Настоящее изобретение относится к демультиплексированию пакетного транспортного потока из пакетов транспортного потока, каждый из которых снабжен кодом систематического прямого обнаружения ошибок, причем каждый из пакетов транспортного потока предназначен одному из множества приемников данных.
Инкапсулирование потоков данных в другой поток является общепринятой практикой и образует основу, например, для модели уровня взаимодействия открытых систем (OSI). Пакетный транспортный поток из пакетов транспортного потока транспортирует, например, один или несколько потоков данных, которые, в свою очередь, опять-таки содержат пакеты данных, причем эти пакеты внедрены в участки данных полезной нагрузки пакетов транспортного потока. Например, в стандарте DVB-H участки MPE (многопротокольной инкапсуляции) и участки MPE-FEC (многопротокольной инкапсуляции с прямой коррекцией ошибок) внедрены в участки данных полезной нагрузки пакетов транспортного потока, и IP-пакеты вновь встраивают в участки данных полезной нагрузки участков MPE.
Разумеется, для каждого транспортного потока может производиться передача не только одного потока данных. Для каждого мультиплекса могут передаваться несколько потоков данных посредством одного общего транспортного потока. Например, различные приемники или приемники данных ассоциированы с различными программами, такими как, например, телепрограммы или радиопередачи. При мультиплексировании пакетов данных для различных приемников или приемников данных их встраивают в пакеты транспортного потока так, что в каждом одном пакете транспортного потока содержится только лишь один участок одного из потоков данных, то есть, каждый пакет транспортного потока назначен в точности одному приемнику данных. Назначение пакетов транспортного потока приемникам данных указано во внутренней части пакетов транспортного потока в так называемом заголовке транспортного потока.
Однако, если защита текущего пакета транспортного потока посредством прямого исправления ошибок (FEC) указывает, что он является ошибочным, то демультиплексор на принимающей стороне может не полагаться на тот факт, что указанный приемник или приемник данных, которому они адресованы, фактически соответствуют реальному приемнику или реальному приемнику данных, которому они адресованы. Следовательно, пакет транспортного потока аннулируют и не подают ни в один из приемников данных, предотвращая пересылку ошибочных данных в приемники данных.
Однако, в приемнике данных, которому они фактически адресованы, соответственно отсутствует один адресованный ему участок потока данных, что может приводить к большим потерям данных. Если пакеты данных внедрены в участки данных полезной нагрузки пакетов транспортного потока, например путем фрагментации, то при потере пакета транспортного потока, адресованного соответствующему приемнику данных, теряется не только участок из адресованного ему потока данных, но, возможно, также, любой пакет данных, часть которого была распределена в потерянный пакет транспортного потока. В случае защиты потока данных посредством FEC с перемежением отсутствие участка из потока данных заведомо приводит к ошибочному заполнению в таблице перемежителя, вследствие чего необходимо аннулировать весь участок потока данных в таблице перемежителя в соответствующем приемнике данных.
Задачей настоящего изобретения является создание концепции для демультиплексирования пакетного потока данных, которая приводит к более эффективной передаче данных в различные приемники данных.
Этот задача решена в соответствии с предметом независимых пунктов прилагаемой формулы изобретения.
Настоящее изобретение основано на выявлении того факта, что более эффективное демультиплексирование пакетного транспортного потока может быть получено тогда, когда, для предварительно определенного пакета транспортного потока, который является ошибочным согласно его коду систематического прямого обнаружения ошибок, определяют значение вероятности для каждого из множества приемников данных, которое указывает, насколько вероятным является то, что предварительно определенный пакет транспортного потока предназначен соответствующему приемнику данных, для последующего распределения предварительно определенного пакета транспортного потока на основании значений вероятности для множества приемников данных, в выбранный один из множества приемников данных, возможно, например, в тот, для которого было определено максимальное значение вероятности.
Согласно вариантам осуществления настоящего изобретения, для определения соответствующего значения вероятности для соответствующего приемника данных используют большинство различных характеристик участков данных полезной нагрузки пакетов транспортного потока, адресованных соответствующему приемнику данных. Например, могут быть оценены избыточности в пакетах данных потока данных, адресованного соответствующему приемнику данных, таких как, например, данные прямого обнаружения ошибок для защиты заголовков пакетов данных соответствующего потока данных или избыточные кросс-уровневые указатели адресов и т.д. Различные поля в пакетах данных остаются одними и теми же для соответствующего приемника данных на протяжении более длительного промежутка времени, и это условие также может использоваться любым приемником данных. Такие постоянные поля включают в себя, например, поля адреса и т.п. Помимо этого, в пакетах данных могут существовать поля синхронизации, которые всегда имеют одно и то же значение и, следовательно, также могут использоваться для формирования или определения соответствующего значения вероятности, например, потому, сто вероятности наступления события для различных приемников данных изменяется по-разному для различных пакетов транспортного потока. Все эти указатели могут вносить вклад в окончательное значение вероятности для соответствующего приемника данных. Например, отдельные вклады суммируют.
Дополнительные предпочтительные варианты реализации вариантов осуществления настоящего изобретения являются объектом зависимых пунктов формулы изобретения. Ниже приведено более подробное объяснение предпочтительных вариантов осуществления настоящего изобретения со ссылкой на чертежи, на которых изображено следующее:
на Фиг. 1 изображена блок-схема устройства для демультиплексирования пакетного транспортного потока согласно одному из вариантов осуществления изобретения;
на Фиг. 2 схематически проиллюстрирована приведенная в качестве примера структура пакетного транспортного потока рядом с потоком данных, адресованным предварительно определенному приемнику данных, согласно одному из вариантов осуществления изобретения; и
на Фиг. 3 схематически проиллюстрировано внутреннее состояние определителя значения вероятности при определении предполагаемого значения вероятности для ассоциированного приемника данных и для иллюстрации этого определения согласно одному из вариантов осуществления изобретения.
На Фиг. 1 показано устройство для демультиплексирования пакетного транспортного потока согласно одному из вариантов осуществления настоящего изобретения. На Фиг. 1 это устройство обозначено в целом номером позиции 10. Таким образом, устройство 10 используется для распределения пакетов 12 транспортного потока из транспортного потока 14 на входе 16 устройства 10 во множество 18 приемников 20 данных, каждый из которых содержит декодер 21, который декодирует распределенный ему поток данных.
Как будет более подробно описано ниже со ссылкой на Фиг. 2 с использованием более конкретного примера, каждый из входящих пакетов 12 транспортного потока снабжен кодом систематического прямого обнаружения ошибок и, следовательно, обеспечивает возможность определения того, является ли соответствующий пакет 12 транспортного потока ошибочным или нет. Последнее определение выполняет, например, устройство 22 обнаружения ошибок в транспортном потоке, возможно, но не обязательно, подключенное позади по ходу относительно входа 16 так, что если оно применяется, то уже при поступлении пакетов 12 транспортного потока на вход устройства 16 устройство 10 информируют о том, является ли соответствующий пакет 12 транспортного потока ошибочным или нет. В альтернативном варианте это определение выполняют в самом устройстве 10.
Таким образом, наряду со входом 16 для транспортного потока 14 устройство 10 содержит выход 24 для каждого приемника 20 данных и содержит внутри себя демультиплексор или распределитель 26, один определитель 28 значения вероятности и по одному средству 30 распределения для каждого приемника данных. Средство 26 распределения подключено между входом 16 и выходом 24. Задачей распределителя является подача пакетов 12 транспортного потока в транспортном потоке 14 в соответственно назначенный приемник данных. В случае безошибочных пакетов 12 транспортного потока распределитель 26 может собирать отдельные пакеты транспортного потока, распределенные в отдельные приемники 20 данных, например, из самих пакетов 12 потока данных, например, по предварительно определенному полю в заголовке пакета транспортного потока, как будет описано ниже со ссылкой на Фиг. 2 с использованием конкретного примера. Распределитель 26 принимает пакеты 12 транспортного потока один за другим из транспортного потока 14 и передает текущий пакет транспортного потока, если он является безошибочным, в назначенный приемник 20 данных. Другие приемники 20 данных не принимают этот пакет данных.
При этом распределитель 26 включает в себя вход, соединенный с входом 16, и выход, каждый из которых предназначен для каждого из выходов 24 для приемников 20 данных. Теперь для каждого приемника 20 данных один вход определителя 28 значения вероятности для соответствующего приемника 20 данных также соединен с соответствующим выходом распределителя 26 для приема пакетов 12 транспортного потока, поданных в соответствующий приемник 20 данных распределителем 26 на входе. Кратко отмечено, что согласно альтернативному варианту осуществления изобретения, это соединение между распределителем 26 и определителями 28 значений вероятности может отсутствовать, когда определенные опции для выполнения, которые более подробно описаны ниже, не применяются. Это будет обсуждено еще раз в конце описания.
Распределитель 26 реализован так, что всегда, когда текущий пакет 12 транспортного потока является ошибочным, он указывает этот факт средству 30 распределения, как указано стрелкой 32. Для этого распределитель 26 соединен со средством 30 распределения. В качестве ответа на указание 32 средство 30 распределения указывает распределителю 26 то, в какой приемник 20 данных должен быть распределен и переслан текущий пакет 12 транспортного потока, несмотря на ошибочность, где это указано стрелкой 34. Согласно одному из вариантов осуществления изобретения, сообщение 34 может содержать в качестве возможного варианта ответа то, что текущий пакет 12 транспортного потока фактически должен быть аннулирован несмотря на все меры, более подробное объяснение которых приведено ниже.
Как более подробно объяснено со ссылкой на Фиг. 2, поток 36 данных из пакетов 38 данных внедрен в участки данных полезной нагрузки пакетов 12 транспортного потока, распределенных в один и тот же приемник данных. Строго говоря, может иметь место, что распределитель 26 реализован только для пересылки участка данных полезной нагрузки из текущего пакета 12 транспортного потока в соответственно назначенный приемник 20 данных или в соответствующий определитель 28 значения вероятности. В идеальном случае, в котором распределитель 26 пересылает каждый пакет 12 транспортного потока или его участок данных полезной нагрузки в надлежащий приемник или в надлежащим образом адресованный приемник 20 данных и соответствующий определитель значения вероятности, в результате, на входе последних модулей 20 или 28 поток 36 данных, адресованный соответствующему приемнику 20 данных, является полным для соответствующего приемника 20 данных. В этом случае каждый приемник 20 данных или соответственно назначенный декодер 21 способны декодировать распределенный потока данных 36 для получения таким образом данных 40 полезной нагрузки, таких как, например, видеоданные или звуковые данные и т.п., поступающие из участков данных полезной нагрузки в пакетах 38 данных.
Определители 28 значения вероятности, существующие для каждого приемника 20 данных, теперь здесь должны определить для текущего пакета 12 транспортного потока, для которого распределитель 26 указывает 32 наличие ошибки, значение вероятности, указывающее, с какой вероятностью фактический пакет 12 транспортного потока распределен в соответствующий приемник 20 данных, то есть, на основании информации из участка данных полезной нагрузки предварительно определенного пакета 12 транспортного потока, который, например, для средства 30 распределения переслан с этой целью из распределителя 26 в определитель 28 значения вероятности. Существует множество различных возможных вариантов определения значения вероятности, более подробное объяснение которых приведено ниже. Как проиллюстрировано на Фиг. 1, каждый определитель 28 значения вероятности может быть разделен на две части, а именно, на элемент 42, выполняющий обновление данных протокола, для объединения участков данных полезной нагрузки пакетов 12 транспортного потока, пересланных до данного момента времени в соответствующий приемник 20 данных, и элемент 44, определяющий предполагаемую вероятность, причем этот вид подразделения приведен просто в качестве примера.
Для каждого приемника 20 данных средство 30 распределения принимает значение вероятности из соответствующего определителя 28 значения вероятности и определяет на основании этих значений вероятности то, в какой приемник 20 данных должен быть распределен текущий пакет 12 транспортного потока или, согласно одному из вариантов осуществления изобретения, что распределение не должно производиться, поскольку значения вероятности не являются достаточно значимыми. Средство 30 распределения реализовано, например, так, что распределяет текущие пакеты 12 транспортного потока в тот приемник 20 данных, для которого значение вероятности является максимальным.
Как будет более подробно объяснено ниже, определители 28 значения вероятности реализованы, например, так, что определяют значения вероятности на основании множества одиночных значений вероятности, например, путем суммирования последних, причем эти одиночные значения вероятности, например, всегда являются мерой подобия участка для участка данных полезной нагрузки текущего пакета 12 транспортного потока относительно информационного содержимого, которое с высокой вероятностью должно быть расположено в текущем пакете транспортного потока в соответствующем положении, если предполагают, что текущий пакет транспортного потока представляет собой полное продолжение уже принятой части потока 36 данных соответствующего приемника 20 данных (то есть, без потери одного из предыдущих пакетов транспортного потока для соответствующего приемника данных) или который присутствует с высокой вероятностью в соответствующем или в случайном участке участка данных полезной нагрузки пакета 12 транспортного потока, распределенного в соответствующий приемник данных, вне зависимости от того факта, какой пакет транспортного потока из пакетов транспортного потока распределен в соответствующий приемник данных, рассматриваемый в данный момент времени. Как упомянуто выше, способ станет более понятным из приведенного ниже описания.
Со ссылкой на Фиг. 2, теперь приведено описание варианта осуществления возможной структуры пакетов 12 транспортного потока и пакетов 38 данных. Применительно к структуре пакетов 38 данных следует отметить, что она может являться одинаковой для всех приемников 20 данных, как описано теперь со ссылкой на Фиг. 2, или что эта структура также может являться различной для приемников 20 данных, то есть, для некоторых приемников 20 данных, проиллюстрированный со ссылкой на Фиг. 2, и иной для других.
В нижней части Фиг. 2 показан приведенный в качестве примера участок транспортного потока 14 с пакетом 12a транспортного потока и со следующим непосредственно после него пакетом 12b транспортного потока. Таким образом, в этой части Фиг. 2 проиллюстрирован, так сказать, транспортный уровень 46. Как проиллюстрировано на Фиг. 2, каждый пакет 12a и 12b транспортного потока содержит заголовок 50 пакета транспортного потока, например, рядом с участком 48 данных полезной нагрузки. Помимо этого, каждый пакет 12a, 12b транспортного потока дополнительно содержит код 52 систематического прямого обнаружения ошибок, то есть, данные 52 избыточности, которые обеспечивают возможность обнаружения ошибок в соответствующем пакете 12a или 12b транспортного потока путем систематического прямого обнаружения ошибок. Данные 52 при их применении дополнительно обеспечивают возможность прямой коррекции ошибок. Данные 52 избыточности могут защищать пакет 12a или 12b транспортного потока, например, полностью или только его заголовок 50 или даже только идентификационный указатель 54. В заголовке 50 пакета транспортного потока расположено, например, поле или идентификационный указатель 54, идентифицирующее (идентифицирующий) приемник 20 данных, в который распределен соответствующий пакет 12a или 12b транспортного потока. В качестве примера, на Фиг. 2 предполагают, что пакет 12a транспортного потока и пакет 12b транспортного потока распределены различными приемниками данных.
В качестве примера, на Фиг. 2 также предполагают, что для приемников 20 данных, которым предназначены пакеты 12a и 12b транспортного потока, адресованные им потоки 36 данных внедрены путем фрагментации в участки 48 данных полезной нагрузки соответствующих пакетов 12a, 12b транспортного потока, которые распределены в соответствующий приемник 20 данных. Таким образом, каждый пакет транспортного потока, в который попадает начало одного из пакетов данных, внедренных в поток данных, содержит в заголовке 50 пакета транспортного потока информацию 56 об указателе, которая указывает 58, где именно в участке 48 данных полезной нагрузки соответствующих пакетов транспортного потока находится начало пакета данных 62, который начинается в соответствующем пакете 12a транспортного потока. В остальной части участка 48 данных полезной нагрузки расположен концевой участок 64 непосредственно предыдущего пакета данных потока данных для этого приемника данных, который еще не расположен в одном из предыдущих пакетов транспортного потока для соответствующего приемника данных. В случае из Фиг. 2 такое попадание начала 60 в участок 48 данных полезной нагрузки проиллюстрировано в качестве примера для пакета 12a транспортного потока. Однако, на Фиг. 2 для пакета 12b транспортного потока в качестве примера проиллюстрирована возможность того, что пакет транспортного потока также может не содержать информацию 56 об указателе в его заголовке 50 пакета транспортного потока, поскольку, например, начало пакета данных для приемника данных, в который распределен пакет 12b транспортного потока, совпадает с началом участка 48 данных полезной нагрузки, или поскольку информационное содержимое участка 48 данных полезной нагрузки соответствует продолжению текущего пакета данных, выходящему все-таки за пределы участка 48 данных полезной нагрузки или продолжающемуся до конца участка 48 данных полезной нагрузки. Здесь следует кратко отметить, что в участке 48 данных полезной нагрузки, помимо, собственно, данных полезной нагрузки для пакетов данных также могут существовать биты заполнения или заполняющая информация, например, в том случае, когда добавление информации 56 об указателе приводит к тому, что пакет текущих данных заканчивается в точности в конце участка 48 данных полезной нагрузки, вследствие чего следующий пакет данных уже не может начинаться в текущем участке данных полезной нагрузки, а в этом случае отсутствие информации 56 об указателе приводит к тому, что в конце участка 48 данных полезной нагрузки, тем не менее, имеется пространство. Последнее применимо, по меньшей мере, тогда, когда, например, пакеты 12a и 12b транспортного потока имеют предварительно определенную длину, или длину, которая может установлена только на предварительно определенных этапах квантования. Этап квантования также может быть указан в заголовке 50 пакета транспортного потока или, иначе, путем менее регулярной передачи.
Таким образом, в варианте осуществления изобретения из Фиг. 2 показано, что пакеты 12b транспортного потока, в которые не попадает начало 60 одного из пакетов 38 данных, распределенных назначенным приемником 20 данных, не содержат информацию об указателе, вследствие чего участок 48 данных полезной нагрузки пакетов транспортного потока, в которые не попадает начало 60, по сравнению с участком 48 данных полезной нагрузки пакетов 12a транспортного потока, в который попадает начало 60, могут быть увеличены за счет отсутствия или исключения информации об указателе, то есть, на длину поля указателя 56. Другими словами, заголовок 50 пакета транспортного потока из пакета 12b транспортного потока может быть меньшим на длину информации 56 об указателе по сравнению с заголовком 50 пакета транспортного потока, и, соответственно, участок 48 данных полезной нагрузки пакета 12b транспортного потока может быть увеличен по сравнению с участком 48 данных полезной нагрузки пакета 12a транспортного потока. Флаг 66 в заголовке 50 пакета транспортного потока каждого пакета 12a, 12b транспортного потока может указывать, существует ли информация 56 об указателе в соответствующем заголовке 50 пакета транспортного потока или нет.
Немного выше плоскости 46 транспортного уровня на Фиг. 2 указана плоскость 68 протокола из потоков 36 данных, например, из потока данных, в который распределен пакет 12a транспортного потока. На Фиг. 2 в качестве примера проиллюстрирован участок, содержащий четыре последовательных пакета 38a-d данных. В качестве примера, пакет 38b данных представляет собой пакет, начало 60 которого попадает в участок 48 данных полезной нагрузки пакета 12a транспортного потока, и первая часть которого соответствует, таким образом, участку 62 в участке 48 данных полезной нагрузки этого пакета 12a транспортного потока. Следующая часть 70 этого пакета 38b данных записана в участок данных полезной нагрузки следующего пакета транспортного потока, ассоциированного с этим приемником данных согласно фрагментарному внедрению, в котором возможно информация об указателе снова указывает на начало следующего пакета 38c данных в этом участке данных полезной нагрузки, если участок 70 не является слишком длинным, и т.д.
Следует кратко упомянуть следующее: несмотря на то, что до настоящего момента в описании из Фиг. 2 было сделано предположение, что пакеты 38a-38d данных могут являться согласованными пакетами данных, имеющими общий порядок следования, дополнительные пакеты данных могут быть вкраплены в поток пакетов 38a-d данных, которые берут на себя иную функцию, такую как, например, передача кода систематической прямой защиты от ошибок для других пакетов данных. Таким образом, например, пакетами 38a-38d данных могут являться участки MPE, между которыми вкраплены участки MPE-FEC. Что касается участка 70, то это может означать, что он не содержится в непосредственно следующем пакете транспортного потока, распределенном в соответствующий приемник данных, но только в следующем через один или в еще более позднем пакете транспортного потока.
Как проиллюстрировано на Фиг. 2, каждый из пакетов 38a-d данных опять-таки может содержать соответствующий участок 72 данных полезной нагрузки и заголовок 74 пакета данных. Кроме того, каждый из пакетов 38a-d данных также может содержать код систематической защиты от ошибок, который формирует вместе с соответствующим словом 38a-d данных, включая заголовок 74 и участок 72 данных полезной нагрузки, кодовое слово систематической прямой коррекции ошибок, но для доходчивости эта возможность не проиллюстрирована на Фиг. 2. Однако, проиллюстрировано, что, например, каждый заголовок 74 пакета данных может содержать участок 76 данных избыточности, посредством которого заголовок 74 формирует кодовое слово систематической прямой коррекции ошибок для обнаружения ошибок и/или коррекции ошибок, при этом остаточная часть 78 заголовка 74 содержит соответствующую связь прямого обнаружения/коррекции ошибок относительно этой части 76 с данными избыточности.
В отличие от пакетов 12a, 12b транспортного потока, пакеты 38a-d данных из Фиг. 2 в качестве примера имеют переменную длину и, например, для указания этой длины содержат указатель 80 длины в их заголовке пакета данных, который указывает длину соответствующего пакета 38a-d данных.
В дополнение к этому, заголовки 74 пакетов данных содержат, например, поле 82 адреса, которое, например, однозначно указывает приемник данных, в который распределен поток 36 данных или который, например, по меньшей мере, однозначно назначен ему. Эта однозначность может относиться к указателям адресов в пакетах данных из потоков данных других приемников данных. В заголовках 74 пакетов данных может существовать еще одно поле 84, содержащее, например, унифицированное значение для всех пакетов данных для задач синхронизации и т.п. или значение, которое является, по меньшей мере, одним и тем же для всех пакетов данных одного и того же типа, например, для участков MPE с одной стороны и для пакетов MPE с другой стороны.
На Фиг. 2 дополнительно указано, что в участки 72 данных полезной нагрузки пакетов 38a-d данных может быть внедрен дополнительный поток 86 данных протокола или плоскости 88 еще более высокого уровня, где, в качестве примера, это внедрение обеспечивает то, что каждый из пакетов 90 данных из этого потока данных, например, без фрагментации, по отдельности внедрен в участок 72 данных полезной нагрузки пакета 38a-d данных, что в качестве примера проиллюстрировано на Фиг. 2 пунктирными линиями. Таким образом, пакеты 90 данных, например, также могут содержать переменную длину. Аналогично пакетам данных протокола более низкого уровня 68, каждый из них может содержать участок 92 данных полезной нагрузки и заголовок 94, и в заголовке 94 также может содержаться, например, указатель 96 длины, который указывает длину соответствующего пакета 90. Кроме того, в каждом пакете 94 дополнительно может существовать, например, поле 98 адреса, указывающее приемник данных, которому они адресованы, или однозначно связанное с приемником данных, которому они адресованы, из потока 36 данных.
После описания со ссылкой на Фиг. 2 варианта компоновки пакета транспортного потока и внедрения в него потоков данных из приемников 20 данных на Фиг. 1 следует отметить следующее: разумеется, вариант из Фиг. 2 представляет собой просто приведенный в качестве примера вариант из множества вариантов, применительно к которому вариант осуществления изобретения из Фиг. 1 является полезным для предотвращения аннулирования пакетов транспортного потока с ошибками, как описано ниже со ссылкой на Фиг. 1 и Фиг. 2. Например, в варианте осуществления изобретения из Фиг. 2 потоком 36 данных может являться поток данных MPE, а потоком 86 данных может являться поток данных протокола IP. Как упомянуто выше, пакеты 38a-d данных предпочтительно защищены кодом прямой защиты от ошибок, где этот код прямой защиты от ошибок может быть расположен в пакетах данных из потока 36 данных, специально предназначенного для этого. Поэтому код прямой коррекции ошибок на Фиг. 2 просто представлен в качестве примера номером позиции 100. Как упомянуто выше, кодом 100 прямой защиты от ошибок может являться код систематической прямой защиты от ошибок, который основан на функциональных возможностях перемежителя, согласно которым код 100 прямой защиты от ошибок защищает участки 72 данных полезной нагрузки пакетов 38a-d данных в устройстве, причем эти участки 72 данных полезной нагрузки вводят в таблицу перемежителя в порядке их появления в потоке 36 данных, например, в столбцах, например, для формирования кодовых слов систематической прямой коррекции ошибок в строках со строками этой таблицы перемежителя с одной стороны и соответствующим участком данных FEC 100 с другой стороны. На Фиг. 2 номером позиции 102 указано то, где таблица 104 перемежителя формирует одно кодовое слово систематической прямой коррекции ошибок для каждой строки 106 при помощи последовательных участков a-e данных полезной нагрузки следующих друг за другом пакетов 38a-38d данных, при этом указана вставка в столбцы в таблице 104 перемежителя и латеральное добавление данных 100 избыточности в таблицу 104 перемежителя.
И вновь со ссылкой на Фиг. 1, путем сравнения Фиг. 1 и Фиг. 2 становится ясно, что каждый определитель 28 значения вероятности имеет множество различных возможных вариантов определения соответствующего значения вероятности для соответствующего приемника 20, причем конкретные примеры этого описаны ниже. Как уже указано выше, в итоге, все эти отдельные вклады могут представлять собой вклады в значение вероятности, которые затем суммируют для получения соответствующего окончательного значения вероятности для соответствующего приемника 20 данных, которое затем используют в средстве 30 распределения вместе с другими значениями вероятности для других приемников 20 данных для определения выбираемого в конце концов приемника данных и информирования о нем 34 делителя 26.
Например, в определителях 38 значений вероятности для каждого приемника 20 данных местоположение первого участка текущего пакета 12 транспортного потока определяют способом, постоянным для всех приемников 20 данных или постоянным только для соответствующего приемника 20 данных, или в зависимости от пакетов 12 транспортного потока, уже распределенных ранее в соответствующий приемник 20 данных, при их поступлении на вход определителя 28 значения вероятности. Этим первым участком может являться, например, информация 56 об указателе. Если информация 56 об указателе всегда расположена в одном и том же местоположении в пакетах 12 транспортного потока или в заголовках 50 пакетов транспортного потока, то определение местоположения для всех приемников 20 данных в определителях 28 значений вероятности является одинаковой. В альтернативном варианте может иметь место то, что заголовки 50 пакетов транспортного потока для различных приемников 20 данных являются различными по каким-либо причинам, и, следовательно, положение информации 56 об указателе для каждого приемника 20 данных в распределенных пакетах 12 транспортного потока является одним и тем же, но иным для пакетов 12 транспортного потока, распределенных в другие приемники 20 данных. В этом случае каждый определитель 28 значения вероятности обращается к информации 56 об указателе или к первому участку в постоянном месте, которое, однако, является иным для других определителей 28 значений вероятности в текущем пакете транспортного потока. Разумеется, структура заголовка 50 пакетов 12 транспортного потока, распределенных в соответствующий приемник 20 данных, также может быть получена из пакетов 12 транспортного потока, ранее распределенных в соответствующий приемник 20 данных в определителях 28. Как только это произошло, определители 28 значений вероятности, например, определяют местоположение второго участка 62 текущего пакета 12 транспортного потока в зависимости от содержимого предварительно определенного пакета 12 транспортного потока в первом участке, а именно, в участке 56, то есть, как будто бы содержимым предварительно определенного пакета 12 транспортного потока в первом участке 56 фактически являлась информация 56 об указателе. В пакете 12b транспортного потока это предположение, очевидно, являлось бы неправильным, что указано номером позиции 56′. Если бы содержимое участка 56′ пакета 12b транспортного потока использовалось в качестве информации об указателе, то, например, местоположение участка 62′ участка 48 данных полезной нагрузки было бы определено как местоположение второго участка. При этом каждый определитель 28 значения вероятности анализировал бы второй участок 62 или 62′ в отношении того, может ли он являться началом пакета 38 данных, распределенного в соответствующий приемник 20 данных, или нет. Для этого приемник данных может, например, производить оценку поля 82 адреса или поля 98 адреса. То есть, если в том месте, в котором должно быть расположено соответствующее поле 82 или 98 в участке 62 или 62′, находится начало пакета данных, адресованного соответствующему приемнику 20 данных, то каждый определитель 28 значения вероятности сравнивает его содержимое с содержимым этих участков, которое в иных случаях является типичным для этих полей в пакетах 38 или 90 данных для соответствующего приемника данных. Результатом является соответствующий вклад в вероятность, который будет внесен в соответствующее значение вероятности для соответствующего приемника 20 данных и на основании которого средство 30 распределения выполняет распределение. Например, в качестве величины вклада может быть использована мера подобия ожидаемого содержимого и фактического содержимого, причем эта мера может быть реализована очень просто, а именно, в двоичной форме, чтобы этот вклад не был бы равен нулю, если они совпадают, и был бы равен нулю, если они не совпадают.
После предыдущего абзаца может иметь место случай, когда каждый определитель 28 значения вероятности исследует первое поле 82 или 98 во втором участке 62 просто в отношении того, соответствует ли оно информации, которая более или менее неизменной для соответствующего приемника данных, например, по меньшей мере, начиная с последнего распределения пакета 12 транспортного потока в соответствующий приемник 20 данных распределителем 26 или средством 30 распределения. Также может иметь место случай, когда определители 28 значений вероятности исследуют два поля во втором участке 62 в отношении того, содержат ли они предварительно определенное соотношение, применяемое между полями 78 и 76 в заголовках 74 пакетов 38a-d данных. Это совпадение или соответствие может не являться указателем отдельного приемника данных применительно к распределению текущего пакета транспортного потока в соответствующий приемник 20 данных, но определители 28 значений вероятности могут использовать это вышеупомянутое исследование для увеличения вклада в вероятность в том случае, если информационное содержимое может быть найдено в участке 62, содержащем информацию, подобную информации, характерной для приемника данных, поскольку тот факт, что вышеупомянутым соответствием в возможных полях 82, 98 не является только совпадение, предполагает, что оно является, по меньшей мере, началом пакета 38a-d данных, вне зависимости от приемника данных, которому они адресованы. Эта величина вклада в вероятность также может использоваться для вышеупомянутого суммирования для итогового значения вероятности для соответствующего приемника 20 данных.
До сих пор было описано, что определители 28 значений вероятности исследуют первое поле 110 участка 62 в отношении того, является ли его содержимое содержимым поля 82 или 98, которое обеспечивает указатель для адресации соответствующего приемника данных, и что исследуют два дальнейших поля 112 и 114 в отношении того, объединяют ли они поля 78 и 76 заголовков 74, или содержат ли они сведения о взаимной связи кода систематического прямого обнаружения ошибок.
В дополнение к этому или в альтернативном варианте определители 28 могут исследовать четвертое и пятое поле в отношении того, имеют ли они предварительно определенную взаимную связь, которая применима к избыточным указателям, то есть, например, ведут ли себя эти поля 116, 118 друг относительно друга как поля 98, 82, которые оба каким-либо образом обеспечивают адресацию приемника 20 данных. Эта связь или контекст также может не являться характерной для приемника данных, но может использоваться определителями 28, например, для увеличения значения вероятности, если дополнительно оказывается, что полем 110 является поле, которое вероятно является характерным для соответствующего приемника данных, как было описано выше.
В описании возможных вариантов исследования для определителей 28 до сих пор не учитывалось, что вследствие наблюдения пакетов 38 данных, полученных до настоящего момента из распределенных пакетов транспортного потока для соответствующего приемника 20 данных, каждый определитель 28 также имеет определенные ожидания относительно содержимого следующего пакета транспортного потока для соответствующего приемника 20 данных. Таким образом, например, может иметь место, что каждый определитель 28 для приемника 20 данных, в который пакет 12 транспортного потока был распределен последним, где был размещен пакет 38 данных, распределенный в соответствующий приемник 20 данных, который имеет длину 80, из чего может быть сделан вывод, что упомянутый пакет данных продолжается за пределы пакета транспортного потока, распределенного последним в соответствующий приемник 20 данных, в зависимости от указателя 80 длины, определяет местоположение участка 120 в начале участка 48 данных полезной нагрузки текущего пакета 12 транспортного потока и анализирует его в отношении того, может ли он являться продолжением еще не завершенного пакета данных соответствующего приемника данных. Например, в конце каждого пакета 38a-d данных может содержаться флаг, который указывает конец соответствующего пакета данных, и сопоставление соответствующего положения в конце участка 120 с таким флагом EOF ("конец файла") может приводить к дополнительной величине вклада в вероятность для итогового значения вероятности для соответствующего приемника данных. Однако, также может иметь место, что в участке 120 расположен участок пакета данных, содержащий информацию, характерную для приемника данных, например, одно из полей 82 или 98. К тому же, для таких полей могут быть предприняты исследования подобия для определения дополнительных величин вклада.
Согласно вышеописанным примерам для возможных исследований, которые могут быть предприняты определителем 28 для получения соответствующих величин вклада в вероятность, каждый из определителей 28 определяет местоположение определенных полей с использованием определенных предположений, которые снова могут быть получены из информации из ранее распределенных пакетов транспортного потока или нет. Если в результате этих исследований получено соответствие или совпадение, то несомненно, что для соответствующего приемника данных вероятность того, что текущий пакет 12 транспортного потока относится к этому приемнику 20 данных, является относительно высокой, поскольку соответствие было определено в определенном положении текущего пакета транспортного потока, и ни в каком ином. В дополнение к этому или в альтернативном варианте может иметь место, что каждый определитель 28 значения вероятности также исследует случайное поле в текущем пакете 12 транспортного потока в отношении того, соответствует ли его содержимое информации, которая является неизменной для соответствующего приемника 20 данных, например, по меньшей мере, с момента последнего распределения пакета 12 транспортного потока в соответствующий приемник данных. Приемник 20 данных, потеряв направленный в него пакет транспортного потока, может потерять представление о том, где в текущем пакете транспортного потока потенциально может быть расположено начало направленного него пакета данных, и, таким образом, одно из полей 98 или 82 может быть расположено, например, в случайном положении в текущем пакете транспортного потока. Кроме того, ранее распределенным пакетом транспортного потока мог являться пакет, который имел ошибку, но, тем не менее, был распределен в текущий приемник данных, который мог быть выровнен по ширине или не выровнен по ширине, и, таким образом, например, указатель 80 длины еще не завершенного пакета данных соответствующего приемника данных может быть ошибочным, и поля 98 и 82 следующего пакета данных могут быть расположены в неожиданном ином положении. Разумеется, если определены сходства значений 82 и/или 98 с типичным информационным содержимым, то полученная в результате этого величина вклада в вероятность для итогового значения вероятности соответствующего приемника 20 данных предпочтительно является меньшей, чем для вышеупомянутых исследований в определенных предварительно заданных локализованных положениях текущего пакета транспортного потока.
Аналогично тому, что было описано выше со ссылкой на локализованные поля, например, в дополнение к этому или также в альтернативном варианте может быть выполнено исследование дополнительный пар полей в случайных местоположениях в отношении того, имеют ли они предварительно определенную взаимную зависимость или связь кода систематического прямого обнаружения ошибок применительно к избыточным указателям в заголовках плоскостей 68 и 88 протокола. Однако, также может иметь место, что последние исследования выполняют в локализованных местах, то есть, в зависимости от положения поля, в котором имеет место подобие информации, характерной для приемника данных, что является, например, типичным для полей 82 или 98, вследствие чего увеличивается вероятность того, что это подобие в случайном поле в случайном положении не возникло случайным образом.
Кроме того, определители 28 могут быть реализованы с возможностью использования того факта, что указатель 80 длины пакетов 38 данных обычно является скоррелированным с информацией 56 об указателе. Причина этого состоит в том, что, например, определитель 28 для приемника 20 данных, с которым ассоциирован поток 36 данных на Фиг. 2, на основании указателя 80 длины и размера еще не принятой части 64 пакета 38a данных, может с высокой вероятностью предположить, что информация 56 об указателе из пакета транспортного потока, который ожидается следующим, содержит информацию 56 об указателе, которая перекрывает размер этого участка 64, что также указано на Фиг. 2 стрелкой 58. Таким образом, соответствующий результат сравнения поля 56 текущего пакета транспортного потока с указателем 80 длины пакета данных соответствующего приемника данных, принятого последним, может использоваться соответствующими определителями 28 для приемников данных, в который существуют такие пакеты 38a данных, которые еще не были полностью приняты, для определения величины вклада в вероятность заново.
Также часто имеет место случай, когда пакеты транспортного потока, которые ассоциированы с соответствующим приемником 20 данных, содержат пакеты, идентичные друг другу или, по меньшей мере, содержащие одно и то же информационное содержимое. Это может иметь место, например, тогда, когда передают определенную карусель данных для соответствующего приемника данных. Идентичное содержимое пакетов 12 транспортного потока, прерывисто повторяющееся в пакетах транспортного потока для таких приемников данных, может, например, относиться к таблице передачи служебных сигналов для такой карусели данных. Определители 28 могут быть реализованы с возможностью определения для соответствующего приемника данных, к которому относится определитель, прерывисто повторяющегося идентичного содержимого среди пакетов 12 транспортного потока, уже распределенных ранее в соответствующий приемник данных, и последующего определения значения вероятности для соответствующего приемника данных путем сравнения содержимого участка данных полезной нагрузки текущего пакета 12 транспортного потока с прерывисто повторяющимся идентичным содержимым.
В предыдущем описании часто имелось в виду, что потоком 36 данных являлся поток, назначенный для приемника данных. Это является, по существу, правильным, но, разумеется, в варианте осуществления изобретения из Фиг. 2 также правильно то, что потоком 86 данных является поток, адресованный в приемник 20 данных. Он просто инкапсулирован в инкапсулирующую структуру, то есть в уровень 68, и вместе с данными инкапсуляции, то есть, с данными 74 заголовка структуры инкапсуляции фрагментирован на пакеты 12 транспортного потока, распределенные в соответствующий приемник 20 данных. Определитель 28 может теперь определять для соответствующего приемника 20 данных, для которого теперь предусмотрен определитель 28, несколько потенциальных местоположений, таких как, например, вышеупомянутые местоположения 116 и 118 в текущем пакете 12 транспортного потока, в котором содержимое данных 74 инкапсуляции, содержащее предварительно определенную взаимную связь, с одной стороны, и пакетов 90 данных потока 86 данных, адресованного соответствующему приемнику 20 данных, с другой стороны, местоположения которых может быть определено для определения значения вероятности или соответствующей величины вклада в вероятность для итогового значения вероятности для соответствующего приемника 20 данных на основании того факта, существует ли предварительно определенная связь между содержимым текущего пакета 12 транспортного потока в определенных нескольких потенциальных местоположениях 116, 118 или нет.
Разумеется, только что упомянутая возможность существует только тогда, когда ожидаемые потенциальные местоположения находятся в пакете транспортного потока, а не в последующих пакетах. Например, может иметь место то, что определители в дополнение к этому или в качестве альтернативы определяют одно или несколько потенциальных местоположений в текущем пакете 12 транспортного потока, в котором может быть расположено содержимое пакетов данных из потока данных, адресованного соответствующему приемнику 20 данных, которое содержит предварительно определенную связь с содержимым данных инкапсуляции в одном из пакетов 12 транспортного потока, уже распределенных ранее в соответствующий приемник 20 данных, и определяют значение вероятности на основании того, существует ли между содержимым предварительно определенного пакета транспортного потока в одном или в нескольких потенциальных местоположениях и пакетов 12 транспортного потока, уже распределенных ранее в соответствующий приемник данных, соответствующая связь или нет. Таким образом, может, например, иметь место то, что для приемника данных, который не полностью принял текущий пакет 38a данных, поле 82 уже относится к уже принятой части этого пакета 38a данных, причем поле 98 внедренного в него пакета 90 данных находится в пакете транспортного потока для соответствующего приемника данных, который все еще ожидается, и именно поэтому в этом случае определитель 28 в текущем пакете транспортного потока сравнивает положение поля, соответствующего полю 98, с содержимым поля 82 для получения (дополнительной) величины вклада в вероятность.
Кроме того, следует отметить, что упомянутые выше величины вклада в вероятность также могут быть объединены по-иному, а не путем суммирования. Например, они могут быть перемножены друг на другом и т.п. Также возможно смешение таких комбинаторных возможностей.
Определители 28 могут использовать дополнительное условие для определения дополнительной величины вклада в вероятность, то есть, тот факт, что обычно временное мультиплексирование, с использованием которого потоки данных, адресованные различным приемникам 20 данных, мультиплексируют в пакеты 12 транспортного потока транспортного потока 14, то есть, временное изменение распределения последовательно расположенных пакетов 12 транспортного потока из транспортного потока 14 относительно отдельных приемников 20 данных происходит не случайным образом, а согласно предварительно определенному шаблону, например, согласно определенному способу оптимизации скорости передачи/качества и т.п., вследствие чего пакеты транспортного потока, адресованные определенному приемнику данных, обычно встречаются в транспортном потоке 14 с предварительно определенным временным шаблоном. Таким образом, определители 28 могут быть реализованы так, что при определении значения вероятности для соответствующего приемника 20 данных учитывают частоту более кратковременного и/или более долговременного распределения прошлых пакетов 12 транспортного потока соответствующего приемника 20 данных.
Эффект вышеупомянутых мер теперь состоит в том, что определители 28 обеспечивают значение вероятности для каждого приемника 20 данных, что делает очевидным для средства 30 распределения то, к какому приемнику 20 данных в настоящий момент относится текущий пакет 12 транспортного потока, содержащий ошибку. Следовательно, этот текущий пакет 12 транспортного потока не нужно аннулировать, несмотря на то, что указатель 54 адреса, как можно предположить, не является надежным.
Соответствующий приемник 20 данных, который принимает его пакет 12 транспортного потока несмотря на то, что он является ошибочным, может целесообразно использовать этот пакет транспортного потока или соответствующие данные полезной нагрузки в нем за счет использования кода 100 прямой защиты от ошибок, которым является, например, код систематической прямой защиты от ошибок. Если кодом 100 прямой защиты от ошибок в потоке 36 данных является код систематической прямой защиты от ошибок с функциональными возможностями перемежителя, то вследствие, тем не менее, распределенного пакета транспортного потока соответствующий приемник данных или его декодер 21 может полностью заполнить таблицу 104 перемежителя более высокой вероятностью, вследствие чего декодирование потока 38 данных в соответствующем приемнике 20 данных декодером 21 соответствующего приемника 20 данных является успешным с более высокой вероятностью, поскольку коррекция ошибок устраняет ошибки в неправильном или ошибочном пакете транспортного потока.
Прежде, чем варианты осуществления изобретения, которые были описаны выше со ссылкой на Фиг. 1 и Фиг. 2, будут снова проиллюстрированы ниже в различных вариантах их реализации со ссылкой на конкретные форматы данных, ниже снова со ссылкой на Фиг. 3 это проверено для описания функциональных возможностей вычислителя 28 значения вероятности с несколько другой точки зрения. На Фиг. 3 текущий пакет транспортного потока, проиллюстрированный как 12′, который подают в приведенный в качестве примера вычислитель значения вероятности, функциональные возможности которого также рассмотрены для описания других вычислителей значения вероятности немного иным образом, чем выше. На Фиг. 3 показано состояние вычислителя значения вероятности в тот момент времени, когда пакет 12′ транспортного потока подан средством 30 распределения с вопросом, ассоциирован ли пакет 12′ транспортного потока, указанный как ошибочный, с соответствующим приемником 20 данных или нет. В этот момент вычислитель 28 значения вероятности имеет определенное состояние, которое, помимо прочего, отличается определенными данными 200, которые могут изменяться во времени более или менее быстро. Это состояние является характерным для приемника данных, что следует из приведенного ниже обсуждения; только лишь обработка иных данных, характерных для данных, может не являться характерной для приемника данных.
Среди этих данных имеются такие данные, например, 200a, 200b, которые не являются характерными для приемника данных, например, типичные значения содержимого поля 84 (Фиг. 2), но также и данные, которые являются характерными или даже уникальными для соответствующего приемника данных, такие как, например, данные 200c и 200d, которые могут, например, соответствовать содержимому 82 или 98 из Фиг. 2 для соответствующего приемника данных и оставаться неизменными на протяжении большого числа пакетов 90 или 38 данных, и вновь данные 200e и 200f, ожидаемые для определенных полей пакета 12' транспортного потока, если этим пакетом 12′ транспортного потока является пакет транспортного потока для соответствующего приемника данных с ожидаемым информационным содержимым в участке данных полезной нагрузки, например, пакет транспортного потока для соответствующего приемника данных с отсутствующей частью еще не завершенного пакета данных этого приемника данных, который был принят последним, как, например, пакет 38a на Фиг. 2, то есть, содержимое которого больше не встречается в потоке данных, поскольку оно более или менее применимо только лишь исключительно для определенного следующего пакета данных, таким образом, так сказать, изменяется от одного пакета данных до другого пакета данных и, следовательно, применимо только для предыдущего пакета данных без потерь из соответствующего приемника данных. Что касается последнего упомянутого случая, то данными 200e и 200f может являться, например, ожидаемое содержимое указательной информации 56 в заголовке пакета 12′ транспортного потока. Среди данных, характерных для приемников 200a, 200b данных, могут иметься данные, содержащиеся не в участке 48 данных полезной нагрузки, а в заголовке 50, например, сам идентификатор 54, поскольку может иметь место то, что ошибочным является иной участок пакета 12′, и равенство фактического содержимого 54 идентификатора содержимому, ожидаемому для соответствующего приемника 20 данных, приводит к увеличению вероятности того, что соответствующий пакет 12′ относится к этому приемнику 20 данных.
Для каждых из этих данных 200a-200f может быть назначено распределение 202 вероятности появления, как оно в качестве примера указано на Фиг. 3 для фрагмента данных 200a. Распределение 202 вероятности появления указывает, с какой вероятностью фрагмент данных 200a следует ожидать во всевозможных местоположениях вдоль длины L текущего пакета 12′ транспортного потока. Распределение 202 вероятности появления может являться неизменным для фрагмента данных, как например, для фрагмента данных 200e, содержащего ожидаемое содержимое для информации 56 об указателе, или также представляющей собой часть изменяющегося во времени состояния вычислителя 28 значения вероятности. Одни из данных 200a и 200b, не являющиеся характерными для приемника данных, могут быть расположены, например, только в пределах участка 48 данных полезной нагрузки, что является широко известным, и тогда затем распределение 202 вероятности появления для этого фрагмента данных 200a является неравным нулю только лишь в пределах возможного интервала 204 расширения участка 48 данных полезной нагрузки. Результатом этого может возникать увеличенный максимум 206 в ходе 202 распределения вероятности появления в зависимости от текущего состояния вычислителя 28 значения вероятности, например, от ожидаемой информации 200e о скачке, основанной на указателе 80 длины пакета данных, принятого последним только лишь фрагментарно, в котором этот указатель длины, например, также представляет собой один фрагмент данных 200. Также могут иметь место неизменные распределения вероятности появления, например, для данных 200, которые относятся к ожидаемому содержимому заголовка 50. Одними из них является, например, информация 56 о скачке или также неупомянутая ранее информация, которая, однако, может существовать, например, порядковый номер в заголовках пакетов транспортного потока, распределенных в определенный приемник данных. Такой порядковый номер представляет собой информацию о пакетах транспортного потока, изменяющуюся характерным для приемников данных образом от одного пакета транспортного потока, распределенного в соответствующий приемник данных, до другого пакета транспортного потока, распределенного в соответствующий приемник данных.
В зависимости от хода 202 распределения вероятности появления, теперь вычислитель 28 значения вероятности может определять появление подобий между содержимым текущего пакета 12′ транспортного потока и данными 200 для всех местоположений в пакете 12′ транспортного потока или только для особых местоположений. Таким образом, для различных или для всех данных 200 значение подобия приводит ко всем или к нескольким местоположениям, или к одному местоположению внутри текущего пакета 12′ транспортного потока, при этом на Фиг. 3 в качестве примера подобие проиллюстрировано как непрерывное по всему пакету 12′ транспортного потока. Произведение значения подобия на соответствующее значение вероятности появления в определенном местоположении, в котором было определено подобие, теперь может быть использовано в качестве вышеописанной величины вклада в вероятность. Как было описано выше, это выполняют для как можно большего количества данных 200, и эти величины вклада могут быть затем просуммированными или умножены, то есть, с дополнительным умножением на весовые коэффициенты этих вкладов или без него.
При каждом распределением пакета транспортного потока вне зависимости от того, содержит ли он ошибку или нет, определитель 28 значения вероятности обновляет свои данные 200 и, следовательно, свое состояние, а также распределения вероятности появления, относящиеся к его состоянию.
В более общем изложении, для каждого приемника 20 данных существует определитель 28 значения вероятности, и этот каждый определитель 28 значения вероятности имеет состояние, характерное для отдельного приемника данных, которое обновляют посредством информационного содержимого пакета транспортного потока каждый раз, когда такой пакет распределяют в приемник данных. Таким образом, состояния различных вычислителей 28 значения вероятности отличаются друг от друга. Поскольку используются эти состояния, то путем сравнения этого состояния с содержимым вызывающего в настоящий момент сомнения пакета 12′ транспортного потока, являющегося ошибочным, определяют, насколько вероятно то, что он относится к надлежащему приемнику 20 данных, значения вероятности определителей 28 являются по-разному высокие, и средство 30 распределения может выбирать приемник данных с самой высокой вероятностью при условии, что она превышает - относительно других значений вероятности или абсолютно - определенное минимальное пороговое значение.
Со ссылкой на Фиг. 3 следует отметить, что вычисление максимума 206 или его положения, например, соответствует определению местоположения положений полей, как упомянуто в приведенном выше описании. Этот поиск или определение местоположения могут производиться на основании информации 56 об указателе или путем обновления или путем прогнозирования того, где будет начинаться новый пакет данных в одном из последующих пакетов транспортного потока. Именно это было описано выше. Исследование подобия в определенном местоположении может соответствовать вычислению элемента соответствующей функции взаимной корреляции при соответствующем смещенном положении с ожидаемым информационным содержимым или с иной мерой подобия в определенном местоположении между пакетом 12′ транспортного потока, имеющим ошибку, с одной стороны и ожидаемым информационным содержимым с другой стороны.
Описанные выше варианты осуществления изобретения необходимо объяснить снова иными словами применительно к конкретным способам широковещательной передачи. Здесь описанные выше варианты осуществления изобретения демонстрируют возможность устойчивого к ошибкам декодирования инкапсулированных потоков данных или способа приема для инкапсулированных пакетно-ориентированных потоков данных с различимыми приемниками данных. Здесь обеспечена возможность распределения пакетов, принятых с ошибками, по отдельным приемникам данных, несмотря на то, что или даже если повреждена структура инкапсуляции. Варианты реализации вышеописанных вариантов осуществления изобретения могут, помимо прочего, но не исключительно, обеспечивать поддержку последовательных и иерархических способов защиты от ошибок на уровне непосредственно задействованных и соседних протокольных уровней.
В качестве способов инкапсуляции могут быть упомянуты, например, многопротокольная инкапсуляция (MPE) и универсальная инкапсуляция потока (GSE), которые могут использоваться, например, в способах цифрового телевещания стандартов DVB-H и DVB-SH.
Как описано выше, может использоваться эвристическая модель прогнозирования на основе частично ошибочных переданных пакетов данных для их распределения на стороне приемника в один из нескольких возможных приемников данных для дальнейшего декодирования. Здесь, как описано выше, могут использоваться различные сведения о принятых пакетах: априорные сведения, которые являются известными вследствие выбранного стандарта передачи, результаты измерений параметров пакетов, которые являются неизменными или непрерывно прогнозируемыми при передаче и т.д.
Как описано на Фиг. 1, такие параметры собирают и прогнозируют для каждого приемника данных из ранее принятых пакетов. На основании этих сведений для каждого дополнительно принятого пакета может быть вычислена предполагаемая вероятность для каждого приемника данных, причем это вычисление выполняют вышеупомянутые вычислители 28 значения вероятности. Поврежденные пакеты 12 могут быть затем распределены в приемник 20 данных с наивысшей предполагаемой вероятностью. Использование нижнего предела может предотвращать прием слишком поврежденных пакетов.
Реализация вышеупомянутых вариантов осуществления изобретения означает просто расширение известных способов передачи на стороне приемника. Совместимость с неподготовленными для этого приемными устройствами остается неизменной. Другими словами, отсутствует необходимость в каких-либо изменениях соответствующих стандартов. Аналогичным образом, отсутствует необходимость в каких-либо видоизменениях на стороне, производящей передачу.
Другими словами, в вышеупомянутых вариантах осуществления изобретения описано расширение способов приема инкапсулированных потоков данных на транспортном уровне и на уровне передачи. Случаем применения с этой точки зрения является инкапсуляция пакетов сети. В соответствующих способах инкапсулированные пакеты 90 данных затем фрагментируют в транспортные пакеты 12. Поскольку в системе с мультиплексированием несколько потоков данных полезной нагрузки обычно передают инкапсулированные параллельно, то транспортные пакеты 12 снабжены идентификаторами, которые распределяют их по потоку данных.
В случае отсутствия ошибок приемник таких потоков данных принимает на основании этого идентификатора 54 решение о том, в какой именно поток данных полезной нагрузки он распределяет принятый транспортный пакет. Если бы он был принят с ошибкой, или если было повреждено, по меньшей мере, поле идентификатора, то поступивший транспортный пакет должен быть аннулирован. Возможно, также должны быть аннулированы несколько следующих пакетов, пока протокол не сможет снова синхронизировать поток данных полезной нагрузки. Обычно эти обстоятельства приводят к более значительным потерям данных полезной нагрузки.
Распределение самих неповрежденных транспортных пакетов 12 по кадру образует предварительное условие для использования вышеупомянутых способов. Оно обычно является заданным априори в системах транспортировки с фиксированной длиной пакетов. Еще одним предварительным условием является просмотр всех задействованных протокольных уровней. Таким образом, вышеупомянутые способы являются частью кросс-уровневой оптимизации.
В дополнение к этому, вышеупомянутыми способами теперь транспортные пакеты 12, принятые с ошибками, также распределяют в отдельные приемники 20 данных полезной нагрузки. Таким образом, при наличии нескольких параллельных приемников 20 потоков данных предотвращен случайный прием ими данных, которые фактически не предназначены для них, и, следовательно, их функционирование и коррекция ошибок на основании данных с ошибками.
При этом производится извлечение и запись или регистрация параметров распределенных пакетов данных полезной нагрузки (см. Фиг. 3). Это обновление производится по отдельности в каждом приемнике данных. Здесь представляют интерес такие параметры, которые, исходя из последовательностного и временного контекста, заранее содержат совокупность высоких параметров или сильную предсказуемость. ими являются, например, параметры, соответствующее значение которых является четко предварительно определенным в стандарте. Все параметры имеют сильную предсказуемость, которая является постоянной во время передачи или значение которой непрерывно изменяется. Ниже вновь приведены примеры выбора таких параметров.
Пакет 12, принятый с ошибкой, ставят в соответствие приемнику 20 данных при помощи так называемой предполагаемой вероятности. Эту вероятность приемник данных или соответствующий вычислитель 28 вычисляет по количеству правил с присвоенными весовыми коэффициентами для формирования предполагаемой вероятности. Эти правила работают для текущего обновления состояния 200 приемника 20 данных и соответствующих параметров еще не распределенного пакета 12. Эти правила здесь имеют тесную связь с уже упомянутыми выше параметрами; а при их перечислении снова приведены примеры. С учетом всех правил путем усреднения, включающего в себя умножение на весовые коэффициенты, может быть вычислена предполагаемая вероятность для каждого нераспределенного пакета для каждого приемника данных. Эта вероятность может непосредственно использоваться в усовершенствованном демультиплексоре или в средстве 30 распределения для принятия решения относительно формирования максимума, но это не является обязательным условием. В альтернативном варианте позади по ходу могут быть подсоединены формирователи плавающего среднего значения или аналогичные фильтры. Усовершенствованный демультиплексор отличается наличием следующих элементов: различение случаев приема транспортных пакетов 12 с ошибками, и в этом случае последующее выполнение оценки для пакета со всеми приемниками 20. Результат затем подают в текущий демультиплексор в качестве альтернативного решения.
Предполагаемая вероятность зависит, помимо прочего, от текущего состояния приемника 20 данных. Правила, по существу, частично являются сложными. Они инициируют анализ процедур поиска внутри пакета 12 транспортного потока и регулируют обновленные параметры 200 в случае успешного поиска внутри пакетов определенных шаблонов, которые указывают точку возобновления с высокой достоверностью. Точка возобновления здесь является значимым и поддающимся проверке шаблоном протокола более высокого уровня 88 или 68 в потоке данных. Помимо этого также существуют простые правила, которые обеспечивают анализ определенных значений в ожидаемом месте присутствия и непосредственно обеспечивают оценку. В зависимости текущего состояния приемника, активизируют или деактивизируют отдельные правила для оптимизации объема вычислений.
Измененный подход демультиплексора в случае ошибки (при приеме) состоит в следующем: для нераспределенного (назначенного) пакета 12 предполагаемую вероятность формируют с каждым приемником 20 данных. После этого пакет распределяют в приемник 20 данных с самой высокой предполагаемой вероятностью. Кроме того, как описано выше, заранее может производиться фильтрация значений. Затем сам приемник 20 данных обрабатывает пакет согласно ошибочному приему; декодер 21, относящийся к приемнику, использует выполняемые в нем способы проверки на наличие ошибок или коррекции ошибок, например, для условного использования пакета или его коррекции для дальнейшего использования.
В дополнение к этому, более низкое пороговое значение для приема пакетов предотвращает получение данных при приеме сильно поврежденных переданных пакетов. Это условие обнаруживают тогда, когда все приемники вычисляют сравнительно низкие показатели приемлемости для такого пакета. В этом случае такие пакеты окончательно аннулируют.
В описанных выше способах существует эффект совместных действий за счет объединения со способами прямой защиты от ошибок. Описанные выше способы обеспечивают возможность использования принятых данных из мультиплексированной передачи для дальнейшей обработки дополнительными способами прямой защиты от ошибок, которые уже существовали согласно стандартам. За счет распределения в отдельные приемники 20, защита от ошибок соответствующего приемника 20 может, тем не менее, считать приемлемыми потенциально поврежденные блоки данных особым образом. Таким образом, повышен потенциал коррекции соответствующей защиты от ошибок.
Ниже приведено подробное объяснение с использованием примера стандарта DVB-H с MPE. Описанный выше способ может использоваться в способе, основанном на широковещательной рассылке данных по протоколу IP согласно стандарту DVB-H. Здесь прием IP-пакетов 40 выполняют с использованием многопротокольной инкапсуляции (MPE). В транспортном потоке 14 стандарта MPEG-2 предназначенные для него данные распределены по отдельным пакетам 12 транспортного потока. Согласно стандарту, адресацию пакета транспортного потока в приемник 20 стандарта MPEG в случае отсутствия ошибок производят по так называемому “идентификатору пакета” (PID), см. номер позиции 56.
В описанных выше способах пакеты 12′ транспортного потока, принятые с ошибками, также распределяют в отдельные приемники 20 данных. Соответствующая структура была проиллюстрирована на Фиг. 1. Здесь каждый приемник 20 данных и его вычислитель 28 управляют текущими параметрами, относящимися к их участку транспортного потока, то есть, к входящему потоку пакетов для упомянутого приемника 20. Демультиплексор 10 транспортного потока усовершенствован так, чтобы для пакетов 12 транспортного потока с установленным флагом TEI (указатель ошибки при транспортировке), то есть, в случае обнаружения ошибки модулем 22, он использует критерии отбора согласно новому способу: каждый приемник 20 данных или его вычислитель спрашивают о его предполагаемой вероятности относительно данного пакета транспортного потока. Пакет посылают в приемник 20, имеющий самое высокое возвращаемое значение. Приемники 20 данных, которые не могут декодировать ошибочные пакеты, аннулируют их после приема. Однако, специализированные приемники данных обеспечивают возможность дальнейшей обработки также и с ошибочными пакетами.
В описанном выше случае стандарта DVB-H новый способ согласно Фиг. 1-Фиг. 3 может обеспечивать поддержку прямой коррекции ошибок MPE-FEC (прямой коррекции ошибок с многопротокольной инкапсуляцией). Таким образом, этот способ обеспечивает возможность реального преобразования с несколькими одновременными потоками 36 данных MPE с такими вариантами реализации защиты от ошибок, в которых коррекцию ошибок выполняют более активно, чем предусмотрено в стандарте, то есть, например, последовательным и иерархическим способами.
Каждый приемник 20 данных MPE-FEC управляет так называемым кадром MPE-FEC, который буферизует данные для коррекции ошибок при помощи блочного кода защиты от ошибок Рида-Соломона (RS) (255,191,64) (см. 100). При объединении вышеописанной обработки поврежденных пакетов 12′ с прямой защитой от ошибок MPE-FEC структура данных для хранения параметров потока пакетов может быть расположена в том же самом месте, что и в кадре MPE-FEC, и если она применяется в случае того же самого протокола.
Описанные выше варианты осуществления изобретения могут непосредственно применяться, помимо прочего, но не исключительно, для иных способов инкапсуляции, таких как MPE и MPE-IFEC (межпакетная FEC) (см. документ Digital Video Broadcasting Project (DVB) (editor): Digital Video Broadcasting (DVB); MPE-IFEG. Digital Video Broadcasting Project (DVB), 11 2008. (DVB Bluebook A131). http://www.dvb.org/) стандарта вещания DVB-SH, для соответствующих способов согласно другим стандартам вещания, таким как ATSC (стандарт ATSC A/53, Часть 1: 8 2009. ATSC Digital Television Standard: Part 1 Digital Television System. http://www.atsc.org/) и другие, и т.д.
Несмотря на то, что выше было приведено много примеров, правила формирования предполагаемой вероятности необходимо снова перечислить ниже в явном виде.
Ниже описаны различные параметры, представляющие интерес для обновления, и соответствующие правила использования этих параметров для распределения пакетов в приемники данных. Все правила могут использоваться вместе путем умножения на весовые коэффициенты для формирования предполагаемой вероятности. Спецификации поиска в этих правилах используют в зависимости от времени и объема работ, когда приемник внутренне обнаруживает потерю синхронности. Этот общий обзор не претендует на полноту. Для общего представления о соответствующих протокольных уровнях и об ошибках в стандарте DVB-H приведена ссылка на публикацию Jaekel, Torsten: DVB-H Data Mapping. 052006. - DiBroC.
Синхронность получают из самой предполагаемой вероятности или из частоты фактических распределений пакетов. Здесь сравнивают средние значения каждого одного прошлого кратковременного и каждого одного прошлого долговременного временного окна. Если кратковременное значение падает ниже определенного порога ниже долговременного значения, то следует предположить, что приемник потерял свою синхронность. Соответственно, приемник активизирует команды поиска.
Поля "длина", такие как, например, 80 и 96, могут быть использованы в качестве указателя положения данных для возобновления. Они дают указатель того, где в одном из следующих пакетов 12 транспортного потока следует искать начало нового IP-пакета. Поля "длина" существуют на уровне MPE (см. 68), IP (см. 88) и UDP (протокола передачи дейтаграмм пользователя). Все они непосредственно зависят друг от друга в случае нефрагментированных IP-пакетов и, следовательно, являются избыточными. Таким образом, эта зависимость также может использоваться для прямого поиска точки возобновления.
Смещение фрагмента, например, 56 используют с фрагментированными IP-пакетами для оповещения о том, что существует продолжающаяся часть IP-пакета. В качестве указателя такого продолжения может использоваться смещение, подходящее для предыдущих IP-пакетов (см. 38a).
IP-адреса, такие как, например, 98 и 82, часто могут быть однозначно распределены по IP-потоку 86 или MPE-сеансу 68. Таким образом, наоборот, производят распределение IP-адреса в MPE-приемник 20. Дополнительно используют тот факт, что в пределах MPE-сеанса используются количество IP-адресов, остающееся одним и тем же. В области техники радиовещания внезапное появление нового адреса является весьма редким, или его даже не следует искать. В связи с этим используют оба адреса: целевой адрес, а также адрес источника.
Порты UDP обычно подчиняются тем же самым условиям, которые были описаны выше для IP-адресов.
Селекторы, такие как TOS (тип обслуживания), TTL (срок действия), протокол, флаги, версия обычно являются неизменными в каждом сеансе. Селекторы более однозначно подчиняются этому условию, чем адреса. К тому же, длина заголовка поля играет соответствующую роль, однако, формально не является селектором.
Контрольная сумма IP (например, 76) заголовка протокола дает информацию о целостности заголовка протокола. Эту связь с целостностью используют для верификации точки возобновления. Поиск возможного начала IP-пакета в пакете транспортного потока также возможен с использованием этой связи путем проб.
Групповые адреса создают связь между MAC-адресом заголовка MPE и целевым адресом протокола IP (см. публикацию Deering, Stephen E.: Host Extensions for IP Multi-casting. Internet Engineering Task Force, 8 1989. (RFC 1112). http://tools.etf.org/html/rfc1112). Таким образом, они работают аналогично полям "длина", распределенным через несколько протокольных уровней. Использование групповых адресов является традиционным при рассылке данных по протоколу IP.
PID (см. 54) является уникальным для каждого приемника (20) и используется демультиплексором для транспортных пакетов, принятых неповрежденными, для их распределения. В пакетах, принятых с ошибками, это поле также может быть проверено. Если PID является правильным для приемника, то он может быть оценен положительно.
Счетчик целостности непрерывно оценивает PID в потоке пакетов. Он может использоваться как поле PID для содействия вычислению предполагаемой вероятности.
Таблицы сигнализации (PSI/SI) регулярно повторно передают в транспортном потоке. Здесь содержимое большинства таблиц изменяется сравнительно редко. Содержимое входящих транспортных пакетов и содержимое уже принятых таблиц могут быть сравнены друг с другом для получения того, следует ли распределять рассматриваемый транспортный пакет в соответствующий приемник данных для сигнализации. Здесь также могут использоваться показатели, которые обеспечивают проверку по подобию.
Кроме того, в этом документе термин "инкапсуляция" означает инкапсуляцию потоков данных определенных протоколов в другой протокол для передачи исходных потоков данных посредством иного не совместимого средства транспортировки данных в качестве тракта транспортировки.
Системы вещания согласно стандарту DVB-H (см. следующие документы: Standard ETSI EN 302 304; 11 2004. Digital Video Broadcasting (DVB); Transmission System for Handheld Terminals (DVB-H). http://TilWW.etsi.org/, Specification ETSI TS 102585; 042008. Digital Video Broadcasting (DVB); System Specifications for Satellite services to Handheld devices (SH) below 3 GHz. http://www.etsi.org/) представляют собой системы на основе протокола IP, которые используют интернет-протокол (IP) для передачи любого мультимедийного контента (радиовещания, телевидения, услуг передачи данных, программного обеспечения и т.д.). Здесь несколько типов мультимедийного контента могут быть объединены в мультиплекс стандарта DVB-H или DVB-SH, для реальной передачи. Это производится путем инкапсулирования потоков данных на основе протокола IP согласно способу многопротокольной инкапсуляции (MPE). (См. документ Standard ETSI EN 301 192; 04 2008. Digital Video Broadcasting (DVB); DVB specification for data broadcasting. http://www.etsi.org/), которая, в свою очередь, основана на пакетной передачи согласно стандарту DVB (см. документ Standard ISO/IEC 13818-1; 12 2000. Information technology - Generic coding of moving pictures and associated audio information: Systems, http://www.iso.org/).
При использовании рассылки данных на основе протокола IP в вышеупомянутых способах (DVB-H и DVB-SH) IP-пакеты, которые, в свою очередь, снова содержат пакеты протокола UDP, передают посредством MPE. Здесь IP-пакеты могут быть посланы по групповым адресам. Следовательно, это предусмотрено следующими документами (Standard ETSI EN 302 304; 11 2004. Digital Video Broadcasting (DVB); Transmission System for Handheld Terminals (DVB-H). http://TilWW.etsi.org/, Digital Video Broadcasting Project (DBV) (editor): IP Datacast over DVBH: Content Delivery Protocols (CDP). Digital Video Broadcasting Project (DVB), 12 2005. (DVB Bluebook A101). http://www.dvb.org/, Schulzrinne, Henning; Casner, Stephen L.; Federick, Ron, Jacobson, Van: RTP: A Transport Protocol for Real-Time Applications. Internet Engineering Task Force, 7 2003. (RFC 3550). http://tools.ietf.org/html/rfc3550).
По сравнению с описанными выше вариантами осуществления изобретения данные варианты реализации демультиплексоров транспортного потока стандарта MPEG2 не реализованы как устойчивые к ошибкам. Распределение в приемник пакетов производят исключительно на основании поля PID транспортного пакета. Пакеты с установленным указателем ошибки (TEI) аннулируют. Подробное объяснение транспортного потока дано в следующем документе (Standard ISO/IEC 13818-1; 12 2000. Information technology - Generic coding of moving pictures and associated audio information: Systems. http://www.iso.org/).
В стандартах DVB-H и DVB-SH предложены способы защиты от ошибок MPE-FEC и MPE-IFEC, основанные на MPE. Помимо неизмененной передачи данных полезной нагрузки при помощи этой необязательной защиты от ошибок, при помощи систематических кодов коррекции ошибок может обеспечиваться передача информации. В настоящее время в стандарте DVB-H способ MPE-FEC может использоваться с кодом Рида-Соломона (RS) (255,191,64), который позволяет улучшить защиту от ошибок в пределах временного интервала. В альтернативном варианте, в стандарте DVB-SH MPE-IFEC может использоваться с тем же самым кодом Рида-Соломона. Этот способ обеспечивает возможность защиты от ошибок, охватывающей несколько временных интервала пакетов.
Алгоритмы декодирования с этими механизмами защиты от ошибок, предложенные и часто реализованные в стандарте и в руководствах по реализации (таких как, например, Digital Video Broadcasting Project (DVB) (editor): DVB-H Implementation Guidelines. Digital Video Broadcasting Project (DVB), 05 2007. (DVB Blluebook A092r2). http.://www.dvb.org/, Specification ETSI TS 102 584; 2010. Digital Video Broadcasting (DVB); DVB-SH Implementation Guidelines Issue 2. http://www.dvb.org/), охватывают собой только лишь основные функциональные возможности, относящиеся исключительно к уровню доступа к сети, и в интересах экономии ресурсов не используют все возможности защиты от ошибок в целевой системе.
Таким образом, участок транспортного потока, принятый с ошибками, приводит к отметке всех охваченных им столбцов таблицы как ошибочных. Аналогичным образом, ошибка при передаче, которая относится только лишь к одному пакету транспортного потока, приводит к аннулированию всего участка транспортного потока и опять-таки всех затронутых им столбцов.
Помимо вышеупомянутого варианта реализации, существуют предложения по последовательному восстановлению принимаемых данных с использованием MPE-FEC также и в тех случаях, когда контроль циклическим избыточным кодом (CRC) дает отрицательный результат на уровне участков транспортного потока (см. публикацию Koppelaar, A.G.C.; Eerenberg, O.; Tolhuizen, L. M. G. M.; Aue, V.: Restoration of IP-datagrams in the DVB-H link layer for TV on mobile. In: Proc. Digest of Technical Papers. International Conference on Consumer Electronics ICCE ′06, 2006, Pg. 409-410).
Дальнейшие предложения (см. публикацию Paavola, J.; Himmanen, H.; Jokela, T.; Poikonen, J.; Ipatov, V.: The Performance Analysis of MPE-FEC Decoding Methods at the DVB-H Link Layer for Efficient IP Packet Retrieval. In: IEEE Transactions on Broadcasting 53 (2007), 3, Pg. 263-275. http://dx.doLorg/10.1109/TBC.2007.891694. DOI 10.1109/TBC.2007.891694) включают в себя иерархическое декодирование переданных данных. Оно основано на последовательных способах. При декапсуляции для каждой группы принятых символов (участок транспортного потока, пакет транспортного потока) различают, были ли содержащиеся символы переданы правильно или ненадежно, или вообще не были переданы.
В этих способах обычно учитывают информацию из уровня обеспечения безопасности (MPEG2-TS), например, из поля TEI, для более точных утверждений о положении ошибочных символов.
В вышеупомянутых предложениях для распределения транспортных пакетов, принятых с ошибками, используют, например, их счетчик целостности поля и PID. Это представляет собой, по существу, возможный, но единственно прагматичный подход. Таким образом, в изложенных выше вариантах осуществления изобретения описана существенно улучшенная, точная и, следовательно, усовершенствованная обработка для распределения пакетов, принятых с ошибками.
Несмотря на то, что некоторые аспекты были описаны применительно к устройству, очевидно, что эти аспекты также представляют собой описание соответствующего способа, вследствие чего блок или элемент устройства также может считаться соответствующим этапом способа или признаком этапа способа. Аналогично этому, те аспекты, которые были описаны применительно к этапу способа или как этап способа, также представляют собой описание соответствующего блока или детали или признака соответствующего устройства. Некоторые или все этапы способа могут быть реализованы посредством аппаратного устройства (или с использованием аппаратного устройства), такого как, например, микропроцессор, программируемый компьютер или электронная схема. В некоторых вариантах осуществления изобретения такое устройство также может выполнять некоторые или несколько из наиболее важных этапов способа.
В зависимости от определенных требований, предъявляемых к реализации, варианты осуществления настоящего изобретения могут быть реализованы аппаратными средствами или посредством программного обеспечения. Вариант реализации может быть осуществлен с использованием цифрового носителя информации, например, гибкого диска, универсального цифрового диска (DVD), диска формата Blu-ray, компакт-диска (CD), постоянного запоминающего устройства (ROM), программируемого постоянного запоминающего устройства (PROM), стираемого программируемого постоянного запоминающего устройства (EPROM), электрически стираемого программируемого постоянного запоминающего устройства (EEPROM) или флэш-памяти, накопителя на жестких дисках или иного магнитного или оптического запоминающего устройства, в котором хранят считываемые при помощи электроники управляющие сигналы, которые могут взаимодействовать или взаимодействуют с программируемой компьютерной системой, обеспечивая возможность выполнения соответствующего способа. Таким образом, цифровой носитель информации может являться компьютерно-читаемым.
Таким образом, согласно настоящему изобретению, некоторые варианты его осуществления включают в себя носитель данных, содержащий считываемые при помощи электроники управляющие сигналы, которые способны взаимодействовать с программируемой компьютерной системой для выполнения одного из описанных здесь способов.
В общем, варианты осуществления настоящего изобретения могут быть реализованы в виде компьютерного программного продукта, имеющего программный код, причем этот программный код способен функционировать так, что обеспечивает выполнение одного из способов при выполнении этого компьютерного программного продукта на компьютере.
Программный код может, например, также храниться на машиночитаемом носителе.
Другие варианты осуществления изобретения включают в себя компьютерную программу для выполнения одного из описанных здесь способов, причем эта компьютерная программа хранится на машиночитаемом носителе.
Другими словами, следовательно, одним из вариантов осуществления способа, предложенного в настоящем изобретении, является компьютерная программа, содержащая программный код для выполнения одного из описанных здесь способов, когда эта компьютерная программа выполняется на компьютере.
Таким образом, еще одним вариантом осуществления способа, предложенного в настоящем изобретении, является носитель данных (или цифровой носитель информации или компьютерно-читаемый носитель), на котором записана компьютерная программа для выполнения одного из описанных здесь способов.
Еще одним вариантом осуществления способа, предложенного в настоящем изобретении, является поток данных или последовательность сигналов, которые представляют компьютерную программу для выполнения одного из описанных здесь способов. Поток данных или последовательность сигналов могут быть сконфигурированы, например, с возможностью их передачи по связи с передачей данных, например, через сеть Интернет.
Еще один вариант осуществления изобретения включает в себя средство обработки, например, компьютер или устройство с программируемой логикой, который сконфигурирован или приспособлен (которое сконфигурировано или приспособлено) для выполнения одного из описанных здесь способов.
Еще один вариант осуществления изобретения включает в себя компьютер, на котором установлена компьютерная программа для выполнения одного из описанных здесь способов.
Согласно настоящему изобретению, еще один вариант его осуществления включает в себя устройство или систему, которое реализовано (которая реализована) для передачи компьютерной программы для выполнения, по меньшей мере, одного из описанных здесь способов в приемник. Передача может производиться электронным или оптическим способом. Приемником может являться, например, компьютер, мобильное устройство, запоминающее устройство или аналогичное устройство. Этим устройством или этой системой может являться, например, файловый сервер для передачи компьютерной программы в приемник.
В некоторых вариантах осуществления изобретения для реализации некоторых или всех функциональных возможностей описанных здесь способов может использоваться устройство с программируемой логикой (например программируемая пользователем вентильная матрица, FPGA). В некоторых вариантах осуществления изобретения программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором для выполнения одного из описанных здесь способов. В общем, в некоторых вариантах осуществления изобретения способы выполняются любым аппаратным устройством. Им может являться пригодное для использования универсальное аппаратное средство, такое как компьютерный процессор (центральный процессор, CPU) или аппаратное средство, специализированное для этих способов, например, специализированная интегральная схема (ASIC).
Описанные выше варианты осуществления изобретения просто приведены для иллюстрации принципов настоящего изобретения. Очевидно, что для других специалистов в данной области техники описанные здесь модификации и изменения компоновок и подробностей являются очевидными. Таким образом, целью является то, чтобы изобретение было ограничено только лишь объемом приведенной ниже формулы изобретения, а не характерными подробностями, представленными в приведенном здесь описании и в объяснении вариантов его осуществления.
ПЕРЕЧЕНЬ АББРЕВИАТУР
DVB - цифровое телевизионное вещание, семейство стандартов для передачи транслируемого контента.
DVB-H - стандарт DVB для портативных устройств, стандарт системы DVB для наземной передачи в терминалы мобильной связи.
DVB-SH - стандарт DVB для портативных устройств со спутниковой связью, стандарт системы DV) для спутниковой и гибридной (спутниковой/наземной) передачи в терминалы мобильной связи.
FEC - прямая коррекция ошибок.
IP - интернет-протокол, протокол сетевого уровня сети Интернет.
IPDC - рассылка данных на основе протокола IP, передача потоков, главным образом, мультимедийных данных при помощи интернет-протоколов.
MAC - управление доступом к среде, здесь уровень адресации стандарта Ethernet.
MPE - многопротокольная инкапсуляция.
MPE-FEC - стандартизованная защита от ошибок в стандарте DVB-H на основе MPE с FEC на основе кода Рида-Соломона.
MPE-IFEC - MPE с межпакетной FEC, стандартизированная защита от ошибок в стандарте DVB-SH на основе MPE с FEC на основе кода Рида-Соломона (альтернатива быстрому торнадо-коду (Raptor Code)) с дополнительным перемежением на уровне защиты от ошибок, распределенным по нескольким пакетам.
MPEG2-TS - транспортный поток согласно стандарту Экспертной группы по вопросам движущихся изображений (MPEG), транспортный поток согласно стандарту Международной организации по стандартизации/Международной электротехнической комиссии ISO/IEC 13818-1, то есть порядок переданного TSP, также именуемый MPEG-TS.
Групповая передача интернет-сообщения в несколько приемников; в отличие от широковещательной передачи здесь сообщение передают только лишь в те сети, в которых расположены приемники для этого сообщения.
PID - идентификатор пакета, адрес услуги на уровне MPEG2-TS. Распределяет TSP на стороне приемника в назначенный приемник, который дополнительно подвергает оценке этот пакет.
PSI/SI - информация, характерная для программы/служебная информация, дополнительные данные для передачи согласно стандарту DVB.
RS - блочный код Рида-Соломона, код систематической прямой защиты от ошибок
TEI - указатель ошибки при транспортировке, битовый переключатель, в котором уровень физической передачи делает на стороне приемника записи о том, имеет ли этот TSP ошибки.
TOS - тип обслуживания, поле IP-заголовка.
TSP - пакет транспортного потока стандарта MPEG-2.
TTL - срок действия, поле IP-заголовка.
UDP - протокол передачи дейтаграмм пользователя, часть интернет-протокола для пакетно-ориентированной передачи данных (транспортный уровень).
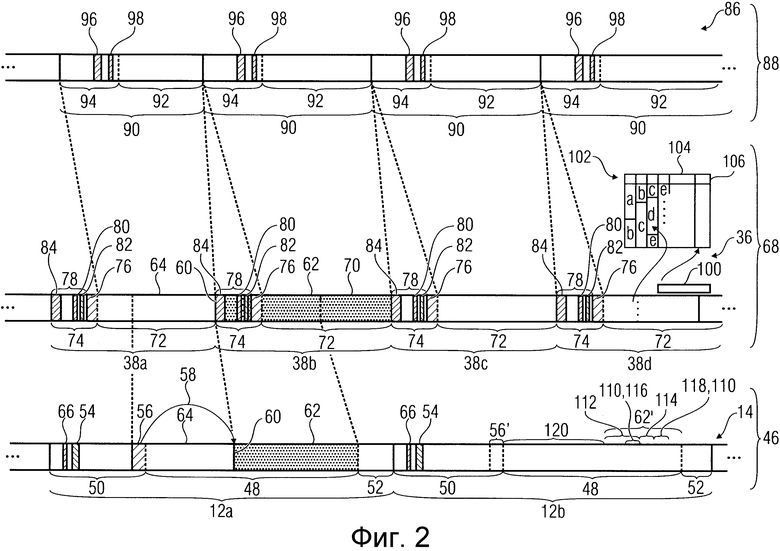
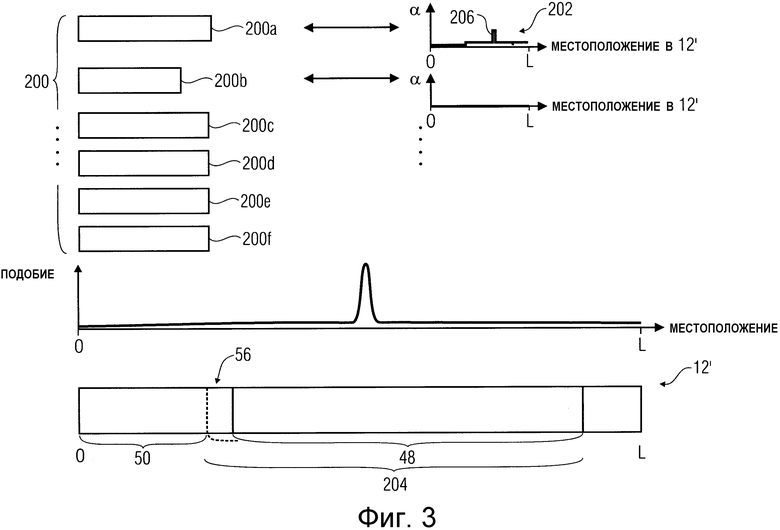
Изобретение относится к демультиплексированию пакетного транспортного потока. Технический результат изобретения заключается в более эффективной передаче данных в приемники. В устройстве для демультиплексирования пакетного транспортного потока (14), состоящего из пакетов (12) транспортного потока, каждый из которых снабжен кодом систематического прямого обнаружения ошибок. Каждый из пакетов распределен в один из множества приемников (20) данных, так что в участок данных полезной нагрузки пакетов транспортного потока, распределенных в один и тот же приемник (20) данных, внедрен поток (36) данных из пакетов (38) данных, защищенных кодом прямой защиты от ошибок, который адресован в соответствующий приемник (20) данных. Устройство определяет для предварительно определенного пакета (12) транспортного потока, являющегося ошибочным согласно коду систематического прямого обнаружения ошибок, значение вероятности для каждого из множества приемников данных, которое указывает, насколько вероятным является то, что предварительно определенный пакет (12) распределен в соответствующий приемник (20) данных. На основании значений вероятности для множества приемников данных распределяет предварительно определенный пакет транспортного потока в выбранный один из множества приемников данных. 4 н. и 14 з.п. ф-лы, 3 ил.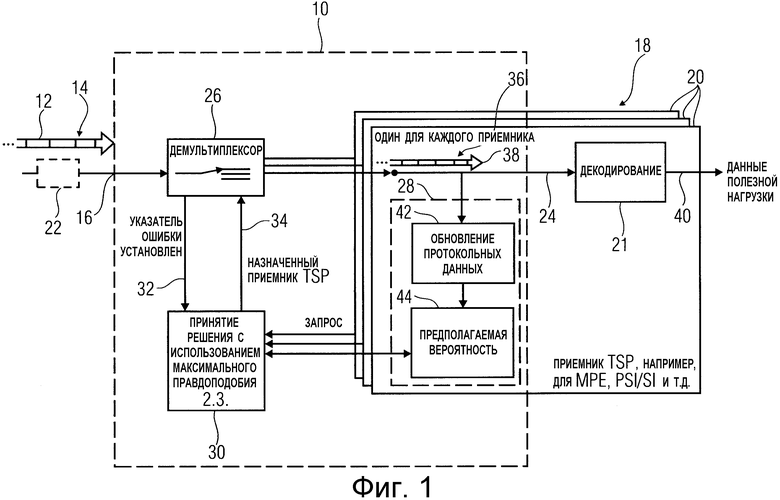
1. Устройство для демультиплексирования пакетного транспортного потока (14) из пакетов (12) транспортного потока, каждый из которых снабжен кодом систематического прямого обнаружения ошибок, причем каждый из пакетов транспортного потока распределен в один из множества приемников (20) данных, так что в участок данных полезной нагрузки пакетов транспортного потока, распределенных в один и тот же приемник (20) данных, внедрен поток (36) данных из пакетов (38) данных, защищенных кодом прямой защиты от ошибок, который адресован в соответствующий приемник (20) данных, при этом устройство реализовано так, чтобы
определять для предварительно определенного пакета (12) транспортного потока, являющегося ошибочным согласно коду систематического прямого обнаружения ошибок, значение вероятности для каждого из множества приемников данных, которое указывает, насколько вероятным является то, что предварительно определенный пакет (12) транспортного потока распределен в соответствующий приемник (20) данных, и
на основании значений вероятности для множества приемников данных распределять предварительно определенный пакет транспортного потока в выбранный один из множества приемников данных.
2. Устройство по п. 1, в котором для каждого приемника данных определение значения вероятности выполняется на основании информации о предварительно определенном пакете транспортного потока, которая является характерной для приемника данных или изменяется характерным для приемников данных образом, от одного пакета транспортного потока, распределенного в соответствующий приемник данных, до другого пакета транспортного потока, распределенного в соответствующий приемник данных.
3. Устройство по п. 1, в котором для каждого приемника данных определение значения вероятности выполняется на основании анализа временного мультиплексирования предыдущих пакетов транспортного потока.
4. Устройство по п. 1, в котором для каждого приемника данных определение значения вероятности выполняется на основании информации об участке данных полезной нагрузки предварительно определенного пакета транспортного потока.
5. Устройство по п. 1, в котором для каждого приемника данных поток данных, адресованный в соответствующий приемник данных, внедрен путем фрагментации в участки (48) данных полезной нагрузки пакета (12) транспортного потока, которые ассоциированы с соответствующим приемником данных, при этом каждый из пакетов (12а) транспортного потока, в которые попадает начало (60) одного из пакетов (18b) данных, содержит один фрагмент информации (56) об указателе, которая указывает, куда в участке (48) данных полезной нагрузки соответствующего пакета (12а) транспортного потока попадает начало (60) соответствующего пакета (38b) данных, при этом устройство реализовано так, чтобы
определять для каждого приемника (20) данных местоположение первого участка (56) предварительно определенного пакета (12) транспортного потока способом, неизменным для всех приемников данных (20) или неизменным для соответствующего приемника (20) данных, или в зависимости от пакетов (12) транспортного потока, ранее уже распределенных в соответствующий приемник (20) данных,
определять местоположение второго участка (62) предварительно определенного пакета (12) транспортного потока в зависимости от содержимого предварительно определенного пакета (12а) транспортного потока в первом участке, как будто бы содержимым предварительно определенного пакета (12) транспортного потока в первом участке являлась информация (56) об указателе,
анализировать второй участок (62) в отношении того, может ли он являться началом пакета (38) данных, распределенного в соответствующий приемник (20) данных, и
в зависимости от результата анализа, определять значение вероятности для соответствующего приемника данных.
6. Устройство по п. 5, при этом устройство реализовано так, чтобы проверять для каждого приемника данных при анализе того, может ли участок являться началом пакета данных, распределенного в соответствующий приемник данных:
соответствует ли первое поле (110; 82, 98) во втором участке (62) информации, неизменной для соответствующего приемника (20) данных, по меньшей мере, с последнего распределения пакета (12) транспортного потока в соответствующий приемник (20) данных,
содержит ли второе поле (116) во втором участке предварительно определенную связь с третьим полем (118) во втором участке применительно к избыточным указателям в данных инкапсуляции и в данных (74) заголовков пакетов (38) данных, распределенных в соответствующий приемник данных, и/или
содержит ли четвертое поле (112) во втором участке предварительно определенную связь кода систематического прямого обнаружения ошибок с пятым полем (114) во втором участке.
7. Устройство по п. 5, в котором пакеты (12b) транспортного потока, в которые не попадает начало одного из пакетов (38) данных, распределенных в соответствующий приемник (20) данных, не содержат информацию (56) об указателе, так что участок (48) данных полезной нагрузки в пакетах (12b) транспортного потока, в который не попадает начало одного из пакетов данных, увеличивается за счет отсутствия информации об указателе по сравнению с участком (48) данных полезной нагрузки в тех пакетах транспортного потока (12а), в которые попадает начало (60) одного из пакетов данных, при этом устройство реализовано так, чтобы
определять местоположение третьего участка (120) в начале участка (48) данных полезной нагрузки в предварительно определенном пакете транспортного потока для каждого приемника данных, в который пакет (12) транспортного потока был распределен последним, в котором был обнаружен пакет (38) данных, распределенный в соответствующий приемник (20) данных и имеющий указатель (80) длины, из чего можно сделать заключение, что упомянутый пакет данных продолжается за пределы пакета транспортного потока, распределенного последним в соответствующий приемник (20) данных, в зависимости от указателя (80) длины,
анализировать третий участок (120) в отношении того, может ли он являться продолжением одного и того же пакета данных, и
в зависимости от результата анализа, определять значение вероятности для соответствующего приемника данных.
8. Устройство по п. 1, при этом устройство реализовано так, чтобы определять значение вероятности для каждого приемника данных в зависимости от того,
соответствует ли случайное поле в предварительно определенном пакете (12) транспортного потока информации, которая являлась неизменной для соответствующего приемника (20) данных, по меньшей мере, начиная с последнего распределения пакета транспортного потока в соответствующий приемник данных,
содержит ли первая случайная пара полей в предварительно определенном пакете транспортного потока, содержащая первое предварительно определенное взаимное расположение друг относительно друга, предварительно определенную взаимную связь по содержимому друг с другом, применительно к избыточным указателям в данных инкапсуляции и в данных заголовков пакетов данных, распределенных в соответствующий приемник данных, и/или
имеет ли первая случайная пара полей в предварительно определенном пакете транспортного потока, которые содержат второе предварительно определенное взаимное расположение друг относительно друга, предварительно определенную связь кода систематического прямого обнаружения ошибок друг с другом.
9. Устройство по п. 1, в котором для каждого приемника (20) данных пакеты (38) данных из потока (36) данных, адресованные, по меньшей мере, в один приемник (20) данных, внедрены путем фрагментации в участки (48) данных полезной нагрузки в пакетах (12) транспортного потока, распределенных в соответствующий приемник (20) данных, и каждый пакет (38) данных из потока (36) данных, адресованный в соответствующий приемник (20) данных, содержит поле (80) "длина", содержащее указатель длины, указывающий длину соответствующего пакета (38) данных, и в котором пакеты (12) транспортного потока содержат информацию (56) об указателе, которая указывает, где в участках (48) данных полезной нагрузки в пакетах (12) транспортного потока расположены начала (60) пакетов (12) данных, при этом устройство реализовано так, чтобы для каждого приемника данных определять значение вероятности для соответствующего приемника данных на основании сравнения указателя длины последнего пакета данных, имеющего начало в одном из пакетов транспортного потока, уже распределенных в соответствующий приемник данных, и информации об указателе из предварительно определенного пакета транспортного потока.
10. Устройство по п. 1, в котором для каждого приемника (20) данных каждый из пакетов (38) данных из потока (36) данных, распределенного в соответствующий приемник (20) данных, содержит, по меньшей мере, один указатель (82, 98), связанный с приемником данных, при этом устройство реализовано так, чтобы
определять одно или несколько потенциальных местоположений в предварительно определенном пакете (12) транспортного потока для каждого приемника данных, в которых может быть расположен указатель, связанный с приемником данных, и
определять значение вероятности для соответствующего приемника данных путем сравнения содержимого предварительно определенного пакета транспортного потока в одном или в нескольких потенциальных местоположениях со значением, связанным с состоянием приемника данных, для соответствующего приемника данных, которое являлось неизменным, по меньшей мере, с последнего распределения пакета транспортного потока в соответствующий приемник данных.
11. Устройство по п. 1, при этом устройство реализовано так, чтобы
определять для каждого приемника данных среди пакетов транспортного потока, ранее уже распределенных в соответствующий приемник данных, периодически повторяющееся идентичное содержимое, и
определять для каждого приемника данных значение вероятности для соответствующего приемника данных путем сравнения содержимого участка (48) данных полезной нагрузки в предварительно определенном пакете (12) транспортного потока с периодически повторяющимся идентичным содержимым.
12. Устройство по п. 1, в котором для каждого приемника данных поток (86) данных, адресованный в соответствующий приемник (20) данных, является инкапсулированным в структуру инкапсуляции и фрагментированным вместе с данными (74) инкапсуляции из структуры инкапсуляции в пакеты (12) транспортного потока, распределенные в соответствующий приемник (20) данных, при этом устройство реализовано так, чтобы
определять для соответствующего приемника данных несколько потенциальных местоположений (116, 118) в пакете (12) транспортного потока, где может быть расположено содержимое данных инкапсуляции и пакетов данных из потока данных, адресованного в соответствующий приемник данных, которые имеют предварительно определенную связь друг с другом, и определять значение вероятности для соответствующего приемника данных на основании того, существует ли между содержимым предварительно определенного потока (12) пакета транспортного в определенных нескольких потенциальных местоположениях (116, 118) предварительно определенная связь или нет, или
определять в предварительно определенных пакетах (12) транспортного потока одно или несколько потенциальных местоположений, где может быть расположено содержимое пакетов (38) данных из потока (36) данных, адресованного в соответствующий приемник (20) данных, содержащих предварительно определенную связь с содержимым данных инкапсуляции в одном из пакетов (12) транспортного потока, ранее уже распределенных в соответствующий приемник (20) данных, и определять значение вероятности на основании того, существует ли между содержимым предварительно определенного пакета транспортного потока в одном или в нескольких потенциальных местоположениях и данными инкапсуляции в пакетах (12) транспортного потока, ранее уже распределенных в соответствующий приемник данных, предварительно определенная связь или нет.
13. Устройство по п. 1, при этом устройство реализовано так, чтобы распределять пакеты (10) транспортного потока, не имеющие ошибок согласно коду систематического прямого обнаружения ошибок, в идентифицированный приемник данных на основании идентификационного указателя (54) соответствующего безошибочного пакета транспортного потока, идентифицирующего приемник (20) данных, в который он распределен.
14. Устройство по п. 1, при этом устройство реализовано так, чтобы при определении значения вероятности для каждого приемника данных учитывать частоту более кратковременного и/или более долговременного распределения прошлых пакетов (12) транспортного потока.
15. Устройство по п. 1, при этом устройство реализовано так, чтобы распределять предварительно определенный пакет (12) транспортного потока на основании значений вероятности для множества приемников (20) данных в приемник данных, имеющий самое высокое значение вероятности.
16. Система для декодирования потока данных, адресованного в предварительно определенный приемник данных, из пакетного транспортного потока из пакетов транспортного потока, каждый из которых снабжен кодом систематического прямого обнаружения ошибок, содержащая
устройство по одному из предыдущих пунктов; и
декодер для декодирования потока данных, внедренного в участки данных полезной нагрузки пакетов транспортного потока, распределенных этим устройством в предварительно определенный приемник данных.
17. Способ демультиплексирования пакетного транспортного потока (14) из пакетов (12) транспортного потока, каждый из которых снабжен кодом систематического прямого обнаружения ошибок, причем каждый из пакетов транспортного потока распределен в один из множества приемников (20) данных, так что в участок данных полезной нагрузки пакетов транспортного потока, распределенных в один и тот же приемник (20) данных, внедрен поток (36) данных из пакетов (38) данных, защищенных кодом прямой защиты от ошибок, который адресован в соответствующий приемник данных (20), при этом способ содержит этапы, на которых:
определяют для предварительно определенного пакета (12) транспортного потока, являющегося ошибочным согласно коду систематического прямого обнаружения ошибок, значение вероятности для каждого из множества приемников данных, которое указывает, насколько вероятным является то, что предварительно определенный пакет (12) транспортного потока распределен в соответствующий приемник (20) данных, и
на основании значений вероятности для множества приемников данных распределяют предварительно определенный пакет транспортного потока в выбранный один из множества приемников данных.
18. Компьютерно-читаемый носитель, содержащий записанную на нем компьютерную программу, содержащую программный код для выполнения способа по п. 17 при выполнении этой программы на компьютере.
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |

