[0001] Настоящая заявка относится к:
предварительной заявке на патент США № 61/667,387, поданной 2 июля 2012,
предварительной заявке на патент США № 61/669,587, поданной 9 июля 2012, и
предварительной заявке на патент США № 61/798,135, поданной 15 марта 2013,
все содержимое каждой из которых включено в настоящее описание по ссылке.
ОБЛАСТЬ ТЕХНИКИ
[0002] Настоящее раскрытие относится к обработке данных видео и, более подробно, настоящее раскрытие описывает методы, относящиеся к генерированию и обработке наборов параметров для видео данных.
УРОВЕНЬ ТЕХНИКИ
[0003] Цифровые возможности видео могут быть включены в широкий диапазон устройств, включающий в себя цифровые телевизоры, цифровые системы прямого вещания, беспроводные системы вещания, персональные цифровые помощники (PDA), ноутбуки или настольные компьютеры, планшетные компьютеры, электронные книги, цифровые камеры, цифровые устройства регистрации, цифровые медиаплееры, видео игровые устройства, пульты видеоигр, сотовые или спутниковые радиотелефоны, так называемые “смартфоны”, видео устройства организации телеконференций, устройства потоковой передачи видео, и т.п. Эти цифровые видео устройства реализуют способы сжатия видео, такие как описаны в стандартах, определенных MPEG-2, MPEG-4, ITU-T H.263, ITU-T H.264/MPEG-4, Часть 10, Усовершенствованное кодирование видео (AVC), стандарт высокоэффективное кодирование видео (HEVC) находящийся в настоящее время в развитии, и расширениях таких стандартов. Цифровые видео устройства могут передавать, принимать, кодировать, декодировать, и/или хранить цифровую информацию видео более эффективно, реализовывая такие способы сжатия видео.
[0004] Способы сжатия видео выполняют пространственное (внутри картинки) предсказание и/или временное (между картинками) предсказание, чтобы уменьшить или удалить избыточность, присущую видео последовательностям. Для основанного на блоке кодирования видео видео-вырезка (то есть, видео кадр или часть видео кадра) может быть разделена на блоки видео, которые могут также упоминаться как блоки дерева, единицы кодирования (CU) и/или узлы кодирования. Блоки видео во внутренне кодированной (I) вырезке картинки кодируют, используя пространственное предсказание относительно опорных выборок в соседних блоках в той же самой картинке. Блоки видео во внешне кодированной (P или B) вырезке картинки могут использовать пространственное предсказание относительно опорных выборок в соседних блоках в той же самой картинке или временное предсказание относительно опорных выборок в других опорных картинках. Картинки могут упоминаться как кадры, и опорные картинки могут упоминаться как опорные кадры.
[0005] Пространственное или временное предсказание приводит к предсказывающему блоку для блока, который должен быть закодирован. Остаточные данные представляют пиксельные разности между первоначальным блоком, который должен быть закодирован, и предсказывающим блоком. Внешне кодированный блок кодируют согласно вектору движения, который указывает на блок опорных выборок, формирующих предсказывающий блок, и остаточным данным, указывающим разность между закодированным блоком и предсказывающим блоком. Внутренне кодированный блок кодируют согласно режиму внутреннего кодирования и остаточным данным. Для дальнейшего сжатия остаточные данные могут быть преобразованы из пиксельной области в область преобразования, приводя к остаточным коэффициентам преобразования, которые затем могут быть квантованы. Квантованные коэффициенты преобразования, первоначально размещенные в двумерном массиве, могут быть сканированы, чтобы сформировать одномерный вектор коэффициентов преобразования, и энтропийное кодирование может быть применено, чтобы достигнуть еще большего сжатия.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0006] Настоящее раскрытие описывает методы построения для наборов параметров при кодировании видео, и более подробно, настоящее раскрытие описывает методы, относящиеся к наборам параметров видео (VPS). VPSs является синтаксической структурой, которая может применяться ко множественным целым последовательностям видео. Согласно методам настоящего раскрытия, VPS может включать в себя элемент синтаксиса смещения, чтобы разрешить осведомленному о медиа элементу сети (MANE) осуществлять пропуск от одного набора элементов синтаксиса фиксированной длины до другого набора элементов синтаксиса фиксированной длины, причем пропущенный элемент синтаксиса потенциально включает в себя элементы синтаксиса переменной длины.
[0007] В одном примере способ обработки видео данных включает в себя обработку одного или более начальных элементов синтаксиса для набора параметров, ассоциированного с потоком битов видео; прием в наборе параметров элемента синтаксиса смещения для набора параметров, при этом элемент синтаксиса смещения идентифицирует элементы синтаксиса, которые должны быть пропущены, в пределах набора параметров; на основании элемента синтаксиса смещения, пропуск элементов синтаксиса в пределах набора параметров; и обработку одного или более дополнительных элементов синтаксиса в наборе параметров, при этом один или более дополнительных элементов синтаксиса находятся после пропущенных элементов синтаксиса в наборе параметров.
[0008] В другом примере способ обработки видео данных включает в себя генерирование одного или более начальных элементов синтаксиса для набора параметров, ассоциированного с потоком битов видео; генерирование элемента синтаксиса смещения для набора параметров, при этом элемент синтаксиса смещения идентифицирует количество элементов синтаксиса, которые должны быть пропущены, в пределах набора параметров; генерирование элементов синтаксиса, которые должны быть пропущены; и генерирование одного или более дополнительных элементов синтаксиса в наборе параметров, при этом один или более дополнительных элементов синтаксиса находятся после элементов синтаксиса, которые должны быть пропущены в наборе параметров.
[0009] В другом примере способ декодирования видео данных включает в себя декодирование одного или более начальных элементов синтаксиса для набора параметров, ассоциированного с потоком битов видео; прием в потоке битов видео элемента синтаксиса смещения для набора параметров, при этом элемент синтаксиса смещения идентифицирует элементы синтаксиса, которые должны быть пропущены, в пределах набора параметров; и декодирование элементов синтаксиса, которые должны быть пропущены.
[0010] В другом примере устройство обработки видео включает в себя элемент обработки видео, сконфигурированный, чтобы обрабатывать один или более начальных элементов синтаксиса для набора параметров, ассоциированного с потоком битов видео; прием в наборе параметров элемента синтаксиса смещения для набора параметров, при этом элемент синтаксиса смещения идентифицирует элементы синтаксиса, которые должны быть пропущены, в пределах набора параметров; на основании элемента синтаксиса смещения, пропуск элементов синтаксиса в пределах набора параметров; и обработку одного или более дополнительных элементов синтаксиса в наборе параметров, при этом один или более дополнительных элементов синтаксиса находятся после пропущенных элементов синтаксиса в наборе параметров.
[0011] В другом примере устройство обработки видео включает в себя элемент обработки видео, сконфигурированный, чтобы генерировать один или более начальных элементов синтаксиса для набора параметров, ассоциированного с потоком битов видео; генерировать элемент синтаксиса смещения для набора параметров, при этом элемент синтаксиса смещения идентифицирует количество элементов синтаксиса, которые должны быть пропущены, в пределах набора параметров; генерировать элементы синтаксиса, которые должны быть пропущены; генерировать один или более дополнительных элементов синтаксиса в наборе параметров, при этом один или более дополнительных элементов синтаксиса находятся после элементов синтаксиса, которые должны быть пропущены в наборе параметров.
[0012] В другом примере устройство обработки видео включает в себя элемент обработки видео, сконфигурированный, чтобы декодировать один или более начальных элементов синтаксиса для набора параметров, ассоциированного с потоком битов видео; прием в потоке битов видео элемента синтаксиса смещения для набора параметров, при этом элемент синтаксиса смещения идентифицирует элементы синтаксиса, которые должны быть пропущены, в пределах набора параметров; и декодировать элементы синтаксиса, которые должны быть пропущены.
[0013] В другом примере устройство обработки видео включает в себя средство для обработки одного или более начальных элементов синтаксиса для набора параметров, ассоциированного с потоком битов видео; средство для приема в наборе параметров элемента синтаксиса смещения для набора параметров, при этом элемент синтаксиса смещения идентифицирует элементы синтаксиса, которые должны быть пропущены, в пределах набора параметров; средство для пропуска элементов синтаксиса в пределах набора параметров на основании элемента синтаксиса смещения; средство для обработки одного или более дополнительных элементов синтаксиса в наборе параметров, при этом один или более дополнительных элементов синтаксиса находятся после пропущенных элементов синтаксиса в наборе параметров.
[0014] В другом примере, считываемый компьютером запоминающий носитель, хранящий инструкции, которые, когда выполняются, вынуждают один или более процессоров обрабатывать один или более начальных элементов синтаксиса для набора параметров, ассоциированного с потоком битов видео; принимать в наборе параметров элемент синтаксиса смещения для набора параметров, при этом элемент синтаксиса смещения идентифицирует элементы синтаксиса, которые должны быть пропущены, в пределах набора параметров; пропускать элементы синтаксиса в пределах набора параметров на основании элемента синтаксиса смещения; и обрабатывать один или более дополнительных элементов синтаксиса в наборе параметров, при этом один или более дополнительных элементов синтаксиса находятся после пропущенных элементов синтаксиса в наборе параметров.
[0015] Подробности одного или более примеров сформулированы в сопроводительных чертежах и описании ниже. Другие признаки, объекты и преимущества будут очевидны из описания и чертежей и из формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0016] ФИГ. 1 является блок-схемой, иллюстрирующей примерную систему кодирования и декодирования видео, которая может использовать методы, описанные в настоящем раскрытии.
[0017] ФИГ. 2 является концептуальной диаграммой, иллюстрирующей примерный порядок декодирования MVC.
[0018] ФИГ. 3 является концептуальной диаграммой, показывающей примерную временную и межвидовую структуру предсказания MVC.
[0019] ФИГ. 4 является блок-схемой, иллюстрирующей примерный кодер видео, который может реализовать методы, описанные в настоящем раскрытии.
[0020] ФИГ. 5 является блок-схемой, иллюстрирующей примерный декодер видео, который может реализовать методы, описанные в настоящем раскрытии.
[0021] ФИГ. 6 является блок-схемой, иллюстрирующей примерный набор устройств, которые являются частью сети.
[0022] ФИГ. 7 является последовательностью операций, показывающей примерный способ для обработки набора параметров в соответствии с методами настоящего раскрытия.
[0023] ФИГ. 8 является последовательностью операций, показывающей примерный способ для генерирования набора параметров в соответствии с методами настоящего раскрытия.
[0024] ФИГ. 9 является последовательностью операций, показывающей примерный способ для декодирования набора параметров в соответствии с методами настоящего раскрытия.
[0025] ФИГ. 10 является последовательностью операций, показывающей примерный способ для обработки набора параметров в соответствии с методами настоящего раскрытия.
[0026] ФИГ. 11 является последовательностью операций, показывающей примерный способ для генерирования набора параметров в соответствии с методами настоящего раскрытия.
[0027] ФИГ. 12 является последовательностью операций, показывающей примерный способ для обработки набора параметров в соответствии с методами настоящего раскрытия.
[0028] ФИГ. 13 является последовательностью операций, показывающей примерный способ для генерирования набора параметров в соответствии с методами настоящего раскрытия.
ПОДРОБНОЕ ОПИСАНИЕ
[0029] Настоящее раскрытие описывает методы построения для наборов параметров при кодировании видео, и более подробно, настоящее раскрытие описывает методы, относящиеся к наборам параметров видео (VPS). В дополнение к VPS другие примеры наборов параметров включают в себя наборы параметров последовательности (SPSs), наборы параметров картинки (PPSs), и наборы параметров адаптации (APSs), причем названы только некоторые.
[0030] Видео кодер кодирует данные видео. Данные видео могут включать в себя одну или более картинок, где каждая из картинок является неподвижным изображением, являющимся частью видео. Когда видео кодер кодирует данные видео, видео кодер генерирует поток битов, который включает в себя последовательность битов, которые формируют закодированное представление данных видео. Поток битов может включать в себя закодированные картинки и ассоциированные данные, при этом закодированная картинка ссылается на закодированное представление картинки. Ассоциированные данные могут включать в себя различные типы наборов параметров, включая VPSs, SPSs, PPSs, и APSs, и потенциально другие синтаксические структуры. SPSs используются для переноса данных, которые являются действительными для целой последовательности видео, тогда как PPSs несут информацию, действительную на основе картинка-за-картинкой. APSs несут адаптивную для картинки информацию, которая также является действительной на основе картинка-за-картинкой, но, как ожидается, будет изменяться более часто чем информация в PPS.
[0031] HEVC также ввел VPS, которые рабочий проект HEVC описывает следующим образом:
набор параметров видео (VPS): синтаксическая структура, содержащая элементы синтаксиса, которые применяются к нулю или более целым закодированным последовательностям видео, как определяется содержимым элемента синтаксиса video_parameter_set_id, найденного в наборе параметров последовательности, на который ссылается элемент синтаксиса seq_parameter_set_id, который найден в наборе параметров картинки, на который ссылается элемент синтаксиса pic_parameter_set_id, найденный в каждом заголовке сегмента вырезки.
[0032] Таким образом, поскольку наборы VPS применяются ко всем закодированным видео последовательностям, VPS включает в себя элементы синтаксиса, которые изменяются нечасто. Механизм VPS, SPS, PPS и APS в некоторых версиях HEVC разделяет передачу нечасто изменяющейся информации от передачи закодированных данных блока видео. Наборы VPS, SPS, PPS и APSs, в некоторых применениях могут быть переданы "вне полосы частот", то есть, транспортированы не вместе с блоками, содержащими закодированные данные видео. Передача вне полосы частот обычно надежна, и может быть желательна улучшенная надежность относительно передачи в полосе частот. В HEVC WD7, идентификатор (ID) для VPS, SPS, PPS или APS может быть закодирован для каждого набора параметров. Каждый SPS включает в себя ID SPS и ID VPS, каждый PPS включает в себя ID PPS и ID SPS, и каждый заголовок вырезки включает в себя ID PPS и возможно ID APS. Таким образом, ID может быть использован для идентификации надлежащего набора параметров, который должен использоваться в различных случаях.
[0033] Как описано выше, видео кодеры обычно кодируют данные видео, и декодеры типично декодируют данные видео. Кодеры и декодеры, однако, не являются единственными устройствами, используемыми для обработки данных видео. Когда видео транспортируется, например как часть основанной на пакетной передаче сети, такой как локальная сеть, региональная сеть, или глобальная сеть, такая как Интернет, устройства маршрутизации и другие такие устройства могут обрабатывать данные видео, чтобы доставить их из устройства источника к устройству назначения. Специальные устройства маршрутизации, иногда называемые «осведомленные о медиа элементы сети» (MANE), могут выполнять различные функции маршрутизации на основании содержимого данных видео. Чтобы определить содержимое данных видео и выполнить эти функции маршрутизации, MANE может обратиться к информации в закодированном потоке битов, такой как информация в VPS или SPS.
[0034] В наборе параметров некоторые элементы синтаксиса закодированы, используя фиксированное количество битов, в то время как некоторые элементы синтаксиса закодированы, используя переменное количество битов. Чтобы обрабатывать элементы синтаксиса переменной длины, устройство может требовать функциональных возможностей энтропийного декодирования. Выполнение энтропийного декодирования, однако, может ввести уровень сложности, который нежелателен для MANE или других элементов сети. Согласно одному методу, введенному в настоящем раскрытии, элемент синтаксиса смещения может быть включен в набор параметров, такой как VPS, чтобы помочь элементам сети в идентификации элементов синтаксиса, которые могут быть декодированы без какого-либо энтропийного декодирования. Элементу синтаксиса смещения могут предшествовать элементы синтаксиса фиксированной длины. Элемент синтаксиса смещения может затем идентифицировать элементы синтаксиса в наборе параметров, которые должны быть закодированы, используя элементы синтаксиса переменной длины. Используя элемент синтаксиса смещения, устройство, такое как MANE, может перескочить через закодированные элементы синтаксиса переменной длины и возобновить обработку элементов синтаксиса фиксированной длины. Элемент синтаксиса смещения может идентифицировать элементы синтаксиса, которые должны быть пропущены, посредством идентификации количества байтов в пределах набора параметров, которые должны быть пропущены. Эти пропущенные байты могут соответствовать пропущенным элементам синтаксиса. Как упомянуто выше, пропущенные элементы синтаксиса могут включать в себя закодированные элементы синтаксиса переменной длины и могут также включать в себя закодированные элементы синтаксиса фиксированной длины.
[0035] В этом контексте, пропуск элементов синтаксиса означает, что MANE может избежать синтаксических разборов или другой обработки элементов синтаксиса, которые закодированы с переменными длинами. Таким образом, MANE может обрабатывать некоторые элементы синтаксиса в VPS (например, элементы фиксированной длины), не имея необходимости выполнять энтропийное декодирование, в то же время пропуская некоторые элементы синтаксиса, которые могут иначе потребовать энтропийного декодирования. Элементы синтаксиса, пропущенные MANE, не ограничены элементами синтаксиса переменной длины, поскольку некоторые элементы синтаксиса фиксированной длины могут также быть пропущены в различных примерах. Видео декодер может быть сконфигурирован для, после приема элемента синтаксиса смещения, по существу игнорирования одного или более элементов синтаксиса, означая, что видео декодер может избежать синтаксического разбора и обработки элементов синтаксиса, которые были пропущены посредством MANE.
[0036] Использование элемента синтаксиса смещения может уменьшить сложность, необходимую для MANE, чтобы обрабатывать части набора параметров, например, избавляя от необходимости MANE выполнять энтропийное декодирование. Дополнительно, использование элемента синтаксиса смещения, как предложено в настоящем раскрытии, может обеспечить использование иерархического формата для наборов параметров. В качестве примера иерархического формата, в VPS, вместо того, чтобы иметь элементы синтаксиса для базового уровня и уровня расширения, смешанных в пределах VPS, все или по существу все элементы синтаксиса базового уровня могут предшествовать всем или по существу всем элементам синтаксиса первого уровня расширения, которые, в свою очередь, могут предшествовать всем или по существу всем элементам синтаксиса для второго уровня расширения, и так далее. Используя элемент синтаксиса смещения, введенный в настоящем раскрытии, MANE может обрабатывать количество элементов синтаксиса фиксированной длины для базового уровня, пропускать количество элементов синтаксиса переменной длины для базового уровня, обрабатывать количество элементов синтаксиса фиксированной длины для первого уровня расширения, пропускать количество элементов синтаксиса переменной длины для первого уровня расширения, обрабатывать количество элементов синтаксиса фиксированной длины для второго уровня расширения, и так далее. Видео декодер может быть сконфигурирован, чтобы синтаксически разбирать и обработать элементы синтаксиса, пропущенные MANE.
[0037] Использование элемента синтаксиса смещения может дополнительно обеспечить будущие расширения для стандарта кодирования видео. Например, даже если другие типы закодированной информации переменной длины были добавлены к потоку битов (например, согласно будущему расширению к HEVC), один или более элементов синтаксиса смещения могут быть определены, чтобы облегчить пропуск таких элементов переменной длины. Другими словами, один или более элементов синтаксиса смещения могут быть использованы для идентификации местоположения элементов синтаксиса фиксированной длины в пределах потока битов, и элементы синтаксиса смещения могут быть модифицированы, чтобы учесть дополнение любых других элементов в потоке битов, для которых декодирования может избежать, например, посредством MANE.
[0038] Настоящее раскрытие дополнительно предлагает включение элементов синтаксиса, относящиеся к согласованию сеанса в наборе параметров видео в противоположность другому набору параметров, такому как SPS. С помощью включения элементов синтаксиса, относящихся к согласованию сеанса в VPS, служебные расходы сигнализации могут быть в состоянии быть уменьшенными, особенно когда VPS описывает информацию для множественных уровней видео в противоположность информации только для единственного уровня. Кроме того, настоящее раскрытие предлагает использовать элементы синтаксиса фиксированной длины для элементов синтаксиса согласований сеанса, и элементы синтаксиса согласований сеанса фиксированной длины могут быть расположены перед любыми элементами синтаксиса переменной длины. Чтобы обрабатывать элементы синтаксиса переменной длины, устройство должно быть в состоянии выполнять энтропийное декодирование. Выполнение энтропийного декодирования, однако, может ввести уровень сложности, который нежелателен для MANE. Таким образом, посредством использования элементов синтаксиса фиксированной длины, которые присутствуют в VPS до каких-либо элементов синтаксиса переменной длины, MANE может быть в состоянии синтаксически разбирать элементы синтаксиса для согласований сеанса, не имея необходимости выполнять энтропийное декодирование.
[0039] Таблица 2 ниже показывает примеры относящихся к согласованию сеанса элементов синтаксиса, которые могут быть включены в VPS. Примеры информации для согласования сеанса включают в себя информацию, идентифицирующую профили, ярусы, и уровни. Рабочий проект HEVC описывает профили, ярусы, и уровни следующим образом.
"Профиль" является поднабором синтаксиса всего потока битов, который определен в соответствии с этой Рекомендацией | Международным Стандартом (Recommendation|International Standard). В пределах границ, наложенных синтаксисом заданного профиля, все еще возможно требовать очень большой вариации в производительности кодеров и декодеров в зависимости от значений, принятых элементами синтаксиса в потоке битов, такими как заданный размер декодированных картинок. Во многих применениях не является в настоящее время ни практичным, ни экономически выгодным, чтобы реализовать декодер, способный к иметь дело со всеми гипотетическими использованиями синтаксиса в пределах конкретного профиля.
Чтобы справляться с этой проблемой, "ярусы" и "уровни" определены в пределах каждого профиля. Уровень яруса является заданным набором ограничений, наложенных на значения элементов синтаксиса в потоке битов. Эти ограничения могут быть простыми пределами в отношении значений. Альтернативно они могут принимать форму ограничений в отношении арифметических комбинаций значений (например, ширина картинки, умноженная на высоту картинки, умноженная на количество картинок, декодированных в секунду). Уровень, определенный для нижнего яруса, является более ограниченным, чем уровень, определенный для более высокого яруса.
[0040] Во время согласований сеанса между клиентом и MANE, клиент может сделать запрос о пригодности в MANE данных видео, закодированных согласно некоторому профилю, уровню, и/или ярусу. MANE может быть в состоянии синтаксически разбирать первую часть (то есть, закодированную часть фиксированной длины) для VPS, которая включает в себя информацию профиля, уровня и яруса. Среди точек операции, доступных в MANE, надлежащая может быть выбрана клиентом, и MANE может отправить соответствующие пакеты клиенту после того, как сеанс согласован.
[0041] Настоящее раскрытие дополнительно предлагает включение элементов синтаксиса для идентификации гипотетического опорного декодера (HRD) в наборе параметров видео в противоположность другому набору параметров, такому как SPS. Параметры HRD идентифицируют гипотетическую модель декодера, которая задает ограничения на изменчивость (вариабельность) согласующихся потоков единиц NAL или согласующихся потоков байтов, которые может производить процесс кодирования. Два типа наборов параметров HRD (параметры HRD NAL и параметры HRD VCL) могут быть включены в VPS. Параметры HRD NAL принадлежат согласованности потока битов Типа II, в то время как параметры HRD VCL принадлежат согласованности всего битового потока. HEVC в настоящее время различал два типа потока битов, которые подлежат согласованности HRD. Первый называют потоком битов Типа I и относится к потоку единиц NAL, содержащему только единицы NAL VCL и единицам NAL данных заполнения для всех единиц доступа в потоке битов. Второй тип потока битов называют потоком битов Типа II и содержит единицы NAL VCL и единицы NAL данных заполнения для всех единиц доступа в потоке битов плюс другие типы дополнительных единиц NAL.
[0042] Методы настоящего раскрытия могут быть применены при кодировании единственного уровня так же как к масштабируемому кодированию и кодированию видео множественных видов. Уровень может, например, быть пространственным масштабируемым уровнем, уровнем масштабируемого качество, видом текстуры, или видом глубины. В HEVC уровень вообще относится к набору единиц NAL уровня кодирования видео (VCL), и ассоциированных единиц NAL не-VCL, которые все имеют значение ID конкретного уровня. Уровни могут быть иерархическими в смысле, что первый уровень может содержать более низкий уровень. Набор уровней иногда используется для обращения к набору уровней, представленных в пределах потока битов, созданного из другого потока битов с помощью операции процесса извлечения подпотока битов. Точка операции в целом относится к потоку битов, созданному из другого потока битов с помощью операции процесса извлечения подпотока битов с другим потоком битов. Точка операции может или включать в себя все уровни в набор уровней или может быть потоком битов, сформированным как поднабор набора уровней.
[0043] ФИГ. 1 является блок-схемой, иллюстрирующей примерную систему 10 кодирования и декодирования видео, которая может использовать методы, описанные в настоящем раскрытии. Как показано на ФИГ. 1, система 10 включает в себя исходное устройство 12, которое генерирует закодированные данные видео, которые должны быть декодированы в более позднее время устройством 14 назначения. Закодированные данные видео могут быть маршрутизированы от исходного устройства 12 к устройству 14 назначения осведомленным о медиа элементом сети (MANE) 29. Исходное устройство 12 и устройство 14 назначения может содержать любое из широкого диапазона устройств, включая настольные компьютеры, портативные (то есть ноутбуки) компьютеры, планшетные компьютеры, телевизионные приставки, телефонные трубки, такие как так называемые "интеллектуальные" («смарт») телефоны, так называемые "интеллектуальные" клавиатуры, телевизоры, камеры, устройства отображения, цифровые медиаплееры, пульты видео игр, устройство потоковой передачи видео, или подобное. В некоторых случаях исходное устройство 12 и устройство 14 назначения может быть оборудовано для беспроводной связи.
[0044] Система 10 может работать в соответствии с различными стандартами кодирования видео, составляющим собственность стандартом, или любым другим способом кодирования множественных видов. Например, видео кодер 20 и видео декодер 30 могут работать согласно стандарту сжатия видео, такому как включая в себя ITU-T H.261, ISO/IEC MPEG-1 Visual, ITU-T H.262 или ISO/IEC MPEG-2 Visual, ITU-T H.263, ISO/IEC MPEG-4 Visual и ITU-T H.264 (также известный как ISO/IEC MPEG-4 AVC), включая его расширения масштабируемого кодирования видео (SVC) и кодирования видео множественных видов (MVC). Недавний, публично доступный совместный проект расширения MVC описан в Advanced video coding for generic audiovisual services”, Recommendation H.264 ITU-T, март 2010. Более новый, публично доступный совместный проект расширения MVC описан в “Advanced video coding for generic audiovisual services,” ITU-T Recommendation H.264 ITU-T, июнь 2011. Текущий объединенный проект расширения MVC был одобрен в январе 2012.
[0045] Кроме того, имеется новый стандарт кодирования видео, а именно, стандарт высокоэффективного кодирования видео (HEVC), развиваемый Объединенной Командой Сотрудничества по кодированию видео (JCT-VC) Группы Экспертов по Кодированию видео ITU-T (VCEG) и ISO/IEC Группа Экспертов по движущимся изображениям (MPEG). Недавний рабочий проект (WD) HEVC, названный HEVC WD7 в дальнейшем, доступен, на 1 июля 2013, по адресу http://phenix.int-evry.fr/jct/doc_end_user/documents/9_Geneva/wg11/JCTVC-I1003-v6.zip.
[0046] Развитие стандарта HEVC является продолжающимся, и более новый рабочий проект (WD) HEVC, названный HEVC WD9 доступен, на 1 июля 2013, по адресу http://phenix.int-evry.fr/jct/doc_end_user/documents/11_Shanghai/wg11/JCTVC-K1003-10.zip. В целях описания видео кодер 20 и видео декодер 30 описаны в контексте HEVC или H.264 стандарта и расширений таких стандартов. Методы настоящего раскрытия, однако, не ограничены конкретным стандартом кодирования. Другие примеры стандартов сжатия видео включают в себя MPEG-2 и ITU-T H.263. Составляющие собственность кодирования методы, такие как названные On2 VP6/VP7/VP8, могут также реализовать один или более методов, описанных здесь. Более новый проект предстоящего стандарта HEVC, названного “HEVC Рабочий Проект 10” или “HEVC WD10,”, описан в Bross et al., “Editors’ proposed corrections to HEVC version 1,” Joint Collaborative Team on Video Coding (JCT-VC) of ITU-T SG16 WP3 and ISO/IEC JTC1/SC29/WG11, 13th Meeting, Incheon, KR, апрель 2013, который на 1 июля 2013, доступен по адресу http://phenix.int-evry.fr/jct/doc_end_user/documents/13_Incheon/wg11/JCTVC-M0432-v3.zip, все содержимое которого тем самым включено по ссылке.
[0047] Методы настоящего раскрытия потенциально применимы к нескольким MVC и/или стандартам кодирования 3D видео, включая 3D Кодирование видео на-основе HEVC (3D-HEVC). Методы настоящего раскрытия могут также быть применимыми к H.264/3D-AVC и H.264/MVC+D стандартам кодирования видео, или их расширениям, так же как и другим стандартам кодирования. Методы настоящего раскрытия могут время от времени быть описаны со ссылками на или использую терминологию конкретного стандарта кодирования видео; однако, такое описание не должно интерпретироваться, чтобы означать, что описанные методы ограничены только таким конкретным стандартом.
[0048] Устройство 14 назначения может принять закодированные данные видео, которые должны быть декодированы, через линию 16 связи. Линия 16 связи может содержать любой тип носителя или устройства, способного к перемещению закодированных данных видео от исходного устройства 12 к устройству 14 назначения. В одном примере, линия 16 связи может содержать коммуникационный носитель, чтобы разрешить исходному устройству 12 передавать закодированные данные видео непосредственно к устройству 14 назначения в реальном времени. Закодированные данные видео могут быть модулированы согласно стандарту связи, такому как протокол беспроводной связи, и переданы к устройству 14 назначения. Коммуникационный носитель может содержать любая беспроводной или проводной коммуникационный носитель, такой как радиочастотный (RF) спектр или одну или более физических линий передачи. Коммуникационный носитель может явиться частью основанной на пакетной передаче сети, такой как локальная сеть, региональная сеть, или глобальная сеть, такая как Интернет. Коммуникационный носитель может включать в себя маршрутизаторы, коммутаторы, базовые станции, или любое другое оборудование, которое может быть полезным, чтобы облегчить связь от исходного устройства 12 к устройству 14 назначения. Линия 16 связи может включать в себя одно или более MANE, такой как MANE 29, которые маршрутизируют данные видео от исходного устройства 12 к устройству 14 назначения.
[0049] Альтернативно, закодированные данные могут быть выведены из интерфейса 22 вывода на устройство 27 хранения. Аналогично, закодированные данные могут быть доступны от устройства 27 хранения с помощью интерфейса ввода. Устройство 27 хранения может включать в себя любой из множества распределенных или локально доступных запоминающих носителей данных, таких как накопитель на жестких дисках, диски Blu-ray, DVD, CD-ROM, флэш-память, энергозависимая или энергонезависимая память, или любые другие подходящие цифровые запоминающие носители для того, чтобы хранить закодированные данные видео. В другом примере устройство 27 хранения может соответствовать файловому серверу или другому промежуточному устройству хранения, которое может считать закодированное видео, генерируемое исходным устройством 12. Устройство 14 назначения может получить доступ к сохраненным данным видео от устройства 27 хранения через потоковую передачу или загрузку. Файловый сервер может быть любым типом сервера, способного к тому, чтобы хранить закодированные данные видео и передавать эти закодированные данные видео к устройству 14 назначения. Примерные файловые серверы включают в себя web-сервер (например, для веб-сайта), сервер FTP, устройства сетевого хранения (NAS), или локальный дисковый накопитель. Устройство 14 назначения может обращаться к закодированным видео данным через любое стандартное соединение данных, включая интернет-соединение. Оно может включать в себя беспроводный канал (например, соединение Wi-Fi), проводное соединение (например, DSL, кабельный модем, и т.д.), или комбинацию обоих, которое является подходящей для того, чтобы обратиться к закодированным видео данным, хранящимся на файловом сервере. Передача закодированных данных видео от устройства 27 хранения может быть потоковой передачей, передачей загрузки, или комбинацией обоих. Данные видео, извлеченные из устройства 27 хранения, могут быть маршрутизированы к устройству 14 назначения, используя один или более MANE, таких как MANE 29.
[0050] Методы настоящего раскрытия не обязательно ограничены беспроводными приложениями или параметрами настройки. Эти методы могут быть применены к кодированию видео в поддержку любого множества мультимедийных приложений, таких как эфирное телевидение, передачи кабельного телевидения, передачи спутникового телевидения, потоковые передачи видео, например, через Интернет, кодирование цифрового видео для хранения на запоминающем носителе данных, декодирование цифрового видео, сохраненного на запоминающем носителе данных, или других приложений. В некоторых примерах система 10 может быть сконфигурирована, чтобы поддерживать одностороннюю или двухстороннюю видео передачу, чтобы поддерживать приложения, такие как потоковая передача видео, воспроизведение видео, вещание видео, и/или видео телефония.
[0051] В примере согласно ФИГ. 1 исходное устройство 12 включает в себя видео источник 18, видео кодер 20 и интерфейс 22 вывода. Видео кодер 20 может, например, генерировать синтаксис смещения, описанный в настоящем раскрытии. В некоторых случаях интерфейс 22 вывода может включать в себя модулятор/демодулятор (модем) и/или передатчик. В исходном устройстве 12 видео источник 18 может включать в себя источник, такой как устройство захвата видео, например, видео камера, видео архив, содержащий ранее захваченное видео, интерфейс подачи видео, чтобы принять видео от поставщика контента видео, и/или систему компьютерной графики для того, чтобы генерировать данные компьютерной графики в качестве исходного видео, или комбинацию таких источников. В качестве одного примера, если видео источник 18 является видео камерой, исходное устройство 12 и устройство 14 назначения могут сформировать так называемые камерофоны или видео телефоны. Однако методы, описанные в настоящем раскрытии, могут быть применимыми к кодированию видео вообще, и могут быть применены к беспроводным и/или проводным приложениям.
[0052] Захваченное, предварительно захваченное, или машинно-генерируемое видео может быть закодировано видео кодером 12. Закодированные данные видео могут быть переданы непосредственно к устройству 14 назначения через интерфейс 22 вывода из исходного устройства 20. Закодированные данные видео могут также (или альтернативно) храниться на устройстве 27 хранения для более позднего доступа устройством 14 назначения или другим устройствам для декодирования и/или воспроизведения.
[0053] Устройство 14 назначения включает в себя интерфейс 28 ввода, видео декодер 30, и устройство 32 отображения. Видео декодер 30 может синтаксически разбирать элемент синтаксиса смещения, описанный в настоящем раскрытии. Как описано выше, видео декодер 30 может в некоторых случаях проигнорировать элемент синтаксиса смещения, таким образом разрешая видео декодеру 30 синтаксически разбирать элементы синтаксиса, пропущенные посредством MANE. В некоторых случаях интерфейс 28 ввода может включать в себя приемник и/или модем. Интерфейс 28 ввода из устройства 14 назначения принимает закодированные данные видео по линии 16 связи. Закодированные данные видео, переданные по линии 16 связи, или предоставленные на устройстве 27 хранения, могут включать в себя множество элементов синтаксиса, генерируемых видео кодером 20 для использования видео декодером, таким как видео декодер 30, при декодировании данных видео. Такие элементы синтаксиса могут быть включены с закодированными видео данными, переданными на коммуникационном носителе, сохраненными на запоминающем носителе, или сохраненными файловым сервером.
[0054] Устройство 32 отображения может быть интегрировано с, или быть внешним к, устройством 14 назначения. В некоторых примерах устройство 14 назначения может включать в себя интегрированное устройство отображения и также быть сконфигурированным, чтобы соединяться с внешним устройством отображения. В других примерах устройство 14 назначения может быть устройством отображения. Вообще, устройство 32 отображения отображает декодированные данные видео пользователю, и может содержать любое из множества устройств отображения, таких как жидкокристаллический дисплей (LCD), плазменный дисплей, дисплей на органических светоизлучающих диодах (OLED), или другой тип устройства отображения.
[0055] Хотя не показано на ФИГ. 1, в некоторых аспектах видео кодер 20 и видео декодер 30 могут каждый быть интегрированы с аудио кодером и декодером, и могут включать в себя соответствующие блоки MUX-DEMUX, или другое аппаратное обеспечение и программное обеспечение, чтобы обрабатывать кодирование и аудио и видео в общем потоке данных или отдельных потоках данных. Если применимо, в некоторых примерах блоки MUX-DEMUX могут соответствовать ITU H.223 протоколу мультиплексора, или другим протоколам, таким как протокол дейтаграмм пользователя (UDP).
[0056] Видео кодер 20 и видео декодер 30 каждый может быть реализован как любое из множества подходящих схем кодера, таких как один или более микропроцессоров, цифровых сигнальных процессоров (DSP), специализированных интегральных схем (ASIC), программируемых пользователем вентильных матриц (FPGA), дискретной логики, программного обеспечения, аппаратного обеспечения, программно-аппаратных средств или любых их комбинаций. Когда методы реализованы частично в программном обеспечении, устройство может сохранить инструкции для программного обеспечения в подходящем, невременном считываемом компьютером носителе и выполнять инструкции в аппаратном обеспечении, используя один или более процессоров, чтобы выполнить методы настоящего раскрытия. Каждый видео кодер 20 и видео декодер 30 может быть включен в один или более кодеров или декодеров, любой из которых может интегрироваться как часть объединенного кодера/декодера (кодек) в соответствующем устройстве.
[0057] JCT-VC работает над развитием стандарта HEVC. Усилия по стандартизации HEVC основаны на развивающейся модели устройства кодирования видео, называемой тестовой моделью HEVC (HM). HM предполагает несколько дополнительных функциональных возможностей устройств кодирования видео относительно существующих устройств согласно, например, ITU-T H.264/AVC. Например, тогда как H.264 обеспечивает девять режимов кодирования с внутренним предсказанием, HM может обеспечить целых тридцать три режима кодирования с внутренним предсказанием.
[0058] В целом, рабочая модель HM описывает, что видео кадр или картинка могут быть разделены на последовательность блоков дерева или наибольших единиц кодирования (LCU), которые включают в себя выборки и яркости и цветности. Блок дерева имеет аналогичную цель макроблоку из стандарта H.264. Вырезка включает в себя ряд последовательных блоков дерева в порядке кодирования. Видео кадр или картинка могут быть разделены на одну или более вырезок. Каждый блок дерева может быть разделен на единицы кодирования (CU) согласно квадродереву. Например, блок дерева, как корневой узел квадродерева, может быть разделен на четыре дочерних узла, и каждый дочерний узел может в свою очередь быть родительским узлом и быть разделен еще на четыре дочерних узла. Заключительный, неразделенный дочерний узел, как листовой узел квадродерева, содержит узел кодирования, то есть закодированный блок видео. Данные синтаксиса, ассоциированные с закодированным потоком битов, могут определить максимальное количество раз, сколько блок дерева может быть разделен, и может также определить минимальный размер узлов кодирования.
[0059] CU включает в себя узел кодирования и единицы предсказания (PU), и единицы преобразования (TU), ассоциированные с узлом кодирования. Размер CU соответствует размеру узла кодирования и должен быть квадратным по форме. Размер CU может ранжироваться от 8×8 пикселей до размера блока дерева с максимумом 64×64 пикселей или более. Каждая CU может содержать одну или более PU и одну или более TU. Данные синтаксиса, ассоциированные с CU, могут описывать, например, разделение CU в одну или более PU. Режим разделения может отличаться между тем, является ли CU закодированной в режиме пропуска или прямом, закодированной в режиме внутреннего предсказания, или закодированной в режиме внешнего предсказания. Единицы PU могут быть разделены, чтобы быть неквадратными по форме. Данные синтаксиса, ассоциированные с CU, могут также описывать, например, разделение CU в одну или более TU согласно квадродереву. TU может быть квадратной или неквадратной по форме.
[0060] Стандарт HEVC обеспечивает преобразования согласно TU, которые могут быть различными для различных CU. TU типично измеряется на основании размера единиц PU в пределах заданной CU, определенной для разделенной LCU, хотя это может не всегда иметь место. Единицы TU типично имеют тот же размер или меньший, чем единицы PU. В некоторых примерах остаточные выборки, соответствующие CU, могут быть подразделены на меньшие единицы, используя структуру квадродерева, известную как “остаточное квадродерево” (RQT). Листовые узлы RQT могут упоминаться как единицы преобразования (TU). Значения пиксельной разности, ассоциированные с единицами TU, могут быть преобразованы, чтобы сформировать коэффициенты преобразования, которые могут быть квантованы.
[0061] Обычно PU включает в себя данные, относящиеся к процессу предсказания. Например, когда PU является закодированной во внутреннем режиме, PU может включать в себя данные, описывающие режим внутреннего предсказания для PU. В качестве другого примера, когда PU является закодированной во внешнем режиме, PU может включать в себя данные, определяющие вектор движения для PU. Данные, определяющие вектор движения для PU, могут описывать, например, горизонтальный компонент вектора движения, вертикальный компонент вектора движения, разрешения для вектора движения (например, пиксельную точность в одну четверть или пиксельную точность в одну восьмую), опорную картинку, на которую вектор движения указывает, и/или список опорных картинок (например, Список 0, Список 1, или Список C) для вектора движения.
[0062] Вообще, TU используется для процессов квантования и преобразования. Заданная CU, имеющая одну или более единиц PU, может также включать в себя одну или более единиц преобразования (TU). Следуя предсказанию, видео кодер 20 может вычислить остаточные значения, соответствующие PU. Остаточные значения содержат значения пиксельной разности, которые могут быть преобразованы в коэффициенты преобразования, квантованы и сканированы, используя единицы TU, чтобы сформировать преобразованные в последовательную форму коэффициенты преобразования для энтропийного кодирования. Настоящее раскрытие обычно использует термин "блок видео", чтобы ссылаться на узел кодирования CU. В некоторых конкретных случаях настоящее раскрытие может также использовать термин "блок видео", чтобы ссылаться на блок дерева, то есть LCU, или CU, которая включает в себя узел кодирования и единицы PU и единицы TU.
[0063] Видео последовательность типично включает в себя последовательность видео кадров или картинок. Группа картинок (GOP) в целом содержит последовательность из одной или более видео картинок. GOP может включать данные синтаксиса в заголовке GOP, заголовке одной или более картинок, или где либо еще, которые описывают количество картинок, включенных в GOP. Каждая вырезка картинки может включать в себя данные синтаксиса вырезки, которые описывают режим кодирования для соответствующей вырезки. Видео кодер 20 типично оперирует над блоком видео в пределах индивидуальных видео вырезок, чтобы закодировать данные видео. Блок видео может соответствовать узлу кодирования в пределах CU. Блоки видео могут иметь фиксированный или переменный размеры, и могут отличаться по размеру согласно указанному стандарту кодирования.
[0064] В качестве примера HM поддерживает предсказание в различных размерах PU. Предполагая, что размер конкретной CU равен 2N×2N, HM поддерживает внутреннее предсказание в размерах PU 2N×2N или N×N, и внешнее предсказание в симметричных размерах PU 2N×2N, 2N×N, N×2N, или N×N. HM также поддерживает асимметричное разделение для внешнего предсказания в размерах PU 2N×nU, 2N×nD, nL×2N, и nR×2N. При асимметричном разделении одно направление CU не разделяется, в то время как другое направление разделяется на 25% и 75%. Часть CU, соответствующая 25%-ому разделению, обозначена “n”, сопровождаемым индикацией «верхний», «нижний», «левый» или «правый». Таким образом, например, “2N×nU” ссылается на CU размером 2N×2N, которая разделена горизонтально с PU размером 2N×0,5N сверху и PU размером 2N×1,5N внизу.
[0065] В настоящем раскрытии “N×N” и “N на N” может использоваться взаимозаменяемо, чтобы ссылаться на измерения в пикселях блока видео в терминах вертикальных и горизонтальных измерений, например, 16×16 пиксели или 16 на 16 пикселей. Вообще блок 16×16 имеет 16 пикселей в вертикальном направлении (y=16) и 16 пикселей в горизонтальном направлении (x=16). Аналогично, блок N×N вообще имеет N пикселей в вертикальном направлении и N пикселей в горизонтальном направлении, где N представляет неотрицательное целочисленное значение. Пиксели в блоке могут быть размещены в строках и колонках. Кроме того, блоки не обязательно должны иметь то же количество пикселей в горизонтальном направлении как в вертикальном направлении. Например, блоки могут содержать пиксели N×M, где М не обязательно равно N.
[0066] После кодирования с внутренним предсказанием или внешним предсказанием, используя единицы PU в CU, видео кодер 20 может вычислить остаточные данные для единиц TU в CU. Единицы PU могут содержать пиксельные данные в пространственной области (также называемой пиксельной областью), и единицы TU могут содержать коэффициенты в области преобразования после применения преобразования, например, дискретного косинусного преобразования (DCT), целочисленного преобразования, вейвлет преобразования, или концептуально подобного преобразования к остаточным видео данным. Остаточные данные могут соответствовать пиксельным разностям между пикселями незакодированной картинки и значениям предсказания, соответствующих единицам PU. Видео кодер 20 может сформировать единицы TU, включая остаточные данные для CU, и затем преобразовать единицы TU, чтобы сформировать коэффициенты преобразования для CU.
[0067] После любого преобразования, чтобы сформировать коэффициенты преобразования, видео кодер 20 может выполнить квантование коэффициентов преобразования. Квантование вообще относится к процессу, в котором коэффициенты преобразования квантуются, чтобы возможно уменьшить объем данных, использованных для представления коэффициентов, обеспечивая дальнейшее сжатие. Процесс квантования может уменьшить битовую глубину, ассоциированную с некоторыми или всеми коэффициентами. Например, значение n-битов может быть округлено в меньшую сторону до m-битового значения во время квантования, где n больше чем m.
[0068] В некоторых примерах видео кодер 20 может использовать заранее заданный порядок сканирования, чтобы сканировать квантованные коэффициенты преобразования, чтобы сформировать преобразованный в последовательную форму вектор, который может быть энтропийно кодирован. В других примерах видео кодер 20 может выполнить адаптивное сканирование. После просмотра квантованных коэффициентов преобразования, чтобы сформировать одномерный вектор, видео кодер 20 может энтропийно кодировать одномерный вектор, например, согласно контекстно-адаптивному кодированию с переменной длиной кода (CAVLC), контекстно-адаптивному двоичному арифметическому кодированию (CABAC), основанному на синтаксисе контекстно-адаптивному двоичному арифметическому кодированию (SBAC), энтропийному кодированию с разделением интервала вероятности (PIPE) или другой методологии энтропийного кодирования. Видео кодер 20 может также энтропийно кодировать элементы синтаксиса, ассоциированные с закодированными видео данными для использования видео декодером 30 при декодировании данных видео.
[0069] Чтобы выполнить CABAC, видео кодер 20 может назначить контекст в пределах контекстной модели символу, который должен быть передан. Контекст может относиться к тому, например, являются ли соседние значения символа ненулевыми или нет. Чтобы выполнить CAVLC, видео кодер 20 может выбрать код с переменной длиной слова для символа, который должен быть передан. Кодовые слова в VLC могут быть построены таким образом, что относительно более короткие коды соответствуют более вероятным символам, в то время как более длинные коды соответствуют менее вероятным символам. Таким образом, использование VLC может достигнуть экономии битов, например, используя ключевые слова равной длины для каждого символа, который должен быть передан. Определение вероятности может быть основано на контексте, назначенном на символ.
[0070] Настоящее раскрытие описывает способы построения для наборов параметров, включая как наборы параметров видео, так и наборы параметров последовательности, которые могут быть применены при кодировании единственного уровня, так же, как масштабируемое кодирование и кодирование множественных видов взаимно совместимым способом. Кодирование видео с множественными видами (MVC) является расширением H.264/AVC. Спецификация MVC кратко описана ниже.
[0071] ФИГ. 2 является графической диаграммой, иллюстрирующей пример кодирования или порядок декодирования MVC в соответствии с одним или более примерами, описанными в настоящем раскрытии. Например, компоновка порядка декодирования, иллюстрированная на ФИГ. 2, упоминается как первоначальное кодирование. На ФИГ. 2, S0-S7 каждый ссылается на различные виды видео с множественными видами. T0-T8 каждое представляет один момент времени вывода. Единица доступа может включать в себя закодированные картинки всех видов для одного момента времени вывода. Например, первая единица доступа включает в себя все виды S0-S7 для момента времени T0 (то есть, картинки 0-7), вторая единица доступа включает в себя все виды S0-S7 для момента времени T1 (то есть картинки 8-15), и т.д. В этом примеры картинки 0-7 находятся в одном и том же моменте времени (то есть, момент времени T0), картинки 8-15 находятся в одном и том же моменте времени (то есть, момент времени T1). Картинки с одним и тем же моментом времени вообще показаны в одно и то же время, и имеется разница по горизонтали, и возможно небольшая разница по вертикали, между объектами в пределах картинок одного и того же момента времени, которые заставляют зрителя воспринимать изображение, которое охватывает 3D объем.
[0072] На ФИГ. 2 каждый из видов включает в себя наборы картинок. Например, вид S0 включает в себя набор картинок 0, 8, 16, 24, 32, 40, 48, 56, и 64, вид S1 включает в себя набор картинок 1, 9, 17, 25, 33, 41, 49, 57, и 65, и т.д. Каждый набор включает в себя две картинки: одна картинка упоминается как компонент вида текстуры, а другая картинка упоминается как компонент вида глубины. Компонент вида текстуры и компонент вида глубины в пределах набора картинок вида можно рассматривать как соответствующие друг другу. Например, компонент вида текстуры в пределах набора картинок вида можно рассматривать как соответствующие компоненту вида глубины в пределах набора картинок вида, и наоборот (то есть компонент вида глубины соответствует своему компоненту вида текстуры в наборе, и наоборот). Как используется в настоящем раскрытии, компонент вида текстуры и компонент вида глубины, которые соответствуют, могут быть рассмотрены как часть одного и того же вида единственной единицы доступа.
[0073] Компонент вида текстуры включает в себя фактический контент изображения, который отображается. Например, компонент вида текстуры может включать в себя компоненты яркости (Y) и цветности (Cb и Cr). Компонент вида глубины может указывать, что относительные глубины пикселей в его соответствующей компоненте виде текстуры. В качестве одного примера, компонент вида глубины может быть аналогичным изображению шкалы серого, которая включает в себя только значения яркости. Другими словами, компонент вида глубины может не передавать контент изображения, а вместо этого обеспечивает меру относительных глубин пикселей в компоненте виде текстуры.
[0074] Например, пиксельное значение, соответствующее чисто белому пикселю в компоненте вида глубины может указывать, что его соответствующий пиксель или пиксели в соответствующем компоненте вида текстуры находится ближе с перспективы (точки зрения) зрителя, и пиксельное значение, соответствующее чисто черному пикселю в компоненте вида глубины может указывать, что его соответствующий пиксель или пиксели в соответствующем компоненте вида текстуры находится дальше от перспективы зрителя. Пиксельные значения, соответствующие различным оттенкам серого между черным и белым указывают различные уровни глубины. Например, очень серый пиксель в компоненте вида глубины указывает, что его соответствующий пиксель в компоненте вида текстуры находится дальше, чем слабо серый пиксель в компоненте вида глубины. Поскольку только одно пиксельное значение, аналогичное шкале серого, необходимо, чтобы идентифицировать глубину пикселей, компонент вида глубины может включать в себя только одно пиксельное значение. Таким образом, значения, аналогичные компонентам цветности, не являются необходимыми при кодировании глубины.
[0075] Компонент вида глубины, использующий только значения яркости (например, значения интенсивности), чтобы идентифицировать глубину, предоставлен в целях иллюстрации и не должен рассматриваться как ограничение. В других примерах любой метод может быть использован, чтобы указать относительные глубины пикселей в компоненте виде текстуры.
[0076] В соответствии с MVC, компоненты вида текстуры являются внешне предсказанными из компонентов вида текстуры в одном и том же виде или из компонентов вида текстуры в одном или более других видах. Компоненты вида текстуры могут быть закодированы в блоках данных видео, которые упоминаются "как блоки видео" и обычно называются "макроблоками" в контексте H.264.
[0077] В MVC предсказание между видами поддерживается компенсацией движения разности, которая использует синтаксис компенсации движения согласно H.264/AVC, но позволяет картинке в другом виде использоваться в качестве опорной картинки для предсказания закодированной картинки. Кодирование двух видов может также поддерживаться посредством MVC. Одно потенциальное преимущество MVC состоит в том, что кодер MVC может взять больше чем два вида в качестве входного 3D видео, и декодер MVC может декодировать такое представление с множественными видами захваченного видео. Любой модуль воспроизведения с декодером MVC может обрабатывать контенты 3D видео с более чем двумя видами.
[0078] В MVC предсказание между видами разрешается между картинками в одной и той же единице доступа (то есть с тем же самым моментом времени). При кодировании картинки в не-базовом виде картинка может быть добавлена в список опорных картинок, если картинка находится в другом виде, но с тем же самым моментом времени. Опорная картинка предсказания между видами может быть помещена в любую позицию списка опорных картинок, точно так же как любая опорная картинка при внешнем предсказании.
[0079] ФИГ. 3 является концептуальной диаграммой, иллюстрирующей примерный шаблон предсказания MVC. В примере на ФИГ. 3 иллюстрированы восемь видов (имеющие идентификаторы вида “S0”-“S7”), и двенадцать временных местоположений (“T0”-“T11”) иллюстрируются для каждого вида. Таким образом, каждая строка на ФИГ. 3 соответствует виду, в то время как каждая колонка указывает временное местоположение. В примере на ФИГ. 3, заглавные "B" и строчные “b” буквы используются для указания различные иерархических отношений между картинками, а не различные методологии кодирования. В целом, картинки с заглавными “B” находятся относительно выше в иерархии предсказания, чем кадры со строчными “b”.
[0080] На ФИГ. 3 вид S0 может быть рассмотрен как базовый вид, и виды S1-S7 могут быть рассмотрены как зависимые виды. Базовый вид включает в себя картинки, которые не являются предсказанным между видами. Картинка в базовом виде может быть внешне предсказана относительно других картинок в том же самом виде. Например, ни одна из картинок в поле зрения S0 не может быть внешне предсказана относительно картинки в любом из видов S1-S7, но некоторые из картинок в виде S0 могут быть внешне предсказаны относительно других картинок в виде S0.
[0081] Зависимый вид включает в себя картинки, которые являются предсказанными между видами. Например, каждый один из видов S1-S7 включает в себя по меньшей мере одну картинку, которая является внешне предсказанной относительно картинки в другом виде. Картинки в зависимом виде могут быть внешне предсказаны относительно картинок в базовом виде, или могут быть внешне предсказаны относительно картинок в других зависимых видах.
[0082] Поток видео, который включает в себя и базовый вид и один или более зависимых видов, может быть декодируемым посредством различных типов видео декодеров. Например, один основной тип видео декодера может быть сконфигурирован, чтобы декодировать только базовый вид. Кроме того, другой тип видео декодера может быть сконфигурирован, чтобы декодировать каждый из видов S0-S7. Декодер, который конфигурируется, чтобы декодировать и базовый вид и зависимые виды, может упоминаться как декодер, который поддерживает кодирование с множественными видами.
[0083] Картинки на ФИГ. 3 обозначены в пересечении каждой строки и каждой колонки на ФИГ. 3. Стандарт H.264/AVC с расширениями MVC может использовать термин «кадр», чтобы представить часть видео, в то время как стандарт HEVC может использовать термин «картинка», чтобы представить часть видео. Настоящее раскрытие использует термин картинка и кадр взаимозаменяемо.
[0084] Картинки на ФИГ. 3 иллюстрируются, используя затемненный блок, включающий в себя букву, которая обозначает, внутренне кодирована ли соответствующая картинка (то есть I-картинка), внешне кодирована в одном направлении (то есть как P-картинка), или внешне кодирована во множественных направлениях (то есть как B-картинка). Обычно предсказания указываются стрелками, где картинки, на которые указывают, используют картинки, из которых указывают для ссылки предсказания. Например, P-картинка вида S2 во временном местоположении T0 предсказана из I-картинки вида S0 во временном местоположении T0.
[0085] Как с кодированием видео с единственным видом, картинки последовательности видео кодирования видео с множественными видами могут быть закодированы с предсказанием относительно картинок в других временных местоположениях. Например, B-картинка вида S0 во временном местоположении T1 имеет стрелку, указывающую на нее из I-картинки вида S0 во временном местоположении T0, указывая, что b-картинка предсказана из I-картинки. Дополнительно, однако, в контексте кодирования видео с множественными видами, картинки могут быть предсказанными между видами. Таким образом, компонент вида (например, компонент вида текстуры) может использовать компоненты вида в других видах для ссылки. В MVC, например, реализуется предсказание между видами, как если компонент вида в другом виде является ссылкой внешнего предсказания. Потенциальные ссылки между видами сигнализируются в расширении MVC набора параметров последовательности (SPS) и могут быть модифицированы процессом построения списка опорных картинок, который разрешает гибкое упорядочение ссылок внешнего предсказания или предсказания между видами.
[0086] ФИГ. 3 обеспечивает различные примеры предсказания между видами. Картинки вида S1, в примере на ФИГ. 3, иллюстрируются как предсказываемые из картинок в других временных местоположениях вида S1, а также как предсказанные между видами из картинок видов S0 и S2 в одних и тех же временных местоположениях. Например, B-картинка вида S1 во временном местоположении T1 предсказывается из каждой из B-картинок вида S1 во временных местоположениях T0 и T2, так же, как B-картинок видов S0 и S2 во временном местоположении T1.
[0087] ФИГ. 3 также иллюстрирует изменения в иерархии предсказания, используя различные уровни затенения, где большая величина затенения (то есть относительно более темная) кадры находятся выше в иерархии предсказания, чем кадры, имеющие меньшее затенение (то есть относительно более светлые). Например, все I-картинки на ФИГ. 3 иллюстрируются с полным затенением, в то время как P-картинки имеют несколько более светлое затенение, и B-картинки (и строчные b-картинки) имеют различные уровни затенения друг относительно друга, но всегда светлее, чем затенение P-картинок и I-картинок.
[0088] Обычно иерархия предсказания может относиться к индексам порядка видов, в котором картинки относительно выше в иерархии предсказания должны быть декодированы прежде декодирования картинок, которые находятся относительно ниже в иерархии. Картинки относительно выше в иерархии могут быть использованы как опорные картинки во время декодирования картинок относительно более низких в иерархии. Индекс порядка вида является индексом, который указывает порядок декодирования компонентов вида в единице доступа. Индексы порядка вида подразумеваются в расширении MVC набора параметров последовательности (SPS), как определено в Приложении H для H.264/AVC (поправка MVC). В SPS для каждого индекса i сигнализируется соответствующий view_id. Декодирование компонентов вида может следовать возрастающему порядку индекса порядка вида. Если все виды представлены, то индексы порядка вида находятся в последовательном порядке от 0 до num_views_minus_1.
[0089] В этом способе картинки, используемые как опорные картинки, декодируются перед картинками, которые зависят от опорных картинок. Индекс порядка вида является индексом, который указывает порядок декодирования компонентов вида в единице доступа. Для каждого индекса i порядка вида сигнализируется соответствующий view_id. Декодирование компонентов вида следует возрастающим порядком индексов порядка вида. Если все виды представлены, то набор индексов порядка вида может содержать последовательно упорядоченный набор от ноля до менее, чем полное количество видов.
[0090] Для некоторых картинок на равных уровнях иерархии порядок декодирования может не имеет значения друг относительно друга. Например, I-картинка вида S0 во временном местоположении T0 может использоваться в качестве опорной картинки для P-картинки вида S2 во временном местоположении T0, которая, в свою очередь, может использоваться в качестве опорной картинки для P-картинки вида S4 во временном местоположении T0. Соответственно, I-картинка вида S0 во временном местоположении T0 должна быть декодирована перед P-картинкой вида S2 во временном местоположении T0, которая в свою очередь, должна быть декодирована перед P-картинкой вида S4 во временном местоположении T0. Однако между видами S1 и S3 порядок декодирования не имеет значения, так как виды S1 и S3 не полагаются на друг друга для предсказания. Вместо этого виды S1 и S3 предсказываются только из других видов, которые находятся выше в иерархии предсказания. Кроме того, вид S1 может быть декодирован перед видом S4, пока вид S1 декодируется после видов S0 и S2.
[0091] В этом способе иерархическое упорядочение может быть использовано для описания видов S0-S7. В настоящем раскрытии нотация “SA>SB” означает, что вид SA должен быть декодирован перед видом SB. Используя эту нотацию S0>S2>S4>S6>S7, в примере на ФИГ. 2. Кроме того, со ссылками на пример на ФИГ. 2, S0>S1, S2>S1, S2>S3, S4>S3, S4>S5, и S6>S5. Любой порядок декодирования для видов, который не нарушает этот иерархическое упорядочение, возможен. Соответственно, возможны много различных порядков декодирования, с ограничениями на основании иерархического упорядочения.
[0092] Расширение MVC SPS описано ниже. Компонент вида может использовать компоненты вида в других видах для ссылки, которую называют предсказанием между видами. В MVC реализуется предсказание между видами, как если компонент вида в другом виде был ссылкой внешнего предсказания. Потенциальные ссылки между видами, однако, сигнализируются в расширении MVC набора параметров последовательности (SPS) (как показано в следующей таблице синтаксиса, Таблице 1) и могут быть модифицированы процессом построения списка опорных картинок, который разрешает гибкое упорядочение ссылок внешнего предсказания или предсказания между видами. Видео кодер 20 представляет пример видео кодера, сконфигурированного, чтобы генерировать синтаксис, как показано в Таблице 1, и видео декодер 30 представляет пример видео декодера, сконфигурированного, чтобы синтаксически разбирать и обработать такой синтаксис.


[0093] В расширении MVC SPS для каждого вида, сигнализируются количество видов, которые могут быть использованным для формирования списка 0 опорных картинок и списка 1 опорных картинок. Отношения предсказания для картинки привязки, которая сигнализируется в расширении MVC SPS, могут отличаться от отношений предсказания для картинки непривязки (сигнализированной в расширении MVC SPS) одного и того же вида.
[0094] Наборы параметров для HEVC описаны ниже. В HEVC WD7, видео, последовательность, картинка и механизм набора параметров адаптации в HEVC разъединяют передачу нечасто изменяющейся информации от передачи закодированных данных блока. Видео, последовательность, картинка и наборы параметров адаптации, в некоторых приложениях, могут быть переданы "вне полосы частот", то есть не транспортированы вместе с единицами, содержащими закодированные данные видео. Передача вне полосы частот обычно надежна.
[0095] В HEVC WD7, идентификатор набора параметров последовательности (VPS), набор параметров последовательности (SPS), набор параметров картинки (PPS) или набор параметров адаптации (APS) видео кодируют, используя элемент синтаксиса переменной длины 'ue (v)'. Каждый SPS включает в себя ID SPS и ID VPS, каждый PPS включает в себя ID PPS и ID SPS, и каждый заголовок вырезки включает в себя ID PPS и возможно ID APS.
[0096] Хотя набор параметров видео (VPS) поддерживается в HEVC WD7, большинство параметров информации уровня последовательности все еще только присутствует в SPS. Существуют несколько проблем или потенциальных недостатков структуры VPS в WD7. В качестве одного примера, существенная величина информации, содержащейся в наборах SPS, может быть или одной и той же для всех SPS или быть одной и той же для по меньшей мере для SPS. Дублирование этой информации в SPS требует более высокой полосы частот. Наборы параметров (включая по меньшей мере VPS, SPS и PPS) может быть необходимо сигнализировать вне полосы частот. Если сигнализируются в полосе частот, такое увеличение скорости передачи в битах эффективно для каждой настройке в случайной точке доступа.
[0097] В качестве второго примера, в потенциальных расширениях HEVC, если аналогичные принципы структуры, как AVC, отслеживаются, то большинство информации описания рабочей точки не может быть включено в SPS или VPS, и вместо этого сообщения SEI могут использоваться для инициализации сеанса и согласований. Таким образом, для MANE может требоваться синтаксически разбирать сообщения SPS, VPS и SEI в вышеупомянутых целях. В качестве третьего примера, некоторая информация, которая присутствует в SPS в WD7, может быть изменена или удалена в расширениях HEVC.
[0098] Чтобы решить потенциальные проблемы, описанные выше, настоящее раскрытие предлагает несколько методов для структуры наборов параметров, включая VPS или другие наборы параметров. Например, согласно методам, описанным в настоящем раскрытии, информация, которая типично является одной и той же для всей закодированной последовательности видео, может присутствовать в VPS, в то время как только элементы синтаксиса, которые могут изменяться в уровне SPS, могут присутствовать в SPS. Другие элементы синтаксиса могут быть исключены из SPS, если уже представлены в VPS.
[0099] В качестве другого примера методов настоящего раскрытия, информация, относящаяся к согласованию сеанса, может быть представлена в VPS. Примеры информации, относящейся к согласованию сеанса, включают в себя информацию профиля, информацию уровня, информацию разрешения кадра, информацию скорости передачи кадра, и информацию частоты следования битов, так же как и другую информацию. В качестве другого примера методов настоящего раскрытия, VPS может быть построен таким способом, что синтаксический разбор информации рабочих точек, которые важны для согласований сеанса, не требует кодирования с переменной длиной кода, включая потенциально информацию и для базового уровня или вида и для уровней или видов расширения. Элементы синтаксиса в VPS могут быть сгруппированы так, чтобы для каждой группы расширение HEVC может обеспечить ноль или более экземпляров, и рабочие точки в расширении HEVC только ссылаются на индекс.
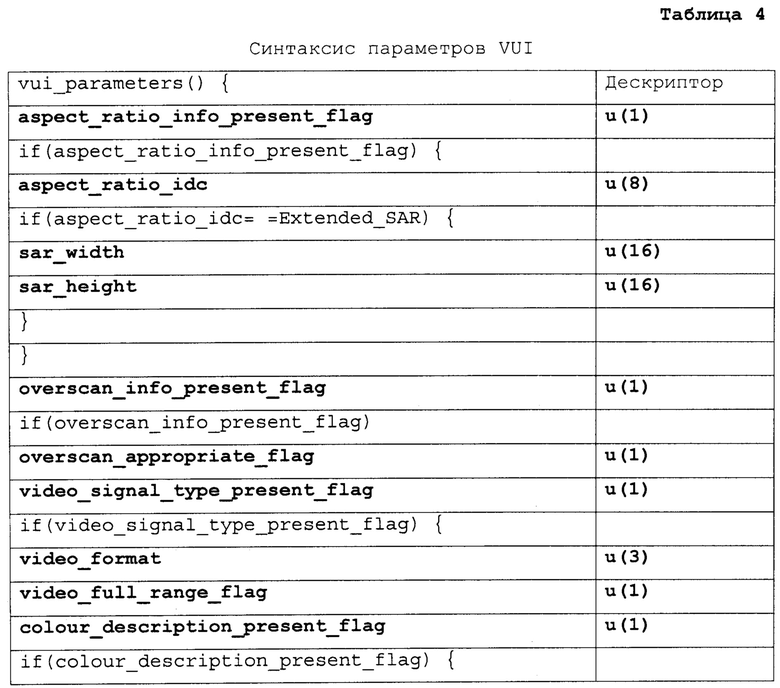
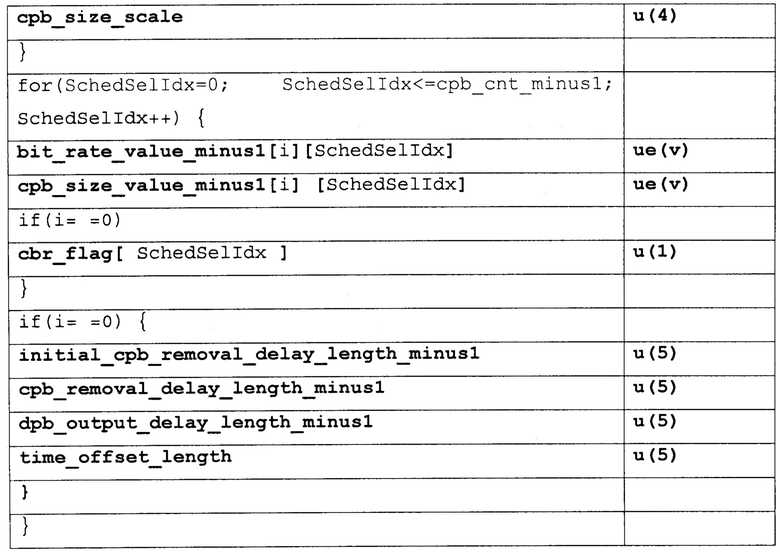
[0100] Различные примеры синтаксиса и семантики для VPS, SPS, информации удобства и простоты использования видео (VUI), и параметров HRD и заголовка вырезки предоставлены ниже. Таблицы 2-6 иллюстрируют первый пример. Таблица 1, представленная выше, показывает пример синтаксиса VPS. Колонки "Дескриптор" в Таблицах 2-6, так же, как в других таблицах в настоящем раскрытии, идентифицируют количество битов для каждого элемента синтаксиса, с “v”, указывающим, что количество битов может быть переменным. Значения количества в колонке "дескриптор" указывают, что элемент синтаксиса передают, используя фиксированное количество битов. Например, “u(8)” обозначает элемент синтаксиса с фиксированным количеством из восьми битов, тогда как “ue(v)” показывает элемент синтаксиса с переменным количеством битов. Чтобы синтаксически разбирать элементы синтаксиса с дескриптором ue (v), устройство синтаксического разбора (такое как видео декодер или MANE) может требовать реализовать энтропийное кодирование, чтобы декодировать и интерпретировать такие элементы синтаксиса.




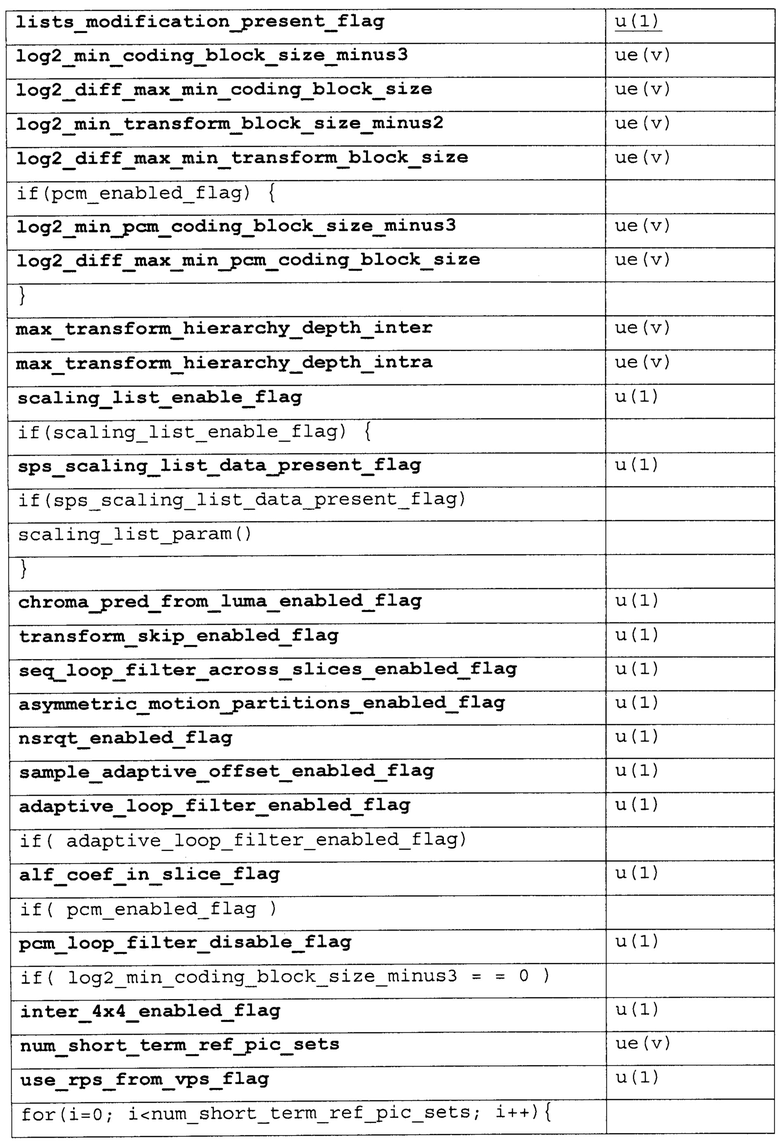
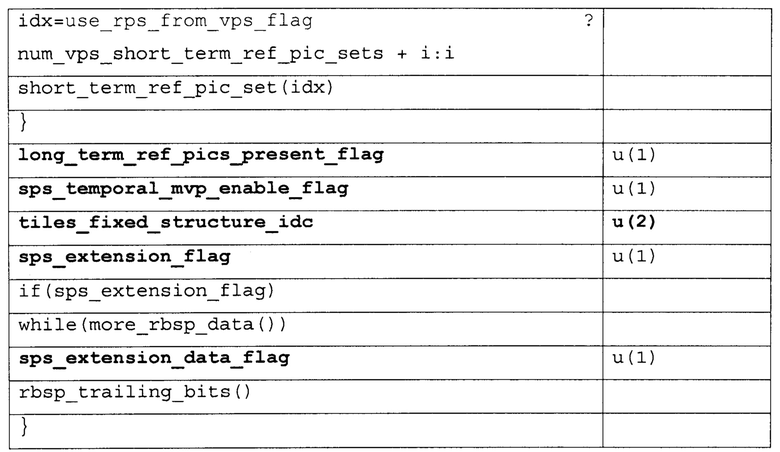


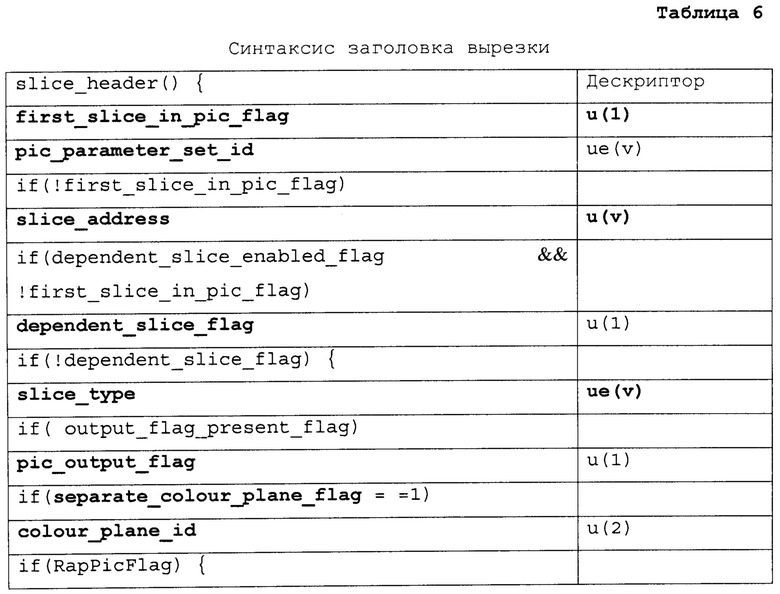



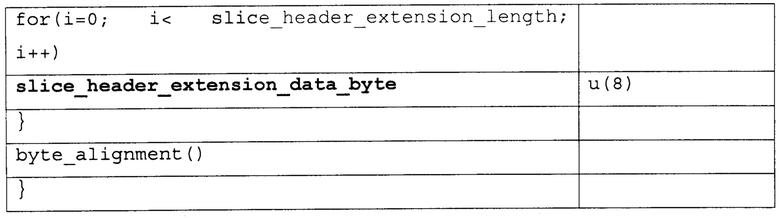
[0101] Семантика RBSP набора параметров видео, такая как показана в Таблице 2 выше, описана ниже. Элемент синтаксиса video_parameter_set_id в Таблице 2 обеспечивает идентификационную информацию для набора параметров видео. Используя значение video_parameter_set_id, другая синтаксическая структура, такая как SPS, может активизировать конкретный VPS. Таблица 3, например, которая показывает пример структуры синтаксиса SPS, также включает в себя элемент синтаксиса video_parameter_set_id. На основании значения элемента синтаксиса video_parameter_set_id в SPS, конкретный VPS, с одним и тем же значением может быть активизировано для того, чтобы кодировать блоки видео, ассоциированные с SPS. Как правило, множественные SPSs будут ассоциированы с одним и тем же VPS. В качестве примера видео декодер 30 может принять в данных видео первый SPS, который включает в себя первое значение для элемента синтаксиса video_parameter_set_id, и видео декодер 30 может также принять второй SPS, который включает в себя то же самое значение для элемента синтаксиса video_parameter_set_id. Первый SPS может быть первой структурой синтаксиса, включающей в себя первую группу элементов синтаксиса, которые применяются к одной или более целым картинкам данных видео, и второй SPS может быть второй структурой синтаксиса, которая включает в себя вторую группу элементов синтаксиса, которые применяются к одной или более другим целым картинкам данных видео. Видео декодер 30 декодирует блоки видео, ассоциированные как с первым SPS так и со вторым SPS, на основании параметров от одного и того же VPS.
[0102] Элементы синтаксиса profile_space, profile_idc, profile_compatability_flag [i], constraint_flags, level_idc, bit_depth_luma_minus8, bit_depth_chroma_minus8, chroma_format_idc, pic_width_in_luma_samples, pic_height_in_luma_samples, pic_cropping_flag, pic_crop_left_offset, pic_crop_right_offset, pic_crop_top_offset, pic_crop_bottom_offset, temporal_id_nesting_flag и separate_colour_plane_flag имеют ту же самую семантику тех элементов синтаксиса с теми же самыми именами элементов синтаксиса в наборе параметров последовательности, как определено в WD7, но согласно предложенным методам настоящего раскрытия, были перемещены из SPS в VPS.
[0103] Элемент синтаксиса profile_space идентифицирует контекст для интерпретации элемента синтаксиса profile_idc, и элемент синтаксиса profile_idc идентифицирует группу профилей. Элементы синтаксиса profile_compatability_flag[i] может идентифицировать, если данные видео совместимы с профилем [i]. Видео декодер 30 может, например, принять в данных видео значения для profile_space и profile_idc, и на основании значения profile_space идентифицировать контекст для интерпретации элемента синтаксиса profile_idc. На основании интерпретированного значения profile_idc видео декодер 30 может идентифицировать группу профилей, и для каждого профиля видео декодер 30 может принять значение для элемента синтаксиса profile_compatability_flag [i], чтобы идентифицировать, если данные видео совместимы с профилем [i]. Элемент синтаксиса profile_idc может, например, иметь 32 ассоциированных флага, причем каждый флаг указывает конкретный аспект профиля. Например, флаг может указывать, если один конкретный инструмент кодирования или обработки включен или выключен, заданный один и тот же профиль.
[0104] Элемент синтаксиса level_idc идентифицирует максимальный уровень, ассоциированный с видео данными, и элемент синтаксиса level_lower_temporal_layers_present_flag идентифицирует, если временной уровень данных видео имеет уровень, который ниже чем максимальный уровень. Элемент синтаксиса level_lower_temporal_layers_present_flag установил равный 1, определяет, что level_idc_temporal_subset [i] может присутствовать. Элемент синтаксиса level_lower_temporal_layers_present_flag установленный равным 0, задает, что level_idc_temporal_subset [i] не присутствует. Элемент синтаксиса level_idc_temporal_subset [i] задает уровень, которому поднабор потока битов, состоящий из всех единиц NAL с temporal_id, меньшим чем или равным I, соответствует.
[0105] Видео декодер 30 может, например, в ответ на прием элемента синтаксиса level_lower_temporal_layers_present_flag, установленный равным 1, принимать элементы синтаксиса level_idc_temporal_subset [i]. Элементы синтаксиса level_idc_temporal_subset [i] могут присутствовать, чтобы идентифицировать уровень, которому временной уровень [i] соответствует.
[0106] Элементы синтаксиса vps_temporal_id_nesting_flag, vps_temporal_id_nesting_flag, vps_max_dec_pic_buffering [i], vps_num_reorder_pics [i], и vps_max_latency_increase [i] имеют ту же самую семантику следующих элементов синтаксиса соответственно в наборе параметров последовательности HEVC WD 7: sps_temporal_id_nesting_flag, sps_temporal_id_nesting_flag, sps_max_dec_pic_buffering [i], sps_num_reorder_pics [i], sps_max_latency_increase [i].
[0107] Элемент синтаксиса next_essential_info_byte_offset является примером элемента синтаксиса смещения, введенного в настоящем раскрытии. Элемент синтаксиса next_essential_info_byte_offset задает смещение в байтах следующего набора профиля и информацию уровня, и другую закодированную информацию фиксированной длины в единице NAL VPS, начиная от начала единицы NAL. MANE 29, например, может принять элемент синтаксиса next_essential_info_byte_offset и определить количество байтов, указанное элементом синтаксиса next_essential_info_byte_offset, и на основании определенного количества байтов, MANE 29 может пропустить один или более закодированных элементов синтаксиса переменной длины, показанных в Таблице 2, таких как элементы синтаксиса переменной длины pic_crop_left_offset, pic_crop_right_offset, pic_crop_top_offset, pic_crop_bottom_offset, и другие элементы синтаксиса переменной длины, показанные в Таблице 2. Видео декодер 30, однако, после приема элемента синтаксиса next_essential_info_byte_offset может проигнорировать значение этого элемента синтаксиса. Таким образом, после синтаксического разбора элемента синтаксиса next_essential_info_byte_offset видео декодер 30 может продолжить синтаксически разбирать элементы синтаксиса переменной длины pic_crop_left_offset, pic_crop_right_offset, pic_crop_top_offset, pic_crop_bottom_offset, и другие элементы синтаксиса переменной длины, показанные в Таблице 2.
[0108] В будущем расширении спецификации HEVC, например, расширении масштабируемого кодирования или 3DV расширение, информация VPS для небазового уровня или вида могут быть включены в единицу NAL VPS после информации VPS для базового уровня или вида. Информация VPS для небазового уровня или вида также может начаться с элементов синтаксиса фиксированной длины, таких как закодированный профиль, уровень, и другая информация, существенная для согласования сеанса. Используя смещение в битах, заданное с помощью next_essential_info_byte_offset, MANE 29 может определить местонахождение и осуществить доступ к этой существенной информации в единице NAL VPS без необходимости выполнять энтропийное декодирование. Некоторые сетевые объекты (например MANE 29), сконфигурированные, чтобы транспортировать и обрабатывать данные видео могут не быть оборудованы для энтропийного декодирования. Используя элемент синтаксиса смещения, как описано в настоящем раскрытии, однако, такие сетевые объекты могут все еще обработать некоторые аспекты набора параметров, и использовать информацию, содержащуюся в обработанном элементе синтаксиса при выполнении маршрутизации для данных видео. Пример информации, которую может обрабатывать сетевой объект при выполнении маршрутизации, включает в себя информацию, относящуюся к согласованию сеанса.
[0109] Элементы синтаксиса nal_hrd_parameters_present_flag [i] и vcl_hrd_parameters_present_flag [i] имеют аналогичную семантику как nal_hrd_parameters_present_flag, и vcl_hrd_parameters_present_flag, которые присутствуют в параметрах VUI WD7, но применимы к представлению i-го временного уровня. Элемент синтаксиса nal_hrd_parameters_present_flag может, например, сигнализировать любые параметры HRD, такие как скорость передачи в битах, размер буфера закодированных картинок (CPB), и начальная задержка удаления CPB (initial_cpb_removal_delay_length_minus1), задержка удаления CPB (cpb_removal_delay_length_minus1), задержка вывода DPB (dpb_output_delay_length_minus1), и длина смещения времени (time_offset_length). Элементы синтаксиса могут, например, включать в себя элемент синтаксиса (cbr_flag) указывающий, является ли частота следования битов для видео даты постоянной или переменной.
[0110] Элемент синтаксиса low_delay_hrd_flag может быть использован для указания времени удаления единицы декодирования из DPB. Элемент синтаксиса sub_pic_cpb_params_present_flag, равный 1, может задавать, что параметры задержки удаления CPB уровня суб-картинок присутствуют, и CPB может работать на уровне единицы доступа или уровне суб-картинок. Элемент синтаксиса sub_pic_cpb_params_present_flag, равный 0, может задавать, что параметры задержки удаления CPB уровня суб-картинок не присутствуют, и CPB работает на уровне единицы доступа. Элемент синтаксиса num_units_in_sub_tick представляет количество единиц времени тактового генератора, работающего на частоте time_scale Гц, которое соответствует одному приращению (называемое тактовым циклом суб-картинки) счетчика тактовых циклов суб-картинки. Параметры HRD, описанные выше, могут быть применимыми ко всем представлениям временного уровня.
[0111] Элемент синтаксиса vui_video_parameters_present_flag установленный равным 1, задает, что синтаксическая структура vui_vps () присутствует в VPS. Этот флаг, установленный равным 0, задает, что элемент синтаксиса vui_vps () не присутствует. Элемент синтаксиса num_vps_short_term_ref_pic_sets задает количество наборов краткосрочных опорных картинок, которые заданы в наборе параметров видео. Элемент синтаксиса bitrate_info_present_flag[i], установленный равным 1, задает, что информация частоты следования битов для i-го временного уровня присутствует в наборе параметров видео. Элемент синтаксиса bitrate_info_present_flag[i], установленный в 0, задает, что информация частоты следования битов для i-го временного уровня не присутствует в VPS.
[0112] Элемент синтаксиса frm_rate_info_present_flag[i], установленный в 1, задает, что информация скорости передачи кадра для i-го временного уровня присутствует в наборе параметров видео. Элемент синтаксиса frm_rate_info_present_flag[i], установленный равным 0, задает, что информация скорости передачи кадра для i-го временного уровня не присутствует в наборе параметров видео.
[0113] Элемент синтаксиса avg_bitrate [i] указывает среднюю частоту следования битов представления i-го временного уровня. Средняя частота следования битов для представления i-го временного уровня в битах в секунду задана посредством BitRateBPS (avg_bitrate [i]) с функцией BitRateBPS (), задаваемой посредством
BitRateBPS (x)=(x & (214−1))* 10(2+(x>>14))
[0114] Средняя частота следования битов может быть выведена согласно времени удаления единицы доступа, заданному в Приложении C стандарта HEVC. Ниже, bTotal является количеством битов во всех единицах NAL представления i-го временного уровня, t1 - время удаления (в секундах) первой единицы доступа, к которой применяется VPS, и t2 - время удаления (в секундах) последней единицы доступа (в порядке декодирования), к которой применяется VPS.
[0115] С x, задающем значения avg_bitrate [i], применяется следующее:
- Если t1 не равен t2, следующее условие может быть верным:
(x & (214−1))= =Round (bTotal ÷ ((t2−t1)* 10(2+ (x>>14))))
- Иначе (t1 равно t2), следующее условие может быть верным:
(x & (214−1))= =0
[0116] Элемент синтаксиса max_bitrate_layer [i] указывает верхнюю границу для частоты следования битов представления i-го временного уровня в любом первом-втором временном окне, времени удаления единицы доступа, как задано в Приложении C. Верхняя граница частоты следования битов текущего масштабируемого уровня в битах в секунду дано BitRateBPS (max_bitrate_layer [i]) с функцией BitRateBPS () задаваемой в Уравнении G-369. Значения частоты следования битов выводятся согласно времени удаления единицы доступа, заданному в Приложении C стандарта HEVC. В последующем описании t1 - любая точка во времени (в секундах), t2 установлена равной t1 + max_bitrate_calc_window [i]÷100, и bTotal - есть количество битов во всех единицах NAL текущего масштабируемого уровня, которые принадлежат единицам доступа с временем удаления, большим чем или равным t1 и меньшим, чем t2. С x, задающим значение max_bitrate_layer [i], следующему условию могут подчиняться все значения t1:
(x & (214−1)) >=bTotal ÷ ((t2−t1)* 10(2+ (x>>14))).
[0117] Элемент синтаксиса constant_frm_rate_idc[i] указывает, является ли скорость передачи кадров представления i-го временного уровня постоянной. В последующем описании временный сегмент tSeg является любым набором из двух или более последовательных единиц доступа, в порядке декодирования, представления текущего временного уровня, fTotal (tSeg) - количество картинок во временном сегменте tSeg, t1 (tSeg) - время удаления (в секундах) первой единицы доступа (в порядке декодирования) временного сегмента tSeg, t2 (tSeg) - время удаления (в секундах) последней единицы доступа (в порядке декодирования) временного сегмента tSeg, и avgFR (tSeg) является средней скоростью передачи кадра во временном сегменте tSeg, которым дают:
avgFR (tSeg)= =Round (fTotal (tSeg)* 256 ÷ (t2 (tSeg)−t1 (tSeg)))
[0118] Если представление i-го временного уровня действительно содержит только одну единицу доступа, или значение avgFR (tSeg) является постоянным по всем временным сегментам представления i-го временного уровня, скорость передачи кадров является постоянной; иначе, скорость передачи кадров не является постоянной. Элемент синтаксиса constant_frm_rate_idc[i], установленный равным 0, указывает, что скорость передачи кадров представления i-го временного уровня не является постоянной. Элемент синтаксиса constant_frm_rate_idc[i], установленный равным 1, указывает, что скорость передачи кадров представления i-го временного уровня является постоянной.
[0119] Элемент синтаксиса constant_frm_rate_idc[i], установленный равным 2, указывает, что скорость передачи кадров представления i-го временного уровня может является или может не является постоянной. Значение constant_frm_rate_idc [i] может быть в диапазоне от 0 до 2 включительно.
[0120] Элемент синтаксиса avg_frm_rate [i] указывает среднюю скорость передачи кадров, в единицах кадров за 256 секунд, представления i-го временного уровня. С fTotal, являющимся количеством картинок в представлении i-го временного уровня, t1 являющимся временем удаления (в секундах) первой единицы доступа, к которой VPS применяется, и t2, являющимся временем удаления (в секундах) последней единицы доступа (в порядке декодирования), к которой применяется VPS, применяется следующее:
[0121] Если t1 не равно t2, следующее условие может быть верным:
avg_frm_rate [i]= =Round (fTotal * 256 
Иначе (t1 равно t2), следующее условие может быть верным:
avg_frm_rate [i]= =0
[0122] Семантика параметров VUI описана ниже. Каждый элемент синтаксиса в параметрах VUI имеет ту же семантику, как элемент синтаксиса с тем же названием в синтаксисе параметров VUI, как задано в WD7.
[0123] Семантики RBSP набора параметров последовательности описаны ниже. Элемент синтаксиса use_rps_from_vps_flag, установленный равным 1, задает, что наборы краткосрочных опорных картинок, включенные в набор параметров последовательности, являются аддитивными к наборам краткосрочных опорных картинок, включенных в набор параметров видео, на который ссылаются. Элемент синтаксиса use_rps_from_vps_flag, установленный равным 0, задает, что наборы краткосрочных опорных картинок, включенные в набор параметров последовательности, замещают наборы краткосрочных опорных картинок, включенные в набор параметров видео, на который ссылаются.
[0124] Альтернативно, элемент синтаксиса num_short_term_ref_pic_sets может не присутствовать в SPS и может всегда логически выводиться, чтобы быть установленным равным 0. Альтернативно, элемент синтаксиса use_rps_from_vps_flag может не присутствовать и может всегда логически выводиться, чтобы быть установленным равным 1. Альтернативно, элемент синтаксиса use_rps_from_vps_flag может не присутствовать и может всегда логически выводиться, чтобы быть установленным равным 0.
[0125] Переменная NumShortTermRefPicSets может быть выведена следующим образом.
NumShortTermRefPicSets = num_short_term_ref_pic_sets
if (use_rps_from_vps_flag)
NumShortTermRefPicSets + = num_vps_short_term_ref_pic_sets
[0126] Семантики заголовка вырезки описаны ниже. Элемент синтаксиса short_term_ref_pic_set_idx задает индекс в списке наборов краткосрочных опорных картинок, заданных в активном наборе параметров последовательности, который может использоваться для создания набора опорных картинок текущей картинки. Элемент синтаксиса short_term_ref_pic_set_idx может быть представлен посредством Ceil(Log2 (NumShortTermRefPicSets)) битов. Значение short_term_ref_pic_set_idx может быть в диапазоне от 0 до num_short_term_ref_pic_sets − 1, включительно, где num_short_term_ref_pic_sets является элементом синтаксиса из активного набора параметров последовательности.
[0127] Переменная StRpsIdx может быть выведена следующим образом.
if (short_term_ref_pic_set_sps_flag)
StRpsIdx = short_term_ref_pic_set_idx
else
StRpsIdx = NumShortTermRefPicSets
[0128] Элемент синтаксиса tiles_fixed_structure_idc, установленный равным 0, указывает, что каждый набор параметров картинки, на который ссылаются посредством любой картинки в закодированной последовательности видео, имеет набор tiles_or_entropy_coding_sync_idc, равный 0. Элемент синтаксиса tiles_fixed_structure_idc, установленный равным 1, указывает, что каждый набор параметров картинки, на который ссылаются посредством любой картинки в закодированной последовательности видео, имеет одно и то же значение элементов синтаксиса num_tile_columns_minus1, num_tile_rows_minus1, uniform_spacing_flag, column_width [i], row_height [i] и loop_filter_across_tiles_enabled_flag, когда присутствуют. Элемент синтаксиса tiles_fixed_structure_idcg, установленный равным 2, указывает, что элементы синтаксиса ячеек в различных наборах параметров картинки, на которые ссылаются посредством картинок в закодированной последовательности видео, могут иметь или могут не иметь одно и то же значение. Значение tiles_fixed_structure_idc может быть в диапазоне от 0 до 2, включительно. Когда элемент синтаксиса tiles_fixed_structure_flag не присутствует, он логически выводится, чтобы быть равным 2.
[0129] Сигнализация элемента синтаксиса tiles_fixed_structure_flag, установленного равным 1, может быть гарантией декодеру, что каждая картинка в закодированной последовательности видео имеет то же самое количество ячеек (элементов), распределенных одинаковым образом, который может быть полезным для распределения рабочей нагрузки в случае мультипотокового декодирования.
[0130] Второй пример, аналогичный первому примеру, описанному выше, описан ниже. В этом втором примере элементы синтаксиса, остающиеся в SPS, могут присутствовать в VPS и условно присутствовать в SPS. Синтаксис и семантика VPS и SPS согласно этому примеру изменены и описаны ниже в Таблицах 7-9.






[0131] Семантика необязательных параметров SPS описана ниже. Семантика элементов синтаксиса и структуры синтаксиса в этой структуре синтаксиса имеют ту же самую семантику, как элементы синтаксиса таковых в SPS с теми же самыми именами элементов синтаксиса, как задано в первом примере.
[0132] Семантика RBSP набора параметров последовательности описана ниже. Элемент синтаксиса sps_parameters_override_flag, установленный равным 1, задает, что значения элементов синтаксиса и структуры синтаксиса от pcm_enabled_flag до tiles_fixed_structure_idc как задано в наборе параметров последовательности, замещают значения тех же самых элементов синтаксиса и структур синтаксиса, как задано в наборе параметров видео, на который ссылаются. Элемент синтаксиса sps_parameters_override_flag, установленный равным 0, значения элементов синтаксиса и структуры синтаксиса от pcm_enabled_flag до tiles_fixed_structure_idc, как задано в наборе параметров видео, на который ссылаются, используются.
[0133] Элемент синтаксиса next_essential_byte_offset, показанный в Таблице 7, может быть обработан и синтаксически разобран посредством MANE 29 и/или видео декодера 30 таким же образом, как описано выше со ссылками на Таблицу 2. Аналогично, элементы синтаксиса, video_parameter_set_id, profile_idc и profile_space могут также генерироваться видео кодером 20 и обрабатываться и синтаксически разбираться видео декодером 30 таким же образом, как описано выше.
[0134] Третий пример является расширенным набором первого примера. В этом третьем примере синтаксис может быть построен способом, который делает расширения легче для реализации. Кроме того, расширение VPS может быть поддержано в этом примере. Построение синтаксиса или построение семантики таблицы синтаксиса, которая является точно такой же как соответствующая в первом примере, не присутствует. Третий пример описан ниже со ссылками на Таблицы 10-19.







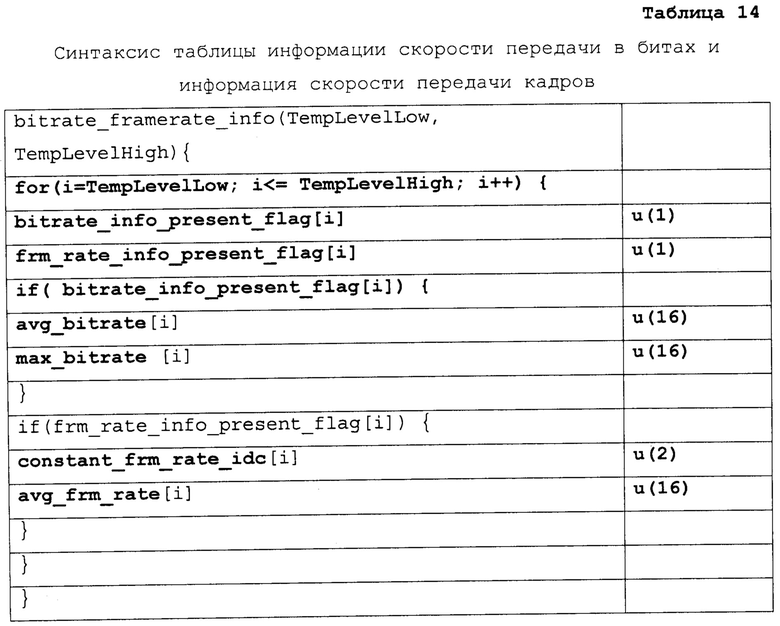




[0135] Семантика RBSP набора параметров видео описана ниже. Элемент синтаксиса byte_alligned_bits задает возможные биты, которые делают биты в единице NAL VPS до num_additional_profile_level_info байта выровненными. Элемент синтаксиса byte_alligned_bits находится в диапазоне от 0 до 7, включительно. Элемент синтаксиса num_additional_profile_level_info задает номер дополнительной таблицы информации профиля и уровня, присутствующего в VPS. Элемент синтаксиса num_additional_rep_fromat_info задает количество дополнительных таблиц информации формата представления, присутствующих в VPS. Элемент синтаксиса num_additional_dependency_operation_points задает количество рабочих точек зависимости, дополнительно присутствующих в потоке битов, независимо от временной масштабируемости. Каждая рабочая точка зависимости может включать в себя временные суб рабочие точки, каждая имеющая одну и ту же структуру уровня. Элемент синтаксиса extension_type задает тип расширения текущего потока битов, с 0, соответствующим 3DV, и 1, соответствующей SVC. Элемент синтаксиса profile_level_index [k] указывает индекс таблице информации уровня, сигнализированной в VPS для текущей k-й рабочей точки зависимости. Элемент синтаксиса ref_format_index указывает индекс таблице информации формата представления, сигнализированной в VPS для текущей k-й рабочей точки зависимости.
[0136] Элемент синтаксиса applicable_lowest_temporal_id [k] и applicable_highest_temporal_id [k] задает соответственно самое низкое значение temporal_id и самое высокое значение temporal_id, соответствующее сигнализированным временным точкам суб-операции k-й рабочей точки зависимости. Альтернативно, элементы синтаксиса applicable_lowest_temporal_id [k] и applicable_highest_temporal_id [k] обе не сигнализируются и логически выводятся, чтобы быть равными 0 и vps_max_temporal_layers_minus1, соответственно. Альтернативно, элемент синтаксиса applicable_lowest_temporal_id [k] не сигнализируется и логически выводится, чтобы быть равным 0. Альтернативно, элемент синтаксиса applicable_highest_temporal_id [k] не сигнализируется и логически выводится, чтобы быть равным vps_max_temporal_layers_minus1.
[0137] Элемент синтаксиса depth_included_flag [k], равный 1, указывает, что текущая рабочая точка зависимости 3DV содержит глубину. Этот флаг, равный 0, указывает, что поток рабочая точка 3DV не содержит глубину. Альтернативно, элемент синтаксиса depth_included_flag [k] не сигнализируется, таким образом указывая, что единица NAL VCL глубины полагается на layer_id_plust1.
[0138] Элемент синтаксиса num_target_output_views_minus1 [k] плюс 1 задает количество целевых видов вывода в k-й рабочей точки зависимости. Элемент синтаксиса num_depedent_layers [k] указывает количество зависимых уровней для декодирования текущей k-й рабочей точки зависимости. Элемент синтаксиса layer_id [k] [j] указывает layer_id j-го целевого выходного вида k-й рабочей точки зависимости. Элемент синтаксиса dependent_layer_id [k] [j] указывает layer_id j-го зависимого вида k-й рабочей точки зависимости. В одной альтернативе флаг сигнализируется, сразу после dependent_layer_id [k] [j], как direct_dependent_flag [k] [j].
[0139] Элемент синтаксиса direct_dependent_flag [k] [j] указывает, является ли j-й зависимый вид непосредственно зависимым видом, подлежащему использованию для выведения RPS между видами. Элемент синтаксиса layer_id [k] указывает самый высокий layer_id текущей k-й (SVC) рабочей точки зависимости. Альтернативно, num_target_output_views_minus1 [k], num_depedent_layers [k], layer_id [k] [j] и dependent_layer_id [k] [j] могут быть сигнализированы как ue (v).
[0140] Элемент синтаксиса num_additional_vui_vps_set_info может задавать количество дополнительных таблиц набора VPS VUI, присутствующих в VPS.
[0141] Для семантики таблицы информации профиля и уровня, элемент синтаксиса profileLevelInfoIdx указывает индекс таблицы информации профиля и уровня. Для семантики таблицы информации формата представления элемент синтаксиса repFormatInfoIdx указывает индекс таблицы информации формата представления.
[0142] Элемент синтаксиса next_essential_byte_offset, показанный в Таблице 7, может быть обработан и синтаксически разобран с помощью MANE 29 и/или видео декодера 30 способом, описанным выше со ссылками на Таблицу 2.
[0143] Для семантики таблицы набора VPS VUI, элемент синтаксиса vuiVpsSetIndex указывает индекс таблицы набора VPS VUI.
[0144] Альтернативно, зависимость вида каждого вида может быть сигнализирована в SPS следующим образом:

[0145] Элемент синтаксиса num_reference_views указывает максимальное количество видов текстуры или глубины, используемых для конструирования поднабора RPS между видами. Элемент синтаксиса ref_view_layer_id [i] идентифицирует layer_id i-го вида текстуры /глубины, используемого для указания i-й (только) опорной картинки в между видами в поднаборе RPS.
[0146] Альтернативно, расширение VPS может быть сигнализировано следующим образом. Когда элемент синтаксиса extension_type указывает SVC, элемент синтаксиса num_additional_dependency_operation_points не сигнализируется, но выводится, чтобы быть равным vps_max_layers_minus1. Задается ограничение, что единицы NAL VCL в пределах единицы доступа находятся в неуменьшающемся порядке layer_id. В MVC элемент синтаксиса layer_id эквивалентен view_idx. В 3DV, элемент синтаксиса view_idx может быть вычислен следующим образом layer_id: view_idx=(layer_idx>>1).



[0147] Элемент синтаксиса depth_present_flag, установленный равным 1, указывает, что могут быть рабочие точки, содержащие глубину. Элемент синтаксиса depth_present_flag, установленный равным 0, указывает, что никакая рабочая точка не содержит глубину.
[0148] Элемент синтаксиса num_target_output_views_minus1 [k] плюс 1 может быть использован для определения количества целевых видов вывода в k-й рабочей точке зависимости. Элемент синтаксиса num_dependent_layers [k] может быть использован для указания количества зависимых уровней для декодирования текущей k-й рабочей точки зависимости. Когда depth_present_flag установлен равным 1, зависимый уровень может быть любым из вида глубины или вида текстуры. Элемент синтаксиса layer_id [k] [j] указывает layer_id j-го целевого вида текстуры вывода k-й рабочей точки зависимости. layer_id вида глубины, ассоциированного с видом текстуры, если имеется, равен layer_id [k] [j]+1.
[0149] Альтернативно, элемент синтаксиса view_idx [k] [j] вместо layer_id [k] [j] может быть сигнализирован для каждого целевого выходного вида. Для каждого view_idx [k] [j], layer_id соответствующего вида текстуры равен (view_idx [k] [j]<< depth_present_flag). Если depth_included_flag [k] равен 1, то layer_id соответствующего вида глубины равен (view_idx [k] [j] << depth_present_flag) +1, который равен (view_idx [k] [j]<<1) +1, так как depth_present_flag должен быть 1 в этом случае. Альтернативно, элемент синтаксиса layer_id [k] [j] может быть изменен на view_idx [k] [j] и является закодированным u(v), с длиной, равной 5 - depth_present_flag. Альтернативно, элемент синтаксиса layer_id [k] [j] может быть изменен на view_idx [k] [j] и является закодированным u(v), с длиной, равной 5- depth_included [k].
[0150] Четвертый пример является расширенным набором второго примера. Синтаксис разработан дружественным к расширению способом. Кроме того, расширение VPS предоставлено в этом примере. Синтаксическая конструкция или конструкция семантики таблицы синтаксиса, которая является точно такой же, как во втором примере, не присутствуют. 


[0151] Элемент синтаксиса next_essential_byte_offset показанный в Таблице 21, может быть обработан и синтаксически разобран посредством MANE 29 и/или видео декодером 30 способом, описанным выше со ссылками на Таблицу 2.
[0152] ФИГ. 4 является блок-схемой, иллюстрирующей примерный кодер видео 20, который может реализовать методы, описанные в настоящем раскрытии. Видео кодер 20 может, например, генерировать структуры синтаксиса, описанные выше со ссылками на Таблицы 1-21. Видео кодер 20 может выполнять внутреннее и внешнее кодирование блоков видео в пределах видео вырезок. Внутреннее кодирование полагается на пространственное предсказание, чтобы уменьшить или удалить пространственную избыточность в видео в пределах заданного кадра или картинки видео. Внешнее кодирование полагается на временное предсказание, чтобы уменьшить или удалить временную избыточность в видео в пределах смежных кадров или картинок последовательности видео. Внутренний режим (I режим) может относиться к любому из нескольких основанных на пространстве режимов сжатия. Внешние режимы, такие как однонаправленное предсказание (P режим) или bi-предсказание (B режим), могут относиться к любому из нескольких основанных на времени режимов сжатия.
[0153] В примере на ФИГ. 4 видео кодер 20 включает в себя модуль 53 разделения, модуль 41 обработки предсказания, модуль 63 фильтров, память 64 картинок, сумматор 50, модуль 52 обработки преобразования, модуль 54 квантования, и модуль 56 энтропийного кодирования. Модуль 41 обработки предсказания включает в себя модуль 42 оценки движения, модуль 44 компенсации движения, и модуль 46 обработки внутреннего предсказания. Для реконструкции блока видео, видео кодер 20 также включает в себя модуль 58 обратного квантования, модуль 60 обработки обратного преобразования, и сумматор 62. Модуль 63 фильтров предназначен, чтобы обеспечить один или более контурных фильтров, таких как фильтр удаления блочности, адаптивный контурный фильтр (ALF), и фильтр адаптивного смещения выборок (SAO). Хотя модуль 63 фильтров показан на ФИГ. 4 как находящийся в контурном фильтре, в других конфигурациях модуль 63 фильтров может быть реализован как пост-контурный фильтр. ФИГ. 4 также показывает устройство 57 пост-обработки, который может выполнить дополнительную обработку в отношении закодированных данных видео, генерируемых видео кодером 20. Методы настоящего раскрытия, которые включают в себя генерирование набора параметров с элементом синтаксиса смещения, могут в некоторых случаях быть реализованы видео кодером 20. В других случаях, однако, методы настоящего раскрытия могут быть реализованы устройством 57 пост-обработки.
[0154] Как показано на ФИГ. 4, видео кодер 20 принимает данные видео, и модуль 53 разделения разделяет данные на блоки видео. Это разделение может также включать в себя разделение на вырезки, плитки (не перекрывающиеся элементы), или другие большие блоки, а также разделение блока видео, например, согласно структуре квадродерева единиц LCU и единиц CU. Видео кодер 20 в целом иллюстрирует компоненты, которые кодируют блоки видео в пределах вырезки видео, которая должна быть закодирована. Вырезка может быть разделена на множественные блоки видео (и возможно на наборы блоков видео, называемых плитками). Модуль 41 обработки предсказания может выбрать один из множества возможных режимов кодирования, таких как один из множества режимов внутреннего кодирования или один из множества режимов внешнего кодирования, для текущего блока видео, на основании результатов ошибки (например, скорость кодирования и уровень искажения). Модуль 41 обработки предсказания может выдать получающийся внутренне или внешне кодированный блок к сумматору 50, чтобы сгенерировать остаточные данные блока, и к сумматору 62, чтобы восстановить закодированный блок для использования в качестве опорной картинки.
[0155] Модуль 46 обработки внутреннего предсказания в пределах модуля 41 обработки предсказания может выполнить внутреннее предсказывающее кодирование текущего блока видео относительно одного или более соседних блоков в том же самом кадре или вырезке что и текущий блок, который должен быть закодирован, чтобы обеспечить пространственное сжатие. Модуль 42 оценки движения и модуль 44 компенсации движения в пределах модуля 41 обработки предсказания выполняют внешнее предсказывающее кодирование текущего блока видео относительно одного или более предсказывающих блоков в одной или более опорных картинках, чтобы обеспечить временное сжатие.
[0156] Модуль 42 оценки движения может быть сконфигурирован, чтобы определить режим внешнего предсказания для видео вырезки согласно заранее заданному шаблону для последовательности видео. Заранее заданный шаблон может обозначать видео вырезки в последовательности как P вырезки, B вырезки или вырезки GPB. Модуль 42 оценки движения и модуль 44 компенсации движения могут быть высоко интегрированными, но иллюстрированы отдельно в концептуальных целях. Оценка движения, выполненная модулем 42 оценки движения, является процессом генерирования векторов движения, которые оценивают движение для блоков видео. Вектор движения, например, может указывать смещение PU блока видео в пределах текущего видео кадра или картинки относительно предсказывающего блока в пределах опорной картинки.
[0157] Предсказывающий блок является блоком, который, как находят, близко соответствует PU блока видео, который должен быть закодирован в терминах пиксельной разности, которая может быть задана суммой абсолютных разностей (SAD), суммой разностей квадратов (SSD), или другими метриками разности. В некоторых примерах видео кодер 20 может вычислить значения для суб-целочисленных пиксельных позиций опорных картинок, сохраненных в памяти 64 картинок. Например, видео кодер 20 может интерполировать значения пиксельных позиций в одну четверть, пиксельных позиций в одну восьмую, или другие фракционные пиксельные позиции опорной картинки. Поэтом, модуль 42 оценки движения может выполнить поиск движения относительно полных пиксельных позиций и фракционных пиксельных позиций и вывести вектор движения с фракционной пиксельной точностью.
[0158] Модуль 42 оценки движения вычисляет вектор движения для PU блока видео во внешне кодированной вырезке, сравнивая позицию PU с позицией предсказывающего блока опорной картинки. Опорная картинка может быть выбрана из первого списка опорных картинок (Список 0) или второго списка опорных картинок (Список 1), каждый из которых идентифицируют одну или более опорных картинок, сохраненных в памяти 64 картинок. Модуль 42 оценки движения посылает вычисленный вектор движения в модуль 56 энтропийного кодирования и модуль 44 компенсации движения.
[0159] Компенсация движения, выполненная модулем 44 компенсации движения, может вовлекать упреждающее извлечение или генерирование предсказывающего блока на основании вектора движения, определенного посредством оценки движения, возможно выполняя интерполяции до суб-пиксельной точности. После приема вектора движения для PU текущего блока видео модуль 44 компенсации движения может определить местонахождение предсказывающего блока, на который вектор движения указывает в одном из списков опорных картинок. Видео кодер 20 формирует остаточный блок видео, вычитая пиксельные значения предсказывающего блока из пиксельных значений текущего закодированного блока видео, формируя значения пиксельной разности. Значения пиксельной разности формируют остаточные данные для блока, и могут включать в себя разностные компоненты как яркости так и цветности. Сумматор 50 представляет компонент или компоненты, которые выполняют эту операцию вычитания. Модуль 44 компенсации движения может также генерировать элементы синтаксиса, ассоциированные с блоками видео и видео вырезкой для использования видео декодером 30 при декодировании блоков видео для видео вырезки.
[0160] Модуль 46 обработки внутреннего предсказания может внутренне предсказать текущий блок, как альтернатива внешнему предсказанию, выполненному модулем 42 оценки движения и модулем 44 компенсации движения, как описано выше. В частности, модуль 46 обработки внутреннего предсказания может определить режим внутреннего предсказания, чтобы использовать, чтобы закодировать текущий блок. В некоторых примерах модуль 46 обработки внутреннего предсказания может закодировать текущий блок, используя различные режимы внутреннего предсказания, например, во время отдельных проходов кодирования, и модуль 46 обработки внутреннего предсказания (или модуль 40 выбора режима, в некоторых примерах), может выбрать соответствующий режим внутреннего предсказания для использования, из проверенных режимов. Например, модуль 46 обработки внутреннего предсказания может вычислить значения «скорость передачи - искажение», используя анализ «скорость передачи - искажение» для различных проверенных режимов внутреннего предсказания, и выбрать режим внутреннего предсказания, имеющий лучшие характеристики «скорость передачи - искажение» среди проверенных режимов. Анализ «скорость передачи - искажение» вообще задает величину искажения (или ошибку) между закодированным блоком и первоначальным незакодированным блоком, который был закодирован, чтобы сформировать закодированный блок, а также частоту следования битов (то есть количество битов), использованных для формирования закодированного блока. Модуль 46 обработки внутреннего предсказания может вычислить отношения из искажений и скоростей передачи для различных закодированных блоков, чтобы определить, какой режим внутреннего предсказания показывает лучшее значение «скорость передачи - искажение» для блока.
[0161] В любом случае, после выбора режима внутреннего предсказания для блока, модуль 46 обработки внутреннего предсказания может предоставить информацию, указывающую выбранный режим внутреннего предсказания для блока, к модулю 56 энтропийного кодирования. Модуль 56 энтропийного кодирования может закодировать информацию, указывающую выбранный режим внутреннего предсказания, в соответствии с методами настоящего раскрытия. Видео кодер 20 может включать в переданные данные конфигурации потока битов, которые могут включать в себя множество таблиц индексов режима внутреннего предсказания и множество модифицированных таблиц индекса режима внутреннего предсказания (также называл таблицы отображения ключевого слова), определения контекстов кодирования для различных блоков, и индикации самого вероятного режима внутреннего предсказания, таблицу индексов режима внутреннего предсказания, и модифицированную таблицу индексов режима внутреннего предсказания, для использования для каждого из контекстов.
[0162] После того как модуль 41 обработки предсказания генерирует предсказывающий блок для текущего блока видео или через внешнее предсказание или через внутреннее предсказание, видео кодер 20 формирует остаточный блок видео, вычитая предсказывающий блок из текущего блока видео. Остаточные данные видео в остаточном блоке могут быть включены в одну или более TU и поданы на модуль 52 обработки преобразования. Модуль 52 обработки преобразования преобразовывает остаточные данные видео в остаточные коэффициенты преобразования, используя преобразование, такое как дискретное косинусное преобразование (DCT) или концептуально аналогичное преобразование. Модуль 52 обработки преобразования может преобразовать остаточные данные видео из пиксельной области в область преобразования, такую как частотная область.
[0163] Модуль 52 обработки преобразования может послать получающиеся коэффициенты преобразования в модуль 54 квантования. Модуль 54 квантования квантует коэффициенты преобразования, чтобы далее уменьшить частоту следования битов. Процесс квантования может уменьшить битовую глубину, ассоциированную с некоторыми или всеми коэффициентами. Степень квантования может быть модифицирована, регулируя параметр квантования. В некоторых примерах модуль 54 квантования может затем выполнить сканирование матрицы, включающей в себя квантованные коэффициенты преобразования. Альтернативно, модуль 56 энтропийного кодирования может выполнить сканирование.
[0164] Вслед за квантованием модуль 56 энтропийного кодирования энтропийно кодирует квантованные коэффициенты преобразования. Например, модуль 56 энтропийного кодирования может выполнить контекстно-адаптивное кодирование с переменной длиной кода (CAVLC), контекстно-адаптивное двоичное арифметическое кодирование (CABAC), основанное на синтаксисе контекстно-адаптивное двоичное арифметическое кодирование (SBAC), энтропийное кодирование с разделением интервала вероятности (PIPE) или другую методологию или метод энтропийного кодирования. После энтропийного кодирования модулем 56 энтропийного кодирования закодированный поток битов может быть передан к видео декодеру 30, или заархивирован для более поздней передачи или поиска видео декодером 30. Модуль 56 энтропийного кодирования может также энтропийно кодировать векторы движения и другие элементы синтаксиса для текущей закодированной вырезки видео.
[0165] Модуль 58 обратного квантования и модуль 60 обработки обратного преобразования применяет обратное квантование и обратное преобразование, соответственно, чтобы восстановить остаточный блок в пиксельной области для более позднего использования в качестве опорного блока опорной картинки. Модуль 44 компенсации движения может вычислить опорный блок, суммируя остаточный блок с предсказывающим блоком одной из опорных картинок в пределах одного из списков опорных картинок. Модуль 44 компенсации движения может также применить один или более фильтров интерполяции к восстановленному остаточному блоку, чтобы вычислить суб-целочисленные пиксельные значения для использования при оценке движения. Сумматор 62 суммирует восстановленный остаточный блок с блоком предсказания со скомпенсированным движением, сформированным модулем 44 компенсации движения, чтобы сформировать опорный блок для хранения в памяти 64 картинок. Опорный блок может использоваться модулем 42 оценки движения и модулем 44 компенсации движения в качестве опорного блока, чтобы внешнее предсказать блок в последующем кадре или картинке видео.
[0166] В этом способе видео кодер 20 на ФИГ. 4 представляет пример видео кодера, сконфигурированного, чтобы генерировать синтаксис, описанный выше в Таблицах 1-21. Видео кодер 20 может, например, генерировать наборы параметров VPS, SPS, PPS, и APS, как описано выше. В одном примере видео кодер 20 может генерировать набор параметров для закодированных данных видео, которые включают в себя один или более начальных элементов синтаксиса фиксированной длины, с последующим элементом синтаксиса смещения. Один или более начальных элементов синтаксиса фиксированной длины могут, например, включать в себя информацию, отнесенную с согласованием сеанса. Элемент синтаксиса смещения может указывать количество байтов, которые должны быть пропущены, когда набор параметров обрабатывается посредством MANE. Количество байтов, которые должны быть пропущены, может, например, включать в себя один или более элементов синтаксиса переменной длины. Видео кодер 20 может включать в набор параметров, после пропущенных байтов, дополнительные элементы синтаксиса фиксированной длины. Дополнительные элементы синтаксиса фиксированной длины могут, например, включать в себя информацию, относящуюся к другому уровню данных видео. В одном примере начальные элементы синтаксиса фиксированной длины могут включать в себя информацию, относящуюся к согласованию сеанса относительно базового уровня, в то время как дополнительные элементы синтаксиса фиксированной длины могут включать в себя информацию, относящуюся к согласованию сеанса относительно небазового уровня.
[0167] Видео кодер 20 может определять значение для элемента синтаксиса смещения на основании количества битов, используемого для кодирования одного или более элементов синтаксиса переменной длины. Например, предположим для первого VPS, что элементы синтаксиса, которые должны быть пропущены, включают в себя три элемента синтаксиса фиксированной длины из 2 битов, 3 битов, и 5 битов, а также четыре элемента синтаксиса переменной длины из 2 битов, 4, битов, 5 битов, и 3 битов. В этом примере элементы синтаксиса фиксированной длины включают в себя в общей сложности 10 битов, в то время как элементы синтаксиса переменной длины включают в себя в общей сложности 14 битов. Таким образом, для первого VPS, видео кодер 20 может установить значение элемента синтаксиса смещения равным 24, включая 24 бита (например, 3 байта) должны быть пропущены. Для второго VPS количество битов для фиксированных элементов синтаксиса снова будет 10, но количество битов, используемых для элементов синтаксиса переменной длины, может быть другим. Таким образом, для второго VPS видео кодер 20 может установить значение для элемента синтаксиса смещения равным другому значению.
[0168] Методы настоящего раскрытия были в целом описаны относительно видео кодера 20, но как упомянуто выше, некоторые из методов настоящего раскрытия могут также быть реализованы устройством 57 пост-обработки. Например, устройство 57 пост-обработки может генерировать VPS для множественных уровней данных видео, генерируемых видео кодером 20.
[0169] ФИГ. 5 является блок-схемой, иллюстрирующей примерный декодер видео 30, который может реализовать методы, описанные в настоящем раскрытии. Видео декодер 30 может, например, конфигурироваться, чтобы обрабатывать и синтаксически разбирать структуры синтаксиса, описанные выше со ссылками на Таблицы 1-21. В примере на ФИГ. 5, видео декодер 30 включает в себя модуль 80 энтропийного декодирования, модуль 81 обработки предсказания, модуль 86 обратного квантования, модуль 88 обработки обратного преобразования, сумматор 90, модуль 91 фильтров и память 92 картинок. Модуль 81 обработки предсказания включает в себя модуль 82 компенсации движения и модуль 84 обработки внутреннего предсказания. Видео декодер 30, в некоторых примерах, может выполнить проход декодирования, в целом обратный проходу кодирования, описанному относительно видео кодера 20 на ФИГ. 4.
[0170] Во время процесса декодирования видео декодер 30 принимает закодированный видео поток битов, который представляет блоки видео закодированной видео вырезки и ассоциированные элементы синтаксиса от видео кодера 20. Видео декодер 30 может принять закодированный видео поток битов от сетевого объекта 79. Сетевой объект 79 может, например, быть сервером, MANE, модулем редактирования/стыковки видео, или другим таким устройством, сконфигурированным, чтобы реализовать один или более методов, описанных выше. Сетевой объект 79 может включать или может не включать в себя видео кодер 20. Как описано выше, некоторые из методов, описанных в настоящем раскрытии, могут быть реализованы сетевым объектом 79 до сетевого объекта 79, передающего закодированный поток битов видео к видео декодеру 30. В некоторых системах декодирования видео сетевой объект 79 и видео декодер 30 могут быть частями отдельных устройств, в то время как в других случаях функциональные возможности, описанные относительно сетевого объекта 79, могут быть выполнены тем же устройством, которое содержит видео декодер 30.
[0171] Сетевой объект 79 представляет пример устройства обработки видео, сконфигурированного, чтобы обрабатывать один или более начальных элементов синтаксиса для набора параметров, ассоциированного с потоком битов видео; принимать в наборе параметров элемент синтаксиса смещения для набора параметров, который идентифицирует элементы синтаксиса, которые должны быть пропущены, в пределах набора параметров, и на основании элемента синтаксиса смещения, пропускать элементы синтаксиса в пределах набора параметров. Сетевой объект 79 может также обработать один или более дополнительных элементов синтаксиса в наборе параметров. Один или более дополнительных элементов синтаксиса находятся после пропущенных элементов синтаксиса в наборе параметров.
[0172] Во время процесса декодирования видео декодер 30 принимает закодированный видео поток битов, который представляет блоки видео закодированной видео вырезки и ассоциированные элементы синтаксиса, от видео кодера 20. Блоки видео могут, например, быть маршрутизированы от видео кодера 20 к видео декодеру 30 через один или более блоков MANE, таких как MANE 29 на ФИГ. 1 или сетевой объект 79 на ФИГ. 5. Модуль 80 энтропийного декодирования из видео декодера 30 энтропийно декодирует поток битов, чтобы сгенерировать квантованные коэффициенты, векторы движения, и другие элементы синтаксиса. Модуль 80 энтропийного декодирования направляет вектора движения и другие элементы синтаксиса к модулю 81 обработки предсказания. Видео декодер 30 может принять элементы синтаксиса на уровне вырезки видео и/или уровне блока видео.
[0173] Как введено выше, модуль 80 энтропийного декодирования может обрабатывать и синтаксически разбирать и элементы синтаксиса фиксированной длины и элементы синтаксиса переменной длины в одном или более наборах параметров, таких как VPS, SPS, PPS, и APS. В одном или более наборов параметров, например VPS, видео декодер 30 может принять элемент синтаксиса смещения, как описано в настоящем раскрытии. В ответ на прием элемента синтаксиса смещения видео декодер 30 может по существу проигнорировать значение элемента синтаксиса смещения. Например, видео декодер 30 может принять элемент синтаксиса смещения, но может продолжить декодировать элементы синтаксиса, включая элементы синтаксиса переменной длины, которые следуют за элементом синтаксиса смещения, не пропуская каких-либо элементов синтаксиса.
[0174] Когда видео вырезка закодирована как внутренне кодированная (I) вырезка, модуль 84 обработки внутреннего предсказания из модуля 81 обработки предсказания могут генерировать данные предсказания для блока видео текущей видео вырезки на основании сигнализированного режима внутреннего предсказания и данные от ранее декодированных блоков текущего кадра или картинки. Когда видео кадр закодирован как внешне кодированная (то есть, B, P или GPB) вырезка, модуль 82 компенсации движения из модуля 81 обработки предсказания формирует предсказывающие блоки для блока видео текущей видео вырезки на основании вектора движения и другие элементы синтаксиса, принятые от модуля 80 энтропийного декодирования. Предсказывающие блоки могут быть сформированы из одной из опорных картинок в пределах одного из списков опорных картинок. Видео декодер 30 может построить списки опорных кадров, Список 0 и Список 1, используя методы построения по умолчанию, на основании опорных картинок, сохраненных в памяти 92 картинок.
[0175] Модуль 82 компенсации движения определяет информацию предсказания для блока видео текущей видео вырезки, синтаксически разбирая вектора движения и другие элементы синтаксиса, и использует информацию предсказания, чтобы сформировать предсказывающие блоки для текущего декодируемого блока видео. Например, модуль 82 компенсации движения использует некоторые из принятых элементов синтаксиса, чтобы определить режим предсказания (например, внутреннее или внешнее предсказание), используемый для кодирования блоков видео в видео вырезке, тип вырезки внешнего предсказания (например, B вырезка, P вырезка, или вырезка GPB), информацию построения для одного или более из списков опорных картинок для вырезки, векторов движения для каждого внешне кодированного блока видео вырезки, статуса внешнего предсказания для каждого внешне кодированного блока видео вырезки, и другую информацию, чтобы декодировать блоки видео в текущей видео вырезке.
[0176] Модуль 82 компенсации движения может также выполнить интерполяцию, на основании фильтров интерполяции. Модуль 82 компенсации движения может использовать фильтры интерполяции, которые используются видео кодером 20 во время кодирования блоков видео, чтобы вычислить интерполированные значения для суб-целочисленных пикселей опорных блоков. В этом случае модуль 82 компенсации движения может определять фильтры интерполяции, используемые видео кодером 20, из принятых элементов синтаксиса, и использовать фильтры интерполяции, чтобы сформировать предсказывающие блоки.
[0177] Модуль 86 обратного квантования обратно квантует, то есть деквантует, квантованные коэффициенты преобразования, предоставленные в потоке битов и декодированные модулем 80 энтропийного декодирования. Процесс обратного квантования может включать в себя использование параметра квантования, вычисленного видео кодером 20 для каждого блока видео в видео вырезке, чтобы определить степень квантования и, аналогично, степень обратного квантования, которое должно быть применено. Модуль 88 обработки обратного преобразования применяет обратное преобразование, например, обратное DCT, обратное целочисленное преобразование, или концептуально аналогичный процесс обратного преобразования к коэффициентам преобразования, чтобы сформировать остаточные блоки в пиксельной области.
[0178] После того как модуль 82 компенсации движения генерирует предсказывающий блок для текущего блока видео на основании вектора движения и других элементов синтаксиса, видео декодер 30 формирует декодированный блок видео, суммируя остаточные блоки из модуля 88 обработки обратного преобразования с соответствующими предсказывающими блоками, генерируемыми модулем 82 компенсации движения. Сумматор 90 представляет компонент или компоненты, которые выполняют эту операцию суммирования. Если желательно, контурные фильтры (или в контуре кодирования или после контура кодирования) могут также быть использованными для сглаживания пиксельных переходов, или иначе улучшить качество видео. Модуль 91 фильтров предназначен, чтобы представить один или более контурных фильтров, таких как фильтр удаления блочности, адаптивный контурный фильтр (ALF), и фильтр адаптивного смещения выборок (SAO). Хотя модуль 91 фильтров показан на ФИГ. 5 как находящийся в контурном фильтре, в других конфигурациях модуль 91 фильтров может быть реализован как пост-контурный фильтр. Декодированные блоки видео в заданном кадре или картинке затем сохраняются в памяти 92 картинок, которая хранит опорные картинки, используемые для последующей компенсации движения. Память 92 картинок также хранит декодированное видео для более позднего представления на устройстве отображения, таком как устройство 32 отображения на ФИГ. 1.
[0179] В этом способе видео декодер 30 на ФИГ. 5 представляет пример видео декодера, сконфигурированного, чтобы синтаксически разбирать синтаксис, описанный выше в Таблицах 1-21. Видео декодер 30 может, например, синтаксически разбирать наборы параметров VPS, SPS, PPS, и APS, как описано выше.
[0180] ФИГ. 6 является блок-схемой, иллюстрирующей примерный набор устройств, которые являются частью сети 150. В этом примере сеть 150 включает в себя устройства 154A, 154B маршрутизации (устройства 154 маршрутизации) и устройство 156 транскодирования. Устройства 154 маршрутизации и устройство 156 транскодирования предназначены, чтобы представить небольшое количество устройств, которые могут формировать часть сети 150. Другие сетевые устройства, такие как коммутаторы, концентраторы, шлюзы, брандмауэры, мосты, и другие такие устройства могут также быть включены в сеть 150. Кроме того, дополнительные сетевые устройства могут быть предоставлены вдоль сетевого пути между серверным устройством 152 и клиентским устройством 158. Серверное устройство 152 может соответствовать исходному устройству 12 (ФИГ. 1), в то время как клиентское устройство 158 может соответствовать устройству 14 назначения (ФИГ. 1), в некоторых примерах. Устройствами 154 маршрутизации может, например, быть MANE, сконфигурированные, чтобы маршрутизировать данные медиа.
[0181] Обычно устройства 154 маршрутизации реализуют один или более протоколов маршрутизации, чтобы обменяться данными сети через сеть 150. Обычно устройства 154 маршрутизации выполняют протоколы маршрутизации, чтобы обнаружить маршруты через сеть 150. Выполняя такие протоколы маршрутизации, устройство 154B маршрутизации может обнаружить маршрут сети от себя до серверного устройства 152 через устройство 154A маршрутизации. Различные устройства согласно ФИГ. 6 представляют примеры устройств, которые могут реализовать методы настоящего раскрытия. Устройства 154 маршрутизации могут, например, быть осведомленными о медиа элементами сети, которые конфигурируются, чтобы синтаксически разбирать элементы синтаксиса набора параметров, такие как VPS, в соответствии с этим раскрытием. Например, устройства 154 маршрутизации могут принять в VPS один или более начальных элементов синтаксиса фиксированной длины и разбирать и обрабатывать элементы синтаксиса фиксированной длины. Начальные элементы синтаксиса фиксированной длины могут, например, быть элементами синтаксиса, относящимися к согласованию сеанса. Устройства 154 маршрутизации могут также принять, в VPS, элемент синтаксиса смещения. Элемент синтаксиса смещения может идентифицировать количество байтов, которые должны быть пропущены. Устройства 154 маршрутизации могут пропустить конкретное количество байтов, и после пропуска конкретного количества байтов, могут продолжить синтаксически разбирать и обрабатывать элементы синтаксиса фиксированной длины в пределах VPS. Пропущенные байты могут включать в себя один или более элементов синтаксиса переменной длины, которые устройства 154 маршрутизации не могут синтаксически разбирать, так как устройства 154 маршрутизации не могут выполнять операции энтропийного декодирования.
[0182] ФИГ. 7 является последовательностью операций, иллюстрирующей пример того, как обработать элемент синтаксиса смещения согласно методам настоящего раскрытия. Методы согласно ФИГ. 7 будут описаны в отношении сетевого устройства, такого как MANE 29 на ФИГ. 1 или одного из устройств 154 маршрутизации на ФИГ. 6. Сетевой объект обрабатывает один или более начальных элементов синтаксиса для набора параметров, ассоциированного с потоком битов видео (171). Один или более начальных элементов синтаксиса могут дополнительно включать в себя элементы синтаксиса фиксированной длины и предшествовать элементу синтаксиса смещения. Один или более начальных элементов синтаксиса могут включать в себя элементы синтаксиса, которые включают в себя информацию, относящуюся к согласованию сеанса. Кроме того, один или более начальных элементов синтаксиса содержат элементы синтаксиса для базового уровня данных видео, и один или более дополнительных элементов синтаксиса содержат элементы синтаксиса для небазового уровня данных видео.
[0183] Сетевой объект принимает в потоке битов видео элемент синтаксиса смещения для набора параметров (172). Элемент синтаксиса смещения идентифицирует количество битов, которые должны быть пропущены, в пределах набора параметров. Элемент синтаксиса смещения может, например, быть частью набора параметров видео. Количество битов, которые должны быть пропущены, может, например, соответствовать одному или более элементам синтаксиса, закодированным, используя кодирование с переменной длиной кода. На основании элемента синтаксиса смещения сетевой объект пропускает количество битов в пределах набора параметров (173). Сетевой объект обрабатывает один или более дополнительных элементов синтаксиса в наборе параметров (174). Один или более дополнительных элементов синтаксиса находятся после количества битов, пропущенных в наборе параметров. Один или более дополнительных элементов синтаксиса могут быть дополнительными элементами синтаксиса фиксированной длины, и один или более дополнительных элементов синтаксиса могут следовать за элементом синтаксиса смещения и следовать за битами, которые должны быть пропущены.
[0184] ФИГ. 8 является последовательностью операций, иллюстрирующей пример того, как обработать элемент синтаксиса смещения согласно методам настоящего раскрытия. Методы согласно ФИГ. 8 описаны ниже в отношении устройства обработки видео, сконфигурированного, чтобы закодировать данные видео или обработать закодированные данные видео. Примеры устройства обработки видео, сконфигурированного, чтобы обрабатывать закодированные данные видео, включают в себя видео кодер 20 из ФИГ. 1 и 4 и устройство 57 пост-обработки видео на ФИГ. 4. Устройства обработки видео генерирует один или более начальных элементов синтаксиса для набора параметров, ассоциированного с потоком битов видео (181). Один или более начальных элементов синтаксиса могут включать в себя элементы синтаксиса фиксированной длины, и один или более начальных элементов синтаксиса могут предшествовать элементу синтаксиса смещения. Один или более начальных элементов синтаксиса могут включать в себя элементы синтаксиса, включая информацию, относящуюся к согласованию сеанса. Один или более начальных элементов синтаксиса могут включать в себя элементы синтаксиса для базового уровня данных видео, и один или более дополнительных элементов синтаксиса могут включать в себя элементы синтаксиса для небазового уровня данных видео.
[0185] Устройства обработки видео генерируют элемент синтаксиса смещения для набора параметров (182). Элемент синтаксиса смещения может идентифицировать количество битов, которые должны быть пропущены, в пределах набора параметров. Элемент синтаксиса смещения может быть частью набора параметров видео. Устройство обработки видео генерирует один или более элементов синтаксиса, которые должны быть пропущены (183). Биты, которые должны быть пропущены, включают в себя один или более элементов синтаксиса, которые должны быть пропущены. Один или более элементов синтаксиса, которые должны быть пропущены, могут включать в себя один или более элементов синтаксиса, закодированных, используя кодирование с переменной длиной кода. Устройство обработки видео генерирует один или более дополнительных элементов синтаксиса в наборе параметров (184). Один или более дополнительных элементов синтаксиса находятся после количества битов, которые должны быть пропущены, в наборе параметров. Один или более дополнительных элементов синтаксиса могут включать в себя дополнительные элементы синтаксиса фиксированной длины, один или более дополнительных элементов синтаксиса могут следовать за элементом синтаксиса смещения и следовать за битами, которые должны быть пропущены.
[0186] ФИГ. 9 является последовательностью операций, иллюстрирующей пример того, как декодировать элемент синтаксиса смещения согласно методам настоящего раскрытия. Методы согласно ФИГ. 9 описаны ниже в отношении видео декодера, такого как видео декодер 30 из ФИГ. 1 и 5. Видео декодер декодирует один или более начальных элементов синтаксиса для набора параметров, ассоциированного с потоком битов видео (191). Видео декодер принимает в потоке битов видео элемент синтаксиса смещения для набора параметров (192). Элемент синтаксиса смещения идентифицирует количество битов, которые должны быть пропущены, в пределах набора параметров. Видео декодер декодирует биты, которые должны быть пропущены (193). В некоторых примерах видео декодер декодирует биты, которые должны быть пропущены, выполняя энтропийное декодирование, чтобы декодировать элементы синтаксиса переменной длины, включенные в биты, которые должны быть пропущены. Видео декодер может, например, декодировать биты, которые должны быть пропущены, так как биты должны быть пропущены, когда данные видео обрабатываются устройством обработки видео, таким как MANE, но биты могут быть необходимыми для того, чтобы декодировать данные видео. MANE, в отличие от видео декодера, может пропустить биты, чтобы выполнить некоторую обработку в отношении данных видео, не имея необходимости полностью декодировать данные видео. В некоторых случаях MANE может даже не обладать всеми функциональными возможностями, необходимыми, чтобы декодировать данные видео.
[0187] ФИГ. 10 является последовательностью операций, иллюстрирующей пример того, как обработать VPS согласно методам настоящего раскрытия. Методы согласно ФИГ. 10 описаны ниже в отношении обобщенного устройства обработки видео. Устройство обработки видео может соответствовать сетевому устройству, такому как MANE 29 на ФИГ. 1 или одному из устройств 154 маршрутизации на ФИГ. 6. Устройство обработки видео может дополнительно соответствовать видео декодеру, такому как видео декодер 30 из ФИГ. 1 и 4. Устройство обработки видео принимает в наборе параметров видео один или более элементов синтаксиса, которые включают в себя информацию, относящуюся к согласованию сеанса (201). Устройство обработки видео принимает в данных видео первый набор параметров последовательности, содержащий первый элемент синтаксиса, идентифицирующий набор параметров видео (202). Первый набор параметров последовательности содержит первую синтаксическую структуру, которая включает в себя первую группу элементов синтаксиса, которые применяются к одной или более целым картинкам данных видео. Устройство обработки видео принимает в данных видео второй набор параметров последовательности, содержащий второй элемент синтаксиса, идентифицирующий набор параметров видео (203). Второй набор параметров последовательности содержит вторую синтаксическую структуру, которая включает в себя вторую группу элементов синтаксиса, которые применяются к одной или более другим целым картинкам данных видео. Устройство обработки видео обрабатывает, на основании одного или более элементов синтаксиса, первый набор блоков видео, ассоциированных с первым набором параметров, и второй набор блоков видео, ассоциированных со вторым набором параметров (204).
[0188] Один или более элементов синтаксиса могут, например, быть элементами синтаксиса фиксированной длины и могут предшествовать, в наборе параметров видео, любым закодированным элементам синтаксиса переменной длины. Один или более элементов синтаксиса могут включать в себя элемент синтаксиса, идентифицирующий профиль стандарта кодирования видео. Один или более элементов синтаксиса могут также или альтернативно включать в себя элемент синтаксиса, идентифицирующий уровень стандарта кодирования видео. Этот уровень может, например, соответствовать одному из множественных уровней, ассоциированных с профилем стандарта кодирования видео.
[0189] Один или более элементов синтаксиса могут включать в себя первый элемент синтаксиса и второй элемент синтаксиса. Первый элемент синтаксиса может идентифицировать контекст для того, чтобы интерпретировать второй элемент синтаксиса, и второй элемент синтаксиса может идентифицировать группу профилей. Устройство обработки видео может принять, в наборе параметров видео, один или более флагов совместимости, каждый из которых ассоциирован с профилем из группы профилей. Значение для каждого из один или более флагов совместимости могут идентифицировать, совместимы ли данные видео с ассоциированным профилем из группы профилей.
[0190] Один или более элементов синтаксиса могут также включать в себя первый элемент синтаксиса, который идентифицирует максимальный временной уровень, ассоциированный с видео данными, и второй элемент синтаксиса, который идентифицирует, если временной уровень данных видео имеет уровень, который ниже чем максимальный временной уровень. В ответ на второй элемент синтаксиса, указывающий, что временной уровень данных видео имеет уровень, который ниже, чем максимальный временной уровень, устройство обработки видео может принять дополнительные элементы синтаксиса, которые идентифицируют уровни для одного или более временных уровней данных видео.
[0191] В случаях, когда устройство обработки видео является видео декодером, видео декодер может декодировать первый набор блоков видео и второй набор блоков видео. В случаях, когда устройство обработки видео является MANE, упомянутый MANE может отправить первый набор блоков видео и второй набор блоков видео к клиентскому устройству.
[0192] ФИГ. 11 является последовательностью операций, иллюстрирующей пример того, как генерировать элементы синтаксиса для включения в VPS согласно методам настоящего раскрытия. Методы согласно ФИГ. 8 описаны ниже в отношении устройства обработки видео, сконфигурированного, чтобы закодировать данные видео или обработать закодированные данные видео. Примеры устройств обработки видео, сконфигурированных, чтобы обрабатывать закодированные данные видео, включают в себя видео кодер 20 из ФИГ. 1 и 4 и устройство 57 пост-обработки видео на ФИГ. 4. Устройство обработки видео генерирует, для включения в набор параметров видео, один или более элементов синтаксиса, которые включают в себя информацию, относящуюся к согласованию сеанса (211). Устройство обработки видео генерирует для включения в данные видео первый набор параметров последовательности, содержащий первый элемент синтаксиса, идентифицирующий набор параметров видео (212). Первый набор параметров последовательности содержит первую синтаксическую структуру, которая включает в себя первую группу элементов синтаксиса, которые применяются к одной или более целым картинкам данных видео. Устройство обработки видео генерирует для включения в данные видео второй набор параметров последовательности, содержащий второй элемент синтаксиса, идентифицирующий набор параметров видео (213). Второй набор параметров последовательности содержит вторую синтаксическую структуру, которая включает в себя вторую группу элементов синтаксиса, которые применяются к одной или более другим целым картинкам данных видео. Устройство обработки видео кодирует, на основании одного или более элементов синтаксиса, первый набор блоков видео, ассоциированных с первым набором параметров, и второй набор блоков видео, ассоциированных со вторым набором параметров (214).
[0193] Один или более элементов синтаксиса могут, например, быть элементами синтаксиса фиксированной длины и могут предшествовать, в наборе параметров видео, любым закодированным элементам синтаксиса переменной длины. Один или более элементов синтаксиса могут включать в себя элемент синтаксиса, идентифицирующий профиль стандарта кодирования видео. Один или более элементов синтаксиса могут далее или альтернативно включать в себя элемент синтаксиса, идентифицирующий уровень стандарта кодирования видео. Уровень может, например, соответствовать одному из множественных уровней, ассоциированных с профилем стандарта кодирования видео.
[0194] Один или более элементов синтаксиса могут включать в себя первый элемент синтаксиса и второй элемент синтаксиса. Первый элемент синтаксиса может идентифицировать контекст для того, чтобы интерпретировать второй элемент синтаксиса, и второй элемент синтаксиса может идентифицировать группу профилей. Устройство обработки видео может принять, в наборе параметров видео, один или более флагов совместимости, каждый из которых ассоциирован с профилем из группы профилей. Значение для каждого из одного или более флагов совместимости могут идентифицировать, совместимы ли данные видео с ассоциированным профилем из группы профилей.
[0195] Один или более элементов синтаксиса могут также включать в себя первый элемент синтаксиса, который идентифицирует максимальный временной уровень, ассоциированный с видео данными, и второй элемент синтаксиса, который идентифицирует, если временной уровень данных видео имеет уровень, который ниже чем максимальный временной уровень. В ответ на второй элемент синтаксиса, указывающий, что временной уровень данных видео имеет уровень, который ниже, чем максимальный временной уровень, устройство обработки видео может принять дополнительные элементы синтаксиса, которые идентифицируют уровни для одного или более временных уровней данных видео.
[0196] ФИГ. 12 является последовательностью операций, иллюстрирующей пример того, как обработать VPS согласно методам настоящего раскрытия. Методы согласно ФИГ. 12 описаны ниже в отношении обобщенного устройства обработки видео. Устройство обработки видео может соответствовать сетевому устройству, такому как MANE 29 на ФИГ. 1, или одному из устройств 154 маршрутизации на ФИГ. 6. Устройство обработки видео может дополнительно соответствовать видео декодеру, такому как видео декодер 30 из ФИГ. 1 и 4. Устройство обработки видео принимает в наборе параметров видео один или более элементов синтаксиса, которые включают в себя информацию, относящуюся к параметрам HRD (221). Устройство обработки видео принимает в данных видео первый набор параметров последовательности, содержащий первый элемент синтаксиса, идентифицирующий набор параметров видео (222). Первый набор параметров последовательности содержит первую синтаксическую структуру, которая включает в себя первую группу элементов синтаксиса, которые применяются к одной или более целым картинкам данных видео. Устройство обработки видео принимает в данных видео второй набор параметров последовательности, содержащий второй элемент синтаксиса, идентифицирующий набор параметров видео (223). Второй набор параметров последовательности содержит вторую синтаксическую структуру, которая включает в себя вторую группу элементов синтаксиса, которые применяются к одной или более другим целым картинкам данных видео. Устройство обработки видео обрабатывает, на основании одного или более элементов синтаксиса, первый набор блоков видео, ассоциированных с первым набором параметров, и второй набор блоков видео, ассоциированных со вторым набором параметров (224).
[0197] ФИГ. 13 является последовательностью операций, иллюстрирующей пример того, как генерировать элементы синтаксиса для включения в VPS согласно методам настоящего раскрытия. Методы согласно ФИГ. 13 описаны ниже в отношении устройства обработки видео, сконфигурированного, чтобы закодировать данные видео или обработать закодированные данные видео. Примеры устройств обработки видео, сконфигурированных, чтобы обрабатывать закодированные данные видео, включают в себя видео кодер 20 из ФИГ. 1 и 4 и устройство 57 пост-обработки видео на ФИГ. 4. Устройство обработки видео генерирует, для включения в набор параметров видео, один или более элементов синтаксиса, которые включают в себя информацию, относящуюся к параметрам HRD (231). Устройство обработки видео генерирует для включения в данные видео первый набор параметров последовательности, содержащий первый элемент синтаксиса, идентифицирующий набор параметров видео (232). Первый набор параметров последовательности содержит первую синтаксическую структуру, которая включает в себя первую группу элементов синтаксиса, которые применяются к одной или более целым картинкам данных видео. Устройство обработки видео генерирует для включения в данные видео второй набор параметров последовательности, содержащий второй элемент синтаксиса, идентифицирующий набор параметров видео (233). Второй набор параметров последовательности содержит вторую синтаксическую структуру, которая включает в себя вторую группу элементов синтаксиса, которые применяются к одной или более другим целым картинкам данных видео. Устройство обработки видео кодирует, на основании одного или более элементов синтаксиса, первый набор блоков видео, ассоциированных с первым набором параметров, и второй набор блоков видео, ассоциированных со вторым набором параметров (234).
[0198] В одном или более примерах описанные функции могут быть реализованы в аппаратном обеспечении, программном обеспечении, программно-аппаратных средствах, или любой их комбинации. Если реализованы в программном обеспечении, функции могут быть сохранены на или переданы, как одна или более инструкций или код, с помощью считываемого компьютером носителя и выполнены основанным на аппаратном обеспечении блоком обработки. Считываемый компьютером носитель может включать в себя считываемый компьютером запоминающий носитель, который соответствует материальному носителю, такому как запоминающие носители данных, или коммуникационные носители, включая любой носителя, который облегчает передачу компьютерной программы от одного места к другому, например, согласно протоколу связи. В этом способе считываемый компьютером носитель в целом может соответствовать (1) материальному считываемому компьютером запоминающему носителю, который является невременным, или (2) коммуникационному носителю, такому как сигнал или несущая. Запоминающие носители данных могут быть любым доступным носителем, к которому могут получить доступ один или более компьютеров или один или более процессоров, чтобы извлечь инструкции, код и/или структуры данных для реализации методов, описанных в настоящем раскрытии. Компьютерный программный продукт может включать в себя считываемый компьютером носитель.
[0199] Посредством примера, а не ограничения, такие считываемые компьютером запоминающие носители могут содержать RAM, ROM, EEPROM, CD-ROM или другое запоминающее устройство на оптических дисках, запоминающее устройство на магнитных дисках, или другие магнитные запоминающие устройства хранения, флэш-память, или любой другой носитель, который может быть использован для хранения желаемого программного кода в форме инструкций или структур данных, и к которому может получить доступ компьютер. Кроме того, любое соединение должным образом называют считываемым компьютером носителем. Например, если инструкции переданы от веб-сайта, сервера, или другого удаленного источника, используя коаксиальный кабель, волоконно-оптический кабель, витую пару, цифровую абонентскую линию (DSL), или беспроводные технологии, такие как инфракрасное излучение, радиоизлучение, и микроволновое излучение, то эти коаксиальный кабель, волоконно-оптический кабель, витая пара, DSL, или беспроводные технологии, такие как инфракрасное излучение, радио- излучение, и микроволновое излучение включены в определение носителя. Нужно подразумевать, однако, что считываемые компьютером запоминающие носители и запоминающие носители данных не включают в себя соединения, несущие, сигналы, или другие временные носители, но вместо этого направлены на невременные, материальные запоминающие носители. Диск и диск, как используется здесь, включают в себя компакт-диск (CD), лазерный диск, оптический диск, цифровой универсальный диск (DVD), дискета и диск Blu-ray, где диски (disks) обычно воспроизводят данные магнитно, в то время как диски (discs) воспроизводят данные оптически с помощью лазеров. Комбинации вышеупомянутого должны также быть включены в рамки считываемого компьютером носителя.
[0200] Инструкции могут быть выполнены одним или более процессорами, такими как одним или более цифровыми сигнальными процессорами (DSPs), микропроцессорами общего назначения, специализированными интегральными схемами (ASICs), программируемыми пользователем вентильными матрицами (FPGAs), или другими эквивалентными интегрированными или дискретными логическими схемами. Соответственно, термин "процессор", как используется здесь, может относиться к любой предшествующей структуре или любой другой структуре, подходящей для реализации способов, описанных в настоящем описании. Кроме того, в некоторых аспектах функциональные возможности, описанные здесь, могут быть предоставлены в пределах специализированного аппаратного обеспечения и/или программных модулей, конфигурируемых для кодирования и декодирования, или объединены в объединенный кодек. Кроме того, способы могли быть полностью реализованы в одной или более схемах или логических элементах.
[0201] Способы настоящего раскрытия могут быть реализованы в широком разнообразии устройств или аппаратов, включая беспроводную телефонную трубку, интегральную схему (IC) или набор IC (например, микропроцессорный набор). Различные компоненты, модули, или блоки описаны в настоящем раскрытии, чтобы подчеркнуть функциональные аспекты устройств, конфигурируемых, чтобы выполнить раскрытые способы, но не обязательно требовать реализации различными блоками аппаратного обеспечения. Вместо этого, как описано выше, различные блоки могут быть объединены в блоке аппаратного обеспечения кодека или предоставлены коллекцией взаимодействующих блоков аппаратного обеспечения, включая один или более процессоров, как описано выше, в соединении с подходящим программным обеспечением и/или программно-аппаратными средствами.
[0202] Были описаны различные примеры. Эти и другие примеры находятся в рамках нижеследующей формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ПАРАМЕТРЫ ГИПОТЕТИЧЕСКОГО ОПОРНОГО ДЕКОДЕРА ПРИ КОДИРОВАНИИ ВИДЕО | 2013 |
|
RU2649297C2 |
| ТЕСТИРОВАНИЕ НА СООТВЕТСТВИЕ БИТОВОГО ПОТОКА | 2013 |
|
RU2613737C2 |
| ИНДИКАЦИЯ И АКТИВАЦИЯ НАБОРОВ ПАРАМЕТРОВ ДЛЯ КОДИРОВАНИЯ ВИДЕО | 2013 |
|
RU2646382C2 |
| ИНДИКАЦИЯ И АКТИВАЦИЯ НАБОРОВ ПАРАМЕТРОВ ДЛЯ КОДИРОВАНИЯ ВИДЕО | 2013 |
|
RU2646381C2 |
| ПАРАМЕТРЫ ГИПОТЕТИЧЕСКОГО ОПОРНОГО ДЕКОДЕРА ПРИ КОДИРОВАНИИ ВИДЕО | 2013 |
|
RU2642359C2 |
| КОДИРОВАНИЕ ВИДЕО С РАСШИРЕННОЙ ПОДДЕРЖКОЙ ДЛЯ АДАПТАЦИИ ПОТОКА И СТЫКОВКИ | 2013 |
|
RU2630173C2 |
| КОДИРОВАНИЕ ЕДИНИЦ NAL SEI ДЛЯ КОДИРОВАНИЯ ВИДЕО | 2013 |
|
RU2619194C2 |
| ИНФОРМАЦИЯ ТАКТИРОВАНИЯ КОДИРОВАНИЯ ДЛЯ КОДИРОВАНИЯ ВИДЕО | 2013 |
|
RU2635228C2 |
| ФЛАГ УРОВНЯ ПОСЛЕДОВАТЕЛЬНОСТИ ДЛЯ ПАРАМЕТРОВ БУФЕРА КОДИРОВАННЫХ НА УРОВНЕ СУБ-КАРТИНОК КАРТИНОК | 2013 |
|
RU2641475C2 |
| СООБЩЕНИЯ ДОПОЛНИТЕЛЬНОЙ ИНФОРМАЦИИ РАСШИРЕНИЯ ТОЧКИ ВОССТАНОВЛЕНИЯ И ПЕРИОДА БУФЕРИЗАЦИИ | 2013 |
|
RU2628215C2 |
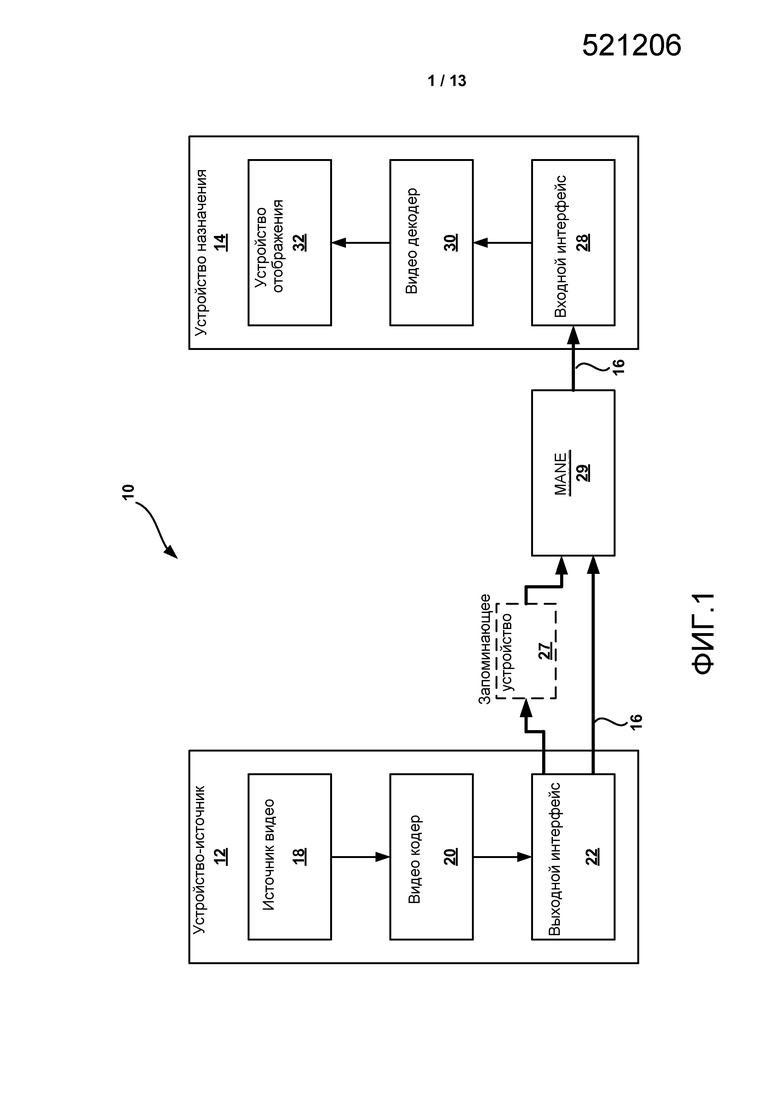
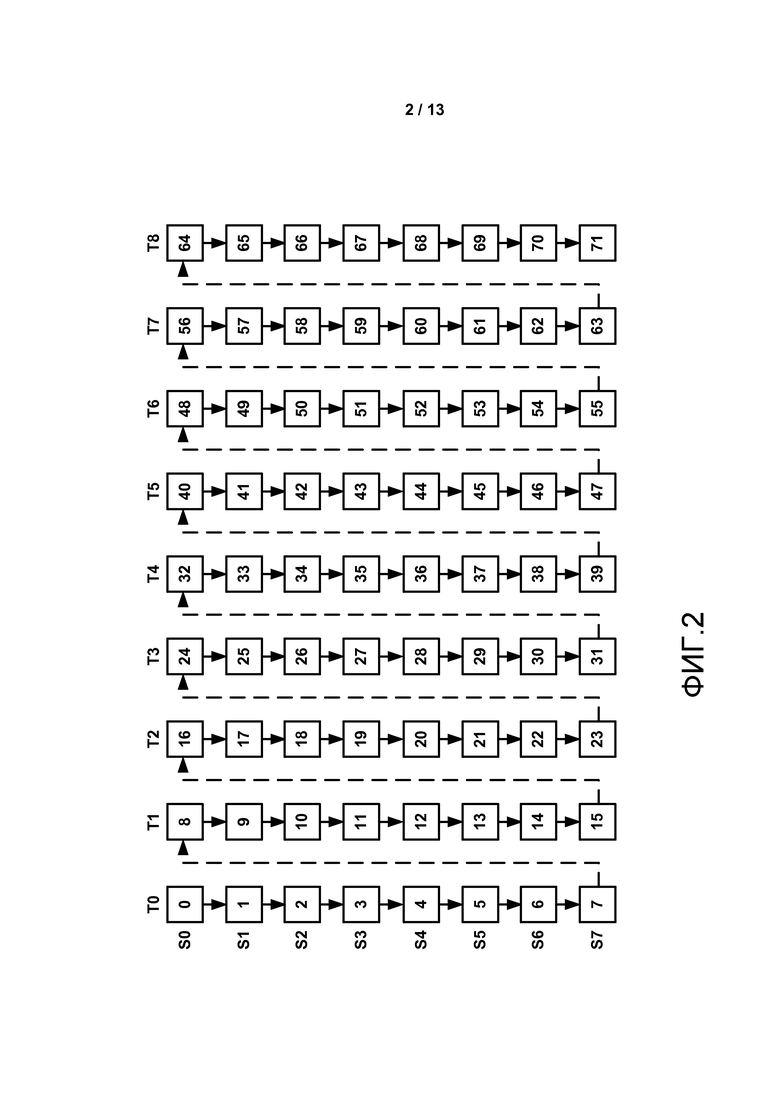
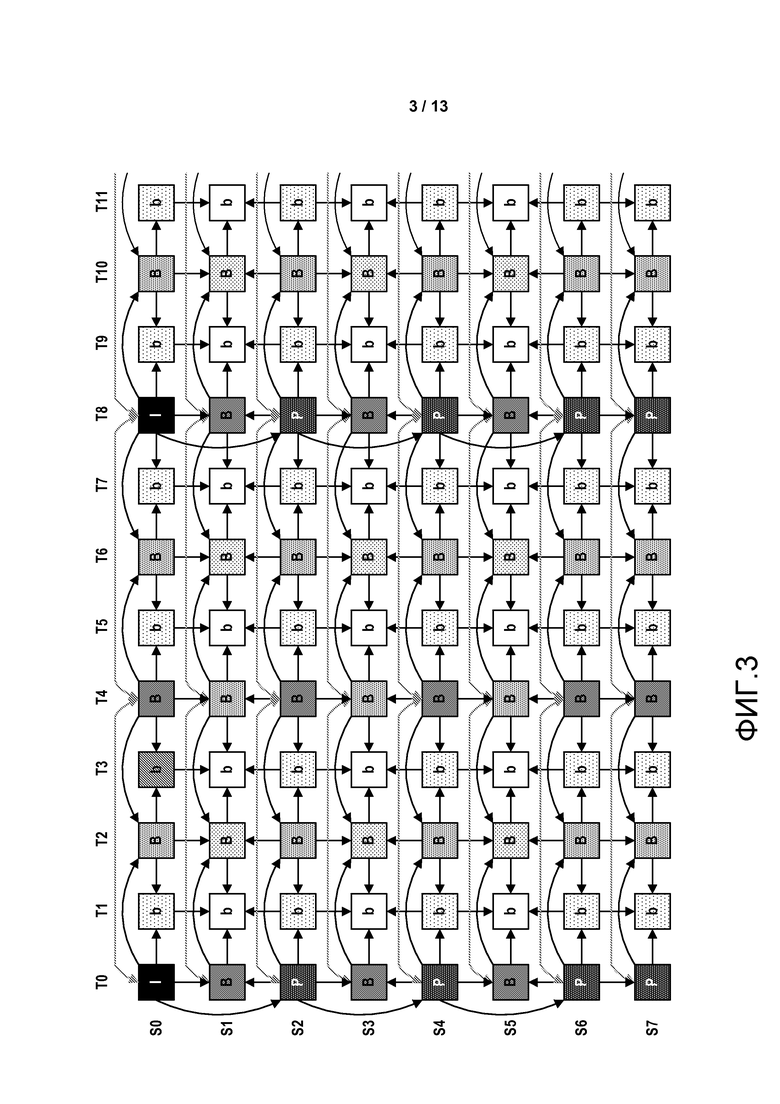
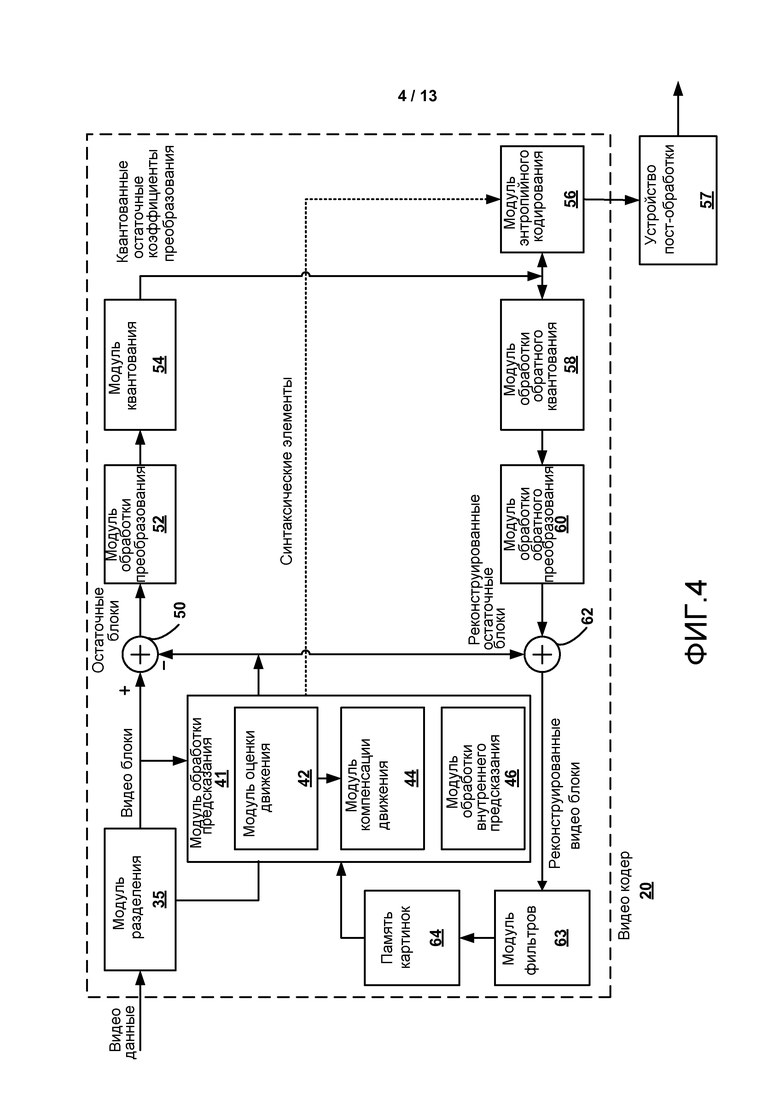
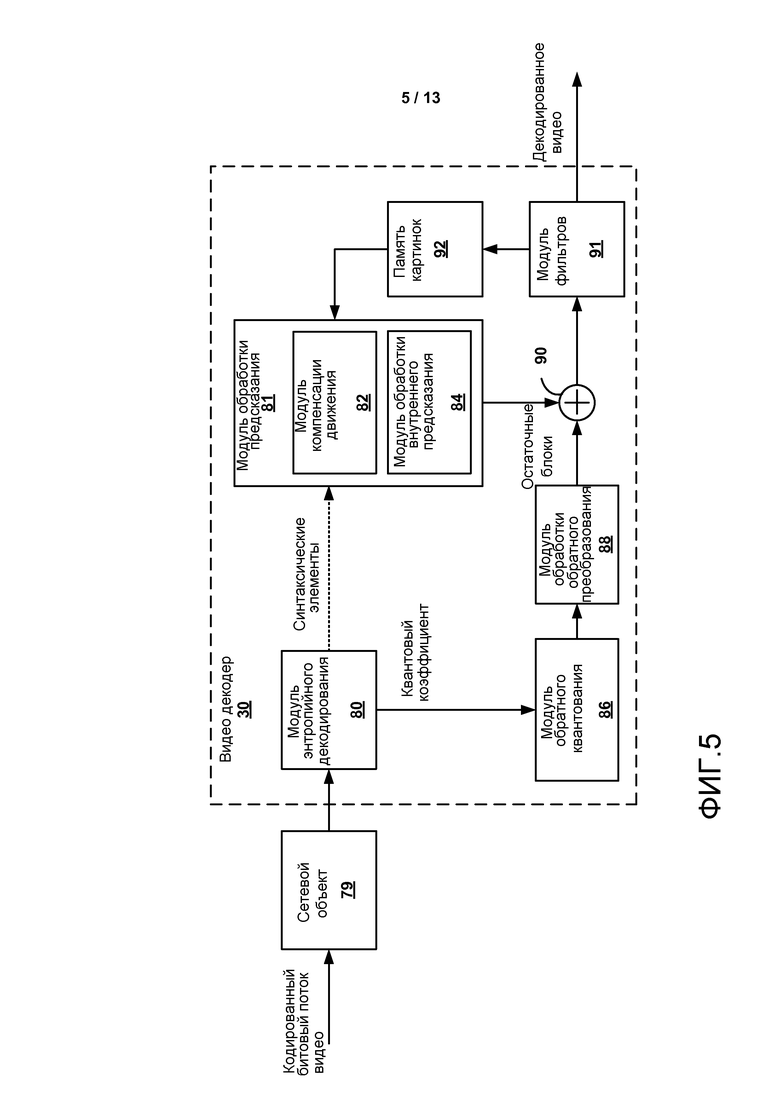
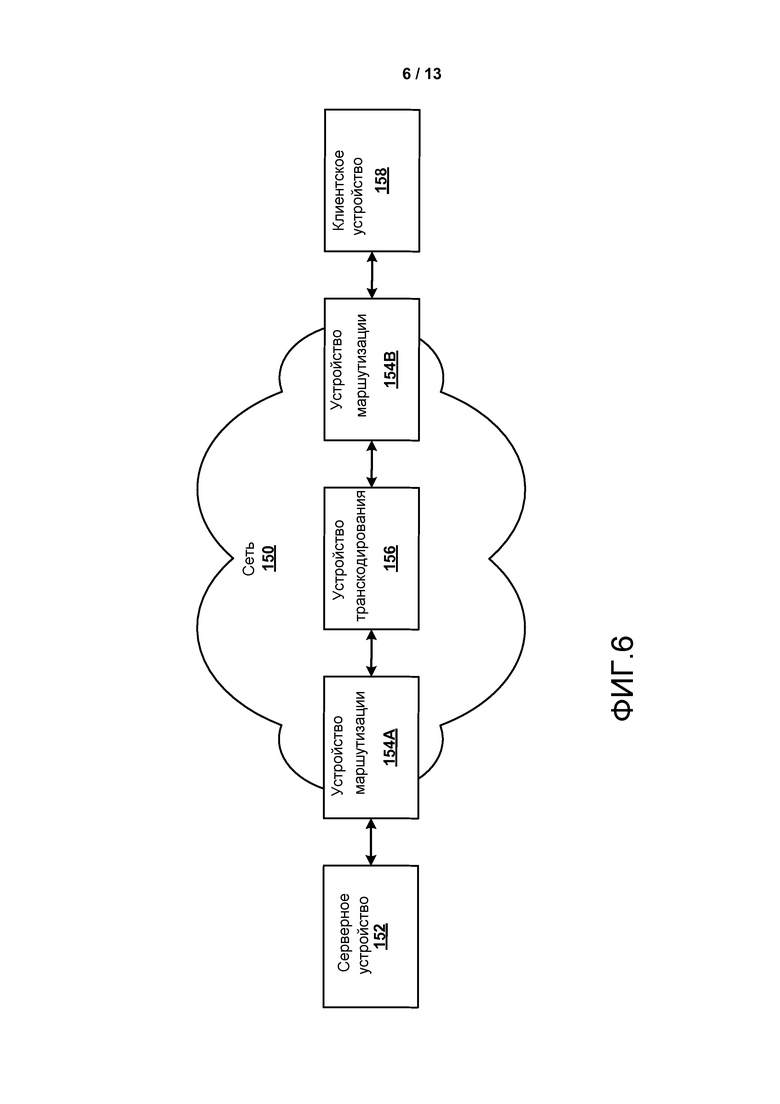
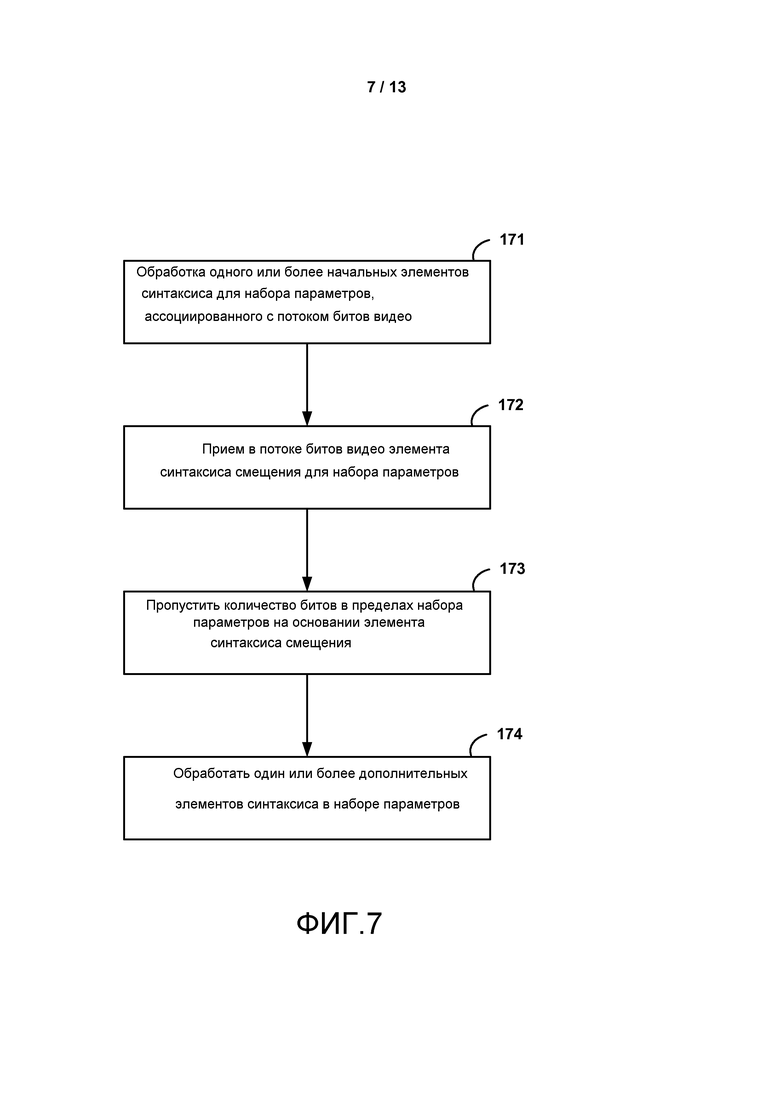
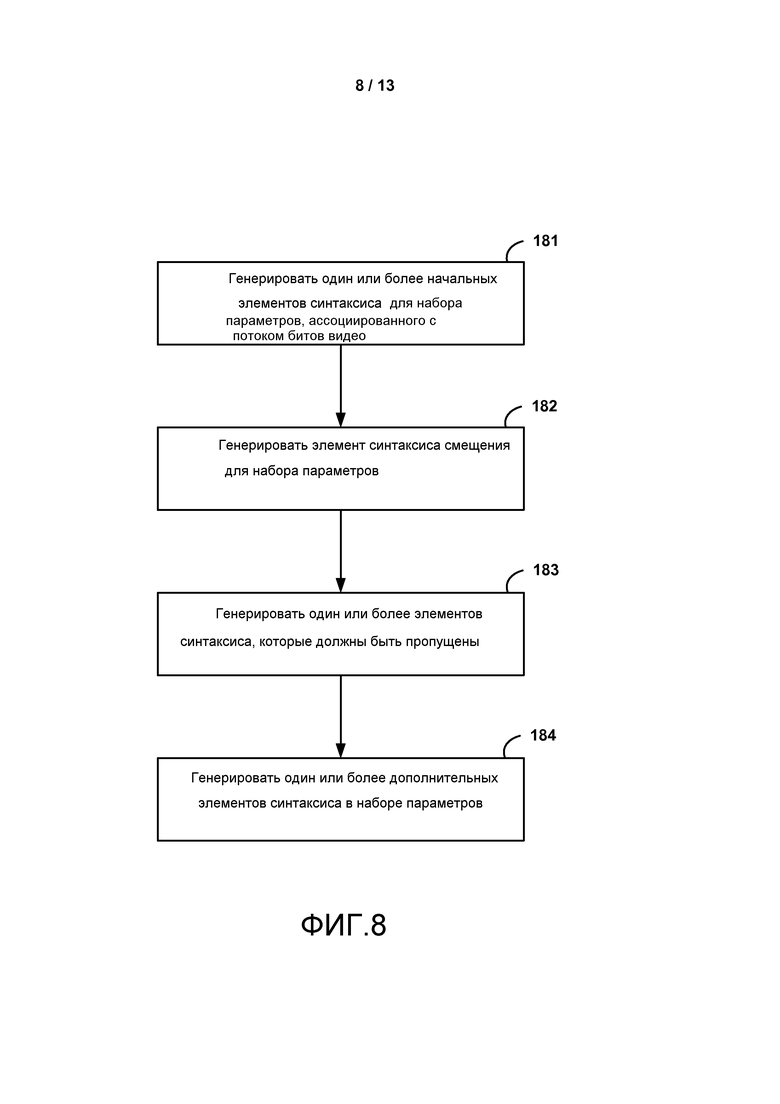
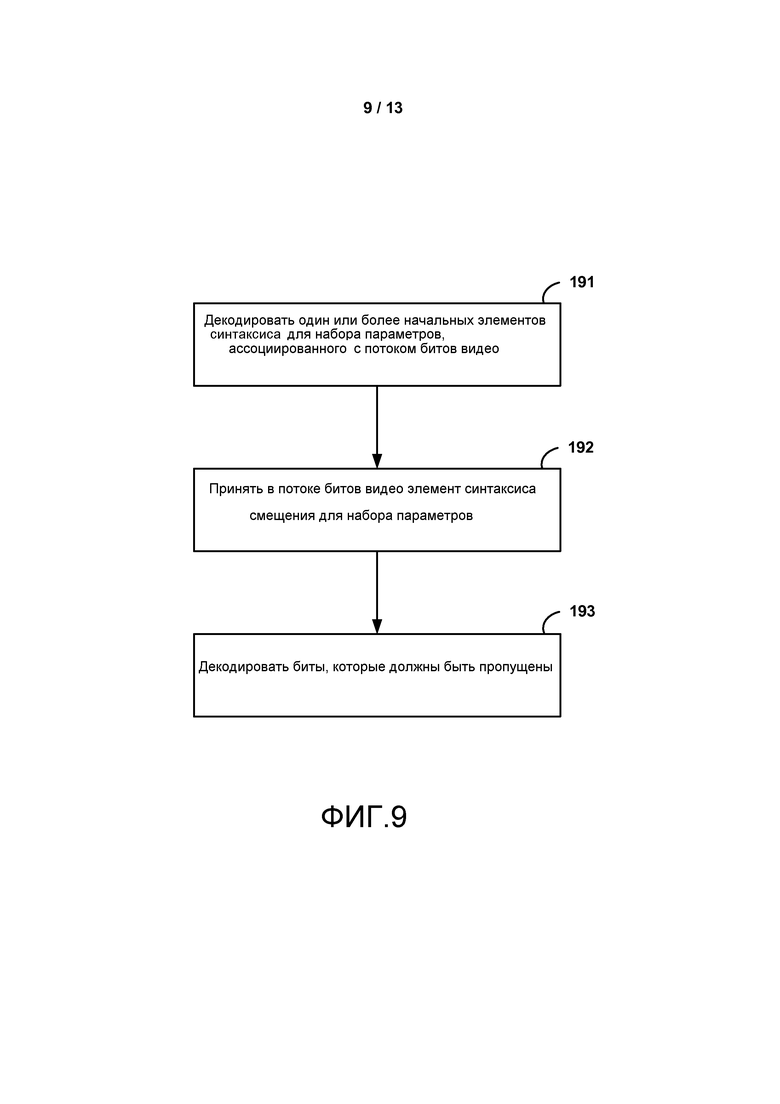
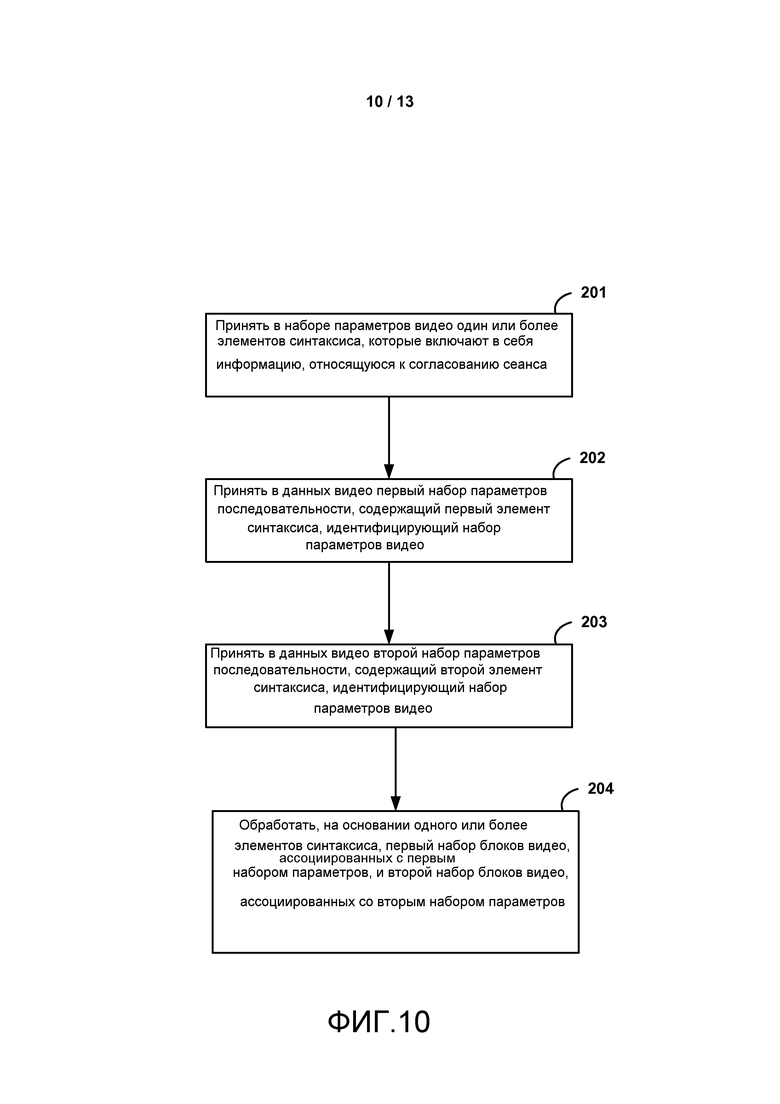
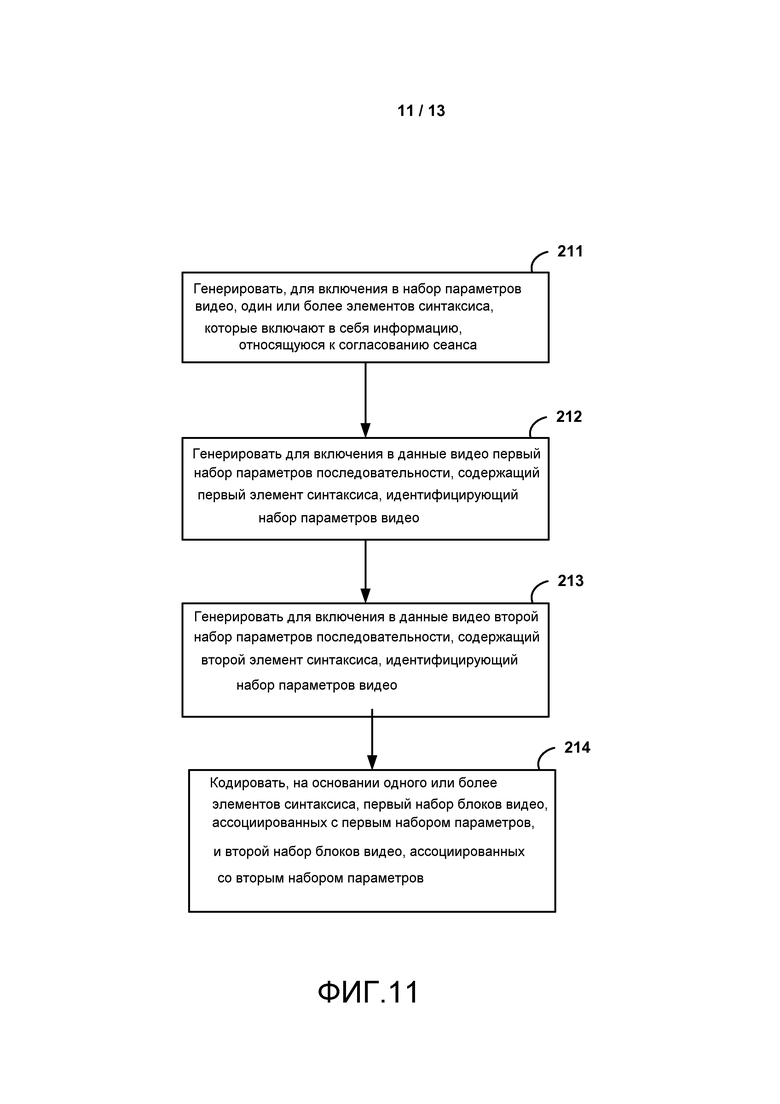
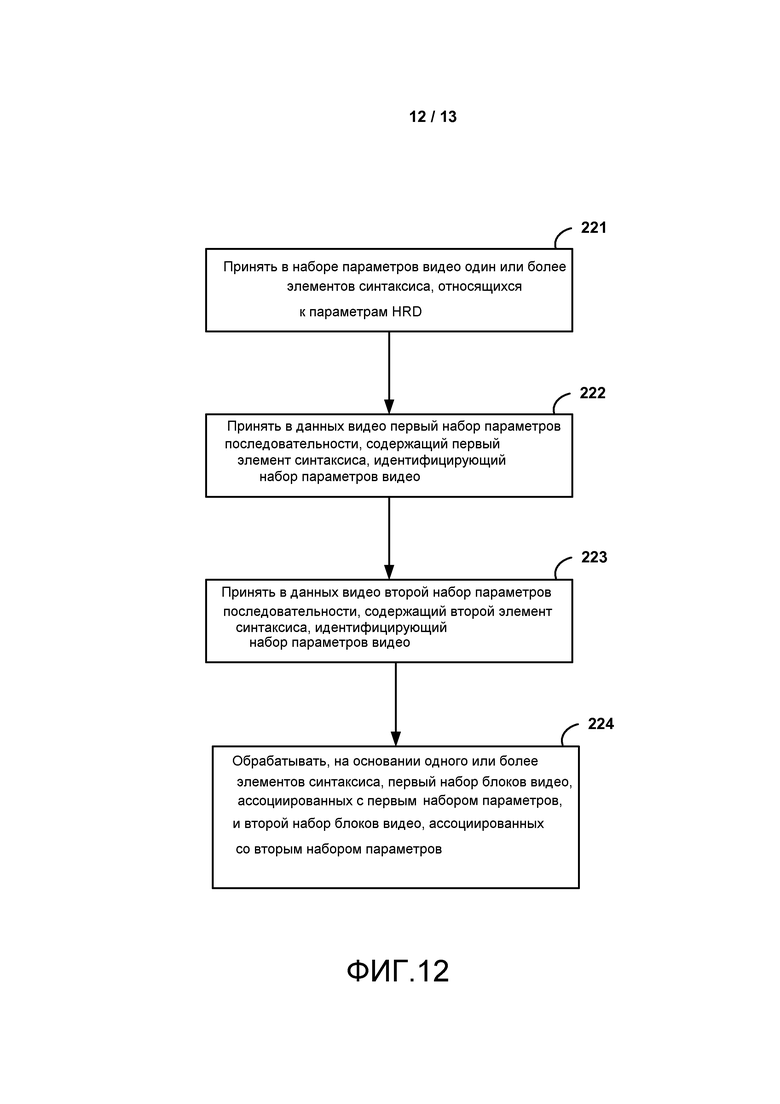
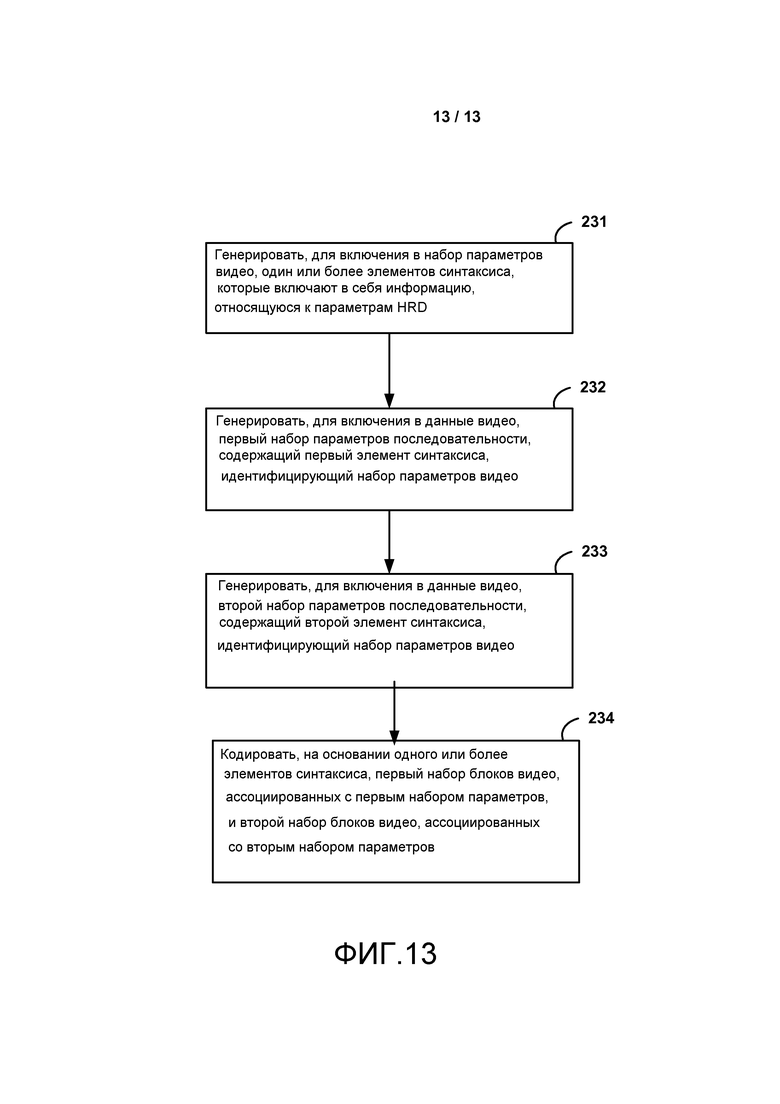
Изобретение относится к области обработки видеоданных. Технический результат – упрощение обработки элементов синтаксиса в наборе параметров видео посредством использования элемента синтаксиса смещения. Способ обработки видеоданных содержит: обработку одного или более начальных элементов синтаксиса в синтаксической структуре набора параметров видео (VPS), ассоциированной с потоком битов видео; прием, в синтаксической структуре VPS, элемента синтаксиса смещения для синтаксической структуры VPS, при этом значение элемента синтаксиса смещения равно количеству байтов в синтаксической структуре VPS, для которых обработка должна быть пропущена, при этом один или более начальных элементов синтаксиса предшествуют элементу синтаксиса смещения в синтаксической структуре VPS; на основании элемента синтаксиса смещения пропуск обработки по меньшей мере одного элемента синтаксиса в синтаксической структуре VPS; обработку одного или более дополнительных элементов синтаксиса в синтаксической структуре VPS, при этом один или более дополнительных элементов синтаксиса расположены после упомянутого по меньшей мере одного элемента синтаксиса в синтаксической структуре VPS. 8 н. и 37 з.п. ф-лы, 13 ил., 21 табл.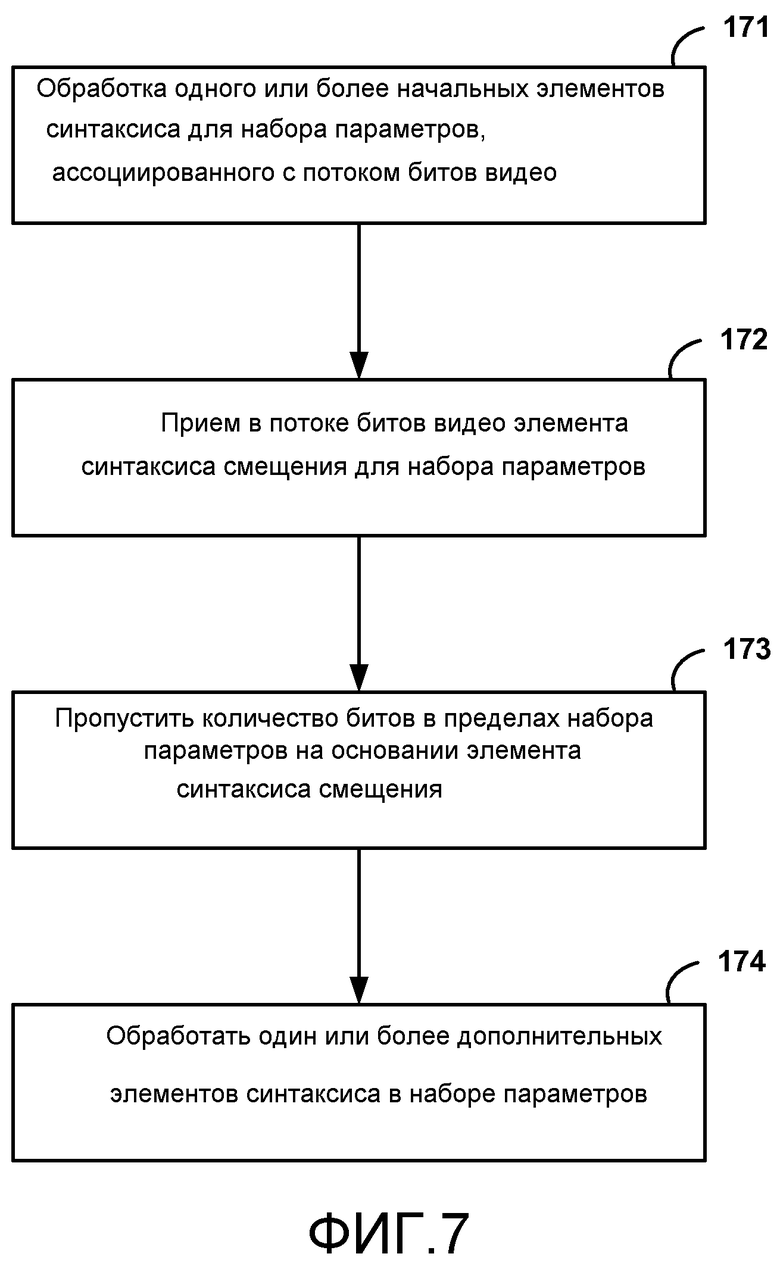
1. Способ обработки видеоданных, причем способ содержит:
обработку одного или более начальных элементов синтаксиса в синтаксической структуре набора параметров видео (VPS), ассоциированной с потоком битов видео, при этом один или более начальных элементов синтаксиса содержат элементы синтаксиса фиксированной длины, которые расположены до каких-либо элементов синтаксиса переменной длины в синтаксической структуре VPS, при этом синтаксическая структура VPS включает в себя информацию, которая применима к нулю или более целым кодированным видеопоследовательностям;
прием, в синтаксической структуре VPS, элемента синтаксиса смещения для синтаксической структуры VPS, при этом значение элемента синтаксиса смещения равно количеству байтов в синтаксической структуре VPS, которые должны быть пропущены, при этом один или более начальных элементов синтаксиса предшествуют элементу синтаксиса смещения в синтаксической структуре VPS;
на основании элемента синтаксиса смещения пропуск обработки по меньшей мере одного элемента синтаксиса в синтаксической структуре VPS;
обработку одного или более дополнительных элементов синтаксиса в синтаксической структуре VPS, при этом один или более дополнительных элементов синтаксиса расположены после упомянутого по меньшей мере одного элемента синтаксиса в синтаксической структуре VPS.
2. Способ по п. 1, в котором упомянутый по меньшей мере один элемент синтаксиса содержит один или более элементов синтаксиса, кодированных, используя кодирование с переменной длиной слова.
3. Способ по п. 1, в котором один или более дополнительных элементов синтаксиса содержат дополнительные элементы синтаксиса фиксированной длины, и в котором один или более дополнительных элементов синтаксиса следуют за элементом синтаксиса смещения и следуют за упомянутым по меньшей мере одним элементом синтаксиса.
4. Способ по п. 1, в котором один или более начальных элементов синтаксиса содержат элементы синтаксиса, которые включают в себя информацию, относящуюся к согласованию сеанса.
5. Способ по п. 1, в котором один или более начальных элементов синтаксиса содержат элементы синтаксиса для базового уровня видеоданных, и один или более дополнительных элементов синтаксиса содержат элементы синтаксиса для не базового уровня видеоданных.
6. Способ по п. 1, в котором синтаксическую структуру VPS определяют посредством содержимого элемента синтаксиса идентификации VPS, найденного в наборе параметров последовательности (SPS), который указывается элементом синтаксиса идентификации SPS, который найден в наборе параметров изображения (PPS), который указывается элементом синтаксиса идентификации PPS, найденным в каждом заголовке сегмента слайса.
7. Способ по п. 1, в котором обработка выполняется осведомленным о мультимедиа элементом сети (MANE), и в котором способ дополнительно содержит направление видеоданных клиентскому устройству.
8. Способ по п. 1, в котором пропуск обработки упомянутого по меньшей мере одного элемента синтаксиса в синтаксической структуре VPS содержит игнорирование значений упомянутого по меньшей мере одного элемента синтаксиса.
9. Способ обработки видеоданных, причем способ содержит:
генерирование одного или более начальных элементов синтаксиса для синтаксической структуры набора параметров видео (VPS), ассоциированной с потоком битов видео, при этом один или более начальных элементов синтаксиса содержат элементы синтаксиса фиксированной длины, которые расположены до каких-либо элементов синтаксиса переменной длины в синтаксической структуре VPS, при этом синтаксическая структура VPS включает в себя информацию, которая применима к нулю или более целым кодированным видеопоследовательностям;
генерирование элемента синтаксиса смещения для синтаксической структуры VPS, при этом значение элемента синтаксиса смещения равно количеству байтов в синтаксической структуре VPS, для которых обработка должна быть пропущена, при этом один или более начальных элементов синтаксиса предшествуют элементу синтаксиса смещения в синтаксической структуре VPS;
генерирование по меньшей мере одного элемента синтаксиса, для которого обработка должна быть пропущена, который соответствует байтам, для которых обработка должна быть пропущена; и
генерирование одного или более дополнительных элементов синтаксиса в синтаксической структуре VPS, при этом один или более дополнительных элементов синтаксиса расположены после упомянутого по меньшей мере одного элемента синтаксиса, для которого обработка должна быть пропущена, в синтаксической структуре VPS.
10. Способ по п. 9, в котором упомянутый по меньшей мере один элемент синтаксиса, для которого обработка должна быть пропущена, содержит один или более элементов синтаксиса, кодированных, используя кодирование с переменной длиной слова.
11. Способ по п. 9, в котором один или более дополнительных элементов синтаксиса содержат дополнительные элементы синтаксиса фиксированной длины, и в котором один или более дополнительных элементов синтаксиса следуют за элементом синтаксиса смещения и следуют за упомянутым по меньшей мере одним элементом синтаксиса, для которого обработка должна быть пропущена.
12. Способ по п. 9, в котором один или более начальных элементов синтаксиса содержат элементы синтаксиса, включающие в себя информацию, относящуюся к согласованию сеанса.
13. Способ по п. 9, в котором один или более начальных элементов синтаксиса содержат элементы синтаксиса для базового уровня видеоданных, и один или более дополнительных элементов синтаксиса содержат элементы синтаксиса для не базового уровня видеоданных.
14. Способ по п. 9, в котором синтаксическую структуру VPS определяют посредством содержимого элемента синтаксиса идентификации VPS, найденного в наборе параметров последовательности (SPS), который указывается элементом синтаксиса идентификации SPS, который найден в наборе параметров изображения (PPS), который указывается элементом синтаксиса идентификации PPS, найденным в каждом заголовке сегмента слайса.
15. Способ по п. 9, в котором способ выполняется видеокодером.
16. Способ по п. 9, в котором способ выполняется устройством пост-обработки, сконфигурированным, чтобы обрабатывать закодированные видеоданные.
17. Способ декодирования видеоданных, причем способ содержит:
декодирование одного или более начальных элементов синтаксиса для синтаксической структуры набора параметров видео (VPS), ассоциированной с потоком битов видео, при этом один или более начальных элементов синтаксиса содержат элементы синтаксиса фиксированной длины, которые расположены до каких-либо элементов синтаксиса переменной длины в синтаксической структуре VPS, при этом синтаксическая структура VPS включает в себя информацию, которая применима к нулю или более целым кодированным видеопоследовательностям;
прием, в потоке битов видео, элемента синтаксиса смещения для синтаксической структуры VPS, при этом значение элемента синтаксиса смещения равно количеству байтов в синтаксической структуре VPS, для которых обработка должна быть пропущена, при этом один или более начальных элементов синтаксиса предшествуют элементу синтаксиса смещения в синтаксической структуре VPS;
игнорирование значения элемента синтаксиса смещения; и
декодирование упомянутого по меньшей мере одного элемента синтаксиса, для которого обработка должна быть пропущена.
18. Способ по п. 17, в котором упомянутый по меньшей мере один элемент синтаксиса, для которого обработка должна быть пропущена, содержит один или более элементов синтаксиса переменной длины, и в котором декодирование упомянутого по меньшей мере одного элемента синтаксиса, для которого обработка должна быть пропущена, содержит выполнение процесса энтропийного декодирования.
19. Устройство обработки видео, содержащее:
память, хранящую видеоданные из потока битов видео; и
один или более процессоров, выполненных с возможностью осуществления операций, содержащих:
обработку одного или более начальных элементов синтаксиса для синтаксической структуры набора параметров видео (VPS), ассоциированной с потоком битов видео, при этом один или более начальных элементов синтаксиса содержат элементы синтаксиса фиксированной длины, которые расположены до каких-либо элементов синтаксиса переменной длины в синтаксической структуре VPS, при этом синтаксическая структура VPS включает в себя информацию, которая применима к нулю или более целым кодированным видеопоследовательностям;
прием, в синтаксической структуре VPS, элемента синтаксиса смещения со значением, равным количеству байтов в синтаксической структуре VPS, которые должны быть пропущены, при этом один или более начальных элементов синтаксиса предшествуют элементу синтаксиса смещения в синтаксической структуре VPS;
на основании элемента синтаксиса смещения пропуск обработки по меньшей мере одного элемента синтаксиса в синтаксической структуре VPS; и
обработку одного или более дополнительных элементов синтаксиса в синтаксической структуре VPS, при этом один или более дополнительных элементов синтаксиса расположены после упомянутого по меньшей мере одного элемента синтаксиса в синтаксической структуре VPS.
20. Устройство обработки видео по п. 19, в котором упомянутый по меньшей мере один элемент синтаксиса содержит один или более элементов синтаксиса, кодированных, используя кодирование с переменной длиной слова.
21. Устройство обработки видео по п. 19, в котором один или более дополнительных элементов синтаксиса содержат дополнительные элементы синтаксиса фиксированной длины, и в котором один или более дополнительных элементов синтаксиса следуют за элементом синтаксиса смещения и следуют за упомянутым по меньшей мере одним элементом синтаксиса.
22. Устройство обработки видео по п. 19, в котором один или более начальных элементов синтаксиса содержат элементы синтаксиса, включающие в себя информацию, относящуюся к согласованию сеанса.
23. Устройство обработки видео по п. 19, в котором один или более начальных элементов синтаксиса содержат элементы синтаксиса для базового уровня видеоданных, и один или более дополнительных элементов синтаксиса содержат элементы синтаксиса для не базового уровня видеоданных.
24. Устройство обработки видео по п. 19, в котором синтаксическая структура VPS определяется посредством содержимого элемента синтаксиса идентификации VPS, найденного в наборе параметров последовательности (SPS), который указывается элементом синтаксиса идентификации SPS, который найден в наборе параметров изображения (PPS), который указывается элементом синтаксиса идентификации PPS, найденным в каждом заголовке сегмента слайса.
25. Устройство обработки видео по п. 19, при этом устройство содержит осведомленный о мультимедиа элемент сети (MANE), выполненный с возможностью направления подпотока битов потока битов видео клиентскому устройству.
26. Устройство обработки видео по п. 19, в котором для пропуска обработки упомянутого по меньшей мере одного элемента синтаксиса в синтаксической структуре VPS упомянутый один или более процессоров выполнены с возможностью игнорирования значений упомянутого по меньшей мере одного элемента синтаксиса.
27. Устройство обработки видео, содержащее:
память, хранящую видеоданные из потока битов видео; и
один или более процессоров, выполненных с возможностью осуществления операций, содержащих:
генерирование одного или более начальных элементов синтаксиса для синтаксической структуры набора параметров видео (VPS), ассоциированной с потоком битов видео, при этом один или более начальных элементов синтаксиса содержат элементы синтаксиса фиксированной длины, которые расположены до каких-либо элементов синтаксиса переменной длины в синтаксической структуре VPS, при этом синтаксическая структура VPS включает в себя информацию, которая применима к нулю или более целым кодированным видеопоследовательностям;
генерирование элемента синтаксиса смещения для синтаксической структуры VPS, при этом значение элемента синтаксиса смещения равно количеству байтов в синтаксической структуре VPS, для которых обработка должна быть пропущена, при этом один или более начальных элементов синтаксиса предшествуют элементу синтаксиса смещения в синтаксической структуре VPS;
генерирование по меньшей мере одного элемента синтаксиса, для которого обработка должна быть пропущена, который соответствует байтам, для которых обработка должна быть пропущена; и
генерирование одного или более дополнительных элементов синтаксиса в синтаксической структуре VPS, при этом один или более дополнительных элементов синтаксиса расположены после упомянутого по меньшей мере одного элемента синтаксиса, для которого обработка должна быть пропущена, в синтаксической структуре VPS.
28. Устройство обработки видео по п. 27, в котором упомянутый по меньшей мере один элемент синтаксиса, для которого обработка должна быть пропущена, содержит один или более элементов синтаксиса, кодированных, используя кодирование с переменной длиной слова.
29. Устройство обработки видео по п. 27, в котором один или более дополнительных элементов синтаксиса содержат дополнительные элементы синтаксиса фиксированной длины, и в котором один или более дополнительных элементов синтаксиса следуют за элементом синтаксиса смещения и следуют за упомянутым по меньшей мере одним элементом синтаксиса, для которого обработка должна быть пропущена.
30. Устройство обработки видео по п. 27, в котором один или более начальных элементов синтаксиса содержат элементы синтаксиса, включающие в себя информацию, относящуюся к согласованию сеансов.
31. Устройство обработки видео по п. 27, в котором один или более начальных элементов синтаксиса содержат элементы синтаксиса для базового уровня видеоданных, и один или более дополнительных элементов синтаксиса содержат элементы синтаксиса для небазового уровня видеоданных.
32. Устройство обработки видео по п. 27, в котором синтаксическая структура VPS определяется посредством содержимого элемента синтаксиса идентификации VPS, найденного в наборе параметров последовательности (SPS), который указывается элементом синтаксиса идентификации SPS, который найден в наборе параметров изображения (PPS), который указывается элементом синтаксиса идентификации PPS, найденным в каждом заголовке сегмента слайса.
33. Устройство обработки видео по п. 27, в котором один или более процессоров содержат видеокодер.
34. Устройство обработки видео по п. 27, в котором устройство обработки видео содержит устройство пост-обработки, выполненное с возможностью обработки закодированных видеоданных.
35. Устройство обработки видео по п. 27, при этом устройство обработки видео содержит по меньшей мере одно из:
интегральной схемы;
микропроцессора; или
устройства беспроводной связи, которое содержит видеокодер.
36. Устройство обработки видео, содержащее:
память, хранящую видеоданные из потока битов видео; и
один или более процессоров, выполненных с возможностью осуществления операций, содержащих:
декодирование одного или более начальных элементов синтаксиса для синтаксической структуры набора параметров видео (VPS), ассоциированной с потоком битов видео, при этом один или более начальных элементов синтаксиса содержат элементы синтаксиса фиксированной длины, которые расположены до каких-либо элементов синтаксиса переменной длины в синтаксической структуре VPS, при этом синтаксическая структура VPS включает в себя информацию, которая применяется к нулю или более целым кодированным видеопоследовательностям;
прием, в потоке битов видео, элемента синтаксиса смещения со значением, равным количеству байтов в синтаксической структуре VPS, для которых обработка должна быть пропущена, при этом один или более начальных элементов синтаксиса предшествуют элементу синтаксиса смещения в синтаксической структуре VPS;
игнорирование значения элемента синтаксиса смещения; и
декодирование упомянутого по меньшей мере одного элемента синтаксиса, для которого обработка должна быть пропущена.
37. Устройство обработки видео по п. 36, в котором упомянутый по меньшей мере один элемент синтаксиса, для которого обработка должна быть пропущена, содержит один или более элементов синтаксиса переменной длины, и в котором декодирование упомянутого по меньшей мере одного элемента синтаксиса, для которого обработка должна быть пропущена, содержит выполнение процесса энтропийного декодирования.
38. Устройство обработки видео по п. 36, при этом устройство обработки видео содержит по меньшей мере одно из:
интегральной схемы;
микропроцессора; или
устройства беспроводной связи, которое содержит видеодекодер.
39. Устройство обработки видео, содержащее:
средство для обработки одного или более начальных элементов синтаксиса для синтаксической структуры VPS, ассоциированного с потоком битов видео, в котором один или более начальных элементов синтаксиса содержат элементы синтаксиса фиксированной длины, которые расположены до каких-либо элементов синтаксиса переменной длины в синтаксической структуре VPS;
средство для приема, в синтаксической структуре VPS, элемента синтаксиса смещения для синтаксической структуры VPS, при этом элемент синтаксиса смещения идентифицирует количество байтов в синтаксической структуре VPS, для которых обработка должна быть пропущена, при этом один или более начальных элементов синтаксиса предшествуют элементу синтаксиса смещения в синтаксической структуре VPS;
средство для пропуска элементов синтаксиса в пределах синтаксической структуры VPS на основании элемента синтаксиса смещения; и
средство для обработки одного или более дополнительных элементов синтаксиса в синтаксической структуре VPS, при этом один или более дополнительных элементов синтаксиса расположены после упомянутого по меньшей мере одного элемента синтаксиса, для которого обработка должна быть пропущена в синтаксической структуре VPS.
40. Долговременный считываемый компьютером запоминающий носитель, хранящий инструкции, которые, когда выполняются, вынуждают один или более процессоров:
обрабатывать один или более начальных элементов синтаксиса для синтаксической структуры VPS, ассоциированного с потоком битов видео, при этом один или более начальных элементов синтаксиса содержат элементы синтаксиса фиксированной длины, которые расположены до каких-либо элементов синтаксиса переменной длины в синтаксической структуре VPS;
принимать, в синтаксической структуре VPS, элемент синтаксиса смещения для синтаксической структуры VPS, при этом элемент синтаксиса смещения идентифицирует количество байтов в синтаксической структуре VPS, для которых обработка должна быть пропущена, при этом один или более начальных элементов синтаксиса предшествуют элементу синтаксиса смещения в синтаксической структуре VPS;
пропускать элементы синтаксиса в пределах синтаксической структуры VPS на основании элемента синтаксиса смещения; и
обрабатывать один или более дополнительных элементов синтаксиса в синтаксической структуре VPS, при этом один или более дополнительных элементов синтаксиса находятся после упомянутого по меньшей мере одного элемента синтаксиса, для которого обработка должна быть пропущена в синтаксической структуре VPS.
41. Долговременный считываемый компьютером запоминающий носитель по п. 40, в котором упомянутый по меньшей мере один элемент синтаксиса содержит один или более элементов синтаксиса, кодированных, используя кодирование с переменной длиной слова.
42. Долговременный считываемый компьютером запоминающий носитель по п. 40, в котором один или более дополнительных элементов синтаксиса содержат дополнительные элементы синтаксиса фиксированной длины, и в котором один или более дополнительных элементов синтаксиса следуют за элементом синтаксиса смещения и следуют за упомянутым по меньшей мере одним элементом синтаксиса.
43. Долговременный считываемый компьютером запоминающий носитель по п. 40, в котором один или более начальных элементов синтаксиса содержат элементы синтаксиса, включающие в себя информацию, относящуюся к согласованию сеанса.
44. Долговременный считываемый компьютером запоминающий носитель по п. 40, в котором один или более начальных элементов синтаксиса содержат элементы синтаксиса для базового уровня видеоданных, и один или более дополнительных элементов синтаксиса содержат элементы синтаксиса для не базового уровня видеоданных.
45. Долговременный считываемый компьютером запоминающий носитель по п. 40, хранящий дополнительные инструкции, которые, когда выполняются, вынуждают один или более процессоров отправлять видеоданные клиентскому устройству.
| Железнодорожный снегоочиститель | 1920 |
|
SU264A1 |
| Перекатываемый затвор для водоемов | 1922 |
|
SU2001A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| СЖАТИЕ ВИДЕОИЗОБРАЖЕНИЙ С ПОМОЩЬЮ АДАПТИВНЫХ КОДОВ С ПЕРЕМЕННОЙ ДЛИНОЙ | 2007 |
|
RU2407219C2 |

