Область техники, к которой относится изобретение
Настоящее изобретение относится к способу и устройству для обработки видео и аудиосигналов и к программе и, в частности, к способу и устройству для обработки видео и аудиосигналов и программе, каждый из которых позволяет более точно разделить и упростить воспроизведение требуемого аудио объекта.
Уровень техники
В последние годы для воспроизведения кинофильмов, игр и тому подобного была использована технология воспроизведения аудио объекта и была разработана система кодирования для обработки аудиосигнала объекта. Например, группа экспертов по движущимся изображениям (MPEG)-H часть 3: стандарт 3D аудио или тому подобное в качестве международного стандарта известен как стандарт о кодирования аудио объекта (например, см. NPL 1).
Такая система кодирования вместе с многоканальной стереосистемой, такой как предшествующая двухканальная стереосистема или 5.1 канальная система в прошлом, может обрабатывать движущийся источник звука или тому подобный, в качестве независимого аудио объекта и может кодировать информацию местоположения, ассоциированную с аудио объектом, вместе с сигнальными данными аудио объекта в виде метаданных. Принимая такой подход, можно легко выполнить процесс обработки конкретного источника звука во время воспроизведения, который сложно было выполнить посредством унаследованной системы кодирования. В частности, например, в качестве процесса обработки конкретного источника звука, операция регулировки уровня громкости, добавление эффекта и тому подобное, может быть выполнена с каждым аудио объектом.
При использовании такого процесса кодирования аудиосигнала объекта, например, при фотографировании движущегося изображения камкордером, смартфоном или тому подобным, тогда голоса членов семьи в качестве цели фотографирования записывают как звуковой объект и звук, отличный от звукового объекта записывают как фоновый звук. В результате, после фотографирования, во время воспроизведения или во время редактирования, голоса членов семьи могут быть обработаны независимо.
Однако в случае, когда получают звуковой объект с помощью мобильного устройства, такого как камкордер или смартфон, нелегко автоматически определить, что должно быть записано как звуковой объект, и что должно быть записано в качестве фонового звука, принимая во внимание параметры вычислительного ресурса или пользовательского интерфейса.
Дополнительно, ранее были предложены различные технологии разделения источника звука в качестве способа разделения звукового объекта. Например, был предложен способ разделения источника звука с использованием множества микрофонов и независимого анализа основных компонентов и т.п. (например, ссылка на PTL 1).
Список цитирования
Непатентная литература
NPL 1
МЕЖДУНАРОДНЫЙ СТАНДАРТ ISO/IEC 23008-3 первое издание 2015-10-15 Информационные технологии. Высокоэффективное кодирование и доставка мультимедиа в гетерогенных средах. Часть 3. 3D-аудио
Патентная литература
PTL 1
Выложенный патент Японии № 2010-233173
Сущность изобретения
Техническая задача
Тем не менее, каждый из этих способов разделения источников звука адаптивно отделяет источник звука от входного звукового сигнала из микрофона, и звук, отличный от звука целевого объекта съемки практически присутствует во многих случаях. Поэтому затруднительно просто и точно отделить требуемый звуковой объект.
Настоящее изобретение было выполнено в свете такой ситуации и позволяет более просто и точно отделить требуемый звуковой объект.
Решение технической задачи
Устройство для обработки видео и аудиосигналов по аспекту настоящего изобретения снабжено частью управления отображением, выполненной с возможностью вызывать отображение видео объекта на основании видеосигнала, частью выбора объекта, выполненной с возможностью выбирать заданный видео объект из одного видео объекта или среди множества видео объектов и частью извлечения, выполненной с возможностью извлекать аудиосигнал видео объекта, выбранного частью выбора объекта, в качестве аудиосигнала объекта.
Часть извлечения может извлекать аудиосигнал объекта из аудиосигнала.
Часть извлечения может извлекать сигнал, отличный от аудиосигнала объекта выбранного видео объекта, в качестве фонового звукового сигнала из аудиосигнала.
Часть выбора объекта может производить информацию местоположения объекта, отображающую позицию выбранного видео объекта в пространстве, и может вызывать часть извлечения извлекать аудиосигнал объекта на основании информации местоположения объекта.
Часть извлечения может извлекать аудиосигнал объекта путем разделения источника звука с использованием информации местоположения объекта.
Часть извлечения может выполнять формирование фиксированного луча в качестве разделения источника звука.
Устройство для обработки видео и аудиосигналов может быть дополнительно снабжено частью распознавания видео объекта, выполненной с возможностью распознавать видео объект на основании видеосигнала, и частью управления отображением, выполненной с возможностью отображать изображение на основании результата распознавания видео объекта вместе с видео объектом.
Часть распознавания видео объекта может распознавать видео объект посредством распознавания лиц.
Часть управления отображением может отображать рамку в виде изображения в области видео объекта.
Часть выбора объекта может выбирать видео объект в ответ на манипуляцию выбора пользователем.
Часть выбора объекта может производить метаданные выбранного видео объекта.
Часть выбора объекта может производить информацию местоположения объекта, в качестве метаданных, указывающую позицию выбранного видео объекта в пространстве.
Часть выбора объекта может производить данные приоритета обработки выбранного видео объекта в качестве метаданных.
Часть выбора объекта может производить информацию распределения, показывающую, как распределена область выбранного видео объекта в качестве метаданных.
Устройство для обработки видео и аудисигналов может быть дополнительно снабжено частью кодирования аудиосигнала, выполненной с возможностью кодировать аудиосигнал объекта и метаданные.
Устройство для обработки видео и аудисигналов может быть дополнительно снабжено частью кодирования видео, выполненной с возможностью кодировать видеосигнал, и частью мультиплексирования, выполненной с возможностью мультиплексировать битовый поток видео, полученный посредством кодирования видеосигнала, и битовый поток аудио, полученный путем кодирования аудиосигнала объекта, и метаданные.
Устройство для обработки видео и аудисигналов может быть дополнительно снабжено частью захвата изображения, выполненной с возможностью получать видеосигнал путем фотографирования.
Также может быть дополнительно предоставлена часть получения звука, выполненной с возможностью получать аудиосигнал путем осуществления получения звука.
Способ обработки видео и аудисигналов или программа одного аспекта настоящего изобретения включает в себя: этап управления отображением для отображения видео объекта на основании видеосигнала; этап выбора объекта для выбора заданного видео объекта из одного видео объекта или из множества видео объектов; и этап извлечения для извлечения аудиосигнала видео объекта, выбранного на этапе выбора объекта, в качестве аудиосигнала объекта.
В одном аспекте настоящего изобретения отображают видео объект на основании видеосигнала, выбирают заданный видео объект из одного видео объекта или из множества видео объектов и извлекают аудиосигнал выбранного видео объекта как сигнал аудиосигнал объекта.
Полезный эффект изобретения
Согласно одному аспекту настоящего изобретения можно более просто и точно разделить требуемый звук объекта.
Следует отметить, что описанный выше эффект не обязательно ограничен, и может быть получен любой из эффектов, описанных в настоящем изобретении.
Краткое описание чертежей
Фиг. 1
Блок-схема изображает пример конфигурации устройства для обработки видео и аудиосигналов.
Фиг. 2 Блок-схема изображает конкретный пример конфигурации устройства для обработки видео и аудиосигналов.
Фиг. 3
Блок-схема алгоритма иллюстрирует процесс кодирования.
Фиг. 4
Вид поясняет алгоритм выбора аудио объекта и отображение изображения прямоугольной рамки.
Фиг. 5
Вид поясняет систему координат информации местоположения объекта.
Фиг. 6
Вид поясняет взаимосвязь между объектом, линзой и поверхностью изображения.
Фиг. 7
Вид поясняет расчет информации местоположения объекта.
Фиг. 8
Таблица показывает синтаксис метаданных, включающие в себя информацию местоположения объекта.
Фиг. 9
Таблица показывает синтаксис метаданных, включающие в себя данные приоритета обработки.
Фиг. 10
Вид поясняет установку приоритета обработки.
Фиг. 11
Таблица показывает синтаксис метаданных, включающие в себя информацию распространения.
Фиг. 12
Вид поясняет расчет информации распространения.
Фиг. 13
Вид поясняет расчет информации распространения.
Фиг. 14
Блок-схема изображает пример конфигурации компьютера.
Описание вариантов осуществления
Далее со ссылкой на чертежи будут описаны варианты осуществления, к каждому из которых применяют настоящее изобретение.
<Первый вариант осуществления>
<Пример конфигурации устройства для обработки видео и аудиосигналов>
В соответствии с настоящим изобретением используют способ распознавания объекта, такой как способ распознавания лиц, с движущимся изображением в качестве цели, результат распознавания представлен пользователю устройства на устройстве отображения, пользователь устройства разделяет звук в направлении, соответствующем объекту, выбранному на основании результата распознавания в качестве объекта звука. Дополнительно, звук, отличный от данного звука, кодируют с использованием технологии кодирования аудио объекта.
Фиг.1 представляет собой блок-схему, изображающую пример конфигурации варианта осуществления устройства для обработки видео и аудиосигналов, к которому применяют настоящее изобретение.
Устройство 11 для обработки видео и аудиосигналов, изображенное на фиг. 1, имеет часть 21 захвата изображения, часть 22 распознавания видео объекта, часть 23 управления отображением результата распознавания видео объекта, часть 24 отображения видео, часть 25 выбора объекта, часть 26 получения звука, часть 27 разделения источника звука, часть 28 кодирования аудио, часть 29 кодирования видео и часть 30 мультиплексирования.
Часть 21 захвата изображения, например, включает в себя блок захвата изображения, включающий в себя элемент захвата изображения, линзу и тому подобное. Часть 21 захвата изображения фотографирует объект и подает видеосигнал результирующего движущегося изображения, полученного в результате фотографирования, на каждую часть 22 распознавания видео объекта и часть 29 кодирования видео.
Часть 22 распознавания видео объекта распознает видео объект на движущемся изображении на основании видеосигнала, подаваемого на него из части 21 захвата изображения, и поставляет результат распознавания вместе с видеосигналом в часть 23 управления отображением результата распознавания объекта видео объекта.
В части 22 распознавания видео объекта распознают (обнаруживают) видео объект на движущемся изображении на основании распознавания лиц, распознавания объекта, захвата движения или тому подобного.
Например, в патенте Японии №4492036 подробно описывают технологию распознавания объекта с использованием известного изображения. Такая технология распознавания объекта с использованием известного изображения стало реалистично доступным способом наряду с развитием новейших технологий машинного обучения и облачной сети. Используя такую технологию распознавания объекта, распознают произвольный объект, результат распознавания представляют пользователю устройства. В результате, нецелевой аудиосигнал из положения объекта, который выбран пользователем устройства, может быть извлечен в качестве сигнала аудио объекта.
Блок 23 управления отображением результата распознавания видео объекта управляет отображением движущегося изображения в части 24 отображения видео на основании результата распознавания видео объекта, и видеосигнала, который поставляют из части 22 распознавания видео объекта. То есть, блок 23 управления отображением результата распознавания видео объекта поставляет видеосигнал в часть 24 отображения видео, чтобы вызвать часть 24 отображения видео отображать на нем движущееся изображение и наложить/отобразить информацию, указывающую позицию видео объекта на движущемся изображении на основании результата распознавания видео объекта.
Дополнительно, блок 23 управления отображением результата распознавания видео объекта поставляет результат распознавания видео объекта в часть 25 выбора объекта.
Часть 24 отображения видео, например, включает в себя жидкокристаллическую панель или тому подобное, и отображает на ней изображение, такое как движущееся изображение, в соответствии с операцией управления, выполненной частью 23 управления отображением результата распознавания видео объекта.
Дополнительно, когда результат распознавания видео объекта, т.е., информация, указывающая позицию видео объекта, отображается вместе с движущимся изображением (видео) на части 24 отображения видео, пользователь устройства выполняет манипуляцию для указания требуемого видео объекта. Затем, в часть 25 выбора объекта подают сигнал, указывающий результат заданной манипуляции пользователем устройства.
Часть 25 выбора объекта выдает информацию местоположения объекта, указывающую позицию в трехмерном пространстве видео объекта, выбранного пользователем устройства, на основании как поставленного результата распознавания видео объекта из части 23 управления отображением результата распознавания видео объекта, так и сигнала, поставленного в ответ на заданную манипуляцию для видео объекта пользователем устройства. Часть 25 выбора объекта поставляет результирующую информацию местоположения объекта в каждую часть 27 разделения источника звука и часть 28 кодирования звука.
Часть 26 получения звука, например, включает в себя микрофон и захватывает звук окружающей обстановки устройства 11 для обработки видео и аудиосиналов и поставляет результирующий аудиосигнал в часть 27 разделения источника звука. В устройстве 11 для обработки видео и аудиосигналов получают контент, включающий в себя движущееся изображение, сфотографированное частью 21 захвата изображения, и голосовой сигнал, полученный частью 26 получения звука. То есть, аудиосигнал, полученный в части 26 получения звука, представляет собой голосовой сигнал, ассоциированный с видеосигналом, полученным в части 21 захвата изображения.
Часть 27 разделения источника звука выполняет разделение источника звука для подаваемого на него аудиосигнала из части 26 получения звука на основании информации местоположения объекта, поданной из части 25 выбора объекта.
Выполняя разделение источника звука в части 27 разделения источника звука, аудиосигнал, полученный в части 26 получения звука, разделяют на аудиосигнал объекта в качестве голосового сигнала видео объекта, выбранного пользователем устройства, и голосового сигнала, отличного от голосового сигнала видео объекта, выбранного пользователем устройства, т.е. фоновый звуковой сигнал в качестве сигнала фонового звука. В этом случае, голосовой сигнал видео объекта, выбранного пользователем устройства, разделяют (извлекают) как звук объекта, словом, аудиосигнал объекта в качестве голосового сигнала аудио объекта.
Часть 27 разделения источника звука поставляет аудиосигнал объекта и фоновый звуковой сигнал, которые получают посредством разделения источника звука, в часть 28 кодирования аудио.
Часть 28 кодирования аудио кодирует аудиосигнал объекта и фоновый звуковой сигнал, которые подают него из части 27 разделения источника звука, и информацию местоположения объекта, которую подают из части 25 выбора объекта, и подает результирующий битовый поток аудио в часть 30 мультиплексирования.
Часть 29 кодирования видео кодирует видеосигнал, подаваемый из части 21 захвата изображения, и поставляет результирующий битовый поток видео в часть 30 мультиплексирования. Часть 30 мультиплексирования мультиплексирует битовый поток видео, поданный из части 29 кодирования видеосигнала, и битовый поток аудио, подаваемого из части 28 кодирования аудио, для получения выходного битового потока в качестве конечный выходных данных. Часть 30 мультиплексирования выводит выходной битовый поток, полученный таким образом.
<Пример конфигурации устройства для обработки видео и аудиосигналов>
Устройство 11 для обработки видео и аудиосигналов, изображенное на фиг. 1, представляет общий вариант осуществления. В дальнейшем, однако, с целью изложения более конкретного описания будет дано описание в отношении технологии распознавания видео объекта в части 22 распознавания видео объекта в случае применения технологии распознавания лиц, в качестве конкретного примера.
В этом случае, устройство 11 для обработки видео и аудиосигналов, например, сконфигурировано, как показано на фиг.2. Следует отметить, что на фиг.2, части, соответствующие тем, которые показаны на фиг.1, соответственно, обозначены одинаковыми ссылочными позициями, и описание здесь опущено.
Устройство 61 для обработки видео и аудиосигналов, изображенное на фиг. 2, имеет часть 21 захвата изображения, часть 71 распознавания лица, часть 72 управления отображением результата распознавания лица, часть 73 отображения видео, часть 74 выбора человека, часть 26 получения звука, часть 27 разделения источника звука, часть 28 кодирования аудио, часть 29 кодирования видео и часть 30 мультиплексирования.
Конфигурация устройства 61 для обработки видео и аудиосигналов отличается от устройства 11 для обработки видео и аудиосигналов тем, что часть 71 распознавания лица до части 74 выбора человека используют вместо части 22 распознавания видео объекта до части 25 выбора объекта, и устройство 61 для обработки видео и аудиосигналов имеет такую же конфигурацию в других местах, что и в устройстве 11 для обработки видео и аудиосигналов.
Часть 71 распознавания лица соответствует части 22 распознавания видео объекта, изображенной на фиг.1. Часть 71 распознавания лица выполняет обработку распознавания лица для видеосигнала, подаваемого из части 21 захвата изображения, чтобы распознавать лицо человека на движущемся изображении, и поставляет результат распознавания вместе с видеосигналом в часть 72 управления отображением результата распознавания лица. То есть, в части 71 распознавания лица распознают (обнаруживают) лицо человека в качестве видео объекта на основании видеосигнала.
Часть 72 управления отображением результата распознавания лица соответствует части 23 управления отображением результата распознавания видео объекта, изображенной на фиг.1. Часть 72 управления отображением результата распознавания лица управляет отображением движущегося изображения в части 73 отображения видео на основании результата распознавания лица и видеосигнала, который подают из части 71 распознавания лица. То есть, часть 72 управления отображением результата распознавания лица поставляет видеосигнал в часть 73 отображения видео, чтобы вызвать часть 73 отображения видео отображать движущееся изображение контента. Дополнительно, часть 72 управления отображением результата распознавания лица вызывает часть 73 отображения видео наложить/отобразить на нем информацию, указывающую позицию человека в качестве видео объекта на движущемся изображении.
Дополнительно, часть 72 управления отображением результата распознавания лица поставляет результат распознавания лица в часть 74 выбора человека.
Часть 73 отображения видео, например, включает в себя жидкокристаллическую панель дисплея или тому подобное, и соответствует части 24 отображения видео, изображенной на фиг.1. Часть 73 отображения видео отображает на ней изображение, такое как движущееся изображение или тому подобное, в соответствии с операцией управления, выполненной частью 72 управления отображением результата распознавания лица.
Дополнительно, часть 73 отображения видео имеет сенсорную панель 81, отображаемую на дисплее посредством наложения в виде изображения на экране дисплея, и сенсорная панель 81 подает сигнал, реагирующий на манипуляцию пользователем устройства, в часть 74 выбора человека. Следует отметить, что, хотя в этом случае, будет дано описание в отношении примера, в котором пользователь устройства манипулирует сенсорной панелью 81, тем самым, выполняя различные виды ввода, в противном случае, используют устройство ввода, такое как мышь, кнопка, клавиатура или тому подобное, тем самым, выполняя манипуляцию ввода.
Когда результат распознавания лица, т.е., информация, указывающая позицию лица человека в качестве видео объекта, отображается вместе с движущимся изображением (видео) на части 73 отображения видео, пользователь устройства выполняет манипуляции на сенсорной панели 81 для указания требуемого человека. Затем, результат выбора человека (лица) пользователем устройства подается с сенсорной панели 81 в часть 74 выбора человека.
Часть 74 выбора человека соответствует части 25 выбора объекта, изображенной на фиг.1. Часть 74 выбора человека выбирает человека, выбранного пользователем устройства, т.е., видео объект, на основании результата распознавания лица, поданного из части 72 управления отображением результата распознавания лица, и результат выбора человека подается с сенсорной панели 81 и производит информацию местоположения объекта, указывающую позицию в трехмерном пространстве этого видео объекта.
Дополнительно, часть 74 выбора человека поставляет результат выбора человека пользователем устройства в часть 73 отображения видео и вызывает часть 73 отображения видео отображать на ней заданное отображение. В результате, часть 74 выбора человека приводит к тому, что результат выбора человека, выполняемый самим пользователем устройства, подтверждается пользователем устройства.
Часть 74 выбора человека поставляет информацию местоположения объекта, полученную в отношении человека, выбранного пользователем устройства, в каждую часть 27 разделения источника звука и часть 28 кодирования аудио.
<Описание процесса кодирования>
Далее будет описана работа устройства 61 для обработки видео и аудиосигналов. То есть в дальнейшем будет дано описание процесса кодирования, выполняемого устройством 61 для обработки видео и аудиосигналов, со ссылкой на блок-схему последовательности операций, показанную на фиг.3.
Например, когда устройство 61 для обработки видео и аудиосигналов получает от пользователя устройства указания сфотографировать изображения голосом в качестве контента, начинают выполнять процесс кодирования. Следует отметить, что, хотя в этом случае, случай, когда движущееся изображение (видео) фотографируют как изображение контента, будет описано в качестве примера, также в дальнейшем движущееся изображение будет просто обозначаться как изображение контента.
При инициировании фотографирования, часть 21 захвата изображения фотографирует объект и последовательно поставляет результирующие видеосигналы в каждую часть 71 распознавания лица и часть 29 кодирования видео. Дополнительно, часть 26 получения звука получает голосовой сигнал и последовательно подает результирующие аудиосигналы в часть 27 разделения источника звука.
На этапе S11 часть 71 распознавания лица определяет лицо человека из изображения контента на основании видеосигнала на основе видеосигнала, подаваемого из части 21 захвата изображения, и поставляет результат обнаружения и видеосигнал в часть 72 управления отображением результата распознавания лица.
Например, часть 71 распознавания лица выполняет обработку распознавания лиц с использованием признака величины, словаря или подобного для видеосигнала, тем самым, обнаруживая лицо человека из изображения. В этом случае, например, распознают (обнаруживают) позицию лица человека на изображении, размер области лица этого человека и т.п. Человек на изображении контента, конкретно, лицо человека, устанавливают как видео объект.
На этапе S12 блок 72 управления отображением результата распознавания лица генерирует сигнал для изображения прямоугольной рамки, используемый для отображения прямоугольных рамок, окружающих соответствующие лица в областях обнаруженных лиц на изображении контента на основании результата обнаружения лица и видеосигнала, которые подают из части 71 распознавания лица.
Следует отметить, что необходимо только, чтобы изображение прямоугольной рамки представляло собой изображение, в котором рамка, окружающая, по меньшей мере, часть области, отображалась в области лица человека в качестве видео объекта, и вся область лица не обязательно ограничено прямоугольной рамкой.
Кроме того, блок 72 управления отображением результата распознавания лица поставляет информацию позиции лица, указывающую позицию отображения и размер изображения прямоугольной рамки, сформированного каждым лицом человека, т.е., позицию и размер области лица человека на изображении в часть 74 выбора человека.
На этапе S13 блок 72 управления отображением результата распознавания лица поставляет сигнал, ассоциированный со сформированным изображением прямоугольной рамки и видеосигнал контента в часть 73 отображения видео. Дополнительно, часть 72 управления отображением результата распознавания лица управляет частью 73 отображения видео таким образом, чтобы отображалось изображение контента, в котором изображение прямоугольной рамки накладывается/отображается на область лица человека.
В результате, изображение прямоугольной рамки в виде изображения на основании результата распознавания видео объекта отображается вместе с изображением контента, одним словом, видео объект на основании видеосигнала отображается на дисплее части 73 отображения видео.
Кстати, в отношении технологии распознавания лиц для обнаружения лица человека из изображения контента были предложены различные технологии. Например, патент Японии № 4264663 (далее также упоминается, как ссылочный литературный документ 1) или тому подобное подробно описывает технологию распознавания лица. Справочный литературный документ 1 описывает, что осуществляют распознавание лица, и изображение прямоугольной рамки накладывают на отображение на основании результата распознавания.
Технология распознавания лица в части 71 распознавания лица или технология отображения наложения изображения прямоугольной рамки посредством части 72 управления отображением результата распознавания лица можно рассматривать как аналогичную технологию, описанную в справочном литературном документе 1. Однако любая технология может также быть доступна до тех пор, пока лицо человека будет распознано, и может быть отображено, окружающая область распознанного лица. Дополнительно, хотя в этом случае, например, описан пример, в котором отображено изображение прямоугольной рамки, отображение никоим образом не ограничено изображением прямоугольной рамки и, таким образом, контур лица человека может быть выделен и отображен или форма изображения может иметь другое очертание, которое может отображаться наложением, пока результат распознавания лица может отображаться на изображении контента, особенно, отображаемом в позиции лица.
При таком отображении изображения контента отображается на части 73 отображения видео, изображение прямоугольной рамки отображается в области лица человека на изображении контента, пользователь устройства, т.е., пользователь, который манипулирует устройством 61 для обработки видео и аудиосигналов, манипулирует сенсорной панелью 81, чтобы выбрать требуемого человека в качестве аудио объекта.
Например, выбор требуемого человека определен указанием изображения прямоугольной рамки, отображаемой в области лица соответствующего человека. Дополнительно, пользователь может выбрать только человека или может выбрать несколько человек из одного человека или нескольких человек (видео объектов), которые отображены в части 73 отображения видео.
В устройстве 61 для обработки видео и аудиосигналов генерируют голосовой сигнал, человеком, выбранным таким образом, т.е., из видео объекта устанавливается как звуковой сигнал объекта. Затем сигнал звукового сигнала объекта извлекают как аудиосигнал объекта из аудиосигнала. Поэтому выбор человека в качестве видео объекта можно назвать манипуляцией для выбора требуемого человека в качестве аудио объекта.
Когда пользователь устройства выбирает требуемого человека, сигнал, реагирующий на манипуляцию выбора пользователем устройства, подается из сенсорной панели 81 в часть 74 выбора человека.
На этапе S14 часть 74 выбора человека выбирает звуковой сигнал объекта, указанный пользователем устройства, на основании сигнала, реагируя на манипуляцию выбора пользователем устройства, который подается из сенсорной панели 81, и информацию позиции лица, поставленную из блока 72 управления отображением результата распознавания лица.
На этапе S15 часть 74 выбора человека управляет частью 73 отображения видео на основании результата выбора аудио объекта на этапе S14 таким образом, что часть 73 отображения видео отображает выделенное изображение прямоугольной рамки, отображаемого в области лица человека, выбранного в качестве аудио объекта, т.е., выбранного изображения прямоугольной рамки.
Например, как показано на фиг.4, предполагают, что изображение контента, в котором находятся три человека HM11-HM13 в качестве субъектов, отображается в части 73 отображения видео.
В этом примере на этапе S11 обнаружены лица HM11-HM13, и на этапе S13 с изображения FR11 прямоугольной рамки по изображение FR13 прямоугольной рамки представляет собой отображаемое наложение в областях лиц соответственно этих людей.
В таком состоянии, предполагают, что пользователь устройства выбирает человека HM11, например, прижатием на изображение FR11 прямоугольной рамки, отображаемого на участке области лица человека HM11 с его/ее отображением. Выполняя манипуляцию выбора, на этапе S14 человек HM11, область лица которой отображается на изображение FR11 прямоугольной рамки, выбирается в качестве аудио объекта. Затем, на этапе S15 изображение FR11 прямоугольной рамки, отображаемое в области лица выбранного человека HM11, отображается с подсветкой.
В этом примере, изображение FR11 прямоугольной рамки нарисовано сплошной линией, которая означает, что изображение FR11 прямоугольной рамки отображается с подсветкой. С другой стороны, изображение FR12 прямоугольной рамки и изображение FR3 прямоугольной рамки лиц, которые не выбраны, нарисованы пунктирными линиями соответственно, что означает, что изображение FR12 прямоугольной рамки и изображение FR13 прямоугольной рамки не отображаются с подсветкой, одним словом, отображаются обычным способом.
Поэтому, когда выбрано изображение FR11 с прямоугольной рамки, состояние отображения изображения FR11 прямоугольной рамки изменяется из состояния нормального отображения, в котором изображение FR11 прямоугольной рамки нарисовано пунктирной линией, в состояние отображения с подсветкой, в котором изображение FR11 прямоугольной рамки обозначено сплошной линией.
Таким образом, изображение прямоугольной рамки человека, выбранного пользователем устройства, отображается на экране дисплея, в другом стиле отображения каждого из других изображений прямоугольной рамки, в результате чего, пользователь устройства может подтвердить, соответствует ли операция манипуляции выбора отображению.
Следует отметить, что случай, когда изображение прямоугольной рамки выбранного человека отображается с подсветкой, описывается в качестве примера, настоящее изобретение никоим образом не ограничивается этим, и поэтому необходимо только, чтобы изображение прямоугольной рамки выбранного человека отображалось на экране дисплея в стиле, отличном от изображения любого другого изображения прямоугольной рамки. Например, изображение прямоугольной рамки выбранного человека может отображаться в цвете или форме, отличной от формы любого другого изображения прямоугольной рамки, или может отображаться с мигающей подсветкой.
Дополнительно, в случае, когда характеристика определенного человека, например, член семьи, ранее была сохранена в части 71 распознавания лица, и конкретное лицо обнаруживается в части 71 распознавания лица, часть 74 выбора человека может выбрать этого конкретного человека как аудио объект без выполнения манипуляции выбора пользователем устройства.
В этом случае информация, указывающая конкретного человека, также предоставляется в часть 74 выбора человека посредством части 71 распознавания лица, в часть 72 управления отображением результата распознавания лица. Затем в момент времени, когда изображение контента и изображение прямоугольной рамки отображается на части 73 отображения видео, часть 73 отображения видео отображает изображение прямоугольной рамки конкретного человека с подсветкой в соответствии с операцией управления части 74 выбора человека.
Таким образом, выполняют подготовку так, что конкретный человек ранее выбирается как аудио объект, в результате чего операция манипуляции выбора пользователем устройства может быть опущена. Дополнительно, в этом случае операция выбора конкретного человека может быть опущена в ответ на последующие манипуляции пользователем устройства.
Кроме того, для изображения прямоугольной рамки, которое является наложением, отображаемым на изображении контента, подобно примеру, например, описанному в справочном литературном документе 1, выполняют обработку автоматического отслеживания изменений вместе с перемещением человека, перемещением области фотографирующего объекта, то есть, при изменении направления фотографирования или тому подобное.
Некоторые общие камкордеры или цифровые камеры снабжены таким механизмом, который обеспечивает фокусировку на области сенсорной панели, к которой прикасается пользователь устройства. Однако также можно выполнить обработку для выбора аудио объекта и обработку для выбора цели фокусировки. Подобно автоматическому следующему изображению прямоугольной рамки, описанному выше, аудио объект, который когда-то был выбран, автоматически отслеживает изменение вместе с перемещением человека или перемещением области объекта фотографирования.
Вернемся к описанию блок-схемы алгоритма, показанной на фиг.3, на этапе S16 часть 74 выбора человека выдает информацию местоположения объекта, указывающую позицию в пространстве аудио объекта, выбранного на этапе S14, на основании информации позиции лица, поставленной из части 72 управления отображением результата распознавания лица.
В общем, информация местоположения объекта, ассоциированная с аудио объектом в стандартах, представленных стандартом MPEG-H часть 3: 3D аудио или тому подобное, например, кодируют с учетом сферической системой координат, изображенной на фиг.5.
На фиг.5, ось X, ось Y и ось Z, которые проходят через начало координат O и взаимно вертикальны друг к другу, являются осями трехмерной ортогональной системы координат. Например, в трехмерной ортогональной системе координат для позиции аудио объекта OB11 в пространстве используют x в качестве X-координаты, указывающей позицию в направлении оси X, y в виде Y-координаты, указывающей позицию в направлении оси Y и z как Z-координата, указывающая позицию в направлении оси Z. В результате позиция аудио объекта OB11 воспроизводится в виде (x, y, z).
С другой стороны, в сферической системе координат используют азимут, угол места и радиус, представляющий собой позицию аудио объекта OB11 в пространстве.
Теперь прямая линия, соединяющая начальную точку О и позицию аудио объекта OB11, представляет собой прямую линию r, и прямая линия, которая получается при проецировании прямой r на плоскость XY, обозначена прямой L.
Таким образом, угол θ между осью X и прямой L является азимутом, указывающим позицию аудио объекта OB11. Кроме того, угол Φ между прямой r и плоскостью XY представляет собой угол места, указывающий позицию аудио объекта OB11, и длина прямой линии r представляет собой радиус, указывающий позицию аудио объекта OB11.
В дальнейшем позиция аудио объекта в пространстве выражается сферической системой координат. В этом случае азимут, угол места и радиус, указывающий, что позиция соответственно описывают как position_azimuth, position_elevation и position_radius.
В общем, трудно измерить размер объекта с движущегося изображения или фактическое расстояние от фотографа. Дополнительно, в устройстве захвата изображения, таком как камкордер, установлено устройство захвата изображения, которое может измерять расстояние до объекта, такое как механизм автоматической фокусировки. В этом случае, однако, в случае, когда позиция субъекта, одним словом, позиция аудио объекта в реальном пространстве вычисляют с использованием процесса распознавания лиц, будет описана в качестве примера.
Иными словами, в дальнейшем, со ссылкой на фиг.6 будет дано описание способа измерения расстояния до объекта в случае, когда в общем устройстве захвата изображения известна форма субъекта.
На фиг. 6, объект 103 фотографируют блоком захвата изображения, включающим в себя элемент захвата изображения, имеющий поверхность 101 формирования изображения, и линзу 102. В настоящем изобретении, блок захвата изображения, включающий в себя элемент захвата изображения и линзу 102, соответствует части 21 захвата изображения. Объект 103 является человеком в реальном пространстве, соответствующий человеку на изображении, который выбран в качестве аудио объекта на этапе S14.
В этом примере на чертеже изображение объекта 103 ширина объекта, как ширина в продольном направлении, равна W2, и на чертеже изображения объекта 103 на поверхности 101 формирования изображения, при фотографировании объекта 103, ширина фотографируемого объекта, как ширина в продольном направлении, равна W1.
Кроме того, на чертеже расстояние в поперечном направлении в пространстве от линзы 102 до объекта 103 обозначено расстоянием d до объекта и на чертеже расстояние в поперечном направлении в пространстве от поверхности 101 формирования изображения до линзы 102 обозначено как фокусное расстояние D.
Следует отметить, что более конкретно, на чертеже расстояние в поперечном направлении от главной точки линзы 102 до объекта 103 является расстоянием d до объекта и на чертеже расстояние в поперечном направлении от поверхности 101 формирования изображения до главной точки линзы 102 является фокусным расстоянием D. Дополнительно, когда линза 102 включает в себя множество линз, главная точка сложной линзы становится главной точкой линзы 102.
В части 74 выбора человека хранят информацию, ассоциированную с частью 21 захвата изображения, такую как фокусное расстояние D и размер, количество пикселей и тому подобное поверхности 101 формирования изображения.
Дополнительно, часть 74 выбора человека может определять взаимосвязь между человеком и размером объекта на изображении и информацией позиции и размера (изображение) объекта на поверхности 101 формирования изображения из информации позиции лица, поставленной из части 72 управления отображением результата распознавания лица, и хранимой информацией, ассоциированной с частью 21 захвата изображения. Следовательно, часть 74 выбора человека может получить информацию ширины W1 изображения из информации положения лица и информации, ассоциированной с частью 21 захвата изображения.
Часть 74 выбора человека вычисляет следующее выражение (1) на основании фокусного расстояния D в качестве известной физической величины, ширину W1 изображения объекта и ширину W2 объекта, которые являются известными физическими значениями, и вычисляют расстояние d до объекта как неизвестное физическое значение.
Выражение

Следует отметить, что хотя ширина W2 объекта является неизвестной величиной, физическое количество, разброс размеров лиц отдельных человек рассматривают как ничтожно малую величину по отношению к расстоянию d до объекта и, следовательно, может быть использован усредненный размер лица человека в качестве ширины W2 объекта. То есть, ширину W2 объекта можно рассматривать как известную физическую величину.
Например, поскольку усредненная ширина лица человека составляет приблизительно 16 cm и усредненная длина лица составляет приблизительно 23,5 cm, эти значения могут быть использованы в качестве ширины объекта. Средние значения ширины лица и длины поверхностей слегка меняются в зависимости от разницы между мужчинами и женщинами, возрастом и т.п. Однако, поскольку пол и приблизительный возраст обнаруженного человека можно оценить по лицу, обнаруженному из изображения контента посредством распознавания изображения или тому подобного, ширина объекта может быть скорректирована с использованием пола или среднего значения по возрасту.
Дополнительно, одна из ширина (длина) в продольном направлении и ширина в поперечном направлении человека в качестве объекта, или как ширина в продольном направлении, так и ширина в поперечном направлении лица объекта может быть использована при вычислении расстояния d до объекта. В этом случае, для простоты описания будет приведен пример случая, когда ширина в продольном направлении лица человека используют в качестве ширины W2 объекта и для определения расстояния d до объекта используют только ширину W2 объекта.
На фиг.6, позиция главной точки линзы 102 соответствует начальной точке О, изображенной на фиг.5, и продольное направление и поперечное направление на фиг. 6 соответствуют направлению оси Z и направлению оси X на фиг.5, соответственно. В частности, на фиг.6, правое направление соответствует направлению фронта на фиг.5, словом, положительному направлению оси X.
Следовательно, расстояние d до объекта, вычисленное из приведенного выше расчета, указывает расстояние до человека, выбранного в качестве аудио объекта в направлении оси X, если смотреть с начала О координат в трехмерной системе ортогональных координат, изображенной на фиг.5.
Более того, аналогично, позиция лица человека, выбранного в качестве аудио объекта на пространстве, также можно получить, используя средний размер лица в качестве известной физической величины.
Например, предполагают, что человек HM11 выбран в качестве аудио объекта на изображении контента, отображаемого на части 73 отображения видео, как показано на фиг.7, и изображение FR11 прямоугольной рамки, окружающее область лица человека HM11, отображается сверху. Следует отметить, что на фиг.7 части, соответствующие тем, которые указаны на фиг.4, соответственно обозначены одинаковые ссылочными позициями, и их описание здесь опущено.
На фиг.7, голова человека HM11, выбранного в качестве аудио объекта, соответствует объекту 103, изображенному на фиг.6.
На фиг.7, центральная позиция изображения контента обозначена позицией A11' и центральная позиция изображения FR11 прямоугольной рамки, отображаемой относительно человека HM11, обозначена позицией A12. Например, часть 74 выбора человека может получить позицию A12' из информации позиции лица, поданной из части 72 управления отображением результата распознавания лица.
Теперь продольному направлению и поперечному направлению на чертеже на изображении контента присваивают направление оси Z (направление Z) и направление оси Y (направление Y) соответственно. Кроме того, позиция A12' в направлении оси Y при просмотре из позиции A11' на изображении контента назначают горизонтальной позиции Y1' объекта изображения, и позиция A12' в направлении Z оси, если смотреть с позиции A11', назначают вертикальную позицию Z1' объекта изображения.
С другой стороны, центральная позиция на поверхности 101 формирования изображения обозначена позицией A11 и позиция, соответствующая позиции A12' на поверхности 101 формирования изображения, обозначена позицией A12. Дополнительно, позиция A12 в направлении Y оси, если смотреть с позиции A11 на поверхности 101 формирования изображения, соответствует горизонтальной позиции Y1 поверхности изображения, и позиция A12 в направлении Z оси при просмотре с позиции A11 на поверхности 101 формирования изображения задана вертикальной позицией Z1 объекта поверхности изображения.
Здесь направление Y оси и направление Z оси на поверхности 101 формирования изображения являются передним направлением и вертикальным направлением на фиг.6 соответственно. Поскольку часть 74 выбора человека может получить позицию A12' из информации позиции лица, поданной в нее из части 72 управления отображением результата распознавания лица, часть 74 выбора человека может получить горизонтальную позицию Y1' объекта изображения и вертикальную позицию Z1' объекта изображения из позиции А12'.
Более того, поскольку часть 74 выбора человека ранее содержит информацию, указывающую размер поверхности 101 формирования изображения в качестве известной информации, часть 74 выбора человека может получить горизонтальную позицию Y1 изображения, отображаемого на поверхности изображения, и изображение вертикальной позиции Z1 изображения из изображения горизонтальной позиции Y1' объекта и вертикальной позиции Z1' объекта изображения. Одним словом, горизонтальная позиция Y1 изображения поверхности изображения и вертикальная позиция Z1 изображения поверхности изображения становятся известными физическими величинами.
Следовательно, часть 74 выбора человека может получить информацию позиции в направлении Y оси и в направлении Z оси объекта 103 на пространстве, одним словом, лицо HM11 из горизонтальной позиции Y1 объекта поверхности изображения и вертикальной позиции Z1 объекта поверхности изображения и ширины W1 изображаемого объекта и ширины W2 объекта, как описано выше.
В этом отношении, позиции в направлении Y оси и в направлении Z оси в пространстве объекта 103, т.е., лица человека, назначают горизонтальной позиции y объекта и вертикальной позиции z объекта, соответственно. На данном этапе, горизонтальная позиция y объекта и вертикальная позиция z объекта могут быть получены из горизонтальной позиции Y1 объекта поверхности изображения и вертикальной позиции Z1 объекта изображения и ширины W1 объекта изображения и ширины W2 объекта путем вычисления следующего выражения (2) и выражение (3).
Выражение 2

Выражение 3

Часть 74 выбора человека получает горизонтальную позицию y объекта и вертикальную позицию z объекта лица человека, выбранного в качестве аудио объекта на фактическом пространстве, путем вычисления выражения (2) и выражения (3).
Кроме того, часть 74 выбора человека вычисляет следующие выражения (4) - (6) на основании горизонтальной позиции y объекта и вертикальной позиции z объекта, полученного таким образом, и расстояние d до объекта, описанного выше, и вычисляет позицию лица данного человека в сферической системе координат.
Выражение 4
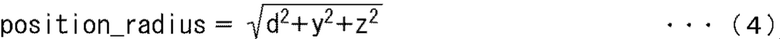
Выражение 5
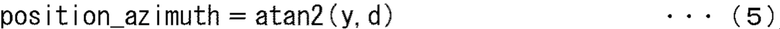
Выражение 6
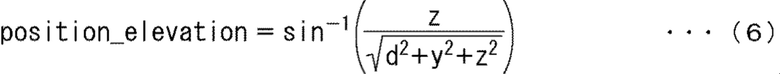
То есть, может быть получен радиус position_radius, указывающий позицию в пространстве человека, выбранного в качестве аудио объекта из расчета выражения (4).
Кроме того, может быть получен азимут position_azimuth, указывающий позицию в пространстве человека, выбранного в качестве аудио объекта из расчета выражения (5). Более того, угол места position_elevation в пространстве человека, выбранного в качестве аудио объекта, может быть получен из расчета выражения (6).
Здесь atan2 (y, d) в выражении (5) определяют из следующего выражения (7).
Выражение 7
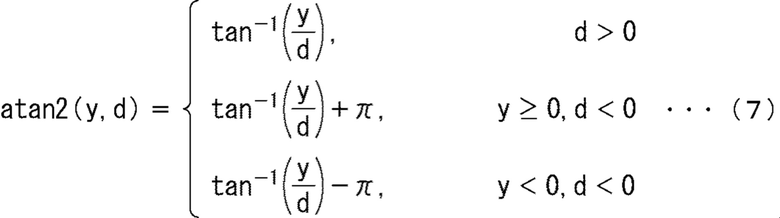
Однако предполагают, что расстояние d до объекта, как показано в следующем выражении (8), ограничено минимальным значением dmin. То есть, когда абсолютное значение расстояния d до объекта, полученного из выражения (1), меньше минимального значения dmin, часть 74 выбора человека использует минимальное значение dmin как значение расстояния d до объекта.
Выражение 8

Часть 74 выбора человека устанавливает информацию, указывающую позицию в пространстве человека, выбранного в качестве аудио объекта, как информацию местоположения объекта. В этом случае, позиция в пространстве человека, выбранного в качестве аудио объекта, выражается азимутом position_azimuth, углом места position_elevation и радиусом position_radius, который получают в процессе, описанным выше.
Таким образом, часть 74 выбора человека может получить информацию местоположения объекта на основании результата распознавания лица в части 71 распознавания лица. Однако, в общем, в части 21 захвата изображения происходит смена света и возникает микровибрация или т.п. Поэтому желательно выполнить сглаживание информации местоположения объекта с использованием фильтра или тому подобного.
Часть 74 выбора человека поставляет полученную таким образом информацию местоположения объекта в каждую часть 27 разделения источника звука и часть 28 кодирования звука, и процесс обработки переходит к этапу S17. Следует отметить, что в случае, когда выбрано множество аудио объектов в описанных выше этапах обработки, информацию местоположения объекта производят для каждого аудио объекта.
На этапе S17 часть 27 разделения источника звука выполняет разделение источника звука для подаваемого на него аудиосигнала из части 26 получения звука на основании информации местоположения объекта, поданной из части 74 выбора человека, тем самым, разделяя аудиосигнал на аудиосигнал объекта и фоновый звуковой сигнал.
Например, в этом случае, позиция аудио объекта в пространстве, словом, позиция источника звука является позицией, обозначенной информацией местоположения объекта и, таким образом, является известной.
Затем, например, часть 27 разделения источника звука разделяет аудиосигнал на аудиосигнал объекта в качестве аудиосигнала объекта и фонового звукового сигнала в качестве сигнала источника звука, отличного от аудио объекта, с использованием технологии фиксированного формирования луча.
В частности, в случае, когда, например, часть 26 получения звука представляет собой микрофонную решетку, включающую в себя множество микрофонов, управление направленностью выполняют для аудиосигнала, полученного в части 26 получения звука, тем самым, позволяя разделить аудиосигнал объекта и фоновой звуковой сигнал, который должен быть отделен от аудиосигнала. Одним словом, аудиосигнал и фоновый звуковой сигнал могут быть извлечены из аудиосигнала.
Другими словами, при формировании фиксированного луча извлекают голосовой сигнал в позиции видео объекта, выбранного в качестве аудио проекта в пространстве, в качестве аудиосигнала объекта из аудиосигнала. Более конкретно, голосовой сигнал, исходящий из определенного направления видео объекта, выбранного в качестве аудиообъекта в пространстве, извлекают в качестве аудиосигнала объекта из аудиосигнала. Затем, извлекают голосовой сигнал, отличный от голосового сигнала аудио объекта, в качестве фонового звукового сигнала из аудиосигнала.
Следует отметить, что способ разделения звука в части 27 разделения источника звука никоим образом не ограничивается формированием фиксированного луча, и может быть использована любая технология, такая как технология, описанная в выложенной заявке на патент Японии № 2010- 233173.
Дополнительно, в этом случае, хотя описание было дано в предположении, что устройство 61 для обработки видео и аудиосигналов является портативным устройством, таким как камкордер, настоящее изобретение никоим образом не ограничивается ими и может также применяться к системы, имеющей большие габаритные размеры до определенной степени, например, система для телеконференции или студийной записи. В таком случае, при использовании в качестве части 26 получения звука решетки микрофонов большого размера, тогда можно улучшить характеристики разделения источника звука.
Дополнительно, например, в качестве части 26 получения звука может использоваться множество микрофонов, включающих в себя направленный микрофон. В этом случае, часть 27 разделения источника звука изменяет направление направленного микрофона на направление, обозначенное позицией объекта информации, в результате чего, аудиосигнал объекта может быть получен из направленного микрофона, и фоновый звуковой сигнал может быть получен из других микрофонов. Иными словами, аудиосигнал объекта может быть извлечен направленным микрофоном, и фоновый звуковой сигнал может быть извлечен другими микрофонами.
На этапе S18 часть 28 кодирования аудио кодирует информацию местоположения объекта, поданную в нее из части 74 выбора человека, и аудиосигнал и фоновый звуковой сигнал, подаваемый из части 27 разделения источника звука. Затем часть 28 кодирования аудио поставляет результирующий битовый поток аудио в часть 30 мультиплексирования.
Например, после того, как аудиосигнал объекта и фоновый звуковой сигнал закодированы независимо друг от друга, они мультиплексируются для формирования битового потока аудио.
Например, система линейной импульсно-кодовой модуляции (PCM) или система необратимого сжатия, как описано в «МЕЖДУНАРОДНОМ СТАНДАРТЕ ISO/IEC 23008-3, первое издание 2015-10-15 Информационные технологии-Высокоэффективное кодирование и доставка медиа в гетерогенных средах - Часть 3: 3D-аудио» (далее также упоминаемый как справочный литературный документ 2) также может использоваться в качестве системы кодирования для аудиосигнала объекта и фонового звукового сигнала.
Дополнительно, информация местоположения объекта обычно является данными, называемыми метаданными, и кодируют в формате, например, как показано на фиг.8 каждый заданный временной интервал.
Фиг.8 является видом, иллюстрирующим пример синтаксиса (кодированного формата) метаданных, включающий в себя информацию местоположения объекта. В метаданных, изображенных на фиг.8, «num_objects» указывает количество аудио объектов, содержащиеся в битовом потоке аудио.
Дополнительно, «tcimsbf» является аббревиатурой «дополнительное целое число двух, наиболее значимый бит (знак) в начале», и закодированный бит обозначает дополнение из 2 заголовка. «Uimsbf» представляет собой аббревиатуру «целое число без знака, наиболее значимый бит в начале», и самый значимый бит обозначает целое число без знака заголовка.
Кроме того, «position_azimuth [i]», «position_elevation [i]» и «position_radius [i]» соответственно указывают информацию местоположения объекта i-го аудио объекта, содержащийся в битовом потоке аудио.
В частности, «position_azimuth [i]» указывает позицию азимута аудио объекта в сферической системе координат, и «position_elevation [i]» указывает позицию угла места аудио объекта в сферической системе координат. Дополнительно, «position_radius [i]» указывает расстояние до позиции аудио объекта в сферической системе координат, то есть, радиус position_radius.
Дополнительно, «gain_factor [i]» указывает информацию коэффициента усиления i-го аудио объекта, содержащийся в битовом потоке аудио.
Таким образом, часть 74 выбора человека производит информацию местоположения объекта, установленную как метаданные аудио объекта. Часть 28 кодирования аудио кодирует информацию местоположения объекта и информацию коэффициента усиления как метаданные.
Вернемся к описанию блок-схемы алгоритма, показанную на фиг.3, на этапе S19 часть 29 кодирования видео кодирует видеосигнал, подаваемый из части 21 захвата изображения, и поставляет результирующий битовой поток видео в часть 30 мультиплексирования.
Следует отметить, что в системе для кодирования видеосигнала в дополнение к известной системе кодирования видео, такой как MPEG-HEVC или MPEG-AVC, могут использоваться различные системы кодирования видео.
На этапе S20 часть 30 мультиплексирования мультиплексирует битовый поток видео, поданный на нее из части 29 кодирования видео, и битовый поток аудио, подаваемый из части 28 кодирования аудио, вместе с системной информацией, используемой для выполнения их синхронизации, и, например, для формирования выходного битового потока. Часть 30 мультиплексирования выводит результирующий выходной битовый поток, и процесс кодирования завершается.
В способе, описанном выше, устройство 61 для обработки видео и аудиосигналов выполняет распознавание лица для видеосигнала и вызывает отображение изображения прямоугольной рамки, указывающей на результат распознавания лица вместе с изображением контента. Дополнительно, устройство 61 для обработки видео и аудиосигналов выбирает аудио объект в ответ на манипуляцию выбора, выполненную пользователем устройства, и производит информацию местоположения объекта аудио объекта.
В результате, сигнал требуемого объекта звука можно разделить более просто и точно. То есть, пользователь устройства может выбирать просто и интуитивно, который из видео объектов (объектов) на изображении контента выбран в качестве аудио объекта, когда он/она просматривает дисплей на части 73 отображения видео. Дополнительно, сигнал желаемого аудио объекта может быть более точно разделен путем получения информации местоположения объекта выбранного аудио объекта.
Если голос человека, выбранного таким образом, кодируют как аудиосигнал объекта, тогда во время воспроизведения уровень громкости голоса, позиция источника звука, качество звука и т.п. могут быть изменены для каждого аудио объекта.
Кстати, в описании, которое было дано до сих пор, был описан пример, в котором, устройство 61 для обработки видео и аудиосигналов фотографирует изображение контента и пользователь устройства выбирает человека, который будет идентифицирован как аудио объект. Однако после фотографирования может быть выбран человек, ассоциированный с аудио объектом.
В таком случае, во время фотографирования изображения контента, например, видеосигнал, полученный посредством фотографирования, и аудиосигнал, полученный посредством получения звука, записывают без кодирования. Затем, после фотографирования при воспроизведении контента, воспроизводят контент на основании видеосигнала и аудиосигнала, и выполняют процесс кодирования, описанный со ссылкой на фиг.3.
Далее будет дано описание способа приема выходного битового потока, полученного из вышеупомянутой обработки, и осуществления воспроизведения контента, в частности, воспроизведения голосового сигнала контента.
Что касается фонового звукового сигнала, содержащегося в битовом потоке аудиосигнала, полученного путем не мультиплексирования выходного битового потока, например, выполняют воспроизведение в соответствии с так называемой многоканальной стереосистемой, такой как унаследованной 2-канальной или 5.1-канальной.
С другой стороны, в отношении аудиосигнала объекта справочный литературный документ 2 описывает систему визуализации для аудио объекта, и выполняют визуализацию в соответствии с системой визуализации для осуществления воспроизведения.
Более конкретно, аудиосигнал объекта сопоставляют и воспроизводят в динамике среды воспроизведения в соответствии с системой под названием «векторное амплитудное панорамирование» (VBAP).
Данная технология представляет собой способ локализации звука в позиции в пространстве аудио объекта путем использования выходных сигналов из трех динамиков, ближайших к позиции в пространстве аудио объекта, обозначенного информацией местоположения объекта. Хотя в справочном литературном документе 2 количество динамиков равно трем, конечно, звук также может быть локализован четырьмя или более динамиками.
Дополнительно, в предшествующем примере описан случай, в котором кодируют и декодируют фоновый звуковой сигнал в соответствии с многоканальной стереосистемой. Тем не менее, система, в которой пространство, близкое к зрителю, которое называется «амбисоник высшего порядка» (HOA), описанным в стандарте в справочном литературном документе 2, выражается сферическими гармониками, поскольку также может быть использован ортогональный базис.
Кроме того, в первом варианте осуществления пользователь устройства, то есть, фотограф, выполняет фотосъемку таким образом, что человек, который должен быть сфотографирован, становится объектом извлечения аудио объекта, в большинстве случаев обычно изображен на экране. Однако, поскольку в случае, когда человек, выбранный в качестве аудио объекта, перемещается за пределы изображения на экране, информацию местоположения объекта можно получить, используя общеизвестную технологию идентификации говорящего человека или тому подобное.
<Второй вариант осуществления>
<Порядок выбора приоритета обработки аудио объекта>
В первом варианте осуществления, описанном выше, пользователь устройства выполняет манипуляцию для выбора человека, голос которого желательно получить в качестве аудио объекта из кандидатов, отображаемых на части 73 отображения видео.
В некоторых случаях невозможно выполнить декодирование и визуализацию всех сигналов аудио объектов с точки зрения удобства вычисления пропускной способности в зависимости от устройства для декодирования выходного битового потока, полученного в устройстве 61 для обработки видео и аудиосигналов, для воспроизведения контента.
Предложен способ добавления приоритета «priority» в качестве метаданных в битовом потоке каждого аудио объекта на стороне устройства для кодирования, и данный способ принят в стандарте, а также в справочном литературном документе 2.
Затем во втором варианте осуществления, к которому применяют настоящую технологию, пользователь устройства может выбрать человека, голос которого желательно получить в качестве аудио объекта из кандидатов, отображаемых на части 73 отображения видео, и может установить приоритет выбранного человека.
В этом случае, метаданные, в которых хранится информация местоположения объекта, например, изображены на фиг.9. Фиг.9 представляет собой таблицу, изображающую пример синтаксиса метаданных.
В дополнение к элементам информации, содержащиеся в метаданных, как показано на фиг.9, дополнительно содержится информация, ассоциированная с приоритетом обработки «objecft_priority [i]» i-го аудио объекта, т.е., аудиосигнал объекта дополнительно включен в состав метаданных, показанных на фиг.8.
В этом примере информацию, ассоциированную с приоритетом обработки «objecft_priority [i]», устанавливают, как данные из 3 бит и могут принимать значение от 0 до 7.
Например, в случае, когда значение приоритета обработки objecft_priority [i] равно 0, приоритет обработки аудио объекта является самым низким, и в случае, когда значение приоритета обработки objecft_priority [i] равно 7, приоритет обработки аудио объекта является самым высоким.
Далее предполагают, что, например, выходной битовый поток, включающий в себя сигналы аудиообъектов трех аудио объектов, в которых, значения приоритета обработки object_priority [i] равны 7, 3 и 0 соответственно, подают в устройство на стороне воспроизведения. Дополнительно, может быть невозможно, чтобы устройство на стороне воспроизведения выполняло визуализацию всех трех аудио объектов.
В таком случае, например, в отношении аудио объекта, в котором значение приоритета обработки object_priority [i] равно 0, устройство на стороне воспроизведения может выполнять простой процесс визуализации, в котором качество звука не принимают во внимание, или отключает визуализацию данного аудио объекта. В результате, даже устройство воспроизведения, имеющее низкую пропускную способность, может реализовать воспроизведение контента в режиме реального времени.
Как описано выше, в случае, когда информация, ассоциированная с приоритетом обработки, сохраняется вместе с информацией местоположения объекта в метаданных, часть 74 выбора человека устройства 61 для обработки видео и аудиосигналов выбирает человека, которого желательно установить как аудио объект, и выполняет установку приоритета обработки на основании сигнала, реагируя на манипуляцию, выполненную пользователем устройства, которая подается с сенсорной панели 81. Затем часть 74 выбора человека поставляет информацию местоположения объекта каждой в часть 27 разделения источника звука и часть 28 кодирования аудио и поставляет информацию, ассоциированную с результирующим приоритетом обработки в часть 28 кодирования аудио.
В результате, часть 28 кодирования аудио кодирует не только информацию местоположения объекта, но также информацию, ассоциированную с приоритетом обработки, для формирования битового потока аудио, в котором сохраняют метаданные, включающие в себя информацию местоположения объекта и информацию, ассоциированную с приоритетом обработки.
В случае, когда приоритет обработки задают пользователем устройства, например, на этапе S15, как показано на фиг.3 и на фиг. 10, изображение прямоугольной рамки отображается вместе с изображением контента на части 73 отображения видео. Следует отметить, что на фиг.10 части, соответствующие тем, которые показаны на фиг.4, соответственно обозначены одинаковыми ссылочными позициями, и здесь их описание опущено.
На фиг.10 изображена ситуация, когда пользователь устройства устанавливает приоритеты обработки для трех человек HM11-HM13, находящиеся в области объекта фотографирования.
В этом примере изображения FR11-FR13 прямоугольной рамки отображаются с подсветкой, и персоны HM11-HM13, соответствующие этим изображениям с прямоугольной рамкой, соответственно, выбираются в качестве аудио объектов.
Дополнительно, в непосредственной близости от изображения FR11 прямоугольной рамки человека HM11 отображается символьная информация «P = 7», указывающая приоритет обработки, установленный для этого человека HM11. Таким образом, указывают, что значение приоритета обработки человека HM11 равно 7 как наивысшее значение.
Аналогично, в непосредственной близости от изображения FR13 прямоугольной рамки человека HM13 отображается символьная информация «P = 0», указывающая приоритет обработки, установленный для этого человека HM13. Таким образом, указывается, что значение приоритета обработки человека HM13 равно 0 как наименьшее значение.
Дополнительно, в примере на фиг. 10, вблизи изображения FR12 прямоугольной рамки человека HM12 отображается изображение CF11 задания приоритета обработки для установки приоритета обработки человека HM12.
Например, изображение CF11 установки приоритета обработки, например, отображается, когда пользователь устройства касается части изображения FR 12 прямоугольной рамки пальцем.
Дополнительно, в рамке отображены значения от 0 до 7 приоритета обработки в изображении CF11 установки приоритета обработки. Пользователь устройства касается изображения рамки, в котором указано значение желаемого приоритета пальцем, что позволяет установить приоритет обработки человека HM12.
Например, когда пользователь устройства прикасается изображения рамки, в которой указано «3», то часть 74 выбора человека устанавливает значение приоритета обработки человека HM12 в качестве аудио объекта равным «3» на основании сигнала, подаваемого из сенсорной панели 81 в ответ на манипуляции, выполненные пользователем устройства.
Следует отметить, что способ определения приоритета обработки никоим образом не ограничивается описанным выше способом, и, таким образом, может быть использован любой способ. Например, может быть принят простой способ, так что приоритет обработки лица, соответствующего изображению прямоугольной рамки, который выбирается пользователем устройства, устанавливается равным 7, и приоритет обработки лица, для которого изображение прямоугольной рамки отсутствует, выбрано значение 0.
Дополнительно, в случае, когда, например, все персоны обнаруженные распознаванием лица, выбираются в качестве аудио объектов или тому подобное, приоритет обработки человека (видео объекта), отличный от людей, выбранных в качестве аудио объекта на этапе S14 обработки кодирования, могут быть выбраны из значений, каждый из которых равен или меньше 6, в зависимости от размера лица на изображении соответствующего человека, то есть, размера изображения прямоугольной рамки.
В процессе кодирования на этапе S16 часть 74 выбора человека формирует информацию местоположения объекта, ассоциированную с аудио объектом, в ответ на манипуляцию, выполненную пользователем устройства, и определяет приоритеты обработки соответствующих аудио объектов. Одним словом, информация местоположения объекта и приоритет обработки производятся как метаданные аудио объекта.
Затем часть 74 выбора человека поставляет информацию местоположения объекта в часть 27 разделения источника звука и поставляет информацию местоположения объекта и информацию, ассоциированную с приоритетом обработки, в часть 28 кодирования аудио.
Дополнительно, на этапе S18 часть 28 кодирования аудио кодирует информацию местоположения объекта, приоритет обработки, аудиосигнал объекта и фоновый звуковой сигнал для формирования битового потока аудио.
Путем установки приоритета обработки аудио объекта способом, описанным выше, в устройстве на стороне воспроизведения процесс обработки может быть автоматически изменен или подобное для аудио объекта в ответ на его мощность вычисления или тому подобное. В результате, например, может быть реализовано подходящее воспроизведение контента, такое как воспроизведение контента в реальном времени.
<Третий вариант осуществления>
<Описание информации распространения>
Дополнительно, при визуализации аудио объекта источник точечного звука считается присутствующим в позиции, обозначенной информацией местоположения объекта, и при этом условии выполняется визуализация посредством VBAP.
Однако более естественно, что на самом деле объект имеет размер, и звук считается генерируемым с поверхности, имеющей определенную заданную область. Затем предлагают способ, с помощью которого в метаданные добавляют данные, называемые данными распространения (далее именуемые как информация распространения), и, используя эти данные во время визуализации, получают ситуацию, при которой звук как бы генерируют из области, в которой присутствует объект, одним словом, с поверхности. Этот способ принят в стандарте, а также в справочном литературном документе 2.
В третьем варианте осуществления, к которому применяют настоящий способ, при распознавании видео объекта, такого как лицо человека, используется размер прямоугольной рамки в качестве результата распознавания видео объекта, что позволяет автоматически устанавливать информацию распространения на стороне устройства 61 для обработки видео и аудиосигналов.
В этом случае, часть 74 выбора человека выбирает человека, как аудио объект на основании сигнала, отвечая на манипуляцию, сделанную пользователем устройства, которая подается с сенсорной панели 81, и устанавливает информацию распространения. Затем часть 74 выбора человека поставляет информацию местоположения объекта в каждую часть 27 разделения источника звука и часть 28 кодирования аудио и поставляет полученную информацию распространения в часть 28 кодирования аудио. Следует отметить, что аналогично случаю из второго варианта осуществления, часть 74 выбора человека может дополнительно быть вызвана также для получения приоритета обработки.
Например, в случае, когда информация, ассоциированная с приоритетом обработки и информацией распространения, содержится вместе с информацией местоположения объекта в метаданных, метаданные становятся состоянием, как показано на фиг.11. На фиг.11 показана таблица, иллюстрирующая пример синтаксиса метаданных.
В дополнение к части информации, содержащейся в метаданных, изображенных на фиг.9, i-й аудио объект, одним словом, информация распространения «spread [i]» аудиосигнала объекта дополнительно включена в состав метаданных, изображенных на фиг.11.
В этом примере, информацию распространения spread [i] устанавливают как данные из 8 бит и задают как информацию угла, указывающую область аудио объекта в пространстве, т.е. информацию угла, указывающую состояние распространения области аудио объекта.
Устройство воспроизведения в качестве устройства на стороне воспроизведения для приема выходного битового потока выполняет визуализацию посредством использования такой информации распространения spread [i]. Следует отметить, что способ конкретного расчета информации распространения spread [i] будет описан ниже.
В настоящем изобретении описан способ использования информации распространения в устройстве воспроизведения в соответствии со стандартным справочным литературным документом 2 со ссылкой на фиг.12.
Предполагают, что, например, относительно точки O отсчета в пространстве аудио объект находится в позиции, обозначенной вектором p0. Здесь, вектор p0 является вектором с началом в точке O в качестве начальной точки и позиция, обозначенная вектором p0, представляет собой позицию, обозначенную информацией местоположения объекта. Кроме того, после этого, позиция, обозначенная вектором p0, будет также упоминаться как позиция p0.
В этом случае, часть 74 выбора человека генерирует информацию угла для вектора p0 в качестве информации распространения spread [i].
В устройстве воспроизведения 18 векторов p1-p18, в которых при просмотре позиции p0 от начальной точки O спереди, позиции в пределах круга C11, полученные на основании угла, заданного информацией распространения spread [i], устанавливают как конечные точки, и начальную точку O устанавливают в качестве начальной точки, получают в виде векторов распространения.
Круг C11 представляет собой круг с позицией p0 как центр, и в этом примере вектор p1 или вектор p4 становится вектором с позицией на окружности круга C11 в качестве конечной точки. Следует отметить, что на фиг.12, каждая точка в круге C11 представляет собой конечную позицию каждого из векторов распространения.
Например, угол между вектором p1 с позиции на окружности круга C11 в качестве конечной точки, и вектором p0 становится углом, обозначенным информацией распространения spread [i].
Следует отметить, что поскольку способ вычисления векторов p1-p18 в качестве векторов распространения на основании информации местоположения объекта и информации распространения spread [i], например, подробно описан в справочном литературном документе 2, поэтом, его описание здесь опущено.
При получении векторов распространения, устройство воспроизведения получает коэффициенты усиления сигналов аудио объектов для каждого громкоговорителя посредством VBAP относительно векторов p1-p18, полученных как векторы распространения, и нормализует эти коэффициенты усиления. Затем, аудиосигнал объекта, умноженный на нормализованный коэффициент усиления, сопоставляют на громкоговоритель для воспроизведения голосового сигнала контента.
Осуществляют визуализацию с использованием информации распространения так, что в результате может быть выражен аудио объект, имеющий направление распространения в пространстве.
В случае, когда вычисляют информацию распространения в части 74 выбора человека устройства 61 для обработки видео и аудиосигналов, часть 74 выбора человека, например, как показано на фиг.13, вычисляет информацию распространения, используя изображение прямоугольной рамки, полученного из результата распознавания видео объекта посредством распознавания лица, более конкретно, из результата распознавания лица.
В примере, показанном на фиг.13, обнаруживают двух человек HM31 и HM32 на изображении контента, отображаемого на части 73 отображения видео. Дополнительно, на изображении контента изображение FR31 прямоугольной рамки является наложением сверху на область лица человека HM31, и изображение FR32 прямоугольной рамки является наложением сверху на лицевую часть человека HM32.
В частности, фиг.13 выражает состояние, в котором изображение контента проецируется на пространство. Таким образом, центральная позиция изображения FR31 прямоугольной рамки и центральная позиция изображения FR32 прямоугольной рамки соответственно становятся позициями, обозначенными информацией местоположения объекта соответствующих аудио объектов.
Когда часть 74 выбора человека на этапе S16 на фиг.3 производит информацию местоположения объекта и информацию, ассоциированную с приоритетом обработки относительно аудио объектов, часть 74 выбора человека дополнительно также производит информацию распространения аудио объектов. Другими словами, информацию местоположения объекта, информацию, ассоциированную с приоритетом обработки, и информацию распространения генерируют как метаданные аудио объекта.
В частности, когда, например, дано описание для человека HM31 в качестве аудио объекта, часть 74 выбора человека получает вектор VB11 с началом O в пространстве в качестве начальной точки и с позицией, обозначенной информацией местоположения объекта, одним словом, центральная позиция изображения FR31 прямоугольной рамки в качестве конечной точки. Затем часть 74 выбора человека устанавливает вектор VB11, полученный таким образом, как вектор p0, описанный со ссылкой на фиг.12. Такой вектор VB11 может быть получен из информации местоположения объекта, сформированный относительно человека MH31.
Дополнительно, часть 74 выбора человека получает вектор VB12. В векторе VB12 начальной точкой является начальная точка O в пространстве и конечной точкой является позиция высоты в продольном направлении (направление Z оси), которое на чертеже совпадает с позицией высоты центральной позиции изображения FR31 прямоугольной рамки на правой стороне на чертеже изображения FR31 прямоугольной рамки. Вектор VB12 задают как вектор p1, описанный со ссылкой на фиг.12.
Здесь позиция конечной точки вектора VB12 в пространстве, например, может быть получено с использованием информации местоположения объекта, формированной относительно человека HM31, изображении FR31 прямоугольной рамки, взаимосвязи между поверхностью 101 формирования изображения и изображением контента, фокусного расстояния D, расстояния d до объекта и тому подобное.
Дополнительно, часть 74 выбора человека вычисляет угол AG11 между вектором VB11 как вектор p0, полученный таким образом, и вектор VB12 как вектор p1 в виде информации распространения spread [i] по отношению к человеку HM31. Более конкретно, часть 74 выбора человека вычисляет информацию распространения spread [i] путем вычисления следующего выражения (9).
Выражение 9

Следует отметить, что в выражении (9) p0 и p1 указывают вектор p0 и вектор p1 соответственно.
Аналогично, часть 74 выбора человека получает вектор VB13 с начальной точкой O в пространстве в качестве начальной точки и с позицией, обозначенной информацией местоположения объекта человека HM32, одним словом, центральную позицию изображения FR32 прямоугольной рамки в качестве конечной точки и устанавливает результирующий вектор VB13 как вектор p0.
Дополнительно, часть 74 выбора человека получает вектор VB14. В векторе VB14 исходной точкой является начальной точкой O в пространстве и позиция высоты в продольном направлении является такой же на чертеже, так что центральная позиция изображения FR32 прямоугольной рамки на стороне правой части на чертеже изображения FR32 прямоугольной рамки является конечной точкой. Результирующий вектор VB13 установлен как вектор p1.
Затем, часть 74 выбора человека получает значение угла AG12 между вектором VB13 и вектором VB14, вычисляя выражение (9), и устанавливает результирующий угол AG12 в качестве информации распространения spread [i] по отношению к человеку HM32.
Следует отметить, что было дано описание способа вычисления информации распространения с использованием только вектора p0 и вектора p1 в этом случае. Однако, при возможности увеличения вычислительной мощности или подобное устройства 61 для обработки видео и аудиосигналов, могут быть получены значения углов между векторами распространения с верхним концом, нижним концом, левым концом и правым концом на чертеже изображения прямоугольной рамки в качестве позиции конечной точки и вектором p0, и среднее значение этих углов может быть использовано в качестве информации распространения spread [i].
Когда информацию распространения рассчитывают описанным выше способом, часть 74 выбора человека поставляет информацию местоположения объекта в часть 27 разделения источника звука и поставляет информацию местоположения объекта, информацию, ассоциированную с приоритетом обработки, и информацию распространения в часть 28 кодирования аудио.
Дополнительно, на этапе S18 часть 28 кодирования аудио кодирует информацию местоположения объекта, информацию, ассоциированную с приоритетом обработки, и информацию распространения, аудиосигнал объекта и фоновый звуковой сигнал для производства битового потока аудио.
Информацию распространения аудио объекта производят описанным выше способом, в результате чего устройство на стороне воспроизведения может выполнять воспроизведение контента, выражающего пространственное распространение аудио объекта без указания информации распространения пользователем устройства.
В данном этапе, описанная выше последовательность операций процесса может быть выполнена аппаратным обеспечением или может быть выполнена программным обеспечением. В случае, когда последовательность операций процесса выполняют программным обеспечением, в компьютер устанавливают программу, составляющую программное обеспечение. В настоящем изобретении компьютер включает в себя компьютер, встроенный в специализированное оборудование, например, персональный компьютер общего назначения, который может выполнять различные функции, устанавливая различные типы программ и тому подобное.
Фиг.14 представляет собой блок-схему, изображающую пример конфигурации аппаратного обеспечения компьютера, который выполняет описанную выше последовательность операций процесса в соответствии с программой.
В компьютере центральный процессор (CPU) 501, память только для чтения (ROM) 502 и память произвольного доступа (RAM) 503 соединены друг с другом через шину 504.
Интерфейс 505 ввода-вывода дополнительно подключен к шине 504. Часть 506 ввода, часть 507 вывода, часть 508 записи, часть 509 связи и привод 510 подключены к интерфейсу 505 ввода-вывода.
Часть 506 ввода включает в себя клавиатуру, мышь, микрофон, элемент захвата изображения или тому подобное. Часть 507 вывода включает в себя дисплей, динамик или тому подобное. Часть 508 записи включает в себя жесткий диск, энергонезависимую память или тому подобное. Часть 509 связи включает в себя сетевой интерфейс. Привод 510 управляет съемным носителем 511 записи, таким как магнитный диск, оптический диск, магнитооптический диск или полупроводниковая память.
В компьютере, сконфигурированном так, как описано выше, CPU 501, например, загружает программу, сохраненную в части 508 записи, в RAM 503 через интерфейс 505 ввода-вывода и шину 504 и выполняет программу, тем самым, выполняя описанной выше процесс.
Например, программа, которая должна быть выполнена компьютером (CPU 501), может быть записана на съемном носителе 511 записи в качестве носителя медиа информации или тому подобного. Дополнительно, программа может быть предоставлена через проводные или беспроводные средства передачи данных, такие как локальная сеть, интернет или цифровое спутниковое вещание.
В компьютере привод 510 оснащен съемным носителем 511 записи, тем самым, позволяя устанавливать программу в части 508 записи через интерфейс 505 ввода-вывода. Дополнительно, программа может быть принята в части 509 связи и может быть установлена в части 508 записи через проводную или беспроводную среду передачи данных. В противном случае, программа может быть предварительно установлена в ROM 502 или в части 508 записи.
Следует отметить, что программа, которая должна быть выполнена компьютером, может быть программой, в соответствии с которой, этапы процесса обработки выполняют в порядке, описанном в настоящем описании, или могут быть программой, в соответствии с которой, этапы процесса обработки выполняют параллельно друг другу или в нужный момент времени при вызове или тому подобное.
Дополнительно, варианты осуществления настоящего изобретения никоим образом не ограничиваются описанными выше вариантами осуществления, и могут быть сделаны различные изменения без отхода от предмета настоящего изобретения.
Например, настоящий способ может принимать конфигурацию облачных вычислений, в которой множество устройств совместно используют одну функцию для совместной обработки информации через сеть.
Дополнительно, этапы, описанные в блок-схеме алгоритма, могут быть выполнены не только одним устройством, но также выполняют совместно множеством устройств.
Более того, в случае, когда множество операций процесса обработки выполняют на одном этапе, множество операций процесса обработки может быть выполнено не только одним устройством, но также может быть выполнено распределенным образом между множеством устройств.
Дополнительно, настоящее изобретение также может быть реализовано следующим образом.
(1) Устройство для обработки видео и аудиосигналов включает в себя:
часть управления отображением, выполненную с возможностью вызывать отображение видео объекта на основании видеосигнала;
часть выбора объекта, выполненную с возможностью выбирать заданный видео объект из одного видео объекта или среди множества видео объектов; и
часть извлечения, выполненную с возможностью извлекать аудио сигнал видео объекта, выбранного частью выбора объекта, в качестве аудиосигнала объекта.
(2) Устройство для обработки видео и аудиосигналов по п.(1), в котором часть извлечения извлекает аудиосигнал объекта из аудиосигнала.
(3) Устройство для обработки видео и аудиосигналов по п.(2), в котором часть извлечения извлекает сигнал, отличный от аудиосигнала объекта выбранного видео объекта, в качестве фонового звукового сигнала из аудиосигнала.
(4) Устройство для обработки видео и аудиосигналов по любому из пунктов (1) - (3), в котором часть выбора объекта производит информацию местоположения объекта, указывающую позицию в пространстве выбранного видео объекта, и часть извлечения извлекает аудиосигнал объекта на основании информации местоположения объекта.
(5) Устройство для обработки видео и аудиосигналов по п.(4), в котором часть извлечения извлекает аудиосигнал объекта посредством разделения источника звука с использованием информации местоположения объекта.
(6) Устройство для обработки видео и аудиосигналов по п.(5), в котором часть извлечения выполняет формирование фиксированного луча в качестве разделения источника звука.
(7) Устройство для обработки видео и аудиосигналов по любому из пунктов (1) - (6), дополнительно включает в себя часть распознавания видео объекта, выполненную с возможностью распознавать видео объект на основании видеосигнала,
в котором часть управления отображением вызывает отображение, на основании результата распознавания, результата распознавания видео объекта вместе с видео объектом.
(8) Устройство для обработки видео и аудиосигналов по п.(7), в котором часть распознавания видео объекта распознает видео объект из распознавания лица.
(9) Устройство для обработки видео и аудиосигналов по п.(7) или п.(8), в котором часть управления отображением вызывает отображение рамки в качестве изображения в области видео объекта.
(10) Устройство для обработки видео и аудиосигналов по любому из пунктов (1) - (9), в котором часть выбора объекта выбирает видео объект в ответ на манипуляцию выбора пользователем.
(11) Устройство для обработки видео и аудиосигналов по любому из пунктов (1) - (10), в котором часть выбора объекта формирует метаданные для выбранного видео объекта.
(12) Устройство для обработки видео и аудиосигналов по п.(11), в котором часть выбора объекта производит информацию местоположения объекта, указывающую позицию в пространстве выбранного видео объекта в качестве метаданных.
(13) Устройство для обработки видео и аудиосигналов по п.(11) или п.(12), в котором часть выбора объекта формирует приоритет обработки выбранного видео объекта в качестве метаданных.
(14) Устройство для обработки видео и аудиосигналов по любому из пунктов (11) - (13), в котором часть выбора объекта производит информацию распространения, указывающую состояние распространения области выбранного видео объекта в качестве метаданных.
(15) Устройство для обработки видео и аудиосигналов по любому из пунктов (11) - (14), дополнительно включает в себя часть кодирования аудио, выполненную с возможностью кодировать аудиосигнал объекта и метаданные.
(16) Устройство для обработки видео и аудиосигналов по п.(15), дополнительно включает себя:
часть кодирования видео, выполненную с возможностью кодировать видеосигнал; и
часть мультиплексирования, выполненную с возможностью мультиплексировать битовый поток видео, полученный посредством кодирования видеосигнала, и битовый поток аудиосигнала, полученный путем кодирования аудиосигнала объекта и метаданные.
(17) Устройство для обработки видео и аудиосигналов по п.п. (1)-(16), дополнительно включает в себя часть захвата изображения, выполненную с возможностью получать видеосигнал путем проведения фотосъемки.
(18) Устройство для обработки видео и аудиосигналов по п.п. (1)-(17) дополнительно включает в себя часть получения звука, выполненную с возможностью получать аудиосигнал путем получения звука.
(19) Способ обработки видео и аудиосигналов включает в себя:
этап управления отображением, вызывающий отображение видео объекта на основании видеосигнала;
этап выбора объекта для выбора заданного видео объекта из одного видео объекта или множества видео объектов; и
этап извлечения аудиосигнала видео объекта, выбранного на этапе выбора объекта, в качестве аудиосигнала объекта.
(20) Программа, в соответствии с которой компьютер выполняет процесс обработки, включает в себя:
этап управления отображением, вызывающий отображение видео объекта на основании видеосигнала;
этап выбора объекта для выбора заданного видео объекта из одного видео объекта или множества видео объектов; и
этап извлечения аудиосигнала видео объекта, выбранного на этапе выбора объекта, в качестве аудиосигнала объекта.
Список ссылочных позиций
11 Устройство для обработки видео и аудиосигналов
22 Часть распознавания видео объекта
23 Часть управления отображением результата распознавания объекта видео
24 Часть отображения видео
25 Часть выбора объекта
26 Часть получения звука
27 Часть разделения источника звука
28 Часть кодирования аудио
71 Часть распознавания лица
72 Часть управления отображением результата распознавания лиц
73 Часть отображения изображения
74 Часть выбора человека
81 Сенсорная панель
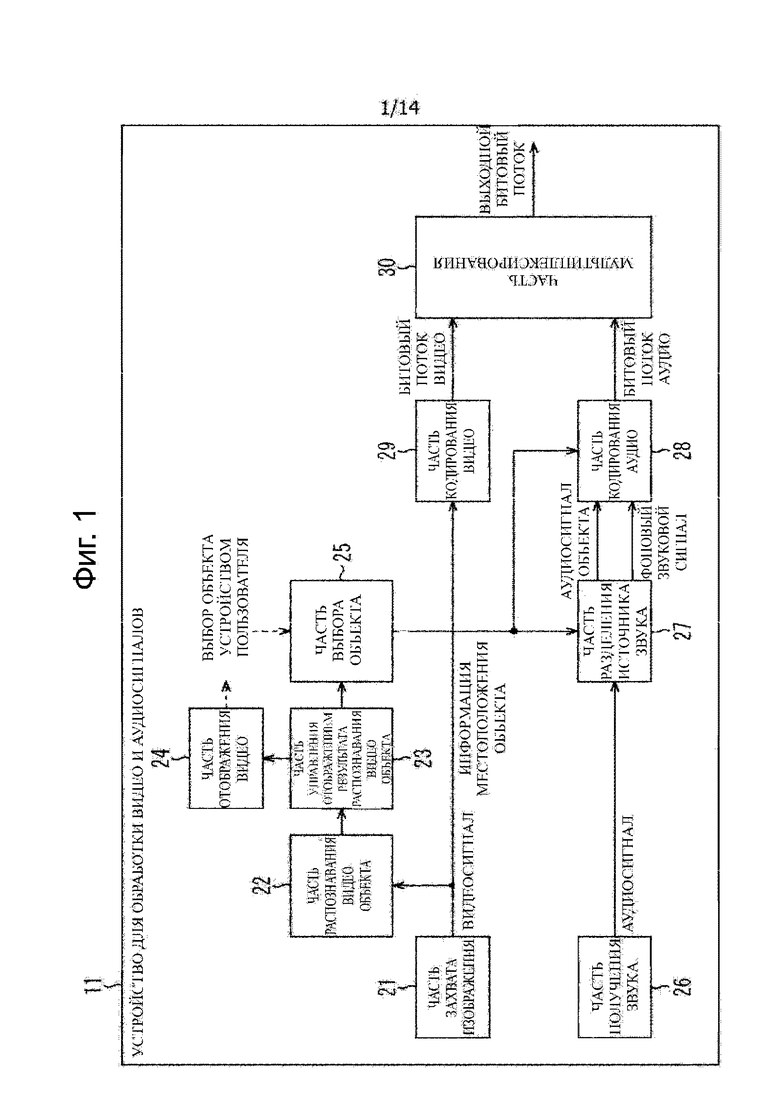
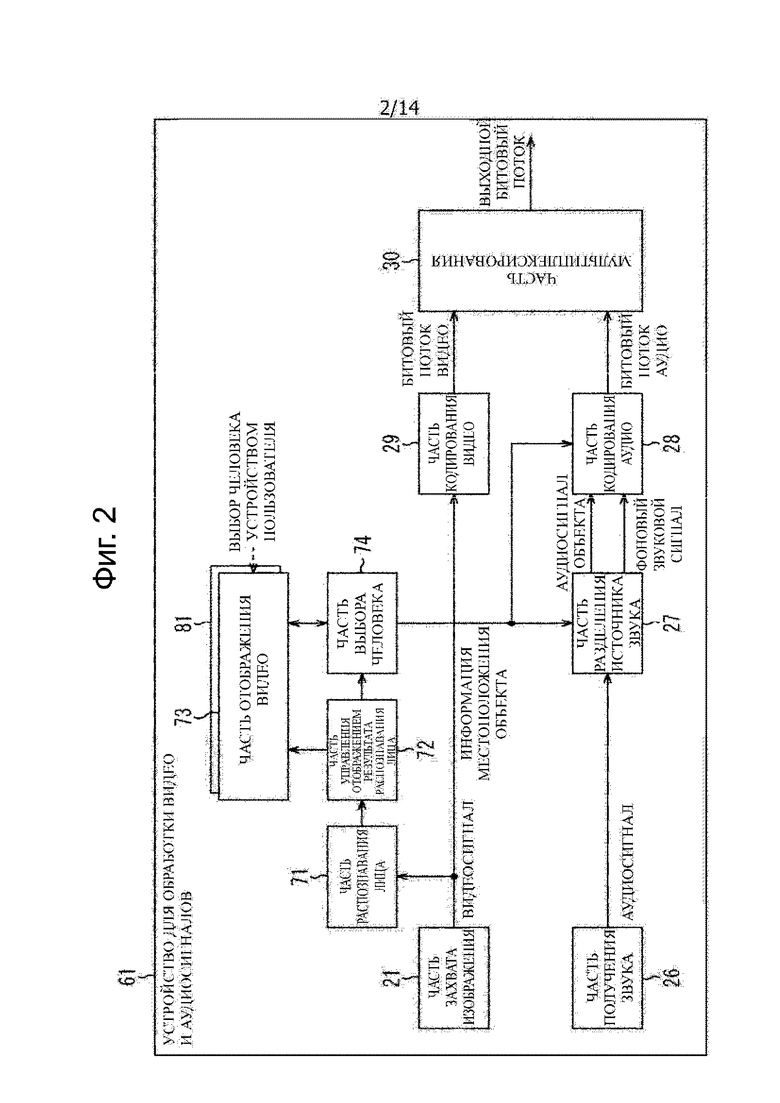
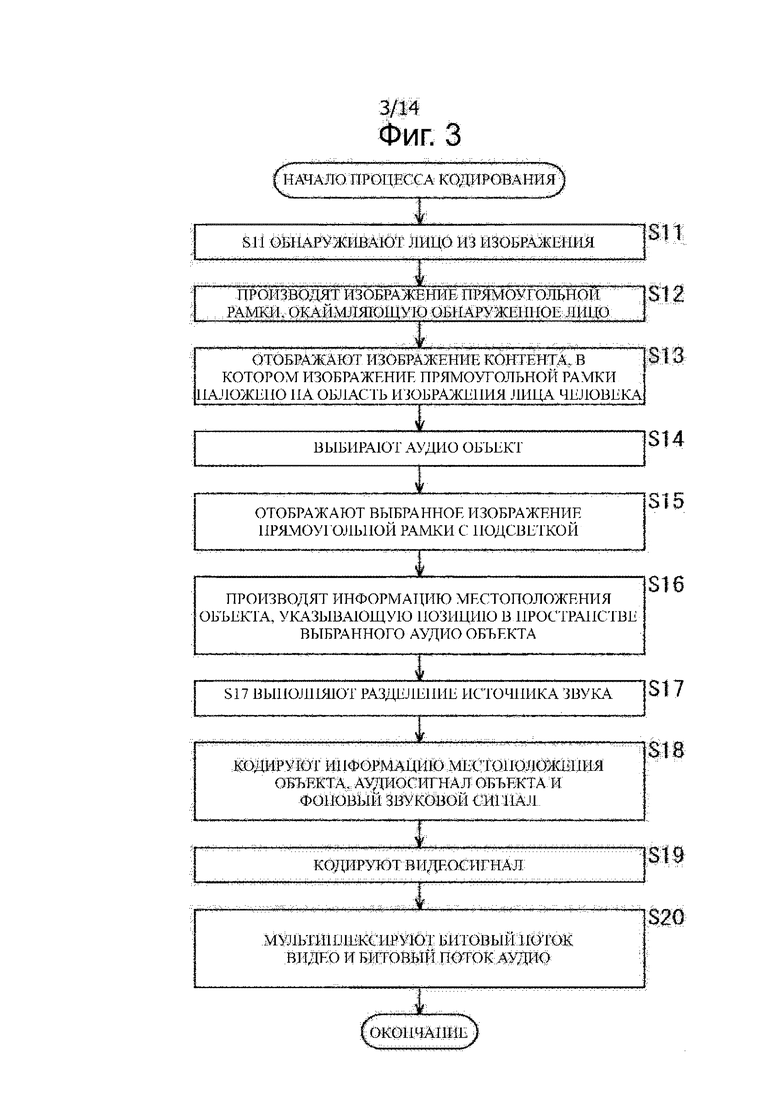
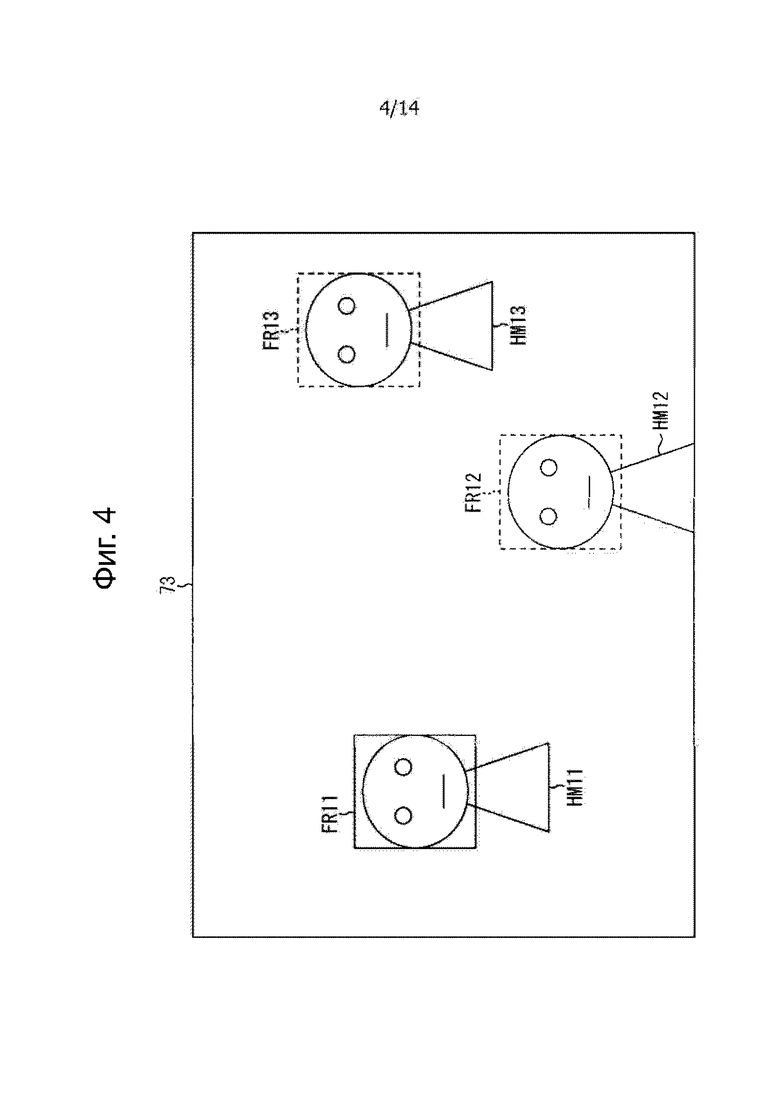
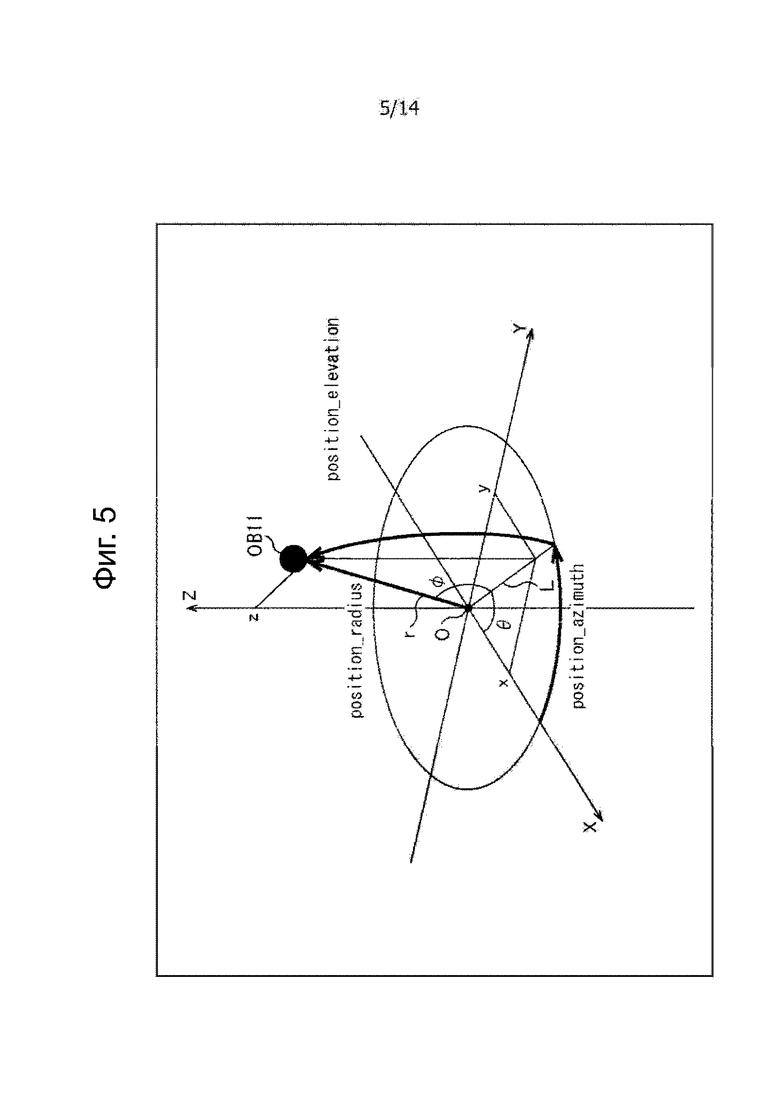
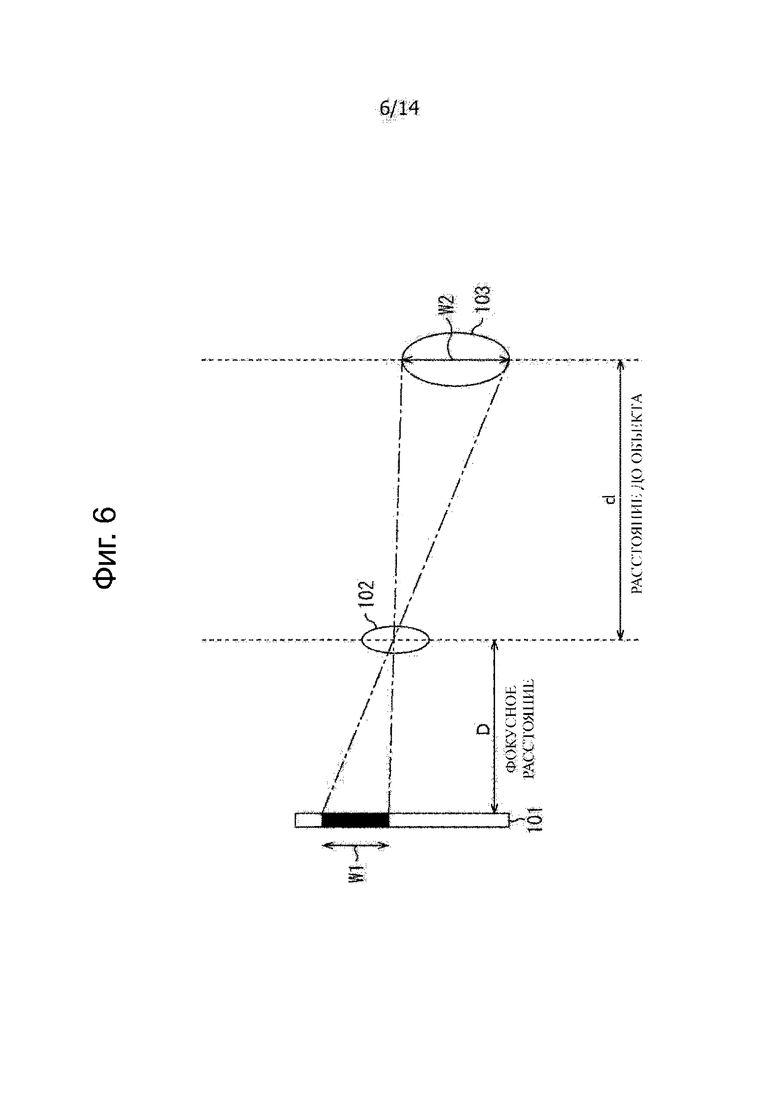
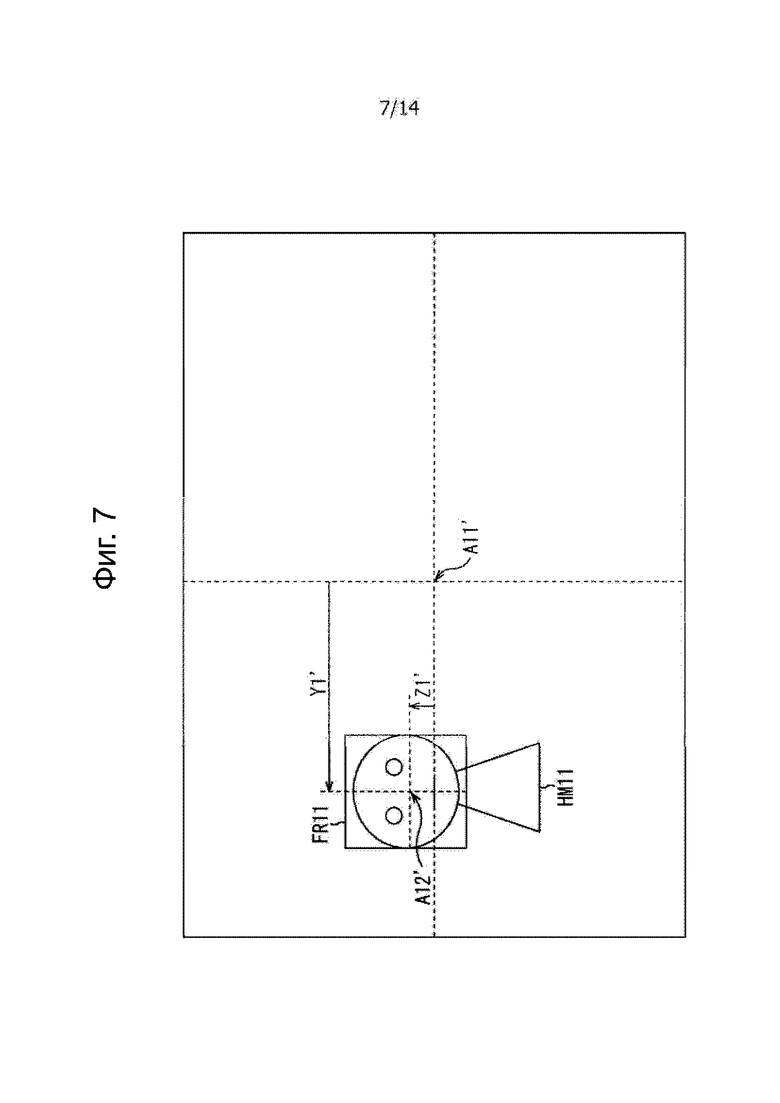

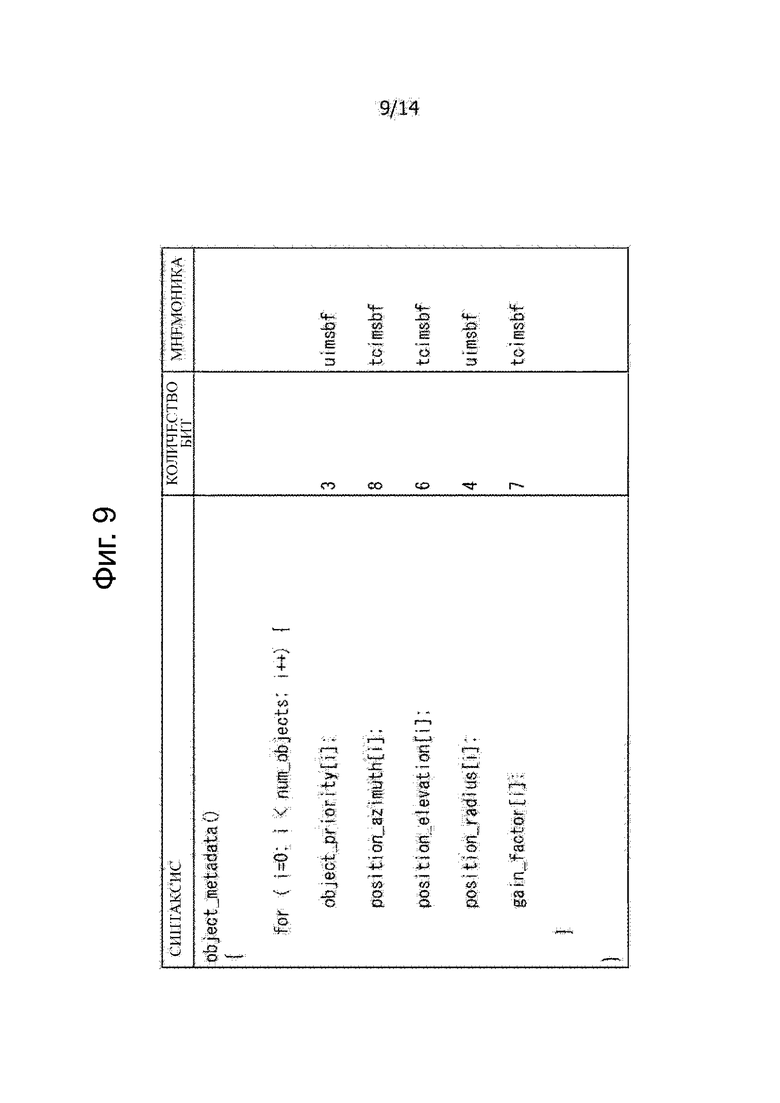
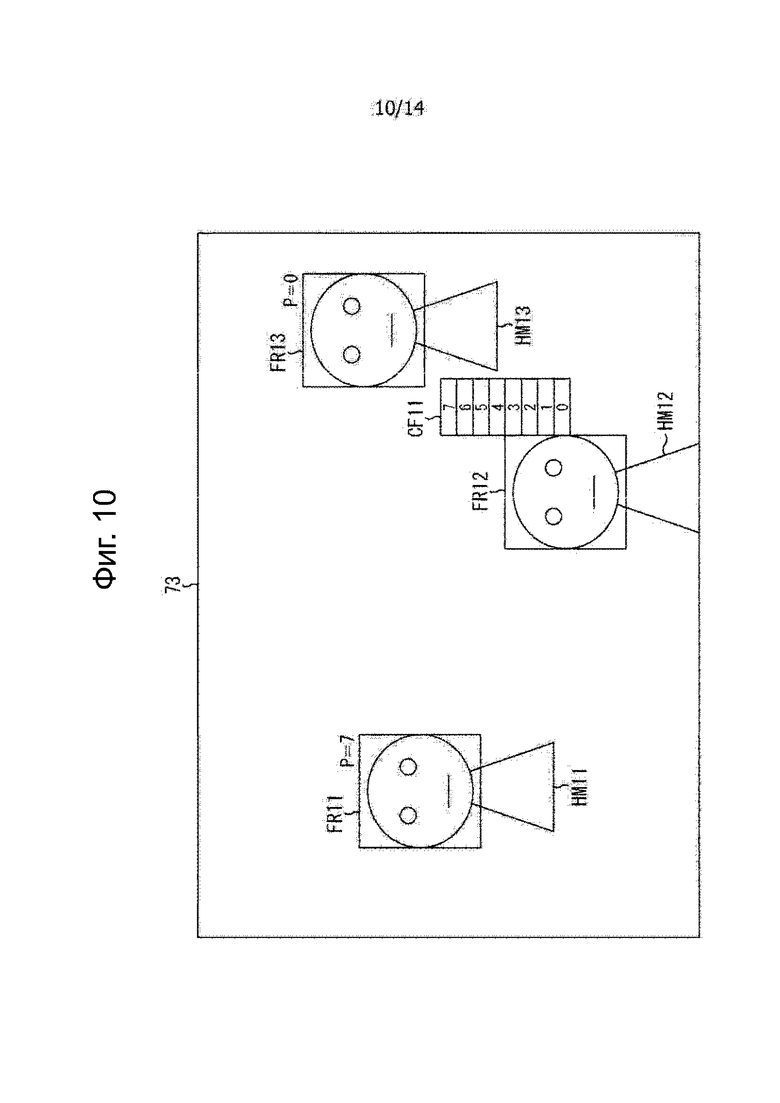

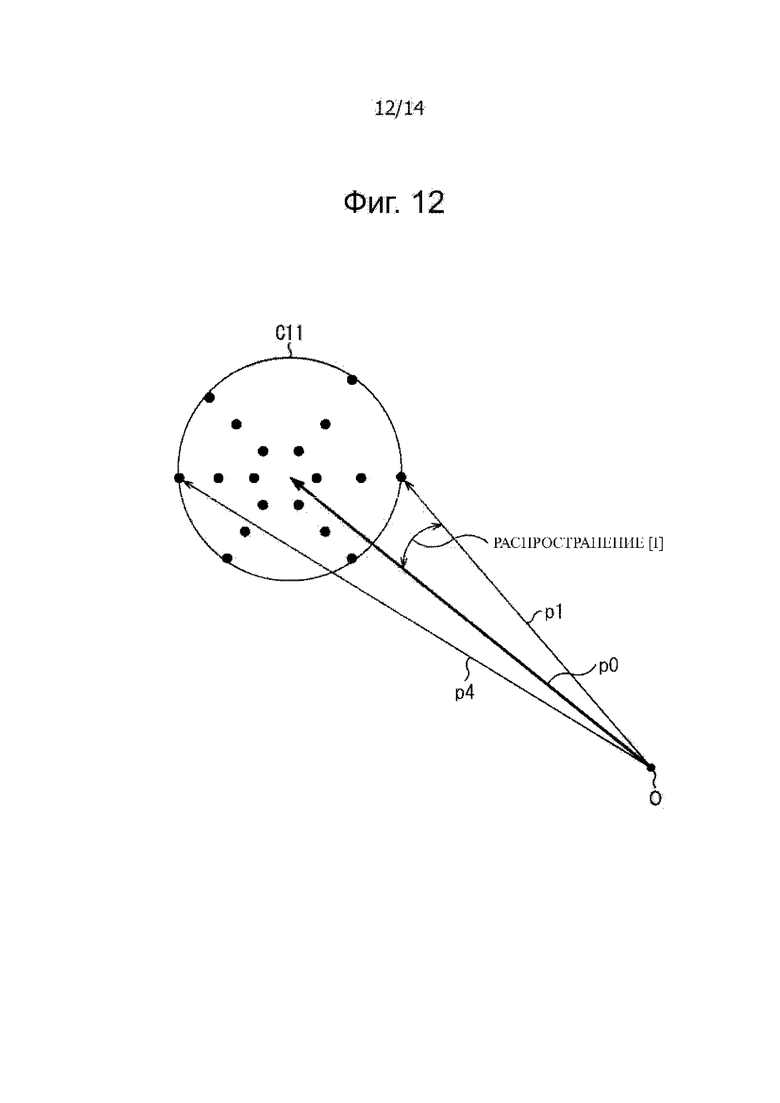
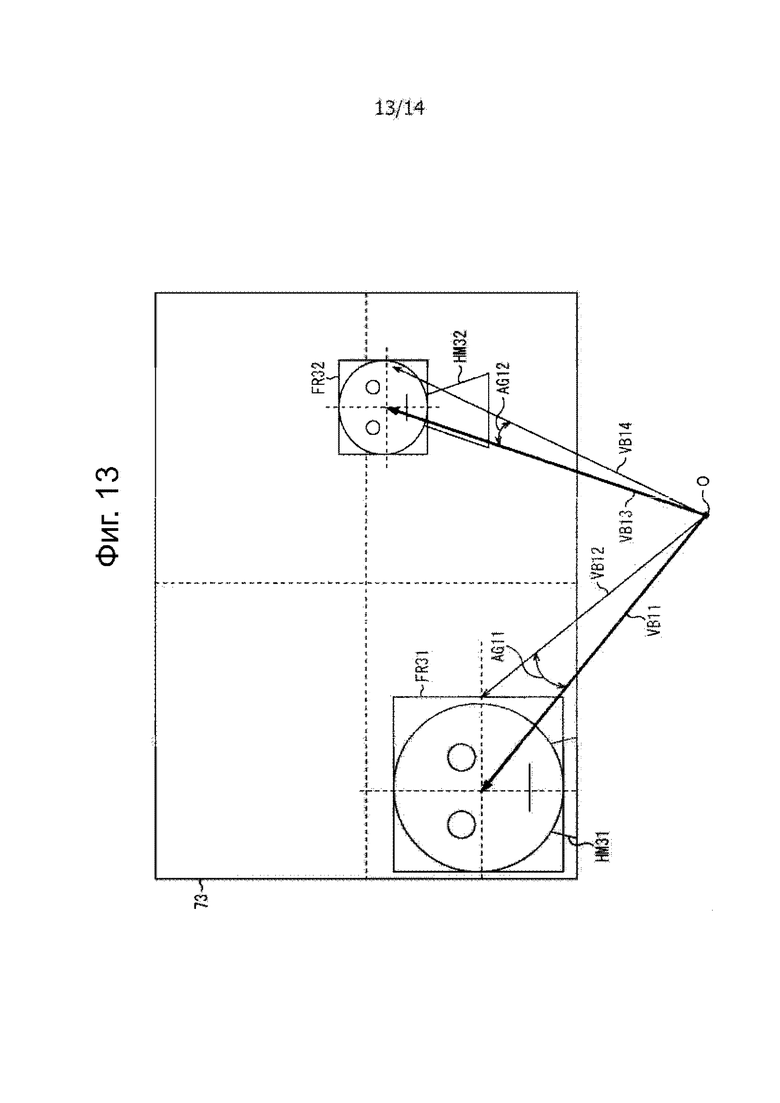
Изобретение относится к вычислительной технике. Технический результат заключается в повышении эффективности управления направленностью для обработки аудио-видеосигнала. Устройство для обработки видео- и аудиосигналов содержит часть управления отображением, выполненную с возможностью вызывать отображение видеообъекта на основании видеосигнала; часть выбора объекта, выполненную с возможностью выбирать заданный видеообъект из одного видеообъекта или среди множества видеообъектов; и часть извлечения, выполненную с возможностью извлекать аудиосигнал видеообъекта, выбранного частью выбора объекта, в качестве аудиосигнала объекта, в котором часть извлечения извлекает аудиосигнал объекта из аудиосигнала, и в котором часть извлечения извлекает сигнал, отличный от аудиосигнала объекта выбранного видеообъекта, в качестве фонового звукового сигнала из аудиосигнала. 3 н. и 15 з.п. ф-лы, 14 ил.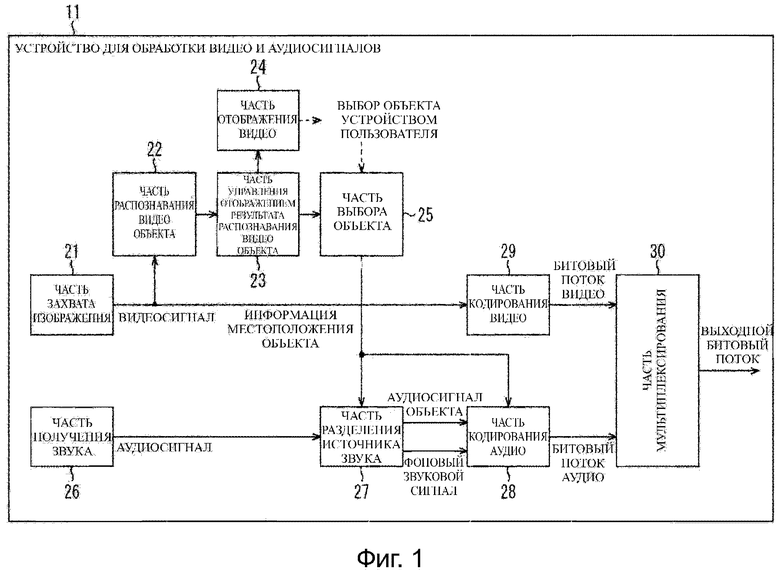
1. Устройство для обработки видео- и аудиосигналов, содержащее:
часть управления отображением, выполненную с возможностью вызывать отображение видеообъекта на основании видеосигнала;
часть выбора объекта, выполненную с возможностью выбирать заданный видеообъект из одного видеообъекта или среди множества видеообъектов; и
часть извлечения, выполненную с возможностью извлекать аудиосигнал видеообъекта, выбранного частью выбора объекта, в качестве аудиосигнала объекта, в котором часть извлечения извлекает аудиосигнал объекта из аудиосигнала, и в котором часть извлечения извлекает сигнал, отличный от аудиосигнала объекта выбранного видеообъекта, в качестве фонового звукового сигнала из аудиосигнала.
2. Устройство для обработки видео- и аудиосигналов по п.1, в котором
часть выбора объекта производит информацию местоположения объекта, указывающую позицию в пространстве выбранного видеообъекта, и
часть извлечения извлекает аудиосигнал объекта на основании информации местоположении объекта.
3. Устройство для обработки видео- и аудиосигналов по п.2, в котором часть извлечения извлекает аудиосигнал объекта через разделение источника звука с использованием информации местоположения объекта.
4. Устройство для обработки видео- и аудиосигналов по п.3, в котором часть извлечения выполняет формирование фиксированного луча в качестве разделения источника звука.
5. Устройство для обработки видео- и аудиосигналов по п.1, дополнительно содержащее часть распознавания видеообъекта, выполненную с возможностью распознавать видеообъект на основании видеосигнала, в котором
часть управления отображением вызывает отображение изображения на основании результата распознавания видеообъекта вместе с видеообъектом.
6. Устройство для обработки видео- и аудиосигналов по п.5, в котором часть распознавания видеообъекта распознает видеообъект из распознавания лиц.
7. Устройство для обработки видео- и аудиосигналов по п.5, в котором часть управления отображением вызывает отображение рамки в виде изображения в области видеообъекта.
8. Устройство для обработки видео- и аудиосигналов по п.1, в котором часть выбора объекта выбирает видеообъект в ответ на манипуляцию выбора пользователем.
9. Устройство для обработки видео- и аудиосигналов по п.1, в котором часть выбора объекта производит метаданные выбранного видеообъекта.
10. Устройство для обработки видео- и аудиосигналов по п.9, в котором часть выбора объекта производит информацию местоположения объекта, указывающую позицию в пространстве выбранного видеообъекта в качестве метаданных.
11. Устройство для обработки видео- и аудиосигналов по п.9, в котором часть выбора объекта производит данные приоритета обработки выбранного видеообъекта в качестве метаданных.
12. Устройство для обработки видео- и аудиосигналов по п.9, в котором часть выбора объекта производит информацию распространения, указывающую состояние распространения области выбранного видеообъекта в качестве метаданных.
13. Устройство для обработки видео- и аудиосигналов по п.9, дополнительно содержащее часть кодирования аудио, выполненную с возможностью кодировать аудиосигнал объекта и метаданные.
14. Устройство для обработки видео- и аудиосигналов по п.13, дополнительно содержащее:
часть кодирования видео, выполненную с возможностью кодировать видеосигнал; и
часть мультиплексирования, выполненную с возможностью мультиплексировать битовый поток видео, полученный посредством кодирования видеосигнала, и битовый поток аудио, полученный путем кодирования аудиосигнала объекта, и метаданные.
15. Устройство для обработки видео- и аудиосигналов по п.1, дополнительно содержащее часть захвата изображения, выполненную с возможностью получать видеосигнал путем проведения фотосъемки.
16. Устройство для обработки видео- и аудиосигналов по п.1, дополнительно содержащее часть получения звука, выполненную с возможностью получать аудиосигнал путем осуществления получения звука.
17. Способ обработки видео- и аудиосигналов, содержащий:
этап управления отображением, вызывающий отображение видеообъекта на основании видеосигнала;
этап выбора объекта для выбора заданного видеообъекта из одного видеообъекта или множества видеообъектов; и
этап извлечения для извлечения аудиосигнала видеообъекта, выбранного на этапе выбора объекта, в качестве аудиосигнала объекта,
в котором на этапе извлечения извлекают аудиосигнал объекта из аудиосигнала, и
в котором на этапе извлечения извлекают сигнал, отличный от аудиосигнала объекта выбранного видеообъекта, в качестве фонового звукового сигнала из аудиосигнала.
18. Носитель записи, содержащий записанную на нем программу, в соответствии с которой компьютер выполняет процесс обработки, содержащий:
этап управления отображением, вызывающий отображение видеообъекта на основании видеосигнала;
этап выбора объекта для выбора заданного видеообъекта из одного видеообъекта или множества видеообъектов; и
этап извлечения для извлечения аудиосигнала видеообъекта, выбранного на этапе выбора объекта, в качестве аудиосигнала объекта,
в котором на этапе извлечения извлекают аудиосигнал объекта из аудиосигнала, и
в котором на этапе извлечения извлекают сигнал, отличный от аудиосигнала объекта выбранного видеообъекта, в качестве фонового звукового сигнала из аудиосигнала.
| Токарный резец | 1924 |
|
SU2016A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Перекатываемый затвор для водоемов | 1922 |
|
SU2001A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| СИНХРОНИЗАЦИЯ ДИСТАНЦИОННОГО АУДИО С ФИКСИРОВАННЫМ ВИДЕО | 2008 |
|
RU2510587C2 |

