ОБЛАСТЬ ТЕХНИКИ
Настоящая заявка относится к области компьютерных технологий и, в частности, к способу и устройству обработки данных.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
Блокчейн (цепочка блоков) является новой практикой применения компьютерных технологий, таких как распределенное хранение данных, двухточечная передача, механизм консенсуса, алгоритм шифрования и т.д., которая требует, чтобы все узлы блокчейна оставались в том же самом состоянии (включая состояние баз данных). Таким образом, когда создается новая транзакция (т.е. генерируются новые данные) в узле блокчейна, новые данные должны быть синхронизированы со всеми узлами блокчейна, и все узлы блокчейна требуют верификации данных.
В современных технологиях способ верификации, используемый узлами блокчейна в отношении данных, обычно определяется посредством контрольной суммы на основе дерева контейнера данных (“ведра”) (например, значения хеша). В одном примере, данные в узлах блокчейна сети (приложения блокчейна, которое было реализовано) сохраняются в структуре дерева Меркла, и дерево Меркла содержит один или более листовых узлов (т.е. контейнеров данных). Одно вычислительное устройство (например, устройство терминала или сервер) обычно используется для узлов блокчейна, чтобы получить контрольную сумму (например, значение хеша) вышеуказанных данных. Например, вычислительное устройство выполняет проход по каждому листовому узлу, ранжирует и стыкует (соединяет) данные листового узла в строку символов и вычисляет контрольную сумму строки символов как контрольную сумму данных соответствующего листового узла. Затем, на основе контрольной суммы данных каждого листового узла, вычислительное устройство вычисляет корневую контрольную сумму (например, корневое значение хеша) дерева Меркла, т.е. контрольную сумму данных в узле блокчейна, и вышеуказанные данные могут быть верифицированы на основе этой контрольной суммы.
Однако, поскольку одно вычислительное устройство используется для вычисления корневой контрольной суммы данных в узлах блокчейна и поскольку каждое вычисление завершается соединением данных листовых узлов в строку символов, потребуется длительное время для выполнения одним вычислительным устройством вышеописанного процесса вычисления, когда совокупная величина данных в одном или нескольких листовых узлах очень велика (например, 10 миллионов фрагментов данных), что приводит к низкой эффективности вычисления и может даже вызывать задержку времени для генерации блока и тормозить нормальные операции блокчейна.
КРАТКОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Задачей вариантов осуществления настоящей заявки является обеспечить способ и устройство обработки данных, чтобы уменьшить время, требуемое для процесса вычисления, повысить эффективность вычисления и гарантировать нормальную генерацию блоков и нормальные операции блокчейна.
Для решения вышеописанной технической проблемы, варианты осуществления настоящей заявки реализованы следующим образом:
варианты осуществления настоящей заявки обеспечивают способ обработки данных, содержащий:
распределение, на серверы в кластере серверов, данных листовых узлов, предварительно сохраненных в узле блокчейна, для того чтобы серверы в кластере серверов вычисляли контрольные суммы данных распределенных листовых узлов, соответственно; и
получение, в соответствии с контрольными суммами данных листовых узлов, вычисленными серверами в кластере серверов, корневой контрольной суммы данных в узле блокчейна.
Опционально, получение, в соответствии с контрольными суммами данных листовых узлов, вычисленными серверами в кластере серверов, корневой контрольной суммы данных в узле блокчейна содержит:
прием корневой контрольной суммы данных в узле блокчейна, отправленной серверами в кластере серверов.
Опционально, получение, в соответствии с контрольными суммами данных листовых узлов, вычисленными серверами в кластере серверов, корневой контрольной суммы данных в узле блокчейна содержит:
определение, в соответствии с контрольными суммами листовых узлов, корневой контрольной суммы дерева Меркла, соответствующего листовым узлам; и
назначение корневой контрольной суммы дерева Меркла корневой контрольной сумме данных в узле блокчейна.
Опционально, распределение, на серверы в кластере серверов, данных листовых узлов, предварительно сохраненных в узле блокчейна, содержит:
в соответствии с числом листовых узлов, предварительно сохраненных в узле блокчейна, соответственно отправку данных предварительно установленного числа листовых узлов на серверы в кластере серверов.
Опционально, контрольные суммы представляют собой значения хеша.
Варианты осуществления настоящей заявки дополнительно обеспечивают способ обработки данных, содержащий:
прием данных листового узла, распределенного узлом блокчейна; и
вычисление контрольной суммы данных распределенного листового узла для получения корневой контрольной суммы данных в узле блокчейна.
Опционально, после приема данных листового узла, распределенного узлом блокчейна, способ дополнительно содержит:
в соответствии с количеством данных листового узла, распределение данных листового узла на предварительно установленные под–листовые узлы; и
вычисление контрольной суммы данных каждого под–листового узла,
и причем,
вычисление контрольной суммы данных распределенного листового узла содержит:
в соответствии с контрольной суммой данных каждого под–листового узла, вычисление контрольной суммы данных распределенного листового узла.
Опционально, в соответствии с количеством данных листового узла, распределение данных листового узла на предварительно установленные под–листовые узлы содержит:
сортировку данных листового узла, последовательный выбор предварительно установленного числа фрагментов данных из отсортированных данных для помещения в под–листовые узлы и установку соответствующих идентификаторов под–узлов для под–листовых узлов,
и причем, в соответствии с контрольной суммой данных каждого под–листового узла, вычисление контрольной суммы данных распределенного листового узла содержит:
в соответствии с идентификаторами под–узлов под–листовых узлов и контрольной суммой каждого из под–листовых узлов, вычисление контрольной суммы данных распределенного листового узла.
Опционально, вычисление контрольной суммы данных распределенного листового узла для получения корневой контрольной суммы данных в узле блокчейна содержит:
вычисление контрольной суммы данных распределенного листового узла и отправку контрольной суммы данных распределенного листового узла на узел блокчейна, для того чтобы узел блокчейна вычислял корневую контрольную сумму данных в узле блокчейна в соответствии с контрольной суммой данных листового узла; или
вычисление контрольной суммы данных распределенного листового узла, получение корневой контрольной суммы данных в узле блокчейна на основе контрольной суммы данных распределенного листового узла и отправку корневой контрольной суммы на узел блокчейна.
Варианты осуществления настоящей заявки обеспечивают устройство обработки данных, содержащее:
модуль распределения данных, сконфигурированный, чтобы распределять, на серверы в кластере серверов, данные листовых узлов, предварительно сохраненные в узле блокчейна, для того чтобы серверы в кластере серверов вычисляли контрольные суммы данных распределенных листовых узлов, соответственно; и
модуль получения корневой контрольной суммы, сконфигурированный, чтобы получать, в соответствии с контрольными суммами данных листовых узлов, вычисленными серверами в кластере серверов, корневую контрольную сумму данных в узле блокчейна.
Опционально, модуль получения корневой контрольной суммы сконфигурирован, чтобы принимать корневую контрольную сумму данных в узле блокчейна, отправленную серверами в кластере серверов.
Опционально, модуль получения корневой контрольной суммы сконфигурирован, чтобы определять, в соответствии с контрольными суммами листовых узлов, корневую контрольную сумму дерева Меркла, соответствующего листовым узлам; и назначать корневую контрольную сумму дерева Меркла корневой контрольной сумме данных в узле блокчейна.
Опционально, модуль распределения данных сконфигурирован, чтобы, в соответствии с числом листовых узлов предварительно сохраненных в узле блокчейна, соответственно отправлять данные предварительно установленного числа листовых узлов на серверы в кластере серверов.
Опционально, контрольные суммы представляют собой значения хеша.
Варианты осуществления настоящей заявки дополнительно обеспечивают устройство обработки данных, содержащее:
модуль приема данных, сконфигурированный, чтобы принимать данные листового узла, распределенного узлом блокчейна; и
модуль получения контрольной суммы, сконфигурированный, чтобы вычислять контрольную сумму данных распределенного листового узла для получения корневой контрольной суммы данных в узле блокчейна.
Опционально, устройство дополнительно содержит:
модуль распределения данных, сконфигурированный, чтобы, в соответствии с количеством данных листового узла, распределять данные листового узла на предварительно установленные под–листовые узлы;
модуль вычисления, сконфигурированный, чтобы вычислять контрольную сумму данных каждого под–листового узла; и причем модуль получения контрольной суммы сконфигурирован, чтобы, в соответствии с контрольной суммой данных каждого под–листового узла, вычислять контрольную сумму данных распределенного листового узла.
Опционально, модуль распределения данных сконфигурирован, чтобы сортировать данные листового узла, последовательно выбирать предварительно установленное число фрагментов данных из отсортированных данных для помещения в под–листовые узлы и устанавливать соответствующие идентификаторы под–узлов для под–листовых узлов, и причем модуль получения контрольной суммы сконфигурирован, чтобы, в соответствии с идентификаторами под–узлов под–листовых узлов и контрольной суммой каждого из под–листовых узлов, вычислять контрольную сумму данных распределенного листового узла.
Опционально, модуль получения контрольной суммы сконфигурирован, чтобы вычислять контрольную сумму данных распределенного листового узла и отправлять контрольную сумму данных распределенного листового узла на узел блокчейна, для того чтобы узел блокчейна вычислял корневую контрольную сумму данных в узле блокчейна в соответствии с контрольной суммой данных листового узла; или вычислять контрольную сумму данных распределенного листового узла, получать корневую контрольную сумму данных в узле блокчейна на основе контрольной суммы данных распределенного листового узла и отправлять корневую контрольную сумму на узел блокчейна.
Из вышеописанных технических решений, обеспечиваемых вариантами осуществления настоящей заявки, можно видеть, что в вариантах осуществления настоящей заявки данные листовых узлов, предварительно сохраненные в узле блокчейна, распределяются на серверы в кластере серверов, для того чтобы серверы в кластере серверов вычисляли контрольные суммы данных распределенных листовых узлов, соответственно; затем, в соответствии с контрольными суммами данных листовых узлов, вычисленными серверами в кластере серверов, дополнительно получается корневая контрольная сумма данных в узле блокчейна. Таким образом, поскольку данные листовых узлов распределяются на кластеры серверов и затем поскольку контрольные суммы данных распределенных листовых узлов вычисляются каждым сервером в кластере серверов, данные могут быть распределены на кластер серверов для параллельного вычисления контрольных сумм данных листовых узлов, тем самым уменьшая время, требуемое вычислительному процессу, повышая эффективность вычисления и гарантируя нормальную генерацию блоков и нормальные операции блокчейна.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Чтобы более четко описать технические решения в вариантах осуществления настоящей заявки или современных технологий, приложенные чертежи, используемые в описании вариантов осуществления или современных технологий, будут кратко описаны ниже. Очевидно, что приложенные чертежи в приведенном ниже описании являются только некоторыми вариантами осуществления в настоящей заявке. На основе этих приложенных чертежей, другие релевантные чертежи могут быть получены специалистами в данной области техники без приложения творческих усилий.
Фиг. 1 представляет собой способ обработки данных в соответствии с настоящей заявкой;
Фиг. 2 представляет собой схематичную диаграмму логики обработки данных в соответствии с настоящей заявкой;
Фиг. 3 представляет собой другой способ обработки данных в соответствии с некоторыми вариантами осуществления настоящей заявки;
Фиг. 4 представляет собой другой способ обработки данных в соответствии с некоторыми вариантами осуществления настоящей заявки;
Фиг. 5 представляет собой схематичную структурную диаграмму системы обработки данных в соответствии с настоящей заявкой;
Фиг. 6 представляет собой другой способ обработки данных в соответствии с некоторыми вариантами осуществления настоящей заявки;
Фиг. 7 представляет собой другой способ обработки данных в соответствии с некоторыми вариантами осуществления настоящей заявки;
Фиг. 8 представляет собой схематичную структурную диаграмму другой системы обработки данных в соответствии с настоящей заявкой;
Фиг. 9 представляет собой устройство обработки данных в соответствии с некоторыми вариантами осуществления настоящей заявки;
Фиг. 10 представляет собой другое устройство обработки данных в соответствии с некоторыми вариантами осуществления настоящей заявки.
ДЕТАЛЬНОЕ ОПИСАНИЕ
Варианты осуществления настоящей заявки обеспечивают способ и устройство обработки данных.
Чтобы обеспечить возможность специалисту в данной области техники лучше понять технические решения настоящей заявки, технические решения в вариантах осуществления настоящей заявки будут ясно и полно описаны ниже со ссылками на приложенные чертежи в вариантах осуществления настоящей заявки. Очевидно, что описанные варианты осуществления являются только некоторыми, но не всеми вариантами осуществления настоящей заявки. На основе вариантов осуществления настоящей заявки, все другие варианты осуществления, которые могут быть получены специалистом в данной области техники без приложения творческих усилий, будут входить в объем настоящей заявки.
Вариант осуществления I
Как показано на фиг. 1, варианты осуществления настоящей заявки обеспечивают способ обработки данных. Объектом для исполнения способа может быть узел блокчейна. Способ может содержать следующие этапы:
На этапе S101, распределение, на серверы в кластере серверов, данных листовых узлов, предварительно сохраненных в узле блокчейна, для того чтобы серверы в кластере серверов вычисляли контрольные суммы данных распределенных листовых узлов, соответственно.
Здесь, листовой узел может не иметь никакого под–узла. Узел блокчейна обычно содержит один или несколько листовых узлов (т.е. контейнеров данных (“ведер”)), и каждый листовой узел хранит некоторое количество данных (которые могут быть, например, данными транзакции). Соответствующее числовое значение может быть установлено для количества данных каждого фрагмента данных, сохраненного в листовом узле. Например, количество данных каждого фрагмента данных находится в пределах диапазона от 100 кБ до 5 MБ и равно 1 MБ в одном примере. Кластер серверов может представлять собой группу, сформированную множеством идентичных или разных серверов, и может обеспечивать соответствующие услуги для одной или нескольких транзакций. Контрольная сумма может быть строкой символов (например, числовым значением или кодом), используемой для проверки файла или данных. В примерном применении, контрольная сумма может представлять собой числовое значение, получаемое вычислением с использованием алгоритма проверки на основе перечня данных или тому подобного. Алгоритм проверки на основе перечня данных может содержать алгоритм проверки циклическим избыточным кодом, алгоритм дайджеста сообщения, безопасный алгоритм хеширования и т.д.
В реализациях, блокчейн может быть децентрализованной распределенной базой данных, которая также упоминается как распределенный реестр. На основе технологии блокчейна, требуется распределенная сеть, сформированная большим количеством памятей записи информации (например, устройств терминалов или серверов). Распространение каждой новой транзакции может использовать распределенную сеть, и в соответствии с протоколом уровня сети одноранговых узлов (P2P), информация, ассоциированная с транзакцией, непосредственно отправляется на все другие узлы блокчейна по сети отдельным узлом блокчейна, чтобы гарантировать, что данные, сохраненные во всех узлах блокчейна в распределенной сети, являются согласованными. Когда узел блокчейна записывает новую транзакцию, данные записанной новой транзакции должны быть синхронизированными с другими узлами блокчейна, при этом другим узлам блокчейна требуется верифицировать данные. Примерный процесс верификации может быть следующим:
узел блокчейна содержит один или несколько листовых узлов, и данные в узле блокчейна распределены на листовые узлы, причем все данные в листовых узлах содержат временные метки приема, и порядок транзакций может быть определен в соответствии с временными метками. При верификации, узел блокчейна может сначала получить листовые узлы, предварительно сохраненные в узле блокчейна. Чтобы иметь возможность быстро определить, какие листовые узлы сохранены в узле блокчейна и число листовых узлов, соответствующий идентификатор узла (например, ID узла (IDentity)), такой как 5 или A8, может быть установлен для каждого листового узла, когда листовой узел генерируется. Когда листовой узел должен быть получен, соответствующий листовой узел отыскивается по предварительно записанным идентификаторам узлов, и данные, сохраненные в каждом листовом узле, могут быть получены.
Поскольку количество сохраненных данных может быть различным вследствие влияний таких факторов, как разные периоды времени и/или разные области, количество данных, накопленных в одном или нескольких листовых узлах, может, как следствие, быть относительно большим, в то время как количество данных в некоторых других листовых узлах может быть относительно малым. Таким образом, может иметься несбалансированность в количествах данных, сохраненных в листовых узлах узла блокчейна. Чтобы не оказывать влияния на генерацию блоков и чтобы снизить время на вычисление контрольной суммы данных в листовом узле, данные в листовом узле могут быть распределены на множество процессоров в кластере серверов для обработки, и вычислительная нагрузка может быть рассредоточена по кластеру серверов, тем самым повышая эффективность вычислений.
После того как узел блокчейна получает данные всех листовых узлов, узел блокчейна может распределять, в единицах листового узла, данные листовых узлов на серверы в кластере серверов. Например, число серверов в кластере серверов может быть равно числу листовых узлов, и тогда узел блокчейна может отправлять данные одного листового узла на каждый сервер в кластере серверов, побуждая каждый сервер в кластере серверов содержать данные только одного листового узла. В дополнение к вышеописанному способу распределения, также может использоваться множество способов распределения. Например, листовые узлы и данные листовых узлов отправляются на серверы в кластере серверов способом случайного распределения. Таким образом, различные серверы могут принимать то же самое число или разные числа листовых узлов. В качестве другого примера, данные листовых узлов могут распределяться в соответствии с количеством данных листовых узлов. В одном примере, узел блокчейна может подсчитывать количество данных каждого листового узла и затем равномерно распределять данные листовых узлов на серверы в кластере серверов. Например, имеется шесть листовых узлов с количеством данных 50 MБ, 20 MБ, 30 MБ, 40 MБ, 10 MБ и 10 MБ, соответственно, и тогда данные листового узла с количеством данных 50 MБ могут отправляться на первый сервер в кластере серверов, данные листовых узлов с количествами данных 20 MБ и 30 MБ могут отправляться на второй сервер в кластере серверов, и данные листовых узлов с количествами данных 40 MБ, 10 MБ и 10 MБ могут отправляться на третий сервер в кластере серверов.
После того как серверы принимают распределенные данные листовых узлов, серверы могут вычислить контрольную сумму принятых данных каждого листового узла. Например, серверы вычисляют значение MD5 принятых данных листовых узлов с использованием алгоритма дайджеста сообщения (например, алгоритма MD5). Если один сервер принимает данные двух листовых узлов, т.е., данные листового узла 1 и данные листового узла 2, соответственно, сервер может вычислить значение MD5 данных листового узла 1 и вычислить значение MD5 данных листового узла 2, тем самым получая контрольную сумму принятых данных каждого листового узла.
На этапе S102, дополнительно получают, в соответствии с контрольными суммами данных листовых узлов, вычисленными серверами в кластере серверов, корневую контрольную сумму данных в узле блокчейна.
В реализациях, после того как серверы в кластере серверов вычислили контрольные суммы данных листовых узлов, каждый сервер может отправить контрольные суммы данных листовых узлов, вычисленные сервером, на узел блокчейна. После того как узел блокчейна принимает контрольные суммы данных всех листовых узлов, сохраненных в узле блокчейна, узел блокчейна может вычислить корневую контрольную сумму данных в узле блокчейна (т.е. состояние) на основе контрольных сумм данных всех листовых узлов. Здесь, когда узел блокчейна вычисляет корневую контрольную сумму данных в узле блокчейна, множество промежуточных узлов могут быть предусмотрены между листовыми узлами и корневым узлом, соответствующим корневой контрольной сумме. Как показано на фиг. 2, A, B, C и D являются листовыми узлами, и A1, A2, A3, …, Ap, B1, B2, B3, …, Bq, C1, C2, C3, …, Cr, и D1, D2, D3, …, Dk представляют данные, соответственно. Принимая контрольную сумму, являющуюся значением хеша в качестве примера, значение хеша листового узла A равно hash(A1A2A3…Ap), значение хеша листового узла B равно hash(B1B2B3…Bq), значение хеша листового узла C равно hash(C1C2C3…Cr), и значение хеша листового узла D равно hash(D1D2D3…Dk). M и N являются промежуточными узлами, и поэтому значение хеша листового узла M равно hash(AB), значение хеша листового узла N равно hash(CD). Тогда, корневая контрольная сумма корневого узла равна hash(MN). Путем сравнения полученной корневой контрольной суммы данных в узле блокчейна с вышеописанной корневой контрольной суммой, вычисленной узлом блокчейна, который отправляет данные новой транзакции, узел блокчейна может верифицировать, являются ли данные новой транзакции действительными. Если данные новой транзакции действительны, узел блокчейна может записать данные, ассоциированные с транзакцией; если данные новой транзакции не действительны, узел блокчейна отклонить запись данных, ассоциированных с транзакцией.
Следует отметить, что вышеописанный процесс вычисления корневой контрольной суммы может также выполняться кластером серверов. В одном примере, сервер администрирования или кластер серверов администрирования может быть предусмотрен в кластере серверов, и сервер администрирования или кластер серверов администрирования может корректировать и управлять другими серверами в кластере серверов. После того как другие серверы в кластере серверов вычислили контрольные суммы данных листовых узлов, другие серверы могут отправить контрольные суммы данных листовых узлов на сервер администрирования или кластер серверов администрирования, соответственно. Сервер администрирования или кластер серверов администрирования может вычислить корневую контрольную сумму данных в узле блокчейна с использованием вышеописанного способа вычисления. Сервер администрирования или кластер серверов администрирования может отправить полученную корневую контрольную сумму данных в узле блокчейна на узел блокчейна, и узел блокчейна принимает корневую контрольную сумму. Затем, узел блокчейна может выполнить верификацию посредством корневой контрольной суммы. На вышеописанное содержание может даваться ссылка в отношении деталей, которые здесь детально не рассматриваются.
Таким образом, контрольные суммы данных листовых узлов в узле блокчейна получают посредством параллельного вычисления множеством серверов в кластере серверов, обеспечивая то, что вычисление корневой контрольной суммы данных в узле блокчейна является независимым от обработки одной машиной, тем самым повышая эффективность вычисления данных контрольной суммы.
Варианты осуществления настоящей заявки обеспечивают способ обработки данных, содержащий: распределение, на серверы в кластере серверов, данных листовых узлов предварительно сохраненных в узле блокчейна, для того чтобы серверы в кластере серверов вычисляли контрольные суммы данных распределенных листовых узлов, соответственно; и дополнительно получение, в соответствии с контрольными суммами данных листовых узлов вычисленными серверами в кластере серверов, корневой контрольной суммы данных в узле блокчейна. Таким образом, так как данные листовых узлов распределяются по кластеру серверов, и затем поскольку контрольные суммы данных распределенных листовых узлов вычисляются каждым сервером в кластере серверов, данные могут распределяться на кластер серверов для параллельного вычисления контрольных сумм данных листовых узлов, тем самым сокращая время, требуемое процессу вычисления, повышая эффективность вычислений и гарантируя нормальную генерацию блоков и нормальные операции блокчейна.
Как показано на фиг. 3, варианты осуществления настоящей заявки обеспечивают способ обработки данных. Объект для исполнения способа может представлять собой кластер серверов, кластер серверов может содержать множество серверов, и каждый сервер может вычислять контрольную сумму данных. Способ может содержать следующие этапы:
На этапе S301, принимают данные листового узла распределенного узлом блокчейна.
В реализациях, когда требуется верифицировать данные в узле блокчейна, узел блокчейна может получать данные листовых узлов, сохраненных в узле блокчейна, и может распределять, в единицах листового узла, данные листовых узлов на серверы в кластере серверов. На соответствующее содержание в вышеописанном этапе S101 можно сослаться в отношении детальных способов распределения и процессов распределения, что не рассматривается здесь детально. Серверы в кластере серверов могут принимать, соответственно, данные листовых узлов, распределенных узлом блокчейна, и на соответствующее содержание в вышеописанном этапе S101 можно сослаться в отношении деталей, что не будет рассматриваться здесь детально.
На этапе S302, вычисляют контрольную сумму данных распределенного листового узла для получения корневой контрольной суммы данных в узле блокчейна.
В реализациях, серверы в кластере серверов могут вычислять контрольную сумму данных каждого принятого листового узла. После того как вычисление завершено, серверы в кластере серверов могут отправлять полученные контрольные суммы данных листовых узлов, соответственно, на узел блокчейна. Узел блокчейна может дополнительно вычислять корневую контрольную сумму данных в узле блокчейна на основе контрольных сумм данных листовых узлов, возвращенных серверами, и на соответствующее содержание в вышеописанном этапе S102 можно сослаться в отношении деталей, что не будет рассматриваться здесь детально.
В некоторых других вариантах осуществления настоящей заявки, корневая контрольная сумма данных в узле блокчейна может также вычисляться кластером серверов. Как описано выше, сервер администрирования или кластер серверов администрирования может быть обеспечен в кластере серверов для агрегированного выполнения вычисления на вычисленной контрольной сумме данных каждого листового узла, чтобы получать корневую контрольную сумму данных в узле блокчейна. На соответствующее содержание в вышеописанном этапе S102 можно сослаться в отношении деталей, что не будет рассматриваться здесь детально.
Варианты осуществления настоящей заявки обеспечивают способ обработки данных, содержащий: распределение, на серверы в кластере серверов, данных листовых узлов, предварительно сохраненных в узле блокчейна, для того чтобы серверы в кластере серверов вычисляли контрольные суммы данных распределенных листовых узлов, соответственно; и дополнительно получение, в соответствии с контрольными суммами данных листовых узлов, вычисленными серверами в кластере серверов, корневой контрольной суммы данных в узле блокчейна. Таким образом, поскольку данные листовых узлов распределены на кластер серверов, и затем поскольку контрольные суммы данных распределенных листовых узлов вычисляются каждым сервером в кластере серверов, данные могут распределяться на кластер серверов для параллельного вычисления контрольных сумм данных листовых узлов, тем самым сокращая время, требуемое процессу вычисления, повышая эффективность вычислений и гарантируя нормальную генерацию блоков и нормальные операции блокчейна.
Вариант осуществления II
Как показано на фиг. 4, варианты осуществления настоящей заявки обеспечивают способ обработки данных. Способ обработки данных может исполняться совместно узлом блокчейна и кластером серверов. Варианты осуществления настоящей заявки будут описаны детально, принимая контрольную сумму, являющуюся значением хеша, в качестве примера. Контрольные суммы в других формах могут исполняться со ссылкой на связанное содержание в вариантах осуществления настоящей заявки, что не будет рассматриваться здесь детально. Способ может содержать следующие этапы:
На этапе S401, в соответствии с числом предварительно сохраненных листовых узлов, узел блокчейна отправляет данные предварительно установленного числа листовых узлов на серверы в кластере серверов, соответственно.
Здесь, предварительно установленное число может быть установлено в соответствии с реальными ситуациями, как 5, 10 и т.д., что не будет рассматриваться детально в вариантах осуществления настоящей заявки.
В реализациях, когда верифицируются данные транзакции, механизм разработки дерева Меркла часто используется для данных в узле блокчейна, чтобы повысить эффективность верификации и сократить потребление ресурсов. Чтобы повысить, в наибольшей степени, эффективность вычисления для контрольных сумм данных в узле блокчейна без изменения существующего механизма разработки данных блокчейна в вариантах осуществления настоящей заявки, данные узла блокчейна в вариантах осуществления настоящей заявки могут по–прежнему использовать механизм разработки дерева Меркла. Дерево Меркла может содержать множество листовых узлов (т.е., участков памяти), и идентификаторы узлов всех листовых узлов в дереве Меркла могут быть записаны в узел блокчейна. Когда данные транзакции требуется верифицировать, идентификаторы узлов всех листовых узлов в дереве Меркла могут быть получены.
Как показано на фиг. 5, узел блокчейна может получать данные всех листовых узлов на основе идентификаторов узлов всех листовых узлов, соответственно, и может также получать число листовых узлов, сохраненных в узле блокчейна, и число серверов в кластере серверов. В соответствии с числом серверов и числом листовых узлов, узел блокчейна может определить число листовых узлов, подлежащих распределению на каждый сервер. Например, имеется всего 10 листовых узлов, и кластер серверов имеет всего 10 серверов. Тогда, данные одного листового узла могут быть отправлены на каждый сервер, или данные группы из двух или четырех листовых узлов могут быть отправлены на один сервер в кластере серверов, соответственно.
В процессе, когда узел блокчейна распределяет данные листовых узлов на кластер серверов, узел блокчейна может также распределять идентификаторы узлов листовых узлов на серверы в кластере серверов. В соответствии с распределенным идентификатором узла, сервер может отправить инструкцию получения данных, содержащую идентификатор узла, на узел блокчейна. Когда узел блокчейна принимает инструкцию получения данных, узел блокчейна может извлечь идентификатор узла в инструкции получения данных, отыскать данные соответствующего листового узла посредством идентификатора узла и отправить данные на соответствующий сервер. Таким образом, кластер серверов может извлекать данные соответствующих листовых узлов из данных соответствующего листового узла, соответственно.
Следует отметить, что, в примерном применении, данные листовых узлов могут также распределяться на серверы в кластере серверов в соответствии с количествами данных листовых узлов, или данные листовых узлов могут также распределяться на серверы в кластере серверов случайным образом. На соответствующее содержание этапа S101 в варианте осуществления I можно сослаться в отношении деталей, что не будет рассматриваться здесь детально.
На этапе S402, кластер серверов вычисляет контрольные суммы данных распределенных листовых узлов.
На этапе S403, кластер серверов отправляет контрольные суммы данных распределенных листовых узлов на узел блокчейна.
На соответствующее содержание этапа в варианте осуществления I можно сослаться в отношении детальных процессов вышеописанных этапа S402 и этапа S403, что не будет рассматриваться здесь детально.
На этапе S404, узел блокчейна определяет, в соответствии с вышеописанными контрольными суммами листовых узлов, корневую контрольную сумму дерева Меркла, соответствующего листовым узлам.
В реализациях, после того как узел блокчейна принимает контрольные суммы листовых узлов, отправленные серверами в кластере серверов, узел блокчейна может построить соответствующее дерево Меркла посредством листовых узлов. Поскольку значения хешей листовых узлов на дереве Меркла были определены, и только значение хеша корневого узла дерева Меркла (т.е., корневая контрольная сумма дерева Меркла) еще не было получено, значение хеша дерева Меркла, соответствующего листовым узлам, может быть вычислено в направлении вверх от значений хешей листовых узлов, тем самым получая корневую контрольную сумму дерева Меркла, соответствующего листовым узлам.
На этапе S405, узел блокчейна назначает корневую контрольную сумму дерева Меркла корневой контрольной сумме данных в узле блокчейна.
В примерном применении, корневая контрольная сумма также может быть вычислена кластером серверов, и обработка может содержать: вычисление контрольных сумм данных распределенных листовых узлов; получение, на основе контрольных сумм данных распределенных листовых узлов, корневой контрольной суммы данных в узле блокчейна, и отправку корневой контрольной суммы в узел блокчейна. На соответствующее содержание в варианте осуществления I можно сослаться в отношении детального процесса, что не будет рассматриваться здесь детально.
Варианты осуществления настоящей заявки обеспечивают способ обработки данных, содержащий: распределение, на серверы в кластере серверов, данных листовых узлов, предварительно сохраненных в узле блокчейна, для того чтобы серверы в кластере серверов вычисляли контрольные суммы данных распределенных листовых узлов, соответственно; и дополнительно получение, в соответствии с контрольными суммами данных листовых узлов, вычисленными серверами в кластере серверов, корневой контрольной суммы данных в узле блокчейна. Таким образом, поскольку данные листовых узлов распределены на кластер серверов, и затем поскольку контрольные суммы данных распределенных листовых узлов вычисляются каждым сервером в кластере серверов, данные могут быть распределены на кластер серверов для параллельного вычисления контрольных сумм данных листовых узлов, тем самым сокращая время, требуемое процессу вычисления, повышая эффективность вычислений и гарантируя нормальную генерацию блоков и нормальные операции блокчейна.
Вариант осуществления III
Как показано на фиг. 6, варианты осуществления настоящей заявки обеспечивают способ обработки данных. Способ обработки данных может исполняться совместно узлом блокчейна и кластером серверов. Варианты осуществления настоящей заявки будут описаны детально, принимая контрольную сумму, являющуюся значением хеша, в качестве примера. Контрольные суммы в других формах могут исполняться со ссылкой на связанное содержание в вариантах осуществления настоящей заявки, что не будет рассматриваться здесь подробно. Способ может содержать следующие этапы:
На этапе S601, узел блокчейна распределяет данные предварительно сохраненного листового узла на серверы в кластере серверов.
На связанное содержание в варианте осуществления I и варианте осуществления II можно сослаться в отношении детального процесса этапа S601, что не будет рассматриваться здесь подробно.
На этапе S602, кластер серверов распределяет, в соответствии с количеством данных листового узла, данные листового узла на предварительно установленные под–листовые узлы.
Здесь, не имеется никакого отношения ассоциации между под–листовыми узлами и листовым узлом, такого как отношение принадлежности, отношение подчинения, материнское отношение или дочернее отношение. Под–листовой узел может быть пакетом данных, содержащим один или несколько фрагментов данных, в то время как листовой узел (контейнер данных) может быть контейнером в дереве Меркла для хранения данных. Число под–листовых узлов может быть больше, чем число листовых узлов. Например, если число листовых узлов равно 5, то число под–листовых узлов может быть равно 20.
В реализациях, один или несколько листовых узлов среди листовых узлов, предварительно сохраненных в узле блокчейна, могут иметь большое количество данных (например, содержать один миллион фрагментов данных и т.д.). Таким образом, когда данные листового узла распределяются на сервер в кластере серверов для вычисления значение хеша листового узла, серверу требуется соединить (состыковать) большое количество данных в листовых узлах, чтобы получить соединенные строки символов, и затем он вычисляет значение хеша соединенной строки символов. Это процесс все еще требует много времени, и потребление ресурсов сервером все еще велико. Ввиду этого, множество под–листовых узлов может быть предварительно установлено, или максимальное количество данных, которое каждый под–листовой узел может вместить, может быть установлено для каждого под–листового узла в соответствии с действительными потребностями, например, 1 ГБ или 500 MБ. Данные листового узла могут быть распределены на предварительно установленное множество под–листовых узлов способом случайного распределения или равномерного распределения.
Может иметься множество путей реализации этапа S602. Опциональный способ обработки будет представлен ниже, который может содержать: сортировку данных листового узла, последовательный выбор предварительно установленного числа фрагментов данных из отсортированных данных для помещения в под–листовые узлы, соответственно, и установку соответствующих идентификаторов под–узлов для под–листовых узлов.
В соответствии со скоростью обработки данных и скоростью вычисления контрольной суммы каждого сервера в кластере серверов и в соответствии с числом серверов в кластере серверов, кластер серверов может определить некоторое количество данных, которое каждый сервер способен обработать при обеспечении высокой общей эффективности обработки данных (например, выше, чем установленный порог эффективности), и затем может определить некоторое количество данных или число фрагментов данных, которое может вместить каждый под–листовой узел. Кластер серверов может вычислить полное количество данных листовых узлов, распределенных на каждый сервер. Затем, кластер серверов может сортировать данные распределенных листовых узлов в соответствии с временными метками, указывающими время, когда данные сохранены в узле блокчейна, последовательно распределять предварительно установленное число фрагментов данных из отсортированного множества фрагментов данных на каждый под–листовой узел и устанавливать соответствующие идентификаторы под–узлов для под–листовых узлов, соответственно, в соответствии с порядком данных, чтобы указывать положение данных под–листового узла в данных всех под–листовых узлов.
Например, под–листовой узел, распределенный сервером в кластере серверов, сохранен с 50 фрагментами данных, каждый фрагмент данных равен 5 MБ, и тогда количество данных равно 250 MБ. Если количество данных, которое может вмещаться каждым под–листовым узлом, равно 25 MБ, то 250/25=10, и поэтому может быть получено 10 под–листовых узлов. Затем, под–листовые узлы нумеруются как 1–10 как идентификаторы под–узлов в соответствии с порядком данных. После вышеописанной обработки, положения хранения 50 фрагментов данных являются следующими: № 1–5 фрагментов данных по порядку сохраняются в под–листовом узле, пронумерованном как 1, № 6–10 элементов данных по порядку сохраняются в под–листовом узле, пронумерованном как 2, № 11–15 элементов данных по порядку сохраняются в под–листовом узле, пронумерованном как 3, и т.д., при этом получая местоположение хранения каждого фрагмента данных. Поскольку каждый фрагмент данных равен 5 MБ, каждый под–листовой узел может содержать 5 фрагментов данных.
На этапе S603, кластер серверов вычисляет контрольную сумму данных каждого под–листового узла.
В реализациях, после того как серверы в кластере серверов получают соответствующие под–листовые узлы, серверы могут получить данные, сохраненные в под–листовых узлах, и затем вычислить контрольную сумму каждого под–листового узла с использованием предварительно установленного алгоритма проверки. Например, данные, сохраненные в под–листовом узле, могут быть отсортированы и затем SHA256 (безопасный хеш–алгоритм 256) может быть использован, чтобы вычислить значение SHA256 (т.е., значение хеша) как контрольную сумму под–листового узла.
На этапе S604, кластер серверов вычисляет контрольную сумму данных распределенного листового узла в соответствии с контрольной суммой данных каждого под–листового узла.
В реализациях, после того как кластер серверов получает контрольную сумму каждого под–листового узла, контрольные суммы под–листовых узлов могут быть отсортированы в соответствии с порядком идентификаторов под–узлов. Затем кластер серверов может агрегированным образом выполнять вычисление на основе контрольных сумм под–листовых узлов с использованием предварительно установленного алгоритма проверки, чтобы получить контрольную сумму соответствующего листового узла, тем самым получая контрольную сумму данных листового узла, распределенного узлом блокчейна.
Например, на основе примера на этапе S602, соответственные значения хешей данных 10 под–листовых узлов могут быть получены посредством обработки на этапе S603. Поскольку данные 10 под–листовых узлов распределяются из данных одного листового узла, агрегированным образом выполненное вычисление, показанное на фиг. 2, может быть выполнено на полученных значениях хешей данных 10 под–листовых узлов, чтобы получить значение хеша соответствующего листового узла.
Следует отметить, что данные под–листовых узлов могут быть получены способом извлечения посредством установленных идентификаторов под–узлов под–листовых узлов. Соответственно, обработка на этапе S604 может быть следующей: вычисление контрольной суммы данных распределенного листового узла в соответствии с идентификаторами под–узлов под–листовых узлов и контрольной суммы каждого под–листового узла. На вышеописанное связанное содержание можно сослаться в отношении детальной обработки, что не будет рассматриваться здесь подробно.
На этапе S605, кластер серверов отправляет контрольную сумму данных распределенного листового узла на узел блокчейна.
На этапе S606, узел блокчейна определяет корневую контрольную сумму дерева Меркла соответственно листовым узлам в соответствии с контрольными суммами листовых узлов.
В реализациях, корневая контрольная сумма данных в узле блокчейна может быть вычислена с использованием предварительно установленного алгоритма проверки на основе контрольных сумм листовых узлов. Например, в соответствии с положениями листовых узлов, соответствующих записанным идентификаторам узлов во всех листовых узлах в узле блокчейна, может быть получено дерево распределения узлов (т.е., дерево Меркла), сформированное листовыми узлами, такое как A–B–C–F, A–B–E и A–D. Когда контрольные суммы листовых узлов (т.е., контрольные суммы B+C+D+E+F) получены, корневая контрольная сумма дерева Меркла может быть вычислена в соответствии с контрольными суммами листовых узлов, при этом получая корневую контрольную сумму данных узла блокчейна.
На этапе S607, узел блокчейна назначает корневую контрольную сумму дерева Меркла корневой контрольной сумме данных в узле блокчейна.
На связанное содержание в варианте осуществления I и варианте осуществления II можно сослаться в отношении детальных процессов этапа S605 и этапа S607, что не будет рассматриваться здесь подробно.
Варианты осуществления настоящей заявки обеспечивают способ обработки данных, содержащий: распределение идентификаторов узлов листовых узлов на кластер серверов, побуждение кластера серверов распределять каждое предварительно установленное число фрагментов данных под–листовым узлам в соответствии с полученными количествами данных, сохраненными в листовых узлах в целевом блокчейне, затем вычисление контрольной суммы каждого под–листового узла, определение контрольных сумм соответствующих листовых узлов и, наконец, предоставление контрольных сумм листовых узлов на узел блокчейна для вычисления контрольной суммы данных в узле блокчейна. Таким образом, данные, сохраненные в листовых узлах, перераспределяются кластером серверов, чтобы получить под–листовые узлы, и затем контрольные суммы под–листовых узлов вычисляются, приводя к тому, что данные равномерно распределяются на кластере серверов вычисления для параллельного вычисления контрольных сумм, тем самым сокращая время, требуемое процессу вычисления, повышая эффективность вычислений и гарантируя нормальную генерацию блоков и нормальные операции блокчейна.
Вариант осуществления IV
Как показано на фиг. 7, варианты осуществления настоящей заявки обеспечивают способ обработки данных. Способ обработки данных может совместно исполняться узлом блокчейна и кластером серверов. Здесь, кластер серверов может дополнительно содержать первый кластер серверов и второй кластер серверов, как показано на фиг. 8. Фиг. 8 обеспечивает систему обработки данных. Система обработки данных может содержать кластеры серверов на двух уровнях, т.е. первый кластер серверов и второй кластер серверов, причем первый кластер серверов находится на уровне ниже узла блокчейна, а второй кластер серверов находится на уровне ниже первого кластера серверов. Вышеописанная иерархическая структура может достигать таких целей, как повторное объединение данных, распределение данных и т.д., чтобы ускорить скорость обработки данных. Варианты осуществления настоящей заявки будут описаны детально, принимая контрольную сумму, являющуюся значением хеша, в качестве примера. Контрольные суммы в других формах могут быть сформированы со ссылкой на связанное содержание в вариантах осуществления настоящей заявки, что не будет рассматриваться здесь детально. Способ может содержать следующие этапы:
На этапе S701, узел блокчейна получает идентификатор узла предварительно сохраненного листового узла.
В реализациях, всякий раз, когда данные сохраняются в узле блокчейна, листовой узел соответственно генерируется в узле блокчейна, и идентификатор узла листового узла также генерируется. Таким образом, блокчейн может содержать множество листовых узлов, и каждый листовой узел хранит некоторое количество данных. Всякий раз, когда генерируется идентификатор узла, идентификатор узла может быть сохранен, и положение листового узла, соответствующего идентификатору узла, во всех листовых узлах узла блокчейна может записываться. Например, сгенерированный идентификатор узла представляет собой F, и положение листового узла, соответствующего идентификатору узла, может представлять собой A–B–C–F.
На этапе S702, узел блокчейна отправляет идентификатор узла на серверы в кластере серверов.
В реализациях, на основе системной структуры, показанной на фиг. 8, узел блокчейна может получать данные, сохраненные в листовых узлах, содержащихся в узле блокчейна, и может разделять идентификаторы узлов листовых узлов на группу или множество групп в соответствии с предварительно разработанным правилом распределения или случайным образом. Каждая группа идентификаторов узлов может быть отправлена на один сервер в первом кластере серверов.
На этапе S703, первый кластер серверов получает, в соответствии с распределенными идентификаторами узлов, данные листовых узлов, соответствующих идентификаторам узлов, из узла блокчейна.
В реализациях, сервер в первом кластере серверов может отправлять инструкцию получения данных, содержащую идентификаторы узлов, на устройство блокчейна и затем извлекать данные листовых узлов в соответствии с идентификаторами узлов из узла блокчейна.
На этапе S704, первый кластер серверов генерирует один или несколько под–листовых узлов в соответствии с полученными количествами данных листовых узлов.
Здесь, как описано выше, не имеется отношения ассоциации между под–листовыми узлами и листовым узлом в вариантах осуществления настоящей заявки, такого как отношение принадлежности, отношение подчинения, материнское отношение или дочернее отношение. Под–листовой узел может быть пакетом данных, содержащим один или несколько фрагментов данных, в то время как листовой узел (контейнер данных) может быть контейнером в дереве Меркла для хранения данных.
В реализациях, количество данных или число фрагментов данных, которое может вмещать под–листовой узел, может быть предварительно установлено, например, 100 MБ или 10 фрагментов. Полное количество данных листовых узлов, распределенных на каждый сервер в первом кластере серверов, может быть вычислено, и один или несколько под–листовых узлов может генерироваться в соответствии с количеством данных или числом фрагментов данных, которое может вмещать каждый под–листовой узел.
На этапе S705, первый кластер серверов сортирует данные листовых узлов, последовательно выбирает предварительно установленное число фрагментов данных из отсортированных данных для помещения в соответствующие под–листовые узлы, соответственно, и устанавливает соответствующие идентификаторы под–узлов для под–листовых узлов.
В реализациях, интервалы времени, требуемые каждому серверу в первом кластере серверов, чтобы вычислять значения хешей для одного и множества фрагментов данных, может предварительно тестироваться периодическим способом тестирования, откуда может выбираться число фрагментов данных, соответствующее относительно короткому интервалу времени и относительно невысокой нагрузке обработки на сервер. Это число фрагментов может быть установлено как предварительно установленное число фрагментов, например, 30 или 50 фрагментов. Поскольку каждый фрагмент данных снабжается временной меткой в процессе хранения или транзакции блокчейна, время сохранения или транзакции каждого фрагмента данных может быть определено посредством временной метки. Таким образом, временная метка в каждом фрагменте данных может быть получена, и множество фрагментов данных может быть отсортировано в соответствии с порядком временных меток. Предварительно установленное число фрагментов данных может быть последовательно выбрано из отсортированного множества фрагментов данных и распределено в соответствующие под–листовые узлы, соответственно. Для обозначения порядка распределенных данных в различных под–листовых узлах, идентификаторы под–узлов могут быть установлены для соответствующих под–листовых узлов на основе распределенных данных.
Например, предварительно установленное число фрагментов равно трем фрагментам, и данные листового узла могут содержать A, B, C, D, E, F, G, H и K. После того как данные отсортированы в соответствии с временными метками, порядок вышеуказанных данных может представлять собой H–G–F–E–D–C–B–A–K. Затем, три фрагмента данных H–G–F могут быть распределены в один под–листовой узел, три фрагмента данных E–D–C могут быть распределены в один под–листовой узел, и три фрагмента данных B–A–K могут быть распределены в один под–листовой узел. Чтобы обозначить порядок данных, сохраненных в трех под–листовых узлах, идентификатор под–узла под–листового узла, где находится H–G–F, может быть установлен как под–узел 1, идентификатор под–узла под–листового узла, где находится E–D–C, может быть установлен как под–узел 2, и идентификатор под–узла под–листового узла, где находится B–A–K, может быть установлен как под–узел 3.
На этапе S706, первый кластер серверов распределяет данные под–листовых узлов на серверы во втором кластере серверов.
В реализациях, могут быть получены индексные данные, такие как текущая оставшаяся ширина полосы и/или скорость передачи данных каждого сервера во втором кластере серверов, соответственно. Вычислительные возможности каждого сервера в первом кластере серверов могут быть оценены на основе полученных индексных данных, и данные соответствующих под–листовых узлов могут быть отправлены на серверы во втором кластере серверов в соответствии с уровнем вычислительных возможностей.
Кроме того, чтобы повысить эффективность вычисления в максимально возможной степени, можно корректировать число под–листовых узлов, распределенных на серверы во втором кластере серверов. В одном примере, могут быть получены индексные данные, такие как текущая оставшаяся ширина полосы и/или скорость передачи данных каждого сервера во втором кластере серверов, соответственно. Вычислительные возможности каждого сервера могут оцениваться на основе полученных индексных данных, и соответствующие под–листовые узлы могут быть распределены на серверы во втором кластере серверов в соответствии с уровнем вычислительных возможностей. Например, второй кластер серверов содержит пять серверов, и два под–листовых узла могут быть распределены на каждый сервер. Если определено посредством вычислений, что сервер во втором кластере серверов имеет более высокопроизводительные вычислительные возможности, то данные 3 из вышеуказанных 10 под–листовых узлов могут быть отправлены на этот сервер. Если посредством вычислений определено, что сервер во втором кластере серверов имеет самые слабые вычислительные возможности, то данные 1 из вышеуказанных 10 под–листовых узлов могут быть отправлены на этот сервер. Вышеописанным способом, сгенерированные один или несколько под–листовых узлов могут быть предоставлены на серверы во втором кластере серверов сбалансированным образом.
На этапе S707, второй кластер серверов вычисляет значение хеша каждого под–листового узла и вводит значение хеша на соответствующие серверы в первом кластере серверов.
В реализациях, после того как сервер во втором кластере серверов принимает соответствующие под–листовые узлы, сервер может извлечь данные в каждом под–листовом узле и отсортировать данные в соответствии с порядком временных меток данных. Сервер может получать строку символов, сформированную отсортированными данными, и использовать предварительно установленный хеш–алгоритм, чтобы вычислять значение хеша этой строки символов, т.е., значение хеша под–листового узла. Вышеописанным способом, второй кластер серверов может получать значение хеша каждого под–листового узла, которое затем может отправляться, через соответствующие серверы, на соответствующие серверы в первом кластере серверов.
На этапе S708, первый кластер серверов определяет значение хеша распределенного листового узла в соответствии со значением хеша каждого под–листового узла и идентификаторами под–узлов под–листовых узлов, отправленными вторым кластером серверов.
В реализациях, после того как серверы в первом кластере серверов принимают контрольные суммы под–листовых узлов, возвращенные вторым кластером серверов, серверы могут получать идентификатор под–узла каждого под–листового узла, соответственно. Затем, серверы могут сортировать под–листовые узлы в соответствии с идентификатором под–узла каждого под–листового узла и могут собирать значения хешей отсортированных под–листовых узлов, чтобы получать значение хеша под–листовых узлов. Например, порядок значений хешей под–листовых узлов может быть определен в соответствии с порядком под–листовых узлов, и отсортированные значения хешей могут формировать строку символов. Значение хеша строки символов может вычисляться с использованием предварительно установленного хеш–алгоритма, и значение хеша является значением хеша, соответствующим листовому узлу. Кроме того, другие способы вычисления значения хеша могут быть использованы для определения значения хеша листового узла. Например, среднее значений хешей одного или нескольких под–листовых узлов может быть вычислено как значение хеша листового узла; альтернативно, значение хеша листового узла может быть получено на основе веса каждого под–листового узла и значения хеша каждого под–листового узла.
На этапе S709, первый кластер серверов отправляет значение хеша распределенного листового узла на узел блокчейна.
На этапе S710, узел блокчейна определяет, в соответствии с контрольными суммами листовых узлов, корневую контрольную сумму дерева Меркла, соответствующего листовым узлам, и назначает корневую контрольную сумму дерева Меркла корневой контрольной сумме данных в узле блокчейна.
Варианты осуществления настоящей заявки обеспечивают способ обработки данных, содержащий: генерирование, в соответствии с количеством данных листовых узлов в узле блокчейна, одного или нескольких под–листовых узлов, распределенных с предварительно установленным числом фрагментов данных, затем распределение под–листовых узлов на второй кластер серверов для вычисления контрольной суммы каждого под–листового узла, определение контрольных сумм соответствующих листовых узлов в соответствии с контрольной суммой каждого под–листового узла, и, наконец, предоставление контрольных сумм листовых узлов на узел блокчейна для вычисления корневой контрольной суммы данных в узле блокчейна. Таким образом, данные, сохраненные в листовых узлах, перераспределяются первым кластером серверов, чтобы получить под–листовые узлы, и затем под–листовые узлы распределяются на второй кластер серверов для вычисления контрольных сумм, приводя к тому, что данные равномерно распределяются на второй кластер серверов для параллельного вычисления контрольных сумм, тем самым сокращая время, требуемое процессу вычисления, повышая эффективность вычислений и гарантируя нормальную генерацию блоков и нормальные операции блокчейна.
Вариант осуществления V
Вышеизложенное характеризует способы обработки данных, обеспеченные вариантами осуществления настоящей заявки. На основе того же самого принципа, варианты осуществления настоящей заявки дополнительно обеспечивают устройство обработки данных, как показано на фиг. 9.
Устройство обработки данных может быть узлом блокчейна, обеспеченным в вышеописанных вариантах осуществления, и, в одном примере, может быть устройством терминала (например, персональным компьютером и т.д.) или сервером. Устройство может содержать модуль 901 распределения данных и модуль 902 получения корневой контрольной суммы, причем
модуль 901 распределения данных сконфигурирован, чтобы распределять, на серверы в кластере серверов, данные листовых узлов, предварительно сохраненных в узле блокчейна, для того чтобы серверы в кластере серверов вычисляли контрольные суммы данных распределенных листовых узлов, соответственно; и
модуль 902 получения корневой контрольной суммы сконфигурирован, чтобы дополнительно получать, в соответствии с контрольными суммами данных листовых узлов, вычисленными серверами в кластере серверов, корневую контрольную сумму данных в узле блокчейна.
В вариантах осуществления настоящей заявки, модуль 902 получения корневой контрольной суммы сконфигурирован, чтобы принимать корневую контрольную сумму данных в узле блокчейна, отправленную серверами в кластере серверов.
В вариантах осуществления настоящей заявки, модуль 902 получения корневой контрольной суммы сконфигурирован, чтобы определять, в соответствии с контрольными суммами листовых узлов, корневую контрольную сумму дерева Меркла, соответствующего листовым узлам; и назначить корневую контрольную сумму дерева Меркла корневой контрольной сумме данных в узле блокчейна.
В вариантах осуществления настоящей заявки, модуль 901 распределения данных сконфигурирован, чтобы, в соответствии с числом листовых узлов, предварительно сохраненных в узле блокчейна, отправлять данные предварительно установленного числа листовых узлов на серверы в кластере серверов, соответственно.
В вариантах осуществления настоящей заявки, контрольная сумма является значением хеша.
Варианты осуществления настоящей заявки обеспечивают устройство обработки данных, сконфигурированное, чтобы распределять, на серверы в кластере серверов, данные листовых узлов, предварительно сохраненные в узле блокчейна, для того чтобы серверы в кластере серверов вычисляли контрольные суммы данных распределенных листовых узлов, соответственно; и дополнительно получать, в соответствии с контрольными суммами данных листовых узлов, вычисленными серверами в кластере серверов, корневую контрольную сумму данных в узле блокчейна. Таким образом, поскольку данные листовых узлов распределены на кластер серверов, и затем поскольку контрольные суммы данных распределенных листовых узлов вычисляются каждым сервером в кластере серверов, данные могут быть распределены на кластер серверов для параллельного вычисления контрольных сумм данных листовых узлов, тем самым сокращая время, требуемое процессу вычисления, повышая эффективность вычислений и гарантируя нормальную генерацию блоков и нормальные операции блокчейна.
Вариант осуществления IV
На основе того же самого принципа, варианты осуществления настоящей заявки дополнительно обеспечивают устройство обработки данных, как показано на фиг. 10.
Устройство обработки данных может быть кластером серверов, обеспеченным в вышеописанных вариантах осуществления, и устройство может содержать модуль 1001 приема данных и модуль 1002 получения контрольной суммы, причем
модуль 1001 приема данных сконфигурирован, чтобы принимать данные листового узла, распределенного узлом блокчейна; и
модуль 1002 получения контрольной суммы сконфигурирован, чтобы вычислять контрольную сумму данных распределенного листового узла для получения корневой контрольной суммы данных в узле блокчейна.
В вариантах осуществления настоящей заявки, устройство дополнительно содержит:
модуль распределения данных, сконфигурированный, чтобы, в соответствии с количеством данных листового узла, распределять данные листового узла на предварительно установленные под–листовые узлы;
модуль вычисления, сконфигурированный, чтобы вычислять контрольную сумму данных каждого под–листового узла; и
соответственно, модуль 1002 получения контрольной суммы сконфигурирован, чтобы, в соответствии с контрольной суммой данных каждого под–листового узла, вычислять контрольную сумму данных распределенного листового узла.
В вариантах осуществления настоящей заявки, модуль распределения данных сконфигурирован, чтобы сортировать данные листового узла, последовательно выбирать предварительно установленное число фрагментов данных из отсортированных данных для помещения в под–листовые узлы, соответственно, и устанавливать соответствующие идентификаторы под–узлов для под–листовых узлов; и
соответственно, модуль 1002 получения контрольной суммы сконфигурирован, чтобы, в соответствии с идентификаторами под–узлов под–листовых узлов и контрольной суммой каждого из под–листовых узлов, вычислять контрольную сумму данных распределенного листового узла.
В вариантах осуществления настоящей заявки, модуль 1002 получения контрольной суммы сконфигурирован, чтобы вычислять контрольную сумму данных распределенного листового узла и отправлять контрольную сумму данных распределенного листового узла на узел блокчейна, для того чтобы узел блокчейна вычислял корневую контрольную сумму данных в узле блокчейна в соответствии с контрольной суммой данных листового узла; или вычислять контрольную сумму данных распределенного листового узла, получать корневую контрольную сумму данных в узле блокчейна на основе контрольной суммы данных распределенного листового узла и отправлять корневую контрольную сумму на узел блокчейна.
Варианты осуществления настоящей заявки обеспечивают устройство обработки данных, сконфигурированное, чтобы распределять, на серверы в кластере серверов, данные листовых узлов, предварительно сохраненных в узле блокчейна, для того чтобы серверы в кластере серверов вычисляли контрольные суммы данных распределенных листовых узлов, соответственно; и дополнительно получать, в соответствии с контрольными суммами данных листовых узлов, вычисленными серверами в кластере серверов, корневую контрольную сумму данных в узле блокчейна. Таким образом, поскольку данные листовых узлов распределяются на кластер серверов, и затем поскольку контрольные суммы данных распределенных листовых узлов вычисляются каждым сервером в кластере серверов, данные могут быть распределены на кластер серверов для параллельного вычисления контрольных сумм данных листовых узлов, тем самым сокращая время, требуемое процессу вычисления, повышая эффективность вычислений и гарантируя нормальную генерацию блоков и нормальные операции блокчейна.
В 1990–х, усовершенствование в технологии может явно разделяться на усовершенствования аппаратных средств (например, улучшения структуры схемы, такой как диод, транзистор или переключатель) или усовершенствования программного обеспечения (улучшения процедуры способа). Однако с развитием технологий, многие современные улучшения процедур способов могут рассматриваться как непосредственные улучшения структур схем аппаратных средств. Разработчики почти всегда получают соответствующую структуру схемы аппаратных средств путем программирования усовершенствованной процедуры способа в схему аппаратных средств. Поэтому, нельзя утверждать, что усовершенствование процедуры способа не может быть реализовано с использованием модуля аппаратных средств. Например, программируемое логическое устройство (PLD) (например, программируемая вентильная матрица (FPGA)) является такой интегральной схемой, логические функции которой определяются пользователем посредством программирования устройства. Разработчик выполняет программирование на свое усмотрение, чтобы “интегрировать” цифровую систему в один элемент PLD, и не запрашивает производителя чипов проектировать и производить чип специализированной интегральной схемы. Кроме того, в настоящее время, такой тип программирования часто реализуется через программное обеспечение “логического компилятора”, а не путем ручного производства чипов IC. Программное обеспечение логического компилятора аналогично компилятору программного обеспечения, используемому для разработки и написания программы, причем конкретный язык программирования должен быть использован для написания исходных кодов перед компиляцией, который упоминается как язык описания аппаратных средств (HDL). Существует не один, а несколько типов HDL, таких как усовершенствованный язык булевых выражений (ABEL), язык описания аппаратных средств Altera (AHDL), Confluence, язык программирования Корнеллского университета (CUPL), HDCal, язык описания аппаратных средств Java (JHDL), Lava, Lola, MyHDL, PALASM, язык описания аппаратных средств Ruby (RHDL) и т.д. В настоящее время наиболее часто используются язык описания аппаратных средств на быстродействующих интегральных схемах (VHDL) и Verilog. Специалист в данной области техники должен также понимать, что было бы легко получить аппаратную схему для реализации логической процедуры способа с использованием вышеописанных HDL для выполнения некоторого логического программирования на процедуре способа и программирования процедуры способа в IC.
Контроллер может быть реализован с использованием любого подходящего способа. Например, контроллер может представлять собой микропроцессор или процессор или считываемый компьютером носитель, который хранит считываемые компьютером программные коды (такие как программное обеспечение или прошивка), которые могут исполняться (микро)процессором, логической схемой, переключателем, специализированной интегральной схемой (ASIC), программируемым логическим контроллером или встроенным микроконтроллером. Примеры контроллера включают в себя, но без ограничения, следующие микроконтроллеры: ARC 625D, Atmel AT91SAM, Microchip PIC18F26K20 и Silicone Labs C8051F320. Контроллер памяти может также быть реализован как часть управляющей логики памяти. Специалист в данной области техники также знает, что, в дополнение к реализации контроллера с использованием считываемых компьютером программных кодов, также можно выполнять логическое программирование на этапах способа, чтобы позволить контроллеру реализовывать те же самые функции в форме логической схемы, переключателя, ASIC, программируемого логического контроллера и встроенного микроконтроллера. Поэтому, контроллер может рассматриваться как компонент аппаратных средств, в то время как устройства, содержащиеся в контроллере и сконфигурированные, чтобы реализовывать различные функции, могут также рассматриваться как структура в компоненте аппаратных средств. Альтернативно, устройства, сконфигурированные, чтобы реализовывать различные функции, могут даже рассматриваться как модули программного обеспечения для реализации способа и структура в компоненте аппаратных средств.
Система, устройство, модуль или блок, описанные в приведенных выше вариантах осуществления, могут быть реализованы компьютерным чипом или объектом или реализованы продуктом, имеющим определенную функцию. Типовым устройством реализации является компьютер. В одном примере, компьютер может быть, например, персональным компьютером, ноутбуком, сотовым телефоном, камерофоном, смартфоном, персональным цифровым ассистентом, медиа–плеером, устройством навигации, устройством электронной почты, игровой консолью, планшетным компьютером или носимым устройством или комбинацией любых из этих устройств.
Для простоты описания, устройство выше разделено на различные модули в соответствии с функциями для описания. Функции модулей могут быть реализованы в одном или нескольких фрагментах программного обеспечения и/или аппаратных средств, когда настоящая заявка реализуется.
Специалист в данной области техники должен понимать, что варианты осуществления настоящего изобретения могут быть обеспечены как способ, система или компьютерный программный продукт. Поэтому, настоящее изобретение может быть реализовано как вариант осуществления полностью в аппаратных средствах, вариант осуществления полностью в программном обеспечении или как вариант осуществления, комбинирующий программное обеспечение и аппаратные средства. Более того, настоящее изобретение может использовать форму компьютерного программного продукта, реализованного на одном или нескольких используемых компьютером носителях хранения (включая, но без ограничения, память на магнитном диске, CD–ROM, оптическую память и т.д.), содержащих используемые компьютером программные коды.
Настоящее изобретение описано со ссылкой на блок–схемы последовательности операций и/или блок–схемы способа, устройства (системы) и компьютерного программного продукта в соответствии с вариантами осуществления настоящего изобретения. Должно быть понятно, что компьютерные программные инструкции могут использоваться для реализации каждого процесса и/или блока в блок–схемах последовательности операций и/или блок–схемах устройства и комбинации процессов и/или блоков в блок–схемах последовательности операций и/или блок–схемах устройства. Эти компьютерные программные инструкции могут быть обеспечены для универсального компьютера, специализированного компьютера, встроенного процессора или процессора других программируемых устройств обработки данных, чтобы генерировать машину, так что инструкции, исполняемые компьютером или процессором других программируемых устройств обработки данных, генерируют устройство для реализации функции, заданной в одном или нескольких процессах в блок–схемах последовательности операций и/или в одном или нескольких блоках в блок–схемах устройства.
Эти компьютерные программные инструкции могут также храниться в считываемой компьютером памяти, которая может инструктировать компьютер или другие программируемые устройства обработки данных работать конкретным образом, так что инструкции, хранящиеся в считываемой компьютером памяти, генерируют производимый продукт, который включает в себя устройство инструкций. Устройство инструкций реализует функцию, заданную в одном или нескольких процессах в блок–схемах последовательности операций и/или в одном или нескольких блоках в блок–схемах устройств.
Эти компьютерные программные инструкции могут быть загружены на компьютер или другое программируемое устройство обработки данных, приводя к тому, что последовательность операционных этапов выполняется на компьютере или другом программируемом устройстве, тем самым генерируя реализуемую компьютером обработку. Поэтому, инструкции, исполняемые на компьютере или других программируемых устройствах, обеспечивают этапы для реализации функции, заданной в одном или нескольких процессах в блок–схемах последовательности операций и/или в одном или нескольких блоках в блок–схемах устройств.
В типовой конфигурации, вычислительное устройство включает в себя один или несколько процессоров (CPU), интерфейсы ввода/вывода, сетевые интерфейсы и память.
Память может включать в себя считываемые компьютером носители, такие как энергозависимая память, память с произвольным доступом (RAM) и/или энергонезависимая память, например, постоянная память (ROM) или флэш–RAM. Память представляет собой пример считываемого компьютером носителя.
Считываемый компьютером носитель включает в себя постоянные, непостоянные, перемещаемые и неперемещаемые носители, которые обеспечивают хранение информации с использованием любого способа или технологии. Информация может представлять собой считываемые компьютером инструкции, структуры данных, программные модули или другие данные. Примеры компьютерных носителей хранения включают в себя, но без ограничения, памяти с произвольным доступом с изменением фазы (PRAM), статические памяти с произвольным доступом (SRAM), динамические памяти с произвольным доступом (DRAM), другие типы памятей с произвольным доступом (RAM), постоянные памяти (ROM), электрически стираемые программируемые постоянные памяти (EEPROM), флэш–памяти или другие технологии памяти, постоянные памяти на компакт–диске (CD–ROM), цифровые универсальные диски (DVD) или другие оптические памяти, кассеты, кассетные или дисковые памяти или другие магнитные устройства памяти или любые другие не относящиеся к средам передачи носители, которые могут использоваться для хранения информации, доступной для вычислительного устройства. В соответствии с определениями в настоящей спецификации, считываемые компьютером носители не включает в себя переходные носители (среды), такие как модулированные сигналы данных и несущие.
Следует дополнительно отметить, что термины “включающий в себя”, “содержащий” или любые другие варианты этих терминов предназначены, чтобы охватывать не исключающее включение, так что процесс, способ, продукт или устройство, содержащее перечень элементов, не только содержит эти элементы, но также содержит другие элементы, которые не перечислены явно, или дополнительно содержит элементы, которые являются присущими такому процессу, способу, продукту или устройству. Элемент, которому предшествует “содержащий …”, не исключает, без дополнительных ограничений, того, что процесс, способ, продукт или устройство, содержащее вышеуказанные элементы, дополнительно содержит дополнительные идентичные элементы.
Специалисту в данной области техники должно быть понятно, что варианты осуществления настоящей заявки могут быть обеспечены как способ, система или компьютерный программный продукт. Поэтому настоящая заявка может быть реализована как полностью аппаратный вариант осуществления, полностью программный вариант осуществления или вариант осуществления, комбинирующий программное обеспечение и аппаратные средства. Более того, настоящая заявка может быть в форме компьютерного программного продукта, реализованного на одном или нескольких используемых компьютером носителях хранения (включая, но без ограничения, магнитную дисковую память, CD–ROM, оптическую память и т.д.), содержащие используемые компьютером программные коды.
Настоящая заявка может быть описана в обычном контексте исполняемой компьютером инструкции, которая исполняется компьютером, такой как программный модуль. Обычно, программный модуль содержит подпрограмму, программу, объект, компонент, структуру данных и т.д. для исполнения конкретной задачи или реализации специального абстрактного типа данных. Настоящая заявка может также быть реализована в распределенных вычислительных средах. В этих распределенных вычислительных средах, удаленные устройства обработки, соединенные через сети связи, выполняют задачи. В распределенных вычислительных средах, программный модуль может быть расположен в локальных и в удаленных компьютерных носителях хранения, включающих в себя устройства хранения.
Варианты осуществления в настоящей спецификации описаны постепенным образом, причем каждый вариант осуществления фокусируется на отличиях от других вариантов осуществления, и варианты осуществления могут ссылаться друг на друга в отношении идентичных или аналогичных частей. В частности, вариант осуществления системы описан относительно простым образом, так как вариант осуществления системы по существу подобен варианту осуществления способа. В отношении соответствующих частей, ссылки могут даваться на вариант осуществления способа.
Выше описаны только варианты осуществления настоящей заявки, которые не используются для ограничения настоящей заявки. Для специалиста в данной области техники, настоящая заявка может иметь различные модификации и изменения. Любая модификация, эквивалентная замена или усовершенствование, выполненные в пределах сущности и принципа настоящей заявки, должны включаться в пункты формулы изобретения настоящей заявки.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И АППАРАТУРА ДЛЯ ВЕРИФИКАЦИИ СОГЛАСОВАННОСТИ | 2018 |
|
RU2733112C1 |
| СИСТЕМА ВЕРИФИЦИРУЕМОГО ОТСЕЧЕНИЯ РЕЕСТРОВ | 2020 |
|
RU2790181C1 |
| Способ масштабирования распределенной информационной системы | 2018 |
|
RU2686818C1 |
| СИСТЕМА И СПОСОБ ЗАЩИТЫ ИНФОРМАЦИИ | 2018 |
|
RU2719311C1 |
| СПОСОБ И УСТРОЙСТВО ОБРАБОТКИ УСЛУГ | 2018 |
|
RU2725690C1 |
| СПОСОБ И УСТРОЙСТВО ОБРАБОТКИ УСЛУГ И КОНСЕНСУСА | 2018 |
|
RU2735096C1 |
| ИЗОЛЯЦИЯ ДАННЫХ В СЕТИ БЛОКЧЕЙН | 2018 |
|
RU2745518C2 |
| СИСТЕМА И СПОСОБ ЗАЩИТЫ ИНФОРМАЦИИ | 2018 |
|
RU2719423C1 |
| УСЛУГА СМАРТ-КОНТРАКТА ВНЕ ЦЕПОЧКИ НА ОСНОВЕ ДОВЕРЕННОЙ СРЕДЫ ИСПОЛНЕНИЯ | 2018 |
|
RU2729700C1 |
| ПЕРЕКРЕСТНАЯ ТОРГОВЛЯ АКТИВАМИ В СЕТЯХ БЛОКЧЕЙНОВ | 2019 |
|
RU2736447C1 |
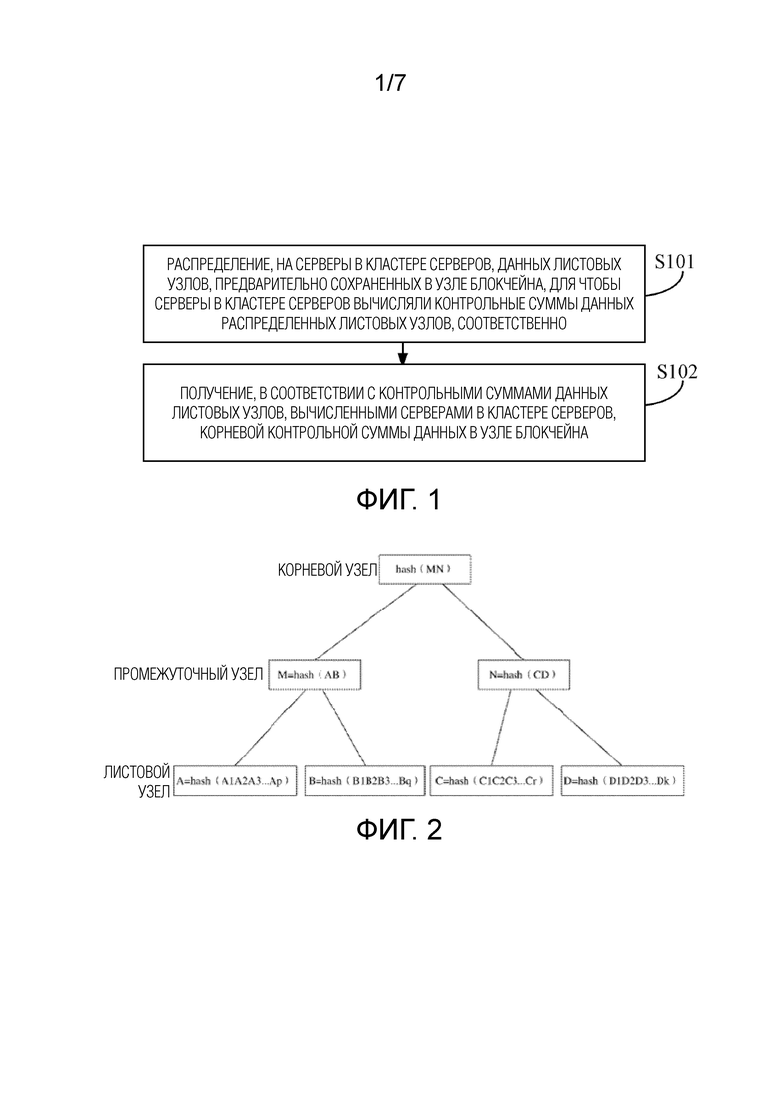
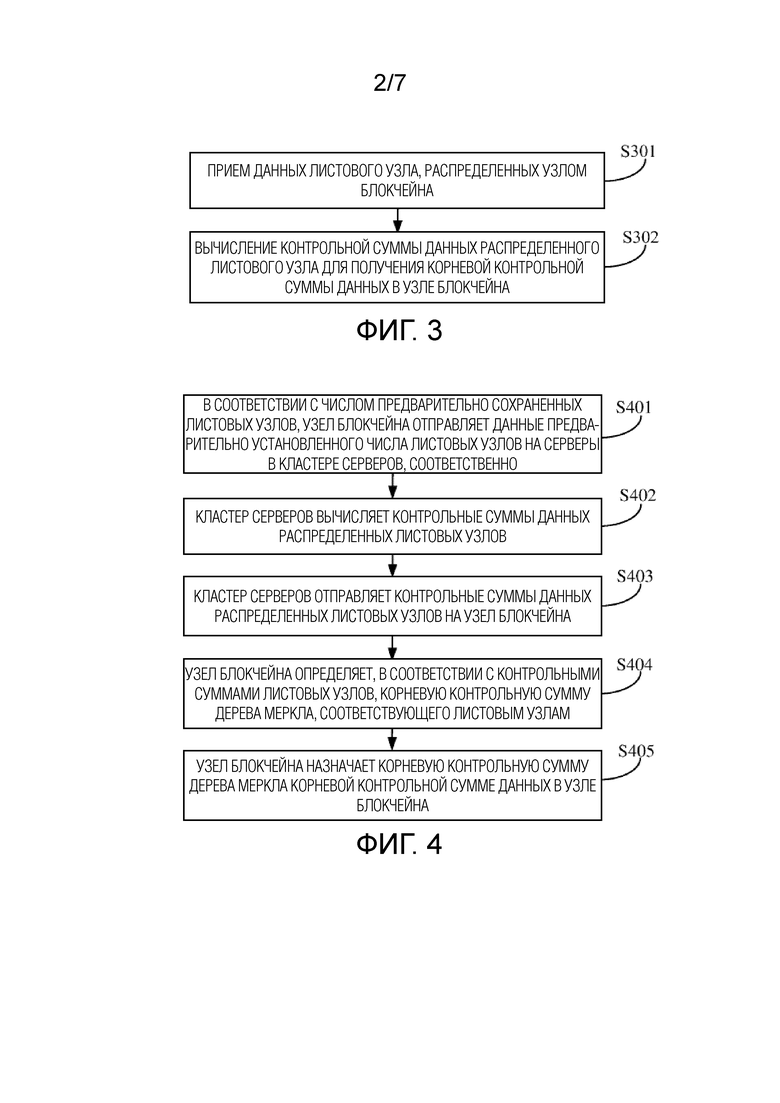
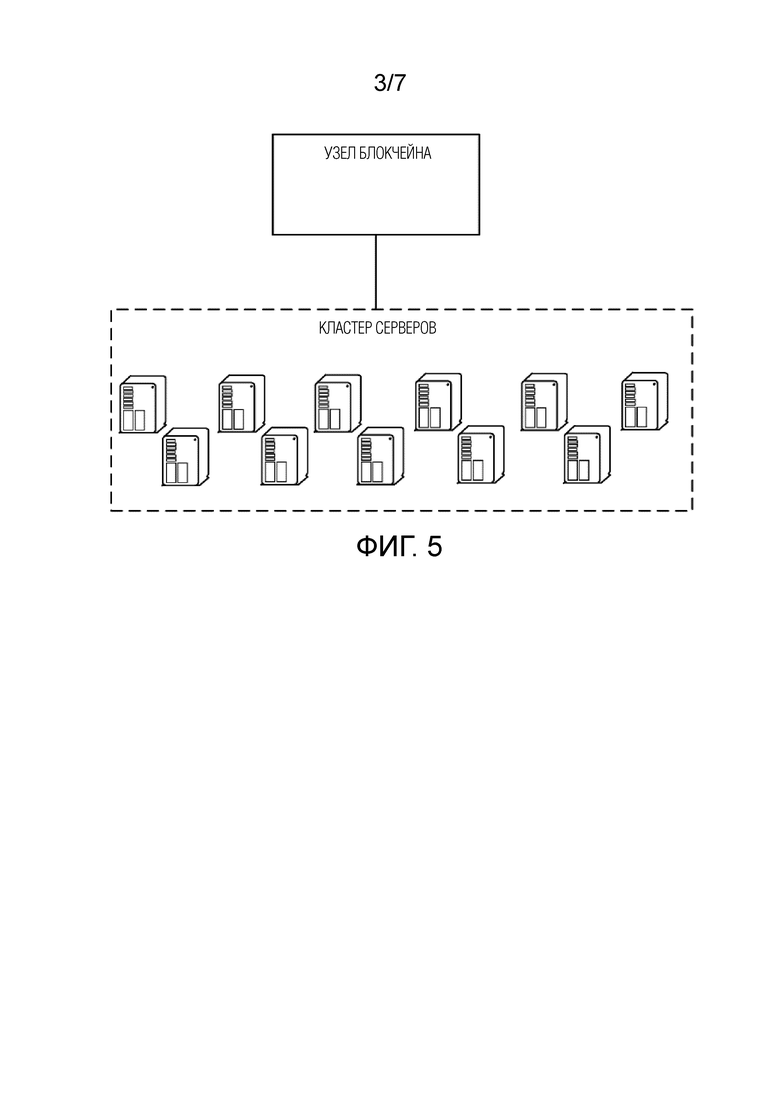
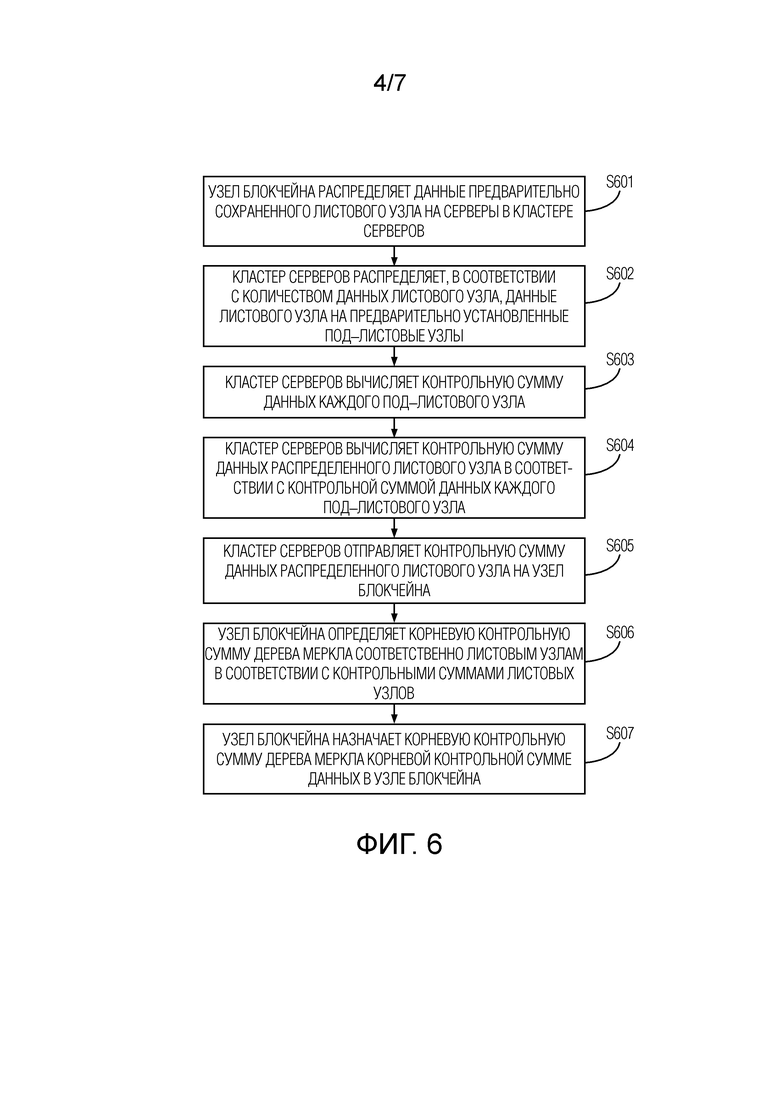
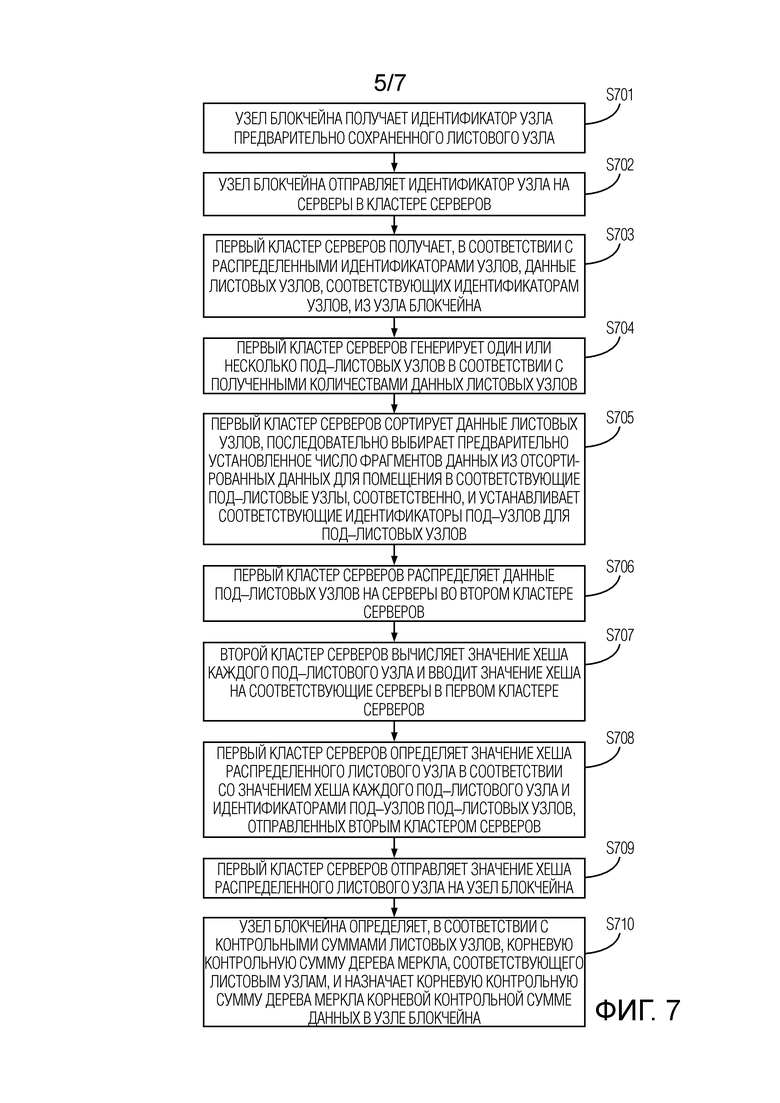
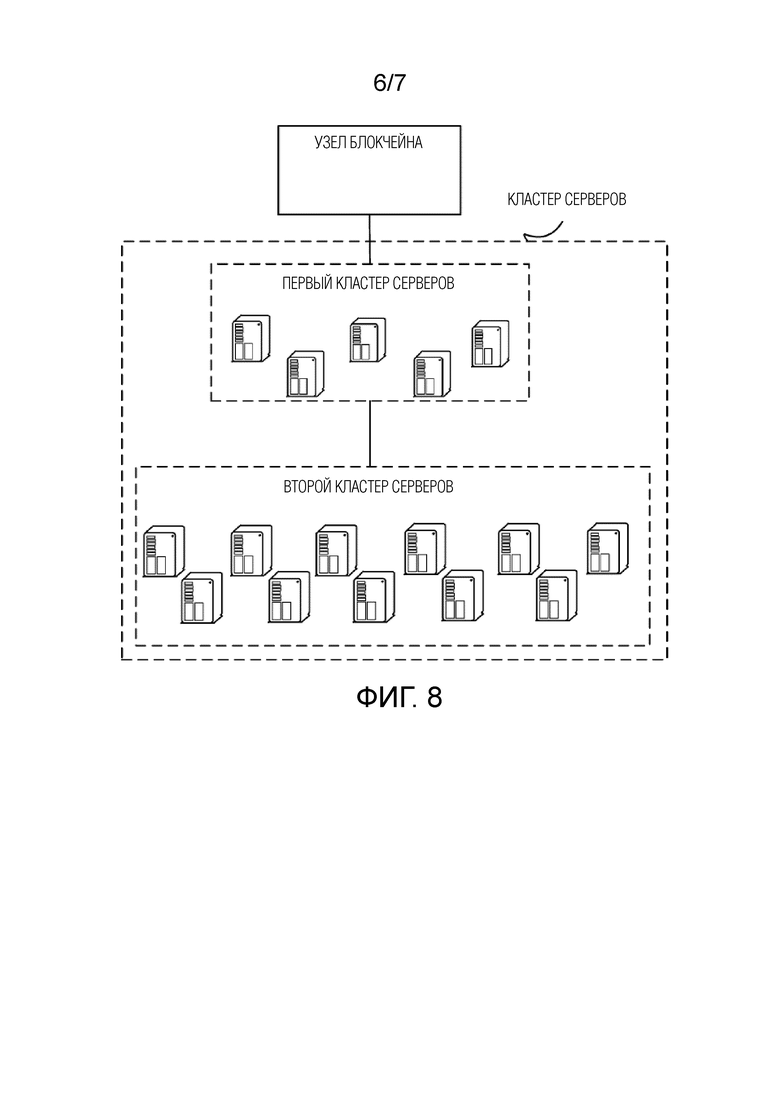
Изобретение относится к обработке данных. Технический результат – повышение вычислительной эффективности. Для этого предусмотрено распределение на серверы в кластере серверов данных листовых узлов, предварительно сохраненных в узле блокчейна, для того чтобы серверы в кластере серверов вычисляли контрольные суммы данных распределенных листовых узлов, соответственно; и получение в соответствии с контрольными суммами данных листовых узлов, вычисленными серверами в кластере серверов, корневой контрольной суммы данных в узле блокчейна. 4 н. и 12 з.п. ф-лы, 10 ил.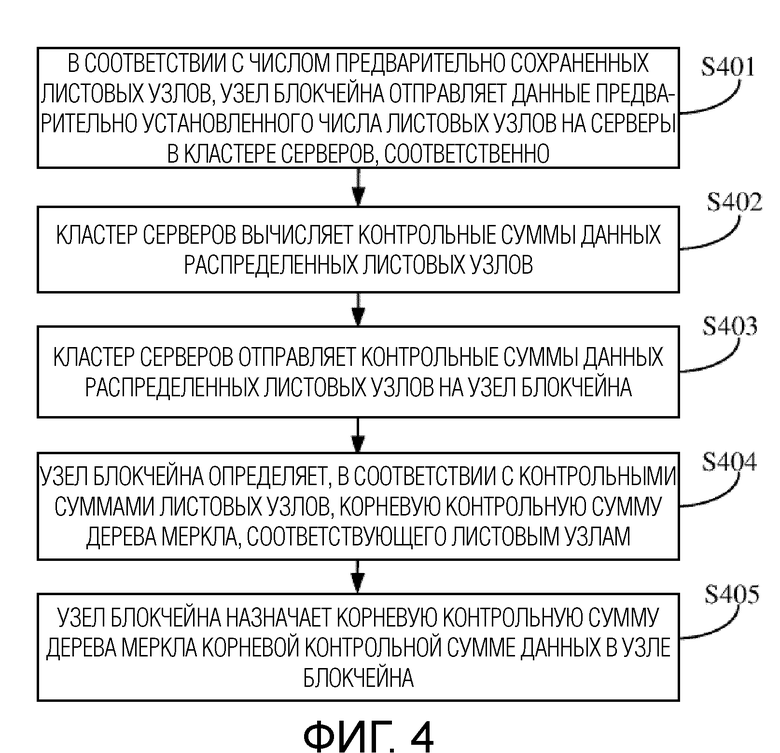
1. Способ обработки данных, содержащий этапы, на которых:
распределяют на серверы в кластере серверов, данные листовых узлов, предварительно сохраненных в узле блокчейна;
устанавливают для каждого из листовых узлов подлистовые узлы;
определяют максимальное количество данных для каждого из подлистовых узлов;
соответственным образом распределяют данные листовых узлов на подлистовые узлы, при этом количество данных каждого из подлистовых узлов соответственно равно или меньше максимального количества данных каждого из подлистовых узлов;
вычисляют контрольную сумму для данных каждого из подлистовых узлов;
вычисляют посредством серверов в кластере серверов и на основе контрольной суммы данных каждого из подлистовых узлов контрольные суммы данных каждого из листовых узлов; и
получают, в соответствии с контрольными суммами данных каждого из листовых узлов, вычисленными серверами в кластере серверов, корневую контрольную сумму данных в узле блокчейна.
2. Способ по п.1, в котором упомянутое получение, в соответствии с контрольными суммами данных листовых узлов, вычисленными серверами в кластере серверов, корневой контрольной суммы данных в узле блокчейна содержит этап, на котором принимают корневую контрольную сумму данных в узле блокчейна, отправленную серверами в кластере серверов.
3. Способ по п.1, в котором упомянутое получение, в соответствии с контрольными суммами данных листовых узлов, вычисленными серверами в кластере серверов, корневой контрольной суммы данных в узле блокчейна содержит этапы, на которых:
определяют, в соответствии с контрольными суммами листовых узлов, корневую контрольную сумму дерева Меркла, соответствующего листовым узлам; и
присваивают корневую контрольную сумму дерева Меркла корневой контрольной сумме данных в узле блокчейна.
4. Способ по п.1, в котором упомянутое распределение, на серверы в кластере серверов, данных листовых узлов, предварительно сохраненных в узле блокчейна, содержит этап, на котором, в соответствии с количеством листовых узлов, предварительно сохраненных в узле блокчейна, соответственно отправляют данные предварительно установленного количества листовых узлов на серверы в кластере серверов.
5. Способ по любому одному из пп.1–4, в котором контрольные суммы представляют собой значения хешей.
6. Способ обработки данных, содержащий этапы, на которых:
принимают, посредством одного из множества серверов в кластере серверов данные листового узла, распределяемого узлом блокчейна;
распределяют, в соответствии с количеством данных листового узла, данные листового узла на множество предварительно установленных подлистовых узлов, при этом количество данных каждого из подлистовых узлов соответственно равно или меньше максимального количества данных каждого из подлистовых узлов;
вычисляют контрольную сумму данных каждого из подлистовых узлов; и
вычисляют, на основе контрольной суммы данных каждого из подлистовых узлов, контрольную сумму данных распределяемого листового узла для получения корневой контрольной суммы данных в узле блокчейна.
7. Способ по п.6, в котором упомянутое распределение, в соответствии с количеством данных листового узла, данных листового узла на множество предварительно установленных под–листовых узлов содержит этапы, на которых:
сортируют данные листового узла;
последовательно выбирают предварительно установленное число фрагментов данных из отсортированных данных для помещения в подлистовые узлы; и
устанавливают соответствующие идентификаторы подузлов для подлистовых узлов,
причем при упомянутом вычислении контрольной суммы данных распределяемого листового узла в соответствии с контрольной суммой данных каждого подлистового узла контрольную сумму данных распределяемого листового узла вычисляют в соответствии с идентификаторами подузлов подлистовых узлов и контрольной суммой каждого из подлистовых узлов.
8. Способ по п.6, в котором упомянутое вычисление контрольной суммы данных распределяемого листового узла для получения корневой контрольной суммы данных в узле блокчейна содержит этапы, на которых:
вычисляют контрольную сумму данных распределяемого листового узла и отправляют контрольную сумму данных распределяемого листового узла в узел блокчейна, с тем чтобы узел блокчейна вычислял корневую контрольную сумму данных в узле блокчейна в соответствии с контрольной суммой данных листового узла; или
вычисляют контрольную сумму данных распределяемого листового узла, получают корневую контрольную сумму данных в узле блокчейна на основе контрольной суммы данных распределяемого листового узла и отправляют корневую контрольную сумму в узел блокчейна.
9. Устройство обработки данных, содержащее:
модуль распределения данных, выполненный с возможностью распределять на серверы в кластере серверов данные листовых узлов, предварительно сохраненных в узле блокчейна, с тем чтобы серверы в кластере серверов соответственно вычисляли контрольные суммы данных распределяемых листовых узлов, при этом модуль распределения данных дополнительно выполнен с возможностью распределять, в соответствии с количеством данных каждого из листовых узлов, данные каждого из листовых узлов на множество предварительно установленных подлистовых узлов, причем количество данных каждого из подлистовых узлов соответственно равно или меньше максимального количества данных каждого из подлистовых узлов; и
модуль получения корневой контрольной суммы, выполненный с возможностью получать, в соответствии с контрольными суммами данных листовых узлов, вычисленными серверами в кластере серверов, корневую контрольную сумму данных в узле блокчейна, при этом контрольные суммы данных листовых узлов вычисляются на основе контрольной суммы данных каждого из подлистовых узлов.
10. Устройство по п.9, в котором модуль получения корневой контрольной суммы выполнен с возможностью принимать корневую контрольную сумму данных в узле блокчейна, отправленную серверами в кластере серверов.
11. Устройство по п.9, в котором модуль получения корневой контрольной суммы выполнен с возможностью определять в соответствии с контрольными суммами листовых узлов корневую контрольную сумму дерева Меркла, соответствующего листовым узлам, и присваивать корневую контрольную сумму дерева Меркла корневой контрольной сумме данных в узле блокчейна.
12. Устройство по п.9, в котором модуль распределения данных выполнен с возможностью, в соответствии с количеством листовых узлов, предварительно сохраненных в узле блокчейна, соответственно отправлять данные предварительно установленного количества листовых узлов на серверы в кластере серверов.
13. Устройство по любому одному из пп.9–12, при этом контрольные суммы представляют собой значения хешей.
14. Устройство обработки данных, содержащее:
модуль приема данных, выполненный с возможностью принимать данные листового узла, распределяемого узлом блокчейна;
модуль распределения данных, выполненный с возможностью распределять, в соответствии с количеством данных листового узла, данные листового узла на множество предварительно установленных подлистовых узлов, причем количество данных каждого из подлистовых узлов соответственно равно или меньше максимального количества данных каждого из подлистовых узлов;
модуль вычисления, выполненный с возможностью вычислять контрольную сумму данных каждого из подлистовых узлов; и
модуль получения контрольной суммы, выполненный с возможностью вычислять, на основе контрольной суммы данных каждого из подлистовых узлов, контрольную сумму данных распределяемого листового узла для получения корневой контрольной суммы данных в узле блокчейна.
15. Устройство по п.14, в котором модуль распределения данных выполнен с возможностью сортировать данные листового узла, последовательно выбирать предварительно установленное число фрагментов данных из отсортированных данных для помещения в подлистовые узлы и устанавливать соответствующие идентификаторы подузлов для подлистовых узлов,
при этом модуль получения контрольной суммы выполнен с возможностью вычислять контрольную сумму данных распределяемого листового узла в соответствии с идентификаторами подузлов подлистовых узлов и контрольной суммой каждого из под–листовых узлов.
16. Устройство по п.14, в котором модуль получения контрольной суммы выполнен с возможностью:
вычислять контрольную сумму данных распределяемого листового узла и отправлять контрольную сумму данных распределяемого листового узла в узел блокчейна, с тем чтобы узел блокчейна вычислял корневую контрольную сумму данных в узле блокчейна в соответствии с контрольной суммой данных листового узла; или
вычислять контрольную сумму данных распределяемого листового узла, получать корневую контрольную сумму данных в узле блокчейна на основе контрольной суммы данных распределяемого листового узла и отправлять корневую контрольную сумму в узел блокчейна.
| WO 2016131576 A1, 25.08.2016 | |||
| CN 105719185 A, 29.06.2016 | |||
| US 5924094 A1, 13.07.1999 | |||
| СПОСОБ СТРУКТУРИЗАЦИИ ХРАНЯЩИХСЯ ОБЪЕКТОВ В СВЯЗИ С ПОЛЬЗОВАТЕЛЕМ НА СЕРВЕРЕ И СЕРВЕР | 2014 |
|
RU2580425C1 |
| СИСТЕМА УПРАВЛЕНИЯ ИНДЕКСАЦИЕЙ ПАРТНЕРСКИХ ОБЪЯВЛЕНИЙ | 2013 |
|
RU2609078C2 |

