ОБЛАСТЬ ТЕХНИКИ
Изобретение относится к области информационных технологий и вычислительной техники, а именно к способу разграничения доступа к данным в базе данных.
УРОВЕНЬ ТЕХНИКИ
В последнее время в связи с ростом объемов данных, хранимых и используемых при работе пользователями на вычислительных устройствах и в различных системах, требуются технические решения, позволяющие предоставлять пользователям доступ только к тем данным баз данных, которые требуются пользователям для осуществления своей деятельности, в частности, для работы. Предоставление пользователям с использованием вычислительных устройств доступа только к необходимым им данным, в частности, без предоставления доступа к данным других пользователей или с предоставлением ограниченного доступа к данным других пользователей, например, на просмотр (чтение) и модификацию (например, изменение, удаление и т.д.) данных, позволяет ускорить работу пользователей с объемами предоставляемых им данных, а также повышает безопасность получения данных пользователям, которые не имеют разрешения на просмотр и/или модификацию таких данных. Также требуются технические решения, позволяющие ограничить определенным пользователям доступ к данным, хранящимся в базах данных, в частности, в общих для множества пользователей базах данных, например, пользователей различных предприятий. Также требуются технические решения, позволяющие пользователям использовать данные, хранящиеся в базах данных, общие, в частном случае, одинаковые для всех пользователей или, по крайней мере, одной группы пользователей. Традиционные способы работы с данными, в том числе способы разграничения данных в базах данных со временем становятся менее эффективными или малоэффективными, что приводит к снижению эффективности работы пользователей и предприятий.
Из уровня техники известны система и способ для обеспечения закупок между компаниями и группами компаний (см. US 7155403B2, опубл. 26.12.2006), причем предлагается способ для обеспечения закупок между множеством компаний со множеством комплексных правил учета с обеспечением безопасного просмотра информации компаниями, причем компании организованы в группы компаний и закупочных объединений для получения скидок и доступа к общим договорам поставщиков.
Недостатками такого технического решения является отсутствие использования слоев данных и использования политики безопасности на уровне строк для обеспечения разграничения доступа пользователям к данным, хранящимся в базе данных. Также недостатком такого решения является отсутствие использования иерархии слоев данных (в частности, родительских и дочерних слоев данных) для обеспечения разграничения доступа к данным, хранящимся в базе данных.
Из уровня техники также известны система и способ сбора и хранения информации казино в системе реляционных баз данных (см. US 20090172035A1, опубл. 02.07.2009), причем способ включает создание реляционной базы данных для хранения и организации информации, а также создание логической модели данных, определяющей, каким образом информация хранится и организована в базе данных, причем логическая модель данных включает предметную область, включающую множество сущностей и отношений, определяющие то, как информация хранится в указанной базе данных.
Недостатками такого технического решения является отсутствие использования слоев данных и использования политики безопасности на уровне строк для обеспечения разграничения доступа пользователям к данным, хранящимся в базе данных. Также недостатком такого решения является отсутствие использования иерархии слоев данных (в частности, родительских и дочерних слоев данных) для обеспечения разграничения доступа к данным, хранящимся в базе данных.
Из уровня техники также известны интегрированные коммуникационные системы и способы для представления продукции и прямых продаж (см. US 20080052193A1, опубл. 28.02.2008), причем способ описывает предоставление интерфейса компании для ERP-системы, связанной с множеством компаний, причем интерфейс предоставляет канал доступа к товарам каждой из компаний, причем компании могут выборочно загружать содержимое из своей ERP-системы и предоставление интерфейса пользователя для отображения содержимого о продукте, и предоставление возможности пользователю приобретать товары, причем транзакции направляются непосредственно в ERP-систему компании-продавца через интерфейс компании.
Недостатками такого технического решения является отсутствие использования слоев данных и использования политики безопасности на уровне строк для обеспечения разграничения доступа пользователям к данным, хранящимся в базе данных. Также недостатком такого решения является отсутствие использования иерархии слоев данных (в частности, родительских и дочерних слоев данных) для обеспечения разграничения доступа к данным, хранящимся в базе данных.
Предлагаемый способ позволяет преодолеть, по крайней мере, часть вышеуказанных недостатков или все указанные недостатки, а также реализовать преимущества настоящего изобретения, как описано в рамках настоящего технического изобретения.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Техническим результатом является повышение надежности разграничения доступа пользователей к данным путем использования слоев данных и политики безопасности на уровне строк.
Согласно одному из вариантов реализации, предлагается способ для разграничения доступа к данным в базе данных, в котором осуществляется создание справочника слоев данных, сохраненного, по крайней мере, в одной таблице, в базе данных сервера базы данных, причем справочник слоев данных содержит, по крайней мере, названия всех слоев данных и содержит идентификаторы слоев данных для наборов данных, хранимых в объектах метаданных бизнес логики сервера приложений сервера компьютерной системы, причем объектами метаданных являются справочники, документы, табличные части документов, итоги и связывающие таблицы справочников, сохраненные в таблицах базы данных сервера базы данных, связанного с сервером компьютерной системы, где идентификатор слоя данных определяет принадлежность набора данных к соответствующему слою данных; осуществляется создание связывающей таблицы пользователей слоев данных в базе данных сервера базы данных, причем в связывающей таблице пользователей слоев данных хранятся связи между пользователями и слоями данных в виде сохраненных связанных идентификаторов пользователей и соответствующих им идентификаторов слоев данных из доступных идентификаторов слоев данных справочника слоев данных, причем связи между пользователями и слоями данных определяют доступность наборов данных для чтения и модификации пользователям связанных с ними слоями данных; осуществляется создание связывающей таблицы дочерних слоев данных в базе данных сервера базы данных, причем в связывающей таблице дочерних слоев данных хранится иерархия между слоями данных в виде сохраненных связанных идентификаторов для дочерних слоев данных и идентификаторов для родительских слоев данных, причем связь между родительскими слоями и дочерними слоями определяет доступность наборов данных дочерних слоев данных для чтения пользователями родительских слоев данных; осуществляется создание политики безопасности на уровне строк (RLS-политики) для каждой из таблиц базы данных сервера базы данных, в которых хранятся справочники, документы, табличные части документов, итоги и связывающие таблицы справочников, и осуществляется сохранение RLS-политик в базе данных сервера базы данных, причем RLS-политика содержит, по крайней мере, одно выражение, возвращающее логический результат, определяющий доступность пользователю наборов данных из таблиц базы данных сервера базы данных в зависимости от идентификаторов слоев данных для таких наборов данных; сервером приложений при добавлении набора данных в справочник осуществляется установление идентификатора слоя данных для добавляемого набора данных и осуществляется сохранение добавляемого набора данных в базу данных сервера базы данных с сохранением для такого набора данных установленного идентификатора слоя; сервером приложений при добавлении набора данных в связывающую таблицу осуществляется установление идентификатора слоя данных для добавляемого набора данных и осуществляется сохранение добавляемого набора данных в базу данных сервера базы данных с сохранением для такого набора данных установленного идентификатора слоя; сервером приложений при добавлении документа осуществляется установление идентификатора слоя данных, по крайней мере, для одного добавляемого набора данных, содержащегося в добавляемом документе, и осуществляется сохранение добавляемого документа и, по крайней мере, одного набора данных документа в базу данных сервера базы данных с сохранением для сохраняемого набора данных документа установленного идентификатора слоя; сервером приложений при добавлении набора данных в табличную часть документа осуществляется установление идентификатора слоя данных для добавляемого набора данных и сохранение добавляемого набора данных в базу данных сервера базы данных с сохранением для такого набора данных установленного идентификатора слоя; сервером компьютерной системы посредством применения RLS-политики, выполняемой сервером базы данных, к запросам, осуществляемым к наборам данных из базы данных сервера базы данных, осуществляется предоставление пользователю доступа к наборам данных и наборов данных для чтения и модификации, идентификаторы слоев данных которых связаны с идентификатором пользователя в связывающей таблице пользователей слоев данных при осуществлении запросов данных из базы данных сервера базы данных пользователем с использованием клиентского приложения, установленного на вычислительном устройстве пользователя, связанном с сервером приложений сервера компьютерной системы; сервером компьютерной системы осуществляется предоставление доступа пользователю родительского слоя к наборам данных и наборов данных дочернего слоя данных для чтения, без возможности их модификации, посредством применения RLS-политики, выполняемой сервером базы данных, к запросам, осуществляемым к наборам данных из базы данных сервера базы данных, с использованием идентификаторов слоев данных для дочерних слоев данных и идентификаторов слоев данных для родительских слоев данных из связывающей таблицы дочерних слоев данных для установления связи между родительским слоем данных и, по крайней мере, одним дочерним слоем данных при осуществлении запроса данных из базы данных сервера базы данных пользователем с использованием клиентского приложения, установленного на вычислительном устройстве пользователя, связанном с сервером приложений сервера компьютерной системы.
В одном из частных вариантов реализации создается справочник исключений справочников, содержащий справочники, наборы данных которых не содержат идентификаторы слоев данных, и при добавлении, по крайней мере, одного набора данных, по крайней мере, одну развязочную таблицу справочника и/или, по крайней мере, в один другой справочник, отличный от справочника исключений справочников, осуществляется: проверка наличия справочника, в который осуществляется добавление набора данных, в справочнике исключений справочников; проверка наличия в добавляемом наборе данных идентификатора слоя данных для добавляемого набора данных при установлении отсутствия справочника в справочнике исключений справочников; получение идентификатора слоя данных из связывающей таблицы пользователей слоев данных и добавление полученного идентификатора слоя данных в добавляемый набор данных в справочнике при установлении отсутствия в добавляемом наборе данных идентификатора слоя данных для добавляемых данных; проверка добавления набора данных в базу данных пользователем или задачей, исполняемой программным кодом; присваивание идентификатора слоя данных, полученного из связывающей таблицы пользователей слоев данных, несохраненным наборам данных связывающих таблиц, связанных с добавляемым набором данных, при добавлении набора данных пользователем; присваивание идентификатора слоя данных, полученного из добавляемого набора данных, несохраненным наборам данных связывающих таблиц, связанных с добавляемым набором данных, при добавлении набора данных задачей, исполняемой программным кодом.
В другом частном варианте реализации создается справочник исключений типов документов, содержащий документы, наборы данных которых не содержат идентификаторы слоев данных, и при добавлении документа в базу данных сервера базы данных осуществляется: проверка наличия типа добавляемого документа в справочнике исключений типов документов; проверка наличия в добавляемом документе идентификатора слоя данных для данных добавляемого документа при установлении отсутствия типа добавляемого документа в справочнике исключений типов документов; получение идентификатора слоя данных из связывающей таблицы пользователей слоев данных и добавление полученного идентификатора в добавляемый документ при установлении отсутствия в добавляемом документе идентификатора слоя данных; проверка осуществления добавления документа в базу данных пользователем или задачей, исполняемой программным кодом; присваивание идентификатора слоя данных, полученного из добавляемого документа, несохраненным наборам данных табличных частей, связанных с добавляемым документом, при добавлении документа в базу данных пользователем; присваивание идентификатора слоя данных, добавленного в документ из полученного из связывающей таблицы пользователей слоев данных, несохраненным наборам данных табличных частей, связанных с добавляемым документом, при добавлении документа в базу данных задачей, исполняемой программным кодом.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Дополнительные цели, признаки и преимущества настоящего изобретения будут понятны из прочтения последующего описания осуществления изобретения со ссылкой на прилагаемые чертежи, на которых:
ФИГ. 1 иллюстрирует примерный вариант системы, реализующей способ, описываемый в рамках настоящего изобретения;
ФИГ. 2 иллюстрирует примерный вариант составных частей сервера приложений, составных частей клиентского приложения, а также взаимодействие между ними и базой данных;
ФИГ. 3 иллюстрирует примерный вариант ограничения доступа пользователей (и групп пользователей) к данным с использованием RLS-политики.
ФИГ. 4 иллюстрирует блок-схему примерного варианта процесса создания новой записи в справочнике и/или развязочной таблице справочника;
ФИГ. 5 иллюстрирует блок-схему примерного варианта процесса сохранения нового документа;
ФИГ. 6 иллюстрирует примерный вариант формирования виртуальных баз данных, согласно настоящему изобретению;
ФИГ. 7 иллюстрирует примерный вариант иерархии виртуальных баз данных, согласно настоящему изобретению;
ФИГ. 8 иллюстрирует способ осуществления настоящего изобретения;
ФИГ. 9 иллюстрирует пример компьютерной системы общего назначения.
ПОДРОБНОЕ ОПИСАНИЕ
Объекты и признаки настоящего изобретения, способы для достижения этих объектов и признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Сущность, приведенная в описании, является ничем иным, как конкретными деталями, обеспеченными для помощи специалисту в области техники в исчерпывающем понимании изобретения, и настоящее изобретение определяется только в объеме приложенной формулы.
Используемые в настоящем описании изобретении термины «компонент», «элемент», «система», «модуль», «часть», «блок», в частности, «составная часть», и подобные, используются для обозначения компьютерных сущностей (например, объектов, связанных с компьютером, вычислительных сущностей), которые могут являться аппаратным обеспечением, в частности, оборудованием (например, устройством, инструментом, аппаратом, аппаратурой, составной частью устройства, в частности, процессором, микропроцессором, печатной платой и т.д.), программным обеспечением (например, исполняемым программным кодом, скомпилированным приложением, программным модулем, частью программного обеспечения и/или кода и т.д.) или микропрограммой (прошивкой/firmware). Так, например, компонент может быть процессом, выполняющемся (исполняющимся) на процессоре, процессором, объектом, исполняемым файлом, программой, функцией, методом, библиотекой, подпрограммой и/или вычислительным устройством (например, микрокомпьютером или компьютером) или комбинацией программного или аппаратного обеспечения.
В частном случае, настоящее изобретение позволяет осуществлять ведение и формирование (управленческой) отчетности предприятия (в частном случае, состоящим (включающем), по крайней мере, из одной компании, являющейся юридическим лицом, например, фирмой, индивидуальным предпринимателем и т.д.), в частности пользователями предприятий (клиентов), использующих систему, описанную в рамках настоящего изобретения. Стоит отметить, что осуществление формирования отчетности может осуществляться в режиме реального времени (онлайн, от англ. online, on-line) или по запросу (по требованию, от англ. on-demand) с гарантированной достоверностью, в частности, достоверностью цифр, которые видят руководители и собственники компаний, например, цифры в отчетах по балансу, отчете о прибылях и убытках (ОПУ), отчете о движении денежных средств (ДДС) и т.д. В общем случае отчетность может содержать недостоверные данные (может быть недостоверной), когда пользователями осуществляется ввод данных не полной информации (данных), в частности, о совершенных операциях, или введенная или вводимая пользователями информация (данные) содержит ошибки. Стоит отметить, что в настоящем изобретении при формировании проводок гарантированно соблюдается правило двойной записи (в частности, отражение хозяйственной операции в дебете одного счета и в кредите другого в одной и той же сумме), т.е. в частном случае никакие данные не появляются из ниоткуда и не исчезают в никуда. В частном случае, ведение учета предприятия осуществляется в единой физической базе данных (в частности, в базе данных (ФИГ. 1, 145)). В частном случае, пользователи используют стандартный набор операций, которые отражаются в отчетности заданным способом, который пользователи не могут изменить. Управленческая отчетность в частном случае является системой показателей, характеризующих деятельность предприятия (являющейся субъектом бюджетного учета, в частности, бюджетного учета), отличную от бюджетной отчетности, составляемой на основе данных управленческого учета для целей предприятия (и/или в частном случае, по крайней мере, одной компании такого предприятия).
В настоящее время многие предприятия используют несколько систем для ведения управленческого учета, например, частично в электронных таблицах и системах (в частности программном обеспечении) для создания и редактирования электронных таблиц, табличных процессоров, (например, Microsoft Excel/Microsoft Office Excel, OpenOffice Calc/Apache OpenOffice.org Calc, WPS spreadsheets и т.д.) и частично в учетных системах. В этом случае для получения управленческой отчетности, например, баланса, пользователям необходимо вручную «сводить» (объединять, консолидировать) данные из различных источников (в частности, из электронных таблиц и учетных систем), что у пользователей занимает значительное время и зачастую приводит к ошибкам в полученных сводных данных. Причем такой подход не позволяет осуществлять управленческий учет в режиме реального времени.
Описываемое изобретение позволяет реализовать применение изменений, осуществляемых, по крайней мере, одним пользователем, по крайней мере, одного предприятия в учетную политику (в частности, пользователем осуществляется выполнение операции, которая вносит изменение только в виртуальную базу данных, к которой имеет доступ такой пользователь, как более подробно описано далее) и принципы формирования управленческой отчетности, для всех (или только определенных) предприятий. Упомянутые изменения (в частности, являющиеся результатом выполнения пользователем, по крайней мере, одной операции) могут включать любые формы управленческой отчетности, причем в частном случае пользователи не могут по своему усмотрению вносить в них изменения. Стоит отметить, что изменения, осуществляемые пользователем, например, изменения (редактирования) в документах, добавление новых документов и удаление существующих документов и т.д., определяются согласно задаваемым правилам, причем такие правила определяют, как именно операции пользователей попадают в отчетность и в частном случае едины для всех пользователей. Так, например, если управленческий отчет «Баланс» содержит раздел «Дебиторская задолженность покупателей», то на сервере приложений (описанном далее) может быть создано (например, администратором описываемой в настоящем изобретении системы или, по крайней мере, ее части, например, администратором сервера приложений) правило разделение упомянутой дебиторской задолженности покупателей на нормальную дебиторскую задолженность и просроченную дебиторскую задолженность, то такое правило будет выполнено у всех пользователей, т.е., по крайней мере, одной частью (в частности, модулем) описываемой системы будет осуществлено разделение упомянутой дебиторской задолженности покупателей на нормальную дебиторскую задолженность и просроченную дебиторскую задолженность у всех пользователей (описываемой системы). Касательно упомянутых принципов формирования управленческой отчетности стоит отметить, что ежедневная работа компании в частном случае состоит из набора (элементарных) операций, выполняемых пользователями. Каждая операция может приводить к изменению состояния активов и пассивов компании. Учетная политика определяет то, каким образом та или иная операция изменяет пассив или актив, и каким образом это изменение попадает в отчетность типа баланса, ОПУ, ДДС и т.д. Так, например, если компания осуществляет продажу товара покупателю с доставкой, то прибыль от этой операции фиксируется не в момент отгрузки товара со склада, а в момент, когда водитель транспортного средства, осуществлявшего доставку, документально подтверждает факт передачи товара покупателю.
В частном случае, описываемое изобретение позволяет пользователям осуществлять упомянутые выше операции по единым заданным правилам учета в одной базе данных. Стоит отметить, что для каждой операции осуществляется задание и исполнение, по крайней мере, одного алгоритма, определяющего то, в какой момент такая операция осуществляет проводки по регистрам (например, регистр сведений, регистр накопления, регистр бухгалтерии, регистр расчета и т.д.) описываемой системы. На основании данных регистров осуществляется создание отчетности и из соблюдения упомянутого выше правила двойной записи общая сумма по всем регистрам всегда равна нулю. Стоит также отметить, что основой учета также являются справочники (в частности, каталоги) статей взаиморасчетов с контрагентами, статей ДДС, статей затрат и т.д. Набор таких статей хранится (задан, например, упомянутым администратором) в виртуальной базе данных 0 (ФИГ. 7, 710) в виде, по крайней мере, одной таблицы, и доступен пользователям для использования (в частности, для просмотра, например, осуществления чтения клиентским приложением (ФИГ. 1, 130; ФИГ. 1, 136) и т.д.), но недоступен для изменения, как более подробно описано далее. В качестве примера для описания настоящего изобретения используется ERP-система (ERP, от англ. Enterprise Resource Planning, планирование ресурсов предприятия - организационная стратегия интеграции производства и операций, управления трудовыми ресурсами, финансового менеджмента и управления активами, ориентированная на непрерывную балансировку и оптимизацию ресурсов предприятия посредством программного обеспечения, обеспечивающего общую модель данных и процессов для всех сфер деятельности, в частности ERP-система является (программным) модулем, реализующим стратегию ERP и, в частном случае, является системой планирования ресурсов предприятия), но стоит понимать, что может быть использована любая компьютерная система, например, примерный вариант которой приведен на ФИГ. 9. В частном случае, ERP-система, описываемая в рамках настоящего изобретения, включает такую упомянутую базу данных и заданные (предустановленные) правила учета, взаимодействие с которой осуществляют взаимодействие (с которой работают) пользователи предприятий. Так, например, в такой ERP-системе существует каталог (справочник) товаров, хранящийся (сохраненный) в базе данных (БД) такой ERP-системы, в частности в базе данных (ФИГ. 1, 145) основного сервера базы данных (ФИГ. 1, 110), по крайней мере, в одной таблице (в которой осуществляется хранение данных о товарах из упомянутого справочника (каталога) товаров). Так, например, одно предприятие может осуществлять продажу компьютерной техники, второе предприятие может осуществлять продажу бытовой химии, причем оба предприятия (в частности, пользователи предприятий, например, бухгалтеры, операторы баз данных и т.д.) сохраняют данные о своих товарах в один и тот же каталог (справочник) товаров, в частности, в упомянутую таблицу базы данных. Таким образом, каталог (справочник) товаров будет содержать такие товары от первого предприятия (осуществляющего продажу/реализацию компьютерной техники), как ноутбуки, мониторы и т.д., являющиеся компьютерной техникой, и такие товары второго предприятия (осуществляющего продажу/реализацию бытовой химии), как мыло, стиральные порошки, чистящие средства и т.д., являющиеся бытовой химией. Стоит отметить, что в справочниках (каталогах) первое и второе (третье и т.д.) предприятия могут осуществлять хранение (сохранение) данных о поставщиках, компаниях (компаниях предприятий), расчетных счетах и т.д., т.е. в частном случае такие справочники (каталоги) являются общими для обеих компаний (пользователей (сотрудников) компаний), так что данные одного предприятия могут быть отображены (предъявлены) пользователями другого предприятия и/или изменены пользователями другого предприятия, что в частном случае может внести путанность и ошибки в данных между предприятиями, и могут помешать работе пользователей с такими данными (например, пользователи предприятий могут ошибочно изменить данные других предприятий или использовать данные других предприятий вместо своих и т.д.). Стоит отметить, что, в частном случае, пользователи (одного предприятия) не могут сохранять данные, общие для всех пользователей, например, пользователей первого предприятия и пользователей второго предприятия, например, информация (данные) о банках (например, банковские идентификационные коды (БИК), наименование банка, корреспондентский счет, адрес и т.д.), курсы валют и т.д. Такие общие данные в частном случае должны быть доступны, как для пользователей первого предприятия, так и для пользователей второго предприятия, т.е. могут быть доступны (в частности, могут быть просмотрены) всем пользователям или, по крайней мере, одной части пользователей – группе пользователей. Таким образом, необходимо реализовать доступ (в частности, отображение пользователям и/или сохранение пользователями данных, в частности в справочники (каталоги) и/или таблицы базы данных) определенной группе пользователей (первой группе пользователей) к данным, сохраненным первой группой пользователей (клиентским данным первой группы пользователей), а также к части данных (общих данных для двух групп пользователей), сохраненных другой группой пользователей (второй группой пользователей), а также реализовать доступ второй группе пользователей к данным, сохраненным второй группой пользователей (клиентским данным второй группы пользователей), и к части данных (общих данных для двух групп пользователей), сохраненных первой группой пользователей. Так, например, пользователям первого предприятия (первой группе пользователей) может быть предоставлен доступ к данным, которые были сохранены такими пользователями первого предприятия (первой группой пользователей), а пользователям второго предприятия (второй группе пользователей) может быть предоставлен доступ к данным, которые были сохранены такими пользователями второго предприятия (второй группой пользователей), причем в частном случае вторая группа пользователей имеет доступ к части данных, сохраненных первой группой пользователей, а первая группа пользователей имеет доступ к части данных, сохраненных второй группой пользователей. Стоит отметить, что пользователи каждого из предприятия могут составлять, по крайней мере, одну группу пользователей, например, группу пользователей, являющихся сотрудниками бухгалтерии первого предприятия, группу пользователей, являющихся сотрудниками отдела реализации первого предприятия, группу пользователей, являющихся сотрудниками бухгалтерии второго предприятия, группу пользователей, являющихся сотрудниками отдела реализации второго предприятия и т.д. Выше приведен пример для двух групп пользователей двух предприятий, хотя, стоит отметить, что настоящее изобретение не ограничивается двумя предприятиями и одной или двумя группами пользователей для предприятия, так, например, предприятий может существовать - два, три, четыре, десять, сто, тысяча и т.д., причем в каждом предприятии может существовать одна, две, три, четыре и т.д. групп пользователей. В частном случае, определенным пользователям или группам пользователей может быть предоставлен доступ (может осуществляться отображение, возможность редактирования, в частности, изменения и удаления) ко всем записям других пользователей или групп пользователей, как описано в рамках настоящего изобретения.
На ФИГ. 1 приведен примерный вариант системы, реализующей способ, описываемый в рамках настоящего изобретения.
Система, посредством которой осуществляется реализация способа, описанного в рамках настоящего изобретения, изображенная на ФИГ. 2, содержит сервер (в частности, удаленный сервер (компьютерной системы)), например, сервер ERP-системы 112, который включает, по крайней мере, сервер приложений 120. Также сервер ERP-системы 112 может включать сервер экспорта 125.
Также, система, изображенная на ФИГ. 2, содержит сервер приложений 120, основной сервер базы данных 110, резервный сервер базы данных 115, сервер экспорта 125, вычислительные устройства пользователя (132, 134) на предприятии 1, предприятии 2 и т.д. с установленными клиентскими приложениями (130, 136), серверы печати (135) и принтеры (140) на упомянутых предприятиях (предприятии 1, предприятии 2 … предприятии N).
Стоит отметить, что элементы (в частном случае, составные части примерного варианта системы, реализующей способ, описываемый в рамках настоящего изобретения), например, основной сервер базы данных 110, резервный сервер базы данных 115, сервер приложений 120, сервер экспорта 125, сервер печати 135, вычислительные устройства пользователей (132, 134) и т.д., изображенные на ФИГ. 1, могут быть связаны между собой посредством локальной вычислительной сети (ЛВС), Интернета, мобильной связи и/или посредством любого другого вида (способа) проводной связи (например, посредством USB-интерфейса, интерфейса стандарта RS-232/COM-порта и т.д.) и/или беспроводной связи (например, Bluetooth, Wi-Fi, мобильной сотовой связи (GSM), в частности, в диапазонах 850/900/1800/1900 MГц, спутниковой связи, транкинговой связи и каналов передачи данных со сверхнизким энергопотреблением, формирующие сложные беспроводные сети с ячеистой топологией (ZigBee) и т.д.).
Стоит отметить, что вычислительными устройствами, в частности, вычислительными устройствами пользователей, могут являться смартфоны, ноутбуки, планшеты, персональные компьютеры, электронные вычислительные машины (ЭВМ), серверы, рабочие станции, моноблоки, компьютерные стенды, настольные компьютеры, испытательные стенды, демонстрационные компьютерные стенды, мобильные (сотовые) устройства, в частности, телефоны, и т.д.
Основной сервер базы данных 110 осуществляет, по крайней мере, управление данными и содержащий, по крайней мере, бизнес-логику (пространство бизнес-логики, компоненты бизнес-логики, элементы бизнес-логики (составные) части бизнес-логики), описанную ниже. Основной сервер базы данных 110 в частном случае содержит СУБД (систему управления базами данных) и обеспечивает функции СУБД по ведению и обслуживанию базы данных 145. В частном случае, основной сервер базы данных 110 может являться (программным) сервером базы данных, в частности, поддерживающих описываемую RLS-технологию, например, «Oracle 11gR2 Enterprise Edition», «Oracle 12c Enterprise Edition», «PostgreSQL 9.6» и т.д., установленным на устройстве хранения данных, по крайней мере, одного вычислительного устройства, например, являющимся компьютером (или специальным компьютерным оборудованием), выделенным и/или специализированным для выполнения определенных сервисных функций. Стоит отметить, что упомянутое устройство хранения данных (хранилище данных) может являться составной частью, по крайней мере, одного основного сервера базы данных 110 и/или может быть связано с ним (проводными или беспроводными типами связи), и является устройством для хранения информации (данных) и может быть реализовано, по крайней мере, одним накопителем на жестких магнитных дисках (НЖМД/HDD, англ. hard (magnetic) disk drive), твердотельным накопителем (SSD, англ. solid-state drive), гибридным жестким диском (SSHD, англ. solid-state hybrid drive), сетью хранения данных (СХД/SAN, англ. Storage Area Network), сетевой системой хранения данных/сетевым хранилищем (NAS, англ. Network Attached Storage) и/или любым другим устройством, позволяющим осуществлять, по крайней мере, запись на устройство, чтение с устройства и/или хранение данных на устройстве. Данные на устройствах хранения данных (в хранилищах данных) могут храниться в любом известном формате, например, в базе данных (БД) 145, например, в виде, по крайней мере, одной таблицы или набора связанных или не связанных между собой таблиц базы данных. Стоит отметить, что, по крайней мере, одна упомянутая база данных 145 может являться иерархической, объектной, объектно-ориентированной, объектно-реляционной, реляционной, сетевой и/или функциональной базой данных, каждая из которых может быть централизованной, сосредоточенной, распределённой, неоднородной, однородной, фрагментированной/секционированной, тиражированной, пространственной, временной, пространственно-временной, циклической, сверх-большой базой данных и т.д., причем для управления, создания и использования баз данных могут использоваться различные системы управления базами данных (СУБД). Также данные на устройствах хранения данных (в хранилищах данных) могут храниться, по крайней мере, в одном файле, в частном случае, в виде текстового файла, либо данные могут храниться в любом, по крайней мере, одном другом известном в настоящее время формате хранения данных (информации) или в формате данных, изобретенном позднее.
Сервер экспорта (от англ. Export server) 125 осуществляет преобразование печатных форм в файлы.
Сервер печати 135 получает задания на печать документов, по крайней мере, от одного сервера приложений 120. Как правило, сервер печати 135 располагается в офисе, где используются клиентские приложения (130, 136), что позволяет существенно снизить нагрузку на каналы связи за счет передачи гораздо меньшего объема данных (в частности, между сервером приложений 120, располагающимся в дата-центре ((от англ. data center), или центр (хранения и) обработки данных (ЦОД/ЦХОД)), и офисом предприятия, в котором располагается вычислительное устройство пользователя (132, 134 и т.д.) с установленным на нем клиентским приложением (130, 136)).
Резервный сервер базы данных 115 используется для обеспечения отказоустойчивости основного сервера базы данных 110 и осуществляет хранения резервных копий данных, хранящихся в базе данных 145.
Стоит отметить, что основной сервер базы данных 110, резервный сервер базы данных 115, сервер приложений 120, сервер экспорта 125 и сервер печати 135 могут быть реализованы, по крайней мере, одним специализированным компьютером и/или специализированным оборудованием (для выполнения на нём сервисного программного обеспечения, в частности, без непосредственного участия человека) и/или, по крайней мере, одним программным компонентом (в частности, приложением) вычислительной системы (в частности, по крайней мере, одного, специализированного компьютера и/или специализированного оборудования), выполняющим сервисные (обслуживающие) функции по запросам, предоставляя доступ к определённым ресурсам или услугам. В частном случае основной сервер базы данных 110 или резервный сервер базы данных 115, или сервер приложений 120, или сервер экспорта 125, или сервер печати 135 может быть реализован программным обеспечением, в частности, программным компонентом (приложением), функционирующим на аппаратном обеспечении, в частности, (универсальном) вычислительном устройстве, например, сервере, компьютере и т.д. В частном случае, основной сервер базы данных 110 или резервный сервер базы данных 115, или сервер приложений 120, или сервер экспорта 125, или сервер печати 135 могут являться удаленными серверами, облачными серверами и т.д.
В частном случае, клиентские приложения (130, 136 и т.д.), установленные на вычислительных устройствах пользователей (ВУ), например, на ВУ 1 (132), ВУ 2 (134), ВУ N и т.д., осуществляют, по крайней мере, представление данных (в зависимости от описываемых операций, например, если операцией является операция по закупке товара, то пользователю осуществляется отображение (представление) списка поставщиков, товаров, остатков товаров на складах и т.д., в частности, по крайней мере, в одном справочнике) и функциональную обработку (которая в частном случае включает изменение данных в справочниках, например, количества товара в заказе поставщику и в заказе покупателя, т.е., в частном случае осуществляется получение клиентским приложением 130 данных от сервера приложений (который в свою очередь их запрашивает из основного сервера базы данных 110) 120, редактирование (где это разрешено логикой описываемой системы) или добавление новых данных пользователями).
Стоит отметить, что, в частном случае, система, реализующая способ, описываемый в настоящем изобретении, может быть реализована программно-аппаратным комплексом трехуровневой архитектуры (схемой трехзвенной архитектуры), в частности, одним уровнем такой схемы является основной сервер базы данных 110 и опционально резервный сервер базы данных 115, другим уровнем является сервер приложений 120 и еще одним уровнем является, по крайней мере, одно клиентское приложение, например, клиентское приложение (клиентский (программный) модуль) 130, клиентское приложение (клиентский (программный) модуль) 136 и остальные клиентские приложения (клиентские (программные) модули). В частном случае, система, реализующая способ, описываемый в настоящем изобретении, и изображенная на ФИГ. 1, в том числе реализованная трехуровневой архитектурой, позволяет осуществлять централизованное ведение бизнес-логик(и) и в случае ее (их) изменений позволяет не осуществлять ее (их) тиражирование в упомянутых клиентских приложениях. Стоит отметить, что в частном случае бизнес-логика является реализацией правил и ограничений автоматизируемых операций и является совокупностью правил, принципов, зависимостей поведения объектов предметной области, поддерживаемых описываемой системой. В частном случае, система, реализующая способ, описываемый в настоящем изобретении, и изображенная на ФИГ. 1, позволяет избежать необходимости устанавливать на вычислительных устройствах пользователей (клиентских компьютерах, компьютерах клиентов, вычислительных устройствах пользователей предприятий, в частности, компаний), например, на вычислительном устройстве (ВУ) пользователя 1 (132), на вычислительном устройстве (ВУ) пользователя 2 (134) и т.д., компоненты (программного) обеспечения управления доступом к данным. Также, в частном случае, система, реализующая способ, описываемый в настоящем изобретении, и изображенная на ФИГ. 1, в том числе реализованная трехуровневой архитектурой, позволяет осуществлять возможность отложенного (во времени) обновления базы данных 145 в случае изменения данных, запрошенных с основного сервера базы данных 110, в автономном режиме. В частном случае, упомянутое обновление данных будет осуществляться в базе данных 145 после следующего соединения клиентского приложения (клиентской программы, клиентского программного обеспечения) 130, клиентского приложения 136 и т.д. с сервером приложений 120.
На ФИГ. 2 показан примерный вариант составных частей сервера приложений 120, составных частей клиентского приложения 130, а также вариант взаимодействия между ними и базой данных. Сервер приложений 120 включает ядро 210 и пространство бизнес-логики (бизнес-логику). Пространство бизнес-логики (бизнес-логика) включает типы документов 212, обработчики (в частности, реализованные скриптами) 214, подтипы документов 216, печатные формы 218, итоги 220, отчеты 222, справочники (каталоги) 224, метаданные 226, модули сервера 228, модули клиентских приложений 230, а также может включать сценарии обработки бизнес-правил, бизнес-правила, экранные формы и т.д., причем обработчики 214, описывающие логику взаимодействия бизнес-объектов, являются бизнес-правилами и сценариями обработки.
В частном случае, модули сервера 228 являются программными библиотеками (сборником подпрограмм или объектов, используемых для разработки программного обеспечения), используемыми описываемыми скриптами, в частности, скриптами сервера приложений 120, и, в частном случае, загружаемые при загрузке (в частности, при запуске) сервера приложений 120.
В частном случае, модули клиентских приложений 230 являются набором программных библиотек, например, для создания и, в частности, функционирования клиентских приложений (например, 130, 136). Так, например, такие модули клиентских приложений 230 могут содержать набор форм для редактирования элементов конфигурации и т.д.
Клиентское приложение 130 включает ядро 210 (в частном случае, являющееся копией ядра сервера приложений 120), метаданные 226 (в частном случае, являющиеся копией метаданных сервера приложений 120), модули клиентских приложений 230 (в частном случае, являющиеся копией модулей клиентских приложений сервера приложений 120) и т.д.
В частном случае, ядро 210 (сервера приложений 120 или клиентского приложения 130) изменяется гораздо реже, чем составные части (элементы) пространства бизнес-логики. Ядро 210 обеспечивает функционирование составных частей пространства бизнес-логики (например, типов документов 212, обработчиков 214, подтипов документов 216, печатных форм 218, итогов 220, отчетов 222, справочников (каталогов) 224, метаданных 226, модулей сервера 228, модулей клиентских приложений 230), причем такие упомянутые составные части хранятся в таблицах (в виде таблиц) базы данных 145 основного сервера базы данных 110.
Ядро 210, в частном случае, является (программным) модулем, который является инвариантной частью описываемой системы и обеспечивает функционирование второй, изменяемой части - пространства бизнес-логики. Ядро 210 обеспечивает функционирование описываемой системы и предоставляет следующие инструменты и механизмы:
- хранения пользователей, их авторизации и проверки прав;
- коммуникации между приложениями;
- доступа к СУБД (сохранения объектов системы в базу данных 145);
- управления изменениями конфигураций (механизм версионирования);
- преобразования "сырых данных" из базы данных 145 в объекты описываемой системы;
- интеграции с другими системами, например, SOAP (от англ. Simple Object Access Protocol - простой протокол доступа к объектам), JSON (от англ. JavaScript Object Notation - текстовый формат обмена данными, основанный на JavaScript), REST (от англ. Representational State Transfer — «передача состояния представления»), XML (от англ. eXtensible Markup Language) - расширяемый язык разметки) и т.д.;
- среду разработки и изменения конфигурации;
- преобразования объектов, их выгрузки и сохранения в базу данных;
- коммуникации между частями (программными и аппаратными модулями) описываемой системы.
Как было сказано выше, в частном случае, пространство бизнес-логики содержит бизнес правила, сценарии обработки бизнес-правил, экранные формы и т.д. Конкретное наполнение пространства бизнес-логики, например, соответствующее конкретному клиенту (в частности, предприятию, например, пользователю предприятия или группе пользователей, по крайней мере, одного предприятия, в частности, пользователю компании предприятия) или конкретному варианту бизнеса (в частности предприятия или компании предприятия) является конфигурацией пространства бизнес-логики (конфигурацией). Конфигурация хранится в базе данных 145.
В частном случае, ядро 210 предоставляет интерфейс и инструменты для реализации бизнес-логики. В частном случае, бизнес-логика, исполняемая на сервере приложений 120, реализуется классами на одном из известных языков программирования (например, C#), унаследованных от соответствующих классов ядра (скриптов).
Одним из типов скриптов являются транзакционные скрипты ассоциируются с подтипом документа и выполняются (исполняются) при сохранении документа этого подтипа, причем транзакционные скрипты, формируют движения по итогам (проводки).
Стоит отметить, что обработчиками 214 могут являться скрипты:
- обработчик событий справочника - является скриптом, автоматически выполняемым в случае ряда событий, происходящих (осуществляемых) с записями справочника, причем для каждого справочника может быть создан свой обработчик событий;
- обработчик событий документа - является скриптом, автоматически выполняемым в случае ряда событий, происходящих (осуществляемых) с документом, причем для каждого типа документа (документов) может быть создан свой обработчик событий.
Стоит также отметить, что экранная логика выполняется на клиентском приложении 130 и реализуется в виде модулей, в частности, модулей клиентских приложений 230, например, на .NET совместимом языке программирования.
Стоит отметить, что пространство бизнес-логики (бизнес-логика, конфигурация) может содержать такие объекты метаданных (являющиеся сущностями данных, структурами данных), как справочники (каталоги) 224, развязочные таблицы справочника (связывающие таблицы справочника, связующие таблицы справочника, таблицы связей справочника, типы развязочных таблиц), документы, табличные части документов, итоги 220 и т.д. Стоит отметить, что данные объектов метаданных в компьютерных информационных системах могут обрабатываться как сущности данных (сущности), имеющие постоянный или переменный наборы значений (в частности, данные). В настоящее время широко распространено использование в компьютерных информационных системах хранение данных в виде сущностей данных, в частном случае сохраненных в таблицах баз данных, для хранения, передачи, предъявления (отображения) и других целей работы с данными. Пользователь может просматривать, передавать и редактировать сущности данных, в частности, данные, содержащиеся в таких сущностях данных. Стоит отметить, что справочники (каталоги) 224, развязочные таблицы справочника (связывающие таблицы справочника, связующие таблицы справочника, таблицы связей справочника, типы развязочных таблиц), документы, табличные части документов, итоги 220 приведены в настоящем описании в качестве примера, и стоит понимать, что настоящее изобретение не ограничивается такими справочниками 224, развязочными таблицами справочника, документами, табличными частями документов, итогами 220. Справочники (каталоги) 224 содержат информацию об объектах, участвующих в бизнес-процессах компаний (например, поставщиках или покупателях или товарах или складах). В частном случае, справочники (каталоги) 224 используются описываемой системой (примерный вариант, который приведен на ФИГ. 1), например, сервером приложений 120 и/или клиентским приложением 130, в тех случаях, когда необходимо исключить неоднозначный ввод данных (информации) пользователями (предприятий), так, например, для того, чтобы каждый пользователь (например, покупатель, продавец, кладовщик, бухгалтер и т.д.) понимали о каком товаре (данные о котором сохранены в базе данных 145) идет речь, каждый такой пользователь должен называть такой товар одинаково, т.е., в частном случае, в базе данных 145 осуществляется хранение, например, одного названия для каждого товара, одних единиц товара для каждого товара и т.д. Стоит отметить, что справочники могут включать обычные (неядерные) справочники (входящие в пространство бизнес-логики) и справочники, относящиеся к ядру («ядерные» справочники, справочники ядра 210), в частном случае, справочники, являющиеся справочниками ядра 210, в которые, в частном случае, пользователями (в частности, группами пользователей) не могут быть добавлены новые поля и/или в которых не могут быть изменены существующие поля, в частности состав полей (в частном случае, не могут быть добавлены новые поля или изменены или удалены существующие поля). В частном случае, справочниками ядра (ядерными справочниками, системными справочниками) могут являться справочники пользователей, групп пользователей, справочники ролей (в частности, предназначенный для ведения списка ролей в системе складского учета и настройки прав для них), справочники документов и т.д.
Отчеты 222 являются (прикладными) объектами конфигурации (бизнес-логики) и используются для обработки накопленной информации и получения сводных данных в удобном для просмотра и анализа виде. Стоит отметить, что отчеты 222 могут существовать трех видов:
- отчеты по итогам, функционал которых полностью реализуется ядром 210;
- виртуальные итоги, с помощью которых может быть создан отчет по сводным данным нескольких итогов;
- пользовательские отчеты, реализуемые администратором (программистом, разработчиком).
Упомянутые развязочные таблицы справочника (хранящиеся в таблицах базы данных 145 основного сервера базы данных 110) используются (в частности, составными частями системы, примерный вариант которой приведен на ФИГ. 1 и ФИГ. 2, например, сервером приложений 120 и/или клиентским приложением 130, и составными частями сервера приложений 120 и/или клиентского приложения 130) для создания связи (в частности, содержат связи, например, являющимися ссылками) между, по крайней мере, одним элементом, по крайней мере, одного справочника, по крайней мере, с одним элементом, по крайней мере, одного другого справочника. Так, например, одна развязочная таблица (связывающая таблица) может содержать связи между одним элементом одного справочника и несколькими элементами другого справочника. В частном случае, связь между элементом одного справочника и несколькими связями является ссылкой.
Упомянутые выше документы (хранящиеся в таблицах базы данных 145 основного сервера базы данных 110, в частности, в виде, по крайней мере, одной записи, по крайней мере, одной таблицы, по крайней мере, одной упомянутой базы данных) содержат информацию о произошедших в компании событиях (например, продажа товара, поступление денежных средств на расчетный счет от покупателя и т.д.). В частном случае, документ состоит из (содержит) заголовков («шапки») документа, набора полей, присущих всем подтипам данного типа документа, в частности, полей, которые могут содержаться в подтипах данного типа документа. Также, документ может включать набор табличных частей, в частном случае являющимся массивом данных, принадлежащих такому документу. Так, например, для Прихода товара заголовками документа могут являться информация о дате прихода товара, кем (каким предприятием, в частности, компании предприятия) была осуществлена поставка товара, на какой склад была осуществлена поставка товара и т.д. Также, стоит отметить, что табличной частью документа, в частном случае, является список заказанных товаров предприятием (частности, компании предприятия), количество заказанных товаров, стоимость заказанных товаров и т.д.
В частном случае, каждый документ состоит из общей «шапки» (набора полей, который существует в любом документе описываемой системы), «шапки» (набора полей, который существует только в данном документе, и набора табличных частей, причем количество табличных частей для одного документа не ограничено, что сильно упрощает формулирование сложной бизнес-логики). Табличная часть позволяет сохранить список записей внутри одного документа (например, товарные строки).
В частном случае, документ содержит информацию (данные) об одном событии.
Стоит отметить, что записью (записью справочника) является конкретная строка (или конкретный объект системы, в частности, бизнес-логики) справочника.
Стоит также отметить, что, в частном случае, в справочниках и развязочных таблицах (справочников) осуществляется хранение статических редко изменяющихся данных. Так, например, список товаров продаваемых или производимых компанией может быть реализован справочником.
Упомянутые выше итоги 220 (хранящиеся в таблицах базы данных 145 основного сервера базы данных 110) содержат информацию (данные) о текущем состоянии измеряемых показателей компании и историю их изменений. Так, например, Итоги 220 могут содержать информацию об остатках товаров (на предприятии, в частности, в компании предприятия, например, на складе). Каждое изменение данных в Итогах 220 называется движением. Так, например, каждый приход или расход товара (на примере остатков товара) являются движениями. Итоги 220 состоят из измерений и переменных. Каждое измерение данных в Итогах 220, например, конкретного итога (прихода или расхода товара), являющегося измеряемым показателем компании, является ссылкой, по крайней мере, на один справочник из Справочников 224, а история их изменений хранится в переменных. Итоги 220 могут иметь несколько измерений, например, два и более. Для итога остатки товара на складе измерениями являются сами товары и склады, а переменными являются количество и стоимость этих товаров. Движения формируются на основании документов (при их сохранении) и, будучи записанными в итоги 220, изменяют значения их переменных для определенных наборов измерений. Приход товара увеличивает остатки оприходованных товаров на указанном в документе прихода складе. Документ расхода наоборот их уменьшает.
Итоги (итог) 220 является объектом описываемой системы (в частности, бизнес-логики), который позволяет описать измеряемый показатель предметной области и хранить историю его изменения. Итоги 220 можно также представлять в виде многомерного куба. Таким образом, документ сохраняет информацию о событии и преобразует свои данные в набор изменений итогов. Так, например, примером итогов 220 являются остатки товаров на складах, причем в итогах 220 осуществляется хранение информации о том, какое количество товара осталось на каждом из складов. Соответственно, документ продажи уменьшает значение итога остатки товаров на складах (для товаров из документа).
Печатные формы 218 используются для вывода объектов системы на печать (на принтер или для экспорта в файл). Печатная форма представляет собой шаблон и скрипт, предоставляющий данные для заполнения шаблона.
Стоит отметить, что атрибутами документов, в частном случае, являются типы документов 212, которые (типы документов) определяются бизнес-логикой. Тип документа является описанием набора полей шапки документа и прочих (его) свойств. Так, типом документов (212) может являться Продажа (товара), Приход (товара) и т.д. Событие, информация о котором содержится (хранится), по крайней мере, в одном документе, может быть «растянуто» во времени, так, например, Продажа содержит этапы Заказа, Набора (в частности, комплектации) на складе, Оплаты, Выдачи и т.д., в связи с чем, типы документов (212) имеют соответствующие (под-событиям) подтипы документов 216, описывающие состояние документов в определенный (в том числе прошедший, настоящий и т.д.) момент (или период) времени и связанные с ним.
Стоит отметить, что справочники содержат справочник исключений справочников, содержащий справочники, наборы данных которых не содержат идентификаторы слоев данных.
Стоит отметить, что справочники содержат справочник исключений типов документов, содержащий типы документов, наборы данных которых не содержат идентификаторы слоев данных.
Стоит отметить, что в рамках настоящего изобретения справочники содержат дополнительный справочник слоев данных («Слои Данных», DataLayer). В частном случае, осуществляется создание (например, администратором описываемой системы) справочника «Слои данных», примерный вариант которого показан в Таблице 1.
Таблица 1.
ное имя (название)
(Caption)
тельно к запол-нению
ный код (идентифи-
катор, ID)
слоя данных
фикатор слоя данных (уникаль-
ный код, значение) слоя данных
НА
НА
сяПапкой
НА
Стоит отметить, что развязочные (связывающие) таблицы (пространства) бизнес-логики содержат развязочные таблицы дочерних слоев данных («Дочерние слои данных») и пользователей слоев данных («Пользователи слоя данных»), в частности, осуществляется создание развязочных таблиц «Дочерние слои данных» (примерный вариант которой приведен в Таблице 2) и «Пользователи слоя данных» (примерный вариант которой приведен в Таблице 3). В частном случае, все данные, которые хранятся в (неядерных) справочниках, развязочных таблицах справочников, документах, табличных частях и итогах 220 содержат (обладают) признак отношения (принадлежности) к определенному слою данных (в частности, обладают признаком (в частности, имеют ссылку на конкретный слой данных из упомянутого справочника слоев данных), к какому слою данных они (данные) относятся), для чего во все упомянутые объекты ((неядерные) справочники, развязочные таблицы справочников, документы, табличные части и итоги 220) осуществляется добавление ссылки на слой данных.
В Таблице 2 приведен примерный вариант развязочной таблицы (в которой определяется, в частности, задается связь между слоями данных, в частном случае, между родительским слоем данных и дочерним слоем данных), в частности, развязочной таблицы Дочерних слоев данных (ChildrenLayers, «Дочерние слои данных») типа Дочерних слоев данных (DataLayerTreeNode) со связью по идентификатору родительского слоя данных (ParentID), в которой идентификатор родительского слоя данных (ParentID) и идентификатор дочернего слоя данных (ChildID), в частном случае, являются ссылками на справочник слоев данных («Слои Данных» (DataLayer)).
Таблица 2.
(Property type..NET Type)
(Property type.Database type)
тельно к
запол-
нению
ского
слоя данных (ParentID)
(иденти-
фикатор (роди-тельского) слоя данных)
(NUMBER (18))
фикатор (дочернего) слоя
данных)
(NUMBER (18))
Стоит отметить, что, например, для двух предприятий может быть создан (в частности, администратором описываемой системы) Базовый Слой Данных и для каждого из двух предприятий может быть создан отдельный Слой Данных, например, Слой Данных 1 для Предприятия 1 и Слой Данных 2 для Предприятия 2. Базовый слой данных является зависимым (Слой Данных 1 и Слой Данных 2 наследуют, в частности, содержат, все данные из базового слоя), в частности, дочерним, к Слою Данных 1 и дочерним к Слою Данных 2, причем данная зависимость (связь) осуществляется посредством развязочной таблицы дочерних слоев данных («Дочерние слои данных»), приведенной выше, так что пользователи, у которых есть доступ к Слою данных 1 (данным Слоя данных 1), по крайней мере, видит все данные Слоя данных 1 и Базового слоя данных и, в частном случае, может их редактировать. Пользователи Предприятия 1 и пользователи Предприятия 2 добавляются (заводятся), в частности, администратором описываемой системы, в справочник пользователей (в частности, являющийся ядерным справочником, в котором перечислены (все) пользователи описываемой системы), в частности, администратором описываемой в настоящем изобретении системы или, по крайней мере, ее части, например, администратором сервера приложений. В развязочную таблицу пользователей слоев данных («Пользователи слоя данных»), примерный вариант который приведен ниже, для Слоя Данных 1 добавляются пользователи (в частности, идентификаторы пользователей) Предприятия 1. В развязочную таблицу пользователей слоев данных («Пользователи слоя данных») для Слоя Данных 2 добавляются пользователи Предприятия 1. Для всех данных (наборов данных), в частности, таблиц базы данных основного сервера базы данных 110, которые должны быть общими для Предприятия 1 и Предприятия 2 в упомянутой развязочной таблице проставляется (задается, устанавливается) другой слой данных, например, базовый слой данных («Базовый слой данных»), в частности, проставляется упомянутый выше признак, в частном случае, идентификатор, отношения (принадлежности) к слою данных, например, администратором описываемой системы, или средствами описываемой системы, например, по крайней мере, одним модулем (составным элементом) описываемой системы. Так, например, если под одной из ролей (с одной из ролей), описываемых в рамках настоящего изобретения, пользователь открывает один из справочников, например, справочник валют, то для записи в этом справочнике администратор описываемой системы (например, программист, разработчик, администратор клиентского приложения, администратор сервера приложений и т.д.) может явно указать, к какому слою данных эта запись (данные, набор данных, например, данные, сохраненные, по крайней мере, в одной ячейке таблицы базы данных) принадлежит. В частном случае, для такой упомянутой роли может не применяться (может не действовать) механизм RLS (не применяться RLS-политика), так что с использованием такой роли может быть изменен слой данных для любой записи в любом справочнике. Стоит отметить, что значения в справочники могут быть добавлены автоматически, причем добавлены в соответствующий слой данных. Так, например, значения курсов валют могут быть загружены автоматически программными модулями, например, скриптами, программными "роботами" с одного из сайтов, например, с сайта Центрального Банка Российской Федерации. Такой программный модуль определяет, в каком слое данных находится (хранится) валюта и добавляет значения для такой валюты в соответствующий (в частном случае, в тот же) слой данных. Стоит отметить, что к таким данным могут относиться, например, данные из справочника валют и курсов валют, и сам справочник валют и курсов валют. Стоит также отметить, что для предприятий может быть проставлено несколько базовых слоев данных.
В Таблице 3 показан примерный вариант развязочной таблицы пользователей слоев данных («Пользователи слоя данных») с типом «Пользователи» предприятия (клиента) со связью по идентификатору слоя данных (DataLayerID), причем идентификатор слоя данных (DataLayerID), в частном случае, является ссылкой на справочник слоев данных (DataLayer), приведенный в таблице выше, а идентификатор пользователя (UserID) идентифицирует пользователя и, в частном случае, является ссылкой на системный справочник пользователей, содержащий пароль пользователя, в котором, в частном случае, содержится логин (от англ. login - имя (идентификатор) учётной записи пользователя), хэш (хеш-сумма) пароля пользователя (результат применения хэш-функции к паролю пользователя), роль пользователя. Стоит отметить, что развязочная (связывающая) таблица пользователей (пользователей слоев данных) содержит связь между пользователями и слоями данных, в частности, в виде сохраненных связанных идентификаторов пользователей и идентификаторов слоев данных. Стоит отметить, что, в частном случае, идентификатор слоя данных является идентификатором предприятия, т.е., в частном случае, определяет принадлежность данных (наборов данных) тому или иному предприятию.
Таблица 3.
ное имя
(название)
(Caption)
(Property type..NET Type)
(Property type.Database type)
нению
катор слоя данных (DataLayerID)
фикатор слоя данных)
катор пользова-
теля (UserID)
фикатор пользователя)
В частном случае, во все несистемные (неядерные) справочники, документы, связующие таблицы, табличные части и итоги осуществляется добавление ссылки (Идентификатор слоя данных (DataLayerID)) на справочник слоев данных (DataLayer). Так же, в частном случае, во все транзакционных скриптов (TransactionScripts) в транзакциях осуществляется добавления заполнения Идентификатор слоя данных (DataLayerID). Стоит отметить, что документы с помощью transactionScripts осуществляют (делают) проводки по Итогам, поскольку документ принадлежит (или содержится) какому-то определенному, по крайней мере, одному слою данных, то проводка должна принадлежать в том же слое данных, таким образом, в скрипте прописывается для проводки такой слой данных из упомянутого документа.
Стоит отметить, что для ограничения доступа пользователей (и групп пользователей) к данным, в настоящем изобретении используется RLS-политика (от англ. row-level security, RLS, безопасность на уровне строк, защита на уровне строк, политика защиты на уровне строк) СУБД. Стоит отметить, что RLS-политика позволяет разграничить доступ к данным (информации), хранящимся в базе данных 145, в частности, на основе определенных знаний о пользователе (пользователях) и группах пользователей. Такими знаниями могут являться роль пользователя на предприятии (в частности, в компании предприятия), должность пользователя, отдел (подразделение), в котором работает пользователь и т.д. RLS-политика (в частном случае, реализованная RLS-технологией) предоставляет возможность создания политик безопасности, которые ограничивают доступ пользователям к определенным данным, хранящимся в базе данных 145, в частности, к строкам (и данным, содержащимся в строках), по крайней мере, в одной таблице базы данных 145, даже если у такого пользователя существуют стандартные права (возможность получать данные из таблицы) на чтение (и изменение, включая удаление и редактирование) данных из упомянутой таблицы (таблиц). Стоит отметить, что при осуществлении связи, по крайней мере, одного объекта базы данных с политикой безопасности контроль доступа осуществляется с использованием логики, например, логики PL/SQL-функции (от англ. Procedural Language/Structured Query Language, PL/SQL - язык программирования, процедурное расширение языка SQL, разработанное компанией Oracle). При этом в базу данных 145 (например, в БД Oracle) осуществляется добавление (специального) пакета (от англ. package - пакеты, которые позволяют группировать наборы именованных блоков кода, и в которых осуществляется хранение состояния сессии базы данных на время жизни, доступное для функций и процедур, входящих в пакет), содержащего (отдельные элементарные) функции и процедуры и обеспечивающего работу со слоями данных. Стоит отметить, что упомянутый пакет является пакетом PL/SQL. Пространство бизнес-логики содержит программный инструмент (который создается, например, программистом, разработчиком), в частности, реализованный скриптом, осуществляющий доступ (в частности запросы) к данным базы данных, который осуществляет проверку у объекта метаданных (например, документа, справочника, итога и т.д.) наличие RLS-политики в СУБД для соответствующих объекту метаданных таблиц (в частности, хранящих данные такого объекта метаданных) базы данных, (в частности, базы данных 145) и, в случае отсутствия RLS-политики, осуществляет создание RLS-политики. В частном случае, исполнение (запуск) упомянутого программного инструмента, в частности, модуля, осуществляется после добавления (в частности, администратором описываемой системы) нового объекта метаданных, в частности, запуск инструмента осуществляется программистом, пользователем или автоматически (в частности, сервером приложений 120). Так, например, для каждого (или, по крайней мере, для одного) справочника, развязочной таблицы, документа, табличной части, итога и т.д., созданных в пространстве бизнес-логики, в базе данных 145 осуществляется создание RLS-политики, ограничивающей доступ пользователя к данным по значениям (идентификаторам) слоя данных, в частности, с каким слоем данных связан пользователь (к какому слою данных привязан пользователь (или группа пользователей)), с таким значением (идентификатором) слоя данных пользователь и получает данные.
Стоит отметить, что для предоставления (и/или ограничения) доступа пользователям к данным справочников, документов, табличных частей документов, итогов и связывающих таблиц справочников на чтение (просмотр) или модификацию (добавление, изменение или удаление) RLS-политика (реализованная программным кодом, в частности, на сценарном языке, например, скриптом) содержит, по крайней мере, одно выражение, в частности, возвращающее логический результат, определяющий то, какие строки таблиц, в которых хранятся упомянутые данные, будут предоставлены для чтения и модификации пользователям, а какие - не будут предоставлены для чтения и модификации пользователям. В частном случае, упомянутые выражения вычисляются для каждой строки таблиц перед другими условиями или функциями (до выполнения других условий и функций), поступающими из запроса пользователя из клиентского приложения. Таким образом, при применении (использовании) RLS-политики строки таблиц (следовательно, данные (в частности, наборы данных), содержащиеся в таких строках), для которых упомянутое выражение RLS-политики вернет логическое ЛОЖЬ, обрабатываться не будут и не будут возвращены на запрос от пользователя (клиентского приложения пользователя).
На ФИГ. 3 показан примерный вариант ограничения доступа пользователей (и групп пользователей) к данным с использованием RLS-политики. Для отображения данных, запрашиваемых пользователем предприятия (например, предприятия 1), клиентское приложение 130, установленное на вычислительном устройстве пользователя 132, отправляет запрос данных (запрашивает данные) (315) из справочника, например, справочника товаров (справочник «Товары» («Articles»)), на сервер приложений 120, в частности, в зависимости от того, какие формы открывает пользователь. Ниже приведен примерный вариант упомянутого запроса данных:
«SELECT
c.ID,
c.NAME as Name
FROM
ARTICLES c.».
В клиентском приложении (например, 130, 136 и т.д.) пользователь открывает, например, форму «Каталог товаров». Чтобы вывести данные по товарам упомянутое клиентское приложение запрашивает у сервера приложений 120 данные справочника товаров. Далее сервер приложений 120 определяет, в какой таблице базы данных 145 хранятся данные справочника товаров и осуществляет (отправляет) запрос (325) в базу данных 145 к соответствующим данным, на получение таких данных из таблицы (запрос данных таблицы), например, из таблицы, в которой хранятся данные справочника «Товары», на основной сервер базы данных 110. Упомянутая таблица, в которой хранятся данные справочника «Товары», приведена в качестве примера и, в частном случае, является таблицей базы данных, в которой хранятся данные (неядерного) справочника, в частности, справочника товаров, причем такая таблица товаров (в частности, справочник товаров) может содержать такие поля, как код товара, наименование товара, артикул товара, габаритные характеристики товара и т.д. Далее основной сервер базы данных 110 средствами СУБД осуществляет поиск RLS-политики для таблицы, например, для таблицы «Товары». Далее основной сервер базы данных 110 применяет найденную RLS-политику к запросу на данные таблицы, например, таблицы «Товары». Так, в частном случае, для каждой таблицы базы данных 145, где должны быть (в которой должны содержаться) слои данных в базе данных 145, должна быть создана RLS-политика. Далее основной сервер базы данных 110 возвращает серверу приложений 120 данные (335) таблицы, например, таблицы «Товары », у которых значение (идентификатор) слоя данных совпадает со значением (идентификатором) слоя данных пользователя, запрашивающего данные. Далее сервер приложений 120 передает данные (в частности, те же данные (345), что основной сервер базы данных 110 вернул серверу приложений 120 таблицы, в частности, таблицы «Товары») в клиентское приложение 130, и клиентское приложение 130 осуществляет предоставление (отображение) полученных данных пользователю предприятия.
Стоит отметить, что пользователю, пользователям, группе пользователей или группам пользователей предприятия 1 предоставляется (средствами RLS-политики) доступ, в частности, для чтения и отображения, только к данным со значением (идентификатором) первого слоя данных для первого предприятия (Слой Данных 1 для Предприятия 1) и базовый слой данных (Базовый Слой Данных), т.е. предоставляется доступ к данным Слоя 1 Предприятия 1 и Базового слоя данных.
Также, пользователю, пользователям, группе пользователей или группам пользователей Предприятия 2 предоставляется (средствами RLS-политики) доступ, в частности, для чтения и отображения, только к данным со значением (идентификатором) второго слоя данных для второго предприятия (Слой Данных 2 для Предприятия 2) и Базовый слой данных, т.е. предоставляется доступ к данным Слоя Данных 2 Предприятия 2 и Базового слоя данных.
Стоит отметить, что пользователь, пользователи, группа пользователей или группы пользователей предприятия 1 (первого предприятия) и предприятия 2 (второго предприятия) не могут изменять или добавлять данные, содержащиеся (хранящиеся) в Базовом слое данных, и данные в Базовом слое данных (т.е., в частном случае, содержащиеся в других слоях данных), которые не указаны в развязочной таблице пользователей слоев данных, что реализовано RLS-политикой.
В частном случае, при добавлении пользователем (в частности, принадлежащим, по крайней мере, одной группе пользователей) новой записи в справочник (например, добавление нового товара в каталог (справочник) товаров) информация (данные) о принадлежности к определенному, по крайней мере, одному слою данных автоматически определяется по текущему пользователю (где, по крайней мере, одному пользователю или группе пользователей соответствует, по крайней мере, один слой данных), т.е. определяется в зависимости от того, с каким слоем данных связан пользователь (к какому слою данных «привязан» пользователь), и осуществляется сохранение записи в базе данных 145 с нужным (соответствующим) значением (идентификатором) слоя данных.
В частном случае, при добавлении новой записи (в частности, алгоритмом скрипта, который запускается при сохранении новой записи) в развязочную таблицу справочника информация (данные) о принадлежности к слою автоматически определяется по текущему слою данных (в частности, слою данных из справочника, к которому относится сохраняемая строка развязочной таблицы) и осуществляется сохранение записи в базе данных 145 с нужным (определенным) значением (идентификатором) слоя данных. Стоит отметить, что запись самого справочника может являться записью (набором данных) дочернего слоя данных (может относиться к дочернему слою данных), в частности, обладать признаком отношения к слою данных, в частном случае, к дочернему слою данных, и не быть доступна пользователям для редактирования (в частном случае, доступ на чтение записи (в частности, данных) предоставляется только на чтение).
Стоит отметить, что при добавлении новой записи в документ информация (данные) о принадлежности к слою данных автоматически определяется по текущему пользователю и запись сохраняется в базе данных 145 с нужным значением (идентификатором) слоя данных.
Стоит также отметить, что при добавлении новой записи в табличную часть документа информация о принадлежности к слою данных автоматически вычитывается (получается) из документа и запись сохраняется в базе данных 145 с нужным значением (идентификатором) слоя данных (в частном случае, данные, которые добавляет пользователь, добавляются только в те виртуальные базы данных, к которым «привязан» (имеет доступ, связан) пользователь).
Также, для всех "проводок" по итогам («проводки» осуществляются (только) документами) используются данные о слое данных из документа. "Проводка" (в частности, контировка) является записью в базе данных 145 об изменении состояния учитываемых товаров.
Стоит отметить, что при добавлении (например, программистом, разработчиком) нового объекта метаданных (справочника, развязочной таблицы, документа, табличной части документа, итога и т.д.) атрибут слоя данных (идентификатор слоя данных, в частности, ссылка на слой данных) добавляется в объект автоматически, в частности, в объект метаданных (документ, справочник, итог(и)). Стоит отметить, что новый объект добавляется (включается) в систему контроля прав доступа (RLS, RLS-политика) к данным слоев данных (данным виртуальных баз данных), в частности, RLS-политика создается средствами СУБД (автоматически) для соответствующей таблицы.
На ФИГ. 4 показана блок-схема примерного варианта процесса создания новой записи (в частности, записи справочника, например, набора полей, записываемых в таблицу базы данных 145) в справочнике или развязочной таблице справочника. Стоит отметить, что при сохранении записи в развязочной таблице одновременно осуществляется сохранение и в записи справочника, к которой относится запись развязочной таблицы. Процесс создания новой записи в справочнике и/или развязочной (связывающей) таблице справочника базы данных 145 начинается в шаге 410. В рамках процесса, представленного на ФИГ. 4, осуществляется создание и сохранение новой записи, по крайней мере, в одной развязочной таблице (неядерного) справочника и/или в справочнике, в частности, в неядерном справочнике (вручную) при добавлении записей (в частности, наборов данных) пользователем (например, в клиентском приложении 130 пользователем компании) или программно (например, посредством периодического выполнения задачи (от англ. task), в частности, сервером приложений 120, в котором прописан слой данных, в частности, базовый слой данных, причем такой задачей (task’ом), например, может являться загрузка и сохранение курсов валют и т.д.). В частном случае, упомянутая задача является специальным служебным пользователем системы, в частности, реализованным скриптом, который видит данные сразу всех слоев данных, причем под таким пользователем осуществляется запуск (выполнение, исполнение) периодических заданий, например, ежедневный импорт (загрузка) курсов валют и т.д. Стоит отметить, что задача также имеет идентификатор пользователя, в частности, в таком же формате, что и описываемый в рамках настоящего изобретения идентификатор пользователя.
В шаге 425 сервером приложений 120 осуществляется проверка того факта, содержится ли (неядерный) справочник в справочнике исключений справочников (списке исключений справочников), в котором не содержится (идентификаторов) слоев данных (который не должен содержать слои данных, в частности, идентификаторы слоев данных). Если в шаге 425 установлено, что упомянутый справочник не содержится в справочнике исключений справочников, то процесс переходит к шагу 430, в противном случае процесс переходит к шагу 460.
В шаге 430 осуществляется, в частности, скриптом (сервера приложений 120), проверка указано ли значение (идентификатор) слоя данных в записи явно. В частном случае, явным добавлением значения (идентификатора) слоя данных является добавление такого значения (идентификатора) слоя данных соответствующим алгоритмом, скриптом, программным кодом и т.д.
Если в шаге 430 установлено, что значение (идентификатор) слоя данных не указано явно, то процесс переходит к шагу 435. Если в шаге 430 установлено, что значение (идентификатор) слоя данных указано явно, то процесс переходит к шагу 445.
В шаге 435 осуществляется получение значения (идентификатора) слоя данных для текущего пользователя (осуществляющего добавление записи) посредством вызова скриптом функции, в частности, скалярной функции, «GET_CURR_USER_DATA_LAYER» из пакета «PACK_DATA_LAYERS» (примерный вариант программного кода которого приведен ниже) базы данных 145. Функция (метод) «GET_CURR_USER_DATA_LAYER» осуществляет отправку запроса в таблицу «DATA_LAYER_TO_USERS» (развязочную таблицу пользователей слоев данных, примерный вариант которой приведен в Таблице 3) с фильтром (в частности, запрос в базе данных 145 с условием WHERE) по текущему пользователю, возвращает код (идентификатор, значение, признак) слоя данных, в частности, добавленный ранее, в частности, в таблицу пользователей слоев данных, например, администратором описываемой системы или, по крайней мере, одним модулем описываемой системы.
Далее в шаге 440 осуществляется сохранение значения (идентификатора, признака, кода) слоя данных, в частности, отношения к определенной виртуальной базе данных, в записи справочника, в который осуществляется добавление записи пользователем.
Далее в шаге 445 осуществляется (в частности, упомянутым скриптом на сервере приложений 120) проверка того факта, является ли текущий пользователь задачей (т.е. сохранение выполняется упомянутой выше задачей (заданием) или (вручную) пользователем). Если в шаге 445 было установлено, что пользователь является задачей (т.е. сохранение выполняется упомянутой выше задачей, а не (вручную) пользователем), то процесс переходит к шагу 450. Если в шаге 445 было установлено, что пользователь не является задачей (т.е. сохранение выполняется не упомянутой выше задачей, а (вручную) пользователем), то процесс переходит к шагу 455.
В шаге 450 всем несохраненным записям всех развязочных таблиц, которые (записи справочника) относятся к добавляемой записи, добавляется значение (идентификатор) слоя данных из добавляемой записи справочника и процесс переходит к шагу 460.
В шаге 455 всем несохраненным записям всех развязочных таблиц, относящихся к добавляемой записи, добавляется значение (идентификатор) слоя данных из текущего пользователя (сохраняющего запись), причем значение (идентификатор) слоя данных для текущего пользователя осуществляется с использованием вызова упомянутой выше (исполнения, выполнения) функции, в частности, скалярной функции, «GET_CURR_USER_DATA_LAYER» из пакета «PACK_DATA_LAYERS» базы данных 145 для осуществления запроса таблицу «CLIENT_TO_USERS» с фильтром по текущему пользователю, определяет предприятие (клиента) и возвращает связанный с (привязанный к) предприятием (клиентом) значение (идентификатор, признак, код,) слоя данных, в частности, идентификатор слоя пользователя, и процесс переходит к шагу 460.
В шаге 460 осуществляется сохранение наборов данных. В частности, осуществляется сохранение наборов данных с соответствующими им идентификаторами слоев данных или без соответствующих им идентификаторов слоев данных, в зависимости от того факта, содержится ли справочник в справочнике исключений, определяемого в шаге 425.
На ФИГ. 5 показана блок-схема примерного варианта процесса сохранения нового документа. Процесс сохранения нового документа, в частности, создание и сохранение новой записи (нового документа) в журнале документов, содержащего документы данного типа, (вручную) пользователем или программно, начинается в шаге 513. Далее в шаге 515 осуществляется проверка того, что тип документа не содержится в справочнике исключений типов (списке исключений типов), в котором (в частности, в документах с определенным типом (определенного типа)) не должно быть слоев данных (не должно содержаться идентификаторов слоев данных), в частном случае, если необходимо исключение, что в каком-то типе документов нет деления данных по слоям данных, т.е. пользователи из разных слоев данных (пользователи, которым назначены разные идентификаторы слоев данных) сохраняют такие документы с доступом к ним всеми пользователями.
Если в шаге 515 установлено, что упомянутый справочник не содержится в справочнике исключений типов (списке исключений типов), то процесс переходит к шагу 517, в противном случае процесс переходит к шагу 529.
В шаге 517 скриптом (выполняемым, в частности, при сохранении документа или справочника) осуществляется проверка указано ли значение (идентификатор) слоя данных явно.
Если в шаге 517 установлено, что значение (идентификатор) слоя данных не указано явно, то процесс переходит к шагу 519. Если в шаге 517 установлено, что значение (идентификатор) слоя данных указано явно, то процесс переходит к шагу 523.
В шаге 519 осуществляется получение значения (идентификатора) слоя данных для текущего пользователя посредством вызова функции, в частности, скалярной функции, GET_CURR_USER_DATA_LAYER из пакета PACK_DATA_LAYERS базы данных 145. Функция (метод) GET_CURR_USER_DATA_LAYER осуществляет отправку запроса в таблицу CLIENT_TO_USERS с фильтром по текущему пользователю, определяет предприятие (клиента) и возвращает связанный с (привязанный к) к предприятием (клиентом) код слоя данных (в частности, идентификатор, значение (идентификатор) слоя данных).
Далее в шаге 521 осуществляется добавление (присваивание) значения (кода, идентификатора, значения) слоя данных в (текущем) документе.
Далее в шаге 523 осуществляется проверка того, является ли текущий пользователь задачей (task’ом). Если в шаге 523 было установлено, что пользователь является задачей (task’ом), то процесс переходит к шагу 525. Если в шаге 523 было установлено, что пользователь не является задачей (task’ом), то процесс переходит к шагу 527.
В шаге 525 (всем) несохраненным записям (всех) табличных частей, относящихся к добавляемой записи документа, присваивается значение (идентификатор) слоя данных из добавляемого документа (причем, в частном случае, документ также является записью в базе данных) и процесс переходит в шаг 529.
В шаге 527 (всем) несохраненным записям (всех) табличных частей, относящихся к добавляемой записи документа, присваивается добавленное (присвоенное) в шаге 521 значение (идентификатор) слоя данных.
В шаге 529 осуществляется сохранение документа. В частности, осуществляется сохранение наборов данных документа с соответствующими им идентификаторами слоев данных или без соответствующих им идентификаторов слоев данных, в зависимости от того факта, содержится ли тип добавляемого документа в справочнике исключений типов документов, определяемого в шаге 515.
ФИГ. 6 иллюстрирует примерный вариант формирования виртуальных баз данных, согласно настоящему изобретению. На ФИГ. 6 показана физическая база данных 145, из данных которой формируются виртуальные базы данных, например, виртуальная база данных 1, виртуальная база данных 2, виртуальная база данных 3 … виртуальная база данных N (соответственно 615, 620, 625, 630), в частном случае, являющиеся частью базы данных 145. Виртуальные базы данных формируются в зависимости от слоев данных для соответствующих пользователей (и/или групп пользователей, в том числе групп супер-пользователей), в частности, средствами RLS-политики, причем каждая такая виртуальная база данных содержит данные (например, справочников, развязочных таблиц, документов, итогов), доступные определенным пользователям (или группам пользователей, в том числе групп супер-пользователей) конкретного предприятия (клиента), причем также могут быть сформированы виртуальные базы данных, данные в которых доступны всем пользователям. как описано в рамках настоящего изобретения. Стоит отметить, что супер-пользователи имеют доступ (для чтения и изменения) ко всем данным во всех виртуальных базах данных. Стоит отметить, что супер-пользователям доступны данные, по крайней мере, одной виртуальной базы данных (например, данные из двух, трех и т.д. виртуальных баз данных). Так, например, группе супер-пользователей 1 (642) доступны все данные виртуальной базы данных 1 (615) и все данные виртуальной базы данных 2 (620), группе супер-пользователей 2 (644) доступны все данные виртуальной базы данных 1 (615) и все данные виртуальной базы данных 3 (625), группе супер-пользователей N (646) доступны все данные виртуальной базы данных 3 (625) и все данные виртуальной базы данных N (630). Также, в частном случае, одной группе пользователей доступны данные только одной виртуальной базы данных, например, группе пользователей 1 (651) доступны данные только виртуальной базы данных 1 (615), группе пользователей 2 (652) доступны только данные виртуальной базы данных 2 (620), группе пользователей 3 (653) доступны только данные виртуальной базы данных 3 (625), группе пользователей N (654) доступны только данные виртуальной базы данных 3 (630) и т.д.
Стоит отметить, что в частном случае виртуальные базы данных содержат те же метаданные (например, метаданные (226, ФИГ. 2)), что и база данных, из данных которой формируются виртуальные базы данных. Так, например, виртуальная база данных 1 (615) содержит все или часть метаданных базы данных 145, виртуальная база данных 2 (620) содержит все или часть метаданных базы данных 145, виртуальная база данных 3 (625) содержит все или часть метаданных базы данных 145, виртуальная база данных N (630) содержит все или часть метаданных базы данных 145 и т.д. Стоит также отметить, что каждая виртуальная база данных может содержать все данные базы данных 145 или часть метаданных, относящихся к данным конкретной виртуальной базы данных.
Стоит отметить, что виртуальная база данных 1 (615) содержит данные (наборы данных), относящиеся к слою данных 1 (т.е. наборы данных имеют идентификаторы слоя данных 1); виртуальная база данных 2 (620) содержит данные (наборы данных), относящиеся к слою данных 2; виртуальная база данных 3 (625) содержит данные (наборы данных), относящиеся к слою данных 3 и т.д.; виртуальная база данных N (630) содержит данные (наборы данных), относящиеся к слою данных N.
ФИГ. 7 иллюстрирует примерный вариант иерархии виртуальных баз данных, согласно настоящему изобретению. На ФИГ. 7 база данных 145 может содержать, по крайней мере, одну виртуальную базу данных, например, может содержать виртуальную базу данных 1 (615), виртуальную базу данных 2 (620), виртуальную базу данных 3 (625), и другие виртуальные базы данных, дочерними для которых могут являться другие виртуальные базы данных, например, виртуальная база данных 0 (710). Так, например, виртуальная база данных 0 (710) может являться дочерней для виртуальной базы данных 1 (615) и/или для виртуальной базы данных 2 (620), и/или для виртуальной базы данных 3 (625). Так, например, виртуальная база данных 1 (615) может быть сформирована для пользователя или группы пользователей (в частности, группы пользователей 1 (651) предприятия 1), виртуальная база данных 2 (620) может быть сформирована для пользователя или группы пользователей (в частности, группы пользователей 2 (652) предприятия 2), виртуальная база данных 3 (625) может быть сформирована для пользователя или группы пользователей (в частности, группы пользователей 3 (652) предприятия 3 и/или предприятия 2), а виртуальная база данных 0 (710), в которой хранятся данные, общие для группы пользователей 1 и группы пользователей 2.
Поскольку, показанная на ФИГ. 7 виртуальная база данных 0 (710) является дочерней для виртуальной базы данных 1 (615), для виртуальной базы данных 2 (620) и для виртуальной базы данных 3 (625), то:
- группа пользователей 1 (651) имеет доступ к виртуальной базе данных 1 (615), в частности, к данным виртуальной базы данных 1 (615), и имеет доступ к виртуальной базе данных 0 (710), в частности, к данным виртуальной базы данных 0 (710);
- группа пользователей 2 (652) имеет доступ к виртуальной базе данных 2 (620), в частности, к данным виртуальной базы данных 2 (620), и имеет доступ к виртуальной базе данных 0 (710), в частности, к данным виртуальной базы данных 0 (710);
- группа пользователей 3 (653) имеет доступ к виртуальной базе данных 3 (625), в частности, к данным виртуальной базы данных 3 (625), и имеет доступ к виртуальной базе данных 0 (710), в частности, к данным виртуальной базы данных 0 (710);
- группа супер-пользователей 1 (642) имеет доступ к виртуальной базе данных 1 (615), в частности, к данным виртуальной базы данных 1 (615), и к виртуальной базе данных 2 (620), в частности, к данным виртуальной базы данных 2 (620), и имеет доступ к виртуальной базе данных 0 (710), в частности, к данным виртуальной базы данных 0 (710);
- группа супер-пользователей 2 (644) имеет доступ к виртуальной базе данных 1 (615), в частности, к данным виртуальной базы данных 1 (615), и к виртуальной базе данных 3 (625), в частности, к данным виртуальной базы данных 3 (625), и имеет доступ к виртуальной базе данных 0 (710), в частности, к данным виртуальной базы данных 0 (710).
Стоит отметить, что виртуальная база данных 1 (615) содержит данные (наборы данных), относящиеся к слою данных 1; виртуальная база данных 2 (620) содержит данные (наборы данных), относящиеся к слою данных 2; виртуальная база данных 3 (625) содержит данные (наборы данных), относящиеся к слою данных 3; виртуальная база данных 0 (710) содержит данные (наборы данных), относящиеся к слою 0. Стоит также отметить, что слой данных 0 является дочерним для слоя данных 2.
ФИГ. 8 иллюстрирует способ осуществления настоящего изобретения. В шаге 808 осуществляется создание справочника слоев данных, сохраненного, по крайней мере, в одной таблице, в базе данных 145 (основного) сервера базы данных 110 удаленного сервера (сервера ERP-системы) 112. Стоит отметить, что справочник слоев данных содержит названия всех слоев данных, а также содержит идентификаторы (значения) слоев данных для наборов данных, хранимых в объектах метаданных бизнес логики сервера приложений сервера системы планирования ресурсов предприятия (ERP-системы). Как было сказано выше, объектами метаданных являются справочники, документы, табличные части документов, итоги и связывающие таблицы справочников, сохраненные в таблицах базы данных 145 основного сервера базы данных 110, связанного с сервером ERP-системы 112. Стоит отметить, что идентификатор слоя данных определяет принадлежность набора данных к соответствующему слою данных.
В шаге 818 осуществляется создание связывающей таблицы пользователей слоев данных в базе данных 145 (основного) сервера базы данных 110 сервера ERP-системы 112. Стоит отметить, что в связывающей таблице пользователей слоев данных хранятся связи между пользователями и слоями данных в виде сохраненных связанных идентификаторов пользователей и соответствующих им идентификаторов слоев данных из доступных идентификаторов слоев данных справочника слоев данных, причем связи между пользователями и слоями данных определяют доступность наборов данных для чтения и модификации пользователям связанных с ними слоями данных.
В шаге 828 осуществляется создание связывающей таблицы дочерних слоев данных в базе данных 145 (основного) сервера базы данных 110 сервера ERP-системы 112. Стоит отметить, что в связывающей таблице дочерних слоев данных хранится иерархия между слоями данных в виде сохраненных связанных идентификаторов для дочерних слоев данных и идентификаторов для родительских слоев данных, причем связь между родительскими слоями и дочерними слоями определяет доступность наборов данных дочерних слоев данных для чтения пользователями родительских слоев данных.
В шаге 838 осуществляется создание политики безопасности на уровне строк (RLS-политики) для каждой из таблиц базы данных сервера базы данных, в которых хранятся справочники, документы, табличные части документов, итоги и связывающие таблицы справочников, и осуществляется сохранение RLS-политик в базе данных сервера базы данных, причем RLS-политика содержит, по крайней мере, одно выражение, возвращающее логический результат, определяющий доступность пользователю наборов данных из таблиц базы данных сервера базы данных в зависимости от идентификаторов слоев данных для таких наборов данных.
В шаге 848 сервером приложений 120 при добавлении набора данных в справочник осуществляется установление (определение, выявление) идентификатора слоя данных для добавляемого набора данных и осуществляется сохранение добавляемого набора данных в базу данных сервера базы данных с сохранением для такого набора данных установленного идентификатора слоя.
В шаге 858 сервером приложений 120 при добавлении набора данных в связывающую таблицу осуществляется установление идентификатора слоя данных для добавляемого набора данных и осуществляется сохранение добавляемого набора данных в базу данных сервера базы данных с сохранением для такого набора данных установленного идентификатора слоя.
Стоит отметить, что при добавлении, по крайней мере, одного набора данных, по крайней мере, одну развязочную таблицу справочника и/или, по крайней мере, в один другой справочник, отличный от справочника исключений справочников, осуществляется проверка наличия справочника, в который осуществляется добавление набора данных, в справочнике исключений справочников. Также, осуществляется проверка наличия в добавляемом наборе данных идентификатора слоя данных для добавляемого набора данных при установлении отсутствия справочника в справочнике исключений справочников. При установлении отсутствия в добавляемом наборе данных идентификатора слоя данных для добавляемых данных осуществляется получение идентификатора слоя данных из связывающей таблицы пользователей слоев данных и добавление полученного идентификатора слоя данных в добавляемый набор данных в справочнике. Далее осуществляется проверка добавления набора данных в базу данных пользователем или задачей, исполняемой программным кодом. Причем, при добавлении набора данных пользователем осуществляется присваивание, в частном случае, добавление, идентификатора слоя данных, полученного из связывающей таблицы пользователей слоев данных, несохраненным наборам данных связывающих таблиц, связанных с добавляемым набором данных. Также, в случае добавления набора данных задачей, исполняемой программным кодом осуществляется присваивание идентификатора слоя данных, полученного из добавляемого набора данных, несохраненным наборам данных связывающих таблиц, связанных с добавляемым набором данных.
В шаге 868 сервером приложений 120 при добавлении документа осуществляется установление идентификатора слоя данных, по крайней мере, для одного добавляемого набора данных, содержащегося в добавляемом документе, и осуществляется сохранение добавляемого документа и, по крайней мере, одного набора данных документа в базу данных сервера базы данных с сохранением для сохраняемого набора данных документа установленного идентификатора слоя.
Стоит отметить, что при добавлении документа в базу данных сервера базы данных осуществляется проверка наличия типа добавляемого документа в справочнике исключений типов документов. Также, при установлении отсутствия типа добавляемого документа в справочнике исключений типов документов осуществляется проверка наличия в добавляемом документе идентификатора слоя данных для данных добавляемого документа. При установлении отсутствия в добавляемом документе идентификатора слоя данных осуществляется получение идентификатора слоя данных из связывающей таблицы пользователей слоев данных и добавление полученного идентификатора в добавляемый документ. Далее осуществляется проверка осуществления добавления документа в базу данных пользователем или задачей, исполняемой программным кодом. Причем, при добавлении документа в базу данных пользователем осуществляется присваивание идентификатора слоя данных, полученного из добавляемого документа, несохраненным наборам данных табличных частей, связанных с добавляемым документом. В случае добавления документа в базу данных задачей, исполняемой программным кодом, осуществляется присвоение идентификатора слоя данных, добавленного в документ из полученного из связывающей таблицы пользователей слоев данных, несохраненным наборам данных табличных частей, связанных с добавляемым документом.
В шаге 878 сервером приложений 120 при добавлении набора данных в табличную часть документа осуществляется установление идентификатора слоя данных для добавляемого набора данных и сохранение добавляемого набора данных в базу данных сервера базы данных с сохранением для такого набора данных установленного идентификатора слоя.
В шаге 898 удаленным сервером (сервером ERP-системы) 112 посредством применения RLS-политики, выполняемой сервером базы данных, к запросам, осуществляемым к наборам данных из базы данных сервера базы данных, осуществляется предоставление пользователю доступа к наборам данных и наборов данных для чтения и модификации, идентификаторы слоев данных которых связаны с идентификатором пользователя в связывающей таблице пользователей слоев данных при осуществлении запросов данных из базы данных сервера базы данных пользователем с использованием клиентского приложения, установленного на вычислительном устройстве пользователя, связанном с сервером приложений сервера ERP-системы 112.
В шаге 899 удаленным сервером (сервером ERP-системы) 112 осуществляется предоставление доступа пользователю родительского слоя к наборам данных и наборов данных дочернего слоя данных для чтения, без возможности их модификации, посредством применения RLS-политики, выполняемой сервером базы данных, к запросам, осуществляемым к наборам данных из базы данных сервера базы данных, с использованием идентификаторов слоев данных для дочерних слоев данных и идентификаторов слоев данных для родительских слоев данных из связывающей таблицы дочерних слоев данных для установления связи между родительским слоем данных и, по крайней мере, одним дочерним слоем данных при осуществлении запроса данных из базы данных сервера базы данных пользователем с использованием клиентского приложения, установленного на вычислительном устройстве пользователя, связанном с сервером приложений сервера ERP-системы.
На ФИГ. 9 показан пример компьютерной системы общего назначения, которая включает в себя многоцелевое вычислительное устройство в виде компьютера 20 или сервера, или модуля описываемой в настоящем изобретении системы, включающего в себя процессор 21, системную память 22 и системную шину 23, которая связывает различные системные компоненты, включая системную память с процессором 21.
Системная шина 23 может быть любого из различных типов структур шин, включающих шину памяти или контроллер памяти, периферийную шину и локальную шину, использующую любую из множества архитектур шин. Системная память включает постоянное запоминающее устройство (ПЗУ) 24 и оперативное запоминающее устройство (ОЗУ) 25. В ПЗУ 24 хранится базовая система ввода/вывода 26 (БИОС), состоящая из основных подпрограмм, которые помогают обмениваться информацией между элементами внутри компьютера 20, например, в момент запуска.
Компьютер 20 также может включать в себя накопитель 27 на жестком диске для чтения с и записи на жесткий диск, не показан, накопитель 28 на магнитных дисках для чтения с или записи на съёмный магнитный диск 29, и накопитель 30 на оптическом диске для чтения с или записи на съёмный оптический диск 31 такой, как компакт-диск, цифровой видео-диск и другие оптические средства. Накопитель 27 на жестком диске, накопитель 28 на магнитных дисках и накопитель 30 на оптических дисках соединены с системной шиной 23 посредством, соответственно, интерфейса 32 накопителя на жестком диске, интерфейса 33 накопителя на магнитных дисках и интерфейса 34 оптического накопителя. Накопители и их соответствующие читаемые компьютером средства обеспечивают энергонезависимое хранение читаемых компьютером инструкций, структур данных, программных модулей и других данных для компьютера 20.
Хотя описанная здесь типичная конфигурация использует жесткий диск, съёмный магнитный диск 29 и съёмный оптический диск 31, специалист примет во внимание, что в типичной операционной среде могут также быть использованы другие типы читаемых компьютером средств, которые могут хранить данные, которые доступны с помощью компьютера, такие как магнитные кассеты, карты флеш-памяти, цифровые видеодиски, картриджи Бернулли, оперативные запоминающие устройства (ОЗУ), постоянные запоминающие устройства (ПЗУ) и т.п.
Различные программные модули, включая операционную систему 35, могут быть сохранены на жёстком диске, магнитном диске 29, оптическом диске 31, ПЗУ 24 или ОЗУ 25. Компьютер 20 включает в себя файловую систему 36, связанную с операционной системой 35 или включенную в нее, одно или более программное приложение 37, другие программные модули 38 и программные данные 39. Пользователь может вводить команды и информацию в компьютер 20 при помощи устройств ввода, таких как клавиатура 40 и указательное устройство 42. Другие устройства ввода (не показаны) могут включать в себя микрофон, джойстик, геймпад, спутниковую антенну, сканер или любое другое.
Эти и другие устройства ввода соединены с процессором 21 часто посредством интерфейса 46 последовательного порта, который связан с системной шиной, но могут быть соединены посредством других интерфейсов, таких как параллельный порт, игровой порт или универсальная последовательная шина (УПШ). Монитор (дисплей) 47 или другой тип устройства визуального отображения также соединен с системной шиной 23 посредством интерфейса, например, видеоадаптера 48. В дополнение к монитору 47, персональные компьютеры обычно включают в себя другие периферийные устройства вывода (не показано), такие как динамики и принтеры.
Компьютер 20 может работать в сетевом окружении посредством логических соединений к одному или нескольким удаленным компьютерам 49. Удаленный компьютер (или компьютеры) 49 может представлять собой другой компьютер, сервер, роутер, сетевой ПК, пиринговое устройство или другой узел единой сети, а также обычно включает в себя большинство или все элементы, описанные выше, в отношении компьютера 20, хотя показано только устройство хранения информации 50. Логические соединения включают в себя локальную сеть (ЛВС) 51 и глобальную компьютерную сеть (ГКC) 52. Такие сетевые окружения обычно распространены в учреждениях, корпоративных компьютерных сетях, Интернете.
Компьютер 20, используемый в сетевом окружении ЛВС, соединяется с локальной сетью 51 посредством сетевого интерфейса или адаптера 53. Компьютер 20, используемый в сетевом окружении ГКС, обычно использует модем 54 или другие средства для установления связи с глобальной компьютерной сетью 52, такой как Интернет.
Модем 54, который может быть внутренним или внешним, соединен с системной шиной 23 посредством интерфейса 46 последовательного порта. В сетевом окружении программные модули или их части, описанные применительно к компьютеру 20, могут храниться на удаленном устройстве хранения информации. Надо принять во внимание, что показанные сетевые соединения являются типичными, и для установления коммуникационной связи между компьютерами могут быть использованы другие средства.
Ниже приведен примерный код упомянутого пакета «PACK_DATA_LAYERS»:
«
CREATE OR REPLACE PACKAGE ULTIMA.PACK_DATA_LAYERS AS
TYPE DATA_LAYER_ID IS RECORD (DATA_LAYER_ID DATA_LAYERS.ID%type);
TYPE DATA_LAYER_LIST IS TABLE OF DATA_LAYER_ID;
-- Функция возвращает код слоя данных для заданного пользователя
FUNCTION GET_USER_DATA_LAYER(vUserID KERNEL.USERS.ID%type) RETURN DATA_LAYERS.ID%type;
-- Функция возвращает код слоя данных для текущего пользователя
FUNCTION GET_CURR_USER_DATA_LAYER RETURN DATA_LAYERS.ID%type;
-- Функция возвращает набор всех слоев данных (включая зависимые слои данных) для указанного пользователя
FUNCTION GET_USER_DATA_LAYERS(vUserID KERNEL.USERS.ID%type) RETURN DATA_LAYER_LIST pipelined;
-- Функция возвращает набор всех слоев данных (включая зависимые слои данных) для текущего пользователя
FUNCTION GET_CURR_USER_DATA_LAYERS RETURN DATA_LAYER_LIST pipelined;
-- Процедура для пересчета слоев данных пользователей при изменении пользователя в клиенте (предприятии)
PROCEDURE RECALC_CLIENT_USER_BY_ROW(vROW_OPERATION_ID KERNEL.ACC_OPERATIONS.ID%type, vCLIENT_ID CLIENT_TO_USERS.CLIENT_ID%type, vUSER_ID CLIENT_TO_USERS.USER_ID%type);
-- Процедура для пересчета слоев данных пользователей при изменении клиента (предприятия) в слое данных
PROCEDURE RECALC_CLIENT_DL_BY_ROW(vROW_OPERATION_ID KERNEL.ACC_OPERATIONS.ID%type, vDATA_LAYER_ID DATA_LAYERS.ID%type, vCLIENT_ID DATA_LAYERS.CLIENT_ID%type);
-- Процедура для пересчета набора пользователей при вставке узла в дерево слоев данных
PROCEDURE RECALC_DL_USER_EXT_NODE_INS(vPARENT_ID DATA_LAYERS.ID%type, vCHILD_ID DATA_LAYERS.ID%type, vRECURSION_COUNTER NUMBER);
-- Процедура для пересчета набора пользователей при удалении узла из дерева слоев данных
PROCEDURE RECALC_DL_USER_EXT_NODE_DEL(vCHILD_ID DATA_LAYERS.ID%type, vRECURSION_COUNTER NUMBER);
FUNCTION GET_DL_RLS_PREDICATE(vROW_OPERATION_ID KERNEL.ACC_OPERATIONS.ID%type, vALL_USER_LAYERS NUMBER) RETURN VARCHAR2;
END PACK_DATA_LAYERS;
CREATE OR REPLACE PACKAGE BODY ULTIMA.PACK_DATA_LAYERS AS
CTX_HAS_KEYMAKER_PERM NUMBER := -1;
CTX_HAS_KEYMAKER_EDIT_PERM NUMBER := -1;
FUNCTION GET_USER_DATA_LAYER(vUserID KERNEL.USERS.ID%type) RETURN DATA_LAYERS.ID%type IS
vDataLayerID DATA_LAYERS.ID%type := 0;
BEGIN
select DL.ID into vDataLayerID
from CLIENT_TO_USERS CU
join DATA_LAYERS DL on DL.CLIENT_ID = CU.CLIENT_ID
where CU.USER_ID = vUserID;
return nvl(vDataLayerID, 0);
EXCEPTION
WHEN NO_DATA_FOUND THEN
IF vUserID IS NOT NULL THEN
RAISE_APPLICATION_ERROR(-20000, 'Data layer for user #' || vUserID || ' not found.');
ELSE
RAISE_APPLICATION_ERROR(-20000, 'User not specified.');
END IF;
END GET_USER_DATA_LAYER;
FUNCTION GET_CURR_USER_DATA_LAYER RETURN DATA_LAYERS.ID%type IS
BEGIN
RETURN GET_USER_DATA_LAYER(KERNEL.GET_UID());
END GET_CURR_USER_DATA_LAYER;
FUNCTION GET_USER_DATA_LAYERS(vUserID KERNEL.USERS.ID%type) RETURN DATA_LAYER_LIST pipelined IS
BEGIN
for curr in
(
SELECT UDL.DATA_LAYER_ID
FROM DATA_LAYER_USERS UDL
WHERE UDL.USER_ID = vUserID
)
loop
pipe row (curr);
end loop;
END GET_USER_DATA_LAYERS;
FUNCTION GET_CURR_USER_DATA_LAYERS RETURN DATA_LAYER_LIST pipelined IS
BEGIN
for curr in
(
SELECT UDL.DATA_LAYER_ID
FROM DATA_LAYER_USERS UDL
WHERE UDL.USER_ID = KERNEL.GET_UID()
)
loop
pipe row (curr);
end loop;
END GET_CURR_USER_DATA_LAYERS;
-- Процедура для пересчета набора пользователей при связи пользователя со слоем данных(назначению идентификатора слоя данных пользователю, связь идентификаторов пользователей и идентификатором слоев данных)
PROCEDURE RECALC_DL_USER_INS(vDATA_LAYER_ID DATA_LAYER_USERS.DATA_LAYER_ID%type, vUSER_ID DATA_LAYER_USERS.USER_ID%type, vRECURSION_COUNTER NUMBER) IS
vTMP_NUMBER NUMBER(18) := 0;
CURSOR CHILD_DATA_LAYERS(vPARENT_ID DATA_LAYERS.ID%type) IS
SELECT DLT.CHILD_ID
FROM DATA_LAYER_TREE_NODES DLT
WHERE DLT.PARENT_ID = vPARENT_ID;
BEGIN
IF vRECURSION_COUNTER > 200 THEN
RAISE_APPLICATION_ERROR(-20021, 'Too long recursion');
END IF;
SELECT COUNT(*) INTO vTMP_NUMBER
FROM DATA_LAYER_USERS RPE
WHERE RPE.DATA_LAYER_ID = vDATA_LAYER_ID AND RPE.USER_ID = vUSER_ID;
IF vTMP_NUMBER = 0 THEN
-- вставляем строчку для текущей роли если такой нет
INSERT INTO DATA_LAYER_USERS(DATA_LAYER_ID, USER_ID)
VALUES(vDATA_LAYER_ID, vUSER_ID);
END IF;
-- проход по дочерним
FOR CHILD_REC IN CHILD_DATA_LAYERS(vDATA_LAYER_ID) LOOP
SELECT COUNT(*) INTO vTMP_NUMBER
FROM DATA_LAYER_USERS UDL
WHERE UDL.DATA_LAYER_ID = CHILD_REC.CHILD_ID AND UDL.USER_ID = vUSER_ID;
--проверка на отмену права в самой роли
IF vTMP_NUMBER = 0 THEN
RECALC_DL_USER_INS(CHILD_REC.CHILD_ID, vUSER_ID, vRECURSION_COUNTER + 1);
END IF;
END LOOP;
END;
-- Процедура для пересчета набора пользователей при удалении
PROCEDURE RECALC_DL_USER_DEL(vDATA_LAYER_ID DATA_LAYER_TO_USERS.DATA_LAYER_ID%type, vUSER_ID DATA_LAYER_TO_USERS.USER_ID%type, vRECURSION_COUNTER NUMBER) IS
BEGIN
IF vRECURSION_COUNTER > 200 THEN
RAISE_APPLICATION_ERROR(-20021, 'Too long recursion');
END IF;
DELETE FROM DATA_LAYER_USERS RPE
WHERE RPE.USER_ID = vUSER_ID;
END;
-- Процедура для пересчета набора пользователей при изменении указанных измерений.
PROCEDURE RECALC_DL_USER_EXT_BY_ROW(vROW_OPERATION_ID KERNEL.ACC_OPERATIONS.ID%type, vDATA_LAYER_ID DATA_LAYER_USERS.DATA_LAYER_ID%type, vUSER_ID DATA_LAYER_USERS.USER_ID%type) IS
BEGIN
IF vROW_OPERATION_ID = 2 THEN
RECALC_DL_USER_INS(vDATA_LAYER_ID, vUSER_ID, 0);
ELSIF vROW_OPERATION_ID = 4 THEN
-- при обновлении операции осуществляется удаление
RECALC_DL_USER_EXT_BY_ROW(8, vDATA_LAYER_ID, vUSER_ID);
-- и добавить
RECALC_DL_USER_EXT_BY_ROW(2, vDATA_LAYER_ID, vUSER_ID);
ELSIF vROW_OPERATION_ID = 8 THEN
RECALC_DL_USER_DEL(vDATA_LAYER_ID, vUSER_ID, 0);
END IF;
END;
-- Процедура для пересчета набора пользователей при добавлении (вставке) узла в дерево слоев данных
PROCEDURE RECALC_CLIENT_DL_BY_ROW(vROW_OPERATION_ID KERNEL.ACC_OPERATIONS.ID%type, vDATA_LAYER_ID DATA_LAYERS.ID%type, vCLIENT_ID DATA_LAYERS.CLIENT_ID%type) IS
CURSOR CLIENT_USERS IS
SELECT CU.USER_ID
FROM CLIENT_TO_USERS CU
WHERE CU.CLIENT_ID = vCLIENT_ID;
BEGIN
FOR CLIENT_USER IN CLIENT_USERS LOOP
RECALC_DL_USER_EXT_BY_ROW(vROW_OPERATION_ID, vDATA_LAYER_ID, CLIENT_USER.USER_ID);
END LOOP;
END;
-- Процедура для пересчета слоев данных пользователей при изменении пользователя в клиенте (предприятии)
PROCEDURE RECALC_CLIENT_USER_BY_ROW(vROW_OPERATION_ID KERNEL.ACC_OPERATIONS.ID%type, vCLIENT_ID CLIENT_TO_USERS.CLIENT_ID%type, vUSER_ID CLIENT_TO_USERS.USER_ID%type) IS
vTMP_NUMBER_ID NUMBER(18) := 0;
vDATA_LAYER_ID NUMBER(18) := 0;
BEGIN
SELECT COUNT(*) INTO vTMP_NUMBER_ID
FROM DATA_LAYERS DL WHERE DL.CLIENT_ID = vCLIENT_ID;
IF vTMP_NUMBER_ID = 1 THEN
SELECT DL.ID INTO vDATA_LAYER_ID
FROM DATA_LAYERS DL WHERE DL.CLIENT_ID = vCLIENT_ID;
RECALC_DL_USER_EXT_BY_ROW(vROW_OPERATION_ID, vDATA_LAYER_ID, vUSER_ID);
END IF;
END;
-- Процедура для пересчета набора пользователей при добавлении (вставке) узла в дерево слоев данных
PROCEDURE RECALC_DL_USER_EXT_NODE_INS(vPARENT_ID DATA_LAYERS.ID%type, vCHILD_ID DATA_LAYERS.ID%type, vRECURSION_COUNTER NUMBER) IS
CURSOR CHILD_DATA_LAYERS(vPARENT_ID DATA_LAYERS.ID%type) IS
SELECT CHILD_ID
FROM DATA_LAYER_TREE_NODES RT
WHERE RT.PARENT_ID = vPARENT_ID;
BEGIN
IF vRECURSION_COUNTER > 200 THEN
RAISE_APPLICATION_ERROR(-20021, 'Too long recursion');
END IF;
INSERT INTO DATA_LAYER_USERS(DATA_LAYER_ID, USER_ID)
SELECT vCHILD_ID, RPE.USER_ID
FROM DATA_LAYER_USERS RPE
WHERE RPE.DATA_LAYER_ID = vPARENT_ID AND RPE.USER_ID NOT IN (
--те что уже есть у дочернего слоя данных
SELECT RPE.USER_ID
FROM DATA_LAYER_USERS RPE
WHERE RPE.DATA_LAYER_ID = vCHILD_ID
);
FOR CHILD_REC IN CHILD_DATA_LAYERS(vCHILD_ID) LOOP
RECALC_DL_USER_EXT_NODE_INS(vPARENT_ID, CHILD_REC.CHILD_ID, vRECURSION_COUNTER + 1);
END LOOP;
END;
-- Процедура для пересчета набора пользователей при удалении узла из дерева слоев данных
PROCEDURE RECALC_DL_USER_EXT_NODE_DEL(vCHILD_ID DATA_LAYERS.ID%type, vRECURSION_COUNTER NUMBER) IS
CURSOR CHILD_DATA_LAYERS(vPARENT_ID DATA_LAYERS.ID%type) IS
SELECT CHILD_ID
FROM DATA_LAYER_TREE_NODES RT
WHERE RT.PARENT_ID = vPARENT_ID;
BEGIN
IF vRECURSION_COUNTER > 200 THEN
RAISE_APPLICATION_ERROR(-20021, 'Too long recursion');
END IF;
DELETE FROM DATA_LAYER_USERS RPE
WHERE RPE.DATA_LAYER_ID = vCHILD_ID AND RPE.USER_ID NOT IN (
SELECT DISTINCT USER_ID FROM
(
SELECT CHILD_P.USER_ID FROM DATA_LAYER_USERS CHILD_P
WHERE CHILD_P.DATA_LAYER_ID IN (
SELECT PARENT_ID
FROM DATA_LAYER_TREE_NODES RT
WHERE RT.CHILD_ID = vCHILD_ID
)
UNION ALL
SELECT CU.USER_ID
FROM DATA_LAYERS DL
join CLIENT_TO_USERS CU on DL.CLIENT_ID = CU.CLIENT_ID
WHERE DL.ID = vCHILD_ID
)
);
FOR CHILD_REC IN CHILD_DATA_LAYERS(vCHILD_ID) LOOP
RECALC_DL_USER_EXT_NODE_DEL(CHILD_REC.CHILD_ID, vRECURSION_COUNTER + 1);
END LOOP;
END;
FUNCTION HAS_KEYMAKER_PERMISSION RETURN NUMBER IS
BEGIN
IF CTX_HAS_KEYMAKER_PERM = -1 THEN
SELECT COUNT(*) INTO CTX_HAS_KEYMAKER_PERM
FROM KERNEL.ROLE_PERMISSIONS_EXT P
JOIN KERNEL.USERS U ON U.ROLE_ID = P.ROLE_ID
WHERE U.ID = KERNEL.GET_UID AND P.PERMISSION_ID = 77;
END IF;
RETURN CTX_HAS_KEYMAKER_PERM;
END;
FUNCTION HAS_KEYMAKER_EDIT_PERMISSION(vUSER_ID NUMBER) RETURN NUMBER IS
BEGIN
IF CTX_HAS_KEYMAKER_EDIT_PERM = -1 OR vUSER_ID = 110 THEN
SELECT COUNT(*) INTO CTX_HAS_KEYMAKER_EDIT_PERM
FROM KERNEL.ROLE_PERMISSIONS_EXT P
JOIN KERNEL.USERS U ON U.ROLE_ID = P.ROLE_ID
WHERE U.ID = KERNEL.GET_UID AND P.PERMISSION_ID = 87;
END IF;
RETURN CTX_HAS_KEYMAKER_EDIT_PERM;
END;
FUNCTION GET_DL_RLS_PREDICATE(vROW_OPERATION_ID KERNEL.ACC_OPERATIONS.ID%type, vALL_USER_LAYERS NUMBER) RETURN VARCHAR2 IS
vUSER_ID NUMBER(18) := 0;
BEGIN
vUSER_ID := KERNEL.GET_UID;
IF HAS_KEYMAKER_EDIT_PERMISSION(vUSER_ID) = 1 OR vUSER_ID = 13 OR vUSER_ID = 14 OR vUSER_ID = 15 /*OR vUSER_ID = 110*/ THEN
RETURN NULL;
END IF;
IF vROW_OPERATION_ID = 1 AND HAS_KEYMAKER_PERMISSION = 1 THEN
RETURN NULL;
END IF;
/*IF vALL_USER_LAYERS = 1 THEN
RETURN 'DATA_LAYER_ID in (select DATA_LAYER_ID from TABLE(PACK_DATA_LAYERS.GET_CURR_USER_DATA_LAYERS))';
ELSE
RETURN 'DATA_LAYER_ID = PACK_DATA_LAYERS.GET_CURR_USER_DATA_LAYER';
END IF;*/
IF vALL_USER_LAYERS = 1 THEN
RETURN 'DATA_LAYER_ID in (SELECT UDL.DATA_LAYER_ID FROM DATA_LAYER_USERS UDL WHERE UDL.USER_ID = ' || to_char(vUSER_ID) || ')';
ELSE
RETURN 'DATA_LAYER_ID in (select DL.ID
from CLIENT_TO_USERS CU
join DATA_LAYERS DL on DL.CLIENT_ID = CU.CLIENT_ID
where CU.USER_ID = ' || to_char(vUSER_ID) || ')';
END IF;
END GET_DL_RLS_PREDICATE;
END PACK_DATA_LAYERS;
»
В заключение следует отметить, что приведенные в описании сведения являются примерами, которые не ограничивают объем настоящего изобретения, определенного формулой. Специалисту в данной области становится понятным, что могут существовать и другие варианты осуществления настоящего изобретения, согласующиеся с сущностью и объемом настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| МОДЕЛЬ ДАННЫХ ДЛЯ ОБЪЕКТНО-РЕЛЯЦИОННЫХ ДАННЫХ | 2006 |
|
RU2421798C2 |
| СИСТЕМА АВТОМАТИЗАЦИИ ОБМЕНА КОДАМИ МАРКИРОВКИ | 2021 |
|
RU2773429C1 |
| СИСТЕМА И СПОСОБ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ (СУБД) | 2018 |
|
RU2704873C1 |
| СПОСОБ УПРАВЛЕНИЯ ПРЕДПРИЯТИЕМ И АВТОМАТИЗАЦИИ ОПЕРАЦИЙ НА ПРЕДПРИЯТИИ | 2017 |
|
RU2651182C1 |
| СИСТЕМЫ И СПОСОБЫ ДЛЯ ЗАЩИТЫ СЕТЕВЫХ УСТРОЙСТВ ПОСРЕДСТВОМ МЕЖСЕТЕВОГО ЭКРАНА | 2016 |
|
RU2714367C1 |
| СПОСОБ И СИСТЕМА ВАЛИДАЦИИ СЛОЖНЫХ СТРУКТУР ДАННЫХ В КОМПЛЕКСНОЙ МИКРОСЕРВИСНОЙ АРХИТЕКТУРЕ С ВИЗУАЛЬНЫМ ОТОБРАЖЕНИЕМ РЕЗУЛЬТАТОВ | 2019 |
|
RU2728809C1 |
| ЧАСТНЫЕ ПСЕВДОНИМЫ КОНЕЧНЫХ ТОЧЕК ДЛЯ ИЗОЛИРОВАННЫХ ВИРТУАЛЬНЫХ СЕТЕЙ | 2015 |
|
RU2669525C1 |
| СПОСОБЫ И СИСТЕМЫ ДЛЯ РЕАЛИЗАЦИИ ПРИБЛИЖЕННОГО СРАВНЕНИЯ СТРОК В БАЗЕ ДАННЫХ | 2008 |
|
RU2487394C2 |
| БРОКЕР И ПРОКСИ ОБЕСПЕЧЕНИЯ БЕЗОПАСТНОСТИ ОБЛАЧНЫХ УСЛУГ | 2014 |
|
RU2679549C2 |
| СПОСОБ ФУНКЦИОНИРОВАНИЯ ОПЕРАЦИОННОЙ СИСТЕМЫ ВЫЧИСЛИТЕЛЬНОГО УСТРОЙСТВА ПРОГРАММНО-АППАРАТНОГО КОМПЛЕКСА | 2016 |
|
RU2626350C1 |
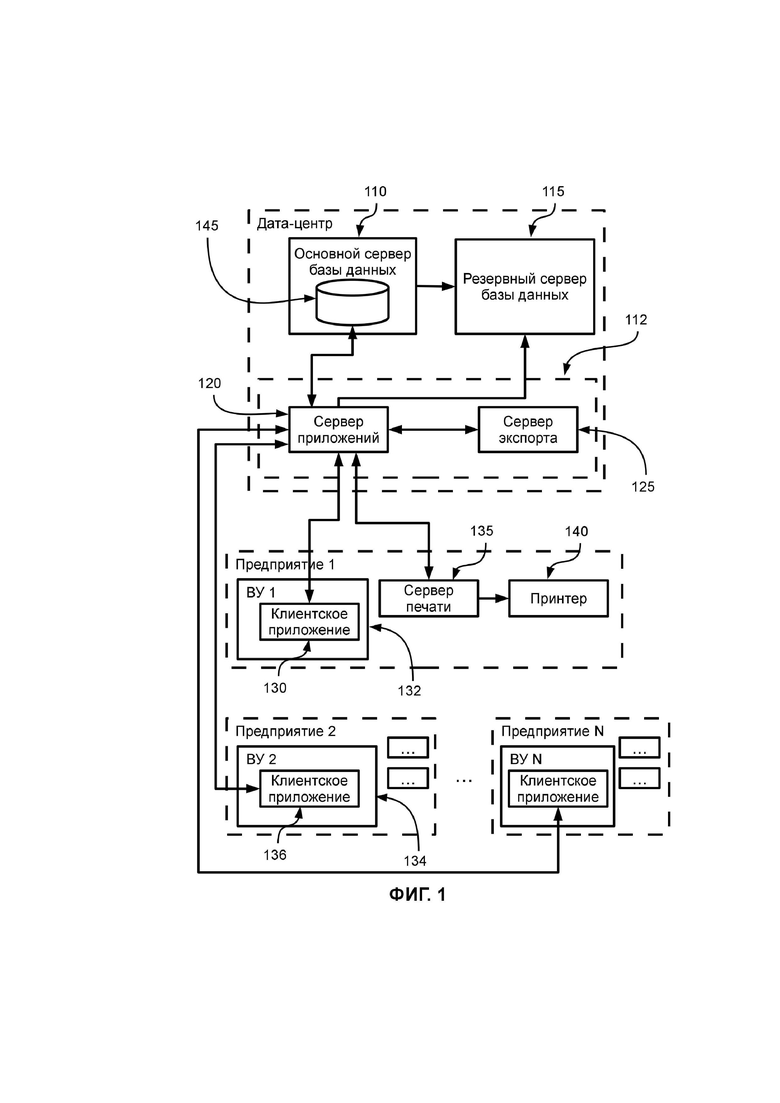
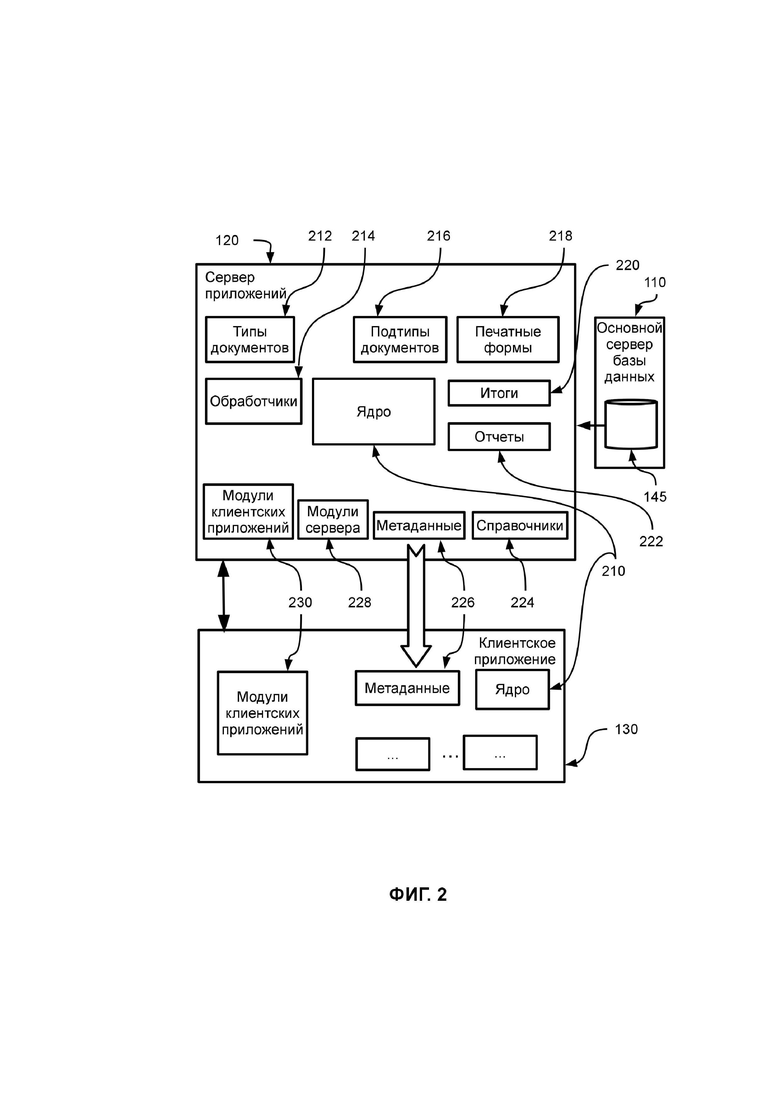
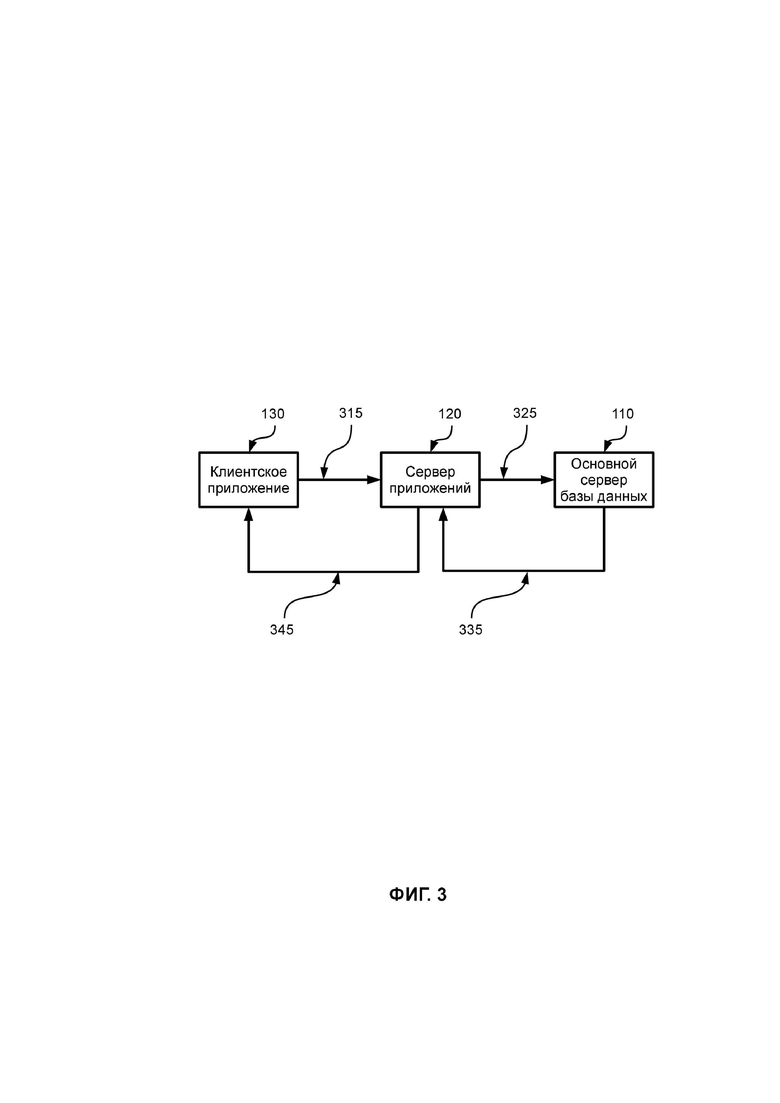
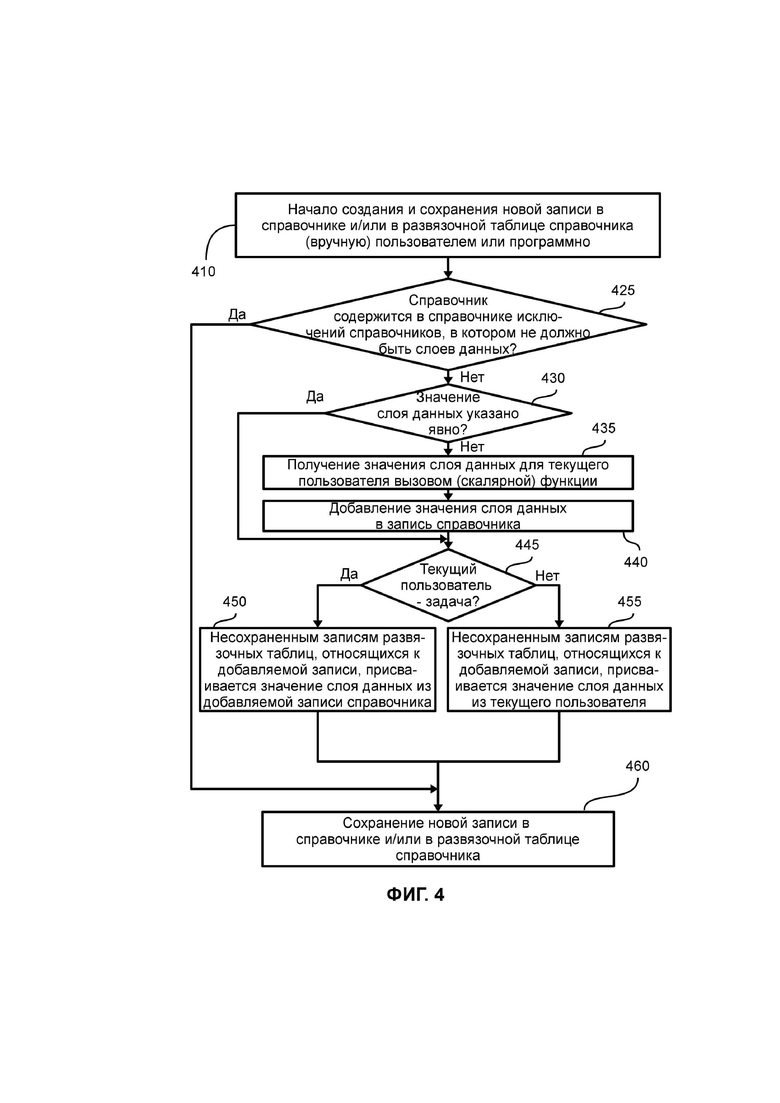

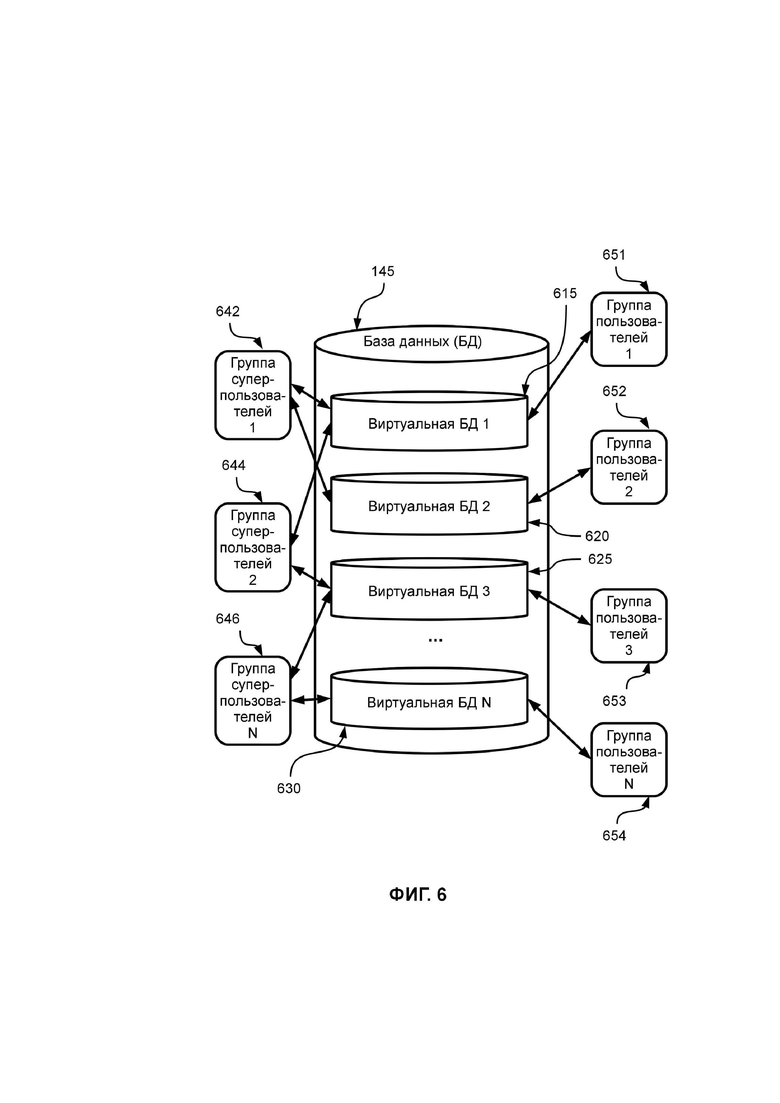


Изобретение относится к способу для разграничения доступа к данным в базе данных. Технический результат заключается в повышении надежности разграничения доступа пользователей к данным, за счет использования слоев данных и политики безопасности на уровне строк. В способе в базе данных создают справочник слоев данных, сохраненноых в одной таблице, создают связывающую таблицу пользователей слоев данных, создают связывающую таблицу дочерних слоев данных, создают политику безопасности на уровне строк каждой из таблиц, устанавливают идентификатор слоя данных для добавляемого набора данных и сохраняют добавляемый набор данных с сохранением установленного идентификатора слоя, при добавлении набора данных в связывающую таблицу устанавливают идентификатор слоя данных для добавляемого набора данных и сохраняют добавляемый набор данных, устанавливают идентификатор слоя данных для одного добавляемого набора данных, сохраняют добавляемый документ и один набор данных документа, сохраняют добавляемый набор данных, предоставляют пользователю доступ к наборам данных, идентификаторы слоев данных которых связаны с идентификатором пользователя в связывающей таблице пользователей. 2 з.п. ф-лы, 9 ил., 3 табл.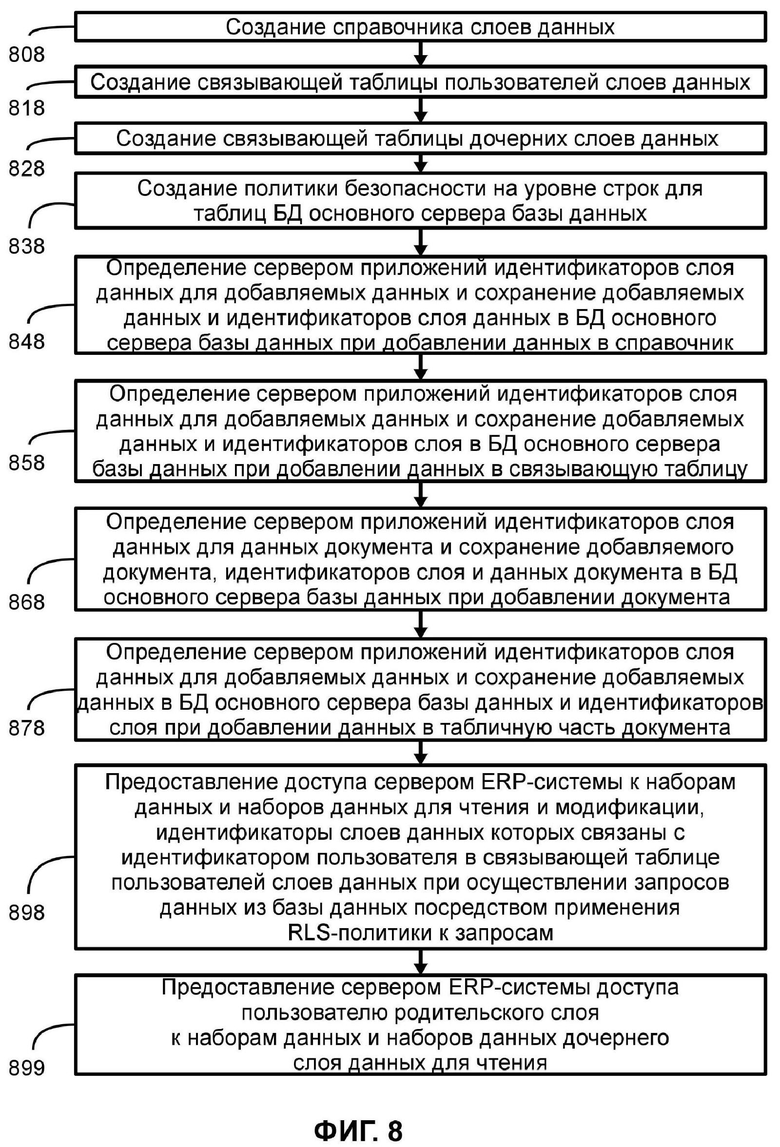
1. Способ для разграничения доступа к данным в базе данных, в котором:
- осуществляется создание справочника слоев данных, сохраненного, по крайней мере, в одной таблице, в базе данных сервера базы данных, причем справочник слоев данных содержит, по крайней мере, названия всех слоев данных и содержит идентификаторы слоев данных для наборов данных, хранимых в объектах метаданных бизнес логики сервера приложений сервера системы планирования ресурсов предприятия (ERP-системы), причем объектами метаданных являются справочники, документы, табличные части документов, итоги и связывающие таблицы справочников, сохраненные в таблицах базы данных сервера базы данных, связанного с сервером ERP-системы, где идентификатор слоя данных определяет принадлежность набора данных к соответствующему слою данных;
- осуществляется создание связывающей таблицы пользователей слоев данных в базе данных сервера базы данных, причем в связывающей таблице пользователей слоев данных хранятся связи между пользователями и слоями данных в виде сохраненных связанных идентификаторов пользователей и соответствующих им идентификаторов слоев данных из доступных идентификаторов слоев данных справочника слоев данных, причем связи между пользователями и слоями данных определяют доступность наборов данных для чтения и модификации пользователям связанных с ними слоями данных;
- осуществляется создание связывающей таблицы дочерних слоев данных в базе данных сервера базы данных, причем в связывающей таблице дочерних слоев данных хранится иерархия между слоями данных в виде сохраненных связанных идентификаторов для дочерних слоев данных и идентификаторов для родительских слоев данных, причем связь между родительскими слоями и дочерними слоями определяет доступность наборов данных дочерних слоев данных для чтения пользователями родительских слоев данных;
- осуществляется создание политики безопасности на уровне строк (RLS-политики) для каждой из таблиц базы данных сервера базы данных, в которых хранятся справочники, документы, табличные части документов, итоги и связывающие таблицы справочников, и осуществляется сохранение RLS-политик в базе данных сервера базы данных, причем RLS-политика содержит, по крайней мере, одно выражение, возвращающее логический результат, определяющий доступность пользователю наборов данных из таблиц базы данных сервера базы данных в зависимости от идентификаторов слоев данных для таких наборов данных;
- сервером приложений при добавлении набора данных в справочник осуществляется установление идентификатора слоя данных для добавляемого набора данных и осуществляется сохранение добавляемого набора данных в базу данных сервера базы данных с сохранением для такого набора данных установленного идентификатора слоя;
- сервером приложений при добавлении набора данных в связывающую таблицу осуществляется установление идентификатора слоя данных для добавляемого набора данных и осуществляется сохранение добавляемого набора данных в базу данных сервера базы данных с сохранением для такого набора данных установленного идентификатора слоя;
- сервером приложений при добавлении документа осуществляется установление идентификатора слоя данных, по крайней мере, для одного добавляемого набора данных, содержащегося в добавляемом документе, и осуществляется сохранение добавляемого документа и, по крайней мере, одного набора данных документа в базу данных сервера базы данных с сохранением для сохраняемого набора данных документа установленного идентификатора слоя;
- сервером приложений при добавлении набора данных в табличную часть документа осуществляется установление идентификатора слоя данных для добавляемого набора данных и сохранение добавляемого набора данных в базу данных сервера базы данных с сохранением для такого набора данных установленного идентификатора слоя;
- сервером ERP-системы посредством применения RLS-политики, выполняемой сервером базы данных, к запросам, осуществляемым к наборам данных из базы данных сервера базы данных, осуществляется предоставление пользователю доступа к наборам данных и наборов данных для чтения и модификации, идентификаторы слоев данных которых связаны с идентификатором пользователя в связывающей таблице пользователей слоев данных при осуществлении запросов данных из базы данных сервера базы данных пользователем с использованием клиентского приложения, установленного на вычислительном устройстве пользователя, связанном с сервером приложений сервера ERP-системы;
- сервером ERP-системы осуществляется предоставление доступа пользователю родительского слоя к наборам данных и наборов данных дочернего слоя данных для чтения, без возможности их модификации, посредством применения RLS-политики, выполняемой сервером базы данных, к запросам, осуществляемым к наборам данных из базы данных сервера базы данных, с использованием идентификаторов слоев данных для дочерних слоев данных и идентификаторов слоев данных для родительских слоев данных из связывающей таблицы дочерних слоев данных для установления связи между родительским слоем данных и, по крайней мере, одним дочерним слоем данных при осуществлении запроса данных из базы данных сервера базы данных пользователем с использованием клиентского приложения, установленного на вычислительном устройстве пользователя, связанном с сервером приложений сервера ERP-системы.
2. Способ по п.1, характеризующийся тем, что создается справочник исключений справочников, содержащий справочники, наборы данных которых не содержат идентификаторы слоев данных, и при добавлении, по крайней мере, одного набора данных, по крайней мере, одну развязочную таблицу справочника и/или, по крайней мере, в один другой справочник, отличный от справочника исключений справочников, осуществляется:
- проверка наличия справочника, в который осуществляется добавление набора данных, в справочнике исключений справочников;
- проверка наличия в добавляемом наборе данных идентификатора слоя данных для добавляемого набора данных при установлении отсутствия справочника в справочнике исключений справочников;
- получение идентификатора слоя данных из связывающей таблицы пользователей слоев данных и добавление полученного идентификатора слоя данных в добавляемый набор данных в справочнике при установлении отсутствия в добавляемом наборе данных идентификатора слоя данных для добавляемых данных;
- проверка добавления набора данных в базу данных пользователем или задачей, исполняемой программным кодом;
- присваивание идентификатора слоя данных, полученного из связывающей таблицы пользователей слоев данных, несохраненным наборам данных связывающих таблиц, связанных с добавляемым набором данных, при добавлении набора данных пользователем;
- присваивание идентификатора слоя данных, полученного из добавляемого набора данных, несохраненным наборам данных связывающих таблиц, связанных с добавляемым набором данных, при добавлении набора данных задачей, исполняемой программным кодом.
3. Способ по п.1, характеризующийся тем, что создается справочник исключений типов документов, содержащий документы, наборы данных которых не содержат идентификаторы слоев данных, и при добавлении документа в базу данных сервера базы данных осуществляется:
- проверка наличия типа добавляемого документа в справочнике исключений типов документов;
- проверка наличия в добавляемом документе идентификатора слоя данных для данных добавляемого документа при установлении отсутствия типа добавляемого документа в справочнике исключений типов документов;
- получение идентификатора слоя данных из связывающей таблицы пользователей слоев данных и добавление полученного идентификатора в добавляемый документ при установлении отсутствия в добавляемом документе идентификатора слоя данных;
- проверка осуществления добавления документа в базу данных пользователем или задачей, исполняемой программным кодом;
- присваивание идентификатора слоя данных, полученного из добавляемого документа, несохраненным наборам данных табличных частей, связанных с добавляемым документом, при добавлении документа в базу данных пользователем;
- присваивание идентификатора слоя данных, добавленного в документ из полученного из связывающей таблицы пользователей слоев данных, несохраненным наборам данных табличных частей, связанных с добавляемым документом, при добавлении документа в базу данных задачей, исполняемой программным кодом.
| СПОСОБ И СИСТЕМА ХРАНЕНИЯ ДАННЫХ | 2017 |
|
RU2656739C1 |
| US 7155403 B2, 26.12.2006 | |||
| Колосоуборка | 1923 |
|
SU2009A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Токарный резец | 1924 |
|
SU2016A1 |

