Изобретение в целом относится к области масштабируемого видеокодирования и декодирования, в частности, к масштабируемому видеокодированию и декодированию, которое расширило бы стандарт высокоэффективного видеокодирования (HEVC). В частности, изобретение относится к способу, устройству и компьютерной программе для предсказания вектора движения в масштабируемом видеокодере и декодере.
Видеокодирование представляет собой способ преобразования последовательности видеоизображений в компактный оцифрованный битовый поток таким образом, чтобы видеоизображения могли быть переданы или сохранены. Устройство для кодирования используется для кодирования видеоизображений, и соответствующее устройство для декодирования доступно для воссоздания битового потока для отображения и просмотра. Общая цель состоит в том, чтобы сформировать битовый поток меньшего размера, чем первоначальная видеоинформация. Это выгодным образом уменьшает пропускную способность, требуемую для сети передачи или устройства хранения, чтобы передать или сохранить код битового потока.
Общие стандартизированные подходы были приняты для формата и способа процесса кодирования, особенно относительно части декодирования. Значительное большинство прошлых видеостандартов разбивают видеоизображения на меньшие секции (называемые макроблоками или блоками). В новом завершаемом стандарте сжатия видео высокоэффективного видеокодирования (HEVC) макроблоки заменены так называемыми наибольшими элементами кодирования (LCU) (также называемыми иерархическими блоками кодирования (CTB)) и разделены и выровнены как блоки, называемые теперь элементами кодирования (CU) в соответствии с характеристиками сегмента рассматриваемого исходного изображения. Это дает возможность более детализированного кодирования областей видеоизображения, которые содержат относительно больше информации, и меньших усилий по кодированию для этих областей с меньшим количеством признаков. Следует отметить, что область изображения также известна под следующими различными терминами в литературе по сжатию видео: пиксельный блок, блок пикселей, блок, элемент кодирования (CU) и макроблок.
В настоящее время определяется масштабируемое расширение HEVC. В этом расширении изображения рассматриваются как состоящие из множества иерархических уровней. Иерархические уровни включают в себя базовый уровень, эквивалентный коллекции низкокачественных версий изображений (или кадров) первоначальной последовательности видеокадров, и один или более улучшающих уровней (также известных как уровни уточнения).
Видеоизображения первоначально обрабатывались посредством индивидуального кодирования каждого макроблока, что напоминает цифровое кодирование неподвижных изображений. Позже модели кодирования допускают предсказание признаков в одном кадре либо на основе соседних макроблоков (пространственное или интра-предсказание), либо посредством ассоциации с аналогичным макроблоком в соседнем кадре (временное предсказание). Это дает возможность использования уже доступной закодированной информации, тем самым сокращая величину битовой скорости кодирования, необходимой в целом. Различия между первоначальным блоком для кодирования и блоком, используемым для предсказания, захватываются в остаточном множестве значений. Затем первоначальный блок кодируется в форме идентификатора блока, используемого для предсказания, и разности. Возможны многие различные типы предсказаний. Эффективное кодирование выбирает наилучший режим предсказания, обеспечивающий наивысшее качество для кодирования блока при декодировании, при этом принимая во внимание размер битового потока, производимый каждым режимом предсказания для представления упомянутого блока в битовом потоке. Общей целью является компромисс между качеством декодированного изображения и сокращением необходимой битовой скорости, также известный как компромисс скорости/искажения.
В случае временного предсказания возможны несколько типов предсказания, и они могут быть собраны в два основных типа: однонаправленное предсказание и двунаправленное предсказание. В случае однонаправленного предсказания блок для предсказания связывается с одним предиктором. Местоположение предиктора кодируется как информация движения. Эта информация движения состоит из индекса опорного кадра, содержащего предиктор, называемого ref_idx в стандарте, и вектора, определенного вертикальным и горизонтальным смещением, которое задает местоположение блока предиктора в указанном кадре. В случае двунаправленного предсказания блок для кодирования связывается с двумя предикторами, взятыми в двух разных опорных кадрах. Как следствие информация движения содержит два индекса опорных кадров и два вектора.
Информация движения сама может сама закодирована с предсказанием. Информация движения, полученная соседнего элемента кодирования в том же самом кадре, может использоваться в качестве пространственных предикторов информации движения. Информация движения, полученная из совмещенного элемента кодирования в других кадрах, может использоваться в качестве временного предиктора информации движения. Информация движения, которая будет закодирована для блока, для кодирования затем кодируется с помощью индекса в используемом предикторе информации движения и разностной информации, представляющей различие между выбранным предиктором информации движения и информацией движения, которая будет закодирована.
Предсказание информации движения на основе информации движения, соответствующей предыдущим изображениям, требует, чтобы кодер и декодер хранили поле движения ранее закодированных изображений. Это поле движения может представлять огромный объем данных для хранения, тем более для видеоматериалов, демонстрирующих большое разрешение, таких как видеоматериалы 4k2k или 8k4k. Чтобы ограничить требования хранения кодеков HEVC, стандарт HEVC принял стратегию, состоящую в использовании сжатых полей движения для предсказания информации движения вместо всего поля движения.
Хранение поля движения требуется только тогда, когда используется информация движения предыдущих изображений. В HEVC использование временных предикторов информации движения может быть деактивировано. В этом случае может быть получено дополнительное сокращение требований хранения кодека HEVC посредством предотвращения хранения какой-либо информации движения.
Одна из основных идей в масштабируемом кодеке состоит в том, чтобы повторно использовать информацию из опорного уровня (RL), закодированного с использованием заданного кодека (например, HEVC), чтобы закодировать информацию улучшающего уровня.
Было бы желательно использовать информацию движения, определенную в опорном уровне, для предсказывающего кодирования информации движения в улучшающем уровне. В частности, если использование временных предикторов информации движения в опорном уровне деактивировано, может случиться, что никакая информация движения не может быть доступна для использования для предсказания информации движения в улучшающем уровне.
Настоящее изобретение было создано, чтобы обратиться к одной или более упомянутых проблем. Оно относится к процессу определения предиктора информации движения в улучшающем уровне схемы масштабируемого кодирования, также известного как процесс выявления движения. Он содержит коррекцию позиции в опорном уровне, используемом для подбора более соответствующей информации движения, доступной вследствие схемы сжатия.
В соответствии с первым аспектом изобретения обеспечен способ кодирования изображения в соответствии с форматом масштабируемого кодирования, упомянутый формат кодирования содержит по меньшей мере опорный уровень и улучшающий уровень, по меньшей мере часть изображения закодирована с предсказанием на основе информации движения, упомянутая информация движения сама закодирована с предсказанием на основе множества предикторов информации движения, причем способ содержит по меньшей мере для области изображения улучшающего уровня этапы, на которых определяют множество предикторов информации движения на основе информации движения другой части изображений, принадлежащих опорному уровню; определяют совмещенную позицию в опорном уровне области изображения для кодирования в улучшающем уровне, чтобы выбрать информацию движения, связанную с упомянутой позицией, как часть упомянутого множества предикторов информации движения и корректируют по меньшей мере одну координату упомянутой совмещенной позиции, причем упомянутая корректировка содержит сложение определенного значения по меньшей мере с одной из координат упомянутой совмещенной позиции, чтобы получить модифицированное значение координаты, и применение функции округления к модифицированному значению координаты.
В соответствии с дополнительным аспектом изобретения обеспечен способ декодирования изображения в соответствии с форматом масштабируемого кодирования, упомянутый формат кодирования содержит по меньшей мере опорный уровень и улучшающий уровень, по меньшей мере часть изображения закодирована с предсказанием на основе информации движения, упомянутая информация движения сама закодирована с предсказанием на основе множества предикторов информации движения, причем способ содержит по меньшей мере для области изображения улучшающего уровня этапы, на которых определяют множество предикторов информации движения на основе информации движения другой части изображений, принадлежащих опорному уровню; определяют совмещенную позицию в опорном уровне области изображения для декодирования в улучшающем уровне, чтобы выбрать информацию движения, связанную с упомянутой позицией, как часть упомянутого множества предикторов информации движения и корректируют по меньшей мере одну координату упомянутой совмещенной позиции, причем упомянутая корректировка содержит сложение определенного значения по меньшей мере с одной из координат упомянутой совмещенной позиции, чтобы получить модифицированное значение координаты, и применение функции округления к модифицированному значению координаты.
В соответствии с другим аспектом изобретения обеспечено устройство для кодирования изображения в соответствии с форматом масштабируемого кодирования, упомянутый формат кодирования содержит по меньшей мере опорный уровень и улучшающий уровень, по меньшей мере часть изображения закодирована с предсказанием на основе информации движения, упомянутая информация движения сама закодирована с предсказанием на основе множества предикторов информации движения, причем устройство содержит по меньшей мере для области изображения улучшающего уровня модуль определения предикторов для определения множества предикторов информации движения на основе информации движения другой части изображений, принадлежащих опорному уровню; модуль определения позиции для определения совмещенной позиции в опорном уровне области изображения для кодирования в улучшающем уровне, чтобы выбрать информацию движения, связанную с упомянутой позицией, как часть упомянутого множества предикторов информации движения и модуль коррекции позиции для коррекции по меньшей мере одной координаты упомянутой совмещенной позиции, причем упомянутая корректировка содержит сложение определенного значения по меньшей мере с одной из координат упомянутой совмещенной позиции, чтобы получить модифицированное значение координаты, и применение функции округления к модифицированному значению координаты.
В соответствии с другим аспектом изобретения обеспечено устройство для декодирования изображения в соответствии с форматом масштабируемого кодирования, упомянутый формат кодирования содержит по меньшей мере опорный уровень и улучшающий уровень, по меньшей мере часть изображения закодирована с предсказанием на основе информации движения, упомянутая информация движения сама закодирована с предсказанием на основе множества предикторов информации движения, причем устройство содержит по меньшей мере для области изображения улучшающего уровня модуль определения предикторов для определения множества предикторов информации движения на основе информации движения другой части изображений, принадлежащих опорному уровню; модуль определения позиции для определения совмещенной позиции в опорном уровне области изображения для декодирования в улучшающем уровне, чтобы выбрать информацию движения, связанную с упомянутой позицией, как часть упомянутого множества предикторов информации движения и модуль коррекции позиции для коррекции по меньшей мере одной координаты упомянутой совмещенной позиции, причем упомянутая корректировка содержит сложение определенного значения по меньшей мере с одной из координат упомянутой совмещенной позиции, чтобы получить модифицированное значение координаты, и применение функции округления к модифицированному значению координаты.
По меньшей мере части способов в соответствии с изобретением могут быть реализованы с помощью компьютера. В соответствии с этим настоящее изобретение может принять форму полностью аппаратного варианта осуществления, полностью программного варианта осуществления (в том числе программно-аппаратного обеспечения, резидентного программного обеспечения, микрокода и т.д.) или варианта осуществления, комбинирующего аспекты программного и аппаратного обеспечения, которые в целом могут упоминаться здесь как "схема", "модуль" или "система". Кроме того, настоящее изобретение может принять форму компьютерного программного продукта, воплощенного в любом материальном носителе, в выражении, имеющем используемый с помощью компьютера программный код, воплощенный на носителе.
Поскольку настоящее изобретение может быть реализовано в программном обеспечении, настоящее изобретение может быть воплощено как машиночитаемый код для предоставления программируемому устройству на любом подходящем носителе. Материальный носитель может содержать запоминающий носитель, такой как гибкий диск, компакт-диск (CD-ROM), накопитель на жестком диске, магнитную ленту или твердотельную память и т.п. Переходный носитель может включить в себя сигнал, такой как электрический сигнал, электронный сигнал, оптический сигнал, акустический сигнал, магнитный сигнал или электромагнитный сигнал, например, микроволновый или радиочастотный сигнал.
Теперь будут описаны варианты осуществления изобретения только в качестве примера и со ссылкой на следующие чертежи, на которых:
Фиг. 1 иллюстрирует блок-схему классического масштабируемого видеокодера;
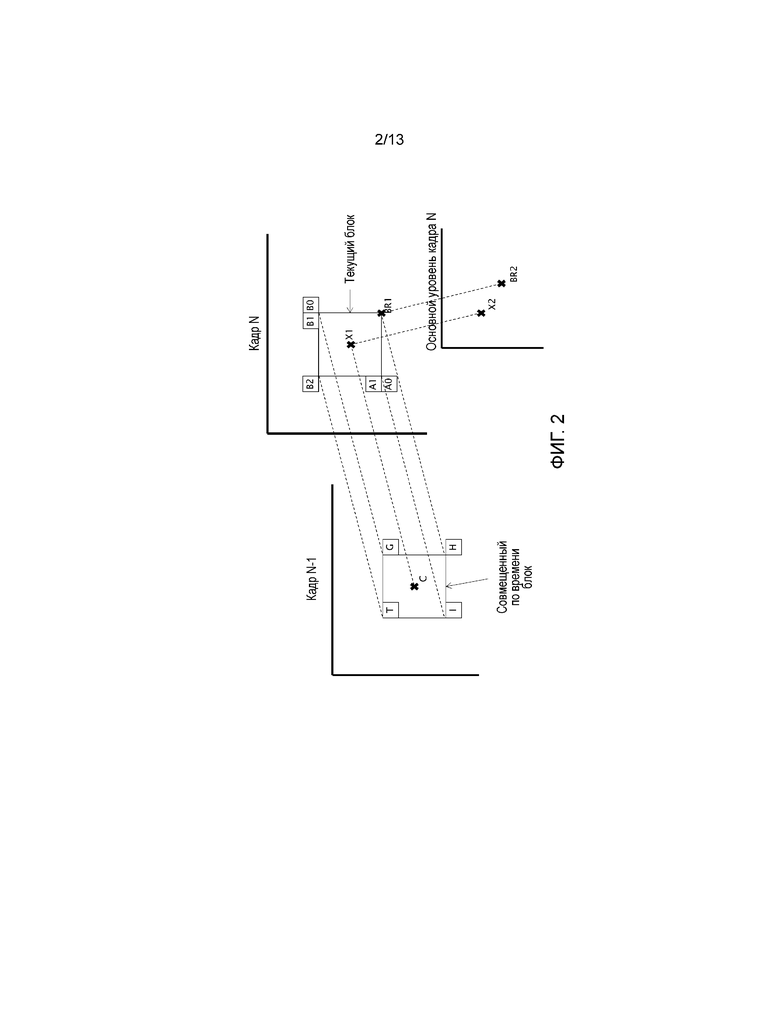
Фиг. 2 иллюстрирует пространственные и временные позиции для предикторов информации движения в варианте осуществления изобретения;
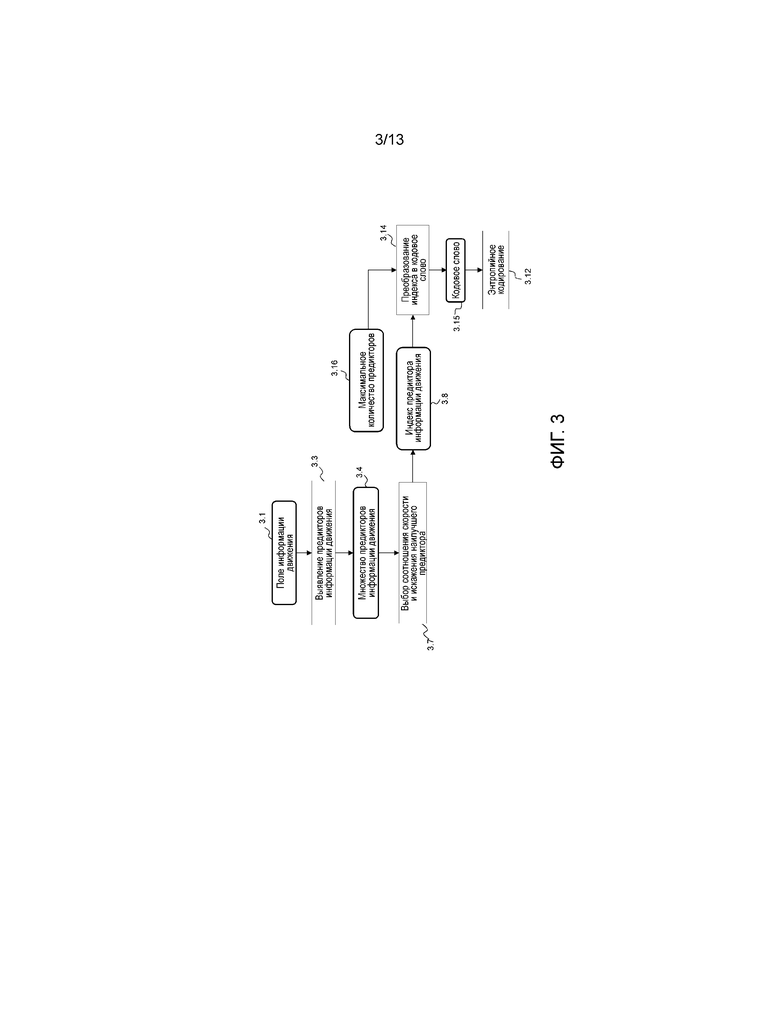
Фиг. 3 иллюстрирует предсказание информации движения в улучшающем уровне с использованием информации движения опорного уровня в варианте осуществления изобретения;
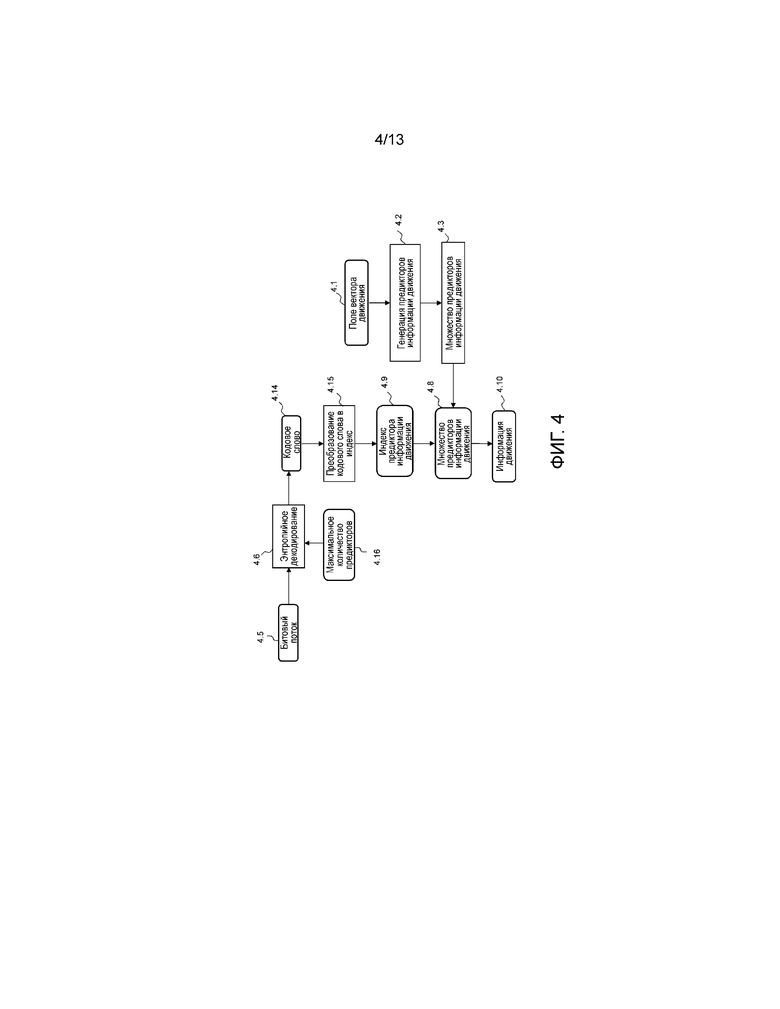
Фиг. 4 иллюстрирует блок-схему последовательности операций для процесса декодирования в варианте осуществления изобретения;
Фиг. 5 иллюстрирует гранулярность информации движения в варианте осуществления изобретения;
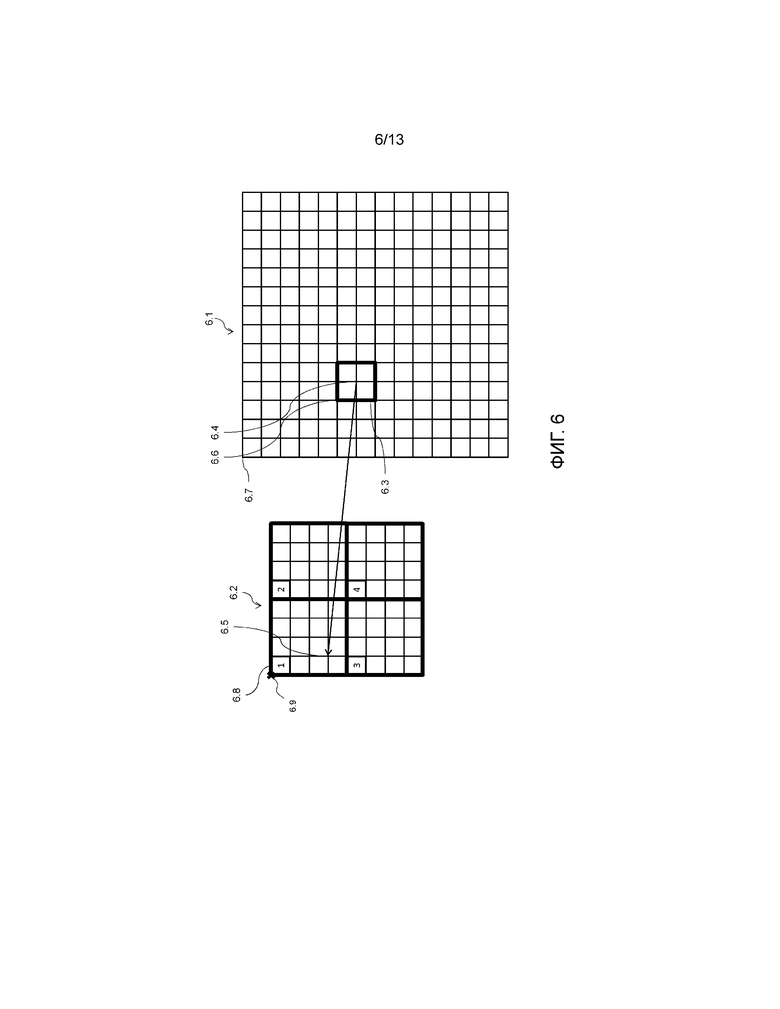
Фиг. 6 схематично иллюстрирует принципы подхода TextureRL в варианте осуществления изобретения;
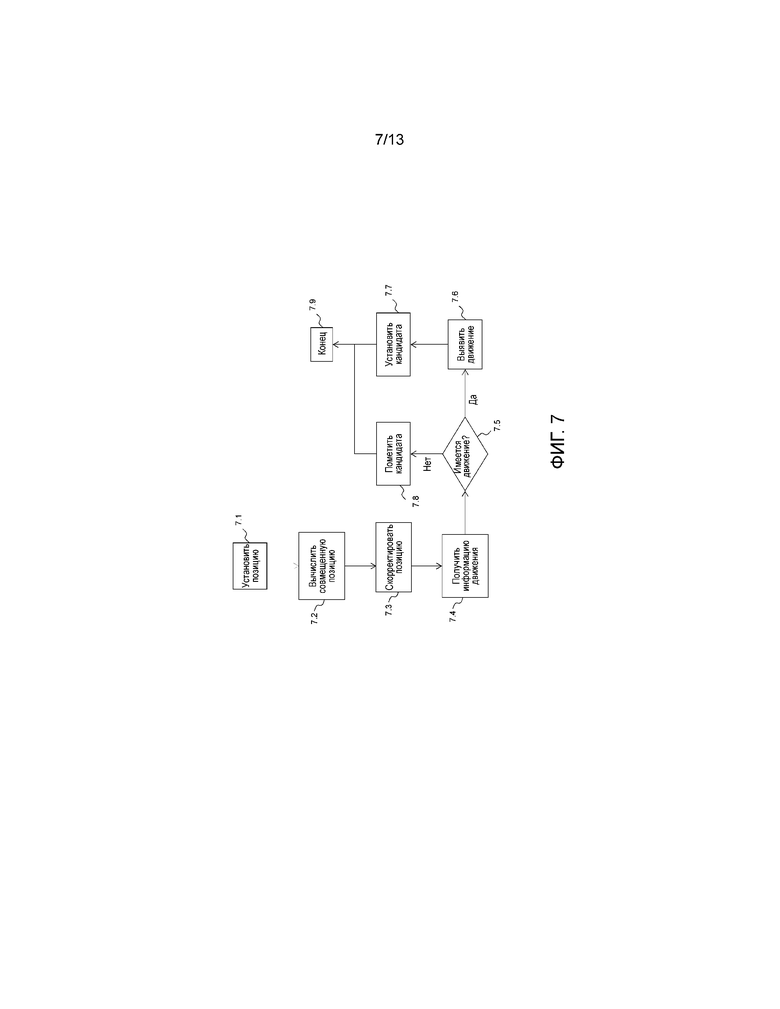
Фиг. 7 иллюстрирует адаптированный процесс выявления предиктора информации движения в контексте AMVP и режиме со слиянием подхода TextureRL в улучшающем уровне в варианте осуществления изобретения;
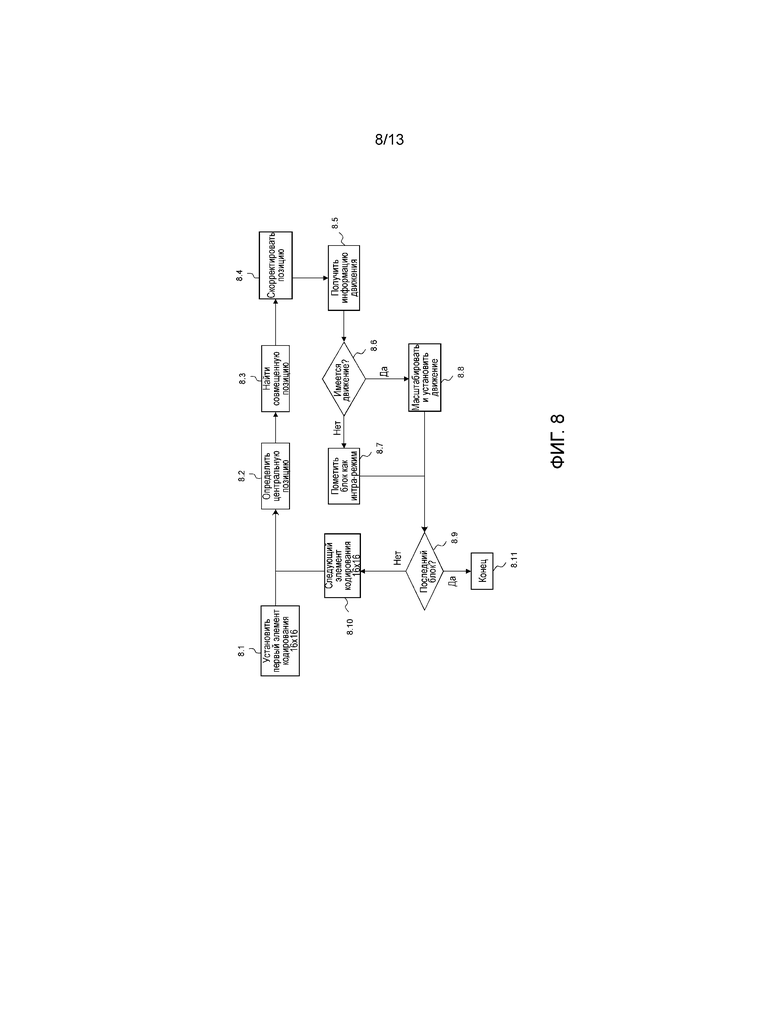
Фиг. 8 иллюстрирует адаптированный процесс в контексте подхода индекса опорного кадра в варианте осуществления изобретения;
Фиг. 9 является блок-схемой последовательности операций процесса выявления информации движения режимов со слиянием в варианте осуществления изобретения;
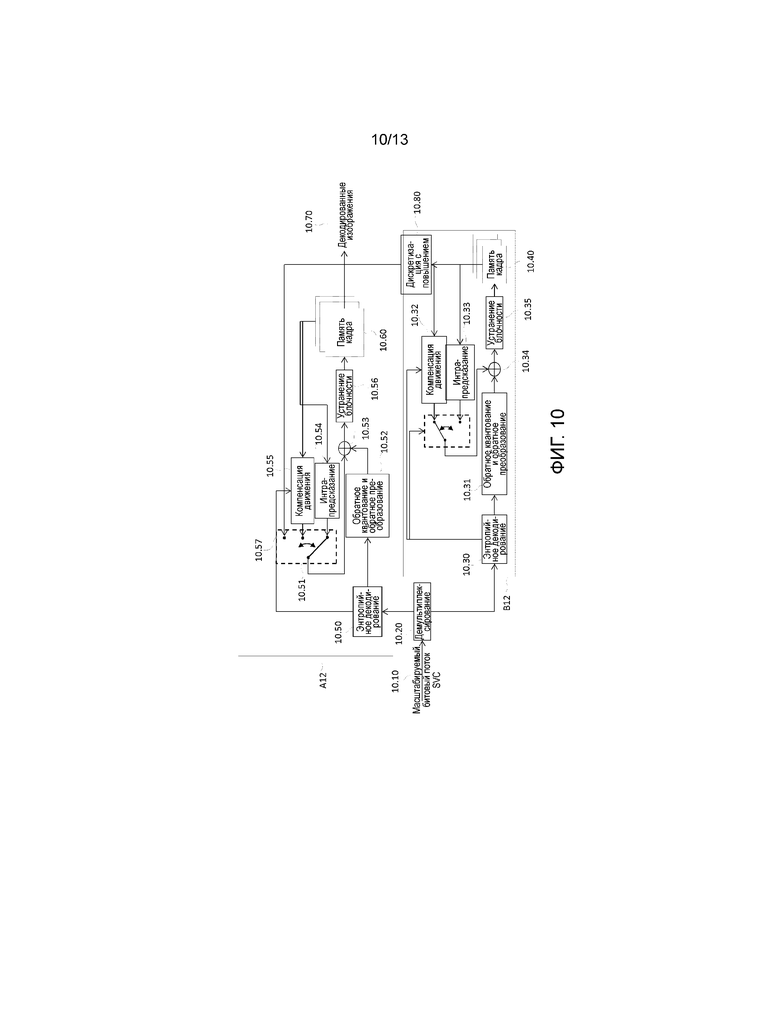
Фиг. 10 представляет блок-схему масштабируемого декодера в варианте осуществления изобретения;
Фиг. 11 является блок-схемой вычислительного устройства для реализации одного или более вариантов осуществления изобретения;
Фиг. 12 показывает выявление множества предикторов информации движения AMVP в варианте осуществления изобретения;
Фиг. 13 иллюстрирует подробные сведения области памяти в варианте осуществления изобретения.
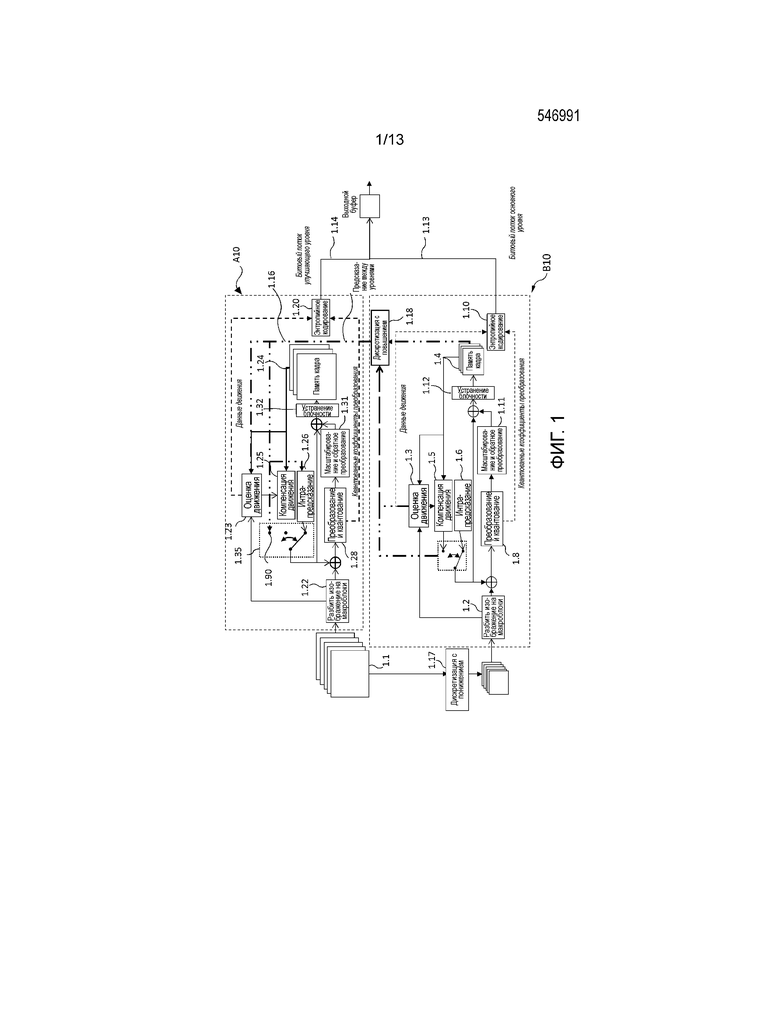
Фиг. 1 иллюстрирует блок-схему классического масштабируемого видеокодера, который может содержать несколько подразделов или каскадов, и который является репрезентативным для масштабируемого расширения HEVC. Здесь проиллюстрированы два подраздела или каскада A10 и B10, производящие данные, соответствующие базовому уровню 1.13, и данные, соответствующие одному улучшающему уровню 1.14. Каждый из подразделов A10 и B10 следует принципам стандартного видеокодера, в которых этапы преобразования, квантования и энтропийного кодирования применяются в двух отдельных проходах, и каждому уровню соответствует один из них.
Первый каскад B10 стремится кодировать базовый уровень, совместимый со стандартами H.264/AVC или HEVC, масштабируемого выходного потока. Входная информация в этот не масштабируемый кодер состоит в первоначальной последовательности изображений кадра, полученной посредством применения понижающей дискретизации 1.17 к изображениям 1.1. Этот кодер последовательно выполняет следующие шаги, чтобы закодировать стандартный битовый поток видео. Изображение или кадр, который будет закодирован (сжат), делится на пиксельные блоки на этапе 1.2, называемые элементами кодирования (CU) в стандарте HEVC. Каждый блок сначала подвергается операции 1.3 оценки движения, которая содержит поиск среди опорных изображений, сохраненных в выделенном буфере 1.4 памяти, опорных блоков, которые обеспечили бы хорошее предсказание блока. Этот этап оценки движения обеспечивает один или более индексов опорных изображений, которые содержат найденные опорные блоки, а также соответствующие векторы движения. Затем этап 1.5 компенсации движения применяет предполагаемые векторы движения к найденным опорным блокам, чтобы получить временной разностный блок, который является разностью между блоком предсказания с компенсацией движения и первоначальным блоком для предсказания. Кроме того, этап 1.6 интра-предсказания определяет режим пространственного предсказания, который обеспечил бы наилучшую производительность для предсказания текущего блока. Вновь вычисляется пространственный разностный блок, но в этом случае как разность между пространственным предиктором и первоначальным блоком для предсказания.
Затем механизм 1.7 выбора режима кодирования выбирает среди пространственных и временных предсказаний режим кодирования, который обеспечивает наилучший компромисс между скоростью и искажением при кодировании текущего блока. В зависимости от выбранного режима предсказания разностный блок предсказания затем подвергается преобразованию (DCT) и квантованию 1.8. Выполняется энтропийное кодирование 1.10 квантованных коэффициентов QTC (и связанных данных движения MD). Сжатые данные 1.13 текстуры, связанные с закодированным текущим блоком 1.2, отправляют на выход.
Чтобы дополнительно улучшить эффективность кодирования, информация движения, связанная с интер-блоками, которые выполняют этап компенсации движения, кодируется с предсказанием с использованием информации движения соседних блоков. Соседние блоки в этом случае содержат соседние в пространстве и, факультативно, соседние во времени блоки. Как следствие, если используются соседние во времени блоки, информация движения ранее закодированных изображений должна быть сохранена, чтобы позволить предсказание. В текущей версии стандарта эта информация сохраняется в сжатой форме кодером и декодером, чтобы ограничить использование памяти процесса кодирования и декодирования. Однако, как упомянуто ранее, когда временной предиктор не используется при предсказании информации движения, хранение поля движения предыдущих изображений не является необходимым.
Затем текущий блок воссоздается посредством обратного квантования (также называемого масштабированием) и обратного преобразования 1.11. Этот этап выполняется при необходимости посредством суммирования между подвергнутой обратному преобразованию разностью и блоком предсказания текущего блока, чтобы сформировать воссозданный блок. Воссозданные блоки добавляются в буфер, чтобы сформировать воссозданный кадр. Затем этот воссозданный кадр подвергается последующей фильтрации 1.12. Воссозданный кадр после этого последующего фильтра сохраняется в буфере памяти 1.4, называемом буфером декодированного изображения (DPB), с тем, чтобы он был доступен для использования в качестве опорного изображения для предсказания любых последующих изображений, которые будут кодироваться.
Наконец, последнему этапу энтропийного кодирования задается режим кодирования и, в случае интер-блока, данные движения, а также ранее вычисленные квантованные коэффициенты DCT. Этот кодер энтропии кодирует каждую из этих частей данных в их двоичную форму и инкапсулирует закодированный блок в контейнер, называемый элементом NAL (элементом сетевого уровня абстракции). Элемент NAL содержит все закодированные элементы кодирования из заданного слоя. Закодированный битовый поток HEVC состоит из последовательности элементов NAL.
Далее второй каскад A10 иллюстрирует кодирование улучшающего уровня с использованием базового уровня в качестве опорного уровня. При этом этот улучшающий уровень придает детализацию пространственного разрешения дискретизированному с повышением базовому уровню. Как проиллюстрировано на фиг. 1, схема кодирования этого улучшающего уровня аналогичная схеме кодирования базового уровня за исключением того, что для каждого элемента кодирования текущего изображения из сжимаемого потока 1.10 рассматриваются дополнительные режимы на основе предсказания между уровнями. Обычно включены следующие модификации.
Дополнительный режим, называемый IntraBL 1.90, состоящий в предсказании блока улучшающего уровня с использованием дискретизированного с повышением совмещенного блока опорного уровня, добавляется к списку режимов, рассматриваемых для блока улучшающего уровня.
Предсказание информации движения, используемое в режимах интер-кодирования, может быть модифицировано, чтобы принять во внимание информацию движения, приходящую из опорного уровня. Кроме того, заданное энтропийное кодирование информации движения может быть применено во время этапа 1.20 энтропийного кодирования.
Для этих новых инструментов промежуточный модуль 1.18 между уровнями может обеспечить информацию (информацию движения, отсчеты), возможно дискретизированную с повышением в соответствии с изменением пространственного разрешения, из опорного уровня разным модулям кодирования улучшающего уровня, таким как модуль 1.23 оценки движения, режим 1.90 IntraBL или модуль 1.26 интра-предсказания. В частности, в подходе с опорным кадром модуль 1.18 дискретизирует с повышением и данные отсчетов, и данные движения полученного в результате кадра в буфере 1.4 DPB для соответствия размерностям улучшающего уровня и вставит полученные в результате данные (изображение и его движение) в буфер 1.24 DPB, который в свою очередь воздействует на операции 1.25 и 1.23.
Фиг. 10 представляет блок-схему масштабируемого декодера, который применяется к масштабируемому битовому потоку, сделанному из двух уровней масштабируемости, например, состоящему из базового уровня и улучшающего уровня. Этот процесс декодирования, таким образом, является противоположной обработкой по отношению к процессу масштабируемого кодирования на фиг. 1. Декодируемый масштабируемый поток 10.10, сделан из одного базового уровня и одного пространственного улучшающего уровня поверх базового уровня, которые демультиплексируются на этапе 10.20 в свои соответствующие уровни.
Первый каскад на фиг. 10 относится к процессу B12 декодирования базового уровня. Этот процесс декодирования начинается с энтропийного декодирования 10.30 каждого элемента кодирования или блока каждого закодированного изображения на базовом уровне. Это энтропийное декодирование 10.30 обеспечивает режим кодирования, информацию движения (индексы опорных изображений и векторы движения интер-кодированных блоков), направление предсказания для интра-предсказания и разностные данные. Эти разностные данные состоят из квантованных и преобразованных коэффициентов DCT. Затем эти квантованные коэффициенты DCT подвергаются операциям 10.31 обратного квантования и обратного преобразования. Компенсация движения 10.32 или интра-предсказание 10.33 данных может быть добавлена к этой разности посредством операции 10.34.
Затем применяется этап 10.35 фильтра удаления блочности. Воссозданное изображение затем сохраняется в буфере 10.40 кадра.
Затем декодированная информация движения для интер-блоков и воссозданные блоки сохраняются в буфере кадра в первом из масштабируемых декодеров на фиг. 10 (B12). Такие кадры содержат данные, которые могут использоваться в качестве опорных данных для предсказания более высокого уровня масштабируемости.
Далее второй каскад на фиг. 10 выполняет декодирование пространственного улучшающего уровня A12 поверх базового уровня, декодированного посредством первого каскада. Это пространственное декодирование улучшающего уровня включает в себя энтропийное декодирование второго уровня, которое обеспечивает режимы кодирования, информацию движения и информацию интра-предсказания, а также преобразованную и квантованную разностную информацию блоков второго уровня.
Следующий этап состоит в предсказании блоков в изображении улучшения. Выбор 10.51 между различными типами предсказания блока (интра-предсказание, интер-предсказание или в случае подхода TextureRL предсказание между уровнями) зависит от режима предсказания, полученного из этапа 10.50 энтропийного декодирования.
Что касается интра-блоков, их обработка зависит от типа элемента интра-кодирования. В случае предсказанного между уровнями интра-блока (режим кодирования IntraBL) 10.57, если разностные данные были закодированы для блока, результат энтропийного декодирования 10.50 подвергается обратному квантованию и обратному преобразованию 10.52 и затем добавляется посредством операции 10.53 к блоку со совмещенным расположением текущего блока в базовом изображении в своей декодированной, подвергнутой последующей фильтрации и дискретизированной с повышением (в случае пространственной масштабируемости) версии. В случае интра-блока такой блок полностью воссоздается через обратное квантование, обратное преобразование для получения разностных данных в пространственной области и затем интра-предсказание 10.54 для получения полностью воссозданного блока.
Что касается интер-блоков, их воссоздание подразумевает их компенсацию 10,55 движения, вычисленную на основе памяти 10.60 кадра, декодирование разностных данных и затем добавление их декодированной разностной информации к их блоку временного предиктора. В этом процессе декодирования интер-блока информация движения, связанная с рассматриваемым блоком, может декодироваться предсказывающим образом как уточнение информации движения совмещенного блока в базовом изображении. Этот аспект будет подробно описан ниже.
Как на базовом уровне, этап 10.56 фильтра удаления блочности может быть применен к изображениям, выданным из этапа 10,53, и они сохраняются в памяти 10.60 кадр, прежде чем они возвращаются посредством декодирования как полностью декодированные кадры 10.70. Следует отметить, что в варианте осуществления изобретения компенсация 10.55 движения фактически использует данные из буфера 10.60 изображения улучшающего уровня и буфера 10.40 изображения базового уровня. Вместе с данными отсчетов модуль 10.80 может отвечать за обеспечение таких данных из опорного уровня посредством их дискретизации с повышением.
Могут быть рассмотрены два подхода для предсказания изображения. В частности, предсказание изображения содержит предсказание информации движения. В обоих подходах затрагивается предсказание информации движения, но по-разному. Два подхода предсказания изображения описаны ниже. Признак этих подходов должен позволить использовать информацию движения опорного уровня слоя для предсказания информации движения на улучшающем уровне. Этот признак будет описан более подробно со ссылкой на фиг. 3 и оказывает влияние на то, каким образом осуществляется доступ к памяти 1.4 кадра на фиг. 1 опорного уровня.
Затем для обоих подходов подробно объяснен случай предсказания информации движения, который является ключевым пунктом этого изобретения.
Первый подход обычно называется TextureRL, поскольку разрешено использование режима IntraBL. Этот подход использует синтаксис низкого уровня на уровне блоков, чтобы сигнализировать использование режима IntraBL. Этот подход иногда упоминается некоторыми экспертами как “подход IntraBL”.
Второй подход, называемый вставкой опорного кадра, состоит в том, чтобы главным образом использовать изменения высокого уровня. В частности, изменение синтаксиса не выполняется на уровне блоков. Основной признак подхода индекса опорного кадра заключается во внедрении изображений (возможно, подвергнутых дискретизации с повышением, когда разрешение является другим) опорного уровня, называемых изображениями ILR (что означает опорные изображения между уровнями), в буфер декодированных изображений улучшающего уровня. Эти изображения затем вставляются в конец заданных списков опорных изображений (список L0 и L1), используемых в качестве опорных изображений в буфере DPB (буфере декодированных изображений). Вставка зависит от типа текущего слоя улучшающего уровня. В P-слое изображение ILR вставляется в конец списка L0. В B-слое изображение ILR вставляется и в конец списка L0, и в конец списка L1. Этот подход иногда упоминается некоторыми экспертами как “подход ref_idx”. Посредством этого подхода информация движения заданного блока может быть закодирована с предсказанием с использованием временного предиктора информации движения опорного уровня, совмещенно расположенного в опорном уровне.
Стоит отметить, что IntraBL в подходе TextureRL и использование вставленного опорного кадра в подходе индекса опорного кадра являются двумя способами использования информации базового уровня для предсказания улучшающего уровня. В описании этого изобретения и ради простоты мы поочередно рассматриваем один из этих подходов, но не оба вместе.
Теперь мы опишем общую информацию относительно информации движения, которая пригодна для обоих подходов.
Типичный видеокодек использует как пространственные, так и временные корреляции между пикселями в соответствующих интра- и интер-режимах. Здесь мы сосредоточены здесь на режимах интер-кодирования, которые используют временную корреляцию между пикселями текущего кадра и ранее закодированными/декодированными кадрами.
В стандарте HEVC (и SHVC посредством расширения) интер-режим является режимом предсказания, который определяет временное направление предсказания. Множества информации движения с 0 по 2 определены в зависимости от этого временного направления. Если направление интер-предсказания равно 0, блок кодируется с помощью режима интра-кодирования, и он не содержит информации движения. Если направление интер-предсказания равно 1, блок содержит информацию движения из списка опорных кадров, называемого L0. Если направление интер-предсказания равно 2, блок содержит информацию движения из другого списка опорных кадров, называемого L1. Если направление интер-предсказания равно 3, блок содержит информацию движения из обоих списков L0 и L1.
Информация движения состоит в следующей информации, индекса (ref_idx) в списке опорных кадров и вектора движения, который имеет два компонента: горизонтальную и вертикальную величины движения. Эти величины соответствуют пространственному смещению в терминах пикселей между позицией текущего блока и блока временного предиктора в опорном кадре. Это смещение может иметь субпиксельную точность (0, 1, 2 или 3 четверти пикселя).
Упомянутые выше направления интер-предсказания 1 и 2 соответствуют однонаправленным предсказаниям и могут использоваться не в I-слоях (интра-кодированных слоях) слои, а в P-слоях (предсказанных слоях) и B-слоях (с двунаправленным предсказанием). Изображение конкретного типа (I, P или B) сделано по меньшей мере из одного слоя такого же типа. Направление интер-предсказания 3 называется двунаправленным предсказанием и может использоваться только в B-слоях. В этом случае рассматриваются два предиктора блока, по одному для каждого из списков L0 и L1. Следовательно, рассматриваются два индекса опорных кадров, а также два вектора движения. Предиктор блока интер-режима для двунаправленного предсказания является средним по пикселям этих двух блоков, на которые указывают эти два вектора движения. Предиктор блока здесь соответствует понятию элемента предсказания или блока предсказания в HEVC или SHVC.
Как описано выше, информация движения в HEVC кодируется посредством кодирования с предсказанием с использованием множества предикторов информации движения, среди которых информация движения со совмещенным во времени местоположением. Таким образом, необходимо, чтобы каждый кадр, который используется в качестве опорного кадра, хранил на сторонах кодера и декодера свою соответствующую информацию движения. Эта информация движения сжата, чтобы уменьшить ее размер в выделенной памяти информации движения.
Таким образом, HEVC использует конкретную гранулярность для представления движения. Это изображено на фиг. 5. Для каждого блока 5.0 из 16×16 пикселей минимальная гранулярность, используемая HEVC, составляет 4×4 пикселей, что дает в результате 16 потенциальных частей информации движения, по одному для каждого блока с размером 4×4. Сжатие информации движения состоит в хранении только информации движения, соответствующей верхнему левому блоку 5.1 с размером 4×4 для заданного блока 5.0.
Процесс сжатия информации движения может произойти, как только был сделан заключительный выбор для блока с размером 16×16, и он был закодирован, но проще визуализировать его как выполняемый, когда было закодировано целое изображение. Ради простоты мы можем полагать, что он выполняется после процесса адаптивного петлевого фильтра и перед тем, как декодированное изображение будет помещено в буфер декодированного изображения (DPB). Этот процесс сжатия может быть описан как конкретный поиск: для заданных координат X и Y пикселя информация движения получается из позиции X’=(X>>)<<4 и Y'=(Y>>4)<<4, где операторы '>>' и '<<' описываются следующим образом.
x>>y представляет арифметический сдвиг вправо целочисленного представления дополнения до двух для x на y двоичных цифр. Эта функция определена только для неотрицательных целочисленных значений y. Биты, смещенные в старшие значащие биты (MSB) в результате сдвига вправо, имеют значение, равное MSB для x до операции сдвига.
x<<y представляет арифметический сдвиг влево целочисленного представления дополнения до двух для x на y двоичных цифр. Эта функция определена только для неотрицательных целочисленных значений y. Биты, смещенные в младшие значащие биты (LSB) в результате сдвига влево, имеют значение, равное 0.
Можно отметить, что некоторые реализации могут использовать буфер для хранения соответствующего сжатого движения.
В конфигурации HEVC векторы движения кодируются посредством кодирования с предсказанием с использованием множества предикторов информации движения. Для интер-кодированного блока имеется 3 подрежима, называемых подрежимами с пропуском (Skip), внешним (Inter) и со слиянием (Merge) кодирования блока. Внешний подрежим использует конкретный способ предсказания движения, называемый AMVP, и использует разностные текстурные данные. Подрежимы с пропуском и со слиянием используют один и тот же способ предсказания движения (но первый не использует разностные данные). Этот способ предсказания дает возможность выбора наилучшего предиктора информации движения из заданного множества, причем множество составлено из пространственной и временной информации движения.
Мы опишем режим предсказания информации движения, называемый режимом со слиянием, и каким образом он применяется к обоим упомянутым выше подходам: TextureRL и индекс опорного кадра. Он используется для двух подрежимов интер-кодирования, подрежимов с пропуском и со слиянием. Затем мы подробно опишем эквивалентную схему, которая может использоваться в режиме AMVP.
Фиг. 3 показывает универсальную блок-схему последовательности операций для схемы предиктора информации движения со слиянием для подрежимов со слиянием и с пропуском на стороне кодера, кратко называемой "режимом со слиянием". Принцип режима со слиянием состоит в том, чтобы использовать предсказание вектора движения для компенсации движения без кодирования уточнения движения. Модуль 3.3 генерации предиктора информации движения генерирует множество 3.4 предикторов информации движения на основе поля 3.1 информации движения, как описано подробно ниже. Выбор 3.7 соотношения скорости и искажения наилучшего предиктора информации движения применяется среди множества 3.4 предикторов информации движения. Он генерирует индекс 3.8 предсказанного вектора движения, который должен быть закодирован.
Модуль 3.14 преобразования преобразовывает упомянутый индекс в усеченный унарный код 3.15: для кодирования значения N генерируется кодовое слово с длиной N+1, за исключением максимального значения N, которому вместо этого требуется N битов. Этот код состоит из N битов, установленных равными 7, и заключительного бита, установленного равным 0. Если значение N равно максимальному количеству кандидатов, то этот конечный бит не является необходимым, и длина кодовой комбинации, таким образом, равна N. Вследствие этого максимального значения количество кандидатов режима со слиянием (обычно 5 для HEVC) может быть выбрано на уровне слоя (синтаксический элемент five_minus_max_num_Merge_cand в HEVC), этап 3.14 принимает во внимание максимальное количество предикторов 3.16.
Сгенерированное кодовое слово 3.15 затем кодируется на этапе энтропийного кодирования 3.12:
- Первый бит использует арифметическое кодирование с заданным контекстом;
- Остальные биты используют кодирование с обходом, т.е. генерируется фактический бит.
Фиг. 4 показывает блок-схему последовательности операций для соответствующего процесса декодирования. На первом этапе модуль 4.2 генерирует множество 4.8 предикторов информации движения на основе поля 4.1 информации движения текущего кадра и предыдущих кадров. Максимальное количество 4.16 предикторов движения декодируется из синтаксического элемента five_minus_max_num_Merge_cand, расположенного в заголовке слоя. Затем оно используется на этапе 4.6, чтобы извлечь кодовое слово 4.14 предиктора информации движения. Это кодовое слово преобразовывается посредством этапа 4.15 в индекс 4.9 предиктора. Предиктор 4.10 информации движения для использования затем извлекается из множества 4.8 в соответствии с этим значением 4.9 индекса предиктора. Этот предиктор затем используется в качестве фактической информации движения во время компенсации движения.
Предиктор информации движения или кандидат содержат всю информацию движения: направление (т.е. доступность вектора движения и опорного индекса в списке), индекс опорного кадра и векторы движения. Несколько кандидатов генерируются посредством процесса выявления в режиме со слиянием, описанного далее, каждый из которых имеет индекс. В стандарте HEVC максимальное количество кандидатов Max_Cand по умолчанию равно 5, но может быть уменьшено до 1. Здесь мы описываем определение предиктора информации движения в режиме со слиянием с заданными частями для подходов TextureRL и индекса опорного кадра.
Фиг. 9 является блок-схемой последовательности операций процесса выявления информации движения режимов со слиянием. На первом этапе выявления и в ядре HEVC, и в подходах TextureRL и индекса опорного кадра, рассматриваются 7 позиций блока с 9.1 по 9,7.
Кроме того, в случае подхода TextureRL рассматривается другой кандидат, SMVP 9.0 (пространственный предиктор вектора движения), как описано выше. Эти позиции являются пространственными и временными позициями, изображенными на фиг. 2. Каждая позиция имеет одно и то же имя на обеих фигурах. Этот SMVP не существует в подходе индекса опорного кадра.
Модуль 9.8 проверяет наличие пространственной информации движения, и в подходе TextureRL также SMVP для улучшающего уровня. Он выбирает по большей мере 4 предиктора информации движения. В этом модуле предиктор является доступным, если он существует на опорном уровне и если этот блок не является интра-кодированным. Кроме того, в дальнейшем в подходе TextureRL любой кандидат, который будет добавлен, также сравнивается с SMVP в дополнение к любой другой информации движения и фактически добавляется, только если он является другим. Например, "Левый" кандидат, обозначенный A1 или 9.1, также сравнивается с SMVP и добавляется в качестве второго, если существует движение в позиции X2, или в ином случае первого. Это сравнение, а также в дальнейшем, выполняется посредством проверки, что:
- Информация движения от двух кандидатов имеет одинаковое направление предсказания;
- Если это имеет место, для каждой части информации движения, связанной с направлением предсказания:
Что делается ссылка на один и тот же кадр (то есть, одинаковое значение индекса ref_idx);
Что векторы движения идентичны и по своим вертикальным, и по горизонтальным координатам
Выбор и проверка этих 5 векторов движения описаны в следующих условиях:
- В подходе TextureRL, если информация движения 9.0 из позиции X2 со совмещенным местоположением центральной позиции X1 элемента PU доступна 9.8, она масштабируется и используется в качестве первого кандидата в списке 9.10.
- Если "Левая" A1 информация 9.1 движения доступна 9.8, что означает, что если она существует и если этот блок не является интра-кодированным, информация движения "Левого” блока выбирается и используется в качестве первого кандидата в списке 9.10.
- Если "Верхняя" B1 информация 9.2 движения доступна 9.8, кандидат "Верхнего" блока сравнивается 9.9 с A1 (если он существует). Если B1 равен A1, B1 не добавляется в список пространственных кандидатов 9.10, в ином случае добавляется.
- Если "Верхняя правая" B0 информация 9.3 движения доступна 9.8, вектор движения "Верхнего правого" сравнивается 9.9 с B1. Если B0 равен B1, B0 не добавляется в список пространственных кандидатов (9.10), в ином случае добавляется.
- Если "Нижний левый" A0 вектор 9.4 движения доступен 9.8, информация движения "Нижнего левого" сравнивается 9.9 с A1. Если А0 равно A1, А0 не добавляется в список пространственных кандидатов 9.10, в ином случае добавляется.
- Если список пространственных кандидатов не содержит 4 кандидата, проверяется 9.8 доступность “Верхней левой" B2 информации 9.5 движения, если она доступна, вектор движения "Верхнего левого" B2 сравнивается 9.9 с A1 и B1. Если B2 равен A1 или B1, B2 не добавляется в список пространственных кандидатов 9.10, в ином случае добавляется.
В конце этого каскада список 9.10 содержит от 0 до 4 кандидатов.
Для временного кандидата могут использоваться две позиции: H 9.6, соответствующая нижней правой позиции BR1 блока со совмещенным местоположением, или центральная C 9.7 блока со совмещенным местоположением ("со совмещенным местоположением" означает блок в той же самой позиции отличающемся по времени кадре), соответствующая центральной позиции X1 текущего блока. Эти позиции изображены на фиг. 2.
Сначала проверяется 9.11 наличие блока в позиции 9.6 H. Если он не доступен, то тогда проверяется 9.11 блок в центральной позиции 9.7. Если по меньшей мере одна информация движения этих позиций доступна, эта временная информация движения может быть масштабирована в случае необходимости 9.12, чтобы она была однородной с информацией движения, приходящей из опорного кадра с индексом 0, для обоих списков L0 и L1 в случае необходимости, чтобы создать временный кандидат 9.13; временный кандидат затем вставляется в список кандидатов в режиме со слиянием сразу после пространственных кандидатов.
Кроме того, заключительная позиция для временного кандидата, H или центр в зависимости от доступности, ограничивается тем, чтобы она оставалась в пределах того же самого блока CTB (иерархического блока кодирования) или его своего правого соседа для сокращения доступов к памяти.
Важно отметить, что для всех уровней и всех подходов, но самое главное на опорном уровне, этот предиктор информации движения условно определяется и добавляется в зависимости от того:
- деактивирован ли упомянутый временной предиктор информации движения (TMVP) на уровне последовательности, например, с использованием флага sps_temporal_mvp_enable_flag, расположенного во множестве SPS (множестве параметров последовательности) - это особенно относится к варианту осуществления изобретения;
- если он активирован на уровне последовательности, деактивирован ли он на уровне слоя, например, с использованием флага enable_temporal_mvp_flag, расположенного в заголовке слоя.
Тот факт, что этот предиктор информации движения может быть деактивирован, вместе с тем, каким образом он затронут сжатием памяти вектора движения, играет важную роль в описанном процессе и в том, каким образом происходит выявление предиктора SMVP 9.0.
Во-вторых, в подходе индекса опорного кадра этот временной предиктор информации движения может приходить из вставленного кадра. Как будет описан ниже, упомянутая информация движения фактически выявляется из поля сжатого движения кадра опорного уровня.
Если количество кандидатов (Nb_Cand) 9.14 строго ниже максимального количества кандидатов Max_Cand, равного 5 по умолчанию и по большей мере, объединенные кандидаты генерируются на этапе 9.15, в ином случае заключительный список кандидатов в режиме со слиянием создан на этапе 9.18. Модуль 9.15 используется только тогда, когда текущий кадр является B-кадром, и он генерирует несколько кандидатов на основе доступных кандидатов в двух списках в режиме со слиянием на этапе 9.15. Эта генерация состоит в объединении одной информации движения кандидата из списка L0 с другой информацией движения другого кандидата из списка L1.
Если количество кандидатов (Nb_Cand) 9.16 строго ниже максимального количества кандидатов Max_Cand, пустые кандидаты информации движения без смещения (0,0) (т.е. все значения вектора движения равны нулю) добавляются на этапе 9.17, и Nb_Cand увеличивается, пока Nb_Cand не станет равен Max_Cand.
В конце этого процесса заключительный список кандидатов в режиме со слиянием создан на этапе 9.18.
Текущая спецификация для SHVC (масштабируемого расширения HEVC) не использует предиктор информации движения, полученный из опорного уровня в режиме AMVP, но это может быть внедрено следующим образом.
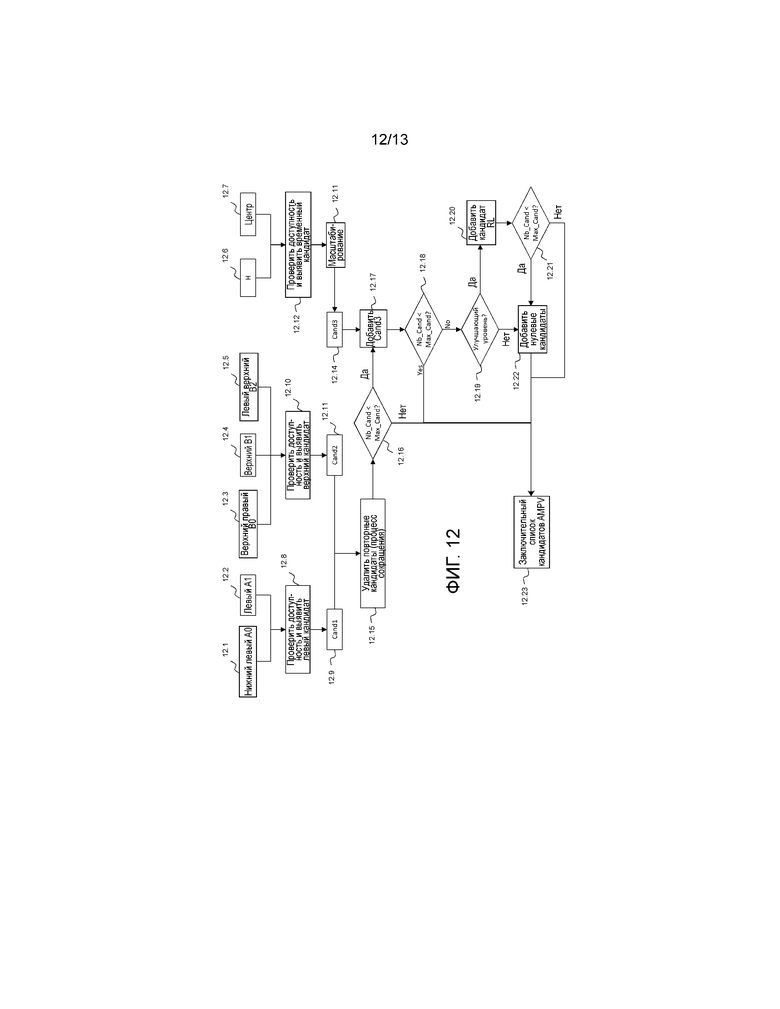
Фиг. 12 показывает выявление множества предикторов информации движения AMVP. Этот процесс используется для кодирования с предсказанием информации движения. По сравнению с режимом со слиянием должна быть передана дополнительная информация: направление предсказания, и для каждой части передаваемой информации движения также передается индекс опорного кадра, индекс предиктора и разность информации движения.
Индекс предиктора зависит от количества кандидатов: HEVC должен сгенерировать максимально 2 предиктора информации движения. В этом случае Max_Cand в этой фигуре установлен равным 2, но можно представить, что используется 3 для улучшающего уровня. Первый пространственный кандидат выбирается среди левых блоков А0 12.1 и A1 12.2 для позиций, подобных позициям для режима со слиянием.
Два пространственных предиктора информации движения режима AMVP выбираются среди верхних и среди левых блоков, включающих в себя верхние угловые блоки и левый угловой блок, снова как для режима со слиянием. Этот левый предиктор Cand1 12.9 выбирается 12.8 среди “Нижнего левого" А0 и "Левого" A1 блоков. В этом заданном порядке оцениваются следующие условия, пока не будет найдено значение информации движения для информации движения из того же самого опорного списка и того же самого опорного изображения или информации движения из другого опорного списка и того же самого опорного изображения.
Предиктор Cand2 12.11 верхней информации движения выбирается на этапе 12.10 среди “Верхнего правого” B0 12.3, "Верхнего" B1 12.4 и "Верхнего левого” B2 12.5 блоков в этом заданном порядке с такими же условиями, как описано ниже. Далее Cand1 и Cand2 сравниваются, чтобы удалить один из этих предикторов информации движения, если они равны 12.15. После этого сокращения количество кандидатов сравнивается с Max_Cand на этапе 12.16: если они равны, список кандидатов информации движения AMVP полностью определен, и процесс заканчивается на этапе 12.23.
В ином случае, если количество кандидатов меньше Max_Cand, временной предиктор Cand3 12.14 движения выявляется, как в режиме со слиянием, и добавляется, если он существует, на этапе 12.17. Чтобы сделать это, нижняя правая (H) 12.6 позиция сначала рассматривается в модуле 12.12 проверки доступности. Если она не существует, выбирается центр блока 12.7 с совмещенным местоположением.
Затем количество добавленных кандидатов снова сравнивается с максимальным количеством кандидатов на этапе 12.18. Если максимальное количество достигнуто, заключительный список предикторов AMVP создан на этапе 12.23. В ином случае этап 12,19 проверяет, создаем ли мы список для улучшающего уровня. Если нет, создание классического списка возобновляется на этапе 12.22, на котором к списку добавляется столько нулевых кандидатов, сколько необходимо, чтобы достигнуть максимума, и, таким образом, он завершается на этапе 12.23. В ином случае происходит заданная обработка, в которой кандидат SMVP получается из опорного уровня после описанного ниже вычисления. Когда это сделано, обычная обработка возобновляется на этапе 12.22.
Мы решили проиллюстрировать использование этого кандидата после Cand3. Безусловно, очевидно предположить использование его перед Cand3 между Cand1 и Cand2 или между Cand2 и Cand3. Во всех случаях дополнительное сравнение может быть выполнено в процессе сокращения, чтобы принять во внимание новый потенциальный SMVP.
При рассмотрении применения режима со слиянием к подходу TextureRL режим со слиянием добавляет новый предиктор информации движения, SMVP, в улучшающем уровне, полученном из его опорного уровня. Упомянутый предиктор информации движения в текущее время приходит из информации движения, используемой при определении временного кандидата в опорном уровне, который сжат. Фиг. 6 схематично иллюстрирует принципы подхода TextureRL. Приведенное здесь описание относится к цветовому компоненту яркости изображения, но процесс относится также к цветовым компонентам цветности.
На фиг. 6 представлено изображение 6.1 улучшающего уровня и его изображение 6.2 опорного уровня с пространственным отношением R (обычно 1, 1,5 или 2) между 6,1 и 6.2. Безотносительно значения R мы используем слово "дискретизация с повышением” в качестве процесса повторной дискретизации, применяемого к опорному уровню для соответствия размерностям улучшающего уровня. Если R равно 1, повторная дискретизация производит вывод, идентичный вводу. Обратная повторная дискретизация называется "дискретизацией с понижением". Изображение улучшающего уровня подразделяется на решетку, представляющую гранулярность изображения. Каждый из меньших квадратов называется отсчетом в следующем тексте.
Теперь для заданного элемента 6.3 предиктора, представленного жирным квадратом, процесс состоит в следующем:
A. Вычисление центрального местоположения 6.4 (xPCtr, yPCtr) рассматриваемого блока предсказания 6.3 яркости, которое выявляется следующим образом:
xPCtr=xP+nPbW/2
yPCtr=yP+nPbH/2
xP, yP определяют верхний левый отсчет 6.6 текущего блока предсказания яркости относительно верхнего левого отсчета 6.7 яркости текущего изображения
nPbW и nPbH определяют ширину и высоту блока предсказания яркости
B. Дискретизация с понижением их координат в соответствии с масштабным коэффициентом R (1, 1.5 и 2.0), чтобы найти совмещенную позицию 6.5 в изображении 6.2 опорного уровня;
xPCtrRL=(xPCtr * PicWRL + ScaledW/2)/ScaledW
yPCtrRL=(yPCtr * PicHRL + ScaledH/2)/ScaledH
Переменные PicWRL и PicHRL установлены равными ширине и высоте изображения опорного уровня.
ScaledH принимает значение R * PicHRL, и ScaledW равно значению R * PicWRL
C. Извлечение информации движения в этом местоположении из изображения 6.2 опорного уровня посредством идентификации блока bIPb 6.8 предсказания яркости с номером 1, покрытия модифицированного местоположения, заданное как ((xPCtrRL>>4)<<4, (yPCtrRL>>4)<<4), в изображении опорного уровня. Это соответствует этапу суммирования движения опорного уровня.
Местоположение яркости (xPRL, yPRL) затем устанавливается равным верхнему левому отсчету 6.8 из блока предсказания яркости со совмещенным местоположением, заданного посредством bIPb относительно верхнего левого отсчета яркости изображения опорного уровня
D. Если соответствующая информация не относится к интра-предсказанию, извлечение векторов MVRL движения и их дискретизация с повышением в соответствии с отношением R. Операция в основном генерирует пространственный вектор движения, значение SMVP которого: SMVP=rnd (R*MVRL (rnd (xPRL/R), rnd (yPRL/R), где rnd(.) представляет процесс округления). Вместе с индексами опорного кадра, связанными с этим пространственным вектором движения, это составляет пространственный предиктор вектора движения, вставленный в начало множества.
Текущая архитектура SHVC для TextureRL предписывает, что векторы движения для значений MVRL опорного уровня стоимости MVRL получаются из буфера сжатия движения опорного уровня, как видно на этапе C выше. Поэтому необходимо, чтобы информация движения, соответствующая блокам 6.8 с размером 4×4, только одна хранилась для всего блока с размером 16×16 посредством процесса сжатия информации движения.
Теперь при рассмотрении подхода индекса опорного кадра, в этом случае информация движения нового кадра, который вставляется в опорный список улучшающего уровня, приходит также из упомянутого поля сжатой информации движения. Эта информация движения тогда может использоваться для определения временного предиктора, как описано выше.
Рассмотрим подробно, как выявляется это движение. Для заданного блока с размером 16×16 выбирается центр этого блока, и эта позиция используется эквивалентно тому, что описано выше, чтобы найти соответствующую информацию движения. Мы собираемся подробно рассмотреть соответствующие этапы для компонента яркости. Обратите внимание на то, что большинство частей существенно идентичны процессу, описанному в отношении фиг. 6, и определения остаются теми же самыми для идентичных переменных.
A. Центральное местоположение (xPCtr, yPCtr) блока предсказания яркости выявляется следующим образом (имена переменных определены в предыдущей секции):
xPCtr=xP+8
yPCtr=yP+8
B. Дискретизация с понижением их координат в соответствии с масштабным коэффициентом R (1, 1,5 и 2,0), чтобы найти совмещенную позицию в изображении опорного уровня;
xPCtrRL=(xPCtr * PicWRL + ScaledW/2)/ScaledW
yPCtrRL=(yPCtr * PicHRL + ScaledH/2)/ScaledH
Переменные PicWRL и PicHRL установлены равными ширине и высоте изображения опорного уровня.
ScaledH принимает значение R * PicHRL, и ScaledW равно значению R * PicWRL.
C. Совмещенная позиция (xRL, yRL) выявляется следующим образом
xRL=(xRef>>4)<<4
yRL=(yRef>>4)<<4.
D. Вектор движения опорного уровня выявляется следующим образом. Операция в основном генерирует векторы движения со значением RL_MV опорного уровня следующим образом: RL_MV = rnd (R*MV (rnd (xPRL/R), rnd (yPRL/R)).
Эта информация затем используется, как если бы она была выводом сжатия информации движения. Это позволяет использовать информацию движения из опорного уровня для предсказания информации движения в улучшающем уровне. В отличие от подхода TextureRL, информация движения имеет более грубую гранулярность, но может использоваться в качестве временного предиктора информации движения и в процессе определения списка в режиме со слиянием, в AMVP, используемом для интер-блоков.
Теперь, когда мы представили полную архитектуру масштабируемого кодека, два подхода и то, каким образом они используют информацию движения для предсказания, мы можем обобщенно представить следующее.
В подходе TextureRL новый предиктор информации движения в улучшающем уровне получается из его опорного уровня. Упомянутый предиктор информации движения обычно приходит из информации движения, используемой при определении временного кандидата в опорном уровне, который сжат. Таким образом, сжатие влияет на его выявление, и, таким образом, режим со слиянием. В режиме AMVP, если присутствует масштабируемый кандидат, то сжатие также повлияет на него. Режимы AMVP и со слиянием в подходе индекса опорного кадра всегда подвергаются влиянию, поскольку они также используют временной предсказанный вектор движения, и если кадр, на который ссылаются, является вставленным, то этот предиктор придет из движения кадра опорного уровня.
В подходе индекса опорного кадра информация движения нового кадра, который вставлен в опорный список улучшающего уровня, приходит также из упомянутой сжатой информации движения.
Как объяснено в отношении фиг. 6, информация движения, сохраненная для опорного уровня, является сжатой. Это означает, что для полного блока с размером 16×16, в котором первоначально существуют вплоть до 16 частей информации движения, по одной для каждого блока с размером 4×4, содержащегося в пределах блока с размером 16×16, сохранена только одна, обычно та, которая относится к верхнему левому блоку с размером 4×4.
В процессе выявления предикторов информации движения, когда необходима информация движения опорного уровня, вследствие этого сжатия доступной является используемая информация движения, а именно, информация движения, связанная с верхним левым блоком с размером 4×4. Вновь, как показано на фиг. 6, при поиске информации движения, связанной с совмещенной точкой 6.5, соответствующей центру 6.4 элемента кодирования для кодирования, используется информация движения, связанная с верхним левым блоком 6.8 с размером 4×4 с номером 1. Можно отметить, что информация движения, связанная с верхним левым блоком с размером 4×4 с номером 3, соответствующим информации движения, сохраненной после сжатия для блока с размером 16×16, расположенного ниже, находится ближе к позиции совмещенной точки 6.5, и, таким образом, вероятно, будет более релевантной, чем информация движения блока 6.8 с размером 4×4.
Это не оптимальный выбор информации движения вследствие процесса сжатия, примененного к информации движения в опорном уровне, может быть оценен как приводящий к потере эффективности кодирования. В варианте осуществления изобретения процесс выявления предиктора информации движения адаптирован для преодоления этой проблемы позиции.
Фиг. 7 подробно показывает адаптированный процесс в контексте подхода TextureRL. Он может быть применен и в AMVP, и в процессе выявления в режиме со слиянием в улучшающем уровне. Этот модифицированный процесс выявления в режиме со слиянием может быть расположен в модуле 1.23 оценки движения на фиг. 1 кодера и в модуле 10.55 оценки движения на фиг. 10 декодера. По существу, все это происходит при определении кандидата SMVP 9.0 на фиг. 9.
Этап 7.1 инициализирует процесс посредством вычисления позиции, для которой следует определить движение в опорном уровне, например, посредством установки информации текущего элемента предиктора (размерности/позиция) и выявления центра упомянутого блока предиктора. Главная адаптация находится на этапе 7.3, который корректирует позицию. Это в первую очередь делается через две следующие возможности.
В первом варианте осуществления для заданной координаты X, полученной для позиции в опорном уровне, например, либо xPCtrRL, либо yPCtrRL, описанных выше, вычисляется новое значение посредством выполнения операции округления в соответствии с двумя параметрами r и M.
Например, новое значение X’ может быть вычислено следующим образом:
X'=⌊((X + r)/M)⌋*M;
где ⌊x⌋ представляет усечение x, что означает взятие его целой части. M может являться степенью 2, в этом варианте осуществления M=16 для соответствия гранулярности сжатого движения стандарта HEVC. В этом варианте осуществления используется r=4, а не более естественный выбор r=8, поскольку это обеспечивает более хорошую эффективность кодирования.
То же самое может быть применено к другой координате. Возможно выбрать другие значения параметров r и M.
Коррекция позиции может быть основана на таблице поиска. В этом случае для заданных координат (X, Y) таблица коррекций F[X, Y] может быть определена по меньшей мере для одной из координат. Эта таблица может быть разной для каждой координаты. Таблица также может быть индексирована только посредством одной из координат, а именно, X или Y. Таблица также может быть уменьшена посредством использования в качестве индекса значения, относящегося к координате, вместо самой координаты, например, коррекция может быть получена как F[X mod M] вместо F [X], где M=2N как типичное значение. В одном примере M=16.
Во всех случаях корректирующее значение (либо значение r, либо таблица по меньшей мере для одного компонента) может быть передано и извлечено из информации синтаксиса высокого уровня, например, в множестве видеопараметров, множестве параметров последовательности, множестве параметров изображения или заголовке слоя. В случае передачи по меньшей мере одного значения r:
- Битовый флаг может указывать, является ли значение r первым значением или вторым, например, 0 и 4 (в этом случае он может рассматриваться как флаг включения/выключения для коррекции);
- Код может указывать явное значение r, например, усеченный унарный код, представляющий значение r минус 4, например, двоичные последовательности '0' для r=4, ‘10’ для R=5, ‘110’, ‘1110’ и '1111' для других значений.
В приведенном выше описании важно отметить, что может быть затронута только одна координата, в частности, абсцисса, поскольку изменение ординаты может привести к извлечению информации движения из другой области памяти и, таким образом, вызвать дополнительные доступы к памяти.
Следуя этому требованию сокращения доступов к памяти, по меньшей мере одно скорректированное значение может быть заменено на другое значение, это другое значение, возможно, является исходным значением, если упомянутое скорректированное значение не соответствует критерию, такому как, удовлетворение порога. Упомянутый порог может представлять собой размерность изображения вдоль этой координаты, чтобы поиск не мог произойти вне изображения. В качестве альтернативы, упомянутый порог может представлять собой предел области памяти вдоль этой координаты. Область памяти обычно соответствует предопределенному множеству самого большого элемента кодирования в опорном уровне. Эта область памяти будет проиллюстрирована более подробно с помощью фиг. 13.
Затем обычное определение предиктора возобновляется на этапе 7.4. Информация движения извлекается из сжатого буфера движения с использованием выданной позиции этапа 7.3. Если это интра-режим (т.е. нет движения), кандидат помечается как таковой на этапе 7.8, в частности, без вычисления и без добавления предиктора к списку кандидатов режима со слиянием, и, таким образом, процесс выявления заканчивается на этапе 7.9. В ином случае соответствующее движение подвергается дискретизациии с повышением для соответствия размерностям улучшающего уровня.
Фиг. 8 иллюстрирует адаптированный процесс в контексте подхода индекса опорного кадра. Он может быть применен и в AMVP, и в процессе выявления в режиме со слиянием в улучшающем уровне. Этот адаптированный процесс расположен либо в буфере 1.24 кадра, либо в модуле 1.23 оценки движения в кодере на фиг. 1 и в буфере 10.60 кадра или в модуле 10.55 оценки движения декодера на фиг. 10. Действительно, он затрагивает содержимое памяти кадра относительно сжатой информации движения.
Таким образом, этап 8.1 инициализирует процесс выявления предиктора информации движения посредством установки текущего блока с размером 16×16 как первого в изображении улучшающего уровня. На этапе 8.2 определяется позиция центра элемента кодирования с размером 16×16, и соответствующая совмещенная позиция в опорном уровне находится на этапе 8.3. Новый этап 8.4, на котором найденная позиция корректируется. Можно сослаться на описанный выше этап 7.1, чтобы увидеть подробные сведения этой корректировки, то же самое применяется и здесь.
На этапе 8.5 проверяется, находится ли движение в той позиции в интра-режиме. Если это так, то движение блока с размером 16×16 устанавливается как интра-режим на этапе 8.7, в ином случае векторы движения получаются и подвергаются дискретизации с повышением для соответствия размерностям улучшающего уровня, и подвергнутые дискретизации с повышением векторы движения, опорные индексы и доступности устанавливаются как предикторы информации движения текущего блока с размером 16×16 на этапе 8.8.
Этап 8.9 готовится к следующей итерации посредством проверки, является ли текущий блок последним в изображении. Если это верно, тогда информация движения для нового кадра полностью определена, и процесс заканчивается на этапе 8.11. В ином случае текущий блок устанавливается равным следующему блоку с размером 16×16 на этапе 8.10, и цикл итерации возвращается обратно к этапу 8.2.
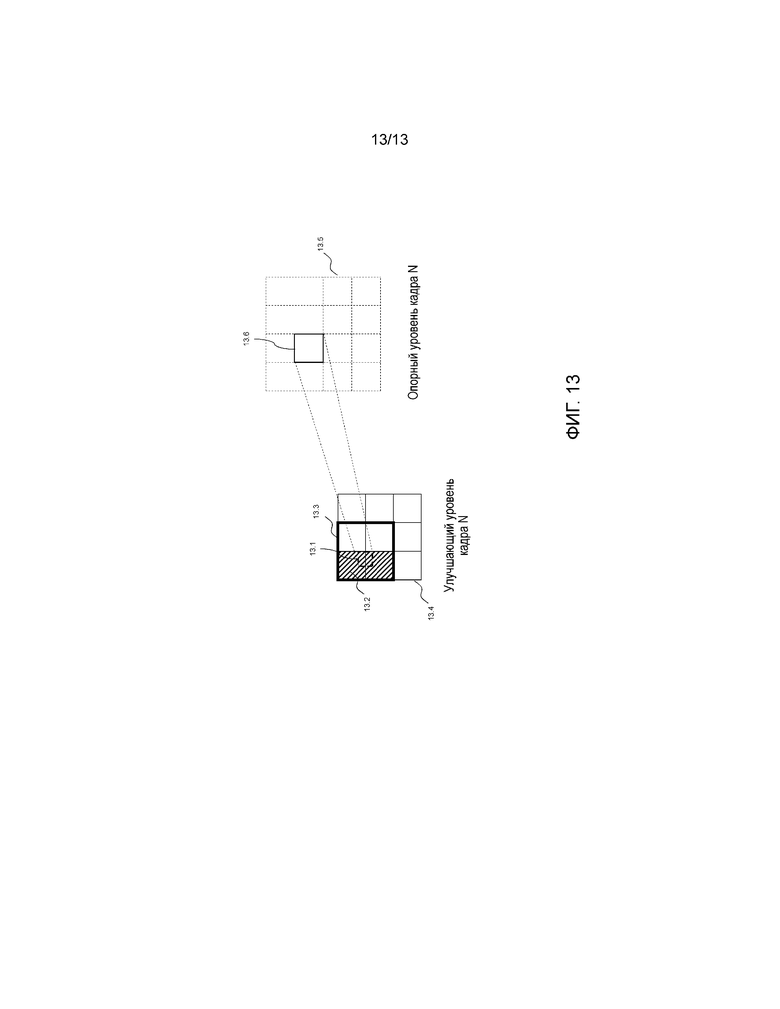
Фиг. 13 иллюстрирует подробные сведения о том, что мы определяем как область памяти. Для заданного изображения 13.4 опорного уровня и его связанного изображения 13.5 улучшающего уровня 13.5 возможно определить область 13.6, к которой применять процесс определения движения, например, блок CTB. Может применяться ограничение доступа к памяти (например, в случае конвейерного кодера или декодирования, в котором блоки CTB улучшающего уровня обрабатываются непосредственно после совмещенных блоков CTB опорного уровня), и, таким образом, мы можем определить в первом аспекте изобретения совмещенную область 13.1 внутри кадра 13.4 опорного уровня. Область памяти, упомянутая на этапах 7.1 и 8.4, соответствует первому аспекту области 13.2, содержащей область 13.1, в данном случае выполненной из двух блоков CTB опорного уровня: скорректированные позиции, найденные для любой части области 13.6, должны оставаться в пределах области 13.2. Менее строгим образом мы можем обеспечить, чтобы область памяти могла содержать дополнительный столбец блоков CTB справа от области 13.2, что дает в результате область 13.3. Можно подразумевать, что ограничение в данном случае основано на области 13,6, но может использоваться любой размер области в улучшающем уровне или увеличенная область памяти в опорном уровне.
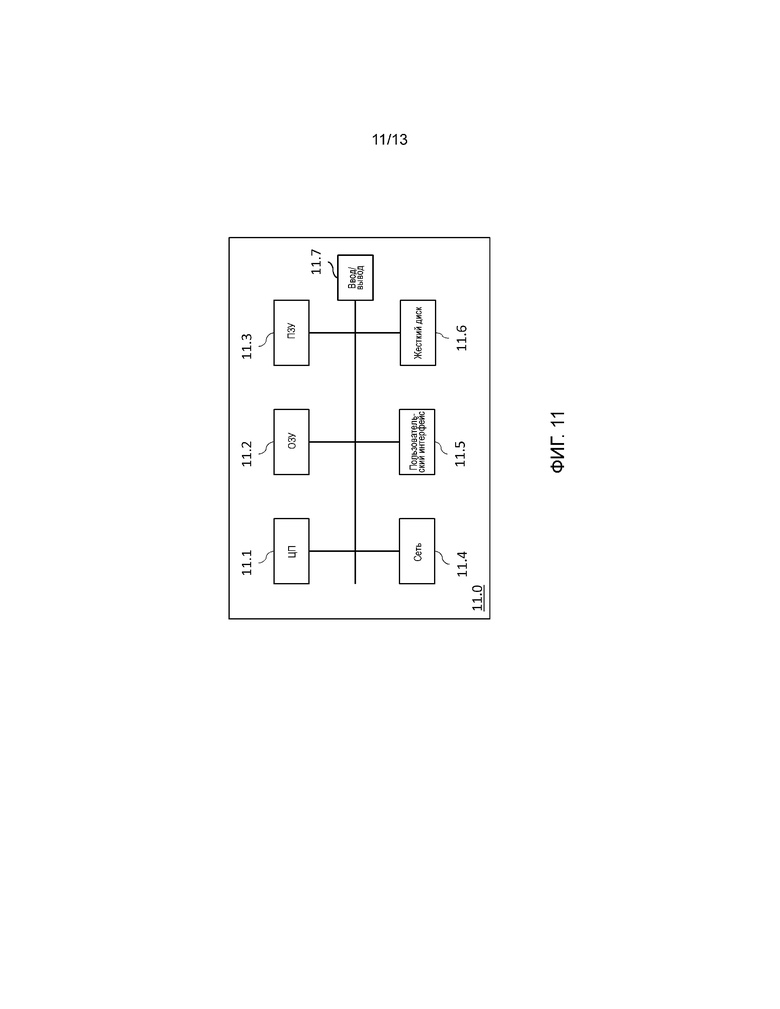
Фиг. 11 является блок-схемой вычислительного устройства 11.0 для реализации одного или более вариантов осуществления изобретения. Вычислительное устройство 11.0 может являться устройством, таким как микрокомпьютер, рабочая станция или портативное устройство. Вычислительное устройство 11.0 содержит шину связи, соединенную с:
- центральным процессором 11.1, таким как микропроцессор, обозначенным как ЦП;
- оперативным запоминающим устройством 11.2, обозначенным как ОЗУ, для хранения исполняемого кода способа вариантов осуществления изобретения, а также регистрами, выполненными с возможностью записывать переменные и параметры, необходимые для реализации способа для кодирования или декодирования по меньшей мере части изображения в соответствии с вариантами осуществления изобретения, емкость памяти может быть расширена факультативным оперативным запоминающим устройством, например, соединенным с портом расширения;
- постоянным запоминающим устройством 11.3, обозначенным как ПЗУ, для хранения компьютерных программ для реализации вариантов осуществления изобретения;
- сетевым интерфейсом 11.4, обычно соединенным с сетью связи, по которой передаются и принимаются цифровые данные для обработки. Сетевой интерфейс 11.4 может являться единственным сетевым интерфейсом или составленным из множества различных сетевых интерфейсов (например, проводных и беспроводных интерфейсов или различных видов проводных или беспроводных интерфейсов). Пакеты данных записываются в сетевой интерфейс для передачи или считываются из сетевого интерфейса для приема под управлением прикладной программы, работающей в ЦП 11.1;
- пользовательским интерфейсом 11.5, который может использоваться для приема ввода от пользователя или отображения информации пользователю;
- жестким диском 11.6, обозначенным как ЖД, который может быть обеспечен как устройство массового хранения;
- модулем 11.7 ввода/вывода, который может использоваться для приема данных от внешних устройств и отправки данных внешним устройства, таким как источник видеосигнала или дисплей.
Исполняемый код может быть сохранен либо в постоянном запоминающем устройстве 11.3, либо на жестком диске 11.6, либо на сменном цифровом носителе, таком как диск. В соответствии с вариантом, исполняемый код программ может быть принят посредством сети связи через сетевой интерфейс 11.4, чтобы перед исполнением быть сохраненным в одном из средств хранения устройства 11.0 связи, таком как жесткий диск 11.6.
Центральный процессор 11.1 выполнен с возможностью управлять и направлять исполнение команд или частей программного кода в соответствии с вариантами осуществления изобретения, эти команды сохранены в одном из упомянутых выше средств хранения. После включения ЦП 11.1 способен исполнять команды, относящиеся к прикладной программе, из ОЗУ 11.2 после того, как эти команды были загружены, например, из программного ПЗУ 11.3 или жесткого диска 11.6. Такая прикладная программа при исполнении посредством ЦП 11.1 заставляет выполнять этапы блок-схем последовательности операций, показанных на фиг. 1-4.
Любой этап алгоритма, показанного на фиг. 7, может быть реализован в программном обеспечении посредством исполнения множества команд или программ с помощью программируемой вычислительной машины, такой как персональный компьютер (ПК), процессор цифровых сигналов (DSP) или микроконтроллер; или в ином случае реализован в аппаратных средствах посредством машины или специализированного компонента, такого как программируемая пользователем вентильная матрица (FPGA) или специализированная интегральная схема (ASIC).
Хотя настоящее изобретение было описано выше со ссылкой на конкретные варианты осуществления, настоящее изобретение не ограничено конкретными вариантами осуществления, и для специалиста в области техники будут очевидны модификации, которые находятся в пределах объема настоящего изобретения.
Множество дополнительных модификаций и изменений появятся у специалистов в области техники после ознакомления с описанными выше иллюстративными вариантами осуществления, которые даны только в качестве примера и которые не предназначены для ограничения объема изобретения, определяемого исключительно посредством приложенной формулы изобретения. В частности, различные признаки из различных вариантов осуществления в соответствующих случаях могут быть взаимозаменяемы.
В формуле изобретения слово "содержит" не исключает другие элементы или этапы и форма единственного числа не исключает множество. Тот лишь факт, что различные признаки изложены во взаимно различных зависимых пунктах формулы изобретения, не указывает, что комбинация этих признаков не может успешно использоваться.


Изобретение относится к области масштабируемого видеокодирования и декодирования. Технический результат – повышение эффективности кодирования/декодирования изображений за счет выбора скорректированной информации движения. Способ кодирования изображения выполняется в соответствии с форматом масштабируемого кодирования, содержащим по меньшей мере опорный уровень и улучшающий уровень, и содержит для области изображения улучшающего уровня этапы, на которых: определяют набор предикторов-кандидатов информации движения, включающий в себя предиктор-кандидат информации движения, на основе информации движения, связанной с частью изображения, принадлежащей опорному уровню; определяют совмещенную позицию в опорном уровне области изображения для кодирования в улучшающем уровне; корректируют по меньшей мере одну координату совмещенной позиции на новое значение; и выбирают, если доступно, информацию движения, связанную со скорректированной позицией в опорном уровне, в качестве предиктора-кандидата информации движения, который должен быть включен в упомянутый набор предикторов-кандидатов информации движения. 6 н.п. ф-лы, 13 ил.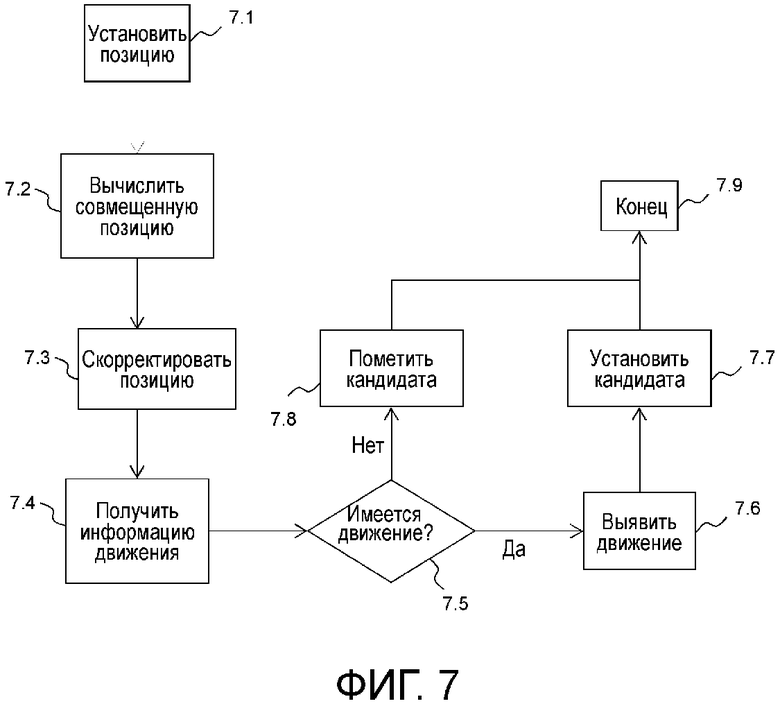
1. Способ кодирования изображения в соответствии с форматом масштабируемого кодирования, причем упомянутый формат кодирования содержит по меньшей мере опорный уровень и улучшающий уровень, по меньшей мере часть изображения закодирована с предсказанием на основе информации движения, упомянутая информация движения сама закодирована с предсказанием на основе предиктора информации движения из набора предикторов-кандидатов информации движения, причем способ содержит по меньшей мере для области изображения улучшающего уровня этапы, на которых:
определяют набор предикторов-кандидатов информации движения, включающий в себя предиктор-кандидат информации движения, на основе информации движения, связанной с частью изображения, принадлежащей опорному уровню; и
определяют совмещенную позицию в опорном уровне области изображения для кодирования в улучшающем уровне,
причем способ дополнительно содержит этапы, на которых:
корректируют по меньшей мере одну координату X упомянутой совмещенной позиции на новое значение X', заданное как X'=((Х+4)>>4)<<4; и
выбирают, если доступно, информацию движения, связанную со скорректированной позицией в опорном уровне, в качестве предиктора-кандидата информации движения, который должен быть включен в упомянутый набор предикторов-кандидатов информации движения.
2. Устройство для кодирования изображения в соответствии с форматом масштабируемого кодирования, причем упомянутый формат кодирования содержит по меньшей мере опорный уровень и улучшающий уровень, по меньшей мере часть изображения закодирована с предсказанием на основе информации движения, упомянутая информация движения сама закодирована с предсказанием на основе предиктора информации движения из набора предикторов-кандидатов информации движения, причем устройство содержит по меньшей мере для области изображения улучшающего уровня:
блок определения предикторов, выполненный с возможностью определения набора предикторов-кандидатов информации движения, включающего в себя предиктор-кандидат информации движения, на основе информации движения, связанной с частью изображения, принадлежащей опорному уровню; и
блок определения позиции, выполненный с возможностью определения совмещенной позиции в опорном уровне области изображения для кодирования в улучшающем уровне,
причем устройство дополнительно содержит:
блок коррекции позиции, выполненный с возможностью коррекции по меньшей мере одной координаты X упомянутой совмещенной позиции на новое значение X', заданное как X'=((Х+4)>>4)<<4; и
блок выбора, выполненный с возможностью выбора, если доступно, информации движения, связанной со скорректированной позицией в опорном уровне, в качестве предиктора-кандидата информации движения, который должен быть включен в упомянутый набор предикторов-кандидатов информации движения.
3. Способ декодирования изображения в соответствии с форматом масштабируемого кодирования, причем упомянутый формат кодирования содержит по меньшей мере опорный уровень и улучшающий уровень, по меньшей мере часть изображения закодирована с предсказанием на основе информации движения, упомянутая информация движения сама закодирована с предсказанием на основе предиктора информации движения из набора предикторов-кандидатов информации движения, причем способ содержит по меньшей мере для области изображения улучшающего уровня этапы, на которых:
определяют набор предикторов-кандидатов информации движения, включающий в себя предиктор-кандидат информации движения, на основе информации движения, связанной с частью изображения, принадлежащей опорному уровню; и
определяют совмещенную позицию в опорном уровне области изображения для декодирования в улучшающем уровне,
причем способ дополнительно содержит этапы, на которых:
корректируют по меньшей мере одну координату X упомянутой совмещенной позиции на новое значение X', заданное как X'=((X+4)>>4)<<4; и
выбирают, если доступно, информацию движения, связанную со скорректированной позицией в опорном уровне, в качестве предиктора-кандидата информации движения, который должен быть включен в упомянутый набор предикторов-кандидатов информации движения.
4. Устройство для декодирования изображения в соответствии с форматом масштабируемого кодирования, причем упомянутый формат кодирования содержит по меньшей мере опорный уровень и улучшающий уровень, по меньшей мере часть изображения закодирована с предсказанием на основе информации движения, упомянутая информация движения сама закодирована с предсказанием на основе предиктора информации движения из набора предикторов-кандидатов информации движения, причем устройство содержит по меньшей мере для области изображения улучшающего уровня:
блок определения предикторов, выполненный с возможностью определения набора предикторов-кандидатов информации движения, включающего в себя предиктор-кандидат информации движения, на основе информации движения, связанной с частью изображения, принадлежащей опорному уровню; и
блок определения позиции, выполненный с возможностью определения совмещенной позиции в опорном уровне области изображения для декодирования в улучшающем уровне,
причем устройство дополнительно содержит:
блок коррекции позиции, выполненный с возможностью коррекции по меньшей мере одной координаты X упомянутой совмещенной позиции на новое значение X', заданное как X'=((X+4)>>4)<<4; и
блок выбора, выполненный с возможностью выбора, если доступно, информации движения, связанной со скорректированной позицией в опорном уровне, в качестве предиктора-кандидата информации движения, который должен быть включен в упомянутый набор предикторов-кандидатов информации движения.
5. Машиночитаемый запоминающий носитель, содержащий процессорно-исполняемый код для выполнения способа кодирования изображения в соответствии с форматом масштабируемого кодирования, причем упомянутый формат кодирования содержит по меньшей мере опорный уровень и улучшающий уровень, по меньшей мере часть изображения закодирована с предсказанием на основе информации движения, упомянутая информация движения сама закодирована с предсказанием на основе предиктора информации движения из набора предикторов-кандидатов информации движения, причем способ содержит по меньшей мере для области изображения улучшающего уровня этапы, на которых:
определяют набор предикторов-кандидатов информации движения, включающий в себя предиктор-кандидат информации движения, на основе информации движения, связанной с частью изображения, принадлежащей опорному уровню; и
определяют совмещенную позицию в опорном уровне области изображения для кодирования в улучшающем уровне,
причем способ дополнительно содержит этапы, на которых:
корректируют по меньшей мере одну координату X упомянутой совмещенной позиции на новое значение X', заданное как X'=((Х+4)>>4)<<4; и
выбирают, если доступно, информацию движения, связанную со скорректированной позицией в опорном уровне, в качестве предиктора-кандидата информации движения, который должен быть включен в упомянутый набор предикторов-кандидатов информации движения.
6. Машиночитаемый запоминающий носитель, содержащий процессорно-исполняемый код для выполнения способа декодирования изображения в соответствии с форматом масштабируемого кодирования, причем упомянутый формат кодирования содержит по меньшей мере опорный уровень и улучшающий уровень, по меньшей мере часть изображения закодирована с предсказанием на основе информации движения, упомянутая информация движения сама закодирована с предсказанием на основе предиктора информации движения из набора предикторов-кандидатов информации движения, причем способ содержит по меньшей мере для области изображения улучшающего уровня этапы, на которых:
определяют набор предикторов-кандидатов информации движения, включающий в себя предиктор-кандидат информации движения, на основе информации движения, связанной с частью изображения, принадлежащей опорному уровню; и
определяют совмещенную позицию в опорном уровне области изображения для декодирования в улучшающем уровне,
причем способ дополнительно содержит этапы, на которых:
корректируют по меньшей мере одну координату X упомянутой совмещенной позиции на новое значение X', заданное как X'=((X+4)>>4)<<4; и
выбирают, если доступно, информацию движения, связанную со скорректированной позицией в опорном уровне, в качестве предиктора-кандидата информации движения, который должен быть включен в упомянутый набор предикторов-кандидатов информации движения.
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| US 6330280 B1, 11.12.2001 | |||
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| SEBASTIEN LASSERRE et al., "Description of the scalable video coding technology proposal by Canon Research Centre France", Joint Collaborative Team on Video Coding (JCT-VC) of ITU-T SG16 WP3 and ISO/IEC JTC1/SC29/WG11, 11th Meeting: Shanghai, CN, 10-19 Oct., 2012, Document: JCTVC-K0041, 78 л., опубл | |||
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| SEUNGWOOK PARK et al., "Modifications of temporal mv memory compression and temporal mv predictor", Joint Collaborative Team on Video Coding (JCT-VC) of ITU-T SG16 WP3 and ISO/IEC JTC1/SC29/WG11, 5th Meeting: Geneva, CH, 16-23 March, 2011, Document: JCTVC-E059, 8 л., опубл | |||
| Способ изготовления электрических сопротивлений посредством осаждения слоя проводника на поверхности изолятора | 1921 |
|
SU19A1 |
| УСОВЕРШЕНСТВОВАННОЕ КОДИРОВАНИЕ УЛУЧШАЮЩЕГО СЛОЯ ДЛЯ МАСШТАБИРУЕМОГО КОДИРОВАНИЯ ВИДЕО | 2008 |
|
RU2463728C2 |

