[0001] По данной заявке испрашивается приоритет Предварительной Заявки США №62/311,248, поданной 21 марта 2016 г., и Предварительной Заявки США №62/401,016, поданной 28 сентября 2016 г., которые во всей своей полноте включены в настоящее описание посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[0002] Данное раскрытие относится к кодированию видео.
ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
[0003] Возможности цифрового видео могут быть включены в широкий диапазон устройств, включая цифровые телевизионные системы, цифровые системы прямого вещания, беспроводные системы вещания, персональные цифровые помощники (PDA), настольные компьютеры или компьютеры класса лэптоп, планшетные компьютеры, устройства для чтения электронных книг, цифровые камеры, цифровые записывающие устройства, цифровые мультимедийные проигрыватели, видеоигровые устройства, видеоигровые консоли, сотовые или спутниковые телефоны, так называемые «интеллектуальные телефоны», устройства для видео телеконференцсвязи, устройства потоковой передачи видео, и подобные. Цифровые видеоустройства реализуют методики кодирования видео, такие как те, что описываются в стандартах, определяемых MPEG-2, MPEG-4, ITU-T H.263, ITU-T H.264/MPEG-4, Часть 10, Усовершенствованное Кодирование Видео (AVC), стандартом Высокоэффективного Кодирования Видео (HEVC), и расширениями таких стандартов. Видеоустройства могут передавать, принимать, кодировать, декодировать, и/или хранить цифровую видеоинформацию более эффективно посредством реализации таких методик кодирования видео.
[0004] Методики кодирования видео включают в себя пространственное (внутри изображения (интра-)) предсказание и/или временное (между изображениями (интер-)) предсказание, чтобы сокращать или удалять избыточность, свойственную видеопоследовательностям. Применительно к основанному на блоках кодированию видео, слайс видео (например, изображение видео или участок изображения видео) может быть разбит на блоки видео, которые также могут именоваться единицами дерева кодирования (CTU), единицами кодирования (CU) и/или узлами кодирования. Блоки видео в интра-кодированном (I) слайсе изображения кодируется, используя пространственное предсказание по отношению к опорным выборкам в соседних блоках в том же самом изображении. Блоки видео в интер-кодированном (P или B) слайсе изображения могут использовать пространственное предсказание по отношению к опорным выборкам в соседних блоках в том же самом изображении или временное предсказание по отношению к опорным выборкам в других опорных изображениях. Изображения могут именоваться кадрами, а опорные изображения могут именоваться опорными кадрами.
[0005] Пространственное или временное предсказание приводит к предсказывающему блоку для блока, который будет кодироваться. Остаточные данные представляют собой пиксельные разности между исходным блоком, который будет кодироваться, и предсказывающим блоком. Интер-кодированный блок кодируется в соответствии с вектором движения, который указывает на блок опорных выборок, формирующих предсказывающий блок, и остаточными данными, указывающими разность между кодированным блоком и предсказывающим блоком. Интра-кодированный блок кодируется в соответствии с режимом интра-кодирования и остаточными данными. Для дополнительного сжатия, остаточные данные могут быть преобразованы из области пикселей в область преобразования, приводя к остаточным коэффициентам преобразования, которые затем могут быть квантованы. Квантованные коэффициенты преобразования, исходно организованные в двумерном массиве, могут быть просканированы для того, чтобы создать одномерный вектор из коэффициентов преобразования, и энтропийное кодирование может быть применено, чтобы добиться еще большего сжатия.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0006] В целом, данное раскрытие описывает методики для организации единиц кодирования (т.е., блоков видеоданных) в основанном на блоках кодировании видео. Эти методики могут быть применены к существующим или будущим стандартам кодирования видео. В частности, эти методики включают в себя кодирование многотипного дерева, включающего в себя дерево области и одно или более деревья предсказания. Деревья предсказания могут происходит от листовых узлов дерева области. Некоторая информация, такая как информация инструмента кодирования, может быть просигнализирована в узлах дерева области, например, чтобы разрешать или запрещать инструменты кодирования для областей, соответствующих узлам дерева области.
[0007] В одном примере, способ декодирования видеоданных включает в себя этапы, на которых: декодируют один или более элементов синтаксиса на уровне дерева области некоторого дерева области из древовидной структуры данных для блока дерева кодирования (CTB) видеоданных, причем дерево области имеет один или более узлов дерева области, в том числе ноль или более не листовых узлов дерева области и один или более листовых узлов дерева области, причем каждый из не листовых узлов дерева области имеет первое число узлов-потомков дерева области, причем первое число составляет, по меньше мере, четыре; определяют, используя элементы синтаксиса на уровне дерева области, каким образом узлы дерева области раздроблены на узлы-потомки дерева области; декодируют один или более элементов синтаксиса на уровне дерева предсказания для каждого из листовых узлов дерева области одного или более деревьев предсказания древовидной структуры данных для CTB, причем каждое из деревьев предсказания имеет один или более узлов дерева предсказания, в том числе ноль или более не листовых узлов дерева предсказания и один или более листовых узлов дерева предсказания, причем каждый из не листовых узлов дерева предсказания имеет второе число узлов-потомков дерева предсказания, причем второе число составляет, по меньшей мере, два, причем каждый из листовых узлов предсказания определяет соответствующие единицы кодирования (CU); определяют, используя элементы синтаксиса на уровне дерева предсказания, каким образом узлы дерева предсказания раздроблены на узлы-потомки дерева предсказания; и декодируют видеоданные, включающие в себя данные предсказания и данные преобразования, для каждой из CU, на основании, по меньшей мере частично, элементов синтаксиса на уровне дерева области и элементов синтаксиса на уровне дерева предсказания.
[0008] В другом примере, устройство, для декодирования видеоданных включает в себя: память, выполненную с возможностью хранения видеоданных; и процессор, реализованный в схеме и выполненный с возможностью: декодирования одного или более элементов синтаксиса на уровне дерева области некоторого дерева области из древовидной структуры данных для блока дерева кодирования (CTB) видеоданных, причем дерево области имеет один или более узлов дерева области, в том числе ноль или более не листовых узлов дерева области и один или более листовых узлов дерева области, причем каждый из не листовых узлов дерева области имеет первое число узлов-потомков дерева области, причем первое число составляет, по меньше мере, четыре; определения, используя элементы синтаксиса на уровне дерева области, каким образом узлы дерева области раздроблены на узлы-потомки дерева области; декодирования одного или более элементов синтаксиса на уровне дерева предсказания для каждого из листовых узлов дерева области одного или более деревьев предсказания древовидной структуры данных для CTB, причем каждое из деревьев предсказания имеет один или более узлов дерева предсказания, в том числе ноль или более не листовых узлов дерева предсказания и один или более листовых узлов дерева предсказания, причем каждый из не листовых узлов дерева предсказания имеет второе число узлов-потомков дерева предсказания, причем второе число составляет, по меньшей мере, два, причем каждый из листовых узлов предсказания определяет соответствующие единицы кодирования (CU); определения, используя элементы синтаксиса на уровне дерева предсказания, каким образом узлы дерева предсказания раздроблены на узлы-потомки дерева предсказания; и декодирования видеоданных, включающих в себя данные предсказания и данные преобразования, для каждой из CU, на основании, по меньшей мере частично, элементов синтаксиса на уровне дерева области и элементов синтаксиса на уровне дерева предсказания.
[0009] В другом примере, устройство для декодирования видеоданных включает в себя: средство для декодирования одного или более элементов синтаксиса на уровне дерева области некоторого дерева области из древовидной структуры данных для блока дерева кодирования (CTB) видеоданных, причем дерево области имеет один или более узлов дерева области, в том числе ноль или более не листовых узлов дерева области и один или более листовых узлов дерева области, причем каждый из не листовых узлов дерева области имеет первое число узлов-потомков дерева области, причем первое число составляет, по меньше мере, четыре; средство для определения, используя элементы синтаксиса на уровне дерева области, каким образом узлы дерева области раздроблены на узлы-потомки дерева области; средство для декодирования одного или более элементов синтаксиса на уровне дерева предсказания для каждого из листовых узлов дерева области одного или более деревьев предсказания древовидной структуры данных для CTB, причем каждое из деревьев предсказания имеет один или более узлов дерева предсказания, в том числе ноль или более не листовых узлов дерева предсказания и один или более листовых узлов дерева предсказания, причем каждый из не листовых узлов дерева предсказания имеет второе число узлов-потомков дерева предсказания, причем второе число составляет, по меньшей мере, два, причем каждый из листовых узлов предсказания определяет соответствующие единицы кодирования (CU); средство для определения, используя элементы синтаксиса на уровне дерева предсказания, каким образом узлы дерева предсказания раздроблены на узлы-потомки дерева предсказания; и средство для декодирования видеоданных, включающих в себя данные предсказания и данные преобразования, для каждой из CU, на основании, по меньшей мере частично, элементов синтаксиса на уровне дерева области и элементов синтаксиса на уровне дерева предсказания.
[0010] В другом примере, машиночитаемый запоминающий носитель информации имеет сохраненные на нем инструкции, которые, когда исполняются, предписывают процессору: декодировать один или более элементов синтаксиса на уровне дерева области некоторого дерева области из древовидной структуры данных для блока дерева кодирования (CTB) видеоданных, причем дерево области имеет один или более узлов дерева области, в том числе ноль или более не листовых узлов дерева области и один или более листовых узлов дерева области, причем каждый из не листовых узлов дерева области имеет первое число узлов-потомков дерева области, причем первое число составляет, по меньше мере, четыре; определять, используя элементы синтаксиса на уровне дерева области, каким образом узлы дерева области раздроблены на узлы-потомки дерева области; декодировать один или более элементов синтаксиса на уровне дерева предсказания для каждого из листовых узлов дерева области одного или более деревьев предсказания древовидной структуры данных для CTB, причем каждое из деревьев предсказания имеет один или более узлов дерева предсказания, в том числе ноль или более не листовых узлов дерева предсказания и один или более листовых узлов дерева предсказания, причем каждый из не листовых узлов дерева предсказания имеет второе число узлов-потомков дерева предсказания, причем второе число составляет, по меньшей мере, два, причем каждый из листовых узлов предсказания определяет соответствующие единицы кодирования (CU); определять, используя элементы синтаксиса на уровне дерева предсказания, каким образом узлы дерева предсказания раздроблены на узлы-потомки дерева предсказания; и декодировать видеоданные, включающие в себя данные предсказания и данные преобразования, для каждой из CU, на основании, по меньшей мере частично, элементов синтаксиса на уровне дерева области и элементов синтаксиса на уровне дерева предсказания.
[0011] Подробности одного или более примеров излагаются на сопроводительных чертежах и в описании ниже. Прочие признаки, цели, и преимущества будут очевидны из описания и чертежей, и из формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0012] Фиг. 1 является структурной схемой, иллюстрирующей примерную систему кодирования и декодирования видео, которая может использовать методики для кодирования видеоданных, используя инфраструктуру двухуровневого многотипного дерева.
[0013] Фиг. 2 является структурной схемой, иллюстрирующей пример кодера видео, который может реализовывать методики для кодирования видеоданных, используя инфраструктуру двухуровневого многотипного дерева.
[0014] Фиг. 3 является структурной схемой, иллюстрирующей пример декодера видео, который может реализовывать методики для кодирования видеоданных, используя инфраструктуру двухуровневого многотипного дерева.
[0015] Фиг. 4 является структурной схемой, иллюстрирующей пример блока дерева кодирования (CTB).
[0016] Фиг. 5 является структурной схемой, иллюстрирующей пример единиц предсказания (PU) у CU.
[0017] Фиг. 6 является концептуальной схемой, иллюстрирующей пример структуры квадродерево-бинарное дерево (QTBT), и соответствующий CTB.
[0018] Фиг. 7 является концептуальной схемой, иллюстрирующей блок кодированный с использованием компенсации движения перекрывающегося блока (OBMC).
[0019] Фиг. 8 является концептуальной схемой, иллюстрирующей пример OBMC, применяемой в HEVC, т.е., основанной на PU OBMC.
[0020] Фиг. 9 является концептуальной схемой, иллюстрирующей пример выполнения суб-PU уровня OBMC.
[0021] Фиг. 10 является концептуальной схемой, иллюстрирующей примеры ассиметричных разбиений движения для 64×64 блока.
[0022] Фиг. 11 является концептуальной схемой, иллюстрирующей примерную схему преобразования, основанную на остаточном квадродереве в соответствии с HEVC.
[0023] Фиг. 12 является концептуальной схемой, иллюстрирующей пример первого уровня многотипного дерева и второй уровень многотипного дерева.
[0024] Фиг. 13 является блок-схемой, иллюстрирующей примерный способ для кодирования блока дерева кодирования в соответствии с методиками данного раскрытия.
[0025] Фиг. 14 является блок-схемой, иллюстрирующей примерный способ для декодирования блока дерева кодирования в соответствии с методиками данного раскрытия.
ПОДРОБНОЕ ОПИСАНИЕ
[0026] При кодировании видео, древовидные структуры данных могут быть использованы, чтобы представлять разбиение блока видео. Например, в Высокоэффективном Кодировании Видео (HEVC), квадродерево используется, чтобы представлять разбиение блока дерева кодирования (CTB) на единицы кодирования (CU). Другие древовидные структуры были использованы для других парадигм основанного на блоках кодирования видео. Например, бинарные деревья были использованы, чтобы представлять разбиение блоков на либо два горизонтальных, либо два вертикальных блока. Многотипные деревья, такие как квадродерево-бинарные деревья (QTBT), могут быть использованы, чтобы объединять квадродеревья и бинарные деревья.
[0027] Стандарты кодирования видео включают в себя ITU-T H.261, ISO/IEC MPEG-1 Визуальный, ITU-T H.262 или ISO/IEC MPEG-2 Визуальный, ITU-T H.263, ISO/IEC MPEG-4 Визуальный и ITU-T H.264 (также известный как ISO/IEC MPEG-4 AVC), включая его расширения Масштабируемое Кодирование Видео (SVC) и Многовидовое Кодирование Видео (MVC). В дополнение, новый стандарт кодирования видео, а именно Высокоэффективное Кодирование Видео (HEVC) или ITU-T H.265, включая его расширения кодирования диапазона и контента экрана, кодирование 3D видео (3D-HEVC) и многовидовые расширения (MV-HEVC) и масштабируемое расширение (SHVC), был недавно разработан Совместной Группой Сотрудничества по Кодированию Видео (JCT-VC), как впрочем и Совместной Группой Сотрудничества по Разработке Расширения Кодирования 3D Видео (JCT-3V) Экспертной Группы в Области Кодирования Видео ITU-T (VCEG) и Экспертной Группы по Кинематографии ISO/IEC (MPEG). В качестве примеров, аспекты исполнения HEVC описываются ниже, которые концентрируются на разбиение блока. Общие концепции и терминология для HEVC и других методик обсуждаются ниже.
[0028] Структура многотипного дерева является видом плоской структуры. Все типы дерева являются одинаково важными для узла дерева, что делает сложным прослеживание многотипного дерева. В дополнение, в обычных методиках кодирования, связанных со структурами многотипного дерева, некоторые инструменты кодирования являются несовместимыми со структурами многотипного дерева и/или структурами QTBT. Например, компенсация движения перекрывающегося блока (OBMC) является менее эффективной, когда используется с многотипными деревьями или QTBT, так как в этих типах дерева отсутствуют границы PU. В данном случае, OBMC может быть применена только к одной стороне границ CU. Подобным образом, не могут быть применены методики перекрывающегося преобразования, поскольку отсутствуют границы PU, а перекрывающимся преобразованиям не разрешено пересекать границы CU. Также сложно определить область, где суб-блоки могут совместно использовать одни и те же значения предсказания параметра квантования (QP), чтобы эффективно сигнализировать вариацию QP при использовании структур многотипного дерева или QTBT.
[0029] Методики данного раскрытия могут быть применены, чтобы преодолеть эти и прочие такие проблемы. Разнообразные методики, обсуждаемые ниже, могут быть применены индивидуально или в любом сочетании.
[0030] В целом, в соответствии с ITU-T H.265, изображение видео может быть разделено на последовательность единиц дерева кодирования (CTU) (или наибольших единиц кодирования (LCU)), которые могут включать в себя выборки как яркости, так и цветности. В качестве альтернативы, CTU могут включать в себя монохромные данные (т.е., только выборки цветности). Данные синтаксиса в битовом потоке могут определять размер для CTU, которая является наибольшей единицей кодирования исходя из числа пикселей. Слайс включает в себя некоторое число последовательных CTU в очередности кодирования. Изображение видео может быть разбито на один или более слайсов. Каждая CTU может быть раздроблена на единицы кодирования (CU) в соответствии с квадродеревом. В целом, структура данных квадродерева включает в себя один узел на CU, с корневым узлом соответствующим CTU. Если CU дробится на четыре суб-CU, то узел, соответствующий CU, включает в себя четыре листовых узла, каждый из которых соответствует одной из суб-CU.
[0031] Каждый узел структуры данных квадродерева может предоставлять данные синтаксиса для соответствующей CU. Например, узел в квадродереве может включать в себя флаг дробления, указывающий, дробится ли CU, соответствующая узлу, на суб-CU. Элементы синтаксиса для CU могут быть определены рекурсивно, и могут зависеть от того, дробится ли CU на суб-CU. Если CU далее не дробится, она именуется листовой CU. В данном раскрытии, четыре суб-CU у листовой CU также будут именоваться листовыми CU даже если отсутствует явное дробление исходной листовой CU. Например, если CU с размером 16×16 далее не дробится, то четыре 8×8 суб-CU также будут именоваться листовыми CU, несмотря на то, что 16×16 CU никогда не была раздроблена.
[0032] CU имеет назначение сходное с макроблоком стандарта H.264, за исключением того, что CU не имеет различия по размеру. Например, CTU может быть раздроблена на четыре узла-потомка (также именуемых суб-CU), и каждый узел-потомок может в свою очередь быть узлом-родителем и быть раздроблен на другие четыре узла-потомка. Итоговый, нераздробленный узел-потомок, именуемый листовым узлом квадродерева, содержит узел кодирования, также именуемый листовым CU. Данные синтаксиса, ассоциированные с кодированным битовым потоком, могут определять максимальное число раз, которое CTU может быть раздроблена, именуемое максимальной глубиной CU, и может также определять минимальный размер узлов кодирования. Соответственно, битовый поток также может определять наименьшую единицу кодирования (SCU). Данное раскрытие использует понятие «блок», чтобы обращаться к любому из CU, единицы предсказания (PU), или единицы преобразования (TU), в контексте HEVC, или сходным структурам данных в контексте других стандартов (например, макроблокам и их суб-блокам в H.264/AVC).
[0033] CU включает в себя узел кодирования и единицы предсказания (PU) и единицы преобразования (TU), ассоциированные с узлом кодирования. Размер CU соответствует размеру узла кодирования и является, как правило, квадратным по форме. Размер CU может находиться в диапазоне от 8×8 пикселей вплоть до размера CTU с максимальным размером, например, 64×64 пикселей или больше. Каждая CU может содержать одну или более PU и одну или более TU. Данные синтаксиса, ассоциированные с CU, могут описывать, например, разбиение CU на одну или более PU. Режимы разбиения могут отличаться между тем, кодируется ли CU в режиме пропуска или непосредственном режиме, кодируется ли в режиме интра-предсказания, или кодируется в режиме интер-предсказания. PU могут быть разбиты, чтобы быть не квадратными по форме. Данные синтаксиса, ассоциированные с CU, также могут описывать, например, разбиение CU на одну или более TU в соответствии с квадродеревом. TU может быть квадратной или не квадратной (например, прямоугольной) по форме.
[0034] Стандарт HEVC допускает преобразования в соответствии с TU, которые могут быть разными для разных CU. Размеры TU, как правило, устанавливаются на основании размера PU в рамках заданной CU, определенной для разбитой CTU, несмотря на то, что это не всегда так. TU, как правило, являются точно такого же размера или меньше чем PU. В некоторых примерах, остаточные выборки, соответствующие CU, могут быть подразделены на меньшие единицы, используя структуру квадродерева известную как «остаточное квадродерево» (RQT). Листовые узлы RQT могут именоваться единицами преобразования (TU). Значения пиксельной разности, ассоциированные с TU, могут быть преобразованы, чтобы создавать коэффициенты преобразования, которые могут быть квантованы.
[0035] В HEVC, листовая CU может включать в себя одну или более единицы предсказания (PU). В целом, PU представляет собой пространственную зону, соответствующую всей или участку соответствующей CU, и может включать в себя данные для извлечения и/или генерирования опорной выборки для PU. Более того, PU включает в себя данные, относящиеся к предсказанию. Например, когда PU является кодируемой в интра-режиме, данные для PU могут быть включены в остаточное квадродерево (RQT), которое может включать данные, описывающие режим интра-предсказания для TU, соответствующей PU. RQT также может именоваться деревом преобразования. В некоторых примерах, режим интра-предсказания может быть просигнализирован в синтаксисе листовой CU, вместо RQT. В качестве другого примера, когда PU является кодируемой в интер-режиме, PU может включать данные, определяющие информацию движения, такую как один или более векторы движения, для PU. Данные, определяющие вектор движения для PU, могут описывать, например, горизонтальный компонент вектора движения, вертикальный компонент вектора движения, разрешение для вектора движения (например, точность в одну четвертую пикселя, и/или точность в одну восьмую пикселя), опорное изображение, на которое указывает вектор движения, и/или список опорных изображений (например, Список 0, Список 1, или Список C) для вектора движения.
[0036] Также в HEVC, листовая CU с одной или более PU также может включать в себя одну или более единицы преобразования (TU). Единицы преобразования могут быть указаны используя RQT (также именуемое структурой квадродерева TU), как обсуждалось выше. Например, флаг дробления может указывать, дробится ли листовая CU на четыре единицы преобразования. Затем, каждая единица преобразования может быть дальше раздроблена на четыре суб-TU. Когда TU далее не дробится, она может именоваться листовой TU. Как правило, применительно к интра-кодированию, все листовые TU, принадлежащие листовой CU, совместно используют один и тот же режим интра-предсказания. Т.е., один и тот же режим интра-предсказания, в целом, применяется, чтобы вычислить предсказанные значения для всех TU у листовой CU. Применительно к интра-кодированию, кодер видео может вычислять остаточное значение для каждой листовой TU, используя режим интра-предсказания, как разность между участком CU, соответствующим TU, и исходным блоком. TU не обязательно ограничивается размером PU. Таким образом, TU могут быть больше или меньше PU. Применительно к интра-кодированию, PU может быть совместно размещена с соответствующей листовой TU для одной и той же CU. В некоторых примерах, максимальный размер листовой TU может соответствовать размеру соответствующей листовой CU.
[0037] Более того, TU у листовой CU в HEVC также могут быть ассоциированы с соответствующими структурами данных квадродерева, именуемыми остаточные квадродеревья (RQT). Т.е., листовая CU может включать в себя квадродерево, указывающее то, каким образом листовая CU разбита на TU. Корневой узел квадродерева TU, как правило, соответствует листовой CU, тогда как корневой узел квадродерева CU, как правило, соответствует CTU (или LCU). TU у RQT, которые не раздроблены, именуются листовыми TU. В целом, данное раскрытие использует понятия CU и TU, чтобы обращаться к листовой CU или листовой TU, соответственно, при условии что не отмечается иное.
[0038] Видеопоследовательность, как правило, включает в себя ряд кадров или изображений видео, начиная с изображения произвольной точки доступа (RAP). Видеопоследовательность может включать в себя данные синтаксиса в наборе параметров последовательности (SPS), которые описывают характеристики видеопоследовательности. Каждый слайс изображения может включать в себя данные синтаксиса слайса, которые описывают режим кодирования для соответствующего слайса. Кодеры видео, как правило, оперируют блоками видео в индивидуальных слайсах видео для того, чтобы кодировать видеоданные. Блок видео может соответствовать узлу кодирования в CU. Блоки видео могут иметь фиксированные или варьирующиеся размеры, и могут отличаться по размеру в соответствии с указанным стандартом кодирования.
[0039] В качестве примера, предсказание может быть выполнено для PU разнообразных размеров. Предполагая, что размер конкретной CU составляет 2N×2N, интра-предсказание может быть выполнено по размерам PU вида 2N×2N или N×N, а интер-предсказание может быть выполнено по симметричным размерам PU вида 2N×2N, 2N×N, N×2N, или N×N. Ассиметричное разбиение для интер-предсказания также может быть выполнено для размеров PU вида 2N×nU, 2N×nD, nL×2N, и nR×2N. При ассиметричном разбиении, одно направление CU не разбивается, тогда как другое направление разбивается на 25% и 75%. Участок CU, соответствующий разбиению 25% указывается посредством «n», сопровождаемого указанием «Верх» (U), «Низ» (D), «Лево» (L), или «Право» (R). Таким образом, например, «2N×nU» относится к 2N×2N CU, которая разбита горизонтально с 2N×0.5N PU сверху и 2N×1.5N PU снизу.
[0040] Фиг. 1 является структурной схемой, иллюстрирующей примерную систему 10 кодирования и декодирования видео, которая может использовать методики для кодирования видео, используя инфраструктуру двухуровневого многотипного дерева. Как показано на Фиг. 1, система 10 включает в себя устройство-источник 12, которое предоставляет закодированные видеоданные, которые будут декодироваться позже устройством-получателем 14. В частности, устройство-источник 12 предоставляет видеоданные устройству-получателю 14 через машиночитаемый носитель 16 информации. Устройство-источник 12 и устройство-получатель 14 могут быть выполнены в виде любого из широкого диапазона устройств, включая настольные компьютеры, компьютеры класса ноутбуки (т.е., лэптоп), планшетные компьютеры, абонентские телевизионные приставки, телефонные трубки, такие как, так называемые, «интеллектуальные» телефоны, так называемые «интеллектуальные» планшеты, телевизионные системы, камеры, дисплейные устройства, цифровые мультимедийные проигрыватели, видеоигровые консоли, устройства потоковой передачи видео, или подобное. В некоторых случаях, устройство-источник 12 и устройство-получатель 14 могут быть оборудованы для беспроводной связи.
[0041] Устройство-получатель 14 может принимать закодированные видеоданные, которые будут декодироваться, через машиночитаемый носитель 16 информации. Машиночитаемый носитель 16 информации может содержать любой тип носителя информации или устройства, выполненного с возможностью перемещения закодированных видеоданных от устройства-источника 12 к устройству-получателю 14. В одном примере, машиночитаемый носитель 16 информации может содержать средство связи, чтобы позволять устройству-источнику 12 передавать закодированные видеоданные непосредственно к устройству-получателю 14 в режиме реального времени. Закодированные видеоданные могут быть модулированы в соответствии со стандартом связи, таким как протокол беспроводной связи, и переданы устройству-получателю 14. Средство связи может содержать любое беспроводное или проводное средство связи, такое как радиочастотный (RF) спектр или одну или более физические линии передачи. Средство связи может формировать часть основанной на пакетах сети, такой как локальная сеть, региональная сеть, или глобальная сеть, такая как Интернет. Средство связи может включать в себя маршрутизаторы, коммутаторы, базовые станции, или любое другое оборудование, которое может быть полезным, чтобы способствовать осуществлению связи от устройства-источника 12 к устройству-получателю 14.
[0042] В некоторых примерах, закодированные данные могут быть выведены из интерфейса 22 вывода на запоминающее устройство. Сходным образом, доступ к закодированным данным на запоминающем устройстве может быть осуществлен посредством интерфейса ввода. Запоминающее устройство может включать в себя любые из разнообразия распределенных или локально доступных носителей информации для хранения данных, таких как жесткий диск, Blu-ray диски, DVD, CD-ROM, флэш-память, энергозависимая или энергонезависимая память, или любые другие подходящие цифровые запоминающие носители информации для хранения закодированных видеоданных. В дополнительном примере, запоминающее устройство может соответствовать файловому серверу или другому промежуточному запоминающему устройству, которое может хранить закодированное видео, сгенерированное устройством-источником 12. Устройство-получатель 14 может осуществлять доступ к хранящимся видеоданным на запоминающем устройстве через потоковую передачу или загрузку. Файловый сервер может быть сервером любого типа, выполненным с возможностью хранения закодированных видеоданных и передачи тех закодированных видеоданных устройству-получателю 14. Примерные файловые серверы включают в себя web-сервер (например, для web-сайта), FTP-сервер, устройства подключаемого к сети накопителя (NAS), или локальный дисковый накопитель. Устройство-получатель 14 может осуществлять доступ к закодированным видеоданным через любое стандартное соединение для передачи данных, включая Интернет соединение. Это может включать в себя беспроводной канал (например, Wi-Fi соединение), проводное соединение (например, DSL, кабельный модем, и т.д.), или сочетание двух видов, которое подходит для осуществления доступа к закодированным видеоданным, хранящимся на файловом сервере. Передача закодированных видеоданных с запоминающего устройства может быть потоковой передачей, передачей загрузки, или их сочетанием.
[0043] Методики данного раскрытия не обязательно ограничиваются беспроводными приложениями или установками. Методики могут быть применены к кодированию видео в поддержку любого из разнообразия мультимедийных приложений, таких как вещание эфирного телевидения, передачи кабельного телевидения, передачи спутникового телевидения, передачи потокового видео через Интернет, такие как динамическая адаптивная потоковая передача через HTTP (DASH), цифровое видео, которое кодируется на носителе информации для хранения данных, декодирования цифрового видео, хранящегося на носителе информации для хранения данных, или других приложений. В некоторых примерах, система 10 может быть выполнена с возможностью поддержки односторонней или двусторонней передачи видео, чтобы поддерживать приложения, такие как потоковой передачи видео, воспроизведения видео, вещания видео, и/или видеотелефонии.
[0044] В примере Фиг. 1, устройство-источник 12 включает в себя источник 18 видео, кодер 20 видео, и интерфейс 22 вывода. Устройство-получатель 14 включает в себя интерфейс 28 ввода, декодер 30 видео, и дисплейное устройство 32. В соответствии с данным раскрытием, кодер 20 видео устройства-источника 12 может быть выполнен с возможностью применения методик для кодирования видеоданных, используя инфраструктуру двухуровневого многотипного дерева. В других примерах, устройство-источник и устройство получатель могут включать в себя другие компоненты или организации. Например, устройство-источник 12 может принимать видеоданные от внешнего источника 18 видео, такого как внешняя камера. Подобным образом, устройство-получатель 14 может взаимодействовать с внешним дисплейным устройством, вместо того, чтобы включать в себя интегрированное дисплейное устройство.
[0045] Иллюстрируемая система 10 Фиг. 1 является лишь одним примером. Методики для кодирования видеоданных, используя инфраструктуру двухуровневого многотипного дерева могут быть выполнены любым устройством кодирования и/или декодирования цифрового видео. Несмотря на то, что в общем, методики данного раскрытия выполняются посредством устройства кодирования видео, методики также могут быть выполнены посредством кодера/декодера видео, как правило, именуемого «КОДЕК». Более того, методики данного раскрытия также могут быть выполнены препроцессором видео. Устройство-источник 12 и устройство-получатель 14 являются лишь примерами таких устройств кодирования, в которых устройство-источник 12 генерирует кодированные видеоданные для передачи устройству-получателю 14. В некоторых примерах, устройства 12, 14 могут работать по существу симметричным образом так, что каждое из устройств 12, 14 включает в себя компоненты кодирования и декодирования видео. Следовательно, система 10 может поддерживать одностороннюю или двухстороннюю передачу видео между видеоустройствами 12, 14, например, применительно к потоковой передаче видео, воспроизведению видео, вещанию видео, или видеотелефонии.
[0046] Источник 18 видео у устройства-источника 12 может включать в себя устройство захвата видео, такое как видеокамера, видеоархив, содержащий ранее захваченное видео, и/или интерфейс подачи видео, чтобы принимать видео от поставщика видеоконтента. В качестве дополнительной альтернативы, источник 18 видео может генерировать основанные на компьютерной графике данные в качестве исходного видео, или сочетание эфирного видео, архивированного видео, и генерируемого компьютером видео. В некоторых случаях, если источником 18 видео является видеокамера, устройство-источник 12 и устройство-получатель 14 могут формировать так называемый камерофоны или видеофоны. Как упомянуто выше, тем не менее, методики, описанные в данном раскрытии, могут быть применены к кодированию видео в целом, и могут быть применены к беспроводным и/или проводным приложениям. В каждом случае, захваченное, предварительно захваченное, или сгенерированное компьютером виде может быть закодировано кодером 20 видео. Закодированная видеоинформация может быть затем выведена интерфейсом 22 вывода на машиночитаемый носитель 16 информации.
[0047] Машиночитаемый носитель 16 информации может включать в себя временные носители информации, такие как беспроводное вещание или передача проводной сети, или запоминающие носители информации (т.е., не временные запоминающие носители информации), такие как жесткий диск, флэш-накопитель, компакт-диск, цифровой видео диск, Blu-ray диск, или другие машиночитаемые носители информации. В некоторых примерах, сетевой сервер (не показан) может принимать закодированные видеоданные от устройства-источника 12 и предоставлять закодированные видеоданные устройству-получателю 14, например, через сетевую передачу. Сходным образом, вычислительное устройство предприятия по производству носителей информации, такого как предприятие штампующее диски, может принимать закодированные видеоданные от устройства-источника 12 и создавать диск, содержащий закодированные видеоданные. Вследствие этого, машиночитаемый носитель 16 информации можно понимать, как включающий в себя один или более машиночитаемые носители информации разнообразных форм, в разнообразных примерах.
[0048] Интерфейс 28 ввода устройства-получателя 14 принимает информации от машиночитаемого носителя 16 информации. Информация машиночитаемого носителя 16 информации может включать в себя информацию синтаксиса, определенную кодером 20 видео, которая также используется декодером 30 видео, которая включает в себя элементы синтаксиса, которые описывают характеристики и/или обработку блоков и других кодированных единиц. Дисплейное устройство 32 отображает декодированные видеоданные пользователю, и может содержать любое из разнообразия дисплейных устройств, такое как электроннолучевая трубка (CRT), жидкокристаллический дисплей (LCD), плазменный дисплей, дисплей на органических светоизлучающих диодах (OLED), или другой тип дисплейного устройства.
[0049] Кодер 20 видео и декодер 30 видео могут работать в соответствии со стандартом кодирования видео, таким как стандарт Высокоэффективного Кодирования Видео (HEVC), также именуемый ITU-T H.265. В качестве альтернативы, кодер 20 видео и декодер 30 видео могут работать в соответствии с другими частными или промышленными стандартами, такими как стандарт ITU-T H.264, альтернативно именуемый MPEG-4, Часть 10, Усовершенствованное Кодирование Видео (AVC), или расширения таких стандартов. Методики данного раскрытия, тем не менее, не ограничиваются любым конкретным стандартом кодирования. Другие примеры стандартов кодирования видео включают в себя MPEG-2 и ITU-T H.263. Несмотря на то, что не показано на Фиг. 1, в некоторых аспектах, кодер 20 видео и декодер 30 видео каждый может быть интегрирован с кодером и декодером аудио, и может включать в себя соответствующие модули MUX-DEMUX, или другое аппаратное обеспечение и программное обеспечение, для обработки кодирования как аудио, так и видео в общем потоке данных или раздельных потоках данных. Если применимо, модули MUX-DEMUX могут быть согласованы с протоколом мультиплексора ITU H.223, или другими протоколами, такими как протокол пользовательских дейтаграмм (UDP).
[0050] Кодер 20 видео и декодер 30 видео каждый может быть реализован в качестве любой из разнообразия подходящих схем кодера, таких как один или более микропроцессоры, цифровые сигнальные процессоры (DSP), проблемно-ориентированные интегральные микросхемы (ASIC), программируемые вентильные матрицы (FPGA), дискретная логика, программное обеспечение, аппаратное обеспечение, встроенное программное обеспечение или любые их сочетания. Когда методики реализуются частично в программном обеспечении, устройство может хранить инструкции для программного обеспечения в подходящем, не временном машиночитаемом носителе информации и исполнять инструкции в аппаратном обеспечении, используя один или более процессоры, чтобы выполнять методики данного раскрытия. Каждое из кодера 20 видео и декодера 30 видео могут быть включены в один или более кодеры или декодеры, любой из которых может быть интегрирован как часть объединенного кодера/декодера (CODEC) в соответствующее устройство.
[0051] В данном раскрытии, «N×N» или «N на N» может быть использовано взаимозаменяемо, чтобы обращаться к пиксельным размерам блока видео исходя из вертикальных и горизонтальных размеров, например 16×16 пикселей или 16 на 16 пикселей. В целом, 16×16 блок будет иметь 16 пикселей в вертикальном направлении (y=16) и 16 пикселей в горизонтальном направлении (x=16). Подобным образом, N×N блок в целом имеет N пикселей в вертикальном направлении и N пикселей в горизонтальном направлении, где N представляет собой не отрицательное целочисленное значение. Пиксели в блоке могут быть организованы в строках и столбцах. Более того, блоки не обязательно имеют число пикселей в горизонтальном направлении точно такое же, как в вертикальном направлении. Например, блоки могут содержать N×M пикселей, где M не обязательно равно N.
[0052] Вслед за интра-предсказывающим или интер-предсказывающим кодированием, использующим PU у CU, кодер 20 видео может вычислять остаточные данные для TU у CU. PU могут содержать данные синтаксиса, описывающие способ или режим генерирования предсказывающих данных пикселя в пространственной области (также именуемой областью пикселя), а TU могут содержать коэффициенты в области преобразования, вслед за применением преобразования, например, дискретного косинусного преобразования (DCT), целочисленного преобразования, вейвлет преобразования, или концептуально сходного преобразования к остаточным видеоданным. Остаточные данные могут соответствовать пиксельным разностям между пикселями незакодированного изображения и значениями предсказания, соответствующими PU. Кодер 20 видео может формировать TU, чтобы они включали квантованные коэффициенты преобразования, представляющие собой остаточные данные для CU. Т.е., кодер 20 видео может вычислять остаточные данные (в форме остаточного блока), преобразовывать остаточный блок чтобы создавать блок остаточных коэффициентов, и затем квантовать коэффициенты преобразования, чтобы сформировать квантованные коэффициенты преобразования. Кодер 20 видео может формировать TU, включающую в себя квантованные коэффициенты преобразования, как впрочем и другую информацию синтаксиса (например, информацию дробления для TU).
[0053] Как отмечалось выше, вслед за любыми преобразованиями, чтобы создать коэффициенты преобразования, кодер 20 видео может выполнять квантование коэффициентов преобразования. Квантование, в целом, относится к процессу, при котором коэффициенты преобразования квантуются, чтобы по возможности сократить объем данных, используемых чтобы представлять коэффициенты, обеспечивая дополнительное сжатие. Процесс квантования может уменьшать битовую глубину, ассоциированную с некоторыми или всеми из коэффициентов. Например, n-битное значение может быть округлено в меньшую сторону до m-битного значения во время квантования, где n больше m.
[0054] Вслед за квантованием, кодер видео может сканировать коэффициенты преобразования, создавая одномерный вектор из двумерной матрицы, включающей в себя квантованные коэффициенты преобразования. Сканирование может быть исполнено, чтобы помещать коэффициенты с более высокой энергией (и, вследствие этого, более низкой частотой) в переднюю часть массива и помещать коэффициенты с более низкой энергией (и вследствие этого, с более высокой частотой) в заднюю часть массива. В некоторых примерах, кодер 20 видео может использовать предварительно определенную очередность сканирования, чтобы сканировать квантованные коэффициенты преобразования, чтобы создавать преобразованный в последовательную форму вектор, который может быть энтропийно закодирован. В других примерах, кодер 20 видео может выполнять адаптивное сканирование. После сканирования квантованных коэффициентов преобразования, чтобы сформировать одномерный вектор, кодер 20 видео может энтропийно кодировать одномерный вектор, например, в соответствии с контекстно-зависимым адаптивным кодированием с переменной длиной кодового слова (CAVLC), контекстно-зависимым адаптивным бинарным арифметическим кодированием (CABAC), основанным на синтаксисе контекстно-зависимым адаптивным бинарным арифметическим кодированием (SBAC), кодированием Энтропийным с Разбиением на Интервалы Вероятности (PIPE) или другой методологией энтропийного кодирования. Кодер 20 видео может также энтропийно кодировать элементы синтаксиса, ассоциированные с кодируемыми видеоданными для использования декодером 30 видео при декодировании видеоданных.
[0055] Чтобы выполнять CABAC, кодер 20 видео может назначать контекст с моделью контекста символу, который будет передаваться. Контекст может относиться к, например, тому, являются или нет соседние значения символа ненулевыми. Чтобы выполнять CAVLC, кодер 20 видео может выбирать код переменной длины для символа, который будет передаваться. Кодовые слова в VLC могут быть сконструированы так, что относительно более короткие коды соответствуют более вероятным символам, тогда как более длинные коды, соответствуют менее вероятным символам. Таким образом, использование VLC может добиваться экономии битов через, например, использование кодовых слов равной длины для каждого символа, который будет передаваться. Определение вероятности может быть основано на контексте, назначенном символу.
[0056] В целом, декодер 30 видео выполняет по существу сходный, хотя и обратный, процесс тому, что выполняется кодером 20 видео, чтобы декодировать закодированные данные. Например, декодер 30 видео обратно квантует и обратно преобразует коэффициенты принятой TU, чтобы воссоздать остаточный блок. Декодер 30 видео использует просигнализированный режим предсказания (интра- или интер-предсказание), чтобы сформировать предсказанный блок. Декодер 30 видео объединяет предсказанный блок и остаточный блок (на основе пиксель-за-пикселем), чтобы воссоздать исходный блок. Может быть выполнена дополнительная обработка, такая как выполнение процесса устранения блочности, чтобы уменьшать визуальные искажения по границам блока. Кроме того, декодер 30 видео может декодировать элементы синтаксиса, используя CABAC, образом по существу сходным с, хотя и обратным, процессом кодирования CABAC кодера 20 видео.
[0057] Кодер 20 видео и декодер 30 видео могут быть выполнены с возможностью выполнения любой из разнообразных методик, обсуждаемых ниже, по отдельности или в любом сочетании.
[0058] Методики данного раскрытия включают в себя структуру двухуровневого многотипного дерева. На первом уровне (именуемом «уровень дерева области»), изображение или блок видеоданных дробится на области, каждая с одним или несколькими типами дерева, которые способны разбить большой блок на небольшие блоки быстро (например, используя квадродерево или шестнадцатеричное дерево). На втором уровне (уровень предсказания), область дополнительно дробится с помощью многотипного дерева (включая нет дальнейшего дробления). Листовой узел дерева предсказания именуется в данном раскрытии единицей кодирования (CU), для простоты.
[0059] Соответственно, нижеследующее может применяться к многотипному дереву данного раскрытия:
a) Корнем дерева предсказания является листовой узел дерева области.
b) «Нет дальнейшего дробления» рассматривается в качестве особого типа дерева как для дерева области, так и дерева предсказания.
c) Кодер 20 видео может сигнализировать, а декодер 30 видео может принимать, максимальные глубины дерева раздельно для дерева области и дерева предсказания. Т.е., управление максимальной глубиной каждого уровня структуры (т.е., дерева области и дерева предсказания) может осуществляться независимой переменной. В качестве альтернативы, максимальная суммарная глубина структуры может быть просигнализирована как сумма максимальной глубины каждого уровня. В одном примере, максимальная глубина(ы) сигнализируется(ются) в наборе параметров последовательности (SPS), наборе параметров изображения (PPS), и/или заголовке слайса. В другом примере, максимальная глубина дерева области и максимальная глубина дерева предсказания на вершине каждой глубины дерева области сигнализируются в заголовке слайса. Например, максимальная глубина дерева области сигнализируется как 3. Затем четыре значения дополнительно сигнализируются, чтобы указать максимальные глубины дерева предсказания сверху глубины0, глубины1, глубины2, и глубины3 дерева области.
d) В качестве альтернативы, информация глубины дерева у дерева области и дерева предсказания может быть просигнализирована совместно. Например, при заданном наибольшем размере CTU, максимальная глубина дерева области может быть просигнализирована сначала в наборе параметров последовательности (SPS), наборе параметров изображения (PPS), и/или заголовке слайса. Затем может быть просигнализировано относительное смещение по отношению к корневому уровню дерева области, включая начальный уровень для дерева предсказания. Наконец, может быть просигнализирована информация уровня дерева предсказания. Отметим, что разные изображения временного уровня могут или могут не иметь одно и то же ограничение глубины дерева. Например, изображение более низкого временного уровня может иметь большую глубину дерева (для либо дерева области, либо дерева предсказания, либо обоих), тогда как изображение более высокого временного уровня может иметь меньшую глубину дерева (для либо дерева области, либо дерева предсказания, либо обоих). Относительное смещение глубины дерева между деревом области и предсказания может или может не быть одинаковым.
e) «Принужденное дробление» (автоматическое дробление без сигнализации при достижении границы изображения/слайса/тайла) может быть только на уровне дерева области или только на уровне дерева предсказания, но не на обоих. Когда самый нижний уровень дерева области по-прежнему не может включать в себя все пиксели границы, заполнение границы задействуется, чтобы включать пиксели границы, используя самый нижний уровень дерева области. Отметим, что не требуется, чтобы глубина дерева из-за «принужденного дробления» ограничивалась предварительно определенными или сигнализируемыми максимальными глубинами дерева.
f) Глубина дерева области и глубина дерева предсказания могут или могут не перекрываться друг с другом. Это может быть извлечено из сигнализируемой информации глубины дерева или сигнализироваться в качестве индивидуального флага в наборе параметров последовательности (SPS), наборе параметров изображения (PPS) и/или заголовке слайса.
g) Информация дробления деревьев предсказания в рамках листового узла дерева области может быть просигнализирована до информации CU (включая, но не ограничиваясь, флаг пропуска, индекс слияния, интер/интра режим, информацию предсказания, информацию движения, информацию преобразования, информацию остатков и квантования) у листового узла дерева области так, что во время анализа, число CU в листовом узле дерева области известно до анализа первой CU в листовом узле дерева области.
[0060] В дополнение или в качестве альтернативы, кодер 20 видео и декодер 30 видео могут быть выполнены с возможностью применения или сигнализации некоторых инструментов кодирования на уровне дерева области. Другими словами, доступность некоторых инструментов кодирования может зависеть от уровня дерева области. Инструмент кодирования может быть применен по границам CU при условии, что эти CU принадлежат к одному и тому же узлу дерева области или листовому узлу дерева области. Некоторые инструменты кодирования могут быть применены и/или просигнализированы только в листовом узле дерева области. Например:
a. OBMC: Флаг или информация режима могут быть просигнализированы на уровне листового узла дерева области, чтобы указывать, разрешена ли OBMC в рамках области, ассоциированной с листовым узлом дерева области. Если OBMC разрешена, границы CU в рамках области рассматриваются точно таким же образом как границы PU в HEVC или граница суб-PU внутри CU в JEM. Т.е., OBMC может быть применена к каждой стороне границ CU внутри области, ассоциированной с листовым узлом дерева области.
1. Разрешена ли OBMC может быть извлечено или частично извлечено на основании кодированной информации, такой как размер области. Например, когда размер области больше пороговой величины (такой как 16×16), OBMC может рассматриваться как включенная, так что нет необходимости в сигнализации. Когда размер области меньше пороговой величины, флаг или информация режима OBMC могут быть просигнализированы.
ii. Перекрывающееся преобразование: преобразование с размером блока покрывающим область всех или группы блоков предсказания в рамках листового узла дерева области и используется чтобы кодировать предсказанные остатки.
1. В одном примере, флаг или информации дерева преобразования сигнализируются на уровне листового узла дерева области, чтобы указывать используется ли перекрывающееся преобразование для области.
a. В одном примере, кроме того, когда сигнализируется информация дерева преобразования, она должна отличаться от дерева предсказания.
b. В другом примере, флаг или информация дерева преобразования сигнализируется на уровне листового узла дерева области, чтобы указывать, используется ли одно преобразование, настолько большое как текущий листовой узел дерева области, или используются несколько преобразований, каждое выровненное с размером блока предсказания.
2. Когда перекрывающееся преобразование используется для области, информация флага кодированного блока (CBF) всех CU внутри области может быть просигнализирована на уровне листа дерева области, вместо уровня CU.
3. В одном примере, когда перекрывающееся преобразование применяется для листового узла дерева области, OBMC всегда применяется для листового узла дерева области.
iii. Режим супер пропуска/слияния: Флаг или информация режима могут быть просигнализированы на уровне листа дерева области, чтобы указывать, что все CU внутри области кодируются в режиме пропуска или режиме слияния, так что информация режима не сигнализируется на уровне CU.
iv. Режим супер интра/интер кодирования: Флаг или индекс информации режима (такой как интра режим или интер режим) могут быть просигнализированы на уровне листа дерева области, чтобы указывать, что CU должны использовать одну и ту же информацию режима.
v. Режим супер FRUC: Флаг или информация режима могут быть просигнализированы на уровне листа дерева области, чтобы указывать, что все CU внутри дерева области кодируются в режиме FRUC.
vi. Информация супер режима (такого как супер пропуск/слияние, супер интра/интер, и супер FRUC) может быть просигнализирована только когда число CU внутри листового узла области дерева больше пороговой величины.
1. Пороговая величина может быть предварительно определенной или сигнализироваться в битовом потоке, как например в VPS, SPS, PPS, или заголовке слайса.
[0061] В дополнение или в качестве альтернативы, кодер 20 видео и декодер 30 видео могут применять и/или кодировать данные, представляющие собой инструменты кодирования, в любом узле дерева области. Например, инструменты фильтрации, такие как адаптивное к выборке смещение (SAO) и/или адаптивный контурный фильтр (ALF) могут отличаться от HEVC тем, что информация SAO может быть просигнализирована на уровне CTU, информация для инструментов фильтрации, таких как SAO и ALF может быть просигнализирована в любом узле (не обязательно листовом узле) дерева области так, что область, которая будет фильтроваться, является областью, ассоциированной с узлом.
[0062] В дополнение или в качестве альтернативы, кодер 20 видео и декодер 30 видео могут быть выполнены с возможностью использования разбиения похожего на тройное дерево с центральной стороной, в верхней части структуры дерева кодирования HEVC-стиля. Например, кодер 20 видео и декодер 30 видео могут использовать новые разбиения, такие как тройное дерево с центральной стороной, в дополнение к AMP или чтобы заменить AMP в качестве типов разбиения PU.
[0063] В дополнение или в качестве альтернативы, листовой узел дерева области может обеспечивать сбалансированную точку для кодирования дельты параметра квантования (QP) между эффективностью кодирования и сложностью. Поскольку соседство хорошо определено в дереве области, предсказатели QP могут быть вычислены на листовых узлах дерева области, используя верхнее, левое, и предыдущие кодированные значения QP. Значение QP может меняться на каждой CU, и CU могут совместно использовать одно и то же базовое значение из их родительского узла дерева области для кодирования.
[0064] Дополнительные примеры, любой или оба из которых могут быть выполнены кодером 20 видео и декодером 30 видео, описываются более подробно в отношении Фиг. 12 ниже.
[0065] Кодер 20 видео может дополнительно отправлять данные синтаксиса, такие как основанные на блоке данные синтаксиса, основанные на изображении данные синтаксиса, и основанные на последовательности данные синтаксиса декодеру 30 видео, например, в заголовке изображения, заголовке блока, заголовке слайса, или других данных синтаксиса, таких как набор параметров последовательности (SPS), набор параметров изображения (PPS), или набор параметров видео (VPS).
[0066] Кодер 20 видео и декодер 30 видео каждый может быть реализован в качестве любого из разнообразия подходящей схемы кодера или декодера, в зависимости от обстоятельств, такой как один или более микропроцессоры, цифровые сигнальные процессоры (DSP), проблемно-ориентированные интегральные микросхемы (ASIC), программируемые вентильные матрицы (FPGA), схема дискретной логики, программное обеспечение, аппаратное обеспечение, встроенное программное обеспечение или любые их сочетания. Каждое из кодера 20 видео и декодера 30 видео может быть включен в один или более кодеры или декодеры, любой из которых может быть интегрирован как часть объединенного кодера/декодера видео (КОДЕКА). Устройство, включающее в себя кодер 20 видео и/или декодер 30 видео может содержать интегральную микросхему, микропроцессор, и/или беспроводное устройство связи, такое как сотовый телефон.
[0067] Фиг. 2 является структурной схемой, иллюстрирующей пример кодера 20 видео, который может реализовывать методики для кодирования видеоданных, используя инфраструктуру двухуровневого многотипного дерева. Кодер 20 видео может выполнять интра- и интер-кодирование блоков видео внутри слайсов видео. Интра-кодирование основано на пространственном предсказании, чтобы сокращать или удалять пространственную избыточность в видео внутри заданного кадра или изображения видео. Интер-кодирование основано на временном предсказании, чтобы сокращать или удалять временную избыточность в видео внутри смежных кадров или изображений видеопоследовательности. Интра-режим (I режим) может относиться к любому из нескольких основанных на пространстве режимов кодирования. Интер-режим, такой как однонаправленное предсказание (P режим) или двунаправленное предсказание (B режим), может относиться к любому из нескольких основанных на времени режимов кодирования.
[0068] Как показано на Фиг. 2, кодер 20 видео принимает текущий блок видео внутри кадра видео, который будет кодироваться. В примере Фиг. 2, кодер 20 видео включает в себя модуль 40 выбора режима, память 64 опорных изображений (которая также может именоваться буфером декодированных изображений (DPB)), сумматор 50, модуль 52 обработки преобразования, модуль 54 квантования, и модуль 56 энтропийного кодирования. Модуль 40 выбора режима, в свою очередь, включает в себя модуль 44 компенсации движения, модуль 42 оценки движения, модуль 46 интра-предсказания, и модуль 48 разбиения. Применительно к воссозданию блока видео, кодер 20 видео также включает в себя модуль 58 обратного квантования, модуль 60 обратного преобразования, и сумматор 62. Фильтр устранения блочности (не показан на Фиг. 2) также может быть включен, чтобы фильтровать границы блока, чтобы удалять искажения блочности из воссозданного видео. Если требуется, фильтр устранения блочности будет, как правило, фильтровать выход сумматора 62. Дополнительные фильтры (в цикле или после цикла) также могут быть использованы в дополнение к фильтру устранения блочности. Такие фильтры не показаны для краткости, но если требуется, могут фильтровать выход сумматора 50 (в качестве фильтра в цикле).
[0069] Во время процесса кодирования, кодер 20 видео принимает кадр или слайс видео, который будет кодироваться. Кадр или слайс может быть разделен на несколько блоков видео. Модуль 42 оценки движения и модуль 44 компенсации движения выполняют интер-предсказывающее кодирование принятого блока видео по отношению к одному или более блокам в одном или более опорных кадрах, чтобы обеспечить временное предсказание. Модуль 46 интра-предсказания может в качестве альтернативы выполнять интра-предсказывающее кодирование принятого блока видео по отношению к одному или более соседним блокам в том же самом кадре или слайсе, что и блок, который будет кодироваться, чтобы обеспечить пространственное предсказание. Кодер 20 видео может выполнять несколько проходов кодирования, например, чтобы выбрать подходящий режим кодирования для каждого блока видеоданных.
[0070] Более того, модуль 48 разбиения может разбивать блоки дерева кодирования видеоданных используя методики данного раскрытия. Т.е., модуль 48 разбиения может исходно разбивать CTB, используя дерево области многотипного дерева, в конечном счете приводя к одному или более листовым узлам дерева области. Модуль 48 разбиения может разбивать дерево области в соответствии с разбиением квадродерева или разбиением шестнадцатеричного дерева, в разнообразных примерах. Разбиение квадродерева включает в себя разбиение каждого не листового узла на четыре узла-потомка, тогда как разбиение шестнадцатеричного дерева включает в себя разбиение каждого не листового узла на шесть узлов-потомков.
[0071] Модуль 48 разбиения может дополнительно разбивать каждый из листовых узлов дерева области, используя соответствующие деревья предсказания. Деревья предсказания могут быть разбиты в качестве бинарных деревьев, тройных деревьев с центральной стороной, и/или квадродеревьев. Т.е., модуль 48 разбиения может разбивать каждый узел дерева предсказания на четыре равного размера части (как в квадродереве), две равного размера части горизонтально или вертикально (как в бинарном дереве), или центральную область и две более мелкие боковые области горизонтально или вертикально (как в тройном дереве с центральной стороной). Дополнительно или в качестве альтернативы, модуль 48 разбиения может разбивать узел дерева предсказания, используя ассиметричное разбиения движения (AMP). В некоторых примерах, разбиение тройного дерева с центральной стороной может заменять AMP, тогда как в других примерах, разбиение тройного дерева с центральной стороной может дополнять AMP. Как объяснено со ссылкой на Фиг. 1, модуль 48 разбиения может генерировать значения элементов синтаксиса, указывающие то, каким образом многотипное дерево для CTB разбито, которые могут быть закодированы посредством модуль 56 энтропийного кодирования.
[0072] Модуль 40 выбора режима может выбирать один из режимов предсказания, (интра, интер, или пропуска), например, на основании результатов ошибки (например, используя анализ скорости-к-искажению), и предоставлять результирующий предсказанный блок сумматору 50, чтобы генерировать остаточные данные, и сумматору 62, чтобы воссоздавать закодированный блок для использования в качестве опорного кадра. Модуль 40 выбора режима также предоставляет элементы синтаксиса, такие как векторы движения (кодированные в соответствии с, например, режимами слияния или AMVP), индикаторы интра-режима, информацию разбиения, и другую такую информацию синтаксиса, модулю 56 энтропийного кодирования.
[0073] Модуль 42 оценки движения и модуль 44 компенсации движения могут быть высоко интегрированными, но иллюстрируются раздельно в концептуальных целях. Оценка движения, выполняемая модулем 42 оценки движения, является процессом генерирования векторов движения, которые оценивают движение для блоков видео. Вектор движения, например, может указывать смещение PU блока видео внутри текущего кадра или изображения видео относительно предсказывающего блока внутри опорного кадра (или другой кодированной единицы) по отношению к текущему блоку, кодируемому внутри текущего кадра (или другой кодированной единицы). Предсказывающий блок является блоком, который найден как наиболее близко совпадающий с блоком, который будет кодироваться, исходя из пиксельной разности, которая может быть определена посредством суммы абсолютной разности (SAD), суммы квадратичной разности (SSD), или других метрик разности. В некоторых примерах, кодер 20 видео может вычислять значения для позиций суб-целочисленного пикселя у опорных изображений, хранящихся в памяти 64 опорных изображений. Например, кодер 20 видео может интерполировать значения позиций одной четвертой пикселя, позиций одной восьмой пикселя, или другие позиции дробного пикселя у опорного изображения. Вследствие этого, модуль 42 оценки движения может выполнять поиск движения по отношению к позициям целого пикселя и позициям дробного пикселя и выводить вектор движения с точностью дробного пикселя.
[0074] Модуль 42 оценки движения вычисляет вектор движения для PU видео блока в слайсе с интер-кодированием посредством сравнения позиции PU с позицией предсказывающего блока опорного изображения. Опорное изображение может быть выбрано из первого списка опорных изображений (Список 0) или второго списка опорных изображений (Список 1), каждый из которых идентифицирует одно или более опорных изображений, хранящихся в памяти 64 опорных изображений. Модуль 42 оценки движения отправляет вычисленный вектор движения модулю 56 энтропийного кодирования и модулю 44 компенсации движения.
[0075] Компенсация движения, выполняемая модулем 44 компенсации движения, может включать выборку или генерирование предсказывающего блока на основании вектора движения, определенного модулем 42 оценки движения. Вновь, модуль 42 оценки движения и модуль 44 компенсации движения могут быть функционально интегрированными, в некоторых примерах. По приему вектора движения для PU текущего блока видео, модуль 44 компенсации движения может определять местоположение предсказывающего блока, на который указывает вектор движения в одном из списков опорных изображений. Сумматор 50 формирует остаточный блок видео посредством вычитания значений пикселя предсказывающего блока из значений пикселя текущего кодируемого блока видео, формируя значения пиксельной разности, как обсуждается ниже. В целом, модуль 42 оценки движения выполняет оценку движения относительно компонентов яркости, и модуль 44 компенсации движения использует векторы движения, вычисленные на основании компонентов яркости для обоих компонентов цветности и компонентов яркости. Модуль 40 выбора режима также может генерировать элементы синтаксиса, ассоциированные с блоками видео и слайсом в видео для использования декодером 30 видео при декодировании блоков видео слайса видео.
[0076] Модуль 46 интра-предсказания может интра-предсказывать текущий блок, в качестве альтернативы интер-предсказанию, выполняемому модулем 42 оценки движения и модулем 44 компенсации движения, как описано выше. В частности, модуль 46 интра-предсказания может определять режим интра-предсказания, чтобы использовать при кодировании текущего блока. В некоторых примерах, модуль 46 интра-предсказания может кодировать текущий блок, используя разнообразные режимы интра-предсказания, например, во время отдельных проходов кодирования, и модуль 46 интра-предсказания (или модуль 40 выбора режима, в некоторых примерах) может выбирать подходящий режим интра-предсказания для использования из протестированных режимов.
[0077] Например, модуль 46 интра-предсказания может вычислять значения скорости-к-искажению, используя анализ скорости-к-искажению для разнообразных протестированных режимов интра-предсказания, и выбирать режим интра-предсказания с наилучшими характеристиками скорости-к-искажению из протестированных режимов. Анализ скорости-к-искажению главным образом определяет величину искажения (или ошибки) между закодированным блоком и исходным, незакодированным блоком, который был закодирован, чтобы создать закодированный блок, как впрочем и скорость передачи битов (т.е., число битов), используемую чтобы создать закодированный блок. Модуль 46 интра-предсказания может вычислять отношения из искажений и скоростей для разнообразных закодированных блоков, чтобы определять, какой режим интра-предсказания показывает наилучшее значение скорости-к-искажению для блока.
[0078] После выбора режима интра-предсказания для блока, модуль 46 интра-предсказания может предоставлять информацию, указывающую выбранный режим интра-предсказания для блока модулю 56 энтропийного кодирования. Модуль 56 энтропийного кодирования может кодировать информацию, указывающую выбранный режим интра-предсказания. Кодер 20 видео может включать в передаваемый битовый поток данные конфигурации, которые могут включать в себя множество таблиц индекса режима интра-предсказания и множество модифицированных таблиц индекса режима интра-предсказания (также именуемых таблицами отображения кодового слова), определения контекстов кодирования для различных блоков, и указания наиболее вероятного режима интра-предсказания, таблицу индекса режима интра-предсказания, и модифицированную таблицу индекса режима интра-предсказания для использования для каждого из контекстов.
[0079] Кодер 20 видео формирует остаточный блок видео посредством вычитания данных предсказания от модуля 40 выбора режима из исходного кодируемого блока видео. Сумматор 50 представляет собой компонент или компоненты, которые выполняют данную операцию вычитания. Модуль 52 обработки преобразования применяет преобразование, такое как дискретное косинусное преобразование (DCT) или концептуально сходное преобразование, к остаточному блоку, создавая блок видео, содержащий значения коэффициента преобразования. Вейвлет преобразования, целочисленные преобразования, суб-полосные преобразования, дискретные синусные преобразования (DST), или другие типы преобразований могут быть использованы вместо DCT. В любом случае, модуль 52 обработки преобразования применяет преобразование к остаточному блоку, создавая блок из коэффициентов преобразования. Преобразование может конвертировать остаточную информацию из области пикселя в область преобразования, такую как частотная область. Модуль 52 обработки преобразования может отправлять результирующие коэффициенты преобразования модулю 54 квантования. Модуль 54 квантования квантует коэффициенты преобразования, чтобы дополнительно уменьшить скорость передачи битов. Процесс квантования может уменьшать битовую глубину, ассоциированную с некоторыми или всеми из коэффициентов. Степень квантования может быть модифицирована посредством регулировки параметра квантования.
[0080] Вслед за квантованием, модуль 56 энтропийного кодирования энтропийно кодирует квантованные коэффициенты преобразования. Например, модуль 56 энтропийного кодирования может выполнять контекстно-зависимое адаптивное кодирование с переменной длиной кодового слова (CAVLC), контекстно-зависимое адаптивное бинарное арифметическое кодирование (CABAC), основанное на синтаксисе контекстно-зависимое адаптивное бинарное арифметическое кодирование (SBAC), кодирование Энтропийное с Разбиением на Интервалы Вероятности (PIPE) или другие методики энтропийного кодирования. В случае основанного на контексте энтропийного кодирования, контекст может быть основан на соседних блоках. Вслед за энтропийным кодированием модулем 56 энтропийного кодирования, закодированный битовый поток может быть передан другому устройству (например, декодеру 30 видео) или заархивирован для передачи или извлечения позже.
[0081] Модуль 57 обратного квантования и модуль 60 обратного преобразования применяют обратное квантование и обратное преобразование, соответственно, чтобы воссоздавать остаточный блок в области пикселя. В частности, сумматор 62 складывает воссозданный остаточный блок с блоком предсказания с компенсацией движения, ранее созданным модулем 44 компенсации движения или модулем 46 интра-предсказания, чтобы создать воссозданный блок видео для хранения в памяти 64 опорных изображений. Воссозданный блок видео может быть использован модулем 42 оценки движения и модулем 44 компенсации движения в качестве опорного блока, чтобы интер-кодировать блок в последующем кадре видео.
[0082] Кроме того, в соответствии с методиками данного раскрытия, модуль 40 выбора режима может выбирать выполнение одного или более «супер режимов» для некоторых деревьев предсказания блока дерева кодирования (CTB). Такие супер-режимы могут включать в себя, например, режим супер пропуска, режим супер слияния, супер интра-режим, супер интер-режим, или режим супер FRUC. В целом, в супер режиме, кодер 20 видео кодирует соответствующую информацию «супер режима» в корневом узле дерева предсказания (или в листовом узле дерева области) у CTB, и применяет данную информацию к всем CU дерева предсказания, так что кодер 20 видео избегает кодирования отдельной соответствующей информации для CU дерева предсказания. Например, применительно к режиму супер пропуска, кодер 20 видео кодирует все CU дерева предсказания используя режим пропуска, и не кодирует какой-либо дополнительной информации предсказания для CU. В качестве другого примера, применительно к супер интра- или интер-режиму, кодер 20 видео будет кодировать информацию интра- или интер-предсказания единожды для дерева предсказания, и применять данную одинаковую информацию предсказания к всем CU дерева предсказания. Кодер 20 видео будет кодировать другую информацию, такую как информацию дробления на уровне дерева области и уровне дерева предсказания, как впрочем и информацию преобразования, как обычно.
[0083] В некоторых примерах, кодер 20 видео разрешает супер-режим только когда число CU, включенных в дерево предсказания, больше пороговой величины. Кодер 20 видео может кодировать элементы синтаксиса, определяющие пороговую величину, например, в наборе параметров последовательности (SPS), наборе параметров изображения (PPS), заголовке слайса, заголовке CTB, или подобном.
[0084] Более того, в соответствии с методиками данного раскрытия, кодер 20 видео может кодировать элементы синтаксиса, представляющие собой один или более разрешенных инструментов кодирования, и также применять разрешенные инструменты кодирования во время кодирования CTB или дерева предсказания CTB. Например, кодер 20 видео может разрешать любое или все из компенсации движения перекрывающегося блока (OBMC), перекрывающиеся преобразования, и/или любой из разнообразных супер-режимов, которые обсуждались выше. Модуль 44 компенсации движения может быть выполнен с возможностью выполнения OBMC, как обсуждается более подробно ниже в отношении, например, Фиг. 7 и 8. Модуль 52 обработки преобразования может быть выполнен с возможностью выполнения перекрывающихся преобразований, как обсуждалось выше.
[0085] Таким образом, кодер 20 видео на Фиг. 2 представляет собой пример кодера видео, выполненного с возможностью: кодирования одного или более элементов синтаксиса на уровне дерева области некоторого дерева области из древовидной структуры данных для блока дерева кодирования (CTB) видеоданных, причем дерево области с одним или более листовыми узлами дерева области; кодирования одного или более элементов синтаксиса на уровне дерева предсказания для каждого из листовых узлов дерева области одного или более деревьев предсказания древовидной структуры данных для CTB, причем деревья предсказания с одним или более листовыми узлами предсказания, определяющими соответствующие единицы кодирования (CU); и кодирования видеоданных для каждой из CU.
[0086] Фиг. 3 является структурной схемой, иллюстрирующей пример декодера 30 видео, который может реализовывать методики для кодирования видеоданных, используя инфраструктуру двухуровневого многотипного дерева. В примере Фиг. 3, декодер 30 видео включает в себя модуль 70 энтропийного декодирования, модуль 72 компенсации движения, модуль 74 интра предсказания, модуль 76 обратного квантования, модуль 78 обратного преобразования, память 82 опорных изображений и сумматор 80. Декодер 30 видео может, в некоторых примерах, выполнять проход декодирования в целом обратно проходу кодирования, описанному в отношении кодера 20 видео (Фиг. 2). Модуль 72 компенсации движения может генерировать данные предсказания на основании векторов движения, принятых от модуля 70 энтропийного декодирования, тогда как модуль 74 интра-предсказания может генерировать данные предсказания на основании индикаторов режима интра-предсказания, принятых от модуля 70 энтропийного декодирования.
[0087] Когда слайс видео кодирован в качестве интра-кодированного (I) слайса, модуль 74 интра предсказания может генерировать данные предсказания для блока видео текущего слайса видео на основании просигнализированного режима интра предсказания и данных из ранее декодированных блоков текущего кадра или изображения. Когда кадр видео кодирован в качестве слайса с интер-кодированием (т.е., B или P), модуль 72 компенсации движения создает предсказывающие блоки для блока видео текущего слайса видео на основании векторов движения и других элементов синтаксиса, принятых от модуля 70 энтропийного декодирования. Предсказывающие блоки могут быть созданы из одного из опорных изображений в одном из списков опорных изображений. Декодер 30 видео может создавать списки опорных изображений, Список 0 и Список 1, используя методики создания по умолчанию основанные на опорных изображениях, хранящихся в памяти 82 опорных изображений.
[0088] Во время процесса декодирования, декодер 30 видео принимает закодированный видео битовый поток, который представляет собой блоки видео закодированного слайса видео и ассоциированные элементы синтаксиса для кодера 20 видео. Модуль 70 энтропийного декодирования декодера 30 видео энтропийно декодирует битовый поток, чтобы сгенерировать квантованные коэффициенты, векторы движения или индикаторы режима интра-предсказания, и другие элементы синтаксиса. Модуль 70 энтропийного декодирования переадресовывает векторы движения и другие элементы синтаксиса модулю 72 компенсации движения. Декодер 30 видео может принимать элементы синтаксиса на уровне слайса видео и/или уровне блока видео.
[0089] Элементы синтаксиса на уровне блока дерева кодирования (CTB) могут включать в себя элементы синтаксиса, указывающие каким образом разбивается многотипное дерево CTB. В частности, модуль 70 энтропийного декодирования может декодировать один или более элементов синтаксиса CTB на уровне дерева области, в конечном счете получая один или более листовые узлы дерева области. Каждый листовой узел дерева области может быть ассоциирован с соответствующими элементами синтаксиса дерева предсказания. Элементы синтаксиса дерева предсказания могут указывать каким образом соответствующий листовой узел дерева области разбивается, например, в соответствии с горизонтальным или вертикальным разбиением бинарного дерева, горизонтальным или вертикальным разбиением тройного дерева с центральной стороной, разбиением квадродерева, или ассиметричным разбиением движения (AMP). Деревья предсказания могут в конечном счете получать одну или более единицы кодирования (CU).
[0090] Модуль 72 компенсации движения определяет информацию предсказания для блока видео у текущего слайса видео посредством анализа векторов движения и других элементов синтаксиса, и использует информацию предсказания, чтобы создавать предсказывающие блоки для текущего декодируемого блока видео. Например, модуль 72 компенсации движения использует некоторые из принятых элементов синтаксиса, чтобы определять режим предсказания (например, интра- или интер-предсказание), использованный чтобы кодировать блок видео у слайса видео, тип слайса интер-предсказания (например, B слайс или P слайс), информацию создания для одного или более из списков опорных изображений для слайса, векторы движения для каждого блока видео с интер-кодированием у слайса, статус интер-предсказания для каждого блока видео с интер-кодированием у слайса, и другую информацию, чтобы декодировать блоки видео в текущем слайсе видео.
[0091] Модуль 72 компенсации движения также может выполнять интерполяцию на основании фильтров интерполяции. Модуль 72 компенсации движения может использовать фильтры интерполяции как использованные кодером 20 видео во время кодирования блоков видео, чтобы вычислять интерполированные значения для суб-целочисленных пикселей опорных блоков. В данном случае, модуль 72 компенсации движения может определять фильтры интерполяции, использованные кодером 20 видео, из принятых элементов синтаксиса и использовать фильтры интерполяции, чтобы создавать предсказывающие блоки.
[0092] Модуль 76 обратного квантования обратно квантует, т.е., де-квантует, квантованные коэффициенты преобразования, предоставленные в битовом потоке и декодированные модулем 70 энтропийного декодирования. Процесс обратного квантования может включать в себя использование параметра QPY квантования, вычисленного декодером 30 видео для каждого блока видео в слайсе видео, чтобы определять степень квантования и, подобным образом, степень обратного квантования, которое должно быть применено.
[0093] Модуль 78 обратного преобразования применяет обратное преобразование, например, обратное DCT, обратное целочисленное преобразование, или концептуально сходный процесс обратного преобразования, к коэффициентам преобразования для того, чтобы создать остаточные блоки в области пикселя.
[0094] После того, как модуль 72 компенсации движения генерирует предсказывающий блок для текущего блока видео на основании векторов движения и других элементов синтаксиса, декодер 30 видео формирует декодированный блок видео посредством суммирования остаточных блоков из модуля 78 обратного преобразования с соответствующими предсказывающими блоками, сгенерированными модулем 72 компенсации движения. Сумматор 80 представляет собой компонент или компоненты, которые выполняют данную операцию суммирования. Если требуется, фильтр устранения блочности также может быть применен, чтобы фильтровать декодированные блоки для того, чтобы удалить искажения блочности. Другие контурные фильтры (либо в цикле кодирования, либо после цикла кодирования) также могут быть использованы, чтобы сглаживать пиксельные переходы, или иным образом улучшать качество видео. Декодированные блоки видео в заданном кадре или изображении затем сохраняются в памяти 82 опорных изображений, которая хранит опорные изображения, используемые для последующей компенсации движения. Память 82 опорных изображений также хранит декодированное видео для представления позже на дисплейном устройстве, таком как дисплейное устройство 32 на Фиг. 1.
[0095] Кроме того, в соответствии с методиками данного раскрытия, модуль 70 энтропийного декодирования может декодировать элементы синтаксиса, представляющие собой разрешен ли один или более «супер режимы» для некоторых деревьев предсказания блока дерева кодирования (CTB). Такие супер-режимы могут включать в себя, например, режим супер пропуска, режим супер слияния, супер интра-режим, супер интер-режим, или режим супер FRUC. В целом, в супер режиме, декодер 30 декодирует соответствующую информацию «супер режима» в корневом узле дерева предсказания (или в листовом узле дерева области) у CTB, и применяет данную информацию к всем CU дерева предсказания, так что декодер 30 видео избегает декодирования отдельной соответствующей информации для CU дерева предсказания. Например, применительно к режиму супер пропуска, декодер 30 видео декодирует все CU дерева предсказания, используя режим пропуска, и не декодирует любую дополнительную информацию предсказания для CU. В качестве другого примера, применительно к супер интра- или интер-режиму, декодер 30 видео будет декодировать информацию интра- или интер-предсказания единожды для дерева предсказания, и применять данную одну и ту же информацию предсказания к всем CU дерева предсказания. Декодер 30 видео будет декодировать другую информацию, такую как информация дробления на уровне дерева области и уровне дерева предсказания, как впрочем и информацию преобразования, как обычно.
[0096] В некоторых примерах, декодер 30 видео разрешает супер-режим только когда число CU, включенных в дерево предсказания, больше пороговой величины. Декодер 30 видео может декодировать элементы синтаксиса, определяющие пороговую величину, например, в наборе параметров последовательности (SPS), наборе параметров изображения (PPS), заголовке слайса, заголовке CTB, или подобном.
[0097] Более того, в соответствии с методиками данного раскрытия, декодер 30 видео может декодировать элементы синтаксиса, представляющие собой один или более разрешенных инструментов кодирования, и также применять разрешенные инструменты кодирования во время декодирования CTB или дерева предсказания у CTB. Например, декодер 30 видео может разрешать любое или все из компенсации движения перекрывающегося блока (OBMC), перекрывающиеся преобразования, и/или любые из разнообразных супер-режимов, которые обсуждались выше. Модуль 72 компенсации движения может быть выполнен с возможностью выполнения OBMC, как обсуждается в целом более подробно ниже со ссылкой на, например, Фиг. 7 и 8. Модуль 78 обратного преобразования может быть выполнен с возможностью выполнения перекрывающихся преобразований, как обсуждалось выше.
[0098] Таким образом, декодер 30 видео на Фиг. 3 представляет собой пример декодера видео, включающего в себя память, выполненную с возможностью хранения видеоданных; и процессор, реализованный в схеме и выполненный с возможностью: декодирования одного или более элементов синтаксиса на уровне дерева области некоторого дерева области из древовидной структуры данных для блока дерева кодирования (CTB) видеоданных, причем дерево области имеет один или более узлов дерева области, в том числе ноль или более не листовых узлов дерева области и один или более листовых узлов дерева области, причем каждый из не листовых узлов дерева области имеет первое число узлов-потомков дерева области, причем первое число составляет, по меньше мере, четыре; определения, используя элементы синтаксиса на уровне дерева области, каким образом узлы дерева области раздроблены на узлы-потомки дерева области; декодирования одного или более элементов синтаксиса на уровне дерева предсказания для каждого из листовых узлов дерева области одного или более деревьев предсказания древовидной структуры данных для CTB, причем каждое из деревьев предсказания имеет один или более узлов дерева предсказания, в том числе ноль или более не листовых узлов дерева предсказания и один или более листовых узлов дерева предсказания, причем каждый из не листовых узлов дерева предсказания имеет второе число узлов-потомков дерева предсказания, причем второе число составляет, по меньшей мере, два, причем каждый из листовых узлов предсказания определяет соответствующие единицы кодирования (CU); определения, используя элементы синтаксиса на уровне дерева предсказания, каким образом узлы дерева предсказания раздроблены на узлы-потомки дерева предсказания; и декодирования видеоданных, включающих в себя данные предсказания и данные преобразования, для каждой из CU, на основании, по меньшей мере частично, элементов синтаксиса на уровне дерева области и элементов синтаксиса на уровне дерева предсказания.
[0099] Фиг. 4 является структурной схемой, иллюстрирующей примерный блок 100 дерева кодирования (CTB). В HEVC, наибольшая единица кодирования в слайсе именуется блоком дерева кодирования (CTB). CTB, такой как CTB 100, содержит структуру данных квадродерева (или просто, квадродерево), узлы которой соответствуют единицам кодирования (CU). В частности, корневой узел структуры данных квадродерева соответствует CTB. Каждый узел в структуре данных квадродерева является либо листовым узлом (не имеющим узлов-потомков), либо узлом-родителем с четырьмя узлами-потомками. CU 102 представляет собой один пример CU, соответствующей листовому узлу квадродерева. Размер CTB находится в диапазоне от 16×16 пикселей до 64×64 пикселей в основном профиле HEVC (несмотря на то, что технически, могут поддерживаться 8×8 размеры CTB). CTB может быть рекурсивно раздроблен на единицы кодирования (CU) в виде квадродерева, такое как показанное на Фиг. 4. Листовые узлы структуры данных квадродерева соответствуют CU, которые включают в себя единицы предсказания (PU) и единицы преобразования (TU).
[0100] CU может быть точно такого же размера как и CTB, несмотря на то, что она может быть настолько малой как 8×8. Каждая единица кодирования может быть закодирована с помощью одного режима предсказания, который может быть либо интра режимом, либо интер режимом. Когда CU является интер-кодированной (т.е., применяется интер-режим предсказания), CU может быть дополнительно разбита на 2 или 4 единицы предсказания (PU) или становиться даже одной PU, когда дальнейшее разбиение не применяется. Когда две PU присутствуют в одной CU, они могут быть прямоугольниками половины размера или двумя размерами прямоугольника с 1/4 или 3/4 размера CU.
[0101] Фиг. 5 является структурной схемой, иллюстрирующей примерные единицы предсказания (PU) у CU. В HEVC, существует восемь режимов разбиения для CU, кодированной с помощью режима интер предсказания, т.е., PART_2N×2N, PART_2N×N, PART_N×2N, PART_N×N, PART_2N×nU, PART_2N×nD, PART_nL×2N и PART_nR×2N, как показано на Фиг. 5. Когда CU является интер кодированной, один набор информации движения присутствует для каждой PU. В дополнение, в соответствии с HEVC, каждая PU кодирована с уникальным режимом интер-предсказания, чтобы извлечь набор информации движения. Когда CU является интра кодированной в соответствии с HEVC, 2N×2N и N×N являются единственными допустимыми формами PU, и внутри каждой PU кодирован один режим интра предсказания (несмотря на то, что режим предсказания цветности сигнализируется на уровне CU). Формы N×N интра PU допускаются только когда текущий размер CU равен наименьшему размеру CU, определенному в SPS, в соответствии с HEVC.
[0102] Фиг. 6 является концептуальной схемой, иллюстрирующей примерную структуру 120 квадродерево-бинарное дерево (QTBT), и соответствующий CTB 122. В VCEG предложении COM16-C966 (J. An, Y.-W. Chen, K. Zhang, H. Huang, Y.-W. Huang, и S. Lei., «Block partitioning structure for next generation video coding», International Telecommunication Union, COM16-C966, сентябрь 2015г.) квадродерево-бинарное дерево (QTBT) было предложено для будущего стандарта кодирования видео позже HEVC. Моделирования показали, что предложенная структура QTBT является более эффективной, чем структура квадродерева в используемом HEVC.
[0103] В предложенной структуре QTBT у COM16-C966, CTB сначала разбивается посредством квадродерева, где дробление квадродерева одного узла может быть повторено до тех пор, пока узел не достигает минимального разрешенного размера листового узла квадродерева (MinQTSize). Если размер листового узла квадродерева не больше максимального разрешенного размера корневого узла бинарного дерева (MaxBTSize), он может быть дополнительно разбит посредством бинарного дерева. Дробление бинарного дерева одного узла может быть повторено до тех пор, пока узел не достигает минимального разрешенного размера листового узла бинарного дерева (MinBTSize) или максимальной разрешенной глубины бинарного дерева (MaxBTDepth). Листовой узел бинарного дерева именуется CU, которая используется для предсказания (например, предсказания внутри изображения или между изображениями) и преобразования без какого-либо дальнейшего разбиения.
[0104] Существует два типа дробления в соответствии с COM16-C966: симметричное горизонтальное дробление и симметричное вертикальное дробление, в дроблении бинарного дерева.
[0105] В одном примере структуры разбиения QTBT, размер CTU устанавливается как 128×128 (выборки яркости и две соответствующие 64×64 выборки цветности), MinQYSize устанавливается как 16×16, MaxBTSize устанавливается как 64×64, MinBTSize (как для ширины, так и высоты) устанавливается как 4, и MaxBTDepth устанавливается как 4. Разбиение квадродерева применяется к CTU сначала, чтобы сгенерировать листовые узлы квадродерева. Листовые узлы квадродерева могут иметь размер от 16×16 (т.е., MinQTSize) до 128×128 (т.е., размер CTU). Если листовой узел квадродерева является 128×128, он не будет в дальнейшем дробится посредством бинарного дерева, поскольку размер превышает MaxBTSize (т.е., 64×64). В противном случае, листовой узел квадродерева будет в дальнейшем разбиваться посредством бинарного дерева. Вследствие этого, листовой узел квадродерева является также корневым узлом для бинарного дерева и имеет глубину бинарного дерева равную 0.
[0106] Когда глубина бинарного дерева достигает MaxBTDepth (4, в одном примере), это означает, что не разрешено дальнейшее дробление. Когда узел бинарного дерева имеет ширину, равную MinBTSize (4, в одном примере), это означает, что не разрешено дальнейшее горизонтальное дробление. Сходным образом, когда узел бинарного дерева имеет высоту равную MinBTSize, это означает, что не разрешено дальнейшее вертикальное дробление. Листовые узлы бинарного дерева именуются CU, и в дальнейшем обрабатываются в соответствии с предсказанием и преобразованием без какого-либо дальнейшего разбиения.
[0107] CTB 122 на Фиг. 6 представляет собой пример разбиения блока посредством использования QTBT, и QTBT 120 на Фиг. 6 представляет собой пример QTBT, соответствующего CTB 122. Сплошные линии представляют собой дробление квадродерева, а пунктирные линии указывают дробление бинарного дерева. В каждом узле дробления (т.е., не листовом) бинарного древа, сигнализируется один флаг, чтобы указать, какой тип дробления (т.е., горизонтальный или вертикальный) используется, где 0 указывает горизонтальное дробление, а 1 указывает вертикальное дробление в данном примере. Применительно к дроблению квадродерева, нет необходимости в указании типа дробления, поскольку оно всегда дробит блок горизонтально и вертикально на 4 суб-блока равного размера. Соответственно, кодер 20 видео может кодировать, а декодер 30 видео может декодировать, элементы синтаксиса (такие как информация дробления) для уровня дерева области у QTBT 120 (т.е., сплошных линий) и элементы синтаксиса (такие как информация дробления) для уровня дерева предсказания у QTBT 120 (т.е., пунктирных линий). Кодер 20 видео может кодировать, а декодер 30 видео может декодировать, видеоданные, такие как данные предсказания и преобразования, для CU у листовых узлов дерева предсказания у деревьев предсказания QTBT 120.
[0108] Li и др., Предварительная Заявка США №62/279,233, поданная 15 января 2016г., описывает структуру многотипного дерева. С помощью способа в '233 предварительной заявке, узел дерева может быть дополнительно раздроблен с помощью нескольких типов дерева, таких как бинарное дерево, симметричное дерево с центральной стороной, и квадродерево. Показаны моделирования того, что структура многотипного дерева была много более эффективной, чем структура квадродерево-бинарное дерево.
[0109] В примере QTBT 120, уровень дерева области включает в себя квадродеревья (где каждый не листовой узел включает в себя четыре узла-потомка), а уровень дерева предсказания включает в себя бинарные деревья (где каждый не листовой узел включает в себя два узла-потомка). В целом, тем не менее, в соответствии с методиками данного раскрытия, дерево области может включать в себя не листовые узлы с первым числом узлов, которое равно или больше четырем (например, четыре, пять, шесть, и т.д. узлов), и каждый листовой узел дерева области может действовать в качестве корневого узла для дерева предсказания с вторым числом узлов, которое равное или больше двух (например, два, три, четыре, и т.д. узла). Каждый листовой узел дерева предсказания может соответствовать CU, которая в соответствии с методикой данного раскрытия, включает информацию предсказания и преобразования, но которой не требуется включать какой-либо дальнейшей информации дробления. Таким образом, единицы предсказания и единицы преобразования, в соответствии с примерами методик данного раскрытия, могут быть точно такого же размера как CU, включающие единицы предсказания и единицы преобразования.
[0110] Фиг. 7 является концептуальной схемой, иллюстрирующей блок 130, кодированный используя компенсацию движения перекрывающегося блока (OBMC). OBMC была предложена при разработке H.263 (Video Coding for Low Bitrate Communication, document Rec. H.263, ITU-T, апрель, 1995г.). В H.263, OBMC выполняется над 8×8 блоками, и векторы движения двух соединенных соседних 8×8 блоков используются для текущего блока, такого как текущий блок 130 Фиг. 7. Например, для первого 8×8 блока 132 в текущем блоке 130, помимо его собственного вектора движения, также применяются сверху и левый соседний вектор движения, чтобы сгенерировать два дополнительных блока предсказания. Таким образом, каждый пиксель в первом 8×8 блоке 132 имеет три значения предсказания, и взвешенное среднее этих трех значений предсказания используется в качестве итогового предсказания. Второй 8×8 блок 134 предсказывается используя свой собственный вектор движения, как впрочем и вектора движения сверху и правого соседних блоков. Третий 8×8 блок 136 предсказывается используя свой собственный вектор движения, как впрочем и вектор движения левого соседнего блока. Четвертый 8×8 блок 138 предсказывается используя свой собственный вектор движения, как впрочем и векторы движения правого соседнего блока.
[0111] Когда соседний блок не кодирован или кодирован используя интра режим, т.е., соседний блок не имеет доступного вектора движения, вектор движения текущего 8×8 блока используется в качестве соседнего вектора движения. Между тем, для третьего 8×8 блока 136 и четвертого 8×8 блока 138 у текущего блока 130 (как показано на Фиг. 7), снизу соседний блок не используется. Другими словами, для каждого MB, никакая информация движения из MB снизу него не будет использоваться для воссоздания пикселей текущего MB во время OBMC.
[0112] Фиг. 8 является концептуальной схемой, иллюстрирующей пример OBMC, как применяемой в HEVC, т.е., основанную на PU OBMC. Chien и др., Заявка США № 13/678,329, поданная 15 ноября 2012 г., и Guo и др., Заявка США №13/311,834, поданная 06 декабря 2011г., описывают применение OBMC, чтобы сглаживать границы PU в HEVC, такие как границы 140, 142. Пример способов, предложенных в заявках Chien и Guo, показан на Фиг. 8. Например, когда CU содержит две (или более) PU, линии/столбцы рядом с границей PU сглаживаются посредством OBMC, в соответствии с методиками этих заявок. Для пикселей помеченных с помощью «A» или «B» в PU0 или PU1, генерируется два значения предсказания, т.е., посредством применения векторов движения PU0 и PU1 соответственно, и взвешенное среднее значений предсказания используется в качестве итогового предсказания.
[0113] Фиг. 9 является концептуальной схемой, иллюстрирующей пример выполнения суб-PU уровня OBMC. В Тестовой Модели 2 Совместного Исследования (JEM) (J. Chen, E. Alshina, G.J. Sullivan, J.-R. Ohm, J. Boyce «Algorithm description of Joint Exploration Test Model 2», JVET-B1001, февраль 2016г.), применяется суб-PU уровня OBMC. В данном примере, OBMC выполняется для всех границ блока С Компенсацией Движения (MC) за исключением правой и нижней границ CU. Более того, OBMC применяется для компонентов как яркости, так и цветности. В HEVC, MC блок соответствует PU. В JEM, когда PU кодирована с помощью суб-PU режима, каждый суб-блок PU является MC блоком. Чтобы обрабатывать границы CU/PU единообразно, OBMC выполняется на уровне суб-блока для всех границ MC блока, где размер суб-блока устанавливается равным 4×4, как иллюстрируется на Фиг. 9.
[0114] В JEM, когда OBMC применяется к текущему суб-блоку (например, блокам затененным с помощью штриховки слева на право в примерах Фиг. 9), помимо текущих векторов движения, векторы движения для четырех соединенных соседних суб-блоков, если доступны и не идентичны текущему вектору движения, также используются чтобы получить блок предсказания для текущего суб-блока. Эти несколько блоков предсказания, которые основаны на нескольких векторах движения, взвешиваются, чтобы сгенерировать итоговый сигнал предсказания текущего суб-блока.
[0115] Обозначим блок предсказания основанный на векторах движения соседних суб-блоков как PN, с N указывающим индекс для сверху-, снизу, слева-, и справа- соседних суб-блоков, и обозначим блок предсказания основанный на векторах движения текущего суб-блока как PC. Когда PN принадлежит той же самой PU, что и PC (и следовательно, содержит точно такую же информацию движения), OBMC не выполняется для PN. В противном случае, каждый пиксель PN складывается с тем же самым пикселем в PC, т.е., четыре строки/столбца PN складываются с PC. Примерные весовые коэффициенты в виде {1/4, 1/8, 1/16, 1/32} могут быть использованы для PN, и соответствующие весовые коэффициенты {3/7, 7/8, 15/16, 31/32} могут быть использованы для PC.
[0116] Исключения могут включать в себя небольшие MC блоки (т.е., когда размер PU равен 8×4, 4×8, или PU является кодированной с помощью режима ATMVP), для которых только две строки/столбца PN складываются с PC. В данном случае, весовые коэффициенты {1/4, 1/8} могут быть использованы для PN и весовые коэффициенты {3/4, 7/8} могут быть использованы для PC. Когда PN генерируется на основании векторов движения вертикально (или горизонтально) соседнего суб-блока, пиксели в одной и той же строке (столбце) у PN могут быть сложены с PC с тем же самым весовым коэффициентом. Для границ PU, OBMC может быть применена по каждой стороне границы. В примере, Фиг. 9, OBMC может быть применена по границе между PU1 и PU2 дважды. Во-первых, OBMC может быть применена с MV у PU2 к затененным блокам по границе внутри PU1. Во-вторых, OBMC может быть применена с MV у PU1 к затененным блокам по границе внутри PU2. В других примерах, OBMC может быть применена к одной стороне границ CU, поскольку при кодировании (кодировании или декодировании) текущей CU, кодер видео не может менять CU, которые кодируются.
[0117] Фиг. 10 является концептуальной схемой, иллюстрирующей примеры ассиметричных разбиений движения для разнообразных 64×64 блоков. Перекрывающееся преобразование является преобразованием, выполняемым по блоку, пересекающему границу PU. В целом, блоки преобразования являются выровненными с блоками предсказания, поскольку границы предсказания обычно представляют разрыв. Вследствие этого, блоки преобразования пересекающие границы блока предсказания могут создавать высокочастотные коэффициенты, которые могут быть вредными для производительности кодирования. Тем не менее, для интер кодированных блоков, которые обычно представляют мало остатков предсказания, блок преобразования больший, чем блок предсказания, иногда может быть полезным, чтобы лучше уплотнять энергию и избегать ненужной сигнализации разнообразных размеров блока преобразования.
[0118] В HEVC, применяется структура кодирования преобразования используя остаточное квадродерево (RQT), которая кратко описана, как обсуждалось в документе «Transform Coding Using the Residual Quadtree (RQT)», доступном по адресу www.hhi.fraunhofer.de/fields-ofcompetence/image-processing/research-groups/image-video-coding/hevc-highefficiency-video-coding/transform-coding-using-the-residual-quadtree-rqt.html. Начиная с CTU, которая, как правило, 64×64 блок изображения в конфигурации по умолчанию HEVC, блок изображения может быть дополнительно раздроблен на меньшие квадратные единиц кодирования (CU). После того, как CTU рекурсивно раздроблена на CU, каждая CU дополнительно делится на единицы предсказания (PU) и единицы преобразования (TU).
[0119] В HEVC, разбиение CU на PU выбирается из нескольких предварительно определенных кандидатов. Предполагая, что CU будет размером 2N×2N, для интра CU, если размер CU составляет 8×8, CU может быть разбита на одну 2N×2N PU или четыре N×N PU, если размер CU больше 8×8, PU всегда равна размеру CU, т.е., 2N×2N. Для Интер CU, размер предсказания может быть 2N×2N, N×2N, 2N×N, или ассиметричными разбиениями движения (AMP) включая 2N×nU, 2N×nD, nL×2N, и nR×2N. Пример ассиметричных разбиений движения для 64×64 блока в соответствии с HEVC показан на Фиг. 10.
[0120] Фиг. 11 является концептуальной схемой, иллюстрирующей примерную схему преобразования основанную на остаточном квадродереве в соответствии с HEVC. Разбиение CU на TU выполняется рекурсивно на основании подхода квадродерева. Вследствие этого, остаточный сигнал CU кодируется посредством структуры дерева, а именно, остаточного квадродерева (RQT). RQT допускает размеры от 4×4 до 32×32 выборок яркости. Фиг. 11 показывает пример, где CU включает в себя 10 TU, помеченных с помощью букв с a до j, и соответствующее разбиение блока. Каждый узел RQT является фактически единицей преобразования (TU).
[0121] Индивидуальные TU обрабатываются в очередности обхода дерева в глубину, которая иллюстрируется на фигуре в качестве алфавитной очередности, что сопровождается рекурсивным Z-сканированием с обходом в глубину. Подход квадродерева обеспечивает адаптацию преобразования к варьирующимся пространственно-частотным характеристикам остаточного сигнала. Как правило, большие размеры блока преобразования, которые имеют большую пространственную поддержку, обеспечивают более хорошее частотное разрешение. Тем не менее, более мелкие размеры блока преобразования, которые имеют меньшую пространственную поддержку, обеспечивают более хорошее пространственное разрешение. Компромисс между двумя, пространственным и частотным разрешениями, выбирается посредством решения по режиму кодера, например, на основании методики оптимизации скорости-к-искажению. Кодер выполняет методику оптимизации скорости-к-искажению, чтобы вычислить взвешенную сумму битов кодирования и искажение воссоздания, т.е., издержки скорости-к-искажению, для каждого режима кодирования (например, конкретной структуре дробления RQT), и выбирает режим кодирования с наименьшими издержками скорости-к-искажению в качестве наилучшего режима.
[0122] Для интер кодированной CU, когда блок преобразования пересекает границу блока предсказания или блока движения, генерируются высокочастотные коэффициенты, которые могут накладывать негативное влияние на производительность кодирования. Для случая ассиметричного разбиения движения (AMP), данная проблем может быть более серьезной, так как блок преобразования на первом и втором уровне будет пересекать соответствующую границу блока движения. Тем не менее, для интер кодированных CU, единица преобразования больше соответствующей PU, например, 2N×2N единица преобразования, может быть по-прежнему полезной, что основано на соображении о том, что 2N×2N преобразование может получать более хороший результат, когда остаток внутри единицы кодирования является небольшим, и использование 2N×2N TU также может экономить биты сигнализации, что может помочь в улучшении эффективности кодирования.
[0123] В HEVC, для Интра кодированной CU, TU не может пересекать границу предсказания, т.е., границу PU. Тем не менее, для Интер кодированной CU, TU может быть настолько большой как размер CU, что означает, что преобразование может быть выполнено по границе предсказания.
[0124] В HEVC, допускается изменение значений QP на уровне CU. Группа квантования определяется в качестве области, где одно базовое значение QP используется, чтобы кодировать разность значений QP для всех CU внутри области. Тем не менее, сходная концепция может быть сложной для определения в существующих структурах многотипного дерева, поскольку логическая группа из листовых узлов может представлять собой очень разнообразные формы, и, следовательно, может быть сложным найти хороший, общий предсказатель для кодирования дельты QP.
[0125] Например, на границах объекта, который может быть разбит используя прямоугольные формы, более низкое значение QP может быть использовано для разбиений переднего плана, а более высокое значение QP может потребоваться для разбиений заднего плана. Желательно использовать разные значения QP для разных разбиений, чтобы дополнительно улучшать воспринимаемое качество закодированного видео.
[0126] Фиг. 12 является концептуальной схемой, иллюстрирующей пример первого уровня 150 многотипного дерева и второй уровень 160' многотипного дерева. Первый уровень 150 также может именоваться деревом области, а второй уровень 160' может именоваться деревом предсказания. Второй уровень 160' соответствует блоку 160 первого уровня 150. В частности, первый уровень 150 разбивается с помощью квадродерева, а второй уровень 160' соответствует листу дерева области, который дополнительно дробится на более мелкие блоки с помощью бинарного дерева и тройного дерева с центральной стороной. В данном примере, CTB разбивается на четыре листа 152, 154, 156, и 158 квадродерева, второй из которых (блок 154) разбивается на четыре дополнительных листа 160, 162, 164, и 166 квадродерева, приводя к первому уровню 150 (с семью суммарно листовыми узлами дерева области). В примере Фиг. 12, блок 160 представляет собой листовой узел дерева области и разбивается (в соответствии с вторым уровнем 160') на первый набор троек 172, 174, 176 с центральной стороной, и правая из которых (176) также разбивается на тройные блоки 178, 184, 186 с центральной стороной, первый из которых (блок 178) разбивается используя бинарное дерево (т.е., на листья бинарного дерева, соответствующие блокам 180, 182). Таким образом, второй уровень 160' включает в себя суммарно шесть листовых узлов. Эти шесть листовых узлов могут соответствовать единицам кодирования (CU), в соответствии с методиками данного раскрытия. Колер 20 видео может кодировать, а декодер 30 видео может декодировать, видеоданные (например, данные предсказания и преобразования) для каждой из CU (например, каждого из блоков 172, 174, 180, 182, 184, и 186).
[0127] В одном примере, кодер 20 видео и декодер 30 видео могут быть выполнены с возможностью разбиения CTB используя многотипное дерево с деревом области, листовые узлы которого разбиваются используя бинарное дерево и/или тройное дерево с центральной стороной. Фиг. 12 иллюстрирует пример, где основанное на квадродереве дерево области находится слева (приводя к первому уровню 150), а основанное на бинарном/тройном дереве дерево предсказания находится справа (приводя к второму уровню 160'). Линии с длинным пунктиром показывают дробление первой глубины листа дерева области второго уровня 160', с помощью горизонтального тройного дерева с центральной стороной, линии с коротким пунктиром представляют дробление второй глубины с помощью вертикального тройного дерева с центральной стороной, и штрих-пунктирная линия для дробления третьей глубины с помощью горизонтального бинарного дерева.
[0128] В одном примере, кодер 20 видео и декодер 30 видео могут сигнализировать/определять является ли OBMC на уровне листа дерева области. В примере Фиг. 12, второй уровень 160' представляет лист дерева области, а внутренние блоки 172, 174, 176, 178, 180, 182, 184, и 186 второго уровня 160' указывают разбиение посредством дерева предсказания. Внутренние линии представляют границы CU для CU листьев дерева предсказания, т.е., блоки 172, 174, 180, 182, 184, и 186. Когда OBMC разрешена для данного листа дерева области (т.е., второго уровня 160'), внутренние линии (т.е., с длинным пунктиром, с коротким пунктиром, и штрих-пунктирные линии) можно рассматривать также, как границы PU у HEVC, так что OBMC PU-границы может быть применена к обеим сторонам границ между блоками 172, 174, 180, 182, 184, и 186. В данном случае, процесс OBMC можно рассматривать как дополнительное уточнение или фильтрацию после кодирования/декодирования всего листа дерева области.
[0129] В одном примере, кодер 20 видео и декодер 30 видео может применять перекрывающееся преобразование на уровне или уровне листа дерева области. Как показано на втором уровне 160' Фиг. 12, лист дерева области содержит несколько CU (т.е., блоки 172, 174, 180, 182, 184, и 186). Когда кодер 20 видео или декодер 30 видео разрешает перекрывающиеся преобразования для листа дерева области, кодер 20 видео и/или декодер 30 видео может применять большое преобразование с точно таким же размером, как у листа дерева области к второму уровню 160' (т.е., всему листу дерева области). Кодер 20 видео или декодер 30 видео может применять дерево преобразования к листу дерева области.
[0130] В одном примере, кодер 20 видео и/или декодер 30 видео может применять режим супер пропуска/слияния на уровне листа дерева области. Когда такой режим супер пропуска/слияния разрешен, кодер 20 видео или декодер 30 видео кодирует (т.е., кодирует или декодирует) все из CU внутри листа дерева области, такие как блоки 172, 174, 180, 182, 184, и 186, показанные на втором уровне 160' Фиг. 12, используя режим пропуска/слияния так, что кодер 20 видео не кодирует, а декодер 30 видео не декодирует флаги пропуска/слияния независимо для каждой CU (т.е., блоков 172, 174, 180, 182, 184, и 186).
[0131] В одном примере, кодер 20 видео и декодер 30 видео применяют базовый QP на уровне листа дерева области. Когда разрешено кодирование дельты QP, кодер 20 видео и декодер 30 видео могут использовать один и тот же базовый QP, чтобы кодировать значения дельты QP для всех CU/блоков внутри листа дерева области (т.е., каждого из блоков 172, 174, 180, 182, 184, и 186).
[0132] Фиг. 13 является блок-схемой, иллюстрирующей пример способа для кодирования блока дерева кодирования в соответствии с методиками данного раскрытия. В целях примера и объяснения, способ Фиг. 13 объясняется по отношению к кодеру 20 видео. Тем не менее, в других примерах, другие модули могу быть сконфигурированы, чтобы выполнять методики Фиг. 13.
[0133] В данном примере, исходно, модуль 40 выбора режима определяет (200) размеры блоков на уровне дерева области для блока дерева кодирования (CTB). Например, модуль 40 выбора режима может исполнять многообразие разных проходов кодирования и определять размеры блоков на уровне дерева области на основании анализа скорости-к-искажению. Модуль 40 выбора режима затем отправляет (202) элементы синтаксиса дерева области модулю 56 энтропийного кодирования, которые будут кодироваться, такие как флаги дробления, указывающие каким образом разбиваются блоки, соответствующие узлам дерева области. Флаги дробления могут дополнительно указывать, когда ветвь дерева области завершается на листовом узле дерева области, который действует в качестве корневого узла для дерева разбиения. В соответствии с методиками данного раскрытия, каждый не листовой узел дерева области дробится на некоторое число узлов-потомков, которые являются, по меньшей мере, четырьмя узлами-потомками, как например, четыре, пять, шесть, и т.д., узлы-потомки.
[0134] Дополнительно, модуль 40 выбора режима определяет, разрешать ли разнообразные инструменты кодирования для CTB, и отправляет элементы синтаксиса модулю 56 энтропийного кодирования, которые будут кодироваться, где элементы синтаксиса представляют собой разрешенные инструменты кодирования. Эти элементы синтаксиса могут быть включены в информацию уровня дерева области, как например листовые узлы дерева области. Элементы синтаксиса могут включать в себя, например, компенсацию движения перекрывающегося блока (OBMC) как обсуждалось выше, перекрывающиеся преобразования, режим супер пропуска, режим супер слияния, режим супер интра-предсказания, режим супер интер-предсказания, и/или режим супер преобразования с повышением частоты кадров (FRUC). В некоторых примерах, модуль 40 выбора режима разрешает супер режимы (такие как режим супер пропуска, режим супер слияния, режим супер интра-предсказания, режим супер интер-предсказания, и/или режим супер FRUC) когда число CU, включенных в листовой узел дерева области, больше пороговой величины. Пороговая величина может быть предварительно определенной, или модуль 56 энтропийного кодирования может кодировать элементы синтаксиса, которые определяют пороговую величину, например, в SPS, PPS, заголовке слайса, или подобном.
[0135] Модуль 40 выбора режима затем может определять (204) размер блоков на уровне дерева предсказания для каждого из листовых узлов дерева области. Вновь, каждый из листовых узлов дерева области также может действовать в качестве корневого узла соответствующего дерева предсказания. Следует понимать, что не все ветви дерева области обязательно одного размера, и, вследствие этого, деревья предсказания у CTB могут начинаться на разнообразных глубинах дерева области. Модуль 40 выбора режима может вновь тестировать разнообразные проходы кодирования и использовать анализ скорости-к-искажению, чтобы определять размеры для блоков, соответствующих уровню дерева предсказания (а именно, посредством выбора размеров блока, которые дают наилучшие протестированные характеристики скорости-к-искажению). Модуль 40 выбора режима может затем предоставлять (206) элементы синтаксиса модулю 56 энтропийного кодирования, чтобы они были энтропийно закодированы, такие как флаги дробления для деревьев предсказания. В соответствии с методиками данного раскрытия, каждый не листовой узел дерева предсказания может быть раздроблен на некоторое число узлов-потомков, т.е., по меньшей мере, два узла-потомка, такие как два, три, четыре, и т.д. узла-потомка. Более того, в некоторых примерах, кодер 20 видео может дробить узлы дерева предсказания на либо два узла-потомка дерева предсказания, либо три узла-потомка дерева предсказания, используя разбиение тройки с центральной стороной.
[0136] В некоторых примерах, кодер 20 видео может кодировать элементы синтаксиса на любом или обоих из уровня дерева области и уровня дерева предсказания. Например, кодер 20 видео может кодировать параметры инструмента фильтрации, такие как параметры адаптивного к выборке смещения (SAO) и/или адаптивного контурного фильтра (ALF), на любом или на обоих из уровня дерева области и уровня дерева предсказания. Кроме того, кодер 20 видео может кодировать эти элементы синтаксиса в любом узле дерева области и/или дерева предсказания, не обязательно только в листовых узлах.
[0137] В соответствии с методиками данного раскрытия, листовые узлы дерева предсказания соответствуют единицам кодирования (CU) с данными предсказания и преобразования. Таким образом, после разбиения узлов дерева предсказания на листовые узлы дерева предсказания, кодер 20 видео может кодировать данные предсказания и преобразования для каждой CU (т.е., листовых узлов дерева предсказания). В частности, модуль 40 выбора режима может определять (208), предсказывать ли CU используя интра-предсказание, интер-предсказание, режим пропуска, и затем отправлять (210) информацию синтаксиса модулю 56 энтропийного кодирования, чтобы энтропийно кодировать информацию предсказания (например, интра-режим, информацию движения, такую как информация режима слияния или режима AMVP, или подобное).
[0138] Модуль 40 выбора режима также предоставляет предсказанный блок CU сумматору 50, который вычисляет остаточный блок для соответствующей CU. Таким образом, кодер 20 видео определяет (212) остаточную информацию для соответствующей CU. Модуль 52 обработки преобразования применяет (214) преобразование к остаточному блоку, чтобы преобразовать остаточные данные, и затем модуль 54 квантования квантует (216) преобразованную остаточную информацию (т.е., коэффициенты преобразования), чтобы создать квантованные коэффициенты преобразования (также именуемые квантованной информацией преобразования). Модуль 56 энтропийного кодирования затем энтропийно кодирует (218) квантованную информацию преобразования. Модуль 56 энтропийного кодирования может дополнительно энтропийно кодировать другие элементы синтаксиса, такие как информация параметра квантования (QP). В соответствии с методиками данного раскрытия, в некоторых примерах, каждый QP для каждой из CU у CTB может быть предсказан из базового QP для всего CTB.
[0139] Таким образом, способ Фиг. 13 представляет собой пример способа кодирования видеоданных, причем способ включает в себя этапы, на которых: определяют, каким образом узлы дерева области на уровне дерева области некоторого дерева области из древовидной структуры данных для блока дерева кодирования (CTB) видеоданных должны быть раздроблены на узлы-потомки дерева области, причем дерево области имеет один или более узлов дерева области, в том числе ноль или более не листовых узлов дерева области и один или более листовых узлов дерева области, причем каждый из не листовых узлов дерева области имеет первое число узлов-потомков дерева области, причем первое число составляет, по меньше мере, четыре; кодируют один или более элементов синтаксиса на уровне дерева области, представляющие собой, по меньшей мере, каким образом деревья области дробятся на узлы дерева области; определяют, каким образом узлы дерева предсказания на уровне дерева предсказания для каждого из листовых узлов дерева области одного или более деревьев предсказания древовидной структуры данных для CTB разбиваются, чтобы быть раздробленными на узлы-потомки дерева предсказания, причем каждое из деревьев предсказания имеет один или более узлов дерева предсказания, в том числе ноль или более не листовых узлов дерева предсказания и один или более листовых узлов дерева предсказания, причем каждый из не листовых узлов дерева предсказания с, по меньшей мере, двумя узлами-потомками дерева предсказания, причем каждый из листовых узлов предсказания определяет соответствующие единицы кодирования (CU); кодируют один или более элементов синтаксиса на уровне дерева предсказания, представляющие собой, по меньшей мере, каким образом деревья предсказания дробятся на узлы дерева предсказания, и кодируют видеоданные, включающие в себя данные предсказания и данные преобразования, для каждой из CU на основании, по меньшей мере частично, элементов синтаксиса на уровне дерева области и элементов синтаксиса на уровне дерева предсказания.
[0140] Фиг. 14 является блок-схемой, иллюстрирующей способ для декодирования блока дерева кодирования в соответствии с методиками данного раскрытия. В целях примера и объяснения, способ Фиг. 14 объясняется в отношении декодера 30 видео. Тем не менее, в других примерах, другие модули могут быть сконфигурированы, чтобы выполнять методики Фиг. 14.
[0141] В данном примере, исходно, модуль 70 энтропийного декодирования энтропийно декодирует (220) элементы синтаксиса уровня дерева области для блока дерева кодирования. Декодер 30 видео затем может определять (222) размеры блоков на уровне дерева области из элементов синтаксиса на уровне дерева области. Например, элементы синтаксиса могут включать в себя флаги дробления, указывающие каким образом блоки, соответствующие узлам дерева области, разбиваются. Флаги дробления могут дополнительно указывать, когда ветвь дерева области завершается в листовом узле дерева области, который действует в качестве корневого узла для дерева разбиения. В соответствии с методиками данного раскрытия, каждый не листовой узел дерева области дробится на некоторое число узлов-потомков, т.е., по меньшей мере, четыре узла-потомка, такие как четыре, пять, шесть, и т.д. узлы-потомки.
[0142] Дополнительно, модуль 70 энтропийного декодирования может декодировать элементы синтаксиса, представляющие собой, разрешены ли разнообразные инструменты кодирования для CTB. Эти элементы синтаксиса могут быть включены в информацию уровня дерева области. Элементы синтаксиса могут представлять, например, компенсацию движения перекрывающегося блока (OBMC), перекрывающиеся преобразования, режим супер пропуска, режим супер слияния, режим супер интра-предсказания, режим супер интер-предсказания, и/или режим супер преобразования с повышением частоты кадров (FRUC), как обсуждалось выше. В некоторых примерах, декодер 30 видео может разрешать супер режимы (такие как режим супер пропуска, режим супер слияния, режим супер интра-предсказания, режим супер интер-предсказания, и/или режим супер FRUC) только когда число CU, включенных в листовой узел дерева области больше пороговой величины. Пороговая величина может быть предварительно определенной, или модуль 70 энтропийного декодирования может декодировать элементы синтаксиса, которые определяют пороговую величину, например, в SPS, PPS, заголовке слайса, или подобном.
[0143] Модуль 70 энтропийного декодирования затем может декодировать (224) элементы синтаксиса дерева предсказания для деревьев предсказания, соответствующих листовым узлам дерева области. Декодер 30 видео может затем определять (226) размеры блоков на уровне дерева предсказания для каждого из листовых узлов дерева области на основании элементов синтаксиса уровня дерева предсказания. Вновь, каждый из листовых узлов дерева области также может действовать в качестве корневого узла соответствующего дерева предсказания. Например, элементы синтаксиса могут включать в себя флаги дробления для деревьев предсказания. В соответствии с методиками данного раскрытия, каждый не листовой узел дерева предсказания может быть раздроблен на некоторое число узлов-потомков, т.е., по меньшей мере, два узла потомка, такие как два, три, четыре, и т.д. узлы-потомки. Более того, в некоторых примерах, декодер 30 видео может дробить узлы дерева предсказания на либо два узла-потомка дерева предсказания, либо три узла-потомка дерева предсказания, используя разбиение тройки с центральной стороной, на основании элементов синтаксиса, сигнализируемых в узлах дерева предсказания.
[0144] В некоторых примерах, декодер 30 видео может декодировать некоторые элементы синтаксиса на любом или обоих из уровня дерева области и уровня дерева предсказания. Например, декодер 30 видео может декодировать параметры инструмента фильтрации, такие как параметры адаптивного к выборке смещения (SAO) и/или адаптивного контурного фильтра (ALF), на любом или обоих из уровня дерева области и уровня дерева предсказания. Кроме того, декодер 30 видео может декодировать эти элементы синтаксиса в любом узле дерева области и/или дерева предсказания, не обязательно только в листовых узлах.
[0145] В соответствии с методиками данного раскрытия, листовые узлы дерева предсказания соответствуют единицам кодирования (CU) с данными предсказания и преобразования. Таким образом, после разбиения узлов дерева предсказания на листовые узлы дерева предсказания, декодер 30 видео может декодировать данные предсказания и преобразования для каждой из CU (т.е., листовых узлов дерева предсказания). В частности, модуль 70 энтропийного декодирования может декодировать (228) информацию синтаксиса представляющую собой информацию предсказания, такую как информация синтаксиса, указывающая, предсказывать ли CU, используя режим интра-предсказания, интер-предсказания, или пропуска. Декодер 30 видео затем может определять (230) режим предсказания для каждой CU, например, предсказывается ли каждая CU используя интра-режим, интер-режим (как прочем и информацию движения, такую как информация режима слияния или режима AMPV), или подобное. Модуль 70 компенсации движения или модуль 74 интра предсказания использует информацию предсказания, чтобы формировать предсказанные блоки для каждой из CU.
[0146] Модуль 70 энтропийного декодирования также энтропийно декодирует (232) квантованную информацию преобразования. Модуль 76 обратного квантования обратно квантует (234) квантованную информацию преобразования, чтобы создать коэффициенты преобразования (также именуемые информацией преобразования). Модуль 78 обратного преобразования обратно преобразует (236) информацию преобразования, чтобы воссоздать остаточные блоки для CU (238). Сумматор 80 складывает (240) остаточные блоки и предсказанные блоки каждой из соответствующих CU чтобы воссоздать CU, и сохраняет CU в памяти 82 опорных изображений для последующего использования в качестве ссылки или для вывода в качестве декодированных видеоданных.
[0147] Таким образом, способ Фиг. 14 представляет собой пример способа декодирования видеоданных, включающего в себя этапы, на которых: декодируют один или более элементов синтаксиса на уровне дерева области некоторого дерева области из древовидной структуры данных для блока дерева кодирования (CTB) видеоданных, причем дерево области имеет один или более узлов дерева области, в том числе ноль или более не листовых узлов дерева области и один или более листовых узлов дерева области, причем каждый из не листовых узлов дерева области имеет первое число узлов-потомков дерева области, причем первое число составляет, по меньше мере, четыре; определяют, используя элементы синтаксиса на уровне дерева области, каким образом узлы дерева области раздроблены на узлы-потомки дерева области; декодируют один или более элементов синтаксиса на уровне дерева предсказания для каждого из листовых узлов дерева области одного или более деревьев предсказания древовидной структуры данных для CTB, причем каждое из деревьев предсказания имеет один или более узлов дерева предсказания, в том числе ноль или более не листовых узлов дерева предсказания и один или более листовых узлов дерева предсказания, причем каждый из не листовых узлов дерева предсказания имеет второе число узлов-потомков дерева предсказания, причем второе число составляет, по меньшей мере, два, причем каждый из листовых узлов предсказания определяет соответствующие единицы кодирования (CU); определяют, используя элементы синтаксиса на уровне дерева предсказания, каким образом узлы дерева предсказания раздроблены на узлы-потомки дерева предсказания; и декодируют видеоданные, включающие в себя данные предсказания и данные преобразования, для каждой из CU, на основании, по меньшей мере частично, элементов синтаксиса на уровне дерева области и элементов синтаксиса на уровне дерева предсказания.
[0148] Следует признать, что в зависимости от примера, некоторые действия или события любой из методик, описанных в данном документе, могут быть выполнены в другой последовательности, могут быть добавлены, объединены, или опущены совсем (например, не все описанные действия или события являются обязательными для реализации на практике методик). Более того, в некоторых примерах, действия или события могут быть выполнены параллельно, например, посредством многопотоковой обработки, обработки с прерываниями, или нескольких процессоров, вместо последовательно.
[0149] В одном или более примерах, описанные функции могут быть реализованы в аппаратном обеспечении, программном обеспечении, встроенном программном обеспечении, или их сочетании. При реализации в программном обеспечении, функции могут быть сохранены на или переданы через, в качестве одной или более инструкций или кода, машиночитаемый носитель информации и исполнены посредством основанного на аппаратном обеспечении модуля обработки. Машиночитаемые носители информации могут включать в себя машиночитаемые запоминающие носители информации, которые соответствуют вещественным носителям информации, таким как носители информации для хранения данных, или средства связи, включающие в себя любой носитель информации, который способствует переносу компьютерной программы из одного места в другое, например, в соответствии с протоколом связи. Таким образом, машиночитаемые носители информации главным образом могут соответствовать (1) вещественным машиночитаемым запоминающим носителям информации, которые не являются временными, или (2) средству связи, такому как сигнал или несущая волна. Носители информации для хранения данных могут быть любыми доступными носителями информации, доступ к которым может быть осуществлен посредством одного или более компьютеров или одного или более процессоров, чтобы извлекать инструкции, код и/или структуры данных для реализации методик, описанных в данном раскрытии. Компьютерный программный продукт может включать в себя машиночитаемый носитель информации.
[0150] В качестве примера, а не ограничения, такие машиночитаемые запоминающие носители информации могут содержать RAM, ROM, EEPROM, CD-ROM или другое оптическое дисковое хранилище, магнитное дисковое хранилище, или другие магнитные запоминающие устройства, флэш-память, или любой другой носитель информации, который может быть использован, чтобы хранить требуемый код программы в форме инструкций или структур данных, и доступ к которому может быть осуществлен посредством компьютера. Также, любое соединение правильно называть машиночитаемым носителем информации. Например, если инструкции передаются от web-сайта, сервера, или другого удаленного источника, используя коаксиальный кабель, оптоволоконный кабель, витую пару, цифровую абонентскую линию (DSL), или беспроводные технологии, такие как инфракрасные, радиосвязи, и микроволновые, тогда коаксиальный кабель, оптоволоконный кабель, витая пара, DSL, или беспроводные технологии, такие как инфракрасные, радиосвязи, и микроволновые включены в определение носителя информации. Тем не менее, следует понимать, что машиночитаемые запоминающие носители информации и носители информации для хранения данных не включают в себя соединения, несущие волны, сигналы, или другие временные носители информации, а вместо этого направлены на не временные, вещественные запоминающие носители информации. Магнитный диск и оптический диск, используемые в данном документе, включают в себя компакт-диск (CD), лазерный диск, оптический диск, цифровой универсальный диск (DVD), флоппи-диск и Blu-ray диск, где магнитные диски обычно воспроизводят данные магнитным образом, тогда как оптические диски воспроизводят данные оптически с помощью лазеров. Сочетания вышеизложенного также должно быть включено в объем машиночитаемых носителей информации.
[0151] Инструкции могут быть исполнены одним или более процессорами, такими как один или более цифровые сигнальные процессоры (DSP), микропроцессоры общего назначения, проблемно-ориентированные интегральные микросхемы (ASIC), программируемые вентильные матрицы (FPGA), или другая эквивалентная интегральная или дискретной логики схема. Соответственно, понятие «процессор», используемое в данном документе, может относиться к любой из вышеизложенных структур или любой другой структуре, подходящей для реализации методик, описанных в данном документе. В дополнение, в некоторых аспектах, функциональность, описанная в данном документе, может быть обеспечена в выделенном аппаратном обеспечении и/или модулях программного обеспечения, выполненных с возможностью кодирования и декодирования, или включена в объединенный кодек. Также, методики могут быть полностью реализованы в одной или более цепях или логических элементах.
[0152] Методики данного раскрытия могут быть реализованы в широком разнообразии устройств или аппаратур, включая беспроводной телефон, интегральная микросхема (IC) или набор IC (например, набор микросхем). Разнообразные компоненты, модули, или блоки, описываются в данном раскрытии чтобы подчеркнуть функциональные аспекты устройств, выполненных с возможностью выполнения раскрытых методик, но не обязательно требуют реализации посредством разных блоков аппаратного обеспечения. Наоборот, как описано выше, разнообразные блоки могут быть объединены в блок кодека аппаратного обеспечения или предоставлены посредством совокупности взаимодействующих блоков аппаратного обеспечения, включая один или более процессоры, как описано выше, в связи с подходящим программным обеспечением и/или встроенным программным обеспечением.
[0153] Были описаны разнообразные примеры. Эти и прочие примеры находятся в рамках объема нижеследующей формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Диапазон минимального размера блока кодирования при кодировании видео | 2020 |
|
RU2796261C1 |
| ДРЕВОВИДНАЯ СТРУКТУРА МНОЖЕСТВЕННОГО ТИПА КОДИРОВАНИЯ ВИДЕО | 2017 |
|
RU2727095C2 |
| СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЙ И УСТРОЙСТВО ДЛЯ ЭТОГО | 2022 |
|
RU2783332C1 |
| СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЙ И УСТРОЙСТВО ДЛЯ ЭТОГО | 2017 |
|
RU2720066C1 |
| СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЙ И УСТРОЙСТВО ДЛЯ ЭТОГО | 2021 |
|
RU2769348C1 |
| СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЙ И УСТРОЙСТВО ДЛЯ ЭТОГО | 2017 |
|
RU2745779C2 |
| СПОСОБ И УСТРОЙСТВО СИГНАЛИЗАЦИИ ФЛАГОВ РЕЖИМА ПРОПУСКАНИЯ | 2021 |
|
RU2801586C1 |
| ПАРАЛЛЕЛЬНАЯ ОБРАБОТКА ВОЛНОВЫХ ФРОНТОВ ДЛЯ КОДИРОВАНИЯ ВИДЕО | 2013 |
|
RU2643652C2 |
| УПРАВЛЕНИЕ МАКСИМАЛЬНЫМ РАЗМЕРОМ ПРЕОБРАЗОВАНИЯ | 2020 |
|
RU2778250C1 |
| ОГРАНИЧЕНИЕ СОГЛАСОВАННОСТИ ДЛЯ СОВМЕЩЕННОГО ОПОРНОГО ИНДЕКСА В КОДИРОВАНИИ ВИДЕО | 2017 |
|
RU2733267C2 |

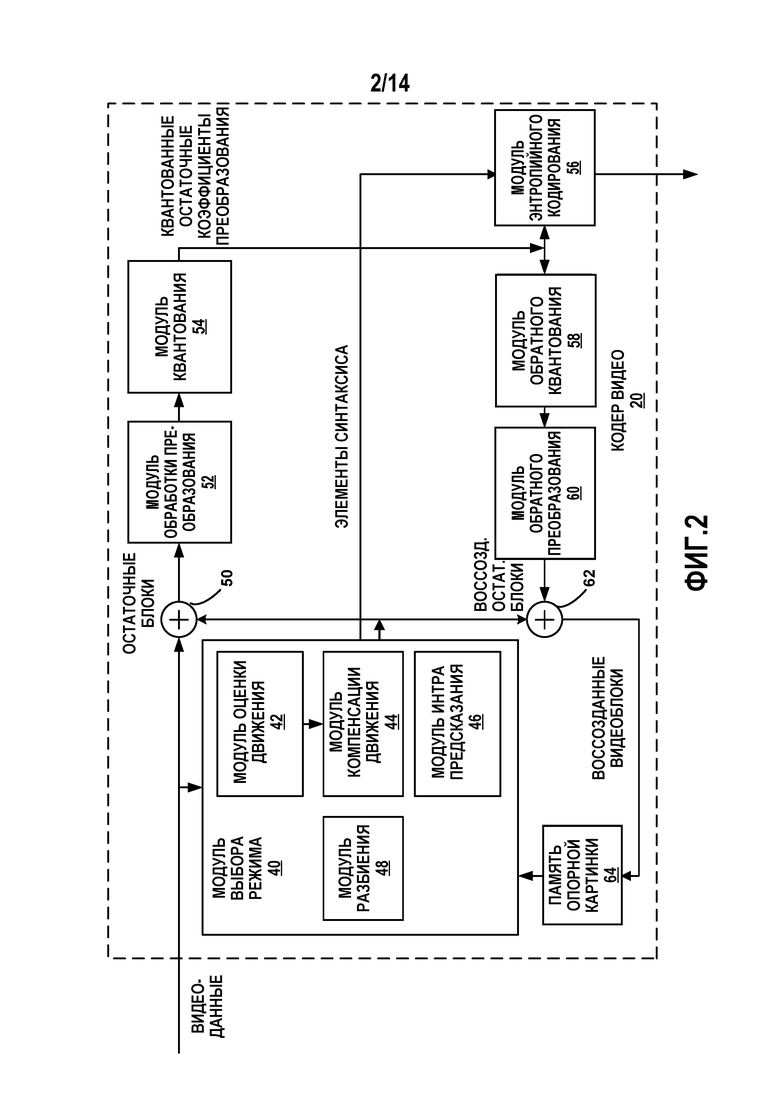

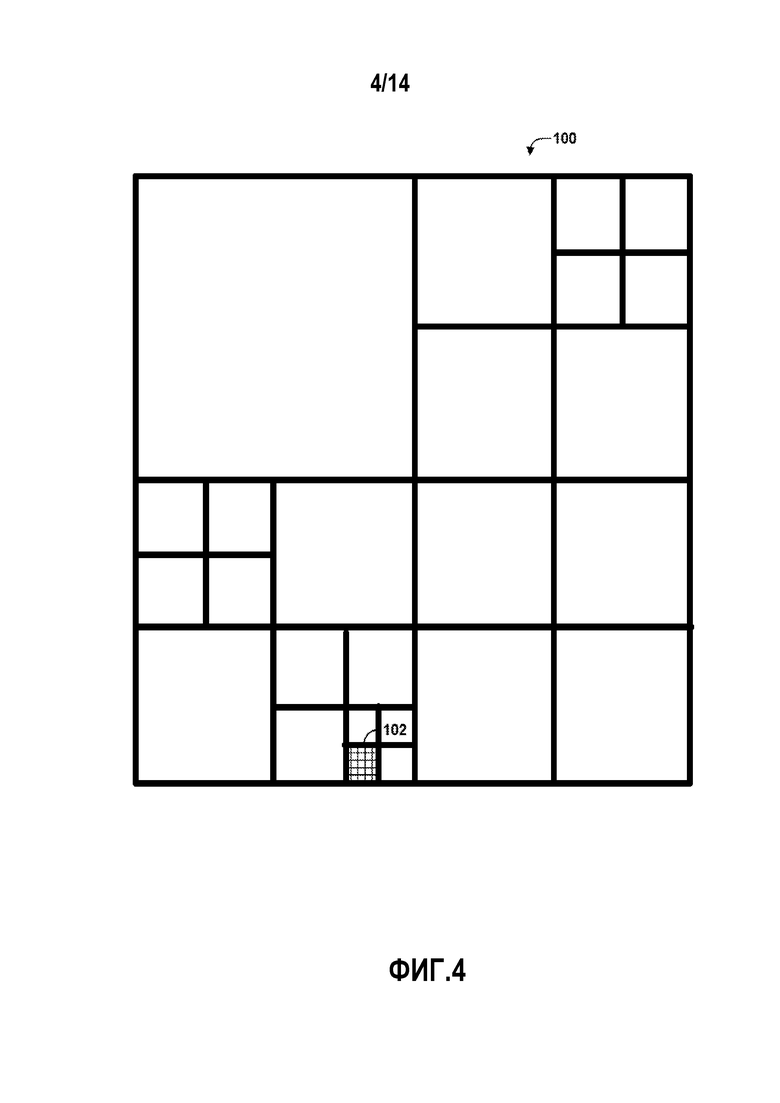


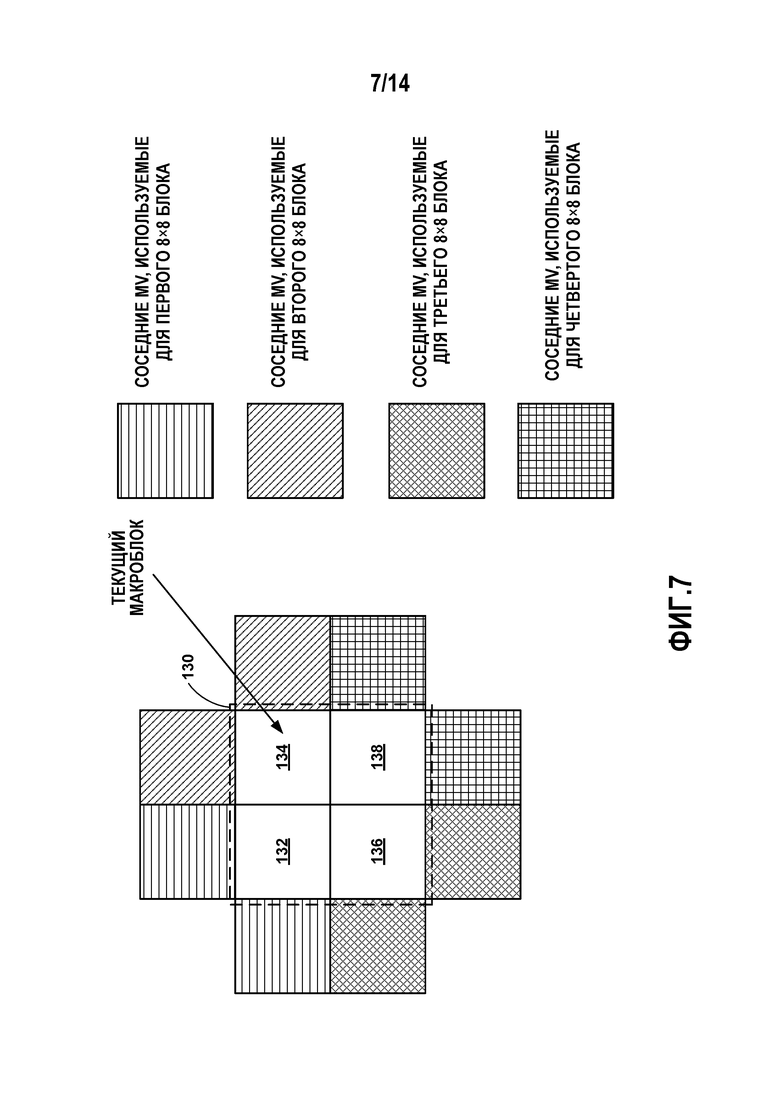

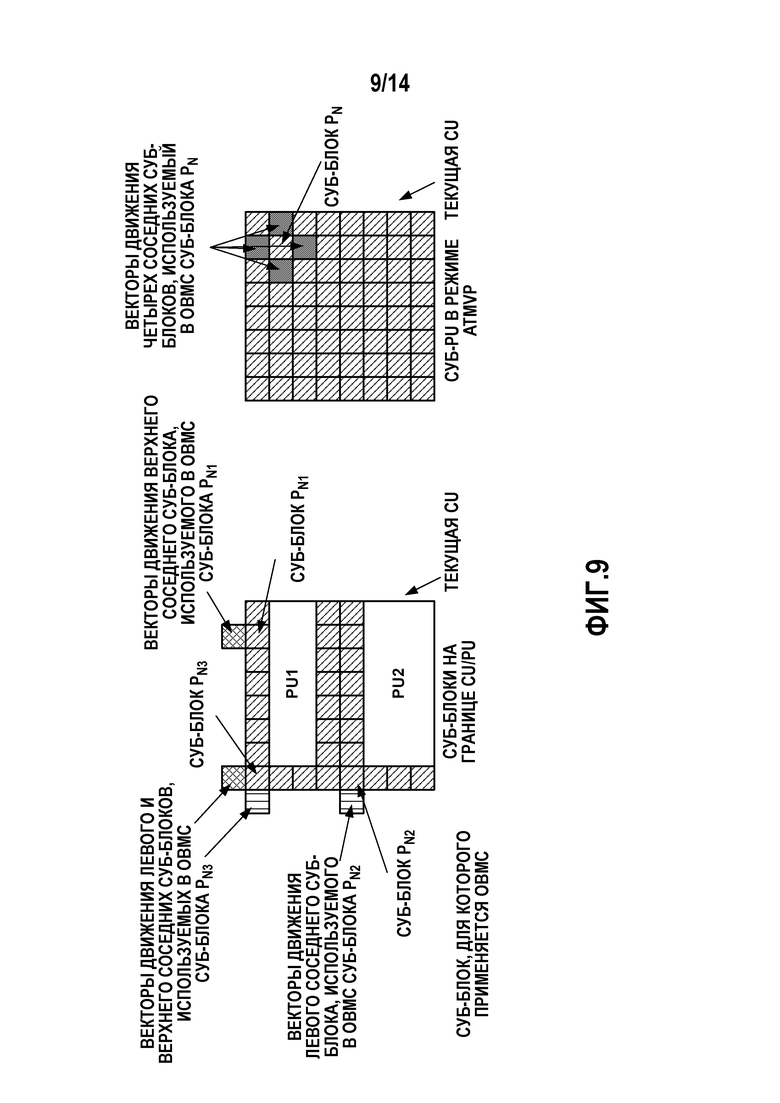

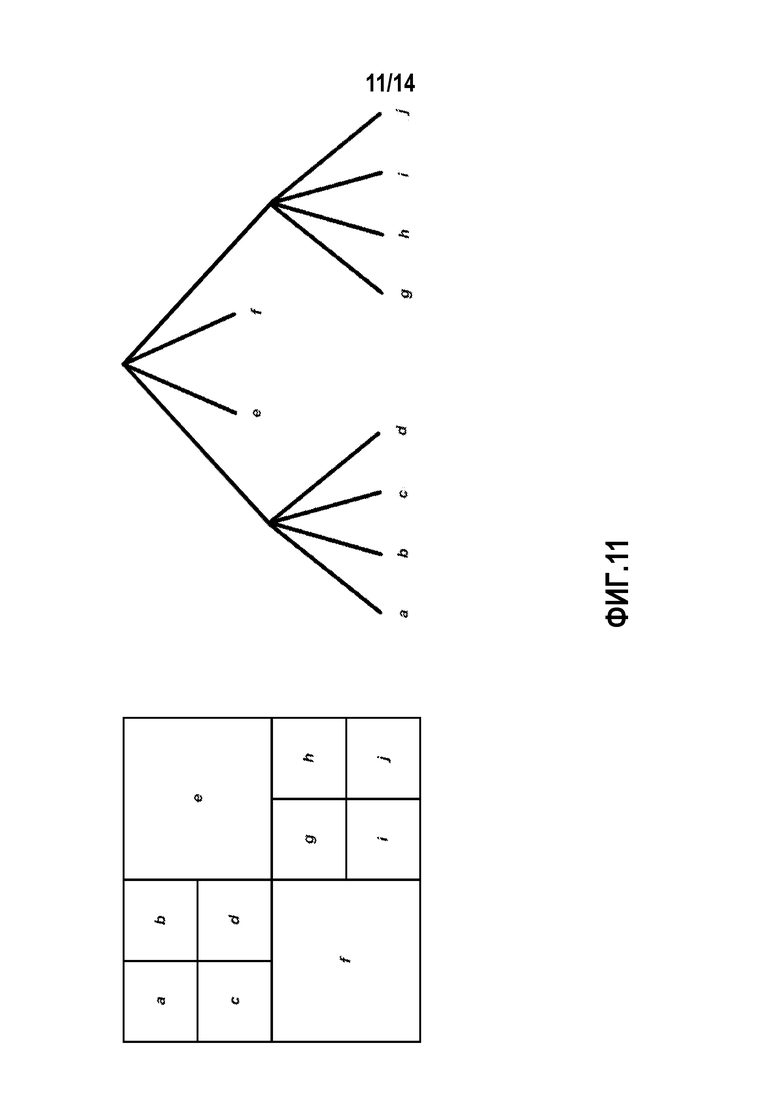

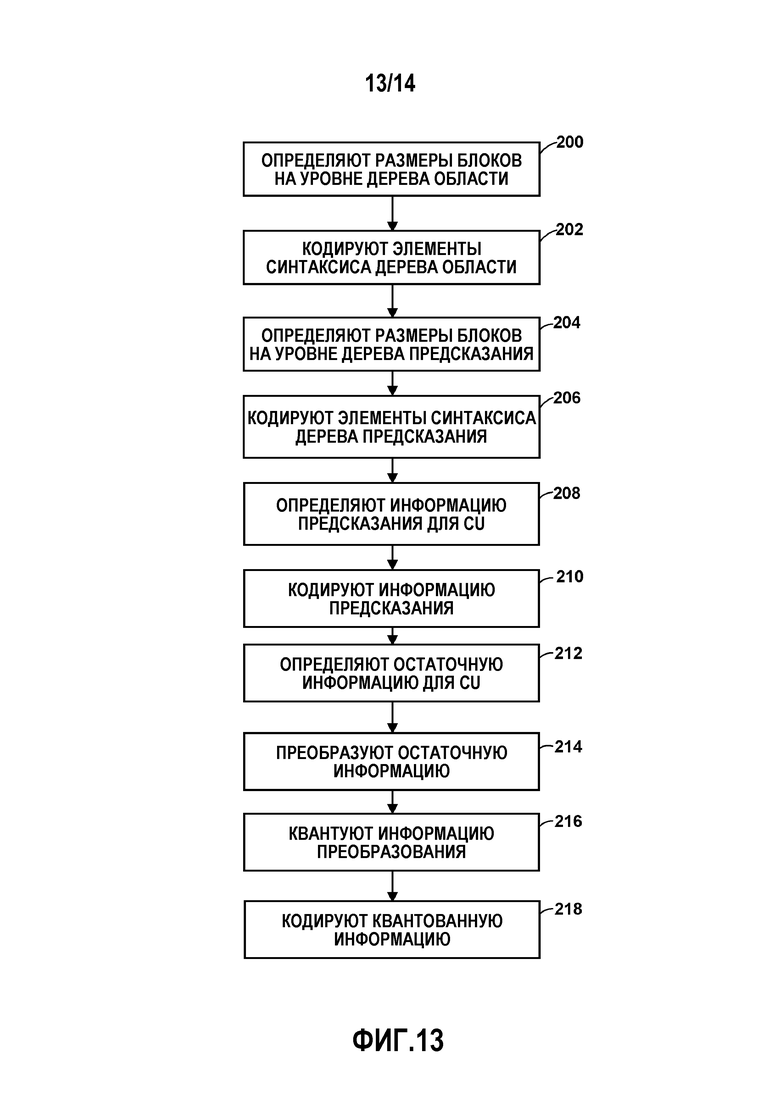
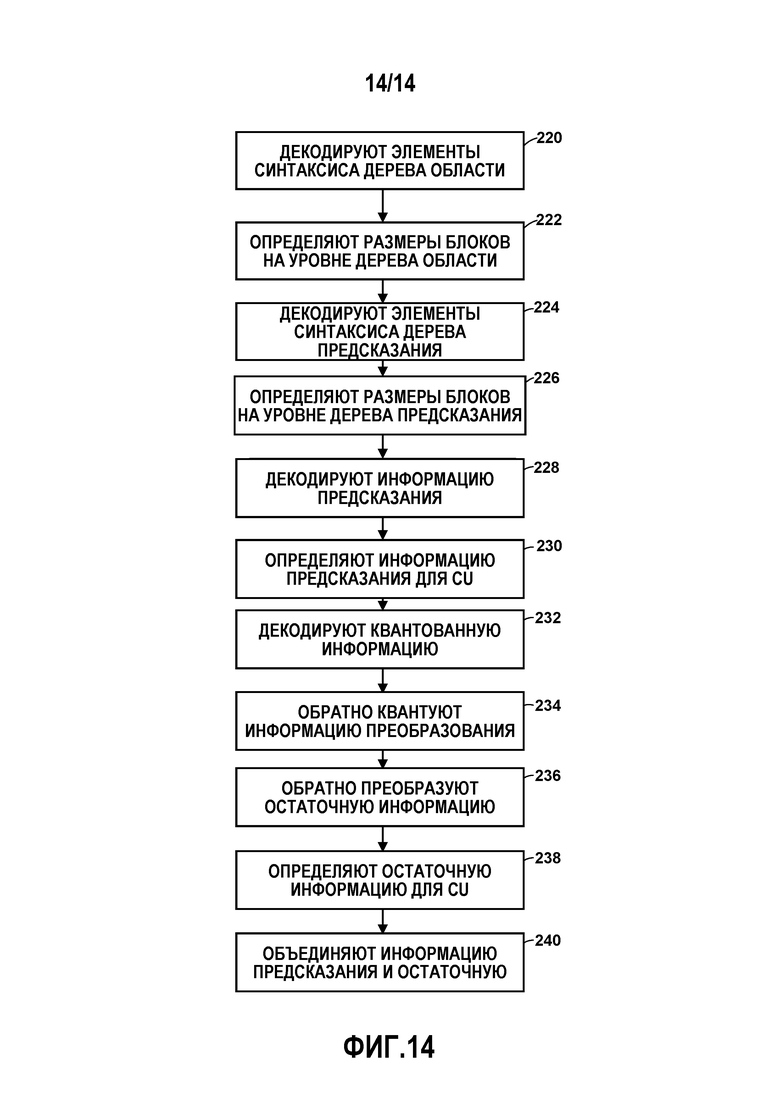
Изобретение относится к декодированию видеоданных. Технический результат изобретения заключается в возможности эффективно сигнализировать вариацию параметра квантования QP при использовании структур многотипного дерева или структуры квадродерево - бинарного дерева QTBT. Способ декодирования видеоданных содержит этапы: декодируют один или более элементов синтаксиса на уровне дерева области некоторого дерева области из древовидной структуры данных для блока дерева кодирования (CTB) видеоданных; определяют, используя элементы синтаксиса на уровне дерева области, каким образом узлы дерева области раздроблены на узлы-потомки дерева области; декодируют один или более элементов синтаксиса на уровне дерева предсказания для каждого из листовых узлов дерева области одного или более деревьев предсказания древовидной структуры данных для CTB; определяют, используя элементы синтаксиса на уровне дерева предсказания, каким образом узлы дерева предсказания раздроблены на узлы-потомки дерева предсказания; декодируют видеоданные, включающие в себя данные предсказания и данные преобразования, для каждой из CU, на основании, по меньшей мере частично, элементов синтаксиса на уровне дерева области и элементов синтаксиса на уровне дерева предсказания. 3 н. и 15 з.п. ф-лы, 14 ил. 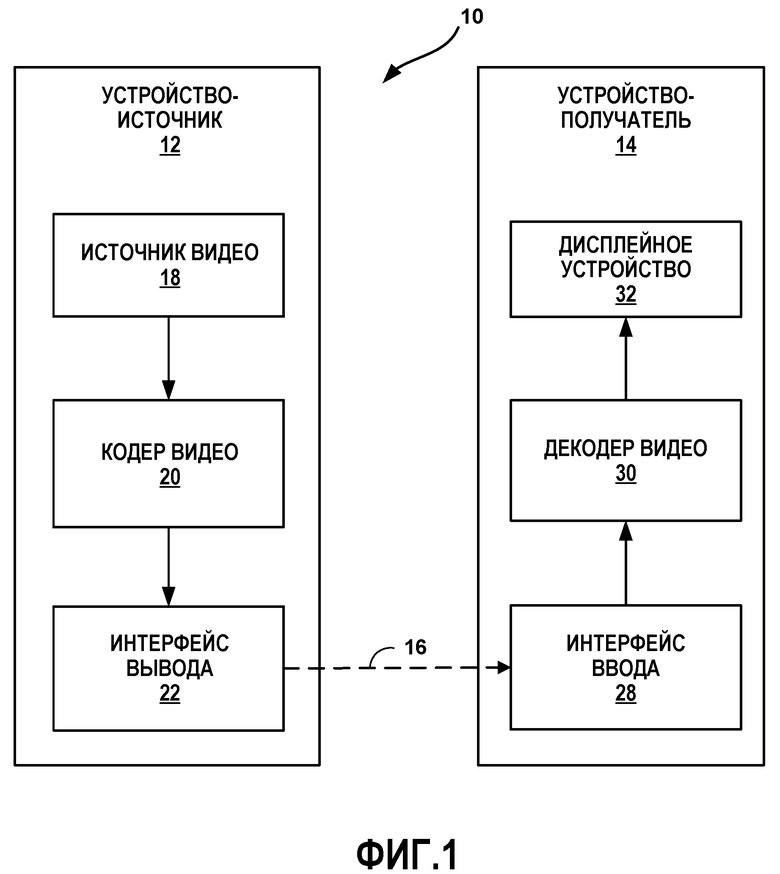
1. Способ декодирования видеоданных, причем способ содержит этапы, на которых:
декодируют один или более элементов синтаксиса на уровне дерева области некоторого дерева области из древовидной структуры данных для блока дерева кодирования (CTB) видеоданных, причем дерево области имеет один или более узлов дерева области, в том числе ноль или более не листовых узлов дерева области и один или более листовых узлов дерева области, причем каждый из не листовых узлов дерева области имеет четыре узла-потомка дерева области;
определяют, используя элементы синтаксиса на уровне дерева области, каким образом узлы дерева области раздроблены на узлы-потомки дерева области;
декодируют один или более элементов синтаксиса на уровне дерева предсказания для каждого из листовых узлов дерева области одного или более деревьев предсказания древовидной структуры данных для CTB, причем каждое из деревьев предсказания имеет корневые узлы, соответствующие одному или более листовым узлам дерева области, и один или более узлов дерева предсказания, в том числе ноль или более не листовых узлов дерева предсказания и один или более листовых узлов дерева предсказания, причем каждый из не листовых узлов дерева предсказания имеет либо два узла-потомка дерева предсказания, либо три узла-потомка дерева предсказания, полученные с использованием разбиения тройного дерева с центральной стороной, с по меньшей мере одним не листовым узлом дерева предсказания, имеющим три узла-потомка дерева предсказания, полученные с использованием разбиения тройного дерева с центральной стороной, причем каждый из листовых узлов дерева предсказания определяет соответствующие единицы кодирования (CU);
определяют, используя элементы синтаксиса на уровне дерева предсказания, каким образом узлы дерева предсказания раздроблены на узлы-потомки дерева предсказания; и
декодируют видеоданные, включающие в себя данные предсказания и данные преобразования, для каждой из CU, на основании, по меньшей мере частично, элементов синтаксиса на уровне дерева области и элементов синтаксиса на уровне дерева предсказания, причем данные предсказания указывают режим предсказания для формирования предсказанного блока для соответствующей одной из CU, и при этом данные преобразования включают в себя коэффициенты преобразования, представляющие преобразованные остаточные данные для соответствующей одной из CU.
2. Способ по п. 1, в котором этап, на котором декодируют элементы синтаксиса на уровне дерева области и декодируют элементы синтаксиса на уровне дерева предсказания, содержит этап, на котором декодируют один или более типов дерева без дальнейшего дробления для по меньшей мере одного из уровня дерева области или уровня дерева предсказания, при этом тип дерева без дальнейшего дробления означает, что никакое дальнейшее дробление не разрешено.
3. Способ по п. 1, дополнительно содержащий этап, на котором декодируют данные, представляющие собой максимальную глубину дерева области для уровня дерева области.
4. Способ по п. 3, дополнительно содержащий этап, на котором декодируют данные, представляющие собой максимальную глубину дерева предсказания для уровня дерева предсказания; и предпочтительно
сумма максимальной глубины дерева области и максимальной глубины дерева предсказания меньше, чем максимальное полное значение глубины.
5. Способ по п. 3, в котором этап, на котором декодируют данные, представляющие собой максимальную глубину дерева области, содержит этап, на котором декодируют данные, представляющие собой максимальную глубину дерева области, из одного или более из набора параметров последовательности (SPS), набора параметров изображения (PPS), или заголовка слайса.
6. Способ по п. 1, дополнительно содержащий этап, на котором декодируют один элемент синтаксиса, который совместно представляет как максимальную глубину дерева области для уровня дерева области, так и максимальную глубину дерева предсказания для уровня дерева предсказания; и предпочтительно
этап, на котором декодируют один элемент синтаксиса, который совместно представляет максимальную глубину дерева области и максимальную глубину дерева предсказания, содержит этап, на котором декодируют один элемент синтаксиса из одного или более из набора параметров последовательности (SPS), набора параметров изображения (PPS), или заголовка слайса.
7. Способ по п. 1, дополнительно содержащий этап, на котором делают вывод о том, что по меньшей мере один узел, содержащий по меньшей мере один из узлов дерева области или по меньшей мере один из узлов дерева предсказания, раздроблен без декодирования данных дробления для узла; и предпочтительно
этап, на котором делают вывод, содержит этап, на котором делают вывод о том, что по меньшей мере один узел раздроблен, на основании блока, которому соответствует узел, пересекающего по меньшей мере одно из границы изображения, границы слайса, или границы тайла.
8. Способ по п. 1, дополнительно содержащий этап, на котором декодируют данные, указывающие, перекрываются ли друг с другом глубина дерева области и глубина дерева предсказания.
9. Способ по п. 1, в котором видеоданные для каждой из CU содержат одно или более из флага пропуска, индекса слияния, элемента синтаксиса, представляющего собой то, является ли CU предсказанной с использованием интер-режима или интра-режима, информации предсказания интра-режима, информации движения, информации преобразования, остаточной информации, или информации квантования.
10. Способ по п. 1, в котором этап, на котором декодируют один или более элементов синтаксиса на уровне дерева области, содержит этап, на котором декодируют один или более элементов синтаксиса, представляющих информацию дробления для деревьев предсказания перед этапом, на котором декодируют видеоданные для каждой из CU; и предпочтительно
способ дополнительно содержит этап, на котором определяют число CU с использованием информации дробления перед этапом, на котором декодируют видеоданные для каждой из CU.
11. Способ по п. 1, в котором этап, на котором декодируют элементы синтаксиса на уровне дерева области, содержит этап, на котором декодируют один или более элементов синтаксиса, представляющих один или более разрешенных инструментов кодирования на уровне дерева области; и предпочтительно
способ дополнительно содержит этап, на котором применяют инструменты кодирования по границам CU, когда границы CU находятся внутри общей области, как указывается посредством одного из листовых узлов дерева области собственно дерева области.
12. Способ по п. 11, в котором этап, на котором декодируют данные, представляющие один или более из разрешенных инструментов кодирования, содержит этап, на котором декодируют информацию режима компенсации движения перекрывающегося блока (OBMC) в каждом из листовых узлов дерева области, представляющую, разрешена ли OBMC для блоков видеоданных, соответствующих одному из листовых узлов дерева области; или
в котором этап, на котором декодируют данные, представляющие один или более из разрешенных инструментов кодирования, содержит этап, на котором декодируют информацию перекрывающихся преобразований в каждом из листовых узлов дерева области, представляющую, разрешены ли перекрывающиеся преобразования для блоков видеоданных, соответствующих одному из листовых узлов дерева области, при этом перекрывающиеся преобразования содержат инструмент кодирования, для которого блоку преобразования разрешено перекрывать границу между двумя блоками предсказания некоторой области, соответствующей одному из листовых узлов дерева области; или
в котором этап, на котором декодируют данные, представляющие один или более из разрешенных инструментов кодирования, содержит этап, на котором декодируют данные в одном или более из листовых узлов дерева области, указывающие, являются ли все из CU внутри области, соответствующей листовому узлу дерева области, кодированными используя один из режима пропуска, режима слияния, интра-режима, интер-режима, или режима преобразования с повышением частоты кадров (FRUC), и при этом, когда все из CU внутри одной из областей являются кодированными, используя общий режим, способ дополнительно содержит этап, на котором предотвращают декодирование информации режима для CU на уровне CU.
13. Способ по п. 1, в котором этап, на котором декодируют элементы синтаксиса на уровне дерева области, содержит этап, на котором декодируют по меньшей мере один из параметров адаптивного к выборке смещения (SAO) или параметров адаптивного контурного фильтра (ALF); или
способ дополнительно содержит этап, на котором декодируют один или более элементов синтаксиса тройного дерева с центральной стороной на по меньшей мере одном из уровня дерева области или уровня дерева предсказания; или
способ дополнительно содержит этап, на котором вычисляют соответствующие параметры квантования (QP) для каждой из CU, при этом этап, на котором вычисляют соответствующие QP, содержит этапы, на которых определяют базовые QP для каждого из листовых узлов дерева области и вычисляют соответствующие QP на основании базовых QP соответствующих листовых узлов дерева области из CU.
14. Способ по п. 1, дополнительно содержащий этап, на котором кодируют видеоданные перед декодированием видеоданных.
15. Устройство для декодирования видеоданных, причем устройство содержит:
память, выполненную с возможностью хранения видеоданных; и
процессор, реализованный в схеме и выполненный с возможностью:
декодирования одного или более элементов синтаксиса на уровне дерева области некоторого дерева области из древовидной структуры данных для блока дерева кодирования (CTB) видеоданных, причем дерево области имеет один или более узлов дерева области, в том числе ноль или более не листовых узлов дерева области и один или более листовых узлов дерева области, причем каждый из не листовых узлов дерева области имеет четыре узла-потомка дерева области;
определения, используя элементы синтаксиса на уровне дерева области, каким образом узлы дерева области раздроблены на узлы-потомки дерева области;
декодирования одного или более элементов синтаксиса на уровне дерева предсказания для каждого из листовых узлов дерева области одного или более деревьев предсказания древовидной структуры данных для CTB, причем каждое из деревьев предсказания имеет корневые узлы, соответствующие одному или более листовым узлам дерева области, и один или более узлов дерева предсказания, в том числе ноль или более не листовых узлов дерева предсказания и один или более листовых узлов дерева предсказания, причем каждый из не листовых узлов дерева предсказания имеет либо два узла-потомка дерева предсказания, либо три узла-потомка дерева предсказания, полученные с использованием разбиения тройного дерева с центральной стороной, с по меньшей мере одним не листовым узлом дерева предсказания, имеющим три узла-потомка дерева предсказания, полученные с использованием разбиения тройного дерева с центральной стороной, причем каждый из листовых узлов дерева предсказания определяет соответствующие единицы кодирования (CU);
определения, используя элементы синтаксиса на уровне дерева предсказания, каким образом узлы дерева предсказания раздроблены на узлы-потомки дерева предсказания; и
декодирования видеоданных, включающих в себя данные предсказания и данные преобразования, для каждой из CU, на основании, по меньшей мере частично, элементов синтаксиса на уровне дерева области и элементов синтаксиса на уровне дерева предсказания, причем данные предсказания указывают режим предсказания для формирования предсказанного блока для соответствующей одной из CU, и при этом данные преобразования включают в себя коэффициенты преобразования, представляющие преобразованные остаточные данные для соответствующей одной из CU.
16. Устройство по п. 15, дополнительно содержащее по меньшей мере одно из:
дисплея, выполненного с возможностью отображения декодированных видеоданных; или
камеры, выполненной с возможностью захвата видеоданных.
17. Устройство по п. 15, при этом устройство выполнено в виде одного или более из камеры, компьютера, мобильного устройства, устройства приемника вещания, или абонентской телевизионной приставки.
18. Машиночитаемый запоминающий носитель информации с сохраненными на нем инструкциями, которые, когда исполняются, предписывают процессору выполнять этапы способа по любому из пп. 1-14.
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Токарный резец | 1924 |
|
SU2016A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| СПОСОБ И УСТРОЙСТВО КОДИРОВАНИЯ ВИДЕО, ИСПОЛЬЗУЮЩИЕ БЛОК ПРЕОБРАЗОВАНИЯ ПЕРЕМЕННОЙ ДРЕВОВИДНОЙ СТРУКТУРЫ, И СПОСОБ И УСТРОЙСТВО ДЕКОДИРОВАНИЯ ВИДЕО | 2011 |
|
RU2547707C2 |

