ОБЛАСТЬ ТЕХНИКИ
[0001] Вариант осуществления настоящего изобретения относится к способу кодирования и способу декодирования.
УРОВЕНЬ ТЕХНИКИ
[0002] В последние годы, способ кодирования изображения со значительно повышенной эффективностью кодирования рекомендуется как ITU-T REC. H.264 и ISO/IEC 14496-10 (далее именуемый “H.264”) в кооперации с ITU-T (International Telecommunication Union Telecommunication Standardization Sector) и ISO (International Organization for Standardization)/IEC (International Electrotechnical Commission).
[0003] В H.264 раскрыта система кодирования с внешним прогнозированием, в которой избыточность во временном направлении устраняется для достижения высокой эффективности кодирования за счет осуществления прогнозирования с компенсацией движения дробной точности с использованием кодированного изображения в качестве опорного изображения.
[0004] Кроме того, предложена система, в которой движущееся изображение, включающее в себя эффект затухания или расплывания, кодируется с более высокой эффективностью, чем в системе кодирования с внешним прогнозированием согласно ISO/IEC MPEG (Moving Picture Experts Group)-1, 2, 4. В этой системе, прогнозирование с компенсацией движения дробной точности производится для входного движущегося изображения, имеющего яркость и две цветоразности, в качестве кадров для прогнозирования изменения светлоты во временном направлении. Затем, с использованием индекса, представляющего комбинацию опорного изображения, весового коэффициента для каждого из яркости и двух цветоразностей, и смещения для каждого из яркости и двух цветоразностей, прогнозируемое изображение умножается на весовой коэффициент, и смещение суммируется с ним.
СПИСОК ЦИТИРОВАНИЯ
ПАТЕНТНАЯ ЛИТЕРАТУРА
[0005] Патентная литература 1: японская выложенная патентная публикация № 2004-7377
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
ТЕХНИЧЕСКАЯ ПРОБЛЕМА
[0006] Однако, в традиционной технологии, как описано выше, поскольку индекс кодируется, будучи поддерживаемым в виде прямых значений, эффективность кодирования снижается. Задачей настоящего изобретения является обеспечение способа кодирования и способа декодирования, способного повышать эффективность кодирования.
РЕШЕНИЕ ПРОБЛЕМЫ
[0007] Устройство кодирования согласно варианту осуществления включает в себя блок установки индекса, блок переконфигурирования индекса и блок энтропийного кодирования. Блок установления индекса устанавливает индекс, который представляет информацию опорного изображения и весового коэффициента. Блок переконфигурирования индекса прогнозирует опорное значение весового коэффициента, причем опорное значение указывает коэффициент, который должен быть установлен, если разность пиксельного значения между опорным изображением и целевым изображением, которое должно быть кодировано, меньше или равна конкретному значению. Блок энтропийного кодирования кодирует значение разности между весовым коэффициентом и опорным значением.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0008] Фиг. 1 - блок-схема, иллюстрирующая пример устройства кодирования согласно первому варианту осуществления.
Фиг. 2 - пояснительная схема, которая иллюстрирует пример прогнозируемой последовательности кодирования для пиксельного блока согласно первому варианту осуществления.
Фиг. 3A - схема, которая иллюстрирует пример размера блока для блока дерева кодирования согласно первому варианту осуществления.
Фиг. 3B - схема, которая иллюстрирует конкретный пример блока дерева кодирования согласно первому варианту осуществления.
Фиг. 3C - схема, которая иллюстрирует конкретный пример блока дерева кодирования согласно первому варианту осуществления.
Фиг. 3D - схема, которая иллюстрирует конкретный пример блока дерева кодирования согласно первому варианту осуществления.
Фиг. 4 - блок-схема, иллюстрирующая пример блока генерирования прогнозируемого изображения согласно первому варианту осуществления.
Фиг. 5 - схема, которая иллюстрирует пример соотношения между векторами движения для прогнозирования с компенсацией движения в двунаправленном прогнозировании согласно первому варианту осуществления.
Фиг. 6 - блок-схема, иллюстрирующая пример блока многокадровой компенсации движения согласно первому варианту осуществления.
Фиг. 7 - пояснительная схема, которая иллюстрирует пример точности фиксированной запятой весового коэффициента согласно первому варианту осуществления.
Фиг. 8A - схема, которая иллюстрирует пример информации параметра WP согласно первому варианту осуществления.
Фиг. 8B - схема, которая иллюстрирует пример информации параметра WP согласно первому варианту осуществления.
Фиг. 9 - схема, которая иллюстрирует пример синтаксиса согласно первому варианту осуществления.
Фиг. 10 - схема, которая иллюстрирует пример синтаксиса набора параметров изображения согласно первому варианту осуществления.
Фиг. 11 - схема, которая иллюстрирует пример синтаксиса заголовка слайса согласно первому варианту осуществления.
Фиг. 12 - схема, которая иллюстрирует пример синтаксиса таблицы весов pred согласно первому варианту осуществления.
Фиг. 13 - схема, которая иллюстрирует пример конфигурации синтаксиса, в явном виде представляющей способ прогнозирования согласно первому варианту осуществления.
Фиг. 14 - блок-схема операций, которая иллюстрирует пример процесса прогнозирования точности фиксированной запятой согласно первому варианту осуществления.
Фиг. 15 - блок-схема операций, которая иллюстрирует пример процесса восстановления точности фиксированной запятой согласно первому варианту осуществления.
Фиг. 16 - блок-схема операций, которая иллюстрирует пример процесса прогнозирования весового коэффициента согласно первому варианту осуществления.
Фиг. 17 - блок-схема операций, которая иллюстрирует пример процесса восстановления весового коэффициента согласно первому варианту осуществления.
Фиг. 18 - блок-схема операций, которая иллюстрирует другой пример процесса прогнозирования весового коэффициента согласно первому варианту осуществления.
Фиг. 19 - блок-схема операций, которая иллюстрирует другой пример процесса восстановления весового коэффициента согласно первому варианту осуществления.
Фиг. 20 - блок-схема операций, которая иллюстрирует пример процесса прогнозирования цветоразностного сигнала согласно первому варианту осуществления.
Фиг. 21 - блок-схема операций, которая иллюстрирует пример процесса восстановления цветоразностного сигнала согласно первому варианту осуществления.
Фиг. 22 - блок-схема операций, которая иллюстрирует другой пример процесса прогнозирования весового коэффициента согласно первому варианту осуществления.
Фиг. 23 - блок-схема операций, которая иллюстрирует другой пример процесса восстановления весового коэффициента согласно первому варианту осуществления.
Фиг. 24 - блок-схема, иллюстрирующая пример конфигурации устройства декодирования согласно второму варианту осуществления.
ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
[0009] Далее следует подробное описание вариантов осуществления со ссылкой на прилагаемые чертежи. Устройство кодирования и устройство декодирования согласно каждому варианту осуществления, представленному ниже, можно реализовать аппаратными средствами, например, БИС (большой интегральной схемы), DSP (цифрового сигнального процессора) или FPGA (вентильной матрицы, программируемой пользователем). Кроме того, устройство кодирования и устройство декодирования согласно каждому варианту осуществления, представленному ниже, можно реализовать, предписывая компьютеру выполнять программу, другими словами, программными средствами. В нижеприведенном описании, термин “изображение” можно надлежащим образом заменить таким термином, как “видео”, “пиксель”, “сигнал изображения”, “картинка” или “данные изображения ”.
[0010] ПЕРВЫЙ ВАРИАНТ ОСУЩЕСТВЛЕНИЯ
В первом варианте осуществления будет описано устройство кодирования, кодирующее движущееся изображение.
[0011] На фиг. 1 показана блок-схема, иллюстрирующая пример конфигурации устройства 100 кодирования согласно первому варианту осуществления.
[0012] Устройство 100 кодирования делит каждый кадр или каждое поле, конфигурирующий(ее) входное изображение, на множество пиксельных блоков и осуществляет кодирование с прогнозированием разделенных пиксельных блоков с использованием параметров кодирования, поступающих от блока 111 управления кодированием, таким образом, генерируя прогнозируемое изображение. Затем устройство 100 кодирования генерирует ошибку прогнозирования путем вычитания прогнозируемого изображения из входного изображения, разделенного на множество пикселей, генерирует кодированные данные путем осуществления ортогонального преобразования и квантования, с последующим энтропийным кодированием сгенерированной ошибки прогнозирования, и выводит сгенерированные кодированные данные.
[0013] Устройство 100 кодирования осуществляет кодирование с прогнозированием, избирательно применяя множество режимов прогнозирования, которые отличаются друг от друга по меньшей мере одним из размера блока пиксельного блока и способа генерирования прогнозируемого изображения. Способ генерирования прогнозируемого изображения можно, в основном, подразделить на два типа, включающие в себя внутреннее прогнозирование, в котором прогнозирование производится в целевом кадре кодирования и внешнее прогнозирование, в котором прогнозирование с компенсацией движения производится с использованием одного или более опорных кадров разных моментов времени. Внутреннее прогнозирование также называется внутриэкранным прогнозированием, внутрикадровым прогнозированием и т.п., и внешнее прогнозирование также называется межэкранным прогнозированием, межкадровым прогнозированием, прогнозированием с компенсацией движения и т.п.
[0014] На фиг. 2 показана пояснительная схема, которая иллюстрирует пример прогнозируемой последовательности кодирования для пиксельного блока согласно первому варианту осуществления. В примере, представленном на фиг. 2, устройство 100 кодирования осуществляет кодирование с прогнозированием от верхней левой стороны к нижней правой стороне в пиксельном блоке. Таким образом, в целевом кадре обработки кодирования f, на левой стороне и верхней стороне целевого пиксельного блока кодирования c, располагаются пиксельные блоки p, кодирование которых закончено. Далее, для упрощения описания, хотя предполагается, что устройство 100 кодирования осуществляет кодирование с прогнозированием в порядке, представленном на фиг. 2, порядок в кодировании с прогнозированием этим не ограничивается.
[0015] Пиксельный блок представляет единицу для обработки изображения, и, например, блок, имеющий размер M×N (здесь, M и N - натуральные числа), блок дерева кодирования, макроблок, подблок, пиксель и т.п., соответствует ему. В нижеприведенном описании пиксельный блок, в основном, используется в значении блока дерева кодирования, но может использоваться в другом значении. Например, в описании единицы прогнозирования, пиксельный блок используется в значении пиксельного блока единицы прогнозирования. Блок может именоваться единицей и т.п. Например, блок кодирования может именоваться единицей кодирования.
[0016] На фиг. 3A показана схема, которая иллюстрирует пример размера блока дерева кодирования согласно первому варианту осуществления. Блок дерева кодирования обычно является пиксельным блоком размером 64×64 как показано на фиг. 3A. Однако блок дерева кодирования не ограничивается этим, но может представлять собой пиксельный блок размером 32×32, пиксельный блок размером 16×16, пиксельный блок размером 8×8, пиксельный блок размером 4×4, и т.п. Здесь, блок дерева кодирования может не быть квадратным но, например, может быть пиксельным блоком размером M×N (здесь, M≠N).
[0017] На фиг. 3B-3D показаны схемы, представляющие конкретные примеры блока дерева кодирования согласно первому варианту осуществления. Фиг. 3B представляет блок дерева кодирования имеющий размер блока 64×64 (N=32). Здесь, N представляет размер опорного блока дерева кодирования. Размер в случае, когда блок дерева кодирования делится, задается как N, и размер в случае, когда блок дерева кодирования не делится, задается как 2N. Фиг. 3C представляет блок дерева кодирования, полученный делением блока дерева кодирования, представленного на фиг. 3B на квадродерево. Блок дерева кодирования, как показано на фиг. 3C, имеет структуру квадродерева. В случае, когда блок дерева кодирования делится, как показано на фиг. 3C, номера присваиваются (назначаются) четырем пиксельным блокам после разделения в порядке сканирования по Z.
[0018] Кроме того, в каждом номере квадродерева, блок дерева кодирования может дополнительно делиться на квадродерево. Соответственно, блок дерева кодирования может делиться иерархическим образом. В таком случае, глубина разделения задается как Depth. Фиг. 3D представляет один из блоков дерева кодирования, полученных делением блока дерева кодирования, представленного на фиг. 3B, на квадродерево, и его размер блока равен 32×32 (N=16). Глубина блока дерева кодирования, представленного на фиг. 3B, равна “0”, и глубина блока дерева кодирования, представленного на фиг. 3D, равна “1”. Кроме того, блок дерева кодирования, имеющий наибольшую единицу, называется большим блоком дерева кодирования, и входной сигнал изображения кодируется в такой единице в растровом порядке сканирования.
[0019] В нижеследующем описании, кодированный целевой блок или блок дерева кодирования входного изображения может именоваться целевым блоком прогнозирования или пиксельным блоком прогнозирования. Кроме того, блок кодирования не ограничивается пиксельным блоком, но по меньшей мере один из кадра, поля, слайса, линии и пикселя может использоваться в качестве блока кодирования.
[0020] Устройство 100 кодирования, как показано на фиг. 1, включает в себя: блок 101 вычитания; блок 102 ортогонального преобразования; блок 103 квантования; блок 104 обратного квантования; блок 105 обратного ортогонального преобразования; блок 106 суммирования; блок 107 генерирования прогнозируемого изображения; блок 108 установки индекса; блок 109 оценивания движения; и блок 110 кодирования. Кроме того, блок 111 управления кодированием, представленный на фиг. 1, управляет устройством 100 кодирования и может быть реализован, например, с использованием ЦП (центрального процессора) и т.п.
[0021] Блок 101 вычитания получает ошибку прогнозирования путем вычитания соответствующего прогнозируемого изображения из входного изображения, разделенного на пиксельные блоки. Блок 101 вычитания выводит ошибку прогнозирования для ввода в блок 102 ортогонального преобразования.
[0022] Блок 102 ортогонального преобразования осуществляет ортогональное преобразование, например, дискретное косинусное преобразование (DCT) или дискретное синусное преобразование (DST) для ошибки прогнозирования, поступающей от блока 101 вычитания, таким образом, получая коэффициент преобразования. Блок 102 ортогонального преобразования выводит коэффициент преобразования для ввода в блок 103 квантования.
[0023] Блок 103 квантования осуществляет процесс квантования для коэффициента преобразования, поступающего от блока 102 ортогонального преобразования, таким образом, получая коэффициент преобразования квантования. В частности, блок 103 квантования осуществляет квантование на основании параметра квантования, назначенного блоком 111 управления кодированием, и информации квантования, например, матрицы квантования. Описанный более подробно, блок 103 квантования получает коэффициент преобразования квантования делением коэффициента преобразования на размер шага квантования, выведенный на основании информации квантования. Параметр квантования представляет тонкость квантования. Матрица квантования используется для взвешивания тонкости квантования для каждой компоненты коэффициента преобразования. Блок 103 квантования выводит коэффициент преобразования квантования для ввода в блок 104 обратного квантования и блок 110 кодирования.
[0024] Блок 104 обратного квантования осуществляет процесс обратного квантования для коэффициента преобразования квантования, поступающего от блока 103 квантования, таким образом, получая коэффициент преобразования восстановления. В частности, блок 104 обратного квантования осуществляет обратное квантование на основании информации квантования, используемой блоком 103 квантования. Описанный подробно, блок 104 обратного квантования получает коэффициент преобразования восстановления путем умножения коэффициента преобразования квантования на размер шага квантования, выведенный на основании информации квантования. Кроме того, информация квантования, используемая блоком 103 квантования, загружается из внутренней памяти блока 111 управления кодированием, которая не показана на фигуре, и используется. Блок 104 обратного квантования выводит коэффициент преобразования восстановления для ввода в блок 105 обратного ортогонального преобразования.
[0025] Блок 105 обратного ортогонального преобразования осуществляет обратное ортогональное преобразование, например, обратное дискретное косинусное преобразование (IDCT) или обратное дискретное синусное преобразование (IDST) для восстановленного коэффициента преобразования, поступающего от блока 104 обратного квантования, таким образом, получая восстановленную ошибку прогнозирования. Здесь, обратное ортогональное преобразование, осуществляемое блоком 105 обратного ортогонального преобразования, соответствует ортогональному преобразованию, осуществляемому блоком 102 ортогонального преобразования. Блок 105 обратного ортогонального преобразования выводит восстановленную ошибку прогнозирования для ввода в блок 106 суммирования.
[0026] Блок 106 суммирования суммирует восстановленную ошибку прогнозирования, поступающую от блока 105 обратного ортогонального преобразования, и соответствующее прогнозируемое изображение, таким образом, генерируя локальное декодированное изображение. Блок 106 суммирования выводит локальное декодированное изображение для ввода в блок 107 генерирования прогнозируемого изображения.
[0027] Блок 107 генерирования прогнозируемого изображения сохраняет локальное декодированное изображение, поступающее от блока 106 суммирования, в памяти (не представленной на фиг. 1) в качестве опорного изображения и выводит опорное изображение, хранящееся в памяти, для ввода в блок 109 оценивания движения. Кроме того, блок 107 генерирования прогнозируемого изображения генерирует прогнозируемое изображение путем осуществления взвешенного прогнозирования с компенсацией движения на основании информации движения и информации параметра WP, поступающей от блока 109 оценивания движения. Блок 107 генерирования прогнозируемого изображения выводит прогнозируемое изображение для ввода в блок 101 вычитания и блок 106 суммирования.
[0028] На фиг. 4 показана блок-схема, иллюстрирующая пример конфигурации блока 107 генерирования прогнозируемого изображения согласно первому варианту осуществления. Блок 107 генерирования прогнозируемого изображения, как показано на фиг. 4, включает в себя: блок 201 многокадровой компенсации движения; память 202; блок 203 однонаправленной компенсации движения; блок 204 управления параметрами прогнозирования; блок 205 выбора опорного изображения; блок 206 памяти кадров; и блок 207 управления опорным изображением.
[0029] Блок 206 памяти кадров сохраняет локальное декодированное изображение, поступающее от блока 106 суммирования в качестве опорного изображения под управлением блока 207 управления опорным изображением. Блок 206 памяти кадров включает в себя множество блоков FM1-FMN памяти (здесь, N≥2) используемых для временного хранения опорного изображения.
[0030] Блок 204 управления параметрами прогнозирования подготавливает множество комбинаций, каждого из номера опорного изображения и параметра прогнозирования в виде таблицы на основании информации движения, поступающей от блока 109 оценивания движения. Здесь, информация движения представляет информацию вектора движения, представляющего отклонение движения, который используется для прогнозирования с компенсацией движения, номера опорного изображения и режима прогнозирования, например, однонаправленного/двунаправленного прогнозирования. Параметр прогнозирования представляет информацию, относящуюся к вектору движения и режиму прогнозирования. Затем блок 204 управления параметрами прогнозирования выбирает комбинацию ссылочного номера и параметра прогнозирования, используемого для генерирования прогнозируемого изображения, на основании входного изображения и выводит выбранную комбинацию для обеспечения ввода номера опорного изображения в блок 205 выбора опорного изображения и для обеспечения ввода параметра прогнозирования в блок 203 однонаправленной компенсации движения.
[0031] Блок 205 выбора опорного изображения представляет собой переключатель, который меняет один из выходных разъемов блоков FM1-FMN памяти кадров, которые включены в блок 206 памяти кадров, на который нужно переключаться, на основании номера опорного изображения, поступающего от блока 204 управления параметрами прогнозирования. Например, когда номер опорного изображения равен “0”, блок 205 выбора опорного изображения соединяет выходной разъем блока FM1 памяти кадров с выходным разъемом блока 205 выбора опорного изображения, и, когда номер опорного изображения равен N-1, блок 205 выбора опорного изображения соединяет выходной разъем блока FMN памяти кадров с выходным разъемом блока 205 выбора опорного изображения. Блок 205 выбора опорного изображения выводит опорное изображение, хранящееся в блоке памяти кадров, к которому подключен выходной разъем, из блоков FM1-FMN памяти кадров, включенных в блок 206 памяти кадров, для ввода в блок 203 однонаправленной компенсации движения и блок 109 оценивания движения.
[0032] Блок 203 компенсации движения однонаправленного прогнозирования осуществляет процесс прогнозирования с компенсацией движения на основании параметра прогнозирования, поступающего от блока 204 управления параметрами прогнозирования, и опорного изображения, поступающего от блока 205 выбора опорного изображения, таким образом, генерируя однонаправлено прогнозируемое изображение.
[0033] На фиг. 5 показана схема, которая иллюстрирует пример соотношения между векторами движения для прогнозирования с компенсацией движения в двунаправленном прогнозировании согласно первому варианту осуществления. При прогнозировании с компенсацией движения, процесс интерполяции осуществляется с использованием опорного изображения, и однонаправлено прогнозируемое изображение генерируется на основании отклонений движений сгенерированного интерполированного изображения и входного изображения от пиксельного блока, расположенного в позиции цели кодирования. Здесь, отклонение является вектором движения. Как показано на фиг. 5, в слайсе двунаправленного прогнозирования (B-слайсе), прогнозируемое изображение генерируется с использованием двух типов опорных изображений и набора векторов движения. В качестве процесса интерполяции, используется процесс интерполяции полупиксельной точности, процесс интерполяции четвертьпиксельной точности и т.п., и, путем осуществления процесса фильтрации для опорного изображения, генерируется значение интерполированного изображения. Например, в H.264, в котором интерполяция до четвертьпиксельной точности может осуществляться для яркостного сигнала, отклонение представляется как четырехкратная целочисленная пиксельная точность.
[0034] Блок 203 компенсации движения однонаправленного прогнозирования выводит однонаправлено прогнозируемое изображение и временно сохраняет однонаправлено прогнозируемое изображение в памяти 202. Здесь, в случае, когда информация движения (параметр прогнозирования) представляет двунаправленное прогнозирование, блок 201 многокадровой компенсации движения осуществляет взвешенное прогнозирование с использованием двух типов однонаправлено прогнозируемых изображений. Соответственно, блок 203 компенсации движения однонаправленного прогнозирования сохраняет однонаправлено прогнозируемое изображение, соответствующее первому типу, в памяти 202 и непосредственно выводит однонаправлено прогнозируемое изображение, соответствующее второму типу, на блок 201 многокадровой компенсации движения. Здесь, однонаправлено прогнозируемое изображение, соответствующее первому типу, будем именовать первым прогнозируемым изображением, и однонаправлено прогнозируемое изображение, соответствующее второму типу, будем именовать вторым прогнозируемым изображением.
[0035] Кроме того, два блока 203 однонаправленной компенсации движения могут подготавливаться и генерировать два однонаправлено прогнозируемых изображения. В таком случае, когда информация движения (параметр прогнозирования) представляет однонаправленное прогнозирование, блок 203 однонаправленной компенсации движения может непосредственно выводить первое однонаправлено прогнозируемое изображение на блок 201 многокадровой компенсации движения в качестве первого прогнозируемого изображения.
[0036] Блок 201 многокадровой компенсации движения осуществляет взвешенное прогнозирование с использованием первого прогнозируемого изображения, поступающего из памяти 202, второго прогнозируемого изображения, поступающего от блока 203 компенсации движения однонаправленного прогнозирования, и информации параметра WP, поступающей от блока 109 оценивания движения, таким образом, генерируя прогнозируемое изображение. Блок 201 многокадровой компенсации движения выводит прогнозируемое изображение для ввода в блок 101 вычитания и блок 106 суммирования.
[0037] На фиг. 6 показана блок-схема, иллюстрирующая пример конфигурации блока 201 многокадровой компенсации движения согласно первому варианту осуществления. Как показано на фиг. 6, блок 201 многокадровой компенсации движения включает в себя: блок 301 компенсации движения по умолчанию; блок 302 взвешенной компенсации движения; блок 303 управления параметрами WP; и блоки 304 и 305 выбора WP.
[0038] Блок 303 управления параметрами WP выводит флаг применения WP и весовую информацию на основании информации параметра WP, поступающей от блока 109 оценивания движения, для ввода флага применения WP в блоки 304 и 305 выбора WP и ввода весовой информации в блок 302 взвешенной компенсации движения.
[0039] Здесь, информация параметра WP включает в себя информацию точности фиксированной запятой весового коэффициента, первый флаг применения WP, первый весовой коэффициент, и первое смещение, соответствующее первому прогнозируемому изображению, и второй флаг применения WP, второй весовой коэффициент, и второе смещение, соответствующее второму прогнозируемому изображению. Флаг применения WP это параметр, который можно устанавливать для каждого соответствующего опорного изображения и компоненты сигнала, и представляет, производится ли взвешенное прогнозирование с компенсацией движения. Весовая информация включает в себя информацию точности фиксированной запятой весового коэффициента, первый весовой коэффициент, первое смещение, второй весовой коэффициент и второе смещение.
[0040] Как описано подробно, когда информация параметра WP поступает от блока 109 оценивания движения, блок 303 управления параметрами WP выводит информацию параметра WP, которая делится на первый флаг применения WP, второй флаг применения WP и весовую информацию, таким образом, вводя первый флаг применения WP в блок 304 выбора WP, вводя второй флаг применения WP в блок 305 выбора WP, и вводя весовую информацию в блок 302 взвешенной компенсации движения.
[0041] Блоки 304 и 305 выбора WP изменяют соединительные концы прогнозируемых изображений на основании флагов применения WP, поступающих от блока 303 управления параметрами WP. В случае, когда соответствующий флаг применения WP равен “0”, каждый из блоков 304 и 305 выбора WP соединяет его выходной конец с блоком 301 компенсации движения по умолчанию. Затем блоки 304 и 305 выбора WP выводят первое и второе прогнозируемые изображения для ввода в блок 301 компенсации движения по умолчанию. С другой стороны, в случае, когда соответствующий флаг применения WP равен “1”, каждый из блоков 304 и 305 выбора WP соединяет его выходной конец с блоком 302 взвешенной компенсации движения. Затем блоки 304 и 305 выбора WP выводят первое и второе прогнозируемые изображения для ввода в блок 302 взвешенной компенсации движения.
[0042] Блок 301 компенсации движения по умолчанию осуществляет обработку усреднения на основании двух однонаправлено прогнозируемых изображений (первого и второго прогнозируемых изображений), поступающих от блоков 304 и 305 выбора WP, таким образом, генерируя прогнозируемое изображение. В частности, в случае, когда первый и второй флаги применения WP равны “0”, блок 301 компенсации движения по умолчанию осуществляет обработку усреднения на основании численного выражения (1).
[0043] P[x, y]=Clip1((PL0[x, y]+PL1[x, y]+offset2)>>(shift2)) (1)
[0044] Здесь, P[x, y] - прогнозируемое изображение, PL0[x, y] - первое прогнозируемое изображение, и PL1[x, y] - второе прогнозируемое изображение. Кроме того, offset2 и shift2 являются параметрами процесса округления в обработке усреднения и определяются на основании внутренней точности вычисления первого и второго прогнозируемых изображений. Когда битовая точность прогнозируемого изображения равна L, и битовая точность первого и второго прогнозируемых изображений равна M (L≤M), shift2 определяется численным выражением (2), и offset2 определяется численным выражением (3).
[0045] shift2=(M-L+1) (2)
[0046] offset2=(1<<(shift2-1) (3)
[0047] Например, битовая точность прогнозируемого изображения равна “8”, и битовая точность первого и второго прогнозируемых изображений равна “14”, shift2=7 на основании численного выражения (2), и offset2=(1<<6) на основании численного выражения (3).
[0048] Кроме того, в случае, когда режим прогнозирования, представленный информацией движения (параметром прогнозирования), является однонаправленным прогнозированием, блок 301 компенсации движения по умолчанию вычисляет окончательное прогнозируемое изображение с использованием только первого прогнозируемого изображения на основании численного выражения (4).
[0049] P[x, y]=Clip1((PLX[x, y]+offset1)>>(shift1)) (4)
[0050] Здесь, PLX[x, y] представляет однонаправлено прогнозируемое изображение (первое прогнозируемое изображение), и X - идентификатор, представляющий “0” или “1” в качестве опорного списка. Например, PLX[x, y] равен PL0[x, y] в случае, когда опорный список равен “0”, и равен PL1[x, y] в случае, когда опорный список равен “1”. Кроме того, offset1 и shift1 являются параметрами для процесса округления и определяются на основании внутренней точности вычисления первого прогнозируемого изображения. Когда битовая точность прогнозируемого изображения равна L, и битовая точность первого прогнозируемого изображения равна M, shift1 определяется численным выражением (5), и offset1 определяется численным выражением (6).
[0051] shift1=(M-L) (5)
[0052] offset1=(1<<(shift1-1) (6)
[0053] Например, в случае, когда битовая точность прогнозируемого изображения равна “8”, и битовая точность первого прогнозируемого изображения равна “14”, shift1=6 на основании численного выражения (5), и offset1=(1<<5) на основании численного выражения (6).
[0054] Блок 302 взвешенной компенсации движения осуществляет взвешенную компенсацию движения на основании двух однонаправлено прогнозируемых изображений (первого и второго прогнозируемых изображений), поступающих от блоков 304 и 305 выбора WP и весовой информации, поступающей от блока 303 управления параметрами WP. В частности, блок 302 взвешенной компенсации движения осуществляет процесс взвешивания на основании численного выражения (7) в случае, когда первый и второй флаги применения WP равны “1”.
[0055] P[x, y]=Clip1(((PL0[x, y]*w0C+PL1[x, y]*w1C+(1<<logWDC))>>(logWDC+1))+((o0C+o1C+1)>>1)) (7)
[0056] Здесь, w0C представляет весовой коэффициент, соответствующий первому прогнозируемому изображению, w1C представляет весовой коэффициент, соответствующий второму прогнозируемому изображению, o0C представляет смещение, соответствующее первому прогнозируемому изображению, и o1C представляет смещение, соответствующее второму прогнозируемому изображению. Далее, будем именовать их первым весовым коэффициентом, вторым весовым коэффициентом, первым смещением и вторым смещением, соответственно. logWDC это параметр, представляющий точность фиксированной запятой каждого весового коэффициента. Кроме того, переменная C представляет компоненту сигнала. Например, в случае пространственного сигнала YUV, яркостный сигнал представляется в виде C=Y, цветоразностный сигнал Cr представляется в виде C=Cr, и цветоразностная компонента Cb представляется в виде C=Cb.
[0057] Кроме того, в случае, когда точность вычисления первого и второго прогнозируемых изображений и точность вычисления прогнозируемого изображения отличаются друг от друга, блок 302 взвешенной компенсации движения реализует процесс округления, управляя logWDC, который является точностью фиксированной запятой, согласно численному выражению (8).
[0058] logWD’C=logWDC+offset1 (8)
[0059] Процесс округления можно реализовать путем замены logWDC, представленного в численном выражении (7), logWD’C, представленным в численном выражении (8). Например, в случае, когда битовая точность прогнозируемого изображения равна “8”, и битовая точность первого и второго прогнозируемых изображений равна “14”, переустанавливая logWDC, можно реализовать пакетный процесс округления для точности вычисления по аналогии с shift2, представленным в численном выражении (1).
[0060] Кроме того, в случае, когда режим прогнозирования, представленный информацией движения (параметром прогнозирования), является однонаправленным прогнозированием, блок 302 взвешенной компенсации движения вычисляет окончательное прогнозируемое изображение с использованием только первого прогнозируемого изображения на основании численного выражения (9).
[0061] P[x, y]=Clip1((PLX[x, y]*wXC+(1<<logWDC-1))>>(logWDC)) (9)
[0062] Здесь, PLX[x, y] представляет однонаправленно прогнозируемое изображение (первое прогнозируемое изображение), wXC представляет весовой коэффициент, соответствующий однонаправленному прогнозированию, и X - идентификатор, представляющий “0” или “1” в качестве опорного списка. Например, PLX[x, y] и wXC равны PL0[x, y] и w0C в случае, когда опорный список равен “0”, и равны PL1[x, y] и w1C в случае, когда опорный список равен “1”.
[0063] Кроме того, в случае, когда точность вычисления первого и второго прогнозируемых изображений и точность вычисления прогнозируемого изображения отличаются друг от друга, блок 302 взвешенной компенсации движения реализует процесс округления, управляя logWDC, который является точностью фиксированной запятой, согласно численному выражению (8), аналогично случаю двунаправленного прогнозирования.
[0064] Процесс округления можно реализовать путем замены logWDC, представленного в численном выражении (7), logWD’C, представленным в численном выражении (8). Например, в случае, когда битовая точность прогнозируемого изображения равна “8”, и битовая точность первых прогнозируемых изображений равна “14”, переустанавливая logWDC, можно реализовать пакетный процесс округления для точности вычисления, аналогичной shift1, представленного в численном выражении (4).
[0065] На фиг. 7 показана пояснительная схема, которая иллюстрирует пример точности фиксированной запятой весового коэффициента согласно первому варианту осуществления, и схема, которая иллюстрирует пример изменений в движущемся изображении, имеющем изменение светлоты во временном направлении и значение градации серого. В примере, представленном на фиг. 7, целевым кадром кодирования является Frame(t), кадр, который располагается на один кадр раньше во времени целевого кадра кодирования, является Frame(t-1), и кадр, который располагается на один кадр позже во времени целевого кадра кодирования, является Frame(t+1). Как показано на фиг. 7, в затухающем изображении, изменяющемся от белого к черному, светлота (значение градации серого) изображения уменьшается с течением времени. Весовой коэффициент представляет степень изменения на фиг. 7, и, как явствует из численных выражений (7) и (9), принимает значение “1,0” в случае отсутствия изменения светлоты. Точность фиксированной запятой является параметром, регулирующим ширину интервала, соответствующую десятичной запятой весового коэффициента, и весовой коэффициент равен 1<<logWDC в случае отсутствия изменения светлоты.
[0066] Кроме того, в случае однонаправленного прогнозирования, различные параметры (второй флаг применения WP, второй весовой коэффициент и информация второго смещения), соответствующие второму прогнозируемому изображению, не используются и могут быть установлены на определенные заранее начальные значения.
[0067] Возвращаясь к фиг. 1, блок 109 оценивания движения осуществляет оценивание движения между множеством кадров на основании входного изображения и опорного изображения, поступающего от блока 107 генерирования прогнозируемого изображения, и выводит информацию движения и информацию параметра WP, таким образом, вводя информацию движения в блок 107 генерирования прогнозируемого изображения и блок 110 кодирования и вводя информацию параметра WP в блок 107 генерирования прогнозируемого изображения и блок 108 установки индекса.
[0068] Блок 109 оценивания движения вычисляет ошибку, например, путем вычисления разности между входным изображением целевого пиксельного блока прогнозирования и множеством опорных изображений, соответствующих той же позиции, что и начальная точка, сдвигает позицию с дробной точностью, и вычисляет оптимальную информацию движения с использованием такого метода, как согласование блоков, для нахождения блока минимальной ошибки и т.п. В случае двунаправленного прогнозирования, блок 109 оценивания движения осуществляет согласование блоков, включающее в себя прогнозирование с компенсацией движения по умолчанию, представленное в численных выражениях (1) и (4), с использованием информации движения, выведенной из однонаправленного прогнозирования, таким образом, вычисляя информацию движения двунаправленного прогнозирования.
[0069] При этом блок 109 оценивания движения может вычислять информацию параметра WP путем осуществления согласования блоков, включающего в себя взвешенное прогнозирование с компенсацией движения, представленное в численных выражениях (7) и (9). Кроме того, для вычисления информации параметра WP, способ вычисления весового коэффициента или смещения с использованием градиента светлоты входного изображения, может использоваться способ вычисления весового коэффициента или смещения в соответствии с накоплением ошибки прогнозирования в момент времени кодирования, и т.п. Кроме того, в качестве информации параметра WP, может использоваться фиксированное значение, определяемое заранее для каждого устройства кодирования.
[0070] Здесь, способ вычисления весового коэффициента, точности фиксированной запятой весового коэффициента и смещения от движущегося изображения, имеющего изменение светлоты во времени, будет описано со ссылкой на фиг. 7. Как описано выше, в затухающем изображении, изменяющемся от белого к черному, как показано на фиг. 7, светлота (значение градации серого) изображения уменьшается с течением времени. Блок 109 оценивания движения может вычислять весовой коэффициент путем вычисления его наклона.
[0071] Точность фиксированной запятой весового коэффициента это информация, представляющая точность наклона, и блок 109 оценивания движения может вычислять оптимальное значение на основании расстояния до опорного изображения во времени и степени изменения светлоты изображения. Например, на фиг. 7, в случае, когда весовой коэффициент между Frame(t-1) и Frame(t+1) равен 0,75 с дробной точностью, 3/4 можно представить в случае точности 1/4, и, соответственно, блок 109 оценивания движения устанавливает точность фиксированной запятой на 2 (1<<2). Поскольку значение точности фиксированной запятой влияет на объем кода случая, когда весовой коэффициент кодируется, в качестве значения точности фиксированной запятой, оптимальное значение можно выбирать с учетом объема кода и точности прогнозирования. Кроме того, значение точности фиксированной запятой может быть фиксированным значением, определяемым заранее.
[0072] Кроме того, в случае, когда наклон не согласуется, блок 109 оценивания движения может вычислять значение смещения, получая значение коррекции (величину отклонения), соответствующее пересечению линейной функции. Например, на фиг. 7, в случае, когда весовой коэффициент между Frame(t-1) и Frame(t+1) равен 0,60 с точностью десятичной запятой, и точность фиксированной запятой равна “1” (1<<1), высока вероятность того, что весовой коэффициент устанавливается равным “1” (что соответствует точности десятичной запятой 0,50 весового коэффициента). В таком случае, поскольку точность десятичной запятой весового коэффициента отклоняется от 0,60, которое является оптимальным значением, на 0,10, блок 109 оценивания движения вычисляет соответствующее значение коррекции на основании максимального значения пикселя и (оно) устанавливается как значение смещения. В случае, когда максимальное значение пикселя равно 255, блок 109 оценивания движения может устанавливать значение, например, 25 (255×0,1).
[0073] В первом варианте осуществления, хотя блок 109 оценивания движения представляется, в порядке примера, как одна функция устройства 100 кодирования, блок 109 оценивания движения не является существенной конфигурацией устройства 100 кодирования, и, например, блок 109 оценивания движения может быть устройством, отличным от устройства 100 кодирования. В таком случае, информация движения и информация параметра WP, вычисленная блоком 109 оценивания движения, может загружаться в устройство 100 кодирования.
[0074] Блок 108 установки индекса принимает информацию параметра WP, поступающую от блока 109 оценивания движения, проверяет опорный список (номер по списку) и опорное изображение (ссылочный номер), и выводит информацию индекса для ввода в блок 110 кодирования. Блок 108 установки индекса генерирует информацию индекса путем отображения информации параметра WP, поступающей от блока 109 оценивания движения, в элемент синтаксиса, который будет описан ниже.
[0075] На фиг. 8A и 8B показаны схемы, демонстрирующие примеры информации параметра WP согласно первому варианту осуществления. Пример информации параметра WP в момент времени P-слайса представлен на фиг. 8A, и пример информации параметра WP в момент времени B-слайса представлен на фиг. 8A и 8B. Номер по списку является идентификатором, представляющим направление прогнозирования. Номер по списку имеет значение “0” в случае однонаправленного прогнозирования. С другой стороны, в случае двунаправленного прогнозирования, может использоваться два типа прогнозирования, и, соответственно, номер по списку имеет два значения “0” и “1”. Ссылочный номер это значение, соответствующее любому из от 1 до N, представленных в блоке 206 памяти кадров. Поскольку информация параметра WP поддерживается для каждого опорного списка и опорного изображения, в случае, когда имеется N опорных изображений, в момент времени B-слайса необходимо 2N фрагментов информации.
[0076] Возвращаясь к фиг. 1, блок 110 кодирования осуществляет процесс кодирования различных параметров кодирования, например, коэффициента преобразования квантования, поступающего от блока 103 квантования, информации движения, поступающей от блока 109 оценивания движения, информации индекса, поступающей от блока 108 установки индекса, и информации квантования, назначенной блоком 111 управления кодированием, таким образом, генерируя кодированные данные. В качестве процесса кодирования можно использовать, например, кодирование методом Хаффмана или арифметическое кодирование.
[0077] Здесь, параметрами кодирования являются такие параметры, как информация прогнозирования, представляющая способ прогнозирования и т.п., информация, относящаяся к квантованному коэффициенту преобразования, и информация, относящаяся к квантованию, которые необходимы для процесса декодирования. Например, возможна конфигурация, в которой внутренняя память, не показанная на фигуре, включена в блок 111 управления кодированием, параметры кодирования поддерживаются во внутренней памяти, и параметры кодирования соседнего пиксельного блока, который был завершен для кодирования, используются при кодировании пиксельного блока. Например, во внутреннем прогнозировании согласно H.264, информацию прогнозирования пиксельного блока можно вывести из информации прогнозирования соседнего блока, который был завершен для кодирования.
[0078] Блок 110 кодирования выводит сгенерированные кодированные данные в надлежащем временном режиме вывода под управлением блока 111 управления кодированием. Различные виды информации, которые представляют собой выходные кодированные данные, например, мультиплексируются блоком мультиплексирования, не показанным на фигуре, и т.п., временно сохраняются в выходном буфере, не показанном на фигуре, и т.п., и затем, например, выводятся в систему хранения (носитель данных) или систему передачи (линию связи).
[0079] Блок 110 кодирования включает в себя блок 110A энтропийного кодирования и блок 110B переконфигурирования индекса.
[0080] Блок 110A энтропийного кодирования осуществляет процесс кодирования, например, процесс кодирования с переменной длиной слова или арифметического кодирования над введенной информацией. Например, в H.264 используется контекстное адаптивное кодирование с переменной длиной слова (CAVLC), контекстное адаптивное двоичное арифметическое кодирование (CABAC) и т.п.
[0081] Для уменьшения длины кода элемента синтаксиса информации индекса, поступающей от блока 108 установки индекса, блок 110B переконфигурирования индекса осуществляет процесс прогнозирования на основании характеристик параметров элемента синтаксиса, вычисляет разность между значением (прямым значением) элемента синтаксиса и прогнозируемым значением, и выводит разность на блок 110A энтропийного кодирования. Конкретный пример процесса прогнозирования будет описан ниже.
[0082] На фиг. 9 показана схема, которая иллюстрирует пример синтаксиса 500, используемого устройством 100 кодирования согласно первому варианту осуществления. Синтаксис 500 иллюстрирует структуру кодированных данных, сгенерированных путем кодирования входного изображения (данных движущегося изображения) с использованием устройства 100 кодирования. При декодировании кодированных данных, устройство декодирования, которое будет описано ниже, осуществляет синтаксический анализ движущегося изображения, обращаясь к синтаксической структуре, такой же, как у синтаксиса 500.
[0083] Синтаксис 500 включает в себя три части, включающие в себя высокоуровневый синтаксис 501, синтаксис 502 уровня слайса и синтаксис 503 уровня дерева кодирования. Высокоуровневый синтаксис 501 включает в себя синтаксическую информацию верхнего слоя, который имеет более высокий уровень, чем слайс. Здесь, слайс представляет прямоугольную область или непрерывную область, включенную в кадр или поле. Синтаксис 502 уровня слайса включает в себя информацию, необходимую для декодирования каждого слайса. Синтаксис 503 уровня дерева кодирования включает в себя информацию, необходимую для декодирования каждого дерева кодирования (другими словами, каждого блока дерева кодирования). Каждая из этих частей включает в себя более детализированный синтаксис.
[0084] Высокоуровневый синтаксис 501 включает в себя синтаксисы уровня последовательности и изображения, например, синтаксис 504 набора параметров последовательности, синтаксис 505 набора параметров изображения и синтаксис 506 набора параметров адаптации.
[0085] Синтаксис 502 уровня слайса включает в себя синтаксис 507 заголовка слайса, синтаксис 508 таблицы весов с одноуровневой адресацией, синтаксис 509 данных слайса и пр. Синтаксис 508 таблицы весов с одноуровневой адресацией вызывается из синтаксиса 507 заголовка слайса.
[0086] Синтаксис 503 уровня дерева кодирования включает в себя синтаксис 510 единицы дерева кодирования, синтаксис 511 единицы преобразования, синтаксис 512 единицы прогнозирования и пр. Синтаксис 510 единицы дерева кодирования может иметь структуру квадродерева. В частности, синтаксис 510 единицы дерева кодирования может рекурсивно дополнительно вызываться как элемент синтаксиса для синтаксиса 510 единицы дерева кодирования. Другими словами, один блок дерева кодирования может подразделяться на квадродеревья. Кроме того, синтаксис 511 единицы преобразования включен в синтаксис 510 единицы дерева кодирования. Синтаксис 511 единицы преобразования вызывается из каждого синтаксиса 510 единицы дерева кодирования, расположенного на хвостовом конце квадродерева. В синтаксисе 511 единицы преобразования описана информация, относящаяся к обратному ортогональному преобразованию, квантованию и пр. В синтаксисах, можно описывать информацию, относящуюся к взвешенному прогнозированию с компенсацией движения.
[0087] На фиг. 10 показана схема, которая иллюстрирует пример синтаксиса 505 набора параметров изображения согласно первому варианту осуществления. Здесь, weighted_pred_flag, например, является элементом синтаксиса, представляющим пригодность или непригодность взвешенного прогнозирования с компенсацией движения согласно первому варианту осуществления для P-слайса. В случае, когда weighted_pred_flag равен “0”, взвешенное прогнозирование с компенсацией движения согласно первому варианту осуществления в P-слайсе непригодно. Соответственно, флаг применения WP, включенный в информацию параметра WP, постоянно установлен равным “0”, и выходные концы блоков 304 и 305 выбора WP подключены к блоку 301 компенсации движения по умолчанию. С другой стороны, в случае, когда weighted_pred_flag равен “1”, взвешенное прогнозирование с компенсацией движения согласно первому варианту осуществления в P-слайсе пригодно.
[0088] В порядке другого примера, в случае, когда weighted_pred_flag равен “1”, пригодность или непригодность взвешенного прогнозирования с компенсацией движения согласно первому варианту осуществления можно задавать для каждой локальной области в слайсе в синтаксисе нижнего слоя (заголовка слайса, блока дерева кодирования, единицы преобразования, единицы прогнозирования и пр.).
[0089] Кроме того, weighted_bipred_idc, например, является элементом синтаксиса, представляющим пригодность или непригодность взвешенного прогнозирования с компенсацией движения согласно первому варианту осуществления для B-слайса. В случае, когда weighted_bipred_idc равен “0”, взвешенное прогнозирование с компенсацией движения согласно первому варианту осуществления в B-слайсе непригодно. Соответственно, флаг применения WP, включенный в информацию параметра WP, постоянно установлен равным “0”, и выходные концы блоков 304 и 305 выбора WP подключены к блоку 301 компенсации движения по умолчанию. С другой стороны, в случае, когда weighted_bipred_idc равен “1”, взвешенное прогнозирование с компенсацией движения согласно первому варианту осуществления в B-слайсе пригодно.
[0090] В порядке другого примера, в случае, когда weighted_bipred_idc равен “1”, пригодность или непригодность взвешенного прогнозирования с компенсацией движения согласно первому варианту осуществления можно задавать для каждой локальной области в слайсе в синтаксисе нижнего слоя (заголовка слайса, блока дерева кодирования, единицы преобразования и пр.).
[0091] На фиг. 11 показана схема, которая иллюстрирует пример синтаксиса 507 заголовка слайса согласно первому варианту осуществления. Здесь, тип слайса представляет тип слайса (I-слайс, P-слайс, B-слайс и т.п.) слайса. Кроме того, pic_parameter_set_id является идентификатором, представляющим синтаксис набора параметров изображения, обозначаемый 505. num_ref_idx_active_override_flag это флаг, представляющий, нужно ли обновлять количество пригодных опорных изображений, и, в случае, когда этот флаг равен “1”, могут использоваться num_ref_idx_l0_active_minus1 и num_ref_idx_l1_active_minus1, которые задают количество опорных изображений опорного списка. Кроме того, pred_weight_table()является функцией, представляющей синтаксис таблицы весов pred, используемый для взвешенного прогнозирования с компенсацией движения, и эта функция вызывается в случае, когда weighted_pred_flag равен “1” в случае P-слайса и в случае, когда weighted_bipred_idc равен “1” в случае B-слайса.
[0092] На фиг. 12 показана схема, которая иллюстрирует пример синтаксиса 508 таблицы весов pred согласно первому варианту осуществления. Здесь, luma_log2_weight_denom представляет точность фиксированной запятой весового коэффициента яркостного сигнала в слайсе и является значением, соответствующим logWDC, представленному в численном выражении (7) или (9). Кроме того, chroma_log2_weight_denom представляет точность фиксированной запятой весового коэффициента цветоразностного сигнала в слайсе и является значением, соответствующим logWDC, представленному в численном выражении (7) или (9). chroma_format_idc это идентификатор, представляющий цветовое пространство, и MONO_IDX это значение, представляющее монохромное видео. Кроме того, num_ref_common_active_minus1 представляет значение, которое получается путем вычитания единицы из количества опорных изображений, включенных в общий список в слайсе.
[0093] luma_weight_l0_flag и luma_weight_l1_flag представляют флаги применения WP яркостных сигналов, соответствующих спискам 0 и 1. В случае, когда этот флаг равен “1”, взвешенное прогнозирование с компенсацией движения яркостного сигнала согласно первому варианту осуществления пригодно для всех областей в слайсе. Кроме того, chroma_weight_l0_flag и chroma_weight_l1_flag представляют флаги применения WP цветоразностных сигналов, соответствующие спискам 0 и 1. в случае, когда этот флаг равен “1”, взвешенное прогнозирование с компенсацией движения цветоразностного сигнала согласно первому варианту осуществления пригодно для всех областей в слайсе. luma_weight_l0[i] и luma_weight_l1[i] являются весовыми коэффициентами i-ых яркостных сигналов в соответствии со списками 0 и 1. Кроме того, luma_offset_l0[i] и luma_offset_l1[i] являются смещениями i-ых яркостных сигналов в соответствии со списками 0 и 1. Это значения, соответствующие w0C, w1C, o0C, o1C, представленным в численном выражении (7) или (9). Здесь, C=Y.
[0094] chroma_weight_l0[i][j] и chroma_weight_l1[i][j] являются весовыми коэффициентами i-ых цветоразностных сигналов в соответствии со списками 0 и 1. Кроме того, chroma_offset_l0[i][j] и chroma_offset_l1[i][j] являются смещениями i-ых цветоразностных сигналов в соответствии со списками 0 и 1. Это значения, соответствующие w0C, w1C, o0C, o1C, представленным в численном выражении (7) или (9). Здесь, C=Cr или Cb. Кроме того, j представляет компоненту цветоразности, и, например, в случае сигнала YUV 4: 2: 0, j=0 представляет компоненту Cr, и j=1 представляет компоненту Cb.
[0095] Здесь будет подробно описан способ прогнозирования каждого элемента синтаксиса, относящегося к взвешенному прогнозированию в конфигурации синтаксиса. Прогнозирование элемента синтаксиса осуществляется блоком 110B переконфигурирования индекса. На Фиг. 13 показана схема, которая иллюстрирует пример конфигурации синтаксиса, в явном виде представляющей способ прогнозирования согласно первому варианту осуществления. В примере, представленном на фиг. 13, хотя каждый элемент синтаксиса, прогнозирование которого было введено, обозначается присоединением префикса “delta”, конфигурация синтаксиса, в основном, имеет такие же составные элементы, как конфигурация синтаксиса, представленная на фиг. 12.
[0096] Прежде всего, будет описан способ межсигнального прогнозирования luma_log2_weight_denom и chroma_log2_weight_denom, представляющих точность фиксированной запятой весового коэффициента. Блок 110B переконфигурирования индекса осуществляет межсигнальный процесс прогнозирования luma_log2_weight_denom и chroma_log2_weight_denom с использованием численного выражения (10) и осуществляет процесс восстановления с использованием численного выражения (11). Здесь, как показано на фиг. 12 и 13, поскольку сначала задается luma_log2_weight_denom, chroma_log2_weight_denom прогнозируется на основании значения luma_log2_weight_denom.
[0097] delta_chroma_log2_weight_denom = (chroma_log2_weight_denom - luma_log2_weight_denom) (10)
[0098] chroma_log2_weight_denom=(luma_log2_weight_denom + delta_chroma_log2_weight_denom) (11)
[0099] На фиг. 14 показана блок-схема операций, которая иллюстрирует пример процесса прогнозирования chroma_log2_weight_denom согласно первому варианту осуществления.
[0100] Прежде всего, блок 110B переконфигурирования индекса выводит luma_log2_weight_denom, установленный в информации индекса в качестве прогнозируемого значения (этап S101).
[0101] Затем блок 110B переконфигурирования индекса вычитает luma_log2_weight_denom из chroma_log2_weight_denom (этап S102) и устанавливает значение их разности как delta_chroma_log2_weight_denom в информации индекса (этап S103).
[0102] На фиг. 15 показана блок-схема операций, которая иллюстрирует пример процесса восстановления chroma_log2_weight_denom согласно первому варианту осуществления.
[0103] Прежде всего, блок 110B переконфигурирования индекса выводит luma_log2_weight_denom который был ранее установлен в информации индекса в качестве прогнозируемого значения (этап S201).
[0104] Затем блок 110B переконфигурирования индекса суммирует luma_log2_weight_denom с delta_chroma_log2_weight_denom (этап S202) и устанавливает суммарное значение в информации индекса как chroma_log2_weight_denom (этап S203).
[0105] В эффекте затухания, в общем случае, поскольку существует малые количество случаев, когда изменения во времени осуществляются по-разному для каждого цветового пространства, точность фиксированной запятой для каждой компоненты сигнала имеет сильную корреляцию с яркостной компонентой и цветоразностной компонентой. Соответственно, осуществляя прогнозирование внутри цветового пространства, как описано выше, можно сократить объем информации, представляющей точность фиксированной запятой.
[0106] В численном выражении (10), хотя яркостная компонента вычитается из цветоразностной компоненты, цветоразностная компонента может вычитаться из яркостной компоненты. В таком случае, численное выражение (11) может изменяться в соответствии с численным выражением (10).
[0107] Затем будет описан способ прогнозирования luma_weight_lx[i] и chroma_weight_lx[i][j], представляющих весовые коэффициенты яркостного и цветоразностного сигнала. Здесь, X - идентификатор, представляющий “0” или “1”. Значения luma_weight_lx[i] и chroma_weight_lx[i][j] увеличиваются или уменьшаются в соответствии со значениями luma_log2_weight_denom и chroma_log2_weight_denom. Например, в случае, когда значение luma_log2_weight_denom равно “3”, luma_weight_lx[i] равно (1 << 3) в случае, когда не предполагается изменения светлоты. С другой стороны, в случае, когда значение luma_log2_weight_denom равно “5”, luma_weight_lx[i] равно (1<<5) в случае, когда не предполагается изменения светлоты.
[0108] Соответственно, блок 110B переконфигурирования индекса осуществляет процесс прогнозирования, причем весовой коэффициент в случае отсутствия изменения светлоты используется как опорный коэффициент (значение по умолчанию). В частности, блок 110B переконфигурирования индекса осуществляет процесс прогнозирования luma_weight_lx[i] с использованием численных выражений (12) и (13) и осуществляет процесс восстановления с использованием численного выражения (14). Аналогично, блок 110B переконфигурирования индекса осуществляет процесс прогнозирования chroma_weight_lx[i] с использованием численных выражений (15) и (16) и осуществляет процесс восстановления с использованием численного выражения (17).
[0109] delta_luma_weight_lx[i] = (luma_weight_lx[i]-default_luma_weight_lx) (12)
[0110] default_luma_weight_lx=(1<<luma_log2_weight_denom) (13)
[0111] luma_weight_lx[i] = (default_luma_weight_lx+ delta_luma_weight_lx[i]) (14)
[0112] delta_chroma_weight_lx[i][j] = (chroma_weight_lx[i][j] - default_chroma_weight_lx) (15)
[0113] default_chroma_weight_lx = (1<<chroma_log2_weight_denom) (16)
[0114] chroma_weight_lx[i][j]=(default_chroma_weight_lx + delta_chroma_weight_lx[i][j]) (17)
[0115] Здесь, default_luma_weight_lx, default_chroma_weight_lx являются значениями по умолчанию в случае отсутствия изменения светлоты в яркостной компоненте и цветоразностной компоненте.
[0116] На фиг. 16 показана блок-схема операций, которая иллюстрирует пример процессов прогнозирования luma_weight_lx[i] согласно первому варианту осуществления.
[0117] Прежде всего, блок 110B переконфигурирования индекса выводит luma_log2_weight_denom, установленный в информации индекса (этап S301), и вычисляет default_luma_weight_lx в качестве прогнозируемого значения (этап S302).
[0118] Затем блок 110B переконфигурирования индекса вычитает default_luma_weight_lx из luma_weight_lx[i] (этап S303) и устанавливает значение их разности в информации индекса как delta_luma_weight_lx[i] (этап S304).
[0119] Повторяя этот процесс в соответствии с количеством опорных изображений, процесс прогнозирования можно применять к luma_weight_lx[i].
[0120] На фиг. 17 показана блок-схема операций, которая иллюстрирует пример процесса восстановления luma_weight_lx[i] согласно первому варианту осуществления.
[0121] Прежде всего, блок 110B переконфигурирования индекса выводит delta_luma_weight_lx[i], который был ранее установлен в информации индекса (этап S401), и вычисляет default_luma_weight_lx в качестве прогнозируемого значения (этап S402).
[0122] Затем блок 110B переконфигурирования индекса суммирует delta_luma_weight_lx[i] с default_luma_weight_lx (этап S403) и устанавливает их суммарное значение в информации индекса как luma_weight_lx[i] (этап S404).
[0123] Хотя здесь проиллюстрирована блок-схема операций для яркостной компоненты, процесс прогнозирования и процесс восстановления можно аналогично реализовать для цветоразностной компоненты (chroma_weight_lx[i][j]).
[0124] Изображение, включающее в себя эффект затухания, затухает в конкретной точке изменения затухания, и, во многих случаях, другие изображения являются обычными естественными изображениями или изображениями, не имеющими эффекта затухания. В таком случае, во многих случаях весовой коэффициент принимает случай отсутствия изменения светлоты. Соответственно, начальное значение в случае отсутствия изменения светлоты выводится на основании точности фиксированной запятой и используется как прогнозируемое значение, благодаря чему, объем кода весового коэффициента может уменьшаться.
[0125] Кроме того, прогнозируемые значения весовых коэффициентов (luma_weight_lx[i] и chroma_weight_lx[i][j]) яркостного и цветоразностного сигнала можно вывести на основании других ссылочных номеров или других номеров POC. В таком случае, когда ссылочный номер, ближайший к целевому слайсу кодирования равен base_idx, блок 110B переконфигурирования индекса осуществляет процесс прогнозирования luma_weight_lx[i] с использованием численного выражения (18) и осуществляет процесс его восстановления с использованием численного выражения (19). Аналогично, блок 110B переконфигурирования индекса осуществляет процесс прогнозирования chroma_weight_lx[i][j] с использованием численного выражения (20) и осуществляет процесс его восстановления с использованием численного выражения (21).
[0126] delta_luma_weight_lx[i] = (luma_weight_lx[i] - luma_weight_lx[base_idx]) (18)
[0127] luma_weight_lx[i] = (delta_luma_weight_lx[i] + luma_weight_lx[base_idx]) (19)
[0128] delta_chroma_weight_lx[i][j] = (chroma_weight_lx[i][j]-chroma_weight_lx[base_idx][j]) (20)
[0129] chroma_weight_lx[i][j] = (delta_chroma_weight_lx[i][j]+chroma_weight_lx[base_idx][j]) (21)
[0130] Здесь, в численных выражениях (18) и (20), i≠base_idx. Для весового коэффициента ссылочного номера, представленного посредством base_idx, численные выражения (18) и (20) не могут использоваться, и, соответственно, численные выражения (12), (13), (15) и (16) могут использоваться.
[0131] На фиг. 18 показана блок-схема операций, которая иллюстрирует другой пример процесса прогнозирования luma_weight_lx[i] согласно первому варианту осуществления.
[0132] Прежде всего, блок 110B переконфигурирования индекса устанавливает baseidx, представляющий ссылочный номер, который является опорным (этап S501). При этом значение baseidx заранее предполагается равным “0”.
[0133] Затем блок 110B переконфигурирования индекса выводит luma_weight_lx[baseidx] из информации индекса в качестве прогнозируемого значения на основании baseidx (этап S502). Кроме того, luma_weight_lx[baseidx] информации индекса, представленной посредством baseidx, например, не прогнозируется, а кодируется как прямое значение.
[0134] Затем блок 110B переконфигурирования индекса вычитает luma_weight_lx[baseidx] из luma_weight_lx[i] (этап S503) и устанавливает значение их разности как delta_luma_weight_lx[i] в информации индекса (этап S504).
[0135] Повторяя этот процесс в соответствии с количеством опорных изображений, процесс прогнозирования можно применять к luma_weight_lx[i], отличному от baseidx.
[0136] На фиг. 19 показана блок-схема операций, которая иллюстрирует другой пример процесса восстановления luma_weight_lx[i] согласно первому варианту осуществления.
[0137] Прежде всего, блок 110B переконфигурирования индекса устанавливает baseidx, представляющий ссылочный номер, который является опорным (этап S601). При этом значение baseidx заранее предполагается равным “0”.
[0138] Затем блок 110B переконфигурирования индекса выводит luma_weight_lx[baseidx] из информации индекса в качестве прогнозируемого значения на основании baseidx (этап S602). Кроме того, luma_weight_lx[baseidx] информации индекса, представленной посредством baseidx, например, не прогнозируется, а кодируется как прямое значение.
[0139] Затем блок 110B переконфигурирования индекса суммирует delta_luma_weight_lx[i] с luma_weight_lx[baseidx] (этап S603) и устанавливает их суммарное значение как luma_weight_lx[i] в информации индекса (этап S604).
[0140] Хотя здесь проиллюстрирована блок-схема операций для яркостной компоненты, процесс прогнозирования и процесс восстановления можно аналогично реализовать для цветоразностной компоненты (chroma_weight_lx[i][j]). Кроме того, хотя в порядке примера были описаны способ прогнозирования и способ восстановления luma_weight_lx[i], можно аналогично прогнозировать и восстанавливать luma_offset_lx[i].
[0141] Кроме того, прогнозируемые значения весовых коэффициентов ((luma_weight_lx[i] и chroma_weight_lx[i][j]) яркостного и цветоразностного сигнала можно вывести с использованием расстояния между целью кодирования и опорным слайсом. В таком случае, блок 110B переконфигурирования индекса осуществляет процесс прогнозирования luma_weight_lx[i] с использованием численного выражения (22) и осуществляет процесс его восстановления с использованием численного выражения (23). Аналогично, блок 110B переконфигурирования индекса осуществляет процесс прогнозирования chroma_weight_lx[i][j] с использованием численного выражения (24) и осуществляет процесс его восстановления с использованием численного выражения (25).
[0142] delta_luma_weight_lx[i] = (luma_weight_lx[i]-luma_weight_lx[i-1]) (22)
[0143] luma_weight_lx[i] = (delta_luma_weight_lx[i] + luma_weight_lx[i-1]) (23)
[0144] delta_chroma_weight_lx[i][j] = (chroma_weight_lx[i][j]-chroma_weight_lx[i-1][j]) (24)
[0145] chroma_weight_lx[i][j] = (delta_chroma_weight_lx[i][j]+chroma_weight_lx[i-1][j]) (25)
[0146] Здесь, в численных выражениях (22) и (24), i≠0.
[0147] Кроме того, поскольку эти процессы прогнозирования и восстановления такие же, как в блок-схеме операций, представленной на фиг. 18 и 19, благодаря включению (i-1)-го значения (i≠0) в baseidx, их описание не будет представлено. Хотя здесь представлена блок-схема операций для яркостной компоненты, процесс прогнозирования и процесс восстановления можно аналогично реализовать для цветоразностной компоненты (chroma_weight_lx[i][j]). Кроме того, хотя в порядке примера были описаны способ прогнозирования и способ восстановления luma_weight_lx[i], также можно аналогично прогнозировать и восстанавливать luma_offset_lx[i].
[0148] Во многих случаях, поскольку к опорному слайсу может обращаться целевой слайс кодирования, слайс, находящийся вблизи целевого слайса кодирования в отношении расстояния во времени или пространстве, устанавливается с точки зрения эффективности кодирования. Здесь, поскольку изменения яркости слайсов, которые непрерывны по расстоянию во времени, имеют высокую корреляцию, корреляции, относящиеся к расстоянию во времени между весовыми коэффициентами и смещениям, также высоки. Таким образом, с использованием весового коэффициента и значения смещения опорного слайса, служащего опорой, весовой коэффициент и значение смещения опорного слайса, который отличается от него во времени, прогнозируются, что позволяет эффективно уменьшать объем кода. Кроме того, поскольку во многих случаях опорные слайсы, которые одинаковы в пространстве, принимают весовые коэффициенты и значения смещения, которые одинаковы, за счет введения прогнозирования по той же причине, объем кода можно уменьшить.
[0149] Затем будет описан способ прогнозирования chroma_offset_lx[i][j], представляющего смещение цветоразностного сигнала. В цветовом пространстве YUV, цветоразностная компонента представляет цвет с использованием величины отклонения от срединного значения. Соответственно, величину изменения на основании изменения светлоты с рассматриваемым срединным значением можно устанавливать как прогнозируемое значение с использованием весового коэффициента. В частности, блок 110B переконфигурирования индекса осуществляет процесс прогнозирования chroma_offset_lx[i][j] с использованием численных выражений (26) и (27) и осуществляет процесс восстановления с использованием численного выражения (28).
[0150] delta_chroma_offset_lx[i][j] = (chroma_offset_lx[i][j]+((MED*chroma_weight_lx[i][j])>>chroma_log2_weight_denom)-MED) (26)
[0151] MED=(MaxChromaValue>>1) (27)
[0152] Здесь, MaxChromaValue представляет максимальную светлоту, при которой получается цветоразностный сигнал. Например, в случае 8-битового сигнала, MaxChromaValue равно 255, и MED равно 128.
[0153] chroma_offset_lx[i][j] = (delta_chroma_offset_lx[i][j]-((MED*chroma_weight_lx[i][j]) >>chroma_log2_weight_denom)+MED) (28)
[0154] На фиг. 20 показана блок-схема операций, которая иллюстрирует пример процесса прогнозирования chroma_offset_lx[i][j] согласно первому варианту осуществления.
[0155] Прежде всего, блок 110B переконфигурирования индекса выводит chroma_log2_weight_denom, установленный в информации индекса (этап S701).
[0156] Затем блок 110B переконфигурирования индекса выводит chroma_offset_lx[i][j], установленный в информации индекса (этап S702).
[0157] Затем блок 110B переконфигурирования индекса выводит срединное значение максимальных значений (максимальных сигналов) цветоразностных сигналов (этап S703).
[0158] Затем блок 110B переконфигурирования индекса выводит delta_chroma_offset_lx[i][j] и устанавливает delta_chroma_offset_lx[i][j] в информации индекса (этап S704).
[0159] На фиг. 21 показана блок-схема операций, которая иллюстрирует пример процесса восстановления chroma_offset_lx[i][j] согласно первому варианту осуществления.
[0160] Прежде всего, блок 110B переконфигурирования индекса выводит chroma_log2_weight_denom, который был ранее установлен в информации индекса (этап S801).
[0161] Затем блок 110B переконфигурирования индекса выводит chroma_offset_lx[i][j], установленный в информации индекса (этап S802).
[0162] Затем блок 110B переконфигурирования индекса выводит срединное значение максимальных значений (максимальных сигналов) цветоразностных сигналов (этап S803).
[0163] Затем блок 110B переконфигурирования индекса выводит chroma_offset_lx[i][j] и устанавливает chroma_offset_lx[i][j] в информации индекса (этап S804).
[0164] Благодаря введению прогнозируемого значения, полученного с учетом величины отклонения от срединного значения с использованием характеристик сигнала цветоразностного сигнала, объем кода значения смещения цветоразностного сигнала может быть меньше, чем в случае, когда значение смещения непосредственно кодируется.
[0165] Далее будет описан метод выведения прогнозируемых значений весового коэффициента и точности фиксированной запятой с использованием способа выведения параметров WP неявного взвешенного прогнозирования во взвешенном прогнозировании, установленном в H.264 и т.п. В неявном взвешенном прогнозировании H.264, весовой коэффициент выводится в соответствии с расстоянием (временным отношением номера POC) во времени между опорными слайсами (смещение обращается в нуль). Расстояние во времени между опорными слайсами получается путем выведения расстояний между целевым слайсом кодирования и опорными слайсами на основании номеров POC, и весовой коэффициент определяется на основании отношения расстояний. В это время, точность фиксированной запятой устанавливается равной фиксированному значению “5”.
[0166] Например, в H.264, весовой коэффициент выводится в соответствии с псевдокодом, представленным в численном выражении (29).
[0167] td=Clip3(-128, 127, POCA-POCB)
tb=Clip3(-128, 127, POCT-POCA)
tx=(td !=0) ? ((16384+abs(td/2))/td): (0)
DistScaleFactor=Clip3(-1024, 1023, (tb*tx+32)>>6)
implicit_luma_weight_l0[i]=64-(DistScaleFactor>>2)
implicit_luma_weight_l1[i]=DistScaleFactor>>2 (29)
[0168] Здесь, POCA представляет номер POC опорного изображения A, соответствующего списку 1, POCB представляет номер POC опорного изображения B, соответствующего списку 0, и POCT представляет номер POC целевого изображения прогнозирования. Кроме того, Clip3(L, M, N) является функцией для осуществления процесса ограничения, чтобы последний аргумент N не выходил за пределы диапазона минимального значения L и максимального значения M, представленного первыми двумя аргументами. Функция abs() является функцией, возвращающей абсолютное значение аргумента. Кроме того, td и tb представляют временные отношения, td представляет разность между номером POC опорного изображения, соответствующего списку 1, и номером POC опорного изображения, соответствующего списку 0, и tb представляет разность между номером POC целевого изображения прогнозирования и номером POC опорного изображения, соответствующего списку 0. На основании таких значений, выводится переменная масштабирования DistScaleFactor в расстоянии весового коэффициента. На основании DistScaleFactor, выводятся весовые коэффициенты (implicit_luma_weight_l0[i] и implicit_luma_weight_l1[i]), соответствующие спискам 0 и 1. Кроме того, цветоразностный сигнал задается аналогично. Блок 110B переконфигурирования индекса прогнозирует точность фиксированной запятой на основании численного выражения (30) с использованием выведенной здесь точности фиксированной запятой implicit_log2_weight_denom.
[0169] delta_luma_log2_weight_denom = (luma_log2_weight_denom-implicit_log2_weight_denom) (30)
[0170] Кроме того, точность фиксированной запятой цветоразностного сигнала можно прогнозировать с использованием численного выражения (30). Это значение восстанавливается с использованием численного выражения (31).
[0171] luma_log2_weight_denom = (delta_luma_log2_weight_denom+implicit_log2_weight_denom) (31)
[0172] Кроме того, точность фиксированной запятой цветоразностного сигнала можно восстанавливать с использованием того же способа, который представлен в численном выражении (31).
[0173] Далее будет описано уравнение для прогнозирования весового коэффициента. Когда неявный весовой коэффициент является implicit_luma_weight_lx[i], блок 110B переконфигурирования индекса прогнозирует весовой коэффициент luma_weight_lx[i] с использованием численного выражения (32) и восстанавливает весовой коэффициент с использованием численного выражения (33).
[0174] if(luma_log2_weight_denom> = implicit_log2_weight_denom){
norm_denom=(luma_log2_weight_denom-implicit_log2_weight_denom)
delta_luma_weight_lx[i]=(luma_weight_lx[i]-(implicit_luma_weight_lx[i]<<norm_denom))
}
else{
norm_denom=(implicit_log2_weight_denom-luma_log2_weight_denom)
delta_luma_weight_lx[i]=(luma_weight_lx[i]-(implicit_luma_weight_lx[i]>>norm_denom))
} (32)
[0175] Здесь, блок 110B переконфигурирования индекса корректирует весовой коэффициент на основании того, больше или меньше неявное взвешенное прогнозирование точности фиксированной запятой, и использует скорректированный весовой коэффициент для прогнозирования.
[0176] if(luma_log2_weight_denom >= implicit_log2_weight_denom){
norm_denom=(luma_log2_weight_denom-implicit_log2_weight_denom)
luma_weight_lx[i]=(delta_luma_weight_lx[i]+(implicit_luma_weight_lx[i]<<norm_denom))
}
else{
norm_denom=(implicit_log2_weight_denom-luma_log2_weight_denom)
luma_weight_lx[i]=(delta_luma_weight_lx[i]+(implicit_luma_weight_lx[i]>>norm_denom))
} (33)
[0177] Хотя в численном выражении (32) представлен пример весового коэффициента яркостной компоненты, используя тот же способ для цветоразностной компоненты, можно вывести прогнозируемое значение.
[0178] На фиг. 22 показана блок-схема операций, которая иллюстрирует другой пример процесса прогнозирования luma_weight_lx[i] согласно первому варианту осуществления.
[0179] Прежде всего, блок 110B переконфигурирования индекса выводит luma_log2_weight_denom, установленный в информации индекса (этап S901).
[0180] Затем блок 110B переконфигурирования индекса выводит implicit_log2_weight_denom и implicit_luma_weight_lx[i] в соответствии со способом выведения неявного взвешенного прогнозирования H.264 (этапы S902 и S903).
[0181] Затем блок 110B переконфигурирования индекса определяет, действительно ли luma_log2_weight_denom больше или равен implicit_log2_weight_denom (этап S904).
[0182] В случае, когда luma_log2_weight_denom больше или равен implicit_log2_weight_denom (Да на этапе S904), блок 110B переконфигурирования индекса вычитает implicit_log2_weight_denom из luma_log2_weight_denom (этап S905) и сдвигает implicit_luma_weight_lx[i] в левую сторону на величину, соответствующую значению разности, таким образом, выводя прогнозируемое значение (этап S906).
[0183] С другой стороны, в случае, когда luma_log2_weight_denom меньше implicit_log2_weight_denom (Нет на этапе S904), блок 110B переконфигурирования индекса вычитает luma_log2_weight_denom из implicit_log2_weight_denom (этап S907) и сдвигает implicit_luma_weight_lx[i] в правую сторону на величину, соответствующую значению разности, таким образом, выводя прогнозируемое значение (этап S908).
[0184] Затем блок 110B переконфигурирования индекса вычитает выведенное прогнозируемое значение из luma_weight_lx[i] (этап S909) и устанавливает значение разности (значение разности) в информации индекса (этап S910).
[0185] На фиг. 23 показана блок-схема операций, которая иллюстрирует другой пример процесса восстановления luma_weight_lx[i] согласно первому варианту осуществления.
[0186] Прежде всего, блок 110B переконфигурирования индекса выводит luma_log2_weight_denom, который был ранее установлен в информации индекса (этап S1001).
[0187] Затем блок 110B переконфигурирования индекса выводит implicit_log2_weight_denom и implicit_luma_weight_lx[i] в соответствии со способом выведения неявного взвешенного прогнозирования H.264 (этапы S1002 и S1003).
[0188] Затем блок 110B переконфигурирования индекса определяет, действительно ли luma_log2_weight_denom больше или равен implicit_log2_weight_denom (этап S1004).
[0189] В случае, когда luma_log2_weight_denom больше или равен implicit_log2_weight_denom (Да на этапе S1004), блок 110B переконфигурирования индекса вычитает implicit_log2_weight_denom из luma_log2_weight_denom (этап S1005) и сдвигает implicit_luma_weight_lx[i] в левую сторону на величину, соответствующую значению разности, таким образом, выводя прогнозируемое значение (этап S1006).
[0190] С другой стороны, в случае, когда luma_log2_weight_denom меньше implicit_log2_weight_denom (Нет на этапе S1004), блок 110B переконфигурирования индекса вычитает luma_log2_weight_denom из implicit_log2_weight_denom (этап S1007) и сдвигает implicit_luma_weight_lx[i] в правую сторону на величину, соответствующую значению разности, таким образом, выводя прогнозируемое значение (этап S1008).
[0191] Затем блок 110B переконфигурирования индекса суммирует выведенное прогнозируемое значение с delta_luma_weight_lx[i] (этап S1009) и устанавливает их суммарное значение в информации индекса (этап S1010).
[0192] Множество вышеописанных способов прогнозирования можно использовать не только независимо, но и совместно. Например, объединяя численные выражения (10), (12) и (13), (15) и (16), и (26) и (27) и т.п., можно эффективно сократить объем кода элемента синтаксиса информации индекса.
[0193] Как описано выше, согласно первому варианту осуществления, блок 108 установки индекса выводит информацию индекса, в которой информация параметра WP отображается в соответствующую конфигурацию синтаксиса, и блок 110B переконфигурирования индекса прогнозирует избыточное представление элемента синтаксиса на основании информации, кодированной в слайсе. Таким образом, согласно первому варианту осуществления, объем кода может быть меньше, чем в случае, когда элемент синтаксиса непосредственно кодируется (является прямым значением).
[0194] Здесь, на основании порядка определения (порядка кодирования) элементов синтаксиса, используемого в целевом слайсе кодирования, выводя прогнозируемое значение как межэкранную корреляцию из элемента синтаксиса, кодирование которого завершено, или выводя прогнозируемое значение из значения по умолчанию, полученного исходя из отсутствия изменения светлоты, можно осуществлять прогнозирование, пользуясь преимуществом характеристик элементов синтаксиса. В результате, достигается преимущество снижения издержек, сопряженных с кодированием элемента синтаксиса.
[0195] Кроме того, между строками таблицы синтаксиса, представленной на фиг. 10-13 согласно первому варианту осуществления в качестве примеров, можно вставлять элемент синтаксиса, не установленный в этом варианте осуществления, или можно включать описание, относящееся к другому условному переходу. Кроме того, таблица синтаксиса может делиться на множество таблиц, или множество таблиц синтаксиса может объединяться. Кроме того, член каждого элемента синтаксиса, представленного в порядке примера, может произвольно изменяться.
[0196] Как описано выше, устройство 100 кодирования согласно первому варианту осуществления решает проблему снижения эффективности кодирования за счет исключения пространственной избыточности с использованием корреляций между параметрами информации, которая должна быть кодирована. Устройство 100 кодирования может снижать объем кода по сравнению с традиционной конфигурацией, в которой элементы синтаксиса, используемые во взвешенном прогнозировании с компенсацией движения, непосредственно кодируются (являются прямыми значениями).
[0197] ВТОРОЙ ВАРИАНТ ОСУЩЕСТВЛЕНИЯ
Во втором варианте осуществления, будет описано устройство декодирования, декодирующее кодированные данные, закодированные устройством кодирования согласно первому варианту осуществления.
[0198] На фиг. 24 показана блок-схема, иллюстрирующая пример конфигурации устройства 800 декодирования согласно второму варианту осуществления.
[0199] Устройство 800 декодирования декодирует кодированные данные, хранящиеся во входном буфере, не показанном на фигуре, и т.п. в декодированное изображение и выводит декодированное изображение в выходной буфер, не показанный на фигуре, в качестве выходного изображения. Кодированные данные, например, выводятся из устройства 100 кодирования, представленного на фиг. 1 и т.п., и поступают на устройство 800 декодирования через систему хранения, систему передачи, буфер и т.п., не показанные на фигуре.
[0200] Устройство 800 декодирования, как показано на фиг. 24, включает в себя: блок 801 декодирования, блок 802 обратного квантования; блок 803 обратного ортогонального преобразования; блок 804 суммирования; блок 805 генерирования прогнозируемого изображения; и блок 806 установки индекса. Блок 802 обратного квантования, блок 803 обратного ортогонального преобразования, блок 804 суммирования и блок 805 генерирования прогнозируемого изображения являются элементами, которые, по существу, идентичны или аналогичны блоку 104 обратного квантования, блоку 105 обратного ортогонального преобразования, блоку 106 суммирования и блоку 107 генерирования прогнозируемого изображения, проиллюстрированным на фиг. 1. Кроме того, блок 807 управления декодированием, представленный на фиг. 24 управляет устройством 800 декодирования и, например, реализуется посредством ЦП и т.п.
[0201] Для декодирования кодированных данных, блок 801 декодирования осуществляет декодирование на основании синтаксиса для каждого кадра или каждого поля. Блок 801 декодирования включает в себя блок 801A энтропийного декодирования и блок 801B переконфигурирования индекса.
[0202] Блок 801A энтропийного декодирования последовательно осуществляет энтропийное декодирование строки кода каждого синтаксиса и регенерирует информацию движения, включающую в себя режим прогнозирования, вектор движения и ссылочный номер, информацию индекса, используемую для прогнозирования взвешенного прогнозирования с компенсацией движения, и параметры кодирования для кодирования целевого блока, например, коэффициента преобразования квантования и пр. Здесь, параметры кодирования являются всеми параметрами, которые необходимы для декодирования информации, относящейся к коэффициенту преобразования, информации, относящейся к квантованию, и пр. помимо вышеописанных.
[0203] В частности, блок 801A энтропийного декодирования имеет функцию для осуществления процесса декодирования, например, процесса декодирования с переменной длиной слова или процесса арифметического декодирования для входных кодированных данных. Например, в H.264, используется контекстное адаптивное кодирование с переменной длиной слова (CAVLC), контекстное адаптивное двоичное арифметическое кодирование (CABAC), и т.п. Такой процесс также называется процессом декодирования.
[0204] Блок 801B переконфигурирования индекса переконфигурирует информацию индекса путем восстановления декодированной информации индекса. В частности, для уменьшения длины кода элементов синтаксиса декодированной информации индекса, блок 801B переконфигурирования индекса осуществляет процесс прогнозирования в соответствии с характеристиками параметров элементов синтаксиса, восстанавливает элементы синтаксиса и переконфигурирует информацию индекса. Конкретный пример процесса прогнозирования будет описан ниже.
[0205] Блок 801 декодирования выводит информацию движения, информацию индекса и коэффициент преобразования квантования, для ввода коэффициента преобразования квантования в блок 802 обратного квантования, ввода информации индекса в блок 806 установки индекса, и ввода информация движения в блок 805 генерирования прогнозируемого изображения.
[0206] Блок 802 обратного квантования осуществляет процесс обратного квантования для коэффициента преобразования квантования, поступающего от блока 801 декодирования, и получает коэффициент преобразования восстановления. В частности, блок 802 обратного квантования осуществляет обратное квантование на основании информации квантования, используемой блоком 801 декодирования. Описанный более подробно, блок 802 обратного квантования умножает коэффициент преобразования квантования на размер шага квантования, выведенный на основании информации квантования, таким образом, выводя коэффициент преобразования восстановления. Блок 802 обратного квантования выводит коэффициент преобразования восстановления для ввода в блок 803 обратного ортогонального преобразования.
[0207] Блок 803 обратного ортогонального преобразования осуществляет обратное ортогональное преобразование, соответствующее ортогональному преобразованию, осуществляемому на стороне кодирования для восстановленного коэффициента преобразования, поступающего от блока 802 обратного квантования, таким образом, получая восстановленную ошибку прогнозирования. Блок 803 обратного ортогонального преобразования выводит восстановленную ошибку прогнозирования для ввода в блок 804 суммирования.
[0208] Блок 804 суммирования суммирует восстановленную ошибку прогнозирования, поступающую от блока 803 обратного ортогонального преобразования, и соответствующее прогнозируемое изображение, таким образом, генерируя декодированное изображение. Блок 804 суммирования выводит декодированное изображение для ввода в блок 805 генерирования прогнозируемого изображения. Кроме того, блок 804 суммирования выводит декодированное изображение в качестве выходного изображения. После этого, выходное изображение временно сохраняется во внешнем выходном буфере, не показанном на фигуре, и т.п. и выводится на систему устройства отображения, например, дисплей или монитор, не показанный на фигуре, или систему видеоустройства, например, во временном режиме вывода под управлением блока 807 управления декодированием.
[0209] Блок 806 установки индекса принимает информацию индекса, поступающую от блока 801 декодирования, преобразует информацию индекса в информацию параметра WP, и выводит информацию параметра WP для ввода в блок 805 генерирования прогнозируемого изображения. В частности, блок 806 установки индекса принимает информацию индекса, которая была обработана для декодирования блоком 801A энтропийного декодирования, и переконфигурируется блоком 801B переконфигурирования индекса. Затем блок 806 установки индекса проверяет список опорных изображений и ссылочный номер, преобразует информацию индекса в информацию параметра WP, и выводит преобразованную информацию параметра WP на блок 805 генерирования прогнозируемого изображения. Информация параметра WP было описано ранее со ссылкой на фиг. 8A и 8B, и, таким образом, его описание не будет представлено.
[0210] Блок 805 генерирования прогнозируемого изображения генерирует прогнозируемое изображение 815 с использованием информации движения, поступающей от блока 801 декодирования, информации параметра WP, поступающей от блока 806 установки индекса, и декодированного изображения, поступающего от блока 804 суммирования.
[0211] Здесь, блок 805 генерирования прогнозируемого изображения будет подробно описан со ссылкой на фиг. 4. Блок 805 генерирования прогнозируемого изображения, аналогично блоку 107 генерирования прогнозируемого изображения, включает в себя: блок 201 многокадровой компенсации движения; память 202; блок 203 однонаправленной компенсации движения; блок 204 управления параметрами прогнозирования; блок 205 выбора опорного изображения; блок 206 памяти кадров; и блок 207 управления опорным изображением.
[0212] Блок 206 памяти кадров сохраняет декодированное изображение, поступающее от блока 106 суммирования, в качестве опорного изображения под управлением блока 207 управления опорным изображением. Блок 206 памяти кадров включает в себя множество блоков FM1-FMN памяти (здесь, N≥2) используемых для временного хранения опорного изображения.
[0213] Блок 204 управления параметрами прогнозирования подготавливает множество комбинаций, каждого из номера опорного изображения и параметра прогнозирования в виде таблицы на основании информации движения, поступающей от блока 801 декодирования. Здесь, информация движения представляет информацию вектора движения, представляющего отклонение движения, который используется для прогнозирования с компенсацией движения, номера опорного изображения и режима прогнозирования, например, однонаправленного/двунаправленного прогнозирования. Параметр прогнозирования представляет информацию, относящуюся к вектору движения и режиму прогнозирования. Затем блок 204 управления параметрами прогнозирования выбирает комбинацию номера опорного изображения и параметра прогнозирования, используемую для генерирования прогнозируемого изображения, на основании информации движения и выводит выбранную комбинацию для обеспечения ввода номера опорного изображения в блок 205 выбора опорного изображения и для обеспечения ввода параметра прогнозирования в блок 203 однонаправленной компенсации движения.
[0214] Блок 205 выбора опорного изображения представляет собой переключатель, который меняет один из выходных разъемов блоков FM1-FMN памяти кадров, которые включены в блок 206 памяти кадров, к которому нужно подключаться, на основании номера опорного изображения, поступающего от блока 204 управления параметрами прогнозирования. Например, когда номер опорного изображения равен “0”, блок 205 выбора опорного изображения соединяет выходной разъем блока FM1 памяти кадров с выходным разъемом блока 205 выбора опорного изображения, и, когда номер опорного изображения равен N-1, блок 205 выбора опорного изображения соединяет выходной разъем блока FMN памяти кадров с выходным разъемом блока 205 выбора опорного изображения. Блок 205 выбора опорного изображения выводит опорное изображение, хранящееся в блоке памяти кадров, к которому подключен выходной разъем, из блоков FM1-FMN памяти кадров, включенных в блок 206 памяти кадров, для ввода в блок 203 однонаправленной компенсации движения. В устройстве 800 декодирования, опорное изображение не используется ни одним блоком, отличным от блока 805 генерирования прогнозируемого изображения, и, соответственно, опорное изображение может не выводиться из блока 805 генерирования прогнозируемого изображения.
[0215] Блок 203 компенсации движения однонаправленного прогнозирования осуществляет процесс прогнозирования с компенсацией движения на основании параметра прогнозирования, поступающего от блока 204 управления параметрами прогнозирования, и опорного изображения, поступающего от блока 205 выбора опорного изображения, таким образом, генерируя однонаправлено прогнозируемое изображение. Прогнозирование с компенсацией движения было описано ранее со ссылкой на фиг. 5, и, таким образом, его описание не будет представлено.
[0216] Блок 203 компенсации движения однонаправленного прогнозирования выводит однонаправлено прогнозируемое изображение и временно сохраняет однонаправлено прогнозируемое изображение в памяти 202. Здесь, в случае, когда информация движения (параметр прогнозирования) представляет двунаправленное прогнозирование, блок 201 многокадровой компенсации движения осуществляет взвешенное прогнозирование с использованием двух типов однонаправлено прогнозируемых изображений. Соответственно, блок 203 компенсации движения однонаправленного прогнозирования сохраняет однонаправлено прогнозируемое изображение, соответствующее первому типу, в памяти 202 и непосредственно выводит однонаправлено прогнозируемое изображение, соответствующее второму типу, на блок 201 многокадровой компенсации движения. Здесь, однонаправлено прогнозируемое изображение, соответствующее первому типу, будем именовать первым прогнозируемым изображением, и однонаправлено прогнозируемое изображение, соответствующее второму типу, будем именовать вторым прогнозируемым изображением.
[0217] Кроме того, два блока 203 однонаправленной компенсации движения могут подготавливаться и генерировать два однонаправлено прогнозируемых изображения. В таком случае, когда информация движения (параметр прогнозирования) представляет однонаправленное прогнозирование, блок 203 однонаправленной компенсации движения может непосредственно выводить первое однонаправлено прогнозируемое изображение на блок 201 многокадровой компенсации движения в качестве первого прогнозируемого изображения.
[0218] Блок 201 многокадровой компенсации движения осуществляет взвешенное прогнозирование с использованием первого прогнозируемого изображения, поступающего из памяти 202, второго прогнозируемого изображения, поступающего от блока 203 компенсации движения однонаправленного прогнозирования, и информации параметра WP, поступающей от блока 109 оценивания движения, таким образом, генерируя прогнозируемое изображение. Блок 201 многокадровой компенсации движения выводит прогнозируемое изображение для ввода в блок 804 суммирования.
[0219] Здесь, блок 201 многокадровой компенсации движения будет подробно описан со ссылкой на фиг. 6. Аналогично блоку 107 генерирования прогнозируемого изображения, блок 201 многокадровой компенсации движения включает в себя: блок 301 компенсации движения по умолчанию; блок 302 взвешенной компенсации движения; блок 303 управления параметрами WP; и блоки 304 и 305 выбора WP.
[0220] Блок 303 управления параметрами WP выводит флаг применения WP и весовую информацию на основании информации параметра WP, поступающей от блока 806 установки индекса для ввода флага применения WP в блоки 304 и 305 выбора WP и ввода весовой информации в блок 302 взвешенной компенсации движения.
[0221] Здесь, информация параметра WP включает в себя информацию точности фиксированной запятой весового коэффициента, первый флаг применения WP, первый весовой коэффициент, и первое смещение, соответствующее первому прогнозируемому изображению, и второй флаг применения WP, второй весовой коэффициент, и второе смещение, соответствующее второму прогнозируемому изображению. Флаг применения WP это параметр, который можно устанавливать для каждого соответствующего опорного изображения и компоненты сигнала, и представляет, производится ли взвешенное прогнозирование с компенсацией движения. Весовая информация включает в себя информацию точности фиксированной запятой весового коэффициента, первый весовой коэффициент, первое смещение, второй весовой коэффициент и второе смещение. Здесь, информация параметра WP представляет такую же информацию, что и в первом варианте осуществления.
[0222] Описывая подробно, когда информация параметра WP поступает от блока 806 установки индекса, блок 303 управления параметрами WP выводит информацию параметра WP, которая делится на первый флаг применения WP, второй флаг применения WP и весовую информацию, таким образом, вводя первый флаг применения WP в блок 304 выбора WP, вводя второй флаг применения WP в блок 305 выбора WP, и вводя весовую информацию в блок 302 взвешенной компенсации движения.
[0223] Блоки 304 и 305 выбора WP изменяют соединительные концы прогнозируемых изображений на основании флагов применения WP, поступающих от блока 303 управления параметрами WP. В случае, когда соответствующий флаг применения WP равен “0”, каждый из блоков 304 и 305 выбора WP соединяет его выходной конец с блоком 301 компенсации движения по умолчанию. Затем блоки 304 и 305 выбора WP выводят первое и второе прогнозируемые изображения для ввода в блок 301 компенсации движения по умолчанию. С другой стороны, в случае, когда соответствующий флаг применения WP равен “1”, каждый из блоков 304 и 305 выбора WP соединяет его выходной конец с блоком 302 взвешенной компенсации движения. Затем блоки 304 и 305 выбора WP выводят первое и второе прогнозируемые изображения для ввода в блок 302 взвешенной компенсации движения.
[0224] Блок 301 компенсации движения по умолчанию осуществляет обработку усреднения на основании двух однонаправлено прогнозируемых изображений (первого и второго прогнозируемых изображений), поступающих от блоков 304 и 305 выбора WP, таким образом, генерируя прогнозируемое изображение. В частности, в случае, когда первый и второй флаги применения WP равны “0”, блок 301 компенсации движения по умолчанию осуществляет обработку усреднения на основании численного выражения (1).
[0225] Кроме того, в случае, когда режим прогнозирования, представленный информацией движения (параметром прогнозирования), является однонаправленным прогнозированием, блок 301 компенсации движения по умолчанию вычисляет окончательное прогнозируемое изображение с использованием только первого прогнозируемого изображения на основании численного выражения (4).
[0226] Блок 302 взвешенной компенсации движения осуществляет взвешенную компенсацию движения на основании двух однонаправлено прогнозируемых изображений (первого и второго прогнозируемых изображений), поступающих от блоков 304 и 305 выбора WP и весовой информации, поступающей от блока 303 управления параметрами WP. В частности, блок 302 взвешенной компенсации движения осуществляет процесс взвешивания на основании численного выражения (7) в случае, когда первый и второй флаги применения WP равны “1”.
[0227] Кроме того, в случае, когда точность вычисления первого и второго прогнозируемых изображений и точность вычисления прогнозируемого изображения отличаются друг от друга, блок 302 взвешенной компенсации движения реализует процесс округления, управляя logWDC, который является точностью фиксированной запятой, согласно численному выражению (8).
[0228] Кроме того, в случае, когда режим прогнозирования, представленный информацией движения (параметром прогнозирования), является однонаправленным прогнозированием, блок 302 взвешенной компенсации движения вычисляет окончательное прогнозируемое изображение с использованием только первого прогнозируемого изображения на основании численного выражения (9).
[0229] Кроме того, в случае, когда точность вычисления первого и второго прогнозируемых изображений и точность вычисления прогнозируемого изображения отличаются друг от друга, блок 302 взвешенной компенсации движения реализует процесс округления, управляя logWDC, который является точностью фиксированной запятой, согласно численному выражению (8), аналогично случаю двунаправленного прогнозирования.
[0230] Точность фиксированной запятой весового коэффициента была описана ранее со ссылкой на фиг. 7, и, таким образом, его описание не будет представлено. Кроме того, в случае однонаправленного прогнозирования, различные параметры (второй флаг применения WP, второй весовой коэффициент и информация второго смещения), соответствующие второму прогнозируемому изображению, не используются и могут быть установлены на определенные заранее начальные значения.
[0231] Блок 801 декодирования использует синтаксис 500, представленный на фиг. 9. Синтаксис 500 представляет структуру кодированных данных, которая является целью декодирования блока 801 декодирования. Синтаксис 500 был описан ранее со ссылкой на фиг. 9, и, таким образом, его описание не будет представлено. Кроме того, синтаксис 505 набора параметров изображения описан со ссылкой на фиг. 10 за исключением того, что декодирование используется вместо кодирования, и, таким образом, его описание не будет представлено. Кроме того, синтаксис 507 заголовка слайса был описан ранее со ссылкой на фиг. 11, за исключением того, что декодирование используется вместо кодирования, и, таким образом, его описание не будет представлено. Кроме того, синтаксис 508 таблицы весов pred был описан ранее со ссылкой на фиг. 12, за исключением того, что декодирование используется вместо кодирования, и, таким образом, его описание не будет представлено.
[0232] Здесь будет подробно описан способ прогнозирования каждого элемента синтаксиса, относящегося к взвешенному прогнозированию в конфигурации синтаксиса. Прогнозирование элемента синтаксиса осуществляется блоком 801B переконфигурирования индекса. Конфигурация синтаксиса, в явном виде представляющая способ прогнозирования согласно второму варианту осуществления, такая же, как во втором варианте осуществления, и представлена на фиг. 13.
[0233] В способе межсигнального прогнозирования luma_log2_weight_denom и chroma_log2_weight_denom, представляющих точность фиксированной запятой весового коэффициента, процесс восстановления осуществляется с использованием численного выражения (11). Детали процесса восстановления представлены на фиг. 15.
[0234] В способе прогнозирования luma_weight_lx[i] и chroma_weight_lx[i][j], представляющих весовые коэффициенты яркостного и цветоразностного сигнала, процесс восстановления осуществляется с использованием численных выражений (14) и (17). Детали процесса восстановления представлены на фиг. 17.
[0235] В способе прогнозирования, в котором прогнозируемые значения весовых коэффициентов (luma_weight_lx[i] и chroma_weight_lx[i][j]) яркостного и цветоразностного сигнала выводятся с другими ссылочными номерами или другими номерами POC, процесс восстановления осуществляется с использованием численных выражений (19) и (21). Детали процесса восстановления представлены на фиг. 19.
[0236] В способе прогнозирования, в котором прогнозируемые значения весовых коэффициентов (luma_weight_lx[i] и chroma_weight_lx[i][j]) яркостного и цветоразностного сигнала выводятся с использованием расстояния между целью кодирования и опорным слайсом, процесс восстановления осуществляется с использованием численных выражений (23) и (25). Детали процесса восстановления такие же, как в блок-схеме операций, представленной на фиг. 19, благодаря включению (i-1)-го значения (i≠0) в baseidx.
[0237] В подходе для выведения прогнозируемых значений весового коэффициента и точности фиксированной запятой с использованием способа выведения параметра WP неявного взвешенного прогнозирования, установленного в H.264 и пр., процесс восстановления осуществляется с использованием численных выражений (31) и (33). Детали процесса восстановления представлены на фиг. 23.
[0238] Множество вышеописанных методов прогнозирования можно использовать не только независимо, но и совместно. Например, объединяя численные выражения (11), (14), (17) и (28), можно эффективно уменьшить объем кода элементов синтаксиса информации индекса.
[0239] Как описано выше, согласно второму варианту осуществления, устройство 800 декодирования устраняет пространственную избыточность с использованием корреляции между параметрами информации, которая должна быть кодирована, что позволяет решить проблему снижения эффективности кодирования. Устройство 800 декодирования может снижать объем кода по сравнению с традиционной конфигурацией, в которой элементы синтаксиса, используемые во взвешенном прогнозировании с компенсацией движения, непосредственно кодируются (являются прямыми значениями).
[0240] МОДИФИКАЦИЯ
В вышеописанных первом и втором вариантах осуществления, описан пример, в котором кадр делится на прямоугольные блоки, каждый из которых имеет размер 16×16 пикселей и т.п. и кодируется/декодируется в порядке от верхнего левого блока экрана к нижнему правому блоку (см. фиг. 2A). Однако порядок кодирования и порядок декодирования не ограничиваются проиллюстрированными в этом примере. Например, кодирование и декодирование может осуществляться в порядке от нижней правой стороны к верхней левой стороне, или кодирование и декодирование может осуществляться по спирали от центра экрана к концу экрана. Кроме того, кодирование и декодирование может осуществляться в порядке от верхней правой стороны к нижней левой стороне, или кодирование и декодирование может осуществляться по спирали от конца экрана к центру экрана. В таком случае, поскольку позиция соседнего пиксельного блока, к которой можно обращаться в соответствии с порядком кодирования, изменяется, позиция может изменяться на надлежащую пригодную позицию.
[0241] В вышеописанных первом и втором вариантах осуществления, хотя описание было представлено с размером целевого блока прогнозирования, например, блока 4×4 пикселя, блока 8×8 пикселей, блока 16×16 пикселей и т.п., проиллюстрированных в порядке примера, целевой блок прогнозирования может не иметь однородную форму блока. Например, целевой блок прогнозирования может иметь размер 16×8 пикселей, 8×16 пикселей, 8×4 пикселя, 4×8 пикселей и т.п. Кроме того, не требуется унифицировать все размеры блока в одном блоке дерева кодирования, и несколько размеров блока, отличающихся друг от друга, может смешиваться. В случае, когда несколько размеров блока, отличающихся друг от друга, смешаны в одном блоке дерева кодирования, объем кода для кодирования или декодирования информации разделения возрастает в соответствии с увеличением количества разделений. Таким образом, предпочтительно выбирать размер блока с учетом баланса между объемом кода информации разделения и качеством локального кодированного изображения или декодированного изображения.
[0242] В вышеописанных первом и втором вариантах осуществления, для упрощения, исчерпывающее описание было представлено для цветовой компоненты сигнала, когда процессы прогнозирования яркостного сигнала и цветоразностного сигнала не отличаются друг от друга. Однако, в случае, когда процессы прогнозирования яркостного сигнала и цветоразностного сигнала отличаются друг от друга, можно использовать один и тот же способ прогнозирования или способы прогнозирования, отличающиеся друг от друга. В случае, когда для яркостного сигнала и цветоразностного сигнала используются способы прогнозирования, отличающиеся друг от друга, кодирование или декодирование может осуществляться с использованием способа прогнозирования, выбранного для цветоразностного сигнала по аналогии со способом для яркостного сигнала.
[0243] В вышеописанных первом и втором вариантах осуществления, для упрощения, исчерпывающее описание было представлено для цветовой компоненты сигнала, когда процессы взвешенного прогнозирования с компенсацией движения яркостного сигнала и цветоразностного сигнала не отличаются друг от друга. Однако, в случае, когда процессы взвешенного прогнозирования с компенсацией движения яркостного сигнала и цветоразностного сигнала отличаются друг от друга, можно использовать один и тот же способ взвешенного прогнозирования с компенсацией движения или способы взвешенного прогнозирования с компенсацией движения, отличающиеся друг от друга. В случае, когда для яркостного сигнала и цветоразностного сигнала используются способы взвешенного прогнозирования с компенсацией движения, отличающиеся друг от друга, кодирование или декодирование может осуществляться с использованием способа взвешенного прогнозирования с компенсацией движения, выбранного для цветоразностного сигнала, аналогичного способу для яркостного сигнала.
[0244] В вышеописанных первом и втором вариантах осуществления, между строками таблицы, представленной в конфигурации синтаксиса, можно вставлять элемент синтаксиса, не установленный в этом варианте осуществления, и можно включать описание, относящееся к другим условным переходам. Альтернативно, таблица синтаксиса может делиться на множество таблиц, или таблицы синтаксиса могут объединяться друг с другом. Кроме того, может отсутствовать необходимость использовать один и тот же член, но термин может произвольно изменяться в соответствии с используемой формой.
[0245] Как описано выше, согласно каждому варианту осуществления, решается проблема кодирования избыточной информации конфигурации синтаксиса во время осуществления взвешенного прогнозирования с компенсацией движения, и реализуется процесс взвешенного прогнозирования с компенсацией движения, имеющий высокую эффективность. Таким образом, согласно каждому варианту осуществления, повышается эффективность кодирования, и улучшается субъективное качество изображения.
[0246] Хотя были описаны некоторые варианты осуществления настоящего изобретения, такие варианты осуществления представлены в качестве примеров и не призваны ограничивать объем изобретения. Эти новые варианты осуществления могут быть реализованы в различных формах, и различные изъятия, замены и изменения могут производиться в них без отхода от принципа изобретения. Эти варианты осуществления и их модификации принадлежат объему или принципу изобретения и принадлежат изобретению, описанному в формуле изобретения и объему, эквивалентному ему.
[0247] Например, программа, реализующая процесс каждого вышеописанного варианта осуществления, может обеспечиваться посредством хранения на считываемом компьютером носителе данных. В качестве носителя данных, носитель данных, где может храниться программа, и который может считываться компьютером, например, магнитный диск, оптический диск (CD-ROM, CD-R, DVD и т.п.), магнитооптический диск (MO и т.п.) или полупроводниковая память, может использоваться независимо от формы хранения.
[0248] Кроме того, программа, реализующая процесс каждого варианта осуществления, может храниться на компьютере (сервере), подключенном к сети, например интернету, и загружаться на компьютер (клиент) через сеть.
ПЕРЕЧЕНЬ ССЫЛОЧНЫХ ПОЗИЦИЙ
[0249] 100 устройство кодирования
101 блок вычитания
102 блок ортогонального преобразования
103 блок квантования
104 блок обратного квантования
105 блок обратного ортогонального преобразования
106 блок суммирования
107 блок генерирования прогнозируемого изображения
108 блок установки индекса
109 блок оценивания движения
110 блок кодирования
110A блок энтропийного кодирования
110B блок переконфигурирования индекса
111 блок управления кодированием
201 блок многокадровой компенсации движения
202 память
203 блок однонаправленной компенсации движения
204 блок управления параметрами прогнозирования
205 блок выбора опорного изображения
206 блок памяти кадров
207 блок управления опорным изображением
301 блок компенсации движения по умолчанию
302 блок взвешенной компенсации движения
303 блок управления параметрами WP
304, 305 блок выбора WP
800 устройство декодирования
801 блок декодирования
801A блок энтропийного декодирования
801B блок переконфигурирования индекса
802 блок обратного квантования
803 блок обратного ортогонального преобразования
804 блок суммирования
805 блок генерирования прогнозируемого изображения
806 блок установки индекса
807 блок управления декодированием
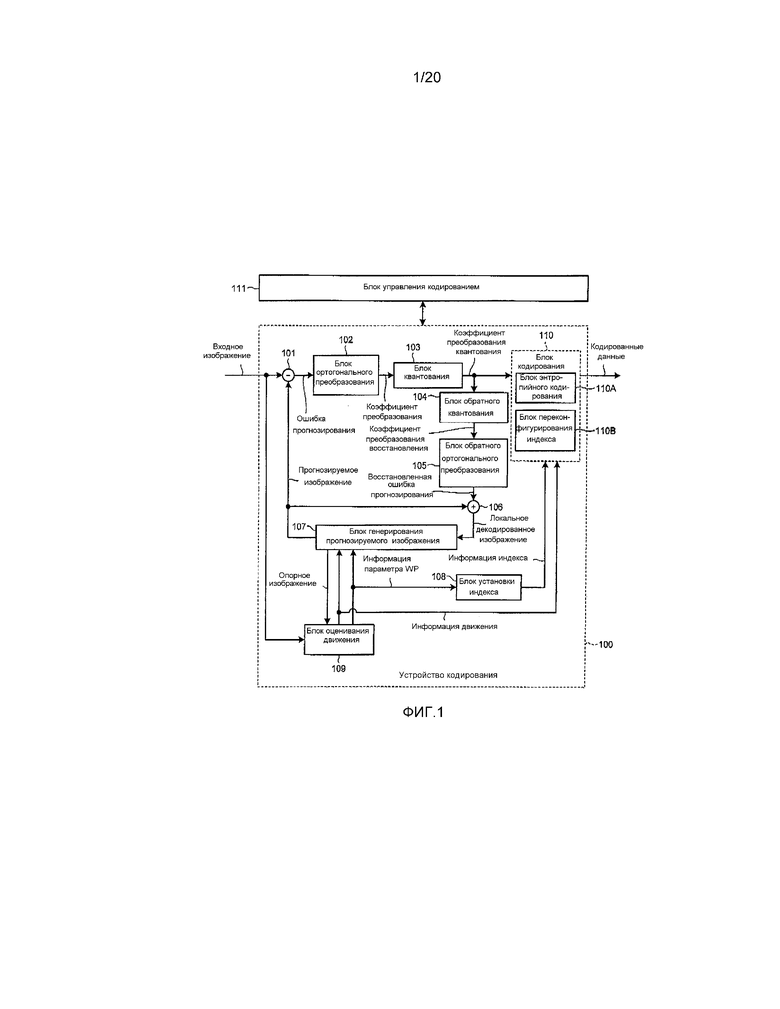
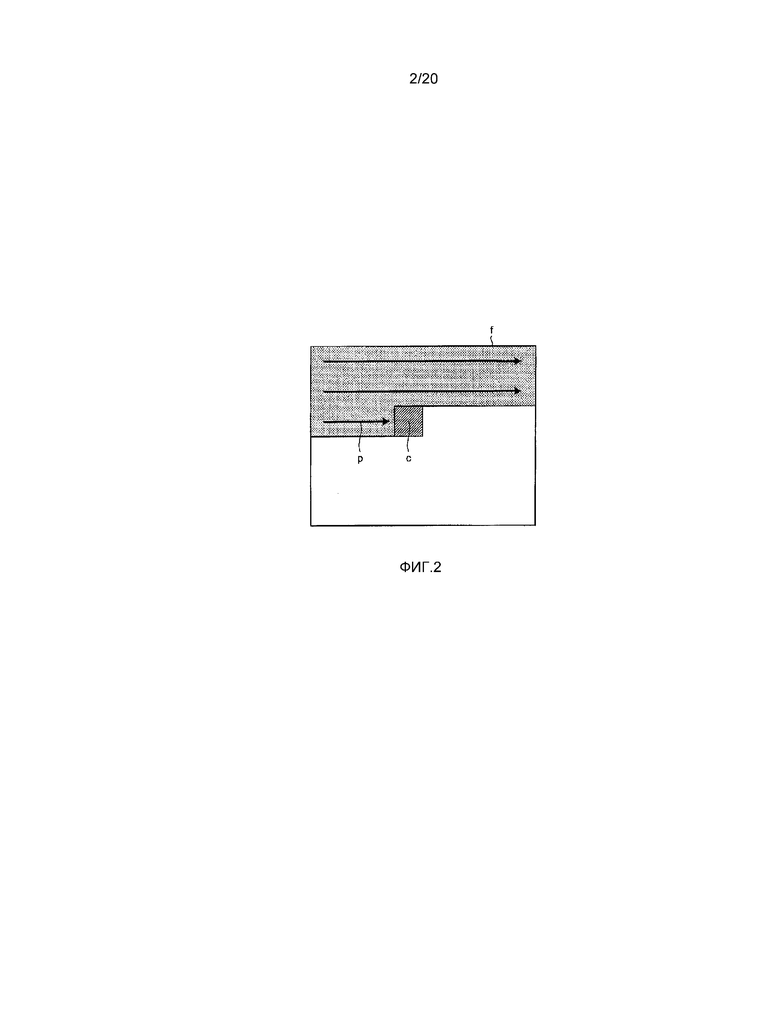

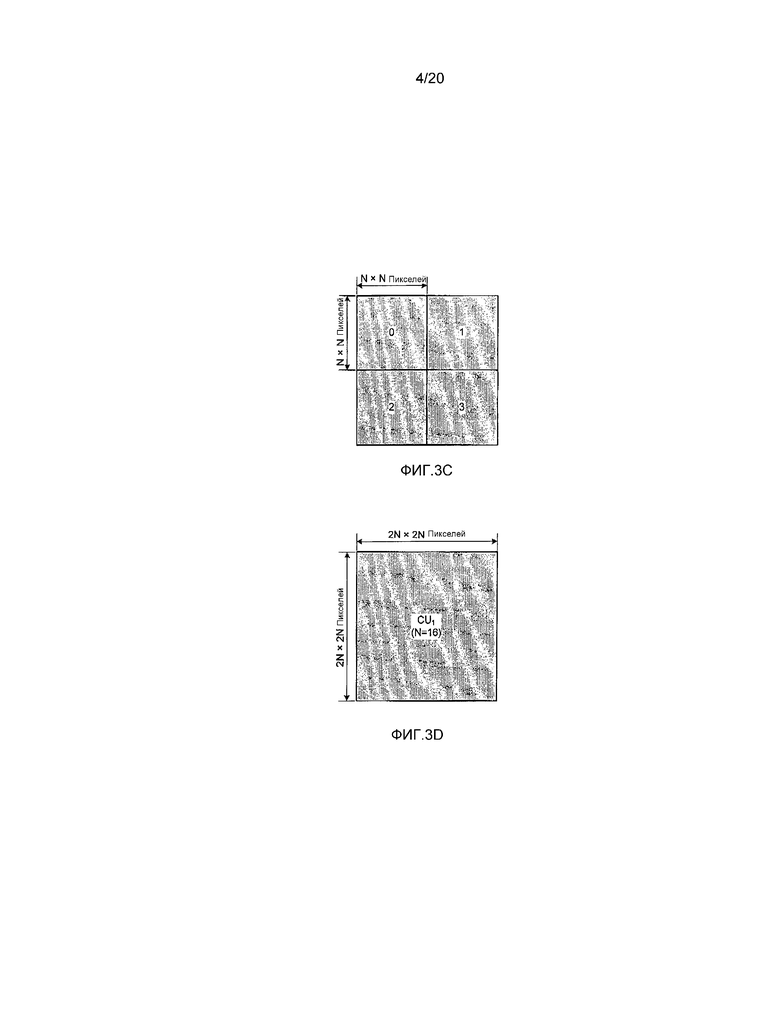
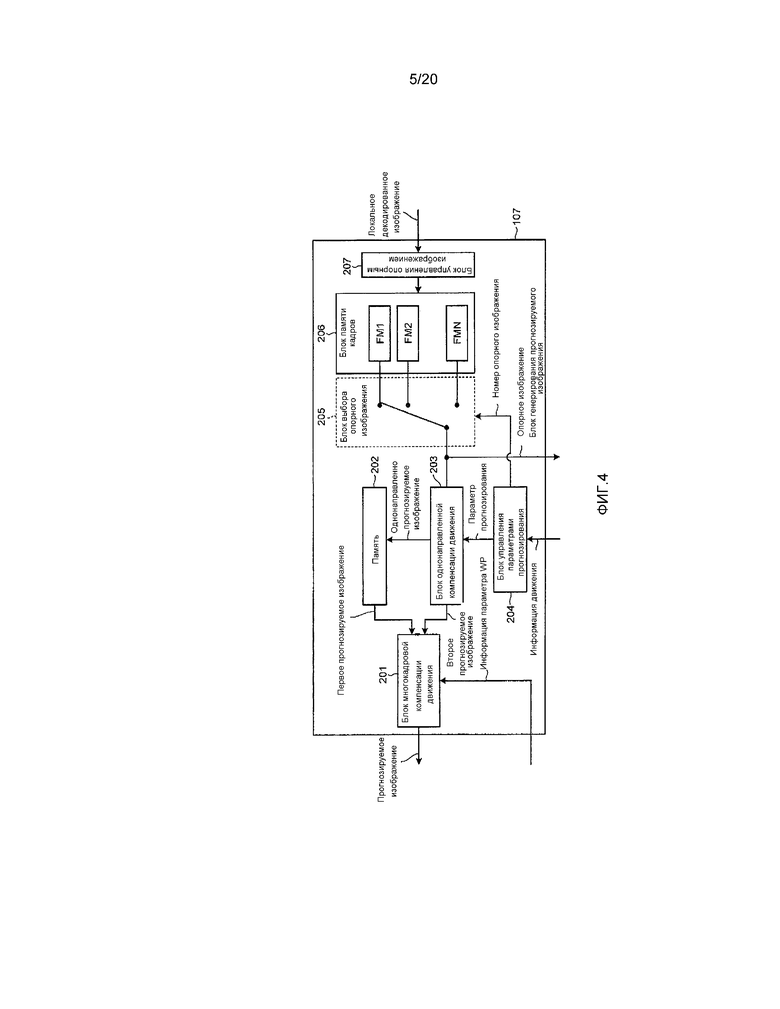

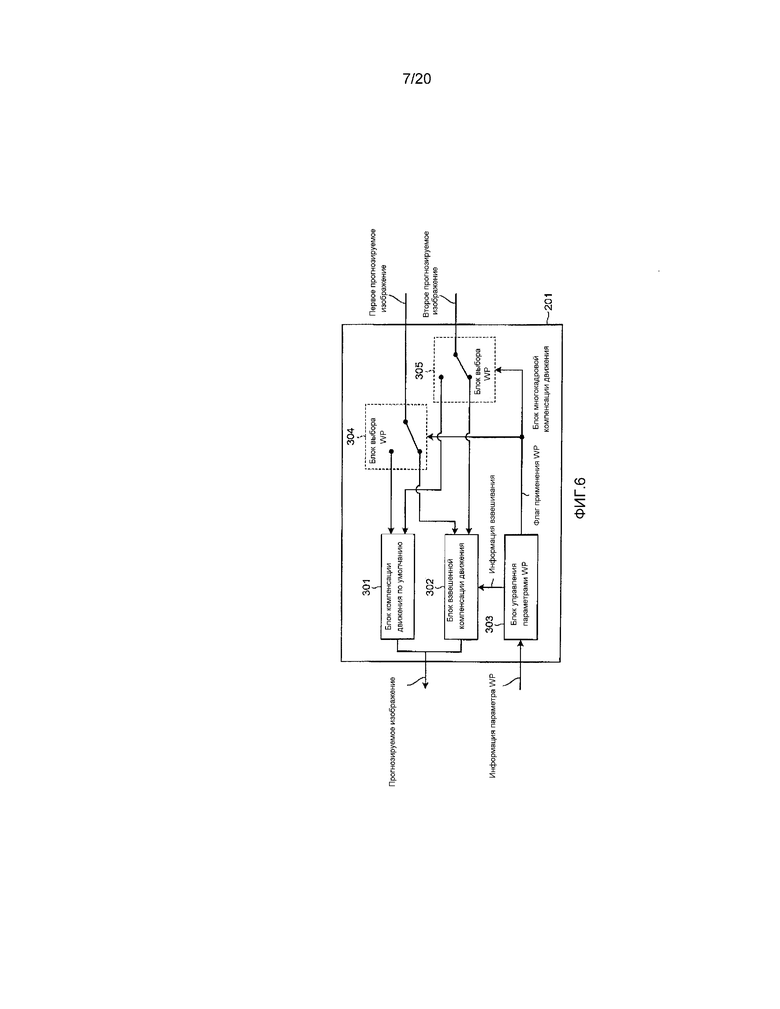
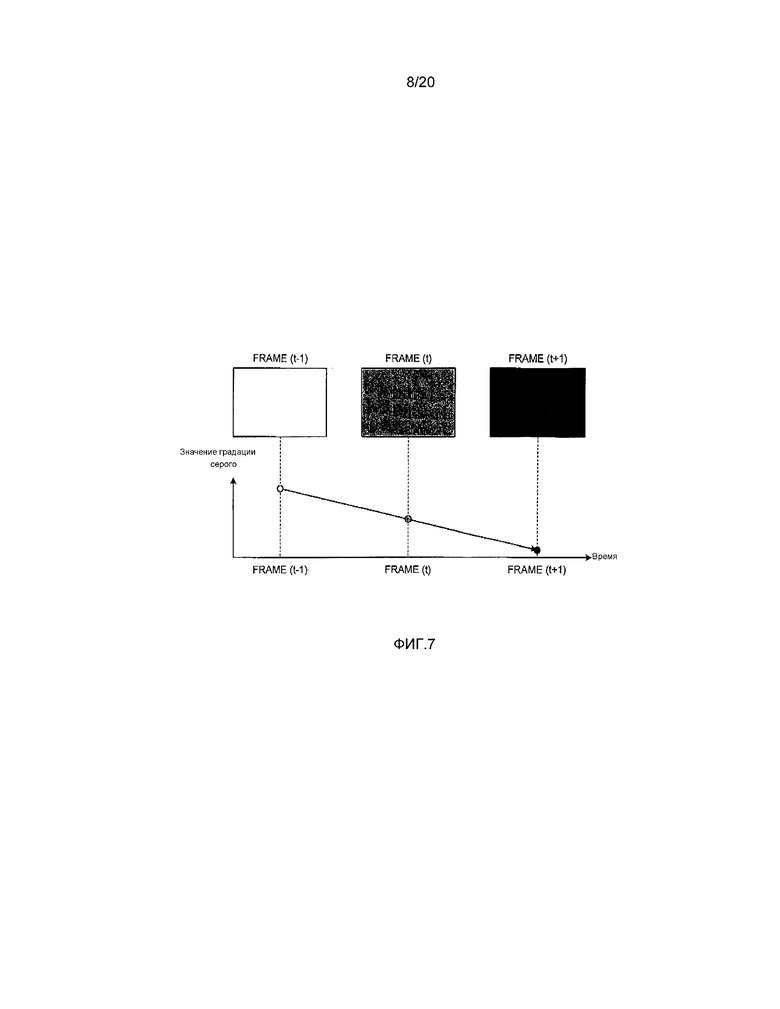
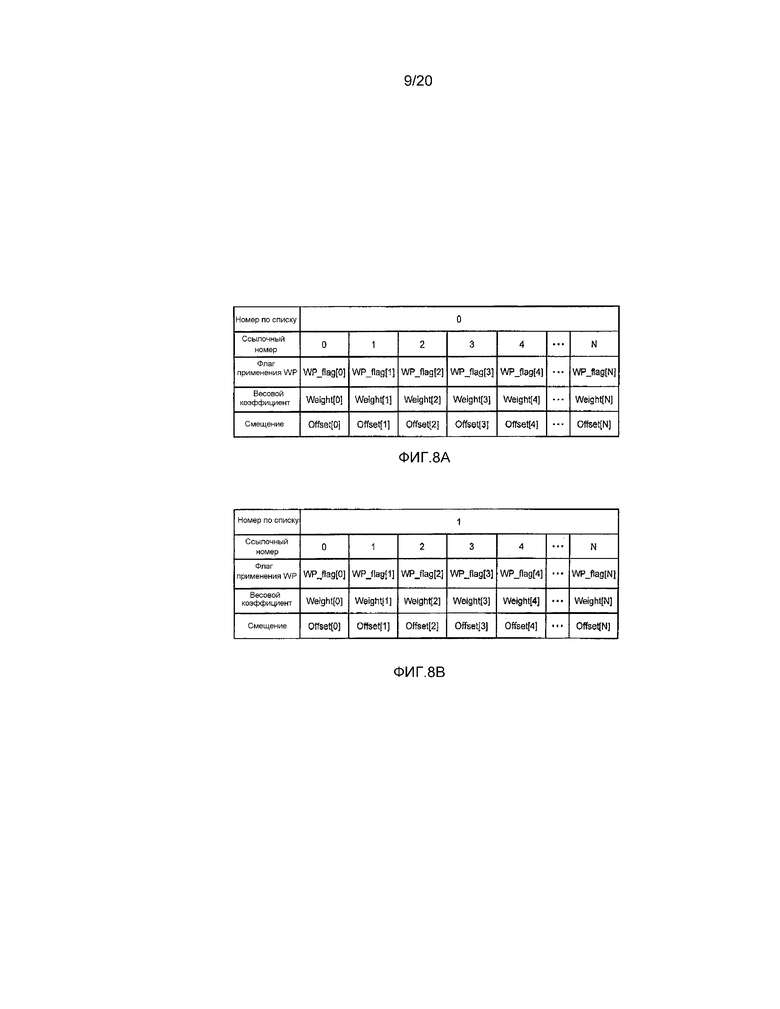
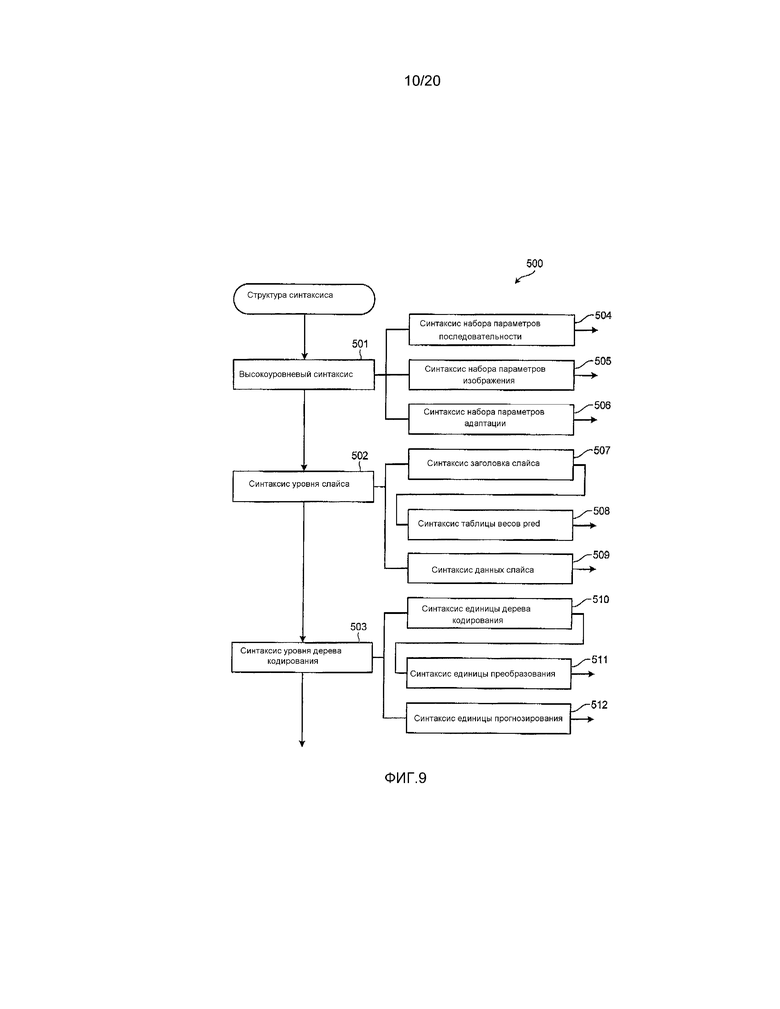



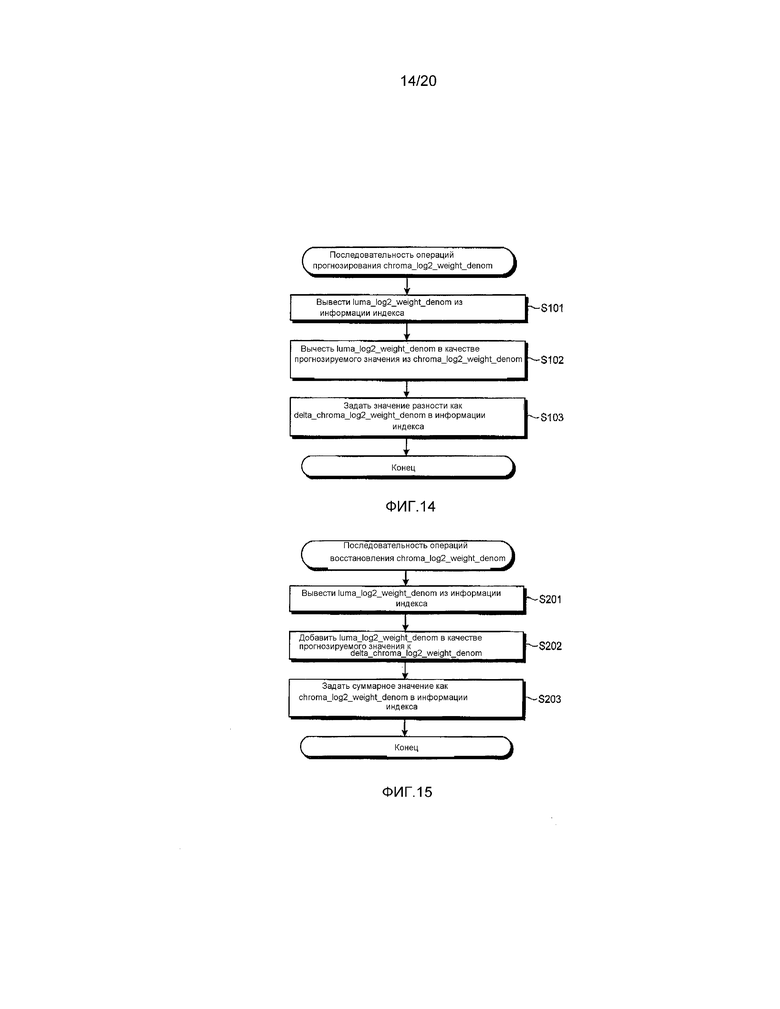
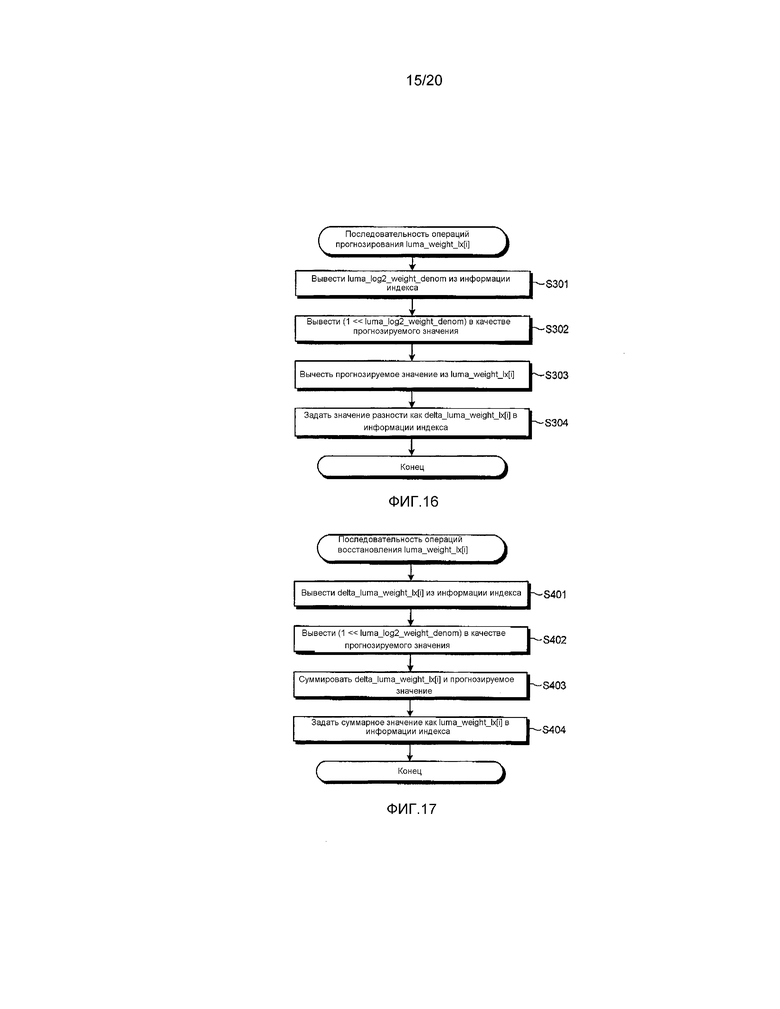
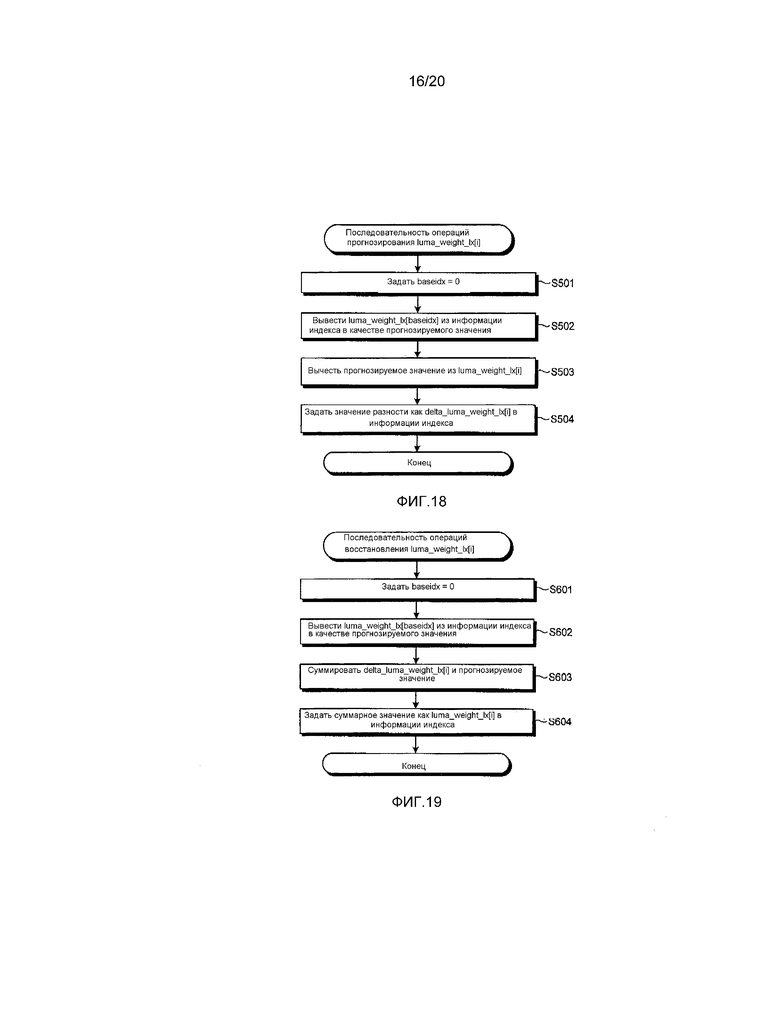
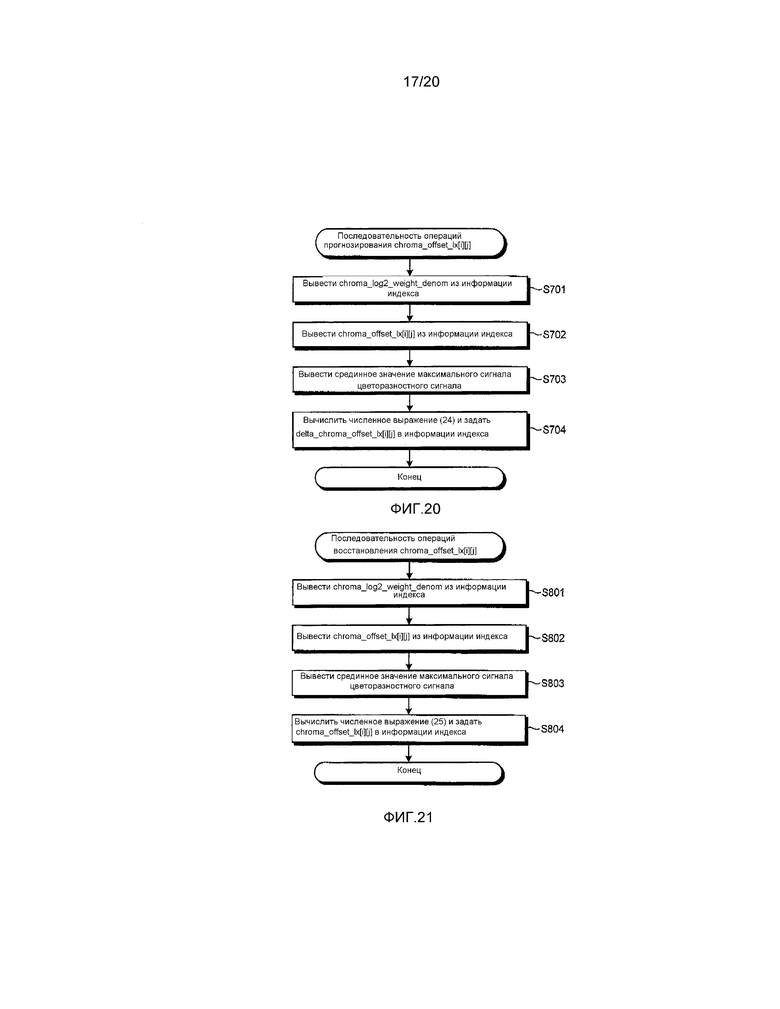
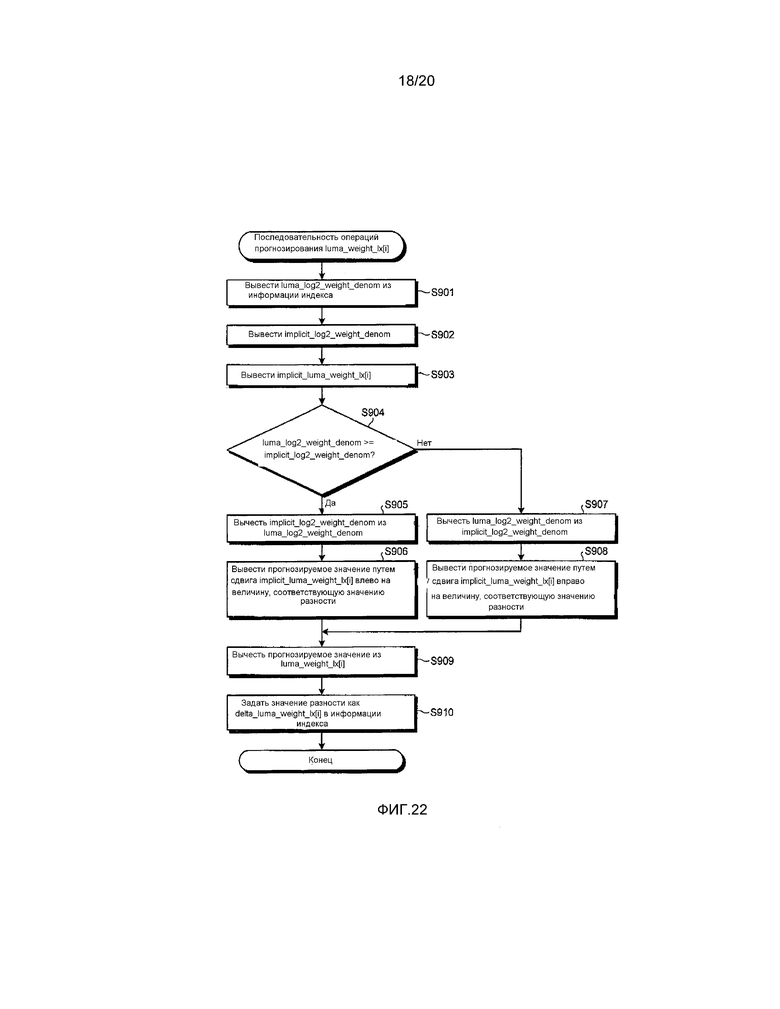
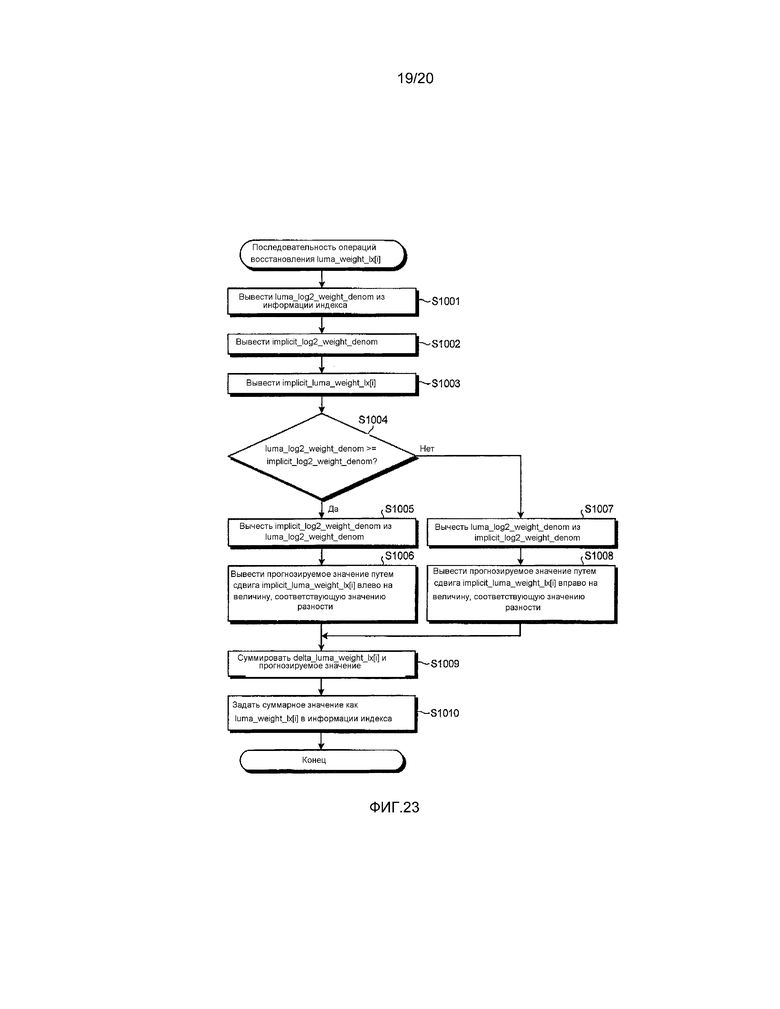
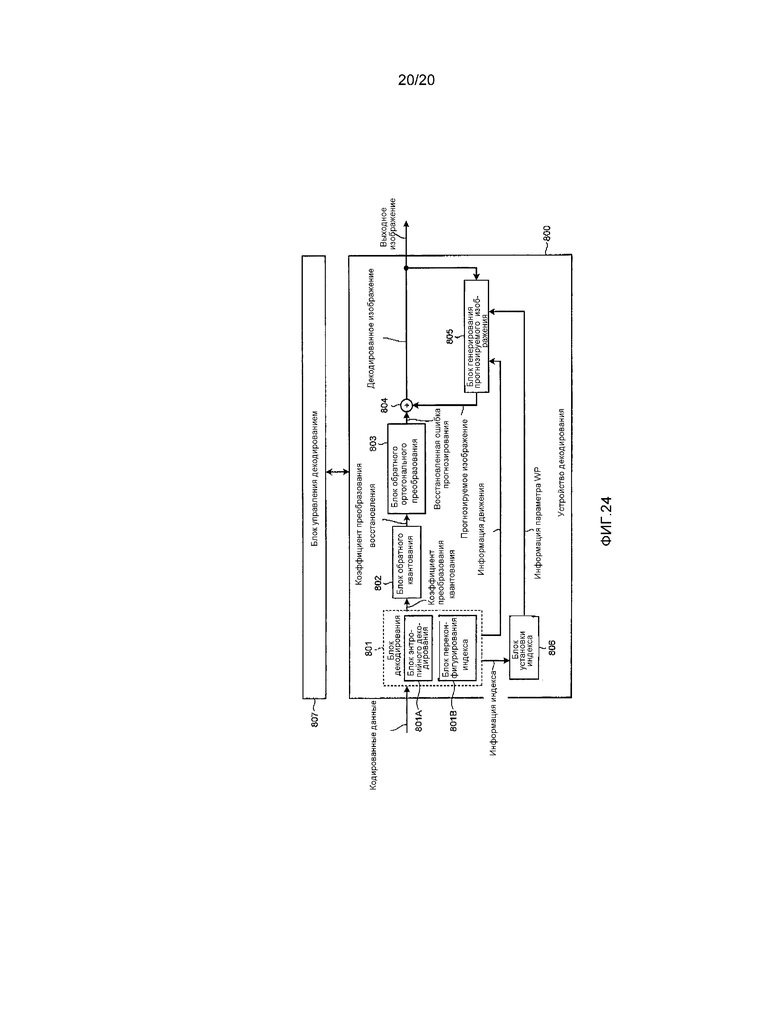
Изобретение относится к способам кодирования и декодирования информации. Технический результат изобретения заключается в повышении эффективности кодирования информации. Способ кодирования включает в себя этап установки индекса, этап прогнозирования и этап кодирования. Этап установки индекса устанавливает индекс, который представляет информацию опорного изображения и весового коэффициента. Этап прогнозирования прогнозирует таким образом, что опорное значение весового коэффициента, когда изменение пиксельного значения между по меньшей мере одним опорным изображением и целевым изображением, которое должно быть кодировано, является конкретной опорой или меньше, выводится в качестве прогнозируемого значения. Этап кодирования кодирует значение разности между весовым и прогнозируемым значениями. 3 н.п. ф-лы, 28 ил.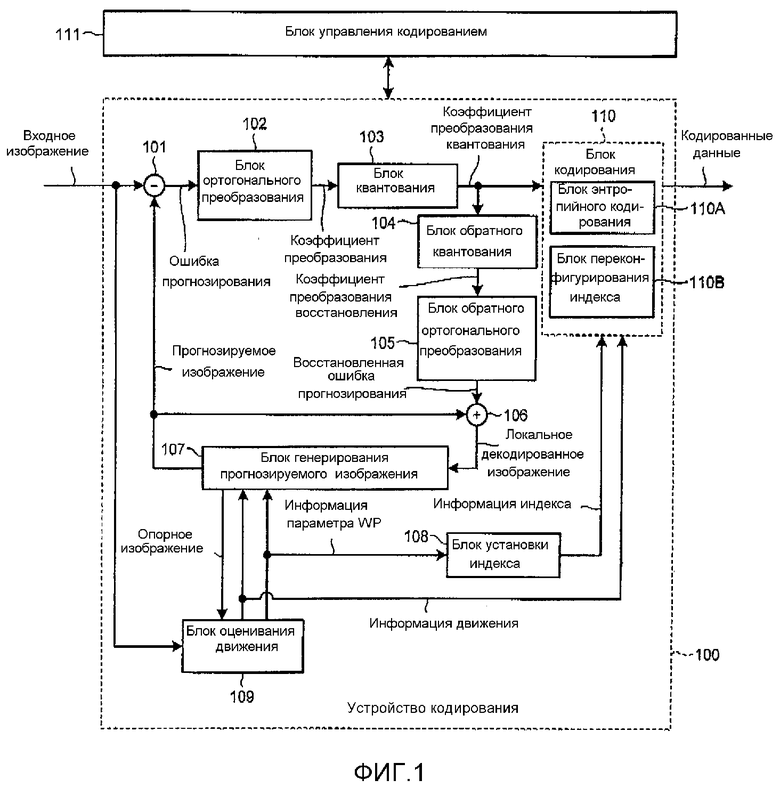
1. Устройство декодирования, содержащее:
функциональный блок суммирования первой точности фиксированной запятой для весового коэффициента яркости и разностного значения между упомянутой первой точностью фиксированной запятой и второй точностью фиксированной запятой для весового коэффициента цветоразности для декодирования упомянутой второй точности фиксированной запятой, причем упомянутую первую точность фиксированной запятой и упомянутое разностное значение получают посредством выполнения декодирования закодированных данных.
2. Способ декодирования, содержащий:
суммирование первой точности фиксированной запятой для весового коэффициента яркости и разностного значения между упомянутой первой точностью фиксированной запятой и второй точностью фиксированной запятой для весового коэффициента цветоразности для декодирования упомянутой второй точности фиксированной запятой, причем упомянутую первую точность фиксированной запятой и упомянутое разностное значение получают посредством выполнения декодирования закодированных данных.
3. Считываемый компьютером носитель, хранящий компьютерную программу, которая побуждает компьютер выполнять:
суммирование первой точности фиксированной запятой для весового коэффициента яркости и разностного значения между упомянутой первой точностью фиксированной запятой и второй точностью фиксированной запятой для весового коэффициента цветоразности для декодирования упомянутой второй точности фиксированной запятой, причем упомянутую первую точность фиксированной запятой и упомянутое разностное значение получают посредством выполнения декодирования закодированных данных.
| КАРБУРАТОР | 1925 |
|
SU2375A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| КАНАЛЬНОЕ КОДИРОВАНИЕ НА ОСНОВЕ КОМПЛЕКСНОГО ПРЕОБРАЗОВАНИЯ С ЧАСТОТНЫМ КОДИРОВАНИЕМ С РАСШИРЕННОЙ ПОЛОСОЙ | 2007 |
|
RU2422987C2 |
| УСТРОЙСТВО ВИДЕОКОДИРОВАНИЯ, СПОСОБ ВИДЕОКОДИРОВАНИЯ, ПРОГРАММА ВИДЕОКОДИРОВАНИЯ, УСТРОЙСТВО ВИДЕОДЕКОДИРОВАНИЯ, СПОСОБ ВИДЕОДЕКОДИРОВАНИЯ И ПРОГРАММА ВИДЕОДЕКОДИРОВАНИЯ | 2006 |
|
RU2391794C2 |

