Данная заявка испрашивает приоритет по предварительной заявке на патент США № 61/588096, поданной 18 января 2012, все содержание которой таким образом включено в документ посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Данное раскрытие относится к кодированию видео (то есть кодированию и/или декодированию видеоданных).
УРОВЕНЬ ТЕХНИКИ
Возможности цифрового видео могут включаться в широкий спектр устройств, включая цифровые телевизоры, цифровые системы прямого вещания, системы беспроводной связи, персональные цифровые ассистенты (PDA), ноутбуки или настольные компьютеры, планшетные компьютеры, устройства чтения электронных книг, цифровые (фото)камеры, устройства цифровой записи, цифровые мультимедийные проигрыватели, устройства видеоигр, игровые приставки, сотовые или спутниковые радиотелефоны, так называемые «интеллектуальные телефоны», видеоустройства видеоконференц-связи, устройства потокового видео и подобное. Устройства цифрового видео реализуют способы сжатия видеоинформации, такие как описанные в стандартах, определенных стандартами MPEG-2, MPEG-4 Экспертной группы по вопросам движущегося изображения, стандартами Международного союза электросвязи - сектора телекоммуникаций (ITU-T) H.263, ITU-T H.264/MPEG-4, Часть 10, Усовершенствованное кодирование видеоизображения (AVC), разрабатываемым в настоящее время стандартом Высокоэффективного кодирования видеоизображений (HEVC) и расширениями таких стандартов. Видео устройства могут передавать, принимать, кодировать, декодировать и/или хранить информацию цифрового видео более эффективно путем реализации таких способов сжатия видео.
Способы сжатия видео выполняют пространственное (внутрикадровое) предсказание и/или временное (межкадровое) предсказание, чтобы уменьшать или удалять избыточность, присущую видеопоследовательностям. Для основанного на блоках кодирования видеоизображения «слайс» (slice) видеоизображения (то есть кадр изображения или часть кадра изображения) может быть разделен на блоки видео, которые могут также именоваться древовидными блоками, единицами кодирования (CU) и/или узлами кодирования. Блоки видео во внутрикадрово-кодируемом (I) слайсе изображения кодируются с использованием пространственного предсказания по отношению к опорным выборкам в соседних блоках в том же изображении. Блоки видео в межкадрово-кодируемом (P или B) слайсе изображения могут использовать пространственное предсказание по отношению к опорным выборкам в соседних блоках в том же изображении или временное предсказание по отношению к опорным выборкам в других опорных изображениях. Изображения могут именоваться кадрами, и опорные изображения могут именоваться опорными кадрами.
Пространственное или временное предсказание дает в результате предсказанный блок для блока, подлежащего кодированию. Остаточные данные представляют пиксельные разности между исходным блоком, подлежащим кодированию, и предсказанным блоком. Блок с межкадровым кодированием кодируется согласно вектору движения, который указывает на блок опорных выборок, образующих предсказанный блок, и остаточным данным, указывающим разность между кодированным блоком и предсказанным блоком. Блок с внутренним кодированием кодируется согласно режиму внутрикадрового кодирования и остаточным данным. Для дополнительного сжатия остаточные данные могут быть преобразованы из пиксельной области в область преобразования, давая в результате остаточные коэффициенты, которые затем могут квантоваться. Квантованные коэффициенты, первоначально организованные в виде двумерного массива, можно сканировать, чтобы создать одномерный вектор коэффициентов, и может применяться энтропийное кодирование, чтобы добиться еще большего сжатия.
КРАТКОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
В общем, данное раскрытие описывает способы для кодирования видео, в которых комбинации мозаичных фрагментов (tiles) и параллельной волновой обработки (WPP) внутри одного изображения не разрешаются. Более конкретно, видеокодер формирует битовый поток, который включает в себя синтаксический элемент, который указывает, кодировано ли изображение согласно либо первому режиму кодирования, либо второму режиму кодирования. В первом режиме кодирования изображение кодируется полностью с использованием WPP. Во втором режиме кодирования каждый мозаичный фрагмент изображения кодируется без использования WPP. Видеодекодер анализирует синтаксический элемент из битового потока и определяет, имеет ли синтаксический элемент конкретное значение. В ответ на определение, что синтаксический элемент имеет конкретное значение, видеодекодер декодирует изображения полностью с использованием WPP. В ответ на определение, что синтаксический элемент не имеет конкретного значения, видеодекодер декодирует каждый мозаичный фрагмент изображения без использования WPP.
В одном аспекте это раскрытие описывает способ декодирования видеоданных. Способ содержит анализ синтаксического элемента из битового потока, который включает в себя кодированное представление изображения в виде видеоданных. Кроме того, способ содержит в ответ на определение, что синтаксический элемент имеет конкретное значение, декодирование изображения полностью с использованием WPP. Способ также содержит в ответ на определение, что синтаксический элемент не имеет конкретного значения, декодирование каждого мозаичного фрагмента изображения без использования WPP, причем изображение имеет один или несколько мозаичных фрагментов. В другом аспекте это раскрытие описывает способ кодирования видеоданных. Способ содержит формирование битового потока, который включает в себя синтаксический элемент, указывающий, кодируется ли изображение согласно первому режиму кодирования или согласно второму режиму кодирования. В первом режиме кодирования изображение кодируется полностью с использованием WPP. Во втором режиме кодирования каждый мозаичный фрагмент изображения кодируется без использования WPP, причем изображение имеет один или несколько мозаичных фрагментов.
В другом аспекте это раскрытие описывает устройство декодирования видео, которое содержит один или несколько процессоров, сконфигурированных для анализа синтаксического элемента из битового потока, включающего в себя кодированное представление изображения в видеоданных. Один или несколько процессоров конфигурируются с возможностью в ответ на определение, что синтаксический элемент имеет конкретное значение, декодировать изображение полностью с использованием WPP. Кроме того, один или несколько процессоров конфигурируются с возможностью в ответ на определение, что синтаксический элемент не имеет конкретного значения, декодировать каждый мозаичный фрагмент изображения без использования WPP, причем изображение имеет один или несколько мозаичных фрагментов.
В другом аспекте это раскрытие описывает устройство кодирования видео, содержащее один или несколько процессоров, сконфигурированных для формирования битового потока, включающего в себя синтаксический элемент, указывающий, кодируется ли изображение согласно первому режиму кодирования или согласно второму режиму кодирования. В первом режиме кодирования изображение кодируется полностью с использованием WPP. Во втором режиме кодирования каждый мозаичный фрагмент изображения кодируется без использования WPP, причем изображение имеет один или несколько мозаичных фрагментов.
В другом аспекте это раскрытие описывает устройство декодирования видео, которое содержит средство для анализа синтаксического элемента из битового потока, включающего в себя кодированное представление изображения в видеоданных. Устройство декодирования видео также содержит средство для декодирования в ответ на определение, что синтаксический элемент имеет конкретное значение, изображения полностью с использованием WPP. Кроме того, устройство декодирования видео содержит средство для декодирования в ответ на определение, что синтаксический элемент не имеет конкретного значения, каждого мозаичного фрагмента изображения без использования WPP, причем изображение имеет один или несколько мозаичных фрагментов.
В другом аспекте это раскрытие описывает устройство кодирования видео, которое содержит средство для формирования битового потока, включающего в себя синтаксический элемент, указывающий, кодируется ли изображение согласно первому режиму кодирования или согласно второму режиму кодирования. В первом режиме кодирования изображение кодируется полностью с использованием WPP. Во втором режиме кодирования каждый мозаичный фрагмент изображения кодируется без использования WPP, причем изображение имеет один или несколько мозаичных фрагментов.
В другом аспекте это раскрытие описывает машиночитаемый носитель данных, который хранит инструкции, которые при исполнении одним или несколькими процессорами устройства декодирования видео конфигурируют устройство декодирования видео для анализа синтаксического элемента из битового потока, включающего в себя кодированное представление изображения в видеоданных. Инструкции также побуждают устройство декодирования видео декодировать в ответ на определение, что синтаксический элемент имеет конкретное значение, изображение полностью с использованием WPP. Кроме того, инструкции побуждают устройство декодирования видео декодировать в ответ на определение, что синтаксический элемент не имеет конкретного значения, каждый мозаичный фрагмент изображения без использования WPP, причем изображение имеет один или несколько мозаичных фрагментов.
В другом аспекте машиночитаемый носитель данных, который хранит инструкции, которые при исполнении одним или несколькими процессорами устройство кодирования видео конфигурируют устройство кодирования видео для формирования битового потока, включающего в себя синтаксический элемент, указывающий, кодировано ли изображение согласно первому режиму кодирования или согласно второму режиму кодирования. В первом режиме кодирования изображение кодируется полностью с использованием WPP. Во втором режиме кодирования каждый мозаичный фрагмент изображения кодируется без использования WPP, причем изображение имеет один или несколько мозаичных фрагментов.
Детали одного или нескольких примеров раскрытия изложены на сопроводительных чертежах и в описании ниже. Другие признаки, объекты и преимущества будут очевидными из описания, чертежей и формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1 - блок-схема, иллюстрирующая примерную систему кодирования видео, которая может использовать способы, описанные в этом раскрытии.
Фиг. 2 - блок-схема, иллюстрирующая примерный видеокодер, который может осуществлять способы, описанные в этом раскрытии.
Фиг. 3 - блок-схема, иллюстрирующая примерный видеодекодер, который может осуществлять способы, описанные в этом раскрытии.
Фиг. 4 - структурная схема, иллюстрирующая примерную работу видеокодера по кодированию видеоданных, в котором не разрешаются комбинации мозаичных фрагментов и параллельной волновой обработки (WPP) внутри одного изображения, в соответствии с одним или несколькими аспектами этого раскрытия.
Фиг. 5 - структурная схема, иллюстрирующая примерную работу видеодекодера по декодированию видеоданных, в котором не разрешаются комбинации мозаичных фрагментов и WPP внутри одного изображения, в соответствии с одним или несколькими аспектами этого раскрытия.
Фиг. 6 - блок-схема, иллюстрирующая другой пример работы видеодекодера по декодированию видеоданных, в котором не разрешаются комбинации мозаичных фрагментов и WPP внутри одного изображения, в соответствии с одним или несколькими аспектами этого раскрытия.
Фиг. 7 - структурная схема, иллюстрирующая примерную работу видеокодера по кодированию видеоданных, в котором каждый ряд блоков дерева кодирования (CTB) изображения находится в отдельном подпотоке, в соответствии с одним или несколькими аспектами этого раскрытия.
Фиг. 8 - структурная схема, иллюстрирующая примерную работу видеодекодера по декодированию видеоданных, в котором каждый ряд CTB-единиц изображения находится в отдельном подпотоке, в соответствии с одним или несколькими аспектами этого раскрытия.
Фиг. 9A - блок-схема, иллюстрирующая первый сегмент примера процесса анализа в контекстно-зависимом адаптивном двоичном арифметическом кодировании (CABAC), чтобы анализировать данные слайса, в соответствии с одним или несколькими аспектами этого раскрытия.
Фиг. 9B - структурная схема, иллюстрирующая продолжение примера процесса анализа в CABAC Фиг. 9A.
Фиг. 10 - концептуальная схема, которая иллюстрирует пример WPP.
Фиг. 11 - концептуальная схема, которая иллюстрирует примерную очередность кодирования, когда изображение разделено на множество мозаичных фрагментов.
ПОДРОБНОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
В ходе кодирования видео изображение может быть разделено на множественные мозаичные фрагменты, волны параллельной волновой обработки (WPP) и/или энтропийные слайсы. Мозаичные фрагменты изображения задаются горизонтальными и/или вертикальными границами мозаичного фрагмента, которые проходят через изображение. Мозаичные фрагменты изображения кодируются в соответствии с порядком растрового сканирования, и блоки дерева кодирования (CTB) внутри каждого мозаичного фрагмента также кодируются в соответствии с порядком растрового сканирования. В WPP каждый ряд CTB-единиц в изображении представляет "WPP волну". Когда видеокодер использует WPP, чтобы кодировать изображение, кодер видео может начинать кодирование CTB-единиц WPP волны слева направо после того, как кодер видео закодировал два или большее число CTB-единиц непосредственно выше WPP волны. Энтропийный слайс может включать в себя серию последовательных CTB-единиц в соответствии с порядком растрового сканирования. Использование информации через границы энтропийных слайсов запрещается для использования в выборе контекстов энтропийного кодирования, но может позволяться для других целей.
В существующих системах кодирования видео изображение может иметь произвольную комбинацию мозаичных фрагментов, WPP волн и энтропийных слайсов. Например, изображение может быть разделено на совокупность мозаичных фрагментов. В этом примере CTB-единицы в некоторых из мозаичных фрагментов могут быть кодированы в соответствии с порядком растрового сканирования, тогда как CTB-единицы в других мозаичных фрагментов могут быть кодированы с использованием WPP. Позволение изображению включать в себя комбинации мозаичных фрагментов, WPP волн и энтропийных слайсов может излишне повышать сложность реализации и затраты для таких систем кодирования видео.
Способы этого раскрытия могут устранить эту проблему. То есть в соответствии со способами этого раскрытия комбинации внутри изображения из любых двух или большего числа мозаичных фрагментов, WPP волн и энтропийных слайсов не разрешаются. Например, видеокодер может формировать битовый поток, который включает в себя синтаксический элемент, указывающий, является ли изображение кодированным согласно первому режиму кодирования или согласно второму режиму кодирования. В первом режиме кодирования изображение кодируется полностью с использованием WPP. Во втором режиме кодирования изображение имеет один или несколько мозаичных фрагментов, и каждый мозаичный фрагмент изображения кодируется без использования WPP.
Кроме того, в этом примере, видеодекодер может анализировать синтаксический элемент из битового потока, который включает в себя кодированное представление изображения. В ответ на определение, что синтаксический элемент имеет конкретное значение, видеодекодер может декодировать изображения полностью с использованием WPP. В ответ на определение, что синтаксический элемент не имеет конкретного значения, видеодекодер может декодировать каждый мозаичный фрагмент изображения без использования WPP. Изображение может иметь один или несколько мозаичных фрагментов.
Сопроводительные чертежи иллюстрируют примеры. Элементы, обозначенные ссылочными позициями на сопроводительных чертежах, соответствуют элементам, обозначенным подобными ссылочными позициями в последующем описании. В этом раскрытии элементы, имеющие имена, которые начинаются с порядковых слов (например, "первый", "второй", "третий" и так далее) не обязательно подразумевают, что у элементов имеется конкретный порядок. Предпочтительнее такие порядковые слова просто используются для ссылки на различные элементы такого же или подобного типа.
На фиг. 1 показана блок-схема, иллюстрирующая примерную систему 10 кодирования видео, которая может использовать способы этого раскрытия. Как используется в описании в документе, термин "кодер видео" относится обобщенно и к видеокодерам, и к видеодекодерам. В этом раскрытии термины "кодирование видео" или "кодирование" могут относиться обобщенно к кодированию видео или декодированию видео.
Как показано на фиг. 1, система 10 кодирования видео включает в себя исходное устройство 12 и целевое устройство 14. Исходное устройство 12 формирует кодированные видеоданные. Соответственно, исходное устройство 12 может именоваться устройством кодирования видео или аппаратом кодирования видео. Целевое устройство 14 может декодировать кодированные видеоданные, сформированные исходным устройством 12. Соответственно, целевое устройство 14 может именоваться устройством декодирования видео или аппаратом декодирования видео. Исходное устройство 12 и целевое устройство 14 могут быть примерами устройств кодирования видео или аппаратов кодирования видео. Исходное устройство 12 и целевое устройство 14 могут содержать широкий спектр устройств, включая настольные компьютеры, мобильные вычислительные устройства, портативные (например, переносные) компьютеры, планшетные компьютеры, телевизионные абонентские приставки, телефонные трубки, такие как так называемые "интеллектуальные" телефоны, телевизионные приемники, камеры, устройства отображения, цифровые мультимедийные проигрыватели, игровые видеоприставки, встроенные в автомобили компьютеры и т.п.
Целевое устройство 14 может принимать кодированные видеоданные от исходного устройства 12 через канал 16. Канал 16 может содержать одну или несколько сред передачи и/или устройств, способных перемещать кодированные видеоданные от исходного устройства 12 на целевое устройство 14. В одном примере канал 16 может содержать одну или несколько сред передачи данных, которые позволяют исходному устройству 12 передавать кодированные видеоданные непосредственно на целевое устройство 14 в реальном времени. В этом примере исходное устройство 12 может модулировать кодированные видеоданные согласно стандарту связи, такому как протокол беспроводной связи, и может передавать модулированные видеоданные на целевое устройство 14. Одна или несколько сред передачи данных могут включать в себя проводные и/или беспроводные среды передачи, такие как радиочастотный (RF) спектр или одна или несколько физических линий передачи. Одна или несколько сред передачи данных могут образовывать подсистему сети с передачей пакетов, такой как локальная сеть, региональная сеть или глобальная сеть (например, сеть Интернет). Одна или несколько сред связи могут включать в себя маршрутизаторы, коммутаторы, базовые станции или другое оборудование, которое содействует передаче данных от исходного устройства 12 на целевое устройство 14.
В другом примере канал 16 может включать в себя в носитель данных, который хранит кодированные видеоданные, сформированные исходным устройством 12. В этом примере целевое устройство 14 может осуществлять доступ к носителю данных посредством доступа к диску или доступа к карте. Носитель данных может включать в себя множество носителей данных для локально-доступных данных, такие как диски формата Blue-ray, цифровые многофункциональные диски (DVD), ПЗУ на компакт-дисках (CD-ROM), флэш-память или другие подходящие носители цифровых данных для хранения кодированных видеоданных.
В дополнительном примере канал 16 может включать в себя файловый сервер или другое промежуточное устройство хранения данных, которое хранит кодированное видеоизображение, сформированное исходным устройством 12. В этом примере целевое устройство 14 может осуществлять доступ к кодированным видеоданным, сохраненным в файловом сервере или другом промежуточном устройстве хранения данных, посредством потоковой передачи или загрузки по сети. Файловый сервер может быть типом сервера, способным хранить кодированные видеоданные и передавать кодированные видеоданные на целевое устройство 14. Примерные файловые серверы включают в себя веб-серверы (например, для веб-сайта), серверы с поддержкой протокола передачи файлов (FTP), устройства подключаемых к сети накопителей (NAS) и локальные накопители на дисках.
Целевое устройство 14 может осуществлять доступ к кодированным видеоданным посредством стандартного информационного соединения, такого как Интернет-соединение. Примерные типы соединений данных включают в себя беспроводные каналы (например, соединения беспроводного доступа стандарта Wi-Fi), проводные соединения (например, цифровую абонентскую линию (DSL), кабельный модем и т.д.) или их комбинации, которые являются подходящими для осуществления доступа к кодированным видеоданным, сохраненным на файловом сервере. Передача кодированных видеоданных от файлового сервера может быть потоковой передачей, передачей загрузки из главной системы или их комбинацией.
Способы этого раскрытия не ограничиваются приложениями или установочными параметрами для беспроводной связи. Способы могут применяться к кодированию видео в поддержке различных мультимедийных приложений, таких как беспроводное телевещание, передачи кабельного телевидения, передачи спутникового телевидения, передачи потокового видео, например, через сеть Интернет, кодирования видеоданных для сохранения на носителе данных, декодирования видеоданных, сохраненных на носителе данных, или других приложений. В некоторых примерах система 10 кодирования видео может быть сконфигурирована с возможностью поддерживать одностороннюю или двустороннюю передачу видео для поддержки приложений, таких как потоковая передача видео, воспроизведение видео, телевизионное вещание и/или видеотелефония.
В примере по фиг. 1 исходное устройство 12 включает в себя источник 18 видеосигнала, видеокодер 20 и выходной интерфейс 22. В некоторых примерах выходной интерфейс 22 может включать в себя модулятор/демодулятор (модем) и/или передатчик. Источник 18 видеосигнала может включать в себя устройство получения видео, например видеокамеру, архив видео, содержащий полученные ранее видеоданные, интерфейс внешнего видеосигнала для приема видеоданных от поставщика видеоконтента и/или систему компьютерной графики для формирования видеоданных или комбинацию таких источников видеоданных.
Видеокодер 20 может закодировать видеоданные от источника 18 видеосигнала. В некоторых примерах исходное устройство 12 непосредственно передает кодированные видеоданные на целевое устройство 14 через выходной интерфейс 22. Кодированные видеоданные также могут сохраняться на носителе данных или файловом сервере для доступа впоследствии целевым устройством 14 для декодирования и/или воспроизведения.
В примере по фиг. 1 целевое устройство 14 включает в себя входной интерфейс 28, видеодекодер 30 и устройство 32 отображения. В некоторых примерах входной интерфейс 28 включает в себя приемник и/или модем. Входной интерфейс 28 может принимать кодированные видеоданные по каналу 16. Устройство 32 отображения может быть встроенным в целевое устройство 14 или может быть внешним к нему. Обычно устройство 32 отображения отображает декодированные видеоданные. Устройство 32 отображения может содержать различные устройства отображения, такие как жидкокристаллический дисплей (LCD), плазменный дисплей, дисплей на органических светодиодах (OLED) или другой тип устройства отображения.
Видеокодер 20 и видеодекодер 30 могут работать согласно стандарту сжатия видеоизображения, такому как стандарт высокоэффективного кодирования видеоизображений (HEVC), разрабатываемый в настоящее время, и могут соответствовать тестовой модели HEVC (HM). Проект будущего стандарта HEVC, называемый "HEVC Working Draft 5" (Рабочий проект 5 по HEVC) или "WD5", описывается в работе Bross и др., "WD5: Working Draft 5 of High-Efficiency Video Coding", (WD5: Рабочий проект 5 по высокоэффективному кодированию видеоизображений) в рабочих материалах WP3 исследовательской группы секторов SG16 Объединенной совместной группы по кодированию видеоизображений (JCT-VC) Международного союза электросвязи - сектора телекоммуникаций (ITU-T) и материалах 7-ой Конференции JTC1/SC29/WG11 ISO/IEC: Женева, Швейцария, ноябрь 2011, которые с 10 октября 2012 доступны для загрузки с адреса: http://phenix.int-evry.fr/jct/doc_end_user/documents/7_Geneva/wg11/JCTVC-G1103-v3.zip, содержание которых полностью включено в документ посредством ссылки. Другой проект будущего стандарта HEVC, называемый "HEVC Working Draft 9" (Рабочий проект 9 по HEVC), описывается авторами Bross и др. в рабочих материалах WP3 исследовательской группы секторов SG16 Объединенной совместной группы по кодированию видеоизображений (JCT-VC) ITU-T и ИСО/МЭК (ISO/IEC) JTC1/SC29/WG11, 11-ая Конференция: Шанхай, Китай, октябрь 2012, которые с 7 ноября 2012 доступны для загрузки с адреса: http://phenix.int-evry.fr/jct/doc_end_user/documents/11_Shanghai/wg11/JCTVC-K1003-v8.zip, содержание которых полностью включено в документ посредством ссылки.
Альтернативно, видеокодер 20 и видеодекодер 30 могут работать согласно другим частным или промышленным стандартам, включая стандарты ITU-T H.261, ISO/IEC MPEG-1 Visual, ITU-T H.262 или ISO/IEC MPEG-2 Visual, ITU-T H.263, ISO/IEC MPEG-4 Visual и ITU-T H.264 (также известный как ISO/1EC MPEG-4 AVC), включая его расширения Масштабируемого кодирования видеоизображений (SVC) и Кодирования многовидовых видеоизображений (MVC). Способы этого раскрытия, однако, не ограничиваются каким-либо конкретным стандартом или способом кодирования.
Снова, фиг. 1 является просто примером, и способы этого раскрытия можно применять к установочным параметрам кодирования видео (например, кодированию видео или декодированию видео), которые не обязательно включают в себя какую-либо передачу данных между устройствами кодирования и декодирования. В других примерах данные извлекаются из локальной памяти, передаются потоком по сети или подобное. Устройство кодирования может закодировать и сохранить данные в памяти, и/или устройство декодирования может извлечь и декодировать данные из памяти. Во многих примерах кодирование и декодирование выполняются устройствами, которые не осуществляют связь друг с другом, а просто кодируют данные в память и/или извлекают и декодируют данные по памяти.
Видеокодер 20 и видеодекодер 30 каждый может быть осуществлен в виде любого из различных подходящих схемных решений, такого как один или несколько микропроцессоров, цифровые процессоры сигналов (DSP), специализированные интегральные схемы (ASIC), программируемые вентильные матрицы (FPGA), дискретная логика, аппаратные средства или любые комбинации таковых. Если способы осуществлены частично программно, устройство может сохранять инструкции для программного обеспечения в подходящем, не являющемся временным машиночитаемом носителе данных и может исполнять инструкции в аппаратных средствах, использующих один или несколько процессоров, чтобы выполнять способы этого раскрытия. Любое из вышеизложенного (включая аппаратные средства, программное обеспечение, комбинацию аппаратных средств и программного обеспечения и т.д.) можно рассматривать являющимся одним или несколькими процессорами. Каждый из видеокодера 20 и видеодекодера 30 может быть включен в один или несколько кодеров или декодеров, любой из которых может встраиваться в виде части комбинированного кодера/декодера (КОДЕК) в соответственное устройство.
Это раскрытие может в целом относиться к видеокодеру 20, "сигнализирущему" некоторую информацию на другое устройство, такое как видеодекодер 30. Термин "сигнализация" может в целом относиться к передаче синтаксических элементов и/или других данных, которые представляют кодированные видеоданные. Такая передача может происходить в реальном или псевдореальном времени. Альтернативно, такая передача может происходить за промежуток времени, такой как мог иметь место при сохранении синтаксических элементов в машиночитаемом носителе данных в кодированном битовом потоке во время кодирования, которые затем могут извлекаться устройством декодирования в любое время, будучи сохраненными в этом носителе.
Как кратко упомянуто выше, видеокодер 20 кодирует видеоданные. Видеоданные могут содержать одно или несколько изображений. Каждое из изображений может быть неподвижным (фотографическим) изображением. В некоторых случаях изображение может именоваться "кадром" видео. Видеокодер 20 может формировать битовый поток, который включает в себя последовательность битов, которые образуют кодированное представление видеоданных. Битовый поток может включать в себя кодированные изображения и связанные с ними данные. Кодированное изображение является кодированным представлением изображения. Связанные с ним данные могут включать в себя наборы параметров последовательности (SPS), наборы параметров изображения (PPS) и другие синтаксические структуры. SPS может содержать параметры, применимые к нулю или большему количеству последовательностей изображений. PPS может содержать параметры, применимые к нулю или большему количеству изображений.
Для формирования кодированного представления изображения видеокодер 20 может разделить изображение на «сетку» блоков дерева кодирования (CTB). В некоторых случаях CTB может именоваться "древовидным блоком", "наибольшей единицей кодирования" (LCU) или "единицей дерева кодирования". CTB-единицы в HEVC могут в общих чертах быть похожими на макроблоки из предшествующих стандартов, например H.264/AVC. Однако CTB не обязательно ограничивается конкретным размером и может включать в себя один или несколько единиц кодирования (CU).
Каждый из CTB-единиц может быть связан с другим равноразмерным блоком пикселов внутри изображения. Каждый пиксел может содержать выборку яркости (luma) и две выборки цветности (chroma). Таким образом, каждый CTB может быть связан с блоком выборок яркости и двумя блоками выборок цветности. Для простоты пояснения в этом раскрытии двумерный массив пикселов может называться пиксельным блоком и двумерный массив выборок может называться блоком выборок. Видеокодер 20 может использовать разделение типа квадрадерево, чтобы разделять пиксельный блок, связанный с CTB, на пиксельные блоки, связанные с CU-единицами, отсюда название "блоки дерева кодирования".
CTB-единицы в изображения могут группироваться в один или несколько слайсов. В некоторых примерах каждый из слайсов включает в себя целое число CTB-единиц. В качестве части кодирования изображения видеокодер 20 может формировать кодированные представления каждого слайса изображения (то есть кодированные слайсы). Чтобы формировать кодированный слайс, видеокодер 20 может закодировать каждый CTB из слайса, чтобы сформировать кодированные представления каждого из CTB-единиц слайса (то есть кодированные CTB-единицы).
Чтобы формировать кодированный CTB, видеокодер 20 может рекурсивно выполнять разделение типа квадрадерево на пиксельном блоке, связанном с CTB, чтобы разделить пиксельный блок на прогрессивно более мелкие пиксельные блоки. Каждый из меньших пиксельных блоков может быть связан с CU. Разделенной CU может быть CU, пиксельный блок которой разделен на пиксельные блоки, связанные с другими CU. Неразделенной CU может быть CU, пиксельный блок которой не является разделенным на пиксельные блоки, связанные с другими CU.
Видеокодер 20 может формировать одну или несколько единиц предсказания (PU) для каждой неразделенной CU. Каждая из PU-единиц CU может быть связана с другим пиксельным блоком внутри пиксельного блока CU. Видеокодер 20 может формировать пиксельные блоки по предсказанию для каждой PU у CU. Предсказанный пиксельный блок для PU может быть блоком пикселов.
Видеокодер 20 может использовать внутрикадровое (intra) предсказание или межкадровое (inter) предсказание, чтобы формировать предсказываемый пиксельный блок для PU. Если видеокодер 20 использует внутрикадровое предсказание, чтобы сформировать предсказанный пиксельный блок PU, видеокодер 20 может формировать предсказываемый пиксельный блок PU на основании декодированных пикселов изображения, связанного с PU. Если видеокодер 20 использует межкадровое предсказание, чтобы сформировать предсказанный пиксельный блок для PU, видеокодер 20 может формировать предсказываемый пиксельный блок для PU на основании декодированных пикселов одного или нескольких изображений, отличных от изображения, связанного с PU.
Видеокодер 20 может формировать остаточный пиксельный блок для CU на основании предсказанных пиксельных блоков PU для CU. Остаточный пиксельный блок для CU может указывать разности между выборками в предсказанных пиксельных блоках для PU-единиц CU и соответствующими выборками в исходной пиксельной единице CU.
Кроме того, в качестве части кодирования неразделенной CU видеокодер 20 может выполнять рекурсивное разделение типа квадрадерево на остаточном пиксельном блоке CU, чтобы разделить остаточный пиксельный блок CU на один или несколько меньших остаточных пиксельных блоков, связанных с единицами преобразования (TU) у CU. Поскольку пикселы в пиксельных блоках, связанных с TU-единицами, каждый включает выборку яркости и две выборки цветности, каждая из TU-единиц может быть связана с остаточным блоком выборок из выборок яркости и двумя остаточными блоками выборок из выборок цветности.
Видеокодер 20 может применять одно или несколько преобразований к остаточным блокам выборок, связанным с TU-единицами, чтобы сформировать блоки коэффициентов (то есть блоки из коэффициентов). Видеокодер 20 может выполнять процесс квантования на каждом из блоков коэффициентов. Квантование в целом относится к процессу, в котором коэффициенты квантуют, чтобы возможно уменьшить объем данных, используемый для представления коэффициентов, обеспечивая дополнительное сжатие.
Видеокодер 20 может формировать наборы синтаксических элементов, которые представляют коэффициенты в блоках квантованных коэффициентов. Видеокодер 20 может применять операции энтропийного кодирования, такие как операции контекстно-зависимого адаптивного двоичного арифметического кодирования (CABAC), по меньшей мере, к некоторым из этих синтаксических элементов. В качестве части выполнения операции энтропийного кодирования видеокодер 20 может выбирать контекст кодирования. В случае CABAC контекст кодирования может указывать вероятности последовательностей двоичных сигналов (bin) со значением 0 и значением 1.
Битовый поток, сформированный видеокодером 20, может включать в себя серию узлов уровня сетевой абстракции (NAL). Каждый из узлов NAL может быть синтаксической структурой, содержащей указание типа данных в узле NAL и байты, содержащие данные. Например, узел NAL может содержать данные, представляющие SPS, PPS, кодированный слайс, дополнительную информацию о расширении (SEI), разделитель модуля доступа, данные заполнителя или другой тип данных. Узлы NAL кодированного слайса являются узлами NAL, которые включают в себя кодированные слайсы.
Видеодекодер 30 может принимать битовый поток. Битовый поток может включать в себя кодированное представление видеоданных, закодированных видеокодером 20. Видеодекодер 30 может анализировать битовый поток, чтобы извлекать синтаксические элементы из битового потока. В качестве части извлечения некоторых синтаксических элементов из битового потока видеодекодер 30 может энтропийно декодировать (например, декодировать по CABAC, декодировать экспоненциальным кодом Голомба и т.д.) данные в битовом потоке. Видеодекодер 30 может восстанавливать изображения из видеоданных на основании синтаксических элементов, извлеченных из битового потока.
Процесс для восстановления видеоданных на основании синтаксических элементов может быть в целом взаимообратным процессу, выполняемому видеокодером 20 для формирования синтаксических элементов. Например, видеодекодер 30 может формировать на основании синтаксических элементов, связанных с CU-единицами, пиксельные блоки по предсказанию для PU-единиц CU. Кроме того, видеодекодер 30 может осуществлять обращенное квантование блоков коэффициентов, связанных с TU-единицами в CU. Видеодекодер 30 может выполнять обратное преобразование на блоках коэффициентов, чтобы восстанавливать остаточные пиксельные блоки, связанные с TU-единицами для CU. Видеодекодер 30 может восстанавливать пиксельный блок для CU на основании предсказанных пиксельных блоков и остаточных пиксельных блоков.
В некоторых примерах видеокодер 20 может делить изображение на множество энтропийных слайсов. Это раскрытие может использовать термин "обычный слайс", чтобы отличать слайсы от энтропийных слайсов. Энтропийный слайс может включать в себя подмножество CU-единиц обычного слайса. В некоторых примерах видеокодер 20 может разделять CU-единицы между энтропийными слайсами так, что ни один из энтропийных слайсов не включает в себя больше элементов кодированного сигнала (например, энтропийно кодированных битов), чем верхний предел. Каждый энтропийный слайс может быть включен в отдельный узел NAL.
В этом раскрытии предсказание внутри изображения может относиться к использованию информации, связанной с первой единицей (например, CTB, CU, PU и т.д.) изображения, для кодирования второй единицы того же изображения. Предсказание внутри изображения через границы энтропийные слайсы позволяется, кроме цели энтропийного кодирования. Например, если кодер видео (например, видеокодер 20 или видеодекодер 30) выполняет внутрикадровое предсказание на конкретной PU, кодер видео может использовать выборки из соседней PU, даже если соседняя PU находится в другом энтропийном слайсе, чем конкретная PU. В этом примере видеокодер, возможно, не сможет использовать выборки из соседней PU, если соседняя PU находится в другом слайсе, чем конкретная PU.
Однако, когда видеокодер выполняет энтропийное кодирование на данных, связанных с конкретной PU, кодеру видео позволяется только выбирать контексты кодирования на основании информации, связанной с соседней PU, если конкретная PU и соседняя PU находятся в одном том же энтропийном слайсе. Вследствие этого ограничения кодер видео может быть способным выполнять операции энтропийного кодирования (то есть энтропийное кодирование или декодирование) на множественных энтропийных слайсах для слайса параллельно. Следовательно, видеодекодер 30 может быть способным анализировать синтаксические элементы множественных энтропийных слайсов параллельно. Однако видеодекодер 30 не является способным восстанавливать пиксельные блоки множественных энтропийных слайсов для слайса параллельно.
Как указано выше, узел NAL кодированного слайса может содержать кодированный слайс. Этот слайс может быть либо энтропийным слайсом, либо обычным слайсом. Заголовок слайса в узле NAL кодированного слайса может включать в себя синтаксический элемент (например, entropy_slice_flag), который указывает, является ли слайс энтропийным слайсом или обычным слайсом. Например, если синтаксический элемент равен 1, слайс в узле NAL кодированного слайса может быть энтропийным слайсом.
Каждый кодированный слайс может включать в себя заголовок слайса и данные слайса. Заголовки слайса для энтропийных слайсов могут отличаться от заголовков слайса обычных слайсов. Например, синтаксические элементы в заголовках слайсов для энтропийных слайсов могут включать в себя подмножество синтаксических элементов из заголовков слайсов для обычных слайсов. Поскольку заголовки слайсов для энтропийных слайсов включают в себя меньше синтаксических элементов, чем заголовки слайсов для обычных слайсов, энтропийные слайсы могут также именоваться легковесными слайсами, слайсами с короткими заголовками слайсов или короткими слайсами. Энтропийный слайс может унаследовать из заголовка слайса обычного слайса, который предшествует энтропийному слайсу в очередности декодирования, синтаксические элементы, исключенные из заголовка слайса для энтропийного слайса.
Традиционно видеокодеры формируют отдельные узлы NAL для каждого энтропийного слайса. Отдельные узлы NAL часто транспортируются по сети в отдельных пакетах. Другими словами, может быть один узел NAL на один пакет в течение передачи узлов NAL по сети. Это может быть трудным для узлов NAL, которые содержат энтропийные слайсы. Если пакет, который содержит узел NAL, включающий в себя обычный слайс, теряется в течение передачи, видеодекодер 30 может быть неспособным использовать энтропийные слайсы, которые наследуют синтаксические элементы из заголовка слайса для обычного слайса. Кроме того, если одна или несколько CTB-единиц первого энтропийного слайса основываются на одной или нескольких CTB-единицах второго энтропийного слайса для предсказания внутри изображения, и пакет, который содержит узел NAL, включающий в себя второй энтропийный слайс, теряется в течение передачи, видеокодер 30 может быть неспособным декодировать CTB-единицы первого энтропийного слайса.
В некоторых примерах кодер видео может кодировать, по меньшей мере, сегменты изображения, используя параллельную волновую обработку (WPP). На фиг. 9, описанной подробно ниже, показана концептуальная схема, которая иллюстрирует пример WPP. Если кодер видео кодирует изображение, используя WPP, кодер видео может разделить CTB-единицы изображения на множество "WPP волн". Каждая из WPP волн может соответствовать отличающемуся ряду CTB-единиц в изображении. Если кодер видео кодирует изображение, используя WPP, кодер видео может начать кодирование верхнего ряда CTB-единиц. После того как кодер видео закодировал две или большее число CTB-единиц верхнего ряда, кодер видео может начать кодирование второго сверху ряда CTB-единиц параллельно с кодированием верхнего ряда CTB-единиц. После того как видеокодер закодировал две или большее число CTB-единиц второго сверху ряда, кодер видео может начинать кодировать третий сверху ряд CTB-единиц параллельно с кодированием верхних рядов CTB-единиц. Эта схема может продолжаться вниз по рядам CTB-единиц в изображении.
Если видеокодер использует WPP, кодер видео может использовать информацию, связанную с пространственно соседними CU вне текущего CTB, чтобы выполнять предсказание внутри изображения на конкретной CU в текущем CTB при условии, что пространственно соседними CU являются левый, выше слева, выше или выше справа для текущего CTB. Если текущим CTB является крайний левый CTB в ряду, отличном от самого верхнего ряда, кодер видео может использовать информацию, связанную со вторым CTB ряда непосредственно выше, чтобы выбирать контекст для кодирования по CABAC одного или нескольких синтаксических элементов для текущего CTB. Иначе, если текущий CTB не является крайним левым CTB в ряду, видеокодер может использовать информацию, связанную с CTB слева от текущего CTB, чтобы выбирать контекст для кодирования по CABAC одного или нескольких синтаксических элементов для текущего CTB. Таким образом, кодер видео может инициализировать состояния CABAC для ряда на основании состояний CABAC ряда непосредственно выше после кодирования двух или большего числа CTB-единиц ряда непосредственно выше.
Таким образом, в ответ на определение, что первый CTB отделен от левой границы изображения одним CTB, кодер видео может сохранить переменные контекста, связанные с первым CTB. Кодер видео может энтропийно кодировать (например, энтропийно закодировать или энтропийно декодировать) на основании, по меньшей мере частично, переменных контекста, связанных с первым CTB, одного или нескольких синтаксических элементов второго CTB, второй CTB является смежным с левой границей изображения и одним рядом CTB-единиц ниже первого CTB.
Кодированные CTB-единицы слайса обычно располагаются в узле NAL кодированного слайса в соответствии с порядком растрового сканирования, даже когда используется WPP. Это может усложнить построение кодеров видео, реализующих WPP. Когда число WPP волн больше единицы и меньше числа рядов CTB в изображении, порядок битового потока (то есть очередность декодирования, если кодированное изображение обрабатывается одним ядром декодера, не декодируется параллельно) кодированных битов для CTB-единиц изменяется по сравнению с тем, когда WPP не применяется, как изложено ниже. CTB, кодированный позднее в очередности битового потока/декодирования, может быть необходимым для предсказания внутри изображения другим кодированным CTB, более ранним в очередности декодирования. Это может разрушить причинно-следственную зависимость битового потока, в которой никакие более ранние данные не зависят от данных, поступающих позже в очередности битового потока/декодирования. Причинно-следственная зависимость битового потока была общеследуемым принципом в проектных решениях кодирования видео, включая стандарты кодирования видеоизображения. Тогда как процесс декодирования работает, процесс декодирования может быть более сложным, если указатель битового потока, который указывает текущую позицию в битовом потоке, может перемещаться назад и вперед внутри сегмента битового потока, связанного с узлом NAL кодированного слайса.
В некоторых примерах видеокодер 20 может делить изображение на один или несколько мозаичных фрагментов. Мозаичные фрагменты могут содержать неперекрывающиеся множества CTB-единиц для изображения. Видеокодер 20 может делить изображение на мозаичные фрагменты путем задания двух или большего количества вертикальных границ мозаичного фрагмента и двух или большего количества горизонтальных границ мозаичного фрагмента. Каждая вертикальная сторона изображения может быть вертикальной границей мозаичного фрагмента. Каждая горизонтальная сторона текущего изображения может быть горизонтальной границей мозаичного фрагмента. Например, если видеокодер 20 определяет четыре вертикальные границы мозаичного фрагмента и три горизонтальные границы мозаичного фрагмента для изображения, текущее изображение делится на шесть мозаичных фрагментов.
Кодер видео, такой как видеокодер 20 или видеодекодер 30, может кодировать CTB-единицы мозаичных фрагментов изображения согласно порядку сканирования мозаичного фрагмента. Чтобы кодировать CTB-единицы согласно порядку сканирования мозаичного фрагмента, кодер видео может кодировать мозаичные фрагменты изображения в соответствии с порядком растрового сканирования. Таким образом, кодер видео может кодировать каждый мозаичный фрагмент в ряду мозаичных фрагментов в порядке слева направо, начиная с верхнего ряда мозаичных фрагментов и затем переходя ниже в изображении. Кроме того, кодер видео может кодировать каждый CTB внутри мозаичного фрагмента в соответствии с порядком растрового сканирования. Таким образом, кодер видео может кодировать каждый CTB данного мозаичного фрагмента изображения до кодирования какого-либо CTB другого мозаичного фрагмента изображения. Другими словами, порядок сканирования мозаичного фрагмента обходит CTB-единицы в порядке растрового сканирования CTB внутри мозаичного фрагмента и обходит мозаичные фрагменты в порядке растрового сканирования мозаичного фрагмента внутри изображения. Следовательно, очередность, в которой кодер видео кодирует CTB-единицы изображения, может быть другим, если изображение разделяется на множественные мозаичные фрагменты, чем если бы изображение не было разделенным на множественные мозаичные фрагменты. Фиг. 10, описанная ниже, является концептуальной схемой, иллюстрирующей примерный порядок сканирования мозаичного фрагмента, когда изображение разделено на множество мозаичных фрагментов.
В некоторых случаях кодер видео может выполнять предсказание внутри изображения через границы мозаичного фрагмента, но не через границы слайса. В других случаях предсказание внутри изображения запрещается через границы мозаичного фрагмента и границы слайса. В случаях, где предсказание внутри изображения запрещается через границы мозаичного фрагмента и границы слайса, кодер видео может быть способным кодировать параллельно множественные мозаичные фрагменты.
В некоторых примерах предсказание внутри изображения через границы мозаичного фрагмента управляется флагом (например, "tile_boundary_independence_idc" (независимость от границы мозаичного фрагмента)). Если флаг равен 1, предсказание внутри изображения через границы мозаичного фрагмента запрещается в пределах изображения. Иначе, предсказание внутри изображения через границы мозаичного фрагмента позволяется, кроме границ мозаичного фрагмента, которые являются также границами изображения или границами слайса. Если предсказание внутри изображения через границы мозаичного фрагмента позволяется, функциональностью мозаичных фрагментов может быть изменение порядка сканирования CTB-единиц по сравнению со случаем, где изображение не имеет мозаичных фрагментов, или эквивалентно - имеет только один мозаичный фрагмент. Если предсказание внутри изображения через границы мозаичного фрагмента не позволяется, кроме изменения порядка сканирования CTB-единиц, мозаичные фрагменты могут также обеспечивать независимое разделение, которое может использоваться, чтобы параллельно кодировать (закодировать и/или декодировать) мозаичные фрагменты. Таким образом, если изображение разделено на, по меньшей мере, первый мозаичный фрагмент и второй мозаичный фрагмент, когда видеодекодер 30 декодирует мозаичные фрагменты без использования WPP, видеодекодер 30 может декодировать параллельно CTB первого мозаичного фрагмента и CTB второго мозаичного фрагмента.
В некоторых случаях изображение может быть разделено на комбинацию мозаичных фрагментов, WPP волн и энтропийных слайсов. Например, изображение может быть разделено на мозаичный фрагмент и набор WPP волн. В другом примере изображение может быть разделено на два мозаичных фрагмента и энтропийный слайс. Допущение комбинации мозаичных фрагментов, WPP волн и энтропийных слайсов внутри изображения может быть трудным, поскольку допущение таких комбинаций может повысить сложность и стоимости видеокодеров и/или видеодекодеров.
Способы этого раскрытия могут решить проблемы, описанные выше. В соответствии со способами этого раскрытия, изображение не может разделяться на какую-либо комбинацию мозаичных фрагментов, WPP волн и энтропийных слайсов. Другими словами, изображение может быть разделено на один или несколько мозаичных фрагментов, изображение может быть разделено на WPP волны или изображение может быть разделено на один или несколько энтропийных слайсов. Однако изображение не может быть разделено ни на одну из следующих комбинаций: (a) мозаичные фрагменты, WPP волны и энтропийные слайсы, (b) мозаичные фрагменты и WPP волны, (c) мозаичные фрагменты и энтропийные слайсы или (d) WPP волны и энтропийные слайсы.
Для осуществления этого видеокодер 20 может включать в битовый поток синтаксический элемент, который указывает, что изображение является кодированным либо согласно первому режиму кодирования, либо согласно второму режиму кодирования. В первом режиме кодирования изображение полностью кодируется с использованием WPP. Таким образом, каждый ряд CTB-единиц в изображении может быть закодирован как WPP волна. Во втором режиме кодирования изображение может иметь один или несколько мозаичных фрагментов. Кроме того, во втором режиме кодирования каждый мозаичный фрагмент изображения может быть закодирован без использования WPP. Например, во втором режиме кодирования видеокодер 20 может для каждого мозаичного фрагмента изображения кодировать CTB-единицы внутри мозаичного фрагмента последовательно в порядке слева направо по рядам CTB-единиц и вниз по рядам CTB-единиц мозаичного фрагмента. Для простоты пояснения этот синтаксический элемент может именоваться в документе синтаксическим элементом режима кодирования.
Видеодекодер 30 может осуществлять анализ синтаксического элемента из битового потока, включающего в себя кодированное представление изображения в видеоданных. В ответ на определение, что синтаксический элемент имеет конкретное значение, видеодекодер 30 может декодировать изображения полностью с использованием WPP. В ответ на определение, что синтаксический элемент не имеет конкретного значения, видеодекодер 30 может декодировать каждый мозаичный фрагмент изображения без использования WPP, причем изображение имеет один или несколько мозаичных фрагментов.
Различные сегменты битового потока могут включать в себя синтаксический элемент режима кодирования. Например, видеокодер 20 может формировать SPS, который включает в себя синтаксический элемент режима кодирования. В этом примере видеодекодер 30 может осуществлять анализ из битового потока SPS, который включает в себя синтаксический элемент режима кодирования. В другом примере видеокодер 20 может формировать PPS, который включает в себя синтаксический элемент режима кодирования. В этом примере видеодекодер 30 может осуществлять анализ из битового потока PPS, который включает в себя синтаксический элемент режима кодирования. Кроме того, если изображение кодируется согласно второму режиму кодирования, битовый поток может включать в себя один или несколько синтаксических элементов, которые указывают, разрешаются ли энтропийные слайсы для изображения. Различные сегменты битового потока могут включать в себя один или несколько синтаксических элементов, которые указывают, разрешаются ли энтропийные слайсы для изображения. Например, SPS может включать в себя один или несколько синтаксических элементов, которые указывают, что энтропийные слайсы разрешаются для изображений, связанных с SPS. В другом примере PPS может включать в себя один или несколько синтаксических элементов, которые указывают, что энтропийные слайсы разрешаются для изображений, связанных с PPS. Например, в этом примере, PPS может включать в себя синтаксический элемент entropy_slice_enabled_flag (флаг разрешения энтропийных слайсов), указывающий, могут ли кодированные слайсы, которые относятся к PPS, состоять из энтропийных слайсов.
Если изображение включает в себя один или несколько энтропийных слайсов, каждый энтропийный слайс, связанный со слайсом изображения, может быть включен в один узел NAL кодированного слайса вместо включения в отдельные узлы NAL. Таким образом, энтропийный слайс может быть определен в виде подмножества слайса, причем процесс энтропийного декодирования энтропийного слайса является независимым от других энтропийных слайсов в том же слайсе.
Как кратко упомянуто выше, битовый поток может включать в себя узлы NAL кодированных слайсов, которые включают в себя кодированные слайсы. Кодированный слайс может содержать заголовок слайса и данные слайса. Данные слайса могут включать в себя один или несколько подпотоков. В соответствии со способами этого раскрытия, если изображение кодируется в первом режиме кодирования (то есть изображение кодируется полностью с использованием WPP), каждый ряд блоков CTB в слайсе представляется одним некоторым из подпотоков. Если изображение кодируется во втором режиме кодирования (то есть каждый мозаичный фрагмент изображения кодируется без использования WPP), каждый мозаичный фрагмент изображения, у которого имеется один или несколько CTB-единиц в слайсе, представляется одним некоторым из подпотоков.
Кроме того, в соответствии со способами этого раскрытия заголовок слайса для кодированного слайса может включать в себя набор синтаксических элементов, которые указывают точки входа для мозаичных фрагментов, WPP волн или энтропийных слайсов внутри данных слайса в узле NAL кодированного слайса. Точкой входа подпотока может быть первый бит подпотока. Кроме того, мозаичные фрагменты, WPP волны или энтропийные слайсы внутри данных слайса в узле NAL кодированного слайса могут включать в себя биты заполнения, которые обеспечивают, что мозаичные фрагменты, WPP волны или энтропийные слайсы являются выровненными по байтам.
На фиг. 2 показана блок-схема, которая иллюстрирует пример видеокодера 20, который сконфигурирован для осуществления способов этого раскрытия. Фиг. 2 приведена с целью пояснения и не должна рассматриваться ограничивающей способы, как в широком смысле проиллюстрировано и описано в этом раскрытии. С целью пояснения, это раскрытие описывает видеокодер 20 в контексте кодирования по HEVC. Однако способы этого раскрытия могут быть применимыми к другим стандартам или способам кодирования.
В примере по фиг. 2 видеокодер 20 включает в себя модуль 100 обработки предсказания, модуль 102 формирования остатка, модуль 104 обработки преобразования, модуль 106 квантования, модуль 108 обратного квантования, модуль 110 обработки обратного преобразования, модуль 112 восстановления, модуль 113 фильтра, буфер 114 декодированных изображений и модуль 116 энтропийного кодирования. Модуль 100 обработки предсказания включает в себя модуль 121 обработки межкадрового предсказания и модуль 126 обработки внутрикадрового предсказания. Модуль 121 обработки межкадрового предсказания включает в себя модуль 122 оценки движения и модуль 124 компенсации движения. В других примерах видеокодер 20 может включать в себя больше, меньше компонентов или другие функциональные компоненты.
Видеокодер 20 может принимать видеоданные. Чтобы закодировать видеоданные, видеокодер 20 может закодировать каждый слайс каждого изображения в видеоданных. В качестве части кодирования слайса видеокодер 20 может закодировать каждый CTB в слайсе. В качестве части кодирования CTB модуль 100 обработки предсказания может выполнять разделение типа «квадрадерево» на пиксельном блоке, связанном с CTB, чтобы разделить пиксельный блок на прогрессивно меньшие пиксельные блоки. Меньшие пиксельные блоки могут связываться с CU-единицами. Например, модуль 100 обработки предсказания может разделить пиксельный блок CTB на четыре равно-размерных суб-блока, разделить один или несколько суб-блоков на четыре равно-размерных суб-суб-блоков, и так далее.
Видеокодер 20 может закодировать CU-единицы в CTB, чтобы сформировать кодированные представления CU-единиц (то есть кодированные CU). Видеокодер 20 может кодировать CU-единицы CTB согласно порядку z-сканирования. Другими словами, видеокодер 20 может закодировать верхнюю левую CU, верхнюю правую CU, нижнюю левую CU и затем нижнюю правую CU в этом порядке. Когда видеокодер 20 кодирует разделенную CU, видеокодер 20 может кодировать CU-единицы, связанные с суб-блоками пиксельного блока для разделенной CU согласно порядку z-сканирования.
В качестве части кодирования CU модуль 100 обработки предсказания может разделить пиксельный блок CU между одним или несколькими PU-единицами в CU. Видеокодер 20 и видеодекодер 30 могут поддерживать PU различного размера. При условии, что размером конкретной CU является 2N×2N, видеокодер 20 и видеодекодер 30 могут поддерживать размеры PU в 2N×2N или N×N для внутрикадрового предсказания и симметричные PU размеров 2N×2N, 2N×N, N×2N, N×N или подобное для межкадрового предсказания. Видеокодер 20 и видеодекодер 30 могут также поддерживать асимметричное разделение для PU размером 2N×nU, 2N×nD, nL×2N и nR×2N для межкадрового предсказания.
Модуль 121 обработки межкадрового предсказания может формировать по предсказанию данные для PU путем выполнения межкадрового предсказания на каждой PU в CU. Данные по предсказанию для PU могут включать в себя пиксельный блок по предсказанию, который соответствует PU, и информацию движения для PU. Слайсами могут быть I-слайсы, P-слайсы или B-слайсы. Модуль 121 обработки межкадрового предсказания может выполнять различные операции для PU в CU в зависимости от того, находится ли PU в I-слайсе, P-слайсе или B-слайсе. В I-слайсе все PU являются предсказанными внутрикадрово. Следовательно, если PU находится в I-слайсе, модуль 121 межкадрового предсказания не выполняет межкадровое предсказание на PU.
Если PU находится в P-слайсе, модуль 122 оценки движения может осуществлять поиск опорных изображений в списке опорных изображений (например, "списке 0") для опорного блока для PU. Опорный блок для PU может быть пиксельным блоком, который наиболее близко соответствует пиксельному блоку в PU. Модуль 122 оценки движения может формировать индекс опорного изображения, который указывает опорное изображение в списке 0, содержащем опорный блок для PU, и вектор движения, который указывает пространственное смещение между пиксельным блоком PU и опорным блоком. Модуль 122 оценки движения может выводить индекс опорного изображения и вектор движения в качестве информации движения для PU. Модуль 124 компенсации движения может сформировать предсказанный пиксельный блок для PU на основании опорного блока, указанного информацией движения для PU.
Если PU находится в B-слайсе, модуль 122 оценки движения может выполнять однонаправленное межкадровое предсказание или двунаправленное межкадровое предсказание для PU. Чтобы выполнять однонаправленное межкадровое предсказание для PU, модуль 122 оценки движения может осуществлять поиск опорных изображений в первом списке опорных изображений ("списке 0") или втором списке опорных изображений ("списке 1") для опорного блока для PU. Модуль 122 оценки движения может выводить в качестве информации движения для PU индекс опорного изображения, который указывает позицию в списке 0 или списке 1 опорного изображения, которое содержит опорный блок, вектор движения, который указывает пространственное смещение между пиксельным блоком PU и опорным блоком, и индикатор направления предсказания, который указывает, находится ли опорное изображение в списке 0 или списке 1.
Для выполнения двунаправленного межкадрового предсказания для PU модуль 122 оценки движения может осуществлять поиск опорных изображений в списке 0 для опорного блока для PU и может также осуществлять поиск опорных изображений в списке 1 для другого опорного блока для PU. Модуль 122 оценки движения может формировать индексы опорных изображений, которые указывают позиции в списке 0 и списке 1 опорных изображений, которые содержат опорные блоки. Кроме того, модуль 122 оценки движения может формировать векторы движения, которые указывают пространственные смещения между опорными блоками и пиксельным блоком для PU. Информация движения для PU может включать в себя индексы опорных изображений и векторы движения для PU. Модуль 124 компенсации движения может сформировать предсказанный пиксельный блок PU на основании опорных блоков, указанных информацией движения для PU.
Модуль 126 обработки внутрикадрового предсказания может формировать предсказанные данные для PU путем выполнения внутрикадрового предсказания на PU. Предсказанные данные для PU могут включать в себя предсказанный пиксельный блок для PU и различные синтаксические элементы. Модуль 126 обработки внутрикадрового предсказания может выполнять внутрикадровое предсказание на PU-единицах в I-слайсе, P-слайсе и B-слайсе.
Для выполнения внутрикадрового предсказания на PU, модуль 126 обработки внутрикадрового предсказания может использовать множественные режимы внутрикадрового предсказания для формирования множественных наборов предсказанных данных для PU. Чтобы использовать режим внутреннего предсказания для формирования множества предсказанных данных для PU, модуль 126 обработки внутрикадрового предсказания может расширять выборки из блоков выборок соседних PU по блокам выборок для PU в направлении, связанном с режимом внутреннего предсказания. Соседние PU могут находиться выше, выше и справа, выше и слева или слева от PU, в предположении очередности кодирования слева - направо, сверху - вниз для множества PU, CU и CTB. Модуль 126 обработки внутрикадрового предсказания может использовать различные числа режимов внутрикадрового предсказания, например 33 направленных режима внутрикадрового предсказания. В некоторых примерах число режимов внутрикадрового предсказания может зависеть от размера пиксельного блока у PU.
Модуль 100 обработки предсказания может выбирать предсказанные данные для PU в CU из числа предсказанных данных, сформированных модулем 121 обработки межкадрового предсказания для PU-единиц или предсказанных данных, сформированных модулем 126 обработки внутрикадрового предсказания для PU-единиц. В некоторых примерах модуль 100 обработки предсказания выбирает предсказанные данные для PU-единиц CU на основании метрик скорости/искажения множеств предсказанных данных. Предсказанные пиксельные блоки для выбранных предсказанных данных могут именоваться в документе выбранными предсказанными пиксельными блоками.
Модуль 102 формирования остатка может формировать на основании пиксельного блока CU и выбранных предсказанных пиксельных блоков PU-единиц в CU остаточный пиксельный блок CU. Например, модуль 102 формирования остатка может формировать остаточный пиксельный блок CU таким образом, что каждая выборка в остаточном пиксельном блоке имеет значение, равное разности между выборкой в пиксельном блоке CU и соответствующей выборкой в выбранном предсказанном пиксельном блоке у PU в CU.
Модуль 100 обработки предсказания может выполнять разделение типа квадрадерева, чтобы разделить остаточный пиксельный блок CU на суб-блоки. Каждый неразделенный остаточный пиксельный блок может связываться с различными TU в CU. Размеры и позиции остаточных пиксельных блоков, связанных с единицами TU в CU, могут или не могут основываться на размерах и позициях пиксельных блоков у PU в CU.
Поскольку пикселы остаточных пиксельных блоков TU-единиц могут содержать выборку яркости и две выборки цветности, каждая из TU-единиц может связываться с блоком выборок яркости и двумя блоками выборок цветности. Модуль 104 обработки преобразования может формировать блоки коэффициентов для каждого TU в CU путем применения одного или нескольких преобразований к остаточным блокам выборок, связанным с TU. Модуль 104 обработки преобразования может применять различные преобразования к остаточному блоку выборок, связанному с TU. Например, модуль 104 обработки преобразования может применять к остаточному блоку выборок дискретное косинусное преобразование (DCT), направленное преобразование или концептуально сходное преобразование.
Модуль 106 квантования может квантовать коэффициенты в блоке коэффициентов, связанном с TU. Процесс квантования может уменьшить битовую глубину, связанную с некоторыми или всеми коэффициентами. Например, n-битовый коэффициент может быть округлен в меньшую сторону к m-битовому коэффициенту в течение квантования, где n больше m. Модуль 106 квантования может квантовать блок коэффициентов, связанный с TU в CU, на основании значения параметра квантования (QP), связанного с CU. Видеокодер 20 может настраивать уровень квантования, применяемый к блокам коэффициентов, связанным с CU, настройкой значения QP, связанного с CU.
Модуль 108 обратного квантования и модуль 110 обработки обратного преобразования могут применять обратное квантование и обращенные преобразования к блоку коэффициентов соответственно, чтобы восстанавливать блок выборок остатка из блока коэффициентов. Модуль 112 восстановления может добавлять восстановленный блок выборок остатка к соответствующим выборкам из одного или нескольких предсказанных блоков выборок, сформированных модулем 100 обработки предсказания, чтобы выдать восстановленный блок выборок, связанный с TU. Путем восстановления блоков выборок для каждой TU в CU таким образом видеокодер 20 может восстанавливать пиксельный блок для CU.
Модуль 113 фильтра может выполнять операцию деблокирования, чтобы уменьшить артефакты блочности в пиксельном блоке, связанном с CU. Буфер 114 декодированных изображений может хранить восстановленные пиксельные блоки после того, как модуль 113 фильтра выполняет одну или несколько деблокирующих операций на восстановленных пиксельных блоках. Модуль 121 (обработки) межкадрового предсказания может использовать опорное изображение, которое содержит восстановленные пиксельные блоки, чтобы выполнять межкадровое предсказание на PU-единицах других изображений. Кроме того, модуль 126 обработки внутрикадрового предсказания может использовать восстановленные пиксельные блоки в буфере 114 декодированных изображений, чтобы выполнять внутрикадровое предсказание на других PU-единицах в том же изображении, что и CU.
Модуль 116 энтропийного кодирования может принимать данные от других функциональных компонентов видеокодера 20. Например, модуль 116 энтропийного кодирования может принимать блоки коэффициентов от модуля 106 квантования и может принимать синтаксические элементы от модуля 100 обработки предсказания. Модуль 116 энтропийного кодирования может выполнять одну или несколько операций энтропийного кодирования над данными для формирования энтропийно кодированных данных. Например, модуль 116 энтропийного кодирования может выполнять операцию контекстно-зависимого адаптивного кодирования с переменной длиной кодового слова (CAVLC), операцию контекстно-зависимого адаптивного двоичного арифметического кодирования (CABAC), операцию кодирования с длиной «из переменной в переменную» (V2V), операцию синтаксического контекстно-зависимого адаптивного двоичного арифметического кодирования (SBAC), операцию вероятностного с разбиением на интервалы энтропийного кодирования (PIPE), операцию кодирования экспоненциальным кодом Голомба или другой тип операции энтропийного кодирования над данными.
Видеокодер 20 может выводить битовый поток, который включает в себя энтропийно кодированные данные, сформированные модулем 116 энтропийного кодирования. Битовый поток может включать в себя серию узлов NAL. Узлы NAL могут включать в себя узлы NAL кодированных слайсов, узлы NAL SPS, узлы NAL PPS и так далее. Чтобы обеспечить, что изображение не включает в себя комбинации мозаичных фрагментов, WPP волн и энтропийных слайсов, битовый поток может включать в себя синтаксический элемент, указывающий, является ли изображение кодированным полностью с использованием WPP или является ли каждый мозаичный фрагмент изображения кодированным без использования WPP.
На фиг. 3 показана блок-схема, иллюстрирующая примерный видеодекодер 30, который сконфигурирован для реализации способов этого раскрытия. Фиг. 3 приводится с целью пояснения и не является ограничивающей способы, как в широком смысле проиллюстрировано и описано в этом раскрытии. С целью пояснения это раскрытие описывает видеодекодер 30 в контексте стандарта кодирования HEVC. Однако способы этого раскрытия могут быть применимыми к другим стандартам или способам кодирования.
В примере по фиг. 3 видеодекодер 30 включает в себя модуль 150 энтропийного декодирования, модуль 152 обработки предсказания, модуль 154 обратного квантования, модуль 156 обработки обратного преобразования, модуль 158 восстановления, модуль 159 фильтра и буфер 160 декодированных изображений. Модуль 152 обработки предсказания включает в себя модуль 162 компенсации движения и модуль 164 обработки внутрикадрового предсказания. В других примерах видеодекодер 30 может включать в себя больше, меньше компонентов или другие функциональные компоненты.
Видеодекодер 30 может принимать битовый поток. Модуль 150 энтропийного декодирования может осуществлять анализ битового потока, чтобы извлекать синтаксические элементы из битового потока. В качестве части анализа битового потока модуль 150 энтропийного декодирования может энтропийно декодировать энтропийно кодированные синтаксические элементы в битовом потоке. Модуль 152 обработки предсказания, модуль 154 обратного квантования, модуль 156 обработки обратного преобразования, модуль 158 восстановления и модуль 159 фильтра могут формировать декодированные видеоданные на основании синтаксических элементов, извлеченных из битового потока.
Битовый поток может содержать серию узлов NAL. Узлы NAL битового потока могут включать в себя узлы NAL кодированных слайсов. В качестве части анализа битового потока модуль 150 энтропийного декодирования может извлекать и энтропийно декодировать синтаксические элементы из узлов NAL кодированного слайса. Каждый из кодированных слайсов может включать в себя заголовок слайса и данные слайса. Заголовок слайса может содержать синтаксические элементы, относящиеся к слайсу. Синтаксические элементы в заголовке слайса могут включать в себя синтаксический элемент, который идентифицирует PPS, связанное с изображением, которое содержит слайс.
Кроме того, видеодекодер 30 может выполнять операцию восстановления на неразделенной CU. Для выполнения операции восстановления на неразделенной CU видеодекодер 30 может выполнять операцию восстановления на каждой TU в CU. Путем выполнения операции восстановления для каждой TU в CU, видеодекодер 30 может восстановить остаточный пиксельный блок, связанный с CU.
В качестве части выполнения операции восстановления на TU в CU модуль 154 обратного квантования может осуществлять обратное квантование, то есть выполнять операцию, обратную квантованию, блоки коэффициентов, связанные с TU. Модуль 154 обратного квантования может использовать значение QP, связанное с CU в TU, чтобы определять уровень квантования и, аналогично, уровень обратного квантования для модуля 154 обратного квантования, для применения.
После того как модуль 154 обратного квантования обращенно квантует блок коэффициентов, модуль 156 обработки обратного преобразования может применять одно или несколько обратных преобразований к блоку коэффициентов для формирования блока выборок остатка, связанного с TU. Например, модуль 156 обработки обратного преобразования может применять к блоку коэффициентов обратное DCT, обратное целочисленное преобразование, обратное преобразование Карунена - Лоэва (KLT), обратное вращательное преобразование, обратное направленное преобразование или другое обратное преобразование.
Если PU кодируется с использованием внутрикадрового предсказания, модуль 164 обработки внутрикадрового предсказания может выполнять внутрикадровое предсказание для формирования предсказанного блока выборок для PU. Модуль 164 обработки внутрикадрового предсказания может использовать режим внутрикадрового предсказания для формирования предсказанного пиксельного блока для PU на основании пиксельных блоков пространственно соседних PU. Модуль 164 обработки внутрикадрового предсказания может определить режим внутрикадрового предсказания для PU на основании одного или нескольких синтаксических элементов, полученных посредством анализа из битового потока.
Модуль 162 компенсации движения может строить первый список опорных изображений (список 0) и второй список опорных изображений (список 1) на основании синтаксических элементов, извлеченных из битового потока. Кроме того, если PU кодирован с использованием межкадрового предсказания, модуль 150 энтропийного декодирования может извлекать информацию движения для PU. Модуль 162 компенсации движения может определять на основании информации движения относительно PU, один или несколько опорных блоков для PU. Модуль 162 компенсации движения может сформировать на основании одного или нескольких опорных блоков для PU предсказанный пиксельный блок для PU.
Модуль 158 восстановления может использовать остаточные пиксельные блоки, связанные с TU-единицами в CU, и предсказанные пиксельные блоки для PU-единиц в CU, то есть либо данные внутрикадрового предсказания, либо данные межкадрового предсказания, в качестве применимых для восстановления пиксельного блока для CU. В частности модуль 158 восстановления может суммировать выборки остаточных пиксельных блоков с соответствующими выборками предсказанных пиксельных блоков, чтобы восстановить пиксельный блок для CU.
Модуль 159 фильтра может выполнять операцию деблокирования, чтобы уменьшить артефакты блочности, связанные с пиксельным блоком CU. Видеодекодер 30 может сохранять пиксельный блок CU в буфере 160 декодированных изображений. Буфер 160 декодированных изображений может обеспечивать опорные изображения для последующей компенсации движения, внутрикадрового предсказания и воспроизведения на устройстве отображения, таком как устройство 32 отображения по фиг. 1. Например, видеодекодер 30 может выполнять на основании пиксельных блоков в буфере декодированных изображений 160 операции внутрикадрового предсказания или межкадрового предсказания на PU-единицах другой CU.
Как упомянуто выше, видеодекодер 30 может принимать битовый поток, который включает в себя синтаксический элемент режима кодирования. Если синтаксический элемент режима кодирования имеет конкретное значение, синтаксический элемент режима кодирования указывает, что изображение кодируется полностью с использованием WPP. В различных примерах синтаксический элемент режима кодирования может находиться в различных сегментах битового потока. Например, SPS может включать в себя синтаксический элемент «режим кодирования». Ниже Таблица 1 приводит примерный синтаксис для SPS, которое включает в себя синтаксический элемент режима кодирования ("tile_mode").
Синтаксис RBSP набора параметров последовательности
Синтаксические элементы с дескриптором типа ue(v) являются беззнаковыми значениями переменной длины, закодированными с использованием кодирования экспоненциальным кодом Голомба с первым левым битом. Синтаксические элементы с дескриптором типа u(1) и u(2) являются беззнаковыми значениями, которые имеют длину в 1 или 2 бита соответственно. В примерном синтаксисе в Таблице 1 синтаксический элемент inter_4×4_enabled_flag задает, может ли применяться межкадровое предсказание к блокам, имеющим размер 4×4 выборок яркости.
Кроме того, в примерном синтаксисе в Таблице 1 синтаксический элемент tile_mode задает режим «мозаичные фрагменты» для изображений, связанных с SPS. Если синтаксический элемент tile_mode равен 0, имеется только один мозаичный фрагмент в каждом из изображений, связанных с SPS. CTB-единицы в одном мозаичном фрагменте каждого изображения кодируются в соответствии с порядком растрового сканирования без использования WPP. Если синтаксический элемент tile_mode равен 1, связанные с SPS изображения находятся в режиме однородно взаимно-расположенных мозаичных фрагментов. Когда изображение находится в режиме однородно взаимно-расположенных мозаичных фрагментов, границы столбца мозаичного фрагмента и границы ряда мозаичного фрагмента являются однородно взаимно-расположенными в каждом изображении, связанном с SPS. В результате, когда изображение находится в режиме однородно взаимно-расположенных мозаичных фрагментов, мозаичные фрагменты изображения имеют одинаковый размер. CTB-единицы внутри каждого из однородно взаимно-расположенных мозаичных фрагментов могут кодироваться в соответствии с порядком растрового сканирования без использования WPP. Если синтаксический элемент tile_mode равен 2, связанные с SPS изображения находятся не в режиме однородно взаимно-расположенных мозаичных фрагментов. Когда изображение находится в режиме неоднородно взаимно-расположенных мозаичных фрагментов, границы столбца мозаичного фрагмента и границы ряда мозаичного фрагмента не являются расположенными однородно по всему изображению, но могут сигнализироваться явно с использованием синтаксических элементов SPS column_width[i] (ширина столбца i) и row_height[i] (высота ряда). CTB-единицы внутри каждого из неоднородно взаимно-расположенных мозаичных фрагментов могут кодироваться в соответствии с порядком растрового сканирования без использования WPP.
Если синтаксический элемент tile_mode равен 3, связанные с SPS изображения кодируются с использованием режима WPP. Другими словами, если синтаксический элемент tile_mode имеет конкретное значение (например, 3), связанные с SPS изображения полностью кодируются с использованием WPP. Если синтаксический элемент tile_mode имеет какое-либо значение, отличное от 3, ни один мозаичный фрагмент любого изображения, связанного с SPS, не кодируется с использованием WPP. Кроме того, когда изображение кодируется с использованием WPP, специальный процесс запоминания инициируется после декодирования двух CTB ряда CTB-единиц изображения. Кроме того, специальный процесс синхронизации инициируется до декодирования первого CTB ряда CTB-единиц изображения. Кроме того, инициируется специальный процесс повторной инициализации состояния CABAC для внутренних переменных, если был закодирован крайний справа CTB ряда.
В упомянутом выше специальном процессе запоминания кодер видео может в ответ на определение, что первый CTB отделяется от левой границы изображения одним CTB, сохранять особые переменные контекста, связанные с первым CTB. В специальном процессе синхронизации кодер видео может энтропийно кодировать (то есть энтропийно закодировать или энтропийно декодировать) на основании, по меньшей мере частично, переменных контекста, связанных с первым CTB, один или несколько синтаксических элементов второго CTB, причем второй CTB, позиционируемый прилегающим к левой границе изображения и позиционируемый на один ряд CTB-единиц ниже, чем первый CTB.
Кроме того, в примерном синтаксисе в Таблице 1 синтаксический элемент num_tile_columns_minus1 задает число столбцов мозаичного фрагмента, разделяющих на части каждое из изображений, связанных с SPS. Когда синтаксический элемент tile_mode равен 0 или 3, можно вывести, что значение синтаксического элемента num_tile_columns_minus1 будет равным 0. Это происходит потому, что изображение имеет только один мозаичный фрагмент, когда синтаксический элемент tile_mode равен 0, и каждый CTB-ряд в изображении является одиночным мозаичным фрагментом, если синтаксический элемент tile_mode равен 3. Синтаксический элемент num_tile_rows_minus1 задает число рядов мозаичного фрагмента, разделяющих на части каждое из изображений, связанных с SPS. Когда синтаксический элемент tile_mode равен 0, можно вывести, что значение синтаксического элемента num_tile_rows_minus1 является равным 0. Когда синтаксический элемент tile_mode равен 3, видеодекодер 30 может автоматически определить (то есть сделать вывод), что значение синтаксического элемента num_tile_rows_minus1 равно высоте изображений в CTB-единицах минус 1. Кроме того, когда синтаксический элемент tile_mode равен 1 или 2, по меньшей мере один элемент из синтаксического элемента num_tile_columns_minus1 и синтаксического элемента num_tile_rows_minus1 имеет значение больше чем 0.
Видеодекодер 30 на основании синтаксических элементов column_width[i] и синтаксических элементов row_height[i] может определять значения ширины и высоты мозаичных фрагментов изображений, связанных с SPS. Синтаксические элементы column_width[i] указывают значения ширины столбцов мозаичных фрагментов изображений, связанных с SPS. Видеодекодер 30 может формировать на основании, по меньшей мере частично, синтаксических элементов column_width[i] вектор columnWidth, который указывает значения ширины столбцов мозаичных фрагментов в изображениях, связанных с SPS. Видеодекодер 30 может использовать следующий псевдокод для формирования вектора columnWidth из синтаксических элементов column_width[i] в SPS.


Видеодекодер 30 может формировать вектор rowHeight, который указывает значения высоты мозаичных фрагментов в изображениях, связанных с SPS. В некоторых примерах видеодекодер 30 может использовать следующий псевдокод для формирования вектора rowHeight.

Кроме того, видеодекодер 30 может формировать вектор colBd, который указывает позиции внутри изображений, связанных с SPS, для крайней левой границы столбца для каждого столбца мозаичных фрагментов. В некоторых примерах видеодекодер 30 может определять вектор colBd, используя следующий псевдокод.

Видеодекодер 30 может формировать вектор rowBd, который указывает позиции внутри изображения, связанного с SPS, верхнюю границу ряда для каждого ряда мозаичных фрагментов. В некоторых примерах видеодекодер 30 может определять вектор rowBd, используя следующий псевдокод.

В примерном синтаксисе в Таблице 1 синтаксический элемент tile_boundary_independence_flag указывает, являются ли мозаичные фрагменты независимо декодируемыми. Например, если tile_boundary_independence_flag равен 1, мозаичные фрагменты являются независимо декодируемыми. Например, если флаг tile_boundary_independence_flag равен 1 и видеодекодер 30 осуществляет декодирование конкретного CTB, все CTB-единицы, граничащие с конкретным CTB, которые не находятся внутри того же мозаичного фрагмента, что и конкретный CTB, определяются являющимися недоступными для предсказания внутри изображения. Кроме того, если tile_boundary_independence_flag равен 1, видеодекодер 30 повторно инициализирует контекст энтропийного кодирования до энтропийного декодирования первого CTB в мозаичном фрагменте.
Если синтаксический элемент tile_boundary_independence_flag равен 0, на доступность CTB-единиц для предсказания внутри изображения не влияют границы мозаичных фрагментов. Другими словами, если синтаксический элемент tile_boundary_independent_flag равен 0, видеодекодер 30 может выполнять внутрикадровое предсказание через границы мозаичного фрагмента. Кроме того, если синтаксический элемент tile_boundary_independence_flag равен 0, модуль 150 энтропийного декодирования может инициировать процесс синхронизации при декодировании первого CTB в мозаичном фрагменте, кроме первого древовидного блока в изображении. В этом процессе синхронизации модуль 150 энтропийного декодирования может использовать информацию, связанную с последним CTB предшествующего мозаичного фрагмента, чтобы выбирать контекст кодирования для энтропийного декодирования одного или нескольких синтаксических элементов первого CTB в мозаичном фрагменте. Кроме того, модуль 150 энтропийного декодирования может выполнять процесс запоминания при декодировании первого CTB второго ряда CTB в мозаичном фрагменте. Процесс запоминания может сохранять переменные контекста для использования в выборе контекста для кодирования по CABAC одного или нескольких синтаксических элементов крайнего левого CTB следующего более низкого ряда CTB-единиц.
Если синтаксический элемент tile_mode равен 0 (то есть имеется только один мозаичный фрагмент на одно изображение), SPS в примерном синтаксисе в Таблице 1 не включает в себя синтаксический элемент tile_boundary_independence_flag. Однако, если синтаксический элемент tile_mode равен 0, видеодекодер 30 может автоматически определить, что значение синтаксического элемента tile_boundary_independence_flag равно 1. Подобным образом, если синтаксический элемент tile_mode равен 3 (то есть изображение кодируется полностью с использованием WPP), SPS в примерном синтаксисе в Таблице 1 не включает в себя синтаксический элемент tile_boundary_independence_flag. Однако, если синтаксический элемент tile_mode равен 3, видеодекодер 30 может автоматически определить, что значение синтаксического элемента tile_boundary_independence_flag должно быть равным 0.
В примерном синтаксисе в Таблице 1 синтаксический элемент loop_filter_across_tile_flag задает, должен ли видеодекодер 30 выполнять операции внутрицикловой фильтрации через границы мозаичного фрагмента. Например, если синтаксический элемент loop_filter_across_tile_flag равен 1, видеодекодер 30 может выполнять операции внутрицикловой фильтрации через границы мозаичного фрагмента. Иначе, если синтаксический элемент loop_filter_across_tile_flag равен 0, видеодекодер 30 может не выполнять операции внутрицикловой фильтрации через границы мозаичного фрагмента. Пример операции внутрицикловой фильтрации может включать в себя деблокирующие фильтры, адаптивные к отчету смещения и адаптивные контурные фильтры.
Если синтаксический элемент tile_mode равен 0 (то есть имеется только один мозаичный фрагмент на одно изображение) или равен 3 (то есть каждое изображение, связанное со SPS, кодируется полностью с использованием WPP), SPS в примерном синтаксисе в Таблице 1 не включает в себя синтаксический элемент loop_filter_across_tile_flag. Однако, если синтаксический элемент tile_mode равен 0, видеодекодер 30 может автоматически определить, что значение синтаксического элемента loop_filter_across_tile_flag равно 0. Если синтаксический элемент tile_mode равен 3, видеодекодер 30 может автоматически определить, что значение синтаксического элемента loop_filter_across_tile_flag равно 1.
Альтернативно, или в дополнение к приему SPS, которое включает в себя синтаксисический элемент режима кодирования, видеодекодер 30 может принимать PPS, которое включает в себя синтаксический элемент режима кодирования. В некоторых примерах, где видеодекодер 30 принимает и SPS, и PPS, которые относятся к одному и тому же изображению, и SPS, и PPS включают в себя синтаксические элементы режима кодирования, видеодекодер 30 может давать приоритет синтаксическому элементу режима кодирования, заданному посредством PPS. В Таблице 2 ниже представлен примерный синтаксис PPS, который включает в себя синтаксический элемент режима кодирования ("tile_mode").
Синтаксис RBSP набора параметров изображения
В примерном синтаксисе в Таблице 2, если синтаксический элемент tile_partition_info_present_flag равен 1, синтаксический элемент tile_mode присутствует. Кроме того, если синтаксический элемент tile_partition_info_present_flag равен 1, синтаксические элементы num_tile_columns_minus1, num_tile_rows_minus1, column_width[i] и row_height[i] могут присутствовать в PPS. Семантика синтаксического элемента tile_mode, синтаксического элемента num_tile_columns_minus1, синтаксического элемента num_tile_rows_minus1, синтаксических элементов column_width и синтаксических элементов row_height может быть такой же, как описано выше относительно примерного синтаксиса SPS в Таблице 1. Если синтаксический элемент tile_partition_info_present_flag равен 0, синтаксические элементы tile_mode, num_tile_columns_minus1, num_tile_rows_minus1, column_width[i] и row_height[i] не присутствуют в PPS.
Таким образом, видеодекодер 30 может определять на основании, по меньшей мере частично, синтаксического элемента режима кодирования (например, tile_mode), имеющего значение, которое указывает, что CTB в изображении не кодируется с использованием WPP, что набор параметров (например, SPS или PPS) включает в себя синтаксический элемент «число столбцов мозаичного фрагмента» (tile column number) и синтаксический элемент «число рядов мозаичного фрагмента» (tile row number). Видеодекодер 30 может также определять на основании синтаксического элемента числа столбцов мозаичного фрагмента число столбцов мозаичных фрагментов. Число столбцов мозаичных фрагментов для каждого изображения, связанного с набором параметров, может быть равным числу столбцов мозаичного фрагмента. Видеодекодер 30 может также определять на основании синтаксического элемента числа рядов мозаичного фрагмента число рядов мозаичного фрагмента. Число рядов мозаичных фрагментов каждого изображения, связанного с набором параметров, может быть равным числу рядов мозаичного фрагмента. Кроме того, видеодекодер 30 может определять, что набор параметров (например, SPS или PPS) включает в себя серию из одного или нескольких синтаксических элементов «ширина столбца» и серию из одного или нескольких синтаксических элементов «высота мозаичных фрагментов». Кроме того, видеодекодер 30 может определять на основании, по меньшей мере частично, синтаксических элементов ширины столбца ширины столбцов мозаичных фрагментов каждого изображения, связанного с набором параметров. Кроме того, видеодекодер 30 может определять на основании, по меньшей мере частично, синтаксических элементов высоты мозаичного фрагмента высоты мозаичных фрагментов каждого изображения, связанного с набором параметров.
Подобным образом видеокодер 20 может формировать набор значений параметров, который включает в себя синтаксический элемент числа столбцов мозаичного фрагмента и синтаксический элемент числа рядов мозаичного фрагмента. Набором параметров может быть набор параметров изображения (PPS) или набор параметров последовательности (SPS). Число столбцов мозаичного фрагмента может быть определено на основании синтаксического элемента числа столбцов мозаичного фрагмента, и число столбцов мозаичных фрагментов каждого изображения, связанного с набором параметров, является равным числу столбцов мозаичного фрагмента. Число рядов мозаичных фрагментов может быть определено на основании синтаксического элемента числа рядов мозаичного фрагмента, и число рядов мозаичных фрагментов каждого изображения, связанного с набором параметров, является равным числу рядов мозаичного фрагмента. Когда видеокодер 20 формирует набор параметров, видеокодер 20 может формировать серию из одного или нескольких синтаксических элементов ширины столбца и серию из одного или нескольких синтаксических элементов высоты ряда. Значения ширины столбцов мозаичных фрагментов каждого изображения, связанного с набором параметров, могут быть определимыми на основании, по меньшей мере частично, синтаксических элементов ширины столбца. Значения высоты рядов мозаичных фрагментов каждого изображения, связанного с набором параметров, могут быть определимыми на основании, по меньшей мере частично, синтаксических элементов высоты ряда.
Кроме того, в примерном синтаксисе в Таблице 2, если синтаксический элемент tile_control_info_present_flag равен 1, синтаксические элементы tile_boundary_independence_flag и loop_filter_across_tile_flag могут присутствовать в PPS. Если синтаксический элемент tile_control_info_present_flag равен 0, синтаксические элементы tile_boundary_independence_flag и loop_filter_across_tile_flag не присутствуют в PPS.
В примерном синтаксисе в Таблице 2, если entropy_slice_enabled_flag равен 1, кодированные слайсы, которые относятся к PPS, могут включать в себя (и могут состоять из) один или несколько энтропийных слайсов. Если синтаксический элемент entropy_slice_enabled_flag равен 0, кодированные слайсы, которые относятся к PPS, не содержат энтропийные слайсы. Когда синтаксический элемент entropy_slice_enabled_flag не присутствует, видеодекодер 30 может автоматически определить (то есть вывести), что синтаксический элемент entropy_slice_enabled_flag равен 0. Семантика для других синтаксических элементов PPS может быть такой же, как семантика, определенная в WD5 HEVC.
В примерном синтаксисе в Таблице 2 PPS включает в себя только синтаксический элемент entropy_slice_enabled_flag, если синтаксический элемент tile_mode равен 0. Как обсуждено выше, видеодекодер 30 может определять на основании синтаксического элемента tile_mode, использовать ли WPP, чтобы декодировать CTB-единицы каждого мозаичного фрагмента изображения. Таким образом, видеодекодер 30 может определять на основании синтаксического элемента режима кодирования (например, tile_mode), имеющего конкретное значение, что битовый поток включает в себя дополнительный синтаксический элемент (например, entropy_slice_enabled_flag), который указывает, разрешаются ли энтропийные слайсы для кодированных представлений изображений, которые относятся к набору параметров (например, SPS или PPS), который включает в себя синтаксический элемент режима кодирования и дополнительный синтаксический элемент.
Как описано выше, узел NAL кодированного слайса может включать в себя кодированное представление слайса. Кодированное представление слайса может включать в себя заголовок слайса, за которым следуют данные слайса. В некоторых примерах видеодекодер 30 может определять на основании, по меньшей мере частично, синтаксического элемента режима кодирования (например, tile_mode), включает ли в себя заголовок слайса совокупность синтаксических элементов «смещение точки входа», из которых могут быть определены точки входа для подпотоков в данных слайса. В ответ на определение, что заголовок слайса включает в себя синтаксические элементы смещения точки входа, видеодекодер 30 может использовать множество синтаксических элементов смещения точки входа, чтобы определить точки входа подпотоков в данных слайса. Другими словами, видеодекодер 30 может определять на основании, по меньшей мере частично, синтаксических элементов смещения позиции в памяти для подпотоков. Если синтаксический элемент режима кодирования имеет значение (например, 3), каждый ряд из CTB-единиц изображения представлен одним некоторым из подпотоков. Если синтаксический элемент режима кодирования имеет другое значение (например, 0, 1 или 2), каждый мозаичный фрагмент изображения, у которого имеется один или несколько CTB-единиц в слайсе, представлен одним некоторым из подпотоков. Заголовок слайса может соответствовать примерному синтаксису из Таблицы 3, ниже.
Синтаксис заголовка слайса
В примерном синтаксисе в Таблице 3 значение синтаксических элементов заголовка слайса "pic_parameter_set_id", "frame_num", "idr_pic_id", "pic_order_cnt_lsb", "delta_pic_order_cnt[0]" и "delta_pic_order_cnt[1]" одинаково во всех заголовках слайсов кодированного изображения. Кроме того, в примерном синтаксисе в Таблице 3 синтаксический элемент first_slice_in_pic_flag указывает, включает ли слайс в себя CU, которая охватывает верхнюю левую выборку яркости изображения. Если синтаксический элемент first_slice_in_pic_flag равен 1, видеодекодер 30 может установить переменные и SliceAddress, и LCUAddress в 0 и видеодекодер 30 может запустить декодирование с первого CTB в изображении.
Кроме того, в примерном синтаксисе в Таблице 3 синтаксический элемент slice_address задает в разрешающей способности гранулярности слайса адрес, с которого начинается слайс. Разрешающей способностью гранулярности слайса является гранулярность, с которой задается слайс. Число битов в синтаксическом элементе slice_address может быть равным (Ceil(Log2(NumLCUsInPicture))+SliceGranularity), где "NumLCUsInPicture" - число CTB-единиц в изображении.
В примерном синтаксисе в Таблице 3 видеодекодер 30 устанавливает переменную LCUAddress в (slice_address>> SliceGranularity). Переменная LCUAddress указывает для слайса LCU часть адреса слайса в порядке растрового сканирования. Видеодекодер 30 устанавливает переменную GranularityAddress в (slice_address - (LCUAddress << SliceGranularity)). Переменная GranularityAddress представляет часть суб-LCU адреса слайса. Переменная GranularityAddress выражается в виде порядка z-сканирования.
Видеодекодер 30 устанавливает переменную SliceAddress (LCUAddress << (log2_diff_max_min_coding_block_size <<1))+ (GranularityAddress << ((log2_diff_max_min_coding_block_size <<1)-SliceGranularity)). Значение log2_diff_max_min_coding_block_size задает разность между максимальным и минимальным размером CU. Видеодекодер 30 может начинать декодирование слайса с наибольшей CU, возможной в начальной координате слайса. Начальная координата слайса может быть координатой верхнего левого пиксела первой CU в слайсе.
Кроме того, в примерном синтаксисе в Таблице 3, синтаксис cabac_init_idc задает индекс для определения таблицы инициализации, используемой в процессе инициализации для переменных контекста. Значение синтаксического элемента cabac_init_idc может находиться в интервале от 0 до 2, включительно.
В примерном синтаксисе в Таблице 3 синтаксический элемент num_entry_offsets задает количество синтаксических элементов entry_offset[i] в заголовке слайса. Другими словами, число синтаксических элементов смещения точки входа в множестве синтаксических элементов смещения точки входа может быть определено на основании синтаксического элемента num_entry_offsets. Когда синтаксический элемент num_entry_offsets не присутствует, видеодекодер 30 может определить, что значение синтаксического элемента num_entry_offsets равно 0. Таким образом, видеодекодер 30 может определять на основании синтаксического элемента num_entry_offsets, сколько синтаксических элементов смещения находится в совокупности синтаксических элементов смещения точки входа. Синтаксический элемент offset_len_minus8, плюс 8, задает длину в битах синтаксических элементов entry_offset[i]. Другими словами, длина в битах каждого из синтаксических элементов смещения точки входа может быть определена на основании синтаксического элемента offset_len_minus8. Таким образом, видеодекодер 30 может определять на основании синтаксического элемента offset_len_minus8 длину в битах для синтаксических элементов смещения. Синтаксический элемент entry_offset[i] задает в байтах i-ое смещение точки входа.
Видеодекодер 30 может осуществлять анализ синтаксических элементов смещения из битового потока на основании, по меньшей мере частично, количества синтаксических элементов смещения, находящихся в совокупности синтаксических элементов смещения, и размера в битах синтаксических элементов смещения. Число подпотоков в узле NAL кодированного слайса может быть равным num_entry_offsets + 1. Значения индексов для подпотоков могут находиться в интервале 0 до num_entry_offsets, включительно. Подпоток 0 узла NAL кодированного слайса может состоять из байтов от 0 до entry_offset[0]-1, включительно, для данных слайса в узле NAL кодированного слайса. Подпоток k для узла NAL кодированного слайса, при k в интервале от 1 до num_entry_offsets - 1, включительно, может состоять из байтов от entry_offset[k-1] до entry_offset[k]-1, включительно, для данных слайса узла NAL кодированного слайса. Последний подпоток узла NAL кодированного слайса (с индексом подпотока, равным num_entry_offsets) может состоять из остальных байтов данных слайса узла NAL кодированного слайса.
В примерном синтаксисе в Таблице 3, если синтаксический элемент tile_mode больше 0, каждый подпоток с индексом подпотока в интервале от 1 до num_entry_offsets - 1 содержит каждый кодированный бит одного мозаичного фрагмента и подпоток с индексом 0 подпотока содержит либо каждый кодированный бит мозаичного фрагмента, либо конечные кодированные биты мозаичного фрагмента. Конечные кодированные биты являются кодированными битами мозаичного фрагмента, кодируемыми в конце мозаичного фрагмента. Кроме того, если синтаксический элемент tile_mode больше 0, последний подпоток (то есть подпоток с индексом подпотока, равным num_entry_offsets) содержит или все кодированные биты мозаичного фрагмента или число начальных кодированных битов мозаичного фрагмента. Начальные кодированные биты мозаичного фрагмента являются кодированными битами, кодируемыми в начале мозаичного фрагмента. Подпоток не содержит кодированные биты более чем одного мозаичного фрагмента. В примерном синтаксисе в Таблице 3 заголовок узла NAL и заголовок слайса в узле NAL кодированного слайса всегда включаются в подпоток 0. Если синтаксический элемент tile_mode равен 0 и синтаксический элемент entropy_slice_enabled_flag равен 1, каждый подпоток содержит каждый кодированный бит одного энтропийного слайса и не содержит кодированные биты другого энтропийного слайса.
В примерном синтаксисе в Таблице 3 синтаксический элемент entropy_slice_address[i] задает начальный адрес в разрешении для гранулярности слайса (i+1)-ого энтропийного слайса в узле NAL кодированного слайса. Размер в битах каждого из синтаксических элементов entropy_slice_address[i] может быть равным (Ceil(log2(NumLCUsInPicture)) + SliceGranularity).
Кроме того, в примерном синтаксисе в Таблице 3 синтаксический элемент "entropy_slice_cabac_init_idc[i]" задает индекс для определения таблицы инициализации, используемой в процессе инициализации, для переменных контекста для (i+1)-ого энтропийного слайса в узле NAL кодированного слайса. Значение entropy_slice_cabac_init_idc[i] находится в интервале от 0 до 2 включительно. Семантика других синтаксических элементов заголовка слайса может быть такой же, как семантика, определенная в WD5 HEVC.
В некоторых примерах синтаксические элементы entry_offset[i] указывают смещения подпотоков в единицах битов. Кроме того, в некоторых примерах заголовок слайса может включать в себя флаг, который указывает, выражена ли единица "entry_offset[i]" байтами (если равен 1) или битами (если равен 0). Этот флаг может находиться в заголовке слайса после синтаксического элемента offset_len_minus8.
Кроме того, в некоторых примерах заголовок слайса может включать в себя синтаксический элемент для каждого подпотока, включая подпоток 0, для указания типа подпотока для соответственного подпотока. В этом примере, если синтаксический элемент для подпотока имеет первое значение, подпоток является мозаичным фрагментом. Если синтаксический элемент для подпотока имеет второе значение, подпоток является энтропийным слайсом.
Как упомянуто выше, кодированное представление может включать в себя заголовок слайса и данные слайса. Данные слайса могут включать в себя один или несколько подпотоков. Если синтаксический элемент режима кодирования имеет первое значение (например, 3), каждый ряд CTB-единиц изображения представлен одним подпотоком из подпотоков. Если синтаксический элемент имеет второе значение (например, 0, 1 или 2), каждый мозаичный фрагмент изображения, у которого имеется одна или несколько CTB-единиц в слайсе, представлен одним подпотоком из подпотоков. Чтобы содействовать WPP или декодированию мозаичных фрагментов слайса параллельно, подпотоки в данных слайса могут включать в себя биты заполнения, которые обеспечивают выравнивание байта для подпотоков. Однако в случаях, где имеется только один мозаичный фрагмент в изображении и энтропийные слайсы не разрешаются, может не требоваться включение таких битов заполнения. Соответственно, видеодекодер 30 может определять на основании, по меньшей мере частично, синтаксического элемента режима кодирования (например, tile_mode), включают ли подпотоки в данных слайса биты заполнения, которые обеспечивают выравнивание байта для подпотоков.
Данные слайса могут соответствовать примерному синтаксису по Таблице 4 ниже.
В примерном синтаксисе в Таблице 4 данные слайса включают в себя функцию coding_tree(). Когда видеодекодер 30 осуществляет анализ данных слайса, видеодекодер 30 может выполнять цикл. В течение каждой итерации цикла видеодекодер 30 активизирует функцию coding_tree(), чтобы осуществлять анализ кодированного CTB в данных слайса. Когда видеодекодер 30 активизирует функцию coding_tree(), чтобы осуществлять анализ конкретного кодированного CTB, видеодекодер 30 может осуществлять анализ синтаксического элемента end_of_slice_flag из данных слайса. Если синтаксический элемент end_of_slice_fiag равен 0, то имеется другой CTB, следующий после конкретного кодированного CTB в слайсе, или энтропийный слайс. Если синтаксический элемент end_of_slice_flag равен 1, конкретный кодированный CTB является последним кодированным CTB слайса или энтропийного слайса.
Кроме того, примерный синтаксис в Таблице 4 включает в себя функцию byte_index(). Функция byte_index() может возвращать индекс байта текущей позиции внутри битов узла NAL. Текущей позицией внутри битов в узле NAL может быть первый непроанализированный бит узла NAL. Если следующим битом в битовом потоке является какой-либо бит из первого байта заголовка узла NAL, функция byte_index() возвращает значение, равное 0.
Синтаксис данных слайса в Таблице 4 является примером. В другом примере синтаксических конструкций для данных слайса условие "if(tile_mode!=0 || entropy_slice_enabled_flag)" в Таблице 4 заменяется условием "if(tile_mode==1 || tile_mode==2 || entropy_slice_enabled_flag)".
На фиг. 4 показана структурная схема последовательностей двоичных сигналов 200 видеокодера 20 для кодирования видеоданных, в котором комбинации мозаичных фрагментов и WPP волн внутри одного изображения не допускаются, в соответствии с одним или несколькими аспектами этого раскрытия. Фиг. 4 приведена в качестве примера. В других примерах способы этого раскрытия могут быть осуществлены с использованием большего числа, меньшего числа или других этапов, чем показаны в примере по фиг. 4.
В примере по фиг. 4 видеокодер 20 формирует первое кодированное изображение путем кодирования изображения согласно первому режиму кодирования (202). Когда видеокодер 20 кодирует изображение согласно первому режиму кодирования, изображение кодируется полностью с использованием WPP. Кроме того, видеокодер 20 может формировать второе кодированное изображение путем кодирования изображения согласно второму режиму кодирования (204). Когда видеокодер 20 кодирует изображение согласно второму режиму кодирования, видеокодер 20 может разделять изображение на один или несколько мозаичных фрагментов. Видеокодер 20 может закодировать каждый мозаичный фрагмент изображения (то есть закодировать каждый CTB в каждом из мозаичных фрагментов) без использования WPP. Например, видеокодер 20 может закодировать CTB-единицы каждого из мозаичных фрагментов в соответствии с порядком растрового сканирования без использования WPP. Видеокодер 20 может затем выбрать первое кодированное изображение или второе кодированное изображение (206). В некоторых примерах видеокодер 20 может выбирать первое кодированное изображение или второе кодированное изображение на основании анализа скорости/искажения для первого и второго кодированных изображений. Видеокодер 20 может формировать битовый поток, который включает в себя выбранное кодированное изображение и синтаксический элемент, указывающий, кодировано ли изображение согласно первому режиму кодирования или согласно второму режиму кодирования (208).
На фиг. 5 показана структурная схема, иллюстрирующая примерное действие 220 видеодекодера 30 для декодирования видеоданных, в котором комбинации мозаичных фрагментов и WPP внутри одного изображения не допускаются, в соответствии с одним или несколькими аспектами этого раскрытия. Фиг. 5 приведена в качестве примера.
В примере по фиг. 5 видеодекодер 30 может осуществлять анализ синтаксического элемента из битового потока, включающего в себя кодированное представление изображения в видеоданных (222). Видеодекодер 30 может определять, имеет ли синтаксический элемент конкретное значение (224). В ответ на определение, что синтаксический элемент имеет конкретное значение ("ДА" 224), видеодекодер 30 может декодировать изображения полностью с использованием WPP (226). В ответ на определение, что синтаксический элемент не имеет конкретного значения ("НЕТ" 224), видеодекодер 30 может декодировать каждый мозаичный фрагмент изображения без использования WPP, причем изображение имеет один или несколько мозаичных фрагментов (228).
На фиг. 6 показана структурная схема, иллюстрирующая примерное действие 230 видеодекодера 30 для декодирования видеоданных, в котором комбинации мозаичных фрагментов и WPP внутри одного изображения не допускаются, в соответствии с одним или несколькими аспектами этого раскрытия. Фиг. 6 приведена в качестве примера. В других примерах способы этого раскрытия могут быть осуществлены с использованием большего числа, меньшего числа или других этапов, чем показаны в примере по фиг. 6. Фиг. 6 может быть более конкретным примером действия 220 по фиг. 5.
В примере по фиг. 6 видеодекодер 30 принимает битовый поток (231). Видеодекодер 30 может осуществлять анализ синтаксического элемента из битового потока (232). В некоторых примерах битовый поток включает в себя SPS, которое включает в себя синтаксический элемент. В других примерах битовый поток включает в себя PPS, которое включает в себя синтаксический элемент.
Затем видеодекодер 30 может определять, имеет ли синтаксический элемент первое значение, например 0 (234). В примере по фиг. 6, если синтаксический элемент имеет первое значение ("ДА" 234), изображение имеет одиночный мозаичный фрагмент и видеодекодер 30 может декодировать одиночный мозаичный фрагмент изображения без использования WPP (236).
Однако, если синтаксический элемент не имеет первое значение ("НЕТ" 234), видеодекодер 30 может определять, имеет ли синтаксический элемент второе значение, например, 1 (238). В ответ на определение, что синтаксический элемент имеет второе значение ("ДА" 238), видеодекодер 30 может определить, что в изображении имеются множественные мозаичные фрагменты с однородным взаиморасположением, и видеодекодер 30 может декодировать каждый из мозаичных фрагментов с однородным взаиморасположением без использования WPP (238).
С другой стороны, если синтаксический элемент не имеет второе значение ("НЕТ" 238), видеодекодер 30 может определять, имеет ли синтаксический элемент третье значение, например, 2 (242). В ответ на определение, что синтаксический элемент имеет третье значение ("ДА" 242), видеодекодер 30 может определить, что в изображении имеются множественные мозаичные фрагменты с неоднородным взаиморасположением, и видеодекодер 30 может декодировать мозаичные фрагменты изображения с неоднородным взаиморасположением без использования WPP (244). Однако в ответ на определение, что синтаксический элемент не имеет третье значение ("НЕТ" 242), видеодекодер 30 может декодировать изображение полностью с использованием WPP (246). Таким образом, если синтаксический элемент имеет первое значение (например, 3), изображение кодировано полностью с использованием WPP, и если синтаксический элемент имеет второе значение, отличающееся от первого значения (например, 0,1 или 2), изображение разделено на один или несколько мозаичных фрагментов, и изображение кодировано без использования WPP.
На фиг. 7 показана структурная схема, иллюстрирующая примерное действие 270 видеокодера 20 для кодирования видеоданных, в котором каждый ряд CTB-единиц изображения находится в отдельном подпотоке, в соответствии с одним или несколькими аспектами этого раскрытия. В некоторых системах кодирования видео существуют различные пути сигнализации точки входа для мозаичных фрагментов и WPP волн. Это может повышать сложность этих систем кодирования видео. Способы этого раскрытия, и как пояснено в отношении фиг. 7 и 8, могут решить эти вопросы обеспечением единообразного синтаксиса для указания точек входа для мозаичных фрагментов, WPP волн и в некоторых примерах энтропийных слайсов.
В примере по фиг. 7 видеокодер 20 сигнализирует, что используется WPP, чтобы закодировать изображение последовательности видеоизображений (272). Видеокодер 20 может сигнализировать различным образом, что используется WPP для кодирования изображения. Например, видеокодер 20 может формировать SPS, которое включает в себя синтаксический элемент (например, "tile_mode"), который указывает, должно ли использоваться WPP, чтобы полностью декодировать изображение. В другом примере видеокодер 20 может формировать PPS, которое включает в себя синтаксический элемент (например, "tile_mode"), который указывает, должно ли использоваться WPP, чтобы декодировать изображение.
Кроме того, видеокодер 20 может выполнять WPP, чтобы формировать множество подпотоков (274). Каждый из подпотоков может включать в себя последовательную серию битов, которая представляет один кодированный ряд CTB-единиц в слайсе изображения. Таким образом, каждый ряд CTB-единиц кодируется как один подпоток. Видеокодер 20 может формировать узел NAL кодированного слайса, который включает в себя множество подпотоков (276). Узел NAL кодированного слайса может включать в себя заголовок слайса и данные слайса, которые соответствуют примерному синтаксису в Таблицах 3 и 4, выше.
На фиг. 8 показана структурная схема, иллюстрирующая примерное действие 280 видеодекодера 30 для декодирования видеоданных, в котором каждый ряд CTB-единиц изображения находится в отдельном подпотоке, в соответствии с одним или несколькими аспектами этого раскрытия. В примере по фиг. 8 видеодекодер 30 принимает битовый поток, который включает в себя узел NAL кодированного слайса (282). Узел NAL кодированного слайса включает в себя множество подпотоков. Каждый из подпотоков может включать в себя последовательную серию битов, которая представляет один ряд CTB-единиц в слайсе изображения. Кроме того, в примере по фиг. 8 видеодекодер 30 определяет на основании одного или нескольких синтаксических элементов в битовом потоке, что слайс кодирован с использованием WPP (284). Например, видеодекодер 30 может определять на основании синтаксического элемента tile_mode, являющегося равным 3, что слайс является кодированным с использованием WPP. В этом примере, если синтаксический элемент tile_mode не равен 3, видеодекодер 30 может декодировать каждый фрагмент из одного или нескольких мозаичных фрагментов изображения без использования WPP.
Затем видеодекодер 30 может декодировать слайс с использованием WPP (286). Когда видеодекодер 30 декодирует слайс, видеодекодер 30 может осуществлять анализ синтаксических элементов, связанных с CTB-единицами в слайсе. Видеодекодер 30 может выполнять процесс анализа для CABAC на некоторых из синтаксических элементов в качестве части анализа синтаксических элементов, связанных с CTB-единицами.
На фиг. 9A показана блок-схема, иллюстрирующая первый сегмент примерного процесса 300 анализа для CABAC, чтобы анализировать данные слайса, в соответствии с одним или несколькими аспектами этого раскрытия. Видеодекодер 30 может выполнять процесс по фиг. 9A при анализе синтаксических элементов с дескриптором ae(v) в данных слайса и в синтаксисе дерева кодирования. Процесс по фиг. 9A может выводить значение синтаксического элемента.
В примере по фиг. 9A модуль 150 энтропийного декодирования видеодекодера 30 выполняет инициализацию процесса анализа для CABAC (302). В некоторых примерах инициализация процесса анализа для CABAC является такой же, как это описано в подпункте 9.2.1 WD5 HEVC.
Кроме того, модуль 150 энтропийного декодирования может определять адрес соседнего CTB (304). Соседним CTB может быть CTB, который содержит блок, который граничит с текущим CTB (то есть CTB, который видеодекодер 30 декодирует в текущий момент) слева, выше слева, выше или выше справа. В некоторых примерах модуль 150 энтропийного декодирования может определять адрес соседнего CTB в виде:
tbAddrT=cuAddress(x0+2*(1<<Log2MaxCUSize)-1, y0-1)
В формуле выше tbAddrT обозначает адрес соседнего CTB, x0 обозначает координату x верхней левой выборки яркости текущего CTB, y0 обозначает координату y верхней левой выборки яркости текущего CTB и Log2MaxCUSize обозначает логарифм по основанию 2 максимального размера CU. Функция cuAddress возвращает адрес CU, который включает в себя координату x, заданную первым параметром, и координату y, заданную вторым параметром.
Затем модуль 150 энтропийного декодирования может использовать адрес соседнего CTB, чтобы определить доступность соседнего CTB для предсказания (306) внутри изображения. Другими словами, модуль 150 энтропийного декодирования может определять, доступна ли информация, связанная с соседним CTB, для использования в выборе контекста CABAC.
Модуль 150 энтропийного декодирования может определять доступность соседнего CTB для предсказания внутри изображения другим образом. Например, модуль 150 энтропийного декодирования может выполнять процесс, описанный в подпункте 6.4.3 WD5, с tbAddrT в качестве входного значения, чтобы определить доступность соседнего CTB для предсказания внутри изображения. В другом примере модуль 150 энтропийного декодирования может определять, что CTB является доступным для предсказания внутри изображения, если не является истинным одно из следующих условий. Если одно из следующих условий является истинным, модуль 150 энтропийного декодирования может определить, что CTB является недоступным для предсказания внутри изображения. Во-первых, модуль 150 энтропийного декодирования может определить, что CTB является недоступным для предсказания внутри изображения, если адрес CTB меньше 0. Во-вторых, модуль 150 энтропийного декодирования может определить, что CTB является недоступным для предсказания внутри изображения, если адрес CTB больше адреса CTB, который модуль 150 энтропийного декодирования в текущий момент анализирует. В-третьих, модуль 150 энтропийного декодирования может определить, что конкретный CTB является недоступным для предсказания внутри изображения, если конкретный CTB принадлежит другому слайсу, чем CTB, который в текущий момент модуль 150 энтропийного декодирования синтаксически анализирует. Например, если адрес конкретного CTB обозначен как tbAddr и адрес CTB, который в текущий момент синтаксически анализирует модуль 150 энтропийного декодирования, обозначен как CurrTbAddr, модуль 150 энтропийного декодирования может определить, что CTB с адресом tbAddr принадлежит другому слайсу, чем CTB с адресом CurrTbAddr. В-четвертых, модуль 150 энтропийного декодирования может определить, что CTB является недоступным для предсказания внутри изображения, если один или несколько синтаксических элементов в битовом потоке указывают, что мозаичные фрагменты изображения, которое в текущий момент декодирует видеодекодер 30, являются независимо декодируемыми и CTB находится в другом мозаичном фрагменте, чем CTB, который в текущий момент синтаксически анализирует модуль 150 энтропийного декодирования. Например, модуль 150 энтропийного декодирования может определить, что CTB является недоступным для предсказания внутри изображения, если равен 1 синтаксический элемент tile_boundary_independence_flag примерного синтаксиса из Таблицы 1, и CTB с адресом tbAddr содержится в другом мозаичном фрагменте, чем CTB с адресом CurrTbAddr.
Кроме того, модуль 150 энтропийного декодирования может определять, находится ли синтаксический элемент, который в текущий момент синтаксически анализирует модуль 150 энтропийного декодирования (то ест, текущий синтаксический элемент), в синтаксической структуре дерева кодирования (308). Если текущий синтаксический элемент не находится в синтаксической структуре дерева кодирования ("НЕТ" 308), модуль 150 энтропийного декодирования может выполнять часть процесса 300 анализа для CABAC, показанного на фиг. 9B. С другой стороны, если текущий синтаксический элемент находится в структуре дерева кодирования ("ДА" 308), модуль 150 энтропийного декодирования может определять, являются ли мозаичные фрагменты текущего изображения (то есть изображения, которое включает в себя текущий CTB) независимо декодируемыми (310). Например, в примерном синтаксисе SPS по Таблице 1 модуль 150 энтропийного декодирования может определить, что мозаичные фрагменты текущего изображения являются независимо декодируемыми, если SPS, связанное с текущим изображением, включает в себя синтаксический элемент tile_boundary_independence_flag, который равен 1. В ответ на определение, что мозаичные фрагменты текущего изображения являются независимо декодируемыми ("ДА" 310), модуль 150 энтропийного декодирования может выполнять часть процесса 300 анализа по CABAC, показанного на фиг. 9B.
Однако в ответ на определение, что мозаичные фрагменты текущего изображения не являются независимо декодируемыми ("НЕТ" 310), модуль 150 энтропийного декодирования может определять, является ли равным 0 значение tbAddr % picWidthInLCUs, где tbAddr - адрес соседнего CTB, % обозначает оператор (деления) по модулю и picWidthlnLCUs указывает ширину текущего изображения в CTB-единицах (то есть LCU-единицах) (312).
В ответ на определение, что tbAddr % picWidthlnLCUs равно 0 ("ДА" 312), модуль 150 энтропийного декодирования может определять, является ли доступным соседний CTB для предсказания (314) внутри изображения. В некоторых примерах модуль 150 энтропийного декодирования может выполнять в действии 306 процесс для определения значения переменной availableFlagT, которая указывает, доступен ли соседний CTB для предсказания внутри изображения. Если переменная availableFlagT равна 1, соседний CTB является доступным для предсказания внутри изображения. В действии 314 модуль 150 энтропийного декодирования может определять, равна ли 1 переменная availableFlagT.
В ответ на определение, что соседний CTB является доступным для предсказания внутри изображения ("ДА" 314), модуль 150 энтропийного декодирования может выполнять процесс синхронизации для процесса анализа по CABAC (316). В некоторых примерах модуль 150 энтропийного декодирования может выполнять процесс синхронизации, описанный в подпункте 9.2.1.3 WD5 HEVC. После выполнения процесса синхронизации или в ответ на определение, что соседний CTB не является доступным для предсказания внутри изображения ("НЕТ" 314), модуль 150 энтропийного декодирования может выполнять процесс декодирования для двоичных решений (дерева решений) до завершения (318). В целом процесс декодирования для двоичных решений перед завершением является специальным процессом декодирования для энтропийного декодирования синтаксических элементов end_of_slice_flag и pcm_flag. Видеодекодер 30 может использовать end_of_slice_flag и pcm_flag для принятия двоичных решений до завершения процесса анализа данных слайса. В некоторых примерах модуль 150 энтропийного декодирования может выполнять процесс декодирования для двоичных решений до завершения, как определено в подпункте 9.2.3.2.4 WD5 HEVC.
После выполнения процесса декодирования для двоичных решений до завершения (318) модуль 150 энтропийного декодирования может выполнять процесс инициализации для процессора арифметического декодирования (320). В некоторых примерах модуль 150 энтропийного декодирования может выполнять процесс инициализации, определенный в подпункте 9.2.1.4 WD5 HEVC. После выполнения процесса инициализации для процессора арифметического декодирования модуль 150 энтропийного декодирования может выполнять часть процесса 300 анализа по CABAC, показанного на фиг. 9B.
Если tbAddr % picWidthlnLCUs не является равным 0 ("НЕТ" 312), модуль 150 энтропийного декодирования может определять, равно ли 2 значение tbAddr % picWidthlnLCUs (322). Другими словами, модуль 150 энтропийного декодирования может определять, является ли равным 2 адрес CTB для соседнего CTB по модулю ширины текущего изображения в CTB-единицах. В ответ на определение, что tbAddr % picWidthlnLCUs не является равным 2, модуль 150 энтропийного декодирования может выполнять часть процесса 300 анализа по CABAC, показанного на фиг. 9B. Однако в ответ на определение, что tbAddr % picWidthlnLCUs является равным 2 ("ДА" 322), модуль 150 энтропийного декодирования может выполнять процесс запоминания (324). В целом процесс запоминания выводит переменные, использованные в процессе инициализации переменных контекста, которые назначены синтаксическим элементам, кроме синтаксического элемента end_of_slice_flag. В некоторых примерах модуль 150 энтропийного декодирования может выполнять процесс запоминания, определенный в подпункте 9.2.1.2 WD5 HEVC. После выполнения процесса запоминания модуль 150 энтропийного декодирования может выполнять часть процесса 300 анализа по CABAC, показанную на фиг. 9B.
На фиг. 9B показана блок-схема, иллюстрирующая продолжение примерного процесса 300 анализа по CABAC, показанного на фиг. 9A. Как показано на фиг. 9B, модуль 150 энтропийного декодирования может преобразовывать в двоичную форму текущий синтаксический элемент (330). Другими словами, модуль 150 энтропийного декодирования может получить представление в двоичной форме текущего синтаксического элемента. Представление в двоичной форме синтаксического элемента может быть набором строк двоичных последовательностей для всех возможных значений синтаксического элемента. Строка двоичных последовательностей является строкой последовательностей двоичных сигналов, которая является промежуточным представлением значений синтаксических элементов от преобразования синтаксического элемента в двоичную форму. В некоторых примерах модуль 150 энтропийного декодирования может выполнять процесс, определенный в подпункте 9.2.2 WD5 HEVC, чтобы получить представление в двоичной форме текущего синтаксического элемента.
Кроме того, модуль 150 энтропийного декодирования может определять последовательность операций процесса кодирования (332). Модуль 150 энтропийного декодирования может определять последовательность операций процесса кодирования, на основании представления в двоичной форме текущего синтаксического элемента и последовательности проанализированных последовательностей двоичных сигналов. В некоторых примерах модуль 150 энтропийного декодирования может определять последовательность операций процесса кодирования, как описано в подпункте 9.2.2.9 документа WD5 HEVC.
Кроме того, модуль 150 энтропийного декодирования может определять индекс контекста для каждой последовательности двоичных значений в представлении в двоичной форме текущего синтаксического элемента (334). Каждая из последовательностей двоичных сигналов в представлении в двоичной форме текущего синтаксического элемента индексируется переменной binIdx, и индекс контекста для последовательностей двоичных сигналов в представлении в двоичной форме текущего синтаксического элемента может быть обозначен как ctxIdx. В некоторых примерах модуль 150 энтропийного декодирования может определять индекс контекста для последовательностей двоичных сигналов в представлении в двоичной форме текущего синтаксического элемента, как определено в подпункте 9.2.3.1 документа WD5 HEVC.
Модуль 150 энтропийного декодирования может выполнять процесс арифметического декодирования для каждого индекса контекста (336). В некоторых примерах модуль 150 энтропийного декодирования может выполнять процесс арифметического декодирования для каждого индекса контекста, как определено в подпункте 9.2.3.2 документа WD5 HEVC. Путем выполнения процесса арифметического декодирования для каждого индекса контекста модуль 150 энтропийного декодирования может сформировать последовательность проанализированных, представленных в двоичной системе элементов.
Модуль 150 энтропийного декодирования может определять, соответствует ли последовательность проанализированных последовательностей двоичных сигналов строке двоичных последовательностей в наборе строк двоичных последовательностей, созданных преобразованием в двоичную форму текущего синтаксического элемента (340). Если последовательность проанализированных последовательностей двоичных сигналов соответствует строке двоичных последовательностей в наборе строк двоичных последовательностей, созданных преобразованием в двоичную форму текущего синтаксического элемента ("ДА" 340), модуль 150 энтропийного декодирования может назначить соответствующее значение текущему синтаксическому элементу (342). После назначения соответствующего значения текущему синтаксическому элементу или в ответ на определение, что последовательность проанализированных последовательностей двоичных сигналов не соответствует строке двоичных последовательностей в наборе строк двоичных последовательностей, созданных преобразованием в двоичную форму текущего синтаксического элемента ("НЕТ" 340), модуль 150 энтропийного декодирования завершил анализ текущего синтаксического элемента.
В некоторых примерах, если текущим синтаксическим элементом является синтаксический элемент mb_type и декодированное значение синтаксического элемента mb_type равно I_PCM, модуль 150 энтропийного декодирования может быть инициализирован после декодирования любого синтаксического элемента pcm_alignment_zero_bit и всех данных pcm_sample_luma и pcm_sample_chroma, как определено в подпункте 9.2.1.2 документа WD5 HEVC.
На фиг. 10 показана концептуальная схема, которая иллюстрирует пример WPP. Как описано выше, изображение может быть разделено на пиксельные блоки, каждый из которых связывается с CTB. Фиг. 10 иллюстрирует пиксельные блоки, связанные с CTB-единицами, в виде как сетки белых квадратов. Изображение включает в себя ряды 350A-350E блоков CTB (совместно, "ряды 350 CTB блоков ").
Первый поток параллельной обработки (например, исполняемый одним из нескольких ядер параллельной обработки) может кодировать CTB-единицы в ряду 350A CTB-единиц. Одновременно, другие потоки (например, исполняемые другими ядрами параллельной обработки) могут осуществлять кодирование CTB-единиц в рядах 350B, 350C и 350D CTB-единиц. В примере по фиг. 10 первый поток в текущий момент кодирует CTB 352A, второй поток в текущий момент кодирует CTB 352B, третий поток в текущий момент кодирует CTB 352C и четвертый поток в текущий момент кодирует CTB 352D. Это раскрытие может называть CTB-единицы 352A, 352B, 352C и 352D совместно как "текущие CTB-единицы 352". Поскольку видеокодер может начинать кодирование ряда CTB после того, как более двух CTB-единиц из ряда непосредственно выше были кодированы, текущие CTB-единицы 352 горизонтально смещаются друг от друга на ширину двух CTB.
В примере по фиг. 10 потоки могут использовать данные из CTB-единиц, обозначенных утолщенными серыми стрелками, для выполнения внутрикадрового предсказания или межкадрового предсказания для CU-единиц в текущих CTB-единицах 352. (Потоки могут также использовать данные из одного или нескольких опорных кадров, чтобы выполнять межкадровое предсказание для CU-единиц.) Чтобы кодировать данный CTB, поток может выбирать один или несколько контекстов CABAC на основании информации, связанной с ранее кодированным CTB. Поток может использовать один или несколько контекстов CABAC, чтобы выполнять CABAC кодирование на синтаксических элементах, связанных с первой CU данного CTB. Если данный CTB не является крайним левым CTB ряда, поток может выбирать один или несколько контекстов CABAC на основании информации, связанной с последней CU в CTB слева от данного CTB. Если данный CTB является крайним левым CTB ряда, поток может выбирать один или несколько контекстов CABAC на основании информации, связанной с последней CU в CTB, который находится выше, и двумя CTB-единицами справа для данного CTB. Потоки могут использовать данные из последней CU в CTB-единицах, обозначенных тонкими черными стрелками, чтобы выбирать контексты CABAC для первых CU текущих CTB-единиц 352.
На фиг. 11 показана концептуальная схема, которая иллюстрирует примерную очередность кодирования CTB для изображения 400, которое разделено на множественные мозаичные фрагменты 402A, 402B, 402C, 402D, 402E и 402F (совместно, "мозаичные фрагменты 402"). Каждый квадратный блок в изображении 400 представляет пиксельный блок, связанный с CTB. Толстые пунктирные линии указывают примерные границы мозаичного фрагмента. Различные типы штриховки соответствуют различным слайсам.
Числа в пиксельных блоках указывают позиции соответствующих CTB (LCU-единиц) в очередности кодирования мозаичного фрагмента для изображения 400. Как проиллюстрировано в примере по фиг. 11, CTB-единицы в мозаичном фрагменте 402A кодируются первыми, за которыми следуют CTB-единицы в мозаичном фрагменте 402B, за которыми следуют CTB-единицы в мозаичном фрагменте 402C, за которыми следуют CTB-единицы в мозаичном фрагменте 402D, за которыми следуют CTB-единицы в мозаичном фрагменте 402E, за которыми следуют CTB-единицы в мозаичном фрагменте 402F. Внутри каждого из мозаичных фрагментов 402 CTB-единицы кодируются в соответствии с порядком растрового сканирования.
Видеокодер может формировать четыре узла NAL кодированных слайсов для изображения 400. Первый узел NAL кодированного слайса может включать в себя кодированные представления CTB-единиц 1-18. Данные слайса первого узла NAL кодированного слайса могут включать в себя два подпотока. Первый подпоток может включать в себя кодированные представления CTB-единиц 1-9. Второй подпоток может включать в себя кодированные представления CTB-единиц 10-18. Таким образом, первый узел NAL кодированного слайса может включать в себя кодированное представление слайса, который содержит множественные мозаичные фрагменты.
Второй узел NAL кодированного слайса может включать в себя кодированные представления CTB-единиц 19-22. Данные слайса второго узла NAL кодированного слайса могут включать в себя один подпоток. Третий узел NAL кодированного слайса может включать в себя кодированные представления CTB-единиц 23-27. Данные слайса третьего узла NAL кодированного слайса могут включать в себя только один подпоток. Таким образом, мозаичный фрагмент 402C может содержать множественные слайсы.
Четвертый узел NAL кодированного слайса может включать в себя кодированные представления CTB-единиц 28-45. Данные слайса четвертого узла NAL кодированного слайса могут включать в себя три подпотока, один из каждого из мозаичных фрагментов 402D, 402E и 402F. Таким образом, четвертый узел NAL кодированного слайса может включать в себя кодированное представление слайса, который содержит множественные мозаичные фрагменты.
В одном или нескольких примерах описанные функции могут быть реализованы в аппаратных средствах, программном обеспечении, микропрограммном обеспечении или любой их комбинации. Если реализованы программно, функции могут в виде одной или нескольких инструкций или машинного кода сохраняться в или передаваться посредством машиночитаемого носителя и исполняться аппаратным блоком обработки. Машиночитаемой носитель может включать в себя машиночитаемый носитель хранения данных, который соответствует материальному носителю, такому как носитель данных, или среду связи, включая любой носитель, который содействует передаче компьютерной программы из одного места в другое, например, согласно протоколу связи. Таким образом, машиночитаемый носитель в целом может соответствовать (1) материальному машиночитаемому носителю данных, который является невременным, или (2) среде связи, такой как сигнал или несущая. Машиночитаемый носитель данных может быть любым доступным носителем, к которому может осуществлять доступ один или несколько компьютеров или один или несколько процессоров, чтобы извлекать инструкции, машинный код и/или структуры данных для реализации способов, описанных в этом раскрытии. Компьютерной программный продукт может включать в себя машиночитаемый носитель.
В качестве примера, а не ограничения, такие машиночитаемые носители данных могут содержать RAM, ROM, EEPROM, CD-ROM или другой накопитель на оптическом диске, накопитель на магнитном диске, или другие магнитные устройства хранения данных, флэш-память, или любой другой носитель, который может использоваться, чтобы хранить требуемый программный код в форме инструкций или структур данных, и к которому может осуществлять доступ компьютер. Кроме того, любое соединение в сущности называют машиночитаемым носителем. Например, если инструкции передаются от веб-сайта, сервера или другого удаленного источника с использованием коаксиального кабеля, волоконно-оптического кабеля, витой пары, цифровой абонентской линии (DSL) или беспроводных технологий, таких как инфракрасная, радиосвязи и микроволновая, то коаксиальный кабель, волоконно-оптический кабель, витая пара, DSL или беспроводные технологии, такие как инфракрасная, радиосвязи и микроволновая, включаются в определение носителя. Следует понимать, однако, что машиночитаемые носители данных и носители данных не включают в себя соединения, несущие, сигналы или другие временные носители, а вместо этого направлены на невременные, материальные носители данных. Магнитный и немагнитный диск, как используется в документе, включают в себя компакт-диск (CD), лазерный диск, оптический диск, цифровой многофункциональный диск (DVD), гибкий диск и диск формата Blue-ray, где магнитные диски обычно воспроизводят данные на основе магнитных свойств, тогда как немагнитные диски воспроизводят данные оптически с помощью лазеров. Комбинации вышеупомянутого также должны включаться в рамки машиночитаемого носителя.
Инструкции могут исполняться одним или несколькими процессорами, такими как один или несколько цифровых процессоров сигналов (DSP), универсальные микропроцессоры, проблемно-ориентированные интегральные микросхемы (ASIC), программируемые вентильные матрицы (FPGA), или другими эквивалентными интегральными или дискретными логическими схемами. Соответственно, термин "процессор", как используется в документе, может относиться к любой вышеприведенной структуре или любой другой структуре, подходящей для выполнения способов, описанных в документе. Кроме того, в некоторых аспектах функциональность, описанная в документе, может обеспечиваться в рамках специализированных аппаратных средств и/или программных модулей, сконфигурированных для кодирования и декодирования, или встраиваться в комбинированный кодек. Кроме того, способы могут быть полностью реализованы в одной или нескольких схемах или логических элементах.
Способы этого раскрытия могут быть осуществлены в широком спектре устройств или аппаратов, включая беспроводную микротелефонную трубку, интегральную схему (IC) или набор IC (например, микропроцессорный набор). Различные компоненты, модули или блоки описываются в этом раскрытии, чтобы подчеркнуть функциональные аспекты устройств, сконфигурированных для выполнения раскрытых способов, но не обязательно требуют реализации другими модулями аппаратных средств. Предпочтительнее, как описано выше, различные модули могут объединяться в аппаратный модуль кодека или обеспечиваться совокупностью аппаратных модулей, имеющих возможность взаимодействия, включая один или несколько процессоров, как описано выше, вместе с подходящим программным обеспечением и/или микропрограммным обеспечением.
Были описаны различные примеры. Эти и другие примеры находятся в рамках последующей формулы изобретения.
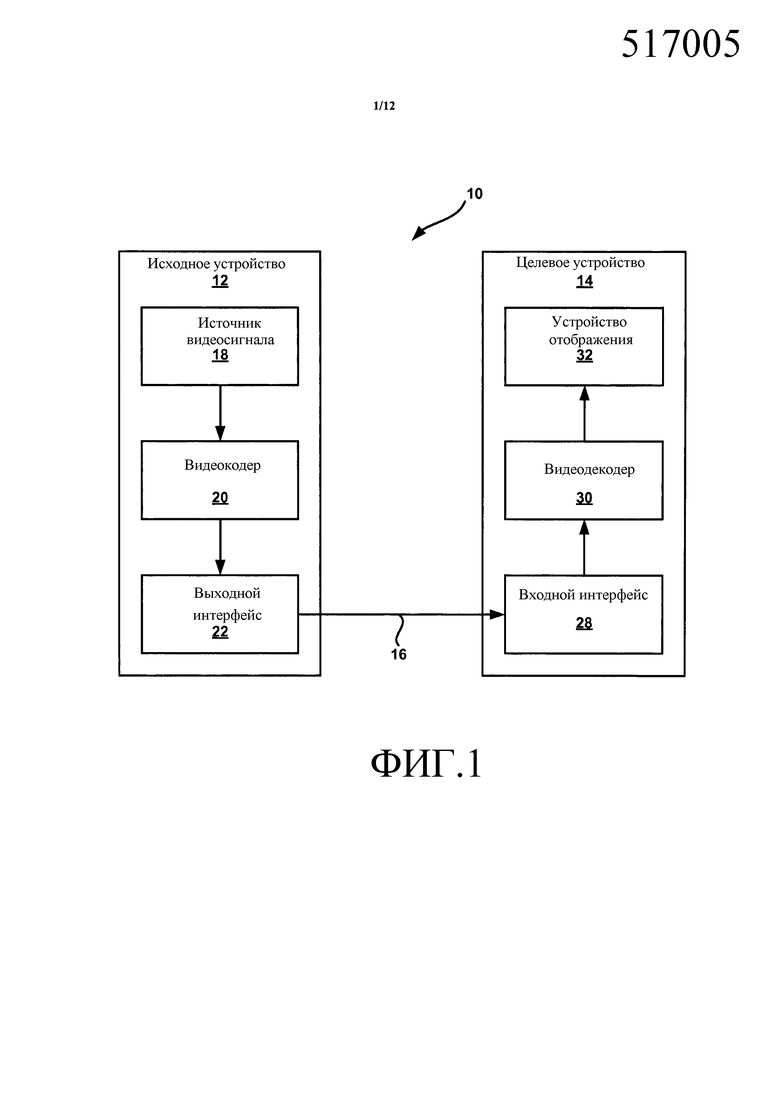
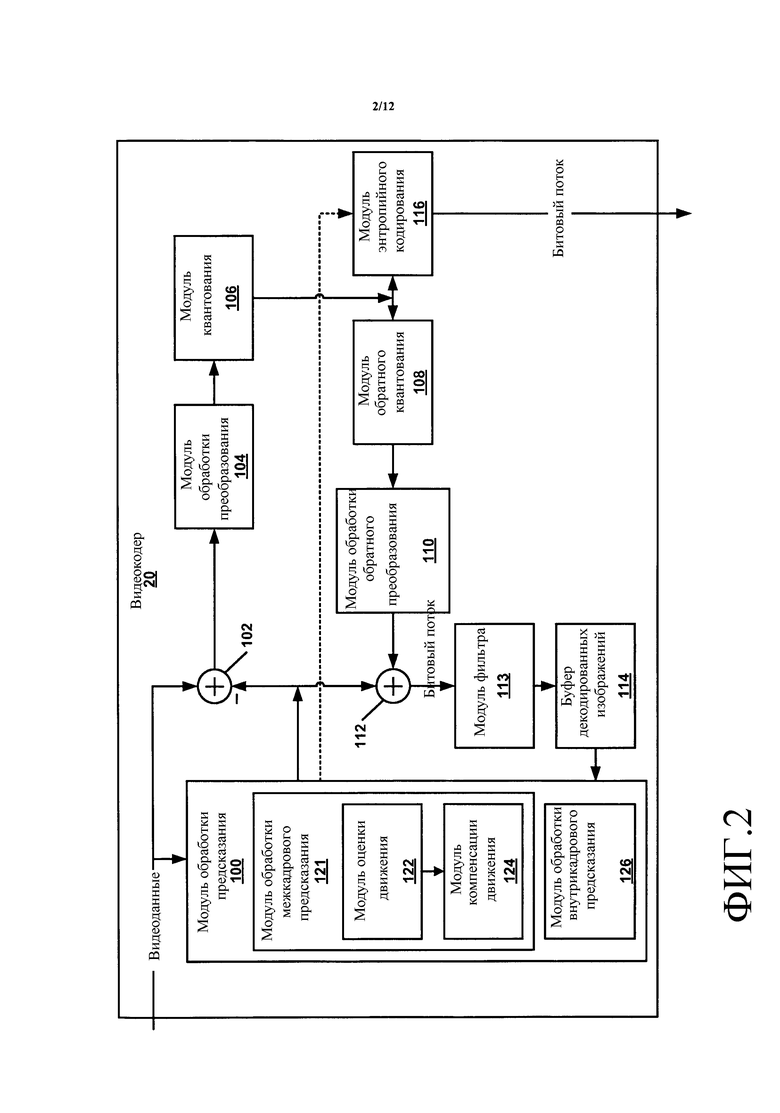
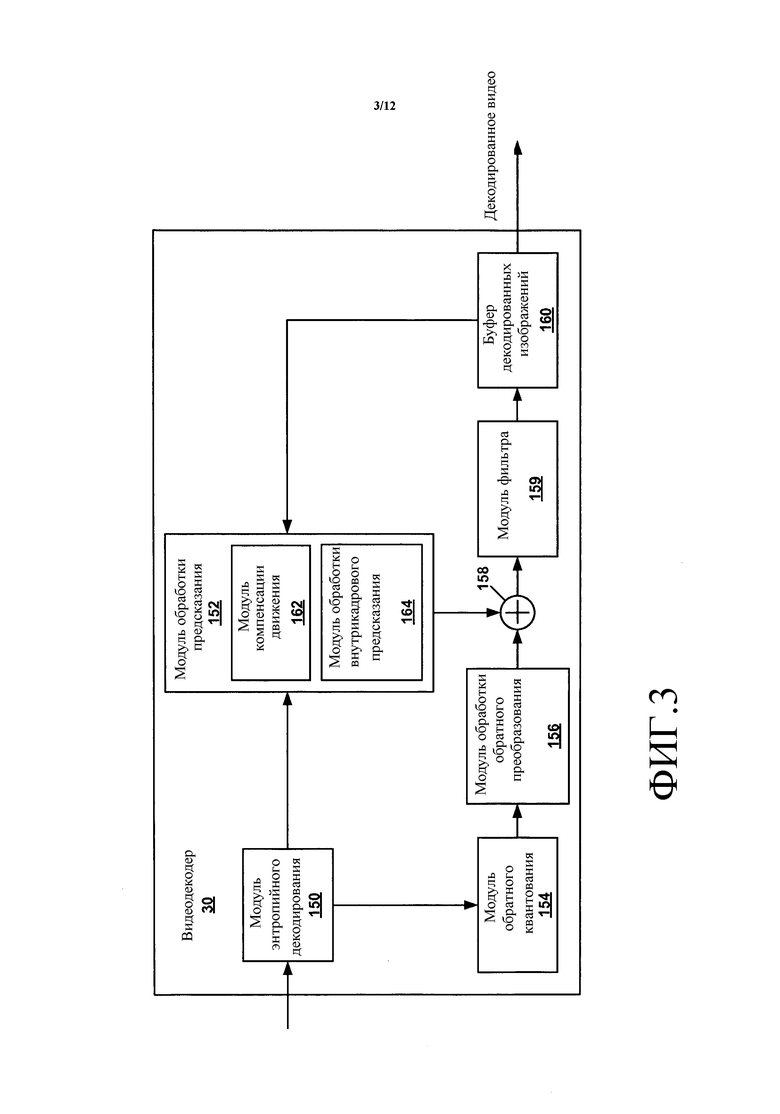
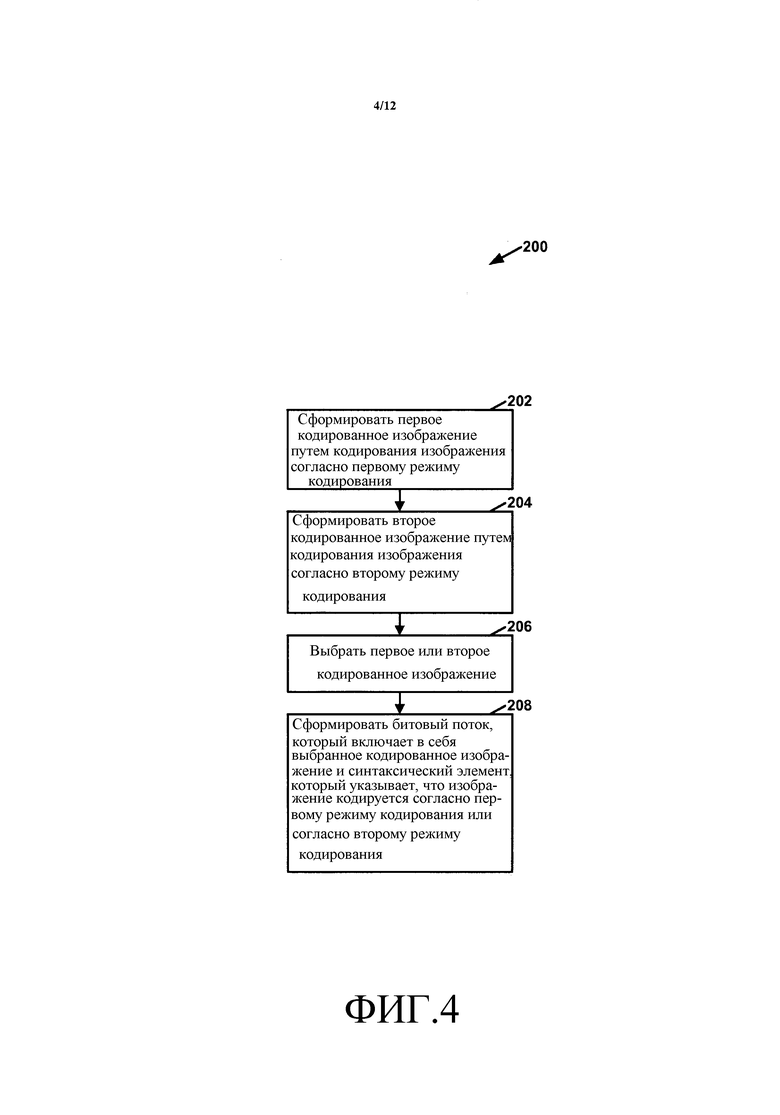
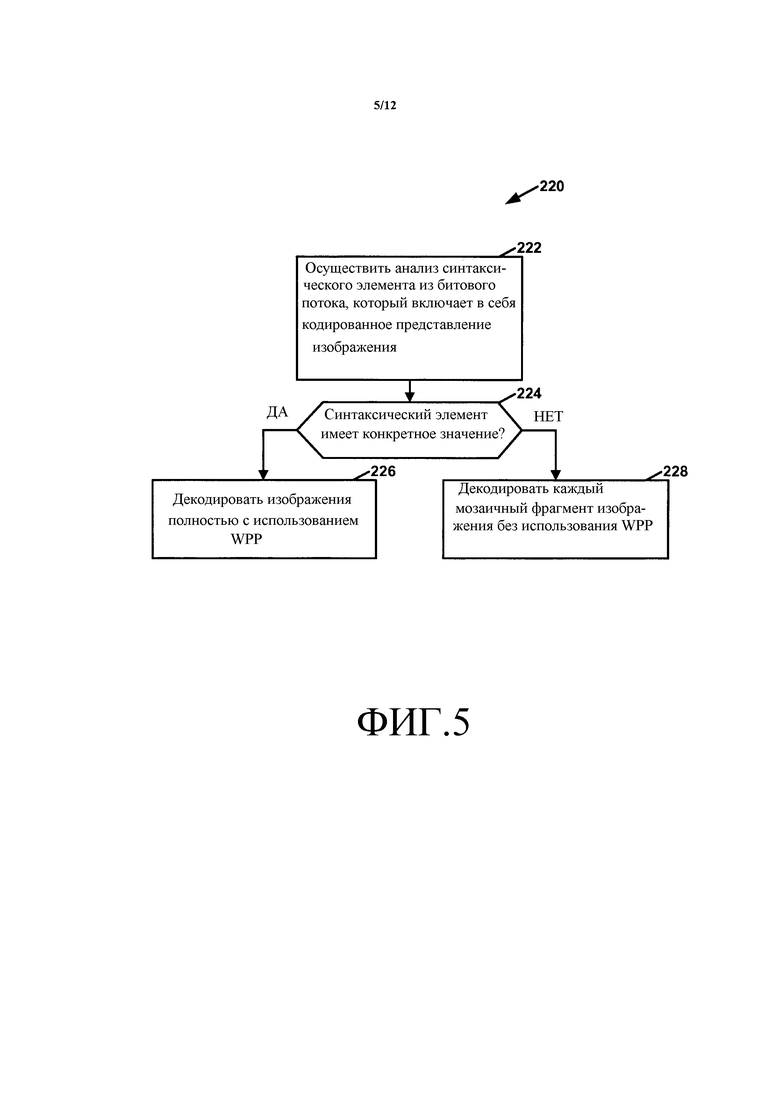
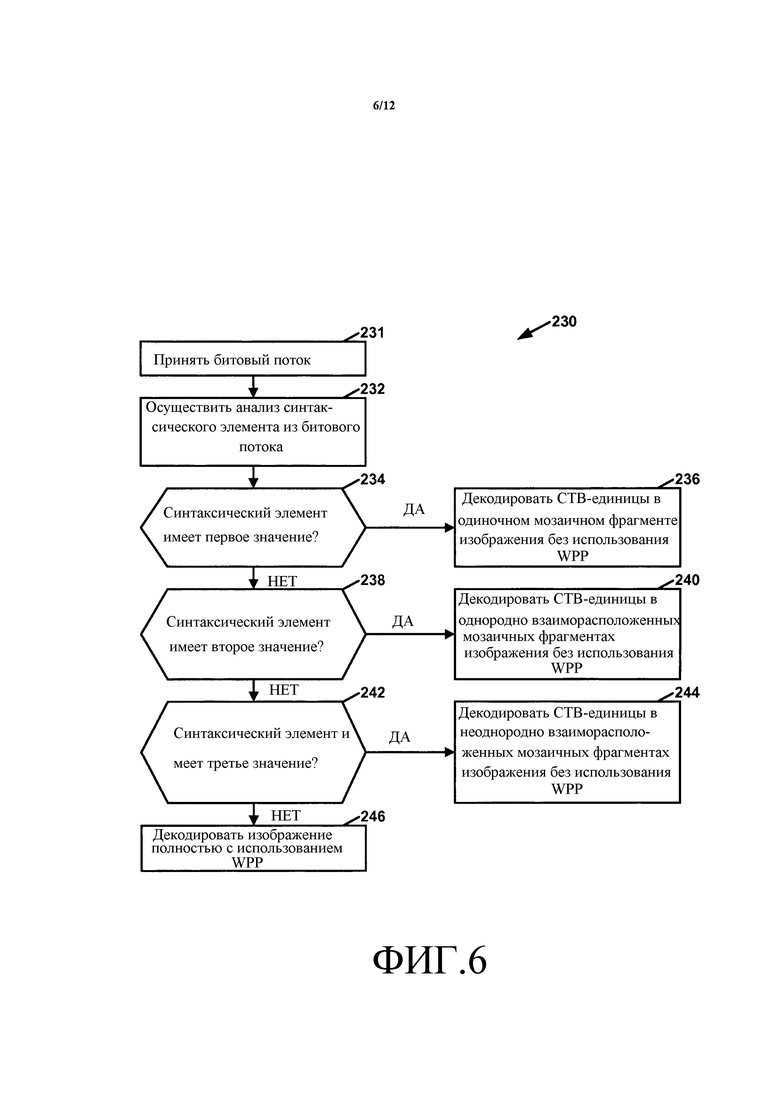
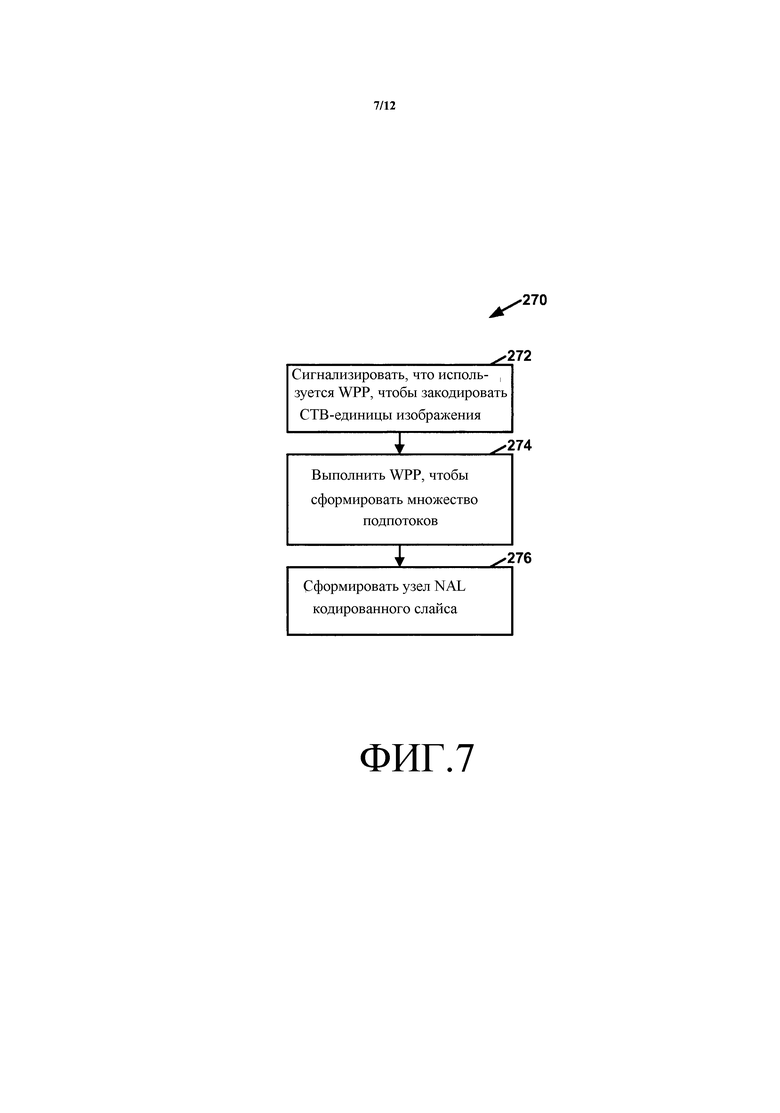
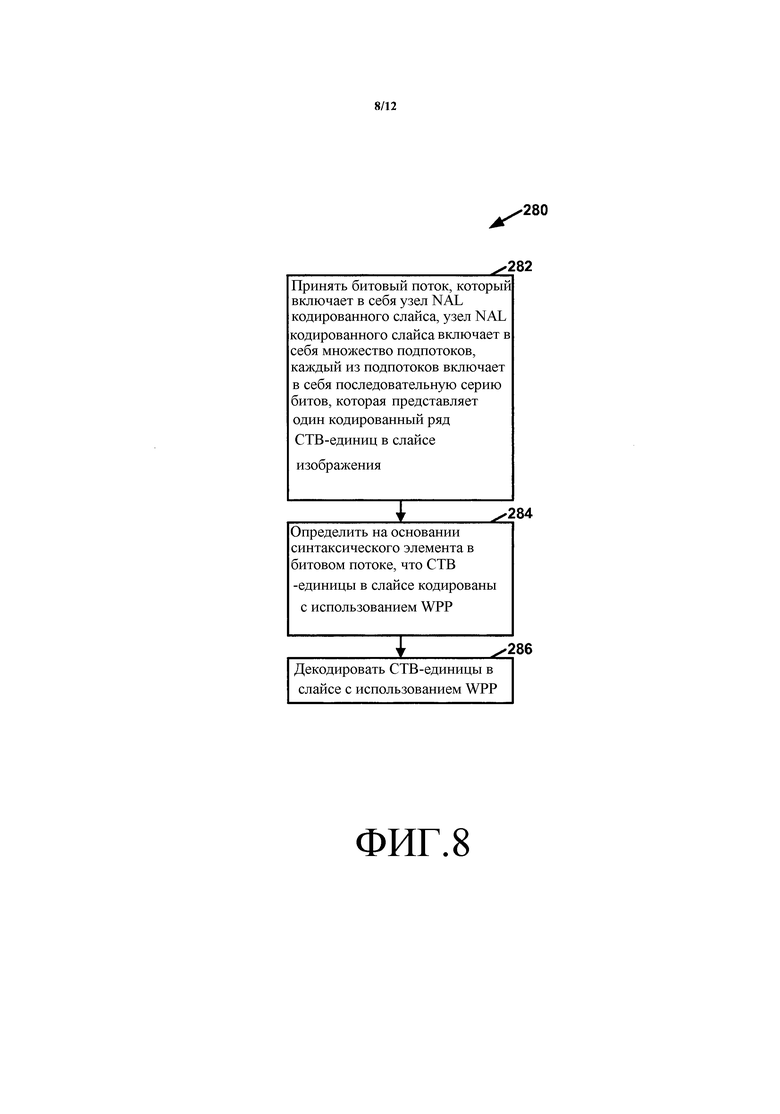
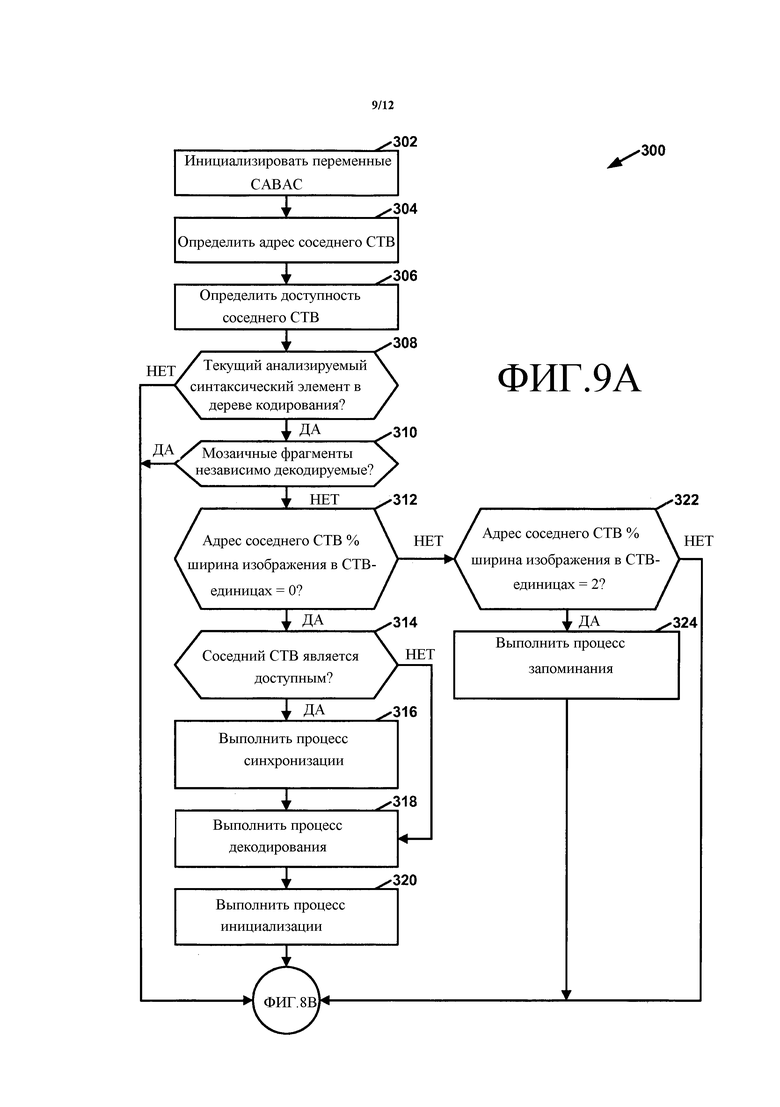
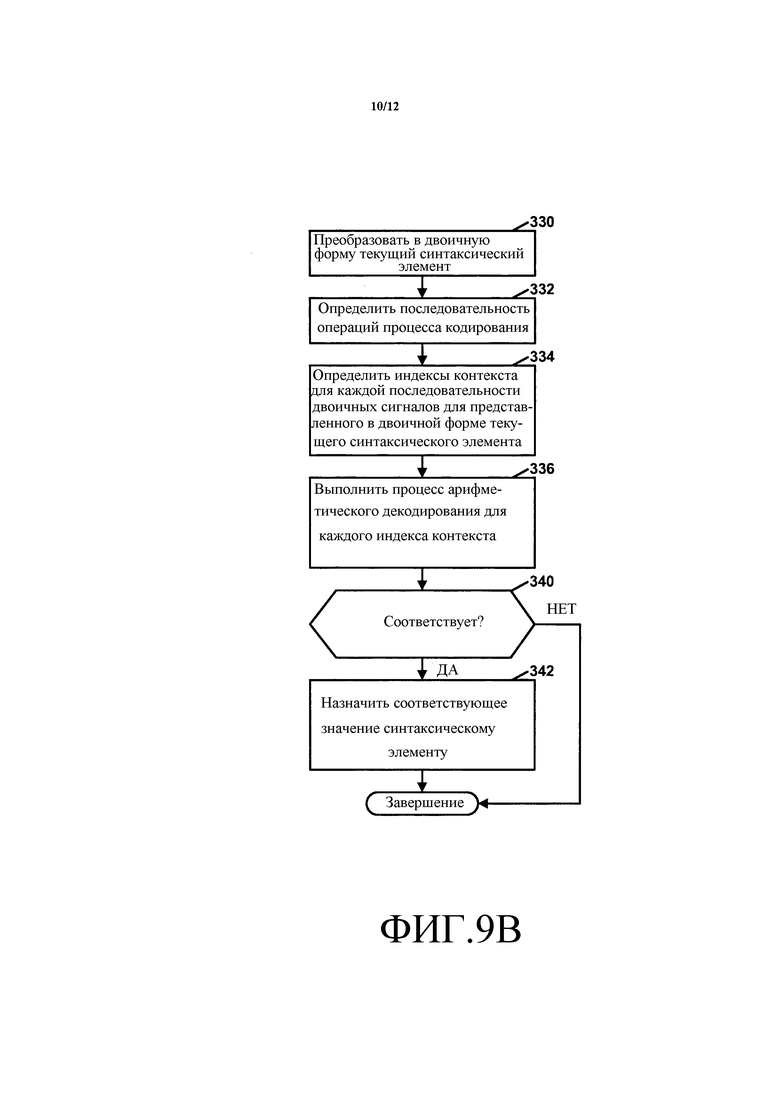
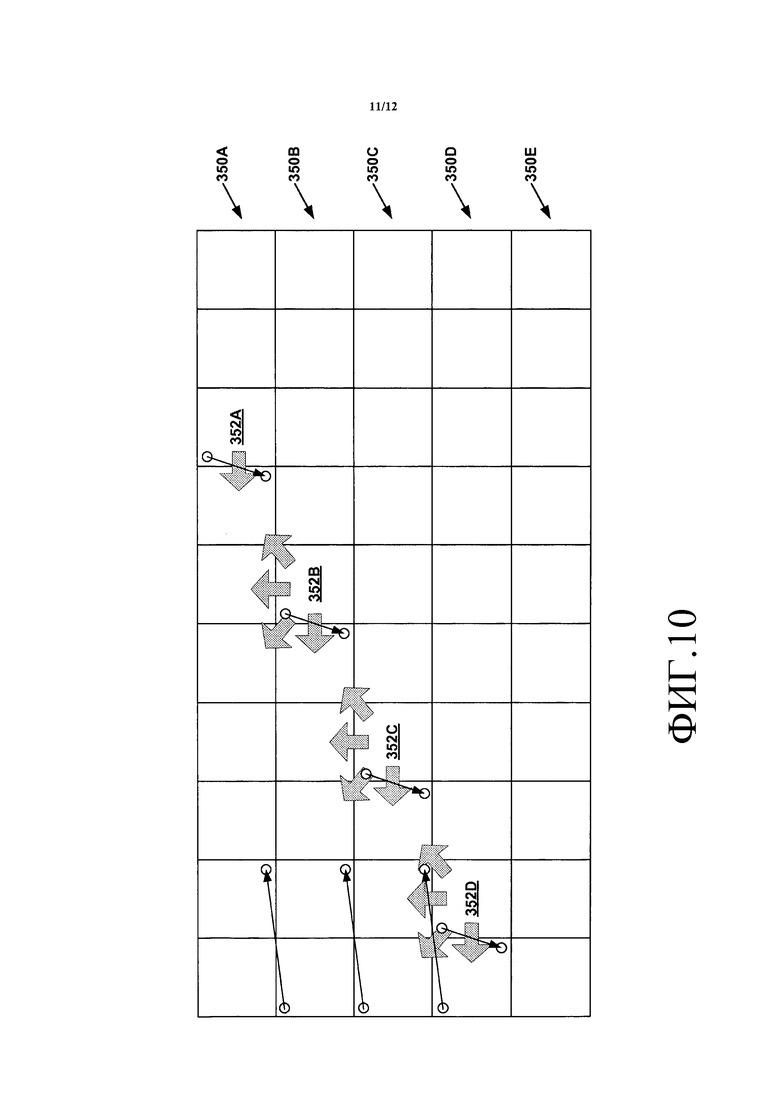
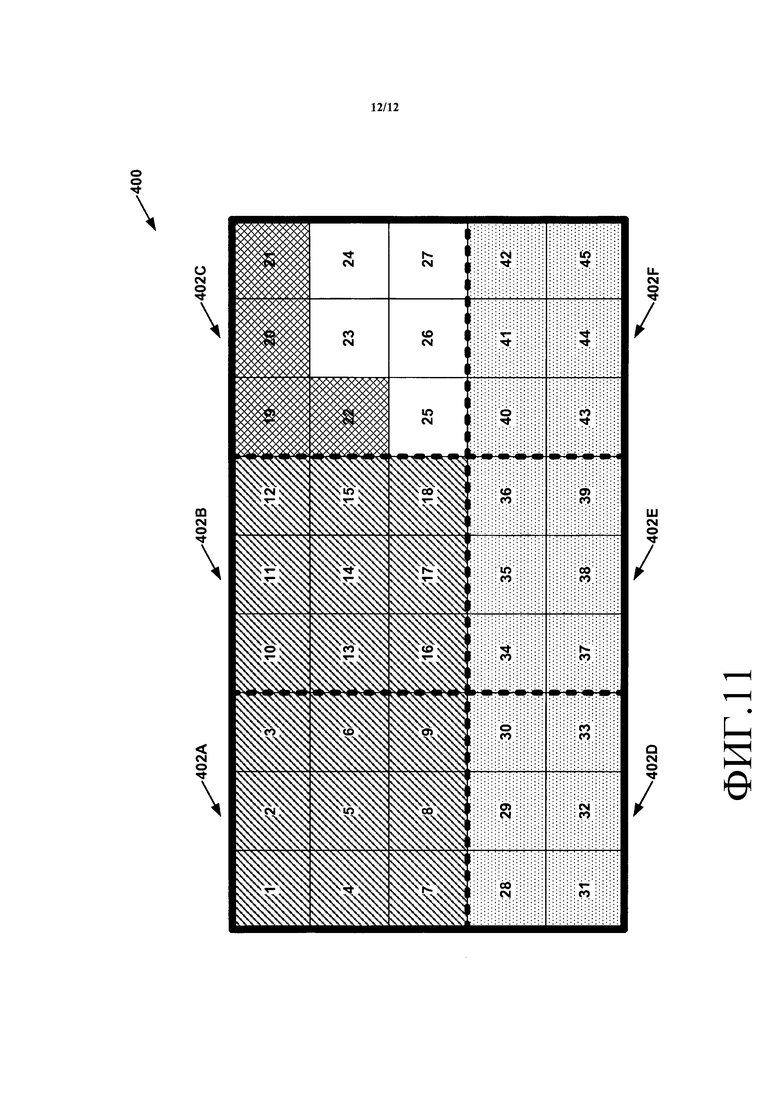
Изобретение относится к технологиям кодирования/декодирования видеоданных. Техническим результатом является повышение эффективности кодирования/декодирования видеоданных за счет обеспечения выборочной параллельной волновой обработки. Предложен способ декодирования видеоданных. Способ включает в себя этап анализа синтаксического элемента из битового потока, причем битовый поток включает в себя узел уровня сетевой абстракции (NAL) кодированного слайса для слайса изображения видеоданных, которое разделено на блоки дерева кодирования (СТВ). Каждый из блоков СТВ ассоциирован с разными равноразмерными блоками пикселов в изображении. Узел уровня сетевой абстракции (NAL) кодированного слайса включает в себя множество подпотоков, причем синтаксический элемент, имеющий конкретное значение, указывающее каждый соответствующий ряд блоков СТВ изображения, формирует соответствующий мозаичный фрагмент изображения. Осуществляют определение, включают ли подпотоки биты заполнения. В ответ на определение, что синтаксический элемент имеет конкретное значение, осуществляют декодирование каждого мозаичного фрагмента изображения с использованием параллельной волновой обработки. 8 н. и 32 з.п. ф-лы, 12 ил., 4 табл.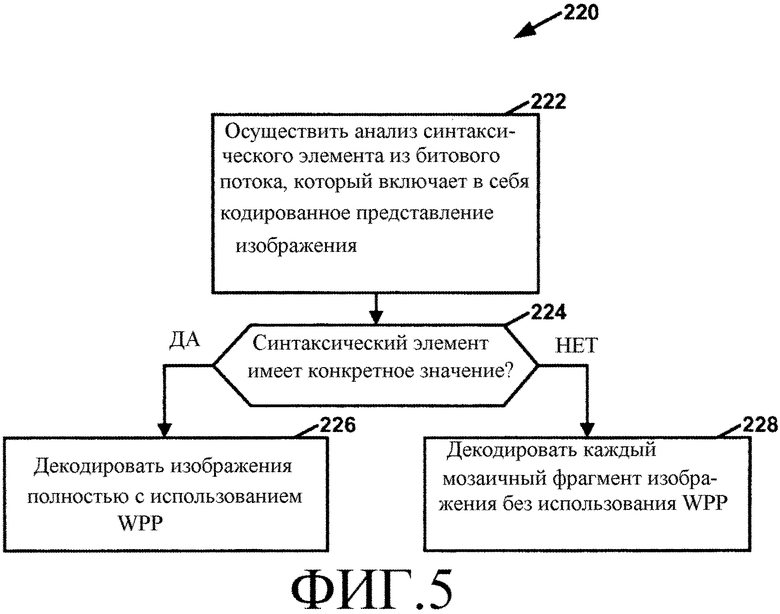
1. Способ декодирования видеоданных, содержащий:
анализ синтаксического элемента из битового потока, причем битовый поток включает в себя узел уровня сетевой абстракции (NAL) кодированного слайса для слайса изображения видеоданных, которое разделено на блоки дерева кодирования (СТВ), причем каждый из блоков СТВ ассоциирован с разными равноразмерными блоками пикселов в изображении, причем узел уровня сетевой абстракции (NAL) кодированного слайса включает в себя множество подпотоков, причем синтаксический элемент, имеющий конкретное значение, указывающее каждый соответствующий ряд блоков СТВ изображения, формирует соответствующий мозаичный фрагмент изображения, причем каждый соответствующий подпоток множества подпотоков содержит все кодированные биты соответствующего мозаичного фрагмента изображения, число конечных кодированных битов соответствующего мозаичного фрагмента или начальных кодированных битов соответствующего мозаичного фрагмента и ни один из подпотоков не содержит кодированные биты более чем одного мозаичного фрагмента изображения;
определение на основании синтаксического элемента, включают ли подпотоки биты заполнения, которые обеспечивают выравнивание по байтам подпотоков;
в ответ на определение, что синтаксический элемент имеет конкретное значение, декодирование каждого мозаичного фрагмента изображения с использованием параллельной волновой обработки (WPP), причем синтаксический элемент, не имеющий конкретного значения, указывает, что каждый мозаичный фрагмент изображения декодируется без использования WPP.
2. Способ по п. 1, дополнительно содержащий анализ из битового потока набора параметров изображения, который включает в себя синтаксический элемент.
3. Способ по п. 1, дополнительно содержащий анализ из битового потока набора параметров последовательности, который включает в себя синтаксический элемент.
4. Способ по п. 1, дополнительно содержащий:
анализ второго синтаксического элемента из битового потока, причем битовый поток включает в себя кодированное представление второго изображения видеоданных, причем второе изображение разделено на блоки СТВ, причем второе изображение разделено на, по меньшей мере, первый мозаичный фрагмент и второй мозаичный фрагмент, и
в ответ на определение, что второй синтаксический элемент не имеет конкретного значения, параллельное декодирование СТВ первого мозаичного фрагмента и СТВ второго мозаичного фрагмента.
5. Способ по п. 1, дополнительно содержащий:
определение, что набор параметров включает в себя синтаксический элемент числа столбцов мозаичного фрагмента и синтаксический элемент числа рядов мозаичного фрагмента;
определение на основании синтаксического элемента числа столбцов мозаичного фрагмента заданного числа столбцов мозаичного фрагмента, причем число столбцов мозаичных фрагментов для каждого изображения, связанного с набором параметров, равно заданному числу столбцов мозаичного фрагмента; и
определение на основании синтаксического элемента числа рядов мозаичного фрагмента заданного числа рядов мозаичного фрагмента, причем число рядов мозаичного фрагмента каждого изображения, связанного с набором параметров, равно заданному числу рядов мозаичного фрагмента.
6. Способ по п. 1, в котором синтаксический элемент является первым синтаксическим элементом, конкретное значение является первым значением и первый синтаксический элемент, имеющий второе значение, указывает, что изображение включает в себя только один мозаичный фрагмент и что битовый поток включает в себя второй синтаксический элемент, второй синтаксический элемент указывает, разрешаются ли энтропийные слайсы для кодированных представлений изображений, которые относятся к набору параметров, который включает в себя первый и второй синтаксические элементы.
7. Способ по п. 1, в котором узел NAL кодированного слайса содержит заголовок слайса и данные слайса, и способ дополнительно содержит:
определение на основании, по меньшей мере частично, синтаксического элемента, включает ли заголовок слайса совокупность синтаксических элементов смещения; и
в ответ на определение, что заголовок слайса включает в себя совокупность синтаксических элементов смещения, использование множества синтаксических элементов смещения, чтобы определить точки входа подпотоков в данных слайса.
8. Способ по п. 1, в котором декодирование изображения с использованием WPP содержит:
в ответ на определение, что первый СТВ отделен от левой границы изображения одним СТВ, сохранение переменных контекста, связанных с первым СТВ; и
энтропийное кодирование на основании, по меньшей мере частично, переменных контекста, связанных с первым СТВ, одного или нескольких синтаксических элементов второго СТВ, второй СТВ является смежным с левой границей изображения и одним рядом СТВ-единиц ниже первого СТВ.
9. Способ кодирования видеоданных, содержащий:
формирование в битовом потоке узла уровня сетевой абстракции (NAL) кодированного слайса для слайса изображения видеоданных, которое разделено на блоки дерева кодирования (СТВ), причем каждый из блоков СТВ ассоциирован с разными равноразмерными блоками пикселов в изображении, причем узел уровня сетевой абстракции (NAL) кодированного слайса включает в себя множество подпотоков,
формирование синтаксического элемента в битовом потоке, причем синтаксический элемент, имеющий конкретное значение, указывающее каждый соответствующий ряд блоков СТВ изображения, формирует соответствующий мозаичный фрагмент изображения, причем подпотоки включают в себя биты заполнения, которые обеспечивают выравнивание по байтам подпотоков, и каждый мозаичный фрагмент изображения кодируется с использованием параллельной волновой обработки (WPP),
причем каждый соответствующий подпоток множества подпотоков содержит все кодированные биты соответствующего мозаичного фрагмента изображения, число конечных кодированных битов соответствующего мозаичного фрагмента или начальных кодированных битов соответствующего мозаичного фрагмента и ни один из подпотоков не содержит кодированные биты более чем одного мозаичного фрагмента изображения, причем синтаксический элемент, не имеющий конкретного значения, указывает, что каждый мозаичный фрагмент изображения декодируется без использования WPP.
10. Способ по п. 9, в котором формирование битового потока содержит формирование набора параметров изображения, который включает в себя синтаксический элемент.
11. Способ по п. 9, в котором формирование битового потока содержит формирование набора параметров последовательности, который включает в себя синтаксический элемент.
12. Способ по п. 9, дополнительно содержащий
включение второго синтаксического элемента в битовый поток, причем битовый поток включает в себя кодированное представление второго изображения видеоданных, причем второе изображение разделено на блоки СТВ, второй синтаксический элемент не имеет конкретного значения, причем второе изображение разделено на по меньшей мере первый мозаичный фрагмент и второй мозаичный фрагмент; и
кодирование параллельно блока дерева кодирования (СТВ) первого мозаичного фрагмента и СТВ второго мозаичного фрагмента.
13. Способ по п. 9, в котором:
формирование битового потока содержит формирование набора параметров, который включает в себя синтаксический элемент числа столбцов мозаичного фрагмента и синтаксический элемент числа рядов мозаичного фрагмента,
число столбцов мозаичного фрагмента является определяемым на основании синтаксического элемента числа столбцов мозаичного фрагмента, и число столбцов мозаичных фрагментов каждого изображения, связанного с набором параметров, равно числу столбцов мозаичного фрагмента, и
число рядов мозаичного фрагмента является определяемым на основании синтаксического элемента числа рядов мозаичного фрагмента, и число рядов мозаичных фрагментов каждого изображения, связанного с набором параметров, равно числу рядов мозаичного фрагмента.
14. Способ по п. 9, в котором синтаксический элемент является первым синтаксическим элементом, конкретное значение представляет собой первое значение, синтаксический элемент имеет второе значение, указывающее, что изображение разделено на одиночный мозаичный фрагмент и битовый поток включает в себя второй синтаксический элемент, второй синтаксический элемент указывает, разрешаются ли энтропийные слайсы для кодированного представления изображений, которые относятся к набору параметров, который включает в себя первый и второй синтаксические элементы.
15. Способ по п. 9, в котором:
узел NAL кодированного слайса содержит заголовок слайса и данные слайса, и
заголовок слайса включает в себя множество синтаксических элементов смещения, из которых могут быть определены точки входа подпотоков в данных слайса.
16. Способ по п. 9, дополнительно содержащий использование WPP, чтобы закодировать каждый мозаичный фрагмент изображения, причем использование WPP, чтобы закодировать каждый мозаичный фрагмент изображения, содержит:
в ответ на определение, что первый СТВ отделен от левой границы изображения одним СТВ, сохранение переменных контекста, связанных с первым СТВ; и
энтропийное кодирование на основании, по меньшей мере частично, переменных контекста, связанных с первым СТВ, одного или нескольких синтаксических элементов второго СТВ, второй СТВ является смежным с левой границей изображения и одним рядом СТВ-единиц ниже первого СТВ.
17. Устройство декодирования видео, которое содержит
носитель данных, выполненный с возможностью хранения видеоданных; и
один или несколько процессоров, сконфигурированных с возможностью:
анализа синтаксического элемента из битового потока, причем битовый поток включает в себя узел уровня сетевой абстракции (NAL) кодированного слайса для слайса изображения видеоданных, которое разделено на блоки дерева кодирования (СТВ), причем каждый из блоков СТВ ассоциирован с разными равноразмерными блоками пикселов в изображении, причем узел уровня сетевой абстракции (NAL) кодированного слайса включает в себя множество подпотоков, причем синтаксический элемент, имеющий конкретное значение, указывающее каждый соответствующий ряд блоков СТВ изображения, формирует соответствующий мозаичный фрагмент изображения, причем каждый соответствующий подпоток множества подпотоков содержит все кодированные биты соответствующего мозаичного фрагмента изображения, число конечных кодированных битов соответствующего мозаичного фрагмента или начальных кодированных битов соответствующего мозаичного фрагмента и ни один из подпотоков не содержит кодированные биты более чем одного мозаичного фрагмента изображения;
определения на основании синтаксического элемента, включают ли подпотоки биты заполнения, которые обеспечивают выравнивание по байтам подпотоков;
в ответ на определение, что синтаксический элемент имеет конкретное значение, декодирования каждого мозаичного фрагмента изображения с использованием параллельной волновой обработки (WPP),
причем синтаксический элемент, не имеющий конкретного значения, указывает, что каждый мозаичный фрагмент изображения декодируется без использования WPP.
18. Устройство декодирования видео по п. 17, в котором один или несколько процессоров сконфигурированы для анализа из битового потока набора параметров изображения, который включает в себя синтаксический элемент.
19. Устройство декодирования видео по п. 17, в котором один или несколько процессоров сконфигурированы для анализа из битового потока набора параметров последовательности, который включает в себя синтаксический элемент.
20. Устройство декодирования видео по п. 17, в котором
один или более процессоров дополнительно выполнены с возможностью:
анализа второго синтаксического элемента из битового потока,
причем битовый поток включает в себя кодированное представление второго изображения видеоданных, причем второе изображение разделено на блоки СТВ, причем второе изображение разделено на, по меньшей мере, первый мозаичный фрагмент и второй мозаичный фрагмент, и
в ответ на определение, что второй синтаксический элемент не имеет конкретного значения, параллельного декодирования СТВ первого мозаичного фрагмента и СТВ второго мозаичного фрагмента.
21. Устройство декодирования видео по п. 17, в котором один или несколько процессоров дополнительно сконфигурированы с возможностью:
определять, что набор параметров включает в себя синтаксический элемент числа столбцов мозаичного фрагмента и синтаксический элемент числа рядов мозаичного фрагмента;
определять на основании синтаксического элемента числа столбцов мозаичного фрагмента заданное число столбцов мозаичного фрагмента, причем число столбцов мозаичных фрагментов каждого изображения, связанного с набором параметров, равно заданному числу столбцов мозаичного фрагмента; и
определять на основании синтаксического элемента числа рядов мозаичного фрагмента заданное число рядов мозаичного фрагмента, причем число рядов мозаичных фрагментов каждого изображения, связанного с набором параметров, равно заданному числу рядов мозаичного фрагмента.
22. Устройство декодирования видео по п. 17, в котором синтаксическим элементом является первый синтаксический элемент, конкретным значением является первое значение и первый синтаксический элемент, имеющий второе значение, указывает, что изображение включает в себя только один мозаичный фрагмент и что битовый поток включает в себя второй синтаксический элемент, второй синтаксический элемент указывает, разрешаются ли энтропийные слайсы для кодированных представлений изображений, которые относятся к набору параметров, который включает в себя первый и второй синтаксические элементы.
23. Устройство декодирования видео по п. 17, в котором узел NAL кодированного слайса включает в себя заголовок слайса и данные слайса и один или несколько процессоров дополнительно сконфигурированы с возможностью:
определять на основании, по меньшей мере частично, синтаксического элемента, включает ли заголовок слайса совокупность синтаксических элементов смещения; и
в ответ на определение, что заголовок слайса включает в себя совокупность синтаксических элементов смещения, использовать совокупность синтаксических элементов смещения, чтобы определять точки входа подпотоков в данных слайса.
24. Устройство декодирования видео по п. 17, в котором, когда один или несколько процессоров используют WPP, чтобы декодировать мозаичные фрагменты изображения, один или несколько процессоров выполнены с возможностью:
в ответ на определение, что первый СТВ отделен от левой границы изображения одним СТВ, сохранять переменные контекста, связанные с первым СТВ; и
энтропийно декодировать на основании, по меньшей мере частично, переменных контекста, связанных с первым СТВ, один или несколько синтаксических элементов второго СТВ, второй СТВ является смежным с левой границей изображения и одним рядом блоков СТВ ниже первого СТВ.
25. Устройство декодирования видео по п. 17, содержащее по меньшей мере одно из:
интегральной схемы;
микропроцессора; или
беспроводного устройства связи.
26. Устройство декодирования видео по п. 17, дополнительно содержащее дисплей, выполненный с возможностью отображения декодированных видеоданных.
27. Устройство кодирования видео, содержащее:
носитель данных, выполненный с возможностью хранения видеоданных; и
один или несколько процессоров, сконфигурированных с возможностью
формирования в битовом потоке узла уровня сетевой абстракции (NAL) кодированного слайса для слайса изображения видеоданных, которое разделено на блоки дерева кодирования (СТВ), причем каждый из блоков СТВ ассоциирован с разными равноразмерными блоками пикселов в изображении, причем узел уровня сетевой абстракции (NAL) кодированного слайса включает в себя множество подпотоков,
формирования синтаксического элемента в битовом потоке, причем синтаксический элемент, имеющий конкретное значение, указывающее каждый соответствующий ряд блоков СТВ изображения, формирует соответствующий мозаичный фрагмент изображения, причем подпотоки включают в себя биты заполнения, которые обеспечивают выравнивание по байтам подпотоков, и каждый мозаичный фрагмент изображения кодируется с использованием параллельной волновой обработки (WPP),
причем каждый соответствующий подпоток множества подпотоков содержит все кодированные биты соответствующего мозаичного фрагмента изображения, число конечных кодированных битов соответствующего мозаичного фрагмента или начальных кодированных битов соответствующего мозаичного фрагмента, и ни один из подпотоков не содержит кодированные биты более чем одного мозаичного фрагмента изображения, причем синтаксический элемент, не имеющий конкретного значения, указывает, что каждый мозаичный фрагмент изображения декодируется без использования WPP.
28. Устройство кодирования видео по п. 27, в котором один или несколько процессоров сконфигурированы с возможностью формирования набора параметров изображения, который включает в себя синтаксический элемент.
29. Устройство кодирования видео по п. 27, в котором один или несколько процессоров сконфигурированы с возможностью формирования набора параметров последовательности, который включает в себя синтаксический элемент.
30. Устройство кодирования видео по п. 27, в котором
один или более процессоров дополнительно выполнены с возможностью:
включения второго синтаксического элемента в битовый поток, причем битовый поток включает в себя кодированное представление второго изображения видеоданных, второе изображение разделено на блоки СТВ, второй синтаксический элемент разделен на по меньшей мере первый мозаичный фрагмент и второй мозаичный фрагмент; и
кодирования параллельно блока дерева кодирования (СТВ) первого мозаичного фрагмента и СТВ второго мозаичного фрагмента.
31. Устройство кодирования видео по п. 27, в котором:
один или несколько процессоров сконфигурированы с возможностью формирования набора параметров, который включает в себя синтаксический элемент числа столбцов мозаичного фрагмента и синтаксический элемент числа рядов мозаичного фрагмента,
число столбцов мозаичного фрагмента является определяемым на основании синтаксического элемента числа столбцов мозаичного фрагмента, и число столбцов мозаичных фрагментов каждого изображения, связанного с набором параметров, равно числу столбцов мозаичного фрагмента, и
число рядов мозаичного фрагмента является определяемым на основании синтаксического элемента числа рядов мозаичного фрагмента, и число рядов мозаичных фрагментов каждого изображения, связанного с набором параметров, равно числу рядов мозаичного фрагмента.
32. Устройство кодирования видео по п. 27, в котором синтаксический элемент является первым синтаксическим элементом, конкретное значение представляет собой первое значение, синтаксический элемент, имеющий второе значение, указывающее, что изображение кодировано согласно второму режиму кодирования, причем изображение разделяется на одиночный мозаичный фрагмент и битовый поток включает в себя второй синтаксический элемент, второй синтаксический элемент указывает, разрешаются ли энтропийные слайсы для кодированного представления изображений, которые относятся к набору параметров, который включает в себя первый и второй синтаксические элементы.
33. Устройство кодирования видео по п. 27, в котором:
узел NAL кодированного слайса содержит заголовок слайса и данные слайса, и
заголовок слайса включает в себя совокупность синтаксических элементов смещения, из которых могут быть определены точки входа подпотоков в данных слайса.
34. Устройство кодирования видео по п. 27, в котором, когда один или несколько процессоров используют WPP, чтобы закодировать СТВ-единицы для каждого мозаичного фрагмента изображения, один или несколько процессоров выполнены с возможностью:
в ответ на определение, что первый СТВ отделен от левой границы изображения одним СТВ, сохранять переменные контекста, связанные с первым СТВ; и
энтропийно кодировать на основании, по меньшей мере частично, переменных контекста, связанных с первым СТВ, один или несколько синтаксических элементов второго СТВ, второй СТВ является смежным с левой границей изображения и одним рядом СТВ-единиц ниже первого СТВ.
35. Устройство кодирования видео по п. 27, в котором устройство кодирования видео содержит по меньшей мере одно из:
интегральной схемы;
микропроцессора; или
беспроводного устройства связи.
36. Устройство кодирования видео по п. 27, дополнительно содержащее камеру, выполненную с возможностью захвата видеоданных.
37. Устройство декодирования видео, содержащее:
средство для анализа синтаксического элемента из битового потока, причем битовый поток включает в себя узел уровня сетевой абстракции (NAL) кодированного слайса для слайса изображения видеоданных, которое разделено на блоки дерева кодирования (СТВ), причем каждый из блоков СТВ ассоциирован с разными равноразмерными блоками пикселов в изображении, причем узел уровня сетевой абстракции (NAL) кодированного слайса включает в себя множество подпотоков, причем синтаксический элемент, имеющий конкретное значение, указывающее каждый соответствующий ряд блоков СТВ изображения, формирует соответствующий мозаичный фрагмент изображения, причем каждый соответствующий подпоток множества подпотоков содержит все кодированные биты соответствующего мозаичного фрагмента изображения, число конечных кодированных битов соответствующего мозаичного фрагмента или начальных кодированных битов соответствующего мозаичного фрагмента и ни один из подпотоков не содержит кодированные биты более чем одного мозаичного фрагмента изображения
средство для определения на основании синтаксического элемента, включают ли подпотоки биты заполнения, которые обеспечивают выравнивание по байтам подпотоков; и
средство для декодирования в ответ на определение, что синтаксический элемент имеет конкретное значение, каждого мозаичного фрагмента изображения с использованием параллельной волновой обработки (WPP),
причем синтаксический элемент, не имеющий конкретного значения, указывает, что каждый мозаичный фрагмент изображения декодируется без использования WPP.
38. Устройство кодирования видео, которое содержит
средство для формирования в битовом потоке узла уровня сетевой абстракции (NAL) кодированного слайса для слайса изображения видеоданных, которое разделено на блоки дерева кодирования (СТВ), причем каждый из блоков СТВ ассоциирован с разными равноразмерными блоками пикселов в изображении, причем узел уровня сетевой абстракции (NAL) кодированного слайса включает в себя множество подпотоков; и
средство для формирования синтаксического элемента в битовом потоке, причем синтаксический элемент, имеющий конкретное значение, указывающее каждый соответствующий ряд блоков СТВ изображения, формирует соответствующий мозаичный фрагмент изображения, причем подпотоки включают в себя биты заполнения, которые обеспечивают выравнивание по байтам подпотоков, и каждый мозаичный фрагмент изображения кодируется с использованием параллельной волновой обработки (WPP),
причем каждый соответствующий подпоток множества подпотоков содержит все кодированные биты соответствующего мозаичного фрагмента изображения, число конечных кодированных битов соответствующего мозаичного фрагмента или начальных кодированных битов соответствующего мозаичного фрагмента и ни один из подпотоков не содержит кодированные биты более чем одного мозаичного фрагмента изображения, причем синтаксический элемент, не имеющий конкретного значения, указывает, что каждый мозаичный фрагмент изображения декодируется без использования WPP.
39. Невременный машиночитаемый носитель данных, который хранит инструкции, которые при исполнении одним или несколькими процессорами устройства декодирования видео конфигурируют устройство декодирования видео, чтобы:
анализировать синтаксический элемент из битового потока, причем битовый поток включает в себя узел уровня сетевой абстракции (NAL) кодированного слайса для слайса изображения видеоданных, которое разделено на блоки дерева кодирования (СТВ), причем каждый из блоков СТВ ассоциирован с разными равноразмерными блоками пикселов в изображении, причем узел уровня сетевой абстракции (NAL) кодированного слайса включает в себя множество подпотоков, причем синтаксический элемент, имеющий конкретное значение, указывающее каждый соответствующий ряд блоков СТВ изображения, формирует соответствующий мозаичный фрагмент изображения, причем каждый соответствующий подпоток множества подпотоков содержит все кодированные биты соответствующего мозаичного фрагмента изображения, число конечных кодированных битов соответствующего мозаичного фрагмента или начальных кодированных битов соответствующего мозаичного фрагмента и ни один из подпотоков не содержит кодированные биты более чем одного мозаичного фрагмента изображения;
определять на основании синтаксического элемента, включают ли подпотоки биты заполнения, которые обеспечивают выравнивание по байтам подпотоков;
в ответ на определение, что синтаксический элемент имеет конкретное значение, декодировать каждый мозаичный фрагмент изображения с использованием параллельной волновой обработки (WPP), причем синтаксический элемент, не имеющий конкретного значения, указывает, что каждый мозаичный фрагмент изображения декодируется без использования WPP.
40. Невременный машиночитаемый носитель данных, который хранит инструкции, которые при исполнении одним или несколькими процессорами устройства кодирования видео конфигурируют устройство кодирования видео, чтобы
формировать в битовом потоке узел уровня сетевой абстракции (NAL) кодированного слайса для слайса изображения видеоданных, которое разделено на блоки дерева кодирования (СТВ), причем каждый из блоков СТВ ассоциирован с разными равноразмерными блоками пикселов в изображении, причем узел уровня сетевой абстракции (NAL) кодированного слайса включает в себя множество подпотоков,
формировать синтаксический элемент в битовом потоке, причем синтаксический элемент, имеющий конкретное значение, указывающее каждый соответствующий ряд блоков СТВ изображения, формирует соответствующий мозаичный фрагмент изображения, причем подпотоки включают в себя биты заполнения, которые обеспечивают выравнивание по байтам подпотоков, и каждый мозаичный фрагмент изображения кодируется с использованием параллельной волновой обработки (WPP),
причем каждый соответствующий подпоток множества подпотоков содержит все кодированные биты соответствующего мозаичного фрагмента изображения, число конечных кодированных битов соответствующего мозаичного фрагмента или начальных кодированных битов соответствующего мозаичного фрагмента и ни один из подпотоков не содержит кодированные биты более чем одного мозаичного фрагмента изображения, причем синтаксический элемент, не имеющий конкретного значения, указывает, что каждый мозаичный фрагмент изображения декодируется без использования WPP.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| АДАПТАЦИЯ ОТБРАСЫВАЕМОГО НИЗКОГО УРОВНЯ ПРИ МАСШТАБИРУЕМОМ КОДИРОВАНИИ ВИДЕОСИГНАЛА | 2007 |
|
RU2414092C2 |

