Область техники, к которой относится изобретение
[1] Настоящий вариант осуществления относится к технологии кодирования изображений и, более конкретно, к способу и устройству преобразования в системе кодирования изображений.
Уровень техники
[2] Потребности в изображениях высокого разрешения и высокого качества, таких как изображения HD (высокого разрешения) и изображения UHD (сверхвысокого разрешения), возрастают в различных областях. Так как данные изображения имеют высокое разрешение и высокое качество, количество информации или битов, подлежащих передаче, повышается по отношению к унаследованным данным изображения. Поэтому, когда данные изображения передаются с использованием носителя, такого как традиционная проводная/беспроводная широкополосная линия, или данные изображения хранятся с использованием существующего носителя хранения, затраты на их передачу и хранение увеличиваются.
[3] Соответственно, существует потребность в высокоэффективном методе сжатия изображений для эффективной передачи, хранения и воспроизведения информации изображений высокого разрешения и высокого качества.
раскрытие изобретения
[4] Настоящий вариант осуществления предусматривает способ и устройство для повышения эффективности кодирования изображений.
[5] Настоящий вариант осуществления также предусматривает способ и устройство для повышения эффективности преобразования.
[6] Настоящий вариант осуществления также предусматривает способ и устройство для повышения эффективности остаточного кодирования на основе множественного преобразования.
[7] Настоящий вариант осуществления также обеспечивает способ и устройство неразделимого вторичного преобразования.
[8] В одном аспекте предусмотрен способ преобразования, выполняемый устройством декодирования. Способ включает в себя получение коэффициентов преобразования для целевого блока, определение набора неразделимого вторичного преобразования (NSST) для целевого блока, выбор одного из множества ядер NSST, включенных в набор NSST, на основании индекса NSST и формирование модифицированных коэффициентов преобразования посредством неразделимого вторичного преобразования коэффициентов преобразования на основании выбранного ядра NSST. Набор NSST для целевого блока определяется на основании по меньшей мере одного из режима внутреннего (интра–) предсказания и размера целевого блока.
[9] В соответствии с другим вариантом осуществления настоящего варианта осуществления, обеспечено устройство декодирования, выполняющее преобразование. Устройство декодирования включает в себя модуль деквантования, выполненный с возможностью получения коэффициентов преобразования для целевого блока посредством выполнения деквантования на квантованных коэффициентах преобразования целевого блока, и обратный преобразователь, выполненный с возможностью определения набора неразделимого вторичного преобразования (NSST) для целевого блока, выбора одного из множества ядер NSST, включенных в набор NSST, на основании индекса NSST, и формирования модифицированных коэффициентов преобразования посредством неразделимого вторичного преобразования коэффициентов преобразования на основании выбранного ядра NSST. Обратный преобразователь определяет набор NSST для целевого блока на основании по меньшей мере одного из режима интра–предсказания и размера целевого блока.
[10] В соответствии с еще одним другим вариантом осуществления настоящего варианта осуществления, обеспечен способ преобразования, выполняемый устройством кодирования. Способ включает в себя получение коэффициентов преобразования для целевого блока, определение набора неразделимого вторичного преобразования (NSST) для целевого блока, выбор одного из множества ядер NSST, включенных в набор NSST, установку индекса NSST и формирование модифицированных коэффициентов преобразования посредством неразделимого вторичного преобразования коэффициентов преобразования на основании выбранного ядра NSST. Набор NSST для целевого блока определяется на основании по меньшей мере одного из режима интра–предсказания и размера целевого блока.
[11] В соответствии с еще одним другим вариантом осуществления настоящего варианта осуществления, обеспечено устройство кодирования, выполняющее преобразование. Устройство кодирования включает в себя преобразователь, выполненный с возможностью получения коэффициентов преобразования для целевого блока посредством выполнения первичного преобразования на остаточных выборках целевого блока, определения набора неразделимого вторичного преобразования (NSST) для целевого блока, выбора одного из множества ядер NSST, включенных в набор NSST, на основании индекса NSST и формирования модифицированных коэффициентов преобразования посредством неразделимого вторичного преобразования коэффициентов преобразования на основании выбранного ядра NSST. Преобразователь определяет набор NSST для целевого блока на основании по меньшей мере одного из режима интра– предсказания и размера целевого блока.
[12] В соответствии с настоящим вариантом осуществления может быть повышена полная эффективность сжатия изображения/видео.
[13] В соответствии с настоящим вариантом осуществления, количество данных, необходимых для остаточной обработки, может быть уменьшено, и эффективность остаточного кодирования может быть повышена за счет эффективного преобразования.
[14] В соответствии с настоящим вариантом осуществления, коэффициенты преобразования, не равные 0, могут быть сконцентрированы на низкочастотном компоненте через вторичное преобразование в частотной области.
[15] В соответствии с настоящим вариантом осуществления, эффективность преобразования может быть повышена посредством применения ядра преобразования переменным/адаптивным образом при выполнении неразделимого вторичного преобразования.
Краткое описание чертежей
[16] Фиг. 1 представляет собой схематичную диаграмму, иллюстрирующую конфигурацию устройства кодирования видео, в котором применяется настоящий вариант осуществления.
[17] Фиг. 2 представляет собой схематичную диаграмму, иллюстрирующую конфигурацию устройства декодирования видео, в котором применяется настоящий вариант осуществления.
[18] Фиг. 3 схематично иллюстрирует схему множественного преобразования в соответствии с настоящим вариантом осуществления.
[19] Фиг. 4 иллюстрирует 65 режимов внутреннего направления режима предсказания.
[20] Фиг. 5 иллюстрирует способ определения набора NSST на основании режима интра–предсказания и размера блока.
[21] Фиг. 6 схематично иллюстрирует пример способа кодирования видео/изображения, включающего в себя способ преобразования в соответствии с настоящим вариантом осуществления.
[22] Фиг. 7 схематично иллюстрирует пример способа декодирования видео/изображения, включающего в себя способ преобразования в соответствии с настоящим вариантом осуществления.
осуществление изобретения
[23] Настоящий вариант осуществления может быть модифицирован в различных формах, и его конкретные примеры будут описаны и проиллюстрированы на чертежах. Однако примеры не предназначены для ограничения варианта осуществления. Термины, применяемые в следующем описании, используются для описания конкретных примеров, но не предназначены для ограничения варианта осуществления. Выражение в единственном числе включает в себя выражение во множественном числе, при условии, что это явно может быть прочитано по–разному. Термины, такие как «включать в себя» и «иметь», предназначены для указания, что существуют признаки, числа, этапы, операции, элементы, компоненты или их сочетания, используемые в следующем описании, и, таким образом, следует понимать, что не исключена возможность существования или добавления одного или более других признаков, чисел, этапов, операций, элементов, компонентов или их сочетаний.
[24] При этом, элементы на чертежах, описанные в варианте осуществления, показаны независимо для удобства при объяснении различных конкретных функций и не означают, что элементы реализуются независимыми аппаратными средствами или независимым программным обеспечением. Например, два или более элементов из таких элементов могут объединяться, образуя один элемент, или один элемент может разделяться на множество элементов. Варианты осуществления, в которых элементы объединены и/или разделены, относятся к варианту осуществления без отклонения от замысла варианта осуществления.
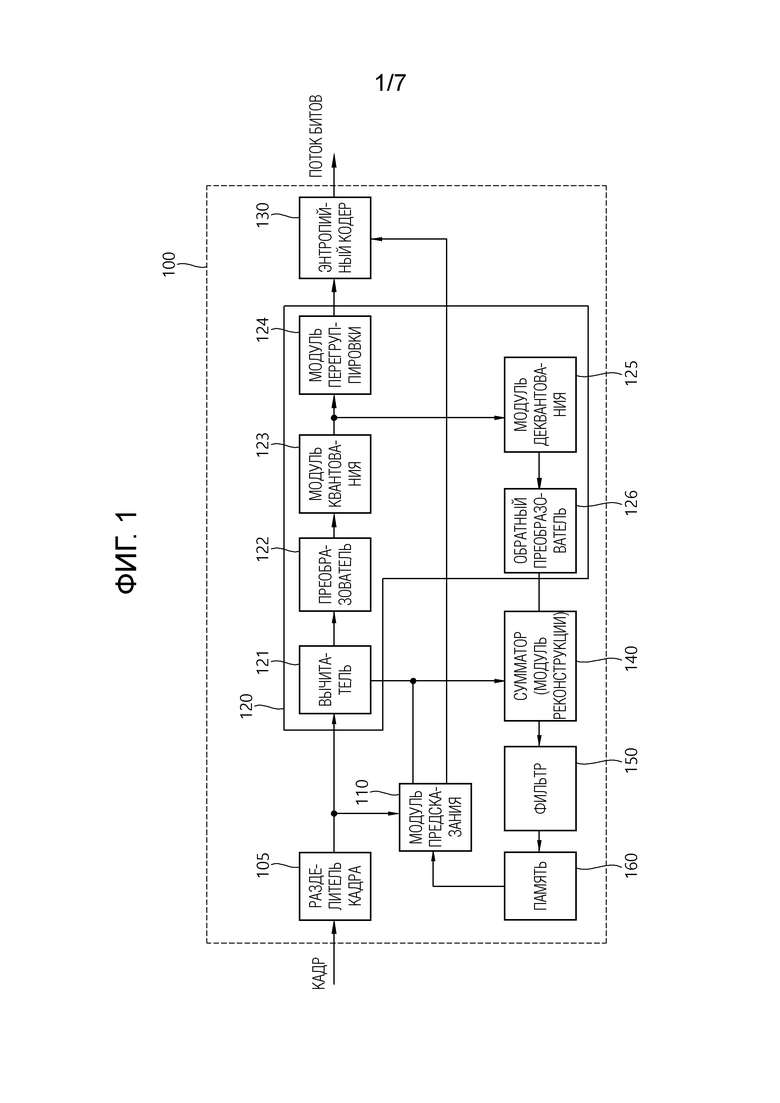
[25] Ниже примеры настоящего варианта осуществления будут подробно описаны с обращением к прилагаемым чертежам. Кроме того, для указания подобных элементов на всех чертежах используются аналогичные ссылочные позиции, и повторное описание подобных элементов не будет приведено.
[26] В настоящем описании термин «кадр» обычно обозначает единицу, представляющую изображение в конкретное время, секция представляет собой единицу, составляющую часть кадра. Один кадр может быть составлена из множества секций, и термины «кадр» и «секция» могут смешиваться друг с другом, если требуют конкретные обстоятельства.
[27] Пиксел или пел (элемент изображения) может означать минимальную единицу, составляющую один кадр (или изображение). Кроме того, «выборка» может использоваться как термин, соответствующий пикселу. Выборка может, в общем, представлять пиксел или значение пиксела, может представлять только пиксел (значение пиксела) компонента яркости и может представлять только пиксел (значение пиксела) компонента цветности.
[28] Единица указывает основную единицу обработки изображения. Единица может включать в себя по меньшей мере одно из конкретной области и информации, связанной с областью. При необходимости, термин «единица» может смешиваться с терминами, такими как блок, область или тому подобное. В обычном случае, блок M×N может представлять набор выборок или коэффициентов преобразования, упорядоченных в M столбцов и N строк.
[29] Фиг. 1 кратко иллюстрирует структуру устройства кодирования видео, в котором применяется настоящий вариант осуществления.
[30] Обращаясь к фиг. 1, устройство 100 кодирования видео может включать в себя модуль 105 разделения кадра, модуль 110 предсказания, модуль 120 остаточной обработки, энтропийный кодер 130, сумматор 140, фильтр 150 и память 160. Модуль 120 остаточной обработки может включать в себя вычитатель 121, преобразователь 122, модуль 123 квантования, модуль 124 перегруппировки, модуль 125 деквантования, обратный преобразователь 126.
[31] Модуль 105 разделения кадра может разделять введенный кадр на по меньшей мере одну единицу обработки.
[32] В одном примере, единица обработки может называться единицей кодирования (CU). В этом случае, единица кодирования может рекурсивно разбиваться от самой большой единицы кодирования (LCU) в соответствии со структурой квадродерева/двоичного дерева (QTBT). Например, одна единица кодирования может быть разбита на множество единиц кодирования большей глубины на основании структуры квадродерева и/или структуры двоичного дерева. В этом случае, например, структура квадродерева может применяться первой, и структура двоичного дерева может применяться позже. В качестве альтернативы, структура двоичного дерева может применяться первой. Процедура кодирования в соответствии с настоящим вариантом осуществления может выполняться на основе конечной единицы кодирования, которая далее не разбивается. В этом случае, наибольшая единица кодирования может использоваться в качестве конечной единицы кодирования на основании эффективности кодирования или тому подобного, в зависимости от характеристик изображения, или единица кодирования может рекурсивно разбиваться на единицы кодирования более низкой глубины при необходимости, и единица кодирования, имеющая оптимальный размер, может использоваться в качестве конечной единицы кодирования. Здесь, процедура кодирования может включать в себя процедуру, такую как предсказание, преобразование и реконструкция, которые будут описаны ниже.
[33] В другом примере, единица обработки может включать в себя единицу кодирования (CU), единицу предсказания (PU) или единицу преобразования (TU). Единица кодирования может разбиваться от наибольшей единицы кодирования (LCU) на единицы кодирования большей глубины в соответствии со структурой квадродерева. В этом случае, наибольшая единица кодирования может непосредственно использоваться в качестве конечной единицы кодирования на основании эффективности кодирования или тому подобного, в зависимости от характеристик изображения, или единица кодирования может рекурсивно разбиваться на единицы кодирования большей глубины при необходимости, и единица кодирования, имеющая оптимальный размер, может использоваться в качестве конечной единицы кодирования. Когда наименьшая единица кодирования (SCU) установлена, единица кодирования может не разбиваться на единицы кодирования меньшие, чем наименьшая единица кодирования. Здесь, конечная единица кодирования относится к единице кодирования, который разделена или разбита на единицу предсказания или единицу преобразования. Единица предсказания представляет собой единицу, которая разделена из единицы кодирования, и может представлять собой единицу предсказания выборки. Здесь, единица предсказания может разделяться на подблоки. Единица преобразования может быть разделена от единицы кодирования в соответствии со структурой квадродерева и может представлять собой единицу для получения коэффициента преобразования и/или единицу для получения остаточного сигнала из коэффициента преобразования. Далее, единица кодирования может упоминаться как блок кодирования (CB), единица предсказания может упоминаться как блок предсказания (PB), и единица преобразования может упоминаться как блок преобразования (TB). Блок предсказания или единица предсказания могут относиться к конкретной области в форме блока в кадре и включать в себя массив выборок предсказания. Также, блок преобразования или единица преобразования могут относиться к конкретной области в форме блока в кадре и включать в себя коэффициент преобразования или массив остаточных выборок.
[34] Модуль 110 предсказания может выполнять предсказание на целевом блоке обработки (далее, текущий блок) и может формировать предсказанный блок, включающий в себя выборки предсказания для текущего блока. Единица предсказания, выполняемого в модуле 110 предсказания, может представлять собой блок кодирования или может представлять собой блок преобразования или может представлять собой блок предсказания.
[35] Модуль 110 предсказания может определять, применяется ли интра–предсказание или применяется межкадровое (интер–) предсказание к текущему блоку. Например, модуль 110 предсказания может определять, следует ли применять интра–предсказание или интер–предсказание в единице CU.
[36] В случае интра–предсказания, модуль 110 предсказания может выводить выборку предсказания для текущего блока на основании опорной выборки вне текущего блока в кадре, которой принадлежит текущий блок (далее, текущий кадр). В этом случае, модуль 110 предсказания может выводить выборку предсказания на основании среднего или интерполяции соседних опорных выборок текущего блока (случай (i)) или может выводить выборку предсказания на основании опорной выборки, существующей в конкретном направлении (предсказания), как выборки предсказания среди соседних опорных выборок текущего блока (случай (ii)). Случай (i) может называться ненаправленным режимом или не–угловым режимом, а случай (ii) может называться направленным режимом или угловым режимом. В интра–предсказании, режимы предсказания могут включать в себя в качестве примера 33 направленных режима и по меньшей мере два ненаправленных режима. Ненаправленные режимы могут включать в себя режим DC и планарный режим. Модуль 110 предсказания может определять режим предсказания, подлежащий применению к текущему блоку, с использованием режима предсказания, применимого к соседнему блоку.
[37] В случае интер–предсказания, модуль 110 предсказания может выводить выборку предсказания для текущего блока на основании выборки, заданной вектором движения в опорном кадре. Модуль 110 предсказания может выводить выборку предсказания для текущего блока путем применения любого одного из режима пропуска, режима объединения и режима предсказания вектора движения (MVP). В случае режима пропуска и режима объединения, модуль 110 предсказания может использовать информацию движения соседнего блока как информацию движения текущего блока. В случае режима пропуска, в отличие от режима объединения, разность (остаток) между выборкой предсказания и исходной выборкой не передается. В случае режима MVP, вектор движения соседнего блока используется в качестве предсказателя вектора движения и, таким образом, используется в качестве предсказателя вектора движения текущего блока, чтобы вывести вектор движения текущего блока.
[38] В случае интер–предсказания, соседний блок может включать в себя пространственный соседний блок, существующий в текущем кадре, и временной соседний блок, существующий в опорном кадре. Опорный кадр, включающий в себя временной соседний блок, может также называться соотнесенным (совмещенным) кадром (colPic). Информация движения может включать в себя вектор движения и индекс опорного кадра. Информация, такая как информация режима предсказания и информация движения, может (энтропийно) кодироваться и затем выводиться в форме потока битов.
[39] Когда информация движения временного соседнего блока используется в режиме пропуска и режиме объединения, в качестве опорного кадра может использоваться самый верхний кадр в списке опорных кадров. Опорные кадры, включенные в список опорных кадров, могут быть выровнены на основании разности счета порядка кадров (POC) между текущим кадром и соответствующим опорным кадром. POC соответствует порядку отображения и может отличаться от порядка кодирования.
[40] Вычитатель 121 формирует остаточную выборку, которая представляет собой разность между исходной выборкой и выборкой предсказания. Если применяется режим пропуска, остаточная выборка может не формироваться, как описано выше.
[41] Преобразователь 122 преобразует остаточные выборки в единицах блока преобразования для формирования коэффициента преобразования. Преобразователь 122 может выполнять преобразование на основании размера соответствующего блока преобразования и режима предсказания, применяемого к блоку кодирования или блоку предсказания, пространственно перекрывающемуся с блоком преобразования. Например, остаточные выборки могут быть преобразованы с использованием ядра преобразования дискретного синусного преобразования (DST), если интра–предсказание применяется к блоку кодирования или блоку предсказания, перекрывающемуся с блоком преобразования, и блок преобразования представляет собой остаточный массив 4×4 и преобразуется с использованием ядра преобразования дискретного косинусного преобразования (DCT) в других случаях.
[42] Модуль 123 квантования может квантовать коэффициенты преобразования для формирования квантованных коэффициентов преобразования.
[43] Модуль 124 перегруппировки перегруппировывает квантованные коэффициенты преобразования. Модуль 124 перегруппировки может перегруппировывать квантованные коэффициенты преобразования в форме блока в одномерный вектор посредством способа сканирования коэффициентов. Хотя модуль 124 перегруппировки описан как отдельный компонент, модуль 124 перегруппировки может представлять собой часть модуля 123 квантования.
[44] Энтропийный кодер 130 может выполнять энтропийное кодирование на квантованных коэффициентах преобразования. Энтропийное кодирование может включать в себя способ кодирования, например, экспоненциальное кодирование Голомба, контекстно–адаптивное кодирование переменной длины (CAVLC), контекстно–адаптивное двоичное арифметическое кодирование (CABAC) или тому подобное. Энтропийный кодер 130 может выполнять энтропийное кодирование или кодирование заданным способом совместно или отдельно на информации (например, значении синтаксического элемента или т.п.), требуемой для реконструкции видео, в дополнение к квантованным коэффициентам преобразования. Энтропийно–кодированная информация может передаваться или сохраняться в единице слоя сетевой абстракции (NAL) в форме потока битов.
[45] Модуль 125 деквантования деквантует (обращенно квантует) значения (коэффициенты преобразования), квантованные модулем 123 квантования, и обратный преобразователь 126 обратно преобразует значения, деквантованные модулем 125 деквантования, чтобы сформировать остаточную выборку.
[46] Сумматор 140 суммирует остаточную выборку с выборкой предсказания, чтобы реконструировать кадр. Остаточная выборка может суммироваться с выборкой предсказания в единицах блока, чтобы сформировать реконструированный блок. Хотя сумматор 140 описан как отдельный компонент, сумматор 140 может представлять собой часть модуля 110 предсказания. При этом сумматор 140 может упоминаться как модуль реконструкции или генератор реконструированных блоков.
[47] Фильтр 150 может применять фильтрацию устранения блочности и/или адаптивное к выборке смещение к реконструированному кадру. Артефакты на границе блока в реконструированном кадре или искажение при квантовании может быть скорректировано посредством фильтрации устранения блочности и/или адаптивного к выборке смещения. Адаптивное к выборке смещение может применяться в единицах выборки после того, как фильтрация устранения блочности завершена. Фильтр 150 может применять адаптивный контурный фильтр (ALF) к реконструированному кадру. ALF может применяться к реконструированному кадру, к которому была применена фильтрация устранения блочности и/или адаптивное к выборке смещение.
[48] Память 160 может хранить реконструированный кадр (декодированный кадр) или информацию, необходимую для кодирования/декодирования. Здесь реконструированный кадр может представлять собой реконструированный кадр, отфильтрованный фильтром 150. Сохраненная реконструированный кадр может использоваться в качестве опорного кадра для (интер–) предсказания других кадров. Например, память 160 может хранить (опорные) кадры, используемые для интер–предсказания. Здесь кадры, используемые для интер–предсказания, могут указываться в соответствии с набором опорных кадров или списком опорных кадров.
[49] Фиг. 2 кратко иллюстрирует структуру устройства декодирования видео, в котором применяется настоящий вариант осуществления.
[50] Обращаясь к фиг. 2, устройство 200 декодирования видео может включать в себя энтропийный декодер 210, модуль 220 остаточной обработки, модуль 230 предсказания, сумматор 240, фильтр 250 и память 260. Модуль 220 остаточной обработки может включать в себя модуль 221 перегруппировки, модуль 222 деквантования, обратный преобразователь 223. Хотя не проиллюстрировано на чертежах, устройство 200 декодирования видео может включать в себя модуль приема для приема потока битов, включающего в себя информацию видео. Модуль приема может быть выполнен в виде отдельного модуля или может быть включен в энтропийный декодер 210.
[51] Когда поток битов, включающий в себя информацию видео, введен, устройство 200 декодирования видео может реконструировать видео в ассоциации с процессом, посредством которого информация видео обрабатывается в устройстве кодирования видео.
[52] Например, устройство 200 декодирования видео может выполнять декодирование видео с использованием модуля обработки, применяемого в устройстве кодирования видео. Таким образом, блок единиц обработки декодирования видео может представлять собой, например, единицу кодирования и, в другом примере, единицу кодирования, единицу предсказания или единицу преобразования. Единица кодирования может разбиваться от наибольшей единицы кодирования в соответствии со структурой квадродерева и/или структурой двоичного дерева.
[53] Единица предсказания и единица преобразования могут дополнительно использоваться в некоторых случаях, и в этом случае, блок предсказания представляет собой блок, полученный или разделенный из единицы кодирования, и может представлять собой единицу предсказания выборки. Здесь, единица предсказания может разделяться на подблоки. Единица преобразования может разбиваться из единицы кодирования в соответствии со структурой квадродерева и может представлять собой единицу, которая выводит коэффициент преобразования, или единицу, которая выводит остаточный сигнал из коэффициента преобразования.
[54] Энтропийный декодер 210 может синтаксически анализировать поток битов, чтобы вывести информацию, требуемую для реконструкции видео или реконструкции кадра. Например, энтропийный декодер 210 может декодировать информацию в потоке битов на основе способа кодирования, такого как экспоненциальное кодирование Голомба, CAVLC, CABAC или т.п., и может выводить значение синтаксического элемента, требуемого для реконструкции видео, и квантованное значение коэффициента преобразования касательно остатка.
[55] Более конкретно, способ энтропийного декодирования CABAC может принимать бин, соответствующий каждому синтаксическому элементу в потоке битов, определять контекстную модель с использованием информации декодирования целевого синтаксического элемента и информации декодирования соседних и декодирования целевых блоков или информации символа/бина, декодированного на предыдущем этапе, предсказывать вероятность формирования бина в соответствии с определенной контекстной моделью и выполнять арифметическое декодирование бина для формирования символа, соответствующего каждому значению синтаксического элемента. Здесь способ энтропийного декодирования CABAC может обновлять контекстную модель с использованием информации символа/бина, декодированного для контекстной модели следующего символа/бина после определения контекстной модели.
[56] Информация о предсказании среди информации, декодированной в энтропийном декодере 210, может быть предоставлена на модуль 250 предсказания, и остаточные значения, то есть квантованные коэффициенты преобразования, на которых энтропийное декодирование было выполнено энтропийным декодером 210, могут вводиться в модуль перегруппировки 221.
[57] Модуль 221 перегруппировки может перегруппировывать квантованные коэффициенты преобразования в форму двумерного блока. Модуль 221 перегруппировки может выполнять перегруппировку, соответствующую сканированию коэффициента, выполняемому устройством кодирования. Хотя модуль 221 перегруппировки описан как отдельный компонент, модуль 221 перегруппировки может представлять собой часть модуля 222 деквантования.
[58] Модуль 222 деквантования может деквантовать квантованные коэффициенты преобразования на основании параметра (де)квантования, чтобы вывести коэффициент преобразования. В этом случае, информация для получения параметра квантования может сигнализироваться из устройства кодирования.
[59] Обратный преобразователь 223 может обратно преобразовывать коэффициенты преобразования, чтобы вывести остаточные выборки.
[60] Модуль 230 предсказания может выполнять предсказание на текущем блоке и может формировать предсказанный блок, включающий в себя выборки предсказания для текущего блока. Единица предсказания, выполняемого в модуле 230 предсказания, может представлять собой блок кодирования или может представлять собой блок преобразования или может представлять собой блок предсказания.
[61] Модуль 230 предсказания может определять, следует ли применять интра–предсказание или интер–предсказание, на основании информации о предсказании. В этом случае, единица для определения того, которое из интра–предсказания и интер–предсказания будет использоваться, может отличаться от единицы для формирования выборки предсказания. Кроме того, единица для формирования выборки предсказания может также отличаться в интер–предсказании и интра–предсказании. Например, то, которое из интер–предсказания и интра–предсказания будет использоваться, может определяться в единице CU. Кроме того, например, при интер–предсказании, выборка предсказания может формироваться путем определения режима предсказания в единице PU, а при интра–предсказании, выборка предсказания может формироваться в единице TU путем определения режима предсказания в единице PU.
[62] В случае интра–предсказания, модуль 230 предсказания может получать выборку предсказания для текущего блока на основании соседней опорной выборки в текущему кадру. Модуль 230 предсказания может получать выборку предсказания для текущего блока путем применения направленного режима или ненаправленного режима на основании соседней опорной выборки текущего блока. В этом случае, режим предсказания, подлежащий применению к текущему блоку, может определяться с использованием режима интра–предсказания соседнего блока.
[63] В случае интер–предсказания, модуль 230 предсказания может получать выборку предсказания для текущего блока на основании выборки, заданной в опорном кадре в соответствии с вектором движения. Модуль 230 предсказания может получать выборку предсказания для текущего блока с использованием одного из режима пропуска, режима объединения и режима MVP. Здесь, информация движения, требуемая для интер–предсказания текущего блока, обеспечиваемая устройством кодирования видео, например, вектор движения и информация об индексе опорного кадра, может быть получена или выведена на основании информации о предсказании.
[64] В режиме пропуска и режиме объединения, информация движения соседнего блока может использоваться в качестве информации движения текущего блока. Здесь, соседний блок может включать в себя пространственный соседний блок и временной соседний блок.
[65] Модуль 230 предсказания может конструировать список кандидатов объединения с использованием информации движения доступных соседних блоков и использовать информацию, указанную индексом объединения на списке кандидатов объединения, в качестве вектора движения текущего блока. Индекс объединения может сигнализироваться устройством кодирования. Информация движения может включать в себя вектор движения и опорный кадр. Когда информация движения временного соседнего блока используется в режиме пропуска и режиме объединения, в качестве опорного кадра может использоваться самый верхний кадр в списке опорных кадров.
[66] В случае режима пропуска, разность (остаток) между выборкой предсказания и исходной выборкой не передается, в отличие от режима объединения.
[67] В случае режима MVP, вектор движения текущего блока может быть выведен с использованием вектора движения соседнего блока в качестве предсказателя вектора движения. Здесь, соседний блок может включать в себя пространственный соседний блок и временной соседний блок.
[68] Когда применяется режим объединения, например, список кандидатов объединения может формироваться с использованием вектора движения реконструированного пространственного соседнего блока и/или вектора движения, соответствующего блоку Col, который представляет собой временной соседний блок. Вектор движения блока–кандидата, выбранного из списка кандидатов объединения, используется в качестве вектора движения текущего блока в режиме объединения. Вышеупомянутая информация о предсказании может включать в себя индекс объединения, указывающий блок–кандидат, имеющий наилучший вектор движения, выбранный из блоков–кандидатов, включенных в список кандидатов объединения. Здесь, модуль 230 предсказания может выводить вектор движения текущего блока с использованием индекса объединения.
[69] Когда применяется режим MVP (предсказание вектора движения) в качестве другого примера, список кандидатов предсказателей вектора движения может формироваться с использованием вектора движения реконструированного пространственного соседнего блока и/или вектора движения, соответствующего блоку Col, который представляет собой временной соседний блок. То есть вектор движения реконструированного пространственного соседнего блока и/или вектор движения, соответствующий блоку Col, который представляет собой временной соседний блок, может использоваться в качестве кандидатов векторов движения. Вышеупомянутая информация о предсказании может включать в себя индекс вектора движения предсказания, указывающий наилучший вектор движения, выбранный из кандидатов векторов движения, включенных в список. Здесь, модуль 230 предсказания может выбирать вектор движения предсказания текущего блока из кандидатов векторов движения, включенных в список кандидатов векторов движения, с использованием индекса вектора движения. Модуль предсказания устройства кодирования может получать разность векторов движения (MVD) между вектором движения текущего блока и предсказателем вектора движения, кодировать MVD и выводить закодированную MVD в форме потока битов. То есть MVD может быть получена посредством вычитания предсказателя вектора движения из вектора движения текущего блока. Здесь модуль 230 предсказания может получать вектор движения, включенный в информацию о предсказании, и выводить вектор движения текущего блока путем суммирования разности векторов движения с предсказателем вектора движения. Кроме того, модуль предсказания может получать или выводить индекс опорного кадра, указывающий опорный кадр, из вышеупомянутой информации о предсказании.
[70] Сумматор 240 может суммировать остаточную выборку с выборкой предсказания, чтобы реконструировать текущий блок или текущий кадр. Сумматор 240 может реконструировать текущий кадр путем суммирования остаточной выборки с выборкой предсказания в единицах блока. Когда применяется режим пропуска, остаток не передается, и таким образом выборка предсказания может становиться реконструированной выборкой. Хотя сумматор 240 описан как отдельный компонент, сумматор 240 может представлять собой часть модуля 230 предсказания. При этом сумматор 240 может упоминаться как модуль реконструкции или генератор реконструированных блоков.
[71] Фильтр 250 может применять фильтрацию устранения блочности, адаптивное к выборке смещение и/или ALF к реконструированному кадру. Здесь адаптивное к выборке смещение может применяться в единицах выборки после фильтрации устранения блочности. ALF может применяться после фильтрации устранения блочности и/или применения адаптивного к выборке смещения.
[72] Память 260 может хранить реконструированный кадр (декодированный кадр) или информацию, необходимую для декодирования. Здесь реконструированный кадр может представлять собой реконструированный кадр, отфильтрованный фильтром 250. Например, память 260 может хранить кадры, используемые для интер–предсказания. Здесь кадры, используемые для интер–предсказания, могут указываться в соответствии с набором опорных кадров или списком опорных кадров. Реконструированный кадр может использоваться в качестве опорного кадра для других кадров. Память 260 может выводить реконструированные кадры в порядке вывода.
[73] Таким образом, как описано выше, при выполнении кодирования видео, предсказание выполняется, чтобы повысить эффективность сжатия. Соответственно, может формироваться предсказанный блок, включающий в себя выборки предсказания для текущего блока, то есть целевого блока кодирования. В этом случае, предсказанный блок включает в себя выборки предсказания в пространственной области (или пиксельной области). Предсказанный блок идентичным образом выводится в устройстве кодирования и устройстве декодирования. Устройство кодирования может повысить эффективность кодирования изображений путем сигнализации остаточной информации об остатке между исходным блоком и предсказанным блоком, а не значения исходной выборки самого исходного блока на устройство декодирования. Устройство декодирования может выводить остаточный блок, включающий в себя остаточные выборки, на основании остаточной информации, может формировать реконструированный блок, включающий в себя реконструированные выборки, путем суммирования остаточного блока и предсказанного блока и может формировать реконструированный кадр, включающий в себя реконструированные блоки.
[74] Остаточная информация может формироваться посредством процедуры преобразования и квантования. Например, устройство кодирования может выводить остаточный блок между исходным блоком и предсказанным блоком, может выводить коэффициенты преобразования путем выполнения процедуры преобразования на остаточных выборках (массиве остаточных выборок), включенных в остаточный блок, может выводить квантованные коэффициенты преобразования путем выполнения процедуры квантования на коэффициентах преобразования и может сигнализировать связанную остаточную информацию на устройство декодирования (через поток битов). В этом случае, остаточная информация может включать в себя информацию, такую как информация значения, информация местоположения, схема преобразования, ядро преобразования и параметр квантования квантованных коэффициентов преобразования. Устройство декодирования может выполнять процедуру деквантования/обратного преобразования на основании остаточной информации и может выводить остаточные выборки (или остаточный блок). Устройство декодирования может формировать кадр реконструкции на основании предсказанного блока и остаточного блока. Устройство кодирования может также выводить остаточный блок путем выполнения деквантования/обратного преобразования на квантованных коэффициентах преобразования для опоры при интер–предсказании последующего кадра и может формировать реконструированный кадр на основании остаточного блока.
[75] Таким образом, в соответствии с настоящим вариантом осуществления, схема множественного преобразования может применяться при выполнении вышеописанного преобразования.
[76] Фиг. 3 схематично иллюстрирует схему множественного преобразования в соответствии с настоящим вариантом осуществления.
[77] Обращаясь к фиг. 3, преобразователь может соответствовать преобразователю устройства кодирования согласно фиг. 1. Обратный преобразователь может соответствовать обратному преобразователю устройства кодирования согласно фиг. 1 или обратному преобразователю устройства декодирования согласно фиг. 2.
[78] Преобразователь может выводить коэффициенты (первичного) преобразования путем выполнения первичного преобразования на основании остаточных выборок (массива остаточных выборок) в остаточном блоке (S310). В этом случае, первичное преобразование может включать в себя адаптивное многоядерное преобразование.
[79] Адаптивное многоядерное преобразование может указывать способ выполнения преобразования дополнительно с использованием дискретного косинусного преобразования (DCT) Типа 2, дискретного синусного преобразования (DST) Типа 7, DCT Типа 8 и/или DST Типа 1. То есть многоядерное преобразование может указывать способ преобразования для преобразования остаточного сигнала (или остаточного блока) пространственной области в коэффициенты преобразования (или коэффициенты первичного преобразования) частотной области на основании множества ядер преобразования, выбранных среди DCT Типа 2, DST Типа 7, DCT Типа 8 и DST Типа 1. В этом случае, коэффициенты первичного преобразования могут называться коэффициентами временного преобразования с точки зрения преобразователя.
[80] Другими словами, если применяется существующий способ преобразования, коэффициенты преобразования могут формироваться путем применения преобразования из пространственной области для остаточного сигнала (или остаточного блока) в частотную область на основании DCT Типа 2. Напротив, если применяется адаптивное многоядерное преобразование, коэффициенты преобразования (или коэффициенты первичного преобразования) могут формироваться путем применения преобразования из пространственной области для остаточного сигнала (или остаточного блока) в частотную область на основании DCT Типа 2, DST Типа 7, DCT Типа 8 и/или DST Типа 1. В этом случае, DCT Типа 2, DST Типа 7, DCT Типа 8 и DST Типа 1 могут называться типом преобразования, ядром преобразования или ядром (базой) преобразования.
[81] В качестве справочной информации, типы преобразования DCT/DST могут определяться на основании базовых функций. Базовые функции могут быть представлены как описано ниже.
[82] Таблица 1

[83] Если выполняется адаптивное многоядерное преобразование, ядро вертикального преобразования и ядро горизонтального преобразования для целевого блока могут выбираться среди ядер преобразования. Вертикальное преобразование для целевого блока может выполняться на основании ядра вертикального преобразования. Горизонтальное преобразование для целевого блока может выполняться на основании ядра горизонтального преобразования. В этом случае, горизонтальное преобразование может указывать преобразование для горизонтальных компонентов целевого блока. Вертикальное преобразование может указывать преобразование для вертикальных компонентов целевого блока. Ядро вертикального преобразования/ядро горизонтального преобразования могут адаптивно определяться на основании режима предсказания целевого блока (CU или подблока), заключающего остаточный блок, и/или индекса преобразования, указывающего поднабор преобразований.
[84] Преобразователь может выводить коэффициенты (вторичного) преобразования путем выполнения вторичного преобразования на основании коэффициентов (первичного) преобразования (S320). Если первичное преобразование представляло собой преобразование из пространственной области в частотную область, вторичное преобразование может рассматриваться как представляющее собой преобразование из частотной области в частотную область. Вторичное преобразование может включать в себя неразделимое преобразование. В этом случае, вторичное преобразование может называться неразделимым вторичным преобразованием (NSST). Неразделимое вторичное преобразование может указывать преобразование для формирования коэффициентов преобразования (или коэффициентов вторичного преобразования) для остаточного сигнала путем выполнения вторичного преобразования на коэффициентах (первичного) преобразования, выведенных через первичное преобразование, на основании матрицы неразделимого преобразования. В этом случае, вертикальное преобразование и горизонтальное преобразование разделено (или горизонтальное и вертикальное преобразование независимо) не применяются, но преобразования могут применяться к коэффициентам (первичного) преобразования сразу на основании матрицы неразделимого преобразования. Другими словами, неразделимое вторичное преобразование может указывать способ преобразования формирования коэффициентов преобразования (или коэффициентов вторичного преобразования) путем выполнения преобразований без разделения вертикальных компонентов и горизонтальных компонентов коэффициентов (первичного) преобразования на основании матрицы неразделимого преобразования. Неразделимое вторичное преобразование может применяться к верхней левой области блока (может далее называться блоком коэффициентов преобразования), конфигурированного посредством коэффициентов (первичного) преобразования. Например, если каждое из ширины (W) и высоты (H) блока коэффициента преобразования равно 8 или более, неразделимое вторичное преобразование 8×8 может применяться к верхней левой области 8×8 блока коэффициентов преобразования. Более того, если каждое из ширины (W) или высоты (H) блока коэффициентов преобразования меньше 8, неразделимое вторичное преобразование 4×4 может применяться к верхней левой области min(8,W)×min(8,H) блока коэффициентов преобразования.
[85] Конкретно, например, если используется входной блок 4×4, неразделимое вторичное преобразование может выполняться как описано далее.
[86] Входной блок X 4×4 может быть представлен, как описано далее.
[87] Уравнение 1

[88] Если X указано в виде вектора, вектор  может быть представлен, как описано далее.
может быть представлен, как описано далее.
[89] Уравнение 2

[90] В этом случае, вторичное неразделимое преобразование может вычисляться, как описано далее.
[91] Уравнение 3

[92] В этом случае,  указывает вектор коэффициента преобразования, и T указывает матрицу (неразделимого) преобразования 16×16.
указывает вектор коэффициента преобразования, и T указывает матрицу (неразделимого) преобразования 16×16.
[93] Вектор коэффициента преобразования 16×1 может выводиться посредством уравнения 3. может быть перегруппирован в блок 4×4 через порядок (горизонтальный, вертикальный, диагональный) сканирования. Однако, в приведенном выше вычислении, например, преобразование Гивенса гиперкуба (HyGT) может использоваться для вычисления неразделимого вторичного преобразования, чтобы уменьшить вычислительную нагрузку неразделимого вторичного преобразования.
[94] При этом, в неразделимом вторичном преобразовании ядро преобразования (или ядро (база) преобразования или тип преобразования) может выбираться на основании режима (в зависимости от режима). В этом случае, режим может включать в себя режим интра–предсказания и/или режим интер–предсказания.
[95] Как описано выше, неразделимое вторичное преобразование может выполняться на основании преобразования 8×8 или преобразования 4×4, определенного на основании ширины (W) и высоты (H) блока коэффициентов преобразования. То есть неразделимое вторичное преобразование может выполняться на основании размера подблока 8×8 или размера подблока 4×4. Например, чтобы выбрать ядро преобразования на основании режима, 35 наборов ядер неразделимого вторичного преобразования, причем каждый набор имеет три ядра для неразделимого вторичного преобразования, могут быть конфигурированы для размера подблока 8×8 и размера подблока 4×4. То есть 35 наборов преобразований могут быть конфигурированы для размера подблока 8×8, и 35 наборов преобразований могут быть конфигурированы для размера подблока 4×4. В этом случае, три ядра преобразования 8×8 могут быть включены в каждый из 35 наборов преобразований для размера подблока 8×8. В этом случае, три ядра преобразования 4×4 могут быть включены в каждый из 35 наборов преобразований для размера подблока 4×4. Однако размер подблока преобразования, число наборов и число ядер преобразования в наборе являются примерами, и может использоваться размер, отличный от 8×8 или 4×4, или может быть конфигурировано n наборов, и в каждый набор могут быть включены k ядер преобразования.
[96] Набор преобразований может называться набором NSST. Ядро преобразования в наборе NSST может называться ядром NSST. Выбор конкретного набора из наборов преобразований может выполняться, например, на основании режима интра–предсказания целевого блока (CU или подблока).
[97] В качестве справочной информации, например, режим интра–предсказания может включать в себя два ненаправленных (или не–угловых) режима интра–предсказания и 65 направленных (или угловых) режимов интра–предсказания. Ненаправленный режим интра–предсказания может включать в себя режим интра–предсказания № 0 (планарный) и режим интра–предсказания № 1 DC. Направленные режимы интра–предсказания могут включать в себя шестьдесят пять режимов интра–предсказания от № 2 до № 66. Однако они представляют собой примеры, и настоящий вариант осуществления может применяться к случаю, где число режимов интра–предсказания отличается. При этом в некоторых случаях, может дополнительно использоваться режим интра–предсказания № 67. Режим интра–предсказания № 67 может указывать режим линейной модели (LM).
[98] Фиг. 4 иллюстрирует 65 режимов внутренних направлений режима предсказания.
[99] Обращаясь к фиг. 4, режимы могут разделяться на режимы интра–предсказания, имеющие горизонтальную направленность, и режимы интра–предсказания, имеющие вертикальную направленность, на основании режима интра–предсказания № 34, имеющего диагональное направление предсказания влево вверх. На фиг. 3, H и V обозначают горизонтальную направленность и вертикальную направленность, соответственно, и числа –32 ~ 32 указывают смещение на 1/32 единицы по местоположению сетки выборок. Режимы интра–предсказания от № 2 до № 3 интра–предсказания имеют горизонтальную направленность, и режимы интра–предсказания от № 34 до № 66 имеют вертикальную направленность. Режим интра–предсказания № 18 и режим интра–предсказания № 50 указывают режим горизонтального интра–предсказания и режим вертикального интра–предсказания, соответственно. Режим интра–предсказания № 2 может называться режимом диагонального интра–предсказания в направлении влево вниз, режим интра–предсказания № 34 может называться режимом диагонального интра–предсказания в направлении влево вверх, и режим интра–предсказания № 66 может называться режимом диагонального интра–предсказания в направлении вправо вверх.
[100] В этом случае, отображение между 35 наборами преобразований и режимами интра–предсказания может быть указано, например, как в следующей таблице. В качестве справочной информации, если режим LM применяется к целевому блоку, вторичное преобразование может не применяться к целевому блоку.
[101] Таблица 2

[102] При этом, если конкретный набор определяется как подлежащий использованию, одно из трех ядер преобразования в конкретном наборе может выбираться на основании индекса NSST. Устройство кодирования может выводить индекс NSST, указывающий конкретное ядро преобразования, на основании проверки скорости–искажения (RD). Индекс NSST может сигнализироваться на устройство декодирования. Устройство декодирования может выбирать одно из трех ядер преобразования в конкретном наборе на основании индекса NSST. Например, значение 0 индекса NSST может указывать первое ядро NSST, значение 1 индекса NSST может указывать второе ядро NSST, и значение 2 индекса NSST может указывать третье ядро NSST. В качестве альтернативы, значение 0 индекса NSST может указывать, что NSST не применяется к целевому блоку. Значения 1–3 индекса NSST могут указывать три ядра преобразования.
[103] Возвращаясь к фиг. 3, преобразователь может выполнять неразделимое вторичное преобразование на основании выбранного ядра преобразования и может получать коэффициенты (вторичного) преобразования. Коэффициенты (вторичного) преобразования могут выводиться как квантованные коэффициенты преобразования через единицу квантования, как описано выше, могут кодироваться и сигнализироваться на устройство декодирования и могут передаваться на деквантование/обратный преобразователь устройства кодирования.
[104] Обратный преобразователь может выполнять последовательность процедур в обратном порядке процедур, выполняемых в преобразователе. Обратный преобразователь может принимать (деквантованные) коэффициенты (вторичного) преобразования, может выводить коэффициенты (первичного) преобразования путем выполнения вторичного преобразования (S350) и может получать остаточный блок (остаточные выборки) путем выполнения первичного преобразования на коэффициентах (первичного) преобразования. В этом случае, коэффициенты первичного преобразования могут называться коэффициентами преобразования, модифицированными с точки зрения обратного преобразователя. Устройство кодирования и устройство декодирования могут формировать блок реконструкции на основании остаточного блока и предсказанного блока и формировать реконструированный кадр на основании реконструированного блока, как описано выше.
[105] При этом, размер ядра преобразования (ядра NSST) для неразделимого вторичного преобразования может быть фиксирован или может не быть фиксирован, и ядро преобразования (ядро NSST) может быть конфигурировано вместе с ядрами преобразования, имеющими разные размеры в пределах одного набора.
[106] Например, набор NSST 4×4 включает в себя только ядра NSST 4×4, и набор NSST 8×8 включает в себя только ядра NSST 8×8 в зависимости от размера целевого блока (или подблока или блока коэффициента преобразования).
[107] В качестве другого примера, смешанный набор NSST может быть конфигурирован, как описано далее. Смешанный набор NSST может включать в себя ядра NSST, имеющие разные размеры. Например, смешанный набор NSST может включать в себя ядро NSST 4×4 в дополнение к ядру NSST 8×8. Набор NSST, включающий в себя только ядра NSST 8×8 или ядра NSST 4×4, по сравнению со смешанным набором NSST, может называться несмешанным набором NSST.
[108] Число ядер NSST, включенных в смешанный набор NSST, может быть фиксировано или может меняться. Например, набор NSST #1 может включать в себя 3 ядра NSST, и набор NSST #2 может включать в себя 4 ядра NSST. Более того, последовательность ядер NSST, включенных в смешанный набор NSST, может не быть фиксирована и может определяться по–разному в зависимости от набора NSST. Например, в наборе NSST #1, ядра 1, 2 и 3 NSST могут отображаться как соответственные индексы 1, 2 и 3 NSST. В наборе NSST #2, ядра 3, 2 и 1 NSST могут отображаться как соответственные индексы 1, 2 и 3 NSST.
[109] Конкретно, определение приоритета ядер NSST, доступных в наборе NSST, может быть основано на размере (например, ядро NSST 8×8 или ядро NSST 4×4) ядер NSST. Например, если соответствующий целевой блок имеет данный размер или более, ядро NSST 8×8 может иметь более высокий приоритет, чем ядро NSST 4×4. В этом случае, индекс NSST, имеющий меньшее значение, может предпочтительно назначаться ядру NSST 8×8.
[110] Более того, определение приоритета ядер NSST, доступных в наборе NSST, может быть основано на последовательности (1–го, 2–го и 3–го) ядер NSST. Например, 1–ое ядро NSST 4×4 может иметь более высокий приоритет, чем 2–ое ядро NSST 4×4.
[111] Конкретно, например, отображение ядер NSST и индексов NSST в наборе NSST может включать в себя варианты осуществления, раскрытые в таблице 3 или 4.
[112] Таблица 3
NSST
[113] Таблица 4
NSST
NSST Типа 1
NSST Типа 2
[114] То, используется ли смешанный набор NSST, может быть указано различными способами. Например, то, используется ли смешанный набор NSST, может быть определено на основании интра–предсказания целевого блока (или CU, включающего в себя целевой блок) и/или размера целевого блока.
[115] Например, используется ли смешанный набор NSST, может быть определено на основании режима интра–предсказания целевого блока. Другими словами, используется ли смешанный набор NSST на основании режима интра–предсказания или используется ли отдельный набор NSST на основании размера подблока, может быть предварительно определено. Соответственно, набор NSST, подходящий для текущего целевого блока, может быть определен, и надлежащее ядро NSST может применяться. Например, используется ли смешанный набор NSST, может быть указано, как в следующей таблице, в зависимости от режима интра–предсказания.
[116] Таблица 5

[117] В этом случае, информация о смешанном типе указывает, применяется ли смешанный набор NSST к целевому блоку, на основании режима интра–предсказания. Это может использоваться в ассоциации со способом, раскрытым в таблице 2. Например, информация о смешанном типе может указывать, будет ли несмешанный набор NSST отображаться и использоваться для каждого режима интра–предсказания, или будет ли конфигурирован и использован смешанный набор NSST, как описано выше в таблице 2. Конкретно, если значение информации о смешанном типе равно 1, вместо несмешанного набора NSST может быть конфигурирован и использован смешанный набор NSST, определенный в системе. В этом случае, смешанный набор NSST, определенный в системе, может указывать смешанный набор NSST. Если значение информации о смешанном типе равно 0, несмешанный набор NSST может использоваться на основании режима интра–предсказания. Информация о смешанном типе может называться меткой смешанного типа, указывающей, используется ли смешанный набор NSST. В соответствии с настоящим вариантом осуществления, два типа наборов NSST (несмешанный набор NSST и смешанный набор NSST) могут использоваться адаптивным/переменным образом на основании метки смешанного типа.
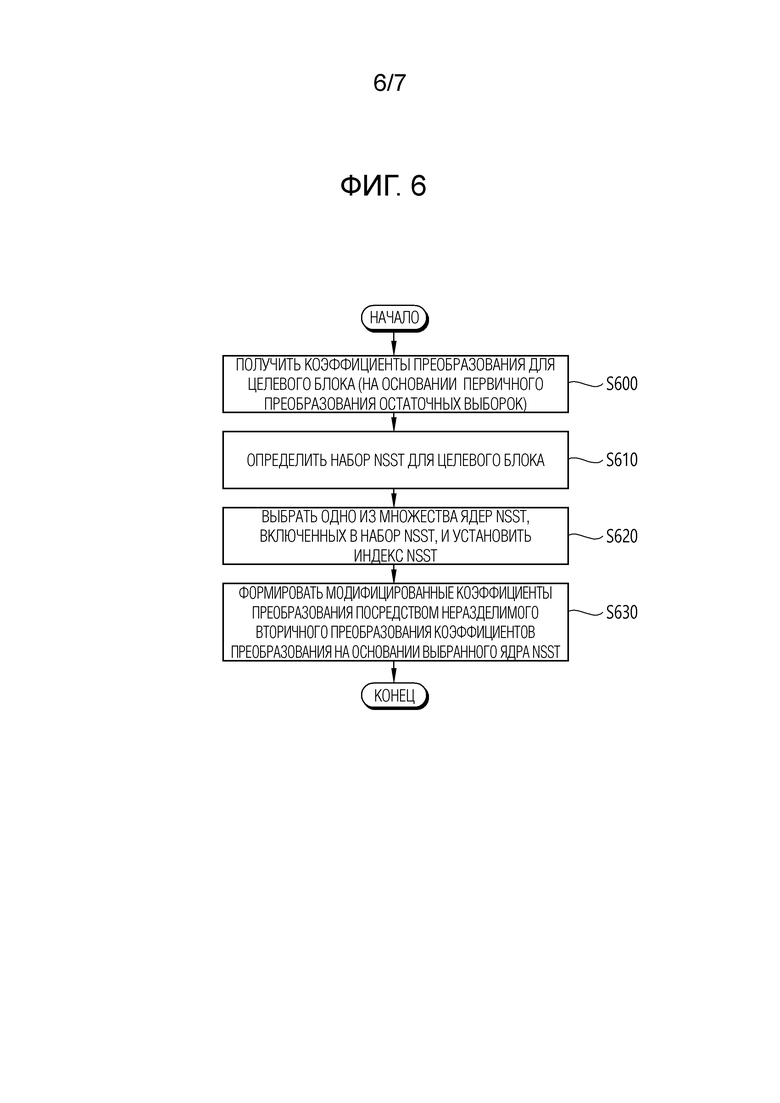
[118] При этом могут быть конфигурированы два или более смешанных наборов NSST. В этом случае, информация о смешанном типе может быть указана как N (N может больше или равно 2) типов различных значений. В этом случае, информация о смешанном типе может называться индексом смешанного типа.
[119] Для другого примера, используется ли смешанный набор NSST, может определяться с учетом режима интра–предсказания, ассоциированного с целевым блоком, и размера целевого блока одновременно. Целевой блок может определяться различными терминами, такими как подблок, блок преобразования и блок коэффициентов преобразования.
[120] Например, вместо информации о смешанном типе может быть конфигурирована информация типа режима. Если значение информации типа режима, соответствующей режиму интра–предсказания, равно 0, набором может быть несмешанный набор NSST. Если нет (например, значение информации типа режима равно 1), различные смешанные наборы NSST могут быть определены на основании размера соответствующего целевого блока. Например, если внутренний режим представляет собой ненаправленный режим (планарный или DC), то может использоваться смешанный NSST. Если внутренний режим представляет собой направленный режим, то может использоваться несмешанный набор NSST.
[121] Фиг. 5 иллюстрирует способ определения набора NSST на основании режима интра–предсказания и размера блока.
[122] Обращаясь к фиг. 5, устройство кодирования (устройство кодирования и/или устройство декодирования) выводит коэффициенты (вторичного) преобразования путем обратного преобразования (квантованных) коэффициентов преобразования (S540) и выводит коэффициенты (первичного) преобразования путем вторичного (обратного) преобразования коэффициентов (вторичного) преобразования (S550). В этом случае, коэффициенты (вторичного) преобразования могут называться коэффициентами временного преобразования, и коэффициенты (первичного) преобразования могут называться модифицированными коэффициентами преобразования. В этом случае, вторичное преобразование может включать в себя неразделимое вторичное преобразование. Неразделимое вторичное преобразование выполняется на основании ядра NSST. Ядро NSST может выбираться из набора NSST. В этом случае, ядро NSST может быть указано из набора NSST на основании информации индекса NSST.
[123] Устройство кодирования может выбирать набор NSST среди кандидатов наборов NSST на основании режима интра–предсказания и размера блока (S545). Например, кандидаты наборов NSST могут включать в себя по меньшей мере один несмешанный набор NSST и по меньшей мере один смешанный набор NSST. Например, кандидаты наборов NSST могут включать в себя по меньшей мере один из набора NSST 8×8 (несмешанного набора 1 NSST), включающего в себя только ядра NSST 8×8, и набора NSST 4×4 (несмешанного набора 2 NSST), включающего в себя только ядра NSST 4×4, и может включать в себя один или более смешанных наборов NSST. В этом случае, например, устройство кодирования может определять конкретный набор NSST из кандидатов наборов NSST на основании того, является ли каждое из ширины (W) и высоты (H) целевого блока равным 8 или более, и на основании номера текущего режима интра–предсказания. Конкретное ядро NSST может быть указано из конкретного набора NSST через информацию индекса NSST, как описано выше.
[124] При этом, индекс NSST может быть бинаризован с использованием различных способов для эффективности кодирования. В этом случае, значение бинаризации может быть эффективно установлено с учетом изменения в статистическом распределении значений индекса NSST, которые кодируются и передаются. То есть в этом случае ядро, подлежащее действительному применению, может выбираться на основании синтаксиса, указывающего размер ядра.
[125] Как описано выше, в соответствии с настоящим вариантом осуществления, число ядер NSST, включенных в каждый набор преобразования (набор NSST) может отличаться. Для эффективного способа бинаризации, бинаризация переменной длины может выполняться на основании усеченной унарной (TU) схемой, как в следующей таблице на основании максимального значения индекса NSST, доступного для каждого набора NSST.
[126] Таблица 6
[127] В этом случае, бинаризованные значения "0" или "1" могут называться бинами. В этом случае, каждый из бинов может кодироваться на основании контекста посредством CABAC/CAVLC. В этом случае, значение контекстного моделирования может определяться на основании по меньшей мере одного из размера целевого блока (подблока, блока преобразования или блока коэффициента преобразования), режима интра–предсказания, значения информации о смешанном типе (информации о смешанном режиме) или максимального значения индекса NSST соответствующего набора NSST. В этом случае, контекстная модель может быть указана на основании контекстного индекса. Контекстный индекс может быть указан как сумма контекстного смещения и контекстного приращения.
[128] Фиг. 6 схематично иллюстрирует пример способа кодирования видео/изображений, включающего в себя способ преобразования в соответствии с настоящим вариантом осуществления. Способ, раскрытый на фиг. 6, может выполняться устройством кодирования, раскрытым на фиг. 1. Конкретно, например, этапы от S600 до S630 на фиг. 6 могут выполняться преобразователем устройства кодирования.
[129] Обращаясь к фиг. 6, устройство кодирования получает коэффициенты преобразования для целевого блока (S600). Устройство кодирования может получать остаточные выборки для целевого блока посредством сравнения между исходным блоком и предсказанным блоком и может получать коэффициенты преобразования для целевого блока посредством первичного преобразования остаточных выборок. Первичное преобразование включает в себя процедуру преобразования остаточных выборок в пространственной области в коэффициенты преобразования в частотной области. В этом случае, целевой блок может включать подблок, блок преобразования или блок коэффициентов преобразования в CU.
[130] Устройство кодирования определяет набор NSST для целевого блока (S610). Набор NSST может включать в себя ядро NSST, используемое для вторичного преобразования. Вторичное преобразование включает в себя неразделимое вторичное преобразование. Набор NSST для целевого блока может быть определен на основании по меньшей мере одного из режима интра–предсказания и размера целевого блока.
[131] Набор NSST может включать в себя ядра NSST 8×8 или ядра NSST 4×4. В этом случае, набор NSST может называться несмешанным набором NSST. То, включает ли в себя набор NSST ядра NSST 8×8 или включает ли в себя ядра NSST 4×4, может быть определено на основании размера целевого блока, как описано выше.
[132] В качестве альтернативы, набор NSST может представлять собой смешанный набор NSST, включающий в себя ядро NSST 4×4 и ядро NSST 8×8. В этом случае, значение индекса, назначенное ядру NSST 8×8, может быть меньшем значения индекса, назначенного ядру NSST 4×4. Например, если размер целевого блока больше заданного опорного размерп, значение индекса, назначенное ядру NSST 8×8, может быть меньше значения индекса, назначенного ядру NSST 4×4. В качестве альтернативы, в противоположность этому, значение индекса, назначенное ядру NSST 4×4, может быть меньше значения индекса, назначенного ядру NSST 8×8.
[133] Набор NSST может включать в себя множество ядер NSST. Число ядер NSST может быть установлено переменным. Например, число ядер NSST, включенных в первый набор NSST, может отличаться от числа ядер NSST, включенных во второй набор NSST.
[134] При этом, то, используется ли несмешанный набор NSST или используется ли смешанный набор NSST в качестве набора NSST для целевого блока, может быть указано на основании информации о смешанном типе или информации о смешанном режиме.
[135] Например, если значение информации о смешанном типе равно 0, то может использоваться несмешанный набор NSST, включающий в себя ядра NSST 8×8 или ядра NSST 4×4. Если значение информации о смешанном типе не равно 0, то может использоваться смешанный набор NSST, включающий в себя ядро NSST 4×4 и ядро NSST 8×8. Если доступно множество смешанных наборов NSST, один из множества смешанных наборов NSST может быть указан на основании значения 1, 2 и т.д. информации о смешанном типе.
[136] Набор NSST для целевого блока может определяться на основании как режима интра–предсказания, так и размера целевого блока. Режим интра–предсказания может представлять собой один из 67 (68, если включен режим LM) режимов интра–предсказания, включая, например, режим LM. Режим интра–предсказания может представлять собой режим предсказания, ассоциированный с целевым блоком, или может представлять собой режим интра–предсказания, конфигурированный в CU, пространственно охватывающем целевой блок или его подблок.
[137] Устройство кодирования выбирает одно из множества ядер NSST, включенных в набор NSST, и устанавливает индекс NSST (S620). Устройство кодирования может выбирать одно из множества ядер NSST, включенных в набор NSST, через повторения вычисления на основании стоимости RD. Устройство кодирования может устанавливать индекс NSST в качестве значения, указывающего выбранное ядро NSST.
[138] Устройство кодирования формирует модифицированные коэффициенты преобразования посредством неразделимого вторичного преобразования коэффициентов преобразования на основании выбранного ядра NSST (S630). Устройство кодирования может кодировать и выводить модифицированные коэффициенты преобразования в соответствии с определенной процедурой. В этом случае, по меньшей мере одно из информации о смешанном типе, информации о смешанном режиме и информации об индексе NSST может кодироваться, как описано далее. Устройство кодирования может выводить закодированную информацию в форме потока битов. Поток битов может передаваться на устройство декодирования по сети или через носитель хранения.
[139] Если информация об индексе NSST закодирована, значение индекса NSST может быть бинаризовано с переменной длиной. В этом случае, например, как раскрыто в таблице 6, значение индекса NSST может быть бинаризовано в соответствии с усеченной унарной (TU) схемой. При этом, значение индекса NSST может быть закодировано на основании контекста, например, как CABAC или CAVLC. В этом случае, контекстная модель может быть определена на основании по меньшей мере одного из размера целевого блока, режима интра–предсказания, значения информации о смешанном типе и максимального значения индекса в наборе NSST.
[140] Фиг. 7 схематично иллюстрирует пример способа кодирования видео/изображений, включающего в себя способ преобразования в соответствии с настоящим вариантом осуществления. Способ, раскрытый на фиг. 7, может выполняться устройством декодирования, раскрытым на фиг. 2. Конкретно, например, на фиг. 7, S700 может выполняться модулем деквантования устройства декодирования, и этапы от S710 до S730 могут выполняться обратным преобразователем устройства декодирования. Между тем, в настоящем варианте осуществления в основном описано устройство декодирования, но способ, раскрытый на фиг. 7, может идентичным образом выполняться в модуле деквантования и обратном преобразователе устройства кодирования.
[141] Обращаясь к фиг. 7, устройство декодирования получает коэффициенты преобразования для целевого блока (S700). Устройство декодирования может получать коэффициенты преобразования путем деквантования квантованных коэффициентов преобразования для целевого блока, полученных из информации, принятой через поток битов. В этом случае, целевой блок может включать подблок, блок преобразования или блок коэффициента преобразования в CU.
[142] Устройство декодирования определяет набор NSST для целевого блока (S710). Набор NSST может включать в себя ядро NSST для вторичного преобразования. Вторичное преобразование включает в себя неразделимое вторичное преобразование. Набор NSST для целевого блока может определяться на основании по меньшей мере одного из режима интра–предсказания и размера целевого блока.
[143] Набор NSST может включать в себя ядра NSST 8×8 или ядра NSST 4×4. В этом случае, набор NSST может называться несмешанным набором NSST. То, включает ли в себя набор NSST ядра NSST 8×8 или включает в себя ядра NSST 4×4, может определяться на основании размера целевого блока, как описано выше.
[144] В качестве альтернативы, набор NSST может представлять собой смешанный набор NSST, включающий в себя ядро NSST 4×4 и ядро NSST 8×8. В этом случае, значение индекса, назначенное ядру NSST 8×8, может быть меньше значения индекса, назначенного ядру NSST 4×4. Например, если размер целевого блока больше заданного опорного размера, значение индекса, назначенное ядру NSST 8×8, может быть меньше значения индекса, назначенного ядру NSST 4×4. В качестве альтернативы, в противоположность этому, значение индекса, назначенное ядру NSST 4×4, может быть меньше значения индекса, назначенного ядру NSST 8×8.
[145] Набор NSST может включать в себя множество ядер NSST. Число ядер NSST может быть установлено переменным. Например, число ядер NSST, включенных в первый набор NSST, может отличаться от числа ядер NSST, включенных во второй набор NSST.
[146] При этом, то, используется ли несмешанный набор NSST или используется ли смешанный набор NSST в качестве набора NSST для целевого блока, может определяться на основании информации о смешанном типе или информации о смешанном режиме.
[147] Например, если значение информации о смешанном типе равно 0, то может использоваться несмешанный набор NSST, включающий в себя ядра NSST 8×8 или ядра NSST 4×4. Если значение информации о смешанном типе не равно 0, то может использоваться смешанный набор NSST, включающий в себя ядро NSST 4×4 и ядро NSST 8×8. Если доступно множество смешанных наборов NSST, один из множества смешанных наборов NSST может быть указан на основании значения 1, 2 и т.д. информации о смешанном типе.
[148] Набор NSST для целевого блока может определяться на основании как режима интра–предсказания, так и размера целевого блока. Режим интра–предсказания может представлять собой, например, один из 67 (68, если включен режим LM) режимов интра–предсказания. Режим интра–предсказания может представлять собой режим предсказания, ассоциированный с целевым блоком, или может представлять собой режим интра–предсказания, конфигурированный в CU, пространственно охватывающем целевой блок или его подблок.
[149] Устройство декодирования выбирает одно из множества ядер NSST, включенных в набор NSST, на основании индекса NSST (S720). Индекс NSST может быть получен через поток битов. Устройство декодирования может получать значение индекса NSST через (энтропийное) декодирование. Значение индекса NSST может быть бинаризованным с переменной–длиной. В этом случае, например, как раскрыто в таблице 6, значение индекса NSST может быть бинаризовано в соответствии с усеченной унарной (TU) схемой. При этом, значение индекса NSST может быть декодировано на основании контекста, например, как CABAC или CAVLC. В этом случае, контекстная модель может определяться на основании по меньшей мере одного из размера целевого блока, режима интра–предсказания, значения информации о смешанном типе и максимального значения индекса в наборе NSST.
[150] Устройство декодирования формирует модифицированные коэффициенты преобразования посредством неразделимого вторичного (обратного) преобразования коэффициентов преобразования на основании выбранного ядра NSST (S730). Устройство декодирования может получать остаточные выборки для целевого блока путем выполнения первичного (обратного) преобразования на модифицированных коэффициентах преобразования.
[151] Устройство декодирования может получать реконструированные выборки путем комбинирования выборок предсказания, полученных на основании результатов интра–предсказания, и остаточных выборок, и может реконструировать кадр на основании реконструированных выборок.
[152] После этого, устройство декодирования может применять процедуру фильтрации в замкнутом контуре, такую как процедура фильтрации устранения блочности, SAO и/или ALF, к реконструированной картинке, чтобы при необходимости повысить субъективное/объективное качество кадра, как описано выше.
[153] Способ в соответствии с настоящим вариантом осуществления может быть реализован в форме программного обеспечения. Устройство кодирования и/или устройство декодирования в соответствии с настоящим вариантом осуществления могут быть включены в устройство для выполнения обработки изображений, такое как ТV, компьютер, смартфон, телевизионная приставка или устройство отображения.
[154] В настоящем варианте осуществления, если варианты осуществления реализованы в программном обеспечении, способ может быть реализован как модуль (процесс или функция), который выполняет вышеописанную функцию. Модуль может храниться в памяти и исполняться процессором. Память может находиться внутри или вне процессора и может быть соединена с процессором посредством различных хорошо известных средств. Процессор может включать в себя специализированную интегральную схему (ASIC), другие чипсеты, логические схемы и/или процессоры данных. Память может включать в себя постоянную память (ROM), память с произвольным доступом (RAM), флэш–память, карту памяти, носитель хранения и/или другие устройства хранения.





Изобретение относится к области вычислительной техники. Технический результат заключается в повышении эффективности кодирования изображений. Способ преобразования в соответствии с настоящим изобретением содержит этапы: получения коэффициентов преобразования для целевого блока; определения набора неразделимого вторичного преобразования (NSST) для целевого блока; выбора одного из множества ядер NSST, включенных в набор NSST, на основании индексе NSST и формирования модифицированных коэффициентов преобразования посредством неразделимого вторичного преобразования коэффициентов преобразования на основании ядра NSST, которое было выбрано, причем набор NSST для целевого блока определяется на основании режима интра–предсказания и/или размера целевого блока. В соответствии с настоящим изобретением может быть уменьшено количество передаваемых данных, которое требуется для остаточной обработки, и может быть повышена эффективность остаточного кодирования. 3 н. и 12 з.п. ф-лы, 7 ил., 6 табл.
1. Способ преобразования, выполняемый устройством декодирования, причем способ содержит этапы, на которых:
принимают индекс неразделимого преобразования;
получают коэффициенты преобразования для целевого блока;
определяют набор неразделимого преобразования для целевого блока;
выбирают одно из множества ядер неразделимого преобразования, включенных в набор неразделимого преобразования, на основании индекса неразделимого преобразования; и
формируют модифицированные коэффициенты преобразования посредством неразделимого преобразования коэффициентов преобразования на основании выбранного ядра неразделимого преобразования,
причем набор неразделимого преобразования для целевого блока определяется на основании по меньшей мере одного из режима интра-предсказания и размера целевого блока, и
причем значение индекса неразделимого преобразования представлено на основании усеченной унарной (TU) бинаризации.
2. Способ по п. 1, в котором набор неразделимого преобразования представляет собой смешанный набор неразделимого преобразования, содержащий ядро неразделимого преобразования 4×4 и ядро неразделимого преобразования 8×8.
3. Способ по п. 2, в котором значение индекса, назначенное ядру неразделимого преобразования 8×8, меньше значения индекса, назначенного ядру неразделимого преобразования 4×4.
4. Способ по п. 2, в котором, если размер целевого блока больше заданного опорного размера, значение индекса, назначенное ядру неразделимого преобразования 8×8, меньше значения индекса, назначенного ядру неразделимого преобразования 4×4.
5. Способ по п. 2, в котором число ядер неразделимого преобразования, включенных в набор неразделимого преобразования, является переменным.
6. Способ по п. 1, дополнительно содержащий этапы, на которых:
получают информацию о смешанном типе; и
определяют, используется ли смешанный набор неразделимого преобразования, на основании информации о смешанном типе.
7. Способ по п. 6, в котором:
если значение информации о смешанном типе равно 0, используется несмешанный набор неразделимого преобразования, включающий в себя ядра неразделимого преобразования 8×8 или ядра неразделимого преобразования 4×4, и
если значение информации о смешанном типе не равно 0, используется смешанный набор неразделимого преобразования, включающий в себя ядро неразделимого преобразования 4×4 и ядро неразделимого преобразования 8×8.
8. Способ по п. 1, в котором набор неразделимого преобразования для целевого блока определяется на основании как режима интра-предсказания, так и размера целевого блока.
9. Способ по п. 1, в котором значение индекса неразделимого преобразования является бинаризованным с переменной длиной.
10. Способ по п. 1, в котором максимальное значение индекса неразделимого преобразования равно 2, и
причем значение 0 индекса неразделимого преобразования представлено последовательностью бина ‘0’, значение 1 индекса неразделимого преобразования представлено последовательностью бина ‘10’ и значение 2 индекса неразделимого преобразования представлено последовательностью бина ‘11’.
11. Способ по п. 1, причем:
значение индекса неразделимого преобразования получают на основании декодирования на основании контекста, и
контекстную модель для декодирования на основании контекста значения индекса неразделимого преобразования определяют на основании по меньшей мере одного из размера целевого блока, режима интра-предсказания, значения информации о смешанном типе и максимального значения индекса в наборе неразделимого преобразования.
12. Способ преобразования, выполняемый устройством кодирования, причем способ содержит этапы, на которых:
получают коэффициенты преобразования для целевого блока;
определяют набор неразделимого преобразования для целевого блока;
выбирают одно из множества ядер неразделимого преобразования, включенных в набор неразделимого преобразования, причем выбранное ядро неразделимого преобразования используется для неразделимого преобразования коэффициентов преобразования для целевого блока;
формируют индекс неразделимого преобразования, указывающий выбранное ядро неразделимого преобразования из набора неразделимого преобразования; и
кодируют информацию об индексе неразделимого преобразования,
причем набор неразделимого преобразования для целевого блока определяется на основании по меньшей мере одного из режима интра-предсказания и размера целевого блока и
причем значение индекса неразделимого преобразования представлено на основании усеченной унарной (TU) бинаризации.
13. Способ по п. 12, в котором максимальное значение индекса неразделимого преобразования равно 2, и
при этом значение 0 индекса неразделимого преобразования представлено последовательностью бина ‘0’, значение 1 индекса неразделимого преобразования представлено последовательностью бина ‘10’ и значение 2 индекса неразделимого преобразования представлено последовательностью бина ‘11’.
14. Цифровой носитель хранения, хранящий информацию, побуждающую устройство декодирования выполнять способ преобразования, причем способ содержит этапы, на которых:
получают индекс неразделимого преобразования;
получают коэффициенты преобразования для целевого блока;
определяют набор неразделимого преобразования для целевого блока;
выбирают одно из множества ядер неразделимого преобразования, включенных в набор неразделимого преобразования, на основании индекса неразделимого преобразовани; и
формируют модифицированные коэффициенты преобразования путем неразделимого преобразования коэффициентов преобразования на основании выбранного ядра неразделимого преобразования;
причем набор неразделимого преобразования для целевого блока определяется на основании по меньшей мере одного из режима интра-предсказания и размера целевого блока и
причем значение индекса неразделимого преобразования представлено на основании усеченной унарной (TU) бинаризации.
15. Цифровой носитель хранения по п. 14, в котором максимальное значение индекса неразделимого преобразования равно 2, и
при этом значение 0 индекса неразделимого преобразования представлено последовательностью бина ‘0’, значение 1 индекса неразделимого преобразования представлено последовательностью бина ‘10’ и значение 2 индекса неразделимого преобразования представлено последовательностью бина ‘11’.
| KR 20120046727 A, 10.05.2012 | |||
| KR 20130030300 A, 26.03.2013 | |||
| KR 20060115404 A, 08.11.2006 | |||
| СПОСОБЫ КОДИРОВАНИЯ/ДЕКОДИРОВАНИЯ ЦИФРОВЫХ ДАННЫХ АУДИО/ВИДЕО СИГНАЛОВ И УСТРОЙСТВА ДЛЯ ИХ ОСУЩЕСТВЛЕНИЯ | 1997 |
|
RU2194361C2 |

