Область техники, к которой относится изобретение
Настоящая технология относится к устройству кодирования и способу кодирования и устройству декодирования и способу декодирования, и программе, в частности, к устройству кодирования и к способу кодирования, устройству декодирования и к способу декодирования, и программе, в которых может быть уменьшен объем расчетов для декодирования аудиосигнала.
Уровень техники
Например, в качестве способа кодирования аудиосигнала, были предложены стандарт усовершенствованного кодирования аудиоданных (ААС), в соответствии с многоканальным кодированием Группы экспертов в области движущегося изображения (MPEG)-2, стандарт MPEG 4 ААС и унифицированное кодирование речи и аудиоданных MPEG-D (USAC), которые представляют собой международные стандарты, (например, см. NPL 1 и NPL 2).
Список литературы
Непатентная литература
[NPL 1] МЕЖДУНАРОДНЫЙ СТАНДАРТ ISO/IEC 14496-3 Четвертое издание 2009-09-01 Information technology-coding of audio-visual objects-part3: Audio
[NPL 2] МЕЖДУНАРОДНЫЙ СТАНДАРТ КОЛЕС 23003-3 Первое издание 2012-04-01 Information technology-coding of audio-visual objects-part3: Unified speech and audio coding
Раскрытие сущности изобретения
Техническая задача
В частности, необходимо обеспечить технологию кодирования, используя большее количество каналов, большее ощущение присутствия при воспроизведении, или передачу множества звуковых материалов (объектов), чем при воспроизведении 5.1 каналов окружающего звука в предшествующем уровне техники.
Например, рассматривается случай кодирования и декодирования аудиосигналов по 24 каналам и множеству объектов, и случай кодирования и декодирования аудиосигнала двух каналов. В этом случае в мобильном устройстве, имеющем недостаточные возможности расчетов, возможно декодировать аудиосигнал по двум каналам в режиме реального времени, однако, возникает случай, когда декодирование аудиосигналов по 24 каналам и множеству объектов в режиме реального времени является трудновыполнимым.
В текущем аудиокодеке, таком как MPEG-D USAC и т.п., поскольку необходимо декодировать аудиосигналы по всем каналам и всем объектам, трудно уменьшить количество расчетов во время декодирования. Поэтому, возникает проблема, состоящая в том, что нет возможности воспроизводить аудиосигнал в режиме реального времени, в зависимости от устройств на стороне декодирования.
Желательно обеспечить устройство кодирования и способ кодирования, устройство декодирования и способ декодирования, и программу, в которых можно было бы уменьшить количество расчетов для декодирования.
Решение задачи
Устройство декодирования, в соответствии с первым вариантом осуществления настоящей технологии, включает в себя по меньшей мере одну схему, выполненную с возможностью получения одного или более кодированных аудиосигналов, включающих в себя множество каналов и/или множество объектов, и информации приоритета для каждого из множества каналов и/или множества объектов и декодирования одного или более кодированных аудиосигналов, в соответствии с информацией приоритета.
По меньшей мере, одна схема может быть выполнена с возможностью декодирования, в соответствии с информацией приоритета по меньшей мере частично, путем декодирования по меньшей мере одного из одного или более кодированных аудиосигналов, для которых степень приоритета, обозначенная информацией приоритета, равна или выше, чем степень, и отказываться от декодирования по меньшей мере других из одного или более кодированных аудиосигналов, для которых степень приоритета, обозначенная информацией приоритета, меньше, чем указанная степень.
По меньшей мере, одна схема выполнена с возможностью изменения степени по меньшей мере частично на основе информации приоритета для множества каналов и/или множества объектов.
По меньшей мере, одна схема может быть выполнена с возможностью получения множества наборов информации приоритета для одного или более кодированных аудиосигналов, и по меньшей мере одна схема может быть выполнена с возможностью декодирования одного или более кодированных аудиосигналов по меньшей мере частично, посредством выбора одного из наборов информации приоритета и декодирования по меньшей мере частично, на основе одного набора информации приоритета.
По меньшей мере, одна схема может быть выполнена с возможностью выбора по меньшей мере одного из наборов информации приоритета в соответствии с возможностями вычислений устройства декодирования.
По меньшей мере, одна схема может быть дополнительно выполнена с возможностью генерирования информации приоритета по меньшей мере частично, на основе кодированного аудиосигнала.
По меньшей мере, одна схема может быть выполнена с возможностью генерирования информации приоритета по меньшей мере частично, на основе давления звука или спектральной формы аудиосигнала одного или более кодированных аудиосигналов.
Информация приоритета для множества каналов и/или множества объектов может содержать по меньшей мере для одного первого канала из множества каналов и/или по меньшей мере для одного первого объекта из множества объектов, информацию приоритета, указывающую разные степени приоритета по меньшей мере одного первого канала и/или по меньшей мере одного первого объекта, в течение периода времени, и по меньшей мере одна схема может быть выполнена с возможностью декодирования на основе информации приоритета по меньшей мере частично, путем определения, для первого канала и/или первого объекта и первого времени в течение периода времени, следует ли декодировать первый канал и/или первый объект в первое время, по меньшей мере частично, на основе степени приоритета для первого канала и/или первого объекта в первое время и степени приоритета для первого канала, и/или первого объекта в другое время перед или после первого времени и в течение периода времени.
По меньшей мере, одна схема может быть дополнительно выполнена с возможностью генерирования аудиосигнала для первого времени по меньшей мере частично, путем добавления выходного аудиосигнала для канала или объекта в это время, и вывода аудиосигнала канала или объекта во второе время перед или после первого времени, в котором выходной аудиосигнал для канала или объекта для времени представляет собой сигнал, получаемый по меньшей мере одной схемой в результате декодирования, в случае, когда выполняется декодирование канала или объекта в течение времени, и нулевые данные в случае, когда не выполняется декодирование канала или объекта в течение времени, и для выполнения регулировки усиления выходного аудиосигнала канала или объекта в это время на основе информации приоритета канала или объекта в это время и информации приоритета канала или объекта в другое время перед или после этого времени.
По меньшей мере, одна схема может быть дополнительно выполнена с возможностью регулирования усиление значения мощности высокой частоты для канала или объектов на основе информации приоритета канала или объекта в первое время и информации приоритета канала или объекта во второе время перед или после первого времени, и генерирования компонента высокой частоты аудиосигнала для первого времени на основе значения мощности высокой частоты, для которого регулируют коэффициент усиления, и аудиосигнал для времени.
По меньшей мере, одна схема может быть дополнительно выполнена с возможностью генерирования, для каждого канала или каждого объекта, аудиосигнал первого времени, в который включен компонент высокой частоты, на основе значения мощности высокой частоты и аудиосигнала для времени, и выполнять регулирование усиления аудиосигнала для первого времени, в который включен компонент высокой частоты.
По меньшей мере, одна схема может быть дополнительно выполнена с возможностью назначения аудиосигнала первого объекта из множества объектов для каждого из по меньшей мере некоторых из множества каналов со значением усиления на основе информации приоритета, и генерирования аудиосигнала каждого из множества каналов.
Способ декодирования или программа, в соответствии с первым вариантом осуществления настоящей технологии включает в себя этапы, на которых: получают информацию приоритета для каждого из множества каналов и/или множества объектов одного или более кодированных аудиосигналов и декодируют множество каналов и/или множество объектов в соответствии с информацией приоритета.
В соответствии с первым вариантом осуществления настоящей технологии получают информацию приоритета для каждого из множества каналов и/или множества объектов одного или более кодированных аудиосигналов; и декодируют множество каналов и/или множество объектов в соответствии с информацией приоритета.
Устройство кодирования, в соответствии со вторым вариантом осуществления настоящей технологии включает в себя: по меньшей мере, одну схему, выполненную с возможностью генерирования информации приоритета для каждого из множества каналов и/или множества объектов аудиосигнала, и сохранения информации приоритета в потоке битов.
По меньшей мере, одна схема может быть выполнена с возможностью генерирования информации приоритета по меньшей мере частично, посредством генерирования множества наборов информации приоритета для каждого из множества каналов и/или множества объектов.
По меньшей мере, одна схема может быть выполнена с возможностью генерирования множества наборов информации приоритета для каждой из множества возможностей расчета устройств декодирования.
По меньшей мере, одна схема может быть выполнена с возможностью генерирования информации приоритета по меньшей мере частично, на основе давления звука или спектральной формы аудиосигнала.
По меньшей мере, одна схема может быть дополнительно выполнена с возможностью кодирования аудиосигналов множества каналов и/или множества объектов аудиосигнала для формирования кодированного аудиосигнала, и указанная по меньшей мере одна схема может быть дополнительно выполнена с возможностью сохранения информации приоритета и кодированного аудиосигнала в потоке битов.
Способ и программа кодирования, в соответствии со вторым вариантом осуществления настоящей технологии включают в себя этапы, на которых: генерируют информацию приоритета для каждого из множества каналов и/или множества объектов аудиосигнала и сохраняют информацию приоритета в потоке битов.
В соответствии со вторым вариантом осуществления настоящей технологии, генерируют информацию приоритета для каждого из множества каналов и/или множества объектов аудиосигнала, и сохраняют информацию приоритета в потоке битов.
Предпочтительные эффекты изобретения
В соответствии с первым вариантом осуществления и вторым вариантом осуществления возможно уменьшить количество вычислений при декодировании.
Эффекты, описанные здесь, не обязательно ограничены этим, и эффекты, описанные здесь, могут представлять собой любой эффект, который описан в данном раскрытии.
Краткое описание чертежей
На фиг. 1 представлена схема, поясняющая поток битов.
На фиг. 2 представлена схема, поясняющая кодирование.
На фиг. 3 представлена схема, поясняющая информацию приоритета.
На фиг. 4 представлена схема, поясняющая значения величин информации приоритета.
На фиг. 5 представлена схема, иллюстрирующая пример конфигурации устройства кодирования.
На фиг. 6 представлена схема, иллюстрирующая модуль кодирования аудиоданных канала.
На фиг. 7 представлена схема, иллюстрирующая модуль кодирования аудиоданных объекта.
На фиг. 8 представлена блок-схема последовательности операций, поясняющая обработку кодирования.
На фиг. 9 представлена схема, иллюстрирующая пример конфигурации устройства декодирования.
На фиг. 10 показан пример конфигурации модуля распаковки/декодирования.
На фиг. 11 представлена блок-схема последовательности операций, поясняющая обработку декодирования.
На фиг. 12 представлена блок-схема последовательности операций, поясняющая избирательную обработку декодирования.
На фиг. 13 показан другой пример конфигурации модуля распаковки/декодирования.
На фиг. 14 представлена блок-схема последовательности операций, поясняющая избирательную обработку декодирования.
На фиг. 15 представлена схема, иллюстрирующая пример синтаксиса метаданных объекта.
На фиг. 16 представлена схема, поясняющая генерирование аудиосигнала.
На фиг. 17 представлена схема, поясняющая генерирование аудиосигнала.
На фиг. 18 представлена схема, поясняющая выбор выходного назначения коэффициента MDCT.
На фиг. 19 представлена схема, поясняющая регулировку усиления аудиосигнала и значения мощности в полосе высокой частоты.
На фиг. 20 представлена схема, поясняющая регулировку усиления аудиосигнала и значения мощности в полосе высокой частоты.
На фиг. 21 представлена схема, иллюстрирующая другой пример конфигурации модуля распаковки/декодирования.
На фиг. 22 представлена блок-схема последовательности операций, поясняющая избирательную обработку декодирования.
На фиг. 23 представлена схема, поясняющая регулировку усиления аудиосигнала.
На фиг. 24 представлена схема, поясняющая регулировку усиления аудиосигнала.
На фиг. 25 представлена схема, иллюстрирующая другой пример конфигурации модуля распаковки/декодирования.
На фиг. 26 представлена блок-схема последовательности операций, поясняющая избирательную обработку декодирования.
На фиг. 27 представлена схема, поясняющая усиление VBAP.
На фиг. 28 представлена схема, поясняющая усиление VBAP.
На фиг. 29 представлена схема, иллюстрирующая другой пример конфигурации модуля распаковки/декодирования.
На фиг. 30 представлена блок-схема последовательности операций, поясняющая обработку декодирования.
На фиг. 31 представлена блок-схема последовательности операций, поясняющая избирательную обработку декодирования.
На фиг. 32 представлена схема, иллюстрирующая пример конфигурации компьютера.
Осуществление изобретения
Ниже, со ссылкой на чертежи, будут описаны варианты осуществления, в которых применяется настоящая технология.
Первый вариант осуществления
Обзор настоящей технологии
При кодировании аудиосигнала каждого канала, который состоит из сигнала множества каналов и аудиосигнала объекта, в настоящей технологии, количество расчетов при декодировании может быть уменьшено путем передачи информации приоритета аудиосигнала каждого канала и информации приоритета аудиосигнала каждого объекта.
Кроме того, в настоящей технологии, на стороне декодирования выполняют преобразование частота-время в случае, когда степень приоритета, которая обозначена информацией приоритета каждого канала или каждым объектом, равна или больше, чем заданная степень приоритета, и преобразование частота-время не выполняется, и результат преобразования частота-время делают равным нулю в случае, когда степень приоритета, которая обозначена в информации приоритета каждого канала или каждым объектом, меньше, чем заданная степень приоритета, и, таким образом, количество расчетов при декодировании аудиосигналов может быть уменьшено.
Ниже будет описан случай, когда аудиосигнал каждого канала, который состоит из сигнала множества каналов и аудиосигнала объекта, кодируют в соответствии со стандартами ААС. Однако, в случае, когда кодирование выполняется другим способом, будет выполняться такая же обработка.
Например, в случае, когда аудиосигнал каждого канала, который состоит из множества каналов, и аудиосигнал множества объектов, кодируют в соответствии со стандартами ААС и передают, аудиосигнал каждого канала или каждый объект кодируют и передают для каждого фрейма.
В частности, как представлено на фиг. 1, кодированный аудиосигнал или информацию, необходимую для декодирования аудиосигнала, сохраняют во множестве элементов (элементах потока битов), и передают поток битов, состоящий из этих элементов потока битов.
В этом примере, в потоке битов для одного фрейма, от элемента EL1 до элемента ELt в количестве t размещают в порядке, начиная от заголовка, и в конце размещают идентификатор TERM, обозначающий конечное положение фрейма относительно информации фрейма.
Например, элемент EL1, расположенный в заголовке, представляет собой область вспомогательных данных, называемую элементом потока данных (DSE), и информация о каждом из множества каналов, такая как информация о смешении аудиосигнала или информации идентификации, описана в DSE.
В элементах от EL2 до ELt, следующих после ЭЛЕМЕНТА El1, содержатся кодированные аудиосигналы.
В частности, элемент, в котором содержится аудиосигнал одного канала, называется SCE, и элемент, в котором содержится аудиосигнал пары из двух каналов, называется СРЕ. Кроме того, аудиосигнал каждого объекта называется SCE. Кроме того, аудиосигнал каждого объекта содержится в SCE.
В настоящей технологии информацию приоритета аудиосигнала каждого канала, которая состоит из сигнала из множества каналов, и информацию приоритета аудиосигнала объекта генерируют и сохраняют в DSE.
Например, как представлено на фиг. 2, предполагается, что кодируют аудиосигналы последовательных фреймов от F11 до F13.
В этом случае, устройство кодирования (кодер) анализирует степень для степени приоритета аудиосигнала каждого канала, для каждого из этих фреймов, и, например, как представлено на фиг. 3, генерирует информацию приоритета каждого канала. Аналогично, устройство кодирования также генерирует информацию приоритета аудиосигнала каждого объекта.
Например, устройство кодирования анализирует степень для степени приоритета аудиосигнала на основе давления звука или спектральной формы аудиосигнала, и корреляции спектральных форм между каналами или между объектами.
На фиг. 3, информация приоритета каждого канала в случае, когда общее количество каналов равно М, иллюстрируется в качестве примера. Таким образом, что касается каждого канала от канала, имеющего номер канала 0, до канала, имеющего номер канала М - 1, цифровое обозначение, обозначающее степень приоритета сигнала этих каналов, представлено, как информация приоритета.
Например, информация приоритета для канала, имеющего номер канала 0, равна 3, и информация приоритета для канала, имеющего номер канала 1, равна 0. Предполагается, что канал, имеющий заданный номер канала m (m=0, 1 …, m - 1), также называется каналом m.
Значение информации приоритета, представленной на фиг. 3, представляет собой любое значение от 0 до 7, как представлено на фиг. 4, по мере того, как значение информации приоритета увеличивается, степень приоритета во время воспроизведения аудиосигнала, то есть, степень важности становится выше.
Поэтому, аудиосигнал, у которого значение информации приоритета равно 0, имеет самую низкую степень приоритета, и аудиосигнал, у которого значение информации приоритета равно 7, имеет самую высокую степень приоритета.
В случае, когда аудиосигнал множества каналов и аудиосигнал множества объектов воспроизводят одновременно, звук, который не является настолько важным по сравнению с другим звуком, включают в звук, воспроизводимый из этих аудиосигналов. Другими словами, даже притом, что конкретный звук из всех звуков не будет воспроизведен, существует звук в степени, которая не приводит к неудобным ощущениям для слушателя.
Поэтому, если не выполняется декодирование аудиосигнала, в котором степень приоритета низкая, если необходимо, возможно предотвратить ухудшение качества звука и уменьшить объем расчетов для декодирования. Поэтому, в устройстве кодирования, степень важности каждого аудиосигнала во время воспроизведения, то есть, информацию приоритета, обозначающую приоритет при декодировании, назначают для каждого аудиосигнала для каждого фрейма таким образом, чтобы можно было бы соответствующим образом выбрать аудиосигнал, который не будет декодирован.
Как описано выше, когда определяют информацию приоритета для каждого аудиосигнала, информацию приоритета сохраняют в DSE элемента EL1, обозначенного на фиг. 1. В частности, в примере на фиг. 3, поскольку количество каналов, которое конфигурирует аудиосигнал для множества каналов, равно М, информацию приоритета каждого из М каналов от канала 0 до каналов М - 1, сохраняют в DSE.
Аналогично, информация приоритета каждого объекта также содержится в DSE элемента EL1. Здесь, например, когда предполагается, что существуют N объектов, с номерами объектов от 0 до N - 1, определяют информацию приоритета каждого из N объектов и сохраняют в DSE.
Ниже объект с заданным номером n объекта (n=0, 1 …, N - 1) также называется объектом n.
Таким образом, если информацию приоритета определяют для каждого аудиосигнала, на стороне воспроизведения, то есть, на стороне декодирования для аудиосигнала, возможно просто определить, какой аудиосигнал является важным во время воспроизведения и должен быть декодирован с приоритетом, то есть, должен использоваться при воспроизведении.
Снова обращаясь к фиг. 2, например, предполагается, что информация приоритета аудиосигналов фрейма F11 и фрейма F13 в заданном канале равна 7, и информация приоритета аудиосигнала фрейма F12 в заданном канале равна 0.
Кроме того, предполагается, что декодирование не выполняется в отношении аудиосигнала, степень приоритета которого ниже, чем заданная степень приоритета на стороне декодирования аудиосигнала, то есть, в устройстве декодирования (декодере).
Здесь, например, если заданная степень приоритета называется пороговым значением, и если пороговое значение равно 4, в примере, описанном выше, декодирование выполняется в отношении аудиосигналов фрейма F11 и фрейма F13, в заданном канале, информация приоритета которого равна 7.
С другой стороны, декодирование не выполняется в отношении аудиосигнала фрейма F12, в заданном канале, информация приоритета которого равна 0.
Поэтому, в этом примере, аудиосигнал фрейма F12 становится сигналом без звука, и аудиосигналы фрейма F11 и фрейма F13 синтезируют, и затем он становится конечным аудиосигналом заданного канала.
Более конкретно, например, во время кодирования каждого аудиосигнала, выполняется преобразование время-частота в отношении аудиосигнала, и информацию, получаемую в результате преобразования время-частота, кодируют, и затем кодированные данные, полученные в результате кодирования, сохраняют в элементе.
Любая обработка может выполняться для преобразования время-частота. Однако ниже будет продолжено описание, в котором модифицируемое дискретное косинусное преобразование (MDCT) выполняется, как преобразование время-частота.
Кроме того, в устройстве декодирования, декодирование выполняется в отношении кодированных данных, и обратное модифицированное дискретное косинусное преобразование (IMDCT) выполняют в отношении коэффициента MDCT, полученного из результата декодирования, и затем генерируют аудиосигнал. Таким образом, здесь IMDCT выполняют, как обратное преобразование (преобразование время-частота) для преобразования время-частота.
Поэтому, более конкретно, IMDCT выполняется в отношении фрейма F11 и фрейма F13, информация приоритета которых равна или выше, чем 4, что представляет собой величину порогового значения, и генерируется аудиосигнал.
Кроме того, IMDCT не выполняют в отношении фрейма F12, информация приоритета которого ниже, чем 4, что представляет собой величину порогового значения, и результат IMDCT равен 0, и затем генерируют аудиосигнал. Таким образом, аудиосигнал фрейма F12 становится сигналом без звука, то есть, нулевыми данными.
Кроме того, в качестве другого примера, в примере, представленном на фиг. 3, когда пороговое значение равно 4, среди аудиосигналов каждого от канала 0 до канала М - 1, декодирование не выполняют для аудиосигналов канала 0, канала 1, и канала М - 2, значение информации приоритета которых ниже, чем пороговое значение, равное 4.
Как описано выше, в соответствии с результатом сравнения между информацией приоритета и пороговым значением, декодирование не выполняют в отношении аудиосигнала, степень приоритета которого, обозначенная информацией приоритета, является низкой, и, таким образом, становится возможным свести к минимуму ухудшение качества звука и уменьшить количество расчетов для декодирования.
Пример конфигурации устройства кодирования
Далее будет описан конкретный вариант осуществления устройства кодирования и устройства декодирования, в которых применяется настоящая технология. Вначале будет описано устройство кодирования.
На фиг. 5 показана схема, иллюстрирующая пример конфигурации устройства кодирования, в котором применяется настоящая технология.
Устройство 11 кодирования на фиг. 5 включает в себя модуль 21 кодирования аудиоканала, модуль 22 кодирования аудиообъекта, модуль 23 ввода метаданных, и модуль 24 формирования пакетов.
Аудиосигнал каждого канала для сигналов множества каналов, количество каналов которых равно М, подают в модуль 21 кодирования аудиоканала. Например, аудиосигнал каждого из каналов подают из микрофонов, соответствующих этим каналам. На фиг. 5 буквами от "№ 0" до "№ М - 1" обозначены номера каналов соответствующих каналов.
Модуль 21 кодирования аудиоканала кодирует переданный аудиосигнал каждого канала, и генерирует информацию приоритета на основе аудиосигнала, и затем подает кодированные данные, полученные путем кодирования, и информацию приоритета в модуль 24 формирования пакетов.
Аудиосигнал каждого из N каналов подают в модуль 22 кодирования аудиообъекта. Например, аудиосигналы объектов, соответственно, подают из микрофонов, соответствующих этим каналам. На фиг. 5 буквами от "№0" до "№N - 1" обозначены номера объектов соответствующих объектов.
Модуль 22 кодирования аудиообъекта кодирует переданный аудиосигнал каждого канала, и генерирует информацию приоритета на основе аудиосигнала, и затем подает кодированные данные, полученные путем кодирования, и информацию приоритета в модуль 24 формирования пакетов.
Модуль 23 ввода метаданных подает метаданные каждого объекта в модуль 24 формирования пакетов. Например, предполагается, что метаданные каждого объекта представляют собой информацию пространственного положения, обозначающую положение объекта в пространстве. Более конкретно, например, информация пространственного положения может представлять собой информацию в виде трехмерных координат, которая обозначает координаты положения объекта в трехмерном пространстве.
Модуль 24 формирования пакетов выполняет формирование пакетов кодированных данных и информации приоритета, подаваемых из модуля 21 кодирования аудиоканала, кодированных данных и информации приоритета, подаваемых из модуля 22 кодирования аудиообъекта, и метаданные, передаваемые из модуля 23 ввода метаданных, и генерирует поток битов для вывода сгенерированного потока битов.
В поток битов, полученный таким образом, включены кодированные данные каждого канала для каждого фрейма, информация приоритета каждого канала, кодированные данные каждого объекта, информация приоритета каждого объекта и метаданные каждого объекта.
Здесь аудиосигнал каждого из М каналов и аудиосигнал каждого из N объектов, сохраненные в потоке битов одного фрейма, представляют собой аудиосигналы одного фрейма, которые должны воспроизводиться одновременно.
Здесь, в качестве информации приоритета аудиосигнала каждого канала или каждого объекта, описан пример, в котором информацию приоритета генерируют в отношении каждого аудиосигнала одного фрейма. Однако, один элемент информации приоритета может быть сгенерирован в отношении аудиосигналов нескольких фреймов, например, в пределах модуля заданного времени.
Пример конфигурации модуля кодирования аудиоканала
Кроме того, более конкретная конфигурация модуля 21 кодирования аудиоканала на фиг. 5 выполнена, например, как представлено на фиг. 6.
Модуль 21 кодирования аудиоканала, представленный на фиг. 6, включает в себя модуль 51 кодирования и модуль 52 генерирования информации приоритета.
Модуль 51 кодирования включает в себя модуль 61 MDCT, и модуль 51 кодирования кодирует аудиосигнал каждого канала, передаваемого извне.
Таким образом, модуль 61 MDCT выполняет MDCT в отношении аудиосигнала каждого канала, передаваемого извне. Модуль 51 кодирования кодирует коэффициент MDCT каждого канала, полученного в результате MDCT, и передает кодированные данные каждого канала, полученные путем кодирования, как результат, то есть, кодированные аудиосигналы в модуль 24 формирования пакетов.
Кроме того, модуль 52 генерирования информации приоритета анализирует аудиосигнал каждого канала, передаваемого извне, и генерирует информацию приоритета аудиосигнала каждого канала, и подает эту информацию приоритета в модуль 24 формирования пакетов.
Пример конфигурации модуля кодирования аудиообъекта
Кроме того, более конкретная конфигурация модуля 22 кодирования аудиообъекта на фиг. 5 составлена, например, как представлено на фиг. 7.
Модуль 22 кодирования аудиообъекта, представленный на фиг. 7, включает в себя модуль 91 кодирования и модуль 92 генерирования информации приоритета.
Модуль 91 кодирования включает в себя модуль 101 MDCT, и модуль 91 кодирования кодирует аудиосигнал каждого объекта, передаваемого извне.
Таким образом, модуль 101 MDCT выполняет MDCT в отношении аудиосигнала каждого объекта, передаваемого извне. Модуль 91 кодирования кодирует коэффициент MDCT каждого канала, полученного в результате MDCT, и передает кодированные данные каждого объекта, полученные в результате кодирования, как результат, то есть, кодированные аудиосигналы в модуль 24 формирования пакетов.
Кроме того, модуль 92 генерирования информации приоритета анализирует аудиосигнал каждого объекта, передаваемого извне, и генерирует информацию приоритета аудиосигнала каждого объекта, и передает информацию приоритета в модуль 24 формирования пакетов.
Описание обработки кодирования
Далее будет описана обработка, выполняемая устройством 11 кодирования.
Когда аудиосигналы множества каналов и аудиосигналы множества объектов, которые одновременно воспроизводят, подают только для одного фрейма, устройство 11 кодирования выполняет обработку кодирования и выводит поток битов, включающий в себя кодированные аудиосигналы.
Ниже, со ссылкой на блок-схему последовательности операций, показанную на фиг. 8, будет описана обработка кодирования, выполняемая устройством 11 кодирования. Обработка кодирования выполняется для каждого фрейма аудиосигнала.
На ЭТАПЕ S11, модуль 52 генерирования информации приоритета модуля 21 кодирования аудиоканала генерируют информацию приоритета переданного аудиосигнала каждого канала и подает информацию приоритета в модуль 24 формирования пакетов. Например, модуль 52 генерирования информации приоритета анализирует аудиосигнал для каждого канала и генерирует информацию приоритета на основе давления звука или спектральной формы аудиосигнала и корреляции спектральных форм между каналами.
На ЭТАПЕ S12, модуль 24 формирования пакетов сохраняет информацию приоритета аудиосигнала каждого канала, передаваемого из модуля 52 генерирования информации приоритета в DSE потока битов. Таким образом, информацию приоритета сохраняют в элементе заголовка потока битов.
На ЭТАПЕ S13, модуль 92 генерирования информации приоритета модуля 22 кодирования аудиообъекта генерирует информацию приоритета переданного аудиосигнала каждого объекта и подает эту информацию приоритета в модуль 24 формирования пакетов. Например, модуль 92 генерирования информации приоритета анализирует аудиосигнал каждого объекта, и генерирует информацию приоритета на основе давления звука или спектральной формы аудиосигнала и корреляции спектральных форм между каналами.
Когда генерируют информацию приоритета аудиосигнала каждого канала или каждого объекта, для каждой степени приоритета, которая представляет собой значение информации приоритета, количество аудиосигналов, которым назначены степени приоритета, может быть определено заранее в отношении количества каналов или количества объектов.
Например, в примере на фиг. 3, количество аудиосигналов, которым назначена информация приоритета, равная "7", то есть, количество каналов, может быть заранее определено, как равное пяти, и количество аудиосигналов, которым назначена информация приоритета, равная "6", может быть заранее определено, как равное трем.
На ЭТАПЕ S14, модуль 24 формирования пакетов сохраняет информацию приоритета аудиосигнала каждого объекта, передаваемого из модуля 92 генерирования информации приоритета в DSE потока битов.
На ЭТАПЕ S15, модуль 24 формирования пакетов сохраняет метаданные каждого объекта в DSE потока битов.
Например, модуль 23 ввода метаданных получает метаданные каждого объекта путем приема ввода от пользователя, который связывается с внешней стороной, или выполняет считывание из внешней области сохранения, и подает метаданные в модуль 24 формирования пакетов. Модуль 24 формирования пакетов сохраняет метаданные, переданные таким образом из модуля 23 ввода метаданных в DSE.
В результате описанной выше обработки информацию приоритета аудиосигналов всех каналов, информацию приоритета аудиосигналов всех объектов и метаданные всех объектов сохраняют в DSE потока битов.
На ЭТАПЕ S16, модуль 51 кодирования модуля 21 кодирования аудиоданных канала кодирует переданный аудиосигнал каждого канала.
В частности, модуль 61 MDCT выполняет MDCT в отношении аудиосигнала каждого канала, и модуль 51 кодирования кодирует коэффициент MDCT каждого канала, полученного в результате MDCT, и подает кодированные данные каждого канала, полученные, как результат кодирования, в модуль 24 формирования пакетов.
На ЭТАПЕ S17, модуль 24 формирования пакетов сохраняет кодированные данные аудиосигнала каждого канала, переданные из модуля 51 кодирования в SCE или СРЕ потока битов. То есть, кодированные данные сохраняют в каждом элементе, расположенном после DSE в потоке битов.
На ЭТАПЕ S18, модуль 91 кодирования модуля 22 кодирования аудиообъекта кодирует переданный аудиосигнал каждого объекта.
В частности, модуль 101 MDCT выполняет MDCT в отношении аудиосигнала каждого объекта, и модуль 91 кодирования кодирует коэффициент MDCT каждого канала, полученного в результате MDCT, и подает кодированные данные каждого объекта, полученные, как результат кодирования, в модуль 24 формирования пакетов.
На ЭТАПЕ S19, модуль 24 формирования пакетов сохраняет кодированные данные аудиосигнала каждого объекта, передаваемые из модуля 91 кодирования в SCE потока битов. Таким образом, кодированные данные, сохраненные в некоторых элементах, располагают после DSE в потоке битов.
В результате описанной выше обработки в отношении фреймов, предназначенных для обработки, может быть получен поток битов, в котором сохраняются информация приоритетов и кодированные данные аудиосигналов всех каналов, информация приоритета и кодированные данные аудиосигналов всех объектов, и метаданные всех объектов.
На ЭТАПЕ S20, модуль 24 формирования пакетов выводит полученный поток битов и заканчивает обработку кодирования.
Как описано выше, устройство 11 кодирования генерирует информацию приоритета аудиосигнала каждого канала и информацию приоритета аудиосигнала каждого объекта, сохраняет информацию приоритета в потоке битов и выводит информацию приоритета. Поэтому, на стороне декодирования, возможно просто проверять, какой аудиосигнал имеет более высокую степень приоритета.
Таким образом, на стороне декодирования, становится возможным избирательно выполнять декодирование кодированного аудиосигнала в соответствии с информацией приоритета. В результате, возможно свести к минимуму ухудшение качества звука для звука, воспроизводимого из аудиосигнала, и уменьшить количество расчетов для декодирования.
В частности, путем сохранения информации приоритета аудиосигнала каждого объекта в потоке битов, на стороне декодирования возможно не только уменьшить количество расчетов для декодирования, но также уменьшить количество расчетов, выполняемых после него для обработки визуализации и т.п.
Пример конфигурации устройства декодирования
Далее будет описано устройство декодирования, в которое вводят поток битов, выводимый из устройства 11 кодирования, описанного выше, и которое декодирует кодированные данные, включенные в поток битов.
Такое устройство декодирования выполнено, например, так, как представлено на фиг. 9.
Устройство 151 декодирования, представленное на фиг. 9, включает в себя модуль 161 распаковки/декодирования, модуль 162 визуализации, и модуль 163 смешивания.
Модуль 161 распаковки/декодирования получает поток битов, выводимый из устройства 11 кодирования, и выполняет распаковку и декодирование потока битов.
Модуль 161 распаковки/декодирования подает аудиосигнал каждого объекта, получаемый путем распаковки и декодирования, и метаданные каждого объекта в модуль 162 визуализации. В это время модуль 161 распаковки/декодирования выполняет декодирование кодированных данных каждого объекта, в соответствии с информацией приоритета, включенной в поток битов.
Кроме того, модуль 161 распаковки/декодирования подает аудиосигнал каждого канала, полученный в результате распаковки и декодирования, в модуль 163 смешивания. В это время модуль 161 распаковки/декодирования выполняет декодирование кодированных данных каждого канала в соответствии с информацией приоритета, включенной в поток битов.
Модуль 162 визуализации генерирует аудиосигналы М каналов на основе аудиосигнала каждого объекта, передаваемого из модуля 161 распаковки/декодирования, и информацию пространственного положения, как метаданные каждого объекта, и передает аудиосигналы в модуль 163 смешивания. В это время модуль 162 визуализации генерирует аудиосигналы каждого из М каналов таким образом, что звуковое изображение каждого объекта будет правильно расположено в положении, обозначенном информацией пространственного положения каждого объекта.
Модуль 163 смешивания выполняет взвешенное суммирование аудиосигнала каждого канала, передаваемого из модуля 161 распаковки/декодирования и аудиосигнала каждого канала, подаваемого из модуля 162 визуализации для каждого канала, и затем генерирует конечный аудиосигнал каждого канала. Модуль 163 смешивания подает конечный аудиосигнал каждого канала, полученный, как описано выше, во внешний громкоговоритель, соответствующий каждому каналу, для воспроизведения звука.
Пример конфигурации модуля распаковки/декодирования
Кроме того, более конкретно, модуль 161 распаковки/декодирования устройства 151 декодирования, представленного на фиг. 9, выполнен, например, как представлено на фиг. 10.
Модуль 161 распаковки/декодирования на фиг. 10 включает в себя модуль 191 получения информации приоритета, модуль 192 получения аудиосигнала канала, модуль 193 декодирования аудиосигнала канала, модуль 194 выбора выхода, модуль 195 вывода нулевого значения, модуль 196 IMDCT, модуль 197 получения аудиосигнала объекта, модуль 198 декодирования аудиосигнала объекта, модуль 199 выбора выхода, модуль 200 вывода нулевого значения и модуль 201 IMDCT.
Модуль 191 получения информации приоритета получает информацию приоритета аудиосигнала каждого канала из переданного потока битов и подает информацию приоритета в модуль 194 выбора выхода, и получает информацию приоритета аудиосигнала каждого объекта из потока битов, и подает информацию приоритета в модуль 199 выбора выхода.
Кроме того, модуль 191 получения информации приоритета получает метаданные каждого объекта из переданного потока битов и передает метаданные в модуль 162 визуализации, и передает поток битов в модуль 192 получения аудиосигнала канала и в модуль 197 получения аудиосигнала объекта.
Модуль 192 получения аудиосигнала канала получает кодированные данные каждого канала из потока битов, получаемого из модуля 191 получения информации приоритета, и подает кодированные данные в модуль 193 декодирования аудиосигнала канала. Модуль 193 декодирования аудиосигнала канала декодирует кодированные данные каждого канала, передаваемые из модуля 192 получения аудиосигнала канала, и передает коэффициент MDCT, полученный в результате декодирования, в модуль 194 выбора выхода.
Модуль 194 выбора выхода последовательно переключает назначение вывода коэффициента MDCT каждого канала, передаваемого из модуля 193 декодирования аудиосигнала канала на основе информации приоритета каждого канала, передаваемой из модуля 191 получения информации приоритета.
Таким образом, в случае, когда информация приоритета заданного канала меньше, чем заданное пороговое значение Р, модуль 194 выбора выхода передает коэффициент MDCT этого канала в модуль 195 вывода нулевого значения, как нулевое значение. Кроме того, в случае, когда информация приоритета заданного канала равна или больше, чем заданное пороговое значение Р, модуль 194 выбора выхода передает коэффициент MDCT этого канала, передаваемый из модуля 193 декодирования аудиосигнала канала, в модуль 196 IMDCT.
Модуль 195 вывода нулевого значения генерирует аудиосигнал на основе коэффициента MDCT, передаваемого из модуля 194 выбора выхода, и передает аудиосигнал в модуль 163 смешивания. В этом случае, поскольку коэффициент MDCT равен нулю, генерируется беззвучный аудиосигнал.
Модуль 196 IMDCT выполняет IMDCT и генерирует аудиосигнал на основе коэффициента MDCT, передаваемого из модуля 194 выбора выхода, и передает этот аудиосигнал в модуль 163 смешивания.
Модуль 197 получения сигнала аудиообъекта получает кодированные данные каждого объекта из потока битов, передаваемого из модуля 191 получения информации о приоритете, и передает кодированные данные в модуль 198 декодирования аудиосигнала объекта. Модуль 198 декодирования аудиосигнала объекта декодирует кодированные данные каждого объекта, передаваемые из модуля 197 получения аудиосигнала объекта, и передает коэффициент MDCT, полученный в результате декодирования, в модуль 199 выбора выхода.
Модуль 199 выбора выхода избирательно переключает выходное назначение коэффициента MDCT каждого канала, передаваемого из модуля 198 декодирования аудиосигнала объекта на основе информации приоритета каждого объекта, передаваемой из модуля 191 получения информации приоритета.
Таким образом, в случае, когда информация приоритета заданного объекта меньше, чем заданное пороговое значение Q, модуль 199 выбора выхода передает коэффициент MDCT этого объекта в модуль 200 вывода нулевого значения, как нулевое значение. Кроме того, в случае, когда информация приоритета заданного объекта равна или выше, чем заданное пороговое значение Q, модуль 199 выбора выхода передает коэффициент MDCT этого объекта, переданный из модуля 198 декодирования аудиосигнала объекта, в модуль 201 IMDCT.
Значение порогового значения Q может быть таким же, как и значение порогового значения Р, или может представлять собой значение, отличное от порогового значения Р. Соответственно, путем определения порогового значения Р и порогового значения Q, в зависимости от возможности расчета и т.п.устройства 151 декодирования, становится возможным уменьшить количество расчетов для декодирования аудиосигнала вплоть до количества расчетов в пределах диапазона, в котором устройство 151 декодирования может выполнять декодирование в режиме реального времени.
Модуль 200 вывода нулевого значения генерирует аудиосигнал на основе коэффициента MDCT, передаваемого из модуля 199 выбора выхода, и передает этот аудиосигнал в модуль 162 визуализации. В этом случае, поскольку коэффициент MDCT равен нулю, генерируется аудиосигнал без звука.
Модуль 201 IMDCT выполняет IMDCT и генерирует аудиосигнал на основе коэффициента MDCT, передаваемого из модуля 199 выбора выхода, и подает аудиосигнал в модуль 162 визуализации.
Описание обработки декодирования
Далее будет описана работа устройства 151 декодирования.
Когда поток битов одного фрейма подают из устройства 11 кодирования, устройство 151 декодирования выполняет обработку декодирования и генерирует аудиосигнал, и выводит аудиосигнал в громкоговоритель. Далее, обработка декодирования, выполняемая устройством 151 декодирования, будет описана со ссыпкой на блок-схему последовательности операций, на фиг. 11.
На ЭТАПЕ S51, модуль 161 распаковки/декодирования получает поток битов, передаваемый из устройства 11 кодирования. Таким образом, принимают поток битов.
На ЭТАПЕ S52, модуль 161 распаковки/декодирования выполняет обработку избирательного декодирования.
Обработка избирательного декодирования будет описана подробно ниже, однако, в обработке избирательного декодирования, кодированные данные каждого канала и кодированные данные каждого объекта избирательно декодируют на основе информации приоритета. Затем аудиосигнал каждого канала, полученный в результате избирательного декодирования, подают в модуль 163 смешивания, и аудиосигнал каждого объекта, полученный в результате избирательного декодирования, подают в модуль 162 визуализации. Кроме того, метаданные каждого объекта, полученные из потока битов, передают в модуль 162 визуализации.
На ЭТАПЕ S53, модуль 162 визуализации выполняет визуализацию аудиосигнала каждого объекта на основе аудиосигнала каждого объекта, передаваемого из модуля 161 распаковки/декодирования и информации пространственного положения, как метаданные каждого объекта.
Например, модуль 162 визуализации генерирует аудиосигнал каждого канала, используя векторное амплитудное панорамирование (VBAP) на основе информации пространственного положения таким образом, что звуковое изображение каждого объекта правильно располагается в положении, обозначенном информацией пространственного положения, и передает аудиосигнал в модуль 163 смешивания.
На ЭТАПЕ S54, модуль 163 смешивания выполняет взвешенное суммирование аудиосигнала каждого канала, передаваемого из модуля 161 распаковки/декодирования, и аудиосигнала каждого канала, передаваемого из модуля 162 визуализации для каждого канала, и передает суммированный аудиосигнал во внешний громкоговоритель. Таким образом, аудиосигнал каждого канала передают в каждый громкоговоритель, соответствующий каждому каналу, поэтому, воспроизводится звук на основе аудиосигнала, передаваемого в каждый громкоговоритель.
Когда аудиосигнал каждого канала передают в громкоговоритель, обработка декодирования заканчивается.
Как описано выше, устройство 151 декодирования получает информацию приоритета из потока битов, и декодирует кодированные данные каждого канала и каждого объекта в соответствии с информацией приоритета.
Описание избирательной обработки декодирования
Далее, со ссылкой на блок-схему последовательности операций, показанную на фиг. 12, будет описана обработка избирательного декодирования, соответствующая обработке на ЭТАПЕ S52, на фиг. 11.
На ЭТАПЕ S81, модуль 191 получения информации приоритета получает информацию приоритета аудиосигнала каждого канала и информацию приоритета аудиосигнала каждого объекта из переданного потока битов, и подает каждый элемент информации приоритета в модуль 194 выбора выхода и в модуль 199 выбора выхода, соответственно.
Кроме того, модуль 191 получения информации приоритета получает метаданные каждого объекта из потока битов и передает эти метаданные в модуль 162 визуализации, и передает поток битов в модуль 192 получения аудиосигнала канала и в модуль 197 получения аудиосигнала объекта.
На ЭТАПЕ S82 модуль 192 получения аудиосигнала канала устанавливает номер канала, равный 0, в канале, предназначенном для обработки, и содержит номер канала.
На ЭТАПЕ S83, модуль 192 получения аудиосигнала канала определяет, меньше или нет содержащийся номер канала, чем количество каналов М.
В случае, когда, на ЭТАПЕ S83, количество каналов меньше, чем М, на ЭТАПЕ S84, модуль 193 декодирования аудиосигнала канала декодирует кодированные данные аудиосигнала канала, предназначенные для обработки.
Таким образом, модуль 192 получения аудиосигнала канала получает кодированные данные канала, подвергаемые обработке, из потока битов, передаваемого из модуля 191 получения информации приоритета, и подает кодированные данные в модуль 193 декодирования аудиосигнала канала.
Затем модуль 193 декодирования аудиосигнала канала декодирует кодированные данные, передаваемые из модуля 192 получения аудиосигнала канала, и передает коэффициент MDCT, полученный в результате декодирования, в модуль 194 выбора выхода.
На ЭТАПЕ S85, модуль 194 выбора выхода определяет, равна или выше информация приоритета канала, который должен быть подвергнут обработке, передаваемая из модуля 191 получения информации приоритета, чем пороговое значение Р, установленное устройством управления на более высоком уровне, который не представлен на чертеже. Здесь пороговое значение Р определяют, например, в зависимости от возможностей расчета устройства 151 декодирования.
В случае, когда определяют, на ЭТАПЕ S85, что информация приоритета равна или выше, чем пороговое значение Р, модуль 194 выбора выхода подает коэффициент MDCT канала, подвергаемого обработке, передаваемого из модуля 193 декодирования аудиосигнала канала, в модуль 196 IMDCT, и обработка переходит на ЭТАП S86. В этом случае, степень приоритета аудиосигнала канала, подвергаемого обработке, равна или выше, чем заданная степень приоритета. Поэтому, выполняется декодирование этого канала, более конкретно, IMDCT.
На ЭТАПЕ S86, модуль 196 IMDCT выполняет IMDCT на основе коэффициента MDCT, подаваемого из модуля 194 выбора выхода, и генерирует аудиосигнал канала, подвергаемого обработке, и передает аудиосигнал в модуль 163 смешения. После генерирования аудиосигнала, обработка переходит на ЭТАП S87.
С другой стороны, в случае, когда определяют, на ЭТАПЕ S85, что информация приоритета ниже, чем пороговое значение Р, модуль 194 выбора выхода передает коэффициент MDCT в модуль 195 вывода нулевого значения, как нулевое значение.
Модуль 195 вывода нулевого значения генерирует аудиосигнал канала, подвергаемого обработке, из коэффициента MDCT, значение которого равно нулю, передаваемого из модуля 194 выбора выхода, и подает аудиосигнал в модуль 163 смешивания. Поэтому, в модуле 195 вывода нулевого значения, по существу, не выполняется обработка для генерирования аудиосигнала, такого как IMDCT.
Аудиосигнал, сгенерированный модулем 195 вывода нулевого значения, представляет собой беззвучный сигнал. После генерирования аудиосигнала обработка переходит на ЭТАП S87.
Если на ЭТАПЕ S85 определяют, что информация приоритета ниже, чем пороговое значение Р, или аудиосигнал генерируют на ЭТАПЕ S86, на ЭТАПЕ S87 модуль 192 получения аудиосигнала канала добавляет единицу к номеру удерживаемого канала для обновления номера канала для канала, подвергаемого обработке.
После обновления номера канала обработка возвращается на ЭТАП S83, и снова выполняется обработка, описанная выше. Таким образом, генерируется аудиосигнал нового канала, подвергаемого обработке.
Кроме того, в случае, когда на ЭТАПЕ S83 определяют, что номер канала для канала, подвергаемого обработке, не меньше, чем М, поскольку аудиосигналы всех каналов были получены, обработка переходит на ЭТАП S88.
На ЭТАПЕ S88 модуль 197 получения аудиосигнала объекта устанавливает номер объекта, как 0, для объекта, подвергаемого обработке, и удерживает этот номер объекта.
На ЭТАПЕ S89 модуль 197 получения аудиосигнала объекта определяет, меньше или нет удерживаемый номер объекта, чем количество объектов N.
В случае, когда на ЭТАПЕ S89 определяют, что номер объекта меньше, чем N, на ЭТАПЕ S90, модуль 198 декодирования аудиосигнала объекта декодирует кодированные данные аудиосигнала объекта, предназначенного для обработки.
Таким образом, модуль 197 получения аудиосигнала объекта получает кодированные данные объекта, передаваемые для обработки, из потока битов, передаваемого из модуля 191 получения информации приоритета, и подает кодированные данные в модуль 198 декодирования аудиосигнала объекта.
Затем модуль 198 декодирования аудиосигнала объекта декодирует кодированные данные, переданные из модуля 197 получения аудиосигнала объекта, и передает коэффициент MDCT, полученный в результате декодирования, в модуль 199 выбора выхода.
На ЭТАПЕ S91 модуль 199 выбора выхода определяет, равна или выше информация приоритета объекта, подвергаемого обработке, подаваемая из модуля 191 получения информации приоритета, чем пороговое значение Q, определенное устройством управления на более высоком уровне, который не представлен на чертеже. Здесь пороговое значение Q, например, определяют в зависимости от возможности расчетов устройства 151 декодирования.
В случае, когда на ЭТАПЕ S91 определяют, что информация приоритета равна или выше, чем пороговое значение Q, модуль 199 выбора выхода подает коэффициент MDCT объекта, подвергаемого обработке, передаваемый из модуля 198 декодирования аудиосигнала объекта, в модуль 201 IMDCT, и обработка переходит на ЭТАП S92.
На ЭТАПЕ S92, модуль 201 IMDCT выполняет IMDCT на основе коэффициента MDCT, передаваемого из модуля 199 выбора выхода, и генерирует аудиосигнал объекта, подвергаемого обработке, и передает этот аудиосигнал в модуль 162 визуализации. После генерирования аудиосигнала обработка переходит на ЭТАП S93.
С другой стороны, в случае, когда определяют, на ЭТАПЕ S91, что информация приоритета ниже, чем пороговое значение Q, модуль 199 выбора выхода подает коэффициент MDCT в модуль 200 вывода нулевого значения, как нулевое значение.
Модуль 200 вывода нулевого значения генерирует аудиосигнал объекта, подвергаемого обработке, из коэффициента MDCT, значение которого равно нулю, подаваемого из модуля 199 выбора выхода, и подает аудиосигнал в модуль 162 визуализации. Поэтому, в модуле 200 вывода нулевого значения, по существу, не выполняется обработка для генерирования аудиосигнала, такого как IMDCT.
Аудиосигнал, генерируемый модулем 200 вывода нулевого значения, представляет собой беззвучный сигнал. После генерирования аудиосигнала, обработка переходит на ЭТАП S93.
Если определяют, что информация приоритета ниже, чем пороговое значение Q на ЭТАПЕ S91, или аудиосигнал генерируют на ЭТАПЕ S92, НА ЭТАПЕ S93, модуль 197 получения аудиосигнала объекта добавляет единицу к удерживаемому номеру объекта, и обновляет номер объекта для объекта, подвергаемого обработке.
После обновления номера канала, обработка возвращается на ЭТАП S89, и обработка, описанная выше, снова выполняется. Таким образом, генерируют аудиосигнал нового объекта, подвергаемого обработке.
Кроме того, в случае, когда на ЭТАПЕ S89 определяют, что номер канала для канала, подвергаемого обработке, не меньше, чем М, поскольку аудиосигналы всех каналов и всех объектов были получены, обработка избирательного декодирования заканчивается, и затем обработка переходит на ЭТАП S53, на фиг. 11.
Как описано выше, устройство 151 декодирования сравнивает информацию приоритета и пороговое значение каждого канала и каждого объекта, и декодирует кодированный аудиосигнал с определением, следует или нет выполнить декодирование кодированного аудиосигнала для каждого канала и каждого объекта фрейма, предназначенного для обработки.
Таким образом, в устройстве 151 декодирования, декодируют только заданное количество кодированных аудиосигналов, зависящих от информации приоритета каждого аудиосигнала, и оставшиеся аудиосигналы не декодируют.
Таким образом, для соответствия окружающей среде воспроизведения, только аудиосигнал, имеющий более высокую степень приоритета, может быть избирательно декодирован. Поэтому возможно минимизировать ухудшение качества звука для звука, воспроизводимого из аудиосигнала, и уменьшить количество расчетов для декодирования.
Кроме того, декодирование кодированного аудиосигнала выполняют на основе информации приоритета аудиосигнала каждого объекта. Поэтому, возможно уменьшить не только количество расчетов для декодирования аудиосигнала, но также и количество расчетов для обработки, выполняемой после этого, такой как обработка в модуле 162 визуализации.
Пример 1 модификации первого варианта осуществления Информация приоритета
В представленном выше описании один элемент информации приоритета генерируют в отношении одного аудиосигнала каждого канала и каждого объекта. Однако может быть сгенерировано множество элементов информации приоритета.
В этом случае, например, множество элементов информации приоритета может быть сгенерировано для каждой возможности расчетов, в соответствии с количеством расчетов для декодирования, то есть, с возможностями расчетов на стороне декодирования.
В частности, например, элементы информации приоритета для устройства, имеющего возможность расчетов, эквивалентные двум каналам, генерируют на основе количества расчетов для декодирования аудиосигналов, эквивалентных двум каналам, в режиме реального времени.
В элементах информации приоритета для устройства, эквивалентных двум каналам, например, среди всех аудиосигналов, элементы информации приоритета генерируют таким образом, что количество аудиосигналов становится большим, которым низкую степень приоритета, то есть, значение, близкое к 0, назначают, как информацию приоритета.
Кроме того, например, элементы информации приоритета для устройства, имеющего возможности расчетов, эквивалентные 24 каналам, также генерируют на основе количества расчетов для декодирования аудиосигналов, эквивалентных 24 каналам в режиме реального времени. В элементах информации приоритета для устройства, эквивалентной 24 каналам, например, среди всех аудиосигналов, элементы информации приоритета генерируют таким образом, что количество аудиосигналов становится большим, которым назначают высокий приоритет, то есть, значение, близкое к 7, в качестве информации приоритета.
В этом случае, например, модуль 52 генерирования информации приоритета, на ЭТАПЕ S11 на фиг. 8, генерирует элементы информации приоритета для устройства, эквивалентные двум каналам, в отношении аудиосигнала каждого канала, и добавляет идентификатор, обозначающий, что элементы информации приоритета для устройства являются эквивалентными двум каналам для элементов информации приоритета, и затем подает элементы информации приоритета в модуль 24 формирования пакетов.
Кроме того, модуль 52 генерирования информации приоритета, на ЭТАПЕ S11, генерирует элементы информации приоритета для устройства, эквивалентные 24 каналам, в отношении аудиосигнала каждого канала, и добавляет идентификатор, обозначающий, что элементы информации приоритета предназначены для устройства, эквивалентного 24 каналам, для элементов информации приоритета, и затем подает элементы информации приоритета в модуль 24 формирования пакетов.
Аналогично, модуль 92 генерирования информации приоритета, на ЭТАПЕ S13, на фиг. 8, также генерирует элементы информации приоритета для устройства, эквивалентного двум каналам, и элементы информации приоритета для устройства, эквивалентные 24 каналам, и добавляет идентификатор, и затем подает элементы информации приоритета в модуль 24 формирования пакетов.
Таким образом, например, множество элементов информации приоритета получают в соответствии с возможностями расчета устройств воспроизведения, таких как портативный аудиопроигрыватель, многофункциональный мобильный телефон, компьютер планшетного типа, телевизионный приемник, персональный компьютер и аудиооборудование высокого качества.
Например, возможность расчетов устройств воспроизведения, таких как портативный аудиопроигрыватель, относительно низкая. Поэтому, в таком устройстве воспроизведения, если кодированный аудиосигнал декодируют на основе элементов информации приоритета для устройства, эквивалентного двум каналам, возможно выполнить воспроизведение аудиосигналов в режиме реального времени.
Как описано выше, в случае, когда множество элементов информации приоритета генерируют в отношении одного аудиосигнала в устройстве 151 декодирования, например, устройство управления инструктирует модуль 191 получения информации приоритета на более высоком уровне для определения, какая информация приоритета среди множества элементов информации приоритета будет использоваться для выполнения декодирования. Инструкция для определения, какая информация приоритета будет использоваться, выполняется при подаче, например, идентификатора.
Определение, какая информация приоритета идентификатора будет использоваться, может быть выполнено заранее для каждого устройства 151 декодирования.
Например, в модуле 191 получения информации приоритета, в случае, когда заранее определяют, какая информация приоритета по идентификатору будет использоваться, или в случае, когда устройство управления обозначает идентификатор на более высоком уровне, на ЭТАПЕ S81 на фиг. 12, модуль 191 получения информации приоритета получает информацию приоритета, к которой добавлен конкретный идентификатор. Затем полученную информацию приоритета подают в модуль 194 выбора выхода или в модуль 199 выбора выхода из модуля 191 получения информации приоритета.
Другими словами, среди множества элементов информации приоритета, сохраненных в потоке битов, один соответствующий элемент информации приоритета выбирают в соответствии с возможностями расчетов устройства 151 декодирования, в частности, модуля 161 распаковки/декодирования.
В этом случае, разные идентификаторы могут использоваться в информации приоритета каждого канала и информации приоритета каждого объекта, и информация приоритета может быть считана из потока битов.
Как описано выше, путем избирательного получения конкретного элемента информации приоритета среди множества элементов информации приоритета, включенных в поток битов, возможно выбрать соответствующую информацию приоритета в соответствии с возможностями расчетов устройства 151 декодирования, и выполнить декодирование. Таким образом, возможно воспроизводить аудиосигнал в режиме реального времени в любом из устройств 151 декодирования.
Второй вариант осуществления
Пример конфигурации модуля распаковки/декодирования
В представленном выше описании описан пример, в котором информация приоритета включена в поток битов, выводимый из устройства 11 кодирования. Однако, в зависимости от устройств кодирования, информация приоритета может быть или может не быть включена в поток битов.
Поэтому, информация приоритета может быть сгенерирована в устройстве 151 декодирования. Например, информация приоритета может быть сгенерирована, используя информацию, обозначающую давление звука аудиосигнала или информацию, обозначающую спектральную форму, которая может быть выделена из кодированных данных аудиосигнала, включенных в поток битов.
В случае, когда информацию приоритета генерируют в устройстве 151 декодирования, как описано выше, модуль 161 распаковки/декодирования устройства 151 декодирования, например, сконфигурирован, как представлено на фиг. 13. На фиг. 13, одинаковые номера ссылочных позиций заданы для элементов, соответствующих случаю на фиг. 10, и их описание не будет повторяться.
Модуль 161 распаковки/декодирования на фиг. 13 включает в себя модуль 192 получения аудиосигнала канала, модуль 193 декодирования аудиосигнала канала, модуль 194 выбора выхода, модуль 195 вывода нулевого значения, модуль 196 IMDCT, модуль 197 получения аудиосигнала объекта, модуль 198 декодирования аудиосигнала объекта, модуль 199 выбора выхода, модуль 200 вывода нулевого значения, модуль 201 IMDCT, модуль 231 генерирования информации приоритета и модуль 232 генерирования информации приоритета.
Конфигурация модуля 161 распаковки/декодирования, представленного на фиг. 13, отличается от модуля 161 распаковки/декодирования, представленного на фиг. 10 тем, что модуль 231 генерирования информации приоритета и модуль 232 генерирования информации приоритета вновь предусмотрены, без предоставления модуля 191 получения информации приоритета, и другие конфигурации являются такими же, как в модуле 161 распаковки/декодирования на фиг. 10.
Модуль 192 получения аудиосигнала канала получает кодированные данные каждого канала из переданного потока битов и подает кодированные данные в модуль 193 декодирования аудиосигнала канала и в модуль 231 генерирования информации приоритета.
Модуль 231 генерирования информации приоритета генерирует информацию приоритета каждого канала на основе кодированных данных каждого канала, передаваемых из модуля 192 получения аудиосигнала канала, и подает информацию приоритета в модуль 194 выбора выхода.
Модуль 197 получения аудиосигнала объекта получает кодированные данные каждого объекта из передаваемого потока битов и подает кодированные данные в модуль 198 декодирования аудиосигнала объекта и в модуль 232 генерирования информации приоритета. Кроме того, модуль 197 получения аудиосигнала объекта получает метаданные каждого объекта из передаваемого потока битов и подает метаданные в модуль 162 визуализации.
Модуль 232 генерирования информации приоритета генерирует информацию приоритета каждого объекта на основе кодированных данных каждого объекта, передаваемых из модуля 197 получения аудиосигнала объекта, и подает информацию приоритета в модуль 199 выбора выхода.
Описание обработки избирательного декодирования
В случае, когда модуль 161 распаковки/декодирования выполнен, как представлено на фиг. 13, устройство 151 декодирования выполняет обработку избирательного декодирования, представленную на фиг. 14, как обработку, соответствующую ЭТАПУ S52 обработки декодирования, представленной на фиг. 11. Ниже обработка избирательного декодирования, выполняемая устройством 151 декодирования, будет описана со ссылкой на блок-схему последовательности операций на фиг. 14.
На ЭТАПЕ S131, модуль 231 генерирования информации приоритета генерирует информацию приоритета каждого канала.
Например, модуль 192 получения аудиосигнала канала получает кодированные данные каждого канала из переданного потока битов, и подает кодированные данные в модуль 193 декодирования аудиосигнала канала и в модуль 231 генерирования информации приоритета.
Модуль 231 генерирования информации приоритета генерирует информацию приоритета каждого канала на основе кодированных данных каждого канала, передаваемых из модуля 192 получения аудиосигнала канала, и подает информацию приоритета в модуль 194 выбора выхода.
Например, в поток битов включены коэффициент шкалы для получения коэффициента MDCT, информация стороны и квантованный спектр, как кодированные данные аудиосигнала. Здесь, коэффициент шкалы представляет собой информацию для обозначения давления звука аудиосигнала, и квантованный спектр представляет собой информацию, обозначающую спектральную форму аудиосигнала.
Модуль 231 генерирования информации приоритета генерирует информацию приоритета аудиосигнала каждого канала на основе коэффициента шкалы и квантованного спектра, включенных в кодированные данные каждого канала. Если информацию приоритета генерируют, используя коэффициент шкалы и квантованный спектр такие, как эти, информация приоритета может быть немедленно получена перед выполнением декодирования кодированных данных, и, таким образом, возможно уменьшить количество расчетов для генерирования информации приоритета.
Кроме того, информация приоритета может быть сгенерирована на основе давления звука аудиосигнала, которое может быть получено путем расчета среднеквадратичного значения коэффициента MDCT или на основе спектральной формы аудиосигнала, который может быть получен по огибающей пика коэффициента MDCT. В этом случае, модуль 231 генерирования информации приоритета соответствующим образом выполняет декодирование кодированных данных или получает коэффициент MDCT из модуля 193 декодирования аудиосигнала канала.
После получения информации приоритета каждого канала задачи обработки с ЭТАПА S132 по ЭТАП S137 выполнены, но такие задачи обработки являются такими же, как и задачи обработки с ЭТАПА S82 по ЭТАП S87 на фиг. 12. Соответственно, их описание не будет здесь повторяться. Однако, в этом случае, поскольку кодированные данные каждого канала уже были получены, выполняется только декодирование кодированных данных на ЭТАПЕ S134.
Кроме того, в случае, когда определяют, что номер канала не меньше, чем М на ЭТАПЕ S133, модуль 232 генерирования информации приоритета генерирует информацию приоритета аудиосигнала каждого объекта, на ЭТАПЕ S138.
Например, модуль 197 получения аудиосигнала объекта получает кодированные данные каждого объекта из переданного потока битов, и подает кодированные данные в модуль 198 декодирования аудиосигнала объекта и в модуль 232 генерирования информации приоритета. Кроме того, модуль 197 получения аудиосигнала объекта получает метаданные каждого объекта из переданного потока битов и подает эти метаданные в модуль 162 визуализации.
Модуль 232 генерирования информации приоритета генерирует информацию приоритета каждого объекта на основе кодированных данных каждого объекта, подаваемых из модуля 197 получения аудиосигнала объекта, и подает информацию приоритета в модуль 199 выбора выхода. Например, аналогично случаю каждого канала, информацию приоритета генерируют на основе коэффициента шкалы и квантованного спектра.
Кроме того, информация приоритета может быть сгенерирована на основе давления звука или формы спектра, полученной из коэффициента MDCT. В этом случае, модуль 232 генерирования информации приоритета соответствующим образом выполняет декодирование кодированных данных или получает коэффициент MDCT из модуля 198 декодирования аудиосигнала объекта.
После получения информации приоритета каждого объекта выполняются задачи обработки с ЭТАПА S139 по ЭТАП S144, и обработка избирательного декодирования заканчивается. Однако, такие задачи обработки являются таким же, как и задачи обработки с ЭТАПА S88 по ЭТАП S93 на фиг. 12. Соответственно, их описание не будет повторяться. Однако, в этом случае, поскольку кодированные данные каждого объекта уже были получены, только декодирование кодированных данных выполняется на ЭТАПЕ S141.
После окончания обработки избирательного декодирования обработка переходит на ЭТАП S53, на фиг. 11.
Как описано выше, устройство 151 декодирования генерирует информацию приоритета аудиосигнала каждого канала и каждого объекта на основе кодированных данных, включенных в поток битов. В результате генерирования информации приоритета в устройстве 151 декодирования таком, как это, становится возможным получить соответствующую информацию приоритета каждого аудиосигнала при малом количестве расчетов, и, таким образом, возможно уменьшить количество расчетов для декодирования или количество расчетов для визуализации. Кроме того, также возможно свести к минимуму ухудшение качества звука для звука, воспроизводимого из аудиосигнала.
В случае, когда модуль 191 получения информации приоритета модуля 161 распаковки/декодирования, представленного на фиг. 10, пытается получить информацию приоритета аудиосигнала каждого канала и каждого объекта из предоставленного потока битов, но в этом случае информация приоритета не может быть получена из потока битов, информация приоритетная может быть сгенерирована. В этом случае, модуль 191 получения информации приоритета выполняет обработку, аналогичную выполняемой модулем 231 генерирования информации приоритета или модулем 232 генерирования информации приоритета, и генерирует информацию приоритета аудиосигнала каждого канала и каждого объекта из кодированных данных.
Третий вариант осуществления
Пороговое значение информации приоритета
Кроме того, в представленном выше описании, что касается каждого канала и каждого объекта, аудиосигнал, предназначенный для декодирования, в частности, коэффициент MDCT, по которому должно быть выполнено IMDCT, выбирают путем сравнения информации приоритета с пороговым значением Р или пороговым значением Q. Однако пороговое значение Р или пороговое значение Q могут динамически изменяться для каждого фрейма аудиосигнала.
Например, в модуле 191 получения информации приоритета модуля 161 распаковки/декодирования, представленного на фиг. 10, информация приоритета каждого канала и каждого объекта может быть получена из потока битов, без выполнения декодирования.
Поэтому, например, модуль 191 получения информации приоритета может получать распределение информации приоритета фрейма, подвергаемого обработке, без считывания информации приоритета аудиосигналов всех каналов. Кроме того, устройство 151 декодирования заранее знает свои собственные возможности по расчету, например, такие как, сколько каналов может быть обработано одновременно, то есть, в режиме реального времени.
Поэтому, модуль 191 получения информации приоритета может определять пороговое значение Р информации приоритета в отношении фрейма, подвергаемого обработке, на основе распределения информации приоритета во фрейме, подвергаемом обработке, и возможностей расчетов устройства 151 декодирования.
Например, пороговое значение Р определяют таким образом, что наибольшее количество аудиосигналов может декодировать в пределах диапазона обработки, выполняемой в режиме реального времени устройством 151 декодирования.
Кроме того, модуль 191 получения информации приоритета может динамически определять пороговое значение Q аналогично случаю порогового значения Р. В этом случае, модуль 191 получения информации приоритета получает распределение информации приоритета на основе информации приоритета аудиосигнала всех объектов, и определяет пороговое значение Q информации приоритета в отношении фрейма, подвергаемого обработке, на основе полученного распределения и возможностей расчетов устройства 151 декодирования.
Возможно выполнять определение порогового значения Р или порогового значения Q при сравнительно малом количестве расчетов.
Таким образом, путем динамического изменения пороговых значений информации приоритета, декодирование может быть выполнено в режиме реального времени, и при этом возможно свести к минимуму ухудшение качества звука для звука, воспроизводимого из аудиосигнала. В частности, в этом случае, нет необходимости подготавливать большое количество элементов информации приоритета, или нет необходимости предоставлять идентификатор для информации приоритета. Поэтому, количество кодов потока битов также может быть уменьшено.
Метаданные объекта
Кроме того, с первого варианта осуществления по третий вариант осуществления, описанных выше, метаданные и информация приоритета объекта для одного фрейма и т.п. содержатся в головном элементе потока битов.
В этом случае, в головном элементе потока битов, синтаксис части, где содержатся метаданные и информация приоритета объекта, является таким же, как и, например, на фиг. 15.
В примере на фиг. 15, в метаданных объекта, содержится информация о пространственном положении и информация приоритета объекта только одного фрейма.
В этом примере "num_objects" обозначает количество объектов. Кроме того, "object_priority [0]" обозначает информацию приоритета 0-ого объекта. Здесь 0-ой объект означает объект, установленный по номеру объекта.
"Position_azimuth [0]" обозначает горизонтальный угол, который представляет трехмерное пространственное положение 0-ого объекта, с точки зрения пользователя, который является слушателем, то есть, с точки зрения заданного исходного положения. Кроме того, "position_elevation [0]" обозначает вертикальный угол, который представляет трехмерное пространственное положение 0-ого объекта, с точки зрения пользователя, который является слушателем. Кроме того, "position_radius [0]" обозначает расстояние от слушателя до 0-ого объекта.
Поэтому, положение объекта в трехмерном пространстве устанавливается этими "position_azimuth [0]", "position_elevation [0]" и "position_radius [0]". Таким образом, эти элементы информации представляют собой элементы информации пространственного положения объекта.
Кроме того, "gain_factor [0]" обозначает усиление 0-ого объекта.
Таким образом, в метаданных, представленных на фиг. 15, "object_priority [0]", "position_azimuth [0]", "position_elevation [0]", "position_radius [0]" и "gain_factor [0]" в отношении объекта располагают в этом порядке, как данные объекта. Затем, в метаданных, элементы данных каждого объекта располагают в массиве, например, в порядке номера объекта для объекта.
Четвертый вариант осуществления
Шумы из-за полной реконфигурации и разрывности аудиосигнала В представленном выше описании описан пример, в котором количество обработки во время декодирования уменьшается путем исключения декодирования IMDCT и т.п., в случае, когда информация приоритета каждого фрейма (ниже, в частности, называется временным интервалом) для каждого канала или каждого объекта, считанного из потока битов в устройстве 151 декодирования, ниже, чем заданное пороговое значение. В частности, в случае, когда информация приоритета ниже, чем пороговое значение, из модуля 195 вывода нулевого значения или модуля 200 вывода нулевого значения выводят беззвучный аудиосигнал, то есть, нулевые данные, в качестве аудиосигнала.
Однако, в этом случае, происходит ухудшение качества звука при прослушивании. В частности, происходит ухудшение качества звука, из-за полной реконфигурации аудиосигнала, и ухудшение качества звука из-за шумов, таких как шумы в виде гула, вызванные разрывностью сигнала.
Ухудшение качества звука из-за полной реконфигурации
Например, когда выводят нулевые данные, как аудиосигнал, в случае, когда информация приоритета ниже, чем пороговое значение, происходит ухудшение качества звука во время переключения выхода нулевых данных и выхода обычного аудиосигнала, который не является нулевыми данными.
Как описано выше, в модуле 161 распаковки/декодирования, IMDCT выполняют относительно коэффициента MDCT для каждого временного интервала, считанного из потока битов в модуле 196 IMDCT или модуле 201 IMDCT. В частности, в модуле 161 распаковки/декодирования, аудиосигнал настоящего временного фрейма генерируют из результата IMDCT или нулевых данных в отношении настоящего временного фрейма и результата IMDCT или нулевых данных в отношении временного интервала перед одним временным интервалом.
Здесь, генерирование аудиосигнала будет описано со ссылкой на фиг. 16. Здесь генерирование аудиосигнала объекта описано, как пример. Однако, генерирование аудиосигнала каждого канала является таким же. Кроме того, в представленном ниже описании, аудиосигнал, выводимый из модуля 200 вывода нулевого значения, и аудиосигнал, выводимый из модуля 201 IMDCT, в частности, также называется сигналом IMDCT. Аналогично, аудиосигнал, выводимый из модуля 195 вывода нулевого значения, и аудиосигнал, выводимый из модуля 196 IMDCT также, в частности, называется сигналом IMDCT.
На фиг. 16, горизонтальное направление обозначает время, и прямоугольники, обозначенные от "данные [n - 1]" до "данные [n + 2]", соответственно, представляют поток битов от временного фрейма (n - 1) до временного фрейма (n + 2) заданного объекта. Кроме того, значение в потоке битов каждого временного фрейма обозначает значение информации приоритета объекта этого временного фрейма. В этом примере значение информации приоритета фрейма равно 7.
Кроме того, прямоугольники, обозначенные, как "MDCT_coef [q]" (q=n - 1, n…) на фиг. 16, представляют коэффициенты MDCT временного фрейма (q), соответственно.
Теперь, если пороговое значение Q равно 4, значение информации приоритета равно "7" временного фрейма (n - 1) равно или больше, чем пороговое значение Q. Поэтому, IMDCT выполняют в отношении коэффициента MDCT временного фрейма (n - 1). Аналогично, значение информации приоритета "7" временного фрейма (n) также равно или больше, чем пороговое значение Q. Поэтому, IMDCT выполняют в отношении коэффициента MDCT временного фрейма (n).
В результате, получают сигнал IMDCT OPS 11 временного фрейма (n - 1) и сигнал IMDCT OPS 12 временного фрейма (n).
В этом случае, модуль 161 распаковки/декодирования суммирует первую половину сигнала IMDCT OPS 12 временного интервала (n) и последнюю половину сигнала IMDCT OPS 11 временного фрейма (n - 1), который расположен на один временной фрейм перед временным фреймом (n), и получает аудиосигнал временного интервала (n), то есть, аудиосигнал периода FL(n). Другими словами, часть сигнала IMDCT OPS 11 в период FL(n) и часть сигнала IMDCT OPS 12 в период FL(n) суммируют с наложением, и воспроизводят аудиосигнал временного фрейма (n) перед кодированием объекта, подвергаемого обработке.
Такая обработка представляет собой обработку, необходимую для сигнала IMDCT, так, чтобы он был полностью реконфигурирован в сигнал перед MDCT.
Однако, в модуле 161 распаковки/декодирования, описанном выше, например, как представлено на фиг. 17, в моменты времени, когда переключают сигнал IMDCT модуля 201 IMDCT и сигнал IMDCT модуля 200 вывода нулевого значения, в соответствии с информацией приоритета каждого временного фрейма, сигнал IMDCT не полностью реконфигурируется в сигнал перед MDCT. Таким образом, если нулевые данные используются вместо исходного сигнала во время суммирования с наложением, сигнал не полностью реконфигурируется. Поэтому, исходный сигнал не воспроизводится, и качество звука при прослушивании аудиосигнала ухудшается.
В примере на фиг. 17, части, соответствующие случаю на фиг. 16, обозначены такой же буквой, и их описание не повторяется.
На фиг. 17, значение информации приоритета временного фрейма (n - 1) равно "7", но элементы информации приоритета от временного фрейма (n) до временного фрейма (n + 2) являются самыми низкими "0".
Поэтому, если пороговое значение Q равняется 4, IMDCT в отношении фрейма (n - 1) выполняют в отношении коэффициента MDCT с помощью модуля 201 IMDCT и затем получают сигнал OPS21 IMDCT временного интервала (n - 1). С другой стороны, IMDCT в отношении временного интервала (n) не выполняется в отношении коэффициента MDCT, нулевые данные, выводимые из модуля 200 вывода нулевого значения, становятся сигналом OPS22 IMDCT временного фрейма (n).
В этом случае, первая половина нулевых данных, которые представляют собой сигнал OPS22 IMDCT временного фрейма (n) и последняя половина сигнала OPS21 IMDCT временного фрейма (n - 1), который расположен на один фрейм перед временным интервалом (n), суммируют, и результат становится конечным аудиосигналом временного фрейма (n). Таким образом, части сигнала OPS22 IMDCT и сигнала OPS21 IMDCT в период FL (n) суммируют с наложением, и результат становится конечным аудиосигналом временного фрейма (n) объекта, подвергаемого обработке.
Таким образом, когда выходной источник сигнала IMDCT переключают с модуля 201 IMDCT на модуль 200 вывода нулевого значения или переключают с модуля 200 вывода нулевого значения на модуль 201 IMDCT, сигнал IMDCT модуля 201 IMDCT не полностью реконфигурируют, при этом происходит ухудшение качества звука при прослушивании.
Ухудшение качества звука из-за генерирования шумов, вызванных разрывом
Кроме того, в случае, когда выходной источник сигнала IMDCT переключают с модуля 201 IMDCT на модуль 200 вывода нулевого значения или переключают модуль 200 вывода нулевого значения на модуль 201 IMDCT, поскольку сигнал не полностью реконфигурирован, в некоторых случаях, сигнал является прерывистым на участке соединения сигнала IMDCT, полученного из IMDCT, и сигнала IMDCT, который становится нулевыми данными. В результате возникают шумы в виде гула на участке соединения, и ухудшается качество звука при прослушании аудиосигнала.
Кроме того, при обработке для улучшения качества звука в модуле 161 распаковки/декодирования, возникает случай, когда обработка репликации спектральной полосы (SBR) и т.п. выполняется в отношении аудиосигнала, получаемого путем суммирования с наложением сигналов IMDCT, выводимых из модуля 201 IMDCT и модуля 200 вывода нулевого значения.
Различные задачи обработки могут быть рассмотрены для обработки после модуля или IMDCT 201 модуля 200 вывода нулевого значения, и далее описание будет продолжено с SBR в качестве примера.
При SBR компонент высокой частоты исходного аудиосигнала перед кодированием генерируют из аудиосигнала компонента низкой частоты, полученного в результате суммирования с наложением, и значения мощности высокой частоты, сохраненного в потоке битов.
В частности, аудиосигнал одного фрейма разделяют на несколько секций, называемых временными интервалами, и аудиосигнал каждого временного интервала разделяют по полосе на сигнал (ниже называется сигналом подполосы низкой частоты) множества подполос низкой частоты.
Затем сигнал каждой подполосы высокой частоты (ниже называется сигналом подполосы высокой частоты) генерируют на основе сигнала подполосы низкой частоты каждой подполосы и значения мощности каждой подполосы на стороне высокой частоты. Например, целевой сигнал подполосы высокой частоты генерируют путем регулирования мощности сигнала подполосы низкой частоты заранее определенной подполосы до величины мощности целевой подполосы высокой частоты, или путем сдвига его частоты.
Кроме того, сигнал подполосы высокой частоты и сигнал подполосы низкой частоты синтезируют, генерируют аудиосигнал, включающий в себя компонент высокой частоты, и аудиосигнал, включающий в себя компонент высокой частоты, сгенерированный в течение каждого временного интервала, комбинируют, и в результате получают аудиосигнал одного временного интервала, включающий в себя компонент высокой частоты.
В случае, когда такой SBR выполняют на этапе, следующем после модуля 201 IMDCT или модуля 200 вывода нулевого значения, в отношении аудиосигнала, состоящего из сигнала IMDCT, выводимого из модуля 201 IMDCT, высокочастотный компонент генерируется SBR. В частности, поскольку сигнал IMDCT, выводимый из модуля 200 вывода нулевого значения, представляет собой нулевые данные, в отношении аудиосигнала, состоящего из сигнала IMDCT, выводимого из модуля 200 вывода нулевого значения, высокочастотный компонент, получаемый SBR, также представляет собой нулевые данные.
Затем, когда источник вывода сигнала IMDCT переключают с модуля 201 IMDCT на модуль 200 вывода нулевого значения или переключают с модуля 200 вывода нулевого значения на модуль 201 IMDCT, сигнал становится прерывистым в отношении также участка соединения на стороне высокой частоты. В таком случае возникают шумы в виде гула, и происходит ухудшение качества звука при прослушивании.
Поэтому, в настоящей технологии, назначение вывода коэффициента MDCT выбирают с учетом предыдущего и следующего временных фреймов, и обработки плавного нарастания, и обработки плавного затухания в отношении аудиосигналов, и, таким образом, снижают ухудшение качества звука, при прослушивании, описанном выше, и улучшается качество звука.
Выбор назначения вывода коэффициента MDCT с учетом предыдущего и следующего временных фреймов
Вначале будет описан выбор назначения вывода коэффициента MDCT с учетом предыдущего и следующего временного фрейма. Здесь описание также будет представлено для аудиосигнала объекта, в качестве примера. Однако описание аналогично случаю аудиосигнала каждого канала. Кроме того, задачи обработки, описанные ниже, выполняются для каждого объекта и каждого канала.
Например, в описанном выше варианте осуществления, было описано, что модуль 199 выбора выхода избирательно переключает назначение выхода коэффициента MDCT каждого объекта на основе информации приоритета настоящего временного фрейма. С другой стороны, в настоящем варианте осуществления, модуль 199 выбора выхода переключает назначение выхода коэффициента MDCT на основе элементов информации приоритета для трех последовательных временных фреймов по времени, которые представляют собой фрейм настоящего времени, временной фрейм на один временной фрейм перед фреймом настоящего времени, и временной фрейм на один фрейм после фрейма настоящего времени. Другими словами, выполняется ли декодирование кодированных данных или нет, выбирают на основе элементов информации приоритета трех последовательных временных фреймов.
В частности, модуль 199 выбора выхода, в случае, когда условная формула, обозначенная в следующей Формуле (1), удовлетворяется в отношении объекта, подвергаемого обработке, подает коэффициент MDCT временного фрейма (n) объекта в модуль 201 IMDCT.
Уравнение 1

В Формуле (1), object_priority [q] (где q=n - 1, n, n + 1) обозначает информацию приоритета каждого временного интервала (q), и thre обозначает пороговое значение Q.
Поэтому, среди трех последовательных временных фреймов настоящего времени и фреймов для времени перед и после фрейма настоящего времени, в случае, когда существует по меньшей мере один или больше временных фреймов, информация приоритета которого равна или выше, чем пороговое значение Q, модуль IMDCT 201 выбирают, как назначение подачи коэффициента MDCT. В этом случае, выполняют декодирование кодированных данных, в частности, IMDCT в отношении коэффициента MDCT. С другой стороны, если элементы информации приоритета всех этих трех временных фреймов меньше, чем пороговое значение Q, коэффициент MDCT равен нулю, и его выводят в модуль 200 вывода нулевого значения. В этом случае, декодирование кодированных данных, в частности, IMDCT в отношении коэффициента MDCT, по существу, не выполняется.
Таким образом, как представлено на фиг. 18, для аудиосигнала, который полностью реконфигурирован из сигнала IMDCT, предотвращается ухудшение качества звука при прослушивании. На фиг. 18, части, соответствующие случаю на фиг. 16, обозначены теми же буквами и т.п., и их описание не повторяется.
В примере, представленном на верхней схеме на фиг. 18, значение информации приоритета каждого временного фрейма является таким же, как и в примере, представленном на фиг. 17. Например, пороговое значение Q, как предполагается, равно 4 на верхней схеме на фиг. 18, информация приоритета временного фрейма (n - 1) равна или больше, чем пороговое значение Q, но элементы информации приоритета от временного фрейма (n) до временного фрейма до (n + 2) ниже, чем пороговое значение Q.
По этой причине, из условной формулы, представленной в Формуле (1), IMDCT выполняют в отношении коэффициентов MDCT временного фрейма (n - 1) и временного фрейма (n), и затем получают сигнал OPS31 IMDCT и сигнал OPS32 IMDCT, соответственно. С другой стороны, во временном фрейме (n + 1), где условная формула не удовлетворяется, IMDCT в отношении коэффициента MDCT не выполняют, и затем нулевые данные представляют собой сигнал OPS33 IMDCT.
Поэтому, аудиосигнал временного фрейма (n), который не полностью реконфигурируют в примере, представленном на фиг. 17, полностью реконфигурируют в примере, представленном на верхней схеме на фиг. 18, и затем предотвращается ухудшение качества звука при прослушивании. Однако, в этом примере, поскольку аудиосигнал не полностью реконфигурируют в следующем временном фрейме (n + 1), выполняется обработка плавного затухания, описанная ниже, во временном фрейме (n) и во временном фрейме (n + 1), и, таким образом, предотвращается ухудшение качества звука при прослушивании.
Кроме того, в примере, представленном на нижней схеме, на фиг. 18, элементы информации приоритета во временном фрейме (n - 1) - временном фрейме (n + 1) ниже, чем пороговое значение Q, и информация приоритета временного фрейма (n + 2) равна или выше, чем пороговое значение Q.
По этой причине, из условной формулы, представленной в Формуле (1), IMDCT не выполняется в отношении коэффициента MDCT во временном фрейме (n), где условная формула не удовлетворяется, и затем нулевые данные представляют собой сигнал OPS41 IMDCT. С другой стороны, IMDCT выполняется в отношении коэффициентов MDCT временного фрейма (n + 1) и временного фрейма (n + 2), и затем сигнал OPS42 IMDCT и сигнал OPS43 IMDCT получают, соответственно.
В этом примере аудиосигнал может быть полностью реконфигурирован во временном фрейме (n + 2), где значение информации приоритета переключают со значения, ниже, чем пороговое значение Q, на значение, равное или выше, чем пороговое значение Q. Поэтому, возможно предотвратить ухудшение качества звука при прослушивании. Однако, даже в этом случае, поскольку аудиосигнал временного фрейма (n + 1) непосредственно перед временным фреймом (n + 2) не полностью реконфигурирован, выполняется описанная ниже обработка плавного нарастания звука во временном фрейме (n + 1) и временном фрейме (n + 2), и, таким образом, предотвращается ухудшение качества звука при прослушивании.
Здесь предварительное считывание информации приоритета выполняют только для одного временного фрейма, и затем назначение выхода коэффициента MDCT выбирают из элементов информации приоритета трех последовательных временных фреймов. По этой причине в примере, представленном на верхней схеме на фиг. 18, выполняют обработку плавного затухания во временном фрейме (n) и во временном фрейме (n + 1), и в примере, представленном на нижней схеме, на фиг. 18, выполняют обработку плавного нарастания во временном фрейме (n + 1) и во временном фрейме (n + 2).
Однако, в случае, когда предварительное считывание информации приоритета может быть выполнено для двух временных фреймов, может быть выполнена обработка плавного затухания во временном фрейме (n + 1) и во временном фрейме (n + 2), в примере, представленном на верхней схеме, на фиг. 18, и обработка плавного нарастания может быть выполнена во временном фрейме (n) и во временном фрейме (n + 1) в примере, представленном на нижней схеме, на фиг. 18.
Обработка плавного нарастания и обработка плавного затухания
Далее будут описаны обработка плавного нарастания и обработка плавного затухания в отношении аудиосигнала. Здесь описание будет выполнено также в отношении аудиосигнала объекта, в качестве примера. Однако описание аналогично случаю аудиосигнала каждого канала. Кроме того, обработка плавного нарастания и обработка плавного затухания выполняются для каждого объекта и каждого канала.
В настоящей технологии, например, как и в примере, представленном на фиг. 18, обработка плавного нарастания или обработка плавного затухания выполняются во временном интервале, где сигнал IMDCT, получаемый в результате IMDCT, и сигнал IMDCT, который представляет собой нулевые данные, суммируют с наложением, и во временном фрейме перед или после описанного выше временного фрейма.
При обработке плавного нарастания выполняют регулировку усиления в отношении аудиосигнала таким образом, что амплитуда (магнитуда) аудиосигнала временного фрейма увеличивается с течением времени. И, наоборот, при обработке плавного затухания выполняют регулировку усиления в отношении аудиосигнала таким образом, что амплитуда (магнитуда) аудиосигнала временного интервала уменьшается с течением времени.
Таким образом, даже в случае, когда участок соединения сигнала IMDCT, получаемый при IMDCT, и сигнала IMDCT, который представляет собой нулевые данные, является прерывистым, возможно предотвратить ухудшение качества звука при прослушивании. Ниже, во время такой регулировки усиления, значение усиления, на которое умножают аудиосигнал, в частности, называется усилением сигнала с плавным изменением.
Кроме того, в настоящей технологии, в SBR, в отношении соединительного участка сигнала IMDCT, получаемого при IMDCT, и сигнала IMDCT, который представляет собой нулевые данные, также выполняют обработку плавного затухания.
Таким образом, при SBR, значение мощности каждой подполосы высокой частоты используется для каждого временного интервала. Однако, в настоящей технологии, значение мощности каждой подполосы высокой частоты умножают на значение усиления, определяемое для обработки плавного нарастания или для обработки плавного затухания в течение каждого временного интервала, и затем выполняют SBR. Таким образом, выполняют регулировку усиления для значения мощности высокой частоты.
Далее, значение усиления, на которое умножают значение мощности каждой подполосы высокой частоты и определяют для каждого временного интервала, в частности, называется усилением с плавным изменением SBR.
В частности, значение усиления с плавным изменением, для усиления SBR, для обработки плавного нарастания определяют таким образом, что оно увеличивалось с течением времени, то есть, чтобы оно увеличивалось в такой степени, как и значение усиления для усиления с плавным изменением SBR следующего временного интервала. И, наоборот, значение усиления для усиления с плавным изменением SBR, для обработки плавного затухания определяют таким образом, чтобы оно увеличивалось настолько же мало, как и значение усиления для усиления с плавным изменением SBR следующего временного интервала.
Таким образом, путем выполнения обработки плавного нарастания или обработки плавного затухания также во время SBR, становится возможным предотвратить ухудшение качества звука при прослушивании, даже когда высокая частота является прерывистой.
В частности, задачи обработки, представленные, например, на фиг. 19 и фиг. 20, выполняются, как регулировка усиления, такая как обработка плавного нарастания или обработка плавного затухания в отношении аудиосигнала и значения мощности высокой частоты. На фиг. 19 и фиг. 20, части, соответствующие случаю на фиг. 18, обозначены теми же буквами или знаками, и их описание не повторяется.
Пример на фиг. 19 представляет собой случай примера, представленного на верхней схеме, на фиг. 18. В этом примере аудиосигналы временного фрейма (n) и временного фрейма (n + 1) умножают на коэффициент усиление сигнала с плавным изменением, обозначенный ломаной линией GN11.
Значение усиления сигнала с плавным изменением, представленное ломаной линией GN11, линейно изменяется от "1" до "0" с течением времени на участке временного фрейма (n), и постоянно равно "0" на участке временного фрейма (n + 1). Поэтому, поскольку аудиосигнал плавно изменяется на нулевые данные, в результате регулирования усиления аудиосигнала, используя усиление сигнала с плавным изменением, возможно подавлять ухудшение качества звука при прослушивании.
Кроме того, в этом примере, значение мощности высокой частоты каждого временного интервала временного фрейма (n) умножают на усиление с плавным изменением SBR, представленное стрелкой GN12.
Значение усиления с плавным изменением SBR, представленное стрелкой GN12, изменяется с "1" до "0" с течением времени, так, что уменьшается до такой малой величины, как и в следующем временном интервале. Поэтому, поскольку компонент высокой частоты аудиосигнала плавно изменяется до нулевых данных, путем регулирования усиления высокой частоты, используя усиление сигнала с плавным изменением SBR, возможно предотвратить ухудшение качества звука при прослушивании.
С другой стороны, пример, представленный на фиг. 20, представляет собой случай примера, иллюстрирующего нижнюю схему на фиг. 18. В этом примере аудиосигнал временного фрейма (n + 1) и временного фрейма (n + 2) умножают на усиление сигнала с плавным изменением, представленное ломаной линией GN21.
Значение усиления сигнала с плавным изменением, представленного ломаной линией GN21, постоянно равно "0" на участке временного фрейма (n + 1), и линейно изменяется с "0" до "1" с течением времени на участке временного фрейма (n + 2). Поэтому, поскольку аудиосигнал плавно изменяется до исходного сигнала от нулевых данных, в результате регулирования усиления аудиосигнала, используя усиление сигнала с плавным изменением, возможно предотвратить ухудшение качества звука при прослушивании.
Кроме того, в этом примере, значение мощности высокой частоты каждого временного интервала временного интервала (n + 2) умножают на усиление с плавным изменением SBR, представленное стрелкой GN22.
Значение усиления с плавным изменением SBR, представленное стрелкой GN22, изменяется от "0" до "1" в течение времени так, что увеличивается до настолько большой величины, что и следующий временной интервал. Поэтому, поскольку компонент высокой частоты аудиосигнала плавно изменяется до исходного сигнала с нулевых данных путем регулирования усиления высокой частоты, используя усиление сигнала с плавным изменением SBR, возможно предотвратить ухудшение качества звука при прослушивании.
Пример конфигурации модуля распаковки и декодирования
В случае, когда выполняется выбор выходного назначения коэффициента MDCT и регулировки усиления, такой как обработка плавного увеличения или обработка плавного затухания, как описано выше, модуль 161 распаковки/декодирования выполнен так, как представлено на фиг. 21. На фиг. 21, части, соответствующие случаю на фиг. 10, обозначены такими же номерами ссылочных позиций, и их описание здесь не повторяется.
Модуль 161 распаковки/декодирования на фиг. 21 включает в себя модуль 191 получения информации приоритета, модуль 192 получения аудиосигнала канала, модуль 193 декодирования аудиосигнала канала, модуль 194 выбора выхода, модуль 195 вывода нулевого значения, модуль 196 IMDCT, модуль 271 суммирования с наложением, модуль 272 регулировки усиления, модуль 273 обработки SBR, модуль 197 получения аудиосигнала объекта, модуль 198 декодирования аудиосигнала объекта, модуль 199 выбора выхода, модуль вывода 200 нулевого значения, модуль 201 IMDCT, модуль 274 суммирования с наложением, модуль 275 регулировки усиления, и модуль 276 обработки SBR.
Конфигурация модуля 161 распаковки/декодирования, представленная на фиг. 21, представляет собой конфигурацию, в которой компоненты от модуля 271 суммирования с наложением до модуля 276 обработки SBR дополнительно предоставлены в конфигурации модуля 161 распаковки/декодирования, представленные на фиг. 10.
Модуль 271 суммирования с наложением суммирует с наложением сигнал IMDCT (аудиосигнал), передаваемый из модуля 195 вывода нулевого значения, или модуля 196 IMDCT, и генерируют аудиосигнал каждого временного фрейма, и затем подает этот аудиосигнал в модуль 272 регулировки усиления.
Модуль 272 регулировки усиления регулирует усиление аудиосигнала, передаваемого из модуля 271 суммирования с наложением, на основе информации приоритета, передаваемой из модуля 191 получения информации приоритета, и подает результат в модуль 273 обработки SBR.
Модуль 273 обработки SBR получает значение мощности каждой подполосы высокой частоты в течение каждого временного интервала из модуля 191 получения информации приоритета, и регулирует усиление значения мощности высокой частоты на основе информации приоритета, подаваемой из модуля 191 получения информации приоритета. Кроме того, модуль 273 обработки SBR выполняет SBR в отношении аудиосигнала, подаваемого из модуля 272 регулировки усиления, используя значение мощности высокой частоты, в котором отрегулировано усиление, и затем подает аудиосигнал, полученный в результате SBR, в модуль 163 смешивания.
Модуль 274 суммирования с наложением суммирует с наложением сигналы IMDCT (аудиосигнал), подаваемый из модуля 200 вывода нулевого значения или модуля 201 IMDCT, и генерируют аудиосигнал каждого временного фрейма, и затем подает этот аудиосигнал в модуль 275 регулировки усиления.
Модуль 275 регулировки усиления регулирует усиление аудиосигнала, передаваемого из модуля 274 суммирования с наложением, на основе информации приоритета, подаваемой из модуля 191 получения информации приоритета, и подает этот аудиосигнал в модуль 276 обработки SBR.
Модуль 276 обработки SBR получает значение мощности каждой подполосы высокой частоты из модуля 191 получения информации приоритета для каждого временного интервала и регулирует усиление значения мощности высокой частоты на основе информации приоритета, подаваемой из модуля 191 получения информации приоритета. Кроме того, модуль 276 обработки SBR выполняет SBR в отношении аудиосигнала, подаваемого из модуля 275 регулирования усиления, используя значение мощности высокой частоты, в котором отрегулировано усиление, и затем подает аудиосигнал, полученный в результате SBR, в модуль 162 визуализации.
Описание обработки избирательного декодирования
Далее будет описана операция устройства 151 декодирования в случае, когда модуль 161 распаковки/декодирования имеет конфигурацию, представленную на фиг. 21. В этом случае, устройство 151 декодирования выполняет обработку декодирования, описанную со ссылкой на фиг. 11. Однако обработка, представленная на фиг. 22, выполняется, как обработка избирательного декодирования на ЭТАПЕ S52.
Далее, со ссылкой на блок-схему последовательности операций, на фиг. 22, будет описана обработка избирательного декодирования, соответствующая обработке на ЭТАПЕ S52, на фиг. 11.
На ЭТАПЕ S181, модуль 191 получения информации приоритета получает значение мощности высокой частоты аудиосигнала каждого канала из представленного потока битов, и передает значение мощности высокой частоты в модуль 273 обработки SBR, и получает значение мощности высокой частоты аудиосигнала каждого объекта из представленного потока битов, и подает значение мощности высокой частоты в модуль 276 обработки SBR.
После получения значения мощности высокой частоты, задачи обработки с ЭТАПА S182 по ЭТАП S187 выполнены, и генерируется аудиосигнал (сигнал IMDCT) канала, подвергаемого обработке. Однако, такие задачи обработки аналогичны выполняемым с ЭТАПА S81 по ЭТАП S86 на фиг. 12, и их описание не будет повторяться.
Однако, на ЭТАПЕ S186, в случае, когда удовлетворяется условие, аналогичное Формуле (1), описанной выше, то есть, в случае, когда по меньшей мере один или больше элементов информации приоритета равен или выше, чем пороговое значение Р среди информации приоритета фрейма настоящего времени канала, предназначенного для обработки, и элементы информации приоритета временных фреймов непосредственно перед и сразу после фрейма настоящего времени канала, подвергаемого обработке, определяют, что информация приоритета равна или выше, чем пороговое значение Р. Кроме того, сигнал IMDCT, генерируемый в модуле 195 вывода нулевого значения или модуле 196 IMDCT, выводят в модуль 271 суммирования с наложением.
В случае, когда не определяют, что информация приоритета равна или выше, чем пороговое значение Р на ЭТАПЕ, S186, или сигнал IMDCT генерируют на ЭТАПЕ S187, выполняется обработка на ЭТАПЕ S188.
На ЭТАПЕ S188, модуль 271 суммирования с наложением выполняет суммирование с наложением сигналов IMDCT, подаваемых из модуля 195 вывода нулевого значения или модуля IMDCT 196, и подает аудиосигнал фрейма настоящего времени, полученного в результате суммирования с наложением, в модуль 272 регулировки усиления.
В частности, например, как описано со ссылкой на фиг. 18, первую половину сигнала IMDCT фрейма настоящего времени и последнюю половину сигнала IMDCT непосредственно перед фреймом настоящего времени суммируют, и они становятся аудиосигналом фрейма настоящего времени.
На ЭТАПЕ S189, модуль 272 регулировки усиления регулирует усиление аудиосигнала, подаваемого из модуля 271 суммирования с наложением на основе информации приоритета канала, подвергаемого обработке, подаваемой из модуля 191 получения информации приоритета, и подает результат регулирования усиления в модуль 273 обработки SBR.
В частности, в случае, когда информация приоритета временного интервала непосредственно перед фреймом настоящего времени равна или выше, чем пороговое значение Р, и информация приоритета фрейма настоящего времени, и информация приоритета временного интервала непосредственно после фрейма настоящего времени ниже, чем пороговое значение Р, модуль 272 регулирования усиления регулирует усиление аудиосигнала по усилению сигнала с плавным изменением, представленного ломаной линией GN11 на фиг. 19. В этом случае, временной фрейм (n) на фиг. 19 соответствует фрейму настоящего времени, и во временном интервале непосредственно после фрейма настоящего времени, как представлено на ломаной линии GN11, выполняется регулировка усиления по усилению сигнала с плавным изменением, равному нулю.
Кроме того, в случае, когда информация приоритета фрейма настоящего времени равна или выше, чем пороговое значение Р, и элементы информации приоритета двух временных интервалов непосредственно перед фреймом настоящего времени ниже, чем пороговое значение Р, модуль 272 регулирования усиления регулирует усиление аудиосигнала по усилению сигнала с плавным изменением, представленному ломаной линией GN21 на фиг. 20. В этом случае, временной фрейм (n + 2) на фиг. 20 соответствует фрейму настоящего времени, и во временном фрейме непосредственно перед фреймом настоящего времени, как представлено на ломаной линии GN21, выполняют регулировку усиления по усилению сигнала с плавным изменением, равному нулю.
Модуль 272 регулирования усиления выполняет регулировку усиления только в случае двух примеров, описанных выше, и не выполняет регулировку усиления в других случаях, и подает аудиосигнал в модуль 273 обработки SBR, в том виде, как он есть.
На ЭТАПЕ S190, модуль 273 обработки SBR выполняет SBR в отношении аудиосигнала, подаваемого из модуля 272 регулирования усиления на основе значения мощности высокой частоты и информации приоритета канала, подвергаемого обработке, подаваемого из модуля 191 получения информации приоритета.
В частности, в случае, когда информация приоритета временного интервала непосредственно перед фреймом настоящего времени равна или выше, чем пороговое значение Р, информация приоритета фрейма настоящего времени и информация приоритета временного интервала непосредственно после фрейма настоящего времени ниже, чем пороговое значение Р, модуль 273 обработки SBR регулирует усиление значения мощности высокой частоты по усилению с плавным изменением SBR, представленному стрелкой GN12 на фиг. 19. Таким образом, значение мощности высокой частоты умножают на усиление с плавным изменением SBR.
Затем модуль 273 обработки SBR выполняет SBR, используя значение мощности высокой частоты, по которому было выполнено SBR, и подает аудиосигнал, полученный в результате регулировки усиления, в модуль 163 смешивания. В этом случае временной интервал (n) на фиг. 19 соответствует фрейму настоящего времени.
Кроме того, в случае, когда информация приоритета фрейма настоящего времени равна или больше, чем пороговое значение Р, и элементы информации приоритета двух временных интервалов непосредственно перед фреймом настоящего времени меньше, чем пороговое значение Р, модуль 273 обработки SBR регулирует усиление значения мощности высокой частоты по усилению с плавным изменением SBR, представленному стрелкой GN22 на фиг. 20. Затем модуль 273 обработки SBR выполняет SBR, используя значение мощности высокой частоты, по которому регулируют усиление, и подает аудиосигнал, полученный в результате SBR, в модуль 163 смешивания. В этом случае временной интервал (n + 2) на фиг. 20 соответствует фрейму настоящего времени.
Модуль 273 обработки SBR выполняет регулировку усиления значения мощности высокой частоты только в случае двух примеров, описанных выше, и не выполняет регулировку усиления в других случаях, и выполняет SBR, используя полученное значение мощности высокой частоты так, как оно есть, и затем подает аудиосигнал, полученный в результате SBR, в модуль 163 смешивания.
После выполненного SBR и получения аудиосигнала фрейма настоящего времени, задачи обработки с ЭТАПА S191 по ЭТАП S196 выполнены. Однако, эти задачи обработки аналогичны представленным с ЭТАПА S87 по ЭТАП S92 на фиг. 12, и их описание не повторяется.
Однако, на ЭТАПЕ S195, в случае, когда удовлетворяется условие в описанной выше Формуле (1), определяется, что информация приоритета равна или выше, чем пороговое значение Q. Кроме того, сигнал IMDCT (аудиосигнал), генерируемый в модуле 200 вывода нулевого значения или в модуле 201 IMDCT, выводят в модуль 274 суммирования с наложением.
Таким образом, когда получают сигнал IMDCT фрейма настоящего времени, задачи обработки с ЭТАПА S197 по ЭТАП S199 выполнены, и генерируется аудиосигнал фрейма настоящего времени. Однако, эти задачи обработки аналогичны обработке с ЭТАПА S188 по ЭТАП S190, и их описание здесь не повторяется.
На ЭТАПЕ S200, когда модуль 197 получения аудиосигнала объекта добавляет единицу к номеру объекта, обработка возвращается на ЭТАП S193. Затем, когда определяют, что номер объекта не меньше, чем N на ЭТАПЕ S193, обработка избирательного декодирования заканчивается, и затем обработка переходит на ЭТАП S53, на фиг. 11.
Как описано выше, модуль 161 распаковки/декодирования выбирает назначение выхода коэффициента MDCT, в соответствии с элементами информации приоритета фрейма настоящего времени во временном фрейме перед и после фрейма настоящего времени. Таким образом, аудиосигнал полностью реконфигурируют на участки, где временной фрейм, в котором информация приоритета равна или выше, чем пороговое значение, и временной фрейм, в котором информация приоритета ниже, чем пороговое значение, переключают, и, таким образом, становится возможным предотвратить ухудшение качества звука при прослушивании.
Кроме того, модуль 161 распаковки/декодирования регулирует усиление аудиосигнала после суммирования с наложением, или значение мощности высокой частоты на основе элементов информации приоритета трех последовательных временных фреймов. Таким образом, выполняют обработку плавного увеличения или обработку плавного затухания соответствующим образом. Таким образом, возникновение шумов в виде гула предотвращается, и, таким образом, возможно предотвратить ухудшение качества звука при прослушивании.
Пятый вариант осуществления
Обработка плавного увеличения и плавного затухания
В описании четвертого варианта осуществления выполняют регулировку усиления в отношении аудиосигнала, полученного в результате суммирования с наложением, и, кроме того, выполняют регулировку усиления в отношении значения мощности высокой частоты во время SBR. В этом случае выполняют отдельную регулировку усиления компонента низкой частоты и компонента высокой частоты конечного аудиосигнала, то есть, обработку плавного увеличения и обработку плавного затухания.
Здесь регулировка усиления может не выполняться немедленно после суммирования с наложением и во время SBR, или регулировка усиления может быть выполнена в отношении аудиосигнала, полученного в результате SBR таким образом, что обработка плавного увеличения и обработка плавного затухания могут быть реализованы при меньшем объеме обработки.
В таком случае, например, регулировка усиления выполняется, как представлено на фиг. 23 и фиг. 24. На фиг. 23 и фиг. 24, части, соответствующие случаю на фиг. 19 и на фиг. 20, обозначены теми же номерами ссылочных позиций и т.п., и их описание не повторяется.
Изменения информации приоритета в примере, представленном фиг. 23, являются такими же, как и в примере случая, представленного на фиг. 19. В этом примере, если пороговое значение Q равно 4, информация приоритета временного фрейма (n - 1) равна или выше, чем пороговое значение Q, но элементы информации приоритета от временного фрейма (n) по временной фрейм (n + 2) меньше, чем пороговое значение Q.
В этом случае выполняют регулировку усиления по аудиосигналу, полученному в результате SBR, во временном фрейме (n) и временном фрейме (n + 1) путем умножения на сигнал с плавным изменением усиления, представленный ломаной линией GN31.
Усиление сигнала с плавным изменением, представленного ломаной линией GN31, является таким же, как усиление сигнала с плавным изменением, представленного ломаной линией GN11 на фиг. 19. Однако, в случае примера на фиг. 23, поскольку аудиосигнал, подвергаемый регулировке усиления, включает в себя как компонент низкой частоты, так и компонент высокой частоты, регулировка усиления компонента низкой частоты и компонента высокой частоты может быть выполнена по одному усилению сигнала с плавным изменением.
В результате регулировки усиления аудиосигнала, используя усиление сигнала с плавным изменением, аудиосигналы плавно изменяются до нулевых данных на участке, где сигнал IMDCT, получаемый в результате IMDCT, и сигнал IMDCT, который представляет собой нулевые данные, суммируют с наложением на участке непосредственно перед этим. Таким образом, возможно предотвратить ухудшение качества звука при прослушивании.
С другой стороны, изменение информации приоритета в примере, представленном на фиг. 24, является таким же, как и в случае, представленном на фиг. 20. В этом примере, если пороговое значение Q равно 4, элементы информации приоритета меньше, чем пороговое значение Q во временном фрейме (n) и временном фрейме (n + 1), но информация приоритета временного фрейма (n + 2) равна или выше, чем пороговое значение Q.
В таком случае усиление регулируют по аудиосигналу, получаемому в результате SBR во временном фрейме (n + 1) и временном фрейме (n + 2), которые умножают на усиление сигнала с плавным изменением, представленное ломаной линией GN41.
Усиление сигнала с плавным изменением, представленное ломаной линией GN41, является таким же, как и усиление сигнала с плавным изменением, представленное ломаной линией GN21 на фиг. 20. Однако, в случае примера на фиг. 24, поскольку аудиосигнал, подвергаемый регулировке усиления, включает в себя как компонент низкой частоты, так и компонент высокой частоты, регулировка усиления компонента низкой частоты и компонента высокой частоты может быть выполнена по одному усилению сигнала с плавным изменением.
В результате регулировки усиления аудиосигнала, используя усиление сигнала с плавным изменением, аудиосигналы плавно изменяются с нулевых данных до исходного сигнала на участке, где сигнал IMDCT, полученный в результате IMDCT, и сигнал IMDCT, который представляет собой нулевые данные, суммируют с наложением и на участке непосредственно перед этим. Таким образом, становится возможным предотвратить ухудшение качества звука при прослушивании.
Пример конфигурации модуля распаковки/декодирования
В случае, когда выполняется регулировка усиления с использованием обработки плавного увеличения или обработки плавного затухания, описанной выше со ссылкой на фиг. 23 и фиг. 24, модуль 161 распаковки/декодирования, например, выполнен, как представлено на фиг. 25. На фиг. 25 части, соответствующие случаю на фиг. 21, обозначены теми же номерами ссылочных позиций, и их описание не повторяется.
Модуль 161 распаковки/декодирования, представленный на фиг. 25, включает в себя модуль 191 получения информации приоритета, модуль 192 получения аудиосигнала, модуль 193 декодирования аудиосигнала канала, модуль 194 выбора выхода, модуль 195 вывода нулевого значения, модуль 196 IMDCT, модуль 271 суммирования с наложением, модуль 273 обработки SBR, модуль 272 регулирования усиления, модуль 197 получения аудиосигнала объекта, модуль 198 декодирования аудиосигнала объекта, модуль 199 выбора выхода, модуль 200 вывода нулевого значения, модуль 201 IMDCT, модуль 274 суммирования с наложением, модуль 276 обработки SBR, и модуль 275 регулировки усиления.
Конфигурация модуля 161 распаковки/декодирования, представленная на фиг. 25, отличается от конфигурации модуля 161 распаковки/декодирования, представленной на фиг. 21 в точке, где каждый из модуля 272 регулирования усиления и модуля 275 регулирования усиления расположены в каскаде после модуля 273 обработки SBR и модуля 276 обработки SBR, соответственно.
В модуле 161 распаковки/декодирования, представленном на фиг. 25, модуль 273 обработки SBR выполняет SBR в отношении аудиосигнала, подаваемого из модуля 271 суммирования с наложением на основе значения мощности высокой частоты, подаваемого из модуля 191 получения информации приоритета, и подает аудиосигнал, полученный в результате, в модуль 272 регулирования усиления. В этом случае, в модуле 273 обработки SBR, не выполняется регулировка усиления для значения мощности высокой частоты.
Модуль 272 регулирования усиления регулирует усиление аудиосигнала, подаваемого из модуля 273 обработки SBR, на основе информации приоритета, подаваемой из модуля 191 получения информации приоритета, и подает аудиосигнал в модуль 163 смешивания.
Модуль 276 обработки SBR выполняет SBR в отношении аудиосигнала, подаваемого из модуля 274 суммирования с наложением на основе значения мощности высокой частоты, подаваемого из модуля 191 получения информации приоритета, и подает аудиосигнал, полученный в результате, в модуль 275 регулировки усиления. В этом случае, в модуле 276 обработки SBR не выполняется регулировка усиления значения мощности высокой частоты.
Модуль 275 регулировки усиления регулирует усиление аудиосигнала, подаваемого из модуля 276 обработки SBR, на основе информации приоритета, подаваемой из модуля 191 получения информации приоритета, и подает аудиосигнал в модуль 162 визуализации.
Описание обработки избирательного декодирования
Затем будет описана операция устройства 151 декодирования в случае, когда модуль 161 распаковки/декодирования, имеет конфигурацию, представленную на фиг. 25. В этом случае устройство 151 декодирования выполняет обработку декодирования, описанную со ссылкой на фиг. 11. Однако обработка, представленная на фиг. 26, выполняется, как обработка избирательного декодирования, на ЭТАПЕ S52.
Далее, со ссылкой на блок-схему последовательности операций на фиг. 26, будет описана обработка избирательного декодирования, соответствующая обработке на ЭТАПЕ S52, на фиг. 11. Задачи обработки после этого, с ЭТАПА S231 по ЭТАП S238, являются такими же, как и задачи обработки с ЭТАПА S181 по ЭТАП S188 на фиг. 22, и их описание здесь не повторяется. Однако, на ЭТАПЕ S232, информация приоритета не поступает в модуль 273 обработки SBR и в модуль 276 обработки SBR.
На ЭТАПЕ S239, модуль 273 обработки SBR выполняет SBR в отношении аудиосигнала, подаваемого из модуля 271 суммирования с наложением на основе значения мощности высокой частоты, подаваемого из модуля 191 получения информации приоритета, и подает аудиосигнал, полученный в результата, в модуль 272 регулировки усиления.
На ЭТАПЕ S240, модуль 272 регулировки усиления регулирует усиление аудиосигнала, подаваемого из модуля 273 обработки SBR на основе информации приоритета канала, подвергаемого обработке, подаваемой из модуля 191 получения информации приоритета, и подает аудиосигнал в модуль 163 смешивания.
В частности, в случае, когда информация приоритета временного интервала непосредственно перед фреймом настоящего времени равна или выше, чем пороговое значение Р, и информация приоритета фрейма настоящего времени, и информация приоритета временного интервала непосредственно после фрейма настоящего времени ниже, чем пороговое значение Р, модуль 272 регулировки усиления регулирует усиление аудиосигнала по усилению сигнала затухания, представленному ломаной линией GN31 на фиг. 23. В этом случае, временной фрейм (n) на фиг. 23 соответствует фрейму настоящего времени, и во временном фрейме непосредственно после фрейма настоящего времени, как представлено ломаной линией GN31, регулировка усиления по усилению сигнала с плавным изменением, равного нулю, не выполняется.
Кроме того, в случае, когда информация приоритета фрейма настоящего времени равна или выше, чем пороговое значение Р, и элементы информации приоритета двух временных фреймов непосредственно перед фреймом настоящего времени ниже, чем пороговое значение Р, модуль 272 регулировки усиления регулирует усиление аудиосигнала по усилению сигнала с плавным изменением, представленному ломаной линией GN41 на фиг. 24. В этом случае, временной фрейм (n + 2) на фиг. 24 соответствует фрейму настоящего времени, и во временном фрейме непосредственно перед фреймом настоящего времени, как представлено ломаной линией GN41, выполняется регулировка усиления по усилению сигнала с плавным изменением, равного нулю.
Модуль 272 регулировки усиления выполняет регулировку усиления только в случае двух примеров, описанных выше, и не выполняет регулировку усиления в других случаях, и подает аудиосигнал в модуль 163 смешивания в том виде, как он есть.
После выполнения регулировки усиления аудиосигнала задачи обработки с ЭТАПА S241 по ЭТАП S247 выполнены. Однако, эти задачи обработки являются аналогичными обработке с ЭТАПА S191 по ЭТАП S197 на фиг. 22, и их описание здесь не повторяется.
Таким образом, когда получают аудиосигнал фрейма настоящего времени объекта, подвергаемого обработке, выполняют задачи обработки на ЭТАПЕ S248 и на ЭТАПЕ S249 и получают конечный аудиосигнал фрейма настоящего времени. Однако, такие, задачи обработки аналогичны представленным с ЭТАПА S239 по ЭТАП S240, и их описание здесь не повторяется.
На ЭТАПЕ S250, когда модуль 197 получения аудиосигнала объекта добавляет единицу к номеру объекта, обработка возвращается на ЭТАП S243. Затем, когда определяют, что номер объекта не меньше чем N на ЭТАПЕ S243, обработка избирательного декодирования заканчивается, и затем обработка переходит на ЭТАП S53, на фиг. 11.
Как описано выше, модуль 161 распаковки/декодирования регулирует усиление аудиосигнала, получаемого в результате SBR, на основе элементов информации приоритета трех последовательных временных фреймов. Таким образом, возникновение шумов в виде гула просто подавляется, и, таким образом, становится возможным предотвратить ухудшение качества звука при прослушивании.
В настоящем варианте осуществления описан пример выбора назначения выхода коэффициента MDCT, используя элементы информации приоритета трех временных фреймов и выполнения регулировки усиления по усилению сигнала с плавным изменением. Однако может выполняться только регулировка усиления по усилению сигнала с плавным изменением.
В таком случае, в модуле 194 выбора выхода и в модуле 199 выбора выхода, назначение выхода коэффициента MDCT выбирают в результате обработки, аналогичной случаю первого варианта осуществления. Затем, в модуле регулировки 272 усиления и в модуле 275 регулировки усиления, в случае, когда информация приоритета фрейма настоящего времени ниже, чем пороговое значение, выполняется обработка плавного увеличения или обработка плавного затухания, путем линейного увеличения или уменьшения усиления сигнала с плавным изменением фрейма настоящего времени. Здесь определение, следует ли выполнить обработку плавного увеличения или следует выполнить обработку плавного затухания, может быть выполнено по информации приоритета фрейма настоящего времени и элементам информации приоритета временного фрейма непосредственно перед и непосредственно после фрейма настоящего времени.
Шестой вариант осуществления
Обработка плавного увеличения и обработка плавного затухания
В частности, в модуле 162 визуализации выполняют, например, VBAP, и генерируется аудиосигнал каждого канала для воспроизведения звука каждого объекта из аудиосигнала каждого объекта.
В частности, при VBAP, для каждого канала, то есть, для каждого громкоговорителя, который воспроизводит звук в отношении каждого объекта, рассчитывают значение усиления (ниже называется усилением VBAP) аудиосигнала для каждого временного фрейма. Затем сумма аудиосигналов каждого канала, умноженная на усиление VBAP того же канала (громкоговорителя), представляет собой аудиосигнал этого канала. Другими словами, что касается каждого объекта, усиление VBAP, рассчитанное для каждого канала, назначают для каждого канала.
Поэтому, что касается аудиосигнала объекта, генерирование шумов в виде гула может быть подавлено, и ухудшение качества звука при прослушивании может быть предотвращено путем соответствующего регулирования усиления VBAP, вместо регулирования усиления аудиосигнала объекта или значения мощности высокой частоты.
В таком случае, например, выполняют линейную интерполяцию и т.п. в отношении усиления VBAP каждого временного фрейма, и усиление VBAP каждой выборки аудиосигнала в каждом временном фрейме рассчитывают, и затем генерируют аудиосигнал каждого канала по полученному усилению VBAP.
Например, значение усиления VBAP первой выборки во временном фрейме, подвергаемом обработке, представляет собой значение усиления VBAP последней выборки во временном фрейме непосредственно перед временным фреймом, подвергаемым обработке. Кроме того, значение усиления VBAP последней выборки во временном фрейме, подвергаемом обработке, представляет собой значение усиления VBAP, рассчитанное по обычному VBAP в отношении временного интервала, подвергаемого обработке.
Затем, во временном интервале, подвергаемом обработке, значение усиления VBAP каждой выборки между первой выборкой и последней выборкой определяют таким образом, что усиление VBAP линейно изменяется от первой выборки до последней выборки.
Однако, в случае, когда информация приоритета временного интервала, подвергаемого обработке, ниже, чем пороговое значение, расчет VBAP не выполняют, значение усиления VBAP каждой выборки определяют, таким образом, что значение усиления VBAP последней выборки временного интервала, подвергаемого обработке, становится равным нулю.
Таким образом, в результате выполнения регулировки усиления аудиосигнала каждого объекта через усиление VBAP, регулировка усиления компонента низкой частоты и компонента высокой частоты может быть выполнена в одно время, и затем предотвращается подавление шумов в виде гула при меньшем количестве обработки, и, таким образом, становится возможным предотвратить ухудшение качества звука при прослушивании.
В случае, когда усиление VBAP определяют для каждой выборки, как описано выше, усиление VBAP для каждой выборки каждого временного фрейма является таким, как, например, представлено на фиг. 27 и фиг. 28.
На фиг. 27 и фиг. 28, части, соответствующие случаю на фиг. 19 и фиг. 20, обозначены теми же номерами ссылочных позиций и т.п., и их описание не повторяется. Кроме того, на фиг. 27 и фиг. 28, "VBAP_gain [q] [s]" (где q=n - 1, n, n + 1, n + 2) обозначает усиление VBAP временного фрейма (q) объекта, подвергаемого обработке, в соответствии с которой индекс громкоговорителя равен s, что устанавливает громкоговоритель, соответствующий заданному каналу.
Пример, представленный на фиг. 27, представляет собой пример, в котором изменение информации приоритета является таким же, как и в случае, представленном на фиг. 19. В этом примере, если пороговое значение Q равно 4, информация приоритета временного фрейма (n - 1) равна или выше, чем пороговое значение Q. Однако информация приоритета меньше, чем пороговое значение Q от временного фрейма (n) до временного фрейма (n +n2).
В таком случае значения усиления VBAP от временного фрейма (n - 1) до временного фрейма (n + 1) представляют собой, например, значения усиления, обозначенные ломаной линией GN51.
В этом примере, поскольку информация приоритета временного фрейма (n - 1) равна или выше, чем пороговое значение Q, усиление VBAP каждой выборки определяют на основе усиления VBAP, рассчитанного по обычному VBAP.
Таким образом, значение усиления VBAP первой выборки временного фрейма (n - 1) является таим же, как и значение усиления VBAP последней выборки временного фрейма (n - 2). Кроме того, что касается объекта, подвергаемого обработке, значение усиления VBAP последней выборки временного фрейма (n - 1) представляет собой значение усиления VBAP канала, соответствующего громкоговорителю s, которое рассчитывают, используя обычное VBAP в отношении временного интервала (n - 1). Затем значение усиления VBAP каждой выборки временного фрейма (n - 1) определяют таким образом, что оно линейно изменяется от первой выборки до последней выборки.
Кроме того, поскольку информация приоритета временного фрейма (n) меньше, чем пороговое значение Q, значение усиления VBAP последней выборки временного фрейма (n) равно нулю.
Таким образом, значение усиления VBAP первой выборки временного фрейма (n) является таким же, как и значение усиления VBAP последней выборки временного фрейма (n - 1), и значение усиления VBAP последней выборки временного фрейма (n) равно нулю. Затем значение усиления VBAP каждой выборки временного интервала (n) определяют так, чтобы оно линейно изменялось от первой выборки до последней выборки.
Кроме того, поскольку информация приоритета временного фрейма (n + 1) меньше, чем пороговое значение Q, значение усиления VBAP последней выборки временного фрейма (n + 1) равно нулю, и в результате, значения усиления VBAP всех выборок временного фрейма (n + 1) равны нулю.
Таким образом, с помощью значения усиления VBAP последней выборки временного фрейма, в которой информация приоритета меньше, чем пороговое значение Q, равное нулю, может выполняться обработка плавного затухания, эквивалентная примеру на фиг. 23.
С другой стороны, изменения информации приоритета в примере, представленном на фиг. 28, являются такими же, как и в примере случая, представленного на фиг. 24. В этом примере, если пороговое значение Q равно 4, элементы информации приоритета от временного фрейма (n - 1) по временной фрейм (n + 1) ниже, чем пороговое значение Q, но элемент информации приоритета временного фрейма (n + 2) выше, чем пороговое значение Q.
В этом случае значения усиления VBAP от временного фрейма (n - 1) по временной фрейм (n + 2) представляют собой, например, значения усиления, обозначенные ломаной линией GN61.
В этом примере, поскольку, как информация приоритета временного фрейма (n), так и информация приоритета временного интервала (n + 1), меньше, чем пороговое значение Q, значения усиления VBAP всех выборок временного интервала (n + 1) равны нулю.
Кроме того, поскольку информация приоритета временного фрейма (n + 2) равна или выше, чем пороговое значение Q в отношении объекта, предназначенного для обработки, значение усиления VBAP каждой выборки определяют на основе усиления VBAP канала, соответствующего громкоговорителю s, которое рассчитывают по обычному VBAP.
Таким образом, значение усиления VBAP первой выборки временного фрейма (n + 2) равно нулю, что представляет собой значение усиления VBAP последней выборки временного фрейма (n + 1), и значение усиления VBAP последней выборки временного фрейма (n + 2) представляет собой значение усиления VBAP, рассчитанное по обычному VBAP в отношении временного фрейма (n + 2). Затем значение усиления VBAP каждой выборки временного фрейма (n + 2) определяют так, чтобы оно линейно изменялось от первой выборки до последней выборки.
Таким образом, по значению усиления VBAP последней выборки временного интервала, в котором информация приоритета ниже, чем пороговое значение Q, равное нулю, может быть выполнена обработка плавного увеличения, эквивалентная примеру на фиг. 24.
Пример конфигурации модуля распаковки/декодирования
В случае, когда регулировка усиления выполняется путем обработки с плавным увеличением или обработки с плавным затуханием, описанных выше со ссылкой на фиг. 27 и фиг. 28, модуль 161 распаковки/декодирования, например, выполнен, как представлено на фиг. 29. На фиг. 29, части, соответствующие случаю на фиг. 25, обозначены теми же номерами ссылочных позиций, и их описание не повторяется.
Модуль 161 распаковки/декодирования, представленный на фиг. 29, включает в себя модуль 191 получения информации приоритета, модуль 192 получения аудиосигнала канала, модуль 193 декодирования аудиосигнала канала, модуль 194 выбора выхода, модуль 195 вывода нулевого значения, модуль 196 IMDCT, модуль 271 суммирования с наложением, модуль 273 обработки SBR, модуль 272 регулировки усиления, модуль 197 получения аудиосигнала объекта, модуль 198 декодирования аудиосигнала объекта, модуль 199 выбора выхода, модуль 200 вывода нулевого значения, модуль 201 IMDCT, модуль 274 суммирования с наложением и модуль 276 обработки SBR.
Конфигурация модуля 161 распаковки/декодирования, представленная на фиг. 29, отличается от конфигурации модуля 161 распаковки/декодирования, представленной на фиг. 25 в том смысле, что модуль 275 регулировки усиления не предусмотрен, и в остальном является такой же, как представлено на фиг. 25.
В модуле 161 распаковки/декодирования, представленном на фиг. 29, модуль 276 обработки SBR выполняет SBR в отношении аудиосигнала, подаваемого из модуля 274 суммирования с наложением на основе значения мощности высокой частоты, подаваемого из модуля 191 получения информации приоритета, и подает аудиосигнал, полученный в результате, в модуль 162 визуализации.
Кроме того, модуль 191 получения информации приоритета получает метаданные и информацию приоритета каждого объекта из переданного потока битов и подает метаданные и информацию приоритета в модуль 162 визуализации. Информация приоритета каждого объекта также поступает в модуль 199 выбора выхода.
Описание обработки декодирования
Далее будет описана операция устройства 151 декодирования в случае, когда модуль 161 распаковки/декодирования имеет конфигурацию, представленную на фиг. 29. Устройство 151 декодирования выполняет обработку декодирования, описанную со ссылкой на фиг. 30. Далее, со ссылкой на блок-схему последовательности операций на фиг. 30, будет описана обработка декодирования, выполняемая устройством 151 декодирования. Однако, на ЭТАПЕ S281, выполняется та же обработка, что и на ЭТАПЕ S51, на фиг. 11, и ее описание не повторяется.
На ЭТАПЕ S282, модуль 161 распаковки/декодирования выполняет обработку избирательного декодирования.
Здесь обработка избирательного декодирования, соответствующая обработке на ЭТАПЕ S282, на фиг. 30, будет описана со ссылкой на блок-схему последовательности операций, на фиг. 31.
Задачи обработки, представленные ниже с ЭТАПА S311 по ЭТАП S328, являются такими же, как и задачи обработки с ЭТАПА S231 по ЭТАП S248 на фиг. 26, и их описание не повторяется. Однако, на ЭТАПЕ S312, модуль 191 получения информации приоритета подает информацию приоритета, полученную из потока битов, также в модуль 162 визуализации.
На ЭТАПЕ S329, когда модуль 197 получения аудиосигнала объекта добавляет единицу к номеру объекта, обработка возвращается на ЭТАП S323. Затем, когда определяют, что номер объекта не меньше, чем N на ЭТАПЕ S323, обработка избирательного декодирования заканчивается, и затем обработка переходит на ЭТАП S283 на фиг. 30.
Поэтому, при обработке избирательного декодирования, представленной на фиг. 31, в отношении аудиосигнала каждого канала, регулировку усиления по усилению сигнала затухания выполняют аналогично случаю пятого варианта осуществления, и в отношении каждого объекта, регулировка усиления не выполняется, и аудиосигнал, полученный SBR, выводят в модуль 162 визуализации в том виде, как он есть.
Возвращаясь к описанию обработки декодирования, на фиг. 30, на ЭТАПЕ S283, модуль 162 визуализации выполняет визуализацию аудиосигнала каждого объекта на основе аудиосигнала каждого объекта, подаваемого из модуля 276 обработки SBR, информации положения, как метаданных каждого объекта, подаваемой из модуля 191 получения информации приоритета, и информации приоритета фрейма настоящего времени каждого объекта.
Например, как описано выше, со ссылкой на фиг. 27 и фиг. 28, что касается каждого канала, модуль 162 визуализации рассчитывает усиление VBAP каждой выборки фрейма настоящего времени на основе информации приоритета фрейма настоящего времени каждого канала и усиления VBAP последней выборки временного фрейма непосредственно перед фреймом настоящего времени. В это время модуль 162 визуализации, соответственно, рассчитывает усиление VBAP, используя VBAP на основе информации положения.
Затем модуль 162 визуализации генерирует аудиосигнал каждого канала на основе значения усиления VBAP каждого канала для каждой выборки, рассчитанной для каждого объекта, и аудиосигнал каждого объекта, и подает аудиосигнал в модуль 163 смешивания.
Здесь, в описании, значения усиления VBAP каждой выборки рассчитывают таким образом, что значения усиления VBAP каждой выборки во временном фрейме изменяются линейно. Однако, усиление VBAP может изменяться нелинейно. Кроме того, в описании, аудиосигнал каждого канала генерируют, используя VBAP. Однако, даже в случае, когда аудиосигнал каждого канала генерируют, используя другие способы, возможно регулировать усиление аудиосигнала каждого объекта, используя обработку, аналогичную случаю VBAP.
После генерирования аудиосигнала каждого канала выполняется обработка на ЭТАПЕ S284, и обработка декодирования заканчивается. Однако, поскольку обработка на ЭТАПЕ S284 является такой же, как и на ЭТАПЕ S54, на фиг. 11, ее описание не повторяется.
Таким образом, устройство 151 декодирования рассчитывает усиление VBAP для каждой выборки на основе информации приоритета в отношении каждого объекта, и во время генерирования аудиосигнала каждого канала, выполняет регулировку усиления аудиосигнала объекта по усилению VBAP. Таким образом, возникновение шумов в виде гула подавляется при меньшем количестве обработки, и, таким образом, возможно предотвратить ухудшение качества звука при прослушивании.
В описаниях с четвертого варианта осуществления по шестой вариант осуществления назначение выхода коэффициента MDCT выбирают, используя информацию приоритета временных интервалов непосредственно перед и после фрейма настоящего времени, или регулировку усиления выполняют по усилению сигнала с плавным изменением и т.п.Однако, не будучи ограниченным этим, может использоваться информация приоритета фрейма настоящего времени, и информация приоритета временных фреймов среди заданного количества временных фреймов перед фреймом настоящего времени, или информация приоритета временных фреймов и заданного количества временных интервалов после фрейма настоящего времени.
В частности, последовательность задач обработки, описанная выше, может выполняться, используя аппаратные средства, или может выполняться программными средствами. В случае, когда последовательность задач обработки выполняется программными средствами, программу, которую конфигурирует программное средство, устанавливают в компьютер. Здесь компьютер включает в себя компьютер, который встроен в специализированные аппаратные средства, или компьютер общего назначения, например, который позволяет выполнять различные функции с помощью устанавливаемых различных программ.
На фиг. 32 показана блок-схема, иллюстрирующая пример конфигурации аппаратных средств компьютера, который выполняет последовательность задач обработки, описанную выше, с помощью программы.
В компьютере центральное процессорное устройство (CPU) 501, постоянное запоминающее устройство (ROM) 502 и оперативное запоминающее устройство (RAM) 503 соединены друг с другом по шине 504.
Кроме того, интерфейс 505 ввода/вывода соединен по шине 504. Модуль 506 ввода, модуль 507 вывода, модуль 508 накопителя, модуль 509 передачи данных и привод 510 соединены с интерфейсом 505 ввода/вывода.
Модуль 506 ввода включает в себя клавиатуру, мышь, микрофон и элемент формирования изображения. Модуль 507 вывода включает в себя дисплей и громкоговорители. Модуль 508 накопителя включает в себя жесткий диск или энергонезависимое запоминающее устройство. Модуль 509 передачи данных включает в себя сетевой интерфейс и т.п. Привод 510 выполняет привод съемных носителей 511, таких как магнитный диск, оптический диск, оптический магнитный диск или полупроводниковое запоминающее устройство.
В компьютере, выполненном, как описано выше, CPU 501 загружает программу, сохраненную в модуле 508 накопителя, через интерфейс 505 ввода/вывода и шину 504 в RAM 503, для выполнения программы, и затем выполняется последовательность задач обработки, описанная выше.
Программа, выполняемая компьютером (CPU 501), может быть предоставлена в виде записи на съемных носителях 511 записи, как пакетные носители и т.п. Кроме того, программа может быть предусмотрена через кабельную или беспроводную среду передачи данных, такую как локальная вычислительная сеть, Интернет или цифровая спутниковая широковещательная передача.
В компьютере программа может быть установлена в модуле 508 накопителя через интерфейс 505 ввода/вывода, путем установки съемных носителей 511 информации в привод 510. Кроме того, программа может быть принята модулем 509 передачи данных через кабельную или беспроводную среду передачи данных, и может быть установлена в модуле 508 накопителя. Кроме того, программа может быть заранее установлена в ROM 502 или в модуле 508 накопителя.
Программа, выполняемая компьютером, может представлять собой программу, в которой выполняются задачи обработки во временной последовательности, в порядке, описанном здесь, или может представлять собой программу, в которой задачи обработки выполняются параллельно, или в необходимые моменты времени, когда выполняется вызов.
Кроме того, вариант осуществления настоящей технологии не ограничен описанными выше вариантами осуществления, и различные модификации могут быть выполнены без выхода за пределы сущности настоящей технологии.
Например, настоящая технология может принимать конфигурацию "облачных" вычислений, в которых одна функция обрабатывается с разделением и во взаимодействии с множеством устройств через сеть.
Кроме того, каждый ЭТАП, описанный в представленных выше блок-схемах последовательности операций, может быть выполнен одним устройством или может быть выполнен с распределением по множеству устройств.
Кроме того, в случае, когда множество задач обработки включено в один этап, задачи обработки, включенные в этот один ЭТАП, могут быть выполнены одним устройством, или могут быть выполнены путем распределения по множеству устройств.
Кроме того, эффекты, описанные здесь, представляют собой только примеры и не ограничены этим, и могут присутствовать другие эффекты.
Кроме того, настоящая технология может иметь такую конфигурацию, как описано ниже.
(1) Устройство декодирования, содержащее:
по меньшей мере одну схему, выполненную с возможностью:
получения одного или более кодированных аудиосигналов, включающих в себя множество каналов и/или множество объектов и информацию приоритета для каждого из множества каналов и/или множества объектов; и
декодирования одного или более кодированных аудиосигналов, в соответствии с информацией приоритета.
(2) Устройство декодирования по (1), в котором по меньшей мере одна схема выполнена с возможностью декодирования, в соответствии с информацией приоритета по меньшей мере частично посредством декодирования по меньшей мере одного из одного или более кодированных аудиосигналов, для которых степень приоритета, обозначенная информацией приоритета, равна или выше, чем степень, и отказа от декодирования по меньшей мере других из одного или более кодированных аудиосигналов, для которых степень приоритета, обозначенная информацией приоритета, меньше, чем степень.
(3) Устройство декодирования по (2), в котором по меньшей мере одна схема выполнена с возможностью изменения степени по меньшей мере частично на основе информации приоритета для множества каналов и/или множества объектов.
(4) Устройство декодирования по любому из (1)-(3), в котором:
по меньшей мере, одна схема выполнена с возможностью получения множества наборов информации приоритета для одного или более кодированных аудиосигналов, и,
по меньшей мере одна схема выполнена с возможностью декодирования одного или более кодированных аудиосигналов по меньшей мере частично посредством выбора одного из наборов информации приоритета и декодирования по меньшей мере частично, на основе одного набора информации приоритета.
(5) Устройство декодирования по (4), в котором по меньшей мере одна схема выполнена с возможностью выбора по меньшей мере одного из наборов информации приоритета в соответствии с вычислительными возможностями устройства декодирования.
(6) Устройство декодирования по любому из (1)-(5), в котором по меньшей мере одна схема дополнительно выполнена с возможностью генерирования информации приоритета по меньшей мере частично, на основе кодированного аудиосигнала.
(7) Устройство декодирования по (6), в котором по меньшей мере одна схема выполнена с возможностью генерирования информации приоритета по меньшей мере частично, на основе давления звука или спектральной формы аудиосигнала одного или более кодированных аудиосигналов.
(8) Устройство декодирования по любому из (1) - (7), в котором:
информация приоритета для множества каналов и/или множества объектов содержит по меньшей мере для одного первого канала из множества каналов и/или по меньшей мере одного первого объекта из множества объектов, информацию приоритета, указывающую разные степени приоритета по меньшей мере одного первого канала и/или по меньшей мере одного первого объекта, в течение периода времени, и
по меньшей мере одна схема выполнена с возможностью декодирования, на основе информации приоритета по меньшей мере частично, посредством определения, для первого канала и/или первого объекта и первого времени в течение периода времени, следует ли декодировать первый канал и/или первый объект в первое время, по меньшей мере частично, на основе степени приоритета для первого канала и/или первого объекта в первое время и степени приоритета для первого канала, и/или первого объекта в другое время перед или после первого времени и в течение периода времени.
(9) Устройство декодирования по любому из (1)-(8), в котором по меньшей мере одна схема дополнительно выполнена с возможностью:
генерирования аудиосигнала для первого времени по меньшей мере частично, посредством добавления выходного аудиосигнала для канала или объекта в это время, и вывода аудиосигнала канала или объекта во второе время перед или после первого времени, при этом выходной аудиосигнал для канала или объекта для времени представляет собой сигнал, получаемый по меньшей мере одной схемой в результате декодирования, в случае, когда выполняется декодирование канала или объекта в течение времени, и нулевые данные в случае, когда не выполняется декодирование канала или объекта в течение времени; и
для выполнения регулировки усиления выходного аудиосигнала канала или объекта в это время на основе информации приоритета канала или объекта в это время и информации приоритета канала или объекта в другое время перед или после этого времени.
(10) Устройство декодирования по (9), в котором по меньшей мере одна схема дополнительно выполнена с возможностью:
регулировки усиления значения мощности высокой частоты для канала или объектов на основе информации приоритета канала или объекта в первое время и информации приоритета канала или объекта во второе время перед или после первого времени, и
генерирования компонента высокой частоты аудиосигнала для первого времени на основе значения мощности высокой частоты, для которого регулируют коэффициент усиления, и аудиосигнал для времени.
(11) Устройство декодирования по (9) или (10), в котором по меньшей мере одна схема дополнительно выполнена с возможностью:
генерирования, для каждого канала или каждого объекта, аудиосигнала первого времени, содержащего компонент высокой частоты, на основе значения мощности высокой частоты и аудиосигнал для времени,
регулировки усиления аудиосигнала для первого времени, в который включен компонент высокой частоты.
(12) Устройство декодирования по любому из (1)-(11), в котором по меньшей мере одна схема, дополнительно выполнена с возможностью назначения аудиосигнала первого объекта из множества объектов для каждого из по меньшей мере некоторых из множества каналов со значением усиления на основе информации приоритета, и генерирования аудиосигнала каждого из множества каналов.
(13) Способ декодирования, содержащий этапы, на которых:
получают информацию приоритета для каждого из множества каналов и/или множества объектов одного или более кодированных аудиосигналов; и
декодируют множество каналов и/или множество объектов в соответствии с информацией приоритета.
(14) По меньшей мере, один энергонезависимый считываемый компьютером носитель информации, хранящий исполняемые инструкции так, что при их выполнении по меньшей мере одним процессором, обеспечивается выполнение по меньшей мере одним процессором способа, содержащего этапы, на которых:
получают информацию приоритета для каждого из множества каналов и/или множества объектов одного или более кодированных аудиосигналов; и
декодируют множество каналов и/или множество объектов в соответствии с информацией приоритета.
(15) Устройство кодирования, содержащее:
по меньшей мере, одну схему, выполненную с возможностью: генерирования информации приоритета для каждого из множества каналов и/или множества объектов аудиосигнала; и
сохранения информации приоритета в потоке битов.
(16) Устройство кодирования по (15), в котором по меньшей мере одна схема выполнена с возможностью генерирования информации приоритета по меньшей мере частично, посредством генерирования множества наборов информации приоритета для каждого из множества каналов и/или множества объектов.
(17) Устройство кодирования по (16), в котором по меньшей мере одна схема выполнена с возможностью генерирования множества наборов информации приоритета для каждой из множества возможностей вычисления устройств декодирования.
(18) Устройство кодирования по любому из (15)-(17), в котором по меньшей мере одна схема выполнена с возможностью генерирования информации приоритета по меньшей мере частично, на основе давления звука или спектральной формы аудиосигнала.
(19) Устройство кодирования по любому из (15)-(18), в котором:
по меньшей мере одна схема дополнительно выполнена с возможностью кодирования аудиосигналов множества каналов и/или множества объектов аудиосигнала для формирования кодированного аудиосигнала, и
по меньшей мере одна схема дополнительно выполнена с возможностью сохранения информации приоритета и кодированного аудиосигнала в потоке битов.
(20) Способ кодирования, содержащий этапы, на которых:
генерируют информацию приоритета для каждого из множества каналов и/или множества объектов аудиосигнала; и
сохраняют информацию приоритета в потоке битов.
(21) По меньшей мере один энергонезависимый считываемый компьютером носитель информации, на котором кодированы исполняемые инструкции так, что при их выполнении по меньшей мере одним процессором, обеспечивается выполнение по меньшей мере, одним процессором способа, содержащего этапы, на которых:
генерируют информацию приоритета для каждого из множества каналов и/или множества объектов аудиосигнала; и
сохраняют информацию приоритета в потоке битов.
Следует понимать для специалиста в данной области техники, что различные модификации, комбинации, подкомбинации и изменения могут возникнуть, в зависимости от конструктивных требований и других факторов, если только они находятся в пределах объема приложенной формулы изобретения или ее эквивалентов.
Список номеров ссылочных позиций
11 устройство кодирования
21 модуль кодирования аудиоканала
22 модуль кодирования аудиообъекта
23 модуль ввода метаданных
24 модуль формирования пакетов
51 модуль кодирования
52 модуль генерирования информации приоритета
61 модуль MDCT
91 модуль кодирования
92 модуль генерирования информации приоритета
101 модуль MDCT
151 устройство декодирования
161 модуль распаковки/декодирования
162 модуль визуализации
163 модуль смешивания
191 модуль получения информации приоритета
193 модуль декодирования аудиосигнала канала
194 модуль выбора выхода 196 модуль IMDCT
198 модуль декодирования аудиосигнала объекта
199 модуль выбора выхода
201 модуль IMDCT
231 модуль генерирования информации приоритета
232 модуль генерирования информации приоритета
271 модуль суммирования с наложением
272 модуль регулировки усиления
273 модуль обработки SBR
274 модуль суммирования с наложением
275 модуль регулировки усиления
276 модуль обработки SBR
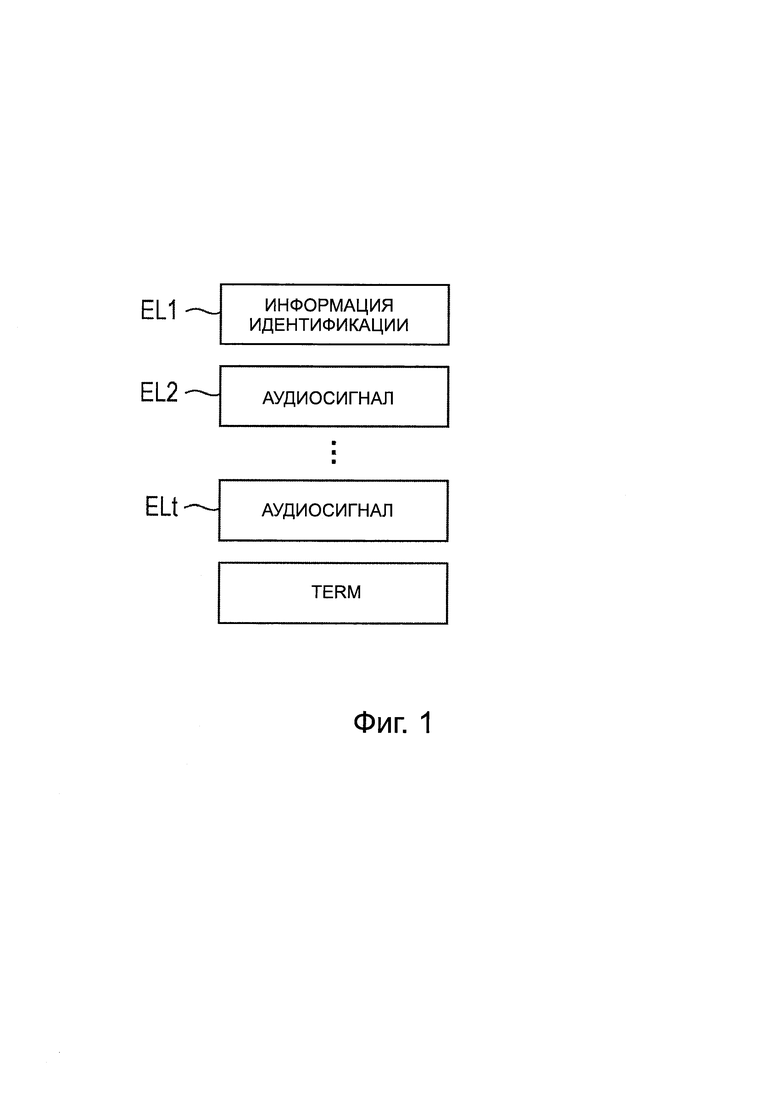
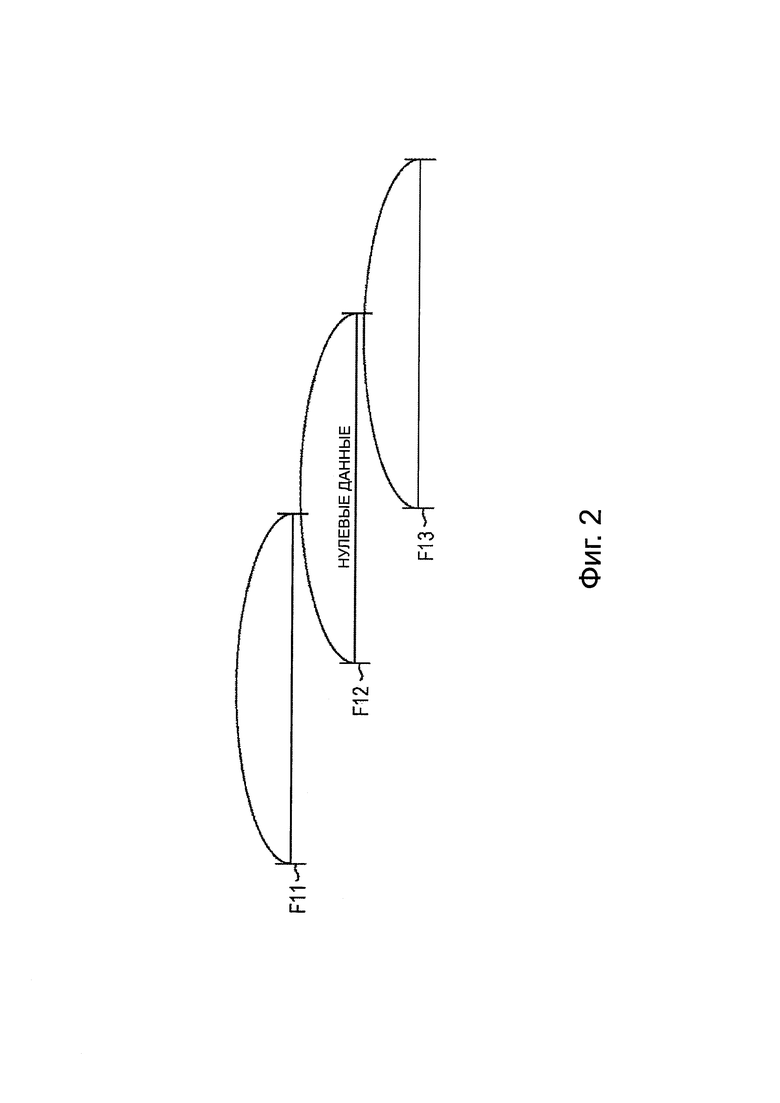



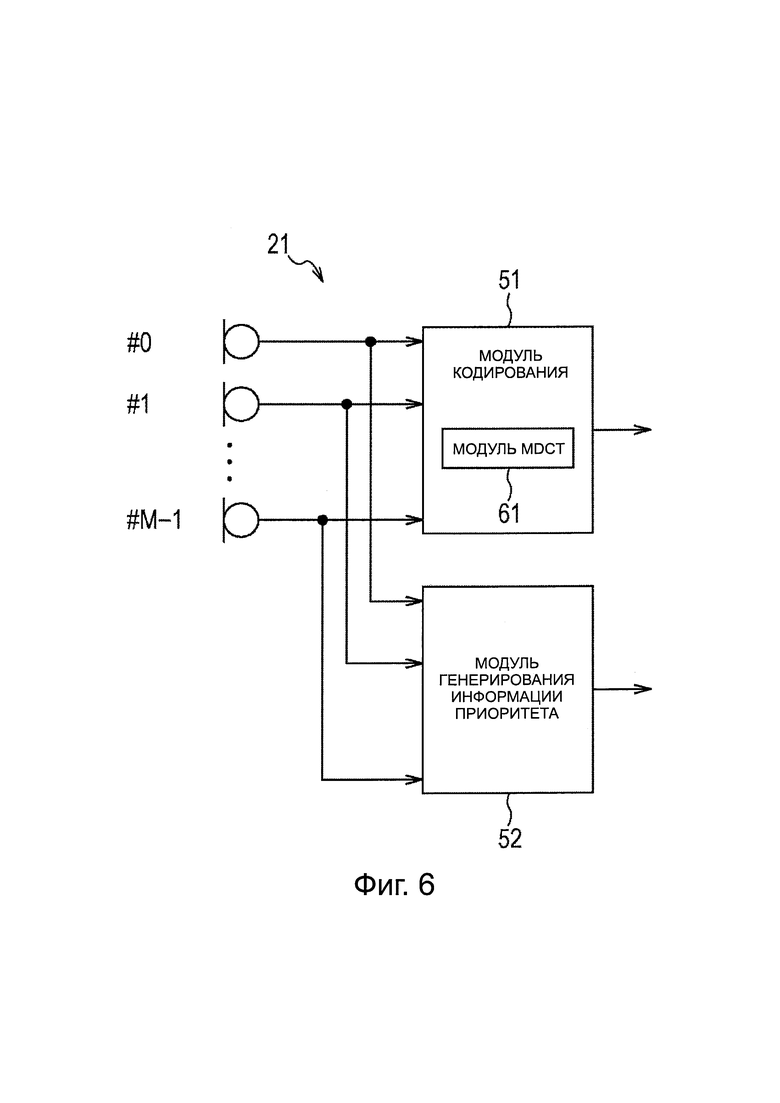
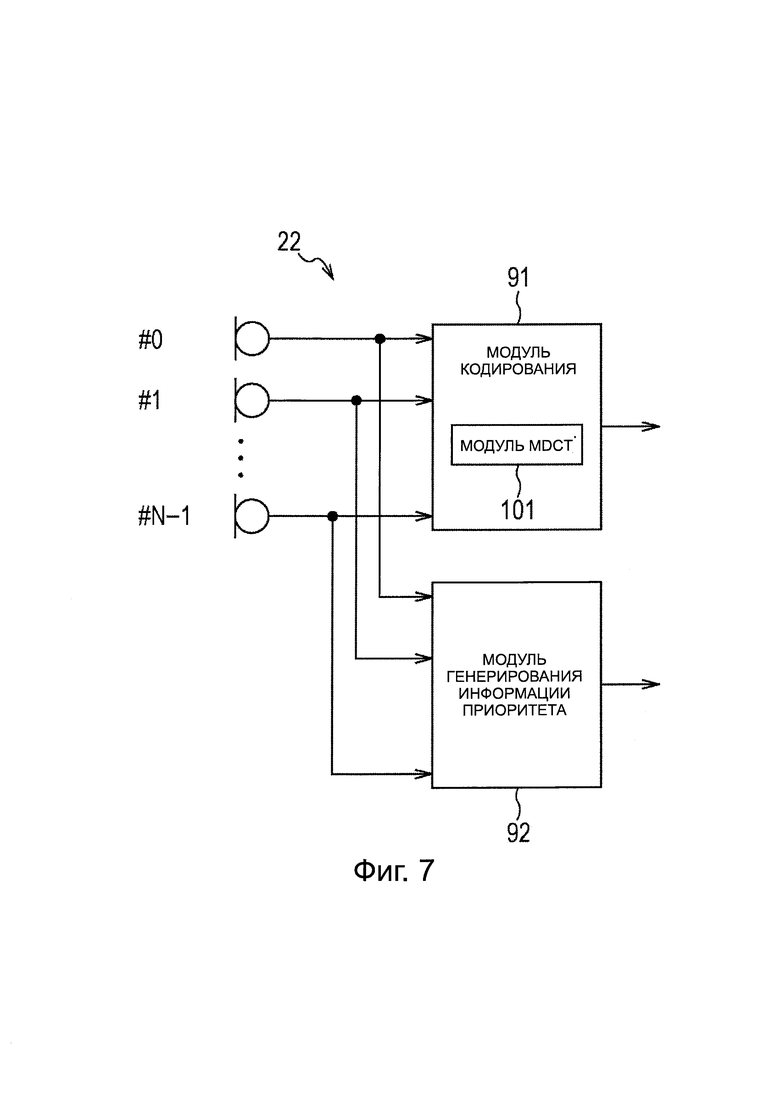
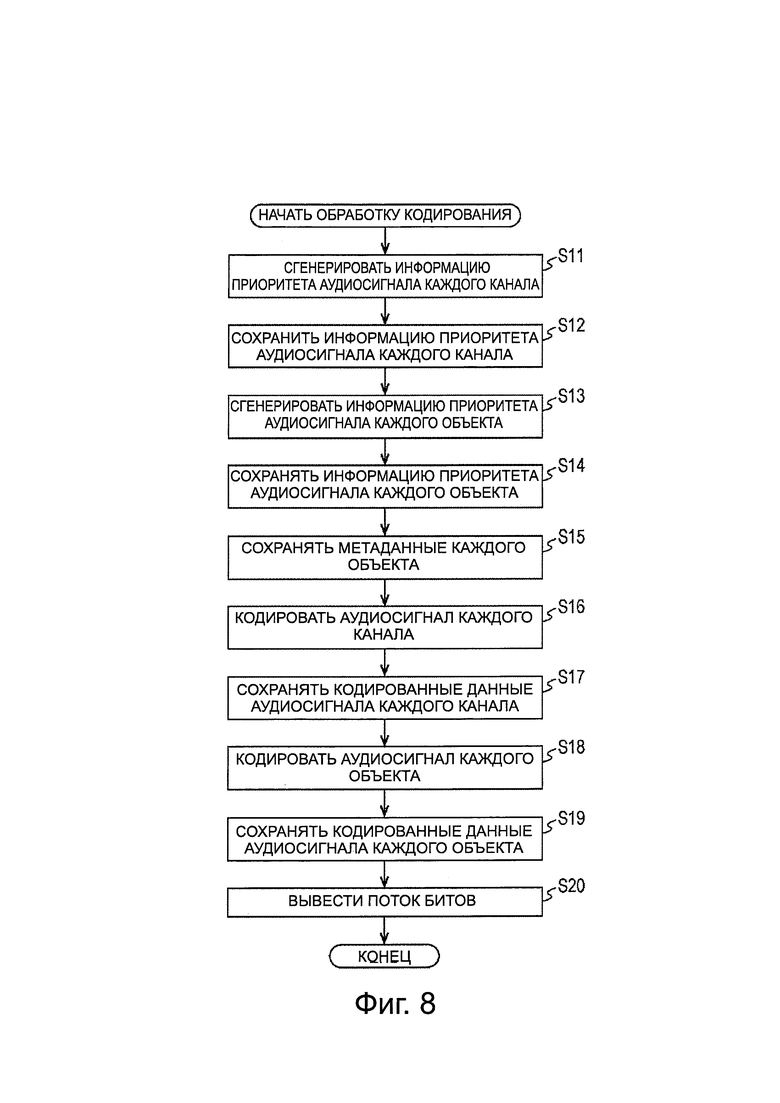
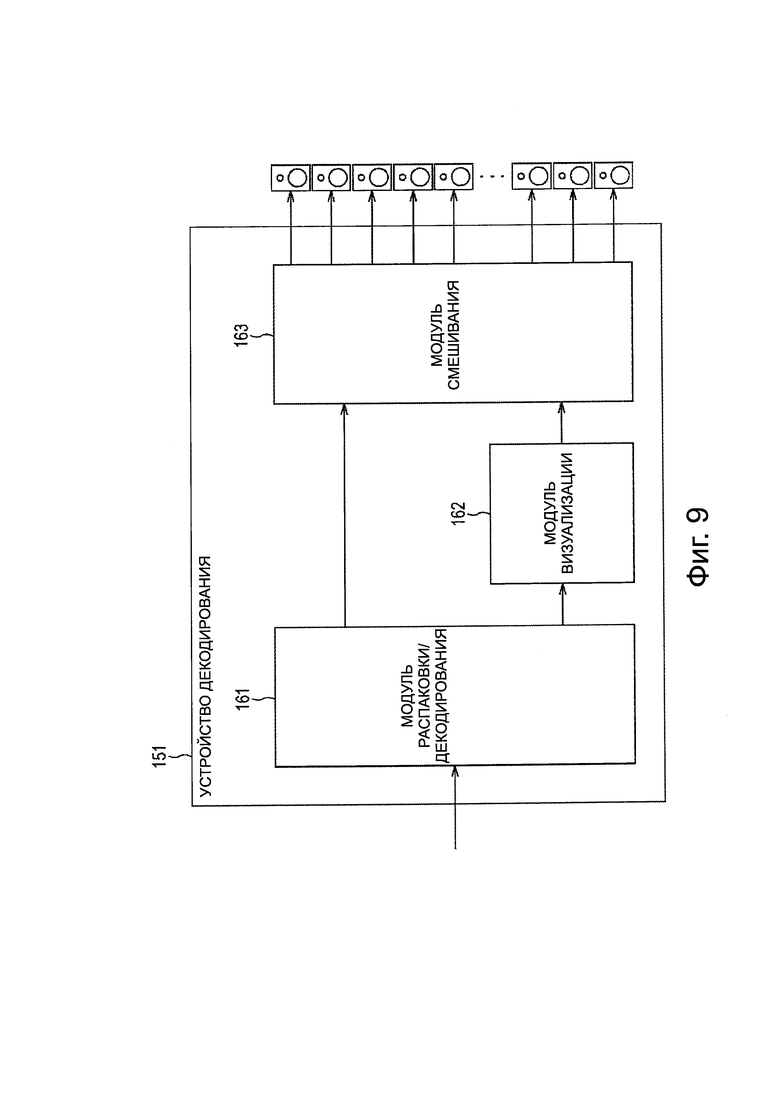
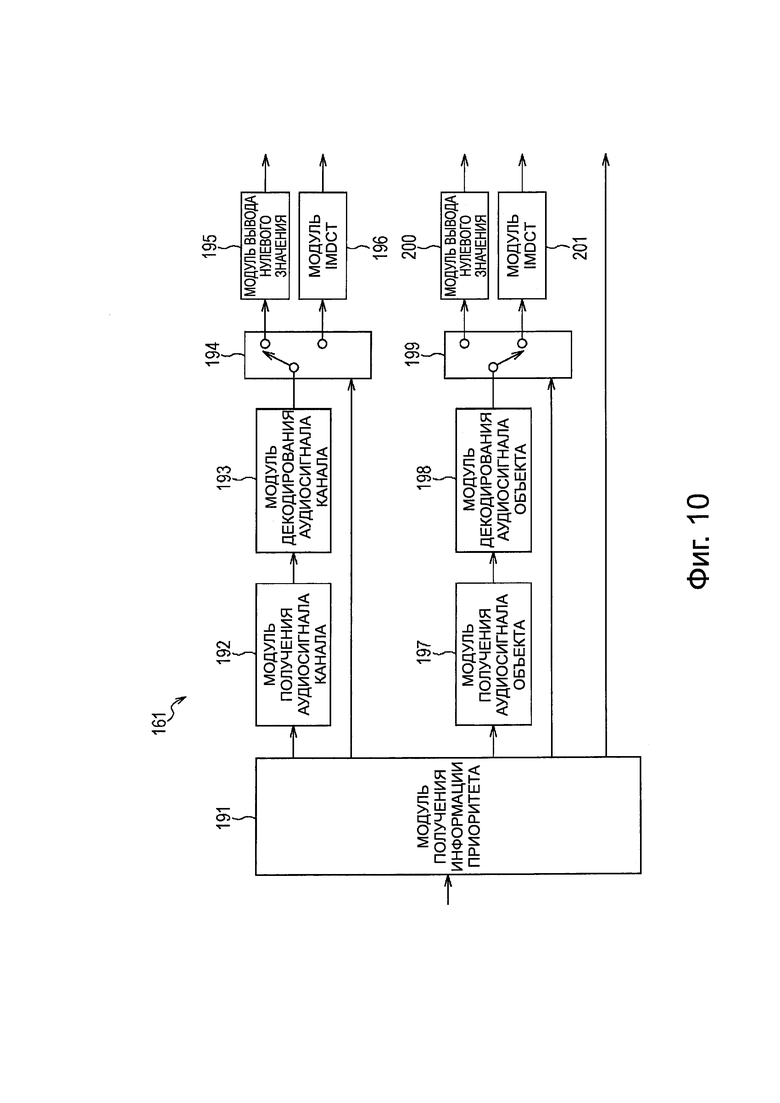
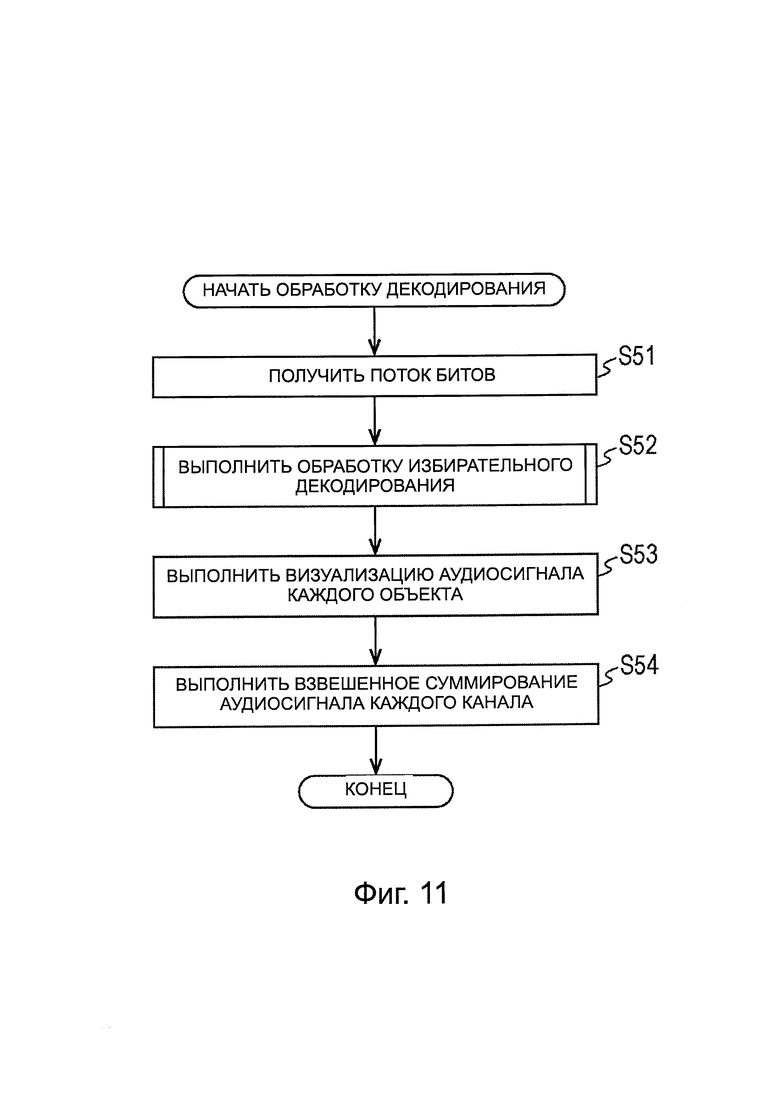
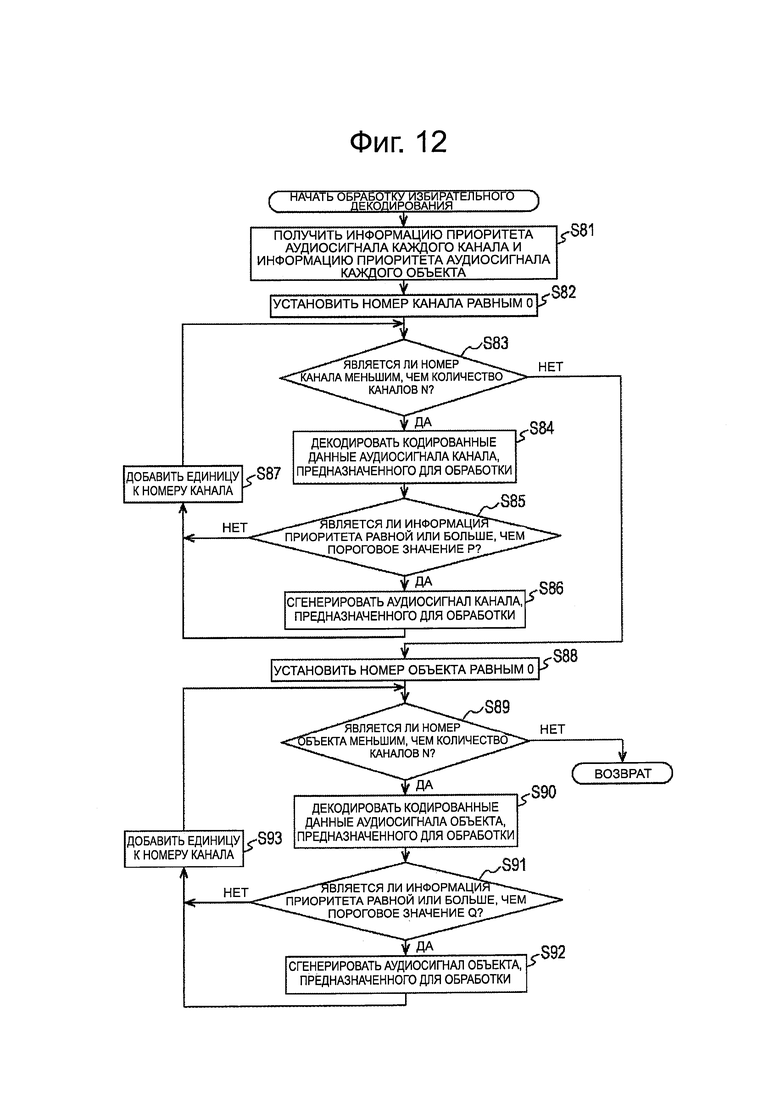
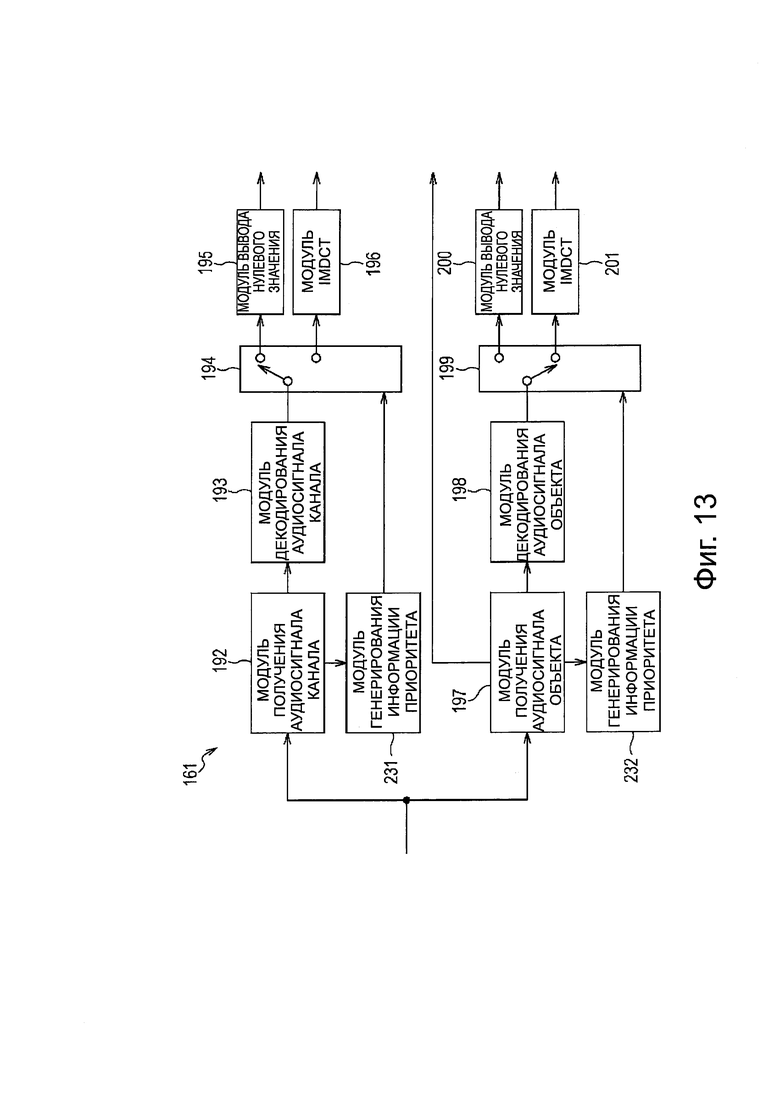
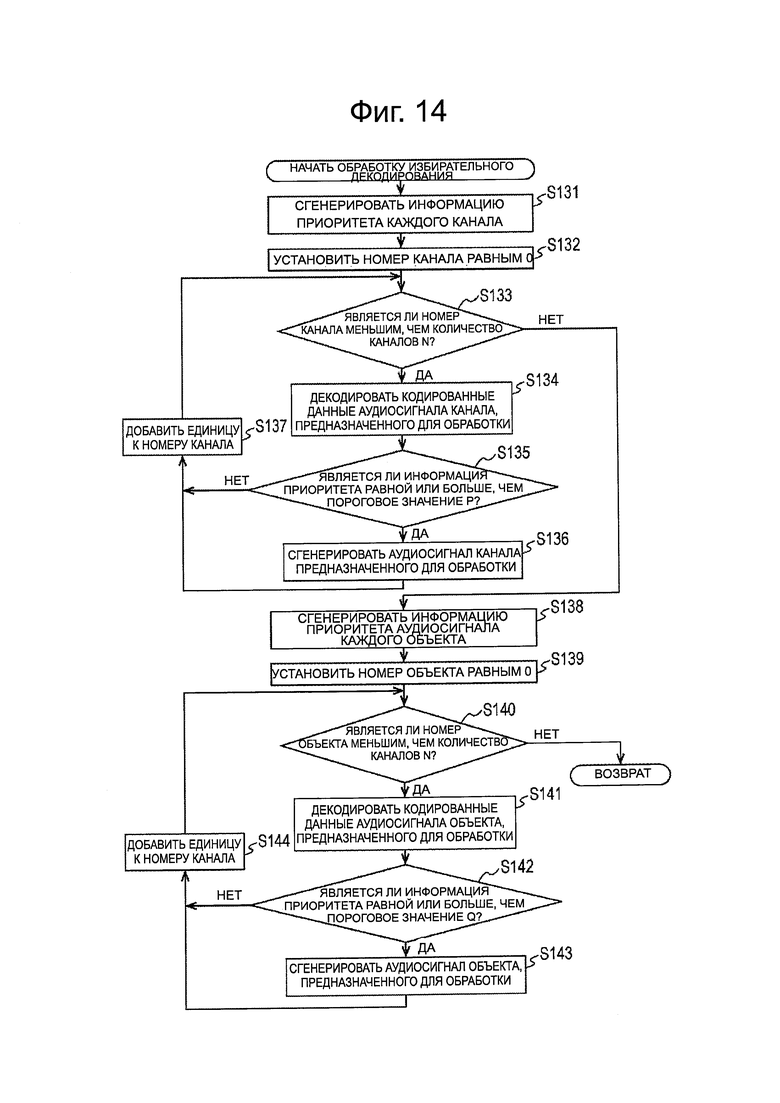
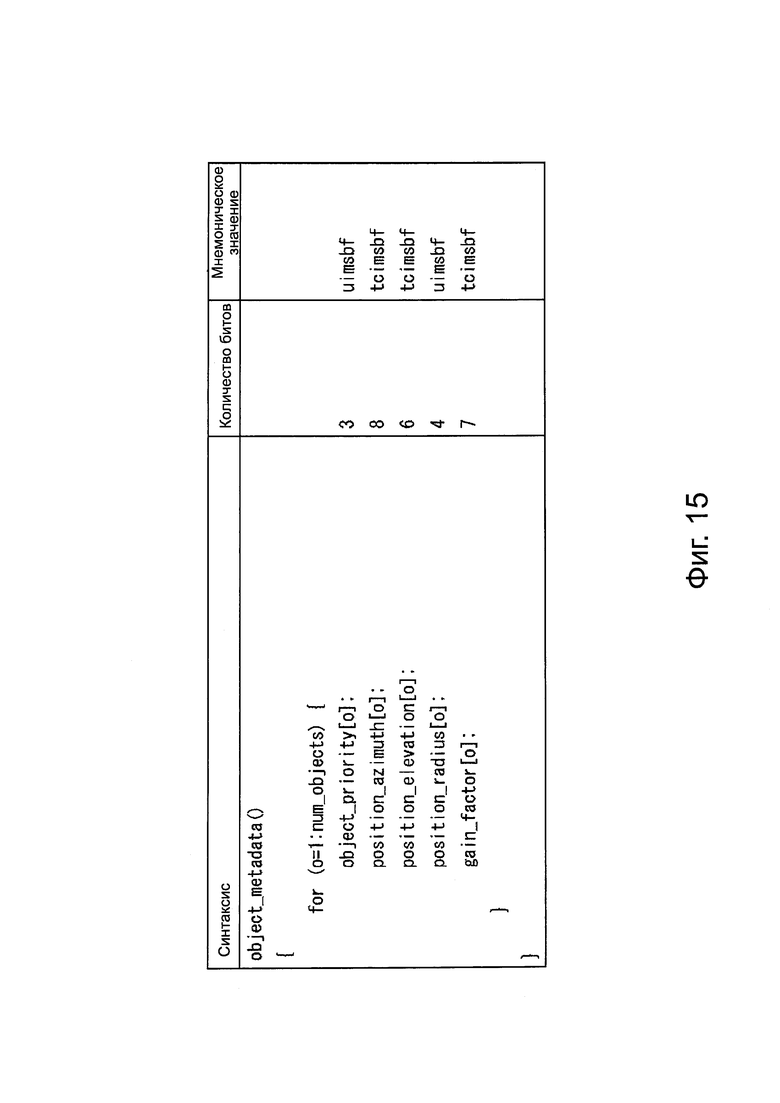
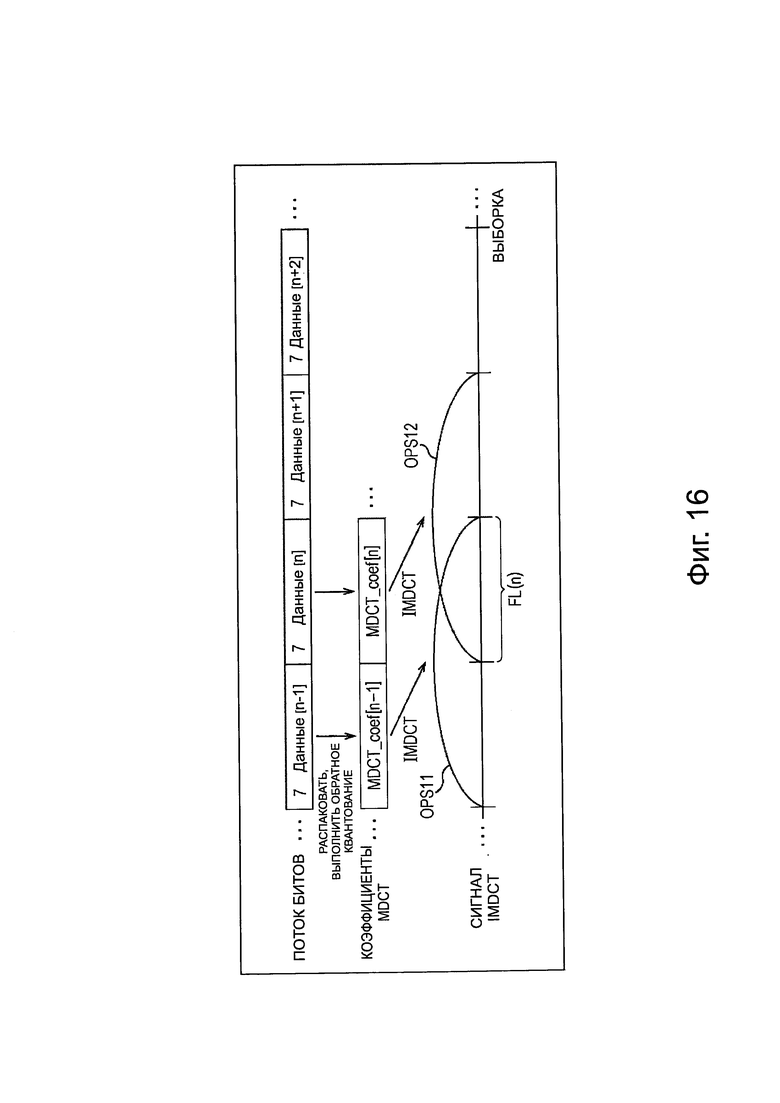
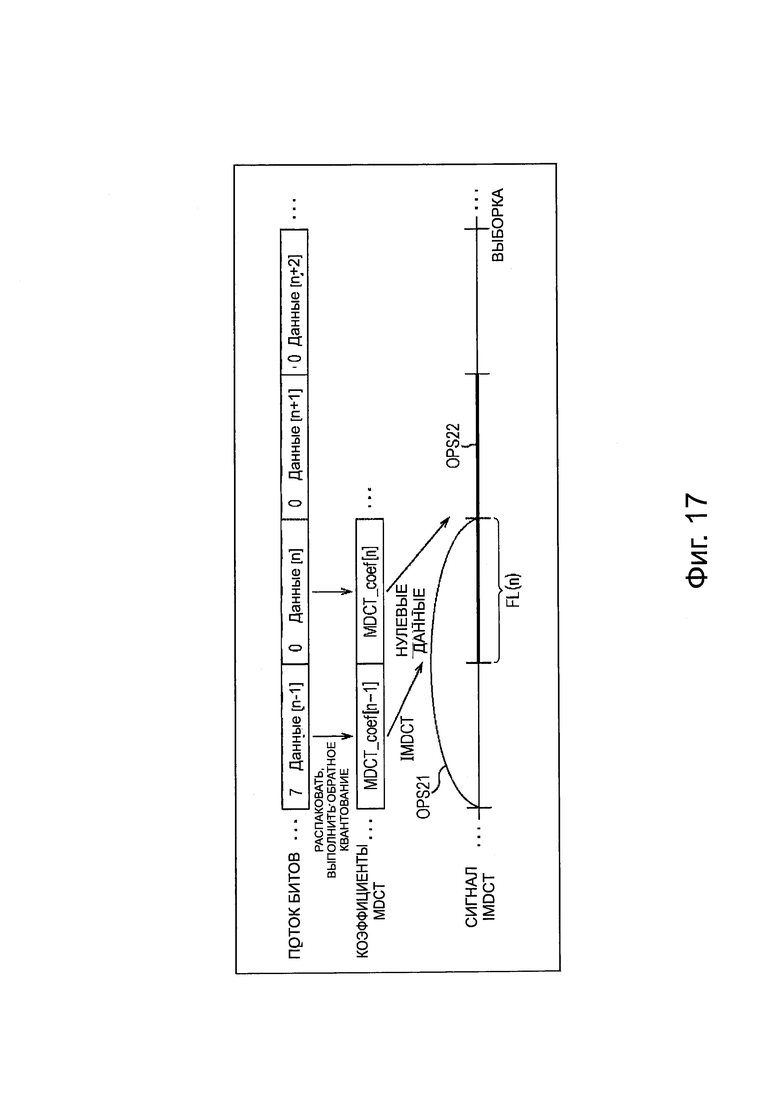
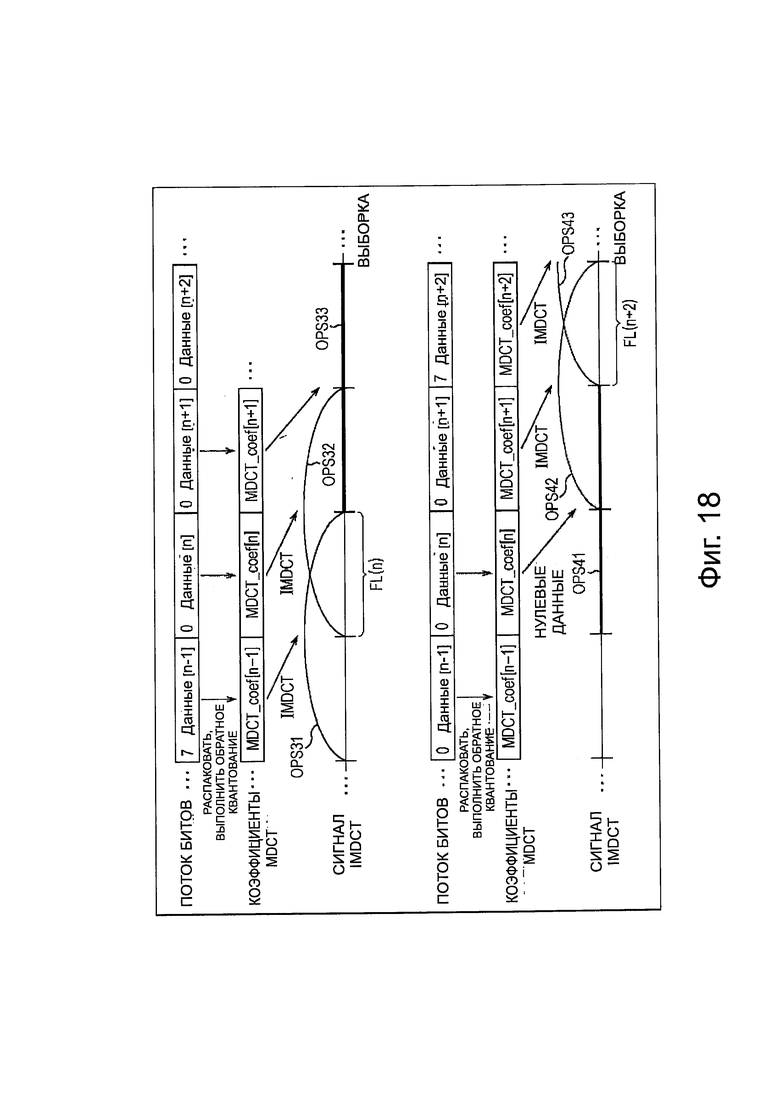
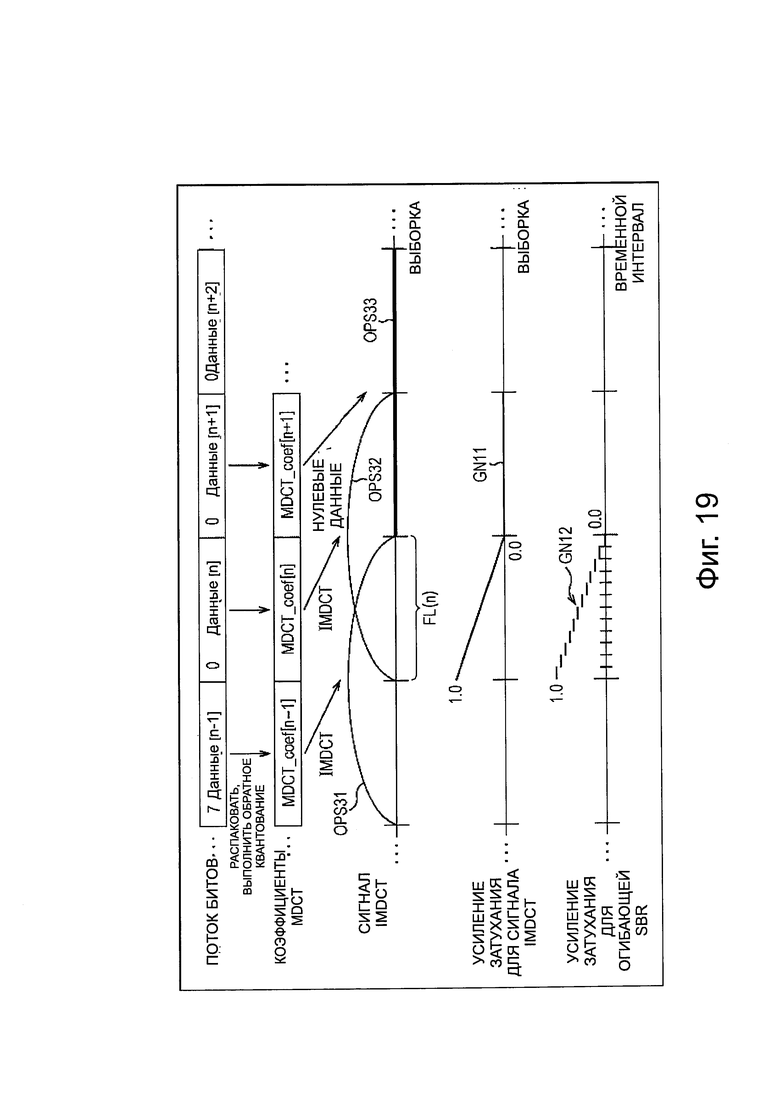
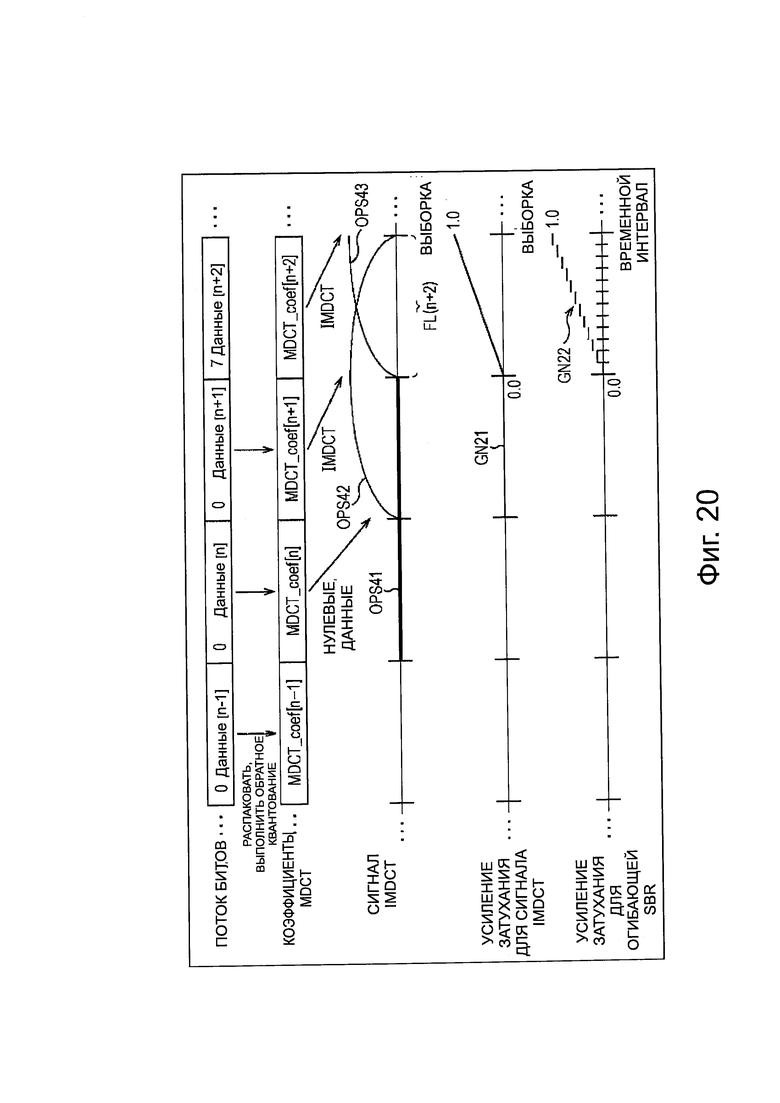
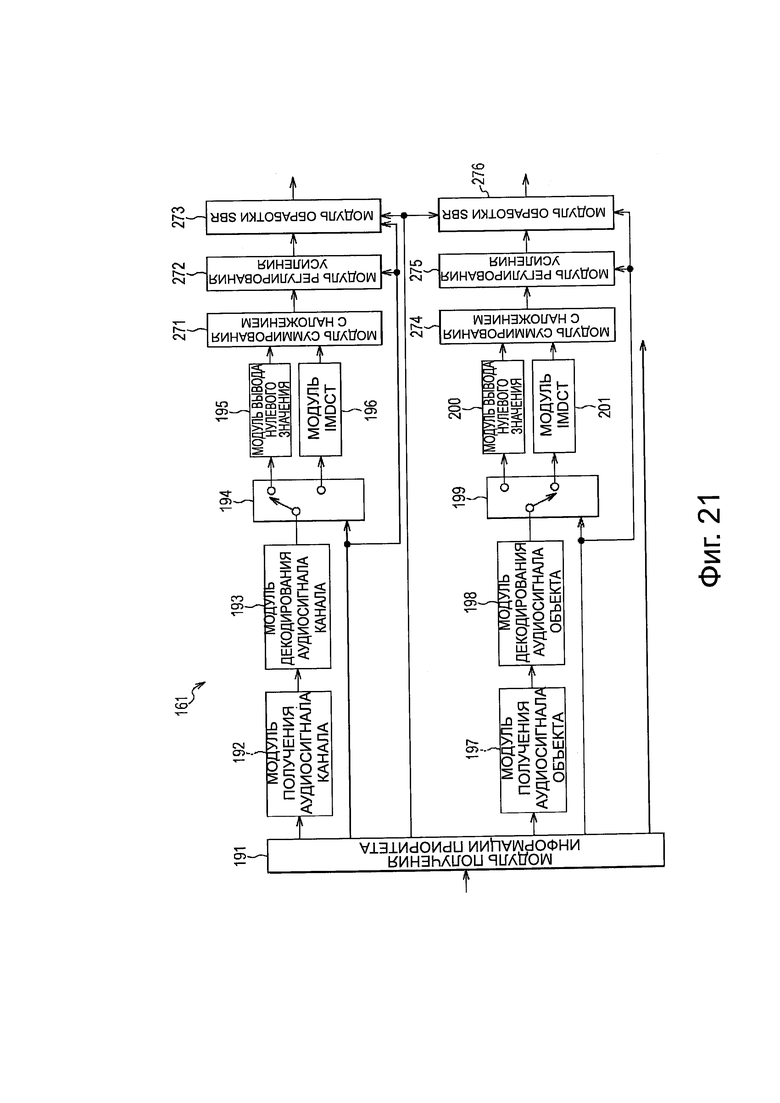

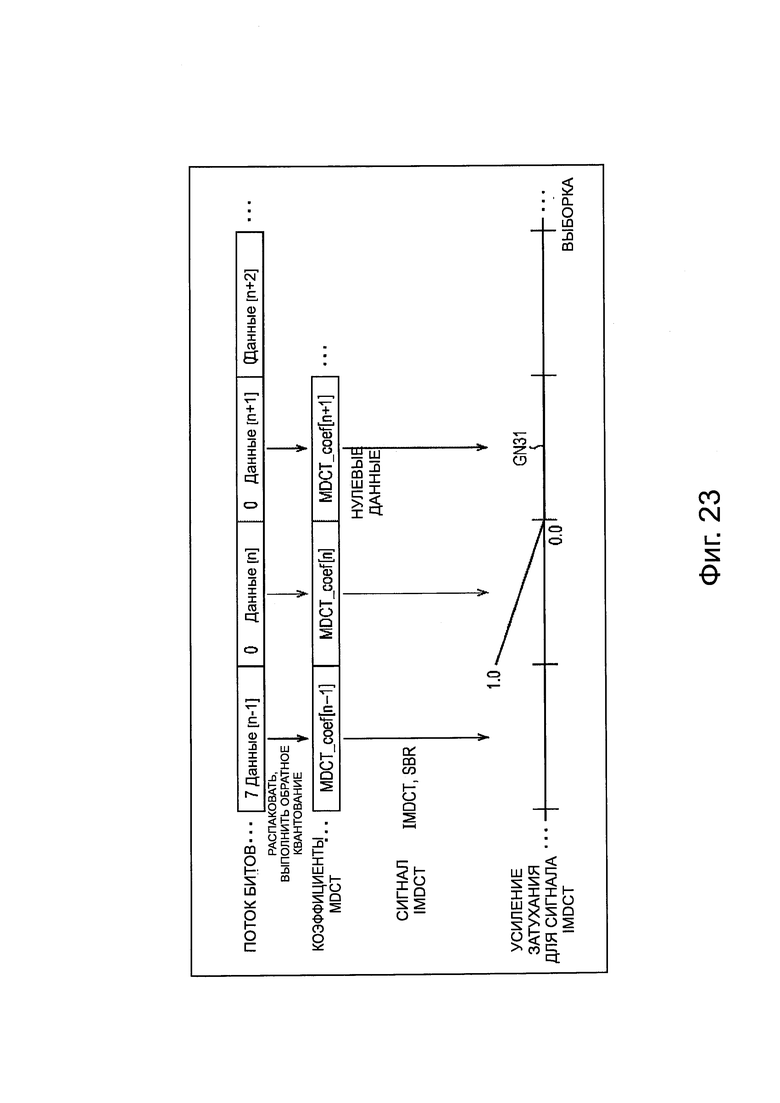
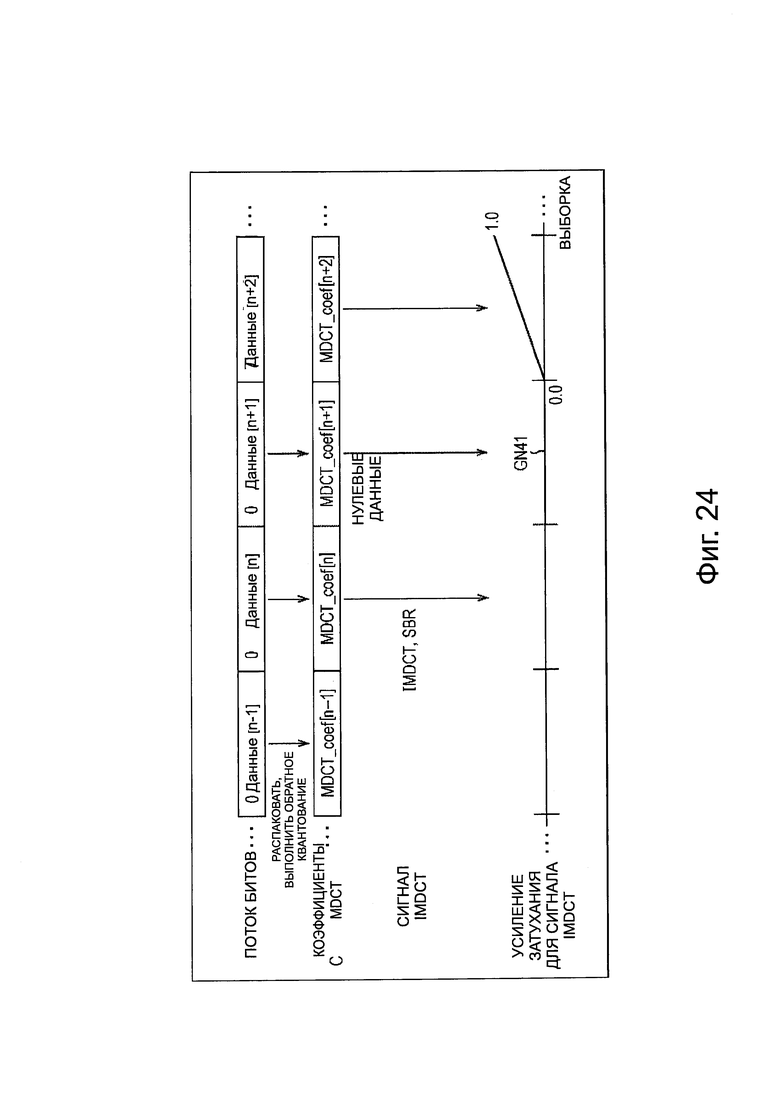
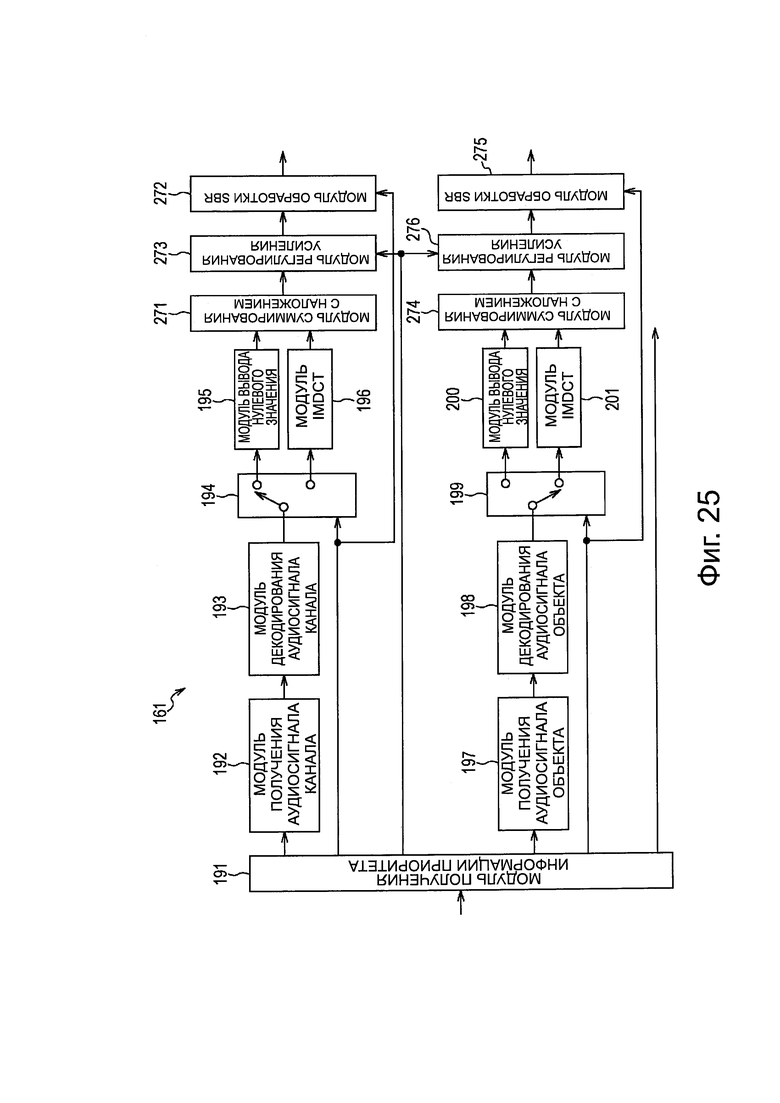
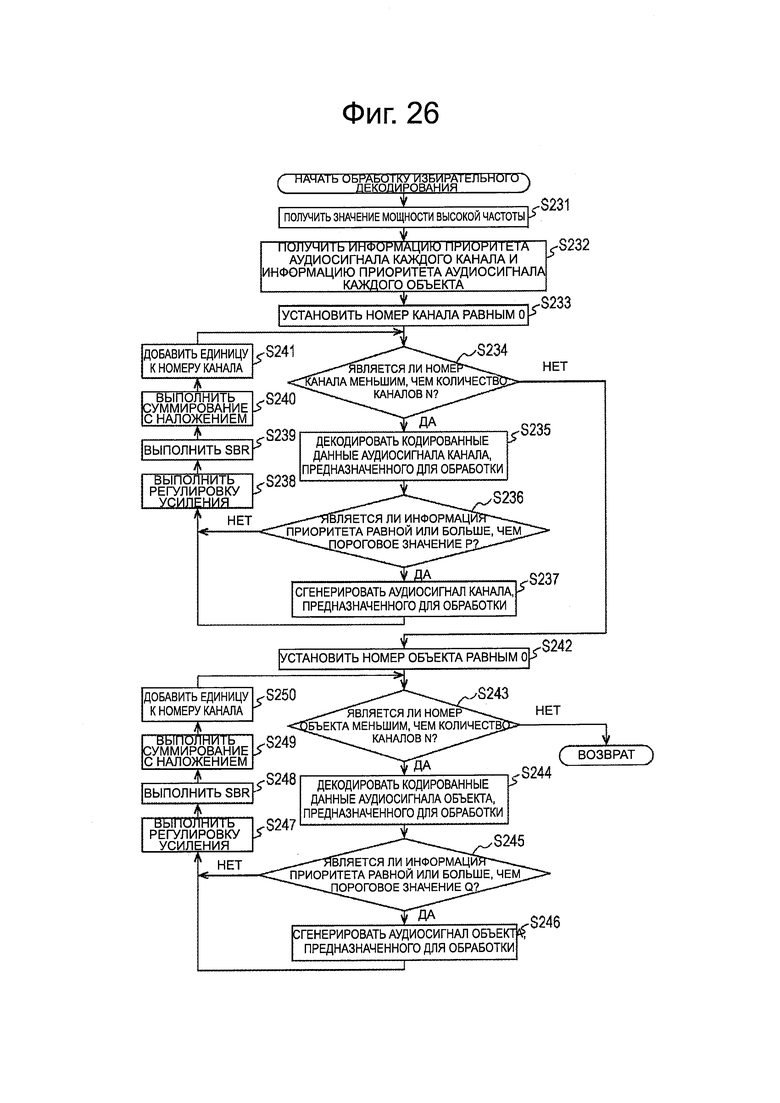
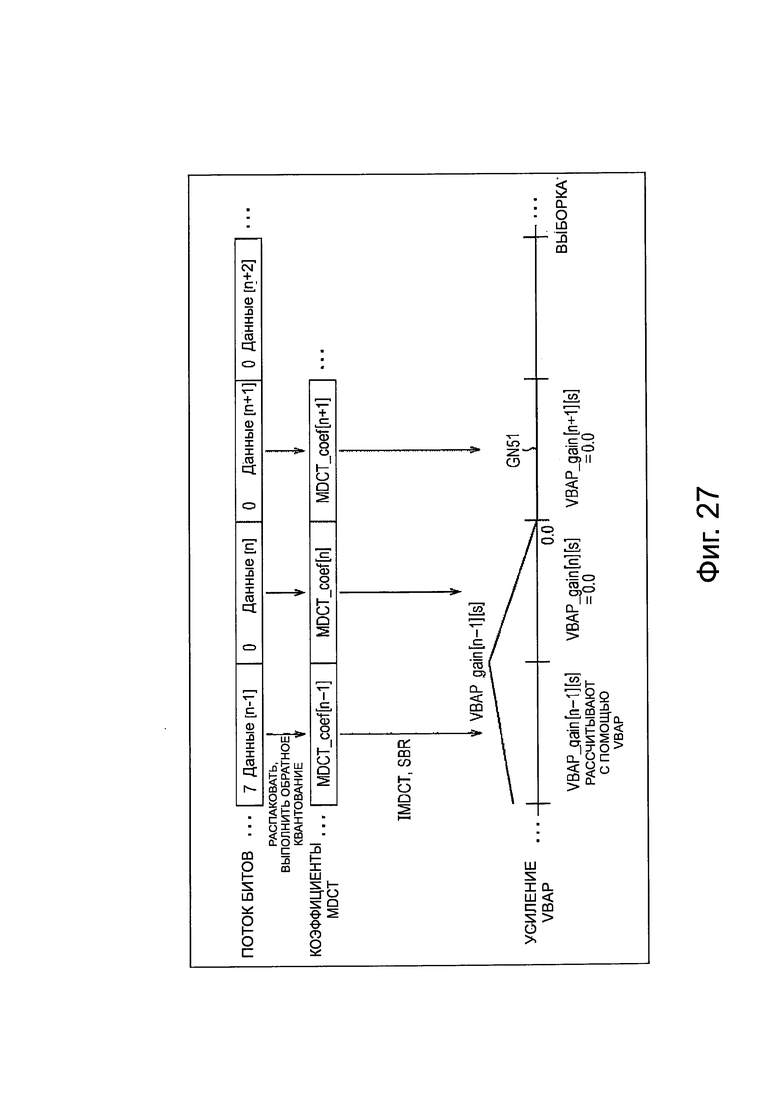
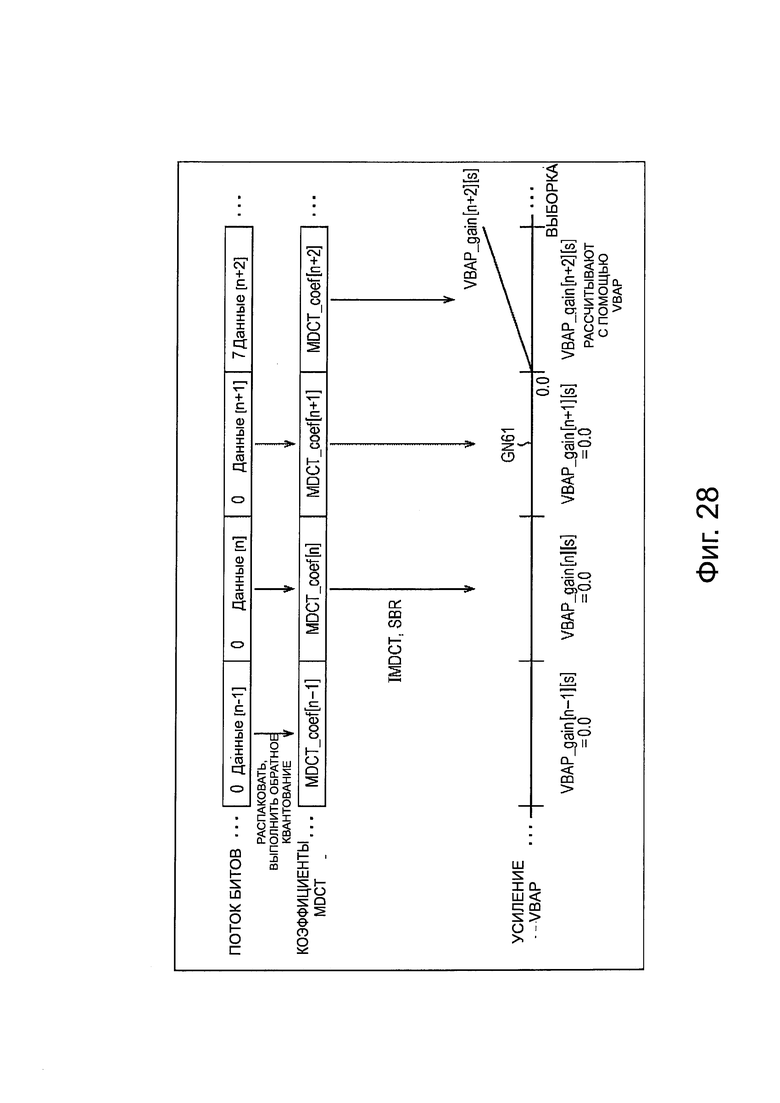
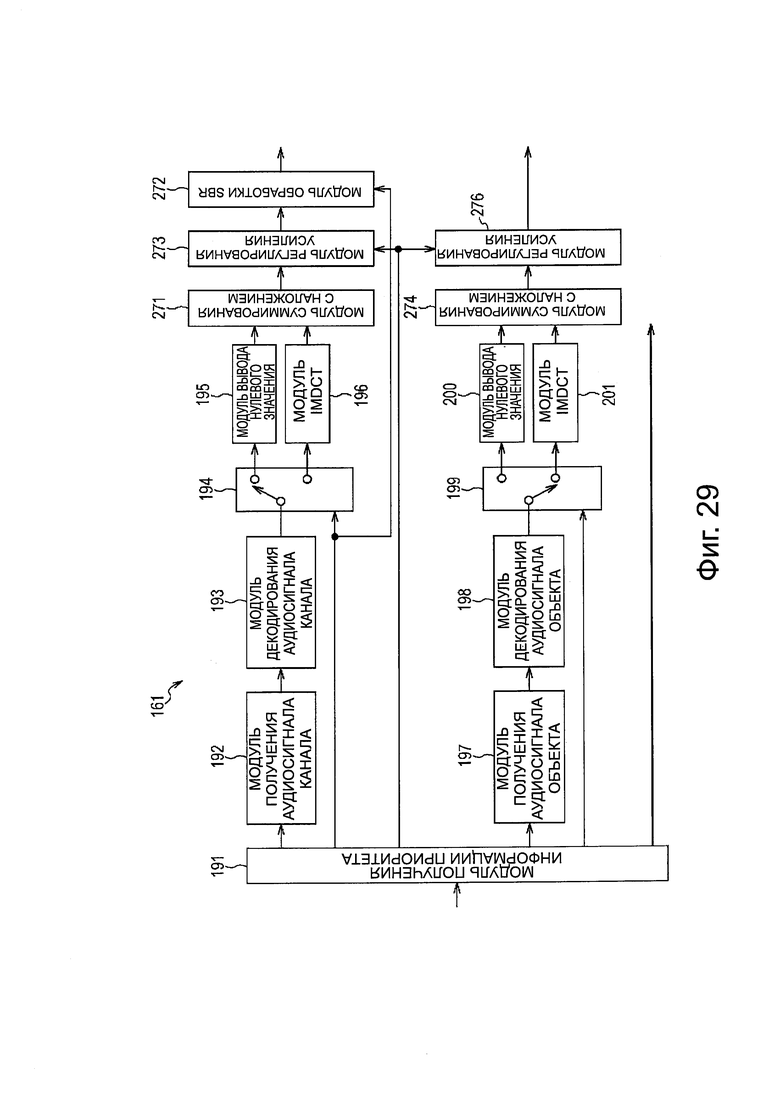
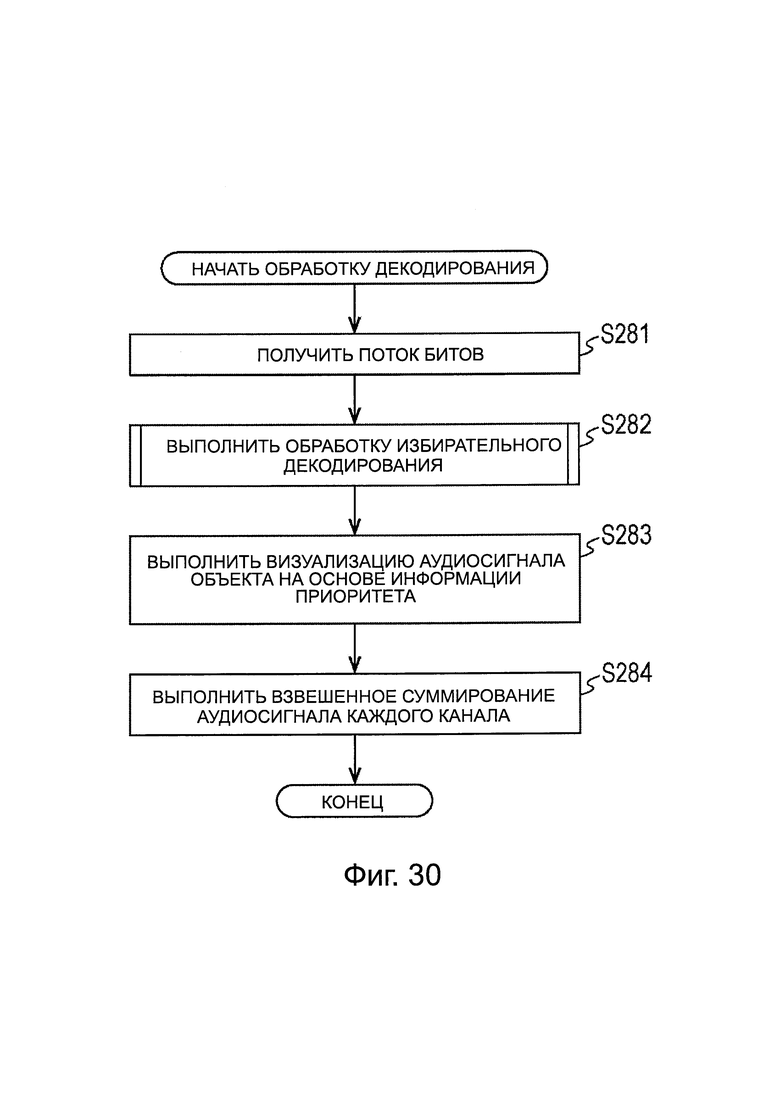
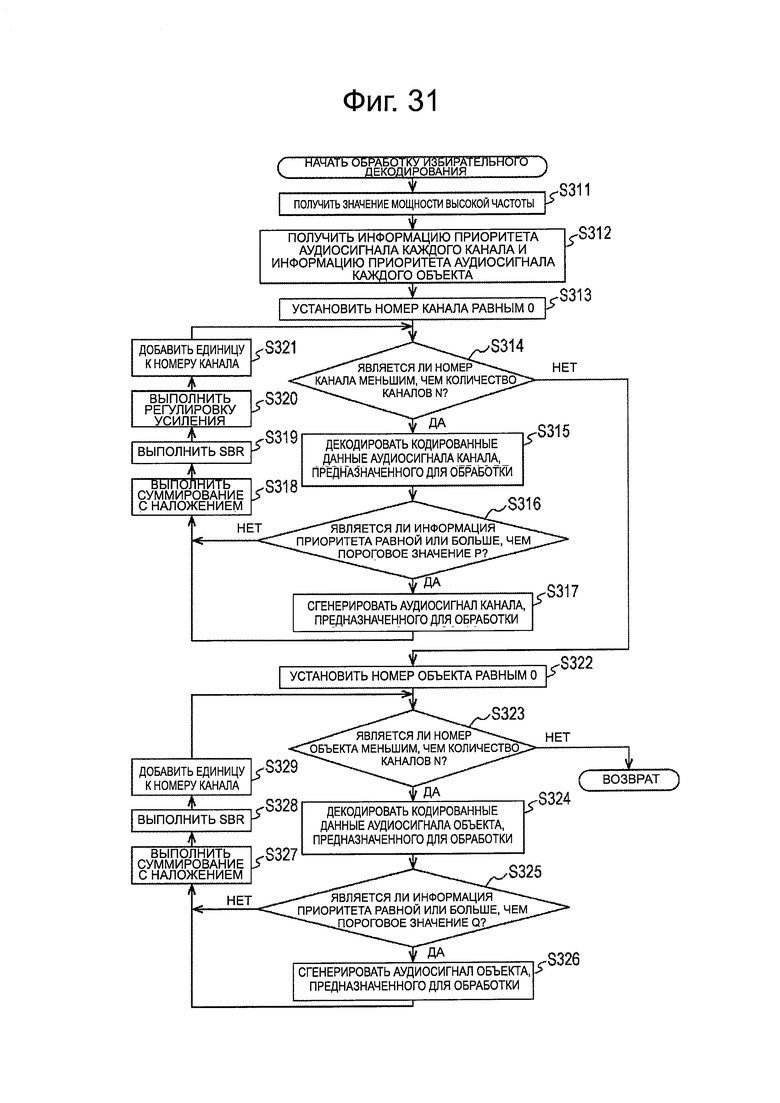
Изобретение относится к кодированию и декодированию аудиосигналов. Технический результат – уменьшение количества расчетов для декодирования аудиосигналов. Устройство декодирования содержит по меньшей мере одну схему, выполненную с возможностью получения одного или более кодированных аудиосигналов, включающих в себя множество каналов и/или множество объектов и информацию приоритета для каждого из множества каналов и/или множества объектов, и декодирования одного или больше кодированных аудиосигналов в соответствии с информацией приоритета. 3 н. и 11 з.п. ф-лы, 32 ил.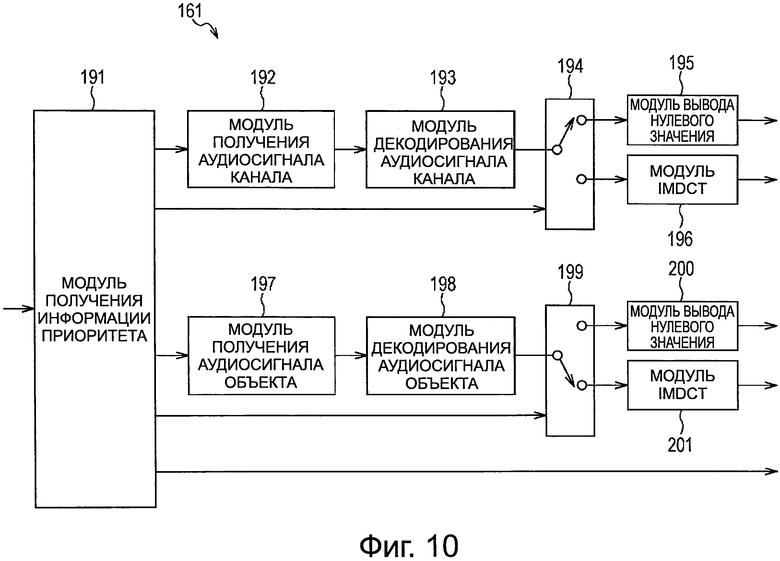
1. Устройство декодирования, содержащее:
по меньшей мере одну схему, выполненную с возможностью:
получения одного или более кодированных аудиосигналов, включающих в себя множество каналов и/или множество объектов и информацию приоритета для каждого из множества каналов и/или множества объектов; и
декодирования одного или более кодированных аудиосигналов в соответствии с информацией приоритета.
2. Устройство декодирования по п. 1, в котором указанная по меньшей мере одна схема выполнена с возможностью декодирования, в соответствии с информацией приоритета по меньшей мере частично, посредством декодирования по меньшей мере одного из одного или больше кодированных аудиосигналов, для которых степень приоритета, указанная информацией приоритета, равна или выше, чем степень, и отказа от декодирования по меньшей мере других из одного или более кодированных аудиосигналов, для которых степень приоритета, указанная информацией приоритета, меньше, чем степень.
3. Устройство декодирования по п. 2, в котором указанная по меньшей мере одна схема выполнена с возможностью изменения степени по меньшей мере частично на основе информации приоритета для множества каналов и/или множества объектов.
4. Устройство декодирования по п. 1, в котором:
указанная по меньшей мере одна схема выполнена с возможностью получения множества наборов информации приоритета для одного или более кодированных аудиосигналов, при этом
указанная по меньшей мере одна схема выполнена с возможностью декодирования одного или более кодированных аудиосигналов по меньшей мере частично посредством выбора одного из наборов информации приоритета и декодирования по меньшей мере частично на основе одного набора информации приоритета.
5. Устройство декодирования по п. 4, в котором указанная по меньшей мере одна схема выполнена с возможностью выбора по меньшей мере одного из наборов информации приоритета в соответствии с вычислительными возможностями устройства декодирования.
6. Устройство декодирования по п. 1, в котором указанная по меньшей мере одна схема дополнительно выполнена с возможностью генерирования информации приоритета по меньшей мере частично на основе кодированного аудиосигнала.
7. Устройство декодирования по п. 6, в котором указанная по меньшей мере одна схема выполнена с возможностью генерирования информации приоритета по меньшей мере частично на основе давления звука или спектральной формы аудиосигнала одного или более кодированных аудиосигналов.
8. Устройство декодирования по п. 1, в котором:
информация приоритета для множества каналов и/или множества объектов содержит по меньшей мере для одного первого канала из множества каналов и/или по меньшей мере одного первого объекта из множества объектов информацию приоритета, указывающую разные степени приоритета по меньшей мере одного первого канала и/или по меньшей мере одного первого объекта в течение периода времени, при этом
указанная по меньшей мере одна схема выполнена с возможностью декодирования, на основе информации приоритета по меньшей мере частично посредством определения, для первого канала и/или первого объекта и первого времени в течение периода времени, следует ли декодировать первый канал и/или первый объект в первое время, по меньшей мере частично, на основе степени приоритета для первого канала и/или первого объекта в первое время и степени приоритета для первого канала, и/или первого объекта в другое время перед или после первого времени и в течение периода времени.
9. Устройство декодирования по п. 1, в котором по меньшей мере одна схема дополнительно выполнена с возможностью:
генерирования аудиосигнала для первого времени по меньшей мере частично посредством добавления выходного аудиосигнала для канала или объекта в указанное время и вывода аудиосигнала канала или объекта во второе время перед или после первого времени, при этом выходной аудиосигнал для канала или объекта для времени представляет собой сигнал, получаемый указанной по меньшей мере одной схемой в результате декодирования, в случае, когда выполняется декодирование канала или объекта в течение времени, и нулевые данные в случае, когда не выполняется декодирование канала или объекта в течение времени; и
для выполнения регулировки усиления выходного аудиосигнала канала или объекта в указанное время на основе информации приоритета канала или объекта в указанное время и информации приоритета канала или объекта в другое время перед или после указанного времени.
10. Устройство декодирования по п. 9, в котором по меньшей мере одна схема дополнительно выполнена с возможностью:
регулировки усиления значения мощности высокой частоты для канала или объектов на основе информации приоритета канала или объекта в первое время и информации приоритета канала или объекта во второе время перед или после первого времени и
генерирования компонента высокой частоты аудиосигнала для первого времени на основе значения мощности высокой частоты, для которого регулируют коэффициент усиления, и аудиосигнал для времени.
11. Устройство декодирования по п. 9, в котором по меньшей мере одна схема дополнительно выполнена с возможностью:
генерирования, для каждого канала или каждого объекта, аудиосигнала первого времени, содержащего компонент высокой частоты, на основе значения мощности высокой частоты и аудиосигнал для времени,
регулировки усиления аудиосигнала для первого времени, содержащего компонент высокой частоты.
12. Устройство декодирования по п. 1, в котором указанная по меньшей мере одна схема дополнительно выполнена с возможностью назначения аудиосигнала первого объекта из множества объектов для каждого из по меньшей мере множества каналов со значением усиления на основе информации приоритета и генерирования аудиосигнала каждого из множества каналов.
13. Способ декодирования, содержащий этапы, на которых:
получают информацию приоритета для каждого из множества каналов и/или множества объектов одного или более кодированных аудиосигналов и
декодируют множество каналов и/или множество объектов в соответствии с информацией приоритета.
14. По меньшей мере один энергонезависимый считываемый компьютером носитель информации, хранящий исполняемые инструкции, вызывающие, при их выполнении по меньшей мере одним процессором, выполнение указанным по меньшей мере одним процессором способа, содержащего этапы, на которых:
получают информацию приоритета для каждого из множества каналов и/или множества объектов одного или более кодированных аудиосигналов и
декодируют множество каналов и/или множество объектов в соответствии с информацией приоритета.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| МАСКИРОВАНИЕ ОШИБКИ ПЕРЕДАЧИ В ЦИФРОВОМ АУДИОСИГНАЛЕ В ИЕРАРХИЧЕСКОЙ СТРУКТУРЕ ДЕКОДИРОВАНИЯ | 2009 |
|
RU2496156C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ АУДИОСИГНАЛОВ | 2006 |
|
RU2383941C2 |
| US 81082129 B2, 31.01.2012. | |||

