Настоящее изобретение относится к интер-уровневому (межуровневому) предсказанию между уровнями с разным динамическим диапазоном значений отсчетов при кодировании изображений и/или видео.
Система зрения человека может воспринимать светимость в диапазоне около 8 порядков величины и около 5 порядков одновременно при адаптации к конкретным условиям освещения [1]. В противоположность этому, за исключением последних нескольких лет динамический диапазон большинства устройств, предназначенных для фиксации и отображения видео, ограничен приблизительно двумя порядками величины. На сегодняшний день, с повсеместным распространением HDR устройств отображения (устройств отображения с расширенным динамическим диапазоном) можно ожидать впечатляющего роста реалистичности изображений и видео при передаче полного диапазона видимого света через систему HDR видео [1]. Для обеспечения возможности плавного перехода от LDR видео (видео с суженным динамическим диапазоном) к HDR видео чрезвычайно полезно обеспечить обратную совместимость будущего стандарта HDR кодирования, дающую возможность воспроизведения видео на устройствах старого образца. До сих пор в технической литературе описаны только несколько подходов к созданию кодирования HDR видео с обратной совместимостью [2-6]. Тогда как подход, описанный в [2], основан на реализации усовершенствованного простого профиля кодека MPEG-4 с глубиной 8 бит, в источниках [3-6] описаны расширения профиля масштабируемого видеокодирования в стандарте H.264/AVC (также называемом SVC). Стандарт SVC допускает использование глубины, составляющей более 8 бит.
Во всех случаях перед кодированием должна быть создана LDR видеопоследовательность исходя из исходных HDR видеоданных посредством тонального отображения. Операторы тонального отображения (TMO), могут работать на всем изображении глобально (глобальные методы), локально (локальные методы) или и так и так. Наиболее важные операторы TMO всесторонне представлены в литературе [1]. Процесс, который восстанавливает HDR видеопоследовательность из LDR видео, можно обозначить как обратное тональное отображение (ITMO) или (предпочтительно) интер-уровневое предсказание (ILP), когда оно используется для масштабируемого видеокодирования [3]. В этом контексте задачей ILP является уменьшение избыточности между уровнями LDR и HDR для уменьшения необходимой скорости передачи бит для передачи остаточной информации. В одном сценарии кодирования предсказание IPL должно осуществляться независимо по отношению к выбранным операторам TMO, чтобы обеспечить общую эффективность. Например, в работах [1] и [4] авторы предлагают использовать простую функцию отображения для глобального изменения масштаба каждого LDR кадра или даже всей LDR последовательности до динамического диапазона HDR последовательности. Однако эффективность такого предсказателя низка во всех случаях, когда LDR видео было создано локальным адаптивным TMO (который обычно создает более привлекательные LDR видео).
Подходы, описанные в [3-6], отличаются некоторой локальной адаптивностью благодаря использованию ILP на основе блоков, однако эти подходы используются в цветовом пространстве, которое не подходит для передачи HDR данных. Кроме того, эти подходы имеют весьма ограниченные возможности для оценки параметров ILP, причем кодирование необходимой побочной информации весьма не эффективно.
Соответственно, целью настоящего изобретения является обеспечение концепции для выполнения интер-уровневого предсказания между уровнями с разными динамическими диапазонами значений отсчетов при кодировании изображений (например, видео), так чтобы эффективность кодирования с точки зрения отношения между качеством кодирования, с одной стороны, то есть, восстанавливаемым качеством, которое страдает от потерь при кодировании, и скоростью кодирования, то есть, необходимым объемом данных, увеличилась.
Эта цель достигается объектом изобретения, представленным в независимых пунктах формулы изобретения, входящих в прилагаемый набор пунктов формулы изобретения.
Базовый вывод, вытекающий из настоящего изобретения, состоит в том, что можно увеличить отношение между качеством кодирования, с одной стороны, и скоростью кодирования, с другой стороны, если обеспечить комбинированное использование глобального предсказателя и локального предсказателя. Глобальный предсказатель выводит функцию глобального тонального отображения на основе статистического анализа пар значений совмещенных отсчетов в первой тонально отображенной версии и второй версии изображения и применяет эту функцию глобального тонального отображения к первой тонально отображенной версии изображения для получения глобально предсказанного опорного изображения для второй версии данного изображения. Локальный предсказатель выводит локально изменяющуюся функцию тонального отображения локально на основе статистического анализа значений совмещенных отсчетов во второй версии изображения и глобально предсказанном опорном изображении в единицах суб-частей, на которые разбиты глобально предсказанное опорное изображение и вторая версия указанного изображения, и применяет локально изменяющуюся функцию тонального отображения к глобально предсказанному опорному изображению для получения глобально и локально предсказанного опорного изображения для второй версии указанного изображения. На стороне декодирования также имеются глобальный предсказатель и локальный предсказатель, каждый из которых выводит функцию глобального тонального отображения и локально изменяющуюся функцию тонального отображения из побочной информации потока данных расширения.
Согласно варианту настоящего изобретения возможно блокирование глобального предсказания. То есть, согласно этим вариантам глобальный предсказатель сконфигурирован для блокирования применения функции глобального тонального отображения в случае разброса пар значений совмещенных отсчетов в первой тонально отображенной версии изображения и второй версии изображения относительно функции глобального тонального отображения, превышающего заранее определенный порог, где в случае упомянутого блокирования локальный предсказатель сконфигурирован для выполнения локального вывода и упомянутого применения к первой тонально отображенной версии изображения, а не глобально предсказанному опорному изображению. Соответственно, передача функции глобального тонального отображения от кодера к декодеру согласно этим вариантам ограничена изображениями, где передача функции глобального тонального отображения и ее применение оправдано, поскольку помогает избежать издержек на передачу для тех изображений, для которых глобальное предсказание в основном приводит к потерям с точки зрения скорости кодирования, затрачиваемых на передачу функции глобального тонального отображения. Возможно оповещение декодера о принятом решении по поводу упомянутого блокирования.
Согласно дополнительным вариантам настоящей заявки локальный предсказатель при выводе локально изменяющейся функции тонального отображения локально сконфигурирован для определения для каждой суб-части наклона и отсекаемого отрезка линии регрессии, через распределение пар значений совмещенных отсчетов в соответствующей суб-части второй версии изображения и глобально предсказанного опорного изображения. Для эффективного кодирования упомянутого наклона и отсекаемого отрезка наклон, определенный для текущей суб-части, можно закодировать в виде остатка предсказания для пространственного предсказания, из наклона соседней суб-части, наклон которой был закодирован ранее. Прямая линия, имеющая наклон текущей суб-части, согласно одному варианту встраивается в распределение пар значений совмещенных отсчетов в соседней суб-части второй версии восстановленного к этому моменту изображения, с одной стороны, и глобально предсказанного опорного изображения, с другой стороны, и определяется отсекаемый отрезок этой прямой линией, где указанный отсекаемый отрезок соответствующей суб-части кодируют в виде остатка предсказания относительно пространственного предсказания отсекаемого отрезка, которое зависит от отсекаемого отрезка прямой линии. Эти варианты с точки зрения авторов изобретения имеют преимущество, согласно которому локально изменяющийся наклон, определенный локальным предсказателем, подходит для, и дает значительные улучшения кодирования из, кодирования с пространственным предсказанием, принимая во внимание тот факт, что корреляция отсекаемого отрезка между соседними суб-частями зависит от локально изменяющегося наклона, и, соответственно, использование локальной корреляции между соседними значениями отсекаемого отрезка в первую очередь становится возможным благодаря встраиванию другой прямой линии с использованием предсказанного наклона текущей суб-части в качестве наклона для соседней суб-части, и использованием результирующего отсекаемого отрезка для пространственного предсказания наклона текущей суб-части.
Вышеупомянутые и другие имеющие выгодные реализации варианты настоящего изобретения являются объектом зависимых пунктов формулы изобретения.
В частности, предпочтительные варианты настоящего изобретения более подробно изложены ниже со ссылками на чертежи, где
на фиг. 1 показана блок-схема устройства для выполнения интер-уровневого предсказания на стороне кодирования согласно одному варианту изобретения;
на фиг. 2 показана блок-схема возможной реализации варианта по фиг. 1;
на фиг. 3а и 3b показаны результирующие функции глобального тонального отображения по фиг. 1 для разных тональных отображений, применяемых для выведения изображения с суженным динамическим диапазоном;
на фиг. 4а и 4b показаны различные результаты кодирования; и
на фиг. 5 показана блок-схема устройства для выполнения интер-уровневого предсказания на стороне декодирования, соответствующая варианту по фиг. 1, согласно одному варианту изобретения.
На фиг. 1 показан вариант устройства 10 для выполнения интер-уровневого предсказания между первой ступенью 12 кодирования изображения для кодирования первой тонально отображенной версии изображения и второй ступенью 14 кодирования изображения для кодирования второй версии изображения. Первая тонально отображенная версия изображения, кодированная первой ступенью 12 кодирования изображения, имеет первый динамический диапазон значений отсчетов. Например, первая ступень 12 кодирования изображения оперирует с целочисленными значениями отсчетов длиной m в битах. Вторая версия изображения, кодированная второй ступенью 14 кодирования изображения, имеет второй динамический диапазон значений отсчетов, который больше первого динамического диапазона значений отсчетов. Например, вторая ступень 14 кодирования изображения может быть сконфигурирована для оперирования с целочисленными значениями отсчетов длиной n в битах, где n>m. В более подробно описанном варианте по фиг. 2 величина n составляет 12, а m составляет 8.
На фиг. 1 показано устройство 10 для выполнения интер-уровневого предсказания, где первая ступень 12 кодирования изображения и вторая ступень 14 кодирования изображения соединены друг с другом, образуя кодер 16 масштабируемого изображения. Первая ступень 12 кодирования изображения имеет вход, соединенный с входом 18 суженного динамического диапазона кодера 16 масштабируемого изображения, и аналогичным образом, вторая ступень 14 кодирования изображения имеет вход, соединенный с входом 20 расширенного динамического диапазона кодера 16 масштабируемого изображения. Выход первой ступени 12 кодированного изображения соединен с выходом 22 потока данных базового уровня кодера 16 масштабируемого изображения, а выход второй ступени 14 кодирования изображения выводит поток данных расширения на выход 24 потока данных расширения кодера 16 масштабируемого изображения. Как будет ясно из фиг. 2, эти выходы не должны физически отличаться друг от друга. Оба потока данных на выходах 22 и 24 могут мультиплексироваться, образуя масштабируемый поток данных, для которого кодер 16 просто должен обеспечить один общий выход.
Устройство 10 подсоединено между первой ступенью 12 кодирования изображения и второй ступенью 14 кодирования изображения. В частности, как показано пунктирными линиями на фиг. 1, глобальный предсказатель 10 может иметь свой вход, соединенный с входом 18, для приема исходной версии первой тонально отображенной версии изображения, поступающей на первую ступень 12 кодирования изображения, с тем чтобы оперировать с первой тонально отображенной версией изображения без потерь при кодировании, которые возможно инициируются первой ступенью 12 кодирования изображения. Этот альтернативный вариант также эквивалентен соединению входа устройства 10 с выходом первой ступени 12 кодирования изображения в случае, когда эта ступень сконфигурирована для кодирования без потерь первой тонально отображенной версии изображения. Однако в случае кодирования с потерями предпочтительно, чтобы устройство 10 имело вход, соединенный с выходом первой ступени 12 кодирования изображения, который, в свою очередь, соединен с выходом 22 или каким-либо другим выходом, на котором можно вывести восстанавливаемую версию первой тонально отображенной версии изображения, при условии, что она является восстанавливаемой на основе потока данных базового уровня на выходе 22, например, во внутреннем буфере во внутреннем контуре предсказания ступени 12 кодирования. Эта восстанавливаемая версия первой тонально отображенной версии изображения также имеется на стороне декодирования на основе потока 22 данных базового уровня, так что интер-уровневое предсказание, дополнительно описанное ниже, может быть точно восстановлено на стороне декодирования.
Устройство для выполнения интер-уровневого предсказания включает в себя глобальный предсказатель 26 и локальный предсказатель 28. Глобальный предсказатель 26 и локальный предсказатель 28 соединены последовательно между входом устройства 10 и выходом устройства 10, используя который устройство 10 выводит опорное изображение на вход интер-уровневого предсказания второй ступени 14 кодирования изображения. Глобальный и локальный предсказатели 26 и 28 соединены с входом 20, где создается вторая версия изображения. Кроме того, глобальный и локальный предсказатели 26 и 28 могут создать побочную информацию и вывести эту побочную информацию на выход 24, чтобы сформировать побочную информацию потока данных расширения, выводимого второй ступенью 14 кодирования изображения. Как показано на фиг. 1 пунктирной линией, идущей от второй ступени кодирования изображения к локальному предсказателю 28, локальный предсказатель 28 и вторая ступень 14 кодирования изображения могут взаимодействовать, как более подробно описывается ниже применительно к более конкретным вариантам устройства 10, показанного на фиг. 1.
На фиг. 1 в качестве иллюстрации также показано, каким образом на кодер 16 масштабируемого изображения могут подаваться первая и вторая версии изображения на входы 18 и 20. Следует подчеркнуть, что возможно и другое техническое решение. В любом случае, согласно техническому решению, показанному на фиг. 1, изображение с расширенным динамическим диапазоном появляется на узле 30. Блок 32 тонального отображения подсоединен между упомянутым узлом 30 и входом 18 для получения тонально отображенной версии изображения на основе изображения с расширенным динамическим диапазоном на узле 30. Как показано на фиг. 1 пунктирными линиями, между узлом 30 и входом 20 может (но не обязательно) быть подсоединен дополнительный блок 34 тонального отображения. То есть, вторая версия изображения, кодированная второй ступенью 14 кодирования изображения, может представлять собой изображение с расширенным динамическим диапазоном на самом узле 30 или может представлять собой его тонально отображенную версию, которая, однако, имеет более широкий динамический диапазон значений отсчетов по сравнению с версией на входе 18.
После описания структуры устройства 10 и его интеграции в кодер 16 масштабируемого изображения и системы для кодирования изображения на узле 30 в поток данных базового уровня и поток данных расширения соответственно разъясняется режим работы устройства 10 и других элементов, показанных на фиг. 1.
Как стало ясно из вышеприведенного обсуждения фиг. 1, назначением всей системы, показанной на фиг. 1, является кодирование изображения на узле 30 масштабируемым образом с получением потока данных базового уровня на выходе 22 в сочетании с потоком данных расширения на выходе 24, так что версию изображения, имеющую суженный динамический диапазон значений отсчетов, можно вывести из потока данных базового уровня, а версию изображения, имеющую более широкий динамический диапазон значений отсчетов, можно вывести из потока данных расширения, когда обеспечено восстановление версии с суженным динамическим диапазоном значений отсчетов. Если более точно, то чтобы уменьшить скорость передачи битов необходимую для передачи, устройство 10 использует избыточности между тонально отображенной версией с более узким динамическим диапазоном и второй версией с более широким динамическим диапазоном путем предоставления второй ступени 14 кодирования изображения предсказанного опорного изображения для входящего второго изображения с более широким динамическим диапазоном. Соответственно, вторая ступень 14 кодирования изображения может быть сконфигурирована только для кодирования остатка предсказанного опорного изображения, то есть, разности между исходно поступившей версией с более широким динамическим диапазоном и версией, полученной посредством интер-уровневого предсказания. Для кодирования указанного остатка вторая ступень 14 кодирования изображения может использовать кодирование с потерями, включая квантование, в том числе, например, кодирование с преобразованием, таким как преобразование DCT на блочной основе или т.п., результаты квантования которого, то есть, уровни коэффициентов преобразования, кодируют в поток данных расширения. Кодированный остаток, представляющий остаток предсказания, выводится второй ступенью 14 кодирования изображения. Глобальный и локальный предсказатели 26 и 28 могут снабдить этот кодированный остаток вышеупомянутой побочной информацией, позволяющей глобальному и локальному предсказателям на стороне декодирования выполнить интер-уровневое предсказание таким же образом, как это делают предсказатели 26 и 28 в устройстве 10.
Как стало ясно из обсуждения, приведенного во вводной части описания настоящего изобретения, блок 32 тонального отображения свободно выбирает функцию тонального отображения, применяемую к изображению 30. В частности, это означает, что блок 32 тонального отображения может применить локально изменяющуюся функцию тонального отображения к отсчетам изображения 30 с расширенным динамическим диапазоном. Важно отметить, что все элементы кодера 16 масштабируемого изображения не зависят от режима работы и действительно выбранной функцией тонального отображения для блока 32 тонального отображения. В реальном сценарии управление блоком 32 тонального отображения может осуществляться кинорежиссером, например, тем, кто управляет функцией тонального отображения блока 32 тонального отображения, с тем чтобы обеспечить красивое представление изображения 30 с расширенным динамическим диапазоном в границах динамического диапазона первой ступени 12 кодирования изображения.
То есть, функция тонального отображения, применяемая блоком 32 тонального отображения, может локально изменяться в рамках изображения на узле 30. В случае, когда изображение относится к видео, и первой ступенью 12 кодирования изображения соответственно является видеокодер, функция тонального отображения, применяемая блоком 32 тонального отображения, также может изменяться во времени. В отдельных видеоизображениях во времени также может изменяться локальное/пространственное отклонение функции тонального отображения. Например, управление блоком 32 тонального отображения может осуществляться так, чтобы функция тонального отображения изменялась при переходе с одной видеосцены на другую, или в рамках одного изображения, например, чтобы функция тонального отображения изменялась при переходе от заднего плана к переднему плану или т.п. Опять же, ступень 12 кодирования, также как устройство 10, не зависит от этих изменений.
Аналогичным образом не обязательный блок 34 тонального отображения может свободно применять пространственное или пространственно/временное изменение функции тонального отображения, применяемой к изображению с расширенным динамическим диапазоном с тем, чтобы получить вторую версию данного изображения, причем опять же устройство 10 и кодер 14 не зависят от указанных изменений. Оператор может управлять блоком 34 тонального отображения таким образом, чтобы обеспечить красивое представление этого изображения в границах динамического диапазона отсчетов, наложенных ступенью 14 кодирования.
Обратимся к фиг. 2, где более подробно показана реализация варианта по фиг. 1 и из которой станет более понятным, что подача сигналов на входы 18 и 20 может выполняться так, чтобы кодеры 12 и 14 функционировали в разных цветовых пространствах, то есть, чтобы версии, обеспечиваемые на входах 18 и 20, содержали отсчеты, представляющие цвет в разных цветовых пространствах соответственно. В этом случае интер-уровневое предсказание, выполняемое устройством 10, может быть реализовано с использованием любого из указанных цветовых пространств или третьего цветового пространства. Кроме того, интер-уровневое предсказание, выполняемое глобальным и локальным предсказателями 26 и 28, более подробно описанное ниже, может относиться просто к компоненте светимости соответствующего цветового пространства. Затем можно использовать преобразование цветового пространства для переходов с одного цветового пространства на другое. Однако следует понимать, что все описанные далее варианты можно легко приспособить к вариантам, где изображения просто определены в шкале серого.
После описания фиг. 1, носящего скорее общий вводный характер, описывается режим работы глобального предсказателя 26 и локального предсказателя 28. Предсказатели 26 и 28 работают двухступенчатым образом. Глобальный предсказатель 26 осуществляет поиск с целью идентификации глобальной взаимосвязи между значениями отсчетов версии изображения с более узким динамическим диапазоном и значениями отсчетов версии изображения с более широким динамическим диапазоном и использования этой глобальной взаимосвязи для выполнения первого шага, состоящего в определении опорного изображения, используемого ступенью 14 кодирования для эффективного кодирования с предсказанием версии изображения с более широким динамическим диапазоном. В частности, глобальный предсказатель 26 сконфигурирован для вывода функции глобального тонального отображения на основе статистического анализа пары значений совместных отсчетов в первой тональной отображенной версии и второй версии изображения и применения этой функции глобального тонального отображения к первой тонально отображенной версии изображения для получения глобально предсказанного опорного изображения для второй версии изображения. Для иллюстрации этого на фиг. 1 показана первая тонально отображенная версия изображения под ссылочной позицией 36 и вторая версия изображения под ссылочной позицией 38. Поскольку обе версии 36 и 38 являются версиями одного и того же изображения, между отсчетами обеих версий 36 и 38 можно определить совмещение. Как было описано выше, отсчеты версии 36 определены в более узком динамическом диапазоне значений отсчетов по сравнению с отсчетами версии 38. Например, отсчеты версии 36 кодируют, используя 8 бит, в то время как отсчеты версии 38 кодируют, используя 12 бит. Маленькими крестиками на фиг. 1 в качестве образца показана совмещенная пара отсчетов. Статистический анализ пар совмещенных отсчетов в версиях 36 и 38 может содержать, например, формирование функции глобального тонального отображения, определенной на возможных значениях версии 36 изображения с суженным динамическим диапазоном, и имеющей для каждого возможного значения центральную тенденцию или среднее значение соответствующих значений отсчетов версии 38 изображения с расширенным динамическим диапазоном. Если более точно, то глобальный предсказатель 26 может быть сконфигурирован для вывода функции 40 глобального тонального отображения для каждого из возможных значений xlow первого динамического диапазона 42 значений отсчетов первой версии 36 (или по меньшей мере поднабора репрезентативных значений поддержки из числа возможных значений) путем определения центральной тенденции распределения значений xHigh отсчетов во второй версии 38 изображения, которые совмещены с отсчетами в первой тонально отображенной версии 36 изображения, где значение xlow равно соответствующему возможному значению. На фиг. 1 в качестве примера одно возможное значение показано пунктирной линией под ссылочной позицией 44, а гистограмма или распределение значений xHigh совмещенных отсчетов в версии 38 изображения, а именно, совмещенных с отсчетами в версии 36 изображения, имеющей это репрезентативное возможное значение 44 из суженного динамического диапазона, показано под ссылочной позицией 46. Как было описано выше, глобальный предсказатель 26 определяет центральную тенденцию этого распределения 46, например, как среднее арифметическое 48 и принимает это значение 48 в качестве значения функции 40 глобального тонального отображения для репрезентативного возможного значения 44. Соответственно, функция 40 глобального тонального отображения выполняет отображение между динамическим диапазоном 42 значений отсчетов версии 36 и вторым динамическим диапазоном 50 значений отсчетов версии 38. В частности, блок 26 глобального тонального отображения получает функцию 40 глобального тонального отображения путем выполнения вышеупомянутой процедуры для разных возможных значений xlow. Глобальный предсказатель 26 может выполнить упомянутую процедуру для каждого возможного значения. Однако, чтобы удерживать непроизводительные вычислительные затраты в приемлемом диапазоне, глобальный предсказатель 26 может выполнить вышеуказанную процедуру просто для опорных точек или подходящего поднабора возможных значений, но не для всех возможных значений, используя интерполяцию между указанными опорными точками с тем, чтобы получить функцию глобального тонального отображения между ними.
Как показано на фиг. 1, глобальный предсказатель 26 может быть сконфигурирован для кодирования функции 40 глобального тонального отображения в качестве побочной информации в поток данных расширения, создаваемый второй ступенью 14 кодирования изображения, и формирующий расширение потока данных базового уровня на выходе первой ступени 12 кодирования изображения.
Применение функции 40 глобального тонального отображения к первой тонально отображенной версии 36 изображения может содержать установку каждого значения отсчета в версии 36 изображения, равным соответствующему значению функции глобального тонального отображения, то есть, среднему значению, на которое отображается значение отсчета суженного динамического диапазона в соответствии с функцией 40 глобального тонального отображения. Соответственно, глобально предсказанное опорное изображение, полученное на выходе глобального предсказателя 26, имеет значения отсчетов, которые уже определены в более широком динамическом диапазоне значений версии 38 изображения, которая должна быть предсказана.
Следует заметить, что глобальный предсказатель 26 не использует какую-либо имеющуюся информацию о тональном отображении, выполняемом в блоке 32 тонального отображения, или какую-либо информацию о необязательном тональном отображении, выполняемом блоком 34 тонального отображения.
Глобальный предсказатель 26 может выполнить кодирование функции 40 глобального тонального отображения дифференциальным образом в направлении увеличения или уменьшения возможных значений xlow, например, кодировать разности 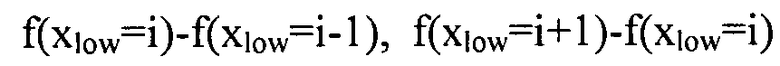 . Однако также возможны другие подходы, например, аппроксимация функции f с использованием подбора аппроксимирующей кривой, например, с использованием аппроксимации Тейлора для степени полинома p>=1 или т.п. с последующим кодированием остатков, причем кодирование остатков может быть выполнено опять же с использованием дифференциального кодирования.
. Однако также возможны другие подходы, например, аппроксимация функции f с использованием подбора аппроксимирующей кривой, например, с использованием аппроксимации Тейлора для степени полинома p>=1 или т.п. с последующим кодированием остатков, причем кодирование остатков может быть выполнено опять же с использованием дифференциального кодирования.
Локальный предсказатель 28 сконфигурирован для вывода локально изменяющейся функции тонального отображения локально на основе статистического анализа значений совмещенных отсчетов во второй версии 38 изображения и глобально предсказанного опорного изображения 52 в единицах суб-частей, на которые разбиты глобально предсказанное опорное изображение 52 и вторая версия 38 изображения, и для применения локально изменяющейся функции тонального отображения к глобально предсказанному опорному изображению 52 для получения глобально и локально предсказанного опорного изображения 54 для второй версии 38 изображения. Указанное разбиение, например, может представлять собой регулярное разбиение на блоки одинакового размера, которые компонуют по столбцам и строкам, как показано пунктирными линиями на фиг. 1, либо может представлять собой какое-либо другое разбиение версии 38 изображения и глобально предсказанного опорного изображения 52 на суб-части с совмещенным границами, на которых суб-части стыкуются друг с другом. Локальный предсказатель 28 при выводе локально изменяющейся функции тонального отображения локально определяет для каждой суб-части 56 наклон 58 и отсекаемый отрезок 60 линии 62 регрессии, через распределение 64 пар значений совмещенных отсчетов в соответствующей суб-части 56 версии 38 изображения и глобально предсказанном опорном изображении 52, то есть, распределения точек  , где i обозначает позиции отсчетов в текущей суб-части 56. На фиг. 1 значения отсчетов в опорном изображении 52 обозначены как xglRef, в то время как значения отсчетов версии 38 изображения обозначены как xhigh. В более конкретном варианте, подробно описанном ниже, наклон обозначен как ω, а упомянутый отсекаемый отрезок как o. Оба эти значения определяют для каждой суб-части 56 локально изменяющуюся функцию тонального отображения на той же самой суб-части 56. Другими словами, локальный предсказатель 28 определяет для каждой суб-части 56 пару, состоящую из наклона 58 и отсекаемого отрезка 60, значения которых кодируют в качестве побочной информации в поток данных расширения на выходе 24, как показано пунктирной стрелкой 66.
, где i обозначает позиции отсчетов в текущей суб-части 56. На фиг. 1 значения отсчетов в опорном изображении 52 обозначены как xglRef, в то время как значения отсчетов версии 38 изображения обозначены как xhigh. В более конкретном варианте, подробно описанном ниже, наклон обозначен как ω, а упомянутый отсекаемый отрезок как o. Оба эти значения определяют для каждой суб-части 56 локально изменяющуюся функцию тонального отображения на той же самой суб-части 56. Другими словами, локальный предсказатель 28 определяет для каждой суб-части 56 пару, состоящую из наклона 58 и отсекаемого отрезка 60, значения которых кодируют в качестве побочной информации в поток данных расширения на выходе 24, как показано пунктирной стрелкой 66.
Как более подробно описано ниже, локальный предсказатель 28 может быть сконфигурирован для квантования наклона 58 и отсекаемого отрезка 60 путем минимизации функции стоимости, которая зависит от соответствующей суб-части 56 версии 38 изображения с расширенным динамическим диапазоном и соответствующей суб-части 56 глобально предсказанного опорного изображения 52, отсчеты которого взвешены с использованием наклона и смещены на отсекаемый отрезок 60. То есть, квантованный наклон 58 и квантованный отсекаемый отрезок 60 выделены для получения окончательного предсказанного опорного изображения следующим образом: значения xglRef в суб-части 56 опорного изображения 52 взвешиваются (умножаются) на ω, и к полученному произведению добавляется o, то есть, 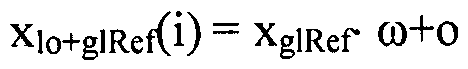 для всех позиций i отсчетов в суб-части 56. Это выполняется для каждой суб-части 56 с использованием соответствующей пары, состоящей из квантованных ω и o.
для всех позиций i отсчетов в суб-части 56. Это выполняется для каждой суб-части 56 с использованием соответствующей пары, состоящей из квантованных ω и o.
Как более подробно описано ниже со ссылками на фиг. 2, локальный предсказатель 28 может быть сконфигурирован для квантования наклона 58 и отсекаемого отрезка 60 путем минимизации функции стоимости, которая монотонно возрастает с необходимой скоростью передачи бит и монотонно возрастает с искажением, вносимым второй ступенью 14 кодирования изображений для кодирования отклонения между соответствующей суб-частью 56 второй версии 38 изображения, с одной стороны, и соответствующей суб-частью 56 глобально предсказанного опорного изображения 52, отсчеты которого взвешены с помощью наклона 58 и смещены на отсекаемый отрезок 60, как было описано выше, с другой стороны. Таким путем выбранная пара, состоящая из (квантованных) наклона 58 и отсекаемого отрезка 60, оптимизирует требуемую функцию стоимости, но не минимизирует отклонение точек пары значений распределения 64 от линии 62 регрессии, причем отклонение не имеет тесной корреляции с указанной функцией стоимости. Указанные квантованные значения можно обозначить как 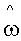
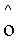
Наконец, на выходе локального предсказателя 28 обеспечивается глобально и локально предсказанное опорное изображение 54, которое отличается в каждой суб-части 56 от глобально предсказанного опорного изображения 52 тем, что каждое значение отсчета опорного изображения 52 взвешено с использованием соответствующего значения 58 наклона соответствующей суб-части с добавлением параметра o к результирующему произведению. Вторая ступень 14 кодирования изображения может использовать это опорное изображение 54 для выполнения интер-уровневого предсказания. В частности, вторая ступень 14 кодирования изображения может кодировать остаток предсказания между глобально и локально предсказанным опорным изображением 54 и версией 38 изображения в поток данных расширения, то есть, 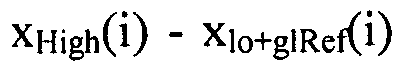 для позиций i совмещенных отсчетов, и может использовать с этой целью, например, кодирование с преобразованием. Однако следует заметить, что вторая ступень 14 кодирования изображения также допускает использование других режимов предсказания, отличных от только что описанного режима интер-уровневого предсказания. То есть, для формирования остатка 68 предсказания на своем выходе для представления версии 38 изображения вторая ступень 14 кодирования изображения может назначить режим предсказания каждому из разделов версии 38 изображения, один из которых относится к предсказанию текущего раздела на основе совмещенного раздела опорного изображения 54. В других режимах предсказания остаток предсказания может определяться на основе других опорных изображений, например путем временного предсказания соответствующего раздела, исходя из ранее закодированных изображений видео, поступивших на вход 20. Такое разбиение на разделы может совпадать или отличаться от разбиения, определяющего суб-части 56.
для позиций i совмещенных отсчетов, и может использовать с этой целью, например, кодирование с преобразованием. Однако следует заметить, что вторая ступень 14 кодирования изображения также допускает использование других режимов предсказания, отличных от только что описанного режима интер-уровневого предсказания. То есть, для формирования остатка 68 предсказания на своем выходе для представления версии 38 изображения вторая ступень 14 кодирования изображения может назначить режим предсказания каждому из разделов версии 38 изображения, один из которых относится к предсказанию текущего раздела на основе совмещенного раздела опорного изображения 54. В других режимах предсказания остаток предсказания может определяться на основе других опорных изображений, например путем временного предсказания соответствующего раздела, исходя из ранее закодированных изображений видео, поступивших на вход 20. Такое разбиение на разделы может совпадать или отличаться от разбиения, определяющего суб-части 56.
Как стало очевидно из вышеприведенного описания, режим работы ступени 14 может содержать кодирование остатка 68 предсказания, причем кодирование может осуществляться без потерь, то есть, может включать квантование, например, квантование коэффициентов преобразования, полученных в результате преобразования остатка предсказания. Соответственно, на стороне декодирования исходная версия версии 38 изображения может быть недоступна. Если более точно, то восстанавливаемая версия версии 38 изображения может отличаться от исходной версии, поступающей на вход 20 в результате вышеупомянутого квантования, входящего в процесс формирования остатка 68 предсказания. Ступень 14 кодирования может предоставить локальному предсказателю 28 восстанавливаемую версию версии 38 изображения для эффективного кодирования побочной информации 66, как более подробно обсуждается ниже. Значения отсчетов восстанавливаемой версии 38 изображения можно обозначить как 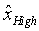
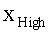
В частности, локальный предсказатель 28 может быть сконфигурирован для кодирования наклона 58, определенного для конкретной суб-части 56 в качестве остатка локального предсказания, исходя из наклона ω соседней суб-части, такой как суб-часть 70, наклон ω которой был закодирован ранее. Например, локальный предсказатель 28 может использовать порядок растрового сканирования для последовательного кодирования строка за строкой значений o и ω наклона и отсекаемого отрезка данной суб-части, начиная с верхней части изображения до его нижней части. В каждой строке сканирование может выполняться слева направо. Соответственно, суб-части наверху и слева могут служить в качестве соседних суб-частей 70, значения наклона которых можно использовать для локального предсказания значения наклона текущей суб-части, например, путем аналогичного комбинирования с использованием среднего значения или т.п.
К сожалению, значения o отсекаемого отрезка очень сильно зависят от значений наклона, и соответственно локальный предсказатель 28 использует обход, чтобы получить предсказатель для отсекаемого отрезка 60 текущей суб-части 56. В частности, локальный предсказатель 28 встраивает прямую линию 72, имеющую наклон текущей суб-части 56 в распределение пар значений совмещенных отсчетов в соседней суб-части 70 версии 38 изображения, реконструируемой на основе остатка 68 предсказания, то есть, 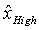
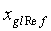
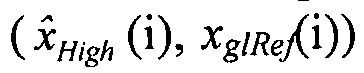 , где i обозначает отсчеты, содержащиеся в соседней суб-части. В частности, остаток 68 предсказания, кодированный с потерями плюс опорное изображение 54 в текущей суб-части 56, то есть,
, где i обозначает отсчеты, содержащиеся в соседней суб-части. В частности, остаток 68 предсказания, кодированный с потерями плюс опорное изображение 54 в текущей суб-части 56, то есть, 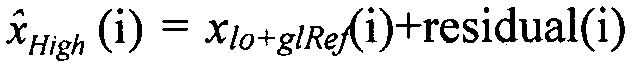 , где i обозначает отсчеты содержащиеся в соседней суб-части, а residual(i), который можно вывести из сигнала 68 остатка, используют вместо исходной версии версии 38 изображения в текущей суб-части 56, то есть, вместо
, где i обозначает отсчеты содержащиеся в соседней суб-части, а residual(i), который можно вывести из сигнала 68 остатка, используют вместо исходной версии версии 38 изображения в текущей суб-части 56, то есть, вместо 
Как станет очевидно из нижеследующего описания, глобальный предсказатель 26 может быть сконфигурирован для блокирования применения функции 40 глобального тонального отображения в случае недопустимого разброса пары значений совмещенных отсчетов в первой тонально отображенной версии 36 изображения и второй версии 38 изображения, то есть, точек (xHigh(i), xLow(i)) для всех позиций отсчетов i в изображении, относительно функции 40 глобального тонального отображения, то есть, f(j), где предполагается, что j относится ко всем возможным значениям xLow, превышающим заранее определенный порог. Если более точно, то распределения 46 относительно средних значений 48 для каждого возможного значения 44 образуют коридор относительно функции 40 глобального тонального отображения, в котором распределены значения отсчетов версии 38 изображения, и если этот коридор слишком широк, то глобальный предсказатель 26 может заблокировать применение функции 40 глобального тонального отображения. В качестве меры разброса или ширины только что упомянутого коридора можно использовать сумму дисперсий распределений 46 для разных возможных значений. В случае блокирования, то есть, в случае вышеупомянутого разброса, превышающего заранее определенный порог, локальный предсказатель 28 может быть сконфигурирован для выполнения локального выведения и применения локально изменяющейся функции тонального отображения для первой версии 36 изображения с тональным отображением, а не для глобально предсказанного опорного изображения 52.
Глобальный предсказатель 26 может сообщить декодирующей стороне об указанном блокировании в побочной информации. Другими словами для изображения, к которому применяется блокирование глобального предсказания, предусмотрена сигнализация блокирования, и функция 40 глобального тонального отображения не должна передаваться в виде побочной информации в поток данных расширения с выхода 24.
Перед описанием одного варианта устройства для выполнения интер-уровневого предсказания на стороне декодирования, которое соответствует устройству по фиг. 1, описывается более подробный вариант устройства по фиг. 1 со ссылками на фиг. 2.
Согласно фиг. 2, кодируют видео с расширенным динамическим диапазоном, и соответственно ступенью 12 кодирования является видеокодер. В частности, используется гибридный видеокодер, который в представленном здесь примере соответствует стандарту H.264. Однако это не является обязательным. Кроме того, из последующего обсуждения будет видно, что можно смешать потоки данных на выходах 22 и 24 в один общий поток данных, но это, естественно, также не является обязательным. В общем случае при описании варианта по фиг. 2 используются те же самые ссылочные позиции, которые использованы на фиг. 1, чтобы избежать повторов при описании функциональных возможностей элементов, имеющихся на обеих фигурах. Вариант по фиг. 2 также следует интерпретировать как демонстрацию возможностей для конкретной реализации элементов по фиг. 1, причем все эти возможности следует рассматривать как индивидуально применяемые к отдельным элементам по фиг. 1.
Далее прежде всего описываются структурные детали в сравнении с фиг. 1. Например, на фиг. 2 показана возможная реализация ступени 12 кодирования в виде гибридного видеокодера, содержащего контур 90 предсказания, поддерживающий режимы пространственного и временного предсказания для блоков входящих изображений, и кодер 92 с преобразованием остатка с потерями, за которым следует энтропийный кодер 94. В частности, гибридный видеокодер 12 по фиг. 2 содержит вычитатель 95, преобразователь 96 и ступень 98 квантования, которые подсоединены между входом гибридного видеокодера 12 и его выходом в упомянутом порядке вместе с энтропийным кодером 94, где преобразователь 96 и ступень 98 квантования образуют вместе преобразователь 92 остатка с потерями. Контур предсказания содержит сумматор 100, деблокирующий фильтр 102, буфер 104 кадров и модуль 106 интер(внешнего)/интра(внутреннего) предсказания, которые соединены друг с другом последовательно в одном контуре, так что выход модуля 106 предсказания соединен с первым входом сумматора 100. Его второй вход через обратный преобразователь 108 подсоединен к выходу ступени 98 квантования. Выход модуля 106 предсказания также подсоединен к входу вычитания вычитателя 95. Также в энтропийный кодер 94 подаются параметры предсказания, определенные модулем 106 предсказания, такие как данные предсказания движения и т.п., как показано пунктирной линией 108.
Соответственно, в процессе функционирования вычитатель 95 вычитает сигнал 110 предсказания из текущего изображения, поступающего на видеокодер 12, на не инвертирующем входе вычитателя 95, в результате чего на выходе вычитателя 95 получают сигнал 112 остатка. Затем преобразователь 96 выполняет спектральное разложение этого сигнала 112 остатка с помощью поблочного преобразования, а ступень 98 квантования выполняет квантование полученных таким образом коэффициентов преобразования, в результате чего возникают потери кодирования. Хотя обратный преобразователь 108 воспроизводит сигнал остатка, который также может быть восстановлен на стороне декодирования, энтропийный кодер 94 выполняет кодирование без потерь (используя энтропийное кодирование) сигнала остатка в поток 22 данных базового уровня вместе с упомянутыми параметрами 107 предсказания, то есть, выбранные режимы предсказания, параметры движения для предсказанных блоков с использованием временного предсказания и параметры интра предсказания для предсказанных блоков с использованием интра предсказания. На выходе сумматора 100, который суммирует восстановленный сигнал 112′ остатка на выходе обратного преобразователя 108 и сигнал 110 предсказания на выходе модуля 106 предсказания, получается восстановленное изображение, которое может (но не обязательно) быть подвергнуто контурной фильтрации необязательным деблокирующим фильтром 102, после чего восстановленное изображение запоминается в буфере 104 кадров. Модуль 106 предсказания способен использовать восстановленные изображения, запомненные в буфере 104 кадров, для выполнения временного предсказания для блоков интер-предсказания следующего кодированного изображения. На стороне декодирования декодер базового уровня содержит эквивалентный контур предсказания, который получает точно те же восстановленные изображения путем применения параметров предсказания к сигналу остатка, переданному посредством сигнала 22 базового уровня.
Как показано на фиг. 2, гибридный кодер 12 может оперировать 8-битовыми значениями отсчетов яркости (luma), представляющих компоненту яркости цветового пространства YCbCr. Соответственно, опорные изображения, хранящиеся в буфере 104 кадров, состоят из отсчетов яркости такой же длины, то есть, 8 бит.
Согласно конкретному примеру, показанному на фиг. 2, видео с расширенным динамическим диапазоном может быть обеспечено на узле 30 в формате цветового пространства RGB, где используются числа с плавающей запятой, указывающие индивидуальные цветовые компоненты для каждого отсчета. Блок 32 тонального отображения по фиг. 2, показанный в качестве примера, реализует два последовательных процесса обработки, а именно, тональное отображение 120, за которым следует преобразование цветов 122. Однако порядок выполнения этих процессов в качестве альтернативы может быть обратным. В то время как процесс 122 преобразования цветов представляет переход, связанный с преобразованием динамического диапазона, от начального цветового пространства видео с расширенным динамическим диапазоном на узле 30, то есть, RGB, к цветовому пространству видеокодера 12, то есть YCbCr, тональное преобразование 120 применяет вышеупомянутую функцию изменяющегося в пространстве-времени тонального отображения к отсчетам видео на узле 30, сужая тем самым динамический диапазон от начального динамического диапазона к динамическому диапазону представления отсчетов шириной 8 бит видеокодера 12.
Согласно варианту по фиг. 2, имеется блок 34 тонального преобразования, который осуществляет переход от HDR представления с плавающей точкой на узле 30 к целочисленному 12-битовому представлению яркости в кодере 14. В частности, чтобы использовать репрезентативный динамический диапазон, используют представление или цветовое пространство LogLuv, где компонента яркости (luma) или светимости (luminance) представлена целочисленными значениями шириной 12 бит, интервал возможных значений которой равномерно разбит на субинтервалы в области логарифмов светимости. Другими словами, блок 34 тонального отображения по фиг. 2 выполняет две функции, а именно: переход от одного цветового пространства к другому, а именно, от RGB к Luv (где компонента L представляет собой логарифм яркости); и пространственное/временное изменение субинтервала, отображаемого блоком 34 тонального отображения на диапазон значений отсчетов яркости, поступающих в кодер 14. Смотри, например, график, показанный под ссылочной позицией 124 на фиг. 2. Интервал представления логарифма светимости, который представлен отсчетами расширенного динамического диапазона показан под ссылочной позицией 126. Другими словами, интервал 126 покрывается при преобразовании всех возможных состояний (с плавающей точкой) цветового представления видео с расширенным динамическим диапазоном на узле 30 в значения светимости и их логарифмирования. Блок 34 тонального преобразования при выполнении тонального преобразования изменяет в пространстве и во времени субинтервал 128, который линейно отображается на целочисленный или динамический диапазон 50 отсчетов яркости видео, поступающего на ступень 14 кодирования, то есть, изменяется ширина интервала 128, а также его положение вдоль оси Lfloat.
Соответственно, на фиг. 2 также показан глобальный предсказатель 26, выполняющий две функции, а именно: преобразование 130 цветового пространства для перехода от цветового пространства кодера 12, то есть, YCbCr к цветовому пространству Luv, за которым следует глобальное тональное отображение 132, которое глобально применяют к отсчетам текущего изображения из буфера 104 кадров кодера 12. Например, отсчеты светимости цветового пространства на выходе ступени 130 преобразования цветового пространства могут все еще иметь более короткую длину в битах, как у кодера 12, то есть, например, 8 бит, в то время как на выходе ступени 132 глобального интер-уровневого предсказания опорное изображение имеет 12 бит, как было подчеркнуто выше в связи с фиг. 1 (что более подробно обсуждается ниже).
Ступень 14 кодирования содержит последовательное соединение вычитателя 140, преобразователя 142, квантователя 144 и энтропийного кодера 146. Преобразователь 130 цветового пространства, блок 132 глобального тонального преобразования и локальный предсказатель 28 подсоединены последовательно между буфером 104 кадров и инвертирующим входом вычитателя 140, образуя интер-уровневое устройство по фиг. 1. Соответственно, вычитатель 140 вычитает опорное изображение 54 с выхода локального предсказателя 28 из текущего кодированного изображения, поступающего из блока 34 тонального преобразования, для получения остатка 148 предсказания, который затем подвергается кодированию с потерями преобразователем 142, выполняющим спектральное разложение, например, поблочное преобразование, такое как DCT преобразование, после чего энтропийный кодер 146 выполняет квантование коэффициентов преобразования в квантователе 144 и энтропийное кодирование (без потерь) уровней квантования коэффициентов преобразования, в результате чего получают остаток 68 предсказания. Как показано под надписью «Вспомогательная информация ILP», вспомогательная информация, созданная глобальным и локальным предсказателями 26 и 28, также подается в энтропийный кодер 146 для формирования потока 24 данных расширения.
Оба потока данных, поток 22 данных базового уровня и поток 24 данных расширения мультиплексируются согласно варианту по фиг. 2, образуя общий поток 150 данных, с помощью мультиплексора 152, однако такое мультиплексирование не является обязательным.
Прежде чем продолжать описание устройства для выполнения интер-уровневого предсказания на стороне декодирования, которое согласовано с вышеописанными вариантами, следует сделать ряд замечаний, касающихся возможного обобщения приведенного выше описания.
Например, хотя в рассмотренных выше вариантах указано, что глобальное и локальное предсказание при интер-уровневом предсказании выполняется в области, где целочисленные значения отсчетов тонально отображенной версии 36 и второй версии 38 изображения относятся к сопряженным областям определения линейных функций субинтервалов вне области логарифмической светимости, вышеописанные варианты не сводятся к этому варианту. Наоборот, также возможно использование другой области светимости. Кроме того, вышеописанные варианты не ограничены выполнением вышеописанного интер-уровневого предсказания для компоненты светимости. Наоборот, эти варианты можно также применить к другим цветовым компонентам.
Кроме того, хотя конкретный вариант по фиг. 2, где, в частности, используется представление шириной 8 бит для отсчетов изображений, кодированных кодером 12, и представление шириной 12 бит для отсчетов кодера 14, можно также использовать другие варианты длины в битах, до тех пор пока длина n в битах, используемая кодером 14, больше, чем длина m в битах, используемая кодером 12.
Что касается ступени 14 кодирования, то следует заметить, что она не ограничена использованием кодирования с преобразованием для кодирования остатка предсказания. Наоборот, для этого можно использовать кодирование остатка предсказания непосредственно в пространственной области. Кроме того, остаток предсказания можно кодировать без потерь согласно одному альтернативному варианту. Что касается энтропийных кодеров, то они не ограничены использованием какого-либо конкретного вида энтропийного кодирования, такого как арифметическое кодирование или кодирование с переменной длиной слова. Наоборот, такие кодеры, реализующие кодирование без потерь, могут использовать методику сжатия без потерь другого типа.
Если более конкретно, то на фиг. 2 показана блок-схема архитектуры масштабируемого видеокодера с расширенным динамическим диапазоном (HDR SVC). Верхняя часть 12 образует базовый уровень с LDR. На нее поступает тонально отображенная необработанная видеопоследовательность в цветовом пространстве YCbCr 4:2:0 (сравните с тональным отображением sRGB→YCbCr на фиг. 2). Базовый уровень представляет собой не модифицированный кодер базового уровня (SVC) (8 бит на компоненту), совместимый со стандартом H.264/AVC.
Используемые для подачи на ступень 14 кодера уровня расширения, исходные HDR видеоданные с плавающей точкой на узле 30 представлены целочисленными значениями с ограниченной точностью. Указанное цветовое пространство должно быть способно представлять расширенный динамический диапазон и полную цветовую гамму с уровнем ошибок ниже порога восприятия. Здесь рассматривается цветовое пространство Lu′ν′ с глубиной 12 бит для компонент яркости и глубиной 8 бит для компонент цветности (сравните с RGB→LHDRu′ν′ на фиг. 2).
Дискретизация составляет 4:2:0, как в случае базового уровня 12 с LDR. Согласно вышеприведенному описанию HDR кодер 14 уровня расширения может оперировать с 12 битами без использования предсказания с компенсацией движения, а использование предсказания с компенсацией движения можно естественным образом объединить с показанным здесь интер-уровневым описанием.
Для уменьшения избыточности HDR видео уровня расширения, поступающее на кодер 14, подвергается в устройстве 10 операции предсказания с использованием механизма интер-уровневого предсказания (ILP). Как было описано выше, задачей ILP 10 является сокращение затрат на передачу уровня 24 расширения HDR. Техническое решение для ILP, как было описано выше, включает механизмы глобального и локального предсказания. Перед осуществлением ILP цветовое пространство с LDR преобразуют в цветовое пространство с HDR (130), так чтобы их разности яркости можно было вычислить перцептуально значимым образом (сравни с YCbCr→LLDRu′ν′ на фиг. 2). Следует снова отметить, что у ILP 10 отсутствует информация о конкретных операторах TMO, и, следовательно, его структура должна быть очень гибкой.
HDR RGB в Luv
Модифицированная версия цветового пространства Lu′ν′, впервые предложенная Larson в [8] используется для представления HDR пиксельных значений с плавающей точкой на узле 30 с помощью целых чисел в кодере 14. Сначала цветовое пространство RGB преобразуется в блоке 34 тонального отображения в CIE(u′ν′):
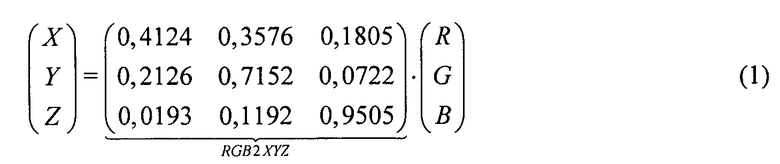

В отличие от [8] здесь блоком 34 отображения затем используется адаптивное логарифмическое отображение для преобразования «светимость в яркость» (luminance to luma)[7]:
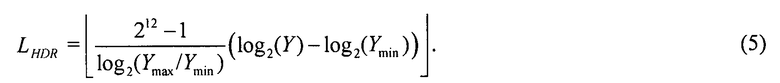
Это позволяет представить покадровый динамический диапазон Ymax/Ymin светимости с помощью 12 бит.
YCbCr в Luv
Для интер-уровневого предсказания ILP 10 необходимо согласовать цветовое пространство базового уровня с цветовым пространством уровня расширения в блоке 130 (сравните с YCbCr→Lu′ν′ на фиг. 2).
Посредством мультиплексирования RGB2XYZ согласно формуле (1) с обращением стандартной матрицы преобразования RGB→YCbCr, RGB2YCbCr [9], можно найти матрицу преобразования YCbCr-XYZ

Заменив коэффициенты первой и последней строки в этой матрице на a,b,c и d,e,f соответственно и подставив x и z в (3) и (4), получим
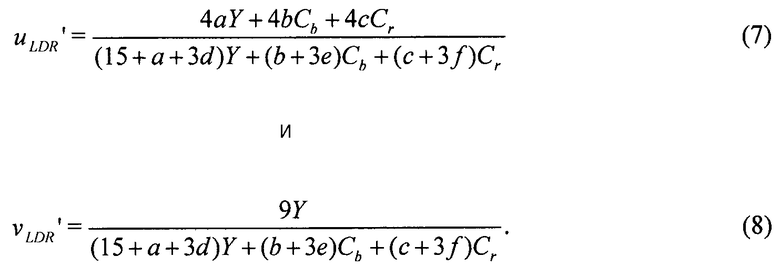
Наконец, к компоненте Y применяют логарифмическое преобразование
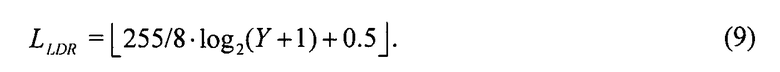
Блок 130 использует формулы (7)-(9) для отсчетов опорных изображений, полученных из буфера 104, и выводит результат в блок 132.
Таким образом, LLDR и LHDR отражают одно и то же соотношение «светимость-яркость», а именно, использованное здесь для примера логарифмическое соотношение, так что любой показатель ошибки между двумя уровнями во время выполнения ILP был перцептуально значимым.
Интер-уровневое предсказание
Поскольку обычно тональное изображение не оказывает большого влияния на цветовые характеристики, для предсказания uHDR′, νHDR′ можно использовать значения uLDR′, νLDR′. Однако для компонент яркости соотношение будет более сложным. Поэтому, предложено использовать совместный глобальный и локальный механизм ILP (132) для уменьшения избыточности между уровнем LDR видео и уровнем HDR видео независимо от использованного прямого TMO.
Глобальное интер-уровневое предсказание
В инфраструктуре на фиг. 2 реализован глобальный ILP 132 на основе определения подходящей справочной таблицы для каждого кадра, которая отображает 256 возможных значений LLDR на адекватное значение в области HDR. Конечно, для каждого пиксельного значения LLDR может быть много разных значений LHDR. Таким образом, используется среднее арифметическое значение, например, всех значений, которые попали в один бин LLDR в качестве восстановленного значения в справочной таблице, g(l), которая, таким образом, является конкретизацией функции 40 на фиг. 1:
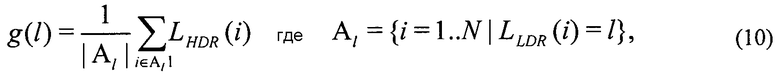
где l=0…255 обозначает индекс бинов, а |Аl| кардинальное число множества Al пикселей, которые попали в этот бин [2].
На фиг. 3 показано соотношение значений LLDR и LHDR и результирующая функция 40 ILP отображения для двух разных TMO 120 [10] для одного кадра тестовой последовательности. В частности, на фиг. 3а и фиг 3b показано соотношение между пиксельными значениями LLDR и LHDR для двух разных TMO (разнесенные пересечения), где на фиг. 3а показан оператор TMO pattanaik00, а на фиг. 3b показан оператор TMO fattal02 [10]. Примерная функция глобального отображения ILP показана непрерывной линией. Хотя имеется сильная корреляция между значениями LDR и HDR для pattanaik00 TMO, на который имеется ссылка на фиг. 3а, это не так, если речь идет о более локальном адаптивном операторе fattal02 TMO, на который имеется ссылка на фиг. 3b. В последнем случае показанная функция 40 отображения ILP, не приведет к хорошим характеристикам сжатия. Характеристики шага 28 локального ILP, как описано в связи с фиг. 2 в следующем разделе, могут даже ухудшится. Таким образом, в структуре фиг. 2 механизм 132 глобального ILP отключен, например, когда среднее дисперсий пикселей по всем бинам превышает пороговое значение. Это пороговое значение не является критическим значением и должно быть большим. Например, можно использовать максимально возможное стандартное отклонение 12-битовых значений (211).
Поскольку отображение «светимости в яркость» в блоке 34 отображения уровня HDR (5) является адаптивным в отношении кадров, глобальное ILP 132 также должно действовать в покадровом режиме в отличие от, например, [4]. Таким образом, в отдельном ITMO функция g(l) отображения может передаваться в каждом изображении, например, в каждом наборе параметров изображения стандарта H.264/AVC. Поскольку обычно эта функция сглажена, она не занимает много бит при дифференциальном энкодировании.
Локальное интер-уровневое предсказание
Предсказание ALP на основе макроблоков (MB), применяемое в блоке 28 и описанное далее применительно к фиг. 2, выполняется с использованием оценки оптимизированных параметров соотношения R-D и цветового пространства, подходящего для представления больших динамических диапазонов. Кроме того, представлен способ для эффективного предсказания параметров ILP каждого MB, исходя из каузальной окрестности, что значительно уменьшает объем необходимой побочной информации. Соответственно, здесь в качестве образцов субблоков 56, упомянутых в связи с фиг. 1, служат макроблоки, известные из стандарта H.264.
Оценка масштаба и смещения
Предсказание ILP на основе MB в блоке 28 основано на линейной модели, которая обеспечивает хороший компромисс между сложностью, требуемой побочной информацией и эффективностью предсказания. Чтобы лучше понять нижеследующие математические выкладки, ссылочные позиции на фиг. 1 используются как общие, и последующее описание также представляет возможный вариант реализации блока 28 по фиг. 1.
Далее вектор, содержащий пиксели в MB 56 в пространстве яркости уровня LDR (LDR, или xglRef) обозначен как l. Вектор совмещенного MB 56 в пространстве LHDR (или xhigh) обозначен как h. Предсказатель 

с масштабом 
Для быстрой оценки w и o с оптимизированным соотношением R-D используется способ двухступенчатого поиска. Сначала получают начальную приближенную оценку, используя простую линейную регрессию, а именно

Горизонтальная черта означает среднее значение отсчетов соответствующей переменной 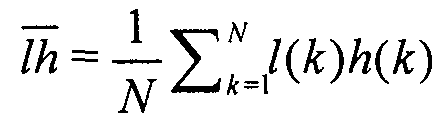 . Здесь w и o представляют собой параметры интер-уровневого предсказания, дающие ошибку предсказания с минимальной энергией, то есть, среднеквадратическая ошибка (MSE) между
. Здесь w и o представляют собой параметры интер-уровневого предсказания, дающие ошибку предсказания с минимальной энергией, то есть, среднеквадратическая ошибка (MSE) между 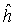
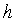
Конечно, параметры w и o нельзя перенести в декодер с произвольной точностью, но они должны быть квантованы в виде целых чисел. Соответственно, для w может быть использован интервал квантования, равный, например, 0,5:

Уравнение 13 модифицируют согласно выражению

Даже в том случае, если использовать решение для (12) и (13) методом наименьших квадратов вместо округленных версий 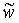
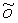
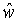
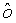
Процедура начинается с начальных приближенных оценок для масштаба 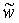
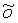
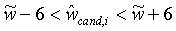
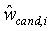
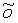
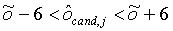
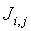

где 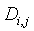
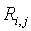
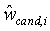
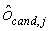
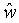
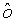
Кодирование параметров масштаба и смещения
Конечно, непосредственная передача
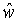
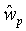
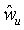
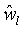
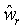
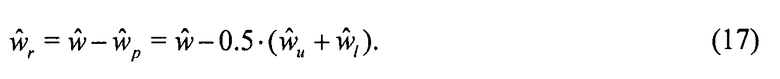
К сожалению, этот же механизм предсказания не походит для кодирования параметра
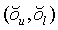
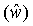
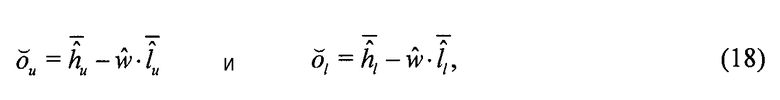
где 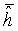
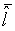
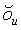
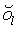
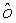

равно или близко к нулю, и поэтому требуемым расходом бит можно пренебречь.
Результаты экспериментов
Был проведен ряд экспериментов. При выполнении этих экспериментов было модифицировано базовое программное обеспечение (JSVM8.12) с тем, чтобы можно было поддерживать механизмы предсказания ILP, представленные в предшествующих разделах. Эксперименты с кодированием были выполнены с тремя тестовыми HDR последовательностями: Panorama, Tunnel и Sun (640×480 пикселей, 30 кадров/с). Тестовая последовательность Panorama была создана путем панорамирования панорамного HDR изображения 8000×4000 пикселей [11]. Весь динамический диапазон составил порядка 1010:1. Обе последовательности Tunnel и Sun общедоступны в Институте Макса Планка [12]. Общий динамический диапазон, представленный в этих последовательностях, составляет 105:1 и 107:1 соответственно. Для оценки качества декодированного HDR видео использовалось два показателя: HDR предсказатель визуального различия (VDP) [13] и перцептуально однородное отношение «пиковый сигнал-шум» (PU PSNR) [14]. Тонально отображенные последовательности LDR уровня были созданы шестью разными общеизвестными операторами TMO, которые являются частью программного пакета pfstmo [10]. Последующие метки в pfstmo в наших экспериментах включают в скобках номер TMO: durand02 (TMO 1), pattanaik00 (TMO 2), fattal02 (TMO 3), mantiuk06 (TMO 4), reinhard02 (TMO 5), drago03 (TMO 6). Все операторы были использованы с их стандартными параметрами, но для reinhard02 была использована локально адаптивная версия.
Результаты кодирования демонстрируют качество уровня расширения HDR, указанного выше на выходе 24, в отношении скорости передачи на уровне расширения вместе с встроенным битовым потоком базового уровня, то есть, скорость на выходах 22 и 24 вместе. Базовый уровень LDR можно просто извлечь из этого битового потока. Из-за недостатка места результаты кодирования для базового уровня здесь не показаны. Было использовано кодирование с фиксированными QP, эквивалентными QP для уровня LDR и HDR, так что можно полагать, что качество для обоих уровней примерно одинаково. Конечно, весьма важной проблемой при использовании SVC является оптимальное распределение бит, но эта проблема не относится к теме текущего обсуждения.
На фиг. 4а и 4b показаны результаты кодирования для тестовой последовательности Panorama, когда уровень LDR был создан оператором TMO 6. В частности, результаты кодирования для тестовой последовательности Panorama обозначены на фиг. 4а как PU PSNR и на фиг. 4b как HDR VDP в зависимости от расхода бит. 4 кривых показывают эффективность глобального, локального и совместного глобально-локального ILP (смотри 10 на фиг. 1 и 2) вместе с базовым случаем, когда предсказание ILP вообще не использовалось (то есть, одновременно LDR и HDR уровень).
Из представленных фигур можно видеть, что совместное глобально-локальное ILP согласно 10 по фиг. 1 и 2 имеет наилучшие характеристики с точки зрения показателей качества PU PSNR и HDR VDP. Поскольку во всех экспериментах результаты для HDR VDP и PU PSNR оказались непротиворечивыми, в остальной части этого раздела показаны результаты для PU PSNR.
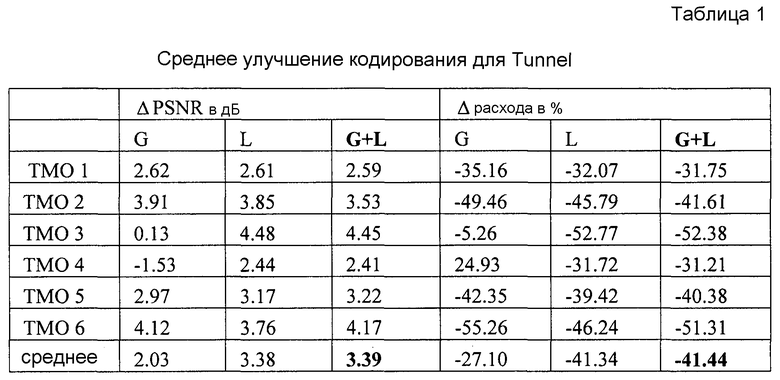
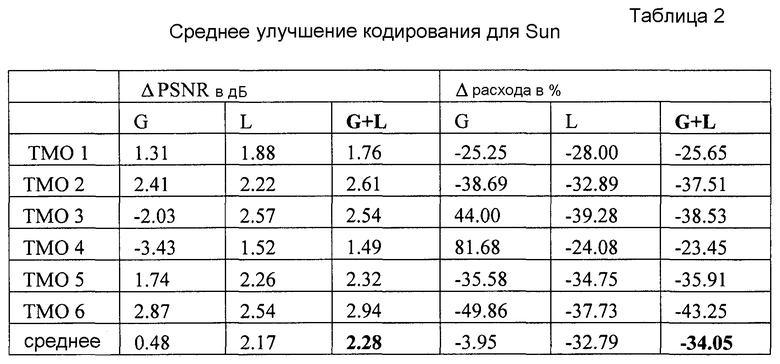
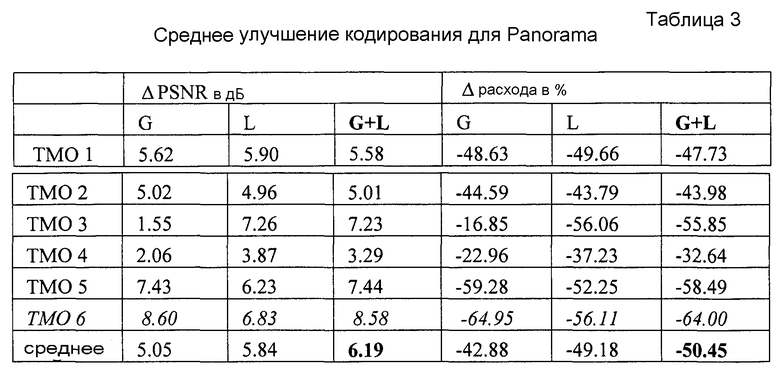
В таблицах 1-3 показаны среднее улучшение PU PSNR (ΔPSNR) или экономия расходуемых бит (Δ расхода) соответственно для трех тестовых последовательностей применительно к случаю одновременного использования уровней LDR и HDR (то есть, отсутствия ILP). Усреднение выполнялось в соответствии с метрикой Bjontegaarg [15]. Результаты для глобального (G), локального (L) и выше рассмотренного совместного (G+L) предсказания ILP даны в таблицах для всех рассматриваемых операторов TMO. Записи в таблице 3, соответствующие кривой R-D по фиг. 4а и 4b, сделаны курсивом (TMO 6). Средние значения в нижней строке таблиц показывают, что варианты настоящего изобретения имеют наилучшие характеристики независимо от того, какой оператор TMO был использован для создания LDR последовательности. Анализируя приведенные результаты, можно обнаружить, что средняя экономия расходуемых бит доходит до 50%, либо приращение качества доходит до 6 дБ. Важно заметить, что в некоторых случаях глобальное ILP дает несколько лучшие результаты для отдельных операторов TMO, чем совместное ILP согласно вышеописанным вариантам в основном из-за меньшего объема необходимой побочной информации. Однако для операторов TMO с сильной локальной адаптивностью этот подход очевидно не годится: например, из Таблицы 2 можно видеть, что для TMO 3 и 4 необходимый расход бит значительно превышает расход бит, необходимый в том случае, когда LDR и HDR уровни кодируют независимо (на 44% или 82% соответственно).
Также важно отметить, что повышение эффективности кодирования представленного здесь способа локально-глобального ILP по сравнению со способами, рассмотренными в литературе [2-6] должны быть даже лучше, чем повышение эффективности при использовании G+L по сравнению с L или G в таблицах 1-3; вдобавок к стратегии совместного ILP смешанный подход для ILP включает использование подходящего HDR цветового пространства, выбор оптимальных параметров для соотношения «расход-искажение» и эффективное кодирование параметров ILP.
Сторона декодирования
На фиг. 5 показано устройство 500 для выполнения интер-уровневого предсказания между первой ступенью 502 декодирования для декодирования первой тонально отображенной версии изображения, имеющей первый динамический диапазон значений отсчетов, и второй ступенью 504 декодирования изображения для декодирования второй версии изображения, имеющей второй динамический диапазон значений отсчетов, превышающий первый динамический диапазон значений отсчетов. На фиг. 5 также показан декодер 506, способный декодировать изображение во втором динамическом диапазоне отсчетов. С этой целью первая ступень 502 декодирования изображения подсоединена между входом 508 и входом устройства 500. На вход 508 поступает поток 22 данных базового уровня. Первая ступень 502 декодирования изображения может (но не обязательно) иметь два выхода, а именно: один выход для вывода восстановленного изображения в первом динамическом диапазоне значений отсчетов для его воспроизведения, где этот вывод показан под ссылочной позицией 510; и второй вывод 512 для вывода результата восстановления изображения в контуре, которое сохраняют в буфере 104 по фиг. 2. Вход устройства 500 может быть подсоединен к любому из этих выходов. Кроме того, выход 510 является необязательным и может не использоваться. Вдобавок, версии на выходах 510 и 512 могут совпадать друг с другом либо отличаться друг от друга благодаря использованию дополнительного фильтра воспроизведения, применяемого для получения версии, воспроизводимой на выходе 510, отличной от версии на выходе 512.
Вторая ступень 504 декодирования изображения подсоединена между входом 514 декодера 506 и выходом 516 декодера 506 для вывода изображения с расширенным динамическим диапазоном. Устройство 500 также соединено с входом 515. Если точнее, то устройство 500 содержит соединение глобального предсказателя 518 и локального предсказателя 520, причем вторая ступень 504 декодирования изображения получает из потока данных расширения остаток 68 предсказания, в то время как глобальный и локальный предсказатели 518 и 520 принимают побочную информацию 41 и 66 соответственно. На выходе локального предсказателя 520 получают опорное изображение 54, которое выводится на опорный вход второй ступени 504 декодирования изображения. По аналогии с описанием фиг. 1, вторая ступень 504 декодирования изображения может быть сконфигурирована для обеспечения доступа локального предсказателя 520 к ранее восстановленным суб-частям текущей версии декодируемого в данный момент изображения с расширенным динамическим диапазоном.
Таким образом, в процессе функционирования первая ступень 502 декодирования изображения восстанавливает первую тонально отображенную версию 36 изображения из потока 22 данных базового уровня. Таким образом, полученная первая тональная версия 36 согласно предпочтительным вариантам изобретения совпадает с версией на входе глобального предсказателя 26 на стороне кодирования, так что потери кодирования, которые могут иметь место на первой ступени 12 кодирования изображения на стороне кодирования, не приведут к отклонениям между состояниями/поведением кодера и декодера.
Глобальный предсказатель 518 сконфигурирован для вывода функции глобального тонального отображения из побочной информации 41 потока данных расширения второй ступени 504 декодирования изображения, причем предсказатель 518 применяет функцию глобального тонального отображения к отсчетам первой тонально отображенной версии 36 изображения для получения глобально предсказанного опорного изображения 52. Поскольку функция глобального тонального отображения с большой вероятностью является монотонно и плавно изменяющейся, глобальный предсказатель 26 по фиг. 1 может быть реализован для кодирования функции глобального тонального отображения в направлении последовательного увеличения или уменьшения возможных значений первого динамического диапазона значений отсчетов с использованием дифференциального кодирования, в то время как глобальный предсказатель 518, в свою очередь, может быть реализован для последовательного декодирования функции глобального тонального отображения в том же самом направлении с использованием дифференциального декодирования. Также существуют и другие возможности, как было упомянуто выше.
Глобальный предсказатель 518, при выведении функции глобального тонального отображения и ее применении к первой тонально отображенной версии 36 изображения, кроме того может быть сконфигурирован для выполнения преобразования цветов 130 по фиг. 2 для значений отсчетов в первой тонально отображенной версии 36 из цветового формата потока 22 данных в цветовой формат потока 24 данных расширения, причем преобразование цветов установлено постоянным независимо от тонально отображенной версии 36 и второй версии 38 изображения, восстановленного второй ступенью 504 декодирования изображения, после чего функция глобального тонального отображения применятся во втором цифровом формате.
Если более точно, то локальный предсказатель 518 воспроизводит функцию 40 глобального тонального отображения, показанную на фиг. 1, исходя из побочной информации 41, и устанавливает значения xlow первой тонально отображенной версии 36 изображения на значение, которое отображается согласно функции 40 тонального отображения, то есть 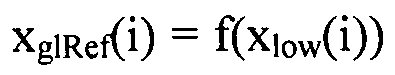 , для всех i позиций отсчетов в изображении. Результатом является глобально предсказанное опорное изображение 52.
, для всех i позиций отсчетов в изображении. Результатом является глобально предсказанное опорное изображение 52.
Локальный предсказатель 520 сконфигурирован для вывода локально изменяющейся функции тонального отображения локально из побочной информации в единицах, соответствующих суб-частям 56, показанным на фиг. 1, на которые разбиты глобально предсказанное опорное изображение 52 и вторая версия 38 изображения, и применения локально изменяющейся функции тонального отображения к глобально предсказанному опорному изображению 42 для получения глобально и локально предсказанного опорного изображения 54.
Как было описано выше, при выводе локально изменяющейся функции тонального отображения локально, локальный предсказатель 520 может для каждой суб-части 56 восстановить наклон 58 и отсекаемый отрезок 60 из побочной информации 66 и, при применении локально изменяющейся функции тонального отображения к глобально предсказанному опорному изображению, выполнить взвешивание (для каждой суб-части 56) отсчетов глобально предсказанного опорного изображения 52 в соответствующей суб-части 56 с использованием упомянутого наклона и добавлением упомянутого отсекаемого отрезка к произведению наклона ω и соответствующего отсчета. То есть, в каждой суб-части 56 локальный предсказатель 520 для каждой позиции отсчета в соответствующей суб-части вычисляет 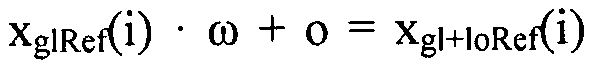 для всех позиций I отсчетов в текущей суб-части, где xglRef - значение отсчета на соответствующей позиции отсчета в суб-части глобального опорного изображения 52, xgl+loRef+ - значение отсчета, вычисленное для совмещенной позиции в той же суб-части 56 глобально и локально предсказанного опорного изображения 54, ω - наклон, полученный из побочной информации 66 для данной суб-части 56, а o - отсекаемый отрезок, определенный для данной суб-части 56 из побочной информации 66.
для всех позиций I отсчетов в текущей суб-части, где xglRef - значение отсчета на соответствующей позиции отсчета в суб-части глобального опорного изображения 52, xgl+loRef+ - значение отсчета, вычисленное для совмещенной позиции в той же суб-части 56 глобально и локально предсказанного опорного изображения 54, ω - наклон, полученный из побочной информации 66 для данной суб-части 56, а o - отсекаемый отрезок, определенный для данной суб-части 56 из побочной информации 66.
Как уже было описано выше, информацию, касающуюся наклона ω и отсекаемого отрезка o для суб-части 56 можно эффективно кодировать в поток данных расширения и побочной информации 66 соответственно. Локальный предсказатель 520 соответственно может быть сконфигурирован для вывода последовательно наклона ω и отсекаемого отрезка o для суб-части 56 из побочной информации 66. Как упоминалось выше, для сканирования суб-частей 56 можно использовать порядок построчного растрового сканирования. Однако можно использовать и другие способы сканирования. В любом случае локальный предсказатель 520 согласно соответствующему варианту декодирует остаток наклона и отсекаемого отрезка для суб-частей 56, исходя из побочной информации 66, и выполняет пространственное предсказание наклона ω для текущей суб-части, исходя из наклона соседней суб-части 70, восстановленного ранее, и восстанавливает наклон ω для текущей суб-части 56 на основе предсказанного наклона и остатка наклона для текущей суб-части. Затем локальный предсказатель 520 подстраивает прямую линию 72, имеющую наклон ω, только что восстановленного текущей суб-части в распределение пар значений совмещенных отсчетов в соседней суб-части 70 второй версии изображения в качестве ранее восстановленного изображения и глобально предсказанное опорное изображение 52, и определяет отрезок 74, отсекаемый прямой линией 72. Затем локальный предсказатель 520 восстанавливает отсекаемый отрезок текущей суб-части 56 на основе полученного таким образом предсказанного отрезка и остатка отсекаемого отрезка для текущей суб-части 56.
В частности, взаимодействие между локальным предсказателем 520 и ступенью 504 декодирования может заключаться в следующем: вторая ступень 504 декодирования изображения заканчивает восстановление конкретной суб-части версии 38 изображения, которая должна быть восстановлена, получив остаток предсказания для данной суб-части, исходя из информации 68 об остатке, и комбинирования остатка, например, путем суммирования с глобально и локально предсказанным опорным изображением его совмещенной суб-части.
Затем вторая ступень 504 декодирования изображения приступает к восстановлению следующей суб-части в вышеупомянутом порядке сканирования из числа суб-частей, которые также используются локальным предсказателем 520. В частности, локальный предсказатель 520 затем декодирует наклон и отсекаемый отрезок для следующей суб-части описанным способом, причем выполняя указанное декодирование, локальный предсказатель 520 способен выполнить вышеупомянутое подстраивание прямой линии с использованием восстановленных значений отсчетов в соседней суб-части версии 38 изображения.
После декодирования наклона и отсекаемого отрезка для текущей суб-части, исходя из побочной информации 66, локальный предсказатель 520 получает глобально и локально предсказанное изображение на текущей суб-части 56 посредством взвешивания и смещения совпадающих отсчетов, в совпадающей суб-части глобально предсказанного изображения 52 с использованием декодированных (с предсказанием) наклона и отсекаемого отрезка, причем ступень 504 декодирования способна восстановить текущую часть, используя соответствующий остаток предсказания, полученную из потока данных предсказания и информации 68 об остатках соответственно. Используя этот показатель, локальный предсказатель 520 и ступень 504 декодирования могут работать попеременно согласно порядку сканирования между упомянутыми суб-частями.
Как также было описано выше, глобальный предсказатель 518 может быть сконфигурирован для блокирования выведения и применения функции 40 глобального тонального отображения в ответ на сигнализацию в побочной информации 66, где локальный предсказатель 520 может быть сконфигурирован (в случае упомянутого блокирования) для применения функции 40 к первой тонально отображенной версии 36 изображения, а не глобально предсказанному опорному изображению 52.
Исключительно ради полноты изложения заметим, что все другие детали, описанные применительно к стороне кодирования, соответствующим образом можно отнести к примеру декодирования, показанному на фиг. 5. Например, вторая ступень 504 декодирования может быть сконфигурирована для преобразования-декодирования остатка 68 предсказания между глобально и локально предсказанным опорным изображением и версией 38 изображения из потока данных расширения, и для восстановления версии 38 изображения на основе остатка 68 предсказания и глобально и локально предсказанного опорного изображения, например, путем их суммирования.
Подводя итог вышесказанному, можно сказать, что здесь на примере вышеописанных вариантов представлена инфраструктура для эффективного кодирования видеоданных с расширенным динамическим диапазоном (HDR). Поскольку схема совместного ILP для вышеописанных вариантов построена на расширении стандарта H.264/AVC, относящемся к кодированию масштабируемого видео, это дает возможность обеспечить кодирование с обратной совместимостью. То есть, из закодированного битового потока можно извлечь видео с суженным динамическим диапазоном (LDR) путем обрезки необязательных частей из закодированного битового потока. Был предложен способ для эффективного интер-уровневого предсказания, обеспечивающий уменьшение соответствующей избыточности при передаче HDR и LDR информации. Этот способ содержит общее преобразование HDR цветового пространства и стратегию совместного глобального и локального предсказания, а также оптимизированную оценку соотношения «расход-искажение» для параметров предсказания и эффективное кодирование необходимой побочной информации. Проведенные эксперименты показали, что представленные выше варианты дают очень хорошие результаты кодирования по сравнению со стратегиями покадрового глобального или поблочного локального предсказания независимо от оператора тонального отображения. Кроме того, по сравнению с независимой передачей LDR и HDR информации имеется возможность уменьшить необходимый расход бит на 50%.
Другими словами, в некоторых из вышеописанных вариантов используется (или может быть реализовано) интер-уровневое предсказание для кодирования видео с расширенным динамическим диапазоном с обратной совместимостью со стандартом SVC. В некоторых вариантах инфраструктура кодирования видео с расширенным динамическим диапазоном и обратной совместимостью основана на стандарте H.264/AVC. Это позволяет извлечь из сжатого битового потока стандартное видео с суженным динамическим диапазоном (LDR), а также с расширенным динамическим диапазоном (HDR). Предложен способ совместного глобально-локального интер-уровневого предсказания для уменьшения избыточности между LDR и HDR уровнями. Этот способ основан на использовании общего цветового пространства, которое может представлять HDR видеоданные без потерь восприятия. Было показано, как можно оценить параметры интер-уровневого предсказания при оптимизации соотношения «расход - искажение» и эффективно закодировать их для уменьшения объема побочной информации. Указанные оценки демонстрируют, что предложенная инфраструктура имеет наилучшие характеристики по сравнению с известным уровнем техники для произвольных операторов тонального отображения. Применительно к одновременному использованию HDR и LDR уровней это обеспечивает экономию расходуемых бит вплоть до 50%.
Другими словами, вышеописанные варианты изобретения воспроизводят схему кодирования видео с расширенным динамическим диапазоном и обратной совместимостью, которая позволяет извлекать видео со стандартным суженным динамическим диапазоном (LDR), а также с расширенным динамическим диапазоном (HDR) из одного сжатого битового потока, где способ совместного глобального и локального интер-уровневого предсказания позволяет уменьшить избыточность между уровнями LDR и HDR видео. При этом используется общее цветовое пространство, которое представляет HDR видеоданные без потерь восприятия Параметры интер-уровневого предсказания можно оценить при оптимизации соотношения «расход-искажение» и эффективно их закодировать для уменьшения объема побочной информации.
На сегодняшний день известно масштабируемое кодирование для HDR видео, предложенное, например, в литературных источниках [2], [6], но следующие аспекты концепции совместного ILP, описанные в приведенных выше вариантах, превосходят известный уровень техники:
интер-уровневое предсказание с использованием комбинированного глобально-локального предсказания;
адаптивное цветовое пространство logLuv для уровня HDR (смотри изобретение 10F5658-IISI заявителей);
способ для определения оптимальных параметров «расход-искажение» для интер-уровневого предсказания;
способ эффективного кодирования указанных параметров для интер-уровневого предсказания:
глобальные параметры: дифференциально закодированная справочная таблица для каждого кадра, например, передаваемая в наборе параметров изображения (к сожалению, это уже упомянуто в [4], но возможно, что в сочетании с локальными параметрами это может претендовать на заявку);
локальные параметры: масштаб, предсказываемый, исходя из верхнего левого макроблока; смещение, предсказываемое, исходя из верхнего левого и совпадающего макроблока базового уровня (возможно использование других локальных окрестностей, а также, например, левого верхнего и правого верхнего макроблоков вдобавок, причем патентная формула не должна зависеть от стандарта H.264, поскольку тот же принцип применяется к блокам кодирования или блокам преобразования внедряемого стандарта HEVC.
Компьютерная программная реализация
Хотя некоторые аспекты были описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствует шагу способа или признаку шага способа. Аналогичным образом, аспекты, описанные в контексте шага способа также представляют описание соответствующего блока, позиции или признака соответствующего устройства. Некоторые либо все шаги способа могут выполняться (или использоваться) аппаратным устройством, подобным, например, микропроцессору, программируемому компьютеру или электронной схеме. В некоторых вариантах один или несколько наиболее важных шагов способа могут выполняться указанным устройством. В зависимости от требований к конкретной реализации, варианты изобретения можно реализовать аппаратными либо программными средствами. Такая реализация может быть осуществлена с использованием цифровой запоминающей среды, например, гибкого диска, диска DVD, диска Blu-Ray, диска CD, ПЗУ (ROM), программируемого ПЗУ (PROM), стираемого программируемого ПЗУ (EPROM), электрически стираемого программируемого ПЗУ (EEPROM) или флэш-памяти, имеющих считываемые электронным путем сигналы управления, которые в них хранятся, причем перечисленные средства совместно функционируют (или способны совместно функционировать) с программируемой компьютерной системой, обеспечивая выполнение соответствующего способа. Таким образом, цифровая запоминающая среда может представлять собой считываемую компьютером среду.
Некоторые варианты согласно изобретению содержат носитель данных, содержащий считываемые электронным образом управляющие сигналы, которые способны совместно функционировать с программируемой компьютерной системой, обеспечивая выполнение одного из описанных здесь способов.
В общем случае варианты настоящего изобретения можно реализовать в виде компьютерного программного продукта с программным кодом, где программный код действует, выполняя один из способов при прогоне компьютерного программного продукта на компьютере. Программный код может храниться, например, на машинно-считываемом носителе.
Другие варианты содержат компьютерную программу для выполнения одного из описанных здесь способов, причем компьютерная программа хранится на считываемом компьютером носителе.
Другими словами, вариант заявленного способа представляет собой компьютерную программу, содержащую программный код для выполнения одного из описанных здесь способов при работе этой компьютерной программы на компьютере.
Еще один вариант заявленных способов представляет собой носитель данных (или цифровую запоминающую среду или считываемую компьютером среду), содержащий записанную на нем компьютерную программу для выполнения одного из описанных здесь способов. Носитель данных, цифровая запоминающая среда или среда записи, как правило, является материальной средой и/или средой, обеспечивающей долговременное хранение.
Дополнительный вариант заявленного способа представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для выполнения одного из описанных здесь способов. Поток данных или последовательность сигналов могут быть, например, сконфигурированы для пересылки через соединение для обмена данными, например, через Интернет.
Другой вариант содержит средство обработки, например, компьютер или программируемое логическое устройство, сконфигурированное или адаптированное для выполнения одного из описанных здесь способов. Еще один вариант содержит компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из описанных здесь способов.
Следующий вариант согласно изобретению содержит устройство или систему, сконфигурированную для пересылки (например, с использованием средств электронной или оптической связи) на приемник компьютерной программы для выполнения одного из описанных здесь способов. Приемником может быть, например, компьютер, мобильное устройство, запоминающее устройство или т.п. Упомянутые устройство или система могут содержать, например, файловый сервер для пересылки компьютерной программы на приемник.
В некоторых вариантах для выполнения некоторых или всех функциональных возможностей описанных здесь способов можно использовать программируемое логическое устройство (например, вентильную матрицу, программируемую пользователем. В некоторых вариантах вентильная матрица, программируемая пользователем, может совместно функционировать с микропроцессором для выполнения одного из описанных здесь способов. В общем случае эти способы предпочтительно выполнять с помощью какого-либо аппаратного средства.
Вышеописанные варианты приведены просто в качестве иллюстрации принципов настоящего изобретения. Понятно, что специалистам в данной области техники очевидны модификации и другие версии описанных компоновок и деталей. Таким образом, здесь предполагается, что изобретение ограничивается только объемом нижеследующей патентной формулы, а не конкретными деталями, представленными при описании и разъяснении предложенных здесь вариантов.
Список использованных источников



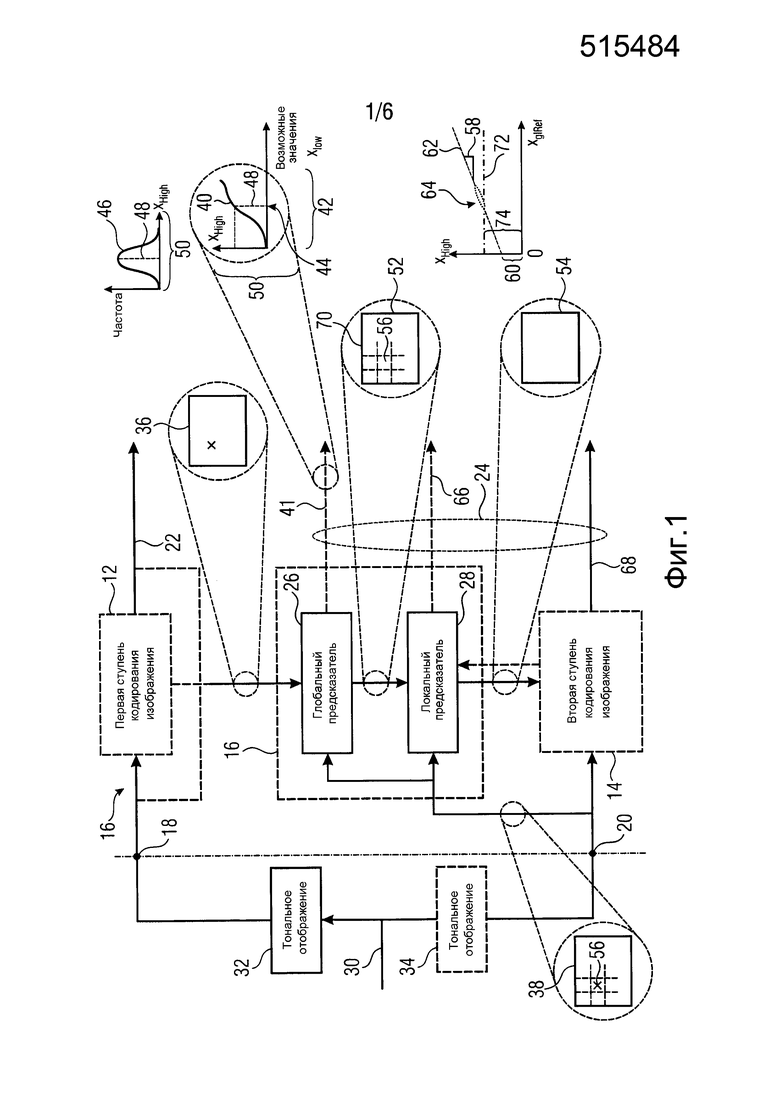
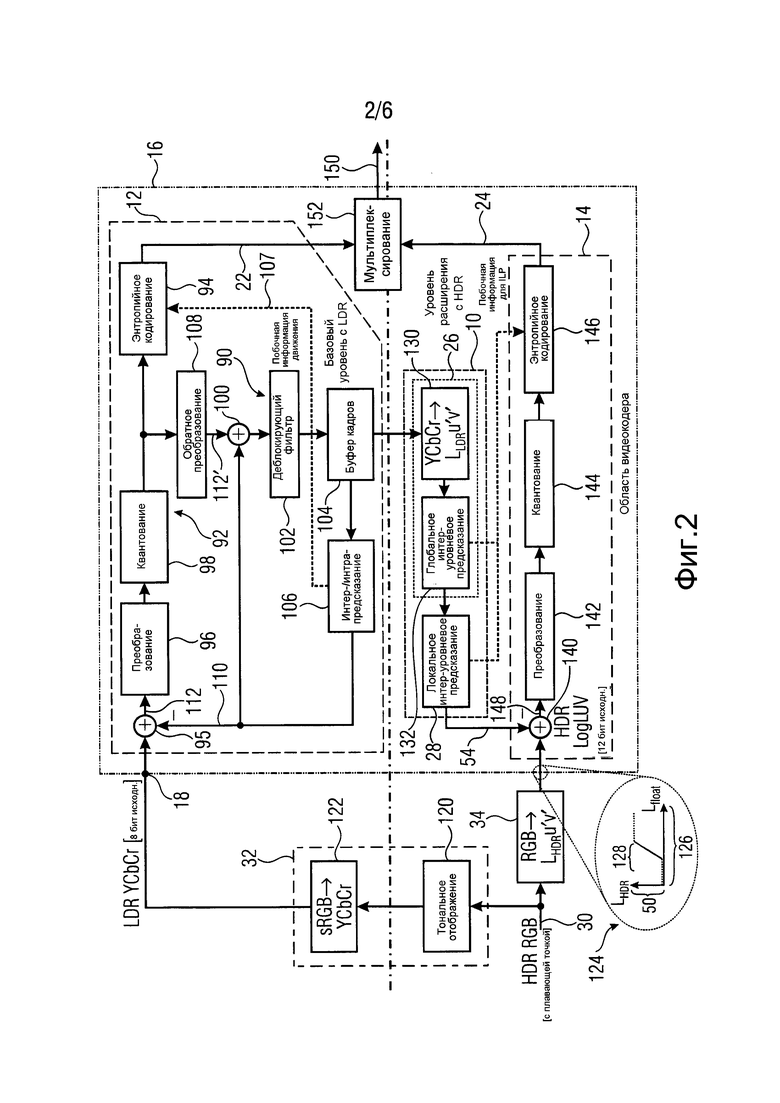
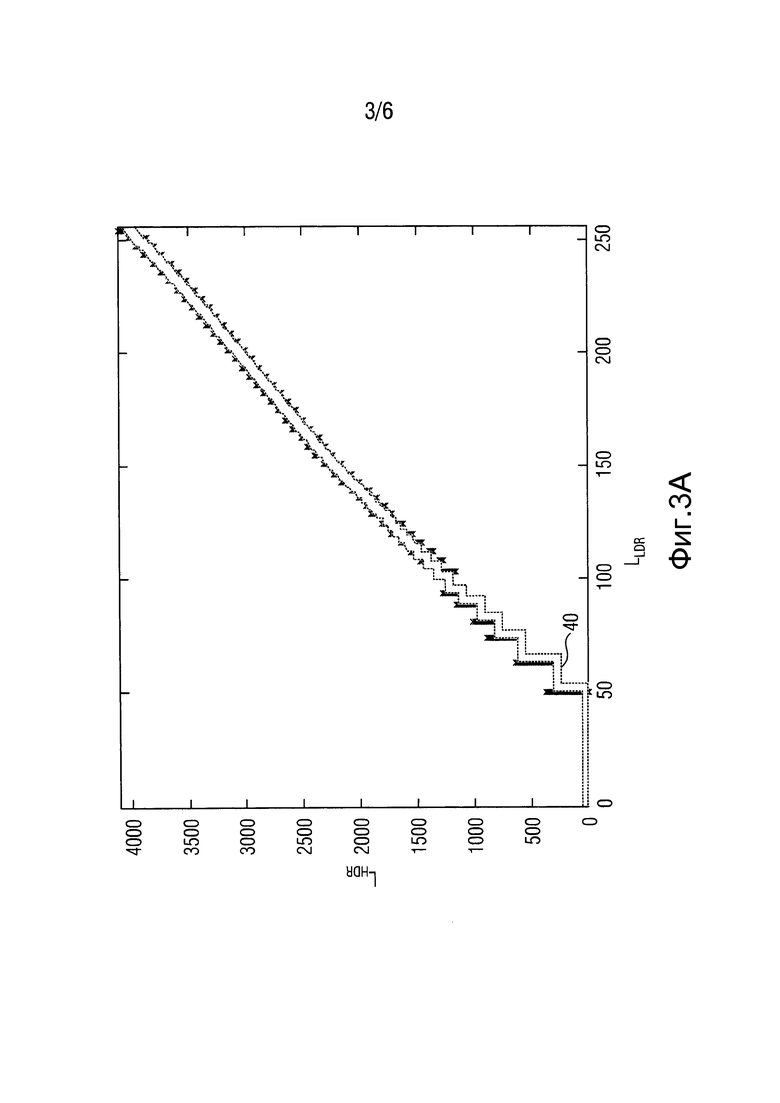
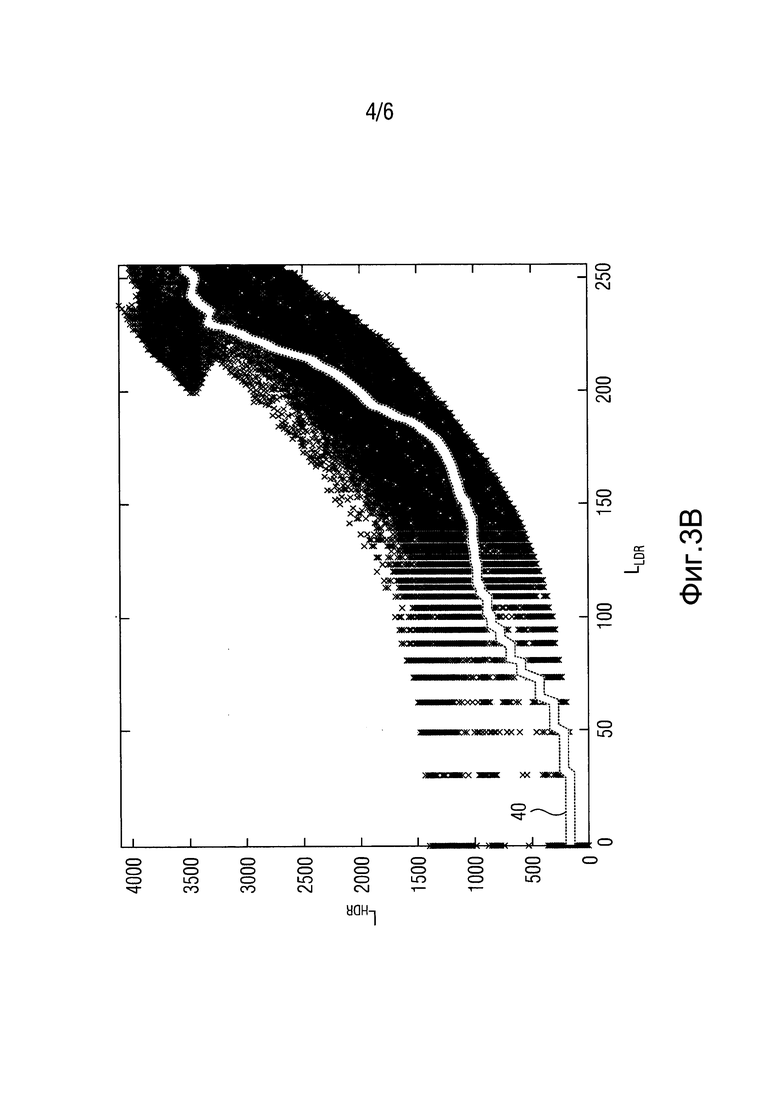
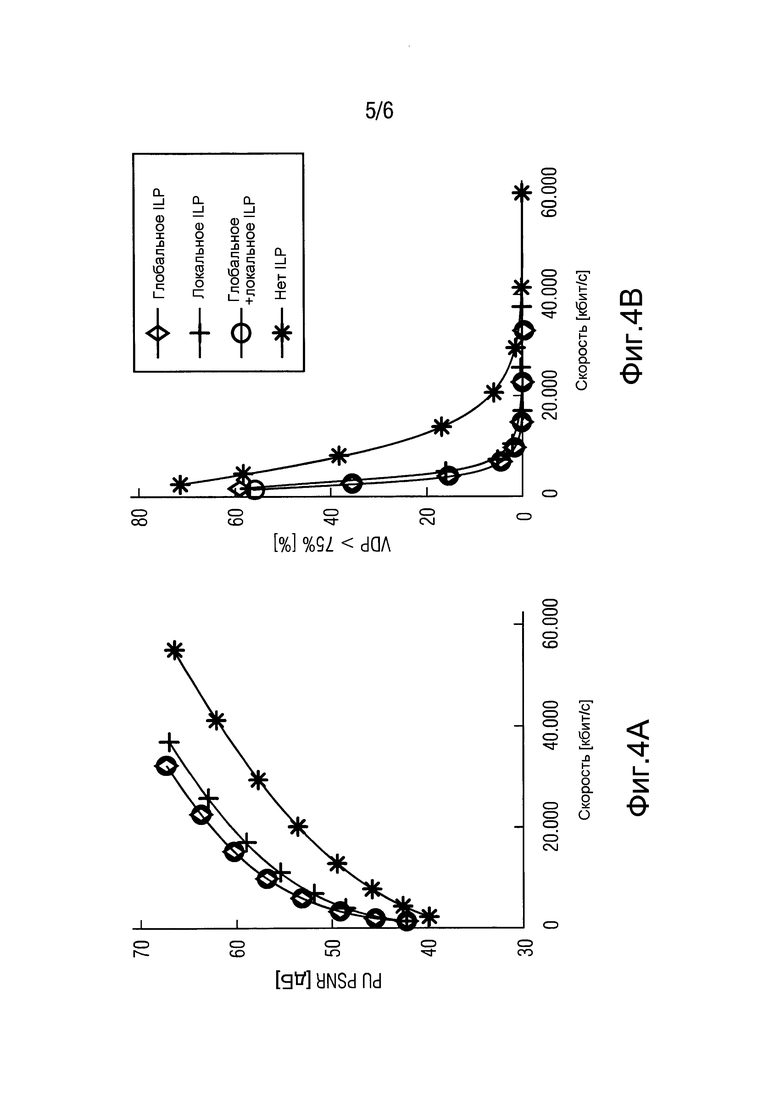
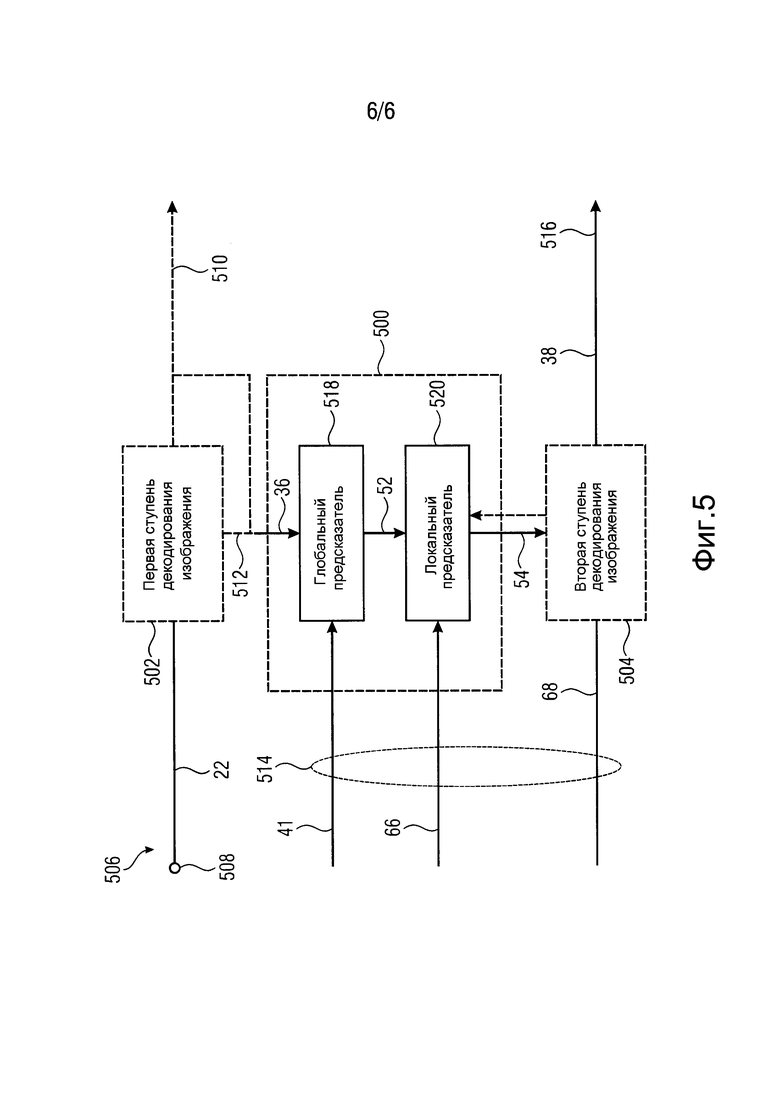
Изобретение относится к вычислительной технике. Технический результат заключается в улучшении соотношения качество/скорость кодирования за счет обеспечения комбинированного использования глобального и локального предсказателей. Устройство для выполнения интер-уровневого предсказания между уровнями с разным динамическим диапазоном значения отсчетов содержит глобальный предсказатель, который выводит функцию глобального тонального отображения на основе статистического анализа пар значений совмещенных отсчетов в первой тонально отображенной версии и второй версии изображения и применяет функцию глобального тонального отображения к первой тонально отображенной версии изображения; и локальный предсказатель, который локально получает локально изменяющуюся функцию тонального отображения на основе статистического анализа значений совмещенных отсчетов во второй версии изображения и глобально предсказанного опорного изображения в единицах суб-частей, на которые разбиты глобально предсказанное опорное изображение и вторая версия изображения, и применяет локально изменяющуюся функцию тонального отображения к глобально предсказанному опорному изображению. 6 н. и 20 з.п. ф-лы, 7 ил., 3 табл.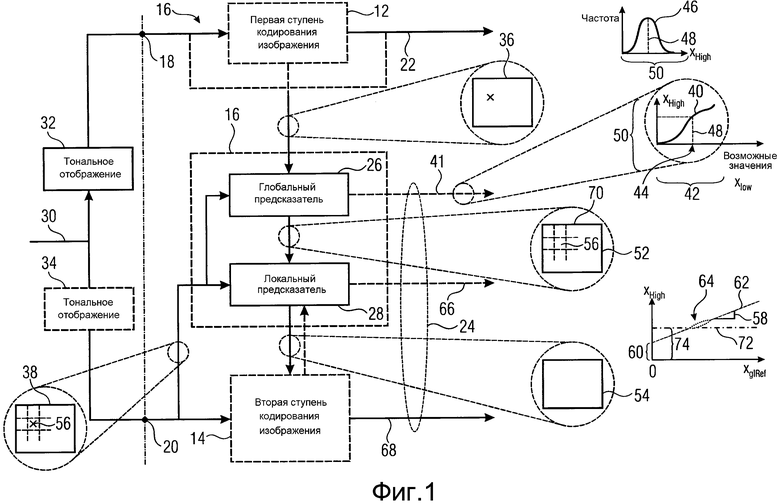
1. Устройство для выполнения интер-уровневого предсказания между первой ступенью (12) кодирования изображения для кодирования первой тонально отображенной версии изображения, имеющей первый динамический диапазон значений отсчетов, и второй ступенью (14) кодирования изображения для кодирования второй версии изображения, имеющей второй динамический диапазон значений отсчетов, превышающий первый динамический диапазон значений отсчетов, причем устройство содержит:
глобальный предсказатель (26), сконфигурированный для вывода функции (40) глобального тонального отображения на основе статистического анализа пар значений совмещенных отсчетов в первой тонально отображенной версии (36) и второй версии (38) изображения и применения функции (40) глобального тонального отображения к первой тонально отображенной версии (36) изображения с тем, чтобы получить глобально предсказанное опорное изображение (52) для второй версии изображения; и
локальный предсказатель (28), сконфигурированный для вывода локально изменяющейся функции тонального отображения локально на основе статистического анализа значений совмещенных отсчетов во второй версии (38) изображения и глобально предсказанном опорном изображении (52) в единицах суб-частей, на которые разбиты глобально предсказанное опорное изображение (52) и вторая версия (38) изображения, и применения локально изменяющейся функции тонального отображения к глобально предсказанному опорному изображению (52) с тем, чтобы получить глобально и локально предсказанное опорное изображение (54) для второй версии (38) изображения;
при этом при выводе локально изменяющейся функции тонального отображения локально, для каждой суб-части, локальный предсказатель (28) сконфигурирован для определения наклона (58) и отсекаемого отрезка (60) линии (62) регрессии через распределение (64) пар значений совмещенных отсчетов в соответствующей суб-части (56) второй версии (38) изображения и глобально предсказанного опорного изображения (52);
и кодирования наклона и отсекаемого отрезка, определенных для суб-частей, в качестве побочной информации в поток данных расширения, генерируемый второй ступенью кодирования изображения, и формирующий уровень расширения относительно потока данных, выводимого первой ступенью кодирования изображения, и
при этом вторая ступень кодирования изображения сконфигурирована для кодирования с потерями остатка предсказания между глобально и локально предсказанным опорным изображением и второй версией изображения в поток данных расширения, и причем локальный предсказатель (28) сконфигурирован для
кодирования наклона (58), определенного для соответствующей суб-части (56), в качестве остатка предсказания для пространственного предсказания, из наклона соседней суб-части, наклон которой был закодирован ранее,
встраивания прямой линии (72), имеющей наклон соответствующей суб-части (56), в распределение пар значений совмещенных отсчетов в соседней суб-части (70) второй версии изображения, при условии, что она является восстанавливаемой на основе остатка предсказания и глобально и локально предсказанного опорного изображения, с одной стороны, и глобально предсказанного опорного изображения, с другой стороны, и определения отсекаемого отрезка прямой линии; и
кодирования отсекаемого отрезка (60) соответствующей суб-части (56) в качестве остатка предсказания относительно пространственного предсказания отсекаемого отрезка в зависимости от отсекаемого отрезка прямой линии (74).
2. Устройство по п. 1, в котором глобальный предсказатель (26) сконфигурирован для вывода функции (40) глобального тонального отображения, для каждого из возможных значений первого динамического диапазона (42) значений отсчетов, по центральной тенденции распределения значений отсчетов во второй версии (38) изображения, которые совмещены с отсчетами в первой тонально отображенной версии (36) изображения, значение которой равно соответствующему возможному значению.
3. Устройство по п. 2, в котором глобальный предсказатель сконфигурирован так, что центральная тенденция представляет собой среднее значение, такое как среднее арифметическое значение.
4. Устройство по п. 1, в котором, при выведении функции глобального тонального отображения и применении функции глобального тонального отображения к первой тонально отображенной версии изображения, глобальный предсказатель сконфигурирован для выполнения преобразования цветов над значениями отсчетов в первой тонально отображенной версии изображения из первого цветового формата во второй цветовой формат, причем преобразование цветов является постоянно установленным независимо от первой тонально отображенной версии и второй версии изображения, а затем выполнения вывода функции глобального тонального отображения и применения функции глобального тонального отображения во втором цветовом формате.
5. Устройство по п. 4, в котором глобальный предсказатель (26) сконфигурирован так, что второй цветовой формат содержит компоненту яркости, которая логарифмически связана со светимостью.
6. Устройство по п. 1, в котором глобальный предсказатель (26) сконфигурирован для кодирования функции глобального тонального отображения в качестве побочной информации в поток данных расширения, генерируемый второй ступенью (14) кодирования изображения, и формирующий уровень расширения относительно потока данных, выводимого первой ступенью (12) кодирования изображения.
7. Устройство по п. 6, в котором глобальный предсказатель (26) сконфигурирован для кодирования функции глобального тонального отображения последовательно в направлении возрастания или убывания возможных значений первого динамического диапазона значений отсчетов с использованием дифференциального кодирования.
8. Устройство по п. 1, в котором локальный предсказатель (28) сконфигурирован для квантования наклона (58) и отсекаемого отрезка (60) путем минимизации функции стоимости, которая зависит от соответствующей суб-части (56) второй версии (38) изображения и соответствующей суб-части (56) глобально предсказанного опорного изображения (52), имеющего свои отсчеты, взвешенные с помощью наклона (58) и смещенные на отсекаемый отрезок (60).
9. Устройство по п. 1, в котором локальный предсказатель (28) сконфигурирован для квантования наклона (58) и отсекаемого отрезка (60) путем минимизации функции стоимости, которая монотонно возрастает с необходимой скоростью передачи данных и монотонно возрастает с искажением, вносимым второй ступенью (14) кодирования изображения для кодирования отклонения между соответствующей суб-частью (56) второй версии (38) изображения и соответствующей суб-частью (56) глобально предсказанного опорного изображения (52), имеющего свои отсчеты, взвешенные с помощью наклона (58) и смещенные на отсекаемый отрезок (60).
10. Устройство по п. 1, в котором глобальный предсказатель (26) сконфигурирован для блокирования применения функции (40) глобального тонального отображения в случае, когда сумма дисперсий распределений пар значений совмещенных отсчетов в первой тонально отображенной версии (36) изображения и второй версии (38) изображения относительно функции (40) глобального тонального отображения превышает заранее определенный порог, при этом локальный предсказатель (28) в случае блокирования сконфигурирован для выполнения локального выведения и упомянутого применения к первой тонально отображенной версии (36) изображения, а не глобально предсказанному опорному изображению (52).
11. Устройство по п. 10, в котором глобальный предсказатель (26) сконфигурирован для сигнализации блокирования применения функции глобального тонального отображения в качестве побочной информации в потоке данных расширения, генерируемом второй ступенью кодирования изображения, и формирующем уровень расширения относительно потока данных, выводимого первой ступенью кодирования изображения.
12. Устройство по п. 1, в котором отсчеты в первой тонально отображенной версии изображения являются целыми числами длины m в битах, а отсчеты второй версии изображения являются длиной n в битах, где n>m.
13. Устройство по п. 1, в котором изображение представляет собой изображение видео, а первая ступень кодирования изображения является гибридным видеокодером, сконфигурированным для кодирования тонально отображенной версии в поток данных.
14. Устройство по п. 1, в котором вторая ступень кодирования сконфигурирована для кодирования с преобразованием остатка предсказания между глобально и локально предсказанным опорным изображением и второй версией изображения в поток данных расширения.
15. Устройство для выполнения интер-уровневого предсказания между первой ступенью декодирования изображения для декодирования первой тонально отображенной версии (36) изображения, имеющей первый динамический диапазон значений отсчетов, и второй ступенью декодирования изображения для декодирования второй версии изображения, имеющей второй динамический диапазон значений отсчетов, превышающий первый динамический диапазон значений отсчетов, причем устройство содержит:
глобальный предсказатель (518), сконфигурированный для вывода функции глобального тонального отображения из побочной информации (41) потока данных расширения второй ступени (504) декодирования изображения и применения функции глобального тонального отображения глобально к отсчетам первой тонально отображенной версии (36) изображения с тем, чтобы получить глобально предсказанное опорное изображение (52) для второй версии изображения; и
локальный предсказатель (520), сконфигурированный для вывода локально изменяющейся функции тонального отображения локально из побочной информации в единицах суб-частей, на которые разбиты глобально предсказанное опорное изображение (52) и вторая версия (38) изображения, и применения локально изменяющейся функции тонального отображения к глобально предсказанному опорному изображению (52) с тем, чтобы получить глобально и локально предсказанное опорное изображение (54) для второй версии изображения;
при этом локальный предсказатель (520) сконфигурирован для
при выводе локально изменяющейся функции тонального отображения локально, восстановления для каждой суб-части (56) наклона (58) и отсекаемого отрезка (60) из побочной информации (66), и
при применении локально изменяющейся функции тонального отображения к глобально предсказанному опорному изображению, взвешивания, для каждой суб-части (56), отсчетов глобально предсказанного опорного изображения (52) в соответствующей суб-части (56), используя наклон и добавляя к упомянутому отсекаемый отрезок,
при этом локальный предсказатель (520) сконфигурирован для вывода последовательно наклона и отсекаемого отрезка для суб-частей из побочной информации путем:
декодирования остатков наклона и отсекаемого отрезка для суб-частей из побочной информации,
предсказания пространственно наклона для текущей суб-части из наклона соседней суб-части, восстановленной ранее, для получения предсказания наклона;
восстановления наклона для текущей суб-части на основе предсказания наклона и остатка наклона для текущей суб-части;
встраивания прямой линии, имеющей наклон текущей суб-части, в распределение пар значений совмещенных отсчетов в соседней суб-части второй версии изображения и глобально предсказанного опорного изображения, и определения отсекаемого отрезка прямой линии, для получения предсказания отсекаемого отрезка; и
восстановления отсекаемого отрезка текущей суб-части (56) на основе предсказания отсекаемого отрезка и остатка отсекаемого отрезка для текущей суб-части (56).
16. Устройство по п. 15, в котором, при выведении функции глобального тонального отображения и применении функции глобального тонального отображения к первой тонально отображенной версии (36) изображения, глобальный предсказатель (518) сконфигурирован для выполнения преобразования цветов над значениями отсчетов в первой тонально отображенной версии (36) изображения из первого цветового формата во второй цветовой формат, причем преобразование цветов является постоянно установленным независимо от первой тонально отображенной версии (36) и второй версии (38) изображения, а затем выполнения применения функции глобального тонального отображения во втором цветовом формате.
17. Устройство по п. 16, в котором глобальный предсказатель сконфигурирован так, что второй цветовой формат содержит компоненту яркости, которая логарифмически связана со светимостью.
18. Устройство по п. 15, в котором глобальный предсказатель (518) сконфигурирован для декодирования функции глобального тонального отображения из побочной информации последовательно в направлении возрастания или убывания возможных значений первого динамического диапазона значений отсчетов с использованием дифференциального декодирования.
19. Устройство по п. 15, в котором глобальный предсказатель (518) сконфигурирован для блокирования выведения и применения функции (40) глобального тонального отображения в ответ на сигнализацию в побочной информации, при этом локальный предсказатель (520) в случае блокирования сконфигурирован для выполнения применения к первой тонально отображенной версии изображения, а не глобально предсказанному опорному изображению.
20. Устройство по п. 15, в котором отсчеты в первой тонально отображенной версии изображения являются целыми числами длины m в битах, а отсчеты второй версии изображения являются длиной n в битах, где n>m.
21. Устройство по п. 15, в котором изображение представляет собой изображение видео, а первая ступень кодирования изображения является гибридным видеокодером, сконфигурированным для кодирования тонально отображенной версии в поток данных.
22. Устройство по п. 15, в котором вторая ступень (504) декодирования сконфигурирована для декодирования с преобразованием остатка (68) предсказания между глобально и локально предсказанным опорным изображением и второй версией изображения из потока данных расширения и восстановления второй версии изображения на основе остатка (68) предсказания и глобально и локально предсказанного опорного изображения (54).
23. Способ для выполнения интер-уровневого предсказания между первой ступенью (12) кодирования изображения для кодирования первой тонально отображенной версии изображения, имеющей первый динамический диапазон значений отсчетов, и второй ступенью (14) кодирования изображения для кодирования второй версии изображения, имеющей второй динамический диапазон значений отсчетов, превышающий первый динамический диапазон значений отсчетов, причем способ содержит:
выведение функции (40) глобального тонального отображения на основе статистического анализа пар значений совмещенных отсчетов в первой тонально отображенной версии (36) и второй версии (38) изображения;
применение функции (40) глобального тонального отображения к первой тонально отображенной версии (36) изображения с тем, чтобы получить глобально предсказанное опорное изображение (52) для второй версии изображения;
выведение локально изменяющейся функции тонального отображения локально на основе статистического анализа значений совмещенных отсчетов во второй версии (38) изображения и глобально предсказанном опорном изображении (52) в единицах суб-частей, на которые разбиты глобально предсказанное опорное изображение (52) и вторая версия (38) изображения, и
применение локально изменяющейся функции тонального отображения к глобально предсказанному опорному изображению (52) с тем, чтобы получить глобально и локально предсказанное опорное изображение (54) для второй версии (38) изображения;
при этом локальный вывод локально изменяющейся функции тонального отображения содержит, для каждой суб-части, определение наклона (58) и отсекаемого отрезка (60) линии (62) регрессии через распределение (64) пар значений совмещенных отсчетов в соответствующей суб-части (56) второй версии (38) изображения и глобально предсказанного опорного изображения (52);
и способ дополнительно содержит кодирование наклона и отсекаемого отрезка, определенных для суб-частей, в качестве побочной информации в поток данных расширения, генерируемый второй ступенью кодирования изображения, и формирующий уровень расширения относительно потока данных, выводимого первой ступенью кодирования изображения, и
при этом вторая ступень кодирования изображения содержит кодирование с потерями остатка предсказания между глобально и локально предсказанным опорным изображением и второй версией изображения в поток данных расширения, и причем кодирование наклона и отсекаемого отрезка содержит
кодирование наклона (58), определенного для соответствующей суб-части (56), в качестве остатка предсказания для пространственного предсказания, из наклона соседней суб-части, наклон которой был закодирован ранее,
встраивание прямой линии (72), имеющей наклон соответствующей суб-части (56), в распределение пар значений совмещенных отсчетов в соседней суб-части (70) второй версии изображения, при условии, что она является восстанавливаемой на основе остатка предсказания и глобально и локально предсказанного опорного изображения, с одной стороны, и глобально предсказанного опорного изображения, с другой стороны, и определения отсекаемого отрезка прямой линии; и
кодирование отсекаемого отрезка (60) соответствующей суб-части (56) в качестве остатка предсказания относительно пространственного предсказания отсекаемого отрезка в зависимости от отсекаемого отрезка прямой линии (74).
24. Способ для выполнения интер-уровневого предсказания между первой ступенью декодирования изображения для декодирования первой тонально отображенной версии (36) изображения, имеющей первый динамический диапазон значений отсчетов, и второй ступенью декодирования изображения для декодирования второй версии изображения, имеющей второй динамический диапазон значений отсчетов, превышающий первый динамический диапазон значений отсчетов, причем способ содержит:
выведение функции глобального тонального отображения из побочной информации (41) потока данных расширения второй ступени (504) декодирования изображения;
применение функции глобального тонального отображения глобально к отсчетам первой тонально отображенной версии (36) изображения с тем, чтобы получить глобально предсказанное опорное изображение (52) для второй версии изображения;
выведение локально изменяющейся функции тонального отображения локально, из побочной информации в единицах суб-частей, на которые разбиты глобально предсказанное опорное изображение (52) и вторая версия (38) изображения, и
применение локально изменяющейся функции тонального отображения к глобально предсказанному опорному изображению (52) с тем, чтобы получить глобально и локально предсказанное опорное изображение (54) для второй версии изображения;
при этом
локальное выведение локально изменяющейся функции тонального отображения содержит восстановление для каждой суб-части (56) наклона (58) и отсекаемого отрезка (60) из побочной информации (66), и
применение локально изменяющейся функции тонального отображения к глобально предсказанному опорному изображению содержит взвешивание для каждой суб-части (56) отсчетов глобально предсказанного опорного изображения (52) в соответствующей суб-части (56), используя наклон и добавляя к упомянутому отсекаемый отрезок,
при этом способ содержит вывод последовательно наклона и отсекаемого отрезка для суб-частей из побочной информации путем:
декодирования остатков наклона и отсекаемого отрезка для суб-частей из побочной информации,
предсказания пространственно наклона для текущей суб-части из наклона соседней суб-части, восстановленной ранее, для получения предсказания наклона;
восстановления наклона для текущей суб-части на основе предсказания наклона и остатка наклона для текущей суб-части;
встраивания прямой линии, имеющей наклон текущей суб-части, в распределение пар значений совмещенных отсчетов в соседней суб-части второй версии изображения и глобально предсказанного опорного изображения, и определения отсекаемого отрезка прямой линии, для получения предсказания отсекаемого отрезка; и
восстановления отсекаемого отрезка текущей суб-части (56) на основе предсказания отсекаемого отрезка и остатка отсекаемого отрезка для текущей суб-части (56).
25. Считываемый компьютером носитель, хранящий компьютерную программу для выполнения, при работе на компьютере, способа по п. 23.
26. Считываемый компьютером носитель, хранящий компьютерную программу для выполнения, при работе на компьютере, способа по п. 24.
| Колосоуборка | 1923 |
|
SU2009A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| УСОВЕРШЕНСТВОВАННОЕ МЕЖУРОВНЕВОЕ ПРЕДСКАЗАНИЕ ДЛЯ РАСШИРЕННОЙ ПРОСТРАНСТВЕННОЙ МАСШТАБИРУЕМОСТИ ПРИ КОДИРОВАНИИ ВИДЕОСИГНАЛА | 2008 |
|
RU2426267C2 |

