Изобретение относится к вычислительной технике, а именно, к способам и устройствам, входящим в состав аппаратуры и программного обеспечения для систем коррекции ошибок при передаче, хранении, чтении и восстановлении цифровых двоичных данных. Оно может быть использовано, преимущественно, для помехоустойчивого кодирования информации в каналах с большим уровнем шума, в частности, в спутниковых и космических сетях связи.
Техническая и экономическая польза применения систем кодирования и последующего исправления ошибок в принятых из канала сообщениях состоит в том, что кодирование при хорошем эффективном последующем декодировании на приемной стороне системы связи многократно повышает к.п.д. используемых каналов, что особенно важно для чрезвычайно дорогих спутниковых и космических сетей связи.
Известен способ декодирования в системе помехоустойчивого кодирования сигналов в цифровой системе радиосвязи [RU 2573263, С2, Н03М 13/15, Н03М 13/23, 20.01.2016], путем преобразования входного сигнала в цифровой вид с помощью дельта-модуляции, заключающийся в том, что цифровое значение ei очередного i-гo отсчета определяется разностью между отсчетом входного сигнала xi и формируемой аппроксимацией этого отсчета уi выраженной зависимостью: 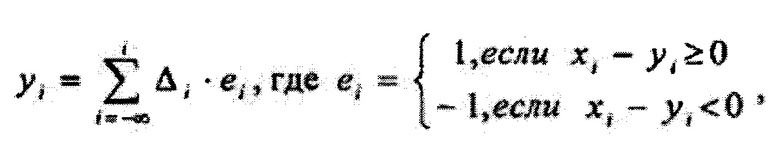
и последующим избыточным кодированием цифровой информации помехоустойчивым циклическим или сверточным кодом, отличающийся использованием последовательности сверточного кода для повышения помехоустойчивости цифрового сигнала, кодированием одновременно пары отсчетов хi,1 и хi,2, позволяющим сохранить информационную скорость канала связи, равную скорости аналого-цифрового преобразования речевого сигнала.
Недостатком этого технического решения является относительно узкая область применения, поскольку способ предназначен, преимущественно, для декодирования речевых сигналов.
Известен также способ порогового декодирования в системе помехоустойчивого кодирования, который реализуется пороговым декодером (ПД) (В.В. Золотарев, Г.В. Овечкин. Помехоустойчивое кодирование. Методы и алгоритмы. Справочник. М., "Горячая линия - телеком", 2004, 124 с, с. 81), заключающийся в том, что, после передачи по каналу связи информационные символы кода (поток U) направляют в информационный регистр, а проверочные символы (поток V) после сложения с другими проверочными символами, полученными из принятых с ошибками информационных символов, поступают в синдромный регистр, а пороговый элемент (ПЭ), являющийся решающим элементом декодера, после суммирования определенных символов синдрома (проверок) принимает решение, что, если число ненулевых символов на входе ПЭ превышает заданное пороговое значение, то он изменяет через обратную связь содержимое ячеек, с которых снимались сигналы на его вход, а также декодируемый символ в крайне правой (на рисунке шестой) ячейке информационного регистра.
Недостатком этого способа декодирования является относительно низкая эффективность декодирования в каналах связи с высоким уровнем шума и довольно значительным числом операций, если количество входов порогового элемента (ПЭ) достаточно велико, что соответствует большому значению кодового расстоянию d в этом коде и, следовательно, его более высокой корректирующей способности.
Наиболее близким по технической сущности к предполагаемому изобретению является способ многопорогового декодирования (МПД) линейного кода [В.В. Золотарев, Г.В. Овечкин. Помехоустойчивое кодирование. Методы и алгоритмы. Справочник. М., "Горячая линия -телеком", 2004, с. 84], заключающийся в том, что сообщение после декодирования первым ПЭ в пороговом декодере направляют во второй декодер, т.е. оно проходит ко второму ПЭ, полностью аналогичному первому, а затем последовательно в третий и т.д.
Этот способ более эффективен по реализуемому им уровню достоверности, так как цепочка ПЭ постепенно снижает на каждом ПЭ количество оставшихся после предыдущих этапов ошибок декодирования.
Однако, этому техническому решению присущ недостаток, заключающийся в относительно большой сложности и относительно низкой оперативности (скорости декодирования), обусловленных достаточно большим числом необходимых операций сложения, подобно случаю обычного порогового декодера (ПД), представленного в [В.В. Золотарев, Г.В. Овечкин. Помехоустойчивое кодирование. Методы и алгоритмы. Справочник. М., "Горячая линия - телеком", 2004, с. 81]. Количество таких затратных по числу операций вычислений растет, поскольку количество ПЭ в многопороговом декодере (МПД) увеличивается по сравнению с обычным ПД в I раз, где I - число итераций декодирования в МПД.
Задача, которая решается в изобретении, направлена на создание способа декодирования, отличающегося меньшей сложностью и высокой оперативностью.
Требуемый технический результат заключается в повышении скорости декодирования путем уменьшения среднего числа операций в МПД для линейных кодов.
Поставленная задача решается, а требуемый технический результат достигается тем, что в способе ускоренного декодирования линейного кода, в котором для декодирования двоичных информационных символов сообщения используют итеративное многопороговое декодирование сверточного или блокового кода, согласно изобретению, перед проведением итеративного многопорогового декодирования сверточного или блокового кода дополнительно вычисляют и запоминают в отдельном блоке памяти суммы проверок для всех декодируемых информационных символов сообщения, после чего во всех пороговых элементах многопорогового декодера последовательно проверяют суммы проверок для информационных символов сообщения и при меньшем их значении по сравнению с установленными значениями порогов, пороговые элементы переходят к декодированию следующих информационных символов сообщения, а при превышении их значения по сравнению с установленными значениями порогов выполняют коррекцию декодируемых информационных символов сообщения и относящихся к нему проверок, причем, в отдельном блоке памяти, в котором запоминают суммы проверок для всех декодируемых информационных символов сообщения, меняют знак суммы для декодируемого символа и значения сумм проверок для тех информационных символов, которые используют те же проверки, что и информационные символы, которые изменены пороговым элементом, после чего пороговый элемент переводят в режим декодирования следующего информационного символа сообщения.
Предложенный способ ускоренного декодирования линейного кода применяется следующим образом.
Суть предложенного изобретения состоит в том, что сумму на ПЭ вычисляют только один раз, причем, на предварительном этапе до начала процедуры декодирования. Эти суммы сразу для всех символов блокового или сверточного кода запоминаются в регистре памяти размером М, соответствующим объему информационной части сообщения.
При этом, алгоритм МПД декодирования реализуется следующим образом. Выбирают первый, а затем последующий и т.д. символ в МПД. Для него в регистре памяти размером М проверяется сумма для ПЭ, которая сравнивается с пороговым значением, соответствующим этому конкретному ПЭ. Если сумма не превышает порогового значения, то производится переход к такому же анализу следующего информационного символа и т.д. Если сумма на ПЭ превышает пороговое значение, то изменяется декодируемый символ в разностном регистре и все проверки в синдромном регистре. Но каждый измененный символ проверки в синдромном регистре влияет и на сумму проверок для целого ряда других информационных символов, конкретные позиции которых определяются выбранным кодом. Поэтому в регистре памяти размером М при изменении декодируемого символа инвертируется соответствующая ему сумма в соответствующей ему ячейке регистра памяти размером М, а также изменяются те суммы для других символов, которые нужно поменять из-за изменения значений проверок для исправленного символа. Количество таких изменяемых сумм имеет порядок d2, а точное их количество зависит от кодовой скорости R кода.
Сравним сложность исходного МПД и нового варианта декодера.
Обычный МПД должен выполнять обычно (I+1)*d операций сложения и иногда ему еще нужно выполнить d операций изменения декодируемого символа и его проверок. Тогда среднее число операций этого МПД декодера будет равно N1~(I+2)*d.
Оценим сложность предлагаемого декодера. Он должен вычислить синдром и первоначальные суммы на ПЭ для каждого информационного символа, для чего нужно выполнить 2*d суммирований. Допустим, что примерная величина d=l5. А затем для всех I итераций, реализуемых в МПД, проверяются суммы проверок, хранящиеся в регистре памяти размером М. Обычно эти суммы меньше, чем пороговые значения для ПЭ. Следовательно, число этих операций равно I. А в случае, если изредка на каком-то ПЭ декодируемый символ изменяется, то, как и в обычном МПД, выполняется d сложений (изменений) символов в синдроме, а также изменяются d2 сумм в регистре памяти размером М. Оценивая частоту коррекций, как 0,01 долю от общего числа просмотров декодируемых символов каждым ПЭ, а количество итераций как I=30, хотя это число может быть и несколько другим, получаем, что среднее число операций предлагаемого декодера в пересчете на один информационный символ равно N2~2*d+I+0,01*I*(d+d2).
В этом случае N1~480, a N2~132.
Для случая d=9 и I=10, что также можно считать вполне реальным вариантом, N1~108, N2~37.
Как следует из сопоставления двух вариантов реализации (МПД прототипа и предлагаемого способа), предложенный способ обеспечивает применительно к рассмотренному примеру увеличение скорости декодирования в 3-4 раза относительно прототипа. Это подтверждает достижение требуемого технического результата.
Предложенный способ можно рассматривать, как дальнейшее развитие способов коррекции ошибок на основе Оптимизационной теории помехоустойчивого кодирования, изложенной в [V.V. Zolotarev, Y.b. Zubarev, G.V. Ovechkin. Optimization Coding Theory and Multithreshold Algorithms. // Geneva, ITU, 2015. Электронная версия http://www.itu.int/pub/S-GEN-OCTMA-2015].
Изобретение относится к способу ускоренного декодирования линейного кода. Технический результат заключается в повышении скорости декодирования. В данном способе для декодирования двоичных информационных символов сообщения используют итеративное многопороговое декодирование сверточного или блокового кода, причем, перед проведением итеративного многопорогового декодирования сверточного или блокового кода дополнительно вычисляют и запоминают в отдельном блоке памяти суммы проверок для всех декодируемых информационных символов сообщения, после чего во всех пороговых элементах многопорогового декодера последовательно проверяют суммы проверок для информационных символов сообщения и при меньшем их значении по сравнению с установленными значениями порогов, пороговые элементы переводят для декодирования следующих информационных символов сообщения, а при их превышении значения по сравнению с установленными значениями порогов выполняют коррекцию декодируемых информационных символов сообщения и относящихся к нему проверок, причем, в отдельном блоке памяти, в котором запоминают суммы проверок для всех декодируемых информационных символов сообщения, меняют знак суммы для декодируемого символа и значения сумм проверок для тех информационных символов, которые используют те же проверки, что и информационные символы, которые изменены пороговым элементом, после чего пороговый элемент переводят в режим декодирования следующего информационного символа сообщения.
Способ ускоренного декодирования линейного кода, в котором для декодирования двоичных информационных символов сообщения используют итеративное многопороговое декодирование сверточного или блокового кода, отличающийся тем, что перед проведением итеративного многопорогового декодирования сверточного или блокового кода дополнительно вычисляют и запоминают в отдельном блоке памяти суммы проверок для всех декодируемых информационных символов сообщения, после чего во всех пороговых элементах многопорогового декодера последовательно проверяют суммы проверок для информационных символов сообщения и при меньшем их значении по сравнению с установленными значениями порогов, пороговые элементы переводят для декодирования следующих информационных символов сообщения, а при их превышении значения по сравнению с установленными значениями порогов выполняют коррекцию декодируемых информационных символов сообщения и относящихся к нему проверок, причем, в отдельном блоке памяти, в котором запоминают суммы проверок для всех декодируемых информационных символов сообщения, меняют знак суммы для декодируемого символа и значения сумм проверок для тех информационных символов, которые используют те же проверки, что и информационные символы, которые изменены пороговым элементом, после чего пороговый элемент переводят в режим декодирования следующего информационного символа сообщения.
| В.В | |||
| Золотарев, Г.В | |||
| Овечкин | |||
| Помехоустойчивое кодирование | |||
| Методы и алгоритмы | |||
| Справочник | |||
| М., "Горячая линия - телеком", 2004, 126 с., с | |||
| Цилиндрический сушильный шкаф с двойными стенками | 0 |
|
SU79A1 |
| ДЕКОДИРОВАНИЕ ВЫСОКОИЗБЫТОЧНЫХ КОДОВ С КОНТРОЛЕМ ЧЕТНОСТИ С ИСПОЛЬЗОВАНИЕМ МНОГОПОРОГОВОГО ПРОХОЖДЕНИЯ СООБЩЕНИЯ | 2004 |
|
RU2337478C2 |
| Способ декодирования линейного каскадного кода | 2017 |
|
RU2667370C1 |
| 0 |
|
SU158721A1 | |
| US 6167552 A, 26.12.2000. | |||

