии с аспектом настоящего изобретения, настоящее изобретение содержит устройство или способ формирования стереофонического сигнала посредством комплексного предсказания в области MDCT, при этом комплексное предсказание выполняется в области MDCT с использованием вещественно-комплексного преобразования, причем этот стереофонический сигнал может быть либо кодированным стереофоническим сигналом на стороне кодера, либо, в качестве альтернативы, быть декодированным/переданным стереофоническим сигналом, когда устройство или способ формирования стереофонического сигнала применяются на стороне декодера.
Предпочтительные варианты осуществления настоящего изобретения впоследствии обсуждены со ссылкой на прилагаемые чертежи, на которых:
фиг.1 - схема предпочтительного варианта осуществления аудиодекодера;
фиг.2 - структурная схема предпочтительного варианта осуществления аудиокодера;
фиг.3a иллюстрирует реализацию вычислителя кодера по фиг.2;
фиг.3b иллюстрирует альтернативную реализацию вычислителя кодера по фиг.2;
фиг.3c иллюстрирует правило комбинирования среднего/бокового сигналов, которое должно применяться на стороне кодера;
фиг.4a иллюстрирует реализацию вычислителя декодера по фиг.1;
фиг.4b иллюстрирует альтернативную реализацию вычислителя декодера в виде матричного вычислителя;
фиг.4c иллюстрирует обратное правило комбинирования среднего/бокового сигналов, соответствующее правилу комбинирования, проиллюстрированному на фиг.3c;
фиг.5a иллюстрирует вариант осуществления аудиокодера, работающего в частотной области, которая предпочтительно является вещественнозначной частотной областью;
фиг.5b иллюстрирует реализацию аудиодекодера, работающего в частотной области;
фиг.6a иллюстрирует альтернативную реализацию аудиокодера, работающего в области MDCT и использующего вещественно-мнимое преобразование;
фиг.6b иллюстрирует аудиодекодер, работающий в области MDCT и использующий вещественно-мнимое преобразование;
фиг.7a иллюстрирует постпроцессор аудиосигнала, использующий стереофонический декодер и присоединенный позднее декодер SBR;
фиг.7b иллюстрирует матрицу повышающего микширования среднего/бокового сигналов;
фиг.8a иллюстрирует подробный вид касательно блока MDCT на фиг.6a;
фиг.8b иллюстрирует подробный вид касательно блока MDCT-1 по фиг.6b;
фиг.9a иллюстрирует реализацию оптимизатора, работающего на уменьшенном разрешении по отношению к выходному сигналу MDCT;
фиг.9b иллюстрирует представление спектра MDCT и соответствующие полосы более низкого разрешения, в которых рассчитывается информация о предсказании;
фиг.10a иллюстрирует реализацию вещественно-мнимого преобразователя на фиг.6a или фиг.6b; и
фиг.10b иллюстрирует возможную реализацию вычислителя мнимого спектра по фиг.10a.
Фиг.1 иллюстрирует аудиодекодер для декодирования кодированного многоканального аудиосигнала, полученного на входной линии 100. Кодированный многоканальный аудиосигнал содержит кодированный первый комбинированный сигнал, сформированный с использованием правила комбинирования для комбинирования сигнала первого канала и сигнала второго канала, представляющих многоканальный аудиосигнал, кодированный остаточный сигнал предсказания и информацию о предсказании. Кодированный многоканальный сигнал может быть потоком данных, таким как битовый поток, который имеет три составляющих в мультиплексированной форме. Дополнительная побочная информация может быть включена в кодированный многоканальный сигнал на линии 100. Сигнал вводится во входной интерфейс 102. Входной интерфейс 102 может быть реализован в качестве демультиплексора потока данных, который выдает кодированный первый комбинированный сигнал на линии 104, кодированный остаточный сигнал на линии 106 и информацию о предсказании на линии 108. Предпочтительно, информация о предсказании является коэффициентом, имеющим вещественную часть, не равную нулю, и/или мнимую часть, отличную от нуля. Кодированный комбинированный сигнал и кодированный остаточный сигнал вводятся в декодер 110 сигналов для декодирования первого комбинированного сигнала, чтобы получать декодированный первый комбинированный сигнал на линии 112. Дополнительно, декодер 110 сигнала сконфигурирован для декодирования кодированного остаточного сигнала, чтобы получать декодированный остаточный сигнал на линии 114. В зависимости от обработки кодирования на стороне аудиокодера, декодер сигнала может содержать энтропийный декодер, такой как декодер Хаффмана, арифметический декодер или любой другой энтропийный декодер, и присоединенный позже каскад деквантования для выполнения операции деквантования, соответствующей операции квантования в ассоциированном аудиокодере. Сигналы на линии 112 и 114 вводятся в вычислитель 115 декодера, который выдает сигнал первого канала на линии 117 и сигнал второго канала на линии 118, причем эти два сигнала являются стереофоническими сигналами многоканального аудиосигнала. Например, когда многоканальный аудиосигнал содержит пять каналов, тогда два сигнала являются двумя каналами из многоканального сигнала. Для того чтобы полностью кодировать такой многоканальный сигнал, имеющий пять каналов, могут применяться два декодера, проиллюстрированных на фиг.1, где первый декодер обрабатывает левый канал и правый канал, второй декодер обрабатывает левый канал объемного звучания и правый канал объемного звучания, а третий монофонический декодер использовался бы для выполнения монофонического кодирования центрального канала. Однако другие компоновки или комбинации кодеров формы сигнала и параметрических кодеров также могут применяться. Альтернативный способ обобщения схемы предсказания на более чем два канала состоял бы в том, чтобы обрабатывать три (или более) сигналов одновременно, то есть предсказывать 3-й комбинированный сигнал по 1-му и 2-му сигналам с использованием двух коэффициентов предсказания, очень похоже на модуль «два в три» объемного звучания MPEG.
Вычислитель 116 декодера сконфигурирован для расчета декодированного многоканального сигнала, содержащего декодированный сигнал 117 первого канала и декодированный сигнал 118 второго канала с использованием декодированного остаточного сигнала 114, информации 108 о предсказании и декодированного первого комбинированного сигнала 112. В частности, вычислитель 116 декодера сконфигурирован, чтобы работать таким образом, чтобы декодированный сигнал первого канала и декодированный сигнал второго канала были по меньшей мере приближением сигнала первого канала и сигнала второго канала многоканального сигнала, введенного в соответствующий кодер, которые комбинируются согласно правилу комбинирования при формировании первого комбинированного сигнала и остаточного сигнала предсказания. Более точно, информация о предсказании на линии 108 содержит вещественнозначную часть, отличную от нуля, и/или мнимую часть, отличную от нуля.
Вычислитель 116 декодера может быть реализован разными способами. Первая реализация проиллюстрирована на фиг.4a. Эта реализация содержит предсказатель 1160, вычислитель 1161 комбинированного сигнала и объединитель 1162. Предсказатель принимает декодированный первый комбинированный сигнал 112 и информацию 108 о предсказании и выдает сигнал 1163 о предсказании. Более точно, предсказатель 1160 сконфигурирован для применения информации 108 о предсказании к декодированному первому комбинированному сигналу 112 или сигналу, выведенному из декодированного первого комбинированного сигнала. Правило выведения для получения сигнала, к которому применяется информация 108 о предсказании, может быть вещественно-мнимым преобразованием или, равным образом, мнимо-вещественным преобразованием, или операцией взвешивания, или, в зависимости от реализации, операцией сдвига фазы или комбинированной операцией взвешивания/сдвига фазы. Сигнал 1163 предсказания вводится вместе с декодированным остаточным сигналом в вычислитель 1161 комбинированного сигнала, для того чтобы рассчитывать декодированный второй комбинированный сигнал 1165. Сигналы 112 и 1165 оба вводятся в объединитель 1162, который комбинирует декодированный первый комбинированный сигнал и второй комбинированный сигнал, чтобы получать декодированный многоканальный аудиосигнал, содержащий декодированный сигнал первого канала и декодированный сигнал второго канала на выходных линиях 1166 и 1167 соответственно. В качестве альтернативы, вычислитель декодера реализован в качестве матричного вычислителя 1168, который принимает, в качестве входного сигнала, декодированный первый комбинированный сигнал или сигнал M, декодированный остаточный сигнал или сигнал D и информацию 108 α о предсказании. Матричный вычислитель 1168 применяет матрицу преобразования, проиллюстрированную как 1169, к сигналам M, D, чтобы получать выходные сигналы L, R, где L - декодированный сигнал первого канала, а R - декодированный сигнал второго канала. Обозначение на фиг.4b имеет сходство со стереофоническим обозначением с левым каналом L и правым каналом R. Это обозначение было применено для того, чтобы обеспечить более легкое понимание, но специалистам в данной области техники должно быть ясно, что сигналы L, R могут быть любой комбинацией сигналов двух каналов в многоканальном сигнале, содержащем сигналы более чем двух каналов. Матричная операция 1169 унифицирует операции в блоках 1160, 1161 и 1162 по фиг.4a в некоторую разновидность «однотактного» матричного вычисления, и входные сигналы в схему фиг.4a и выходные сигналы из схемы фиг.4a идентичны входным сигналам в матричный вычислитель 1168 и выходным сигналам из матричного вычислителя 1168.
Фиг.4c иллюстрирует пример для обратного правила комбинирования, применяемого объединителем 1162 на фиг.4a. В частности, правило комбинирования является подобным правилу комбинирования стороны декодера в широко известном кодировании средним/боковым сигналами, L=M+S, и R=M-S. Должно быть понятно, что сигнал S, используемый обратным правилом комбинирования на фиг.4c, является сигналом, рассчитанным вычислителем комбинированного сигнала, то есть комбинированием сигнала предсказания на линии 1163 и декодированного остаточного сигнала на линии 114. Должно быть понятно, что в этом описании изобретения сигналы на линиях иногда называются по номерам ссылки для линий или иногда указываются номерами ссылки, которые были приписаны линиям. Поэтому обозначение является таким, что линия, имеющая определенный сигнал, является указывающей на сам сигнал. Линия может быть физической линией в реализации с жесткой логикой. В компьютеризованной реализации, однако, физической линии не существует, но сигнал, представленный линией, передается из одного вычислительного модуля в другой вычислительный модуль.
Фиг.2 иллюстрирует аудиокодер для кодирования многоканального аудиосигнала 200, содержащего сигналы двух или более каналов, где сигнал первого канала проиллюстрирован позицией 201, а второй канал проиллюстрирован позицией 202. Оба сигнала вводятся в вычислитель 203 кодера для расчета первого комбинированного сигнала 204 и остаточного сигнала 205 предсказания с использованием сигнала 201 первого канала и сигнала 202 второго канала, и информации 206 о предсказании, так что остаточный сигнал 205 предсказания, при комбинировании с сигналом предсказания, выведенным из первого комбинированного сигнала 204 и информации 206 о предсказании, дает в результате второй комбинированный сигнал, где первый комбинированный сигнал и второй комбинированный сигнал являются получаемыми из сигнала 201 первого канала и сигнала 202 второго канала с использованием правила комбинирования.
Информация о предсказании формируется оптимизатором 207 для расчета информации 206 о предсказании, так чтобы остаточный сигнал предсказания удовлетворял цели 208 оптимизации. Первый комбинированный сигнал 204 и остаточный сигнал 205 вводятся в кодер 209 сигнала для кодирования первого комбинированного сигнала 204, чтобы получать кодированный первый комбинированный сигнал 210, и для кодирования остаточного сигнала 205, чтобы получать кодированный остаточный сигнал 211. Оба кодированных сигнала 210, 211 вводятся в выходной интерфейс 212 для комбинирования кодированного первого комбинированного сигнала 210 с кодированным остаточным сигналом 211 предсказания и информацией 206 предсказания, чтобы получать кодированный многоканальный сигнал 213, который подобен кодированному многоканальному сигналу 100, введенному во входной интерфейс 102 аудиодекодера, проиллюстрированного на фиг.1.
В зависимости от реализации, оптимизатор 207 принимает любой из сигнала 201 первого канала и сигнала 202 второго канала или, как проиллюстрировано линиями 214 и 215, первый комбинированный сигнал 214 и второй комбинированный сигнал 215, выведенные из объединителя 2031 по фиг.3a, который будет обсужден позже.
Предпочтительная цель оптимизации проиллюстрирована на фиг.2, при которой максимизируется выигрыш от кодирования, то есть как можно больше снижается скорость передачи битов. При этой цели оптимизации, остаточный сигнал D минимизируется относительно α. Другими словами, это означает, что информация α о предсказании выбирается так, чтобы минимизировалось ||S-αM||2. Это дает в результате решение для проиллюстрированного на фиг.2. Сигналы S, M выдаются поблочным образом и предпочтительно являются сигналами спектральной области, где обозначение ||...|| означает норму аргумента по модулю 2 и где <...>, как обычно, иллюстрирует скалярное произведение. Когда сигнал 201 первого канала и сигнал 202 второго канала вводятся в оптимизатор 207, тогда оптимизатор должен был бы применять правило комбинирования, где примерное правило комбинирования проиллюстрировано на фиг.3c. Однако, когда первый комбинированный сигнал 214 и второй комбинированный сигнал 215 вводятся в оптимизатор 207, тогда оптимизатору 207 не нужно самостоятельно реализовывать правило комбинирования.
Другие цели оптимизации могут относиться к перцепционному качеству. Цель оптимизации может состоять в том, чтобы получалось максимальное перцепционное качество. Затем, оптимизатор требовал бы дополнительной информации из перцепционной модели. Другие реализации цели оптимизации могут относиться к получению минимальной или постоянной скорости передачи битов. В таком случае оптимизатор 207 был бы реализован, чтобы выполнять операцию квантования/энтропийного кодирования, для того чтобы определять требуемую скорость передачи битов для определенных значений, так чтобы α могло быть установлено, чтобы удовлетворять требованиям, таким как минимальная скорость передачи битов или, в качестве альтернативы, постоянная скорость передачи битов. Другие реализации цели оптимизации могут относиться к минимальному использованию ресурсов кодера или декодера. В случае реализации такой цели оптимизации, информация о требуемых ресурсах для определенной оптимизации имелась бы в распоряжении в оптимизаторе 207. Дополнительно, комбинация этих целей оптимизации или других целей оптимизации может применяться для управления оптимизатора 207, который рассчитывает информацию 206 о предсказании.
Вычислитель 203 кодера на фиг.2 может быть реализован разными способами, где примерная первая реализация проиллюстрирована на фиг.3a, в которой явное правило комбинирования выполняется в объединителе 2031. Альтернативная примерная реализация проиллюстрирована на фиг.3b, где используется матричный вычислитель 2039. Объединитель 2031 на фиг.3a может быть реализован, чтобы выполнять правило комбинирования, проиллюстрированное на фиг.3c, которое является примерным широко известным правилом кодирования средним/боковым сигналами, где весовой коэффициент 0,5 применяется к обеим ветвям. Однако другие весовые коэффициенты или полностью отсутствующие весовые коэффициенты могут быть реализованы в зависимости от реализации. Дополнительно, должно быть отмечено, что могут применяться другие правила комбинирования, такие как правила линейного комбинирования или правила нелинейного комбинирования, до тех пор пока существует соответствующее обратное правило комбинирования, которое может применяться в объединителе 1162 декодера, проиллюстрированного на фиг.4a, который применяет правило комбинирования, которое является обратным по отношению к правилу комбинирования, применяемому кодером. За счет предсказания согласно настоящему изобретению может использоваться любое обратимое правило предсказания, поскольку влияние на форму сигнала «уравновешивается» предсказанием, то есть какая-нибудь ошибка включается в переданный остаточный сигнал, поскольку операция предсказания, выполняемая оптимизатором 207 в комбинации с вычислителем 203 кодера, является сохраняющей форму сигнала последовательностью операций.
Объединитель 2031 выдает первый комбинированный сигнал 204 и второй комбинированный сигнал 2032. Первый комбинированный сигнал вводится в предсказатель 2033, а второй комбинированный сигнал 2032 вводится в вычислитель 2034 остаточного сигнала. Предсказатель 2033 рассчитывает сигнал 2035 предсказания, который комбинируется со вторым комбинированным сигналом 2032, чтобы в заключение получать остаточный сигнал 205. В частности, объединитель 2031 сконфигурирован для комбинирования сигналов 201 и 202 двух каналов многоканального аудиосигнала двумя разными способами, чтобы получать первый комбинированный сигнал 204 и второй комбинированный сигнал 2032, где два разных способа проиллюстрированы в примерном варианте осуществления на фиг.3c. Предсказатель 2033 сконфигурирован для применения информации о предсказании к первому комбинированному сигналу 204 или сигналу, выведенному из первого комбинированного сигнала, чтобы получать сигнал 2035 предсказания. Сигнал, выведенный из комбинированного сигнала, может выводиться посредством любой нелинейной или линейной операции, где предпочтительно вещественно-мнимое преобразование/мнимо-вещественное преобразование, которые могут быть реализованы с использованием линейного фильтра, такого как FIR-фильтр, выполняющий взвешенные суммирования определенных значений.
Вычислитель 2034 остаточного сигнала на фиг.3a может выполнять операцию вычитания, так чтобы сигнал предсказания вычитался из второго комбинированного сигнала. Однако возможны другие операции в вычислителе остаточного сигнала. Соответственно, вычислитель 1161 комбинированного сигнала на фиг.4a может выполнять дополнительную операцию, где декодированный остаточный сигнал 114 и сигнал 1163 предсказания складываются вместе, чтобы получать второй комбинированный сигнал 1165.
Фиг.5a иллюстрирует предпочтительную реализацию аудиокодера. По сравнению с аудиокодером, проиллюстрированным на фиг.3a, сигнал 201 первого канала является спектральным представлением сигнала 55a первого канала временной области. Соответственно, сигнал 202 второго канала является спектральным представлением сигнала 55b канала временной области. Преобразование из временной области в спектральное представление выполняется время-частотным преобразователем 50 для сигнала первого канала и время-частотным преобразователем 51 для сигнала второго канала. Предпочтительно, но не обязательно, спектральные преобразователи 50, 51 реализованы в качестве вещественнозначных преобразователей. Алгоритм преобразования может быть дискретным косинусным преобразованием, преобразованием FFT (быстрым преобразованием Фурье), где используется только вещественная часть, MDCT или любым другим преобразованием, дающим вещественнозначные спектральные значения. В качестве альтернативы, оба преобразования могут быть реализованы в качестве мнимого преобразования, такого как DST (дискретное синусное преобразование), MDST или FFT, где используется только мнимая часть, а вещественная часть отбрасывается. Любое другое преобразование, дающее только мнимые значения, также может использоваться. Одним из стремлений использования чисто вещественнозначного преобразования или чисто мнимого преобразования является вычислительная сложность, поскольку для каждого спектрального значения должно обрабатываться лишь одиночное значение, такое как модуль или вещественная часть, либо, в качестве альтернативы, фаза или мнимая часть. В противоположность полному комплексному преобразованию, такому как FFT, два значения, то есть вещественная часть и мнимая часть для каждой спектральной линии, должны были бы обрабатываться, что является увеличением вычислительной сложности согласно коэффициенту по меньшей мере 2. Еще одна причина для использования вещественнозначного преобразования здесь состоит в том, что каждое преобразование обычно критически дискретизируется, а отсюда дает пригодную (и обычно используемую) область для квантования и энтропийного кодирования сигнала (стандартной парадигмы «перцепционного кодирования аудиосигнала», реализованной в «MP3», AAC или подобных системах кодирования аудиосигнала).
Фиг.5a дополнительно иллюстрирует вычислитель 2034 остаточного сигнала в качестве сумматора, который принимает боковой сигнал на своем «плюсовом» входе и который принимает сигнал предсказания, выданный предсказателем 2033 на своем «минусовом» входе. Дополнительно, фиг.5a иллюстрирует ситуацию, что информация управления предсказателем пересылается из оптимизатора в мультиплексор 212, который выдает мультиплексированный битовый поток, представляющий кодированный многоканальный аудиосигнал. В частности, операция предсказания выполняется таким образом, чтобы боковой сигнал предсказывался по среднему сигналу, как проиллюстрировано уравнениями справа по фиг.5a.
Предпочтительно, информация 206 управления предсказателем является коэффициентом, как проиллюстрировано справа на фиг.3b. В варианте осуществления, в котором информация управления предсказанием содержит только вещественную часть, такую как вещественная часть комплексного значения α или модуль комплексного значения α, где эта часть соответствует коэффициенту, отличному от нуля, значительный выигрыш от кодирования может получаться, когда средний сигнал и боковой сигнал подобны друг другу вследствие структуры своей формы сигнала, но имеют разные амплитуды.
Однако, когда информация управления предсказанием содержит только вторую часть, которая может быть мнимой частью комплекснозначного коэффициента или информацией о фазе комплекснозначного коэффициента, где мнимая часть или информация о фазе отличны от нуля, настоящее изобретение добивается значительного выигрыша от кодирования для сигналов, которые сдвинуты по фазе по отношению друг к другу на значение, отличное от 0° или 180°, и которые имеют, кроме фазового сдвига, подобные характеристики формы сигнала и подобные амплитудные зависимости.
Предпочтительно, информация управления предсказанием является комплекснозначной. В таком случае, значительный выигрыш от кодирования может быть получен для сигналов, являющихся разными по амплитуде и являющихся сдвинутыми по фазе. В ситуации, в которой время-частотные преобразования дают комплексные спектры, операция 2034 была бы комплексной операцией, в которой вещественная часть информации управления предсказанием применяется к вещественной части комплексного спектра M, а мнимая часть информации о комплексном предсказании применяется к мнимой части комплексного спектра. Затем, в сумматоре 2034, результат этой операции предсказания является предсказанным вещественным спектром и предсказанным мнимым спектром, и предсказанный вещественный спектр вычитался бы из вещественного спектра бокового сигнала S (по полосам), а предсказанный мнимый спектр вычитался бы из мнимой части спектра S, для получения комплексного остаточного спектра D.
Сигналы L и R временной области являются вещественнозначными сигналами, но сигналы частотной области могут быть вещественнозначными или комплекснозначными. Когда сигналы частотной области являются вещественнозначными, то преобразование является вещественнозначным преобразованием. Когда сигналы частотной области являются комплексными, то преобразование является комплекснозначным преобразованием. Это означает, что входной сигнал во время-частотное преобразование и выходной сигнал частотно-временного преобразования являются вещественнозначными наряду с тем, что сигналы частотной области, например, могли бы быть комплекснозначными сигналами области QMF.
Фиг.5b иллюстрирует аудиодекодер, соответствующий аудиокодеру, проиллюстрированному на фиг.5a. Подобно элементам относительно фиг.1, аудиодекодер имеет подобные номера ссылок.
Битовый поток, выдаваемый мультиплексором 212 битового потока на фиг.5a, вводится в демультиплексор 102 битового потока на фиг.5b. Демультиплексор 102 битового потока демультиплексирует битовый поток на сигнал M понижающего микширования и остаточный сигнал D. Сигнал M понижающего микширования вводится в деквантователь 110a. Остаточный сигнал D вводится в деквантователь 110b. Дополнительно, демультиплексор 102 битового потока демультиплексирует информацию 108 управления предсказателем из битового потока и вводит таковую в предсказатель 1160. Предсказатель 1160 выдает предсказанный боковой сигнал α·M, а объединитель 1161 комбинирует боковой сигнал, выдаваемый деквантователем 110b, с предсказанным боковым сигналом, для того чтобы в заключение получать реконструированный боковой сигнал S. Сигнал затем вводится в объединитель 1162, который, например, выполняет обработку сложения/вычитания, как проиллюстрировано на фиг.4c, что касается кодирования средним/боковым сигналами. В частности, блок 1162 выполняет (обратное) декодирование средним/боковым сигналами для получения представления в частотной области левого канала и представления в частотной области правого канала. Представление в частотной области затем преобразуется в представление во временной области посредством соответствующих частотно-временных преобразователей 52 и 53.
В зависимости от реализации системы, частотно-временные преобразователи 52, 53 являются вещественнозначными частотно-временными преобразователями, когда представление в частотной области является вещественнозначным представлением, или комплекснозначными частотно-временными преобразователями, когда представление в частотной области является комплекснозначным представлением.
Для повышения эффективности, однако, выполнение вещественнозначного преобразования является предпочтительным, как проиллюстрировано в другой реализации на фиг.6a для кодера и фиг.6b для декодера. Вещественнозначные преобразования 50 и 51 реализуются посредством MDCT. Дополнительно, информация о предсказании рассчитывается в качестве комплексного значения, имеющего вещественную часть и мнимую часть. Поскольку оба спектра M, S являются вещественнозначными спектрами и поскольку не существует мнимой части спектра, предусмотрен вещественно-мнимый преобразователь 2070, который рассчитывает оцененный мнимый спектр 600 из вещественнозначного спектра сигнала M. Вещественно-мнимый преобразователь 2070 является частью оптимизатора 207, и мнимый спектр 600, оцененный блоком 2070, вводится в каскад 2071 оптимизатора α вместе с вещественным спектром M, для того чтобы рассчитывать информацию 206 о предсказании, которая теперь имеет вещественнозначный коэффициент, указанный на 2073, и мнимый коэффициент, указанный на 2074. Далее, в соответствии с этим вариантом осуществлением, вещественнозначный спектр первого комбинированного сигнала M умножается на вещественную часть 2073 αR, чтобы получать сигнал предсказания, который затем вычитается из вещественнозначного спектра бокового сигнала. Дополнительно, мнимый спектр 600 умножается на мнимую часть αI, проиллюстрированную на 2074, для получения дополнительного сигнала предсказания, где этот сигнал предсказания затем вычитается из вещественнозначного спектра бокового сигнала, как указано на 2034b. Затем, остаточный сигнал D предсказания квантуется в квантователе 209b наряду с тем, что вещественнозначный спектр M квантуется/кодируется в блоке 209a. Дополнительно, предпочтительно квантовать и кодировать информацию α о предсказании в квантователе/энтропийном кодере 2072 для получения кодированного комплексного значения α, например, которое пересылается в мультиплексор 212 битового потока по фиг.5a и которое в заключение вводится в битовый поток в качестве информации о предсказании.
Касательно положения модуля 2072 квантования/кодирования (Q/C) для α отмечено, что умножители 2073 и 2074 предпочтительно используют в точности идентичное (квантованное) α, которое также будет использоваться в декодере. Отсюда можно было бы переместить 2072 непосредственно на выход 2071 или можно было бы учесть, что квантование уже принято во внимание в последовательности операций оптимизации в 2071.
Хотя можно было бы рассчитывать комплексный спектр на стороне кодера, поскольку вся информация имеется в распоряжении, предпочтительно выполнять вещественно-комплексное преобразование в блоке 2070 в кодере, так чтобы создавались подобные условия по отношению к декодеру, проиллюстрированному на фиг.6b. Декодер принимает вещественнозначный кодированный спектр первого комбинированного сигнала и вещественнозначное спектральное представление кодированного остаточного сигнала. Дополнительно, кодированная комплексная информация о предсказании получается в 108, и энтропийное декодирование и квантование выполняется в блоке 65 для получения вещественной части αR, проиллюстрированной на 1160b, и мнимой части αI, проиллюстрированной на 1160c. Средние сигналы, выведенные элементами 1160b и 1160c взвешивания, прибавляются к декодированному и деквантованному остаточному сигналу предсказания. В частности, спектральные значения, введенные в схему 1160c взвешивания, где мнимая часть комплексного коэффициента предсказания используется в качестве весового коэффициента, выводятся из вещественнозначного спектра M вещественно-мнимым преобразователем 1160a, который предпочтительно реализован таким же образом, как блок 2070 по фиг.6a, относящийся к стороне кодера. На стороне декодера комплекснозначного представления среднего сигнала или бокового сигнала не имеется в распоряжении, что противоречит стороне кодера. Причина состоит в том, что только кодированные вещественнозначные спектры передавались из кодера в декодер вследствие скоростей передачи битов и соображений сложности.
Вещественно-мнимый преобразователь 1160a или соответствующий блок 2070 по фиг.6a может быть реализован, как опубликовано в WO 2004/013839 A1 или WO 2008/014853 A1, либо в патенте US № 6980933. В качестве альтернативы, может быть применена любая другая реализация, известная в данной области техники, а предпочтительная реализация обсуждена в контексте фиг.10a, 10b.
Более точно, как проиллюстрировано на фиг.10a, вещественно-мнимый преобразователь 1160a содержит селектор 1000 спектрального кадра, присоединенный к вычислителю 1001 мнимого спектра. Селектор 1000 спектрального кадра принимает указание текущего кадра i на входе 1002 и, в зависимости от реализации, информацию управления на управляющем входе 1003. Например, когда указание на линии 1002 указывает, что должен рассчитываться мнимый спектр для текущего кадра i, и когда информация 1003 управления указывает, что только текущий кадр должен использоваться для такого расчета, то селектор 1000 спектрального кадра выбирает только кадр i и пересылает эту информацию в вычислитель мнимого спектра. В таком случае вычислитель мнимого спектра использует только спектральные линии текущего кадра i для взвешенного комбинирования линий, расположенных в текущем кадре (блок 1008), что касается частоты, близкой к или вокруг текущей спектральной линии k, для которой мнимая линия должна рассчитываться, как проиллюстрировано в 1004 на фиг.10b. Однако, когда селектор 1000 спектрального кадра принимает информацию 1003 управления, указывающую, что предыдущий кадр i-1 и следующий кадр i+1 также должны использоваться для расчета мнимого спектра, то вычислитель мнимого спектра дополнительно принимает значения из кадров i-1 и i+1 и выполняет взвешенное комбинирование линий в соответствующих кадрах, как проиллюстрировано на 1005 для кадра i-1 и на 1006 для кадра i+1. Результаты операций взвешивания комбинируются посредством взвешенного комбинирования в блоке 1007, чтобы в заключение получать мнимую линию k для кадра fi, которая затем умножается на мнимую часть информации о предсказании в элементе 1160c, чтобы получать сигнал предсказания для этой линии, который затем прибавляется к соответствующей линии среднего сигнала в сумматоре 1161b для декодера. В кодере выполняется та же самая операция, но выполняется вычитание в элементе 2034b.
Должно быть отмечено, что информация 1003 управления дополнительно может указывать, что следует использовать большее количество кадров, чем два окружающих кадра, или, например, что следует использовать только текущий кадр и в точности один или более предыдущих кадров, но не используя «будущие» кадры, для того чтобы снизить систематическую задержку.
Дополнительно, должно быть отмечено, что постадийное взвешенное комбинирование, проиллюстрированное на фиг.10b, в котором в первой операции объединяются линии из одного кадра, а впоследствии результаты из этих операций покадрового комбинирования комбинируются сами собой, также может выполняться в другом порядке. Другой порядок означает, что на первом этапе линии для текущей частоты k из некоторого количества смежных кадров, указанных информацией 103 управления, комбинируются посредством взвешенного комбинирования. Это взвешенное комбинирование выполняется для линий k, k-1, k-2, k+1, k+2, и т.д., в зависимости от количества смежных линий, которые должны использоваться для оценки мнимой линии. Затем результаты от этих «повременных» комбинаций подвергаются взвешенному комбинированию в «частотном направлении», чтобы в заключение получать мнимую линию k для кадра fi. Веса устанавливаются, чтобы предпочтительно иметь значение между -1 и 1, и веса могут быть реализованы в простой комбинации FIR- (с конечной импульсной характеристикой) или IIR- (с бесконечной импульсной характеристикой) фильтров, которая выполняет линейное комбинирование спектральных линий или спектральных сигналов из разных частот и разных кадров.
Как указано на фиг.6a и 6b, предпочтительным алгоритмом преобразования является алгоритм преобразования MDCT, который применяется в прямом направлении в элементах 50 и 51 на фиг.6a и который применяется в обратном направлении в элементах 52, 53 вслед за операцией комбинирования в объединителе 1162, работающем в спектральной области.
Фиг.8a иллюстрирует более подробную реализацию блока 50 или 51. В частности, последовательность отсчетов аудиосигнала временной области вводится в устройство 500 оконного анализа, который выполняет операцию обработки методом окна с использованием окна анализа и, в частности, выполняет эту операцию кадр за кадром, но с использованием шага или перекрытия 50%. Результат устройства оконного анализа, то есть последовательность кадров, обработанных методом окна отсчетов, вводится в блок 501 преобразования MDCT, который выдает последовательность вещественнозначных кадров MDCT, где эти кадры подвержены влиянию наложения спектров. В качестве примера, устройство оконного анализа применяет окна анализа, имеющие длину в 2048 отсчетов. Затем блок 501 преобразования MDCT выдает спектры MDCT, имеющие 1024 вещественных спектральных линий или значений MDCT. Предпочтительно устройство 500 оконного анализа и/или преобразователь 501 MDCT являются управляемыми посредством сигнала 502 управления длиной окна или длиной преобразования, например, так, чтобы для переходных участков в сигнале длина окна/длина преобразования уменьшалась, для того чтобы получать лучшие результаты кодирования.
Фиг.8b иллюстрирует операцию обратного MDCT, выполняемую в блоках 52 и 53. В качестве примера, блок 52 содержит блок 520 для выполнения покадрового преобразования обратного MDCT. Например, когда кадр значений MDCT имеет 1024 значения, тогда выходной сигал этого обратного преобразования MDCT имеет 2048 подверженных влиянию наложения спектров временных отсчетов. Такой кадр подается в устройство 521 оконного синтеза, который применяет окно синтеза к этому кадру из 2048 отсчетов. Обработанный методом окна кадр затем пересылается в процессор 522 перекрытия/суммирования, который, в качестве примера, применяет перекрытие 50% между двумя последовательными кадрами, а затем выполняет сложение отсчет за отсчетом, так что блок 2048 отсчетов в заключение дает в результате 1024 новых отсчета свободного от наложения спектров выходного сигнала. Вновь предпочтительно применять управление длиной окна/преобразования с использованием информации, например, которая передается в побочной информации кодированного многоканального сигнала, как указано на 523.
Значения предсказания могли бы рассчитываться для каждой отдельной спектральной линии спектра MDCT. Однако было обнаружено, что это необязательно, и значительное количество побочной информации может сберегаться посредством выполнения расчета информации о предсказании для каждой полосы. В другом изложении спектральный преобразователь 50, проиллюстрированный на фиг.9, который, например, является процессором MDCT, как обсуждено в контексте фиг.8a, дает спектр высокого разрешения по частоте, имеющий определенные спектральные линии, проиллюстрированные на фиг.9b. Этот высокочастотный спектр разрешения используется селектором 90 спектральных линий, который выдает спектр низкого разрешения по частоте, который содержит определенные полосы B1, B2, B3, …, BN. Этот спектр низкого разрешения по частоте пересылается в оптимизатор 207 для расчета информации о предсказании, так что информация о предсказании рассчитывается не для каждой спектральной линии, но только для каждой полосы. Для этой цели оптимизатор 207 принимает спектральные линии на каждую полосу и рассчитывает операцию оптимизации, начиная с допущения, что одно и то же значение α используется для всех спектральных линий в полосе.
Предпочтительно, полосы профилированы психоакустическим образом, так чтобы полоса пропускания полос увеличивалась от более низких частот к более высоким частотам, как проиллюстрировано на фиг.9b. В качестве альтернативы, хотя не настолько предпочтительны, как реализация с увеличением полосы пропускания, полосы частот с равными размерами также могли бы использоваться, где каждая полоса частот имеет по меньшей мере две или типично гораздо большее количество, такое как по меньшей мере 30 частотных линий. Типично, для спектра с 1024 спектральными линиями рассчитывается менее чем 30 комплексных значений α, а предпочтительно более чем 5 значений α. Что касается спектров с менее чем 1024 спектральными линиями (например, 128 линиями), предпочтительно, меньшее количество полос частот (например, 6) используется для α.
Для расчета значений α не обязательно требуется спектр MDCT высокого разрешения. В качестве альтернативы, гребенка фильтров, имеющая разрешение по частоте, подобное разрешению, требуемому для расчета значений α, также может использоваться. Когда должны быть реализованы полосы, увеличивающиеся по частоте, то эта гребенка частот должна иметь меняющуюся полосу пропускания. Однако, когда достаточна постоянная полоса пропускания от низких до высоких частот, то может использоваться традиционная гребенка фильтров с субполосами равной ширины.
В зависимости от реализации, знак значения, указанного на фиг.3b или 4b, может быть инвертирован. Чтобы оставались совместимыми, однако, необходимо, чтобы эта инверсия знака использовалась на стороне кодера, а также на стороне декодера. По сравнению с фиг.6a, фиг.5a иллюстрирует обобщенный вид кодера, где элемент 2033 является предсказателем, который управляется информацией 206 управления предсказателем, которая определяется в элементе 207 и которая воплощена в качестве побочной информации в битовом потоке. Вместо MDCT, используемого на фиг.6a в блоках 50, 51, обобщенное время/частотное преобразование используется на фиг.5a, как обсуждено. Как очерчено ранее, фиг.6a является последовательностью операций, которая соответствует последовательности операций декодера на фиг.6b, где L обозначает сигнал левого канала, R обозначает сигнал правого канала, M обозначает средний сигнал или сигнал понижающего микширования, S обозначает боковой сигнал, а D обозначает остаточный сигнал. В качестве альтернативы, L также называется сигналом 201 первого канала, R также называется сигналом 202 второго канала, M также называется первым комбинированным сигналом 204, а S также называется вторым комбинированным сигналом 2032.
Предпочтительно, модули 2070 в кодере и 1160a в декодере должны в точности совпадать, для того чтобы гарантировать правильное кодирование формы сигнала. Это предпочтительно применяется к случаю, в котором эти модули используют некоторую форму приближения, такую как усеченные фильтры, или когда используется только один или два вместо трех кадров MDCT, то есть текущий кадр MDCT на линии 60, предыдущий кадр MDCT на линии 61 и следующий кадр MDCT на линии 62.
Дополнительно, предпочтительно, чтобы модуль 2070 в кодере на фиг.6a использовал неквантованный спектр M MDCT в качестве входного сигнала, хотя модуль 1160a вещественно-мнимого преобразования (R2I) в декодере имеет только квантованный спектр MDCT, имеющийся в распоряжении в качестве входного сигнала. В качестве альтернативы, можно использовать реализацию, в которой кодер использует квантованные коэффициенты MDCT в качестве входного сигнала в модуль 2070. Однако использование неквантованного спектра MDCT в качестве входного сигнала в модуль 2070 является предпочтительным подходом с перцепционной точки зрения.
Впоследствии, несколько аспектов вариантов осуществления настоящего изобретения обсуждены подробнее.
Стандартное параметрическое стереофоническое кодирование полагается на способность области комплексных (гибридных) QMF с избыточной дискретизацией предоставлять возможность для меняющейся по времени и частоте перцепционно оправданной обработки сигналов без привнесения артефактов наложения спектров. Однако в случае кодирования с понижающим микшированием/остаточным сигналом (как используется для высоких скоростей передачи битов, рассмотренных здесь), получающийся в результате унифицированный стереофонический кодер действует в качестве кодера формы сигнала. Это предоставляет возможность работы в области с критической дискретизацией, подобной области MDCT, поскольку парадигма кодирования формы сигнала гарантирует, что хорошо сохраняется свойство подавления наложения спектров цепи преобразования MDCT-мнимое MDCT.
Однако, чтобы быть способными пользоваться улучшенной эффективностью кодирования, которая может достигаться в случае стереофонических сигналов с межканальными временными или фазовыми разностями посредством комплекснозначного коэффициента α предсказания, комплекснозначное представление частотной области сигнала DMX понижающего микширования требуется в качестве входного сигнала в комплекснозначную матрицу повышающего микширования. Это может получаться посредством использования преобразования MDST в дополнение к преобразованию MDCT для сигнала DMX. Спектр MDST может вычисляться (точно или в качестве приближения) по спектру MDCT.
Более того, параметризация матрицы повышающего микширования может быть упрощена посредством передачи комплексного коэффициента α предсказания вместо параметров MPS. Отсюда только два параметра (вещественная и мнимая часть α) передаются вместо трех (ICC, CLD и IPD). Это возможно вследствие избыточности параметризации MPS в случае кодирования с понижающим микшированием/остаточным сигналом. Параметризация MPS включает в себя информацию об относительной величине декорреляции, которая должна быть добавлена в декодере (то есть энергетическом соотношении между сигналами RES и DMX), и эта информация является избыточной, когда передаются реальные сигналы DMX и RES.
Вследствие той же самой причины, коэффициент g усиления, показанный в матрице повышающего микширования, приведенной выше, является вышедшим из употребления в случае кодирования с понижающим микшированием/остаточным сигналом. Отсюда матрица повышающего микширования для кодирования с понижающим микшированием/остаточным сигналом с комплексным предсказанием теперь имеет вид:
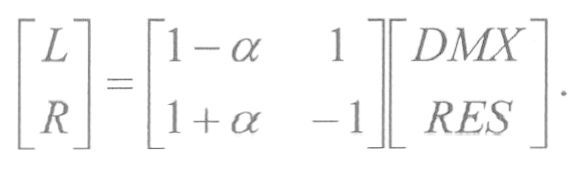
По сравнению с уравнением 1169 на фиг.4b, знак альфа инвертирован в этом уравнении, и DMX=M, а RES=D. Поэтому это является альтернативной реализацией/обозначением по отношению к фиг.4b.
Два возможных варианта имеются в распоряжении для расчета остаточного сигнала предсказания в кодере. Один из возможных вариантов состоит в том, чтобы использовать квантованные спектральные значения MDCT понижающего микширования. Это имело бы следствием такое же распределение ошибки квантования, как при кодировании M/S, поскольку кодер и декодер используют идентичные значения для формирования предсказания. Другой возможный вариант состоит в том, чтобы использовать неквантованные спектральные значения MDCT. Это подразумевает, что кодер и декодер не будут использовать одни и те же данные для формирования предсказания, которое предоставляет возможность пространственного перераспределения ошибки кодирования согласно мгновенным маскирующим свойствам сигнала за счет до некоторой степени сниженного выигрыша от кодирования.
Предпочтительно вычислять спектр MDST прямо в частотной области посредством двумерной фильтрацией с FIR трех смежных кадров MDCT, как обсуждено. Последнее может рассматриваться в качестве «вещественно-мнимого» (R2I) преобразования. Сложность вычисления MDST в частотной области может быть уменьшена разными способами, что означает, что рассчитывается только приближение спектра MDST:
- С ограничением количества отводов FIR-фильтра.
- С оценкой MDST только по текущему кадру MDCT.
- С оценкой MDST по текущему и предыдущему кадру MDCT.
Пока одно и то же приближение используется в кодере и декодере, свойства кодирования формы сигнала не подвергаются влиянию. Такие приближения спектра MDST, однако, могут приводить к снижению выигрыша от кодирования, достигаемого комплексным предсказанием.
Если лежащий в основе кодер MDCT поддерживает переключение формы окна, коэффициенты двухмерного FIR-фильтра, используемого для вычисления спектра MDST, должны быть адаптированы под реальные формы окна. Коэффициенты фильтра, применяемые к спектру MDCT текущего кадра, зависят от полного окна, то есть набор коэффициентов требуется для каждого типа окна и для каждого оконного перехода. Коэффициенты фильтра, применяемые к спектру MDCT предыдущего/следующего кадра, зависят только от половины окна, перекрывающейся с текущим кадром, то есть, что касается таковых, набор коэффициентов требуется только для каждого типа окна (нет дополнительных коэффициентов для переходов).
Если лежащий в основе кодер MDCT использует переключение длины преобразования, включение предыдущего и/или следующего кадра MDCT в приближение становится более сложным вблизи переходов между разными длинами преобразований. Вследствие разного количества коэффициентов MDCT в текущем и предыдущем/следующем кадре, двухмерная фильтрация является более сложной в этом случае. Чтобы избежать повышения вычислительной и конструктивной сложности, предыдущий/следующий кадр может быть исключен из фильтрации на переходах длины преобразования за счет уменьшенной точности приближения для соответствующих кадров.
Более того, особое внимание должно быть уделено самой нижней и самой верхней частям спектра MDST (близким к постоянному току и fs/2), где имеется в распоряжении меньшее количество окружающих коэффициентов MDCT для фильтрации с FIR, чем требуется. Здесь, последовательность операций фильтрации должна быть приспособлена для правильного вычисления спектра MDST. Это может делаться либо посредством использования симметричного расширения спектра MDCT для недостающих коэффициентов (согласно периодичности спектров дискретных по времени сигналов), либо посредством соответствующей адаптации коэффициентов фильтра. Обработка этих специальных случаев, конечно, может быть упрощена за счет уменьшенной точности поблизости от границ спектра MDST.
Вычисление точного спектра MDST по переданным спектрам MDCT в декодере увеличивает задержку декодера на один кадр (здесь, предполагаемый имеющим значение 1024 отсчета).
Дополнительная задержка может избегаться посредством использования приближения спектра MDST, которое не требует спектра MDCT следующего кадра в качестве входного сигнала.
Последующий маркированный список обобщает преимущества основанного на MDCT унифицированного стереофонического кодирования над основанным на QMF унифицированным стереофоническим кодированием:
- Лишь небольшое увеличение вычислительной сложности (когда не используется SBR).
- Увеличение в отношении точной реконструкции, если спектры MDCT не квантованы. Отметим, что это не так для основанного на QMF унифицированного стереофонического кодирования.
- Естественное расширение кодирования M/S и стереофонического кодирования интенсивности.
- Более ясная архитектура, которая упрощает настройку кодера, поскольку обработка и квантование/кодирование стереофонического сигнала могут быть тесно связаны. Отметим, что в основанном на QMF унифицированном стереофоническом кодировании кадры объемного звучания MPEG и кадры MDCT не выровнены и что полосы масштабного коэффициента не совпадают с полосами параметров.
- Эффективное кодирование стереофонических параметров, поскольку должны передаваться только два параметра (комплексное число α) вместо трех параметров, как в объемном звучании MPEG (ICC, CLD, IPD).
- Нет дополнительной задержки декодера, если спектр MDST вычисляется в качестве приближения (без использования следующего кадра).
Важные свойства реализации могут быть обобщены, как изложено ниже:
a) спектры MDST вычисляются посредством двухмерной фильтрации с FIR по текущему, предыдущему и следующему спектрам MDCT. Разные компромиссные соотношения сложности/качества для вычисления (приближения) MDST возможны посредством сокращения количества отводов FIR-фильтра и/или количества используемых кадров MDCT. В частности, если смежный кадр не имеется в распоряжении вследствие потери кадра во время передачи и переключения длины преобразования, такой конкретный кадр исключается из оценки MDST. Для случая переключения длины преобразования, исключение сигнализируется в битовом потоке.
b) Только два параметра, вещественная и мнимая часть комплексного коэффициента α предсказания, передаются вместо ICC, CLD и IPD. Вещественная и мнимая части α обрабатываются независимо, ограничиваются диапазоном [-3,0, 3,0] и квантуются с величиной шага 0,1. Если определенный параметр (вещественная или мнимая часть α) не используется в данном кадре, это сигнализируется в битовом потоке, и неуместный параметр не передается. Параметры кодируются время-разностным образом или частотно-разностным образом и, в заключение, кодирование Хаффмана применяется с использованием словаря кодов масштабных коэффициентов. Коэффициенты предсказания адаптируются каждую вторую полосу масштабных коэффициентов, что дает в результате разрешение по частоте, подобное таковому у объемного звучания MPEG. Эта схема квантования и кодирования дает в результате среднюю скорость передачи битов приблизительно 2 кбит/с для стереофонической побочной информации в пределах типичной конфигурации, имеющей целевую скорость передачи битов в 96 кбит/с.
Детали предпочтительной или альтернативной реализации содержат:
c) Для каждого из двух параметров α: один может выбирать не дифференциальное (PCM) или дифференциальное (DPCM) кодирование на покадровой или попотоковой основе, сигнализируемое соответствующим битом в битовом потоке. Что касается кодирования DPCM, возможны время- или частотно-разностное кодирование. Вновь, это может сигнализироваться с использованием однобитного флага.
d) Вместо повторного использования предварительно определенного словаря кодов, такого как словарь масштабных коэффициентов AAC, также можно использовать специальный инвариантный или настраивающийся под сигнал словарь кодов, чтобы кодировать значения параметра α, или можно вернуться к кодовым словам постоянной длины (например, 4-битным), беззнаковым или поразрядного дополнения до двух.
e) Диапазон значений параметров α, а также величина шага квантования параметра могут выбираться произвольным образом и оптимизироваться по рассматриваемым характеристикам сигнала.
f) Количество и спектральная и/или временная ширина активных полос параметра α могут выбираться произвольным образом и оптимизироваться по заданным характеристикам сигнала. В частности, конфигурация полос может сигнализироваться на покадровой или попотоковой основе.
g) В дополнение к или вместо механизмов, намеченных в общих чертах в пункте a), приведенном выше, она может сигнализироваться явным образом посредством бита на каждый кадр в битовом потоке, что спектр MDCT только текущего кадра используется для вычисления приближения спектра MDST, то есть, что смежные кадры MDCT не учитываются.
Варианты осуществления относятся к системе согласно настоящему изобретению для унифицированного стереофонического кодирования в области MDCT. Оно дает возможность использовать преимущества унифицированного стереофонического кодирования в системе USAC MPEG даже на более высоких скоростях передачи битов (где не используется SBR) без значительного увеличения вычислительной сложности, которое сопутствовало бы основанному на QMF подходу.
Следующие два списка обобщают аспекты предпочтительной конфигурации, описанные раньше, которые могут использоваться в качестве альтернативы друг другу или в дополнение к другим аспектам:
1a) общая концепция: комплексное предсказание MDCT бокового сигнала по MDCT и MDST среднего сигнала;
1b) рассчитать/аппроксимировать MDST по MDCT («R2I») в частотной области с использованием 1 или более кадров (3 кадра привносят задержку);
1c) усечение фильтра (даже вплоть до 2 отводов на 1 кадр, то есть [-1 0 1]) для уменьшения вычислительной сложности;
1d) надлежащая обработка DC и fs/2;
1e) надлежащая обработка переключения формы окна;
1f) не использовать предыдущий/следующий кадр, если он имеет другой размер преобразования;
1g) предсказание, основанное на неквантованных или квантованных коэффициентах MDCT в кодере;
2a) непосредственно квантовать и кодировать вещественную и мнимую часть комплексного коэффициента предсказания (то есть нет параметризации объемного звучания MPEG);
2b) использовать равномерный квантователь для этого (величину шага, например, 0,1);
2c) использовать надлежащее разрешение по частоте для коэффициентов предсказания (например, 1 коэффициент на 2 полосы масштабных коэффициентов);
2d) сокращенная сигнализация, если все коэффициенты предсказания являются вещественными;
2e) явный бит для каждого кадра для принудительного применения операции 1-кадрового R2I.
В варианте осуществления кодер дополнительно содержит: спектральный преобразователь (50, 51) для преобразования представления во временной области сигналов двух каналов в спектральное представление сигналов двух каналов, содержащих сигналы субполосы для сигналов двух каналов, при этом объединитель (2031), предсказатель (2033) и вычислитель (2034) остаточного сигнала сконфигурированы, чтобы обрабатывать каждый сигнал субполосы отдельно, так чтобы первый комбинированный сигнал и остаточный сигнал получались для множества субполос, при этом выходной интерфейс (212) сконфигурирован для комбинирования кодированного первого комбинированного сигнала и кодированного остаточного сигнала для множества субполос.
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, причем блок или устройство соответствуют этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, либо признака соответствующего устройства.
В варианте осуществления настоящего изобретения применяется надлежащая обработка переключения формы окна. Когда рассматривается фиг.10a, информация 109 о форме окна может вводиться в вычислитель 1001 мнимого спектра. Более точно, вычислитель мнимого спектра, который выполняет вещественно-мнимое преобразование вещественнозначного спектра, такого как спектр MDCT (такой как элемент 2070 на фиг.6a или элемент 1160a на фиг.6b), может быть реализован в качестве IIR-фильтра или FIR-фильтра. Коэффициенты FIR или IIR в этом модуле 1001 вещественно-мнимого преобразования зависят от формы окна левой половины и правой половины текущего кадра. Эта форма окна может быть другой для синусоидального окна или окна KBD (выведенного Кайзером-Бесселем) и, при условии заданной конфигурации последовательности окна, может быть длинным окном, стартовым окном, старт-стопным окном или коротким окном. Модуль вещественно-мнимого преобразования может содержать двухмерный FIR-фильтр, где одно измерение является временным измерением, где два последовательных кадра MDCT вводятся в FIR-фильтр, а второе измерение является частотным измерением, где вводятся частотные коэффициенты кадра.
Следующая таблица дает разные коэффициенты фильтра MDST для текущей последовательности окна для разных форм окна и разных реализаций левой половины и правой половины окна.
Параметры фильтра MDST для текущего окна
окна
Правая половина: Синусоидальная форма
Правая половина: Форма KBD
0,000000,
-0,500000, 0,000000, 0,000000]
0,000000,
-0,581427, 0,000000,-0,091497]
0,000000,
-0,567149, -0,103791, -0,102658]
0,000000,
-0,608574, -0,047969, -0,150512]
0,000000,
-0,567149, 0,103791, -0,102658]
0,000000,
-0,608574, 0,047969, -0,150512]
0,000000,
-0,634298, 0,000000, -0,205316]
0,000000,
-0,635722, 0,000000, -0,209526]
окна
Правая половина: Форма KBD
Правая половина: Синусоидальная форма
0,000000,
-0,540714, -0,057238, -0,045748]
0,000000,
-0,540714, 0,057238, -0,045748]
0,000000,
-0,567861, -0,105207, -0,104763]
0,000000,
-0,607863, -0,046553, -0,148406]
0,000000,
-0,607863, 0,046553, -0,148406]
0,000000,
-0,567861, 0,105207, -0,104763]
0,000000,
-0,635010, -0,001416, 0,207421]
0,000000,
-0,635010, 0,001416, -0,207421]
Дополнительно, информация 109 о форме окна дает информацию о форме окна для предыдущего окна, когда предыдущее окно используется для расчета спектра MDST по спектру MDCT. Соответствующие коэффициенты фильтра MDST для предыдущего окна заданы в следующей таблице.
Параметры фильтра MDST для предыдущего окна
последовательность
окна
Форма KBD
0,318310,
0,250000, 0,106103, 0,000000]
0,213077,
0,186579, 0,123714, 0,059509]
0,039790,
0,039645, 0,039212, 0,038498]
0,026631,
0,026577, 0,026413, 0,026142]
Отсюда, в зависимости от информации 109 о форме окна, вычислитель 1001 мнимого спектра на фиг.10a адаптируется посредством применения разных наборов коэффициентов фильтра.
Информация о форме окна, которая используется на стороне декодера, рассчитывается на стороне кодера и передается в качестве побочной информации вместе с выходным сигналом кодера. На стороне декодера, информация 109 о форме окна извлекается из битового потока демультиплексором битового потока (например, 102, на фиг.5b) и выдается в вычислитель 1001 мнимого спектра, как проиллюстрировано на фиг.10a.
Когда информация 109 о форме окна сигнализирует, что предыдущий кадр имел другой размер преобразования, то предпочтительно, чтобы предыдущий кадр не использовался для расчета мнимого спектра из вещественнозначного спектра. То же самое справедливо, когда посредством интерпретации информации 109 о форме окна обнаруживается, что следующий кадр имеет другой размер преобразования. В таком случае следующий кадр не используется для расчета мнимого спектра из вещественнозначного спектра. В таком случае, когда, например, предыдущий кадр имел размер преобразования, отличный от текущего кадра, и когда следующий кадр вновь имеет другой размер преобразования по сравнению с текущим кадром, то только текущий кадр, то есть спектральные значения текущего окна используются для оценки мнимого спектра.
Предсказание в кодере основано на неквантованных или квантованных частотных коэффициентах, таких как коэффициенты MDCT. Когда предсказание, проиллюстрированное элементом 2033 на фиг.3a, основано на неквантованных данных, тогда вычислитель 2034 остаточного сигнала предпочтительно также оперирует неквантованными данными и выходным сигналом вычислителя остаточного сигнала, то есть остаточный сигнал 205 квантуется до энтропийного кодирования и передачи в декодер. В альтернативном варианте осуществления, однако, предпочтительно, чтобы предсказание было основано на квантованных коэффициентах MDCT. В таком случае квантование может происходить до объединителя 2031 на фиг.3a, так чтобы первый квантованный канал и второй квантованный канал были основой для расчета остаточного сигнала. В качестве альтернативы квантование также может происходить после объединителя 2031, так чтобы первый комбинированный сигнал и второй комбинированный сигнал рассчитывались в неквантованной форме и квантовались перед тем, как рассчитывается остаточный сигнал. Вновь, в качестве альтернативы, предсказатель 2033 может работать в неквантованной области, и сигнал 2035 предсказания квантуется до ввода в вычислитель остаточного сигнала. В таком случае полезно, чтобы второй комбинированный сигнал 2032, который также вводится в вычислитель 2034 остаточного сигнала, также квантуется до того, как вычислитель остаточного сигнала рассчитывает остаточный сигнал 070 на фиг.6a, что может реализовываться в пределах предсказателя 2033 на фиг.3a, оперирует теми же самыми квантованными данными, что и имеются в распоряжении на стороне декодера. В таком случае может гарантироваться, что спектр MDST, оцененный в кодере с целью выполнения расчета остаточного сигнала, является в точности таким же, как спектр MDST на стороне декодера, используемый для выполнения обратного предсказания, то есть для расчета бокового сигнала из остаточного сигнала. Для этой цели первый комбинированный сигнал, такой как сигнал M на линии 204 по фиг.6a, квантуется до ввода в блок 2070. Затем спектр MDST, рассчитываемый с использованием квантованного спектра MDCT текущего кадра, и, в зависимости от информации управления, квантованный спектр MDCT предыдущего или следующего кадра вводятся в умножитель 2074, и выходной сигнал умножителя 2074 по фиг.6a вновь будет неквантованным спектром. Этот неквантованный спектр будет вычитаться из спектра, введенного в сумматор 2034b, и, в заключение, будет квантоваться в квантователе 209b.
В варианте осуществления вещественная часть и мнимая часть комплексного коэффициента предсказания для каждой полосы предсказания кодируются непосредственно, то есть без примерной параметризации объемного звучания MPEG. Квантование может выполняться с использованием равномерного квантователя, например, с величиной шага в 0,1. Это означает, что не применяются никакие логарифмические величины шага квантования, но применяются любые линейные величины шага. В реализации диапазон значений для вещественной части и мнимой части комплексного коэффициента предсказания находится в диапазоне от -3 до 3, что означает, что 60 или, в зависимости от деталей реализации, 61 шаг квантования использовался для вещественной части и мнимой части комплексного коэффициента предсказания.
Предпочтительно, вещественная часть, применяемая в умножителе 2073 на фиг.6a, и мнимая часть 2074, применяемая на фиг.6a, квантуются до применения, так чтобы вновь такое же значение для предсказания использовалось на стороне кодера, как имеется в распоряжении на стороне декодера. Это гарантирует, что остаточный сигнал предсказания покрывает - кроме привнесенной ошибки квантования - любые ошибки, которые могут возникать, когда неквантованный коэффициент предсказания применяется на стороне кодера наряду с тем, что квантованный коэффициент предсказания применяется на стороне декодера. Предпочтительно, квантование применяется таким образом, чтобы по мере возможности одинаковое состояние и идентичные сигналы были в распоряжении на стороне кодера и на стороне декодера. Отсюда предпочтительно квантовать входной сигнал в вещественно-мнимый вычислитель 2070 с использованием такого же квантования, как применяется в квантователе 209a. Дополнительно, предпочтительно квантовать вещественную часть и мнимую часть коэффициента предсказания для выполнения умножений в элементе 2073 и элементе 2074. Квантование является таким же, как применяется в квантователе 2072. Дополнительно, боковой сигнал, выведенный блоком 2031 на фиг.6a, также может квантоваться до сумматоров 2034a и 2034b. Однако выполнение квантования квантователем 209b вслед за сложением, где сложение этими сумматорами применяется с неквантованным боковым сигналом, не является проблематичным.
В дополнительном варианте осуществления настоящего изобретения сокращенная сигнализация применяется, если вещественны все коэффициенты предсказания. Может быть ситуация, что все коэффициенты предсказания для определенного кадра, то есть для одного и того же временного участка аудиосигнала, рассчитаны вещественными. Такая ситуация может возникать, когда полный средний сигнал и полные боковые сигналы вообще не сдвинуты или немного сдвинуты по фазе относительно друг друга. Для того чтобы экономить биты, это указывается одиночным указателем вещественности. В таком случае мнимой части коэффициента предсказания не нужно сигнализироваться в битовом потоке с кодовым словом, представляющим нулевое значение. На стороне декодера интерфейс декодера с битовым потоком, такой как демультиплексор битового потока, будет интерпретировать этот указатель вещественности и, в таком случае, не будет искать кодовые слова для мнимой части, но будет предполагать все биты, находящиеся в соответствующей секции битового потока в качестве битов для вещественнозначных коэффициентов предсказания. Более того, предсказатель 2033 при приеме указания, что все мнимые части коэффициентов предсказания в кадре являются нулевыми, не будет нужным рассчитывать спектр MDST или вообще мнимый спектр из вещественнозначного спектра MDCT. Отсюда элемент 1160a в декодере по фиг.6b будет деактивирован, и обратное предсказание будет происходить с использованием вещественнозначного коэффициента предсказания, примененного в умножителе 1160b по фиг.6b. То же самое справедливо для стороны кодера, где элемент 2070 будет деактивирован, и предсказание будет происходить только с использованием умножителя 2073. Эта побочная информация предпочтительно используется в качестве дополнительного бита на кадр, и декодер будет считывать этот битовый кадр за кадром, для того чтобы решать, будет или нет активным вещественно-мнимый преобразователь 1160a для кадра. Отсюда предоставление этой информации дает в результате уменьшенный размер битового потока вследствие более эффективной сигнализации всех мнимых частей коэффициентов предсказания, имеющих значение ноль для кадра, и дополнительно дает меньшую сложность для декодера для такого кадра, что приводит непосредственно к сниженному потреблению батареи такого процессора, например, реализованного в мобильном устройстве с батарейным питанием.
Комплексное стереофоническое предсказание в соответствии с предпочтительными вариантами осуществления по настоящему изобретению является инструментом для эффективного кодирования пар каналов с помощью разностей уровней и/или фаз между каналами. С использованием комплекснозначного параметра α, левый и правый каналы реконструируются посредством следующей матрицы, где dmxIm обозначает MDST, соответствующее MDCT каналов dmxRe понижающего микширования.
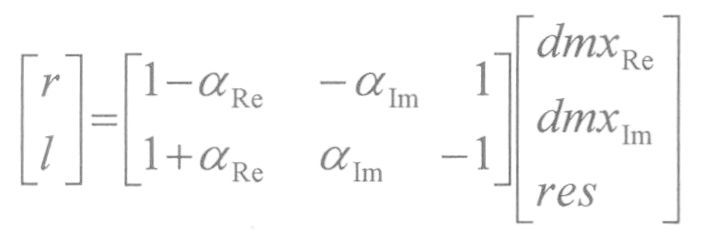
Вышеприведенное уравнение является еще одним представлением, которое разделено относительно вещественной части и мнимой части α и представляет собой уравнение для объединенной операции предсказания/комбинирования, в которой не обязательно рассчитывается предсказанный сигнал S.
Следующие элементы данных предпочтительно используются для этого средства:
1: Все полосы используют комплексное стереофоническое предсказание
0: комплексное предсказание не используется, используется L/R
1: используется комплексное предсказание
1: αIm передается для всех полос предсказания
1: Использовать текущий и предыдущий кадр для оценки MDST
1: Время-разностное кодирование коэффициентов предсказания
Эти элементы данных рассчитываются в кодере и помещаются в побочную информацию стереофонического или многоканального аудиосигнала. Элементы извлекаются из побочной информации на стороне декодера выделителем побочной информации и используются для управления вычислителем декодера, чтобы выполнять соответствующее действие.
Комплексное стереофоническое предсказание требует спектра MDCT понижающего микширования текущей пары каналов, а в случае complex_coef==1 - оценки спектра MDST понижающего микширования текущей пары каналов, то есть мнимой ответной части спектра MDCT. Оценка MDST понижающего микширования вычисляется из понижающего микширования MDCT текущего кадра, а в случае use_prev_frame==1 - понижающего микширования MDCT предыдущего кадра. Понижающее микширование MDCT предыдущего кадра группы g окна и группового окна b получается из реконструированного левого и правого спектров такого кадра.
При вычислении оценки MDST понижающего микширования используется длина преобразования MDCT с четным значением, которая зависит от последовательности окна, а также filter_coefs и filter_coefs_prev, которые являются массивами, содержащими в себе основные компоненты фильтра, и которые выводятся согласно предыдущим таблицам.
Для всех коэффициентов предсказания разность до предыдущего (по времени или частоте) значения кодируется с использованием словаря кодов Хаффмана. Коэффициенты предсказания не передаются для полос предсказания, для которых cplx_pred_used=0.
Коэффициенты обратного квантованного предсказания alpha_re и alpha_im заданы согласно
alpha_re=alpha_q_re*0,1
alpha_im=alpha_q_im*0,1.
Должно быть подчеркнуто, что изобретение применимо не только к стереофоническим сигналам, то есть многоканальным сигналам, имеющим только два канала, но также применимо к двум каналам или многоканальному сигналу, имеющему три или более каналов, таким как сигнал 5.1 или 7.1.
Согласно настоящему изобретению кодированный аудиосигнал может храниться на цифровом запоминающем носителе или может передаваться в среде передачи, такой как беспроводная среда передачи или проводная среда передачи, такая как Интернет.
В зависимости от требований определенной реализации, варианты осуществления изобретения могут быть реализованы в аппаратном обеспечении или в программном обеспечении. Реализация может выполняться с использованием цифрового запоминающего носителя, например гибкого диска, DVD, CD, ROM, PROM, EPROM, EEPROM или памяти FLASH, имеющего электронным образом считываемые сигналы управления, хранимые на нем, которые взаимодействуют (или способны к взаимодействию) с программируемой компьютерной системой, так чтобы выполнялся соответствующий способ.
Некоторые варианты осуществления согласно изобретению содержат некратковременный или вещественный носитель данных, содержащий электронным образом считываемые сигналы управления, которые способны к взаимодействию с программируемой компьютерной системой, так чтобы выполнялся один из способов, описанных в материалах настоящей заявки.
В общем, варианты осуществления настоящего изобретения могут быть реализованы в качестве компьютерного программного продукта с управляющей программой, причем управляющая программа является действующей для выполнения одного из способов, когда компьютерный программный продукт исполняется на компьютере. Управляющая программа, например, может храниться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из способов, описанных в материалах настоящей заявки, хранимую на машиночитаемом носителе.
Другими словами, вариант осуществления способа согласно настоящему изобретению поэтому является компьютерной программой, содержащей управляющую программу для выполнения одного из способов, описанных в материалах настоящей заявки, когда компьютерная программа исполняется на компьютере.
Дополнительным вариантом осуществления способов согласно настоящему изобретению поэтому является носитель данных (или цифровой запоминающий носитель, или компьютерно-читаемый носитель), содержащий записанную на нем компьютерную программу для выполнения одного из способов, описанных в материалах настоящей заявки.
Дополнительным вариантом осуществления способа согласно настоящему изобретению поэтому является поток данных или последовательность сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в материалах настоящей заявки. Поток данных или последовательность сигналов, например, могут быть сконфигурированы, чтобы передаваться через соединение передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, сконфигурированное или приспособленное для выполнения одного из способов, описанных в материалах настоящей заявки.
Дополнительный вариант осуществления содержит компьютер, содержащий установленную на нем компьютерную программу для выполнения одного из способов, описанных в материалах настоящей заявки.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения некоторых или всех из функциональных возможностей способов, описанных в материалах настоящей заявки. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, для того чтобы выполнять один из способов, описанных в материалах настоящей заявки. Обычно способы предпочтительно выполняются каким-нибудь аппаратным устройством.
Описанные выше варианты осуществления являются лишь иллюстративными для принципов настоящего изобретения. Понятно, что модификации и варианты компоновок и деталей, описанных в материалах настоящей заявки, будут очевидны специалистам в данной области техники. Поэтому замысел состоит в том, чтобы ограничиваться только объемом прилагаемой формулы изобретения, а не конкретными деталями, представленными в качестве описания и пояснения вариантов осуществления, приведенных в материалах настоящей заявки.
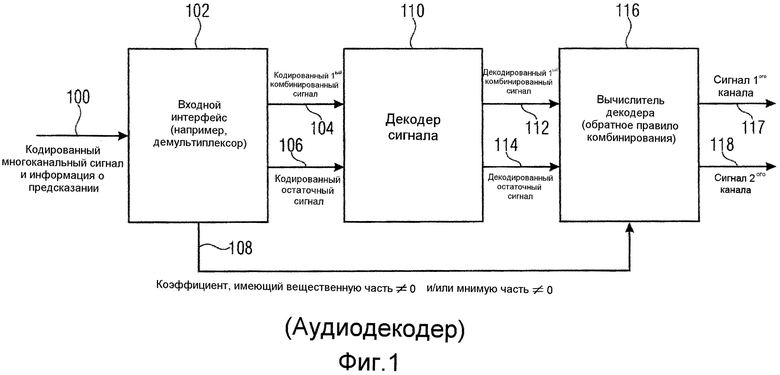
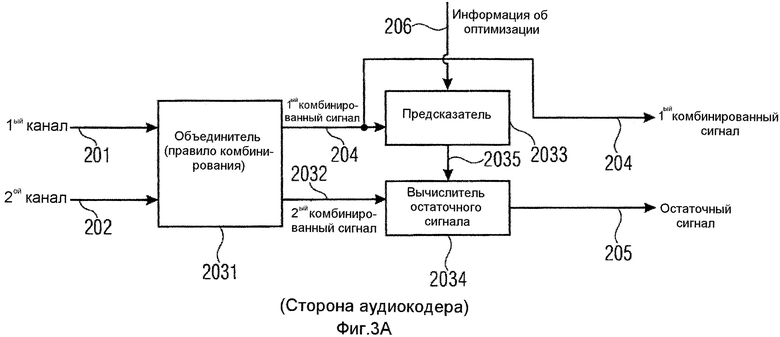
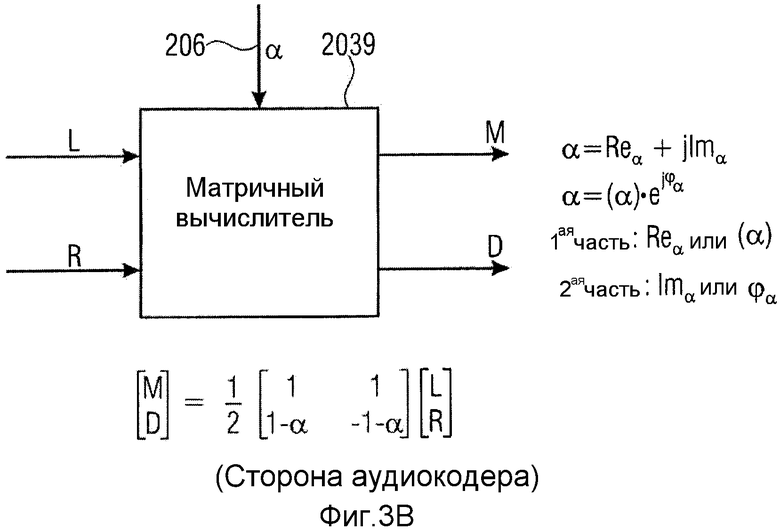
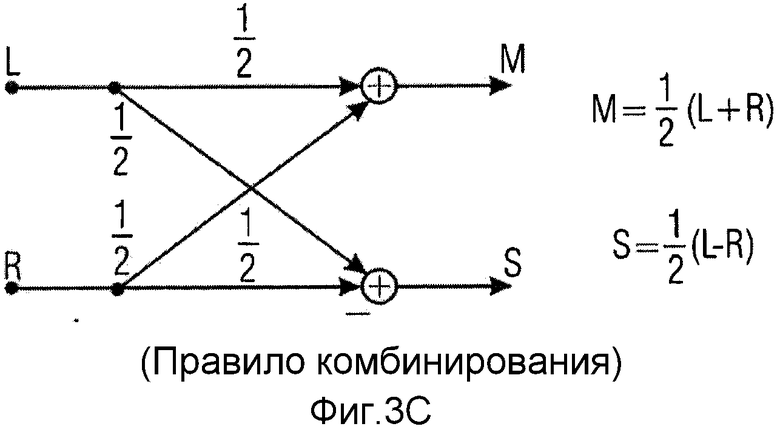
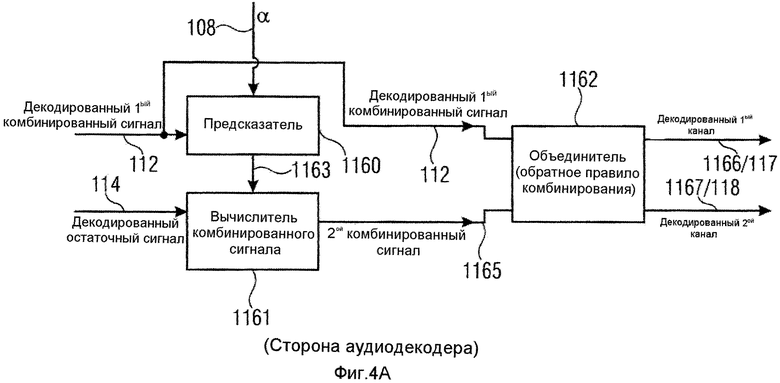
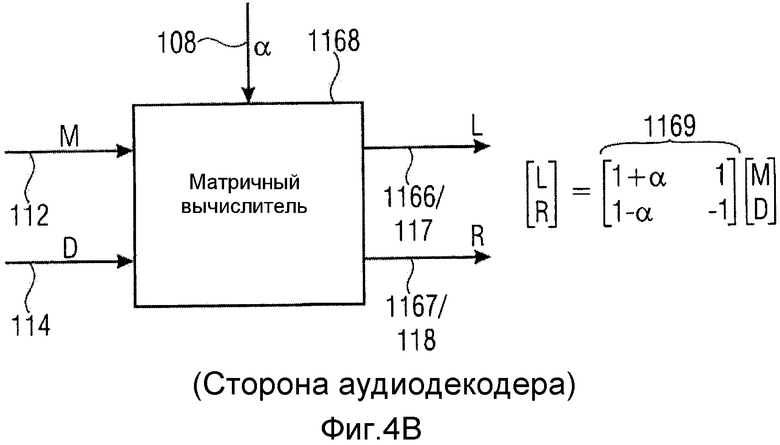
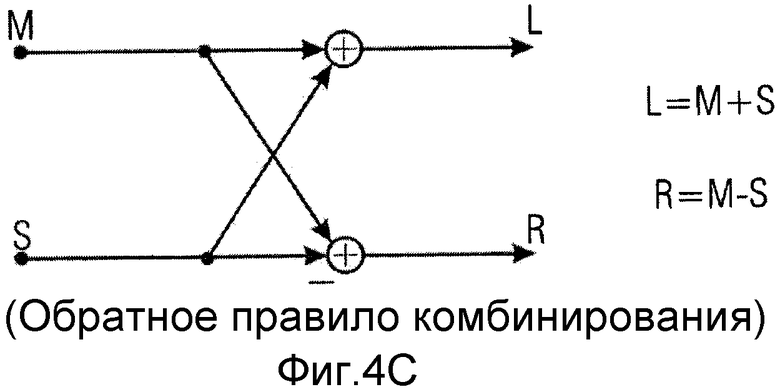
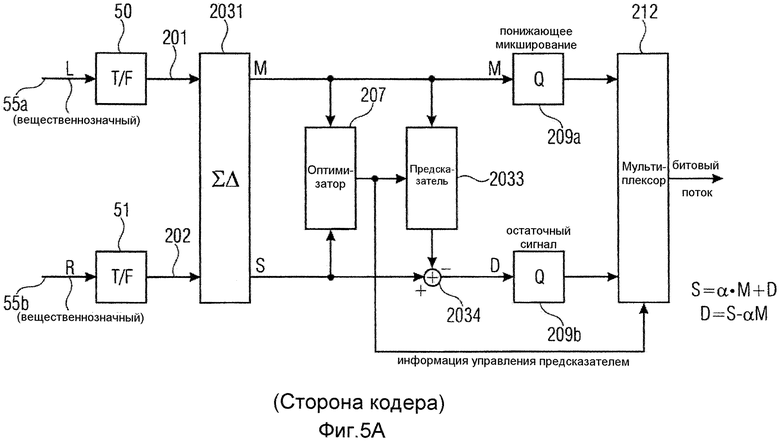
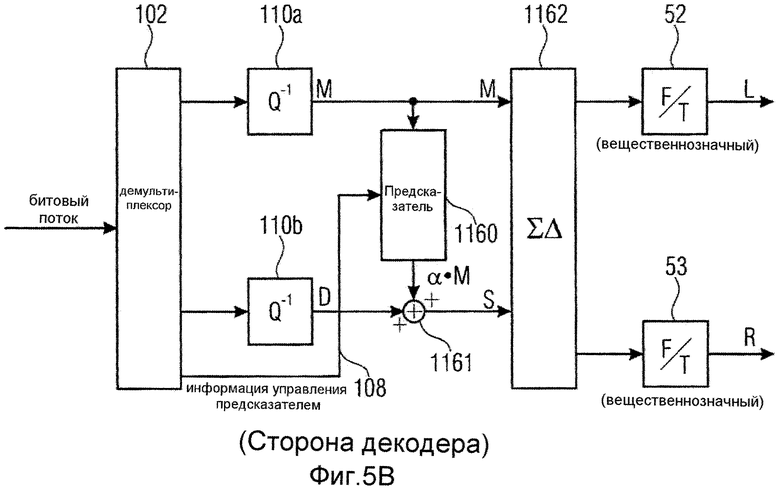
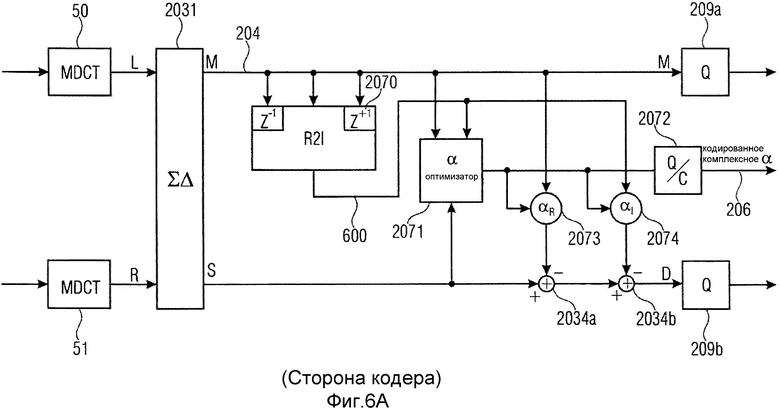
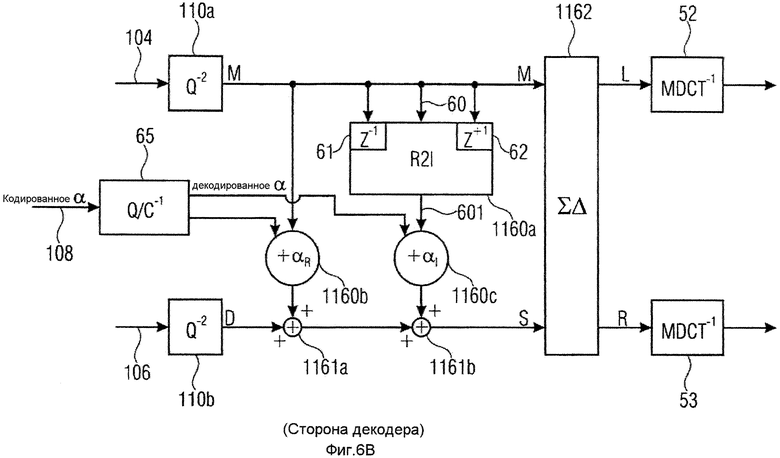
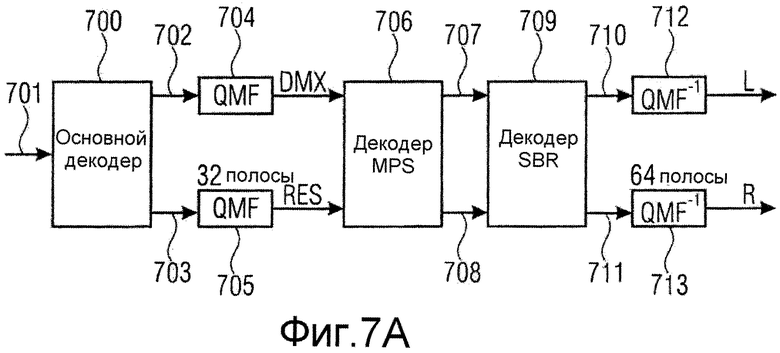
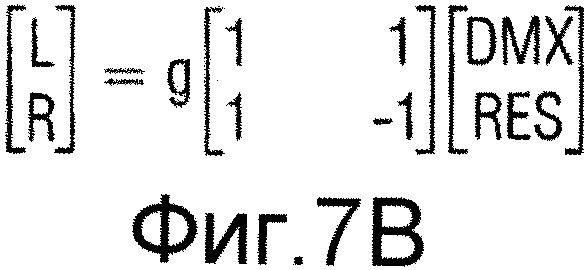
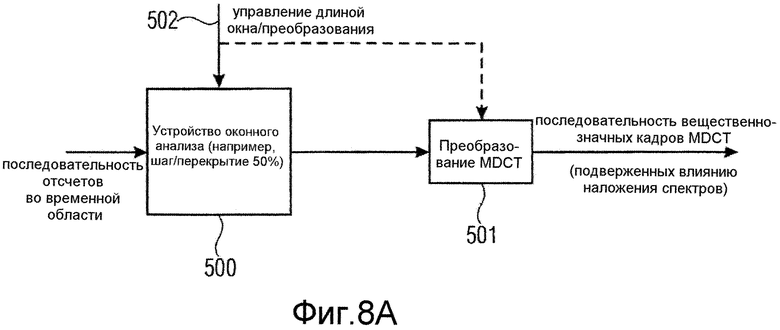
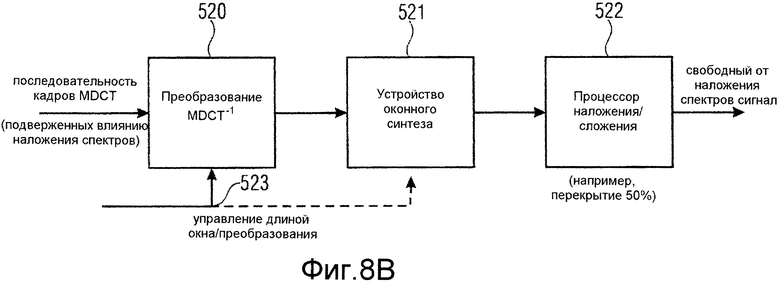
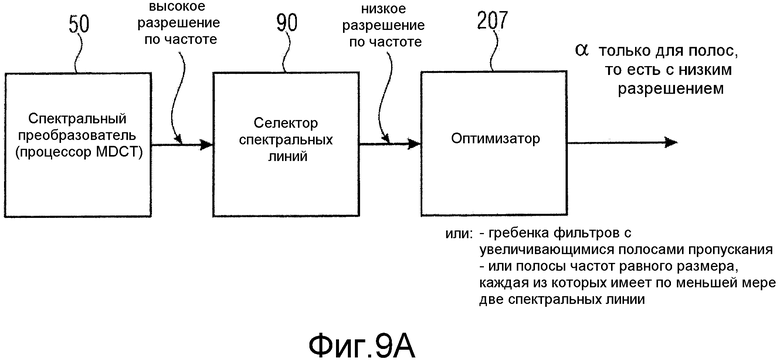
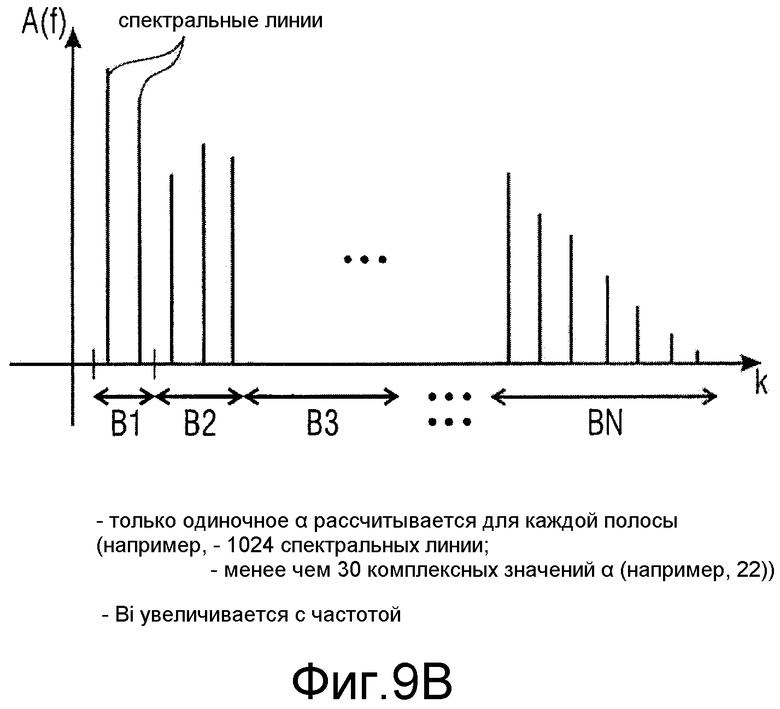
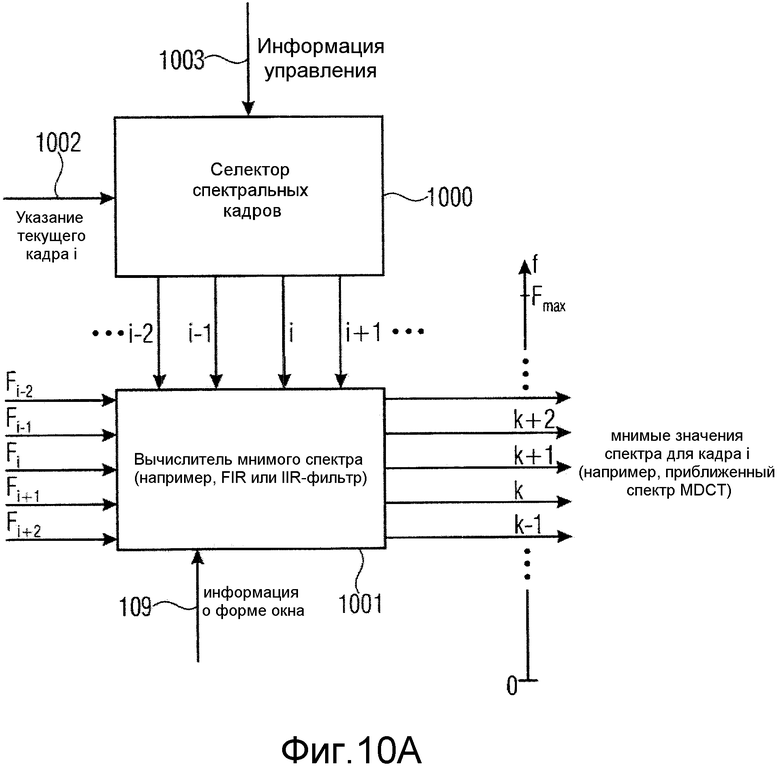
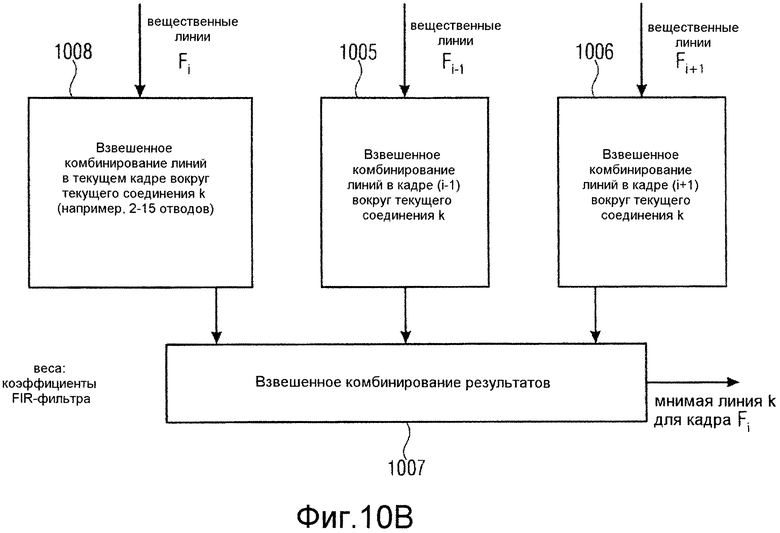
Изобретение относится к средствам кодирования и декодирования. Технический результат заключается в повышении качества аудиосигнала. Комбинируют два аудиоканала для получения первого комбинированного сигнала в качестве среднего сигнала и остаточного сигнала, который может быть выведен с использованием предсказанного бокового сигнала, выведенного из среднего сигнала. Первый комбинированный сигнал и остаточный сигнал предсказания кодируются и записываются в поток данных вместе с информацией о предсказании, выведенной оптимизатором на основании цели оптимизации. Декодер использует остаточный сигнал предсказания, первый комбинированный сигнал и информацию о предсказании для получения декодированного сигнала первого канала и декодированного сигнала второго канала. В примере кодера или в примере декодера вещественно-мнимое преобразование может применяться для оценки мнимой части спектра первого комбинированного сигнала. Для расчета сигнала предсказания, вещественнозначный первый комбинированный сигнал умножается на вещественную часть комплексной информации о предсказании, а оцененная мнимая часть первого комбинированного сигнала умножается на мнимую часть комплексной информации о предсказании. 6 н. и 16 з.п. ф-лы, 20 ил.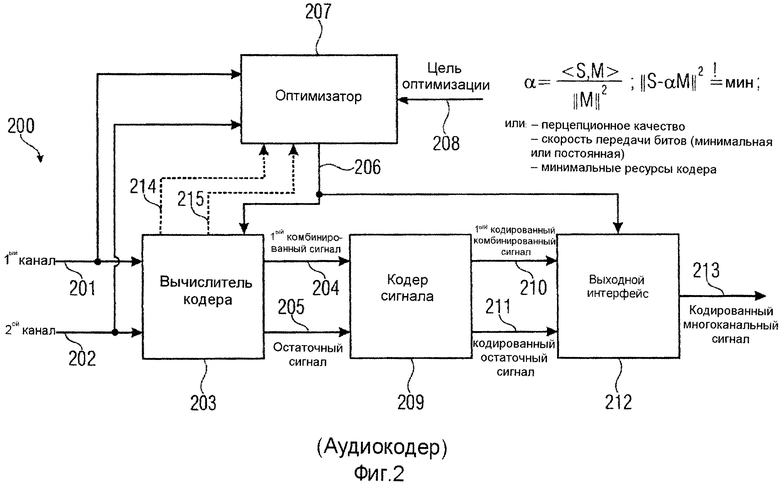
1. Аудиодекодер для декодирования кодированного многоканального аудиосигнала (100), причем кодированный многоканальный аудиосигнал содержит кодированный первый комбинированный сигнал, сформированный на основании правила комбинирования для комбинирования аудиосигнала первого канала и аудиосигнала второго канала многоканального аудиосигнала, кодированный остаточный сигнал предсказания и информацию о предсказании, содержащий:
декодер (110) сигнала для декодирования кодированного первого комбинированного сигнала (104), чтобы получать декодированный первый комбинированный сигнал (112), и для декодирования кодированного остаточного сигнала (106), чтобы получать декодированный остаточный сигнал (114); и
вычислитель (116) декодера для расчета декодированного многоканального сигнала, содержащего декодированный сигнал (117) первого канала и декодированный сигнал (118) второго канала, с использованием декодированного остаточного сигнала (114), информации (108) о предсказании и декодированного первого комбинированного сигнала (112), так что декодированный сигнал (117) первого канала и декодированный сигнал (118) второго канала являются по меньшей мере приближениями сигнала первого канала и сигнала второго канала многоканального сигнала, при этом информация (108) о предсказании содержит вещественную часть, отличную от нуля, и/или мнимую часть, отличную от нуля,
при этом информация (108) о предсказании содержит мнимый коэффициент, отличный от нуля,
при этом вычислитель (116) декодера содержит предсказатель (1160), сконфигурированный для оценки (1160а) мнимой части декодированного первого комбинированного сигнала (112) с использованием вещественной части декодированного первого комбинированного сигнала (112),
при этом предсказатель (1160) сконфигурирован для умножения мнимой части (601) декодированного первого комбинированного сигнала на мнимый коэффициент информации (108) о предсказании при получении сигнала предсказания;
при этом вычислитель (116) декодера дополнительно содержит вычислитель (1161) комбинированного сигнала, сконфигурированный для линейного комбинирования сигнала предсказания и декодированного остаточного сигнала, чтобы получать второй комбинированный сигнал (1165); и
при этом вычислитель (116) декодера дополнительно содержит объединитель (1162) для комбинирования второго комбинированного сигнала (1165) и декодированного первого комбинированного сигнала, чтобы получать декодированный сигнал (117) первого канала и декодированный сигнал (118) второго канала.
2. Аудиодекодер по п. 1, в котором вычислитель (116) декодера содержит:
предсказатель (1160) для применения информации (108) о предсказании к декодированному первому комбинированному сигналу (112) или к сигналу (601), выведенному из декодированного первого комбинированного сигнала, чтобы получать сигнал (1163) предсказания;
вычислитель (1161) комбинированного сигнала для расчета второго комбинированного сигнала (1165) посредством комбинирования декодированного остаточного сигнала (114) и сигнала (1163) предсказания; и
объединитель (1162) для комбинирования декодированного первого комбинированного сигнала (112) и второго комбинированного сигнала (1165), чтобы получать декодированный многоканальный аудиосигнал, содержащий декодированный сигнал (117) первого канала и декодированный сигнал (118) второго канала.
3. Аудиодекодер по п. 1,
в котором кодированный первый комбинированный сигнал (104) и кодированный остаточный сигнал (106) были сформированы с использованием время-спектрального преобразования с формированием наложения спектров,
при этом декодер дополнительно содержит:
спектрально-временной преобразователь (52, 53) для формирования сигнала первого канала временной области и сигнала второго канала временной области с использованием алгоритма спектрально-временного преобразования, приведенного в соответствие алгоритму время-спектрального преобразования;
процессор (522) наложения/сложения для проведения обработки наложения-сложения для сигнала первого канала временной области и для сигнала второго канала временной области, чтобы получать свободный от наложения спектров первый сигнал временной области и свободный от наложения спектров второй сигнал временной области.
4. Аудиодекодер по п. 1, в котором информация (108) о предсказании содержит вещественный коэффициент, отличный от нуля,
в котором предсказатель (1160) сконфигурирован для умножения декодированного первого комбинированного сигнала на вещественный коэффициент, чтобы получать первую часть сигнала предсказания, и
в котором вычислитель комбинированного сигнала сконфигурирован для линейного комбинирования декодированного остаточного сигнала и первой части сигнала предсказания.
5. Аудиодекодер по п. 1,
в котором каждый из кодированного или декодированного первого комбинированного сигнала (104) и кодированного или декодированного остаточного сигнала (106) предсказания содержит первое множество сигналов субполосы,
при этом информация о предсказании содержит второе множество параметров информации о предсказании, причем второе множество является меньшим, чем первое множество,
при этом предсказатель (1160) сконфигурирован для применения одного и того же параметра предсказания к по меньшей мере двум разным сигналам субполосы декодированного первого комбинированного сигнала,
при этом вычислитель (116) декодера, или вычислитель (1161) комбинированного сигнала, или объединитель (1162) сконфигурированы для выполнения обработки по субполосам; и
при этом аудиодекодер дополнительно содержит гребенку (52, 53) фильтров синтеза для комбинирования сигналов субполосы декодированного первого комбинированного сигнала и декодированного второго комбинированного сигнала, чтобы получать первый декодированный сигнал временной области и второй декодированный сигнал временной области.
6. Аудиодекодер по п. 2,
в котором предсказатель (1160) сконфигурирован для фильтрации по меньшей мере двух следующих по времени кадров, причем один из двух следующих по времени кадров предшествует или следует за текущим кадром первого комбинированного сигнала, чтобы получать оцененную мнимую часть текущего кадра первого комбинированного сигнала с использованием линейного фильтра (1004, 1005, 1006, 1007).
7. Аудиодекодер по п. 2,
в котором декодированный первый комбинированный сигнал содержит последовательность вещественнозначных кадров сигнала, и
в котором предсказатель (1160) сконфигурирован для оценки (1160а) мнимой части текущего кадра сигнала с использованием только текущего вещественнозначного кадра сигнала или с использованием текущего вещественнозначного кадра сигнала и любого из только одного или более предшествующих или только одного или более последующих вещественнозначных кадров сигнала, или с использованием текущего вещественнозначного кадра сигнала и одного или более предыдущих вещественнозначных кадров сигнала и одного или более последующих вещественнозначных кадров сигнала.
8. Аудиодекодер по п. 2, в котором предсказатель (1160) сконфигурирован для приема информации (109) о форме окна и для использования разных коэффициентов фильтра для расчета мнимого спектра, причем разные коэффициенты фильтра зависят от разных форм окна, указанных информацией (109) о форме окна.
9. Аудиодекодер по п. 6,
в котором декодированный первый комбинированный сигнал ассоциирован с разными длинами преобразования, указанными указателем длины преобразования, включенным в кодированный многоканальный сигнал (100), и
в котором предсказатель (1160) сконфигурирован, чтобы использовать только один или более кадров первого комбинированного сигнала, имеющего одну и ту же ассоциированную длину преобразования для оценки мнимой части для текущего кадра для первого комбинированного сигнала.
10. Аудиодекодер по п. 2,
в котором предсказатель (1160) сконфигурирован для использования множества субполос декодированного первого комбинированного сигнала, смежных по частоте, для оценки мнимой части первого комбинированного сигнала, и
при этом, в случае низких или высоких частот, используется симметричное расширение по частоте текущего кадра первого комбинированного сигнала для субполос, ассоциированных с частотами, более низкими или равными нулю или более высокими или равными половине частоты выборки, на которой основан текущий кадр, или в котором коэффициенты фильтра у фильтра, включенного в предсказатель (1160а), установлены в другие значения для отсутствующих субполос по сравнению с неотсутствующими субполосами.
11. Аудиодекодер по п. 1, в котором информация (108) о предсказании включена в кодированный многоканальный сигнал в квантованном и энтропийно кодированном представлении,
при этом аудиодекодер дополнительно содержит декодер (65) информации о предсказании для энтропийного декодирования или деквантования, чтобы получать декодированную информацию о предсказании, используемую предсказателем (1160), или
в котором кодированный многоканальный аудиосигнал содержит блок данных, указывающий в первом состоянии, что предсказатель (1160) должен использовать по меньшей мере один кадр, предшествующий или следующий по времени за текущим кадром декодированного первого комбинированного сигнала, и указывающий во втором состоянии, что предсказатель (1160) должен использовать только один кадр декодированного первого комбинированного сигнала для оценки мнимой части для текущего кадра декодированного первого комбинированного сигнала, и в котором предсказатель (1160) сконфигурирован для считывания состояния блока данных для действия соответствующим образом.
12. Аудиодекодер по п. 1, в котором информация (108) о предсказании содержит кодовые слова или разности между последовательными по времени или смежными по частоте комплексными значениями, и
при этом аудиодекодер сконфигурирован для выполнения этапа энтропийного декодирования и последующего этапа декодирования разности, чтобы получать последовательные по времени квантованные комплексные значения предсказания или комплексные значения предсказания для смежных частотных полос.
13. Аудиодекодер по п. 1, в котором кодированный многоканальный сигнал содержит, в качестве побочной информации, указатель вещественности, указывающий, что все коэффициенты предсказания для кадра кодированного многоканального сигнала являются вещественнозначными,
при этом декодер аудиосигналов сконфигурирован для извлечения указателя вещественности из кодированного многоканального аудиосигнала (100), и
при этом вычислитель (116) декодера сконфигурирован, чтобы не рассчитывать мнимый сигнал для кадра, для которого указатель вещественности является указывающим только вещественнозначные коэффициенты предсказания.
14. Аудиокодер для кодирования многоканального аудиосигнала, содержащего сигналы двух или более каналов, содержащий:
вычислитель (203) кодера для расчета первого комбинированного сигнала (204) и остаточного сигнала (205) предсказания с использованием сигнала (201) первого канала и сигнала (202) второго канала, и информации (206) о предсказании, так что остаточный сигнал предсказания, при комбинировании с сигналом предсказания, выведенным из первого комбинированного сигнала, или сигналом, выведенным из первого комбинированного сигнала и информации (206) о предсказании, дает в результате второй комбинированный сигнал (2032), причем первый комбинированный сигнал (204) и второй комбинированный сигнал (2032) являются выводимыми из сигнала (201) первого канала и сигнала (202) второго канала с использованием правила комбинирования; оптимизатор (207) для расчета информации (206) о предсказании, так чтобы остаточный сигнал (205) предсказания удовлетворял цели (208) оптимизации;
кодер (209) сигнала для кодирования первого комбинированного сигнала (204) и остаточного сигнала (205) предсказания, чтобы получать кодированный первый комбинированный сигнал (210) и кодированный остаточный сигнал (211); и
выходной интерфейс (212) для комбинирования кодированного первого комбинированного сигнала (210), кодированного остаточного сигнала (211) предсказания и информации (206) о предсказании, чтобы получать кодированный многоканальный аудиосигнал,
при этом сигнал первого канала является спектральным представлением блока отсчетов;
при этом сигнал второго канала является спектральным представлением блока отсчетов,
при этом спектральные представления являются или чисто вещественными спектральными представлениями, или чисто мнимыми спектральными представлениями,
при этом оптимизатор (207) сконфигурирован для расчета информации (206) о предсказании в качестве вещественного коэффициента, отличного от нуля, и/или в качестве мнимого коэффициента, отличного от нуля,
при этом вычислитель (203) кодера содержит вещественно-мнимый преобразователь (2070) или мнимо-вещественный преобразователь для выведения спектрального представления преобразования из первого комбинированного сигнала, и при этом вычислитель (203) кодера сконфигурирован, чтобы рассчитывать первый комбинированный сигнал (204) и первый остаточный сигнал (2032), так что сигнал предсказания выводится из преобразованного спектра с использованием мнимого коэффициента.
15. Аудиокодер по п. 14, в котором вычислитель (203) кодера содержит:
объединитель (2031) для комбинирования сигнала (201) первого канала и сигнала (202) второго канала двумя разными способами, чтобы получать первый комбинированный сигнал (204) и второй комбинированный сигнал (2032);
предсказатель (2033) для применения информации (206) о предсказании к первому комбинированному сигналу (204) или сигналу (600), выведенному из первого комбинированного сигнала (204), чтобы получать сигнал (2035) предсказания; и
вычислитель (2034) остаточного сигнала для расчета остаточного сигнала (205) предсказания посредством комбинирования сигнала (2 035) предсказания и второго комбинированного сигнала (2032).
16. Аудиокодер по п. 15, в котором предсказатель (2033) содержит квантователь для квантования сигнала первого канала, сигнала второго канала, первого комбинированного сигнала или второго комбинированного сигнала, чтобы получать один или более квантованных сигналов, и при этом предсказатель (2033) сконфигурирован для расчета остаточного сигнала с использованием квантованных сигналов.
17. Аудиокодер по п. 14,в котором сигнал первого канала является спектральным представлением блока отсчетов;
в котором сигнал второго канала является спектральным представлением блока отсчетов,
при этом спектральные представления являются или чисто вещественными спектральными представлениями, или чисто мнимыми спектральными представлениями,
в котором оптимизатор (207) сконфигурирован для расчета информации (206) о предсказании в качестве вещественного коэффициента, отличного от нуля, и/или в качестве мнимого коэффициента, отличного от нуля, и
в котором вычислитель (203) кодера сконфигурирован, чтобы рассчитывать первый комбинированный сигнал и остаточный сигнал предсказания, так что сигнал предсказания выводится из чисто вещественного спектрального представления или чисто мнимого спектрального представления с использованием вещественного коэффициента.
18. Аудиокодер по п. 14,
в котором предсказатель (2033) сконфигурирован для умножения первого комбинированного сигнала (204) на вещественную часть информации (2073) о предсказании, чтобы получать первую часть сигнала предсказания;
для оценки (2070) мнимой части (600) первого комбинированного сигнала с использованием первого комбинированного сигнала (204);
для умножения мнимой части первого комбинированного сигнала на мнимую часть информации (2074) о предсказании, чтобы получать вторую часть сигнала предсказания; и
при этом вычислитель (2034) остаточного сигнала сконфигурирован для линейного комбинирования сигнала первой части сигнала предсказания или сигнала второй части сигнала предсказания и второго комбинированного сигнала, чтобы получать остаточный сигнал (205) предсказания.
19. Способ декодирования кодированного многоканального аудиосигнала (100), причем кодированный многоканальный аудиосигнал содержит кодированный первый комбинированный сигнал, сформированный на основании правила комбинирования для комбинирования аудиосигнала первого канала и аудиосигнала второго канала многоканального аудиосигнала, кодированный остаточный сигнал предсказания и информацию о предсказании, содержащий этапы, на которых:
декодируют (110) кодированный первый комбинированный сигнал (104), чтобы получать декодированный первый комбинированный сигнал (112), и декодируют кодированный остаточный сигнал (106), чтобы получать декодированный остаточный сигнал (114); и
рассчитывают (116) декодированный многоканальный сигнал, содержащий декодированный сигнал (117) первого канала и декодированный сигнал (118) второго канала, с использованием декодированного остаточного сигнала (114), информации (108) о предсказании и декодированного первого комбинированного сигнала (112), так что декодированный сигнал (117) первого канала и декодированный сигнал (118) второго канала являются по меньшей мере приближениями сигнала первого канала и сигнала второго канала многоканального сигнала, при этом информация (108) о предсказании содержит вещественную часть, отличную от нуля, и/или мнимую часть, отличную от нуля,
при этом информация (108) о предсказании содержит мнимый коэффициент, отличный от нуля,
при этом мнимую часть декодированного первого комбинированного сигнала (112) оценивают (1160а) с использованием вещественной части декодированного первого комбинированного сигнала (112),
при этом мнимую часть (601) декодированного первого комбинированного сигнала умножают на мнимый коэффициент информации (108) о предсказании при получении сигнала предсказания;
при этом сигнал предсказания и декодированный остаточный сигнал линейно комбинируют, чтобы получать второй комбинированный сигнал (1165); и
при этом второй комбинированный сигнал (1165) и декодированный первый комбинированный сигнал комбинируют, чтобы получать декодированный сигнал (117) первого канала и декодированный сигнал (118) второго канала.
20. Способ кодирования многоканального аудиосигнала, содержащего сигналы двух или более каналов, содержащий этапы, на которых:
рассчитывают (203) первый комбинированный сигнал (204) и остаточный сигнал (205) предсказания с использованием сигнала (201) первого канала и сигнала (202) второго канала, и информацию (206) о предсказании, так что остаточный сигнал предсказания, при комбинировании с сигналом предсказания, выведенным из первого комбинированного сигнала, или сигналом, выведенным из первого комбинированного сигнала и информации (206) о предсказании, дает в результате второй комбинированный сигнал (2032), причем первый комбинированный сигнал (204) и второй комбинированный сигнал (2032) являются выводимыми из сигнала (201) первого канала и сигнала (202) второго канала с использованием правила комбинирования;
рассчитывают (207) информацию (206) о предсказании, так чтобы остаточный сигнал (205) предсказания удовлетворял цели (208) оптимизации;
кодируют (209) первый комбинированный сигнал (204) и остаточный сигнал (205) предсказания, чтобы получать кодированный первый комбинированный сигнал (210) и кодированный остаточный сигнал (211); и
комбинируют (212) кодированный первый комбинированный сигнал (210), кодированный остаточный сигнал (211) предсказания и информацию (206) о предсказании, чтобы получать кодированный многоканальный аудиосигнал,
при этом сигнал первого канала является спектральным представлением блока отсчетов;
при этом сигнал второго канала является спектральным представлением блока отсчетов,
при этом спектральные представления являются или чисто вещественными спектральными представлениями, или чисто мнимыми спектральными представлениями,
при этом информацию (206) о предсказании рассчитывают в качестве вещественнозначного коэффициента, отличного от нуля, и/или в качестве мнимого коэффициента, отличного от нуля,
выполняют вещественно-мнимое преобразование (2070) или мнимо-вещественное преобразование для выведения спектрального представления преобразования из первого комбинированного сигнала, и
при этом первый комбинированный сигнал (204) и первый остаточный сигнал (2032) рассчитывают так, чтобы сигнал предсказания выводился из преобразованного спектра с использованием мнимого коэффициента.
21. Машиночитаемый носитель, содержащий набор команд для выполнения, при исполнении на компьютере или процессоре, способа по п. 19.
22. Машиночитаемый носитель, содержащий набор команд для выполнения, при исполнении на компьютере или процессоре, способа по п. 20.
| WO 9016136 A1, 27.12.1990 | |||
| WO 2009141775 A1, 26.11.2009 | |||
| WO 2011124608 A1, 13.10.2011 | |||
| WO 2004013839 A1, 12.02.2004 | |||
| WO 2008014853 A1, 07.02.2008 | |||
| US 2005165587 A1, 28.07.2005 | |||
| АДАПТИВНОЕ ОСТАТОЧНОЕ АУДИОКОДИРОВАНИЕ | 2006 |
|
RU2380766C2 |

