Настоящая заявка имеет отношение к кодированию массива выборок (элементов дискретизации), такому как кодирование изображений или видео.
Распараллеливание кодера и декодера очень важно из-за увеличения требований к обработке из-за стандарта HEVC, а также из-за ожидаемого увеличения видео разрешения. Многоядерная архитектура становится доступной в широком диапазоне современных электронных устройств. Следовательно, требуются эффективные способы предоставления возможности использования многоядерной архитектуры.
Кодирование или декодирование LCU происходит при растровом сканировании, с помощью которого вероятность CABAC адаптируют к конкретным особенностям каждого изображения. Пространственные зависимости существуют между смежными LCU. Каждая LCU (наибольшая единица кодирования) зависит от ее левой, верхней, верхней-левой и верхней-правой соседних LCU, из-за различных компонент, например, вектора движения, предсказания, внутреннего предсказания и других. Из-за предоставления возможности распараллеливания при декодировании эти зависимости обычно необходимо прерывать или они прерываются в современных применениях.
Были предложены некоторые концепции распараллеливания, а именно, волновая обработка данных. Мотивацией для дополнительного исследования является использование методов, которые снижают потерю эффективности кодирования и таким образом уменьшают затраты в отношении битового потока для подходов распараллеливания в кодере и декодере. Кроме того, обработка с низкой задержкой была невозможна с помощью доступных методов.
Таким образом задачей настоящего изобретения является обеспечение концепции кодирования массивов выборок, которая предоставляет возможность меньшей задержки при сравнительно меньшем ухудшении эффективности кодирования.
Эту задачу обеспечивают с помощью содержимого прилагаемых независимых пунктов формулы изобретения.
Если энтропийное кодирование текущей части предопределенного энтропийного слайса основано на соответствующих оценках вероятности предопределенного энтропийного слайса, которые адаптируют, используя ранее закодированную часть предопределенного энтропийного слайса, но не только, но также и на оценках вероятности, которые используются при энтропийном кодировании пространственно соседнего, по порядку энтропийных слайсов предыдущего энтропийного слайса в его соседней части, то оценки вероятности, используемые при энтропийном кодировании, адаптируют к фактической статистической информации символов более близко, таким образом снижая уменьшение эффективности кодирования, обычно вызываемое концепциями более низкой задержки. Временные взаимосвязи могут использоваться дополнительно или альтернативно.
Например, зависимость от оценок вероятности, которые используются при энтропийном кодировании пространственно соседнего, по порядку энтропийных слайсов предыдущего энтропийного слайса, может вовлекать инициализацию оценок вероятности в начале энтропийного кодирования предопределенного энтропийного слайса. Обычно оценки вероятности инициализируются в значения, адаптированные к статистической информации символов характерной смеси материала массива выборок. Чтобы избежать передачи значений инициализации оценок вероятности, они известны кодеру и декодеру по определению. Однако, такие предопределенные значения инициализации естественно являются просто компромиссом между битрейтом (частотой следования битов) дополнительной информации с одной стороны и эффективностью кодирования с другой стороны, поскольку значения инициализации естественно - более или менее - отклоняются от фактической типовой статистической информации кодируемого в настоящее время материала массива выборок. Адаптирование вероятности во время кодирования энтропийного слайса адаптирует оценки вероятности к фактической статистической информации символов. Этот процесс ускоряют с помощью инициализации оценок вероятности в начале энтропийного кодирования текущего/предопределенного энтропийного слайса, используя уже адаптированные оценки вероятности только что упомянутого пространственно соседнего, по порядку энтропийных слайсов предыдущего энтропийного слайса, поскольку последние значения уже, до некоторой степени, адаптированы к фактической статистической информации рассматриваемого в настоящее время символа массива выборок. Кодирование с низкой задержкой может, однако, быть доступно с помощью использования при инициализации оценок вероятности для предопределенных/текущих энтропийных слайсов, данные оценки вероятности используются в его соседней части, вместо того, чтобы обнаруживаться в конце энтропийного кодирования предыдущего энтропийного слайса. С помощью этих мер все еще возможна волновая обработка данных.
Дополнительно, вышеупомянутая зависимость от оценок вероятности, которые используются при энтропийном кодировании пространственно соседнего, по порядку энтропийных слайсов предыдущего энтропийного слайса, может вовлекать процесс адаптирования, состоящий из адаптирования оценок вероятности, непосредственно используемых при энтропийном кодировании текущего/предопределенного энтропийного слайса. Адаптирование оценки вероятности вовлекает использование только что закодированной части, то есть только что закодированного символа(ов), для адаптирования текущего состояния оценок вероятности к фактической статистической информации символов. С помощью этих мер инициализированные оценки вероятности адаптируются с некоторой скоростью адаптирования к фактической статистической информации символа. Данная скорость адаптирования увеличивается с помощью выполнения только что упомянутого адаптирования оценки вероятности, основываясь не только на кодируемом в настоящее время символе текущего/предопределенного энтропийного слайса, но также и в зависимости от оценок вероятности, которые были обнаружены в соседней части пространственно соседнего, по порядку энтропийных слайсов предыдущего энтропийного слайса. Снова, с помощью выбора пространственно соседней текущей части текущего энтропийного слайса и соседней части предыдущего энтропийного слайса, соответственно, волновая обработка данных все еще возможна. Преимуществом от соединения адаптирования собственной оценки вероятности по текущему энтропийному слайсу с адаптированием вероятности предыдущего энтропийного слайса является увеличение скорости, с которой происходит адаптирование к фактической статистической информации символов, поскольку множество символов, через которые перемещаются в текущем и предыдущем энтропийных слайсах, вносят вклад в адаптирование, а не просто символы текущего энтропийного слайса.
Предпочтительные воплощения вариантов осуществления настоящего изобретения являются объектом зависимых пунктов формулы изобретения. Дополнительно, предпочтительные варианты осуществления описаны по отношению к фигурам, среди которых:
фиг. 1 показывает структурную схему примерного кодера;
фиг. 2 показывает схематическую диаграмму разделения изображения на слайсы и части слайсов (то есть блоки или единицы кодирования) наряду с порядком кодирования, определенным между ними;
фиг. 3 показывает последовательность операций функционирования примерного кодера, такого как кодер на фиг. 1;
фиг. 4 показывает схематическую диаграмму для объяснения функционирования примерного кодера, такого как кодер на фиг. 1;
фиг. 5 показывает схематическую диаграмму параллельного работающего воплощения кодера и декодера;
фиг. 6 показывает структурную схему примерного декодера;
фиг. 7 показывает последовательность операций функционирования примерного декодера, такого как декодер на фиг. 6;
фиг. 8 показывает схематическую диаграмму примерного битового потока, являющегося результатом схемы кодирования на фиг. 1 - 6;
фиг. 9 схематично показывает пример вычисления вероятности с помощью других LCU;
фиг. 10 показывает график, иллюстрирующий результаты RD для внутреннего способа (4 потока) в сравнении с HM3.0;
фиг. 11 показывает график, иллюстрирующий результаты RD для способа с низкой задержкой (1 поток) по сравнению с HM3.0;
фиг. 12 показывает график, иллюстрирующий результаты RD для способа произвольного доступа (1 поток) по сравнению с HM3.0;
фиг. 13 показывает график, иллюстрирующий результаты RD для способа с низкой задержкой (4 потока) по сравнению с HM3.0;
фиг. 14 схематично и примерно иллюстрирует возможные соединения энтропийных слайсов;
фиг. 15 схематично и примерно иллюстрирует возможную сигнализацию энтропийного слайса;
фиг. 16 схематично и примерно иллюстрирует кодирование, сегментацию, перемежение и декодирование данных энтропийного слайса через фрагменты;
фиг. 17 схематично и примерно иллюстрирует возможное соединение между кадрами;
фиг. 18 схематично и примерно иллюстрирует возможное использование соотнесенной информации;
фиг. 19 схематично показывает возможность прохождения волны наклонно в пределах пространственного/временного пространства, заполненного последовательными массивами выборок; и
фиг. 20 схематично показывает другой пример для подразделения энтропийных слайсов на фрагменты.
Для облегчения понимания нижеизложенных мер для улучшения обеспечения низкой задержки при меньшем количестве недостатков по отношению к эффективности кодирования, кодер на фиг. 1 сначала описан в более общих чертах без предварительного обсуждения предпочтительных концепций вариантов осуществления настоящей заявки и как он может встраиваться в вариант осуществления на фиг. 1. Нужно упомянуть, однако, что структура, показанная на фиг. 1, служит просто в качестве иллюстративной среды, в которой могут использоваться варианты осуществления настоящей заявки. Обобщения и альтернативные варианты для кодеров и декодеров в соответствии с вариантами осуществления настоящего изобретения также кратко обсуждаются.
Фиг. 1 показывает кодер для кодирования массива 10 выборок в энтропийно закодированный поток 20 данных. Как показано на фиг. 1, массив 10 выборок может быть одной из последовательностей 30 массивов выборок, и кодер может быть сконфигурирован для кодирования последовательности 30 в поток 20 данных.
Кодер на фиг. 1 в общем случае обозначен ссылочным символом 40 и содержит предварительный кодер 42, за которым следует каскад 44 энтропийного кодирования, выход которого выводит поток 20 данных. Предварительный кодер 42 сконфигурирован для приема и обработки массива 10 выборок для описания его содержимого посредством синтаксических элементов с предопределенным синтаксисом, причем каждый синтаксический элемент является соответствующим одним из предопределенного набора типов синтаксических элементов, которые, в свою очередь, связанны с соответствующей семантикой.
При описании массива 10 выборок, используя синтаксические элементы, предварительный кодер 42 может подразделять массив 10 выборок на единицы 50 кодирования. Термин «единица кодирования» может, по причинам, указанным более подробно ниже, альтернативно называться «единицами дерева кодирования» (CTU). Одна возможность того, как предварительный кодер 42 может подразделять массив 10 выборок на единицы 50 кодирования, для примера показана на фиг. 2. В соответствии с данным примером данное разделение регулярно разделяет массив 10 выборок на единицы 50 кодирования, так, чтобы последние были расположены в строках и столбцах, чтобы без зазора охватывать весь массив 10 выборок без наложения. Другими словами, предварительный кодер 42 может быть сконфигурирован для описания каждой единицы 50 кодирования посредством синтаксических элементов. Некоторые из этих синтаксических элементов могут формировать информацию подразделения для дополнительного подразделения соответствующей единицы 50 кодирования. Например, посредством подразделения на множество деревьев, информация подразделения может описывать подразделение соответствующей единицы 50 кодирования на блоки 52 предсказания, причем предварительный кодер 42 связывает режим предсказания со связанными параметрами предсказания для каждого из этих блоков 52 предсказания. Это подразделение предсказания может предоставлять возможность, чтобы блоки 52 предсказания были различного размера, как иллюстрировано на фиг. 2. Предварительный кодер 42 может также связывать остаточную информацию подразделения с блоками 52 предсказания для дополнительного подразделения блоков 52 предсказания на остаточные блоки 54 для описания ошибки предсказания для каждого блока 52 предсказания. Таким образом, предварительный кодер может быть сконфигурирован для генерации синтаксического описания массива 10 выборок в соответствии с гибридной схемой кодирования. Однако, как уже отмечено выше, только что упомянутый способ, с помощью которого предварительный кодер 42 описывает массив 10 выборок посредством синтаксических элементов, был представлен просто в целях иллюстрации, и он может также воплощаться по-другому.
Предварительный кодер 42 может использовать пространственные взаимосвязи между содержимым соседних единиц 50 кодирования из массива 10 выборок. Например, предварительный кодер 42 может предсказывать синтаксические элементы для некоторой единицы 50 кодирования из синтаксических элементов, определенных для ранее закодированных единиц 50 кодирования, которые являются пространственно смежными с кодируемой в настоящее время единицей 50 кодирования. На фиг. 1 и 2, например, верхняя и левая соседние элементы служат для предсказания, которое иллюстрировано стрелками 60 и 62. Кроме того, предварительный кодер 42 в способе внутреннего предсказания уже может экстраполировать закодированное содержимое соседних единиц 50 кодирования в текущую единицу 50 кодирования для получения предсказания выборок текущей единицы 50 кодирования. Как иллюстрировано на фиг. 1, предварительный кодер 42 может, без использования пространственных взаимосвязей, во временной области предсказывать выборки и/или синтаксические элементы для текущей единицы 50 кодирования из ранее закодированных массивов выборок, как иллюстративно показано на фиг. 1 посредством стрелки 64. То есть данное предсказание с компенсацией движения может использоваться предварительным кодером 42, и сами векторы движения могут быть объектом временного предсказания из векторов движения ранее закодированных массивов выборок.
То есть предварительный кодер 42 может описывать содержимое массива 10 выборок по отношению к единицам кодирования, и для этой цели он может использовать пространственное предсказание. Пространственное предсказание ограничено для каждой единицы 50 кодирования пространственно соседними единицами кодирования того же самого массива 10 выборок таким образом, что когда придерживаются порядка 66 кодирования среди единиц 50 кодирования массива 10 выборок, через соседние единицы кодирования, служащие в качестве опоры предсказания для пространственного предсказания, в общем случае уже перемещались по порядку 66 кодирования перед текущей единицей 50 кодирования. Как показывается на фиг. 2, порядок 66 кодирования, определенный среди единиц 50 кодирования, может, например, быть порядком растрового сканирования, согласно которому через единицы 50 кодирования перемещаются строка за строкой сверху вниз. Необязательно, подразделение массива 10 на массив тайлов может приводить к тому, что порядок сканирования 66 перемещается - по порядку растрового сканирования - через единицы 50 кодирования, которые создают один тайл, сначала перед переходом к следующему по порядку тайлу, который, в свою очередь, может также иметь тип растрового сканирования. Например, пространственное предсказание может вовлекать просто соседние единицы 50 кодирования в пределах строки единиц кодирования выше строки единиц кодирования, в пределах которой находится текущая единица 50 кодирования, и единицу кодирования в пределах той же самой строки единиц кодирования, но слева относительно текущей единицы кодирования. Как будет объяснено более подробно ниже, это ограничение на пространственную взаимосвязь/пространственное предсказание предоставляет возможность параллельной волновой обработки данных.
Предварительный кодер 42 направляет синтаксические элементы к каскаду 44 энтропийного кодирования. Как только что изложено, некоторые из этих синтаксических элементов закодированы с предсказанием, то есть представляют ошибки предсказания. Предварительный кодер 42 может, таким образом, расцениваться как кодер с предсказанием. Кроме того, предварительный кодер 42 может быть кодером с преобразованием, сконфигурированном для преобразования остатков кодов предсказания содержимого единиц 50 кодирования.
Примерная внутренняя структура каскада 44 энтропийного кодирования также показана на фиг. 1. Как показано, каскад 44 энтропийного кодирования может необязательно содержать средство представления в символьной форме для преобразования каждого из синтаксических элементов, принятых из предварительного кодера 42, количество возможных состояний которого превышает количество элементов алфавита символов, в последовательность символов si алфавита символов, основываясь на которой работает средство (движок) 44 энтропийного кодирования. Кроме этого необязательного средства 70 представления в символьной форме средство 44 энтропийного кодирования может содержать средство 72 выбора контекста и средство 74 инициализации, средство 76 управления оценкой вероятности, средство 78 адаптирования оценки вероятности и ядро 80 энтропийного кодирования. Выходной сигнал ядра энтропийного кодирования формирует выходной сигнал каскада 44 энтропийного кодирования. Кроме того, ядро 80 энтропийного кодирования содержит два входа, а именно, один - для приема символов si последовательности символов, а другой - для приема оценки pi вероятности для каждого из символов.
Из-за свойств энтропийного кодирования эффективность кодирования по отношению к степени сжатия увеличивается с улучшением оценки вероятности: чем лучше оценка вероятности соответствует фактической статистической информации символа, тем лучше степень сжатия.
В примере на фиг. 1 средство 72 выбора контекста сконфигурировано для выбора для каждого символа si соответствующего контекста ci среди набора доступных контекстов, которыми управляет средство 76 управления. Нужно отметить, однако, что выбор контекста формирует просто необязательную особенность и ее можно не использовать, например, используя одинаковый контекст для каждого символа. Однако, если используется выбор контекста, то средство 72 выбора контекста может быть сконфигурировано для выполнения выбора контекста, по меньшей мере частично основываясь на информации, которая относится к единицам кодирования вне текущей единицы кодирования, а именно, которая относится к соседним единицам кодирования в пределах ограниченной близости, как обсуждается выше.
Средство 76 управления содержит запоминающее устройство, которое сохраняет для каждого доступного контекста связанную с ним оценку вероятности. Например, алфавит символа может быть двоичным алфавитом, так что просто одно значение вероятности, вероятно, придется сохранять для каждого доступного контекста.
Средство 74 инициализации может периодически инициализировать или повторно инициализировать оценки вероятности, сохраненные в средстве 76 управления для доступных контекстов. Возможные моменты времени, в которые может выполняться такая инициализация, обсуждаются дополнительно ниже.
Средство 78 адаптирования имеет доступ к парам символов si и соответствующим оценкам pi вероятности и, соответственно, адаптирует оценки вероятности в средстве 76 управления. То есть каждый раз, когда оценка вероятности применяется ядром 80 энтропийного кодирования для энтропийного кодирования соответствующего символа si в поток 20 данных, средство 78 адаптирования может изменять эту оценку вероятности в соответствии со значением данного текущего символа si, так, чтобы эта оценка pi вероятности была лучше адаптирована к фактической статистической информации символа, когда кодируют следующий символ, который связан с данной оценкой вероятности (посредством его контекста). То есть средство 78 адаптирования принимает оценку вероятности для выбранного контекста от средства 76 управления наряду с соответствующим символом si и адаптирует оценку pi вероятности, соответственно так, чтобы для следующего символа si того же самого контекста ci использовалась адаптивная оценка вероятности.
Ядро 80 энтропийного кодирования, например, сконфигурировано для работы в соответствии со схемой арифметического кодирования или со схемой энтропийного кодирования с разделением интервала вероятности. При арифметическом кодировании ядро 80 энтропийного кодирования, например, непрерывно обновляет свое состояние, когда кодирует последовательность символов, состоянием, например, определяемым интервалом вероятности, определенным с помощью значения ширины интервала вероятности и значения смещения интервала вероятности. Когда работает в конвейерной концепции, ядро 80 энтропийного кодирования, например, разделяет область возможных значений оценок вероятности на различные интервалы с выполнением энтропийного кодирования с фиксированной вероятностью по отношению к каждому из этих интервалов, таким образом получая подпоток для каждого из подинтервалов, эффективность кодирования которых, соответственно, настраивается для связанного интервала вероятности. В случае энтропийного кодирования выходом потока 20 данных является арифметически закодированный поток данных, передающий информацию к стороне декодирования, которая предоставляет возможность эмуляции или повторного выполнения процесса подразделения данного интервала.
Естественно, возможно для состояния 44 энтропийного кодирования энтропийно кодировать всю информацию, то есть все синтаксические элементы/символы si, относящиеся к массиву 10 выборок, с помощью инициализации оценок вероятности просто один раз в его начале, и затем непрерывного обновления оценки вероятности с помощью средства 78 адаптирования. Это, однако, привело бы к созданию потока 20 данных, который пришлось бы последовательно декодировать на стороне декодирования. Другими словами, не было бы возможности, чтобы какой-либо декодер подразделял результирующий поток данных на несколько подпорций и декодировал подпорции параллельно. Это, в свою очередь, препятствовало бы всем усилиям уменьшить задержку.
Соответственно, как будет изложено более подробно ниже, удобно подразделять множество данных, описывающих массив 10 выборок, на так называемые энтропийные слайсы. Каждый из этих энтропийных слайсов, соответственно, охватывает отличающийся набор синтаксических элементов, относящихся к массиву 10 выборок. Если бы каскад 44 энтропийного кодирования, однако, энтропийно кодировал каждый энтропийный слайс полностью независимо друг от друга, сначала инициализируя оценку вероятности один раз с последующим постоянным обновлением оценок вероятности отдельно для каждого энтропийного слайса, то эффективность кодирования уменьшилась бы из-за увеличенного процента от данных, которые относятся и описывают массив 10 выборок, для которого используемые оценки вероятности (все же) менее точно адаптированы к фактической статистической информации символа.
Для преодоления только что упомянутых проблем при согласовании необходимости низкой задержки кодирования с одной стороны и высокой эффективности кодирования с другой стороны, может использоваться следующая схема кодирования, которая далее описана по отношению к фиг. 3.
Сначала данные, описывающие массив 10 выборок, подразделяют на порции, называемые в последующем «энтропийными слайсами». Подразделение 80 не обязательно должно быть без наложений. С другой стороны, это подразделение может по меньшей мере частично соответствовать пространственному подразделению массива 10 выборок на различные порции. То есть согласно подразделению 80, синтаксические элементы, описывающие массив 10 выборок, могут распределяться на различные энтропийные слайсы в зависимости от расположения единицы 50 кодирования, которая относится к соответствующему синтаксическому элементу. См., например, фиг. 2. Фиг. 2 показывает примерное подразделение массива 10 выборок на различные порции 12. Каждая порция соответствует соответствующему энтропийному слайсу. В качестве примера показано, что каждая порция 12 соответствует строке единиц 50 кодирования. Другие разделения, однако, также могут выполняться. Однако, предпочтительно, если разделение массива 10 выборок на порции 12 придерживается вышеупомянутого порядка 66 кодирования, так, чтобы порции 12 охватывали последовательные прохождения единиц 12 кодирования по порядку 66 кодирования. Даже если так, однако, не требуется, чтобы начальное и конечное положения порции 12 по порядку 66 кодирования совпадали с левым и правым краями строк единиц 50 кодирования, соответственно. Необязательно даже совпадение с границами единиц 50 кодирования, которые непосредственно следуют друг за другом, и порядок 66 кодирования.
С помощью такого разделения массива 10 выборок среди порций 12 определяют порядок 16 энтропийных слайсов, по которому порции 12 следуют друг за другом по порядку 66 кодирования. Кроме того, для каждого энтропийного слайса определяется соответствующая траектория 14 энтропийного кодирования, а именно, фрагмент траектории 66 кодирования, направленный к соответствующей порции 12. В примере на фиг. 2, где порции 12 совпадают со строками единиц 50 кодирования, траектории 14 энтропийного кодирования из каждой точки энтропийного слайса вдоль направления строки параллельны друг другу, то есть в данном случае с левой стороны в правую сторону.
Нужно отметить, что было бы возможно ограничить пространственные предсказания, выполняемые предварительным кодером 42, и получение контекста, выполняемое средством 72 выбора контекста, так, чтобы они не пересекали границы слайса, то есть так, чтобы пространственные предсказания и результаты выборы контекста не зависели от данных, соответствующих другому энтропийному слайсу. Таким образом, «энтропийные слайсы» соответствуют обычному определению «слайсов» в H.264, например, которые декодируются полностью независимо друг от друга, за исключением нижеизложенной зависимости инициализации/адаптирования вероятности. Однако, также допустимо предоставлять возможность, чтобы пространственные предсказания и результаты выборы контекста, то есть вообще говоря зависимости, пересекали границы слайса, для использования локальных/пространственных взаимозависимостей, поскольку обработка WPP все еще может выполняться, в то время когда рассматривается инверсия предварительного кодирования, то есть восстановление, основанное на синтаксических элементах, и выбор энтропийного контекста. До сих пор энтропийные слайсы так или иначе соответствовали «зависимым слайсам».
Подразделение 80 может, например, выполняться с помощью каскада 44 энтропийного кодирования. Подразделение может быть фиксированным или может изменяться среди множества последовательностей 30. Разделение может устанавливаться по определению или может сообщаться в потоке 20 данных.
Основываясь на энтропийных слайсах может происходить фактическое энтропийное кодирование, то есть 82. Для каждого энтропийного слайса энтропийное кодирование может быть структурировано на начальную фазу 84 и фазу 86 продолжения. Начальная фаза 84 вовлекает, например, инициализацию оценок вероятности, а также вызов процесса фактического энтропийного кодирования для соответствующего энтропийного слайса. Фактическое энтропийное кодирование затем выполняется во время фазы 86 продолжения. Энтропийное кодирование во время фазы 86 выполняется вдоль соответствующей траектории 14 энтропийного кодирования. Начальной фазой 84 для каждого энтропийного слайса управляют таким образом, что энтропийное кодирование множества энтропийных слайсов запускается последовательно, используя порядок 16 энтропийных слайсов.
Затем, чтобы избежать вышеизложенного недостатка, который является результатом энтропийного кодирования каждого энтропийного слайса полностью независимо друг от друга, процессом энтропийного кодирования 82 управляют таким образом, что текущая часть, например, текущая единица кодирования текущего энтропийного слайса энтропийно кодируется, основываясь на соответствующих оценках вероятности текущего энтропийного слайса, которые адаптируются, используя ранее закодированные части текущего энтропийного слайса, то есть части текущего энтропийного слайса слева от текущей единицы 50 кодирования в случае на фиг. 2, и на оценках вероятности, которые используются при энтропийном кодировании пространственно соседних, по порядку 16 энтропийных слайсов предыдущих энтропийных слайсов в его соседней части, то есть в соседней единице кодирования.
Чтобы описать приведенную выше зависимость более четко, ссылка сделана к фиг. 4. Фиг. 4 иллюстрирует n-1-й, n-й и n+1-й энтропийные слайсы по порядку 16 энтропийных слайсов с помощью ссылочного знака 90. Каждый энтропийный слайс 90 охватывает последовательность синтаксических элементов, описывающих порцию 12 массива 10 выборок, с которой связан соответствующий энтропийный слайс 90. Вдоль траектории 14 энтропийного кодирования энтропийный слайс 19 сегментирован на последовательность сегментов 92, каждый из которых соответствует соответствующей одной из единиц 50 кодирования порции 12, к которой относится энтропийный слайс 90.
Как описано выше, оценки вероятности, используемые при энтропийном кодировании энтропийных слайсов 90, непрерывно обновляются во время фазы 86 продолжения вдоль траектории 14 энтропийного кодирования так, чтобы оценки вероятности все лучше и лучше адаптировались к фактической статистической информации символа соответствующего энтропийного слайса 90 - то есть оценки вероятности связывают с соответствующим энтропийным слайсом. Хотя оценки 94 вероятности, используемые для энтропийного кодирования энтропийного слайса 90, во время фазы 86 продолжения непрерывно обновляются, на фиг. 4 просто состояния оценок 94 вероятности, которые появляются в начальном и конечном положениях сегментов 92, иллюстрируются и упоминаются дополнительно ниже. В частности, состояние до энтропийного кодирования первого сегмента 92, которое инициализируется во время начальной фазы 84, показано как 96, состояние, обнаруживающееся после кодирования первого фрагмента, иллюстрируется как 98, и состояние, обнаруживающееся после кодирования первых двух фрагментов, указывается как 100. Те же самые элементы показаны на фиг. 4 также для энтропийного слайса n-1 по порядку 16 энтропийных слайсов, и следующего энтропийного слайса, то есть энтропийного слайса n+1.
Теперь, для обеспечения вышеизложенной зависимости, начальное состояние 96 для энтропийного кодирования n-го энтропийного слайса 90 устанавливается в зависимости от любого промежуточного состояния оценок 94 вероятности, обнаруженного во время кодирования предыдущего энтропийного слайса n-1. «Промежуточное состояние» должно обозначать любое состояние оценок 94 вероятности, исключая начальное состояние 96 и конечное состояние, обнаруживаемое после энтропийного кодирования всего энтропийного слайса n-1. Делая так, энтропийное кодирование последовательности энтропийных слайсов 90 по порядку 16 энтропийных слайсов может параллелизовываться со степенью параллелизации, которая определяется отношением количества сегментов 92, предшествующих состоянию, используемому для инициализации оценок 94 вероятности для энтропийного кодирования следующего энтропийного слайса, то есть a, и количеством сегментов 92, следующих за этой стадией, то есть b. В частности на фиг. 4 a для примера устанавливают равным, с помощью инициализации, то есть адаптирования, состояния 100, таким образом, чтобы устанавливать состояние 96 текущего энтропийного слайса равным состоянию 100 предыдущего энтропийного слайса, иллюстрировано с помощью стрелки 104.
С помощью этих мер энтропийное кодирование любого сегмента 92 после состояния 100 по порядку 14 траектории энтропийного кодирования будет зависеть от оценки 94 вероятности, которую адаптируют во время фазы 86 продолжения, основываясь на предыдущих фрагментах того же самого энтропийного слайса, а также от оценки вероятности, которая используется при энтропийном кодировании третьего сегмента 92 предыдущего энтропийного слайса 90.
Соответственно, энтропийное кодирование энтропийных слайсов 90 может выполняться параллельно при конвейерном планировании. Единственными ограничениями, введенными на время планирования, является то, что энтропийное кодирование некоторого энтропийного слайса может начинаться сразу после окончания энтропийного кодирования a-го сегмента 92 предыдущего энтропийного слайса. Энтропийные слайсы 90 непосредственно друг после друга по порядку 16 энтропийных слайсов не подлежат каким-либо другим ограничениям относительно выравнивания по времени процедуры энтропийного кодирования во время фазы 86 продолжения.
Однако, в соответствии с другим вариантом осуществления, дополнительно и/или альтернативно используется более интенсивное соединение. В частности, как иллюстрируется на фиг. 4 с помощью обычных стрелок 106, адаптирование оценки вероятности во время фазы 86 продолжения приводит к тому, что данные единицы кодирования, соответствующей некоторому сегменту 92, изменяют оценки 94 вероятности из состояния в начале соответствующего сегмента 92 до завершения этого сегмента 92, таким образом улучшая аппроксимацию фактической статистической информации символа, как обозначено выше. То есть для энтропийного слайса n-1 выполняется адаптирование 106, просто зависящее от данных энтропийного слайса n-1, и то же самое относится к адаптированию 106 оценки вероятности энтропийного слайса n, и т.д. Например, можно выполнять инициализацию, как объясняется выше с помощью стрелок 104, с помощью выполнения адаптирования 106 оценки вероятности без дальнейшего взаимного влияния между энтропийными слайсами 90. Однако, чтобы ускорить аппроксимацию оценки вероятности к фактической статистической информации символа, адаптирования 106 оценки вероятности последовательных энтропийных слайсов могут соединяться так, чтобы адаптирование 106 оценки вероятности предыдущего n-1 энтропийного слайса также влияло или учитывалось, когда адаптируется результат адаптирования оценки вероятности текущего энтропийного слайса n. Это иллюстрируется на фиг. 4 с помощью стрелки 108, обращенной от состояния 110 пространственно соседних оценок 94 вероятности для энтропийного кодирования n-1-го энтропийного слайса 90 к состоянию 100 оценок 94 вероятности энтропийного кодирования n-го энтропийного слайса 90. Когда используют вышеизложенную инициализацию состояния 96, соединение 108 адаптирования вероятности может, например, использоваться в любом из b состояний оценки вероятности, обнаруживающихся после энтропийного кодирования b сегментов 92 предыдущего энтропийного слайса. Точнее, оценки вероятности, обнаруживающиеся непосредственно после энтропийного кодирования первого сегмента 92 текущего энтропийного слайса, могут быть результатом обычного адаптирования 106 вероятности и с помощью учета 108 состояний оценки вероятности, являющихся результатом адаптирования 106 оценок вероятности во время энтропийного кодирования (a+1)-го сегмента 92 предыдущего энтропийного слайса n-1. «Учет» может, например, вовлекать некоторую операцию усреднения. Пример будет дополнительно изложен ниже. Другими словами, состояние 98 оценок 94 вероятности энтропийного кодирования n-го энтропийного слайса 90 в начале энтропийного кодирования его сегмента 92 может быть результатом усреднения предыдущего состояния 96 оценок 94 вероятности для энтропийного кодирования текущего энтропийного слайса n, которые адаптируются, используя адаптирование 106, и состояния перед энтропийным кодированием (a+1)-го сегмента 92 предыдущего энтропийного слайса n-1, измененного согласно адаптированию 106 вероятности. Аналогично, состояние 100 может быть результатом усреднения результата адаптирования 106, выполненного во время энтропийного кодирования текущего энтропийного слайса n, и результатом адаптирования вероятности во время энтропийного кодирования (a+2)-го сегмента 92 предыдущего энтропийного слайса n-1, и т.д.
Более конкретно, предполагают, что
p(n)->{i, j}, причем i, j обозначает положение любой единицы кодирования (причем (0,0) является левой верхней позицией и (I, J) является правой нижней позицией), i∈{1...I} и j∈{1...J}, I является количеством столбцов, J является количеством строк и p() определяет порядок 66 траектории,
P{i, j} является оценкой вероятности, используемой при энтропийном кодировании единицы кодирования {i, j}; и
T(P{i, j}) является результатом адаптирования 106 вероятности P{i, j}, основываясь на единице кодирования {i, j}.
Затем, оценки 106 вероятности последовательных энтропийных слайсов 90 могут объединяться для замены обычного внутреннего адаптирования энтропийного слайса согласно Pp(n+1)=T(Pp(n)), на
Pp(n+1)=среднее значение (T(Pp(n)), T(P{i, j}1), ..., T(P{i, j}N))
где N может быть 1 или больше 1 и {i, j}1...N выбирают из (находятся в пределах) любого предыдущего (по порядку 16 энтропийных слайсов) энтропийного слайса 90 и связанной с ним порции 12, соответственно. Функция «среднее значение» может быть одной из взвешенного суммирования, срединной функции и т.д. p(n)={i, j} является текущей единицей кодирования, и p(n+1) является следующей в соответствии с порядком 14 и 66 кодирования, соответственно. В представленных вариантах осуществления p(n+1)={i+1, j}.
Предпочтительно, {i, j}1...N соответствует для каждого k∈{1...N} {i, j}1...N={ik, jk} и ik<i+3 и jk<j, причем p(n)={i, j} является текущей единицей кодирования (то есть любой из второй или последующей единиц кодирования текущего энтропийного слайса), то есть они не расположены вне волны.
В последнем альтернативном варианте планирование во времени энтропийного кодирования, когда параллельно выполняют энтропийное кодирование энтропийных слайсов 90, более интенсивно соединяется друг с другом. То есть во время фазы 86 продолжения следующий сегмент 92 на линии текущего энтропийного слайса может начинаться сразу после окончания соответствующего сегмента предыдущего энтропийного слайса, который расположен дальше по порядку траектории 14 энтропийного кодирования.
Другими словами, вышеупомянутое обсуждение показывает пример, в котором декодер 40, и в частности, каскад 44 энтропийного кодирования сконфигурирован для выполнения для энтропийного слайса 90, такого как n-й, инициализации его оценок 94 вероятности перед декодированием первого сегмента 92, соответствующего первой единице кодирования/первому блоку 50 из порции 12, соответствующей n-му энтропийному слайсу вдоль соответствующей траектории 14 кодирования, с помощью оценок вероятности, обнаруживающихся после энтропийного декодирования второй единицы кодирования/блока 50 из порции 12, соответствующей порядку 16 энтропийных слайсов, предыдущего энтропийного слайса вдоль соответствующей траектории 14 кодирования. Дополнительно, или альтернативно, декодер 40 и, в частности, каскад 44 энтропийного кодирования, могут конфигурироваться для выполнения для каждого энтропийного слайса 90 энтропийного декодирования и адаптирования оценки вероятности таким образом, что, после того, как текущая часть/блок/единица 50 кодирования текущего энтропийного слайса была энтропийно декодирована, основываясь на соответствующих оценках 94 вероятности из текущего энтропийного слайса 90, соответствующие оценки 94 вероятности из текущего энтропийного слайса адаптируются в зависимости от этой текущей части текущего энтропийного слайса и оценок вероятности, которые обнаруживаются при энтропийном декодировании соседней части/блока/единицы 50 кодирования пространственно соседнего предыдущего энтропийного слайса, такого как слайс в вышеупомянутой соседней строке во втором столбце справа от текущей части/блока/единицы кодирования текущего энтропийного слайса.
Как стало ясно из вышеупомянутого обсуждения, оценка вероятности должна адаптироваться/управляться для каждого энтропийного слайса 50 отдельно. Это может быть сделано с помощью последовательной обработки энтропийных слайсов и сохранения состояний оценки вероятности в качестве состояний, которые для примера показаны и упомянуты относительно фиг. 4, то есть 96, 98, 100, 110 и 102, на соответствующем запоминающем устройстве 120 оценки вероятности (см. фиг. 1). Альтернативно, больше одного каскада 44 энтропийного кодирования может обеспечиваться для декодирования энтропийных слайсов параллельно. Это иллюстрируется на фиг. 5, где показано множество реализаций каскадов 44 энтропийного кодирования, каждый связан с соответствующим одним из энтропийных слайсов и соответствующими порциями 12 массива 10 выборок, соответственно. Фиг. 5 также иллюстрирует процесс декодирования и его возможные воплощения при использовании параллельных реализаций соответствующего каскада 130 энтропийного декодирования. На каждый каскад 130 энтропийного декодирования подается соответствующий один из энтропийных слайсов, передаваемых через поток 20 данных.
Фиг. 5 показывает, что каскады энтропийного кодирования 44 и соответствующие каскады декодирования 130 не работают параллельно полностью независимо друг от друга. Вместо этого сохраненные состояния оценки вероятности, такие как состояния, которые хранятся в запоминающем устройстве 120, передают от одного каскада, соответствующего соответствующему энтропийному слайсу, к другому каскаду, относящемуся к энтропийному слайсу, следующему в соответствии с порядком 16 энтропийных слайсов.
Фиг. 5 показывает в иллюстративных целях также возможный порядок перемещения для перемещения через результаты возможного разделения единиц 50 кодирования, такой как порядок 140 перемещения, определенный среди блоков 52 предсказания в пределах одной единицы 50 кодирования. Для всех этих блоков 52 предсказания соответствующие синтаксические элементы содержатся в пределах соответствующего сегмента 92 и соответствуют значениям этих синтаксических элементов, оценки 94 вероятности адаптируются во время перемещения по траектории 140, причем адаптирование во время перемещения через единицы 50 кодирования определяется вышеупомянутым «T». В CABAC согласно H.264 и HEVC, «T» выполняют, основываясь на таблице, то есть «таблице маршрута», определяющей переходы из текущего состояния оценки вероятности для текущего контекста к следующему состоянию в зависимости от текущего значения символа, связанного с этим контекстом.
Перед переходом на фиг. 6, которая показывает вариант осуществления декодера, соответствующий варианту осуществления кодера на фиг. 1, нужно отметить, что предсказывающая сущность предварительного кодера 42 служит просто иллюстративным вариантом осуществления. В соответствии даже с альтернативными вариантами осуществления, предварительный кодер 42 может быть оставлен с синтаксическими элементами, с которыми работает каскад 44 энтропийного кодирования, которые являются, например, исходными типовыми значениями массива 10 выборок. Даже альтернативно, предварительный кодер 42 может быть сконфигурирован для формирования разложения поддиапазонов массива 10 выборок, так как в JPEG. Дополнительная сущность средства 72 выбора контекста была уже упомянута выше. То же самое применяется относительно средства инициализации 74. То же самое может реализовываться по-другому.
Фиг. 6 показывает декодер 200, соответствующий кодеру 40 на фиг. 1. Из фиг. 6 видно, что конструкция декодера 200 по существу отражает конструкцию кодера 40. То есть декодер 200 содержит вход 202 для приема потока 20 данных, за которым следует последовательное соединение каскада 204 энтропийного декодирования и средства 206 создания. Каскад 204 энтропийного декодирования энтропийно декодирует энтропийные слайсы, переданные в потоке 20 данных, и направляет, в свою очередь, декодированные символы si и синтаксические элементы, соответственно, к средству 206 создания, которое, в свою очередь, запрашивает синтаксические элементы от каскада 204 энтропийного декодирования с помощью соответствующего запроса 208. Другими словами, средство 206 создания также отвечает за анализ потока синтаксических элементов, созданного предварительным кодером 42 в пределах кодера. Соответственно, средство 206 создания запрашивает последовательно синтаксические элементы из каскада 204 энтропийного декодирования. Каскад 204 энтропийного декодирования имеет по существу такую же структуру, как каскад 44 энтропийного кодирования. Соответственно, те же самые ссылочные знаки внутренних блоков каскада 204 энтропийного декодирования снова используются. Средство 70 представления в символьной форме, если представлено, преобразовывает запросы синтаксических элементов в запросы символов, и ядро 80 энтропийного декодирования отвечает соответствующим значением символа si, средство 70 представления в символьной форме отображает последовательности принятых символов, формирующих действительные слова символов, с синтаксическими элементами, и направляет их к средству 206 создания. Средство 206 создания восстанавливает массив 10 выборок из потока синтаксических элементов, принятого от каскада 204 энтропийного декодирования, такого, который изложен выше, используя декодирование с предсказанием, и т.д. Точнее, средство 206 создания также использует порядок 66 кодирования и выполняет декодирование по единицам кодирования с выполнением предсказания 60, 62 и 64. Одно или большее количество предсказаний для синтаксических элементов или для значений выборок объединяются, например, суммируются, при желании с помощью использования остатка предсказания, полученного из синтаксических элементов потока синтаксических элементов. Ядро 80 энтропийного декодирования, а также ядро 80 энтропийного кодирования поддерживает концепцию арифметического декодирования или концепцию энтропийного декодирования с разделением интервала вероятности. В случае арифметического декодирования ядро 80 энтропийного декодирования может непрерывно обновлять внутреннее состояние в форме частичного значения ширины интервала и такого значения, как значение смещения, указывающее на этот частичный интервал. Обновление выполняют, используя прибывающий поток данных. Текущий частичный интервал подразделяют аналогично ядру 80 энтропийного кодирования, используя оценку pi вероятности, обеспеченную для каждого символа si посредством средства 72 выбора контекста наряду со средством 76 управления оценкой вероятности. Средство 78 адаптирования выполняет адаптирование оценки вероятности, используя значение si декодированного символа для обновления значений pi оценки вероятности контекста ci, связанного с символом si, с помощью средства 72 выбора контекста. Инициализация с помощью средства 74 инициализации выполняется в тех же самых реализациях и таким же образом, как на стороне кодирования.
Декодер на фиг. 6 работает аналогично функционированию кодера, который описан выше относительно фиг. 3. На этапе 230 массив 10 выборок подразделяют на энтропийные слайсы. См., например, фиг. 8. Фиг. 8 показывает поток 20 данных, который прибывает на вход 202 и, в частности, энтропийные слайсы 90, содержащиеся в нем. На этапе 230 каждый из этих энтропийных слайсов 90 связывают с порцией 12, данный соответствующий энтропийный слайс 90 связывают таким образом, чтобы могли выполняться вышеописанные инициализация оценки вероятности и адаптирование оценки вероятности, основываясь на соответствующем предыдущем энтропийном слайсе. Подразделение массива выборок, или точнее, связывание энтропийных слайсов 90 с соответствующими им порциями 12, может выполняться с помощью средства 206 создания. Связывание может обеспечиваться с помощью различных мер, таких как побочная информация, содержащаяся в потоке 20 данных в не энтропийно кодированных порциях, или по определению.
Энтропийные слайсы 90 затем в процессе энтропийного декодирования 232 энтропийно декодируют способом, который отражает обработку 82 кодирования, а именно, с выполнением для каждого энтропийного слайса 90 начальной фазы 234 и фазы 236 продолжения с инициализацией оценки вероятности и адаптированием тем же способом и в тех же самых реализациях, как в процедуре кодирования.
Та же самая параллелизация, которая описана выше относительно кодирования, возможна на стороне декодирования. Реализации 130 каскада энтропийного декодирования, показанные на фиг. 5, могут каждая воплощаться, как показано относительно каскада 204 энтропийного декодирования на фиг. 6. Запоминающее устройство 240 оценки вероятности может использоваться для сохранения состояния оценок вероятности для использования в каскаде 130 энтропийного декодирования, отвечающем за энтропийное декодирование последующего энтропийного слайса по порядку 16 энтропийного кодирования.
После описания вариантов осуществления настоящей заявки обсуждаемые концепции описываются далее, снова используя другую формулировку. В дальнейшем описаны несколько дополнительных аспектов настоящей заявки. В последующем вышеупомянутые единицы 50 кодирования называют LCU (наибольшей единицей кодирования), таким образом адаптируя формулировку к перспективному стандарту HEVC.
Сначала рассмотренное выше адаптирование 106 вероятности кратко обсуждается снова относительно фиг. 9.
Текущая LCU использует оценки вероятности, такие как вероятности CABAC, доступные после кодирования предыдущей левой LCU. Например, LCU на фиг. 9, обозначенную x, как предполагается, энтропийно кодируют, используя оценку p1 вероятности, которая адаптирована до завершения энтропийного кодирования левосторонних LCU слева от LCU x. Однако, если информация используется не только от левой, но также и от одной или большего количества других LCU, которые уже обработаны и доступны, то могут обеспечиваться лучшие результаты при адаптировании вероятности.
Как описано выше, при энтропийном декодировании и энтропийном кодировании энтропийных слайсов новые оценки вероятности вычисляются перед кодированием или декодированием каждой LCU с помощью уже существующих вероятностей (оценок вероятности) от других LCU. Точнее, адаптирование вероятности выполняется не только от любых предшествующих LCU текущего энтропийного слайса, но также и от LCU энтропийных слайсов, предшествующих по порядку энтропийных слайсов. Этот подход снова представлен на фиг. 9. Начальная вероятность текущей LCU, которая обозначена X на фиг. 9, может вычисляться соответственно:
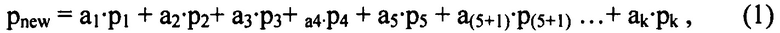
где a1, ..., ak являются коэффициентами взвешивания LCU.
Протестировано, какое взвешивание вероятностей обеспечивает лучшие результаты. В данном эксперименте использовались только соседние LCU. Исследование показывает использование взвешивания: 75% от левой LCU и 25% от верхней правой LCU. На фиг. 10-13 представлены результаты. Графики, озаглавленные, используя «prob. Adapt.», используют описанное выше адаптирование вероятности.
Однако при адаптировании оценки вероятности могут использоваться не только смежные блоки. У каждой ближайшей LCU есть собственные соседи, использование которых для оптимизации вероятности может быть существенным. Другими словами, могут применяться не только LCU из ближайшей верхней строки. На фиг. 9 можно видеть пример, в котором в качестве источников оценок вероятности были взяты сначала соседи и могут быть взяты каждая верхняя правая LCU каждой следующей верхней строки, сравни p5 и pk.
Нужно признать, что некоторая сложность введена с помощью вышеизложенного повторного вычисления вероятности или адаптирования оценки вероятности. Новое вычисление оценки вероятности происходит, например, в три этапа: сначала, оценки вероятности каждого кандидата должны быть получены от каждого состояния контекста. Это делают с помощью сохранения на запоминающем устройстве 120 и 240, соответственно, или с помощью направления параллельных обработок декодирования энтропийного слайса n таким образом, что эти состояния доступны одновременно. Затем, при использовании уравнения (1), будет создаваться оптимизированная вероятность (pnew). То есть некоторое усреднение, например, может использоваться для объединения адаптированных оценок вероятности различных энтропийных слайсов. В качестве последнего этапа новое состояние контекста преобразовывается из pnew и заменяет старое. То есть средство 76 управления оценкой вероятности заимствует новые оценки вероятности, полученные таким образом. Это выполнение для каждого синтаксического элемента, в частности, используя операции умножения, может чрезвычайно увеличивать сложность. Единственным способом устранения этого недостатка является попытка избежать этих трех этапов. Если количество кандидатов и их весовые коэффициенты определены, то предварительно рассчитанная таблица может аппроксимироваться для каждой ситуации. Таким образом необходим только один простой доступ к данным таблицы с помощью индексов кандидатов (состояний контекста).
Утверждается, что эта методика может обеспечивать хорошие результаты для обоих применений - с использованием и без использования энтропийных слайсов. Первое применение использует только один слайс в кадре, таким образом адаптирование вероятности оптимизировано без каких-либо других изменений. В случае энтропийных слайсов адаптирование вероятностей происходит в пределах каждого слайса, независимо от других слайсов. Это учитывает быстрое изучение вероятностей текущей LCU.
В вышеупомянутом описании также представлено использование второй LCU верхней линии, то есть использование второй LCU для инициализации оценки вероятности. Параллелизация кодирования и декодирования возможна, если обеспечиваются некоторые условия битового потока, которые упомянуты выше (энтропийных слайсов). Зависимость вероятностей CABAC между LCU должна быть устранена. Волновая параллельная обработка важна, чтобы сделать первую LCU каждой линии независимой от последней LCU предыдущей линии. Это может обеспечиваться, если, например, вероятности CABAC повторно инициализируются в начале каждой линии LCU. Однако, этот способ не оптимален, потому что каждая повторная инициализация теряет обеспеченные вероятности CABAC, которые адаптированы к специфическим особенностям изображения. Этот недостаток можно уменьшать, если инициализация вероятностей CABAC первой LCU каждой линии происходит с помощью вероятностей, полученных после второй LCU предыдущей линии.
Как описано выше, увеличение скорости адаптирования вероятности может обеспечиваться с помощью соединения адаптирования вероятностей пространственно соседних энтропийных слайсов. В частности, другими словами, приведенное выше обсуждение также предвосхищает декодер, такой как декодер на фиг. 6, для восстановления массива (10) выборок из энтропийно закодированного потока данных, сконфигурированный для энтропийного декодирования (выполняемого с помощью каскада энтропийного декодирования) множества энтропийных слайсов в потоке данных энтропийного кодера для восстановления различных порций (12) массива выборок, связанных с энтропийными последовательностями, соответственно, с помощью выполнения для каждого энтропийного слайса энтропийного декодирования вдоль соответствующей траектории (14) энтропийного кодирования, используя соответствующие оценки вероятности, адаптирования (выполняемого с помощью средства 78 адаптирования) соответствующих оценок вероятности вдоль соответствующей траектории энтропийного кодирования, используя ранее декодированную часть соответствующего энтропийного слайса, запуска энтропийного декодирования множества энтропийных слайсов последовательно, используя порядок (16) энтропийных слайсов, и выполнения при энтропийном декодировании предопределенного энтропийного слайса энтропийного декодирования текущей части (x) предопределенного энтропийного слайса, основываясь на соответствующих оценках вероятности предопределенного энтропийного слайса, которые адаптируются, используя ранее декодированную часть предопределенного энтропийного слайса (включающего в себя p1, например), и оценках вероятности, которые используются при энтропийном декодировании пространственно соседнего, по порядку энтропийных слайсов предыдущего энтропийного слайса (слайса, содержащего X, например) в соседней части (такой как p4) пространственно соседнего энтропийного слайса.
Различные порции могут быть строками блоков (например, LCU или макроблоков) массива выборок. Последний может быть видео. Траектория энтропийного кодирования может распространяться по строкам. Энтропийное кодирование, и таким образом также адаптирование вероятности, может адаптироваться к контексту. Порядок энтропийных слайсов может в общем случае выбираться таким образом, чтобы по порядку энтропийных слайсов различные порции следовали друг за другом в направлении (16), повернутом относительно траекторий (14) энтропийного кодирования энтропийных слайсов, которые, в свою очередь, распространяются по существу параллельно друг другу. С помощью этих мер «волна» в настоящее время декодируемых частей (таких как p1, p4, p5+1 и pk на данной фигуре) энтропийных слайсов может в общем случае располагаться вдоль линии, формирующей угол к направлению энтропийного слайса, который меньше, чем направление последовательности порций. Волне, вероятно, придется иметь наклон 1y на 2x для положений блока для того, чтобы верхний левый опорный элемент всегда был там для всех потоков, обрабатывающих слайсы параллельно.
Декодер может быть сконфигурирован для выполнения для каждого энтропийного слайса энтропийного декодирования вдоль соответствующей траектории энтропийного кодирования в единицах частей порции массива выборок соответствующего энтропийного слайса так, чтобы энтропийные слайсы состояли из одного и того же количества частей, соответственно, и последовательность частей порций вдоль траекторий энтропийного слайса была выровнена друг относительно друга в направлении, поперечном к траекториям энтропийного слайса. Текущая часть порции предопределенного энтропийного слайса принадлежит результирующей сетке из частей (например, LCU или макроблоков). При выполнении для каждого энтропийного слайса энтропийного декодирования вдоль соответствующей траектории энтропийного кодирования, декодер может сохранять смещения/сдвиги между начальными временами между непосредственно следующими друг за другом энтропийными слайсами по порядку энтропийных слайсов так, чтобы волна в настоящее время декодируемых частей энтропийных слайсов формировала диагональ, такую как соответствующая линии с наклоном положений блоков 0,5x по отношению к траектории энтропийного слайса и направлению по порядку энтропийных слайсов. Смещение/сдвиг могут соответствовать двум частям для всех пар непосредственно следующих друг за другом энтропийных слайсов. Альтернативно, декодер может просто не допускать, чтобы расстояние между в настоящее время декодируемыми частями непосредственно следующих друг за другом (и непосредственно граничащих, пока рассматривают их порции 12 массива выборок) энтропийных слайсов стало меньше двух частей. См., фигуру выше: как только часть/блок p4 декодирована, часть/блок справа от нее декодируется согласно порядку 16 траекторий, и одновременно, если имеется, X декодируется или любая из предшествующих частей/блоков). С помощью этих мер декодер может использовать оценки вероятности, которые уже адаптированы, основываясь на содержимом части/блока p4, то есть части в пределах пространственно соседней порции, выровненной к части порции 12 предопределенного энтропийного слайса, следующей за текущей частью X по порядку 16 траекторий для определения оценок вероятности, которые будут использоваться при декодировании X. В случае постоянного смещения при декодировании непосредственно следующих друг за другом энтропийных слайсов двух частей, декодер имеет возможность использовать оценки вероятности, которые уже адаптированы, основываясь на содержимом части/блока p4 одновременно для энтропийного декодирования последующей части (то есть части справа от p4) пространственно соседнего энтропийного слайса.
Как описано выше, взвешенное суммирование уже адаптированных оценок вероятности может использоваться для определения оценок вероятности, которые будут использоваться для декодирования X.
Как также описано выше, порядок энтропийных слайсов может также проходить через границы кадра.
Нужно отметить, что только что изложенное заимствование вероятности из предшествующих энтропийных слайсов может выполняться для каждой части текущего/предопределенного энтропийного слайса, для которого доступны такие соседние части в предшествующих энтропийных слайсах. То есть это также верно для первой части вдоль направления 16 траектории, и для этой самой первой части/блока (крайней левой в каждом энтропийном слайсе на данной фигуре) заимствование равняется описанной выше инициализации.
Для лучшего адаптирования, также в этом случае, 2 вышеупомянутых способа могут также объединяться вместе. Результаты этого процесса с 1 и 4 потоками, то есть параллельно используя единицы обработки, иллюстрируются на фиг. 10 - фиг. 13 (графики 2LCU+Prob.Adap или 2LCU).
Для лучшего понимания контекста вышеупомянутых вариантов осуществления и, в частности, описанных ниже дополнительных вариантов осуществления, а именно - использование LCU, можно сначала взглянуть на структуру H.264/AVC.
Кодированная видео последовательность в H.264/AVC состоит из последовательности единиц доступа, которые собраны в потоке единиц NAL, и они используют только один набор параметров последовательности. Каждая видео последовательность может декодироваться независимо. Кодированная последовательность состоит из последовательности кодированных изображений. Кодированный кадр может быть всем кадром или одним полем. Каждое изображение делится на макроблоки фиксированного размера (в HEVC: LCU). Несколько макроблоков или LCU могут объединяться вместе в один слайс. Изображение поэтому является совокупностью из одного или большего количества слайсов. Цель этого разделения данных состоит в предоставлении возможности независимого декодирования выборок в области изображения, которая представлена данным слайсом, без использования данных от других слайсов.
Методика, которую также часто называют «энтропийные слайсы», является делением традиционного слайса на дополнительные подслайсы. В частности, это означает разделение энтропийно кодированных данных одного слайса. Расположение энтропийных слайсов в слайсе может иметь различные разновидности. Самой простой разновидностью является использование каждой строки LCU/макроблоков в кадре в качестве одного энтропийного слайса. Альтернативно, столбцы или отдельные области могут использоваться в качестве энтропийных слайсов, которые даже могут прерываться и переключаться друг с другом, например, как слайс 1 на фиг. 14.
Очевидная цель концепции энтропийного слайса состоит в предоставлении возможности параллельного использования CPU/GPU и мультиядерной архитектуры для улучшения времени процесса декодирования, то есть для ускорения процесса. Текущий слайс может делиться на разделы, которые могут анализироваться и восстанавливаться независимо от других данных слайса. Хотя некоторые преимущества могут обеспечиваться с помощью подхода энтропийного слайса, в связи с этим появляются некоторые недостатки.
Прежде всего, главная цель состоит в создании битового потока, который подходит для процесса параллельного кодирования и декодирования. Нужно учитывать, что LCU можно кодировать, только если соседние LCU (левая, верхняя, верхняя-правая) уже доступны в качестве закодированной версии для использования пространственной информации и информации о движении для предсказания. Чтобы предоставить возможность параллелизма с помощью разделения, должен реализовываться сдвиг между обработкой слайсов (например, сдвиг на 2 LCU, который является типичным для волнового подхода). Из-за адаптирования вероятностей CABAC, LCU использует вероятности, которые доступны от предыдущей закодированной LCU. В отношении порядка растрового сканирования проблемой, которая возникает с помощью разделения изображения, является недопущение параллелизма, так как первая LCU каждой линии зависит от последней LCU предыдущей линии. На это воздействует то, что зависимости вероятностей CABAC между слайсами необходимо убирать, так, чтобы несколько слайсов могли начинаться одновременно. Одним способом сделать это является обычная повторная инициализация CABAC, посредством чего, однако, все заимствованные данные будут потеряны. В результате битрейт может увеличиваться.
Затем каждый слайс генерирует свой собственный битовый субпоток, который может помещаться последовательно в главный поток. Но необходимо передавать в декодер специальную информацию, так, чтобы эти слайсы и их положения в главном потоке могли правильно идентифицироваться. Поддерживаются два сценария сигнализации. Информация расположения может храниться в заголовке изображения (информация длины слайса) или в каждом заголовке слайса (точки, как начало кода). Выравнивание байта в конце каждого энтропийного слайса и информация расположения увеличивают потери.
Для устранения недостатков, введенных сигнализацией для энтропийных слайсов, важно использовать хорошую методику кодирования для сигнализации. Значимый недостаток сигнализации энтропийного слайса вводится в кадр, если начальные коды используются для каждого слайса, то есть слишком много дополнительных байтов (например, минимум 4 байта на слайс) добавляется к битовому потоку. Конечно, вставка энтропийных слайсов 90, используя начальные коды, имеет преимущество в сценариях с низкой задержкой, где кодер должен иметь возможность мгновенно выводить энтропийные слайсы. В таких случаях нет никакой возможности предварительной передачи информации точки входа.
В менее строгих сценариях с низкой задержкой, однако, возможность сохранения длины слайса (смещений) кажется более подходящей. Одним известным способом кодирования такой информации является кодирование с переменной длиной кода (VLC) или экспоненциальное кодирование Голомба. Главной особенностью VLC является добавление пустой информации (нолей) перед реальной информацией. С помощью этих нолей может определяться код, который хранит информацию о длине смещения. Авторы предлагают другую методику для реализации этого, схема которой показана на фиг. 15, где =EntropySliceSize - количество байтов, содержащихся в энтропийном слайсе. Каждое следующее X (смещение) определяется как разность в размере между предыдущим уже закодированным и переданным смещением энтропийного слайса и текущим слайсом. Главные особенности этой концепции формируются из разностных значений, в зависимости от размера X, таким образом количество данных может уменьшаться и составлять 3 бита, что предоставляет возможность извлекать точную информацию о размере каждого энтропийного слайса с помощью декодера. По сравнению с VLC может быть получена экономия количества битов в заголовке энтропийного слайса.
То есть, в соответствии с аспектом фиг. 15, например, обеспечивается концепция энтропийного кодирования информационного сигнала, которая предоставляет возможность более высокой степени сжатия, несмотря на возможность параллельную обработки, по сравнению с доступными в настоящее время концепциями. В соответствии с этим аспектом, энтропийно кодированная секция 20 потока данных, в который кодируется массив выборок, содержит энтропийные слайсы, такие как 90 на фиг. 8, в которые различные порции 12 массива выборок энтропийно кодируются, и заголовок, иллюстрированный пунктирными линиями 300 на фиг. 9, содержит информацию, которая показывает начальные позиции 302 энтропийных слайсов 90, измеренные в области энтропийного декодирования, в пределах энтропийно закодированного потока данных, данная информация содержит для предопределенного энтропийного слайса разностное значение, раскрывающее разность между начальной позицией предыдущего энтропийного слайса n-1 и начальной позицией предопределенного энтропийного слайса n, поток данных включает в себя данные разностные значения, как последовательность битов VLC.
В частности, последовательность битов VLC может иметь префикс переменной длины y, указывающий, что разность x попадает в y-ю последовательность количества z интервалов [0,2a-1], [2a, 2b+2a-1], [2b+2a, 2c+2b+2a-1] и так далее, и кодированный с помощью PCM суффикс y-й последовательности длин a, b, c... Если a, b, c... выбирают так, чтобы они были степенью двух, если соответствующий y добавляют, то есть так, чтобы a+1, b+2, c+3 и так далее, все были степенями двух, то выравнивание байта может сохраняться. Число z не ограничено тремя, как для примера выбрано на фиг. 15.
Кодер, такой как кодер на фиг. 1, соответственно сконструирован для преобразования разности последовательных начальных позиций в последовательность битов VLC, то есть с помощью сначала определения префикса, то есть в котором подинтервале находится разность (y-я), и затем устанавливая суффикс плюс разность начальная позиция минус y-я из 0, 2a, 2b+2a и так далее. Декодер, такой как на фиг. 6, соответственно сконструирован для получения начальной позиции текущего энтропийного слайса n из последовательности битов VLC, то есть с помощью сначала изучения префикса для получения y, затем устанавливая разностное значение для значения суффикса плюс y-й 0, 2a, 2b+2a и так далее, и затем добавляя разность для начальной точки предыдущего энтропийного слайса n-1.
С помощью сегментации энтропийных слайсов может обеспечиваться дополнительное преимущество, а именно, передача с низкой задержкой и ускорение декодирования.
В видео потоке предоставление возможности более высоких разрешений (Full-HD, QUAD-HD и т.д.) приводит к большему количеству данных, которые должны передаваться. Для чувствительных к времени сценариев, так называемых случаев использования с низкой задержкой (<145 миллисекунд), время передачи становится критическим фактором. Рассматривают линию передачи данных ADSL для приложений видео конференц-связи. В данном случае так называемые точки потока с произвольным доступом, обычно они относятся к I-кадрам, будут кандидатами на создание узкого места во время передачи.
Чтобы решить эту проблему и минимизировать задержку передачи и время декодирования, то есть сквозную задержку, может применяться новая методика для схемы перемежения энтропийных слайсов для параллельной передачи и обработки.
HEVC предусматривает так называемую волновую обработку данных на стороне декодера. Ее собираются обеспечивать при помощи энтропийных слайсов. В обычном случае данные всего слайса доставляются в один момент времени. Процесс декодирования начинается, как только закодированные данные прибывают в средство волнового декодера. Чтобы уменьшить время, когда декодер может начинать и завершать кадр, сегментация энтропийных слайсов на маленькие фрагменты, используя подход перемежения, используется в соответствии с настоящим вариантом осуществления. Следовательно, кодер может доставлять данные, соответствующие определенному энтропийному слайсу, к транспортному уровню раньше, чем в обычном случае. Это приводит в таком случае к более быстрой передаче и более раннему началу параллельного процесса декодирования в клиенте.
Создание фрагментов слайсов может дополнительно обеспечиваться с помощью разделения энтропийного слайса на дополнительные слайсы, сохраняя все зависимости (зависимые слайсы). Если так сделано в каждой наибольшей единице кодирования (LCU)/единице дерева кодирования (CTU), то эти фрагменты могут перемежаться, дополнительно используя методы уровня системы, которые учитывают передачу фрагментов в перемежаемой форме и восстановление или по меньшей мере обеспечение информации об исходном порядке декодирования фрагментов посредством дополнительной сигнализации. Такая сигнализация может быть порядковым номером декодирования (DON), таким как определенный в IETF RTP формат полезной нагрузки для H.264/AVC (RFC 3984). Другой системный способ может состоять в применении фрагментов волнового подпотока к другому транспортному потоку, как в системах MEPG-2, с помощью назначения различных PID для каждого из них, далее мультиплексируя и с помощью этого перемежая их в транспортном канале.
Данный подход может также применяться через границы кадра, в случае, если слайс(ы) следующего кадра или энтропийный слайс(ы) уже могут декодироваться, например, волновым способом, основываясь на знании запрошенной информации для декодирования энтропийного слайса следующего кадра из-за доступности межкадровых ссылок. Эти данные, которые уже могут декодироваться, кадра, следующего по порядку декодирования, могут быть получены из максимальной разрешенной/переданной длины вектора движения или дополнительной информации в потоке, указывающей зависимости частей данных от предыдущего кадра(ов)), или из схемы фиксированных ссылок, указывающей положение, передаваемое в фиксированном в последовательности положении, такой как набор параметров. Это будет дополнительно изложено ниже.
Изображение может кодироваться с помощью одного энтропийного слайса на строку(и) наибольших единиц кодирования (LCU), как изображено на фиг. 2 и 9. Предпочтительно использовать волновые методы на стороне декодера. Во время процесса кодирования битовый поток каждого слайса может делиться на сегменты постоянного размера. Затем результирующие сегменты перемежаются и могут передаваться для передачи. Постоянный размер сегментов может создавать проблему в конце битового потока из-за его переменной длины.
Существуют два возможных обобщенных решения. Первым решением является генерация однобайтовых сегментов (обычно битовый поток, представляющий слайс, выровнен к байту), и управление расходом байтов с помощью каждого средства декодера, то есть декодер определяет завершение энтропийного слайса.
Вторым является использование кода завершения в конце слайса. В последнем случае могут использоваться сегменты переменной длины, но это может также приводить к большему количеству данных. Другим способом является передача длины энтропийного слайса. Один такой альтернативный вариант описан ниже.
Размер сегмента и способ перемежения может передаваться или в одном SEI-сообщении или в SPS.
Схема передачи показана на фиг. 16.
Таким образом, в соответствии с аспектом фиг. 16, например, обеспечена концепция энтропийного кодирования массива выборок, которая обеспечивает более низкую задержку по сравнению с доступными в настоящее время концепциями. В соответствии с этим аспектом кодированный поток 20 данных, в который кодируется информационный сигнал, содержит слайсы, такие как энтропийные слайсы 90 или просто полностью независимо декодируемые слайсы (показаны с левой стороны), в которые различные порции 12 информационного сигнала (с предсказанием и/или энтропийно) кодируются, причем данные слайсы 90 подразделяются на фрагменты (заштрихованные прямоугольники 310), которые располагаются в кодированном потоке 20 данных перемежаемым способом (показаны с правой стороны), перемежение представлено скобкой 312.
Как обозначено выше и описано относительно других аспектов, слайсы могут быть энтропийными слайсами 90, которые, в свою очередь, могут быть соответствующими подмножествами слайсов кадров, и соответственно, кодированный поток данных может быть энтропийно кодированным потоком 20 данных.
Перемежение 312 слайсов 90 предоставляет возможность более низкой задержки, так как декодер, отвечающий за декодирование любого из слайсов 90, не должен ждать в течение промежутка времени, израсходованного на предыдущие слайсы других декодеров (согласно порядку 16 слайсов). Вместо этого все доступные декодеры имеют возможность начинать декодировать связанные с ними слайсы, как только первый фрагмент 310 доступен, и потенциальные зависимости между частями определяют, сравни с волновым подходом.
Различные порции 12 могут энтропийно кодироваться в энтропийные слайсы 90, используя оценки вероятности, которые устанавливаются независимо среди энтропийных слайсов, или используя заимствование между энтропийными слайсами оценки вероятности, как описано выше, например, именно в которых различные порции 12 кодируются в энтропийные слайсы 90 вдоль соответствующих траекторий 14 энтропийного кодирования, и зависимые энтропийные слайсы имеют соответствующие им порции 12, закодированные в них, используя оценки вероятностей, полученные в том числе из оценок вероятности, используемых в энтропийных слайсах более высокого ранга в пространственно соседних частях соответствующей порции, как описано ранее.
Энтропийно закодированный поток 20 данных может дополнительно содержать заголовок, как показано в качестве дополнительной возможности на фиг. 16. Заголовок 300 может связываться с кадром (массивом выборок) последовательности 30, заголовок 300 содержит информацию, которая показывает длину энтропийных слайсов. Информация, относящаяся к длине энтропийных слайсов 90, может кодироваться в пределах заголовка 300, как описано выше, используя коды VLC. Используя знание о длине энтропийных слайсов, на стороне декодирования может идентифицироваться последний фрагмент, связанный с каждым из энтропийных слайсов 90, и его длину. Однако могут также использоваться начальные коды или другие схемы указания. Начальные положения слайса могут также идентифицироваться просто с помощью процесса декодирования, который знает завершение слайса. Поэтому может быть возможно просто полагаться на указание от декодера, но это требует сигнализации между декодерами и в некоторых случаях, если «более ранний» энтропийный слайс завершается позже, чем «более поздний» слайс в потоке. Это может потребовать для определенных случаев «адаптивной» сигнализации в потоке, которая может быть основана на начальных кодах.
Например, энтропийные слайсы 90 могут располагаться после заголовка 300, как иллюстрировано на фиг. 16.
Фрагменты 310 могут иметь равную длину, по меньшей мере пока это касается начальной смежной порции последовательности фрагментов 310 от первого из фрагментов по порядку, в котором фрагменты располагаются в энтропийно кодированном потоке 20 данных. Последующие фрагменты могут изменяться по длине. Последующие фрагменты могут быть равны длине начальной смежной порции последовательности или меньше этой длины. Длина последующих фрагментов может получаться из вышеупомянутой информации в заголовке 300, которая раскрывает длину энтропийных слайсов 90 или положение начала. Фрагменты 310 могут располагаться в энтропийно кодированном потоке 20 данных циклически в соответствии с порядком, определенным среди энтропийных слайсов. Для энтропийных слайсов, фрагменты которых полностью находятся в предыдущих циклах, они могут пропускаться в текущем и последующем циклах.
Другие информационные сигналы, чем последовательность массива выборок, такие как видеосигнал, могут также передаваться через поток 20 данных. Различные порции 12 таким образом должны не быть порциями предопределенного массива выборок, такого как изображение/кадр.
Как описано выше, энтропийные слайсы 90 могут иметь различные порции 12 массива 10 выборок, закодированные в них посредством кодирование с предсказанием, используя предсказание между энтропийными слайсами и/или межкадровое предсказание, энтропийное кодирование ошибки предсказания для предсказания между энтропийными слайсами и/или межкадрового предсказания. То есть, как описано выше, различные порции могут быть пространственно отличающимися порциями кадра 10 или множества кадров 30. Последний случай применяется, если слайс(ы) следующего кадра(ов) или энтропийный слайс(ы) могут быть уже декодированы, например, волновым способом, основываясь на знании запрошенной информации для декодирования энтропийного слайса следующего кадра из-за доступных межкадровых ссылок. Уже декодированные данные кадра, следующего по порядку декодирования, могут получаться из максимальной разрешенной/переданной длины вектора движения или из дополнительной информации в потоке, указывающей зависимости частей данных от предыдущего кадра(ов)), и предсказание между энтропийными слайсами может вовлекать внутреннее предсказание, в то время как межкадровое предсказание может вовлекать предсказание с компенсацией движения. Пример изложен ниже.
Вышеупомянутая независимость установки оценки вероятности среди энтропийных слайсов может относиться и к адаптированию вероятности, а также к моделированию содержимого. То есть содержимое, выбранное в пределах энтропийного слайса, может выбираться независимо из других энтропийных слайсов, и оценка вероятности содержимого может также инициализироваться и адаптироваться независимо от любого другого энтропийного слайса.
Соответствующий энтропийный декодер может быть построен следующим образом.
Энтропийный декодер, сконфигурированный для декодирования энтропийно закодированного потока 20 данных, который содержит энтропийные слайсы 90, в которые различные порции кадра энтропийно кодируются, причем энтропийные слайсы подразделяются на фрагменты 310, которые располагаются в энтропийно кодированном потоке 20 данных перемежаемым способом, может быть сконфигурирован, как показано на фиг. 6, и может дополнительно содержать деперемежитель, сконфигурированный для деперемежения фрагментов 310, показан с помощью символа 314 на фиг. 16.
В частности, как иллюстрировано на фиг. 5, энтропийный декодер может содержать множество энтропийных декодеров 130, таких как потоки, выполняющиеся в различных ядрах обработки, причем деперемежитель может быть сконфигурирован, для каждого энтропийного слайса, для направления его фрагментов 310 к энтропийному декодеру 44, связанному с соответствующим энтропийным слайсом.
Другими словами, энтропийные слайсы могут разделяться на фрагменты, которые, в свою очередь, могут перемежаться, и декодер может содержать деперемежитель для деперемежения фрагментов и может начинать обрабатывать энтропийные слайсы параллельно вдоль траекторий 16 даже перед приемом любого из энтропийных слайсов в целом. Следует вспомнить, что длина фрагментов, предпочтительно, измеряется в области энтропийного кодирования, а не в синтаксической области так, чтобы соответствовать, например, множеству определенных пространственных частей/блоков на изображении и т.п., хотя последняя возможность также будет доступна.
Далее описано возможное использование временных зависимостей. То же самое может использоваться в дополнение, или альтернативно к уже описанным вариантам осуществления улучшения оценки вероятности.
Образец волновой обработки данных, как он описан в данном случае, можно расширять на энтропийное кодирование с новым вычислением вероятностей для каждой LCU, чтобы использовать также временные зависимости между кадрами.
Как известно, вероятности будут повторно инициализироваться в начале каждого кадра (первая LCU). Таким образом вероятности, которые были уже получены в предыдущем кадре, теряются. Чтобы уменьшить потерю эффективности кодирования, можно передавать конечное состояние изображения (сравни 320) или, в случае использования энтропийного слайса, конечное состояние слайса (сравни 322) вероятностей от опорного кадра 324 к первой LCU 50 текущего кадра 10 или энтропийного слайса 12, соответственно (фиг. 17). Такие данные соответствующего слайса в опорном кадре могут быть получены не только в конечном положении, но также и в предыдущем положении в опорных слайсах, так как параллельная волновая обработка данных может также проходить через границы кадра, то есть пока кодируют слайс кадра, процесс кодирования слайса предыдущего кадра еще может быть не закончен. Поэтому сигнализация может использоваться для указания опорной позиции, или она может обозначаться с помощью схемы.
Используя вышеупомянутое замечание, можно таким образом, для инициализации в начальной фазе 84 и 234, соответственно, устанавливать P{i, j}, причем {i, j} обозначает первую CU 50 в k-м энтропийном слайсе текущего массива выборок, равную, или по меньшей мере зависящую от любой T(P{i, j}’), причем {i, j}' обозначает CU в пределах предыдущего (по порядку кодирования массива выборок, который может быть равен порядку представления) массива выборок, или комбинации нескольких T(P{i, j}’). Это может быть сделано только для k=0, или для каждого энтропийного слайса k∈{1...K}, причем K обозначает количество энтропийных слайсов в текущем кадре. Временная инициализация может быть сделана дополнительно или альтернативно к описанной выше пространственной инициализации. То есть P{i, j}, причем {i, j} обозначает первую CU 50 в k-м энтропийном слайсе, может устанавливаться равным некоторой комбинации (такой как среднее значение sme) T(P{i, j}’) и T(P{i, j}spatial), причем {i, j}' обозначает CU в пределах предыдущего (ранее декодированного) массива выборок или комбинацию нескольких T(P{i, j}’), и {i, j}spatial обозначает CU в пределах предыдущего энтропийного слайса текущего массива выборок. Пока {i, j}' рассматривают, P{i, j}, причем {i, j} обозначает первую (по порядку 14 энтропийного кодирования) CU 50 в k-м (по порядку 14 энтропийного кодирования) энтропийном слайсе текущего массива выборок, может быть установлен равным T(P{i, j}’), причем {i, j}' обозначает последнюю (по порядку 14 энтропийного кодирования) CU в пределах k-го (по порядку энтропийных слайсов) энтропийного слайса в предыдущем (по порядку кодирования массива выборок) массиве выборок или последнюю CU в пределах последнего (по порядку энтропийных слайсов) энтропийного слайса в предыдущем (по порядку кодирования массивов выборок) массиве выборок. Снова, данная временная инициализация может выполняться только для первого энтропийного слайса в массиве выборок.
Процесс анализа конечного состояния опорного кадра тестировался с помощью способа адаптирования вероятностей, эти результаты иллюстрируются на фиг. 10 - фиг. 19 (временной график).
Другая возможность использования данных от других кадров состоит в том, чтобы обмениваться полученными вероятностями между соотнесенными LCU. Главная идея основана на утверждении, что свойства опорного кадра отличаются от текущего кадра не очень сильно. Чтобы ускорить изучение вероятностей по LCU в кадре, можно попытаться передавать конечное состояние каждой LCU к соответствующей LCU в текущем кадре. Это предложение иллюстрируется на фиг. 18.
Под опорным кадром могут пониматься различные возможности. Например, кадр, который кодируется последним, может использоваться в качестве опорного кадра. Иначе последний закодированный кадр только от того же самого временного уровня может назначаться в качестве опорного.
Кроме того, данный подход может объединяться с уже предложенными выше способами, как использование последней (слайса) информации из опорного кадра, адаптирование вероятностей и использование второй LCU верхней линии.
Вышеупомянутый процесс пространственного адаптирования может изменяться так, чтобы он был
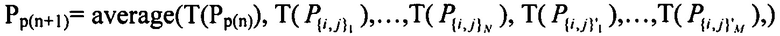
где N может быть 1 или больше 1 и {i, j}1...N выбирают из (находится в пределах) любого предыдущего (по порядку 16 энтропийных слайсов) энтропийного слайса 90 в текущем массиве 10 выборок и связанной с ним порции 12, соответственно, и M может быть 1 или больше 1 и {i, j}'1...M находится в пределах предыдущего массива выборок 350. Может случиться так, что по меньшей мере одна из CU 50 {i, j}'1...M совмещена с p(n). Относительно возможных выборов CU 50 {i, j}1...N ссылка сделана к вышеупомянутому описанию. Функция «среднее значение» может быть одной из взвешенного суммирования, срединной функции и т.д.
Вышеупомянутый процесс пространственного адаптирования может быть заменен на
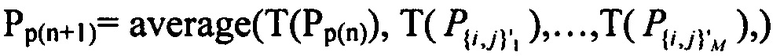
где M может быть 1 или больше 1 и {i, j}'1...M находится в пределах предыдущего массива выборок. Может случиться так, что по меньшей мере {i, j}'1...M совмещена с p(n). Относительно возможных выборов {i, j}1...N ссылка сделана к вышеупомянутому описанию. Функция «среднее значение» может быть одной из взвешенного суммирования, срединной функции и т.д. Может случиться так, что по меньшей мере {i, j}'1...M совмещена с p(n).
В качестве определенного расширения использования соотнесенной информации может применяться подход для использования полученных данных от других блоков из одного или даже большего количества опорных кадров.
Ранее упомянутые методы используют полученную информацию только от непосредственных соседей в текущем кадре или в опорных кадрах. Однако это не подразумевает, что полученные вероятности в данном случае являются лучшими. Смежные LCU, согласно разделениям изображения (разностная информация), не всегда имеют лучшие модели вероятностей. Предполагается, что лучшие результаты могут обеспечиваться с помощью блоков, на основе которых будет выполняться предсказание. И таким образом, этот соответствующий блок может использоваться в качестве опорного для текущего LCU.
Таким образом, в вышеприведенном примере адаптирования {i, j}1...N и/или {i, j}'1...M могут выбираться в зависимости от использования CU в качестве источников параметров предсказания для p(n).
Представленные схемы адаптирования/инициализации временной вероятности могут также использоваться без энтропийных слайсов или с одним энтропийным слайсом в кадре.
В соответствии с последним аспектом, увеличение скорости адаптирования вероятности обеспечивается с помощью объединения адаптирования вероятности во временной области соседних/связанных кадров. Описанное является декодером, таким как декодер на фиг. 6, причем данный декодер сконфигурирован для восстановления последовательности массивов выборок из потока данных энтропийного кодера, и сконфигурирован для энтропийного декодирования текущего кадра потока данных энтропийного кодера для восстановления текущего массива выборок последовательности массивов выборок, выполнения энтропийного декодирования вдоль траектории энтропийного кодирования и использования оценок вероятности и адаптирования оценок вероятности вдоль траектории энтропийного кодирования, используя ранее декодированную часть текущего кадра, причем каскад энтропийного декодирования сконфигурирован для инициализации или определения оценки вероятности для текущего кадра, основываясь на оценках вероятности, используемых при декодировании ранее декодированного кадра энтропийно закодированного потока данных.
То есть, например, оценки вероятности для текущего кадра инициализируются, основываясь на оценках вероятности, являющихся результатом после завершения декодирования ранее декодированного кадра энтропийно закодированного потока данных. Поэтому требования к буферу являются низкими, так как просто конечное состояние оценок вероятности должно буферизоваться до начала декодирования текущего кадра. Конечно, этот аспект объединяется с аспектом на фиг. 1-9 в том, что для первых частей каждой порции 12 используются не только оценки вероятности, используемые для пространственно соседних частей в предшествующих энтропийных слайсах (если доступны), но также и взвешенным образом, например, конечное состояние оценок вероятности (например, пространственно) соответствующего энтропийного слайса в предыдущем кадре. Такие данные соответствующей части в опорном кадре могут быть получены не только в конечном положении, но также и от предшествующего положения в опорных слайсах, так как параллельная волновая обработка данных может также проходить через границы кадра, то есть когда кодируют слайс кадра, процесс кодирования слайса предыдущего кадра возможно еще не закончен. Поэтому, сигнализация может использоваться для указания опорного положения, или оно может быть обозначено с помощью схемы.
Дополнительно, например, оценки вероятности, используемые для кодирования частей/блоков ранее декодированного кадра, буферизируются все, а не только конечное состояние, и декодер будет энтропийно декодировать предопределенный энтропийный слайс (со ссылкой к вышеупомянутому описанию пространственно объединенного получения вероятности), выполнять энтропийное декодирование текущей части (X) предопределенного энтропийного слайса, основываясь на соответствующих оценках вероятности предопределенного энтропийного слайса, которые адаптированы, используя ранее декодированную часть предопределенного энтропийного слайса (включающего в себя p1, например), и на оценках вероятности, которые используются при энтропийном декодировании пространственно соответствующей части энтропийного слайса ранее декодированного кадра, при желании, дополнительно используя оценки вероятности, которые используются при энтропийном декодировании пространственно соседнего, по порядку энтропийных слайсов предыдущего энтропийного слайса (слайса, содержащего X, например) в соседней части (такого как p4) пространственно соседнего энтропийного слайса, как описано выше. Как было также описано выше, пространственное соответствие между частями и идентификация соответствующей части для заимствования вероятности для текущего кадра среди ранее декодированного кадра может определяться с помощью информации движения, такой как индексы движения, векторы движения и т.п., текущей части/блока.
До сих пор волна, распространяющаяся во время волновой обработки данных, прежде всего описана, как распространяющаяся наискось через один массив 10 выборок, причем кодирование/декодирование выполняется один массив выборок за другим. Однако, это не является необходимостью. Ссылка сделана к фиг. 19. Фиг. 19 показывает порцию последовательности массивов выборок, причем массивы выборок последовательности определены среди нее и изображены, как расположенные по порядку 380 кодирования массивов выборок, который может совпадать или может не совпадать с порядком времени представления. Фиг. 19 для примера показывает разделение массивов 10 выборок на четыре энтропийных слайса каждый. Уже закодированные/декодированные энтропийные слайсы показаны заштрихованными. Четыре потока кодирования/декодирования (каскада кодирования/декодирования) 382 в настоящее время выполняются на этих четырех энтропийных слайсах 12 массива выборок, имеющего индекс n. Однако, фиг. 19 показывает оставшийся поток номер 5, и возможно, что этот дополнительный поток 382, имеющий номер 5 на фиг. 19, работает для кодирования/декодирования следующего массива выборок на линии, то есть n+1, в порциях, для которых гарантируется, что соответствующие опорные порции в закодированном/декодированном в настоящее время кадре n уже доступны, то есть уже обработаны любым из потоков 1-4. Эти порции являются опорными, например, при предсказаниях, показанных как 64 на фиг. 1.
Фиг. 19 для примера показывает с помощью пунктирной 384 линии, распространяющейся через массив n+1 выборок, который уже совмещен с границей между обработанной, то есть закодированной/декодированной порцией массива n выборок, то есть заштрихованной порцией в пределах n массива выборок с одной стороны, и еще не обработанной порцией, то есть незаштрихованной порцией массива n выборок с другой стороны. С помощью двунаправленных стрелок фиг. 19 также показывает максимальную возможную длину векторов движения, измеренных в направлении столбца и строки, то есть ymax и xmax, соответственно. Соответственно, фиг. 19 также показывает с помощью штрихпунктирной линии 386 смещенную версию линии 384, а именно, линию 386, которая располагается отдельно от линии 384 на минимальном возможном расстоянии так, чтобы расстояние не упало ниже ymax в направлении столбца и xmax в направлении строки. Как может быть замечено, существуют единицы 50 кодирования в массиве n+1 выборок, для которых любая опорная порция в массиве n выборок, как гарантируется, будет найдена, как полностью содержащаяся в пределах уже обработанной порции этого массива n выборок, а именно те, которые находятся в половине массива n+1 выборок, находящейся на верхней стороне относительно линии 386. Соответственно, поток 5 уже имеет возможность работать для декодирования/кодирования этих единиц кодирования, как показано на фиг. 19. Как может быть замечено, даже шестой поток может обрабатывать второй энтропийный слайс по порядку 16 энтропийных слайсов массива n+1 выборок. В связи с этим волна распространяется не только пространственно, но также и во временной области через пространственно-временное пространство, заполненное последовательностью 30 массивов выборок.
Следует отметить, что только что упомянутый волновой аспект действительно также работает в комбинации с вышеизложенными взаимосвязями оценок вероятности по границам энтропийного слайса.
Дополнительно, относительно вышеизложенного аспекта фрагмента, нужно также отметить, что разделение энтропийных слайсов на меньшие части, то есть фрагменты, не ограничено выполнением в области энтропийного кодирования, то есть в энтропийно сжатой области. Если подумать о вышеприведенном обсуждении: энтропийные слайсы, которые описаны выше, имеют преимущество сокращения потери эффективности кодирования несмотря на возможность волновой обработки данных из-за происхождения оценок вероятности от ранее закодированных/декодированных энтропийных слайсов того же самого или ранее закодированного/декодированного кадра, то есть инициализации и/или адаптирования оценок вероятности, основываясь на оценках вероятности таких предыдущих энтропийных слайсов. Каждый из этих энтропийных слайсов, как предполагается, энтропийно кодируется/декодируется одним потоком в случае волновой обработки данных. То есть, когда разделяют энтропийные слайсы, не является необходимым обрабатывать фрагменты, которые могут кодироваться/декодироваться параллельно. Вместо этого кодер просто обеспечивается возможностью выводить разделы битового потока его энтропийного слайса до завершения энтропийного кодирования, и декодер обеспечивается возможностью обрабатывать эти разделы, то есть фрагменты, до приема оставшихся фрагментов того же самого энтропийного слайса. Кроме того, перемежение должно быть разрешено на стороне приема. Чтобы позволить последнее деперемежение, однако, не требуется выполнять разделение в области энтропийного кодирования. В частности, можно выполнять вышепредставленное разделение энтропийных слайсов на меньшие фрагменты без серьезной потери эффективности кодирования, периодически просто перезагружая внутреннее состояние интервала вероятности, то есть значение ширины интервала вероятности, и значение смещения, соответственно, ядра энтропийного кодирования/декодирования. Оценки вероятности, однако, не перезагружаются. Вместо этого они непрерывно обновляются/адаптируются с начала до завершения энтропийных слайсов, соответственно. С помощью этих мер можно разделять энтропийные слайсы на отдельные фрагменты, причем разделение выполняется в области синтаксических элементов, а не в области сжатого битового потока. Разделение может быть результатом пространственного разделения, как изложено ниже, для облегчения передачи к декодеру границ между фрагментами. Каждый из фрагментов может обеспечиваться своим собственным заголовком фрагмента, который раскрывает, например, его начальную позицию в массиве выборок, измеренную, например, по порядку 14 кодирования относительно начального положения соответствующего энтропийного слайса наряду с индексом его энтропийного слайса, или относительно известного местоположения массива 10 выборок, такого как верхний левый угол.
Для более ясного описания подразделения энтропийных слайсов на фрагменты в соответствии с последним вариантом осуществления, ссылка сделана к фиг. 20. Фиг. 20 показывает, просто в иллюстративных целях, массив 10 выборок, как подразделенный на четыре энтропийных последовательности. Кодируемые в настоящее время порции массива 10 выборок показаны заштрихованными. Три потока в настоящее время выполняют энтропийное кодирование массива 10 выборок и выводят фрагменты энтропийных слайсов на основе непосредственного рассмотрения: см. например, первый энтропийный слайс по порядку 16 энтропийных слайсов, который соответствует порции 12 массива 10 выборок. После того, как раздел 12a порции 12 закодирован, кодер формирует фрагмент 390 из него, то есть ядро 80 энтропийного кодирования выполняет некоторую завершающую процедуру для завершения арифметического битового потока, полученного из подпорции 12a в случае арифметического кодирования для формирования фрагмента 390. Процедура кодирования затем возобновляется по отношению к последующей подпорции 12b энтропийного слайса 12 по порядку 14 кодирования, начиная новый энтропийный битовый поток. Это подразумевает, например, что перезагружаются внутренние состояния, такие как значение ширины интервала вероятности и значение смещения интервала вероятности ядра 80 энтропийного кодирования. Оценки вероятности, однако, не перезагружаются. Их оставляют неизменными. Это иллюстрируется на фиг. 20 с помощью стрелки 392. На фиг. 20 для примера показывается, что энтропийный слайс или порцию 12 разделяют больше чем на две подпорции, и соответственно, даже второй 1b фрагмент подлежит некоторому энтропийному завершению перед достижением конечной порции 12 по порядку 14 кодирования, после чего начинается следующий фрагмент на линии, и т.д.
Одновременно, другой поток обрабатывает второй энтропийный слайс или порцию 12 по порядку 16 энтропийных слайсов. После окончания первой подпорции этого второго энтропийного слайса/порции 12, фрагмент 2a выводится, после чего начинается энтропийное кодирование оставшейся части второго энтропийного слайса, сохраняя, однако, оценку вероятности, которая действительна в конце фрагмента 2a.
С помощью оси 394 времени фиг. 20 иллюстрирует, что фрагменты 390 выводятся, как только они завершены. Это приводит к перемежению, аналогичному перемежению, изображенному на фиг. 16. Каждый фрагмент можно пакетировать в пакет и транспортировать к стороне декодирования через некоторый транспортный уровень в любом порядке. Транспортный уровень иллюстрируется, используя стрелку 396.
Декодер должен повторно назначать фрагменты подпорциям 12a, 12b и т.д. Для этой цели каждый фрагмент 390 может иметь секцию 398 заголовка, которая раскрывает начальное расположение связанной с ним подпорции 12a или 12b, то есть подпорции синтаксических элементов, описывающие одно и то же, энтропийно кодируются в соответствующем фрагменте. При использовании этой информации декодер имеет возможность связывать каждый фрагмент 390 с его энтропийной последовательностью и с его подпорцией в пределах порции 12 этого энтропийного слайса.
В целях иллюстрации фиг. 20 также для примера показывает возможность, когда не требуется, чтобы переход между последовательными подпорциями 12a и 12b энтропийного слайса 12 совпадал с границей между последовательными единицами 50 кодирования. Вместо этого данный переход может определяться на более глубоком уровне вышеупомянутого примерного разделения единиц кодирования на несколько деревьев. Информация расположения, содержащаяся в заголовках 398, может указывать начало подпорции, связанной с текущим фрагментом 390, достаточно точно, чтобы идентифицировать соответствующий подблок соответствующего блока кодирования, то есть расположение в пределах последовательности синтаксических элементов, которая описывает соответствующий подблок.
Как стало ясно от вышеприведенного обсуждения, почти отсутствие потери эффективности кодирования является результатом подразделения энтропийных слайсов на фрагменты. Просто процессы энтропийного завершения и пакетирования могут вовлекать некоторую потерю эффективности кодирования, но с другой стороны уменьшение задержки является огромным.
Снова следует отметить, что только что упомянутый пространственный аспект разделения на фрагменты действительно также работает в комбинации с вышеизложенными соединениями оценки вероятности по границам энтропийного слайса, в пространственной и временной области.
Декодер, такой как декодер на фиг. 6, может отменять передачу фрагмента следующим образом. В частности, декодер может проверять, которому энтропийному слайсу принадлежит текущий фрагмент. Эта проверка может выполняться, основываясь на вышеупомянутой информации расположения. Затем может проверяться, соответствует или нет текущий фрагмент первой подпорции порции соответствующего энтропийного слайса вдоль траектории 14 энтропийного кодирования. Если «да», то декодер может энтропийно декодировать текущий фрагмент при адаптировании соответствующих оценок вероятности и учитывать состояние соответствующих оценок вероятности, которые обнаруживаются в конце энтропийного декодирования текущего фрагмента, когда энтропийно декодируют другой фрагмент, который соответствует второй подпорции порции предопределенного энтропийного слайса вдоль траектории энтропийного кодирования. «Учет» может вовлекать урегулирование оценок вероятности в начале фрагмента 1b, равного оценкам вероятности, обнаруживая их непосредственно, с помощью адаптирования вероятности, начиная с состояния оценки вероятности в начале фрагмента 1a, в конце 1a подпорции фрагмента 12a, или равного объединению его с энтропийными оценками вероятности от других энтропийных слайсов, как описано выше. Пока рассматривается инициализация вероятности в начале первого фрагмента 12a, ссылка сделана к вышеупомянутому обсуждению, поскольку оно также формирует начало соответствующего энтропийного слайса. Другими словами, если текущий слайс является вторым или последующим фрагментом по порядку 14, то декодер может энтропийно декодировать текущий фрагмент, используя оценки вероятности, которые зависят от оценок вероятности, обнаруживающихся в конце энтропийно декодированного фрагмента, который соответствует подпорции порции предопределенного энтропийного слайса, предшествующей подпорции, соответствующей текущему фрагменту, вдоль траектории 14 энтропийного кодирования.
Приведенное выше описание показывает различные способы, которые могут использоваться для параллельного кодирования и декодирования, а также использоваться для оптимизации уже существующих процессов в перспективном стандарте видео кодирования HEVC. Был представлен короткий краткий обзор энтропийных слайсов. Показано, как они могут формироваться, какие преимущества могут обеспечиваться с помощью разделения на слайсы и какие недостатки могут быть результатом этих методов. Было предложено множество способов, которые, как предполагается, улучшают процесс изучения вероятностей по LCU (наибольшей единице кодирования) в кадре, с помощью лучшего использования локальных зависимостей между LCU, а также временных зависимостей между LCU различных кадров. Утверждается, что различные комбинации обеспечивают усовершенствования для обеих концепций с параллелизацией кодирования и декодирования и без нее.
Повышение эффективности при высокоэффективном кодировании, например, с помощью наилучшего объединения предложенных подходов, составляет -0,4% при внутреннем, -0,78% при низкой задержке и -0,63% при произвольном доступе по сравнению с HM3.0 без использования энтропийных слайсов или -0,7% при внутреннем, -1,95% при низкой задержке и -1,5% при произвольном доступе по сравнению с подходом энтропийного слайса с обычной повторной инициализацией.
В частности, выше были представлены в том числе следующие методы:
для использования не только локальных, но также и временных зависимостей LCU для оптимизации адаптирования вероятностей CABAC перед кодированием каждой LCU, см. фиг. 1-9, 17 и 18;
для обеспечения большей гибкости при декодировании, также энтропийные слайсы могут использоваться так, чтобы определенные области в кадре стали независимыми друг от друга;
для предоставления возможности минимальной сигнализации начальной позиции слайса/энтропийных слайсов для параллелизации, например, волновой обработки данных, см. фиг. 15;
для предоставления возможности транспортировки с низкой задержкой в параллелизованной среде кодер - передатчик - приемник - декодер посредством перемежаемой транспортировки энтропийных слайсов/слайсов, см. фиг. 16.
Все способы, которые упомянуты выше, были объединены и тестировались в HM3.0. Полученные результаты, где контрольная точка - HM3.0 без какого-либо воплощения энтропийного слайса, представлены в таблицах 1 и 2 (где 2LCU является использованием второй LCU верхней линии; 2LCU+Prob.Adap является способом 2LCU, объединенным со способом адаптирования вероятностей; относящийся к времени - использование временных зависимостей (конечное состояние опорного кадра) с адаптированием вероятностей для каждой LCU).
Однако, интересно знать, как предложенные подходы затрагивают волновую обработку данных с повторной инициализацией вероятностей в начале каждой линии LCU. Эти результаты иллюстрируются в таблицах 3 и 4 (где orig_neiInit является сравнением HM3.0 без использования энтропийных слайсов с использованием энтропийных слайсов с повторной инициализацией).
neiInit
neiInit
Вышеуказанные результаты показывают, что значительно большее использование зависимостей в пределах и между кадрами и рациональное применение уже полученной информации предотвращает усредненные потери.
Подход волновой обработки данных для кодирования и декодирования видео HEVC объединяет возможность использовать зависимости между смежными LCU, а также временные зависимости кадра с концепцией волновой параллельной обработки. Таким образом потери могут уменьшаться, и может обеспечиваться увеличение эффективности.
Увеличение скорости адаптирования вероятности обеспечивается с помощью вычисления адаптирования вероятности пространственно соседних энтропийных слайсов.
Как уже упомянуто выше, все вышеупомянутые аспекты могут объединяться друг с другом, и таким образом упоминание определенных возможностей воплощения по отношению к определенному аспекту должно, конечно, также относиться к другим аспектам.
Хотя некоторые аспекты описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствуют этапу способа или особенности этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента или особенности соответствующего устройства. Некоторые или все этапы способа могут выполняться (или использоваться) с помощью аппаратного устройства, как, например, микропроцессор, программируемый компьютер или электронная схема. В некоторых вариантах осуществления один или большее количество самых важных этапов способа могут выполняться с помощью такого устройства.
Упомянутые выше изобретенные кодированные сигналы могут храниться на цифровом носителе данных или могут передаваться по среде передачи, такой как беспроводная среда передачи или проводная среда передачи, такая как Интернет.
В зависимости от определенных требований воплощения варианты осуществления изобретения могут воплощаться в аппаратных средствах или в программном обеспечении. Воплощение может выполняться, используя цифровой носитель данных, например, гибкий диск, DVD (цифровой универсальный диск), Blu-Ray, CD (компакт диск), ПЗУ (постоянное запоминающее устройство), ППЗУ (программируемое ПЗУ), СППЗУ (стираемое программируемое ПЗУ), ЭСППЗУ (электрически стираемое программируемое ПЗУ) или флеш-память, имеющий сохраненные на нем считываемые с помощью электроники управляющие сигналы, которые взаимодействуют (или могут взаимодействовать) с программируемой компьютерной системой таким образом, что выполняется соответствующий способ. Поэтому цифровой носитель данных может быть считываемым компьютером носителем.
Некоторые варианты осуществления согласно изобретению содержат носитель информации, имеющий считываемые с помощью электроники управляющие сигналы, которые могут взаимодействовать с программируемой компьютерной системой таким образом, что выполняется один из описанных способов.
В общем случае варианты осуществления настоящего изобретения могут воплощаться как компьютерный программный продукт с программным кодом, программный код используется для выполнения одного из способов, когда данный компьютерный программный продукт выполняется на компьютере. Программный код может, например, храниться на считываемом компьютером носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из описанных способов, хранящуюся на считываемом компьютером носителе.
Другими словами, вариантом осуществления изобретенного способа поэтому является компьютерная программа, имеющая программный код для выполнения одного из описанных способов, когда данная компьютерная программа выполняется на компьютере.
Дополнительным вариантом осуществления изобретенных способов поэтому является носитель информации (или цифровой носитель данных, или считываемый компьютером носитель), содержащий записанную на нем компьютерную программу для выполнения одного из описанных способов. Носитель информации, цифровой носитель данных или записанный носитель обычно являются материальными и/или не временными.
Дополнительным вариантом осуществления изобретенного способа поэтому является поток данных или последовательность сигналов, представляющие компьютерную программу для выполнения одного из описанных способов. Поток данных или последовательность сигналов могут, например, конфигурироваться для перемещения через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, сконфигурированное или адаптированное для выполнения одного из описанных способов.
Дополнительный вариант осуществления содержит компьютер, установленную на нем компьютерную программу для выполнения одного из описанных способов.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, сконфигурированную для перемещения на приемник (например, с помощью электроники или оптически) компьютерной программы для выполнения одного из описанных способов. Приемник может, например, быть компьютером, мобильным устройством, запоминающим устройством или подобным устройством. Устройство или система могут, например, содержать файловый сервер для передачи на приемник компьютерной программы.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения некоторых или всех функциональных возможностей описанных способов. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может совместно работать с микропроцессором для выполнения одного из описанных способов. В общем случае способы предпочтительно выполняются с помощью любого аппаратного устройства.
Вышеописанные варианты осуществления являются просто иллюстративными для принципов настоящего изобретения. Подразумевается, что модификации и изменения описанных структур и деталей будут очевидны специалистам. Поэтому существует намерение, чтобы изобретение было ограничено только объемом формулы изобретения рассматриваемого патента, а не конкретными подробностями, представленными посредством описания и объяснения вариантов осуществления в данной работе.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОДИРОВАНИЕ МАССИВА ВЫБОРОК ДЛЯ НИЗКОЙ ЗАДЕРЖКИ | 2012 |
|
RU2643647C1 |
| КОДИРОВАНИЕ МАССИВА ВЫБОРОК ДЛЯ НИЗКОЙ ЗАДЕРЖКИ | 2018 |
|
RU2666628C1 |
| КОДИРОВАНИЕ МАССИВА ВЫБОРОК ДЛЯ НИЗКОЙ ЗАДЕРЖКИ | 2022 |
|
RU2787846C1 |
| КОДИРОВАНИЕ МАССИВА ВЫБОРОК ДЛЯ НИЗКОЙ ЗАДЕРЖКИ | 2019 |
|
RU2763532C2 |
| КОДИРОВАНИЕ МАССИВА ВЫБОРОК ДЛЯ НИЗКОЙ ЗАДЕРЖКИ | 2012 |
|
RU2610668C2 |
| КОДИРОВАНИЕ МАССИВА ВЫБОРОК ДЛЯ НИЗКОЙ ЗАДЕРЖКИ | 2023 |
|
RU2825247C2 |
| КОДИРОВАНИЕ ИЗОБРАЖЕНИЙ С МАЛОЙ ЗАДЕРЖКОЙ | 2021 |
|
RU2785714C1 |
| КОДИРОВАНИЕ ИЗОБРАЖЕНИЙ С МАЛОЙ ЗАДЕРЖКОЙ | 2021 |
|
RU2784930C1 |
| КОДИРОВАНИЕ ИЗОБРАЖЕНИЙ С МАЛОЙ ЗАДЕРЖКОЙ | 2013 |
|
RU2603531C2 |
| КОДИРОВАНИЕ ИЗОБРАЖЕНИЙ С МАЛОЙ ЗАДЕРЖКОЙ | 2019 |
|
RU2758037C2 |
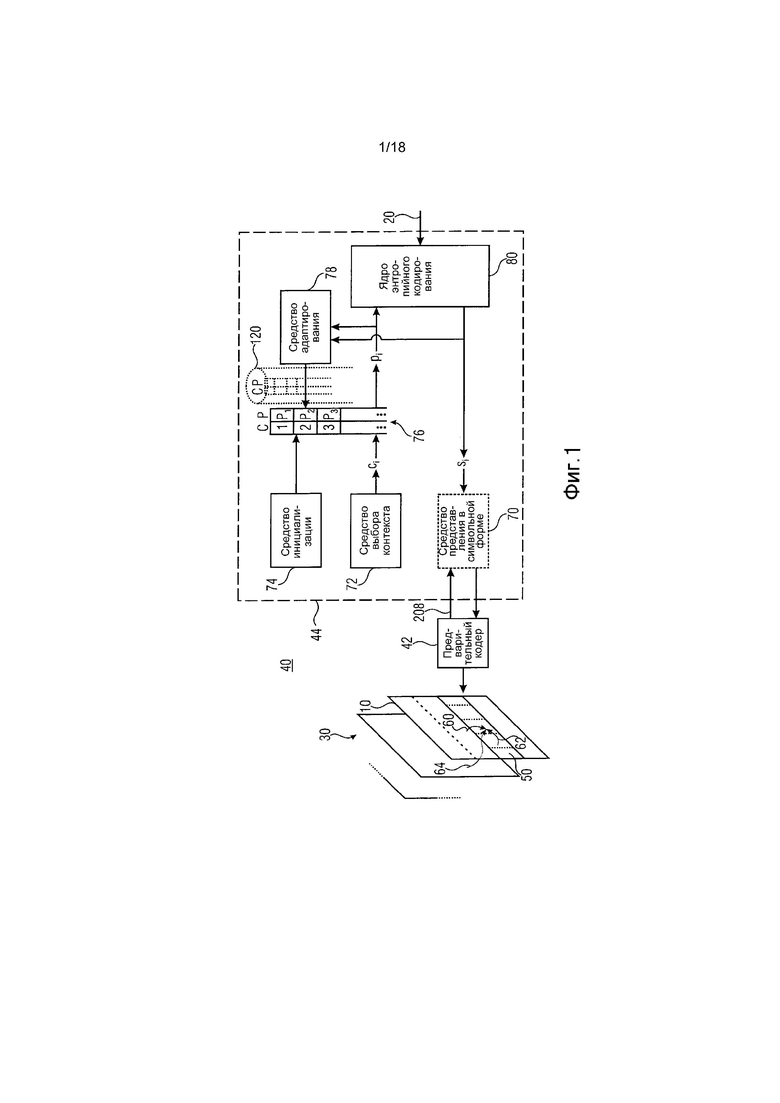
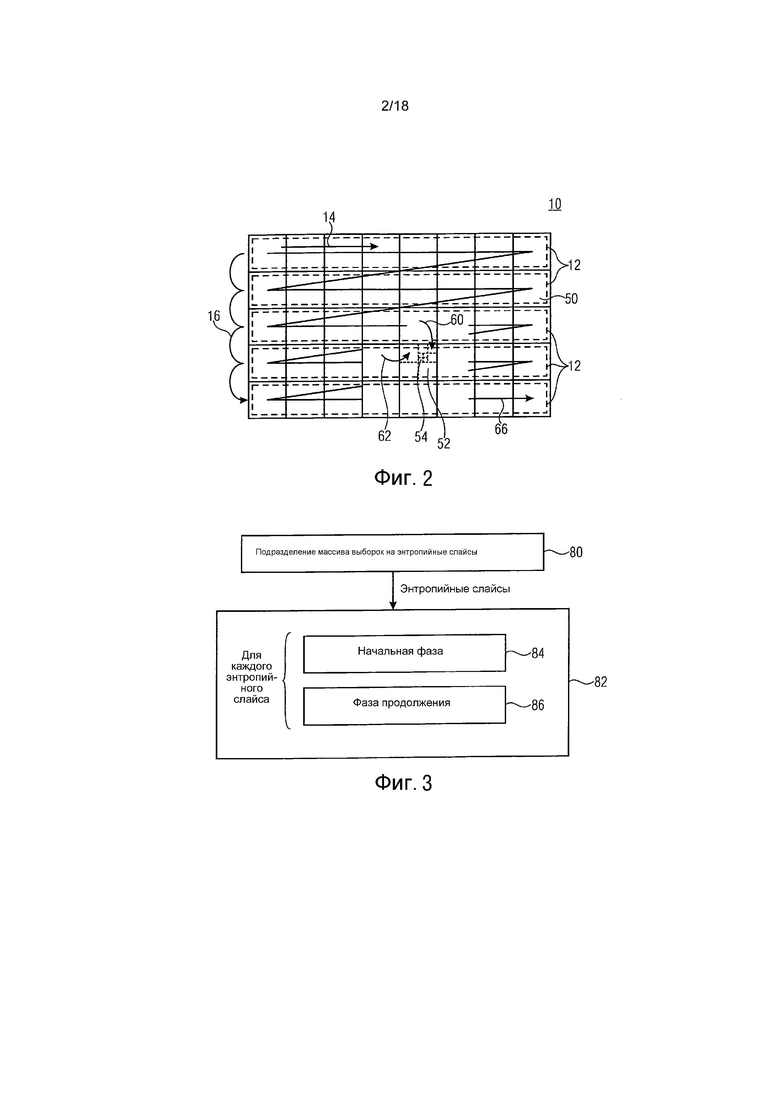
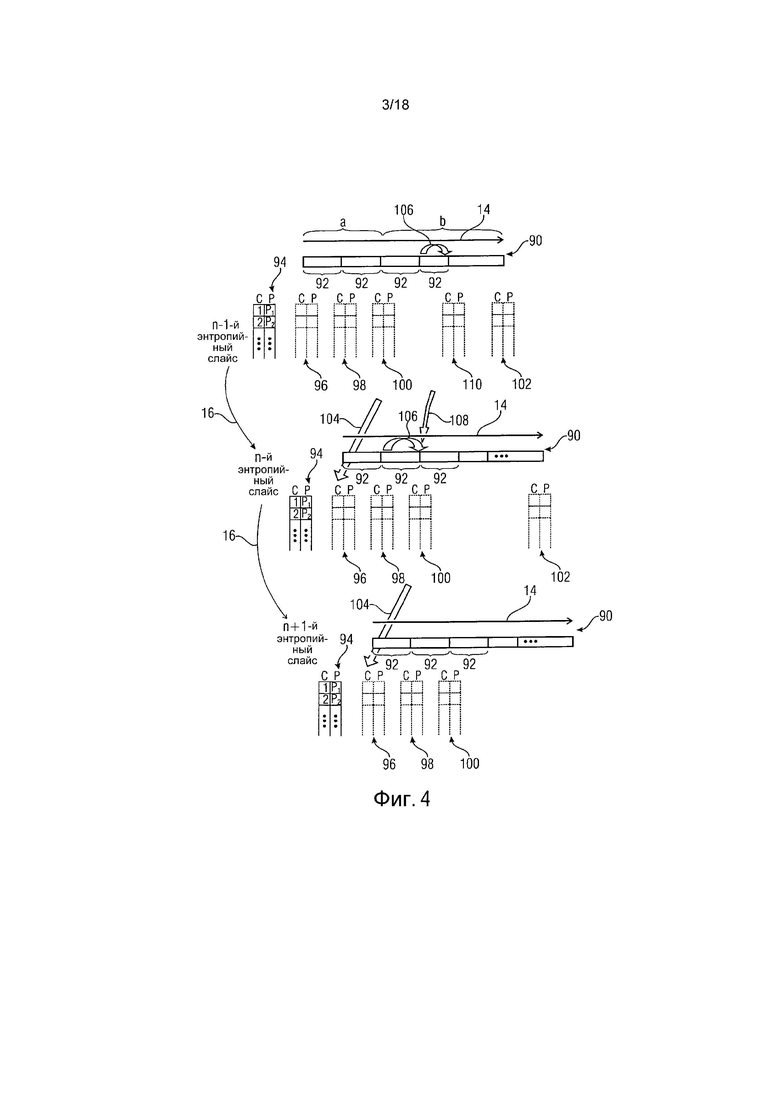
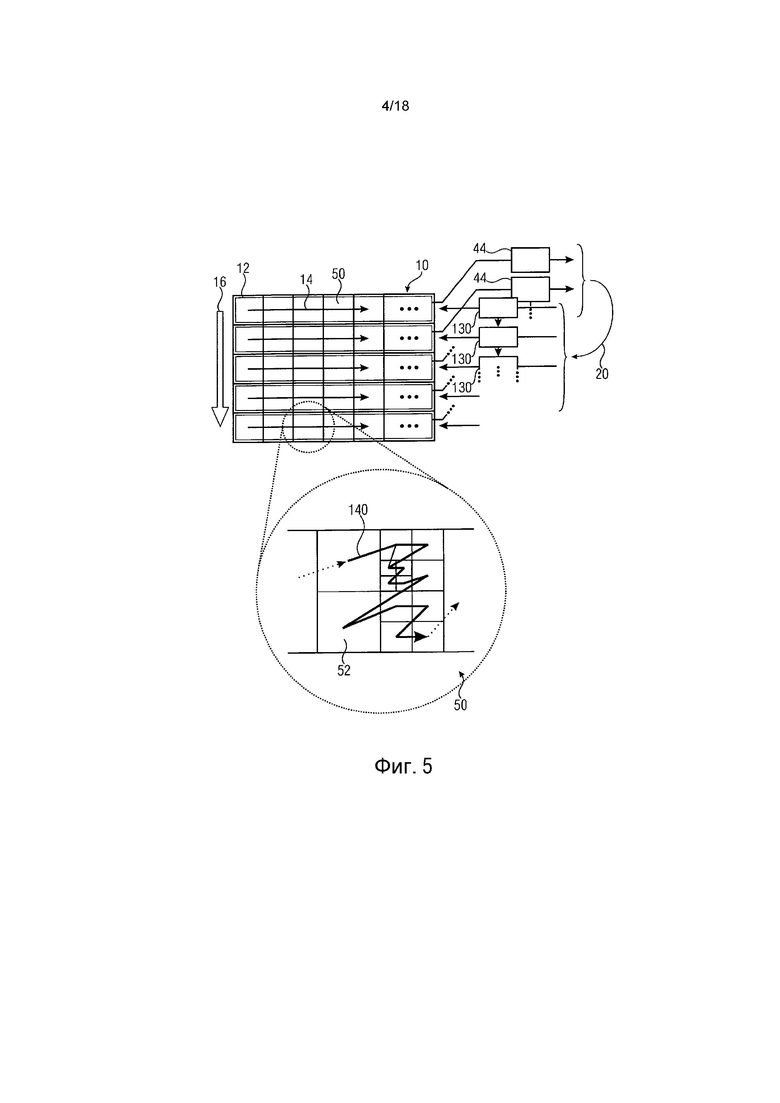
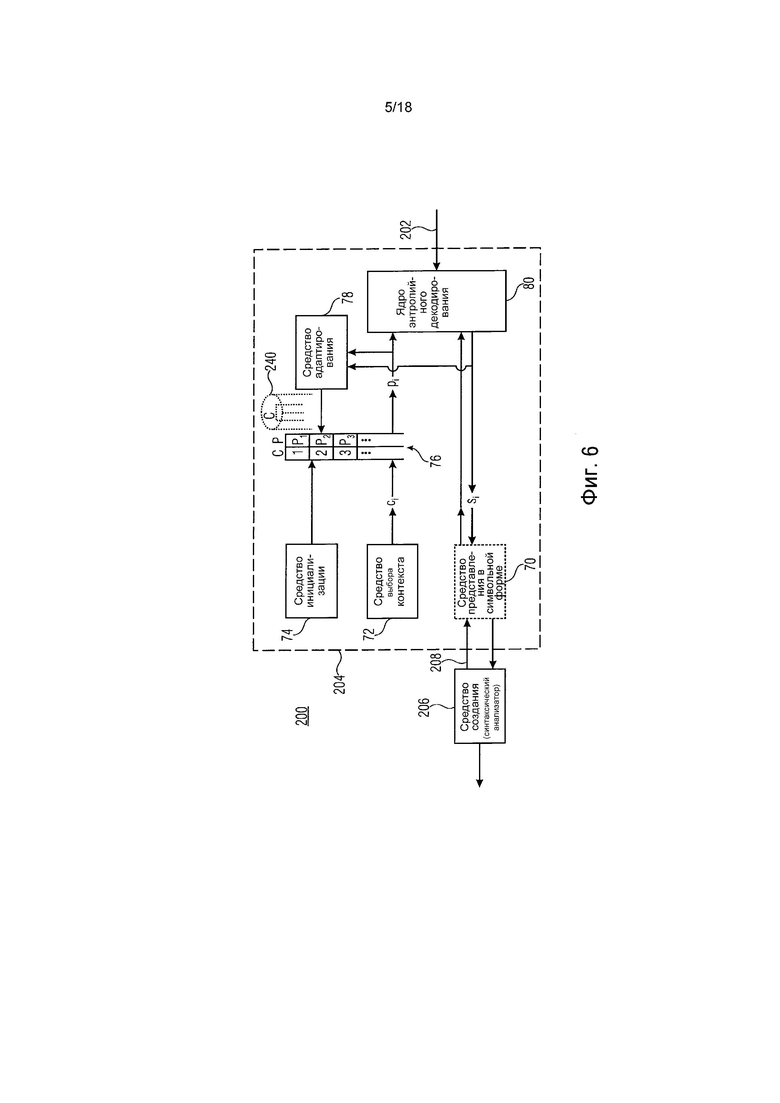
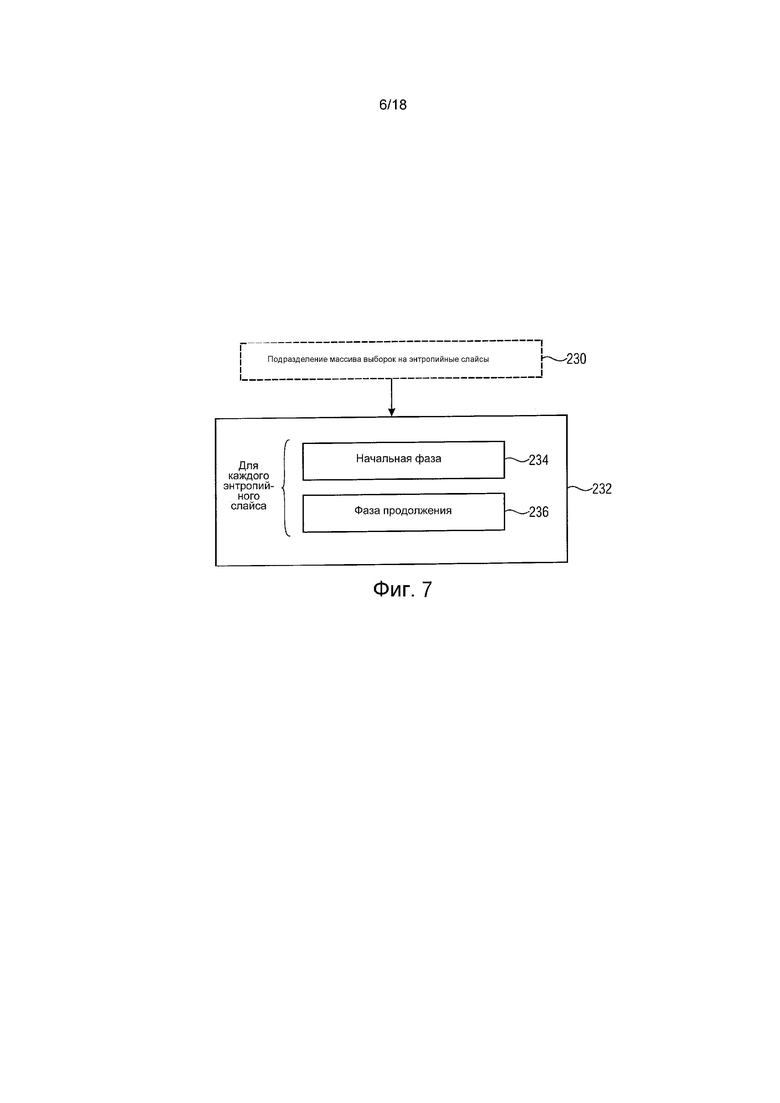
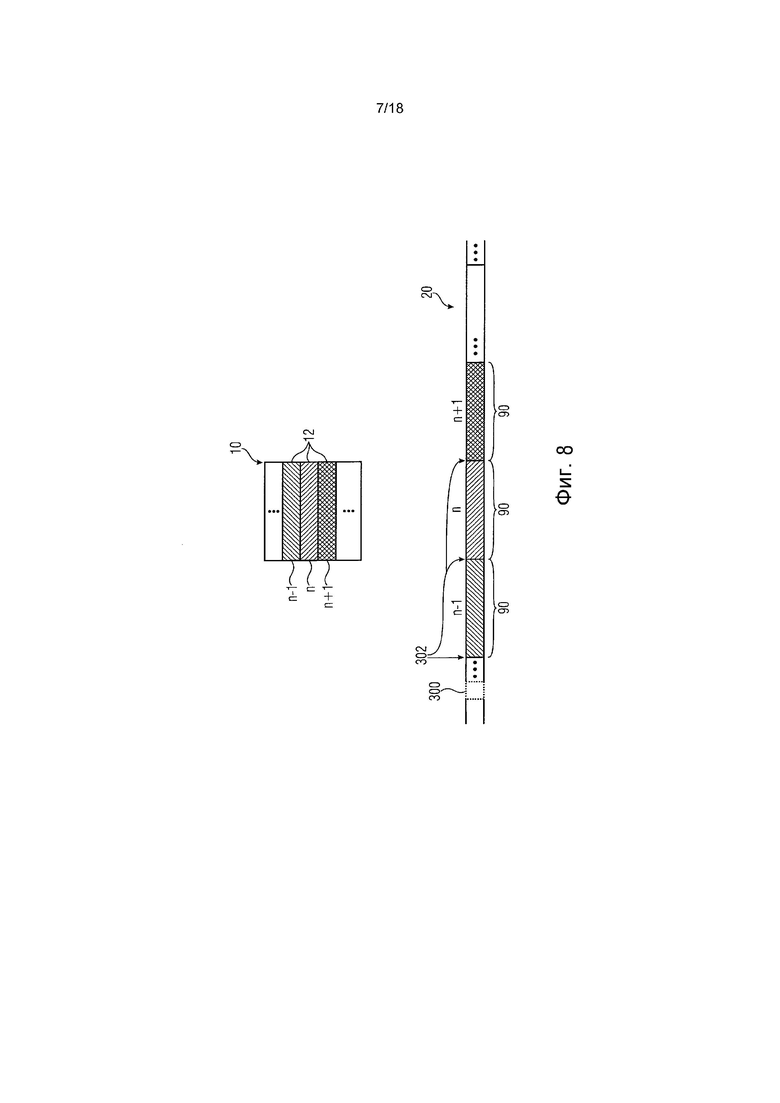
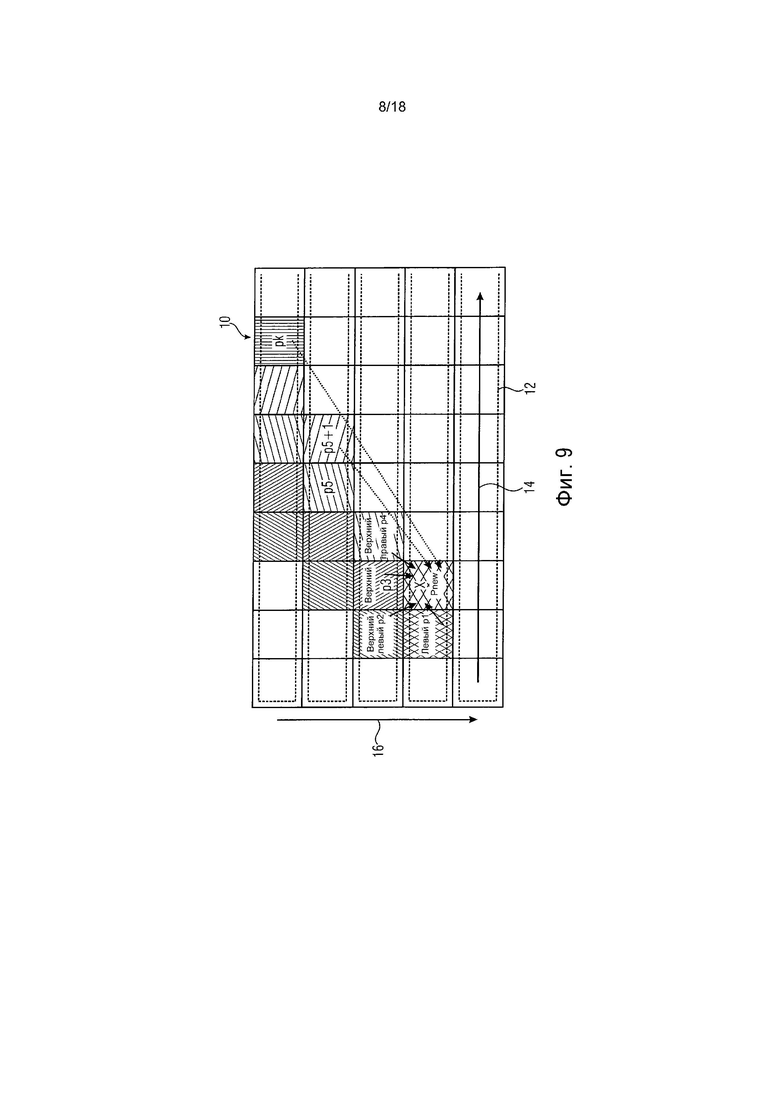
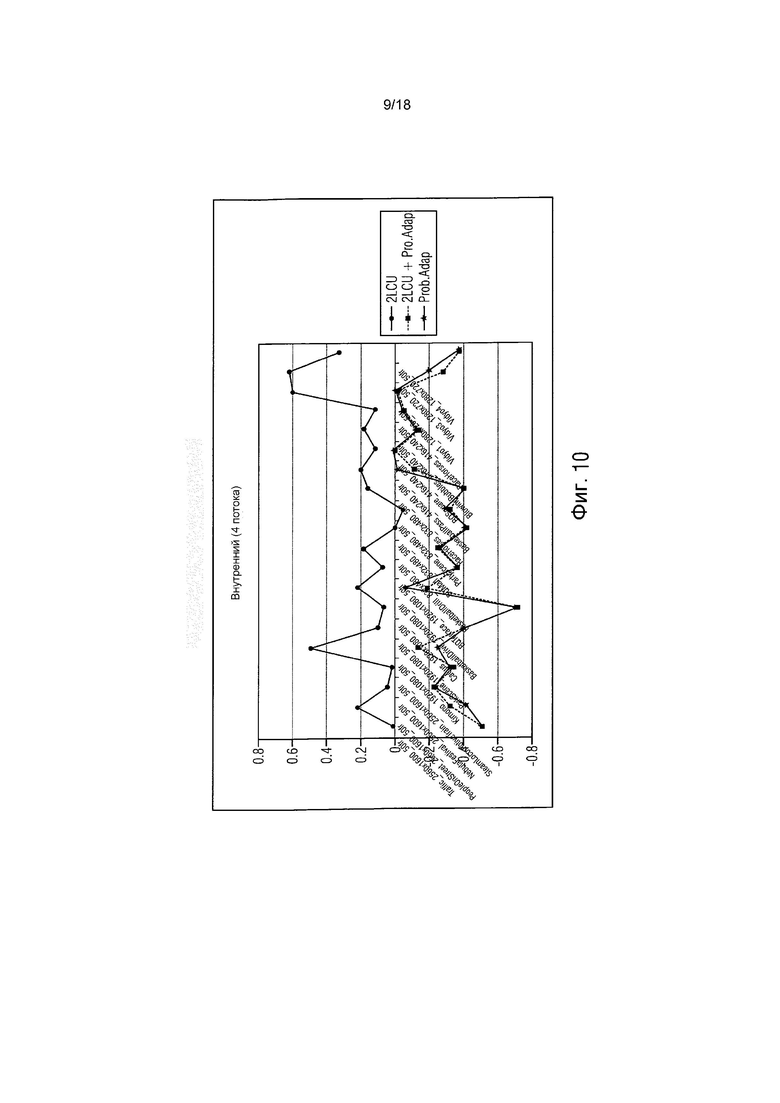
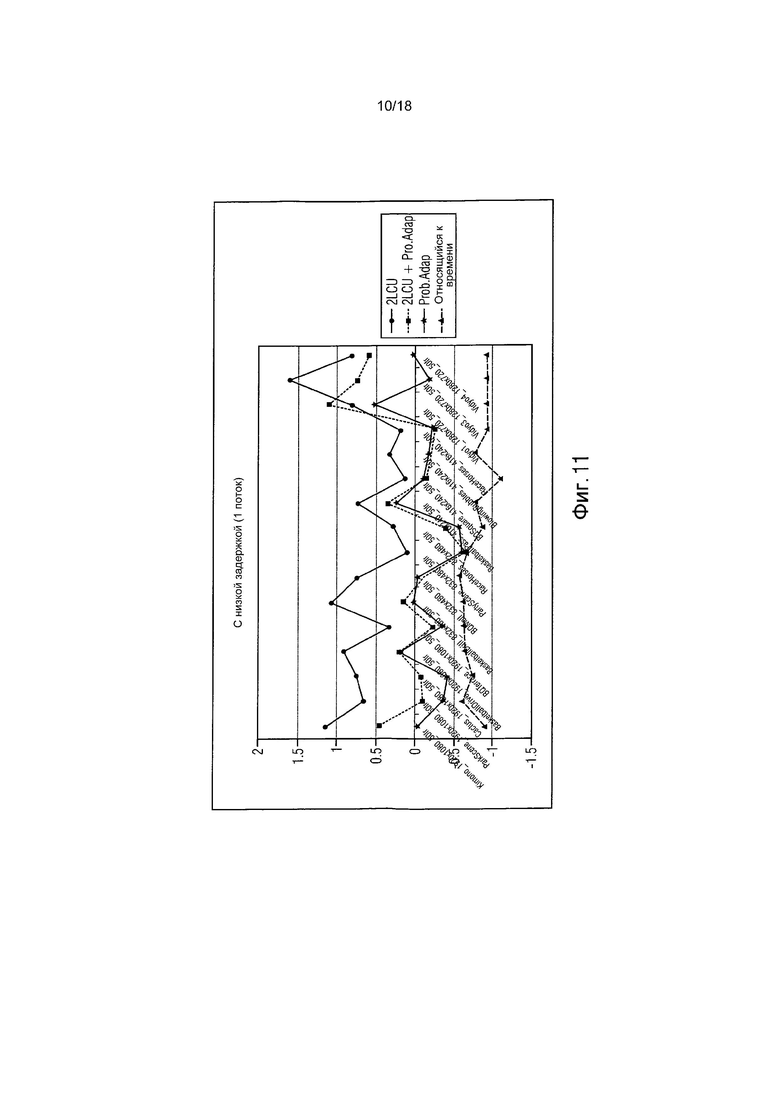
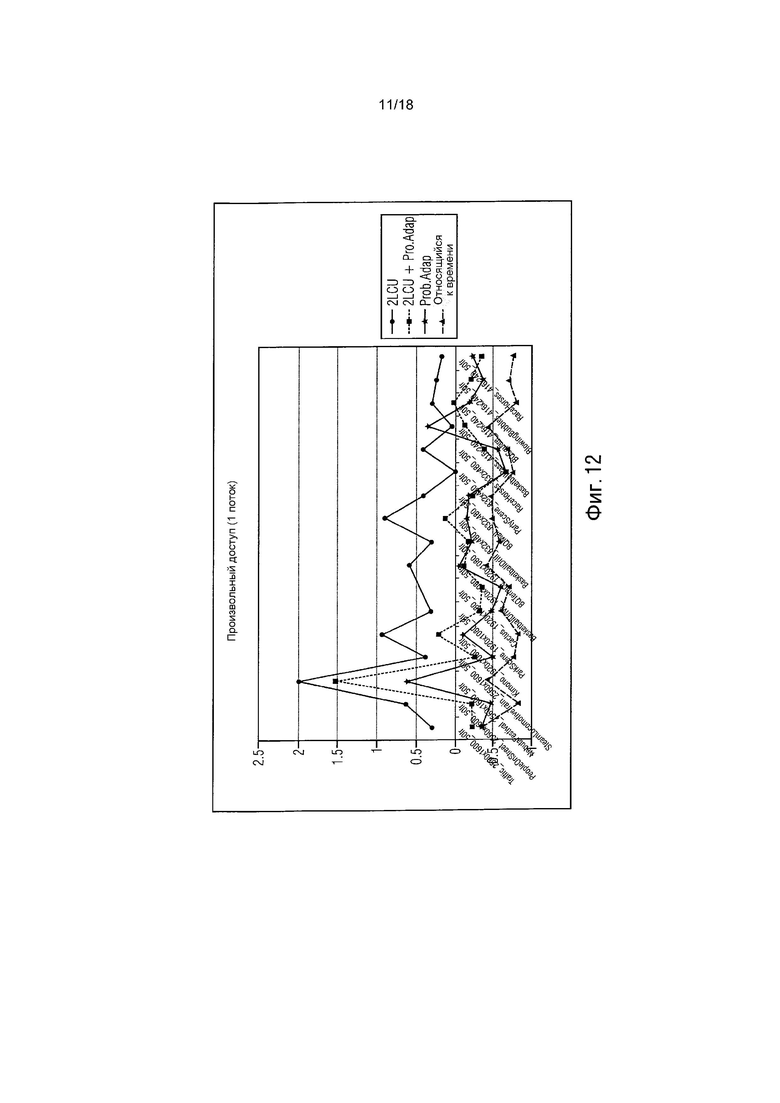
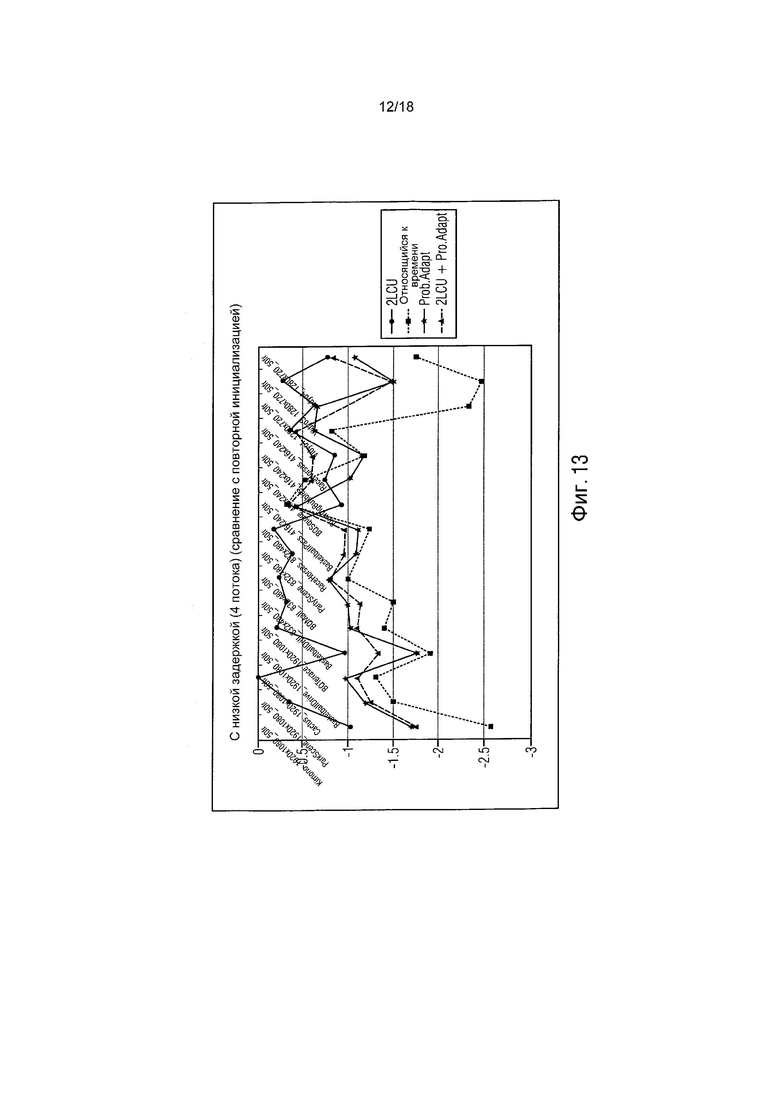
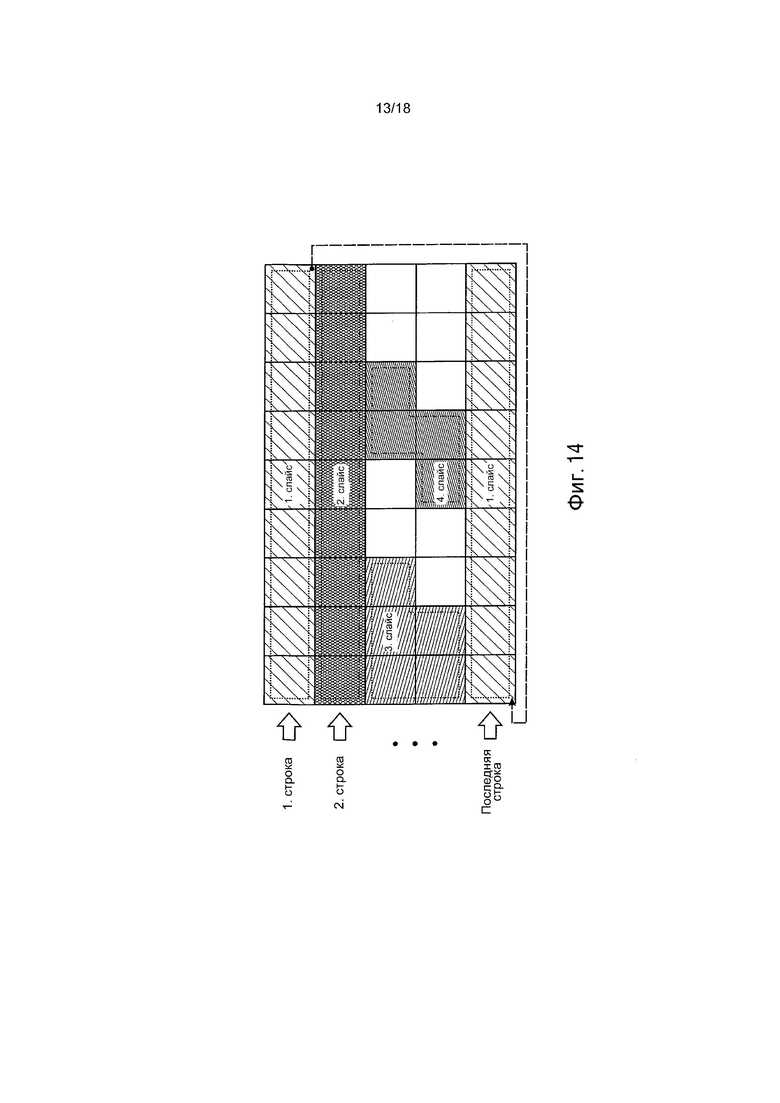
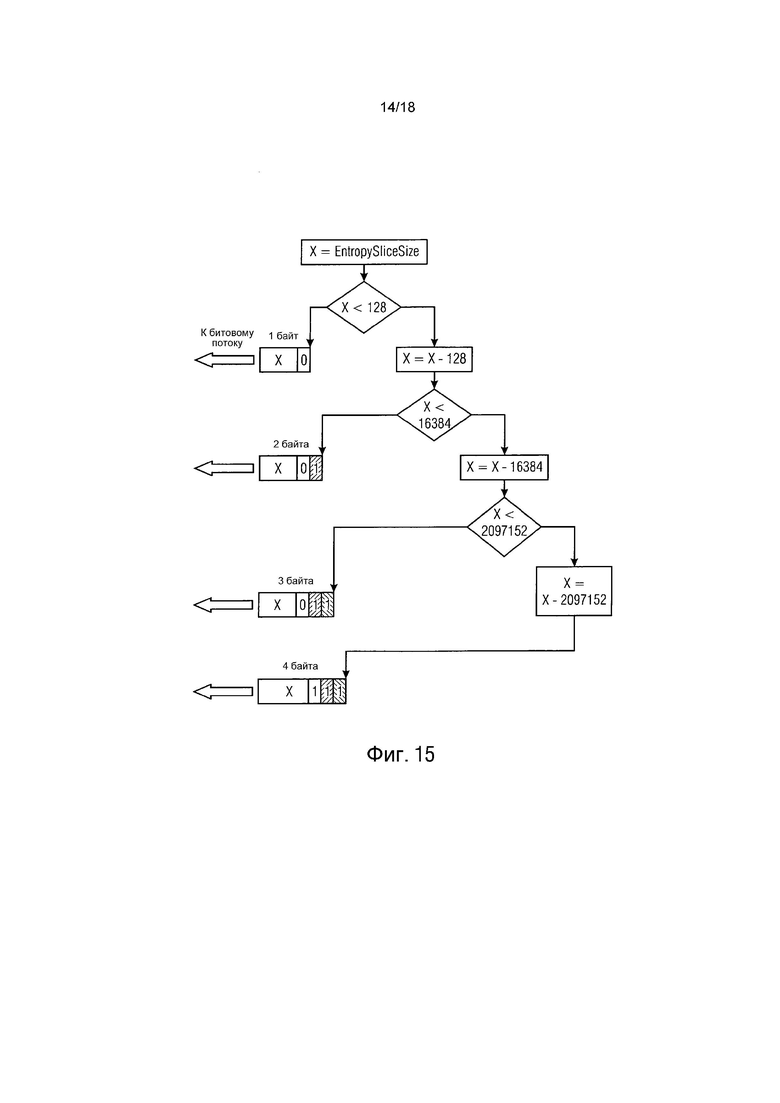
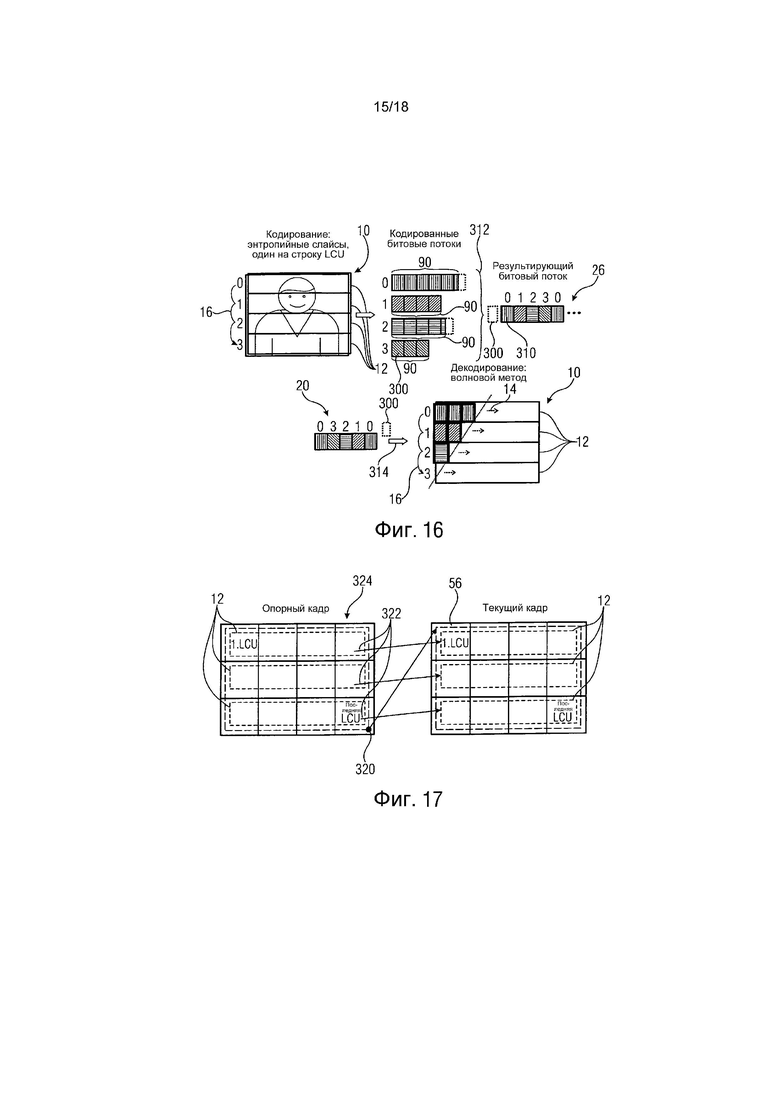
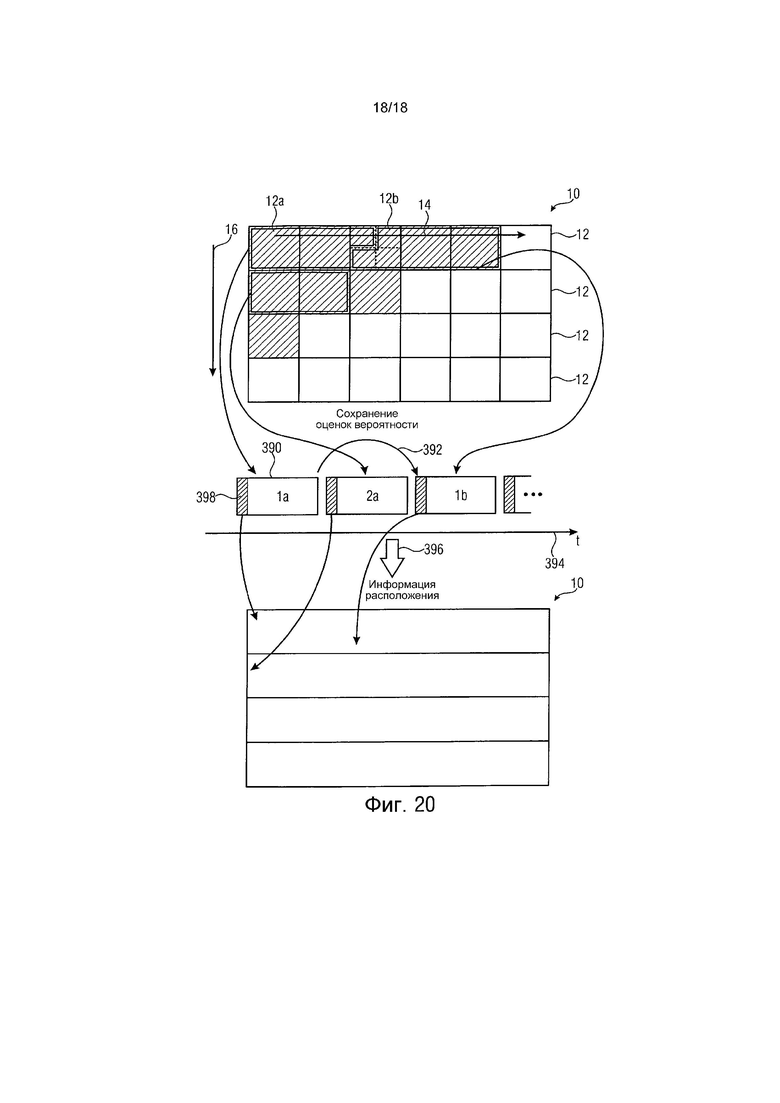
Изобретение относится к средствам для кодирования массива выборок. Технический результат заключается в уменьшении задержки кодирования. Энтропийно кодируют множество поднаборов слайсов в энтропийно закодированном потоке данных, причем каждый поднабор слайсов содержит энтропийно закодированные данные для соответствующей другой порции массива выборок, и при этом разные порции формируют строки блоков массива выборок, причем каждая строка имеет одно и то же количество блоков. Энтропийно кодируют каждый поднабор слайсов, вдоль соответствующей траектории энтропийного кодирования, идущей параллельно вдоль строк блоков, используя первую оценку вероятности. Инициализируют первую оценку вероятности перед кодированием первого блока первой строки, соответствующей поднабору слайсов, на основе второй оценки вероятности второго блока второй строки. Причем вторая строка является пространственно соседней для первой строки и соответствует предыдущему поднабору слайсов. Причем энтропийное кодирование предыдущего поднабора слайсов начинается перед энтропийным кодированием упомянутого поднабора слайсов. Адаптируют первую оценку вероятности вдоль траектории энтропийного кодирования, используя ранее декодированную часть поднабора слайсов. 4 н. и 26 з.п. ф-лы, 20 ил., 4 табл.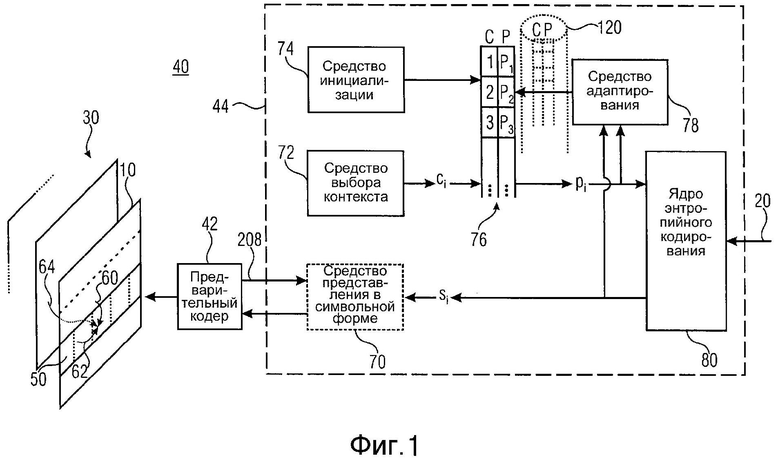
1. Декодер для восстановления массива выборок из энтропийно закодированного потока данных, содержащий:
энтропийный декодер, выполненный с возможностью энтропийно декодировать множество поднаборов слайсов в энтропийно закодированном потоке данных так, чтобы восстанавливать разные порции массива выборок, причем каждый поднабор слайсов содержит энтропийно закодированные данные для соответствующей порции массива выборок, и при этом разные порции формируют строки блоков массива выборок, причем каждая строка имеет одно и то же количество блоков, причем энтропийный декодер выполнен с возможностью:
выполнения, для каждого поднабора слайсов, энтропийного декодирования вдоль соответствующей траектории энтропийного кодирования, идущей параллельно вдоль строк блоков, используя первую оценку вероятности посредством:
инициализации первой оценки вероятности перед декодированием первого блока первой строки, соответствующей поднабору слайсов, на основе второй оценки вероятности второго блока второй строки, причем вторая строка является пространственно соседней для первой строки и соответствует предыдущему поднабору слайсов, причем энтропийное декодирование предыдущего поднабора слайсов начинается перед энтропийным декодированием упомянутого поднабора слайсов, и
адаптации первой оценки вероятности вдоль траектории энтропийного кодирования, используя ранее декодированную часть поднабора слайсов.
2. Декодер по п. 1, причем энтропийный декодер выполнен с возможностью энтропийного декодирования множества поднаборов слайсов в порядке поднаборов слайсов, причем порядок поднаборов слайсов выбран так, что по порядку поднаборов слайсов разные порции следуют друг за другом в направлении, повернутом относительно траекторий энтропийного кодирования поднаборов слайсов.
3. Декодер по п. 1, причем энтропийный декодер выполнен с возможностью хранения второй оценки вероятности и использования сохраненной второй оценки вероятности для инициализации первой оценки вероятности.
4. Декодер по п. 1, причем энтропийный декодер выполнен с возможностью, при энтропийном декодировании текущей части поднабора слайсов, адаптации первой оценки вероятности на основе третьей оценки вероятности порции второй строки, причем порция второй строки является пространственно соседней для порции первой строки, соответствующей текущей части поднабора слайсов.
5. Декодер по п. 4, причем энтропийный декодер выполнен с возможностью адаптации первой оценки вероятности на основе среднего первой оценки вероятности, адаптированной с использованием ранее декодированной части поднабора слайсов и третей оценки вероятности.
6. Декодер по п. 2, причем энтропийный декодер выполнен с возможностью направления энтропийного декодирования непосредственно следующих друг за другом поднаборов слайсов по порядку поднаборов слайсов так, чтобы не допускать того, что расстояние между в настоящее время декодируемыми блоками порций, соответствующих непосредственно следующим друг за другом поднаборам слайсов, измеренное в блоках вдоль траекторий энтропийного кодирования, стало меньше двух блоков.
7. Декодер по п. 2, причем энтропийный декодер выполнен с возможностью направления энтропийного декодирования непосредственно следующих друг за другом поднаборов слайсов по порядку поднаборов слайсов так, чтобы расстояние между декодируемыми в настоящее время блоками порций, соответствующих непосредственно следующим друг за другом поднаборам слайсов, измеренное в блоках вдоль траекторий энтропийного кодирования, оставалось равным двум блокам.
8. Декодер по п. 1, в котором поднаборы слайсов подразделяются на фрагменты, и декодер дополнительно содержит деперемежитель для деперемежения фрагментов, и энтропийный декодер сконфигурирован для начала энтропийного декодирования поднаборов слайсов параллельно вдоль траекторий энтропийного кодирования даже перед приемом целиком любого из поднаборов слайсов.
9. Декодер по п. 1, в котором массив выборок является текущим массивом выборок последовательности массивов выборок, и энтропийный декодер сконфигурирован для энтропийного декодирования поднабора слайсов на основе первой оценки вероятности, которая адаптирована, используя вторую оценку вероятности, ранее декодированной части поднабора слайсов и четвертой оценке вероятности, использованной при энтропийном декодировании ранее декодированного кадра энтропийно закодированного потока данных, относящегося к одному из других массивов выборок, отличному от текущего массива выборок.
10. Декодер по п. 1, причем декодер является, по меньшей мере, частью программируемого логического устройства, программируемой логической матрицы, микропроцессора, компьютера или аппаратных средств.
11. Способ для восстановления массива выборок из энтропийно закодированного потока данных, содержащий этапы, на которых:
энтропийно декодируют множество поднаборов слайсов в энтропийно закодированном потоке данных так, чтобы восстанавливать разные порции массива выборок, причем каждый поднабор слайсов содержит энтропийно закодированные данные для соответствующей порции массива выборок, и при этом разные порции формируют строки блоков массива выборок, причем каждая строка имеет одно и то же количество блоков, причем этап энтропийного декодирования содержит этапы, на которых:
энтропийно декодируют, для каждого поднабора слайсов, вдоль соответствующей траектории энтропийного кодирования, идущей параллельно вдоль строк блоков, используя первую оценку вероятности посредством:
инициализации первой оценки вероятности перед декодированием первого блока первой строки, соответствующей поднабору слайсов, на основе второй оценки вероятности второго блока второй строки, причем вторая строка является пространственно соседней для первой строки и соответствует предыдущему поднабору слайсов, причем энтропийное декодирование предыдущего поднабора слайсов начинается перед энтропийным декодированием упомянутого поднабора слайсов, и
адаптации первой оценки вероятности вдоль траектории энтропийного кодирования, используя ранее декодированную часть поднабора слайсов.
12. Способ по п. 11, в котором энтропийное декодирование множества поднаборов слайсов выполняют в порядке поднаборов слайсов, причем порядок поднаборов слайсов выбран так, что по порядку поднаборов слайсов разные порции следуют друг за другом в направлении, повернутом относительно траекторий энтропийного кодирования поднаборов слайсов.
13. Способ по п. 11, дополнительно содержащий этап, на котором сохраняют вторую оценку вероятности и используют сохраненную вторую оценку вероятности для инициализации первой оценки вероятности.
14. Способ по п. 11, дополнительно содержащий этап, на котором для энтропийного декодирования текущей части поднабора слайсов адаптируют первую оценку вероятности на основе третьей оценки вероятности порции второй строки, причем порция второй строки является пространственно соседней для порции первой строки, соответствующей текущей части поднабора слайсов.
15. Способ по п. 14, причем адаптация содержит этап, на котором адаптируют первую оценку вероятности на основе среднего первой оценки вероятности, адаптированной с использованием ранее декодированной части поднабора слайсов, и третей оценки вероятности.
16. Способ по п. 12, дополнительно содержащий этап, на котором направляют энтропийное декодирование непосредственно следующих друг за другом поднаборов слайсов по порядку поднаборов слайсов так, чтобы не допускать того, что расстояние между в настоящее время декодируемыми блоками порций, соответствующих непосредственно следующим друг за другом поднаборам слайсов, измеренное в блоках вдоль траекторий энтропийного кодирования, стало меньше двух блоков.
17. Способ по п. 12, дополнительно содержащий этап, на котором направляют энтропийное декодирование непосредственно следующих друг за другом поднаборов слайсов по порядку поднаборов слайсов так, чтобы расстояние между декодируемыми в настоящее время блоками порций, соответствующих непосредственно следующим друг за другом поднаборам слайсов, измеренное в блоках вдоль траекторий энтропийного кодирования, оставалось равным двум блокам.
18. Способ по п. 11, в котором поднаборы слайсов подразделяются на фрагменты, и способ дополнительно содержит этап, на котором деперемежают фрагменты, и начинают энтропийное декодирование поднаборов слайсов параллельно вдоль траекторий энтропийного кодирования даже перед приемом целиком любого из поднаборов слайсов.
19. Способ по п. 11, в котором массив выборок является текущим массивом выборок последовательности массивов выборок, и при этом способ содержит этап, на котором энтропийно декодируют поднабор слайсов на основе первой оценки вероятности, которая адаптирована, используя вторую оценку вероятности, ранее декодированной части поднабора слайсов и четвертой оценке вероятности, использованной при энтропийном декодировании ранее декодированного кадра энтропийно закодированного потока данных, относящегося к одному из других массивов выборок, отличному от текущего массива выборок.
20. Способ для кодирования массива выборок в поток энтропийно закодированных данных, содержащий этапы, на которых:
энтропийно кодируют множество поднаборов слайсов в энтропийно закодированном потоке данных, причем каждый поднабор слайсов содержит энтропийно закодированные данные для соответствующей другой порции массива выборок, и при этом разные порции формируют строки блоков массива выборок, причем каждая строка имеет одно и то же количество блоков, причем этап энтропийного кодирования содержит этапы, на которых:
энтропийно кодируют, для каждого поднабора слайсов, вдоль соответствующей траектории энтропийного кодирования, идущей параллельно вдоль строк блоков, используя первую оценку вероятности посредством:
инициализации первой оценки вероятности перед кодированием первого блока первой строки, соответствующей поднабору слайсов, на основе второй оценки вероятности второго блока второй строки, причем вторая строка является пространственно соседней для первой строки и соответствует предыдущему поднабору слайсов, причем энтропийное кодирование предыдущего поднабора слайсов начинается перед энтропийным кодированием упомянутого поднабора слайсов, и
адаптации первой оценки вероятности вдоль траектории энтропийного кодирования, используя ранее декодированную часть поднабора слайсов.
21. Способ по п. 20, в котором энтропийное кодирование множества поднаборов слайсов выполняют в порядке поднаборов слайсов, причем порядок поднаборов слайсов выбран так, что по порядку поднаборов слайсов разные порции следуют друг за другом в направлении, повернутом относительно траекторий энтропийного кодирования поднаборов слайсов.
22. Способ по п. 20, дополнительно содержащий этап, на котором сохраняют вторую оценку вероятности и используют сохраненную вторую оценку вероятности для инициализации первой оценки вероятности.
23. Способ по п. 20, дополнительно содержащий этап, на котором для энтропийного кодирования текущей части поднабора слайсов адаптируют первую оценку вероятности на основе третьей оценки вероятности порции второй строки, причем порция второй строки является пространственно соседней для порции первой строки, соответствующей текущей части поднабора слайсов.
24. Способ по п. 23, в котором адаптация содержит этап, на котором адаптируют первую оценку вероятности на основе среднего первой оценки вероятности, адаптированной с использованием ранее кодированной части поднабора слайсов, и третей оценки вероятности.
25. Способ по п. 21, дополнительно содержащий этап, на котором направляют энтропийное кодирование непосредственно следующих друг за другом поднаборов слайсов по порядку поднаборов слайсов так, чтобы не допускать того, что расстояние между в настоящее время кодируемыми блоками порций, соответствующих непосредственно следующим друг за другом поднаборам слайсов, измеренное в блоках вдоль траекторий энтропийного кодирования, стало меньше двух блоков.
26. Способ по п. 21, дополнительно содержащий этап, на котором направляют энтропийное кодирование непосредственно следующих друг за другом поднаборов слайсов по порядку поднаборов слайсов так, чтобы расстояние между кодируемыми в настоящее время блоками порций, соответствующих непосредственно следующим друг за другом поднаборам слайсов, измеренное в блоках вдоль траекторий энтропийного кодирования, оставалось равным двум блокам.
27. Способ по п. 20, в котором массив выборок является текущим массивом выборок последовательности массивов выборок, и при этом способ содержит этап, на котором энтропийно кодируют поднабор слайсов на основе первой оценки вероятности, которая адаптирована, используя вторую оценку вероятности, ранее декодированной части поднабора слайсов и четвертой оценке вероятности, использованной при энтропийном кодировании ранее кодированного кадра, относящегося к одному из массивов выборок, отличному от текущего массива выборок.
28. Не временный считываемый компьютером носитель для хранения данных, ассоциированных с видео, содержащий:
поток данных, сохраненный в не временном считываемом компьютером носителе, причем поток данных содержит энтропийно закодированную информацию, ассоциированную с массивом выборок, причем энтропийно закодированная информация включает в себя множество поднаборов слайсов, причем каждый поднабор слайсов содержит энтропийно закодированные данные для соответствующей другой порции массива выборок, и разные порции формируют строки блоков массива выборок, причем каждая строка имеет одно и то же количество блоков, причем энтропийно закодированная информация кодирована в поток данных для хранения в упомянутом не временном считываемом компьютером носителе посредством операций, включающих в себя:
энтропийное кодирование, для каждого поднабора слайсов, вдоль соответствующей траектории энтропийного кодирования, идущей параллельно вдоль строк блоков, используя первую оценку вероятности посредством:
инициализации первой оценки вероятности перед кодированием первого блока первой строки, соответствующей поднабору слайсов, на основе второй оценки вероятности второго блока второй строки, причем вторая строка является пространственно соседней для первой строки и соответствует предыдущему поднабору слайсов, причем энтропийное кодирование предыдущего поднабора слайсов начинается перед энтропийным кодированием упомянутого поднабора слайсов, и
адаптации первой оценки вероятности вдоль траектории энтропийного кодирования, используя ранее кодированную часть поднабора слайсов.
29. Не временный считываемый компьютером носитель по п. 28, в котором энтропийное кодирование множества поднаборов слайсов выполняется в порядке поднаборов слайсов, причем порядок поднаборов слайсов выбран так, что по порядку поднаборов слайсов разные порции следуют друг за другом в направлении, повернутом относительно траекторий энтропийного кодирования поднаборов слайсов.
30. Не временный считываемый компьютером носитель по п. 28, в котором операции дополнительно содержат сохранение второй оценки вероятности и использование сохраненной второй оценки вероятности для инициализации первой оценки вероятности.
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| УПЛОТНЕНИЕ ВАЛА | 1998 |
|
RU2146343C1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| УСТРОЙСТВО ДЛЯ СЖАТИЯ ДАННЫХ (ВАРИАНТЫ) | 1994 |
|
RU2093957C1 |

