ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение относится к аудиоустройству и к способу предоставления аудиоустройством аудио, и, в частности, к аудиоустройству и к способу предоставления аудио, посредством которых виртуальное аудио, вызывающее ощущение поднятия источника звука, формируется и предоставляется посредством использования множества динамиков, расположенных в одной и той же плоскости.
УРОВЕНЬ ТЕХНИКИ
С развитием технологии видео- и звуковой обработки контент, имеющий высокое качество изображений и звука, поставлен на серийное производство. Пользователи, которые требуют контент, имеющий высокое качество изображений и звука, хотят реалистичного видео и аудио, и в силу этого, активно проводятся исследования в области трехмерного видео и трехмерного аудио.
Трехмерное аудио представляет собой технологию, в которой множество динамиков расположены в различных местоположениях в горизонтальной плоскости и выводят идентичный аудиосигнал или различные аудиосигналы, за счет этого предоставляя возможность пользователю воспринимать ощущение пространства. Тем не менее, фактическое аудио предоставляется в различных местоположениях в горизонтальной плоскости и также предоставляется на различных высотах. Следовательно, требуется разрабатывать технологию для эффективного воспроизведения аудиосигнала, предоставляемого на различных высотах.
В предшествующем уровне техники, как проиллюстрировано на фиг.1A, аудиосигнал фильтруется посредством фильтра преобразования тембра (например, корректирующего фильтра, основывающегося на HRTF (передаточной функции слухового аппарата человека)), соответствующего первой высоте, и множество аудиосигналов формируются посредством копирования фильтрованного аудиосигнала. Множество модулей применения усиления, соответственно, усиливают или ослабляют сформированное множество аудиосигналов на основе значений усиления, соответствующих множеству динамиков, через которые должны выводиться сформированное множество аудиосигналов, и усиленные или ослабленные звуковые сигналы, соответственно, выводятся через соответствующие динамики. Соответственно, виртуальное аудио, вызывающее ощущение поднятия источника звука, может формироваться посредством использования множества динамиков, расположенных в одной и той же плоскости.
Тем не менее, в способе формирования виртуальных аудиосигналов предшествующего уровня техники, зона наилучшего восприятия является узкой, и по этой причине, в случае фактического воспроизведения аудио через систему, его эффективность ограничена. Иными словами, в предшествующем уровне техники, как проиллюстрировано на фиг.1B, поскольку аудио оптимизировано и подготовлено посредством рендеринга только в одной точке (например, в области 0, расположенной в центре), пользователь не может нормально прослушивать виртуальный аудиосигнал, вызывающий ощущение поднятия источника звука, в области (например, в области X, расположенной левее от центра) вместо одной точки.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Техническая задача
Настоящее изобретение предоставляет аудиоустройство и способ предоставления аудио для него, посредством которых пользователь может прослушивать виртуальный аудиосигнал в различных областях на основе значения задержки, так что множество виртуальных аудиосигналов формируют звуковое поле, имеющее плоскую волну.
Кроме того, настоящее изобретение предоставляет аудиоустройство и способ предоставления аудио для него, посредством которых пользователь может прослушивать виртуальный аудиосигнал в различных областях на основе различных значений усиления согласно частоте на основе вида канала аудиосигнала, из которого должен формироваться виртуальный аудиосигнал.
Техническое решение
Согласно аспекту идеи изобретения, предусмотрен способ предоставления аудио, осуществляемый посредством аудиоустройства, включающий в себя: прием аудиосигнала, включающего в себя множество каналов; формирование множества виртуальных аудиосигналов, которые должны, соответственно, выводиться во множество динамиков, посредством применения аудиосигнала, имеющего канал, из множества каналов, вызывающего ощущение поднятия источника звука, к фильтру, причем фильтр обрабатывает аудиосигнал таким образом, что он имеет ощущение поднятия источника звука; применение комбинированного значения усиления и значения задержки к множеству виртуальных аудиосигналов таким образом, что множество виртуальных аудиосигналов, которые, соответственно, выводятся через множество динамиков, формируют звуковое поле, имеющее плоскую волну; и соответствующий вывод множества виртуальных аудиосигналов, к которым применяются комбинированное значение усиления и значение задержки, через множество динамиков.
Формирование может включать в себя: копирование фильтрованного аудиосигнала таким образом, что он соответствует числу динамиков; и применение значения усиления при панорамировании, соответствующего каждому из множества динамиков, к каждому из множества аудиосигналов, полученных посредством копирования, таким образом, что фильтрованный аудиосигнал имеет виртуальное ощущение поднятия источника звука, с тем чтобы формировать множество виртуальных аудиосигналов.
Применение может включать в себя: умножение виртуального аудиосигнала, соответствующего, по меньшей мере, двум динамикам, из множества динамиков, используемых для того, чтобы реализовывать звуковое поле, имеющее плоскую волну, на комбинированное значение усиления; и применение значения задержки к виртуальному аудиосигналу, соответствующему, по меньшей мере, двум динамикам.
Применение может включать в себя применение значения усиления, равное 0, к аудиосигналу, соответствующему динамику, отличному, по меньшей мере, от двух динамиков из множества динамиков.
Применение может включать в себя: применение значения задержки к множеству виртуальных аудиосигналов, соответственно соответствующих множеству динамиков; и умножение множества виртуальных аудиосигналов, к которым применяется значение задержки, на конечное значение усиления, полученное посредством умножения значения усиления при панорамировании и комбинированного значения усиления.
Фильтр, который обрабатывает аудиосигнал таким образом, что он имеет ощущение поднятия источника звука, может представлять собой фильтр, основывающийся на передаточной функции слухового аппарата человека (HRTF).
Соответственно, вывод может включать в себя смешивание виртуального аудиосигнала, соответствующего конкретному каналу, с аудиосигналом, имеющим конкретный канал, с тем чтобы выводить аудиосигнал, полученный посредством смешивания, через динамик, соответствующий конкретному каналу.
Согласно другому аспекту идеи изобретения, предусмотрено аудиоустройство, включающее в себя: модуль ввода, выполненный с возможностью принимать аудиосигнал, включающий в себя множество каналов; модуль формирования виртуального аудио, выполненный с возможностью применять аудиосигнал, имеющий канал, из множества каналов, вызывающий ощущение поднятия источника звука, к фильтру, чтобы с тем чтобы формировать множество виртуальных аудиосигналов, которые должны, соответственно, выводиться во множество динамиков, причем фильтр выполнен с возможностью обрабатывать аудиосигнал таким образом, что он имеет ощущение поднятия источника звука; процессор виртуального аудио, выполненный с возможностью применять комбинированное значение усиления и значение задержки к множеству виртуальных аудиосигналов таким образом, что множество виртуальных аудиосигналов, соответственно, выводимых через множество динамиков, формируют звуковое поле, имеющее плоскую волну; и модуль вывода, выполненный с возможностью, соответственно, выводить множество виртуальных аудиосигналов, к которым применяются комбинированное значение усиления и значение задержки, через множество динамиков.
Процессор виртуального аудио может быть дополнительно выполнен с возможностью копировать фильтрованный аудиосигнал таким образом, что он соответствует числу динамиков, и применять значение усиления при панорамировании, соответствующее каждому из множества динамиков, к каждому из множества аудиосигналов, полученных посредством копирования, таким образом, что фильтрованный аудиосигнал имеет виртуальное ощущение поднятия источника звука, с тем чтобы формировать множество виртуальных аудиосигналов.
Процессор виртуального аудио может быть дополнительно выполнен с возможностью умножать виртуальный аудиосигнал, соответствующий, по меньшей мере, двум динамикам, из множества динамиков, для реализации звукового поля, имеющего плоскую волну, на комбинированное значение усиления и применять значение задержки к виртуальному аудиосигналу, соответствующему, по меньшей мере, двум динамикам.
Процессор виртуального аудио может быть дополнительно выполнен с возможностью применять значение усиления, равное 0, к аудиосигналу, соответствующему динамику, отличному, по меньшей мере, от двух динамиков из множества динамиков.
Процессор виртуального аудио может быть дополнительно выполнен с возможностью применять значение задержки к множеству виртуальных аудиосигналов, соответственно соответствующих множеству динамиков, и умножать множество виртуальных аудиосигналов, к которым применяется значение задержки, на конечное значение усиления, полученное посредством умножения значения усиления при панорамировании и комбинированного значения усиления.
Фильтр, выполненный с возможностью обрабатывать аудиосигнал таким образом, что он имеет ощущение поднятия источника звука, может представлять собой фильтр, основывающийся на передаточной функции слухового аппарата человека (HRTF).
Модуль вывода может быть дополнительно выполнен с возможностью смешивать виртуальный аудиосигнал, соответствующий конкретному каналу, с аудиосигналом, имеющим конкретный канал, с тем чтобы выводить аудиосигнал, полученный посредством смешивания, через динамик, соответствующий конкретному каналу.
Согласно другому аспекту идеи изобретения, предусмотрен способ предоставления аудио, осуществляемый посредством аудиоустройства, включающий в себя: прием аудиосигнала, включающего в себя множество каналов; применение аудиосигнала, имеющего канал, из множества каналов, вызывающий ощущение поднятия источника звука, к фильтру, который обрабатывает аудиосигнал таким образом, что он имеет ощущение поднятия источника звука; формирование множества виртуальных аудиосигналов посредством применения различных значений усиления к аудиосигналу согласно частоте на основе вида канала аудиосигнала, из которого должен формироваться виртуальный аудиосигнал; и соответствующий вывод множества виртуальных аудиосигналов через множество динамиков.
Формирование может включать в себя: копирование фильтрованного аудиосигнала таким образом, что он соответствует числу динамиков; определение ипсилатерального динамика и контралатерального динамика на основе вида канала аудиосигнала, из которого должен формироваться виртуальный аудиосигнал; применение повышающего фильтра полосы низких частот к виртуальному аудиосигналу, соответствующему ипсилатеральному динамику, и применение фильтра верхних частот к виртуальному аудиосигналу, соответствующему контралатеральному динамику; и умножение, на значение усиления при панорамировании, аудиосигнала, соответствующего ипсилатеральному динамику, и аудиосигнала, соответствующего контралатеральному динамику, с тем чтобы формировать множество виртуальных аудиосигналов.
Согласно другому аспекту идеи изобретения, предусмотрено аудиоустройство, включающее в себя: модуль ввода, который принимает аудиосигнал, включающий в себя множество каналов; модуль формирования виртуального аудио, который применяет аудиосигнал, имеющий канал, вызывающий ощущение поднятия источника звука, из множества каналов, к фильтру, который обрабатывает аудиосигнал таким образом, что он имеет ощущение поднятия источника звука, и формирует множество виртуальных аудиосигналов посредством применения различных значений усиления к аудиосигналу согласно частоте на основе вида канала аудиосигнала, из которого должен формироваться виртуальный аудиосигнал; и модуль вывода, который, соответственно, выводит множество виртуальных аудиосигналов через множество динамиков.
Модуль формирования виртуального аудио может копировать фильтрованный аудиосигнал таким образом, что он соответствует числу динамиков, определять ипсилатеральный динамик и контралатеральный динамик на основе вида канала аудиосигнала, из которого должен формироваться виртуальный аудиосигнал, применять повышающий фильтр полосы низких частот к виртуальному аудиосигналу, соответствующему ипсилатеральному динамику, и применять фильтр верхних частот к виртуальному аудиосигналу, соответствующему контралатеральному динамику, и умножать, на значение усиления при панорамировании, аудиосигнал, соответствующий ипсилатеральному динамику, и аудиосигнал, соответствующий контралатеральному динамику, с тем чтобы формировать множество виртуальных аудиосигналов.
Согласно другому аспекту идеи изобретения, предусмотрен способ предоставления аудио, осуществляемый посредством аудиоустройства, включающий в себя: прием аудиосигнала, включающего в себя множество каналов; определение того, следует или нет подготавливать посредством рендеринга аудиосигнал, имеющий канал, вызывающий ощущение поднятия источника звука, из множества каналов, в форме, вызывающей ощущение поднятия источника звука; применение некоторых из множества каналов, вызывающих ощущение поднятия источника звука, к фильтру, который обрабатывает некоторые каналы таким образом, что они имеют ощущение поднятия источника звука, на основе результата определения; применение значения усиления к сигналу, к которому применяется фильтр, с тем чтобы формировать множество виртуальных аудиосигналов; и соответствующий вывод множества виртуальных аудиосигналов через множество динамиков.
Определение может включать в себя определение того, следует или нет подготавливать посредством рендеринга аудиосигнал, имеющий канал, вызывающий ощущение поднятия источника звука, в форме, вызывающей ощущение поднятия источника звука, на основе корреляции и подобия между множеством каналов.
Согласно другому аспекту идеи изобретения, предусмотрен способ предоставления аудио, осуществляемый посредством аудиоустройства, включающий в себя: прием аудиосигнала, включающего в себя множество каналов; применение, по меньшей мере, некоторых из множества каналов к фильтру, который обрабатывает, по меньшей мере, некоторые каналы таким образом, что они имеют ощущение поднятия источника звука, с тем чтобы формировать виртуальный аудиосигнал; повторное кодирование, посредством кодека, выполняемого посредством внешнего устройства, сформированного виртуального аудиосигнала; и вывод повторно кодированного виртуального аудиосигнала наружу.
Преимущества изобретения
Как описано выше, согласно различным вариантам осуществления настоящего изобретения, пользователь прослушивает виртуальный аудиосигнал, вызывающий ощущение поднятия источника звука, которое предоставляется посредством аудиоустройства, в различных местоположениях.
Краткое описание чертежей
Фиг.1A и 1B являются схемами для описания способа предоставления виртуального аудио предшествующего уровня техники,
Фиг.2 является блок-схемой, иллюстрирующей конфигурацию аудиоустройства согласно примерному варианту осуществления настоящего изобретения.
Фиг.3 является схемой для описания виртуального аудио, имеющего звуковое поле на основе плоских волн согласно примерному варианту осуществления настоящего изобретения,
Фиг.4-7 являются схемами для описания способа рендеринга 11.1-канального аудиосигнала, чтобы выводить подготовленный посредством рендеринга аудиосигнал через 7.1-канальный динамик, согласно различным примерным вариантам осуществления настоящего изобретения,
Фиг.8 является схемой для описания способа предоставления аудио, осуществляемого посредством аудиоустройства, согласно примерному варианту осуществления настоящего изобретения,
Фиг.9 является блок-схемой, иллюстрирующей конфигурацию аудиоустройства согласно другому примерному варианту осуществления настоящего изобретения,
Фиг.10 и 11 являются схемами для описания способа рендеринга 11.1-канального аудиосигнала, чтобы выводить подготовленный посредством рендеринга аудиосигнал через 7.1-канальный динамик, согласно различным примерным вариантам осуществления настоящего изобретения,
Фиг.12 является схемой для описания способа предоставления аудио, осуществляемого посредством аудиоустройства, согласно другому примерному варианту осуществления настоящего изобретения,
Фиг.13 является схемой для описания способа предшествующего уровня техники рендеринга 11.1-канального аудиосигнала, чтобы выводить подготовленный посредством рендеринга аудиосигнал через 7.1-канальный динамик,
Фиг.14-20 являются схемами для описания способа вывода 11.1-канального аудиосигнала через 7.1-канальный динамик посредством использования множества способов рендеринга, согласно различным примерным вариантам осуществления настоящего изобретения,
Фиг.21 является схемой для описания примерного варианта осуществления, в котором рендеринг выполняется посредством использования множества способов рендеринга, когда используется канальный расширяющий кодек, имеющий такую структуру, как стандарт объемного звучания MPEG, согласно примерному варианту осуществления настоящего изобретения, и
Фиг.22-25 являются схемами для описания системы предоставления многоканального аудио согласно примерному варианту осуществления настоящего изобретения.
Наилучший режим осуществления изобретения
Далее подробно описываются примерные варианты осуществления идеи изобретения со ссылкой на прилагаемые чертежи. Варианты осуществления идеи изобретения предоставляются таким образом, что это раскрытие сущности является все всеобъемлющим и полным и полностью передает принцип идеи изобретения для специалистов в данной области техники. Тем не менее, идея изобретения может быть осуществлена во множестве других форм и не должна быть истолкована как ограниченная вариантами осуществления, изложенными в данном документе. Тем не менее, это не ограничивает идею изобретения рамками конкретных вариантов осуществления, и следует понимать, что идея изобретения охватывает все модификации, эквиваленты и замены в пределах идеи и объема идеи изобретения. Аналогичные номера ссылок ссылаются на аналогичные элементы по всему описанию. Размеры структур, проиллюстрированных на прилагаемых чертежах, и интервал между элементами могут быть чрезмерно увеличены для ясности описания.
Следует понимать, что хотя термины, включающие в себя обычное число, такие как "первый" или "второй", используются в данном документе для того, чтобы описывать различные элементы, эти элементы не должны быть обязательно ограничены посредством этих терминов. Эти термины используются только для того, чтобы отличать один элемент от другого элемента.
В нижеприведенном описании, технические термины используются только для пояснения конкретного примерного варианта осуществления без ограничения идеи изобретения. Термины в форме единственного числа могут включать в себя формы множественного числа, если не указано обратное. Если не указано иное, все термины (в том числе технические и научные термины), используемые в данном документе, имеют тот же смысл, под которым они обычно понимаются специалистами в области техники, которой принадлежат примерные варианты осуществления. Следует дополнительно понимать, что термины, к примеру, заданные в общераспространенных словарях, должны быть интерпретированы как имеющие смысл, который является согласованным с их смыслом в контексте релевантной области техники, и не должны интерпретироваться в идеализированном или излишне формальном смысле, если это явно не задано в данном документе.
В примерных вариантах осуществления, "...модуль" или "...блок", описанный в данном документе, выполняет, по меньшей мере, одну функцию или операцию и может реализовываться в аппаратных средствах, программном обеспечении или комбинации аппаратных средств и программного обеспечения. Кроме того, множество "...модулей" или множество "...блоков" могут быть интегрированы в качестве, по меньшей мере, одного модуля и в силу этого реализованы, по меньшей мере, с помощью одного процессора (не показан), за исключением "...модуля" или "...блока", который реализуется с помощью специальных аппаратных средств.
В дальнейшем в этом документе подробнее описываются примерные варианты осуществления со ссылкой на прилагаемые чертежи. Аналогичные номера означают аналогичные элементы во всем описании чертежей, и повторяющееся описание идентичного элемента не предоставляется.
Фиг.2 является блок-схемой, иллюстрирующей конфигурацию аудиоустройства 100 согласно примерному варианту осуществления настоящего изобретения. Как проиллюстрировано на фиг.2, аудиоустройство 100 может включать в себя модуль 110 ввода, модуль 120 формирования виртуального аудио, процессор 130 виртуального аудио и модуль 140 вывода. Согласно примерному варианту осуществления настоящего изобретения, аудиоустройство 100 может включать в себя множество динамиков, которые могут быть расположены в идентичной горизонтальной плоскости.
Модуль 110 ввода может принимать аудиосигнал, включающий в себя множество каналов. В этом случае, модуль 110 ввода может принимать аудиосигнал, включающий в себя множество каналов, вызывающих различные ощущения поднятия источника звука. Например, модуль 110 ввода может принимать 11.1-канальные аудиосигналы.
Модуль 120 формирования виртуального аудио может подавать аудиосигнал, который имеет канал, вызывающий ощущение поднятия источника звука, из множества каналов в фильтр преобразования тембра, который обрабатывает аудиосигнал таким образом, чтобы имелось ощущение поднятия источника звука, за счет этого формируя множество виртуальных аудиосигналов, которые должны выводиться через множество динамиков. В частности, модуль 120 формирования виртуального аудио может использовать корректирующий HRTF-фильтр для моделирования звука, который формируется с поднятием выше фактических местоположений множества динамиков, расположенных в горизонтальной плоскости, посредством использования этих динамиков. В этом случае, корректирующий HRTF-фильтр может включать в себя информацию (т.е. передаточную частотную характеристику) тракта от пространственного местоположения источника звука в два уха пользователя. Корректирующий HRTF-фильтр может распознавать трехмерный звук согласно явлению, при котором характеристика сложного тракта, такая как отражение посредством ушных раковин, изменяется в зависимости от направления передачи звука, в дополнение к интерауральной разности уровней (ILD) и интерауральной разности времен (ITD), которая возникает, когда звук достигает двух ушей, и т.д. Поскольку корректирующий HRTF-фильтр имеет уникальную характеристику в угловом направлении пространства, корректирующий HRTF-фильтр может формировать трехмерный звук посредством использования этой уникальной характеристики.
Например, когда вводятся 11.1-канальные аудиосигналы, модуль 120 формирования виртуального аудио может применять аудиосигнал, который имеет верхний левый передний канал из 11.1-канальных аудиосигналов, к корректирующему HRTF-фильтру, с тем чтобы формировать семь аудиосигналов, которые должны выводиться через множество динамиков, имеющих 7.1-канальную схему размещения.
В примерном варианте осуществления настоящего изобретения, модуль 120 формирования виртуального аудио может копировать аудиосигнал, полученный через фильтрацию посредством фильтра преобразования тембра, таким образом, что он соответствует числу динамиков, и может, соответственно, применять значения усиления при панорамировании, соответственно соответствующие динамикам, к аудиосигналам, которые получаются через копию, для аудиосигнала таким образом, что он имеет виртуальное ощущение поднятия источника звука, за счет этого формируя множество виртуальных аудиосигналов. В другом примерном варианте осуществления настоящего изобретения, модуль 120 формирования виртуального аудио может копировать аудиосигнал, полученный через фильтрацию посредством фильтра преобразования тембра, таким образом, что он соответствует числу динамиков, за счет этого формируя множество виртуальных аудиосигналов. В этом случае, значения усиления при панорамировании могут применяться посредством процессора 130 виртуального аудио.
Процессор 130 виртуального аудио может применять комбинированное значение усиления и значение задержки к множеству виртуальных аудиосигналов таким образом, то множество виртуальных аудиосигналов, которые выводятся через множество динамиков, составляют звуковое поле, имеющее плоскую волну. Подробно, как проиллюстрировано на фиг.3, процессор 130 виртуального аудио может формировать виртуальный аудиосигнал, с тем чтобы составлять звуковое поле, имеющее плоскую волну, вместо формирования зоны наилучшего восприятия в одной точке, за счет этого предоставляя возможность пользователю прослушивать виртуальный аудиосигнал в различных точках.
В примерном варианте осуществления настоящего изобретения, процессор 130 виртуального аудио может умножать виртуальный аудиосигнал, соответствующий, по меньшей мере, двум динамикам для реализации звукового поля, имеющего плоскую волну, из множества динамиков, на комбинированное значение усиления, и может применять значение задержки к виртуальному аудиосигналу, соответствующему, по меньшей мере, двум динамикам. Процессор 130 виртуального аудио может применять значение усиления "0" к аудиосигналу, соответствующему динамику, отличному, по меньшей мере, от двух из множества динамиков. Например, модуль 120 формирования виртуального аудио формирует семь виртуальных аудиосигналов, с тем чтобы формировать 11.1-канальный аудиосигнал, соответствующий верхнему левому переднему каналу, в качестве виртуального аудиосигнала, и при реализации сигнала FLTFL, который должен воспроизводиться в качестве сигнала, соответствующего левому переднему каналу из сформированных семи виртуальных аудиосигналов, процессор 130 виртуального аудио может умножать, на комбинированное значение усиления, виртуальные аудиосигналы, соответственно соответствующие переднему центральному каналу, левому переднему каналу и левому каналу объемного звучания из множества 7.1-канальных динамиков, и может применять значение задержки к аудиосигналам, чтобы обрабатывать множество виртуальных аудиосигналов, которые должны выводиться через динамики, соответственно соответствующие переднему центральному каналу, левому переднему каналу и левому каналу объемного звучания. Кроме того, при реализации сигнала FLTFL процессор 130 виртуального аудио может умножать, на комбинированное значение усиления "0", виртуальные аудиосигналы, соответственно соответствующие правому переднему каналу, правому каналу объемного звучания, левому заднему каналу и правому заднему каналу, которые являются контралатеральными каналами в 7.1-канальных динамиках.
В другом примерном варианте осуществления настоящего изобретения, процессор 130 виртуального аудио может применять значение задержки к множеству виртуальных аудиосигналов, соответственно соответствующих множеству динамиков, и может применять конечное значение усиления, которое получается посредством умножения значения усиления при панорамировании и комбинированного значения усиления, к множеству виртуальных аудиосигналов, к которым применяется значение задержки, за счет этого формируя звуковое поле, имеющее плоскую волну.
Модуль 140 вывода может выводить обработанное множество виртуальных аудиосигналов через динамики, соответствующие им. В этом случае, модуль 140 вывода может смешивать виртуальный аудиосигнал, соответствующий конкретному каналу, с аудиосигналом, имеющим конкретный канал, с тем чтобы выводить аудиосигнал, полученный посредством смешивания, через динамик, соответствующий конкретному каналу. Например, модуль 140 вывода может смешивать виртуальный аудиосигнал, соответствующий левому переднему каналу, с аудиосигналом, который формируется посредством обработки верхнего левого переднего канала, с тем чтобы выводить аудиосигнал, полученный посредством смешивания, через динамик, соответствующий левому переднему каналу.
Аудиоустройство 100 предоставляет возможность пользователю прослушивать виртуальный аудиосигнал, вызывающий ощущение поднятия источника звука, предоставленный посредством аудиоустройства 100, в различных местоположениях.
В дальнейшем в этом документе подробно описывается со ссылкой на фиг.4-7 способ рендеринга 11.1-канального аудиосигнала в виртуальный аудиосигнал, с тем чтобы выводить, через 7.1-канальный динамик, аудиосигнал, соответствующий каждому из каналов, вызывающих различные ощущения поднятия источника звука, из 11.1-канальных аудиосигналов, согласно примерному варианту осуществления.
Фиг.4 является схемой для описания способа рендеринга 11.1-канального аудиосигнала, имеющего верхний левый передний канал, в виртуальный аудиосигнал, с тем чтобы выводить виртуальный аудиосигнал через 7.1-канальный динамик, согласно различным примерным вариантам осуществления настоящего изобретения.
Во-первых, когда вводится 11.1-канальный аудиосигнал, имеющий верхний левый передний канал, модуль 120 формирования виртуального аудио может применять входной аудиосигнал, имеющий верхний левый передний канал, к фильтру H преобразования тембра. Кроме того, модуль 120 формирования виртуального аудио может копировать аудиосигнал, соответствующий верхнему левому переднему каналу, к которому применяется фильтр H преобразования тембра, в семь аудиосигналов и затем может, соответственно, вводить семь аудиосигналов во множество модулей применения усиления, соответственно соответствующих 7-канальным динамикам. В модуле 120 формирования виртуального аудио, семь модулей применения усиления могут умножать аудиосигнал с преобразованным тембром на 7-канальные усиления "GTFL,FL, GTFL,FR, GTFL,FC, GTFL,SL, GTFL,SR, GTFL,BL и GTFL,BR" при панорамировании, с тем чтобы формировать 7-канальные виртуальные аудиосигналы.
Кроме того, процессор 130 виртуального аудио может умножать виртуальный аудиосигнал из входных 7-канальных виртуальных аудиосигналов, соответствующий, по меньшей мере, двум динамикам для реализации звукового поля, имеющего плоскую волну, из множества динамиков, на комбинированное значение усиления, и может применять значение задержки к виртуальному аудиосигналу, соответствующему, по меньшей мере, двум динамикам. Подробно, как проиллюстрировано на фиг.3, при необходимости преобразовывать аудиосигнал, имеющий левый передний канал, в плоскую волну, которая вводится в местоположении под конкретным углом (например, 30 градусов), процессор 130 виртуального аудио может умножать аудиосигнал на комбинированные значения усиления "AFL,FL, AFL,FC и AFL,SL", необходимые для комбинирования на основе плоских волн посредством использования динамиков, которые имеют левый передний канал, передний центральный канал, левый канал объемного звучания и представляют собой динамики, расположенные в полуплоскости (например, в левой полуплоскости и в центре в левом сигнале, а в правом сигнале, в правой полуплоскости и в центре), идентичной полуплоскости направления падения, и могут применять значения задержки "dTFL,FL, dTFL,FC и dTFL,SL" к сигналу, получаемому через умножение, с тем чтобы формировать виртуальный аудиосигнал, имеющий формы плоских волн. Это может быть выражено в качестве следующего уравнения:
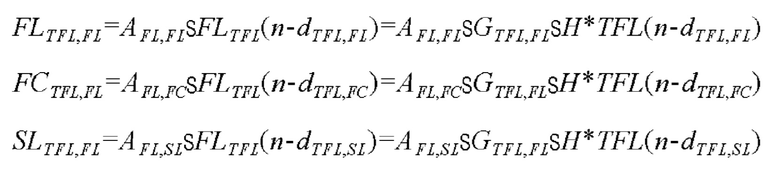
Кроме того, процессор 130 виртуального аудио может задавать, равными 0, комбинированные значения усиления "AFL,FR, AFL,SR, AFL,BL и AFL,BR" виртуальных аудиосигналов, выводимых через динамики, которые имеют правый передний канал, правый канал объемного звучания, правый задний канал и левый задний канал и не находятся в полуплоскости, идентичной полуплоскости направления падения.
Следовательно, как проиллюстрировано на фиг.4, процессор 130 виртуального аудио может формировать семь виртуальных аудиосигналов "FLTFLW, FRTFLW, FCTFLW, SLTFLW, SRTFLW, BLTFLW и BRTFLW" для реализации плоской волны.
На фиг.4 описывается то, что модуль 120 формирования виртуального аудио умножает аудиосигнал на значение усиления при панорамировании, и процессор 130 виртуального аудио умножает аудиосигнал на комбинированное значение усиления, но это представляет собой просто примерный вариант осуществления. В других примерных вариантах осуществления, процессор 130 виртуального аудио может умножать аудиосигнал на конечное значение усиления, полученное посредством умножения значения усиления при панорамировании и комбинированного значения усиления.
Подробно, как раскрыто на фиг.6, процессор 130 виртуального аудио может сначала применять значение задержки к множеству виртуальных аудиосигналов, тембры которых преобразуются посредством фильтра H преобразования тембра, и затем может применять конечное значение усиления к виртуальным аудиосигналам со значением задержки, применяемым к ним, с тем чтобы формировать множество виртуальных аудиосигналов, имеющих звуковое поле, имеющее форму плоских волн. В этом случае, процессор 130 виртуального аудио может интегрировать значения усиления при панорамировании "G" модулей применения усиления модуля 120 формирования виртуального аудио по фиг.4 и комбинированные значения усиления "A" модулей применения усиления процессора 130 виртуального аудио по фиг.4, чтобы вычислять конечное значение усиления "PTFL,FL". Это может быть выражено в качестве следующего уравнения:
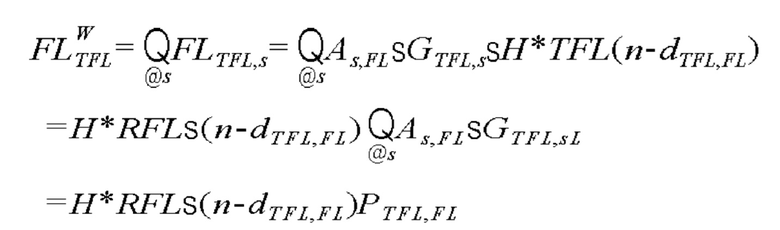 ,
,
где s обозначает элемент S={FL, FR, FC, SL, SR, BL, BR}.
На фиг.4-6, выше описан примерный вариант осуществления, в котором аудиосигнал, соответствующий верхнему левому переднему каналу из 11.1-канальных аудиосигналов, подготовлен посредством рендеринга в виртуальный аудиосигнал, но аудиосигналы, соответственно соответствующие верхнему правому переднему каналу, верхнему левому каналу объемного звучания и верхнему правому каналу объемного звучания, вызывающим различные ощущения поднятия источника звука из 11.1-канальных аудиосигналов, могут быть подготовлены посредством рендеринга посредством вышеописанного способа.
Подробно, как проиллюстрировано на фиг.7, аудиосигналы, соответственно соответствующие верхнему левому переднему каналу, верхнему правому переднему каналу, верхнему левому каналу объемного звучания и верхнему правому каналу объемного звучания, могут быть, соответственно, подготовлены посредством рендеринга во множество виртуальных аудиосигналов посредством множества модулей комбинирования виртуальных каналов, которые включают в себя модуль 120 формирования виртуального аудио и процессор 130 виртуального аудио, и множество виртуальных аудиосигналов, полученных посредством рендеринга, могут смешиваться с аудиосигналами, соответственно соответствующими 7.1-канальным динамикам и выводу.
Фиг.8 является схемой для описания способа предоставления аудио, осуществляемого посредством аудиоустройства 100, согласно примерному варианту осуществления настоящего изобретения.
Во-первых, на этапе S810 аудиоустройство 100 может принимать аудиосигнал. В этом случае, принимаемый аудиосигнал может представлять собой многоканальный аудиосигнал (например, 11.1-канальный), вызывающий несколько ощущений поднятия источника звука.
На этапе S820 аудиоустройство 100 может применять аудиосигнал, имеющий канал, вызывающий ощущение поднятия источника звука, из множества каналов, к фильтру преобразования тембра, который обрабатывает аудиосигнал таким образом, что он имеет ощущение поднятия источника звука, за счет этого формируя множество виртуальных аудиосигналов, которые должны выводиться через множество динамиков.
На этапе S830 аудиоустройство 100 может применять комбинированное значение усиления и значение задержки к сформированному множеству виртуальных аудиосигналов. В этом случае, аудиоустройство 100 может применять комбинированное значение усиления и значение задержки к множеству виртуальных аудиосигналов, так что множество виртуальных аудиосигналов имеют звуковое поле на основе плоских волн.
На этапе S840 аудиоустройство 100 может, соответственно, выводить сформированное множество виртуальных аудиосигналов во множество динамиков.
Как описано выше, аудиоустройство 100 может применять значение задержки и комбинированное значение усиления к множеству виртуальных аудиосигналов, чтобы подготавливать посредством рендеринга виртуальный аудиосигнал, имеющий звуковое поле на основе плоских волн, и в силу этого, пользователь прослушивает виртуальный аудиосигнал, вызывающий ощущение поднятия источника звука, предоставленное посредством аудиоустройства 100, в различных местоположениях.
В вышеописанном примерном варианте осуществления, чтобы пользователь прослушивал виртуальный аудиосигнал, вызывающий ощущение поднятия источника звука, в различных местоположениях вместо одной точки, виртуальный аудиосигнал может обрабатываться таким образом, что он имеет звуковое поле на основе плоских волн, но это представляет собой просто примерный вариант осуществления. В других примерных вариантах осуществления, чтобы пользователь прослушивал виртуальный аудиосигнал, вызывающий ощущение поднятия источника звука, в различных местоположениях, виртуальный аудиосигнал может обрабатываться посредством другого способа. Подробно, аудиоустройство 100 может применять различные значения усиления к аудиосигналам согласно частоте на основе вида канала аудиосигнала, из которого должен формироваться виртуальный аудиосигнал, за счет этого предоставляя возможность пользователю прослушивать виртуальный аудиосигнал в различных областях.
В дальнейшем в этом документе, описывается способ предоставления виртуального аудиосигнала согласно другому примерному варианту осуществления настоящего изобретения со ссылкой на фиг.9-12. Фиг.9 является блок-схемой, иллюстрирующей конфигурацию аудиоустройства 900 согласно другому примерному варианту осуществления настоящего изобретения. Во-первых, аудиоустройство 900 может включать в себя модуль 910 ввода, модуль 920 формирования виртуального аудио и модуль 930 вывода.
Модуль 910 ввода может принимать аудиосигнал, включающий в себя множество каналов. В этом случае, модуль 910 ввода может принимать аудиосигнал, включающий в себя множество каналов, вызывающих различные ощущения поднятия источника звука. Например, модуль 910 ввода может принимать 11.1-канальный аудиосигнал.
Модуль 920 формирования виртуального аудио может подавать аудиосигнал, который имеет канал, вызывающий ощущение поднятия источника звука, из множества каналов в фильтр, который обрабатывает аудиосигнал таким образом, что имелось ощущение поднятия источника звука, и может применять различные значения усиления к аудиосигналу согласно частоте, на основе вида канала аудиосигнала, из которого должен формироваться виртуальный аудиосигнал, за счет этого формируя множество виртуальных аудиосигналов.
Подробно, модуль 920 формирования виртуального аудио может копировать фильтрованный аудиосигнал таким образом, что он соответствует числу динамиков, и может определять ипсилатеральный динамик и контралатеральный динамик на основе вида канала аудиосигнала, из которого должен формироваться виртуальный аудиосигнал. Подробно, модуль 920 формирования виртуального аудио может определять, в качестве ипсилатерального динамика, динамик, расположенный в идентичном направлении, и может определять, в качестве контралатерального динамика, динамик, расположенный в противоположном направлении, на основе вида канала аудиосигнала, из которого должен формироваться виртуальный аудиосигнал. Например, когда аудиосигнал, из которого должен формироваться виртуальный аудиосигнал, представляет собой аудиосигнал, имеющий верхний левый передний канал, модуль 920 формирования виртуального аудио может определять, в качестве ипсилатеральных динамиков, динамики, соответственно соответствующие левому переднему каналу, левому каналу объемного звучания и левому заднему каналу, расположенным в направлении, идентичном или в направлении, ближайшем к направлению верхнего левого переднего канала, и может определять, в качестве контралатеральных динамиков, динамики, соответственно соответствующие правому переднему каналу, правому каналу объемного звучания и правому заднему каналу, расположенным в направлении, противоположном направлению верхнего левого переднего канала.
Кроме того, модуль 920 формирования виртуального аудио может применять повышающий фильтр полосы низких частот к виртуальному аудиосигналу, соответствующему ипсилатеральному динамику, и может применять фильтр верхних частот к виртуальному аудиосигналу, соответствующему контралатеральному динамику. Подробно, модуль 920 формирования виртуального аудио может применять повышающий фильтр полосы низких частот к виртуальному аудиосигналу, соответствующему ипсилатеральному динамику для регулирования общего баланса тембра, и может применять фильтр верхних частот, который фильтрует высокочастотную область, влияющую на локализацию звуковых изображений, к виртуальному аудиосигналу, соответствующему контралатеральному динамику.
Обычно, низкочастотный компонент аудиосигнала главным образом влияет на локализацию звуковых изображений на основе ITD, а высокочастотный компонент аудиосигнала главным образом влияет на локализацию звуковых изображений на основе ILD. В частности, когда слушатель перемещается в одном направлении в ILD, усиление при панорамировании может быть эффективно задано, и посредством регулирования степени, в которой левый источник звука перемещается вправо или правый источник звука перемещается влево, слушатель непрерывно прослушивает плавный аудиосигнал. Тем не менее, в ITD, звук из близкого динамика сначала слышится ушами, и в силу этого, когда слушатель перемещается, возникает смена направления локализации слева вправо.
Смена направления локализации слева вправо должна обязательно разрешаться при локализации звуковых изображений. Чтобы разрешать такую проблему, процессор 920 виртуального аудио может удалять низкочастотный компонент, который влияет на ITD в виртуальных аудиосигналах, соответствующих контралатеральным динамикам, расположенным в направлении, противоположном источнику звука, и может фильтровать только высокочастотный компонент, который оказывает доминирующее влияние на ILD. Следовательно, смена направления локализации слева вправо, вызываемая посредством низкочастотного компонента, предотвращается, и местоположение звукового изображения может поддерживаться посредством ILD на основе высокочастотного компонента.
Кроме того, модуль 920 формирования виртуального аудио может умножать, на значение усиления при панорамировании, аудиосигнал, соответствующий ипсилатеральному динамику, и аудиосигнал, соответствующий контралатеральному динамику, с тем чтобы формировать множество виртуальных аудиосигналов. Подробно, модуль 920 формирования виртуального аудио может умножать, на значение усиления при панорамировании для локализации звуковых изображений, аудиосигнал, который соответствует ипсилатеральному динамику и проходит через повышающий фильтр полосы низких частот, и аудиосигнал, который соответствует контралатеральному динамику и проходит через фильтр верхних частот, за счет этого формируя множество виртуальных аудиосигналов. Иными словами, модуль 920 формирования виртуального аудио может применять различные значения усиления к аудиосигналу согласно частотам множества виртуальных аудиосигналов, с тем чтобы формировать множество виртуальных аудиосигналов на основе местоположения звукового изображения.
Модуль 930 вывода может выводить множество виртуальных аудиосигналов через динамики, соответствующие им. В этом случае, модуль 930 вывода может смешивать виртуальный аудиосигнал, соответствующий конкретному каналу, с аудиосигналом, имеющим конкретный канал, с тем чтобы выводить аудиосигнал, полученный посредством смешивания, через динамик, соответствующий конкретному каналу. Например, модуль 930 вывода может смешивать виртуальный аудиосигнал, соответствующий левому переднему каналу, с аудиосигналом, который формируется посредством обработки верхнего левого переднего канала, с тем чтобы выводить аудиосигнал, полученный посредством смешивания, через динамик, соответствующий левому переднему каналу.
В дальнейшем в этом документе подробно со ссылкой на фиг.10 описывается способ рендеринга 11.1-канального аудиосигнала в виртуальный аудиосигнал, с тем чтобы выводить, через 7.1-канальный динамик, аудиосигнал, соответствующий каждому из каналов, вызывающих различные ощущения поднятия источника звука, из 11.1-канальных аудиосигналов, согласно примерному варианту осуществления.
Фиг.10 и 11 являются схемами для описания способа рендеринга 11.1-канального аудиосигнала, чтобы выводить подготовленный посредством рендеринга аудиосигнал через 7.1-канальный динамик, согласно различным примерным вариантам осуществления настоящего изобретения.
Во-первых, когда вводится 11.1-канальный аудиосигнал, имеющий верхний левый передний канал, модуль 920 формирования виртуального аудио может применять входной аудиосигнал, имеющий верхний левый передний канал, к фильтру H преобразования тембра. Кроме того, модуль 920 формирования виртуального аудио может копировать аудиосигнал, соответствующий верхнему левому переднему каналу, к которому применяется фильтр H преобразования тембра, в семь аудиосигналов и затем может определять ипсилатеральный динамик и контралатеральный динамик согласно местоположению аудиосигнала, имеющего верхний левый передний канал. Иными словами, модуль 920 формирования виртуального аудио может определять, в качестве ипсилатеральных динамиков, динамики, соответственно соответствующие левому переднему каналу, левому каналу объемного звучания и левому заднему каналу, расположенным в направлении, идентичном направлению аудиосигнала, имеющего верхний левый передний канал, и может определять, в качестве контралатеральных динамиков, динамики, соответственно соответствующие правому переднему каналу, правому каналу объемного звучания и правому заднему каналу, расположенным в направлении, противоположном направлению аудиосигнала, имеющего верхний левый передний канал.
Кроме того, модуль 920 формирования виртуального аудио может фильтровать виртуальный аудиосигнал, соответствующий ипсилатеральному динамику из множества скопированных виртуальных аудиосигналов, посредством использования повышающего фильтра полосы низких частот. Кроме того, модуль 920 формирования виртуального аудио может вводить виртуальные аудиосигналы, проходящие через повышающий фильтр полосы низких частот, во множество модулей применения усиления, соответственно соответствующих левому переднему каналу, левому каналу объемного звучания и левому заднему каналу, и может умножать аудиосигнал на значения многоканального усиления при панорамировании "GTFL,FL, GTFL,SL и GTFL,BL" для локализации аудиосигнала в местоположении верхнего левого переднего канала, за счет этого формируя 3-канальный виртуальный аудиосигнал.
Кроме того, модуль 920 формирования виртуального аудио может фильтровать виртуальный аудиосигнал, соответствующий контралатеральному динамику из множества скопированных виртуальных аудиосигналов, посредством использования фильтра верхних частот. Кроме того, модуль 920 формирования виртуального аудио может вводить виртуальные аудиосигналы, проходящие через фильтр верхних частот, во множество модулей применения усиления, соответственно соответствующих правому переднему каналу, правому каналу объемного звучания и правому заднему каналу, и может умножать аудиосигнал на значения многоканального усиления при панорамировании "GTFL,FR, GTFL,SR и GTFL,BR" для локализации аудиосигнала в местоположении верхнего левого переднего канала, за счет этого формируя 3-канальный виртуальный аудиосигнал.
Кроме того, в виртуальном аудиосигнале, соответствующем переднему центральному каналу вместо ипсилатерального динамика или контралатерального динамика, модуль 920 формирования виртуального аудио может обрабатывать виртуальный аудиосигнал, соответствующий переднему центральному каналу, посредством использования способа, идентичного способу для ипсилатерального динамика, или способа, идентичного способу для контралатерального динамика. В примерном варианте осуществления настоящего изобретения, как проиллюстрировано на фиг.10, виртуальный аудиосигнал, соответствующий переднему центральному каналу, может обрабатываться посредством способа, идентичного способу для виртуального аудиосигнала, соответствующего ипсилатеральному динамику.
На фиг.10, выше описан примерный вариант осуществления, в котором аудиосигнал, соответствующий верхнему левому переднему каналу из 11.1-канальных аудиосигналов, подготовлен посредством рендеринга в виртуальный аудиосигнал, но аудиосигналы, соответственно соответствующие верхнему правому переднему каналу, верхнему левому каналу объемного звучания и верхнему правому каналу объемного звучания, вызывающим различные ощущения поднятия источника звука из 11.1-канальных аудиосигналов, могут быть подготовлены посредством рендеринга посредством способа, описанного выше со ссылкой на фиг.10.
В другом примерном варианте осуществления настоящего изобретения, аудиоустройство 1100, проиллюстрированное на фиг.11, может реализовываться посредством интегрирования способа предоставления виртуального аудио, описанного выше со ссылкой на фиг.6, и способа предоставления виртуального аудио, описанного выше со ссылкой на фиг.10. Подробно, аудиоустройство 1100 может выполнять преобразование тембра для входного аудиосигнала посредством использования фильтра H преобразования тембра, может фильтровать виртуальные аудиосигналы, соответствующие ипсилатеральному динамику посредством использования повышающего фильтра полосы низких частот для применения различных значений усиления к аудиосигналам, и может фильтровать аудиосигналы, соответствующие контралатеральному динамику, посредством использования фильтра верхних частот согласно частоте на основе вида канала аудиосигнала, из которого должен формироваться виртуальный аудиосигнал. Кроме того, аудиоустройство 100 может применять значение задержки "d" и конечное значение усиления "P" к множеству виртуальных аудиосигналов таким образом, что множество виртуальных аудиосигналов составляют звуковое поле, имеющее плоскую волну, за счет этого формируя виртуальный аудиосигнал.
Фиг.12 является схемой для описания способа предоставления аудио, осуществляемого посредством аудиоустройства 900, согласно другому примерному варианту осуществления настоящего изобретения.
Во-первых, на этапе S1210 аудиоустройство 900 может принимать аудиосигнал. В этом случае, принимаемый аудиосигнал может представлять собой многоканальный аудиосигнал (например, 11.1-канальный), вызывающий несколько ощущений поднятия источника звука.
На этапе S1220 аудиоустройство 900 может применять аудиосигнал, имеющий канал, вызывающий ощущение поднятия источника звука, из множества каналов, к фильтру, который обрабатывает аудиосигнал таким образом, что он имеет ощущение поднятия источника звука. В этом случае, аудиосигнал, имеющий канал, вызывающий ощущение поднятия источника звука, из множества каналов, может представлять собой аудиосигнал, имеющий верхний левый передний канал, и фильтр, который обрабатывает аудиосигнал таким образом, что он имеет ощущение поднятия источника звука, может представлять собой корректирующий HRTF-фильтр.
На этапе S1230 аудиоустройство 900 может применять различные значения усиления к аудиосигналу согласно частоте на основе вида канала аудиосигнала, из которого должен формироваться виртуальный аудиосигнал, за счет этого формируя множество виртуальных аудиосигналов.
Подробно, аудиоустройство 900 может копировать фильтрованный аудиосигнал таким образом, что он соответствует числу динамиков, и может определять ипсилатеральный динамик и контралатеральный динамик на основе вида канала аудиосигнала, из которого должен формироваться виртуальный аудиосигнал. Аудиоустройство 900 может применять повышающий фильтр полосы низких частот к виртуальному аудиосигналу, соответствующему ипсилатеральному динамику, может применять фильтр верхних частот к виртуальному аудиосигналу, соответствующему контралатеральному динамику, и может умножать, на значение усиления при панорамировании, аудиосигнал, соответствующий ипсилатеральному динамику, и аудиосигнал, соответствующий контралатеральному динамику, с тем чтобы формировать множество виртуальных аудиосигналов.
На этапе S1240 аудиоустройство 900 может выводить множество виртуальных аудиосигналов.
Как описано выше, аудиоустройство 900 может применять различные значения усиления к аудиосигналу согласно частоте на основе вида канала аудиосигнала, из которого должен формироваться виртуальный аудиосигнал, и в силу этого, пользователь прослушивает виртуальный аудиосигнал, вызывающий ощущение поднятия источника звука, предоставленное посредством аудиоустройства 900, в различных местоположениях.
В дальнейшем в этом документе, описывается другой примерный вариант осуществления настоящего изобретения. Подробно, фиг.13 является схемой для описания способа предшествующего уровня техники рендеринга 11.1-канального аудиосигнала, чтобы выводить подготовленный посредством рендеринга аудиосигнал через 7.1-канальный динамик. Во-первых, кодер 1310 может кодировать 11.1-канальный канальный аудиосигнал, множество объектных аудиосигналов и фрагменты информации траектории, соответствующие множеству объектных аудиосигналов, с тем чтобы формировать поток битов. Кроме того, декодер 1320 может декодировать принимаемый поток битов, чтобы выводить 11.1-канальный канальный аудиосигнал в модуль 1340 смешивания, и выводить множество объектных аудиосигналов и фрагменты информации траектории, соответствующие этому модулю 1330 рендеринга объектов. Модуль 1330 рендеринга объектов может подготавливать посредством рендеринга объектные аудиосигналы в 11.1-канальные посредством использования информации траектории и может выводить объектные аудиосигналы, подготовленные посредством рендеринга в 11.1-канальные, в модуль 1340 смешивания. Модуль 1340 смешивания может смешивать 11.1-канальный канальный аудиосигнал с объектными аудиосигналами, подготовленными посредством рендеринга в 11.1-канальные, с тем чтобы формировать 11.1-канальные аудиосигналы, и может выводить сформированные 11.1-канальные аудиосигналы в модуль 1350 рендеринга виртуального аудио. Как описано выше со ссылкой на фиг.2-12, модуль 1350 рендеринга виртуального аудио может формировать множество виртуальных аудиосигналов посредством использования аудиосигналов, соответственно, имеющих четыре канала (например, верхний левый передний канал, верхний правый передний канал, верхний левый канал объемного звучания и верхний правый канал объемного звучания), предоставляющих различные ощущения поднятия источника звука из 11.1-канальных аудиосигналов, и может смешивать сформированное множество виртуальных аудиосигналов с другими каналами, чтобы выводить 7.1-канальный аудиосигнал.
Тем не менее, как описано выше, в случае если виртуальный аудиосигнал формируется посредством равномерной обработки аудиосигналов, имеющих четыре канала, вызывающие различные ощущения поднятия источника звука из 11.1-канальных аудиосигналов, когда аудиосигнал, который имеет широкую полосу частот, такой как аплодисменты или звук дождя, не имеет межканальной взаимной корреляции (ICC) (т.е. имеет низкую корреляцию), и имеет импульсную характеристику, подготовлен посредством рендеринга в виртуальный аудиосигнал, качество аудио ухудшается. В частности, поскольку качество аудио более сильно ухудшается при формировании виртуального аудиосигнала, операция рендеринга для формирования виртуального аудиосигнала может выполняться через понижающее микширование на основе тембра без выполнения для аудиосигнала, имеющего импульсную характеристику, за счет этого предоставляя лучшее качество звука.
В дальнейшем в этом документе, описывается примерный вариант осуществления, в котором вид рендеринга аудиосигнала определяется на основе информации рендеринга аудиосигнала, со ссылкой на фиг.14-16.
Фиг.14 является схемой для описания способа, в котором аудиоустройство осуществляет различные способы рендеринга для 11.1-канального аудиосигнала согласно информации рендеринга аудиосигнала, с тем чтобы формировать 7.1-канальный аудиосигнал, согласно различным примерным вариантам осуществления настоящего изобретения.
Кодер 1410 может принимать и кодировать 11.1-канальный канальный аудиосигнал, множество объектных аудиосигналов, информацию траектории, соответствующую множеству объектных аудиосигналов, и информацию рендеринга аудиосигнала. В этом случае, информация рендеринга аудиосигнала может обозначать вид аудиосигнала и может включать в себя, по меньшей мере, одну из информации относительно того, представляет собой входной аудиосигнал или нет аудиосигнал, имеющий импульсную характеристику, информации относительно того, представляет собой входной аудиосигнал или нет аудиосигнал, имеющий широкую полосу частот, и информации относительно того, имеет или нет входной аудиосигнал низкую ICC. Кроме того, информация рендеринга аудиосигнала может включать в себя информацию относительно способа сигнала рендеринга аудио. Иными словами, информация рендеринга аудиосигнала может включать в себя информацию в отношении того, каким из способа тембрального рендеринга и способа пространственного рендеринга подготовлен посредством рендеринга аудиосигнал.
Декодер 1420 может декодировать аудиосигнал, полученный посредством кодирования, чтобы выводить 11.1-канальный канальный аудиосигнал и информацию рендеринга аудиосигнала в модуль 1440 смешивания и выводить множество объектных аудиосигналов, информацию траектории, соответствующую им, и информацию рендеринга аудиосигнала в модуль 1440 смешивания.
Модуль 1430 рендеринга объектов может формировать 11.1-канальный объектный аудиосигнал посредством использования множества объектных аудиосигналов, вводимых в него, и информации траектории, соответствующей им, и может выводить сформированный 11.1-канальный объектный аудиосигнал в модуль 1440 смешивания.
Первый модуль 1440 смешивания может смешивать 11.1-канальный канальный аудиосигнал, вводимый в него, с 11.1-канальным объектным аудиосигналом, с тем чтобы формировать 11.1-канальные аудиосигналы. Кроме того, первый модуль 1440 смешивания может включать в себя модуль рендеринга, который подготавливает посредством рендеринга 11.1-канальные аудиосигналы, сформированные из информации рендеринга аудиосигнала. Подробно, первый модуль 1440 смешивания может определять то, представляет собой аудиосигнал или нет аудиосигнал, имеющий импульсную характеристику, представляет собой аудиосигнал или нет аудиосигнал, имеющий широкую полосу частот, и имеет или нет аудиосигнал низкую ICC, на основе информации рендеринга аудиосигнала. Когда аудиосигнал представляет собой аудиосигнал, имеющий импульсную характеристику, аудиосигнал представляет собой аудиосигнал, имеющий широкую полосу частот, или аудиосигнал имеет низкую ICC, первый модуль 1440 смешивания может выводить 11.1-канальные аудиосигналы в первый модуль 1450 рендеринга. С другой стороны, когда аудиосигнал не имеет вышеописанных характеристик, первый модуль 1440 смешивания может выводить 11.1-канальные аудиосигналы во второй модуль 1460 рендеринга.
Первый модуль 1450 рендеринга может подготавливать посредством рендеринга четыре аудиосигнала, вызывающие различные ощущения поднятия источника звука из 11.1-канальных аудиосигналов, вводимых в него, посредством использования способа тембрального рендеринга. Подробно, первый модуль 1450 рендеринга может подготавливать посредством рендеринга аудиосигналы, соответственно соответствующие верхнему левому переднему каналу, верхнему правому переднему каналу, верхнему левому каналу объемного звучания и верхнему правому каналу объемного звучания из 11.1-канальных аудиосигналов, в левый передний канал, правый передний канал, левый канал объемного звучания и верхний правый канал объемного звучания посредством использования способа понижающего микширования первого канала и может смешивать аудиосигналы, имеющие четыре канала, полученные через понижающее микширование с аудиосигналами, имеющими другие каналы, чтобы выводить 7.1-канальный аудиосигнал во второй модуль 1470 смешивания.
Второй модуль 1460 рендеринга может подготавливать посредством рендеринга четыре аудиосигнала, которые имеют различные ощущения поднятия источника звука из 11.1-канальных аудиосигналов, вводимых в него, в виртуальный аудиосигнал, вызывающий ощущение поднятия источника звука, посредством использования способа пространственного рендеринга, описанного выше со ссылкой на фиг.2-13.
Второй модуль 1470 смешивания может выводить 7.1-канальный аудиосигнал, который выводится, по меньшей мере, через один из первого модуля 1450 рендеринга и второго модуля 1460 рендеринга.
В вышеописанном примерном варианте осуществления, выше описано, что первый модуль 1450 рендеринга и второй модуль 1460 рендеринга подготавливают посредством рендеринга аудиосигнал посредством использования, по меньшей мере, одного из способа тембрального рендеринга и способа пространственного рендеринга, но это представляет собой просто примерный вариант осуществления. В других примерных вариантах осуществления, модуль 1430 рендеринга объектов может подготавливать посредством рендеринга объектный аудиосигнал посредством использования, по меньшей мере, одного из способа тембрального рендеринга и способа пространственного рендеринга на основе информации рендеринга аудиосигнала.
Кроме того, в вышеописанном примерном варианте осуществления, выше описано, что информация рендеринга аудиосигнала определяется посредством анализа аудиосигнала перед кодированием. Тем не менее, например, информация рендеринга аудиосигнала может формироваться и кодироваться звукоинженером по смешиванию для отражения намерения создания контента и может получаться посредством различных способов.
Подробно, кодер 1410 может анализировать множество канальных аудиосигналов, множество объектных аудиосигналов и информации траектории, с тем чтобы формировать информацию рендеринга аудиосигнала. Подробнее, кодер 1410 может извлекать функции, которые используются в значительной степени для того, чтобы классифицировать аудиосигнал, и может изучать извлеченные признаки для классификатора, чтобы анализировать то, имеют или нет множество канальных аудиосигналов или множество объектных аудиосигналов, вводимых в него, импульсную характеристику. Кроме того, кодер 1410 может анализировать информацию траектории объектных аудиосигналов, и когда объектные аудиосигналы являются статическими, кодер 1410 может формировать информацию рендеринга, которая обеспечивает возможность выполнения рендеринга посредством использования способа тембрального рендеринга. Когда объектные аудиосигналы включают в себя движение, кодер 1410 может формировать информацию рендеринга, которая обеспечивает возможность выполнения рендеринга посредством использования способа пространственного рендеринга. Иными словами, в аудиосигнале, который имеет импульсный признак и имеет статическую характеристику, имеющую движение, кодер 1410 может формировать информацию рендеринга, которая обеспечивает возможность выполнения рендеринга посредством использования способа тембрального рендеринга, а в противном случае, кодер 1410 может формировать информацию рендеринга, которая обеспечивает возможность выполнения рендеринга посредством использования способа пространственного рендеринга. В этом случае то, обнаруживается или нет движение, может оцениваться посредством вычисления расстояния перемещения в расчете на кадр объектного аудиосигнала.
Когда анализ того, посредством какого из способа тембрального рендеринга и способа пространственного рендеринга выполняется рендеринг, основан на мягком решении вместо жесткого решения, кодер 1410 может выполнять рендеринг посредством комбинирования операции рендеринга на основе способа тембрального рендеринга и операции рендеринга на основе способа пространственного рендеринга на основе характеристики аудиосигнала. Например, как проиллюстрировано на фиг.15, когда вводятся первый объектный аудиосигнал OBJ1, первая информация TRJ1 траектории и значение RC весового коэффициента рендеринга, которые кодер 1410 анализирует характеристику аудиосигнала, чтобы формировать, модуль 1430 рендеринга объектов может определять значение WT весового коэффициента для способа тембрального рендеринга и значение WS весового коэффициента для способа пространственного рендеринга посредством использования значения RC весового коэффициента рендеринга. Кроме того, модуль 1430 рендеринга объектов может умножать входной первый объектный аудиосигнал OBJ1 на значение WT весового коэффициента для способа тембрального рендеринга, чтобы выполнять рендеринг на основе способа тембрального рендеринга, и может умножать входной первый объектный аудиосигнал OBJ1 на значение WS весового коэффициента для способа пространственного рендеринга, чтобы выполнять рендеринг на основе способа пространственного рендеринга. Кроме того, как описано выше, модуль 1430 рендеринга объектов может выполнять рендеринг для других объектных аудиосигналов.
В качестве другого примера, как проиллюстрировано на фиг.16, когда вводятся первый канальный аудиосигнал CH1 и значение RC весового коэффициента рендеринга, которые кодер 1410 анализирует характеристику аудиосигнала, чтобы формировать, первый модуль 1440 смешивания может определять значение WT весового коэффициента для способа тембрального рендеринга и значение WS весового коэффициента для способа пространственного рендеринга посредством использования значения RC весового коэффициента рендеринга. Кроме того, первый модуль 1440 смешивания может умножать входной первый канальный аудиосигнал CH1 на значение WT весового коэффициента для способа тембрального рендеринга, чтобы выводить значение, полученное через умножение, в первый модуль 1450 рендеринга, и может умножать входной первый канальный аудиосигнал CH1 на значение WS весового коэффициента для способа пространственного рендеринга, чтобы выводить значение, полученное через умножение, во второй модуль 1460 рендеринга. Кроме того, как описано выше, первый модуль 1440 смешивания может умножать другие канальные аудиосигналы на значение весового коэффициента, чтобы, соответственно, выводить значения, полученные через умножение, в первый модуль 1450 рендеринга и второй модуль 1460 рендеринга.
В вышеописанном примерном варианте осуществления, выше описано, что кодер 1410 получает информацию рендеринга аудиосигнала, но это представляет собой просто примерный вариант осуществления. В других примерных вариантах осуществления, декодер 1420 может получать информацию рендеринга аудиосигнала. В этом случае, кодер 1410 может не передавать информацию рендеринга, и декодер 1420 может непосредственно формировать информацию рендеринга.
Кроме того, в другом примерном варианте осуществления, декодер 1420 может формировать информацию рендеринга, которая обеспечивает возможность рендеринга канального аудиосигнала посредством использования способа тембрального рендеринга, и обеспечивает возможность рендеринга объектного аудиосигнала посредством рендеринга посредством использования способа пространственного рендеринга.
Как описано выше, операция рендеринга может выполняться посредством различных способов согласно информации рендеринга аудиосигнала, и не допускается ухудшение качества звука вследствие характеристики аудиосигнала.
В дальнейшем в этом документе, описывается способ определения способа рендеринга канального аудиосигнала посредством анализа канального аудиосигнала, когда объектный аудиосигнал не разделяется, и имеется только канальный аудиосигнал, в котором все аудиосигналы подготавливаются посредством рендеринга и смешиваются. В частности, описывается способ, который анализирует объектный аудиосигнал, чтобы извлекать компонент объектного аудиосигнала из канального аудиосигнала, выполняет рендеринг, предоставляющий виртуальное ощущение поднятия источника звука, для объектного аудиосигнала посредством использования способа пространственного рендеринга и выполняет рендеринг для окружающего аудиосигнала посредством использования способа тембрального рендеринга.
Фиг.17 является схемой для описания примерного варианта осуществления, в котором рендеринг выполняется посредством различных способов согласно тому, обнаруживаются или нет аплодисменты из четырех верхних аудиосигналов, вызывающих различные 11.1-канальные ощущения поднятия источника звука.
Во-первых, модуль 1710 обнаружения аплодисментов может определять то, обнаруживаются или нет аплодисменты из четырех верхних аудиосигналов, вызывающих различные ощущения поднятия источника звука, в 11.1-канальном.
В случае если модуль 1710 обнаружения аплодисментов использует жесткое решение, модуль 1710 обнаружения аплодисментов может определять следующий выходной сигнал.
Когда аплодисменты обнаруживаются: TFLA=TFL, TFRA=TFR, TSLA=TSL, TSRA=TSR, TFLG=0, TFRG=0, TSLG=0, TSRG=0
Когда аплодисменты не обнаруживаются: TFLA=0, TFRA=0, TSLA=0, TSRA=0, TFLG=TFL, TFRG=TFR, TSLG=TSL, TSRG=TS
В этом случае, выходной сигнал может вычисляться посредством кодера вместо модуля 1710 обнаружения аплодисментов и может передаваться в форме флагов.
В случае если модуль 1710 обнаружения аплодисментов использует мягкое решение, модуль 1710 обнаружения аплодисментов может умножать сигнал на значения весовых коэффициентов "α и β" для того, чтобы определять выходной сигнал на основе того, обнаруживаются или нет аплодисменты, и интенсивности аплодисментов.
TFLA = αTFLTFL, TFRA = αTFRTFR, TSLA = αTSLTSL, TSRA = αTSRTSR, TFLG = βTFLTFL, TFRG = βTFRTFR, TSLG = βTSLTSL, TSRG = βTSRTSR
Сигналы "TFLG, TFRG, TSLG и TSRG" из выходных сигналов могут выводиться в модуль 1730 пространственного рендеринга и могут быть подготовлены посредством рендеринга посредством способа пространственного рендеринга.
Сигналы "TFLA, TFRA, TSLA и TSRA" из выходных сигналов могут определяться в качестве компонентов аплодисментов и могут выводиться в модуль 1720 анализа рендеринга.
Способ, в котором модуль 1720 анализа рендеринга определяет компонент аплодисментов и анализирует способ рендеринга, описывается со ссылкой на фиг.18. Модуль 1720 анализа рендеринга может включать в себя преобразователь 1721 частоты, модуль 1723 вычисления когерентности, модуль 1725 определения способа рендеринга и разделитель 1727 сигналов.
Преобразователь 1721 частоты может преобразовывать сигналы "TFLA, TFRA, TSLA и TSRA", вводимые в него, в частотные области, чтобы выводить сигналы "TFLAF, TFRAF, TSLAF и TSRAF". В этом случае, преобразователь 1721 частоты может представлять сигналы в качестве подполосных выборок гребенки фильтров, к примеру, гребенки квадратурных зеркальных фильтров (QMF), и затем может выводить сигналы "TFLAF, TFRAF, TSLAF и TSRAF".
Модуль 1723 вычисления когерентности может вычислять сигнал "xLF", который является когерентностью между сигналами "TFLAF и TSLAF", сигнал "xRF", который является когерентностью между сигналами "TFRAF и TSRAF", сигнал "xFF", который является когерентностью между сигналами "TFLAF и TFRAF", и сигнал "xSF", который является когерентностью между сигналами "TSLAF и TSRAF", для каждой из множества полос частот. В этом случае, когда один из двух сигналов равен 0, модуль 1723 вычисления когерентности может вычислять когерентность как равную 1. Это обусловлено тем, что способ пространственного рендеринга используется, когда сигнал локализуется только в одном канале.
Модуль 1725 определения способа рендеринга может вычислять значения весовых коэффициентов "wTFLF, wTFRF, wTSLF и wTSRF", которые должны использоваться для способа пространственного рендеринга, из когерентностей, вычисленных посредством модуля 1723 вычисления когерентности, как выражено в следующем уравнении:
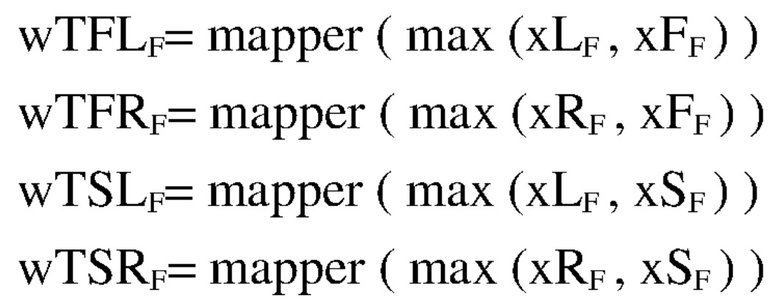 ,
,
где max обозначает функцию, которая выбирает большое число из двух коэффициентов, а mapper обозначает различные типы функций, которые соотносят значение между 0 и 1 со значением между 0 и 1 посредством нелинейного отображения.
Модуль 1725 определения способа рендеринга может использовать различные модули преобразования для каждой из множества полос частот. Подробно, сигналы значительно смешиваются, поскольку помехи при передаче сигналов, вызываемые посредством задержки, становятся более серьезными, и полоса пропускания становится более широкой на высокой частоте, и в силу этого, когда различные модули преобразования используются для каждой полосы частот, качество звука и степень разделения сигналов улучшается в большей степени по сравнению со случаем, в котором идентичный модуль преобразования используется во всех полосах частот. Фиг.19 является графиком, показывающим характеристику модуля преобразования, когда модуль 1725 определения способа рендеринга использует модули преобразования, имеющие различные характеристики для каждой полосы частот.
Кроме того, когда отсутствует сигнал (т.е. когда значение функции подобия равно 0 или 1, и панорамирование выполняется только на одной стороне), модуль 1723 вычисления когерентности может вычислять когерентность как равную 1. Тем не менее, поскольку сигнал, соответствующий боковому лепестку или минимальному уровню шума, вызываемому посредством преобразования в частотную область, формируется, когда значение функции подобия имеет значение подобия, равное или меньше порогового значения, посредством задания порогового значения (например, 0,1), способ пространственного рендеринга может выбираться, за счет этого исключая возникновение шума. Фиг.20 является графиком для определения значения весового коэффициента для способа рендеринга согласно значению подобия. Например, когда значение функции подобия равно или меньше 0,1, значение весового коэффициента может задаваться таким образом, чтобы выбирать способ пространственного рендеринга.
Разделитель 1727 сигналов может умножать сигналы "TFLAF, TFRAF, TSLAF и TSRAF", которые преобразуются в частотные области, на значения весовых коэффициентов "wTFLF, wTFRF, wTSLF и wTSRF", определенные посредством модуля 1725 определения способа рендеринга, чтобы преобразовывать сигналы "TFLAF, TFRAF, TSLAF и TSRAF" в частотные области, и затем может выводить сигналы "TFLAS, TFRAS, TSLAS и TSRAS" в модуль 1730 пространственного рендеринга.
Кроме того, разделитель 1727 сигналов может выводить, в модуль 1740 тембрального рендеринга, сигналы "TFLAT, TFRAT, TSLAT и TSRAT", полученные посредством вычитания сигналов "TFLAS, TFRAS, TSLAS и TSRAS", выводимых в модуль 1730 пространственного рендеринга, из сигналов "TFLAF, TFRAF, TSLAF и TSRAF" вводимых в него.
Как результат, сигналы "TFLAS, TFRAS, TSLAS и TSRAS", выводимые в модуль 1730 пространственного рендеринга, могут составлять сигналы, соответствующие объектам, локализованным в четыре верхних канальных аудиосигнала, а сигналы "TFLAT, TFRAT, TSLAT и TSRAT", выводимые в модуль 1740 тембрального рендеринга, могут составлять сигналы, соответствующие рассеянным звукам.
Следовательно, когда аудиосигнал, такой как аплодисменты или звук дождя, который имеют низкую когерентность между каналами, подготовлен посредством рендеринга посредством, по меньшей мере, одного из способа тембрального рендеринга и способа пространственного рендеринга посредством вышеописанного процесса, дальнейшее ухудшение качества звука минимизируется.
Фактически, многоканальный аудиокодек может в значительной степени использовать ICC для сжатия данных, к примеру, стандарт объемного звучания MPEG. В этом случае, разность канальных уровней (CLD) и ICC могут быть главным образом использованы в качестве параметров. Пространственное кодирование аудиообъектов (SAOC) по стандарту MPEG, которое представляет собой технологию объектного кодирования, может иметь форму, аналогичную ему. В этом случае, внутренняя операция кодирования может использовать технологию канального расширения, которая расширяет сигнал от сигнала понижающего микширования до многоканального аудиосигнала.
Фиг.21 является схемой для описания примерного варианта осуществления, в котором рендеринг выполняется посредством использования множества способов рендеринга, когда используется канальный расширяющий кодек, имеющий такую структуру, как стандарт объемного звучания MPEG, согласно примерному варианту осуществления настоящего изобретения.
Декодер канального кодека может разделять канал потока битов, соответствующего аудиосигналу верхнего уровня, на основе CLD, и затем декоррелятор может корректировать когерентность между каналами на основе ICC. Как результат, высушенный канальный источник звука и рассеянный канальный источник звука могут разделяться друг от друга и выводиться. Высушенный канальный источник звука может быть подготовлен посредством рендеринга посредством способа пространственного рендеринга, а рассеянный канальный источник звука может быть подготовлен посредством рендеринга посредством способа тембрального рендеринга.
Чтобы эффективно использовать настоящую структуру, канальный кодек может отдельно сжимать и передавать аудиосигнал среднего уровня и аудиосигнал верхнего уровня, либо в древовидной структуре поля "один-к-двум"/"два-к-трем"(OTT/TTT), аудиосигнал среднего уровня и аудиосигнал верхнего уровня могут разделяться друг от друга и затем могут передаваться посредством сжатия разделяемых каналов.
Кроме того, аплодисменты могут обнаруживаться для каналов верхних уровней и могут передаваться в качестве потока битов. Декодер может подготавливать посредством рендеринга источник звука, канал которого разделяется на основе CLD, посредством использования способа пространственного рендеринга при операции вычисления сигналов "TFLA, TFRA, TSLA и TSRA", которые являются данными канала, равными аплодисментам. В случае если фильтрация, взвешивание и суммирование, которые являются рабочими характеристиками пространственного рендеринга, выполняются в частотной области, умножение, взвешивание и суммирование могут выполняться, и в силу этого, фильтрация, взвешивание и суммирование могут выполняться без добавления дополнительных операций. Кроме того, при операции рендеринга рассеянного источника звука, сформированного на основе ICC, посредством использования способа тембрального рендеринга, рендеринг может выполняться через взвешивание и суммирование, и в силу этого, пространственный рендеринг и тембральный рендеринг могут выполняться посредством добавления небольшого числа операций.
В дальнейшем в этом документе, описывается система предоставления многоканального аудио согласно различным примерным вариантам осуществления настоящего изобретения со ссылкой на фиг.22-25. В частности, фиг.22-25 иллюстрируют систему предоставления многоканального аудио, которая предоставляет виртуальный аудиосигнал, вызывающий ощущение поднятия источника звука, посредством использования динамиков, расположенных в идентичной плоскости.
Фиг.22 является схемой для описания системы предоставления многоканального аудио согласно первому примерному варианту осуществления настоящего изобретения.
Во-первых, аудиоустройство может принимать многоканальный аудиосигнал из носителей/среды передачи. Кроме того, аудиоустройство может декодировать многоканальный аудиосигнал и может смешивать канальный аудиосигнал, который соответствует динамику в декодированном многоканальном аудиосигнале, с аудиосигналом с интерактивными эффектами, выводимым снаружи, с тем чтобы формировать первый аудиосигнал.
Кроме того, аудиоустройство может выполнять обработку аудиосигналов в вертикальной плоскости для канальных аудиосигналов, вызывающих различные ощущения поднятия источника звука в декодированном многоканальном аудиосигнале. В этом случае, обработка аудиосигналов в вертикальной плоскости может быть операцией формирования виртуального аудиосигнала, вызывающего ощущение поднятия источника звука, посредством использования динамика в горизонтальной плоскости, и может использовать вышеописанную технологию формирования виртуальных аудиосигналов.
Кроме того, аудиоустройство может смешивать обработанный в вертикальной плоскости аудиосигнал с аудиосигналом с интерактивными эффектами, выводимым снаружи, с тем чтобы формировать второй аудиосигнал.
Кроме того, аудиоустройство может смешивать первый аудиосигнал со вторым аудиосигналом, чтобы выводить сигнал, получаемый посредством смешивания, в соответствующий аудиодинамик в горизонтальной плоскости.
Фиг.23 является схемой для описания системы предоставления многоканального аудио согласно второму примерному варианту осуществления настоящего изобретения.
Во-первых, аудиоустройство может принимать многоканальный аудиосигнал из носителей/среды передачи. Кроме того, аудиоустройство может смешивать многоканальный аудиосигнал с аудиосигналом с интерактивными эффектами, выводимым снаружи, с тем чтобы формировать первый аудиосигнал.
Кроме того, аудиоустройство может выполнять обработку аудиосигналов в вертикальной плоскости для первого аудиосигнала таким образом, что он соответствует схеме размещения аудиодинамика в горизонтальной плоскости, и может выводить сигнал, получаемый посредством обработки, в соответствующий аудиодинамик в горизонтальной плоскости.
Кроме того, аудиоустройство может кодировать первый аудиосигнал, для которого выполнена обработка аудиосигналов в вертикальной плоскости, и может передавать аудиосигнал, полученный посредством кодирования, во внешнее приемное аудиовидео(AV)-устройство. В этом случае, аудиоустройство может кодировать аудиосигнал в формате, который поддерживается посредством существующего приемного AV-устройства, таком как формат Dolby Digital, DTS-формат и т.п.
Внешнее приемное AV-устройство может обрабатывать первый аудиосигнал, для которого выполнена обработка аудиосигналов в вертикальной плоскости, и может выводить аудиосигнал, полученный посредством обработки, в соответствующий аудиодинамик в горизонтальной плоскости.
Фиг.24 является схемой для описания системы предоставления многоканального аудио согласно третьему примерному варианту осуществления настоящего изобретения.
Во-первых, аудиоустройство может принимать многоканальный аудиосигнал из носителей/среды передачи и может принимать аудиосигнал с интерактивными эффектами, выводимый снаружи (например, из удаленного контроллера).
Кроме того, аудиоустройство может выполнять обработку аудиосигналов в вертикальной плоскости для принимаемого многоканального аудиосигнала таким образом, что он соответствует схеме размещения аудиодинамика в горизонтальной плоскости, и также может выполнять обработку аудиосигналов в вертикальной плоскости для принимаемого аудиосигнала с интерактивными эффектами таким образом, что он соответствует схеме размещения динамиков.
Кроме того, аудиоустройство может смешивать многоканальный аудиосигнал и аудиосигнал с интерактивными эффектами, для которого выполнена обработка аудиосигналов в вертикальной плоскости, с тем чтобы формировать первый аудиосигнал, и может выводить первый аудиосигнал в соответствующий аудиодинамик в горизонтальной плоскости.
Кроме того, аудиоустройство может кодировать первый аудиосигнал и может передавать аудиосигнал, полученный посредством кодирования, во внешнее приемное AV-устройство. В этом случае, аудиоустройство может кодировать аудиосигнал в формате, который поддерживается посредством существующего приемного AV-устройства, таком как формат Dolby Digital, DTS-формат и т.п.
Затем внешнее приемное AV-устройство может обрабатывать первый аудиосигнал, для которого выполнена обработка аудиосигналов в вертикальной плоскости, и может выводить аудиосигнал, полученный посредством обработки, в соответствующий аудиодинамик в горизонтальной плоскости.
Фиг.25 является схемой для описания системы предоставления многоканального аудио согласно четвертому примерному варианту осуществления настоящего изобретения.
Аудиоустройство может сразу передавать многоканальный аудиосигнал, вводимый из носителей/среды передачи, во внешнее приемное AV-устройство.
Внешнее приемное AV-устройство может декодировать многоканальный аудиосигнал и может выполнять обработку аудиосигналов в вертикальной плоскости для декодированного многоканального аудиосигнала таким образом, что он соответствует схеме размещения аудиодинамика в горизонтальной плоскости.
Кроме того, внешнее приемное AV-устройство может выводить многоканальный аудиосигнал, для которого выполнена обработка аудиосигналов в вертикальной плоскости, через динамик в горизонтальной плоскости.
Следует понимать, что примерные варианты осуществления, описанные в данном документе, должны рассматриваться только в описательном смысле, а не для целей ограничения. Описания признаков или аспектов в каждом примерном варианте осуществления типично должны рассматриваться как доступные для других аналогичных признаков или аспектов в других примерных вариантах осуществления. Хотя один или более примерных вариантов осуществления описаны со ссылкой на чертежи, специалисты в данной области техники должны понимать, что различные изменения в форме и подробностях могут вноситься в них без отступления от сущности и объема изобретения, определяемого прилагаемой формулой изобретения.
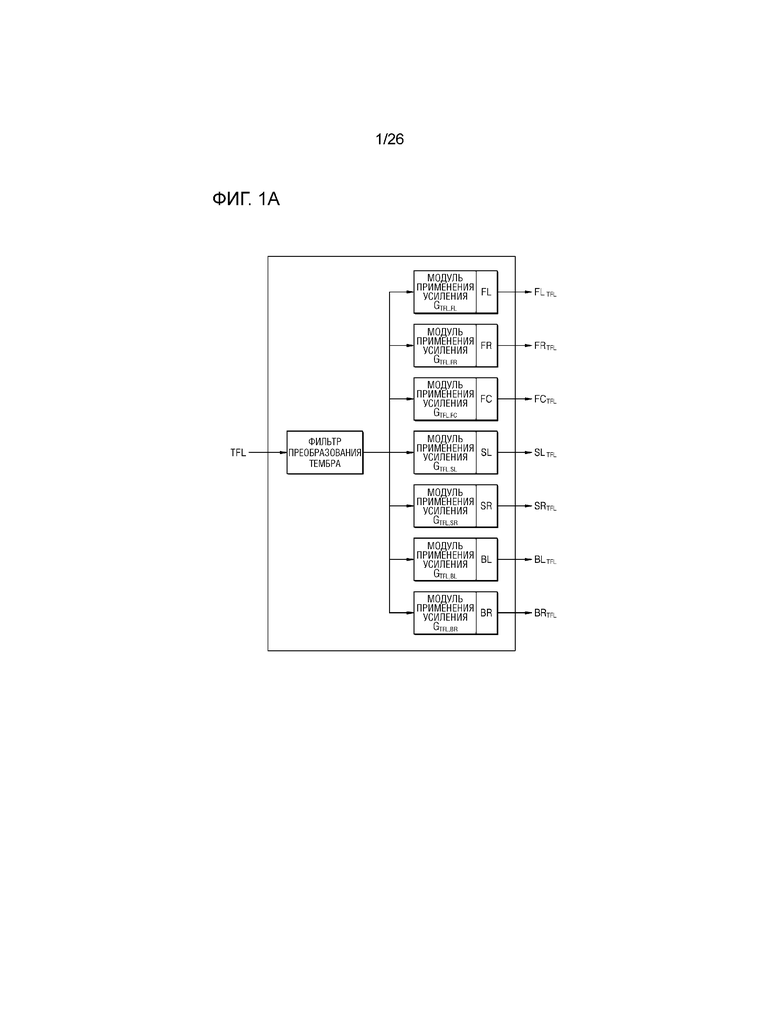
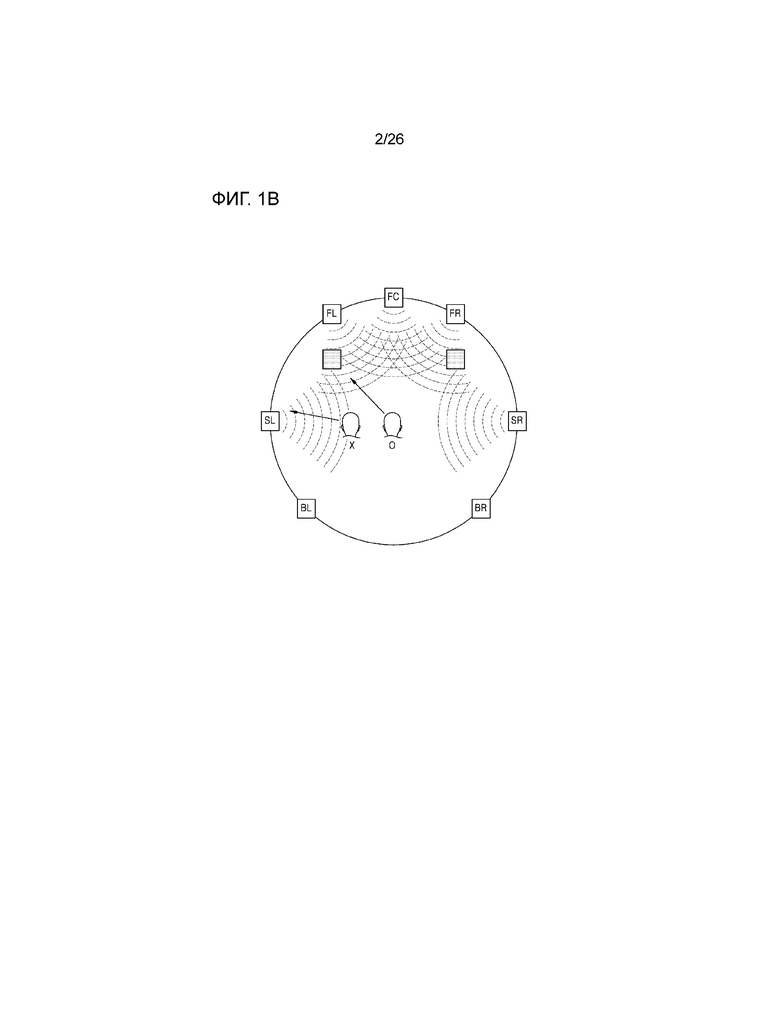
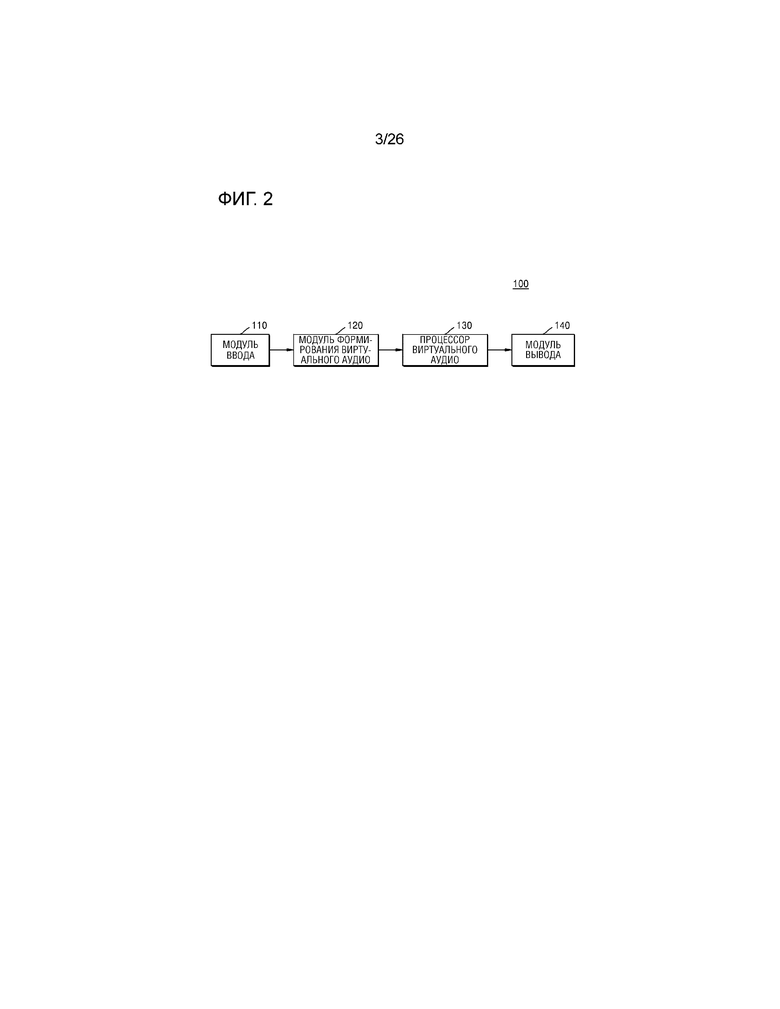
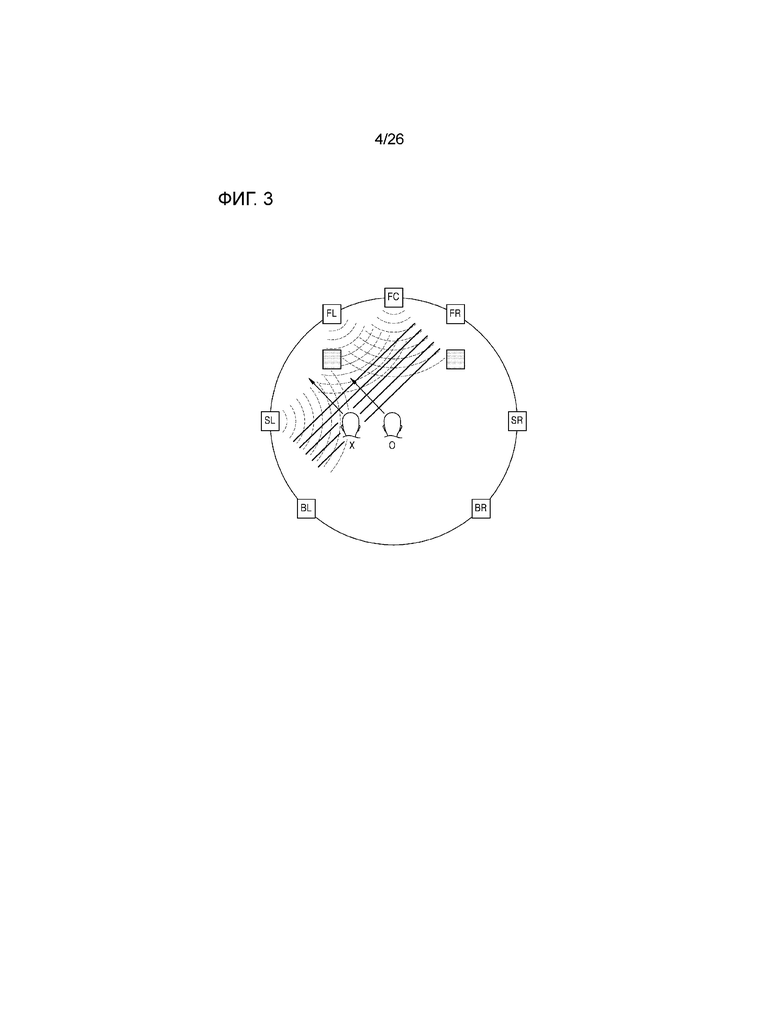
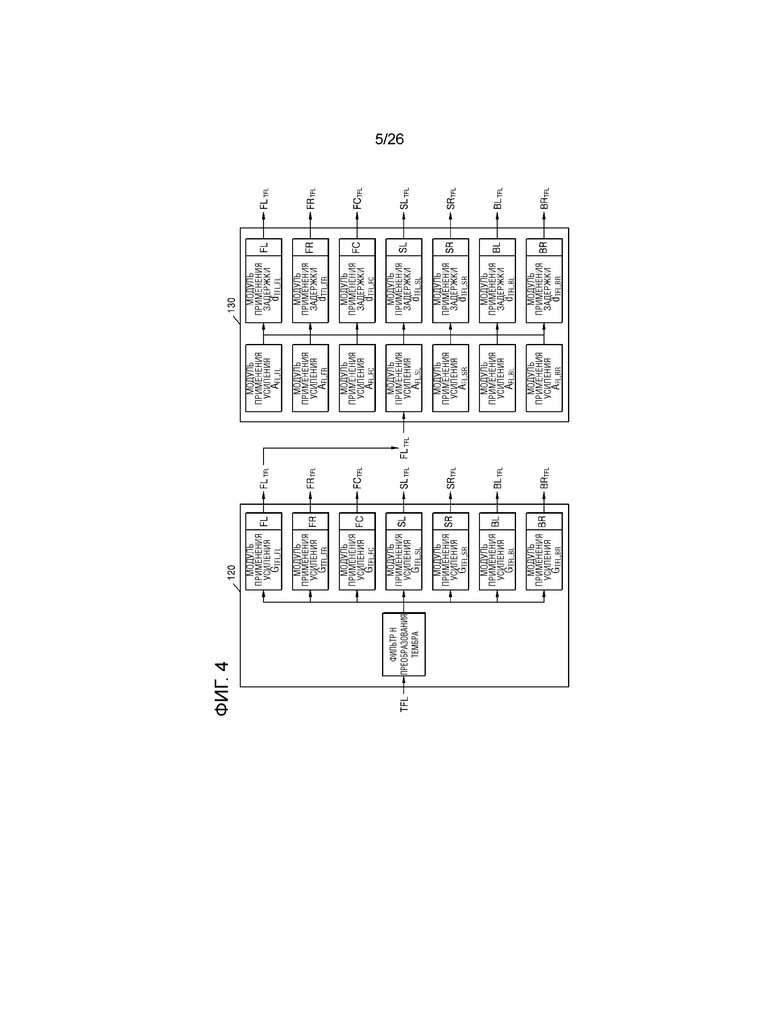
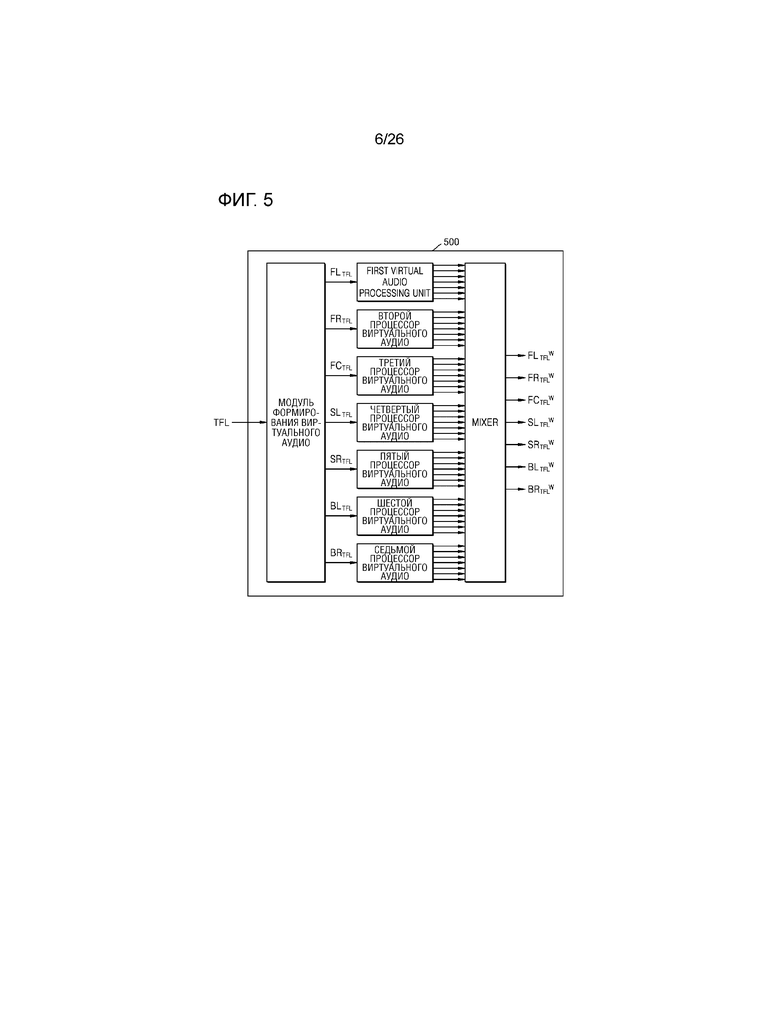
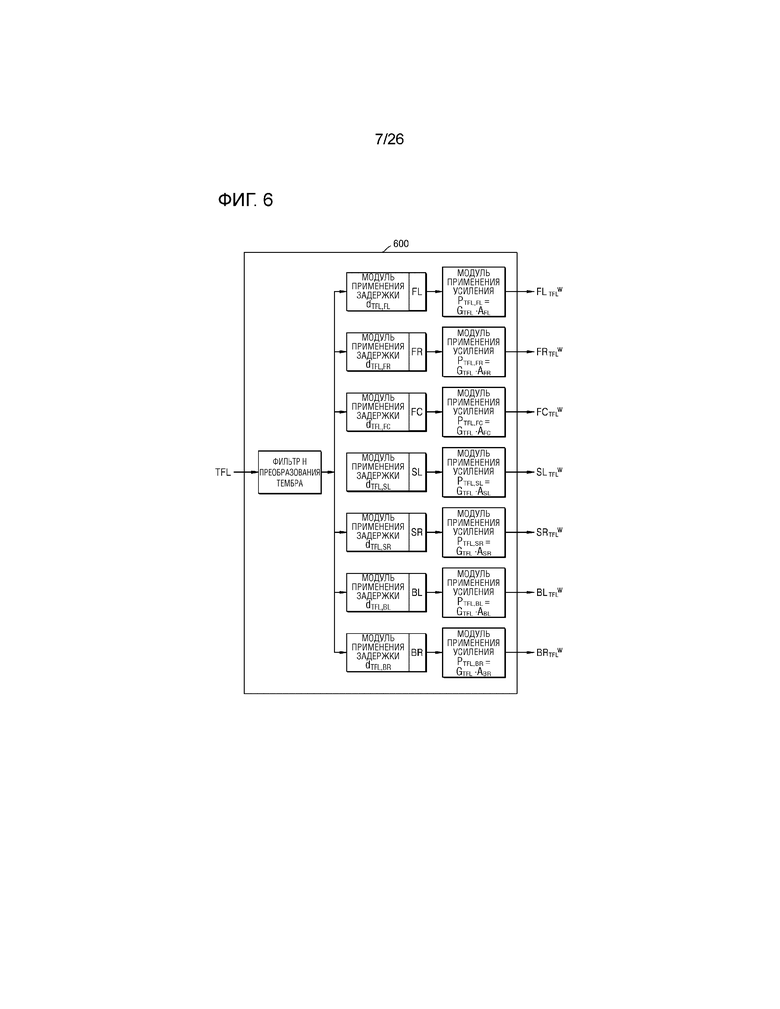
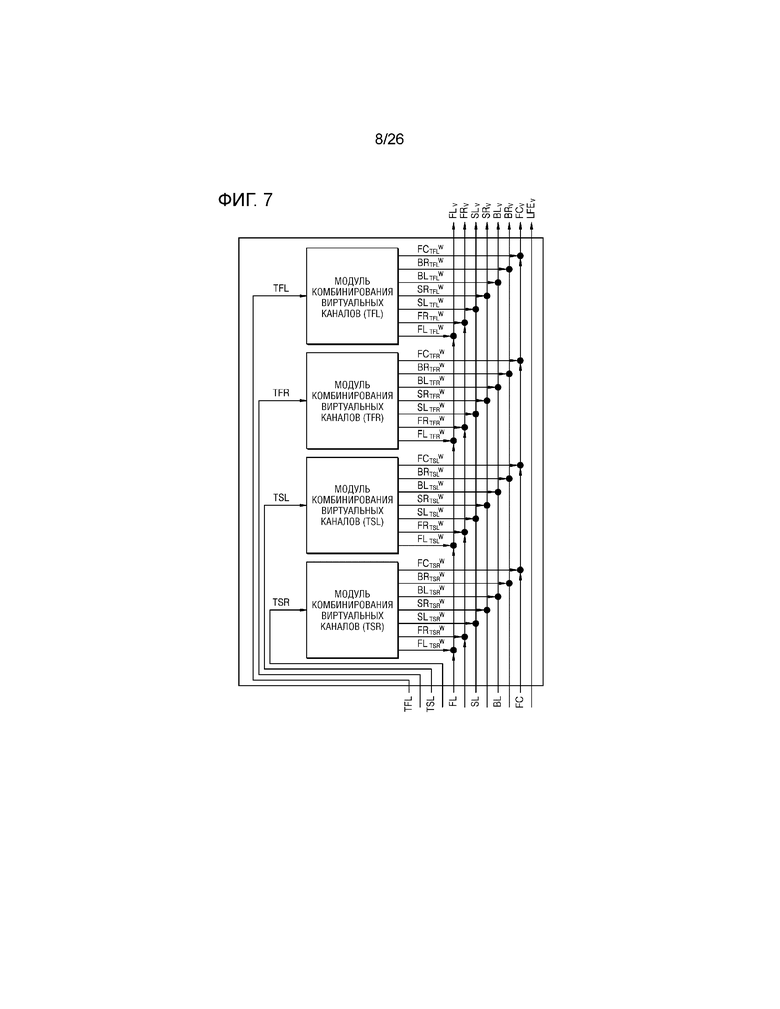
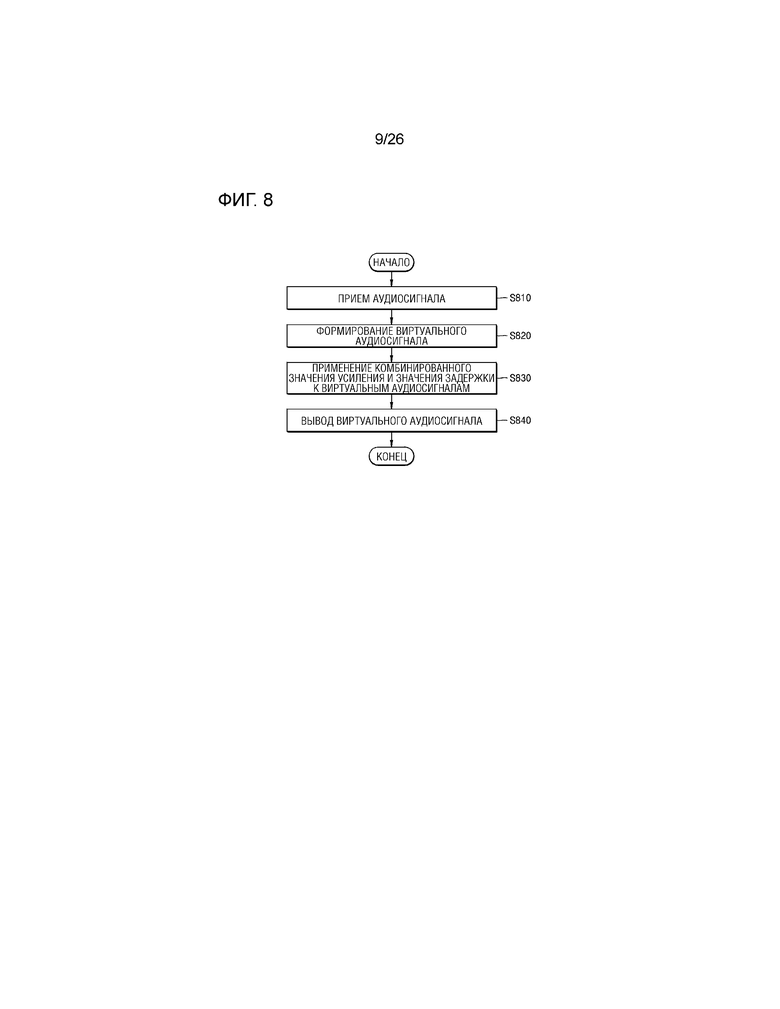
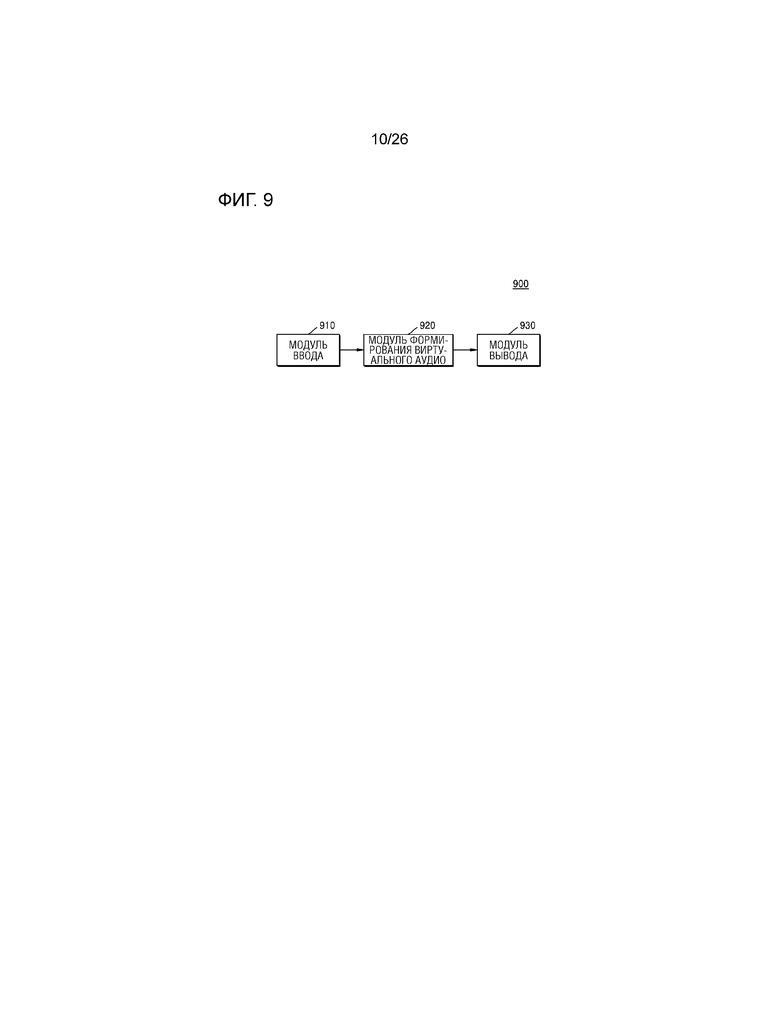
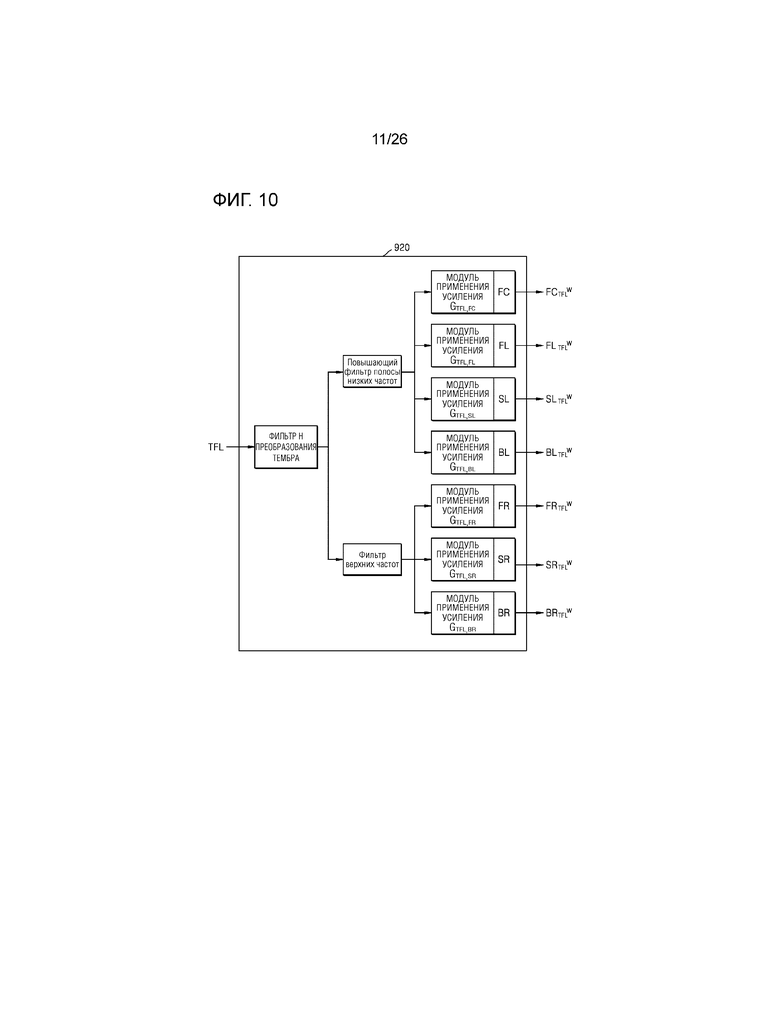
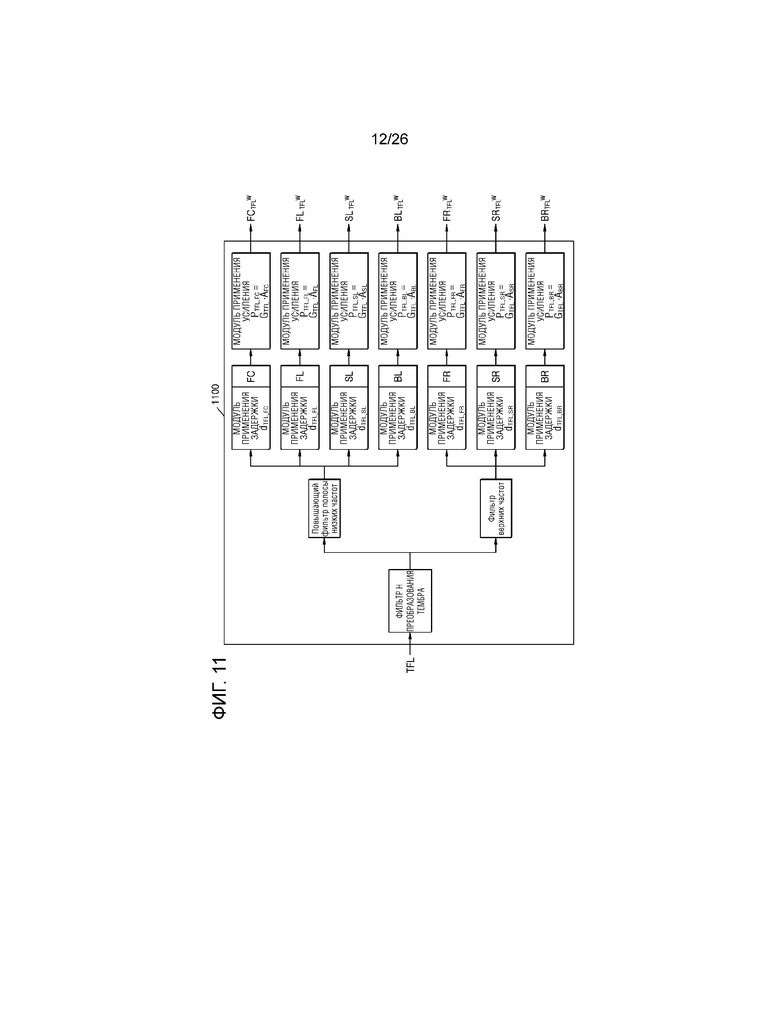
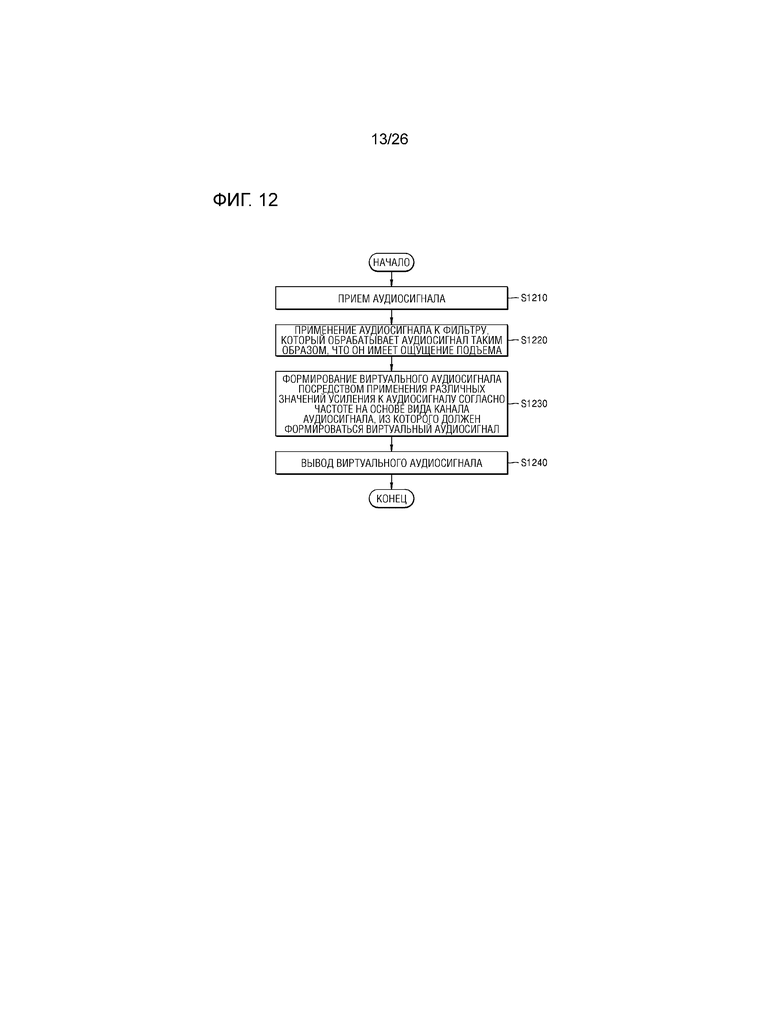
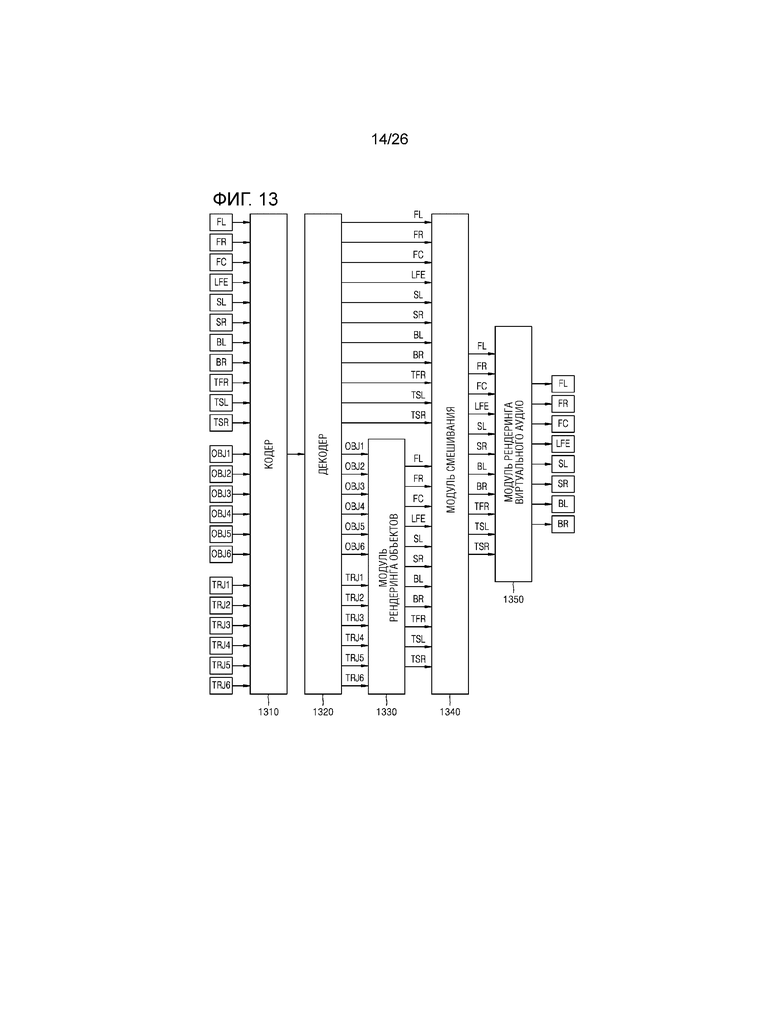

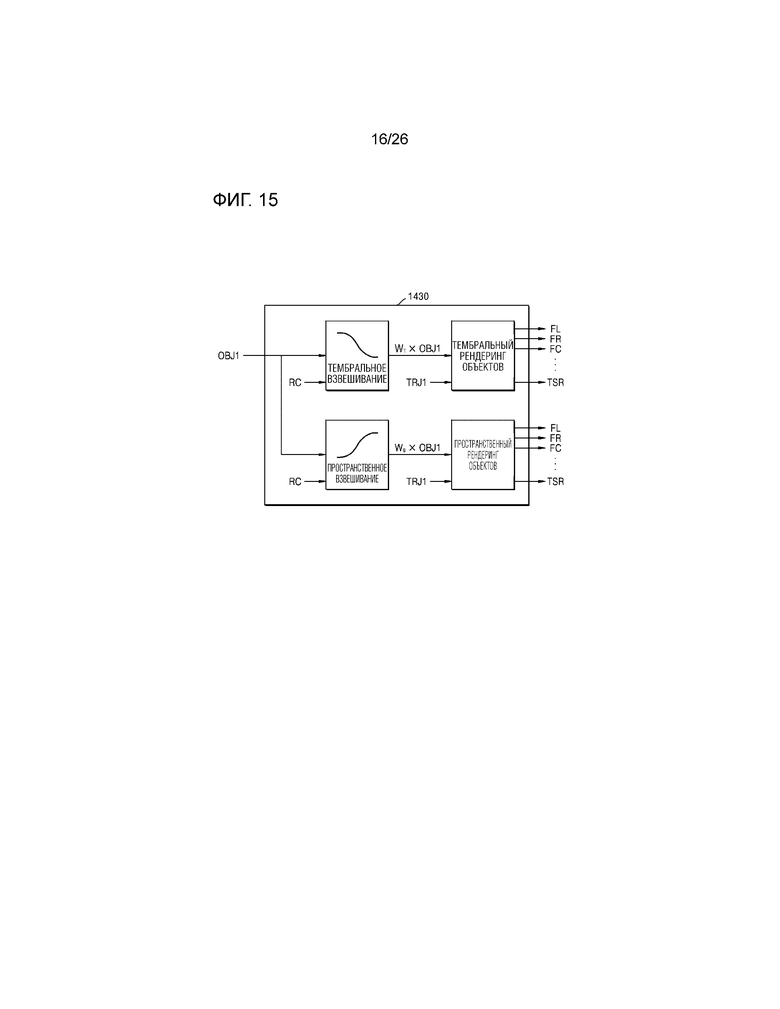
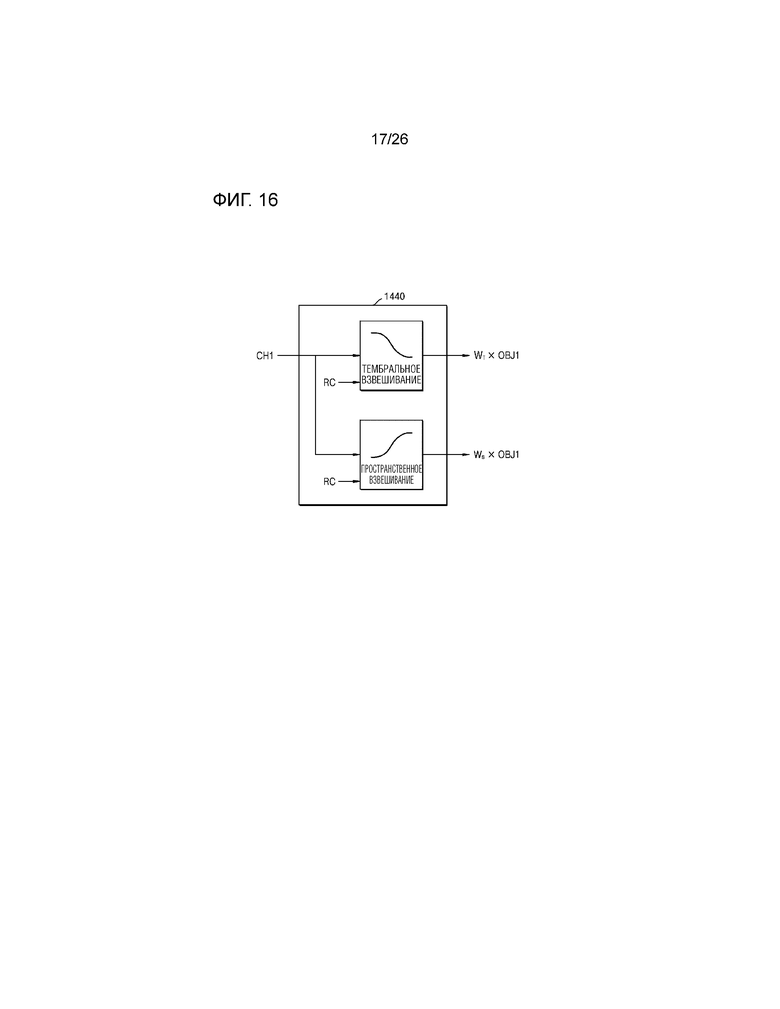
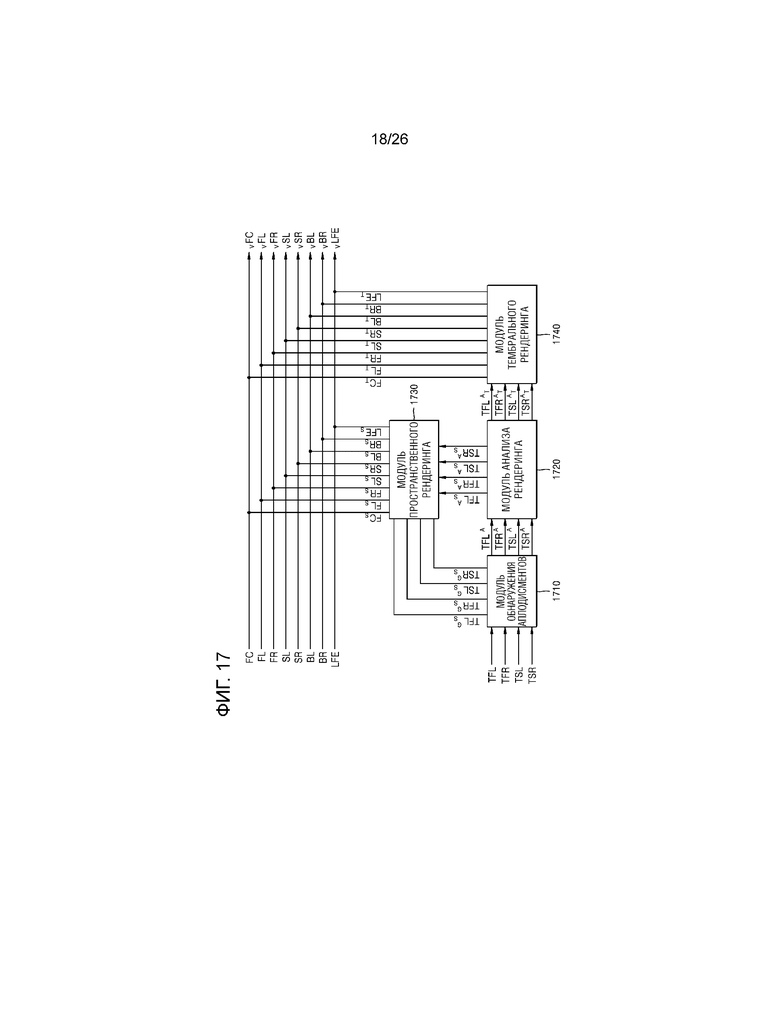
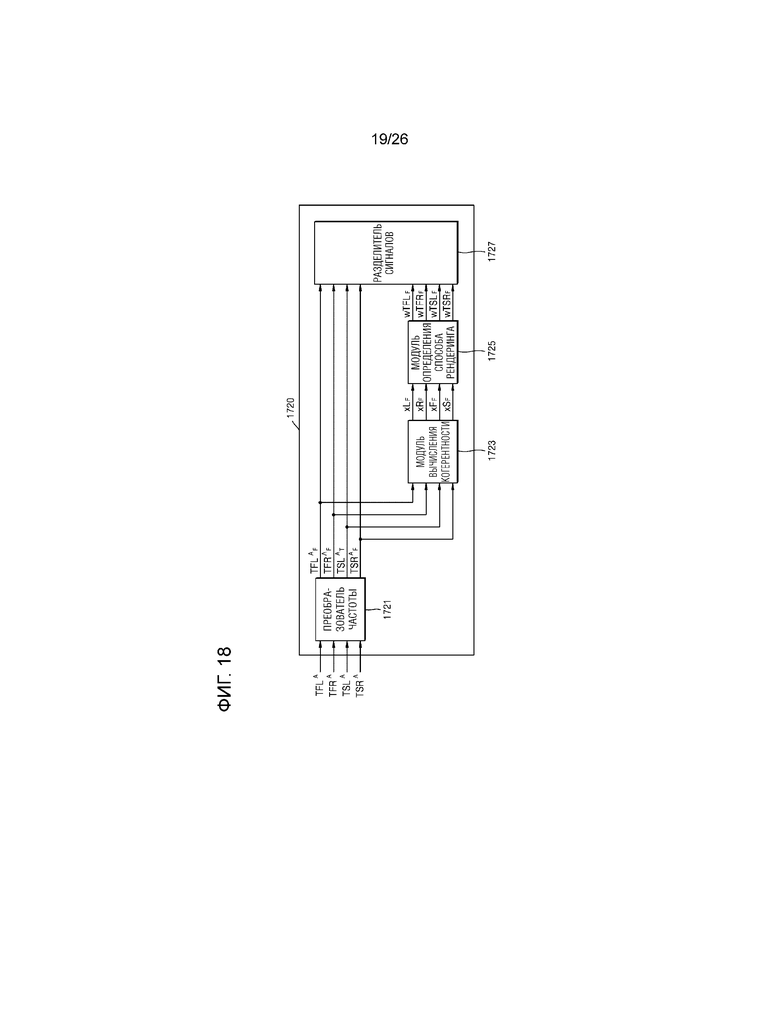
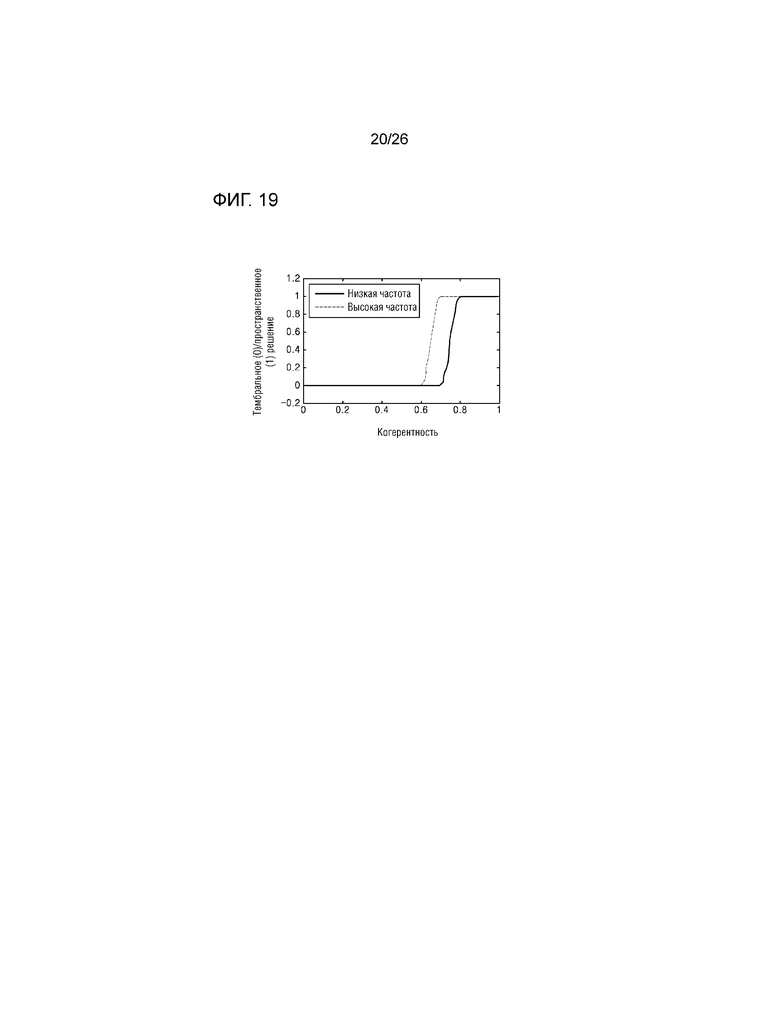
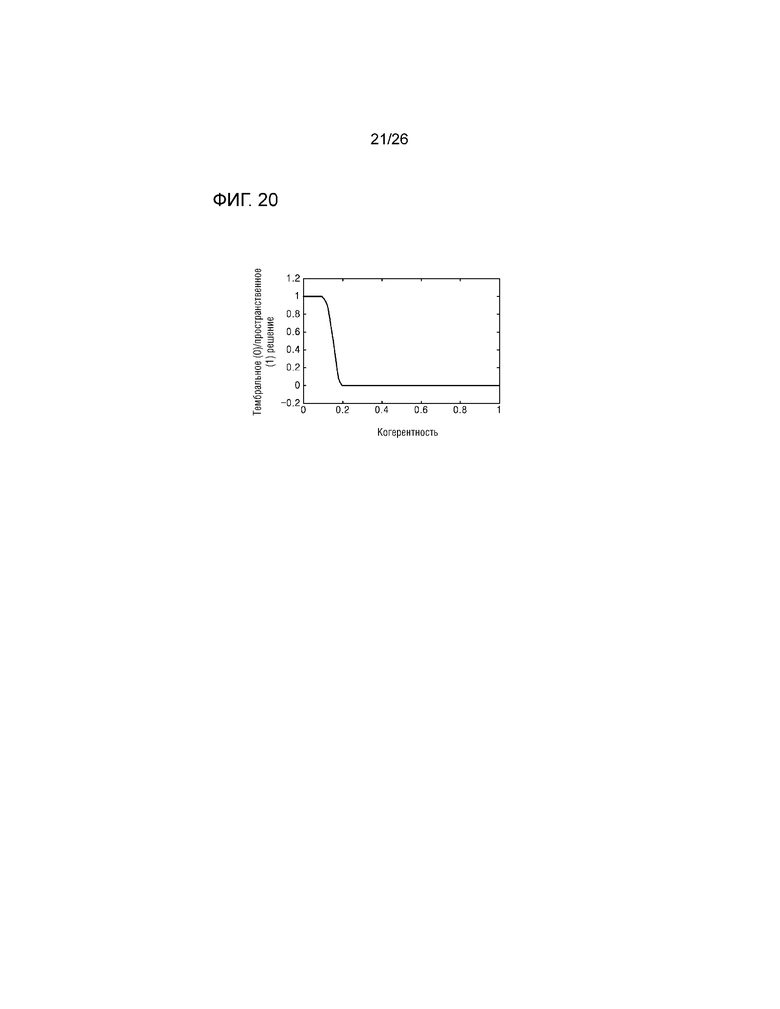
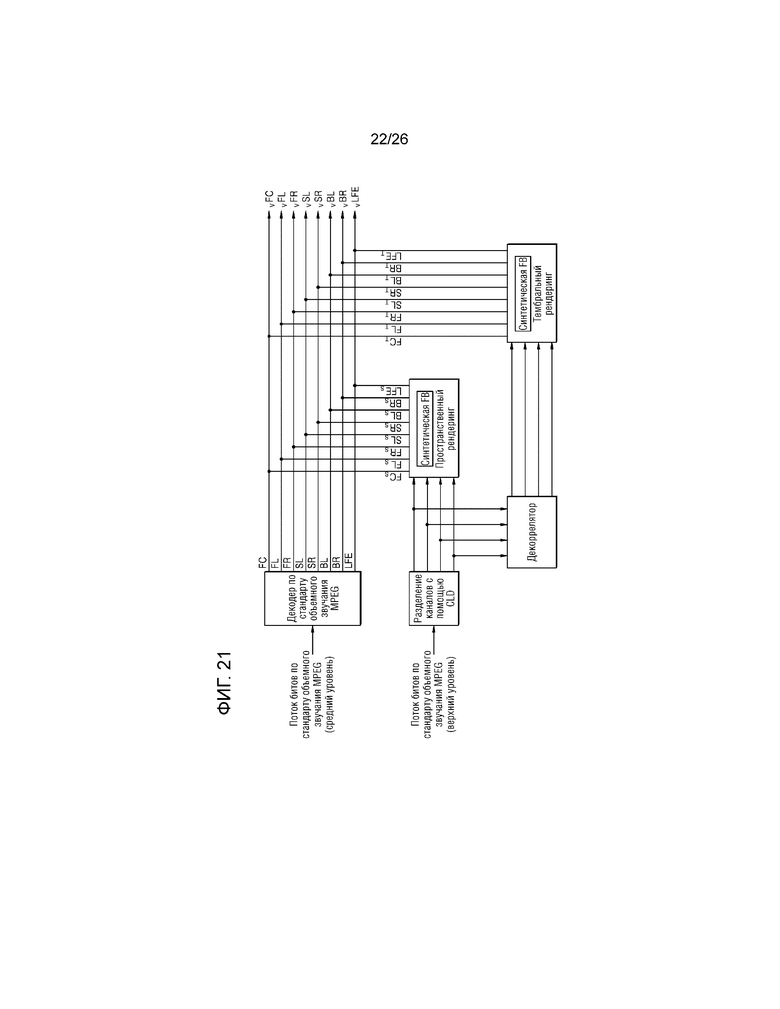
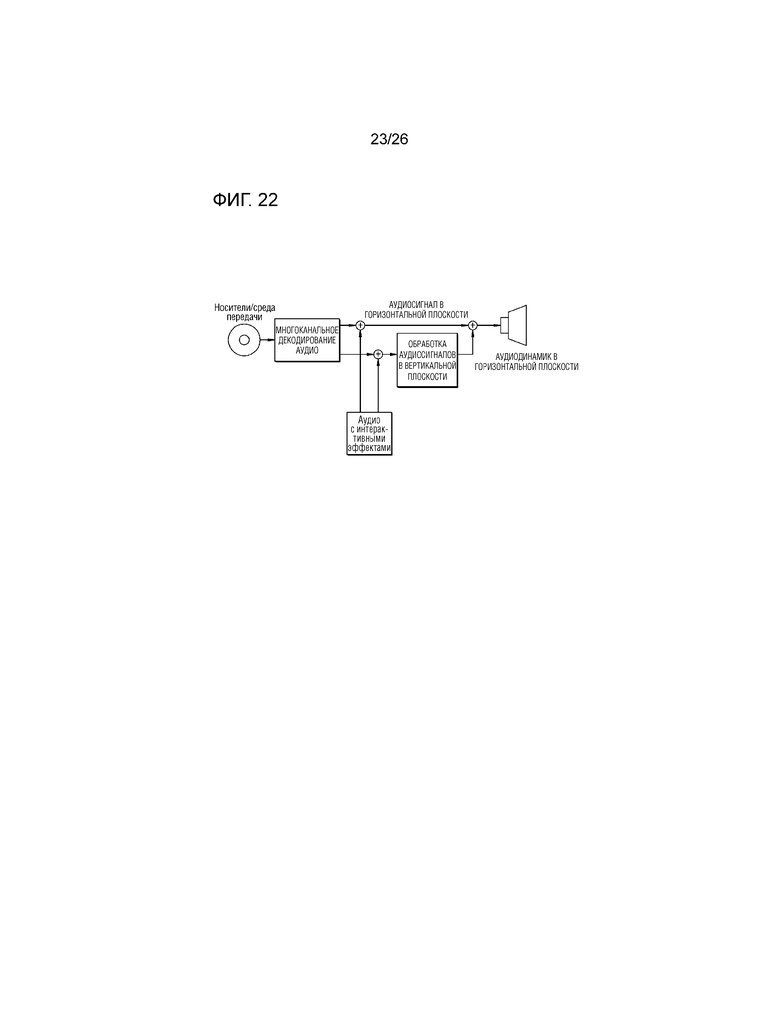
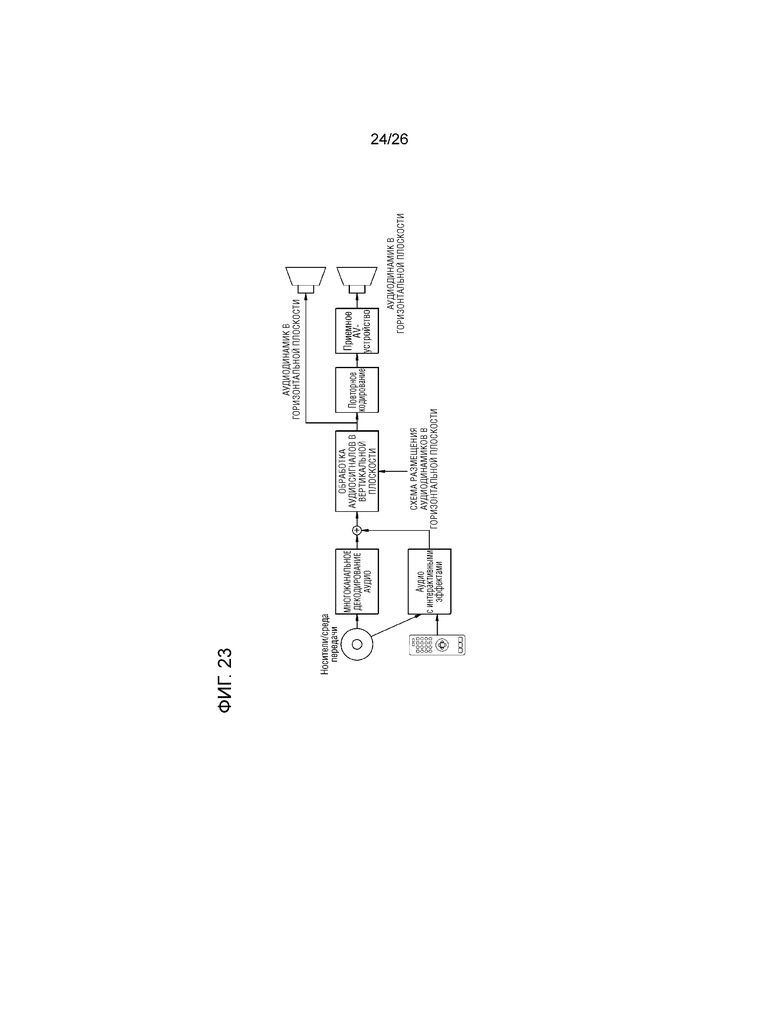
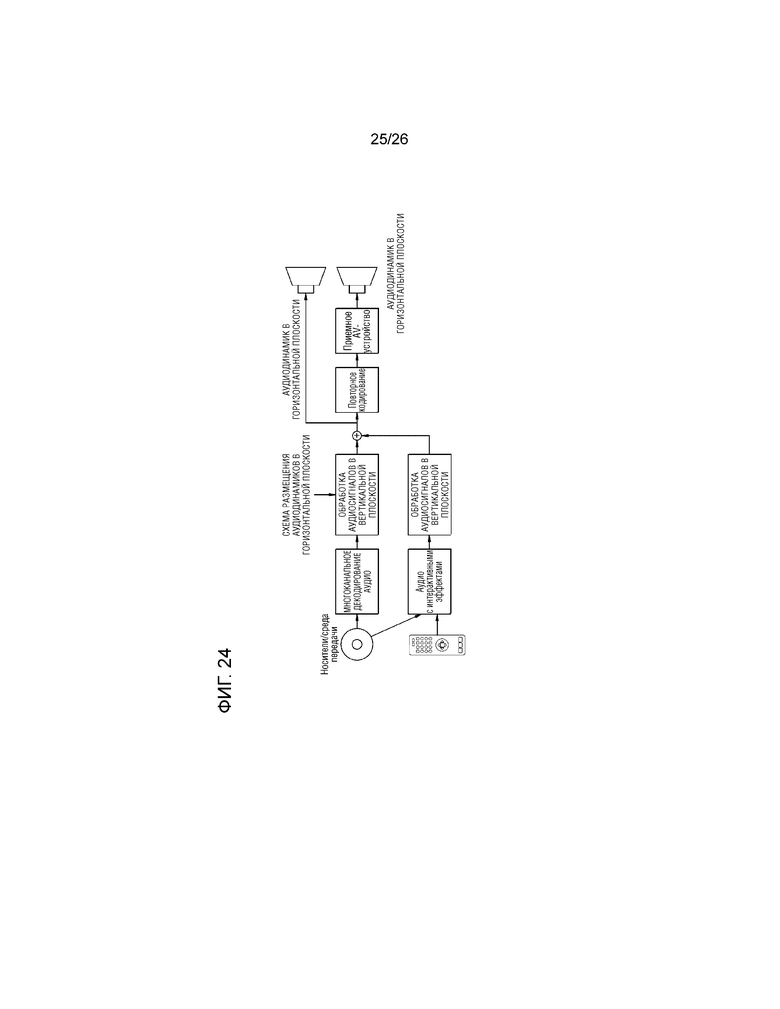
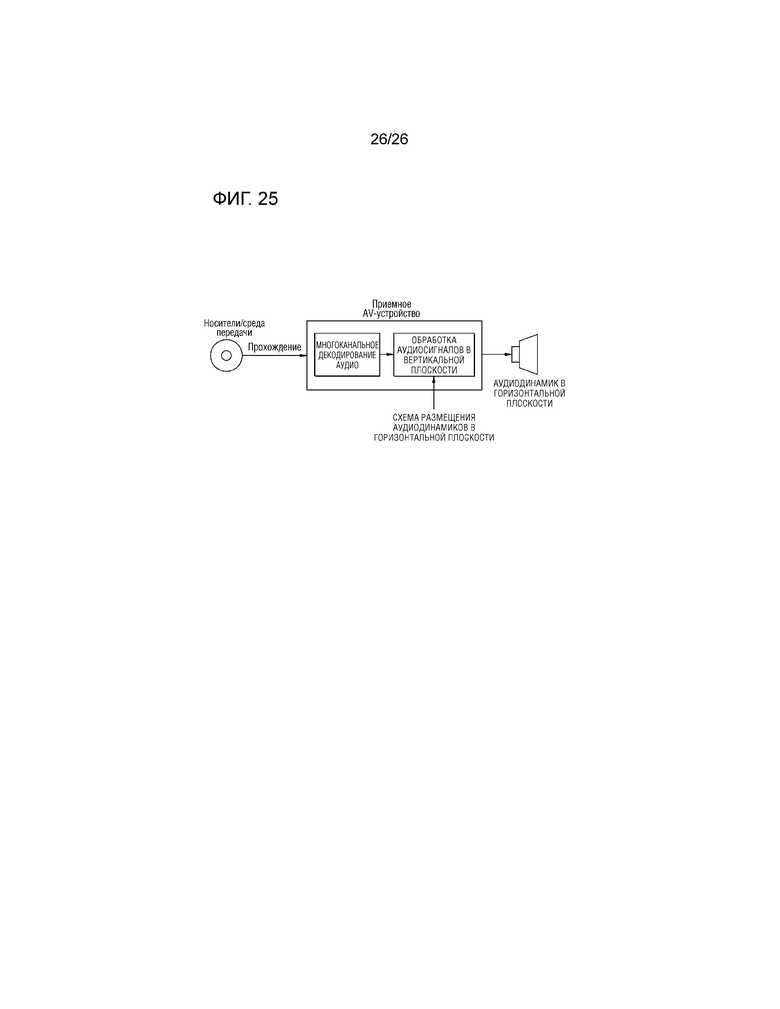
Изобретение относится к средствам для предоставления аудиоустройством аудио. Технический результат заключается в расширении области в которой можно прослушивать виртуальный аудиосигнал. Принимают аудиосигнал, включающий в себя множество каналов. Применяют к аудиосигналу, имеющему канал, из множества каналов, вызывающего ощущение подъема, фильтр, с тем чтобы формировать множество виртуальных аудиосигналов, которые должны, соответственно, выводиться во множество динамиков. Применяют комбинированные значения усиления и значения задержки к множеству виртуальных аудиосигналов таким образом, что множество виртуальных аудиосигналов, соответственно, выводимых через множество динамиков, формируют звуковое поле, имеющее плоскую волну. Выводят множества виртуальных аудиосигналов, к которым применяются комбинированное значение усиления и значение задержки, через множество динамиков. Фильтр обрабатывает аудиосигнал таким образом, что он имеет ощущение подъема. 2 н. и 2 з.п. ф-лы, 26 ил.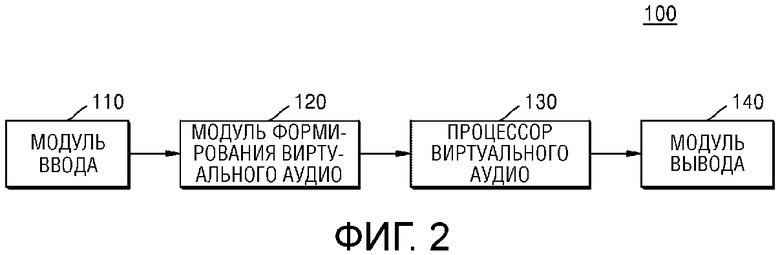
1. Способ рендеринга аудиосигнала, содержащий этапы, на которых:
принимают множество сигналов входных каналов, включающее в себя сигнал входного канала, обеспечивающий ощущение поднятия источника звука, и битовый аудиопоток, включающий в себя информацию рендеринга;
формируют множество выходных сигналов для моделирования звука, формируемого с поднятием выше фактического расположения множества динамиков, посредством фильтрации с использованием фильтра, основывающегося на передаточной функции слухового аппарата человека (HRTF), и применения усилений при панорамировании в отношении сигнала входного канала, обеспечивающего ощущение поднятия источника звука, причем усиления при панорамировании применяются на основе диапазона частот и вида сигнала входного канала, обеспечивающего ощущение поднятия источника звука, причем упомянутое моделирование звука основывается на одном из тембрального рендеринга и пространственного рендеринга, определяемом информацией рендеринга; и
выводят упомянутое множество выходных сигналов через упомянутое множество динамиков, размещенных в горизонтальной плоскости.
2. Способ по п.1, в котором упомянутое применение усилений при панорамировании дополнительно содержит этап, на котором изменяют усиления при панорамировании для каждого из упомянутого множества выходных сигналов на основе того, является ли каждый из данного множества выходных сигналов сигналом ипсилатерального канала или сигналом контралатерального канала.
3. Способ по п.1, в котором сигнал входного канала, обеспечивающий ощущение поднятия источника звука, включает в себя сигнал верхнего правого канала или сигнал верхнего левого канала.
4. Устройство рендеринга аудиосигнала, содержащее:
по меньшей мере один процессор, выполненный с возможностью:
принимать множество сигналов входных каналов, включающее в себя сигнал входного канала, обеспечивающий ощущение поднятия источника звука, и битовый аудиопоток, включающий в себя информацию рендеринга;
формировать множество выходных сигналов для моделирования звука, формируемого с поднятием выше фактического расположения множества динамиков, посредством фильтрации с использованием фильтра, основывающегося на передаточной функции слухового аппарата человека (HRTF), и применения усилений при панорамировании в отношении сигнала входного канала, обеспечивающего ощущение поднятия источника звука, причем усиления при панорамировании применяются на основе диапазона частот и вида сигнала входного канала, обеспечивающего ощущение поднятия источника звука, при этом упомянутое моделирование звука основывается на одном из тембрального рендеринга и пространственного рендеринга, определяемом информацией рендеринга; и
выводить упомянутое множество выходных сигналов через упомянутое множество динамиков, размещенных в горизонтальной плоскости.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| KR 1020070033860 A, 27.03.2007 | |||
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| KR 1020120029783, 27.03.2012 | |||
| KR 100677629 B1, 26.01.2007 | |||
| KR 1020090054583 A, 01.06.2009 | |||
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| JP 2012156610 A, 16.08.2012 | |||
| EP 1868416 A2, 19.12.2007 | |||
| RU 2010150762 A, 20.06.2012. | |||

