УРОВЕНЬ ТЕХНИКИ
Одинаковый тип данных часто вводится и сохраняется во многих разных форматах. Например, некоторые даты существуют в форме ВВГГММДД (19990101), другие даты в формате ММ/ДД/ВВГГ (01/01/1999), помимо этого, другие даты в формате М/Д/ГГ (1/1/99). Чтобы выполнять анализ над данными, они преобразуются в одинаковый формат. Например, некоторый анализ может предписывать, что телефонные номера должны форматироваться, придерживаясь формы (206) 555-1212, тогда как другой анализ может предписывать, чтобы форматирование было снято с телефонных номеров (т.е. 2065551212). Разные способы могут использоваться для преобразования данных. Например, могут быть использованы разные функции преобразования и/или может быть разработана управляющая программа для преобразования данных.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Это краткое изложение сущности изобретения приведено, чтобы предоставить подборку концепций в упрощенной форме, которые дополнительно описаны ниже в подробном описании. Это краткое изложение сущность изобретения не предназначено для идентификации ключевых признаков или существенных признаков заявленного изобретения, и не предназначено для использования в качестве содействия в определении объема заявленного изобретения.
Правила форматирования данных для преобразования элементов данных из одной формы в другую форму определяются автоматически на основании примерного набора выходных данных, например, пользовательских правок. Эвристика машинного обучения применяется к исходным данным, а так же и примерным выходным данным (например, пользовательским правкам), чтобы определять правило форматирования данных, которое может применяться к дополнительным элементам данных. Например, пользователь может осуществлять правки, которые добавляют/удаляют символы из данных, сцепляют данные, извлекают данные, переименовывают данные и тому подобное. Посредством изучения исходных значений наряду с отредактированными значениями, может выводиться правило, которое заключает в себе этот тип преобразования, а затем такое правило может применяться в отношении дополнительных исходных значений, чтобы автоматически формировать требуемые отредактированные значения или выходные данные. Эвристика машинного обучения может запускаться автоматически в ответ на событие (например, после предопределенного количества правок, произведенных в отношении одного и того же типа данных), или запускаться вручную (например, путем выбора опции пользовательского интерфейса). Правило форматирования данных может быть применено к другим данным, а результаты форматирования - допускать ревизию со стороны пользователя. На основании дальнейших правок/ревизий, правило форматирования данных может обновляться. Правила форматирования данных могут сохраняться для более позднего использования и/или модификации. Также может быть представлен уровень достоверности, чтобы содействовать пользователю в определении того, был ли элемент(ы) переформатирован правильно.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг.1 иллюстрирует примерное вычислительное окружение;
Фиг.2 показывает систему для форматирования данных на основании правок, произведенных в отношении документа;
Фиг.3 иллюстрирует определение правила форматирования данных на основании пользовательских правок в отношении столбца и применение правила форматирования данных к другим ячейкам в пределах столбца;
Фиг.4 показывает пример осуществления пользователем правок в отношении элементов в столбце номера социального страхования;
Фиг.5 иллюстрирует пример осуществления пользователем правок для изменения форматирования дат;
Фиг.6 показывает элементы пользовательского интерфейса, которые можно использовать, чтобы взаимодействовать с форматированием элементов;
Фиг.7 показывает пользовательский интерфейс для разрешения/запрета заполнения по образцу;
Фиг.8 показывает иллюстративную последовательность операций для форматирования данных по образцу.
ПОДРОБНОЕ ОПИСАНИЕ
Далее, со ссылкой на чертежи, на которых одинаковые номера представляют подобные элементы, будут описаны различные варианты осуществления. В частности, Фиг.1 и соответствующее обсуждение предназначены для представления краткого общего описания пригодной вычислительной среды, в которой могут быть реализованы варианты осуществления.
Обычно, программные модули включают в себя процедуры, программы, компоненты, структуры данных и другие типы структур, которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных. Другие конфигурации компьютерной системы также могут использоваться, в том числе, карманные устройства, многопроцессорные системы, основанную на микропроцессоре или программируемую бытовую электронику, миникомпьютеры, универсальные вычислительные машины и тому подобное. Распределенные вычислительные среды также могут использоваться в тех случаях, когда задачи выполняются удаленными вычислительными устройствами, которые связаны через сети связи. В распределенном компьютерном окружении, программные модули могут быть расположены как в локальных, так и в удаленных запоминающих устройствах.
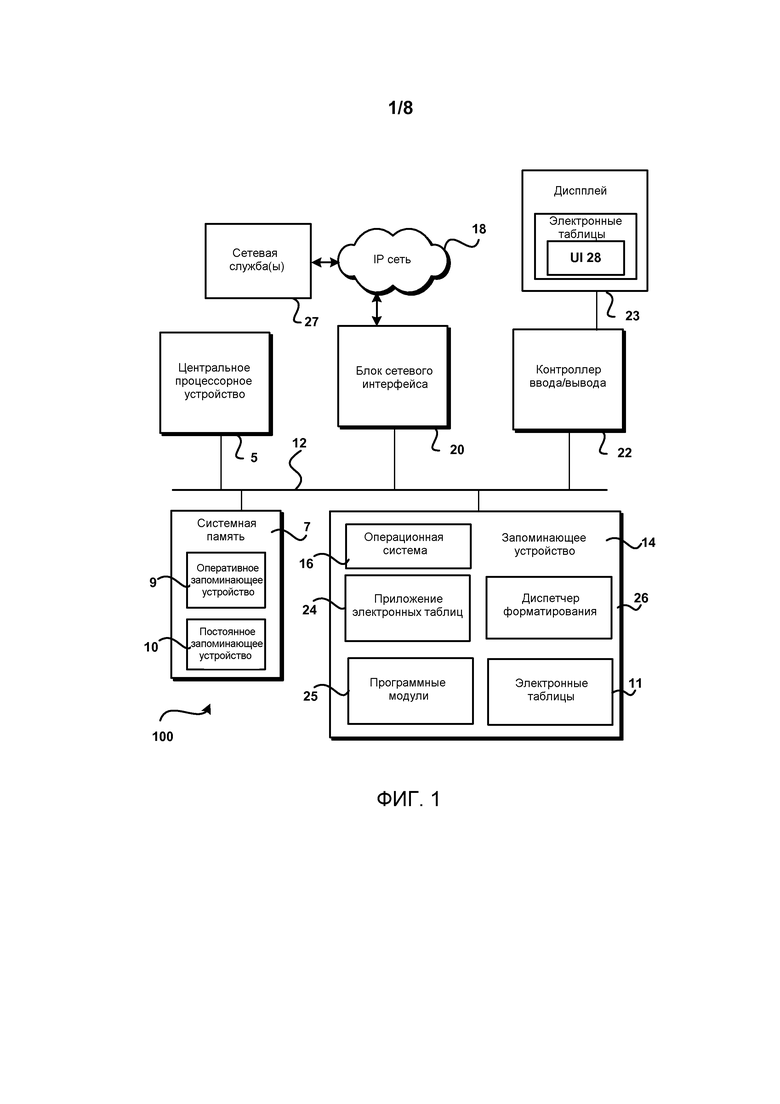
Далее, со ссылкой на Фиг.1, будет описано иллюстративное компьютерное окружение для компьютера 100, используемого в различных вариантах осуществления. Компьютерное окружение, показанное на Фиг.1, включает в себя вычислительные устройства, каждое из которых может быть сконфигурировано в качестве сервера, настольного или мобильного компьютера, либо некоторого другого типа вычислительного устройства, и включает в себя центральное процессорное устройство 5 («ЦПУ», «CPU»), системную память 7, включающую в себя оперативное запоминающее устройство 9 («ОЗУ», «RAM») и постоянное запоминающее устройство 10 («ПЗУ», «ROM»), и системную шину 12, которая присоединяет память к центральному процессорному устройству 5 («ЦПУ»).
Базовая система ввода-вывода, содержащая базовые процедуры, которые помогают пересылать информацию между элементами в пределах компьютера, к примеру, во время запуска, хранится в ПЗУ 10. Компьютер 100 дополнительно включает в себя запоминающее устройство 14 большой емкости для хранения операционной системы 16, электронной таблицы 11, приложения 24 электронных таблиц, других программных модулей 25 и диспетчера 26 форматирования, который будет подробнее описан ниже.
Запоминающее устройство 14 большой емкости присоединено к ЦПУ 5 через контроллер запоминающего устройства (не показан), присоединенный к шине 12. Запоминающее устройство 14 большой емкости и связанные с ним машинно-читаемые носители обеспечивают энергонезависимое хранилище для компьютера 100. Хотя описание машинно-читаемых носителей, содержащееся в материалах настоящей заявки, ссылается на запоминающее устройство большой емкости, такое как жесткий диск или привод CD-ROM (ПЗУ на компакт-диске), машинно-читаемые носителем могут быть любыми доступными носителями, которые могут подвергаться доступу компьютером 100.
В качестве примера, а не ограничения, машинно-читаемые носители могут содержать компьютерные носители данных и среды связи. Компьютерные носители данных включают в себя энергозависимые и энергонезависимые, съемные и несъемные носители, реализованные любым способом или технологией для хранения информации, такой как машинно-читаемые команды, структуры данных, программные модули или другие данные. Машинно-читаемые носители включают в себя, но не в качестве ограничения, ОЗУ, ПЗУ, стираемое программируемое запоминающее устройство («EPROM»), электрически стираемое программируемое запоминающее устройство («EEPROM»), флэш-память или другую технологию твердотельной памяти, CD-ROM, цифровой многофункциональный диск («DVD») или другое оптическое запоминающее устройство, магнитные кассеты, магнитную ленту, накопитель на магнитных дисках или другие магнитные запоминающие устройства, либо любой другой носитель, который может использоваться для хранения требуемой информации и который может подвергаться доступу компьютером 100.
Компьютер 100 работает в сетевом окружении, используя логические соединения с удаленными компьютерами посредством сети 18, такой как Интернет. Компьютер 100 может подсоединяться к сети 18 посредством блока сетевого интерфейса 20, подключенного к шине 12. Сетевое соединение может быть беспроводным и/или проводным. Блок сетевого интерфейса 20 может также использоваться для подсоединения к другим типам сетей и удаленным вычислительным системам, таким как сетевая служба(ы) 27. Компьютер 100 может также включать в себя контроллер 22 ввода/вывода для получения и обработки входных данных от ряда других устройств, в том числе, клавиатуру, мышь или электронное перо (не показано на Фиг.1). Аналогично, контроллер 22 ввода/вывода может обеспечивать ввод/вывод в IP-телефон, экран 23 дисплея, принтер или другой тип устройства вывода.
Как упоминалось вкратце выше, ряд программных модулей и файлов данных может сохраняться в запоминающем устройстве 14 и ОЗУ 9 компьютера 100, включая операционную систему 16, пригодную для управления работой компьютера, такую как операционная система WINDOWS 7® от корпорации Майкрософт, Редмонд, Вашингтон. Запоминающее устройство 14 и ОЗУ 9 могут также хранить один или более программных модулей. В частности, запоминающее устройство 14 и ОЗУ 9 могут хранить одну или более прикладных программ, включая приложение 24 электронной таблицы и программные модули 25. Согласно варианту осуществления, приложением 24 электронной таблицы является приложение электронной таблицы EXCEL от корпорации Майкрософт. Также могут использоваться другие приложения электронной таблицы. Пользовательский интерфейс, такой как UI 28, позволяет пользователю взаимодействовать с приложением, таким как приложение 24 электронной таблицы.
Диспетчер 26 форматирования может располагаться внешне от приложения 24 электронной таблицы, как показано, или может являться частью приложения 24 электронной таблицы. Дополнительно все/некоторые из выполняемых функций, обеспечиваемых диспетчером 26 форматирования, могут располагаться внутренне/внешне по отношению к приложению 24 электронной таблицы.
Диспетчер 26 форматирования сконфигурирован формировать одно или более правил форматирования данных для преобразования данных из одной формы в другую форму, основываясь на исходных данных и примерных выходных данных, например пользовательских правках. Согласно варианту осуществления, диспетчер 26 форматирования применяет эвристику машинного обучения к исходным данным, а также примерным выходным данным (пользовательским правкам), чтобы определять правило(а) форматирования данных, которое может применяться к данным. Например, пользователь может осуществлять правки, которые добавляют/удаляют символы из данных, сцепляют данные, извлекают данные, переименовывают данные и тому подобное. В ответ на правки, формируется правило(а) форматирования данных, которое применяется к другим данным в пределах документа (например, электронной таблицы). Форматирование, которое применяется к данным, может допускать ревизию со стороны пользователя, так что пользователь может принимать/отклонять изменения. Форматирование, применяемое к данным, может также содержать форматирование метаданных. Согласно варианту осуществления, уровень достоверности, определяемый из правила форматирования, связан с форматированием, которое применяется к данным, так что пользователь может более легко распознавать, когда данные переформатированы правильно. Например, высокий уровень достоверности показывает что, скорее всего, данные отформатированы правильно, при этом сниженный уровень достоверности может показывать, что пользователь может желать пересмотреть результаты. Эвристика машинного обучения может запускаться автоматически в ответ на событие (например, после выполнения заранее определенного количества правок в отношении одного и того же типа данных) или запускаться вручную (например, путем выбора пункта меню пользовательского интерфейса). На основании дополнительных правок/ревизий, правило форматирования данных может обновляться. Правила форматирования данных могут также сохраняться для более позднего использования и/или модификации. Например, пользователь может модифицировать правило (например, шрифт), вследствие чего применение правила форматирования данных следует модифицированному правилу.
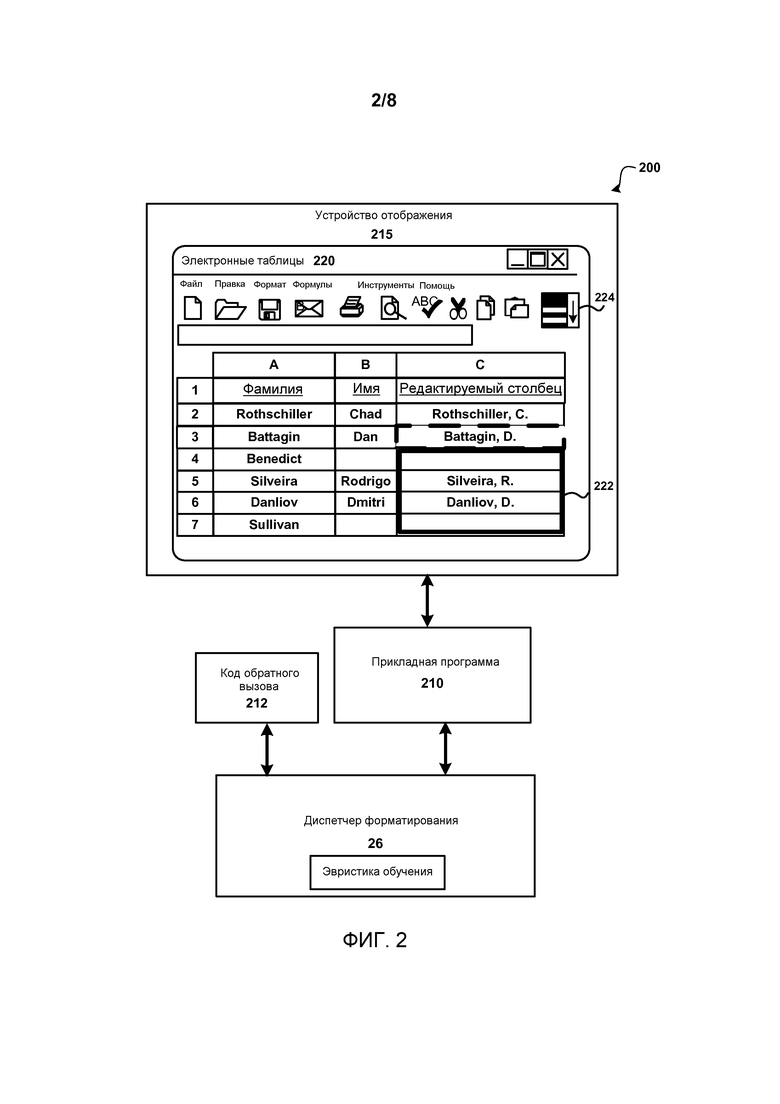
Фиг.2 показывает систему для форматирования данных на основе на правок, произведенных в отношении документа. Как изображено, система 200 включает в себя диспетчер 26 форматирования, прикладную программу 210, ответный код 212 и устройство 215 отображения. Используемым вычислительным устройством(и) может быть любой тип вычислительного устройства, который сконфигурирован выполнять операции, относящиеся к автоматическому форматированию данных, на основании пользовательских правок к документу. Например, некоторыми из вычислительных устройств могут быть: мобильные вычислительные устройства (например, сотовые телефоны, планшеты, смартфоны, лаптопы и тому подобное); настольные вычислительные устройства и серверы.
Для того чтобы облегчить коммуникацию с диспетчером 26 форматирования, могут быть реализованы одна или более процедур обратного вызова (callback), изображенный на Фиг.2 как код 212 обратного вызова. Согласно одному варианту осуществления, прикладная программа 210 является приложением электронной таблицы.
Устройство 215 отображения сконфигурировано отображать документ, такой как документ 220 электронной таблицы, и элементы пользовательского интерфейса, используемые для взаимодействия с документом. Как изображено, электронная таблица 220 показывает три столбца, в том числе, столбец фамилии (А), столбец имени (В) и отредактированный столбец (С). В текущем примере пользователь произвел правки в отношении отредактированного столбца. В ячейке С2 пользователь ввел для той строки, строки 2, фамилию (которая также содержится в ячейке А2), через запятую, после которой идут первые инициалы (которые также содержатся в ячейке В2). В ячейке С3 пользователь ввел для той строки, строки 3, фамилию (которая также содержится в ячейке А3), через запятую, после которой идут первые инициалы (которые также содержатся в ячейке В3).
Как правило, диспетчер 26 форматирования определяет, когда пользователь правит/модифицирует данные, которые соответствуют шаблону, который можно заполнить и применить к дополнительным данным в электронной таблице, и автоматически заполняет столбец результатами, которые получаются после применения правила форматирования данных. В ответ на правки, диспетчер 26 форматирования использует информацию, которая связана с правками, чтобы получить правило форматирования данных, которое применяется к другим данным в пределах электронной таблицы. Согласно варианту осуществления, информация включает в себя примеры выходных данных, которые являются результатом правок к тексту, который отображается в пределах правленых ячеек (например, ячеек С2 и С3), и примеры входных данных, которые связаны с правками. В таком случае, столбец А и столбец В включают в себя примеры входных данных, которые связаны с редактируемыми столбцами (например, ячейки А2 и В2 являются примером входных данных для примера выходных данных С2, а ячейки А3 и В3 являются примером входных данных для примера выходных данных С3). Эти примеры входных/выходных данных определяются диспетчером 26 форматирования и подаются в процесс, который формирует правило форматирования данных для других аналогично форматированных ячеек (например, ячеек С4:С7 (222)). Эвристика машинного обучения получает набор примеров входных/выходных данных, определяет шаблон, формирует правило форматирования данных, а затем диспетчер 26 форматирования применяет правила форматирования данных к диапазону выходных данных, чтобы формировать по-новому отформатированные значения. Согласно варианту осуществления, примерная эвристика машинного обучения описана в «Automatic String Processing in Spreadsheets Using Input-Output Examples» («Автоматическая обработка строк в электронных таблицах с использованием примеров входных-выходных данных»), Sumit Gulwani (Сумит Гулвани), Остин, Техас. Могут использоваться другие эвристики машинного обучения. Как правило, может использоваться любая эвристика, которая берет исходные данные, а также правки данных в качестве входных данных и создает правило форматирования данных, которое может применяться к другим данным, чтобы в результате были получены данные, отформатированные аналогичным образом. Согласно варианту осуществления, функционал эвристики машинного обучения включен в диспетчер 26 форматирования. Функционал может также располагаться в других местах.
Диспетчер 26 форматирования автоматически применяет правило форматирования данных к другим ячейкам в пределах электронной таблицы, которые отформатированы аналогичным образом. Согласно варианту осуществления, правило форматирования данных автоматически применяется к выходному диапазону ячеек, которые заполняют столбец редактируемого столбца. В текущем примере, выходной диапазон включает в себя ячейки C4:C7. Рамка 222 показывает, что применение правил форматирования данных к ячейкам C4:C7 приводит к значениям, размещенным в пределах ячеек C5 и C6. Согласно варианту осуществления, правило форматирования данных, которое применяется к выходному ряду, является динамичным. Другими словами, когда значение правится в пределах выходного диапазона, правило форматирования данных обновляется, используя дополнительный пример(ы) входных/выходных данных.
Правило форматирования данных может формировать ноль или более значений для каждой из ячеек. Например, значение не возвращается для ячеек С4 и С7, так как нет имени в соответствующей ячейке в столбце В. Более чем один потенциальный результат может формироваться посредством правила форматирования данных, когда правило форматирования данных не уверено в результате. Согласно варианту осуществления, перед тем, как автоматически переформатировать данные, правило форматирования данных применяется к предопределенному количеству ячеек, чтобы определить, формирует ли применение правила форматирования результаты, которые соответствуют предопределенному пороговому уровню достоверности или превышают его. Например, если применение правила форматирования к предопределенному количеству ячеек приводит к низкому уровню достоверности, правило форматирования данных не применяется автоматически. Согласно варианту осуществления, правило форматирования данных применяется к ячейкам в выходном диапазоне и определяется процентная доля ячеек, которые имеют один ответ. Согласно варианту осуществления, процентная доля ячеек, которые имеют ноль ответов, исключается из вычисления. Когда процентная доля выше предопределенного порогового значения (например, 70%), ячейки в выходном диапазоне автоматически заполняются, используя результаты, обеспеченные посредством правила форматирования данных. Когда пороговое значение не достигнуто, результаты могут не применяться к ячейке и больше правок получается до того, как будет создано новое правило форматирования данных, или результаты могут применяться к ячейке и к ячейке может применяться индикатор (например, подсвечивание, форматирование), который показывает уровень достоверности ниже порогового значения. Уникальный результат, формируемый применением правила форматирования данных к ячейке, является хорошим показателем того, что правило форматирования данных формирует точные результаты. Другие пороговые значения и/или правила могут использоваться, чтобы определить, формирует ли правило форматирования данных точные результаты.
Много типов правил форматирования данных могут создаваться, основываясь на пользовательских правках, например, сцеплении двух столбцов, извлечении информации из столбца (например, извлечении доменного имени верхнего уровня из адреса, извлечении адреса электронной почты) и тому подобном. Обычно, правило форматирования данных может вычисляться, основываясь на любой деятельности, связанной с редактированием. В некоторых случаях больше, чем два примера входных/выходных данных могут использоваться, чтобы сформировать точные результаты. Например, эвристика машинного обучения может быть только на 50% точной с двумя примерами и быть на 95% точной, при использовании трех примеров.
Правило форматирования данных может также быть получено на основе выбора в пределах пользовательского интерфейса (например, значка (иконки) 224), или какой-нибудь другой пункт меню может быть выбран. Примерные правки могут вручную выбираться пользователем (например, пользователь выбирает примерные ячейки) и/или примеры могут автоматически определяться диспетчером 26 форматирования. Например, диспетчер 26 форматирования может просматривать данные и определять примеры входных/выходных данных из данных (например, столбец с наименьшим количеством значений может рассматриваться как выходной столбец, а остальные столбцы могут рассматриваться как входные столбцы).
Фиг.3-6 показывают примеры ячеек, форматированных на основе на пользовательских правок.
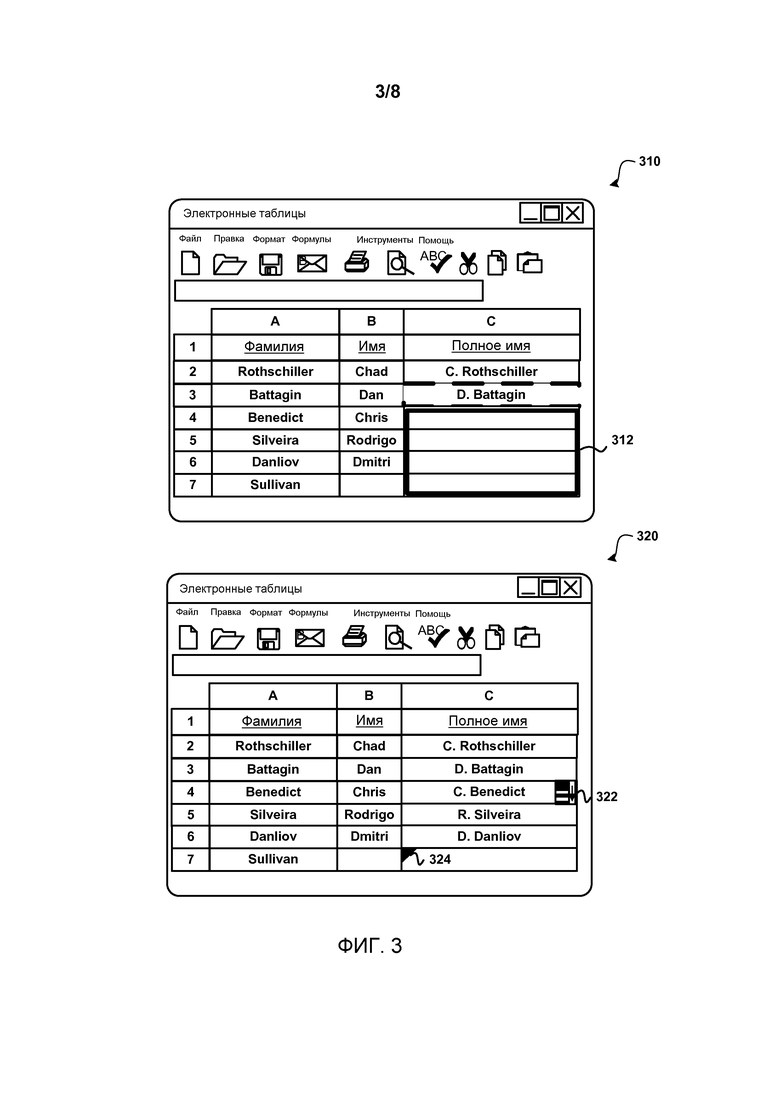
Фиг.3 иллюстрирует определение правила форматирования данных на основании пользовательских правок в отношении столбца и применение правила форматирования данных к другим ячейкам в пределах столбца. Как изображено, пользователь осуществляет правки в отношении столбца «Полное имя» (С) электронной таблицы 310. В текущем примере пользователь ввел первые инициалы, за которыми следует точка и пробел, за которыми следует фамилия. Фамилия содержится в столбце А электронной таблицы 310, и первые инициалы содержатся в столбце В электронной таблицы. В ответ на осуществляемые пользователем правки в отношении ячеек С2 и С3, эвристикой машинного обучения формируется правило форматирования данных, которое может применяться к другим ячейкам в пределах документа.
В текущем примере примеры входных/выходных включают в себя текст в столбце С и текст в столбцах А и В для каждой строки, которая редактировалась. Входные данные могут определяться посредством сканирования документа, чтобы обнаружить данные, которые могут использоваться при применении правила форматирования данных, чтобы создать требуемый результат. В таком случае, правило форматирования данных создает правило, которое получает первые инициалы из столбца В и фамилию из столбца А, а также вставляет знак точки и знак пробела после первых инициалов. Выходной диапазон 312 обозначает ячейки, к которым применяется правило форматирования данных.
Обращаясь к электронной таблице 320, может быть видно, что автоматическое применение правила форматирования данных привело к заполнению ячейки С3:С6 именем, которое включает в себя первые инициалы, затем точку и пробел, за которыми следует фамилия. Ячейка С7 не была заполнена, так как применение правила форматирования данных не привело к точному результату, поскольку столбец с фамилией пустой.
Электронная таблица 320 также показывает элемент 322 пользовательского интерфейса, соответствующий ревизии, который может использоваться для принятия/отклонения изменения, произведенного применением правила форматирования данных. Элемент 324 пользовательского интерфейса, соответствующий коррекции ошибок, также размещается возле места, где правило форматирования данных не применялось (в этом случае отсутствуют данные из первого столбца) или где применение правила форматирования данных может не быть определено как точное (см. Фиг.6 и связанное с ней описание для более детального обсуждения относительно элемента пользовательского интерфейса, соответствующего ревизии, и элемента пользовательского интерфейса, соответствующего коррекции ошибок).
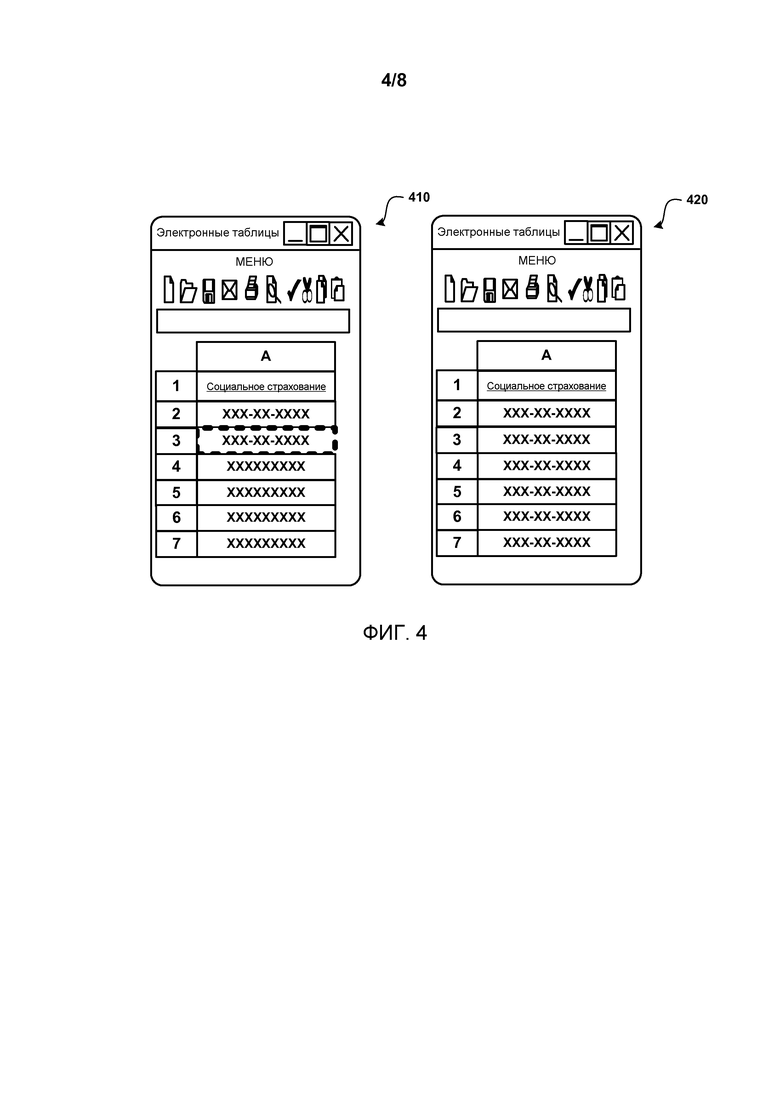
Фиг.4 показывает пример осуществляемых пользователем правок к пунктам в столбце номера социального страхования. Пользователь изменил форматирование номера социального страхования из формата “XXXXXXXXX” в “XXX-XX-XXXX” (где Х является любым числом, 0-9). В других примерах символы могут быть нечисловыми символами. Согласно варианту осуществления, после того, как пользователь осуществил две или более правок, диспетчером форматирования используются входные/выходные примеры для формирования правила форматирования данных, которое применяется к другим данным в столбце. В текущем примере примерами входных данных является исходный текст, который содержался в ячейках А2 и А3, а примерами выходных данных является редактируемый текст, показанный в ячейках А2 и А3. Больше или меньше правок может накопиться до момента предоставления примеров входных/выходных данных. Например, в некоторых случаях (таких как этот) одного примера входных/выходных данных может быть достаточно, чтобы сформировать точное правило форматирования данных. В более сложных сценариях может использоваться редактирования большего количества примеров входных/выходных данных. Далее, любые дополнительные правки, производимые пользователем, могут использоваться диспетчером форматирования для обновления правила форматирования данных. Применение правила форматирования данных к ячейкам А4:А7 приводит к электронной таблице, которая проиллюстрирована экранным изображением 420. Согласно варианту осуществления, ячейки, которые уже содержат данные, не изменяются автоматически. Взамен пользователь может получить запрос утвердительно принять предложенные изменения до того, как они будут выполнены в отношении ячеек, содержащих данные. Ячейки могут также изменяться автоматически, а пользователю может быть предоставлена возможность отменять изменения.
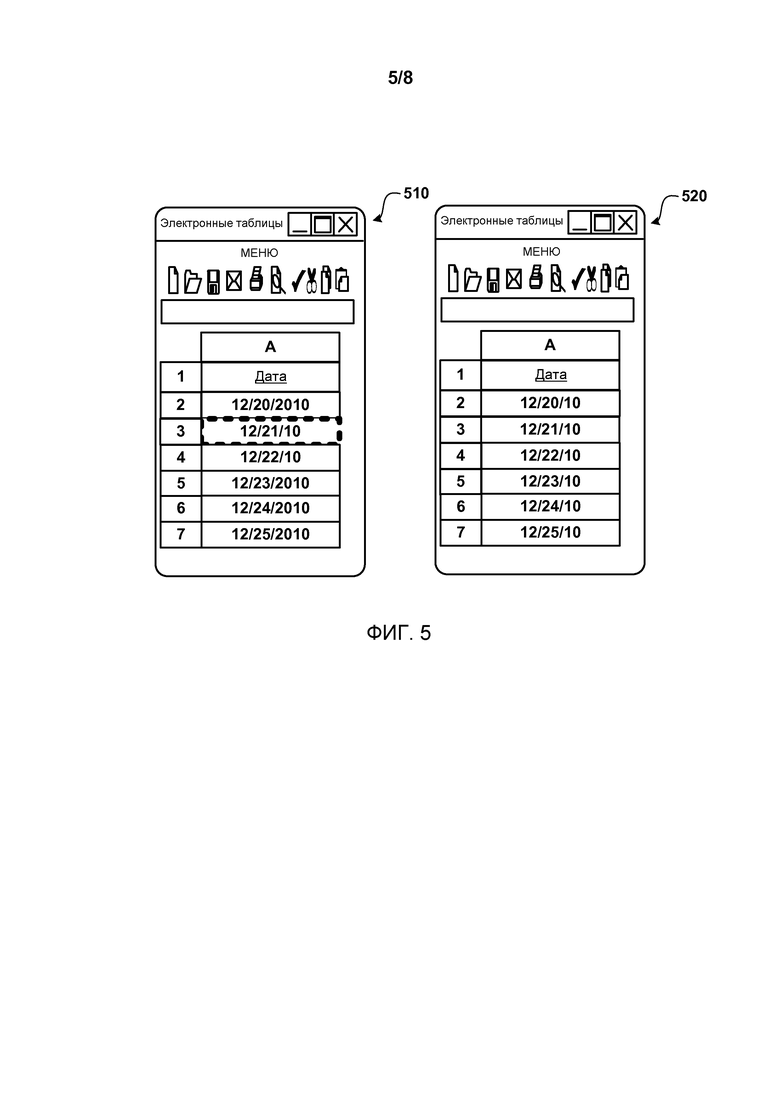
Фиг.5 показывает пример выполнения пользователем правок для изменения форматирования дат. Пользователь изменил форматирование двух дат в электронной таблице 510 с формата “MM/DD/CCYY” на “MM/DD/YY”.
В текущем примере пользователь изменил форматирование дат в ячейках А4 и А3. Входные примеры включают в себя исходный текст в ячейках А3 и А4, а выходные примеры включают в себя отредактированный текст, как показано в ячейках А3 и А4 на экранном изображении 520. Применение сформированного правила форматирования данных приводит к экранному изображению 520. Как показано, правки могут производиться где угодно в пределах аналогично форматированных данных, а применение правила форматирования данных может не только заполнять, как показано на Фиг.2-4, но также применяться к другим ячейкам (например, ячейка А2).
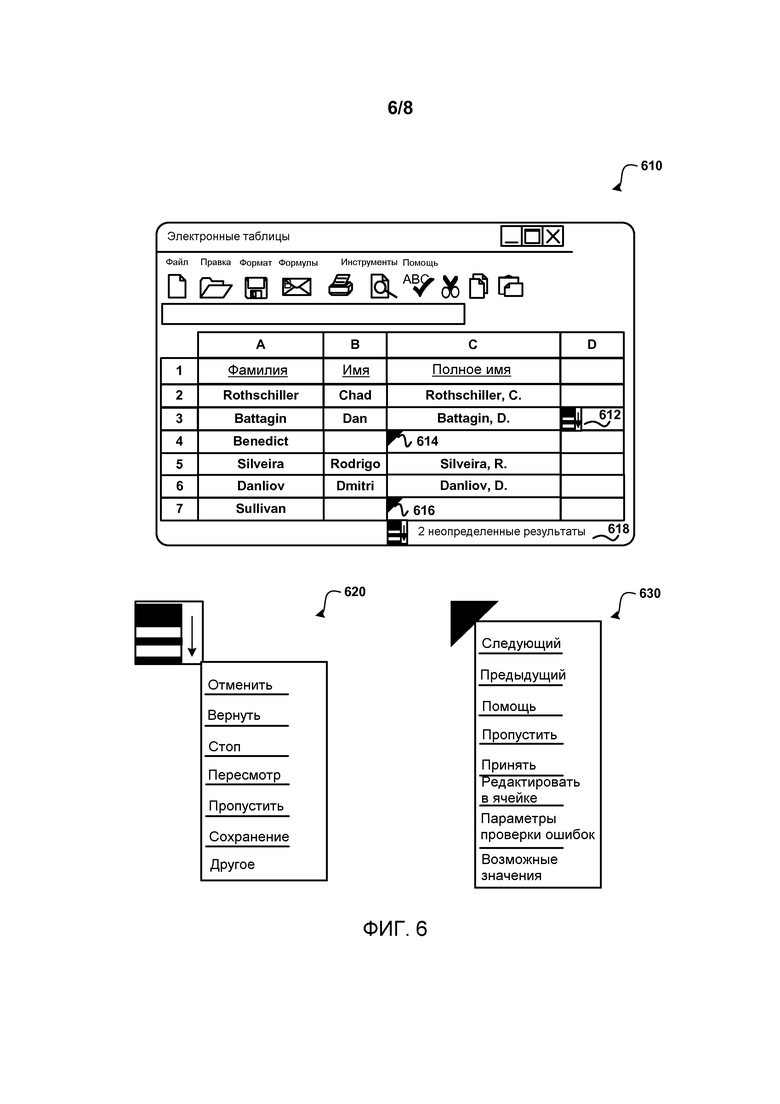
Фиг.6 показывает элементы пользовательского интерфейса, которые можно использовать, чтобы взаимодействовать с форматированием элементов. Как показано, электронная таблица 610 показывает элементы 612 и 618 пользовательского интерфейса, соответствующие ревизии, и элементы 614 и 616 пользовательского интерфейса, соответствующие коррекции ошибок.
Ячейка может быть отмечена элементом пользовательского интерфейса, соответствующим коррекции ошибок, когда ячейка отмечена как имеющая значение, которое несовместимо и/или не определено как точное. Согласно варианту осуществления, ячейка с несовместимыми данными означает, что либо значение ячейки не соответствует тому, что формирует правило форматирования данных, либо значение в пределах ячейки было сформировано правилом форматирования данных, но имеется более одного возможного результата. Как только правило форматирования данных было применено к определенному выходному диапазону, любые результаты, которые являются несовместимыми, помечаются. Согласно варианту осуществления, результат считается несовместимым, когда количество возможных результатов было более или менее одного результата (например, нет результатов или 2 или больше результатов, обеспеченных правилом форматирования данных) или предварительно существующее значение является несовместимым с результатом, обеспечиваемым правилом форматирования данных. Другая эвристика может также использоваться. Например, результат может считаться несовместимым, когда количество результатов превышает заранее определенное количество результатов и/или какое-либо другое условие.
Элемент пользовательского интерфейса, соответствующий коррекции ошибок, может быть выбран. При выборе, элемент пользовательского интерфейса, соответствующий коррекции ошибок, отображает различные выбираемые пункты (630). Согласно варианту осуществления, варианты выбора включают пункт «Следующий», пункт «Предыдущий», пункт «Помощь», пункт «Пропустить», пункт «Принять», пункт «Редактировать в ячейке», пункт «Параметры Проверка ошибок» и пункт «Возможные значения». Больше или меньше пунктов могут быть включены в меню 630. Пункт «Следующий» обеспечивает переход к следующей ячейке, которая отмечена как ошибочная. Пункт «Предыдущий» обеспечивает переход к предыдущей ошибке. Пункт «Помощь» представляет экран помощи. Пункт «Пропустить» пропускает текущую ошибку и убирает элемент пользовательского интерфейса, соответствующий коррекции ошибок, с отображения. Пункт «Принять» убирает состояние ошибки и добавляет ассоциированный пример входных/выходных данных для ячейки, чтобы сформировать новое правило форматирования данных. Пункт «Редактировать в ячейке» обеспечивает перевод пользователя в режим редактирования в ячейке. Когда пользователь редактирует одну или больше таких ошибочных ячеек, то правка интерпретируется как пример входных/выходных данных и вычисляется новое/обновленное правило форматирования данных. Согласно варианту осуществления, обновленное правило форматирования данных применяется к оставшимся ошибочным ячейкам, которые связаны с правилом форматирования данных. Пункт «Параметры Проверка ошибок» предоставляет пользователю различные опции, относящиеся к обнаружению ошибок. Пункт «Возможные значения» при выборе отображает перечень других возможных значений для ячейки при ее переформатировании. Например, может отображаться каждый результат, который формируется посредством правила форматирования данных.
Элемент 612 пользовательского интерфейса, соответствующий ревизии, представляет различные пункты для взаимодействия с ячейками, которые были отформатированы с использованием правила форматирования данных. Согласно варианту осуществления, меню 620 ревизии содержит пункт «Отмена», пункт «Повтор», пункт «Стоп», пункт «Пересмотр», пункт «Пропустить все», пункт «Сохранение» и пункт «Другое». Больше или меньше пунктов может быть включено в меню 620. Операция отмены возвращает документ (например, столбец документа, к которому было применено правило форматирования данных) в состояние, в котором он был непосредственно до применения к ячейкам правила форматирования данных. Пункт «Повтор» восстанавливает данные в ячейках, которые ранее были отменены пользователем. Пункт «Стоп» деактивирует автоматический режим автоматического заполнения при применении правила форматирования данных. Пункт «Пересмотр» назначает активную ячейку в качестве первой ячейки в текущем диапазоне преобразования (например, выходном диапазоне) с пометкой ошибки. Пункт «Пропустить все» убирает пометки ошибок и любое соответствующее форматирование ошибок из ячеек в текущем заполняемом ряду. Пункт «Сохранить» позволяет пользователю сохранить текущее правило форматирования данных. Пункт «Сохранить» сохраняет информацию, связанную с правилом, такую как столбец(ы), который можно ввести, а также любые примеры входных/выходных данных. Пункт «Другое» предоставляет другие опции.
Фиг.7 показывает пользовательский интерфейс для разрешения/запрещения заполнения по образцу. Экранное изображение 700 включает в себя пункт 702, который позволяет пользователю включать/отключать автоматическое заполнение данных по образцу. Другие пункты могут также быть включены в состав пользовательского интерфейса, такие как требуемое количество правок/выборов перед получением правила форматирования данных, следует ли перезаписывать существующие данные с/без подтверждения, и тому подобное.
Далее, со ссылкой на Фиг.8 будет описана иллюстративная последовательность операций форматирования данных по образцу. При чтении описания процедур, представляемых здесь, следует понимать, что логические операции различных вариантов осуществления реализуются (1) как последовательность выполняемых компьютером действий или программных модулей, исполняемых в вычислительной системе, и/или (2) как взаимосвязанные схемы машинной логики или схемные модули внутри вычислительной системы. Реализация является вопросом выбора, зависящим от эксплуатационных требований, налагаемых на вычислительную систему, реализующую изобретение. Соответственно, логические операции, иллюстрирующие и составляющие варианты осуществления, описанные здесь, упоминаются по-разному, как операции, структурные устройства, действия или модули. Эти операции, структурные устройства, действия и модули могут быть реализованы в виде программного обеспечения, встроенного программного обеспечения (Firmware), специализированной цифровой логики, и любых их комбинаций.
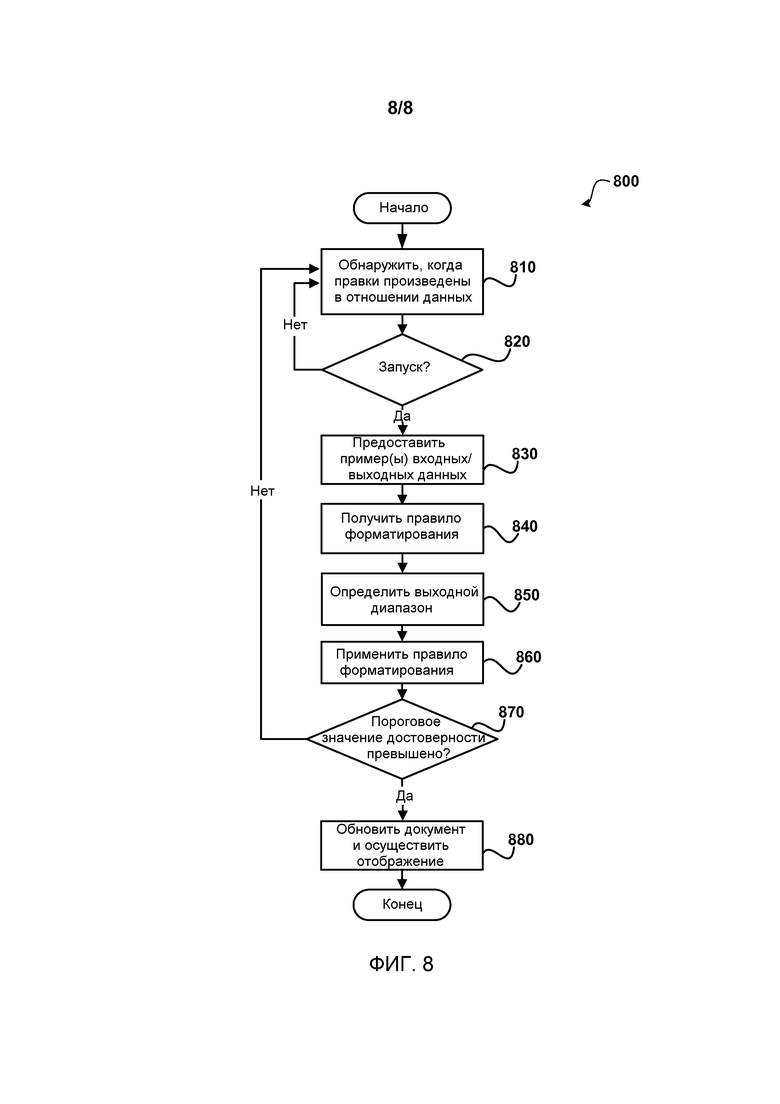
После стартового блока процесс 800 переходит к операции 810, где обнаруживаются правки, произведенные с данными внутри документа. Правками могут быть любые правки в документе. Согласно варианту осуществления, правки есть в отношении данных, которые содержатся в пределах ячеек документа (то есть электронной таблицы, таблицы, списка), которые относятся к одному и тому же типу данных и аналогично отформатированы. Обычно, каждая ячейка в пределах колонки может содержать одинаковый тип данных (то есть даты, адреса, имена, номера и подобное). Правки, которые применяются к каждому из элементов, соответствуют шаблону, который может применяться к другим ячейкам, имеющим тот же самый тип элемента.
Перейдя к операции 820 принятия решения, производится определение того, превысило ли количество правок заранее определенное количество правок и инициирован ли процесс получения правила форматирования данных, которое должно применяться к другим аналогично форматированным ячейкам. Согласно варианту осуществления, количество правок для инициирования получения правила форматирования данных составляет два. Точка инициирования может быть установлена в другие значения вручную/автоматически. Например, точка инициирования может основываться на предполагаемой точности применения правила форматирования данных к другим аналогичным элементам данных в пределах документа. В некоторых случаях точка инициирования может быть одна, тогда как в других их может быть три или более.
Когда точка инициирования не была достигнута, процесс возвращается к операции 810, чтобы выявить, когда сделаны последующие правки.
Когда точка инициирования была достигнута, процесс перетекает к операции 830, где примеры входных/выходных данных получаются и подаются в эвристику машинного обучения, чтобы получить правило форматирования данных. Примеры входных/выходных данных обеспечивают примеры данных в состоянии до и состоянии после относительно правок данных. Например, когда есть правки к существующим данным, тогда примерами входных данных являются данные до правки, а примерами выходных данных являются данные после правки. Когда есть правки в отношении новой ячейки, примерами выходных данных являются отредактированные данные в ячейке, а примерами входных данных являются данные, связанные с созданием выходных (например, один или более столбцов данных).
Переходя к операции 840, получают правило форматирования данных. Согласно варианту осуществления, правило форматирования данных является функцией, которая получает текстовый ввод (например, из одной или более ячеек) и производит ноль или более результатов. Правило форматирования данных ориентировано на форматирование других аналогичных элементов в пределах документа (например, других ячеек в пределах столбца), чтобы они соответствовали правкам, сделанным пользователем.
При переходе к операции 850 определяется выходной диапазон. Выходной диапазон определяет элементы, к которым правило форматирования данных должно применяться. Например, другими элементами могут быть все или часть ячеек в столбце, в котором элементы редактировались пользователем и являются основанием для правила форматирования данных. В некоторых примерах выходным диапазоном являются ячейки в пределах столбца, которые имеют тот же тип элемента (например, дата, номер, адрес и тому подобное). В других примерах выходным диапазоном являются все ячейки со значениями, которые являются смежными относительно друг друга, и которые являются смежными с редактируемыми ячейками.
Перейдя к операции 860, правило форматирования данных применяется к каждому из элементов в определенном выходном диапазоне. Любые результаты, производимые посредством применения правила форматирования данных, могут временно сохраняться, прежде чем осуществлять какие-либо изменения в документе.
При перемещении к операции 870 принятия решения, производится определение относительно того, привело ли применение правила форматирования данных к точным результатам. Согласно варианту осуществления, точность оценивается количеством результатов, возвращаемых правилом форматирования данных, когда оно применяется к элементу. Когда количество результатов для элемента равно нулю, правило форматирования данных не имеет достаточно данных, чтобы формировать результат. Когда количество результатов больше одного, точность результатов может быть сомнительной. Когда количество результатов есть единица, тогда результат, вероятнее всего, точный. Количество/процентная доля ячеек, оцененных как имеющие точный результат, может использоваться для определения того, когда превышается предельный уровень достоверности (например, >70%, 80%, 90%). Когда уровень достоверности не превышен, процесс перетекает к операции 810, чтобы выявить больше правок. Обычно, чем больше примеров получается, тем точнее результаты. Когда уровень достоверности превышен, процесс перетекает к операции 880.
При операции 880 документ обновляется результатами, созданными посредством применения правила форматирования данных к каждому из элементов. Например, ячейки, имеющие один результат, обновляются этим результатом. Ячейки, имеющие разное количество результатов, могут маркироваться индикатором ошибки, как обсуждалось ранее. Может также отображаться элемент пользовательского интерфейса, соответствующий ревизии, что позволяет пользователю выполнять различные операции, связанные с применением правила форматирования данных.
Затем процесс следует к блоку окончания и возвращается для обработки других действий.
Вышеприведенные изложение, примеры и сведения представляют полное описание производства и использования состава изобретения. Так как многие варианты осуществления могут осуществляться без отступления от существа и объема изобретения, изобретение заключается в прилагаемой формуле изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ВРЕМЕННОЕ ФОРМАТИРОВАНИЕ И ПОСТРОЕНИЕ ДИАГРАММЫ ВЫБРАННЫХ ДАННЫХ | 2011 |
|
RU2607980C2 |
| НАСТРАИВАЕМЫЕ ТАБЛИЧНЫЕ СТИЛИ ДИНАМИЧЕСКИХ ТАБЛИЦ | 2006 |
|
RU2419851C2 |
| ПОЛЬЗОВАТЕЛЬСКИЙ ИНТЕРФЕЙС ДЛЯ РЕДАКТИРОВАНИЯ ЗНАЧЕНИЯ ПО МЕСТУ | 2012 |
|
RU2627113C2 |
| СОВМЕСТНАЯ РАБОТА МНОЖЕСТВЕННЫХ КЛИЕНТОВ ДЛЯ ОСУЩЕСТВЛЕНИЯ ДОСТУПА И ОБНОВЛЕНИЯ СТРУКТУРИРОВАННЫХ ЭЛЕМЕНТОВ ДАННЫХ | 2008 |
|
RU2504001C2 |
| МНОЖЕСТВЕННОЕ УСЛОВНОЕ ФОРМАТИРОВАНИЕ | 2007 |
|
RU2431181C2 |
| УСТРОЙСТВА И СПОСОБЫ ДЛЯ ПРЕДСТАВЛЕНИЯ ИНФОРМАЦИИ ПОЛЬЗОВАТЕЛЮ НА ТАКТИЛЬНОЙ ВЫХОДНОЙ ПОВЕРХНОСТИ МОБИЛЬНОГО УСТРОЙСТВА | 2012 |
|
RU2571552C2 |
| СИСТЕМА И СПОСОБ АВТОМАТИЧЕСКОГО ЗАВЕРШЕНИЯ ФОРМУЛ ЭЛЕКТРОННОЙ ТАБЛИЦЫ | 2005 |
|
RU2406131C2 |
| ИЗВЛЕЧЕНИЕ ЗНАЧЕНИЙ АТРИБУТОВ НА ОСНОВЕ ИДЕНТИФИЦИРОВАННЫХ ЗАПИСЕЙ | 2014 |
|
RU2683507C2 |
| ДЕЙСТВИЯ В ЭЛЕКТРОННОЙ ТАБЛИЦЕ С УЧЕТОМ МЕСТОПОЛОЖЕНИЯ | 2011 |
|
RU2608473C2 |
| БЕСКОДОВОЕ СОВМЕСТНОЕ ИСПОЛЬЗОВАНИЕ ОБЪЕКТОВ ЭЛЕКТРОННЫХ ТАБЛИЦ | 2011 |
|
RU2599540C2 |

Изобретение относится к средствам форматирования данных на основе примеров. Технический результат заключается в обеспечении возможности автоматического форматирования данных электронной таблицы. Определяют, когда правки произведены в отношении множества элементов в пределах документа электронной таблицы, причем каждые из этого множества элементов являются связанными. Автоматически создают правило форматирования данных на основе примеров входных данных, которые относятся к разным столбцам документа электронной таблицы, и примеров выходных данных в одном и том же столбце документа электронной таблицы, причем примеры входных данных и примеры выходных данных ассоциированы с упомянутыми правками. Автоматически применяют правило форматирования данных к другим элементам в пределах документа электронной таблицы, которые относятся к одному и тому же типу данных, при этом правило форматирования данных стремится форматировать эти другие элементы в формат, как определено примерами входных данных и примерами выходных данных, причем упомянутые другие элементы отличаются от упомянутого множества элементов. Отображают упомянутые другие элементы, отражая применение правила форматирования данных. 3 н. и 17 з.п. ф-лы, 8 ил.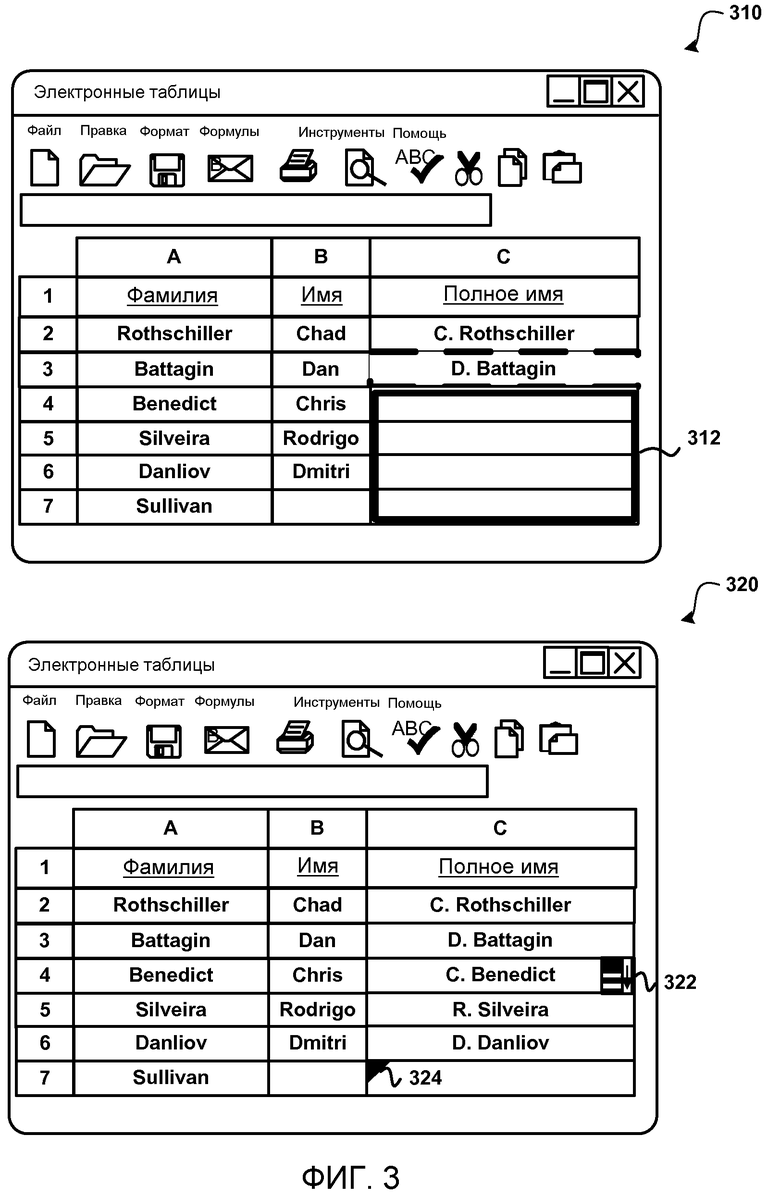
1. Способ форматирования данных на основе примеров, содержащий этапы, на которых:
определяют, когда правки произведены в отношении множества элементов в пределах документа электронной таблицы, причем каждые из этого множества элементов являются связанными;
автоматически создают правило форматирования данных на основе примеров входных данных, которые относятся к разным столбцам документа электронной таблицы, и примеров выходных данных в одном и том же столбце документа электронной таблицы, причем примеры входных данных и примеры выходных данных ассоциированы с упомянутыми правками;
автоматически применяют правило форматирования данных к другим элементам в пределах документа электронной таблицы, которые относятся к одному и тому же типу данных; при этом правило форматирования данных стремится форматировать эти другие элементы в формат, как определено примерами входных данных и примерами выходных данных, причем упомянутые другие элементы отличаются от упомянутого множества элементов; и
отображают упомянутые другие элементы, отражая применение правила форматирования данных.
2. Способ по п. 1, в котором при упомянутом автоматическом создании правила форматирования данных на основе примеров входных данных и примеров выходных данных подают информацию, относящуюся к каждому из примеров, в эвристику машинного обучения, которая создает правило форматирования данных.
3. Способ по п. 1, в котором правки производятся в отношении разных ячеек в пределах одного и того же столбца электронной таблицы.
4. Способ по п. 1, дополнительно содержащий этап, на котором отображают графический пользовательский интерфейс рядом с по меньшей мере одним из упомянутых других элементов, форматированных согласно правилу форматирования данных, который, будучи выбранным, предоставляет опции для выполнения операций, относящихся к форматированному элементу.
5. Способ по п. 4, в котором отображение графического пользовательского интерфейса содержит отображение меню, содержащего опции для отмены форматирования, повторения форматирования, останова форматирования, просмотра потенциально возможных ошибок и игнорирования ошибок.
6. Способ по п. 1, дополнительно содержащий этап, на котором отображают индикатор с форматированным элементом, когда уровень достоверности находится ниже заранее определенного порогового значения.
7. Способ по п. 1, в котором при упомянутом применении правила форматирования данных к другим элементам данных применяют правило форматирования данных к другим элементам в пределах по меньшей мере одного из одного и того же столбца и одной и той же строки.
8. Способ по п. 1, в котором при упомянутом определении того, когда правки произведены в отношении элементов одного и того же типа данных, определяют, когда правки произведены в отношении первого столбца, который включает в себя данные, которые также включены во второй столбец и третий столбец.
9. Способ по п. 1, дополнительно содержащий этап, на котором отображают элемент пользовательского интерфейса, который позволяет сохранить правило форматирования данных для последующего использования.
10. Машиночитаемый носитель данных, на котором сохранены машиноисполняемые команды для форматирования данных на основе примеров, содержащие:
определение примеров выходных данных по множеству элементов в пределах одного и того же столбца документа электронной таблицы;
автоматическое создание правила форматирования данных на основе примеров входных данных, которые относятся к разным столбцам документа электронной таблицы, и упомянутых примеров выходных данных в пределах одного и того же столбца документа электронной таблицы;
автоматическое применение правила форматирования данных к другим элементам в пределах упомянутого одного и того же столбца документа электронной таблицы; при этом правило форматирования данных стремится форматировать эти другие элементы в формат, как определено примерами входных данных и примерами выходных данных, причем упомянутые другие элементы отличаются от упомянутого множества элементов; и
отображение упомянутых других элементов, отражая применение правила форматирования данных.
11. Машиночитаемый носитель данных по п. 10, при этом упомянутое автоматическое создание правила форматирования данных на основе примеров входных данных и примеров выходных данных содержит подачу информации, относящейся к каждому из примеров, в эвристику машинного обучения, которая создает правило форматирования данных на основе примеров.
12. Машиночитаемый носитель данных по п. 10, в котором машиноисполняемые команды дополнительно содержат отображение графического пользовательского интерфейса рядом с по меньшей мере одним из упомянутых других элементов, форматированных согласно правилу форматирования данных, который, будучи выбранным, предоставляет опции для просмотра изменений форматирования.
13. Машиночитаемый носитель данных по п. 10, в котором машиноисполняемые команды дополнительно содержат отображение элемента пользовательского интерфейса в упомянутом одном и том же столбце, когда уровень достоверности находится ниже заранее определенного порогового значения.
14. Машиночитаемый носитель данных по п. 10, при этом упомянутое определение примеров выходных данных содержит анализ первого столбца, который включает в себя данные, которые также включены во второй столбец и третий столбец.
15. Машиночитаемый носитель данных по п. 10, в котором машиноисполняемые команды дополнительно содержат отображение элемента пользовательского интерфейса, который позволяет сохранить правило форматирования данных для последующего использования.
16. Система для форматирования данных на основе примеров, содержащая:
сетевое соединение, которое сконфигурировано для соединения с сетью;
процессор, память и машиночитаемый носитель данных;
операционную среду, хранимую на машиночитаемом носителе данных и исполняющуюся на процессоре;
устройство отображения;
приложение электронной таблицы;
электронную таблицу; при этом электронная таблица содержит элементы, скомпонованные в строках и столбцах; и
диспетчер форматирования, работающий вместе с приложением электронной таблицы, который выполнен с возможностью осуществлять действия, содержащие:
определение того, когда правки произведены в отношении множества элементов в пределах одного и того же столбца электронной таблицы;
автоматическое создание правила форматирования данных, при этом правило форматирования данных основывается на примерах входных данных, которые относятся к разным столбцам электронной таблицы, и примерах выходных данных в пределах одного и того же столбца электронной таблицы, причем примеры входных данных и примеры выходных данных ассоциированы с упомянутыми правками;
автоматическое применение правила форматирования данных к другим элементам в пределах упомянутого одного и того же столбца электронной таблицы; при этом правило форматирования данных стремится форматировать эти другие элементы в формат, как определено примерами входных данных и примерами выходных данных, причем упомянутые другие элементы отличаются от упомянутого множества элементов; и
отображение упомянутых элементов на устройстве отображения, отражая применение правила форматирования данных.
17. Система по п. 16, в которой упомянутые действия дополнительно содержат отображение графического пользовательского интерфейса рядом с по меньшей мере одним из элементов, форматированных согласно правилу форматирования данных, который, будучи выбранным, предоставляет опции для просмотра изменений форматирования.
18. Система по п. 16, в которой упомянутые действия дополнительно содержат отображение элемента пользовательского интерфейса в упомянутом одном и том же столбце, когда уровень достоверности находится ниже заранее определенного порогового значения.
19. Система по п. 16, в которой упомянутое определение того, когда правки произведены в отношении множества элементов одного и того же типа данных, содержит определение того, когда правки произведены в отношении первого столбца, который включает в себя данные, которые также включены во второй столбец и третий столбец.
20. Система по п. 16, в которой упомянутые действия дополнительно содержат отображение элемента пользовательского интерфейса, который позволяет сохранить правило форматирования данных для последующего использования.
| US 7222294 B2, 22.05.2007;US 6697999 B1, 24.02.2004 | |||
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| ДИНАМИЧЕСКИЕ ПОРОГИ ДЛЯ УСЛОВНЫХ ФОРМАТОВ | 2007 |
|
RU2439683C2 |

