Заявление об установлении приоритета
Данная заявка по закону 35 в Cводе законов США, 119(е) притязает на приоритет заявки на патент США № 62/017.193, поданной 25 июня 2014 г., содержимое которое полностью включено в настоящий документ путем ссылки.
Уровень техники
Интернет обеспечивает доступ к самой разнообразной информации. Например, по Интернету доступны файлы цифровых изображений, видео- и/или аудиофайлы, а также ресурсы веб-страниц по конкретным темам или конкретным сообщениям печати. Что касается ресурсов веб-страниц, многие из этих ресурсов предназначены для упрощения выполнения конкретных функций, таких как банковские операции, заказ номеров в гостиницах, совершение покупок и т.д., или для предоставления структурированной информации, такой как электронные энциклопедии, базы данных по фильмам и т.д.
Имеется целый ряд поисковых систем для идентификации конкретных ресурсов веб-страниц, доступных по Интернету. С появлением планшетных компьютеров и смартфонов нативные приложения, которые обеспечивают выполнение тех же функций, что обеспечиваются благодаря использованию ресурсов веб-страниц, в настоящее время предоставляются в большом числе.
Информационные потребности пользователя могут при этом удовлетворяться путем предоставления результатов поиска, в которых устанавливается либо один из конкретных ресурсов веб-страниц, либо нативное приложение (или и то, и другое), которые обеспечивают выполнение тех же функций, что обеспечиваются благодаря использованию ресурсов веб-страниц, или представляют одинаковую или очень похожую информацию в виде ресурса веб-страницы.
Сущность изобретения
Настоящее изобретение относится к созданию глубинных ссылок нативных приложений и, в частности, к системам и способам для автоматического генерирования глубинных ссылок нативных приложений.
В целом, один аспект изобретения, излагаемого в данном описании, может быть осуществлен в способах, которые включают в себя действия приема данных привязки к издателям для нативных приложений, которые задают, для каждого нативного приложения, связанного издателя для нативного приложения; для каждого нативного приложения из набора нативных приложений - определения на основе данных привязки к издателям того, связано ли оно с издателем, который предоставляет контент, адресуемый с помощью URI, определяемых для нативного приложения; только для нативных приложений, которые определены как связанные с издателем, который предоставляет контент, адресуемый с помощью URI, определяемых для нативного приложения: выбора URI на основе шаблона URI для нативного приложения, индексирования контента, доступного с помощью URI для нативного приложения в индексе, который допускает возможность поиска поисковой системой. Другие варианты осуществления данного аспекта включают в себя соответствующие системы, устройство и компьютерные программы, выполненные с возможностью осуществления действий способов, кодированных на запоминающих устройствах компьютера.
Еще один аспект изобретения, излагаемого в данном описании, может быть осуществлен в способах, которые включают в себя действия определения шаблона унифицированного идентификатора ресурса (URI) для нативного приложения; инстанцирования нативного приложения и выбора первого URI на основе шаблона URI для генерирования страницы приложения в среде отображения нативного приложения; индексирования данных страницы приложения на странице приложения в индексе, который допускает возможность поиска поисковой системой; итеративной обработки связанных ссылками страниц приложения для нативного приложения вплоть до наступления события остановки, причем итеративная обработка включает в себя для каждой итерации, определение по странице приложения исходящих URI, в том числе, на первой странице приложения; выбор одного или более из исходящих URI для генерирования одной или более следующих страниц приложения в среде отображения нативного приложения; индексирование данных страницы приложения для каждой из этих одной или более следующих страниц приложения в индексе. Другие варианты осуществления данного аспекта включают в себя соответствующие системы, устройство и компьютерные программы, выполненные с возможностью осуществления действий способов, кодированных на запоминающих устройствах компьютера.
Конкретные варианты осуществления изобретения, излагаемого в данном описании, могут быть осуществлены таким образом, чтобы реализовать одно или более из следующих преимуществ. Генерирование глубинных ссылок облегчает разработчикам приложений возможность участия в индексировании нативных приложений, что, в свою очередь, помогает управлять использованием и повторным задействованием их приложений. Система также снижает барьер для участия.
Детали одного или более вариантов осуществления изобретения, излагаемого в данном описании, объясняются в прилагаемых чертежах и приведенном ниже описании. Другие признаки, аспекты и преимущества изобретения станут понятными из описания, чертежей и формулы изобретения.
Краткое описание чертежей
Фиг. 1 представляет блок-схему примера среды, в которой генерируются глубинные ссылки для нативных приложений.
Фиг. 2 представляет блок-схему системы обхода и индексирования.
Фиг. 3 представляет функциональную схему примера процесса для генерирования глубинных ссылок для нативных приложений.
Фиг. 4 представляет функциональную схему еще одного примера процесса для генерирования глубинных ссылок для нативных приложений.
Одинаковые ссылочные позиции и обозначения на различных чертежах означают одинаковые элементы.
Подробное описание
Система предоставляет результаты поиска нативных приложений. В данном контексте нативное приложение действует независимо от программы-браузера пользовательского устройства. Нативное приложение представляет собой приложение, специально предназначенное для выполнения на конкретной операционной системе пользовательского устройства и машинных микропрограммных средствах, а не в браузере. Нативные приложения при этом отличаются от браузеров, браузерных приложений и визуализируемых браузерами ресурсов. Последним требуются все или, по меньшей мере, некоторые элементы или команды, загружаемые с веб-сервера каждый раз, когда они инстанцируются или визуализируются. Кроме того, браузерные приложения и визуализируемые браузерами ресурсы могут обрабатываться всеми поддерживающими сеть мобильными устройствами в браузере и, следовательно, не являются специфическими для операционной системы, поскольку являются нативными приложениями. Кроме того, в данном контексте результат поиска нативного приложения представляет собой результат поиска, который соответствует конкретному нативному приложению и который при выборе вызывает конкретное нативное приложение.
Примеры нативного приложения включают в себя приложения для создания текстовых документов, редактирования фотографий, проигрывания музыки, взаимодействия с системой дистанционного банковского обслуживания и так далее. Мобильные нативные приложения предназначены для работы на мобильных устройствах, таких как смартфоны, планшеты и так далее. Нативные веб-приложения предназначены для исполнения в рамках (и визуально, и функционально) программных средств веб-браузера. На очень высоком уровне нативные приложения, или попросту «приложения», предоставляют пользователю доступ к контенту и/или функциональным возможностям.
Поисковые системы Интернета предоставляют возможность поиска индексированной подборки веб-страниц, которые существуют в Интернете. Типичная поисковая система предоставляет в ответ на запрос список результатов, соответствующих запросу, часто с гиперссылками, позволяющими пользователю быстро перемещаться к интересующему результату. Пользователь может получать указываемый ссылкой результат, благодаря чему ему предоставляется веб-страница (страницы), содержащая контент о знаменитости, продукте, бизнесе и т.д. Ссылки могут быть на «домашнюю страницу» сайта (например, на стартовую страницу с поиском для сайта, собирающего информацию о приготовлении пищи, такую как рецепты) или на «страницу с контентом», доступ к которой пользователь может осуществлять при перемещении с домашней страницы сайта (например, конкретный рецепт на сайте с информацией о приготовлении пищи). Ссылки на страницы с контентом, в отличие от домашних страниц, называются «глубинными ссылками» (а процесс обхода, индексирования и обслуживания указанных страниц с контентом аналогичным образом называется «созданием глубинных ссылок»).
Возможность перемещения посредством навигации на страницу, а также доступность контента и функциональные возможности, которые предоставляет страница, обусловлены отчасти характером публикуемой страницы. Например, некоторые страницы могут содержать динамический контент (например, асинхронный JavaScript и XML (AJAX), Adobe Flash и т.д.), который сложно или невозможно обходить и получать. Следовательно, эти страницы могут оказаться недоступными в ответ на поиск, пользователь может не суметь сохранить страницу в виде закладки или подобном виде, а перемещение по странице с помощью элементов управления браузера (например, вперед или назад по истории) может не действовать в соответствии с назначением.
Некоторые нативные приложения не имеют некоторых из основных свойств веб-сайтов касательно создания ссылок. Во-первых, когда поисковая система обходит нативное приложение, она не может просто проверить существующую ссылку на страницу в исходящих ссылках страницы, как она может путем просмотра HTML веб-страницы. Во-вторых, многие нативные приложения не ссылаются друг на друга так, как веб-сайты делают по своей природе, поэтому поисковые системы не могут опираться на обход сети для обнаружения глубинных ссылок приложения, как они могут для обнаружения веб-ссылок. Это представляет сложность для поисковых систем нативных приложений в том отношении, что намного труднее обнаруживать ссылки, которые поддерживают нативные приложения. Если поисковая система нативного приложения не может обнаруживать ссылки, то она не может индексировать их, получать их и предоставлять их пользователям.
Кроме того, некоторые нативные приложения имеют соответствующие веб-страницы для URI, доступ к которым осуществляют нативные приложения, а другие не имеют. Из тех, которые не имеют соответствующих веб-приложений, некоторые нативные приложения сохраняют дубликат или соответствующий контент и функциональные возможности между нативным приложением и веб-платформами, а другие нативные приложения имеют небольшую или большую степень различий между мобильными платформами и веб-платформами.
Некоторые системы для индексирования нативных приложений опираются на то, что разработчики публикуют свои глубинные ссылки нативных приложений либо в виде разметки HTML на своих веб-страницах, либо на своих существующих картах веб-сайта. То есть, поставщик нативного приложения должен иметь и веб-платформу, и, по меньшей мере, карту для страниц нативного приложения на веб-сайте. Некоторые службы, обеспечивающие создание глубинных ссылок нативных приложений, также опираются на разработчиков, публикующих свои глубинные ссылки нативных приложений на своих веб-страницах.
В соответствии с настоящим изобретением, глубинные ссылки нативных приложений могут автоматически генерироваться в целях индексирования. Имеется множество способов для генерирования глубинных ссылок нативных приложений в зависимости от характера глубинных ссылок нативных приложений. Например, некоторые нативные приложения поддерживают глубинные ссылки, имеющие URI, которые соответствуют основанным на веб-технологии унифицированным указателям ресурса (URL), таким как http://www.example.com и т.д. Другие нативные приложения используют специальный URI, который не обязательно соответствует конкретному протоколу НТТР.
Для нативных приложений, которые поддерживают создание глубинных ссылок на основе основанных на веб-технологии URL, процесс генерирования глубинных ссылок нативных приложений включает в себя следующее:
1) Разработчики нативных приложений проверяют свой официальный веб-сайт с централизованной службой индексирования. Затем данная служба индексирует нативное приложение на основе ранее индексированных сетевых URL, обнаруживаемых посредством обхода сети.
2) Система обхода и индексирования данных нативных приложений проверяет информацию о регистрации, такую как файл манифеста, нативного приложения, чтобы определить, поддерживает ли оно соответствующую URL-структуру веб-сайта.
3) Если наивное приложение все-таки поддерживает соответствующую URL-структуру, система обхода и индексирования данных нативных приложений может определять и приоритизировать ссылки на основе таких критериев, как популярность. Система обхода и индексирования данных нативных приложений будет также учитывать любой неиндексированный тег в информации о регистрации, который задает, какой путь URL не должен индексироваться.
В соответствии со вторым аспектом настоящего изобретения, для нативных приложений, которые поддерживают специальное создание глубинных ссылок, система реализует способ, включающий в себя следующие этапы:
1) Разработчики нативных приложений реализуют прикладной программный интерфейс (API) индексирования нативных приложений, который позволяет задавать адрес URI конкретного документа нативного приложения, его соответствующий URL веб-узла (при его наличии) и все исходящие глубинные ссылки приложений и их соответствующие URL веб-узла (при их наличии), которые находятся в документе.
2) Как только нативное приложение обновлено в цифровом источнике распространения, система обхода и индексирования данных нативных приложений проверяет нативное приложение, чтобы определить, использует ли оно API индексирования нативных приложений. Если да, то система обхода и индексирования данных нативных приложений запускает нативное приложение и ищет ссылку на «домашнюю страницу» нативных приложений. Система обхода и индексирования данных нативных приложений также ищет любые исходящие URI-ссылки на странице приложения. Если имеются исходящие URI, то система обхода и индексирования данных нативных приложений будет индексировать каждую из этих ссылок (или только связанных ссылок) и будет также, в свою очередь, обрабатывать следующие страницы нативных приложений для исходящих URI. Таким образом, система обхода и индексирования данных нативных приложений способна автоматически обнаруживать ссылки. При этом на каждом этапе система обхода и индексирования данных нативных приложений может проверять текущую ссылку страницы приложения на соответствие ссылке на источник в качестве способа проверки подлинности.
3) Система обхода и индексирования данных нативных приложений может использоваться для сохранения списка тех ссылок, которые в действительности просматриваются пользователем в нативном приложении, и предоставлять этот список в систему обхода и индексирования данных нативных приложений. Система обхода и индексирования данных нативных приложений использует этот список в качестве дополнительного источника ссылок помимо автоматического обнаружения, описанного на предыдущем этапе. Кроме того, списки ссылок, которые в действительности просматриваются, могут использоваться для определения популярности ссылки, а затем система обхода и индексирования данных нативных приложений может приоритизировать обход на основе популярности ссылок.
В связи с этим, системы и способы, излагаемые в настоящем документе, могут обеспечивать автоматическое индексирование глубинных ссылок нативных приложений. Данные системы и способы могут дополнительно определять и использовать приоритизацию ссылок по фактической активности пользователя. Приоритизация позволяет, помимо прочего, оптимизировать использование ресурсов поиска. Наконец, излагаются системы и способы, которые могут согласовывать приложения с соответствующими веб-сайтами и без них, снимая ограничения существующих методов, которые требуют от приложений публиковать ссылки посредством соответствующих веб-страниц.
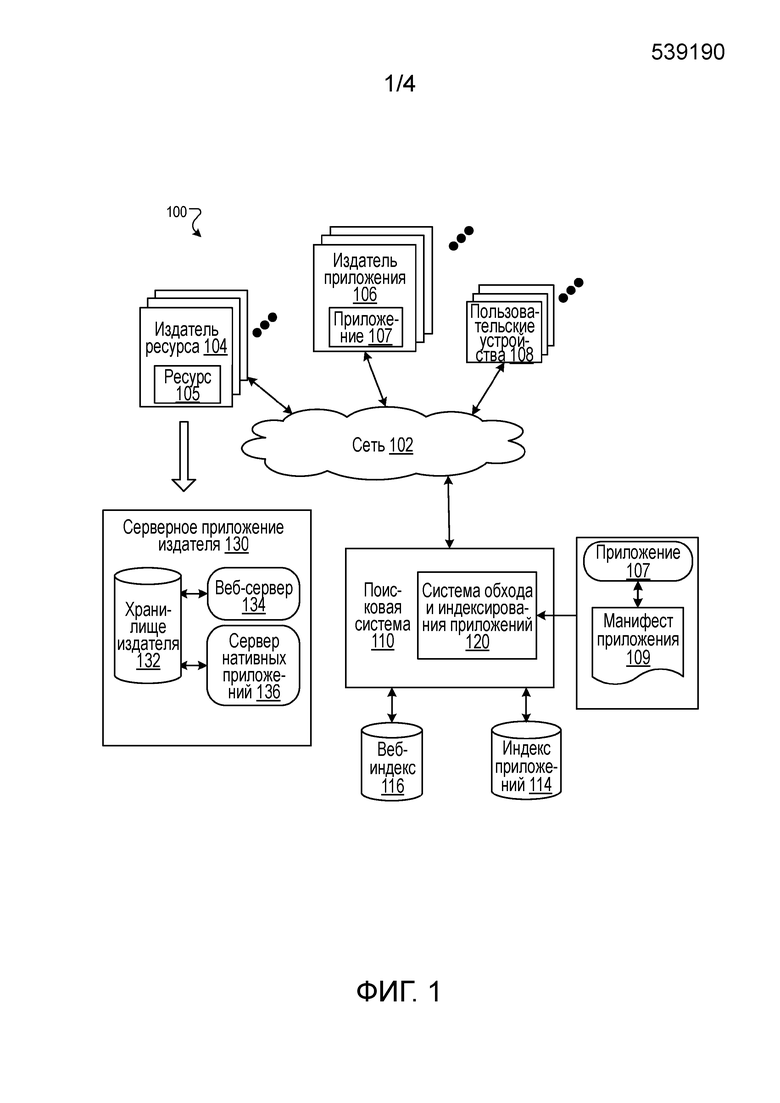
Фиг. 1 представляет собой блок-схему примера среды 100, в которой генерируются глубинные ссылки для нативных приложений. Вычислительная сеть 102, такая как Интернет, соединяет веб-сайты 104 издателя ресурса, издателей 106 приложений, пользовательские устройства 108 и поисковую систему 120.
Веб-сайт 104 издателя ресурса содержит один или более веб-ресурсов 105, связанных с доменом и размещаемых одним или более серверами в одном или более местоположений. Как правило, веб-сайт издателя ресурса представляет собой набор веб-страниц, форматированных на языке разметки гипертекста (HTML), которые могут содержать текст, изображения, мультимедийный контент и элементы программирования. Каждый веб-сайт 104 поддерживается издателем контента, являющимся сущностью, которая управляет, администрирует и/или владеет веб-сайтом 104.
Ресурс веб-страницы представляет собой любые данные, которые могут предоставляться веб-сайтом 104 издателя по сети 102 и которые имеют адрес ресурса, например, унифицированный указатель ресурса (URL). Веб-ресурсы могут представлять собой, например, HTML-страницы, файлы изображений, видеофайлы, аудиофайлы и источники новостных каналов. Ресурсы могут включать в себя внедренную информацию, например, метаинформацию и гиперссылки, и/или внедренные команды, например, клиентские сценарии.
Веб-сайт 106 издателя приложения может также содержать один или более веб-ресурсов 105 и также предоставляет нативные приложения 107. Нативное приложение 107 представляет собой приложение, специально предназначенное для выполнения на конкретной операционной системе пользовательского устройства и машинных микропрограммных средствах. Нативные приложения 107 могут включать в себя множество версий, предназначенных для исполнения на различных платформах. Например, нативные приложения, соответствующие веб-сайту базы данных кинофильмов, могут содержать первое нативное приложение, которое исполняется на первом типе смартфона, второе нативное приложение, которое исполняется на втором типе смартфона, и третье нативное приложение, которое исполняется на первом типе планшета, и т.д.
Страница приложения представляет собой конкретную среду отображения в нативном приложении, в которой отображается контент, такой как текст, изображения и т.п. Страница приложения является зависящей от конкретного нативного приложения, а нативное приложение является специализированным для конкретной операционной системы пользовательского устройства 108. Страница приложения отличается от визуализируемого веб-ресурса тем, что страница приложения генерируется в нативном приложении и является специализированной для него, в то время как веб-ресурс может визуализироваться в любом браузере, для которого ресурс веб-страницы является совместимым, и является независимым от операционной системы пользовательского устройства.
Некоторые издатели 104 и 106 могут быть одинаковыми и предоставлять одинаковый контент и в веб-ресурсах, и в нативных приложениях. Администрирование передачи такого контента регулируется серверным приложением 130 издателя. Серверное приложение 130 издателя содержит хранилище 132 издателя, которое хранит контент, предоставляемый издателем, веб-сервер 134, который предоставляет контент из хранилища издателя в виде веб-ресурсов (например, веб-страниц), и сервер 136 нативных приложений, который регулирует запросы от нативного приложения. Веб-страницы соответствуют страницам нативных приложений, и, следовательно, для многих URI нативных приложений имеются соответствующие URI веб-страниц. Некоторые нативные приложения могут также попросту использовать те же URL, что и веб-страницы, которым они соответствуют. Контент хранилища 132 издателя доступно для хранения и на веб-ресурсах, и на соответствующих страницах веб-приложений. В связи с этим, такой контент называется «синхронизированным» контентом.
Примерами таких издателей являются издатели новостей, которые могут иметь «мобильное новостное приложение» для чтения новостного контента на мобильном устройстве. Новостной контент (например, текст новостного материала), предоставляемый в веб-ресурсах 105, является таким же контентом, как и предоставляемый соответствующими страницами приложения нативного приложения 107.
Пользовательское устройство 108 представляет собой электронное устройство, которое способно запрашивать и принимать ресурсы 105 веб-страниц и нативные приложения 107 по сети 102. Примеры пользовательских устройств 108 включают в себя персональные компьютеры, устройства мобильной связи и планшетные компьютеры.
Веб-индекс 116 представляет собой индекс контента издателя, который, например, создан по результатам обхода веб-сайтов 104 издателя, путем приема новостных каналов данных с веб-сайтов 104 издателя или иными подходящими способами сбора и индексирования данных.
Индекс 114 наивных приложений хранит данные, относящиеся к нативным приложениям 107. Индекс 114 приложений хранит, например, список нативных приложений, предоставляемых издателями 104, и идентификаторов, которые идентифицируют нативные приложения. Кроме того, в некоторых реализациях издатели 104 могут задавать, что некоторые нативные приложения 107 используются для доступа к синхронизированным данным и их отображения, и данная информация может храниться в индексе приложения. Например, издатель новостей может задавать, что приложение для чтения новостей, которое он предоставляет, отображает синхронизированный контент, который отображается на веб-сайте издателя новостей.
Пользовательские устройства 108 подают поисковые запросы в поисковую систему 110. В ответ на каждый запрос поисковая система 110 осуществляет доступ к веб-индексу 116 и индексу 114 приложений для идентификации контента, который относится к запросу. Поисковая система 110 может, например, идентифицировать ресурсы и приложения в форме результатов поиска веб-ресурсов и результатов поиска нативных приложений, соответственно, с помощью генератора 116 результатов поиска. После генерирования результаты поиска предоставляются в пользовательское устройство 108, от которого был принят запрос.
Результат поиска веб-ресурсов представляет собой данные, генерируемые поисковой системой 110, которая идентифицирует веб-ресурс на основе контента ресурса, который удовлетворяет конкретному поисковому запросу. Результат поиска веб-ресурсов для ресурса может содержать заголовок веб-страницы, фрагмент текста, извлеченного из ресурса, и унифицированный идентификатор ресурса (URI) для данного ресурса, например, унифицированный указатель ресурса (URL) веб-страницы. При выборе в пользовательском устройстве результат поиска веб-ресурсов инициирует генерирование пользовательским устройством запроса для ресурса, расположенного в URL. Веб-ресурс, который принимается, отображается после этого в приложении-браузере.
Результат поиска нативных приложений задает нативное приложение и генерируется в ответ на поиск по индексу 114 приложений и веб-индексу 116, как подробнее описывается ниже. При выборе в пользовательском устройстве результат поиска нативных приложений инициирует запрос нативным приложением, установленным на пользовательском устройстве, синхронизированного контента. Как только нативное приложение принимает запрошенный контент, нативное приложение отображает контент в пользовательском интерфейсе нативного приложения.
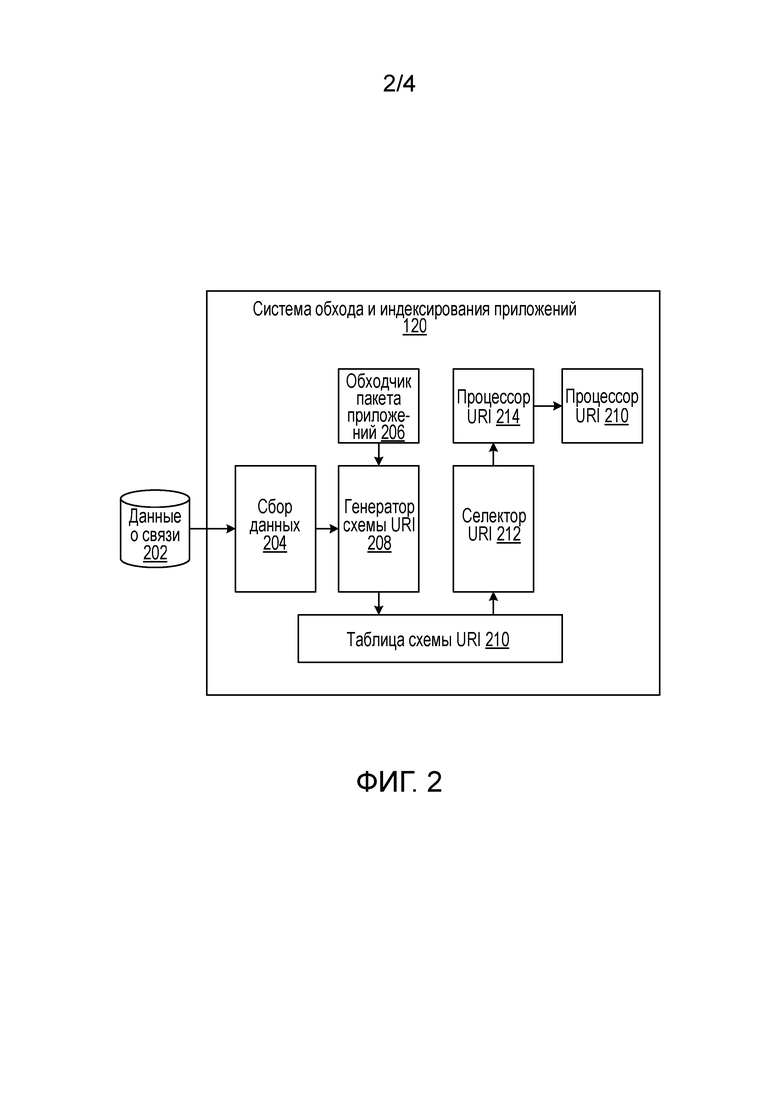
Для генерирования индекса 114 приложений поисковая система использует систему 120 обхода и индексирования приложений. Фиг. 2 представляет собой блок-схему системы 120 обхода и индексирования приложений. Действие системы 120 применительно к нативным приложениям, которые используют URL, описывается со ссылкой на фиг. 3. Изменение действия нативных приложений, которые используют URL, описывается со ссылкой на фиг. 4.
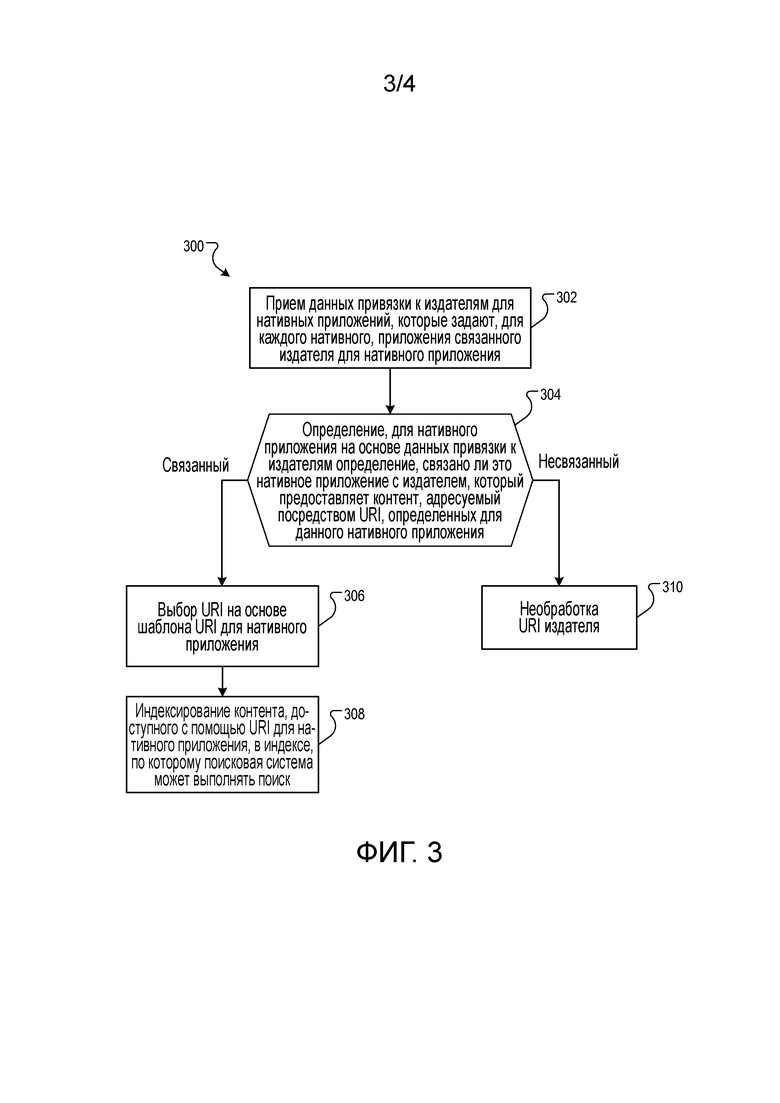
Фиг. 3 представляет собой функциональную схему примера процесса 300 для генерирования глубинных ссылок для нативных приложений. Процесс 300 реализуется в устройстве обработки данных одного или более компьютеров.
Процесс 300 принимает в устройстве 204 сбора данных данные 202 привязки к издателям для нативных приложений, которые задают, для каждого нативного приложения, связанного издателя для нативного приложения (302). Например, издатели предоставляют данные о том, что конкретное нативное приложение связано с издателем, такие как связь идентификатора нативного приложения с идентификатором сайта издателя. Одним из примеров идентификатора сайта является доменное имя, но могут использоваться и другие типы данных для задания связи между издателем и нативным приложением.
Процесс 300 для нативного приложения на основе данных привязки к издателям определяет, связано ли нативное приложение с издателем, который предоставляет контент, адресуемый посредством URI, определенных для нативного приложения (304). Например, обходчик 206 пакета приложений извлекает из файла 109 манифеста приложения (или иных данных, задающих подобные спецификации приложения) схему, хост и путь формата URI для нативного приложения. Например, в случае манифеста для Android из секции интент-фильтра извлекается следующее:
<data android:scheme="http"
android:host="example.com"
android:pathPrefix="/gizmos" />
Здесь схема - "http", хост - "example.com", а путь - "/gizmos". Данный процесс определяет шаблон URI для нативного приложения и то, определяет ли шаблон URI связанного издателя для нативного приложения, который совпадает со связанным издателем для нативного приложения, заданным данными 202 привязки к издателям. Чтобы проиллюстрировать, для приведенного выше примера данных, если данные 202 о связи задают схему "http" для нативного приложения и хост "example.com", а манифест 109 нативного приложения 107 задает ту же схему и хост, то нативное приложение связано с хостом.
Если результат определения является положительным, генератор 208 схемы URI сохраняет данные для нативного приложения в таблице 210 схемы URI, а затем процесс 300 выбирает URI-идентификаторы на основе шаблона URI для нативного приложения (306). Например, в некоторых реализациях селектор 212 URI получает шаблон URI из таблицы 210 схемы URI. Селектор 212 после этого отыскивает в веб-индексе 116 URL, которые содержат шаблон URI. В приведенном выше примере подходящие URL, которые содержат http://example.com/gizmos/, будут обрабатываться селектором 212. Селектор 212 может отбрасывать URL, которые могут содержать указание на то, что они не должны анализироваться при обходе; которые недавно отыскивались и индексировались для нативного приложения, которые указаны как удаленные или неактивные; или URL, которые соответствуют каким-либо иным критериям исключения.
Остальные выбираемые URL предоставляются процессору 214 URI, который собирает данные из контента, доступного с помощью URL. Процесс 300 после этого индексирует контент, доступный с помощью URL, для нативного приложения в индексе, который допускает возможность поиска поисковой системой (308). Сбор и индексирование данных может осуществляться любым подходящим процессом. В одном из примеров реализации система 120 создает экземпляр (инстанцирует) виртуальной машины, эмулирующей операционную систему для пользовательского устройства. Виртуальная машина может в некоторых реализациях являться модифицированной версией операционной системы и содержит средства извлечения (экстракторы), которые извлекают данные из страниц приложений, как подробнее описывается ниже.
Система 120 также инстанцирует в виртуальной машине нативное приложение 107, которое генерирует страницы приложений для отображения на пользовательском устройстве в нативном приложении 107, а затем осуществляет доступ в виртуальной машине к страницам приложения нативного приложения, генерируемым в ответ на обработку выбранных URL. Для каждой страницы приложения система 110 генерирует данные о странице приложения, описывающие контент страницы приложения. Контент страницы может содержать, например, текст, отображаемый на странице приложения; изображения, отображаемые на странице приложения; ссылки на странице приложения на другие страницы приложения или другие веб-ресурсы; и прочий контент, который подходит для индексирования.
В некоторых реализация виртуальная машина содержит экстракторы, которые извлекают данные контента для индексирования. Извлеченные данные контента представляют собой, например, данные, которые предоставляются в процесс визуализации нативного приложения. Процесс визуализации визуализирует контент на основе данных для отображения на пользовательском устройстве. Использование экстракторов предусматривает более точную идентификацию различного контента страницы приложения. Например, текстовый экстрактор извлекает текстовые данные, предоставляемые в процесс визуализации нативного приложения. Текстовые данные задают текст, который должен визуализироваться в странице приложения. Таким образом, вместо того, чтобы обрабатывать изображение страницы приложения или обрабатывать двоичные данные отображения, виртуальная машина принимает фактический текст, который должен визуализироваться в среде нативного приложения 107.
Аналогичным образом могут использоваться другие экстракторы, такие как экстрактор изображений и экстрактор списков. Экстрактор изображений предоставляет данные об изображении, которое должно визуализироваться в среде нативного приложения 107, а экстрактор списков предоставляет данные о списке прокручиваемых элементов, который визуализируется в среде нативного приложения 107. Могут также извлекаться другие данные, такие как данные о ссылках страницы приложения, описывающие ссылки на странице приложения, которые ссылаются на другую страницу приложения; данные о ссылках веб-страницы, описывающие ссылки на странице приложения, которые ссылаются на веб-ресурс, упоминаемый унифицированным указателем ресурса, и которые при выборе инстанцируют приложение-браузер, который визуализирует ресурс в среде браузера отдельно от нативного приложения; и т.д.
Описанные выше экстракторы и другие подходящие экстракторы данных могут быть реализованы с помощью подходящих обработчиков данных для конкретной операционной системы. Например, для операционной системы AndroidTM экстракторы могут быть реализованы с помощью объектов TextView, объектов ImageView и объектов ListView, соответственно. Виртуальная машина обрабатывает объекты для извлечения соответствующих данных, например, путем введения команд, которые инициируют сохранение виртуальной машиной для индексирования соответствующих данных, которые предоставляются для визуализации.
Возвращаясь к 304, если результат определения является отрицательным, то процесс 300 не обрабатывает URI-идентификаторы издателя (310). Это упрощает индексирование контента издателя только для нативных приложений, которые связаны с издателем (например, публикуются издателем или утверждаются издателем для отображения контента издателя).
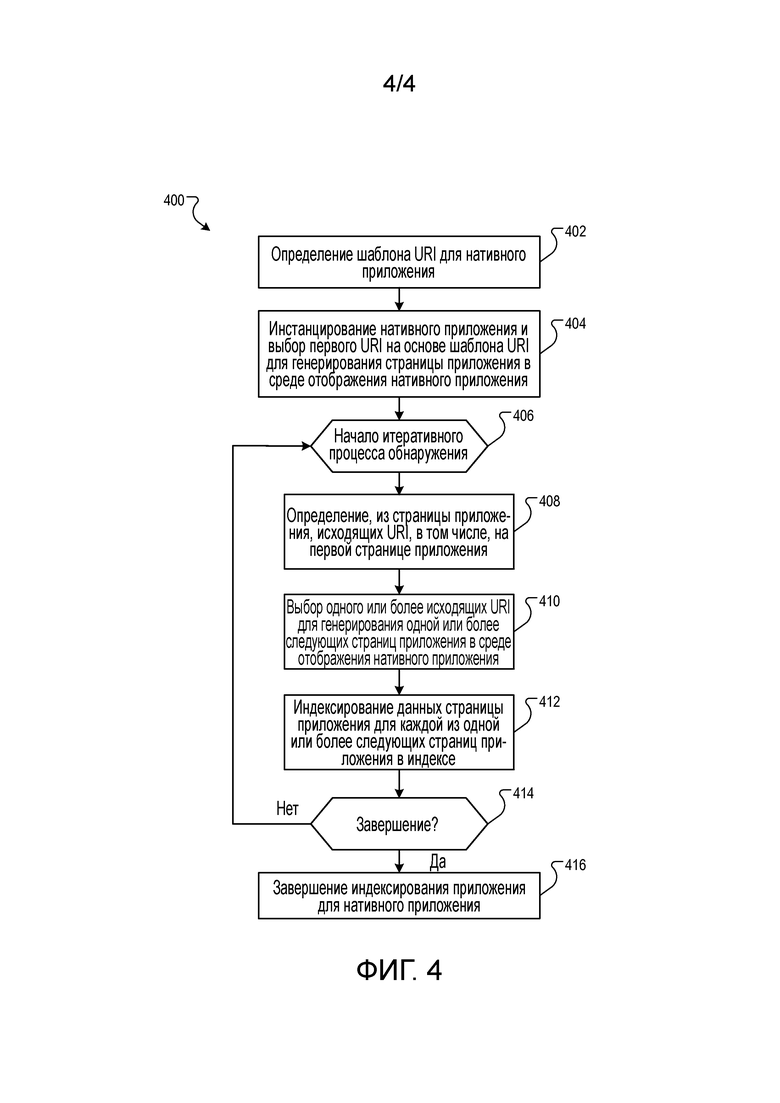
Для нативных приложений, поддерживающих конфигурируемое создание глубинных ссылок, которое не обязательно соответствует веб-сайту, для генерирования глубинных ссылок используется другой процесс. Фиг. 4 представляет функциональную схему еще одного примера процесса для генерирования глубинных ссылок для нативных приложений. Процесс 400 реализуется в устройстве обработке данных одного или более компьютеров.
Процесс 400 определяет шаблон URI для нативного приложения (402). Например, может осуществляться доступ к манифесту 109 приложения для определения схемы URI. Схема URI может использоваться для задания URI-ресурса нативного приложения «верхнего уровня», либо может использоваться для выбора URI, которые уже индексированы для нативного приложения.
Процесс 400 инстанцирует нативное приложение и выбирает первый URI на основе шаблона URI для генерирования страницы приложения в среде отображения нативного приложения (404). Например, инстанцируется виртуальная машина, и на виртуальной машине инстанцируется также нативное приложение. URI предоставляется в нативное приложение, и визуализируется страница приложения.
Процесс 400 начинает итеративный процесс обнаружения (406). Данный процесс будет продолжаться до тех пор, пока не будет обработан полный набор URI.
Процесс 400 определяет по странице приложения исходящие URI, в том числе, на первой странице приложения (408). Например, API нативного приложения определяет по данным страницы приложения URI, которые ссылаются на другие URI нативного приложения. Такое определение может выполняться, например, путем обработки текста, извлеченного из страницы приложения, для согласований с шаблоном URI, генерируемой по манифесту 109; либо на основе API, выбирающего текст разметки, который задает исходящие URI.
Процесс 400 выбирает один или более исходящих URI для генерирования одной или более следующих страниц приложения в среде отображения нативного приложения (410). В некоторых реализациях выбираются все исходящие URI. В некоторых реализациях выбираются только исходящие URI, согласующиеся с шаблоном URI нативного приложения.
Процесс 400 индексирует данные страницы приложения для каждой из указанных одной или более следующих страниц приложения в индексе (412). Как описано выше, система 110 может использовать виртуальную машину или какую-либо иную конструкцию для извлечения данных страницы приложения для индексирования.
Процесс 400 определяет, завершился ли итеративный процесс обнаружения (414). Если итеративный процесс обнаружения завершился, то процесс 400 завершает индексирование приложения для нативного приложения (416). В противном случае, процесс 400 возвращается к этапу 406 и начинает еще одну итерацию.
В некоторых реализациях, когда реальные пользователи просматривают контент в нативных приложениях, API нативного приложения может использоваться для извещения системы 120 обхода и индексирования приложений о ссылках, которые в действительности просматриваются пользователями. Система 120 обхода и индексирования приложений может использовать эту информацию в качестве дополнительного источника ссылок помимо естественного обнаружения, описанного выше. Кроме того, система 120 обхода и индексирования приложений может также приоритизировать обход на основе популярности ссылок.
Варианты осуществления изобретения и операций, излагаемых в данном описании, могут быть реализованы в цифровых электронных схемах, либо в компьютерных программных средствах, микропрограммных средствах или аппаратных средствах, включая структуры, излагаемые в данном описании, и их структурные эквиваленты, либо в комбинациях одного или более из них. Варианты осуществления изобретения, излагаемого в данном описании, могут быть реализованы в виде одной или более компьютерных программ, т.е. одного или более модулей компьютерных программных команд, кодированных в запоминающем носителе компьютера для исполнения устройством обработки данных или для управления его работой. В качестве альтернативы или в дополнение, программные команды могут кодироваться в искусственно генерируемом распространяющемся сигнале, например, генерируемом машиной электрическом, оптическом или электромагнитном сигнале, который генерируется для кодирования информации для передачи в подходящее принимающее устройство для исполнения устройством обработки данных. Запоминающий носитель компьютера может представлять собой - либо быть включенным в - машиночитаемое запоминающее устройство, машиночитаемую запоминающую подложку, массив или устройство памяти с произвольной или последовательной выборкой, либо комбинацию одного или более из них. Кроме того, несмотря на то, что запоминающий носитель компьютера не является распространяющимся сигналом, запоминающий носитель компьютера может являться источником или адресатом компьютерных программных команд, кодированных в искусственно генерируемом распространяющемся сигнале. Запоминающий носитель компьютера может также представлять собой - либо быть включенным в - один или более отдельных физических компонентов или сред (например, множество CD, дисков или иные запоминающие устройства).
Операции, излагаемые в данном описании, могут быть реализованы в виде операций, выполняемых устройством обработки данных с данными, хранящимися в одном или более машиночитаемых запоминающих устройств или принимаемыми из других источников.
Термин «устройство обработки данных» охватывает все виды устройств, приспособлений и машин для обработки данных, включая в качестве примера программируемый процессор, компьютер, систему на кристалле или множество систем на кристалле, либо комбинации вышеуказанного. Данное устройство может содержать, помимо аппаратных средств, код, который создает среду выполнения для рассматриваемой компьютерной программы, например, код, который составляет микропрограммные средства процессора, пакет протоколов, систему управления базами данных, операционную систему, межплатформенную среду исполнения, виртуальную машину или комбинацию одного или более из них. Устройство и среда выполнения могут реализовывать различные отличающиеся друг от друга инфраструктуры модели вычислений, такие как веб-службы, распределенные вычисления и инфраструктуры сетевых коллективных вычислений.
Компьютерная программа (иначе называемая программой, программным средством, программным приложением, сценарием или кодом) может быть записана в любой форме языка программирования, включая компилируемые или интерпретируемые языки, декларативные или процедурные языки, и может быть развернута в любой форме, в том числе, в виде автономной программы или в виде модуля, компонента, подпрограммы, объекта или иного блока, подходящего для использования в вычислительной среде. Компьютерная программа может, но не обязательно должна соответствовать файлу в файловой системе. Программа может храниться в части файла, которая содержит другие программы или данные (например, один или более сценариев, хранящихся в документе на языке разметки), в одном файле, предназначенном для рассматриваемой программы, или во множестве согласованных файлов (например, файлов, которые хранят один или более модулей, подпрограмм или частей кода). Компьютерная программа может быть развернута для выполнения на одном компьютере или на множестве компьютеров, которые расположены в одном месте или распределены по множеству мест и взаимодействуют с помощью сети передачи данных.
Потоки процессов и логические потоки, описанные в данном описании, могут осуществляться одним или более программируемыми процессорами, выполняющими одну или более компьютерных программ для осуществления действий путем выполнения операций над входными данными и генерирования выходных результатов. Процессоры, подходящие для выполнения компьютерной программы, включают в себя в качестве примера и универсальные, и специализированные микропроцессоры, а также любой один или более процессоров любого вида цифрового компьютера. Как правило, процессор принимает команды и данные из постоянного запоминающего устройства или оперативного запоминающего устройства, либо из обоих. Важнейшими элементами компьютера являются процессор для выполнения действий в соответствии с командами и одно или более запоминающих устройств для хранения команд и данных. Как правило, компьютер также содержит одно или более массовых запоминающих устройств для хранения данных, например, магнитные, магнитооптические диски или оптические диски, либо функционально связан с ними для приема от них данных или передачи на них данных или и того, и другого. Однако компьютер не обязательно должен содержать такие устройства. Кроме того, компьютер может быть встроен в другое устройство, например, мобильный телефон, персональный цифровой помощник (PDA), мобильный аудиоплеер или видеоплеер, игровую приставку, приемник Глобальной Системы Позиционирования (GPS) или переносное запоминающее устройство (например, флэш-накопитель с интерфейсом универсальной последовательной шины (USB). Устройства, подходящие для хранения компьютерных программных команд и данных, включают в себя все формы энергонезависимой памяти, мультимедийных и запоминающих устройств, включая в качестве примера полупроводниковые запоминающие устройства, например, стираемое программируемое постоянное запоминающее устройство (EPROM), электрически-стираемое программируемое постоянное запоминающее устройство (EEPROM) и устройства флэш-памяти; магнитные диски, например, внутренние жесткие диски и съемные диски; магнитооптические диски; и диски CD-ROM и DVD-ROM. Процессор и память могут комплектоваться специализированными логическими схемами или входить в их состав.
Для обеспечения взаимодействия с пользователем варианты осуществления изобретения, излагаемого в данном описании, могут быть реализованы на компьютере, имеющем устройство отображения, например, монитор с ЭЛТ (электронно-лучевой трубкой) или ЖКД (жидкокристаллическим дисплеем) для отображения информации пользователю, а также клавиатуру и указательное устройство, например, мышь или трекбол, с помощью которых пользователь может обеспечивать ввод в компьютер. Для обеспечения взаимодействия с пользователем могут также использоваться другие виды устройств; например, обеспечиваемая с пользователем обратная связь может представлять собой любую форму сенсорной обратной связи, например, визуальную обратную связь, акустическую обратную связь или тактильную обратную связь, а ввод от пользователя может приниматься в любой форме, включая акустический, речевой или тактильный ввод. Кроме того, компьютер может взаимодействовать с пользователем путем отправки документов в устройство, которое используется пользователем, и приема от него документов; например, путем отправки веб-страниц в веб-браузер на пользовательском устройстве пользователя в ответ на запросы, принимаемые от веб-браузера.
Варианты осуществления изобретения, излагаемого в данном описании, могут быть реализованы в вычислительной системе, которая содержит внутренний компонент, например, в виде сервера данных, либо которая содержит компонент промежуточного уровня, например, сервер приложений, либо которая содержит внешний компонент, например, компьютер пользователя, имеющий графический пользовательский интерфейс или веб-браузер, с помощью которого пользователь может взаимодействовать с реализацией изобретения, излагаемого в данном описании, либо любую комбинацию одного или более таких компонентов заднего плана, промежуточного уровня или переднего плана. Компоненты системы могут взаимодействовать с помощью любой формы или среды цифровой передачи данных, например, сети передачи данных. Примеры сетей передачи данных включают в себя локальную вычислительную сеть (ʺLANʺ) и глобальную вычислительную сеть (ʺWANʺ), объединенную сеть (например, Интернет) и одноранговые сети (например, специальные одноранговые сети).
Вычислительная сеть может включать в себя пользователей и серверы. Пользователь и сервер, как правило, удалены друг от друга и обычно взаимодействуют по сети передачи данных. Взаимоотношение пользователя и сервера возникает благодаря компьютерным программам, выполняемым на соответствующих компьютерах и имеющих взаимоотношение «пользователь-сервер» друг с другом. В некоторых вариантах осуществления сервер передает данные (например, HTML-страницу) в пользовательское устройство (например, в целях отображения данных пользователю, взаимодействующему с пользовательским устройством, и приема от него вводимых пользователем данных). Данные, генерируемые в пользовательском устройстве (например, результат взаимодействия пользователя), могут приниматься от пользовательского устройства в сервере.
Несмотря на то, что данное описание содержит множество конкретных подробностей реализации, они должны трактоваться не как ограничения на объем любых изобретений или того, что может быть заявлено, а, скорее, как описания признаков, характерных для конкретных вариантов осуществления конкретных изобретений. Некоторые признаки, которые излагаются в данном описании применительно к отдельным вариантам осуществления, могут также быть реализованы вместе в одном варианте осуществления. И наоборот, различные признаки, которые излагаются применительно к одному варианту осуществления, могут также быть реализованы во множестве вариантов осуществления по отдельности или в любой подходящей подкомбинации. Кроме того, несмотря на то, что признаки могли быть изложены выше как действующие в некоторых комбинациях и даже изначально заявляемые в таком качестве, один или более признаков из заявляемой комбинации могут в некоторых случаях быть исключены из комбинации, а заявляемая комбинация может быть направлена на подкомбинацию или вариант подкомбинации.
Аналогичным образом, несмотря на то, что операции отображены на чертежах в конкретном порядке, это не следует понимать как требующее того, чтобы такие операции выполнялись в конкретном изображенном порядке или в последовательном порядке, или чтобы для достижения необходимых результатов выполнялись все иллюстрированные операции. При определенных условиях многозадачность и параллельная обработка могут оказаться предпочтительными. Кроме того, разделение различных компонентов системы в вышеописанных вариантах осуществления не следует понимать как требующее такого разделения во всех вариантах осуществления, при этом следует понимать, что описанные программные компоненты и системы, как правило, могут быть объединены друг с другом в едином программном продукте или упакованы во множество программных продуктов.
Таким образом, описаны конкретные варианты осуществления изобретения. Прочие варианты осуществления находятся в пределах объема. определяемого нижеследующей формулой изобретения. В некоторых случаях действия, перечисленные в формуле изобретения, могут выполняться в другом порядке и, тем не менее, достигать необходимых результатов. Кроме того, процессы, показанные на прилагаемых чертежах, не обязательно требуют конкретного изображенного порядка или последовательного порядка для достижения необходимых результатов. В некоторых реализациях многозадачность и параллельная обработка могут оказаться предпочтительными.
| название | год | авторы | номер документа |
|---|---|---|---|
| ГЛУБИННЫЕ ССЫЛКИ ДЛЯ НАТИВНЫХ ПРИЛОЖЕНИЙ | 2015 |
|
RU2774319C2 |
| ПОИСКОВЫЕ РЕЗУЛЬТАТЫ ДЛЯ НАТИВНЫХ ПРИЛОЖЕНИЙ | 2015 |
|
RU2665888C2 |
| ПОИСКОВЫЕ РЕЗУЛЬТАТЫ ДЛЯ НАТИВНЫХ ПРИЛОЖЕНИЙ | 2015 |
|
RU2710293C2 |
| ВЕРИФИКАЦИЯ КОНТЕНТА СОБСТВЕННОГО ПРИЛОЖЕНИЯ | 2015 |
|
RU2713608C2 |
| ВЕРИФИКАЦИЯ КОНТЕНТА СОБСТВЕННОГО ПРИЛОЖЕНИЯ | 2015 |
|
RU2679959C2 |
| ИНИЦИИРОВАНИЕ И РАНЖИРОВАНИЕ НАТИВНЫХ ПРИЛОЖЕНИЙ | 2015 |
|
RU2660602C1 |
| ИНИЦИИРОВАНИЕ И РАНЖИРОВАНИЕ НАТИВНЫХ ПРИЛОЖЕНИЙ | 2015 |
|
RU2642379C1 |
| ОПТИМИЗИРОВАННАЯ ДЛЯ ПАКЕТНОЙ ОБРАБОТКИ АРХИТЕКТУРА ВИЗУАЛИЗАЦИИ И ВЫБОРКИ | 2014 |
|
RU2659481C1 |
| Система и способ управления браузерным приложением, постоянный машиночитаемый носитель и электронное устройство | 2015 |
|
RU2633180C2 |
| ОПТИМИЗИРОВАННЫЙ ПРОЦЕСС ВИЗУАЛИЗАЦИИ В БРАУЗЕРЕ | 2014 |
|
RU2665920C2 |
Изобретение относится к созданию глубинных ссылок нативных приложений, а именно к автоматическому генерированию глубинных ссылок нативных приложений. Технический результат - обеспечение автоматического индексирования глубинных ссылок нативных приложений. Способ автоматического индексирования глубинных ссылок нативных приложений содержит этапы, на которых принимают данные привязки к издателям для нативных приложений, которые задают, для каждого нативного приложения, связанного издателя для этого нативного приложения, для каждого нативного приложения из набора нативных приложений, определяют на основе данных привязки к издателям, связано ли это нативное приложение с издателем, который предоставляет контент, адресуемый посредством унифицированных идентификаторов ресурса, определенных для данного нативного приложения, только для нативных приложений, которые определены как связанные с издателем, который предоставляет контент, адресуемый посредством унифицированных идентификаторов ресурса, определенных для нативного приложения выбирают унифицированные идентификаторы ресурса на основе шаблона URI для нативного приложения, и индексируют контент, доступный с помощью унифицированного идентификатора ресурса для нативного приложения, в индексе, который приспособлен для поиска по нему поисковой системой. 6 н. и 16 з.п. ф-лы, 4 ил.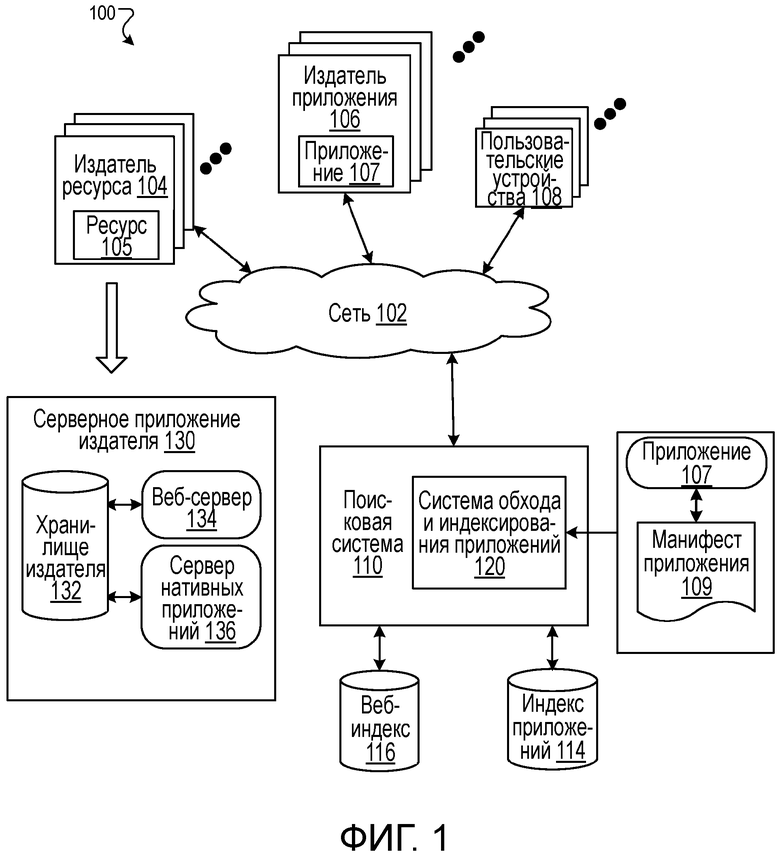
1. Компьютерно-реализуемый способ автоматического индексирования глубинных ссылок нативных приложений, осуществляемый устройством обработки данных, содержащим один или более компьютеров, обменивающихся данными, каковой способ содержит этапы, на которых:
принимают данные привязки к издателям для нативных приложений, которые задают, для каждого нативного приложения, связанного издателя для этого нативного приложения;
для каждого нативного приложения из набора нативных приложений, определяют на основе данных привязки к издателям, связано ли это нативное приложение с издателем, который предоставляет контент, адресуемый посредством унифицированных идентификаторов ресурса (URI), определенных для данного нативного приложения;
только для нативных приложений, которые определены как связанные с издателем, который предоставляет контент, адресуемый посредством унифицированных идентификаторов ресурса, определенных для нативного приложения:
выбирают унифицированные идентификаторы ресурса на основе шаблона URI для нативного приложения; и
индексируют контент, доступный с помощью унифицированного идентификатора ресурса для нативного приложения, в индексе, который приспособлен для поиска по нему поисковой системой.
2. Компьютерно-реализуемый способ по п. 1, в котором упомянутое определение на основе данных привязки к издателям того, связано ли нативное приложение с издателем, который предоставляет контент, адресуемый посредством URI, определенных для нативного приложения, содержит этапы, на которых:
определяют шаблон URI для нативного приложения;
определяют, задает ли шаблон URI связанного издателя для нативного приложения, который совпадает со связанным издателем для нативного приложения, заданным данными привязки к издателям; и
определяют, что нативное приложение связано с издателем, только в тех случаях, когда шаблон URI для нативного приложения задает связанного издателя для нативного приложения, который совпадает со связанным издателем для нативного приложения, заданным данными привязки к издателям.
3. Компьютерно-реализуемый способ по п. 2, в котором упомянутое определение шаблона URI для нативного приложения содержит этап, на котором обрабатывают файл манифеста нативного приложения для данных, описывающих шаблон URI.
4. Компьютерно-реализуемый способ по п. 2, в котором данные привязки к издателям для каждого нативного приложения задают связь между доменом издателя и идентификатором нативного приложения, соответствующим нативному приложению.
5. Компьютерно-реализуемый способ по п. 4, в котором упомянутое определение того, задает ли шаблон URI связанного издателя для нативного приложения, содержит этап, на котором определяют, имеется ли в URI имя хоста, которое соответствует домену издателя, причем соответствие имени хоста URI домену издателя приводит к положительному результату определения, а несоответствие имени хоста URI домену издателя приводит к отрицательному результату определения.
6. Компьютерно-реализуемый способ по п. 2, в котором при упомянутом выборе URI на основе шаблона URI для нативного приложения выбирают из индекса те URI, которые включают в себя шаблон URI.
7. Компьютерно-реализуемый способ по п. 6, в котором URI являются унифицированными указателями ресурса (URL).
8. Компьютерно-реализуемый способ по п. 2, в котором упомянутый выбор URI на основе шаблона URI для нативного приложения содержит этапы, на которых:
инстанцируют нативное приложение и выбирают первый URI на основе шаблона URI для генерирования страницы приложения в среде отображения нативного приложения;
выполняют итеративную обработку связанных ссылками страниц приложения для нативного приложения вплоть до наступления события остановки, причем итеративная обработка включает в себя, для каждой итерации, этапы, на которых:
определяют, из страницы приложения, исходящие URI, в том числе, на первой странице приложения; и
выбирают один или более из исходящих URI для генерирования одной или более следующих страниц приложения в среде отображения нативного приложения.
9. Компьютерно-реализуемый способ автоматического индексирования глубинных ссылок нативных приложений, осуществляемый устройством обработки данных, содержащим один или более компьютеров, обменивающихся данными, каковой способ содержит этапы, на которых:
определяют шаблон унифицированного идентификатора ресурса (URI) для нативного приложения;
инстанцируют нативное приложение и выбирают первый URI на основе шаблона URI для генерирования страницы приложения в среде отображения нативного приложения;
индексируют данные страницы приложения этой страницы приложения в индексе, который приспособлен для поиска по нему поисковой системой;
выполняют итеративную обработку связанных ссылками страниц приложения для нативного приложения вплоть до наступления события остановки, причем итеративная обработка включает в себя, для каждой итерации, этапы, на которых:
определяют, из страницы приложения, исходящие URI, в том числе, на первой странице приложения;
выбирают один или более из исходящих URI для генерирования одной или более следующих страниц приложения в среде отображения нативного приложения;
индексируют данные страницы приложения для каждой из одной или более следующих страниц приложения в индексе.
10. Компьютерно-реализуемый способ по п. 9, в котором упомянутый выбор одного или более из исходящих URI для генерирования одной или более следующих страниц приложения в среде отображения нативного приложения содержит этапы, на которых:
для каждого исходящего URI определяют, согласуется ли этот исходящий URI с шаблоном URI; и
выбирают только те исходящие URI, которые согласуются с шаблоном URI.
11. Компьютерно-реализуемый способ по п. 10, в котором при упомянутом определении того, согласуется ли исходящий URI с шаблоном URI, определяют, содержит ли исходящий URI шаблон URI.
12. Система для автоматического индексирования глубинных ссылок нативных приложений, содержащая:
устройство обработки данных; и
программные средства, хранящиеся в энергонезависимом машиночитаемом носителе, хранящим команды, которые являются исполняемыми устройством обработки данных и которые при таком исполнении предписывают устройству обработки данных выполнять операции, включающие в себя операции, чтобы:
принимать данные привязки к издателям для нативных приложений, которые задают, для каждого нативного приложения, связанного издателя для этого нативного приложения;
для каждого нативного приложения из набора нативных приложений, определять на основе данных привязки к издателям, связано ли это нативное приложение с издателем, который предоставляет контент, адресуемый посредством унифицированных идентификаторов ресурса (URI), определенных для данного нативного приложения;
только для нативных приложений, которые определены как связанные с издателем, который предоставляет контент, адресуемый посредством унифицированных идентификаторов ресурса, определенных для нативного приложения:
выбирать унифицированные идентификаторы ресурса на основе шаблона URI для нативного приложения; и
индексировать контент, доступный с помощью унифицированного идентификатора ресурса для нативного приложения, в индексе, который приспособлен для поиска по нему поисковой системой.
13. Система по п. 12, в которой упомянутое определение на основе данных привязки к издателям того, связано ли нативное приложение с издателем, который предоставляет контент, адресуемый посредством URI, определенных для нативного приложения, содержит:
определение шаблона URI для нативного приложения;
определение того, задает ли шаблон URI связанного издателя для нативного приложения, который совпадает со связанным издателем для нативного приложения, заданным данными привязки к издателям; и
определение того, что нативное приложение связано с издателем, только в тех случаях, когда шаблон URI для нативного приложения задает связанного издателя для нативного приложения, который совпадает со связанным издателем для нативного приложения, заданным данными привязки к издателям.
14. Система по п. 13, в которой упомянутое определение шаблона URI для нативного приложения включает в себя обработку файла манифеста нативного приложения для данных, описывающих шаблон URI.
15. Система по п. 13, в которой данные привязки к издателям для каждого нативного приложения задают связь между доменом издателя и идентификатором нативного приложения, соответствующим нативному приложению.
16. Система по п. 15, в которой упомянутое определение того, задает ли шаблон URI связанного издателя для нативного приложения, содержит определение того, имеется ли в URI имя хоста, которое соответствует домену издателя, причем соответствие имени хоста URI домену издателя приводит к положительному результату определения, а несоответствие имени хоста URI домену издателя приводит к отрицательному результату определения.
17. Система по п. 13, в которой упомянутый выбор URI на основе шаблона URI для нативного приложения содержит выбор из индекса тех URI, которые включают в себя шаблон URI.
18. Система по п. 17, в которой URI являются унифицированными указателями ресурса (URL).
19. Система по п. 18, в которой упомянутый выбор URI на основе шаблона URI для нативного приложения содержит:
инстанцирование нативного приложения и выбор первого URI на основе шаблона URI для генерирования страницы приложения в среде отображения нативного приложения;
итеративную обработку связанных ссылками страниц приложения для нативного приложения вплоть до наступления события остановки, причем итеративная обработка включает в себя для каждой итерации:
определение, из страницы приложения, исходящих URI, в том числе, на первой странице приложения; и
выбор одного или более из исходящих URI для генерирования одной или более следующих страниц приложения в среде отображения нативного приложения.
20. Система для автоматического индексирования глубинных ссылок нативных приложений, содержащая:
устройство обработки данных; и
программные средства, хранящиеся в энергонезависимой машиночитаемом носителе, хранящем команды, которые являются исполняемыми устройством обработки данных и которые при таком исполнении предписывают устройству обработки данных выполнять операции, содержащие:
определение шаблона унифицированного идентификатора ресурса (URI) для нативного приложения;
инстанцирование нативного приложения и выбор первого URI на основе шаблона URI для генерирования страницы приложения в среде отображения нативного приложения;
индексирование данных страницы приложения этой страницы приложения в индексе, который приспособлен для поиска по нему поисковой системой;
итеративную обработку связанных ссылками страниц приложения для нативного приложения вплоть до наступления события остановки, причем итеративная обработка включает в себя для каждой итерации:
определение, из страницы приложения, исходящих URI, в том числе, на первой странице приложения;
выбор одного или более из исходящих URI для генерирования одной или более следующих страниц приложения в среде отображения нативного приложения;
индексирование данных страницы приложения для каждой из одной или более следующих страниц приложения в индексе.
21. Энергонезависимый машиночитаемый носитель, хранящий команды, которые являются исполняемыми устройством обработки данных и которые при таком исполнении предписывают устройству обработки данных выполнять операции, содержащие этапы, на которых:
принимают данные привязки к издателям для нативных приложений, которые задают, для каждого нативного приложения, связанного издателя для этого нативного приложения;
для каждого нативного приложения из набора нативных приложений, определяют на основе данных привязки к издателям, связано ли это нативное приложение с издателем, который предоставляет контент, адресуемый посредством унифицированных идентификаторов ресурса (URI), определенных для данного нативного приложения;
только для нативных приложений, которые определены как связанные с издателем, который предоставляет контент, адресуемый посредством унифицированных идентификаторов ресурса, определенных для нативного приложения:
выбирают унифицированный идентификатор ресурса на основе шаблона URI для нативного приложения;
индексируют контент, доступный с помощью унифицированных идентификаторов ресурса для нативного приложения, в индексе, который приспособлен для поиска по нему поисковой системой.
22. Энергонезависимый машиночитаемый носитель, хранящий команды, которые являются исполняемыми устройством обработки данных и которые при таком исполнении предписывают устройству обработки данных выполнять операции, содержащие этапы, на которых:
определяют шаблон унифицированного идентификатора ресурса (URI) для нативного приложения;
инстанцируют нативное приложение и выбирают первый URI на основе шаблона URI для генерирования страницы приложения в среде отображения нативного приложения;
индексируют данные страницы приложения этой страницы приложения в индексе, который приспособлен для поиска по нему поисковой системой;
выполняют итеративную обработку связанных ссылками страниц приложения для нативного приложения вплоть до наступления события остановки, причем итеративная обработка содержит, для каждой итерации, этапы, на которых:
определяют, из страницы приложения, исходящие URI, в том числе, на первой странице приложения;
выбирают один или более из исходящих URI для генерирования одной или более следующих страниц приложения в среде отображения нативного приложения;
индексируют данные страницы приложения для каждой из одной или более следующих страниц приложения в индексе.
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| US 8219572 B2, 10.07.2012 | |||
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Электромеханический полосовой фильтр | 1957 |
|
SU110847A1 |

