Настоящее изобретение относится к способу и устройству для предоставления компенсационных смещений для набора восстановленных выборок изображения. Изобретение дополнительно относится к способу и устройству для кодирования или декодирования последовательности цифровых изображений.
Изобретение может применяться в области техники обработки цифровых сигналов и, в частности, в области сжатия видео с использованием компенсации движения, чтобы уменьшать пространственные и временные избыточности в видеопотоках.
Множество форматов сжатия видео, таких как, например, H.263, H.264, MPEG-1, MPEG-2, MPEG-4, SVC, используют дискретное косинусное преобразование (DCT) на основе блоков и компенсацию движения для того, чтобы удалять пространственные и временные избыточности. Они зачастую упоминаются в качестве прогнозирующих видеоформатов. Каждый кадр или изображение видеосигнала разделяется на слайсы (вырезка), которые кодируются и могут декодироваться независимо. Слайс типично представляет собой прямоугольную часть кадра либо, если обобщать, часть кадра или весь кадр. Дополнительно, каждый слайс может быть разделен на макроблоки (MB), и каждый макроблок дополнительно разделяется на блоки, типично блоки по 64×64, 32×32, 16×16 или 8×8 пикселов.
В стандарте высокоэффективного кодирования видео (HEVC), могут использоваться блоки от 64×64 до 4×4. Сегментирование организуется согласно структуре в виде дерева квадрантов на основе наибольшей единицы кодирования (LCU). LCU соответствует квадратному блоку 64×64. Если LCU должна быть разделена, флаг разбиения указывает, что LCU разбивается на 4 блока 32×32. Аналогичным образом, если какой-либо из этих 4 блоков должен разбиваться, флаг разбиения задается как "истина", и блок 32×32 разделяется на 4 блока 16×16 и т.д. Когда флаг разбиения задается как "ложь", текущий блок представляет собой единицу CU кодирования. CU имеет размер, равный 64×64, 32×32, 16×16 или 8×8 пикселов.
Предусмотрено два семейства режимов кодирования для кодирования блоков изображения: режимы кодирования на основе пространственного прогнозирования, называемые "внутренним (интра-) прогнозированием", и режимы кодирования на основе временного прогнозирования (внешний (интер), объединение, пропуск). В режимах пространственного и временного прогнозирования, остаток вычисляется посредством вычитания прогнозирования из исходного блока.
Внутренний блок, в общем, прогнозируется посредством процесса внутреннего прогнозирования из кодированных пикселов на причинной границе. При внутреннем прогнозировании кодируется направление прогнозирования.
Временное прогнозирование состоит в нахождении в опорном кадре, предыдущем или будущем кадре видеопоследовательности, части изображения или опорной области, которая является ближайшей к блоку, который должен быть кодирован. Этот этап типично известен в качестве оценки движения. Затем, блок, который должен быть кодирован, прогнозируется с использованием опорной области на этапе, типично называемом "компенсацией движения", при этом разность между блоком, который должен быть кодирован, и опорной частью кодируется, вместе с элементом информации движения относительно вектора движения, который указывает опорную область для использования для компенсации движения. При временном прогнозировании кодируется по меньшей мере один вектор движения.
Чтобы дополнительно уменьшать затраты на кодирование информации движения, вместо непосредственного кодирования вектора движения, при условии, что движение является гомогенным, вектор движения может быть кодирован с точки зрения разности между вектором движения и предиктором вектора движения, типично вычисляемой из одного или более векторов движения блоков, окружающих блок, который должен быть кодирован.
В H.264, например, векторы движения кодируются относительно среднего предиктора, вычисленного из векторов движения, расположенных в причинном окружении блока, который должен быть кодирован, например, из трех блоков, расположенных выше и слева от блока, который должен быть кодирован. Только разность, называемая "остаточным вектором движения", между средним предиктором и вектором движения текущего блока кодируется в потоке битов для того, чтобы уменьшать затраты на кодирование.
Кодирование с использованием остаточных векторов движения дает некоторую экономию скорости передачи битов, но требует того, чтобы декодер выполнял идентичное вычисление предиктора вектора движения, чтобы декодировать значение вектора движения блока, который должен быть декодирован.
Процессы кодирования и декодирования могут заключать в себе процесс декодирования кодированного изображения. Этот процесс типично выполняется на стороне кодера в целях будущей оценки движения, что позволяет кодеру и соответствующему декодеру иметь идентичные опорные кадры.
Чтобы восстанавливать кодированный кадр, остаток обратно квантуется и обратно преобразуется, чтобы предоставлять "декодированный" остаток в пиксельной области. Первое восстановление затем фильтруется посредством одного или нескольких видов процессов постфильтрации. Эти постфильтры применяются для восстановленного кадра на стороне кодера и декодера, чтобы идентичный опорный кадр использовался на обеих сторонах. Цель этой постфильтрации состоит в том, чтобы удалять артефакт сжатия. Например, H.264/AVC использует фильтр удаления блочности. Этот фильтр может удалять артефакты блочности вследствие DCT-квантования остатка и блочной компенсации движения. В текущем HEVC-стандарте, используются 3 типа контурных фильтров: фильтр удаления блочности, адаптивное к выборке смещение (SAO) и адаптивный контурный фильтр (ALF).
Фиг. 1 является блок-схемой последовательности операций способа, иллюстрирующей этапы процесса контурной фильтрации в известной HEVC-реализации. На начальном этапе 101, кодер или декодер формирует восстановление полного кадра. Затем, на этапе 102 фильтр удаления блочности применяется для этого первого восстановления, чтобы формировать восстановление 103 с удаленной блочностью. Цель фильтра удаления блочности состоит в том, чтобы удалять артефакты блочности, сформированные посредством остаточного квантования и блочной компенсации движения или блочного внутреннего прогнозирования. Эти артефакты являются визуально важными на низких скоростях передачи битов. Фильтр удаления блочности работает с возможностью сглаживать границы блоков согласно характеристикам двух соседних блоков. Учитываются режим кодирования каждого блока, параметры квантования, используемые для остаточного кодирования, и соседние пиксельные разности на границе. Идентичный критерий/классификация применяется для всех кадров, и дополнительные данные не передаются. Фильтр удаления блочности повышает визуальное качество текущего кадра посредством удаления артефактов блочности, и он также улучшает оценку движения и компенсацию движения для последующих кадров. Фактически, высокие частоты артефакта блочности удаляются, и в силу этого данные высокие частоты не должны компенсироваться с помощью остатка текстуры следующих кадров.
После фильтра удаления блочности восстановление с удаленной блочностью фильтруется посредством контурного фильтра на основе адаптивного к выборке смещения (SAO) на этапе 104. Результирующий кадр 105 затем фильтруется с помощью адаптивного контурного фильтра (ALF) на этапе 106, чтобы формировать восстановленный кадр 107, который должен отображаться и использоваться в качестве опорного кадра для следующих внешних кадров.
Цель контурного SAO-фильтра и ALF состоит в том, чтобы улучшать восстановление кадра посредством отправки дополнительных данных, в отличие от фильтра удаления блочности, в котором информация не передается.
Принцип контурного SAO-фильтра состоит в том, чтобы классифицировать каждый пиксел на класс и суммировать идентичное значение смещения с соответствующим пиксельным значением каждого пиксела класса. Таким образом, одно смещение передается для каждого класса. Контурная SAO-фильтрация предоставляет два вида классификации для области кадра: краевое смещение и полосовое смещение.
Классификация краевых смещений заключает в себе определение класса для каждого пиксела посредством сравнения его соответствующего пиксельного значения с пиксельными значениями двух соседних пикселов. Кроме того, два соседних пиксела зависят от параметра, который указывает направление 2 соседних пикселов. Эти направления составляют 0 градусов (горизонтальное направление), 45 градусов (диагональное направление), с 90 градусов (вертикальное направление) и 135 градусов (второе диагональное направление). Далее, эти направления называются "типом" классификации краевых смещений.
Второй тип классификации является классификацией полосовых смещений, которая зависит от пиксельного значения. Класс в полосовом SAO-смещении соответствует диапазону пиксельных значений. Таким образом, идентичное смещение добавляется во все пикселы, имеющие пиксельное значение в данном диапазоне пиксельных значений.
Для обеспечения большей адаптации к контенту кадра, предложено применять SAO-фильтрацию на основе структуры в виде дерева квадрантов для того, чтобы кодировать SAO. Следовательно, область кадра, которая соответствует концевому узлу дерева квадрантов, может фильтроваться или не фильтроваться посредством SAO таким образом, что фильтруются только некоторые области. Кроме того, когда активируется SAO, используется только одна SAO-классификация: краевое смещение или полосовое смещение, согласно связанным параметрам, передаваемым для каждой классификации. В завершение, для каждого концевого SAO-узла, передается SAO-классификация, а также ее параметры и смещения всех классов.
Основное преимущество дерева квадрантов заключается в том, чтобы эффективно придерживаться локальных свойств сигнала. Тем не менее, это требует выделенного кодирования в потоке битов. Также может быть предусмотрено другое решение, заменяющее кодирование на основе дерева квадрантов SAO-параметров на кодирование на уровне LCU.
Изображение видеоданных, которые должны кодироваться, может предоставляться в качестве набора двумерных матриц (также известных как цветовые каналы) значений выборки, каждая запись которых представляет интенсивность цветового компонента, к примеру, показатель отклонений яркости сигнала яркости и цвета сигнала цветности от нейтрального полутонового цвета к синему или красному (YUV), или показатель интенсивности компонентов красного, зеленого или синего света (RGB). YUV-модель задает цветовое пространство с точки зрения одного компонента сигнала (Y) яркости и двух компонентов цветности (UV). В общем, Y означает компонент сигнала яркости (яркость), а U и V - компоненты цветности (цвета) или сигнала цветности.
SAO-фильтрация типично применяется независимо для компонента сигнала яркости и для компонентов сигнала U и V цветности.
Известная реализация полосового SAO-смещения разбивает диапазон пиксельных значений на предварительно заданные 32 диапазона идентичного размера, как проиллюстрировано на фиг. 2. Минимальное значение диапазона пиксельных значений систематически равно 0, а максимальное значение зависит от битовой глубины пиксельных значений согласно следующей взаимосвязи Max=2Bitdepth-1. Например, когда битовая глубина составляет 8 битов, максимальное значение пиксела может составлять 255. Таким образом, диапазон пиксельных значений находится между 0 и 255. Для этой битовой глубины в 8 битов, каждый класс включает в себя диапазон из 16 пиксельных значений. Кроме того, для полосового SAO-смещения рассматриваются 2 группы классов. Первая содержит 16 последовательных классов в центре диапазона пиксельных значений, как проиллюстрировано серым цветом на фиг. 2. Вторая группа также содержит 16 классов, но на обоих концах диапазона пиксельных значений, как проиллюстрировано с помощью штриховки на фиг. 2. Для полосового SAO-смещения области кадра группа, используемая для классификации, и 16 смещений вставляются в поток битов.
Фиг. 3 является блок-схемой последовательности операций, иллюстрирующей этапы способа для выбора смещений в кодере для области 303 текущего кадра. Область кадра содержит N пикселов. На начальном этапе 301 переменные Sumj и SumNbPixj задаются равными значению нуль для каждого из 16 диапазонов; j обозначает текущее число диапазонов или классов. Sumj обозначает сумму разности между значением пикселов в диапазоне j и значением их соответствующих исходных пикселов. SumNbPixj обозначает число пикселов в диапазоне j.
На этапе 302, счетная переменная j задается равной значению нуль. Затем, первый пиксел области 303 кадра извлекается на этапе 304. Предполагается, что обрабатываемая текущая SAO-группа известна (первая или вторая, как проиллюстрировано на фиг. 2). Если на этапе 305 определено то, что пиксельное значение Pi не находится в текущей SAO-группе, то значение счетной переменной i увеличивается на этапе 308, чтобы классифицировать последующие пикселы области 303 кадра. В противном случае, если на этапе 305 определено то, что пиксельное значение Pi находится в текущей SAO-группе, число j диапазонов (или число классов), соответствующее значению Pi, находится на этапе 306. На следующем этапе 307 соответствующая переменная SumNbPixj увеличивается, и разность между Pi и его исходным значением Pi org суммируется с Sumj. На следующем этапе счетная переменная i увеличивается, чтобы применять классификацию к другим пикселам области 303 кадра. На этапе 309 определяется то, все или нет N пикселов области 303 кадра классифицированы (т.е. i≥=N); если да, Offsetj для каждого класса вычисляется на этапе 310, чтобы формировать таблицу 311 смещений, представляющую смещение для каждого класса j в качестве окончательного результата алгоритма выбора смещения. Это смещение вычисляется в качестве среднего разности между пиксельными значениями пикселов класса j и их соответствующими исходными пиксельными значениями. Offsetj для класса j задается посредством следующего уравнения:

Фиг. 4 является блок-схемой последовательности операций способа, иллюстрирующей этапы процесса декодирования, применяющего полосовые SAO-смещения к соответствующим группам классов. Этот процесс также может применяться на стороне кодера, чтобы формировать опорный кадр, используемый для оценки и компенсации движения последующих кадров.
Начальный этап 401 процесса заключает в себе декодирование значений смещения для каждого класса пиксельных значений, чтобы формировать таблицу 402 смещений. На стороне кодера таблица 402 смещений является результатом алгоритма выбора, показанного на фиг. 3. Таким образом, на стороне кодера, этап 401 заменяется посредством алгоритма выбора смещения по фиг. 3.
На этапе 403 счетная переменная i задается равной 0. Пиксел Pi извлекается на этапе 405 из области 404 кадра, которая содержит N пикселов. На этапе 406 определяется то, принадлежит или нет пиксел Pi текущей группе классов. Если определено, что пиксел Pi находится в текущей группе классов, идентифицируется связанное число j классов, и связанное значение Offsetj смещения извлекается на этапе 409 из таблицы 402 смещений. Извлеченное значение Offsetj смещения затем суммируется с пиксельным значением Pi на этапе 410, чтобы формировать фильтрованное пиксельное значение P′i на этапе 411. Фильтрованное пиксельное значение затем вставляется в фильтрованную область 415 кадра на этапе 412 в соответствующем пикселе.
Если на этапе 406 определяется то, что пиксел Pi не находится в группе полосовых SAO-смещений, то пиксельное значение Pi помещается в фильтрованную область 415 кадра на этапе 412 без фильтрации. После этапа 412 счетная переменная i увеличивается, чтобы фильтровать, при необходимости, последующие пикселы области 404 текущего кадра. После того, как на этапе 414 определено то, что все N пикселов области кадра обработаны (т.е. i≥=N) фильтрованная область 415 кадра восстанавливается и может добавляться в восстановленный SAO-кадр (см. кадр 105 по фиг. 1).
Недостаток известного процесса для выбора компенсаций состоит в том, что он не адаптируется к различным изменениям в контенте пикселов изображений и к различным типам компонентов пикселов изображений.
Настоящее изобретение разработано, чтобы разрешать одну или более вышеприведенных проблем.
Согласно первому аспекту настоящего изобретения, предусмотрен способ предоставления компенсационных смещений для набора восстановленных выборок изображения, причем каждая выборка имеет значение выборки, при этом способ содержит:
- выбор, на основе критерия искажения в зависимости от скорости передачи, классификации из множества предварительно определенных классификаций, причем каждая упомянутая предварительно определенная классификация имеет диапазон классификации, меньший полного диапазона значений выборки, и состоит из множества классов, каждый из которых задает диапазон значений выборки в упомянутом диапазоне классификации, причем в этот класс помещается выборка, если ее значение выборки находится в диапазоне рассматриваемого класса; и
- ассоциирование с каждым классом выбранной классификации компенсационного смещения для применения к значению выборки каждой выборки рассматриваемого класса.
Согласно второму аспекту настоящего изобретения, предусмотрен способ кодирования изображения, состоящего из множества выборок, при этом способ содержит:
- кодирование выборок;
- декодирование закодированных выборок, чтобы предоставлять восстановленные выборки;
- выполнение контурной фильтрации в отношении восстановленных выборок, причем контурная фильтрация содержит применение компенсационных смещений к значениям выборки соответствующих восстановленных выборок, причем каждое компенсационное смещение ассоциировано с диапазоном значений выборки, при этом компенсационные смещения предоставляются согласно способу, осуществляющему вышеуказанный первый аспект настоящего изобретения; и
- формирование потока битов закодированных выборок.
Согласно третьему аспекту настоящего изобретения, предусмотрен способ декодирования изображения, состоящего из множества выборок, причем каждая выборка имеет значение выборки, при этом способ содержит:
- прием закодированных значений выборки;
- прием закодированных данных классификации;
- прием закодированных компенсационных смещений;
- декодирование данных классификации и выбор, на основе декодированных данных классификации, классификации из множества предварительно определенных классификаций, причем каждая упомянутая предварительно определенная классификация имеет диапазон классификации, меньший полного диапазона значений выборки, и состоит из множества классов, каждый из которых задает диапазон значений выборки в упомянутом диапазоне классификации, причем в этот класс помещается выборка, если ее значение выборки находится в диапазоне рассматриваемого класса;
- декодирование закодированных выборок, чтобы предоставлять восстановленные значения выборки, и декодирование закодированных компенсационных смещений;
- ассоциирование декодированных компенсационных смещений, соответственно, с классами выбранной классификации; и
- выполнение контурной фильтрации в отношении восстановленных значений выборки, причем контурная фильтрация содержит применение декодированного компенсационного смещения, ассоциированного с каждым классом выбранной классификации, к восстановленным значениям выборки в диапазоне рассматриваемого класса.
Согласно четвертому аспекту настоящего изобретения, предусмотрен сигнал, переносящий информационный набор данных для изображения, представленного посредством потока битов видео, причем изображение содержит набор восстанавливаемых выборок, причем каждая восстанавливаемая выборка имеет значение выборки, при этом информационный набор данных содержит: данные классификации, связанные с классификацией, выбранной посредством кодера из множества предварительно определенных классификаций, причем каждая упомянутая предварительно определенная классификация имеет диапазон классификации, меньший полного диапазона значений выборки, и состоит из множества классов, каждый из которых задает диапазон значений выборки в упомянутом диапазоне классификации, причем в этот класс помещается выборка, если ее значение выборки находится в диапазоне рассматриваемого класса, и каждый класс из множества классов выбранной классификации ассоциирован с компенсационным смещением для применения к значениям выборки восстанавливаемых выборок в диапазоне рассматриваемого класса.
Согласно пятому аспекту настоящего изобретения, предусмотрено устройство для предоставления компенсационных смещений для набора восстановленных выборок изображения, причем каждая выборка имеет значение выборки, причем устройство содержит:
- средство для выбора, на основе критерия искажения в зависимости от скорости передачи, классификации из множества предварительно определенных классификаций, причем каждая упомянутая предварительно определенная классификация имеет диапазон классификации, меньший полного диапазона значений выборки, и состоит из множества классов, каждый из которых задает диапазон значений выборки в упомянутом диапазоне классификации, причем в этот класс помещается выборка, если ее значение выборки находится в диапазоне рассматриваемого класса; и
- средство для ассоциирования с каждым классом выбранной классификации компенсационного смещения для применения к значению выборки каждой выборки рассматриваемого класса.
Согласно шестому аспекту настоящего изобретения, предусмотрено устройство кодирования для кодирования изображения, состоящего из множества выборок, причем устройство содержит:
- кодер для кодирования выборок;
- декодер для декодирования закодированных выборок, чтобы предоставлять восстановленные выборки;
- контурный фильтр для фильтрации восстановленных выборок, причем средство контурной фильтрации содержит средство применения смещений для применения компенсационных смещений к значениям выборки соответствующих восстановленных выборок, причем каждое компенсационное смещение ассоциировано с диапазоном значений выборки, при этом компенсационные смещения предоставляются посредством устройства, осуществляющего вышеуказанный пятый аспект настоящего изобретения; и
- формирователь потоков битов для формирования потока битов закодированных выборок.
Согласно седьмому аспекту настоящего изобретения, предусмотрено устройство для декодирования изображения, состоящего из множества выборок, причем каждая выборка имеет значение выборки, причем устройство содержит:
- средство для приема закодированных значений выборки;
- средство для приема закодированных данных классификации;
- средство для приема закодированных компенсационных смещений;
- средство для декодирования данных классификации и для выбора, на основе декодированных данных классификации, классификации из множества предварительно определенных классификаций, причем каждая упомянутая предварительно определенная классификация имеет диапазон классификации, меньший полного диапазона значений выборки, и состоит из множества классов, каждый из которых задает диапазон значений выборки в упомянутом диапазоне классификации, причем в этот класс помещается выборка, если ее значение выборки находится в диапазоне рассматриваемого класса;
- средство для декодирования закодированных выборок, чтобы предоставлять восстановленные значения выборки, и для декодирования закодированных компенсационных смещений;
- средство для ассоциирования декодированных компенсационных смещений, соответственно, с классами выбранной классификации; и
- средство для выполнения контурной фильтрации в отношении восстановленных значений выборки, причем контурная фильтрация содержит применение декодированного компенсационного смещения, ассоциированного с каждым классом выбранной классификации, к восстановленным значениям выборки в диапазоне рассматриваемого класса.
Восьмой аспект настоящего изобретения предоставляет способ декодирования изображения, состоящего из множества выборок, причем каждая выборка имеет значение выборки, при этом способ содержит:
- прием закодированных значений выборки;
- прием закодированных данных классификации, связанных с классификацией, выбранной посредством кодера из множества предварительно определенных классификаций, причем каждая упомянутая предварительно определенная классификация имеет диапазон классификации, меньший полного диапазона значений выборки, и состоит из множества классов, каждый из которых задает диапазон значений выборки в упомянутом диапазоне классификации, причем в этот класс помещается выборка, если ее значение выборки находится в диапазоне рассматриваемого класса;
- прием закодированных компенсационных смещений, ассоциированных, соответственно, с классами выбранной классификации;
- декодирование закодированных значений выборки, чтобы предоставлять восстановленные значения выборки, и декодирование закодированных данных классификации и компенсационных смещений; и
- выполнение контурной фильтрации в отношении восстановленных значений выборки, причем контурная фильтрация содержит применение декодированного компенсационного смещения, ассоциированного с каждым классом выбранной классификации, к восстановленным значениям выборки в диапазоне рассматриваемого класса.
Кодер может выбирать классификацию любым подходящим способом, в том числе на основе критерия искажения в зависимости от скорости передачи или в зависимости от свойств статистического распределения значений выборки.
В контексте настоящего изобретения, выборка может соответствовать одному пикселу с значением выборки, соответствующим соответствующему пиксельному значению. Альтернативно, выборка может содержать множество пикселов, и значение выборки может соответствовать пиксельному значению, определенному из пиксельных значений множества пикселов.
По меньшей мере, части способов согласно изобретению могут быть реализованы компьютером. Соответственно, настоящее изобретение может принимать форму полностью аппаратного варианта осуществления, полностью программного варианта осуществления (включающего в себя микропрограммное обеспечение, резидентное программное обеспечение, микрокод и т.д.) или варианта осуществления, комбинирующего программные и аппаратные аспекты, которые могут совместно, в общем, упоминаться в данном документе как "схема", "модуль" или "система". Кроме того, настоящее изобретение может принимать форму компьютерного программного продукта, осуществленного в любом материальном носителе, в представлении, имеющем применимый компьютером программный код, осуществленный на носителе.
Поскольку настоящее изобретение может быть реализовано в программном обеспечении, настоящее изобретение может быть осуществлено в качестве считываемого компьютером кода для предоставления в программируемое устройство на любом подходящем носителе. Материальный носитель может содержать носитель данных, такой как гибкий диск, CD-ROM, жесткий диск, устройство на магнитных лентах или полупроводниковое запоминающее устройство и т.п. Переходная несущая среда может включать в себя такой сигнал, как электрический сигнал, электронный сигнал, оптический сигнал, акустический сигнал, магнитный сигнал либо электромагнитный сигнал, например, микроволновый или RF-сигнал.
Таким образом, согласно девятому аспекту настоящего изобретения, предусмотрен компьютерный программный продукт для программируемого устройства, причем компьютерный программный продукт содержит последовательность инструкций для реализации способа, осуществляющего любой из вышеуказанных первого, второго, третьего и восьмого аспектов, при загрузке и исполнении посредством программируемого устройства.
Согласно десятому аспекту настоящего изобретения, предусмотрен считываемый компьютером носитель данных, хранящий инструкции компьютерной программы для реализации способа, осуществляющего любой из вышеуказанных первого, второго, третьего и восьмого аспектов.
Далее описываются варианты осуществления изобретения, только в качестве примера и со ссылкой на прилагаемые чертежи, на которых:
Фиг. 1 является блок-схемой последовательности операций способа, иллюстрирующей этапы процесса контурной фильтрации предшествующего уровня техники;
Фиг. 2 графически иллюстрирует классификацию адаптивных к выборке полосовых смещений HEVC-процесса предшествующего уровня техники;
Фиг. 3 является блок-схемой последовательности операций способа, иллюстрирующей этапы процесса для определения компенсационных смещений для полосового SAO-смещения HEVC;
Фиг. 4 является блок-схемой последовательности операций способа, иллюстрирующей этапы процесса фильтрации на основе полосового SAO-смещения HEVC;
Фиг. 5 является блок-схемой, схематично иллюстрирующей систему передачи данных, в которой могут быть реализованы один или более вариантов осуществления изобретения;
Фиг. 6 является блок-схемой, иллюстрирующей компоненты устройства обработки, в котором могут быть реализованы один или более вариантов осуществления изобретения;
Фиг. 7 является блок-схемой последовательности операций, иллюстрирующей этапы способа кодирования согласно вариантам осуществления изобретения;
Фиг. 8 является блок-схемой последовательности операций способа, иллюстрирующей этапы процесса контурной фильтрации в соответствии с одним или более вариантами осуществления изобретения;
Фиг. 9 является блок-схемой последовательности операций, иллюстрирующей этапы способа декодирования согласно вариантам осуществления изобретения;
Фиг. 10 является блок-схемой последовательности операций, иллюстрирующей этапы способа для определения классификации полосовых SAO-смещений согласно первому варианту осуществления изобретения;
Фиг. 11 является блок-схемой последовательности операций, иллюстрирующей этапы способа для определения адаптированной классификации согласно варианту осуществления изобретения;
Фиг. 12 является блок-схемой последовательности операций, иллюстрирующей этапы способа для определения адаптированной классификации согласно альтернативному варианту осуществления изобретения;
Фиг. 13 иллюстрирует несколько размеров полезного диапазона для классификации в соответствии с вариантом осуществления изобретения;
Фиг. 14 иллюстрирует несколько размеров классов для классификации в соответствии с вариантом осуществления изобретения;
Фиг. 15 иллюстрирует несколько размеров классов в полезном диапазоне для классификации в соответствии с вариантом осуществления изобретения;
Фиг. 16 иллюстрирует несколько центральных позиций полезного диапазона первой группы для классификации в соответствии с вариантом осуществления изобретения;
Фиг. 17 иллюстрирует несколько центральных позиций полезного диапазона второй группы для классификации в соответствии с вариантом осуществления изобретения; и
Фиг. 18 иллюстрирует выбор искажения в зависимости от скорости передачи для классификации параметров в соответствии с вариантом осуществления изобретения.
Фиг. 19a и 19b иллюстрируют возможные позиции полезного диапазона в полном диапазоне в соответствии с другим вариантом осуществления изобретения.
Фиг. 20A иллюстрирует псевдокод, применяемый в предшествующем уровне техники для того, чтобы кодировать SAO-параметры на уровне LCU.
Фиг. 20B иллюстрирует улучшенный псевдокод согласно варианту осуществления изобретения для того, чтобы кодировать SAO-параметры на уровне LCU.
Фиг. 21 является блок-схемой последовательности операций способа, соответствующей псевдокоду по фиг. 20A.
Фиг. 22 является блок-схемой последовательности операций способа, соответствующей псевдокоду по фиг. 20B.
Фиг. 23 является блок-схемой последовательности операций способа для использования при пояснении кодирования SAO-параметров согласно дополнительному варианту осуществления настоящего изобретения.
Фиг. 24 иллюстрирует псевдокод, используемый для того, чтобы кодировать SAO-параметры, в соответствии с еще одним другим вариантом осуществления настоящего изобретения.
Фиг. 25 является блок-схемой последовательности операций способа, соответствующей псевдокоду по фиг. 24.
Фиг. 26 является блок-схемой последовательности операций способа для использования в пояснении кодирования SAO-параметров согласно еще одному дополнительному варианту осуществления настоящего изобретения.
Фиг. 5 иллюстрирует систему передачи данных, в которой могут быть реализованы или более вариантов осуществления изобретения. Система передачи данных содержит передающее устройство, в этом случае сервер 501, который выполнен с возможностью передавать пакеты данных из потока данных в приемное устройство, в этом случае клиентский терминал 502, через сеть 500 передачи данных. Сеть 500 передачи данных может быть глобальной вычислительной сетью (WAN) или локальной вычислительной сетью (LAN). Эта сеть, например, может представлять собой беспроводную сеть (Wi-Fi/802.11a или b или g), Ethernet-сеть, Интернет-сеть либо смешанную сеть, состоящую из нескольких различных сетей. В конкретном варианте осуществления изобретения, система передачи данных может быть системой цифровой телевизионной широковещательной передачи, в которой сервер 501 отправляет идентичный контент данных в несколько клиентов.
Поток 504 данных, предоставленный посредством сервера 501, может состоять из мультимедийных данных, представляющих видео- и аудиоданные. Потоки аудио- и видеоданных, в некоторых вариантах осуществления изобретения, могут захватываться посредством сервера 501 с использованием микрофона и камеры, соответственно. В некоторых вариантах осуществления, потоки данных могут быть сохранены на сервере 501 или приняты посредством сервера 501 от другого поставщика данных либо сформированы на сервере 501. Сервер 501 содержит кодер для кодирования видео- и аудиопотоков, в частности, чтобы предоставлять сжатый поток битов для передачи, которая является более компактным представлением данных, представленных в качестве ввода в кодер.
Чтобы получать лучшее отношение качества передаваемых данных к количеству передаваемых данных, сжатие видеоданных может выполняться, например, в соответствии с HEVC-форматом или H.264/AVC-форматом.
Клиент 502 принимает передаваемый поток битов и декодирует восстановленный поток битов, чтобы воспроизводить видеоизображения на устройстве отображения и аудиоданные посредством громкоговорителя.
Хотя сценарий потоковой передачи рассматривается в примере по фиг. 5, следует принимать во внимание, что в некоторых вариантах осуществления изобретения передача данных между кодером и декодером может выполняться с использованием, например, устройства хранения данных, такого как оптический диск.
В одном или более вариантах осуществления изобретения, видеоизображение передается с данными, представляющими компенсационные смещения для применения к восстановленным пикселам изображения, чтобы предоставлять фильтрованные пикселы в конечном изображении.
Фиг. 6 схематично иллюстрирует устройство 600 обработки, сконфигурированное с возможностью реализовывать по меньшей мере один вариант осуществления настоящего изобретения. Устройство 600 обработки может быть таким устройством, как микрокомпьютер, рабочая станция или легкое портативное устройство. Устройство 600 содержит шину 613 связи, соединенную со следующим:
- центральный процессор 611, такой как микропроцессор, обозначаемый CPU;
- постоянное запоминающее устройство 607, обозначаемое ROM, для сохранения компьютерных программ для реализации изобретения;
- оперативное запоминающее устройство 612, обозначаемое RAM, для сохранения исполняемого кода способа вариантов осуществления изобретения, а также регистров, сконфигурированных с возможностью записывать переменные и параметры, необходимые для реализации способа кодирования последовательности цифровых изображений и/или способа декодирования потока битов согласно вариантам осуществления изобретения; и
- интерфейс 602 связи, подключенный к сети 603 связи, по которой передаются или принимаются цифровые данные, которые должны быть обработаны.
Необязательно, устройство 600 также может включать в себя следующие компоненты:
- средство 604 хранения данных, такое как жесткий диск, для сохранения компьютерных программ для реализации способов одного или более вариантов осуществления изобретения и данных, используемых или сформированных во время реализации одного или более вариантов осуществления изобретения;
- накопитель 605 на дисках для диска 606, причем накопитель на дисках выполнен с возможностью считывать данные с диска 606 или записывать данные на упомянутый диск;
- экран 609 для отображения данных и/или выступания в качестве графического интерфейса с пользователем, посредством клавиатуры 610 или любого другого средства указания.
Устройство 600 может подключаться к различным периферийным устройствам, такими как, например, цифровая камера 620 или микрофон 608, подключенным к плате ввода-вывода (не показана), с тем чтобы предоставлять мультимедийные данные в устройство 600.
Шина связи предоставляет связь и функциональную совместимость между различными элементами, включенными в устройство 600 или подключенными к нему. Представление шины не является ограничивающим, и, в частности, центральный процессор выполнен с возможностью передавать инструкции в любой элемент устройства 600 непосредственно или посредством другого элемента устройства 600.
Диск 606 может быть заменен посредством любого носителя информации, такого как, например, компакт-диск (CD-ROM), перезаписываемый или нет, Zip-диск или карта памяти, и в общих чертах, посредством средства хранения информации, которое может считываться посредством микрокомпьютера или посредством микропроцессора, интегрированного или нет в устройство, возможно съемного и сконфигурированного с возможностью сохранять одну или более программ, выполнение которых обеспечивает возможность реализации способа кодирования последовательности цифровых изображений и/или способа декодирования потока битов согласно изобретению.
Исполняемый код может быть сохранен либо в постоянном запоминающем устройстве 607 на жестком диске 604, либо на съемном цифровом носителе, таком как, например, диск 606, как описано выше. Согласно разновидности, исполняемый код программ может быть принят посредством сети 603 связи через интерфейс 602, чтобы сохраняться на одном из средств хранения устройства 600 перед выполнением, таком как жесткий диск 604.
Центральный процессор 611 выполнен с возможностью управлять и направлять выполнение инструкций или части программного кода программы или программ согласно изобретению, инструкций, которые сохраняются на одном из вышеуказанных средств хранения. При включении питания программа или программы, которые сохраняются в энергонезависимом запоминающем устройстве, например, на жестком диске 604 или в постоянном запоминающем устройстве 607, передаются в оперативное запоминающее устройство 612, которое в таком случае содержит исполняемый код программы или программ, а также регистры для сохранения переменных и параметров, необходимых для реализации изобретения.
В этом варианте осуществления, устройство является программируемым устройством, которое использует программное обеспечение для того, чтобы реализовывать изобретение. Тем не менее, альтернативно настоящее изобретение может быть реализовано в аппаратных средствах (например, в форме специализированной интегральной схемы, или ASIC).
Фиг. 7 иллюстрирует блок-схему кодера согласно по меньшей мере одному варианту осуществления изобретения. Кодер представляется посредством соединенных модулей, причем каждый модуль выполнен с возможностью реализовывать, например, в форме инструкций программирования, которые должны быть выполнены посредством CPU 611 устройства 600 по меньшей мере один соответствующий этап способа, реализующего по меньшей мере один вариант осуществления кодирования изображения из последовательности изображений согласно одному или более вариантам осуществления изобретения.
Исходная последовательность цифровых изображений i0-in 701 принимается как ввод посредством кодера 70. Каждое цифровое изображение представляется посредством набора выборок, известных как пикселы.
Поток 710 битов выводится посредством кодера 70 после реализации процесса кодирования. Поток 710 битов содержит множество единиц кодирования или слайсов, причем каждый слайс содержит заголовок слайса для передачи значений для кодирования параметров кодирования, используемых для того, чтобы кодировать слайс, и тело слайса, содержащее кодированные видеоданные.
Входные цифровые изображения i0-i0 701 разделяются на блоки пикселов посредством модуля 702. Блоки соответствуют частям изображения и могут иметь переменные размеры (например, 4×4, 8×8, 16×16, 32×32, 64×64 пикселов). Режим кодирования выбирается для каждого входного блока. Предоставляются два семейства режимов кодирования: режимы кодирования на основе кодирования с пространственным прогнозированием (внутреннего прогнозирования) и режимы кодирования на основе временного прогнозирования (внешнее кодирование, объединение, пропуск). Возможные режимы кодирования тестируются.
Модуль 703 реализует процесс внутреннего прогнозирования, при котором данный блок, который должен быть кодирован, прогнозируется посредством предиктора, вычисленного из пикселов окружения упомянутого блока, который должен быть кодирован. Индикатор относительно выбранного внутреннего предиктора и разность между данным блоком и его предиктором кодируются для того, чтобы предоставлять остаток, если выбирается внутреннее кодирование.
Временное прогнозирование реализуется посредством модуля 704 оценки движения и модуля 705 компенсации движения. Во-первых, выбирается опорное изображение из числа набора 716 опорных изображений, и часть опорного изображения, также называемая "опорной областью", или часть изображения, которая является ближайшей областью к данному блоку, который должен быть кодирован, выбирается посредством модуля 704 оценки движения. Модуль 705 компенсации движения затем прогнозирует блок, который должен быть кодирован, с использованием выбранной области. Разность между выбранной опорной областью и данным блоком, также называемая "остаточным блоком", вычисляется посредством модуля 705 компенсации движения. Выбранная опорная область указывается посредством вектора движения.
Таким образом, в обоих случаях (пространственное и временное прогнозирование), остаток вычисляется посредством вычитания прогнозирования из исходного блока.
При внутреннем прогнозировании, реализованном посредством модуля 703, кодируется направление прогнозирования. При временном прогнозировании кодируется по меньшей мере один вектор движения.
Информация относительно вектора движения и остаточного блока кодируется, если выбирается внешнее прогнозирование. Чтобы дополнительно снижать скорость передачи битов, при условии что движение является гомогенным, вектор движения кодируется посредством разности относительно предиктора вектора движения. Предикторы векторов движения из набора предикторов информации движения получаются из поля 718 векторов движения посредством модуля 717 прогнозирования и кодирования векторов движения.
Кодер 70 дополнительно содержит модуль 706 выбора для выбора режима кодирования посредством применения критерия затрат на кодирование, к примеру, критерия искажения в зависимости от скорости передачи. Чтобы дополнительно уменьшать избыточность, преобразование (к примеру, DCT) применяется посредством модуля 707 преобразования к остаточному блоку, преобразованные полученные данные затем квантуются посредством модуля 708 квантования и энтропийно кодируются посредством модуля 709 энтропийного кодирования. В завершение, кодированный остаточный блок кодируемого текущего блока вставляется в поток 710 битов.
Кодер 70 также выполняет декодирование кодированного изображения для того, чтобы формировать опорное изображение для оценки движения последующих изображений. Это позволяет кодеру и декодеру, принимающим поток битов, иметь идентичные опорные кадры. Модуль 711 обратного квантования выполняет обратное квантование квантованных данных, после чего выполняется обратное преобразование посредством модуля 712 обратного преобразования. Модуль 713 обратного внутреннего прогнозирования использует информацию прогнозирования, чтобы определять то, какой предиктор использовать для данного блока, и модуль 714 обратной компенсации движения фактически добавляет остаток, полученный посредством модуля 712, в опорную область, полученную из набора 716 опорных изображений.
Постфильтрация затем применяется посредством модуля 715, чтобы фильтровать восстановленный кадр пикселов. В вариантах осуществления изобретения, используется контурный SAO-фильтр, в котором компенсационные смещения суммируются с пиксельными значениями восстановленных пикселов восстановленного изображения.
Фиг. 8 является блок-схемой последовательности операций способа, иллюстрирующей этапы процесса контурной фильтрации согласно по меньшей мере одному варианту осуществления изобретения. На начальном этапе 801 кодер формирует восстановление полного кадра. Затем, на этапе 802 фильтр удаления блочности применяется для этого первого восстановления, чтобы формировать восстановление 803 с удаленной блочностью. Цель фильтра удаления блочности состоит в том, чтобы удалять артефакты блочности, сформированные посредством остаточного квантования и блочной компенсации движения или блочного внутреннего прогнозирования. Эти артефакты являются визуально важными на низких скоростях передачи битов. Фильтр удаления блочности работает с возможностью сглаживать границы блоков согласно характеристикам двух соседних блоков. Учитываются режим кодирования каждого блока, параметры квантования, используемые для остаточного кодирования, и соседние пиксельные разности на границе. Идентичный критерий/классификация применяется для всех кадров, и дополнительные данные не передаются. Фильтр удаления блочности повышает визуальное качество текущего кадра посредством удаления артефактов блочности, и он также улучшает оценку движения и компенсацию движения для последующих кадров. Фактически, высокие частоты артефакта блочности удаляются, и в силу этого данные высокие частоты не должны компенсироваться с помощью остатка текстуры следующих кадров.
После фильтра удаления блочности восстановление с удаленной блочностью фильтруется посредством контурного фильтра на основе адаптивного к выборке смещения (SAO) на этапе 804 на основе классификации пикселов 814, определенной в соответствии с вариантами осуществления изобретения. Результирующий кадр 805 затем может фильтроваться с помощью адаптивного контурного фильтра (ALF) на этапе 806, чтобы формировать восстановленный кадр 807, который должен отображаться и использоваться в качестве опорного кадра для следующих внешних кадров.
На этапе 804 каждый пиксел области кадра классифицируется на класс определенной классификации согласно своему пиксельному значению. Класс соответствует определенному диапазону пиксельных значений. Идентичное значение компенсационного смещения суммируется с пиксельным значением всех пикселов, имеющих пиксельное значение в данном диапазоне пиксельных значений.
Далее подробнее поясняется определение классификации пикселов для фильтрации на основе адаптивного к выборке смещения в отношении любого из фиг. 10-17.
Фиг. 9 иллюстрирует блок-схему декодера 90, который может быть использован для того, чтобы принимать данные из кодера согласно варианту осуществления изобретения. Декодер представляется посредством соединенных модулей, причем каждый модуль выполнен с возможностью реализовывать, например, в форме инструкций программирования, которые должны быть выполнены посредством CPU 611 устройства 600, соответствующий этап способа, реализованного посредством декодера 90.
Декодер 90 принимает поток 901 битов, содержащий единицы кодирования, каждая из которых состоит из заголовка, содержащего информацию относительно параметров кодирования, и тела, содержащего кодированные видеоданные. Как пояснено относительно фиг. 7, кодированные видеоданные энтропийно кодируются, и индексы предикторов векторов движения кодируются, для данного блока, для предварительно определенного числа битов. Принятые кодированные видеоданные энтропийно декодируются посредством модуля 902. Остаточные данные затем деквантуются посредством модуля 903, и затем обратное преобразование применяется посредством модуля 904, чтобы получать пиксельные значения.
Данные режима, указывающие режим кодирования, также энтропийно декодируются, и на основе режима внутреннее декодирование или внешнее декодирование выполняется для кодированных блоков данных изображений.
В случае внутреннего режима внутренний предиктор определяется посредством модуля 905 обратного внутреннего прогнозирования на основе режима внутреннего прогнозирования, указываемого в потоке битов.
Если режим является внешним, информация прогнозирования движения извлекается из потока битов, с тем чтобы находить опорную область, используемую посредством кодера. Информация прогнозирования движения состоит из индекса опорного кадра и остатка вектора движения. Предиктор вектора движения добавляется в остаток вектора движения, чтобы получать вектор движения посредством модуля 910 декодирования на основе векторов движения.
Модуль 910 декодирования на основе векторов движения применяет декодирование на основе векторов движения для каждого текущего блока, кодированного посредством прогнозирования движения. После того, как получен индекс предиктора вектора движения для текущего блока, фактическое значение вектора движения, ассоциированного с текущим блоком, может быть декодировано и использовано для того, чтобы применять обратную компенсацию движения посредством модуля 906. Часть опорного изображения, указываемая посредством декодированного вектора движения, извлекается из опорного изображения 908, чтобы применять обратную компенсацию 906 движения. Данные 911 поля векторов движения обновляются с помощью декодированного вектора движения, с тем чтобы использоваться для обратного прогнозирования следующих декодированных векторов движения.
В завершение, получается декодированный блок. Постфильтрация применяется посредством модуля 907 постфильтрации, аналогично модулю 815 постфильтрации, применяемому в кодере, как описано со ссылкой на фиг. 8. Декодированный видеосигнал 909 в завершение предоставляется посредством декодера 90.
Фиг. 10 является блок-схемой последовательности операций, иллюстрирующей этапы способа согласно первому варианту осуществления изобретения для классификации восстановленных пикселов изображения для применения компенсационных смещений. В этом варианте осуществления, классы для классификации восстановленных пикселов области кадра согласно их пиксельному значению определяются на основе статистического распределения значений восстановленного пиксела области кадра. Центр, полезный диапазон и число пикселов в расчете на класс определяются на основе распределения пиксельных значений. В этом варианте осуществления, декодер может применять совершенно идентичный процесс, что и декодер для сегментации распределения.
На начальном этапе процесса, модуль 1002 сканирует область 1001 текущего кадра, чтобы определять статистическое распределение пиксельных значений пикселов области 1001 кадра и формировать соответствующую гистограмму 1003. В одном конкретном варианте осуществления, этот процесс заключает в себе обновление таблицы, которая содержит число пикселов для каждого пиксельного значения, т.е. для каждого пиксельного значения, число пикселов, имеющих это пиксельное значение, сводится в таблицу. Таблица содержит число ячеек, равных MAX (максимальному пиксельному значению), определенному согласно выражению Max=2Bitdepth-1, на основе битовой глубины пикселов.
Модуль 1004 затем определяет центр сформированной гистограммы 1003. Полезный диапазон пиксельных значений гистограммы затем определяется посредством модуля 1006 согласно распределению пиксельных значений, представленных в гистограмме 1003, и при необходимости на основе центра гистограммы. В завершение, определяются равновероятные классы, задающие диапазоны пиксельных значений. Таким образом, предоставляется таблица 1009, содержащая диапазон пиксельных значений каждого класса, или альтернативно, таблица, которая содержит пиксельные значения каждого пиксела.
В некоторых вариантах осуществления изобретения, определение равновероятных классов может зависеть от предварительно определенного числа 1000 классов.
На этапе 1004 различные алгоритмы могут использоваться для того, чтобы определять центр сформированной гистограммы 1003. В одном варианте осуществления, могут быть найдены минимальное значение MinHist и максимальное значение MaxHist гистограммы. Чтобы находить минимальное значение MinHist, ячейки Histk гистограммы сканируются от пиксельного значения 0 до первой ячейки Histk гистограммы, которая не равна 0. Кроме того, чтобы находить MaxHist, ячейки сканируются в обратном порядке (от максимального пиксельного значения MAX до первой ячейки Histk гистограммы, которая не равна 0). Центр CenterHist гистограммы вычисляется следующим образом:
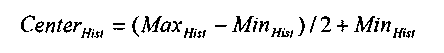
В альтернативном варианте осуществления, центр гистограммы считается центром взвешенного среднего распределения. Если считается, что значение ячейки Histk гистограммы представляет собой число пикселов, которые имеют значение k, CenterHist вычисляется следующим образом:
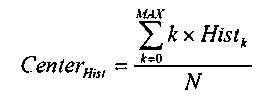 ,
,
где N является числом пикселов в области текущего кадра. На этапе 1006 одна потенциальная технология для определения полезного диапазона сформированной гистограммы заключается в том, чтобы выбирать MinHist и MaxHist, описанные выше, для обоих концов полезного диапазона.
В другом варианте осуществления, минимальное значение MinRange гистограммы определяется посредством сканирования от 0 до первого Histk, которое имеет значение, выше порогового значения α. Аналогичным образом, MaxRange определяется посредством обратного сканирования от максимального пиксельного значения MAX до первого Histk, которое превышает пороговое значение α. Пороговое значение α может быть предварительно определенным значением. Альтернативно, пороговое значение α может зависеть от числа пикселов в области кадра и/или от типа компонента входного сигнала (сигнала цветности и сигнала яркости).
В одном конкретном варианте осуществления, можно считать, что число классов известно на стороне кодера и декодера. Число классов пиксельных значений может зависеть, например, от числа пикселов в области текущего кадра согласно каждому компоненту (сигналу яркости, сигналу U и V цветности).
Чтобы формировать равновероятные классы, задается число NbPixRange пикселов в полезном диапазоне 1007. Число NbPixRange пикселов в полезном диапазоне определяется посредством сканирования каждой ячейки Histk гистограммы от k=MinRange до k=MaxRange. Затем, определенное число пикселов в полезном диапазоне, NbPixRange, делится на число 1000 классов, чтобы определять оптимальное число NbPixclasses пикселов в каждом классе.
Фиг. 11 является блок-схемой последовательности операций способа, иллюстрирующей этапы алгоритма для определения равновероятных классов согласно варианту осуществления изобретения. На начальном этапе 1101 число j классов задается равным 0, и текущее пиксельное значение k задается равным MinRange. Для равновероятной классификации класс идентифицируется посредством его диапазона пиксельных значений. Таким образом, число j классов идентифицируется посредством диапазона [Minj;Maxj] от минимального пиксельного значения Minj до максимального пиксельного значения Maxj.
На этапе 1103, минимальное пиксельное значение Minj текущего класса, индексированное посредством j, задается равным текущему пиксельному значению k. Затем SumNbPixj задается равным 0 на этапе 1104.
SumNbPixj соответствует числу пикселов в диапазоне j. Затем, число пикселов, имеющих пиксельное значение k (Histk), суммируется с SumNbPixj на этапе 1105. На этапе 1106 определяется то, превышает или нет сумма числа SumNbPixj пикселов для текущего класса j число NbPixclasses пикселов в классах. Если это условие не удовлетворяется, значение k увеличивается на этапе 1107, и число Histk пикселов для пиксельного значения k суммируется с SumNbPixj на этапе 1105. Если определено, что SumNbPixj>NbPixclasses, или если k достигает максимального значения MaxRange полезного диапазона, максимальное значение для текущего класса j равно текущему значению k на этапе 1108. На этой стадии задается класс j, т.е. диапазон [Minj; Maxj] класса j определен. Переменная k увеличивается на этапе 1109 во избежание получения идентичного пиксельного значения в нескольких классах. Кроме того, переменная j также увеличивается на этапе 1110, чтобы задавать диапазон пиксельных значений для следующего класса. Если переменная j превышает число NbPixclasses классов, то можно считать, что все классы заданы на этапе 1112.
Как следствие, кодер должен определять значение смещения для каждого класса j, как описано относительно фиг. 3, и передавать его в декодер. Кодер и декодер должны фильтровать область кадра, как описано в отношении фиг. 4.
Можно отметить, что в этом варианте осуществления, число NbClasses классов не зависит от пиксельных значений, поскольку число классов предварительно определяется на основе значения синтаксиса. Следовательно, в этом варианте осуществления, синтаксический анализ полосового SAO-смещения является независимым от декодирования других кадров. Можно отметить, что синтаксический анализ на предмет полосового SAO-смещения включает в себя синтаксический анализ каждого смещения.
В дополнительном варианте осуществления для определения равновероятной классификации, число классов может быть определено согласно распределению пиксельных значений в сформированной гистограмме. Фактически, когда амплитуда полезного диапазона является высокой или низкой, число классов должно оказывать влияние на эффективность кодирования. Следовательно, лучшая адаптируемая классификация может предоставляться посредством определения числа пикселов в каждом классе, а также число пиксельных значений.
Фиг. 12 является блок-схемой последовательности операций способа, иллюстрирующей этапы алгоритма согласно дополнительному варианту осуществления для предоставления более адаптируемой классификации. Эта блок-схема последовательности операций способа основана на блок-схеме последовательности операций способа по варианту осуществления по фиг. 11, при этом модули с аналогичными окончаниями номеров выполняют эквивалентные функции. Тем не менее, модули 1206 и 1211 принятия решений этого варианта осуществления работают в тестовых условиях, отличных от тестовых условий, в которых работают соответствующие модули 1106 и 1111 по фиг. 11.
В этом варианте осуществления, модуль 1206 принятия решений прекращает контур на основе значений k и выбирает Maxj для класса j, если SumNbPixj>NbPixclasses ИЛИ если k достигает максимального значения MaxRange полезного диапазона, ИЛИ если k-Minj строго ниже максимального диапазона для класса (MaxClassRange). k-Minj соответствует числу пиксельных значений в текущем диапазоне класса j. MaxClassRange является предварительно определенным максимальным числом пиксельных значений в диапазоне. Этот диапазон может зависеть от битовой глубины, числа N пикселов в области кадра и типа сигнала (сигнал яркости, сигнал U и V цветности). Например, когда битовая глубина составляет 8, MaxClassRange для компонента сигнала яркости может быть равным 16, аналогично HEVC-реализации.
Преимущество варианта осуществления по фиг. 12 по сравнению с вариантом осуществления по фиг. 11 заключается в его эффективности кодирования для распределения пиксельных значений с большой амплитудой. Этот вариант осуществления является более адаптируемым к распределению.
Можно отметить, что в этом варианте осуществления, определенное число классов зависит от пиксельных значений, и в силу этого, синтаксический анализ текущего кадра зависит от декодирования предыдущих кадров. Для обеспечения большей надежности к ошибкам при передаче, число NbClasses классов вставляется в поток битов. Передача таких данных оказывает незначительное влияние на эффективность кодирования.
Основное преимущество первого варианта осуществления классификации по фиг. 10-12 состоит в том, что классификация адаптирована к распределению пиксельных значений. Кроме того, центр, полезный диапазон и размер каждого класса и их число не должны обязательно передаваться. Следовательно, аналогично известной HEVC-реализации, дополнительные данные, помимо данных, представляющих смещение каждого класса, не должны передаваться для определенной классификации.
Ниже описывается дополнительный вариант осуществления изобретения для определения классификации, который заключает в себе передачу в служебных сигналах параметров классификации, со ссылкой на фиг. 13. Цель дополнительного варианта осуществления классификации состоит в том, чтобы предоставлять оптимальную классификацию распределения пиксельных значений. Отличие по сравнению с предыдущим вариантом осуществления заключается в том, что классификация определяется не непосредственно на основе распределения пиксельных значений, а на основе критерия искажения в зависимости от скорости передачи. В дополнительном варианте осуществления, кодер выбирает классификацию, лучше всего адаптированную к распределению пиксельных значений, из числа предварительно заданных потенциальных классификаций. Этот выбор основан на критерии искажения в зависимости от скорости передачи. Как указано в предыдущих вариантах осуществления, определяются центр, полезный диапазон и размер классов сформированной гистограммы, представляющей распределение пиксельных значений. В дополнительном варианте осуществления, эти параметры передаются в потоке битов. Чтобы минимизировать влияние передачи таких данных, размеры классов и связанных диапазонов выбираются из числа предварительно заданных значений. Следовательно, кодер вставляет центр выбранной классификации, индекс, связанный с выбранной классификацией, и размеры классов классификации в поток битов.
Чтобы предоставлять адаптацию к распределению пиксельных значений, несколько размеров диапазонов пиксельных значений задаются, как проиллюстрировано на фиг. 13. На фиг. 13, полный диапазон пиксельных значений разделяется на 32 поддиапазона. Для первой группы классов, связанных с пиксельными значениями, расположенными в центре диапазона пиксельных значений, представлено 4 примера 1301, 1302, 1303, 1304. Первый пример 1301 содержит 26 диапазонов из потенциальных 32 диапазонов. Таким образом, полезный диапазон 1301 представляет 13/16-ую полного диапазона. Аналогичным образом, 1302 представляет только 8 диапазонов из 32 потенциальных диапазонов, т.е. 1/4-ую полезного диапазона, 1303 представляет 1/8-ую полного диапазона и 1304, 1/16-ую полного диапазона. Для предложенной схемы могут рассматриваться все возможные размеры от полного диапазона до диапазона, соответствующего только одному пиксельному значению. Число возможных полезных диапазонов должно быть предварительно определено согласно эффективности кодирования или предварительно определено для числа пикселов в области кадра.
Фиг. 13 также показывает несколько примеров размеров для второй группы классов, связанных с пиксельными значениями, расположенными на краях диапазона пиксельных значений. Вторая группа включает в себя две подгруппы классов, по одной, расположенной к каждому краю гистограммы. Примеры 1305, 1306, 1307, 1308 представляют, соответственно, число пиксельных значений, идентичное числу пиксельных значений из примеров 1301, 1302, 1303, 1304 первой группы.
В вариантах осуществления изобретения, размер классов, т.е. диапазон пиксельных значений в расчете на класс, не является фиксированным, по сравнению со способами предшествующего уровня техники. Фиг. 14 показывает примеры нескольких размеров 1401-1406. В этом примере, размеры классов составляют от 32 пикселов 1401 до только 1 пиксела 1406. Эти размеры классов могут быть комбинированы со всеми возможными полезными диапазонами, как описано выше относительно фиг. 13. В этом варианте осуществления, считается, что все классы имеют идентичный размер для конкретного диапазона пиксельных значений. Таким образом, для группы, данные, представляющие размер полезного диапазона и размер классов, вставляются в поток битов.
В другом варианте осуществления, размеры классов для данного полезного диапазона адаптируются согласно позиции класса в полезном диапазоне. Более точно, размеры класса адаптированы к распределению пиксельных значений. В дополнительном варианте осуществления, эти размеры предварительно определяются для каждого полезного диапазона согласно распределению пиксельных значений. Фактически, гистограмма распределения пиксельных значений, в общем, соответствует гауссову распределению. Чем ближе к центру гистограммы пиксельное значение, тем больше число пикселов, имеющих пиксельное значение, близкое к этому значению. Это означает то, что ячейка Histk гистограммы около центра имеет большее значение (число соответствующих пикселов), чем ячейка Histk гистограммы на обоих концах полезного диапазона гистограммы.
Фиг. 15 показывает примеры двух описанных вариантов осуществления для размеров классов. Пример 1501 представляет фиксированный размер 8 пиксельных значений для полезного диапазона из 32 пиксельных значений. 1502 представляет фиксированный размер 4 пиксельных значений для идентичного размера полезного диапазона.
Пример 1503 иллюстрирует другой вариант осуществления для адаптивных размеров классов для текущего диапазона из 32 пиксельных значений. В этом примере, классы на обоих концах полезного диапазона больше, т.е. имеют более широкий диапазон пиксельных значений, чем классы в центре, соответственно, с 8 пиксельными значениями и 2 пиксельными значениями. Между этими классами, 2 других класса имеют диапазон из 4 пиксельных значений.
Размеры классов для второй группы также могут быть адаптированы к распределению пиксельных значений. Цель второй группы текущей HEVC-реализации состоит в том, чтобы использовать только два конца гистограммы. Фактически, оба конца гистограммы содержат экстремальные значения, которые зачастую связаны с высокими частотами, на которых ошибка (вследствие кодирования с потерями) обычно является более высокой по сравнению с низкими частотами. Аналогично первой группе, несколько размеров классов могут тестироваться на предмет полезных диапазонов второй группы. В этом случае, для двух подгрупп второй группы, подразделения 1501 и 1502 могут сравниваться с критерием искажения в зависимости от скорости передачи.
Кроме того, может применяться вариант осуществления, в котором адаптируются размеры классов. Пример 1504 иллюстрирует предложенные адаптированные размеры классов для первого диапазона (левого) второй группы. Кроме того, пример 1505 иллюстрирует предложенные адаптированные размеры классов для второй подгруппы (правой) второй группы. В этом случае, классы содержат большее число пиксельных значений на обоих концах, чем классы около центра.
Цель второй группы состоит в том, чтобы использовать оба конца гистограммы; следовательно, иногда полезно использовать обратную адаптацию размеров для второй группы. В этом случае, пример 1504 используется для второй подгруппы (правой), а примера 1505 используется для первой подгруппы (левой) второй группы. В этом варианте осуществления, классы содержат меньше пиксельных значений на обоих концах, чем классы около центра. В этом случае, цель не состоит в том, чтобы формировать равновероятную классификацию классов, в том, чтобы находить лучшую сегментацию обоих концов второй группы.
Поскольку статистическое распределение пиксельных значений не обязательно центрируется в середине полного диапазона пиксельных значений, центр распределения на основе полезного диапазона должен определяться и передаваться в потоке битов с данными изображений. Фиг. 16 показывает пример полного диапазона с различными центральными позициями для полезного диапазона, соответствующего одной четверти полного диапазона. В отличие от примера 1302 по фиг. 13, для четырех примеров по фиг. 16, 1601, 1602, 1603, 1604, центр полезного диапазона не находится в центре полного диапазона. Это решение дает возможность адаптации выбранной классификации к распределению пиксельных значений.
Определенный центр затем может быть кодирован для передачи в потоке битов. Несколько технологий могут быть предусмотрены для кодирования данных.
Если считается, что битовая глубина области текущего кадра составляет 8 битов, число позиций, которые могут рассматриваться для центрального значения, соответствует 256 минус размер минимального полезного диапазона. Например, по сравнению с фиг. 13, минимальный размер полезного диапазона равен 2, и эти 2 класса могут содержать, по меньшей мере, 1 пиксел. Таким образом, для этого конкретного примера, центр может принимать значение между 1-254, так что 254 позиции могут рассматриваться для центра.
Другое решение состоит в том, чтобы определять количественно центральное значение. В одном варианте осуществления, центр кодируется согласно размеру классов. Таким образом, например, если размер классов (или минимальный размер всех классов текущего полезного диапазона, когда используется схема адаптированных размеров классов) равен одному пиксельному значению, центр не определяется количественно и может представлять собой все возможные центральные позиции для текущего полезного диапазона. Если размер классов составляет 16 пиксельных значений, как проиллюстрировано на фиг. 16, могут рассматриваться только пиксельные значения каждые 16 пиксельных значений. Таким образом, на фиг. 16, центр для примеров 1601, 1602, 1603 и 1604 составляет, соответственно, 9, 23, 27 и 6. В другом варианте осуществления, могут рассматриваться только центральные позиции, равные кратному максимального размера классов, заданных в алгоритме. Таким образом, центр равен пиксельному значению, деленному на максимальный размер классов. Это обеспечивает уменьшение с точки зрения числа битов, которое должно быть передано.
Кроме того, теоретически наиболее вероятный центр является центром полного диапазона. Таким образом, данные, передаваемые для того, чтобы определять центральную позицию на стороне декодера, представляют собой разность между центром полного диапазона и центром полезного диапазона текущей классификации. Таким образом, например, на фиг. 16, данные, передаваемые относительно центра для примеров 1601, 1602, 1603, 1604, соответственно, составляют 16-9=7, 16-23=-7, 16-27=-11, 16-6=10.
Для второй группы центр гистограммы не должен обязательно кодироваться. Таким образом, несколько схем могут рассматриваться, чтобы кодировать смещение двух подгрупп для второй группы. Предложенные варианты осуществления относительно квантования центрального значения, описанные для первой группы, могут легко распространяться на предложенные варианты осуществления для второй группы.
В вариантах осуществления изобретения, позиция полезного диапазона (выбранной классификации) может указываться с идентичной точностью или степенью детализации по полному диапазону, т.е. независимо от позиции классификации в полном диапазоне. Это имеет место в примерах 1601-1604, показанных на фиг. 16, в которых позиции (центральные позиции) составляют 9, 23, 27 и 6. Полный диапазон помечается от 0 до 32. Предусмотрено 32 возможных позиции, и степень детализации является идентичной по полному диапазону.
Тем не менее, также можно, как показано на фиг. 19a и 19b, предоставлять большее число возможных позиций в одной части полного диапазона, чем в другой части полного диапазона. Другими словами, степень детализации позиции варьируется в зависимости от того, где выполняется классификация в полном диапазоне. Эти варианты осуществления предлагают неравномерное квантование полного диапазона (здесь помечен от 0 до 32) с переменной степенью детализации, чтобы более точно размещать центр классификации (полезный диапазон) в наиболее важных (или вероятных) частях полного диапазона. Кроме того, неравномерное квантование дает возможность ограничения числа битов, требуемых для того, чтобы передавать в служебных сигналах позицию классификации, при этом по-прежнему обеспечивая соответствующую точность в важных частях полного диапазона. Эта большая степень детализации может применяться, например, в середине полного диапазона, как представлено на фиг. 19a. На этом чертеже, возможные центральные позиции соответствуют индексам, которые представляются посредством полужирной сплошной линии. Интервал между двумя возможными центральными позициями меньше в середине полного диапазона, чем на концах. Таким образом, центральная позиция может задаваться более точно в середине полного диапазона, чем на концах полного диапазона.
На фиг. 19b, интервал между двумя возможными центральными позициями меньше на обоих концах полного диапазона, чем в середине. Например, этот вариант осуществления может быть, в частности, полезным в случае равенства важных значений выборки экстремальным значениям распределения.
Если обобщать, более точное квантование может применяться в любом месте в полном диапазоне.
Когда используется переменное квантование, как описано выше, диапазон классификации (размер полезного диапазона) может быть фиксированным для всех позиций. Например, диапазон классификации может содержать четыре класса, каждый их которых состоит из 8 пиксельных значений.
Также можно инструктировать диапазону классификации/размерам классов меняться в зависимости от позиции, так что на фиг. 19a диапазон классификации составляет, скажем, 8 пиксельных значений в позициях 12-20, 16 пиксельных значений в позициях 10 и 26 и 32 пиксельных значения в позициях 2 и 28.
Переменное квантование, описанное в данном документе, может быть использовано независимо от способа, применяемого для определения диапазона классификации. Этот способ, например, может использовать свойства статистического распределения значений выборки или использовать критерий искажения в зависимости от скорости передачи.
Переменное квантование может быть предварительно определено как в кодере, так и в декодере. Например, кодер и декодер могут назначать индексы возможным центральным позициям (или левым позициям), например, на фиг. 19a, позиция 2 представляет собой индекс 0, позиция 6 представляет собой индекс 1, позиция 10 представляет собой индекс 2, позиция 12 представляет собой индекс 3, позиция 13 представляет собой индекс 4 и т.д. Затем, для кодера достаточно передавать в декодер индекс выбранной классификации. Альтернативно, информация относительно переменного квантования может быть определена в кодере и передана в служебных сигналах в декодер через поток битов.
В одном конкретном варианте осуществления, можно считать, что центр гистограммы всегда является центром полного диапазона. Таким образом, в этом случае рассматривается только одно смещение. Обе группы масштабируются к центру с идентичным смещением. Следовательно, только одни данные должны быть кодированы: смещение первого диапазона второй группы. Примеры 1701, 1702, 1703 и 1704 по фиг. 17 являются примерами таких смещений. В примерах 1701, 1702, 1703, 1704 смещения составляют, соответственно, 4, 6, 10 и 0. Смещение может быть непосредственно кодировано без прогнозирования.
В дополнительном варианте осуществления, обе подгруппы второй группы имеют независимую позицию в полном диапазоне, как проиллюстрировано в примерах 1705, 1706, 1707 и 1708. Могут рассматриваться два способа кодирования.
В первом, центр несуществующей первой группы кодируется с размером полезного диапазона этой несуществующей первой группы.
Второй способ независимого кодирования обеих групп заключается в том, чтобы передавать 2 смещения из двух концов полного диапазона (по одному для каждой группы). Таким образом, для примеров 1705, 1706, 1707 и 1708, передаваемое смещение составляет, соответственно, 11 и 32-28=4 для 1705, 21 и 0 для 1706, 3 и 32-16=32 для 1707, 7 и 32-31=1 для 1708.
Фиг. 18 является блок-схемой последовательности операций способа, иллюстрирующей этапы алгоритма выбора искажения в зависимости от скорости передачи согласно варианту осуществления изобретения. Для упрощения пояснения, рассматривается только выбор для первой группы без адаптированных размеров классов. Выбор для других вариантов осуществления, описанных ранее, может быть легко адаптирован.
На начальном этапе 1801 вычисляется статистика для области текущего кадра. Это заключает в себе определение переменных Histk и Sumk для всех пиксельных значений k. Histk соответствует числу пикселов, имеющих пиксельное значение, равное значению k, и Sumk соответствует сумме разностей между всеми пикселами, имеющими пиксельное значение, равное значению k, и их исходными пиксельными значениями. Алгоритм включает в себя 3 контура для трех параметров: размер S классов, размер R диапазона и центр C. Первый контур тестирует каждый возможный размер класса на этапе 1803. Например, размер задан на фиг. 14. Смещение для каждого поддиапазона полного диапазона вычисляется на этапе 1804. Например, если битовая глубина составляет 8, и размер классов составляет 16, то вычисляется искажение и смещение для 32 возможных диапазонов в полном диапазоне. В силу своих свойств, смещение и искажение вычисляются посредством линейной комбинации Histk и Sumk для всех значений k в текущем диапазоне. Затем, для каждого возможного диапазона R 1805 и каждого возможного центра C 1806, функция затрат на искажение в зависимости от скорости передачи оценивается на этапе 1807. Эта оценка основана на критерии искажения в зависимости от скорости передачи. Когда протестированы все центры C 1808, все диапазоны 1809 и все размеры 1810, наилучшие параметры S, R, C выбираются на этапе 1811 на основе лучшей функции затрат на искажение в зависимости от скорости передачи. Преимущества этой второй схемы для того, чтобы формировать равновероятную классификацию, включают в себя уменьшение сложности и повышение эффективности кодирования. Выбор классификации центра, диапазона и размера классов обеспечивает оптимальный выбор искажения в зависимости от скорости передачи по сравнению с вариантами осуществления, в которых классификация основана на статистическом распределении пиксельных значений. Конечно, этот вариант осуществления обеспечивает повышение в отношении эффективности кодирования по сравнению с текущей HEVC-реализацией. Эта схема является менее сложной на стороне декодера по сравнению с предыдущей, поскольку распределение пикселов не должно обязательно определяться в декодере. Кроме того, эта схема может быть менее сложной по сравнению с известными технологиями в HEVC, поскольку в некоторых группах используется меньшее число классов.
Алгоритм, представленный на фиг. 18, выполняет выбор на основе полного искажения в зависимости от скорости передачи для всех параметров полосового смещения: размер S классов, диапазон R, позиция значения, представляющего центр C. Чтобы ограничивать сложность, можно фиксировать некоторые параметры. В одной конкретной реализации алгоритма по фиг. 18, размер S и диапазон R задаются фиксированно равными данным значениям, известным посредством кодера и декодера. Например, S может представлять 8 пиксельных значений, и R может представлять 32 пиксельных значения, соответствующие 4 классам по 8 пикселов. Как следствие, единственный параметр, который должен быть оптимизирован, представляет собой значение, представляющее центр C.
Поскольку варианты осуществления изобретения учитывают повторное сегментирование пиксельных значений в диапазоне пиксельных значений при определении классификации пикселов, классификация может быть адаптирована, соответственно, к различным распределениям пиксельных значений. В частности, классификация может быть адаптирована согласно типу компонента пикселов. Например, в случае набора пикселов компонента сигнала цветности пиксельные значения зачастую являются более низкими по сравнению с пиксельными значениями пикселов сигнала яркости/сигнала цветности. Помимо этого, пиксельные значения сигнала U цветности имеют распределение, отличное относительно распределения пиксельных значений сигнала V цветности, которые имеют более концентрированные и относительно более высокие пиксельные значения. Кроме того, в случае пикселов компонента сигнала цветности распределение пиксельных значений зачастую в большей степени сконцентрировано вокруг пиковых пиксельных значений по сравнению с распределением пиксельных значений пикселов сигнала яркости/сигнала цветности, которое предоставляет более широко разнесенное распределение.
Как видно выше, во избежание определения распределения пикселов на стороне декодера, параметры S, R и C передаются в потоке битов в дополнение к SAO-типу (без SAO, краевое смещение или полосовое смещение) и значениям компенсационных смещений. Когда размер класса и диапазон являются фиксированными, только C передается, чтобы давать возможность декодеру извлекать центр диапазона.
В случае фиксированных S и R одно известное решение кодировать SAO-параметры состоит в применении псевдокода по фиг. 20A, описанного в форме блок-схемы последовательности операций способа посредством фиг. 21.
Процесс начинается посредством определения SAO-параметров, включающих в себя тип SAO (сохранен в кодовом слове sao_type_idx), значение, представляющее центр полезного диапазона (сохранено в кодовом слове sao_band_position), когда используется тип полосового смещения, и SAO-смещение (сохранено в кодовых словах sao_offset). На фиг. 20A, cldx представляет индекс цветового компонента, к которому применяется SAO, rx и rx представляют позицию области, к которой применяется SAO, и i является индексом класса значений выборки.
Кодирование SAO-параметров начинается после этого на этапе 2003 с кодирования SAO-типа с использованием экспоненциального кода Голомба без знака (ue(v)) (т.е. кода переменной длины без знака). Если SAO-тип представляет собой тип 5 (полосовое смещение), кодирование продолжается с кодированием значения, представляющего позицию центра полезного диапазона, с использованием кода фиксированной длины без знака размера 5 (u (5)) на этапе 2017. Затем, кодирование четырех смещений, соответствующих четырем классам, содержащимся в диапазоне, выполняется итеративно на этапах 2019-2025. Здесь, каждое смещение кодируется с использованием экспоненциального кода Голомба со знаком (se(v)) (т.е. кода для кодирования переменной длины (VLC) со знаком). Процесс кодирования затем завершается на этапе 2027.
Если SAO-тип не представляет собой полосовое смещение, сначала проверяется то, представляет собой или нет SAO-тип "без SAO" ("без SAO" означает, что смещение не применяется к рассматриваемым выборкам). Если выбрано "без SAO", процесс кодирования прекращается на этапе 2027.
В противном случае, продолжается итеративное кодирование четырех краевых смещений на этапах 2007-2013. С другой стороны, процесс кодирования прекращается на этапе 2027.
VLC-коды, в общем, используются, когда диапазон значений для представления является относительно высоким, но некоторые значения в этом диапазоне являются более вероятными, чем другие. В таком случае, наиболее вероятным значениям присваивается короткий код, в то время как менее вероятным значениям присваивается длинный код. Основной недостаток этих кодов состоит в том, что они вызывают более высокую сложность декодирования по сравнению с кодами фиксированной длины (FLC). Фактически, VLC-код должен считываться побитово, поскольку конечный размер кода неизвестен, тогда как все биты FLC-кода могут считываться непосредственно, поскольку его размер известен.
На фиг. 20B и 22, предлагается альтернатива этому процессу кодирования с заменой VLC-кодов на FLC-коды.
Этот процесс кодирования начинается с этапа 2201, который является идентичным этапу 2001. На этапе 2203, VLC-кодирование кодового слова sao_type_idx заменяется FLC-кодированием. 3 бита необходимы здесь для того, чтобы кодировать 6 возможных значений SAO-типа (т.е. тип "без SAO", 4 типа "краевое смещение" и тип "полосовое смещение"). Затем проверяется то, представляет собой или нет SAO-тип "без SAO". В этом случае, более ничего не кодируется, и процесс завершается на этапе 2215. В противном случае, проверяется то, представляет собой или нет тип SAO "полосовое смещение". Если да, значение, представляющее позицию центра диапазона, кодируется в кодовом слове sao_band_position в форме FLC-кода без знака размера 5. Фактически, в этом примере, с размером класса 8 значений выборки и диапазона, составленного из четырех классов, 28 различных позиций являются возможными для полного диапазона 256 значений.
После этого этапа выполняется кодирование четырех SAO-смещений на этапах 2211-2213. Здесь FLC-код заменяет VLC-код этапа 2023 и 2011. Вместо использования VLC-кода максимум в 5 битов, покрывающего значения целочисленного смещения от -31 до 32, здесь, используется FLC-код размера в 2 бита, в общем, допускающий кодирование только 4 различных значений (-2, -1, 1, 2). Уменьшение числа возможных значений имеет эффект концентрации кодирования на наиболее часто используемых значениях смещения.
Процесс прекращается после кодирования со смещением на этапе 2215.
Следует отметить, что в другом варианте осуществления, диапазон, представленный посредством смещений, может быть расширен посредством кодирования, в заголовке изображения, заголовке слайса или LCU-заголовке, коэффициента умножения, который должен применяться к смещениям, полученным посредством 2-битового кода. Например, когда коэффициент умножения равен 4, кодированные смещения (-2, -1, 1, 2) становятся (-8, -4, 4, 8). Коэффициент умножения также может быть стандартизированным (фиксированным) или логически выводиться из другой LCU. Например, коэффициент умножения, применимый к предыдущей LCU, может предположительно применяться к текущей LCU.
Аналогично в другом варианте осуществления, значение сдвига, кодированное в заголовке изображения, заголовке слайса или LCU-заголовке, может применяться к смещениям, полученным посредством 2-битового кода. Например, при значении сдвига в 5, кодированные смещения (-2, -1, 1, 2) становятся (3, 4, 6, 7). С другой стороны, значение сдвига также может быть стандартизированным (фиксированным) или логически выводиться из другой LCU. Например, значение сдвига, применимое к предыдущей LCU, может предположительно применяться к текущей LCU.
Тесты показывают то, что наличие меньшего числа возможных значений смещения не снижает существенно производительность SAO-способа. Очевидно, что потери, вызываемые посредством подавления некоторых значений смещения, компенсируются посредством подавления значительных затрат с точки зрения скорости передачи битов менее вероятных значений смещения.
Дополнительные тесты также показывают то, что число различных значений смещения дополнительно может сокращаться до 3 и даже 2 смещений (требующих только одного бита для того, чтобы кодировать) без значительных потерь производительности.
На фиг. 23, предлагается дополнительное улучшение процесса кодирования. Здесь рассматривается, что значения смещения, используемые в случае типа краевого смещения, могут логически выводиться непосредственно из типа краевого смещения. В этом случае, кодирование значений краевого смещения не требуется. Напомним, что каждый тип краевого смещения ассоциирован с 4 классами в зависимости от направления сигнала, и каждый класс имеет ассоциированное значение смещения. Этот вариант осуществления обусловлен посредством тестов, показывающих то, что, в общем, для данного типа краевого смещения и данного класса, значения смещения находятся близко друг к другу и, в общем, являются идентичными. Как следствие, предлагается фиксировать для каждого типа краевого смещения набор из 4 значений смещения. Например, предлагается следующее ассоциирование:
- вертикальное краевое смещение (-2, -1, 1, 2)
- горизонтальное краевое смещение (-2, -1, 1, 3)
- первое диагональное краевое смещение (-3, -2, -1, 1)
- второе диагональное краевое смещение (-1, 1, 2, 3)
Этапы 2301 и 2303 на фиг. 23 являются идентичными этапам 2201 и 2203, уже поясненным со ссылкой на фиг. 22. На этапах 2305 и 2307, проверяется то, представляет собой или нет SAO-тип "полосовое смещение" или "без SAO", соответственно. В обоих случаях, смещения не кодируются. В случае если SAO-тип представляет собой "краевое смещение", при считывании значения типа краевого смещения, декодер должен логически выводить значения смещения из типа краевого смещения благодаря известному ассоциированию с фиксированными значениями смещения.
В варианте осуществления по фиг. 23, если SAO-тип представляет собой "полосовое смещение", значение, представляющее позицию центра диапазона, кодируется на этапе 2309, и четыре значения смещения кодируются итеративно на этапах 2311-2317. Процесс кодирования завершается на этапе 2319.
В варианте осуществления по фиг. 24 и 25, применяется другая модификация процесса кодирования, описанного на фиг. 20A и 21. Как уже упомянуто в предыдущем варианте осуществления, FLC-код в 5 битов используется для того, чтобы кодировать информацию, представляющую позицию центра диапазона (sao_band_position), тогда как используются только 28 различных позиций. При этом условии, четыре FLC-кода, каждый с длиной 5 битов, остаются неиспользуемыми. Здесь предлагается воспользоваться преимуществом этих четырех резервных FLC-кодов, чтобы удалять кодовое слово, используемое для того, чтобы кодировать SAO-тип. Новое кодовое слово, SAO_band_position_and_EO, должно быть использовано для того, чтобы совместно кодировать позиции диапазона и типы краевых смещений. Это новое кодовое слово также имеет длину 5 битов.
Как обычно, процесс начинается на этапе 2501 с задания SAO-параметров. Этот процесс продолжается на этапе 2503 посредством кодирования флага длиной в 1 бит (SAO_LCU_flag), указывающего то, используется SAO или нет. Если SAO не используется (этап 2505), процесс прекращается (этап 2507).
Если SAO используется, на этапе 2509 проверяется то, какой тип SAO используется. Если SAO-тип представляет собой "полосовое смещение", то на этапе 2513, первые 28 кодов кодового слова SAO_band_position_and_EO используются для того, чтобы кодировать значение, представляющее позицию центра диапазона. Если SAO-тип представляет собой "краевое смещение", то на этапе 2511 последние четыре кода кодового слова SAO_band_position_and_EO используются для того, чтобы кодировать тип краевого смещения (вертикальное, горизонтальное, первое диагональное или второе диагональное). После этапов 2511 или 2513 выполняется кодирование четырех значений смещения на этапах 2515-2521.
В этой связи, хотя резервные кодовые слова используются в настоящем варианте осуществления для того, чтобы кодировать тип краевого смещения, следует принимать во внимание, что резервные кодовые слова альтернативно могут быть использованы в других целях. Любая другая информация, которая должна отправляться из кодера в декодер, может быть кодирована с использованием резервных кодовых слов.
На фиг. 26, предлагается дополнительный вариант осуществления для определения смещений, которые должны применяться в случае полосового смещения. Этот вариант осуществления обусловлен посредством тестов, показывающих то, что в случае полосового смещения, большая часть смещений имеет низкие амплитуды по абсолютному значению. Фактически, значения смещения, в общем, равны -2, -1, 1 и 2. Когда число классов в диапазоне уменьшается до 4, например, как в примере по фиг. 20A-25, число различных групп 4 значений смещения также сокращается. В вышеприведенном примере с 4 различными значениями смещений и 4 классами, число различных групп составляет 44=256. В вариантах осуществления по фиг. 21, 22, 23 и 25, 8 битов используются для того, чтобы кодировать значения смещения (4 значения смещения, каждое из которых кодируется с использованием 2 битов). Здесь, считается, что все группы 4 смещений имеют идентичную вероятность выбора. Тем не менее, некоторые из этих групп являются менее вероятными, чем другие. Посредством удаления менее вероятных групп, можно уменьшать число битов, требуемое для того, чтобы кодировать их. Как следствие, вместо кодирования 4 различных значений смещения с использованием 2 битов для каждого значения смещения, предлагается назначать индексы различным группам 4 значений смещения и кодировать индекс, причем индекс кодируется с использованием менее 8 битов благодаря удалению менее вероятных групп. Вероятности групп могут быть определены посредством применения SAO для набора обучающих последовательностей и вычисления статистики по группам. Таблица, собирающая все возможные группы, упорядоченные согласно их вероятности выбора, может быть предварительно определена и известна посредством кодера и декодера. В этой таблице, каждая группа смещений должна быть ассоциирована со значением индекса. Число битов, выделяемое кодированию индексов групп, может быть фиксированным (стандартизированным) либо фиксированным для последовательности, кадра, слайса или LCU и кодироваться в соответствующих заголовках. Поднабор групп в таблице, соответствующий наиболее вероятным группам, должен быть определен посредством кодера и декодера в зависимости от числа битов, выделяемых индексному кодированию.
Вариант осуществления, представляющий выбор наилучшей группы, описывается на фиг. 26. Процесс начинается с этапа 2601, на котором инициализируется переменная j. Эта переменная j постепенно увеличивается, чтобы давать возможность тестирования всех возможных групп смещений. В предложенном варианте осуществления, рассматриваются группы из 4 смещений, но могут рассматриваться другие числа смещений. На этапе 2603 тестируется то, все или нет группы протестированы (например, NbOffsetGroup может быть равным 128). Если да, процесс прекращается, и кодируется кодовое слово менее 8 битов, соответствующее выбранной группе. Если нет, процесс продолжает инициализацию переменной i, позволяющей тестировать все классы в диапазоне (этап 2605). На этапе 2606, переменная SumDiff(j), представляющая сумму разности между исходными выборками и SAO-фильтрованными кодированными выборками, соответствующими группе j смещений, инициализируется равной 0. Здесь, рассматриваются только 4 класса, но другие числа классов, согласованные с числом смещений, являются возможными. На этапе 2607, если остается несколько классов для тестирования, инициализируется переменная k, позволяющая тестировать все возможные выборки в диапазоне выборок, соответствующих классу i. На этапах 2611-2619 вычисляется сумма абсолютных значений разностей между кодированными выборками, фильтрованными со смещением класса i в группе j смещений, и исходными выборками в рассматриваемом классе i. Здесь, orig(k) представляет собой среднее исходных значений выборки, соответствующих кодированному значению enc(k). Filter(i,j) представляет собой значение смещения, соответствующее классу i, в группе j смещений. SumDiff(j) представляет собой сумму разностей, вычисленных для всех классов, составляющих диапазон (здесь 4 класса). В контуре, содержащем этапы 2621-2626, сравниваются все вычисленные суммы разностей, и выбирается индекс группы, имеющей минимальную сумму. Выбранный индекс соответствует группе смещений, позволяющей, при применении к кодированным выборкам, минимизировать разность между фильтрованными выборками и исходной выборкой.
В ходе процесса синтаксического кодирования, кодирование значений смещения, как представлено, например, посредством этапов 2211-2213 на фиг. 22, заменяется на кодирование индекса, соответствующего выбранной группе смещений.
Классификация пикселов компонента сигнала яркости выполняется отдельно от классификации пикселов компонента сигнала U или V цветности, и в силу этого, каждая классификация может быть адаптирована соответствующим образом, так что каждый класс имеет аналогичное число пикселов.
Таким образом, способы вариантов осуществления изобретения предоставляют более гибкий подход к классификации, который может быть адаптирован с возможностью обеспечивать более оптимальную классификацию независимо для обоих сигналов яркости или сигнал цветности, в силу этого приводя к повышению эффективности кодирования.
Хотя настоящее изобретение описано выше в отношении конкретных вариантов осуществления, настоящее изобретение не ограничено конкретными вариантами осуществления, и для специалистов в данной области техники должны быть очевидными модификации, которые находятся в пределах объема настоящего изобретения.
Например, хотя предыдущие варианты осуществления описаны относительно пикселов изображения и их соответствующих пиксельных значений, следует принимать во внимание, что в контексте изобретения, группа пикселов может рассматриваться вместе с соответствующим пиксельным значением группы. Таким образом, выборка может соответствовать одному или более пикселов изображения.
Дополнительные аспекты настоящего изобретения задаются ниже.
Согласно первому дополнительному аспекту изобретения, предусмотрен способ предоставления компенсационных смещений для набора восстановленных выборок изображения, причем каждая выборка имеет соответствующее значение выборки, причем значения выборки множества выборок набора могут представляться посредством статистического распределения значений выборки, при этом способ содержит:
- определение, в зависимости от свойств статистического распределения значений выборки, множества классов для повторного сегментирования выборок согласно их соответствующему значению выборки, причем каждый класс задает соответствующий диапазон значений выборки; и
- ассоциирование, с определенным классом, соответствующего компенсационного смещения для применения к соответствующему значению выборки каждой выборки упомянутого класса.
Поскольку в этом аспекте изобретения статистическое распределение значений выборки учитывается при определении классификации выборок, классификация может быть адаптирована, соответственно, ко всем возможным диапазонам значений выборки. Кроме того, классификация может быть адаптирована согласно типу компонента выборок. Например, в случае пикселов, соответствующих сигналу цветности, распределение пиксельных значений зачастую в большей степени сконцентрировано вокруг пиковых пиксельных значений по сравнению с распределением пиксельных значений сигнала яркости, которое предоставляет более широко разнесенное распределение. Таким образом, способы вариантов осуществления изобретения предоставляют более гибкий подход к классификации, который может быть адаптирован с возможностью обеспечивать более оптимальную классификацию независимо для обоих сигналов яркости или сигнал цветности, в силу этого приводя к повышению эффективности кодирования.
В варианте осуществления, свойства статистического распределения содержат определенный центр статистического распределения значений выборки изображения.
В варианте осуществления, свойства статистического распределения содержат полезный диапазон значений выборки статистического распределения.
В варианте осуществления, классы определяются таким образом, что выборки совместно используются практически равномерно между классами.
В варианте осуществления, выборки набора могут иметь по меньшей мере первый тип компонента или второй тип компонента, при этом множество классов определяется в зависимости от типа компонента набора выборок.
В варианте осуществления, число классов предварительно определяется, причем диапазон значений выборки, заданных для каждого класса, определяется в зависимости от свойств статистического распределения.
В другом варианте осуществления, число классов и диапазон значений выборки, заданных для каждого класса, определяются в зависимости от свойств статистического распределения.
В варианте осуществления, число классов определяется в зависимости от числа выборок, имеющего значение выборки в полезном диапазоне.
В варианте осуществления, число классов определяется согласно типу компонента.
В варианте осуществления, способ включает в себя определение максимального числа значений выборки в расчете на класс согласно числу значений выборки в полезном диапазоне.
В варианте осуществления, определение множества классов содержит выбор, из множества предварительно определенных классификаций, классификации, задающей множество классов, адаптированных к свойствам статистического распределения.
В варианте осуществления, диапазон значений выборки для каждого класса, центр статистического распределения и/или полезный диапазон значений выборки определяется на основе критериев искажения в зависимости от скорости передачи.
В варианте осуществления, диапазон значений выборки для каждого класса, центр статистического распределения и/или полезный диапазон значений выборки предварительно определяются. В варианте осуществления, полезный диапазон значений выборки определяется на основе сравнения значений выборки относительно порогового значения, при этом пороговое значение зависит от общего числа выборок, пороговое значение зависит от типа компонента выборок, или пороговое значение является предварительно определенным значением.
В варианте осуществления, компенсационное смещение для каждого класса определяется из среднего разности между значением выборки каждой восстановленной выборки класса и соответствующим значением выборки соответствующего исходного изображения.
В варианте осуществления, набор выборок представляет собой один из множества наборов выборок изображения, причем идентичное число классов определяется для каждого набора.
В варианте осуществления, значение выборки представляет битовую глубину, при этом полезный диапазон, диапазон каждого класса и/или центр статистического распределения зависят от битовой глубины.
В варианте осуществления, диапазон значений выборки для данного класса зависит от позиции класса в полезном диапазоне.
В варианте осуществления, диапазон значений выборки для данного класса, расположенный на краю статистического распределения, превышает диапазон значений выборки для данного класса в центральной области распределения.
В варианте осуществления, центр статистического распределения определяется на основе полезного диапазона.
В варианте осуществления, множество классов содержит первую группу классов, расположенных в центральной части статистического распределения, и вторую группу классов, включающую в себя первую и вторую подгруппу классов, расположенных в соответствующих краевых частях статистического распределения.
В варианте осуществления, позиции второй подгруппы классов в статистическом распределении предоставляются в качестве данных для кодирования.
В варианте осуществления, позиции подгрупп второй группы являются независимыми от полного диапазона статистического распределения.
В варианте осуществления, центр статистического распределения не предоставляется для кодирования.
В варианте осуществления, позиция полезного диапазона (классификации) в полном диапазоне выбирается из множества возможных позиций, распределенных по полному диапазону, причем интервал между двумя последовательными позициями меньше, по меньшей мере, в одной части полного диапазона, чем в другой части полного диапазона.
Например, часть, имеющая меньший интервал, может быть в середине полного диапазона.
Согласно другому примеру, часть, имеющая меньший интервал, может быть на одном или обоих концах полного диапазона.
Позиции могут быть центральными позициями. Альтернативно, они могут быть конечными позициями.
Возможным позициям могут назначаться индексы.
В варианте осуществления, диапазон значений выборки для каждого класса, центр статистического распределения и/или полезный диапазон значений выборки предварительно определяются.
В варианте осуществления, могут формироваться, по меньшей мере, два различных типа значений смещения, при этом один из типов представляет собой так называемые значения полосового смещения, которые, как описано выше, ассоциированы, соответственно, с классами (диапазонами значений выборки). Один или более других типов значений смещения могут представлять собой так называемые значения краевого смещения. Может быть предусмотрен различный тип значений краевого смещения в расчете на направление, например, четыре различных типа согласно, соответственно, четырем различным направлениям. Таким образом, может быть предусмотрен набор значений краевого смещения в расчете на направление. После этого может выбираться один тип значения смещения (полосовое или краевое). Критерий выбора не ограничивается, но один подходящий критерий представляет собой критерий искажения в зависимости от скорости передачи. Только выбранный тип SAO-фильтрации (полосовое или краевое смещение) затем применяется посредством кодера и декодера. Выбор может быть выполнен для каждой области кадра. Дополнительно, может быть возможным выбирать "без SAO", т.е. не применять ни полосовое, ни краевое смещение, например, если значительное улучшение не получается посредством ни одного типа. В варианте осуществления, выбранный тип SAO-фильтрации кодируется и передается посредством кодера в декодер.
В варианте осуществления, код фиксированной длины используется для того, чтобы кодировать выбранный тип.
В варианте осуществления, когда выбранный тип представляет собой полосовое смещение, кодируется значение, представляющее позицию полезного диапазона. Позиция может быть центральной позицией или конечной позицией полезного диапазона.
В варианте осуществления, код фиксированной длины используется для того, чтобы кодировать позицию полезного диапазона.
В варианте осуществления, когда число различных кодовых слов, разрешенных посредством длины кода фиксированной длины, используемого для того, чтобы кодировать кодовые слова, соответствующие значениям, представляющим позицию полезного диапазона, выше фактического числа различных возможных позиций, резервные кодовые слова используются для того, чтобы кодировать другую информацию. Например, в одном варианте осуществления, резервные кодовые слова используются для того, чтобы кодировать тип (направление) краевого смещения.
В варианте осуществления, компенсационные смещения кодируются с помощью кодов фиксированной длины. Это может применяться к полосовым смещениям или краевым смещениям либо к обоим типам смещения.
В варианте осуществления, число различных компенсационных смещений, разрешенных посредством длины кода фиксированной длины, ниже числа возможных компенсационных смещений.
В варианте осуществления, коэффициент умножения применяется к значениям компенсационных смещений, и умноженные значения компенсационных смещений используются для фильтрации.
В варианте осуществления, коэффициент умножения передается из кодера в декодер.
В варианте осуществления, значение сдвига применяется к значениям компенсационных смещений, и сдвинутые значения компенсационных смещений используются для фильтрации.
В варианте осуществления, значение сдвига передается из кодера в декодер.
В варианте осуществления, значения краевого смещения, по меньшей мере, для одного типа (направления) предварительно определяются.
В варианте осуществления, кодируется флаг, указывающий то, должны или нет применяться компенсационные смещения для набора восстановленных выборок изображения.
В варианте осуществления, группы значений полосового смещения предварительно задаются, причем каждое смещение группы ассоциировано с одним классом полезного диапазона.
В варианте осуществления, каждой группе назначается индекс.
В варианте осуществления, предварительно заданные группы собираются в таблице, причем табличный порядок зависит от вероятности выбора каждой группы.
В варианте осуществления, вероятность выбора каждой группы вычисляется посредством применения способов предоставления компенсационных смещений, осуществляющих настоящее изобретение, к набору обучающих последовательностей.
В варианте осуществления, выбирается группа значений полосового смещения из предварительно заданных групп значений полосового смещения, которая имеет минимальную разность между исходными выборками и фильтрованными выборками.
В варианте осуществления, индексы групп кодируются с использованием кода фиксированной длины.
В варианте осуществления, число различных кодированных индексов групп, разрешенных посредством длины кода фиксированной длины, ниже числа возможных различных групп.
В варианте осуществления, поднабор групп полосовых смещений в возможных различных группах определяется в зависимости от вероятности выбора каждой группы и длины кода фиксированной длины.
В варианте осуществления, длина кода фиксированной длины, используемого для того, чтобы кодировать индексы групп полосовых смещений, предварительно определяется.
В варианте осуществления, длина кода фиксированной длины, используемого для того, чтобы кодировать индексы групп компенсационных смещений, кодируется в заголовке последовательности, группе заголовка изображения, заголовке изображения, заголовке слайса или LCU-заголовке.
Согласно второму дополнительному аспекту изобретения, предусмотрен способ кодирования изображения, состоящего из множества выборок, при этом способ содержит:
- кодирование выборок;
- декодирование закодированных выборок, чтобы предоставлять восстановленные выборки;
- выполнение контурной фильтрации в отношении восстановленных выборок, причем контурная фильтрация содержит применение компенсационных смещений к значениям выборки соответствующих восстановленных выборок, причем каждое компенсационное смещение ассоциировано с диапазоном значений выборки, при этом компенсационные смещения предоставляются согласно способу по первому дополнительному аспекту; и
- формирование потока битов закодированных выборок.
В варианте осуществления, способ включает в себя передачу, в потоке битов, закодированных данных, представляющих соответствующие компенсационные смещения для каждого класса.
В варианте осуществления, способ включает в себя передачу, в потоке битов, закодированных данных классификации, задающих множество определенных классов.
В варианте осуществления, данные классификации содержат данные, представляющие центр статистического распределения.
В варианте осуществления, данные классификации содержат данные, представляющие диапазон значений выборки, заданных для каждого из множества классов.
В варианте осуществления, способ включает в себя, данные классификации содержат данные, представляющие полезный диапазон статистического распределения.
Согласно третьему дополнительному аспекту изобретения, предусмотрен способ декодирования изображения, состоящего из множества выборок, при этом способ содержит:
- прием закодированных выборок;
- декодирование закодированных выборок, чтобы предоставлять восстановленные выборки;
- выполнение контурной фильтрации в отношении восстановленных выборок, причем контурная фильтрация содержит применение компенсационных смещений к значениям выборки соответствующих восстановленных выборок, причем каждое компенсационное смещение ассоциировано с диапазоном значений выборки, при этом компенсационные смещения предоставляются согласно способу по любому из предыдущих вариантов осуществления.
Другой из дополнительных аспектов изобретения предоставляет способ декодирования изображения, состоящего из множества значений выборки, при этом способ содержит:
- прием закодированных значений выборки;
- прием закодированных данных классификации, задающих множество классов, ассоциированных с соответствующими компенсационными смещениями, предоставленными согласно способу по любому из предыдущих вариантов осуществления, причем каждое компенсационное смещение соответствует диапазону значений выборки;
- декодирование закодированных выборок, чтобы предоставлять восстановленные выборки, и декодирование закодированных компенсационных смещений; и
- выполнение контурной фильтрации в отношении восстановленных выборок, причем контурная фильтрация содержит применение принимаемых компенсационных смещений к выборкам изображений соответствующих выборок, согласно значению выборки для выборки.
В варианте осуществления, данные классификации содержат данные, представляющие центр статистического распределения, данные, представляющие диапазон значений выборки, заданных для каждого из множества классов, и/или данные, представляющие полезный диапазон статистического распределения.
Согласно еще одному из дополнительных аспектов изобретения, предусмотрен сигнал, переносящий информационный набор данных для изображения, представленного посредством потока битов видео, причем изображение содержит набор восстанавливаемых выборок, при этом каждая восстанавливаемая выборка после восстановления имеет соответствующее значение выборки, причем значения выборки множества восстановленных выборок набора могут представляться посредством статистического распределения значений выборки; при этом информационный набор данных содержит: данные классификации, представляющие множество классов, ассоциированных с соответствующими компенсационными смещениями для применения к значениям выборки соответствующих восстановленных выборок, при этом данные классификации определяются согласно статистическому распределению.
В варианте осуществления, данные классификации содержат данные, представляющие центр статистического распределения, данные, представляющие диапазон значений выборки, заданных для каждого из множества классов, и/или данные, представляющие полезный диапазон статистического распределения.
Согласно другому из дополнительных аспектов изобретения, предусмотрено устройство для предоставления компенсационных смещений для набора восстановленных выборок изображения, причем каждая выборка имеет соответствующее значение выборки, причем значения выборки множества выборок набора могут представляться посредством статистического распределения значений выборки, причем устройство содержит:
- средство для определения, в зависимости от свойств статистического распределения значений выборки, множества классов для повторного сегментирования выборок согласно их соответствующему значению выборки, причем каждый класс задает соответствующий диапазон значений выборки; и
- средство для ассоциирования, с определенным классом, соответствующего компенсационного смещения для применения к соответствующему значению выборки каждой выборки упомянутого класса.
Другой из дополнительных аспектов изобретения предоставляет устройство кодирования для кодирования изображения, состоящего из множества выборок, причем устройство содержит:
- кодер для кодирования выборок;
- декодер для декодирования закодированных выборок, чтобы предоставлять восстановленные выборки;
- контурный фильтр для фильтрации восстановленных выборок, причем средство контурной фильтрации содержит средство применения смещений для применения компенсационных смещений к значениям выборки соответствующих восстановленных выборок, причем каждое компенсационное смещение ассоциировано с диапазоном значений выборки, при этом компенсационные смещения предоставляются посредством устройства предыдущего варианта осуществления; и
- формирователь потоков битов для формирования потока битов закодированных выборок.
Еще один другой из дополнительных аспектов изобретения предоставляет устройство декодирования для декодирования изображения, состоящего из множества выборок, причем устройство содержит: приемное устройство для приема закодированных выборок, декодер для декодирования закодированных выборок, чтобы предоставлять восстановленные выборки; контурный фильтр для контурной фильтрации восстановленные выборки, причем контурный фильтр содержит средство для применения компенсационных смещений к значениям выборки соответствующих восстановленных выборок, причем каждое компенсационное смещение ассоциировано с диапазоном значений выборки, при этом компенсационные смещения предоставляются посредством устройства согласно предыдущему варианту осуществления.
Другой из дополнительных аспектов изобретения предоставляет устройство декодирования для декодирования изображения, состоящего из множества значений выборки, причем устройство содержит: приемное устройство для приема закодированных значений выборки и приема закодированных данных классификации, задающих множество классов, ассоциированных с соответствующими компенсационными смещениями, предоставленными посредством устройства согласно предыдущему варианту осуществления, причем каждое компенсационное смещение соответствует диапазону значений выборки; декодер для декодирования закодированных выборок, чтобы предоставлять восстановленные выборки, и декодирования закодированных компенсационных смещений; и контурный фильтр для контурной фильтрации восстановленные выборки, причем контурный фильтр содержит средство для применения принимаемых компенсационных смещений к выборкам изображений соответствующих выборок, согласно значению выборки для выборки.
Множество дополнительных модификаций и изменений предполагаются специалистами в данной области техники после прочтения вышеприведенных иллюстративных вариантов осуществления, которые приводятся только в качестве примера и которые не имеют намерение ограничивать объем изобретения, который определяется исключительно посредством прилагаемой формулы изобретения. В частности, при необходимости различные признаки из различных вариантов осуществления могут меняться местами.
В формуле изобретения, слово "содержащий" не исключает другие элементы или этапы, и единственное число не исключает множества. Простой факт того, что различные признаки упомянуты во взаимно различных зависимых пунктах формулы изобретения, не означает того, что комбинация этих признаков не может быть преимущественно использована.

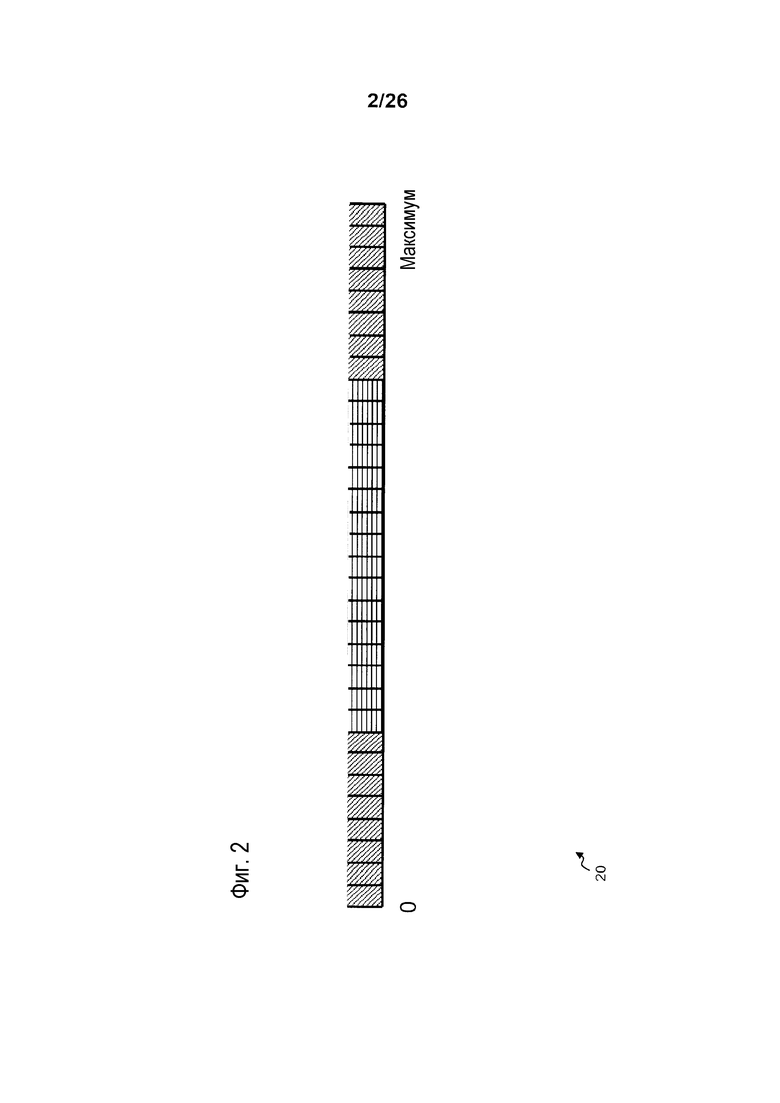




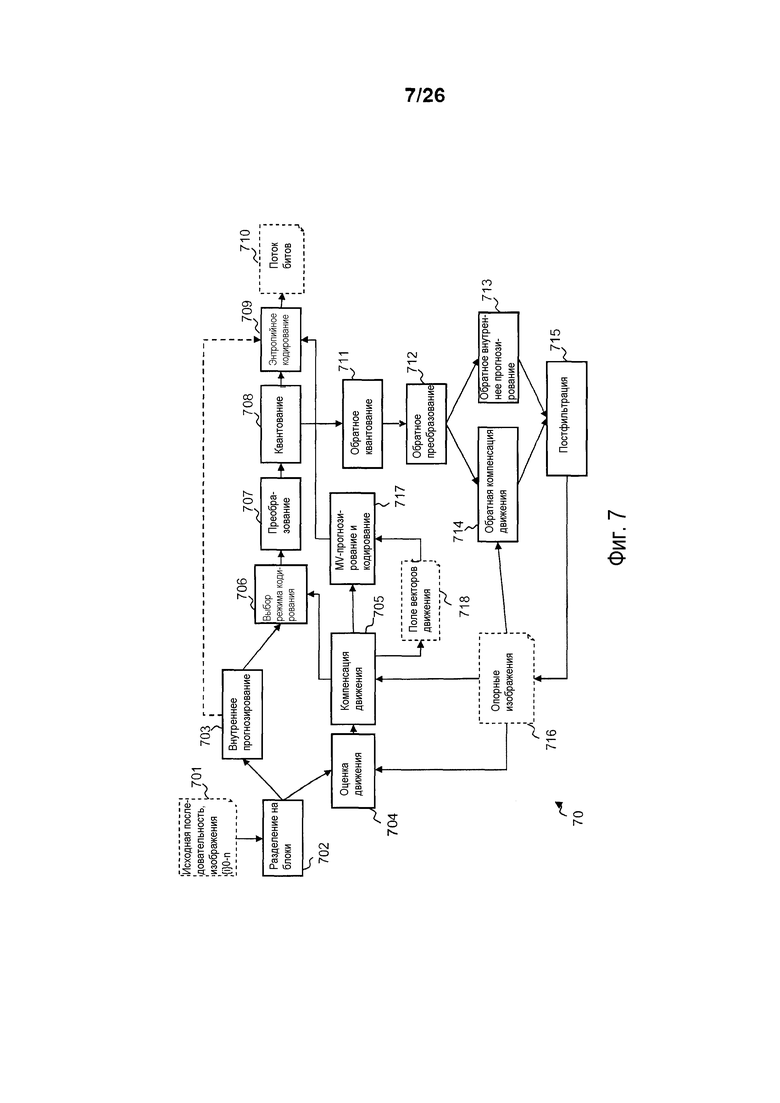
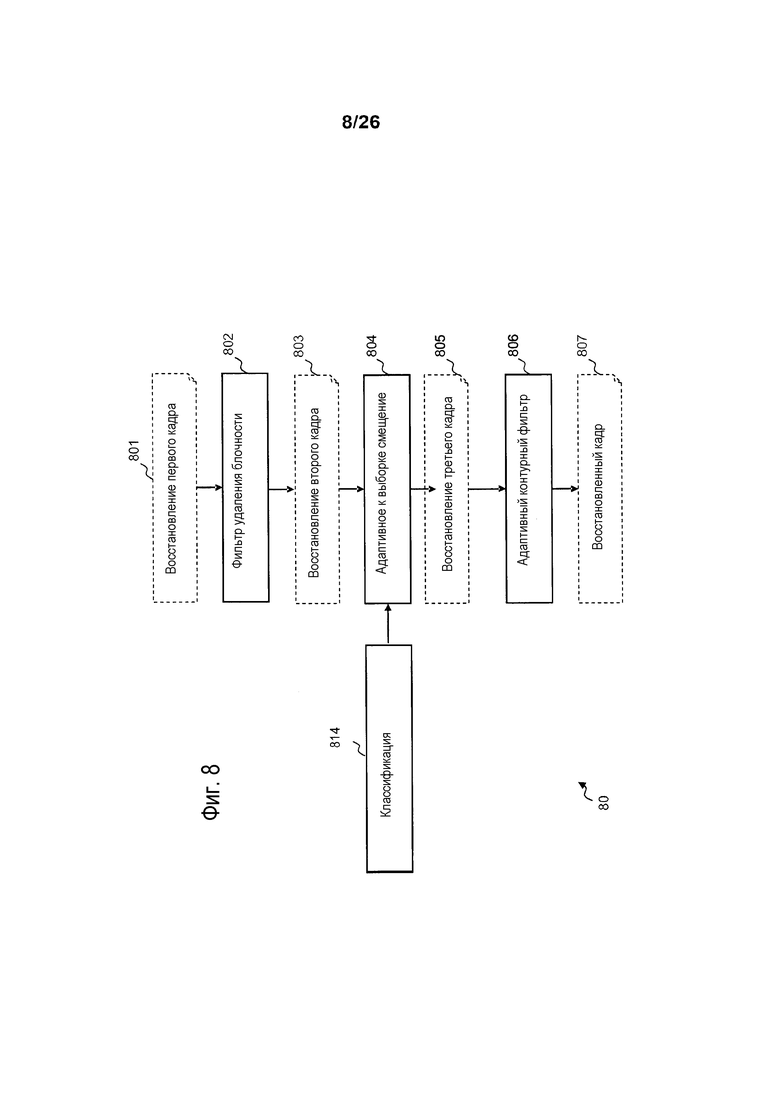

















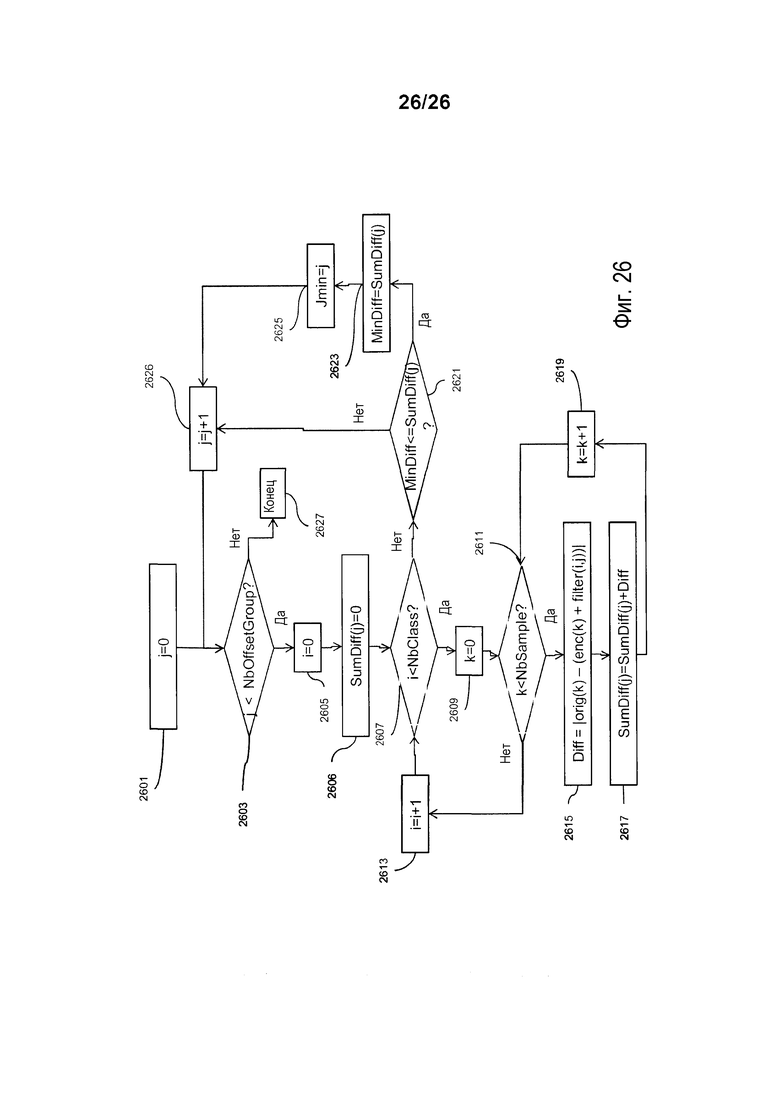
Изобретение относится к способу предоставления компенсационных смещений для набора восстановленных выборок изображения. Техническим результатом является уменьшение пространственных и временных избыточностей в видеопотоках. Способ содержит этапы, на которых выбирают, на основе критерия скорость-искажение, классификацию из множества предварительно определенных классификаций, причем каждая упомянутая предварительно определенная классификация имеет диапазон классификации, равный одной восьмой полного диапазона значений выборки, и состоит из четырех классов, каждый из которых задает диапазон значений выборки в упомянутом диапазоне классификации, причем в этот класс помещается выборка, если ее значение выборки находится в диапазоне рассматриваемого класса; и ассоциируют с каждым классом выбранной классификации компенсационное смещение для применения к значению выборки каждой выборки рассматриваемого класса. 10 н. и 19 з.п. ф-лы, 28 ил.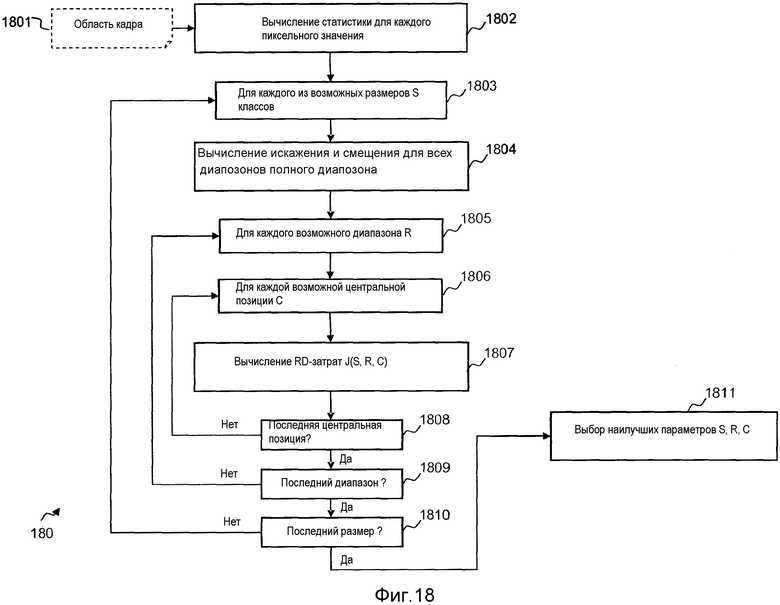
1. Способ предоставления компенсационных смещений для использования при выполнении контурной фильтрации с адаптивным к выборке смещением в отношении набора восстановленных выборок изображения, причем каждая выборка имеет значение выборки, при этом способ содержит этапы, на которых:
выбирают, на основе критерия скорость-искажение, классификацию из множества предварительно определенных классификаций, причем каждая упомянутая предварительно определенная классификация имеет диапазон классификации, равный одной восьмой полного диапазона значений выборки, и состоит из четырех классов, каждый из которых задает диапазон значений выборки в упомянутом диапазоне классификации, причем в этот класс помещается выборка, если ее значение выборки находится в диапазоне рассматриваемого класса; и
ассоциируют с каждым классом выбранной классификации компенсационное смещение для применения к значению выборки каждой выборки рассматриваемого класса.
2. Способ по п. 1, в котором компенсационное смещение для каждого класса определяется из среднего разности между значением выборки каждой восстановленной выборки класса и соответствующим значением выборки соответствующего исходного изображения.
3. Способ по п. 1, в котором значение выборки представляет битовую глубину и по меньшей мере одно из диапазона классификации, диапазона каждого класса и центра выбранной классификации зависит от битовой глубины.
4. Способ кодирования изображения, состоящего из множества выборок, при этом способ содержит этапы, на которых:
кодируют выборки;
декодируют закодированные выборки, чтобы предоставлять восстановленные выборки;
выполняют контурную фильтрацию с адаптивным к выборке смещением в отношении восстановленных выборок, причем контурная фильтрация содержит этап, на котором применяют компенсационные смещения к значениям выборки соответствующих восстановленных выборок, причем каждое компенсационное смещение ассоциировано с диапазоном значений выборки, при этом компенсационные смещения предоставляются посредством выбора, на основе критерия скорость-искажение, классификации из множества предварительно определенных классификаций, причем каждая упомянутая предварительно определенная классификация имеет диапазон классификации, равный одной восьмой полного диапазона значений выборки, и состоит из четырех классов, каждый из которых задает диапазон значений выборки в упомянутом диапазоне классификации, причем в этот класс помещается выборка, если ее значение выборки находится в диапазоне рассматриваемого класса, и посредством ассоциирования с каждым классом выбранной классификации компенсационного смещения для применения к значению выборки каждой выборки рассматриваемого класса; и
формируют поток битов закодированных выборок.
5. Способ по п. 4, дополнительно содержащий этап, на котором передают, в потоке битов, закодированные данные, представляющие компенсационные смещения, ассоциированные, соответственно, с множеством классов выбранной классификации.
6. Способ по п. 4, дополнительно содержащий этап, на котором передают, в потоке битов, закодированные данные классификации, связанные с выбранной классификацией.
7. Способ по п. 6, в котором данные классификации содержат данные, представляющие центр выбранной классификации.
8. Способ по п. 6, в котором данные классификации содержат данные, представляющие индекс, связанный с выбранной классификацией.
9. Способ по п. 6, в котором данные классификации содержат данные, представляющие позицию выбранной классификации в полном диапазоне значений выборки.
10. Способ по п. 9, в котором позиция является конечной позицией выбранной классификации.
11. Способ по п. 10, в котором конечная позиция представляется как сдвиг от одного конца упомянутого полного диапазона.
12. Способ декодирования изображения, состоящего из множества выборок, причем каждая выборка имеет значение выборки, при этом способ содержит этапы, на которых:
принимают закодированные значения выборки;
принимают закодированные данные классификации;
принимают закодированные компенсационные смещения;
декодируют данные классификации и выбирают, на основе декодированных данных классификации, классификацию из множества предварительно определенных классификаций, причем каждая упомянутая предварительно определенная классификация имеет диапазон классификации, равный одной восьмой полного диапазона значений выборки, и состоит из четырех классов, каждый из которых задает диапазон значений выборки в упомянутом диапазоне классификации, причем в этот класс помещается выборка, если ее значение выборки находится в диапазоне рассматриваемого класса;
декодируют закодированные выборки, чтобы предоставлять восстановленные значения выборки, и декодируют закодированные компенсационные смещения;
ассоциируют декодированные компенсационные смещения, соответственно, с классами выбранной классификации; и
выполняют контурную фильтрацию в отношении восстановленных значений выборки, причем контурная фильтрация содержит этап, на котором применяют декодированное компенсационное смещение, ассоциированное с каждым классом выбранной классификации, к восстановленным значениям выборки в диапазоне рассматриваемого класса.
13. Способ по п. 12, в котором данные классификации содержат данные, представляющие центр выбранной классификации.
14. Способ по п. 12, в котором данные классификации содержат данные, представляющие индекс, связанный с выбранной классификацией.
15. Способ по п. 12, в котором данные классификации содержат данные, представляющие позицию выбранной классификации в полном диапазоне значений выборки.
16. Способ по п. 15, в котором позиция является конечной позицией выбранной классификации.
17. Способ по п. 16, в котором конечная позиция представляется как сдвиг от одного конца упомянутого полного диапазона.
18. Долговременный считываемый компьютером носитель данных, хранящий инструкции компьютерной программы для реализации способа по п. 1.
19. Устройство для предоставления компенсационных смещений для использования при выполнении контурной фильтрации с адаптивным к выборке смещением в отношении набора восстановленных выборок изображения, причем каждая выборка имеет значение выборки, причем устройство содержит:
блок выбора, который выбирает, на основе критерия скорость-искажение, классификацию из множества предварительно определенных классификаций, причем каждая упомянутая предварительно определенная классификация имеет диапазон классификации, равный одной восьмой полного диапазона значений выборки, и состоит из четырех классов, каждый из которых задает диапазон значений выборки в упомянутом диапазоне классификации, причем в этот класс помещается выборка, если ее значение выборки находится в диапазоне рассматриваемого класса; и
блок ассоциирования, который ассоциирует с каждым классом выбранной классификации компенсационное смещение для применения к значению выборки каждой выборки рассматриваемого класса.
20. Устройство кодирования для кодирования изображения, состоящего из множества выборок, причем устройство содержит:
кодер, который кодирует выборки;
декодер, который декодирует закодированные выборки, чтобы предоставлять восстановленные выборки;
контурный фильтр с адаптивным к выборке смещением, который фильтрует восстановленные выборки, причем контурный фильтр содержит блок применения смещений, который применяет компенсационные смещения к значениям выборки соответствующих восстановленных выборок, причем каждое компенсационное смещение ассоциировано с диапазоном значений выборки;
средство предоставления компенсационных смещений, содержащее блок выбора, который выбирает, на основе критерия скорость-искажение, классификацию из множества предварительно определенных классификаций, причем каждая упомянутая предварительно определенная классификация имеет диапазон классификации, равный одной восьмой полного диапазона значений выборки, и состоит из четырех классов, каждый из которых задает диапазон значений выборки в упомянутом диапазоне классификации, причем в этот класс помещается выборка, если ее значение выборки находится в диапазоне рассматриваемого класса, и также содержащее блок ассоциирования, который ассоциирует с каждым классом выбранной классификации компенсационное смещение для применения к значению выборки каждой выборки рассматриваемого класса; и
формирователь потоков битов, который формирует поток битов закодированных выборок.
21. Устройство для декодирования изображения, состоящего из множества выборок, причем каждая выборка имеет значение выборки, причем устройство содержит:
блоки приема значений выборки, который принимает закодированные значения выборки;
блок приема данных классификации, который принимает закодированные данные классификации;
блок приема компенсационных смещений, который принимает закодированные компенсационные смещения;
декодер данных классификации, который декодирует данные классификации;
блок выбора, который выбирает, на основе декодированных данных классификации, классификацию из множества предварительно определенных классификаций, причем каждая упомянутая предварительно определенная классификация имеет диапазон классификации, равный одной восьмой полного диапазона значений выборки, и состоит из четырех классов, каждый из которых задает диапазон значений выборки в упомянутом диапазоне классификации, причем в этот класс помещается выборка, если ее значение выборки находится в диапазоне рассматриваемого класса;
блок декодирования значений выборки, который декодирует закодированные значения выборки, чтобы предоставлять восстановленные значения выборки;
блок декодирования компенсационных смещений, который декодирует закодированные компенсационные смещения;
блок ассоциирования, который ассоциирует декодированные компенсационные смещения, соответственно, с классами выбранной классификации; и
контурный фильтр с адаптивным к выборке смещением, который выполняет контурную фильтрацию с адаптивным к выборке смещением в отношении восстановленных значений выборки, причем контурная фильтрация содержит применение декодированного компенсационного смещения, ассоциированного с каждым классом выбранной классификации, к восстановленным значениям выборки в диапазоне рассматриваемого класса.
22. Долговременный считываемый компьютером носитель данных, хранящий инструкции компьютерной программы для реализации способа по п. 4.
23. Долговременный считываемый компьютером носитель данных, хранящий инструкции компьютерной программы для реализации способа по п. 12.
24. Устройство долговременного хранения мультимедиа, хранящее сигнал, несущий информационный набор данных для изображения, представляемого потоком битов видео, причем изображение содержит набор восстанавливаемых выборок, каждая восстанавливаемая выборка имеет значение выборки, причем информационный набор данных содержит: данные классификации, связанные с классификацией, выбранной кодером из множества предварительно определенных классификаций, причем каждая упомянутая предварительно определенная классификация имеет диапазон классификации, равный одной восьмой полного диапазона значений выборки, и состоит из четырех классов, каждый из которых задает диапазон значений выборки в упомянутом диапазоне классификации, причем в этот класс помещается выборка, если ее значение выборки находится в диапазоне рассматриваемого класса, и каждый класс из упомянутого множества классов выбранной классификации ассоциирован с компенсационным смещением для применения, при контурной фильтрации с адаптивным к выборке смещением, к значениям выборки восстанавливаемых выборок в диапазоне рассматриваемого класса.
25. Устройство долговременного хранения мультимедиа по п. 24, при этом данные классификации содержат данные, представляющие центр выбранной классификации.
26. Устройство долговременного хранения мультимедиа по п. 24, при этом данные классификации содержат данные, представляющие индекс, связанный с выбранной классификацией.
27. Устройство долговременного хранения мультимедиа по п. 24, при этом данные классификации содержат данные, представляющие позицию выбранной классификации в полном диапазоне значений выборки.
28. Устройство долговременного хранения мультимедиа по п. 27, при этом позиция является конечной позицией выбранной классификации.
29. Устройство долговременного хранения мультимедиа по п. 28, при этом конечная позиция представляется как сдвиг от одного конца упомянутого полного диапазона.
| US20090262223 A1, 22.10.2009 | |||
| US20100046612 A1, 25.02.2010 | |||
| US20060232709 A1, 19.10.2006 | |||
| СПОСОБ ФИЛЬТРАЦИИ ДЛЯ УМЕНЬШЕНИЯ БЛОЧНОСТИ, УЧИТЫВАЮЩИЙ РЕЖИМ intra-BL, И ИСПОЛЬЗУЮЩИЙ ЕГО МНОГОУРОВНЕВЫЙ ВИДЕОКОДЕР/ВИДЕОДЕКОДЕР | 2006 |
|
RU2355125C1 |

