Изобретение относится к области обработки цифровых данных с помощью электрических устройств, в частности к методам цифровых вычислений или обработки данных, предназначенных для специфических функций, в том числе информационного поиска, а также структурирования баз данных для этой цели.
В настоящее время способы прямого ускорения работы распределенных систем практически исчерпаны, и большинство разработчиков переключились на разработку систем их параллельного выполнения, что позволило бы добиться линейного ускорения при добавления новых участников системы.
Под распределенной системой принято понимать совокупность компьютеров, объединенную в общую сеть обмена данными.
Блокчейн - это вид распределенной системы, в которой все узлы (компьютеры) системы согласуют пораундово новое состояние системы (согласуют общее решение по перечню допущенных транзакций в систему), при этом все узлы (компьютеры) системы хранят одинаково как текущее состояние системы, так и предыдущие состояния в виде связанных между собой блоков данных, где блоки данных - это набор транзакций, обработка которых переводит одно состояние системы в другое. Благодаря применяемой технологии хранения и передачи блоков в такой распределенной системе серьезно упрощаются процессы проверки данных при взаимодействии узлов (компьютеров) системы.
Известна модель взаимодействия между параллельной работой блокчейнов [заявка на изобретение US 20160330034 A1, опубл. 10.11.2016], названная впоследствии сайдчейн, которая раскрывает новые методы взаимодействия двух блокчейнов по переносу цифровых ценностей из одного блокчейна, названного основным или родительским, в другой блокчейн, названный сайдчейном, с возможностью последующего возврата этих ценностей и с защитой от появления двойной траты как при нахождении ценностей внутри сайдчейна, так и в процессе передачи как в сайдчейн, так и из сайдчейна. Таким образом реализована возможность создания вокруг родительского блокчейна множество паралельно работающих сайдчейнов, которые, работая независимо друг от друга, могут передавать ценности, созданные внутри родительского блокчейна между собой, через родительский блокчейн. Также возможна схема с многоуровневыми сайдченами, когда сайдчейн верхнего уровня выступает родительским блокчейном для другого сайдчейна.
К достоинствам известной модели можно отнести следующие показатели:
- осуществляется безопасный перенос ценности из родительского блокчейна в сайдчейны и обратно, в частности благодаря тому, что исключена возможность возникновения двойной траты при переносе ценностей;
- если несколько транзакций были совершены внутри сайдчейна, они производятся без нагрузки на родительский блокчейн, следовательно такой способ теоретически позволяет добиться большей производительности, чем обычный блокчейн, и, следовательно, позволяет масштабировать модель.
К недостаткам известной модели можно отнести то, что реализовать описанную ранее в качестве положительного результата возможность масштабирования и повышения производительности на практике не представляется возможным, так как данная модель основывается на методе упрощенной проверке платежа (simplified payment verification - SPV), что обуславливает наличие существенного периода ожидания в 1-2 дня при переходе и возврате ценностей между родительским блокчейном и сайдчейном (пункт [0042] US 20160330034 А1).
Впоследствии описанную выше модель с использованием похожих связей между блокчейнами для масштабирования развили в способе масштабирования проекта Cosmos [Электронный ресурс. Режим доступа к ресурсу: https://cosmos.network/whitepaper - свободный]. Все основные действия происходят в сайдчейнах, названных в этом проекте "зонами". Родительский блокчейн (в этом способе назван Cosmos hub) используется в большинстве своем только как гарант по переносу транзакций (как ценностных, так и иных) между зонами. Проблема заключается в том, что при захвате большинства узлов в блокчейн-сети, у лица, имеющего доступ к большинству узлов в блокчейн-сети, возникает возможность производить двойные траты. Суть способа использования сайдчейнов, предлагаемая в указанном техническом решении, основывается на том, что центральный (главный родительский) блокчейн имеет гораздо большую защищенность по сравнению с сайдчейнами в силу большей децентрализованности. Таким образом, сайдчены, которые не могут "доверять" друг другу из-за проблем с безопасностью в силу низкой децентрализованности, могут "доверять" центральному блокчейну и используют его как надежную среду для передачи ценностей.
К достоинствам способа, используемого в проекте Cosmos, можно отнести, тот факт, что в отличии от модели, описанной в заявке на изобретение US 20160330034 A1, вместо упрощенной проверки платежа (SPV) применяется межблокчейновое взаимодействие (Inter-blockchain Communication - IBC), что существенно уменьшает время на передачу транзакций между Cosmos HUB и зонами. В результате возможно масштабирование пропускной способности системы.
Недостатками данного способа является то, что любая межзонная транзакция должна пройти через Cosmos HUB, что в несколько раз увеличивает время межзонных транзакций относительно внутризональных. Время межзонной транзакции будет равно сумме времен регистрации транзакции в зоне источнике, регистрации факта транзакции в Cosmos HUB, регистрации в зоне получателя. Существует верхний предел пропускной способности по обработке транзакций у Cosmos HUB, связанный с тем, что Cosmos HUB представляет собой обычный блокчейн. При увеличении количества зон, вероятность появления межзонных транзакций увеличивается. Все межзонные транзакции проходят через Cosmos HUB. В случае если количество межзонных транзакций в единицу времени превысят пропускную способность Cosmos HUB, часть межзонных транзакций будет ожидать очереди. Таким образом предел пропускной способности Cosmos HUB ограничивает и пропускную способность всей системы. Узлы любого сайдчейна независимы от узлов других сайдчейнов, поэтому в случае захвата злоумышленником большинства узлов сайдчейна, он монополизирует право работы в этом сайдчейне. С точки зрения работы всей системы это не нанесет вред всем остальным участникам, так как неправомерные действия захваченного сайдчейна не будут пропущены Cosmos HUB. Однако пользователи захваченного сайдчейна не смогут работать в нем без разрешения захватчика.
Проект Zilliqa предлагает еще один поход к созданию распределенной системы с линейным масштабированием [Электронный ресурс. Режим доступа к ресурсу: https://docs.zilliqa.com/whitepaper.pdf - свободный). В этом проекте предлагается, что все узлы системы равноправны, но организуются в отдельные блокчейны. В проекте присутсвует два вида блокчейнов - "DS committee" и "shard". Каждую эпоху (значительный временной промежуток, в проекте Zilliqa предложен промежуток в 20 часов) из числа всех узлов выбирается небольшое количество узлов, которые входят в блокчейн - "DS committee", затем участники "DS committee" распределяют оставшиеся узлы системы на множество параллельно выполняющихся блокчейнов "shard".
Работа по проведению транзакции между блокчейнами "shard" немного отличается от модели сайдчейнов, описанной выше. Внутри блокчейна "shard" все транзакции обрабатываются и складываются в "микро блоки" с довольно малой периодичностью (в документации не указано время создания "микро блока"). Затем все подготовленные "микро блоки" всех "shard" направляются для включения в "окончательный блок" ("final block") в блокчейн "DS committee". Каждые раунд "DS committee" (в документации указано, что раунд "DS committee" длится 2 минуты) узлы "DS committee" проверяют все поступившие "микро блоки" и формируют блок, включающий в себя проверенные "микро блоки". Таким образом "окончательный блок" содержит в себе все данные для изменения состояния из прошлого блока к новому. Этот "окончательный блок" рассылается всем узлам всех "shard" для включения в их локальную блокчейн цепочку.
К преимуществам системы взаимодействий проекта Zilliqa можно отнести то, что в отличие от системы сайдчейнов необходимо два действия для регистрации межчейновой транзакции: регистрация в "мирко блоке", а затем регистрация в "окончательном блоке". В системе с сайдчейнами - регистрация в сайдчейне отправки, корневом блокчейне и сайдчейне назначения. Если будет произведен захват отдельного "shard", то в конце "эпохи" все узлы будут перетасованы, что серьезно снизит вероятность повторение захвата. При этом пользователи системы воспринимают всю систему блокчейнов как одну плафторму. В отличие, например, от системы сайдчейнов, где каждый сайдчейн и корневой блокчейн - это отдельные сущности и при работе с такой системой необходимо знать различия между ними.
К недостаткам проекта Zilliqa относится длительное время регистрации любой транзакции, так как оно складывается из времени регистрации в "микро блоке" блокчейна "shard" и времени регистрации "окончательного блока" в блокчейне "DS committee". При этом в документации время регистрации "окончательного блока" в блокчейне "DS committee" предложено установить в 2 минуты. В системе сайдчейнов, каждый узел принадлежит одному из блокчейнов системы, следовательно в его базе данных хранится только данные одной блокчейн цепочки. В проекте Zilliqa все узлы каждую эпоху меняют принадлежность к конкретным блокчейнам, поэтому на каждом узле системы необходимо хранение данных всех блокчейн цепочек.
Техническая проблема, на решение которой направлено настоящее изобретение, заключается в необходимости создания такой распределенной системы, которая бы одновременно обладала высокой пропускной способностью сети (скоростью транзакций), масштабируемостью, универсальностью, защищенностью сети и данных, а также низкой латентностью.
Технический результат заявляемого способа масштабирования обработки данных в распределенной системе заключается в уменьшении времени между регистрацией межгрупповой транзакции в группе отправления и регистрации межгрупповой транзакции в группе назначения при сохранении безопасности транзакций.
Указанный технический результат достигается за счет того, что в способе масштабирования обработки данных в распределенной системе, заключающемся в том, что
- первоначально компьютеры связывают между собой общей сетью обмена данными, образуя распределенную систему,
- затем эти компьютеры распределяют в логические группы
- и осуществляют транзакции от одной группы к другой, обрабатывая их в группах независимо от других групп,
согласно настоящему изобретению,
- первоначально во все компьютеры вносят настройки системы
- и запускают постоянно повторяемый раундами процесс выработки общего управленческого решения по всем управленческим запросам, не обработанным ранее,
- при этом в начале процесса выработки общего управленческого решения каждый компьютер в составе своей группы, при наличии к этому времени в этой группе зарегистрированной по меньшей мере одной управленческой транзакции, совместным решением группы передает все имеющиеся одобренные в группе управленческие транзакции предварительно назначенной общим управленческим решением ведущей группе этого раунда, которая после получения от других групп списка управленческих транзакций для обработки исключает невалидные транзакции, составляет из всех направленных от групп управленческих транзакций список, являющийся кандидатом на легитимный список управленческих транзакций этого раунда и одобренный заданным количеством компьютеров, и рассылает его для подтверждения всем группам,
- затем каждая группа, получив упомянутый список-кандидат от ведущей группы этого раунда, согласовывает его с каждым компьютером, входящим в эту группу, и отправляет результат согласования, представляющий собой количество компьютеров, согласовавших этот список, обратно в ведущую группу,
- как только ведущая группа получит от групп ответы с результатами согласования и если общее количество компьютеров, согласовавших список-кандидат в этих ответах, составит заданное количество компьютеров в системе, то этот список-кандидат становится легитимным списком управленческих транзакций этого раунда, и ведущая группа рассылает его вместе с собранными подтверждениями по всем компьютерам, каждый из которых, получив этот список, сохраняет его у себя и выполняет изменения в общих списках настройки системы в соответствии с присланным списком.
Возможны варианты развития основного технического решения, заключающиеся в том, что:
- статус ведущей группы переходит между всеми группами системы по очереди, начиная от первой группы в списке групп системы, который имеется на каждом компьютере, с учетом того, что в случае если в раунде ведущей группой была последняя в списке, то в следующий раунд ведущей группой будет первая в списке;
- очередность смены статуса ведущей группы устанавливается на следующее заданное количество раундов, при этом также устанавливается интервал следующего установления очередности смены заданного статуса ведущей группы;
- статус ведущей группы устанавливается по заданной функции назначения ведущей группы;
- при передаче транзакции от одной группы к другой осуществляется проверка этих транзакций;
- проверка этих транзакций осуществляется компьютерами валидационной группы, которая назначается общим управленческим решением для каждой группы и в которую входят компьютеры из числа, не входящих в проверяемую группу, при этом проверка транзакций проводится каждым компьютером из валидационной группы по тем же правилам, что применяются в проверяемой группе, и результат проверки отправляется компьютерам группы назначения транзакции, причем, транзакции от проверяемой группы могут быть обработаны в группе назначения только после получения одобрения от заданного количества компьютеров валидационной группы;
- проверка этих транзакций осуществляется всеми остальными компьютерами системы, при этом проверка транзакций проводится каждым компьютером по тем же правилам, что применяются в проверяемой группе, и результат проверки отравляется компьютерам группы назначения транзакции, причем, транзакции от проверяемой группы могут быть обработаны в группе назначения только после получения одобрения от заданного количества компьютеров системы;
- проверка этих транзакций осуществляется остальными группами системы, при этом проверка транзакций проводится каждым компьютером из проверяющей группы по тем же правилам, что применяются в проверяемой группе, и результат проверки отравляется компьютерам группы назначения транзакции, причем, транзакции от проверяемой группы могут быть обработаны в группе назначения только после получения одобрения от заданного количества остальных групп системы;
- проверка этих транзакций осуществляется назначенными группами системы, которые назначаются общим управленческим решением для каждой группы, при этом проверка транзакций проводится каждым компьютером из назначенной группы по тем же правилам, что применяются в проверяемой группе, и результат проверки отравляется компьютерам группы назначения транзакции, причем, транзакции от проверяемой группы могут быть обработаны в группе назначения только после получения одобрения от заданного количества компьютеров назначенных групп.
Таким образом, за счет указанной совокупности существенных признаков удалось существенно уменьшить время между регистрацией межгрупповой транзакции в группе отправления и регистрации межгрупповой транзакции в группе назначения, по сравнению с аналогами. Это стало возможным благодаря разделению компьютеров системы на уровни, что позволило создать многоуровневую систему принятия решений, т.к. все группы участвуют в принятии управленческих решений многостадийным образом. При этом по сравнению с аналогами уменьшено количество взаимодействий при масштабировании, поскольку транзакции передаются от группы к группе непосредственно, т.е. напрямую, без использования единой подсистемы проверки межгрупповых транзакций, в отличие от проекта Zilliqa в котором такие транзакции сначала передаются группе "DS committee", затем в ней обрабатываются, а затем рассылаются во все группы, а так как обработка транзакций в группе "DS committee" занимает две минуты, то и доставка транзакций между группами занимает не менее двух минут. Благодаря тому, что сразу после начала работы все группы могут обрабатывать транзакции пользователей независимо друг от друга и совершать передачу межгрупповых транзакций между собой, достигается увеличение скорости обработки относительно одиночной группы. На основании совокупности существенных признаков реализован механизм создания новых групп и распределения компьютеров системы в эти новые группы для того, чтобы система могла масштабироваться далее автоматически и непрерывно.
Одновременно с этим сохранена безопасность системы, поскольку в случае выхода из строя или попадания под воздействие деструктивного программного кода большинства компьютеров одной группы, что может привести к созданию и отправке невалидных транзакций - система быстро отреагирует, приняв совместное управленческое решение о расформировании этой группы и вывода компьютеров, участвовавших в создании невалидных транзакций, из системы.
При этом введение дополнительных этапов проверки транзакций лишь дополнительно усиливает и так обеспеченный должный уровень безопасности, поскольку позволяет выполнить проверку во время передачи транзакции между группами, не дожидаясь принятия более долгого управленческого решения. Так как во время дополнительного этапа проверки безопасности компьютерам, участвующим в проверке, нет необходимости достигать совместное решение по результатам проверки, а все они принимают решения независимо и параллельно, то время такой проверки даже меньше выработки совместного решения группы по регистрации проверяемой транзакции, что позволяет выполнять этап дополнительной проверки в течение нескольких секунд. Таким образом, дополнительный этап проверки увеличивает время между регистрацией межгрупповой транзакции в группе отправления и регистрации межгрупповой транзакции в группе назначения на несколько секунд, что гораздо меньше, чем этот же период у проекта Zilliqa - две минуты.
Сущность заявляемого способа поясняется нижеследующим описанием и фигурами.
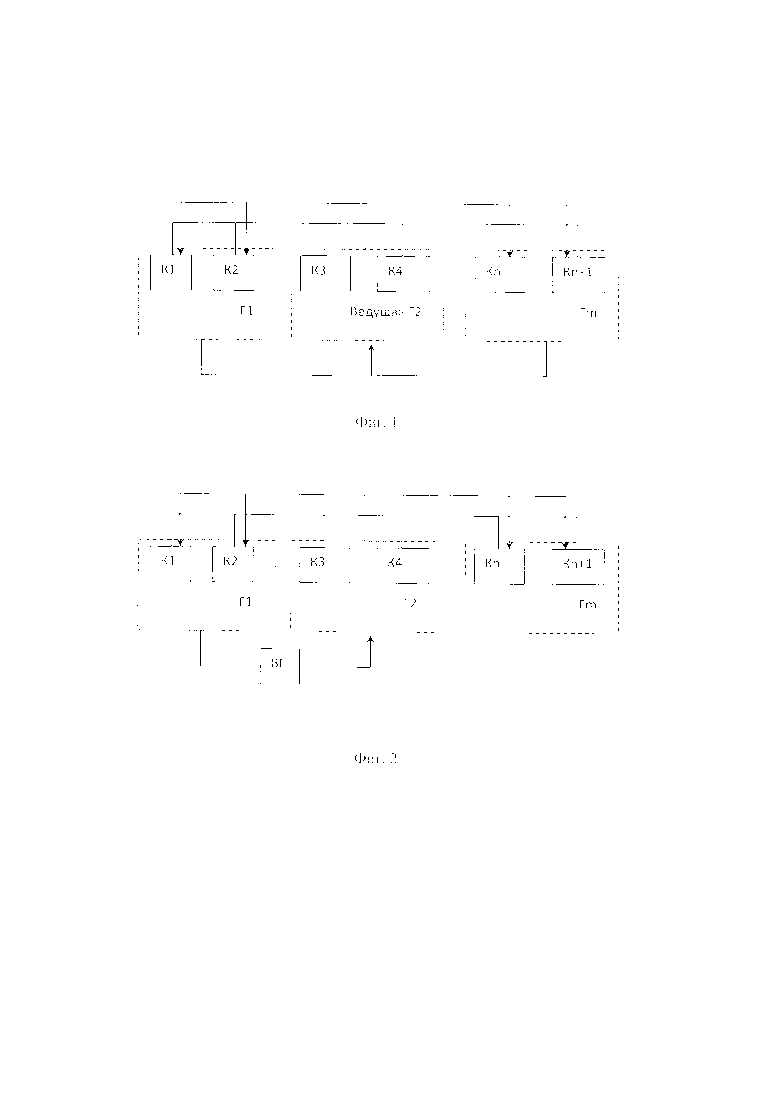
На Фиг. 1 представлена блок схема заявляемого способа по п. 1 формулы.
На Фиг. 2 представлена блок схема заявляемого способа по п. 6 формулы.
Способ масштабирования обработки данных в распределенной системе (Фиг. 1) включает следующие этапы.
Первоначально имеющиеся компьютеры (К1…Кn+1) связывают между собой общей сетью обмена данными, образуя распределенную систему. Это может быть реализовано в виде подключения всех компьютеров к сети интернет, или к единой локальной системе связи, или к единой шине данных.
Затем эти компьютеры распределяют в логические группы (Г1…Гm) и осуществляют транзакции непосредственно от одной группы к другой, обрабатывая их в группах независимо от других групп. Предпочтительным вариантом является распределение компьютеров по меньшей мере в три группы, поскольку в случае если из трех групп выйдет из строя одна группа, двух оставшихся будет достаточно для того, чтобы продолжить работу и восстановить численность групп, добавив новую. Если изначально группы две, то в случае выхода из строя одной из групп, одна группа не сможет легитимно добавить новую группу, для восстановления полной работоспособности системы, придется дожидаться восстановления работоспособности вышедшей из строя группы.
Правила начального распределения компьютеров в логические группы вносятся разработчиками в эти компьютеры перед запуском системы. После запуска системы, компьютеры сами в соответствии с заданными правилами распределяются по начальным группам.
При этом при начальном разделении на группы можно руководствоваться равномерным распределением по количеству компьютеров в каждой группе. В процессе работы системы управленческим решением может быть принято то, что появляется новая группа, в которую входят компьютеры, которые ранее входили в другие группы.
При этом во все компьютеры вносят настройки системы и запускают постоянно повторяемый раундами процесс выработки общего управленческого решения по всем управленческим запросам, не обработанным ранее.
Под настройками системы понимается совокупность данных о сетевых адресах всех компьютеров, их принадлежность к группам, а также их публичные ключи для идентификации в сообщениях и др. При этом благодаря тому, что в начале работы они одинаковы на всех компьютерах и в процессе выработки общего управленческого решения все изменения в них вносятся одинаковые, то на всех работающих компьютерах системы постоянно имеется одинаковый набор настроек системы. Все эти данные единообразно хранятся на каждом компьютере в виде списков. Например, в одном списке указаны пронумерованные группы. В другом - перечислены все компьютеры, принадлежность к группе, адрес для связи и публичный ключ.
В начале работы в настройки системы вносятся также и параметры, которые учитываются при работе сети. Эти параметры называются "заданными". Но в процессе работы системы управленческим решением эти параметры могут изменяться.
Внесение настроек в компьютеры возможно, например, двумя способами. Первый подразумевает внесение данных в каждый компьютер вручную, т.е. при непосредственном доступе пусконаладчика к каждому компьютеру, например, с помощью подключения к ним накопителя данных с имеющейся на нем базой данных настроек системы. Второй способ применим для формирования распределенной системы из совершенно независимых компьютеров и подразумевает создание алгоритма пуска для того, чтобы компьютеры сами обменялись данными. В этом случае все компьютеры подключаются к общему серверу, содержащему базу данных настроек, и получают от него необходимый настройки.
В начале процесса выработки общего управленческого решения каждый компьютер в составе своей группы, при наличии к этому времени в этой группе зарегистрированной по меньшей мере одной управленческой транзакции, совместным решением группы передает все имеющиеся одобренные в группе управленческие транзакции предварительно назначенной общим управленческим решением ведущей группе этого раунда.
Причем в каждый период времени все компьютеры системы кроме обработки транзакций пользователей участвуют в формировании общей позицию по управлению для принятия управленческих решений по добавлению удалению компьютеров в/из системы, создания новых групп для масштабирования работы системы, удаления сбойных групп, распределения компьютеров по группам и другими вопросами, затрагивающими работу всей системы.
Для своевременного принятия общих управленческих решений в процессе работы системы прямо с момента начала работы системы выполняется постоянно повторяемый процесс выработки общего управленческого решения по всем управленческим запросам, не обработанным до этого. Время от начала работы процесса выработки общего управленческого решения до его окончания называется раундом.
Ведущей группой называется группа, дополнительно выполняющая в текущем раунде функцию составителя из всех направленных от групп управленческих транзакций одного легитимного списка одобренных заданным количеством компьютеров управленческих транзакций.
Каждый раунд для работы процесса выработки общего управленческого решения необходимо, чтобы все компьютеры системы знали, какая группа является ведущей в этом раунде.
Способ назначения статуса ведущей группы вырабатывается в ходе принятия согласованного управленческого решения. Возможно несколько вариантов реализации такого назначения. Статус ведущей группы может переходить между всеми группами системы по очереди, начиная от первой группы в списке групп системы, который имеется на каждом компьютере, с учетом того, что в случае если в раунде ведущей группой была последняя в списке, то в следующий раунд ведущей группой будет первая в списке. Очередность смены статуса ведущей группы может устанавливаться на следующее заданное количество раундов, при этом также устанавливается интервал следующего установления очередности смены заданного статуса ведущей группы, например, установить очередность на XX раундов вперед и через каждые XX/10 раундов повторять установку очередности. Статус ведущей группы также может устанавливаться по заданной функции назначения ведущей группы, по которой, зная номер раунда, можно вычислить номер ведущий группы.
Далее ведущая группа после получения в установленное время от других групп списка управленческих транзакций для обработки исключает невалидные транзакции, составляет из всех направленных от групп управленческих транзакций список, являющийся кандидатом на легитимный список управленческих транзакций этого раунда и одобренный заданным количеством компьютеров, и рассылает его для подтверждения всем группам.
Затем каждая группа, получив упомянутый список-кандидат от ведущей группы этого раунда, согласовывает его с каждым компьютером, входящим в эту группу, и отправляет результат согласования, представляющий собой количество компьютеров, согласовавших этот список, обратно в ведущую группу.
Как только ведущая группа получит от групп ответы с результатами согласования и если общее количество компьютеров, согласовавших список-кандидат в этих ответах, составит заданное количество компьютеров в системе, то этот список-кандидат становится легитимным списком управленческих транзакций этого раунда. Здесь наиболее предпочтительным является заданное количество больше половины компьютеров, что позволит обеспечить дополнительное повышение безопасности транзакции.
Теперь ведущая группа рассылает его вместе с собранными подтверждениями по всем компьютерам, каждый из которых, получив этот список, сохраняет его у себя и выполняет изменения в общих списках настройки системы в соответствии с присланным списком.
В случае выхода из строя во время раунда ведущей группы легитимный список одобренных управленческих транзакций не составляется, а продолжает свое составление в следующем раунде со следующей ведущей группой.
При передаче транзакции от одной группы к другой дополнительно может осуществляться выборочная или постоянная проверка этих транзакций различными вариантами.
Например, проверка этих транзакций может осуществляться компьютерами валидационной группы (ВГ), которая назначается общим управленческим решением для каждой группы и в которую входят компьютеры из числа, не входящих в проверяемую группу (Фиг. 2). При этом проверка транзакций проводится каждым компьютером из валидационной группы по тем же правилам, что применяются в проверяемой группе, и результат проверки отравляется компьютерам группы назначения транзакции. Причем, транзакции от проверяемой группы могут быть обработаны в группе назначения только после получения одобрения от заданного количества компьютеров валидационной группы.
Проверка этих транзакций также может осуществляться всеми остальными компьютерами системы. При этом проверка транзакций проводится каждым компьютером по тем же правилам, что применяются в проверяемой группе, и результат проверки отравляется компьютерам группы назначения транзакции. Причем, транзакции от проверяемой группы могут быть обработаны в группе назначения только после получения одобрения от заданного количества компьютеров системы.
Возможен вариант, когда проверка этих транзакций осуществляется остальными группами системы. При этом проверка транзакций проводится каждым компьютером из проверяющей группы по тем же правилам, что применяются в проверяемой группе, и результат проверки отравляется компьютерам группы назначения транзакции. Причем, транзакции от проверяемой группы могут быть обработаны в группе назначения только после получения одобрения от заданного количества остальных групп системы.
Возможен другой вариант, когда проверка этих транзакций осуществляется назначенными группами системы, которые назначаются общим управленческим решением для каждой группы. При этом проверка транзакций проводится каждым компьютером из назначенной группы по тем же правилам, что применяются в проверяемой группе, и результат проверки отравляется компьютерам группы назначения транзакции. Причем, транзакции от проверяемой группы могут быть обработаны в группе назначения только после получения одобрения от заданного количества компьютеров назначенных групп.
Примеры осуществления заявляемого способа.
Пример 1. Для тестирования было развернуто программное обеспечение системы на 900 компьютерах. Затем эти компьютеры были подключены к сети Интернет. На каждом компьютере были сгенерированы криптографические ключи для идентификации в процессе обмена сообщениями. После этого было сформулировано правило распределения на группы, в которое были занесены данные о предпочтении размера группы в 9 компьютеров. Затем это правило, все Интернет адреса компьютеров, их криптографические ключи были собраны в одну базу данных и реплицированы на все компьютеры, участвующие в тесте. Таким образом, внесены первоначальные настройки системы. При начале работы сети в соответствии с внесенным правилом компьютеры разделились на 100 групп по 9 компьютеров.
Затем на компьютеры системы подавался поток сгенерированных транзакций, содержащий как внутригрупповые, так и межгрупповые транзакции. При этом средняя нагрузка на каждую группу составляла две тысячи транзакций в секунду. В результате продолжительного теста среднее время регистрации внутригрупповых и межгрупповых транзакций составило 1 и 2 секунды, соответственно.
Пример 2. Создание распределенной системы управления логистикой на предприятии.
Для работы системы было выделено 15 компьютеров. Их разместили по 2 компьютера в отделе приемки, выдачи и складе. И 9 компьютеров разместили в других помещениях организации с более строгим допуском. Эти компьютеры связывали локальной сетью организации.
После этого было сформулировано правило распределения на группы, в которое были занесены данные о предпочтении размера группы в 5 компьютеров и соответствия 2 компьютеров в группе одному месту расположения. Затем данные о расположении компьютеров, правило распределения в группы, адреса компьютеров в локальной сети и их криптографические ключи были собраны в одну базу данных и реплицированы на все 15 компьютеров.
После начала работы, компьютеры распределились на три группы и начали обрабатывать и регистрировали данные перемещения в пределах своей ответственности и создавали межгрупповые транзакции при перемещении товаров между отделами приемки, склада и отгрузки.
В процессе работы были произведены замеры времени регистрации транзакций. В результате было зафиксировано среднее время регистрации транзакции внутри группы 0.3 секунды, а между группами 1 секунду.
Изобретение относится к области обработки цифровых данных. Технический результат заключается в уменьшении времени между регистрацией межгрупповой транзакции в группе отправления и регистрации межгрупповой транзакции в группе назначения при сохранении безопасности транзакций. Такой результат достигается тем, что первоначально компьютеры связывают между собой общей сетью обмена данными, образуя распределенную систему, затем эти компьютеры распределяют в логические группы и осуществляют транзакции от одной группы к другой, обрабатывая их в группах независимо от других групп, в начале процесса выработки общего управленческого решения каждый компьютер в составе своей группы, при наличии к этому времени в этой группе зарегистрированной по меньшей мере одной управленческой транзакции, совместным решением группы передает все имеющиеся одобренные в группе управленческие транзакции предварительно назначенной общим управленческим решением ведущей группе этого раунда, которая после получения от других групп списка управленческих транзакций для обработки исключает невалидные транзакции, составляет из всех направленных от групп управленческих транзакций список, являющийся кандидатом на легитимный список управленческих транзакций этого раунда и одобренный заданным количеством компьютеров, и рассылает его для подтверждения всем группам, затем каждая группа, получив упомянутый список-кандидат от ведущей группы этого раунда, согласовывает его с каждым компьютером, входящим в эту группу, и отправляет результат согласования, обратно в ведущую группу, как только ведущая группа получит от групп ответы с результатами согласования и если общее количество компьютеров, согласовавших список-кандидат в этих ответах, составит заданное количество компьютеров в системе, то этот список-кандидат становится легитимным списком управленческих транзакций этого раунда, и ведущая группа рассылает его вместе с собранными подтверждениями по всем компьютерам. 8 з.п. ф-лы, 2 ил.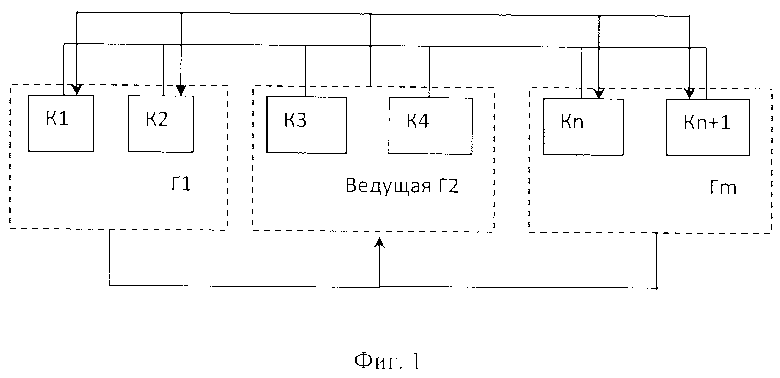
1. Способ масштабирования обработки данных в распределенной системе, заключающийся в том, что первоначально компьютеры связывают между собой общей сетью обмена данными, образуя распределенную систему, затем эти компьютеры распределяют в логические группы и осуществляют транзакции от одной группы к другой, обрабатывая их в группах независимо от других групп, отличающийся тем, что первоначально во все компьютеры вносят настройки системы и запускают постоянно повторяемый раундами процесс выработки общего управленческого решения по всем управленческим запросам, не обработанным ранее, при этом в начале процесса выработки общего управленческого решения каждый компьютер в составе своей группы, при наличии к этому времени в этой группе зарегистрированной по меньшей мере одной управленческой транзакции, совместным решением группы передает все имеющиеся одобренные в группе управленческие транзакции предварительно назначенной общим управленческим решением ведущей группе этого раунда, которая после получения от других групп списка управленческих транзакций для обработки исключает невалидные транзакции, составляет из всех направленных от групп управленческих транзакций список, являющийся кандидатом на легитимный список управленческих транзакций этого раунда и одобренный заданным количеством компьютеров, и рассылает его для подтверждения всем группам, затем каждая группа, получив упомянутый список-кандидат от ведущей группы этого раунда, согласовывает его с каждым компьютером, входящим в эту группу, и отправляет результат согласования, представляющий собой количество компьютеров, согласовавших этот список, обратно в ведущую группу, как только ведущая группа получит от групп ответы с результатами согласования и если общее количество компьютеров, согласовавших список-кандидат в этих ответах, составит заданное количество компьютеров в системе, то этот список-кандидат становится легитимным списком управленческих транзакций этого раунда, и ведущая группа рассылает его вместе с собранными подтверждениями по всем компьютерам, каждый из которых, получив этот список, сохраняет его у себя и выполняет изменения в общих списках настройки системы в соответствии с присланным списком.
2. Способ масштабирования обработки данных в распределенной системе по п. 1, отличающийся тем, что статус ведущей группы переходит между всеми группами системы по очереди, начиная от первой группы в списке групп системы, который имеется на каждом компьютере, с учетом того, что в случае если в раунде ведущей группой была последняя в списке, то в следующий раунд ведущей группой будет первая в списке.
3. Способ масштабирования обработки данных в распределенной системе по п. 1, отличающийся тем, что очередность смены статуса ведущей группы устанавливается на следующее заданное количество раундов, при этом также устанавливается интервал следующего установления очередности смены заданного статуса ведущей группы.
4. Способ масштабирования обработки данных в распределенной системе по п. 1, отличающийся тем, что статус ведущей группы устанавливается по заданной функции назначения ведущей группы.
5. Способ масштабирования обработки данных в распределенной системе по п. 1, отличающийся тем, что при передаче транзакции от одной группы к другой осуществляется проверка этих транзакций.
6. Способ масштабирования обработки данных в распределенной системе по п. 5, отличающийся тем, что проверка этих транзакций осуществляется компьютерами валидационной группы, которая назначается общим управленческим решением для каждой группы и в которую входят компьютеры из числа, не входящих в проверяемую группу, при этом проверка транзакций проводится каждым компьютером из валидационной группы по тем же правилам, что применяются в проверяемой группе, и результат проверки отравляется компьютерам группы назначения транзакции, причем, транзакции от проверяемой группы могут быть обработаны в группе назначения только после получения одобрения от заданного количества компьютеров валидационной группы.
7. Способ масштабирования обработки данных в распределенной системе по п. 5, отличающийся тем, что проверка этих транзакций осуществляется всеми остальными компьютерами системы, при этом проверка транзакций проводится каждым компьютером по тем же правилам, что применяются в проверяемой группе, и результат проверки отравляется компьютерам группы назначения транзакции, причем, транзакции от проверяемой группы могут быть обработаны в группе назначения только после получения одобрения от заданного количества компьютеров системы.
8. Способ масштабирования обработки данных в распределенной системе по п. 5, отличающийся тем, что проверка этих транзакций осуществляется остальными группами системы, при этом проверка транзакций проводится каждым компьютером из проверяющей группы по тем же правилам, что применяются в проверяемой группе, и результат проверки отравляется компьютерам группы назначения транзакции, причем, транзакции от проверяемой группы могут быть обработаны в группе назначения только после получения одобрения от заданного количества остальных групп системы.
9. Способ масштабирования обработки данных в распределенной системе по п. 5, отличающийся тем, что проверка этих транзакций осуществляется назначенными группами системы, которые назначаются общим управленческим решением для каждой группы, при этом проверка транзакций проводится каждым компьютером из назначенной группы по тем же правилам, что применяются в проверяемой группе, и результат проверки отравляется компьютерам группы назначения транзакции, причем, транзакции от проверяемой группы могут быть обработаны в группе назначения только после получения одобрения от заданного количества компьютеров назначенных групп.
| СПОСОБ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ДАННЫХ ДЛЯ ПРИНЯТИЯ УПРАВЛЕНЧЕСКИХ РЕШЕНИЙ ПО ПРОЕКТУ И ПОРТФЕЛЮ ПРОЕКТОВ | 2011 |
|
RU2480830C2 |
| Токарный резец | 1924 |
|
SU2016A1 |
| СКРЕП КОРПУСОВ УЛЬЯ | 0 |
|
SU181439A1 |
| СИСТЕМА И СПОСОБ ДЛЯ МНОГОФАКТОРНОЙ АУТЕНТИФИКАЦИИ ЛИЧНОСТИ НА ОСНОВЕ БЛОКЧЕЙНА | 2016 |
|
RU2667801C1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |

