Перекрестная ссылка на соответствующие заявки
Настоящее описание представляет собой заявку на национальной фазе Международной заявки на патент PCT/JP2019/036316, поданную 17 сентября 2019 года, в настоящее время опубликованную как WO2020/059688. Международная заявка на патент PCT/JP2019/036316 претендует на преимущество и приоритет Временной заявки на патент США № 62/734,232, поданной 20 сентября 2018 г., Временной заявки на патент США 62/734, 232 и Международной заявки на патент PCT/JP2019/036316,опубликованной в настоящее время как WO2020/059688, настоящим полностью включенные в настоящее описание путем ссылки.
Область техники
[0001] Настоящее описание относится к кодированию видеосигналов, и в частности к технологиям сигнализации параметров набора фрагментов для закодированного видеосигнала.
Предпосылки создания изобретения
[0002] Возможности цифрового видео можно применять в широком спектре устройств, включая цифровые телевизоры, ноутбуки или настольные компьютеры, планшетные компьютеры, устройства цифровой записи, цифровые медиаплееры, устройства для видеоигр, сотовые телефоны, включая так называемые смартфоны, медицинские устройства визуализации и т. п. Цифровое видео может быть закодировано в соответствии со стандартом кодирования видеосигналов. Стандарты кодирования видеосигналов могут включать в себя методики сжатия видео. Примеры стандартов кодирования видеосигналов включают в себя ISO/IEC MPEG-4 Visual и ITU-T H.264 (также известный как ISO/IEC MPEG-4 AVC), а также высокоэффективное кодирование видеоизображений (HEVC). HEVC описан в документе High Efficiency Video Coding (HEVC), Rec. ITU-T H.265, декабрь 2016 г., включенном в настоящий документ путем ссылки и далее называемом в настоящем документе ITU-T H.265. В настоящее время рассматриваются расширения и усовершенствования ITU-T H.265 для разработки стандартов кодирования видеосигналов следующего поколения. Например, Экспертная группа по кодированию видеосигналов ITU-T (VCEG) и ISO/IEC (Экспертная группа по вопросам движущихся изображений (MPEG)) (совместно именуемые Объединенной группой по исследованию видео (JVET)) изучают потенциальную потребность в стандартизации будущей технологии кодирования видеосигналов с возможностью сжатия, которая значительно превышает возможности сжатия нынешнего стандарта HEVC. В документе The Joint Exploration Model 7 (JEM 7), Algorithm Description of Joint Exploration Test Model 7 (JEM 7), ISO/IEC JTC1/SC29/WG11: JVET-G1001, июль 2017 г., г. Турин, Италия, который включен в настоящий документ посредством ссылки, описаны функции кодирования, являющиеся предметом скоординированного исследования тестовой модели JVET, как потенциально способные усовершенствовать технологию кодирования видеосигналов сверх возможностей ITU-T H.265. Следует отметить, что функции кодирования JEM 7 реализованы в эталонном программном обеспечении JEM. Употребляемый в настоящем документе термин JEM можно использовать для общей ссылки на алгоритмы, включенные в JEM 7, и реализации эталонного программного обеспечения JEM. Кроме того, в ответ на «Общий конкурс предложений по сжатию видео с возможностями, выходящим за рамки HEVC», совместно опубликованный VCEG и MPEG, на 10-м совещании ISO/IEC JTC1/SC29/WG11 16-20 апреля 2018 года в г. Сан-Диего, штат Калифорния, США, разные группы предложили множество описаний кодирования видеосигналов. В результате после множества описаний кодирования видеосигналов проект спецификации кодирования видеосигналов описан в «Универсальном кодировании видеосигналов (проект 1)», 10-е совещание ISO/IEC JTC1/SC29/WG11 16-20 апреля 2018 г. в г. Сан-Диего, штат Калифорния, США - документе JVET-J1001-v2, который включен в данное описание путем ссылки и называется JVET-J1001. «Универсальное кодирование видеосигналов (проект 2)», 11-е совещание ISO/IEC JTC1/SC29/WG11 10-18 июля 2018 г. в г. Любляна, Словения - документ JVET-K1001-v5, который включен в данное описание путем ссылки и называется JVET-K1001, представляет собой обновление JVET-J1001.
[0003] Благодаря методикам сжатия видео снижаются требования к данным для хранения и передачи видеоданных за счет использования присущей избыточности в видеопоследовательности. Методики сжатия видео могут предусматривать подразделение видеопоследовательности на последовательно меньшие части (т. е. группы кадров в видеопоследовательности, кадр в группе кадров, срезы в кадре, блоки кодового дерева (например, макроблоки) в срезе, блоки кодирования в элементе кодового дерева и т. д.). Методики кодирования с внутренним прогнозированием (например, внутрикадровое (пространственное)) и методики внешнего прогнозирования (т. е. межкадровое (временное)) можно использовать для генерирования значений разности между кодируемым элементом видеоданных и опорным элементом видеоданных. Значения разности могут называться остаточными данными. Остаточные данные могут быть закодированы как квантованные коэффициенты преобразования. Элементы синтаксиса могут относиться к остаточным данным и опорному блоку кодирования (например, индексам режима внутреннего прогнозирования, векторам движения и векторам блоков). Остаточные данные и элементы синтаксиса можно подвергать энтропийному кодированию. Энтропийно закодированные остаточные данные и элементы синтаксиса могут быть включены в совместимый битовый поток. Совместимые битовые потоки и соответствующие метаданные можно форматировать в соответствии со структурами данных.
Изложение сущности изобретения
[0004] В одном примере раскрывается способ декодирования видеоданных. Способ содержит синтаксический анализ множества параметров изображения, включенного в заголовок изображения изображения в видеоданных; синтаксический анализ текущего флага, включенного в заголовок подызображения, сгенерированного путем разделения изображения; определение, основываясь на текущем флаге, определен ли конкретный один из множества параметров подызображения на основании заголовка подызображения или заголовка изображения, конкретный один из множества параметров подызображения соответствует конкретному одному из множества параметров изображения, и реконструкцию подызображение, основываясь на конкретном одном из множества параметров подызображения, когда конкретный один из множества параметров подызображения определен из заголовка подызображения.
[0005] В одном примере раскрывается электронное устройство для декодирования битового потока. Электронное устройство содержит по меньшей мере один процессор; и запоминающее устройство, соединенное с по меньшей мере одним процессором. Запоминающее устройство хранит программу, которая, при исполнении по меньшей мере одним процессором, побуждает по меньшей мере один процессор выполнять: синтаксический анализ множества параметров изображения, включенного в заголовок изображения изображения в видеоданных; синтаксический анализ текущего флага, включенного в заголовок подызображения, сгенерированного путем разделения изображения; определение, основываясь на текущем флаге, определен ли конкретный один из множества параметров подызображения на основании заголовка подызображения или заголовка изображения, конкретный один из множества параметров подызображения соответствует конкретному одному из множества параметров изображения, и реконструкцию подызображения, основываясь на конкретном одном из множества параметров подызображения, когда конкретный один из множества параметров подызображения определен из заголовка подызображения.
Краткое описание графических материалов
[0006] [ФИГ. 1] На ФИГ. 1 приведена блок-схема, иллюстрирующая пример системы, которая может быть выполнена с возможностью кодирования и декодирования видеоданных в соответствии с одной или более методиками настоящего описания. [ФИГ. 2] На ФИГ. 2 представлена концептуальная схема, иллюстрирующая закодированные видеоданные и соответствующие структуры данных в соответствии с одной или более методиками по настоящему описанию. [ФИГ. 3] На ФИГ. 3 представлена концептуальная схема, иллюстрирующая структуру данных, позволяющую инкапсулировать закодированные видеоданные и соответствующие метаданные в соответствии с одной или более методиками по настоящему описанию. [ФИГ. 4] На ФИГ. 4 представлена концептуальная схема, иллюстрирующая пример компонентов, которые могут быть включены в вариант реализации системы, которая может быть выполнена с возможностью кодирования и декодирования видеоданных в соответствии с одной или более методиками по настоящему описанию. [ФИГ. 5] На ФИГ. 5 приведена блок-схема, иллюстрирующая пример видеокодера, который может быть выполнен с возможностью кодирования видеоданных в соответствии с одной или более методиками настоящего описания. [ФИГ. 6] На ФИГ. 6 представлена блок-схема, иллюстрирующая пример видеодекодера, который может быть выполнен с возможностью декодирования видеоданных в соответствии с одной или более методиками согласно настоящему описанию. [ФИГ. 7] На ФИГ. 7 представлена концептуальная схема, иллюстрирующая закодированные видеоданные и соответствующие структуры данных в соответствии с одной или более методиками по настоящему описанию.
Описание вариантов осуществления
[0007] В целом в настоящем описании представлены различные методики кодирования видеоданных. В частности, в настоящем описании представлены способы сигнализации параметров набора фрагментов закодированного видеосигнала. Сигнализацию параметров набора фрагментов в соответствии с методиками, описанными в настоящем документе, можно, в частности, использовать для улучшения характеристик системы распределения видеосигналов за счет уменьшения ширины полосы передачи и/или обеспечения распараллеливания видеокодера и/или декодера. Следует отметить, что, хотя методики настоящего описания описаны применительно к ITU-T H.264, ITU-T H.265, JVET-J1001 и JVET- K1001, они в целом применимы к кодированию видеосигналов. Например, описанные в настоящем документе методики кодирования могут быть использованы в системах кодирования видеосигналов (включая системы кодирования видеосигналов на основании будущих стандартов кодирования видеосигналов), включая блочные структуры, методики внутреннего прогнозирования, методики внешнего прогнозирования, методики преобразования, методики фильтрации и/или методики энтропийного кодирования, отличные от включенных в ITU-T H.265. Таким образом, ссылка на ITU-T H.264, ITU-T H.265, JVET-J1001 и JVET-K1001 предназначена для описательных целей и не должна толковаться как ограничивающая объем методик, описанных в настоящем документе. Следует дополнительно отметить, что включение документов путем ссылки в настоящий документ не должно толковаться как ограничение или создание двусмысленности в отношении употребляемых в настоящем документе терминов. Например, в случае, если включенная ссылка содержит определение термина, отличное от другой включенной ссылки и/или от определения, используемого в настоящем документе, термин следует интерпретировать таким образом, что он в широком смысле включает в себя каждое соответствующее определение и/или каждое из конкретных определений в виде альтернативы.
[0008] В одном примере устройство содержит один или более процессоров, выполненных с возможностью передавать сигнал значения для элемента синтаксиса в элементе уровня сетевой абстракции, указывающего на включение структуры синтаксиса уровня набора фрагментов в элемент уровня сетевой абстракции и передавать сигналы значений для одного или более параметров набора фрагментов, включенных в структуру синтаксиса уровня набора фрагментов.
[0009] В одном примере энергонезависимый машиночитаемый носитель данных содержит хранящиеся на нем команды, при исполнении которых один или более процессоров устройства передают сигнал значения для элемента синтаксиса в элементе уровня сетевой абстракции, указывающего на включение структуры синтаксиса уровня набора фрагментов в элемент уровня сетевой абстракции, и передают сигналы значений для одного или более параметров набора фрагментов, включенных в структуру синтаксиса уровня набора фрагментов.
[0010] В одном примере аппарат содержит средства для сигнализации значения для элемента синтаксиса в элементе уровня сетевой абстракции, указывающего на включение структуры синтаксиса уровня набора фрагментов в элемент уровня сетевой абстракции, и средства для сигнализации значений для одного или более параметров набора фрагментов, включенных в структуру синтаксиса уровня набора фрагментов.
[0011] В одном примере устройство содержит один или более процессоров, выполненных с возможностью осуществления синтаксического анализа значения для элемента синтаксиса в элементе уровня сетевой абстракции, указывающего на включение структуры синтаксиса уровня набора фрагментов в элемент уровня сетевой абстракции, синтаксического анализа значений для одного или более параметров набора фрагментов, включенных в структуру синтаксиса уровня набора фрагментов, и генерирования видеоданных на основании синтаксически проанализированных значений для одного или более параметров набора фрагментов.
[0012] В одном примере энергонезависимый машиночитаемый носитель данных содержит хранящиеся на нем команды, при исполнении которых один или более процессоров устройства осуществляют синтаксический анализ значения для элемента синтаксиса в элементе уровня сетевой абстракции, указывающего на включение структуры синтаксиса уровня набора фрагментов в элемент уровня сетевой абстракции и осуществляют синтаксический анализ значений для одного или более параметров набора фрагментов, включенных в структуру синтаксиса уровня набора фрагментов, и генерируют видеоданные на основании синтаксически проанализированных значений для одного или более параметров набора фрагментов.
[0013] В одном примере аппарат содержит средства для синтаксического анализа значения для элемента синтаксиса в элементе уровня сетевой абстракции, указывающего на включение структуры синтаксиса уровня набора фрагментов в элемент уровня сетевой абстракции, средства для синтаксического анализа значений для одного или более параметров набора фрагментов, включенных в структуру синтаксиса уровня набора фрагментов, и средства для генерирования видеоданных на основании синтаксически проанализированных значений для одного или более параметров набора фрагментов.
[0014] Подробности одного или более примеров изложены в приведенном ниже описании и на сопроводительных чертежах. Прочие признаки, объекты и преимущества будут понятны из описания, и чертежей, и формулы изобретения.
[0015] Видеосодержимое обычно включает в себя видеопоследовательности, состоящие из ряда кадров. Последовательность кадров может также называться группой изображений (GOP). Каждый видеокадр или изображение может включать в себя один или более срезов, причем срез включает в себя множество видеоблоков. Видеоблок включает в себя массив значений пикселей (также называемых выборками), которые могут быть предикативно закодированы. Видеоблоки могут быть упорядочены в соответствии с типом сканирования (например, растровое сканирование). Видеокодер выполняет предикативное кодирование видеоблоков и их секций. ITU-T H.264 определяет макроблок, включающий в себя 16 × 16 выборок яркости. ITU-T H.265 определяет аналогичную структуру элемента кодового дерева (CTU) (который может называться наибольшим блоком кодирования (LCU)), причем изображение может быть разделено на CTU равного размера, и каждый CTU может включать в себя блоки кодового дерева (CTB), содержащие 16 × 16, 32 × 32 или 64 × 64 выборок яркости. Используемый в настоящем описании термин «видеоблок» может по существу относиться к области изображения или, более конкретно, может относиться к наибольшему массиву значений пикселя, которые могут быть предикативно закодированы, его секциям и/или соответствующим структурам. В соответствии с ITU-T H.265 каждый видеокадр или изображение могут быть дополнительно разделены и могут включать в себя один или более фрагментов, причем фрагмент представляет собой последовательность элементов кодового дерева, соответствующих прямоугольной области изображения.
[0016] Согласно ITU-T H.265 CTU состоит из соответствующих CTB для каждого компонента видеоданных (например, яркости (Y) и цветности (Cb и Cr)). В ITU-T H.265 CTU может быть дополнительно разделен в соответствии со структурой разделения квадродерева (QT), что обеспечивает разделение блоков CTB элемента CTU на блоки кодирования (CB). Таким образом, в ITU-T H.265 CTU может быть разделен на концевые узлы квадродерева. В ITU-T H.265 один CB яркости вместе с двумя соответствующими CB цветности и связанными с ними элементами синтаксиса называются блоком кодирования (CU). В ITU-T H.265 посредством сигнализации может быть указан минимально допустимый размер CB. В ITU-T H.265 наименьший минимально допустимый размер CB яркости составляет 8 × 8 выборок яркости. В ITU-T H.265 решение о кодировании области изображения с использованием внутреннего или внешнего прогнозирования принимают на уровне CU.
[0017] В ITU-T H.265 CU связан со структурой элемента прогнозирования (PU) с корнем в CU. В ITU-T H.265 структуры PU позволяют разделять CB яркости и цветности для генерирования соответствующих опорных выборок. Таким образом, согласно ITU-T H.265 CB яркости и цветности могут быть разделены на соответствующие блоки прогнозирования (PB) яркости и цветности, причем PB включает в себя блок значений выборки, для которых применяют одно и то же прогнозирование. В ITU-T H.265 CB может быть разделен на 1, 2 или 4 PB. ITU-T H.265 поддерживает размеры PB от 64 × 64 до 4 × 4 выборок. В ITU-T H.265 поддерживаются квадратные PB для внутреннего прогнозирования, причем CB может формировать PB, или CB может быть разделен на четыре квадратных PB (т. е. типы размеров PB внутреннего прогнозирования включают в себя M × M или M/2 × M/2, где M представляет собой высоту и ширину квадрата CB). Помимо квадратных PB в ITU-T H.265 поддерживаются прямоугольные PB для внешнего прогнозирования, причем CB может быть уменьшен вдвое по вертикали или горизонтали для формирования PB (т. е. типы PB с внешним прогнозированием включают в себя M × M, M/2 × M/2, M/2 × M или M × M/2). Следует отметить, что в ITU-T H.265 для внешнего прогнозирования дополнительно поддерживаются четыре асимметричных разделения PB, причем CB разделяют на два PB на одной четверти высоты (вверху или внизу) или ширины (слева или справа) CB (т. е. асимметричные разделения включают в себя M/4 × M слева, M/4 × M справа, M × M/4 сверху и M × M/4 снизу). Данные внутреннего прогнозирования (например, элементы синтаксиса режима внутреннего прогнозирования) или данные внешнего прогнозирования (например, элементы синтаксиса данных движения), соответствующие PB, используют для создания опорных и/или прогнозированных значений выборки для PB.
[0018] JEM определяет CTU, имеющий максимальный размер 256 × 256 выборок яркости. JEM определяет структуру блоков квадродерева и двоичного дерева (QTBT). В JEM структура QTBT позволяет осуществлять дополнительное разделение концевых узлов квадродерева в соответствии со структурой двоичного дерева (BT). Таким образом, в JEM структура двоичного дерева позволяет рекурсивно разделять концевые узлы квадродерева по вертикали или горизонтали. Таким образом, структура двоичного дерева в JEM допускает квадратные и прямоугольные концевые узлы, причем каждый концевой узел включает в себя CB. Как показано на ФИГ. 2, изображение, включенное в GOP, может включать в себя срезы, причем каждый срез включает в себя последовательность CTU, а каждый CTU может быть разделен в соответствии со структурой QTBT. В JEM CB используют для прогнозирования без какого-либо дальнейшего разделения. Таким образом, в JEM CB может быть блоком значений выборки, к которым применяют такое же прогнозирование. Таким образом, концевой узел JEM QTBT может быть аналогом PB в ITU-T H.265.
[0019] Данные внутреннего прогнозирования (например, элементы синтаксиса в режиме внутреннего прогнозирования) или данные внешнего прогнозирования (например, элементы синтаксиса данных движения) могут связывать PU с соответствующими опорными выборками. Остаточные данные могут включать в себя соответствующие массивы значений расхождения, соответствующих каждому компоненту видеоданных (например, яркости (Y) и цветности (Cb и Cr)). Остаточные данные могут находиться в области пикселей. Для получения коэффициентов преобразования к значениям расхождения для пикселя может быть применено преобразование, такое как дискретное косинусное преобразование (DCT), дискретное синусное преобразование (DST), целочисленное преобразование, преобразование элементарных волн или концептуально подобное преобразование. Следует отметить, что в ITU-T H.265 CU могут быть дополнительно разделены на элементы преобразования (TU). Другими словами, массив значений расхождения для пикселей может быть разделен для получения коэффициентов преобразования (например, четыре преобразования 8×8 могут быть применены к массиву остаточных значений 16×16, соответствующих CB яркости 16×16), такие секции могут называться блоками преобразования (TB). Коэффициенты преобразования могут быть квантованы в соответствии с параметром квантования (QP). Квантованные коэффициенты преобразования (которые могут называться значениями уровня) могут быть энтропийно кодированы согласно методике энтропийного кодирования (например, контентно-адаптивное кодирование с переменной длиной (CAVLC), контекстно-адаптивное двоичное арифметическое кодирование (CABAC), энтропийное кодирование с разделением по интервалам вероятности (PIPE) и т. д.). Элементы синтаксиса, такие как элемент синтаксиса, указывающий режим прогнозирования, могут также быть дополнительно энтропийно кодированы. Энтропийно кодированные квантованные коэффициенты преобразования и соответствующие энтропийно кодированные элементы синтаксиса могут формировать совместимый битовый поток, который можно использовать для воспроизведения видеоданных. Процесс бинаризации может быть выполнен с элементами синтаксиса в рамках процесса энтропийного кодирования. Бинаризация означает процесс преобразования синтаксиса в последовательность из одного или более битов. Эти биты могут называться «двоичными значениями».
Как описано выше, данные внутреннего или внешнего прогнозирования используют для получения опорных значений выборки для блока значений выборки. Разница между значениями выборки, включенными в текущий PB или структуру области изображения другого типа, и соответствующими опорными выборками (например, полученными с использованием прогнозирования) может называться остаточными данными. Как описано выше, данные внутреннего прогнозирования или данные внешнего прогнозирования могут связывать область изображения (например, PB или CB) с соответствующими опорными выборками. Для кодирования с внутренним прогнозированием режим внутреннего прогнозирования может указывать местоположение опорных выборок в изображении. В ITU-T H.265 определенные возможные режимы внутреннего прогнозирования включают в себя режим планарного (т. е. подбор поверхности) прогнозирования (predMode: 0), режим прогнозирования DC (т. е. плоское полное усреднение) (predMode: 1) и 33 режима углового прогнозирования (predMode: 2-34). В JEM определенные возможные режимы внутреннего прогнозирования включают в себя режим планарного прогнозирования (predMode: 0), режим прогнозирования DC (predMode: 1) и 65 режимов углового прогнозирования (predMode: 2-66). Следует отметить, что режимы планарного прогнозирования и прогнозирования DC могут называться режимами ненаправленного прогнозирования, а режимы углового прогнозирования могут называться режимами направленного прогнозирования. Следует отметить, что методики, описанные в настоящем документе, могут быть в целом применимы, независимо от количества определенных возможных режимов прогнозирования.
[0020] В случае кодирования с внешним прогнозированием вектор движения (MV) идентифицирует опорные выборки в изображении, отличном от изображения видеоблока, который подлежит кодированию, и тем самым использует временную избыточность в видео. Например, текущий видеоблок может быть спрогнозирован из опорного (-ых) блока (-ов), находящегося (-ихся) в ранее кодированном (-ых) кадре (-ах), и вектор движения может быть использован для указания местоположения опорного блока. Вектор движения и связанные данные могут описывать, например, горизонтальный компонент вектора движения, вертикальный компонент вектора движения, разрешение для вектора движения (например, точность в одну четверть пикселя, половину пикселя, один пиксель, два пикселя, четыре пикселя), направление прогнозирования и/или значение индекса опорного кадра. Стандарт кодирования, такой как, например, ITU-T H.265, может дополнительно поддерживать прогнозирование вектора движения. Прогнозирование вектора движения позволяет задавать вектор движения с использованием векторов движения соседних блоков. Примеры прогнозирования вектора движения включают в себя расширенное прогнозирование вектора движения (AMVP), временное прогнозирование вектора движения (TMVP), так называемый режим «слияния», а также «пропуск» и «прямое» логическое определение движения. Кроме того, JEM поддерживает расширенное временное прогнозирование вектора движения (ATMVP), пространственно-временное прогнозирование вектора движения (STMVP), режим определения вектора движения с соответствием схеме (PMMVD), который представляет собой специальный режим слияния, основанный на способах преобразования с повышением частоты кадров (FRUC), а также прогнозирование с компенсацией движения путем аффинного преобразования.
[0021] Остаточные данные могут включать в себя соответствующие массивы разностных значений, соответствующие каждому компоненту видеоданных. Остаточные данные могут находиться в области пикселей. Для получения коэффициентов преобразования к массиву разностных значений можно применять преобразование, такое как дискретное косинусное преобразование (DCT), дискретное синусное преобразование (DST), целочисленное преобразование, вейвлет-преобразование или концептуально подобное преобразование. Согласно ITU-T H.265 CU связан со структурой элемента преобразования (TU) с корнем на уровне CU. Таким образом, в ITU-T H.265, как описано выше, массив значений расхождения может быть разделен для получения коэффициентов преобразования (например, четыре преобразования 8 × 8 могут быть применены к массиву остаточных значений 16 × 16). Следует отметить, что в ITU-T H.265 TB необязательно совмещены с PB.
[0022] Следует отметить, что в JEM соответствующие CB остаточные значения используют для получения коэффициентов преобразования без дополнительного разделения. Таким образом, в JEM концевой узел QTBT может быть аналогичен как PB, так и TB в ITU-T H.265. Следует отметить, что в JEM основное преобразование и последующие вторичные преобразования можно применять (в видеокодере) для получения коэффициентов преобразования. В видеодекодере используют обратный порядок преобразований. В JEM применение вторичного преобразования для получения коэффициентов преобразования может дополнительно зависеть от режима прогнозирования.
[0023] На коэффициентах преобразования можно выполнять процесс квантования. Квантование аппроксимирует коэффициенты преобразования по амплитудам, ограниченным набором указанных значений. Квантование можно использовать, чтобы варьировать объем данных, требуемых для представления группы коэффициентов преобразования. Квантование может быть реализовано путем деления коэффициентов преобразования на коэффициент масштабирования и применения соответствующих функций округления (например, округления до ближайшего целого числа). Квантованные коэффициенты преобразования могут называться значениями уровня коэффициента. Обратное квантование (или «деквантизация») может включать умножение значений уровня коэффициента на коэффициент масштабирования квантования. Следует отметить, что используемый в настоящем документе термин «процесс квантования» в некоторых случаях может относиться к делению на коэффициент масштабирования с получением значений уровня или в некоторых случаях умножению на коэффициент масштабирования для восстановления коэффициентов преобразования. Таким образом, в некоторых случаях процесс квантования может относиться к квантованию, а в некоторых - к обратному квантованию.
[0024]
В приведенных в настоящем документе уравнениях могут быть использованы следующие арифметические операторы:

Кроме того, могут быть использованы следующие математические функции:
Log2(x): логарифм x по основанию 2;
Min(x, y)=
Max(x, y)=
Ceil(x): наименьшее целое число, больше x или равное x.
В отношении примера синтаксиса, используемого в настоящем документе, могут быть применены следующие определения логических операторов:
x && y: булево логическое «и» для x и y
х | | у: булево логическое «или» для х и у
! : булево логическое «не»
x ? y : z. Если x имеет значение TRUE или не равно 0, оценивают значение y; в противном случае оценивают значение z.
Кроме того, могут быть применены следующие реляционные операторы:
Следует дополнительно отметить, что в описаниях синтаксиса, используемого в настоящем документе, могут быть применены следующие описания:
- b(8): байт, имеющий любой шаблон битовых строк (8 бит). Процесс синтаксического анализа для этого дескриптора определяется возвращаемым значением функции read_bits(8).
-f(n): битовая строка с фиксированным шаблоном, состоящая из n битов, записанных (слева направо) с первым левым битом. Процесс синтаксического анализа для этого дескриптора определяется возвращаемым значением функции read_bits(n).
-u(n): целое число без знака, состоящее из n битов.
-ue(v): целое число без знака 0-го порядка, элемент синтаксиса, закодированный способом Exp-Golomb, с первым битом, расположенным слева.
Как описано выше, в соответствии с ITU-T H.265 каждый видеокадр или изображение могут быть разделены таким образом, что они включают один или более срезов, и дополнительно разделены таким образом, что они включают один или более фрагментов. На ФИГ. 2 представлена концептуальная схема, иллюстрирующая пример группы изображений, включающих срезы. В примере, показанном на ФИГ. 2, изображение Изобр.4 показано как включающее два среза (т. е. Срез1 и Срез2), причем каждый срез включает последовательность CTU (например, в порядке растрового сканирования). Следует отметить, что срез представляет собой последовательность из одного или более сегментов среза, начинающуюся с независимого сегмента среза и содержащую все последующие зависимые сегменты среза (если таковые имеются), предшествующие следующему независимому сегменту среза (если таковые имеются) в пределах одного и того же элемента доступа. Сегмент среза, как и срез, представляет собой последовательность элементов кодового дерева. В примерах, описанных в настоящем документе, в некоторых случаях термины «срез» и «сегмент среза» могут быть использованы взаимозаменяемо для указания последовательности элементов кодового дерева. Следует отметить, что в ITU-T H.265 фрагмент может состоять из элементов кодового дерева, содержащихся в более чем одном срезе, а срез может состоять из элементов кодового дерева, содержащихся в более чем одном фрагменте. Однако ITU-T H.265 предусматривает обязательно выполнение одного или обоих из следующих условий: (1) Все элементы кодового дерева в срезе принадлежат к одному и тому же фрагменту; и (2) все элементы кодового дерева в фрагменте принадлежат одному и тому же срезу. Наборы фрагментов могут быть использованы для определения границ для зависимостей кодирования (например, зависимостей внутреннего прогнозирования, зависимостей энтропийного кодирования и т. д.) и, таким образом, могут обеспечивать параллелизм при кодировании.
[0025] В соответствии с ITU-T H.265 закодированная видеопоследовательность (CVS) может быть инкапсулирована (или структурирована) в виде последовательности элементов доступа, причем каждый элемент доступа включает в себя видеоданные, структурированные в виде элементов уровня сетевой абстракции (NAL). В соответствии с ITU-T H.265 битовый поток описан как включающий последовательность элементов NAL, образующих одну или более CYS. Следует отметить, что ITU-T H.265 поддерживает многоуровневые расширения, включая расширения диапазона формата (RExt), масштабируемость (SHVC), многовидовые (MV-HEVC) и 3-D (3D-HEVC) расширения. Благодаря многоуровневым расширениям видеопрезентация может включать в себя базовый уровень и один или более дополнительных улучшенных уровней. Например, с базовым уровнем можно обеспечивать видеопрезентацию, имеющую базовый уровень качества (например, отображение с высоким разрешением), а с улучшенным уровнем можно обеспечивать видеопрезентацию, имеющую повышенный уровень качества (например, отображение сверхвысокой четкости). В соответствии с ITU-T H.265 улучшенный уровень может быть закодирован путем привязки к базовому уровню. Другими словами, например, изображение в улучшенном уровне может быть закодировано (например, с помощью способов внешнего прогнозирования) путем привязки к одному или более изображениям (включая их масштабированные версии) на базовом уровне. Согласно ITU-T H.265 каждый элемент NAL может включать в себя идентификатор, указывающий уровень видеоданных, с которым ассоциирован элемент NAL. Следует отметить, что извлечение битового подпотока может относиться к процессу, в котором устройство, принимающее совместимый битовый поток, формирует новый совместимый битовый поток путем отбрасывания и/или изменения данных в принятом битовом потоке. Например, извлечение битового подпотока может быть использовано для формирования нового совместимого битового потока, соответствующего конкретному представлению видео (например, высококачественному представлению).
[0026] Согласно примеру, показанному на ФИГ. 2, каждый срез видеоданных, включенный в изображение Изобр.4 (т. е. Срез1 и Срез2), показан как инкапсулированный в элемент NAL. Согласно ITU-T H.265 каждое из видеопоследовательности, GOP, изображения, среза и CTU может быть ассоциировано с метаданными, которые описывают свойства кодирования видеосигналов. ITU-T H.265 определяет наборы параметров, которые могут быть использованы для описания свойств видеоданных и/или кодирования видеосигналов. Согласно ITU-T H.265 наборы параметров могут быть инкапсулированы в виде элемента NAL специального типа или могут быть переданы в виде сообщения. Элементы NAL, включающие закодированные видеоданные (например, срез), могут называться элементами NAL VCL (уровня кодирования видеосигналов), а элементы NAL, включающие метаданные (например, наборы параметров), могут называться элементами NAL, не относящиеся к VCL (не-VCL). Кроме того, ITU-T H.265 позволяет передавать сообщения с информацией для дополнительной оптимизации (SEI). Согласно ITU-T H.265 сообщения SEI облегчают выполнение процессов, относящихся к декодированию, отображению или другим операциям, однако для создания выборок яркости или цветности в процессе декодирования сообщения SEI могут не потребоваться. Согласно ITU-T H.265 сообщения SEI могут быть переданы в битовом потоке с использованием элементов NAL, не относящихся к VCL. Кроме того, сообщения SEI могут быть переданы с помощью некоторых средств, отличных от средств, присутствующих в битовом потоке (т. е. передаваемых за пределами полосы).
[0027] На ФИГ. 3 представлен пример битового потока, включающего множество CVS, причем CVS представлена элементами NAL, включенными в соответствующий элемент доступа. В примере, показанном на ФИГ. 3, элементы NAL, не относящиеся к VCL, включают соответствующие элементы набора параметров (т. е. наборы параметров видеосигнала (VPS), наборы параметров последовательности (SPS) и набор параметров изображения (PPS)) и элемент NAL ограничителя элемента доступа. ITU-T H.265 определяет семантику заголовка элемента NAL, которая определяет тип структуры данных полезной нагрузки необработанной последовательности байтов (RBSP), включенной в элемент NAL.
[0028] В таблице 1 проиллюстрирован общий синтаксис элемента NAL, представленный в ITU-T H.265, и который дополнительно используется в JVET-K1001.
В ITU-T H.265 представлена следующая общая семантика элемента NAL:
NumBytesInNalUnit определяет размер элемента NAL в байтах. Это значение требуется для декодирования элемента NAL. Некоторая форма определения границ элемента NAL необходима для того, чтобы можно было определить NumBytesInNalUnit. Один такой способ определения границ указан в [Annex B в ITU-T H.265] для формата байтового потока. Другие способы определения границ могут быть указаны за пределами настоящего описания.
ПРИМЕЧАНИЕ 1. Уровень кодирования видеосигналов (VCL) указан для эффективного представления содержимого видеоданных. NAL задают для форматирования этих данных и предоставления информации заголовка способом, подходящим для передачи по различным каналам связи или носителям данных. Все данные содержатся в элементах NAL, каждый из которых содержит целое число байтов. Элемент NAL определяет общий формат для применения как в пакетно-ориентированных системах, так и в системах с битовым потоком. Формат элементов NAL как для пакетно-ориентированного транспортного потока, так и для байтового потока идентичен, за исключением того, что каждому первому элементу NAL может предшествовать префикс стартового кода и дополнительные байты заполнения в указанном формате байтового потока [Annex B ITU-T H.265].
rbsp_byte[i] представляет собой i-й байт RBSP. RBSP указывают в виде упорядоченной последовательности байтов следующим образом:
RBSP содержит следующую строку битов данных (SODB):
- Если SODB пустой (т. е. имеет нулевую длину битов), RBSP также является пустым.
- В противном случае RBSP содержит SODB следующим образом:
1) Первый байт RBSP содержит (наиболее значимые, самые левые) восемь битов SODB; следующий байт RBSP содержит следующие восемь битов SODB и т. д. до тех пор, пока не останется менее восьми битов SODB.
2) rbsp_trailing_bits( ) присутствуют после SODB следующим образом:
i) Первые (наиболее значимые, самые левые) биты конечного байта RBSP содержат остальные биты SODB (при наличии).
ii) Следующий бит состоит из одного rbsp_stop_one_bit, равного 1.
iii) Когда rbsp_stop_one_bit не является последним битом байт-синхронизированного байта, имеется один или более rbsp_alignment_zero_bit, что приводит к байтовой синхронизации.
3) Один или более cabac_zero_word 16-битных элементов синтаксиса, равных 0×0000, могут присутствовать в некоторых RBSP после rbsp_trailing_bits( ) в конце RBSP.
Синтаксические структуры, имеющие эти свойства RBSP, обозначены в синтаксических таблицах с использованием суффикса «_rbsp». Эти структуры переносятся в пределах элементов NAL в виде содержимого байтов данных rbsp_byte[i]. Связь синтаксических структур RBSP с элементами NAL указана в [таблице 3, в настоящем документе].
ПРИМЕЧАНИЕ 2. Если известны границы RBSP, декодер может извлекать SODB из RBSP путем конкатенации битов байтов RBSP и отбрасывания rbsp_stop_one_bit, который является последним (наименее значимым, самым правым) битом, равным 1, и отбрасывания любых последующих (менее значимых, правее) битов, которые следуют за ним, которые равны 0. Данные, необходимые для процесса декодирования, содержатся в части SOBS RBSP.
emulation_prevention_three_byte представляет собой байт, равный 0×03. При наличии в элементе NAL emulation_prevention_three_byte он должен быть исключен в процессе декодирования.
Последний байт элемента NAL не должен быть равен 0×00.
В пределах элемента NAL следующие трехбайтовые последовательности не должны происходить в каком-либо байт-синхронизированном положении:
- 0×000000
- 0×000001
- 0×000002
В пределах элемента NAL любая четырехбайтовая последовательность, которая начинается с 0×000003, отличная от следующих последовательностей, не должна происходить в каком-либо байт-синхронизированном положении:
- 0×00000300
- 0×00000301
- 0×00000302
- 0×00000303
В таблице 2 проиллюстрирован синтаксис заголовка элемента NAL, представленный в ITU-T H.265.
В ITU-T H.265 обеспечены следующие определения для соответствующих элементов синтаксиса, представленных в таблице 2.
forbidden_zero_bit должен быть равен 0.
nuh_layer_id указывает идентификатор уровня, к которому относится VCL элемент NAL, или идентификатор уровня, к которому применяется не-VCL элемент NAL.
nuh_temporal_id_plus1 минус 1 указывает временной идентификатор для элемента NAL. Значение nuh_temporal_id_plus1 не должно быть равно 0.
В отношении nal_unit_type, nal_unit_type указывает тип структуры данных RBSP, содержащихся в элементе NAL. В таблице 3 проиллюстрированы типы элемента NAL, представленные в ITU-T H.265.
RSV_IRAP_VCL2 3
Для краткости полное описание каждого из типов элементов NAL в ITU-T H.265 не представлено в настоящем документе. Однако дана ссылка на соответствующие разделы ITU-T H.265.
[0029] Как описано выше, JVET-K1001 представляет собой проект спецификации кодирования видеосигналов. Таблица 4 иллюстрирует синтаксис заголовка элемента NAL в JVET-K1001.
В JVET-K1001 обеспечены следующие определения для соответствующих элементов синтаксиса, представленных в таблице 4.
forbidden_zero_bit должен быть равен 0.
В отношении nal_unit_type JVET-K1001 обеспечивает определение типов элементов NAL.
JVET-K1001 дополнительно предоставляет синтаксис набора параметров базовой последовательности. Таблица 5 иллюстрирует синтаксис набора параметров последовательности, представленного в JVET-K1001.
Ниже приведены основные определения соответствующих элементов синтаксиса, показанных в таблице 5.
Параметр sps_seq_parameter_set_id обеспечивает идентификатор для SPS для ссылки на другие элементы синтаксиса. Значение sps_seq_parameter_set_id должно находиться в диапазоне от 0 до 15 включительно.
chroma_format_idc определяет выборку цветности относительно выборки яркости. Значение chroma_format_idc должно находиться в диапазоне от 0 до 3 включительно.
Если параметр separate_colour_plane_flag равен 1, это указывает на то, что три цветовых компонента формата цветности 4:4:4 кодируются с разделением. Если параметр separate_color_path_flag равняется 0, это указывает на то, что цветовые компоненты не кодируются отдельно. Когда separate_colour_plane_flag отсутствует, предполагается, что он равен 0. Если параметр separate_colour_plane_flag равен 1, закодированное изображение состоит из трех отдельных компонентов, каждый из которых состоит из закодированных образцов одной цветовой плоскости (Y, Cb или Cr) и использует синтаксис монохромного кодирования. В этом случае каждая цветовая плоскость связана с конкретным значением colour_plane_id.
Параметр pic_width_in_luma_samples определяет ширину каждого декодированного изображения в единицах выборок яркости.
pic_height_in_luma_samples определяет высоту каждого декодированного изображения в единицах выборок яркости.
Параметр bit_depth_luma_minus8 определяет битовую глубину выборок массива яркости и значение смещения диапазона параметров квантования яркости.
bit_depth_chroma_minus8 определяет битовую глубину выборок массивов цветности и значение смещения диапазона параметров квантования цветности.
Если параметр qtbtt_dual_tree_intra_flag равен 1, это указывает на то, что для I срезов каждый CTU разделен на блоки кодирования с 64 × 64 выборками яркости с использованием неявного разделения дерева квадрантов и что эти блоки кодирования являются корнем двух отдельных структур синтаксиса кодирования дерева квадрантов для яркости и цветности.
Параметр log2_ctu_size_minus2 плюс 2 определяет размер блока дерева кодирования яркости каждого CTU.
log2_min_qt_size_intra_slices_minus2 плюс 2 определяет минимальный размер яркости листового блока, полученный при разделении CTU на срезы с slice_type, равным 2 (I).
Параметр log2_min_qt_size_inter_slices_minus2 плюс 2 определяет минимальный размер яркости листового блока, полученного при разделении CTU на срезы с slice_type, равным 0 (B) или 1 (P).
Параметр max_mtt_hierarchy_depth_inter_slices определяет максимальную иерархическую глубину для блоков кодирования в результате разделения многотипного дерева листового элемента дерева квадрантов на срезы с slice_type, равным 0 (B) или 1(P).
Параметр max_mtt_hierarchy_depth_intra_slices определяет максимальную иерархическую глубину для блоков кодирования в результате разделения многотипного дерева листового элемента дерева квадрантов на срезы с slice_type, равным 2 (I).
Если параметр sps_cclm_enabled_flag равен 0, это указывает на то, что линейная модель поперечного компонента внутреннего прогнозирования от компонента яркости до компонента цветности отключена. Если параметр sps_cclm_enabled_flag равен 1, это указывает на то, что линейная модель поперечного компонента внутреннего прогнозирования от компонента яркости до компонента цветности включена.
Если параметр sps_temporal_mvp_enabled_flag равен 1, это указывает на то, что slice_temporal_mvp_enabled_flag присутствует в заголовках среза срезов с slice_type, не равным I в CVS. Если параметр sps_temporal_mvp_enabled_flag равен 0, это указывает на то, что slice_temporal_mvp_enabled_flag отсутствует в заголовках среза и что временные средства прогнозирования вектора движения не используются в CVS.
Если параметр sps_sbtmvp_enabled_flag равен 1, это указывает на то, что временные средства прогнозирования вектора движения на основе подблоков могут использоваться при декодировании изображений со всеми срезами, имеющими slice_type, не равный I в CVS. Если параметр sps_sbtmvp_enabled_flag равен 0, это указывает на то, что временные средства прогнозирования вектора движения на основе подблоков не используются в CVS. Когда ps_sbtmvp_enabled_flag отсутствует, предполагается, что он равен 0.
log2_sbtmvp_default_size_minus2 определяет выведенное значение элемента синтаксиса log2_sbtmvp_active_size_minus2 в заголовках срезов с slice_type, не равных I в CVS, если slice_sbtmvp_size_override_flag равен 0.
Если параметр sps_amvr_enabled_flag равен 1, это указывает на то, что адаптивное разрешение разницы векторов движения используется при кодировании вектора движения. Если параметр amvr_enabled_flag равен 0, это указывает на то, что адаптивное разрешение разницы векторов движения не используется при кодировании вектора движения.
sps_affine_enabled_flag определяет, может ли использоваться компенсация движения на основе аффинной модели для внешнего прогнозирования. Если параметр sps_affine_enabled_flag равен 0, синтаксис должен быть ограничен таким образом, что в CVS не используется компенсация движения на основе аффинной модели, а merge_affine_flag, inter_affine_flag и cu_affine_type_flag отсутствуют в синтаксисе блока кодирования CVS. В противном случае (sps_affine_enabled_flag равен 1), в CVS может использоваться компенсация движения на основе аффинной модели.
sps_affine_type_flag определяет, можно ли использовать компенсацию движения на основе аффинной модели с 6 параметрами для внешнего прогнозирования. Если параметр sps_affine_type_flag равен 0, синтаксис должен быть ограничен таким образом, что в CVS не используется компенсация движения на основе аффинной модели с 6 параметрами, а cu_affine_type_flag отсутствует в синтаксисе блока кодирования в CVS. В противном случае (sps_affine_type_flag равен l), в CVS может использоваться компенсация движения на основе аффинной модели с 6 параметрами. Если значение sps_affine_type_flag отсутствует, предполагается, что он равен 0.
Если параметр sps_mts_intra_enabled_flag равен 1, это указывает на то, что eu_mts_flag может присутствовать в синтаксисе остаточного кодирования для блоков внутреннего кодирования. Если параметр sps_mts_intra_enabled_flag равен 0, это указывает на то, что cu_mts_flag отсутствует в синтаксисе остаточного кодирования для блоков внутреннего кодирования.
sps_mts_inter_enabled_flag указывает на то, что cu_mts_flag может присутствовать в синтаксисе остаточного кодирования для блоков внешнего кодирования. Если параметр sps_mts_inter_enabled_flag равен 0, это указывает на то, что cu_mts_flag отсутствует в синтаксисе остаточного кодирования для блоков внешнего кодирования.
JVET-K1001 дополнительно предоставляет синтаксис набора параметров базового изображения. Таблица 6 иллюстрирует синтаксис набора параметров изображения в JVET-K1001.
В JVET-K1001 обеспечены следующие определения для соответствующих элементов синтаксиса, представленных в таблице 6.
pps_pic_parameter_set_id определяет PPS для ссылки на другие элементы синтаксиса. Значение параметра pps_pic_parameter_set_id должно находиться в диапазоне от 0 до 63 включительно.
pps_seq_parameter_set_id определяет значение sps_seq_parameter_set_id для активного SPS. Значение pps_seq_parameter_set_id должно находиться в диапазоне от 0 до 15 включительно.
Если параметр transform_skip_enabled_flag равен 1, это указывает на то, что transform_skip_flag может присутствовать в синтаксисе остаточного кодирования. Если параметр transform_skip_enabled_flag равен 0, это указывает на то, что преобразование skip_flag отсутствует в синтаксисе остаточного кодирования.
JVET-K1001 дополнительно предоставляет синтаксис ограничителя элемента доступа. Таблица 7 иллюстрирует синтаксис ограничителя элемента доступа в JVET-K1001.
В JVET-K1001 обеспечены следующие определения для соответствующих элементов синтаксиса, представленных в таблице 7.
pic_type указывает на то, что значения slice_type для всех срезов закодированного изображения в элементе доступа, содержащем элемент NAL ограничителя элемента доступа, являются членами набора, указанного в таблице 8 для данного значения pic_type. В соответствии с данной версией настоящего описания значение pic_type в битовых потоках должно быть равно 0, 1 или 2. Другие значения pic_type зарезервированы для использования в будущем. Декодеры, соответствующие данной версии настоящего описания, игнорируют зарезервированные значения pic_type.
Следует отметить, что срез B представляет собой срез, в котором разрешено внешнее прогнозирование с двойным прогнозированием, внешнее прогнозирование с одиночным прогнозированием и внутреннее прогнозирование; P-срез представляет собой срез, в котором разрешено внешнее прогнозирование с одиночным прогнозированием и внутреннее прогнозирование; а I срез представляет собой срез, в котором разрешено только внутреннее прогнозирование. Следует отметить, что в некоторых случаях срезы B и P в совокупности называются внешними срезами.
[0030]
JVET-K1001 дополнительно предоставляет синтаксис конца последовательности, синтаксис конца битового потока и синтаксис данных заполнителя. Таблица 9 иллюстрирует синтаксис конца последовательности, представленный в JVET-K1001, таблица 10 иллюстрирует синтаксис конца битового потока, представленный в JVET-K1001, а таблица 11 иллюстрирует синтаксис конца битового потока, представленного в JVET-K1001.
В JVET-K1001 обеспечены следующие определения для соответствующих элементов синтаксиса, представленных в таблице 11.
ff_byte представляет собой байт, равный 0xFF.
JVET-K1001 дополнительно предоставляет синтаксис уровня среза, включающий заголовок среза. Таблица 12 иллюстрирует синтаксис уровня среза, представленный в JVET-JK001, а таблица 13 иллюстрирует заголовок среза, представленный в JVET-K1001.
В JVET-K1001 обеспечены следующие определения для соответствующих элементов синтаксиса, представленных в таблице 13.
Параметр slice_pic_parameter_set_id определяет значение pps_pic_parameter_set_id для используемого PPS. Значение параметра slice_pic_parameter_set_id должно находиться в диапазоне от 0 до 63 включительно.
Параметр slice_address определяет адрес первого CTB в срезе при растровом сканировании CTB изображения.
Параметр slice_type определяет тип кодирования среза в соответствии с таблицей 14.
Когда параметр nal_unit_type имеет значение в диапазоне [должен быть определен] включительно, т. е. изображение представляет собой изображение IRAP, параметр slice_type должен быть равен 2.
Параметр log2_diff_ctu_max_bt_size определяет разницу между размером CTB для яркости и максимальным размером (шириной или высотой) блока кодирования для яркости, который может быть разделен с использованием двоичного разделения.
Если параметр sbtmvp_size_override_flag равен 1, это означает, что для текущего среза присутствует элемент синтаксиса log2_sbtmvp_active_size_minus2. Если параметр sbtmvp_size_override_flag равен 0, это означает, что элемент синтаксиса log2_atmvp_active_size_minus2 отсутствует и предполагается, что log2_sbtmvp_size_active_minus2 равен log2_sbtmvp_default_size_minus2.
Параметром log2_sbtmvp_active_size_minus2 плюс 2 указывают значение размера подблока, используемого для получения параметров движения для основанного на подблоке TMVP текущего среза. Когда log2_sbtmvp_size_active_minus2 отсутствует, предполагается, что он равен log2_sbtmvp_default_size_minus2. Эта переменная может быть получена следующим образом:
Log2SbtmvpSize=log2_sbtmvp_size_active_minus2+2
Параметр slice_temporal_mvp_enabled_flag определяет, могут ли быть использованы временные средства прогнозирования вектора движения для внешнего прогнозирования. Если параметр slice_temporal_mvp_enabled_flag равен 0, элементы синтаксиса текущего изображения должны быть ограничены таким образом, чтобы при декодировании текущего изображения не были использованы временные средства прогнозирования вектора движения. В противном случае (slice_temporal_mvp_enabled_flag равен 1) при декодировании текущего изображения могут быть использованы временные средства прогнозирования вектора движения. При его отсутствии значение slice_temporal_mvp_enabled flag принимают равным 0.
Если параметр mvd_l1_zero_flag равен 1, это означает, что структура синтаксиса mvd_coding(x0, y0, 1) синтаксически не анализируется, а переменной MvdL1[ x0 ][ y0 ][ compIdx ] присваивается значение 0 для compIdx=0..1. Если параметр mvd_l1_zero_flag равен 0, это указывает на выполнение синтаксического анализа структуры синтаксиса mvd_coding(x0, y0, 1).
Если параметр collocated_ffom_10_flag равен 1, это означает, что связанное изображение, используемое для временного прогнозирования вектора движения, получают из списка 0 опорных изображений. Если параметр collocated_from_10_flag равен 0, это означает, что связанное изображение, используемое для временного прогнозирования вектора движения, получают из списка 1 опорных изображений. Когда параметр collocated_from_10_flag отсутствует, предполагается, что он равен 1.
Параметр six_minus_max_num_merge_cand определяет максимальное количество объединяемых кандидатов на прогнозирование вектора движения (MVP), поддерживаемых в срезе, вычитаемом из 6. Максимальное количество объединяемых кандидатов MVP, MaxNumMergeCand, получают следующим образом:
MaxNumMergeCand=6 - six_minus_max_num_merge_cand
Значение MaxNumMergeCand должно находиться в диапазоне от 1 до 6 включительно.
Если параметр dep_quant_enabled_flag равен 0, это указывает на то, что зависимое квантование отключено. Если параметр dep_quant_enabled_flag равен 1, это указывает на то, что зависимое квантование включено.
Если параметр sign_data_hiding_enabled_flag равен 0, это указывает на то, что скрытие знакового бита отключено. Если параметр sign_data_hiding_enabled_flag равен 1, это указывает на то, что скрытие знакового бита включено. Когда sign_data_hiding_enabled_flag отсутствует, предполагается, что он равен 0.
JVET-K1001 дополнительно предоставляет синтаксис конечных битов RBSP и синтаксис байтовой синхронизации. Таблица 15 иллюстрирует синтаксис конечных битов RBSP, представленный в JVET-K1001, а таблица 16 иллюстрирует синтаксис байтовой синхронизации, представленный в JVET-K1001.
Как описано выше, в соответствии с ITU-T H.265 каждый видеокадр или изображение могут быть разделены таким образом, что они включают один или более фрагментов. В ITU-T H.265 структура фрагментов для изображения передается с использованием сигналов набора параметров изображения. В таблице 17 представлена часть синтаксиса PPS, указанного в ITU-T H.265, включая соответствующие элементы синтаксиса для передачи сигналов структуры фрагмента.
В H.265 обеспечены следующие определения для соответствующих элементов синтаксиса, представленных в таблице 17.
Если параметр tiles_enabled_flag равен 1, это указывает на наличие более одного фрагмента на каждом изображении, относящемся к PPS. Если параметр tiles_enabled_flag равен 0, это указывает на наличие только одного фрагмента на каждом изображении, относящемся к PPS. Требованием соответствия битовому потоку является то, что значение tiles_enabled_flag должно быть одинаковым для всех PPS, активированных в пределах CVS.
Параметр num_tile_complex_minus1 плюс 1 указывает на число столбцов, разделяющих изображение. Параметр num_tile_columns_minus1 должен находиться в диапазоне от 0 до PicWidthlnCtbsY - 1 включительно. При его отсутствии значение num_tile_columns_minus1 принимают равным 0.
Параметр num_tile_rows_minus1 плюс 1 указывает число строк фрагментов, разделяющих изображение, параметр num tile rows_minus1 должен находиться в диапазоне от 0 до PicHeightlnCtbsY - 1 включительно. При его отсутствии значение num_tile_rows_minus1 принимают равным 0. Если параметр tiles_enabled_flag равен 1, параметры num_tile_columns_minus1 и num_tile_rows_minus1 не должны быть равны 0.
Если параметр uniform_spacing_flag равен 1, это указывает на то, что границы столбцов фрагмента и границы строк фрагмента аналогичным образом равномерно распределены по всему изображению. Если параметр uniform_spacing_flag равен 0, это указывает на то, что границы столбцов фрагмента и границы строк фрагмента аналогичным образом не распределены равномерно по изображению, а передаются явным образом с использованием элементов синтаксиса column_width_minus1[i] и row_height_minus1[i]. При его отсутствии значение uniform_spacing_flag принимают равным 1.
Параметр column_width_minus1[i] плюс 1 определяет ширину i-го столбца фрагмента в элементах блоков кодового дерева.
Параметр row_height_minus1[i] плюс 1 определяет высоту i-й строки фрагмента в элементах блоков кодового дерева.
Как описано выше, в JVET-K1001 не предусмотрен механизм передачи сигналов структуры фрагмента. В настоящем описании описаны способы сигнализации общей структуры битового потока, включая заголовок изображения и параметры набора фрагментов.
[0031] На ФИГ. 1 представлена блок-схема, иллюстрирующая пример системы, которая может быть выполнена с возможностью кодирования (т. е. кодирования и/или декодирования) видеоданных в соответствии с одной или более методиками согласно настоящему описанию. Система 100 представляет собой пример системы, которая может инкапсулировать видеоданные в соответствии с одной или более методиками настоящего описания. Как показано на ФИГ. 1, система 100 включает в себя устройство-источник 102, среду 110 связи и устройство 120 назначения. В показанном на ФИГ. 1 примере устройство-источник 102 может включать в себя любое устройство, выполненное с возможностью кодирования видеоданных и передачи закодированных видеоданных в среду 110 связи. Устройство 120 назначения может включать в себя любое устройство, выполненное с возможностью приема кодированных видеоданных через среду 110 связи и декодирования кодированных видеоданных. Устройство-источник 102 и/или устройство 120 назначения могут включать в себя вычислительные устройства, оборудованные для проводной и/или беспроводной связи, и могут включать в себя, например, телевизионные приставки, цифровые видеомагнитофоны, телевизоры, настольные компьютеры, ноутбуки или планшетные компьютеры, игровые консоли, медицинские устройства визуализации и мобильные устройства, включая, например, смартфоны, сотовые телефоны, персональные игровые устройства.
[0032] Среда 110 связи может включать в себя любую комбинацию средств беспроводной и проводной связи и/или запоминающих устройств. Среда 110 связи может включать в себя коаксиальные кабели, оптоволоконные кабели, кабели витой пары, беспроводные передатчики и приемники, маршрутизаторы, коммутаторы, ретрансляторы, базовые станции или любое другое оборудование, которое может обеспечивать связь между различными устройствами и объектами. Среда 110 связи может включать в себя одну или более сетей. Например, среда 110 связи может включать в себя сеть, выполненную с возможностью обеспечения доступа к Всемирной паутине, например Интернету. Сеть может работать в соответствии с комбинацией одного или более телекоммуникационных протоколов. Телекоммуникационные протоколы могут включать в себя фирменные аспекты и/или могут включать в себя стандартизированные телекоммуникационные протоколы. Примеры стандартизированных телекоммуникационных протоколов включают в себя стандарты: цифрового видеовещания (DVB), Комитета по усовершенствованным телевизионным системам (ATSC), цифрового вещания с комплексными услугами (ISDB), спецификации интерфейса передачи данных по кабелю (DOCSIS), глобальной системы мобильной связи (GSM), множественного доступа с кодовым разделением (CDMA), партнерского проекта по системам 3-го поколения (3GPP), Европейского института телекоммуникационных стандартов (ETSI), Интернет-протокола (IP), протокола беспроводных приложений (WAP) и Института инженеров по электротехнике и электронике (IEEE).
[0033] Запоминающие устройства могут включать в себя устройства или носители любого типа, выполненные с возможностью хранения данных. Носитель данных может включать в себя материальные или энергонезависимые машиночитаемые носители. Машиночитаемый носитель может представлять собой оптические диски, электрически перепрограммируемое постоянное запоминающее устройство, магнитное запоминающее устройство или любой другой пригодный цифровой носитель данных. В некоторых примерах запоминающее устройство или его части могут быть описаны как энергонезависимое запоминающее устройство, а в других примерах части запоминающих устройств могут быть описаны как энергозависимое запоминающее устройство. Примеры энергозависимых запоминающих устройств могут включать в себя оперативные запоминающие устройства (RAM), динамические оперативные запоминающие устройства (DRAM) и статические оперативные запоминающие устройства (SRAM). Примеры энергонезависимых запоминающих устройств могут включать в себя жесткие магнитные диски, оптические диски, дискеты, флеш-память или виды электрически программируемых запоминающих устройств (EPROM) или электрически стираемых и программируемых (EEPROM) запоминающих устройств. Запоминающее (-ие) устройство (-а) может (могут) включать в себя карты памяти (например, карту памяти Secure Digital (SD)), внутренние/внешние жесткие диски и/или внутренние/внешние твердотельные накопители. Данные могут храниться в запоминающем устройстве в соответствии с определенным форматом файла.
[0034] На ФИГ. 4 представлен концептуальный чертеж, иллюстрирующий пример компонентов, которые могут быть включены в вариант реализации системы 100. В примере варианта реализации, показанном на ФИГ. 4, система 100 включает в себя одно или более вычислительных устройств 402A-402N, сеть 404 телевизионного вещания, сайт 406 поставщика услуг телевизионного вещания, глобальную сеть 408, локальную сеть 410 и один или более сайтов 412A-412N поставщика контента. Вариант реализации, показанный на ФИГ. 4, представляет собой пример системы, которая может быть выполнена с возможностью обеспечения распределения цифрового мультимедийного контента, такого как, например, фильм, прямой репортаж спортивного мероприятия и т. п., а также распределения данных и приложений, и предоставления мультимедийных данных, связанных с ними, на множество вычислительных устройств, таких как вычислительные устройства 402A-402N, и обеспечения доступа к ним. В примере, показанном на ФИГ. 4, вычислительные устройства 402A-402N могут включать любое устройство, выполненное с возможностью приема данных от одной или более из сети 404 телевизионного вещания, глобальной сети 408 и/или локальной сети 410. Например, вычислительные устройства 402A-402N могут быть оборудованы средствами проводной и/или беспроводной связи и могут быть выполнены с возможностью приема услуг по одному или более каналам передачи данных, и могут включать в себя телевизоры, включая так называемые «интеллектуальные» телевизоры, телевизионные приставки и цифровые видеомагнитофоны. Вычислительные устройства 402A-402N могут дополнительно представлять собой настольные, портативные или планшетные компьютеры, игровые консоли, мобильные устройства, включая, например, смартфоны, сотовые телефоны и персональные игровые устройства.
[0035] Сеть 404 телевизионного вещания представляет собой пример сети, выполненной с возможностью обеспечения распределения цифрового мультимедийного контента, который может включать в себя телевизионное вещание. Например, сеть 404 телевизионного вещания может включать в себя сети эфирного телевидения общего пользования, сети поставщика услуг спутниковой телевизионной связи общего пользования или предоставляемых по подписке и сети поставщика услуг кабельного телевидения общего пользования или предоставляемых по подписке и/или поставщиков экзотических услуг или услуг Интернета. Следует отметить, что хотя в некоторых примерах сеть 404 телевизионного вещания можно главным образом использовать для предоставления услуг телевизионного вещания, по сети 404 телевизионного вещания можно также передавать данные и обеспечивать услуги других типов в соответствии с любой комбинацией телекоммуникационных протоколов, описанных в настоящем документе. Следует дополнительно отметить, что в некоторых примерах сеть 404 телевизионного вещания выполнена с возможностью обеспечения двусторонней связи между сайтом 406 поставщика услуг телевизионного вещания и одним или более вычислительными устройствами 402A-402N. Сеть 404 телевизионного вещания может содержать любую комбинацию беспроводных и/или проводных средств связи. Сеть 404 телевизионного вещания может включать в себя коаксиальные кабели, оптоволоконные кабели, кабели с витой парой, беспроводные передатчики и приемники, маршрутизаторы, коммутаторы, ретрансляторы, базовые станции или любое другое оборудование, которое может быть использовано для обеспечения связи между различными устройствами и объектами. Сеть 404 телевизионного вещания может функционировать в соответствии с протоколами из комбинации одного или более телекоммуникационных протоколов. Телекоммуникационные протоколы могут включать в себя фирменные аспекты и/или могут включать в себя стандартизированные телекоммуникационные протоколы. Примеры стандартизированных телекоммуникационных протоколов включают в себя стандарты DVB, стандарты ATSC, стандарты ISDB, стандарты DTMB, стандарты DMB, стандарты спецификации интерфейса передачи данных по кабелю (DOCSIS), стандарты HbbTV, стандарты W3C и стандарты UPnP.
[0036] Как показано на ФИГ. 4, сайт 406 поставщика услуг телевизионного вещания может быть выполнен с возможностью распределения услуг телевизионного вещания по сети 404 телевизионного вещания. Например, сайт 406 поставщика услуг телевизионного вещания может включать в себя одну или более широковещательных станций, поставщика услуг кабельного телевидения, поставщика услуг спутникового телевидения или поставщика услуг телевидения с возможностью выхода в Интернет. Например, сайт 406 поставщика услуг телевизионного вещания может быть выполнен с возможностью приема передачи, включающей в себя набор телепрограмм, передаваемых по спутниковой восходящей/нисходящей линии связи. Как показано на ФИГ. 4, сайт 406 поставщика услуг телевизионного вещания может дополнительно обмениваться данными с глобальной сетью 408 и может быть выполнен с возможностью приема данных от сайтов 412A-412N поставщика контента. Следует отметить, что в некоторых примерах сайт 406 поставщика услуг телевизионного вещания может включать в себя телевизионную студию, предоставляющую контент.
[0037] Глобальная сеть 408 может включать в себя сеть пакетной передачи данных и функционировать в соответствии с комбинацией одного или более телекоммуникационных протоколов. Телекоммуникационные протоколы могут включать в себя фирменные аспекты и/или могут включать в себя стандартизированные телекоммуникационные протоколы. Примеры стандартизированных телекоммуникационных протоколов включают в себя стандарты глобальной системы мобильной связи (GSM), стандарты множественного доступа с кодовым разделением каналов (CDMA), стандарты партнерского проекта по системам 3-го поколения (3 GPP), стандарты Европейского института телекоммуникационных стандартов (ETSI), Европейские стандарты (EN), IP-стандарты, стандарты согласно протоколу беспроводной передачи данных (WAP) и стандарты Института инженеров по электротехнике и электронике (IEEE), такие как, например, один или более стандартов IEEE 802 (например, Wi-Fi). Глобальная сеть 408 может содержать любую комбинацию беспроводных и/или проводных средств связи. Глобальная сеть 408 может включать в себя коаксиальные кабели, оптоволоконные кабели, кабели с витой парой, Ethernet-кабели, беспроводные передатчики и приемники, маршрутизаторы, коммутаторы, ретрансляторы, базовые станции или любое другое оборудование, которое может быть использовано для обеспечения связи между различными устройствами и объектами. В одном примере глобальная сеть 408 может включать в себя Интернет. Локальная сеть 410 может включать в себя сеть пакетной передачи данных и функционировать в соответствии с комбинацией одного или более телекоммуникационных протоколов. Локальную сеть 410 можно отличать от глобальной сети 408 на основании уровней доступа и/или физической инфраструктуры. Например, локальная сеть 410 может включать в себя защищенную домашнюю сеть.
[0038] Как также показано на ФИГ. 4, сайты 412A-412N поставщика контента представляют собой примеры сайтов, которые могут предоставлять мультимедийный контент на сайт 406 поставщика услуг телевизионного вещания и/или вычислительные устройства 402A-402N. Например, сайт поставщика контента может включать студию, имеющую один или более контент-серверов студии, выполненных с возможностью предоставления мультимедийных файлов и/или потоков данных на сайт 406 поставщика услуг телевизионного вещания. В одном примере сайты 412A-412N поставщика контента могут быть выполнены с возможностью предоставления мультимедийного контента с применением набора IP-протоколов. Например, сайт поставщика контента может быть выполнен с возможностью предоставления мультимедийного контента на приемник в соответствии с протоколом потоковой передачи в режиме реального времени (RTSP), HTTP или т. п. Сайты 412A-412N поставщика контента могут быть дополнительно выполнены с возможностью предоставления данных, включая гипертекстовый контент и т. п., на одно или более из вычислительных устройств 402A-402N приемников и/или сайт 406 поставщика услуг телевизионного вещания посредством глобальной сети 408. Сайты 412A-412N поставщика контента могут включать в себя один или более веб-серверов. Данные, предоставляемые сайтом 412A-412N поставщика данных, могут быть определены в соответствии с форматами данных.
[0039] Как показано на ФИГ. 1, устройство-источник 102 включает в себя источник 104 видео, видеокодер 106, инкапсулятор 107 данных и интерфейс 108. Источник 104 видео может включать в себя любое устройство, выполненное с возможностью захвата и/или хранения видеоданных. Например, источник 104 видео может включать в себя видеокамеру и запоминающее устройство, функционально связанное с ней. Видеокодер 106 может включать в себя любое устройство, выполненное с возможностью приема видеоданных и генерирования совместимого битового потока, представляющего видеоданные. Совместимый битовый поток может относиться к битовому потоку, который видеодекодер может принимать и из которого он может воспроизводить видеоданные. Аспекты совместимого битового потока могут быть определены в соответствии со стандартом кодирования видеосигналов. При формировании совместимого битового потока видеокодер 106 может сжимать видеоданные. Сжатие может происходить с потерями (заметными или незаметными для зрителя) или без потерь. На ФИГ. 5 представлена блок-схема, иллюстрирующая пример видеокодера 500, выполненного с возможностью реализации методик кодирования видеоданных, описанных в настоящем документе. Следует отметить, что, хотя приведенный в качестве примера видеокодер 500 показан как имеющий различные функциональные блоки, такая иллюстрация представлена исключительно для описания и не ограничивает видеокодер 500 и/или его подкомпоненты конкретной архитектурой аппаратного или программного обеспечения. Функции видеокодера 500 могут быть реализованы с использованием любой комбинации аппаратных, программно-аппаратных и/или программных вариантов реализации.
[0040] Видеокодер 500 может быть выполнен с возможностью выполнения кодирования с внутренним прогнозированием и кодирования с внешним прогнозированием областей изображения и, таким образом, может называться гибридным видеокодером. В примере, показанном на ФИГ. 5, видеокодер 500 принимает исходные видеоблоки. В некоторых примерах исходные видеоблоки могут включать в себя области изображения, разделенные в соответствии со структурой кодирования. Например, исходные видеоданные могут включать в себя макроблоки, CTU, CB, их подразделы и/или другой эквивалентный блок кодирования. В некоторых примерах видеокодер 500 может быть выполнен с возможностью выполнения дополнительных подразделений исходных видеоблоков. Следует отметить, что описанные в настоящем документе методики в целом применимы к кодированию видеосигналов, независимо от методов разделения исходных видеоданных до и/или во время кодирования. В примере, показанном на ФИГ. 5, видеокодер 500 включает в себя сумматор 502, генератор 504 коэффициента преобразования, блок 506 квантования коэффициента, блок 508 обратного квантования и обработки коэффициента преобразования, сумматор 510, блок 512 обработки внутреннего прогнозирования, блок 514 обработки внешнего прогнозирования, блок 516 фильтрации и блок 518 энтропийного кодирования. Как показано на ФИГ. 5, видеокодер 500 принимает исходные видеоблоки и выводит битовый поток.
[0041] В примере, показанном на ФИГ. 5, видеокодер 500 может генерировать остаточные данные путем вычитания прогнозируемого видеоблока из исходного видеоблока. Выбор прогнозируемого видеоблока подробно описан ниже. Сумматор 502 представляет собой компонент, выполненный с возможностью осуществления указанной операции вычитания. В одном примере вычитание видеоблоков происходит в пиксельной области. Генератор 504 коэффициентов преобразования применяет преобразование, такое как дискретное косинусное преобразование (DCT), дискретное синусное преобразование (DST) или концептуально подобное преобразование, к остаточному блоку или его подразделам (например, четыре преобразования 8 × 8 можно применять к массиву остаточных значений 16 × 16) для получения набора остаточных коэффициентов преобразования. Генератор 504 коэффициента преобразования может быть выполнен с возможностью осуществления любых и всех комбинаций преобразований, включенных в семейство дискретных тригонометрических преобразований, включая их аппроксимации. Генератор 504 коэффициента преобразования выполнен с возможностью вывода коэффициентов преобразования в блок 506 квантования коэффициента. Блок 506 квантования коэффициента может быть выполнен с возможностью осуществления квантования коэффициентов преобразования. При процессе квантования может уменьшаться битовая глубина, связанная с некоторыми или всеми коэффициентами. Степень квантования может влиять на изменение зависимости искажений от скорости передачи (т. е. скорости передачи битов в зависимости от качества видеосигнала) закодированных видеоданных. Степень квантования может быть изменена путем регулировки параметра квантования (QP). Параметр квантования может быть определен на основании значений уровня среза и/или значений уровня CU (например, дельта-значений QP CU). Данные QP могут включать в себя любые данные, используемые для определения QP для квантования конкретного набора коэффициентов преобразования. Как показано на ФИГ. 5, квантованные коэффициенты преобразования (которые могут называться значениями уровня) выводят в блок 508 обратного квантования и обработки коэффициента преобразования. Блок 508 обратного квантования и обработки коэффициента преобразования может быть выполнен с возможностью применения обратного квантования и обратного преобразования для генерирования восстановленных остаточных данных. Как показано на ФИГ. 5, в сумматоре 510 восстановленные остаточные данные могут быть добавлены к прогнозируемому видеоблоку. Таким образом, кодированный видеоблок может быть восстановлен, а полученный в результате восстановленный видеоблок может быть использован для оценки качества кодирования для данного прогнозирования, преобразования и/или квантования. Видеокодер 500 может быть выполнен с возможностью осуществления множества прогонов кодирования (например, выполнения кодирования с изменением одного или более из прогнозирования, параметров преобразования и параметров квантования). Связанное со скоростью искажение битового потока или других системных параметров может быть оптимизировано на основании оценки восстановленных видеоблоков. Восстановленные видеоблоки можно дополнительно сохранять и использовать в качестве опорных для прогнозирования последующих блоков.
[0042] Как показано на ФИГ. 5, блок 512 обработки внутреннего прогнозирования может быть выполнен с возможностью выбора режима внутреннего прогнозирования для видеоблока, подлежащего кодированию. Блок 512 обработки внутреннего прогнозирования может быть выполнен с возможностью оценки кадра и определения режима внутреннего прогнозирования, используемого при кодировании текущего блока. Как описано выше, возможные режимы внутреннего прогнозирования могут включать в себя режимы планарного прогнозирования, режимы прогнозирования DC и режимы углового прогнозирования. Кроме того, следует отметить, что в некоторых примерах режим прогнозирования для компонента цветности может быть выведен из режима прогнозирования для компонента яркости. Блок 512 обработки внутреннего прогнозирования выполнен с возможностью выбора режима внутреннего прогнозирования после выполнения одного или более прогонов кодирования. В одном примере блок 512 обработки внутреннего прогнозирования выполнен с возможностью выбора режима прогнозирования на основании анализа зависимости искажений от скорости передачи. Как показано на ФИГ. 5, блок 512 обработки внутреннего прогнозирования выводит данные внутреннего прогнозирования (например, элементы синтаксиса) в блок 518 энтропийного кодирования и на генератор 504 коэффициента преобразования. Как описано выше, преобразование, выполняемое для остаточных данных, может зависеть от режима (например, матрица вторичного преобразования может быть определена на основании режима прогнозирования).
[0043] Как показано на ФИГ. 5, блок 514 обработки внешнего прогнозирования может быть выполнен с возможностью осуществления кодирования с внешним прогнозированием для текущего видеоблока. Блок 514 обработки внешнего прогнозирования может быть выполнен с возможностью приема исходных видеоблоков и вычисления вектора движения для элементов PU видеоблока. Вектор движения может указывать смещение в PU видеоблока в пределах текущего видеокадра относительно прогнозируемого блока в опорном кадре. Кодирование с внешним прогнозированием может использовать одно или более опорных изображений. Прогнозирование движения может дополнительно быть однонаправленным (с использованием одного вектора движения) или двунаправленным (с использованием двух векторов движения). Блок 514 обработки внешнего прогнозирования может быть выполнен с возможностью выбора прогнозируемого блока путем вычисления разности пикселей, определяемой, например, суммой абсолютной разности (SAD), суммой квадратов разностей (SSD) или другими метрическими показателями разности. Как описано выше, вектор движения может быть определен и указан в соответствии с прогнозированием вектора движения. Блок 514 обработки внешнего прогнозирования может быть выполнен с возможностью осуществления прогнозирования вектора движения, как описано выше. Блок 514 обработки внешнего прогнозирования может быть выполнен с возможностью генерирования прогнозируемого блока с использованием данных прогнозирования движения. Например, блок 514 обработки внешнего прогнозирования может размещать прогнозируемый видеоблок в буфере кадра (не показан на ФИГ. 5). Следует отметить, что блок 514 обработки внешнего прогнозирования может быть дополнительно выполнен с возможностью применения одного или более интерполяционных фильтров к восстановленному остаточному блоку для вычисления значений субцелочисленных пикселей для использования при оценке движения. Блок 514 обработки внешнего прогнозирования может выводить данные прогнозирования движения для вычисленного вектора движения в блок 518 энтропийного кодирования.
[0044] Кроме того, как показано на ФИГ. 5, блок 516 фильтрации принимает восстановленные видеоблоки и параметры кодирования и выводит измененные восстановленные видеоданные. Блок 516 фильтрации может быть выполнен с возможностью осуществления деблокирования и/или фильтрации с адаптивным смещением отсчетов (SAO). SAO-фильтрация представляет собой нелинейное сопоставление амплитуды, которое можно использовать для улучшения восстановления путем добавления смещения к восстановленным видеоданным. Следует отметить, что, как показано на ФИГ. 5, блок 512 обработки внутреннего прогнозирования и блок 514 обработки внешнего прогнозирования могут принимать измененный восстановленный видеоблок посредством блока 216 фильтрации. Блок 518 энтропийного кодирования принимает квантованные коэффициенты преобразования и данные синтаксиса прогнозирования (т. е. данные внутреннего прогнозирования и данные прогнозирования движения). Следует отметить, что в некоторых примерах блок 506 квантования коэффициента выполнен с возможностью осуществления сканирования матрицы, включающей в себя квантованные коэффициенты преобразования, перед выводом коэффициентов в блок 518 энтропийного кодирования. В других примерах сканирование может быть выполнено блоком 518 энтропийного кодирования. Блок 518 энтропийного кодирования может быть выполнен с возможностью энтропийного кодирования в соответствии с одной или более методик, описанных в настоящем документе. Таким образом, видеокодер 500 представляет собой пример устройства, выполненного с возможностью генерирования закодированных видеоданных в соответствии с одной или более методик, описанных в настоящем документе.
[0045] Возвращаясь к ФИГ. 1 отметим, что инкапсулятор 107 данных может принимать закодированные видеоданные и генерировать совместимый битовый поток, например последовательность элементов NAL в соответствии с определенной структурой данных. Устройство, принимающее совместимый битовый поток, может восстанавливать из него видеоданные. Кроме того, как описано выше, извлечение битового подпотока может относиться к процессу, при котором устройство, принимающее совместимый с ITU-T H.265 битовый поток, создает новый совместимый с ITU-T H.265 битовый поток путем отбрасывания и/или изменения данных в принятом битовом потоке. Следует отметить, что термин «соответствующий битовый поток» можно использовать вместо термина «совместимый битовый поток».
[0046] В одном примере инкапсулятор 107 данных может быть выполнен с возможностью генерации синтаксиса в соответствии с одной или более методиками, описанными в настоящем документе. Следует отметить, что необязательно размещать инкапсулятор 107 данных в том же физическом устройстве, что и видеокодер 106. Например, функции, описанные как выполняемые видеокодером 106 и инкапсулятором 107 данных, могут быть распределены между устройствами, показанными на ФИГ. 4. В одном примере изображение может быть разделено на наборы фрагментов и фрагменты, причем набор фрагментов представляет собой последовательность фрагментов, а фрагмент представляет собой последовательность элемента кодового дерева. Набор фрагментов может охватывать прямоугольную область изображения. На ФИГ. 7 представлен пример изображения, разделенного на шесть наборов фрагментов. В примере, проиллюстрированном на ФИГ. 7, каждый набор фрагментов имеет прямоугольную форму. Каждый набор фрагментов может иметь разное количество фрагментов, расположенных в разном количестве столбцов фрагментов и строк фрагментов. Хотя в другом примере все наборы фрагментов могут иметь одинаковое количество фрагментов. Кроме того, количество столбцов фрагментов и количество строк фрагментов в каждом наборе фрагментов может быть изменено на каждом изображении. Флаг может передаваться для указания того, что количество столбцов фрагментов и количество строк фрагментов в каждом наборе фрагментов зафиксировано в закодированной видеопоследовательности. Следует отметить, что «набор фрагментов» вместо этого можно назвать «срезом». Таким образом, термины «набор фрагментов» (англ. "tileset" и "tileset") и «срез» могут использоваться взаимозаменяемо.
[0047]
Как описано выше, таблица 4 иллюстрирует общий синтаксис элемента NAL, представленный в JVET-K1001. Кроме того, как описано выше, JVET-K1001 обеспечивает определение типов элементов NAL. Однако следует отметить, что «На начальной точке синтаксиса высокого уровня», 11-е совещание ISOTEC JTC1/SC29/WG11 10T 8 июля 2018 г. в г. Любляна, Словения, документ JVET-K0325, который включен в настоящий документ путем ссылки и упоминается как JVET-K0325, представляет типы элементов NAL, которые будут добавлены в JVET-K1001. В одном примере в соответствии с методиками, описанными в настоящем документе, инкапсулятор 107 данных может быть выполнен с возможностью передачи сигнала одного или более типов элементов NAL, перечисленных в таблице 18.
SUFFIX_SEI_NUT
В соответствии с таблицей 18 можно определить следующее:
изображение внутренней точки произвольного доступа (IRAP): Закодированное изображение, для которого каждый VCL элемент NAL имеет nal_unit_type, равный IRAP_NUT.
не-IRAP изображение: Закодированное изображение, для которого каждый VCL элемент NAL имеет nal_unit_type, равный NON_IRAP_NUT.
Сигнализация заголовка изображения как элемента NAL показана в таблице 18. Параметры синтаксиса сигнализации в заголовке изображения и разрешение их перекрытия в заголовке набора фрагментов могут обеспечить экономию битов и при этом обеспечить гибкость. В некоторых примерах в соответствии с методиками, описанными в настоящем документе, один и тот же заголовок изображения может применяться ко множеству изображений. Это может обеспечить дополнительную экономию битов. Кроме того, наличие заголовка изображения в качестве его собственного элемента NAL позволяет легко ссылаться на один и тот же заголовок изображения для множества изображений.
[0048] Заголовок, относящийся к параметру фрагмента, может иметь следующие аспекты: 1. Он может относиться к более чем одному фрагменту, например, к набору фрагментов или совокупности фрагментов, таким образом, это может быть заголовок набора фрагментов; и/или 2. При необходимости, он может выборочно замещать некоторые из параметров из заголовка изображения. Управление им может осуществляться с помощью набора флагов наличия в заголовке набора фрагментов.
[0049]
Следует отметить, что в альтернативном примере PICH_NUT может представлять собой не-VCL элемент NAL, который активируется для каждого изображения/набора фрагментов. Например, таблица элементов NAL в этом случае может быть такой, как показано в таблице 18A:
SUFFIX_SEI_NUT
В одном примере можно использовать следующие определения фрагмента, столбца фрагмента, строки фрагмента и набора фрагментов. Следует отметить, что слова «набор фрагментов» используются для обозначения взаимозаменяющих понятий “tileset” and “tile set”, означающих одно и то же.
фрагмент: Прямоугольная область блоков кодового дерева (CTB)в пределах конкретного столбца фрагментов и конкретной строки фрагментов на изображении.
столбец фрагмента: Прямоугольная область блоков CTB, имеющая высоту, равную высоте изображения, и ширину, указанную элементами синтаксиса в наборе параметров изображения.
строка фрагмента: Прямоугольная область блоков CTB, имеющая высоту, указанную элементами синтаксиса в наборе параметров изображения, и ширину, равную ширине изображения.
набор фрагментов: Набор из одного или более фрагментов. В одном примере набор фрагментов должен иметь прямоугольную форму. Набор фрагментов может включать только целое число смежных фрагментов. В одном примере в наборе фрагментов каждый фрагмент должен примыкать к другому фрагменту вдоль столбца или строки, или же наборы фрагментов должны содержать только один фрагмент.
В одном примере NONIRAP_NUT может представлять собой закодированный не-IRAP набор фрагментов tileset_layer_rbsp( ) и IRAP_NUT может представлять собой закодированный IRAP набор фрагментов tileset_layer_rbsp( ). Битовый поток, полученный в процессе извлечения битового подпотока, который извлекает данные только для набора фрагментов IRAP, может декодироваться независимо. Первое изображение или фрагмент изображения в этом извлеченном битовом потоке, соответствующем набору фрагментов, представляет собой IRAP-изображение или фрагмент изображения.
[0050] В таблице 19 проиллюстрирован пример синтаксиса tileset_layer_rbsp( ), который может передаваться инкапсулятором 107 данных в соответствии с методиками, описанными в настоящем документе.
В таблице 20 проиллюстрирован пример синтаксиса tileset_header( ), который может передаваться инкапсулятором 107 данных в соответствии с методиками, описанными в настоящем документе.
В соответствии с таблицей 20 соответствующие элементы синтаксиса могут быть основаны на следующих определениях:
Параметр ts_pic_header_id определяет значение pic_header_id для заголовка изображения, применяемого к этому набору фрагментов. Значение ts_pic_header_id должно находиться в диапазоне от 0 до 232 -1 включительно.
Параметр tile_set_id определяет идентификатор набора фрагментов для данного набора фрагментов.
Параметр first_tile_id определяет идентификатор TileId (идентификатор фрагмента) первого фрагмента в наборе фрагментов с идентификатором tile_set_id, который присутствует в tileset_data(), который следует за этим tileset_header().
Параметр num_tiles_in_setdata определяет число фрагментов в наборе фрагментов с идентификатором tile_set_id, которые присутствуют в tileset_data(), который следует за этим tileset_header().
В таблице 21 проиллюстрирован пример синтаксиса tileset_header(), который может передаваться инкапсулятором 107 данных в соответствии с методиками, описанными в настоящем документе.
В соответствии с таблицей 21 соответствующие элементы синтаксиса могут быть основаны на следующих определениях:
Параметр ts_pic_header_id определяет значение pic_header_id для заголовка изображения, применяемого к этому набору фрагментов. Значение ts_pic_header_id должно находиться в диапазоне от 0 до 232 -1 включительно.
Параметр first_tile_set_id определяет идентификатор набора фрагментов для первого набора фрагментов в tileset_data(), который следует за tileset_header().
Параметр num_tile_set_ids_minus1 плюс 1 определяет число наборов фрагментов, имеющихся в tileset_data(), которые следуют за этим tileset_header().
Параметр first_tile_id_in_first_tileset определяет идентификатор TileId (идентификатор фрагмента) первого фрагмента в первом наборе фрагментов, который присутствует в tileset_data(), который следует за этим tileset_header().
Параметр num_tiles_in_setdata_in_last_tileset определяет число фрагментов в последнем наборе фрагментов, которые присутствуют в tileset_data(), который следует за этим tileset_header().
В таблице 22 проиллюстрирован пример синтаксиса tileset_header(), который может передаваться инкапсулятором 107 данных в соответствии с методиками, описанными в настоящем документе.
В соответствии с таблицей 22 соответствующие элементы синтаксиса могут быть основаны на следующих определениях:
Параметр first_tile_set_id определяет идентификатор набора фрагментов для первого набора фрагментов в tileset_data(), который следует за этим tileset_header().
Параметр num_tile_set_ids_minus 1 плюс 1 определяет число наборов фрагментов, имеющихся в tileset_data(), которые следуют за этим tileset_header().
Параметр first_tile_id_in_first_tileset определяет идентификатор TileId (идентификатор фрагмента) первого фрагмента в первом наборе фрагментов, который присутствует в tileset_data(), который следует за этим tileset_header().
Параметр num_tiles_in_setdata_in_first_tileset определяет число фрагментов в первом наборе фрагментов, которые присутствуют в tileset_data(), который следует за этим tileset_header().
Параметр num_tiles_in_setdata_in_last_tileset определяет число фрагментов в последнем наборе фрагментов, которые присутствуют в tileset_data(), который следует за этим tileset_header().
В таблице 22А проиллюстрирован пример синтаксиса tileset_header(), который может передаваться инкапсулятором 107 данных в соответствии с методиками, описанными в настоящем документе. В данном примере в tileset_data() включено только полное целое число наборов фрагментов. Для этого требуется передача меньшего числа элементов синтаксиса в tilset_header().
В соответствии с таблицей 22А соответствующие элементы синтаксиса могут быть основаны на следующих определениях:
Параметр first_tile_set_id определяет идентификатор набора фрагментов для первого набора фрагментов в tileset_data(), который следует за tileset_header().
Параметр num_tile_set_ids_minus1 плюс 1 определяет число наборов фрагментов, имеющихся в tileset_data(), которые следуют за этим tileset_header().
В таблице 23 проиллюстрирован пример синтаксиса tileset_coding_parameters(), который может передаваться инкапсулятором 107 данных в соответствии с методиками, описанными в настоящем документе.
В соответствии с таблицей 23 соответствующие элементы синтаксиса могут быть основаны на следующих определениях:
Если параметр tileset_log2_diff_ctu_max_bt_size_present_flag равен 1, это указывает на то, что параметр tileset_log2_diff_ctu_max_bt_size присутствует. Если параметр tileset_log2_diff_ctu_max_bt_size_present_flag равен 0, это указывает на отсутствие tileset_log2_diff_ctu_max_bt_size. Если tileset_log2_diff_ctu_max_bt_size отсутствует, предполагается, что он равен log2_diff_ctu_max_bt_size из структуры pic_header(), соответствующей ts_pic_header_id в данном tilset_header(), активном для данного набора фрагментов.
Параметр tileset_log2_diff_ctu_max_bt_size определяет разницу между размером CTB для яркости и максимальным размером (шириной или высотой) блока кодирования для яркости, который может быть разделен с использованием двоичного разделения для данного набора фрагментов. Применяется семантика log2_diff_ctu_max_bt_size, но для набора фрагментов.
Если параметр tileset_sbtmvp_size_override_flag_present_flag равен 1, это указывает на то, что присутствует tileset_sbtmvp_size_override_flag, и если tileset_sbtmvp_size_override_flag равен 1, то присутствует log2_tileset_sbtmvp_active_size_minus2. Если параметр tileset_sbtmvp_size_override_flag_present_flag равен 0, это указывает на то, что отсутствуют tileset_sbtmvp_size_override_flag и log2_tileset_sbtmvp_active_size_minus2. Если отсутствуют tileset_sbtmvp_size_override_flag present_flag и log2_tileset_sbtmvp_active_size_minus2, соответственно предполагается, что они равны структуре sbtmvp _size_override_flag и log2_sbtmvp_active_size_minus2 из структуры pic_header(), соответствующей ts_pic_header_id в данном tilset_header(), активном для данного набора фрагментов.
Если параметр tilset_sbtmvp_size_override_flag равен 1, это означает, что для текущего набора фрагментов присутствует элемент синтаксиса log2_tilset_sbtmvp_active_size_minus2. Если параметр sbtmvp_size_override_flag равен 0, это означает, что элемент синтаксиса log2_tilset_sbtmvp_active_size_minus2 отсутствует и предполагается, что log2_tileset_sbtmvp_size_active_minus2 равен log2_sbtmvp_size_active_minus2.
Параметром log2_tilset_sbtmvp_active_size_minus2 плюс 2 указывают значение размера подблока, используемого для получения параметров движения для основанного на подблоке TMVP для текущего набора фрагментов. Когда log2_tilset_sbtmvp_size_active_minus2 отсутствует, предполагается, что он равен log2_sbtmvp_size_active_minus2. Эта переменная может быть получена следующим образом:
Log2SbtmvpSize=log2_tileset_sbtmvp_size_active_minus2+2
Если параметр tileset_tmvp_info_present_flag равен 1 то, это указывает, что временно может присутствовать набор фрагментов mvp_enabled_flag, tileset_mvd_l1_zero_flag и tileset_collocated_from_10_flag. Если параметр tileset_tmvp_info_present_flag равен 0, это указывает на то, что отсутствуют tileset_temporal_mvp_enabled_flag, tileset_mvd_l1_zero_flag и tileset_collocated_from_10_flag. Если отсутствуют tileset_temporal_mvp_enabled_flag, tileset_mvd_l1_zero_flag и tileset_collocated_from_10_flag, соответственно предполагается, что они равны структуре pic_temporal_mvp_enabled_flag, mvd_l1_zero_flag и collocated_from_10_flag из структуры pic_header(), соответствующей ts_pic_header_id в данном tilset_header(), активном для данного набора фрагментов.
Параметр tileset_temporal_mvp_enabled_flag определяет, могут ли быть использованы временные средства прогнозирования вектора движения для внешнего прогнозирования для текущего набора фрагментов. Если параметр tileset_temporal_mvp_enabled_flag равен 0, элементы синтаксиса текущего набора фрагментов должны быть ограничены таким образом, чтобы при декодировании текущего набора фрагментов не были использованы временные средства прогнозирования вектора движения. В противном случае (tileset_temporal_mvp_enabled_flag равен 1) при декодировании текущего набора фрагментов могут быть использованы временные средства прогнозирования вектора движения. Если отсутствует значение tileset_temporal_mvp_enabled_flag, предполагается, что он равен pic_temporal_mvp_enabled_flag из структуры pic_header(), соответствующей ts_pic_header_id в данном tilset_header(), активном для данного набора.
Если параметр tilset_mvd_l1_zero_flag равен 1, это означает, что структура синтаксиса mvd_coding(x0, y0, 1) синтаксически не анализируется, а переменной MvdL1[ x0 ][ y0 ][ compIdx ] присвоено значение 0 для compIdx=0..1 для текущего набора фрагментов. Если mvd_l1_zero_flag равен 0, это указывает на выполнение синтаксического анализа структуры синтаксиса mvd_coding(x0, y0, 1) для текущего набора фрагментов.
Если параметр tileset_collocated_from_10_flag равен 1, это означает, что для текущего набора фрагментов связанное изображение, используемое для временного прогнозирования вектора движения, получают из списка 0 опорных изображений. Если параметр collocated_from_10_flag равен 0, это означает, что для текущего набора фрагментов связанное изображение, используемое для временного прогнозирования вектора движения, получают из списка 1 опорных изображений. Если параметр tileset_collocated_from_10_flag отсутствует, предполагается, что он равен collocated_from_10_flag из структуры pic_header(), соответствующей ts_pic_header_id в данном tilset_header(), активном для данного набора.
Если параметр tileset_six_minus_max_num_merge_cand_present_flag равен 1, это указывает на то, что параметр tileset_six_minus_max_num_merge_cand присутствует. Если параметр tileset_six_minus_max_num_merge_cand_present_flag равен 0, это указывает на отсутствие tileset_six_minus_max_num_merge_cand. Если параметр tileset_six_minus_max_num_merge_cand отсутствует, предполагается, что он равен six_minus_rnax_num_merge_cand из структуры pic_header(), соответствующей ts_pic_header_id в данном tilset_header(), активном для данного набора фрагментов.
Параметр tileset_six_minus_max_num_merge_cand определяет максимальное количество объединяемых кандидатов на прогнозирование вектора движения (MVP), поддерживаемых в текущем наборе фрагментов, вычитаемое из 6. Максимальное количество объединяемых кандидатов MVP, MaxNumMergeCand, получают следующим образом:
MaxNumMergeCand=6 - tilset_six_minus_max_num_merge_cand
Значение MaxNumMergeCand должно находиться в диапазоне от 1 до 6 включительно.
Если параметр tileset_dep_quant_info_present_flag равен 1, это указывает на то, что параметр tileset_dep_quant_enabled_flag присутствует. Если параметр tileset_dep_quant_info_present_flag равен 0, это указывает на отсутствие tileset_dep_quant_enabled_flag. Если параметр tileset_dep_quant_enabled_flag отсутствует, предполагается, что он равен dep_quant_enabled_flag из структуры pic_header(), соответствующей ts_pic_header_id в данном tilset_header(), активном для данного набора фрагментов.
Если параметр tileset_dep_quant_enabled_flag равен 0, это указывает на то, что зависимое квантование для текущего набора фрагментов отключено. Если параметр tileset_dep_quant_enabled_flag равен 1, это указывает на то, что зависимое квантование для текущего набора фрагментов включено.
Если параметр tileset_sign_data_hiding_enabled_flag равен 0, это указывает на то, что скрытие знакового бита для текущего набора фрагментов отключено. Если параметр tile_sign_data_hiding_enabled_flag равен 1, это указывает на то, что скрытие знакового бита для текущего набора фрагментов включено. Если параметр tile_sign_data_hiding_enabled_flag отсутствует, предполагается, что он равен sign_data_hiding_enabled_flag из структуры pic_header(), соответствующей ts_pic_header_id в данном tilset_header(), активном для данного набора фрагментов.
В таблице 24 проиллюстрирован пример синтаксиса tileset_data(), который может передаваться инкапсулятором 107 данных в соответствии с методиками, описанными в настоящем документе.
В соответствии с таблицей 24 соответствующие элементы синтаксиса могут быть основаны на следующих определениях:
Если параметр end_of_tileset_flag равен 0, это указывает на то, что в наборе фрагментов следует другой CTU. Если параметр end_of_tileset_flag равен 1, это указывает на конец среза набора фрагментов, т. е. что в наборе фрагментов не следует дополнительный CTU.
В таблице 25 проиллюстрирован пример синтаксиса rbsp_tileset_trailing_bits(), который может передаваться инкапсулятором 107 данных в соответствии с методиками, описанными в настоящем документе.
В таблице 26 проиллюстрирован пример синтаксиса pic_header_rbsp( ), который может передаваться инкапсулятором 107 данных в соответствии с методиками, описанными в настоящем документе.
В таблице 27 проиллюстрирован пример синтаксиса pic_header(), который может передаваться инкапсулятором 107 данных в соответствии с методиками, описанными в настоящем документе.
В соответствии с таблицей 24 соответствующие элементы синтаксиса могут быть основаны на следующих определениях:
pps_pic_parameter_set_id определяет PPS для ссылки на другие элементы синтаксиса. Значение параметра pps_pic_parameter_set_id должно находиться в диапазоне от 0 до 63 включительно.
Параметр pic_header_id определяет заголовок изображения для ссылки на другие элементы синтаксиса. Значение параметра pps_pic_parameter_set_id должно находиться в диапазоне от 0 до 232-1 включительно.
Параметр picture_type определяет тип кодирования изображения в соответствии с таблицей 28. В соответствии с данной версией настоящего описания значение pic_type в битовых потоках должно быть равно 0, 1 или 2. Другие значения pic_type зарезервированы для использования в будущем. Декодеры, соответствующие данной версии настоящего описания, игнорируют зарезервированные значения pic_type.
Параметр log2_diff_ctu_max_bt_size определяет разницу между размером CTB для яркости и максимальным размером (шириной или высотой) блока кодирования для яркости, который может быть разделен с использованием двоичного разделения.
Если параметр sbtmvp_size_override_flag равен 1, это означает, что для текущего среза фрагментов присутствует элемент синтаксиса log2_sbtmvp_active_size_minus2. Если параметр sbtmvp_size_override_flag равен 0, это означает, что элемент синтаксиса log2_atmvp_active_size_minus2 отсутствует и предполагается, что log2_sbtmvp_size_active_minus2 равен log2_sbtmvp_default_size_minus2.
Параметром log2_sbtmvp_active_size_minus2 плюс 2 указывают значение размера подблока, используемого для получения параметров движения для основанного на подблоке TMVP текущего среза. Когда log2_sbtmvp_size_active_minus2 отсутствует, предполагается, что он равен log2_sbtmvp_default_size_minus2. Эта переменная может быть получена следующим образом:
Log2SbtmvpSize=log2_sbtmvp_size_active_minus2+2
Параметр pic_temporal_mvp_enabled_flag определяет, могут ли быть использованы временные средства прогнозирования вектора движения для внешнего прогнозирования для текущего изображения. Если параметр pic_temporal_mvp_enabled_flag равен 0, элементы синтаксиса текущего изображения должны быть ограничены таким образом, чтобы при декодировании текущего изображения не были использованы временные средства прогнозирования вектора движения. В противном случае (pic_temporal_mvp_enabled_flag равен 1) при декодировании текущего изображения могут быть использованы временные средства прогнозирования вектора движения. При его отсутствии значение pic_temporal_mvp_enabled_flag принимают равным 0.
Если параметр mvd_l1_zero_flag равен 1, это означает, что структура синтаксиса mvd_coding(x0, y0, 1) синтаксически не анализируется, а переменной MvdL1[ x0 ][ y0 ][ compIdx ] присваивается значение 0 для compIdx=0..1. Если параметр mvd_l1_zero_flag равен 0, это указывает на выполнение синтаксического анализа структуры синтаксиса mvd_coding(x0, y0, 1).
Если параметр collocated_from_10_flag равен 1, это означает, что связанное изображение, используемое для временного прогнозирования вектора движения, получают из списка 0 опорных изображений. Если параметр collocated_from_10_flag равен 0, это означает, что связанное изображение, используемое для временного прогнозирования вектора движения, получают из списка 1 опорных изображений. Когда параметр collocated__from_10_flag отсутствует, предполагается, что он равен 1.
Параметр six_minus_max_num_merge_cand определяет максимальное количество объединяемых кандидатов на прогнозирование вектора движения (MVP), поддерживаемых в срезе, вычитаемом из 6. Максимальное количество объединяемых кандидатов MVP, MaxNumMergeCand, получают следующим образом:
MaxNumMergeCand=6 - six_minus_max_num_merge_cand
Значение MaxNumMergeCand должно находиться в диапазоне от 1 до 6 включительно.
Если параметр dep_quant_enabled_flag равен 0, это указывает на то, что зависимое квантование отключено. Если параметр dep_quant_enabled_flag, равен 1, это указывает на то, что зависимое квантование включено.
Если параметр sign_data_hiding_enabled_flag равен 0, это указывает на то, что скрытие знакового бита отключено. Если параметр sign_data_hiding_enabled_flag равен 1, это указывает на то, что скрытие знакового бита включено. Когда sign_data_hiding_enabled_flag отсутствует, предполагается, что он равен 0.
Следует отметить, что в одном примере один или более элементов синтаксиса в pic_header() может передаваться в PPS_NUT вместо PICH_NUT.
[0051] В таблице 29 проиллюстрирован пример синтаксиса rbsp_pic_header_trailing_bits( ), который может передаваться инкапсулятором 107 данных в соответствии с методиками, описанными в настоящем документе.
Следует отметить, что в некоторых примерах заголовок изображения может применяться к одному или более изображениям. Кроме того, в некоторых примерах параметры в заголовке изображения могут быть переопределены для набора фрагментов в соответствии с параметрами набора фрагментов. В некоторых примерах осуществления определенные ограничения могут применяться для переопределения параметров в заголовке изображения для набора фрагментов.
[0052] Как описано выше, в ITU-T H.265 некоторые или все структуры фрагмента, т. е. один или более параметров, связанных с фрагментом и/или набором фрагментов для изображения, передаются с использованием набора параметров изображения. В одном примере в соответствии с методиками, описанными в настоящем документе, структура фрагмента может передаваться в наборе параметров изображения, причем, как представлено выше, набор параметров изображения идентифицируется в picture_header( ). В другом примере некоторые или все из структур фрагмента, т. е. один или более параметров, связанных с фрагментом и/или набором фрагментов, могут передаваться в наборе параметров последовательности (SPS).
[0053] Таким образом, устройство-источник 102 представляет собой пример устройства, выполненного с возможностью передавать сигнал значения для элемента синтаксиса в элементе уровня сетевой абстракции, указывающего на включение структуры синтаксиса уровня набора фрагментов в элемент уровня сетевой абстракции и передавать сигналы значений для одного или более параметров набора фрагментов, включенных в структуру синтаксиса уровня набора фрагментов.
[0054] Снова обращаясь к ФИГ. 1 отметим, что интерфейс 108 может включать в себя любое устройство, выполненное с возможностью приема данных, сгенерированных инкапсулятором 107 данных, а также передачи и/или сохранения данных в среде связи. Интерфейс 108 может включать в себя карту сетевого интерфейса, такую как карта Ethernet, и может включать в себя оптический приемопередатчик, радиочастотный приемопередатчик или устройство любого другого типа, способное отправлять и/или принимать информацию. Интерфейс 108 может дополнительно включать в себя интерфейс компьютерной системы, позволяющий сохранять файл в запоминающем устройстве. Например, интерфейс 108 может включать в себя набор микросхем, поддерживающий протоколы шины с взаимосвязью периферийных компонентов (PCI) и с экспресс-взаимосвязью периферийных компонентов (PCIe), проприетарные протоколы шин, протоколы универсальной последовательной шины (USB), I2C или любую другую логическую и физическую структуру, которую можно использовать для соединения одноранговых устройств.
[0055] Как показано на ФИГ. 1, устройство 120 назначения включает в себя интерфейс 122, декапсулятор 123 данных, видеодекодер 124 и дисплей 126. Интерфейс 122 может включать в себя любое устройство, выполненное с возможностью приема данных из среды связи. Интерфейс 122 может включать в себя карту сетевого интерфейса, такую как карта Ethernet, и может включать в себя оптический приемопередатчик, радиочастотный приемопередатчик или устройство любого другого типа, выполненное с возможностью приема и/или отправки информации. Интерфейс 122 может дополнительно включать в себя интерфейс компьютерной системы, позволяющий извлекать совместимый битовый поток видео из запоминающего устройства. Например, интерфейс 122 может включать в себя набор микросхем, поддерживающий протоколы шины PCI и PCIe, проприетарные протоколы шин, протоколы USB, I2C или любую другую логическую и физическую структуру, которую можно использовать для соединения одноранговых устройств. Декапсулятор 123 данных может быть выполнен с возможностью приема и анализа любого из примерных структур синтаксиса, описанных в настоящем документе.
[0056] Видеодекодер 124 может включать в себя любое устройство, выполненное с возможностью приема битового потока (например, извлечения битового подпотока MCTS) и/или его приемлемых вариаций и воспроизведения из него видеоданных. Дисплей 126 может включать в себя любое устройство, выполненное с возможностью отображения видеоданных. Дисплей 126 может предусматривать одно из множества устройств отображения, таких как жидкокристаллический дисплей (ЖКД), плазменный дисплей, дисплей на органических светодиодах (OLED) или дисплей другого типа. Дисплей 126 может включать в себя дисплей высокой четкости или дисплей сверхвысокой четкости. Следует отметить, что, хотя в проиллюстрированном на ФИГ. 1 примере видеодекодер 124 описан как выводящий данные на дисплей 126, видеодекодер 124 может быть выполнен с возможностью вывода видеоданных на устройства и/или их подкомпоненты различных типов. Например, видеодекодер 124 может быть выполнен с возможностью вывода видеоданных в любую среду связи, как описано в настоящем документе.
[0057] На ФИГ. 6 представлена блок-схема, иллюстрирующая пример видеодекодера, который может быть выполнен с возможностью декодирования видеоданных в соответствии с одной или более методиками согласно настоящему описанию. В одном примере видеодекодер 600 может быть выполнен с возможностью декодирования данных преобразования и восстановления остаточных данных из коэффициентов преобразования на основании декодированных данных преобразования. Видеодекодер 600 может быть выполнен с возможностью осуществления декодирования с внутренним прогнозированием и декодирования с внешним прогнозированием и, таким образом, может называться гибридным декодером. Видеодекодер 600 может быть выполнен с возможностью синтаксического анализа любой комбинации элементов синтаксиса, описанных выше в таблицах 1-27. Видеодекодер 600 может выполнять декодирование видеосигналов на основании значений синтаксически проанализированных элементов синтаксиса. Например, выполнение различных способов декодирования видеосигналов зависит от отношения изображения к конкретному типу.
[0058] В примере, представленном на ФИГ. 6, видеодекодер 600 включает в себя блок 602 энтропийного декодирования, блок 604 обратного квантования и обработки коэффициента преобразования, блок 606 обработки внутреннего прогнозирования, блок 608 обработки внешнего прогнозирования, сумматор 610, блок 612 концевой фильтрации и опорный буфер 614. Видеодекодер 600 может быть выполнен с возможностью декодирования видеоданных способом, совместимым с системой кодирования видеосигналов. Следует отметить, что, хотя указанный в примере видеодекодер 600 проиллюстрирован как имеющий различные функциональные блоки, такая иллюстрация предназначена только для описания и не ограничивает видеодекодер 600 и/или его подкомпоненты конкретной архитектурой аппаратного или программного обеспечения. Функции видеодекодера 600 могут быть реализованы с использованием любой комбинации аппаратных, программно-аппаратных и/или программных вариантов реализации.
[0059] Как показано на ФИГ. 6, блок 602 энтропийного декодирования принимает энтропийно закодированный битовый поток. Блок 602 энтропийного декодирования может быть выполнен с возможностью декодирования элементов синтаксиса и квантованных коэффициентов из битового потока в соответствии с процессом, обратным процессу энтропийного кодирования. Блок 602 энтропийного декодирования может быть выполнен с возможностью осуществления энтропийного декодирования в соответствии с любым из описанных выше способов энтропийного кодирования. Блок 602 энтропийного декодирования может определять значения для элементов синтаксиса в закодированном битовом потоке способом, совместимым со стандартом кодирования видеосигналов. Как показано на ФИГ. 6, блок 602 энтропийного декодирования может определять параметр квантования, значения квантованного коэффициента, данные преобразования и данные для прогнозирования из битового потока. В примере, представленном на ФИГ. 6, блок обратного квантования и блок 604 обработки коэффициента преобразования принимают параметр квантования, квантованные значения коэффициентов, данные преобразования и данные для прогнозирования от блока 602 энтропийного декодирования и выводят восстановленные остаточные данные.
[0060] Как также показано на ФИГ. 6, восстановленные остаточные данные могут быть переданы в сумматор 610, а сумматор 610 может добавлять восстановленные остаточные данные к прогнозируемому видеоблоку и генерировать восстановленные видеоданные. Прогнозируемый видеоблок может быть определен в соответствии с методикой прогнозирования видео (т. е. внутреннего прогнозирования и межкадрового прогнозирования). Блок 606 обработки внутреннего прогнозирования может быть выполнен с возможностью приема элементов синтаксиса внутреннего прогнозирования и извлечения прогнозируемого видеоблока из опорного буфера 614. Опорный буфер 614 может включать в себя запоминающее устройство, выполненное с возможностью хранения одного или более кадров видеоданных. Элементы синтаксиса внутреннего прогнозирования могут идентифицировать режим внутреннего прогнозирования, такой как описанные выше режимы внутреннего прогнозирования. Блок 608 обработки внешнего прогнозирования может принимать элементы синтаксиса внешнего прогнозирования и генерировать векторы движения для идентификации блока прогнозирования в одном или более опорных кадрах, хранящихся в опорном буфере 616. Блок 608 обработки внешнего прогнозирования выполнен с возможностью создания блоков с компенсацией движения с возможным выполнением интерполяции на основании интерполяционных фильтров. Идентификаторы интерполяционных фильтров, используемых для оценки движения с точностью до субпикселя, могут быть включены в элементы синтаксиса. Блок 608 обработки внешнего прогнозирования может использовать интерполяционные фильтры для вычисления интерполированных значений для субцелочисленных пикселей опорного блока. Блок 614 концевой фильтрации может быть выполнен с возможностью осуществления фильтрации восстановленных видеоданных. Например, блок 614 концевой фильтрации может быть выполнен с возможностью осуществления деблокирования и/или фильтрации с адаптивным смещением отсчетов (SAO), например, на основании параметров, указанных в битовом потоке. Кроме того, следует отметить, что в некоторых примерах блок 614 концевой фильтрации может быть выполнен с возможностью осуществления специализированной дискреционной фильтрации (например, визуальных улучшений, таких как уменьшения искажений, возникающих на изображении вблизи резких краев). Как показано на ФИГ. 6, восстановленный видеоблок может быть выведен видеодекодером 600. Таким образом, видеодекодер 600 представляет собой пример устройства, выполненного с возможностью осуществления синтаксического анализа значения для элемента синтаксиса в элементе уровня сетевой абстракции, указывающего на включение структуры синтаксиса уровня набора фрагментов в элемент уровня сетевой абстракции, синтаксического анализа значений для одного или более параметров набора фрагментов, включенных в структуру синтаксиса уровня набора фрагментов, и генерирования видеоданных на основании синтаксически проанализированных значений для одного или более параметров набора фрагментов.
[0061] В одном или более примерах описанные функции могут быть реализованы в виде аппаратного обеспечения, программного обеспечения, программно-аппаратного обеспечения или любой их комбинации. При реализации в программном обеспечении функции можно хранить или передавать в виде одной или более команд или кода на машиночитаемом носителе и выполнять аппаратным блоком обработки. Машиночитаемые носители могут включать в себя машиночитаемые носители данных, которые соответствуют материальным носителям, таким как носители данных, или среду связи, включающую в себя любую среду, обеспечивающую передачу компьютерной программы из одного местоположения в другое, например, согласно протоколу связи. Таким образом, машиночитаемые носители обычно могут соответствовать (1) материальным машиночитаемым носителям, которые являются энергонезависимыми, или (2) среде связи, такой как сигнал или несущая волна. Носители данных могут быть любыми доступными носителями, к которым может обращаться один или более компьютеров или один или более процессоров для извлечения команд, кода и/или структур данных для реализации методик, описанных в настоящем документе. Компьютерный программный продукт может включать в себя машиночитаемый носитель.
[0062] В качестве примера, но не для ограничения, такой машиночитаемый носитель может представлять собой RAM, ROM, EEPROM, CD-ROM или другой накопитель на оптических дисках, накопитель на магнитных дисках или другие магнитные запоминающие устройства, флеш-память, или любой другой носитель, который можно использовать для хранения требуемого программного кода в виде команд или структур данных и к которому может получать доступ компьютер. Кроме того, любое соединение, строго говоря, называется машиночитаемым носителем. Например, при передаче команд с веб-сайта, сервера или другого удаленного источника с использованием коаксиального кабеля, оптоволоконного кабеля, витой пары, цифровой абонентской линии (DSL) или беспроводных технологий, таких как инфракрасные, радио- и СВЧ-сигналы, коаксиальный кабель, оптоволоконный кабель, витая пара, DSL или беспроводные технологии, такие как инфракрасные, радио- и СВЧ-сигналы, включены в определение носителя/среды. Однако следует понимать, что машиночитаемые носители и носители данных не включают в себя соединения, несущие волны, сигналы или другие преходящие носители, а обозначают энергонезависимые материальные носители данных. В настоящем документе термин «диск» относится к диску, который воспроизводит данные оптическим способом с помощью лазеров, например компакт-диск (CD), лазерный диск, оптический диск, универсальный цифровой диск (DVD) и диск Blu-ray, и к диску, который обычно воспроизводит данные магнитным способом (например, гибкий диск). Комбинации вышеперечисленного также должны быть включены в объем термина «машиночитаемый носитель».
[0063] Команды могут быть выполнены одним или более процессорами, такими как один или более цифровых сигнальных процессоров (DSP), микропроцессоров общего назначения, специализированных интегральных схем (ASIC), программируемых пользователем вентильных матриц (FPGA) или других эквивалентных интегральных или дискретных логических схем. Соответственно, употребляемый в настоящем документе термин «процессор» может относиться к любой из вышеуказанных структур или к любой другой структуре, подходящей для реализации описанных в настоящем документе методик. Кроме того, в некоторых аспектах описанные в настоящем документе функциональные возможности могут быть обеспечены в специальных аппаратных и/или программных модулях, выполненных с возможностью кодирования и декодирования или включенных в комбинированный кодек. Кроме того, методики могут быть полностью реализованы в одной или более схемах или логических элементах.
[0064] Методики настоящего описания могут быть реализованы в самых разных устройствах или аппаратах, включая беспроводную телефонную трубку, интегральную схему (IC) или набор IC (например, набор микросхем). Различные компоненты, модули или блоки описаны в настоящем документе для выделения функциональных аспектов устройств, выполненных с возможностью осуществления описанных методик, но они не обязательно должны быть реализованы в виде различных аппаратных блоков. Скорее, как описано выше, различные блоки могут быть объединены в аппаратный блок кодека или представлены набором взаимодействующих аппаратных блоков, включая один или более процессоров, как описано выше, в сочетании с подходящим программным обеспечением и/или программно-аппаратным обеспечением.
[0065] Более того, каждый функциональный блок или различные элементы устройства базовой станции и терминального устройства, используемые в каждом из вышеупомянутых вариантов осуществления, могут быть реализованы или исполнены схемой, которая обычно представляет собой интегральную схему или множество интегральных схем. Схема, выполненная с возможностью исполнения функций, описанных в настоящем техническом описании, может содержать процессор общего назначения, цифровой сигнальный процессор (DSP), специализированную интегральную схему (ASIC) или интегральную схему общего применения, программируемую пользователем вентильную матрицу (FPGA) или другие программируемые логические устройства, схемы на дискретных компонентах или транзисторные логические схемы, дискретный аппаратный компонент или их комбинацию. Процессор общего назначения может представлять собой микропроцессор, или в альтернативном варианте осуществления процессор может представлять собой стандартный процессор, контроллер, микроконтроллер или машину состояний. Процессор общего назначения или каждая схема, описанная выше, могут быть сконфигурированы цифровой схемой или могут быть сконфигурированы аналоговой схемой. Дополнительно, когда по мере развития технологии полупроводниковых материалов появится технология изготовления интегральных схем, которая заменит собой существующие технологии изготовления интегральных схем, можно также использовать интегральную схему, изготовленную по данной технологии.
[0066] Описаны различные примеры. Эти и другие примеры включены в объем следующей формулы изобретения.
[0067] <Перекрестная ссылка>
Настоящая непредварительная заявка испрашивает приоритет согласно §119 раздела 35 Свода законов США по предварительной заявке на патент США № 62/734 232 от 20 сентября 2018 г., содержание которой полностью включено в настоящий документ путем ссылки.
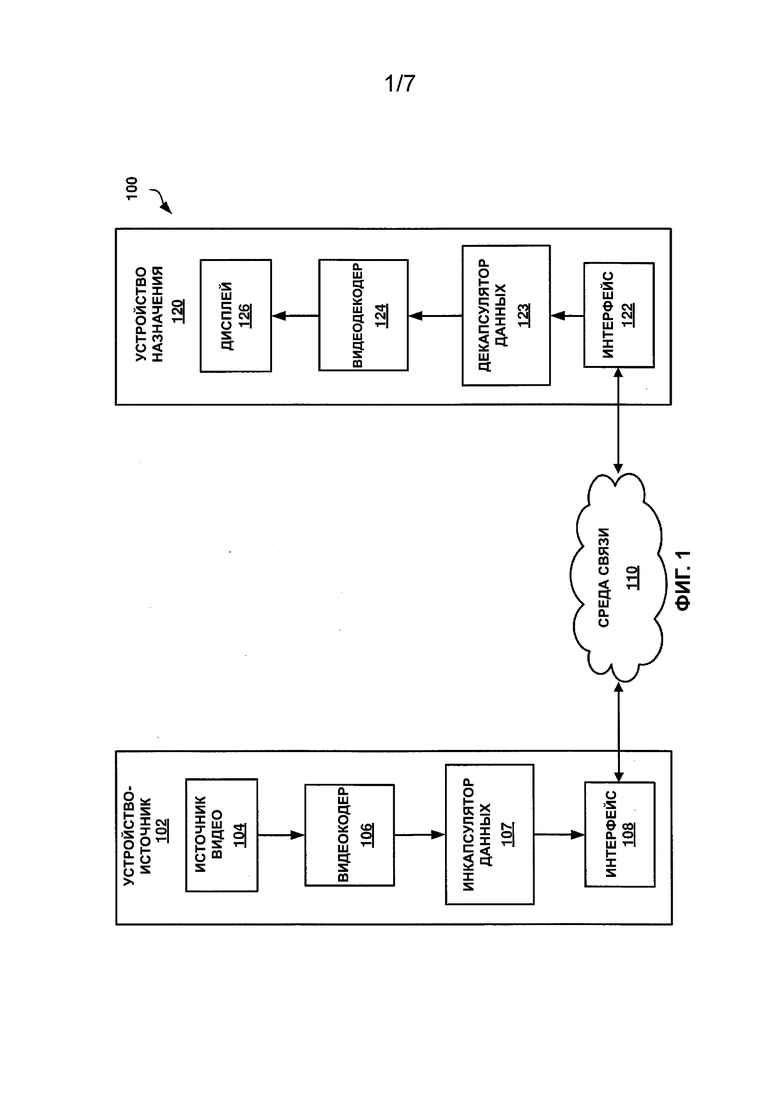
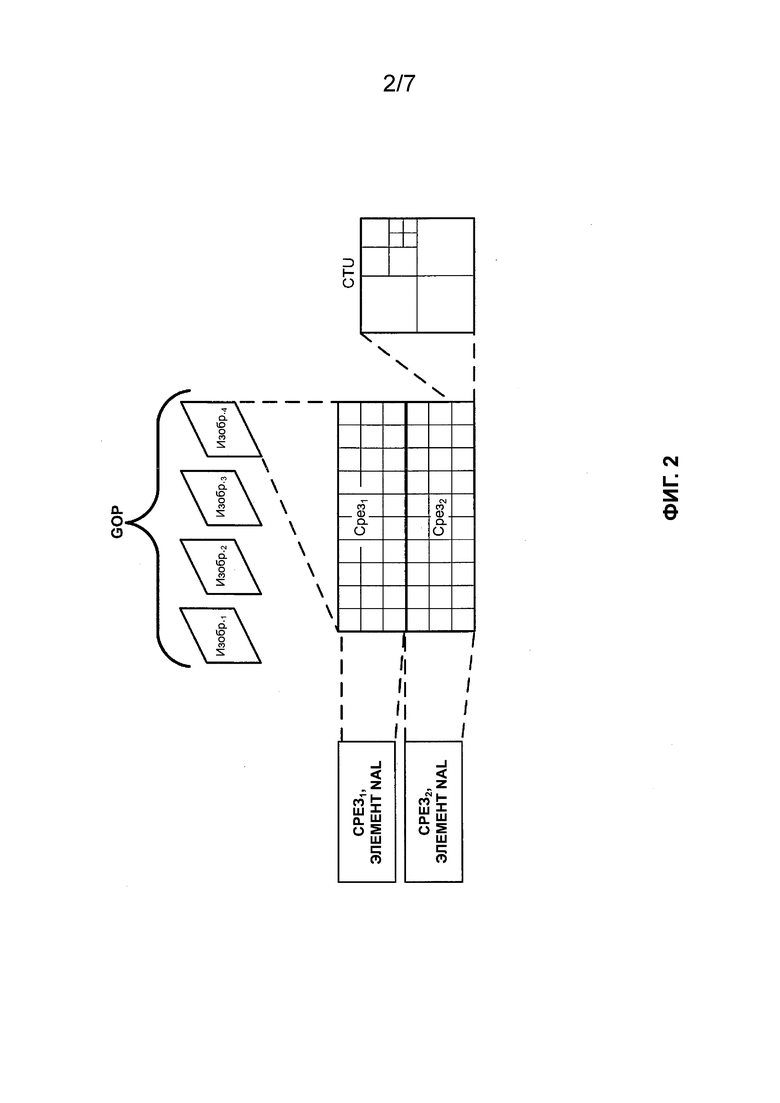
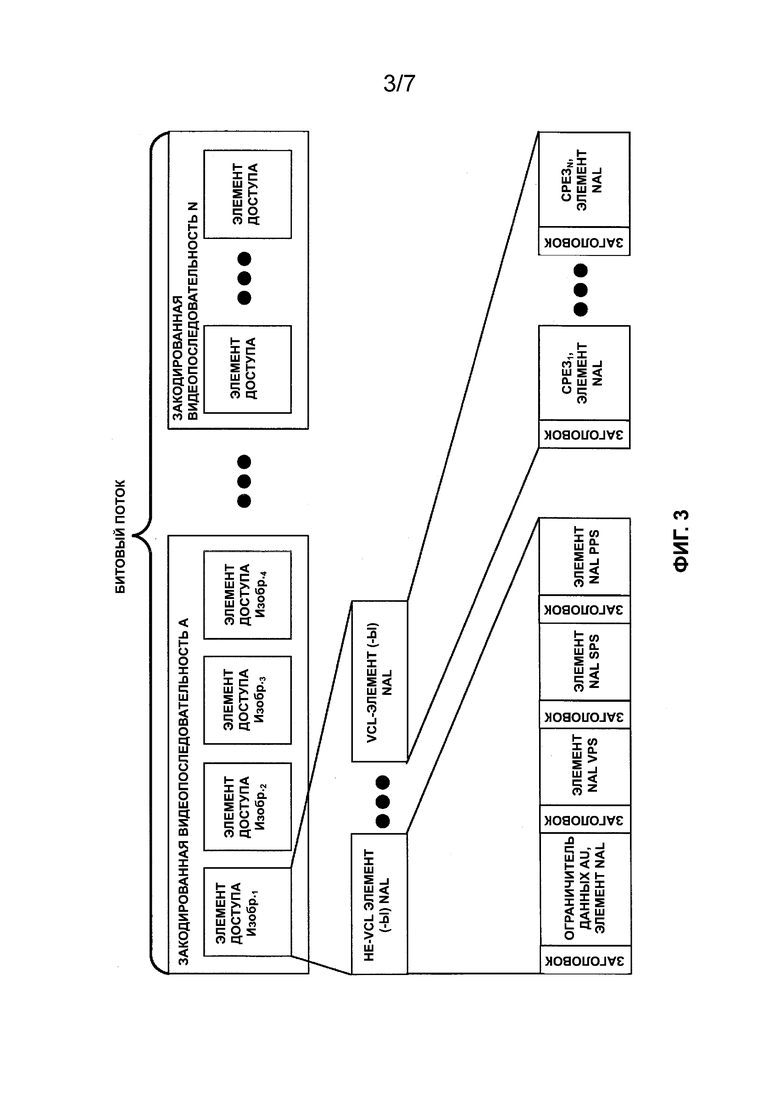

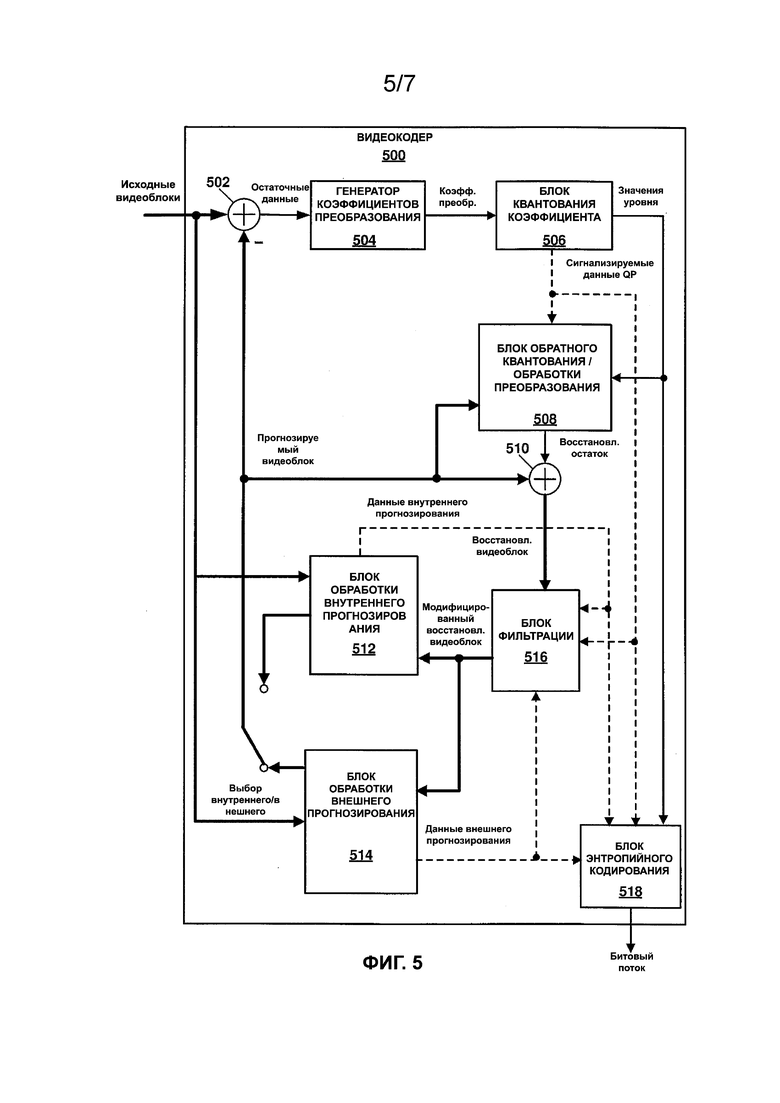


Изобретение относится к области кодирования видеосигналов, и в частности к технологиям сигнализации параметров набора фрагментов для закодированного видеосигнала. Технический результат заключается в повышении эффективности кодирования. Предложен способ сигнализации параметров набора фрагментов. Значение для элемента синтаксиса передают в элементе уровня сетевой абстракции (NAL). Значение для элемента синтаксиса указывает на то, что структура синтаксиса уровня набора фрагментов включена в элемент NAL. Передают значения для одного или более параметров набора фрагментов, включенных в структуру синтаксиса уровня набора фрагментов. 2 н. и 16 з.п. ф-лы, 7 ил., 29 табл.
1. Способ декодирования видеоданных, содержащий:
синтаксический анализ множества параметров изображения, включенного в заголовок изображения изображения в видеоданных;
синтаксический анализ текущего флага, включенного в заголовок подызображения, сгенерированного путем разделения изображения;
определение, основываясь на текущем флаге, определен ли конкретный один из множества параметров подызображения на основании заголовка подызображения или заголовка изображения, при этом конкретный один из множества параметров подызображения соответствует конкретному одному из множества параметров изображения, и
реконструкцию подызображения, основываясь на конкретном одном из множества параметров подызображения, когда конкретный один из множества параметров подызображения определен на основании заголовка подызображения, при этом
заголовок изображения не относится к уровню кодирования видеосигналов (не-VCL) элементов уровня сетевой абстракции (NAL) в видеоданных,
множество параметров изображения в заголовке изображения включают в себя по меньшей мере один из множества элементов синтаксиса и
множество элементов синтаксиса включает в себя разрешенный флаг на временное прогнозирование вектора движения (MVP), указывающий, является ли разрешенным для изображения временный предиктор вектора движения.
2. Способ по п. 1, содержащий также реконструкцию подызображения, основываясь на конкретном одном из множества параметров изображения, без синтаксического анализа конкретного одного из множества параметров подызображения из заголовка подызображения, когда конкретный один из множества параметров подызображения определен на основании заголовка изображения.
3. Способ по п. 1, в котором текущий флаг указывает, включен ли конкретный один из множества параметров подызображения в заголовок подызображения для переопределения конкретного одного из множества параметров изображения.
4. Способ по п. 1, в котором подызображение представляет собой набор фрагментов, включающий в себя один или более фрагментов, выделенных из изображения, и заголовок подызображения представляет собой заголовок набора фрагментов.
5. Способ по п. 1, в котором подызображение представляет собой срез, выделенный из изображения, и заголовок подызображения представляет собой заголовок среза.
6. Способ по п. 1, в котором множество элементов синтаксиса включает в себя флаг разности векторов движения (MVD), указывающий, выполнялся ли синтаксический анализ синтаксической структуры кодирования MVD, и
флаг MVD представляет собой flag mvd_l1_zero_flag.
7. Способ по п. 1, в котором:
множество элементов синтаксиса включает в себя флаг собранного изображения, указывающий, получено ли собранное изображение, использованное для временного MVP, из списка опорных изображений, имеющий номер списка, равный нулю.
8. Способ по п. 7, в котором:
разрешенный флаг MVP представляет собой flag pic_temporal_mvp_enabled_flag и
флаг собранного изображения представляет собой flag collocated_from_l0_flag.
9. Способ по п. 1, в котором:
выполняют синтаксический анализ конкретного одного из множества параметров подызображения из заголовка подызображения, когда текущий флаг равен единице, и
определяют, что конкретный один из множества параметров изображения должен равняться конкретному одному из множества параметров изображения, без синтаксического анализа конкретного одного из множества параметров подызображения из заголовка подызображения, когда текущий флаг равен нулю.
10. Электронное устройство для декодирования битового потока, содержащее:
по меньшей мере один процессор и
запоминающее устройство, соединенное с по меньшей мере одним процессором и хранящее программу, которая, при исполнении по меньшей мере одним процессором, побуждает по меньшей мере один процессор выполнять:
синтаксический анализ множества параметров изображения, включенного в заголовок изображения изображения в видеоданных;
синтаксический анализ текущего флага, включенного в заголовок подызображения, сгенерированного путем разделения изображения;
определение, основываясь на текущем флаге, определен ли конкретный один из множества параметров подызображения на основании заголовка подызображения или заголовка изображения, конкретный один из множества параметров подызображения соответствует конкретному одному из множества параметров изображения; и
реконструкцию подызображения, основываясь на конкретном одном из множества параметров подызображения, когда конкретный один из множества параметров подызображения определен из заголовка подызображения, при этом
заголовок изображения не относится к уровню кодирования видеосигналов (не-VCL) элементов уровня сетевой абстракции (NAL) в видеоданных,
множество параметров изображения в заголовке изображения включают в себя по меньшей мере один из множества элементов синтаксиса и
множество элементов синтаксиса включает в себя разрешенный флаг на временное прогнозирование вектора движения (MVP), указывающий, является ли разрешенным для изображения временный предиктор вектора движения.
11. Электронное устройство по п. 10, в котором множество инструкций, при исполнении по меньшей мере одним процессором, также побуждают по меньшей мере один процессор выполнять:
реконструкцию подызображения, основываясь на конкретном одном из множества параметров изображения, без синтаксического анализа конкретного одного из множества параметров подызображения из заголовка подызображения, когда конкретный один из множества параметров подызображения определен на основании заголовка изображения.
12. Электронное устройство по п. 10, в котором текущий флаг указывает, включен ли конкретный один из множества параметров подызображения в заголовок подызображения для переопределения конкретного одного из множества параметров изображения.
13. Электронное устройство по п. 10, в котором подызображение представляет собой набор фрагментов, включающий в себя один или более фрагментов, выделенных из изображения, и заголовок подызображения представляет собой заголовок набора фрагментов.
14. Электронное устройство по п. 10, в котором подызображение представляет собой срез, выделенный из изображения, и заголовок подызображения представляет собой заголовок среза.
15. Электронное устройство по п. 10, в котором множество элементов синтаксиса включает в себя флаг собранного изображения, указывающий, получено ли собранное изображение, использованное для временного MVP, из списка опорных изображений, имеющий номер списка, равный нулю, и
флаг собранного изображения представляет собой flag collocated_from_l0_flag.
16. Электронное устройство по п. 15, в котором множество элементов синтаксиса включает в себя флаг MVD, указывающий, выполнялся ли синтаксический анализ синтаксической структуры кодирования MVD.
17. Электронное устройство по п. 16, в котором:
разрешенный флаг MVP представляет собой flag pic_temporal_mvp_enabled_flag и
флаг MVD представляет собой flag mvd_l1_zero_flag.
18. Электронное устройство по п. 10, в котором:
синтаксический анализ конкретного одного из множества параметров подызображения из заголовка подызображения выполняют, когда текущий флаг равен единице, и
определяют, что конкретный один из множества параметров изображения должен равняться конкретному одному из множества параметров изображения, без синтаксического анализа конкретного одного из множества параметров подызображения из заголовка подызображения, когда текущий флаг равен нулю.
| СПОСОБ ДЕКОДИРОВАНИЯ ИЗОБРАЖЕНИЯ, СПОСОБ КОДИРОВАНИЯ ИЗОБРАЖЕНИЯ, УСТРОЙСТВО ДЕКОДИРОВАНИЯ ИЗОБРАЖЕНИЯ, УСТРОЙСТВО КОДИРОВАНИЯ ИЗОБРАЖЕНИЯ И УСТРОЙСТВО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ИЗОБРАЖЕНИЯ | 2013 |
|
RU2646333C2 |
| ПАРАЛЛЕЛЬНАЯ ОБРАБОТКА ВОЛНОВЫХ ФРОНТОВ ДЛЯ КОДИРОВАНИЯ ВИДЕО | 2013 |
|
RU2643652C2 |
| WO 2014168972 A1 | |||
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| US 2013101035 A1, 2013-04-25 | |||
| WO 2018011042 A1, 2018-01-18 | |||
| WANG, YE-KUI et al | |||
| Spec text for the agreed starting point on slicing and tiling, Joint Video Experts Team (JVET) of ITU-T SG16 WP3 and ISO/IEC JTC 1/SC 29/WG 11, 12th Meeting, Macao, [JVET-L0686-v2], | |||

