ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение относится к способу и устройству для определения карты глубин для изображения и, в частности, касается определения карты глубин на основе оцененных значений несоответствия.
УРОВЕНЬ ТЕХНИКИ
Трехмерные (3D) дисплеи добавили третье измерение в процесс видения путем предоставления двум глазам наблюдателя разных видов наблюдаемой сцены. Этого можно достичь, предоставив пользователю очки для разделения двух отображаемых видов. Однако, поскольку считается, что это вызывает неудобство для пользователя, во многих сценариях предпочтение отдается использованию автостереоскопических дисплеев, в которых используются средства (такие как ступенчатые линзы или барьеры) для разделения видов и передачи их в разных направлениях, где они по отдельности могут достигать глаз пользователя. Для стереодисплеев требуется два вида, в то время как для автостереоскопических дисплеев, как правило, требуется больше видов (например, девять видов).
Однако реальные дисплеи по большей части не имеют идеальных рабочих характеристик и, как правило, не способны представлять совершенные трехмерные изображения.
Например, автостереоскопические 3D дисплеи на основе ступенчатых линз претерпевают размытие вне плоскости экрана. Этот эффект аналогичен известному эффекту размытия по глубине резкости в системах камер.
Также качество представленных трехмерных изображений зависит от качества принятых данных изображений, и, в частности, трехмерное восприятие зависит от качества принятой информации о глубине.
Информация трехмерного изображения часто обеспечивается множеством изображений, соответствующих разным направлениям видения для данной сцены. В частности, видеоконтент, такой как фильмы или телевизионные программы, создается во всевозрастающем объеме для обеспечения 3D информации. Упомянутую информацию можно захватить (отснять), используя специальные 3D камеры, которые захватывают два мгновенных изображения со слегка сдвинутых положений камер.
Однако во многих приложениях обеспечиваемые таким образом изображения не могут напрямую соответствовать требуемым направлениям, либо может потребоваться больше изображений. Например, для автостереоскопических дисплеев требуется больше двух изображений, а в действительности часто используют от 9 до 26 изображений видов.
Для создания изображений, соответствующих разным направлениям видения, можно использовать обработку, обеспечивающую сдвиг точки видения. Как правило, это выполняется путем использования алгоритма сдвига видения, который использует изображение для одного направления видения вместе с соответствующей информацией о глубине. Однако, чтобы создать новые видимые изображения без значительных артефактов, обеспечиваемая информация о глубине должна быть достаточно точной.
К сожалению, во многих приложениях и сценариях использования информация о глубине не может быть такой точной, как это требуется. В действительности, во многих сценариях информация о глубине создается посредством оценки и получения значений глубины путем сравнения изображений вида для разных направлений видения.
Во многих приложениях трехмерные сцены захватывают в виде стереоизображений, используя две камеры на чуть разных позициях. Затем можно создать конкретные значения глубины путем оценки несоответствий между соответствующими объектами изображения в упомянутых двух изображениях. Однако такое извлечение и оценка значений глубины являются проблематичными и в большинстве случаев приводят к получению неидеальных значений глубины. Опять же, это может привести к появлению артефактов и снижению качества трехмерного изображения. Искажение трехмерного изображения и артефакты чаще всего появляются в текстовых объектах изображения, таких как, например, блоки субтитров. Являясь скорее всего частью сцены, текстовые объекты изображения, по большей части, являются изолированными объектами, которые не воспринимаются в качестве составной части или встроенной части сцены. Кроме того, изменения глубины для текстовых объектов изображения, как правило, наиболее заметны для наблюдателя. Также при типовом применении рассчитывают на то, что текст (особенно такой, как субтитры) будет резким и в фокусе с четкими краями. Соответственно, это очень важно, в частности, для высококачественного представления текстовых объектов изображения, таких как блоки субтитров.
Следовательно, усовершенствованный подход к определению подходящей информации о глубине для текстовых объектов изображения даст положительный эффект, и, в частности, будет иметь преимущество подход, позволяющий повысить гибкость, упростить реализацию, уменьшить сложность, улучшить трехмерное восприятие и/или повысить качество воспринимаемого изображения.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Соответственно, изобретение ориентировано на предпочтительное смягчение, уменьшение или исключение одного или более из вышеупомянутых недостатков по отдельности или в любом их сочетании.
Согласно одному аспекту изобретения обеспечено устройство для определения карты глубин для изображения, причем устройство содержит: блок изображений для снабжения первого изображения соответствующей картой глубин, содержащей первые значения глубин, по меньшей мере для некоторых пикселей первого изображения; блок вероятностей для определения карты вероятностей для первого изображения, содержащей значения вероятности по меньшей мере для некоторых пикселей изображения; причем значение вероятности для пикселя указывает вероятность того, что упомянутый пиксель принадлежит текстовому объекту изображения; блок глубин для создания измененной карты глубин для первого изображения, причем блок глубин выполнен с возможностью определения измененного значения глубины по меньшей мере для первого пикселя в виде взвешенного объединения первого значения глубины соответствующей карты глубин для первого пикселя и значения глубины текстового объекта изображения, одинакового для множества пикселей, причем упомянутое взвешивание зависит от значения вероятности для первого пикселя.
Этот подход во многих вариантах осуществления позволяет создать улучшенную карту глубин, которая при ее использовании для обработки изображения может обеспечить повышенное качество. Например, во многих вариантах осуществления и сценариях улучшенное представление текстовых объектов изображения, таких как субтитры, можно достичь, используя измененную карту глубин. Упомянутое усовершенствование может быть особенно значительным, когда измененную карту глубин используют для сдвига вида изображения и/или при представлении трехмерных изображений на автостереоскопическом дисплее. Данный подход кроме того допускает сдвиг глубины представления для текстовых объектов изображения при смягчении или уменьшении искажений, несоответствий и/или артефактах.
Упомянутые карты могут быть полными или частичными. Например, карта вероятностей может содержать значения вероятностей только для одного поднабора пикселей/групп пикселей. Значение вероятности для данного пикселя может представлять оценку вероятности или вероятность того, что данный пиксель (или его часть) принадлежит текстовому объекту изображения. Например, значение вероятности может указывать, насколько близко определенное значение некоторого свойства соответствует ожидаемому значению для данного текстового объекта изображения. Например, для первого изображения можно применить обработку для создания одного значения (или набора значений). Вероятность того, что данный пиксель принадлежит текстовому объекту изображения, можно представить тем, насколько близко это значение соответствует ожидаемому значению. Например, к первому изображению можно применить обработку, которая даст число в интервале [a;b], причем, например, a=0, а b=1. Для пикселя, принадлежащего текстовому объекту изображения, ожидаемое значение упомянутого определенного свойства может быть равно b, в то время как для пикселя, не принадлежащего текстовому объекту изображения, это ожидаемое значение может быть равно a. Таким образом, упомянутое определенное значение может непосредственно представлять собой значение свойства, указывающее вероятность того, принадлежит ли соответствующий пиксель текстовому объекту изображения. Например, для a=0 и b=1, чем выше упомянутое значение, тем более вероятно, что соответствующий пиксель принадлежит текстовому объекту изображения. Точная обработка и определение упомянутого значения может отличаться в разных вариантах осуществления в зависимости от предпочтений и требований отдельного варианта осуществления.
Текстовым объектом изображения может быть область/зона/поднабор или сегмент изображения, содержащего текст. Текстовым объектом изображения, в частности, может быть субтитровый объект изображения. Текстовый объект изображения может соответствовать одному или более символам либо может включать в себя, например, ограничивающую область для текста.
Взвешенное объединение, в частности, может представлять собой взвешенную сумму первого значения глубины и значения глубины текстового объекта изображения с весовыми коэффициентами, зависящими от значения вероятности. В некоторых вариантах осуществления это взвешенное объединение может, в частности, представлять собой взвешенное суммирование монотонной функции первого значения глубины и значения глубины текстового объекта изображения с весовыми коэффициентами, зависящими от значения вероятности.
Значение глубины текстового объекта изображения может быть заранее определенным значением. В частности, значение глубины текстового объекта изображения может быть фиксированным и/или постоянным во временной и/или в пространственной области. Значение глубины текстового объекта изображения может представлять собой необходимую глубину для текстовых объектов изображения. Значение глубины текстового объекта изображения может указывать предпочтительную глубину для текстовых объектов изображения и может быть фиксированным и/или заранее определенным. В частности, значение глубины текстового объекта изображения может указывать предпочтительную глубину для текстовых объектов изображения и может не зависеть от свойств глубины сцены, представленной упомянутым первым изображением. В действительности, текстовые объекты изображения, как правило, могут представлять собой наложенную графику, не являющуюся частью сцены, представленной первым изображением, а значение глубины текстового объекта изображения может представлять предпочтительную глубину для наложенной графики/текстовых объектов изображения, не являющихся частью данной сцены. Значение глубины текстового объекта изображения связано с текстовыми объектами изображения и может быть одинаковым для множества пикселей или групп пикселей. Во многих вариантах осуществления значение глубины текстового объекта изображения не зависит от свойств первого изображения и/или соответствующей карты глубин.
Первым изображением может быть изображение, являющееся частью множества изображений, соответствующих разным углам видения, или, например, может быть одиночно изолированным и независимым изображением (имеющим соответствующую карту глубин). В некоторых вариантах осуществления первым изображением может быть изображение временной последовательности изображений, например, кадром из видеопоследовательности.
Согласно необязательному признаку изобретения блок вероятностей выполнен с возможностью определения групп пикселей для первого изображения, причем каждая группа пикселей содержит множество пикселей; и причем блок вероятностей выполнен с возможностью определения значений вероятности для групп пикселей.
Это может обеспечить улучшенные рабочие характеристики и/или упрощенное функционирование, и/или уменьшить сложность, и/или потребность в ресурсах. Определенное значение вероятности для группы пикселей может быть присвоено всем пикселям, принадлежащим данной группе пикселей.
Согласно необязательному признаку изобретения блок глубин выполнен с возможностью определения весовых коэффициентов для упомянутого взвешенного объединения в ответ на первое значение вероятности для группы пикселей, которой принадлежит первый пиксель, и вторым значением вероятности для соседней группы пикселей; причем взвешивание первого значения вероятности и второго значения вероятности зависит от позиции первого пикселя в группе пикселей, которой принадлежит первый пиксель.
Это позволяет улучшить рабочие характеристики во многих сценариях. В частности, этот подход позволяет определить значения вероятности с более низким разрешением, чем разрешение пикселей изображения, позволяя увеличить эффективное разрешение для объединения уровней глубины.
В некоторых вариантах осуществления весовые коэффициенты для упомянутого взвешенного объединения можно определить в ответ на интерполированное значение вероятности, причем интерполированное значение вероятности определяют в ответ на пространственную интерполяцию между первым значением вероятности для группы пикселей, которой принадлежит первый пиксель, и вторым значением вероятности для соседней группы пикселей; при этом упомянутая интерполяция зависит от позиции первого пикселя в группе пикселей, которой принадлежит первый пиксель.
Карта вероятностей может содержать множество значений вероятности и, в частности, может содержать множество значений вероятности для каждого из множества пикселей или групп пикселей. Аналогичным образом, упомянутое объединение может быть построено для каждого пикселя по меньшей мере для некоторых пикселей, имеющих разные значения вероятности и имеющих таким образом независимые объединения. Таким образом значения вероятности и упомянутое объединение могут изменяться по всему изображению (для разных пикселей по-разному).
Согласно необязательному признаку изобретения блок вероятностей выполнен с возможностью определения значений вероятности для групп пикселей упомянутого изображения, причем каждая группа пикселей содержит по меньшей мере один пиксель; при этом блок вероятностей выполнен с возможностью определения сначала классификационной карты, содержащей значения для групп пикселей, указывающих, обозначены ли упомянутые группы пикселей как принадлежащие текстовому объекту изображения или не принадлежащие текстовому объекту изображения; и для создания карты вероятностей в ответ на фильтрацию классификационной карты.
Это может обеспечить упрощенную реализацию и/или улучшенные рабочие характеристики/результаты.
Согласно необязательному признаку изобретения классификационная карта содержит двоичные значения для групп пикселей, причем каждое двоичное значение указывает, либо что группа пикселей обозначена как принадлежащая текстовому объекту изображения, или что упомянутая группа пикселей обозначена как не принадлежащая текстовому объекту изображения.
Это может обеспечить упрощенную реализацию и/или улучшенные рабочие характеристики/результаты. В частности, во многих сценариях это позволит обеспечить более робастную и надежную начальную классификацию групп пикселей. Фильтрация может обеспечить преобразование упомянутой двоичной классификации в недвоичные значения вероятностей, которые также отражают характеристики временного и/или пространственного окружения данной группы пикселей.
Согласно необязательному признаку изобретения фильтрация содержит фильтрацию с двоичным расширением, применяемую к классификационной карте.
Это может улучшить рабочие характеристики и, в частности, улучшить совместимость обнаруженных зон, соответствующих текстовым объектам изображения. Во многих сценариях это помогает уменьшить образование «дыр» в упомянутых зонах.
Согласно необязательному признаку изобретения фильтрация содержит временную фильтрацию.
Это, например, дает возможность повысить устойчивость и совместимость и обеспечить улучшенное восприятие пользователя, например, при просмотре изображений, созданных путем сдвига на основе измененной карты глубин.
Согласно необязательному признаку изобретения временная фильтрация является асимметричной.
Это может обеспечить улучшенные рабочие характеристики во многих приложениях и сценариях.
Согласно необязательному признаку изобретения фильтрация содержит пространственную фильтрацию.
Это может обеспечить улучшенные рабочие характеристики во многих приложениях и сценариях.
Согласно необязательному признаку изобретения пространственная фильтрация содержит фильтр мягкого максимума, являющийся фильтром, имеющим предел максимального выходного значения.
Это может обеспечить улучшенные рабочие характеристики во многих приложениях и сценариях. В частности, это позволяет с успехом создать профили глубины для зон, соответствующих текстовым объектам изображения. Например, во многих сценах фильтр мягкого максимума позволяет создать совместимую область глубин, соответствующую текстовому объекту изображения, при сокращении количества или размера «дыр» и/или при обеспечении плавного перехода на краях текстового объекта изображения.
Фильтр мягкого максимума может представлять собой каскад из фильтра и ограничителя, который ограничивает максимальный выход. Например, фильтр нижних частот может выполнять операцию, соответствующую каскаду, состоящему из фильтра нижних частот, и ограничителя, ограничивающего максимальное выходное значение фильтра нижних частот. Таким образом, фильтр мягкого максимума может соответствовать фильтру, имеющему предел максимального выходного значения.
Согласно необязательному признаку изобретения пространственная фильтрация содержит по меньшей мере два последовательных пространственных фильтров мягкого максимума.
Это может обеспечить улучшенные рабочие характеристики во многих приложениях и сценариях. В частности, это позволяет с успехом создать профили глубины для зон, соответствующих текстовым объектам изображения. Например, во многих сценариях фильтры мягкого максимум позволяют создать совместимую область глубин, соответствующую текстовому объекту изображения. Во многих вариантах осуществления эти фильтры могут уменьшить количество или размера «дыр», обеспечивая также плавный переход на краях текстового объекта изображения.
Эти два последовательных пространственных фильтра мягкого максимума могут быть выполнены так, что они будут иметь разные конструктивные/рабочие параметры, и, в частности, у этих двух фильтров могут отличаться базовые измерения, масштабный коэффициент и/или максимальное значение. Во многих вариантах осуществления параметры для первого фильтра можно оптимизировать, чтобы уменьшить образование «дыр» и обеспечить улучшенную совместимость, в то время как параметры второго фильтра можно оптимизировать так, чтобы обеспечить желаемый профиль изменения глубины на краях текстового объекта изображения.
Согласно необязательному признаку изобретения первые значения глубины соответствуют несоответствиям объектов изображения во множестве изображений, соответствующих разным направлениям видения для сцены первого изображения.
Во многих вариантах осуществления изобретение может улучшить карту глубин, созданную на основе оценки несоответствий, и, в частности, может уменьшить искажения и артефакты, связанные с текстовыми объектами изображения.
В некоторых вариантах осуществления блок изображений выполнен с возможностью оценки несоответствий для объектов изображения во множестве изображений.
Согласно необязательному признаку изобретения весовой коэффициент глубины текстового объекта изображения увеличивают, а весовой коэффициент первого значения глубины уменьшают для увеличения значения вероятности.
Это может обеспечить улучшенные рабочие характеристики во многих приложениях и сценариях.
Согласно аспекту изобретения обеспечен способ определения карты глубин для изображения, причем способ содержит этапы: снабжения первого изображения соответствующей картой глубин, содержащей первые значения глубины, по меньшей мере для некоторых пикселей первого изображения; определения карты вероятностей для первого изображения, содержащей значения вероятности по меньшей мере для некоторых пикселей изображения; причем значение вероятности для пикселя указывает вероятность того, что упомянутый пиксель принадлежит текстовому объекту изображения; и создания измененной карты глубин для первого изображения, причем упомянутое создание содержит определение измененного значения глубины по меньшей мере для первого пикселя в виде взвешенного объединения первого значения глубины соответствующей карты глубин для первого пикселя и значения глубины текстового объекта изображения, одинакового для множества пикселей, причем упомянутое взвешивание зависит от значения вероятности для первого пикселя.
Эти и другие аспекты, признаки и преимущества изобретения станут очевидными и будут разъяснены со ссылками на вариант (варианты) осуществления, описанные ниже.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Варианты осуществления изобретения описаны исключительно как примеры со ссылками на чертежи, на которых:
Фиг. 1 - пример дисплейной системы, содержащей устройство согласно некоторым вариантам известного уровня техники;
Фиг. 2 - пример видимых изображений, проецируемых с автостереоскопического дисплея;
Фиг. 3 - пример изображения и соответствующих обнаруженных текстовых зон;
Фиг. 4 - пример позиционирования блока субтитров на карте глубин; и
Фиг. 5 - примеры входного изображения и карт вероятностей, созданных для него в устройстве согласно некоторым вариантам осуществления изобретения.
ПОДРОБНОЕ ОПИСАНИЕ НЕКОТОРЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Последующее описание сфокусировано на вариантах осуществления изобретения, применимых к системе для определения измененной карты глубин с целью ее использования при создании изображений для разных направлений видения сцены, как например, на подходе для создания дополнительных изображений с целью представления входного стереоизображения на авто стереоскопическом дисплее. Однако следует понимать, что изобретение не ограничено этим применением, но может быть использовано во многих других приложениях и системах.
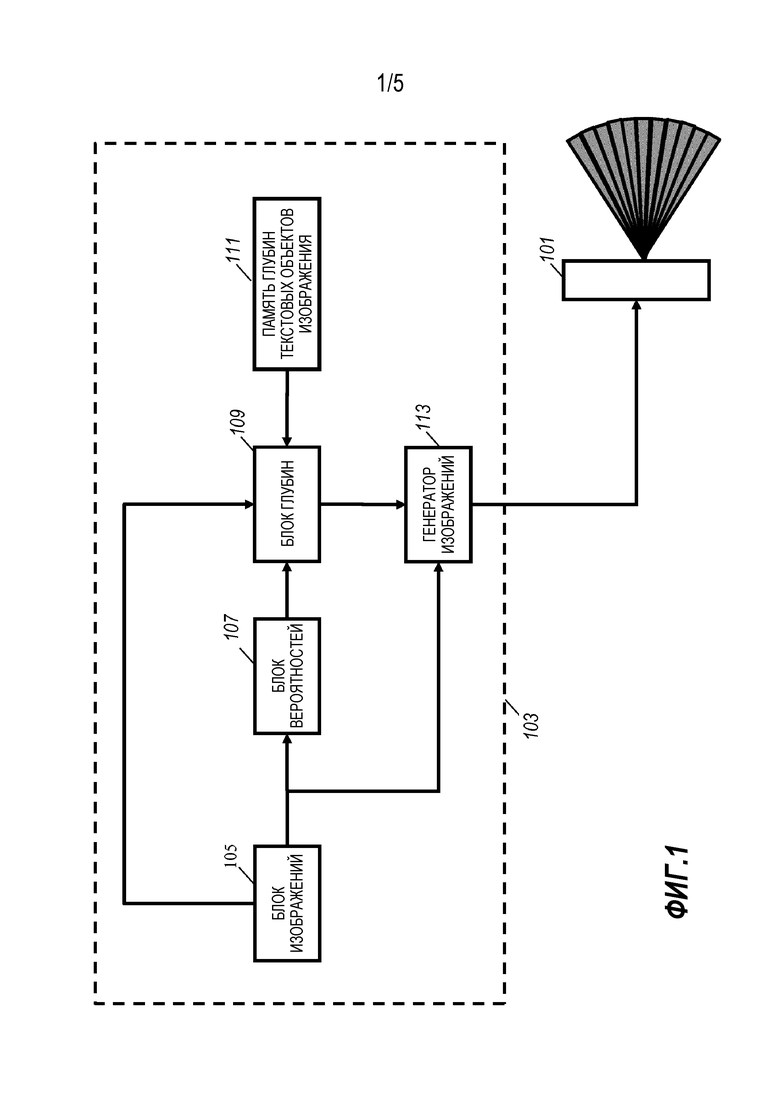
На фиг. 1 показан пример системы согласно некоторым вариантам осуществления окна. В данном конкретном примере изображения, соответствующие разным видам автостереоскопического дисплея 101, создают из входного трехмерного изображения. Входное трехмерное изображение может быть представлено, например, одним изображением с соответствующей картой глубин, или, например, может быть представлено стереоизображениями, из которых извлекают соответствующую карту глубин. В некоторых вариантах осуществления этим изображением может быть изображение из временной последовательности изображений, например, кадр из видеопоследовательности/видеосигнала.
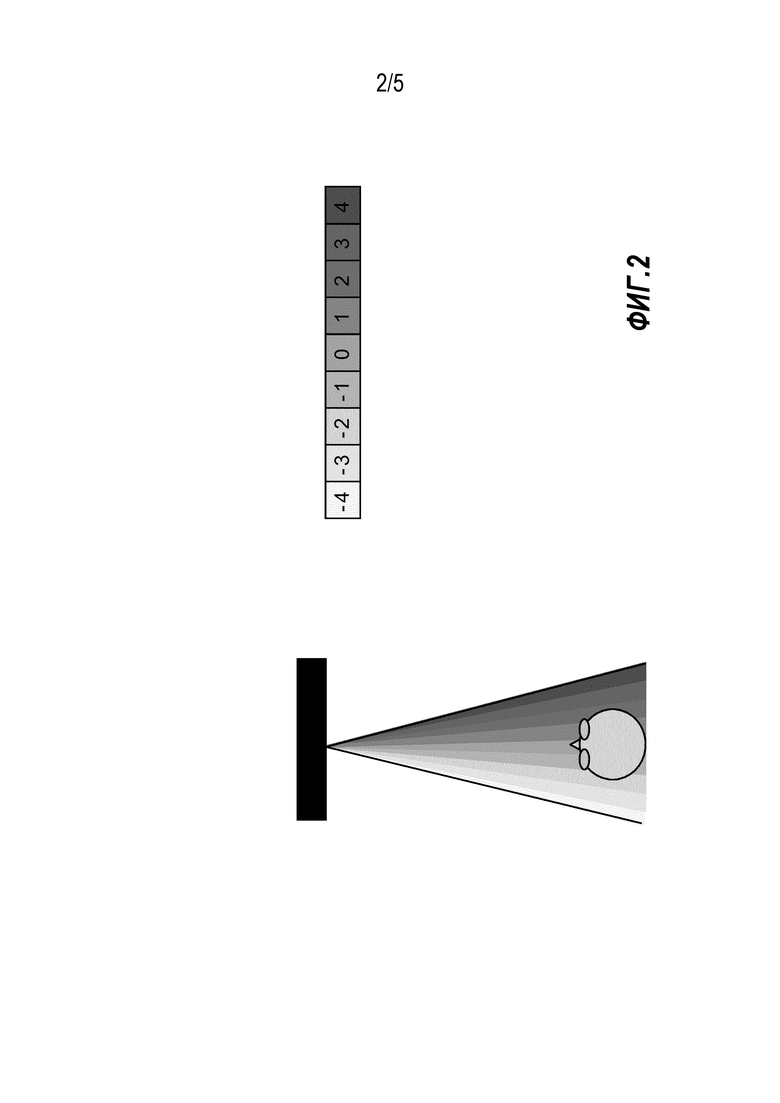
Как правило, автостереоскопические дисплеи создают «конусы» видов, причем каждый конус содержит множество видов, которые соответствуют разным углам видения сцены. Создают разность углов видения между соседними (или в некоторых случаях дальше расположенными) видами, соответствующую разности углов видения между правым и левым глазом пользователя. Соответственно, наблюдатель, левый и правый глаз которого видит два подходящих вида, будет наблюдать трехмерный эффект. Пример автостереоскопического дисплея, создающего девять разных видов в каждом конусе видения, показан на фиг. 2.
В автостереоскопических дисплеях, как правило, используются средства, такие как составные линзы или параллаксные барьеры/барьерные маски, для разделения видов и передачи их в разных направлениях, так, что они достигают глаз пользователя индивидуально. Для стереодисплеев требуется два вида, но в большинстве автостереоскопических дисплеев, как правило, используется больше видов. В действительности, в некоторых дисплеях плавное изменение направлений вида выполняется по изображению таким образом, что разные части изображения могут проецироваться в разных направлениях видения. Таким образом, в некоторых современных автостереоскопических дисплеях может применяться более плавное и непрерывное распределение областей изображения по направлениям видения по сравнению с автостереоскопическими дисплеями, воспроизводящими фиксированное количество законченных видов. Такой автостереоскопический дисплей часто называют дисплеем, обеспечивающим частичные, а не полные виды. Более полную информацию о частичных видах можно найти, например, в WO 2006/117707.
Однако общим для большинства автостереоскопических дисплеев является то, что для них требуется создавать информацию изображения для относительно большого количества разных направлений видения. Однако, как правило, данные трехмерного изображения обеспечиваются в виде стереоизображения или в виде изображения с картой глубин. Для создания необходимых направлений видения, как правило, применяют алгоритмы сдвига видов изображения для создания подходящих значений пикселей для воспроизведения. Однако, такие алгоритмы, как правило, являются субоптимальными и могут внести артефакты или искажения.
Авторы изобретения установили, что упомянутые артефакты, искажения и снижение качества могут особенно доминировать, восприниматься и/или быть значительными в связи с текстовыми объектами изображения, в частности, с субтитровыми объектами изображения. Таким образом, когда изображения, содержащие текст, принимаются и представляются, например, с помощью автостереоскопического дисплея, вокруг блоков субтитров и аналогичных текстовых объектов часто могут восприниматься артефакты.
Для решения упомянутых проблем можно применить алгоритмы, направленные на идентификацию упомянутых объектов изображения. Затем к идентифицированным объектам изображения можно применить фиксированный уровень глубины, чтобы позиционировать весь текст на фиксированной глубине. Однако такое обнаружение, как правило, вызывает большие трудности, и точная сегментация в текстовых объектах изображения (и нетекстовых объектах изображения), как правило, не возможна. В результате упомянутые подходы также часто приводят к воспринимаемым артефактам.
Например, можно идентифицировать поле субтитров, и можно установить уровень глубины для этого поля на глубине экрана. На фиг. 3 показан пример того, как это можно реализовать.
Упомянутое поле субтитров используют для размещения субтитров на глубине экрана. На фиг. 3 показано, как это можно сделать. В этом примере поле субтитров обнаружено в яркостном изображении с текстом субтитров (фиг. 3а). В этом примере обнаружение субтитров может выполняться по каждому блоку пикселей размером 8×8 с использованием признаков, извлеченных из каждого блока 8×8. Каждый черный блок сначала можно классифицировать как часть субтитра (показанного белым цветом на фиг. 3b) или не классифицировать как часть субтитра (показано черным цветом на фиг. 3b). В конце концов, определяют ограниченное поле субтитров путем интегрирования результатов обнаружения сначала по горизонтали и нахождения старт-стопной позиции по координате y, а затем путем интегрирования результатов обнаружения по горизонтали и нахождения старт-стопной позиции для координаты x. В частности, границы поля субтитров можно установить по минимальному прямоугольнику, который включает в себя блоки, классифицированные как принадлежащие полю субтитров.
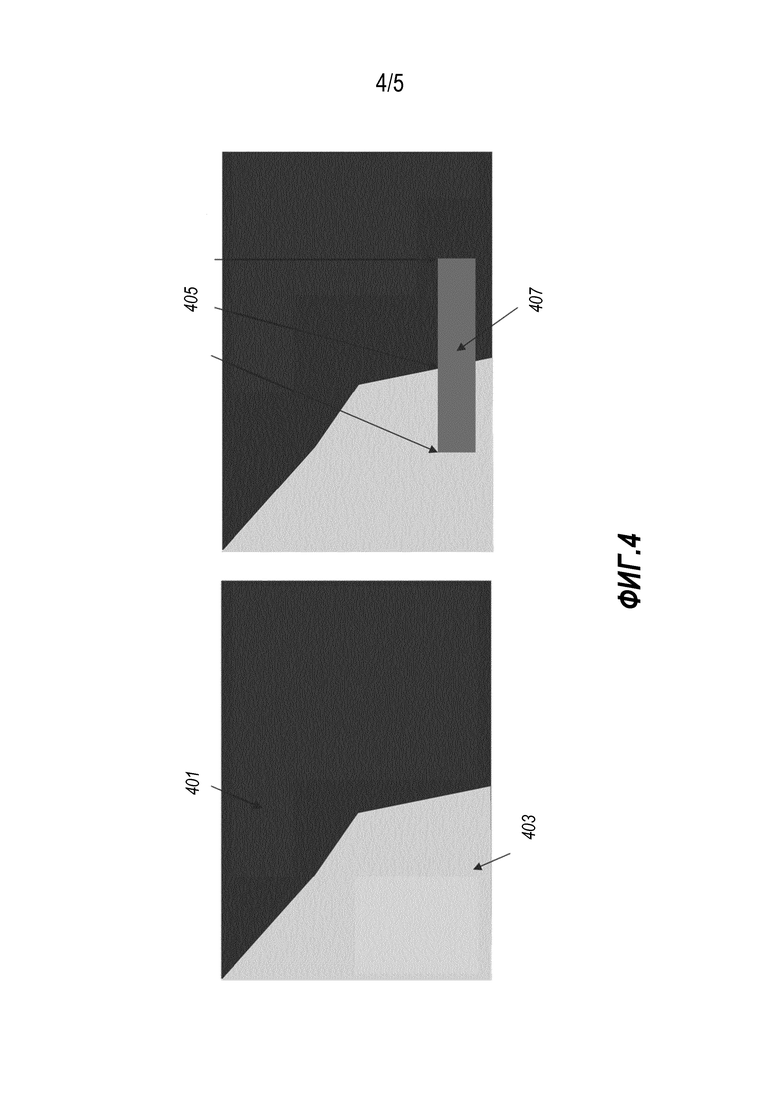
Затем для пикселей внутри поля субтитров можно установить конкретное значение глубины и, в частности, его можно установить равным глубине экрана или дисплея. Это может сократить артефакты и уменьшить размытие, внесенное автостереоскопическим дисплеем в объекты, находящиеся не на уровне экрана. Такой подход проиллюстрирован на фиг. 4, где показано изображение с сечением 401, которое находится за глубиной экрана, и с сечением 403, которое находится перед экраном. Описанный подход позволяет идентифицировать блок 405 субтитров и позиционировать его на глубине экрана.
Однако хотя такое решение позволяет в результате получить резкий (в частности, без размытия за плоскостью экрана) и геометрически правильный субтитровый объект, привнесенные крутые края в карте глубин (из-за текстового поля) часто могут привести к весьма заметным текстурным искажениям (срывам) вблизи границ текстового поля (как показано под ссылочной позицией 407 на фиг. 4). Кроме того, когда само текстовое поле распадается на множестве более мелких текстовых полей, также становятся видимыми ошибки воспроизведения. Например, некоторые символы в предложении могут быть резкими, в то время как другие символы могут быть размытыми. Кроме того, такая картина может быстро изменяться во времени, что на практике, как правило, заметно пользователю.
На практике было обнаружено, что попытка идентификации области субтитров и установки глубины этой области (в частности) равной глубине экрана, как правило приводит к различным проблемам. Прежде всего шум в алгоритме обнаружения может часто привести к тому, что обнаруженное поле распадется на два или более отдельных полей. Это может случиться из-за множества старт-стопных позиций, возможно существующих по координате x и/или y. Кроме того, старт-стопная позиция обнаруженного поля, как правило, чувствительна к ошибкам классификации. В результате, результирующая карта глубин может оказаться нестабильной во времени, что приводит к видимым временным ошибкам в изображениях, отображаемых автостереоскопическим дисплеем.
Устройство по фиг. 1 может смягчить или устранить некоторые из недостатков известных подходов. Устройство содержит драйвер 103 дисплея, приводящий в действие автостереоскопический дисплей 101. Драйвер 103 дисплея содержит функциональные возможности для создания множества видимых изображений для автостереоскопического дисплея 101 и их подачи. Видимые изображения создаются для разных направлений видения, используя алгоритм сдвига вида, который в качестве входа имеет входное изображение и карту глубин. Однако, скорее чем просто идентификация и установка области субтитров на глубину экрана, система выполнена с возможностью обработки входной карты глубин (принятой от внешнего источника или внутреннего источника, и часто создаваемой драйвером 103 дисплея из изображений, соответствующих разным направлениям видения, в частности, стереоизображения) для создания измененной карты глубин, в которой используется дополнительная перекомпоновка глубины субтитров. Это по большей части обеспечивает по существу улучшенное визуальное восприятие, в том числе сокращение или смягчение видимых артефактов вокруг субтитров или других текстовых объектов изображения.
Упомянутый подход применительно к драйверу 103 дисплея содержит создание карты вероятностей также называемой α-картой, содержащей значения вероятности, которые указывают, принадлежат ли соответствующие пиксели текстовому объекту изображения. Таким образом, в отличие от простого двоичного обозначения, определяющего, является ли данный пиксель или группа пикселей текстовым объектом изображения, карта вероятностей обеспечивает недвоичные, а часто по существу непрерывные значения, которые указывают оцененную вероятность того, что данный пиксель или группа пикселей принадлежат или не принадлежат текстовому объекту изображения. Значения вероятностей в карте вероятностей также называемые α-значениями, как правило, представлены дискретными значениями, и в большинстве вариантов осуществления каждое значение можно представить значениями по меньшей мере с 4, но как правило, по меньшей мере 8, 16, 32, 64, 128, 256 или даже с большим числом дискретных уровней. Во многих вариантах осуществления каждое значение вероятности может быть представлено двоичным значением, состоящим поменьше мере из 3, 4, 6, 8, 10, или 16 бит.
В этом подходе уровень глубины по меньшей мере для некоторых пикселей не создается просто путем выбора исходного значения глубины или установки этого уровня на заранее определенный уровень глубины (такой как уровень экрана). Скорее, по меньшей мере некоторые значения глубины в измененной карте глубин создают путем взвешенного объединения исходного значения глубины и значения глубины текстового объекта изображения, которое является особо предпочтительным уровнем глубины для текстовых объектов изображения (например, глубина экрана). Взвешивание уровней глубины для данного пикселя определяют на основе значения вероятности для данного пикселя.
В частности, если 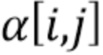 обозначает значение карты вероятностей на пиксельной позиции
обозначает значение карты вероятностей на пиксельной позиции 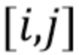 , измененный уровень глубины для измененной карты глубины можно определить как:
, измененный уровень глубины для измененной карты глубины можно определить как:
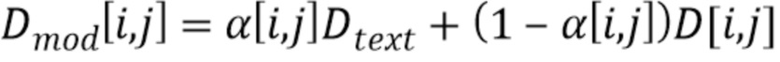
где 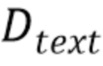 обозначает глубину текстового объекта изображения, а
обозначает глубину текстового объекта изображения, а 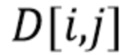 - исходный уровень глубины.
- исходный уровень глубины.
Таким образом, в этом подходе измененную карту глубины создают для обеспечения уровней глубины, которые более непрерывно покрывают разность между исходным уровнем глубины и уровнем глубины, необходимым для текстовых объектов изображения. Таким путем текстовый объект изображения можно эффективным образом пространственно (в направлении глубины) «вписать» между исходным представлением глубины и требуемой глубиной.
На практике было обнаружено, что упомянутый подход обеспечивает по существу более привлекательные визуальные восприятия со значительно уменьшенным восприятием артефактов и искажений вокруг текстовых объектов изображения, в частности, таких как блоки субтитров.
Другое преимущество данного подхода состоит в том, что использование результатов обнаружения текстового объекта изображения для создания карты вероятностей дает возможность применить пространственные и временные фильтры для улучшения результирующих воспроизводимых изображений. Кроме того, упомянутую фильтрацию можно выполнить, не затрагивая исходную карту глубин.
Драйвер 103 дисплея содержит блок 105 изображений, который выполнен с возможностью обеспечения изображения с соответствующей картой глубин, содержащей значения глубины по меньшей мере для некоторых пикселей изображения. Упомянутое изображение будем называть входным изображением, а упомянутую карту глубин входной картой глубин (а упомянутый пиксель и значения глубины - входным пикселем и входными значениями глубины).
В некоторых вариантах осуществления блок 105 изображений можно скомпоновать просто для приема входного изображения входной карты глубины от любого подходящего внутреннего или внешнего источника. Например, из сети (такой как Интернет), широковещательного сигнала, оператора мультимедиа и т.д. можно принять видеосигнал, содержащий трехмерные изображения, представленные одним изображением и соответствующей картой глубин.
В некоторых вариантах осуществления блок 105 изображений может быть выполнен с возможностью создания входного изображения и/или входной карты глубин. В частности, во многих вариантах осуществления блок 105 изображений может быть выполнен с возможностью приема трехмерного изображения, сформированного множеством изображений, соответствующих разным направлениям видения, например, стереоизображение, и упомянутый блок может быть выполнен с возможностью оценки несоответствия для создания входной карты глубин.
Значения глубины, содержащиеся в картах глубин, могут быть представлены любым подходящим образом, в частности, в виде значения координаты (z) глубины или в виде значения несоответствия, представляющее сдвиги между изображениями разных направлений видения.
В данном примере входные значения глубины представляют собой наблюдаемые или оцененные значения глубины. В частности, это могут быть значения, созданные путем оценки несоответствий, выполняемой либо во внешнем источнике, либо самим блоком 105 изображений. Соответственно, значения глубины часто оказываются относительно неточными и могут содержать несколько ошибок и погрешностей.
Также во входном сигнале текстовый объект изображения, такой как субтитры, может находиться не на предпочтительной глубине при воспроизведении на автостереоскопическом дисплее. Это возможно, например, из-за того, что для разных дисплеев технически оптимальная глубина (например, в соответствии с резкостью) будет разной, или из-за субъективных предпочтений, изменяющихся в зависимости от конкретного приложения.
Например, для телевизионных программ и кинофильмов субтитры, как правило, находятся спереди экрана, то есть, на уровне глубины, которая обеспечивает появление субтитров перед экраном, причем часто как самый передний объект. Однако, для многих автостереоскопических дисплеев на упомянутых уровнях глубины вносится значительно размытие, и поэтому может оказаться предпочтительным располагать субтитры в глубине экрана. Как было описано, драйвер 103 дисплея может соответствующим образом выполнить плавную перенастройку уровней глубины для оцениваемых текстовых объектов изображения.
В частности, блок 105 изображений связан с блоком 107 вероятностей, который выполнен с возможностью создания карты вероятностей, содержащей значения вероятности, указывающие вероятность того, что соответствующий пиксель принадлежит текстовому объекту изображения.
Значение вероятности для данного пикселя может представлять оценку вероятности или достоверности того, что он принадлежит текстовому объекту изображения. Эта вероятность может быть, например, индикатором того, насколько близко группа пикселей, содержащая данный пиксель, совпадает с набором ожидаемых значений характеристик для текстовых объектов изображения. Чем ближе это соответствие, те выше вероятность того, что пиксель принадлежит текстовому объекту изображения.
Вероятность принадлежности пикселя текстовому объекту изображения может быть основана на учете того, что текстовый объект изображения включает в себя только те пиксели, которые являются частью текстового символа. Однако во многих вариантах осуществления, как правило, можно считать, что текстовый объект изображения включает в себя ограниченное поле. Например, можно считать, что текстовый объект изображения включает в себя окружающее поле субтитров. Следует понимать, что точные характеристики и свойства, учитываемые при представлении текстового объекта изображения, будут зависеть от конкретных предпочтений и требований упомянутого отдельного варианта осуществления, и, в частности, что определение значений вероятности может быть адаптировано для отражения предпочтительных характеристик и свойств того объекта, который рассматривается как текстовое поле.
Например, в некоторых вариантах осуществления субтитры могут быть обеспечены в виде белых символов в сером или черном поле. В упомянутом примере возможно весьма желательно считать, что текстовый объект изображения включает в себя все поле субтитров, то есть, можно определить вероятность, указывающую принадлежность пикселей полю субтитров, результатом чего является плавное позиционирование поля субтитров на желаемой глубине. В других приложениях субтитры могут обеспечиваться просто в виде белых символов в верхней части подстилающего изображения. В упомянутом примере нет ограничивающего поля, и упомянутая вероятность может указывать вероятность принадлежности пикселя текстовому символу.
Во многих вариантах осуществления текстовый объект изображения может в частности представлять собой объект наложенного графического изображения, и, в частности, может представлять собой субтитровый или заголовочный объект изображения.
Следует понимать, что в других вариантах осуществления могут быть использованы другие подходы для определения карты вероятностей, и ниже будет описан конкретный пример, обеспечивающий высокоэффективное функционирование с высокими рабочими характеристиками.
Блок 107 вероятностей связан с блоком 109 глубин, который выполнен с возможностью создания измененной карты глубин. Блок 109 глубин кроме того связан с блоком 105 изображений и памятью/хранилищем 111, в котором хранится значение глубины текстового объекта изображения. Блок 109 глубин соответственно принимает входную карту глубин, значение глубины текстового объекта изображения и карту вероятностей и переходит к получению взвешенного объединения входных значений глубины и значений глубины текстового объекта изображения, причем взвешивание зависит от упомянутого значения вероятности.
В частности, как было описано ранее, упомянутое объединение может представлять собой линейную комбинацию, в частности, взвешенное суммирование значения входной глубины и значения глубины текстового объекта изображения с весовыми коэффициентами, зависящими от упомянутого значения вероятности. Однако следует понимать, что возможно использование других взвешенных объединений, причем относительный вклад входного уровня глубины и уровня глубины текстового объекта изображения зависит от упомянутого значения вероятности. Например, в некоторых вариантах осуществления возможно использование нелинейных объединений.
Таким образом, упомянутое объединение (для данного пикселя) обеспечивает выходное значение глубины в функции входного значения глубины, значения глубины текстового объекта изображения и значения вероятности (для данного пикселя), причем вклад в выходное значение глубины соответственно от входного значения глубины и значения глубины текстового объекта изображения будет зависеть от упомянутого значения вероятности.
Упомянутая взвешенное объединение таково, что весовой коэффициент глубины текстового объекта изображения увеличивается, а весовой коэффициент первого значения глубины уменьшается при возрастании значения упомянутой вероятности. Таким образом, принадлежность данного пикселя текстовому объекту изображения оценивается как более вероятная, чем ближе выходное значение глубины к значению глубины текстового объекта изображения, и принадлежность данного пикселя текстовому объекту изображения оценивается как менее вероятная, чем ближе выходное значение глубины к входному значению глубины. Точная взаимосвязь будет зависеть от предпочтений и требований конкретного варианта осуществления.
Во многих вариантах осуществления выходное значение глубины для данного пикселя может являться функцией значения вероятности, причем упомянутая функция представляет собой функцию, которая для нулевого значения вероятности выводит входное значение глубины для упомянутого пикселя, а для единичного значения вероятности выводит значение глубины текстового объекта изображения. Эта функция значения вероятности, в частности, может являться монотонной. Упомянутая функция значения вероятности для данного пикселя может отображать диапазон вероятности от 0 до 1 на диапазон значений глубины от входного значения глубины для упомянутого пикселя до значения глубины текстового объекта изображения.
В большинстве вариантов осуществления значение глубины текстового объекта изображения может быть заранее определенным, и, в частности может быть константой для всех изображений и/или для изображения в целом. Однако, в некоторых вариантах осуществления значение глубины текстового объекта изображения может изменяться в разных областях изображения, например, предпочтительное значение глубины текстового объекта изображения для нижележащей части изображения может отличаться от предпочтительного значения глубины текстового объекта изображения для верхней части изображения.
Блок 109 глубин в данном примере связан с генератором 113 изображений, который выполнен с возможностью создания видимых изображений для автостереоскопического дисплея 101. Генератор 113 изображений принимает измененную карту глубин от блока 109 глубин, причем он кроме того связан с блоком 105 изображений, от которого он принимает входное изображение. Генератор 113 изображений выполнен с возможностью создания изображений видов для автостереоскопического дисплея 101 путем выполнения сдвига видения для создания изображений видов для конкретных направлений видения, связанных с разными видами, создаваемыми автостереоскопическим дисплеем 101. Генератор 113 изображений выполнен с возможностью создания упомянутых изображений с помощью алгоритма сдвига видов на основе входного изображения и измененной карты глубин. Таким образом создаются изображения видов для представления пикселей на глубинах, которые плавно отражают правдоподобность принадлежности текстовым объектам изображения. В результате проецируемое трехмерное изображение, воспринимаемое наблюдателем по большей части будет более согласованно воспроизводить текстовый объект изображения с более плавным переходом между текстовыми объектами изображения и другими областями изображения. Это, как правило, существенно нивелирует воспринимаемые недостатки 3D представления.
Таким образом, в этом примере генератор 113 изображений использует входное изображение и измененную карту глубин для создания изображения сцены входного изображения, но с другим направлением видения, отличным от направления видения входного изображения.
Следует понимать, что специалистам в данной области техники известно много разных алгоритмов сдвига вида, и что можно использовать любой подходящий алгоритм, не выходя за рамки настоящего изобретения.
В некоторых вариантах осуществления блок 105 изображений может непосредственно принять карту глубин вместе с входным изображением. В некоторых случаях карты глубин могут быть созданы одновременно и в одном и том же месте, когда текстовые объекты изображения включены и/или добавлены, например, в захваченное изображение. В некоторых случаях карта глубин таким образом может быть создана с уровнями глубины для текстовых объектов изображения, таких как субтитры, на конкретной предпочтительной глубине. Таким образом, карта глубин для текстового объекта изображения может иметь полностью завершенную и согласованную область, соответствующую зоне текстового объекта изображения, причем все значения глубины в этой области могут быть идентичными. Это позволяет позиционировать текстовый объект изображения с небольшой ошибкой и малым числом артефактов. Однако, даже в этом случае уровень глубины текстового объекта изображения может не совпадать с предпочтительным уровнем глубины для конкретного сценария использования. Например, уровень глубины, подходящий для видения с использованием подхода, предусматривающего использование очков, может оказаться неидеальным для представления с использованием автостереоскопического дисплея. Кроме того, резкие изменения глубины могут привести к артефактам при выполнении сдвига видения.
Кроме того, во многих приложениях карта глубины может создаваться не одновременно и размещаться в виде вложения текстового объекта изображения (такого как субтитры). Например, во многих сценариях трехмерное изображение может быть представлено стереоизображениями с субтитрами, включенными в оба изображения, и с глубиной субтитров, регулируемой на основе несоответствия упомянутых двух стереоизображений. Такое трехмерное стереопредставление не включает в себя карту глубин, и, следовательно, упомянутая карта может быть создана, если это необходимо, в качестве операции постобработки. В действительности, во многих сценариях карта глубин может создаваться в конечном пользовательском устройстве.
Например, блок 105 изображений может быть выполнен с возможностью приема множества изображений, соответствующих разным направлениям видения для одной и той же сцены. В частности, можно принять стереоизображение, содержащее изображение для левого глаза и изображение для правого глаза. Стереоизображение может включать в себя текстовый объект изображения, например, субтитр с глубиной изображения, отражаемой на основе несоответствия упомянутых двух изображений.
Блок 105 изображений кроме того может быть выполнен с возможностью создания карты глубин в ответ на обнаружение несоответствия между изображениями с разных направлений видения. Таким образом, блок 105 изображений может перейти к нахождению соответствующих объектов изображения в изображениях, определить относительный сдвиг/несоответствие между ними и присвоить соответствующий уровень глубины упомянутым объектам изображения. Следует понимать, что для определения глубины на основе оценки несоответствия можно использовать любой подходящий алгоритм.
Упомянутая оценка несоответствия может привести к созданию относительно точных карт глубин. Однако эти карты глубин, как правило, все еще будут содержать относительно большое число ошибок и, как правило, не будут полностью согласованными. В частности, артефакты и несоответствия могут появляться в большом количестве вокруг обширных и резких изменений глубины, которые особенно часто могут появляться для текстовых объектов изображения.
Таким образом, непосредственное использование карты глубин, созданной на основе оценки несоответствий для изображений с разных направлений, по большей части приводит к видимому ухудшению качества и появлению артефактов, например, при выполнении сдвига видения.
Однако создание измененной карты глубин на основе определения вероятностей и слияния значения глубины, определенной на основе несоответствия, и желаемого значения глубины для текстовых объектов изображения по большей части приводит к фактическому улучшению изображения и особенно фактическому улучшению воспринимаемого качества вокруг текстовых объектов изображения с увеличенной совместимостью и сокращением артефактов. В частности, наличие ошибок, несовместимостей или артефактов, которые, как правило, могут появляться вокруг текстовых объектов изображения при выполнении оценки несоответствия, можно существенно смягчить, используя описанный подход.
Далее описывается особый подход для определения карты вероятностей.
В этом подходе определение значений вероятности может выполняться для групп пикселей, которые могут содержать множество пикселей. Таким образом, хотя принципы, описанные далее, могут быть применены к отдельным пикселям, в этом конкретном примере они реализуются на основе группы пикселей и, в частности, на основе прямоугольных блоков. В этом конкретном примере каждая группа пикселей представляет собой блок из 8×8 пикселей.
Соответственно, в этом примере блок 107 вероятностей содержит функциональные средства для определения групп пикселей для входного изображения, причем каждая группа пикселей содержит множество пикселей. Затем на основе этих групп пикселей определяют значения вероятности.
В этом подходе блок 107 вероятностей выполнен с возможностью определения сначала классификационной карты, содержащей значения для упомянутых групп пикселей, причем каждое значение указывает, обозначена ли соответствующая группа пикселей, как принадлежащая или не принадлежащая текстовому объекту изображения.
В этом конкретном варианте осуществления классификационные значения являются двоичными значениями, причем каждое значение соответственно указывает, что соответствующая группа пикселей обозначена как принадлежащая текстовому объекту изображения, или, что эта группа пикселей обозначена как не принадлежащая текстовому объекту изображения. Этот подход может упростить процесс классификации во многих вариантах осуществления и может обеспечить получение робастных решений. Кроме того, он может упростить обработку и (как было обнаружено) привести к созданию карт вероятностей, которые хорошо подходят для последующего согласования или объединения разных уровней глубины. В действительности, было обнаружено, что это приводит к созданию трехмерных изображений, воспринимаемых как высококачественные изображения.
Однако следует понимать, что в других вариантах осуществления значения классификационной карты могут быть не двоичными, например, в процессе классификации объекта могут создаваться значения с мягким решением для указания о том, принадлежат ли группы пикселей текстовому объекту изображения. Например, эти значения могут представлять собой набор дискретных значений в интервале [0,1], причем 1 представляет обозначение принадлежности текстовому объекту изображения, а 0 представляет обозначение не принадлежности текстовому объекту изображения, и со значениями между 0 и 1, отражающими, насколько близко данная группа пикселей соответствует требованиям для ее обозначения, как принадлежащей текстовому объекту изображения. В действительности эти значения в некоторых вариантах осуществления можно рассматривать как исходные значения вероятности, а классификационную карту можно рассматривать в качестве исходной карты вероятностей.
Блок 107 вероятностей может реализовать процесс классификации текстового объекта изображения для входного изображения, который обеспечивает двоичное решение, указывающее, принадлежит или нет каждая группа пикселей текстовому объекту изображения.
Следует понимать, что для обозначения принадлежности групп пикселей текстовому объекту изображения можно использовать другие алгоритмы. В качестве простого примера можно оценить распределение цвета в группе пикселей, и, если преимущественно имеют место пиксельные цвета, соответствующие цветам, использованным для полей субтитров (например, белый и черный), то группу пикселей можно обозначить как группу, являющуюся текстовым объектом изображения, а в противном случае ее можно обозначить как группу, не являющуюся текстовым объектом изображения.
Следует понимать, что в большинстве вариантов осуществления может быть использован значительно более сложный алгоритм классификации или обозначения. Например, классификация может быть основана на множестве признаков, которые вычисляют для каждого блока. Признаками могут быть, например, средний градиент пикселей по горизонтали и количество пикселей в определенном интервале гистограммы интенсивности пикселей. Затем может быть использован подход на основе машинного обучения, такой как AdaBoost (http://cseweb.ucsd.edu/~yfreund/papers/IntroToBoosting.pdf; date: 20-05-2015) для (автоматического) обучения так называемого «строгого классификатора» путем линейного комбинирования, например, 50 «слабых» классификационных правил. Заметим, что для выбора используют, как правило, гораздо больший набор признаков-кандидатов (например, >300) с тем, чтобы можно было сделать правильный выбор. Для получения упомянутого большого набора признаков-кандидатов в качестве входа для множества операций пространственной свертки (фильтр) с изменяющимся базовым размером используют упомянутый средний градиент горизонтальных пикселей, и таким образом каждый признак может создать, например, 10 новых признаков-кандидатов. Обучение классификатора выполняется на уровне блока 8×8 с использованием данного набора обучающих изображений. Затем можно использовать результирующий алгоритм для классификации каждого блока как принадлежащего или не принадлежащего текстовому объекту изображения.
Как упоминалось выше, созданные классификационные значения в описанном примере являются двоичными значениями, которые указывают либо, что группа пикселей обозначена как принадлежащая текстовому объекту изображения, либо, что она обозначена как не принадлежащая текстовому объекту изображения. Однако в некоторых вариантах осуществления процесс классификации может породить значения с мягким решением, которые можно использовать вместо двоичных значений. Например, классификатор AdaBooster может по сути дела использовать и создавать индикаторы с мягким решением, которые сравнивают с порогом для обозначения группы пикселей. Однако в некоторых вариантах осуществления эти значения с мягким решением могут вместо этого использоваться для классификационной карты без выполнения сравнения с порогом для создания двоичных значений.
Вторая фаза создания карты вероятностей состоит в переходе к применению фильтрации к созданной классификационной карте. Фильтрация может наложить временные или пространственные ограничения и сгладить классификационную карту.
В частности, при возвращении процесса классификации к двоичным результатам классификации с жестким решением, эти исходные двоичные значения можно преобразовать в недвоичные значения, которые указывают вероятность принадлежности или не принадлежности отдельных групп пикселей (или пикселей) текстовому объекту изображения. Таким образом, исходно двоичное классификационное обозначение можно преобразовать в постепенно изменяющиеся недвоичные значения вероятности посредством фильтрации, применяемой к классификационной карте. Это преобразование не только позволяет обеспечить относительно несложную эффективную обработку с относительно низкими требованиями к ресурсам, но (как это было установлено) обеспечить очень хорошие результаты со значениями вероятности, отражающими не только классификацию самой упомянутой группы, но также, каким образом это относится к другим классификациям во временном и/или пространственном соседстве упомянутой группы пикселей. В действительности этот подход, как правило, приводит к созданию карты вероятностей, имеющую высокую степень совместимости, и которая хорошо подходит для манипуляций с глубиной текстовых объектов изображения.
Упомянутая фильтрация может содержать множество операций фильтрации. Во многих вариантах осуществления эта фильтрация может содержать множество последовательных фильтрующих операций, причем, как правило, последующая операция фильтрации выполняется по результату предшествующей операции фильтрации.
Далее описывается пример конкретного подхода с множеством последовательно выполняемых фильтрующих операций. Однако следует понимать, что это просто пример, и что в других вариантах осуществления может быть использован только поднабор из числа описанных фильтрующих операций и что порядок фильтрующих операций может быть другим в других вариантах осуществления. Например, в некоторых вариантах осуществления временная фильтрация может применяться перед пространственной фильтрацией, в то время как в других вариантах осуществления пространственная фильтрация может применяться перед временной фильтрацией.
В этом примере операции фильтрации выполняются с групповым разрешением по группам пикселей, причем каждая группа пикселей содержит множество пикселей. В частности, все фильтры работают с блочным (8×8) разрешением. В этом описании индексы 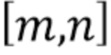 относятся соответственно к блочным индексам. Результирующая карта вероятностей также получается с блочным разрешением. Во время создания измененной карты глубин значения вероятности могут интерполироваться для обеспечения более высокого разрешения и, в частности, обеспечения уровневого разрешения (по пиксельному уровню). В качестве конкретного примера, можно интерполировать (например, линейно)
относятся соответственно к блочным индексам. Результирующая карта вероятностей также получается с блочным разрешением. Во время создания измененной карты глубин значения вероятности могут интерполироваться для обеспечения более высокого разрешения и, в частности, обеспечения уровневого разрешения (по пиксельному уровню). В качестве конкретного примера, можно интерполировать (например, линейно) 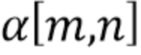 для вычисления
для вычисления 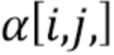 , являющегося пиксельным уровнем.
, являющегося пиксельным уровнем.
В некоторых вариантах осуществления такая фильтрация может включать в себя фильтрацию с двоичным расширением, применяемую к классификационной карте.
Например, 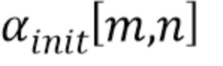 может обозначать результат грубого обнаружения для блочных индексов
может обозначать результат грубого обнаружения для блочных индексов 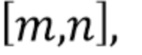 то есть, двоичные значения классификационной карты. Результат грубого обнаружения либо принимает значение 1 (принадлежность текстовому объекту изображения) или 0 (не принадлежность текстовому объекту изображения). Для увеличения плотности результата (то есть, для увеличения размера обнаруженных зон),
то есть, двоичные значения классификационной карты. Результат грубого обнаружения либо принимает значение 1 (принадлежность текстовому объекту изображения) или 0 (не принадлежность текстовому объекту изображения). Для увеличения плотности результата (то есть, для увеличения размера обнаруженных зон), 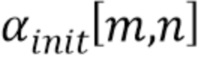 сначала можно отфильтровать, используя (как правило, двоичный) фильтр с расширением, в частности, крестообразный фильтр с морфологическим расширением:
сначала можно отфильтровать, используя (как правило, двоичный) фильтр с расширением, в частности, крестообразный фильтр с морфологическим расширением:
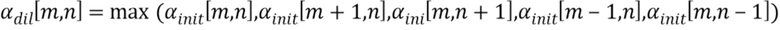
Таким образом, зоны, определенные как принадлежащие текстовым объектам изображения, увеличиваются, увеличивая тем самым вероятность приобщения групп пикселей текстового объекта изображения, и обеспечивая увеличенное перекрытие и т.д. между ними.
Блок 107 вероятностей также может применить временную фильтрацию нижних частот. Если выполнена фильтрация с расширением, то эту временную фильтрацию можно применить к результату фильтрации с расширением. В противном случае, ее можно применить, например, прямо к классификационной карте.
Во многих вариантах осуществления временная фильтрация может быть асимметричной, то есть, эффект пропускания нижних частот может быть более значительным в одном направлении, чем в другом. В частности, временная константа для изменения, направленного на увеличение вероятности принадлежности групп пикселей текстовым объектам изображения, меньше, чем временная константа для изменения, направленного на уменьшение вероятности принадлежности групп пикселей текстовым объектам изображения.
В качестве конкретного примера, к выходу фильтра с расширением (или, например, непосредственно к классификационной карте) может быть применен временной асимметричный рекурсивный фильтр. Конкретный пример фильтра, подходящего для многих вариантов осуществления, может представлять собой:

где верхний индекс t относится к номеру кадра.
Этот фильтр может обеспечить быстрое изменение глубины при начальном обнаружении текста. Однако эффект текста на карте глубин будет уменьшаться лишь постепенно при удалении текста. Суммарным эффектом будет улучшение временной стабильности. Заметим, что 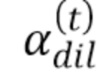 , как правило, устанавливают в нуль для всех блоков при
, как правило, устанавливают в нуль для всех блоков при 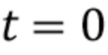 .
.
В некоторых вариантах осуществления фильтрация содержит пространственную фильтрацию. Эта фильтрация может выполняться непосредственно на классификационной карте (например, после фильтрации с расширением, если она имеет место) или может, например, выполняться после временной фильтрации.
В некоторых вариантах осуществления пространственная фильтрация может быть реализована линейным фильтром нижних частот. Однако во многих вариантах осуществления пространственная фильтрация, в частности, может включать в себя по меньшей мере один фильтр мягкого максимума.
Фильтр мягкого максимума может представлять собой каскад, состоящий из фильтра и ограничителя, который ограничивает максимальное значение выхода. Например, фильтр мягкого максимума нижних частот может выполнять операцию, соответствующую каскаду, состоящему из фильтра нижних частот и ограничителя, ограничивающего максимальное значение выхода фильтра нижних частот. Таким образом, фильтр мягкого максимума может соответствовать фильтру, имеющему предел максимального выходного значения. Максимальным значением может быть значение, равное 1, но следует иметь ввиду, что это значение может отличаться в разных вариантах осуществления.
В частности, фильтр мягкого максимума может представлять собой фильтр, выполняющий стандартную операцию фильтрации, например, фильтр нижних частот, но умножающий выход фильтра на значение, превышающее 1, так что выход фильтра смещается в сторону более высоких значений, после чего выбирается минимальное значение из полученного выходного значения и предварительно определенного максимального значения. Определенный таким образом фильтр мягкого максимума состоит из трех компонент: компоненты, выполняющей операцию (стандартной) фильтрации, множителя и предварительно установленного максимума. Таким образом, фильтрация с использованием мягкого максимума может содержать применение пространственной фильтрации (нижних частот) с ограничением максимального выхода фильтра. Как правило, фильтрация нижних частот может представлять собой двухступенчатый процесс, содержащий первую фильтрацию с использованием (как правило, нормализованного) фильтра нижних частот, с последующим масштабированием выходных значений фильтра с использованием коэффициента масштабирования, который, как правило, заранее определен. Затем результирующий масштабированный выход ограничивается до упомянутого максимального значения. Однако упомянутое масштабирование можно рассматривать как часть общей фильтрации, причем такое масштабирование может быть реализовано, например, с использованием (базовых) коэффициентов масштабирования пространственного фильтра. Упомянутое максимальное значение, как правило, определяют заранее.
Использование фильтра мягкого максимума может обеспечить улучшенные рабочие характеристики. В частности, как правило, это может обеспечить создание областей, в которых внутренние пиксели указаны (почти наверняка) как текстовые объекты изображения, при обеспечении мягкого и постепенного перехода к границам области. Такая характеристика особенно подходит, например, для идентификации полей субтитров с использованием значений вероятности.
В некоторых вариантах осуществления пространственная фильтрация может содержать по меньшей мере два последовательных пространственных фильтра мягкого максимума. Разные фильтры мягкого максимума могут иметь разные характеристики. В частности, пространственная фильтрация может обеспечить две функции. Одна из них состоит в заполнении областей, соответствующих текстовым объектам изображения, то есть, в создании перекрытия обнаруженных областей так, чтобы предпочтительно отсутствовали зазоры в обнаруженных областях. Другая функция состоит в обеспечении пространственного сглаживания так, чтобы переходы вокруг обнаруженных зон стали сглаженными и постепенными. Обе функции приводят к улучшению визуального восприятия.
Таким образом, в этом конкретном примере первый фильтр мягкого максимума может быть применен для заполнения обнаруженных областей, соответствующих текстовым объектам изображения. Затем может быть применен второй фильтр мягкого максимума к результату первого фильтра мягкого максимума для создания сглаженных переходов.
В качестве конкретного примера после временной фильтрации некоторые текстовые объекты могут привести к созданию весьма редко заполненной карты индикаторов зон, принадлежащих текстовым объектам изображения. Таким образом, чтобы заполнить «дыры», например, внутри поля субтитров может быть применен фильтр мягкого максимума. Например, можно использовать фильтр мягкого максимума с базовой высотой в 21 блок и базовой шириной в 35 блоков:
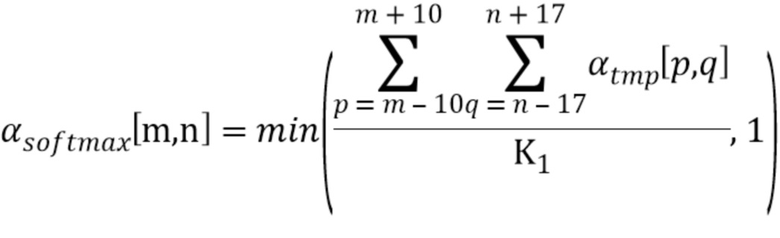
где
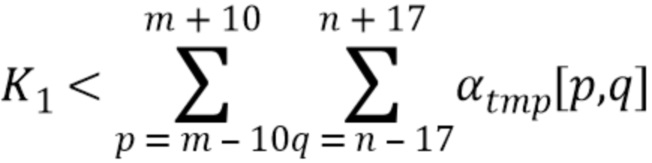
В качестве конкретного примера 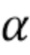 можно представить 8-битовыми числами, так что значение 1 представлено как 255. В этом примере можно использовать значение
можно представить 8-битовыми числами, так что значение 1 представлено как 255. В этом примере можно использовать значение 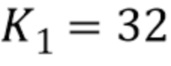 . Во многих вариантах осуществления упомянутый фильтр мягкого максимума может заполнить «дыры» между символами и словами.
. Во многих вариантах осуществления упомянутый фильтр мягкого максимума может заполнить «дыры» между символами и словами.
За первым фильтром мягкого максимума может следовать второй фильтр мягкого максимума, который стремится удалить жесткую пространственную границу между областью карты глубин, соответствующей текстовому объекту изображения, и окружающими областями карты глубин и обеспечить таким образом мягкий переход между текстом и остальной частью трехмерного изображения, когда оно присутствует.
Второй фильтр мягкого максимума может соответствовать первому фильтру, но иметь другие параметры, и, в частности, иметь более крупный деноминатор, с тем чтобы действие фильтра было более похожим на действие фильтра нижних частот и менее похожим на действие фильтра максимума. В данном конкретном примере могут быть использованы базовый размер по высоте, равный 11 пикселям и по ширине, равный 25 пикселям:
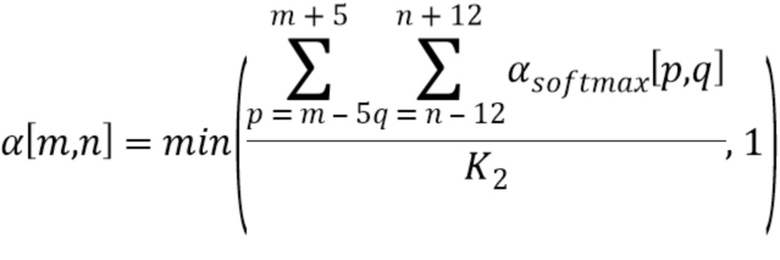
Опять же можно представить 8-битовыми числами, а подходящим значением для деноминатора может быть 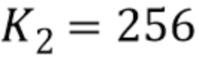 .
.
Использование дух последовательных фильтров мягкого максимума может не только привести к улучшенным рабочим характеристикам, но также позволяет упростить реализацию. В частности, можно использовать один и тот же алгоритм или функцию с изменяемыми значениями параметров. В действительности, во многих вариантах осуществления данные изображения можно более эффективно (многократно) использовать, применив, например, интегральный подход к изображению.
На фиг. 5 показаны примеры результатов, полученных с использованием описанного полхода для определения карты вероятностей. На фиг. 5 показано входное изображение 501 и классификационная карта 503 после двоичной фильтрации с расширением и временной фильтрации. Как можно видеть из этой фигуры, карта вероятностей на этом этапе может быть заполнена очень редко (белый цвет указывает зоны с высокой вероятностью принадлежности текстовому объекту изображения, а черный цвет указывает зоны с низкой вероятностью принадлежности текстовому объекту изображения). Здесь показан выход 505 первого фильтра мягкого максимума. Как можно видеть, упомянутая фильтрация приводит к значительному увеличению зоны, принадлежность которой текстовому объекту изображения считается вероятной. Однако, упомянутый переход является достаточно резким. Также показан выход 507 второго фильтра мягкого максимума. Как можно видеть, это весьма точно соответствует выходу первого фильтра мягкого максимума, но с фактически сглаженными переходами, что дает гораздо более плавное изменение глубины в изображении, воспроизводимом автостереоскопическим дисплеем 101.
В описанном примере классификационная карта и обработка ее фильтрации выполнялась с использованием групп пикселей и, в частности, пиксельных блоков, содержащих множество пикселей. В этом примере в действительности использовались блоки 8×8 пикселей. Это уменьшает разрешение в 64 раза и соответственно позволяет получить фактически более эффективную обработку с пониженными требованиями. Кроме того, авторы изобретения установили, что упомянутое уменьшение разрешения можно применять не в ущерб достижению желаемых рабочих характеристик и желаемого качества воспринимаемого изображения.
Однако для повышения качества воспринимаемого изображения весовые коэффициенты для упомянутого взвешенного объединения можно создавать с более высоким разрешением, чем разрешение по уровням блоков, и, в частности, может быть создано с пиксельным разрешением.
Этого можно достичь, используя интерполяцию между значениями глубины на основе блоков. Для создания значений глубины для отдельных пикселей блоков можно использовать, например, интерполяцию между значениями вероятности для соседних блоков. Весовые коэффициенты для такой интерполяции можно определить на основе позиции пикселя в группе пикселей.
Например, можно выполнить интерполяцию между первым и вторым значением глубины. Для пикселя, находящегося практически на границе между группами пикселей для первого и второго значений глубины, значение глубины можно определить фактически равным весовому коэффициенту первого и второго значений глубины. Например, можно выполнить простое усреднение. Однако для пикселя в центре одной группы пикселей значение глубины можно определить просто равным значению глубины, определенному для данной группы пикселей.
Следует понимать, что приведенное выше описание для ясности содержит описание вариантов осуществления изобретения со ссылками на разные функциональные схемы, блоки и процессы. Однако очевидно, что можно использовать любое подходящее распределение функциональных возможностей между разными функциональными схемами, блоками или процессорами, не выходя за рамки объема изобретения. Например, показанные функциональные возможности, подлежащие выполнению отдельными процессорами или контроллерами, могут выполняться одним и тем же процессором или контроллерами. Таким образом, ссылки на конкретные функциональные блоки или схемы должны рассматриваться только как ссылки на подходящие средства, обеспечивающие описанные функциональные возможности, но не указывающие точную логическую или физическую структуру, или организацию.
Изобретение можно реализовать в любом подходящем виде включая аппаратное обеспечение, программное обеспечение, программно-аппаратное обеспечение или любого их сочетания. Изобретение может, но не обязательно, быть реализовано по меньшей мере частично в виде компьютерного программного обеспечения, выполняемого на одном или нескольких процессорах данных и/или цифровых процессорах сигналов. Элементы и компоненты варианта осуществления изобретения могут быть физически, функционально и логически реализованы любым подходящим способом. В действительности упомянутые функциональные возможности можно реализовать в едином блоке, во множестве блоков или в виде части других функциональных блоков. Как таковое, изобретение можно реализовать в виде одного блока или можно физически и функционально распределить его между разными блоками, схемами и процессорами.
Хотя настоящее изобретение было описано в связи с некоторыми вариантами его осуществления, не предполагается, что изобретение сводится к конкретному описанному здесь виду. Скорее объем настоящего изобретения ограничен только сопроводительной формулой изобретения. Вдобавок, хотя может появиться признак, подлежащий описанию вместе с конкретными вариантами осуществления, специалистам в данной области техники должно быть ясно, что различные признаки описанных вариантов осуществления можно объединить согласно изобретению. В формуле изобретения термин, «содержащий» не исключает наличия других элементов или этапов.
Кроме того, хотя они перечислены по отдельности, множество средств, элементов, схем или этапов способов можно реализовать, например, одной схемой, блоком или процессором. Вдобавок, хотя отдельные признаки могут быть включены в разные пункты формулы изобретения, они могут быть успешно объединены, и включение их в разные пункты формулы изобретения не предполагает, что объединение признаков не может оказаться невозможными/или успешным. Также включение признака в одну категорию пунктов формулы изобретения не предполагает ограничение по этой категории, а скорее указывает, что данный признак равным образом применим к другим категориям пунктов формулы изобретения при необходимости. Кроме того, порядок следования признаков в формуле изобретения не предполагает какой-либо конкретный порядок, в котором эти признаки должны работать и, в частности, порядок отдельных этапов в пункте формулы изобретения, относящемся к способу, не предполагает, что эти этапы должны выполняться в упомянутом порядке. Скорее, эти этапы могут выполняться в любом подходящем порядке. Вдобавок, ссылки на единственное число не исключают множественного числа. Так, ссылки на «a», «an», «первый», «второй» и т.д. не исключают множественного числа. Ссылочные позиции в формуле изобретения обеспечены просто в качестве поясняющего примера, что нельзя трактовать как любого характера ограничение объема формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОПРЕДЕЛЕНИЯ КАРТЫ ГЛУБИНЫ ДЛЯ ИЗОБРАЖЕНИЯ | 2016 |
|
RU2721175C2 |
| ОБЪЕДИНЕНИЕ ДАННЫХ 3D ИЗОБРАЖЕНИЯ И ГРАФИЧЕСКИХ ДАННЫХ | 2010 |
|
RU2538335C2 |
| ОБРАБОТКА 3D ОТОБРАЖЕНИЯ СУБТИТРОВ | 2009 |
|
RU2517402C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ФОРМИРОВАНИЯ ТРЕХМЕРНОГО ИЗОБРАЖЕНИЯ | 2015 |
|
RU2692432C2 |
| МЕТАДАННЫЕ ДЛЯ ФИЛЬТРАЦИИ ГЛУБИНЫ | 2013 |
|
RU2639686C2 |
| ОСНОВАННОЕ НА ЗНАЧИМОСТИ ОТОБРАЖЕНИЕ ДИСПАРАТНОСТИ | 2012 |
|
RU2580439C2 |
| ГЕНЕРИРОВАНИЕ ИЗОБРАЖЕНИЯ ДЛЯ АВТОСТЕРЕОСКОПИЧЕСКОГО ДИСПЛЕЯ | 2016 |
|
RU2707726C2 |
| СПОСОБЫ И СИСТЕМЫ ДЛЯ ПРЕДСТАВЛЕНИЯ ТРЕХМЕРНЫХ ИЗОБРАЖЕНИЙ ДВИЖЕНИЯ С АДАПТИВНОЙ К СОДЕРЖИМОМУ ИНФОРМАЦИЕЙ | 2009 |
|
RU2546546C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ НАЛОЖЕНИЯ ТРЕХМЕРНОЙ ГРАФИКИ НА ТРЕХМЕРНОЕ ВИДЕОИЗОБРАЖЕНИЕ | 2009 |
|
RU2537800C2 |
| ДЕКОДЕР, КОДЕР, КОМПЬЮТЕРНАЯ ПРОГРАММА И СПОСОБ | 2017 |
|
RU2744169C2 |


Изобретение относится к области вычислительной техники. Технический результат заключается в повышении качества воспринимаемого изображения. Устройство содержит блок изображений, который снабжает изображение соответствующей картой глубин, блок вероятностей определяет карту вероятностей для изображения, содержащую значения вероятности, указывающей вероятность того, что пиксели принадлежат текстовому объекту изображения, блок глубин создает измененную карту глубин, в которой определены измененные значения глубины в виде взвешенных объединений входных значений и значение глубины текстового объекта изображения, соответствующее предпочтительной глубине для текста. Взвешивание зависит от вероятности значения для упомянутых пикселей. Такой подход обеспечивает более мягкое изменение глубины для текстовых объектов, что приводит к сокращению артефактов и искажений, например, при выполнении сдвига видов с использованием карт глубин. 3 н. и 12 з.п. ф-лы, 5 ил.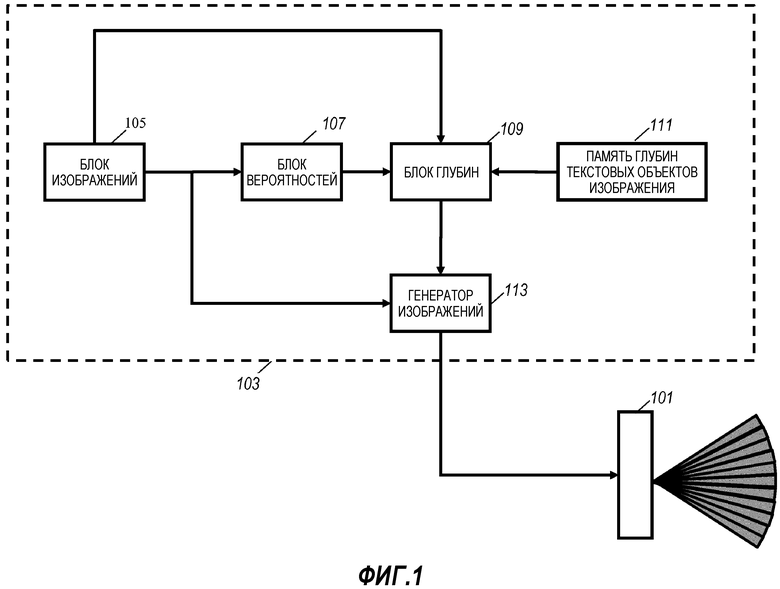
1. Устройство для определения карты глубин для изображения, причем устройство содержит:
блок (105) изображений для снабжения первого изображения соответствующей картой глубин, содержащей первые значения глубин, для, по меньшей мере, некоторых пикселей первого изображения;
блок (107) вероятностей для определения карты вероятностей для первого изображения, содержащей значения вероятности для, по меньшей мере, некоторых пикселей изображения, причем значение вероятности для пикселя указывает вероятность того, что этот пиксель принадлежит текстовому объекту изображения;
блок (109) глубин для создания измененной карты глубин для первого изображения, причем блок глубин выполнен с возможностью определения измененного значения глубины для, по меньшей мере, первого пикселя в виде взвешенного объединения первого значения глубины соответствующей карты глубин для первого пикселя и значения глубины текстового объекта изображения, которое является одинаковым для множества пикселей, причем упомянутое взвешивание зависит от значения вероятности для первого пикселя.
2. Устройство по п. 1, в котором блок (107) вероятностей выполнен с возможностью определения групп пикселей для первого изображения, причем каждая группа пикселей содержит множество пикселей; при этом блок вероятностей выполнен с возможностью определения значений вероятности для групп пикселей.
3. Устройство по п. 2, в котором блок (109) глубин выполнен с возможностью определения весовых коэффициентов для упомянутого взвешенного объединения в качестве реакции на первое значение вероятности для группы пикселей, которой принадлежит первый пиксель, и второе значение вероятности для соседней группы пикселей; причем взвешивание первого значения вероятности и второго значения вероятности зависит от позиции первого пикселя в группе пикселей, которой принадлежит первый пиксель.
4. Устройство по п. 1, в котором блок (107) вероятностей выполнен с возможностью определения значений вероятности для групп пикселей изображения, причем каждая группа пикселей содержит по меньшей мере один пиксель; при этом блок (107) вероятностей выполнен с возможностью сначала определять классификационную карту, содержащую значения для групп пикселей, указывающие, обозначены ли группы пикселей как принадлежащие текстовому объекту изображения или не принадлежащие текстовому объекту изображения, и создавать карту вероятностей в качестве реакции на фильтрацию классификационной карты.
5. Устройство по п. 4, при этом классификационная карта содержит двоичные значения для групп пикселей, причем каждое двоичное значение указывает, либо что группа пикселей обозначена как принадлежащая текстовому объекту изображения, либо что данная группа пикселей обозначена как не принадлежащая текстовому объекту изображения.
6. Устройство по п. 5, в котором упомянутая фильтрация содержит фильтрацию с двоичным расширением, применяемую к классификационной карте.
7. Устройство по п. 4, при этом первое изображение является частью временной последовательности изображений, и упомянутая фильтрация содержит временную фильтрацию нижних частот.
8. Устройство по п. 7, в котором временная фильтрация является асимметричной, так что временная константа для увеличения вероятности принадлежности группы пикселей текстовому объекту изображения отличается от временной константы для уменьшения вероятности принадлежности группы текстовому объекту изображения.
9. Устройство по п. 4, в котором упомянутая фильтрация содержит пространственную фильтрацию.
10. Устройство по п. 9, в котором пространственная фильтрация содержит фильтр мягкого максимума, являющийся фильтром, имеющим предел максимального выходного значения.
11. Устройство по п. 9, в котором пространственная фильтрация содержит по меньшей мере два последовательных пространственных фильтра мягкого максимума.
12. Устройство по п. 1, при этом первые значения глубины соответствуют несоответствиям объектов изображения во множестве изображений, соответствующих разным направлениям видения для сцены первого изображения.
13. Устройство по п. 1, при этом весовой коэффициент глубины текстового объекта изображения увеличивается, а весовой коэффициент первого значения глубины уменьшается для увеличивающегося значения вероятности.
14. Способ определения карты глубин для изображения, содержащий этапы:
снабжения первого изображения соответствующей картой глубин, содержащей первые значения глубины, для, по меньшей мере, некоторых пикселей первого изображения;
определения карты вероятностей для первого изображения, содержащей значения вероятности для, по меньшей мере, некоторых пикселей изображения, причем значение вероятности для пикселя указывает вероятность того, что этот пиксель принадлежит текстовому объекту изображения; и
создания измененной карты глубин для первого изображения, каковое создание содержит определение измененного значения глубины для, по меньшей мере, первого пикселя в виде взвешенного объединения первого значения глубины соответствующей карты глубин для первого пикселя и значения глубины текстового объекта изображения, которое является одинаковым для множества пикселей, причем упомянутое взвешивание зависит от значения вероятности для первого пикселя.
15. Машиночитаемый носитель, содержащий средства кода компьютерной программы, выполненные с возможностью осуществления всех этапов по п. 14 при исполнении данной программы на компьютере.
| US2013156294 A1, 20.06.2013 | |||
| WO2014072926 A1, 15.05.2014 | |||
| WO2008062351 A1, 29.05.2008 | |||
| US2013084007 A1, 04.04.2013 | |||
| WO2006117707 A2, 09.11.2006. |

