УРОВЕНЬ ТЕХНИКИ
[001] Инженеры используют сжатие (также называемое кодирование источника), чтобы уменьшать битрейт цифрового видео. Сжатие уменьшает стоимость хранения и передачи видеоинформации посредством преобразования информации в форму более низкой скорости передачи данных. Распаковка (также называемая декодирование) восстанавливает версию исходной информации из сжатой формы. "Кодек" является системой кодера/декодера.
[002] За последние два десятилетия, были приняты различные стандарты видеокодеков, включая сюда стандарты ITU-T H.261, H.262 (MPEG-2 или ISO/IEC 13818-2), H.263 и H.264 (MPEG-4 AVC или ISO/IEC 14496-10), стандарты MPEG-1 (ISO/IEC 11172-2) и MPEG-4 Visual (ISO/IEC 14496-2), и стандарт SMPTE 421M (VC-1). В более позднее время, был одобрен стандарт H.265/HEVC (ITU-T H.265 или ISO/IEC 23008-2). Расширения стандарта H.265/HEVC (например, для кодирования/декодирования масштабируемого видео, для кодирования/декодирования видео с более высокой точностью исходя из глубины битов отсчетов или частоты дискретизации цветности, для контента захвата экрана, или для многовидового кодирования/декодирования) в текущее время находятся в разработке. Стандарт видеокодека обычно определяет варианты выбора для синтаксиса кодированного битового видеопотока, параметров детализации в битовом потоке, когда конкретные признаки используются в кодировании и декодировании. Во многих случаях, стандарт видеокодека также обеспечивает подробности об операциях декодирования, которые декодер должен выполнять, чтобы достигать согласовывающихся результатов в декодировании. Помимо стандартов кодеков, различные коммерческие форматы кодеков определяют другие варианты выбора для синтаксиса кодированного битового видеопотока и соответствующих операций декодирования.
[003] В общем, способы сжатия видео включают в себя "интра-картиночное" сжатие и "интер-картиночное" сжатие. Способы интра-картиночного сжатия сжимают индивидуальные картинки, и способы интер-картиночного сжатия сжимают картинки со ссылкой на предшествующую и/или последующую картинку (часто называемую опорная или анкерная картинка) или картинки.
[004] Методы интер-картиночного сжатия часто используют оценку движения и компенсацию движения, чтобы уменьшать скорость передачи данных посредством использования временной избыточности в видеопоследовательности. Оценка движения является обработкой для оценки движения между картинками. В одном общем способе, кодер, использующий оценку движения, пытается сопоставить текущий блок значений отсчетов в текущей картинке с потенциально подходящим блоком (блоком-кандидатом) такого же размера в области поиска в другой картинке, опорной картинке. Опорная картинка является, в общем, картинкой, которая содержит значения отсчетов, которые могут использоваться для предсказания в обработке декодирования других картинок.
[005] Для текущего блока, когда кодер находит точное или "достаточно близкое" соответствие в области поиска в опорной картинке, кодер параметризует изменение в положении между текущим блоком и блоком-кандидатом в качестве данных движения, таких как вектор движения ("MV"). MV является обычно двумерным значением, имеющим горизонтальную компоненту MV, которая указывает пространственное смещение влево или вправо, и вертикальную компоненту MV, которая указывает пространственное смещение вверх или вниз. В общем, компенсация движения является обработкой восстановления картинок из опорной картинки (картинок) с использованием данных движения.
[006] В некоторых методах кодирования, блоки текущей картинки сопоставляются с блоками одной или более опорных картинок. Однако такие способы сопоставления могут испытывать уменьшенную производительность, когда должно сохраняться или сопоставляться большое количество блоков. В других методах кодирования, точность вектора движения может изменяться (например, на основе от картинки к картинке), но принятие решения в отношении того, когда изменять точность вектора движения, может быть трудной задачей. В еще других методах кодирования, выполняется обнаружение изменения сцены. Однако такие способы обнаружения могут не обнаруживать эффективно или точно изменения сцены, включающие в себя контент экрана.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[007] В итоге, подробное описание представляет новаторские решения в решениях стороны кодера, которые используют результаты основывающегося на хешировании подбора блоков в выполнении различных задач и операций во время кодирования. Например, некоторые из новаторских решений относятся к способам построения хеш-таблиц, которые включают в себя некоторые (но не все) гомогенные блоки. Другие новаторские решения относятся к определению разрешения вектора движения на основе основывающегося на хешировании подбора блоков. Например, блоки картинки могут классифицироваться на множество категорий и количество блоков, назначенных каждой категории, может использоваться в определении того, какую точность вектора движения использовать. Другие новаторские решения относятся к обнаружению изменения сцены с использованием, по меньшей мере, частично, информации основывающегося на хешировании подбора блоков. Например, картинки могут идентифицироваться на различных этапах изменения сцены (например, во время устойчивой сцены, непосредственно перед изменением сцены, во время перехода между сценами, и в начале новой сцены). Информация изменения сцены может использоваться в выборе долгосрочных опорных картинок и/или при регулировке качества картинок во время кодирования.
[008] Предшествующие и другие задачи, признаки, и преимущества изобретения станут более ясными из последующего подробного описания, которое продолжается со ссылкой на сопровождающие фигуры.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[009] Фиг. 1 является схемой иллюстративной вычислительной системы, в которой могут осуществляться некоторые описанные варианты осуществления.
[010] Фиг. 2a и 2b являются диаграммами иллюстративных сетевых сред, в которых могут осуществляться некоторые описанные варианты осуществления.
[011] Фиг. 3 является схемой иллюстративной системы кодера, совместно с которой могут осуществляться некоторые описанные варианты осуществления.
[012] Фиг. 4a и 4b являются схемами, иллюстрирующими иллюстративный кодер видео, совместно с которым могут осуществляться некоторые описанные варианты осуществления.
[013] Фиг. 5 является схемой, иллюстрирующей среду рабочего стола компьютера с контентом, который может обеспечивать ввод для захвата экрана.
[014] Фиг. 6 является схемой, иллюстрирующей комбинированное видео с естественным видеоконтентом и искусственно созданным видеоконтентом.
[015] Фиг. 7 является таблицей, иллюстрирующей хеш-значения для блоков-кандидатов в основанном на хеше сопоставлении блоков.
[016] Фиг. 8a-8c являются таблицами, иллюстрирующими иллюстративные структуры данных, которые организуют блоки-кандидаты для основанного на хеше сопоставления блоков.
[017] Фиг. 9a-9c являются таблицами, иллюстрирующими иллюстративные структуры данных, которые организуют блоки-кандидаты для итеративного основанного на хеше сопоставления блоков.
[018] Фиг. 10a-10c являются схемами, иллюстрирующими шаблоны блоков-кандидатов.
[019] Фиг. 11 является блок-схемой последовательности операций, иллюстрирующей способ для выбора однородных блоков с использованием критерия равномерного выбора во время построения хеш-таблицы.
[020] Фиг. 12a и 12b являются схемами, иллюстрирующими компенсацию движения со значениями MV, имеющими пространственное смещение целочисленных отсчетов и пространственное смещение дробных отсчетов, соответственно.
[021] Фиг. 13 является блок-схемой последовательности операций, иллюстрирующей метод для выбора точности MV в зависимости от результатов классификации блоков.
[022] Фиг. 14 является блок-схемой последовательности операций, иллюстрирующей метод для выполнения классификации блоков, используемой при выборе точности MV.
[023] Фиг. 15 является блок-схемой последовательности операций, иллюстрирующей метод для обнаружения изменения сцены во время кодирования видео.
ПОДРОБНОЕ ОПИСАНИЕ
[024] Подробное описание представляет новаторские решения в решениях стороны кодера, которые используют способы основывающегося на хешировании подбора, чтобы улучшать производительность различных типов операций. Например, некоторые из новаторских решений относятся к способам построения хеш-таблиц, которые включают в себя некоторые (но не все) гомогенные блоки (например, которые включают в себя только те однородные блоки, которые удовлетворяют критериям выбора). Другие новаторские решения относятся к определению разрешения вектора движения на основе основывающегося на хешировании подбора блоков. Например, блоки картинки могут классифицироваться на множество категорий и количество блоков, назначенных каждой категории, может использоваться в определении того, какую точность вектора движения использовать. Другие новаторские решения относятся к обнаружению изменения сцены с использованием, по меньшей мере, частично, информации основывающегося на хешировании подбора блоков. Например, картинки могут идентифицироваться на различных этапах изменения сцены (например, во время устойчивой сцены, непосредственно перед изменением сцены, во время перехода между сценами, и в начале новой сцены). Информация изменения сцены может использоваться в выборе долгосрочных опорных картинок и/или при регулировке качества картинок во время кодирования.
[025] В частности, новаторские решения могут обеспечивать вычислительно эффективные способы для установки параметров во время кодирования искусственно созданного видеоконтента, такого как контент захвата экрана.
[026] Хотя операции, здесь описанные, находятся в местах, описанных как выполняющиеся посредством кодера видео, во многих случаях операции могут выполняться посредством другого типа инструмента обработки мультимедиа (например, кодера изображений).
[027] Некоторые из новаторских решений, здесь описанных, проиллюстрированы со ссылкой на синтаксические элементы и операции, характерные для стандарта H.265/HEVC. Например, ссылка делается на черновую версию JCTVC-P1005 стандарта H.265/HEVC - "High Efficiency Video Coding (HEVC) Range Extensions Text Specification: Draft 6", JCTVC-P1005_v1, февраль 2014. Новаторские решения, здесь описанные, также могут осуществляться для других стандартов или форматов.
[028] Многие из новаторских решений, здесь описанных, могут улучшать обработки принятия решений при кодировании некоторого искусственно созданного видеоконтента, такого как контент захвата экрана от модуля захвата экрана. Контент захвата экрана обычно включает в себя повторяющиеся структуры (например, графику, текстовые символы). Контент захвата экрана обычно кодируется в формате (например, YUV 4:4:4 или RGB 4:4:4) с высоким разрешением дискретизации цветности, хотя он также может кодироваться в формате с более низким разрешением дискретизации цветности (например, YUV 4:2:0). Общие сценарии для кодирования/декодирования контента захвата экрана включают в себя конференц-связь удаленного рабочего стола и кодирование/декодирование графических наложений на естественное видео или другое видео "смешанного контента". Эти новаторские решения также могут использоваться для естественного видеоконтента, но могут не быть настолько эффективными.
[029] Более широко, являются возможными различные альтернативы для примеров, здесь описанных. Например, некоторые из способов, здесь описанных, могут изменяться посредством изменения порядка описанных действий способа, посредством разделения, повторения, или пропуска некоторых действий способа, и т.д. Различные аспекты раскрытой технологии могут использоваться в комбинации или раздельно. Разные варианты осуществления используют одно или более из описанных новаторских решений. Некоторые из новаторских решений, здесь описанных, направлены на одну или более из проблем, отмеченных в уровне техники. Обычно, заданный способ/инструмент не решает все такие проблемы.
I. ИЛЛЮСТРАТИВНЫЕ ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ.
[030] Фиг. 1 иллюстрирует обобщенный пример подходящей вычислительной системы (100), в которой могут осуществляться несколько из описанных новаторских решений. Вычислительная система (100) не предназначена, чтобы предлагать какое-либо ограничение в отношении объема использования или функциональных возможностей, так как новаторские решения могут осуществляться в разнообразных вычислительных системах общего назначения или специального назначения.
[031] Со ссылкой на фиг. 1, вычислительная система (100) включает в себя один или более блоков (110, 115) обработки и память (120, 125). Блоки (110, 115) обработки исполняют исполнимые компьютером инструкции. Блок обработки может быть центральным блоком обработки ("CPU") общего назначения, процессором в специализированной интегральной схеме ("ASIC") или любым другим типом процессора. В многопроцессорной системе, множество блоков обработки исполняют исполнимые компьютером инструкции, чтобы увеличивать мощность обработки. Например, фиг. 1 показывает центральный блок (110) обработки также как блок обработки графики или блок совместной обработки (115). Материальная память (120, 125) может быть энергозависимой памятью (например, регистрами, кэшем, RAM), энергонезависимой памятью (например, ROM, EEPROM, флэш-памятью, и т.д.), или некоторой комбинацией упомянутых двух, доступной для блока (блоков) обработки. Память (120, 125) хранит программное обеспечение (180), осуществляющее одно или более новаторских решений для решений кодера на основе результатов основывающегося на хешировании подбора блоков (например, для построения хеш-таблиц, для выбора точности MV, и для обнаружения изменений сцены и приятия решений на основе изменений сцены), в форме исполнимых компьютером инструкций, подходящих для исполнения посредством блока (блоков) обработки.
[032] Вычислительная система может иметь дополнительные признаки. Например, вычислительная система (100) включает в себя хранилище (140), одно или более устройств (150) ввода, одно или более устройств (160) вывода, и одно или более соединений (170) передачи данных. Механизм взаимного соединения (не показан), такой как шина, контроллер, или сеть, взаимно соединяет компоненты вычислительной системы (100). Обычно, программное обеспечение операционной системы (не показано) обеспечивает операционную среду для другого программного обеспечения, исполняющегося в вычислительной системе (100), и координирует действия компонентов вычислительной системы (100).
[033] Материальное хранилище (140) может быть съемным или несъемным, и включает в себя магнитные диски, магнитные ленты или кассеты, CD-ROM, DVD, или любой другой носитель, который может использоваться, чтобы хранить информацию и к которому может осуществляться доступ внутри вычислительной системы (100). Хранилище (140) хранит инструкции для программного обеспечения (180), осуществляющего одно или более новаторских решений для решений кодера на основе результатов основывающегося на хешировании подбора блоков.
[034] Устройство (устройства) (150) ввода может быть сенсорным устройством ввода, таким как клавиатура, мышь, перо, или шаровой указатель, речевым устройством ввода, сканирующим устройством, или другим устройством, которое обеспечивает ввод в вычислительную систему (100). Для видео, устройство (устройства) (150) ввода может быть камерой, видеокартой, картой TV-тюнера, модулем захвата экрана, или аналогичным устройством, которое принимает видеовход в аналоговой или цифровой форме, или CD-ROM или CD-RW, которое считывает видеовход в вычислительную систему (100). Устройство (устройства) (160) вывода может быть устройством отображения, принтером, громкоговорителем, устройством записи CD, или другим устройством, которое обеспечивает вывод из вычислительной системы (100).
[035] Соединение (соединения) (170) передачи данных обеспечивает возможность связи по носителю передачи данных с другой вычислительной сущностью. Носитель передачи данных доставляет информацию, такую как исполнимые компьютером инструкции, аудио или видео ввод или вывод, или другие данные в модулированном сигнале данных. Модулированный сигнал данных является сигналом, который имеет одну или более из его характеристик установленными или измененными таким образом, чтобы кодировать информацию в сигнале. В качестве примера, и не ограничения, носители передачи данных могут использовать электрическую, оптическую, RF, или другую несущую.
[036] Новаторские решения могут быть описаны в общем контексте считываемых компьютером запоминающих носителей. Считываемые компьютером запоминающие носители являются любыми доступными материальными носителями, к которым может осуществляться доступ внутри вычислительной среды. В качестве примера, с вычислительной системой (100), считываемые компьютером носители включают в себя память (120, 125) и/или хранилище (140). Признак считываемые компьютером запоминающие носители не включает в себя сигналы и несущие волны. В дополнение, признак считываемые компьютером запоминающие носители не включает в себя соединения передачи данных (например, 170).
[037] Новаторские решения могут быть описаны в общем контексте исполнимых компьютером инструкций, как, например, инструкций, включенных в программные модули, которые исполняются в вычислительной системе на целевом реальном или виртуальном процессоре. В общем, программные модули включают в себя процедуры, программы, библиотеки, объекты, классы, компоненты, структуры данных, и т.д., которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных. Функциональные возможности программных модулей могут комбинироваться или разделяться между программными модулями, как требуется в различных вариантах осуществления. Исполнимые компьютером инструкции для программных модулей могут выполняться внутри локальной или распределенной вычислительной системы.
[038] Признаки "система" и "устройство" используются здесь взаимозаменяемо. Если контекст явным образом не указывает иное, никакой признак не имеет следствием какое-либо ограничение по типу вычислительной системы или вычислительного устройства. В общем, вычислительная система или вычислительное устройство может быть локальным или распределенным, и может включать в себя любую комбинацию аппаратного обеспечения специального назначения и/или аппаратного обеспечения общего назначения с программным обеспечением, осуществляющим функциональные возможности, здесь описанные.
[039] Раскрытые способы также могут осуществляться с использованием специализированного вычислительного аппаратного обеспечения, сконфигурированного с возможностью выполнять любой из раскрытых способов. Например, раскрытые способы могут осуществляться посредством интегральной схемы (например, ASIC (такой как цифровой сигнальный процессор ("DSP") ASIC, блок обработки графики ("GPU"), или программируемое логическое устройство ("PLD"), такое как программируемая пользователем вентильная матрица ("FPGA")), специально сконструированной или сконфигурированной, чтобы осуществлять любой из раскрытых способов.
[040] Для представления, подробное описание использует признаки, такие как "определять" и "использовать", чтобы описывать компьютерные операции в вычислительной системе. Эти признаки являются высокоуровневыми абстракциями для операций, выполняемых посредством компьютера, и не должны смешиваться с действиями, выполняемыми человеком. Фактические компьютерные операции, соответствующие этим признакам, изменяются в зависимости от варианта осуществления.
II. ИЛЛЮСТРАТИВНЫЕ СЕТЕВЫЕ СРЕДЫ.
[041] Фиг. 2a и 2b показывают иллюстративные сетевые среды (201, 202), которые включают в себя кодеры (220) видео и декодеры (270) видео. Кодеры (220) и декодеры (270) соединены по сети (250) с использованием подходящего протокола связи. Сеть (250) может включать в себя сеть Интернет или другую компьютерную сеть.
[042] В сетевой среде (201), показанной на фиг. 2a, каждый инструмент (210) связи реального времени ("RTC") включает в себя как кодер (220), так и декодер (270) для двунаправленной передачи данных. Заданный кодер (220) может формировать вывод, согласующийся с вариантом или расширением стандарта H.265/HEVC, стандарта SMPTE 421M, стандарта ISO-IEC 14496-10 (также известного как H.264 или AVC), другого стандарта, или коммерческого формата, при этом соответствующий декодер (270) принимает кодированные данные от кодера (220). Двунаправленная передача данных может быть частью видео конференц-связи, телефонного видеовызова, или другим сценарием связи двух сторон или множества сторон. Хотя сетевая среда (201) на фиг. 2a включает в себя два инструмента (210) связи реального времени, сетевая среда (201) может вместо этого включать в себя три или более инструментов (210) связи реального времени, которые участвуют в связи множества сторон.
[043] Инструмент (210) связи реального времени управляет кодированием посредством кодера (220). Фиг. 3 показывает иллюстративную систему (300) кодера, которая может быть включена в инструмент (210) связи реального времени. Альтернативно, инструмент (210) связи реального времени использует другую систему кодера. Инструмент (210) связи реального времени также управляет декодированием посредством декодера (270).
[044] В сетевой среде (202), показанной на фиг. 2b, инструмент (212) кодирования включает в себя кодер (220), который кодирует видео для доставки в множество инструментов (214) проигрывания, которые включают в себя декодеры (270). Однонаправленная передача данных может обеспечиваться для системы видео наблюдения, системы наблюдения веб-камерами, представления конференц-связи удаленного рабочего стола или другого сценария, в котором видео кодируется и отправляется из одного местоположения в одно или более другие местоположения. Хотя сетевая среда (202) на фиг. 2b включает в себя два инструмента (214) проигрывания, сетевая среда (202) может включать в себя больше или меньше инструментов (214) проигрывания. В общем, инструмент (214) проигрывания осуществляет связь с инструментом (212) кодирования, чтобы определять поток видео для приема инструментом (214) проигрывания. Инструмент (214) проигрывания принимает поток, буферизует принятые кодированные данные для соответствующего периода, и начинает декодирование и проигрывание.
[045] Фиг. 3 показывает иллюстративную систему (300) кодера, которая может быть включена в инструмент (212) кодирования. Альтернативно, инструмент (212) кодирования использует другую систему кодера. Инструмент (212) кодирования также может включать в себя логику контроллера стороны сервера для управления соединениями с одним или более инструментами (214) проигрывания. Инструмент (214) проигрывания также может включать в себя логику контроллера стороны клиента для управления соединениями с инструментом (212) кодирования.
III. ИЛЛЮСТРАТИВНЫЕ СИСТЕМЫ КОДЕРА.
[046] Фиг. 3 является блок-схемой иллюстративной системы (300) кодера, совместно с которой могут осуществляться некоторые описанные варианты осуществления. Система (300) кодера может быть инструментом кодирования общего назначения, выполненным с возможностью работы в любом из множества режимов кодирования, как, например, режиме кодирования с низкой задержкой для связи реального времени, режиме транскодирования, и режиме кодирования с более высокой задержкой для формирования мультимедиа для проигрывания из файла или потока, или она может быть инструментом кодирования специального назначения, адаптированным для одного такого режима кодирования. Система (300) кодера может быть выполнена с возможностью для кодирования конкретного типа контента (например, контента захвата экрана). Система (300) кодера может осуществляться как модуль операционной системы, как часть прикладной библиотеки или как изолированное приложение. В целом, система (300) кодера принимает последовательность видеокадров (311) источника от источника (310) видео и формирует кодированные данные в качестве вывода в канал (390). Кодированные данные, выводимые в канал, могут включать в себя контент, кодированный с использованием решений стороны кодера, как описано в данном документе.
[047] Источник (310) видео может быть камерой, картой тюнера, запоминающими носителями, модулем захвата экрана, или другим источником цифрового видео. Источник (310) видео формирует последовательность видеокадров с частотой кадров, равной, например, 30 кадров в секунду. Как здесь используется, признак "кадр", в общем, указывает на исходные, кодированные или восстановленные данные изображения. Для видео с прогрессивным сканированием, кадр является кадром видео с прогрессивным сканированием. Для чередующегося видео, в иллюстративных вариантах осуществления, для кадра чередующегося видео чередование может устраняться до кодирования. Альтернативно, два комплементарных поля чередующегося видео кодируются вместе как одиночный видеокадр или кодируются как два отдельно кодированных поля. Помимо указания кадра видео с прогрессивным сканированием или кадра видео с чередующимся сканированием, признак "кадр" или "картинка" может указывать одиночное неспаренное видеополе, комплементарную пару видеополей, плоскость видеообъекта, которая представляет видеообъект в заданный момент времени, или область интереса в более большом изображении. Плоскость видеообъекта или область может быть частью более большого изображения, которое включает в себя множество объектов или областей сцены.
[048] Прибывающий исходный кадр (311) сохраняется в области (320) памяти временного хранения исходных кадров, которая включает в себя множество областей (321, 322,..., 32n) хранения буферов кадров. Буфер (321, 322, и т.д.) кадров хранит один исходный кадр в области (320) хранения исходных кадров. После того, как один или более из исходных кадров (311) были сохранены в буферах (321, 322, и т.д.) кадров, модуль (330) выбора кадров выбирает индивидуальный исходный кадр из области (320) хранения исходных кадров. Порядок, в котором кадры выбираются модулем (330) выбора кадров для ввода в кодер (340), может отличиться от порядка, в котором кадры формируются источником (310) видео, например, кодирование некоторых кадров может задерживаться в порядке, чтобы обеспечивать возможность сначала кодировать некоторые более поздние кадры и, таким образом, обеспечивать временное обратное предсказание. Перед кодером (340), система (300) кодера может включать в себя процессор предварительной обработки (не показан), который выполняет предварительную обработку (например, фильтрацию) выбранного кадра (331) до кодирования. Предварительная обработка может включать в себя преобразование цветового пространства в первичные (например, яркости) и вторичные (например, разности цветности в направлении к красному и в направлении к синему) компоненты и обработку повторной дискретизации (например, чтобы уменьшать пространственное разрешение компонент цветности) для кодирования. Обычно, до кодирования, видео преобразуется в цветовое пространство, такое как YUV, в котором значения отсчетов компоненты яркости (Y) представляют значения яркости или интенсивности, и значения отсчетов компонент цветности (U, V) представляют значения цветовой разности. Точные определения значений цветовой разности (и операции преобразования в/из цветового пространства YUV в другое цветовое пространство, такое как RGB) зависят от реализации. В общем, как здесь используется, признак YUV указывает любое цветовое пространство с компонентой яркости и одной или более компонентами цветности, включая сюда Y'UV, YIQ, Y'IQ и YDbDr, также как варианты, такие как YCbCr и YCoCg. Значения отсчетов цветности могут дополнительно дискретизироваться на более низкую частоту дискретизации цветности (например, для формата YUV 4:2:0), или значения отсчетов цветности могут иметь такое же разрешение, что и значения отсчетов яркости (например, для формата YUV 4:4:4). Или, видео может кодироваться в другом формате (например, формате RGB 4:4:4, формате GBR 4:4:4 или формате BGR 4:4:4).
[049] Кодер (340) кодирует выбранный кадр (331), чтобы формировать кодированный кадр (341), и также формирует сигналы (342) операций управления памятью ("MMCO") или информацию набора опорных картинок ("RPS"). RPS является набором кадров, которые могут использоваться для ссылки в компенсации движения для текущего кадра или любого последующего кадра. Если текущий кадр не является первым кадром, который был кодирован, при выполнении его обработки кодирования, кодер (340) может использовать один или более ранее кодированных/декодированных кадров (369), которые были сохранены в области (360) памяти временного хранения декодированных кадров. Такие сохраненные декодированные кадры (369) используются в качестве опорных кадров для интер-кадрового предсказания контента текущего исходного кадра (331). Информация (342) MMCO/RPS указывает декодеру, какие восстановленные кадры могут использоваться в качестве опорных кадров, и, следовательно, должна сохраняться в области хранения кадров. Иллюстративные способы для принятия решений в отношении того, какие опорные картинки сохранять в RPS, описываются ниже.
[050] В общем, кодер (340) включает в себя множество модулей кодирования, которые выполняют задачи кодирования, как, например, разделение на мозаичные элементы, оценка интра-предсказания и предсказание, оценка движения и компенсация, частотные преобразования, квантование и энтропийное кодирование. Точные операции, выполняемые кодером (340), могут изменяться в зависимости от формата сжатия. Формат выходных кодированных данных может быть вариантом или расширением формата H.265/HEVC, формата Windows Media Video, формата VC-1, формата MPEG-x (например, MPEG-1, MPEG-2, или MPEG-4), формата H.26x (например, H.261, H.262, H.263, H.264), или другого формата.
[051] Кодер (340) может разделять кадр на множество мозаичных элементов одного и того же размера или разных размеров. Например, кодер (340) разделяет кадр вдоль строк мозаичных элементов и столбцов мозаичных элементов, которые, с границами кадра, определяют горизонтальные и вертикальные границы мозаичных элементов внутри кадра, где каждый мозаичный элемент является прямоугольной областью. Мозаичные элементы часто используются, чтобы обеспечивать варианты выбора для параллельной обработки. Кадр также может быть организован как один или более срезов, где срез может быть целым кадром или областью кадра. Срез может декодироваться независимо от других срезов в кадре, что улучшает устойчивость к ошибкам. Контент среза или мозаичного элемента дополнительно разделяется на блоки или другие наборы значений отсчетов в целях кодирования и декодирования.
[052] Для синтаксиса согласно стандарту H.265/HEVC, кодер разделяет контент кадра (или среза или мозаичного элемента) на единицы дерева кодирования. Единица дерева кодирования ("CTU") включает в себя значения отсчетов яркости, организованные как блок дерева кодирования ("CTB") яркости, и соответствующие значения отсчетов цветности, организованные как два блока CTB цветности. Размер единицы CTU (и ее блоков CTB) выбирается кодером, и может быть, например, 64×64, 32×32 или 16×16 значений отсчетов. CTU включает в себя одну или более единиц кодирования. Единица кодирования ("CU") имеет блок кодирования ("CB") яркости и два соответствующие блока CB цветности. Например, CTU с CTB яркости 64×64 и двумя блоками CTB цветности 64×64 (формат YUV 4:4:4) может разделяться на четыре единицы CU, при этом каждая CU включает в себя CB яркости 32×32 и два блока CB цветности 32×32, и при этом каждая CU возможно разделяется дополнительно на более малые единицы CU. Или, в качестве другого примера, CTU с CTB яркости 64×64 и двумя блоками CTB цветности 32×32 (формат YUV 4:2:0) может разделяться на четыре единицы CU, при этом каждая CU включает в себя CB яркости 32×32 и два блока CB цветности 16×16, и при этом каждая CU возможно разделяется дополнительно на более малые единицы CU. Наименьший допустимый размер единицы CU (например, 8×8, 16×16) может сигнализироваться в битовом потоке.
[053] В общем, CU имеет режим предсказания, такой как интер или интра. CU включает в себя одну или более единиц предсказания в целях сигнализации информации предсказания (такой как подробности режима предсказания, значения смещения, и т.д.) и/или обработки предсказания. Единица предсказания ("PU") имеет блок предсказания ("PB") яркости и два блока PB цветности. Для интра-предсказанной CU, PU имеет такой же размер, что и CU, если CU не имеет наименьший размер (например, 8×8). В этом случае, CU может разделяться на четыре более малых единицы PU (например, каждая 4×4, если наименьший размер CU равняется 8×8) или PU может иметь наименьший размер CU, как указано посредством синтаксического элемента для CU. CU также имеет одну или более единиц преобразования для целей кодирования/декодирования остатка, где единица преобразования ("TU") имеет блок преобразования ("TB") и два блока TB цветности. PU в интра-предсказанной CU может содержать одиночную TU (равную в размере единице PU) или множество единиц TU. Кодер принимает решение в отношении того, как разделять видео на единицы CTU, единицы CU, единицы PU, единицы TU, и т.д.
[054] В вариантах осуществления H.265/HEVC, срез может включать в себя одиночный сегмент среза (независимый сегмент среза) или разделяться на множество сегментов среза (независимый сегмент среза и один или более зависимых сегментов среза). Сегмент среза является целым числом единиц CTU, упорядоченных последовательно в сканировании мозаичного элемента, содержащихся в одиночной единице уровня сетевой абстракции ("NAL"). Для независимого сегмента среза, заголовок сегмента среза включает в себя значения синтаксических элементов, которые применяются для независимого сегмента среза. Для зависимого сегмента среза, усеченный заголовок сегмента среза включает в себя несколько значений синтаксических элементов, которые применяются для этого зависимого сегмента среза, и значения других синтаксических элементов для зависимого сегмента среза выводятся из значений для предшествующего независимого сегмента среза в порядке декодирования.
[055] Как здесь используется, признак "блок" может указывать макроблок, единицу предсказания, единицу данных остатка, или CB, PB или TB, или некоторый другой набор значений отсчетов, в зависимости от контекста.
[056] Возвращаясь к фиг. 3, кодер представляет интра-кодированный блок исходного кадра (331) исходя из предсказания из других, ранее восстановленных значений отсчетов в кадре (331). Для основанного на копии блока ("BC") интра-предсказания, модуль интра-картиночной оценки или модуль оценки движения оценивает смещение блока по отношению к другим, ранее восстановленным значениям отсчетов в том же кадре. Опорная область интра-кадрового предсказания является областью значений отсчетов в кадре, которые используются, чтобы генерировать значения предсказания BC для блока. Область интра-кадрового предсказания может указываться с помощью значения вектора блока ("BV"), которое может представляться в битовом потоке как значение вектора движения ("MV"). Для интра-пространственного предсказания для блока, модуль интра-картиночной оценки оценивает экстраполяцию соседних восстановленных значений отсчетов в блок. Информация предсказания (такая как значения BV/MV для интра-предсказания BC, или режим предсказания (направление) для интра-пространственного предсказания) может энтропийно кодироваться и выводиться. Модуль интра-кадрового предсказания (или модуль компенсации движения для значений BV/MV) применяет информацию предсказания, чтобы определять значения интра-предсказания.
[057] Кодер (340) представляет кодированный интер-кадровым образом, предсказанный блок исходного кадра (331) исходя из предсказания из одного или более опорных кадров (369). Модуль оценки движения оценивает движение блока по отношению к упомянутым одному или более опорным кадрам (369). Модуль оценки движения может выбирать точность MV (например, точность MV целочисленного отсчета, точность MV 1/2-отсчета, или точность MV 1/4-отсчета), например, с использованием подхода, здесь описанного, затем использовать выбранную точность MV во время оценки движения. Когда используется множество опорных кадров, множество опорных кадров может быть из разных временных направлений или одного и того же временного направления. Опорная область предсказания с компенсацией движения является областью значений отсчетов в опорном кадре (кадрах), которые используются, чтобы генерировать значения предсказания с компенсацией движения для блока значений отсчетов текущего кадра. Модуль оценки движения выводит информацию движения, такую как информация MV, которая энтропийно кодируется. Модуль компенсации движения применяет векторы MV к опорным кадрам (369), чтобы определять значения предсказания с компенсацией движения для интер-кадрового предсказания.
[058] Кодер может определять различия (если есть какие-либо) между значениями предсказания блока (интра или интер) и соответствующими исходными значениями. Эти значения остатка предсказания дополнительно кодируются с использованием частотного преобразования, квантования и энтропийного кодирования. Например, кодер (340) устанавливает значения для параметра квантования ("QP") для картинки, мозаичного элемента, среза и/или другой части видео, и квантует коэффициенты преобразования соответствующим образом. Энтропийный кодер кодера (340) сжимает значения квантованных коэффициентов преобразования также как некоторую вспомогательную информацию (например, информацию MV, выбранную точность MV, параметры фильтрации SAO, информацию обновления RPS, значения QP, решения в отношении режимов, другие выборы параметров). Обычные способы энтропийного кодирования включают в себя экспоненциальное кодирование Голомба, кодирование Голомба-Райса, арифметическое кодирование, дифференциальное кодирование, кодирование Хаффмана, кодирование длин серий, кодирование последовательностей переменной длины с использованием кодов переменной длины ("V2V"), кодирование последовательностей переменной длины с использованием кодов фиксированной длины ("V2F"), кодирование Лемпеля-Зива ("LZ"), кодирование со словарем, энтропийное кодирование с разделением на вероятностные интервалы ("PIPE"), и комбинации вышеупомянутого. Энтропийный кодер может использовать разные методы кодирования для разных типов информации, может применять множество способов в комбинации (например, посредством применения кодирования Голомба-Райса, за которым следует арифметическое кодирование), и может выбирать из множества кодовых таблиц в пределах конкретного способа кодирования.
[059] Адаптивный фильтр устранения блочности включается в контур компенсации движения в кодере (340), чтобы сглаживать разрывы между строками и/или столбцами границ блоков в декодированном кадре. Другая фильтрация (такая как фильтрация устранения окантовочных помех, адаптивная контурная фильтрация ("ALF"), или фильтрация SAO) может альтернативно или дополнительно применяться в качестве операций внутриконтурной фильтрации.
[060] Кодированные данные, сформированные кодером (340), включают в себя синтаксические элементы для различных уровней синтаксиса битового потока. Для синтаксиса согласно стандарту H.265/HEVC, например, набор параметров картинок ("PPS") является синтаксической структурой, которая содержит синтаксические элементы, которые могут быть ассоциированы с картинкой. PPS может использоваться для одиночной картинки, или PPS может повторно использоваться для множества картинок в последовательности. PPS обычно сигнализируется отдельно от кодированных данных для картинки (например, одна единица NAL для PPS, и одна или более других единиц NAL для кодированных данных для картинки). Внутри кодированных данных для картинки, синтаксический элемент указывает то, какой PPS использовать для картинки. Аналогично, для синтаксиса согласно стандарту H.265/HEVC, набор параметров последовательности ("SPS") является синтаксической структурой, которая содержит синтаксические элементы, которые могут быть ассоциированы с последовательностью картинок. Битовый поток может включать в себя одиночный SPS или множество наборов SPS. SPS обычно сигнализируется отдельно от других данных для последовательности, и синтаксический элемент в упомянутых других данных указывает то, какой SPS использовать.
[061] Кодированные кадры (341) и информация (342) MMCO/RPS (или информация, эквивалентная информации (342) MMCO/RPS, так как зависимости и структуры упорядочения для кадров являются уже известными в кодере (340)) обрабатываются посредством эмулятора (350) обработки декодирования. Эмулятор (350) обработки декодирования осуществляет некоторые из функциональных возможностей декодера, например, задачи декодирования для восстановления опорных кадров. Способом, совместимым с информацией (342) MMCO/RPS, эмулятор (350) обработки декодирования определяет, должен ли заданный кодированный кадр (341) восстанавливаться и сохраняться для использования в качестве опорного кадра в интер-кадровом предсказании последующих кадров, подлежащих кодированию. Если кодированный кадр (341) должен сохраняться, эмулятор (350) обработки декодирования моделирует обработку декодирования, которая бы проводилась декодером, который принимает кодированный кадр (341), и формирует соответствующий декодированный кадр (351). Таким образом, когда кодер (340) использует декодированный кадр (кадры) (369), которые были сохранены в области (360) хранения декодированных кадров, эмулятор (350) обработки декодирования также использует декодированный кадр (кадры) (369) из области (360) хранения как часть обработки декодирования.
[062] Область (360) памяти временного хранения декодированных кадров включает в себя множество областей (361, 362,..., 36n) хранения буферов кадров. Способом, совместимым с информацией (342) MMCO/RPS, эмулятор (350) обработки декодирования управляет содержимым области (360) хранения, чтобы идентифицировать любые буферы (361, 362, и т.д.) кадров с кадрами, которые более не нужны кодеру (340) для использования в качестве опорных кадров. После моделирования обработки декодирования, эмулятор (350) обработки декодирования сохраняет вновь декодированный кадр (351) в буфере (361, 362, и т.д.) кадров, который был идентифицирован таким образом.
[063] Кодированные кадры (341) и информация (342) MMCO/RPS буферизуются во временной области (370) кодированных данных. Кодированные данные, которые агрегируются в области (370) кодированных данных, содержат, как часть синтаксиса элементарного кодированного битового видеопотока, кодированные данные для одной или более картинок. Кодированные данные, которые агрегируются в области (370) кодированных данных, также могут включать в себя метаданные мультимедиа, относящиеся к кодированным видеоданным (например, как один или более параметров в одном или более сообщениях дополнительной информации расширения ("SEI") или сообщениях информации удобства в использовании видео ("VUI")).
[064] Агрегированные данные (371) из временной области (370) кодированных данных обрабатываются посредством канального кодера (380). Канальный кодер (380) может пакетировать и/или мультиплексировать агрегированные данные для передачи или сохранения в качестве мультимедийного потока (например, согласно формату потока мультимедийной программы или транспортного потока, такому как ITU-T H.222.0 | ISO/IEC 13818-1, или формату транспортного протокола реального времени сети Интернет, такому как IETF RFC 3550), в этом случае канальный кодер (380) может добавлять синтаксические элементы как часть синтаксиса потока передачи мультимедиа. Или, канальный кодер (380) может организовывать агрегированные данные для сохранения в виде файла (например, согласно формату контейнера мультимедиа, такому как ISO/IEC 14496-12), в этом случае канальный кодер (380) может добавлять синтаксические элементы как часть синтаксиса файла хранения мультимедиа. Или, более широко, канальный кодер (380) может осуществлять один или более протоколов мультиплексирования или транспортных протоколов системы мультимедиа, в этом случае канальный кодер (380) может добавлять синтаксические элементы как часть синтаксиса протокола (протоколов). Канальный кодер (380) обеспечивает вывод в канал (390), который представляет хранилище, соединение передачи данных, или другой канал для вывода. Канальный кодер (380) или канал (390) также может включать в себя другие элементы (не показаны), например, для кодирования с прямой коррекцией ошибок ("FEC") и модуляции аналогового сигнала.
IV. ИЛЛЮСТРАТИВНЫЕ КОДЕРЫ ВИДЕО.
[065] Фиг. 4a и 4b являются блок-схемой обобщенного кодера (400) видео, совместно с которым могут осуществляться некоторые описанные варианты осуществления. Кодер (400) принимает последовательность видеокартинок, включающих в себя текущую картинку, в качестве входного видеосигнала (405) и формирует кодированные данные в кодированном битовом видеопотоке (495) в качестве вывода.
[066] Кодер (400) основывается на блоках и использует блочный формат, который зависит от реализации. Блоки могут дополнительно подразделяться на разных этапах, например, на этапах предсказания, частотного преобразования и/или энтропийного кодирования. Например, картинка может разделяться на блоки 64×64, блоки 32×32 или блоки 16×16, которые могут, в свою очередь, разделяться на меньшие блоки значений отсчетов для кодирования и декодирования. В вариантах осуществления кодирования для стандарта H.265/HEVC, кодер разделяет картинку на единицы CTU (блоки CTB), единицы CU (блоки CB), единицы PU (блоки PB) и единицы TU (блоки TB).
[067] Кодер (400) сжимает картинки с использованием интра-картиночного кодирования и/или интер-картиночного кодирования. Многие из компонентов кодера (400) используются как для интра-картиночного кодирования, так и для интер-картиночного кодирования. Точные операции, выполняемые этими компонентами, могут изменяться в зависимости от типа информации, которая сжимается.
[068] Модуль (410) мозаичных элементов необязательно разделяет картинку на множество мозаичных элементов одного и того же размера или разных размеров. Например, модуль (410) мозаичных элементов разделяет картинку вдоль строк мозаичных элементов и столбцов мозаичных элементов, которые, с границами картинки, определяют горизонтальные и вертикальные границы мозаичных элементов внутри картинки, где каждый мозаичный элемент является прямоугольной областью. В вариантах осуществления H.265/HEVC, кодер (400) разделяет картинку на один или более срезов, причем каждый срез включает в себя один или более сегментов среза.
[069] Общее управление (420) кодированием принимает картинки для входного видеосигнала (405) также как обратную связь (не показана) от различных модулей кодера (400). В целом, общее управление (420) кодированием обеспечивает сигналы управления (не показаны) в другие модули (такие как модуль (410) мозаичных элементов, модуль преобразования/модуль масштабирования/модуль квантования (430), модуль масштабирования/модуль обратного преобразования (435), модуль (440) интра-картиночной оценки, модуль (450) оценки движения, управление (460) фильтрацией и модуль переключения интра/интер), чтобы устанавливать и изменять параметры кодирования во время кодирования. Например, во время кодирования общее управление (420) кодированием может управлять решениями в отношении создания хеш-таблиц, точности MV, и того, какие опорные картинки сохранять в RPS. Общее управление (420) кодированием также может оценивать промежуточные результаты во время кодирования, например, выполняя анализ отношения искажения к скорости передачи. Общее управление (420) кодированием формирует общие данные (422) управления, которые указывают решения, принятые во время кодирования, так что соответствующий декодер может принимать совместимые решения. Общие данные (422) управления обеспечиваются в модуль форматирования заголовков/энтропийный кодер (490).
[070] Если текущая картинка предсказывается с использованием интер-картиночного предсказания, модуль (450) оценки движения оценивает движение блоков значений отсчетов в текущей картинке входного видеосигнала (405) по отношению к одной или более опорным картинкам. Буфер ("DPB") (470) декодированных картинок буферизует одну или более восстановленных ранее кодированных картинок для использования в качестве опорных картинок. Когда используется множество опорных картинок, множество опорных картинок может быть из разных временных направлений или одного и того же временного направления.
[071] Работая с общим управлением (420) кодированием и словарем (451) хешей блоков, модуль (450) оценки движения может выбирать точность MV (например, точность MV целочисленного отсчета, точность MV 1/2-отсчета, или точность MV 1/4-отсчета) с использованием подхода, здесь описанного, затем использовать выбранную точность MV во время оценки движения. Для основывающегося на хешировании подбора блоков во время оценки движения, модуль (450) оценки движения может использовать словарь (451) хешей блоков, чтобы находить значение MV для текущего блока. Словарь (451) хешей блоков является структурой данных, которая организует блоки-кандидаты для основывающегося на хешировании подбора блоков. Словарь (451) хешей блоков является примером хеш-таблицы. На фиг. 4b, словарь (451) хешей блоков построен на основе входных значений отсчетов. Альтернативно, словарь хешей блоков может строиться на основе восстановленных значений отсчетов и обновляться во время кодирования, чтобы сохранять информацию о новых блоках-кандидатах, по мере того, как эти блоки-кандидаты становятся доступными для использования в основывающемся на хешировании подборе блоков.
[072] Модуль (450) оценки движения формирует в качестве вспомогательной информации данные (452) движения, такие как данные MV, значения индексов режимов слияния, и данные выбора опорных картинок, и выбранная точность MV. Они обеспечиваются в модуль форматирования заголовков/энтропийный кодер (490) также как модуль (455) компенсации движения.
[073] Модуль (455) компенсации движения применяет векторы MV к восстановленной опорной картинке (картинкам) из DPB (470). Модуль (455) компенсации движения формирует предсказания с компенсацией движения для текущей картинки.
[074] В отдельном пути внутри кодера (400), модуль (440) интра-картиночной оценки определяет то, как выполнять интра-картиночное предсказание для блоков значений отсчетов текущей картинки входного видеосигнала (405). Текущая картинка может полностью или частично кодироваться с использованием интра-картиночного кодирования. С использованием значений восстановления (438) текущей картинки, для интра-пространственного предсказания, модуль (440) интра-картиночной оценки определяет то, как пространственно предсказывать значения отсчетов текущего блока текущей картинки из соседних, ранее восстановленных значений отсчетов текущей картинки. Модуль (440) интра-картиночной оценки может определять направление пространственного предсказания для использования для текущего блока.
[075] Или, для интра-предсказания BC с использованием значений BV/MV, модуль (440) интра-картиночной оценки или модуль (450) оценки движения оценивает смещение значений отсчетов текущего блока в разные опорные области-кандидаты внутри текущей картинки, в качестве опорной картинки. Для основывающегося на хешировании подбора блоков, модуль (440) интра-картиночной оценки или модуль (450) оценки движения может использовать словарь хешей блоков (не показан), чтобы находить значение BV/MV для текущего блока. Или, для режима интра-картиночного кодирования на основе словаря, пиксели блока кодируются с использованием предыдущих значений отсчетов, сохраненных в словаре или другом местоположении, где пиксель является набором совместно расположенных значений отсчетов (например, триплетом RGB или триплетом YUV).
[076] Модуль (440) интра-картиночной оценки формирует в качестве вспомогательной информации данные (442) интра-предсказания, такие как информация режима, направление режима предсказания (для интра-пространственного предсказания), и смещения и длины (для режима словаря). Данные (442) интра-предсказания обеспечиваются в модуль форматирования заголовков/энтропийный кодер (490) также как модуль (445) интра-картиночного предсказания.
[077] Согласно данным (442) интра-предсказания, модуль (445) интра-картиночного предсказания пространственно предсказывает значения отсчетов текущего блока текущей картинки из соседних, ранее восстановленных значений отсчетов текущей картинки. Или, для интра-предсказания BC, модуль (445) интра-картиночного предсказания или модуль (455) компенсации движения предсказывает значения отсчетов текущего блока с использованием ранее восстановленных значений отсчетов опорной области интра-картиночного предсказания, что указывается посредством значения BV/MV для текущего блока. Или, для интра-картиночного режима словаря, модуль (445) интра-картиночного предсказания восстанавливает пиксели с использованием смещений и длин.
[078] Модуль переключения интра/интер выбирает то, будет ли предсказание (458) для заданного блока предсказанием с компенсацией движения или интра-картиночным предсказанием.
[079] Различие (если есть какое-либо) между блоком предсказания (458) и соответствующей частью исходной текущей картинки входного видеосигнала (405) обеспечивает значения остатка (418), для блока режима без пропуска. Во время восстановления текущей картинки, для блока режима без пропуска, восстановленные значения остатка комбинируются с предсказанием (458), чтобы формировать приблизительное или точное восстановление (438) исходного контента из видеосигнала (405). (В сжатии с потерями, некоторая информация теряется из видеосигнала (405).)
[080] В модуле преобразования/модуле масштабирования/модуле квантования (430), модуль частотного преобразования преобразует видеоинформацию пространственной области в данные частотной области (то есть, спектральные, преобразованные). Для основанного на блоках кодирования видео, модуль частотного преобразования применяет дискретное косинусное преобразование ("DCT"), его целочисленное приближение, или другой тип прямого блочного преобразования (например, дискретное синусное преобразование или его целочисленное приближение) к блокам данных остатка предсказания (или данным значений отсчетов, если предсказание (458) является нулевым), формируя блоки коэффициентов частотного преобразования. Модуль преобразования/модуль масштабирования/модуль квантования (430) может применять преобразование с переменными размерами блоков. Кодер (400) также может пропускать этап преобразования в некоторых случаях.
[081] Модуль масштабирования/модуль квантования масштабирует и квантует коэффициенты преобразования. Например, модуль квантования применяет скалярное квантование мертвой зоны к данным частотной области с размером шага квантования, который изменяется на основе от картинки к картинке, на основе от мозаичного элемента к мозаичному элементу, на основе от среза к срезу, на основе от блока к блоку, на основе конкретной частоты или на другой основе. Данные (432) квантованных коэффициентов преобразования обеспечиваются в модуль форматирования заголовков/энтропийный кодер (490).
[082] В модуле масштабирования/модуле обратного преобразования (435), модуль масштабирования/модуль обратного квантования выполняет обратное масштабирование и обратное квантование над квантованными коэффициентами преобразования. Когда этап преобразования не пропускается, модуль обратного частотного преобразования выполняет обратное частотное преобразование, формируя блоки восстановленных значений остатка предсказания или значений отсчетов. Для блока режима без пропуска, кодер (400) комбинирует восстановленные значения остатка со значениями предсказания (458) (например, значениями предсказания с компенсацией движения, значениями интра-картиночного предсказания), чтобы формировать восстановление (438). Для блока режима пропуска или блока режима словаря, кодер (400) использует значения предсказания (458) в качестве восстановления (438).
[083] Для пространственного интра-картиночного предсказания, значения восстановления (438) могут обеспечиваться по обратной связи в модуль (440) интра-картиночной оценки и модуль (445) интра-картиночного предсказания. Для интра-предсказания BC, значения восстановления (438) могут аналогично обеспечиваться по обратной связи, чтобы обеспечивать восстановленные значения отсчетов. Также, значения восстановления (438) могут использоваться для предсказания с компенсацией движения последующих картинок.
[084] Значения восстановления (438) могут дополнительно фильтроваться. Управление (460) фильтрацией определяет то, как выполнять фильтрацию устранения блочности над значениями восстановления (438), для заданной картинки видеосигнала (405). Управление (460) фильтрацией формирует данные (462) управления фильтром, которые обеспечиваются в модуль форматирования заголовков/энтропийный кодер (490) и модуль слияния/фильтр (фильтры) (465).
[085] В модуле слияния/фильтре (фильтрах) (465), кодер (400) осуществляет слияние контента из разных мозаичных элементов в восстановленную версию картинки. Кодер (400) избирательно выполняет фильтрацию устранения блочности согласно данным (462) управления фильтром. Альтернативно или дополнительно может применяться другая фильтрация (такая как фильтрация устранения окантовочных помех или ALF). Границы мозаичных элементов могут избирательно фильтроваться или не фильтроваться вовсе, в зависимости от настроек кодера (400), и кодер (400) может обеспечивать синтаксис внутри кодированного битового потока, чтобы указывать, была ли или нет такая фильтрация применена.
[086] DPB (470) буферизует восстановленную текущую картинку для использования в последующем предсказании с компенсацией движения. В частности, опорные картинки в RPS могут буферизоваться в DPB (470). Однако, DPB (470) имеет ограниченное пространство памяти. Если восстановленная текущая картинка сохраняется в DPB (470) для использования в качестве опорной картинки, другая картинка может удаляться из DPB (470) (и отбрасываться из RPS). Общее управление (420) кодированием принимает решение в отношении того, какие картинки сохранять в RPS и буферизовать в DPB (470). С использованием словаря (451) хешей блоков, общее управление (420) кодированием может принимать решения в отношении того, какие опорные картинки сохранять в RPS, как описано ниже.
[087] Модуль форматирования заголовков/энтропийный кодер (490) форматирует и/или энтропийно кодирует общие данные (422) управления, данные (432) квантованных коэффициентов преобразования, данные (442) интра-предсказания, данные (452) движения и данные (462) управления фильтром. Для данных (452) движения, модуль форматирования заголовков/энтропийный кодер (490) может выбирать и энтропийно кодировать значения индексов режимов слияния, или может использоваться устанавливаемый по умолчанию предсказатель MV. В некоторых случаях, модуль форматирования заголовков/энтропийный кодер (490) также определяет дифференциалы MV для значений MV (по отношению к предсказателям MV), затем энтропийно кодирует дифференциалы MV, например, с использованием контекстно-адаптивного двоичного арифметического кодирования.
[088] Модуль форматирования заголовков/энтропийный кодер (490) обеспечивает кодированные данные в кодированном битовом видеопотоке (495). Формат кодированного битового видеопотока (495) может быть вариантом или расширением формата H.265/HEVC, формата Windows Media Video, формата VC-1, формата MPEG-x (например, MPEG-1, MPEG-2, или MPEG-4), формата H.26x (например, H.261, H.262, H.263, H.264), или другого формата.
[089] В зависимости от реализации и требуемого типа сжатия, модули кодера (400) могут добавляться, пропускаться, разделяться на множество модулей, комбинироваться с другими модулями, и/или заменяться на подобные модули. В альтернативных вариантах осуществления, кодеры с разными модулями и/или другими конфигурациями модулей выполняют один или более из описанных способов. Конкретные варианты осуществления кодеров обычно используют вариант или дополненную версию кодера (400). Отношения, показанные между модулями внутри кодера (400), указывают общие потоки информации в кодере; другие отношения не показаны ради простоты.
V. ТИПЫ ВИДЕО.
[090] Подходы, описанные в данном документе, для создания хеш-таблиц, выбора точности MV, и определения изменений сцены могут применяться при кодировании любого типа видео. В частности, однако, эти подходы могут улучшать производительность при кодировании некоторого искусственно созданного видеоконтента, такого как контент захвата экрана.
[091] В общем, контент захвата экрана представляет вывод экрана компьютера или другого устройства отображения. Фиг. 5 показывает среду (510) рабочего стола компьютера с контентом, который может обеспечивать ввод для захвата экрана. Например, видео контента захвата экрана может представлять последовательность изображений всего рабочего стола (511) компьютера. Или, видео контента захвата экрана может представлять последовательность изображений для одного из окон среды рабочего стола компьютера, такого как окно (513) приложения, включающее в себя игровой контент, окно (512) браузера с контентом веб-страницы или окно (514) с контентом текстового процессора.
[092] Как генерируемый компьютером, искусственно созданный видеоконтент, контент захвата экрана имеет тенденцию иметь относительно малое количество дискретных значений отсчетов, по сравнению с естественным видеоконтентом, который захватывается с использованием видеокамеры. Например, область контента захвата экрана часто включает в себя одиночный единообразный цвет, тогда как область в естественном видеоконтенте более вероятно включает в себя цвета, которые постепенно изменяются. Также, контент захвата экрана обычно включает в себя разные структуры (например, графику, текстовые символы), которые точно повторяются от кадра к кадру, даже если контент может пространственно смещаться (например, вследствие прокрутки). Контент захвата экрана обычно кодируется в формате (например, YUV 4:4:4 или RGB 4:4:4) с высоким разрешением дискретизации цветности, хотя он также может кодироваться в формате с более низким разрешением дискретизации цветности (например, YUV 4:2:0, YUV 4:2:2).
[093] Фиг. 6 показывает комбинированное видео (620), которое включает в себя естественный видеоконтент (621) и искусственно созданный видеоконтент. Искусственно созданный видеоконтент включает в себя графику (622) помимо естественного видеоконтента (621) и тикер (623), бегущий ниже естественного видеоконтента (621). Как и контент захвата экрана, показанный на фиг. 5, искусственно созданный видеоконтент, показанный на фиг. 6, имеет тенденцию иметь относительно малое количество дискретных значений отсчетов. Он также имеет тенденцию иметь разные структуры (например, графику, текстовые символы), которые точно повторяются от кадра к кадру или постепенно смещаются от кадра к кадру (например, вследствие прокрутки).
VI. ПРИМЕРЫ ОСНОВЫВАЮЩЕГОСЯ НА ХЕШИРОВАНИИ ПОДБОРА БЛОКОВ.
[094] В различных новаторских решениях, здесь описанных, кодер видео использует результаты основывающегося на хешировании подбора блоков, когда принимает решения в отношении параметров во время кодирования. Этот раздел описывает примеры основывающегося на хешировании подбора блоков.
A. ОСНОВЫВАЮЩИЙСЯ НА ХЕШИРОВАНИИ ПОДБОР БЛОКОВ.
[095] Когда кодер использует основывающийся на хешировании подбор блоков, кодер определяет хеш-значение для каждого из множества блоков-кандидатов одной или более опорных картинок. Хеш-таблица хранит хеш-значения для блоков-кандидатов. Кодер также определяет хеш-значение для текущего блока посредством такого же подхода хеширования, и затем ищет в хеш-таблице соответствующее хеш-значение. Если два блока являются идентичными, их хеш-значения являются одинаковыми. С использованием хеш-значений, кодер может быстро и эффективно идентифицировать блоки-кандидаты, которые имеют такое же хеш-значение, что и текущий блок, и отфильтровывать блоки-кандидаты, которые имеют другие хеш-значения. В зависимости от реализации и целей основывающегося на хешировании подбора блоков, кодер затем может дополнительно оценивать те блоки-кандидаты, которые имеют такое же хеш-значение, что и текущий блок. (Разные блоки могут иметь одно и то же хеш-значение. Таким образом, среди блоков-кандидатов с одним и тем же хеш-значением, кодер может дополнительно идентифицировать блок-кандидат, который соответствует текущему блоку.)
[096] В некоторых иллюстративных вариантах осуществления, хеш-значения для блоков-кандидатов определяются из входных значений отсчетов для картинок (опорных картинок), которые включают в себя блоки-кандидаты. Во время основывающегося на хешировании подбора блоков, кодер определяет хеш-значение для текущего блока с использованием входных значений отсчетов. Кодер сравнивает его (или иным образом использует хеш-значение) с хеш-значениями, определенными из входных значений отсчетов для блоков-кандидатов. Как бы то ни было, восстановленные значения отсчетов из соответствующего блока используются, чтобы представлять текущий блок. Таким образом, операции предсказания все еще используют восстановленные значения отсчетов.
[097] Альтернативно, блоки-кандидаты, рассматриваемые в основывающемся на хешировании подборе блоков, включают в себя восстановленные значения отсчетов. То есть, блоки-кандидаты являются частью ранее кодированного затем восстановленного контента в картинке. Хеш-значения для блоков-кандидатов определяются из восстановленных значений отсчетов. Во время основывающегося на хешировании подбора блоков, кодер определяет хеш-значение для текущего блока с использованием входных значений отсчетов. Кодер сравнивает его (или иным образом использует хеш-значение) с хеш-значениями, определенными из восстановленных значений отсчетов для блоков-кандидатов.
[098] Фиг. 7 иллюстрирует хеш-значения (700) для блоков-кандидатов B(x, y) в основывающемся на хешировании подборе блоков, где x и y указывают горизонтальную и вертикальную координаты, соответственно, для верхнего левого положения заданного блока-кандидата. Блоки-кандидаты имеют хеш-значения, определенные с использованием хеш-функции h(). Для блока-кандидата B(x, y) в опорной картинке, кодер определяет хеш-значение h(B) для блока-кандидата из входных значений отсчетов для опорной картинки. Кодер может определять хеш-значения для всех блоков-кандидатов в опорной картинке. Или, кодер может отсеивать некоторые блоки-кандидаты.
[099] В общем, хеш-функция h() дает n возможных хеш-значений, обозначенных h0 по hn-1. Для заданного хеш-значения, блоки-кандидаты с этим хеш-значением группируются. Например, на фиг. 7, блоки-кандидаты B(1266, 263), B(1357, 365), B(1429, 401), B(502, 464),... имеют хеш-значение h0. Группы могут включать в себя разные количества блоков-кандидатов. Например, на фиг. 7, группа для хеш-значения h4 включает в себя одиночный блок-кандидат, в то время как группа для хеш-значения h0 включает в себя более, чем четыре блока-кандидата.
[0100] Этим способом, возможные блоки-кандидаты распределяются на n категорий. Например, если хеш-функция h() формирует 12-битные хеш-значения, блоки-кандидаты разделяются на 212=4,096 категорий. Количество блоков-кандидатов в расчете на хеш-значение может дополнительно уменьшаться посредством устранения излишних, идентичных блоков с этим хеш-значением, или посредством отсеивания блоков-кандидатов, имеющих некоторые шаблоны значений отсчетов. Также, кодер может итеративно уменьшать количество блоков-кандидатов с использованием разных хеш-функций.
[0101] Хеш-функция, используемая для основывающегося на хешировании подбора блоков, зависит от варианта осуществления. Хеш-функция может формировать хеш-значения с 8 битами, 12 битами, 16 битами, 24 битами, 32 битами, или некоторым другим количеством бит. Если хеш-значение имеет меньшее количество бит, структура данных включает в себя меньшее количество категорий, но каждая категория может включать в себя больше блоков-кандидатов. С другой стороны, использование хеш-значений с более большим количеством бит имеет тенденцию увеличивать размер структуры данных, которая организует блоки-кандидаты. Если хеш-значение имеет более большое количество бит, структура данных включает в себя больше категорий, но каждая категория может включать в себя меньшее количество блоков-кандидатов. Хеш-функция h() может быть криптографической хеш-функцией, частью криптографической хеш-функции, функцией циклического контроля избыточности ("CRC"), частью CRC, или другой хеш-функцией (например, использующей операции усреднения и XOR для определения сигнатуры блока-кандидата или текущего блока). Некоторые типы хеш-функции (например, функция CRC) отображают аналогичные блоки в разные хеш-значения, что может быть эффективным при поиске соответствующего блока, который точно соответствует текущему блоку. Другие типы хеш-функции (например, локально-чувствительная хеш-функция) отображают аналогичные блоки в одно и то же хеш-значение.
[0102] Во время основывающегося на хешировании подбора блоков, с помощью хеш-функции h(), кодер определяет хеш-значение для текущего блока Bтекущий. На фиг. 7, хеш-значение h(Bтекущий) равняется h3. С использованием хеш-значения текущего блока, кодер может идентифицировать блоки-кандидаты, которые имеют такое же хеш-значение (показанные в обведенном прямоугольнике на фиг. 7), и отфильтровывать другие блоки-кандидаты. Когда хеш-функция отображает аналогичные блоки в разные хеш-значения, идентифицированные блоки-кандидаты (такое же хеш-значение, что и у текущего блока) включают в себя блоки, которые могут быть идентичными текущему блоку. Когда хеш-функция отображает аналогичные блоки в одно и то же хеш-значение, идентифицированные блоки-кандидаты (такое же хеш-значение, что и у текущего блока) включают в себя блоки, которые могут быть идентичными текущему блоку или могут быть близкими приближениями текущего блока. В любом случае, из этих идентифицированных блоков-кандидатов, кодер может дополнительно идентифицировать соответствующий блок для текущего блока (например, с использованием операций сопоставления блоков по отсчетам, с использованием второй хеш-функции).
[0103] В целом, так как сравнения хеш-значений являются намного более простыми, чем сопоставление блоков по отсчетам, основывающийся на хешировании подбор блоков может делать обработку оценки блоков-кандидатов в опорной картинке (картинках) намного более эффективной. Также, хеш-значения для блоков-кандидатов могут повторно использоваться в основывающемся на хешировании подборе блоков для разных блоков внутри картинки во время кодирования. В этом случае, стоимость вычисления хеш-значений для блоков-кандидатов может амортизироваться по отношению к операциям основывающегося на хешировании подбора блоков для всей картинки, для других картинок, которые используют ту же опорную картинку, и для других решений стороны кодера, которые используют хеш-значения.
B. СТРУКТУРЫ ДАННЫХ ДЛЯ ОСНОВЫВАЮЩЕГОСЯ НА ХЕШИРОВАНИИ ПОДБОРА БЛОКОВ.
[0104] В некоторых иллюстративных вариантах осуществления, кодер использует структуру данных, которая организует блоки-кандидаты согласно их хеш-значениям. Структура данных может помогать делать основывающийся на хешировании подбор блоков вычислительно более эффективным. Структура данных реализует, например, словарь хешей блоков или хеш-таблицу, как описано в данном документе.
[0105] Фиг. 8a иллюстрирует иллюстративную структуру (800) данных, которая организует блоки-кандидаты для основывающегося на хешировании подбора блоков. Для хеш-функции h(), n возможными хеш-значениями являются h0 по hn-1. Блоки-кандидаты с одним и тем же хеш-значением классифицируются в один и тот же список блоков-кандидатов. Заданный список блоков-кандидатов может включать в себя ноль или более записей. Например, список блоков-кандидатов для хеш-значения h2 не имеет никаких записей, список для хеш-значения h6 имеет две записи, и список для хеш-значения h1 имеет более, чем четыре записи.
[0106] Запись(hi, k) включает в себя информацию для k-ого блока-кандидата с хеш-значением hi. Как показано на фиг. 8b, запись в списке блоков-кандидатов может включать в себя адрес блока B(x, y) (например, горизонтальную и вертикальную координаты для верхнего левого положения блока). Или, как показано на фиг. 8c, запись в списке блоков-кандидатов может включать в себя адрес блока B(x, y) и хеш-значение от второй хеш-функции, которое может использоваться для итеративного основывающегося на хешировании подбора блоков.
[0107] Во время основывающегося на хешировании подбора блоков для текущего блока, кодер определяет хеш-значение текущего блока h(Bтекущий). Кодер сохраняет список блоков-кандидатов с одним и тем же хеш-значением и исключает другие n-1 списков. Чтобы выбирать соответствующий блок, кодер может сравнивать текущий блок с блоком-кандидатом (блоками-кандидатами), если есть какие-либо, в сохраненном списке блоков-кандидатов. Таким образом, посредством простой операции поиска с использованием хеш-значения h(Bтекущий), кодер может устранять (n-1)/n блоков-кандидатов (в среднем), и сосредоточиваться на оставшихся 1/n блоках-кандидатах (в среднем) в сохраненном списке, что значительно уменьшает количество операций сопоставления блоков по отсчетам.
[0108] Для разных опорных картинок могут использоваться разные структуры данных. Альтернативно, запись для блока-кандидата в структуре данных хранит информацию, указывающую опорную картинку, которая включает в себя блок-кандидат, что может использоваться в основывающемся на хешировании подборе блоков.
[0109] Также, разные структуры данных могут использоваться для разных размеров блоков. Например, одна структура данных включает в себя хеш-значения для блоков-кандидатов 8×8, вторая структура данных включает в себя хеш-значения для блоков-кандидатов 16×16, третья структура данных включает в себя хеш-значения для блоков-кандидатов 32×32, и так далее. Структура данных, используемая во время основывающегося на хешировании подбора блоков, зависит от размера текущего блока. Альтернативно, одиночная, унифицированная структура данных может использоваться для разных размеров блоков. Хеш-функция может формировать n-битное хеш-значение, где m бит n-битного хеш-значения указывают хеш-значение среди возможных блоков заданного размера блока согласно m-битной хеш-функции, и оставшиеся n-m бит n-битного хеш-значения указывают заданный размер блока. Например, первые два бита 14-битной хеш-функции могут указывать размер блока, в то время как оставшиеся 12 бит указывают хеш-значение согласно 12-битной хеш-функции. Или, хеш-функция может формировать m-битное хеш-значение независимо от размера блока, и запись для блока-кандидата в структуре данных хранит информацию, указывающую размер блока для блока-кандидата, что может использоваться в основывающемся на хешировании подборе блоков.
[0110] Для картинки высокого разрешения, структура данных может хранить информацию, представляющую очень большое количество блоков-кандидатов. Чтобы уменьшать объем памяти, используемый для структуры данных, кодер может устранять излишние значения. Например, кодер может пропускать добавление идентичных блоков к структуре данных. В общем, уменьшение размера структуры данных посредством устранения идентичных блоков может причинять вред эффективности кодирования. Таким образом, посредством приятия решения в отношении того, устранять ли идентичные блоки, кодер может обеспечивать компромиссное соотношение размера памяти для структуры данных и эффективности кодирования. Кодер также может отсеивать блоки-кандидаты, в зависимости от контента блоков.
C. ИТЕРАТИВНОЕ ОСНОВЫВАЮЩИЙСЯ НА ХЕШИРОВАНИИ ПОДБОР БЛОКОВ.
[0111] Когда кодер использует одиночную хеш-функцию с n возможными хеш-значениями, кодер может исключать n-1 списков блоков-кандидатов на основе хеш-значения текущего блока, но кодер может все еще быть должен выполнять операции сопоставления блоков по отсчетам для оставшегося блока-кандидата (блоков-кандидатов), если есть какие-либо, для списка с соответствующим хеш-значением. Также, при обновлении структуры данных, которая организует блоки-кандидаты, кодер может быть должен выполнять операции сопоставления блоков по отсчетам, чтобы идентифицировать идентичные блоки. Коллективно, эти операции сопоставления блоков по отсчетам могут быть вычислительно интенсивными.
[0112] Поэтому, в некоторых иллюстративных вариантах осуществления, кодер использует итеративное основывающийся на хешировании подбор блоков. Итеративное основывающийся на хешировании подбор блоков может ускорять обработку сопоставления блоков и также ускорять обработку обновления структуры данных, которая организует блоки-кандидаты.
[0113] Итеративное основывающийся на хешировании подбор блоков использует множество хеш-значений, определенных с помощью разных хеш-функций. Для блока B (текущего блока или блока-кандидата), в дополнение к хеш-значению h(B), кодер определяет другое хеш-значение h'(B) с использованием другой хеш-функции h'(). С помощью первого хеш-значения h(Bтекущий) для текущего блока, кодер идентифицирует блоки-кандидаты, которые имеют такое же хеш-значение для первой хеш-функции h(). Чтобы дополнительно исключать некоторые из этих идентифицированных блоков-кандидатов, кодер использует второе хеш-значение h'(Bтекущий) для текущего блока, которое определяется с использованием другой хеш-функции. Кодер сравнивает второе хеш-значение h'(Bтекущий) со вторыми хеш-значениями для ранее идентифицированных блоков-кандидатов (которые имеют такое же первое хеш-значение), чтобы отфильтровывать большее количество блоков-кандидатов. Хеш-таблица отслеживает хеш-значения для блоков-кандидатов согласно разным хеш-функциям.
[0114] В примере из фиг. 8a, если h(Bтекущий)=h3, кодер выбирает блоки-кандидаты с записью(3, 0), записью(3, 1), записью(3, 2), записью(3, 3),... для дополнительного уточнения. Как показано на фиг. 8c, для блока-кандидата 6, запись включает в себя адрес блока и второе хеш-значение h'(B) от хеш-функции h'(). Кодер сравнивает второе хеш-значение h'(Bтекущий) для текущего блока со вторыми хеш-значениями h'(B) для соответствующих блоков-кандидатов с записью(3, 0), записью(3, 1), записью(3, 2), записью(3, 3),.... На основе результатов сравнений вторых хеш-значений, кодер может исключать большее количество блоков-кандидатов, оставляя блоки-кандидаты, если есть какие-либо, которые имеют первое и второе хеш-значения, совпадающие с h(Bтекущий) и h'(Bтекущий), соответственно. Кодер может выполнять сопоставление блоков по отсчетам над любыми оставшимися блоками-кандидатами, чтобы выбирать соответствующий блок.
[0115] Фиг. 9a-9c показывают другой пример итеративного основывающегося на хешировании подбора блоков, которое использует другую структуру данных. Структура (900) данных на фиг. 9a организует блоки-кандидаты посредством первого хеш-значения от первой хеш-функции h(), которая имеет n1 возможных хеш-значений. Структура (900) данных включает в себя списки для хеш-значений из h0... hn1-1. В примере, кодер определяет первое хеш-значение h(Bтекущий)=h2 для текущего блока, и выбирает список для h2 из структуры (900).
[0116] Как показано на фиг. 9b, список (910) для h2 включает в себя множество списков, которые дополнительно организуют оставшиеся блоки-кандидаты посредством второго хеш-значения от второй хеш-функции h'(), которая имеет n2 возможных хеш-значений. Список (910) включает в себя списки для хеш-значений из h'0... h'n2-1, при этом каждый включает в себя записи с адресами блоков (например, горизонтальной и вертикальной координатами для верхних левых положений соответствующих блоков-кандидатов), как показано для записи (920) на фиг. 9c. В примере, кодер определяет второе хеш-значение h'(Bтекущий)=h'0 для текущего блока, и выбирает список для h'0 из списка (910). Для блоков-кандидатов в списке для h'0, кодер может выполнять сопоставление блоков по отсчетам, чтобы выбирать соответствующий блок. В этом примере, списки для вторых хеш-значений являются конкретными для заданного списка для первого хеш-значения. Альтернативно, имеется один набор списков для вторых хеш-значений, и кодер идентифицирует любые блоки-кандидаты, которые находятся (1) в соответствующем списке для первых хеш-значений и также (2) в соответствующем списке для вторых хеш-значений.
[0117] Помимо основывающегося на хешировании подбора блоков, вторая хеш-функция h'() может использоваться, чтобы упрощать обработку обновления структуры данных, которая организует блоки-кандидаты. Например, когда кодер проверяет, является ли новый блок-кандидат идентичным блоку-кандидату, уже представленному в структуре данных, кодер может использовать множество хеш-значений с разными хеш-функциями, чтобы отфильтровывать неидентичные блоки. Для оставшихся блоков-кандидатов, кодер может выполнять сопоставление блоков по отсчетам, чтобы идентифицировать какой-либо идентичный блок.
[0118] В предшествующих примерах, итеративное основывающийся на хешировании подбор блоков и обновление используют две разные хеш-функции. Альтернативно, кодер использует три, четыре или более хеш-функций, чтобы дополнительно ускорять основывающийся на хешировании подбор блоков или отфильтровывать неидентичные блоки, и, тем самым, уменьшать количество операций сопоставления блоков по отсчетам. Также, для кодера низкой сложности или для более быстрых обработок принятия решений, кодер может пропускать операции сопоставления блоков по отсчетам, когда хеш-значения совпадают. Для хеш-функций с большим количеством возможных хеш-значений, имеется высокая вероятность того, что два блока являются идентичными, если хеш-значения для упомянутых двух блоков совпадают. В частности, в некоторых иллюстративных вариантах осуществления решений стороны кодера, описанных ниже, кодер учитывает, в качестве результатов основывающегося на хешировании подбора блоков, совпадают ли хеш-значения, но не выполняет какие-либо операции сопоставления блоков по отсчетам.
VII. УПРАВЛЕНИЕ РАЗМЕРОМ ХЕШ-ТАБЛИЦ
[0119] Этот раздел представляет различные подходы к управлению размером хеш-таблиц, используемых в основывающемся на хешировании подборе блоков. В некоторых решениях, размер хеш-таблицы уменьшается посредством отсеивания (невключения) блоков-кандидатов, имеющих некоторые шаблоны значений отсчетов (например, посредством отсеивания однородных блоков). В конкретном варианте осуществления, для каждого из множества блоков-кандидатов (например, в опорной картинке), кодер оценивает, удовлетворяет ли блок-кандидат критерию сложности. Если это так, кодер определяет хеш-значение блока для блока-кандидата и добавляет хеш-значение блока в хеш-таблицу. Хеш-значение блока может вычисляться с использованием исходных значений отсчетов или восстановленных значений отсчетов. Если блок-кандидат не удовлетворяет критерию сложности, кодер не определяет хеш-значение блока для блока-кандидата. Например, критерий сложности может удовлетворяться для заданного блока-кандидата, если (a) по меньшей мере, одна строка заданного блока-кандидата имеет неравномерные значения отсчетов, и/или (b) по меньшей мере, один столбец заданного блока-кандидата имеет неравномерные значения отсчетов. С помощью этого критерия, кодер может отсеивать гомогенные блоки (однородные блоки), блоки со строками равномерных значений отсчетов (горизонтально однородные блоки) и блоки со столбцами равномерных значений отсчетов (вертикально однородные блоки). Более широко, при оценке того, удовлетворяет ли заданный блок-кандидат критерию сложности, кодер может вычислять метрику сложности для блока-кандидата и сравнивать метрику сложности с порогом.
[0120] Фиг. 10a-10c показывают шаблоны блоков-кандидатов, которые кодер может отсеивать во время построения хеш-таблицы до того, как хеш-значение блока для блока-кандидата добавляется в хеш-таблицу. Фиг. 10a показывает блок (1000) с равномерными значениями отсчетов. Фиг. 10b показывает блок (1010), чьи строки, каждая, имеют равномерные значения отсчетов (горизонтально однородный блок), хотя значения могут отличаться от строки к строке. Фиг. 10c показывает блок (1020), чьи столбцы, каждый, имеют равномерные значения отсчетов (вертикально однородный блок), хотя значения могут отличаться от столбца к столбцу. Например, чтобы идентифицировать эти шаблоны блоков-кандидатов, кодер может проверять, имеет ли каждая строка или каждый столбец блока-кандидата равномерные значения отсчетов.
[0121] Однако исключение однородных блоков (например, всех однородных блоков) как кандидатов в хеш-таблице может оказывать отрицательное влияние на преимущества основывающегося на хешировании подбора в некоторых ситуациях. Например, некоторые алгоритмы кодирования работают более эффективно, когда находится точное соответствие (например, посредством завершения обработки сопоставления как только находится совпадение хешей). В дополнение, исключение однородных блоков как кандидатов может уменьшать вероятность точного соответствия. Поэтому, могут реализовываться улучшения в эффективности кодирования посредством сохранения, по меньшей мере, некоторых однородных блоков в хеш-таблице.
[0122] В подходах, представленных в этом разделе, размер хеш-таблицы управляется таким образом, чтобы некоторые однородные блоки включались в хеш-таблицу (например, это может улучшать шансы нахождения совпадения хешей и/или точного соответствия, и как результат улучшать эффективность кодирования), в то время как другие однородные блоки все еще исключаются. Например, включение туда только некоторых однородных блоков (например, только относительно малой пропорции однородных блоков в заданной картинке) может все еще обеспечивать преимущества улучшенной эффективности кодирования также при сохранении преимуществ меньшей хеш-таблицы.
[0123] В некоторых вариантах реализации, в хеш-таблицу включаются только однородные блоки, которые удовлетворяют критерию равномерного выбора. Критерий равномерного выбора может включать в себя проверку, выровнены ли координаты заданного однородного блока с конкретными делениями картинки. Например, опорная картинка может разделяться на сетку с конкретным горизонтальным и вертикальным расстоянием (например, сетку 16 на 16 пикселей, сетку 16 на 8 пикселей, и т.д.). Если однородный блок выровнен с сеткой (например, если координата начального пикселя блока выровнена горизонтально и/или вертикально), то он может выбираться как соответствующий критериям. Формулируя другим способом, рассмотрим блок с размерами ширины на высоту (W×H), который начинается в координатах (x, y). Критерий равномерного выбора может определяться как:
x % M==0 && y % N=0
где M и N являются предварительно определенными числами (например, одним и тем же числом или разными числами). Другим способом формулировки критерия выбора является:
x & (M-1)==0 && Y & (N-1)==0
где M и N являются оба степенями 2. В некоторых вариантах реализации, M и N являются оба 16. Например, если однородный блок находится в координатах 32, 32, то он будет выбираться при использовании значений M=16 и N=16 (как будут блоки в 0,0 и 32,0 и 64,0 и 0,32 и 0,64 и так далее), в то время как однородный блок в координатах 35, 32 не будет выбираться. В некоторых вариантах реализации, M устанавливается на ширину (W) блоков и N устанавливается на высоту (H) блоков.
[0124] Фиг. 11 показывает способ (1100) для выбора конкретных однородных блоков во время построения хеш-таблицы. Кодер изображений или кодер видео, такой как кодер, описанный со ссылкой на фиг. 3 или фиг. 4a-4b, может выполнять способ (1100).
[0125] Кодер получает (1110) следующий блок-кандидат и оценивает (1120), удовлетворяет ли блок-кандидат критерию сложности. Например, в некоторых иллюстративных вариантах осуществления, критерий сложности удовлетворяется, если (a) по меньшей мере, одна строка заданного блока-кандидата имеет неравномерные значения отсчетов, и/или (b) по меньшей мере, один столбец заданного блока-кандидата имеет неравномерные значения отсчетов, и критерий сложности не удовлетворяется, если (a) блок имеет строки равномерных значений отсчетов (горизонтально однородный блок) и/или (b) блок имеет столбцы равномерных значений отсчетов (вертикально однородный блок). Или, более обще, кодер может вычислять метрику сложности для блока-кандидата, затем сравнивать метрику сложности с порогом. Например, метрика сложности является счетчиком ненулевых коэффициентов AC в ненулевом горизонтальном положении и/или ненулевом вертикальном положении для блока-кандидата после частотного преобразования (например, DCT), и порог равняется нулю. Критерий сложности удовлетворяется, если имеются какие-либо ненулевые коэффициенты AC вне верхней строки коэффициентов AC и левого столбца коэффициентов AC для блока-кандидата. Альтернативно, кодер учитывает другую метрику сложности. Критерий сложности может оцениваться, по меньшей мере, частично, посредством сравнения хеш-значений секций (например, строк, столбцов, подблоков) блока-кандидата.
[0126] Если блок-кандидат удовлетворяет критерию сложности, кодер определяет (1130) хеш-значение блока для блока-кандидата и добавляет (1140) хеш-значение блока в хеш-таблицу. Хеш-значение блока может определяться с использованием любого подхода хеширования.
[0127] Если блок-кандидат не удовлетворяет критерию сложности (например, блок-кандидат является горизонтально однородным и/или вертикально однородным), блок-кандидат проверяется для определения (1160) того, удовлетворяет ли он критерию равномерного выбора. Если блок-кандидат удовлетворяет критерию равномерного выбора, кодер определяет (1130) хеш-значение блока для блока-кандидата и добавляет (1140) хеш-значение блока в хеш-таблицу. Хеш-значение блока может определяться с использованием любого подхода хеширования. В противном случае (если блок-кандидат не удовлетворяет критерию равномерного выбора), никакое хеш-значение блока для блока-кандидата не добавляется в хеш-таблицу.
[0128] В некоторых вариантах реализации, блок-кандидат удовлетворяет критерию равномерного выбора, когда, по меньшей мере, одна из начальной координаты x и y (например, координата верхнего левого пикселя) блока-кандидата является делимой без остатка на предварительно определенное значение. Например, если предварительно определенное значение равняется 16, то значение координаты x, которое равняется 0, 16, 32, 48, и т.д., будет удовлетворять условию. Предварительно определенное значение может быть разным для координат x и y. В некоторых вариантах реализации, предварительно определенное значение для координаты x устанавливается на ширину блока-кандидата и предварительно определенное значение для координаты y устанавливается на высоту блока-кандидата.
[0129] Кодер определяет (1150), продолжать ли со следующим блоком-кандидатом. Если это так, кодер продолжает посредством получения (1110) следующего блока-кандидата и оценки (1120), удовлетворяет ли следующий блок-кандидат критерию сложности. Этим способом, кодер может избирательно определять хеш-значения блоков для множества блоков-кандидатов (например, для блоков-кандидатов картинки, такой как опорная картинка), в зависимости от того, удовлетворяют ли соответствующие блоки-кандидаты критерию сложности и критерию равномерного выбора.
VIII. ОПРЕДЕЛЕНИЕ РАЗРЕШЕНИЯ MV.
[0130] Этот раздел представляет различные подходы для адаптивного определения разрешения вектора движения ("MV") во время кодирования, в зависимости от результатов основывающегося на хешировании подбора блоков (например, соответствующих хеш-значений). Посредством выбора подходящих значений точности MV для разрешения MV во время кодирования, эти подходы могут обеспечивать сжатие, которое является эффективным в терминах производительности отношения искажения к скорости передачи и/или вычислительной эффективности кодирования и декодирования. Точность MV может определяться для картинки, блока, среза, и т.д.
A. РАЗНЫЕ ТОЧНОСТИ MV.
[0131] При кодировании искусственно созданного видеоконтента, значения MV обычно представляют пространственные смещения целочисленных отсчетов (целочисленную точность MV), и очень малое количество значений MV представляют пространственные смещения дробных отсчетов (дробную точность MV). Это обеспечивает возможности для эффективного определения точности MV (например, для всей картинки сразу, или для части картинки), чтобы улучшать общую производительность.
[0132] Фиг. 12a показывает компенсацию движения с MV (1220), имеющим пространственное смещение целочисленных отсчетов. MV (1220) указывает пространственное смещение четырех отсчетов влево, и одного отсчета вверх, по отношению к совместно расположенному положению (1210) в опорной картинке для текущего блока. Например, для текущего блока 4×4 в положении (64, 96) в текущей картинке, MV (1220) указывает 4×4 область (1230) предсказания, чье положение является (60, 95) в опорной картинке. Область (1230) предсказания включает в себя восстановленные значения отсчетов в положениях целочисленных отсчетов в опорной картинке. Кодер или декодер не должен выполнять интерполяцию, чтобы определять значения области (1230) предсказания.
[0133] Фиг. 12b показывает компенсацию движения с MV (1221), имеющим пространственное смещение дробных отсчетов. MV (1221) указывает пространственное смещение, равное 3.75 отсчетов влево, и 0.5 отсчетов вверх, по отношению к совместно расположенному положению (1210) в опорной картинке для текущего блока. Например, для текущего блока 4×4 в положении (64, 96) в текущей картинке, MV (1221) указывает 4×4 область (1231) предсказания, чье положение является (60.25, 95.5) в опорной картинке. Область (1231) предсказания включает в себя интерполированные значения отсчетов в положениях дробных отсчетов в опорной картинке. Кодер или декодер выполняет интерполяцию, чтобы определять значения отсчетов области (1231) предсказания. Когда разрешены пространственные смещения дробных отсчетов, имеется больше областей-кандидатов предсказания, которые могут соответствовать текущему блоку, и, таким образом, качество предсказания с компенсацией движения обычно улучшается, по меньшей мере, для некоторых типов видеоконтента (например, естественного видеоконтента).
B. ПРЕДСТАВЛЕНИЕ ЗНАЧЕНИЙ MV.
[0134] Значения MV обычно представляются с использованием целочисленных значений, чей смысл зависит от точности MV. Для точности MV целочисленного отсчета, например, целочисленное значение, равное 1, указывает пространственное смещение, равное 1 отсчету, целочисленное значение, равное 2, указывает пространственное смещение, равное 2 отсчетам, и так далее. Для точности MV 1/4-отсчета, например, целочисленное значение, равное 1, указывает пространственное смещение, равное 0.25 отсчета. Целочисленные значения, равные 2, 3, 4 и 5, указывают пространственные смещения, равные 0.5, 0.75, 1.0 и 1.25 отсчета, соответственно. Независимо от точности MV, целочисленное значение может указывать величину пространственного смещения, и отдельное значение флага может указывать, является ли смещение отрицательным или положительным. Горизонтальная компонента MV и вертикальная компонента MV заданного значения MV могут представляться с использованием двух целочисленных значений. Таким образом, смысл двух целочисленных значений, представляющих значение MV зависит от точности MV. Например, для значения MV, имеющего горизонтальное смещение 2 отсчета и никакого вертикального смещения, если точность MV является точностью MV 1/4-отсчета, значение MV представляется как (8, 0). Если точность MV является точностью MV целочисленной отсчета, однако, значение MV представляется как (2, 0).
[0135] Значения MV в битовом потоке кодированных видеоданных являются обычно энтропийно кодированными (например, на основе компонент MV). Значение MV также может дифференциально кодироваться по отношению к предсказанному значению MV (например, на основе компонент MV). Во многих случаях, значение MV равняется предсказанному значению MV, таким образом, дифференциальное значение MV равняется нулю, что может кодироваться очень эффективно. Дифференциальное значение MV (или значение MV, если предсказание MV не используется) может энтропийно кодироваться с использованием экспоненциального кодирования Голомба, контекстно-адаптивного двоичного арифметического кодирования или другой формы энтропийного кодирования. Хотя точное отношение между значением MV (или дифференциальным значением MV) и кодированными битами зависит от формы используемого энтропийного кодирования, в общем, меньше значений кодируются более эффективно (то есть, с использованием меньшего количества бит), так как они являются более общими, и более большие значения кодируются менее эффективно (то есть, с использованием большего количества бит), так как они являются менее общими.
C. АДАПТИВНАЯ ТОЧНОСТЬ MV - ВВЕДЕНИЕ.
[0136] Чтобы подытожить предшествующие два раздела, использование значений MV с точностью MV целочисленного отсчета имеет тенденцию уменьшать скорость передачи данных, ассоциированный с сигнализацией значений MV, и уменьшать вычислительную сложность кодирования и декодирования (посредством избегания интерполяции значений отсчетов в положениях дробных отсчетов в опорных картинках), но может уменьшать качество предсказания с компенсацией движения, по меньшей мере, для некоторых типов видеоконтента. С другой стороны, использование значений MV с точностью MV дробного отсчета имеет тенденцию увеличивать скорость передачи данных, ассоциированный с сигнализацией значений MV, и увеличивать вычислительную сложность кодирования и декодирования (посредством включения туда интерполяции значений отсчетов в положениях дробных отсчетов в опорных картинках), но может улучшать качество предсказания с компенсацией движения, по меньшей мере, для некоторых типов видеоконтента. В общем, вычислительная сложность, скорость передачи данных для сигнализации значений MV, и качество предсказания с компенсацией движения увеличиваются по мере того, как точность MV увеличивается (например, от целочисленного отсчета к 1/2-отсчету, или от 1/2-отсчета к 1/4-отсчету), вплоть до точки падения эффективности.
[0137] При кодировании искусственно созданного видеоконтента, добавленные стоимости точности MV дробного отсчета (в терминах скорости передачи данных и вычислительной сложности) могут быть неоправданными. Например, если большинство значений MV представляют пространственные смещения целочисленных отсчетов, и очень малое количество значений MV представляют пространственные смещения дробных отсчетов, добавленные стоимости точности MV дробного отсчета не оправданы. Кодер может пропускать поиск в положениях дробных отсчетов (и операции интерполяции для определения значений отсчетов в этих положениях) во время оценки движения. Для такого контента, скорость передачи данных и вычислительная сложность могут уменьшаться, без значительного штрафа для качества предсказания с компенсацией движения, посредством использования значений MV с точностью MV целочисленного отсчета.
[0138] Так как точность MV дробного отсчета может все еще быть полезной для других типов видеоконтента (например, естественного видео, захваченного камерой), кодер и декодер могут быть выполнены с возможностью переключаться между точностями MV. Например, кодер и декодер могут использовать точность MV целочисленного отсчета для искусственно созданного видеоконтента, но использовать точность MV дробного отсчета (такую как точность MV 1/4-отсчета) для естественного видеоконтента. Подходы, которым кодер может следовать при выборе точности MV, описываются в следующем разделе. Кодер может сигнализировать выбранную точность MV в декодер с использованием одного или более синтаксических элементов в битовом потоке.
[0139] В одном подходе к сигнализации точности MV, когда адаптивный выбор точности MV активирован, кодер выбирает точность MV на основе от среза к срезу. Значение флага в наборе параметров последовательности ("SPS"), наборе параметров картинок ("PPS") или другой синтаксической структуре указывает, активирован ли адаптивный выбор точности MV. Если это так, один или более синтаксических элементов в заголовке среза для заданного среза указывает выбранную точность MV для блоков этого среза. Например, значение флага, равное 0, указывает точность MV 1/4-отсчета, и значение флага, равное 1, указывает точность MV целочисленного отсчета.
[0140] В другом подходе к сигнализации точности MV, кодер выбирает точность MV на основе от картинки к картинке или на основе от среза к срезу. Синтаксический элемент в PPS указывает один из трех режимов точности MV: (0) точность MV 1/4-отсчета для значений MV среза (срезов) картинки, ассоциированной с PPS, (1) точность MV целочисленного отсчета для значений MV среза (срезов) картинки, ассоциированной с PPS, или (2) адаптивную для среза точность MV в зависимости от значения флага, сигнализированного в расчете на заголовок среза, где значение флага в заголовке среза может указывать точность MV 1/4-отсчета или точность MV целочисленного отсчета для значений MV среза.
[0141] В еще другом подходе к сигнализации точности MV, когда адаптивный выбор точности MV активирован, кодер выбирает точность MV на основе от CU к CU. Один или более синтаксических элементов в структуре для заданной CU указывают выбранную точность MV для блоков этой CU. Например, значение флага в синтаксической структуре CU для CU указывает, имеют ли значения MV для всех единиц PU, ассоциированных с CU, точность MV целочисленного отсчета или точность MV 1/4-отсчета.
[0142] В любом из этих подходов, кодер и декодер могут использовать разные точности MV для горизонтальной и вертикальной компонент MV. Это может быть полезным при кодировании искусственно созданного видеоконтента, который был масштабирован горизонтально или вертикально (например, с использованием точности MV целочисленного отсчета в немасштабированном измерении, и с использованием точности MV дробного отсчета в масштабированном измерении). В некоторых иллюстративных вариантах осуществления, если управление скоростью не может достигаться единственно посредством регулировки значений QP, кодер может изменять размеры видео горизонтально или вертикально, чтобы уменьшать скорость передачи данных, затем кодировать измененное в размерах видео. На стороне декодера, видео масштабируется назад в свои исходные размеры после декодирования. Кодер может сигнализировать точность MV для горизонтальных компонент MV и также сигнализировать точность MV для вертикальных компонент MV в декодер.
[0143] Более широко, когда адаптивный выбор точности MV активирован, кодер выбирает точность MV и сигнализирует выбранную точность MV некоторым способом. Например, значение флага в SPS, PPS или другой синтаксической структуре может указывать, активирован ли адаптивный выбор точности MV. Когда адаптивная точность MV активирована, один или более синтаксических элементов в синтаксисе уровня последовательности, синтаксисе уровня GOP, синтаксисе уровня картинки, синтаксисе уровня среза, синтаксисе уровня мозаичного элемента, синтаксисе уровня блока или другой синтаксической структуре могут указывать выбранную точность MV для горизонтальной и вертикальной компонент значений MV. Или, один или более синтаксических элементов в синтаксисе уровня последовательности, синтаксисе уровня GOP, синтаксисе уровня картинки, синтаксисе уровня заголовка среза, синтаксисе уровня данных среза, синтаксисе уровня мозаичного элемента, синтаксисе уровня блока или другой синтаксической структуре могут указывать точности MV для разных компонент MV. Когда имеются две доступные точности MV, значение флага может указывать выбор между упомянутыми двумя точностями MV. Когда имеется больше доступных точностей MV, целочисленное значение может быть выбором между этими точностями MV.
[0144] Помимо модификаций для сигнализации/осуществления синтаксического разбора синтаксических элементов, которые указывают выбранную точность (точности) MV, декодирование может модифицироваться, чтобы изменять то, как сигнализированные значения MV интерпретируются, в зависимости от выбранной точности MV. Подробности того, как значения MV кодируются и восстанавливаются, могут изменяться в зависимости от точности MV. Например, когда точность MV является точностью целочисленного отсчета, предсказанные значения MV могут округляться до ближайшего целого числа, и дифференциальные значения MV могут указывать смещения целочисленного отсчета. Или, когда точность MV является точностью 1/4-отсчета, предсказанные значения MV могут округляться до ближайшего смещения 1/4-отсчета, и дифференциальные значения MV могут указывать смещения 1/4-отсчета. Или, значения MV могут сигнализироваться некоторым другим способом. Когда значения MV имеют точность MV целочисленного отсчета и видео использует дискретизацию цветности 4:2:2 или 4:2:0, значения MV цветности могут выводиться посредством масштабирования, и т.д., что может давать результатом смещения 1/2-отсчета для цветности. Или, значения MV цветности могут округляться до целочисленных значений.
[0145] Альтернативно, кодер не изменяет то, как значения MV предсказываются или как различия MV сигнализируются в битовом потоке, и также декодер не изменяет то, как значения MV предсказываются или как различия MV восстанавливаются, но интерпретация восстановленных значений MV изменяется в зависимости от выбранной точности MV. Если выбранная точность MV является точностью целочисленного отсчета, восстановленное значение MV масштабируется посредством коэффициента, равного 4, до использования в обработке компенсации движения (которая работает при точности четверти отсчета). Если выбранная точность MV является точностью четверти отсчета, восстановленное значение MV не масштабируется до использования в обработке компенсации движения.
D. ОПРЕДЕЛЕНИЕ РАЗРЕШЕНИЯ MV С ИСПОЛЬЗОВАНИЕМ КАТЕГОРИЙ.
[0146] Когда разрешение MV может адаптироваться во время кодирования видео, кодер выбирает точность MV для единицы видео (например, точность MV для одной или обеих компонент значений MV для единицы). Кодер может выбирать точность MV для использования в зависимости от результатов классификации блоков на множество категорий, что может включать в себя основывающийся на хешировании подбор блоков (например, соответствующие хеш-значения) в одной или более из операций классификации. Выбор точности MV также может зависеть от других факторов, таких как классификация блоков как гомогенных блоков (например, горизонтально и/или вертикально однородных блоков). Эти подходы могут обеспечивать вычислительно эффективный способ для выбора соответствующих точностей MV.
1. ИЛЛЮСТРАТИВНЫЕ СПОСОБЫ ДЛЯ ВЫБОРА ТОЧНОСТИ MV.
[0147] Фиг. 13 показывает обобщенный метод (1300) для выбора точности MV в зависимости от результатов классификации блоков. Метод (1300) может выполняться посредством кодера, такого как кодер, описанный со ссылкой на фиг. 3 или фиг. 4a и 4b, или посредством другого кодера.
[0148] Кодер кодирует видео, чтобы формировать кодированные данные, и затем выводит кодированные данные в битовом потоке. Как часть кодирования, кодер разделяет (1310) единицу видео на множество блоков (например, разделяет картинку, срез, или другую единицу видео). Затем, для каждого из блоков, кодер классифицирует (1320) блок в одну из множества категорий. Категории могут содержать однородную категорию, которая использует однородные критерии классификации, и/или категорию совпадения хешей, которая использует критерии классификации основывающегося на хешировании подбора. На основе классификаций (например, счетчиков блоков в одной или более из множества категорий), кодер определяет (1330) точность MV для единицы видео. Например, кодер может определять, использовать ли целочисленную точность MV или дробную точность MV (например, точность MV 1/4-отсчета).
[0149] Фиг. 14 показывает метод (1400) для выполнения классификации блоков, используемой при выборе точности MV. Способ (1400) может выполняться посредством кодера, такого как кодер, описанный со ссылкой на фиг. 3 или фиг. 4a и 4b, или посредством другого кодера. Метод (1400) может использоваться для осуществления классификации (1320) блоков, описанной выше по отношению к фиг. 13.
[0150] Чтобы классифицировать блок, метод (1400) сначала назначает блок категории (1410) всех блоков. Назначение блока категории всех блоков может выполняться посредством увеличения счетчика блока, ассоциированного с категорией всех блоков, на единицу.
[0151] Метод (1400) далее определяет, соответствует (1420) ли блок совместно расположенному блоку в опорной картинке (например, соответствует блоку в, по меньшей мере, одной из одной или более опорных картинок, используемых блоком), и, если это так, назначает блок категории (1430) совместно расположенных соответствий. Назначение блока категории совместно расположенных соответствий может выполняться посредством увеличения счетчика блока, ассоциированного с категорией совместно расположенных соответствий, на единицу.
[0152] Если блок не соответствует совместно расположенному блоку в опорной картинке, метод (1400) переходит к проверке (1440) того, является ли блок однородным блоком (например, удовлетворяет ли блок однородным критериям классификации, которые могут удовлетворяться, если блок является горизонтально однородным и/или вертикально однородным), и, если это так, назначает блок однородной категории (1450). Назначение блока однородной категории может выполняться посредством увеличения счетчика блока, ассоциированного с однородной категорией, на единицу.
[0153] Если блок не является однородным блоком, способ (1400) переходит к проверке (1460) того, удовлетворяет ли блок критериям классификации основывающегося на хешировании подбора (например, находится ли хеш-значение для блока в хеш-таблице, сгенерированной из блоков-кандидатов одной или более опорных картинок), и, если это так, назначает блок категории (1470) совпадения хешей. Назначение блока категории совпадения хешей может выполняться посредством увеличения счетчика блока, ассоциированного с категорией совпадения хешей, на единицу.
[0154] Как только блок классифицирован, способ (1400) переходит к классификации следующего блока (1480), если какие-либо остаются (например, чтобы классифицировать все блоки из единицы видео).
[0155] Способ (1400) может выполняться, чтобы классифицировать множество блоков единицы видео на множество категорий посредством увеличения счетчика, ассоциированного с каждой категорией, когда блок назначается категории.
[0156] В некоторых вариантах реализации, классифицируются блоки текущей картинки. Текущая картинка может разделяться на неперекрывающиеся блоки ширины (W) на высоту (H). В одном варианте осуществления, W=H=8. Кодер может выполнять основывающийся на хешировании подбор блоков для всех блоков в текущей картинке. Диапазон поиска может быть одной (или более) опорными картинками для текущей картинки. В одном варианте осуществления, первая опорная картинка в списке 0 опорных картинок используется для выполнения сопоставления хешей.
[0157] В некоторых вариантах реализации, блоки классифицируются с использованием следующих четырех категорий. Первая категория называется "T" (например, категория всех блоков). Все блоки назначаются категории "T".
[0158] Вторая категория называется "C" (например, категория совместно расположенных соответствий). Блок, который соответствует совместно расположенному блоку в опорной картинке, назначается категории "C". Если используется более, чем одна опорная картинка, блок назначается, если он соответствует совместно расположенному блоку в, по меньшей мере, одной из опорных картинок.
[0159] Третья категория называется "S" (например, однородная или "гладкая" категория). Блок, который не был назначен категории "C" и который являлся однородным (например, горизонтально и/или вертикально однородным) назначается категории "S".
[0160] Четвертая категория называется "M" (например, категория совпадения хешей). Блок, который не был назначен какой-либо из категории "C" или категории "S", но который имеет хеш-значение, найденное в хеш-таблице, сгенерированной из блоков-кандидатов одной или более опорных картинок, назначается категории "M".
[0161] В вариантах осуществления, которые используют категории "T", "C", "S", и "M", может вычисляться CSMRate (например, значение пропорции), которое является:
CSMRate=(C+S+M)/T
CSMRate указывает процентное содержание блоков "C", "S", и "M" в картинке (или другой единице видео). Также может вычисляться AverageCSMRate, которое является средним значением CSMRate для текущей картинки и CSMRate некоторого количества "Ncsm" предыдущих кодированных картинок. Также может вычисляться MRate, которое является MRate=M/T (процентное содержание блоков "M"). AverageMRate является средним значением для MRate для текущей картинки и MRate некоторого количества "Nm" предыдущих кодированных картинок.
[0162] С использованием категорий, описанных выше, и значений, вычисленных из категорий "T", "C", "S", и "M", одно или более из следующих правил могут применяться (индивидуально или в комбинации), чтобы определять точность MV (например, чтобы принимать решение в отношении того, использовать ли целочисленную точность MV или дробную точность MV, такую как точность 1/4-пикселя).
[0163] Правило 1: Если CSMRate больше, чем порог, использовать целочисленную точность MV. В противном случае, использовать точность 1/4-пикселя. (Если пропорция соответствий текущей картинки является слишком медленной, использовать MV дробной точности.)
[0164] Правило 2: Если AverageCSMRate больше, чем порог, использовать целочисленную точность MV. В противном случае, использовать точность 1/4-пикселя. (Если пропорция соответствий картинок в скользящем окне является слишком медленной, использовать MV дробной точности.)
[0165] Правило 3: Если MRate больше, чем порог, использовать целочисленную точность MV. В противном случае, использовать точность 1/4-пикселя. (Если пропорция соответствий несовместно расположенных негладких блоков выше, чем порог, использовать MV целочисленной точности.)
[0166] Правило 4: Если AverageMRate больше, чем порог, использовать целочисленную точность MV. В противном случае, использовать точность 1/4-пикселя. (Если средняя пропорция соответствий несовместно расположенных негладких блоков картинок в скользящем окне выше, чем порог, использовать MV целочисленной точности.)
[0167] Правило 5: Если C==T, использовать целочисленную точность MV. В противном случае, использовать точность 1/4-пикселя. (Если все блоки в текущей картинке соответствуют совместно размещенным блокам в опорной картинке (две картинки являются идентичными), использовать MV целочисленной точности. В некоторых вариантах реализации, это может не иметь значительного влияния на эффективность кодирования, но может помогать сберегать время кодирования, так как использование MV целочисленной точности в обработке кодирования может пропускать некоторые операции над дробными пикселями, как, например, оценку движения над дробными пикселями.)
[0168] Правило 6: Если M>(T-C-S)/отношение1, использовать целочисленную точность MV. В противном случае, использовать точность 1/4-пикселя. (Если процентное содержание сопоставленных блоков во всех несовместно расположенных негладких блоках выше, чем порог, использовать MV целочисленной точности.)
[0169] Правило 7: Если CSMRate>порог1 и MRate>порог2, использовать целочисленную точность MV. В противном случае, использовать точность 1/4-пикселя. (Если процентное содержание блоков CSM больше, чем некоторый порог (в некоторых вариантах реализации, этот порог находится рядом с 1, чтобы гарантировать, что большинство блоков являются подходящими для использования MV целочисленной точности) и процентное содержание блоков M больше, чем некоторый порог (например, чтобы гарантировать, что мы также можем находить некоторое соответствие для несовместно расположенных негладких блоков), использовать MV целочисленной точности.)
[0170] Правило 8: Если AverageCSMRate+AverageMRate>порога3, использовать целочисленную точность MV. В противном случае, использовать точность 1/4-пикселя. (Аналогичное условие вышеописанному условию, но учитывающее картинки в скользящем окне.)
[0171] В одном иллюстративном варианте осуществления, применяются следующие установки. Размер блока равняется 8×8. Сопоставление хешей выполняется только для первой опорной картинки в списке 0 опорных картинок. Ncsm и Nm оба устанавливаются на 31 (включая сюда текущую картинку, всего 32 картинки). В иллюстративном варианте осуществления, решение в отношении точности вектора движения принимается в следующем порядке (первое условие "если", которое удовлетворяется, устанавливает точность MV, и если никакие из условий "если" не удовлетворяются, условие "иначе" будет устанавливать точность 1/4-пикселя):
Если CSMRate<0.8, использовать точность 1/4-пикселя.
Если T==C, использовать целочисленную точность.
Если AverageCSMRate<0.95, использовать точность 1/4-пикселя.
Если M>(T-C-S)/3, использовать целочисленную точность.
Если CSMRate>0.99 && MRate>0.01, использовать целочисленную точность.
Если AverageCSMRate+AverageMRate>1.01, использовать целочисленную точность.
Иначе, использовать точность 1/4-пикселя.
[0172] В способах, описанных в этом разделе, кодер может выбирать между использованием точности MV 1/4-отсчета и точности MV целочисленного отсчета. Более широко, кодер выбирает между множеством доступных точностей MV, которые могут включать в себя точность MV целочисленного отсчета, точность MV 1/2-отсчета, точность MV 1/4-отсчета и/или другую точность MV. Выбранная точность MV может применяться для горизонтальных компонент и/или вертикальных компонент значений MV для единицы видео.
[0173] В способах, описанных в этом разделе, основывающийся на хешировании подбор блоков использует хеш-значения, определенные из входных значений отсчетов единицы и (для блоков-кандидатов) входных значений отсчетов для одной или более опорных картинок. Альтернативно, для блоков-кандидатов, представленных в хеш-таблице, основывающийся на хешировании подбор блоков может использовать хеш-значения, определенные из восстановленных значений отсчетов.
[0174] В способах, описанных в этом разделе, при определении точности MV для единицы видео, кодер также может учитывать другие факторы, такие как то, содержат ли несопоставленные блоки значительный объем естественного видеоконтента (захваченного камерой видео), как описано в следующих разделах.
2. АЛЬТЕРНАТИВЫ И ВАРИАНТЫ
[0175] Когда кодер использует один и тот же шаблон мозаичных элементов от картинки к картинке, кодер может повторять точности MV в расчете на мозаичный элемент от картинки к картинке. Совместно расположенные мозаичные элементы от картинки к картинке могут использовать одну и ту же точность MV. Аналогично, совместно расположенные срезы от картинки к картинке могут использовать одну и ту же точность MV. Например, предположим, что видео изображает рабочий стол компьютера, и часть рабочего стола имеет окно, отображающее естественный видеоконтент. Точность MV дробного отсчета может использоваться внутри этой области рабочего стола от картинки к картинке независимо от того, кодированы ли другие области, которые показывают текст или другой воспроизводимый контент, с использованием точности MV целочисленного отсчета.
[0176] Кодер может регулировать величину склонности к или против точности MV целочисленного отсчета на основе, по меньшей мере, частично степени уверенности, что точность MV целочисленного отсчета является подходящей. Кодер также может регулировать величину склонности к или против точности MV целочисленного отсчета на основе, по меньшей мере, частично целевой вычислительной сложности кодирования и/или декодирования (с предпочтением точности MV целочисленного отсчета, чтобы уменьшать вычислительную сложность). Например, кодер может регулировать пороги, используемые в операциях сравнения, чтобы делать более вероятным или менее вероятным, что выбирается точность MV целочисленного отсчета.
[0177] Выбранная точность MV может быть для горизонтальных компонент MV и/или вертикальных компонент MV значений MV блоков внутри единицы видео, где горизонтальным компонентам MV и вертикальным компонентам MV разрешается иметь разные точности MV. Или, выбранная точность MV может быть как для горизонтальных компонент MV, так и для вертикальных компонент MV значений MV блоков внутри единицы видео, где горизонтальные компоненты MV и вертикальные компоненты MV имеют одну и ту же точность MV.
[0178] В большинстве предшествующих примеров выбора точности MV, кодированное видео в битовом потоке включает в себя один или более синтаксических элементов, которые указывают выбранную точность MV для единицы. Декодер осуществляет синтаксический разбор синтаксического элемента (элементов), указывающего выбранную точность MV, и интерпретирует значения MV согласно выбранной точности MV. Альтернативно, кодированное видео в битовом потоке может испытывать недостаток каких-либо синтаксических элементов, которые указывают выбранную точность MV. Например, даже если битовый поток поддерживает сигнализацию значений MV с точностью MV дробного отсчета, кодер может ограничивать оценку движения для единицы видео, чтобы использовать только значения MV с дробными частями, равными нулю, и только значения MV, которые указывают смещения целочисленного отсчета, используются в компенсации движения. Декодер восстанавливает и применяет значения MV при точности MV дробного отсчета (где значения MV указывают смещения целочисленного отсчета). Это может уменьшать вычислительную сложность декодирования посредством избегания операций интерполяции.
IX. ОБНАРУЖЕНИЕ ИЗМЕНЕНИЙ СЦЕНЫ С ИСПОЛЬЗОВАНИЕМ СОПОСТАВЛЕНИЯ ХЕШЕЙ.
[0179] Этот раздел представляет различные подходы для обнаружения изменений сцены на основе сопоставления хешей. Изменения сцены могут обнаруживаться во время кодирования видео. Например, картинки, которые идентифицируются как картинки изменения сцены, могут использоваться, чтобы улучшать эффективность кодирования (например, опорные картинки могут определяться на основе, по меньшей мере, частично, того, является ли заданная картинка картинкой изменения сцены).
A. ОБНАРУЖЕНИЕ КАРТИНКИ ИЗМЕНЕНИЯ СЦЕНЫ.
[0180] Изменение сцены обнаруживается с использованием, по меньшей мере, частично, информации, указывающей то, сколько блоков текущей картинки имеют совпадения хешей в хеш-таблице (в общем, называемой "пропорция соответствий", "отношение соответствий", или "R") по отношению к предыдущим картинкам. В некоторых вариантах реализации, пропорция соответствий вычисляется как: R=(C+S+M)/T. Альтернативно, пропорция соответствий может вычисляться как: R=(C+M)/T или как R=M/T. Для текущей картинки, пропорция соответствий обозначается как "Rcurr". В дополнение, может вычисляться средняя пропорция соответствий из предыдущих картинок (предыдущих для текущей картинки). Например, может поддерживаться среднее всех предыдущих кодированных картинок или среднее по некоторому количеству предыдущих картинок (например, с использованием скользящего окна). Средняя пропорция соответствий обозначается как "Ravg".
[0181] В некоторых вариантах реализации, если Rcurr меньше (например, значительно меньше), чем Ravg, то текущая картинка может идентифицироваться как картинка изменения сцены. В некоторых вариантах реализации, если Rcurr<a*Ravg, то текущая картинка обнаруживается как картинка изменения сцены. Значение "a" (весовое значение) устанавливается на 0.5 в одном конкретном варианте осуществления.
B. ВЫБОР ДОЛГОСРОЧНЫХ ОПОРНЫХ КАРТИНОК.
[0182] В кодировании видео, компенсация движения из опорных картинок используется, чтобы удалять временную избыточность. Таким образом, опорные картинки могут быть очень важными для эффективности кодирования. В некотором варианте реализации, используются как краткосрочные опорные картинки, так и долгосрочные опорные картинки. Краткосрочные опорные картинки являются обычно некоторым количеством картинок, не слишком далекими от текущей картинки кодирования. Долгосрочные опорные картинки могут храниться в буфере декодированных изображений ("DPB") в течение относительно более длительного времени. Долгосрочные опорные картинки являются полезными для улучшения эффективности кодирования для некоторого контента экрана, где могут появляться дублированные сцены или позже в видеопоследовательности могут появляться дублированные окна. В некоторых вариантах реализации, картинки до изменения сцены (например, непосредственно перед изменением сцены) сохраняются как долгосрочные опорные картинки, в то время как картинки во время изменения сцены не сохраняются.
[0183] Чтобы проиллюстрировать различные примеры выбора долгосрочных опорных картинок, используется следующая иллюстративная последовательность картинок:
f0(s0), f1(s0), f2(s0), f3(s0), f4(s0), f5(s0), f6(s0), f7(s0->1), f8(s0->1), f9(s0->1), f10(s0->1), f11(s1) f12(s1)
В этой иллюстративной последовательности имеется 13 картинок (обозначенных "f0" по "f12) и две сцены (обозначенные "s0" и "s1"). Переход между первой сценой и второй сценой обозначен как "s0->1". Как изображено в иллюстративной последовательности, картинки f0 по f6 принадлежат первой сцене s0, картинки f7 по f10 являются переходными картинками от первой сцены s0 к второй сцене s1, и картинки f11 и f12 принадлежат второй сцене s1. Если иллюстративная последовательность картинок содержит контент экрана, то пропорция соответствий для f0, f1, f2, f3, f4, f5, и f6 является вероятней всего относительно высокой, пропорция соответствий для f7, f8, f9, f10, и f11 является вероятней всего относительно низкой, и пропорция соответствий для f12 является вероятней всего относительно высокой.
[0184] На основе результатов различных ситуаций кодирования, сохранение последней картинки предыдущей сцены может быть полезным в улучшении эффективности кодирования. Поэтому, с иллюстративной последовательностью выше, f6 будет сохраняться как долгосрочная опорная картинка. В некоторых вариантах реализации, решение в отношении того, сохранять ли заданную картинку в качестве долгосрочной опорной картинки, принимается при кодировании текущей картинки. Например, решение в отношении того, сохранять ли fn-1 в качестве долгосрочной опорной картинки, принимается при кодировании fn (текущей картинки). В одном конкретном варианте осуществления, если следующие два условия удовлетворяются, то fn-1 сохраняется в качестве долгосрочной опорной картинки:
1. Пропорция соответствий Rn (Rcurr для текущей картинки fn) ниже, чем порог (что указывает, что fn обнаруживается как картинка изменения сцены).
2. Пропорции соответствий всех предыдущих X картинок (Rn-1, Rn-2,... Rn-X) выше, чем порог (что указывает устойчивую сцену, которая может обрезать картинки во время изменения сцены, как, например, f7, f8, f9).
С использованием вышеупомянутых двух условий, может обнаруживаться начало изменения сцены, которое происходит непосредственно следуя за устойчивой сценой из X картинок. С использованием вышеупомянутой иллюстративной последовательности, если упомянутые два условия применяются при кодировании текущей картинки f7, может быть найдено, что пропорция соответствий для f7 ниже, чем порог (что указывает, что f7 является картинкой изменения сцены), в то время как предыдущие X картинок (например, f6, f5, f4, и т.д.) могут быть обнаружены, большими, чем порог. Как результат, если упомянутые два условия удовлетворяются, то f6 может сохраняться как долгосрочная опорная картинка.
C. РЕГУЛИРОВКА КАЧЕСТВА КАРТИНОК.
[0185] В иллюстративной последовательности выше, если имеется много картинок во второй сцене s1 (с очень малым изменением среди них), кодирование первого малого количества картинок в s1 с более хорошим качеством может быть полезным для улучшения эффективности кодирования. В некотором варианте реализации, QPI и lambdaI используются, чтобы кодировать интра-картинку, и другие значения QP и значения лямбда используются, чтобы кодировать картинки P и B (например, обычно более большие, чем QPI и lambdaI, и также могут быть разными для разных картинок P и B).
[0186] В некоторых вариантах реализации, текущая картинка кодируется с более хорошим качеством (например, кодируется с использованием QPI и lambdaI), если текущая картинка обнаруживается как начало (или рядом с началом) новой сцены посредством основывающегося на хешировании подбора блоков. Например, посредством кодирования картинок в, или рядом с, начале устойчивой сцены с более высоким качеством, эффективность кодирования и/или качество последующих картинок в той же устойчивой сцене могут улучшаться.
[0187] Если предварительный анализ разрешен, обнаружение того, находится ли текущая картинка в начале новой устойчивой сцены, может быть непосредственной задачей. Например, следующие X картинок после текущей картинки могут проверяться. Если текущая картинка имеет пропорцию соответствий, которая является относительно низкой, в то время как следующие X картинок имеют пропорцию соответствий, которая является относительно высокой, кодер может кодировать текущую картинку с относительно высоким качеством. Например, с использованием иллюстративной последовательности выше, кодер может находить, что пропорция соответствий для f11 является относительно низкой, в то время как пропорции соответствий для f12, f13, и f14 являются относительно высокими. В этой ситуации, f11 может определяться как находящаяся в начале новой устойчивой сцены и, поэтому, кодироваться с более хорошим качеством. В одном конкретном варианте осуществления, если следующие два условия удовлетворяются, текущая картинка fn кодируется с более хорошим качеством (например, кодируется с QPI и lambdaI):
1. Пропорция соответствий Rn ниже, чем порог (что указывает, что fn обнаруживается как начало новой сцены).
2. Пропорции соответствий всех будущих X картинок (Rn+1, rn+2,... Rn+X) выше, чем порог (что указывает устойчивую сцену).
[0188] Если предварительный анализ не разрешен, кодер может не быть способным принять решение в начале новой устойчивой сцены, и может вместо этого быть должен ждать малого количества картинок до того, как новая устойчивая сцена может подтверждаться. Например, кодер может ждать некоторое количество картинок X, чтобы подтверждать, что новая устойчивая сцена была достигнута, и затем кодировать текущую картинку с улучшенным качеством. Например, со ссылкой на иллюстративную последовательность выше, если f12, f13, f14, и f15 (где X=4) имеют относительно высокую пропорцию соответствий (например, и f11 имеет относительно низкую пропорцию соответствий), то f15 может кодироваться с улучшенным качеством. В одном конкретном варианте осуществления, если следующие два условия удовлетворяются, текущая картинка fn кодируется с более хорошим качеством (например, кодируется с QPI и lambdaI):
1. Пропорция соответствий текущей картинки и предыдущих X картинок (Rn, Rn-1, Rn-2,... Rn-X) выше, чем порог.
2. Пропорция соответствий картинки n-X-1 (Rn-X-1) ниже, чем порог.
D. ИЛЛЮСТРАТИВНЫЕ ВАРИАНТЫ ОСУЩЕСТВЛЕНИЯ.
[0189] Различные способы могут обеспечиваться для обнаружения изменений сцены с использованием основывающегося на хешировании подбора блоков. В дополнение, результаты информации изменения сцены могут использоваться для других целей, как, например, выбора долгосрочных опорных картинок и установок качества картинок во время кодирования.
[0190] Фиг. 15 показывает обобщенный способ (1500) для обнаружения изменения сцены во время кодирования видео с использованием, по меньшей мере, частично, результатов основывающегося на хешировании подбора блоков. Способ (1500) может выполняться посредством кодера, такого как кодер, описанный со ссылкой на фиг. 3 или фиг. 4a и 4b, или посредством другого кодера.
[0191] Кодер кодирует видео, чтобы формировать кодированные данные, которые кодер выводит как часть битового потока. Во время кодирования, кодер вычисляет (1510) пропорцию соответствий для текущей картинки. Пропорция соответствий вычисляется с использованием, по меньшей мере, частично, основывающегося на хешировании подбора блоков для текущей картинки (с учетом одной или более опорных картинок). В некоторых вариантах реализации, пропорция соответствий вычисляется посредством классификации блоков текущей картинки на множество категорий. В некоторых вариантах реализации, пропорция соответствий вычисляется как R=(C+S+M)/T, или как R=(C+M)/T, или как R=M/T.
[0192] Кодер затем вычисляет (1520) среднюю пропорцию соответствий для множества предыдущих картинок. Может вычисляться средняя пропорция соответствий посредством вычисления индивидуальной пропорции соответствий для каждой из предыдущей картинки и усреднения индивидуальных пропорций соответствий. В некоторых вариантах реализации, пропорция соответствий вычисляется посредством классификации блоков заданной предыдущей картинки на множество категорий. В некоторых вариантах реализации, пропорция соответствий вычисляется как R=(C+S+M)/T, или как R=(C+M)/T, или как R=M/T.
[0193] Кодер затем вычисляет (1530) взвешенную среднюю пропорцию соответствий. Например, кодер может умножать среднюю пропорцию соответствий на весовое значение, которое меньше, чем 1.0. В одном конкретном варианте осуществления, используется весовое значение, равное 0.5.
[0194] Кодер затем определяет (1540), является ли текущая картинка картинкой изменения сцены, на основе пропорции соответствий для текущей картинки и взвешенной средней пропорции соответствий. Например, текущая картинка может определяться как картинка изменения сцены, если пропорция соответствий для текущей картинки меньше, чем взвешенная средняя пропорция соответствий.
[0195] Могут приниматься различные решения, когда текущая картинка обнаруживается как картинка изменения сцены. Например, картинка непосредственно перед текущей картинкой может выбираться в качестве долгосрочной опорной картинки. В дополнение, информация о том, когда картинка (или картинки) вовлечена в изменение сцены, может использоваться при определении параметров качества картинки во время кодирования.
[0196] В виду многих возможных вариантов осуществления, к которым могут применяться принципы раскрытого изобретения, следует понимать, что проиллюстрированные варианты осуществления являются только предпочтительными примерами изобретения и не должны браться в качестве ограничивающих объем изобретения. Скорее, объем изобретения определяется посредством последующей формулы изобретения. Мы, поэтому, заявляем в качестве нашего изобретения все, что попадает в объем и сущность этой формулы изобретения.
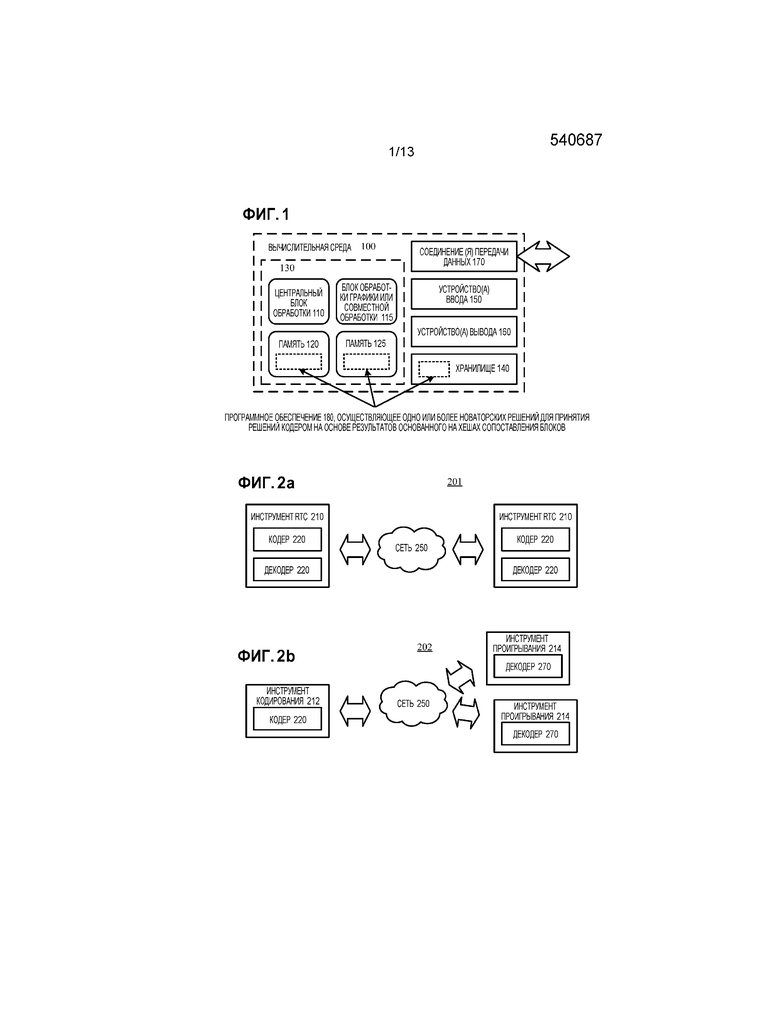
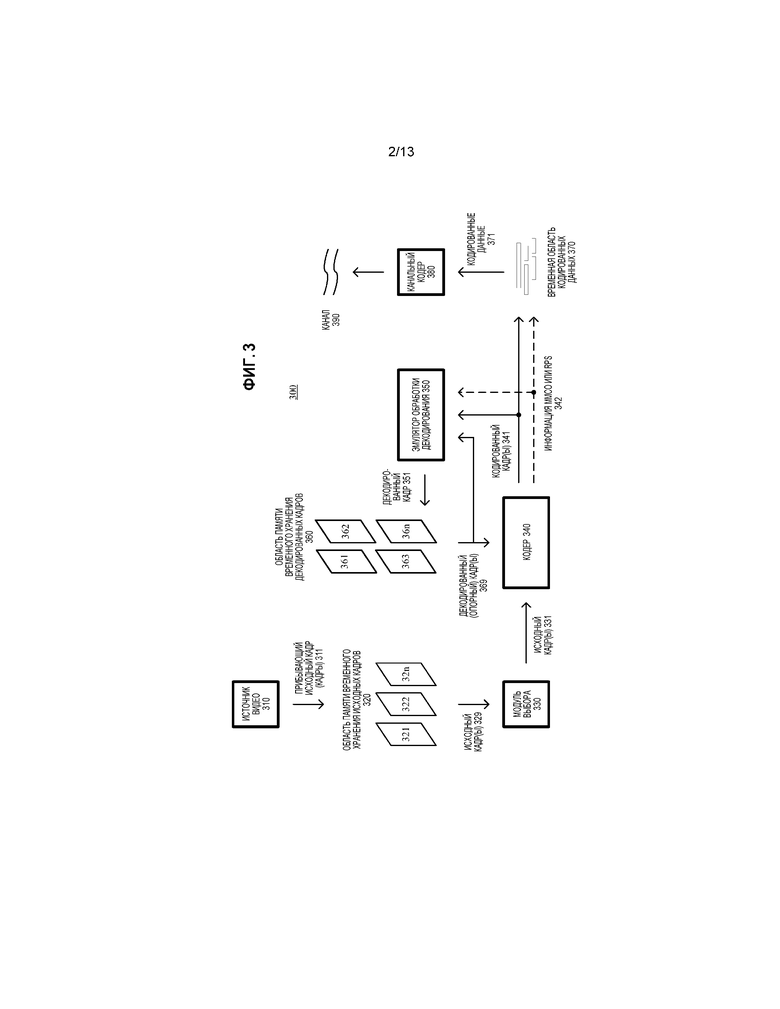
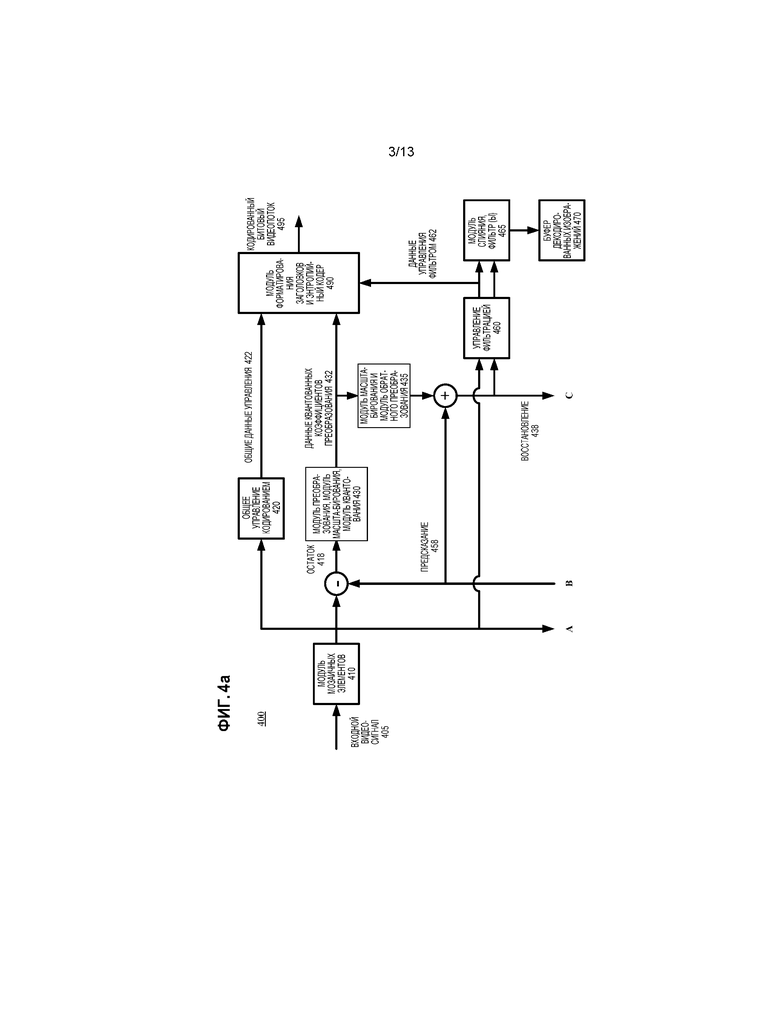
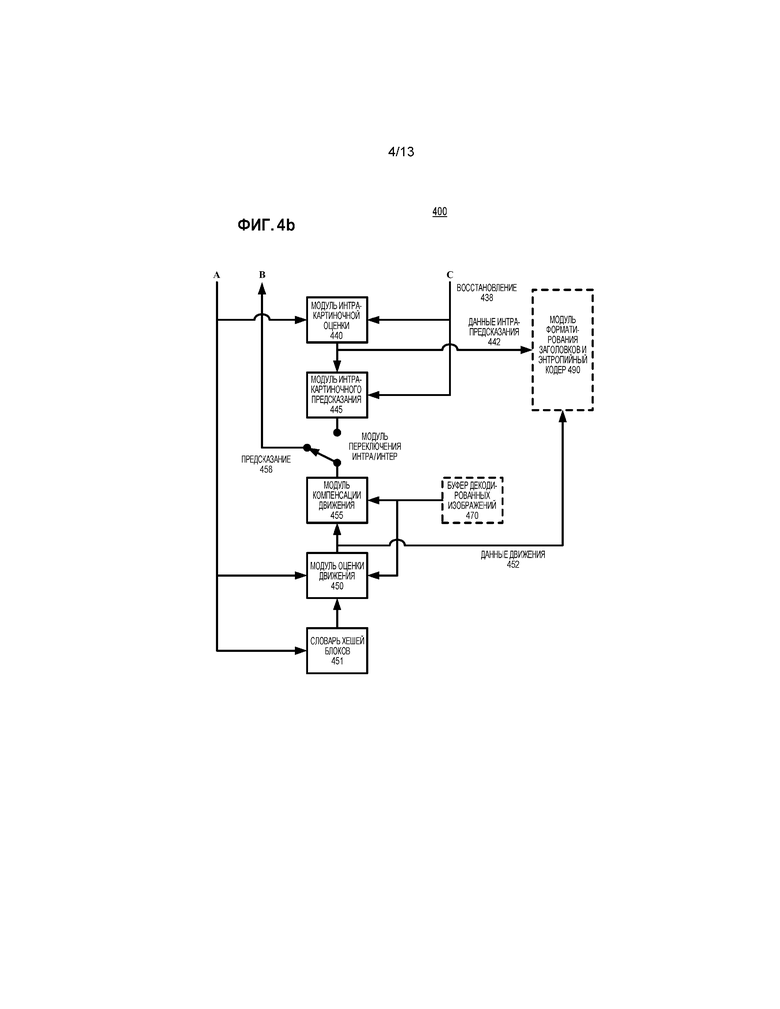
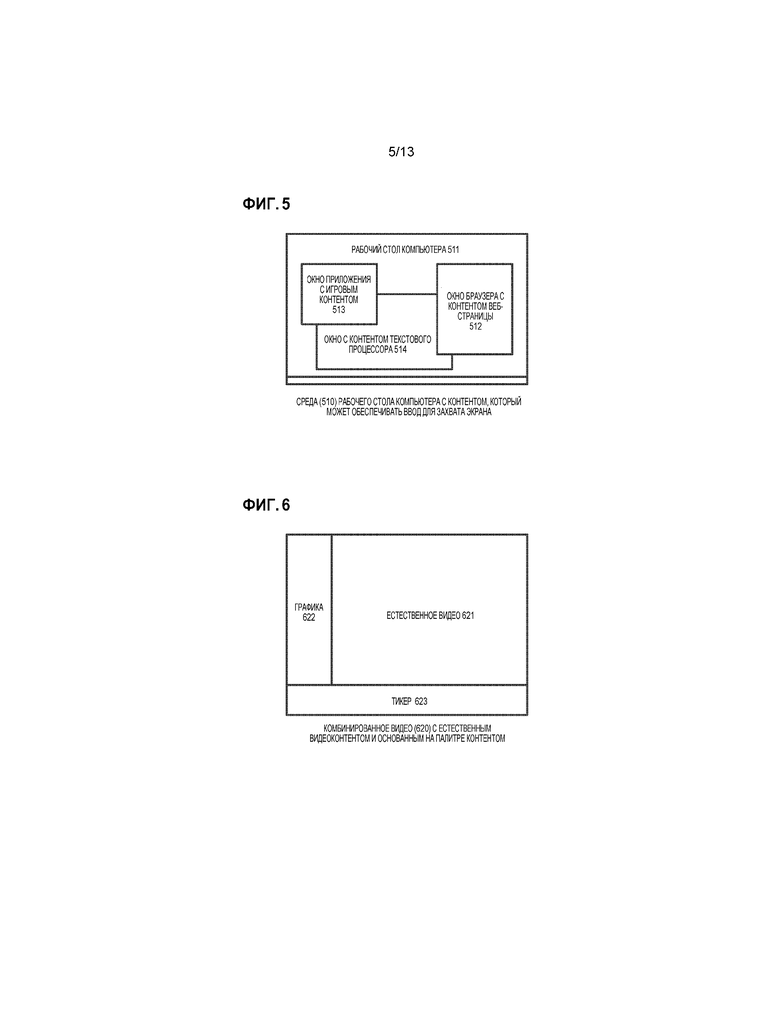



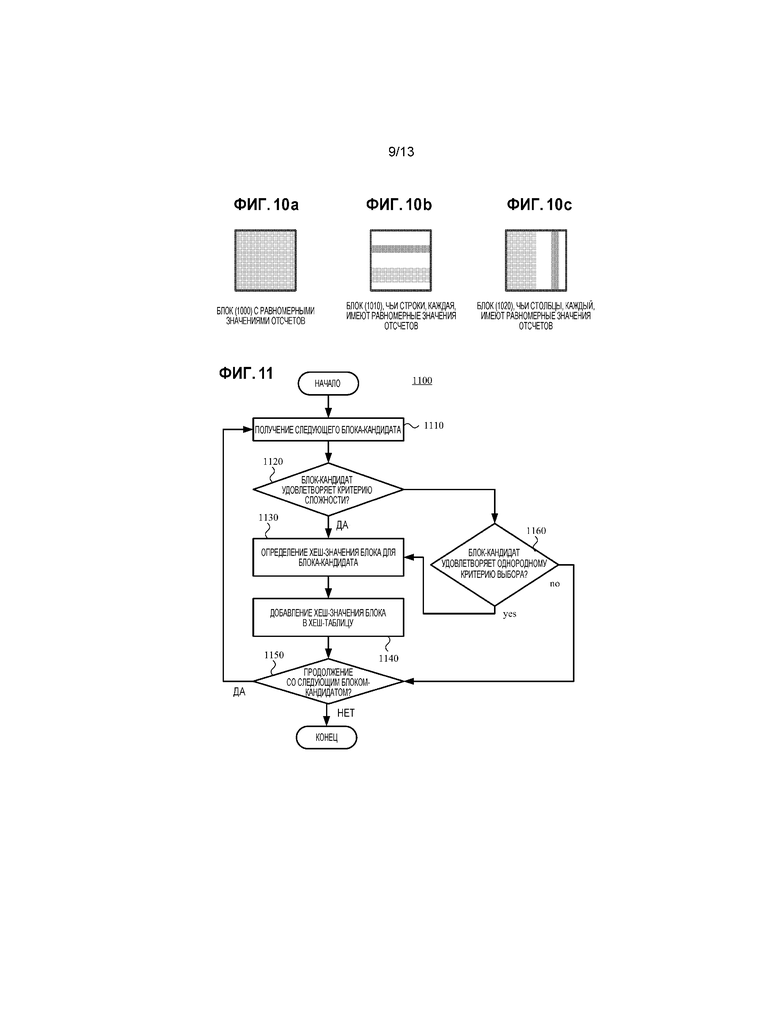
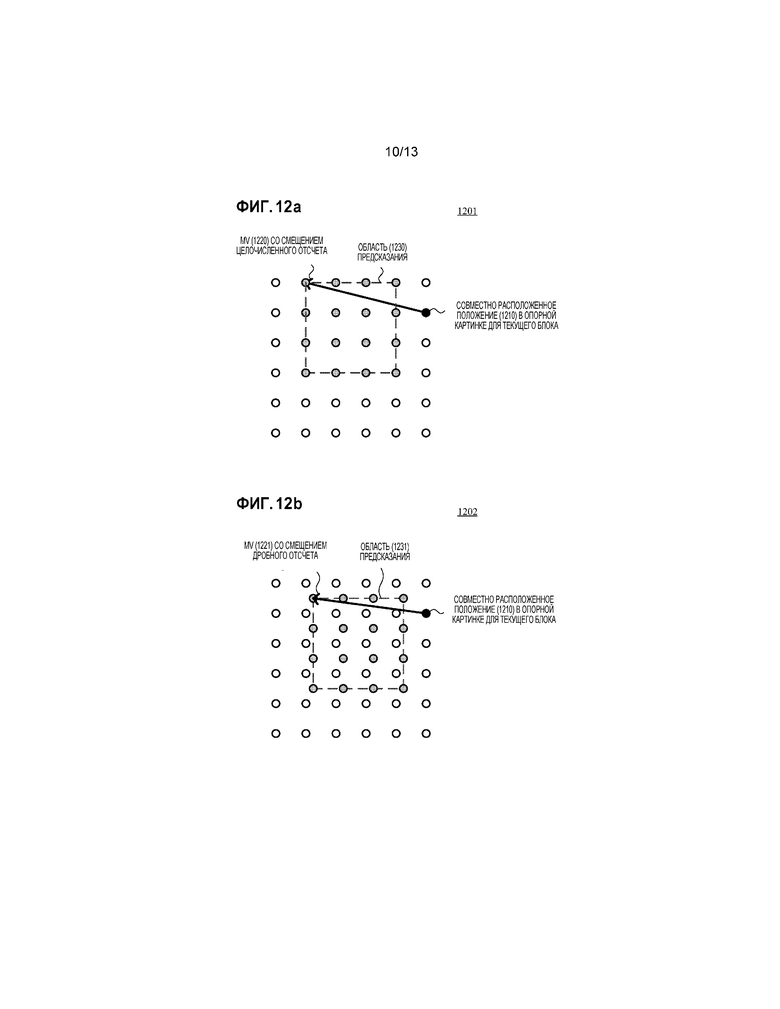
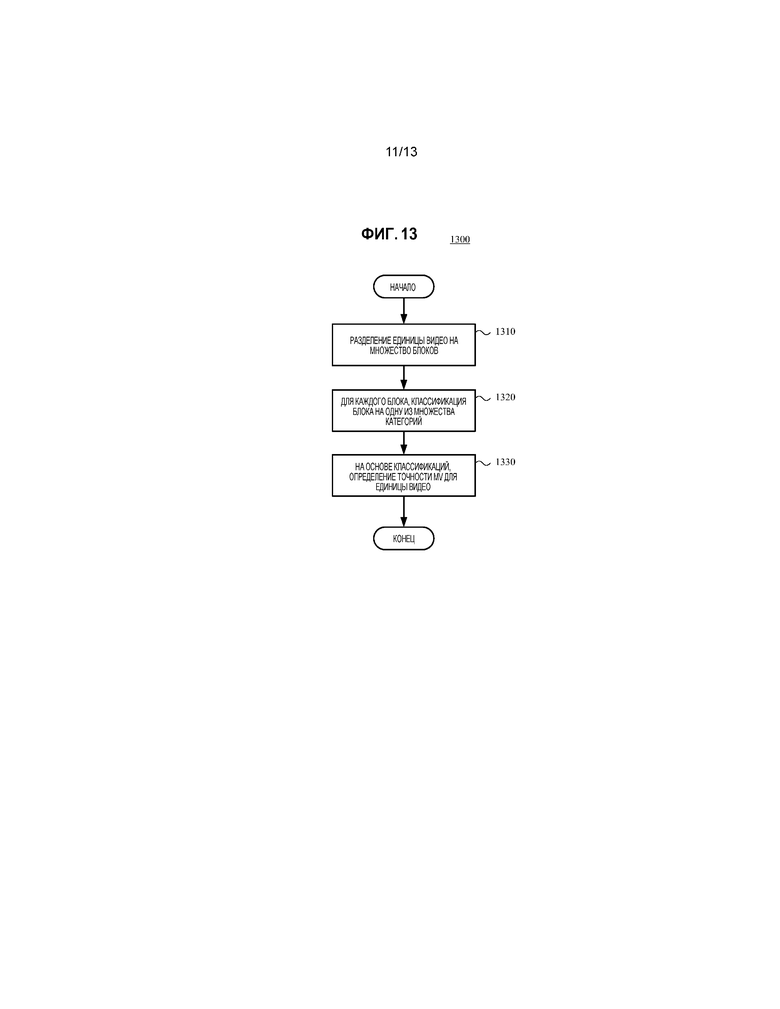
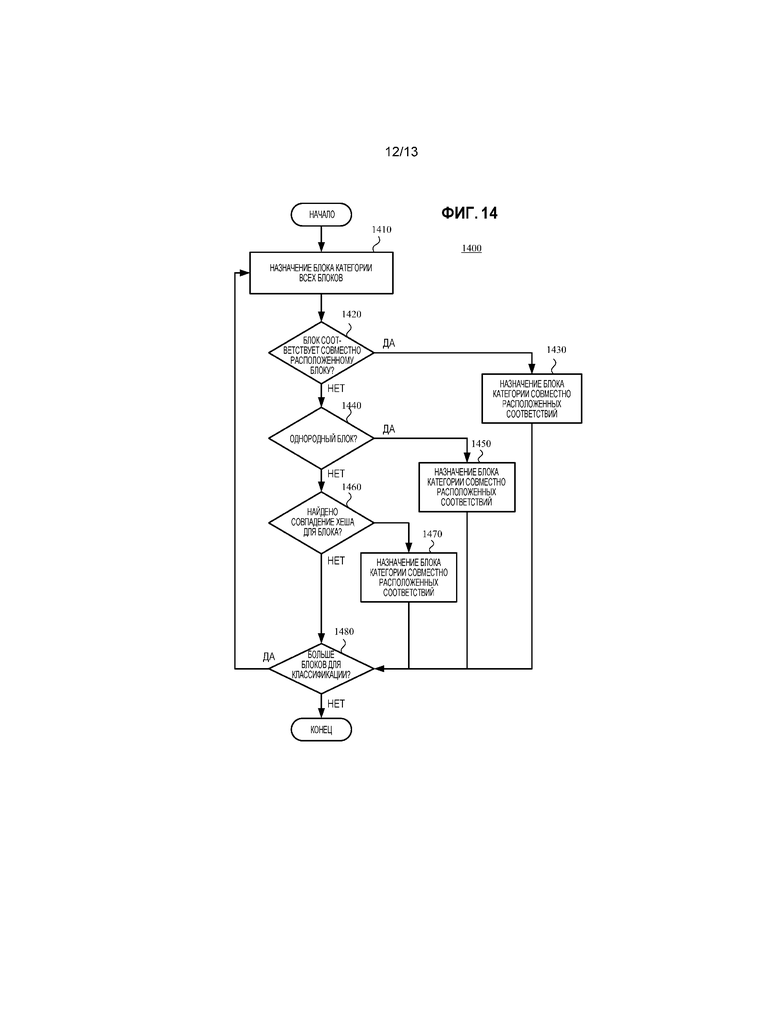
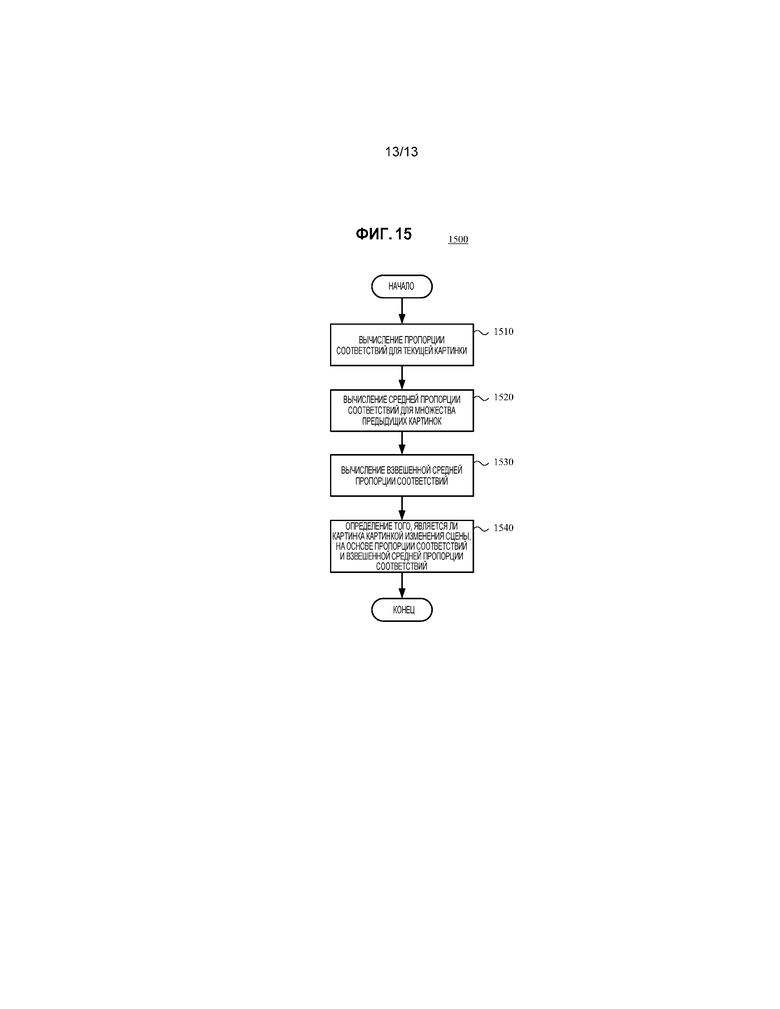
Изобретение относится к вычислительной технике. Технический результат заключается в улучшении производительности при кодировании видеоконтента. Компьютерно-реализуемый способ построения хеш-таблицы для основывающегося на хешировании подбора блоков, в котором для каждого из множества потенциально подходящих блоков в картинке видеоданных: оценивают, удовлетворяет ли потенциально подходящий блок критерию сложности для отсеивания гомогенных блоков, причем гомогенный блок представляет собой однородный блок; если потенциально подходящий блок не удовлетворяет критерию сложности: оценивают, удовлетворяет ли потенциально подходящий блок критерию равномерного выбора, причем критерий равномерного выбора состоит в том, выровнены ли координаты потенциально подходящего блока с конкретными делениями упомянутой картинки; если потенциально подходящий блок удовлетворяет критерию равномерного выбора: определяют хеш-значение блока для потенциально подходящего блока и добавляют это хеш-значение блока в хеш-таблицу; и если потенциально подходящий блок не удовлетворяет критерию равномерного выбора, не включают потенциально подходящий блок в хеш-таблицу. 3 н. и 5 з.п. ф-лы, 24 ил.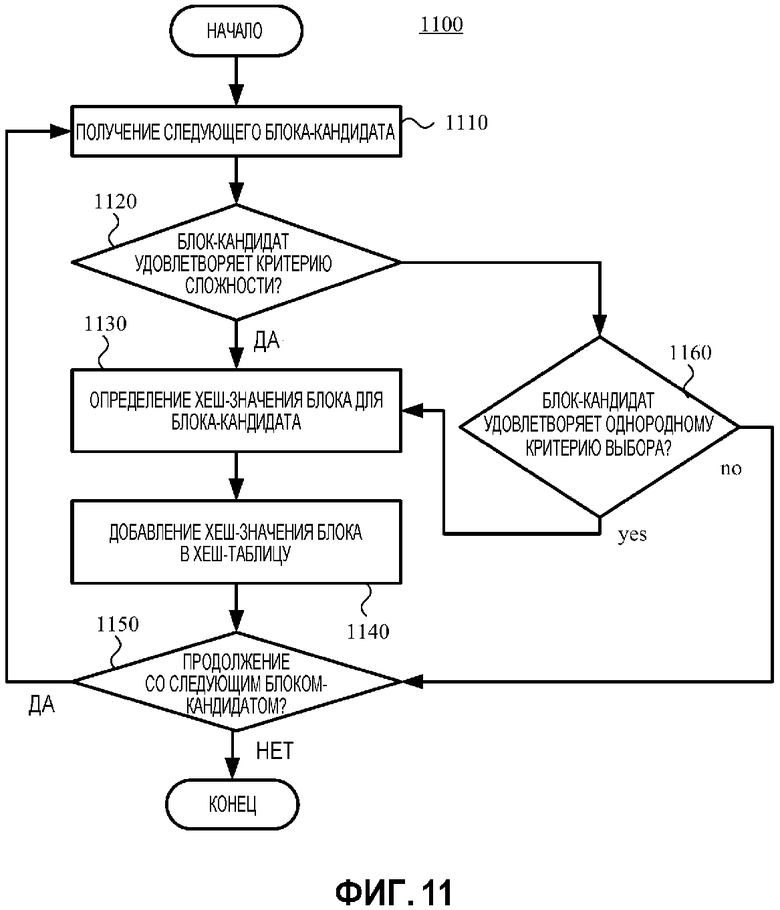
1. Компьютерно-реализуемый способ построения хеш-таблицы для основывающегося на хешировании подбора блоков, при этом способ содержит этапы, на которых:
для каждого из множества потенциально подходящих блоков в картинке видеоданных:
оценивают, удовлетворяет ли потенциально подходящий блок критерию сложности для отсеивания гомогенных блоков, причем гомогенный блок представляет собой однородный блок;
если потенциально подходящий блок не удовлетворяет критерию сложности:
оценивают, удовлетворяет ли потенциально подходящий блок критерию равномерного выбора, причем критерий равномерного выбора состоит в том, выровнены ли координаты потенциально подходящего блока с конкретными делениями упомянутой картинки;
если потенциально подходящий блок удовлетворяет критерию равномерного выбора:
определяют хеш-значение блока для потенциально подходящего блока и
добавляют это хеш-значение блока в хеш-таблицу; и
если потенциально подходящий блок не удовлетворяет критерию равномерного выбора, не включают потенциально подходящий блок в хеш-таблицу.
2. Способ по п. 1, дополнительно содержащий, если потенциально подходящий блок удовлетворяет критерию сложности, этапы, на которых:
определяют хеш-значение блока для потенциально подходящего блока; и
добавляют это хеш-значение блока в хеш-таблицу.
3. Способ по п. 1, в котором потенциально подходящий блок не удовлетворяет критерию сложности, когда потенциально подходящий блок является одним или более из горизонтально однородного и вертикально однородного.
4. Способ по п. 1, в котором критерий равномерного выбора основывается на начальных координатах потенциально подходящего блока.
5. Способ по п. 1, в котором потенциально подходящий блок удовлетворяет критерию равномерного выбора, когда по меньшей мере одна из начальной координаты x и y потенциально подходящего блока является делимой без остатка на предварительно определенное значение.
6. Способ по п. 1, в котором потенциально подходящий блок удовлетворяет критерию равномерного выбора, когда начальная координата x потенциально подходящего блока является делимой без остатка на первое предварительно определенное значение и начальная координата y потенциально подходящего блока является делимой без остатка на второе предварительно определенное значение.
7. Вычислительное устройство, содержащее блок обработки и память, выполненные с возможностью осуществлять способ по любому из пп. 1-6.
8. Машиночитаемый носитель, на котором сохранены машиноисполняемые инструкции, которые при их исполнении вычислительным устройством предписывают вычислительному устройству выполнять способ по любому из пп. 1-6.
| Колосоуборка | 1923 |
|
SU2009A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| JP 2013058873 A, 28.03.2013 | |||
| СПОСОБ УЛУЧШЕНИЯ ЦИФРОВЫХ ИЗОБРАЖЕНИЙ | 2005 |
|
RU2298226C1 |

