Область техники
Примеры и неограничивающие варианты осуществления настоящего изобретения относятся, в общем, к области аудиокодирования, а именно, к области квантования аудиосигнала.
Предпосылки создания изобретения
Аудиокодеры и аудиодекодеры имеют множество различных применений в системах связи, мультимедийных системах и системах хранения данных. Аудиокодеры используют для кодирования аудиосигналов, например, речевых сигналов, и в частности, для обеспечения эффективной передачи или хранения аудиосигнала, тогда как аудиодекодеры формируют синтезированный сигнал на основе принятого кодированного сигнала. Пару из аудиокодера и аудиодекодера называют аудиокодеком.
При реализации аудиокодека, таким образом, стоит задача экономии пропускной способности передачи и объема хранимых данных с одновременным поддержанием высокого качества синтезированного аудиосигнала. Важна также устойчивость к ошибкам передачи, в особенности в мобильных применениях и применениях IP-телефонии. С другой стороны, сложность аудиокодека ограничена вычислительной мощностью платформы приложений.
Речевой кодек (речевой кодер и речевой декодер) можно рассматривать как аудиокодек, оптимизированный для кодирования и декодирования именно речевых сигналов. В типовом речевом кодере входной речевой сигнал обрабатывают в виде фрагментов, которые называют кадрами. Как правило, длина кадра составляет от 10 до 30 мс, и при этом в кодере, дополнительно, может быть доступен будущий сегмент, содержащий, например, от 5 до 15 мс от непосредственно следующего кадра. Длина кадра может быть фиксированной (например, равной 20 мс) или может быть различной для различных кадров. Каждый кадр может быть дополнительно подразделен на набор подкадров. Для каждого кадра речевой кодер определяет параметрическое представление входного сигнала. Эти параметры квантуют и передают по каналу связи или сохраняют на носителе данных в цифровой форме. На приемном конце, на основе принятых параметров, речевой декодер формирует синтезированный сигнал. Формирование параметров и квантование, как правило, основаны на кодовых книгах, которые содержат кодовые векторы, оптимизированные для соответствующих задач квантования. Во многих случаях для высоких степеней сжатия необходимы в высокой степени оптимизированные кодовые книги. Часто эффективность квантователя может быть повышена, при заданной степени сжатия, за счет применения предсказания на основе одного или более предшествующих кадров и/или на основе одного или более последующих кадров. Такое квантование далее будет называться квантованием с предсказанием, в отличие от квантования без предсказания, не опирающегося ни на какую информацию из предшествующих кадров. Квантование с предсказанием позволяет использовать корреляцию между текущим аудиокадром и по меньшей мере одним из соседних аудиокдаров для получения предсказания текущего кадра, то есть, например, можно кодировать только расхождение относительно предсказания. Для такого кодирования необходимы специальные кодовые книги.
Квантование с предсказанием может приводить к возникновению различных проблем в случае ошибок при передаче или хранении данных. При квантовании с предсказанием новый кадр не может быть корректно декодирован, даже в случае его безошибочного приема, если по меньшей один из предшествующих кадров, на котором основано предсказание, отсутствует или содержит ошибки. Соответственно, иногда может быть практичным применение квантования без предсказания, например, через заранее заданные интервалы времени (или через фиксированное количество кадров), что позволяет исключить длинные серии распространения ошибок. Для подобного типа квантования без предсказания, выполняемого время от времени, которое также называют квантованием «со страховочной сеткой», могут применяться один или более критериев выбора, на основе которых для каждого индивидуального кадра выбирают квантование с предсказанием или квантование без предсказания, с целью ограничения распространения ошибки в случае нарушения целостности кадров.
Сущность изобретения
В соответствии с одним из примеров осуществления настоящего изобретения предложен способ, включающий вычисление первой ошибки квантования, которая описывает ошибку, полученную в результате квантования без предсказания для аудиопараметра фрагмента аудиосигнала, вычисление второй ошибки квантования, которая описывает ошибку, полученную в результате квантования с предсказанием для упомянутого аудиопараметра упомянутого фрагмента аудиосигнала, определение, превосходит ли упомянутая вторая ошибка квантования упомянутую первую ошибку квантования по меньшей мере на адаптивный запас, который зависит от количества последовательных фрагментов аудиосигнала, предшествующих упомянутому фрагменту аудиосигнала, в котором было выполнено квантование упомянутого аудиопараметра с использованием упомянутого квантования с предсказанием, предоставление упомянутого аудиопараметра упомянутого фрагмента аудиосигнала, квантованного с использованием упомянутого квантования без предсказания, в качестве части кодированного аудиосигнала по меньшей мере в том случае, когда результат упомянутого определения положительный, и предоставление, в противном случае, упомянутого аудиопараметра упомянутого фрагмента аудиосигнала, квантованного с использованием упомянутого квантования с предсказанием, в качестве части кодированного аудиосигнала.
В соответствии с другим примером осуществления настоящего изобретения предложено устройство, включающее процессорный компонент, сконфигурированный для вычисления первой ошибки квантования, которая описывает ошибку, полученную в результате квантования без предсказания для аудиопараметра фрагмента аудиосигнала, процессорный компонент, сконфигурированный для вычисления второй ошибки квантования, которая описывает ошибку, полученную в результате квантования с предсказанием для упомянутого аудиопараметра упомянутого фрагмента аудиосигнала, процессорный компонент, сконфигурированный для определения, превосходит ли упомянутая вторая ошибка квантования упомянутую первую ошибку квантования по меньшей мере на адаптивный запас, который зависит от количества последовательных фрагментов аудиосигнала, предшествующих упомянутому фрагменту аудиосигнала, в котором было выполнено квантование упомянутого аудиопараметра с использованием упомянутого квантования с предсказанием, процессорный компонент, сконфигурированный для предоставления упомянутого аудиопараметра упомянутого фрагмента аудиосигнала, квантованного с использованием упомянутого квантования без предсказания, в качестве части кодированного аудиосигнала по меньшей мере в том случае, когда результат упомянутого определения положительный, и процессорный компонент, сконфигурированный, в обратном случае, для предоставления упомянутого аудиопараметра упомянутого фрагмента аудиосигнала, квантованного с использованием упомянутого квантования с предсказанием, в качестве части кодированного аудиосигнала.
В соответствии с еще одним из примеров осуществления настоящего изобретения предложено устройство, включающее средства вычисления первой ошибки квантования, которая описывает ошибку, полученную в результате квантования без предсказания для аудиопараметра фрагмента аудиосигнала, средства вычисления второй ошибки квантования, которая описывает ошибку, полученную в результате квантования с предсказанием для упомянутого аудиопараметра упомянутого фрагмента аудиосигнала, средства определения, превосходит ли упомянутая вторая ошибка квантования упомянутую первую ошибку квантования по меньшей мере на адаптивный запас, который зависит от количества последовательных фрагментов аудиосигнала, предшествующих упомянутому фрагменту аудиосигнала, в котором было выполнено квантование упомянутого аудиопараметра с использованием упомянутого квантования с предсказанием, средства предоставления упомянутого аудиопараметра упомянутого фрагмента аудиосигнала, квантованного с использованием упомянутого квантования без предсказания, в качестве части кодированного аудиосигнала по меньшей мере в том случае, когда результат упомянутого определения положительный, и средства предоставления, в обратном случае, упомянутого аудиопараметра упомянутого фрагмента аудиосигнала, квантованного с использованием упомянутого квантования с предсказанием, в качестве части кодированного аудиосигнала.
В соответствии с еще одним из примеров осуществления настоящего изобретения предложена компьютерная программа, включающая машиночитаемый программный код, который сконфигурирован, когда упомянутый программный код исполняют на вычислительном устройстве, для обеспечения выполнения по меньшей мере следующего: вычисление первой ошибки квантования, которая описывает ошибку, полученную в результате квантования без предсказания для аудиопараметра фрагмента аудиосигнала, вычисление второй ошибки квантования, которая описывает ошибку, полученную в результате квантования с предсказанием для упомянутого аудиопараметра упомянутого фрагмента аудиосигнала, определение, превосходит ли упомянутая вторая ошибка квантования упомянутую первую ошибку квантования по меньшей мере на адаптивный запас, который зависит от количества последовательных фрагментов аудиосигнала, предшествующих упомянутому фрагменту аудиосигнала, в котором было выполнено квантование упомянутого аудиопараметра с использованием упомянутого квантования с предсказанием, предоставление упомянутого аудиопараметра упомянутого фрагмента аудиосигнала, квантованного с использованием упомянутого квантования без предсказания, в качестве части кодированного аудиосигнала по меньшей мере в том случае, когда результат упомянутого определения положительный, и предоставление, в противном случае, упомянутого аудиопараметра упомянутого фрагмента аудиосигнала, квантованного с использованием упомянутого квантования с предсказанием, в качестве части кодированного аудиосигнала.
Упомянутая выше компьютерная программа может быть реализована на энергозависимом или энергонезависимом машиночитаемом носителе информации, например, в виде компьютерного программного продукта, включающего компьютерную программу в соответствии с описанным выше примером осуществления настоящего изобретения, хранимую на упомянутом носителе информации. Примеры осуществления изобретения, рассмотренные а настоящей заявке, не следует интерпретировать как накладывающие ограничения на область применения приложенной формулы изобретения. Глагол «включает» и его производные в настоящей заявке не исключает существование неперечисленных отличительных признаков. Отличительные признаки, описанные ниже, могут свободно комбинироваться друг с другом, если в прямой форме не будет указано обратное.
Некоторые из отличительных признаков настоящего изобретения изложены в приложенной формуле изобретения. Однако аспекты настоящего изобретения, как относящиеся к его структуре, так и к способу его функционирования, а также дополнительные цели и преимущества настоящего изобретения, могут быть поняты более детально на основе приведенного ниже описания нескольких конкретных примеров осуществления настоящего изобретения, которое следует рассматривать в сочетании с приложенными чертежами.
Краткое описание чертежей
Варианты осуществления настоящего изобретения, исключительно в качестве примера, а не ограничения, проиллюстрированы на приложенных чертежах.
На фиг. 1 эскизно проиллюстрированы некоторые из компонентов системы в соответствии с одним из примеров осуществления настоящего изобретения.
На фиг. 2 проиллюстрирован способ в соответствии с одним из примеров осуществления настоящего изобретения.
На фиг. 3 проиллюстрирован способ в соответствии с одним из примеров осуществления настоящего изобретения.
На фиг. 4 проиллюстрирован способ в соответствии с одним из примеров осуществления настоящего изобретения.
На фиг. 5 проиллюстрирован способ в соответствии с одним из примеров осуществления настоящего изобретения.
На фиг. 6 эскизно проиллюстрированы некоторые из компонентов устройства в соответствии с одним из примеров осуществления настоящего изобретения.
Описание некоторых вариантов осуществления изобретения
Несмотря на применение описанного выше способа квантования со страховочной сеткой, который обеспечивает преимущества в общей эффективности кодирования, как при наличии ошибок хранения и передачи, так и при их отсутствии, по сравнению с использованием исключительно квантования с предсказанием, остается потенциально нерешенной проблема, связанная с применением квантования с предсказанием.
Обычно, в зависимости от характеристик входного аудиосигнала, квантование с предсказанием позволяет получить характеристики, превышающие характеристики квантования без предсказания, для 70-90% от всех кадров. Лучшие характеристики квантования с предсказанием могут быть особенно ярко выражены для тех фрагментов речевого сигнала, которые имеют постоянные спектральные характеристики (например, вокализированная речь), простирающиеся на десятки последовательных кадров, что опционально может приводить к длинным сериям последовательных кадров, для которых применяют квантование с предсказанием.
В качестве примера, один из способов повышения качества квантования со страховочной сеткой, описанного выше, за счет более частого применения квантования без предсказания включает использование выигрыша предпочтения для выбора квантования без предсказания вместо квантования с предсказанием, несмотря на более высокую эффективность квантования, достигаемую при квантовании с предсказанием. То есть, для выбора квантования с предсказанием вместо квантования без предсказания, эффективность квантования с предсказанием должна превышать эффективность квантования без предсказания на фиксированный заранее заданный запас (или на фиксированный заранее заданный коэффициент). В качестве подобного примера, необходимое условие для выбора квантования с предсказанием может требовать, например, чтобы квантование с предсказанием было в 1,3 раза лучше в отношении ошибки квантования, чем квантование без предсказания (например, чтобы ошибка квантования, полученная в результате квантования с предсказанием, умноженная на 1,3 была меньше, чем ошибка квантования, полученная в результате квантования без предсказания для того же самого кадра), что позволяет снизить частоту применения квантования с предсказанием. Такой вариант позволяет сократить серии последовательных кадров, квантуемых с предсказанием (в зависимости от применяемого значения для упомянутого фиксированного заранее заданного запаса), и соответственно, позволяет повысить устойчивость к ошибкам передачи или хранения данных, но с другой стороны, такой вариант может снижать эффективность квантования в случае безошибочного канала передачи данных или безошибочного хранения. При этом, также, выбор значения для упомянутого фиксированного заранее заданного запаса может быть нетривиальной задачей, поскольку несет в себе риск получения слишком коротких или слишком длинных серий последовательных кадров, квантуемых с предсказанием.
В качестве другого примера, способ квантования со страховочной сеткой может включать назначение максимального значения длины серии последовательных кадров, квантуемых с предсказанием. Такой способ позволяет эффективно ограничить максимальную дистанцию распространения ошибки в случае пропадания кадра или ошибочного кадра, однако он не позволяет учитывать разницу в эффективности, обеспечиваемую квантованием с предсказанием для аудиосигналов с различными характеристиками. Соответственно, такой подход также несет риск получения слишком коротких или слишком длинных серий последовательных кадров, квантуемых с предсказанием. При этом, также, принудительное завершение серии последовательных кадров, квантуемых с предсказанием, может приходиться на кадр, в котором эффективность квантования с предсказанием выше, чем эффективность квантования без предсказания, что несет риск кратковременного значительного снижения качества аудиосигнала. В основе настоящего изобретения лежит следующее соображение: применение способа квантования со страховочной сеткой для прерывания серии последовательных кадров, квантуемых с предсказанием, за счет обязательного квантования кадра без предсказания, позволяет превентивно исключить потенциальное распространение ошибки, но с другой стороны принудительное прерывание серии кадров, квантуемых с предсказанием, особенно на кадре, для которого выигрыш в эффективности, обеспечиваемый квантованием с предсказанием, значителен, с большой вероятностью краткосрочно ухудшит общую эффективность квантования, что, соответственно, приведет к ухудшению качества аудиосигнала. Соответственно, предложено, чтобы критерии выбора, применяемые для выбора между квантованием с предсказанием и квантованием без предсказания для заданного кадра, были сконфигурированы таким образом, чтобы обеспечивать предпочтение квантования без предсказания вместо квантования с предсказанием, с помощью коэффициента, который увеличивается с ростом длины серии последовательных кадров, для которых было выбрано квантование с предсказанием. Одновременно с этим могут оцениваться один или более дополнительных критериев выбора для выбора между квантованием с предсказанием и квантованием без предсказания.
Соответственно, варианты осуществления настоящего изобретения позволяют повысить эффективность кодирования при наличии ошибок в канале передачи данных, содействуя укорочению слишком длинных серии последовательных кадров, в которых применялось квантование с предсказанием, но вместе с тем получить повышенную эффективность благодаря квантованию с предсказанием, если его эффективность явно превышает эффективность квантования без предсказания Такой подход может давать увеличение реальной средней ошибки квантования, однако упомянутые критерии выбора могут быть оптимизированы таким образом, чтобы ошибка квантования поддерживалась на уровне, при котором любые возможные результирующие погрешности в моделировании аудиосигнала были достаточны малы, и ошибка была бы едва слышимой или совсем не слышимой.
Спектральное искажение (spectral distortion, SD) является одним из примеров часто используемой меры, отражающей величину ошибки квантования, при этом спектральное искажение может также использоваться для оценки слышимости ошибки квантования. Например, если спектральное искажение вследствие квантования не превышает 1 дБ, искажение, как правило, не слышимо для человеческого уха. В способе квантования со страховочной сеткой может использоваться этот факт, например, квантование без предсказания может выбираться всякий раз, когда оно дает спектральное искажение, не превышающее заранее заданного порога, например, 1 дБ. Рассмотрим данный аспект более подробно. В общем случае нет необходимости использовать для квантования конкретного фрагмента аудиосигнала квантование с предсказанием, которое бы давало, например, очень низкое спектральное искажение, например, равное 0,5 дБ, если квантование без предсказания для того же самого фрагмента аудиосигнала дает спектральное искажение, равное 0,9 дБ, уже достаточно низкое с точки зрения человеческого слуха. В подобном случае, несмотря на то, что объективная ошибка квантования, полученная в результате квантования без предсказания, является большей для отдельного фрагмента аудиосигнала, результирующую ошибку квантования все-равно можно считать неслышимой, и следовательно, для данного фрагмента аудиосигнала предпочтительней выбрать квантование без предсказания, обеспечивающее ограничение или предотвращение распространения ошибки квантования в случае нарушения целостности или потери кадра. Если произошло нарушение целостности или потеря фрагмента аудиосигнала, предшествующего текущему фрагменту аудиосигнала, то квантование с предсказанием не будет эффективным, однако параметры, полученные в результате квантования без предсказания, могут быть корректно декодированы. При подобном подходе преимущества, полученные за счет применения квантования без предсказания вместо квантования с предсказанием, могут быть слышимы только в фрагментах аудиосигнала с одной или более ошибками, тогда как для безошибочных каналов, как правило, слышимого снижения качества сигнала не происходит. Следовательно, такой способ может применяться как часть подхода со страховочной сеткой в целях обеспечения достаточного качества квантования, как в условиях безошибочного канала передачи, так и в условиях нарушения целостности кадров или ошибок в кадрах, опционально, одновременно с дополнительными критериями для выбора между квантованием с предсказанием и квантования без предсказания.
В соответствии с приведенным выше описанием, очевидно, подходящая мера ошибки, которая может сравниваться с заранее заданным порогом, может быть связана со спектральным искажением в некотором диапазоне частот, для исходного фрагмента аудиосигнала и фрагмента аудиосигнала, полученного в результате квантования. Эта мера ошибки может вычисляться как для квантования с предсказанием, так и для квантования без предсказания. Вычисление меры ошибки, выраженной спектральным искажением в некотором диапазоне частот, может также применяться, например, для параметров спектральной частоты иммитанса (immittance spectral frequency, ISF) или параметров частоты спектральной линии (line spectral frequency, LSF), принадлежащих фрагменту аудиосигнала.
Спектральное искажение SD для соответствующего фрагмента аудиосигнала (например, кадра аудиосигнала) может быть выражено следующим уравнением:
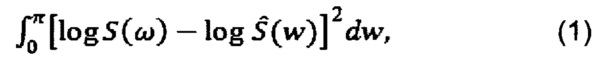
где 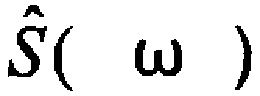 и S(ω) - спектры речевого кадра с квантованием и без квантования соответственно.
и S(ω) - спектры речевого кадра с квантованием и без квантования соответственно.
Мера в виде такого спектрального искажения может быть особенно точной для кодовой книги и для выбора типа квантования параметров линейного упреждающего кодирования (linear predictive coding, LPC) в сегменте аудиосигнала, однако вычислительные затраты на определение спектрального искажения в соответствии с уравнением (1) могут быть снижены, если использовать более вычислительно простые способы.
В этом отношении рассматриваемая мера ошибки может включать меру ошибки, которая по меньшей мере аппроксимирует спектральное искажение (например, в соответствии с уравнением 1). Такая мера ошибки может быть получена, например, комбинированием взвешенных расхождений между некоторой составляющей исходного фрагмента аудиосигнала и соответствующей составляющей фрагмента аудиосигнала, полученного в результате квантования. Например, такая мера ошибки может быть психоакустически значимой мерой ошибки и может быть получена комбинированием взвешенных среднеквадратичных ошибок. При этом взвешивание ошибок быть психоакустически значимым. Выражение «психоакустически значимое взвешивание» означает, что спектральные составляющие аудиосигнала, воспринимаемые человеческим слухом, получают больший вес, чем составляющие, заведомо не воспринимаемые. Такое взвешивание может быть реализовано с использованием набора весовых коэффициентов, которые могут применяться как множители для соответствующих составляющих взвешиваемого фрагмента аудиосигнала или соответствующих составляющих взвешиваемого аудиопараметра, с получением взвешенных составляющих, которые затем комбинируют (например, суммируют) и получают взвешенную меру ошибки. Весовые коэффициенты, пригодные для такой цели, могут быть вычислены несколькими различными способами.
Один из примеров психоакустически значимой ошибки может включать взвешенную ошибку, например, взвешенное среднеквадратическое расхождение между исходными (неквантоваными) параметрами ISF и соответствующими квантованными параметрами ISF. Другой пример психоакустически значимой ошибки может включать взвешенную ошибку, например, взвешенное среднеквадратическое расхождение между исходными (не квантованными) параметрами ISF и соответствующими квантованными параметрами ISF.
Нужно понимать, что в общем случае рассматриваемая мера ошибки может быть определена на основе полностью квантованного фрагмента аудиосигнала или на основе частично квантованного фрагмента аудиосигнала, например, на основе одного или более избранных квантованных параметров в соответствующим фрагменте аудиосигнала, например, параметров ISF или параметров LSF, упомянутых выше.
На фиг. 1 показана эскизная блок-схема примера системы, в которой может быть реализован выбор квантования с предсказанием или квантования без предсказания, в соответствии с одним из вариантов осуществления настоящего изобретения. В настоящем документе термины «квантование без предсказания и квантование «со страховочной сеткой» могут использоваться как синонимы. Система, проиллюстрированная на фиг. 1 включает первое электронное устройство 100 и второе электронное устройство 150. Первое электронное устройство 100 сконфигурировано для кодирования аудиоданных, например, для их широкополосной передачи, а второе электронное устройство 150 сконфигурировано для декодирования кодированных аудиоданных. Первое электронное устройство 100 имеет в своем составе компонент 1111 ввода аудиоданных, который связан, через микросхему 120, с передающим компонентом (ТХ) 112. Компонент 111 ввода аудиоданных может представлять собой, например, микрофон, микрофонную установку, интерфейс к другому устройству, предоставляющему аудиоданные, или интерфейс к памяти, или к файловой системе, из которых могут быть считаны аудиоданные.
Микросхема 120 может представлять собой, например, интегральную схему, которая содержит схемы аудиокодера, некоторые из функциональных блоков которого эскизно показаны на чертеже. Проиллюстрированные блоки включают компонент 124 параметризации и компонент 125 квантования. Передающий компонент 112 сконфигурирован для обеспечения передачи данных в другое устройство, например, в электронное устройство 1150, по проводной или беспроводной линии связи. Кодер 121 из состава микросхемы 120 можно рассматривать как один из примеров устройства, соответствующего настоящему изобретению, а компонент квантования - как представляющий собой соответствующие процессорные компоненты.
Электронное устройство 150 включает приемный компонент 162, который связан, через микросхему 170, с компонентом 161 вывода аудиоданных. Приемный компонент 162 сконфигурирован для обеспечения приема данных из другого устройства, например, из электронного устройства 150, по проводной или беспроводной линии связи. Микросхема 170 может представлять собой, например, интегральную схему, которая содержит схемы аудиодекодера 171, компонент 174 синтеза из состава которого показан на чертеже. Компонент 161 вывода аудиоданных может представлять собой, например, громкоговоритель или интерфейс к другому устройству, в которое перенаправляют декодированные аудиоданные.
Понятно, что соединения, показанные на фиг. 1, могут быть реализованы через различные не показанные компоненты.
Ниже функционирование системы, показанной на фиг. 1, будет рассмотрено более подробно на примере фиг. 2-5.
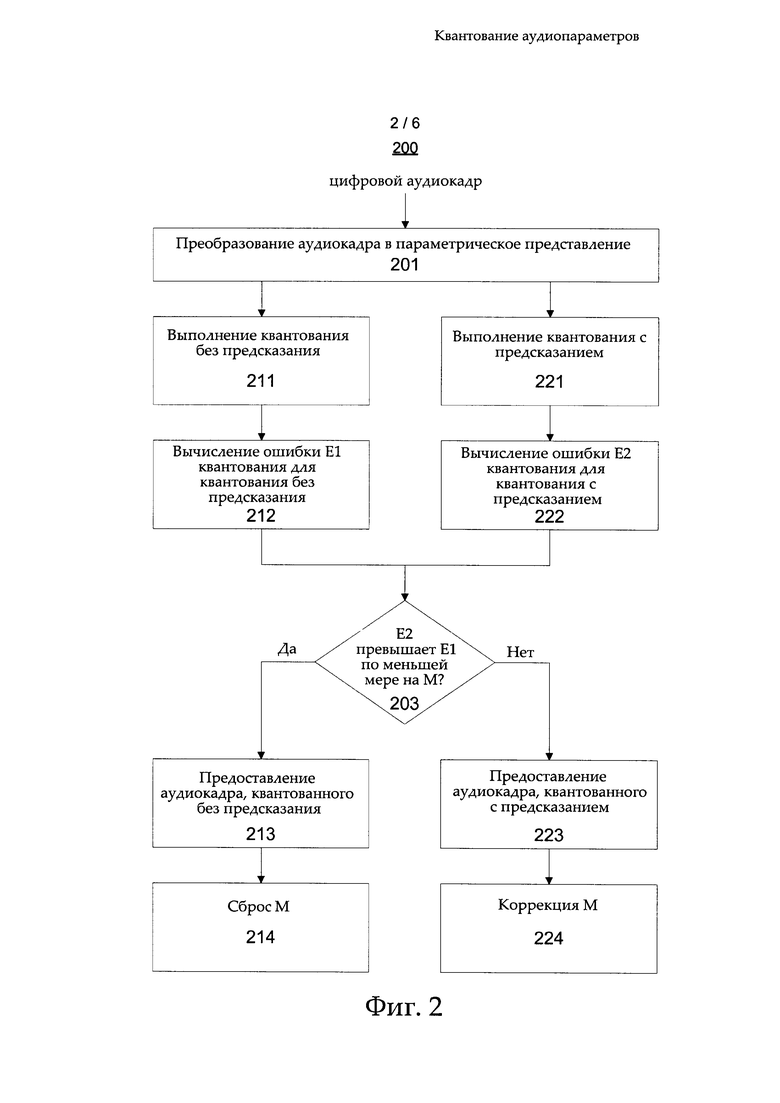
На фиг. 2 показана блок-схема алгоритма, иллюстрирующая работу аудикодера 121, в виде шагов примера способа 200. Когда аудиосигнал вводят в электронное устройство 100, например, через компонент 111 ввода аудиоданных, он может быть предоставлен в аудиокодер 120 для кодирования. Перед предоставлением аудиосигнала в аудиокодер 121 он может быть подвергнут предварительной обработке. Например, если аудиосигнал является аналоговым, он может быть сначала преобразован в цифровую форму и т.п.
Аудиокодер 121 обрабатывает аудиосигнал, например, в виде аудиокадров длиной 20 мс, с предварительным просмотром в 10 мс. Каждый аудиокадр представляет собой фрагмент аудиосигнала. Компонент 124 параметризации сначала преобразует текущий аудиокадр в параметрическое представление (шаг 201). Параметрическое представление кадра аудиосигнала может включать один или более аудиопараметров, описывающих аудиосигнал внутри кадра. При этом аудиопараметры могут быть скалярными (одиночными) или векторными. В рассмотренном ниже примере обработка данных в соответствии с различными вариантами осуществления настоящего изобретения описана на примере параметров LSF и/или ISF, исключительно в качестве неограничивающего примера.
Компонент 125 квантования выполняет, с одной стороны, квантование без предсказания над одним или более параметрами аудиокадра (шаг 211), например, с использованием кодовой книги без предсказания. Компонент 125 квантования может выполнять квантование избранных параметров только на этом этапе, тогда как квантование дополнительных параметров может выполняться на следующих этапах (например, после выбора типа квантования, с предсказанием или без, на основе шага 203). Также, компонент 125 квантования вычисляет значение меры ошибки, которая описывает ошибку E1 квантования, полученную в результате квантования без предсказания для одного или более аудиопараметров аудиокадра (шаг 212). На примере LSF-вектора, который содержит параметры LSF, описывающие спектральные характеристики аудиокадра, ошибка Е1 квантования может включать, например, среднеквадратичное расхождение между параметрами LSF, квантованными при помощи квантования без предсказания и исходными (неквантованными) параметрами LSF для аудиокадра или взвешенное среднеквадратическое расхождение между параметрами LSF, квантованными при помощи квантования без предсказания и исходными (неквантованными) параметрами LSF для аудиокадра, где взвешивание выполняется на основе психоакустической значимости.
Компонент 125 квантования выполняет, с другой стороны, квантование с предсказанием для одного или более параметров аудиокадра (шаг 221), например, с использованием кодовой книги с предсказанием. Снова, компонент 125 квантования на этом этапе может выполнять квантование лишь избранных параметров (например, после выбора одного из типов квантования, с предсказанием или без, на шаге 203), тогда как квантование остальных параметров может выполняться на последующих этапах. Также, компонент 125 квантования вычисляет значение меры ошибки, которая описывает ошибку Е2 квантования, полученную в результате квантования с предсказанием для одного или более аудиопараметров аудиокадра (шаг 212). Как и в случае шага 212, рассматривая в качестве примера аудиопараметра LSF-вектор, ошибка Е1 квантования может включать, например, среднеквадратическую ошибку или (психоакустически) взвешенное среднеквадратичное расхождение между параметрами LSF, квантованными с предсказанием и исходными (неквантованными) параметрами LSF для аудиокадра.
Квантование с предсказанием может включать, например, использование любого способа предсказания, известного на существующем уровне техники, для вычисления предсказанного значения аудиопараметра (например, LSF-вектора или его составляющей) в текущем аудиокадре i на основе значения соответствующего аудиопараметра (например, LSF-вектора или его составляющей) в одном или более кадров, предшествующих аудиокадру i (например, аудиокадров i-j, где j=1, …, jmax) и/или на основе одного или более кадров, следующих за аудиокадром i (например, аудиокадров i+k, где k=1, kmax) и использование квантователя для квантования разности между исходным (неквантованным) значением аудиопараметра в текущем аудиокадре и предсказанным значением (например, на основе кодовой книги для режима с предсказанием).
В этом отношении, для квантования с предсказанием, в компоненте 125 квантования может применяться линейная или нелинейная модель предсказания. В качестве пояснительного и неограничивающего примера, предсказание при этом может включать вычисление предсказанного значения аудиопараметра для аудиокадра i на основе значения соответствующего аудиопараметра в ближайшем (например, последнем по времени) предшествующем кадре i-1 с использованием одного из следующего: авторегрессивная модель предсказания (autoregressive, AR), модель предсказания на основе скользящего среднего (moving average, MA) и модель предсказания на основе авторегрессивного скользящего среднего (autoregressive moving average, ARMA). Затем компонент 125 квантования выбирает для текущего кадра квантование с предсказанием или квантование без предсказания на основе найденных соответствующих ошибок E1 и Е2 предсказания. С этой целью компонент 125 квантования может определять, превосходит ли ошибка Е2 квантования ошибку E1 квантования по меньшей мере на адаптивный запас М (шаг 203). Адаптивный запас М зависит от количества последовательных кадров, предшествующих текущему аудиокадру, в которых один или более аудиопараметров были квантованы с использованием квантования с предсказанием. Другими словами, адаптивный запас М для текущего кадра зависит от количества кадров между ближайшим предшествующим аудиокадром, для которого было выбрано квантование без предсказания, и текущим кадром. Это количество кадров может быть названо (текущей) длиной L серии предсказания, а определение адаптивного запаса М будет описано ниже в настоящем документе.
Если определение на шаге 203 имеет положительный результат, то есть, если ошибка Е2 квантования превосходит ошибку Е1 квантования по меньшей мере на адаптивный запас М, компонент 125 квантования предоставляет один или более аудиопараметров текущего кадра, квантованного с использованием квантования без предсказания (шаг 213), в качестве кодированного аудиосигнала. И наоборот, если определение на шаге 203 не имеет положительного результата, то есть, если ошибка Е2 квантования не превосходит ошибку E1 квантования по меньшей мере на адаптивный запас М, компонент 125 квантования предоставляет один или более аудиопараметров текущего кадра, квантованного с использованием квантования с предсказанием (шаг 223), в качестве кодированного аудиосигнала.
В компоненте 125 квантования, альтернативно или в дополнение, могут применяться один или более дополнительных критериев, которые могут иметь результатом выбор квантования без предсказания, и соответственно, способ 200 может быть изменен, например, путем введения одного или более дополнительных шагов определения или выбора, до или после шага 203. В этой связи, в качестве одного из примеров, в одном из таких вариантов способа 200, компонент 125 квантования перед шагом 203 может определять, является ли ошибка Е квантования меньшей, чем заранее заданный порог Eth, при этом может выполняться переход к шагу 213, если определение дает положительный результат, и переход к шагу 203, если определение не дает положительного результата. Пороговое значение Eth может быть порогом, ниже которого ошибку квантования можно считать неслышимой. Подходящее значение для порога Е1 будет различным для различных аудиопараметров, а также, возможно, для различных весовых функций, применяемых для взвешивания ошибки квантования, и соответственно, должно быть вычислено эмпирически и автономно. Однако когда подходящее значение порога Eth будет найдено, рост вычислительной сложности в кодере из-за проверки на шаге 302 станет минимальным. В качестве примера, пороговое значение Eth может быть назначено равным значению, которое соответствует спектральному искажению в диапазоне от 0,8 до 1,0 дБ, например, 0,9 дБ.
В качестве одного из примеров определения адаптивного запаса М в зависимости от длины L серии предсказания, запас М может быть увеличен относительно своего исходного значения М0 на заранее заданное значение MS для каждого аудиокадра между текущим аудиокадром и ближайшим предшествующим ему аудиокадром, для которого было выбрано квантования без предсказания. В качестве другого примера определения адаптивного запаса М в зависимости от длины L серии предсказания, запас М может быть увеличен относительно своего исходного значения М0 на заранее заданное значение MS для каждого аудиокадра после заранее заданного порога L0 между текущим аудиокадром и ближайшим предшествующим ему аудиокадром, для которого было выбрано квантования без предсказания. Другими словами, запас М может быть увеличен относительно своего исходного значения М0, на заранее заданную величину Ms, (L-L0) раз, где L>L0.
В качестве одного из примеров, порог L0 может быть выбран равным заранее заданному значению, например, 3 (т.е. L0=3), но с равным успехом может быть выбрано и любое другое подходящее значение. В качестве другого примера, значение порога L0 может назначаться (или корректироваться) в зависимости от аудиохарактеристик текущего кадра и/или одного или более кадров, непосредственно предшествующих текущему кадру. В качестве другого примера, значение порога L0 может назначаться (или корректироваться) в зависимости от режима кодирования, применяемого аудиокодером 121 или компонентом 125 квантования для текущего кадра и/или для одного или более кадров, непосредственно предшествующих текущему кадру.
В рамках способа 200 адаптивный запас М либо сбрасывают до исходного значения М0 (шаг 214) для следующего аудиокадра, если для текущего кадра было выбрано квантование без предсказания, или корректируют (шаг 224) на заранее заданную величину MS для следующего аудиокадра, если для текущего аудиокадра было выбрано квантование с предсказанием.
В качестве другого примера, альтернативно, сброс значения адаптивного запаса М (шаг 214) и/или коррекция адаптивного запаса М (шаг 224) может выполняться в зависимости от того, какой тип квантования был выбран для ближайшего предшествующего кадра (т.е. последнего по времени предшествующего кадра), после приема следующего аудиокадра, но перед сравнением ошибок Е1 и Е2 квантования. В качестве еще одного примера, вместо явного сброса значения адаптивного запаса М (шаг 214) и коррекции адаптивного запаса М (шаг 224), адаптивный запас М может вычисляться на основе длины L серии предсказаний или на основе длины L серии предсказаний и заранее заданного порога L0. Альтернативно, значение адаптивного запаса М может быть получено из таблицы, к которой имеет доступ компонент 125 квантования и в которой хранят значения адаптивного запаса М в требуемом диапазоне значений длины L серии предсказаний. Примеры в этой связи будут приведены в настоящем описании ниже.
Исходное значение М0 адаптивного запаса М может быть нулевым или по существу нулевым. Альтернативно, исходное значение М0 адаптивного запаса М может быть несколько выше нуля. Применение исходного значения М0, несколько большего нуля, позволяет гарантировать, что вместо квантования с предсказанием будет отдано предпочтение квантованию без предсказания, даже если длина L серии предсказаний равна нулю (или ниже порогового значения L0). Заранее заданная величина Ms, на которую корректируют адаптивный запас М для применения в следующем аудиокадре, может быть небольшим положительным значением, предназначенным для постепенного увеличения адаптивного запаса М в каждом последующем кадре, чтобы в конце концов фактически принудительно предоставить, в качестве части кодированного аудиосигнала, один или более аудиопараметров аудиокадра, квантованных с использованием квантования без предсказания.
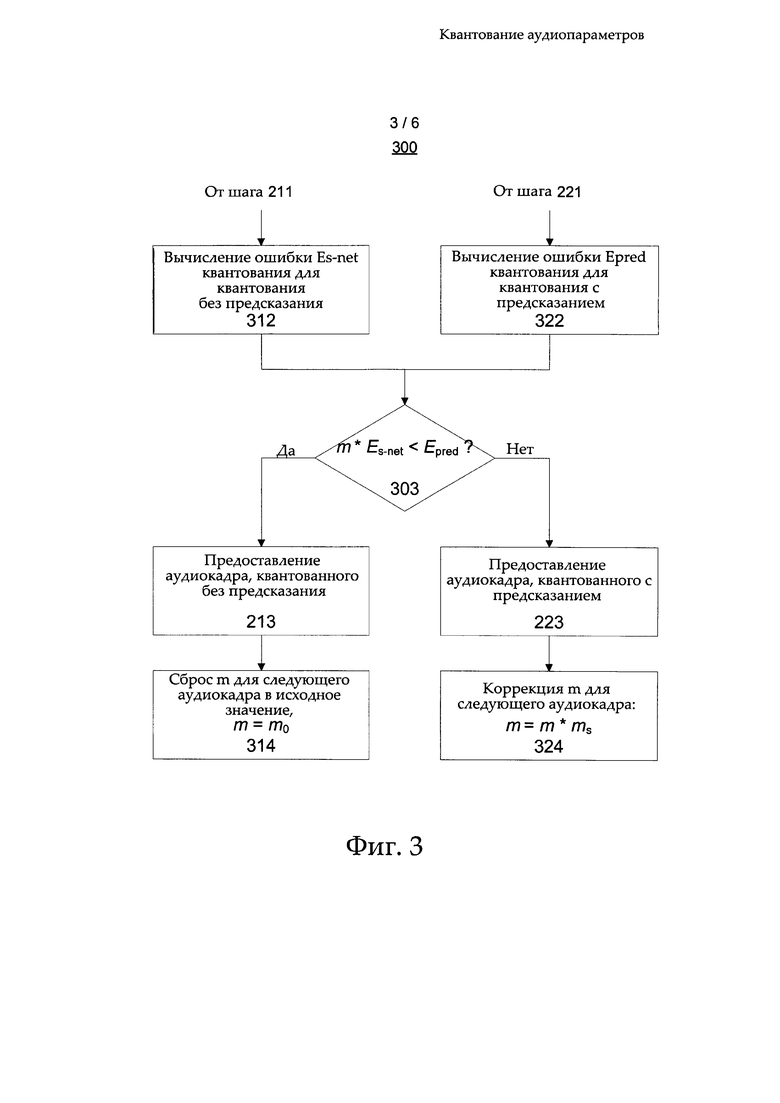
На фиг. 3 показана блок-схема алгоритма, иллюстрирующая работу аудикодера 121, в виде шагов примера способа 300. Способ 300 служит примером осуществления настоящего изобретения в базовой структуре, описанной выше в отношении способа 200. В способе 300 используются те же шаги 201, 211 и 221, что и в способе 200.
В способе 300 компонент 125 квантования может вычислять ошибку Es-net квантования в результате квантования без предсказания одного или более аудиопараметров текущего аудиокадра (шаг 312). В качестве примера, ошибка Es-net квантования может включать среднеквадратическое расхождение между аудиопараметрами, квантованными с предсказанием и соответствующими исходными (не квантованными) аудиопараметрами в текущем аудиокадре. В качестве другого примера, ошибка Es-net квантования может включать психоакустически значимую меру ошибки, например, спектральное искажение или (психоакустически) взвешенную среднеквадратическое расхождение между аудиопараметрами, квантованными без предсказания, и соответствующими исходными (неквантованными) аудиопараметрами в текущем аудиокадре. На примере параметров LSF, в качестве одного или более аудиопараметров, ошибка квантования Es-net может быть получена, например, в виде взвешенного среднеквадратического расхождения между параметрами LSF, квантованными без предсказания и исходными параметрами LSF для текущего кадра f, например, в соответствии с уравнением (2).

где N - длина квантованного вектора (например, количество элементов в векторе), QLsfspi - оптимальное значение р вектора LSF для кадра i, квантованное при помощи квантования со страховочной сеткой, Lsfpi - исходное, неквантованное значение р вектора LSF для кадра i, a Wpi - психоакустически значимое весовое векторное значение р для кадра i. В этой связи примеры подходящего весового вектора W включают весовую функцию wend, описанную в разделе 6.8.2.4 рекомендации G.718 (06/2008) ITU-T (International Telecommunication Union, Telecommunication standardization sector, сектор стандартизации телекоммуникаций Международного союза электросвязи) озаглавленном «Устойчивое к ошибочным кадрам, узкополосное и широкополосное встроенное кодирование с переменным битрейтом для голосовых и аудиоданных в диапазоне 8-32 кбит/с» (Frame error robust narrow-band and wideband embedded variable bit-rate coding of speech and audio from 8-32 kbit/s) и весовой вектор wmid, описанный в разделе 6.8.2.6 упомянутой рекомендации G.718 ITU-T.
Продолжим рассмотрение способа 300. Компонент 125 квантования может вычислять ошибку Epred квантования в результате квантования с предсказанием одного или более аудиопараметров текущего аудиокадра (шаг 322). В качестве примера, ошибка Epred квантования может включать среднеквадратическое расхождение между аудиопараметрами, квантованными с предсказанием, и соответствующими исходными (неквантованными) аудиопараметрами в текущем аудиокадре. В качестве другого примера, ошибка Epred квантования может включать психоакустически значимую меру ошибки, например, спектральное искажение или (психоакустически) взвешенное среднеквадратическое расхождение между аудиопараметрами, квантованными без предсказания, и соответствующими исходными (неквантованными) аудиопараметрами в текущем аудиокадре. Снова, на примере параметров LSF, в качестве одного или более аудиопараметров, ошибка квантования Epred может быть получена, например, в виде взвешенного среднеквадратического расхождения между параметрами LSF, квантованными без предсказания и исходными параметрами LSF для текущего кадра i, например, в соответствии с уравнением (3).
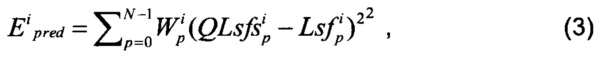
где, снова, N - длина квантованного вектора (например, количество элементов в векторе), QLsfsppi - оптимальное значение р вектора LSF квантованное с предсказанием, для кадра i, Lsfpi, снова, - исходное, неквантованное значение р вектора LSF для кадра i, a Wpi, снова, - психоакустически значимое весовое векторное значение р для кадра i, например, в соответствии с уравнением (3). При этом соображения относительно подходящего весового вектора W, изложенные в контексте уравнения (2) остаются верными и для уравнения (3). Вернемся к описанию способа 300. Компонент 125 квантования выбирает один из типов квантования, с предсказанием или без, на основе ошибок Es-net и Epred квантования. А именно, компонент 125 квантования может определять, является ли масштабированное значение ошибки 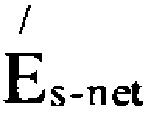 квантования меньшим, чем ошибка Epred квантования, где - ошибка Es⋅net квантования, масштабированная с использованием текущего значения адаптивного коэффициента m масштабирования, например,
квантования меньшим, чем ошибка Epred квантования, где - ошибка Es⋅net квантования, масштабированная с использованием текущего значения адаптивного коэффициента m масштабирования, например, 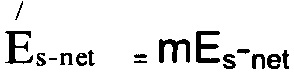 (шаг 303).
(шаг 303).
Если определение на шаге 303 имеет положительный результат, то есть, если ошибка Es-net квантования, масштабированная с использованием текущего значения адаптивного коэффициента m масштабирования, меньше ошибки Epred, компонент 125 квантования предоставляет один или более аудиопараметров текущего кадра, например, по меньшей мере параметры LSF, квантованные с использованием квантования без предсказания (шаг 213), в качестве кодированного аудиосигнала. И наоборот, если определение на шаге 303 не дает положительного результата, то есть, если ошибка Es-net квантования, масштабированная с использованием текущего значения адаптивного коэффициента m масштабирования, не меньше ошибки Epred, компонент 125 квантования предоставляет один или более аудиопараметров текущего кадра, например, по меньшей мере параметры LSF, квантованные с использованием квантования с предсказанием (шаг 223), в качестве кодированного аудиосигнала.
В способе 300, если компонент 125 квантования выбрал квантование без предсказания для одного или более аудиопараметров в текущем аудиокадре i, компонент 125 квантования может также сбрасывать адаптивный коэффициент m масштабирования, который будет использоваться компонентом 125 квантования в следующем кадре i+1, путем присвоения адаптивному коэффициенту m масштабирования исходного значения m0, т.е. присваивают m=m0 (шаг 314). Это соответствует сбросу адаптивного запаса М в его исходное значение М0 на шаге 214 в способе 200.
И наоборот, если компонент 125 квантования выбрал квантование без предсказания для одного или более аудиопараметров в текущем аудиокадре i, компонент 125 квантования может также корректировать адаптивный коэффициент m масштабирования, который будет использоваться компонентом 125 квантования в следующем кадре i+1, путем умножения адаптивного коэффициента m масштабирования на заранее заданный коэффициент ms масштабирования, т.е. назначают m=m*ms (шаг 324). Это соответствует коррекции адаптивного запаса М на заранее заданную величину Ms на шаге 224 способа 200.
Исходное значение m0 для адаптивного коэффициента m масштабирования может быть равно единице (например, m0=1) или по существу единице. В качестве альтернативного варианта данного способа исходное значение m0 может быть несколько меньшим единицы, например, лежать в диапазоне 0,9-0,99, что гарантирует выбор в пользу квантования без предсказания вместо квантования с предсказанием, даже когда длина L серии предсказаний равна 0, т.е. в кадре, непосредственно следующим за кадром, для которого было выбрано квантование без предсказания. В качестве альтернативного примера, который позволяет гарантировать постоянное предпочтение выбору квантования без предсказания, условие на шаге 303 может быть переписано как
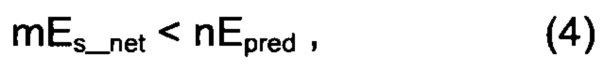
где заранее заданный коэффициент n равен, например, значению в диапазоне 1,01-1,1, например, n=1,05, и при этом исходное значение m0 коэффициента m масштабирования принимают равным единице (например, m0=1).
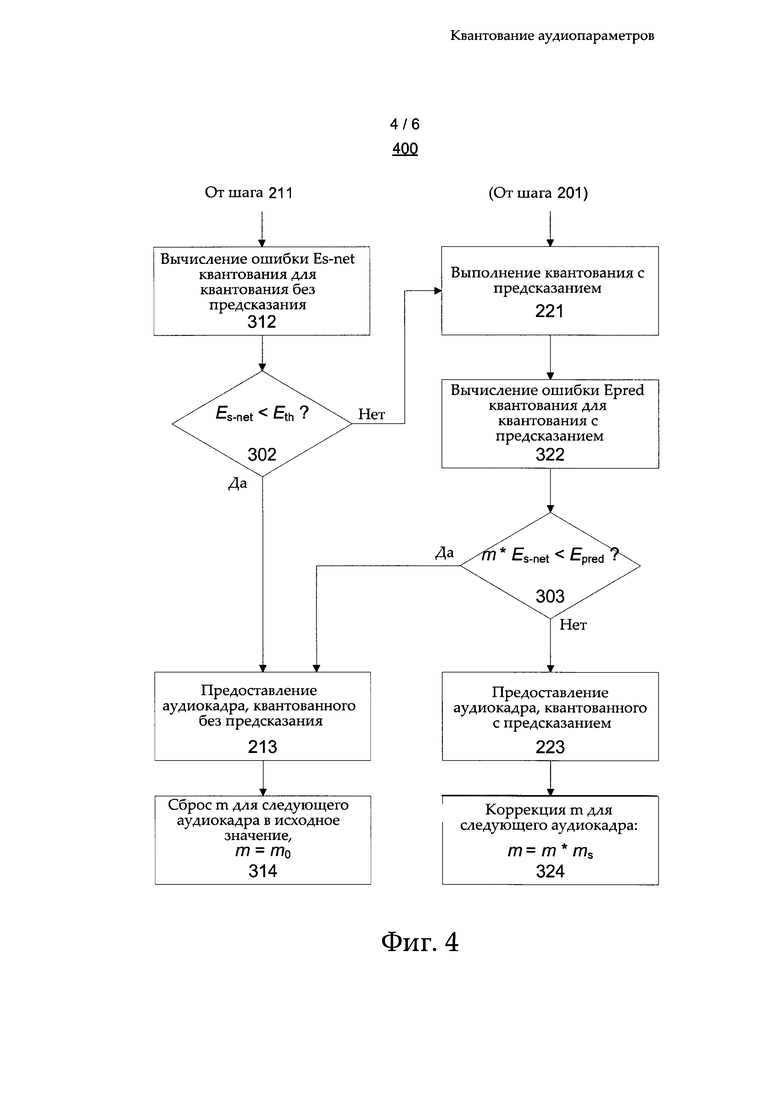
Заранее заданный коэффициент ms масштабирования может представлять собой положительное значение, меньшее единицы, что позволяет уменьшить адаптивный коэффициент m масштабирования для следующего кадра i+1. В этих целях заранее заданный коэффициент ms масштабирования может быть принят равным значению, выбранному из диапазона 0,75-0,95, например, ms=0,8. Это соответствует увеличению адаптивного запаса М в каждом следующем кадре серии последовательных аудиокадров, для которых было выбрано квантование с предсказанием. На фиг. 4 показана блок-схема алгоритма, иллюстрирующая работу аудикодера 121, в виде шагов примера способа 400. Способ 400 представлен как альтернативный вариант способа 300 и служит еще одним примером осуществления настоящего изобретения в базовой структуре, описанной выше в отношении способа 200. Все шаги способа 400 идентичны шагам способа 300, но при этом перед шагом 303 определения добавлен еще один шаг 302 проверки.
На шаге 302 обеспечивают дополнительный критерий для выбора квантования без предсказания для одного или более аудиопараметров текущего аудиокадра. А именно, компонент 125 квантования может выбирать квантование без предсказания, если ошибка Es-net квантования меньше, чем заранее заданный порог Eth. И наоборот, компонент 125 квантования может переходить к шагу 303 определения, если ошибка Es-net квантования не меньше, чем заранее заданный порог Eth. Если проверка на шаге 302 дает положительный результат, в способе 400 выполняют переход к квантованию с предсказанием одного или более параметров аудиокадра (шаг 221) и затем к вычислению ошибки Epred квантования в результате квантования без предсказания одного или более аудиопараметров текущего аудиокадра (шаг 322). Следовательно, обработка данных, необходимая для квантования с предсказанием (шаг 212), и вычисление ошибки Epred квантования (шаг 322) могут быть опущены, если они не требуются, что позволяет сэкономить вычислительные ресурсы.
В одном из вариантов способа 400 шаги 221 и 322 могут выполняться параллельно шагам 211 и 312, перед переходом к шагу 302. В таком варианте, если проверка на шаге 302 дает положительный результат, в способе 400 выполняют переход к шагу 213, тогда как если проверка на шаге 302 не дает положительного результата, в способе 400 выполняют переход к шагу 303.
В соответствии с приведенным выше описанием для ошибки Е1 квантования, в контексте способа 400 соображения, остаются верными соображения относительно порога Eth, приведенные в контексте способа 200: подходящее значение для порога Eth будет различным для различных аудиопараметров, а также, возможно, для различных весовых функций, применяемых для взвешивания ошибки квантования, и соответственно, должно быть вычислено эмпирически и автономно, при этом, например, порог Eth может быть выбран равным значению, соответствующему спектральному искажению в диапазоне от 0,8 до 1,0 дБ, например, 0,9 дБ. Способ 400, опционально, может включать один или более шагов определения для оценки соответствующих одного или более правил выбора, которые могут приводить к выбору квантования без предсказания. Например, такой шаг (или шаги) определения могут быть внедрены до или после шага 302.
На фиг. 5 показана блок-схема алгоритма, иллюстрирующая работу аудикодера 121, в виде шагов примера способа 500. Способ 500 представлен как альтернативный вариант способа 400 и служит еще одним примером осуществления настоящего изобретения в базовой структуре, описанной выше в отношении способа 200. В способе 500 шаги 314 и 324 способа 400 заменены на соответствующие шаги 414 и 424, а все остальные шаги 500 совпадают со способом 400. Данный способ рассмотрен здесь как модификация способа 400, однако аналогичная модификация может быть также проведена над способом 300.
В способе 500, если компонент 125 квантования выбрал квантование без предсказания для одного или более аудиопараметров в текущем аудиокадре i, компонент 125 квантования может также сбрасывать адаптивный коэффициент m масштабирования, который будет использоваться компонентом 125 квантования в следующем кадре i+1, путем присвоения адаптивному коэффициенту m масштабирования исходного значения m0 (в соответствии с предшествующим описанием, в контексте шага 314), а также сбрасывать счетчик, указывающий на текущую длину L серии предсказаний до нулевого значения (шаг 414).
И наоборот, если компонент 125 квантования выбрал квантование без предсказания для одного или более аудиопараметров в текущем аудиокадре i, компонент 125 квантования может также увеличивать счетчик, указывающий на текущую длину L серии предсказаний, на единицу, и затем корректировать адаптивный коэффициент m масштабирования, который будет использоваться компонентом 125 квантования в следующем кадре i+1, путем умножения адаптивного коэффициента m масштабирования на заранее заданный коэффициент ms (в соответствии с предшествующим описанием в контексте шага 324), при условии, что текущая длина L серии предсказаний превосходит порог L0 (шаг 424). Соответственно, адаптивный коэффициент m масштабирования сохраняет свое исходное значение m0 до тех пор, пока текущая длина L серии предсказаний не превзойдет порог L0, при этом коррекцию адаптивного коэффициента m масштабирования с использованием коэффициента ms масштабирования выполняют для каждого кадра серии предсказаний, длина которой превышает порог L0.
В контексте примеров 300, 400 и 500, описанных выше, коррекция адаптивного коэффициента m масштабирования описана, как выполняющаяся либо сбросом коэффициента m масштабирования в исходное значение m0 (шаги 314, 414), либо коррекцией коэффициента m масштабирования с присвоением нового значения (шаги 324, 424), и его использования при обработке следующего аудиокадра в компоненте 125 квантования.
В этом отношении, в качестве альтернативного подхода для любого из способов 300, 400 и 500, упомянутые шаги сброса и коррекции могут быть опущены, а значение адаптивного коэффициента m масштабирования может вычисляться на основе текущей длины L серии предсказаний. С этой целью соответствующий способ 300, 400 может также включать отслеживание текущего значения длины L серии предсказаний, например, согласно соответствующему описанию шагов 414 и 424 способа 500.
В этом отношении, в качестве одного из примеров, адаптивный коэффициент m масштабирования может вычисляться на основе длины L серии предсказаний, например, в соответствии с уравнением (5а) или на основе длины L серии предсказаний и заранее заданного порога L0, например, согласно уравнению (5b).

В этой связи, в качестве другого примера, адаптивный коэффициент m масштабирования может быть получен индексацией таблицы, к которой имеет доступ компонент 125 квантования. Подобная таблица может быть сконфигурирована для хранения соответствующего значения адаптивного коэффициента m масштабирования для каждого значения в заранее заданном диапазоне значений L, например, от 0 до Lmax, где Lmax - максимально предполагаемая (или допустимая) длина L серии предсказаний. Вычисление адаптивного коэффициента m масштабирования или доступ к таблице для нахождения значения адаптивного коэффициента m масштабирования может быть реализовано, например, как дополнительный шаг перед шагом 303 (в способах 300, 400, 505) или перед шагом 302 (в способах 400, 500).
Полученные квантованные аудиокадры могут быть переданы передатчиком 112 как часть кодированных аудиоданных в битовом потоке, вместе с дополнительной информацией, например, вместе с указанием на тип использованного квантования. Альтернативно, квантованные аудиокадры и опциональное указание на тип применяемого квантования могут быть сохранены в память электронного устройства 100 для последующего декодирования и/или последующей передачи передатчиком 112.
В электронном устройстве 150 битовый поток принимают с помощью приемного компонента 162 и предоставляют в декодер 171. В декодере 171 синтезирующий компонент 174 формирует синтезированный аудиосигнал на основе квантованных параметров из принятого битового потока. Восстановленный аудиосигнал может быть затем передан в компонент 161 вывода аудиоданных, возможно, после дополнительной обработки, например, цифро-аналогового преобразования.
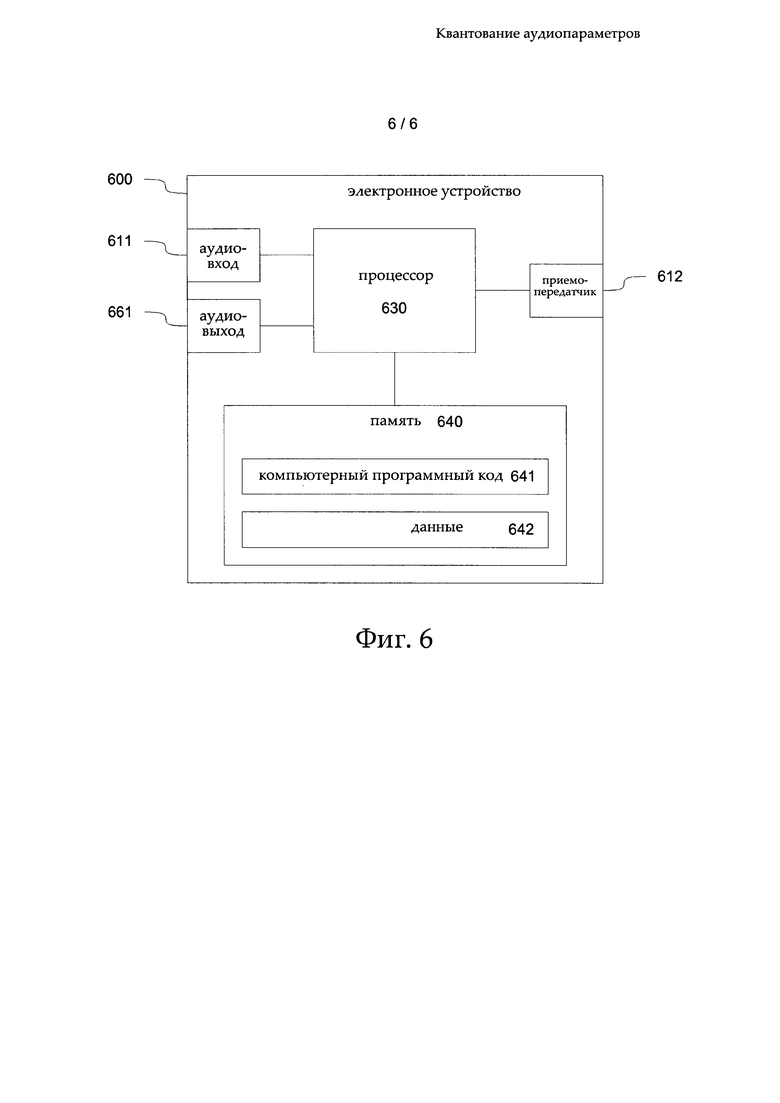
Блоки на фиг. 2-5 могут также рассматриваться как схематически представленные, отдельные блоки обработки данных из состава компонента 125 квантования. На фиг. 6 показана эскизная блок-схема примера электронного устройства 600, в котором, в виде программного обеспечения, может быть реализован выбор квантования с предсказанием или квантования без предсказания, в соответствии с одним из вариантов осуществления настоящего изобретения. Электронное устройство 600 может быть, например, мобильным телефоном. Оно включает процессор 630, который соединен с компонентом 611 ввода аудиоданных, компонентом вывода 661 аудиоданных, приемопередатчиком (RX/TX) 612 и памятью 640. Необходимо понимать, что проиллюстрированные соединения в электронном устройстве 600 могут быть реализованы при помощи различных дополнительных элементов, не показанных на чертеже.
Компонент 611 ввода аудиоданных может быть, например, микрофоном, микрофонной установкой или интерфейсом к источнику аудиоданных. Компонент 661 вывода аудиоданных может быть, например, громкоговорителем. Память 640 включает раздел 641 для хранения компьютерного программного кода и раздел 642 для хранения данных. Хранимый компьютерный программный код включает код для кодирования аудиосигналов с использованием выбираемого типа квантования, а также, возможно, код для декодирования аудиосигналов. Процессор 630 сконфигурирован для исполнения доступного ему программного кода. Если доступный код хранится в памяти 640, процессор 630 может извлекать этот код, в соответствующих целях, из раздела 641 памяти 640 всякий раз, когда это необходимо. Нужно понимать, что для исполнения могут быть доступны и различные другие программные коды, например, программный код операционной системы или программные коды различных приложений.
Хранимый код, используемый для кодирования аудиоданных, или процессор 630 в комбинации с памятью 640 могут также рассматриваться как примеры устройств, соответствующие вариантам осуществления настоящего изобретения. Память 640, в которой хранят программный код, может рассматриваться как пример компьютерного программного продукта в соответствии с одним из примеров осуществления настоящего изобретения.
Когда пользователь или, например, процедура, запущенная на электронном устройстве 600, выбирает режим функционирования электронного устройства 600, при котором необходимо кодирования входного аудиосигнала, приложение, предоставляющее эту функцию, обеспечивает извлечение, процессором 630 из памяти 640, кода для кодирования аудиоданных. Затем аудиосигналы, принятые через компонент 611 ввода аудиоданных, предоставляют в процессор 630 после преобразования в цифровые аудиосигналы (в случае приема аналоговых аудиосигналов), и возможно, дополнительных шагов предварительной обработки, необходимых или применяемых перед предоставлением аудиосигналов в процессор 630.
Процессор 630 исполняет извлеченный код, который используют для кодирования цифрового аудиосигнала. Кодирование может соответствовать кодированию, описанному выше в отношении фиг. 1, со ссылками на фиг. 2-5. Код, используемый для кодирования, таким образом, может рассматриваться как компьютерный программный код, который обеспечивает, например, выполнение кодирования, описанного выше в отношении фиг. 1, со ссылками на фиг. 2-5, когда этот компьютерный программный код исполняют на процессоре 630 или другом вычислительном устройстве. Кодированный аудиосигнал сохраняют в разделе 642 для хранения данных в памяти 640 для использования в дальнейшем или передают с помощью приемопередатчика 612 в другое электронное устройство.
Процессор 630 может также извлекать код для декодирования из памяти 640 и исполнять его с целью декодирования кодированного аудиосигнала, который либо принят при помощи приемопередатчика 612, либо извлечен из раздела 642 для хранения данных в памяти 640. Декодирование может соответствовать декодированию, описанному выше в отношении фиг. 1. Декодированный цифровой аудиосигнал затем может быть предоставлен в компонент 661 вывода аудиоданных. В случае, когда компонент 661 вывода аудиоданных включает громкоговоритель, декодированный аудиосигнал, например, может быть представлен пользователю при помощи громкоговорителя после преобразования в аналоговый аудиосигнал и опциональных дополнительных шагов постобработки. Альтернативно, декодированный аудиосигнал может быть сохранен в разделе 642 для хранения данных в памяти 640.
Функции, проиллюстрированные с использованием компонента 125 квантования на фиг. 1, или функции, проиллюстрированные с использованием процессора 630, исполняющего программный код 641 на фиг. 6, могут также рассматриваться как средства вычисления первой ошибки квантования, описывающей ошибку в результате квантования без предсказания аудиопараметра фрагмента аудиосигнала, средства вычисления второй ошибки квантования, описывающей ошибку в результате квантования с предсказанием упомянутого аудиопараметра упомянутого фрагмента аудиосигнала, средства определения, превосходит ли упомянутая вторая ошибка квантования упомянутую первую ошибку квантования по меньшей мере на адаптивный запас, который зависит от количества последовательных фрагментов аудиосигнала, предшествующих упомянутому фрагменту аудиосигнала, в котором было выполнено квантование упомянутого аудиопараметра с использованием упомянутого квантования с предсказанием, средства предоставления упомянутого аудиопараметра упомянутого фрагмента аудиосигнала, квантованного с использованием упомянутого квантования без предсказания в качестве части кодированного аудиосигнала по меньшей мере в случае, когда результат упомянутого определения положителен, и средства предоставления, в противном случае, упомянутого аудиопараметра упомянутого фрагмента аудиосигнала, квантованного с использованием упомянутого квантования с предсказанием, в качестве части кодированного аудиосигнала. Программные коды 641 могут также рассматриваться как включающие эти средства в форме функциональных модулей или кодовых компонентов.
Фундаментально новые элементы настоящего изобретения были проиллюстрированы, описаны и отмечены как применяемые в предпочтительных вариантах осуществления настоящего изобретения, однако нужно понимать, что специалистами в данной области техники могут выполняться различные опущения, замены и изменения в форме и деталях описанных устройств и способов, без выхода за рамки настоящего изобретения. Например, безоговорочно предполагается, что все комбинации этих элементов и/или шагов способов, которые выполняют по существу одну и ту же функцию по существу одним и тем же образом для получения одинаковых результатов, попадают в объем правовой защиты настоящего изобретения. При этом нужно понимать, что структуры и/или элементы, и/или шаги способов, проиллюстрированные и/или описанные в связи с любой описанной формой или вариантом осуществления изобретения, могут входить в состав любой другой заявленной или описанной, или предполагаемой формы или варианта осуществления изобретения, в зависимости от принятого конструкторского решения. Соответственно, они ограничены только приложенной формулой изобретения. Также, в формуле изобретения, пункты типа «средства плюс функция» имеют целью охватить структуры, описанные в настоящем документе как выполняющие указанную функцию, и не только структурные эквиваленты, но также и эквивалентные структуры.


Изобретение относится к средствам для аналого-цифрового преобразования аудио. Технический результат заключается в повышении эффективности аналого-цифрового преобразования аудио. Вычисляют первую ошибку квантования, которая описывает ошибку, полученную в результате квантования без предсказания для аудиопараметра фрагмента аудиосигнала. Вычисляют вторую ошибку квантования, которая описывает ошибку, полученную в результате квантования с предсказанием для упомянутого аудиопараметра фрагмента аудиосигнала. Определяют, превосходит ли вторая ошибка квантования первую ошибку квантования, по меньшей мере, на адаптивный запас, который зависит от количества последовательных фрагментов аудиосигнала, предшествующих упомянутому фрагменту аудиосигнала, в котором было выполнено квантование упомянутого аудиопараметра с использованием квантования с предсказанием. Предоставляют упомянутый аудиопараметр фрагмента аудиосигнала, квантованный с использованием квантования без предсказания, в качестве части кодированного аудиосигнала в том случае, когда результат упомянутого определения положительный. Иначе предоставляют упомянутый аудиопараметр фрагмента аудиосигнала, квантованного с использованием квантования с предсказанием, в качестве части кодированного аудиосигнала. 3 н. и 20 з.п. ф-лы, 6 ил.
1. Способ кодирования аудиосигнала путем обработки последовательности фрагментов аудиосигнала, включающий
вычисление первой ошибки квантования, которая описывает ошибку, полученную в результате квантования без предсказания для аудиопараметра фрагмента аудиосигнала,
вычисление второй ошибки квантования, которая описывает ошибку, полученную в результате квантования с предсказанием для упомянутого аудиопараметра фрагмента аудиосигнала,
определение, превосходит ли упомянутая вторая ошибка квантования упомянутую первую ошибку квантования, по меньшей мере, на адаптивный запас, который зависит от количества последовательных фрагментов аудиосигнала, предшествующих упомянутому фрагменту аудиосигнала, в котором было выполнено квантование упомянутого аудиопараметра с использованием квантования с предсказанием,
предоставление упомянутого аудиопараметра фрагмента аудиосигнала, квантованного с использованием квантования без предсказания, в качестве части кодированного аудиосигнала, по меньшей мере, в том случае, когда результат упомянутого определения положительный, и
предоставление, в противном случае, упомянутого аудиопараметра упомянутого фрагмента аудиосигнала, квантованного с использованием квантования с предсказанием, в качестве части кодированного аудиосигнала.
2. Способ по п. 1, в котором упомянутый адаптивный запас увеличивают относительно его заранее заданного исходного значения на заранее заданную величину для каждого фрагмента аудиосигнала между упомянутым фрагментом аудиосигнала и ближайшим предшествующим фрагментом аудиосигнала, в котором было выполнено квантование упомянутого аудиопараметра с использованием упомянутого квантования с предсказанием.
3. Способ по п. 2, в котором упомянутое заранее заданное исходное значение является нулевым.
4. Способ по п. 1, в котором упомянутое определение включает определение, является ли упомянутая первая ошибка квантования, умноженная на адаптивный коэффициент масштабирования, меньшей, чем упомянутая вторая ошибка квантования, при этом упомянутый адаптивный коэффициент масштабирования представляет собой адаптивный запас для упомянутого фрагмента аудиосигнала.
5. Способ по п. 4, включающий уменьшение упомянутого коэффициента масштабирования на заранее заданную величину в случае, когда квантование упомянутого фрагмента аудиосигнала было выполнено с использованием упомянутого квантования с предсказанием.
6. Способ по п. 4, также включающий уменьшение упомянутого коэффициента масштабирования на заранее заданную величину в случае, когда квантование упомянутого фрагмента аудиосигнала было выполнено с использованием квантования с предсказанием, и упомянутое количество последовательных фрагментов аудиосигнала превышает заранее заданное пороговое значение.
7. Способ по любому из пп. 4-6, также включающий сброс упомянутого коэффициента масштабирования в заранее заданное исходное значение в случае, когда квантование упомянутого фрагмента аудиосигнала было выполнено с использованием квантования без предсказания.
8. Способ по п. 7, в котором упомянутое заранее заданное исходное значение равно единице.
9. Способ по п. 6, в котором упомянутое заранее заданное пороговое значение равно трем.
10. Способ по любому из пп. 1-9, в котором упомянутый аудиопараметр включает вектор спектральной частоты иммитанса и/или вектор частоты спектральной линии, которые являются представлением спектральных характеристик упомянутого фрагмента аудиосигнала.
11. Способ по любому из пп. 1-10, в котором
упомянутую первую ошибку квантования получают с помощью комбинирования взвешенных расхождений между составляющей упомянутого аудиопараметра и соответствующей составляющей упомянутого аудиопараметра, полученной в результате упомянутого квантования без предсказания, и
упомянутую вторую ошибку квантования получают с помощью комбинирования взвешенных расхождений между составляющей упомянутого аудиопараметра и соответствующей составляющей упомянутого аудиопараметра, полученной в результате упомянутого квантования с предсказанием.
12. Машиночитаемый носитель, содержащий машиночитаемый программный код, сконфигурированный для обеспечения выполнения способа по любому из пп. 1-11, когда упомянутый программный код исполняют в вычислительном устройстве.
13. Устройство для кодирования аудиосигнала путем обработки последовательности фрагментов аудиосигнала, сконфигурированное для
вычисления первой ошибки квантования, которая описывает ошибку, полученную в результате квантования без предсказания для аудиопараметра фрагмента аудиосигнала,
вычисления второй ошибки квантования, которая описывает ошибку, полученную в результате квантования с предсказанием для упомянутого аудиопараметра фрагмента аудиосигнала,
определения, превосходит ли упомянутая вторая ошибка квантования упомянутую первую ошибку квантования, по меньшей мере, на адаптивный запас, который зависит от количества последовательных фрагментов аудиосигнала, предшествующих упомянутому фрагменту аудиосигнала, в котором было выполнено квантование упомянутого аудиопараметра с использованием упомянутого квантования с предсказанием,
предоставления упомянутого аудиопараметра упомянутого фрагмента аудиосигнала, квантованного с использованием упомянутого квантования без предсказания, в качестве части кодированного аудиосигнала, по меньшей мере, в том случае, когда результат упомянутого определения положительный, и
предоставления, в противном случае, упомянутого аудиопараметра фрагмента аудиосигнала, квантованного с использованием квантования с предсказанием, в качестве части кодированного аудиосигнала.
14. Устройство по п. 13, также сконфигурированное для увеличения упомянутого адаптивного запаса относительно его заранее заданного исходного значения на заранее заданную величину для каждого фрагмента аудиосигнала между упомянутым фрагментом аудиосигнала и ближайшим предшествующим фрагментом аудиосигнала, в котором было выполнено квантование упомянутого аудиопараметра с использованием квантования с предсказанием.
15. Устройство по п. 14, в котором упомянутое заранее заданное исходное значение является нулевым.
16. Устройство по п. 13, в котором упомянутое определение включает определение, является ли упомянутая первая ошибка квантования, умноженная на адаптивный коэффициент масштабирования, меньшей, чем упомянутая вторая ошибка квантования, при этом упомянутый адаптивный коэффициент масштабирования представляет собой адаптивный запас для упомянутого фрагмента аудиосигнала.
17. Устройство по п. 16, также сконфигурированное для уменьшения упомянутого коэффициента масштабирования на заранее заданную величину в случае, когда квантование упомянутого фрагмента аудиосигнала было выполнено с использованием квантования с предсказанием.
18. Устройство по п. 16, также сконфигурированное для уменьшения упомянутого коэффициента масштабирования на заранее заданную величину в случае, когда квантование упомянутого фрагмента аудиосигнала было выполнено с использованием квантования с предсказанием, и упомянутое количество последовательных фрагментов аудиосигнала превышает заранее заданное пороговое значение.
19. Устройство по любому из пп. 16-18, также сконфигурированное для сброса упомянутого коэффициента масштабирования в заранее заданное исходное значение в случае, когда квантование упомянутого фрагмента аудиосигнала было выполнено с использованием квантования без предсказания.
20. Устройство по п. 19, в котором упомянутое заранее заданное исходное значение равно единице.
21. Устройство по п. 18, в котором упомянутое заранее заданное пороговое значение равно трем.
22. Устройство по любому из пп. 13-21, в котором упомянутый аудиопараметр включает вектор спектральной частоты иммитанса и/или вектор частоты спектральной линии, которые являются представлением спектральных характеристик упомянутого фрагмента аудиосигнала.
23. Устройство по любому из пп. 13-22, также сконфигурированное для вычисления упомянутой первой ошибки квантования с помощью комбинирования взвешенных расхождений между составляющей упомянутого аудиопараметра и соответствующей составляющей упомянутого аудиопараметра, полученной в результате квантования без предсказания, и вычисления упомянутой второй ошибки квантования с помощью комбинирования взвешенных расхождений между составляющей упомянутого аудиопараметра и соответствующей составляющей упомянутого аудиопараметра, полученной в результате квантования с предсказанием.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| СПОСОБ ОБРАБОТКИ КОЖИ | 0 |
|
SU395440A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| US 6574593 B1, 03.06.2003 | |||
| US 7209878 B2, 24.04.2007 | |||
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| КОДИРУЮЩЕЕ УСТРОЙСТВО, ДЕКОДИРУЮЩЕЕ УСТРОЙСТВО И СПОСОБ | 2012 |
|
RU2488897C1 |

