ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение в целом относится к обработке цифрового видеосигнала и в частности к способу, устройству и системе для кодирования и декодирования поднабора единиц преобразования видеоданных.
УРОВЕНЬ ТЕХНИКИ
В настоящее время существует множество приложений для видеокодирования, включающих в себя приложения для передачи и хранения видеоданных. Также уже разработано множество стандартов видеокодирования, кроме того, все новые разрабатываются в настоящее время. Последние разработки в стандартизации видеокодирования привели к формированию группы, названной «Объединенная рабочая группа по видеокодированию» («Joint Collaborative Team on Video Coding», JCT-VC). Объединенная рабочая группа (JCT-VC) по видеокодированию включает в себя участников Исследовательской группы 16, Вопрос 6 (Study Group 16, Question 6, SG16/Q6) Сектора стандартизации электросвязи (Telecommunication Standardisation Sector) (ITU-T) Международного союза электросвязи (International Telecommunication Union, ITU), известной в качестве Экспертной группы по видеокодированию (Video Coding Experts Group, VCEG), и участников Международной организации по стандартизации/Объединенного технического комитета 1 Международной электротехнической комиссии/Подкомиссии 29/Рабочей группы 11 (International Organisations for Standardisation/International Electrotechnical Commission Joint Technical Committee 1/Subcommittee 29/Working Group 11, ISO/IEC JTC1/SC29/WG11), также известных в качестве Экспертной группы по движущимся изображениям (Moving Picture Experts Group, MPEG).
Объединенная рабочая группа (JCT-VC) по видеокодированию имеет целью создание нового стандарта видеокодирования, чтобы значительно превосходить существующий в настоящее время стандарт видеокодирования, известный как «H.264/MPEG-4 AVC». Стандарт H.264/MPEG-4 AVC сам по себе является большим улучшением над предыдущими стандартами видеокодирования, такими как MPEG-4 и ITU-T H.263. Новый разрабатываемый стандарт видеокодирования назвали «высокоэффективным видеокодированием (high efficiency video coding, HEVC)». Объединенная рабочая группа JCT-VC по видеокодированию также рассматривает проблемы реализации, возникающие из-за предлагаемой для высокоэффективного видеокодирования (HEVC) технологии, которая создает трудности при масштабировании вариантов реализации стандартов для функционирования с высоким разрешением или высокой частотой кадров.
Стандарт видеокодирования H.264/MPEG-4 AVC вызывает трудности в достижении высокой эффективности сжатия при кодировании остаточных коэффициентов для представления видеоданных.
Видеоданные образуются последовательностью кадров, причем каждый кадр имеет двумерный массив отсчетов (дискретизации). Как правило, кадры включают в себя один канал яркости и два канала цветности. Информация о цвете обычно представляется с использованием цветового пространства, такого как YUV, где Y является каналом яркости, а UV являются двумя каналами цветности. Цветовое пространство, такое как YUV, обеспечивает преимущество в том, что большая часть содержимого кадра содержится в каналах яркости, а относительно более малая часть содержимого, хранящегося в каналах UV, является достаточной для восстановления цветного кадра. Каналы цветности могут также дискретизироваться с понижением частоты в более низкое пространственное разрешение с незначительной потерей качества восприятия.
Широко используемый формат цветности, известный в качестве 4:2:0, приводит в результате к тому, что каждый канал цветности имеет половину разрешающей способности по вертикали и по горизонтали. Каждый кадр раскладывается в массив наибольших единиц кодирования (LCU). Наибольшие единицы кодирования (LCU) имеют фиксированный размер, причем размерности краев являются степенью двух и имеют равную ширину и высоту, такую как 64 отсчета яркости. Дерево кодирования делает возможным подразделение каждой наибольшей единицы кодирования (LCU) на четыре единицы кодирования (CU), причем каждая имеет половину ширины и высоты родительской наибольшей единицы кодирования (LCU). Каждая из единиц кодирования (CU) может быть дополнительно подразделена на четыре единицы кодирования (CU) одинаково размера. Такой процесс подразделения может применяться рекурсивно, пока не будет достигнут размер наименьшей единицы кодирования (SCU), позволяя задавать единицы кодирования (CU) вплоть до минимального поддерживаемого размера. Рекурсивное подразделение наибольшей единицы кодирования в иерархию единиц кодирования имеет структуру дерева квадрантов и упоминается в качестве дерева кодирования. Процесс подразделения кодируется в битовом потоке передачи данных в качестве последовательности флагов, кодируемых в качестве бинов (ячеек). Поэтому единицы кодирования имеют квадратную форму.
Набор единиц кодирования существует в дереве кодирования, которые дополнительно не подразделяются, занимая листовые узлы дерева кодирования. Деревья преобразования существуют в единицах кодирования. Дерево преобразования может дополнительно разлагать единицу кодирования с использованием структуры дерева квадрантов, используемой для дерева кодирования. В листовых узлах дерева преобразования остаточные данные кодируются с использованием единиц преобразования (TU). В отличие от дерева кодирования дерево преобразования может подразделять единицы кодирования в единицы преобразования, имеющие не квадратную форму. Дополнительно, структура дерева преобразования не требует, чтобы единицы преобразования (TU) занимали всю область, предоставляемую родительской единицей кодирования.
Каждая единица кодирования в листовых узлах деревьев кодирования подразделяется на один или более массивов предсказанных отсчетов данных, при этом каждый известен в качестве единицы предсказания (PU). Каждая единица предсказания (PU) содержит предсказание части данных введенного видеокадра, извлеченной посредством применения процесса внутреннего (интра-) предсказания или внешнего (интер-) предсказания.
Несколько способов могут использоваться для кодирования единицы предсказания (PU) внутри единицы кодирования (CU). Одиночная единица предсказания (PU) может занимать всю область единицы кодирования (CU), либо единица кодирования (CU) может быть разделена на две прямоугольных единицы предсказания (PU) с равными размерами, либо по горизонтали, либо по вертикали. Дополнительно, единицы кодирования (CU) могут быть разделены на четыре квадратных единицы предсказания (PU) с равными размерами.
Видеокодер сжимает видеоданные в битовый поток посредством преобразования видеоданных в последовательность синтаксических элементов. Схема контекстно-адаптивного двоичного арифметического кодирования (CABAC) определена внутри разрабатываемого стандарта высокоэффективного видеокодирования (HEVC) с использованием идентичной схемы арифметического кодирования, которая определена в стандарте видеосжатия MPEG4-AVC/H.264. В разрабатываемом стандарте высокоэффективного видеокодирования (HEVC), когда используется контекстно-адаптивное двоичное арифметическое кодирование (CABAC), каждый синтаксический элемент выражается в качестве последовательности бинов. Каждый бин либо кодируется с обходом, либо кодируется арифметически. Обходное кодирование используется, когда бин равновероятно является 0 или 1. В данном случае никакого дополнительного сжатия не достигается. Арифметическое кодирование используется для бинов, которые имеют неравновероятностное распределение. Каждый арифметически кодированный бин связан с информацией, известной в качестве «контекста». Контексты содержат вероятностное значение бина («valMPS») и вероятностное состояние, целое число, которое отображается в оцененную вероятность вероятностного значения бина. Создание такой последовательности бинов, содержащей сочетание кодированных с обходом бинов и арифметически кодированных бинов, из синтаксического элемента известно в качестве «бинаризации» («преобразования в двоичную форму») синтаксического элемента.
В видеокодере или видеодекодере, поскольку информация отдельного контекста доступна для каждого бина, выбор контекста для бинов обеспечивает средство для улучшения эффективности кодирования. В частности эффективность кодирования может быть улучшена посредством выбора конкретного бина так, чтобы статистические свойства от предыдущих экземпляров бина, в которых использовалась информация связанного контекста, коррелировались со статистическими свойствами текущего экземпляра бина. Такой выбор контекста часто использует пространственно локальную информацию для определения оптимального контекста.
В разрабатываемом стандарте высокоэффективного видеокодирования (HEVC) и в H.264/MPEG-4 AVC извлекается предсказание для текущего блока на основе данных опорных отсчетов или из других кадров, или из соседних зон внутри текущего блока, которые были предварительно декодированы. Разность между предсказанием и искомыми данными отсчета дискретизации известна в качестве остатка. Представление остатка в частотной области является двумерным массивом остаточных коэффициентов. Принято считать, что верхний левый угол двумерного массива содержит остаточные коэффициенты, представляющие собой низкочастотную информацию.
В типичных видеоданных большинство изменений в значениях отсчетов являются постепенными, приводя в результате к преобладанию низкочастотной информации внутри остатка. Это проявляется в том, что более большие абсолютные значения остаточных коэффициентов располагаются в верхнем левом углу двумерного массива.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Задача настоящего изобретения состоит в существенном преодолении, или по меньшей мере улучшении, одного или более недостатков существующих вариантов выполнений.
Согласно одному аспекту настоящего раскрытия предложен способ декодирования единицы преобразования кодированных видеоданных с использованием декодирования Голомба-Райса, при этом способ содержит этапы, на которых:
определяют значимые остаточные коэффициенты для поднабора единицы преобразования;
выбирают предварительно определенный параметр Райса для декодирования Голомба-Райса поднабора единицы преобразования, причем предварительно определенный параметр Райса смещен от установки на ноль, когда определенное количество значимых остаточных коэффициентов выше предварительно определенной пороговой величины; и
декодируют поднабор единицы преобразования с использованием предварительно определенного параметра Райса в качестве начального параметра для декодирования Голомба-Райса.
Согласно другому аспекту настоящего раскрытия предложено устройство для декодирования единицы преобразования кодированных видеоданных с использованием декодирования Голомба-Райса, при этом устройство содержит:
средство для определения значимых остаточных коэффициентов для поднабора единицы преобразования;
средство для выбора предварительно определенного параметра Райса для декодирования Голомба-Райса поднабора единицы преобразования, причем предварительно определенный параметр Райса смещен от установки на ноль, когда определенное количество значимых остаточных коэффициентов выше предварительно определенной пороговой величины; и
средство для декодирования поднабора единицы преобразования с использованием предварительно определенного параметра Райса в качестве начального параметра для декодирования Голомба-Райса.
Согласно другому аспекту настоящего раскрытия предложена система для декодирования единицы преобразования кодированных видеоданных с использованием декодирования Голомба-Райса, при этом система содержит:
память для хранения данных и компьютерной программы;
процессор, соединенный с упомянутой памятью для исполнения упомянутой компьютерной программы, причем упомянутая компьютерная программа содержит инструкции для:
определения значимых остаточных коэффициентов для поднабора единицы преобразования;
выбора предварительно определенного параметра Райса для декодирования Голомба-Райса поднабора единицы преобразования, причем предварительно определенный параметр Райса смещен от установки на ноль, когда определенное количество значимых остаточных коэффициентов выше предварительно определенной пороговой величины; и
декодирования поднабора единицы преобразования с использованием предварительно определенного параметра Райса в качестве начального параметра для декодирования Голомба-Райса.
Согласно другому аспекту настоящего раскрытия предложен считываемый компьютером носитель, имеющий сохраненную на себе компьютерную программу для декодирования единицы преобразования кодированных видеоданных с использованием декодирования Голомба-Райса, при этом программа содержит:
код для определения значимых остаточных коэффициентов для поднабора единицы преобразования;
код для выбора предварительно определенного параметра Райса для декодирования Голомба-Райса поднабора единицы преобразования, причем предварительно определенный параметр Райса смещен от установки на ноль, когда определенное количество значимых остаточных коэффициентов выше предварительно определенной пороговой величины; и
код для декодирования поднабора единицы преобразования с использованием предварительно определенного параметра Райса в качестве начального параметра для декодирования Голомба-Райса.
Согласно другому аспекту настоящего раскрытия предложен способ декодирования потока видеоданных для определения значения текущего остаточного коэффициента в декодированном потоке видеоданных, при этом способ содержит этапы, на которых:
принимают единицу преобразования остаточных коэффициентов из потока видеоданных;
определяют позицию текущего остаточного коэффициента единицы преобразования;
декодируют текущий остаточный коэффициент с использованием свободного от зависимости декодирования Голомба-Райса, когда позиция текущего остаточного коэффициента в единице преобразования больше предварительно определенной пороговой величины, причем свободное от зависимости декодирование Голомба-Райса использует предварительно определенное значение Голомба-Райса;
декодируют текущий остаточный коэффициент с использованием основанного на зависимости декодирования Голомба-Райса для текущего коэффициента, когда позиция текущего остаточного коэффициента в единице преобразования меньше предварительно определенной пороговой величины, при этом основанное на зависимости декодирование Голомба-Райса использует значение ранее декодированного остаточного коэффициента для выбора значения Голомба-Райса; и
определяют значение для текущего остаточного коэффициента с использованием выбранного значения декодирования Голомба-Райса.
Согласно другому аспекту настоящего раскрытия предложен способ декодирования единицы преобразования кодированных видеоданных с использованием декодирования Голомба-Райса, при этом способ содержит этапы, на которых:
определяют параметр квантования для единицы преобразования;
определяют значимые остаточные коэффициенты для поднабора единицы преобразования;
выбирают предварительно определенный параметр Райса для декодирования Голомба-Райса поднабора единицы преобразования, причем предварительно определенный параметр Райса смещен от установки на ноль, когда определенный параметр квантования ниже предварительно определенной пороговой величины; и
декодируют поднабор единицы преобразования с использованием предварительно определенного параметра Райса в качестве начального параметра для декодирования Голомба-Райса.
Согласно другому аспекту настоящего раскрытия предложено устройство для декодирования единицы преобразования кодированных видеоданных с использованием декодирования Голомба-Райса, при этом устройство содержит:
средство для определения значимых остаточных коэффициентов для поднабора единицы преобразования;
средство для определения параметра квантования для единицы преобразования;
средство для выбора предварительно определенного параметра Райса для декодирования Голомба-Райса поднабора единицы преобразования, причем предварительно определенный параметр Райса смещен от установки на ноль, когда определенный параметр квантования ниже предварительно определенной пороговой величины; и
средство для декодирования поднабора единицы преобразования с использованием предварительно определенного параметра Райса в качестве начального параметра для декодирования Голомба-Райса.
Согласно другому аспекту настоящего раскрытия предложена система для декодирования единицы преобразования кодированных видеоданных с использованием декодирования Голомба-Райса, при этом система содержит:
память для хранения данных и компьютерной программы;
процессор, соединенный с упомянутой памятью для исполнения упомянутой компьютерной программы, причем упомянутая компьютерная программа содержит инструкции для:
определения значимых остаточных коэффициентов для поднабора единицы преобразования;
определения параметра квантования для единицы преобразования;
выбора предварительно определенного параметра Райса для декодирования Голомба-Райса поднабора единицы преобразования, причем предварительно определенный параметр Райса смещен от установки на ноль, когда определенный параметр квантования ниже предварительно определенной пороговой величины; и
декодирования поднабора единицы преобразования с использованием предварительно определенного параметра Райса в качестве начального параметра для декодирования Голомба-Райса.
Согласно другому аспекту настоящего раскрытия предложен считываемый компьютером носитель, имеющий сохраненную на себе компьютерную программу для декодирования единицы преобразования кодированных видеоданных с использованием декодирования Голомба-Райса, при этом программа содержит:
код для определения значимых остаточных коэффициентов для поднабора единицы преобразования;
код для определения параметра квантования для единицы преобразования;
код для выбора предварительно определенного параметра Райса для декодирования Голомба-Райса поднабора единицы преобразования, причем предварительно определенный параметр Райса смещен от установки на ноль, когда определенный параметр квантования ниже предварительно определенной пороговой величины; и
код для декодирования поднабора единицы преобразования с использованием предварительно определенного параметра Райса в качестве начального параметра для декодирования Голомба-Райса.
Согласно другому аспекту настоящего раскрытия предложен способ декодирования единицы преобразования кодированных видеоданных с использованием декодирования Голомба-Райса, при этом способ содержит этапы, на которых:
определяют параметр квантования для единицы преобразования;
определяют ширину и высоту для единицы преобразования;
определяют значимые остаточные коэффициенты для поднабора единицы преобразования;
выбирают предварительно определенный параметр Райса для декодирования Голомба-Райса поднабора единицы преобразования, причем предварительно определенный параметр Райса смещен от установки на ноль, когда определенный параметр квантования ниже или равен предварительно определенной пороговой величине, причем ширина больше предварительно определенной пороговой величины и высота больше предварительно определенной пороговой величины; и
декодируют поднабор единицы преобразования с использованием предварительно определенного параметра Райса в качестве начального параметра для декодирования Голомба-Райса.
Согласно другому аспекту настоящего раскрытия предложено устройство для декодирования единицы преобразования кодированных видеоданных с использованием декодирования Голомба-Райса, при этом устройство содержит:
средство для определения значимых остаточных коэффициентов для поднабора единицы преобразования;
средство для определения параметра квантования для единицы преобразования;
средство для определения ширины и высоты для единицы преобразования;
средство для выбора предварительно определенного параметра Райса для декодирования Голомба-Райса поднабора единицы преобразования, причем предварительно определенный параметр Райса смещен от установки на ноль, когда определенный параметр квантования ниже или равен предварительно определенной пороговой величине, причем ширина больше предварительно определенной пороговой величины и высота больше предварительно определенной пороговой величины; и
средство для декодирования поднабора единицы преобразования с использованием предварительно определенного параметра Райса в качестве начального параметра для декодирования Голомба-Райса.
Согласно другому аспекту настоящего раскрытия предложена система для декодирования единицы преобразования кодированных видеоданных с использованием декодирования Голомба-Райса, при этом система содержит:
память для хранения данных и компьютерной программы;
процессор, соединенный с упомянутой памятью для исполнения упомянутой компьютерной программы, причем упомянутая компьютерная программа содержит инструкции для:
определения значимых остаточных коэффициентов для поднабора единицы преобразования;
определения параметра квантования для единицы преобразования;
определения ширины и высоты для единицы преобразования;
выбора предварительно определенного параметра Райса для декодирования Голомба-Райса поднабора единицы преобразования, причем предварительно определенный параметр Райса смещен от установки на ноль, когда определенный параметр квантования ниже или равен предварительно определенной пороговой величине, причем ширина больше предварительно определенной пороговой величины и высота больше предварительно определенной пороговой величины; и
декодирования поднабора единицы преобразования с использованием предварительно определенного параметра Райса в качестве начального параметра для декодирования Голомба-Райса.
Согласно другому аспекту настоящего раскрытия предложен считываемый компьютером носитель, имеющий сохраненную на себе компьютерную программу для декодирования единицы преобразования кодированных видеоданных с использованием декодирования Голомба-Райса, при этом программа содержит:
код для определения значимых остаточных коэффициентов для поднабора единицы преобразования;
код для определения параметра квантования для единицы преобразования;
код для определения ширины и высоты для единицы преобразования;
код для выбора предварительно определенного параметра Райса для декодирования Голомба-Райса поднабора единицы преобразования, причем предварительно определенный параметр Райса смещен от установки на ноль, когда определенный параметр квантования ниже или равен предварительно определенной пороговой величине, при этом ширина больше предварительно определенной пороговой величины и высота больше предварительно определенной пороговой величины; и
код для декодирования поднабора единицы преобразования с использованием предварительно определенного параметра Райса в качестве начального параметра для декодирования Голомба-Райса.
Также раскрыты и другие аспекты.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Теперь по меньшей мере один вариант осуществления настоящего изобретения будет описан со ссылкой на следующие чертежи, на которых:
Фиг. 1 является принципиальной блок-схемой, изображающей функциональные модули видеокодера;
Фиг. 2 является принципиальной блок-схемой, изображающей функциональные модули видеодекодера;
Фиг. 3A и 3B образуют принципиальную блок-схему компьютерной системы общего назначения, в которой могут применяться кодер и декодер с Фиг. 1 и 2, соответственно;
На Фиг. 4A и 4B изображена пространственная структура примерной единицы преобразования;
Фиг. 5 является принципиальной блок-схемой, изображающей структуру синтаксического элемента примерной единицы преобразования;
Фиг. 6A является принципиальной блок-схемой, изображающей способ кодирования единицы преобразования (TU);
Фиг. 6B является блок-схемой последовательности операций, изображающей способ декодирования единицы преобразования (TU);
Фиг. 7 является принципиальной блок-схемой, изображающей структуру синтаксического элемента поднабора примерной единицы преобразования с Фиг. 5;
Фиг. 8A является блок-схемой последовательности операций, изображающей способ кодирования поднабора единицы преобразования;
Фиг. 8B является блок-схемой последовательности операций, изображающей способ декодирования поднабора единицы преобразования;
Фиг. 9 является таблицей, изображающей двоичные представления остаточных коэффициентов с кодовыми словами Голомба-Райса;
Фиг. 10 является таблицей, изображающей двоичные представления остаточных коэффициентов с экспоненциальными кодовыми словами Голомба нулевого порядка;
Фиг. 11 является таблицей, изображающей таблицу поиска для определения значения параметра Голомба-Райса на основе текущего значения параметра Голомба-Райса и значения предыдущего остаточного коэффициента;
Фиг. 12A является блок-схемой последовательности операций, изображающей способ кодирования остаточного коэффициента;
Фиг. 12B является блок-схемой последовательности операций, изображающей способ декодирования остаточного коэффициента;
Фиг. 13 является блок-схемой последовательности операций, изображающей способ определения значения параметра K, используемого способом декодирования остаточного коэффициента с использованием декодирования Голомба-Райса;
На Фиг. 14A изображено средство бинаризации для декодирования оставшихся абсолютных значений остаточных коэффициентов для поднабора единицы преобразования (TU);
На Фиг. 14B изображено другое средство бинаризации для декодирования оставшихся абсолютных значений остаточных коэффициентов для поднабора единицы преобразования (TU); и
На Фиг. 15 изображена другая примерная единица преобразования.
ПОДРОБНОЕ ОПИСАНИЕ, ВКЛЮЧАЮЩЕЕ В СЕБЯ ЛУЧШИЕ ВАРИАНТЫ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Там, где делается ссылка на любом одном или более сопроводительных чертежах на этапы и/или признаки, которые имеют одни и те же ссылочные позиции, такие этапы и/или признаки для данного описания имеют одну и ту же функцию(и) или действие(я), пока не появляется противоположный смысл.
Свойство преобладания низкочастотной информации в верхнем левом углу двумерного массива остаточных коэффициентов может использоваться схемой бинаризации для минимизации размера остаточных коэффициентов в битовом потоке.
Одним аспектом бинаризации является выбор контекстов для использования при кодировании синтаксических элементов, соответствующих отдельным флагам. Один флаг может использовать более одного контекста. Определение, какой контекст должен использоваться для конкретного экземпляра флага, зависит от другой уже доступной информации и известно в качестве «моделирования контекста». Моделирование контекста является процессом, посредством которого выбирается контекст, который наиболее точно представляет статистические свойства настоящего экземпляра флага. Например, зачастую значение флага подвержено влиянию значений соседних экземпляров одного и того же флага, при этом в таких случаях контекст может быть выбран на основе значений соседних экземпляров флага. Из-за того, что большинство информации кадра содержится в канале яркости, при моделировании контекста зачастую используются отдельные контексты для канала яркости в отличие от каналов цветности. Однако контексты обычно совместно используются каналами цветности, поскольку статистические свойства двух каналов цветности относительно схожи.
В версии 6 экспериментальной модели высокоэффективного видеокодирования (HEVC) («HM-6.0») единица преобразования (TU) разделяется на некоторое количество поднаборов, и остаточные коэффициенты сканируются в каждом поднаборе за два прохода. В первом проходе кодируются флаги, указывающие состояние остаточных коэффициентов, в виде имеющих ненулевое значение (значимых) или имеющих нулевое значение (незначимых). Эти данные известны в качестве карты значимости. Во втором проходе осуществляется кодирование абсолютного значения и знака значимых остаточных коэффициентов, которое известно в качестве уровней коэффициентов.
Предоставляемый шаблон сканирования обеспечивает сканирование двумерного массива остаточных коэффициентов в одномерный массив. В HM 6.0 предоставляемый шаблон сканирования используется для обработки как карты значимости, так и уровней коэффициентов. Посредством сканирования карты значимости с использованием предоставляемого шаблона сканирования может быть определено местоположение последнего значимого коэффициента на двумерной карте значимости. Шаблоны сканирования могут быть горизонтальными, вертикальными или диагональными.
В HM-6.0 обеспечивается поддержка остаточных блоков, также известных в качестве единиц преобразования (TU), имеющих как квадратную форму, так и не квадратную форму. Каждая единица преобразования (TU) содержит набор остаточных коэффициентов. Остаточные блоки, имеющие размерности сторон одинакового размера, известны в качестве квадратных единиц преобразования (TU), а остаточные блоки, имеющие размерности сторон не одинакового размера, известны в качестве не квадратных единиц преобразования (TU).
Размеры единицы преобразования (TU), поддерживаемые в HM-6.0, составляют 4x4, 8x8, 16x16, 32x32, 4x16, 16x4, 8x32 и 32x8. Размеры единицы преобразования (TU) обычно описываются с точки зрения отсчетов яркости. Однако, когда используется формат цветности 4:2:0, каждый отсчет дискретизации цветности занимает область в 2x2 отсчетов яркости. Соответственно, при сканировании единиц преобразования (TU) для кодирования остаточных данных цветности используются шаблоны сканирования половины размерностей по горизонтали и по вертикали, такие как 2x2 для остаточного блока яркости 4x4. С целью сканирования и кодирования остаточных коэффициентов единицы преобразования (TU) 16x16, 32x32, 4x16, 16x4, 8x32 и 32x8 разделяются на некоторое количество подблоков, то есть: до нижнего уровня сканирования единицы преобразования (TU), имеющего размер 4x4 с соответствующей картой, существующей внутри HM-6.0.
В HM 6.0 подблоки для вышеупомянутых размеров единиц преобразования (TU) совместно располагаются с поднаборами в единице преобразования (TU). В другом варианте реализации поднаборы могут не располагаться совместно с подблоками, имеющими размеры, отличающиеся от размеров подблоков. Установленные флаги значимых коэффициентов внутри части карты значимости, совместно расположенных внутри одного подблока, называются группой значимых коэффициентов.
Для единиц преобразования (TU) 16x16, 32x32, 4x16, 16x4, 8x32 и 32x8 кодирование карты значимости использует двухуровневое сканирование. Сканирование верхнего уровня выполняет сканирование, такое как сканирование обратно по диагонали вниз влево, для кодирования или вывода флагов, представляющих группы значимых коэффициентов каждого подблока. Внутри подблоков сканирование, такое как сканирование обратно по диагонали вниз влево, выполняются для кодирования флагов значимых коэффициентов для подблоков, имеющих флаг группы значимый коэффициентов со значением один. Для единицы преобразования (TU) 16x16 используется сканирование 4x4 верхнего уровня. Для единицы преобразования (TU) 32x32 используется сканирование 8x8 верхнего уровня. Для размеров единиц преобразования (TU) 16x4, 4x16, 32x8 и 8x32, используются, соответственно, сканирования 4x1, 1x4, 8x2 и 2x8 верхнего уровня.
В каждой единице преобразования (TU) данные остаточного коэффициента могут кодироваться в битовый поток. Каждый «остаточный коэффициент» является некоторым количеством, представляющим характеристики изображения внутри единицы преобразования в частотной (DCT) области и занимающим уникальное местоположение внутри единицы преобразования. Единица преобразования является блоком отсчетов остаточных данных, которые могут преобразовываться между пространственной и частотной областями. В частотной области единица преобразования (TU) кодирует отсчеты остаточных данных в качестве данных остаточных коэффициентов. Размерности сторон единиц преобразования имеют размеры степени двух (2), находясь в диапазоне от 4 отсчетов до 32 отсчетов для канала «Яркость», и от 2 до 16 отсчетов для канала «Цветность». Листовые узлы дерева единицы преобразования (TU) могут содержать либо единицу преобразования (TU), либо вообще ничего в случае, когда не требуется никаких данных остаточных коэффициентов.
Поскольку пространственное представление единицы преобразования является двумерным массивом отсчетов остаточных данных, как описано подробно ниже, то представление в частотной области, являющееся результатом преобразования, такого как модифицированное дискретное косинусное преобразование (DCT), также является двумерным массивом остаточных коэффициентов. Спектральные характеристики данных типичных отсчетов внутри единицы преобразования (TU) являются такими, что представление в частотной области более компактно, чем пространственное представление. Дополнительно, преобладание низкочастотной спектральной информации, типичной для единицы преобразования (TU), приводит в результате к кластеризации остаточных коэффициентов с большими значениями по направлению к верхнему левому углу единицы преобразования (TU), где представлены низкочастотные остаточные коэффициенты.
Модифицированные дискретные косинусные преобразования (DCT) или модифицированные дискретные синусные преобразования (DST) могут использоваться для реализации остаточного преобразования. Варианты реализации остаточного преобразования сконфигурированы с возможностью поддержки каждого требуемого размера единицы преобразования (TU). В видеокодере остаточные коэффициенты от остаточного преобразования масштабируются и квантуются. Масштабирование и квантование уменьшают абсолютное значение остаточных коэффициентов, уменьшая размер данных, кодированных в битовый поток, за счет снижения качества изображения.
После выполнения остаточного преобразования выполняется процесс квантования. Цель процесса квантования состоит в достижении более высокой степени сжатия посредством понижения точности абсолютных значений остаточных коэффициентов. Данное понижение точности абсолютных значений является процессом с потерями и таким образом оказывает влияние на визуальное качество. Уровнем понижения точности управляют посредством параметра квантования (QP). Чем выше значение параметра, тем сильнее ухудшается визуальное качество. Параметр квантования можно изменять на уровне единицы преобразования (TU) посредством использования синтаксического элемента дельта-qp, описываемого ниже.
Разрабатываемый стандарт высокоэффективного видеокодирования (HEVC) стремится к достижению высокоэффективного сжатия видеоданных. Оценка и анализ статистических данных могут использоваться для достижения высокоэффективного сжатия видеоданных. Разрабатываемый стандарт высокоэффективного видеокодирования (HEVC) стремится к кодированию или декодированию видеоданных при высоких скоростях передачи битов. Схема контекстно-адаптивного двоичного арифметического кодирования (CABAC), используемая в разрабатываемом стандарте высокоэффективного видеокодирования (HEVC), поддерживает «равновероятностный» режим функционирования, называемый «обходным кодированием». В данном режиме бин не связывается с контекстом из модели контекстов, и таким образом этап обновления модели контекстов отсутствует. В таком режиме множество смежных бинов могут параллельно считываться из битового потока при условии, что каждый бин кодирован с обходом, что увеличивает пропускную способность. Например, варианты реализации аппаратного обеспечения могут параллельно записывать/считывать группы смежных кодированных с обходом данных для увеличения пропускной способности кодирования/декодирования битового потока.
Фиг. 1 является принципиальной блок-схемой, изображающей функциональные модули видеокодера 100. Фиг. 2 является принципиальной блок-схемой, изображающей функциональные модули соответствующего видеодекодера 200. Видеокодер 100 и видеодекодер 200 могут быть реализованы с использованием компьютерной системы 300 общего назначения, показанной на Фиг. 3A и 3B, в которой различные функциональные модули могут быть реализованы посредством специализированного аппаратного обеспечения внутри компьютерной системы 300, посредством программного обеспечения, исполняемого внутри компьютерной системы 300, или альтернативно посредством сочетания специализированного аппаратного обеспечения и исполняемого программного обеспечения внутри компьютерной системы 300.
Как показано на Фиг. 3A, компьютерная система 300 включает в себя: компьютерный модуль 301; устройства ввода, такие как клавиатура 302, координатно-указательное устройство 303 типа «мышь», сканнер 326, камера 327 и микрофон 380; и устройства вывода, включающие в себя принтер 315, устройство 314 отображения и громкоговорители 317. Приемопередающее устройство 316 с внешним Модулятором-Демодулятором (Модемом) может использоваться компьютерным модулем 301 для осуществления связи с и от сети 320 связи через соединение 321. Сеть 320 связи может быть глобальной сетью (WAN), такой как Интернет, сеть сотовой связи или частная WAN. В которой соединение 321 является телефонной линией связи, модем 316 может быть традиционным модемом «коммутируемой линии передачи». Альтернативно, соединение 321 является соединением с большой емкостью (например, кабелем), модем 316 может быть широкополосным модемом. Беспроводной модем может также использоваться для беспроводного соединения с сетью 320 связи.
Компьютерный модуль 301 обычно включает в себя по меньшей мере один процессор 305 и память 306. Например, память 306 может иметь полупроводниковую оперативную память (RAM) и полупроводниковую постоянную память (ROM). Компьютерный модуль 301 также включает в себя некоторое количество интерфейсов ввода/вывода (I/O), включающих в себя: аудио-видео интерфейс 307, который соединяется с устройством 314 видеоотбражения, громкоговорителями 317 и микрофоном 380; интерфейс 313 ввода-вывода, который соединяется с клавиатурой 302, мышью 303, сканнером 326, камерой 327 и в качестве дополнительной возможности ручкой (джойстиком) управления или другим устройством взаимодействия с пользователем (не изображено); и интерфейс 308 для внешнего модема 316 и принтера 315. В некоторых вариантах реализации модем 316 может быть встроен в компьютерный модуль 301, например, в интерфейс 308. Компьютерный модуль 301 также имеет интерфейс 311 с локальной сетью, который позволяет соединяться компьютерной системе 300 через соединение 323 с локальной сетью 322 связи, известной в качестве Локальной Сети (Local Area Network, LAN). Как изображено на Фиг.3A, локальная сеть 322 связи может также соединяться с широкомасштабной сетью 320 через соединение 324, которое обычно включает в себя так называемое устройство «межсетевого экрана» или устройство со схожей функциональностью. Интерфейс 311 с локальной сетью может содержать печатную плату EthernetTM, устройство беспроводной связи BluetoothTM или устройство беспроводной связи IEEE 802.11; однако для интерфейса 311 может использоваться множество других типов интерфейсов.
Интерфейсы 308 и 313 ввода-вывода могут предоставлять любую из или обе возможности последовательного и параллельного соединения, причем последовательное соединение обычно реализуется согласно стандартам Универсальной Последовательной Шины (Universal Serial Bus, USB) и имеет соответствующие разъемы USB (не изображены). Предоставляются устройства 309 хранения, и они обычно включают в себя накопитель (HDD) 310 на жестких дисках. Могут также использоваться другие устройства хранения, такие как накопитель на гибких дисках и накопитель на магнитной ленте (не изображены). Дисковод 312 оптических дисков обычно предоставляется для функционирования в качестве источника долговременного хранения данных. Переносные устройства памяти, такие оптические диски (например, CD-ROM, DVD, Blu-ray DiscTM), USB-RAM, переносные, внешние накопители на жестких дисках и гибкие диски, например, могут использоваться в качестве соответствующих источников данных для системы 300. Как правило, любое из HDD 310, дисковода 312 оптических дисков, сетей 320 и 322 или камеры 327 может выступать в качестве источника видеоданных, которые должны быть кодированы, или с устройством 314 отображения в качестве получателя декодированных видеоданных, которые следует хранить или воспроизводить.
Компоненты с 305 по 313 компьютерного модуля 301 обычно осуществляют связь через взаимосвязанную шину 304 и по принципу, который приводит в результате к традиционному режиму функционирования компьютерной системы 300, известному специалистам в соответствующем уровне техники. Например, процессор 305 соединен с системной шиной 304 с использованием соединения 318. Аналогично, память 306 и дисковод 312 оптических дисков соединены с системной шиной 304 посредством соединений 319. Примеры компьютеров, в которых могут использоваться описанные устройства, включают в себя персональные компьютеры IBM и совместимые устройства, Sun Sparcstations, Apple MacTM или подобные компьютерные системы.
По необходимости или желанию кодер 100 и декодер 200, а также способы, описываемые ниже, могут быть реализованы с использованием компьютерной системы 300, в которой кодер 100, декодер 200 и процессы, которые будут описаны, могут быть реализованы в качестве одной или более программ 333 приложений программного обеспечения, исполняемых внутри компьютерной системы 300. В частности кодер 100, декодер 200 и этапы описываемых способов могут осуществляться посредством инструкций 331 (см. Фиг. 3B) в программном обеспечении 333, которые выполняются внутри компьютерной системы 300. Инструкции 331 программного обеспечения могут быть образованы в качестве одного или более модулей кода, каждый из которых предназначен для выполнения одной или более конкретных задач. Программное обеспечение может также быть разделено на две отдельные части, в которых первая часть и соответствующие модули кода выполняют описанные способы, а вторая часть и соответствующие модули кода управляют пользовательским интерфейсом между первой частью и пользователем.
Программное обеспечение может храниться на считываемом компьютером носителе, включающем в себя устройства хранения, описываемые ниже, например. Программное обеспечение загружается в компьютерную систему 300 со считываемого компьютером носителя и затем исполняется компьютерной системой 300. Считываемый компьютером носитель, имеющий такое программное обеспечение или компьютерную программу, записанные на считываемом компьютером носителе, является компьютерным программным продуктом. Использование компьютерного программного продукта в компьютерной системе 300 предпочтительно реализует преимущественное устройство для реализации кодера 100, декодера 200 и описанных способов.
Программное обеспечение 333 обычно хранится на HDD 310 или в памяти 306. Программное обеспечение загружается в компьютерную систему 300 со считываемого компьютером носителя и исполняется компьютерной системой 300. Таким образом, например, программное обеспечение 333 может храниться на оптическим образом считываемом дисковом носителе хранения информации (например, CD-ROM) 325, который считывается дисководом 312 оптических дисков.
В некоторых случаях, программы 333 приложений могут поставляться пользователю кодированными на одном или более CD-ROM 325, и считываться через соответствующий дисковод 312, или альтернативно могут считываться пользователем из сетей 320 или 322. В качестве еще одного дополнения программное обеспечение также может загружаться в компьютерную систему 300 с другого считываемого компьютером носителя. К считываемому компьютером носителю хранения информации относится любой невременной материальный носитель хранения информации, который предоставляет записанные инструкции и/или данные в компьютерную систему 300 для исполнения и/или обработки. Примеры таких носителей хранения информации включают в себя гибкие диски, магнитную ленту, CD-ROM, DVD, Диск Blu-ray, накопитель на жестких дисках, ROM или интегральную схему, память USB, магнитооптический диск или считываемую компьютером карту, такую как карта PCMCIA и т.п., независимо от того, являются ли такие устройства внутренними или внешними по отношению к компьютерному модулю 301. Примеры временных или нематериальных считываемых компьютером сред передачи, которые также могут участвовать в предоставлении программного обеспечения, программ приложений, инструкций и/или видеоданных или кодированных видеоданных в компьютерный модуль 301, включают в себя радио или инфракрасные каналы передачи, а также сетевое соединение с другим компьютером или сетевым устройством, и Интернет или внутренние сети, включающие в себя передачи электронной почты и информации, записанной на Веб-сайтах и т.п.
Вторая часть программ 333 приложений и соответствующие упомянутые выше модули кода могут исполняться для реализации одного или более графических пользовательских интерфейсов (GUI), которые следует визуализировать или иным образом представлять на устройстве 314 отображения. Посредством обычного манипулирования клавиатурой 302 и мышью 303 пользователь компьютерной системы 300 и приложения может манипулировать интерфейсом функционально адаптированным образом для предоставления инструкций управления и/или ввода для приложений, относящихся к графическому пользовательскому интерфейсу(ам). Также могут быть реализованы и другие формы функционально адаптированных пользовательских интерфейсов, такие как, аудиоинтерфейс с использованием речевых подсказок, выводимых через громкоговорители 317, и пользовательских голосовых инструкций, вводимых через микрофон 380.
Фиг. 3B является подробной принципиальной блок-схемой процессора 305 и «памяти» 334. Память 334 представляет собой логическое объединение всех модулей памяти (включающих в себя HDD 309 и полупроводниковую память 306), к которым компьютерный модуль 301 с Фиг. 3A может осуществлять доступ.
Когда осуществляется включение компьютерного модуля 301 из исходного состояния, то исполняется программа 350 самотестирования (POST) при включении. Программа 350 POST обычно хранится в ROM 349 полупроводниковой памяти 306 с Фиг. 3A. Устройство аппаратного обеспечения, такое как ROM 349, хранящее программное обеспечение, иногда упоминается в качестве встроенного микропрограммного обеспечения. Программа 350 POST исследует аппаратное обеспечение внутри компьютерного модуля 301 для гарантирования надлежащего функционирования и обычно проверяет процессор 305, память 334 (309, 306) и модуль 351 программного обеспечения базовых систем (BIOS) ввода-вывода, также обычно хранящийся в ROM 349, на правильное функционирование. Как только программа 350 POST завершилась успешно, BIOS 351 приводит в действие накопитель 310 на жестких дисках с Фиг. 3A. Приведение накопителя 310 на жестких дисках в действие вызывает программу 352 начального загрузчика, которая находится на накопителе 310 на жестких дисках, для исполнения через процессор 305. Она загружает операционную систему 353 в память 306 RAM, после чего операционная система 353 начинает функционирование. Операционная система 353 является приложением на уровне системы, исполняемым процессором 305, для выполнения различных высокоуровневых функций, включающих в себя управление процессором, управление запоминающим устройством, управление устройствами, управление хранением, интерфейсом приложений программного обеспечения и универсальным пользовательским интерфейсом.
Операционная 353 система управляет запоминающим устройством 334 (309, 306), чтобы гарантировать, что каждый процесс или приложение, запущенные в компьютерном модуле 301, имеют достаточно памяти, в которой могут исполняться без конфликтов с памятью, выделенной другому процессу. Кроме того, различные типы памяти, доступной в системе 300 с Фиг. 3A, должны использоваться должным образом так, чтобы каждый процесс мог функционировать эффективно. Соответственно, объединенная память 334 не предназначена для изображения того, как выделяются конкретные сегменты памяти (пока не указано обратное), а скорее для предоставления общего вида памяти, к которой может осуществлять доступ компьютерная система 300, и того, как она используется.
Как показано на Фиг. 3B, процессор 305 включает в себя некоторое количество функциональных модулей, включающих в себя блок 339 управления, арифметико-логическое устройство (ALU) 340 и локальную или внутреннюю память 348, иногда называемую кэш-памятью. Кэш-память 348 обычно включает в себя некоторое количество регистров 344-346 хранения в секции регистров. Одна или более внутренних шин 341 осуществляют функциональную взаимосвязь этих функциональных модулей. Процессор 305 также обычно имеет один или более интерфейсов 342 для осуществления связи с внешними устройствами через системную шину 304, используя соединение 318. Память 334 соединяется с шиной 304, используя соединение 319.
Программа 333 приложения включает в себя последовательность инструкций 331, которые могут включать в себя инструкции циклов и условных ветвлений. Программа 333 также может включать в себя данные 332, которые используется при исполнении программы 333. Инструкции 331 и данные 332 хранятся в ячейках 328, 329, 330 и 335, 336, 337 памяти, соответственно. В зависимости от относительного размера инструкций 331 и ячеек 328-330 памяти конкретная инструкция может быть сохранена в одиночной ячейке памяти, как изображено посредством инструкции, изображенной в ячейке 330 памяти. Альтернативно, инструкция может быть сегментирована на некоторое количество частей, каждая из которых хранится в отдельной ячейке памяти, как изображено посредством сегментов инструкций, изображенных в ячейках 328 и 329 памяти.
В целом, в процессор 305 подается набор инструкций, которые в нем исполняются. Процессор 305 ожидает последующего ввода, на который процессор 305 реагирует посредством исполнения другого набора инструкций. Каждый ввод может предоставляться от одного или более из некоторого количества источников, включающих в себя данные, сгенерированные одним или более устройствами 302, 303 ввода, данные, принятые от внешнего источника через одну из сетей 320, 302, данные, извлеченные из одного из устройств 306, 309 хранения или данные, извлеченные из носителя 325 хранения, вставленного в соответствующей считыватель 312, все из которых изображены на Фиг. 3A. Исполнение набора инструкций может в некоторых случаях приводить в результате к выводу данных. Исполнение может также вовлекать сохранение данных или переменных в память 334.
Кодер 100, декодер 200 и описываемые способы используют входные переменные 354, которые хранятся в памяти 334 в соответствующих ячейках 355, 356, 357 памяти. Кодер 100, декодер 200 и описываемые способы создают выходные переменные 361, которые хранятся в памяти 334 в соответствующих ячейках 362, 363, 364 памяти. Промежуточные переменные 358 могут храниться в ячейках 359, 360, 366 и 367 памяти.
В процессоре 305 с Фиг. 3B регистры 344, 345, 346, арифметико-логическое устройство (ALU) 340, и блок 339 управления функционируют совместно для выполнения последовательностей микроопераций, необходимых для выполнения циклов «выборки, декодирования и исполнения» для каждой инструкции в наборе инструкций, составляющем программу 333. Каждый цикл выборки, декодирования и исполнения содержит:
(a) операцию выборки, которая осуществляет выборку или считывает инструкцию 331 из ячейки 328, 329, 330 памяти;
(b) операцию декодирования, в которой блок 339 управления определяет, какая инструкция была выбрана; и
(c) операцию исполнения, в которой блок 339 управления и/или ALU 340 исполняет инструкцию.
После этого для следующей инструкции может исполняться новый цикл выборки, декодирования и исполнения. Схожим образом может выполняться цикл сохранения, посредством которого блок 339 управления сохраняет или записывает некоторое значение в ячейку 332 памяти.
Каждый этап или подпроцесс в процессах, которые будут описываться, связан с одним или более сегментами программы 333 и обычно выполняется секцией 344, 345, 347 регистров, ALU 340 и блоком 339 управления в процессоре 305, функционирующих совместно для выполнения циклов выборки, декодирования и исполнения для каждой инструкции в наборе инструкций для обозначенных сегментов программы 333.
Кодер 100, декодер 200 и описываемые способы альтернативно могут быть реализованы в специализированном аппаратном обеспечении, таком как одна или более интегральных схем, выполняющих функции или подфункции описываемых способов. Такое специализированное аппаратное обеспечение может включать в себя графические процессоры, цифровые сигнальные процессоры, специализированные интегральные схемы (ASIC), программируемые пользователем вентильные матрицы (FPGA) или один или более микропроцессоров и связанную память.
Как описано выше, видеокодер 100 может быть реализован в качестве одного или более модулей кода программного обеспечения программы 333 приложения программного обеспечения, находящейся на накопителе 310 на жестких дисках и управляемой при ее исполнении процессором 305. В частности видеокодер 100 содержит модули 102-112, 114 и 115, каждый из которых может быть реализован в качестве одного или более модулей кода программного обеспечения программы 333 приложения программного обеспечения.
Несмотря на то, что видеокодер 100 с Фиг. 1 является примером конвейера видеодекодирования высокоэффективного видеокодирования (HEVC), стадии обработки, выполняемые модулями 102-112, 114 и 115, являются общими с другими видеокодеками, такими как VC-1 или H.264/MPEG-4 AVC. Видеокодер 100 принимает некодированные данные 101 кадров в качестве последовательности кадров, включающих в себя отсчеты яркости и цветности. Видеокодер 100 разделяет каждый кадр данных 101 кадров в иерархические наборы единиц кодирования (CU), которые могут быть представлены, например, в качестве дерева единиц кодирования (CU).
Видеокодер 100 задействуется посредством вывода, из модуля 110 мультиплексирования, массива предсказанных отсчетов данных, известного в качестве единицы 120 предсказания (PU). Модуль 115 разности выводит разность между единицей 120 предсказания (PU) и соответствующим массивом отсчетов данных, принятых из данных 101 кадров, при этом разность известна в качестве остаточных отсчетов 122 данных.
Остаточные отсчеты 122 данных из модуля 115 разности принимаются модулем 102 преобразования, который преобразовывает разность из пространственного представления в представления в частотной области для создания коэффициентов 124 преобразования для каждой единицы преобразования (TU) в дереве преобразования. Для разрабатываемого стандарта высокоэффективного видеокодирования (HEVC) преобразование в представление в частотной области реализуется с использованием модифицированного дискретного косинусного преобразования (DCT), в котором традиционное DCT изменяется, чтобы быть реализованным с использованием сдвигов и дополнений. Затем коэффициенты 124 преобразования вводятся в модуль 103 масштабирования и квантования и масштабируются и квантуются для создания остаточных коэффициентов 126. Процесс масштабирования и квантования приводит в результате к потере точности.
Остаточные коэффициенты 126 берутся в качестве ввода в модуль 105 обратного масштабирования, который инвертирует масштабирование, выполняемое модулем 103 масштабирования и квантования для создания, перемасштабированных коэффициентов 128 преобразования, которые являются перемасштабированными версиями остаточных коэффициентов 126. Остаточные коэффициенты 126 также берутся в качестве ввода в модуль 104 энтропийного кодера, который кодирует остаточные коэффициенты в кодированном битовом потоке 113. Вследствие потери точности, происходящей из-за модуля 103 масштабирования и квантования, перемасштабированные коэффициенты 128 преобразования не идентичны исходным коэффициентам 124 преобразования. Перемасштабированные коэффициенты 128 преобразования из модуля 105 обратного масштабирования затем выводятся в модуль 106 обратного преобразования. Модуль 106 обратного преобразования выполняет обратное преобразование из частотной области в пространственную область, чтобы создать представление 130 в пространственной области перемасштабированных коэффициентов 128 преобразования, идентичных представлению в пространственной области, которое создается в декодере.
Модуль 107 оценки движения создает векторы 132 движения посредством сравнения данных 101 кадров с предыдущими данными кадров, хранящимися в модуле 112 буфера кадров, сконфигурированном внутри памяти 306. Векторы 132 движения затем вводятся в модуль 108 компенсации движения, который создает внешне-предсказанные опорные отсчеты 134 посредством фильтрации отсчетов, хранящихся в модуле 112 буфера кадров, с учетом пространственного смещения, извлеченного из векторов 132 движения. Не изображенные на Фиг. 1 векторы 132 движения затем передаются в качестве синтаксических элементов в модуль 104 энтропийного кодера для кодирования в кодированном битовом потоке 113. Модуль 109 внутрикадрового предсказания создает внутренне-предсказанные опорные отсчеты 136 с использованием отсчетов 138, полученных из модуля 114 суммирования, который суммирует вывод 120 из модуля 110 мультиплексирования и вывод 130 из модуля 106 обратного преобразования.
Единицы преобразования (PU) могут кодироваться с использованием способов внешнего предсказания или внутреннего предсказания. Решение о том, использовать ли внутреннее предсказание или внешнее предсказание, принимается согласно компромиссу по искажениям относительно частоты следования битов (битрейта) между желаемой частотой следования битов результирующего кодированного битового потока 113 и величиной искажения качества изображения, введенного либо способом внутреннего предсказания, либо внешнего предсказания. Если используется внутреннее предсказание, то выбирается один режим внутреннего предсказания из набора возможных режимов также согласно компромиссу по искажениям относительно частоты следования битов. Один режим внутреннего предсказания выбирается для каждой единицы предсказания.
Модуль 110 мультиплексирования выбирает либо внутренне-предсказанные опорные отсчеты 136 из модуля 109 внутрикадрового предсказания, либо внешне-предсказанные опорные 134 отсчеты из блока 108 компенсации движения в зависимости от текущего режима 142 предсказания, определяемого логикой управления, не изображенной, но известной в уровне техники. Режим 142 предсказания также предоставляется в энтропийный кодер 104 и как таковой используется для определения или иным образом установления порядка сканирования единиц преобразования, как будет описано далее. Межкадровое предсказание использует только порядок сканирования по диагонали, тогда как внутрикадровое предсказание может использовать порядок сканирования по диагонали, сканирования по горизонтали или сканирования по вертикали.
Модуль 114 суммирования создает сумму 138, которая вводится в модуль 111 деблокирующего фильтра. Модуль 111 деблокирующего фильтра выполняет фильтрацию вдоль границ блоков, создавая деблокированные отсчеты 140, которые записываются в модуль 112 буфера кадров, сконфигурированный внутри памяти 306. Модуль 112 буфера кадров является буфером с достаточной емкостью для содержания данных из множества прошлых кадров для последующего обращения к ним.
В видеокодере 100 остаточные отсчеты 122 данных внутри одной единицы преобразования (TU) определяются посредством нахождения разности между отсчетами данных в данных 101 введенного кадра и предсказанием 120 отсчетов данных в данных 101 введенного кадра. Разность обеспечивает пространственное представление остаточных коэффициентов единицы преобразования (TU). Остаточные коэффициенты единицы преобразования (TU) преобразовываются в двумерную карту значимости.
Карта значимости остаточных коэффициентов в единице преобразования (TU) затем сканируется в конкретном порядке, известном в качестве порядка сканирования, чтобы образовать одномерный список значений флагов, названный списком флагов значимых коэффициентов. Порядок сканирования может описываться или иным образом определяться посредством шаблона сканирования, такого как шаблон сканирования, принятый с режимом 142 предсказания от модуля 109 внутреннего предсказания. Шаблон сканирования может быть горизонтальным, вертикальным, диагональным или зигзагообразным.
В версии 6 экспериментальной модели высокоэффективного видеокодирования (HEVC) (то есть, в «HM_6.0») выполняется сканирование в обратном направлении. Однако также возможно сканирование и в прямом направлении. В версии 6.0 эталонной модели HEVC (то есть, в «HM_6.0»), операция сканирования начинается с одного остаточного коэффициента после последнего значимого коэффициента (где «после» означает в направлении обратного сканирования остаточных коэффициентов) и продолжается, пока не будет достигнуто верхнее левое местоположение карты значимости. Операции сканирования, имеющие данное свойство, и которые согласуются с версией 6.0 эталонной модели HEVC, известны в качестве «обратных сканирований». В эталонной версии 6.0 программного обеспечения HEVC (то есть, в «HM_6.0»), местоположение последнего значимого коэффициента сигнализируется посредством кодирования координат коэффициента в единице преобразования (TU). Использование прилагательного «последний» в данном контексте зависит от конкретного порядка сканирования. То, что может быть «последним» ненулевым остаточным коэффициентом или соответствующим флагом значимого коэффициента со значением один согласно одному шаблону сканирования, может не быть «последним» согласно другому шаблону сканирования.
Список флагов значимых коэффициентов, указывающий значимость каждого остаточного коэффициента перед последним значимым коэффициентом, кодируется в битовый поток. Не обязательно, чтобы значение флага последнего значимого коэффициента явно кодировалось в битовый поток, потому что предшествующее кодирование местоположения флага последнего значимого коэффициента косвенно указывает, что данный остаточный коэффициент был значимым.
Кластеризация остаточных коэффициентов с большими значениями по направлению к верхнему левому углу единицы преобразования (TU) приводит в результате к тому, что большинство флагов значимости впереди по списку являются значимыми, тогда как далее по списку находится меньше флагов значимости.
Как описано выше, видеокодер 100 также содержит модуль 104 энтропийного кодера, который реализует способ энтропийного кодирования. Модуль 104 энтропийного кодера создает синтаксические элементы из входящих данных 126 остаточных коэффициентов (или остаточных коэффициентов), принятых от модуля 103 масштабирования и квантования. Модуль 104 энтропийного кодера выводит кодированный битовый поток 113 и будет описываться более подробно ниже. Для разрабатываемого стандарта высокоэффективного видеокодирования (HEVC) кодированный битовый поток 113 схематически изображается в единицах уровня абстракции сети (NAL). Каждый слайс (вырезка) кадра содержится в одной единице NAL.
Существует несколько альтернатив для способа энтропийного кодирования, реализуемого в модуле 104 энтропийного кодера. Разрабатываемый стандарт высокоэффективного видеокодирования (HEVC) поддерживает контекстно-адаптивное двоичное арифметическое кодирование (CABAC), вариант контекстно-адаптивного двоичного арифметического кодирования (CABAC), найденный в H.264/MPEG-4 AVC. Альтернативная схема энтропийного кодирования известна в качестве кодера с разбиением энтропии на вероятностные интервалы.
Для видеокодера 100, поддерживающего многочисленные способы видеокодирования, один из поддерживаемых способов энтропийного кодирования выбирается согласно конфигурации кодера 100. Дополнительно при кодировании единиц кодирования из каждого кадра модуль 104 энтропийного кодера записывает кодированный битовый поток 113 так, что каждый кадр имеет один или более слайсов на кадр, причем каждый слайс содержит данные изображения для части кадра. Создание одного слайса на кадр уменьшает служебную информацию, связанную со схематическим изображением границы каждого слайса. Однако также возможно разделение кадра на множество слайсов.
Видеодекодер 200 с Фиг. 2 может быть реализован в качестве одного или более модулей кода программного обеспечения программы 333 приложения программного обеспечения, находящейся на накопителе 310 на жестких дисках и управляемой в своем исполнении процессором 305. В частности видеодекодер 200 содержит модули 202-208 и 210, каждый из которых может быть реализован в качестве одного или более модулей кода программного обеспечения программы 333 приложения программного обеспечения. Несмотря на то, что видеодекодер 200 описан со ссылкой на конвейер видеодекодирования с высокоэффективным видеокодированием (HEVC), стадии обработки, выполняемые модулями 202-208 и 209, являются общими для других видеокодеков, которые используют энтропийное кодирование, таких как H.264/MPEG-4 AVC, MPEG-2 и VC-1.
Кодированный битовый поток, такой как кодированный битовый поток 113, принимается видеодекодером 200. Кодированный битовый поток 113 может быть считан из памяти 306, накопителя 310 на жестких дисках, CD-ROM, диска Blu-rayTM или другого считываемого компьютером носителя хранения информации. Альтернативно кодированный битовый поток 113 может быть принят от внешнего источника, такого как сервер, соединенный с сетью 320 связи, или радиочастотный приемник. Кодированный битовый поток 113 содержит кодированные синтаксические элементы, представляющие собой данные кадров, которые должны быть декодированы.
Кодированный битовый поток 113 вводится в модуль 202 энтропийного декодера, который извлекает синтаксические элементы из кодированного битового потока 113 и передает значения синтаксических элементов в другие блоки в видеодекодере 200. В модуле 202 энтропийного декодера могут быть реализованы многочисленные способы энтропийного декодирования, такие как те, что описаны со ссылкой на модуль 104 энтропийного кодера. Данные 220 синтаксического элемента, представляющие собой данные остаточных коэффициентов, передаются в модуль 203 обратного масштабирования и преобразования, а данные 222 синтаксических элементов, представляющие собой информацию векторов движения, передаются в модуль 204 компенсации движения. Модуль 203 обратного масштабирования и преобразования выполняет обратное масштабирование над данными остаточных коэффициентов для создания восстановленных коэффициентов преобразования. Модуль 203 затем выполняет обратное преобразование для преобразования восстановленных коэффициентов преобразования из представления в частотной области в представление в пространственной области, создавая остаточные отсчеты 224, такое как обратное преобразование, описанное со ссылкой на модуль 106 обратного преобразования.
Модуль 204 компенсации движения использует данные 222 векторов движения из модуля 202 энтропийного декодера, объединенные с данными 226 предыдущих кадров из блока 208 буфера кадров, сконфигурированного внутри памяти 306, для создания внешне-предсказанных опорных отсчетов 228 для единицы предсказания (PU), являющихся предсказанием выводимых данных декодированного кадра. Когда синтаксический элемент указывает, что текущая единица кодирования была кодирована с использованием внутреннего предсказания, то модуль 205 внутрикадрового предсказания создает внутренне-предсказанные опорные отсчеты 230 для единицы предсказания (PU) с использованием отсчетов, пространственно соседствующих с единицей предсказания (PU). Пространственно соседствующие отсчеты получаются из суммы 232, выводимой из модуля 210 суммирования. Модуль 206 мультиплексирования выбирает внутренне-предсказанные опорные отсчеты или внешне-предсказанные опорные отсчеты для единицы предсказания (PU) в зависимости от текущего режима предсказания, который указывается синтаксическим элементом в кодированном битовом потоке 113. Массив 234 отсчетов, выводимый из модуля 206 мультиплексирования, добавляется к остаточным отсчетам 224 из модуля 203 обратного масштабирования и преобразования посредством модуля 210 суммирования для создания суммы 232, которая затем вводится в каждый из модуля 207 деблокирующего фильтра и модуля 205 внутрикадрового предсказания. В отличие от кодера 100 модуль 205 внутрикадрового предсказания принимает режим 236 предсказания от энтропийного декодера 202. Мультиплексор 206 принимает сигнал выбора внутрикадрового предсказания/межкадрового предсказания от энтропийного декодера 202. Модуль 207 деблокирующего фильтра выполняет фильтрацию вдоль границ блока данных для сглаживания дефектов изображения, видимых вдоль границ блока данных. Вывод из модуля 207 деблокирующего фильтра записывается в модуль 208 буфера кадров, сконфигурированный внутри памяти 306. Модуль 208 буфера кадров обеспечивает достаточное хранение, чтобы содержать множество декодированных кадров для обращения к ним в будущем. Декодированные кадры 209 также выводятся из модуля 208 буфера кадров.
Теперь со ссылкой на Фиг. 4A и Фиг. 4B будет описана пространственная структура примерной единицы 400 преобразования (TU).
На Фиг. 4A изображена примерная единица 400 преобразования (TU). Единица 400 преобразования имеет прямоугольную пространственную структуру и может изменяться в размере от 4x4 до 32x32. Ширина и высота единицы 400 преобразования (TU) принимает значения, которые являются целыми числами степени двух (2).
Как описано выше, единицы преобразования (TU) содержат остаточные коэффициенты. Может быть задано двухуровневое сканирование, которое разделяет единицу 400 преобразования (TU) на набор из одного или более поднаборов 401. Каждый поднабор состоит из шестнадцати (16) последовательных остаточных коэффициентов в порядке 403 сканирования, кроме первого поднабора в порядке сканирования, который может содержать меньше шестнадцати (16) остаточных коэффициентов, в зависимости от позиции последнего значимого коэффициента. Как видно на Фиг. 4B, примерная единица 400 преобразования имеет позицию 451 последнего значимого коэффициента по отношению к порядку 403 сканирования.
Как видно на Фиг. 4A, на верхнем уровне единицы 400 преобразования сканирование выполняется посредством сканирования каждого низшего уровня с использованием сканирования, такого как сканирование обратно по диагонали вниз влево. На нижнем уровне единицы 400 преобразования, также известном в качестве «уровня поднабора», сканирование может быть выполнено с использованием такого сканирования, как сканирование обратно по диагонали вниз влево. На верхнем уровне сканирования единицы 400 преобразования может быть принято решение о том, чтобы не выполнять сканирования на низшем уровне следующего поднабора, если следующий поднабор не содержит значимых остаточных коэффициентов.
Единица 400 преобразования содержит поднабор 452 без значимых остаточных коэффициентов. В данном примере этап сканирования на низшем уровне может быть пропущен для поднабора 452, и высокоуровневое сканирование переходит к следующему поднабору в порядке 403 сканирования. Верхний левый поднабор 405 единицы 400 преобразования имеет индекс поднабора, равный нулю. Другие поднаборы имеют задаваемые приращением индексы в порядке, противоположном порядку сканирования.
Теперь со ссылкой на Фиг. 5 и Фиг. 7 будет описана структура синтаксического элемента единицы преобразования (TU), такой как единица 400 преобразования (TU). Часть 501 битового потока из битового потока 113 содержит синтаксические элементы единицы 400 преобразования (TU) и состоит из следующих синтаксических элементов:
(i) delta_qp (дельта_qp) 502: Синтаксический элемент 502 delta_qp содержит информацию о разности между значением параметра квантования, используемого для квантования единицы 400 преобразования (TU), и значением предварительно определенного параметра квантования.
(ii) last_significant_xy (xy_последнего_значимого) 503: Синтаксический элемент 503 last_significant_xy содержит информацию о позиции последнего значимого остаточного коэффициента в единице 400 преобразования (TU).
(iii) Данные 504 остаточных коэффициентов поднабора: Данные остаточных коэффициентов поднабора состоят из нуля или более блоков 701 и содержат информацию о значениях остаточных коэффициентов единицы 400 преобразования (TU).
Как видно на Фиг. 7, блок 701 содержит информацию о значениях остаточных коэффициентов одиночного поднабора единицы преобразования (TU) и состоит из следующих синтаксических элементов:
(i) significant_coeff_group_flag (флаг_группа_значимых_коэффициентов) 702: Синтаксический элемент 702 significant_coeff_group_flag кодируется один раз на поднабор, и когда он является ложным, то делается вывод о том, что все остаточные коэффициенты являются нулевыми, и данные 703, 704, 705 706 и 707 остаточных коэффициентов отсутствуют в блоке 701. Иначе (когда синтаксический элемент 702 significant_ceoff_group_flag является истинным), то по меньшей мере один остаточный коэффициент в поднаборе имеет ненулевое значение, и некоторое сочетание данных 703, 704, 705, 706 и 707 остаточных коэффициентов присутствует в блоке 701.
(ii) Блок 703, состоящий из нуля или более значений significant_coeff_flag (флаг_значимый_коэффициент): Блок 703 присутствует, если significant_coeff_group_flag 702 указывает присутствие блока 703. Значения significant_coeff_flag 702 присутствуют в блоке 703 для каждого остаточного коэффициента поднабора кроме последнего значимого остаточного коэффициента для указания, больше ли абсолютное значение данного остаточного коэффициента, чем ноль.
(iii) Блок 704, состоящий из нуля или более значений coeff_abs_level_greater1_flag (флаг_абсолютный_уровень_коэффициента_превосходит_1): Блок 704 присутствует, если significant_coeff_group_flag 702 указывает присутствие блока 704. Значения coeff_abs_level_greater1_flag присутствуют в блоке 703, для каждого остаточного коэффициента поднабора, для которого указано, что абсолютное значение больше нуля, для указания больше ли абсолютное значение данного остаточного коэффициента, чем один.
(iv) Блок 705, состоящий из нуля или более значений coeff_abs_level_greater2_flag (флаг_абсолютный_уровень_коэффициента_превосходит_2): блок 705 присутствует, если significant_coeff_group_flag 702 указывает присутствие блока 705. Значения coeff_abs_level_greater2_flag присутствуют в блоке 705, для каждого остаточного коэффициента поднабора, для которого указано, что абсолютное значение больше единицы, для указания больше ли абсолютное значение данного остаточного коэффициента, чем два.
(v) Блок 706, состоящий из нуля или более значений coeff_sign_flag (флаг_знак_коэффициента): блок 706 присутствует, если significant_coeff_group_flag 702 указывает присутствие блока 706. Значения coeff_sign_flag присутствуют в блоке 706, для каждого остаточного коэффициента, для которого указано, что абсолютное значение больше нуля, для указания арифметического знака данного остаточного коэффициента.
(vi) Блок 707, состоящий из нуля или более значений coeff_abs_level_remaining (оставшийся_абсолютный_уровень_коэффициента): Каждое значение coeff_abs_level_remaining блока 707 является кодовым словом Голомба-Райса для заданного значения абсолютного значения остаточного коэффициента минус три (то есть, оставшееся абсолютное значение остаточного коэффициента). Блок 707 присутствует, если significant_coeff_group_flag 702 указывает присутствие блока 707. Значения coeff_abs_level_remaining присутствуют в блоке 707 для каждого остаточного коэффициента, для которого указано, что абсолютное значение больше двух. Значения coeff_abs_level_remaining задают значение кодового слова Голомба-Райса для оставшегося абсолютного значения остаточного коэффициента данного остаточного коэффициента.
Теперь со ссылкой на Фиг. 6A будет описан способ 650 кодирования единицы преобразования (TU). Способ 650 может быть реализован в качестве части модулей 104 энтропийного кодера из кодера 100. Как описано выше, модули 102-112, 114 и 115 кода программного обеспечения, образующие кодер 100 находятся на накопителе 310 на жестких дисках и управляются при их исполнении процессором 305.
Способ 650 будет описан посредством примера со ссылкой на часть 501 битового потока с Фиг. 5. Способ 650 кодирует delta_qp 502, last_significant_xy 503 и данные 504 в часть 501 битового потока.
Способ 650 начинается на этапе 651 кодирования значения дельта-qp, на котором значение дельта-qp кодируется посредством модуля 104 кодера, исполняемого процессором 305, и сохраняется в памяти 306.
Затем на этапе 652 кодирования последней значимой позиции позиция последнего значимого остаточного коэффициента кодируется в часть 501 битового потока посредством модуля 104 кодера, исполняемого процессором 305. Часть 501 битового потока может быть сохранена в памяти 306. Позиция последнего значимого остаточного коэффициента, ширина и высота единицы преобразования и информация о порядке 403 сканирования используются для определения количества поднаборов, которые должны быть кодированы в единице преобразования (TU).
Способ 650 переходит к этапу 653 кодирования поднабора, на котором данные 504 поднабора кодируются посредством модуля 104 кодера и сохраняются внутри памяти 306.
Затем на этапе 654 принятия решения модуль 104 кодера определяет, следует ли еще кодировать поднаборы 504 в часть 501 битового потока, на основе информации о позиции последнего значимого остаточного коэффициента в единице преобразования (TU) и используемого порядка 403 сканирования. Если модуль 104 кодера определяет, что есть еще поднаборы 504, которые должны быть кодированы, то способ 650 возвращается на этап 653 кодирования поднабора. Как таковой, способ 650 итеративно повторяет этапы 653 и 654, пока все поднаборы от поднабора, содержащего последний значимый коэффициент, до первого поднабора не окажутся обработанными. Иначе способ 650 завершается.
Теперь со ссылкой на Фиг. 6B будет описан способ 600 декодирования единицы преобразования (TU). Способ 600 может быть реализован в качестве части модуля 202 энтропийного декодера из декодера 200. Как описано выше, модули 202-208 и 210 кода программного обеспечения, образующие декодер 200, находятся на накопителе 310 на жестких дисках и управляются при их исполнении процессором 305.
Снова, способ 600 будет описан посредством примера со ссылкой на часть 501 битового потока с Фиг. 5, кодированного в соответствии со способом 650. Способ 600 декодирует блоки 502, 503, 504 данных из части 501 битового потока.
Способ 600 начинается на этапе 601 декодирования значения дельта-qp, на котором значение флага дельта-qp определяется посредством модуля 202 декодера, исполняемого процессором 305. Значение флага дельта-qp может храниться в памяти 306.
Затем на этапе 602 декодирования последней значимой позиции позиция последнего значимого остаточного коэффициента в единице преобразования (TU) определяется посредством модуля 202 декодера. Позиция последнего значимого остаточного коэффициента, ширина и высота единицы преобразования и информация о порядке 403 сканирования используются для определения количества поднаборов, которые должны быть декодированы в единице преобразования (TU).
Способ 600 переходит к этапу 603 декодирования поднабора, где данные 504 поднабора декодируются посредством модуля 202 декодера, исполняемого процессором 305. Данные декодированного поднабора могут быть сохранены внутри памяти 306.
Затем на этапе 604 принятия решения модуль 202 декодера определяет, следует ли еще декодировать поднаборы 504 из части 501 битового потока, на основе информации о позиции последнего значимого остаточного коэффициента в единице преобразования (TU) и используемого порядка 403 сканирования.
Если модуль 202 декодера определяет, что есть еще поднаборы 504, которые должны быть декодированы, то способ 600 возвращается на этап 603 декодирования поднабора. Иначе способ 600 завершается.
Теперь со ссылкой на Фиг. 8A будет описан способ 850 кодирования поднабора единицы преобразования (TU). Способ 850 может быть реализован в качестве части модуля 104 энтропийного кодера из кодера 100. Как описано выше, модули 102-112, 114 и 115 кода программного обеспечения, образующие кодер 100, находятся на накопителе 310 на жестких дисках и управляются при их исполнении процессором 305.
Способ 850 будет описан посредством примера со ссылкой на блок 701 с Фиг. 7. Способ 850 кодирует блоки 702, 703, 704, 705, 706, 707 в часть 501 битового потока.
Способ 850 начинается с этапа кодирования 851 флага значимая группа, где модуль 104 кодера, исполняемый процессором 305, кодирует значение significant_coeff_group_flag 702 и сохраняет кодированное значение в памяти 306.
Затем на этапе 852, если значение significant_coeff_group_flag 702 указывает, что поднабор содержит данные, которые должны быть кодированы для блоков 703, 704, 705 706, 707, то способ 850 переходит на этап 853. Иначе способ 850 завершается.
На этапе 853 кодирования модуль 104 кодера, исполняемый процессором 305, кодирует блок 703 значений significant_coeff_flag. Модуль 104 кодера определяет одно значение significant_coeff_flag для каждого остаточного коэффициента поднабора, кроме последнего значимого остаточного коэффициента единицы преобразования (TU). Значения significant_coeff_flag могут быть сохранены в памяти 306.
Затем на этапе 854 кодирования модуль 104 кодера кодирует блок 704 значений coeff_abs_level_greater1_flag. Модуль 104 кодера определяет одно значение coeff_abs_level_greater1_flag для каждого остаточного коэффициента поднабора с абсолютным значением, большим, чем ноль. Кодированные значения coeff_abs_level_greater1_flag могут быть сохранены в памяти 306.
На этапе 855 кодирования модуль 104 кодера кодирует блок 705 значений coeff_abs_level_greater2_flag. Модуль 104 кодера определяет одно значение coeff_abs_level_greater2_flag для каждого остаточного коэффициента поднабора с абсолютным значением, большим, чем один. Кодированные значения coeff_abs_level_greater2_flag могут быть сохранены в памяти 306.
Затем на этапе 856 кодирования модуль 104 кодера, исполняемый процессором 305, кодирует блок 706 значений coeff_sign_flag. Модуль 104 кодера определяет одно значение coeff_sign_flag для каждого остаточного коэффициента поднабора с абсолютным значением, большим, чем ноль. Кодированные значения coeff_sign_flag могут быть сохранены в памяти 306.
На этапе 857 кодирования модуль 104 кодера кодирует блок 707 значений coeff_abs_level_remaining. Модуль 104 кодера определяет одно значение coeff_abs_level_remaining для каждого остаточного коэффициента поднабора с абсолютным значением, большим, чем два. Кодированные значения coeff_abs_level_remaining могут быть сохранены в памяти 306. После этапа 857 способ 850 завершается.
Теперь со ссылкой на Фиг. 8B будет описан способ 800 декодирования поднабора единицы преобразования (TU). Способ 800 может быть реализован в качестве части модуля 202 энтропийного декодера из декодера 200. Как описано выше, модули 202-208 и 210 кода программного обеспечения, образующие декодер 200 находятся на накопителе 310 на жестких дисках и управляются при их исполнении процессором 305.
Способ 800 будет описан посредством примера со ссылкой на блок 701 с Фиг. 7. Способ 800 декодирует блоки 702, 703, 704, 705, 706, 707 из части 501 битового потока.
Способ 800 начинается на этапе 801 декодирования флага значимая группа, на котором модуль 202 декодера декодирует значение significant_coeff_group_flag 702. Декодированное значение significant_coeff_group_flag 702 может быть сохранено в памяти 306.
Затем на этапе 802, если модуль 202 декодера определяет, что значение significant_coeff_group_flag 702 указывает, что поднабор содержит блоки 703, 704, 705, 706, 707 данных остаточных коэффициентов, то способ 800 переходит к этапу 803. Иначе способ 800 завершается.
На этапе 803 декодирования модуль 202 декодера, исполняемый процессором 305, декодирует блок 703 значений significant_coeff_flag. Модуль 202 декодера определяет одно значение significant_coeff_flag для каждого остаточного коэффициента поднабора, кроме последнего значимого остаточного коэффициента единицы преобразования (TU). Декодированные значения significant_coeff_flag могут быть сохранены в памяти 306.
Затем на этапе 804 декодирования модуль 202 декодера декодирует блок 704 значений coeff_abs_level_greater1_flag. Модуль 202 декодера определяет одно значение coeff_abs_level_greater1_flag для каждого остаточного коэффициента поднабора, для которого на этапе 803 было определено, что абсолютное значение больше нуля. Декодированные значения coeff_abs_level_greater1_flag могут быть сохранены в памяти 306.
На этапе 805 декодирования модуль 202 декодера, исполняемый процессором 305, декодирует блок 705 значений coeff_abs_level_greater2_flag. Модуль 202 декодера определяет одно значение coeff_abs_level_greater2_flag для каждого остаточного коэффициента поднабора, для которого на этапе 804 было определено, что абсолютное значение больше единицы. Декодированные значения coeff_abs_level_greater2_flag могут быть сохранены в памяти 306.
Затем на этапе 806 декодирования модуль 202 декодера декодирует блок 706 значений coeff_sign_flag. Модуль 202 декодера определяет одно значение coeff_sign_flag для каждого остаточного коэффициента поднабора, для которого на этапе 803 было определено, что абсолютное значение больше нуля. Значения coeff_sign_flag могут быть сохранены в памяти 306.
Способ 800 завершается на этапе 807, на котором модуль 202 декодера декодирует блок 707 значений coeff_abs_level_remaining. Модуль 202 декодера определяет одно значение coeff_abs_level_remaining для каждого остаточного коэффициента поднабора, для которого на этапе 805 было определено, что абсолютное значение больше двух. Также на этапе 807 модуль 202 декодера определяет значение кодового слова Голомба-Райса для оставшегося абсолютного значения остаточного коэффициента данного остаточного коэффициента.
Выполняя этап 807, способ 800 завершается.
Теперь со ссылкой на Фиг. 9, Фиг. 10, Фиг. 14A и Фиг. 14B будут описаны параметризованные коды Голомба-Райса и их использование в версии 6.0 эталонной модели HEVC и способах, описываемых в данном документе.
Параметризованные коды Голомба-Райса являются классом универсальных префиксных двоичных кодов, используемых для представления значений оставшихся абсолютных значений остаточных коэффициентов у остаточных коэффициентов единицы преобразования (TU). Префиксный двоичный код является двоичным представлением значения, в котором каждое двоичное кодовое слово имеет уникальный префикс. Такой уникальный префикс позволяет отличать конкретное кодовое слово от других кодовых слов, что необходимо для однозначной идентификации значений, представляемых кодовыми словами.
Каждое кодовое слово параметризованного кода Голомба-Райса может состоять из двух частей: части параметризованного усеченного префикса Райса и возможно пустой части суффикса экспоненциального кода Голомба нулевого порядка. Часть усеченного префикса Райса зависит от параметра K, который может принимать значения 0, 1, 2, 3, 4. Для каждого значения параметра K задается пороговая величина. Если кодируемое значение оставшегося абсолютного значения остаточного коэффициента не достигает пороговой величины, то данное значение кодируется с помощью усеченного кода Райса без экспоненциального суффикса Голомба.
Если кодируемое значение оставшегося абсолютного значения остаточного коэффициента больше или равно пороговой величине, то предварительно определенное усеченное кодовое слово Райса кодируется для указания того, что кодированное значение больше или равно пороговой величине. Дополнительно, значение, равное исходному кодированному значению минус значение пороговой величины, кодируется с использованием экспоненциального кода Голомба нулевого порядка.
В таблице 900, как видно на Фиг. 9, содержатся примерные усеченные кодовые слова Райса для значений от 0 до 15 и значений 0 и 1 параметра K.
В таблице 1000, как видно на Фиг. 10, содержатся примерные экспоненциальные кодовые слова Голомба нулевого порядка. Например, с использованием кода Голомба-Райса с параметром K=0 значение десять (10) будет представлено усеченным префиксом «11111111» Райса и экспоненциальным суффиксом «110» Голомба нулевого порядка, образующими кодовое слово «11111111110» Голомба-Райса. Когда значение параметра K известно, кодовое слово Голомба-Райса может быть однозначно идентифицировано из заданной двоичной последовательности.
Каждое кодовое слово параметризованного кода Голомба-Райса имеет фиксированную длину, которая зависит от параметра K и кодированного значения. Ограниченное количество кодовых слов может иметь заданную длину. Как таковые, для набора кодированных значений, некоторые кодированные значения представлены более короткими кодовыми словами, в то время как другие кодированные значения будут представлены более длинными кодовыми словами. Для кодирования видеоданных кодовые слова могут выделяться кодированным значениям для минимизации всей длины всех кодовых слов, кодированных в битовый поток 113. Разные значения оставшихся абсолютных значений остаточных коэффициентов имеют разную частоту появления в данных единицы преобразования (TU). Уменьшение всей длины кодового слова может достигаться посредством назначения кодовых слов кодированным значениям так, чтобы длина кодового слова соответствовала частоте появления кодированного значения. Например, более частым значениям оставшихся абсолютных значений остаточных коэффициентов могут быть назначены более короткие кодовые слова, значениям оставшихся абсолютных значений остаточных коэффициентов с одной и той же частотой могут быть назначены кодовые слова одной и тот же длины.
Параметр K параметризованного кода Голомба-Райса позволяет управлять распределением длины кодового слова среди кодовых слов. Более малые значения параметра K выделяют более оптимальные кодовые слова значениям с более малыми абсолютными значениями, в то время как более большие значения параметра K выделяют более оптимальные кодовые слова значениям с более большими абсолютными значениями. Поэтому для того, чтобы выделить оптимальные кодовые слова в целом, описанные способы определяют значение параметра K на основе частоты появления заданного значения оставшегося абсолютного значения остаточного коэффициента.
В разрабатываемом стандарте HEVC истинные частоты значений оставшихся абсолютных значений остаточных коэффициентов, такие как значения оставшегося абсолютного значения остаточных коэффициентов, не известны заранее, таким образом, оценка значения параметра K выполняется внутри некоторого поднабора. Чтобы гарантировать правильное декодирование параметризованных кодовых слов Голомба-Райса, кодер 100 и декодер 200 могут быть сконфигурированы с возможностью использования одного и того же значения параметра K для декодирования конкретного кодового слова. Как таковая, оценка значения частоты ограничивается информацией, доступной в декодере 200.
Оценка значения частоты может состоять из двух фаз: начальной оценки и адаптации.
Фаза начальной оценки обеспечивает начальное оцененное значение для параметра K. Фаза адаптации обеспечивает дополнительную коррекцию по отношению к значению параметра K, поскольку осуществляется декодирование значений оставшегося абсолютного значения остаточных коэффициентов, и больше информации становится доступно для анализа.
Начальная оценка гарантирует более оптимальное выделение кодовых слов. С другой стороны начальную оценку обычно трудно реализовать эффективным способом, поскольку до декодирования не доступно никакой информации о значениях оставшегося абсолютного значения остаточных коэффициентов. Эффективный способ начального определения оценки параметра K может обеспечить значительные улучшения эффективности кодирования.
В течение начальной оценки параметра K возможно обнаружить случаи, в которых дополнительная адаптация не окажет значительного влияния на значение параметра K и поэтому может быть пропущена. Фаза адаптации улучшает эффективность кодирования в целом. Однако для широкого класса практических случаев адаптация избыточна, потому что начальная оценка обеспечивает оптимальное значение параметра K, и дополнительная адаптация не нужна. Один недостаток фазы адаптации состоит в том, что последовательные значения упомянутого значения coeff_abs_level_remaining не могут декодироваться параллельно, потому что каждое значение не может быть декодировано без знания значения параметра K, который оценивается адаптивно после декодирования предыдущего значения coeff_abs_level_remaining.
Теперь со ссылкой на Фиг. 11 и Фиг. 12A будет описан способ 1250 кодирования блока значений coeff_abs_level_remaining поднабора единицы преобразования (TU).
Способ 1250 может быть реализован в качестве части модуля 104 энтропийного кодера из кодера 100. Как описано выше, модули 102-112, 114 и 115 кода программного обеспечения, образующие кодер 100, находятся на накопителе 310 на жестких дисках и управляются при их исполнении процессором 305.
Способ 1250 будет описан посредством примера со ссылкой на блок 707 значений coeff_abs_level_remaining с Фиг.7. Способ 1250 кодирует ноль или более значений coeff_abs_level_remaining в блок 707 части 501 потока.
Способ 1250 начинается на этапе 1251 инициализации, в котором параметр K Голомба-Райса первоначально оценивается модулем 104 кодера, исполняемым процессором 305. Начальное значение K может быть сохранено в памяти 306. Также на этапе 1251 модуль 104 кодера определяет необходимость адаптации параметра K в течение кодирования.
Затем на этапе 1257 принятия решения, если модуль 104 кодера определяет, что адаптация необходима, то способ 1250 переходит на этап 1252. Этап 1257 принятия решения по адаптации будет описан более подробно ниже. Иначе способ 1250 переходит на этап 1255.
На этапе 1252 принятия решения, если модуль 104 кодера определяет, что есть еще значения coeff_abs_level_remaining, которые должны быть кодированы, то способ 1250 переходит на этап 1253. Иначе, способ 1250 завершается.
На этапе 1253 кодирования модуль 104 кодера выполняет кодирование кодового слова Голомба-Райса в блок 707 в соответствии с начальным значением параметра K Голомба-Райса, как описано выше со ссылкой на Таблицы 900 и 1000.
Затем на этапе 1254 обновления модуль 104 кодера выполняет адаптацию значения параметра K, который должен быть использован для кодирования следующего значения coeff_abs_level_remaining. Следующее значение Kn+1 параметра K определяется на этапе 1254 на основе двух параметров: текущего значения параметра Kn и последнего декодированного значения coeff_abs_level_remaining. Этап 1254 может быть определен с использованием таблицы 1100 поиска, как показано на Фиг. 11. Таблица 1100 поиска может храниться в памяти 306 и/или на накопителе 310 на жестких дисках. Таблица 1100 поиска предоставляет значения для Kn+1 с использованием значения Kn в качестве столбца и абсолютного значения остаточного коэффициента в качестве строки. Например, если текущее значение параметра K составляет один (1) и последнее декодированное значение coeff_abs_level_remaining составляет двенадцать (12), то следующее значение параметра K составляет три (3).
На этапе 1255 принятия решения, если модуль 104 кодера определяет, что есть еще значения coeff_abs_level_remaining, которые должны быть кодированы, то способ 1250 переходит на этап 1256. Иначе способ 1250 завершается.
На этапе 1256 кодирования модуль 104 кодера выполняет кодирование кодового слова Голомба-Райса в блок 707 и сохраняет кодированное кодовое слово Голомба-Райса в памяти 306.
Теперь со ссылкой на Фиг. 11 и Фиг. 12B будет описан способ 1200 декодирования блока значений coeff_abs_level_remaining поднабора единицы преобразования (TU). Декодирование выполняется в соответствии со способом 1200 с использованием декодирования Голомба-Райса. Способ 1200 может быть реализован в качестве части модуля 202-208 энтропийного декодера из декодера 200. Как описано выше, модули 202-208 и 210 кода программного обеспечения, образующих декодер 200, находятся на накопителе 310 на жестких дисках и управляются при их исполнении процессором 305.
Способ 1200 будет описан посредством примера со ссылкой на блок 707 значений coeff_abs_level_remaining с Фиг. 7. Способ 1200 декодирует ноль или более значений coeff_abs_level_remaining (то есть, значения оставшегося абсолютного значения остаточного коэффициента) из блока 707 части 501 битового потока.
Способ 1200 начинается на этапе 1201 инициализации, на котором параметр K Голомба-Райса первоначально определяется модулем 202 декодера, исполняемым процессором 305. Также на этапе 1201 модуль 202 декодера определяет необходимость в адаптации параметра K в течение декодирования. Этап 1201 является тем же самым, что и этап 1251.
Затем на этапе 1207 принятия решения, если модуль 202 декодера определяет, что адаптация необходима, как будет описано ниже, то способ 1200 переходит на этап 1202. Иначе способ 1200 переходит на этап 1205.
Затем на этапе 1202 принятия решения, если модуль 202 декодера определяет, что есть еще значения coeff_abs_level_remaining, которые должны быть декодированы, то способ 1200 переходит на этап 1203. Иначе способ 1200 завершается.
На этапе 1203 декодирования модуль 202 декодера выполняет декодирование кодового слова Голомба-Райса из блока 707, сохраненного в памяти 306
Затем на этапе 1204 обновления модуль 202 декодера выполняет адаптацию значения параметра K, который должен быть использован для декодирования Голомба-Райса следующего значения coeff_abs_level_remaining поднабора. Процедура адаптации, выполняемая на этапе 1204, является той же самой, что и процедура адаптации, используемая на этапе 1254, описанном выше.
На этапе 1205 принятия решения, если модуль 202 декодера определяет, что есть еще значения coeff_abs_level_remaining, которые должны быть декодированы, то способ 1200 переходит на этап 1206. Иначе способ 1200 завершается.
На этапе 1206 декодирования модуль 202 декодера выполняет декодирование кодового слова Голомба-Райса из блока 707 с использованием декодирования Голомба-Райса. Декодированное кодовое слово Голомба-Райса может быть сохранено в памяти 306.
Теперь со ссылкой на Фиг. 14A и Фиг. 14B будет описано адаптивное и неадаптивное декодирование значений оставшихся абсолютных значений остаточных коэффициентов.
На Фиг. 14A изображено средство 1400 бинаризации coeff_abs_level_remaining. Модуль 1400 средства бинаризации может быть реализован с использованием компьютерной системы 300, в которой различные функциональные модули 1414, 1413, 1406, 1407 и 1410 могут быть реализованы посредством программного обеспечения, исполняемого внутри компьютерной системы 300. Альтернативно, средство 1400 бинаризации может быть реализован посредством специализированного аппаратного обеспечения внутри компьютерной системы 300. В качестве еще одной альтернативы средство 1400 бинаризации может быть реализовано посредством сочетания специализированного аппаратного обеспечения и программного обеспечения, исполняемого внутри компьютерной системы 300.
Средство 1400 бинаризации может быть реализовано в качестве части модуля 202 декодера из декодера 200. Альтернативно, средство 1400 бинаризации также может быть реализовано в качестве части модуля 104 кодера из декодера 100.
Средство 1400 бинаризации декодирует значения оставшихся абсолютных значений остаточных коэффициентов для поднабора единицы преобразования (TU).
Средство 1400 бинаризации использует адаптивную оценку параметра K. Средство 1400 бинаризации содержит модуль 1414 начальной оценки K0, который выполняет начальную оценку параметра K, как описано выше.
Модуль 1413 декодирует оставшееся абсолютное значение V0 остаточного коэффициента. Модуль 1413 принимает введенное кодовое слово 1402 Голомба-Райса и первоначально оцененное значение 1401 параметра K. Как только модуль 1413 завершил декодирование, то выводится декодированное значение 1412 оставшегося абсолютного значения остаточного коэффициента, как видно на Фиг. 14A.
Модуль 1406 выполняет адаптацию значения параметра K на основе первоначально оцененного значения 1401 параметра K и значения 1404, декодированного модулем 1403, как описано выше.
Модуль 1407 декодирует оставшееся абсолютное значение V1 остаточного коэффициента. Модуль 1407 принимает в качестве ввода кодовое слово 1403 Голомба-Райса и оцененное значение 1405 параметра K. Как только модуль 1407 заканчивает декодирование, то выводится декодированное значение 1411 оставшегося абсолютного значения остаточного коэффициента.
Модуль 1410 выполняет адаптацию значения параметра K на основе предыдущего значения 1405 параметра K и значения 1408, декодированного модулем 1407.
Оцененное значение 1409 параметра K может использоваться следующим модулями 1415 декодирования Голомба-Райса и адаптации. Модуль 1410 зависит от данных, предоставляемых модулем 1407, которые зависят от данных, предоставляемых модулем 1406, которые зависят от данных, предоставляемых модулем 1413. Как таковое параллельное исполнение модулей 1413 и 1410 декодирования является сложным. Дополнительные модули 1415 декодирования и адаптации также зависят как от входных данных 1416, так и от предварительно оцененных значений параметра K. Однако этапы адаптации, такие как этапы 1406 и 1410, не влияют на фактическое значение параметра K, если значение параметра K уже является оптимальным. Отказ от этапов адаптации, где она является избыточной, может улучшить пропускную способность декодирования без значительного влияния на эффективность кодирования.
На Фиг. 14B изображено другое средство 1450 бинаризации coeff_abs_level_remaining. Опять, модуль 1450 средства бинаризации может быть реализован с использованием компьютерной системы 300, в которой различные функциональные модули 1414, 1413, 1406, 1407 и 1410 могут быть реализованы посредством программного обеспечения, исполняемого внутри компьютерной системы 300. Альтернативно, средство 1450 бинаризации может быть реализовано посредством специализированного аппаратного обеспечения внутри компьютерной системы 300. В качестве еще одной альтернативы средство 1450 бинаризации может быть реализовано посредством сочетания специализированного аппаратного обеспечения и программного обеспечения, исполняемого внутри компьютерной системы 300.
Опять, средство 1450 бинаризации может быть реализовано в качестве части модуля 202 декодера из декодера 200. Альтернативно, средство 1450 бинаризации также может быть реализовано в качестве части модуля 104 кодера из декодера 100.
Средство 1450 бинаризации не использует адаптивную оценку параметра K. Средство 1450 бинаризации достигает параллельности посредством декодирования множества остаточных коэффициентов за тактовый цикл.
Модуль 1458 выполняет начальную оценку параметра K, как описано выше.
Модуль 1454 декодирует оставшееся абсолютное значение V0 остаточного коэффициента, как описано выше.
Модуль 1454 затем принимает вводимое кодовое слово 1452 Голомба-Райса и первоначально оцененное значение 1451 параметра K. Модуль 1456 декодирует оставшееся абсолютное значение V1 остаточного коэффициента. Модуль 1456 принимает в качестве ввода кодовое слово 1453 Голомба-Райса и первоначально оцененное значение 1451 параметра K.
Дополнительные модули 1460 декодирования также будут принимать свои соответствующие вводимые кодовые слова 1459 Голомба-Райса и первоначально оцененное значение 1451 параметра K.
Модули 1454, 1456 и все дополнительные модули 1460 декодирования не имеют никаких зависимостей от данных и могут исполняться параллельно.
Теперь со ссылкой на Фиг. 13 будет описан способ 1300 определения значения параметра K для декодирования блока значений coeff_abs_level_remaining поднабора единицы преобразования (TU).
Способ 1300 используется как кодером 100, так и декодером 200 для гарантирования правильного декодирования данных. Как таковой, способ 1300 может быть реализован в качестве части модулей 104 энтропийного кодера 100. Дополнительно способ 1300 может быть реализован в качестве части модуля 202 энтропийного декодера из декодера 200.
Способ 1300 будет описан посредством примера со ссылкой на декодер 200.
Способ 1300 начинается на этапе 1301, на котором модуль 202 декодера, исполняемый процессором 305, анализирует предварительно декодированную информацию для текущего поднабора и предварительно декодированные поднаборы единицы преобразования (TU). К предварительно декодированной информации для текущего поднабора можно осуществлять доступ из памяти 306. Этап 1301 будет описан более подробно ниже.
Затем на этапе 1302 модуль 202 декодера определяет, будет ли декодирование использовать адаптацию, и определяет значение для параметра K. Этап 1302 будет описан более подробно ниже.
На этапе 1303 значение параметра K, оцененное на этапе 1302, присваивается модулем 202 декодера переменной, сконфигурированной внутри памяти 306, содержащей параметр K. Выполняя этап 1303, способ 1300 завершается.
В одном варианте реализации этап 1301 может проанализировать, больше ли количество ненулевых остаточных коэффициентов в текущем поднаборе, чем предварительно определенное значение T пороговой величины. Если количество ненулевых (значимых) остаточных коэффициентов больше предварительно определенной пороговой величины, то параметру K присваивается значение Kсмещение смещения. Значение смещения приведет в результате к параметру K, имеющему ненулевое значение, которое смещено от нуля на значение Kсмещение. Значение Kсмещение может быть предварительно определенным значением и установлено в один (1). Иначе параметру K присваивается значение Kноль установки на ноль.
Для экспериментальной модели HEVC 6.0 («HM-6.0») значение T пороговой величины, используемое для принятия решения, составляет четырнадцать (14). Значение Kсмещение смещения параметра K составляет один (1), а значение Kноль установки на ноль составляет ноль (0).
В другом варианте реализации значение параметра Q квантования и индекс I текущего поднабора могу быть проанализированы на этапе 1301. В таком варианте реализации, если значение параметра Q квантования меньше предварительно определенной пороговой величины TQ и значение индекса I поднабора меньше предварительно определенной пороговой величины Iподнабор, то параметру K присваивается значение Kсмещение смещения. Иначе параметру K присваивается значение Kноль установки на ноль.
Для экспериментальной модели HEVC 6.0 («HM-6.0») значение пороговой величины параметра TQ квантования, используемого для принятия решения, составляет десять (10), а значение индекса Iподнабор поднабора, используемое для принятия решения, составляет один (1). Значение Kсмещение смещения параметра K составляет один (1), а значение Kноль установки на ноль составляет ноль (0).
Значения ширины и высоты единицы преобразования могут дополнительно быть проанализированы на этапе 1301. В таком варианте реализации, если значения ширины и высоты единицы преобразования превосходят предварительно определенные пороговые величины Tширина и Tвысота, то параметру K присваивается значение Kсмещение смещения. Иначе параметру K присваивается значение Kноль установки на ноль.
Для экспериментальной модели HEVC 6.0 («HM-6.0») значения пороговой величины ширины и высоты Tширина и Tвысота единицы преобразования, используемые для принятия решения, составляют восемь (8) и восемь (8). Значение Kсмещение смещения параметра K составляет один (1), а значение Kноль установки на ноль составляет ноль (0).
Решение об использовании адаптации в течение кодирования или декодирования поднабора может быть принято на этапе 1302 на основе индекса поднабора. Если индекс равен или превосходит предварительно определенное значение Imax, то на этапе 1257 способа 1250 кодирования и на этапе 1207 способа 1200 декодирования, способ переходит на этап 1205 декодирования и на этап 1255 кодирования и не использует адаптацию параметра K. Наличие фиксированного параметра K Райса можно рассматривать в качестве свободного от зависимости кодирования или декодирования Голомба-Райса. Иначе способ переходит на этап 1202 способа 1200 и этап 1252 способа 1250 и использует адаптацию параметра K. Наличие адаптивного параметра K Райса можно рассматривать в качестве основанного на зависимости кодирования или декодирования Голомба-Райса.
Для экспериментальной модели HEVC 6.0 («HM_6.0») значение пороговой величины индекса Imax составляет шесть (6). На Фиг. 15 изображена примерная единица 1500 преобразования, в которой значение шесть (6) пороговой величины индекса Imax используется на этапе 1302 для принятия решения об использовании адаптации в течение кодирования или декодирования поднабора. В примере на Фиг. 15 предполагается использование шаблона сканирования обратно по диагонали. Единица 1500 преобразования разделена на шестнадцать поднаборов, таких как поднабор 1510. Каждый поднабор на Фиг. 15 помечен либо буквой «A», либо буквой «F», при этом поднаборы, помеченные буквой «A», указывают поднаборы, которые кодируются и декодируются с использованием адаптивных параметров K Райса; в то время как поднаборы, помеченные «F», указывают поднаборы, использующие фиксированные параметры K Райса, при использовании значения шесть (6) пороговой величины для индекса Imax на этапе 1302. Значение шесть для индекса Imax приводит в результате к поднаборам «A», использующим адаптивные параметры K Райса внутри поднабора. Поднабор, помеченный буквой «F», указывает поднаборы в позициях в TU 1500, в которых значение шесть (6) пороговой величины для индекса Imax приводит в результате к поднаборам, использующим фиксированный параметр Райса. Значение пороговой величины индекса Imax является одним и тем же для всех поднаборов в TU 1500, местоположение поднабора в TU 1500 сравнивается с пороговой величиной для определения, следует ли использовать адаптивный параметр Райса для кодирования и декодирования. Значение указателя Imax пороговой величины используется для выбора границы между адаптивными и фиксированными поднаборами на Фиг. 15. Порядок поднабора начинается в нуле (0) для верхнего левого поднабора 1520 и продолжается в обратном порядке сканирования с поднабором 1530 в качестве поднабора один (1) и поднабора 1540 в качестве поднабора два (2).
В другом варианте реализации решение об использовании адаптации в течение кодирования или декодирования поднабора может быть принято на этапе 1302 на основе некоторого количества G1 остаточных коэффициентов, большего, чем один, и некоторого количества G2 остаточных коэффициентов, большего, чем два, в некотором предварительно кодированном или декодированном поднаборе. Однако такой способ не применяется к случаю, когда нет какого-либо предварительно кодированного или декодированного поднабора. Когда существует предварительно кодированный или декодированный поднабор, то, если значение (G2 - G1) больше предварительно определенной пороговой величины T21, на этапе 1257 способа 1250 кодирования (или на этапе 1207 способа 1200 декодирования) способ 1250 переходит на этап 1255 способа 1250 кодирования (или на этап 1205 способа 1200 декодирования) и не использует адаптацию параметра K. Иначе способ 1250 переходит на этап 1252 способа 1250 кодирования (или способ 1200 переходит на этап 1202 способа 1200 декодирования) и использует адаптацию параметра K.
Для экспериментальной модели HEVC 6.0 значение пороговой величины индекса T21 составляет четыре (4).
Способы 1250 и 1300 при применении в видеокодере 100 и способы 1200 и 1300 при применении в декодере 200 позволяют вариантам реализации осуществлять более эффективное сжатие данных кадров, таких как данные 101 кадров. Описанные способы также позволяют вариантам реализации осуществлять увеличение пропускной способности осуществления синтаксического анализа кодированного битового потока, такого как кодированный битовый поток 113. Более эффективное сжатие данных кадров возникает посредством использования лучшей оценки параметра K Голомба-Райса, что делает возможным назначение более коротких кодовых слов кодированным символам. Более высокая пропускная способность может быть достигнута посредством позволения вариантам реализации использовать описанные способы декодирования кодовых слов Голомба-Райса, которые могут декодировать более одного кодового слова за один раз, посредством устранения зависимости от данных между кодовыми словами.
ПРОМЫШЛЕННАЯ ПРИМЕНИМОСТЬ
Описанные варианты выполнения применимы к компьютерной техники и техники обработки данных и в частности к цифровой обработке сигналов для кодирования и декодирования сигналов, таких как видеосигналы.
Выше описаны только некоторые варианты осуществления настоящего изобретения, однако с ними могут производиться модификации и/или изменения без отступления от объема и сущности изобретения, при этом варианты осуществления являются иллюстративными, а не накладывающими ограничения.
В контексте данной спецификации слово «содержащий» означает «включающий в себя преимущественно, но не обязательно исключительно» или «имеющий», или «включающий в себя», а не «состоящий только из». Разновидности слова «содержащий», такие как «содержать» и «содержит», имеют измененные соответствующим образом значения.
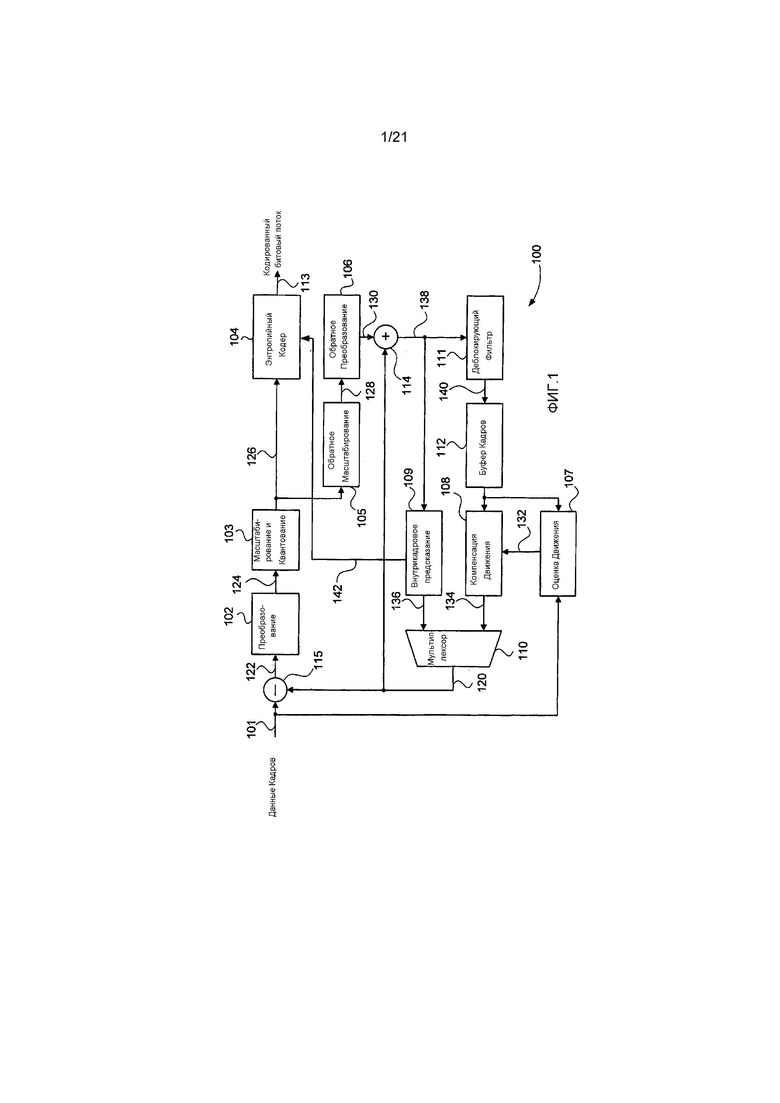
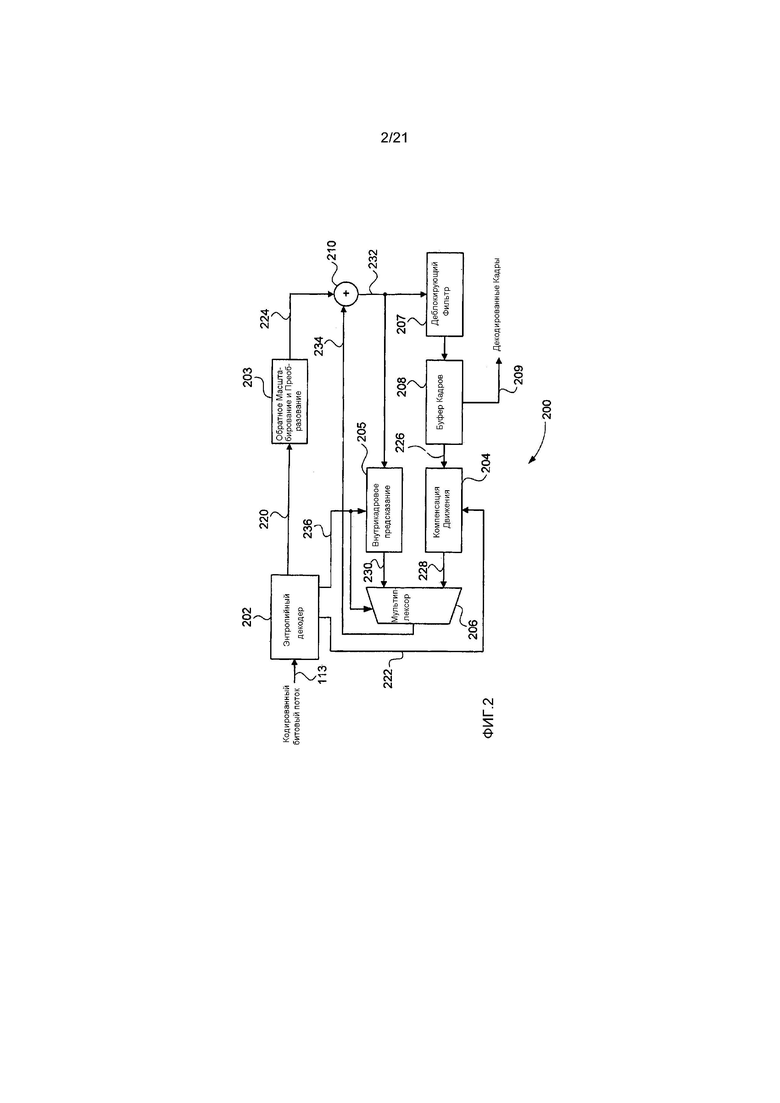
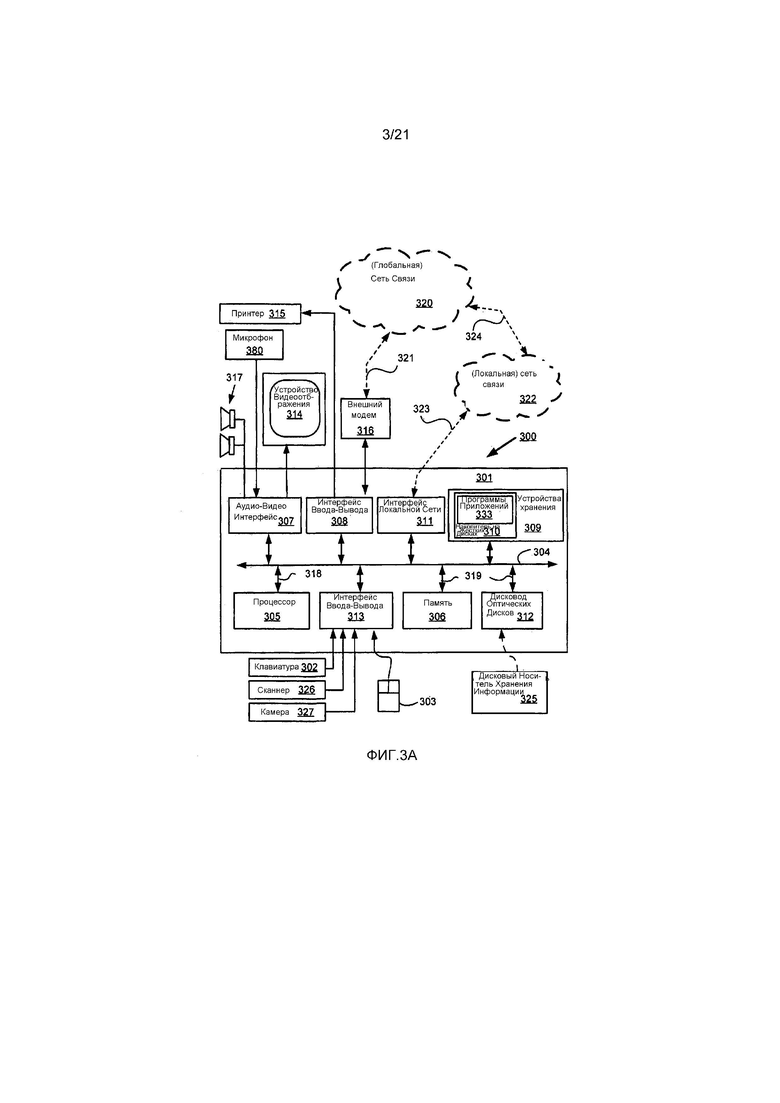
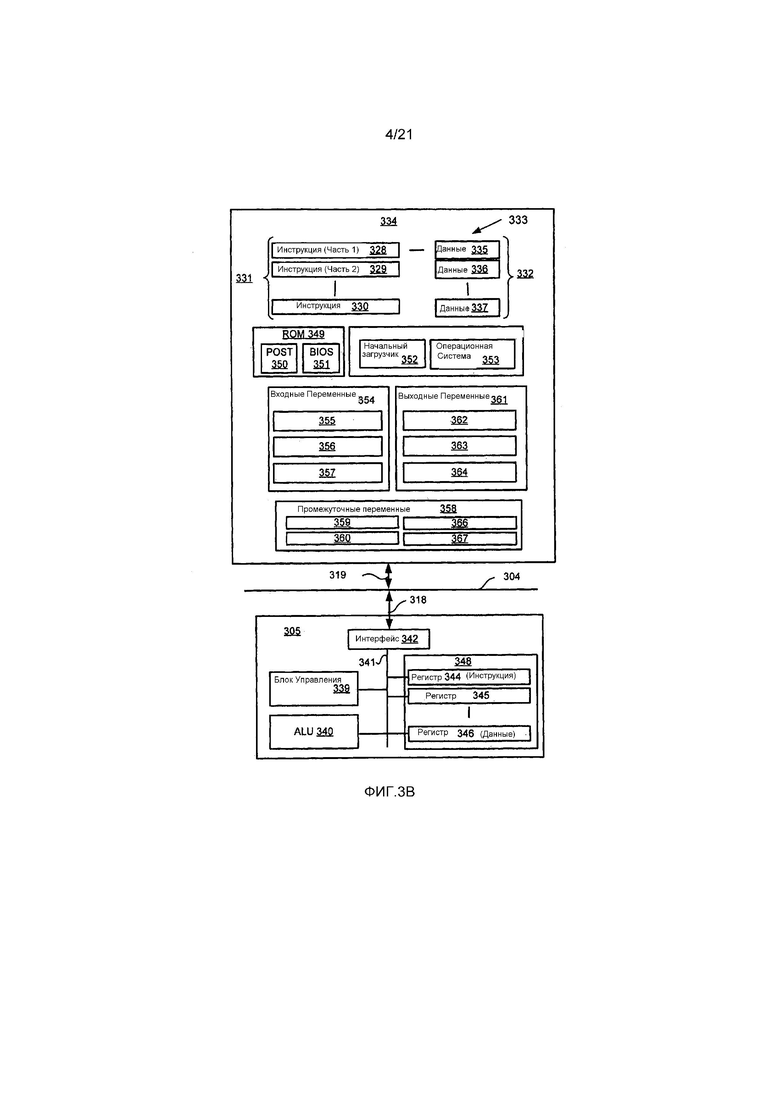
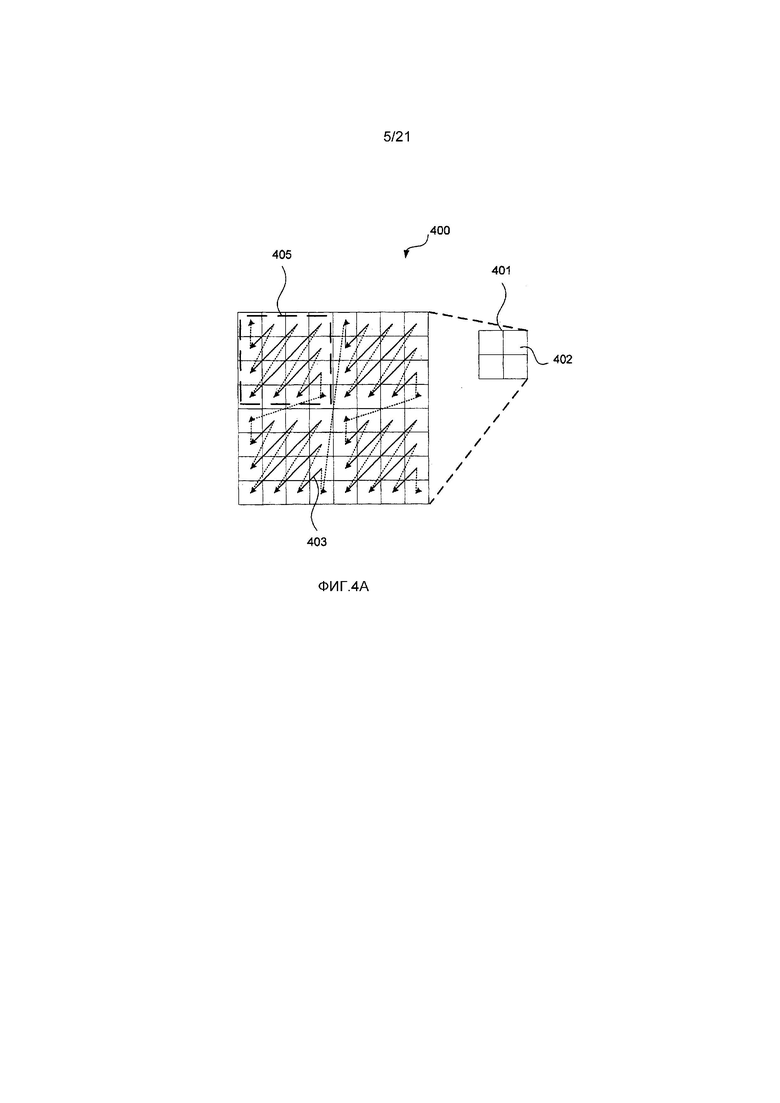
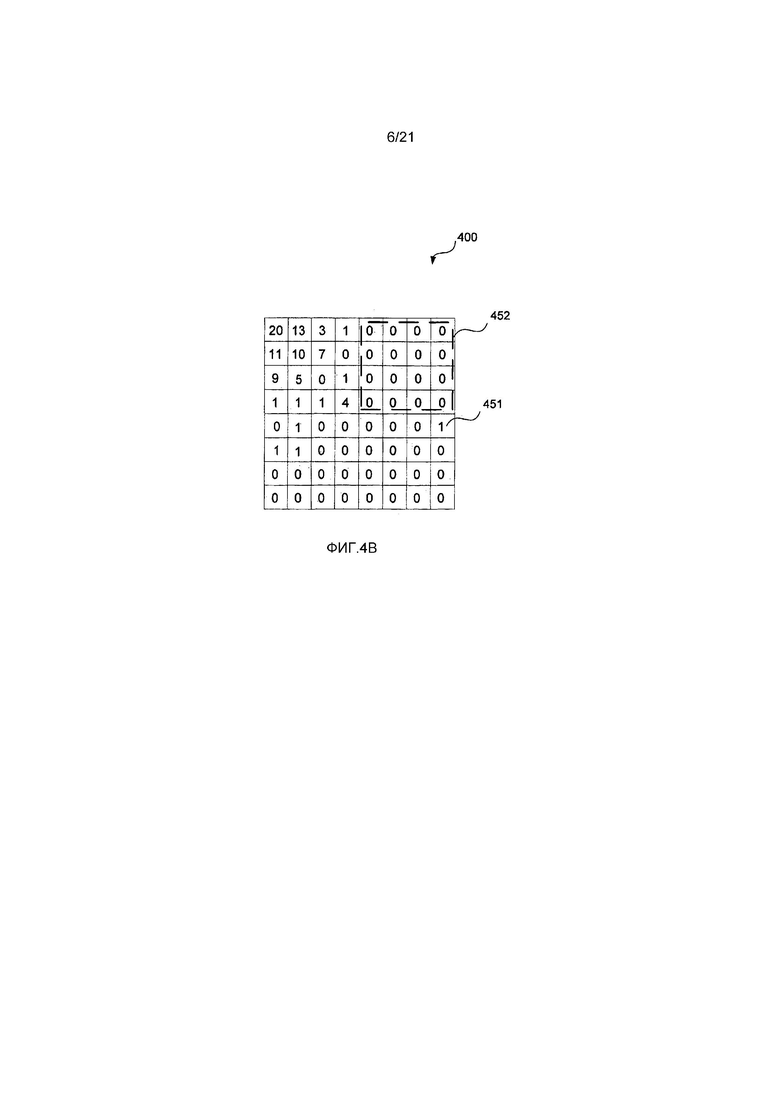
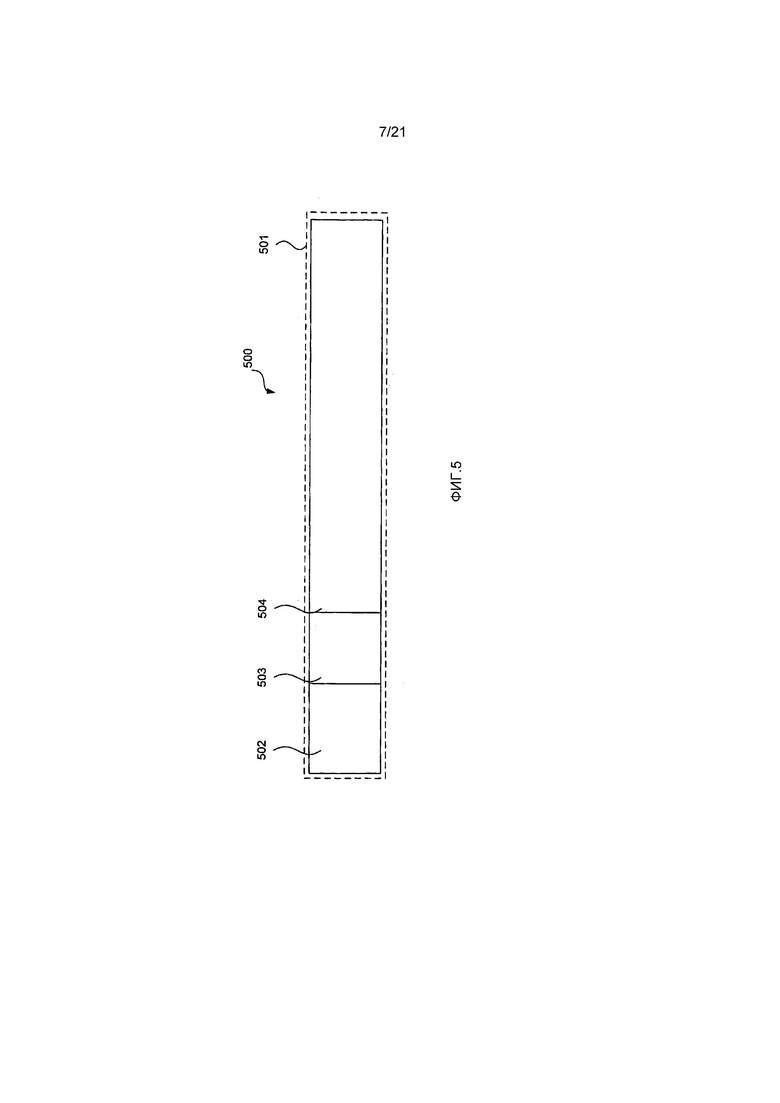
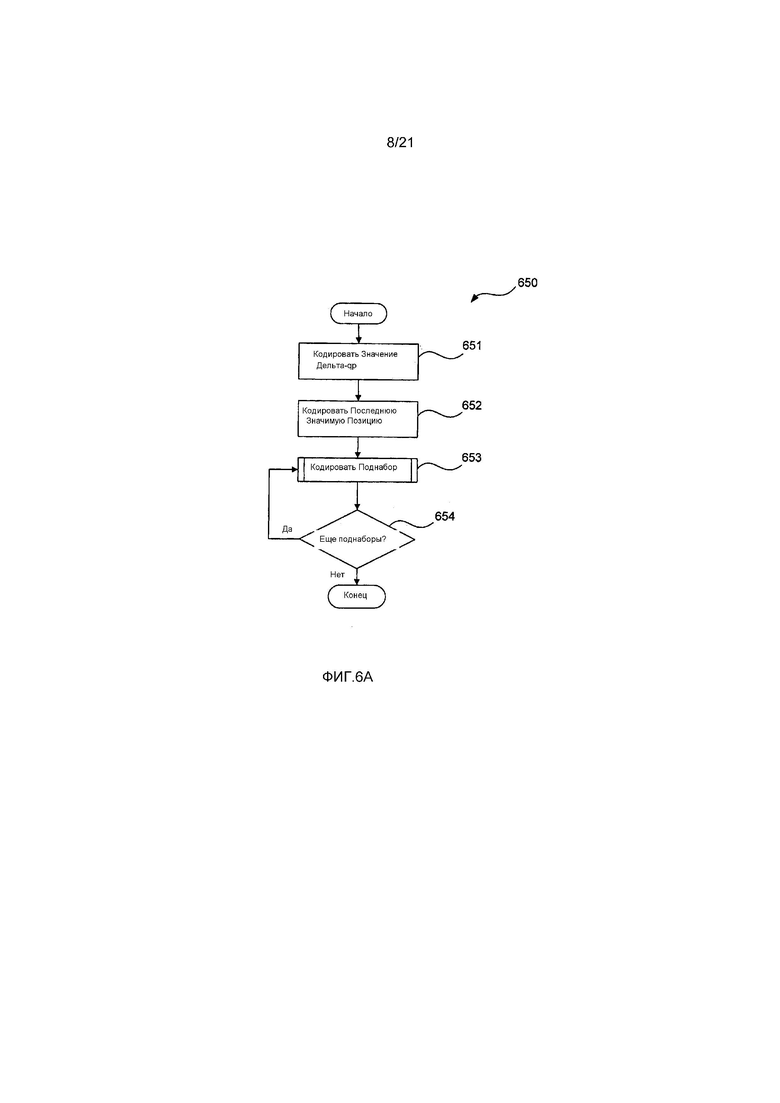
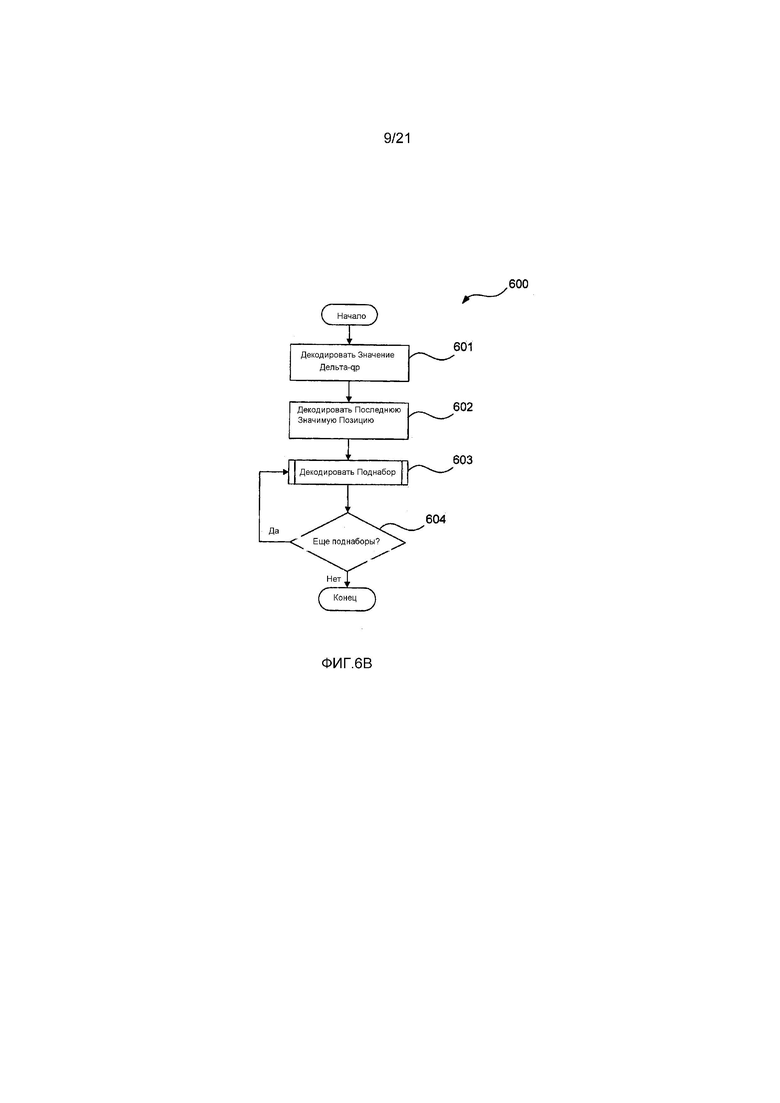
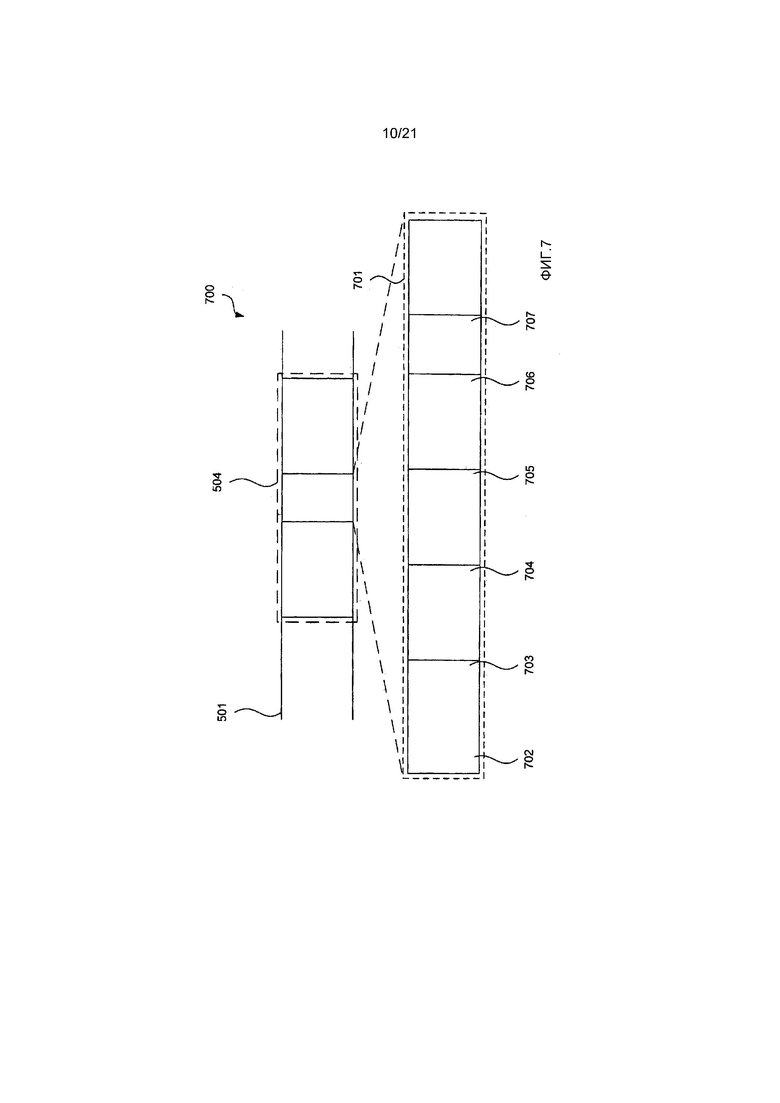
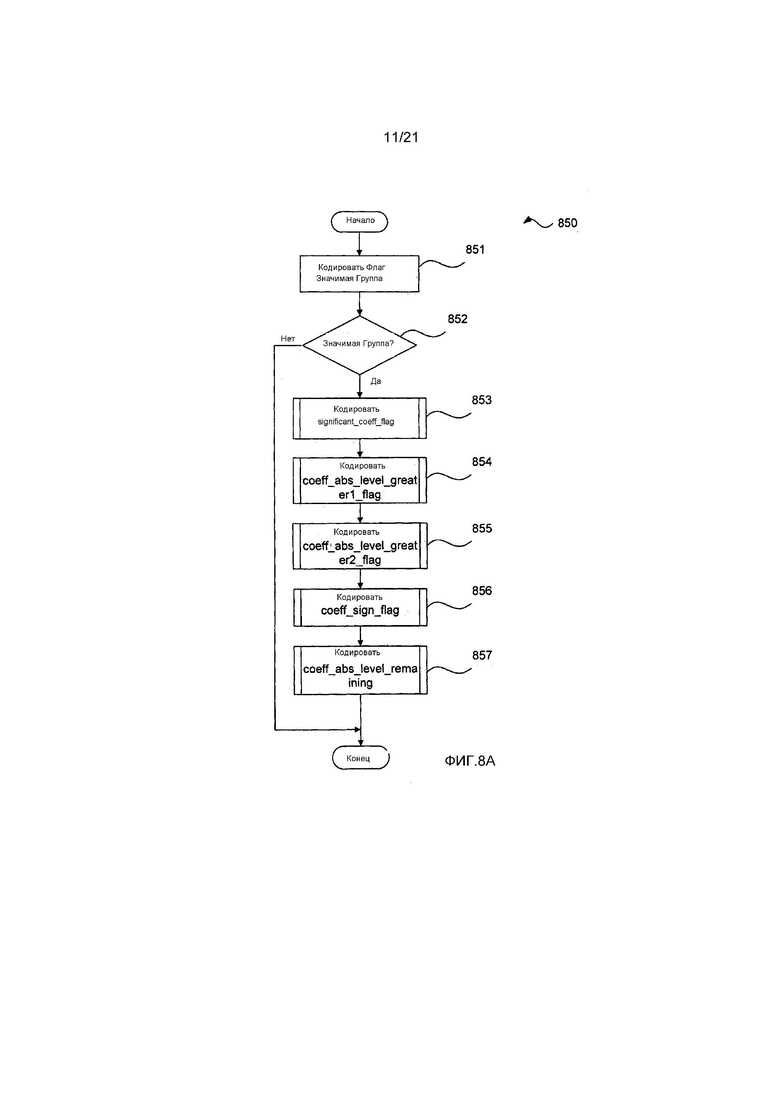
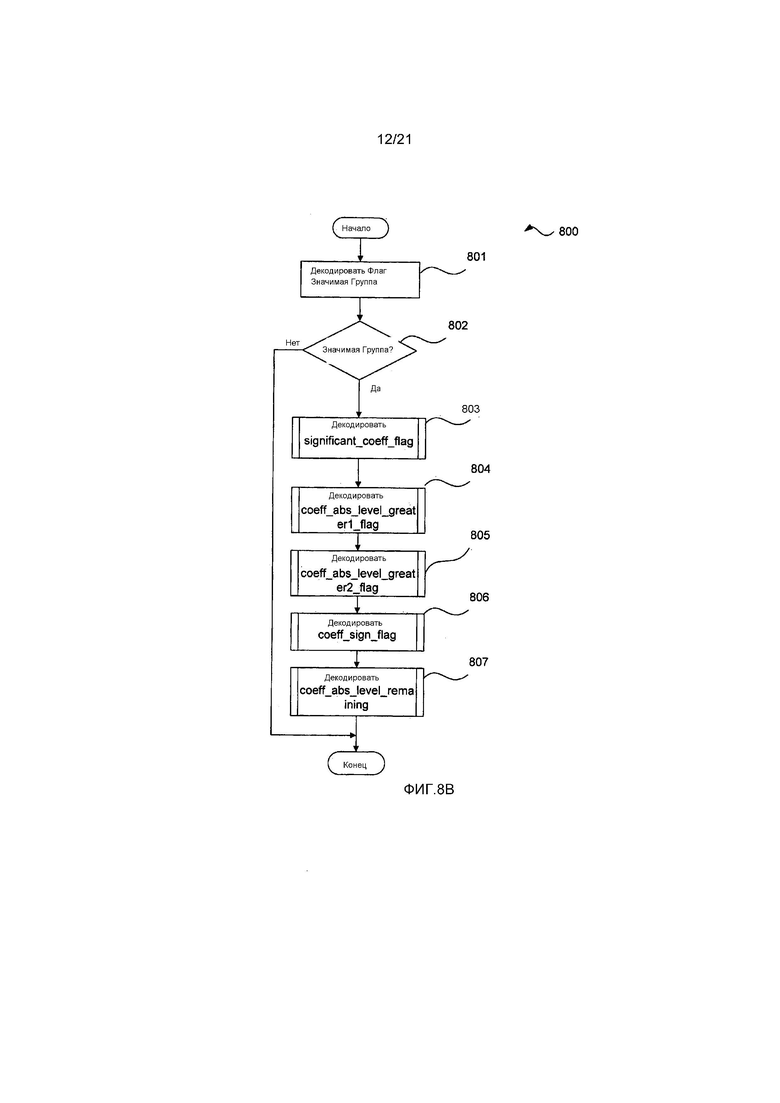



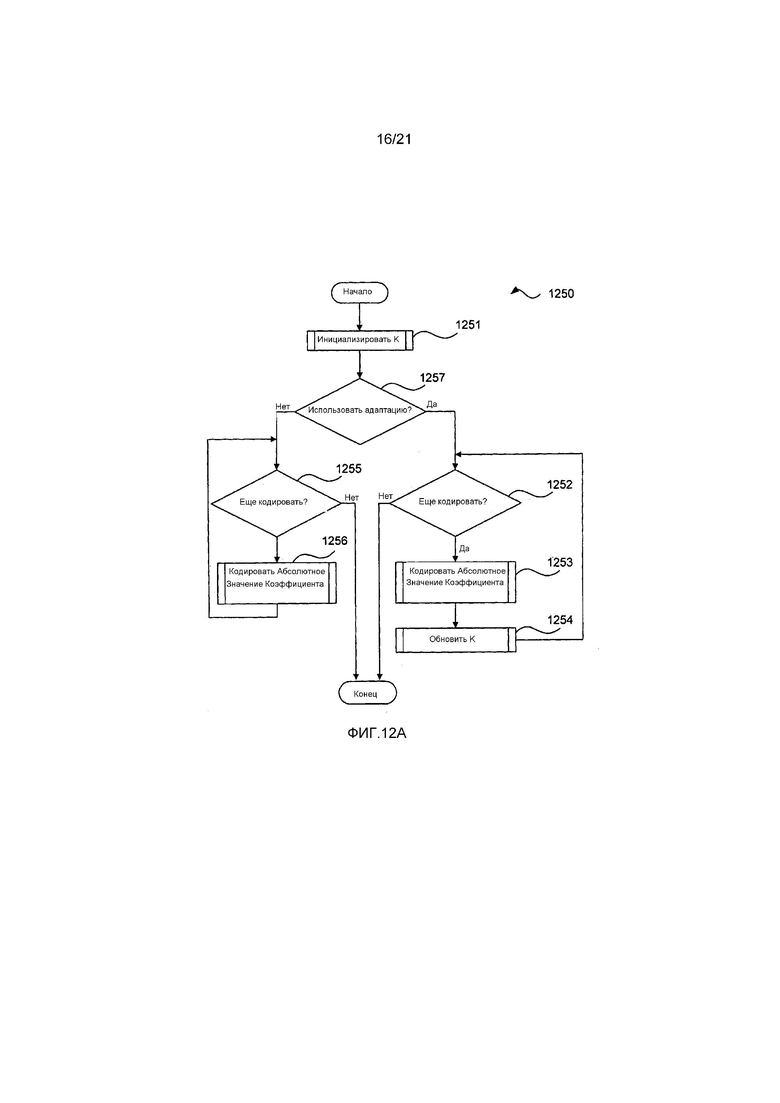
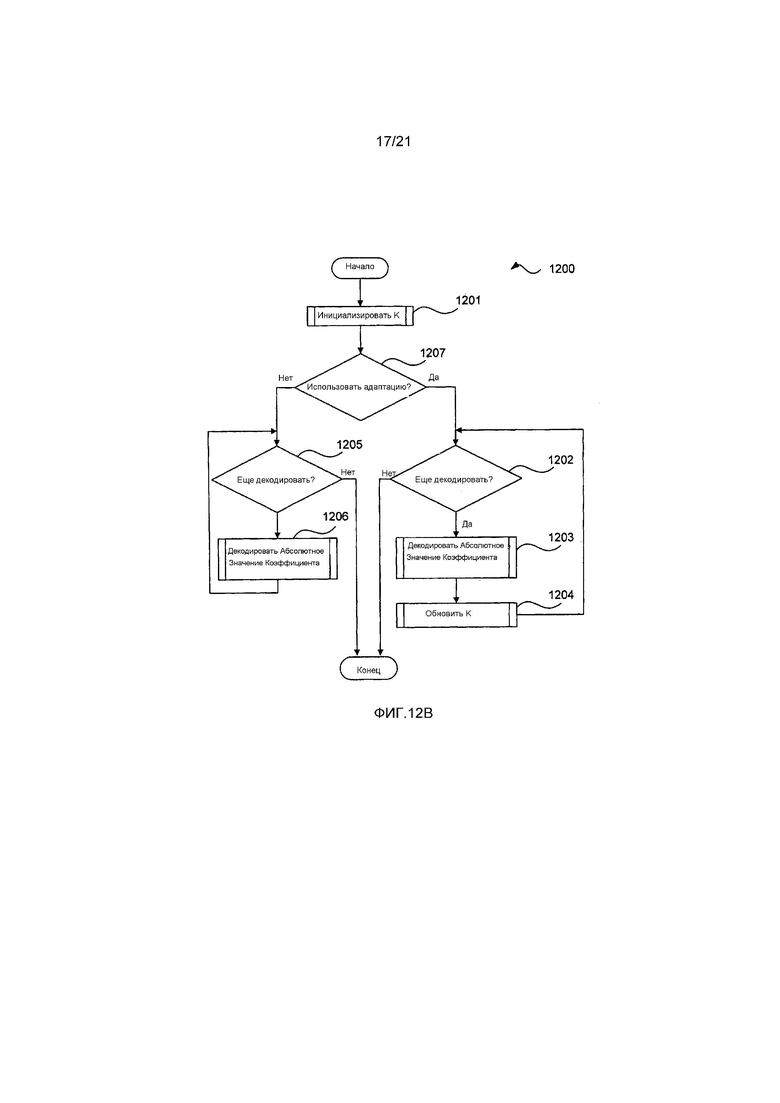
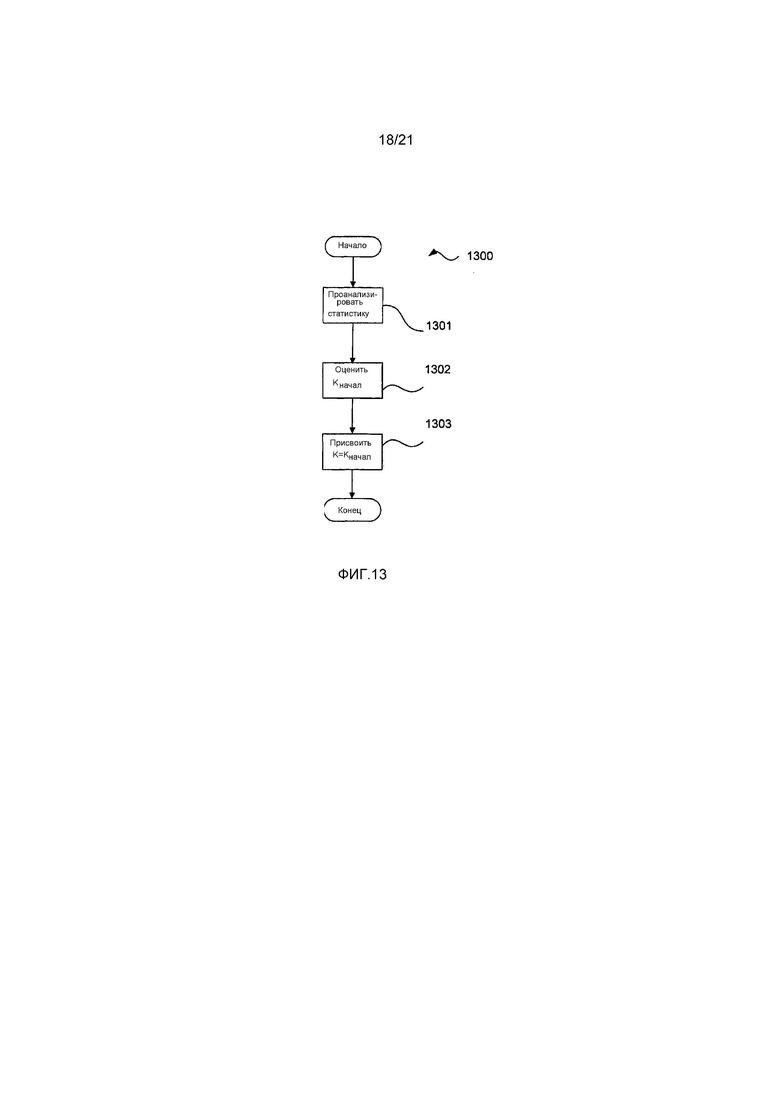
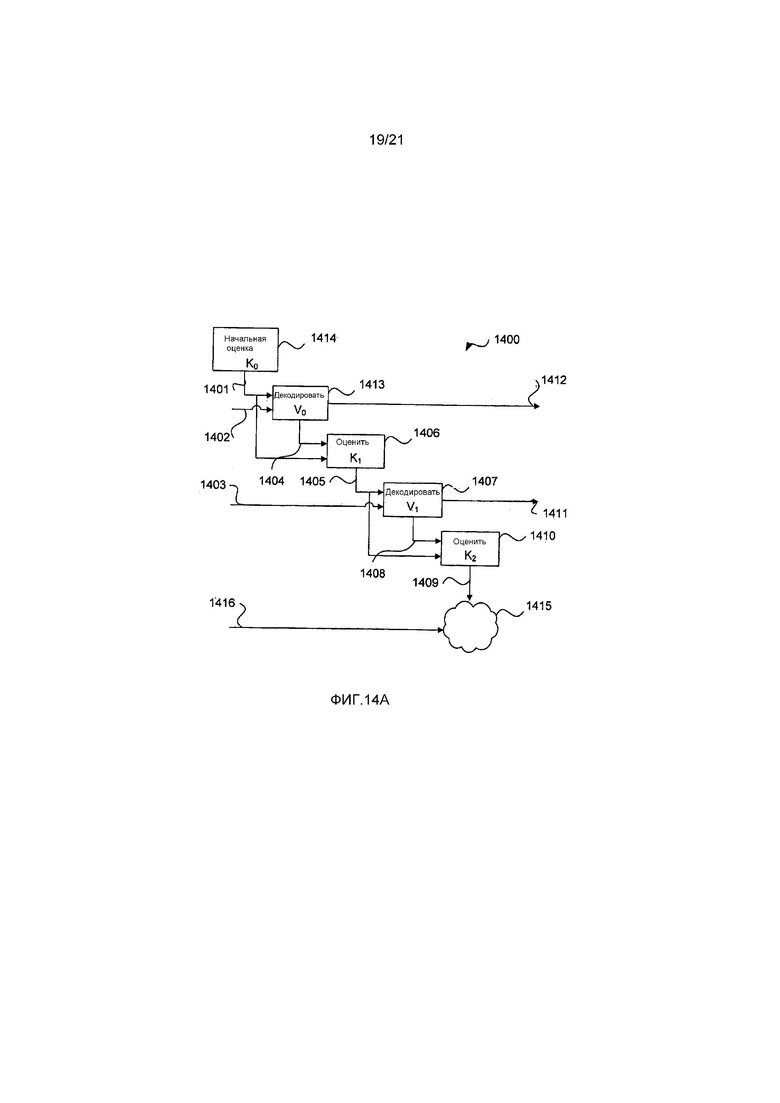
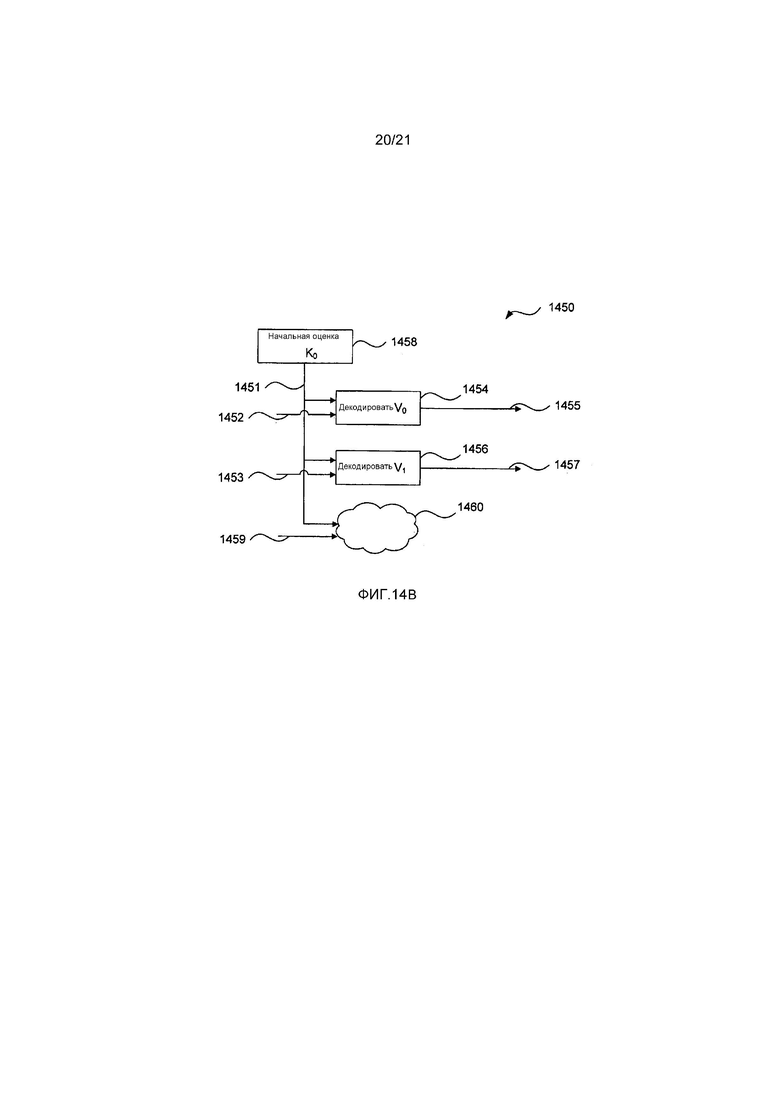
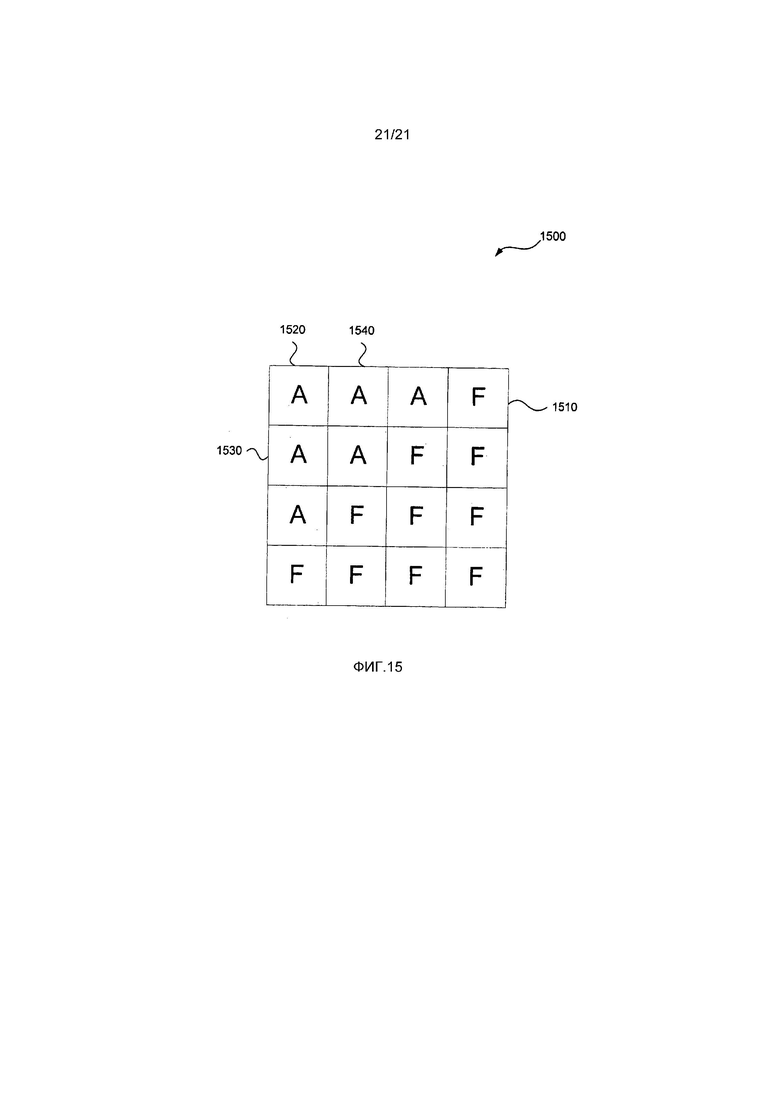
Изобретение относится к вычислительной технике. Технический результат заключается в повышении эффективности кодирования за счет начального определения оценки параметра Райса. Способ декодирования изображений для декодирования множества поднаборов единицы преобразования с использованием Голомб-Райс-декодирования, который содержит определение исходного значения для Голомб-Райс-декодирования целевого поднабора единицы преобразования из информации, связанной с ранее декодированными значениями остаточных коэффициентов для предыдущего поднабора упомянутой единицы преобразования; и декодирование упомянутого целевого поднабора с использованием определенного исходного значения в качестве исходного параметра Райса для Голомб-Райс-декодирования. 6 н. и 8 з.п. ф-лы, 21 ил.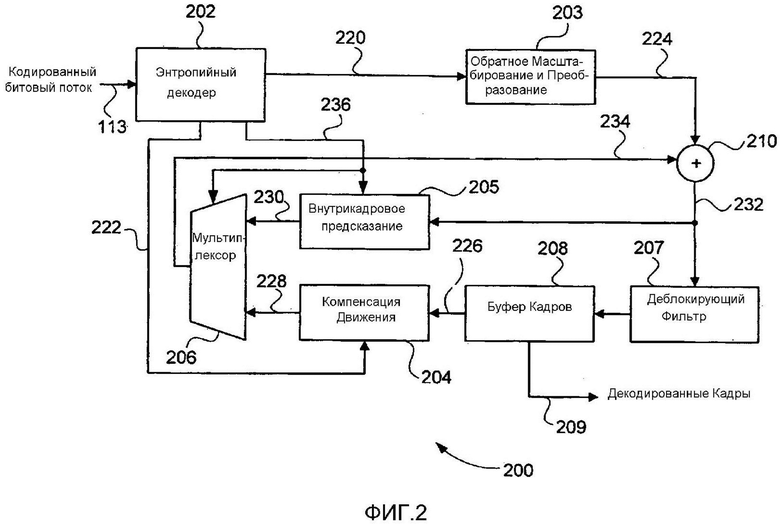
1. Способ декодирования изображений для декодирования множества поднаборов единицы преобразования с использованием Голомб-Райс-декодирования, причем способ содержит:
определение исходного значения для Голомб-Райс-декодирования целевого поднабора единицы преобразования из информации, связанной с ранее декодированными значениями остаточных коэффициентов для предыдущего поднабора упомянутой единицы преобразования; и
декодирование упомянутого целевого поднабора с использованием определенного исходного значения в качестве исходного параметра Райса для Голомб-Райс-декодирования.
2. Способ декодирования изображений по п. 1, в котором исходное значение для Голомб-Райс-декодирования для цветности определяют независимо от исходного значения для Голомб-Райс-декодирования для яркости.
3. Способ декодирования изображений по п. 1, в котором предыдущий поднабор представляет собой нижний правый поднабор единицы преобразования, если целевой поднабор представляет собой верхний правый поднабор единицы преобразования.
4. Способ декодирования изображений по п. 1, в котором предыдущий поднабор представляет собой верхний правый поднабор единицы преобразования, если целевой поднабор представляет собой нижний левый поднабор единицы преобразования.
5. Способ декодирования изображений по п. 1, в котором предыдущий поднабор представляет собой нижний левый поднабор единицы преобразования, если целевой поднабор представляет собой верхний левый поднабор единицы преобразования.
6. Способ кодирования изображений для кодирования множества поднаборов единицы преобразования с использованием Голомб-Райс-кодирования, причем способ содержит:
определение исходного значения для Голомб-Райс-кодирования целевого поднабора единицы преобразования из информации, связанной с ранее кодированными значениями остаточных коэффициентов для предыдущего поднабора упомянутой единицы преобразования; и
кодирование упомянутого целевого поднабора с использованием определенного исходного значения в качестве исходного параметра Райса для Голомб-Райс-кодирования.
7. Способ кодирования изображений по п. 6, в котором исходное значение для Голомб-Райс-кодирования для цветности определяют независимо от исходного значения для Голомб-Райс-кодирования для яркости.
8. Способ кодирования изображений по п. 6, в котором предыдущий поднабор представляет собой нижний правый поднабор единицы преобразования, если целевой поднабор представляет собой верхний правый поднабор единицы преобразования.
9. Способ кодирования изображений по п. 6, в котором предыдущий поднабор представляет собой верхний правый поднабор единицы преобразования, если целевой поднабор представляет собой нижний левый поднабор единицы преобразования.
10. Способ кодирования изображений по п. 6, в котором предыдущий поднабор представляет собой нижний левый поднабор единицы преобразования, если целевой поднабор представляет собой верхний левый поднабор единицы преобразования.
11. Устройство декодирования изображений для декодирования множества поднаборов единицы преобразования с использованием Голомб-Райс-декодирования, причем устройство содержит:
средство для определения исходного значения для Голомб-Райс-декодирования целевого поднабора единицы преобразования из информации, связанной с ранее декодированными значениями остаточных коэффициентов для предыдущего поднабора упомянутой единицы преобразования; и
средство для декодирования упомянутого целевого поднабора с использованием определенного исходного значения в качестве исходного параметра Райса для Голомб-Райс-декодирования.
12. Устройство кодирования изображений для кодирования множества поднаборов единицы преобразования с использованием Голомб-Райс-кодирования, причем способ содержит:
средство для определения исходного значения для Голомб-Райс-кодирования целевого поднабора единицы преобразования из информации, связанной с ранее кодированными значениями остаточных коэффициентов для предыдущего поднабора упомянутой единицы преобразования; и
средство для кодирования упомянутого целевого поднабора с использованием определенного исходного значения в качестве исходного параметра Райса для Голомб-Райс-кодирования.
13. Считываемый компьютером носитель с записанной на нем компьютерной программой для декодирования множества поднаборов единицы преобразования с использованием Голомб-Райс-декодирования, причем программа содержит:
код для определения исходного значения для Голомб-Райс-декодирования целевого поднабора единицы преобразования из информации, связанной с ранее декодированными значениями остаточных коэффициентов для предыдущего поднабора упомянутой единицы преобразования; и
код для декодирования упомянутого целевого поднабора с использованием определенного исходного значения в качестве исходного параметра Райса для Голомб-Райс-декодирования.
14. Считываемый компьютером носитель с записанной на нем компьютерной программой для кодирования множества поднаборов единицы преобразования с использованием Голомб-Райс-кодирования, причем программа содержит:
код для определения исходного значения для Голомб-Райс-кодирования целевого поднабора единицы преобразования из информации, связанной с ранее кодированными значениями остаточных коэффициентов для предыдущего поднабора упомянутой единицы преобразования; и
код для кодирования упомянутого целевого поднабора с использованием определенного исходного значения в качестве исходного параметра Райса для Голомб-Райс-кодирования.
| US 6987468 B1, 17.01.2006 | |||
| US 6560365 B1, 06.05.2003 | |||
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| ПРЕДСКАЗАТЕЛЬНОЕ КОДИРОВАНИЕ БЕЗ ПОТЕРЬ ДЛЯ ИЗОБРАЖЕНИЙ И ВИДЕО | 2005 |
|
RU2355127C2 |

