ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
[0001] Данная заявка заявляет приоритет предварительной заявки на патент США №61/504005, поданной 1 июля 2011 г., и предварительной заявки на патент США №61/636429, поданной 20 апреля 2012 г.; обе эти заявки ссылкой включаются в данное раскрытие полностью во всех отношениях.
ОБЛАСТЬ ТЕХНИЧЕСКОГО ПРИМЕНЕНИЯ
[0002] Одна или несколько реализаций, в общем, относятся к обработке звуковых сигналов и, конкретнее, к гибридной обработке звука на основе объектов и каналов для использования в кинематографических, домашних и других средах.
ПРЕДПОСЫЛКИ
[0003] Не следует полагать, что предмет изобретения, обсуждаемый в разделе предпосылок, представляет собой известный уровень техники единственно в результате его упоминания в разделе предпосылок. Аналогично, не следует полагать, что проблема, упоминаемая в разделе предпосылок или связанная с предметом изобретения в разделе предпосылок, является признанной на известном уровне техники. Предмет изобретения в разделе предпосылок лишь представляет различные подходы, которые сами по себе также могут представлять собой изобретения.
[0004] С момента введения звука в фильмы происходило устойчивое развитие технологии, предназначенной для фиксации художественного замысла создателя звуковой дорожки кинокартины и для его точного воспроизведения в среде кинотеатра. Основополагающая роль звука в кинематографии заключается в содействии сюжету на экране. Типичные звуковые дорожки для кинематографии содержат множество различных звуковых элементов, соответствующих элементам и изображениям на экране, диалогам, шумам и звуковым эффектам, которые исходят от различных элементов на экране и сочетаются с музыкальным фоном и эффектами окружающей среды, создавая общее впечатление от просмотра. Художественный замысел создателей и продюсеров отображает их желание воспроизводить указанные звуки таким образом, который как можно точнее соответствует тому, что демонстрируется на экране в том, что касается положения, интенсивности, перемещения и других аналогичных параметров источников звука.
[0005] Современная авторская разработка, распространение и проигрывание кинофильмов страдает от ограничений, которые сдерживают создание по-настоящему жизненного и создающего эффект присутствия звука. Традиционные аудиосистемы на основе каналов передают звуковое содержимое в форме сигналов, подаваемых на громкоговорители, для отдельных громкоговорителей в такой среде проигрывания, как стереофоническая система или система 5.1. Внедрение цифровой кинематографии создало такие новые стандарты звука в фильмах, как объединение до 16 звуковых каналов, что позволяет увеличить творческие возможности создателей содержимого, а также больший охват и реалистичность впечатлений от прослушивания для зрителей. Введение окружающих систем 7.1 обеспечило новый формат, который увеличивает количество окружающих каналов путем разбиения существующего левого и правого окружающих каналов на четыре зоны, что, таким образом, расширяет пределы возможностей операторов обработки и синтеза звука и операторов микширования при управлении местоположениями звуковых элементов в кинотеатре.
[0006] Для дальнейшего улучшения пользовательского восприятия, проигрывание звука в виртуальных трехмерных средах стало областью усиленных проектно-конструкторских разработок. Представление звука в пространстве использует звуковые объекты, которые представляют собой звуковые сигналы со связанными параметрическими описаниями источников для положений кажущегося источника (например, трехмерных координат), ширины кажущегося источника и других параметров. Звук на основе объектов во все возрастающей мере используется для многих современных мультимедийных приложений, таких как цифровые кинофильмы, видеоигры, симуляторы и трехмерное видео.
[0007] Решающим является выход за пределы традиционных сигналов, подаваемых на громкоговорители, и звука на основе каналов как средств распространения звука в пространстве, и существует значительный интерес к описанию звука на основе моделей, которое является многообещающим для того, чтобы давать слушателю/кинопрокатчику свободу выбора конфигурации проигрывания, которая соответствует их индивидуальным потребностям или бюджету, со звуком, данные которого представляются специально для выбранной ими конфигурации. На высоком уровне в настоящее время существует четыре основных формата пространственного описания звука: сигналы, подаваемые на громкоговорители, где звук описывается как сигналы, предназначенные для громкоговорителей в номинальных положениях громкоговорителей; сигнал, подаваемый на микрофон, где звук описывается как сигналы, захватываемые виртуальными или фактическими микрофонами в предварительно определяемом массиве; описание на основе моделей, в котором звук описывается в терминах последовательности звуковых событий в описываемых положениях; и бинауральный, в котором звук описывается сигналами, которые достигают ушей пользователя. Эти четыре формата описания часто связаны с одной или несколькими технологиями представления данных, которые преобразовывают звуковые сигналы в сигналы, подаваемые на громкоговорители. Современные технологии представления данных включают панорамирование, при котором аудиопоток преобразовывается в сигналы, подаваемые на громкоговорители, с использованием набора законов панорамирования и известных, или предполагаемых, положений громкоговорителей (как правило, представление данных происходит перед распространением); амбифонию, при которой сигналы микрофонов преобразовываются в подаваемые сигналы для масштабируемого массива громкоговорителей (как правило, представление данных происходит после распространения); WFS (синтез волнового поля), при котором звуковые события преобразовываются в соответствующие сигналы громкоговорителей для синтеза звукового поля (как правило, представление данных происходит после распространения); и бинауральную технологию, в которой бинауральные сигналы L/R (левый/правый) доставляются в уши L/R, как правило, с использованием наушников, но также с использованием громкоговорителей и подавления перекрестных помех (представление данных происходит до или после распространения). Среди этих форматов наиболее общим является формат подачи сигналов на громкоговорители, поскольку он является простым и эффективным. Наилучшие акустические результаты (наиболее точные, наиболее достоверные) достигаются путем микширования/текущего контроля и распространения непосредственно в сигналы, подаваемые на громкоговорители, поскольку между создателем содержимого и слушателем обработка отсутствует. Если проигрывающая система известна заранее, описание сигналов, подаваемых на громкоговорители, обычно обеспечивает наивысшую точность воспроизведения. Однако во многих применениях на практике проигрывающая система неизвестна. Наиболее адаптируемым считается описание на основе моделей, поскольку оно не делает предположений о технологии представления данных, и поэтому оно легче всего применяется для любой технологии представления данных. Несмотря на то, что описание на основе моделей эффективно собирает пространственную информацию, оно становится чрезвычайно неэффективным по мере увеличения количества источников звука.
[0008] В течение многих лет системы для кинематографии характеризовались дискретными экранными каналами в форме левого, центрального, правого и, иногда, «внутреннего левого» и «внутреннего правого» каналов. Эти дискретные источники обычно имеют достаточную амплитудно-частотную характеристику и коммутируемую мощность для того, чтобы позволять точно размещать звуки в разных областях экрана и допускать тембральное согласование по мере того, как звуки перемещаются, или панорамируются, между местоположениями. Современные разработки по усилению восприятия слушателя стремятся к точному воспроизведению местоположения звуков относительно слушателя. В установке 5.1 окружающие «зоны» включают массив громкоговорителей, все из которых несут одинаковую звуковую информацию в пределах каждой, левой окружающей или правой окружающей зоны. Указанные массивы могут быть эффективны для эффектов «окружающей среды» и рассеянного окружающего звука, однако в повседневной жизни многие звуковые эффекты возникают из случайно размещенных точечных источников. Например, в ресторане кажется, что окружающая музыка играет со всех сторон, в то время как из определенных точек возникают дискретные звуки: разговор человека – из одной точки, стук ножа по тарелке – из другой. Наличие возможности дискретного размещения этих звуков вокруг зрительного зала может создавать усиленное ощущение реальности, не являясь при этом слишком заметным. Также важной составляющей четкости окружающего звука являются звуки сверху. В реальном мире звуки приходят со всех направлений, и не всегда – из единственной горизонтальной плоскости. Дополнительное чувство реальности может достигаться, если звуки могут слышаться сверху, иными словами из «верхней полусферы». Современные системы, однако, не предлагают по-настоящему точного воспроизведения звука для разных типов звука для ряда разных сред проигрывания. Потребуется еще немало сделать в области обработки, знания и конфигурации фактических сред проигрывания, чтобы, используя существующие системы, попытаться точно воспроизводить местоположение определенных звуков и, таким образом, сделать современные системы негодными к употреблению для большинства применений.
[0009] То, что является необходимым, представляет собой систему, которая поддерживает несколько экранных каналов, что в результате приводит к повышенной четкости и улучшенной аудиовизуальной когерентности для звуков или диалога на экране и к возможности точно располагать источники где угодно в окружающих зонах, улучшая аудиовизуальный переход от экрана в помещение. Например, если герой на экране смотрит внутрь помещения в направлении источника звука, звукоинженер («оператор микширования») должен иметь возможность точно размещать звук так, чтобы он совпадал с линией взгляда героя и чтобы этот эффект был единообразным для всех зрителей. Однако при традиционном микшировании окружающего звука 5.1 или 7.1 эффект сильно зависит от положения посадочного места слушателя, что является неблагоприятным для большинства крупных сред прослушивания. Повышенное разрешение окружающего звука создает новые возможности для использования звука центрированным в помещении образом, в отличие от традиционного подхода, где содержимое создается в предположении единственного слушателя в «зоне наилучшего восприятия».
[0010] Помимо пространственных проблем, многоканальные системы на современном уровне техники страдают в отношении тембра. Например, при воспроизведении массивом громкоговорителей может страдать тембральное качество некоторых звуков, таких как шипение пара, выходящего из поврежденной трубы. Способность направлять определенные звуки в единственный громкоговоритель дает оператору микширования возможность устранять искажения при воспроизведении массивом и добиваться более реалистичного восприятия зрителями. Традиционно, окружающие громкоговорители не поддерживают столь же полный диапазон звуковых частот и уровень, которые поддерживают большие экранные каналы. В прошлом это создавало трудности для операторов микширования, уменьшая их возможности свободно перемещать широкополосные звуки от экрана в помещение. В результате, владельцы кинотеатров не ощущали необходимости в модернизации конфигурации окружающих каналов, что препятствовало широкому внедрению более высококачественных установок.
КРАТКОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
[0011] Системы и способы описываются для формата звука для кинематографии и системы обработки данных, которая включает новый слой громкоговорителей (конфигурацию каналов) и связанный формат пространственного описания. Определена система адаптивного звука и формат, который поддерживает несколько технологий представления данных. Аудиопотоки передаются наряду с метаданными, которые описывают «замысел оператора микширования», включающий требуемое положение аудиопотока. Указанное положение может быть выражено как названный канал (из каналов в пределах предварительно определенной конфигурации каналов) или как информация о трехмерном положении. Такой формат – каналы плюс объекты - сочетает оптимальные способы описания звуковой картины на основе каналов и на основе моделей. Аудиоданные для системы адаптивного звука содержат некоторое количество независимых монофонических аудиопотоков. Каждый поток имеет связанные с ним метаданные, которые описывают, будет поток представлять собой поток на основе каналов или поток на основе объектов. Потоки на основе каналов содержат информацию представления данных, кодированную посредством названия канала; а потоки на основе объектов содержат информацию местоположения, кодированную через математические выражения, кодированные в дополнительных связанных метаданных. Оригинальные независимые аудиопотоки упаковываются как единая двоичная последовательность, которая содержит все аудиоданные. Данная конфигурация позволяет представлять звук в соответствии с аллоцентрической системой отсчета, в которой представление данных местоположения звука основывается на характеристиках среды проигрывания (например, на размере помещения, его форме и т.д.) для соответствия замыслу оператора микширования. Метаданные положения объекта содержат соответствующую информацию аллоцентрической системы координат, необходимую для правильного проигрывания звука с использованием положений доступных громкоговорителей в помещении, которое подготовлено для проигрывания адаптивного звукового содержимого. Это позволяет оптимально микшировать звук для определенной среды проигрывания, которая может отличаться от среды микширования, испытываемой звукоинженером.
[0012] Система адаптивного звука повышает качество звука в различных помещениях посредством таких преимуществ, как усовершенствованное управление коррекцией амплитудно-частотной характеристики в помещении и окружающими басами с тем, чтобы оператор микширования мог свободно обращаться к громкоговорителям (как находящимся на экране, так и вне экрана) без необходимости думать о тембральном согласовании. Система адаптивного звука добавляет в традиционные последовательности операций на основе каналов гибкость и возможности динамических звуковых объектов. Указанные звуковые объекты позволяют создателям контролировать дискретные звуковые элементы независимо от конкретных конфигураций проигрывающих громкоговорителей, в том числе верхних громкоговорителей. Система также вносит новую эффективность в процесс компоновки, позволяя звукоинженерам эффективно фиксировать все их замыслы а затем, в ходе текущего контроля в реальном времени или автоматически, генерировать версии окружающего звука 7.1 или 5.1.
[0013] Система адаптивного звука упрощает распространение, выделяя звуковую сущность художественного замысла в единый файл дорожки в устройстве обработки данных для цифровой кинематографии, который может точно проигрываться в широком диапазоне конфигураций кинотеатров. Система обеспечивает оптимальное воспроизведение художественного замысла, когда средства микширования и представления данных используют одинаковую конфигурацию каналов и единый инвентарь с нисходящей адаптацией к конфигурации представления данных, т.е. с понижающим микшированием.
[0014] Эти и другие преимущества представлены через варианты осуществления изобретения, которые направлены на звуковую платформу для кинематографии, обращаясь к ограничениям современных систем, и доставляют впечатления от звука, который находится за пределами досягаемости систем, доступных в настоящее время.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
[0015] В нижеследующих графических материалах сходные ссылочные позиции используются для ссылки на сходные элементы. Несмотря на то, что следующие фигуры изображают различные примеры, одна или несколько реализаций не ограничиваются примерами, изображенными на указанных фигурах.
[0016] ФИГ. 1 представляет собой общий вид сверху среды создания и проигрывания звука, использующей систему адаптивного звука согласно одному из вариантов осуществления изобретения.
[0017] ФИГ. 2 иллюстрирует объединение данных на основе каналов и на основе объектов с целью генерирования адаптивного звукового микса согласно одному из вариантов осуществления изобретения.
[0018] ФИГ. 3 представляет собой блок-схему, иллюстрирующую последовательность операций создания, упаковки и представления данных адаптивного звукового содержимого согласно одному из вариантов осуществления изобретения.
[0019] ФИГ. 4 представляет собой блок-схему этапа представления данных системы адаптивного звука согласно одному из вариантов осуществления изобретения.
[0020] ФИГ. 5 представляет собой таблицу, в которой перечисляются типы метаданных и связанные элементы метаданных для системы адаптивного звука согласно одному из вариантов осуществления изобретения.
[0021] ФИГ. 6 представляет собой схему, которая иллюстрирует компоновку и окончательную обработку для системы адаптивного звука согласно одному из вариантов осуществления изобретения.
[0022] ФИГ. 7 представляет собой схему одного из примеров последовательности операций процесса упаковки цифрового кинофильма с использованием файлов адаптивного звука согласно одному из вариантов осуществления изобретения.
[0023] ФИГ. 8 представляет собой вид сверху одного из примеров схемы расположения предполагаемых местоположений громкоговорителей для их использования с системой адаптивного звука в типовом зрительном зале.
[0024] ФИГ. 9 представляет собой вид спереди одного из примеров размещения предполагаемых местоположений громкоговорителей на экране для использования в типовом зрительном зале.
[0025] ФИГ. 10 представляет собой вид сбоку одного из примеров схемы расположения предполагаемых местоположений громкоговорителей для их использования с системой адаптивного звука в типовом зрительном зале.
[0026] ФИГ. 11 представляет собой один из примеров расположения верхних окружающих громкоговорителей и боковых окружающих громкоговорителей относительно начала отсчета согласно одному из вариантов осуществления изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
[0027] Описываются системы и способы для системы адаптивного звука и связанного звукового сигнала и формата данных, которые поддерживают несколько технологий представления данных. Особенности для одного или нескольких вариантов осуществления изобретения, описываемые в данном раскрытии, могут реализовываться в аудиосистеме или аудиовизуальной системе, которая обрабатывает исходную звуковую информацию в системе микширования, представления данных и проигрывания, которая содержит один или несколько компьютеров или устройств обработки данных, исполняющих команды программного обеспечения. Любой из описываемых вариантов осуществления изобретения может использоваться сам по себе или совместно с какими-либо другими вариантами в любом сочетании. Несмотря на то, что различные варианты осуществления изобретения могли быть мотивированы различными недостатками на известном уровне техники, которые могут обсуждаться или упоминаться в одном или нескольких местах в данном описании, варианты осуществления изобретения необязательно обращаются к какому-либо из этих недостатков. Иными словами, различные варианты осуществления изобретения могут обращаться к различным недостаткам, которые могут обсуждаться в данном описании. Некоторые варианты осуществления изобретения могут лишь частично обращаться к некоторым недостаткам или только к одному недостатку, описываемому в данном описании, а некоторые варианты осуществления изобретения могут не обращаться ни к одному из этих недостатков.
[0028] Для целей настоящего описания нижеследующие термины имеют следующие связанные значения.
[0029] Канал, или звуковой канал: монофонический звуковой сигнал, или аудиопоток, плюс метаданные, в которых положение закодировано как идентификатор канала, например «левый передний» или «правый верхний окружающий». Канальный объект может управлять несколькими громкоговорителями, например, левые окружающие каналы (Ls) будут подаваться на громкоговорители массива Ls.
[0030] Конфигурация каналов: предварительно определенный набор зон громкоговорителей со связанными номинальными местоположениями, например, 5.1, 7.1 и т.д.; 5.1 относится к шестиканальной аудиосистеме окружающего звука, содержащей передние левый и правый каналы, центральный канал, два окружающих канала и сверхнизкочастотный канал; 7.1 относится к восьмиканальной системе окружающего звука, в которой к системе 5.1 добавлено два дополнительных окружающих канала. Примеры конфигураций 5.1 и 7.1 включают системы Dolby® surround.
[0031] Громкоговоритель: преобразователь звука или набор преобразователей, которые представляют данные звукового сигнала.
[0032] Зона громкоговорителей: массив из одного или нескольких громкоговорителей, которые могут быть однозначно отнесены и которые принимают единственный, например, левый окружающий, звуковой сигнал, обычно находятся в кинотеатре и, в частности, предназначены для исключения или включения в представление данных объекта.
[0033] Канал громкоговорителя, или канал сигнала, подаваемого на громкоговоритель: звуковой канал, который связан с названным громкоговорителем, или зоной громкоговорителей, в пределах определенной конфигурации громкоговорителей. Канал громкоговорителя обычно представляется с использованием связанной зоны громкоговорителей.
[0034] Группа каналов громкоговорителей: набор из одного или нескольких каналов громкоговорителей, соответствующих конфигурации каналов (например, со стереодорожками, монодорожками и т.д.).
[0035] Объект, или канал объекта: один или несколько звуковых каналов с таким параметрическим описанием источника, как положение кажущегося источника (например, трехмерные координаты), ширина кажущегося источника и т.д. Аудиопоток плюс метаданные, в которых положение закодировано как трехмерное положение в пространстве.
[0036] Звуковая программа: полный набор каналов громкоговорителей и/или объектных каналов и связанных метаданных, которые описывают требуемое представление звука в пространстве.
[0037] Аллоцентрическая система отсчета: пространственная система отсчета, в которой звуковые объекты определяются в пределах среды представления данных относительно таких признаков, как стены и углы помещения, стандартные местоположения громкоговорителей и местоположение экрана (например, передний левый угол помещения).
[0038] Эгоцентрическая система отсчета: пространственная система отсчета, в которой объекты определяются относительно перспективы (зрителей) слушателя, и которая часто определяется относительно углов по отношению к слушателю (например, 30 градусов справа от слушателя).
[0039] Кадр: кадры представляют собой короткие, независимо декодируемые сегменты, на которые разделяется полная звуковая программа. Размер и границы аудиокадров обычно выровнены с видеокадрами.
[0040] Адаптивный звук: звуковые сигналы на основе каналов и/или на основе объектов плюс метаданные, которые представляют данные звуковых сигналов на основе среды проигрывания.
[0041] Описываемый в данном раскрытии формат звука для кинематографии и система обработки данных, также именуемая «системой адаптивного звука», используют новую технологию описания и представления пространственных данных звука, позволяющую усиливать эффект присутствия у зрителей, повышать художественный контроль, гибкость и масштабируемость системы и простоту установки и обслуживания. Варианты осуществления звуковой платформы для кинематографии включают несколько дискретных компонентов, в том числе инструментальные средства микширования, устройство упаковки/кодер, устройство распаковки/декодер, компоненты окончательного микширования и представления данных в кинотеатре, новые схемы громкоговорителей и объединенные в сеть усилители. Система включает рекомендации для новой конфигурации каналов, подлежащей использованию создателями и кинопрокатчиками. Система использует описание на основе моделей, которое поддерживает несколько таких характерных признаков, как: единый инвентарь с нисходящей и восходящей адаптацией к конфигурации представления данных, т.е. отсроченное представление данных и обеспечение возможности оптимального использования доступных громкоговорителей; улучшенный охват звука, включение оптимизированного понижающего микширования во избежание корреляции между каналами; повышенное пространственное разрешение через сквозное управление массивами (например, звуковой объект динамически приписывается к одному или нескольким громкоговорителям в пределах массива окружающего звука); и поддержка альтернативных способов представления данных.
[0042] ФИГ. 1 представляет собой общий вид сверху среды создания и проигрывания звука, использующей систему адаптивного звука, согласно одному из вариантов осуществления изобретения. Как показано на ФИГ. 1, полная, непрерывная среда 100 содержит компоненты создания содержимого, упаковки, распространения и/или проигрывания/представления данных в большое количество конечных устройств и вариантов использования. Система 100 в целом ведет свое начало от содержимого, захваченного из и для некоторого количества разных вариантов использования, которые включают восприятие 112 зрителями. Элемент 102 захвата данных содержимого включает, например, кинематографию, телевидение, прямую трансляцию, содержимое, генерируемое пользователем, записанное содержимое, игры, музыку и т.п. и может включать звуковое/визуальное или чисто звуковое содержимое. Содержимое по мере продвижения через систему 100 от этапа 102 захвата данных к восприятию 112 конечными пользователями проходит несколько ключевых этапов обработки через дискретные компоненты системы. Указанные этапы процесса включают предварительную обработку звука 104, инструментальные средства и процессы 106 авторской разработки, кодирование аудиокодеком 108, который ведет сбор, например, аудиоданных, дополнительных метаданных и информации воспроизведения, и объектные каналы. Для успешного и защищенного распространения посредством различных носителей, к объектным каналам могут применяться такие разнообразные воздействия обработки, как сжатие (с потерями или без потерь), шифрование и т.п. Для воспроизведения и передачи определенного восприятия 112 пользователем адаптивного звука, затем применяются соответствующие специфичные для конечных точек процессы 110 декодирования и представления данных. Восприятие 112 звука представляет проигрывание звукового или аудиовизуального содержимого через соответствующие громкоговорители и проигрывающие устройства, и может представлять любую среду, в которой слушатель испытывает воспроизведение захваченного содержимого, такую как кинотеатр, концертный зал, открытый кинотеатр, дом или помещение, кабинка для прослушивания, автомобиль, игровая приставка, наушники или гарнитура, система оповещения или другая проигрывающая среда.
[0043] Данный вариант осуществления системы 100 включает аудиокодек 108, который способен эффективно распространять и хранить в памяти многоканальные звуковые программы, и поэтому может именоваться как «гибридный» кодек. Кодек 108 сочетает традиционные аудиоданные на основе каналов со связанными метаданными, образуя звуковые объекты, которые облегчают создание и доставку звука, который является адаптированным и оптимизированным для представления данных и проигрывания в средах, которые, возможно, отличаются от среды микширования. Это позволяет звукоинженеру кодировать его или ее замысел в том, как конечный звук должен слышаться слушателем, на основе фактической среды прослушивания слушателем.
[0044] Традиционные аудиокодеки на основе каналов действуют в предположении, что звуковая программа будет воспроизводиться массивом громкоговорителей, находящихся в предварительно определенных положениях относительно слушателя. Для создания полной многоканальной звуковой программы, звукоинженеры обычно микшируют большое количество отдельных аудиопотоков (например, диалог, музыку, эффекты) с целью создания требуемого общего восприятия. При микшировании звука решения обычно принимаются путем прослушивания звуковой программы, воспроизводимой массивом громкоговорителей, находящихся в предварительно определенных положениях, например, в частности, в системе 5.1 или 7.1 в определенном кинотеатре. Конечный, микшированный сигнал служит вводом в аудиокодек. Пространственно точные звуковые поля достигаются при воспроизведении только тогда, когда громкоговорители размещаются в предварительно определенных положениях.
[0045] Одна из новых форм кодирования звука, называемая кодированием звуковых объектов, предусматривает в качестве ввода в кодер отдельные источники звука (звуковые объекты) в форме отдельных аудиопотоков. Примеры звуковых объектов включают диалоговые дорожки, отдельные инструменты, отдельные звуковые эффекты и другие точечные источники. Каждый звуковой объект связан с пространственными параметрами, которые могут включать в качестве неограничивающих примеров положение звука, ширину звука и информацию скорости. Для распространения и хранения, звуковые объекты и связанные параметры затем кодируются. Окончательное микширование и представление данных звукового объекта выполняется на стороне приема в цепи распространения звука как часть проигрывания звуковой программы. Этот этап может основываться на сведениях о фактических положениях громкоговорителей, поэтому результатом является система распространения звука, которая является настраиваемой в соответствии с условиями прослушивания конкретным пользователем. Две указанные формы кодирования, на основе каналов и на основе объектов, оптимально действуют для разных условий входного сигнала. Аудиокодеры на основе каналов обычно более эффективны для кодирования входных сигналов, содержащих плотные смеси разных источников звука, а также для рассеянных звуков. Кодеры звуковых объектов, наоборот, более эффективны для кодирования небольшого количества высоконаправленных источников звука.
[0046] В одном из вариантов осуществления изобретения, способы и компоненты системы 100 включают систему кодирования, распространения и декодирования звука, сконфигурированную для генерирования одного или нескольких битовых потоков, содержащих как традиционные звуковые элементы на основе каналов, так и элементы кодирования звуковых объектов. Такой комбинированный подход обеспечивает бóльшую эффективность кодирования и гибкость представления данных по сравнению с взятыми по отдельности подходами на основе каналов и на основе объектов.
[0047] Другие особенности описываемых вариантов осуществления изобретения включают расширение обратно совместимым образом предварительно определенного аудиокодека на основе каналов для включения элементов кодирования звуковых объектов. Новый «слой расширения», содержащий элементы кодирования звуковых объектов, определяется и добавляется к «основному», или «обратно совместимому», слою битового потока аудиокодека на основе каналов. Такой подход позволяет унаследованным декодерам обрабатывать один или несколько битовых потоков, которые содержат слой расширения, и, в то же время, обеспечивает улучшенное впечатление от прослушивания для пользователей с новыми декодерами. Один из примеров усиления пользовательского восприятия включает управление представлением данных звукового объекта. Дополнительным преимуществом этого подхода является то, что звуковые объекты могут добавляться или модифицироваться повсюду на протяжении цепочки распространения без декодирования/микширования/повторного кодирования многоканального звука, кодированного аудиокодеком на основе каналов.
[0048] В отношении системы координат, пространственные эффекты звуковых сигналов являются решающими при обеспечении для слушателя впечатления эффекта присутствия. Звуки, которые подразумеваются как исходящие из определенной области зрительного экрана или помещения должны воспроизводиться через громкоговоритель (громкоговорители), расположенный в том же самом относительном местоположении. Поэтому первичным элементом метаданных звука для звукового события в описании на основе моделей является положение, хотя могут также описываться и такие другие параметры, как размер, ориентация, скорость и дисперсия звука. Для передачи положения трехмерное пространственное описание звука на основе моделей требует трехмерной системы координат. Система координат, используемая для передачи (эвклидова, сферическая и т.д.), обычно выбирается для удобства или компактности, однако для обработки представления данных могут использоваться и другие системы координат. В дополнение к системе координат, для представления местоположений объектов в пространстве, требуется система отсчета. Выбор надлежащей системы отсчета может быть решающим фактором точного воспроизведения звука системами на основе положения во множестве различных сред. В аллоцентрической системе отсчета положение источника звука определяется относительно таких признаков в пределах среды представления данных, как стены и углы помещения, стандартные местоположения громкоговорителей и местоположение экрана. В эгоцентрической системе отсчета местоположения представляются относительно перспективы слушателя, как, например, «передо мной, немного влево», и т.д. Научные исследования пространственного восприятия (звука и др.) показали, что наиболее универсальным является использование эгоцентрической перспективы. Однако для кинематографа по ряду причин более подходящей является аллоцентрическая система. Например, точное местоположение звукового объекта является более важным, когда связанный объект находится на экране. При использовании аллоцентрической системы отсчета для каждого положения прослушивания и для экрана любого размера, звук будет локализоваться в одном и том же положении на экране, например, на треть левее середины экрана. Другой причиной является то, что операторы микширования склонны рассуждать и микшировать в аллоцентрическом исчислении, и средства панорамирования компонуются в аллоцентрической системе отсчета (стены помещения), и операторы микширования ожидают, что представляться эти средства будут именно таким образом, например, «этот звук должен находиться на экране», «этот звук должен находиться за экраном» или «от левой стены» и т.д.
[0049] Несмотря на использование аллоцентрической системы отсчета в среде для кинематографии, существуют некоторые случаи, для которых может быть полезна эгоцентрическая система отсчета. Эти случаи включают закадровые звуки, т.е. звуки, которые не присутствуют в «пространстве фильма», например, музыкальное сопровождение, для которого может требоваться однородное эгоцентрическое представление. Другой случай – эффекты в ближней зоне (например, жужжание комара в левом ухе слушателя), которые требуют эгоцентрического представления. В настоящее время не существует средств для представления данных такого ближнего звукового поля с использованием наушников или громкоговорителей ближней зоны. Кроме того, бесконечно удаленные источники звука (и результирующие плоские волны) кажутся приходящими из постоянного эгоцентрического положения (например, 30 градусов слева), и такие звуки легче описать в эгоцентрическом исчислении, а не в аллоцентрическом.
[0050] В некоторых случаях, можно использовать аллоцентрическую систему отсчета до тех пор, пока определено номинальное положение прослушивания, несмотря на то, что некоторые примеры требуют эгоцентрического представления, данные которого до сих пор невозможно представить. И хотя аллоцентрическая система отсчета может являться более полезной и подходящей, представление звука должно быть расширяемым, поскольку многие новые особенности, в том числе и эгоцентрическое представление, могут оказаться более желательными в некоторых приложениях и средах прослушивания. Варианты осуществления системы адаптированного звука включают гибридный подход к пространственному описанию, который включает рекомендуемую конфигурацию каналов для оптимальной точности воспроизведения и для представления данных рассеянных или сложных, многоточечных источников (например, толпа на стадионе, окружающая среда) с использованием эгоцентрической системы отсчета плюс аллоцентрическое описание звука на основе моделей – для того, чтобы допускалось высокое пространственное разрешение и масштабируемость.
Компоненты системы
[0051] Со ссылкой на ФИГ. 1, оригинальные данные 102 звукового содержимого, в первую очередь, обрабатываются в блоке 104 предварительной обработки. Блок 104 предварительной обработки системы 100 содержит компонент фильтрации объектных каналов. Во многих случаях, звуковые объекты содержат отдельные источники звука, что позволяет панорамировать звуки независимо. В некоторых случаях, как, например, при создании звуковых программ с использованием природного или «производственного» звука, может оказаться необходимым извлечение отдельных звуковых объектов из записи, которая содержит несколько источников звука. Варианты осуществления изобретения включают способ выделения независимых звуковых сигналов из более сложного сигнала. Нежелательные элементы, подлежащие отделению от независимых сигналов источников, могут включать в качестве неограничивающих примеров другие независимые источники звука и фоновый шум. Кроме того, для воссоздания «сухих» источников звука может устраняться реверберация.
[0052] Устройство 104 предварительной обработки данных также включает функциональную возможность разделения источников и обнаружения типа содержимого. Система предусматривает автоматическое генерирование метаданных путем анализа входного звука. Позиционные метаданные получаются из многоканальной записи путем анализа относительных уровней коррелированного входного сигнала между парами каналов. Обнаружение типа содержимого, такого как «речь» или «музыка», может выполняться, например, путем извлечения и классификации характерных признаков.
Инструментальные средства авторской разработки
[0053] Блок 106 инструментальных средств авторской разработки включает характерные признаки, предназначенные для усовершенствования авторской разработки звуковых программ путем оптимизации ввода и кодификации творческого замысла звукоинженера, позволяя ему создавать конечный звуковой микс, как только она будет оптимизирована для проигрывания практически в любой среде проигрывания. Это выполняется путем использования звуковых объектов и позиционных данных, которые связываются и кодируются вместе с оригинальным звуковым содержимым. Для того, чтобы точно разместить звуки по периметру зрительного зала, звукоинженеру необходимо иметь контроль над тем, как звук будет в конечном счете представляться на основе фактических ограничений и характерных признаков среды проигрывания. Система адаптивного звука предусматривает такой контроль, позволяя звукоинженеру изменять то, каким образом звуковое содержимое разрабатывается и микшируется путем использования звуковых объектов и позиционных данных.
[0054] Звуковые объекты можно считать группами звуковых элементов, которые могут восприниматься как исходящие из определенного физического местоположения, или местоположений, в зрительном зале. Такие объекты могут быть неподвижными, или они могут перемещаться. В системе 100 адаптивного звука звуковые объекты управляются метаданными, которые, среди прочего, подробно описывают местоположение звука в данный момент времени. Когда объекты подвергаются текущему контролю, или проигрываются в кинотеатре, их данные представляются согласно позиционным метаданным с использованием громкоговорителей, которые имеются в наличии, вместо обязательного вывода в физический канал. Дорожка в сессии может представлять собой звуковой объект, а стандартные данные панорамирования могут быть аналогичны позиционным метаданным. Таким образом, содержимое, размещаемое на экране, может эффективно панорамироваться точно так же, как в случае содержимого на основе каналов, однако данные содержимого, размещаемого в окружающих каналах, могут при желании представляться в отдельный канал. Несмотря на то, что использование звуковых объектов обеспечивает необходимый контроль над дискретными эффектами, другие особенности звуковой дорожки кинофильма эффективнее работают в среде на основе каналов. Например, многие эффекты окружающей среды или реверберация фактически выигрывают от подачи в массивы громкоговорителей. И хотя они могут обрабатываться как объекты с шириной, достаточной для заполнения массива, более полезным является сохранение некоторых функциональных возможностей на основе каналов.
[0055] В одном из вариантов осуществления изобретения, система адаптивного звука в дополнение к звуковым объектам поддерживает «тракты», где тракты представляют собой эффективно субмикшированные сигналы на основе каналов, или стэмы. В зависимости от замысла создателя содержимого, они могут получаться для конечного проигрывания (представления данных) либо по отдельности, либо объединенные в единый тракт. Указанные тракты могут создаваться в таких различных конфигурациях на основе каналов, как 5.1, 7.1, и являются распространяемыми на такие более обширные форматы, как 9.1 и массивы, включающие верхние громкоговорители.
[0056] ФИГ. 2 иллюстрирует сочетание данных на основе каналов и объектов при генерировании адаптивного звукового микса согласно одному из вариантов осуществления изобретения. Как показано в процессе 200, данные 202 на основе каналов, которые, например, могут представлять собой данные окружающего звука 5.1 или 7.1, представленные в форме данных с импульсно-кодовой модуляцией (PCM), объединяются с данными 204 звуковых объектов, образуя адаптивный звуковой микс 208. Данные 204 звуковых объектов генерируются путем объединения элементов оригинальных данных на основе каналов со связанными метаданными, которые указывают некоторые параметры, имеющие отношение к местоположению звуковых объектов.
[0057] Как концептуально показано на ФИГ. 2, инструментальные средства авторской разработки обеспечивают возможность создания звуковых программ, которые одновременно содержат комбинацию групп каналов громкоговорителей и объектных каналов. Например, звуковая программа может содержать один или несколько каналов громкоговорителей, необязательно, организованных в группы (или дорожки, например, стереофоническую дорожку или дорожку 5.1), и описательные метаданные для одного или нескольких каналов громкоговорителей, один или несколько объектных каналов, и описательные метаданные для одного или нескольких объектных каналов. В пределах звуковой программы, каждая группа каналов громкоговорителей и каждый объектный канал могут быть представлены с использованием одной или нескольких частот дискретизации. Например, приложения Digital Cinema (D-Cinema) поддерживают частоты дискретизации 48 кГц и 96 кГц, однако также могут поддерживаться и другие частоты дискретизации. Кроме того, также могут поддерживаться принятие, сохранение в памяти и редактирование каналов с различными частотами дискретизации.
[0058] Создание звуковой программы требует этапа звуковой сценографии, который включает объединение звуковых элементов как суммы составных звуковых элементов с отрегулированными уровнями для создания требуемого нового звукового эффекта. Инструментальные средства авторской разработки системы адаптивного звука позволяют создавать звуковые эффекты как совокупность звуковых объектов с относительными положениями, используя пространственно-визуальный графический пользовательский интерфейс звуковой сценографии. Например, визуальное отображение объекта, генерирующего звук (например, автомобиля), может использоваться в качестве шаблона для сборки звуковых элементов (шум выхлопа, шуршание шин, шум двигателя) в качестве объектных каналов, содержащих звук и соответствующее положение в пространстве (возле выхлопной трубы, шин и капота). Каналы отдельных объектов могут затем связываться и обрабатываться как группа. Инструментальное средство 106 авторской разработки включает несколько элементов пользовательского интерфейса, позволяющих звукоинженеру вводить управляющую информацию и просматривать параметры микширования, а также совершенствовать функциональные возможности системы. Процесс звуковой сценографии и авторской разработки также совершенствуется путем допуска связывания и обработки объектных каналов и каналов громкоговорителей как группы. Одним из примеров является объединение объектного канала с дискретным, сухим источником звука с набором каналов громкоговорителей, которые содержат связанный реверберированный сигнал.
[0059] Инструментальное средство 106 авторской разработки поддерживает возможность объединения нескольких звуковых каналов, общеизвестную под наименованием «микширование». Поддерживается множество способов микширования, которые могут включать традиционное микширование на основе уровней и микширование на основе громкости. При микшировании на основе уровней к звуковым каналам применяется широкополосное масштабирование, и масштабированные звуковые каналы затем суммируются. Коэффициенты широкополосного масштабирования для каждого канала выбираются так, чтобы они управляли абсолютным уровнем результирующего микшированного сигнала, а также относительными уровнями микшированных каналов в микшированном сигнале. При микшировании на основе громкости, один или несколько входных сигналов модифицируются с использованием масштабирования зависящих от частоты амплитуд, где зависящая от частоты амплитуда выбирается так, чтобы она обеспечивала требуемую воспринимаемую абсолютную и относительную громкость и, в то же время, сохраняла воспринимаемый тембр входного звука.
[0060] Инструментальные средства авторской разработки допускают возможность создания каналов громкоговорителей и групп каналов громкоговорителей. Это позволяет связывать метаданные с каждой из групп каналов громкоговорителей. Каждая из групп каналов громкоговорителей может помечаться в соответствии с типом содержимого. Тип содержимого распространяется посредством текстового описания. Типы содержимого могут включать в качестве неограничивающих примеров диалог, музыку и эффекты. Каждой из групп каналов громкоговорителей могут присваиваться уникальные команды о том, как следует выполнять повышающее микширование из одной конфигурации каналов в другую, где повышающее микширование определяется как создание М звуковых каналов из N звуковых каналов, где M>N. Команды повышающего микширования могут включать в качестве неограничивающих примеров следующие команды: флаг разблокирования/блокирования, указывающий допустимость повышающего микширования; матрицу повышающего микширования, предназначенную для управления присваиванием между каждым входным и выходным каналами; а разблокирование по умолчанию и установки матрицы могут присваиваться на основе типа содержимого, например, разблокировать повышающее микширование только для музыки. Каждой из групп каналов громкоговорителей также могут присваиваться уникальные команды о том, каким образом выполнять понижающее микширование от одной конфигурации каналов к другой, где понижающее микширование определяется как создание Y звуковых каналов из X звуковых каналов, где Y>X. Команды понижающего микширования могут включать в качестве неограничивающих примеров следующие команды: матрицу, предназначенную для управления присваиванием между каждым входным и выходным каналами; и настройки матрицы по умолчанию, которые могут присваиваться на основе типа содержимого, например, диалог должен подвергаться понижающему микшированию на экран; эффекты должны подвергаться понижающему микшированию за пределы экрана. Каждый канал громкоговорителей также может быть связан с флагом метаданных, блокирующим управление басами в ходе представления данных.
[0061] Варианты осуществления изобретения включают характерный признак, который допускает создание объектных каналов и групп объектных каналов. Изобретение позволяет связывать метаданные с каждой из групп объектных каналов. Каждая из групп объектных каналов может помечаться в соответствии с типом содержимого. Тип содержимого распространяется посредством текстового описания, где типы содержимого могут включать в качестве неограничивающих примеров диалог, музыку и эффекты. Каждой из групп объектных каналов могут присваиваться метаданные для описания того, как следует представлять данные объекта (объектов).
[0062] Информация положения предусматривается для указания требуемого положения кажущегося источника. Положение может указываться с использованием эгоцентрической или аллоцентрической системы отсчета. Эгоцентрическая система отсчета является подходящей тогда, когда положение источника должно опираться на слушателя. Для описания положения в эгоцентрической системе пригодны сферические координаты. Аллоцентрическая система отсчета является типичной системой отсчета для кинематографических или других аудиовизуальных представлений, где положение источника указывается относительно таких объектов в среде представления, как положение экрана видеомонитора или границы помещения. Информация трехмерной (3D) траектории предоставляется для того, чтобы позволять интерполировать положение, или для использования других решений представления данных, таких как разблокирование «привязки к режиму». Информация размера представляется для указания требуемого воспринимаемого размера кажущегося источника звука.
[0063] Пространственное квантование предусматривается посредством элемента управления «привязка к ближайшему громкоговорителю», которое указывает замысел звукоинженера, или оператора микширования, представить данные объекта в точности одним громкоговорителем (потенциально жертвуя пространственной точностью). Предел допустимого пространственного искажения может указываться посредством пороговых значений допусков возвышения и азимута с тем, чтобы, если пороговое значение превышается, функция «привязка» не выполнялась. В дополнение к пороговым значениям расстояний, может указываться параметр скорости плавного перехода, предназначенный для контроля над тем, насколько быстро движущийся объект перейдет, или совершит скачок, из одного громкоговорителя в другой, когда требуемое положение находится между громкоговорителями.
[0064] В одном из вариантов осуществления изобретения, для некоторых метаданных положения используются зависимые пространственные метаданные. Например, метаданные могут автоматически генерироваться для «ведомого» объекта путем связывания его с «ведущим» объектом, за которым должен следовать ведомый объект. Для ведомого объекта может задаваться задержка во времени или относительная скорость. Также могут предусматриваться механизмы, позволяющие определять акустический центр тяжести для наборов, или групп, объектов с тем, чтобы данные объекта могли представляться таким образом, чтобы он воспринимался как движущийся около другого объекта. В этом случае один или несколько объектов могут вращаться вокруг некоторого объекта, или определенной области, как господствующей точки или приямка помещения. Тогда акустический центр тяжести можно было бы использовать на этапе представления данных для того, чтобы способствовать определению информации местоположения для каждого и звуков на основе объектов, даже если окончательная информация местоположения будет выражаться как местоположение относительно помещения, в отличие от местоположения относительно другого объекта.
[0065] Когда представляются данные объекта, он, в соответствии с метаданными положения и местоположением проигрывающих громкоговорителей, присваивается одному или нескольким громкоговорителям. С целью ограничения громкоговорителей, которые могли бы использоваться, с объектом могут связываться дополнительные метаданные. Использование ограничений может запрещать использование указанных громкоговорителей или только подавлять указанные громкоговорители (допускать в громкоговоритель, или громкоговорители, меньше энергии, чем могло бы применяться). Наборы громкоговорителей, подлежащие ограничению, могут включать в качестве неограничивающих примеров какие-либо названные громкоговорители, или зоны громкоговорителей (например, L, C, R и т.д.), или такие зоны громкоговорителей, как передняя стена, задняя стена, левая стена, правая стена, потолок, пол, громкоговорители в помещении и т.д. Аналогично, в ходе указания требуемого микширования нескольких звуковых элементов, можно вызвать превращение одного или нескольких звуковых элементов в неслышимые, или «замаскированные», по причине присутствия других, «маскирующих» звуковых элементов. Например, если обнаруживаются «замаскированные» звуковые элементы, их можно идентифицировать посредством графического дисплея.
[0066] Как описано в другом месте, описание звуковой программы может адаптироваться для представления данных на широком выборе установок громкоговорителей и конфигураций каналов. Когда автором разрабатывается звуковая программа, важно выполнять текущий контроль программы в ожидаемых конфигурациях проигрывания с тем, чтобы убедиться, что достигаются требуемые результаты. Данное изобретение включает возможность выбора целевых конфигураций проигрывания и осуществлять текущий контроль результата. Кроме того, система может автоматически отслеживать худший случай уровней сигнала (т.е. самые высокие уровни), которые могли бы генерироваться в каждой из ожидаемых конфигураций воспроизведения и предусматривать указатель, если будет возникать обрезка или ограничение.
[0067] ФИГ. 3 представляет собой блок-схему, иллюстрирующую последовательность операций создания, упаковки и представления данных адаптивного звукового содержимого согласно одному из вариантов осуществления изобретения. Последовательность операций 300 по ФИГ. 3 разделена на три отдельные группы задач, помеченных как создание/авторская разработка, упаковка и демонстрация. В общем, гибридная модель трактов и объектов, показанная на ФИГ. 2, позволяет выполнять большинство задач, – звуковую сценографию, редактирование, предварительное микширование и окончательное микширование, – таким же образом, каким они выполняются в настоящее время, без добавления к современным процессам избыточных служебных данных. В одном из вариантов осуществления изобретения, функциональная возможность адаптации звука предусматривается в форме программного обеспечения, аппаратно-программного обеспечения или схемы, которая используется в сочетании с оборудованием для генерирования и обработки звука, где указанное оборудование может представлять собой новые аппаратные системы или модификации существующих систем. Например, для рабочих станций цифрового звука могут предусматриваться модульные приложения, позволяющие оставлять без изменения существующие методики панорамирования в ходе звуковой сценографии и редактирования. Таким образом, можно сформировать как тракты, так и объекты для рабочей станции в рабочей станции 5.1 или аналогичных монтажных, оснащенных окружающими каналами. Метаданные объектов и звука записываются в ходе сессии по подготовке этапов предварительного и окончательного микширования в дублирующем кинотеатре.
[0068] Как показано на ФИГ. 3, создание или авторская разработка задач включает ввод пользователем, например, в нижеследующем примере, звукоинженером, управляющих сигналов 302 микширования в микшерный пульт или звуковую рабочую станцию 304. В одном из вариантов осуществления изобретения, метаданные встраиваются в поверхность микшерного пульта, позволяя регуляторам настройки каналов, панорамирования и обработки звука работать как с трактами, или стэмами, так и со звуковыми объектами. Метаданные могут редактироваться с использованием поверхности пульта или пользовательского интерфейса рабочей станции, а текущий контроль звука осуществляется с использованием модуля 306 представления данных и окончательной обработки (RMU). Аудиоданные трактов и объектов и связанные метаданные записываются в ходе сессии окончательной обработки с целью создания «контрольной копии», которая включает адаптивный звуковой микс 310, и любые другие конечные выдаваемые данные 308 (такие как окружающий микс 7.1 или 5.1 для кинотеатров). Для того чтобы позволить звукоинженерам помечать отдельные звуковые дорожки в ходе сессии микширования, могут использоваться существующие инструментальные средства авторской разработки (например, такие цифровые звуковые рабочие станции, как Pro Tools). Варианты осуществления изобретения распространяют эту концепцию, позволяя пользователем помечать отдельные субсегменты в пределах дорожки для содействия поиску или быстрой идентификации звуковых элементов. Пользовательский интерфейс для микшерного пульта, который позволяет определять и создавать метаданные, может реализовываться через элементы графического пользовательского интерфейса, физические элементы управления (например, ползунки и кнопки) или любые их комбинации.
[0069] На этапе упаковки файл контрольной копии заключается в оболочку с использованием процедур заключения в оболочку согласно промышленному стандарту MXF, хешируется и, необязательно, зашифровывается для обеспечения целостности звукового содержимого при доставке к оборудованию упаковки данных цифровой кинематографии. Данный этап может выполняться устройством 312 обработки данных цифровой кинематографии (DCP), или любым подходящим устройством для обработки звука, в зависимости от конечной среды проигрывания, такой как кинотеатр 318, оснащенный стандартным окружающим звуком, кинотеатр 320, допускающий адаптивный звук, или какая-либо другая среда проигрывания. Как показано на ФИГ. 3, устройство 312 обработки данных выводит соответствующие звуковые сигналы 314 и 316 в зависимости от демонстрирующей среды.
[0070] В одном из вариантов осуществления изобретения, контрольная копия адаптивного звука содержит адаптивный аудио микс наряду со стандартным DCI-совместимым миксом с импульсно-кодовой модуляцией (РСМ). Микс РСМ может представляться модулем представления данных и окончательной обработки в дублирующем кинотеатре или, по желанию, создаваться отдельным прогоном микширования. Звук РСМ образует в устройстве 312 обработки данных для цифровой кинематографии файл стандартной основной звуковой дорожки, а адаптивный звук образует файл дополнительной дорожки. Указанный файл дорожки может быть совместимым с существующими промышленными стандартами и может игнорироваться DCI-совместимыми серверами, которые не могут его использовать.
[0071] В одном из примеров поигрывающей среды для кинематографии DCP, содержащий файл дорожки адаптивного звука, распознается сервером как достоверный пакет и принимается сервером, а затем передается в виде потока в устройство обработки адаптивных аудиоданных для кинематографии. Система, для которой доступны как линейный РСМ, так и адаптивные звуковые файлы, может по необходимости переключаться между ними. Для распространения на этап демонстрации, схема упаковки адаптивного звука допускает доставку в кинотеатр пакетов одного типа. Пакет DCP содержит как файл РСМ, так адаптивные звуковые файлы. Для обеспечения защищенной доставки содержимого кинофильма, или другого сходного содержимого, может включаться использование ключей защиты, таких как доставка сообщения, зашифрованного на определенном ключе (KDM).
[0072] Как показано на ФИГ. 3, методология адаптивного звука реализуется путем создания для звукоинженера возможности выражения его замысла в отношении представления данных и проигрывания звукового содержимого через звуковую рабочую станцию 304. Управляя некоторыми элементами управления ввода, инженер способен указывать, где и как проигрывать звуковые объекты и звуковые элементы в зависимости от среды прослушивания. Метаданные генерируются в звуковой рабочей станции 304 в ответ на входные данные 302 микширования инженера, обеспечивая очереди на представление данных, которые управляют пространственными параметрами (например, положением, скоростью, интенсивностью, тембром и т.д.) и указывают, какой громкоговоритель (громкоговорители), или группы громкоговорителей, в среде прослушивания проигрывают соответствующие звуки в ходе демонстрации. Метаданные связываются с соответствующими аудиоданными в рабочей станции 304 или RMU 306 с целью упаковки и передачи посредством DCP 312.
[0073] Графический пользовательский интерфейс и средства программного обеспечения, которые обеспечивают управление рабочей станцией 304 инженером, содержат, по меньшей мере, часть инструментальных средств 106 авторской разработки по ФИГ. 1.
Гибридный аудиокодек
[0074] Как показано на ФИГ. 1, система 100 включает гибридный аудиокодек 108. Этот компонент содержит систему кодирования, распространения и декодирования звука, которая сконфигурирована для генерирования единого битового потока, содержащего как традиционные звуковые элементы на основе каналов, так и элементы кодирования звуковых объектов. Гибридная система кодирования звука выстраивается вокруг системы кодирования на основе каналов, которая сконфигурирована для генерирования единого (унифицированного) битового потока, который одновременно совместим с первым декодером (например, может им декодироваться), сконфигурированным для декодирования аудиоданных, кодированных в соответствии с первым протоколом кодирования (на основе каналов), и один или несколько вторичных декодеров, сконфигурированных для декодирования аудиоданных, кодированных в соответствии с одним или несколькими вторичными протоколами декодирования (на основе объектов). Битовый поток может включать как кодированный данные (в форме пакетов данных), декодируемые первым декодером (и игнорируемые любым из вторичных декодеров), и кодированные данные (например, другие пакеты данных), декодируемые одним или несколькими вторичными декодерами (и игнорируемые первым декодером). Декодированный звук и связанная информация (метаданные) из первого и одного или нескольких вторичных декодеров может затем объединяться таким образом, чтобы представление данных как информации на основе каналов, так и информации на основе объектов происходило одновременно для воссоздания точной копии среды, каналов, пространственной информации и объектов, представленных в гибридную систему кодирования (например, в пределах трехмерного пространства или среды прослушивания).
[0075] Кодек 108 генерирует битовый поток, содержащий информацию кодированного звука и информацию, относящуюся к нескольким наборам положений каналов (громкоговорителей). В одном из вариантов осуществления изобретения, один набор положений каналов фиксируется и используется для протокола кодирования на основе каналов, в то время как другой набор положений каналов является адаптивным и используется для протокола кодирования на основе звуковых объектов, и, таким образом, конфигурация каналов для звукового объекта может изменяться в зависимости от времени (в зависимости от того, где в звуковом поле размещается объект). Таким образом, гибридная система кодирования звука может нести информацию о двух наборах местоположений громкоговорителей для проигрывания, где один набор может являться фиксированным и представлять собой подмножество другого набора. Устройства, поддерживающие унаследованную информацию кодированного звука, могут декодироваться и представлять данные для звуковой информации из фиксированного подмножества, в то время как устройство, способное поддерживать больший набор, может декодировать и представлять данные для дополнительной информации кодированного звука, которая может переменным во времени образом приписываться разным громкоговорителям из большего набора. Кроме того, система не зависит от первого и одного или нескольких вторичных декодеров, одновременно присутствующих в системе и/или устройстве. Поэтому унаследованное и/или существующее устройство/система, содержащая только декодер, поддерживающий первый протокол, может выводить полностью совместимое звуковое поле, данные которого подлежат представлению через традиционные системы воспроизведения на основе каналов. В данном случае, неизвестный, или неподдерживаемый, участок (участки) протокола гибридного битового потока (т.е. звуковая информация, представленная вторичным протоколом кодирования) может игнорироваться системой или устройством декодера, поддерживающего первый протокол гибридного кодирования.
[0076] В другом варианте осуществления изобретения, кодек 108 сконфигурирован для работы в режиме, где первая подсистема кодирования (поддерживающая первый протокол) содержит комбинированное представление всей информации звукового поля (каналов и объектов), представляемое как в первой, так и в одной или нескольких вторичных подсистемах кодера, присутствующих в гибридном кодере. Это обеспечивает то, что гибридный битовый поток включает обратную совместимость с декодерами, поддерживающими только протокол первой подсистемы кодера, позволяя звуковым объектам (как правило, переносимым в одном или нескольких вторичных протоколах кодера) быть отображаемыми и представляемыми в декодерах, поддерживающих только первый протокол.
[0077] В еще одном варианте осуществления изобретения, кодек 108 включает две или большее количество подсистем кодирования, где каждая их этих подсистем сконфигурирована для кодирования аудиоданных в соответствии с отличающимся протоколом и сконфигурирована для объединения выводов подсистем с целью генерирования гибридного формата (унифицированного) битового потока.
[0078] Одной из выгод вариантов осуществления изобретения является возможность переноса гибридного битового потока кодированного звука через широкий выбор систем распространения содержимого, где каждая из систем распространения традиционно поддерживает только данные, кодированные в соответствии с первым протоколом кодирования. Это исключает необходимость в модификации/изменении протокола любой системы и/или транспортного уровня с целью специальной поддержки гибридной системы кодирования.
[0079] Системы кодирования звука, как правило, используют стандартизированные элементы битового потока, позволяющие передавать дополнительные (произвольные) данные внутри самого битового потока. Эти дополнительные (произвольные) данные, как правило, пропускаются (т.е. игнорируются) в ходе декодирования кодированного звука, заключенного в битовом потоке, но могут использоваться с иными целями чем декодирование. Разные стандарты кодирования звука выражают эти дополнительные поля данных с использованием уникальной номенклатуры. Элементы битового потока указанного общего типа могут включать в качестве неограничивающих примеров вспомогательные данные, пропущенные поля, элементы потока данных, заполняющие элементы, служебные данные и элементы вложенных потоков данных. Если не обусловлено иное, использование выражения «произвольные данные» в данном документе не подразумевает определенный тип или формат дополнительных данных, но, наоборот, его следует интерпретировать как общее выражение, которое охватывает любой или все примеры, связанные с настоящим изобретением.
[0080] Канал данных, обеспечиваемый посредством «произвольных» элементов битового потока первого протокола кодирования в комбинированном битовом потоке гибридной системы кодирования, может нести один или несколько вторичных (зависимых или независимых) битовых потоков аудиоданных (кодированных в соответствии с одним или несколькими вторичными протоколами кодирования). Один или несколько вторичных битовых звуковых потоков могут разбиваться на блоки из N дискретных значений и уплотняться в поля «вспомогательных данных» первого битового потока. Первый битовый поток декодируется соответствующим (дополнительным) декодером. Кроме того, вспомогательные данные первого битового потока могут извлекаться и снова объединяться в один или несколько вторичных битовых потоков аудиоданных, декодируемых устройством обработки данных, поддерживающим синтаксис одного или нескольких вторичных битовых потоков, а затем совместно или независимо комбинироваться и представляться. Кроме того, также можно поменять роли первого и второго битовых потоков так, чтобы блоки данных первого битового потока уплотнялись во вспомогательные данные второго битового потока.
[0081] Элементы битового потока, связанные со вторым протоколом кодирования также переносят и передают характеристики информации (метаданные) лежащего в их основе звука, которые могут в качестве неограничивающих примеров включать требуемое положение, скорость и размер источника звука. Эти метаданные используются в ходе процессов декодирования и представления данных для воссоздания надлежащего (то есть оригинального) положения связанного звукового объекта, переносимого в применимом битовом потоке. Также можно переносить вышеописанные метаданные, которые применимы к звуковым объектам, содержащимся в одном или нескольких вторичных битовых потоках, присутствующих в гибридном потоке, в элементах битового потока, связанных с первым протоколом кодирования.
[0082] Элементы битового потока, связанные с одни, первым или вторым, протоколом кодирования или с обоими протоколами кодирования гибридной системы кодирования, переносят/передают контекстные метаданные, которые идентифицируют пространственные параметры (например, сущность свойств самого сигнала) и дополнительную информацию, описывающую тип сущности лежащего в ее основе звука в форме специальных классов звука, которые переносятся в гибридном битовом потоке кодированного звука. Такие метаданные могут указывать, например, присутствие речевого диалога, музыки, диалога на фоне музыки, аплодисментов, пения и т.д., и могут использоваться для адаптивной модификации поведения взаимосвязанных модулей предварительной и последующей обработки в восходящем направлении или в нисходящем направлении относительно гибридной системы кодирования.
[0083] В одном из вариантов осуществления изобретения, кодек 108 сконфигурирован для работы с совместно используемым, или общим, битовым пулом, в котором биты, доступные для кодирования «делятся» между всеми или частью подсистем кодирования, поддерживающих один или несколько протоколов. Такой кодек может распределять доступные биты (из общего, «совместно используемого» битового пула) между подсистемами кодирования с целью оптимизации общего качества звука в унифицированном битовом потоке. Например, в течение первого промежутка времени, кодек может присваивать больше доступных битов первой подсистеме кодирования, и меньше доступных битов – остальным подсистемам, в то время как в течение второго промежутка времени, кодек может присваивать меньше доступных битов первой подсистеме кодирования, и больше доступных битов – остальным подсистемам кодирования. Решение о том, каким образом распределять биты между подсистемами кодирования, может зависеть, например, от результатов статистического анализа совместно используемого битового пула и/или от анализа звукового содержимого, кодируемого каждой из подсистем. Кодек может присваивать биты из совместно используемого пула таким образом, чтобы унифицированный битовый поток, сконструированный путем уплотнения выводов подсистем кодирования, сохранял постоянную длину кадра/битовую скорость передачи данных в течение заданного промежутка времени. Также, в некоторых случаях, возможно изменение длины кадра/битовой скорости передачи данных в течение заданного промежутка времени.
[0084] В альтернативном варианте осуществления изобретения, кодек 108 генерирует унифицированный битовый поток, включающий данные, кодированные в соответствии с первым протоколом кодирования, конфигурируемые и передаваемые как независимый подпоток потока кодированных данных (который будет декодироваться декодером, поддерживающим первый протокол кодирования), а данные, кодируемые в соответствии со вторым протоколом, передаются как независимый или зависимый подпоток потока кодированных данных (поток, который будет игнорироваться декодером, поддерживающим первый протокол). В более общем смысле, в одном из классов вариантов осуществления изобретения, кодек генерирует унифицированный битовый поток, включающий два или большее количество независимых, или зависимых подпотоков (где каждый подпоток включает данные, кодированные в соответствии с отличающимся, или идентичным, протоколом кодирования).
[0085] В еще одном альтернативном варианте осуществления изобретения, кодек 108 генерирует унифицированный битовый поток, включающий данные, кодированные в соответствии с первым протоколом кодирования, сконфигурированный и передаваемый с уникальным идентификатором битового потока (который будет декодироваться декодером, поддерживающим первый протокол кодирования, связанный с уникальным идентификатором битового потока), и данные, кодированные в соответствии со вторым протоколом, сконфигурированные и передаваемые с уникальным идентификатором битового потока, который декодер, поддерживающий первый протокол, будет игнорировать. В более общем смысле, в одном из классов вариантов осуществления изобретения, кодек генерирует унифицированный битовый поток, включающий два или большее количество подпотоков (где каждый подпоток включает данные, кодируемые в соответствии с отличающимся, или идентичным, протоколом кодирования, и где каждый подпоток несет уникальный идентификатор битового потока). Вышеописанные способы и системы, предназначенные для создания унифицированного битового потока, предусматривают возможность передавать (в декодер) недвусмысленный сигнал о том, какое перемежение и/или протокол был использован в гибридном битовом потоке (например, передавать сигнал о том, используются ли данные AUX, SKIP, DSE или описанный подход на основе подпотоков).
[0086] Гибридная система кодирования сконфигурирована для поддержки устранения перемежения/разуплотнения и повторного перемежения/повторного уплотнения битовых потоков, поддерживающих один или несколько вторичных протоколов, в первый битовый поток (поддерживающий первый протокол) в любой точке обработки повсюду в системе доставки мультимедийных данных. Гибридный кодек также сконфигурирован для обладания способностью кодирования входных аудиопотоков с различными частотами дискретизации в один битовый поток. Это создает средства для эффективного кодирования и распространения источников звуковых сигналов, содержащих сигналы с разными по своему существу полосами пропускания. Например, диалоговые дорожки обычно имеют существенно меньшую ширину полосы пропускания, чем дорожки музыки и эффектов.
Представление данных
[0087] В одном из вариантов осуществления изобретения, система адаптивного звука допускает упаковку нескольких (например, до 128) дорожек, обычно, в качестве сочетания трактов и объектов. Основной формат аудиоданных для системы адаптивного звука включает несколько независимых монофонических аудиопотоков. Каждый поток содержит связанные с ним метаданные, которые указывают, является данный поток потоком на основе каналов или потоком на основе объектов. Потоки на основе каналов содержат информацию представления данных, кодированную посредством названия, или метки, канала; а потоки на основе объектов содержат информацию местоположения, кодированную через математические выражения, закодированные в дополнительных связанных метаданных. Оригинальные независимые аудиопотоки затем упаковываются в единую двоичную последовательность, которая содержит все аудиоданные в упорядоченном виде. Такая конфигурация адаптивных данных позволяет представлять данные звука в соответствии с аллоцентрической системой отсчета, в которой окончательное местоположение представления данных звука основывается на среде проигрывания так, чтобы оно соответствовало замыслу оператора микширования. Таким образом, происхождение звука может указываться в системе отсчета помещения для проигрывания (например, середина левой стены), а не из определенного помеченного громкоговорителя или группы громкоговорителей (например, левой окружающей). Метаданные положения объекта содержат информацию соответствующей аллоцентрической системы отсчета, необходимую для правильного проигрывания звука с использованием положений доступных громкоговорителей в помещении, которое подготовлено для проигрывания адаптивного звукового содержимого.
[0088] Оператор представления данных принимает битовый поток, кодирующий звуковые дорожки, и обрабатывает содержимое в соответствии с типом сигнала. Тракты подаются на массивы, что потенциально будет требовать иных задержек и обработки уравнивания, чем отдельные объекты. Процесс поддерживает представление данных указанных трактов и объектов в несколько (до 64) выходных сигналов громкоговорителей. ФИГ. 4 представляет собой блок-схему этапа представления данных системы адаптивного звука согласно одному из вариантов осуществления изобретения. Как показано в системе 400 по ФИГ. 4, несколько входных сигналов, таких как звуковые дорожки, в количестве до 128, которые включают адаптивные звуковые сигналы 402, создаются определенными компонентами этапов создания, авторской разработки и упаковки системы 300, такими как RMU 306 и устройство 312 обработки данных. Эти сигналы содержат тракты на основе каналов и объекты, которые используются оператором 404 представления данных. Звук на основе каналов (тракты) и объекты вводятся в устройство 406 управления уровнем, которое обеспечивает управление выходными уровнями, или амплитудами, различных звуковых составляющих. Некоторые звуковые составляющие могут обрабатываться компонентом 408 коррекции массивов. Адаптивные звуковые сигналы затем пропускаются через компонент 410 обработки в цепи В, который генерирует несколько (например, до 64) выходных сигналов, подаваемых на громкоговорители. В общем, сигналы цепи В относятся к сигналам, обрабатываемым усилителями мощности, разделителями спектра сигнала и громкоговорителями, в отличие от содержимого цепи А, которое составляет звуковую дорожку на кинопленке.
[0089] В одном из вариантов осуществления изобретения, оператор 404 представления данных запускает алгоритм представления данных, который как можно лучше, разумно использует возможности окружающих громкоговорителей в кинотеатре. Путем улучшения коммутации мощности и амплитудно-частотных характеристик окружающих громкоговорителей, а также путем поддержания одинакового опорного уровня текущего контроля для каждого выходного канала, или громкоговорителя, в кинотеатре, объекты, панорамируемые между экранными и окружающими громкоговорителями, могут сохранять уровень их звукового давления и иметь более близкое тембральное согласование, что важно, без увеличения общего уровня звукового давления в кинотеатре. Массив соответствующим образом указанных окружающих громкоговорителей, как правило, будет иметь достаточный запас по уровню для воспроизведения максимального доступного динамического диапазона в пределах окружающей звуковой дорожки 7.1 или 5.1 (т.е. на 20 дБ выше опорного уровня), однако маловероятно, чтобы единичный окружающий громкоговоритель имел такой же запас по уровню, что и большой многопозиционный экранный громкоговоритель. Как результат, вероятны случаи, когда объект, помещенный в окружающее поле потребует большего звукового давления, чем звуковое давление, достижимое с использованием единственного окружающего громкоговорителя. В этих случаях, оператор представления данных будет распространять звук по соответствующему количеству громкоговорителей с целью достижения требуемого уровня звукового давления. Система адаптивного звука улучшает качество и коммутацию мощности окружающих громкоговорителей, обеспечивая улучшение достоверности представления данных. Она предусматривает поддержку управления басами окружающих громкоговорителей через использование необязательных задних сверхнизкочастотных громкоговорителей, которые позволяют каждому окружающему громкоговорителю достигать улучшенной коммутации мощности, одновременно потенциально используя корпуса громкоговорителей меньшего размера. Она также позволяет добавлять боковые окружающие громкоговорители ближе к экрану, чем в современной практике, для того, чтобы обеспечить плавный переход объектов от экрана к окружению.
[0090] Путем использования метаданных для указания информации местоположения звуковых объектов наряду с определенными процессами представления данных, система 400 предоставляет создателям содержимого всесторонний, гибкий способ выхода за пределы ограничений существующих систем. Как определено выше, современные системы создают и распространяют звук, который является фиксированным в местоположениях определенных громкоговорителей с ограниченными сведениями о типе содержимого, передаваемого в звуковой сущности (в той части звука, которая проигрывается). Система 100 адаптивного звука предусматривает новый, гибридный подход, который включает возможности как для звука, специфичного для местоположений громкоговорителей (левый канал, правый канал и т.д.), так и для объектно-ориентированных звуковых элементов, которые содержат обобщенную пространственную информацию, которая может в качестве неограничивающих примеров включать местоположение, размер и скорость. Такой гибридный подход обеспечивает сбалансированный подход к точности (обеспечиваемой фиксированными местоположениями громкоговорителей) и гибкости представления данных (обобщенные звуковые объекты). Система также предусматривает дополнительную полезную информацию о звуковом содержимом, которую создатель содержимого спаривает со звуковой сущностью в момент создания содержимого. Эта информация обеспечивает значительную, подробную информацию о характерных свойствах звука, которая может использоваться чрезвычайно действенными способами в ходе представления данных. Указанные характерные свойства могут включать в качестве неограничивающих примеров тип содержимого (диалог, музыка, эффект, шумовой эффект, фон/окружающая среда и т.д.), характерные свойства в пространстве (трехмерное положение, трехмерный размер, скорость) и информацию представления данных (привязку к местоположению громкоговорителя, весовые коэффициенты каналов, коэффициент усиления, информация управления басами и т.д.).
[0091] Система адаптивного звука, описываемая в данном раскрытии, предусматривает значительную информацию, которая может использоваться для представления данных широко варьируемым количеством конечных точек. Во многих случаях, применяемая оптимальная методика представления данных в значительной степени зависит от устройства в конечной точке. Например, системы домашних кинотеатров и звуковые панели могут содержать 2, 3, 5, 7 или даже 9 отдельных громкоговорителей. Системы многих других типов, такие как телевизоры, компьютеры и музыкальные аппаратные модули содержат лишь два громкоговорителя, и почти все традиционно используемые устройства имеют бинауральный выход для наушников (ПК, ноутбук, планшетный компьютер, сотовый телефон, музыкальный проигрыватель и т.д.). Однако для традиционного звука, распространяемого в настоящее время (монофонические, стереофонические каналы, каналы 5.1, 7.1) устройства в конечных точках часто нуждаются в принятии упрощенных решений и компромиссах для представления данных и воспроизведения звука, который в настоящее время распространяется в форме, специфичной для каналов/громкоговорителей. Кроме того, имеется немного или совсем не имеется информации, передаваемой в отношении фактического содержимого, которое распространяется (диалог, музыка, окружение), а также имеется немного или совсем не имеется информации о замысле создателя содержимого для воспроизведения звука. Однако система 100 адаптивного звука предоставляет эту информацию и, потенциально, доступ к звуковым объектам, которые могут использоваться для создания захватывающего пользовательского впечатления нового поколения.
[0092] Система 100 позволяет создателю содержимого внедрять пространственный замысел микса в битовом потоке, используя такие метаданные, как метаданные положения, размера, скорости и т.д., через уникальные и веские метаданные и формат передачи адаптивного звука. Это позволяет намного увеличить гибкость при воспроизведении звука в пространстве. С точки зрения пространственного представления данных, адаптивный звук позволяет адаптировать микс к точному положению громкоговорителей в конкретном помещении, избегая пространственного искажения, которое возникает тогда, когда геометрия системы проигрывания не идентична системе авторской разработки. В современных системах воспроизведения звука, где передается только звук для канала громкоговорителя, замысел создателя содержимого неизвестен. Система 100 использует метаданные, передаваемые по всему конвейеру создания и распространения. Система воспроизведения, ориентированная на адаптивный звук, может использовать эту информацию метаданных для воспроизведения содержимого тем способом, который согласуется с оригинальным замыслом создателя содержимого. Более того, микс может адаптироваться к точной конфигурации аппаратного обеспечения системы воспроизведения. В настоящее время, в таком оборудовании для представления данных, как телевизоры, домашние кинотеатры, звуковые панели, переносные аппаратные модули музыкальных проигрывателей и т.д., существует множество различных возможных конфигураций и типов громкоговорителей. Когда эти системы в настоящее время передают специфичную для каналов звуковую информацию (т.е. звук левого и правого каналов или многоканальный звук), система должна обрабатывать звук так, чтобы он соответствующим образом согласовывался с возможностями оборудования для представления данных. Одним из примеров является стандартный стереофонический звук, передаваемый на звуковую панель, содержащую больше двух громкоговорителей. В современном звуковоспроизведении, где передается только звук для каналов громкоговорителей, замысел создателя содержимого неизвестен. Путем использования метаданных, передаваемых по всему процессу создания и распространения, система воспроизведения, ориентированная на адаптивный звук, может использовании эту информацию для воспроизведения содержимого тем способом, который согласуется с оригинальным замыслом создателя содержимого. Например, некоторые звуковые панели содержат боковые дополнительные громкоговорители, предназначенные для создания ощущения охвата. Для адаптивного звука, пространственная информация и тип содержимого (такой, как эффекты окружающей среды) могут использоваться звуковой панелью для передачи на указанные боковые дополнительные громкоговорители только соответствующего звука.
[0093] Система адаптивного звука допускает неограниченную интерполяцию громкоговорителей в системе во всех передних/задних, левых/правых, верхних/нижних, ближних/дальних размерах. В современных системах звуковоспроизведения не существует информации о том, каким образом обрабатывать звук тогда, когда может быть желательно расположить звук так, чтобы он воспринимался слушателем как находящийся между двумя громкоговорителями. В настоящее время для звука, который присваивается только определенному громкоговорителю, вводится коэффициент пространственного квантования. В случае адаптивного звука, пространственное расположение звука может быть известно точно, и оно может соответствующим образом воспроизводиться системой звуковоспроизведения.
[0094] В отношении представления данных наушниками, замысел создателя реализуется путем приведения передаточных функций, относящихся к голове (HRTF), в соответствие с положением в пространстве. Когда звук воспроизводится через наушники, пространственная виртуализация может достигаться путем применения передаточной функции, относящейся к голове, которая обрабатывает звук, добавляя воспринимаемые свойства, которые создают восприятие звука, проигрываемого в трехмерном пространстве, а не через наушники. Точность пространственного воспроизведения зависит от выбора подходящей HRTF, которая может меняться на основе нескольких факторов, включающих положение в пространстве. Использование пространственной информации, предусматриваемое системой адаптивного звука, может в результате приводить к выбору одной HRTF, или постоянно изменяющегося количества HRTF для того, чтобы значительно усилить восприятие воспроизведения.
[0095] Пространственная информация, передаваемая системой адаптивного звука, может использоваться не только создателем содержимого для создания захватывающего развлекательного впечатления (от фильма, телевизионной программы, музыки и т.д.), но также пространственная информация может указывать, где располагается слушатель относительно таких физических объектов, как здания или представляющие интерес географические точки. Это могло бы позволить пользователю взаимодействовать с виртуализированным звуковым впечатлением, которое связано с реальным миром, т.е. с дополнительной реальностью.
[0096] Варианты осуществления изобретения допускают пространственное повышающее микширование путем выполнения усовершенствованного повышающего микширования посредством считывания метаданных только в том случае, если аудиоданные объектов недоступны. Сведения о положении всех объектов и их типов позволяют оператору повышающего микширования лучше различать элементы в дорожках на основе каналов. Для создания высококачественного повышающего микширования с минимальными слышимыми искажениями или с их отсутствием существующим алгоритмам повышающего микширования приходится выводить такую информацию, как тип звукового содержимого (речь, музыка, эффекты окружающей среды), а также местоположение различных элементов в аудиопотоке. Во многих случаях указанная выведенная информация может оказаться неверной или несоответствующей. Для адаптивного звука дополнительная информация, доступная из метаданных, относящихся, например, к типу звукового содержимого, положению в пространстве, скорости, размеру звукового объекта и т.д., может использоваться алгоритмом повышающего микширования для создания высококачественного результата воспроизведения. Система также пространственно соотносит звук и видеоизображение, точно располагая звуковой объект на экране по отношению к видимым элементам. В этом случае, возможно захватывающее впечатление от воспроизведения звука/видеоизображения, в особенности, на экранах большого размера, если воспроизводимое местоположение некоторых звуковых элементов в пространстве соответствует элементам изображения на экране. Одним из примеров является диалог в фильме или телевизионной программе, пространственно совпадающий с человеком или героем, который говорит на экране. Для обычного звука на основе каналов громкоговорителей не существует простого способа определения того, где в пространстве должен располагаться диалог для того, чтобы он совпадал с местоположением человека или героя на экране. Для звуковой информации, доступной через адаптивный звук, такое аудиовизуальное выравнивание может достигаться. Визуальное позиционное и пространственное звуковое выравнивание также может использоваться для таких неролевых/недиалоговых объектов, как автомобили, грузовики, анимация и т.д.
[0097] Система 100 способствует обработке пространственной маскировки, поскольку сведения о пространственном замысле микширования, доступные через метаданные адаптивного звука, означают, что микс может быть адаптирован к любой конфигурации громкоговорителей. Однако, возникает риск понижающего микширования объектов в таком же или почти таком же местоположении по причине ограничений проигрывающей системы. Например, объект, который, как подразумевается, подлежит панорамированию в левый задний канал, может подвергаться понижающему микшированию в левый передний канал, если окружающие каналы отсутствуют, однако если, в то же время, в левом переднем канале возникает более громкий элемент, подвергнутый понижающему микшированию объект будет маскироваться и исчезать из микса. С использованием метаданных адаптивного звука пространственная маскировка может предугадываться оператором представления данных, и параметры понижающего микширования в пространстве и/или по громкости для каждого объекта могут корректироваться так, чтобы все звуковые элементы микса оставались воспринимаемыми точно так же, как и в оригинальном миксе. Так как оператор представления данных понимает пространственную взаимосвязь между миксом и системой проигрывания, он имеет возможность «привязывать» объекты к ближайшим громкоговорителям вместо создания паразитного изображения между двумя или большим количеством громкоговорителей. Несмотря на то, что может несколько искажаться пространственное представление микса, это также позволяет оператору представления данных избегать непреднамеренного паразитного изображения. Например, если угловое положение левого громкоговорителя на этапе микширования не соответствует угловому положению левого громкоговорителя в воспроизводящей системе, использование функции привязки к ближайшему громкоговорителю может позволить избежать воспроизведения проигрывающей системой постоянного паразитного изображения левого канала этапа микширования.
[0098] В отношении обработки содержимого, система 100 адаптивного звука позволяет создателю содержимого создавать отдельные звуковые объекты и добавлять информацию о содержимом, которая может передаваться в воспроизводящую систему. Это допускает большую гибкость при обработке звука перед воспроизведением. С точки зрения обработки содержимого и представления данных, система адаптивного звука позволяет адаптировать обработку к типу объекта. Например, диалоговое усиление может применяться только к диалоговым объектам. Диалоговое усиление относится к способу обработки звука, который содержит диалог, таким образом, чтобы слышимость и/или разборчивость диалога повышалась и/или улучшалась. Во многих случаях обработка звука, которая применяется к диалогу, является неподходящей для недиалогового звукового содержимого (т.е. музыки, эффектов окружающей среды и т.д.) и в результате может приводить к нежелательным слышимым искажениям. Для адаптивного звука, звуковой объект может содержать только диалог в одном из фрагментов содержимого, и он может соответствующим образом помечаться так, чтобы решение представления данных могло избирательно применять диалоговое усиление только к диалоговому содержимому. Кроме того, если звуковой объект представляет собой только диалог (а не, как часто бывает, смесь диалога и другого содержимого), то обработка диалогового усиления может обрабатывать исключительно диалог (таким образом, ограничивая любую обработку, выполняемую на любом другом содержимом). Аналогично, управление басами (фильтрация, ослабление, усиление) может быть нацелено на определенные объекты на основе их типа. Управление басами относится к избирательному выделению и обработке только басовых (или еще более низких) частот в определенном фрагменте содержимого. В современных звуковых системах и механизмах доставки, этот процесс является «слепым», т.е. применяется ко всему звуку. Для адаптивного звука, определенные звуковые объекты, для которых управление басами является подходящим, могут идентифицироваться по метаданным, и обработка представления данных может применяться соответственно.
[0099] Система 100 адаптивного звука также предусматривает сжатие динамического диапазона и избирательное повышающее микширование на основе объектов. Традиционные звуковые дорожки имеют такую же длительность, как и само содержимое, в то время как звуковой объект может появляться в содержимом лишь в течение ограниченного количества времени. Метаданные, связанные с объектом, могут содержать информацию о его средней и пиковой амплитуде сигнала, а также о времени его появления, или времени нарастания (в особенности, для кратковременного материала). Эта информация могла бы позволять устройству сжатия лучше адаптировать его постоянные сжатия и времени (нарастания, высвобождения и т.д.) для лучшего соответствия содержимому. Для избирательного повышающего микширования создатели содержимого могут выбрать указание в битовом потоке адаптивного звука того, следует подвергать объект повышающему микшированию или нет. Эта информация позволяет оператору представления данных адаптивного звука и оператору повышающего микширования различать, какие звуковые элементы могут безопасно подвергаться повышающему микшированию, в то же время не нарушая замысел создателя.
[00100] Варианты осуществления изобретения также позволяют системе адаптивного звука выбирать предпочтительный алгоритм представления данных из некоторого количества доступных алгоритмов представления данных и/или форматов окружающего звука. Примеры доступных алгоритмов представления данных включают: бинауральный, стереодипольный, амбиофонический, синтез волнового поля (WFS), многоканальное панорамирование, необработанные стэмы с метаданными положения. Другие алгоритмы включают двойной баланс и амплитудное панорамирование на векторной основе.
[00101] Бинауральный формат распространения использует двухканальное представление звукового поля на основе сигнала, присутствующего в левом и правом ушах. Бинауральная информация может создаваться посредством внутриканальной записи или синтезироваться с использованием моделей HRTF. Проигрывание бинаурального представления, как правило, осуществляется через наушники или путем использования подавления перекрестных помех. Проигрывание через произвольную схему громкоговорителей потребовало бы анализа сигнала для определения связанного звукового поля и/или источника (источников) сигнала.
[00102] Стереодипольный способ представления данных представляет собой трансауральный процесс подавления перекрестных помех с тем, чтобы сделать бинауральные сигналы пригодными для проигрывания через стереофонические громкоговорители (например, на+и – 10 градусов от центра).
[00103] Амбиофония представляет собой формат распространения и способ воспроизведения, который кодируется в четырехканальной форме, называемой форматом В. Первый канал, W – это сигнал ненаправленного давления; второй канал, Х – это градиент направленного давления, содержащий переднюю и заднюю информацию; третий канал, Y, содержит лево и право, и Z – верх и низ. Эти каналы определяют дискретное значение первого порядка для полного звукового поля в данной точке. Амбиофония использует все доступные громкоговорители для воссоздания дискретизированного (или синтезированного) звукового поля в пределах массива громкоговорителей так, чтобы когда некоторые из громкоговорителей толкают, другие – тащили.
[00104] Синтез волнового поля представляет собой способ представления данных для звуковоспроизведения на основе точного построения волнового поля вторичными источниками. WFS основывается на принципе Гюйгенса и реализуется как массивы громкоговорителей (десятки или сотни), которые окружают кольцом пространство прослушивания и скоординированным, сфазированным образом действуют для воссоздания каждой отдельной звуковой волны.
[00105] Многоканальное панорамирование представляет собой формат распространения и/или способ представления данных и может именоваться звуком на основе каналов. В этом случае, звук отображается как некоторое количество дискретных источников для проигрывания через равное количество громкоговорителей, расположенных под определенными углами относительно слушателя. Создатель содержимого/оператор микширования может создавать виртуальные изображения путем панорамирования сигналов между смежными каналами с целью создания восприятия направления; для создания восприятия направления и свойств окружающей среды, в несколько каналов могут микшироваться первичные отражения, реверберация и т.д.
[00106] Необработанные стэмы с метаданными положения представляет собой формат распространения, который также может именоваться звуком на основе объектов. В этом формате, отчетливые источники звука «с близкого микрофона» представляются наряду с метаданными положения и среды. Данные виртуальных источников представляются на основе метаданных, проигрывающего оборудования и среды прослушивания.
[00107] Формат адаптивного звука представляет собой гидрид формата многоканального панорамирования и формата необработанных стэмов. Способом представления данных в настоящем варианте осуществления изобретения является многоканальное панорамирование. Для звуковых каналов, представление данных (панорамирование) происходит в момент авторской разработки, в то время как для объектов представление данных (панорамирование) происходит при проигрывании.
Метаданные и формат передачи адаптивного звука
[00108] Как изложено выше, метаданные генерируются на этапе создания с целью кодирования определенной информации положения для звуковых объектов и для сопровождения звуковой программы с целью содействия при представлении данных звуковой программы и, в частности, для описания звуковой программы способом, который позволяет представлять данные звуковой программы для широкого выбора проигрывающего оборудования и сред проигрывания. Метаданные генерируются для данной программы и редакторов и операторов микширования, которые создают, собирают, редактируют и обрабатывают звук в ходе компоновки. Важным характерным признаком формата адаптивного звука является возможность контроля над тем, каким образом звук будет транслироваться в системы и среды воспроизведения, которые отличаются от среды микширования. В частности, данный кинотеатр может обладать меньшими возможностями, чем среда микширования.
[00109] Оператор представления данных адаптивного звука нацелен на наилучшее использование доступного оборудования для воссоздания замысла оператора микширования. Кроме того, инструментальные средства авторской разработки адаптивного звука позволяют оператору микширования предварительно просматривать и корректировать то, каким образом данные микса будут представляться в различных конфигурациях проигрывания. Все значения метаданных могут обусловливаться средой проигрывания и конфигурацией громкоговорителей. Например, на основе конфигурации или режима проигрывания для данного звукового элемента может указываться другой уровень микширования. В одном из вариантов осуществления изобретения список обусловленных режимов проигрывания является расширяемым и включает следующие режимы: (1) проигрывание только на основе каналов: 5.1, 7.1, 7.1 (с верхними), 9.1; и (2) проигрывание дискретными громкоговорителями: трехмерное, двумерное (без верхних).
[00110] В одном из вариантов осуществления изобретения, метаданные контролируют, или диктуют, различные особенности адаптивного звукового содержимого и являются организованными на основе различных типов, в том числе: программные метаданные, метаданные звука и метаданные представления данных (для каналов и объектов). Каждый тип метаданных включает один или несколько элементов метаданных, которые предусматривают значения для характеристик, на которые ссылается идентификатор (ID). ФИГ. 5 представляет собой таблицу, которая перечисляет типы метаданных и связанные элементы метаданных для системы адаптивного звука, согласно одному из вариантов осуществления изобретения.
[00111] Как показано в таблице 500 по ФИГ. 5, метаданные первого типа представляют собой программные метаданные, которые включают элементы метаданных, определяющие частоту кадров, счет дорожек, расширяемое описание каналов и описание этапа микширования. Элемент метаданных «частота кадров» описывает частоту кадров звукового содержимого в единицах кадров в секунду (fps). Формат необработанного звука не требует включения кадрирования звука или метаданных, поскольку звук доставляется в виде полных дорожек (длительность катушки или всего кинофильма), а не сегментов звука (длительность объекта). Необработанный формат не требует переноса всей информации, необходимой для разблокирования адаптивного аудиокодера с целью кадрирования аудиоданных и метаданных, включая фактическую частоту кадров. Таблица 1 показывает ID, примеры значений и описание элемента метаданных «частота кадров».
ТАБЛИЦА 1
[00112] Элемент метаданных «счет дорожек» указывает количество звуковых дорожек в кадре. Один из примеров декодера/устройства обработки данных адаптивного звука может одновременно поддерживать до 128 звуковых дорожек, в то время как формат адаптивного звука будет поддерживать любое количество звуковых дорожек. Таблица 2 показывает ID, примеры значений и описание элемента метаданных «счет дорожек».
ТАБЛИЦА 2
[00113] Звук на основе каналов может приписываться нестандартным каналам, и элемент метаданных «описание расширяемых каналов» позволяет миксам использовать новые положения каналов. Для каждого канала расширения должны создаваться следующие метаданные, показанные в Таблице 3.
ТАБЛИЦА 3
[00114] Элемент метаданных «описание этапа микширования» определяет частоту, на которой определенный громкоговоритель генерирует половину мощности полосы пропускания. Таблица 4 показывает ID, примеры значений и описание элемента метаданных «описание этапа микширования», где LF - нижняя частота, HF - верхняя частота, точка 3 дБ – край полосы пропускания громкоговорителя.
ТАБЛИЦА 4
Номер громкоговорителя – целое число.
0<номер громкоговорителя<nMixSpeakers–1
[00115] Как показано на ФИГ. 5, вторым типом метаданных являются метаданные звука. Каждый звуковой элемент на основе каналов или на основе объектов состоит из звуковой сущности и метаданных. Звуковая сущность представляет собой монофонический аудиопоток, переносимый одной или несколькими звуковыми дорожками. Связанные метаданные описывают, каким образом сохраняется в памяти звуковая сущность (метаданные звука, например, частота дискретизации), или то, каким образом должны представляться ее данные (метаданные представления данных, например, требуемое положение источника звука). В общем, звуковые дорожки являются непрерывными по всей длительности звуковой программы. Редактор программы, или оператор микширования, отвечает за приписывание звуковых элементов дорожкам. Ожидается, что использование дорожек будет разреженным, т.е. среднее количество одновременно используемых дорожек может составлять лишь 16-32. В типичной реализации, звук будет эффективно передаваться с использованием кодера без потерь. Однако возможны альтернативные реализации, например, передача некодированных аудиоданных или аудиоданных, кодированных с потерями. В типичной реализации, формат состоит из звуковых дорожек количеством до 128, где каждая дорожка имеет единственную частоту дискретизации и единую систему кодирования. Каждая дорожка длится в течение длительности фильма (поддержка катушки в явном виде отсутствует). Присваивание объектов дорожкам (уплотнение во времени) входит в обязанности создателя содержимого (оператора микширования).
[00116] Как показано на ФИГ. 3, метаданные звука включают элементы «частота дискретизации», «битовая глубина» и «системы кодирования». Таблица 5 показывает ID, примеры значений и описание элемента метаданных «частота дискретизации».
ТАБЛИЦА 5
[00117] Таблица 6 показывает ID, примеры значений и описание элемента метаданных «битовая глубина» (для РСМ и сжатия без потерь).
ТАБЛИЦА 6
[00118] Таблица 7 показывает ID, примеры значений и описание элемента метаданных «система кодирования».
ТАБЛИЦА 7
[00119] Как показано на ФИГ. 5, метаданные третьего типа представляют собой метаданные представления данных. Метаданные представления данных указывают значения, которые помогают оператору представления данных устанавливать соответствие максимально близко к замыслу оператора оригинального микширования независимо от среды проигрывания. Набор элементов метаданных для звука на основе каналов и звука на основе объектов отличается. Первое поле метаданных представления данных делает выбор между двумя типами звука – звуком на основе каналов и звуком на основе объектов, как показано в Таблице 8.
ТАБЛИЦА 8
[00120] Метаданные представления данных для звука на основе каналов содержат элемент метаданных «положение», который указывает положение источника звука как одно или несколько положений громкоговорителей. Таблица 9 показывает ID и значения элемента метаданных «положение» для случая на основе каналов.
ТАБЛИЦА 9
[00121] Метаданные представления данных для звука на основе каналов также содержат элемент «управление представлением данных», который указывает некоторые характеристики в отношении проигрывания звука на основе каналов, как показано в Таблице 10.
ТАБЛИЦА 10
[00122] Для звука на основе объектов, метаданные включают элементы, аналогичные элементам для звука на основе каналов. Таблица 11 представляет ID и значения для элемента метаданных «положение объекта». Положение объекта описывается одним из трех способов: трехмерными координатами; плоскостью и двумерными координатами; или линией и одномерной координатой. Способ представления данных может адаптироваться на основе типа информации положения.
ТАБЛИЦА 11
[00123] ID и значения элементов метаданных «управление представлением метаданных объектов» показаны в Таблице 12. Эти величины обеспечивают дополнительные элементы управления, или оптимизации, представления данных для звука на основе объектов.
ТАБЛИЦА 12
vbap: амплитудное панорамирование на векторной основе
dbap: амплитудное панорамирование на основе расстояния
2D: в сочетании с ObjPos2D, использовать vbap только с тремя положениями (виртуальных) источников 1D: в сочетании с ObjPos1D, использовать попарное панорамирование между двумя положениями (виртуальных) источников
[00124] В одном из вариантов осуществления изобретения метаданные, описанные выше и проиллюстрированные на ФИГ. 5, генерируются и сохраняются как один или несколько файлов, которые связываются, или индексируются, с соответствующим звуковым содержимым, так чтобы аудиопотоки обрабатывались системой адаптивного звука, интерпретирующей метаданные, генерируемые оператором микширования. Следует отметить, что вышеописанные метаданные представляют собой один из примеров набора идентификаторов ID, значений и определений, и для использования в системе адаптивного звука в них могут включаться другие, или дополнительные, элементы метаданных.
[00125] В одном из вариантов осуществления изобретения, с каждым из аудиопотоков на основе каналов и на основе объектов связывается два (или больше) наборов элементов метаданных. Первый набор метаданных применяется к ряду аудиопотоков для первых условий среды проигрывания, и второй набор метаданных применяется к ряду аудиопотоков для вторых условий среды проигрывания. Второй, или последующий, набор элементов метаданных замещает первый набор элементов метаданных для данного аудиопотока на основе условий среды проигрывания. Условия могут включать такие факторы, как размер помещения, форму, состав материала внутри помещения, текущую заполненность и плотность людей в помещении, характеристики окружающего шума, характеристики окружающего света и какие-либо иные факторы, которые могут оказывать влияние на звук или даже на настроение в среде проигрывания.
Компоновка и окончательная обработка
[00126] Ступень 110 представления данных системы 100 обработки адаптивного звука может включать этапы компоновки аудиозаписи, которые приводят к созданию конечного микса. В одном из кинематографических применений, тремя основными категориями звука, используемого при микшировании звукозаписи для кинофильма, являются диалог, музыка и эффекты. Эффекты состоят из звуков, которые не являются диалогом или музыкой (например, окружающий шум, фоновый/постановочный шум). Звуковые эффекты могут записываться, или синтезироваться, звукорежиссером, или они могут браться из библиотек эффектов. Одна из подгрупп эффектов, которые включают специальные источники шума (например, звуки шагов, дверей и т.д.), известна как шумовые эффекты и осуществляется звукооформителями. Звуки разных типов соответствующим образом помечаются и панорамируются звукорежиссерами.
[00127] ФИГ. 6 иллюстрирует пример последовательности операций процесса компоновки в системе адаптивного звука согласно одному из вариантов осуществления изобретения. Как показано на схеме 600, все отдельные звуковые составляющие музыки, диалога, шумовых эффектов и эффектов сводятся вместе в дублирующем кинотеатре в ходе окончательного микширования 606, и средство (средства) 604 микширования при перезаписи используют предварительные миксы (также известные как «микшированный минус») наряду с отдельными звуковыми объектами и позиционными данными для создания стэмов в качестве способа группировки, например, диалога, музыки, эффектов, шумовых эффектов и фоновых звуков. В дополнение к формированию конечного микса 606, музыка и все стэмы эффектов могут использоваться в качестве основы для создания версий фильма, дублированных на других языках. Каждый стэм состоит из тракта на основе каналов и из нескольких звуковых объектов с метаданными. Для формирования конечного микса, стэмы объединяют. Используя информацию панорамирования объектов как из звуковой рабочей станции, так и из микшерного пульта, блок 608 представления данных и окончательной обработки представляет данные звука в местоположения громкоговорителей в дублирующем кинотеатре. Это представление данных позволяет операторам микширования слышать, как сочетаются тракты на основе каналов и звуковые объекты, а также дает возможность представить данные в разных конфигурациях. Оператор микширования может использовать условные метаданные, которые для значимых профилей являются данными по умолчанию, с целью контроля над тем, каким образом данные содержимого представляются в окружающие каналы. Таким образом, операторы микширования полностью сохраняют контроль над тем, как проигрывается кинофильм во всех масштабируемых средах. После каждого из этапов 604 перезаписи и этапа 606 окончательного микширования, или после обоих этих этапов, может включаться этап текущего контроля, позволяющий оператору микширования прослушать и оценить промежуточное содержимое, генерируемое в ходе каждого из этих этапов.
[00128] В ходе сессии окончательной обработки указанны стэмы, объекты и метаданные сводятся вместе в пакете 614 адаптивного звука, который изготавливается оператором 610 контрольной копии. Этот пакет также содержит обратно совместимый (с унаследованными 5.1 или 7.1) микс 612 окружающего звука для кинотеатров. Модуль 608 представления данных/окончательной обработки (RMU) может в случае необходимости представлять данные этого выходного сигнала, таким образом, исключая необходимость в каких-либо дополнительных этапах последовательности операций при генерировании существующих выдаваемых данных на основе каналов. В одном из вариантов осуществления изобретения, звуковые файлы упаковываются с использованием заключения в стандартную оболочку материального коммуникативного формата (MXF). Главный файл адаптивного звукового микса также может использоваться для генерирования других выдаваемых данных, таких как пользовательские многоканальные или стереофонические миксы. Разумные профили и условные метаданные допускают управляемые представления данных, которые могут значительно сокращать время, необходимое для создания таких миксов.
[00129] В одном из вариантов осуществления изобретения, система упаковки может использоваться для создания пакета цифровой фильмокопии для выдаваемых данных, включающих адаптивный звуковой микс. Файлы звуковых дорожек могут сцепляться вместе, препятствуя ошибкам синхронизации с файлами дорожек адаптивного звука. Некоторые страны требуют добавления файлов дорожек в ходе этапа упаковки, например, добавления дорожек для лиц с ограниченным слухом (HI) или дорожек описания для лиц с ограниченным зрением (VI-N) к главному файлу звуковых дорожек.
[00130] В одном из вариантов осуществления изобретения, массив громкоговорителей в среде проигрывания может включать любое количество громкоговорителей окружающего звука, размещенных и обозначенных в соответствии со стандартами окружающего звука. Любое количество дополнительных громкоговорителей для точного представления данных звукового содержимого на основе объектов также может размещаться на основе условий среды проигрывания. Эти дополнительные громкоговорители могут устанавливаться звукоинженером, и данная установка представляется системе в форме установочного файла, который используется системой для представления в определенный громкоговоритель, или громкоговорители, в пределах общего массива громкоговорителей данных составляющих адаптивного звука на основе объектов. Указанный установочный файл содержит, по меньшей мере, список обозначений громкоговорителей и присваивания каналов отдельным громкоговорителям, информацию в отношении группировки громкоговорителей и динамического присваивания на основе относительного положения громкоговорителей в среде проигрывания. Указанное время выполнения отображения используется характерным признаком «привязка к» в системе, которая представляет данные звукового содержимого точечных источников на основе объектов в определенный громкоговоритель, который по замыслу звукоинженера является ближайшим к воспринимаемому местоположению звука.
[00131] ФИГ. 7 представляет собой схему одного из примеров последовательности операций процесса упаковки цифровой фильмокопии с использованием файлов адаптивного звука согласно одному из вариантов осуществления изобретения. Как показано на схеме 700, звуковые файлы, включающие как файлы адаптивного звука, так и звуковые файлы окружающего звука 5.1 или 7.1, вводятся в блок 704 заключения в оболочку/шифрования. В одном из вариантов осуществления изобретения, при создании пакета цифровой фильмокопии в блоке 706, файл PCM MXF (с прилагаемыми соответствующими дополнительными дорожками) зашифровывается с использованием технических условий SMPTE в соответствии с существующей практикой. MXF адаптивного звука упаковывается как файл вспомогательной дорожки и, необязательно, зашифровывается посредством технических условий SMPTE с использованием симметричного ключа управления содержимым. Этот единый DCP 708 может затем доставляться любому серверу, совместимому с требованиями организации Digital Cinema Initiatives (DCI). В общем, любые установки, которые не оснащены походящим образом, будут просто игнорировать файл дополнительной дорожки, содержащий звуковую дорожку адаптивного звука, и будет использовать существующий файл главной звуковой дорожки для стандартного проигрывания. Установки, оснащенные соответствующими устройствами обработки данных адаптивного звука будут способны принимать и воспроизводить звуковую дорожку адаптивного звука там, где это применимо, при необходимости возвращаясь к стандартной звуковой дорожке. Компонент 704 заключения в оболочку/шифрования также может доставлять входной сигнал непосредственно в блок 710 распространения KDM с целью генерирования соответствующего ключа защиты для использования в сервере цифрового кинотеатра. Другие элементы фильма, или файлы, такие как субтитры 714 и изображения 716 могут заключаться в оболочку и зашифровываться наряду с аудиофайлами 702. В этом случае, могут включаться некоторые этапы обработки, такие как сжатие 712 в случае файлов 716 изображений.
[00132] В отношении управления содержимым, система 100 адаптивного звука позволяет создателю содержимого создавать отдельные звуковые объекты и добавлять информацию о содержимом, которое должно передаваться в воспроизводящую систему. Это позволяет значительно увеличить гибкость при управлении звуковым содержимым. С точки зрения управления содержимым, способы адаптивного звука делают возможными несколько характерных признаков. Эти признаки включают изменение языка содержимого просто путем замещения диалогового объекта для экономии места, эффективности скачивания, географической адаптации проигрывания и т.д. Фильмы, телевизионные и другие развлекательные программы, как правило, распространяются по всему миру. Это часто требует, чтобы язык фрагмента содержимого менялся в зависимости от того, где оно будет воспроизводиться (французский – для фильмов, демонстрируемых во Франции, немецкий – для ТВ программ, показываемых в Германии). В настоящее время это часто требует создания, упаковки и распространения полностью независимой звуковой дорожки. В случае адаптивного звука и его неотъемлемой концепции звуковых объектов, диалог для фрагмента содержимого может представлять собой независимый звуковой объект. Это позволяет легко менять язык содержимого без обновления или изменения других элементов звуковой дорожки, таких как музыка, эффекты и т.д. Это может применяться не только для иностранных языков, но также для языка, неподходящего для некоторых зрителей (например, телевизионные программы для детей, фильмы для показа в самолетах и т.д.), целевой рекламы и т.д.
Соображения по установке и оборудованию
[00133] Формат файла адаптивного звука и связанные устройства обработки данных допускают изменения в установке, калибровке и обслуживании оборудования кинотеатра. При введении много большего количества потенциальных выходных сигналов громкоговорителей, каждый из которых корректируется и балансируется по отдельности, существует потребность в разумной и оперативной автоматической коррекции амплитудно-частотной характеристики помещения, которая может осуществляться через возможность ручной регулировки какой-либо автоматической коррекции амплитудно-частотной характеристики помещения. В одном из вариантов осуществления изобретения, система адаптивного звука использует оптимизированное средство частотной коррекции с 1/12-октавной полосой частот. Для более точного баланса звука в кинотеатре, может обрабатываться до 64 выходных сигналов. Система также допускает плановый контроль выходных сигналов отдельных громкоговорителей от вывода устройства обработки данных для кинематографии вплоть до звука, воспроизводимого в зрительном зале. Для гарантии того, что предпринято соответствующее действие, могут создаваться локальные или сетевые предупреждения. Гибкая система представления данных может автоматически удалять поврежденный громкоговоритель или усилитель из цепи воспроизведения и представлять данные в обход его, делая возможным продолжение показа.
[00134] Устройство обработки данных для кинематографии может быть подключено к серверу цифрового кинотеатра через существующие главные звуковые разъемы 8×AES и подключение к сети Ethernet для потоковых данных адаптивного звука. Проигрывание окружающего содержимого 7.1 или 5.1 использует существующие соединения PCM. Поток данных адаптивного звука передается по сети Ethernet в устройство обработки данных для кинематографии с целью декодирования и представления данных, а связь между сервером и устройством обработки данных для кинематографии позволяет идентифицировать и синхронизировать звук. В случае какой-либо проблемы с проигрыванием дорожки адаптивного звука, звук возвращается обратно к звуку PCM для Dolby Surround 7.1 или 5.1.
[00135] Несмотря на то, что варианты осуществления изобретения были описаны в отношении систем окружающего звука 5.1 и 7.1, следует учитывать, что в сочетании с указанными вариантами осуществления изобретения могут использоваться многие другие современные и будущие конфигурации окружающего звука, в том числе 9.1, 11.1 и 13.1 и далее.
[00136] Система адаптивного звука рассчитана как на создателей содержимого, так и на кинопрокатчиков – для принятия решения о том, каким образом должны представляться данные в различных конфигурациях проигрывающих громкоговорителей. Идеальное используемое количество выходных каналов громкоговорителей будет изменяться в соответствии с размером помещения. Рекомендуемое расположение громкоговорителей, таким образом, зависит от множества факторов, таких как размер, состав, конфигурация посадочных мест, среда, средние размеры зрительных залов и т.д. Примеры, или образцы, конфигураций и схем расположения громкоговорителей, представлены в данном раскрытии лишь с целью иллюстрации и не предназначены для ограничения объема ни одного из заявленных вариантов осуществления изобретения.
[00137] Рекомендуемая схема расположения громкоговорителей для системы адаптивного звука остается совместимой с существующими системами для кинематографии, что является жизненно важным для того, чтобы не компрометировать проигрывание существующих форматов 5.1 и 7.1 на основе каналов. Для того чтобы сохранить замысел звукоинженера адаптивной звукозаписи и замысел операторов микширования содержимого 7.1 и 5.1, положения существующих экранных каналов не должны чересчур радикально изменяться в попытке усилить, или подчеркнуть, введение новых местоположений громкоговорителей. В отличие от использования всех доступных 64 выходных каналов, данные формата адаптивного звука могут точно представляться в кинотеатре в такие конфигурации громкоговорителей, как 7.1, что даже позволяет использовать этот формат (и связанные с ним выгоды) в существующих кинотеатрах без внесения изменений в усилители или громкоговорители.
[00138] В зависимости от конструкции кинотеатра, разные местоположения громкоговорителей могут обладать разной эффективностью, поэтому в настоящее время отсутствует определяемое отраслевыми техническими условиями идеальное количество или расположение каналов. Адаптивный звук, как предполагается, является по-настоящему адаптируемым и способным точно проигрываться в различных зрительных залах, имеют они ограниченное количество проигрывающих каналов или много каналов с очень гибкими конфигурациями.
[00139] ФИГ. 8 представляет собой вид 800 сверху одного из примеров схемы расположения предполагаемых местоположений громкоговорителей для использования с системой адаптивного звука по типичному алгоритму, и ФИГ. 9 представляет собой вид 900 спереди указанного примера схемы расположения предполагаемых местоположений громкоговорителей на экране зрительного зала. Исходное положение, предпочтительное в данном случае, соответствует положению 2/3 расстояния обратно от экрана к задней стене на средней линии экрана. Стандартные экранные громкоговорители 801 показаны в их обычных положениях относительно экрана. Изучение восприятия возвышения плоскости экрана показало, что дополнительные громкоговорители 804 за экраном, такие как левый центральный (Lc) и правый центральный (Rc) экранные громкоговорители (в местоположениях левого дополнительного и правого дополнительного каналов в форматах пленки 70 мм), могут оказаться полезными при создании более плавного панорамирования через экран. Поэтому указанные необязательные громкоговорители являются рекомендуемыми, особенно в зрительных залах с экранами шириной более 12 м (40 футов). Все экранные громкоговорители должны располагаться под углом с тем, чтобы они были нацелены в направлении исходного положения. Рекомендуемое размещение сверхнизкочастотного громкоговорителя 810 за экраном должно оставаться неизменным, включая сохранение асимметричного размещения корпуса относительно центра помещения во избежание возбуждения стоячих волн. В задней части кинотеатра могут располагаться дополнительные сверхнизкочастотные громкоговорители 816.
[00140] Окружающие громкоговорители 802 должны по отдельности соединяться проводами с задней частью стойки усилителей и должны там, где это возможно, по отдельности усиливаться назначенным каналом усиления мощности, соответствующим коммутируемой мощности громкоговорителя в соответствии с техническим паспортом. В идеальном случае, окружающие громкоговорители должны определяться техническими условиями для обработки повышенного SPL для каждого отдельного громкоговорителя, а также, там, где это возможно, для более широкой амплитудно-частотной характеристики. Как показывает практика, для кинотеатра среднего размера интервал между окружающими громкоговорителями должен находиться в пределах 2-3 м (6 футов 6 дюймов - 9 футов 9 дюймов), где левый и правый окружающие громкоговорители размещаются симметрично. Однако, считается, что, в противоположность использованию абсолютных расстояний между громкоговорителями, интервал между окружающими громкоговорителями является наиболее эффективным под углами, стягиваемыми от данного слушателя между смежными громкоговорителями. Для оптимального проигрывания повсюду в зрительном зале, угловое расстояние между смежными громкоговорителями должно составлять 30 градусов или менее при отсчете от каждого из четырех углов основной области прослушивания. Хорошие результаты могут достигаться при интервале до 50 градусов. Для каждой зоны громкоговорителей, там, где это возможно, громкоговорители должны сохранять равный линейный интервал вблизи зоны посадочных мест. Линейный интервал за пределами области прослушивания, например, между передним рядом и экраном, может быть немного больше. ФИГ. 11 представляет собой один из примеров расположения верхних окружающих громкоговорителей 808 и боковых окружающих громкоговорителей 806 относительно исходного положения согласно одному из вариантов осуществления изобретения.
[00141] Дополнительные боковые окружающие громкоговорители 806 должны монтироваться ближе к экрану, чем рекомендуется на практике в настоящее время – начиная приблизительно с одной трети расстояния до задней части зрительного зала. В ходе проигрывания звуковых дорожек Dolby Surround 7.1 или 5.1 эти громкоговорители не используются как боковые окружающие, но позволяют осуществлять плавный переход и лучшее тембральное согласование при панорамировании объектов от экранных громкоговорителей к окружающим зонам. Для максимального усиления ощущения пространства, окружающие массивы следует располагать так же низко, как используемые на практике, подвергая из следующим ограничениям: вертикальное размещение окружающих громкоговорителей в передней части массива должно быть достаточно близким к высоте акустического центра экранного громкоговорителя и достаточно высоким для сохранения хорошего охвата через зону посадочных мест в соответствии с направленностью громкоговорителя. Вертикальное размещение окружающих громкоговорителей должно быть таким, чтобы они образовывали прямую линию спереди назад и (как правило) были наклонены вверх так, чтобы относительное возвышение окружающих громкоговорителей над слушателями сохранялось в направлении задней части кинотеатра по мере того, как увеличивается возвышение посадочных мест, как показано на ФИГ. 10, которая представляет собой вид сбоку одного из примеров схемы расположения предполагаемых местоположений громкоговорителей для использования с системой адаптивного звука в типичном зрительном зале. На практике, этого проще всего достичь, выбирая возвышение для самого переднего и самого заднего боковых окружающих громкоговорителей и размещая остальные громкоговорители на линии между этими точками.
[00142] С целью обеспечения оптимального охвата для каждого громкоговорителя по всей зоне посадочных мест боковые окружающие громкоговорители 806, задние громкоговорители 816 и верхние окружающие громкоговорители 808 должны быть нацелены в направление положения начала отсчета в кинотеатре в соответствии с определенными руководящими принципами в отношении интервала, положения, угла и т.д.
[00143] Варианты осуществления системы и формата адаптивного звука для кинематографии достигают повышенных уровней эффекта присутствия и вовлечения зрительного зала по сравнению с современными системами, предлагая новые мощные инструментальные средства авторской разработки для операторов микширования и новое устройство обработки данных для кинематографии, которые отличаются гибким средством представления данных, которое оптимизирует качество звука и окружающие эффекты звуковой дорожки для каждой схемы размещения и характеристик громкоговорителей в помещении. Кроме того, система сохраняет обратную совместимость и минимизирует воздействие на современные последовательности операций производства и распространения.
[00144] Несмотря на то, что варианты осуществления изобретения были описаны в отношении примеров и реализаций в кинематографической среде, где адаптивное звуковое содержимое связано с содержанием фильма, с целью использования в системах обработки данных для цифровой кинематографии, следует отметить, что варианты осуществления изобретения также могут реализовываться в некинематографических средах. Адаптивное звуковое содержимое, включающее звук на основе объектов и звук на основе каналов, может использоваться в сочетании с каким-либо связанным содержимым (связанной аудиозаписью, видеозаписью, графикой и т.д.) или оно может составлять автономное звуковое содержимое. Среда проигрывания может представлять собой любую среду от наушников или мониторов в ближней зоне до малых и больших помещений, автомобилей, открытых площадок, концертных залов и т.д.
[00145] Особенности системы 100 могут реализовываться в подходящей сетевой среде обработки звука на компьютерной основе, предназначенной для обработки файлов цифрового или оцифрованного звука. Части системы адаптивного звука могут включать одну или несколько сетей, которые содержат любое необходимое количество отдельных машин, в том числе один или несколько маршрутизаторов (не показаны), которые служат для буферирования и перенаправления данных, передаваемых между компьютерами. Такая сеть может быть построена на различных сетевых протоколах и может представлять собой Интернет, глобальную сеть (WAN), локальную сеть (LAN) или любую их комбинацию. В одном из вариантов осуществления изобретения, где сеть включает Интернет, одна или несколько машин могут быть сконфигурированы для доступа в Интернет через программы-навигаторы.
[00146] Один или несколько компонентов, блоков, процессов или других функциональных составляющих могут реализовываться через компьютерную программу, которая контролирует исполнение вычислительным устройством системы на основе процессора. Также следует отметить, что различные функции, раскрытые в данном описании, могут описываться с использованием любого количества комбинаций аппаратного обеспечения, программно-аппаратного обеспечения и/или как данные, и/или как команды, воплощенные в различных машиночитаемых, или читаемых компьютером, носителей данных, исходя из характеристик их поведения, регистровой пересылки, логических компонентов и др. Читаемые компьютером носители данных, в которых могут воплощаться указанные форматированные данные и/или команды, включают в качестве неограничивающих примеров физические (постоянные), энергонезависимые носители данных в различных формах, такие как оптические, магнитные или полупроводниковые носители данных.
[00147] Если контекст явно не требует иного, повсюду в данном описании и формуле изобретения слова «содержать», «содержащий» и т.п. следует толковать во включающем смысле, в противоположность исключающему или исчерпывающему смыслу; то есть в смысле «включающий в качестве неограничивающего примера». Слова, использующие форму единственного или множественного числа, также соответственно включают форму множественного или единственного, числа. Кроме того, выражения «в данном раскрытии», «в соответствии с данным раскрытием», «выше», «ниже» и схожие по смыслу слова относятся к данной заявке в целом, а не только к каким-либо частям данной заявки. Когда слово «или» используется со ссылкой на список из двух или большего количества элементов, это слово охватывает все следующие интерпретации слова: любой из элементов в списке, все элементы в списке, все элементы в списке и любая комбинация элементов в списке.
[00148] Несмотря на то, что одна или несколько реализаций были описаны посредством примеров и исходя из конкретных вариантов осуществления изобретения, следует понимать, что одна или несколько реализаций не ограничиваются раскрытыми вариантами осуществления изобретения. Наоборот, они предназначаются для охвата различных модификаций и сходных схем, что должно быть очевидно для специалистов в данной области. Поэтому объем прилагаемой формулы изобретения должен соответствовать самой широкой интерпретации с тем, чтобы он охватывал все такие модификации в сходных схемах.
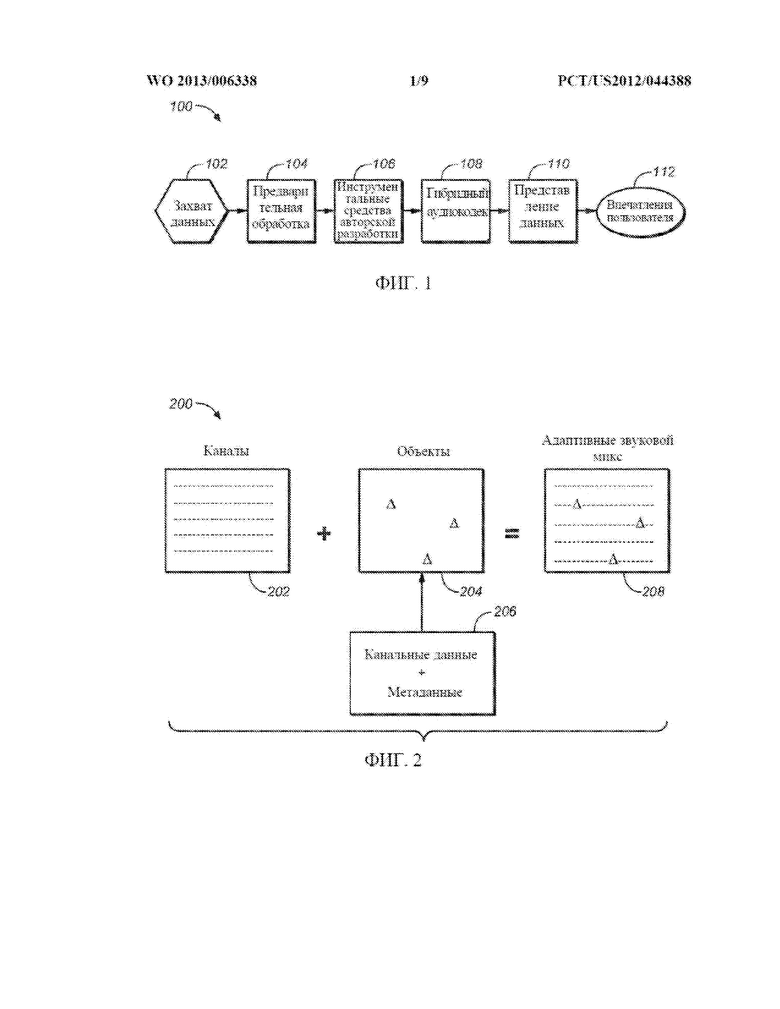
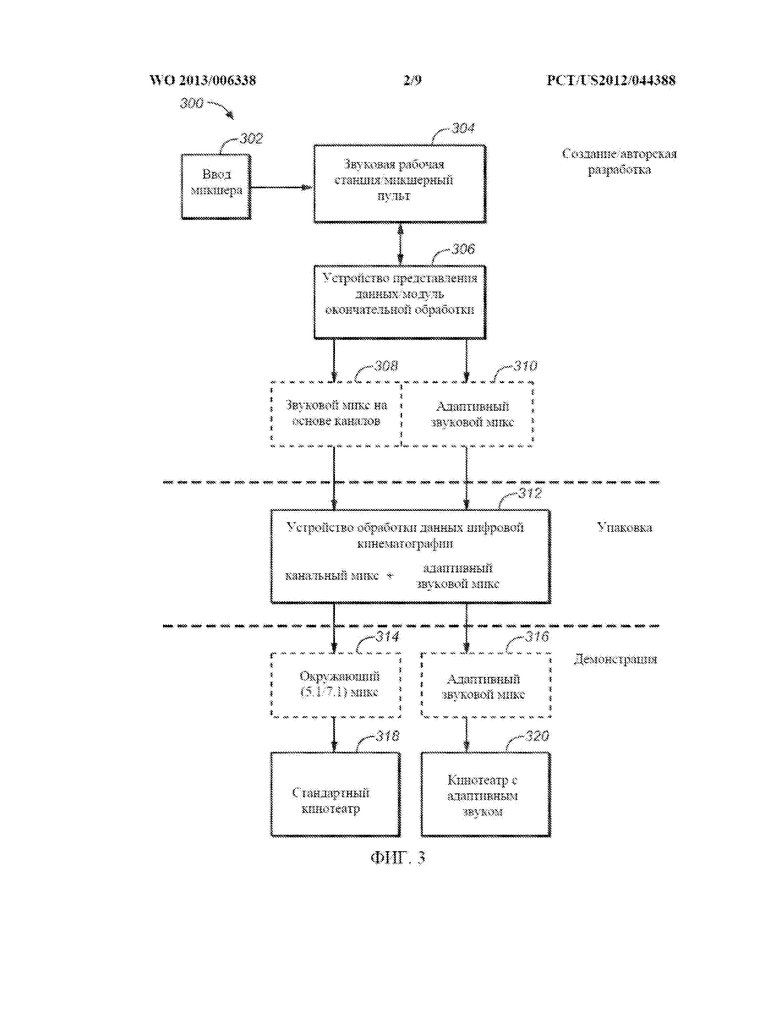
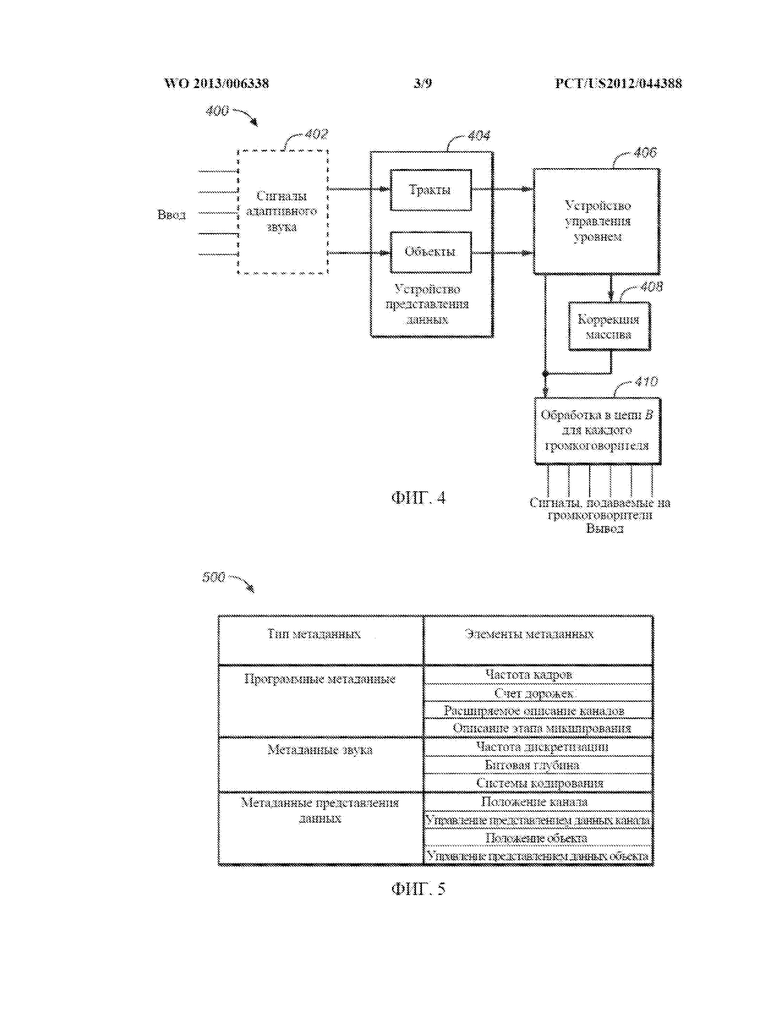
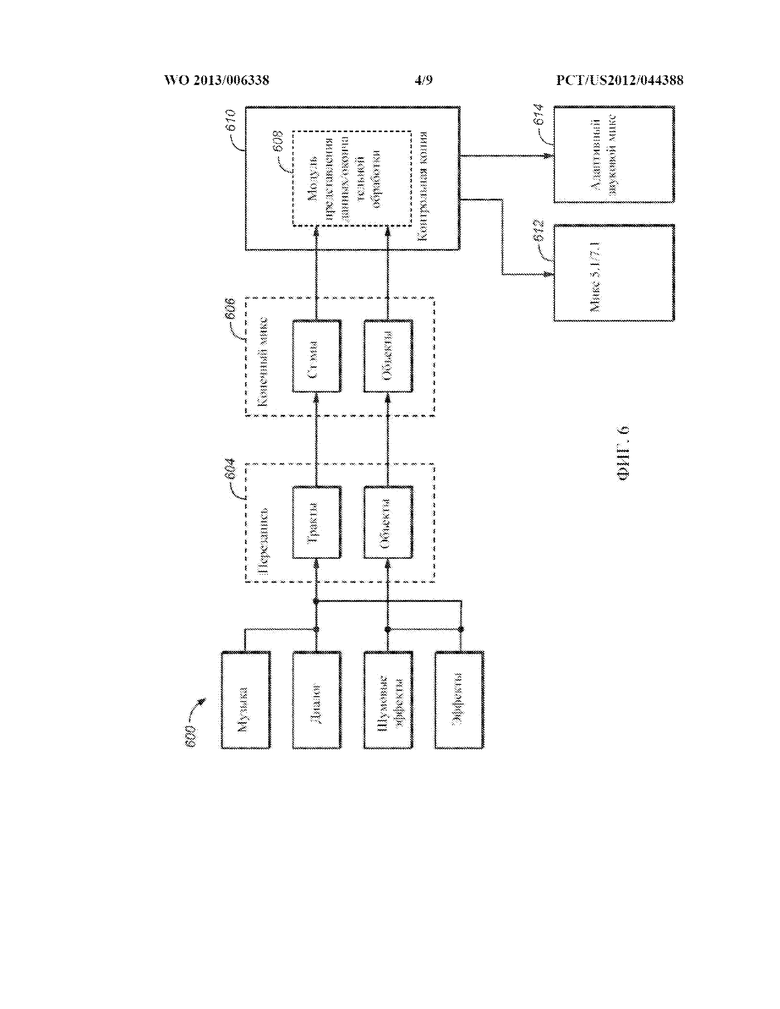
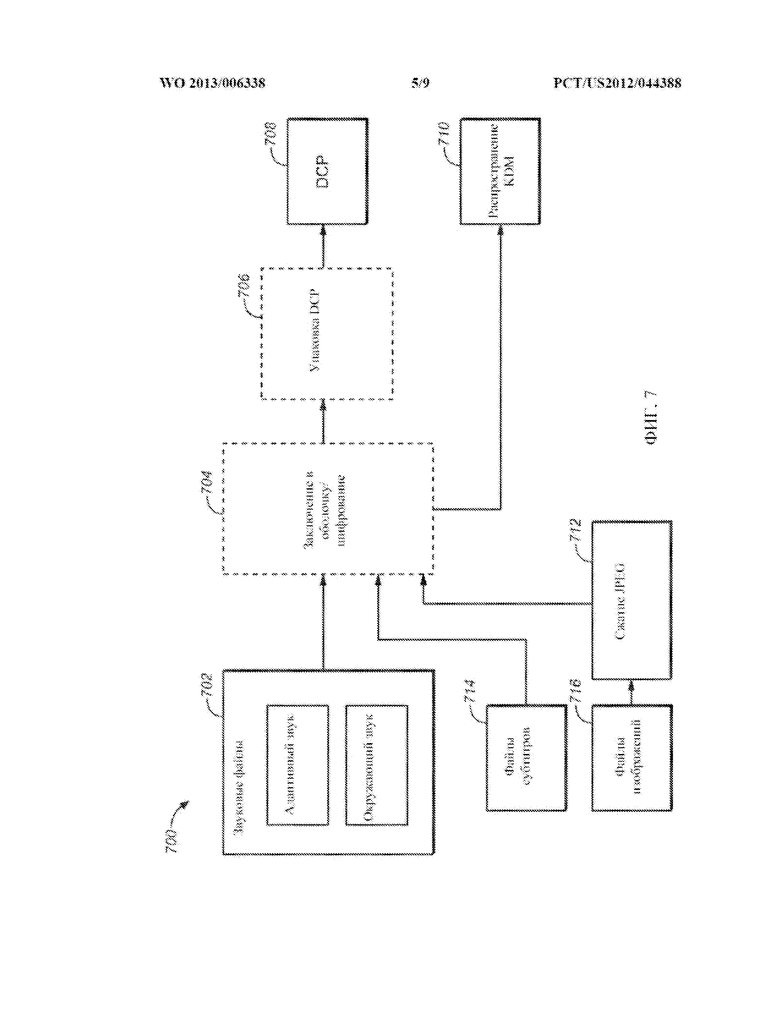
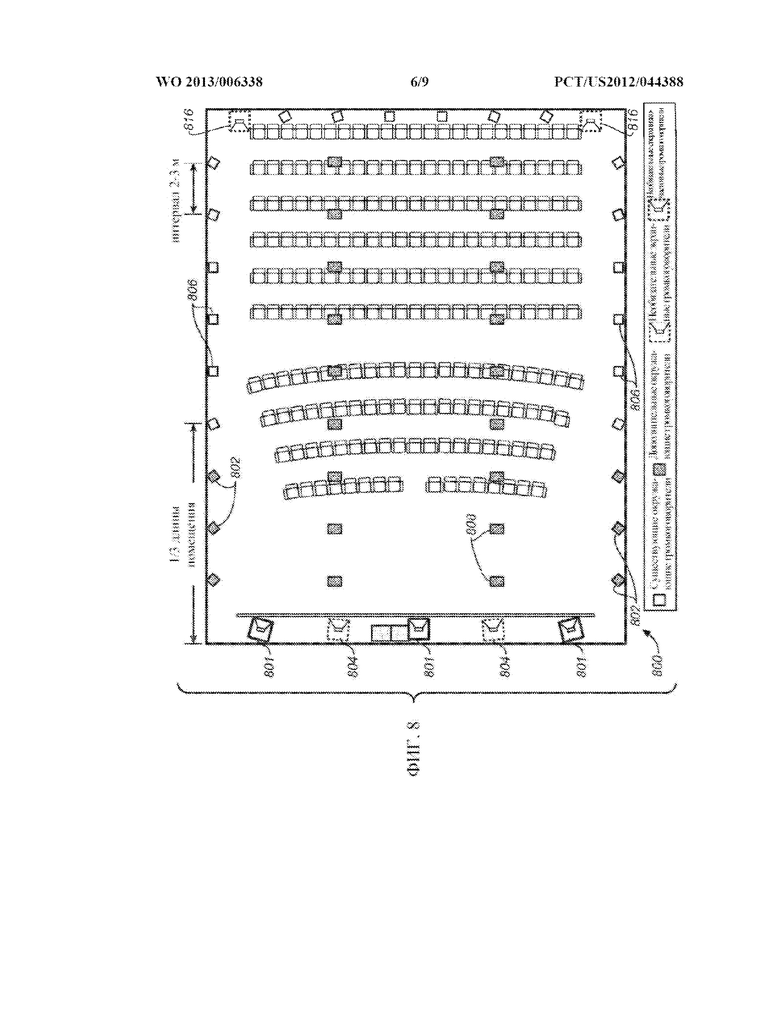
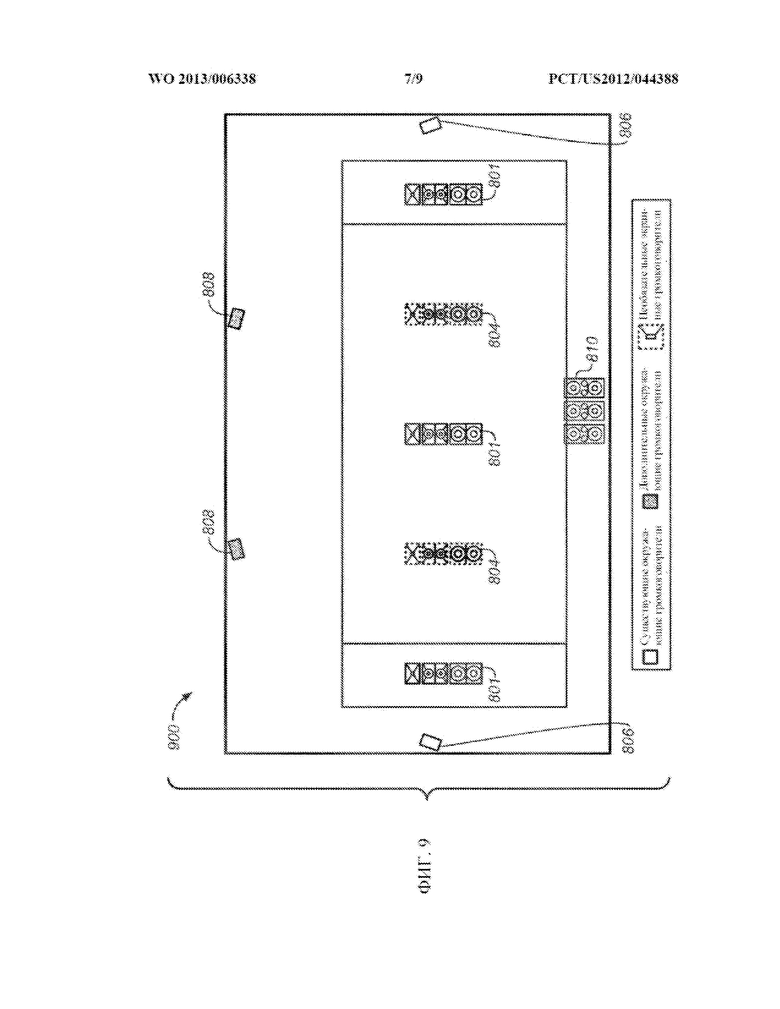
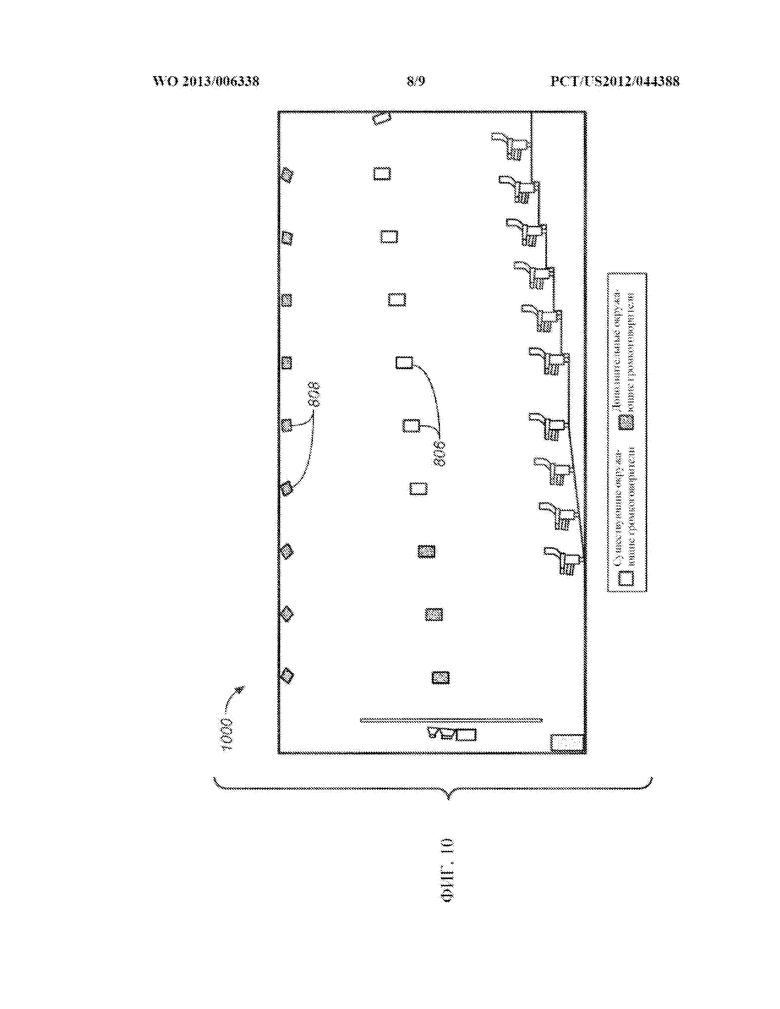
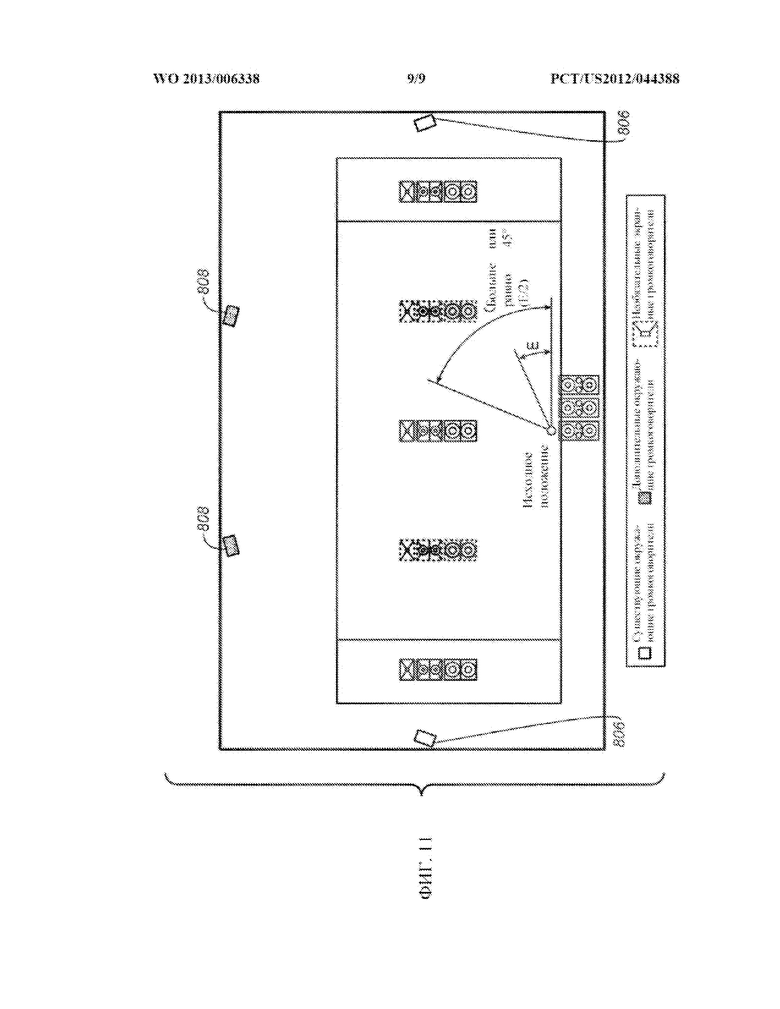
Изобретение относится к обработке звуковых сигналов. Технический результат – повышение эффективности системы путем генерирования и представления звуковых сигналов в различных средах проигрывания. Предложенная система адаптивного звука обрабатывает аудиоданные, содержащие некоторое количество независимых монофонических аудиопотоков. С одним или несколькими из потоков были связаны метаданные, которые описывают, является указанный поток потоком на основе каналов или потоком на основе объектов. Потоки на основе каналов содержат информацию представления данных, кодированную посредством названия канала; а потоки на основе объектов содержат информацию местоположения, кодированную через выражения местоположения, закодированные в связанных метаданных. Кодек упаковывает независимые аудиопотоки в единую двоичную последовательность, которая содержит все аудиоданные. Такая конфигурация позволяет представлять данные звука в соответствии с аллоцентрической системой отсчета, в которой местоположение представления данных звука основывается на характеристиках среды проигрывания. Метаданные положения объектов содержат соответствующую информацию аллоцентрической системы отсчета, необходимую для верного проигрывания звука с использованием положений доступных громкоговорителей в помещении, которое приспособлено для проигрывания адаптивного звукового содержимого. 5 н. и 13 з.п. ф-лы, 11 ил., 12 табл.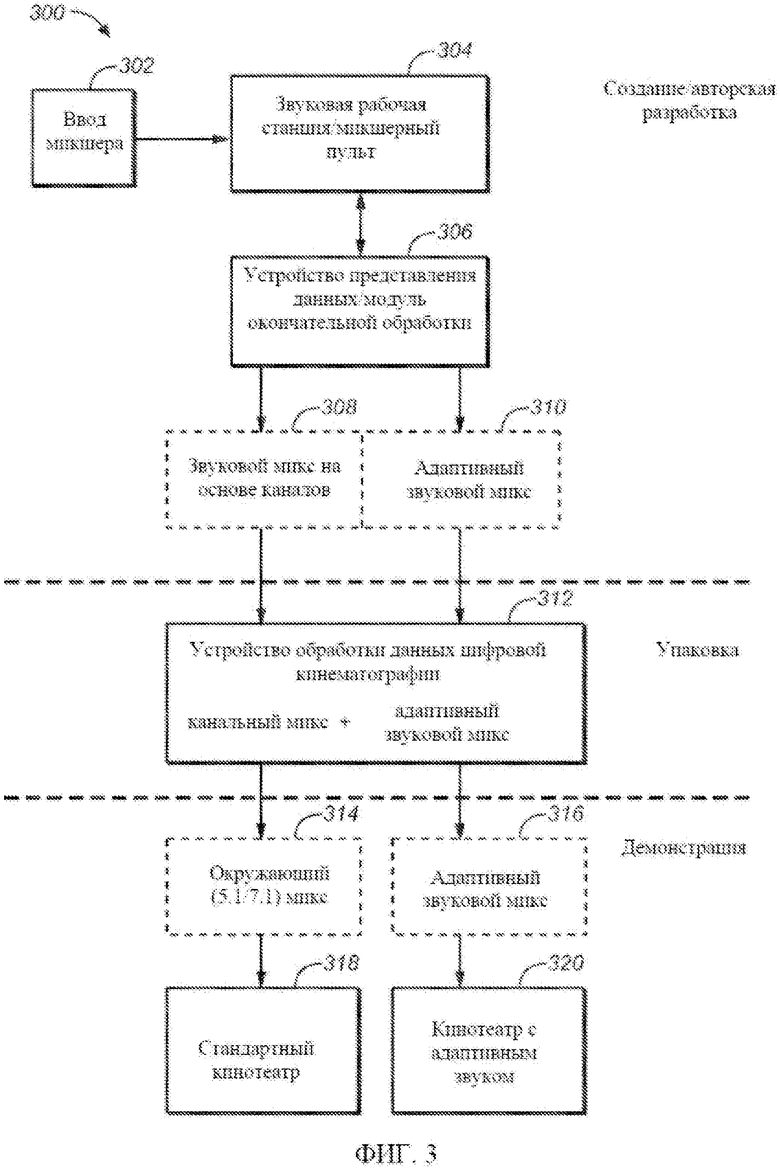
1. Система, предназначенная для обработки звуковых сигналов, которая содержит:
компонент авторской разработки, сконфигурированный для приема ряда звуковых сигналов звуковой программы, и для генерирования адаптивного звукового микса для звуковой программы, содержащего ряд монофонических аудиопотоков и одного или нескольких наборов метаданных, связанных с каждым из ряда монофонических аудиопотоков и определяющих местоположение проигрывания соответствующего монофонического аудиопотока, и для генерирования первого набора метаданных и второго набора метаданных, связанных с одним или несколькими из ряда монофонических аудиопотоков, при этом по меньшей мере один из ряда монофонических аудиопотоков идентифицируется как звук на основе каналов и по меньшей мере один из других из ряда монофонических аудиопотоков идентифицируется как звук на основе объектов, и при этом местоположение проигрывания звука на основе каналов содержит обозначения громкоговорителей для громкоговорителей в массиве громкоговорителей, и при этом местоположение проигрывания звука на основе объектов содержит местоположение в трехмерном пространстве; и также при этом первый набор метаданных по умолчанию применяют к одному или нескольким из ряда монофонических аудиопотоков, и второй набор метаданных связан со специфическими условиями среды проигрывания и его применяют к одному или нескольким из ряда монофонических аудиопотоков вместо первого набора метаданных, если условия среды проигрывания соответствуют специфическим условиям среды проигрывания; и
систему представления данных, связанную с компонентом авторской разработки и сконфигурированную для приема битового потока, внутри которого заключен ряд монофонических аудиопотоков и наборы метаданных, и для представления ряда монофонических аудиопотоков в ряд сигналов, подаваемых на громкоговорители, соответствующих громкоговорителям в среде проигрывания, в соответствии с наборами метаданных на основе условий среды проигрывания.
2. Система по п. 1, отличающаяся тем, что каждый набор метаданных содержит элементы метаданных, связанные с каждым потоком на основе объектов, при этом элементы метаданных для каждого потока на основе объектов описывают пространственные параметры, управляющие проигрыванием соответствующего звука на основе объектов и содержащие один или несколько следующих параметров: положение звука, ширина звука и скорость звука; и также при этом каждый набор метаданных содержит элементы метаданных, связанные с каждым потоком на основе каналов, и массив громкоговорителей содержит громкоговорители, расположенные в определенной конфигурации окружающего звука, и при этом элементы метаданных, связанные с каждым потоком на основе каналов, содержат обозначения каналов окружающего звука громкоговорителей в массиве громкоговорителей в соответствии с определенным стандартом окружающего звука.
3. Система по п. 1, отличающаяся тем, что массив громкоговорителей содержит дополнительные громкоговорители, предназначенные для проигрывания потоков на основе объектов и расположенные в среде проигрывания в соответствии с установочными командами от пользователя на основе условий среды проигрывания, и при этом условия проигрывания зависят от переменных, содержащих: размер и форму помещения среды проигрывания, заполненность, состав материалов и окружающий шум; и также при этом система принимает от пользователя установочный файл, который содержит по меньшей мере список конфигураций громкоговорителей и присваивания каналов отдельным громкоговорителям массива громкоговорителей, информацию в отношении группировки громкоговорителей и присваивания на основе относительного положения громкоговорителей в среде проигрывания.
4. Система по п. 1, отличающаяся тем, что компонент авторской разработки содержит микшерный пульт, имеющий элементы управления, приводимые в действие пользователем для определения уровней проигрывания ряда монофонических аудиопотоков, содержащих оригинальное звуковое содержимое, и при этом элементы метаданных, связанные с каждым соответствующим потоком на основе объектов, автоматически генерируют при вводе пользователем управляющих сигналов в микшерный пульт.
5. Система по п. 1, отличающаяся тем, что наборы метаданных содержат метаданные, делающие возможным повышающее микширование или понижающее микширование по меньшей мере одного из монофонических аудиопотоков на основе каналов и монофонических аудиопотоков на основе объектов в соответствии с переходом от первой конфигурации массива громкоговорителей ко второй конфигурации массива громкоговорителей.
6. Система по п. 3, отличающаяся тем, что наборы метаданных содержат метаданные, идентифицирующие тип содержимого монофонического аудиопотока; при этом тип содержимого выбирают из группы, которая состоит из: диалога, музыки и эффектов, и каждый тип содержимого воплощен в соответствующем наборе потоков на основе каналов или потоков на основе объектов, и также при этом составляющие звука для каждого типа содержимого передают в определенные группы громкоговорителей из одной или нескольких групп громкоговорителей, обозначенных в пределах массива громкоговорителей.
7. Система по п. 6, отличающаяся тем, что громкоговорители массива громкоговорителей размещают в определенных положениях в пределах среды проигрывания, и при этом элементы метаданных, связанные с каждым соответствующим потоком на основе объектов, определяют, что одну или несколько составляющих звука представляют в сигнал, подаваемый на громкоговоритель, для проигрывания через громкоговоритель, ближайший к присвоенному местоположению громкоговорителя составляющей звука, что указано метаданными положения.
8. Система по п. 1, отличающаяся тем, что местоположение громкоговорителя содержит положение в пространстве в среде проигрывания относительно экрана или поверхности, которая окружает среду проигрывания, и при этом поверхность содержит переднюю плоскость, заднюю плоскость, левую плоскость, правую плоскость, верхнюю плоскость и нижнюю плоскость.
9. Система по п. 1, отличающаяся тем, что также содержит кодек, связанный с компонентом авторской разработки и компонентом представления данных и сконфигурированный для приема ряда монофонических аудиопотоков и метаданных и для генерирования единого цифрового битового потока, упорядоченным образом содержащего ряд монофонических аудиопотоков.
10. Система по п. 9, отличающаяся тем, что компонент представления данных также содержит средства для выбора одного из алгоритмов представления данных, используемого компонентом представления данных, при этом алгоритм представления данных выбирают из группы, которая состоит из: бинаурального алгоритма, стереодипольного алгоритма, амбифонии, синтеза волнового поля (WFS), многоканального панорамирования, необработанных стэмов с метаданными положения, двойного баланса и амплитудного панорамирования на векторной основе.
11. Система по п. 1, отличающаяся тем, что местоположение проигрывания для каждого из ряда монофонических аудиопотоков независимо определяют относительно эгоцентрической системы отсчета или аллоцентрической системы отсчета, при этом эгоцентрическая система отсчета определяется относительно слушателя в среде проигрывания и при этом аллоцентрическая система отсчета определяется относительно одной из характеристик среды проигрывания.
12. Способ авторской разработки звуковых сигналов для представления данных, который включает этапы, на которых:
принимают ряд звуковых сигналов звуковой программы;
генерируют адаптивный звуковой микс для звуковой программы, содержащий ряд монофонических аудиопотоков и один или несколько наборов метаданных, связанных с каждым из ряда монофонических аудиопотоков и определяющих местоположение проигрывания соответствующего монофоническего аудиопотока, включающих первый набор метаданных и второй набор метаданных, связанные с одним или несколькими из ряда монофонических аудиопотоков, при этом по меньшей мере один из ряда монофонических аудиопотоков идентифицируется как звук на основе каналов и при этом по меньшей мере один из других из ряда монофонических аудиопотоков идентифицируется как звук на основе объектов, и при этом местоположение проигрывания звука на основе каналов содержит обозначения громкоговорителей для громкоговорителей в массиве громкоговорителей, и местоположение проигрывания звука на основе объектов содержит местоположение в трехмерном пространстве относительно среды проигрывания, содержащей массив громкоговорителей; и также при этом первый набор метаданных применяют к одному или нескольким из ряда монофонических аудиопотоков для первых условий среды проигрывания, и второй набор метаданных применяют к одному или нескольким из ряда монофонических аудиопотоков для вторых условий среды проигрывания; и
заключают ряд монофонических аудиопотоков и один или несколько наборов метаданных внутрь битового потока для передачи в систему представления данных, сконфигурированную для представления ряда монофонических аудиопотоков в ряд сигналов, подаваемых на громкоговорители, соответствующих громкоговорителям в среде проигрывания, в соответствии по меньшей мере с двумя наборами метаданных на основе условий среды проигрывания.
13. Способ по п. 12, отличающийся тем, что каждый набор метаданных содержит элементы метаданных, связанные с каждым потоком на основе объектов, элементы метаданных для каждого потока на основе объектов описывают пространственные параметры, управляющие проигрыванием соответствующего звука на основе объектов и содержащие один или несколько следующих параметров: положение звука, ширина звука и скорость звука; и также при этом каждый набор метаданных содержит элементы метаданных, связанные с каждым потоком на основе каналов, и массив громкоговорителей содержит громкоговорители, расположенные в определенной конфигурации окружающего звука, и при этом элементы метаданных, связанные с каждым потоком на основе каналов, содержат обозначения каналов окружающего звука громкоговорителей в массиве громкоговорителей в соответствии с определенным стандартом окружающего звука.
14. Способ по п. 12, отличающийся тем, что массив громкоговорителей содержит дополнительные громкоговорители, предназначенные для проигрывания потоков на основе объектов и расположенные в среде проигрывания, способ также включает прием установочных команд от пользователя на основе условий среды проигрывания, и при этом условия проигрывания зависят от переменных, включающих: размер и форму помещения среды проигрывания, заполненность, состав материалов и окружающий шум; установочные команды также содержат по меньшей мере список обозначений громкоговорителей и присваивание каналов отдельным громкоговорителям в массив громкоговорителей, информацию в отношении группировки громкоговорителей и присваивания на основе относительного положения громкоговорителей в среде проигрывания.
15. Способ по п. 14, отличающийся тем, что также включает этапы, на которых:
принимают из микшерного пульта, имеющего элементы управления, приводимые в действие пользователем для определения уровней проигрывания ряда монофонических аудиопотоков, содержащих оригинальное звуковое содержимое; и
автоматически генерируют при приеме пользовательского ввода элементов метаданных, связанных с каждым соответствующим потоком на основе объектов.
16. Способ представления данных звуковых сигналов, который включает этапы, на которых:
принимают битовый поток, внутри которого заключен ряд монофонических аудиопотоков и по меньшей мере два набора метаданных в битовом потоке из компонента авторской разработки, сконфигурированного для приема ряда звуковых сигналов звуковой программы и генерирования для звуковой программы ряда монофонических аудиопотоков и одного или нескольких наборов метаданных, связанных с каждым из ряда монофонических аудиопотоков и определяющих местоположение проигрывания соответствующего монофонического аудиопотока, включающих первый набор метаданных и второй набор метаданных, связанные с одним или несколькими из ряда монофонических аудиопотоков, при этом по меньшей мере один из ряда монофонических аудиопотоков идентифицируется как звук на основе каналов и при этом по меньшей мере один из других из ряда монофонических аудиопотоков идентифицируется как звук на основе объектов, и при этом местоположение проигрывания звука на основе каналов содержит обозначения громкоговорителей для громкоговорителей в массиве громкоговорителей, и местоположение проигрывания звука на основе объектов содержит местоположение в трехмерном пространстве относительно среды проигрывания, содержащей массив громкоговорителей; и также при этом первый набор метаданных применяют к одному или нескольким из ряда монофонических аудиопотоков для первых условий среды проигрывания, и второй набор метаданных применяют к одному или нескольким из ряда монофонических аудиопотоков для вторых условий среды проигрывания; и
представляют ряд монофонических аудиопотоков в ряд сигналов, подаваемых на громкоговорители, соответствующих громкоговорителям в среде проигрывания, в соответствии по меньшей мере с двумя наборами метаданных на основе условий среды проигрывания.
17. Система, предназначенная для обработки звуковых сигналов, содержащая компонент авторской разработки, сконфигурированный для:
приема ряда звуковых сигналов звуковой программы;
генерирования адаптивного звукового микса для звуковой программы, содержащего ряд монофонических аудиопотоков и один или несколько наборов метаданных, связанных с каждым из ряда монофонических аудиопотоков и определяющих местоположение проигрывания соответствующего монофонического аудиопотока, включающих первый набор метаданных и второй набор метаданных, связанные с одним или несколькими из ряда монофонических аудиопотоков, при этом по меньшей мере один из ряда монофонических аудиопотоков идентифицируется как звук на основе каналов и при этом по меньшей мере один из других из ряда монофонических аудиопотоков идентифицируется как звук на основе объектов, и при этом местоположение проигрывания звука на основе каналов содержит обозначения громкоговорителей для громкоговорителей в массиве громкоговорителей, и местоположение проигрывания звука на основе объектов содержит местоположение в трехмерном пространстве относительно среды проигрывания, содержащей массив громкоговорителей; а также при этом первый набор метаданных применяют к одному или нескольким из ряда монофонических аудиопотоков для первых условий среды проигрывания, и второй набор метаданных применяют к одному или нескольким из ряда монофонических аудиопотоков для вторых условий среды проигрывания; и
заключения ряда монофонических аудиопотоков и по меньшей мере двух наборов метаданных внутрь битового потока для передачи в систему представления данных, сконфигурированную для представления ряда монофонических аудиопотоков в ряд сигналов, подаваемых на громкоговорители, соответствующих громкоговорителям в среде проигрывания, в соответствии по меньшей мере с двумя наборами метаданных на основе условий среды проигрывания.
18. Система, предназначенная для обработки звуковых сигналов, содержащая систему представления данных, сконфигурированную для:
приема битового потока, внутри которого заключен ряд монофонических аудиопотоков и по меньшей мере два набора метаданных в битовом потоке из компонента авторской разработки, сконфигурированного для приема ряда звуковых сигналов звуковой программы и генерирования для звуковой программы ряда монофонических аудиопотоков и одного или нескольких наборов метаданных, связанных с каждым из ряда монофонических аудиопотоков и определяющих местоположение проигрывания соответствующего монофонического аудиопотока, включающих первый набор метаданных и второй набор метаданных, связанные с одним или несколькими из ряда монофонических аудиопотоков, при этом по меньшей мере один из ряда монофонических аудиопотоков идентифицируется как звук на основе каналов и при этом по меньшей мере один из других из ряда монофонических аудиопотоков идентифицируется как звук на основе объектов, и при этом местоположение проигрывания звука на основе каналов содержит обозначения громкоговорителей для громкоговорителей в массиве громкоговорителей, и местоположение проигрывания звука на основе объектов содержит местоположение в трехмерном пространстве относительно среды проигрывания, содержащей массив громкоговорителей; и также при этом первый набор метаданных применяют к одному или нескольким из ряда монофонических аудиопотоков для первых условий среды проигрывания, и второй набор метаданных применяют к одному или нескольким из ряда монофонических аудиопотоков для вторых условий среды проигрывания; и
представляют ряд монофонических аудиопотоков в ряд сигналов, подаваемых на громкоговорители, соответствующих громкоговорителям в среде проигрывания, в соответствии по меньшей мере с двумя наборами метаданных на основе условий среды проигрывания.
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| КОДИРОВАНИЕ СТЕРЕОФОНИЧЕСКИХ СИГНАЛОВ | 2003 |
|
RU2316154C2 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Перекатываемый затвор для водоемов | 1922 |
|
SU2001A1 |

