ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
Данная заявка заявляет приоритет предварительной заявки на патент США №61/584478, поданной 9 января 2012 г., озаглавленной «Method and System for Encoding Audio Data with Adaptive Low Frequency Compensation», и заявки на патент США №13/588890, поданной 17 августа 2012 г., озаглавленной «Method and System for Encoding Audio Data with Adaptive Low Frequency Compensation», каждая из которых ссылкой полностью включается в настоящее раскрытие.
ПРЕДПОСЫЛКИ ИЗОБРЕТЕНИЯ
1. Область техники
Изобретение относится к обработке звуковых сигналов и, в частности, к кодированию аудиоданных с адаптивной низкочастотной коррекцией. Некоторые варианты осуществления изобретения являются пригодными для кодирования аудиоданных в соответствии с одним из форматов, известных как Dolby Digital (AC-3) и Dolby Digital Plus (E-AC-3), или в соответствии с другим форматом кодирования. Dolby, Dolby Digital и Dolby Digital Plus являются товарными знаками Dolby Laboratories Licensing Corporation.
2. Уровень техники
Несмотря на то, что изобретение не ограничивается использованием при кодировании аудиоданных в соответствии с форматом AC-3 (Dolby Digital) (или с форматом Dolby Digital Plus), для удобства оно будет описано в вариантах осуществления, где оно кодирует битовый аудиопоток в соответствии с форматом АС-3. Кодированный битовый поток АС-3 включает от одного до шести каналов звукового содержимого и метаданные, указывающие по меньшей мере на одну из характеристик звукового содержимого. Звуковое содержимое представляет собой аудиоданные, которые были сжаты с использованием перцептуального кодирования звука.
Подробности кодирования АС-3 (также известного как Dolby Digital) хорошо известны и изложены во многих опубликованных источниках, включая следующие: стандарт сжатия цифрового звука ATSC A52/A (AC-3), Revision A, Комитета по перспективным телевизионным системам, 20 августа. 2001; препринт 3796 «Flexible Perceptual Coding for Audio Transmission and Storage» за авторством Craig C. Todd et al., 96-я Конвенция Общества инженеров по звуковой технике (AES), 26 февраля, 1994; статья «Design and Implementation of AC-3 Coders» за авторством Steve Vernon, IEEE Trans. Consumer Electronics, Vol.41, No. 3, август 1995; глава «Dolby Digital Audio Coding Standards» за авторством Robert L. Andersen и Grant A. Davidson в работе «The Digital Signal Processing Handbook», издание второе, гл. редактор Vijay K. Madisetti, CRC Press, 2009; препринт 3365 «High Quality, Low-Rate Audio Transform Coding for Transmission and Multimedia Applications» за авторством Bosi et al., 93-я Конвенция AES, 1992; и патенты США №№5583962; 5632005; 5633981; 5727119; и 6021386.
Подробности кодирования Dolby Digital (AC-3) и Dolby Digital Plus (иногда именуемого Enhanced AC-3, или «E-AC-3») изложены в статье «Introduction to Dolby Digital Plus, an Enhancement to the Dolby Digital Coding System», препринт 6196, 117-я Конвенция AES, 28 октября 2004, и в технических условиях Dolby Digital /Dolby Digital Plus Specification (ATSC A/52:2010), доступных по ссылке
http://www.atsc.org/cms/index.php/standards/published-standards.
При кодировании АС-3 битового аудиопотока блоки входных дискретных значений аудиоданных, подлежащие кодированию, претерпевают преобразование из временной области в частотную, в результате приводящее к блокам данных в частотной области, обычно именуемым коэффициентами преобразования, частотными коэффициентами или частотными составляющими, которые располагаются в равномерно расположенных элементах разрешения по частоте. Частотный коэффициент в каждом элементе разрешения затем преобразуется (например, на ступени 7 BFPE системы по ФИГ. 1) в формат с плавающей запятой, включающий экспоненту и мантиссу.
Типичные варианты осуществления кодеров АС-3 (и Dolby Digital Plus, и других кодеров аудиоданных) реализуют психоакустическую модель для анализа данных в частотной области на полосовой основе (т.е., как правило, на основе 50 неравномерно распределенных полос, являющихся приближениями полосы частот, хорошо известной психоакустической шкалы, известной как шкала Барка) с целью определения оптимального распределения битов каждой из мантисс. Данные мантисс затем квантуются (например, в квантователе 6 системы по ФИГ. 1) в некоторое количество битов, соответствующих определенному распределению битов. Квантованные данные мантисс затем форматируют (например, в форматере 8 системы по ФИГ. 1) в кодированный выходной битовый поток.
Как правило, распределение битов мантисс основывается на разности между тонко гранулированным спектром (представляемым для каждого элемента разрешения по частоте значением спектральной плотности мощности («PSD»)) и грубо гранулированной кривой маскировки (представляемой значением маски для каждой полосы частот). Также как правило, психоакустическая модель реализует низкочастотную коррекцию (иногда именуемую «lowcomp»-коррекцией или «lowcomp») для определения корректирующих значений (иногда именуемых в настоящем раскрытии значениями параметра «lowcomp») с целью коррекции значений кривой маскировки для низкочастотных полос. Каждое значение параметра lowcomp может вычитаться из предварительного значения кривой маскировки для отличающейся одной из низкочастотных полос с целью генерирования окончательного значения кривой маскировки для указанной полосы.
Как отмечалось, распределение битов мантисс при звуковом кодировании может основываться на разности между спектром сигнала и кривой маскировки. Простой алгоритм реализации такого распределения битов может предполагать, что шум квантования в одной конкретной полосе частот не зависит от распределений битов в соседних полосах. Однако это предположение, как правило, не является обоснованным, в особенности, на низких частотах, по причинам ограниченной избирательности по частоте и высокого уровня перекрытия между полосами в банке фильтров декодера, а также по причине просачивания из одной полосы в соседние полосы на низких частотах, где наклон кривой маскировки может быть равен или может превышать наклон переходных амплитудно-частотных характеристик банка фильтров.
Таким образом, процесс распределения битов мантисс при звуковом кодировании часто включает процесс низкочастотной коррекции, который определяет скорректированную кривую маскировки. Скорректированная кривая маскировки затем используется для определения значения отношения «сигнал-маска» для каждой частотной составляющей аудиоданных. Низкочастотная коррекция представляет собой процесс коррекции избирательности декодера с целью улучшения производительности кодирования на низких частотах для сигналов с выраженными низкочастотными тональными составляющими. Как правило, низкочастотная коррекция представляет собой коррекцию частотной характеристики банка фильтров, которая для удобства может встраиваться в вычисление функции возбуждения, которая используется для определения значений отношения сигнал-маска. Как более подробно будет обсуждаться ниже, типичная реализация низкочастотной коррекции выполняет поиск выраженных низкочастотных составляющих сигнала путем поиска частотных полос со значением PSD на 12 дБ меньше, чем значение PSD для следующей (более высокочастотной) полосы.
Когда указанное значение PSD обнаруживается, значение функции возбуждения для полосы немедленно уменьшается на 18 дБ (или на величину до 18 дБ). Это уменьшение затем медленно восстанавливается на 3 дБ для каждой последующей полосы.
ФИГ. 1 представляет собой кодер, сконфигурированный для выполнения кодирования AC-3 (или Enhanced АС-3) на входных аудиоданных 1 во временной области. Банк 2 анализирующих фильтров преобразовывает входные аудиоданные 1 во временной области в аудиоданные 3 в частотной области, а ступень 7 кодирования блоков с плавающей запятой (BFPE) генерирует представление с плавающей запятой каждой частотной составляющей данных 3, включающее экспоненту и мантиссу для каждого элемента разрешения по частоте. Вывод данных в частотной области из ступени 7 иногда будет именоваться в настоящем раскрытии как аудиоданные 3 в частотной области. Вывод аудиоданных в частотной области со ступени 7 затем кодируется, что заключается в квантовании его мантисс в квантователе 6 и ограничении дискретности изменения его экспонент (на ступени 10 ограничения дискретности изменения экспонент) и кодировании (на ступени 11 кодирования экспонент) экспонент с ограниченной дискретностью изменения, генерируемых на ступени 10. Форматер 8 генерирует кодированный битовый поток 9 AC-3 (или Enhanced AC-3) в ответ на вывод квантованных данных из квантователя 6 и вывод данных кодированных дифференциальных экспонент из ступени 11.
Квантователь 6 выполняет распределение битов и квантование на основе управляющих данных (в том числе данных маскировки), генерируемых контроллером 4. Данные маскировки (определяющие кривую маскировки) генерируются исходя из данных 3 в частотной области на основе психоакустической модели (реализуемой контроллером 4) человеческого слуха и слухового восприятия. Психоакустическая модель учитывает зависящие от частоты пороги человеческого слуха и психоакустическое явление, именуемое маскировкой, посредством которого интенсивная частотная составляющая, близкая к одной или нескольким более слабым частотным составляющим, склонна маскировать более слабые составляющие, делая их неслышимыми для слушателя. Это делает возможным пропуск более слабых частотных составляющих при кодировании аудиоданных и, таким образом, достижение более высокой степени сжатия без неблагоприятного воздействия на воспринимаемое качество кодированных аудиоданных (битовый поток 9). Данные маскировки включают значение кривой маскировки для каждой полосы частот аудиоданных 3 в частотной области. Указанные значения кривой маскировки представляют уровень сигнала, маскируемый ухом человека в каждой полосе частот. Квантователь 6 использует эту информацию для принятия решения о том, как наилучшим образом использовать доступное количество информационных битов для представления данных в частотной области каждой из полос частот входного звукового сигнала.
Для коррекции значений кривой маскировки для низкочастотных полос, контроллер 4 может реализовывать традиционный процесс низкочастотной коррекции (иногда именуемый в настоящем раскрытии «lowcomp»-коррекцией) для генерирования значений параметра «lowcomp». Скорректированные значения кривой маскировки используются для генерирования значений отношения сигнал-маска для каждой частотной составляющей аудиоданных 3 в частотной области. Низкочастотная коррекция является характерным признаком психоакустической модели, обычно используемой в ходе кодирования аудиоданных AC-3 (и Dolby Digital Plus). Lowcomp-коррекция улучшает кодирование высокотональных низкочастотных составляющих (входных аудиоданных, подлежащих кодированию), предпочтительно, уменьшая маску в значимом диапазоне частот и, как следствие, выделяя больше битов кодовым словам, используемым для кодирования этих составляющих.
Lowcomp-коррекция определяет параметр lowcomp для каждой низкочастотной полосы. Параметр lowcomp для каждой полосы фактически вычитается из значения «возбуждения» (которое определяется хорошо известным образом) для этой полосы, а результирующие значения разности используются для определения скорректированных значений кривой маскировки. Уменьшение значения возбуждения для полосы (например, путем вычитания из него параметра lowcomp или увеличения значения параметра lowcomp, который из него вычитается) в результате приводит к увеличению количества битов, выделяемых кодированной версии звукового сигнала в указанной полосе, по следующей причине. Несмотря на то, что значение возбуждения для полосы необязательно равно конечному (скорректированному) значению маски (которое фактически вычитается из значения аудиоданных для указанной полосы), оно используется для вычисления окончательного значения маски (указанное окончательное значение маски учитывает абсолютные пороги слышимости и, потенциально, другие широкополосные и/или полосовые корректировки). Поскольку количество кодирующих битов, выделенных звуковому сигналу в полосе, больше, если больше отношение «сигнал-маска» для этой полосы, уменьшение значения маски для полосы могло бы увеличивать количество битов, выделяемых кодированной версии звукового сигнала в этой полосе.
Поэтому уменьшение значения возбуждения для полосы обычно приводит к уменьшенному значению маски для этой полосы и, следовательно, к увеличению количества выделенных битов для этой полосы.
Далее мы более подробно опишем способ, согласно которому традиционная lowcomp-коррекция могла бы обычно выполняться психоакустической моделью (например, моделью, реализуемой контроллером 4 по ФИГ. 1). Контроллер 4 может просматривать низкочастотные полосы (в диапазоне от 0 Гц до 2,5 КГц с частотой дискретизации 48 КГц) для поиска резкого (12 дБ) увеличения спектральной плотности мощности (PSD) между текущей полосой частот и следующей (более высокочастотной) полосой, что является одной из характеристик сильной тональной составляющей. В ответ на определение в низкочастотной полосе PSD, указывающей сильную тональную составляющую, применяется lowcomp-коррекция, вызывающая выделение большего количества битов данным, используемым для кодирования определенной сильной низкочастотной тональной составляющей.
Следует понимать, что при кодировании AC-3 и Dolby Digital Plus каждая составляющая аудиоданных 3 в частотной области (т.е. содержимое каждого преобразованного элемента разрешения) имеет представление с плавающей запятой, включающее мантиссу и экспоненту. Для упрощения вычисления кривой маскировки, семейство кодеров Dolby Digital использует при получении кривой маскировки только экспоненты. Или, иначе выражаясь, кривая маскировки зависит от значений экспонент коэффициентов преобразования, но не зависит от значений мантисс коэффициентов преобразования. Так как интервал экспонент является довольно ограниченным (обычно, целочисленными значениями от 0 до 24), то, в целях вычисления кривой маскировки, значения экспонент отображаются в шкалу PSD с большим интервалом (обычно, целочисленных значений от 0 до 3072). Таким образом, самые громкие частотные составляющие (т.е. те, которые имеют экспоненту, равную 0) отображаются в значение PSD, равное 3072, в то время как самые мягкие составляющие данных в частотной области (т.е., те, которые имеют экспоненту, равную 24) отображаются в значение PSD, равное 0.
Известно, что при традиционном кодировании Dolby Digital (или Dolby Digital Plus) вместо абсолютных экспонент кодируются дифференциальные экспоненты (т.е. разность между последовательными экспонентами). Дифференциальные экспоненты могут принимать только одно из пяти значений: 2, 1, 0, -1 и -2. Если дифференциальная экспонента находится за пределами этого интервала, одна из экспонент, подвергнутых вычитанию, изменяется таким образом, чтобы дифференциальная экспонента (после изменения) находилась в пределах указанного интервала (это традиционный способ известен как «ограничение дискретности изменения экспоненты», или «ограничение дискретности изменения»). Ступень 10 ограничения дискретности изменения экспонент в кодере по ФИГ. 1 генерирует экспоненты с ограниченной дискретностью изменения в ответ на направленные к ней исходные экспоненты путем выполнения операции ограничения дискретности изменения.
Рассмотрим пример типичной реализации lowcomp-коррекции, в которой психоакустическая модель (например, модель, реализуемая контроллером 4 по ФИГ. 1) просматривает низкочастотные полосы, где полоса «N+1» представляет собой следующую полосу, и текущая полоса «N» имеет меньшую частоту, чем следующая полоса. Просмотр может происходить от самой низкочастотной полосы до полосы номер 22 и, как правило, не включает последнюю полосу канала LFE (низкочастотных эффектов). Если определяется, что значение PSD для полосы N+1 за вычетом значения PSD для полосы N равно 256 (что указывает на резкое увеличение (12 дБ) PSD при переходе от значения PSD для текущей полосы, N, к следующей (более высокочастотной) полосе, N+1), lowcomp-коррекция выполняется путем немедленного уменьшения функции возбуждения, вычисленной для текущей полосы (т.е. уменьшения значения возбуждения для этой полосы), на 18 дБ. Значение возбуждения для указанной полосы уменьшается путем вычитания параметра lowcomp, равного 384, из значения возбуждения, которое было бы определено для этой полосы в противном случае. Это уменьшение значения возбуждения медленно восстанавливается (например, на величину до 3 дБ на каждую последующую полосу).
Для последующих полос, т.е. полос с более высокой частотой, чем у полосы, для которой изначально предназначается lowcomp, если определяется, что разность в PSD между одной полосой и следующей полосой меньше 256, параметр lowcomp (который вычитается из значения возбуждения для этой полосы), либо сохраняет то же значение, что и для предыдущей полосы, либо уменьшается до меньшего значения. До тех пор, пока впервые не определено (в ходе просмотра всех полос частот), что разность в PSD между двумя смежными полосами не равна 256, lowcomp-коррекция не выполняется (т.е. из значений возбуждения полос «вычитается» параметр lowcomp, имеющий нулевое значение).
Несмотря на то, что традиционный lowcomp-процесс является полезным для тональных сигналов с выраженными низкочастотными составляющими, недостатком является то, что критерий разности PSD 12 дБ, который запускает уменьшение маски, часто встречается в большом количестве нетональных сигналов, имеющих низкочастотное содержимое. Хорошо известным примером такого нетонального сигнала являются аудиоданные, служащие признаком аплодисментов толпы, и они будут упоминаться в настоящем раскрытии как образец нетонального сигнала этого типа (который в типичных вариантах осуществления настоящего изобретения различается с тональным сигналом). Авторы изобретения осознали, что перераспределение кодирующих битов от низких к средним/высоким частотам (относительно распределения кодирующих битов, которое могло бы использоваться при традиционном кодировании AC-3 или E-AC-3 с традиционной lowcomp-коррекцией) улучшает воспринимаемое качество аплодисментов и других нетональных сигналов, воспроизводимых вслед за декодированием версий сигналов, кодированных AC-3 (или E-AC-3), и поэтому было бы желательно отключать lowcomp-коррекцию таких нетональных сигналов в ходе их кодирования AC-3 или E-AC-3 (т.е. в ходе кодирования таких сигналов было бы желательно переключать lowcomp-коррекцию в положение ВЫКЛ.). Авторы изобретения также осознали, что отключение lowcomp-коррекции в ходе кодирования AC-3 (или E-AC-3) тональных сигналов, имеющих низкочастотное содержимое (например, сигналов, генерируемых камертон-дудками), в ходе такого кодирования ухудшает воспринимаемое качество тональных сигналов при их воспроизведении вслед за декодированием их версий, кодированных AC-3 (или E-AC-3).
Таким образом, авторы изобретения осознали, что было бы желательно реализовать кодер, который может адаптивно применять низкочастотную коррекцию в ходе кодирования звуковых сигналов, содержащих выраженные низкочастотные тональные составляющие, но не в ходе кодирования звуковых сигналов, которые не содержат выраженные низкочастотные тональные составляющие (например, аплодисментов или других звуковых сигналов, имеющих низкочастотное нетональное содержимое), и что это следует сделать таким образом, чтобы не требовались изменения декодера (т.е. образом, который допускает декодирование традиционным декодером кодированного звука, который был сгенерирован кодером согласно изобретению).
Некоторые традиционные способы кодирования звука, в которых распределение битов мантисс основывается на разности между спектром сигнала и кривой маскировки, в ходе генерирования значений маскировки для полосовых аудиоданных в частотной области, подлежащих кодированию, в дополнение к низкочастотной коррекции выполняют по меньшей мере один процесс коррекции значений маскировки.
Например, некоторые традиционные аудиокодеры (например, кодеры AC-3 и E-AC-3) реализуют распределение дельта-битов, которое представляет собой подготовку к параметрической коррекции кривой маскировки для каждого подлежащего кодированию звукового канала в соответствии с дополнительным усовершенствованным психоакустическим анализом. Кодер передает дополнительные коды битового потока, обозначаемые как дельты, которые переносят разности между использованной кривой маскировки и используемой по умолчанию кривой маскировки (т.е. разность между значением маскировки, определяемым используемой по умолчанию моделью маскировки на каждой частоте, и значением маскировки, определяемым усовершенствованной моделью маскировки, фактически используемой на той же частоте).
Функция распределения дельта-битов, как правило, вынуждена представлять собой ступенчатую лестничную функцию (например, со ступенями+6 дБ вплоть до+18 дБ). Каждый шаг ступени лестницы соответствует корректировке уровня маскировки для целого числа сопредельных половинных полос Барка. Ступени лестницы включают некоторое количество неперекрывающихся сегментов переменной длины. Для эффективности передачи, эти сегменты кодируются неравномерно.
Традиционным применением распределения дельта-битов является традиционный процесс BABNDNORM, предназначенный для коррекции уровня маскировки. В процессе BABNDNORM (одном из примеров процесса коррекции кривой маскировки), для перцептуальных полос номер 29 и выше (из числа частотных полос Барка, используемых при кодировании AC-3 и Enhanced AC-3), энергия сигнала в каждой перцептуальной полосе, используемой для доставки функции возбуждения, масштабируется значением, обратно пропорциональным ширине перцептуальной полосы. Поскольку все перцептуальные полосы ниже полосы 29 имеют единичную ширину полосы (т.е. включают только единственный элемент разрешения по частоте), в масштабировании энергий сигнала для полос ниже 29 нет необходимости. На постепенно увеличивающихся частотах функция возбуждения и, следовательно, оценка порога маскировки уменьшаются. Это увеличивает распределение битов на более высоких частотах, особенно в канале объединения сигналов. Некоторые аудиокодеры, которые реализуют кодирование AC-3 (или E-AC-3), конфигурируются для реализации процесса BABNDNORM в качестве одного из этапов кодирования.
ФИГ. 5 представляет собой график значений полосовой PSD (перцептуальной энергии; верхняя кривая) полосовых аудиоданных в частотной области, график масштабированных значений полосовой PSD (вторая кривая сверху), генерируемых путем применения к аудиоданным традиционного процесса BABNDNORM, график функции возбуждения (третья кривая сверху), генерируемой (например, традиционным кодером AC-3 или E-AC-3) для использования при маскировке аудиоданных, и график масштабированной версии функции возбуждения (нижняя кривая), генерируемой (например, традиционным кодером AC-3 или E-AC-3) путем применения к функции возбуждения традиционного процесса BABNDNORM. Каждая из этих четырех кривых представлена в шкале перцептуальных полос (частот Барка). Очевидно, что две верхние кривые начинают расходиться одна с другой в полосе 29, и две нижние кривые также начинают расходиться одна с другой в полосе 29.
ФИГ. 6 представляет собой график спектра частот звукового сигнала (кривая по ФИГ. 6, имеющая самый широкий динамический диапазон), график используемой по умолчанию кривой маскировки, предназначенной для маскировки звукового сигнала (вторая кривая снизу), и график масштабированной версии кривой маскировки (нижняя кривая), генерируемой (например, традиционным кодером AC-3 или E-AC-3) путем применения к кривой маскировки традиционного процесса BABNDNORM. Из ФИГ. 6 очевидно, что на постепенно возрастающих частотах процесс BABNDNORM снижает кривую маскировки на большие величины.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
В первом классе вариантов осуществления изобретения, изобретение представляет собой способ распределения битов мантисс, предназначенный для определения распределения битов мантисс значений аудиоданных для аудиоданных в частотной области, подлежащих кодированию (в том числе путем квантования). Этот способ распределения битов включает этап определения значений маскировки для значений аудиоданных, который заключается в выполнении адаптивной низкочастотной коррекции на аудиоданных каждой полосы частот из набора низкочастотных полос аудиоданных так, чтобы эти значения маскировки были пригодны для определения значений отношения сигнал-маска, которые определяют распределение битов мантисс для указанных аудиоданных. Адаптивная низкочастотная коррекция включает этапы:
(a) выполнения обнаружения тональности на аудиоданных с целью генерирования данных управления коррекцией, указывающих, имеет ли выраженное тональное содержимое каждая полоса частот из набора низкочастотных полос; и
(b) выполнения низкочастотной коррекции на аудиоданных в каждой полосе частот из набора низкочастотных полос, имеющей выраженное тональное содержимое, что указывается данными управления коррекцией и заключается в коррекции предварительного значения маскировки для указанной каждой из полос частот, имеющих выраженное тональное содержимое, но в невыполнении низкочастотной коррекции на аудиоданных в любой другой полосе частот из набора низкочастотных полос так, чтобы значение маскировки для каждой указанной полосы частот представляло собой нескорректированное предварительное значение маскировки.
В некоторый вариантах осуществления изобретения в первом классе этап (а) включает этап выполнения обнаружения тональности на аудиоданных с целью генерирования данных управления коррекцией, указывающих, имеет ли выраженное тональное содержимое каждая из полос частот из по меньшей мере подмножества полос частот аудиоданных (необязательно низкочастотных полос), и этап определения значений маскировки для значений аудиоданных также включает этап:
(c) выполнения процесса коррекции значений маскировки первым способом для указанной каждой полосы частот аудиоданных, имеющей выраженное тональное содержимое, что указывается данными управления коррекцией и заключается в коррекции предварительного значения маскировки для указанной каждой полосы частот, имеющей выраженное тональное содержимое, и выполнения процесса коррекции значений маскировки вторым способом для указанной каждой полосы частот аудиоданных, в которых отсутствует выраженное тональное содержимое, что указывается данными управления коррекцией.
Например, процесс коррекции значений маскировки может представлять собой процесс BABNDNORM, указанная каждая полоса частот может представлять собой перцептуальную полосу, и этап (с) может включать этап выполнения процесса BABNDNORM с первой постоянной масштабирования для указанной каждой полосы частот, имеющей выраженное тональное содержимое, и выполнение процесса BABNDNORM со второй постоянной масштабирования для указанной каждой полосы частот, в которой отсутствует выраженное тональное содержимое.
Другой вариант осуществления изобретения представляет собой способ кодирования, включающий любой из вариантов осуществления указанного способа распределения мантисс.
Во втором классе вариантов осуществления изобретения, изобретение представляет собой способ кодирования звука, который преодолевает ограничения традиционных способов кодирования, которые применяют низкочастотную коррекцию ко всем входным звуковым сигналам (включая сигналы, как с тональным, так и с нетональным низкочастотным содержимым) или не применяют низкочастотную коррекцию ни к одному входному звуковому сигналу. Эти варианты осуществления изобретения избирательно (адаптивно) применяют низкочастотную коррекцию в ходе кодирования звуковых сигналов, содержащих выраженные низкочастотные тональные составляющие, но не в ходе кодирования звуковых сигналов, которые не содержат выраженные низкочастотные тональные составляющие (например, аплодисментов или других звуковых сигналов, имеющих низкочастотное нетональное содержимое, но не выраженное тональное низкочастотное содержимое). Адаптивная низкочастотная коррекция выполняется способом, который позволяет декодеру выполнять декодирование кодированного звука без определения того (или его информирования о том), применялась ли низкочастотная коррекция в ходе кодирования или нет.
Типичный вариант осуществления изобретения во втором классе представляет собой способ кодирования звука, включающий этапы:
(a) выполнения обнаружения тональности на аудиоданных в частотной области с целью генерирования данных управления коррекцией, указывающих имеет ли выраженное тональное содержимое каждая низкочастотная полоса набора по меньшей мере из некоторых низкочастотных полос аудиоданных; и
(b) выполнения низкочастотной коррекции для генерирования скорректированного значения маскировки для аудиоданных в каждой указанной низкочастотной полосе, имеющей выраженное тональное содержимое, что указывается данными управления коррекцией, и генерирования значения маскировки для аудиоданных в каждой другой низкочастотной полосе в наборе без выполнения низкочастотной коррекции.
В некоторых вариантах осуществления изобретения, способ кодирования звука представляет собой способ кодирования AC-3 или Enhanced AC-3. В этих вариантах осуществления изобретения, низкочастотная коррекция предпочтительно выполняется (т.е. переключается в положение ВКЛ., или включается) для полос частот входных аудиоданных, для которых изначально предназначалась lowcomp-коррекция (т.е. полос частот, указывающих выраженное, долговременное, стационарное («тональное») низкочастотное содержимое), и иначе не выполняется (т.е. переключается в положение ВЫКЛ., или фактически отключается). В этих вариантах осуществления изобретения, в ответ на данные управления коррекцией, указывающие, что низкочастотную коррекцию не следует выполнять на полосе частот аудиоданных (например, на данные управления коррекцией, указывающие, что полоса включает нетональное звуковое содержимое, а не выраженное тональное содержимое), этап (b) предпочтительно включает этап «повторного ограничения дискретности изменения экспонент» аудиоданных в указанной полосе с целью генерирования модифицированных аудиоданных для этой полосы, указанные модифицированные аудиоданные для полосы включают модифицированную экспоненту. Повторное ограничение дискретности изменения экспонент генерирует модифицированные аудиоданные для полосы таким образом, что предотвращается равенство -2 дифференциальной экспоненты для этой полосы (например, так, что экспонента аудиоданных в следующей, более высокочастотной полосе за вычетом модифицированной экспоненты модифицированных аудиоданных для данной полосы должна быть равна 2, 1, 0 или -1). Таким образом, lowcomp-коррекция не будет применяться к полосе, поскольку не будет удовлетворяться критерий применения к полосе lowcomp-коррекции (увеличение PSD для полосы на 12 дБ относительно PSD для следующей, более низкочастотной полосы; этот критерий не может удовлетворяться, если не выполняется равенство -2 экспоненты модифицированных (подвергнутых «повторному ограничению дискретности изменения экспонент») аудиоданных для полосы за вычетом экспоненты следующей, более низкочастотной полосы).
Конкретнее, в некоторых указанных вариантах осуществления изобретения, для каждой полосы («N-й» полосы), для которой повторное ограничение дискретности изменения экспонент препятствует равенству дифференциальной экспоненты -2, lowcomp-коррекция «не применяется» (или переключается в положение ВЫКЛ., или фактически отключается) в следующем смысле. Модифицированная дифференциальная экспонента для полосы (в результате повторного ограничения дискретности изменения экспонент) равна -1, 0, 1 или 2. Таким образом, если дифференциальная экспонента для предыдущей (более низкочастотной) полосы («(N-1)-й» полосы) была равна -2 (что может происходить, если этап обнаружения тональности указывал сильное тональное содержимое для «(N-1)-й» полосы с целью предотвращения повторного ограничения дискретности изменения экспонент и отсутствие тонального содержимого для «N-й» полосы - для запуска повторного ограничения дискретности изменения экспонент для «N-й» полосы), и lowcomp-коррекция применила (традиционным образом) полную корректировку маски для «(N-1)-й» полосы (т.е. обнаружение тональности согласно изобретению не предотвратило осуществление этого посредством lowcomp), традиционная lowcomp-коррекция (без повторного ограничения дискретности изменения экспонент) применял бы последовательность постепенно уменьшающихся корректировок маски (для небольшого количества полос, следующих за «(N-1)-й» полосой, в том числе для «N-й» полосы) до тех пор, пока он не достигнет полосы, для которой он выполняет нулевую корректировку (в предположении, что ни одна из дифференциальных экспонент для этих полос не равна -2). В вариантах осуществления изобретения, описываемых в настоящем абзаце, когда повторное ограничение дискретности изменения экспонент (согласно изобретению) препятствует равенству -2 дифференциальной экспоненты для полосы («N-й» полосы; т.е. поскольку этап обнаружения тональности согласно изобретению указывает нетональное содержимое для этой полосы), если lowcomp-коррекция применила корректировку маски для предыдущей полосы («(N-1)-й» полосы»), допускается продолжение lowcomp-коррекцией ее последовательности постепенно уменьшающихся корректировок маски для N-й полосы (и, возможно, также и для небольшого количества последующих полос) до тех пор, пока она не достигнет первой полосы, для которой она выполняет нулевую корректировку. В этот момент, предотвращается совершение lowcomp-коррекцией какой-либо дальнейшей корректировки маски до тех пор, пока обнаружение тональности согласно изобретению не укажет тональный сигнал.
В других вариантах осуществления изобретения, когда этап обнаружения тональности согласно изобретению указывает нетональное содержимое для какой-либо низкочастотной полосы (или для всех совместно рассматриваемых низкочастотных полос) в наборе, к которому традиционно могла бы применяться lowcomp-коррекция, lowcomp-коррекция «не применяется» (или переключается в положение OFF, или фактически отключается) в следующем смысле. В ответ на указание этапом обнаружения тональности согласно изобретению нетонального содержимого по меньшей мере для одной низкочастотной полосы в наборе, вычитание ненулевых параметров lowcomp из функции возбуждения для всех полос в наборе прекращается (например, немедленно). В этот момент, предотвращается выполнений lowcomp-коррекцией каких-либо корректировок маски (вплоть до начала зондирования по полосам следующего набора аудиоданных в частотной области).
В некоторых вариантах осуществления изобретения, данные управления коррекцией указывают, имеет ли тональное содержимое каждая отдельная низкочастотная полоса в наборе, и низкочастотная коррекция избирательно применяется (или не применяется) к каждой отдельной низкочастотной полосе в этом наборе. В других вариантах осуществления изобретения, данные управления коррекцией указывают, имеют ли выраженное тональное содержимое низкочастотные полосы в наборе (рассматриваемом совместно), и низкочастотная коррекция либо применяется ко всем низкочастотным полосам в наборе, либо не применяется ни к одной низкочастотной полосе в наборе (в зависимости от содержимого данных управления коррекцией).
В некоторых вариантах осуществления изобретения во втором классе, этап (а) включает этап выполнения обнаружения тональности на аудиоданных с целью генерирования данных управления коррекцией, указывающих, имеет ли тональное содержимое каждая полоса частот из по меньшей мере подмножества полос частот (необязательно низкочастотных полос) аудиоданных, и этап определения значений маскировки для значений аудиоданных также включает этап:
(c) выполнения процесса коррекции значений маскировки первым способом для указанной каждой полосы частот аудиоданных, имеющих выраженное тональное содержимое, что указывается данными управления коррекцией, и выполнения процесса коррекции значений маскировки вторым способом для указанной каждой полосы частот аудиоданных, в которых отсутствует выраженное тональное содержимое, что указывается данными управления коррекцией.
Например, процесс коррекции значений маскировки может представлять собой процесс BABNDNORM, указанная каждая полоса частот может представлять собой перцептуальную полосу, и этап (с) может включать этап выполнения процесса BABNDNORM с первой постоянной масштабирования для указанной каждой полосы частот, имеющей выраженное тональное содержимое, и выполнение процесса BABNDNORM со второй постоянной масштабирования для указанной каждой полосы частот, в которой отсутствует выраженное тональное содержимое.
В другом классе вариантов осуществления изобретения, изобретение представляет собой аудиокодер, сконфигурированный для генерирования кодированных аудиоданных в ответ на аудиоданные в частотной области, что заключается в выполнении адаптивной низкочастотной коррекции на аудиоданных, указанный кодер содержит:
детектор тональности (например, элемент 15 по ФИГ. 2), сконфигурированный для выполнения обнаружения тональности на аудиоданных с целью генерирования данных управления коррекцией, указывающих, имеет ли тональное содержимое каждая низкочастотная полоса набора по меньшей мере из некоторых низкочастотных полос аудиоданных; и
ступень управления низкочастотной коррекцией (например, реализуемую элементом 4 по ФИГ. 2), подключенную и сконфигурированную для адаптивного включения (избирательного включения или фактического отключения) в ответ на данные управления коррекцией применения низкочастотной коррекции к каждой низкочастотной полосе из указанного набора низкочастотных полос аудиоданных.
Детектор тональности сконфигурирован для определения того, следует ли применять низкочастотную коррекцию к аудиоданным каждой полосы частот из набора низкочастотных полос (т.е. путем генерирования данных управления коррекцией, указывающих, следует ли переключить в положение ВКЛ. низкочастотную коррекцию каждой из полос частот из набора низкочастотных полос, поскольку эта полоса имеет выраженное тональное содержимое, или переключить в положение ВЫКЛ., потому в этой полосе отсутствует выраженное тональное содержимое, в ходе кодирования аудиоданных указанного набора низкочастотных полос). Ступень управления низкочастотной коррекцией сконфигурирована для адаптивного включения применения низкочастотной коррекции к аудиоданным каждой полосы из набора низкочастотных полос в ответ на данные управления коррекцией способом, который не требует изменений декодера (т.е. способом, который позволяет декодеру выполнять декодирование кодированных аудиоданных без определения того (или информирования его о том), применялась ли низкочастотная коррекция к какой-либо низкочастотной полосе в ходе кодирования или нет.
В ответ на данные управления коррекцией, указывающие, что полоса частот аудиоданных, подлежащих кодированию, служит признаком нетонального сигнала (для которого следует отключить низкочастотную коррекцию), предпочтительный вариант осуществления ступени управления низкочастотной коррекцией «повторно ограничивает дискретность изменения экспонент» аудиоданных этой полосы путем искусственной модификации ее экспоненты. Повторное ограничение дискретности изменения экспонент генерирует модифицированные аудиоданные для полосы таким образом, что предотвращается равенство -2 дифференциальной экспоненты для этой полосы (например, так, что модифицированная экспонента модифицированных аудиоданных для этой полосы за вычетом экспоненты аудиоданных в следующей, более низкочастотной полосе должна быть равна 2, 1, 0 или -1). В типичных вариантах осуществления кодера, lowcomp-коррекция не будет применяться к полосе, поскольку не будет удовлетворяться критерий применения к полосе lowcomp-коррекции (увеличение PSD для полосы на 12 дБ относительно PSD для следующей низкочастотной полосы; этот критерий не может удовлетворяться, если предотвращается равенство -2 экспоненты модифицированных аудиоданных для полосы за вычетом экспоненты для следующей более низкочастотной полосы).
Другая особенность изобретения представляет собой способ декодирования кодированных аудиоданных, включающий этапы приема сигнала, служащего признаком кодированных аудиоданных, где кодированные аудиоданные были сгенерированы путем кодирования аудиоданных в соответствии с любым из вариантов осуществления способа кодирования согласно изобретению, и декодирование кодированных аудиоданных для генерирования сигнала, служащего признаком аудиоданных.
Другая особенность изобретения представляет собой систему, включающую кодер, сконфигурированный (например, запрограммированный) для выполнения любого из вариантов осуществления способа кодирования согласно изобретению с целью генерирования кодированных аудиоданных в ответ на аудиоданные, и декодер, сконфигурированный для декодирования кодированных аудиоданных с целью восстановления аудиоданных.
Другие особенности изобретения включают систему или устройство (например, кодер или процессор), сконфигурированное (например, запрограммированное) для выполнения любого из вариантов осуществления способа изобретения, и машиночитаемый носитель данных (например, диск), который хранит код, предназначенный для реализации любого из вариантов осуществления способа изобретения или его этапов. Например, система согласно изобретению может представлять собой или включать программируемый процессор общего назначения, процессор цифровой обработки сигналов или микропроцессор, запрограммированный программным обеспечением или аппаратно-программным обеспечением и/или иначе сконфигурированный для выполнения любой из множества операций на данных, включая любой из вариантов осуществления способа изобретения или его этапов. Указанный процессор общего назначения может представлять собой или включать компьютерную систему, включающую устройство ввода, память, и схему обработки данных, запрограммированную (и/или иначе сконфигурированную) для выполнения одного из вариантов осуществления способа изобретения (или его этапов) в ответ на направляемые в нее данные.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
ФИГ. 1 - блок-схема традиционной системы кодирования.
ФИГ. 2 - блок-схема системы кодирования, сконфигурированной для выполнения одного из вариантов осуществления способа изобретения.
ФИГ. 3 - график экспонент и экспонент с ограниченной дискретностью изменения для аудиоданных в частотной области, указывающих (тональный) сигнал камертона-дудки в зависимости от элемента разрешения по частоте.
ФИГ. 4 - график экспонент и экспонент с ограниченной дискретностью изменения для аудиоданных в частотной области, указывающих (нетональный) сигнал аплодисментов в зависимости от элемента разрешения по частоте.
ФИГ. 5 - график значений полосовой PSD (перцептуальной энергии) полосовых аудиоданных в частотной области (верхняя кривая), график масштабированных значений полосовой PSD, генерируемых путем применения традиционного процесса BABNDNORM к аудиоданным (вторая кривая сверху), график функции возбуждения, генерируемой для использования при маскировке аудиоданных (третья кривая сверху), и график масштабированной версии функции возбуждения, генерируемой путем применения традиционного процесса BABNDNORM к функции возбуждения (нижняя кривая). Каждая из этих четырех кривых представлена в шкале перцептуальных полос (частот Барка).
ФИГ. 6 - график спектра частот звукового сигнала, график используемой по умолчанию кривой маскировки, предназначенной для маскировки звукового сигнала (вторая кривая снизу), и график масштабированной версии кривой маскировки, генерируемой путем применения к кривой маскировки традиционного процесса BABNDNORM (нижняя кривая).
ФИГ. 7 - блок-схема системы, включающей кодер, сконфигурированный для выполнения любого из вариантов осуществления способа кодирования согласно изобретению с целью генерирования кодированных аудиоданных в ответ на аудиоданные, и декодера, сконфигурированного для декодирования кодированных аудиоданных с целью восстановления аудиоданных.
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Один из вариантов осуществления системы, сконфигурированной для реализации способа изобретения, будет описан со ссылкой на ФИГ. 2. Система по ФИГ. 2 представляет собой кодер AC-3 (или Enhanced AC-3), который сконфигурирован для генерирования кодированного битового аудиопотока 9 AC-3 (или Enhanced AC-3) в ответ на входные аудиоданные 1 во временной области. Элементы 2, 4, 6, 7, 8, 10 и 11 системы по ФИГ. 2 являются аналогичными аналогично пронумерованным элементам вышеописанной системы по ФИГ. 1.
Банк 2 анализирующих фильтров преобразовывает входные аудиоданные 1 во временной области в аудиоданные 3 в частотной области, а ступень 7 BFPE генерирует представление каждой частотной составляющей данных 3 с плавающей запятой, включающее экспоненту и мантиссу для каждого элемента разрешения по частоте. Аудиоданные в частотной области из ступени 7 (иногда также именуемые в настоящем раскрытии аудиоданными 3 в частотной области) затем кодируются, что заключается в квантовании их мантисс в квантователе 6. Форматер 8 сконфигурирован для генерирования кодированного битового потока 9 AC-3 (или Enhanced AC-3) в ответ на вывод данных квантованных мантисс из квантователя 6 и вывод кодированных данных дифференциальных экспонент из ступени 11. Квантователь 6 выполняет распределение битов и квантование на основе управляющих данных (в том числе данных маскировки), генерируемых контроллером 4.
Контроллер 4 сконфигурирован для выполнения низкочастотной коррекции на каждой низкочастотной полосе из набора низкочастотных полос аудиоданных 3 путем коррекции предварительного значения маскировки (значения возбуждения) для указанной полосы. Скорректированные данные маскировки для этой полосы, направленные контроллером 4 в квантователь 6, определяются скорректированным значением маскировки для указанной полосы.
Поскольку система по ФИГ. 2 представляет собой кодер AC-3 (или Enhanced AC-3), контроллер 4 реализует для анализа данных в частотной области психоакустическую модель на основе 50 неравномерно распределенных перцептуальных полос, который являются приближениями полос частот хорошо известной шкалы Барка. Другие варианты осуществления изобретения используют психоакустическую модель для анализа данных в частотной области (и/или для реализации низкочастотной коррекции, а также, необязательно, другого процесса коррекции значений маскировки) на другой полосовой основе (т.е. на основе какого-либо набора равномерно или неравномерно распределенных полос частот).
Кодер по ФИГ. 2 включает ступень 18 повторного ограничения дискретности изменения экспонент и детектор 15 тональности согласно изобретению. Ступень 10 ограничения дискретности изменения экспонент по ФИГ. 2 подключена и сконфигурирована для направления экспонент с ограниченной дискретностью изменения, которые она генерирует, в детектор 15 тональности и ступень 18 повторного ограничения дискретности изменения экспонент. Ступень 18 повторного ограничения дискретности изменения экспонент сконфигурирована для генерирования экспонент с повторно ограниченной дискретностью изменения, которые вызывают выполнение контроллером 4 (действующим в ответ на экспоненты с повторно ограниченной дискретностью изменения) низкочастотной коррекции на одной из полос частот только в ответ на данные управления коррекцией (генерируемые детектором 15 и направляемые на ступень 18), указывающие, что на этой полосе следует выполнить низкочастотную коррекцию. В ответ на данные управления коррекцией (генерируемые детектором 15 и направляемые на ступень 18), которые указывают, что на полосе частот аудиоданных 3 не следует выполнять низкочастотную коррекцию, контроллер 4 не выполняет низкочастотную коррекцию на этой полосе, и, вместо этого, данные маскировки направляются контроллером 4 в квантователь 6 для полосы, которая определяется нескорректированным предварительным значением маскировки (значением возбуждения) для указанной полосы.
Данные маскировки, направляемые контроллером 4 в квантователь 6 для каждой полосы частот данных 3 в частотной области, включают значение кривой маскировки для этой полосы. Эти значения кривой маскировки представляют величину сигнала, маскируемую человеческим ухом в каждой полосе частот. Как и в системе по ФИГ. 1, квантователь 6 по ФИГ. 2 использует эту информацию для принятия решения о том, как наилучшим образом использовать доступное количество информационных битов для представления составляющих каждой из полос частот входного звукового сигнала.
Конкретнее, контроллер 4 сконфигурирован для вычисления значений PSD в ответ на экспоненты с повторно ограниченной дискретностью изменения, направляемые в него из ступени 18 с целью вычисления полосовых значений PSD в ответ на значения PSD, с целью вычисления кривой маскировки в ответ на полосовые значения PSD, и с целью определения данных распределения битов мантисс («данных маскировки» по ФИГ. 2) в ответ на кривую маскировки.
Аудиокодер по ФИГ. 2 сконфигурирован для генерирования кодированных аудиоданных 9, которое заключается в выполнении адаптивной низкочастотной коррекции на аудиоданных 3. Для реализации этой низкочастотной коррекции, система по ФИГ. 2 включает ступень 15 обнаружения тональности (детектор тональности) и ступень 18 адаптивного повторного ограничения дискретности изменения экспонент, соединенные, как показано, и контроллер 4 выполняет низкочастотную коррекцию в ответ на экспоненты с повторно ограниченной дискретностью изменения, генерируемые на ступени 18. Ступень 10 ограничения дискретности изменения экспонент подключена для приема необработанных экспонент аудиоданных 3 в частотной области и сконфигурирована для определения экспоненты с ограниченной дискретностью изменения для каждой низкочастотной полосы из вышеупомянутого набора низкочастотных полос аудиоданных 3 способом, который будет более подробно описываться ниже.
Детектор 15 тональности подключен для приема оригинальных (необработанных) экспонент аудиоданных 3 и экспонент с ограниченной дискретностью изменения, генерируемых ступенью 10 в ответ на указанные оригинальные экспоненты в ходе зондирования (от низкой частоты к высокой) по набору низкочастотных полос аудиоданных 3.
Ступень 10 сконфигурирована для определения разности между экспонентами аудиоданных 3 в частотной области для последовательных частотных полос данных 3 и для генерирования версии с ограниченной дискретностью изменения для каждой такой экспоненты (экспоненты с ограниченной дискретностью изменения). Ограничение дискретности изменения экспонент выполняется вышеупомянутым традиционным способом в ходе зондирования (от низкой частоты к высокой) по данным 3 в частотной области (включая полосы частот из набора низкочастотных полос, на которых должна выполняться низкочастотная коррекция) так, чтобы в ходе зондирования экспонента с ограниченной дискретностью изменения генерировалась для каждого элемента разрешения по частоте. Ступень 10 определяет дифференциальную экспоненту для каждой полосы (экспонента каждого «следующего» элемента разрешения, «N+1» минус экспонента текущего (более низкочастотного) элемента разрешения, «N»). Если дифференциальная экспонента для элемента разрешения «N» превышает 2 (т.е. exp(N+1)-exp(N)>2), то ступень 10 определяет экспоненту с ограниченной дискретностью изменения для элемента разрешения «N+1» как наименьшую экспоненту (tentexp(N+1)), которая удовлетворяет условию tentexp(N+1)-exp(N)=2. В этом случае, экспонента с ограниченной дискретностью изменения для элемента разрешения N (tentexp(N)) равна оригинальной экспоненте для элемента разрешения N (tentexp(N)=exp(N)), и ступень 10 направляет на ступень 18 значение дифференциальной экспоненты с ограниченной дискретностью изменения, равное 2 для элемента разрешения N. Если дифференциальная экспонента для элемента разрешения «N» меньше -2 (т.е. exp(N+1)-exp(N)<-2), то ступень 10 определяет экспоненту с ограниченной дискретностью изменения для элемента разрешения «N» как наибольшую экспоненту (tentexp(N)), которая удовлетворяет условию exp(N+1)-tentexp(N)=-2. В этом случае, экспонента с ограниченной дискретностью изменения для элемента разрешения N+1 (tentexp(N+1)) равна оригинальной экспоненте для элемента разрешения N+1 (tentexp(N+1)=exp(N+1)), и ступень 10 направляет на ступень 18 значение дифференциальной экспоненты с ограниченной дискретностью изменения, равное -2 для элемента разрешения N.
Детектор 15 тональности сконфигурирован для выполнения обнаружения тональности на оригинальных экспонентах, включающих аудиоданные 3, и на экспонентах с ограниченной дискретностью изменения, генерируемых ступенью 10 в ответ на эти оригинальные экспоненты в ходе зондирования (от низкой частоты к высокой) по набору низкочастотных полос аудиоданных 3. Крутая характеристика подъемов и падений для значений PSD (как функция частоты) тонального сигнала подразумевает то, что такой сигнал является подвергнутым ограничению дискретности изменения экспонент чаще, чем нетональный сигнал (например, нетональный сигнал, характерный для аплодисментов).
Например, ФИГ. 3 представляет собой график экспонент и экспонент с ограниченной дискретностью изменения для аудиоданных в частотной области, указывающих тональных сигнал (сигнал камертона-дудки) в зависимости от элемента разрешения по частоте. ФИГ. 4 представляет собой график экспонент и экспонент с ограниченной дискретностью изменения для аудиоданных в частотной области, указывающих нетональный сигнал (аплодисменты), также нанесенный на график зависимости от элемента разрешения по частоте. При более низких частотах, на которых, как правило, выполняется низкочастотная коррекция, каждый элемент разрешения по частоте (по ФИГ. 3 и 4) соответствует единственной полосе частот. Как становится очевидным при рассмотрении ФИГ. 3, в низкочастотном диапазоне имеется много полос частот (например, элементы разрешения 7, 11, 14, 15, 20 и 23), в которых существует ненулевая разность между экспонентой и соответствующей экспонентой с ограниченной дискретностью изменения (генерируемой исходя из этой экспоненты, например, ступенью 10) для тонального сигнала. Как становится очевидным при рассмотрении ФИГ. 4, в низкочастотном диапазоне имеется меньшее количество полос частот (только элемент разрешения 34), в которых имеется ненулевая разность между экспонентой и соответствующей экспонентой с ограниченной дискретностью изменения для нетонального сигнала.
Таким образом, один из типичных вариантов осуществления детектора 15 тональности определяет меру среднеквадратичной разности между экспонентами и соответствующими экспонентами с ограниченной дискретностью изменения из набора аудиоданных в частотной области (или другую меру, указывающую разность между экспонентами и соответствующими экспонентами с ограниченной дискретностью изменения для таких данных). Например, в ходе зондирования (от низкой частоты к высокой) по низкочастотным полосам (указанного набора низкочастотных полос данных 3) от первой (низшей) полосы частот по полосу N+1 одна из реализаций детектора 15 генерирует меру тональности для полосы N+1 как среднеквадратичную разность между оригинальной экспонентой и экспонентой с ограниченной дискретностью изменения для каждой полосы в интервале от первой полосы до полосы N+1.
Такая мера среднеквадратичной разности используется для определения данных управления коррекцией, указывающих тональность (присутствие или отсутствие выраженного тонального содержимого) звукового сигнала в частотной области от низшей полосы частот по текущую полосу частот (полоса N+1). Для каждого частотного диапазона (от низшей полосы частот по текущую полосу частот), если мера среднеквадратичной разности (для частотного диапазона) имеет значение меньше специального предварительно определенного порогового значения (например, экспериментально определенного порогового значения), то детектор 15 направляет (на ступень 18) данные управления коррекцией с первым значением (например, двоичным разрядом, равным нулю), для указания нетонального звукового сигнала. Это запускает повторное ограничение ступенью 18 дискретности изменения значения дифференциальной экспоненты, направляемого ступенью 10 для текущей полосы, посредством чего запускается переключение контроллером 4 совместимой с декодером lowcomp-коррекции в положение ВЫКЛ. (т.е. предотвращение применения контроллером 4 традиционной низкочастотной коррекции на текущей полосе). В примере, описываемом ниже, взято пороговое значение, равное 0,05.
Для каждого диапазона частот (от низшей полосы частот по текущую полосу частот), если мера среднеквадратичной разности (для диапазона частот) имеет значение, большее или равное пороговому значению, детектор 15 направляет (на ступень 18) данные управления коррекцией со вторым значением (например, двоичным разрядом, равным единице), указывая тональный звуковой сигнал. Это отключает повторное ограничение ступенью 18 дискретности изменения значения дифференциальной экспоненты, направленного ступенью 10 для текущей полосы, посредством чего допускается прохождение этого значения (направляемого на вывод ступени 10) через ступень 18 в контроллер 4 без изменений и, таким образом, запускает переключение контроллером 4 совместимой с декодером lowcomp-коррекции в положение ВКЛ. (т.е. позволяет контроллеру 4 применять традиционную низкочастотную коррекцию на текущей полосе).
В альтернативных вариантах осуществления изобретения, детектор 15 генерирует данные управления коррекцией другим способом, но так, чтобы данные управления коррекцией указывали тональность (или нетональность) звукового сигнала, определяемого данными 3 в каждой полосе частот данных 3 или в каждой низкочастотной полосе данных 3, или в диапазоне частот, включающем набор (или подмножество) низкочастотных полос данных 3, на которых подлежит выполнению адаптивная низкочастотная коррекция. Например, в некоторых вариантах осуществления изобретения, детектор 15 реализуется как специальный детектор тональности, который действует на выходе ступени 7 BFPE (не именно на экспонентах из вывода ступени 7 BFPE и выводе экспонент с ограниченной дискретностью изменения из ступени 10).
В другом примере, в некоторых вариантах осуществления изобретения, детектор 15 (или другой детектор тональности, используемый в любом из вариантов осуществления изобретения) представляет собой детектор аплодисментов, сконфигурированный для генерирования данных управления коррекцией, указывающих, представляет ли набор низкочастотных полос аудиоданных (например, каждая низкочастотная полоса в наборе) аплодисменты. В этом контексте, термин «аплодисменты» используется в широком смысле, который может значить, либо только аплодисменты, либо аплодисменты и/или оживление в толпе. Низкочастотная коррекция будет отключаться (переключаться в положение ВЫКЛ.) для каждой полосы частот в наборе, которая указывает на аплодисменты, что указывается данными управления коррекцией, или на всех полосах в наборе, если по меньшей мере одна из полос в наборе указывает на аплодисменты, что указывается данными управления коррекцией. Низкочастотная коррекция может выполняться на аудиоданных в каждой полосе частот в наборе, которая не указывает на аплодисменты, что указывается данными управления коррекцией.
В ответ на данные управления коррекцией из детектора 15, указывающие нетональный звуковой сигнал (например, указывающие, что звуковой сигнал, определяемый данными 3, представляет собой нетональный сигнал в низкочастотной диапазоне от низшей полосы частот данных 3 по текущую полосу (полосу N)), ступень 18 выполняет повторное ограничение дискретности изменения экспоненты с ограниченной дискретностью изменения для текущей полосы. Конкретнее, если дифференциальная экспонента с ограниченной дискретностью изменения для текущей полосы (экспонента с ограниченной дискретностью изменения для полосы N+1 минус экспонента с ограниченной дискретностью изменения для полосы N) равна -2 (что является признаком резкого увеличения (12 дБ) PSD от предыдущей полосы, N, к текущей (более высокочастотной) полосе, N+1), ступень 18 определяет дифференциальную экспоненту с ограниченной дискретностью изменения для полосы N+1 как равную -1. Таким образом, в ответ на данные управления коррекцией из детектора 15, указывающие нетональный звуковой сигнал (например, указывающие, что звуковой сигнал, определяемый данными 3, представляет собой нетональный сигнал в низкочастотном диапазоне от низшей полосы частот данных 3 по текущую полосу частот (полосу N) данных 3), контроллер 4 не выполняет низкочастотную коррекцию на текущей полосе частот (N) аудиоданных 3.
В ответ на данные управления коррекцией из детектора 15, указывающие тональный звуковой сигнал (например, указывающие, что звуковой сигнал, определяемый данными 3, представляет собой тональный сигнал в низкочастотном диапазоне от низшей полосы частот данных 3 по текущую полосу (полосу N) данных 3), ступень 18 пропускает напрямую в контроллер 4 разность экспонент с ограниченной дискретностью изменения для текущей полосы (без изменения разности экспонент с ограниченной дискретностью изменения), и допускается выполнение контроллером 4 низкочастотной коррекции на текущей полосе частот (N) аудиоданных 3. Конкретнее, контроллер 4 выполняет низкочастотную коррекцию на текущей полосе частот (N) аудиоданных 3, если значение разности экспонент с ограниченной дискретностью изменения, выводимое из ступени 10 (и проходящее напрямую в контроллер 4 через ступень 18) для этой полосы равно -2.
Более обобщенно, детектор тональности согласно типичным вариантам осуществления изобретения сконфигурирован для определения того, следует ли применять низкочастотную коррекцию к аудиоданным каждой полосы частот из набора низкочастотных полос (т.е. путем генерирования данных управления коррекцией, указывающих, следует ли переключить в положение ВКЛ. низкочастотную коррекцию каждой полосы частот из набора низкочастотных полос из-за того, что эта полоса имеет выраженное тональное содержимое, или переключить в положение ВЫКЛ. из-за того, что в полосе отсутствует выраженное тональное содержимое, в ходе кодирования аудиоданных указанного набора низкочастотных полос). Ступень управления низкочастотной коррекцией согласно типичным вариантам осуществления изобретения сконфигурирована для адаптивного включения применения низкочастотной коррекции к аудиоданным каждой полосы из набора низкочастотных полос в ответ на данные управления коррекцией способом, который не требует изменений декодера (т.е. способом, который позволяет декодеру выполнять декодирование кодированных аудиоданных без определения того (и без его информирования о том), применялась низкочастотная коррекция к какой-либо из полос частот в ходе кодирования или нет).
В типичных вариантах осуществления изобретения, в ответ на данные управления коррекцией, указывающие, что полоса частот аудиоданных, подлежащих кодированию, служит признаком нетонального сигнала (для которого следует отключить низкочастотную коррекцию), предпочтительный вариант осуществления ступени управления низкочастотной коррекцией подвергает «повторному ограничению дискретности изменения экспонент» аудиоданные с ограниченной дискретностью изменения (например, дифференциальную экспоненту с ограниченной дискретностью изменения) для этой полосы путем искусственной модификации значимой дифференциальной экспоненты, определяемой данными с ограниченной дискретностью изменения. Повторное ограничение дискретности изменения экспонент генерирует модифицированные аудиоданные для полосы так, чтобы не выполнялось равенство -2 модифицированной (подвергнутой повторному ограничению дискретности изменения) дифференциальной экспоненты для этой полосы (т.е. так, чтобы модифицированная экспонента модифицированных аудиоданных для указанной полосы за вычетом экспоненты аудиоданных в следующей, более низкочастотной полосе была равна 2, 1, 0 или -1). В типичных вариантах осуществления кодера согласно изобретению, lowcomp-коррекция не будет применяться к указанной полосе, поскольку не будет удовлетворяться критерий применения к этой полосе lowcomp-коррекции (увеличение PSD на 12 дБ для этой полосы относительно следующей, более низкочастотной полосы; этот критерий не может удовлетворяться, поскольку не выполняется равенство -2 экспоненты модифицированных аудиоданных для полосы за вычетом экспоненты для следующей, более низкочастотной полосы).
Низкочастотная коррекция может быть переключена в режим ВЫКЛ. (в соответствии с типичными вариантами осуществления изобретения) без изменения декодера путем искусственной модификации («повторного ограничения дискретности изменения») экспонент для низкочастотных полос таким образом, чтобы дифференциальная экспонента (для смежных низкочастотных полос) никогда не была равна -2 (т.е. чтобы избегать возрастания PSD на 12 дБ в ходе просмотра от более низкочастотных к более высокочастотным полосам), и чтобы, таким образом, избежать применения lowcomp-коррекции. Для достижения такого эффекта, когда детектор тональности согласно изобретению указывает нетональный сигнал, экспоненты с ограниченной дискретностью изменения для низкочастотных полос подвергаются повторному ограничению дискретности изменения. Это не требует изменения в психоакустической модели, используемой для генерирования данных маскировки (отношений сигнал-маска) для квантования значений мантисс и, таким образом, генерирует кодированные данные, которые могут декодироваться традиционными декодерами. Конкретнее, в ходе просмотра низкочастотных полос, где полоса «N+1» является следующей полосой, а текущая полоса («N») имеет более низкую частоту, чем следующая полоса, если предварительно определяется, что дифференциальная экспонента (экспонента для полосы N+1 минус экспонента для полосы N) равна -2, экспонента одной из полос изменяется (подвергается «повторному ограничению дискретности изменения») так, чтобы дифференциальная экспонента модифицированных значений экспонент была равна -1 (т.е. модифицированная экспонента для полосы N+1 за вычетом экспоненты для полосы N равна -1, или экспонента для полосы N+1 за вычетом модифицированной экспоненты для полосы N равна -1). Предпочтительно, если экспонента для полосы N+1 за вычетом экспоненты для полосы N равна -2, эта разность увеличивается до -1 путем уменьшения («повторного ограничения дискретности изменения») для полосы N (текущей полосы) так, чтобы экспонента для полосы N+1 за вычетом модифицированной экспоненты для полосы N была равна -1. Последняя реализация повторного ограничения дискретности изменения экспонент, как правило, является предпочтительной, так как увеличение значений экспоненты обычно является нежелательным, поскольку существует допущение, что соответствующие мантиссы могут быть полностью нормированными. Увеличение значения экспоненты, соответствующего полностью нормированной мантиссе, может в результате приводить к перенормированной, или усеченной, мантиссе, что является нежелательным. Поэтому если экспонента для полосы N+1 за вычетом экспоненты для полосы N равна -2, с целью увеличения этой разности до -1, как правило, предпочтительным является уменьшение на единицу экспоненты для полосы N (а не увеличение на единицу экспоненты для полосы N+1).
Когда детектор тональности согласно изобретению указывает тональный сигнал, экспоненты входных частотных составляющих звука не подвергаются повторному ограничению дискретности изменения, и низкочастотная коррекция применяется к тональному сигналу традиционным образом (т.е. к традиционно тентированным значениям, служащим признаками тонального сигнала).
Авторы изобретения выполнили испытание прослушивания, в котором сравнивались рабочие характеристики традиционного кодера E-AC-3 с таковыми для модифицированной версии кодера E-AC-3 (реализующего адаптивную lowcomp-коррекцию, относящуюся к типу, описанному со ссылкой на ФИГ. 2). Испытание показало выгоды последнего (модифицированного) кодера не только для испытанных сигналов аплодисментов, но также и для некоторых сигналов, не содержащих аплодисменты. Конкретнее, на 192 Кбит/с с пороговым значением детектора тональности, равным 0,05 (т.е. детектор тональности конфигурировался для генерирования управляющих данных, указывающих нетональный сигнал, для которого следует переключить lowcomp-коррекцию в положение ВЫКЛ. (путем повторного ограничения дискретности изменения экспонент для подлежащих кодированию аудиоданных в частотной области), когда мера среднеквадратичной разности между экспонентами и экспонентами с ограниченной дискретностью изменения для звука в частотной области имеет значение меньше порогового значения 0,05), среднее процентное содержание блоков, для которых lowcomp-коррекция переключалась в положение ВЫКЛ., составляло 0,5% и 80%, соответственно, для входного звука камертона-дудки (кратковременный, высокотональный, низкочастотный) и аплодисментов (в высокой степени нетональный, низкочастотный).
Как указывалось, резкое возрастание и падение характеристик PSD тонального сигнала предполагает, что такие сигналы подвергаются ограничению дискретности изменения экспонент чаще, чем нетональные сигналы, и поэтому среднеквадратичная разность между экспонентами и экспонентами с ограниченной дискретностью изменения может служить указателем тональности. Значение указателя тональности меньше порогового значения (определяемого экспериментально) предполагает нетональные сигналы для которых, lowcomp-коррекция должна переключаться в положение ВЫКЛ.; и наоборот. В типичных реализациях, значение указателя тональности вычисляется (например, детектором 15 по ФИГ. 2) в ходе зондирования по полосам частот подлежащих кодированию аудиоданных (например, данных 3 по ФИГ. 2) до тех пор, пока частота текущей полосы частот не достигнет частоты начала объединения сигналов (когда используется объединение сигналов). Если используется Адаптивное гибридное преобразование (AHT), действие адаптивной lowcomp-обработки может отключаться, и вместо нее может проводиться традиционная (неадаптивная) lowcomp-обработка. AHT описано в технических условиях Dolby Digital /Dolby Digital Plus Specification, и в главе «Dolby Digital Audio Coding Standards» за авторством Robert L. Andersen и Grant A. Davidson в работе «The Digital Signal Processing Handbook», издание второе, главный редактор Vijay K. Madisetti, CRC Press, 2009, на которые выше даны ссылки.
В первом классе вариантов осуществления изобретения, изобретение представляет собой способ распределения битов мантисс, предназначенный для определения распределения битов мантисс значений аудиоданных для подлежащих кодированию аудиоданных в частотной области (в том числе путем прохождения ими квантования). Способ распределения включает этап определения значений маскировки для значений аудиоданных (например, в контроллере 4 по ФИГ. 2), что заключается в выполнении адаптивной низкочастотной коррекции на аудиоданных каждой полосы частот из набора низкочастотных полос аудиоданных так, чтобы значения маскировки были пригодны для определения значений отношения сигнал-маска, которые определяют распределение битов мантисс для указанных аудиоданных. Адаптивная низкочастотная коррекция включает этапы:
(a) выполнения обнаружения тональности на аудиоданных (например, в детекторе 15 тональности по ФИГ. 2) с целью генерирования данных управления коррекцией, указывающих, имеет ли выраженное тональное содержимое каждая полоса частот в наборе низкочастотных полос; и
(b) выполнения низкочастотной коррекции на аудиоданных в каждой полосе частот из набора низкочастотных полос, имеющей выраженное тональное содержимое, что указывается данными управления коррекцией и заключается в коррекции предварительного значения маскировки для указанной каждой полосы частот, имеющей выраженное тональное содержимое, и в невыполнении низкочастотной коррекции на аудиоданных в любой другой полосе частот из набора низкочастотных полос так, чтобы значение маскировки для каждой указанной другой полосы частот представляло собой нескорректированное предварительное значение маскировки.
В некоторых вариантах осуществления изобретения в первом классе этап (а) включает этап выполнения обнаружения тональности (например, в детекторе 15 тональности по ФИГ. 2) на аудиоданных с целью генерирования данных управления коррекцией, указывающих имеет ли выраженное тональное содержимое каждая полоса частот из по меньшей мере подмножества полос частот аудиоданных, и этап определения значений маскировки для аудиоданных также включает этап:
(c) выполнения процесса коррекции значений маскировки первым способом для указанной каждой полосы частот аудиоданных, имеющей выраженное тональное содержимое, что указывается данными управления коррекцией и заключается в коррекции предварительного значения маскировки для указанной каждой полосы частот, имеющей выраженное тональное содержимое, и в выполнении процесса коррекции значений маскировки вторым способом для указанной каждой полосы частот аудиоданных, в которой отсутствует выраженное тональное содержимое, что указывается данными управления коррекцией.
Например, процесс корректировки значений маскировки может представлять собой процесс BABNDNORM, указанная каждая полоса частот может представлять собой перцептуальную полосу, и этап (с) может включать этап выполнения процесса BABNDNORM с первой постоянной масштабирования для указанной каждой полосы частот, имеющей выраженное тональное содержимое, и выполнение процесса BABNDNORM со второй постоянной масштабирования для указанной каждой полосы частот, в которой отсутствует выраженное тональное содержимое.
Другой вариант осуществления изобретения представляет собой способ кодирования, включающий любой из вариантов осуществления указанного способа распределения мантисс.
Во втором классе вариантов осуществления изобретения изобретение представляет собой способ кодирования звука, который преодолевает ограничения традиционных способов кодирования, которые применяют низкочастотную коррекцию ко всем входным звуковым сигналам (включая сигналы, как с тональным, так и с нетональным низкочастотным содержимым), или не применяют низкочастотную коррекцию ни к одному входному звуковому сигналу. Эти варианты осуществления изобретения избирательно (адаптивно) применяют низкочастотную коррекцию в ходе кодирования звуковых сигналов, имеющих выраженные низкочастотные тональные составляющие, но не в ходе кодирования звуковых сигналов, которые не содержат выраженные низкочастотные тональные составляющие (например, аплодисментов или других звуковых сигналов, имеющих низкочастотное нетональное содержимое, но не выраженное тональное низкочастотное содержимое). Адаптивная низкочастотная коррекция выполняется способом, который позволяет декодеру выполнять декодирование кодированного звука без определения того (или его информирования о том), применялась ли низкочастотная коррекция в ходе кодирования или нет.
Типичный вариант осуществления изобретения во втором классе представляет собой способ кодирования звука, включающий этапы:
(a) выполнения обнаружения тональности на аудиоданных в частотной области (например, в детекторе 15 тональности по ФИГ. 2) с целью генерирования данных управления коррекцией, указывающих имеет ли выраженное тональное содержимое каждая низкочастотная полоса набора по меньшей мере из некоторых низкочастотных полос аудиоданных; и
(b) выполнения низкочастотной коррекции (например, в контроллере 4 по ФИГ. 2) с целью генерирования скорректированного значения маскировки для аудиоданных в каждой указанной низкочастотной полосе, имеющей выраженное тональное содержимое, что указывается данными управления коррекцией, и генерирования значения маскировки для аудиоданных в каждой другой низкочастотной полосе в наборе без выполнения низкочастотной коррекции (например, в контроллере 4 по ФИГ. 2).
В некоторых вариантах осуществления изобретения во втором классе, способ кодирования представляет собой способ кодирования AC-3 или Enhanced AC-3. В этих вариантах осуществления изобретения, низкочастотная коррекция предпочтительно выполняется (т.е. переключается в положение ВКЛ., или включается) для полос частот входных аудиоданных, на которые изначально рассчитана lowcomp-коррекция (т.е. полос частот, служащих признаками выраженного, долговременного, стационарного («тонального») низкочастотного содержимого), и иначе не выполняется (т.е. переключается в положение ВЫКЛ., или фактически отключается). В этих вариантах осуществления изобретения в ответ на данные управления коррекцией, указывающие, что низкочастотную коррекцию на полосе частот аудиоданных проводить не следует (например, данные управления коррекцией указывают, что эта полоса включает нетональное звуковое содержимое, а не выраженное тональное содержимое), этап (b) предпочтительно включает этап «повторного ограничения дискретности изменения экспонент» аудиоданных в указанной полосе с целью генерирования для этой полосы модифицированных аудиоданных, указанные модифицированные аудиоданные для полосы включают модифицированную экспоненту. Повторное ограничение дискретности изменения экспонент генерирует модифицированные аудиоданные для полосы так, чтобы предотвращалось равенство -2 дифференциальной экспоненты для полосы (например, так, что модифицированная экспонента модифицированных аудиоданных для полосы за вычетом экспоненты аудиоданных в следующей, более низкочастотной полосе должна быть равна 2, 1, 0 или -1). Таким образом, lowcomp-коррекция не будет применяться к полосе, поскольку не будет удовлетворяться критерий применения к полосе lowcomp-коррекции (увеличение PSD для полосы на 12 дБ относительно PSD для следующей, более низкочастотной полосы; этот критерий не может удовлетворяться, если предотвращается равенство -2 экспоненты модифицированных (подвергнутых «повторному ограничению дискретности изменения экспонент») аудиоданных для полосы за вычетом экспоненты для следующей полосы с более низкой частотой).
В некоторых вариантах осуществления изобретения во втором классе, этап (а) включает этап выполнения обнаружения тональности (например, в детекторе 15 тональности по ФИГ. 2) на аудиоданных с целью генерирования данных управления коррекцией, указывающих имеет ли выраженное тональное содержимое каждая полоса частот по меньшей мере из подмножества полос частот аудиоданных, и этап определения значений маскировки для значений аудиоданных также включает этап:
(c) выполнения процесса коррекции значений маскировки (например, в контроллере 4 по ФИГ. 2) первым способом для указанной каждой полосы частот аудиоданных, имеющей выраженное тональное содержимое, что указывается данными управления коррекцией, и выполнение процесса коррекции значений маскировки вторым способом для указанной каждой полосы частот аудиоданных, в которой отсутствует выраженное тональное содержимое, что указывается данными управления коррекцией.
Например, процесс коррекции значений маскировки может представлять собой процесс BABNDNORM, указанная каждая полоса частот может представлять собой перцептуальную полосу, и этап (с) может включать этап выполнения процесса BABNDNORM с первой постоянной масштабирования для указанной каждой полосы частот, имеющей выраженное тональное содержимое, и выполнения процесса BABNDNORM со второй постоянной масштабирования для указанной каждой полосы частот, в которой отсутствует выраженное тональное содержимое.
Как указывалось, некоторые варианты осуществления способа кодирования (и способа распределения битов мантисс) согласно изобретению используют данные управления коррекцией согласно изобретению для модификации особенностей кодирования/декодирования BABNDNORM.
В одном из классов вариантов осуществления изобретения, способ кодирования согласно изобретению использует данные управления коррекцией согласно изобретению для модификации особенностей кодирования/декодирования BABNDNORM следующим образом. Способы как низкочастотной коррекции в традиционном BABNDNORM, так и адаптивной низкочастотной коррекции имеют сходную цель, а именно: перераспределение кодирующих битов в направлении более высоких частот за счет более низких частот. Однако традиционный BABNDNORM обладает дополнительными затратами на передачу дельт в декодер.
Для оптимального использования как BABNDNORM, так и адаптивной низкочастотной коррекции согласно изобретению, кодер конфигурируется для корректировки постоянной масштабирования BABNDNORM для перцептуальной полосы на основе адаптивного решения lowcomp-коррекции для этой полосы. Например, в одной из реализаций системы по ФИГ. 2, если данные управления коррекцией, генерируемые для полосы детектором 15 тональности, указывают, что низкочастотную коррекцию следует отключить (переключить в положение ВЫКЛ.), ступень генерирования данных маскировки контроллера 4 выбирает постоянную масштабирования BABNDNORM (в ответ на данные управления коррекцией) так, чтобы пороговое значение маскировки уменьшалось на меньшую величину. Если данные управления коррекцией, генерируемые для полосы детектором 15 тональности, указывают, что низкочастотную коррекцию следует включить (переключить в положение ВКЛ.), ступень генерирования данных маскировки выбирает постоянную масштабирования BABNDNORM (в ответ на данные управления коррекцией) так, чтобы пороговое значение маскировки уменьшалось на большую величину.
В некоторых вариантах осуществления способа изобретения, когда этап обнаружения тональности указывает нетональное содержимое для какой-либо низкочастотной полосы (или для всех совместно рассматриваемых низкочастотных полос) в наборе, к которому обычно применяется lowcomp-коррекция, lowcomp-коррекция «не применяется» (или переключается в положение ВЫКЛ., или фактически отключается) в следующем смысле. В ответ на указание этапом обнаружения тональности нетонального содержимого по меньшей мере для одной низкочастотной полосы в наборе, прекращается (например, немедленно) вычитание ненулевых параметров lowcomp из значений возбуждения для всех полос в наборе. В этот момент, предотвращается выполнение lowcomp-коррекцией какой-либо корректировки маски (вплоть до начала нового зондирования по полосам из следующего набора аудиоданных в частотной области).
Как указывалось выше, в некоторых вариантах осуществления способа изобретения, данные управления коррекцией указывают, имеет ли выраженное тональное содержимое каждая отдельная низкочастотная полоса в наборе, и низкочастотная коррекция избирательно применяется (или не применяется) к каждой отдельной низкочастотной полосе в наборе. В других вариантах осуществления способа изобретения, данные управления коррекцией указывают, имеют ли выраженное тональное содержимое низкочастотные полосы в наборе (рассматриваемом совместно), и низкочастотная коррекция либо применяется ко всем низкочастотным полосам в наборе, либо не применяется ни к одной из низкочастотных полос в наборе (в зависимости от содержимого данных управления коррекцией). Один из классов вариантов осуществления изобретения реализует принятие двоичного (широкополосного) решения о том, включить или отключить lowcomp-коррекцию для всего низкочастотного диапазона. В некоторых вариантах осуществления изобретения в этом классе, если обнаружение тональности указывает, что lowcomp-коррекцию следует отключить, повторное ограничение дискретности изменения экспонент будет исключать все дифференциальные экспоненты со значением -2 из низкочастотного диапазона lowcomp так, чтобы параметр lowcomp всегда был равен 0. Однако другие варианты осуществления способа изобретения реализуют более тонко гранулированное принятие решения о тональности так, что для lowcomp-коррекции допускается сохранение активности для некоторых диапазонов частот из всего низкочастотного диапазона, но она отключается в других диапазонах частот.
Другая особенность изобретения представляет собой систему, включающую кодер, сконфигурированный для выполнения любого из вариантов осуществления способов кодирования согласно изобретению с целью генерирования кодированных аудиоданных в ответ на аудиоданные, и декодер, сконфигурированный для декодирования кодированных аудиоданных с целью восстановления аудиоданных. Примером такой системы является система по ФИГ. 7. Система по ФИГ. 7 включает кодер 90, который сконфигурирован (например, запрограммирован) для выполнения любого из вариантов осуществления способа кодирования согласно изобретению с целью генерирования кодированных аудиоданных в ответ на аудиоданные, подсистему 91 доставки и декодер 92. Подсистема 91 доставки сконфигурирована для хранения в памяти кодированных аудиоданных, генерируемых кодером 90 и/или для передачи сигнала, служащего признаком кодированных аудиоданных. Декодер 92 подключен и сконфигурирован (например, запрограммирован) для приема кодированных аудиоданных из подсистемы 91 (например, путем считывания или отыскания кодированных аудиоданных из памяти подсистемы 91 или приема сигнала, служащего признаком кодированных аудиоданных, которые были переданы подсистемой 91), и для декодирования кодированных аудиоданных с целью восстановления аудиоданных (а также, как правило, для генерирования и вывода сигнала, служащего признаком аудиоданных).
Другая особенность изобретения представляет собой способ (например, способ, выполняемый декодером 92 по ФИГ. 7), предназначенный для декодирования кодированных аудиоданных, включающий этапы приема сигнала, служащего признаком кодированных аудиоданных, где кодированные аудиоданные были сгенерированы путем кодирования аудиоданных в соответствии с любым из вариантов осуществления способа кодирования согласно изобретению, и декодирования кодированных аудиоданных с целью генерирования сигнала, служащего признаком аудиоданных.
Изобретение может реализовываться как аппаратное обеспечение, программно-аппаратное обеспечение или программное обеспечение, или как их сочетание (например, как программируемая логическая матрица). Если не указано иное, алгоритмы или процессы, включенные как часть изобретения, по существу не относятся к какому-либо конкретному компьютеру или другому устройству. В частности, с программами, написанными в соответствии с идеями настоящего раскрытия, могут использоваться различные машины общего назначения, или для выполнения требуемых этапов способа может быть более удобным конструирование более специализированного устройства (например, интегральных микросхем). Таким образом, изобретение может реализовываться в одной или нескольких компьютерных программах, исполняемых на одной или нескольких программируемых компьютерных системах (например, на компьютерной системе, которая реализует кодер по ФИГ. 2), каждая из которых включает по меньшей мере один процессор, по меньшей мере одну систему хранения данных (в том числе энергозависимую и энергонезависимую память, и/или запоминающие элементы), по меньшей мере одно устройство или порт ввода и по меньшей мере одно устройство или порт вывода. Управляющая программа применяется к входным данным для выполнения функций, описываемых в настоящем раскрытии, и для генерирования выходной информации. Выходная информация известным образом применяется к одному или нескольким устройствам.
Для установления связи с компьютерной системой, любая указанная программа может реализовываться на любом желаемом языке программирования (в том числе на машинном языке, языке ассемблера или высокоуровневом процедурном, логическом или объектно-ориентированном языке программирования). В любом случае, этот язык может представлять собой компилируемый или интерпретируемый язык.
Например, при реализации последовательностями команд компьютерного программного обеспечения различные функции и этапы вариантов осуществления изобретения могут реализовываться многопотоковыми последовательностями команд программного обеспечения, запускаемыми на подходящем аппаратном обеспечении цифровой обработки сигналов, и в этом случае, различные устройства, этапы и функции вариантов осуществления изобретения могут соответствовать частям команд программного обеспечения.
Каждая такая компьютерная программа предпочтительно хранится в памяти или загружается на носители данных или устройство хранения данных (например, твердотельное запоминающее устройство или носитель, или магнитный, или оптический носитель данных), читаемый программируемым компьютером общего или специального назначения, с целью конфигурирования и приведения в действие этого компьютера, когда носители данных или устройство хранения данных считывается компьютерной системой с целью выполнения процедур, описываемых в настоящем раскрытии. Система согласно изобретению также может реализовываться как машиночитаемый носитель данных, конфигурируемый компьютерной программой (т.е. хранящий ее в памяти), где носитель данных, сконфигурированный таким образом, вызывает работу компьютерной системы специальным и предварительно определенным образом с целью выполнения функций, описанных в настоящем раскрытии.
Было описано несколько вариантов осуществления изобретения. Тем не менее, следует понять, что без отступления от духа и объема изобретения могут делаться различные модификации. В свете вышеописанных идей, возможны многочисленные модификации и изменения настоящего изобретения. Следует понимать, что в пределах объема прилагаемой формулы изобретения изобретение может применяться на практике иначе, чем это конкретно описано в настоящем раскрытии.


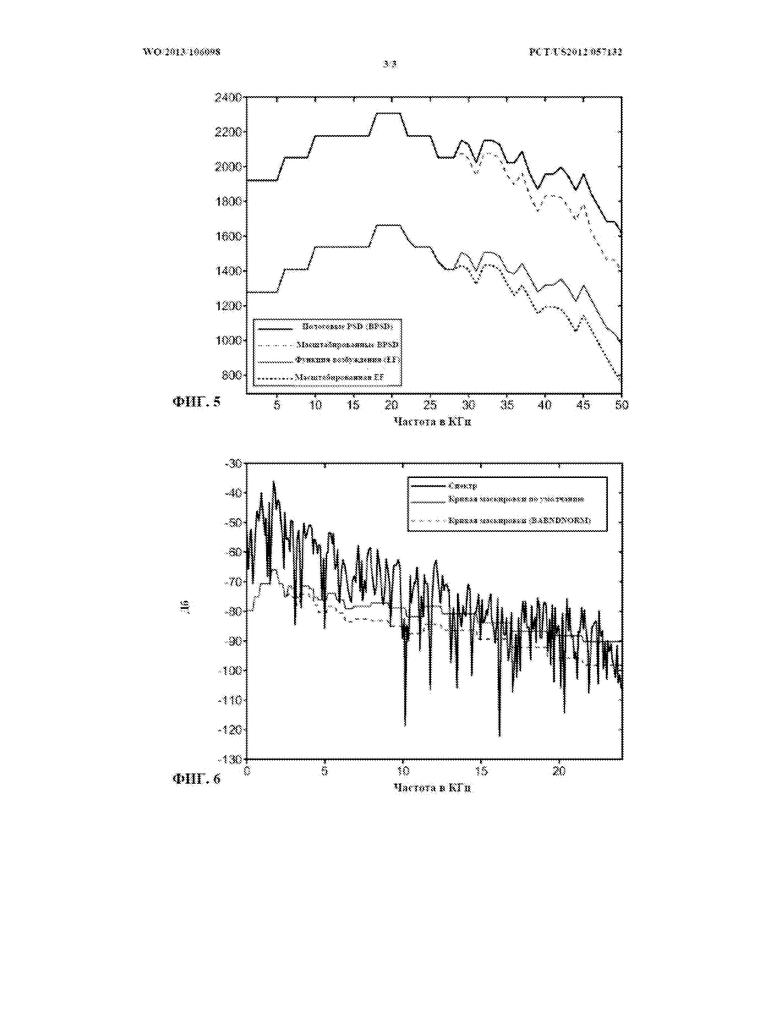
Изобретение относится к вычислительной технике. Технический результат заключается в адаптивном применении низкочастотной коррекции в ходе кодирования звуковых сигналов, содержащих выраженные низкочастотные тональные составляющие, без изменения декодера. Способ кодирования звука, включающий выполнение обнаружения тональности на аудиоданных в частотной области с целью генерирования данных управления коррекцией, указывающих, имеет ли выраженное тональное содержимое каждая низкочастотная полоса набора по меньшей мере из некоторых низкочастотных полос аудиоданных; генерирование предварительного значения маскировки для аудиоданных в полосе для каждой указанной низкочастотной полосы; определение значений маскировки для аудиоданных полосы для каждой из указанных низкочастотных полос, при этом значения маскировки для аудиоданных в каждой указанной низкочастотной полосе, имеющей выраженное тональное содержимое, что указывается данными управления коррекцией, получают путем выполнения низкочастотной коррекции для коррекции предварительного значения маскировки аудиоданных в полосе, и значение маскировки для каждой другой низкочастотной полосы в наборе представляет собой предварительное значение маскировки для аудиоданных полосы. 4 н. и 24 з.п. ф-лы, 7 ил.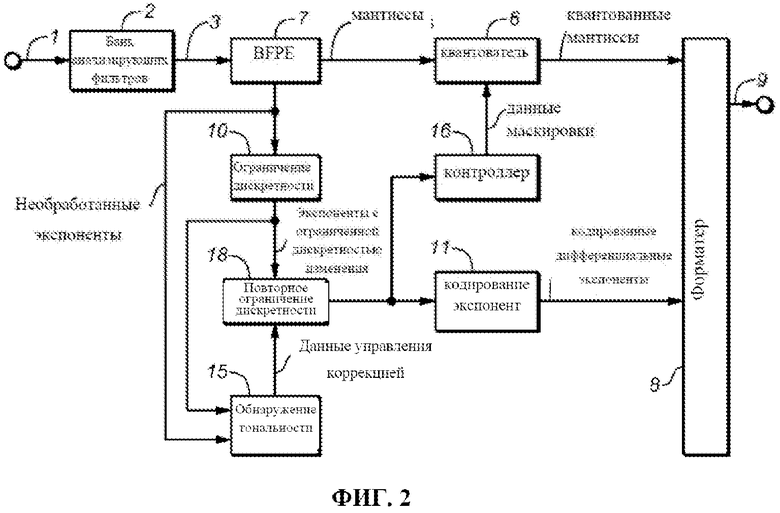
1. Способ кодирования звука, включающий этапы:
(a) выполнения обнаружения тональности на аудиоданных в частотной области с целью генерирования данных управления коррекцией, указывающих, имеет ли выраженное тональное содержимое каждая низкочастотная полоса набора по меньшей мере из некоторых низкочастотных полос аудиоданных;
(b) генерирования предварительного значения маскировки для аудиоданных в полосе для каждой указанной низкочастотной полосы;
(c) определения значений маскировки для аудиоданных полосы для каждой из указанных низкочастотных полос, при этом значения маскировки для аудиоданных в каждой указанной низкочастотной полосе, имеющей выраженное тональное содержимое, что указывается данными управления коррекцией, получают путем выполнения низкочастотной коррекции для коррекции предварительного значения маскировки аудиоданных в полосе, и значение маскировки для каждой другой низкочастотной полосы в наборе представляет собой предварительное значение маскировки для аудиоданных полосы,
при этом аудиоданные в частотной области содержат значение экспоненты для каждой указанной низкочастотной полосы набора, и при этом этап (а) включает этап определения для каждой указанной низкочастотной полосы набора разности между экспонентами и соответствующими экспонентами с ограниченной дискретностью изменения для аудиоданных.
2. Способ по п. 1, отличающийся тем, что данные управления коррекцией указывают, представляет ли аплодисменты по меньшей мере одна полоса из набора, и этап (с) включает этап:
генерирования значения маскировки без выполнения низкочастотной коррекции для аудиоданных в каждой низкочастотной полосе из набора, которая представляет аплодисменты или шум толпы, что указывается данными управления коррекцией.
3. Способ по п. 1, отличающийся тем, что этап (с) включает этап повторного ограничения дискретности изменения экспонент аудиоданных в каждой низкочастотной полосе из набора, в которой отсутствует выраженное тональное содержимое, что указывается данными управления коррекцией, с целью генерирования модифицированных аудиоданных, включающих модифицированную экспоненту по меньшей мере для одной указанной низкочастотной полосы, в которой отсутствует выраженное тональное содержимое.
4. Способ по п. 3, отличающийся тем, что этап повторного ограничения дискретности изменения экспонент генерирует модифицированную экспоненту по меньшей мере для одной указанной низкочастотной полосы, в которой отсутствует выраженное тональное содержимое, так, что экспонента аудиоданных в следующей, более высокочастотной полосе за вычетом указанной модифицированной экспоненты должна иметь одно из значений: 2, 1, 0 и -1.
5. Способ по п. 1, отличающийся тем, что этап (а) включает этап выполнения обнаружения тональности на аудиоданных с целью генерирования данных управления коррекцией, указывающих, имеет ли выраженное тональное содержимое каждая полоса частот по меньшей мере в подмножестве полос частот аудиоданных, при этом указанный способ дополнительно включает этап:
(d) выполнения процесса коррекции значений маскировки первым способом для указанной каждой полосы частот аудиоданных, имеющей выраженное тональное содержимое, что указывается данными управления коррекцией, и выполнения коррекции значений маскировки вторым способом для указанной каждой полосы частот аудиоданных, в которой отсутствует выраженное тональное содержимое, что указывается данными управления коррекцией.
6. Способ по п. 5, отличающийся тем, что процесс коррекции значений маскировки представляет собой процесс BABNDNORM, и этап (d) включает этап выполнения процесса BABNDNORM с первой постоянной масштабирования для указанной каждой полосы частот, имеющей выраженное тональное содержимое, и выполнения процесса BABNDNORM со второй постоянной масштабирования для указанной каждой полосы частот, в которой отсутствует выраженное тональное содержимое.
7. Способ по п. 1, отличающийся тем, что мера разности представляет собой меру среднеквадратичной разности между экспонентами и соответствующими экспонентами с ограниченной дискретностью изменения для аудиоданных.
8. Способ по п. 1, отличающийся тем, что данные управления коррекцией указывают, имеет ли выраженное тональное содержимое каждая отдельная низкочастотная полоса в наборе, и на этапе (с) низкочастотную коррекцию избирательно выполняют или не выполняют на каждой отдельной низкочастотной полосе в наборе.
9. Способ по п. 1, отличающийся тем, что данные управления коррекцией указывают, имеют ли выраженное тональное содержимое низкочастотные полосы в наборе при совместном рассмотрении, и низкочастотную коррекцию выполняют на этапе (с) на всех низкочастотных полосах в наборе, когда данные управления коррекцией указывают, что низкочастотные полосы в совместно рассматриваемом наборе имеют выраженное тональное содержимое.
10. Звуковой кодер, сконфигурированный для генерирования кодированных аудиоданных в ответ на аудиоданные в частотной области, в том числе путем выполнения адаптивной низкочастотной коррекции на аудиоданных, содержащий:
детектор тональности, сконфигурированный для выполнения обнаружения тональности на аудиоданных с целью генерирования данных управления коррекцией, указывающих, имеет ли выраженное тональное содержимое каждая низкочастотная полоса набора по меньшей мере из некоторых низкочастотных полос аудиоданных; и
ступень управления низкочастотной коррекцией, подключенную и сконфигурированную для того, чтобы в ответ на данные управления коррекцией адаптивно включать применение низкочастотной коррекции к каждой низкочастотной полосе из набора низкочастотных полос аудиоданных, в том числе путем генерирования предварительного значения маскировки для аудиоданных в полосе для каждой указанной низкочастотной полосы, и определения значений маскировки для аудиоданных в полосе для каждой указанной низкочастотной полосы, при этом значение маскировки для аудиоданных для каждой указанной низкочастотной полосы, имеющей выраженное тональное содержимое, что указывается данными управления коррекцией, получено путем выполнения низкочастотной коррекции для коррекции предварительного значения маскировки аудиоданных в полосе, и значение маскировки для каждой другой низкочастотной полосы в наборе представляет собой предварительное значение маскировки для аудиоданных полосы, при этом аудиоданные частотной области содержат значение экспоненты для каждой указанной низкочастотной полосы набора, и детектор тональности сконфигурирован для обнаружения для каждой указанной низкочастотной полосы набора меры разности между экспонентами и соответствующими экспонентами с ограниченной дискретностью изменения для аудиоданных.
11. Кодер по п. 10, отличающийся тем, что данные управления коррекцией указывают, представляет ли по меньшей мере одна полоса из набора по меньшей мере шум толпы и/или аплодисменты.
12. Кодер по п. 10, отличающийся тем, что ступень управления низкочастотной коррекцией сконфигурирована для адаптивного включения применения низкочастотной коррекции к аудиоданным каждой полосы из набора низкочастотных полос в ответ на данные управления коррекцией способом, который позволяет декодеру выполнять декодирование кодированных аудиоданных без определения того или без его информирования о том, применялась низкочастотная коррекция к любой низкочастотной полосе в ходе кодирования или нет.
13. Кодер по п. 10, отличающийся тем, что ступень управления низкочастотной коррекцией сконфигурирована для повторного ограничения дискретности изменения экспонент аудиоданных в каждой указанной низкочастотной полосе, в которой отсутствует выраженное тональное содержимое, что указывается данными управления коррекцией, с целью генерирования модифицированных аудиоданных, включающих по меньшей мере одну модифицированную экспоненту.
14. Кодер по п. 13, отличающийся тем, что ступень управления низкочастотной коррекцией сконфигурирована для повторного ограничения дискретности изменения экспонент аудиоданных в каждой указанной низкочастотной полосе, в которой отсутствует выраженное тональное содержимое, что указывается данными управления коррекцией и заключается в генерировании модифицированной экспоненты по меньшей мере для одной указанной низкочастотной полосы, в которой отсутствует выраженное тональное содержимое, так, что указанная экспонента аудиоданных в следующей, более высокочастотной полосе за вычетом указанной модифицированной экспоненты должна иметь одно из значений: 2, 1, 0 и -1.
15. Кодер по п. 10, отличающийся тем, что мера разности представляет собой меру среднеквадратичной разности между экспонентами и соответствующими экспонентами с ограниченной дискретностью изменения для аудиоданных.
16. Кодер по п. 10, отличающийся тем, что указанный кодер представляет собой процессор, запрограммированный программным обеспечением, которое реализует детектор тональности и ступень управления низкочастотной коррекцией.
17. Кодер по п. 10, отличающийся тем, что указанный кодер представляет собой процессор цифровой обработки сигналов.
18. Кодер по п. 10, отличающийся тем, что детектор тональности сконфигурирован для выполнения обнаружения тональности на аудиоданных с целью генерирования данных управления коррекцией, указывающих, имеет ли выраженное тональное содержимое каждая полоса частот по меньшей мере из подмножества полос частот аудиоданных, и где кодер содержит ступень коррекции значений маскировки, сконфигурированную для выполнения процесса коррекции значений маскировки первым способом для указанной каждой полосы частот аудиоданных, имеющей выраженное тональное содержимое, что указывается указанными данными управления коррекцией, и для выполнения коррекции значений маскировки вторым способом для указанной каждой полосы частот аудиоданных, в которой отсутствует выраженное тональное содержимое, что указывается данными управления коррекцией.
19. Кодер по п. 18, отличающийся тем, что процесс коррекции значений маскировки представляет собой процесс BABNDNORM, и ступень коррекции значений маскировки сконфигурирована для выполнения процесса BABNDNORM с первой постоянной масштабирования для указанной каждой полосы частот, имеющей выраженное тональное содержимое, и для выполнения процесса BABNDNORM со второй постоянной масштабирования для указанной каждой полосы частот, в которой отсутствует выраженное тональное содержимое.
20. Система для обработки аудиоданных, содержащая:
кодер, сконфигурированный для генерирования кодированных аудиоданных в ответ на аудиоданные в частотной области, в том числе путем выполнения адаптивной низкочастотной коррекции на аудиоданных; и
декодер, сконфигурированный для декодирования кодированных аудиоданных с целью восстановления аудиоданных, при этом кодер содержит:
детектор тональности, сконфигурированный для выполнения обнаружения тональности на аудиоданных с целью генерирования данных управления коррекцией, указывающих, имеет ли выраженное тональное содержимое каждая низкочастотная полоса набора по меньшей мере из некоторых низкочастотных полос аудиоданных;
ступень управления низкочастотной коррекцией, подключенную и сконфигурированную для того, чтобы в ответ на данные управления коррекцией адаптивно включать применение низкочастотной коррекции к каждой низкочастотной полосе из набора низкочастотных полос аудиоданных, в том числе путем генерирования предварительного значения маскировки для аудиоданных в полосе для каждой указанной низкочастотной полосы, и определения значений маскировки для аудиоданных в полосе для каждой указанной низкочастотной полосы, при этом значение маскировки для аудиоданных для каждой указанной низкочастотной полосы, имеющей выраженное тональное содержимое, что указывается данными управления коррекцией, получено путем выполнения низкочастотной коррекции для коррекции предварительного значения маскировки аудиоданных в полосе, и значение маскировки для каждой другой низкочастотной полосы в наборе представляет собой предварительное значение маскировки для аудиоданных полосы, при этом аудиоданные частотной области содержат значение экспоненты для каждой указанной низкочастотной полосы набора, и детектор тональности сконфигурирован для обнаружения для каждой указанной низкочастотной полосы набора меры разности между экспонентами и соответствующими экспонентами с ограниченной дискретностью изменения для аудиоданных.
21. Система по п. 20, отличающаяся тем, что данные управления коррекцией указывают, представляет ли по меньшей мере одна полоса из набора шум толпы или аплодисменты.
22. Система по п. 20, отличающаяся тем, что декодер сконфигурирован для декодирования кодированных аудиоданных без определения того, или его информирования о том, применялась низкочастотная коррекция к какой-либо низкочастотной полосе в ходе кодирования или нет.
23. Система по п. 20, отличающаяся тем, что ступень управления низкочастотной коррекцией сконфигурирована для повторного ограничения дискретности изменения экспонент аудиоданных в каждой указанной низкочастотной полосе, в которой отсутствует выраженное тональное содержимое, что указывается данными управления коррекцией, с целью генерирования модифицированных аудиоданных, включающих по меньшей мере одну модифицированную экспоненту.
24. Система по п. 23, отличающаяся тем, что ступень управления низкочастотной коррекцией сконфигурирована для повторного ограничения дискретности изменения экспонент аудиоданных в каждой указанной низкочастотной полосе, в которой отсутствует выраженное тональное содержимое, что указывается данными управления коррекцией и заключается в генерировании модифицированной экспоненты по меньшей мере для одной указанной низкочастотной полосы, в которой отсутствует выраженное тональное содержимое, так, что указанная экспонента аудиоданных в следующей, более высокочастотной полосе за вычетом указанной модифицированной экспоненты должна иметь одно из значений: 2, 1, 0 и -1.
25. Способ декодирования кодированных аудиоданных, включающий этапы:
приема сигнала, служащего признаком кодированных аудиоданных; и
декодирования кодированных аудиоданных с целью генерирования сигнала, служащего признаком аудиоданных,
при этом кодированные аудиоданные были сгенерированы путем:
(a) выполнения обнаружения тональности на аудиоданных в частотной области с целью генерирования данных управления коррекцией, указывающих, имеет ли выраженное тональное содержимое каждая низкочастотная полоса из набора по меньшей мере некоторых низкочастотных полос аудиоданных;
(b) генерирования предварительного значения маскировки для аудиоданных в полосе для каждой указанной низкочастотной полосы; и
(c) определения значений маскировки для аудиоданных полосы для каждой из указанных низкочастотных полос, при этом значение маскировки для аудиоданных в указанной каждой низкочастотной полосе, имеющей выраженное тональное содержимое, что указывается данными управления коррекцией, получают путем выполнения низкочастотной коррекции для коррекции предварительного значения маскировки аудиоданных в полосе, и значение маскировки для аудиоданных в каждой другой низкочастотной полосе в наборе представляет собой предварительное значение маскировки для аудиоданных полосы, при этом аудиоданные в частотной области содержат значение экспоненты для каждой указанной низкочастотной полосы набора, и при этом этап (а) включает этап определения для каждой указанной низкочастотной полосы набора разности между экспонентами и соответствующими экспонентами с ограниченной дискретностью изменения для аудиоданных.
26. Способ по п. 25, отличающийся тем, что данные управления коррекцией указывают, представляет ли шум толпы или аплодисменты по меньшей мере одна полоса из набора, и этап (с) включает этап:
генерирования значения маскировки без выполнения низкочастотной коррекции для аудиоданных в каждой низкочастотной полосе из набора, которая представляет аплодисменты или шум толпы, что указывается данными управления коррекцией.
27. Способ по п. 25, отличающийся тем, что этап (с) включает этап повторного ограничения дискретности изменения экспонент аудиоданных в каждой низкочастотной полосе из набора, в которой отсутствует выраженное тональное содержимое, что указывается данными управления коррекцией, с целью генерирования модифицированных аудиоданных, включающих модифицированную экспоненту для по меньшей мере одной указанной низкочастотной полосы, в которой отсутствует выраженное тональное содержимое.
28. Способ по п. 27, отличающийся тем, что этап повторного ограничения дискретности изменения экспонент генерирует модифицированную экспоненту по меньшей мере для одной указанной низкочастотной полосы, в которой отсутствует выраженное тональное содержимое, так, что экспонента аудиоданных в следующей, более высокочастотной полосе за вычетом указанной модифицированной экспоненты должна иметь одно из значений: 2, 1, 0 и -1.
| US 7333930 B2, 19.02.2008 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| RU 2010101881 A, 27.07.2011. | |||

