Один или несколько аспектов относятся, в основном, к многопоточным процессорам, и прежде всего к управлению выполнением потоков в таких процессорах.
Процессор может включать в себя множественные аппаратные потоки, имеющие выполняющиеся одновременно команды. Такой процессор, как говорят, реализует одновременную многопоточность (SMT), которая является техникой, используемой для повышения полной эффективности процессора путем разрешения выполнения множественных независимых потоков для лучшего использования предоставляемых современными архитектурами процессоров ресурсов.
Путем управления выполнением потоков многопоточного процессора могут быть получены дополнительные полезные действия.
Недостатки известного уровня техники преодолеваются при осуществлении способа управления выполнением потоков в вычислительном окружении, охарактеризованного в п. 1 формулы, а также в соответствующих системе и машиночитаемом информационном носителе.
Технический результат, достигаемый при осуществлении изобретения, заключается, в частности, в возможности совместного использования конвейера потоками с разным приоритетом.
Другие варианты осуществления и аспекты подробно описываются в настоящем документе и считаются частью заявленного изобретения.
Один или несколько аспектов, прежде всего, указаны и явным образом заявлены в качестве примеров в пунктах формулы изобретения в конце технического описания. Ранее указанные и другие цели, признаки и преимущества являются очевидными из последующего подробного описания, предпринятого совместно с сопровождающими чертежами, на которых:
Фиг. 1 изображает один пример вычислительного окружения для охвата и использования одного или нескольких аспектов управления выполнением потоков,
Фиг. 2 изображает другой пример вычислительного окружения для охвата и использования одного или нескольких аспектов управления выполнением потоков,
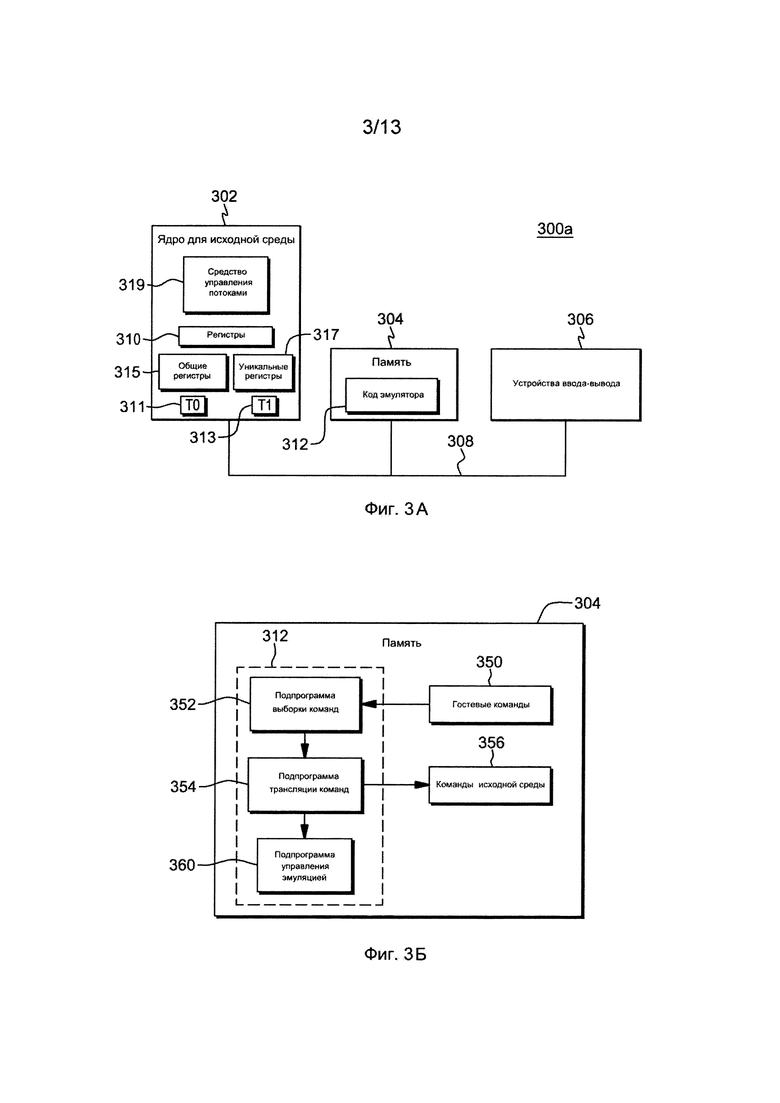
Фиг. 3А изображает еще один пример вычислительного окружения для охвата и использования одного или нескольких аспектов управления выполнением потоков,
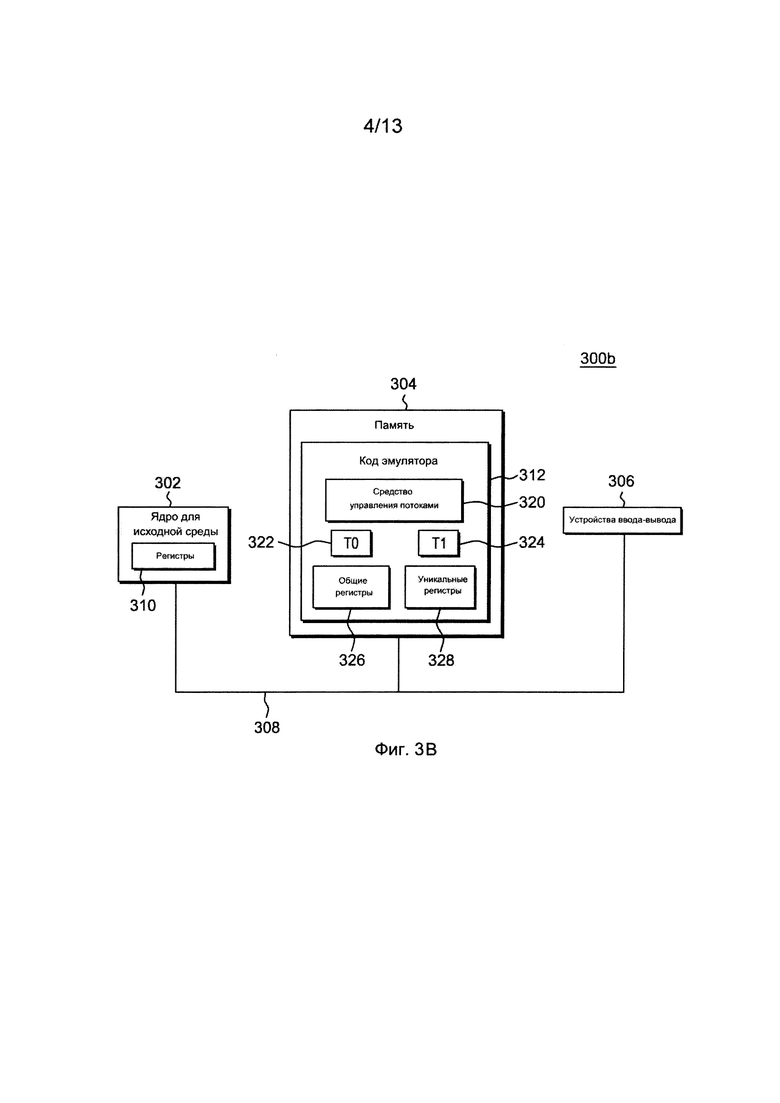
Фиг. 3Б изображает более подробную информацию по памяти вычислительного окружения на фиг. 3А,
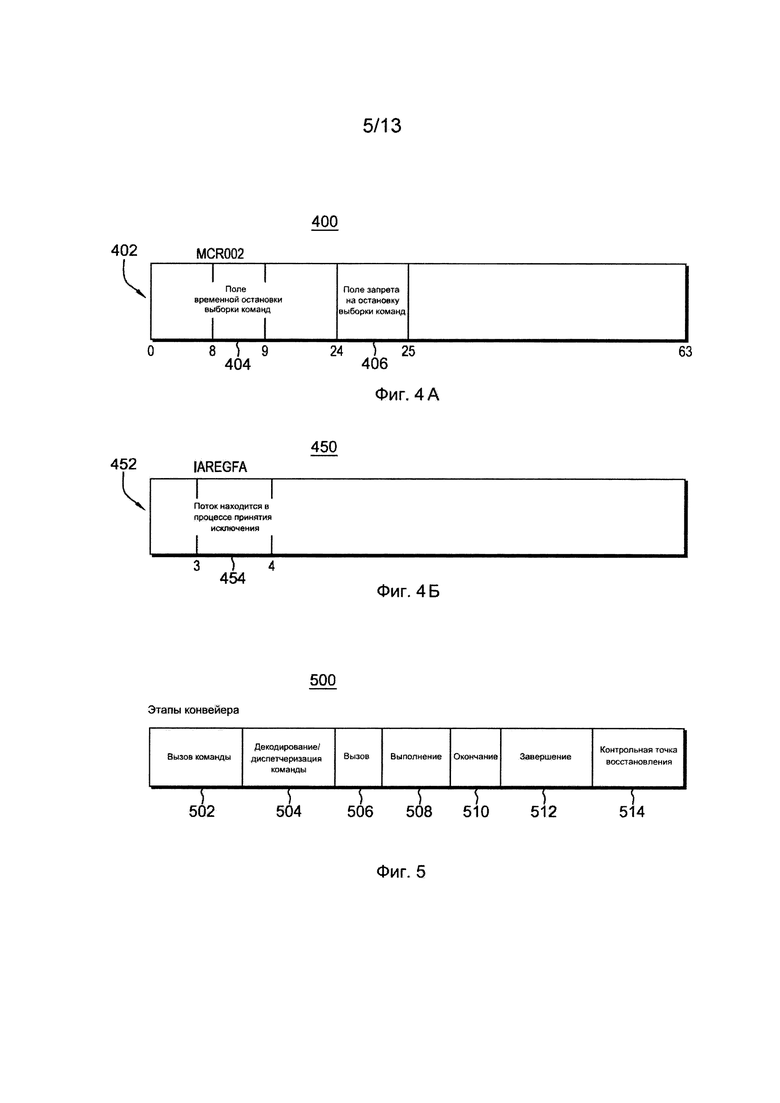
Фиг. 3В изображает другой пример вычислительного окружения для охвата и использования одного или нескольких аспектов управления выполнением потоков,
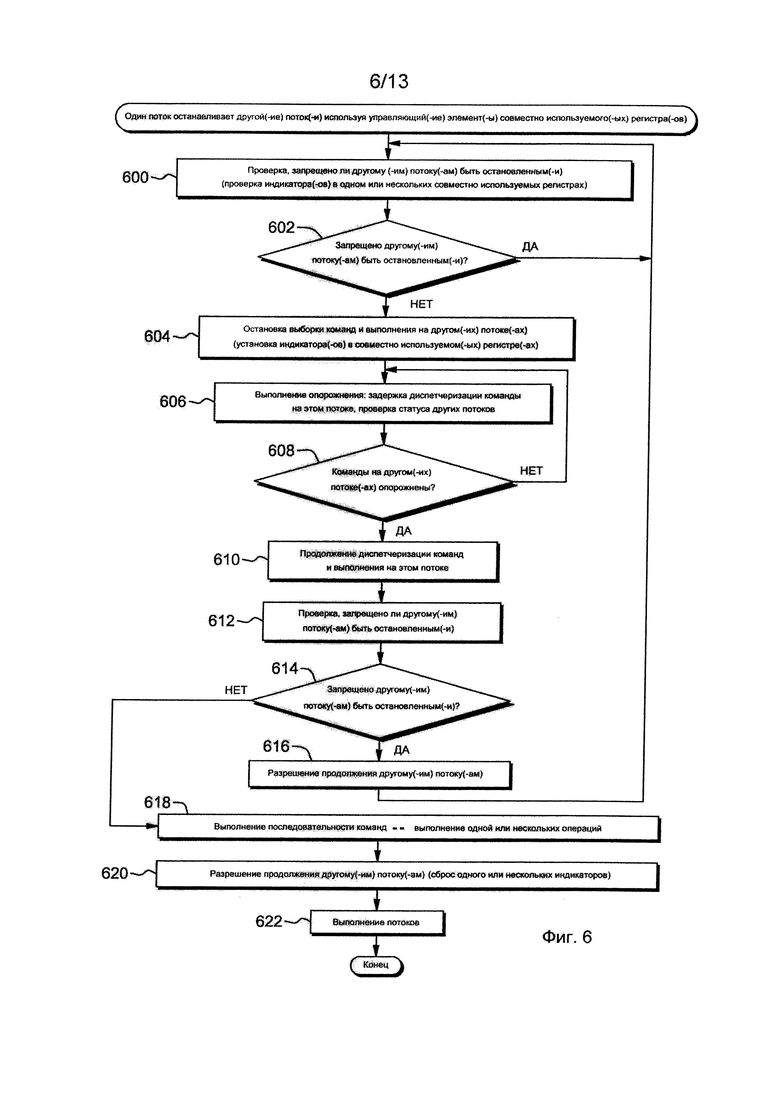
Фиг. 4А изображает один пример регистра управления, используемого согласно одному аспекту управления выполнением потоков,
Фиг. 4Б изображает один пример регистра адреса команды, используемого согласно одному аспекту управления выполнением потоков,
Фиг. 5 изображает один пример этапов конвейера,
Фиг. 6 изображает один пример логики для управления выполнением потоков в многопоточном процессоре,
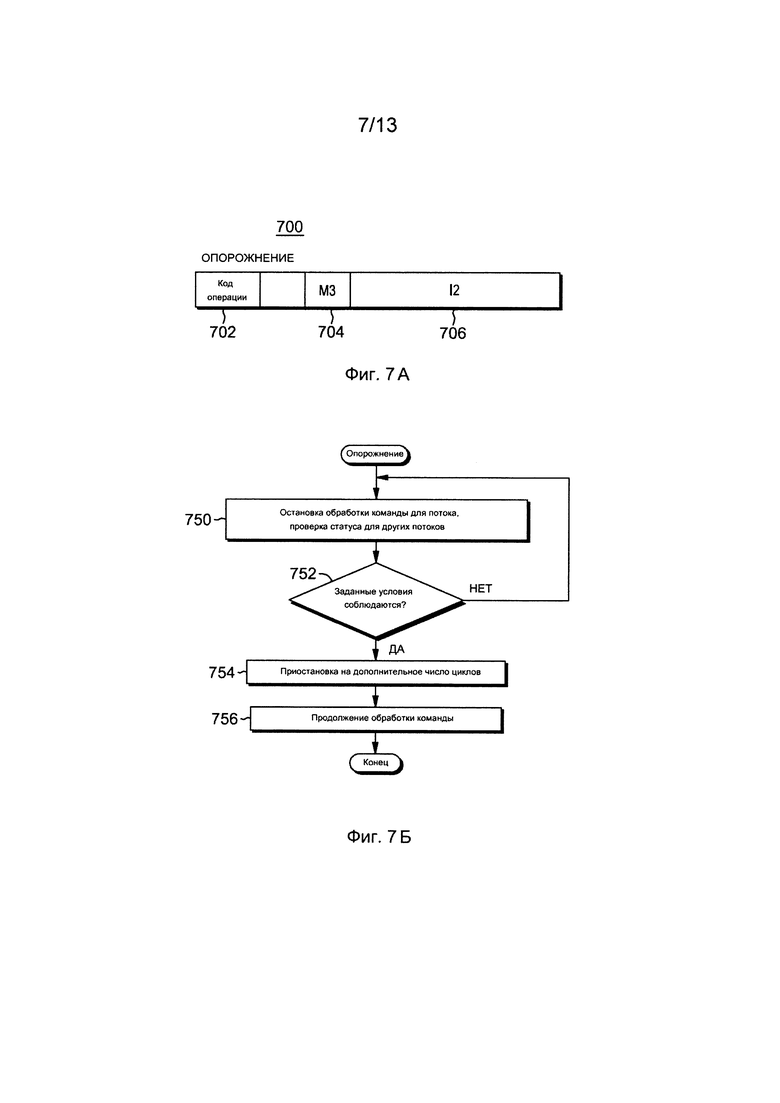
Фиг. 7А изображает один пример формата команды опорожнения,
Фиг. 7Б изображает один вариант осуществления логики, связанной с командой опорожнения на фиг. 7А,
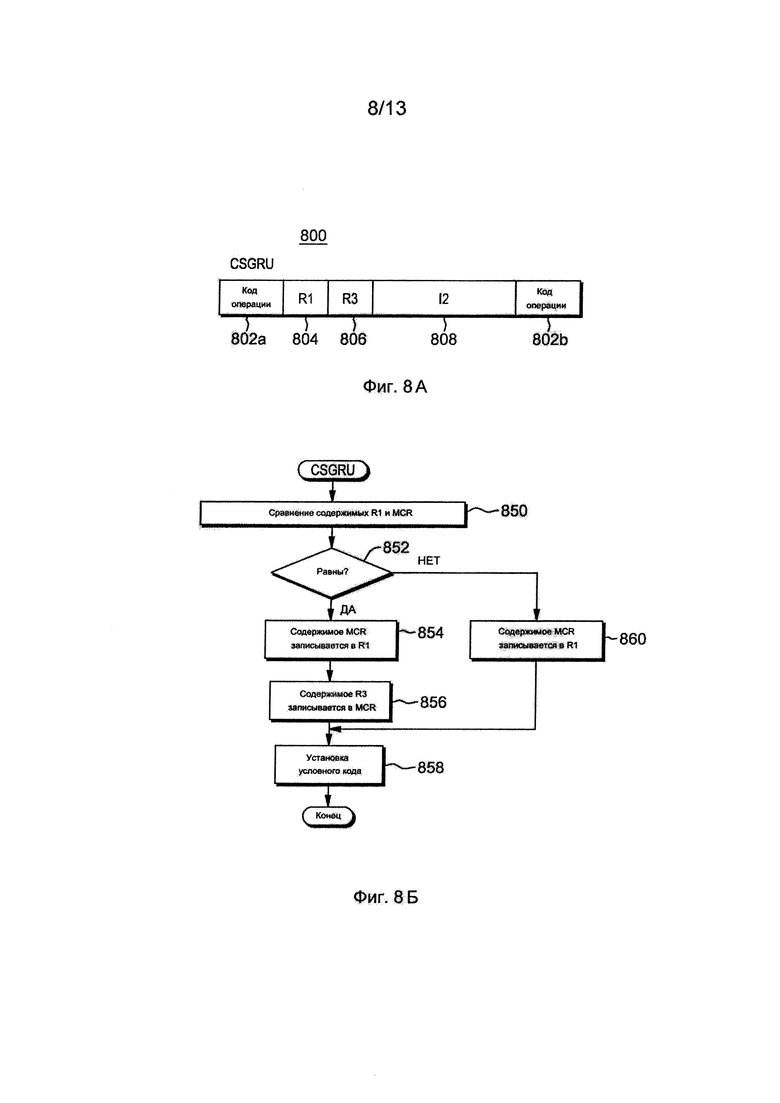
Фиг. 8А изображает один пример формата команды сравнения и замены регистра модуля состояния процессора,
Фиг. 8Б изображает один вариант осуществления логики, связанной с командой сравнения и замены регистра модуля состояния процессора на фиг. 8А,
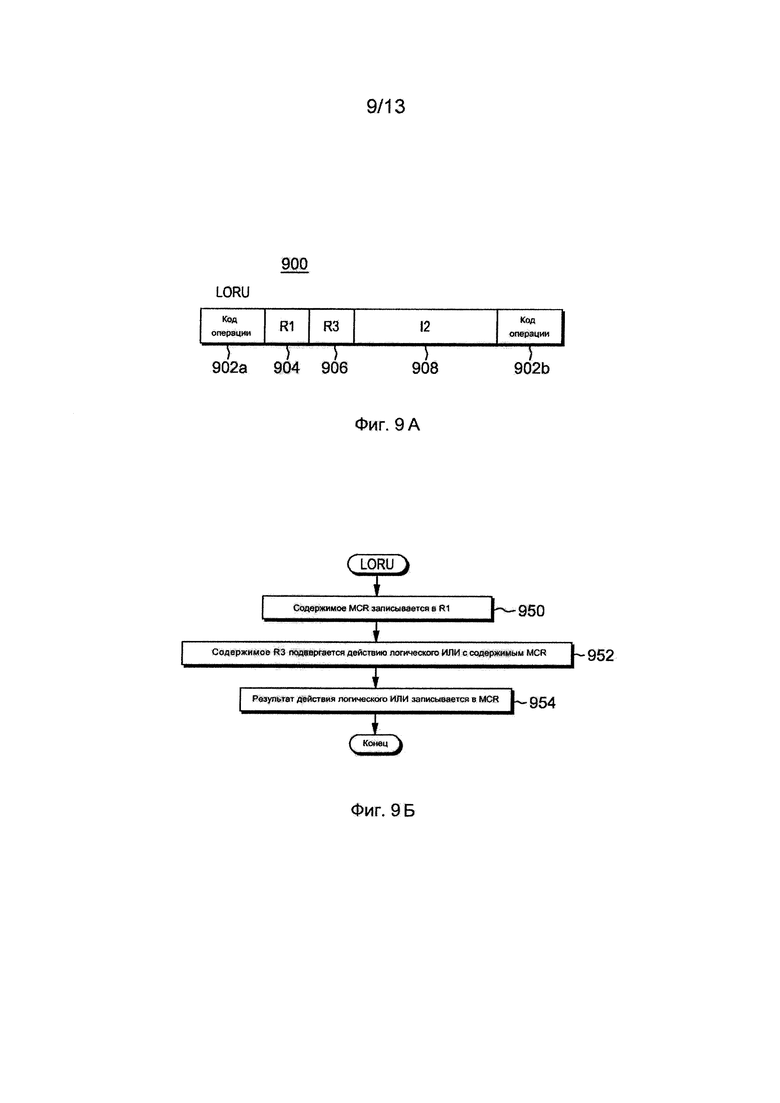
Фиг. 9А изображает один пример формата команды загрузки и логического ИЛИ регистра модуля состояния процессора,
Фиг. 9Б изображает один вариант осуществления логики, связанной с командой загрузки и логического ИЛИ регистра модуля состояния процессора на фиг. 9А,
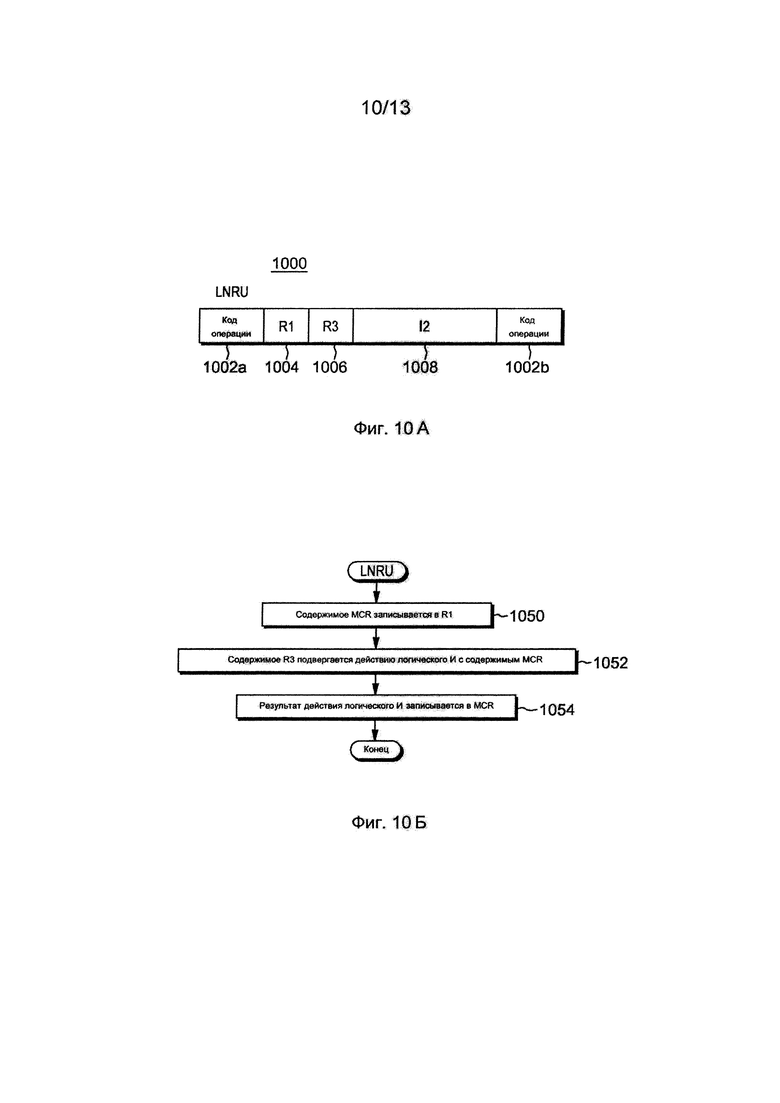
Фиг. 10А изображает один пример формата команды загрузки и логического И регистра модуля состояния процессора,
Фиг. 10Б изображает один вариант осуществления логики, связанной с командой загрузки и логического И регистра модуля состояния процессора на фиг. 10А,
Фиг. 11А, 11Б изображают один пример логики, связанной с взаимной блокировкой, используемой одной или несколькими командами, и
Фиг. 12 изображает один вариант осуществления компьютерного программного продукта.
Подробное описание
Согласно одному или нескольким аспектам предоставляется инструмент для управления выполнением потоков (например, аппаратных потоков) в ядре (например, в процессоре физического оборудования, также называемом в настоящем документе ядром процессора или процессорным ядром), работающем в вычислительном окружении. Ядро поддерживает, например, многопоточность, такую как одновременную многопоточность (SMT), что означает возможность наличия по существу множественных логических центральных вычислительных устройств (ЦП), одновременно действующих на тех же аппаратных средствах физического процессора. Каждый из этих логических ЦП считается потоком.
В таком многопоточном окружении для одного потока может оказаться желательной остановка выполнения других потоков на ядре процессора. Такая потребность может возникнуть в ответ на выполнение критической последовательности или другой последовательности, нуждающейся в ресурсах ядра процессора или в управлении ресурсами ядра процессора способом, в рамках которого другие потоки могут вмешаться в его выполнение. В одном из вариантов, в качестве части инструмента, может оказаться желательным ожидание до тех пор, пока некоторое условие не окажется удовлетворенным для всех потоков на ядре процессора. Например, предположим, программное обеспечение, или встроенное программное обеспечение, работающее на особом аппаратном потоке, намеревается выполнить действие системы, которое в первую очередь требует от всего ядра процессора отсутствия производства каких-либо сохранений, то есть, отсутствия производства каких-либо сохранений на всех потоках на ядре процессора. Для выявления того, остановлены ли другие потоки, предоставляется команда, называемая в настоящем документе командой опорожнения ("DRAIN INSTRUCTION"), которая, согласно одному аспекту, отслеживает состояние потоков на ядре процессора.
Кроме того, согласно одному или нескольким аспектам, в рамках управления выполнением потоков могут использоваться различные элементарные команды. Эти команды воздействуют на регистры, доступные для потоков процессора SMT и для совместного использования ими, а не для хранения или памяти. (Термины «память» и «хранение» используются в настоящем документе взаимозаменяемым образом, если неявно или явно не указано иное.) Это позволяет множественным потокам сообщаться друг с другом и делиться информацией с помощью совместно используемых регистров, а не памяти. Такие упомянутые в настоящем документе команды, как команда сравнения и замены регистра модуля состояния процессора или команда сравнения и замены регистра, команда загрузки и логического ИЛИ регистра модуля состояния процессора или команда загрузки и логического ИЛИ регистра, а также команда загрузки и логического И регистра модуля состояния процессора или команда загрузки и логического И регистра управляют доступом к совместно используемой взаимной блокировке использования регистров, как описано в настоящем документе.
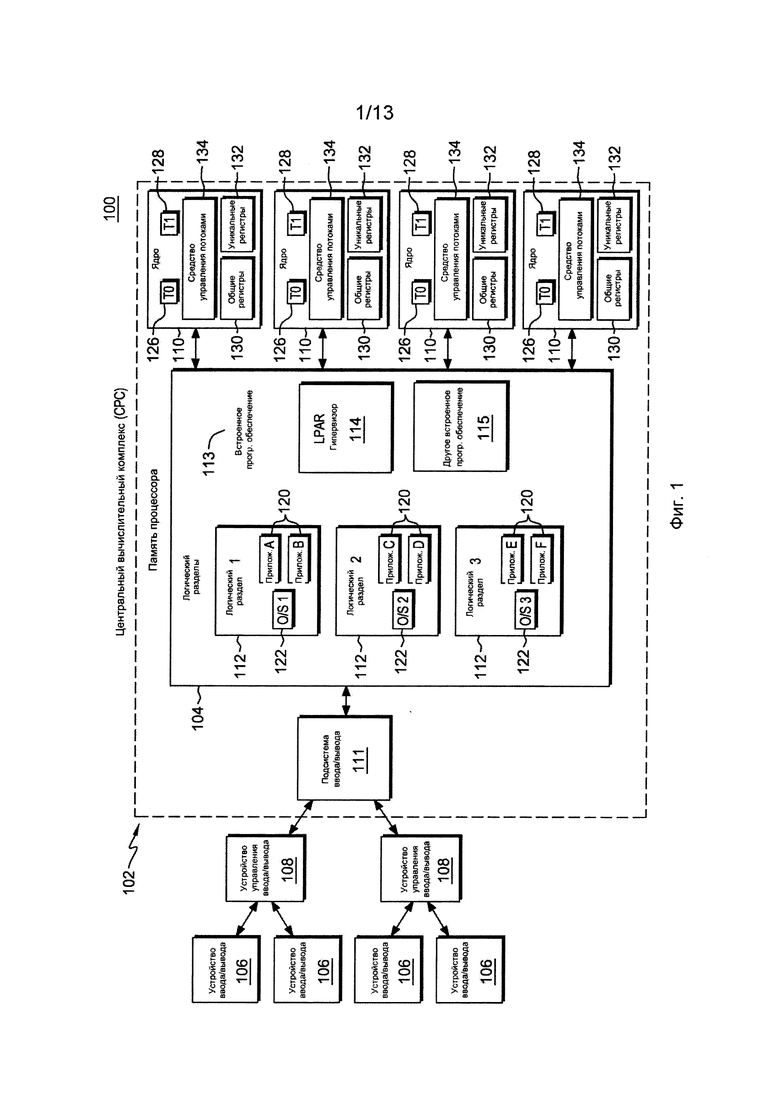
Один пример вычислительного окружения для охвата и использования одного или нескольких аспектов управления выполнением потоков описан со ссылками на фиг. 1. Согласно фиг. 1, в одном примере, вычислительное окружение 100 основано на z/Архитектуре, предлагаемой International Business Machines (IBM®) Corporation, Армонк, Нью-Йорк), z/Архитектура описана в публикации IBM под названием «z/Архитектура, принципы работы» (z/Architecture, Principles of Operation), публикация № SA 22-7932-09, 10-й выпуск, сентябрь 2012.
z/Архитектура, IBM, а также Z/VM, Z/OS, Power и POWERPC (упоминаемые в настоящем документе) являются зарегистрированными торговыми марками International Business Machines Corporation, Армонк, Нью-Йорк. Другие используемые здесь наименования могут быть представлены зарегистрированными торговыми марками, торговыми марками или названиями продукта International Business Machines Corporation или других компаний.
В качестве примера, вычислительное окружение 100 включает в себя центральный вычислительный комплекс (СРС) 102, присоединенный к одному или нескольким устройствам 106 ввода/вывода (I/O) через одно или несколько устройств 108 управления. Центральный вычислительный комплекс 102 включает в себя, например, память 104 процессора (известную также под названием оперативная память, основная память, центральная память), соединенную с одним или несколькими процессорными ядрами 110, и с подсистемой 111 ввода/вывода, каждый из указанных элементов описан ниже.
Память 104 процессора включает в себя, например, один или несколько разделов 112 (например, логических разделов), а также встроенное программное обеспечение 113 процессора, которое включает в себя, например, гипервизор 114 логических разделов и другое встроенное программное обеспечение 115 процессора. Один пример гипервизора 114 логического раздела представлен администратором ресурсов процессора/системы Processor Resource/Systems Manager™ (PR/SM), предлагаемым International Business Machines Corporation, Армонк, Нью-Йорк.
Логический раздел функционирует как отдельная система и имеет в себе одно или несколько приложений 120 и, факультативно, резидентную операционную систему (O/S) 122, которая может отличаться для каждого логического раздела. В одном варианте осуществления операционная система является z/OS операционной системой, z/VM операционной системой, z/Linux операционной системой или операционной системой TPF, предлагаемой International Business Machines Corporation, Армонк, Нью-Йорк.
Логическими разделами 112 управляет гипервизор 114 логических разделов, который реализован посредством встроенного программного обеспечения, функционирующего на ядрах 110. При рассмотрении в настоящем документе, встроенное программное обеспечение включает в себя, например, микрокод и/или милликод процессорного ядра. Он включает в себя, например, команды аппаратного уровня и/или структуры данных, используемые в реализации высокоуровневого машинного кода. В одном варианте он включает в себя, например, проприетарный код, обычно поставляемый как микрокод, который включает в себя выверенное программное обеспечение или микрокод, специфичный для используемого оборудования и управляющий доступом операционной системы к оборудованию системы.
Процессорные ядра 110 являются физическими процессорными ресурсами, выделенными логическим разделам. Конкретно, каждый логический раздел 112 имеет один или несколько логических процессоров, каждый из которых представляет собой, полностью или частично, выделенное разделу ядро 110. Логические процессоры конкретного раздела 112 могут быть либо выделены разделу таким образом, что базовый ядерный ресурс 110 резервируется для данного раздела, либо быть используемыми совместно с другим разделом таким образом, что базовый ядерный ресурс является потенциально доступным другому разделу.
В одном из вариантов по меньшей мере одно из ядер является процессором многопоточности, таким как процессор одновременной многопоточности, который включает в себя множественные потоки (то есть, одновременно работающие множественные логические ЦП). В одном примере, ядро включает в себя два потока, но в других вариантах осуществления, может иметься более двух потоков. Упоминаемые в настоящем документе два потока Т0 (126) и Т1 (128), являются только одним примером.
Для поддержки одновременной многопоточности аппаратные средства ядра процессора содержат полное архитектурно спроектированное состояние (например, z/Архитектурное и микроархитектурное состояние) для каждого потока. Таким образом, предоставляются регистры 130 всего процессора, которые являются общими для всех потоков (упоминаемые в настоящем документе как общие регистры), а также специфичные для потока регистры 132, которые являются уникальными для потока (упоминаемые в настоящем документе как уникальные регистры). Использование этих регистров описано далее ниже.
Для управления выполнением множественных потоков ядро 110 включает в себя аппаратные средства и/или логику для обеспечения такого управления, как описано в настоящем документе. Эти аппаратные средства и/или логика для удобства упоминаются в настоящем документе как средство 134 управления потоками.
Подсистема 111 ввода/вывода направляет поток информации между устройствами 106 ввода-вывода и основной памятью 104. Оно соединено с центральным вычислительным комплексом, в котором оно может быть частью центрального вычислительного комплекса или быть отдельным от него. Подсистема I/O освобождает процессорные ядра от задачи сообщения непосредственно с устройствами ввода-вывода и позволяет производить обработку данных одновременно с обработкой ввода/вывода. Для обеспечения связи подсистема I/O использует коммуникационные адаптеры I/O. Существуют различные типы коммуникационных адаптеров, например каналы, адаптеры I/O, платы PCI, платы Ethernet, карты Small Computer Storage Interface (SCSI) и т.д. В конкретном описанном в настоящем документе примере коммуникационные адаптеры I/O являются каналами, и поэтому, подсистема I/O упоминается в настоящем документе как канальная подсистема. Тем не менее, данный пример является только одним из многих. Также могут использоваться и другие типы подсистем I/O.
Подсистема I/O использует один или несколько трактов ввода/вывода в качестве коммуникационных трактов при управлении потоком информации к устройствам 106 ввода-вывода или от них. В этом конкретном примере эти тракты называются канальными трактами, поскольку коммуникационные адаптеры являются каналами.
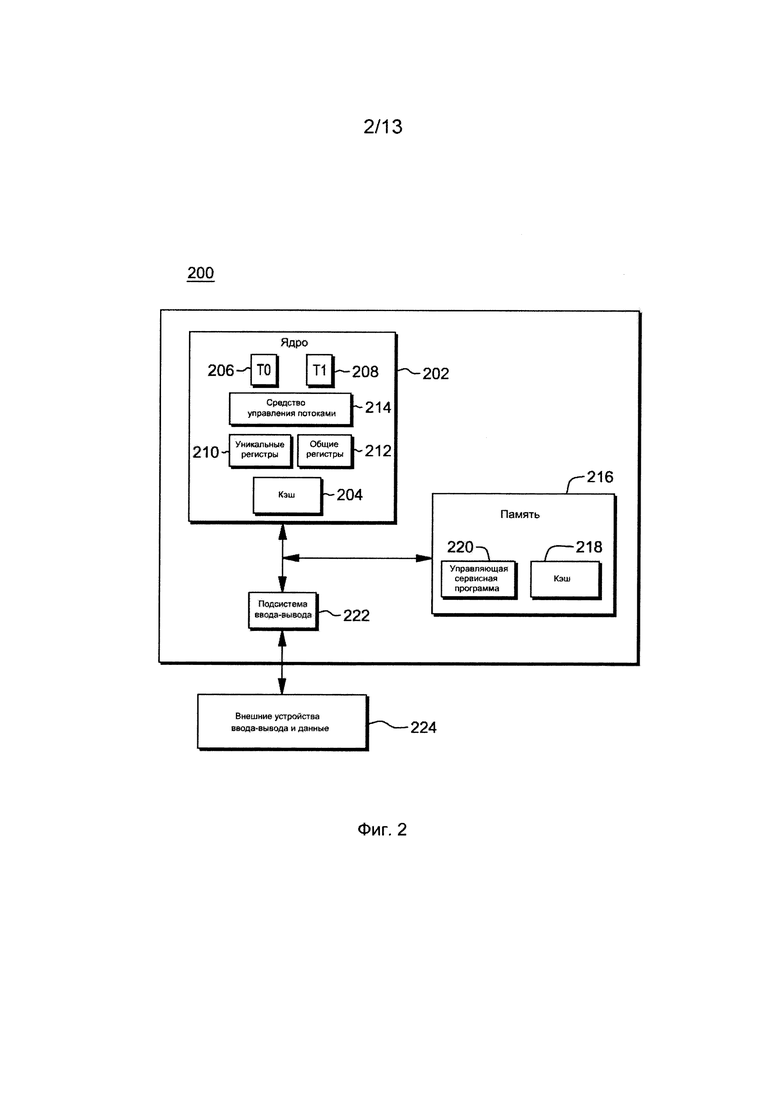
Другой пример вычислительного окружения для охвата и использования одного или нескольких аспектов управления выполнением потоков описан со ссылками на фиг. 2. В этом примере вычислительное окружение 200 включает в себя неразбитое на разделы окружение, реализованное на основании z/Архитектуры (или другой архитектуры в другом варианте осуществления). Оно включает в себя ядро 202, которое включает в себя, например, один или несколько кэшей 204, по меньшей мере два потока Т0 (206), Т1 (208), единый набор регистров 210 для потоков, и уникальный набор регистров 212 для каждого потока, а также средство 214 управления потоками.
Ядро 202 коммуникативно соединено с памятью 216, имеющей один или несколько кэшей 218 и по меньшей мере одну управляющую сервисную программу 220, такую как операционная система, а для ввода/вывода (I/O) - подсистему 222. Подсистема I/O 222 коммуникативно соединена с внешними устройствами 224 ввода-вывода, которые могут включать в себя, например, устройства ввода данных, датчики и/или устройства вывода, такие как дисплеи.
Другой вариант осуществления вычислительного окружения для охвата и использования одного или нескольких аспектов управления выполнением потоков описан со ссылками на фиг. 3А. В этом примере вычислительное окружение 300а включает в себя, например, предназначенное для исходной среды ядро 302, память 304, а также одно или несколько устройств ввода-вывода и/или интерфейсов 306, соединенных друг с другом через, например, одну или несколько шин 308 и/или другие присоединения. Например, вычислительное окружение 300а может включать в себя процессор PowerPC или сервер Power Systems, предлагаемые International Business Machines Corporation, Армонк, Нью-Йорк, HP Superdome с процессорами Intel Itanium II, предлагаемые Hewlett Packard, Пало-Альто, Калифорния, и/или другие машины, основанные на архитектурах, предлагаемых International Business Machines Corporation, Hewlett Packard, Intel, Oracle или другими.
Предназначенное для исходной среды ядро 302 включает в себя один или несколько предназначенных для исходной среды регистров 310 и/или один или несколько регистров особого назначения, используемых в процессе обработки в окружении, которые включают в себя информацию, представляющую состояние окружения на некоторый конкретный момент времени. Кроме того, предназначенное для исходной среды ядро может включать в себя, например, по меньшей мере два потока Т0 (311), Т1 (313), ряд общих регистров 315 для потоков, ряд специфичных для потока регистров 317 для каждого потока, и средство 319 управления потоками.
Кроме того, предназначенное для исходной среды ядро 302 выполняет команды и код, которые сохраняются в памяти 304. В одном конкретном примере процессорное ядро выполняет сохраняемый в памяти 304 код 312 эмулятора. Этот код позволяет вычислительному окружению, сконфигурированному в одной архитектуре, эмулировать одну или несколько других архитектур. Например, код 312 эмулятора позволяет основанным на отличных от z/Архитектуры архитектурах машинам, таким как процессоры PowerPC, серверы Power Systems, серверы HP Superdome или другие, эмулировать z/Архитектуру и выполнять программное обеспечение и команды, разработанные на основе z/Архитектуры.
В другом варианте осуществления, как показано на фиг. 3В, ядро 302 является однопоточным ядром, но многопоточное ядро эмулируется и включается в пределы кода 312 эмулятора. Например, код 312 эмулятора включает в себя эмулированное средство 320 управления потоками, эмулированные потоки 322, 324, эмулированные общие регистры 326 и эмулированные уникальные регистры 328, каждый из которых основан на архитектуре, отличающейся от архитектуры предназначенного для исходной среды ядра 302, такой как z/Архитектура.
Более подробная относящаяся к коду 312 эмулятора информация приводится со ссылками на фиг. 3Б. Сохраняемые в памяти 304 гостевые команды 350 содержат команды программного обеспечения (например, согласованные с машинными командами), которые разработаны для выполнения в архитектуре, отличной от таковой предназначенного для исходной среды ядра 302. Например, гостевые команды 350 могут быть разработаны для выполнения на ядре 202 с z/Архитектурой, но вместо этого, они эмулируются на предназначенном для исходной среды ядре 302, которое может быть, например, представлено процессором Intel Itanium II. В одном примере, код 312 эмулятора включает в себя подпрограмму 352 выборки команд для получения одной или нескольких гостевых команд 350 из памяти 304 и, факультативно, для предоставления локальной буферизации для полученных команд. Он также включает в себя подпрограмму 354 трансляции команд для выявления типа полученной гостевой команды и для трансляции гостевой команды в одну или несколько соответствующих собственных команд 356. Такая трансляция включает в себя, например, идентификацию функции, которая подлежит выполнению посредством гостевой команды, и выбор предназначенной для исходной среды команды (команд) для выполнения этой функции.
Кроме того, код 312 эмулятора включает в себя подпрограмму 360 управления эмуляцией для принуждения команд исходной среды к выполнению. Подпрограмма 360 управления эмуляцией может принуждать предназначенное для исходной среды ядро 302 к выполнению подпрограммы из команд исходной среды, которые эмулируют одну или несколько ранее полученных гостевых команд и, в конце такого выполнения, возвращать управление подпрограмме выборки команд для эмуляции получения следующей гостевой команды или группы гостевых команд. Гостевые команды могут быть представлены командами средства управления потоками, описанного в настоящем документе. Выполнение команд 356 исходной среды может включать в себя загрузку данных в регистр из памяти 304, сохранение данных обратно в память из регистра, или выполнение арифметической или логической операции некоторого типа, как задано подпрограммой трансляции.
Каждая подпрограмма, например, реализуется в программном обеспечении, сохраняемом в памяти и выполняемом посредством предназначенного для исходной среды ядра 302. В других примерах, одна или несколько из числа подпрограмм или операций, реализуются во встроенном программном обеспечении, аппаратных средствах, программном обеспечении или в некоторой комбинации из этих средств. Регистры эмулированного процессора могут быть эмулированы с помощью регистров 310 предназначенного для исходной среды ядра или при помощи местоположений в памяти 304. В предпочтительных вариантах осуществления гостевые команды 350, команды 356 исходной среды и код 312 эмулятора могут находиться в той же самой памяти или могут быть рассредоточены среди различных запоминающих устройств.
Описанные выше вычислительные окружения являются только примерами пригодных к использованию вычислительных окружений. Могут быть использованы другие окружения, в том числе, но не ограничиваясь, другие неразбитые на разделы окружения, другие разбитые на разделы окружения и/или другие эмулированные окружения, варианты осуществления не ограничиваются каким-либо окружением.
Как указано выше, с каждым потоком связаны несколько регистров. Одним из совместно используемых регистров, общим для потоков, является регистр управления, такой как регистр (MCR), MCR002 управления милликодом, пример которого изображен на фиг. 4А. MCR002 (400) включает в себя различные управляющие элементы для SMT, которые задают логику работы потоков. В одном варианте осуществления MCR002 (400) включает в себя несколько полей 402, которые поля, используемые согласно одному или нескольким аспектам, включают в себя, например:
(А) Поле 404 временной остановки выборки команд: два бита этого поля взаимно-однозначно соответствуют потокам 0 и 1 (если потоков более двух, то может быть представлено более двух битов). Когда бит является «1»b, он становится эффективной временной универсальный отменой, позволяющей блокировать выборку команд независимо от состояния других битов управления, и
(Б) Поле 406 запрета на остановку выборки команд: два бита этого поля взаимно-однозначно соответствуют потокам 0 и 1 (если потоков более двух, то может быть представлено более двух битов). Когда бит является «1»b, это указывает, что данный поток входит в секцию кода (например, критическую секцию), в которой другому поток не позволено включение бита остановки выборки команд для данного потока.
Другим используемым регистром является регистр адреса команды, который является уникальным для каждого потока. Этот регистр, называемый IAREGFA, включает в себя информацию по прерыванию программы, обнаруженную аппаратными средствами. Пример IAREGFA изображен на фиг. 4Б. Как показано, IAREGFA 450 включает в себя несколько полей 452. Одно поле, используемое согласно одному или нескольким аспектам, представлено полем 454, указывающим на то, что поток находится в процессе принятия исключения.
Каждый из вышеупомянутых регистров может включать в себя большее или меньшее число полей и/или иметь отличные поля. Кроме того, могут быть использованы и другие регистры. Описанные в настоящем документе регистры и поля являются примерами регистров и/или полей, которые могут использоваться. Кроме того, MCR и IAREGFA являются всего лишь примерами наименований регистров. Являются возможными самые разнообразные вариации.
Для увеличения пропускной способности по командам каждый поток использует конвейер команд для обработки, обеспечивающей одновременное выполнение множественных операций. Конвейер команд включает в себя несколько этапов, и один пример такого конвейера описан со ссылками на фиг. 5. Согласно фиг. 5, конвейер 500, который поддерживает производимую не по порядку обработку, включает в себя, например, этап 502 вызова команды, на котором команды выбираются из памяти, этап 504 декодирования/диспетчеризации команды, на котором образуются группы диспетчеризации/завершения, и команды размещаются в очередь задач, этап 506 вызова, на котором команды вызываются (не по порядку), этап 508 выполнения, на котором команды выполняются (не по порядку), этап 510 окончания, на котором команды заканчиваются (не по порядку), этап 512 завершения, который обращается к архитектурной контрольной точке, и этап 514 контрольной точки восстановления. Другие конвейеры могут включать в себя большее или меньшее число этапов и/или иметь отличные этапы. Описанные в настоящем документе этапы являются только примерами.
В одном из вариантов в группе может быть размещено до трех команд (прежде всего, микроопераций). Однако определенные команды, такие как команды ветвления заканчивают группу также и в том случае, когда она не является полной. Полная группа команд направляется в ту же очередь задач, а затем, следующая группа входит в другую очередь задач.
Согласно аспекту настоящего изобретения предоставляется инструмент, позволяющий одному работающему на ядре потоку останавливать один или несколько других выполняющихся на ядре потоков с целью выполнения одной или нескольких операций. В описанных в настоящем документе примерах ядро представлено структурой SMT 2, что указывает на существование двух потоков. Однако в других вариантах осуществления может быть представлено более двух потоков.
Один вариант осуществления используемой для управления выполнением одного или нескольких потоков логики описан со ссылками на фиг. 6. В этом примере выполняющийся на ядре поток 0 (Т0) пытается остановить выполняющийся на ядре поток 1 (Т1), и поэтому, описание относится к Т0 и Т1, однако, в других вариантах осуществления Т1 может пытаться остановить Т0, и/или может быть представлено более одного потока, выполняющихся на останавливаемом ядре. Например, Т0 может останавливать T1, Т2, Т3 и т.д. Кроме того, в описанных в настоящем документе примерах логика выполняется встроенным программным обеспечением ядра, однако, в одних или несколько других вариантах осуществления, она может выполняться программным обеспечением общего назначения. Являются возможными самые разнообразные вариации.
Как описано со ссылками на фиг. 6, в одном варианте осуществления один поток останавливает выполнение другого потока, и при остановке используются один или несколько управляющих элементов (например, индикаторов, битов и т.д.) в одном или нескольких регистрах (например, аппаратных регистрах), которые совместно используются потоками.
Согласно фиг. 6, в одном варианте осуществления, поток 0 проверяет, запрещено ли Т1 (или в других вариантах осуществления, одному или нескольким потокам ядра) быть остановленным, ЭТАП 600. В одном из вариантов это выявляется путем проверки выбранного бита (например, бита 25) в MCR002, а также выбранного бита (например, бита 4) в IAREGFA. Это достигается, в одном примере, путем тестирования посредством Т0 точки ветвления, обозначаемого как STPIFALW. STPIFALW тестирует выбранные биты MCR002 и IAREGFA. Например, если MCR0002.25 (то есть, биту 25 из MCR002) задано нулевое значение, и IAREGIFA.4 (то есть, биту 4 из IAREGIFA) задано нулевое значение, то позволяется остановка выборки команд потока Т1.
Если STPIFALW указывает на запрет остановки Т1, ИНФОРМАЦИОННЫЙ ЗАПРОС 602, то обработка продолжается к ЭТАПУ 600. Однако если Т1 не запрещает своей остановки, как указывается посредством STPIFALW, и прежде всего MCR002.25=0 и IAREGFA.4=0, то обработка продолжается посредством остановки Т0 выборки команд и выполнения Т1, ЭТАП 604. В одном из вариантов это включает в себя задание Т0 бита временной остановки выборки команд для Т1 (например, MCR002.9), который останавливает выборку команд и выполнение на Т1. Этот бит задается с помощью, например, команды сравнения и замены регистра (CSGRU) модуля состояния процессора или команды загрузки и логического ИЛИ регистра модуля состояния процессора, каждая из которых описывается ниже.
После этого, Т0 выполняет операцию опорожнения для всех потоков (DRAIN ALLTIDS), ЭТАП 606, которая задерживает диспетчеризацию команды для Т0 до тех пор, пока все команды на Т1 не окажутся опорожненными или очищенными из конвейера, и запрашивает Т1 о состоянии. В одном примере, команда опорожнения используется для выполнения операции опорожнения, пример которой описан ниже.
В то время как конвейер опорожняется от команд на других потоках, ИНФОРМАЦИОННЫЙ ЗАПРОС 608, обработка продолжается к ЭТАПУ 606. Однако в ответ на опорожнение команд Т1, Т0 продолжает диспетчеризацию команд и выполнение для Т0, ЭТАП 610.
После этого, Т0 вновь проверяет, запрещает ли Т1 (и другие потоки, если таковые имеются) свою остановку, для удостоверения в том, что Т1 не изменяет свое состояние после его тестирования, но прежде его остановки, ЭТАП 612. Эта проверка выполняется, как описано выше, с помощью STPIFALW. Если Т1 теперь запрещает свою остановку, ИНФОРМАЦИОННЫЙ ЗАПРОС 614, то Т0 позволяет Т1 продолжение выполнения путем отключения бита 9 из MCR002 (то есть, задания ему нулевого значения), ЭТАП 616. Обработка переходит к ЭТАПУ 600.
В противном случае, если Т1 не запрещает своей остановки, ИНФОРМАЦИОННЫЙ ЗАПРОС 614, то Т0 выполняет последовательность команд (например, одну или несколько операций), которая послужила причиной остановки Т1, ЭТАП 618. После того, как эта последовательность команд завершается, Т1 позволяется продолжение, ЭТАП 620. Таким образом, Т0 сбрасывает бит 9 в MCR002 при помощи, например, команды загрузки и логического И регистра модуля (LNRU) состояния процессора или CSGRU, как описано ниже. После этого оба потока выполняются в обычном порядке, ЭТАП 622.
Как описано выше, для управления выполнением одного или нескольких потоков многопоточного процессора используются несколько команд. Каждая из этих команд описана ниже.
Обращаясь к фиг. 7А-7Б, описан один вариант осуществления команды опорожнения. Прежде всего, фиг. 7А изображает один вариант осуществления формата команды опорожнения, а фиг. 7Б изображает один вариант осуществления связанной с командой опорожнения логики.
Со ссылкой на фиг. 7А, команда опорожнения 700 включает в себя поле 702 кода операции, включающее в себя код операции, идентифицирующий операцию опорожнения, поле 704 маски (М3), включающее в себя значение, указывающее на отсчет приостановки, означающий число циклов, на протяжении которых приостановлена обработка, и поле 706 (12) команды, указывающее на тип опорожнения, который, в этом примере, является опорожнением всех TIDS (идентификаторов потока), что означает, что все потоки подлежат опорожнению.
При функционировании и со ссылками на фиг. 7Б, поток Т0 останавливает обработку команд для Т0 на этапе конвейера по декодированию или диспетчеризации команд до тех пор, пока не окажутся соблюденными заданные условия, ЭТАП 750. Заданные биты поля 12 команды (например, биты 0:31 12, которые являются, например, битами 16:47 поля текста команды, включающего в себя все поля команды) задают, какие одно или несколько аппаратных условий должны быть соблюдены прежде возобновления обработки команды. В одном варианте осуществления заданные условия включают в себя межпоточное управление (например, бит 0 поля 12, бит 16 поля текста команды), которое проверяет состояние Т1 (или других потоков) для выявления того, была ли остановлена обработка на Т1. Когда бит 0 поля 12 является «1»b, он задает, что все другие условия опорожнения должны быть соблюдены на обоих потоках с целью продолжения производства обработки на данном потоке (другой поток (потоки) не являются заблокированными посредством ОПОРОЖНЕНИЯ на данном потоке). При использовании этой функции следует проявлять осмотрительность для предотвращения зависаний.
В одних или несколько вариантах осуществления в поле 12 могут быть заданы другие условия. Единица в заданной позиции бита указывает на необходимость соблюдения условия прежде возобновления обработки команды, если более одного бита являются включенными, все выбранные условия должны быть соблюдены. При реализации, в одном варианте осуществления, когда бит 16 текста команды (то есть, бит 0 поля 12) равняется 1, логические ИЛИ обоих (или всех) функций состояния аппаратных потоков выполняются на побитовой основе прежде осуществления операции логического ИЛИ совместно для всех функций, выбранных для выявления окончательного значения того, являются ли удовлетворенными условия ОПОРОЖНЕНИЯ.
Производится выявление относительно того, соблюдаются ли заданные условия, ИНФОРМАЦИОННЫЙ ЗАПРОС 752. При несоблюдении остановка продолжается, ЭТАП 750. В противном случае, если условия соблюдаются, обработка приостанавливается на дополнительное число циклов, ЭТАП 754. Это дополнительное число может быть представлено нолем или большим числом, и задается в поле М3 команды опорожнения. Например, поле М3 задает дополнительное число циклов в диапазоне между 0 и 15, в качестве примеров, для остановки после того, как будут удовлетворены условия, заданные в поле 12. Вслед за приостановкой на дополнительное число циклов возобновляется выполнение производящей обработку команды, ЭТАП 756.
В одном варианте осуществления, если предшествующая команда и команда опорожнения диспетчеризируются одновременно, предшествующей команде позволяется завершение диспетчеризации и нормальное прохождение через конвейер, но команда опорожнения и все последующие команды блокируются при диспетчеризации до тех пор, пока условия не окажутся удовлетворенными. Следует обратить внимание на то, что команда опорожнения в плане задержки обработки воздействует только на данный поток. Для остановки другого потока используется описанная в настоящем документе техника. Однако заданный бит (например, бит 0 в 12), когда равняется 1, указывает на то, что все заданные условия на всех потоках должны быть соблюдены с целью продолжения производства обработки после команды опорожнения на данном потоке.
Как указано, поле М3 команды задает число дополнительных циклов для приостановки на конвейере. Это может использоваться в связи с любыми из позволенных условий в поле 12. Это может также быть задано с помощью всех нулевых значений в поле 12, что дает безотлагательную задержку по счету числа циклов при отправке. Имеется приостановка в один цикл при диспетчеризации команды опорожнения также и в том случае, когда поле М3 является нолем. Поэтому данный счет задает число циклов для задержки плюс один цикл. Наряду с другими командами, аппаратные средства могут выдать команду опорожнения, и она может быть выдана не по порядку, поскольку она затрагивает только предварительные этапы конвейера.
Эта команда предназначается для использования в тех случаях, когда необходимые для обеспечения корректного функционирования взаимные блокировки не встроены в аппаратные средства. В большинстве случаев аппаратные средства автоматически покрывают окна предшествующих команд в конвейере.
Условный код этой командой не изменяется.
Другой используемой командой является команда сравнения и замены регистра модуля состояния процессора, описываемая со ссылками на фиг. 8А-8Б. Прежде всего, фиг. 8А изображают один вариант осуществления формата команды сравнения и замены регистра модуля состояния процессора, а фиг. 8Б, изображает один вариант осуществления логики, связанной с командой сравнения и замены регистра модуля состояния процессора. Следует отметить, что модуль состояния процессора в обсуждаемых в настоящем документе командах относится к конкретному модулю в выполняющем команду ядре. Однако использование конкретного модуля не является необходимым. Это может быть выполнено другими модулями или попросту ядром.
Со ссылкой на фиг. 8А, команда CSGRU 800 включает в себя по меньшей мере одно поле 802а, 802b кода операции, включающее в себя код операции, задающий операцию по сравнению и замене регистра, первое поле (R1) 804 регистра, второе поле (R3) 806 регистра, и поле (I2) 808 команды, каждое из которых описано ниже.
При функционировании и со ссылками на фиг. 8Б, содержимое регистра модуля состояния процессора (называемого в настоящем документе MCR), задаваемое 10-битовым числом абсолютного регистра, обозначенным в выбранных битах (например, битах 22:31 текста команды (например, биты 6:15 поля (808) I2)), сравнивается с содержимым общего регистра (GR), заданным в R1, ЭТАП 850. Если они являются равными, ИНФОРМАЦИОННЫЙ ЗАПРОС 852, то содержимое MCR записывается в общий регистр, заданный в R1, ЭТАП 854, а содержимое общего регистра, заданного в R3, записывается в MCR, ЭТАП 856. Кроме того, условному коду задается нулевое значение, ЭТАП 858, и обработка CSGRU завершается.
Возвращаясь к ИНФОРМАЦИОННОМУ ЗАПРОСУ 852, если содержимое MCR и регистра, заданного в R1, не являются равными, то содержимое MCR записывается в регистр, заданный в R1, ЭТАП 860, а условному коду задается значение единица, ЭТАП 858. Это завершает обработку CSGRU.
Функция считывания-сравнения-замены CSGRU является элементарной операцией при наблюдении со стороны данного потока Т0 и других потоков данного процессора (например, Т1). В одном варианте осуществления для предотвращения межпоточных зависаний CSGRU выполняется с включенной опцией SLOW. Опция SLOW обозначается путем задания выбранному биту (например, биту 17) I2 (808) значения единица, и используется для запроса медленного режима, что означает одновременное пребывание во всем конвейере только одной команды. Кроме того, с помощью этой команды выполняется взаимная блокировка, как описано ниже, и поэтому, выбранному биту (например, биту 16) I2 (808), упоминаемому в настоящем документе как ILOCK, задается значение единица.
В одном варианте осуществления эта команда отклоняется и перевыпускается, если другая выбранная команда, такая как RSR (считывание специального регистра), WSR (запись специального регистра), NSR (логическое И специального регистра), OSR (логическое ИЛИ специального регистра), XSR (исключающее ИЛИ специального регистра), TRBIT (бит регистра тестирования), RASR (считывание абсолютного специального регистра), WASR (запись абсолютного специального регистра), TARBIT (бит абсолютного регистра тестирования), NASR (логическое И абсолютного специального регистра), OASR (логическое ИЛИ абсолютного специального регистра), XASR (исключающее ИЛИ абсолютного специального регистра), LORU (загрузка и логическое ИЛИ регистра модуля состояния процессора), LNRU (загрузка и логическое И регистра модуля состояния процессора) или CSGRU (сравнение и замена регистра модуля состояния процессора) находится в конвейере для этого потока (Т0) или какого-либо другого потока, а бит ILOCK (например, I2 бит 16) включен для другой команды. Эта команда выпускается, например, только после того, как все предшествующие команды из этого потока были выпущены, а также вынуждает все будущие команды этого потока к зависимости от нее.
Параметры настройки условного кода включают в себя, например: СС0 - равный результат сравнения, регистр модуля состояния процессора заменяется посредством GR R1, СС1 - неравный результат сравнения, регистр модуля состояния процессора является неизменным.
Другой используемой командой является команда загрузки и логического ИЛИ регистра модуля состояния процессора (LORU), описанная со ссылками на фиг. 9А-9Б. Прежде всего, фиг. 8А изображает один вариант осуществления формата команды загрузки и логического ИЛИ регистра модуля состояния процессора, а фиг. 9Б изображает один вариант осуществления логики, связанной с командой загрузки и логического ИЛИ модуля состояния процессора.
Со ссылкой на фиг. 9А, команда LORU 900 включает в себя по меньшей мере одно поле 902а, 902b кода операции, включающее в себя код операции, определяющий операцию загрузки и логического ИЛИ по регистру, первое поле (R1) 904 регистра, второе поле (R3) 906 регистра, и поле (I2) 908 команды, каждое из которых описано ниже.
При функционировании и со ссылками на фиг. 9Б, содержимое регистра модуля состояния процессора (упоминаемого в настоящем документе как MCR), задаваемое 10-битовым числом абсолютного регистра, обозначенным в выбранных битах (например, битах 22:31 текста команды (например, биты 6:15 поля (908) I2)), сравнивается с содержимым общего регистра (GR), заданным в R1, ЭТАП 950. Кроме того, задаваемое в R3 содержимое общего регистра, подвергается действию логического ИЛИ с содержимым MCR, ЭТАП 952, и результат записывается в MCR, ЭТАП 954.
Функция считывания-логического ИЛИ-замены в LORU является элементарной операцией, при наблюдении со стороны данного потока Т0, а также других потоков (например, Т1) данного процессора. В одном варианте осуществления для предотвращения межпоточных зависаний LORU выполняется с включенной опцией SLOW. Опция SLOW обозначается путем задания выбранному биту (например, биту 17) I2 (908) значения единица. Кроме того, с помощью этой команды выполняется взаимная блокировка, как описано ниже, и поэтому, выбранному биту (например, биту 16) I2 (908), упоминаемому в настоящем документе как ILOCK, задается значение единица.
В одном варианте осуществления эта команда отклоняется и перевыпускается, если другая выбранная команда, такая как RSR (считывание специального регистра), WSR (запись специального регистра), NSR (логическое И специального регистра), OSR (логическое ИЛИ специального регистра), XSR (исключающее ИЛИ специального регистра), TRBIT (бит регистра тестирования), RASR (считывание абсолютного специального регистра), WASR (запись абсолютного специального регистра), TARBIT (бит абсолютного регистра тестирования), NASR (логическое И абсолютного специального регистра), OASR (логическое ИЛИ абсолютного специального регистра), XASR (исключающее ИЛИ абсолютного специального регистра), LORU (загрузка и логическое ИЛИ регистра модуля состояния процессора), LNRU (загрузка и логическое И регистра модуля состояния процессора) или CSGRU (сравнение и замена регистра модуля состояния процессора) находится в конвейере для этого потока (Т0) или какого-либо другого потока, а бит ILOCK (например, I2 бит 16) включен для другой команды. Эта команда выпускается, например, только после того, как все предшествующие команды от этого потока были выпущены, а также вынуждает все будущие команды этого потока к зависимости от нее.
Условный код остается неизменным.
Другой используемой командой является команда загрузки и логического И регистра модуля состояния процессора (LNRU), описанная со ссылками на фиг. 10А-10Б. Прежде всего, фиг. 10А изображает один вариант осуществления формата команды загрузки и логического И регистра модуля состояния процессора, а фиг. 10Б изображает один вариант осуществления логики, связанной с командой загрузки и логического И регистра модуля состояния процессора.
Со ссылкой на фиг. 10А, команда LNRU 1000 включает в себя по меньшей мере одно поле 1002а, 1002b кода операции, включающее в себя код операции, задающий операцию загрузки и логического ИЛИ по регистру, первое поле (R1) 1004 регистра, второе поле (R3) 1006 регистра, и поле (I2) 1008 команды, каждое из которых описано ниже.
При функционировании и со ссылками на фиг. 10Б, содержимое регистра модуля состояния процессора (упоминаемого в настоящем документе как MCR), задаваемое 10-битовым числом абсолютного регистра, обозначенным в выбранных битах (например, битах 22:31 текста команды (например, биты 6:15 поля (1008) I2)), загружается в общий регистр, заданный в R1, ЭТАП 1050. Кроме того, задаваемое в R3 содержимое общего регистра, подвергается действию логического И с содержимым MCR, ЭТАП 1052, и результат записывается в MCR, ЭТАП 1054.
Функция считывания-логического И-замены в LNRU является элементарной операцией, при наблюдении со стороны данного потока Т0, а также других потоков (например, Т1) данного процессора. В одном варианте осуществления для предотвращения межпоточных зависаний LNRU выполняется с включенной опцией SLOW. Опция SLOW обозначается путем задания выбранному биту (например, биту 17) I2 (1008) значения единица. Кроме того, с помощью этой команды выполняется взаимная блокировка, как описано ниже, и поэтому, выбранному биту (например, биту 16) I2 (1008), упоминаемому в настоящем документе как ILOCK, задается значение единица.
В одном варианте осуществления эта команда отклоняется и перевыпускается, если другая выбранная команда, такая как RSR (считывание специального регистра), WSR (запись специального регистра), NSR (логическое И специального регистра), OSR (логическое ИЛИ специального регистра), XSR (исключающее ИЛИ специального регистра), TRBIT (бит регистра тестирования), RASR (считывание абсолютного специального регистра), WASR (запись абсолютного специального регистра), TARBIT (бит абсолютного регистра тестирования), NASR (логическое И абсолютного специального регистра), OASR (логическое ИЛИ абсолютного специального регистра), XASR (исключающее ИЛИ абсолютного специального регистра), LORU (загрузка и логическое ИЛИ регистра модуля состояния процессора), LNRU (загрузка и логическое И регистра модуля состояния процессора) или CSGRU (сравнение и замена регистра модуля состояния процессора) находится в конвейере для этого потока (Т0) или какого-либо другого потока, а бит ILOCK (например, I2 бит 16) включен для другой команды. Эта команда выпускается, например, только после того, как все предшествующие команды от этого потока были выпущены, а также вынуждает все будущие команды этого потока к зависимости от нее.
Условный код остается неизменным.
Вместо памяти в качестве средств совместно используемой коммуникации LNRU, а также LORU и CSGRU, используют регистры, которые доступны для всех потоков в ядре SMT. Эти регистры являются, например, аппаратными регистрами, которые являются отдельными от памяти или системы хранения данных процессора. Например, в одной структуре ядра, имеется примерно 64 регистра, которые являются совместно используемыми (общими) для всех потоков на ядре, потоки могут свободно считывать и записать эти совместно используемые регистры. В некоторых случаях, для регистров управления, когда оба потока пытаются записать в них без специальных взаимных блокировок, обновление одного из потоков может быть потеряно. В других случаях, только одному из потоков разрешают «владеть» ресурсом, который управляется посредством битов в регистре. Поэтому, эти элементарные команды, воздействующие на совместно используемые регистры, используются для управления и распоряжения доступом к этим совместно используемым регистрам.
Каждый из регистров LNRU, LORU и CSGRU позволяет производить элементарные операции между общими регистрами и MCR в параллельных потоках при помощи взаимной блокировки для управления межпоточными операциями и выполнением. Как указано, каждая из команд имеет бит ILOCK, и когда этот бит включен для выполняющейся в конвейере команды, если вторая команда входит в конвейер со своим также заданным битом ILOCK, то вторая команда отклоняется (и повторно выполняется позже, по завершении первой команды). Этим гарантирована элементарность получения доступов к этим регистрам между потоками.
Имеются, например, два типа взаимно блокирующих команд: команда с единственной микрооперацией  ор, такая как LNRU и LORU, и команда с двумя ор, такая как CSGRU. Для команды с единственной ор взаимная блокировка задается при выпуске ор (команда типа RSR и WSR), и очищается при завершении ор для типа RSR и на контрольной точке для типа WSR. В командах с двумя ор взаимная блокировка задается на выпуске первой ор (RSR) и очищается в контрольной точке второй ор (типа WSR).
ор, такая как LNRU и LORU, и команда с двумя ор, такая как CSGRU. Для команды с единственной ор взаимная блокировка задается при выпуске ор (команда типа RSR и WSR), и очищается при завершении ор для типа RSR и на контрольной точке для типа WSR. В командах с двумя ор взаимная блокировка задается на выпуске первой ор (RSR) и очищается в контрольной точке второй ор (типа WSR).
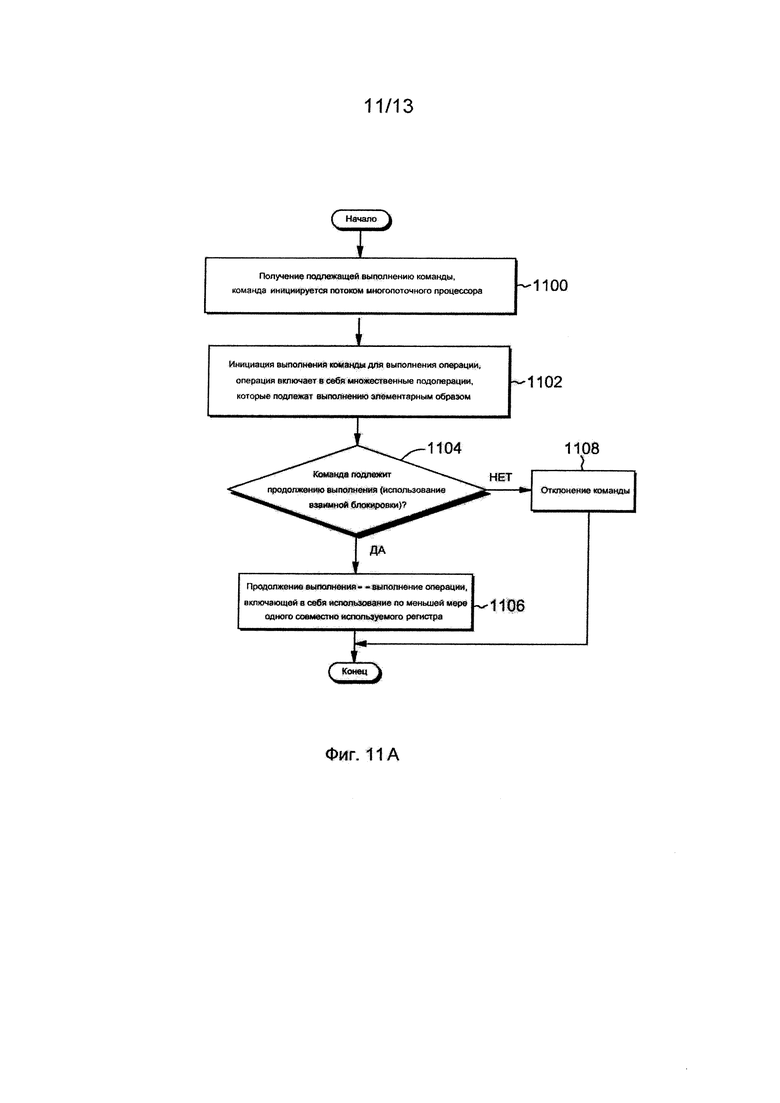
Более подробная информация относительно взаимных блокировок и использования взаимных блокировок описана со ссылками на фиг. 11А-11Б. Данная логика выполняется посредством ядра, и прежде всего посредством конвейера, на котором выпускается команда.
При обращении первоначально к фиг. 11А, подлежащую выполнению команду (например, LNRU, LORU, CSGRU) получает многопоточный процессор, ЭТАП 1100. Выполнение команды инициируется многопоточным процессором для выполнения операции, ЭТАП 1102. Операция включает в себя множественные подоперации, которые подлежат выполнению элементарным образом (atomically - англ.). Производится выявление того, подлежит ли команда продолжению выполнения, ИНФОРМАЦИОННЫЙ ЗАПРОС 1104. При выявлении используется, например, взаимная блокировка для выявления того, имеет ли команда элементарный доступ к одному или нескольким регистрам, совместно используемым некоторым потоком, а также одним или несколькими другими потоками.
Если команда подлежит продолжению выполнения, то продолжается выполнение, которое включает в себя выполнение операции с помощью по меньшей мере одного совместно используемого регистра, ЭТАП 1106. В противном случае, если команда не подлежит продолжению выполнения, она отклоняется, ЭТАП 1108.
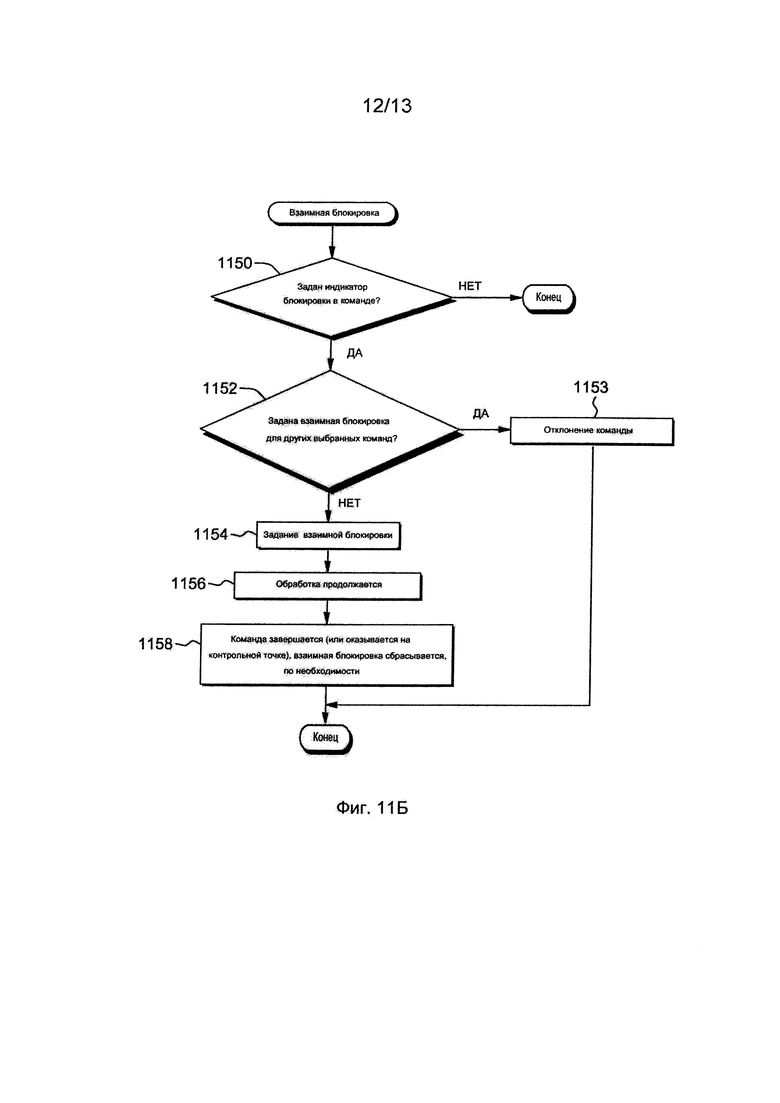
Более подробная информация относительно взаимных блокировок приведена со ссылками на фиг. 11Б. Первоначально, когда команда вводит модуль состояния процессора, в одном примере, осуществляется проверка относительно того, задано ли индикатору блокировки, такому как бит ILOCK (например, бит 32 текста команды, известному также под названием бита 16 из 12) поступающей команды значение (например, значение 1), ИНФОРМАЦИОННЫЙ ЗАПРОС 1150. Если бит ILOCK не задан, взаимная блокировка обработки завершается, однако если бит ILOCK в поступающей команды задан, производится дальнейшее выявление того, задана ли блокировка, называемая взаимной блокировкой, ИНФОРМАЦИОННЫЙ ЗАПРОС 1152. Взаимная блокировка размещается в аппаратном регистре, доступном для множественных потоков.
Если взаимная блокировка задана (например, биту задается значение единица), что указывает на производство обработки другой команды с заданным битом ILOCK, то поступающая команда отклоняется, ЭТАП 1153.
Однако если блокировка не задана, то она задается, ЭТАП 1154, и обработка команды продолжается (например, в конвейере) ЭТАП 1156. Когда команда завершается (или оказывается на контрольной точке), взаимная блокировка сбрасывается (например, ей задается нулевое значение), ЭТАП 1158.
Более подробная информация относительно взаимной блокировки включает в себя:
(А) Взаимная блокировка может быть задана посредством конвейера 0 когда, например:
- в конвейере 0 имеется команда, которая требует задания взаимной блокировки, и она выпускается в одиночку,
- в конвейере 0 имеется команда, которая требует задания взаимной блокировки и в конвейере 1 имеется другая команда, для которой задание блокировки является нежелательным - обе команды из того же потока,
- в конвейере 0 имеется команда, которая требует задания взаимной блокировки и в конвейере 1 имеется другая команда, которая требует задания блокировки, но команда в конвейере 0 является более старой - обе команды из того же потока,
- в конвейере 0 имеется команда, которая требует задания взаимной блокировки и в конвейере 1 имеется другая команда, для которой задание блокировки является нежелательным - две команды из различных потоков,
- в конвейере 0 имеется команда, которая требует задания взаимной блокировки и в конвейере 1 имеется другая команда, которая требует задания блокировки - две команды из различных потоков - и LFSR (регистр сдвига с линейной обратной связью) указывает на конвейер 0. LFSR используется для получения псевдослучайного числа, затем старший значащий бит числа используется для псевдослучайного выбора между двумя конвейерами (то есть, случайного выбора того, какой конвейер задает взаимную блокировку).
В одном из вариантов взаимная блокировка является вектором, имеющим по биту для каждой возможной команды в группе диспетчеризации. Например, в одном примере, в группе диспетчеризации может быть представлено до трех команд, и поэтому, взаимная блокировка включает в себя три бита, по одному для каждой команды. Когда бит задан, например, к 1, это указывает на то, что связанная с этим битом команда имеет взаимную блокировку.
Блокировка может также быть задана посредством конвейера 1, как описано выше, однако конвейер 0 заменяется на конвейер 1, а конвейер 1 на конвейер 0.
(Б) Задание взаимной блокировки выполняется в тех случаях, когда, например:
- имеется допустимая команда в канале И
- ILOCK задан И
- задан predec_rd (то есть, ранний указатель команды считывания типа (RSR)) ИЛИ predec_wr (то есть, ранний указатель команды записи типа (WSR)) И
- команда в конвейере не очищается/исключается по условию И
- взаимная блокировка может быть задана этим конвейером (согласно (А)) И
- взаимная блокировка еще не задана.
(В) Взаимная блокировка обновляется в тех случаях, когда, например:
- имеется допустимая команда в канале И
- ILOCK задан И
- задан predec_rd ИЛИ predec_wr И
- команда в конвейере не очищается/исключается по условию И
- взаимная блокировка уже задана И
GTAG (идентификатор группы диспетчеризации, включающей в себя команду) = interlock. GTAG (то есть, идентификатор, связанный с командой = идентификатору, который задает взаимную блокировку), И
- команда th_id (идентификатор потока) = interlock.th_id.
В одном варианте осуществления сброс взаимной блокировки выполняется по завершении группы, если отсутствует какая-либо микрооперация (ор) записывающего типа в группе, захватившей блокировку. Если в группе имеется ор записывающего типа, но она не захватывает блокировку, то блокировка также разблокируется по данному завершению (незахват блокировки = бит ILOCK равняется 0 - поэтому бит ILOCK для CSGRU также задается в части WSR таким образом, что он не разблокируется по завершении RSR). Если команда записывающего типа также захватывает блокировку, то блокировка разблокируется только на контрольной точке. Таким образом обеспечивается элементарность. Имеется исключение для CSGRU: когда WSR находится во второй группе, следовательно, RSR первой группы задает блокировку, a WSR во второй группе разблокирует блокировку. В этом случае, первая группа должна поступать перед второй группой (которая имеет GTAG, который превышает на 1 значение GTAG первой группы).
Отклонение ор в группе может не сбрасывать блокировку, если эта ор не удерживает ее. Отклонение разблокирует блокировки только тогда, в одном примере, когда отсутствуют какие-либо другие микро-операции в группе, которые также удерживают блокировку.
Отмена ор в группе может не сбрасывать блокировку, если эта ор не удерживает ее. Отмена разблокирует блокировки только тогда, в одном примере, когда отсутствуют какие-либо другие микро-операции в группе, которые также удерживают блокировку.
При поступлении исключающего условия осуществляется проверка относительно того, может ли быть разблокирована взаимная блокировка. Проблема состоит в том, что исключающее условие должно разблокировать блокировку только в том случае, если захватившая ее команда еще не была завершена. Если захватившая блокировку команда уже завершена, исключающее условие не должно иметь никакого влияния на блокировку (это является верным для захватившей блокировку команды записывающего типа, поскольку такая команда разблокирует ее на контрольной точке. Для команды считывающего типа разблокирование уже было выполнено по завершении). Единственным исключением является CSGRU, для которого его часть считывающего типа может уже быть завершена, но при наличии исключающего условия прежде завершения части записывающего типа, блокировка должна быть разблокирована (если часть записывающего типа завершается, поступающее после этого события исключающее условие не должно иметь какого-либо эффекта на взаимную блокировку).
Сброс в случае потребности в очищении задающей блокировку команды: если, например, блокировка более не удерживается какими-либо командами данной группы, выполняется только фактический сброс. Например, если очистка наталкивается на первую ор в группе, и эта ор удерживает блокировку, то блокировка освобождается (само собой разумеется, две другие микро-операции могут удерживать ее также, но они очищаются). Если очистка поступает ко второй ор в группе, и эта ор удерживает блокировку, то блокировка освобождается только в том случае, например, если также и первая ор не удерживает ее (третья ор очищается в любом случае, поэтому отсутствует какая-либо необходимость в ее проверке).
(Г) Взаимная блокировка сбрасывается в тех случаях, когда, например:
- Взаимная блокировка уже задана И
- Отсутствуют обновления из (В) И
(
Захватившая блокировку команда завершается:
- Блокирующая команда считывания завершается И
- это не является завершением первой группы CSGRU ИЛИ
(
Захватившая блокировку команда находится на контрольной точке:
- блокирующая команда записи находится на контрольной точке И
Interlock.GTAG = Instruction.GTAG
ИЛИ
- если имеет место завершение второй группы CSGRU, то следует ожидание достижения контрольной точки И
- Interlock.GTAG+1 = Instruction.GTAG
)
ИЛИ
Блокирующая ор отклоняется, а какие-либо другие держатели блокировки в данной группе отсутствуют
ИЛИ
Блокирующая ор отменяется, а какие-либо другие держатели блокировки в данной группе отсутствуют
ИЛИ
Блокирующая ор очищается/исключается по условию, а какие-либо другие держатели блокировки в данной группе отсутствуют
ИЛИ
идет процесс восстановления
)
(Е) Отклонение в случаях, когда, например:
1) взаимная блокировка заблокирована И
the instruction.th_id ! = (не равно) interlock.th_id И
the instruction.GTAG ! = interlock.GTAG
Для кода операции CSGRU, это устраняет отклонение ор WSR, когда взаимная блокировка была заблокирована посредством ор RSR (они имеют одинаковый GTAG и одинаковый идентификатор потока).
Это в равной мере является верным для таких групп, как (RSR, х, WSR), когда выпуск осуществляется по порядку, но RSR по некоторым причинам отклоняется, и следовательно, WSR блокирует блокировку. В таком случае, если отклонение осуществляется на основе идентификатора отдельной команды, RSR не может войти, поскольку блокировки заблокирована, и полная группа не может завершиться  мертвая блокировка, поскольку WSR не может разблокировать блокировку. Решение должно использовать GTAG таким образом, что RSR может войти, и по совершении вхождения, WSR также может завершиться и разблокировать блокировку.
мертвая блокировка, поскольку WSR не может разблокировать блокировку. Решение должно использовать GTAG таким образом, что RSR может войти, и по совершении вхождения, WSR также может завершиться и разблокировать блокировку.
2) одинаковый поток на обоих конвейерах И
ILOCK включен на обоих конвейерах И
действующий конвейер удерживает младшую команду
действующая младшая команда должна быть отклонена (в случае, когда бит взаимной блокировки еще не включен посредством более старой команды).
В случае, когда взаимная блокировка включена, более старая команда также должна быть отклонена посредством условия (1) (если это не является WSR команды CSGRU).
3) различные потоки на обоих каналах И
ILOCK включен на обоих конвейерах И
номер действующего конвейера не равняется значению LFSR (который является 0 для конвейера 0 и 1 для конвейера 1) команда current pipe_x должна быть отклонена (в случае, когда бит взаимной блокировки еще не включен посредством более старой команды).
В случае, когда взаимная блокировка включена, обе команды должны быть отклонены посредством условия (1) (если только одна из них не является WSR команды CSGRU).
В настоящем документе описывается один вариант осуществления техники для одного потока для остановки выполнения одного или нескольких других потоков многопоточного процессора. Техника реализуется для предотвращения зависаний и для обеспечения завершения всех связанных с другими потоками команд прежде, чем они окажутся остановленными. Эта техника включает в себя в одном аспекте команду опорожнения конвейера, которая обнаруживает информацию о состоянии всех аппаратных потоков процессора (или выбранных потоков в другом варианте осуществления) для выявления того, удовлетворяются ли условия, перед продолжением выполнения операций на этом потоке.
Кроме того, один вариант осуществления этой техники использует элементарные команды, такие как CSGRU, LORU и LNRU для действия на совместно используемых регистрах. Например, когда два или более потоков совместно используют общее ядро в многопоточной основной структуре (например, SMT), они зачастую должны сообщаться друг с другом и делиться информацией, это может включать в себя семафоры, блокировки и т.д. Это также может включать в себя встроенное программное обеспечение, милликод, или это может включать в себя программное обеспечение. Потоки могут использовать существующие команды ISA, которые сообщаются через память. Однако они могут оказаться медленными и сопряженными с конфликтами сохранения против загрузки или загрузки против сохранения (обычно известными как Operand Store Compare (сравнение операндов сохранения) (OSC)). Кроме того, если коммуникация осуществляется посредством встроенного программного обеспечения, сообщение через память может быть нежелательным или невозможным, микропрограммная подпрограмма может оказаться посреди критической последовательности, где операнды загрузки и сохранения являются запрещенными. Таким образом, эти команды воздействуют на регистры вместо памяти.
Хотя элементарные команды описаны относительно управления выполнением потоков, они могут использоваться и для других целей. Каждая команда является обособленной от описанного в настоящем документе использования, и может быть применена в других ситуациях.
Согласно фиг. 12, в одном примере, компьютерный программный продукт 1200 включает в себя, например, один или несколько энергонезависимых машиночитаемых информационных носителей 1202 для хранения на них машиночитаемых средств программного кода, логики и/или команд 1204 для предоставления и оказания содействия в использовании одного или нескольких вариантов осуществления.
Настоящее изобретение может быть представлено системой, способом и/или компьютерным программным продуктом. Компьютерный программный продукт может включать в себя машиночитаемый информационный носитель (или носители), имеющий на нем машиночитаемые программные команды для принуждения процессора к выполнению аспектов настоящего изобретения.
Машиночитаемый информационный носитель может быть представлен материальным устройством, которое способно удерживать и сохранять команды для использования посредством устройства выполнения команд. Машиночитаемый информационный носитель может быть представлен, например, в том числе, но не ограничиваясь, устройством электронной памяти, магнитным запоминающим устройством, оптическим запоминающим устройством, электромагнитным запоминающим устройством, полупроводниковым запоминающим устройством или любой подходящей комбинацией из вышеупомянутого. Неисчерпывающий список более конкретных примеров машиночитаемых информационных носителей включает в себя следующее: портативная компьютерная дискета, жесткий диск, оперативная память (RAM), постоянная память (ROM), стираемая программируемая постоянная память (EPROM или флэш-память), статическая оперативная память (SRAM), переносной компакт-диск для однократной записи данных (CD-ROM), цифровой универсальный диск (DVD), карта памяти, гибкий диск, механически закодированное устройство, такое как перфокарты или выступающие структуры в канавке с записанными на них командами, а также любая подходящая комбинация из вышеупомянутого. Машиночитаемый информационный носитель, как он рассматривается в настоящем документе, не подлежит истолкованию в качестве представленного преходящими сигналами как таковыми, такими как радиоволны или другие свободно распространяющиеся электромагнитные волны, электромагнитные волны, распространяющиеся через волновод или другие среды передачи (например, проходящие через волоконно-оптический кабель световые импульсы), или передаваемые через провода электрические сигналы.
Описанные в настоящем документе машиночитаемые программные команды могут быть загружены в соответствующие устройства вычисления/обработки с машиночитаемого информационного носителя или во внешний компьютер или во внешнее устройство хранения через сеть, например, Интернет, локальную сеть, глобальную сеть и/или беспроводную сеть. Сеть может содержать медные кабели передачи, волокна оптической передачи, беспроводную передачу, маршрутизаторы, брандмауэры, переключения, шлюзы и/или граничные серверы. Карта сетевого адаптера или сетевой интерфейс в каждом устройстве вычисления/обработки получает машиночитаемые программные команды из сети и направляет машиночитаемые программные команды для хранения в машиночитаемый информационный носитель в соответствующем устройстве вычисления/обработки.
Машиночитаемые программные команды для выполнения операций настоящего изобретения могут быть представлены командами ассемблера, командами архитектуры системы команд (ISA), машинными командами, машинно-зависимыми командами, микрокодом, командами встроенного программного обеспечения, присваивающими значение состоянию данными, или иным исходным кодом или объектным кодом, записанным на любой комбинации из одного или нескольких языков программирования, включая сюда объектно-ориентированные языки программирования, такие как Smalltalk, С++ и т.п., а также обычные языки процедурного программирования, такие как язык программирования «С» или подобные языки программирования. Машиночитаемые программные команды могут выполняться полностью на компьютере пользователя, частично на компьютере пользователя, как автономный пакет программного обеспечения, частично на компьютере пользователя и частично на удаленном компьютере или полностью на удаленном компьютере или сервере. В последнем сценарии удаленный компьютер может быть присоединен к компьютеру пользователя через любой тип сети, включая сюда локальную сеть (LAN) или глобальную сеть (WAN), или присоединение может быть сделано к внешнему компьютеру (например, через Интернет с использованием Интернет-провайдера). В некоторых вариантах осуществления электронные схемы, включающие в себя, например, программируемые логические схемы, программируемые на месте вентильные матрицы (FPGA) или программируемые логические матрицы (PLA) могут выполнять машиночитаемые программные команды посредством использования информации о состоянии машиночитаемых программных команд для настройки электронной схемы с целью выполнения аспектов настоящего изобретения.
Аспекты настоящего изобретения описаны в настоящем документе с отсылками на иллюстрации в виде блок-схем и/или блок-диаграмм для способов, устройств (систем) и компьютерных программных продуктов согласно вариантам осуществления изобретения. Подразумевается, что каждый блок иллюстраций в виде блок-схем и/или блок-диаграмм, а также комбинации блоков на иллюстрациях в виде блок-схем и/или блок-диаграмм, может быть реализован посредством машиночитаемых программных команд.
Такие машиночитаемые программные команды могут быть предоставлены процессору универсального компьютера, специализированного компьютера или другого программируемого устройства обработки данных для образования машины таким образом, что выполняющиеся посредством процессора компьютера или другого программируемого устройства обработки данных команды создают средства для реализации функций/действий, заданных в блоке или блоках блок-схемы и/или блок-диаграммы. Такие машиночитаемые программные команды также могут быть сохранены в машиночитаемом информационном носителе, который может управлять компьютером, программируемым устройством обработки данных и/или другими устройствами для их функционирования особым способом таким образом, что сохраняющий на нем команды машиночитаемый информационный носитель представляет собой изделие, содержащее команды, которые реализуют аспекты функций/действий, заданных в блоке или блоках блок-схемы и/или блок-диаграммы.
Машиночитаемые программные команды могут также быть загружены в компьютер, другое программируемое устройство обработки данных или другое устройство для принуждения к выполнению на компьютере, другом программируемом устройстве или другом устройстве серии эксплуатационных этапов для получения такого компьютерно-реализованного процесса, что выполняемые на компьютере, другом программируемом устройстве или другом устройстве инструкции реализуют функции/действия, заданные в блоке или блоках блок-схемы и/или блок-диаграммы.
Блок-схемы и блок-диаграммы на чертежах показывают архитектуру, функциональность и функционирование возможных реализаций систем, способов и компьютерных программных продуктов согласно различным вариантам осуществления настоящего изобретения. В этом отношении каждый блок в блок-схемах или блок-диаграммах может представлять модуль, сегмент или участок команд, который содержит одну или несколько исполнимых команд для реализации указанной логической функции (функций). В некоторых альтернативных реализациях указанные в блоках функции могут осуществляться в порядке, отличном от приведенного на чертежах. Например, два блока, показанные по очереди, могут, фактически, быть выполнены по существу одновременно, или блоки могут иногда выполняться в обратном порядке, в зависимости от включенной функциональности. Необходимо также отметить, что каждый блок на иллюстрациях в виде блок-схем и/или блок-диаграмм, а также в комбинациях блоков на иллюстрациях в виде блок-схем и/или блок-диаграмм, может быть реализован посредством основанных на аппаратных средствах систем особого назначения, которые выполняют указанные функции или действия или выполняют комбинации аппаратных и компьютерных команд особого назначения.
Хотя различные варианты осуществления описаны выше, они являются только примерами. Например, вычислительные окружения другой архитектуры могут быть использованы для охвата и использования одного или нескольких вариантов осуществления. Кроме того, один или несколько аспектов изобретения являются применимыми к видам многопоточности, отличным от SMT. Кроме того, могут быть использованы различные команды, форматы команд, поля команд и/или значения команд. Являются возможными самые разнообразные вариации.
Кроме того, другие типы вычислительных окружений могут извлечь выгоду и использоваться. В качестве примера, является применимой подходящая для сохранения и/или выполнения программного кода система обработки данных, которая включает в себя по меньшей мере два процессора, соединенных прямо или косвенно через системную шину с элементами памяти. Элементы памяти включают в себя, например, локальную память, используемую в процессе фактического выполнения программного кода, запоминающее устройство большого объема и кэш-память, которая предоставляет временное сохранение по меньшей мере части программного кода с целью уменьшения числа выборок из запоминающего устройства большого объема в процессе выполнения.
Устройства ввода-вывода или устройства I/O (в том числе, но не ограничиваясь, клавиатуры, дисплеи, позиционирующие устройства, DASD (запоминающее устройство прямого доступа), устройство записи на ленту, CD, DVD, карты флэш-памяти и другие носители памяти и т.д.) могут быть соединены с системой или непосредственно или через переходные контроллеры I/O. С системой также могут быть соединены сетевые адаптеры для предоставления системе обработки данных возможности установления соединения с другими системами обработки данных или с удаленными принтерами или с запоминающими устройствами посредством переходных частных сетей или сетей общего пользования. Модемы, кабельные модемы и платы Ethernet являются всего несколькими примерами из числа доступных типов сетевых адаптеров.
Используемая в настоящем документе терминология служит исключительно целям описания конкретных вариантов осуществления и не предназначается для ограничения изобретения. При использовании в настоящем документе, формы единственного числа предназначены для включения в себя также и форм множественного числа, если только контекст не указывает на иное недвусмысленным образом. В последующем изложении подразумевается, что термины «содержит» и/или «содержащий» при их использовании в данном техническом описании задают присутствие заявленных признаков, целочисленных переменных, этапов, операций, элементов и/или компонентов, но не исключают присутствия или добавления одного или нескольких других признаков, целочисленных переменных, этапов, операций, элементов, компонентов и/или образованных ими групп.
Соответствующие структуры, материалы, действия и эквиваленты всех средств или этапов, равно как функциональные элементы в пунктах формулы изобретения ниже, если вообще есть в наличии, предназначаются для включения в себя любой структуры, материала или действия для выполнения функции в сочетании с другими требуемыми элементами, как конкретным образом заявлено. Описание одного или нескольких вариантов осуществления представлено в целях иллюстрации и описания, но не предназначается для полного охвата или ограничения изобретения в заявленном виде. Многие модификации и изменения являются очевидными для средних специалистов в области техники. Вариант осуществления был выбран и описан с целью наилучшего объяснения различных аспектов и практического применения, а также для обеспечения другим средним специалистам в области техники возможности понимания различных вариантов осуществления с различными модификациями, как они подходят для конкретно рассматриваемого использования.
| название | год | авторы | номер документа |
|---|---|---|---|
| ВОССТАНОВЛЕНИЕ КОНТЕКСТА ПОТОКА В МНОГОПОТОЧНОЙ КОМПЬЮТЕРНОЙ СИСТЕМЕ | 2015 |
|
RU2670909C9 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ БЛОКИРОВКИ СИГНАЛА СИНХРОНИЗАЦИИ В МНОГОПОТОЧНОМ ПРОЦЕССОРЕ | 2000 |
|
RU2233470C2 |
| ДИСПЕТЧЕРИЗАЦИЯ МНОЖЕСТВЕННЫХ ПОТОКОВ В КОМПЬЮТЕРЕ | 2015 |
|
RU2666249C2 |
| РАСШИРЕНИЕ СОГЛАСУЮЩЕГО ПРОТОКОЛА ДЛЯ ИНДИКАЦИИ СОСТОЯНИЯ ТРАНЗАКЦИИ | 2015 |
|
RU2665306C2 |
| РАСШИРЕНИЕ И СОКРАЩЕНИЕ АДРЕСА В МНОГОПОТОЧНОЙ КОМПЬЮТЕРНОЙ СИСТЕМЕ | 2015 |
|
RU2661788C2 |
| КЛАССИФИКАЦИЯ ОБНАРУЖЕНИЯ СОБЫТИЙ С ПОМОЩЬЮ ИДЕНТИФИКАТОРА ПОТОКА И УРОВНЯ ПРИВИЛЕГИЙ ПОТОКА | 2001 |
|
RU2268483C2 |
| БЛОКИРОВАНИЕ ИСХОДНЫХ РЕГИСТРОВ В УСТРОЙСТВЕ ОБРАБОТКИ ДАННЫХ | 2002 |
|
RU2282235C2 |
| КОМАНДА ЗАПУСКА ВИРТУАЛЬНОГО ВЫПОЛНЕНИЯ ДЛЯ ДИСПЕТЧЕРИЗАЦИИ МНОЖЕСТВЕННЫХ ПОТОКОВ В КОМПЬЮТЕРЕ | 2015 |
|
RU2667791C2 |
| ОБЛАСТЬ УПРАВЛЕНИЯ ДЛЯ АДМИНИСТРИРОВАНИЯ МНОЖЕСТВЕННЫМИ ПОТОКАМИ В КОМПЬЮТЕРЕ | 2015 |
|
RU2662695C2 |
| СПОСОБ ФУНКЦИОНИРОВАНИЯ ОПЕРАЦИОННОЙ СИСТЕМЫ ВЫЧИСЛИТЕЛЬНОГО УСТРОЙСТВА ПРОГРАММНО-АППАРАТНОГО КОМПЛЕКСА | 2016 |
|
RU2626350C1 |
Изобретение относится к средствам управления выполнением потоков в многопоточном процессоре. Техническим результатом является возможность совместного использования контейнера потоками с разным приоритетом. Способ выполняется посредством потока, работающего на процессоре, включает операции: остановка выполнения других потоков на ядре процессора, в ответ на выполнение критической последовательности или другой последовательности, нуждающейся в ресурсах ядра процессора или в управлении ресурсами ядра процессора, причем остановка включает: выявление того, запрещает ли другой поток свою остановку, остановку выборки команд и выполнения на другом потоке, определение того, что выполнение другого потока в процессоре прекратилось, если выполнение другого потока на процессоре прекратилось, то получение для другого потока информации о состоянии, выполнение потоком операций в процессоре и разрешение выполнения другого потока в процессоре. Система реализует способ. 3 н. и 4 з.п. ф-лы, 12 ил.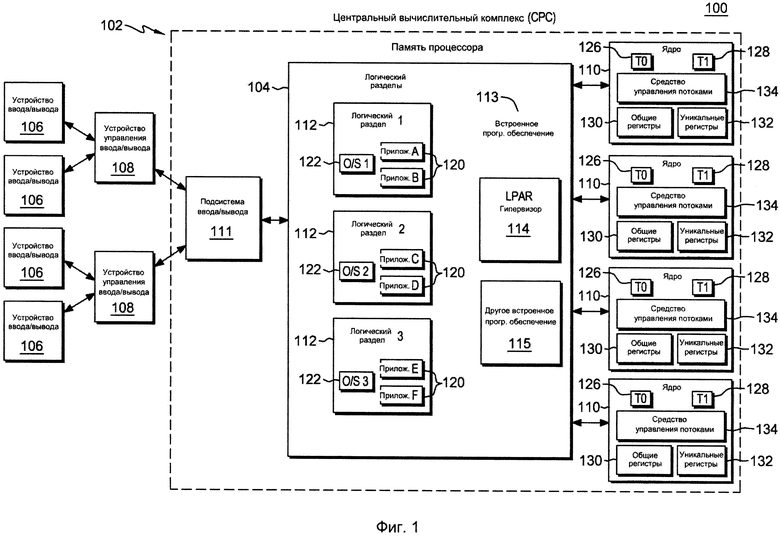
1. Способ управления выполнением потоков в вычислительном окружении, включающий:
выполняемую посредством потока, работающего в процессоре вычислительного окружения, остановку выполнения другого потока, выполняющегося в процессоре, причем при остановке используется один или несколько управляющих элементов в одном или нескольких совместно используемых регистрах процессора, причем один или несколько совместно используемых регистров совместно используются потоком и другим потоком, причем указанная остановка включает:
выявление того, запрещает ли другой поток свою остановку, путем проверки управляющего элемента из числа одного или нескольких управляющих элементов в одном или нескольких совместно используемых регистрах процессора и управляющего элемента в одном или нескольких регистрах процессора, уникальных для другого потока,
остановку выборки команд и выполнения на другом потоке при указании управляющими элементами того, что другой поток не запрещает свою остановку,
определение того, что выполнение другого потока в процессоре прекратилось,
получение для другого потока информации о состоянии, указывающей, выполнялись ли команды, относящиеся к другому потоку, в процессоре до своего завершения, путем использования команды опорожнения для удержания диспетчеризации команды на потоке, для запрашивания состояния другого потока и для очистки из конвейера только команд другого потока,
выполнение потоком одной или нескольких операций в процессоре после того, как этот поток остановил выполнение в процессоре другого потока, и
выполняемое при завершении одной или нескольких операций разрешение выполнения другого потока в процессоре.
2. Способ по п. 1, причем остановка выполнения другого потока также включает выявление на основании информации о состоянии того, было ли потоком остановлено выполнение другого потока, причем одну или несколько операций выполняют при выявлении того, что другой поток прекратил выполняться в процессоре.
3. Способ по п. 1, причем выявление того, запрещает ли другой поток свою остановку, включает:
проверку первого выбранного индикатора в первом регистре, совместно используемом потоком и другим потоком, и проверку второго выбранного индикатора во втором регистре, уникальном для другого потока,
остановку выборки команд и выполнения на другом потоке при указании первым индикатором и вторым индикатором на отсутствие запрещения другим потоком своей остановки.
4. Способ по п. 1, причем команда опорожнения задает одно или несколько условий, подлежащих удовлетворению до выполнения одной или нескольких операций и относящихся к состоянию другого потока, причем выполнение одной или нескольких операций осуществляют на основании результата команды опорожнения, указывающего на удовлетворение одного или нескольких условий.
5. Способ по п. 3, включающий также:
повторное выявление на основании проверки, указывающей на остановку выполнения другого потока, того, запрещает ли другой поток свою остановку,
разрешение выполнения на другом потоке на основании повторного выявления, указывающего на запрещение другим потоком своей остановки, и
выполнение одной или нескольких операций на основании повторного выявления, указывающего на отсутствие запрещения другим потоком своей остановки.
6. Система для управления выполнением потоков в вычислительном окружении, содержащая средства, приспособленные к выполнению всех этапов способа по любому из предшествующих пунктов.
7. Машиночитаемый информационный носитель, содержащий хранящиеся в нем команды, которые при их выполнении в компьютерной системе обеспечивают выполнение всех этапов способа по любому из пп. 1-5.
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Кипятильник для воды | 1921 |
|
SU5A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |

