Уровень техники
[0001] Голосовые пользовательские интерфейсы все в большей степени используются в управлении компьютерами и другими электронными устройствами. Одним особенно полезным применением голосового пользовательского интерфейса является применение с переносными электронными устройствами, такими как мобильные телефоны, часы, планшетные компьютеры, устанавливаемые на голову устройства, устройства виртуальной или дополненной реальности и т.д. Другим полезным применением является применение с электронными системами в транспортных средствах, такими как автомобильные системы, которые объединяют возможности навигации и аудио. Еще одним полезным применением является применение с приборами и другими устройствами, традиционно неассоциированными с компьютерами, такими как освещение, бытовые приборы, отопление и канализация, системы безопасности и т.д., ассоциированные с категорией "Интернета вещей" (IoT). Такие применения, как правило, характеризуются нетрадиционными конструктивными параметрами, которые ограничивают полезность более традиционной клавиатуры или устройства ввода с сенсорным экраном и/или использование в ситуациях, когда желательно побуждать пользователя оставаться сфокусированным на других задачах, например, когда пользователь едет или идет.
[0002] Голосовые пользовательские интерфейсы продолжают эволюционировать из ранних рудиментарных интерфейсов, которые могут понимать только простые и непосредственные команды, в более сложные интерфейсы, которые отвечают на запросы на естественном языке, и которые могут понимать контекст и организовывать дискуссионные диалоги или переговоры с пользователями. Многие голосовые пользовательские интерфейсы объединяют как первоначальное преобразование речи в текст, которое преобразует звукозапись человеческого голоса в текст, так и семантический анализ, который анализирует текст в попытке определять смысл пользовательского запроса. На основе определенного смысла записанного голоса пользователя может быть предпринято действие, такое как выполнение поиска или иное управление компьютером или другим электронным устройством.
[0003] Требования к вычислительным ресурсам для голосового пользовательского интерфейса, например, с точки зрения ресурсов процессора и/или памяти, могут быть существенными, и, в результате, некоторые традиционные подходы к голосовому пользовательскому интерфейсу применяют клиент-серверную архитектуру, когда голосовые входные данные принимаются и записываются относительно маломощным клиентским устройством, запись передается по сети, такой как Интернет, онлайн-службе для преобразования речи в текст и семантической обработки, и надлежащий ответ формируется онлайн-службой и передается обратно клиентскому устройству. Онлайн-службы могут выделять существенные вычислительные ресурсы для обработки голосовых входных данных, позволяя реализовать более сложную функциональную возможность распознавания речи и семантического анализа, чем может быть реализовано в ином случае локально в клиентском устройстве. Однако, клиент-серверный подход обязательно требует, чтобы клиент был в сети (т.е., на связи с онлайн-службой) при обработке голосовых входных данных. В частности, в мобильных и автомобильных применениях, непрерывная онлайн-связность не может быть гарантирована все время и во всех местоположениях, таким образом клиент-серверный голосовой пользовательский интерфейс может отключаться в клиентском устройстве всякий раз, когда устройство находится в "автономном" режиме и, таким образом, отсоединено от онлайн-службы.
Сущность изобретения
[0004] Эта спецификация направлена, в целом, на различные реализации, которые обеспечивают автономную семантическую обработку в устройстве с голосовым управлением с ограниченными ресурсами. Различные реализации, описанные в данном документе, могут, например, предоставлять возможность или иначе способствовать предоставлению более надежного в эксплуатации голосового устройства, которое приспособлено эффективно обрабатывать голосовые запросы, независимо от того, имеет или нет устройство доступ к сети. Также, даже в ситуациях, в которых устройство имеет доступ к сети, устройство может быть приспособлено обрабатывать голосовые запросы без необходимости доступа к сети, тем самым, экономя ресурсы для обработки и полосу пропускания, которая ассоциируется с таким доступом. Дополнительно, в некоторых случаях, устройство с голосовым управлением с ограниченными ресурсами может быть приспособлено выполнять действие в ответ на голосовой запрос более быстро, чем если используется доступ к сети, в частности, когда доступно лишь медленное и/или низкокачественное соединение с сетью.
[0005] Автономный семантический процессор такого устройства использует автономную грамматическую модель с пониженными требованиями к ресурсам, чтобы выполнять грамматический разбор голосовых запросов, принимаемых устройством. В некоторых реализациях автономная грамматическая модель может быть обновлена, чтобы включать в себя сопоставления между так называемыми "длиннохвостыми" голосовыми запросами и ответными действиями, которые имеют возможность выполнения посредством устройства с ограниченными ресурсами, использующего автономную грамматическую модель. Таким образом, пользователи могут добавлять специализированные сопоставления запрос-действие к автономным грамматикам, используемым автономными семантическими процессорами, ассоциированными с пользовательскими персональными вычислительными устройствами.
[0006] Следовательно, в некоторых реализациях, способ может включать в себя: семантическую обработку запроса, выданного в устройстве с ограниченными ресурсами, чтобы идентифицировать одно или более возможных ответных действий, которые являются выполнимыми посредством устройства с ограниченными ресурсами; анализ статистических данных выполнения возможного ответного действия, чтобы выбирать, из одного или более возможных ответных действий, удовлетворяющее требованиям ответное действие, при этом статистические данные выполнения возможного ответного действия относятся к выполнению одного или более возможных ответных действий устройством с ограниченными ресурсами следом за выдачей запроса; и обновление автономной грамматической модели, хранящейся в устройстве с ограниченными ресурсами, чтобы включать в нее сопоставление между выданным запросом и удовлетворяющим требованиям ответным действием, при этом автономная грамматическая модель сопоставляет запросы с действиями, которые имеют возможность выполнения посредством устройства с ограниченными ресурсами в автономном режиме. Возможности, производительность и эффективность устройства с ограниченными ресурсами могут, таким образом, быть улучшены.
[0007] В некоторых реализациях способ может дополнительно включать в себя предоставление, в качестве выходных данных для пользователя, эксплуатирующего устройство с ограниченными ресурсами, одной или более подсказок, предлагающих выполнение соответствующих одного или более возможных действий. В некоторых реализациях анализ может включать в себя статистические данные анализа, принадлежащие реакции пользователя на одну или более подсказок. В некоторых реализациях одна или более подсказок могут включать в себя выбираемый графический элемент. В некоторых реализациях одна или более подсказок могут включать в себя звуковую или тактильную подсказку.
[0008] В некоторых реализациях способ может дополнительно включать в себя передачу автономной грамматической модели устройству с ограниченными ресурсами для хранения устройством с ограниченными ресурсами и для использования семантическим процессором устройства с ограниченными ресурсами в автономном режиме. В некоторых реализациях передача автономной грамматической модели устройству с ограниченными ресурсами динамически обновляет автономную грамматическую модель, сохраненную в устройстве с ограниченными ресурсами.
[0009] В некоторых реализациях выданный запрос может быть голосовым запросом, и автономная грамматическая модель сопоставляет голосовые запросы с действиями. В некоторых реализациях способ может дополнительно включать в себя сбор данных, указывающих выполнение одного или более возможных действий посредством множества устройств с ограниченными ресурсами, ассоциированных с пользователем, который эксплуатирует устройство с ограниченными ресурсами. В некоторых реализациях анализ статистических данных может быть основан на собранных данных.
[0010] В некоторых реализациях семантическая обработка может быть выполнена с помощью онлайновой грамматической модели, при этом автономная грамматическая модель имеет пониженные требования к ресурсам относительно онлайновой грамматической модели. В некоторых реализациях способ может дополнительно включать в себя ограничение доступа к одному или более из сопоставления, выданного запроса и автономной грамматики для устройства с ограниченными ресурсами.
[0011] Кроме того, некоторые реализации включают в себя устройство, включающее в себя память и один или более процессоров, функционирующих, чтобы исполнять инструкции, сохраненные в памяти, где инструкции конфигурируются, чтобы выполнять любой из вышеупомянутых способов. Некоторые реализации также включают в себя долговременный компьютерно-читаемый носитель хранения, хранящий компьютерные инструкции, исполняемые одним или более процессорами, чтобы выполнять любой из вышеупомянутых способов.
[0012] Следует понимать, что все сочетания вышеупомянутых концепций и дополнительных концепций, описанных более подробно в данном документе, рассматриваются как часть предмета изобретения, раскрытого в данном документе. Например, все сочетания заявленного предмета изобретения, указанные в конце этого описания, рассматриваются как часть предмета изобретения, раскрытого в данном документе.
Краткое описание чертежей
[0013] Фиг. 1 иллюстрирует примерную архитектуру компьютерной системы.
[0014] Фиг. 2 - это блок-схема примерного распределенного окружения обработки голосовых входных данных.
[0015] Фиг. 3 - это блок-схема последовательности операций, иллюстрирующая примерный способ обработки голосовых входных данных с помощью окружения на фиг. 2.
[0016] Фиг. 4 иллюстрирует примерную грамматическую модель для использования в обработке голосовых входных данных в области действий.
[0017] Фиг. 5 - это блок-схема последовательности операций, иллюстрирующая примерный способ построения и/или обновления автономной грамматической модели.
Подробное описание изобретения
[0018] В реализациях, обсуждаемых далее в данном документе, автономный семантический процессор устройства с голосовым управлением с ограниченными ресурсами использует автономную грамматическую модель с пониженными требованиями к ресурсам, чтобы выполнять грамматический разбор голосовых запросов, принимаемых устройством. В некоторых реализациях автономная грамматическая модель может быть обновлена, чтобы включать в себя сопоставления между так называемыми "длиннохвостыми" голосовыми запросами и ответными действиям, которые являются выполнимыми посредством устройства с ограниченными ресурсами, использующего автономную грамматическую модель. Когда используется в данном документе, "длиннохвостый запрос" является запросом, который является уникальным или возникает относительно нечасто в объеме поиска запросов. В некоторых случаях, длиннохвостый запрос может быть буквально длинным (например, включать в себя относительно большое число лексем), но это не требуется. В качестве примера, голосовой запрос "воспроизведение <имя исполнителя>" может быть использован многими пользователями большой популяции, чтобы инициировать воспроизведение конкретного исполнителя, и, таким образом, не будет считаться длиннохвостым запросом. Напротив, предположим, что один конкретный пользователь пытается инициировать воспроизведение исполнителя с помощью такой фразы как "Я реально настроен на какого-нибудь <имя исполнителя>". Последний запрос будет вероятно квалифицирован как длиннохвостый запрос (если в будущем большое число пользователей не начнет использовать его таким же образом).
[0019] Дополнительные подробности, касающиеся выбранных реализаций, обсуждаются далее в данном документе. Будет понятно, однако, что другие реализации рассматриваются, таким образом, реализации, обсуждаемые в данном документе, не являются исключительными.
Примерное аппаратное и программное окружение
[0020] Теперь обратимся к чертежам, на которых аналогичные номера обозначают аналогичные части повсюду на нескольких видах. Фиг. 1 является блок-схемой электронных компонентов в примерной компьютерной системе 10. Система 10 типично включает в себя, по меньшей мере, один процессор 12, который связывается с множеством периферийных устройств через подсистему 14 шины. Эти периферийные устройства могут включать в себя подсистему 16 хранения, включающую в себя, например, подсистему 18 памяти и подсистему 20 файлового хранилища, устройства 22 ввода пользовательского интерфейса, устройства 24 вывода пользовательского интерфейса и подсистему 26 сетевого интерфейса. Устройства ввода и вывода предоставляют возможность взаимодействия пользователя с системой 10. Подсистема 26 сетевого интерфейса предоставляет интерфейс с внешними сетями и соединяется с соответствующими интерфейсными устройствами в других компьютерных системах.
[0021] В некоторых реализациях устройства 22 ввода пользовательского интерфейса могут включать в себя клавиатуру, указательные устройства, такие как мышь, трэкбол, сенсорная панель или графический планшет, сканер, сенсорный экран, встроенный в дисплей, устройства звукового ввода, такие как системы распознавания голоса, микрофоны и/или другие типы устройств ввода. В целом, использование термина "устройство ввода" предназначается, чтобы включать в себя все возможные типы устройств и способов ввода информации в компьютерную систему 10 или в сеть передачи данных.
[0022] Устройства 24 вывода пользовательского интерфейса могут включать в себя подсистему отображения, принтер, факсимильный аппарат или невизуальные дисплеи, такие как устройства звукового вывода. Подсистема отображения может включать в себя катодно-лучевую трубку (CRT), плоскопанельное устройство, такое как жидкокристаллический дисплей (LCD), проекционное устройство или некоторый другой механизм для создания видимого изображения. Подсистема отображения может также предусматривать невизуальное отображение, например, через устройства звукового вывода. В целом, использование термина "устройство вывода" предназначается, чтобы включать в себя все возможные типы устройств и способы вывода информации из компьютерной системы 10 пользователю или другому прибору или компьютерной системе.
[0023] Подсистема 16 хранения хранит программирование и структуры данных, которые предоставляют функциональность некоторых или всех модулей, описанных в данном документе. Например, подсистема 16 хранения может включать в себя логику для выполнения выбранных аспектов способов, описанных далее в данном документе.
[0024] Эти программные модули, в целом, исполняются процессором 12 отдельно или в сочетании с другими процессорами. Подсистема 18 памяти, используемая в подсистеме 16 хранения, может включать в себя множество запоминающих устройств, включающих в себя основное оперативное запоминающее устройство (RAM) 28 для хранения инструкций и данных во время исполнения программы и постоянное запоминающее устройство (ROM) 30, в котором хранятся фиксированные инструкции. Подсистема 20 файлового хранилища может предоставлять постоянное хранилище для файлов программы и данных и может включать в себя накопитель на жестком диске, накопитель на гибком диске вместе с ассоциированными съемными носителями, CD-ROM-накопитель, оптический накопитель или картриджи съемных накопителей. Модули, реализующие функциональность некоторых реализаций, могут быть сохранены посредством подсистемы 20 файлового хранилища в подсистеме 16 хранения, или в других машинах, доступных посредством процессора(ов) 12.
[0025] Подсистема 14 шины предоставляет механизм для предоставления возможности различным компонентам и подсистемам системы 10 связываться друг с другом как положено. Хотя подсистема 14 шины показана схематично как единственная шина, альтернативные реализации подсистемы шины могут использовать множество шин.
[0026] Система 10 может иметь различные типы, включающие в себя мобильное устройство, переносное электронное устройство, встроенное устройство, настольный компьютер, переносной компьютер, планшетный компьютер, носимое устройство, рабочую станцию, сервер, вычислительный кластер, blade-сервер, серверную ферму и любую другую систему обработки данных или вычислительное устройство. Кроме того, функциональность, реализуемая посредством системы 10, может быть распределена между множеством систем, взаимосвязанных друг с другом по одной или более сетям, например, в клиент-серверной, одноранговой или другой сетевой конфигурации. Вследствие постоянно меняющейся природы компьютеров и сетей описание системы 10, изображенной на фиг. 1, предназначается только в качестве конкретного примера в целях иллюстрации некоторых реализаций. Множество других конфигураций системы 10 являются возможными, имеющими больше или меньше компонентов, чем компьютерная система, изображенная на фиг. 1.
[0027] Реализации, обсуждаемые далее в данном документе, могут включать в себя один или более способов, реализующих различные сочетания функциональности, описанной в данном документе. Другие реализации могут включать в себя долговременный компьютерно-читаемый носитель хранения, хранящий инструкции, исполняемые процессором, чтобы выполнять способ, такой как один или более способов, описанных в данном документе. Также другие реализации могут включать в себя устройство, включающее в себя память и один или более процессоров, функционирующих, чтобы исполнять инструкции, сохраненные в памяти, чтобы выполнять способ, такой как один или более способов, описанных в данном документе.
[0028] Различный программный код, описанный далее в данном документе, может быть идентифицирован на основе приложения, в котором он реализуется в конкретной реализации. Однако, следует понимать, что любая конкретная программная номенклатура, которая следует, используется просто для удобства. Кроме того, при наличии бесконечного числа способов, которыми компьютерные программы могут быть организованы в алгоритмы, процедуры, способы, модули, объекты и т.п., также как различные способы, которыми функциональность программы может быть назначена между различными уровнями программного обеспечения, которые постоянно находятся в типовом компьютере (например, операционные системы, библиотеки, API, приложения, апплеты и т.д.), следует понимать, что некоторые реализации могут не быть ограничены конкретной реализацией и назначением функциональности программы, описанной в данном документе.
[0029] Кроме того, будет понятно, что различные операции, описанные в данном документе, которые могут быть выполнены посредством какого-либо программного кода, или выполнены в любых алгоритмах, последовательностях операций или т.п., могут быть объединены, разделены, переупорядочены, пропущены, выполнены последовательно или параллельно и/или реализованы с помощью других технологий, и, следовательно, некоторые реализации не ограничиваются конкретными последовательностями операций, описанными в данном документе.
Распределенная среда обработки голосовых входных данных
[0030] Фиг. 2 иллюстрирует примерное распределенное окружение 50 обработки голосовых входных данных, например, для использования с устройством 52 с голосовым управлением на связи с онлайн-службой, такой как онлайн-служба 54 поиска. В реализациях, обсуждаемых далее в данном документе, например, устройство 52 с голосовым управлением описывается как мобильное устройство, такое как сотовый телефон или планшетный компьютер. Другие реализации могут использовать широкое разнообразие других устройств с голосовым управлением, однако, ссылки далее в данном документе на мобильные устройства существуют просто с целью упрощения дальнейшего обсуждения. Бесчисленные другие типы устройств с голосовым управлением могут использовать описанную в данном документе функциональность, включающую в себя, например, портативные компьютеры, часы, устанавливаемые на голову устройства, устройства виртуальной или дополненной реальности, другие носимые устройства, аудио/видеосистемы, навигационные системы, автомобильные и другие системы транспортных средств, и т.д. Кроме того, многие из таких устройств с голосовым управлением могут рассматриваться как ограниченные по ресурсам, в которых объемы памяти и/или обрабатывающие способности таких устройств могут быть ограничены на основе технологических, экономических или других причин, в частности, когда сравниваются со способностями онлайновых или облачных служб, которые могут выделять практически неограниченные вычислительные ресурсы отдельным задачам. Некоторые такие устройства могут также считаться автономными устройствами до такой степени, что такие устройства могут быть приспособлены для работы в "автономном" режиме и быть не соединены с онлайн-службой, по меньшей мере, часть времени, например, на основе ожидания, что такие устройства могут испытывать временные нарушения сетевой связности время от времени при обычном использовании.
[0031] Онлайн-служба 54 поиска в некоторых реализациях может быть реализована как облачная служба, применяющая облачную инфраструктуру, например, использующую серверную ферму или кластер высокопроизводительных компьютеров, на которых работает программное обеспечение, подходящее для обработки больших объемов запросов от множества пользователей. В иллюстрированной реализации онлайн-служба 54 поиска приспособлена для опроса одной или более баз данных, чтобы находить запрошенную информацию, например, предоставлять список веб-сайтов, содержащих запрошенную информацию. Онлайн-служба 54 поиска может не быть ограничена голосовыми поисками и может также быть приспособлена для обработки других типов поисков, например, текстовых поисков, поисков на основе изображений и т.д. В других реализациях онлайн-система не должна обязательно управлять поиском и может быть ограничена обработкой голосовых запросов для несвязанных с поиском действий, таких как настройка предупреждений или напоминаний, организация списков, инициирование связи с другими пользователями через телефон, текст, электронную почту и т.д., или выполнение других действий, которые могут быть инициированы через голосовые входные данные. В целях этого описания, голосовые запросы и другие формы голосового ввода могут совокупно называться голосовыми запросами, независимо от того, пытаются ли голосовые запросы инициировать поиск, задавать вопрос, выдавать команду и т.д. В целом, следовательно, любые голосовые входные данные, например, включающие в себя слова или фразы, могут рассматриваться как голосовой запрос в контексте иллюстрированных реализаций.
[0032] В реализации на фиг. 2 голосовые входные данные, принятые устройством 52 с голосовым управлением, обрабатываются прикладной программой (или "приложением") 56 с голосовым управлением, которая в некоторых реализациях может быть поисковым приложением. В других реализациях голосовые входные данные могут быть обработаны в операционной системе или микропрограммном обеспечении устройства с голосовым управлением. Приложение 56 в иллюстрированной реализации включает в себя модуль 58 голосового действия, модуль 60 онлайн-интерфейса и модуль 62 воспроизведения/синхронизации. Модуль 58 голосового действия принимает голосовые входные данные, направленные приложению, и координирует анализ голосовых входных данных и выполнение одного или более действий для пользователя устройства 52 с голосовым управлением. Модуль 60 онлайн-интерфейса предоставляет интерфейс с онлайн-службой 54 поиска, включающий в себя перенаправление голосовых входных данных службе 54 и прием ответов на них. Модуль 62 воспроизведения/синхронизации организует воспроизведение ответа пользователю, например, через визуальное отображение, произносимый звук или другой интерфейс обратной связи, подходящий для конкретного устройства с голосовым управлением. Кроме того, в некоторых реализациях, модуль 62 также управляет синхронизацией с онлайн-службой 54 поиска, например, всякий раз, когда ответ или действие влияет на данные, сохраняемые для пользователя в онлайн-службе поиска (например, когда голосовые входные данные запрашивают создание встречи, которая сохраняется в облачном календаре).
[0033] Приложение 56 полагается на различные модули промежуточного программного обеспечения, инфраструктуры, операционной системы и/или микропрограммного обеспечения, чтобы обрабатывать голосовые входные данные, включающие в себя, например, модуль 64 потокового воспроизведения голоса в текст и модуль 66 семантического процессора, включающий в себя модуль 68 синтаксического анализатора, модуль 70 диспетчера диалогов и модуль 72 построителя действия.
[0034] Модуль 64 принимает аудиозапись голосовых входных данных, например, в форме цифровых аудиоданных, и преобразует цифровые аудиоданные в одно или более текстовых слов или фраз (также называемых в данном документе "лексемами"). В иллюстрированной реализации модуль 64 также является модулем потокового воспроизведения, так что голосовые входные данные преобразуются в текст на полексемной основе и в реальном времени или почти реальном времени, так что лексемы могут быть выведены из модуля 64 эффективно одновременно с пользовательской речью, и, таким образом, прежде чем пользователь произносит полностью высказанный запрос. Модуль 64 может полагаться на одну или более локально сохраненных автономных акустических и/или языковых моделей 74, которые вместе моделируют соотношение между аудиосигналом и фонетическими блоками в языке, вместе с последовательностями слов в языке. В некоторых реализациях может быть использована единственная модель 74, в то время как в других реализациях могут поддерживаться множество моделей, например, чтобы поддерживать множество языков, множество говорящих и т.д.
[0035] Тогда как модуль 64 преобразует речь в текст, модуль 66 пытается распознавать семантику или смысл текста, выводимого модулем 64, с целью формулирования надлежащего ответа. Модуль 68 грамматического разбора, например, полагается на одну или более грамматических моделей 76, чтобы сопоставлять текст с конкретными действиями и идентифицировать атрибуты, которые ограничивают выполнение таких действий, например, входные переменные для таких действий. В некоторых реализациях единственная модель 76 может быть использована, в то время как в других реализациях могут поддерживаться множество моделей, например, чтобы поддерживать различные действия или области действий (т.е., совокупности связанных действий, таких как связанные с передачей данных действия, связанные с поиском действия, звуковые/визуальные действия, связанные с календарем действия, связанные с управлением устройством действия и т.д.).
[0036] В качестве примера, автономная грамматическая модель 76 может поддерживать действие, такое как "установка напоминания", имеющее параметр типа напоминания, который указывает, какой тип напоминания следует установить, параметр элемента, который указывает один или более элементов, ассоциированных с напоминанием, и параметр времени, который указывает время активации напоминания и напоминания пользователю. Модуль 64 грамматического разбора может принимать последовательность лексем, такую как "напомнить мне", "зайти за", "хлебом" и "после работы", и сопоставлять последовательность лексем с действием установки напоминания с параметром типа напоминания, установленным в "напоминание о покупке", параметром элемента, установленным в "хлеб", и параметром времени "17:00", так что в 17:00 этого дня пользователь получает напоминание "купить хлеб".
[0037] Модуль 68 грамматического разбора может также работать вместе с модулем 70 диспетчера диалогов, который организует диалог с пользователем. Диалог, в этом контексте, ссылается на набор голосовых входных данных и ответов аналогично беседе между двумя людьми. Модуль 70, следовательно, поддерживает "состояние" диалога, чтобы предоставлять возможность использования информации, полученной от пользователя в предыдущих голосовых входных данных, при обработке последующих голосовых входных данных. Таким образом, если пользователь должен был сказать "напомнить мне зайти за хлебом", ответ может быть сформирован, чтобы сказать "ОК, когда Вы хотите получить напоминание?", так что следующие голосовые входные данные "после работы" были бы привязаны обратно к первоначальному запросу создания напоминания.
[0038] Модуль 72 построителя действия принимает грамматически разобранный текст от модуля 68 грамматического разбора, представляющий интерпретацию голосовых входных данных, и формирует действие вместе с какими-либо ассоциированными параметрами для обработки посредством модуля 62 приложения 56 с голосовым управлением. Модуль 72 построителя действия может полагаться на одну или более автономных моделей 78 действий, которые объединяют различные правила для создания действий из грамматически разобранного текста. В некоторых реализациях, например, действия могут быть определены как функции F, так что F(IT)=AU, где T представляет тип интерпретации входных данных, а U представляет тип выходного действия. F может, следовательно, включать в себя множество входных пар (T, U), которые сопоставляются друг с другом, например, как f(it)=au, где it является входной первичной переменной типа t, а au является выходным модульным аргументом или параметром типа u. Будет понятно, что некоторые параметры могут быть непосредственно приняты в качестве голосовых входных данных, в то время как некоторые параметры могут быть определены другими способами, например, на основе местоположения пользователя, демографической информации или на основе другой информации, конкретной для пользователя. Например, если пользователь должен был сказать "напомнить мне зайти за хлебом в продуктовый магазин", параметр местоположения может не быть определяемым без дополнительной информации, такой как текущее местоположение пользователя, известный маршрут пользователя между работой и домом, привычный для пользователя продуктовый магазин, и т.д.
[0039] Будет понятно, что в некоторых реализациях модели 74, 76 и 78 могут быть объединены в меньшее количество моделей или разделены на дополнительные модели, какой может быть функциональность модулей 64, 68, 70 и 72. Кроме того, модели 74-78 называются в данном документе автономными моделями, поскольку модели хранятся локально на устройстве 52 с голосовым управлением и, таким образом, доступны в автономном режиме, когда устройство 52 не находится на связи с онлайн-службой 54 поиска.
[0040] Кроме того, онлайн-служба 54 поиска, как правило, содержит дополнительные функциональные возможности для обработки голосовых входных данных, например, с помощью процессора 80 голосовых запросов, который полагается на различные акустические/языковые, грамматические и/или модели 82 действий. Будет понятно, что в некоторых реализациях, особенно когда устройство 52 с голосовым управлением является устройством с ограниченными ресурсами, процессор 80 голосовых запросов и модели 82, используемые им, могут реализовывать более сложную и интенсивную для вычисленных ресурсов функциональность голосовой обработки, чем функциональность, локальная по отношению к устройству 52 с голосовым управлением. В других реализациях, однако, дополнительная онлайн-функциональность может не использоваться.
[0041] В некоторых реализациях, как онлайн, так и автономная функциональность может поддерживаться, например, так, что онлайн-функциональность используется всякий раз, когда устройство находится на связи с онлайн-службой, в то время как автономная функциональность используется, когда связности не существует. В других реализациях различные действия или области действий могут быть назначены онлайн- и автономной функциональности, и, в то время как в также других реализациях онлайн-функциональность может быть использована, только когда автономной функциональности не удается адекватно обрабатывать конкретные голосовые входные данные.
[0042] Фиг. 3, например, иллюстрирует алгоритм 100 обработки голоса, который может выполняться устройством 52 с голосовым управлением, чтобы обрабатывать голосовые входные данные. Алгоритм 100 начинается в блоке 102 приемом голосовых входных данных, например, в форме цифрового аудиосигнала. В этой реализации выполняется первоначальная попытка перенаправить голосовые входные данные онлайн-службе поиска (блок 104). Если неуспешно, например, вследствие отсутствия связности или отсутствия ответа от онлайн-службы поиска, блок 106 передает управление блоку 108, чтобы преобразовывать голосовые входные данные в текстовые лексемы (блок 108, например, с помощью модуля 64 на фиг. 2), выполнять грамматический разбор текстовых лексем (блок 110, например, с помощью модуля 68 на фиг. 2) и строить действие из грамматически разобранного текста (блок 112, например, с помощью модуля 72 на фиг. 2). Результирующее действие затем используется, чтобы выполнять воспроизведение на клиентской стороне и синхронизацию (блок 114, например, с помощью модуля 62 на фиг. 2), и обработка голосовых входных данных завершается.
[0043] Возвращаясь к блоку 106, если попытка перенаправить голосовые входные данные онлайн-службе поиска является успешной, блок 106 обходит блоки 108-112 и передает управление непосредственно блоку 114, чтобы выполнять воспроизведение на клиентской стороне и синхронизацию. Обработка голосовых входных данных затем завершается. Будет понятно, что в других реализациях, как отмечено выше, автономная обработка может быть предпринята перед онлайн-обработкой, например, чтобы избегать ненужных передач данных, когда голосовые входные данные могут быть обработаны локально.
Динамически обновляемая автономная грамматическая модель для автономного устройства с ограниченными ресурсами
[0044] Как описано выше, в некоторых реализациях, устройство с голосовым управлением может иметь ограниченные ресурсы и может испытывать недостаток исходной вычислительной мощности и/или функциональных возможностей хранения онлайн-службы. Большая часть сложности в связи с реализацией голосового пользовательского интерфейса осуществляется в моделях, используемых различными модулями, которые реализуют такую функциональность, включающих в себя, например, грамматические модели, которые сопоставляют текст с действиями.
[0045] Грамматическая модель, в этом отношении, может ссылаться на любые структуры данных, подходящие для сопоставления одних или более текстовых слов или фраз (совокупно называемых в данном документе "лексемами") с одним или более действиями, которые должны быть реализованы посредством устройства. Текстовые слова или фразы, сопоставленные с конкретным действием, могут также считаться составляющими отдельные голосовые запросы, сопоставленные с действием. Грамматическая модель может быть реализована, например, как граф переходных состояний или в других подходящих структурах данных. Кроме того, грамматическая модель может быть сформирована множеством способов, например, посредством программирования, посредством обучения и т.д.
[0046] Действие может ссылаться практически на любую операцию, которая может быть выполнена конкретным устройством, такую как выполнение поиска, размещение вызова, текстовое сообщение, отправка электронной почты, настройка воспроизведения, получение указаний, настройка встречи, изменение настроек устройства, создание заметки, воспроизведение песни или видеозаписи, изменение громкости и т.д. В некоторых реализациях действия могут быть сгруппированы в совокупности, называемые областями действий, например, область действия связи (для посылки вызовов, отправки сообщений и т.д.), область мультимедийных действий (для воспроизведения песен, воспроизведения видеозаписей и т.д.), область действий планирования (для создания напоминаний, создания встреч и т.д.) и область навигационных действий (для отображения карт, получения указаний и т.д.), среди прочего. Будет понятно, что грамматические модели могут изменяться для различных языков, для различных говорящих, также как для различных конечных пользовательских приложений.
[0047] Польза грамматической модели основывается, по меньшей мере, частично на числе различных сопоставлений, созданных для различных действий. Язык постоянно развивается, и различные говорящие могут произносить различные инструкции, чтобы выполнять те же самые действия, например, на основе различий в возрасте, стране, регионе и т.д. Число сопоставлений, осуществленных в грамматической модели, однако, как правило, увеличивает и объем памяти, требуемой для хранения модели, и интервал времени обработки и ресурсы, требуемые для идентификации конкретного соответствия в модели.
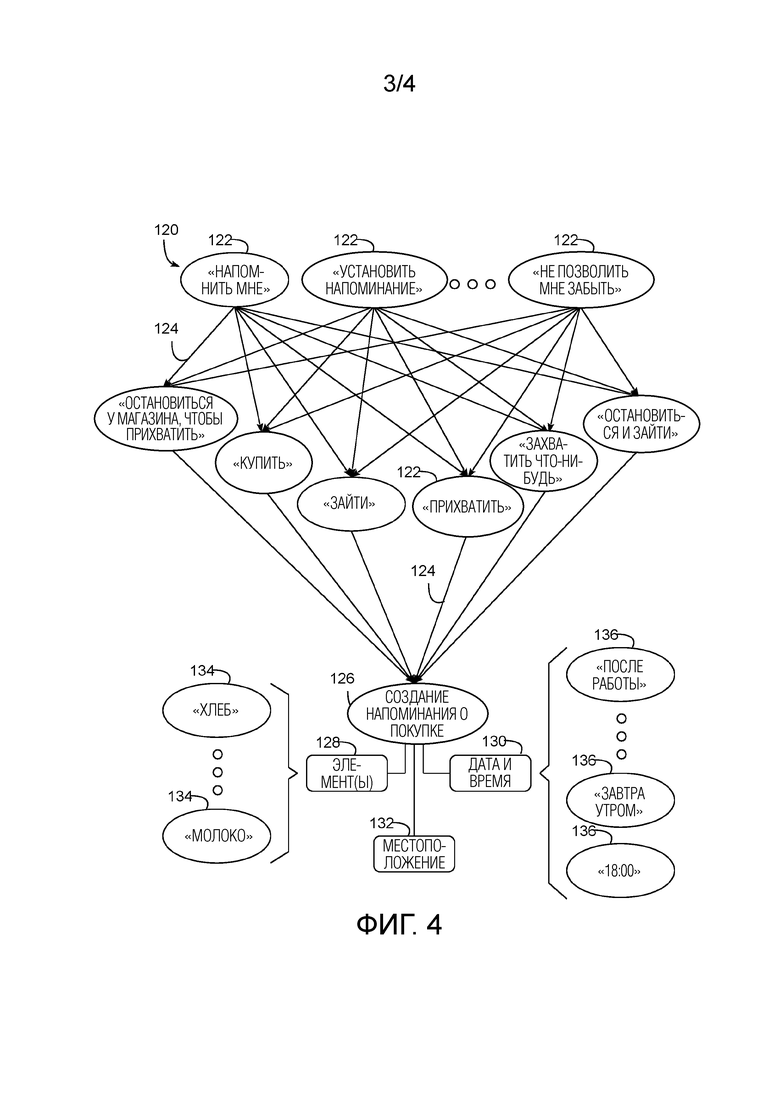
[0048] С учетом обширных вычислительных ресурсов, доступных во многих онлайн-службах, многие такие службы применяют большие и сложные грамматические модели, приспособленные для обработки широкого множества сопоставлений. Фиг. 4, например, иллюстрирует фрагмент примерной грамматической модели 120, реализованной как граф переходов конечных состояний, объединяющий множество состояний 122 и переходов 124, сопоставленных с действием 126 "создания напоминания о покупке", имеющего параметры 128, 130 и 132 элемента, временной даты и местоположения. Как видно на чертеже, множество лексем поддерживаются как для инициирования напоминания (например, "напомнить мне", "установить напоминание", "не позволить мне забыть" и т.д.) и для указания того, что напоминание является напоминанием о покупке (например, "остановиться у магазина, чтобы взять", "купить", "зайти", "взять", "захватить что-то", "остановиться и зайти" и т.д.), приводя в результате к большому числу потенциальных сопоставлений и, таким образом, синонимичных фраз или голосовых запросов, которые могут быть использованы для создания напоминания о покупке.
[0049] Кроме того, для каждого параметра 128, 130, 132, большое число потенциальных значений может быть сопоставлено в грамматической модели. Для списка элементов 128, например, могут быть возможны бесчисленные наименования продуктов и описания 134 (например, "хлеб", "молоко" и т.д.), включающие в себя как общие термины для элементов, также как и конкретные торговые наименования. Для параметра 130 временной даты могут поддерживаться различные фразы 136, ассоциированные с временами и/или датами, включающие в себя как числовые значения (например, "18:00"), так и нечисловые значения (например, "после работы", "завтра утром" и т.д.). Что касается параметра 132 местоположения, могут быть указаны адреса (например, "главная улица, 101"), обобщенные местоположения (например, "продуктовый магазин"), фирменные наименования (например, конкретный продуктовый магазин) и т.д. В некоторых реализациях один или более параметров могут быть необязательными. Кроме того, в некоторых реализациях, один или более параметров могут быть определены на основе неголосовых данных, например, текущего GPS-местоположения, любимых пользовательских фирм, знания типичных рабочих часов пользователя и т.д., а в некоторых случаях, на основе сочетания голосовых и неголосовых данных (например, когда пользователь излагает "продуктовый магазин", и эти входные данные, в сочетании с известным маршрутом пользователя домой, используются для идентификации конкретного продуктового магазина по маршруту). Кроме того, в некоторых реализациях могут быть получены параметры на основе диалогов или бесед, так что параметры предполагаются, по меньшей мере, частично из предыдущих голосовых входных данных.
[0050] Граф 120 представляет лишь небольшой поднабор потенциальных сопоставлений, которые могут быть включены в грамматическую модель, и будет понятно, что для того, чтобы охватывать все возможные варианты голосовых запросов, которые могут быть приняты от пользователя, сопоставления для всех этих возможных вариантов должны быть включены в грамматическую модель. Онлайн-службы, лишенные многих ограничений ресурсов индивидуальных компьютеров и электронных устройств, могут позволять содержать в себе большие количества сопоставлений, чтобы максимизировать полезность грамматической модели. Как следствие, однако, грамматические модели, используемые онлайн-службами (которые называются в данном документе "онлайновыми" грамматическими моделями), как правило, являются слишком большими и/или слишком интенсивными для процессора, чтобы использоваться в индивидуальных компьютерах и электронных устройствах, особенно во многих типах устройств, имеющих наибольшую необходимость в голосовых пользовательских интерфейсах.
[0051] В реализациях, обсуждаемых в данном документе, однако, автономная грамматическая модель может быть создана меньшей и/или менее процессорно-интенсивной для использования в автономном устройстве с голосовым управлением с ограниченными ресурсами, тем самым, приспосабливаясь к ограничениям памяти и/или обработки устройства. Кроме того, автономная грамматическая модель может быть сформирована на основе голосовых запросов, выдаваемых в одном или более конкретных устройствах с ограниченными ресурсами одним или более конкретными пользователями, в дополнение к или вместо голосовых запросов, часто выдаваемых на множестве устройств с ограниченными ресурсами большим числом пользователей. В результате, автономная грамматическая модель целесообразно содержит голосовые запросы, которые являются специализированными для небольшого числа отдельных устройств с ограниченными ресурсами и/или ограниченного числа пользователей таких устройства(в) с ограниченными ресурсами), так что автономный семантический процессор будет целесообразно отвечать на голосовые запросы, которые вероятно должны быть использованы в конкретном устройстве(ах) с ограниченными ресурсами, в то же время имея уменьшенные требования к ресурсам по сравнению с онлайновой грамматической моделью.
[0052] В различных реализациях автономная грамматическая модель может быть создана на основе статистического анализа выполнения действия в устройствах с ограниченными ресурсами следом за выдачей голосовых запросов. Например, в некоторых реализациях, запрос, выданный в устройстве с ограниченными ресурсами, может быть семантически обработан, чтобы идентифицировать одно или более возможных ответных действий, которые являются выполнимыми посредством устройства с ограниченными ресурсами. Так называемые "статистические данные выполнения возможного ответного действия" могут быть проанализированы, чтобы выбирать, из одного или более возможных ответных действий, удовлетворяющее требованиям ответное действие. Статистические данные выполнения возможного ответного действия могут относиться к выполнению одного или более возможных ответных действий посредством устройства с ограниченными ресурсами следом за выдачей запроса. Удовлетворяющее требованиям ответное действие может быть действием, которое выполняется посредством устройства следом за выдачей голосовых запросов. Дополнительно, в некоторых реализациях, выполнение действия следом за выдачей голосового запроса может требоваться, чтобы удовлетворять одному или более критериям соответствия требованиям. Например, критерии соответствия требованиям могут относиться к соответствию между выданным запросом и выполненным действием (например, соответствие выше порогового значения). Соответствие может зависеть, например, от одного или более следующих факторов: прошедшее время между голосовым запросом и выполнением действия, были ли какие-либо вмешивающиеся действия, было ли выполнение действия вызвано в ответ на подсказку, предоставленную устройством, и число возможных действий, для которых были предоставлены подсказки. В некоторых примерах критерии соответствия требованиям могут относиться непосредственно к одному или более вышеописанным факторам. Например, выполненное действие может считаться удовлетворяющим требованиям действием, если прошедшее время между выдачей запроса и выполнением действия ниже порогового значения, и/или не было вмешивающихся действий. Аналогично, выполненное действие может считаться удовлетворяющим требованиям действием, если действие было выполнено в ответ на подсказку, предоставленную устройством.
[0053] Автономная грамматическая модель, сохраненная в устройстве с ограниченными ресурсами - которая может сопоставлять запросы с действиями, которые являются выполняемыми посредством устройства с ограниченными ресурсами - может затем быть обновлена, чтобы содержать сопоставление между выданным запросом и удовлетворяющим требованиям ответным действием. В результате, не все запросы, поддерживаемые онлайновой грамматической моделью, включаются в автономную грамматическую модель, но объем занимаемой памяти для автономной грамматической модели и требования по обработке, необходимые для использования автономной грамматической модели, уменьшаются, чтобы лучше учитывать ограничения ресурсов автономного устройства.
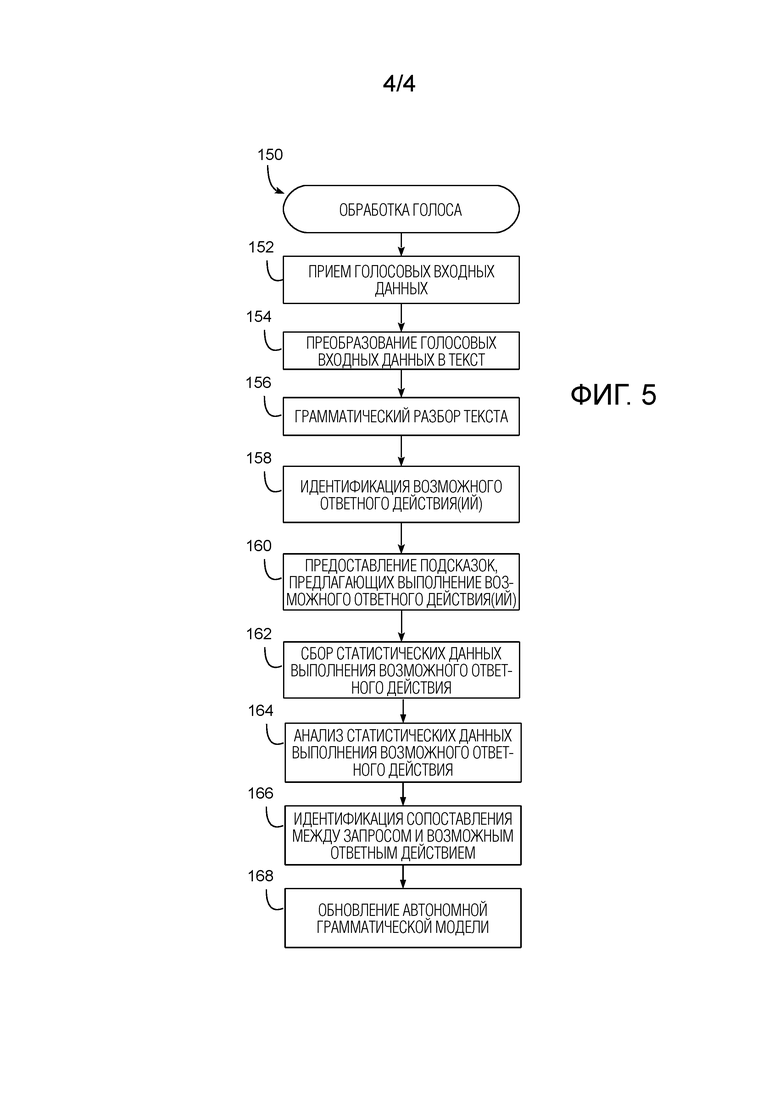
[0054] Фиг. 5, например, иллюстрирует алгоритм 150, подходящий для выполнения онлайновой или автономной службой, чтобы строить автономную грамматическую модель, по меньшей мере, частично на основе анализа статистических данных выполнения возможного ответного действия. Алгоритм 150 может выполняться посредством той же службы, которая обрабатывает голосовые запросы, или может быть совсем другой службой.
Кроме того, алгоритм 150 может быть использован, чтобы первоначально формировать автономную грамматическую модель или формировать обновленную грамматическую модель, которая используется для замены ранее сформированной автономной грамматической модели.
[0055] Блоки 152-156 алгоритма 150 являются аналогичными различным блокам алгоритма 100, изображенного на фиг. 3. В блоке 152 голосовые входные данные принимаются, например, в форме цифрового аудиосигнала. В блоке 154 голосовые входные данные преобразуются в текстовые лексемы (например, с помощью модуля 64 и/или 82 на фиг. 2). В блоке 110 текстовые лексемы могут быть грамматически разобраны (например, с помощью модуля 68 и/или 82 на фиг. 2).
[0056] В блоке 158 одно или более возможных действий, которые потенциально являются ответными на выданный запрос, могут быть идентифицированы, например, посредством модулей 64, 68 и 72 устройства 52 с ограниченными ресурсами или, если в режиме онлайн, посредством модуля 82. В некоторых реализациях идентификация возможных ответных действий, выполняемых в блоке 158, может быть выполнена способом, аналогичным операциям блока 112. Предположим, что пользователь выдает конкретный длиннохвостый запрос, такой как "парень, я уверен, что смог бы отдать предпочтение каким-нибудь Crazy Hair". Семантический процессор (например, 66 или 82 на фиг. 2) может определять, с помощью различных технологий, таких как идентификация объекта из графа знаний, и т.д., что "Crazy Hair" ссылается на музыкального исполнителя. На основе этого определения может быть дополнительно определено, что следующим логическим действием (т.е., возможным ответным действием) устройства 52 будет открытие музыкального проигрывателя и воспроизведение музыки, записанной группой The Crazy Hair Band.
[0057] В различных реализациях может быть множество идентифицированных потенциально возможных ответных действий. Например, может быть множество вариантов для воспроизведения музыки конкретным исполнителем. Потоковое приложение может передавать музыкальный поток из "канала" потоковой передачи, ассоциированного с исполнителем (и/или с музыкой, ассоциированной с аналогичными музыкальными стилями), устройству с ограниченными ресурсами по одной или более сетям. Другое приложение музыкального проигрывателя может воспроизводить музыку, сохраненную локально на устройстве с ограниченными ресурсами. В таком сценарии открытие любого приложения для воспроизведения The Crazy Hair Band будет составлять возможное действие, которое является потенциально ответным на запрос "парень, я уверен, что смог бы отдать предпочтение каким-нибудь Crazy Hair".
[0058] Многие пользователи могут эксплуатировать множество устройств с ограниченными ресурсами, например, как часть скоординированной "экосистемы", в которой пользователь может выдавать длиннохвостые голосовые запросы. Например, пользователь может эксплуатировать как мобильный телефон, так и интеллектуальные часы. В некоторых случаях, интеллектуальные часы могут соединяться с мобильным телефоном с помощью маломощной и/или малого радиуса действия беспроводной технологии, такой как Bluetooth, Wi-Fi и т.д., но это не требуется. Если пользователь выдает длиннохвостый голосовой запрос в одном из устройств (например, говорит в микрофон интеллектуальных часов), пользователь может пожелать, чтобы ответное действие было выполнено на этом же устройстве или на другом устройстве. Соответственно, в различных реализациях, одно или более возможных ответных действий, которые являются выполняемыми в одном или обоих устройствах, могут быть идентифицированы в блоке 158.
[0059] В некоторых вариантах осуществления, и как указано в блоке 160, одна или более подсказок, соответствующих одному или более возможным ответным действиям, идентифицированным в блоке 158, могут быть предоставлены пользователю в устройстве 52 с ограниченными ресурсами. Каждая подсказка может предлагать выполнение соответствующего возможного ответного действия в устройстве 52 с ограниченными ресурсами. Подсказки могут приходить в различных формах, таких как звуковая, визуальная и/или тактильная (например, вибрация) обратная связь. Например, и продолжая сценарий, описанный выше, пользователю может быть представлено два выбираемых графических элемента, один, чтобы инициировать потоковый проигрыватель, чтобы воспроизводить канал Брюса Спрингстина, и другой, чтобы инициировать воспроизведение локально сохраненного контента Брюса Спрингстина.
[0060] Подсказки могут быть представлены (например, выведены на устройстве с ограниченными ресурсами в различных формах и способах. Например, в некоторых реализациях, подсказки могут быть представлены в части графического пользовательского интерфейса другого приложения. Приложение может быть, например, веб-браузером, приложением социальной сети, приложением интеллектуального персонального помощника и т.д. Подсказка может быть представлена визуально как всплывающее окно, гиперссылка (текстовая или графическая по внешнему виду) и/или как так называемая "карточка", которую пользователь может выбирать, игнорировать и/или отвергать. Дополнительно или альтернативно, подсказка может быть представлена звуковым образом. Например, в ответ на голосовой запрос, для которого может быть множество возможных ответных действий, устройство с ограниченными ресурсами может звуковым образом выводить что-то типа "Вы имели в виду выполнение действия x или выполнение действия y"?
[0061] Дополнительно, и как отмечено выше, некоторые пользователи могут эксплуатировать множество устройств как часть одной скоординированной экосистемы. В некоторых таких реализациях одна или более подсказок могут быть предоставлены в одном или более из множества устройств. Предположим, что пользователь выдает голосовой запрос "найти указания к местоположению X" на своих интеллектуальных часах. В то время как интеллектуальные часы могут иметь дисплей, если пользователь управляет автомобилем или едет на велосипеде, может быть нежелательно, чтобы пользователь реагировал на визуальную подсказку, представленную на дисплее. Однако, мобильный телефон пользователя может иметь динамик, или может быть спарен с другим аудиоустройством, таким как автомобильная стереосистема или Bluetooth-наушники, носимые пользователем. Такой динамик может быть подходящим для предоставления слышимой подсказки пользователю. В таком случае, в ответ на выдачу пользователем голосового запроса на ее интеллектуальных часах, телефон пользователя может инструктировать предоставление звуковой подсказки пользователю, например, "Вы имели в виду местоположение X в городе A или городе B?"
[0062] В блоке 162 статистические данные выполнения возможного ответного действия могут быть собраны от одного или более устройств с ограниченными ресурсами, эксплуатируемых пользователем. В различных реализациях статистические данные выполнения возможного ответного действия могут относиться к и/или указывать выполнение одного или более возможных ответных действий, идентифицированных в блоке 158. В различных реализациях устройство с ограниченными ресурсами может собирать эти статистические данные само, например, наблюдая и записывая поведение пользователя в различные интервалы времени после выдачи голосового запроса. В некоторых реализациях устройство с ограниченными ресурсами может наблюдать и записывать различные данные, принадлежащие реакции пользователя (или ее отсутствию) на подсказки, предоставленные в блоке 160, такие как, насколько быстро пользователь отреагировал на подсказку, отклонил ли пользователь подсказку и проинструктировал устройству с ограниченными ресурсами выполнять альтернативное действие, и т.д.
[0063] В блоке 164 статистические данные выполнения возможного ответного действия, собранные в блоке 162, могут быть проанализированы. Если подсказки не были предоставлены в блоке 160, тогда одно или более наблюдаемых пользовательских взаимодействий с одним или более устройствами с ограниченными ресурсами после выдачи запроса могут составлять косвенное (или обстоятельственное) доказательство соответствия между выданным запросом и одним или более потенциально ответными действиями. Но предположим, что относительно длительный период времени проходит между выдачей голосового запроса и инициированием каких-либо возможных ответных действий. Что может быть менее доказывающим такое соответствие, особенно если в промежутке времени, пользователь эксплуатирует одно или более устройств с ограниченными ресурсами, чтобы выполнять одно или более действий, неидентифицированных в блоке 158 в качестве возможных ответных действий.
[0064] Предположим, что пользователь выдает конкретный длиннохвостый запрос, такой как "парень, я уверен, что смог бы отдать предпочтение какому-нибудь Спрингстину". Как отмечено выше, модули 64, 68 и 72 устройства 52 с ограниченными ресурсами, или, если в режиме онлайн, модуль 82, могут идентифицировать одно или более возможных ответных действий, которые подразумевают воспроизведение музыки Брюса Спрингстина. Например, одно возможное ответное действие может быть открытием приложения потоковой передачи для передачи потока канала Брюса Спрингстина; другое может быть открытием приложения музыкального проигрывателя, чтобы воспроизводить локально сохраненные песни Брюса Спрингстина. Если статистические данные, собранные в блоке 162, указывают, что после выдачи голосового запроса пользователь непосредственно открыл приложение потокового проигрывателя музыки, чтобы проигрывать в потоковом режиме канал Брюса Спрингстина, затем, в блоке 164, может быть определено, что существует более сильное соответствие между выданным пользовательским запросом и приложением потоковой передачи, чем существует между выданным запросом и музыкальным проигрывателем для воспроизведения локально сохраненной музыки.
[0065] Дополнительно или альтернативно, предположим, что одна или более подсказок были предоставлены в блоке 160. Пользовательский ответ на одну или более подсказок, будь то в форме выбора графического значка или в форме предоставления голосового ответа на звуковую подсказку, может быть проанализирован. Поскольку подсказки предоставляются в ответ на выданный запрос, утвердительный пользовательский ответ на подсказку может предоставлять более непосредственное доказательство соответствия между выданным запросом и действием, инициированным по подсказке. В дополнение к тому, отреагировал ли пользователь на подсказку, также может быть оценка того, насколько быстро пользователь отреагировал на подсказку, на сколько альтернативных подсказок была реакция, и т.д.
[0066] На основе анализа в блоке 164, в блоке 166, одно или более сопоставлений между выданным запросом и одним или более возможными ответными действиями могут быть идентифицированы. В некоторых реализациях устройство 52 с ограниченными ресурсами может передавать идентифицированное одно или более сопоставлений обратно модулю 82 (или другому онлайн-компоненту). В ситуациях, в которых сопоставления содержат или ссылаются на конфиденциальную информацию (секретный пароль, чтобы открывать дверь гаража, например), сопоставления могут быть анонимизированы перед передачей. Дополнительно или альтернативно, пользователь может конфигурировать устройство 52, чтобы сохранять сопоставления в устройстве 52 как закрытые сопоставления и не предоставлять сопоставления модулю 82.
[0067] В блоке 168 одна или более автономных грамматических моделей (например, 76 на фиг. 2), применяемых одним или более устройствами с ограниченными ресурсами, эксплуатируемыми пользователем, могут быть обновлены (например, в устройстве 52 и/или модуле 82), чтобы содержать одно или более сопоставлений, идентифицированных в блоке 166. Например, автономная грамматика может быть упакована в модуле 82 и распространена одному или более автономным устройствам с голосовым управлением с ограниченными ресурсами (например, множеству устройств, эксплуатируемых конкретным пользователем, который использует характерный длиннохвостый голосовой запрос). Одно или более автономных устройств с ограниченными ресурсами могут, в свою очередь, принимать и распаковывать запакованную автономную грамматическую модель и сохранять модель на соответствующих устройствах. Упаковка может быть использована, чтобы сжимать автономную грамматическую модель, чтобы уменьшать размер передачи и иначе форматировать модель способом, который является используемым соответствующими устройствами. Соответственно, устройство с ограниченными ресурсами может после этого использовать автономную грамматику, когда находится в автономном режиме или даже в онлайновом режиме, чтобы обрабатывать голосовые запросы.
[0068] В дополнение к или вместо алгоритма 150, используемого для построения первоначальной автономной грамматической модели, алгоритм 150 также может быть использован для обновления автономной грамматической модели, например, чтобы лучше отслеживать изменения в использовании со временем, объединять дополнительные длиннохвостые голосовые запросы для конкретных пользователей и т.д. Такие обновления могут считаться динамическими обновлениями в том, что устройство с ограниченными ресурсами может быть обновлено либо как часть обновления системы, обновления приложения, либо как фоновое обновление, которое в ином случае является скрытым от пользователя.
[0069] В некоторых реализациях сопоставления между длиннохвостыми запросами и ответными действиями могут быть объединены в онлайновую грамматическую модель в дополнение к одной или более автономным грамматическим моделям. Таким образом, если новый пользователь выдает длиннохвостый запрос, который ранее был идентифицирован и сопоставлен с другим пользователем, то же сопоставление может быть добавлено в одну или более автономных грамматик, используемых одним или более устройствами с ограничением ресурсов, эксплуатируемыми новым пользователем. Однако, в некоторых реализациях, пользователи могут отказаться от такого сотрудничества, чтобы сохранять приватность, анонимность и/или секретность своих потенциально чувствительных длиннохвостых запросов.
[0070] В то время как несколько реализаций были описаны и иллюстрированы в данном документе, множество других средств и/или структур для выполнения функции и/или получения результатов и/или одного или более преимуществ, описанных в данном документе, могут быть использованы, и каждая из таких разновидностей и/или модификаций считается находящейся в рамках реализаций, описанных в данном документе. Более обобщенно, все параметры, габариты, материалы и конфигурации, описанные в данном документе, считаются примерными, и что фактические параметры, габариты, материалы и/или конфигурации будут зависеть от конкретного применения или применений, для которых учения используется/используются. Специалисты в данной области техники поймут или будут иметь возможность устанавливать с помощью не более чем обычного экспериментирования множество эквивалентов для конкретных реализаций, описанных в данном документе. Следовательно, должно быть понятно, что вышеописанные реализации представлены только в качестве примера, и что, в рамках прилагаемой формулы изобретения и эквивалентов к ней, реализации могут быть применены на практике иначе, чем конкретно описано и заявлено. Реализации настоящего изобретения направлены на каждый отдельный признак, систему, изделие, материал, комплект и/или способ, описанный в данном документе. Помимо этого, любая комбинация двух или более таких признаков, систем, изделий, материалов, комплектов и/или способов, если такие признаки, системы, изделия, материалы, комплекты и/или способы не являются взаимно несогласованными, включается в рамки настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОНЕЧНЫЙ АВТОМАТ УНИФИЦИРОВАННОГО ОБМЕНА СООБЩЕНИЯМИ | 2008 |
|
RU2470364C2 |
| ПРИОРИТИЗАЦИЯ КРИТЕРИЕВ ВЫБОРА ПОСРЕДСТВОМ ИНТЕЛЛЕКТУАЛЬНОГО АВТОМАТИЗИРОВАННОГО ПОМОЩНИКА | 2011 |
|
RU2546606C2 |
| ОПРЕДЕЛЕНИЕ НАМЕРЕНИЯ ПОЛЬЗОВАТЕЛЯ НА ОСНОВЕ ОНТОЛОГИЙ ПРЕДМЕТНЫХ ОБЛАСТЕЙ | 2011 |
|
RU2541221C2 |
| АКТИВНОЕ ЗАПРАШИВАНИЕ ВВОДА ИНТЕЛЛЕКТУАЛЬНЫМ АВТОМАТИЗИРОВАННЫМ ПОМОЩНИКОМ | 2011 |
|
RU2541208C2 |
| ПЕРЕФРАЗИРОВАНИЕ ПОЛЬЗОВАТЕЛЬСКИХ ЗАПРОСОВ И РЕЗУЛЬТАТОВ ПОСРЕДСТВОМ ИНТЕЛЛЕКТУАЛЬНОГО АВТОМАТИЗИРОВАННОГО ПОМОЩНИКА | 2011 |
|
RU2541202C2 |
| РАЗРЕШЕНИЕ НЕОДНОЗНАЧНОСТИ НА ОСНОВЕ АКТИВНОГО ЗАПРАШИВАНИЯ ВВОДА ИНТЕЛЛЕКТУАЛЬНЫМ АВТОМАТИЗИРОВАННЫМ ПОМОЩНИКОМ | 2011 |
|
RU2546605C2 |
| ВЫВЕДЕНИЕ НАМЕРЕНИЯ ПОЛЬЗОВАТЕЛЯ НА ОСНОВЕ ПРЕДЫДУЩИХ ВЗАИМОДЕЙСТВИЙ С ГОЛОСОВЫМ ПОМОЩНИКОМ | 2011 |
|
RU2544787C2 |
| ОРКЕСТРОВКА СЛУЖБ ДЛЯ ИНТЕЛЛЕКТУАЛЬНОГО АВТОМАТИЗИРОВАННОГО ПОМОЩНИКА | 2011 |
|
RU2556416C2 |
| ПЕРСОНАЛИЗИРОВАННЫЙ СЛОВАРЬ ДЛЯ ЦИФРОВОГО ПОМОЩНИКА | 2011 |
|
RU2541219C2 |
| ИСПОЛЬЗОВАНИЕ ТЕКСТА ОПОВЕЩЕНИЯ О СОБЫТИИ В КАЧЕСТВЕ ВВОДА В АВТОМАТИЗИРОВАННЫЙ ПОМОЩНИК | 2011 |
|
RU2546604C2 |

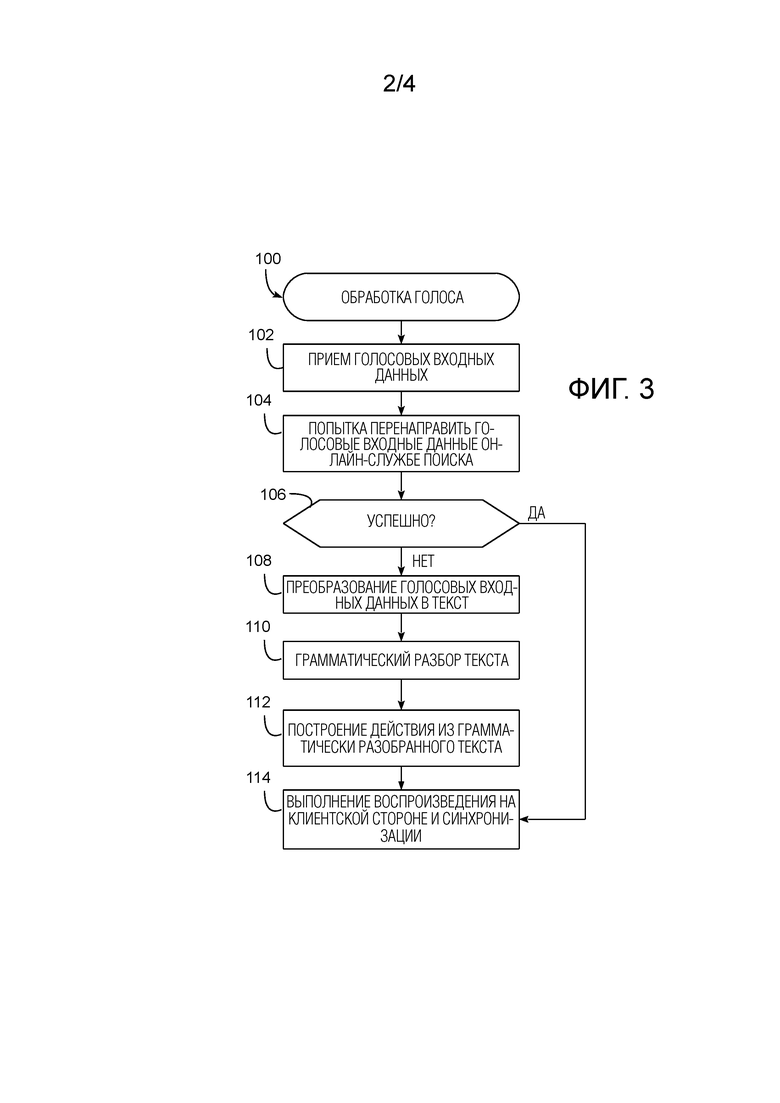
Изобретение относится к области вычислительной техники для семантической обработки данных. Технический результат заключается в повышении точности обработки голосовых запросов. Технический результат достигается за счет семантической обработки длиннохвостого голосового запроса, выданного в первом устройстве с ограниченными ресурсами скоординированной экосистемы устройств с ограниченными ресурсами, управляемых пользователем, чтобы идентифицировать одно или более возможных ответных действий, которые являются выполнимыми посредством одного или более устройств с ограниченными ресурсами, при этом длиннохвостый голосовой запрос является уникальным или возникает относительно нечасто в объеме поиска запросов; анализа реакций пользователя на одну или более подсказок, чтобы выбирать из одного или более возможных ответных действий удовлетворяющее требованиям ответное действие; и обновления автономной грамматической модели, чтобы включать в нее сопоставление между выданным длиннохвостым голосовым запросом и удовлетворяющим требованиям ответным действием. 3 н. и 9 з.п. ф-лы, 5 ил.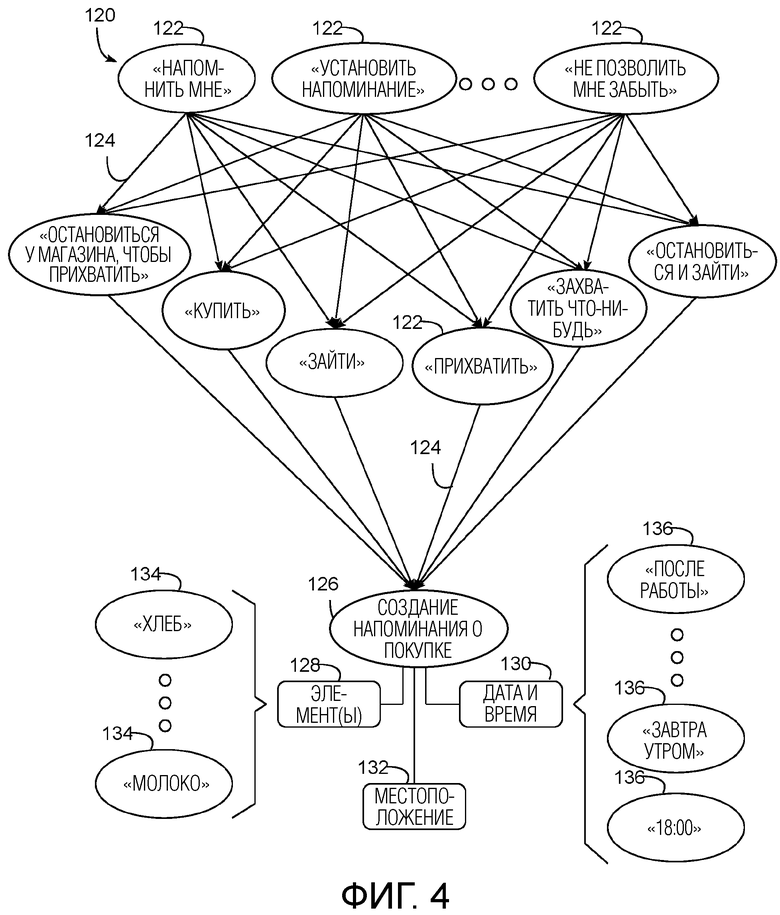
1. Способ семантической обработки и обновления автономной грамматической модели, содержащий этапы, на которых:
семантически обрабатывают, посредством онлайнового семантического процессора, длиннохвостый голосовой запрос, выданный в первом устройстве с ограниченными ресурсами скоординированной экосистемы устройств с ограниченными ресурсами, управляемых пользователем, чтобы идентифицировать одно или более возможных ответных действий, которые являются выполнимыми посредством одного или более устройств с ограниченными ресурсами, при этом длиннохвостый голосовой запрос является уникальным или возникает относительно нечасто в объеме поиска запросов;
предоставляют, в качестве выходных данных в одном или более устройствах с ограниченными ресурсами, одну или более подсказок, предлагающих выполнение соответствующего одного или более возможных действий;
анализируют одну или более реакций пользователя на одну или более подсказок, чтобы выбирать, из одного или более возможных ответных действий, удовлетворяющее требованиям ответное действие; и
обновляют автономную грамматическую модель, сохраненную в каждом из устройств с ограниченными ресурсами в упомянутой скоординированной экосистеме, чтобы включать в нее сопоставление между выданным длиннохвостым голосовым запросом и удовлетворяющим требованиям ответным действием, при этом автономная грамматическая модель сопоставляет голосовые запросы с действиями, которые являются выполнимыми посредством каждого устройства с ограниченными ресурсами скоординированной экосистемы устройств с ограниченными ресурсами в автономном режиме.
2. Способ по п. 1, в котором одна или более подсказок содержат выбираемый графический элемент.
3. Способ по п. 1, в котором одна или более подсказок содержат звуковую или тактильную подсказку.
4. Способ по п. 1, дополнительно содержащий этап, на котором передают автономную грамматическую модель каждому устройству с ограниченными ресурсами скоординированной экосистемы устройств с ограниченными ресурсами для хранения и для использования соответствующими семантическими процессорами каждого устройства с ограниченными ресурсами скоординированной экосистемы устройств с ограниченными ресурсами в автономном режиме.
5. Способ по п. 4, в котором упомянутая передача динамически обновляет автономную грамматическую модель, сохраненную в устройстве с ограниченными ресурсами.
6. Способ по п. 1, в котором семантическая обработка выполняется с помощью онлайновой грамматической модели, при этом автономная грамматическая модель имеет уменьшенные требования к ресурсам относительно онлайновой грамматической модели.
7. Способ по п. 1, дополнительно содержащий этап, на котором ограничивают доступ к одному или более из сопоставления, выданного запроса и автономной грамматики для устройства с ограниченными ресурсами.
8. Система семантической обработки и обновления автономной грамматической модели, включающая в себя память и один или более процессоров, функционирующих, чтобы исполнять инструкции, сохраненные в памяти, содержащие инструкции, чтобы:
семантически обрабатывать длиннохвостый голосовой запрос, выданный в первом устройстве с ограниченными ресурсами скоординированной экосистемы устройств с ограниченными ресурсами, управляемых пользователем, чтобы идентифицировать одно или более возможных ответных действий, которые являются выполнимыми посредством одного или более устройств с ограниченными ресурсами, при этом длиннохвостый голосовой запрос является уникальным или возникает относительно нечасто в объеме поиска запросов;
предоставлять, в качестве выходных данных в одном или более устройствах с ограниченными ресурсами, одну или более подсказок, предлагающих выполнение соответствующего одного или более возможных действий;
анализировать одну или более реакций пользователя на одну или более подсказок, чтобы выбирать, из одного или более возможных ответных действий, удовлетворяющее требованиям ответное действие; и
обновлять автономную грамматическую модель, сохраненную в каждом из устройств с ограниченными ресурсами в упомянутой скоординированной экосистеме, чтобы включать в нее сопоставление между выданным длиннохвостым голосовым запросом и удовлетворяющим требованиям ответным действием, при этом автономная грамматическая модель сопоставляет голосовые запросы с действиями, которые являются выполнимыми посредством каждого устройства с ограниченными ресурсами скоординированной экосистемы устройств с ограниченными ресурсами в автономном режиме.
9. Система по п. 8, в которой одна или более подсказок содержат выбираемый графический элемент.
10. Система по п. 8, в которой одна или более подсказок содержат звуковую или тактильную подсказку.
11. Система по п. 8, дополнительно содержащая инструкции, чтобы передавать автономную грамматическую модель каждому устройству с ограниченными ресурсами скоординированной экосистемы устройств с ограниченными ресурсами для хранения и для использования соответствующими семантическими процессорами каждого устройства с ограниченными ресурсами скоординированной экосистемы устройств с ограниченными ресурсами в автономном режиме.
12. По меньшей мере один долговременный компьютерно-читаемый носитель, хранящий инструкции, которые, когда исполняются компьютерной системой, инструктируют выполнение посредством компьютерной системы следующих операций, на которых:
семантически обрабатывают, посредством онлайнового семантического процессора, длиннохвостый голосовой запрос, выданный в первом устройстве с ограниченными ресурсами скоординированной экосистемы устройств с ограниченными ресурсами, управляемых пользователем, чтобы идентифицировать одно или более возможных ответных действий, которые являются выполнимыми посредством одного или более устройств с ограниченными ресурсами, при этом длиннохвостый голосовой запрос является уникальным или возникает относительно нечасто в объеме поиска запросов;
предоставляют, в качестве выходных данных в одном или более устройствах с ограниченными ресурсами, одну или более подсказок, предлагающих выполнение соответствующего одного или более возможных действий;
анализируют одну или более реакций пользователя на одну или более подсказок, чтобы выбирать, из одного или более возможных ответных действий, удовлетворяющее требованиям ответное действие; и
обновляют автономную грамматическую модель, сохраненную в каждом из устройств с ограниченными ресурсами в упомянутой скоординированной экосистеме, чтобы включать в нее сопоставление между выданным длиннохвостым голосовым запросом и удовлетворяющим требованиям ответным действием, при этом автономная грамматическая модель сопоставляет голосовые запросы с действиями, которые являются выполнимыми посредством каждого устройства с ограниченными ресурсами скоординированной экосистемы устройств с ограниченными ресурсами в автономном режиме.
| СИНХРОННОЕ ПОНИМАНИЕ СЕМАНТИЧЕСКИХ ОБЪЕКТОВ, РЕАЛИЗОВАННОЕ С ПОМОЩЬЮ ТЭГОВ РЕЧЕВОГО ПРИЛОЖЕНИЯ | 2004 |
|
RU2349969C2 |
| RU 2011122784 A, 20.12.2012 | |||
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |

