Настоящее изобретение относится к кодированию коэффициентов преобразования, таких как коэффициенты преобразования блока коэффициентов преобразования изображения.
В кодеках для блочного изображения и/или видеоизображение или кадр кодируется в единицах блоков. Среди них кодеки на основе преобразования подвергают блоки изображения или кадра преобразованию для получения блоков коэффициентов преобразования. Например, изображение или кадр может кодироваться с предсказанием, причем остаток предсказания кодируется с преобразованием в единицах блоков и затем кодируются результирующие уровни коэффициентов преобразования коэффициентов преобразования этих блоков преобразования, используя энтропийное кодирование.
Чтобы повысить эффективность энтропийного кодирования, используются контексты, чтобы точно оценить вероятность символов уровней коэффициента преобразования, подлежащих кодированию. Однако в последние годы повысились требования, налагаемые на кодеки картинок и/или изображений. В дополнение к яркостной и цветовой составляющим кодеки иногда должны передавать карты глубины, значения прозрачности и т. п. Кроме того, размеры блока преобразования являются переменными во все большем и большем интервале. Вследствие этого многообразия кодеки имеют все большее и большее количество разных контекстов с разными функциями для определения контекста из уже кодированных коэффициентов преобразования.
Другой возможностью достижения высокой степени сжатия при умеренной сложности является насколько возможно точная корректировка схемы символизации статистики коэффициентов. Однако, чтобы точно выполнять эту адаптацию к фактической статистике, также является обязательным учет различных факторов, тем самым делая необходимым огромное количество различающихся схем символизации.
Следовательно, существует потребность в сохранении низкой сложности кодирования коэффициентов преобразования, в то же время поддерживая возможность достижения высокой эффективности кодирования.
Задачей настоящего изобретения является обеспечение такой схемы кодирования коэффициентов преобразования.
Эта задача достигается предметом находящихся на рассмотрении независимых пунктов формулы изобретения.
Согласно аспекту настоящего изобретения устройство для кодирования множества коэффициентов преобразования, имеющих уровни коэффициента преобразования, в поток содержит символизатор, выполненный с возможностью отображения текущего коэффициента преобразования на первый набор из одного или нескольких символов в соответствии с первой схемой символизации, причем уровень коэффициента преобразования текущего коэффициента преобразования находится в пределах первого интервала уровней, и, если уровень коэффициента преобразования текущего коэффициента преобразования находится в пределах второго интервала уровней, на объединение из второго набора символов, на который отображается максимальный уровень первого интервала уровней в соответствии с первой схемой символизации, и третьего набора символов в зависимости от положения уровня коэффициента преобразования текущего коэффициента преобразования в пределах второго интервала уровней, в соответствии со второй схемой символизации, которая является параметризуемой в соответствии с параметром символизации. Кроме того, устройство содержит контекстно-адаптивный энтропийный кодер, выполненный с возможностью, если уровень коэффициента преобразования текущего коэффициента преобразования находится в пределах первого интервала уровней, энтропийного кодирования первого набора из одного или нескольких символов в поток данных, и, если уровень коэффициента преобразования текущего коэффициента преобразования находится в пределах второго интервала уровней, энтропийного кодирования второго набора из одного или нескольких символов в поток данных, в котором контекстно-адаптивный энтропийный кодер выполнен с возможностью, при энтропийном кодировании по меньшей мере одного предопределенного символа второго набора из одного или нескольких символов в поток данных, использования контекста в зависимости, посредством функции, параметризуемой посредством параметра функции, с параметром функции, установленным в первую установку, от ранее кодированного коэффициента преобразования. Кроме того, устройство содержит определитель параметра символизации, выполненный с возможностью, если уровень коэффициента преобразования текущего коэффициента преобразования находится в пределах второго интервала уровней, определения параметра символизации для отображения на третий набор символов в зависимости, посредством функции с параметром функции, установленным на вторую установку, от ранее кодированных коэффициентов преобразования. Средство вставки выполнено с возможностью, если уровень коэффициента преобразования текущего коэффициента преобразования находится в пределах второго интервала уровней, вставки третьего набора символов в поток данных.
Согласно другому аспекту настоящего изобретения устройство для кодирования множества коэффициентов преобразования разных блоков преобразования, причем каждый имеет уровень коэффициента преобразования, в поток данных содержит символизатор, выполненный с возможностью отображения уровня коэффициента преобразования для текущего коэффициента преобразования в соответствии со схемой символизации, которая является параметризуемой в соответствии с параметром символизации, на набор символов; средство вставки, выполненное с возможностью вставки набора символов для текущего коэффициента преобразования в поток данных; и определитель параметра символизации, выполненный с возможностью определения параметра символизации для текущего коэффициента преобразования в зависимости, посредством функции, параметризуемой посредством параметра функции, от ранее обработанных коэффициентов преобразования, в котором устройства вставки, десимволизатор и определитель параметра символизации выполнены с возможностью последовательной обработки коэффициентов преобразования разных блоков преобразования, в котором параметр функции изменяется в зависимости от размера блока преобразования текущего коэффициента преобразования, типа информационной составляющей блока преобразования текущего коэффициента преобразования и/или частотного участка, на котором располагается текущий коэффициент преобразования в блоке преобразования.
Идеей настоящего изобретения является использование одной и той же функции для зависимости контекста и зависимости параметра символизации от ранее кодированных/декодированных коэффициентов преобразования. Использование одной и той же функции - с изменяющимся параметром функции - может даже использоваться в отношении разных размеров блока преобразования и/или частотных участков блоков преобразования в случае коэффициентов преобразования, пространственно расположенных в блоках преобразования. Другой разновидностью этой идеи является использование одной и той же функции для зависимости параметра символизации от ранее кодированных/декодированных коэффициентов преобразования для различных размеров блока преобразования текущего коэффициента преобразования, разных типов информационной составляющей блока преобразования текущего коэффициента преобразования и/или разных частотных участков, на которых располагается текущий коэффициент преобразования в блоке преобразования.
Подробные и выгодные аспекты настоящего изобретения являются предметом зависимых пунктов формулы изобретения. Кроме того, предпочтительные варианты осуществления настоящего изобретения описываются ниже в отношении фигур, среди которых:
фиг. 1 изображает схему блока коэффициентов преобразования, содержащего коэффициенты преобразования, подлежащие кодированию, и изображает совместное использование параметризуемой функции для выбора контекста и определения параметра символизации в соответствии с вариантом осуществления настоящего изобретения;
фиг. 2 изображает схему принципа символизации для уровней коэффициента преобразования, использующего две разные схемы в двух интервалах уровней;
фиг. 3 изображает схематический график двух кривых вероятности появления, определенных по возможным уровням коэффициента преобразования для двух разных контекстов;
фиг. 4 изображает блок-схему устройства для кодирования множества коэффициентов преобразования согласно варианту осуществления;
фиг. 5a и 5b изображают схемы структуры для результирующего потока данных согласно разным вариантам осуществления;
фиг. 6 изображает блок-схему кодера изображений согласно варианту осуществления;
фиг. 7 изображает блок-схему устройства для декодирования множества коэффициентов преобразования согласно варианту осуществления;
фиг. 8 изображает блок-схему декодера изображений согласно варианту осуществления;
фиг. 9 изображает схему блока коэффициентов преобразования для иллюстрации сканирования и шаблона согласно варианту осуществления;
фиг. 10 изображает блок-схему устройства для декодирования множества коэффициентов преобразования согласно другому варианту осуществления;
фиг. 11a и 11b изображают схемы принципов символизации для уровней коэффициента преобразования, объединяющих две или три разные схемы в пределах частичных интервалов всего диапазона интервалов;
фиг. 12 изображает блок-схему устройства для кодирования множества коэффициентов преобразования согласно другому варианту осуществления; и
фиг. 13 изображает схему блока коэффициентов преобразования для иллюстрации, согласно другому варианту осуществления, порядка сканирования среди блоков коэффициентов преобразования, следуя порядку подблоков, определенному среди подблоков, на которые блок коэффициентов преобразования подразделяется, чтобы иллюстрировать другой вариант осуществления для разработки параметризуемой функции для выбора контекста и определения параметра символизации.
В отношении описания ниже отмечается, что одни и те же ссылочные позиции используются на этих фигурах для элементов, встречающихся на более чем одной из этих фигур. Следовательно, описание такого элемента в отношении одной фигуры в равной степени должно применяться к описанию другой фигуры, на которой встречается этот элемент.
Кроме того, описание, представленное ниже, предварительно предполагает, что коэффициенты преобразования кодируются как двумерно расположенные, чтобы формировать блок преобразования, такой как блок преобразования картинки. Однако настоящая заявка не ограничивается кодированием изображения и/или видео. Скорее, подлежащие кодированию коэффициенты преобразования альтернативно могут представлять собой коэффициенты преобразования одномерного преобразования, такого как, например, используемые, например, при кодировании аудио или т. п.
Чтобы объяснить проблемы, с которыми сталкиваются варианты осуществления, описанные ниже, и то, как варианты осуществления, описанные ниже, решают эти проблемы, ссылка предварительно делается на фиг. 1-3, которые изображают пример коэффициентов преобразования блока преобразования и их общий метод энтропийного кодирования, который затем улучшается описанными ниже вариантами осуществления.
Фиг. 1 в качестве примера изображает блок 10 коэффициентов 12 преобразования. В настоящем варианте осуществления коэффициенты преобразования расположены двумерно. В частности, они показаны в качестве примера как регулярно расположенные по столбцам и строкам, хотя также возможно другое двумерное расположение. Преобразованием, которое привело к коэффициентам 12 преобразования или блоку 10 преобразования, может быть дискретное косинусное преобразование (DCT) или некоторое другое преобразование, которое разбивает блок (преобразования) картинки, например, или некоторый другой блок пространственно расположенных значений на составляющие с разной пространственной частотой. В настоящем примере на фиг. 1 коэффициенты 12 преобразования расположены двумерно в столбцах i и строках j, чтобы соответствовать частотным парам (fx(i), fy(j)) частот fx(i), fy(j), измеренных по разным пространственным направлениям x, y, таким как направления, перпендикулярные друг другу, где fx/y(i)<fx/y(i+1), и (i, j) представляет собой положение соответствующего коэффициента в блоке 10 преобразования.
Часто коэффициенты 12 преобразования, соответствующие более низким частотам, имеют более высокие уровни коэффициента преобразования по сравнению с коэффициентами преобразования, соответствующими более высоким частотам. Следовательно, часто многие коэффициенты преобразования около составляющих с самыми высокими частотами блока 10 преобразования квантуются в ноль и могут не иметь необходимости кодирования. Скорее, порядок 14 сканирования может определяться среди коэффициентов 12 преобразования, который одномерно располагает двумерно расположенные коэффициенты 12 (i, j) преобразования в последовательность коэффициентов по порядку, т. е. (i, j)→k, так что вероятно, что уровни коэффициента преобразования имеют тенденцию монотонного уменьшения по этому порядку, т. е. вероятно, что уровень коэффициента коэффициента k больше уровня коэффициента коэффициента k+1.
Например, зигзагообразное или растровое сканирование может определяться среди коэффициентов 12 преобразования. В соответствии со сканированием блок 10 может сканироваться по диагоналям, например, от коэффициента преобразования составляющей постоянного тока (DC) (верхний левый коэффициент) до коэффициента преобразования с самой большой частотой (нижний правый коэффициент) или наоборот. Альтернативно может использоваться сканирование по строкам или по столбцам коэффициентов преобразования между только что упомянутыми коэффициентами преобразования крайних составляющих.
Как описано дополнительно ниже, при кодировании блока преобразования положение последнего ненулевого коэффициента L преобразования в порядке 14 сканирования сначала может кодироваться в поток данных, причем затем просто кодируются коэффициенты преобразования из DC-коэффициента преобразования по пути 14 сканирования до последнего ненулевого коэффициента L преобразования - необязательно по этому направлению или противоположному направлению.
Коэффициенты 12 преобразования имеют уровни коэффициента преобразования, которые могут быть со знаком или без знака. Например, коэффициенты 12 преобразования могут быть получены посредством вышеупомянутого преобразования с последующим квантованием в набор возможных значений квантования, причем каждый ассоциируется с соответствующим уровнем коэффициента преобразования. Функция квантования, используемая для квантования коэффициентов преобразования, т. е. отображения коэффициентов преобразования на уровни коэффициента преобразования, может быть линейной или нелинейной. Другими словами, каждый коэффициент 12 преобразования имеет уровень коэффициента преобразования из интервала возможных уровней. Фиг. 2, например, изображает пример, где уровни x коэффициента преобразования определяются в диапазоне уровней [0, 2N-1]. Согласно альтернативному варианту осуществления может не быть верхней границы диапазона интервала. Кроме того, фиг. 2 иллюстрирует только положительные уровни коэффициента преобразования, хотя они также могут быть со знаком. Что касается знаков коэффициентов 12 преобразования и их кодирования, необходимо отметить, что существуют разные возможности в отношении всех вариантов осуществления, кратко изложенных ниже, чтобы кодировать эти знаки, и все эти возможности должны быть в пределах объема этих вариантов осуществления. Что касается фиг. 2, это означает, что также может не быть нижней границы интервала диапазона уровней коэффициента преобразования.
В любом случае, чтобы кодировать уровни коэффициента преобразования коэффициентов 12 преобразования, используются разные схемы символизации, чтобы охватывать разные участки или интервалы 16, 18 интервала 20 диапазона. Более точно, уровни коэффициента преобразования в пределах первого интервала 16 уровней, за исключением тех, которые равны максимальному уровню первого интервала 16 уровней, могут просто символизироваться в набор из одного или нескольких символов в соответствии с первой схемой символизации. Уровни коэффициента преобразования, однако, лежащие в пределах второго интервала 18 уровней, отображаются на объединение наборов символов первой и второй схем символизации. Как будет отмечено ниже, третий и дальнейшие интервалы могут следовать, соответствующим образом, за вторым интервалом.
Как показано на фиг. 2, второй интервал 18 уровней лежит выше первого интервала 16 уровней, но перекрывается с последним на максимальном уровне первого интервала 16 уровней, которым является 2 в примере на фиг. 2. Для уровней коэффициента преобразования, лежащих в пределах второго интервала 18 уровней, соответствующий уровень отображается на объединение первого набора символов, соответствующего максимальному уровню первого интервала уровней в соответствии с первой схемой символизации, и второго набора символов в зависимости от положения уровня коэффициента преобразования в пределах второго интервала 18 уровней в соответствии со второй схемой символизации.
Другими словами, первая схема 16 символизации отображает уровни, охватываемые первым интервалом 16 уровней, на набор первых последовательностей символов. Изобретатели просят отметить, что длительность последовательностей символов в пределах набора последовательностей символов первой схемы символизации может даже быть просто одним двоичным символом в случае двоичного алфавита и в случае первого интервала 16 уровней, просто охватывающего два уровня коэффициента преобразования, таких как 0 и 1. Согласно варианту осуществления настоящей заявки, первая схема символизации представляет собой усеченную унарную бинаризацию уровней в интервале 16. В случае двоичного алфавита символы могут называться бинами.
Как описано более подробно ниже, вторая схема символизации отображает уровни в пределах второго интервала 18 уровней на набор вторых последовательностей символов с изменяющейся длительностью, причем вторая схема символизации является параметризуемой в соответствии с параметром символизации. Вторая схема символизации может отображать уровни в пределах интервала 18, т. е. x - максимальный уровень первого интервала, на код Райса, имеющий параметр Райса.
В частности, вторая схема 18 символизации может быть выполнена так, что параметр символизации изменяет частоту, с которой длительность последовательностей символов второй схемы увеличивается от нижней границы второго интервала 18 уровней до его верхней границы. Очевидно, что увеличенная длительность последовательностей символов расходует большую частоту передачи данных в потоке данных, в который должны кодироваться коэффициенты преобразования. Обычно предпочтительно, если длительность последовательности символов, на которую отображается некоторый уровень, коррелируется с фактической вероятностью, с которой уровень коэффициента преобразования, подлежащий кодированию в данный момент, принимает соответствующий уровень. Конечно, последнее утверждение также действительно для уровней вне второго интервала 18 уровней в пределах первого интервала 16 уровней или для первой схемы символизации в общем.
В частности, как показано на фиг. 3, коэффициенты преобразования обычно проявляют некоторую статистику или вероятность появления некоторых уровней коэффициента преобразования. Фиг. 3 изображает график, ассоциирующий с каждым возможным уровнем x коэффициента преобразования вероятность, с которой соответствующий уровень коэффициента преобразования фактически принимается рассматриваемым коэффициентом преобразования. Более точно фиг. 3 изображает две такие ассоциации или кривые распределения вероятности, а именно для двух коэффициентов разных контекстов. Т. е. фиг. 3 предполагает, что коэффициенты преобразования различаются по их контексту, такому как определенному значениями коэффициента преобразования соседних коэффициентов преобразования. В зависимости от контекста фиг. 3 изображает, что кривая распределения вероятности, которая ассоциирует значение вероятности с каждым уровнем коэффициента преобразования, может зависеть от контекста рассматриваемого коэффициента преобразования.
Согласно описанным ниже вариантам осуществления символы последовательностей символов первой схемы 16 символизации энтропийно кодируются контекстно-адаптивным образом. Т. е. контекст ассоциируется с символами, и распределение вероятностей алфавита, ассоциированное с выбранным контекстом, используется для энтропийного кодирования соответствующего символа. Символы последовательностей символов второй схемы символизации вставляются в поток данных непосредственно или используя распределение фиксированной вероятности алфавита, такое равновероятное распределение, согласно которому все элементы алфавита равновероятны.
Контексты, используемые при энтропийном кодировании символов первой схемы символизации, должны выбираться надлежащим образом, чтобы иметь возможность получения хорошей адаптации оцененного распределения вероятности алфавита к фактической статистике алфавита. Т. е. схема энтропийного кодирования может быть выполнена с возможностью обновления текущей оценки распределения вероятности алфавита контекста, всякий раз когда кодируется/декодируется символ, имеющий этот контекст, тем самым аппроксимируя фактическую статистику алфавита. Аппроксимация является более быстрой, если контексты выбираются надлежащим образом, т. е. достаточно точно, но не со слишком многими разными контекстами, чтобы избежать слишком редкой ассоциации символов с некоторыми контекстами.
Подобно параметр символизации для коэффициента должен выбираться в зависимости от ранее кодированных/декодированных коэффициентов, чтобы аппроксимировать фактическую статистику алфавита максимально точно. Слишком детальное многообразие не является критическим вопросом в данном случае, так как параметр символизации непосредственно определяется из ранее кодированных/декодированных коэффициентов, но определение должно точно соответствовать корреляции зависимости кривой распределения вероятности во втором интервале 18 от ранее кодированных/декодированных коэффициентов.
Как описано более подробно ниже, варианты осуществления для кодирования коэффициентов преобразования, дополнительно описанные ниже, являются полезными в том, что общая функция используется для достижения адаптивности контекста и определения параметра символизации. Является важным выбор правильного контекста, как подчеркнуто выше, для достижения высокой эффективности кодирования или степени сжатия, и это же применимо в отношении параметра символизации. Варианты осуществления, описанные ниже, позволяют достигать этой цели поддержанием низкими издержек для конкретизации зависимости от ранее кодированных/декодированных коэффициентов. В частности, изобретатели настоящей заявки нашли способ нахождения хорошего компромисса между реализацией эффективной зависимости от ранее кодированных/декодированных коэффициентов с одной стороны и уменьшением количества проприетарной логики для конкретизации индивидуальных зависимостей контекста с другой стороны.
Фиг. 4 изображает устройство для кодирования множества коэффициентов преобразования, имеющих уровни коэффициента преобразования, в поток данных согласно варианту осуществления настоящего изобретения. Отмечается, что в последующем описании предполагается, что алфавитом символов является двоичный алфавит, хотя это предположение, как подчеркнуто выше, не является критичным для настоящего изобретения, и, следовательно, все эти объяснения должны интерпретироваться только как иллюстративные для расширения на другие алфавиты символов.
Устройство по фиг. 4 предназначено для кодирования множества коэффициентов преобразования, поступающих на вход 30, в поток 32 данных. Устройство содержит символизатор 34, контекстно-адаптивный энтропийный кодер 36, определитель 38 параметра символизации и устройство 40 вставки.
Символизатор 34 имеет свой вход, подсоединенный ко входу 30, и выполнен с возможностью отображения текущего коэффициента преобразования, поступающего в данный момент на его вход, на символы таким образом, который описан выше в отношении фиг. 2. Т. е. символизатор 34 выполнен с возможностью отображения текущего коэффициента преобразования на первый набор из одного или нескольких символов в соответствии с первой схемой символизации, если уровень x коэффициента преобразования текущего коэффициента преобразования находится в пределах первого интервала 16 уровней, и, если уровень коэффициента преобразования текущего коэффициента преобразования находится в пределах второго интервала 18 уровней, на объединение второго набора символов, на который отображается максимальный уровень первого интервала 16 уровней в соответствии с первой схемой символизации, и третьего набора символов в зависимости от положения уровня коэффициента преобразования текущего коэффициента преобразования в пределах второго интервала 18 уровней в соответствии со второй схемой символизации. Другими словами, символизатор 34 выполнен с возможностью отображения текущего коэффициента преобразования на первую последовательность символов первой схемы символизации, в случае если уровень коэффициента преобразования текущего коэффициента преобразования находится в пределах первого интервала 16 уровней, но вне второго интервала уровней, и на объединение последовательности символов первой схемы символизации для максимального уровня первого интервала 16 уровней и последовательности символов второй схемы символизации, в случае если уровень коэффициента преобразования текущего коэффициента преобразования находится в пределах второго интервала уровней.
Символизатор 34 имеет два выхода, а именно один для последовательностей символов первой схемы символизации, и другой - для последовательностей символов второй схемы символизации. Устройство 40 вставки имеет вход для приема последовательностей 42 символов второй схемы символизации, и контекстно-адаптивный энтропийный кодер 36 имеет вход для приема последовательностей 44 символов первой схемы символизации. Кроме того, символизатор 34 имеет вход параметра для приема параметра 46 символизации с выхода определителя 38 параметра символизации.
Контекстно-адаптивный энтропийный кодер 36 выполнен с возможностью энтропийного кодирования символа первых последовательностей 44 символов в поток 32 данных. Устройство 40 вставки выполнено с возможностью вставки последовательностей 42 символов в поток 32 данных.
Вообще говоря, как энтропийный кодер 36, так и устройство 40 вставки последовательно сканируют коэффициенты преобразования. Очевидно, что устройство 40 вставки просто работает для коэффициентов преобразования, уровень коэффициента преобразования которых лежит в пределах второго интервала 18 уровней. Однако, как более подробно описано ниже, существуют разные возможности для определения порядка между работой энтропийного кодера 36 и устройства 40 вставки. Согласно первому варианту осуществления устройство кодирования по фиг. 4 выполнено с возможностью сканирования коэффициентов преобразования при одном единственном сканировании, так что устройство 40 вставки вставляет последовательность 42 символов коэффициента преобразования в поток 32 данных после энтропийного кодирования энтропийного кодера первой последовательности 44 символов, относящейся к этому же коэффициенту преобразования, в поток 32 данных и перед энтропийным кодированием энтропийного кодера последовательности 44 символов, относящейся к следующему коэффициенту преобразования в строке, в поток данных 32.
Согласно альтернативному варианту осуществления устройство использует два сканирования, в котором во время первого сканирования контекстно-адаптивный энтропийный кодер 36 последовательно кодирует последовательности 44 символов в поток 32 данных для каждого коэффициента преобразования, причем устройство 40 вставки затем вставляет последовательности 42 символов для тех коэффициентов преобразования, уровень коэффициента преобразования которых лежит в пределах второго интервала 18 уровней. Могут быть еще более сложные схемы, согласно которым, например, контекстно-адаптивный энтропийный кодер 36 использует несколько сканирований для кодирования индивидуальных символов первых последовательностей 44 символов в поток 32 данных, такой как первый символ или бин в первом сканировании, за которым следует второй символ или бин последовательностей 44 во втором сканировании и т. д.
Как уже указано выше, контекстно-адаптивный энтропийный кодер 36 выполнен с возможностью энтропийного кодирования по меньшей мере одного предопределенного символа последовательностей 44 символов в поток 32 данных контекстно-адаптивным образом. Например, адаптивность контекста может использоваться для всех символов последовательностей 44 символов. Альтернативно контекстно-адаптивный энтропийный кодер 36 может ограничивать адаптивность контекста только символами в первом положении и последовательностями символов первой схемы символизации, или в первом и втором, или в первом-третьем положениях и т. д.
Как описано выше, для адаптивности контекста кодер 36 управляет контекстами посредством сохранения и обновления оценки распределения вероятности алфавита для каждого контекста. Каждый раз, когда кодируется символ некоторого контекста, обновляется сохраненная на данный момент оценка распределения вероятности алфавита, используя фактическое значение этого символа, таким образом аппроксимируя фактическую статистику алфавита этого контекста.
Аналогично определитель 38 параметра символизации выполнен с возможностью определения параметра 46 символизации для второй схемы символизации и ее последовательностей 42 символов в зависимости от ранее кодированных коэффициентов преобразования.
Более точно, контекстно-адаптивный энтропийный кодер 36 выполнен так, что он использует, или выбирает, для текущего коэффициента преобразования контекст в зависимости, посредством функции, параметризуемой посредством параметра функции, и с параметром функции, установленным на первую установку, от ранее кодированных коэффициентов преобразования, тогда как определитель 38 параметра символизации выполнен с возможностью определения параметра 46 символизации в зависимости, посредством этой же функции и с параметром функции, установленным на вторую установку, от ранее кодированных коэффициентов преобразования. Установки могут отличаться, но, тем не менее, так как определитель 38 параметра символизации и контекстно-адаптивный энтропийный кодер 36 используют одну и ту же функцию, могут быть уменьшены издержки логики. Только параметр функции может различаться между выбором контекста энтропийного кодера 36 с одной стороны и определением параметра символизации определителя 38 параметра символизации с другой стороны.
Что касается зависимости от ранее кодированных коэффициентов преобразования, необходимо отметить, что эта зависимость ограничивается до степени, с которой эти ранее кодированные коэффициенты преобразования уже были кодированы в поток 32 данных. Полагая, например, что такой ранее кодированный коэффициент преобразования лежит в пределах второго интервала 18 уровней, но его последовательность 42 символов еще не была вставлена в поток 32 данных. В этом случае определитель 38 параметра символизации и контекстно-адаптивный энтропийный кодер 36 просто знают из первой последовательности 44 символов этот ранее кодированный коэффициент преобразования, который лежит в пределах второго интервала 18 уровней. В этом случае максимальный уровень первого интервала 16 уровней может служить в качестве представителя для этого ранее кодированного коэффициента преобразования. Поскольку зависимость «от ранее кодированных коэффициентов преобразования» должна быть понятна широким образом, чтобы охватывать зависимость от «информации о других коэффициентах преобразования, ранее кодированных/вставленных в поток 32 данных». Кроме того, коэффициенты преобразования, лежащие «за пределами» положения последнего ненулевого коэффициента L, могут подразумеваться равными нулю.
Чтобы завершить описание фиг. 4, выходы энтропийного кодера 36 и устройства 40 вставки показаны подсоединенными к общему выходу 48 устройства через переключатель 50, эта же соединяемость существует между входами для ранее вставленной/кодированной информации определителя 38 параметра символизации и контекстно-адаптивного энтропийного кодера 36 с одной стороны и выходами энтропийного кодера 36 и устройства 40 вставки с другой стороны. Переключатель 50 соединяет выход 48 с любым одним из выходов энтропийного кодера 36 и устройства 40 вставки в порядке, упомянутом выше в отношении различных возможностей использования одного, двух или трех сканирований для кодирования коэффициентов преобразования.
Чтобы объяснить общее использование параметризуемой функции в отношении контекстно-адаптивного энтропийного кодера 36 и определителя 38 параметра символизации более конкретными терминами, ссылка делается на фиг. 1. Функция, которая совместно используется энтропийным кодером 36 и определителем 38 параметра символизации, указывается позицией 52 на фиг. 1, а именно g(f(x)). Функция применяется к набору ранее кодированных коэффициентов преобразования, которые, как объяснено выше, могут определяться так, чтобы охватывать эти ранее кодированные коэффициенты, имеющие некоторую пространственную зависимость относительно текущего коэффициента. Конкретные варианты осуществления для этой функции изложены более подробно ниже. Вообще говоря, f представляет собой функцию, которая объединяет набор уровней ранее кодированных коэффициентов в скалярную величину, в которой g представляет собой функцию, которая проверяет, в каком интервале лежит скалярная величина. Другими словами, функция g(f(x)) применяется к набору x ранее кодированных коэффициентов преобразования. На фиг. 1 коэффициент 12 преобразования, указанный малым крестиком, обозначает, например, текущий коэффициент преобразования, и заштрихованные коэффициенты 12 преобразования указывают набор x коэффициентов преобразования, к которым применяется функция 52 для получения параметра 46 символизации и индекса 54 энтропийного контекста, индексирующего контекст для текущего коэффициента x преобразования. Как показано на фиг. 1, локальный шаблон, определяющий относительное пространственное расположение вокруг текущего коэффициента преобразования, может использоваться для определения набора x относящихся, ранее кодированных коэффициентов преобразования из всех ранее кодированных коэффициентов преобразования. Как можно видеть на фиг. 1, шаблон 56 может охватывать непосредственно соседний коэффициент преобразования ниже и справа от текущего коэффициента преобразования. Посредством выбора шаблона, подобного этому, последовательности 42 и 44 символов коэффициентов преобразования на одной диагонали сканирования 140 могут кодироваться параллельно, так как ни один из коэффициентов преобразования на диагонали не попадает в шаблон 56 другого коэффициента преобразования на этой же диагонали. Конечно, подобные шаблоны могут быть найдены для сканирований по строкам и столбцам.
Чтобы обеспечить более точные примеры для обычно используемой функции g(f(x)) и соответствующих параметров функции, ниже такие примеры обеспечиваются с использованием соответствующих формул. В частности, устройство по фиг. 4 может быть выполнено так, что функцией 52, определяющей взаимосвязь между набором x ранее кодированных коэффициентов преобразования с одной стороны и номером 54 индекса контекста, индексирующим контекст, и параметром 46 символизации с другой стороны, может быть
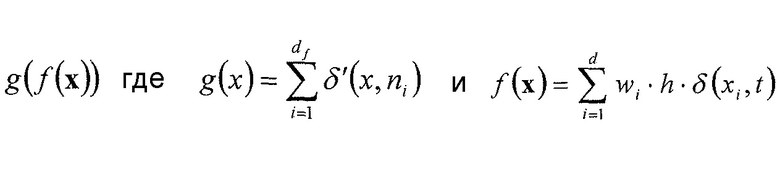
с
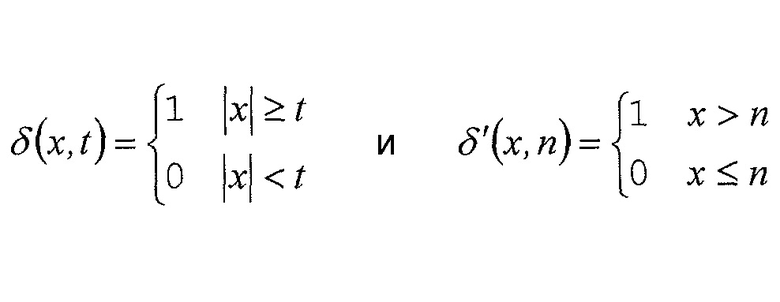
где
t и 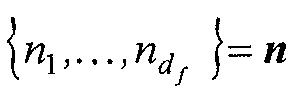 и необязательно wi, образуют параметр функции,
и необязательно wi, образуют параметр функции,
x={x1,…,xd} с xi с 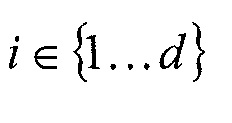 , представляющим ранее декодированный коэффициент i преобразования,
, представляющим ранее декодированный коэффициент i преобразования,
wi представляют собой взвешивающие значения, каждое из которых может быть равно единице или не равно единице, и
h представляет собой постоянную или функцию xi.
Из этого следует, что g(f(x)) лежит в пределах [0,df]. Если g(f(x)) используется для определения номера ctxoffset смещения индекса контекста, который суммируется с по меньшей мере одним номером ctxbase смещения базового индекса контекста, тогда диапазон значений результирующего индекса ctx=ctxbase+ctxoffset контекста равен [ctxbase; ctxbase+df]. Всякий раз, когда упоминается, что отличающиеся наборы контекстов используются для энтропийного кодирования символов последовательностей 44 символов, тогда ctxbase выбирается иным образом, так что [ctxbase,1; ctxbase+df] не перекрывается с [ctxbase,2; ctxbase+df]. Это, например, верно для
- коэффициентов преобразования, принадлежащих блокам преобразования различающегося размера;
- коэффициентов преобразования, принадлежащих блокам преобразования различающегося типа информационной составляющей, такого как глубина, яркость, цветность и т. п.
- коэффициентов преобразования, принадлежащих различающимся частотным участкам одного и того же блока преобразования;
Как упомянуто выше, параметром символизации может быть параметр k Райса. Т. е. (абсолютные) уровни в пределах интервала 16, т. е. X, с X+M=x (где M представляет собой максимальный уровень интервала 16, и x представляет собой (абсолютный) уровень коэффициента преобразования) отображаются на строку бинов, имеющую префикс и суффикс, причем префикс представляет собой унарный код 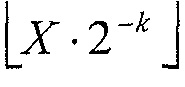 , и суффикс представляет собой двоичный код остатка от
, и суффикс представляет собой двоичный код остатка от 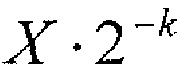 .
.
df также может формировать часть параметра функции. d также может формировать часть параметра функции.
Различие в параметре функции, такое как между выбором контекста и определением параметра символизации, требует просто одного различия или в t, 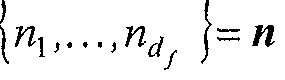 , df (если формирует часть параметра функции), или d (если формирует часть параметра функции).
, df (если формирует часть параметра функции), или d (если формирует часть параметра функции).
Как объяснено выше, индекс i может индексировать коэффициенты 12 преобразования в пределах шаблона 56. xi может устанавливаться в ноль в случае соответствующего положения шаблона, лежащего вне блока преобразования. Кроме того, контекстно-адаптивный энтропийный кодер 36 может быть выполнен так, что зависимость контекста от ранее кодированных коэффициентов преобразования посредством функции такая, что xi равен уровню коэффициента преобразования ранее кодированного коэффициента i преобразования в случае, если он находится в пределах первого интервала 16 уровней, и равен максимальному уровню первого интервала 16 уровней, в случае если уровень коэффициента преобразования ранее кодированного коэффициента i преобразования находится в пределах второго интервала 18 уровней, или такая что xi равен уровню коэффициента преобразования ранее кодированного коэффициента i преобразования, независимо от уровня коэффициента преобразования ранее кодированного коэффициента i преобразования, находящегося в пределах первого или второго интервала уровней.
Что касается определителя параметра символизации, он может быть выполнен так, что, при определении параметра символизации, xi равен уровню коэффициента преобразования ранее кодированного коэффициента i преобразования, независимо от уровня коэффициента преобразования ранее кодированного коэффициента i преобразования, находящегося в пределах первого или второго интервала уровней.
Устройство дополнительно может быть выполнено так, что n1≤…≤ 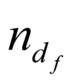 применяется в любом случае.
применяется в любом случае.
Устройство также может быть выполнено так, что h=|xi|-t.
В другом варианте осуществления устройство может быть выполнено с возможностью пространственного определения ранее кодированных коэффициентов преобразования в зависимости от относительного пространственного расположения коэффициентов преобразования относительно текущего коэффициента преобразования, т. е. основываясь на шаблоне вокруг положения текущего коэффициента преобразования.
Устройство может быть дополнительно выполнено с возможностью определения положения последнего ненулевого коэффициента L преобразования среди коэффициентов преобразования блока 10 коэффициентов преобразования в соответствии с предопределенным порядком 14 сканирования и вставки информации о положении в поток 32 данных, причем множество коэффициентов преобразования охватывает коэффициенты преобразования с последнего ненулевого коэффициента L преобразования до начала предопределенного порядка сканирования, т. е. коэффициента преобразования DC-составляющей.
В другом варианте осуществления символизатор 34 может быть выполнен с возможностью использования модифицированной первой схемы символизации для символизации последнего коэффициента L преобразования. Согласно модифицированной первой схеме символизации могут отображаться только ненулевые уровни коэффициента преобразования в пределах первого интервала 16 уровней, тогда как предполагается, что нулевой уровень не применяется для последнего коэффициента L преобразования. Например, первый бин усеченной унарной бинаризации может подавляться для коэффициента L.
Контекстно-адаптивный энтропийный кодер может быть выполнен с возможностью использования отдельного набора контекстов для энтропийного кодирования первого набора из одного или нескольких символов для последнего ненулевого коэффициента преобразования, отдельно от контекстов, используемых при энтропийном кодировании первого набора из одного или нескольких символов за исключением последнего ненулевого коэффициента преобразования.
Контекстно-адаптивный энтропийный кодер может обходить множество коэффициентов преобразования в противоположном порядке сканирования, проходя от последнего ненулевого коэффициента преобразования до DC-коэффициента преобразования блока коэффициентов преобразования. Это также может применяться или может не применяться для вторых последовательностей 42 символов.
Устройство также может быть выполнено с возможностью кодирования множества коэффициентов преобразования в поток 32 данных в двух сканированиях, причем контекстно-адаптивный энтропийный кодер 36 может быть выполнен с возможностью энтропийного кодирования первых последовательностей 44 символов для коэффициентов преобразования в поток 32 данных в порядке, соответствующем первому сканированию коэффициентов преобразования, причем устройство 40 вставки выполнено с возможностью последующей вставки последовательностей 42 символов для коэффициентов преобразования, имеющих уровень коэффициента преобразования в пределах второго интервала 18 уровней, в поток 32 данных в порядке, соответствующем появлению коэффициентов преобразования, имеющих уровень коэффициента преобразования в пределах второго интервала 18 уровней во втором сканировании коэффициентов преобразования. Пример для результирующего потока 32 данных показан на фиг. 5a; он может содержать необязательно информацию 57 о положении L, за которой следуют последовательности 42 символов в энтропийно кодированной форме (по меньшей мере некоторые в контекстно-адаптивной энтропийно кодированной форме) и дополнительно за которой следуют последовательности 44 символов, вставленные непосредственно или с использованием, например, режима обхода (равновероятный алфавит).
В другом варианте осуществления устройство может быть выполнено с возможностью кодирования множества коэффициентов преобразования в поток 32 данных последовательно в одном сканировании, в котором контекстно-адаптивный энтропийный кодер 36 и устройство 40 вставки выполнены с возможностью, для каждого коэффициента преобразования в порядке сканирования одного сканирования, вставки последовательностей 42 символов соответствующих коэффициентов преобразования, имеющих уровень коэффициента преобразования в пределах второго интервала 18 уровней, в поток 32 данных, непосредственно после энтропийного кодирования контекстно-адаптивного энтропийного кодера последовательностей 44 символов в поток 32 данных, вместе с которыми он формирует объединение, на которое отображаются эти же коэффициенты преобразования, так что последовательности 42 символов распределяются в поток 32 данных между последовательностями 44 символов коэффициентов преобразования. Результат показан на фиг. 5b.
Устройство 40 вставки может быть выполнено с возможностью вставки последовательностей 42 символов в поток данных непосредственно или с использованием энтропийного кодирования, использующего распределение фиксированной вероятности. Первая схема символизации может представлять собой схему усеченной унарной бинаризации. Вторая схема символизации может быть такой, что последовательности 42 символов из кода Райса.
Как уже отмечено выше, варианты осуществления по фиг. 4 могут быть воплощены в кодере изображения/видео. Пример такого кодера изображения/видео или кодера картинок показан на фиг. 6. Кодер картинок в целом указан ссылочной позицией 60 и содержит устройство 62, соответствующее устройству, например, показанному на фиг. 4. Кодер 60 выполнен с возможностью, при кодировании картинки 64, преобразования блоков 66 картинки 64 в блоки 10 коэффициентов преобразования, которые затем обрабатываются устройством 62, чтобы кодировать, на блок 10 преобразования, множество его коэффициентов преобразования. В частности, устройство 62 обрабатывает блоки 10 преобразования блок преобразования за блоком преобразования. Выполняя таким образом, устройство 62 может использовать функцию 52 для блоков 10 разных размеров. Например, иерархическое подразделение по многим деревьям может использоваться для разбиения картинки 64 или его блоков с древовидными корнями, на блоки 66 разных размеров. Блоки 10 преобразования, являющиеся результатом применения преобразования к этим блокам 66, следовательно, также имеют разный размер и, хотя, следовательно, функция 52 может оптимизироваться для разных размеров блоков посредством использования разных параметров функции, поддерживаются низкими общие издержки для обеспечения таких разных зависимостей для параметра символизации с одной стороны и индекса контекста с другой стороны.
Фиг. 7 изображает устройство для декодирования множества коэффициентов преобразования, имеющих уровни коэффициента преобразования, из потока 32 данных, которые подходят к устройству, кратко изложенному выше в отношении фиг. 4. В частности, устройство по фиг. 7 содержит контекстно-адаптивный энтропийный декодер 80, десимволизатор 82 и средство 84 извлечения, а также определитель 86 параметра символизации. Контекстно-адаптивный энтропийный декодер 80 выполнен с возможностью, для текущего коэффициента преобразования, энтропийного декодирования первого набора из одного или нескольких символов, т. е. последовательности 44 символов, из потока 32 данных. Десимволизатор 82 выполнен с возможностью отображения первого набора из одного или нескольких символов, т. е. последовательности 44 символов, на уровень коэффициента преобразования в пределах первого интервала 16 уровней в соответствии с первой схемой символизации. Более точно, контекстно-адаптивный энтропийный декодер 80 и десимволизатор 82 работают интерактивным образом. Десимволизатор 82 информирует контекстно-адаптивный энтропийный декодер 80 посредством сигнала 88, при каком символе, последовательно декодируемом декодером 80 из потока 32 данных, была завершена достоверная последовательность символов первой схемы символизации.
Средство 84 извлечения выполнено с возможностью, если уровнем коэффициента преобразования, на который отображается первый набор из одного или нескольких символов, т. е. последовательность 44 символов, в соответствии с первой схемой символизации, является максимальный уровень первого интервала 16 уровней, извлечения второго набора символов, т. е. последовательности 42 символов, из потока 32 данных. Снова, десимволизатор 82 и средство 84 извлечения могут работать во взаимодействии. Т. е. десимволизатор 82 может информировать средство 84 извлечения сигналом 90, когда достоверная последовательность символов второй схемы символизации была завершена, после чего средство 84 извлечения может завершить извлечение последовательности 42 символов.
Десимволизатор 82 выполнен с возможностью отображения второго набора символов, т. е. последовательности 42 символов, на положение в пределах второго интервала 18 уровней в соответствии со второй схемой символизации, которая, как уже отмечено выше, является параметризуемой в соответствии с параметром 46 символизации.
Контекстно-адаптивный энтропийный декодер 80 выполнен с возможностью, при энтропийном декодировании по меньшей мере одного предопределенного символа первой последовательности 44 символов, использования контекста в зависимости, посредством функции 52, от ранее декодированных коэффициентов преобразования. Определитель 86 параметра символизации выполнен с возможностью, если уровнем коэффициента преобразования, на который отображается первая последовательность 44 символов в соответствии с первой схемой символизации, является максимальный уровень первого интервала 16 уровней, определения параметра 46 символизации в зависимости, посредством функции 52, от ранее декодированных коэффициентов преобразования. С этой целью входы энтропийного декодера 80 и определителя 86 параметра символизации соединены посредством переключателя 92 с выходом десимволизатора 82, на который десимволизатор 82 выводит значения xi коэффициентов преобразования.
Как описано выше, для адаптивности контекста декодер 80 управляет контекстами посредством сохранения и обновления оценки распределения вероятности алфавита для каждого контекста. Каждый раз, когда декодируется символ некоторого контекста, сохраненная в данный момент оценка распределения вероятности алфавита обновляется с использованием фактического/декодированного значения этого символа, таким образом аппроксимируя фактическую статистику алфавита символов этого контекста.
Аналогично определитель 86 параметра символизации выполнен с возможностью определения параметра 46 символизации для второй схемы символизации и ее последовательностей 42 символов в зависимости от ранее декодированных коэффициентов преобразования.
Как правило, все возможные модификации и дополнительные подробности, описанные выше в отношении кодирования, также являются переносимыми на устройство для декодирования на фиг. 7.
Фиг. 8 изображает как приложение к фиг. 6. Т. е. устройство по фиг. 7 может быть реализовано в декодере 100 картинок. Декодер 100 картинок по фиг. 7 содержит устройство по фиг. 7, а именно устройство 102. Декодер 100 картинок выполнен с возможностью, при декодировании или восстановлении картинки 104, повторного преобразования блоков 106 картинки 104 из блоков 10 коэффициентов преобразования, множество коэффициентов преобразования которых устройство 102 декодирует из потока 32 данных, который поступает, в свою очередь, на декодер 100 картинок. В частности, устройство 102 обрабатывает блоки 10 преобразования блок за блоком и может, как уже отмечено выше, использовать функцию 52 обычно для блоков 106 разных размеров.
Необходимо отметить, что кодер и декодер 60 и 100 картинок соответственно могут быть выполнены с возможностью использования кодирования с предсказанием с применением преобразования/повторного преобразования к остатку предсказания. Кроме того, поток 32 данных может иметь информацию о подразделении, кодированную в нем, которая сигнализирует декодеру 100 картинок подразделение на блоки, индивидуально подвергаемые преобразованию.
Ниже вышеупомянутые варианты осуществления снова описываются другими словами и с предоставлением больших подробностей по конкретным аспектам, при этом эти подробности могут индивидуально переносится на вышеупомянутые варианты осуществления. Т. е. вышеупомянутые варианты осуществления, относящиеся к конкретному методу контекстного моделирования для кодирования элементов синтаксиса, относящихся к коэффициентам преобразования, таким как в кодерах блочного изображения и видео, и аспекты его описаны и выделены дополнительно ниже.
Варианты осуществления могут относиться к области цифровой обработки сигналов и, в частности, к способу и устройству для декодеров и кодеров изображения и видео. В частности, кодирование коэффициентов преобразования и связанных с ними элементов синтаксиса в кодеках блочного изображения и видео может выполняться согласно описанным вариантам осуществления. Поскольку некоторые варианты осуществления представляли улучшенное контекстное моделирование для кодирования элементов синтаксиса, относящихся к коэффициентам преобразования, посредством энтропийного кодера, который применяет вероятностное моделирование. Кроме того, вывод параметра Райса, который используется для адаптивной бинаризации оставшихся абсолютных коэффициентов преобразования, может выполняться так, как описано выше в отношении параметра символизации. Унификация, упрощение, дружелюбная параллельная обработка и умеренное использование памяти касательно памяти контекстов представляют собой преимущества вариантов осуществления по сравнению с непосредственным контекстным моделированием.
Другими словами, варианты осуществления настоящего изобретения могут открыть новый подход для выбора контекстной модели элементов синтаксиса, относящихся к кодированию коэффициентов преобразования в кодерах блочного изображения и видео. Кроме того, были описаны правила вывода параметра символизации, такого как параметр Райса, который управляет бинаризацией оставшегося значения абсолютных коэффициентов преобразования. Существенно, что вышеописанные варианты осуществления использовали простой и общий набор правил для выбора контекстной модели для всех или для части элементов синтаксиса, относящихся к кодированию коэффициентов преобразования.
Первой схемой символизации, упомянутой выше, может быть усеченная унарная бинаризация. Если это так, coeff_significant_flag, coeff_abs_greater_1 и coeff_abs_greater_2 могут называться бинарными элементами синтаксиса или символами, которые формируют первый, второй и третий бин, являющийся результатом усеченной унарной бинаризации коэффициента преобразования. Как описано выше, усеченная унарная бинаризация может просто представлять префикс, который может сопровождаться суффиксом, который сам является кодом Райса в случае уровня коэффициента преобразования, попадающего в пределы второго интервала 18 уровней. Другим суффиксом может быть экспоненциальный код Голомба, такой как 0-порядка, таким образом формируя другой интервал уровней, следующий за первым и вторым интервалами 16 и 18 на фиг. 2 (не показан на фиг. 2).
Вывод параметра Райса для адаптивной бинаризации оставшегося абсолютного коэффициента преобразования может выполняться, как описано выше, на основе этого же набора правил 52, что и используемый для выбора контекстной модели.
Что касается порядка сканирования, отмечается, что он может изменяться по сравнению с вышеприведенным описанием. Кроме того, разные размеры и формы блока могут поддерживаться устройствами по фиг. 4 и 6 с использованием, однако, этого же набора правил, т. е. с использованием этой же функции 52. Следовательно, может достигаться унифицированная и упрощенная схема для выбора контекстной модели элементов синтаксиса, относящихся к кодированию коэффициентов преобразования, объединенной с гармонизацией для вывода параметра символизации. Таким образом, выбор контекстной модели и вывод параметра символизации могут использовать одну и ту же логику, которая, например, может быть аппаратно-реализованными, запрограммированными аппаратными средствами или подпрограммой системы программного обеспечения.
Для достижения общей и простой схемы для выбора контекстной модели и вывода параметра символизации, такого как параметр Райса, уже кодированные коэффициенты преобразования блока или формы могут оцениваться так, как описано выше. Чтобы оценивать уже кодированные коэффициенты преобразования, разделение при кодировании coeff_significant_flag, который является первым бином, являющимся результатом бинаризации (которая может упоминаться как кодирование карты значимостей), и оставшегося абсолютного значения уровня коэффициента преобразования выполняется с использованием общей функции 52.
Кодирование знаковой информации может выполняться чередующимся образом, т. е. посредством кодирования знака непосредственно после кодирования абсолютного коэффициента преобразования. Таким образом, все коэффициенты преобразования будут кодироваться только за один проход сканирования. Альтернативно знаковая информация может кодироваться по отдельному пути сканирования до тех пор, пока значения f(x) оценки основываются только на информации об абсолютном уровне.
Как отмечено выше, коэффициенты преобразования могут кодироваться за единственный проход сканирования или за многочисленные проходы сканирования. Это может делаться возможным посредством, или может описываться посредством, набора c отсечений, коэффициенты ci которого указывают количество символов (первой и второй) символизации коэффициентов преобразования, обработанных при сканировании i. В случае пустого набора отсечений, будет использоваться одно сканирование. Чтобы иметь улучшенные результаты для выбора контекстной модели и вывода параметра символизации, первый параметр c0 отсечения набора c отсечений должен быть больше единицы.
Отметьте, что набор c отсечений может выбираться равным c={c0; c1} с c0=1 и c1=3 и |c|=2, где c0 указывает количество бинов/символов первой бинаризации, охватываемой при первом сканировании, и c1=3, указывающее положение символа в первой бинаризации, до которого охватываются символы первой бинаризации, является вторым сканированием. Другой пример приводится, когда схема кодирует первый бин, являющийся результатом бинаризации для всего блока или формы при первом проходе сканирования, затем второй бин для всего блока или формы при втором проходе сканирования, причем c0 равно единице, c1 равно двум и т. д.
Локальный шаблон 56 для кодирования coeff_significant_flag, т. е. первого бина из процесса бинаризации, может быть разработан так, как показано на фиг. 1 или как показано на фиг. 9. В качестве унификации и упрощения локальный шаблон 56 может использоваться для всех размеров и форм блока. Вместо оценки количества соседей только с неравенством нулю коэффициентов преобразования, все коэффициенты преобразования вводятся в функцию 52 в виде xi. Отметьте, что локальный шаблон 56 может быть фиксированным, т. е. независимым от положения текущего коэффициента преобразования или индекса сканирования и независимым от ранее кодированных коэффициентов преобразования, или адаптивным, т. е. зависимым от положения текущего коэффициента преобразования или индекса сканирования и/или ранее кодированных коэффициентов преобразования, и размер может быть фиксированным или адаптивным. Кроме того, когда размер и форма шаблона корректируются, делая возможным покрытие всех положений сканирования блока или формы, все уже кодированные коэффициенты преобразования или все уже кодированные коэффициенты преобразования до определенного предела используются для процесса оценки.
В качестве примера фиг. 9 изображает другой пример для локального шаблона 56, который может использоваться для блока 10 преобразования размером 8×8 с диагональным сканированием 14. L обозначает последнее значимое положение сканирования, и положения сканирования, отмеченные посредством x, обозначают текущее положение сканирования. Отметьте, что для других порядков сканирования локальный шаблон может быть модифицирован для соответствия порядку 14 сканирования. Например, в случае прямого диагонального сканирования локальный шаблон 56 может быть отображен зеркально относительно диагоналей.
Выбор контекстной модели и вывод параметра символизации могут основываться на разных значениях f(x) оценки, являющихся результатом оценки уже кодированных соседей xi. Эта оценка выполняется для всех положений сканирования, имеющих уже кодированные соседи, охватываемые локальным шаблоном 56. Локальный шаблон 56 имеет переменный или фиксированный размер и может зависеть от порядка сканирования. Однако форма и размер шаблона представляет собой адаптацию к порядку сканирования только и, поэтому, вывод значений f(x) является независимым от порядка 140 сканирования и формы и размера шаблона 56. Отметьте, что посредством установки размера и формы шаблона 56 таких, что становится возможным покрытие всех положений сканирования блока 10 для каждого положения сканирования, достигается использование всех уже кодированных коэффициентов преобразования в текущем блоке или форме.
Как изложено выше, выбор индексов контекстной модели и вывод параметра символизации используют значения f(x) оценки. Обычно обобщенный набор функций отображения отображает результирующие значения f(x) оценки на индекс контекстной модели и на конкретный параметр символизации. В дополнение к этому, дополнительная информация в виде текущего пространственного положения текущего коэффициента преобразования внутри блока или формы 10 преобразования или последнего значимого положения L сканирования может использоваться для выбора контекстных моделей, относящихся к кодированию коэффициентов преобразования и для вывода параметра символизации. Отметьте, что информация, являющаяся результатом оценки и пространственного определения местоположения, или последняя информация могут объединяться и, поэтому, является возможным конкретное взвешивание. После процесса оценки и вывода все параметры (индексы контекстной модели, параметр символизации) являются доступными для кодирования всего уровня коэффициента преобразования или коэффициента преобразования до конкретного предела.
В качестве примерной конфигурации представленного изобретения, размер набора отсечений является пустым. Это означает, что каждый коэффициент преобразования передается полностью перед обработкой следующих коэффициентов преобразования в соответствии с порядком сканирования.
Значения f(x) оценки могут являться результатом оценки уже кодированных соседей xi, охватываемых локальным шаблоном 56. Конкретная функция ft(x) отображения отображает входной вектор на значение оценки, используемое для выбора контекстной модели и параметра Райса. Входной вектор x может состоять из значений xi коэффициентов преобразования соседей, охватываемых локальным шаблоном 56, и зависит от схемы перемежения. Например, если набор c отсечений является пустым, и знак кодируется в отдельном проходе сканирования, вектор x состоит только из абсолютных коэффициентов xi преобразования. Обычно значения входного вектора x могут быть со знаком или без знака. Функция отображения может быть сформулирована следующим образом с входным вектором x размерности d (при данном t в качестве постоянного ввода).
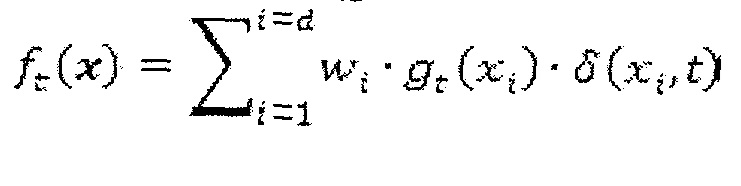
Более конкретно, функция ft(x) отображения может определяться следующим образом с входным вектором x размерности d (при данном t в качестве постоянного ввода).
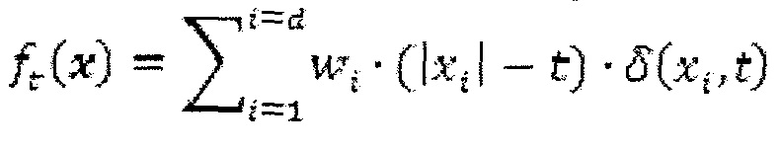
Т. е. gt(xi) может быть равна (|xi|-t). В последней формуле функция δ определяется следующим образом (при данном t в качестве постоянного ввода):
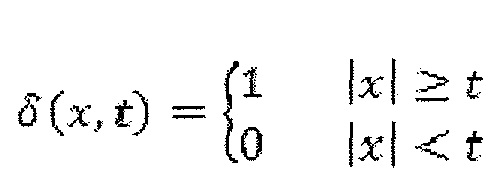
Другим видом значения оценки является количество уровней соседних абсолютных коэффициентов преобразования, которые больше или меньше конкретного значения t, определяемого следующим образом:
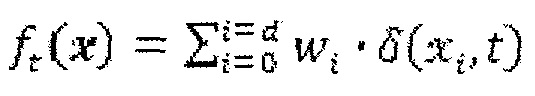
Отметьте, что для обоих видов значений оценки возможен дополнительный весовой коэффициент, который управляет важностью конкретного соседа. Например, весовой коэффициент wi является более высоким для соседей с более коротким пространственным расстоянием, чем для соседей с большим пространственным расстоянием. Кроме того, взвешивание не учитывается при установке всех wi в единицу.
В качестве примерной конфигурации представленного изобретения, f0, f1, f2 и f3 представляют собой значения оценки в отношении t {0, 1, 2, 3} и δ(xi), как определено в (1). Для этого примера f0 используется для вывода индекса контекста первого бина, f1 - для второго бина, f2 - для третьего бина, и f3 - для параметра Райса. В другой примерной конфигурации f0 используется для выбора контекстной модели первого бина, тогда как f1 берется для выбора контекстной модели второго, третьего бина и параметра Райса. В данном случае параметр Райса служит в качестве представителя также для других параметров символизации.
Выбор контекстной модели для всех элементов синтаксиса или индексов бина при энтропийном кодировании и параметр символизации используют одну и ту же логику посредством применения значений f(x) оценки. Обычно конкретное значение f(x) оценки отображается другой функцией g(x, n) отображения на индекс контекстной модели или параметр символизации. Конкретная функция отображения определяется следующим образом с d в качестве размерности входного вектора n.
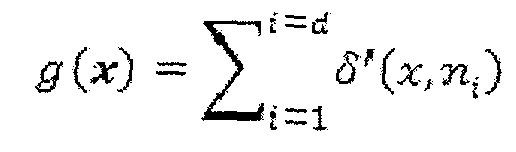
Для этого отображения функция δ(x, n) может определяться следующим образом.
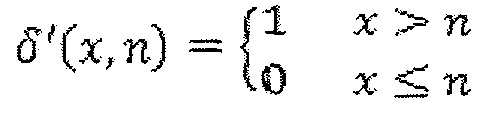
Размерность d входного вектора n и значения вектора n могут быть переменными и зависеть от элемента синтаксиса или индекса бина. Кроме того, пространственное расположение внутри блока или формы преобразования может использоваться для добавления или вычитания (или для перемещения) выбранного индекса контекстной модели.
Первое положение сканирования при сканировании коэффициентов преобразования при кодировании/декодировании их, может представлять собой последнее положение L сканирования при применении направления сканирования на фиг. 1, указывающего от DC к самой высокой частоте. Т. е. по меньшей мере первое сканирование из сканирований для обхода коэффициентов для кодирования/декодирования их, может указывать от коэффициента L к DC. Для этого положения L сканирования индекс первого бина может не учитываться в качестве последней информации, уже сигнализировавшей, что это положение сканирования состоит из коэффициента преобразования, неравного нулю. Для этого положения сканирования отдельный индекс контекстной модели может использоваться для кодирования второго и третьего бина, являющихся результатом бинаризации коэффициента преобразования.
В качестве примерной конфигурации представленного изобретения результирующее значение f0 оценки используется в качестве входного значения вместе с входным вектором n={1,2,3,4,5}, и результирующее значение представляет собой индекс контекстной модели для первого бина. Отметьте, что, в случае значения оценки равного нулю, индекс контекста равен нулю. Эта же схема применяется со значением f1 оценки и входным вектором n={1,2,3,4}, и результирующее значение представляет собой индекс контекстной модели для второго и третьего бина бинаризации. Для параметра Райса используется f3 и n={0,5,19}. Отметьте, что максимальный параметр Райса равен трем, и, поэтому, не выполняется изменение в максимальном параметре Райса по сравнению с современным состоянием представленным изобретением. Альтернативно f1 может использоваться для вывода параметра Райса. Для этой конфигурации входной вектор должен быть модифицирован в n={3,9,21}. Отметьте, что лежащий в основе набор правил является одинаковым для всех элементов синтаксиса или индексов бина и для параметра Райса, только параметры или наборы порогов (входной вектор n) являются разными. Кроме того, в зависимости от диагонали текущего положения сканирования, индекс контекстной модели может модифицироваться, как указано выше, посредством добавления или вычитания конкретной величины. Эквивалентным описанием для этого является выбор другого непересекающегося набора контекстных моделей. В примерной реализации результирующий индекс контекстной модели для первого бина перемещается на 2*|ctx0|, если текущее положение сканирования лежит на первых двух диагоналях. Если текущее положение сканирования лежит на третьей и четвертой диагонали, индекс контекстной модели для первого бина перемещается на |ctx0|, где |ctx0| представляет собой количество максимальных контекстных моделей, являющихся результатом вывода, основанного на значениях оценки, приводя к непересекающимся наборам контекстных моделей. Этот принцип используется для плоскостей яркости только для примерной реализации, в то время как дополнительное смещение не добавляется в случае цветности, исключая разбавление контекста (т. е. кодируется недостаточное количество бинов с адаптивной контекстной моделью, и статистика не может отслеживаться контекстной моделью). Этот же метод может применяться к индексу контекстной модели второго и третьего бина. В данном случае в примерной конфигурации представленного изобретения пороговыми диагоналями являются третья и десятая. Снова, этот метод применяется только к сигналу яркости. Отметьте, что также является возможным расширить этот метод на сигналы цветности. Кроме того, отметьте, что дополнительное смещение индекса в зависимости от диагоналей может быть сформулировано следующим образом.
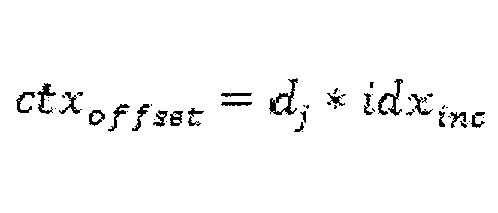
В данной формуле dj обозначает вес для диагонали текущего положения сканирования, и idxinc обозначает размер шага. Кроме того, отметьте, что индекс смещения может инвертироваться для практических реализаций. Для заявленной примерной реализации инверсия устанавливает дополнительный индекс на ноль, если текущее положение сканирования лежит на первой и второй диагонали, перемещается на |ctx0| для третьей и четвертой диагонали, и равно 2*|ctx0| в противном случае. Посредством использования данной формулы такое же поведение, что и для примерной конфигурации достигается при установке d0 и d1 на 2, d3 и d4 - на 1, и все оставшиеся диагональные коэффициенты - на 0.
Даже если индекс контекстной модели одинаков для разных размеров блока или типов плоскости (например, яркость и цветность), базовый индекс контекстной модели может быть разным, приводя к другому набору контекстных моделей. Например, может использоваться один и тот же базовый индекс для размеров блока больше 8×8 в яркости, тогда как базовый индекс может быть другим для 4×4 и 8×8 в яркости. Чтобы иметь значительное количество контекстных моделей, базовый индекс, однако, может группироваться разным образом.
В качестве примерной конфигурации контекстные модели для блоков 4×4 и оставшихся блоков могут быть разными в яркости, тогда как один и тот же базовый индекс может использоваться для сигнала цветности. В другом примере один и тот же базовый индекс может использоваться как для сигнала яркости, так и для сигнала цветности, тогда как контекстные модели для яркости и цветности являются различными. Кроме того, контекстные модели для второго и третьего бинов могут группироваться, приводя к меньшему количеству памяти контекстов. Если вывод индекса контекстной модели для второго и третьего бина одинаков, одна и та же контекстная модель может использоваться для передачи второго и третьего бина. Посредством правильного объединения группирования и взвешивания базового индекса, может достигаться значительное количество контекстных моделей, приводя к экономии памяти контекстов.
В предпочтительном варианте осуществления изобретения набор c отсечений является пустым. Т. е. используется только одно сканирование. Для этого предпочтительного варианта осуществления знаковая информация может перемежаться с использованием этого же прохода сканирования или может кодироваться в отдельном проходе сканирования. В другом предпочтительном варианте осуществления размер c набора равен единице и с0, первое и единственное значение набора c отсечений, равно трем. Оно соответствует примеру, показанному выше с использованием двух сканирований. В этом предпочтительном варианте осуществления выбор контекстной модели может выполняться для всех трех бинов, являющихся результатом усеченной унарной бинаризации, тогда как вывод параметра символизации, такой как выбор параметра Райса, может выполняться с использованием этой же функции 52.
В предпочтительном варианте осуществления размер локального шаблона равен пяти. Размер локального шаблона может быть равен четырем. Для этого предпочтительного варианта осуществления сосед с пространственным расстоянием два в вертикальном направлении может удаляться по сравнению с фиг. 8. В другом предпочтительном варианте осуществления размер шаблона является адаптивным и корректируется к порядку сканирования. Для этого предпочтительного варианта осуществления сосед, который кодируется на этапе обработки перед этим, не включается в шаблон как в случае на фиг. 1 и 8. Выполняя так, укорачивается зависимость или задержка, приводя к более высокому порядку обработки. В другом предпочтительном варианте осуществления размер и форма шаблона корректируются в достаточно большой степени (например, один и тот же размер блока или формы текущего блока или формы). В другом предпочтительном варианте осуществления могут использоваться два локальных шаблона, и они могут объединяться весовым коэффициентом. Для этого предпочтительного варианта осуществления локальные шаблоны могут отличаться размером и формой.
В предпочтительном варианте осуществления f0 может использоваться для выбора индекса контекстной модели для первого бина, и f1 - для второго бина, третьего бина и параметра Райса. В этом предпочтительном варианте осуществления входной вектор n={0,1,2,3,4,5} приводит к 6 контекстным моделям. Входной вектор n для индекса второго и третьего бина может быть одинаковым и n={0,1,2,3,4}, тогда как входной вектор n для параметра Райса может быть n={3,9,21}. Кроме того, в предпочтительном варианте осуществления вышеупомянутые частотные участки блока преобразования, в пределах которых используются отдельные наборы контекстов, могут формироваться посредством непересекающихся наборов диагоналей (или строк) диагонального (растрового) сканирования. Например, разные номера базового смещения контекста могут существовать для первой и второй диагоналей, второй и третьей диагоналей и четвертой и пятой диагоналей, если смотреть от DC-составляющей, так что выбор контекста для коэффициентов на этих диагоналях происходит в непересекающихся наборах контекстов. Отметьте, что первая диагональ равна единице. Для второго и третьего индекса бина диагонали, лежащие в диапазоне между [0,2], имеют весовой коэффициент два, и диагонали, лежащие в диапазоне между [3,9], имеют весовой коэффициент единицу. Эти дополнительные смещения используются в случае сигнала яркости, тогда как весовые коэффициенты для цветности все равны нулю. Также для этого предпочтительного варианта осуществления контекстная модель для второго и третьего индекса бина первого положения сканирования, которое представляет собой последнее значимое положение сканирования, отделена от остальных контекстных моделей. Это означает, что процесс оценки может никогда не выбрать эту отдельную контекстную модель.
В предпочтительном варианте осуществления блоки или формы яркости 4×4 используют единственный набор контекста для первого бина, тогда как контекстные модели для остальных размеров или формы блоков являются одинаковыми. В данном предпочтительном варианте осуществления нет разделения между размером или формой блока для сигнала цветности. В другом предпочтительном варианте осуществления изобретения нет разделения между размерами или формой блока, приводит к одинаковому базовому индексу или наборам контекстных моделей для всех размеров и формы блока. Отметьте, что для обоих предпочтительных вариантов осуществления разные наборы контекстных моделей используются для сигналов яркости и цветности.
Ниже показан вариант осуществления, использующий бинаризацию модифицированного параметра Райса согласно вышеупомянутым вариантам осуществления, но без контекстно-адаптивного энтропийного кодирования. Согласно этой альтернативной схеме кодирования используется только схема бинаризации Райса (с необязательным добавлением суффикса экспоненциального кода Голомба). Таким образом, не требуется адаптивная контекстная модель для кодирования коэффициента преобразования. Для этой альтернативной схемы кодирования вывод параметра Райса использует этого же правило, что и для вышеупомянутых вариантов осуществления.
Другими словами, чтобы уменьшить сложность и память контекстов и улучшить задержку в конвейере кодирования, описывается альтернативная схема кодирования, которая основывается на этом же наборе правил или логики. Для этой альтернативной схемы кодирования блокируется выбор контекстной модели для первых трех бинов, являющихся результатом бинаризации, и первые три бина, являющиеся результатом усеченной унарной бинаризации, т. е. первой схемы символизации, могут кодироваться с фиксированной равновероятностью (т. е. с вероятностью 0,5). Альтернативно схема усеченной унарной бинаризации опускается, и корректируются границы интервалов схемы бинаризации. При таком использовании левая граница интервала Райса, т. е. интервал 18, равна 0 вместо 3 (с исчезновением интервала 16). Правая/верхняя граница для этого применения может не модифицироваться, или из нее может вычитаться 3. Вывод параметра Райса может модифицироваться в смысле значений оценки и в смысле входного вектора n.
Таким образом, согласно только что кратко описанным модифицированным вариантам осуществления устройство для декодирования множества коэффициентов преобразования разных блоков преобразования, причем каждый имеет уровень коэффициента преобразования, из потока 32 данных может быть выполнено и может работать так, как показано и описано в отношении фиг. 10.
Устройство на фиг. 10 содержит средство 120 извлечения, выполненное с возможностью извлечения набора символов или последовательности 122 символов из потока 32 данных для текущего коэффициента преобразования. Извлечение выполняется так, как описано выше в отношении средства 84 извлечения на фиг. 7.
Десимволизатор 124 выполнен с возможностью отображения набора 122 символов на уровень коэффициента преобразования для текущего коэффициента преобразования в соответствии со схемой символизации, которая является параметризуемой в соответствии с параметром символизации. Отображение может использовать исключительно схему параметризуемой символизации, такую как бинаризация Райса, или может использовать эту схему параметризуемой символизации просто в качестве префикса или суффикса общей символизации текущего коэффициента преобразования. В случае фиг. 2, например, схема параметризуемой символизации, т. е. вторая, формировала суффикс относительно последовательности символов первой схемы символизации.
Чтобы представить большее количество примеров, ссылка делается на фиг. 11a и b. Согласно фиг. 11a, диапазон 20 интервала коэффициентов преобразования подразделяется на три интервала 16, 18 и 126, вместе охватывающих диапазон 20 интервала и перекрывающие друг друга на соответствующем максимальном уровне соответствующего нижнего интервала. Если уровень x коэффициента находится в пределах наибольшего интервала 126, общей символизацией является объединение последовательности 44 символов первой схемы 128 символизации, символизирующей уровни в пределах интервала 16, причем последовательность символов образует префикс, за которым следует первый суффикс, а именно последовательность 42 символов второй схемы 130 символизации, символизирующей уровни в пределах интервала 18, и за которым дополнительно следует второй суффикс, а именно последовательность 132 символов третьей схемы 134 символизации, символизирующей уровни в пределах интервала 126. Последней может быть экспоненциальный код Голомба, такой как порядка 0. Если уровень x коэффициента находится в пределах среднего интервала 18 (но не в пределах интервала 126), общей символизацией является объединение только префикса 44, за которым следует первый суффикс 42. Если уровень x коэффициента находится в пределах самого нижнего интервала 16 (но не в пределах интервала 18), общая символизация состоит только из префикса 44. Общая символизация составляется так, что она без префикса. Без третьей символизации символизация по фиг. 11a может соответствовать символизации по фиг. 2. Третья схема 134 символизации может представлять собой бинаризацию Голомба-Райса. Вторая схема 130 символизации может формировать параметризуемую символизацию, хотя она также может быть первой 128.
Альтернативная общая символизация показана на фиг. 1. В данном случае объединяются только две схемы символизации. По сравнению с фиг. 11a, первая схема символизации была исключена. В зависимости от x в пределах интервала 136 схемы 134 или интервала 138 схемы 130 (вне интервала 136) символизация x содержит префикс 140 и суффикс 142 или только префикс 140.
Кроме того, устройство по фиг. 10 содержит определитель 144 параметра символизации, подсоединенный между выходом десимволизатора и входом параметра десимволизатора 124. Определитель 144 выполнен с возможностью определения параметра 46 символизации для текущего коэффициента преобразования в зависимости, посредством функции 52, от ранее обработанных коэффициентов преобразования (поскольку выводимых из десимволизированных фрагментов или частей, десимволизированных/обработанных/декодированных до сих пор).
Средство 120 извлечения, десимволизатор 124 и определитель 144 параметра символизации выполнены с возможностью последовательной обработки коэффициентов преобразования разных блоков преобразования, как было описано выше. Т. е. сканирование 140 может обходить в противоположном направлении блок 10 преобразования. Может использоваться несколько сканирований, таких что, например, для разных фрагментов символизации, т. е. префикса и суффикса(ов).
Параметр функции изменяется в зависимости от размера блока преобразования текущего коэффициента преобразования, типа информационной составляющей блока преобразования текущего коэффициента преобразования и/или частотного участка, на котором располагается текущий коэффициент преобразования в блоке преобразования.
Устройство может быть выполнено так, что функцией, задающей взаимосвязь между ранее декодированными коэффициентами преобразования с одной стороны и параметром символизации с другой стороны, является g(f(x)), причем эта функция уже была описана выше.
Как также было описано выше, может использоваться пространственное определение ранее обработанных коэффициентов преобразования в зависимости от относительного пространственного расположения относительно текущего коэффициента преобразования.
Устройство может работать очень легко и быстро, так как средство 120 извлечения может быть выполнено с возможностью извлечения набора символов из потока данных непосредственно или с использованием энтропийного декодирования, используя распределение фиксированной вероятности. Схема параметризуемой символизации может быть такой, что набор символов из кода Райса, и параметром символизации является параметр Райса.
Другими словами, десимволизатор 124 может быть выполнен с возможностью ограничения схемы символизации до интервала уровней, такого как 18 или 138 из интервала 20 диапазона коэффициентов преобразования, так что набор символов представляет префикс или суффикс в отношении других участков общей символизации текущего коэффициента преобразования, такого как 44 и 132, или 143. Что касается других символов, они также могут извлекаться из потока данных непосредственно или с использованием энтропийного декодирования, используя распределение фиксированной вероятности, но фиг. 1-9 показали, что также может использоваться энтропийное кодирование с использованием адаптивности контекста.
Устройство по фиг. 10 может использоваться в качестве устройства 102 в декодере 102 картинок на фиг. 8.
Ради полноты, фиг. 12 изображает устройство для кодирования множества коэффициентов преобразования разных блоков преобразования, причем каждый имеет уровень коэффициента преобразования, в поток 32 данных, соответствующий устройству по фиг. 10.
Устройство по фиг. 12 содержит символизатор 150, выполненный с возможностью отображения уровня коэффициента преобразования для текущего коэффициента преобразования в соответствии со схемой символизации, которая является параметризуемой в соответствии с параметром символизации, на набор символов или последовательность символов.
Устройство 154 вставки выполнено с возможностью вставки набора символов для текущего коэффициента преобразования в поток 32 данных.
Определитель 156 параметра символизации выполнен с возможностью определения параметра 46 символизации для текущего коэффициента преобразования в зависимости, посредством функции 52, параметризуемой посредством параметра функции, от ранее обработанных коэффициентов преобразования, и может, с этой целью быть подсоединен между выходом устройства 152 вставки и входом параметра символизатора 150, или альтернативно между выходом и входом символизатора 150.
Устройство 154 вставки, символизатор 150 и определитель 156 параметра символизации могут быть выполнены с возможностью последовательной обработки коэффициентов преобразования разных блоков преобразования, и параметр функции изменяется в зависимости от размера блока преобразования текущего коэффициента преобразования, типа информационной составляющей блока преобразования текущего коэффициента преобразования и/или частотного участка, на котором располагается текущий коэффициент преобразования в блоке преобразования.
Как указано выше в отношении устройства декодирования по фиг. 10, устройство по фиг. 12 может быть выполнено так, что функцией, задающей взаимосвязь между ранее декодированными коэффициентами преобразования с одной стороны и параметром символизации с другой стороны, является g(f(x)), и ранее обработанные коэффициенты преобразования могут пространственно определяться в зависимости от относительного пространственного расположения относительно текущего коэффициента преобразования. Средство вставки может быть выполнено с возможностью вставки набора символов в поток данных непосредственно или с использованием энтропийного кодирования, используя распределение фиксированной вероятности, и схема символизации может быть такой, что набор символов из кода Райса, и параметром символизации является параметра Райса. Символизатор может быть выполнен с возможностью ограничения схемы символизации до интервала уровней из интервала 20 диапазона коэффициентов преобразования, так что набор символов представляет префикс или суффикс в отношении других частей общей символизации текущего коэффициента преобразования.
Как упомянуто выше, в предпочтительной реализации вариантов осуществления по фиг. 10-12, выбор контекстной модели для первых трех бинов блокируется по сравнению с вариантами осуществления по фиг. 1-9. Для этого предпочтительного варианта осуществления результирующие бины из усеченной унарной бинаризации 128 кодируются с фиксированной вероятностью 0,5. В другом предпочтительном варианте осуществления усеченная унарная бинаризация 128 исключается, как показано на фиг. 11b, и границы для интервала Райса корректируются, приводя к тому же интервальному диапазону, что и в современном уровне техники (т. е. левая и правая границы минус 3). Для этого предпочтительного варианта осуществления правило выведения параметра Райса модифицируется по сравнению с вариантом осуществления по фиг. 1-9. Вместо использования f1 в качестве значения оценки, может использоваться, например, f0. Кроме того, входной вектор может корректироваться до n={4,10,22}.
Другой вариант осуществления, описанный ниже в данном документе, иллюстрирует возможность виртуального обладания разными шаблонами для выбора/зависимости шаблона с одной стороны и определения параметра символизации с другой стороны. Т. е. шаблон коэффициентов xi остается таким же как для выбора/зависимости контекста, так и для определения параметра символизации, но коэффициенты xi, которые участвуют в оказании влияния на f(x), эффективно интерпретируются по-разному между выбором/зависимостью контекста и определением параметра символизации посредством соответствующей установки wi: все коэффициенты xi, для которых весовые коэффициенты wi равны нулю, не оказывают влияние на f(x) соответствующим образом, разработка участков шаблона, где wi равны нулю, разными между выбором/зависимостью контекста с одной стороны и определением параметра символизации с другой стороны, эффективно приводит к разным «эффективным шаблонам» для выбора/зависимости контекста и определения параметра символизации. Другими словами, посредством установки некоторых wi на ноль для некоторых положений i шаблона для одного из выбора/зависимости контекста и определения параметра символизации, в тоже время устанавливая wi в этих некоторых положениях i шаблона на ненулевые значения для другого из выбора/зависимости контекста и определения параметра символизации, шаблон упомянутого в первый раз одного из выбора/зависимости контекста и определения параметра символизации эффективно меньше шаблона последнего из выбора/зависимости контекста и определения параметра символизации. Снова, как уже указано выше, шаблон может охватывать все коэффициенты преобразования блока, например, независимо от положения кодируемого в данный момент коэффициента преобразования.
См. например, фиг. 13, изображающую блок 10 коэффициентов преобразования, примерно состоящих из массива коэффициентов 12 преобразования 16×16. Блок 10 коэффициентов преобразования подразделяется на подблоки 200 из коэффициентов 12 преобразования 4×4 каждый. Подблоки 200, поэтому, располагаются регулярно в массиве 4×4. Согласно настоящему варианту осуществления, для кодирования блока 10 коэффициентов преобразования карта значимости кодируется в потоке 32 данных, причем карта значимости указывает положения значимых уровней 12 коэффициента преобразования, т. е. уровней коэффициента преобразования, не равных 0. Тогда уровни коэффициента преобразования минус единица из этих значимых коэффициентов преобразования могут кодироваться в потоке данных. Кодирование последних из упомянутых уровней коэффициента преобразования может выполняться так, как описано выше, а именно посредством смешанной схемы контекстно-адаптивного энтропийного кодирования и кодирования переменной длины, используя общую параметризуемую функцию для выбора контекста и определения параметра символизации. Некоторый порядок сканирования может использоваться, чтобы преобразовать в последовательную форму или упорядочивать значимые коэффициенты преобразования. Один пример такого порядка сканирования показан на фиг. 13: подблоки 200 сканируются от самой высокой частоты (снизу справа) до DC (вверху слева), и в каждом подблоке 200 коэффициенты 12 преобразования сканируются перед тем, как будет выполнено обращение к коэффициентам преобразования следующего подблока в порядке подблоков. Это изображено стрелками 202, указывающими сканирование подблоков, и 204, иллюстрирующими участок фактического сканирования коэффициентов. Индекс сканирования может передаваться в потоке 32 данных, чтобы предоставить возможность выбора из числа нескольких путей сканирования для сканирования подблоков 200 и/или коэффициентов 12 преобразования в подблоках соответственно. На фиг. 13 диагональное сканирование изображено как для сканирования 202 подблоков, так и для сканирования коэффициентов 12 преобразования в каждом подблоке. Следовательно, на декодере будет декодироваться карта значимостей, и уровни коэффициента преобразования значимых коэффициентов преобразования будут декодироваться с использованием только что упомянутого порядка сканирования и с использованием вышеупомянутых вариантов осуществления, применяющих параметризуемую функцию. В описании, более подробно описанном ниже, xS и yS обозначают столбец подблока и строку подблока, измеренных от положения DC, т. е. от верхнего левого углу блока 10, в котором располагается кодируемый/декодируемый в данный момент коэффициент преобразования. xP и yP обозначают положение кодируемого/декодируемого в данный момент коэффициента преобразования, измеренное от верхнего левого угла (положения DC-коэффициента) текущего подблока (xS, yS). Это изображено на фиг. 13 для верхнего правого подблока 200. xC и yC обозначают положение декодируемых/кодируемых в данный момент коэффициентов преобразования, измеренное в коэффициентах преобразования от DC-положения. Кроме того, так как размер блока для блока 10 на фиг. 13, а именно 16×16, был выбран только для целей иллюстрации, вариант осуществления, дополнительно кратко описанный ниже, использует log2TrafoSize в качестве параметра, обозначающего размер блока 10, который, как предполагается, является квадратным. log2TrafoSize указывает двоичный логарифм количества коэффициентов преобразования в каждой строке коэффициентов преобразования блока 10, т. е. log2 длины краев блока 10, измеренной в коэффициентах преобразования. CtxIdxInc в конечном счете выбирает контекст. Кроме того, в конкретном варианте осуществления, кратко изложенном ниже, предполагается, что вышеупомянутые сигналы карты значимостей coded_sub_block_flag, т. е. двоичный элемент синтаксиса или флаг, для подблоков 200 блока 10, чтобы сигнализировать по подблокам, располагается ли или нет в соответствующем подблоке 200 любой значимый коэффициент преобразования, т. е. располагаются ли только незначимые коэффициенты преобразования в соответствующем подблоке 200. Если флаг равен нулю, только незначимые коэффициенты преобразования располагаются в соответствующем подблоке.
Таким образом, согласно данному варианту осуществления нижеследующее выполняется контекстно-адаптивным энтропийным декодером/кодером, чтобы выбрать контекст significant_coeff_flag, т. е. флаг, который является частью карты значимостей и сигнализирует для некоторого коэффициента преобразования подблока, для которого coded_sub_block_flag сигнализирует, что соответствующий подблок 200 содержит ненулевые коэффициенты преобразования, является ли соответствующий коэффициент значимым, т. е. ненулевым, или нет.
Входами для этого процесса являются индекс cIdx цветовой составляющей, текущее положение (xC, yC) сканирования коэффициентов, индекс scanIdx порядка сканирования, размер log2TrafoSize блока преобразования. Выходом этого процесса является ctxIdxInc.
Переменная sigCtx зависит от текущего положения (xC, yC), индекса cIdx цветовой составляющей, размера блока преобразования и ранее декодированных бинов элемента синтаксиса coded_sub_block_flag. Для вывода sigCtx применяется следующее.
- Если log2TrafoSize равен 2, sigCtx выводится с использованием ctxIdxMap[], определенного в таблице 1 следующим образом.
sigCtx=ctxIdxMap[yC<<2)+xC]
- Иначе, если xC+yC равен 0, sigCtx выводится следующим образом.
sigCtx=0
- Иначе, sigCtx выводится с использованием предыдущих значений coded_sub_block_flag следующим образом.
- Горизонтальное и вертикальное положения xS и yS подблока устанавливаются равными (xC>>2) и (yC>>2) соответственно.
- Переменная prevCsbf устанавливается равной 0.
- Когда xS меньше (1<<(log2TrafoSize-2))-1, применяется следующее.
prevCsbf+=coded_sub_block_flag[xS+1][yS]
- Когда yS меньше (1<<(log2TrafoSize-2))-1, применяется следующее.
prevCsbf+=(coded_sub_block_flag[xS][yS+1]<<1)
- Внутренние положения подблока xP и yP устанавливаются равными (xC & 3) и (yC & 3), соответственно.
- Переменная sigCtx выводится следующим образом.
- Если prevCsbf равен 0, применяется следующее.
sigCtx=(xP+yP==0)?2:(xP+yP<3)?1:0
- Иначе, если prevCsbf равен 1, применяется следующее.
sigCtx=(yP==0)?2:(yP==1)?1:0
- Инчае, если prevCsbf равен 2, применяется следующее.
sigCtx=(xP==0)?2:(xP==1)?1:0
- Иначе (prevCsbf равен 3), применяется следующее.
sigCtx=2
- Переменная sigCtx модифицируется следующим образом.
- Если cIdx равен 0, применяется следующее.
- Когда (xS+yS) больше 0, применяется следующее.
sigCtx+=3
- Переменная sigCtx модифицируется следующим образом.
- Если log2TrafoSize равен 3, применяется следующее.
sigCtx+=(scanIdx == 0)?9:15
- Иначе применяется следующее.
sigCtx+=21
- Иначе (cIdx больше 0), применяется следующее.
- Если log2TrafoSize равен 3, применяется следующее.
sigCtx+=9
- Иначе, применяется следующее.
sigCtx+=12
Приращение ctxIdxInc индекса контекста выводится с использованием индекса cIdx цветовой составляющей и sigCtx следующим образом.
- Если cIdx равен 0, ctxIdxInc выводится следующим образом.
ctxIdxInc=sigCtx
- Иначе (cIdx больше 0), ctxIdxInc выводится следующим образом.
ctxIdxInc=27+sigCtx
Как описано выше, для каждого значимого коэффициента преобразования дополнительные элементы синтаксиса или наборы символов могут передаваться в потоке данных, чтобы сигнализировать его уровни. Согласно вариантам осуществления, кратко изложенным ниже, для одного значимого коэффициента преобразования передаются следующие элементы синтаксиса или наборы коэффициентов преобразования: coeff_abs_level_greater1_flag, coeff_abs_level_greater2_flag (необязательный) и coeff_abs_level_remaining, так что уровень TransCoeffLevel кодируемого/декодируемого в данный момент значимого коэффициента преобразования равен

с
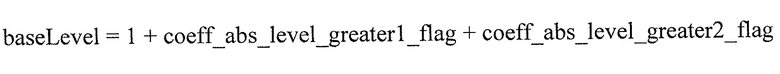
Изобретатели просят отметить, что significant_coeff_flag по определению равен 1 для значимых коэффициентов преобразования, и, следовательно, может рассматриваться как часть кодирования коэффициента преобразования, а именно часть его энтропийно кодированных символов.
Контекстно-адаптивный энтропийный декодер/кодер, например, выполняет выбор контекста для coeff_abs_level_greater1_flag следующим образом. Например, индекс i сканирования текущего подблока увеличивается вдоль пути 202 сканирования в направлении DC, и индекс n сканирования текущего коэффициента увеличивается в соответствующем подблоке, в котором располагается положение кодируемого/декодируемого в данный момент коэффициента преобразования, вдоль пути 204 сканирования, причем, как подчеркнуто выше, существуют разные возможности для путей 202 и 204 сканирования, и они могут фактически быть переменными в соответствии с индексом scanIdx.
Входами для этого процесса выбора контекста coeff_abs_level_greater1_flag являются индекс cIdx цветовой составляющей, индекс i сканирования текущего подблока и индекс n сканирования текущего коэффициента в текущем подблоке.
Выходом этого процесса является ctxIdxInc.
Переменная ctxSet задает текущий набор контекстов и для ее вывода применяется следующее.
- Если данный процесс вызывается в первый раз для индекса i сканирования текущего подблока, применяется следующее.
- Переменная ctxSet инициализируется следующим образом.
- Если индекс i сканирования текущего подблока равен 0, или cIdx больше 0, применяется следующее.
ctxSet=0
- Иначе (i больше 0, и cIdx равен 0), применяется следующее.
ctxSet=2
- Переменная lastGreater1Ctx выводится следующим образом.
- Если текущий подблок с индексом i сканирования является первым, подлежащим обработке в данном подпункте для текущего блока преобразования, переменная lastGreater1Ctx устанавливается равной 1.
- Иначе, переменная lastGreater1Ctx устанавливается равной значению greater1Ctx, которое было выведено во время последнего вызова процесса, заданного в данном подпункте для элемента синтаксиса coeff_abs_level_greater1_flag для предыдущего подблока с индексом i+1 сканирования.
- Когда lastGreater1Ctx равна 0, ctxSet увеличивается на единицу следующим образом.
ctxSet=ctxSet+1
- Переменная greater1Ctx устанавливается равной 1.
- Иначе (этот процесс не вызывается в первый раз для индекса i сканирования текущего подблока), применяется следующее.
- Переменная ctxSet устанавливается равной переменной ctxSet, которая была выведена во время последнего вызова процесса, заданного в данном подпункте.
- Переменная greater1Ctx устанавливается равной переменной greater1Ctx, которая была выведена во время последнего вызова процесса, заданного в данном подпункте.
- Когда greater1Ctx больше 0, переменная lastGreater1Flag устанавливается равной элементу синтаксиса coeff_abs_level_greater1_flag, который использовался во время последнего вызова процесса, заданного в этом подпункте, и greater1Ctx модифицируется следующим образом.
- Если lastGreater1Flag равен 1, greater1Ctx устанавливается равной 0.
- Иначе (lastGreater1Flag равен 0), greater1Ctx увеличивается на 1.
Приращение ctxIdxInc индекса контекста выводится с использованием набора ctxSet текущего контекста и текущего контекста greater1Ctx следующим образом.
ctxIdxInc=(ctxSet* 4)+Min(3, greater1Ctx)
Когда cIdx больше 0, ctxIdxInc модифицируется следующим образом.
ctxIdxInc=ctxIdxInc+16
Процесс выбора контекста coeff_abs_level_greater2_flag может выполняться так же, как и coeff_abs_level_greater2_flag со следующим отличием:
Приращение ctxIdxInc индекса контекста устанавливается равным переменной ctxSet следующим образом.
ctxIdxInc=ctxSet
Когда cIdx больше 0, ctxIdxInc модифицируется следующим образом.
ctxIdxInc=ctxIdxInc+4
Для выбора параметра символизации нижеследующее выполняется определителем параметра символизации для определения параметра символизации, который в данном случае содержит cLastAbsLevel и cLastRiceParam.
Входом для данного процесс является запрос бинаризации для элемента синтаксиса coeff_abs_level_remaining[n], и baseLevel.
Выходом данного процесса является бинаризация элемента синтаксиса.
Переменные cLastAbsLevel и cLastRiceParam выводятся следующим образом.
- Если n равен 15, cLastAbsLevel и cLastRiceParam устанавливаются равными 0.
- Иначе (n меньше 15), cLastAbsLevel устанавливается равным baseLevel+coeff_abs_level_remaining[n+1], и cLastRiceParam устанавливается равным значению cRiceParam, которое было выведено во время вызова процесса бинаризации, задаваемого в данном подпункте для элемента синтаксиса coeff_abs_level_remaining[n+1] этого же блока преобразования.
Переменная cRiceParam выводится из cLastAbsLevel и cLastRiceParam как:
cRiceParam
Min(cLastRiceParam+(cLastAbsLevel>(3* (1<<cLastRiceParam))?1:0), 4)
Переменная cTRMax выводится из cRiceParam как:
cTRMax=4<<cRiceParam
Бинаризация coeff_abs_level_remaining может состоять из префиксной части и (когда присутствует) суффиксной части.
Префиксная часть бинаризации выводится посредством вызова, например, процесса бинаризации Райса для префиксной части Min(cTRMax, coeff_abs_level_remaining[n]).
Когда строка бинов префикса равна строке бинов длиной 4, например, со всеми битами равными 1, строка бинов может состоять из строки бинов префикса и строки бинов суффикса. Строка бинов суффикса может выводиться с использованием бинаризации экспоненциального кода Голомба порядка k для суффиксной части (coeff_abs_level_remaining[n] - cTRMax) с экспоненциальным кодом Голомба порядка k, установленным равным cRiceParam+1, например.
Необходимо отметить, что вышеупомянутые варианты осуществления могут изменяться. Например, зависимость от индекса cIdx цветовой составляющей может быть удалена. Например, рассматривается только одна цветовая составляющая. Кроме того, все явные значения могут изменяться. Постольку только что кратко описанные примеры должны интерпретироваться широко, чтобы также включать в себя варианты.
В вышеприведенном примере варианты осуществления, кратко описанные выше, могут полезно использоваться следующим образом. В частности, определение CtxIdxInc для coeff_abs_level_greater1_flag с одной стороны и определение параметра символизации для coeff_abs_level_remaining гармонизируется применением вышеупомянутых функций f и g посредством установки параметров функции следующим образом.
С этой целью фиг. 16 в качестве примера изображает «текущий коэффициент преобразования», изображенный крестиком 206. Он является представителем для любого коэффициента преобразования, с которым ассоциируется любой из упомянутых ниже элементов синтаксиса. Он располагается в (xP, yP)=(1,1) и (xC, yC)=(1,5) в текущем подблоке (xS, yS)=(0,1). Правый соседний подблок находится в (xS, yS)=(1,1), нижний соседний подблок находится в (xS, yS)=(0,2), и непосредственно ранее кодированный подблок зависит от пути 202 сканирования. В данном случае в качестве примера показано диагональное сканирование 202, и подблок, кодированный/декодированный непосредственно перед текущим подблоком, находится в (xS, yS)=(1,0).
Изобретатели снова переписывают формулы для общей параметризуемой функции
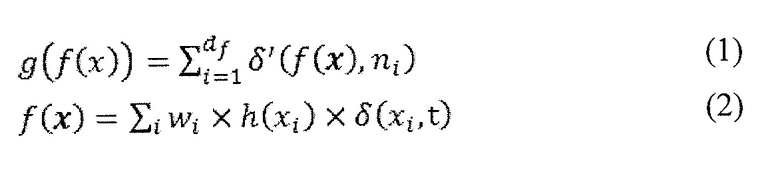
Для выбора контекста significant_coeff_flag для текущего коэффициента 206, нижеследующее может вычисляться устройством энтропийного кодирования/декодирования. Т. е. оно использует функцию (1) с (2) с параметрами t, h и w функции, установленными следующим образом.
Для функции (2) wi=1 для всех xi в соседних подблоках справа и ниже текущего подблока, и wi=0 в другом месте в блоке 10;
h(xi)=1 для всех xi в соседнем подблоке справа от текущего подблока; если присутствует, он был ранее сканирован при сканировании 202 подблоков; в случае, если доступны более одного сканирования 202, все могут быть такими, что, независимо от scanIdx, соседний подблок справа имеет свои коэффициенты, кодированные/декодированные перед текущим подблоком;
h(xi)=24+1 для всех xi в соседнем подблоке ниже текущего подблока, ранее сканированного при сканировании подблоков (независимо от scanIdx);
h(xi)=0 иначе;
t=1;
Если значение f равно 0, это сигнализирует случай, что никакой из соседних подблоков справа и ниже текущего подблока Nachbarn не содержит никакого значимого коэффициента преобразования;
Если значение f попадает между 1 и 16, оба включительно, то это соответствует тому факту, что coded_sub_block_flag равен 1 в правом соседнем подблоке
Если значение f является кратным 24+1 (без остатка), то это соответствует тому факту, что coded_sub_block_flag равен 1 в нижнем соседнем подблоке
Если значение f является кратным 24+1, но с остатком, то это означает, что coded_sub_block_flag равен 1 для обоих соседних подблоков, а именно одного справа и одного ниже от текущего подблока;
Для функции (1) n устанавливается следующим образом с df равным 3:
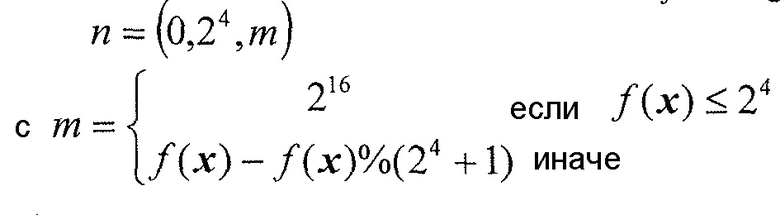
Посредством этой меры переменная составляющая индекса контекста определяется с использованием g(f), причем вышеупомянутые параметры функции основываются на уже кодированных/декодированных коэффициентах.
Для выбора контекста coeff_abs_greater1_flag, нижеследующее может вычисляться устройством энтропийного кодирования/декодирования. Т. е. оно использует функцию (1) с (2) с параметрами функции, установленными следующим образом:
Для функции (2) параметры устанавливаются следующим образом:
wi=1 устанавливается для всех xi в непосредственно предшествующем подблоке и текущем подблоке, и нулю для всех других.
h(xi)=1 для всех xi в текущем подблоке с |xi|=1
h(xi)=24 для всех xi в текущем подблоке с |xi|>1
h(xi)=216 для всех xi в непосредственно предшествующем подблоке
t=2
Для функции (1) n устанавливается следующим образом с df равным 8:
n =(0,1,2,24,216,216+1,216+2,216+24)
Для выбора контекста coeff_abs_greater2_flag нижеследующее может вычисляться устройством энтропийного кодирования/декодирования. В частности, оно использует функцию (1) с (2) с параметром функции, установленным так, как описано выше в отношении coeff_abs_greater2_flag, но с df равным 1:
n =(216)
Для определения параметра символизации для coeff_abs_level_remaining определитель параметра символизации может использовать общую функцию (1) с параметром функции, установленным следующим образом:
Для функции (2) параметры устанавливаются следующим образом:
wi=1 для всех xi в текущем подблоке, но нулю в другом месте
h(xi)=1 для наиболее последнего - в соответствии с внутренним сканированием 204 коэффициентов - посещенного коэффициента xi, для которого был кодирован coeff_abs_level_remaining, т. е. уровень которого попадает в интервал, соответствующий схеме символизации;
h(xi)=0 в другом месте в шаблоне
t=0
Для функции (1) n устанавливается следующим образом
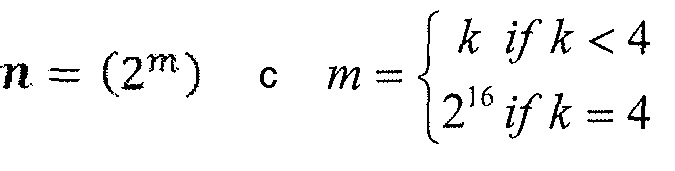 , где k представляет собой параметр символизации, например, параметр Райса, для вышеупомянутого наиболее последнего - в соответствии с внутренним сканированием 204 коэффициентов - посещенного коэффициента. Используя результирующую g(f), определяется параметр символизации для текущего коэффициента 206.
, где k представляет собой параметр символизации, например, параметр Райса, для вышеупомянутого наиболее последнего - в соответствии с внутренним сканированием 204 коэффициентов - посещенного коэффициента. Используя результирующую g(f), определяется параметр символизации для текущего коэффициента 206.
Нижеследующий синтаксис может использоваться для пересылки только что кратко изложенных элементов синтаксиса.


Синтаксис указывает, что уровень коэффициента преобразования состоит из coeff_abs_level_remaining и baseLevel, причем baseLevel состоит из 1+coeff_abs_level_greater1_flag[n]+coeff_abs_level_greater2_flag[n]. 1 используется, так как в этом расположении (или в момент, когда уровни восстанавливаются в декодере) элементом синтаксиса является significant_coeff_flag=1. «Первым набором» тогда будет TU-код (код Райса с параметризацией, равной 0) - из этого формируются первые 3 элемента синтаксиса. «Второй набор» тогда формирует элемент синтаксиса coeff_abs_level_remaining.
Так как граница сдвигается между «первым» и «вторым набором», максимальное значение определяется или посредством coeff_abs_greater1_flag, coeff_abs_greater2_flag или significant_coeff_flag, следовательно, ветвлениями в зависимости от элементов синтаксиса в таблице.
Вышеупомянутые установки параметров функции мотивируются еще в незначительной степени следующим.
g(f) формирует сумму соседних коэффициентов и, используя результат, выводятся контекст и параметр десимволизации, причем более поздняя модификация может исполняться в зависимости от пространственного положения.
g(x) принимает одно единственное значение. Это значение соответствует результату функции f(x). Зная его, может выводиться выбор контекста и также параметризация параметра Райса.
significant_coeff_flag: Так как само h может представлять собой функцию от x, f(x) или любая другая функция может связываться в цепочку снова и снова. Функцией f(x) с wi=1 для всех положений в правом блоке 4×4, t=1 и h, является функция, которая выполнена подобно f(x), но инвертирована, так что, в конечном счете, приводит к значению 0 или 1, т. е. h(x)=min(1, f(x)).
Эквивалентно, для второго ввода это применимо к нижнему подблоку 4×4. Тогда prevCsbf=h0+2×h1, причем prevCsbf также может быть функцией h в f(x).
Если устанавливается t=∞, могут выводиться значения элемента синтаксиса coded_sub_block_flag. Таким образом, значение между 0 и включая 3 получается в качестве результата для самого крайнего значения f(x). Параметр n для g(x) тогда будет или (xP+yP), xP, yP или (0,0). Если результатом является f(x)=0, тогда n=(xP+yP, xP+yP+3), для f(x)=1 результатом является n=(yP, yP+1), для f(x)=2 результатом является n=(xP, xP+1), и для f(x)=3 результатом является n=(0,0). Так сказать, f(x) может оцениваться непосредственно, чтобы определять n. Остальные формулы выше просто описывают адаптацию в зависимости от яркости/цветности и дополнительную зависимость от глобального положения и сканирования. В случае просто блока 4×4 f(x) может быть выполнена так, что значение для prevCsbf=4 (также может быть другим), и, таким образом, может воспроизводиться таблица отображения.
coeff_abs_level_greater1_flag: В данном случае оценка подблоков является подобной, причем оценивается только предшествующий подблок. Результатом является, например, 1 или 2 (он должен иметь только два разных значения), причем t=2. Это соответствует выбору базового индекса в зависимости от уже декодированных уровней в предыдущем подблоке. Таким образом может получена прямая зависимость от уровней, расположенных в подблоке. Фактически, включение одним индексом выполняется тогда, когда был декодирован 0 (ограниченный до 3, начиная с 1), и как только будет декодирована 1, он устанавливается в 0. Если расположение не принимается во внимание, параметризация может исполняться следующим образом, начиная с 0. wi=1 для всех уровней в одном и том же подблоке и t=3, т. е. f(x) обеспечивает количество уровней с coeff_abs_greater1_flag=1. Для дополнительной функции f(x) t=2, т. е. количество положений с кодированным элементом синтаксиса coeff_abs_greater1_flag. Первая функция ограничена, т. е. h0=f(x)=min(f0(x),2) и вторая функция ограничивается h1=f(x)=max(f1(x),1). Все они связываются с дельта-функцией (0, если h1=1, иначе h0). Для coeff_abs_greater2_flag используется только вывод набора (wi устанавливается на 0 для сцепленной внутренней функции).
coeff_abs_level_remaining: Выбор ограничивается только текущим подблоком, и n выводится так, как описано выше.
Что касается только что кратко изложенного варианта осуществления, отмечается следующее. В частности, согласно вышеупомянутому описанию существуют разные возможности в отношении определения шаблона: шаблоном может быть движущийся шаблон, положение которого определяется в зависимости от положения текущего коэффициента 206. Краткий обзор такого примерного движущегося шаблона изображен на фиг. 13 пунктирной линией 208. Шаблон состоит из текущего подблока, в котором располагается текущий коэффициент 206, соседних подблоков справа и ниже текущего подблока, а также одного или нескольких подблоков, которые непосредственно предшествуют текущему подблоку при сканировании 202 подблоков или при любом из сканирований 202 подблоков, если имеется несколько из них, среди которых один является выбираемым с использованием индекса сканирования, как объяснено выше. В качестве альтернативы, шаблон 208 может просто охватывать все коэффициенты 12 преобразования блока 10.
В вышеупомянутом примере имеются дополнительные разные возможности для выбора значений h и n. Эти значения, следовательно, могут устанавливаться по-разному. Это в некоторой степени также верно в отношении wi, что касается этих весовых коэффициентов, которые устанавливаются в единицу. Они могут устанавливаться на другое ненулевое значение. Они еще не должны быть равны друг другу. Так как wi умножается на h(xi), это же значение произведения может достигаться установкой ненулевых wi другим образом. Кроме того, параметр символизации не должен быть параметром Райса или, другими словами, схема символизации не ограничивается схемой символизации Райса. Что касается выбора индекса контекста, ссылка делается на вышеприведенное описание, где уже было отмечено, что окончательный индекс контекста может быть получен добавлением индекса контекста, полученного с использованием функции g(f), к некоторому индексу смещения, который, например, является характерным для соответствующего типа элемента синтаксиса, т. е. характерным для significant_coeff_flag, coeff_abs_level_greater1_flag и coeff_abs_level_greater2_flag.
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствует этапу способа или признаку этапа способа. Аналогично аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента или признака соответствующего устройства. Некоторые или все этапы способа могут исполняться посредством (или используя) аппаратного устройства, подобного, например, микропроцессору, программируемому компьютеру или электронной схеме. В некоторых вариантах осуществления некоторый один или несколько из наиболее важных этапов способа могут исполняться таким устройством.
В зависимости от некоторых требований к реализации варианты осуществления изобретения могут быть реализованы аппаратными или программными средствами. Реализация может выполняться с использованием цифровой запоминающей среды, например, дискеты, цифрового многофункционального диска (DVD), диска Blu-Ray, компакт-диска (CD), постоянного запоминающего устройства (ROM), программируемого ROM (PROM), стираемого программируемого ROM (EPROM), электрически-стираемого программируемого ROM (EEPROM) или флэш-памяти, имеющих хранимые на них сигналы управления, считываемые электронным образом, которые взаимодействуют (или способны взаимодействовать) с программируемой компьютерной системой, так что выполняется соответствующий способ. Поэтому, цифровая запоминающая среда может быть считываемой компьютером.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий сигналы управления, считываемые электронным образом, которые способны взаимодействовать с программируемой компьютерной системой, так что выполняется один из способов, описанных в данном документе.
Обычно варианты осуществления настоящего изобретения могут быть реализованы в виде продукта компьютерной программы с программным кодом, причем программный код действует для выполнения одного из способов, когда продукт компьютерной программы выполняется на компьютере. Программный код, например, может храниться на машиносчитываемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из способов, описанных в данном документе, хранимую на машиносчитываемом носителе.
Другими словами, вариант осуществления обладающими признаками изобретения способа, поэтому, представляет собой компьютерную программу, имеющую программный код для выполнения одного из способов, описанных в данном документе, когда компьютерная программа выполняется на компьютере.
Другой вариант осуществления обладающих признаками изобретения способов, поэтому, представляет собой носитель данных (или цифровую запоминающую среду или считываемую компьютером среду), содержащий записанную на ней компьютерную программу для выполнения одного из способов, описанных в данном документе. Носитель данных, цифровая запоминающая среда или записанная среда обычно являются материальными и/или долговременными.
Другой вариант осуществления обладающими признаками изобретения способа, поэтому, представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью пересылки по соединению передачи данных, например, посредством Интернета.
Другой вариант осуществления содержит средство обработки, например компьютер, или программируемое логическое устройство, выполненное или адаптированное для выполнения одного из способов, описанных в данном документе.
Другой вариант осуществления содержит компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, описанных в данном документе.
Другой вариант осуществления согласно изобретению содержит устройство или систему, выполненную с возможностью пересылки (например, электронным или оптическим образом) на приемник компьютерной программы для выполнения одного из способов, описанных в данном документе. Приемником, например, может быть компьютер, мобильное устройство, устройство памяти или т. п. Устройство или система, например, могут содержать файловый сервер для пересылки компьютерной программы на приемник.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая вентильная матрица) может использоваться для выполнения некоторых или всех функциональных возможностей способов, описанных в данном документе. В некоторых вариантах осуществления программируемая вентильная матрица может взаимодействовать с микропроцессором, чтобы выполнять один из способов, описанных в данном документе. Как правило, способы предпочтительно выполняются любым аппаратным устройством.
Вышеописанные варианты осуществления являются просто иллюстративными для принципов настоящего изобретения. Понятно, что модификации и изменения устройства и деталей, описанных в данном документе, очевидны для специалиста в данной области техники. Намерением, поэтому, является ограничение только объемом рассматриваемой формулы изобретения и не конкретными подробностями, представленными описанием и объяснением вариантов осуществления в данном документе.
Таким образом, в первом аспекте настоящего изобретения обеспечено устройство для декодирования множества коэффициентов (12) преобразования, имеющих уровни коэффициента преобразования, из потока (32) данных, содержащее
контекстно-адаптивный энтропийный декодер (80), выполненный с возможностью, для текущего коэффициента (x) преобразования, энтропийного декодирования первого набора (44) из одного или нескольких символов из потока (32) данных;
десимволизатор (82), выполненный с возможностью отображения первого набора (44) из одного или нескольких символов на уровень коэффициента преобразования в пределах первого интервала (16) уровней в соответствии с первой схемой символизации;
средство (84) извлечения, выполненное с возможностью, если уровень коэффициента преобразования, на который отображается первый набор из одного или нескольких символов в соответствии с первой схемой символизации, представляет собой максимальный уровень первого интервала (16) уровней, извлечения второго набора символов (42) из потока (32) данных,
в котором десимволизатор (82) выполнен с возможностью отображения второго набора (42) символов на положение в пределах второго интервала (18) уровней в соответствии со второй схемой символизации, которая является параметризуемой в соответствии с параметром символизации,
в котором контекстно-адаптивный энтропийный декодер (80) выполнен с возможностью, при энтропийном декодировании по меньшей мере одного предопределенного символа первого набора (44) из одного или нескольких символов из потока (32) данных, использования контекста в зависимости, посредством функции, параметризуемой посредством параметра функции (52), с параметром функции, установленным на первую установку, от ранее декодированных коэффициентов преобразования, и
в котором устройство дополнительно содержит определитель (86) параметра символизации, выполненный с возможностью, если уровень коэффициента преобразования, на который первый набор (44) из одного или нескольких символов отображается в соответствии с первой схемой символизации, представляет собой максимальный уровень первого интервала (16) уровней, определения параметра (46) символизации в зависимости, посредством функции (52) с параметром функции, установленным на вторую установку, от ранее декодированных коэффициентов преобразования.
Причем устройство выполнено так, что функцией, задающей взаимосвязь между ранее декодированными коэффициентами преобразования с одной стороны и номером смещения индекса контекста для индексирования контекста, и параметром символизации с другой стороны, является
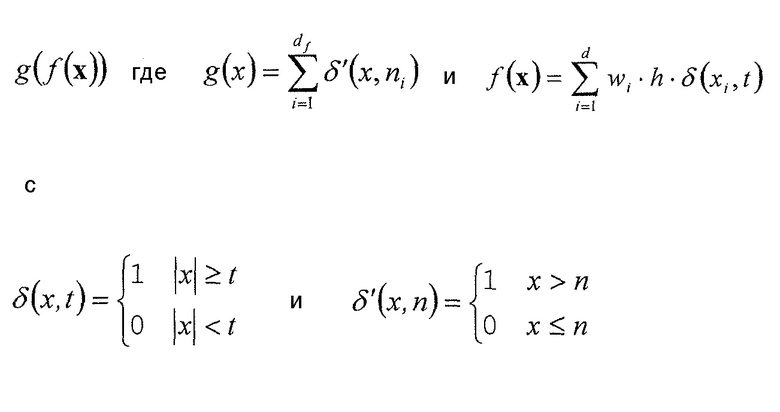
где
t, wi и  образуют параметр функции,
образуют параметр функции,
x={x1,…,xd} с xi с  , представляющим ранее декодированный коэффициент i преобразования,
, представляющим ранее декодированный коэффициент i преобразования,
wi представляют собой взвешивающие значения, каждое из которых может быть равно единице или не равно единице, и
h представляет собой постоянную или функцию xi.
В упомянутом устройстве контекстно-адаптивный энтропийный кодер выполнен так, что зависимость контекста от ранее декодированных коэффициентов преобразования посредством функции
такая, что xi равен уровню коэффициента преобразования ранее декодированного коэффициента i преобразования в случае, когда он находится в пределах первого интервала уровней, и равен максимальному уровню первого интервала уровней в случае, если уровень коэффициента преобразования ранее декодированного коэффициента i преобразования находится в пределах второго интервала уровней, или
такая, что xi равен уровню коэффициента преобразования ранее декодированного коэффициента i преобразования, независимо от уровня коэффициента преобразования ранее декодированного коэффициента i преобразования, находящегося в пределах первого или второго интервала уровней.
В упомянутом устройстве средство установки параметра символизации выполнено так, что зависимость параметра символизации от ранее декодированных коэффициентов преобразования посредством функции
такая, что xi равен уровню коэффициента преобразования ранее декодированного коэффициента i преобразования, независимо от уровня коэффициента преобразования ранее декодированного коэффициента i преобразования, находящегося в пределах первого или второго интервала уровней.
Причем устройство выполнено так, что n1≤…≤  .
.
Причем устройство выполнено так, что h равно |xi|-t.
Причем устройство выполнено с возможностью пространственного определения ранее кодированных коэффициентов преобразования в зависимости от относительного пространственного расположения коэффициентов преобразования относительно текущего коэффициента преобразования.
Причем устройство выполнено с возможностью извлечения информации о положении последнего ненулевого коэффициента преобразования из числа коэффициентов преобразования блока коэффициентов преобразования в соответствии с предопределенным порядком (14) сканирования из потока (32) данных, в котором множество коэффициентов преобразования охватывает коэффициенты преобразования от последнего ненулевого коэффициента преобразования в соответствии с порядком сканирования до DC-коэффициента преобразования блока коэффициентов преобразования.
В упомянутом устройстве символизатор выполнен с возможностью использования модифицированной первой схемы символизации для отображения первого набора из одного или нескольких символов последнего ненулевого коэффициента преобразования, в котором содержатся только уровни ненулевого коэффициента преобразования в пределах первого интервала уровней, тогда как предполагается, что нулевой уровень не применяется для последнего коэффициента преобразования.
В упомянутом устройстве контекстно-адаптивный энтропийный декодер выполнен с возможностью использования отдельного набора контекстов для энтропийного декодирования первого набора из одного или нескольких символов для последнего ненулевого коэффициента преобразования, отдельного от контекстов, используемых при энтропийном декодировании первого набора из одного или нескольких символов кроме последнего ненулевого коэффициента преобразования.
В упомянутом устройстве контекстно-адаптивный энтропийный декодер обходит множество коэффициентов преобразования в противоположном порядке сканирования, ведя от последнего ненулевого коэффициента преобразования к DC-коэффициенту преобразования блока коэффициентов преобразования.
Причем устройство выполнено с возможностью декодирования множества коэффициентов преобразования из потока данных при двух сканированиях, в котором контекстно-адаптивный энтропийный декодер выполнен с возможностью энтропийного декодирования первого набора символов для коэффициентов преобразования из потока данных в порядке, соответствующем первому сканированию коэффициентов преобразования, в котором средство извлечения выполнено с возможностью последующего извлечения второго набора символов для коэффициентов преобразования, для которых первый набор символов отображается на максимальный уровень первого интервала уровней, из потока данных в порядке, соответствующем присутствию коэффициентов преобразования, для которых первый набор символов отображается на максимальный уровень первого интервала уровней, в рамках второго сканирования коэффициентов преобразования.
Причем устройство выполнено с возможностью декодирования множества коэффициентов преобразования из потока данных последовательно при одном сканировании, в котором вторые наборы символов распределяются в потоке данных между первыми наборами символов коэффициентов преобразования, и в котором контекстно-адаптивный энтропийный декодер и средство извлечения выполнены с возможностью, для каждого коэффициента преобразования в порядке сканирования одного сканирования, извлечения вторых наборов символов соответствующих коэффициентов преобразования, для которых первый набор символов отображается на максимальный уровень первого интервала уровней, из потока данных непосредственно после энтропийного декодирования контекстно-адаптивного энтропийного декодера первого набора из одного или нескольких символов соответствующих коэффициентов преобразования, для которых первый набор символов отображается на максимальный уровень первого интервала уровней, из потока данных.
В упомянутом устройстве средство извлечения выполнено с возможностью извлечения второго набора символов из потока данных непосредственно или с использованием энтропийного декодирования, используя распределение фиксированной вероятности.
В упомянутом устройстве первая схема символизации представляет собой схему усеченной унарной бинаризации.
В упомянутом устройстве вторая схема символизации такая, что второй набор символов из кода Райса.
Во втором аспекте настоящего изобретения обеспечен декодер картинок (изображений), содержащий устройство по любому из предшествующих пунктов, в котором декодер картинок выполнен с возможностью, при декодировании картинки, повторного преобразования блоков картинки из блоков коэффициентов преобразования, в котором устройство выполнено с возможностью последовательного декодирования множества коэффициентов преобразования блоков коэффициентов преобразования, блок коэффициентов преобразования за блоком коэффициентов преобразования, с использованием функции для блоков коэффициентов преобразования разных размеров, для блоков коэффициентов преобразования разных размеров и/или для блоков коэффициентов преобразования разного типа информационной составляющей.
В упомянутом декодере устройство выполнено с возможностью использования разных наборов контекстов, из которых контекст для текущего коэффициента преобразования выбирается в зависимости от ранее декодированных коэффициентов преобразования, для разных частотных участков блоков коэффициентов преобразования, для блоков коэффициентов преобразования разных размеров и/или для блоков коэффициентов преобразования разного типа информационной составляющей.
В третьем аспекте настоящего изобретения обеспечено устройство для кодирования множества коэффициентов преобразования, имеющих уровни коэффициента преобразования, в поток (32) данных, содержащее
символизатор (34), выполненный с возможностью отображения текущего коэффициента преобразования
на первый набор из одного или нескольких символов в соответствии с первой схемой символизации, если уровень коэффициента преобразования текущего коэффициента преобразования находится в пределах первого интервала (16) уровней, и
если уровень коэффициента преобразования текущего коэффициента преобразования находится в пределах второго интервала (18) уровней, на объединение второго набора символов, на который максимальный уровень первого интервала (16) уровней отображается в соответствии с первой схемой символизации, и третьего набора символов в зависимости от положения уровня коэффициента преобразования текущего коэффициента преобразования в пределах второго интервала (18) уровней, в соответствии со второй схемой символизации, которая является параметризуемой в соответствии с параметром (46) символизации;
контекстно-адаптивный энтропийный кодер (36), выполненный с возможностью, если уровень коэффициента преобразования текущего коэффициента преобразования находится в пределах первого интервала уровней, энтропийного кодирования первого набора из одного или нескольких символов в поток данных, и, если уровень коэффициента преобразования текущего коэффициента преобразования находится в пределах второго интервала уровней, энтропийного кодирования второго набора из одного или нескольких символов в поток данных, в котором контекстно-адаптивный энтропийный кодер выполнен с возможностью, при энтропийном кодировании по меньшей мере одного предопределенного символа второго набора из одного или нескольких символов в поток данных, использования контекста в зависимости, посредством функции, параметризуемой посредством параметра функции, с параметром функции, установленным на первую установку, от ранее кодированных коэффициентов преобразования; и
определитель (38) параметра символизации, выполненный с возможностью, если уровень коэффициента преобразования текущего коэффициента преобразования находится в пределах второго интервала уровней, определения параметра (46) символизации для отображения на третий набор символов в зависимости, посредством функции с параметром функции, установленным на вторую установку, от ранее кодированных коэффициентов преобразования; и
средство (40) вставки, выполненное с возможностью, если уровень коэффициента преобразования текущего коэффициента преобразования находится в пределах второго интервала уровней, вставки третьего набора символов в поток данных.
Причем устройство выполнено так, что функцией (52), определяющей взаимосвязь между ранее кодированными коэффициентами преобразования с одной стороны и номером (56) индекса контекста, индексирующим контекст, и параметром (46) символизации с другой стороны, является
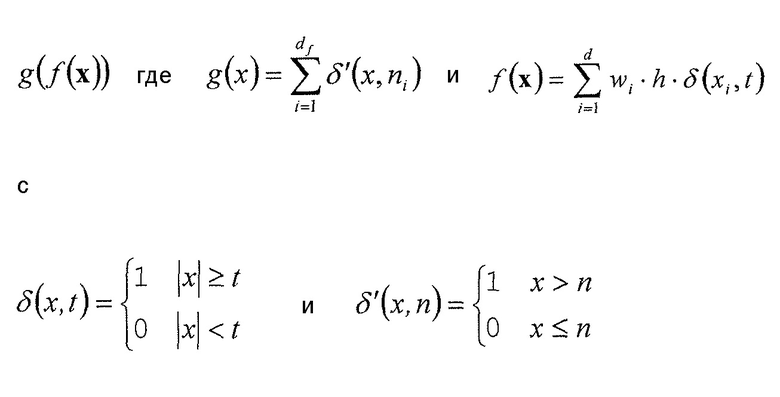
где
t, wi и образуют параметр функции,
x={x1,…,xd} с xi с  , представляющим ранее декодированный коэффициент i преобразования,
, представляющим ранее декодированный коэффициент i преобразования,
wi представляют собой взвешивающие значения, каждое из которых может быть равно единице или не равно единице, и
h представляет собой постоянную или функцию xi.
В упомянутом устройстве контекстно-адаптивный энтропийный кодер (36) выполнен так, что зависимость контекста от ранее кодированных коэффициентов преобразования посредством функции
такая, что xi равен уровню коэффициента преобразования ранее кодированного коэффициента i преобразования в случае, когда он находится в пределах первого интервала (16) уровней, и равен максимальному уровню первого интервала (16) уровней в случае, если уровень коэффициента преобразования ранее кодированного коэффициента i преобразования находится в пределах второго интервала (18) уровней, или
такая, что xi равен уровню коэффициента преобразования ранее кодированного коэффициента i преобразования, независимо от уровня коэффициента преобразования ранее кодированного коэффициента i преобразования, находящегося в пределах первого или второго интервала уровней.
В упомянутом устройстве определитель (38) параметра символизации выполнен так, что зависимость параметра символизации от ранее кодированных коэффициентов преобразования посредством функции
такая, что xi равен уровню коэффициента преобразования ранее кодированного коэффициента i преобразования, независимо от уровня коэффициента преобразования ранее кодированного коэффициента i преобразования, находящегося в пределах первого или второго интервала уровней.
Причем устройство выполнено так, что n1≤…≤ .
Причем устройство выполнено так, что h равно |xi|-t.
Причем выполнено с возможностью пространственного определения ранее кодированных коэффициентов преобразования в зависимости от относительного пространственного расположения коэффициентов преобразования относительно текущего коэффициента преобразования.
Причем устройство выполнено с возможностью определения положения последнего ненулевого коэффициента преобразования из числа коэффициентов преобразования блока коэффициентов преобразования в соответствии с предопределенным порядком сканирования, и вставки информации о положении в поток данных, в котором множество коэффициентов преобразования охватывает коэффициенты преобразования от последнего ненулевого коэффициента преобразования до начала предопределенного порядка сканирования.
В упомянутом устройстве символизатор выполнен с возможностью использования модифицированной первой схемы символизации для символизации последнего коэффициента преобразования, в котором содержатся только уровни ненулевого коэффициента преобразования в пределах первого интервала уровней, тогда как предполагается, что нулевой уровень не применяется для последнего коэффициента преобразования.
В упомянутом устройстве контекстно-адаптивный энтропийный кодер выполнен с возможностью использования отдельного набора контекстов для энтропийного кодирования первого набора из одного или нескольких символов для последнего ненулевого коэффициента преобразования, отдельного от контекстов, используемых при энтропийном кодировании первого набора из одного или нескольких символов кроме последнего ненулевого коэффициента преобразования.
В упомянутом устройстве контекстно-адаптивный энтропийный кодер выполнен с возможностью обхода множества коэффициентов преобразования в противоположном порядке сканирования, ведя от последнего ненулевого коэффициента преобразования к DC-коэффициенту преобразования блока коэффициентов преобразования.
Причем устройство выполнено с возможностью кодирования множества коэффициентов преобразования в поток данных при двух сканированиях, в котором контекстно-адаптивный энтропийный кодер выполнен с возможностью энтропийного кодирования первого и второго наборов символов для коэффициентов преобразования в поток данных в порядке, соответствующем первому сканированию коэффициентов преобразования, в котором средство вставки выполнено с возможностью последующей вставки третьего набора символов для коэффициентов преобразования, имеющих уровень коэффициента преобразования в пределах второго интервала уровней, в поток данных в порядке, соответствующем присутствию коэффициентов преобразования, имеющих уровень коэффициента преобразования в пределах второго интервала уровней в рамках второго сканирования коэффициентов преобразования.
Причем устройство выполнено с возможностью кодирования множества коэффициентов преобразования в поток данных последовательно при одном сканировании, в котором контекстно-адаптивный энтропийный кодер и средство вставки выполнены с возможностью, для каждого коэффициента преобразования в порядке сканирования одного сканирования, вставки третьих наборов символов соответствующих коэффициентов преобразования, имеющих уровень коэффициента преобразования в пределах второго интервала уровней, в поток данных непосредственно после энтропийного кодирования контекстно-адаптивного энтропийного кодера второго набора из одного или нескольких символов соответствующих коэффициентов преобразования, имеющих уровень коэффициента преобразования в пределах второго интервала уровней, в поток данных, так что третьи наборы символов распределяются в потоке данных между первыми и вторыми наборами символов коэффициентов преобразования.
В упомянутом устройстве средство вставки выполнено с возможностью вставки третьего набора символов в поток данных непосредственно или с использованием энтропийного кодирования, используя распределение фиксированной вероятности.
В упомянутом устройстве первая схема символизации представляет собой схему усеченной унарной бинаризации.
В упомянутом устройстве вторая схема символизации такая, что третий набор символов из кода Райса.
В четвертом аспекте настоящего изобретения обеспечен кодер картинок, содержащий устройство по любому из вышеописанных аспектов, в котором кодер картинок выполнен с возможностью, при кодировании картинки, преобразования блоков картинки в блоки коэффициентов преобразования, в котором устройство (62) выполнено с возможностью кодирования множества коэффициентов преобразования блоков коэффициентов преобразования, блок коэффициентов преобразования за блоком коэффициентов преобразования, с использованием функции (52) для блоков разных размеров.
В упомянутом кодере устройство выполнено с возможностью использования разных наборов контекстов, из которых контекст для текущего коэффициента преобразования выбирается в зависимости от ранее кодированных коэффициентов преобразования, для разных частотных участков блоков коэффициентов преобразования.
В пятом аспекте настоящего изобретения обеспечено устройство для декодирования множества коэффициентов (12) преобразования разных блоков преобразования, причем каждый имеет уровень коэффициента преобразования, из потока (32) данных, содержащее
средство извлечения, выполненное с возможностью извлечения набора символов из потока данных для текущего коэффициента преобразования;
десимволизатор, выполненный с возможностью отображения набора символов на уровень коэффициента преобразования для текущего коэффициента преобразования в соответствии со схемой символизации, которая является параметризуемой в соответствии с параметром символизации, и
определитель параметра символизации, выполненный с возможностью определения параметра (46) символизации для текущего коэффициента преобразования в зависимости, посредством функции (52), параметризуемой посредством параметра (46) функции, от ранее обработанных коэффициентов преобразования,
в котором средство извлечения, символизатор и определитель параметра символизации выполнены с возможностью последовательной обработки коэффициентов преобразования разных блоков преобразования, в котором параметр функции изменяется в зависимости от размера блока преобразования текущего коэффициента преобразования, типа информационной составляющей блока преобразования текущего коэффициента преобразования и/или частотного участка, на котором располагается текущий коэффициент преобразования в блоке преобразования.
Причем устройство выполнено так, что функцией, задающей взаимосвязь между ранее декодированными коэффициентами преобразования с одной стороны и параметром символизации с другой стороны, является
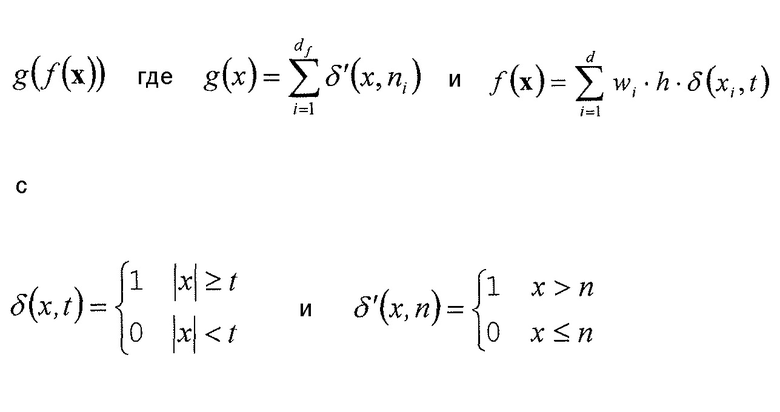
где
t, wi и образуют параметр функции,
x={x1,…,xd} с xi с , представляющим ранее обработанный коэффициент i преобразования,
wi представляют собой взвешивающие значения, каждое из которых может быть равно единице или не равно единице, и
h представляет собой постоянную или функцию xi.
Причем устройство выполнено так, что n1≤…≤ .
Причем устройство выполнено так, что h равно |xi|-t.
Причем устройство выполнено с возможностью пространственного определения ранее обработанных коэффициентов преобразования в зависимости от относительного пространственного расположения относительно текущего коэффициента преобразования.
В упомянутом устройстве средство извлечения выполнено с возможностью извлечения набора символов из потока данных непосредственно или с использованием энтропийного декодирования, используя распределение фиксированной вероятности.
В упомянутом устройстве схема символизации такая, что набор символов из кода Райса, и параметр символизации представляет собой параметр Райса.
В упомянутом устройстве десимволизатор выполнен с возможностью ограничения схемы символизации интервалом (18) уровней из интервала (20) диапазона коэффициентов преобразования, так что набор символов представляет префикс или суффикс в отношении других частей общей символизации текущего коэффициента преобразования.
В шестом аспекте настоящего изобретения обеспечено устройство для кодирования множества коэффициентов (12) преобразования разных блоков преобразования, причем каждый имеет уровень коэффициента преобразования, в поток (32) данных, содержащее
символизатор, выполненный с возможностью отображения уровня коэффициента преобразования для текущего коэффициента преобразования в соответствии со схемой символизации, которая является параметризуемой в соответствии с параметром символизации, на набор символов;
средство вставки, выполненное с возможностью вставки набора символов для текущего коэффициента преобразования в поток данных; и
определитель параметра символизации, выполненный с возможностью определения параметра (46) символизации для текущего коэффициента преобразования в зависимости, посредством функции (52), параметризуемой при помощи параметра (46) функции, от ранее обработанных коэффициентов преобразования,
в котором средство вставки, символизатор и определитель параметра символизации выполнены с возможностью последовательной обработки коэффициентов преобразования разных блоков преобразования, в котором параметр функции изменяется в зависимости от размера блока преобразования текущего коэффициента преобразования, типа информационной составляющей блока преобразования текущего коэффициента преобразования и/или частотного участка, на котором располагается текущий коэффициент преобразования в блоке преобразования.
Причем устройство выполнено так, что функцией, задающей взаимосвязь между ранее декодированными коэффициентами преобразования с одной стороны и параметром символизации с другой стороны, является
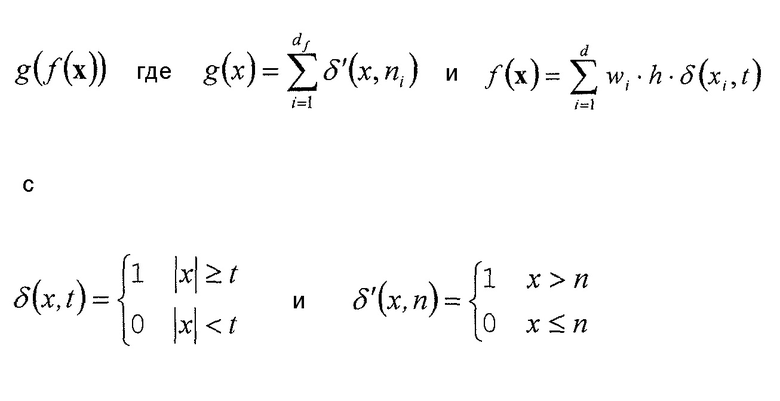
где
t, wi и образуют параметр функции,
x={x1,…,xd} с xi с , представляющим ранее обработанный коэффициент i преобразования,
wi представляют собой взвешивающие значения, каждое из которых может быть равно единице или не равно единице, и
h представляет собой постоянную или функцию xi.
Причем устройство выполнено так, что n1≤…≤ .
Причем устройство выполнено так, что h равно |xi|-t.
Причем устройство выполнено с возможностью пространственного определения ранее обработанных коэффициентов преобразования в зависимости от относительного пространственного расположения относительно текущего коэффициента преобразования.
В упомянутом устройстве средство вставки выполнено с возможностью вставки набора символов в поток данных непосредственно или с использованием энтропийного кодирования, используя распределение фиксированной вероятности.
В упомянутом устройстве схема символизации такая, что набор символов из кода Райса, и параметр символизации представляет собой параметр Райса.
В упомянутом устройстве символизатор выполнен с возможностью ограничения схемы символизации интервалом (18) уровней из интервала (20) диапазона коэффициентов преобразования, так что набор символов представляет префикс или суффикс в отношении других частей общей символизации текущего коэффициента преобразования.
В седьмом аспекте настоящего изобретения обеспечен способ декодирования множества коэффициентов (12) преобразования, имеющих уровни коэффициента преобразования, из потока (32) данных, содержащий
для текущего коэффициента (x) преобразования, энтропийное декодирование первого набора (44) из одного или нескольких символов из потока (32) данных;
десимволизирующее отображение первого набора (44) из одного или нескольких символов на уровень коэффициента преобразования в пределах первого интервала (16) уровней в соответствии с первой схемой символизации;
если уровень коэффициента преобразования, на который отображается первый набор из одного или нескольких символов в соответствии с первой схемой символизации, представляет собой максимальный уровень первого интервала (16) уровней, извлечение второго набора символов (42) из потока (32) данных,
в котором десимволизирующее отображение содержит отображение второго набора (42) символов на положение в пределах второго интервала (18) уровней в соответствии со второй схемой символизации, которая является параметризуемой в соответствии с параметром символизации,
энтропийное декодирование включает в себя энтропийное декодирование по меньшей мере одного предопределенного символа первого набора (44) из одного или нескольких символов из потока (32) данных с использованием контекста в зависимости, посредством функции, параметризуемой посредством параметра функции (52), с параметром функции, установленным на первую установку, от ранее декодированных коэффициентов преобразования, и
в котором способ дополнительно содержит,
если уровень коэффициента преобразования, на который первый набор (44) из одного или нескольких символов отображается в соответствии с первой схемой символизации, представляет собой максимальный уровень первого интервала (16) уровней, определение параметра (46) символизации в зависимости, посредством функции (52) с параметром функции, установленным на вторую установку, от ранее декодированных коэффициентов преобразования.
В восьмом аспекте настоящего изобретения обеспечен способ кодирования множества коэффициентов преобразования, имеющих уровни коэффициента преобразования, в поток (32) данных, содержащий
символизирующее отображение текущего коэффициента преобразования
на первый набор из одного или нескольких символов в соответствии с первой схемой символизации, если уровень коэффициента преобразования текущего коэффициента преобразования находится в пределах первого интервала (16) уровней, и
если уровень коэффициента преобразования текущего коэффициента преобразования находится в пределах второго интервала (18) уровней, на объединение второго набора символов, на который максимальный уровень первого интервала (16) уровней отображается в соответствии с первой схемой символизации, и третьего набора символов в зависимости от положения уровня коэффициента преобразования текущего коэффициента преобразования в пределах второго интервала (18) уровней в соответствии со второй схемой синхронизации, которая является параметризуемой в соответствии с параметром (46) символизации;
контекстно-адаптивное энтропийное кодирование, включающее в себя, если уровень коэффициента преобразования текущего коэффициента преобразования находится в пределах первого интервала уровней, энтропийное кодирование первого набора из одного или нескольких символов в поток данных, и, если уровень коэффициента преобразования текущего коэффициента преобразования находится в пределах второго интервала уровней, энтропийное кодирование второго набора из одного или нескольких символов в поток данных, в котором контекстно-адаптивное энтропийное кодирование включает в себя, при энтропийном кодировании по меньшей мере одного предопределенного символа второго набора из одного или нескольких символов в поток данных, использование контекста в зависимости, посредством функции, параметризуемой посредством параметра функции, с параметром функции, установленным в первую установку, от ранее кодированных коэффициентов преобразования; и
если уровень коэффициента преобразования текущего коэффициента преобразования находится в пределах второго интервала уровней, определение параметра (46) символизации для отображения на третий набор символов в зависимости, посредством функции с параметром функции, установленным на вторую установку, от ранее кодированных коэффициентов преобразования; и,
если уровень коэффициента преобразования текущего коэффициента преобразования находится в пределах второго интервала уровней, вставку третьего набора символов в поток данных.
В девятом аспекте настоящего изобретения обеспечен способ декодирования множества коэффициентов (12) преобразования разных блоков преобразования, причем каждый имеет уровень коэффициента преобразования, из потока (32) данных, содержащий
извлечение набора символов из потока данных для текущего коэффициента преобразования;
десимволизирующее отображение набора символов на уровень коэффициента преобразования для текущего коэффициента преобразования в соответствии со схемой символизации, которая является параметризуемой в соответствии с параметром символизации, и
определение параметра (46) символизации для текущего коэффициента преобразования в зависимости, посредством функции (52), параметризуемой посредством параметра (46) функции, от ранее обработанных коэффициентов преобразования,
в котором извлечение, символизирующее отображение и определение последовательно выполняются над коэффициентами преобразования разных блоков преобразования, в котором параметр функции изменяется в зависимости от размера блока преобразования текущего коэффициента преобразования, типа информационной составляющей блока преобразования текущего коэффициента преобразования и/или частотного участка, на котором располагается текущий коэффициент преобразования в блоке преобразования.
В десятом аспекте настоящего изобретения обеспечен способ кодирования множества коэффициентов (12) преобразования разных блоков преобразования, причем каждый имеет уровень коэффициента преобразования, в поток (32) данных, содержащий
символизирующее отображение уровня коэффициента преобразования для текущего коэффициента преобразования в соответствии со схемой символизации, которая является параметризуемой в соответствии с параметром символизации, на набор символов;
вставку набора символов для текущего коэффициента преобразования в поток данных; и
определение параметра (46) символизации для текущего коэффициента преобразования в зависимости, посредством функции (52), параметризуемой посредством параметра (46) функции, от ранее обработанных коэффициентов преобразования,
в котором вставка, символизирующая отображение и определение последовательно выполняются над коэффициентами преобразования разных блоков преобразования, в котором параметр функции изменяется в зависимости от размера блока преобразования текущего коэффициента преобразования, типа информационной составляющей блока преобразования текущего коэффициента преобразования и/или частотного участка, на котором располагается текущий коэффициент преобразования в блоке преобразования.
В одиннадцатом аспекте настоящего изобретения обеспечена компьютерная программа, имеющая программный код для выполнения, при исполнении на компьютере, способа по любому из вышеописанных аспектов.
В двенадцатом аспекте настоящего изобретения обеспечен декодер для декодирования потока данных, содержащего кодированное видео, включающее в себя информацию, связанную с множеством коэффициентов преобразования, ассоциированных с кодированным видео, причем декодер содержит:
контекстно-адаптивный энтропийный декодер, выполненный с возможностью, для текущего коэффициента преобразования, энтропийного декодирования с использованием процессора первого символа из потока данных, используя контекст, определяемый путем применения операции, связанной с по меньшей мере первым ранее декодированным коэффициентом преобразования;
десимволизатор, выполненный с возможностью, для текущего коэффициента преобразования, отображения с использованием процессора второго символа из потока данных на уровень коэффициента преобразования на основе параметра символизации, определяемого путем применения операции, связанной с по меньшей мере вторым ранее декодированным коэффициентом преобразования; и
декодер изображений, выполненный возможностью применения с использованием процессора кодирования с предсказанием на основе остаточного сигнала предсказания для восстановления блока изображения видео,
при этом остаточный сигнал предсказания ассоциирован с энтропийно декодированным первым символом и уровнем коэффициента преобразования, и
декодер выполнен с возможностью определения первого ранее декодированного коэффициента преобразования на основе относительного пространственного расположения текущего коэффициента преобразования относительно множества коэффициентов преобразования.
При этом декодер выполнен с возможностью извлечения из потока данных информации о положении последнего ненулевого коэффициента преобразования из числа коэффициентов преобразования блока коэффициентов преобразования вдоль предопределенного порядка сканирования, при этом множество коэффициентов преобразования охватывает коэффициенты преобразования блока коэффициентов преобразования от последнего ненулевого коэффициента преобразования по порядку сканирования до DC-коэффициента преобразования блока коэффициентов преобразования.
В упомянутом декодере десимволизатор выполнен с возможностью использования первой схемы символизации для отображения первого символа последнего ненулевого коэффициента преобразования на первый уровень, меньший или равный максимальному уровню, при этом нулевой уровень не применяется для последнего коэффициента преобразования.
В упомянутом декодере контекстно-адаптивный энтропийный декодер выполнен с возможностью энтропийного декодирования первого символа для последнего ненулевого коэффициента преобразования с использованием контекста, который отличается от контекста, используемого при энтропийном декодировании первого символа коэффициента преобразования, отличного от последнего ненулевого коэффициента преобразования.
В упомянутом декодере контекстно-адаптивный энтропийный декодер проходит по коэффициентам преобразования блока коэффициентов преобразования в порядке сканирования, начиная с последнего ненулевого коэффициента преобразования, до DC-коэффициента преобразования блока коэффициентов преобразования.
При этом декодер выполнен с возможностью декодирования множества коэффициентов преобразования из потока данных за два сканирования, при этом контекстно-адаптивный энтропийный декодер выполнен с возможностью энтропийного декодирования первого символа для коэффициентов преобразования из потока данных в порядке, соответствующем первому сканированию коэффициентов преобразования,
декодер, содержащий средство извлечения, выполненное с возможностью последовательного извлечения из потока данных вторых символов для коэффициентов преобразования, для которых первые символы отображены на максимальный уровень, ассоциированный с соответствующим первым символом, в порядке, соответствующем второму сканированию коэффициентов преобразования.
При этом декодер выполнен с возможностью последовательного декодирования множества коэффициентов преобразования из потока данных за одно сканирование, при этом вторые символы располагаются в потоке данных между первыми символами коэффициентов преобразования, и при этом контекстно-адаптивный энтропийный декодер и средство извлечения декодера выполнены с возможностью, для каждого коэффициента преобразования в порядке сканирования одного сканирования, извлекать из потока данных вторые символы соответствующих коэффициентов преобразования, для которых первые символы отображены на максимальный уровень, ассоциированный с соответствующим первым символом, непосредственно следом за энтропийным декодированием контекстно-адаптивным энтропийным декодером первых символов соответствующих коэффициентов преобразования, для которых первые символы отображены на максимальный уровень.
Упомянутый декодер дополнительно содержит средство извлечения, выполненное с возможностью извлечения второго символа непосредственно из потока данных или с использованием энтропийного декодирования, использующего распределение фиксированной вероятности.
В упомянутом декодере десимволизатор выполнен с возможностью отображать первый символ на уровень коэффициента преобразования, меньший или равный максимальному уровню, ассоциированному с первым символом, на основе схемы усеченной унарной бинаризации.
В упомянутом декодере десимволизатор выполнен с возможностью отображения второго символа на основе кода Райса.
В тринадцатом аспекте настоящего изобретения обеспечен кодер для кодирования в поток данных информации, связанной с множеством коэффициентов преобразования, ассоциированных с видео, причем кодер содержит:
кодер изображений, выполненный возможностью применения с использованием процессора кодирования с предсказанием к блоку изображения видео для получения остаточного сигнала предсказания, связанного с блоком,
контекстно-адаптивный энтропийный кодер, выполненный с возможностью, для текущего коэффициента преобразования, связанного с остаточным сигналом предсказания, энтропийного кодирования с использованием процессора первого символа в поток данных, используя контекст, определяемый путем применения операции, связанной с по меньшей мере первым ранее кодированным коэффициентом преобразования; и
символизатор, выполненный с возможностью отображения с использованием процессора уровня коэффициента преобразования текущего коэффициента преобразования на второй символ на основе параметра символизации, определяемого путем применения операции, связанной с по меньшей мере вторым ранее кодированным коэффициентом преобразования,
при этом кодер выполнен с возможностью определения первого ранее кодированного коэффициента преобразования на основе относительного пространственного расположения текущего коэффициента преобразования относительно множества коэффициентов преобразования.
При этом кодер выполнен с возможностью вставки в поток данных информации о положении последнего ненулевого коэффициента преобразования из числа коэффициентов преобразования блока коэффициентов преобразования вдоль предопределенного порядка сканирования, при этом множество коэффициентов преобразования охватывает коэффициенты преобразования блока коэффициентов преобразования от последнего ненулевого коэффициента преобразования по порядку сканирования до DC-коэффициента преобразования блока коэффициентов преобразования.
В упомянутом кодере символизатор выполнен с возможностью использования первой схемы символизации для отображения первого символа последнего ненулевого коэффициента преобразования на первый уровень, меньший или равный максимальному уровню, при этом нулевой уровень не применяется для последнего коэффициента преобразования.
В упомянутом кодере контекстно-адаптивный энтропийный кодер выполнен с возможностью энтропийного кодирования первого символа для последнего ненулевого коэффициента преобразования с использованием контекста, который отличается от контекста, используемого при энтропийном кодировании первого символа коэффициента преобразования, отличного от последнего ненулевого коэффициента преобразования.
В упомянутом кодере контекстно-адаптивный энтропийный кодер проходит по коэффициентам преобразования блока коэффициентов преобразования в порядке сканирования, начиная с последнего ненулевого коэффициента преобразования, до DC-коэффициента преобразования блока коэффициентов преобразования.
При этом кодер выполнен с возможностью кодирования множества коэффициентов преобразования в поток данных за два сканирования, при этом контекстно-адаптивный энтропийный кодер выполнен с возможностью энтропийного кодирования первого символа для коэффициентов преобразования в поток данных в порядке, соответствующем первому сканированию коэффициентов преобразования,
кодер, содержащий средство вставки, выполненное с возможностью последовательной вставки в поток данных вторых символов для коэффициентов преобразования, для которых первые символы отображены на максимальный уровень, ассоциированный с соответствующим первым символом, в порядке, соответствующем второму сканированию коэффициентов преобразования.
При этом кодер выполнен с возможностью последовательного кодирования множества коэффициентов преобразования в поток данных за одно сканирование, при этом вторые символы располагаются в потоке данных между первыми символами коэффициентов преобразования, и при этом контекстно-адаптивный энтропийный кодер и средство вставки кодера выполнены с возможностью, для каждого коэффициента преобразования в порядке сканирования одного сканирования, вставлять в поток данных вторые символы соответствующих коэффициентов преобразования, для которых первые символы отображены на максимальный уровень, ассоциированный с первым символом, непосредственно следом за энтропийным кодированием контекстно-адаптивным энтропийным кодером первых символов соответствующих коэффициентов преобразования, для которых первые символы отображены на максимальный уровень.
Упомянутый кодер дополнительно содержит средство вставки, выполненное с возможностью вставки второго символа в поток данных или с использованием энтропийного кодирования, использующего распределение фиксированной вероятности.
В упомянутом кодере символизатор выполнен с возможностью отображать первый символ на уровень коэффициента преобразования, меньший или равный максимальному уровню, ассоциированному с первым символом, на основе схемы усеченной унарной бинаризации.
В упомянутом кодере символизатор выполнен с возможностью отображения второго символа на основе кода Райса.
В четырнадцатом аспекте настоящего изобретения обеспечен способ для декодирования потока данных, содержащего кодированное видео, включающее в себя информацию, связанную с множеством коэффициентов преобразования, ассоциированных с кодированным видео, причем способ содержит:
энтропийное декодирование, для текущего коэффициента преобразования, первого символа из потока данных, используя контекст, причем энтропийное декодирование содержит применение операции, связанной с по меньшей мере первым ранее декодированным коэффициентом преобразования, для определения контекста;
отображение, для текущего коэффициента преобразования, второго символа из потока данных на уровень коэффициента преобразования на основе параметра символизации, причем отображение содержит применение операции, связанной с по меньшей мере вторым ранее декодированным коэффициентом преобразования, для определения параметра символизации;
применение кодирования с предсказанием на основе остатка предсказания для восстановления блока изображения видео, при этом остаточный сигнал предсказания ассоциирован с энтропийно декодированным первым символом и уровнем коэффициента преобразования; и
определение первого ранее декодированного коэффициента преобразования на основе относительного пространственного расположения текущего коэффициента преобразования относительно множества коэффициентов преобразования.
Упомянутый способ дополнительно содержит извлечение из потока данных информации о положении последнего ненулевого коэффициента преобразования из числа коэффициентов преобразования блока коэффициентов преобразования вдоль предопределенного порядка сканирования, при этом множество коэффициентов преобразования охватывает коэффициенты преобразования блока коэффициентов преобразования от последнего ненулевого коэффициента преобразования по порядку сканирования до DC-коэффициента преобразования блока коэффициентов преобразования.
Упомянутый способ дополнительно содержит:
последовательное декодирование множества коэффициентов преобразования из потока данных за одно сканирование, при этом вторые символы располагаются в потоке данных между первыми символами коэффициентов преобразования, и
для каждого коэффициента преобразования в порядке сканирования одного сканирования, извлечение из потока данных вторых символов соответствующих коэффициентов преобразования, для которых первые символы отображены на максимальный уровень, ассоциированный с соответствующим первым символом, непосредственно следующее за энтропийным декодированием первых символов соответствующих коэффициентов преобразования, для которых первые символы отображены на максимальный уровень.
Упомянутый способ дополнительно содержит извлечение второго символа непосредственно из потока данных или с использованием энтропийного декодирования, использующего фиксированное распределение вероятности.
Упомянутый способ дополнительно содержит отображение первого символа на уровень коэффициента преобразования, меньший или равный максимальному уровню, ассоциированному с первым символом, на основе схемы усеченной унарной бинаризации.
В упомянутом способе отображение второго символа основано на коде Райса.
В пятнадцатом аспекте настоящего изобретения обеспечен долговременный считываемый компьютером носитель для хранения информации, связанной с множеством коэффициентов преобразования, ассоциированных с кодированным видео, содержащий:
поток данных, хранящийся на долговременном считываемом компьютером носителе, причем поток данных содержит кодированную информацию, связанную с первыми и вторыми символам текущего коэффициента преобразования, при этом первые и вторые символы обрабатываются на основе множества операций для восстановления блока изображения видео, причем множество операций содержит:
энтропийное декодирование первого символа из потока данных, используя контекст, причем энтропийное декодирование содержит применение операции, связанной с по меньшей мере первым ранее декодированным коэффициентом преобразования, для определения контекста;
отображение второго символа из потока данных на уровень коэффициента преобразования на основе параметра символизации, причем отображение содержит применение операции, связанной с по меньшей мере вторым ранее декодированным коэффициентом преобразования, для определения параметра символизации;
применение кодирования с предсказанием на основе остатка предсказания для восстановления блока изображения, при этом остаточный сигнал предсказания ассоциирован с энтропийно декодированным первым символом и уровнем коэффициента преобразования; и
определение первого ранее декодированного коэффициента преобразования на основе относительного пространственного расположения текущего коэффициента преобразования относительно множества коэффициентов преобразования.
В упомянутом считываемом компьютером носителе множество операций дополнительно содержит извлечение из потока данных информации о положении последнего ненулевого коэффициента преобразования из числа коэффициентов преобразования блока коэффициентов преобразования вдоль предопределенного порядка сканирования, при этом множество коэффициентов преобразования охватывает коэффициенты преобразования блока коэффициентов преобразования от последнего ненулевого коэффициента преобразования по порядку сканирования до DC-коэффициента преобразования блока коэффициентов преобразования.
В упомянутом считываемом компьютером носителе множество операций дополнительно содержит извлечение второго символа непосредственно из потока данных или с использованием энтропийного декодирования, использующего распределение фиксированной вероятности.
В упомянутом считываемом компьютером носителе отображение второго символа основано на коде Райса.
В шестнадцатом аспекте настоящего изобретения обеспечен декодер для декодирования потока данных, содержащего кодированное видео, включающее в себя информацию, связанную с множеством коэффициентов преобразования, ассоциированных с кодированным видео, причем декодер содержит:
контекстно-адаптивный энтропийный декодер, выполненный с возможностью, для текущего коэффициента преобразования, энтропийного декодирования с использованием процессора первого символа на основе контекста, при этом контекст определяется на основе операции, включающей в себя первый ранее декодированный коэффициент преобразования;
средство извлечения, выполненное с возможностью, используя процессор, извлечения второго символа текущего коэффициента преобразования из потока данных;
десимволизатор, выполненный с возможностью, для текущего коэффициента преобразования, отображать второй символ на уровень коэффициента преобразования на основе параметра символизации, при этом уровень коэффициента преобразования больше, чем максимальный уровень, связанный с первым символом, и параметр символизации определяется на основе операции, включающей в себя второй ранее декодированный коэффициент преобразования; и
декодер изображений, выполненный с возможностью применения, используя процессор, кодирования с предсказанием на основе остаточного сигнала предсказания для восстановления блока изображения видео, при этом остаточный сигнал предсказания ассоциирован с энтропийно декодированным первым символом и уровнем коэффициента преобразования, при этом декодер выполнен с возможностью определения первого ранее декодированного коэффициента преобразования на основе относительного пространственного расположения текущего коэффициента преобразования относительно множества коэффициентов преобразования.
Упомянутый декодер выполнен с возможностью извлечения из потока данных информации о положении последнего ненулевого коэффициента преобразования из числа коэффициентов преобразования блока коэффициентов преобразования вдоль предопределенного порядка сканирования, при этом множество коэффициентов преобразования охватывает коэффициенты преобразования блока коэффициентов преобразования от последнего ненулевого коэффициента преобразования по порядку сканирования до DC-коэффициента преобразования блока коэффициентов преобразования.
В упомянутом декодере десимволизатор выполнен с возможностью использования первой схемы символизации для отображения первого символа последнего ненулевого коэффициента преобразования на уровень, меньший или равный максимальному уровню, при этом нулевой уровень не применяется для последнего коэффициента преобразования.
В упомянутом декодере контекстно-адаптивный энтропийный декодер выполнен с возможностью энтропийного декодирования первого символа для последнего ненулевого коэффициента преобразования с использованием контекста, который отличается от контекста, используемого при энтропийном декодировании первого символа коэффициента преобразования, отличного от последнего ненулевого коэффициента преобразования.
В упомянутом декодере контекстно-адаптивный энтропийный декодер проходит по коэффициентам преобразования блока коэффициентов преобразования в порядке сканирования, начиная с последнего ненулевого коэффициента преобразования, до DC-коэффициента преобразования блока коэффициентов преобразования.
Упомянутый декодер выполнен с возможностью декодирования множества коэффициентов преобразования из потока данных за два сканирования, при этом контекстно-адаптивный энтропийный декодер выполнен с возможностью энтропийного декодирования первого символа для коэффициентов преобразования из потока данных в порядке, соответствующем первому сканированию коэффициентов преобразования, причем декодер содержит средство извлечения, выполненное с возможностью последовательного извлечения из потока данных вторых символов для коэффициентов преобразования, для которых первые символы отображены на максимальный уровень, в порядке, соответствующем второму сканированию коэффициентов преобразования.
Упомянутый декодер выполнен с возможностью декодирования множества коэффициентов преобразования из потока данных последовательно за одно сканирование, при этом вторые символы располагаются в потоке данных между первыми символами коэффициентов преобразования, и при этом контекстно-адаптивный энтропийный декодер и средство извлечения выполнены с возможностью, для каждого коэффициента преобразования в порядке сканирования упомянутого одного сканирования, извлекать из потока данных вторые символы соответствующих коэффициентов преобразования, для которых первые символы отображены на максимальный уровень, непосредственно следом за энтропийным декодированием контекстно-адаптивным энтропийным декодером первых символов соответствующих коэффициентов преобразования, для которых первые символы отображены на максимальный уровень.
В упомянутом декодере средство извлечения выполнено с возможностью извлечения второго символа непосредственно из потока данных или с использованием энтропийного декодирования, использующего распределение фиксированной вероятности.
В упомянутом декодере десимволизатор выполнен с возможностью отображать первый символ на уровень коэффициента преобразования, меньший или равный максимальному уровню, ассоциированному с первым символом, на основе схемы усеченной унарной бинаризации.
В упомянутом декодере десимволизатор выполнен с возможностью отображения второго символа на основе кода Райса.
В семнадцатом аспекте настоящего изобретения обеспечен кодер для кодирования в поток данных информации, связанной с множеством коэффициентов преобразования, ассоциированных с видео, причем кодер содержит:
кодер изображений, выполненный возможностью применения с использованием процессора кодирования с предсказанием к блоку изображения видео для получения остаточного сигнала предсказания, связанного с блоком;
контекстно-адаптивный энтропийный кодер, выполненный с возможностью, для текущего коэффициента преобразования, связанного с остаточным сигналом предсказания, энтропийного кодирования, используя процессор, первого символа в поток данных, используя контекст, при этом контекст определяется на основе операции, включающей в себя первый ранее кодированный коэффициент преобразования; и
символизатор, выполненный с возможностью отображения, используя процессор, уровня коэффициента преобразования текущего коэффициента преобразования на второй символ на основе параметра символизации, при этом уровень коэффициента преобразования больше, чем максимальный уровень, ассоциированный с первым символом, и параметр символизации определяется на основе операции, включающей в себя второй ранее кодированный коэффициент преобразования, при этом кодер выполнен с возможностью определения первого ранее кодированного коэффициента преобразования на основе относительного пространственного расположения текущего коэффициента преобразования относительно множества коэффициентов преобразования.
Упомянутый кодер выполнен с возможностью вставки в поток данных информации о положении последнего ненулевого коэффициента преобразования из числа коэффициентов преобразования блока коэффициентов преобразования вдоль предопределенного порядка сканирования, при этом множество коэффициентов преобразования охватывает коэффициенты преобразования блока коэффициентов преобразования от последнего ненулевого коэффициента преобразования по порядку сканирования до DC-коэффициента преобразования блока коэффициентов преобразования.
В упомянутом кодере символизатор выполнен с возможностью использования первой схемы символизации для отображения первого символа последнего ненулевого коэффициента преобразования на уровень коэффициента преобразования, при этом нулевой уровень не применяется для последнего коэффициента преобразования.
В упомянутом кодере контекстно-адаптивный энтропийный кодер выполнен с возможностью энтропийного кодирования первого символа для последнего ненулевого коэффициента преобразования с использованием контекста, который отличается от контекста, используемого при энтропийном кодировании первого символа коэффициента преобразования, отличного от последнего ненулевого коэффициента преобразования.
В упомянутом кодере контекстно-адаптивный энтропийный кодер проходит по коэффициентам преобразования блока коэффициентов преобразования в порядке сканирования, начиная с последнего ненулевого коэффициента преобразования, до DC-коэффициента преобразования блока коэффициентов преобразования.
Упомянутый кодер выполнен с возможностью кодирования множества коэффициентов преобразования из потока данных за два сканирования, при этом контекстно-адаптивный энтропийный кодер выполнен с возможностью энтропийного кодирования первого символа для коэффициентов преобразования в поток данных в порядке, соответствующем первому сканированию коэффициентов преобразования, причем кодер содержит средство вставки, выполненное с возможностью последовательной вставки в поток данных вторых символов для коэффициентов преобразования, для которых первые символы отображены на максимальный уровень, в порядке, соответствующем второму сканированию коэффициентов преобразования.
Упомянутый кодер выполнен с возможностью кодирования множества коэффициентов преобразования в поток данных последовательно за одно сканирование,
при этом вторые символы располагаются в потоке данных между первыми символами коэффициентов преобразования, и при этом контекстно-адаптивный энтропийный кодер и средство вставки кодера выполнены с возможностью, для каждого коэффициента преобразования в порядке сканирования упомянутого одного сканирования, вставлять в поток данных вторые символы соответствующих коэффициентов преобразования, для которых первые символы отображены на максимальный уровень, непосредственно следом за энтропийным кодированием контекстно-адаптивным энтропийным кодером первых символов соответствующих коэффициентов преобразования, для которых первые символы отображены на максимальный уровень.
Упомянутый кодер дополнительно содержит средство вставки, выполненное с возможностью вставки второго символа в поток данных непосредственно или с использованием энтропийного кодирования, использующего распределение фиксированной вероятности.
В упомянутом кодере символизатор выполнен с возможностью отображать первый символ на уровень коэффициента преобразования, меньший или равный максимальному уровню, на основе схемы усеченной унарной бинаризации.
В упомянутом кодере символизатор выполнен с возможностью отображения второго символа на основе кода Райса.
В восемнадцатом аспекте настоящего изобретения обеспечен долговременный считываемый компьютером носитель для хранения информации, связанной с множеством коэффициентов преобразования, ассоциированных с кодированным видео, содержащий:
поток данных, хранящийся на долговременном считываемом компьютером носителе, причем поток данных содержит кодированную информацию, связанную с первыми и вторыми символам текущего коэффициента преобразования, и инструкции для обработки первых и вторых символов на основе способа, содержащего:
энтропийное декодирование для текущего коэффициента преобразования первого символа, используя контекст, при этом контекст определяется на основе операции, включающей в себя первый ранее декодированный коэффициент преобразования;
извлечение второго символа текущего коэффициента преобразования из потока данных;
отображение для текущего коэффициента преобразования второго символа на уровень коэффициента преобразования на основе параметра символизации, при этом уровень коэффициента преобразования больше, чем максимальный уровень, ассоциированный с первым символом, и параметр символизации определяется на основе операции, включающей в себя второй ранее декодированный коэффициент преобразования; и
применение кодирования с предсказанием на основе остаточного сигнала предсказания для восстановления блока изображения видео, при этом остаточный сигнал предсказания ассоциирован с энтропийно декодированным первым символом и уровнем коэффициента преобразования, при этом первый ранее декодированный коэффициент преобразования определяется на основе относительного пространственного расположения текущего коэффициента преобразования относительно множества коэффициентов преобразования.
В способе согласно упомянутому долговременному считываемому компьютером носителю дополнительно содержится извлечение из потока данных информации о положении последнего ненулевого коэффициента преобразования из числа коэффициентов преобразования блока коэффициентов преобразования вдоль предопределенного порядка сканирования, при этом множество коэффициентов преобразования охватывает коэффициенты преобразования блока коэффициентов преобразования от последнего ненулевого коэффициента преобразования по порядку сканирования до DC-коэффициента преобразования блока коэффициентов преобразования.
В способе согласно упомянутому долговременному считываемому компьютером носителю дополнительно содержится отображение первого символа на уровень коэффициента преобразования, меньший или равный максимальному уровню, на основе схемы усеченной унарной бинаризации.
В способе согласно упомянутому долговременному считываемому компьютером носителю отображение второго символа основано на коде Райса.
В девятнадцатом аспекте настоящего изобретения обеспечен способ для декодирования потока данных, содержащего кодированное видео, включающее в себя информацию, связанную с множеством коэффициентов преобразования, ассоциированных с кодированным видео, причем способ содержит:
энтропийное декодирование для текущего коэффициента преобразования первого символа, используя контекст, при этом контекст определяется на основе операции, включающей в себя первый ранее декодированный коэффициент преобразования;
извлечение второго символа текущего коэффициента преобразования из потока данных;
отображение для текущего коэффициента преобразования второго символа на уровень коэффициента преобразования на основе параметра символизации, при этом уровень коэффициента преобразования больше, чем максимальный уровень, ассоциированный с первым символом, и параметр символизации определяется на основе операции, включающей в себя второй ранее декодированный коэффициент преобразования; и
применение кодирования с предсказанием на основе остаточного сигнала предсказания для восстановления блока изображения видео, при этом остаточный сигнал предсказания ассоциирован с энтропийно декодированным первым символом и уровнем коэффициента преобразования, при этом первый ранее декодированный коэффициент преобразования определяется на основе относительного пространственного расположения текущего коэффициента преобразования относительно множества коэффициентов преобразования.
Упомянутый способ дополнительно содержит извлечение из потока данных информации о положении последнего ненулевого коэффициента преобразования из числа коэффициентов преобразования блока коэффициентов преобразования вдоль предопределенного порядка сканирования, при этом множество коэффициентов преобразования охватывает коэффициенты преобразования блока коэффициентов преобразования от последнего ненулевого коэффициента преобразования по порядку сканирования до DC-коэффициента преобразования блока коэффициентов преобразования.
Упомянутый способ дополнительно содержит:
декодирование множества коэффициентов преобразования из потока данных последовательно за одно сканирование, при этом вторые символы располагаются в потоке данных между первыми символами коэффициентов преобразования, и для каждого коэффициента преобразования в порядке сканирования упомянутого одного сканирования, извлечение из потока данных вторых символов соответствующих коэффициентов преобразования, для которых первые символы отображены на максимальный уровень, непосредственно следом за энтропийным декодированием первых символов соответствующих коэффициентов преобразования, для которых первые символы отображены на максимальный уровень.
Упомянутый способ дополнительно содержит извлечение второго символа непосредственно из потока данных или с использованием энтропийного декодирования, использующего распределение фиксированной вероятности.
Упомянутый способ дополнительно содержит отображение первого символа на уровень коэффициента преобразования, меньший или равный максимальному уровню, на основе схемы усеченной унарной бинаризации.
В упомянутом способе отображение второго символа основано на коде Райса.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОДИРОВАНИЕ КОЭФФИЦИЕНТОВ ПРЕОБРАЗОВАНИЯ | 2022 |
|
RU2782697C1 |
| КОДИРОВАНИЕ КОЭФФИЦИЕНТОВ ПРЕОБРАЗОВАНИЯ | 2022 |
|
RU2827975C2 |
| КОДИРОВАНИЕ КОЭФФИЦИЕНТОВ ПРЕОБРАЗОВАНИЯ | 2021 |
|
RU2761510C1 |
| КОДИРОВАНИЕ КОЭФФИЦИЕНТОВ ПРЕОБРАЗОВАНИЯ | 2019 |
|
RU2745248C1 |
| КОДИРОВАНИЕ КОЭФФИЦИЕНТОВ ПРЕОБРАЗОВАНИЯ | 2013 |
|
RU2641235C2 |
| КОДИРОВАНИЕ КОЭФФИЦИЕНТОВ ПРЕОБРАЗОВАНИЯ | 2013 |
|
RU2708967C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ЭНТРОПИЙНОГО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ВИДЕОСИГНАЛА | 2021 |
|
RU2768379C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ЭНТРОПИЙНОГО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ВИДЕОСИГНАЛА | 2018 |
|
RU2738317C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ЭНТРОПИЙНОГО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ВИДЕОСИГНАЛА | 2022 |
|
RU2785817C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ЭНТРОПИЙНОГО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ВИДЕОСИГНАЛА | 2018 |
|
RU2753238C1 |
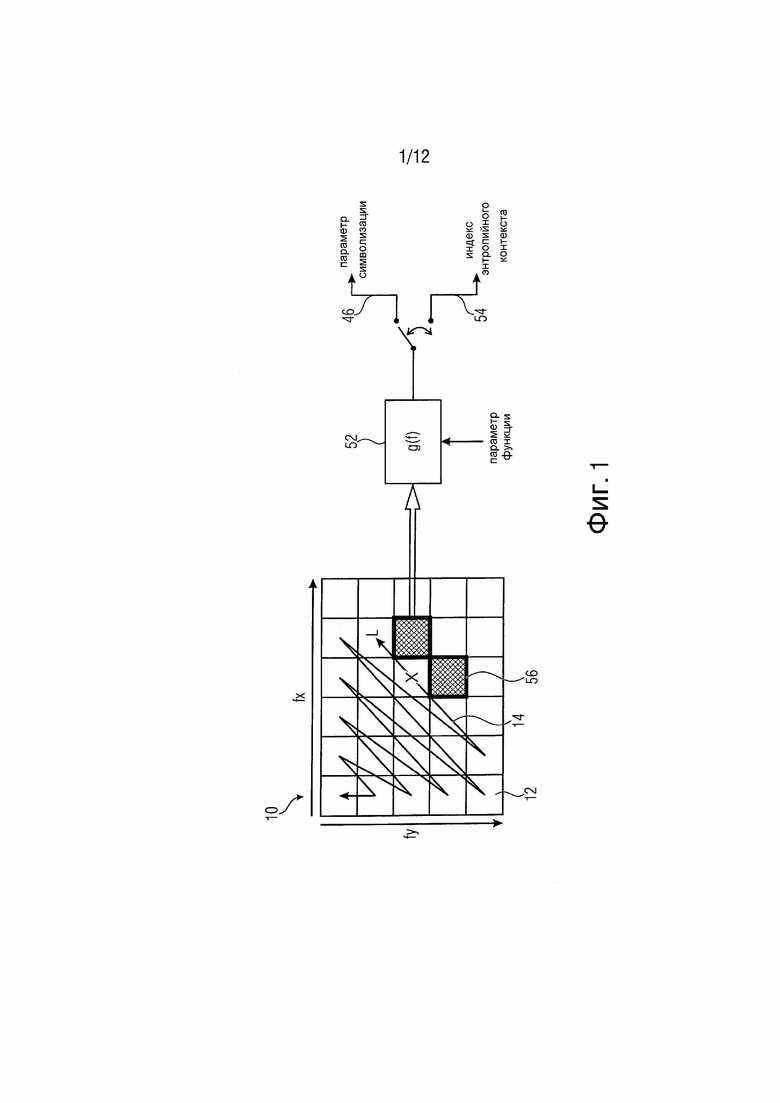
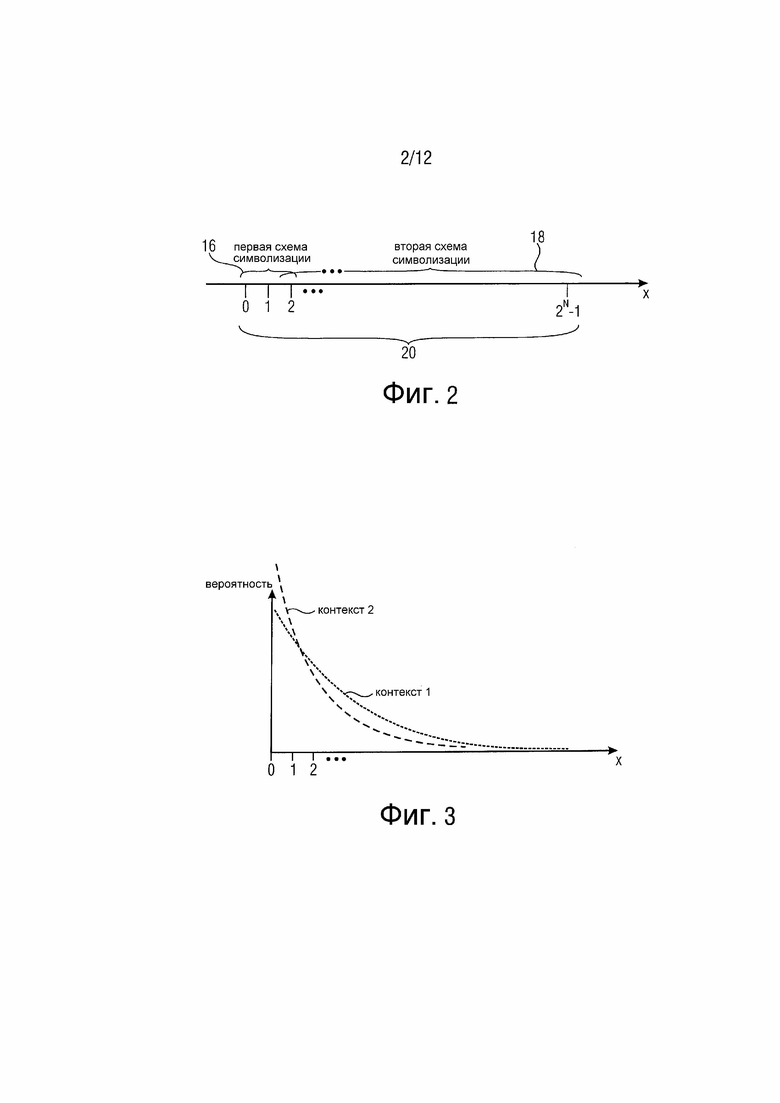
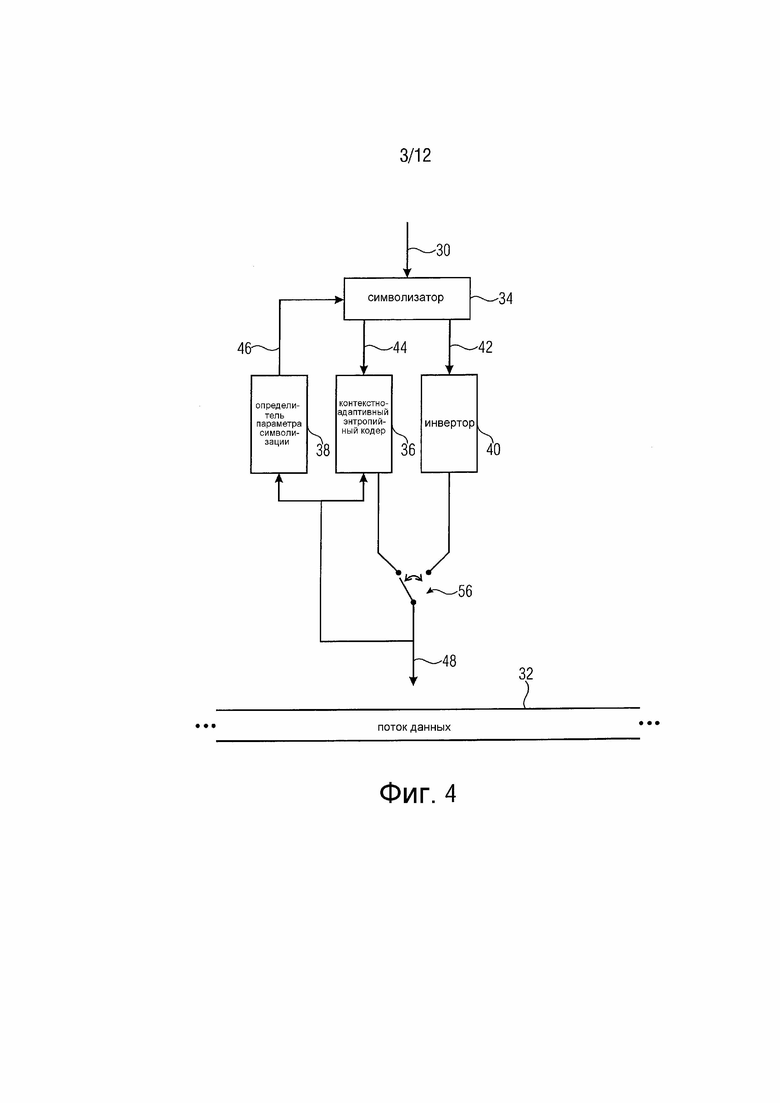
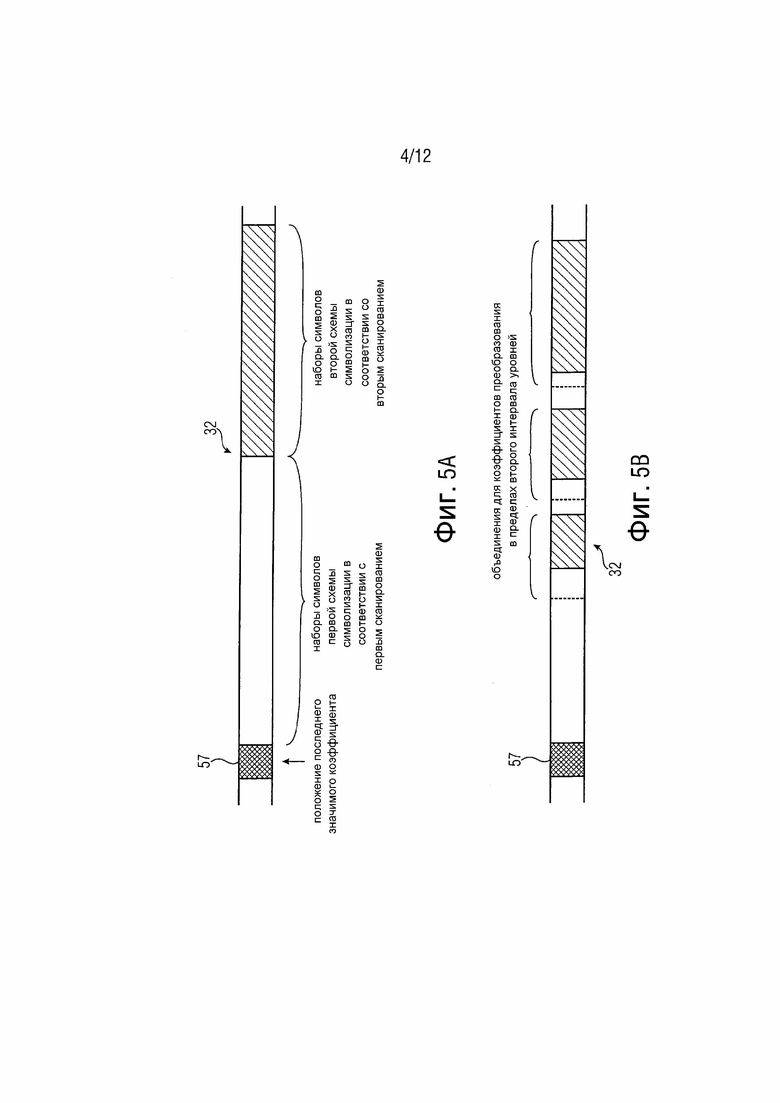
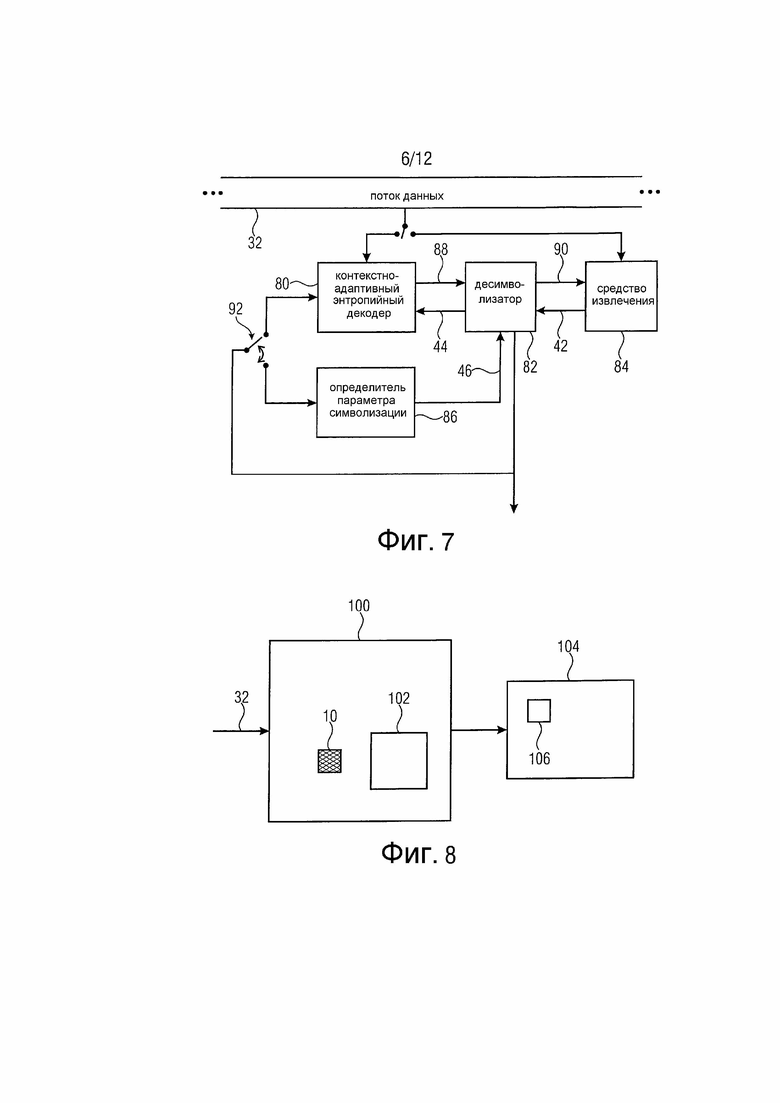
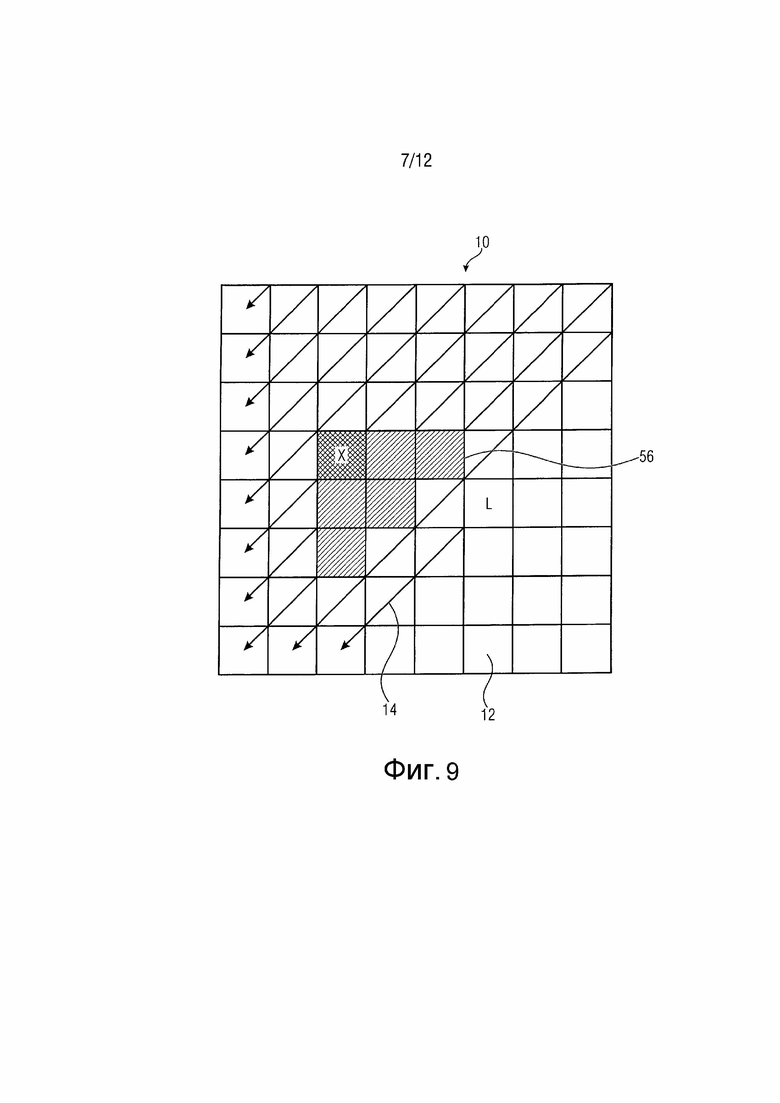
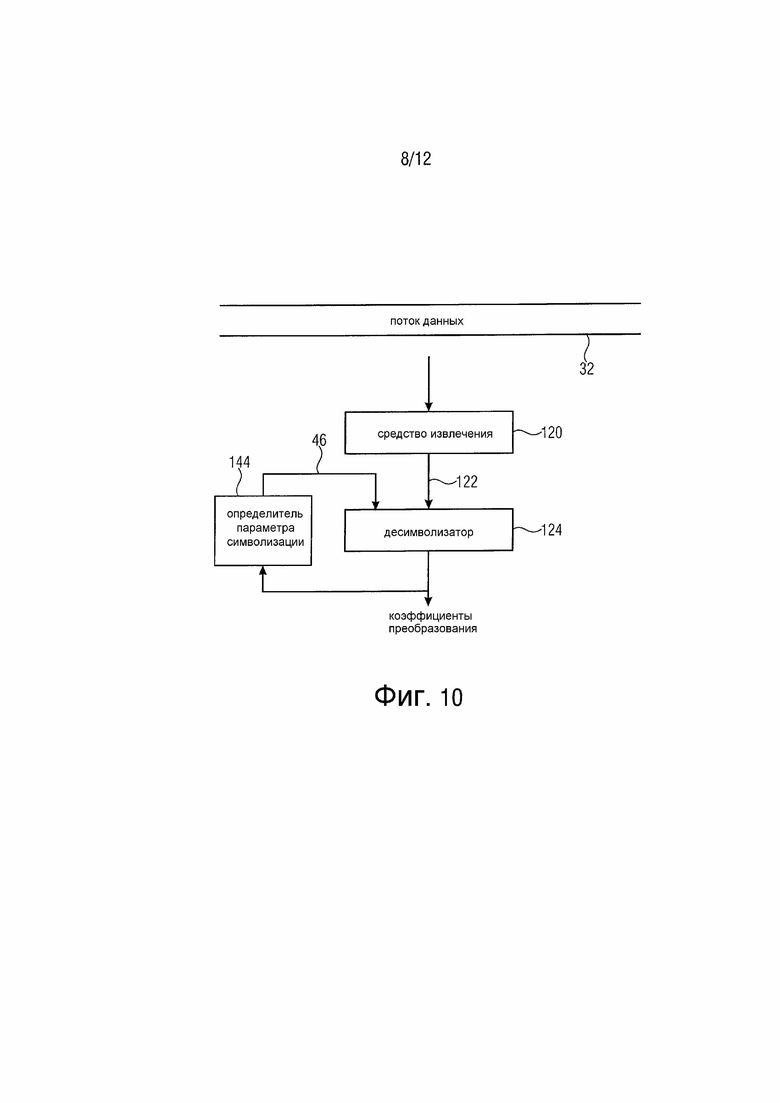
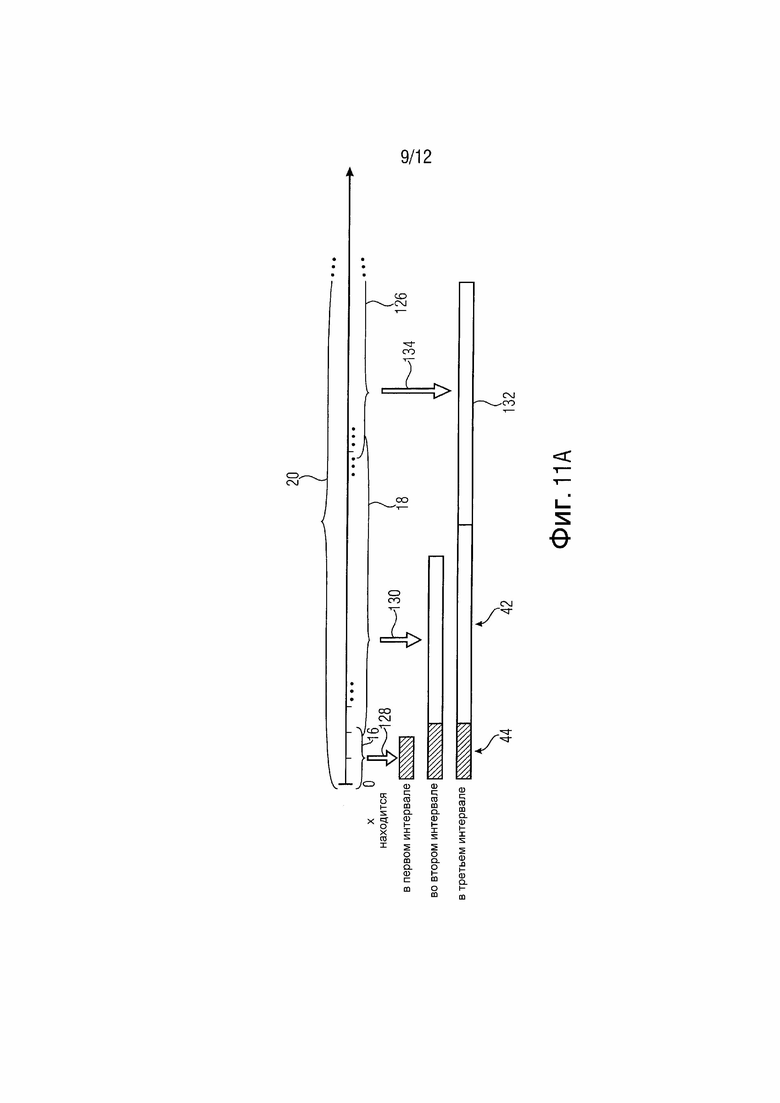
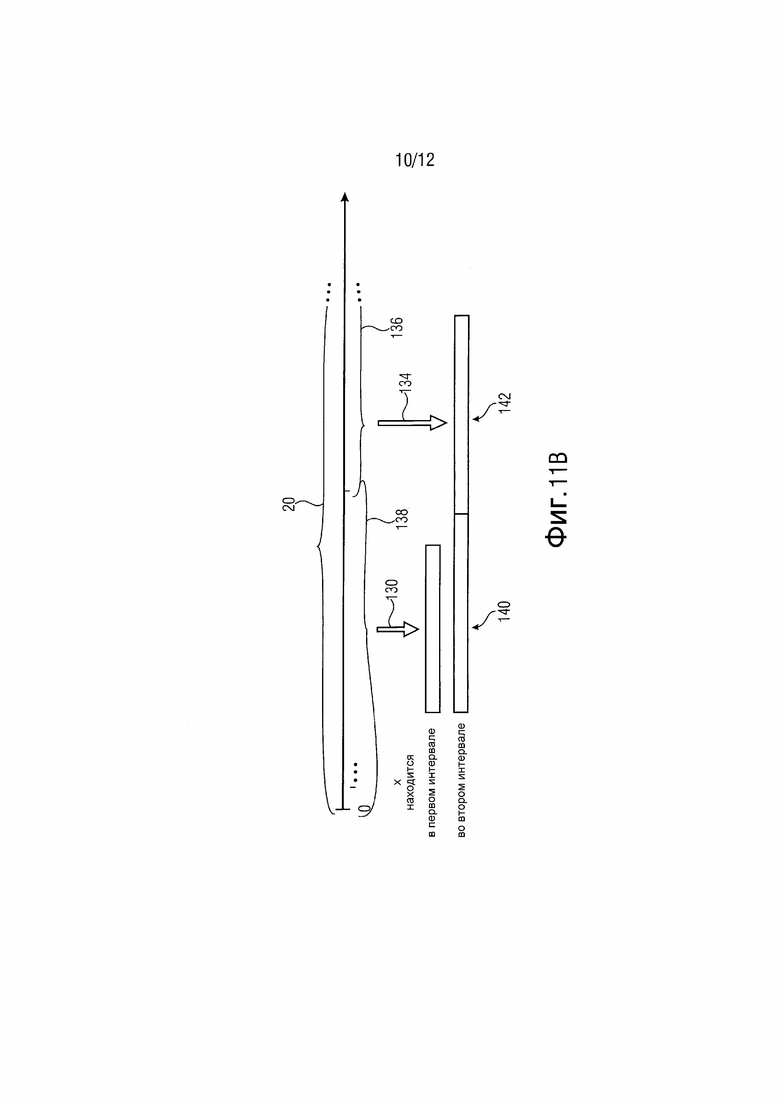
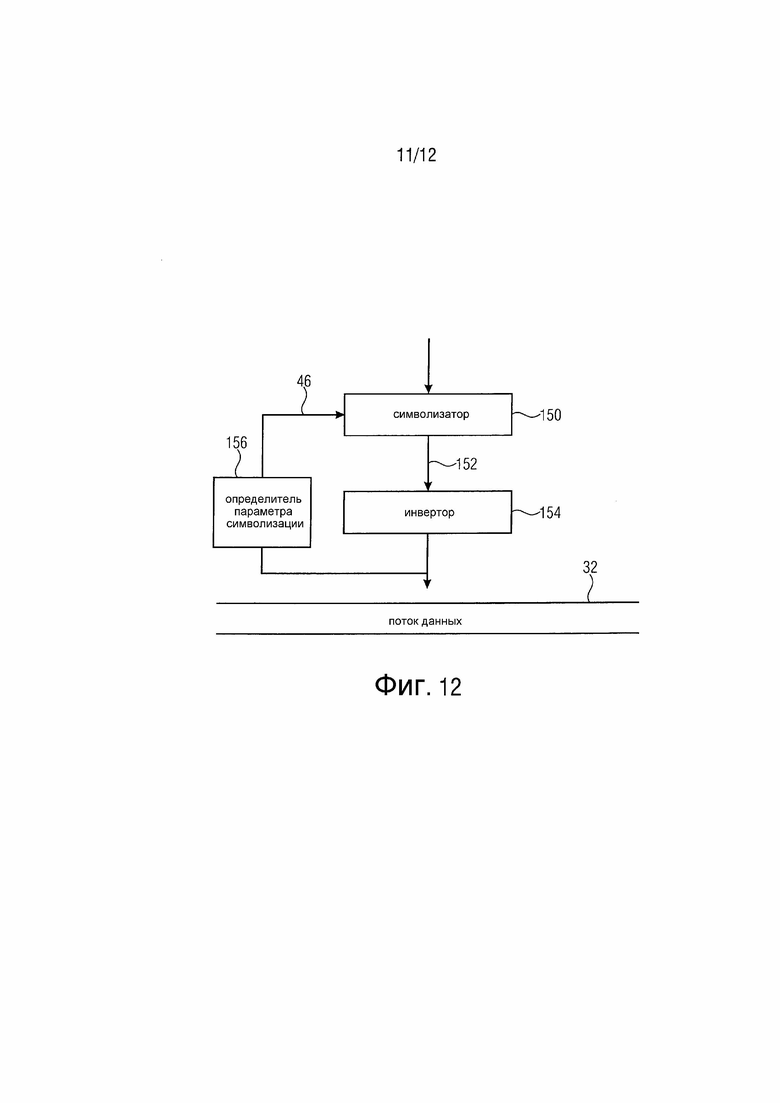
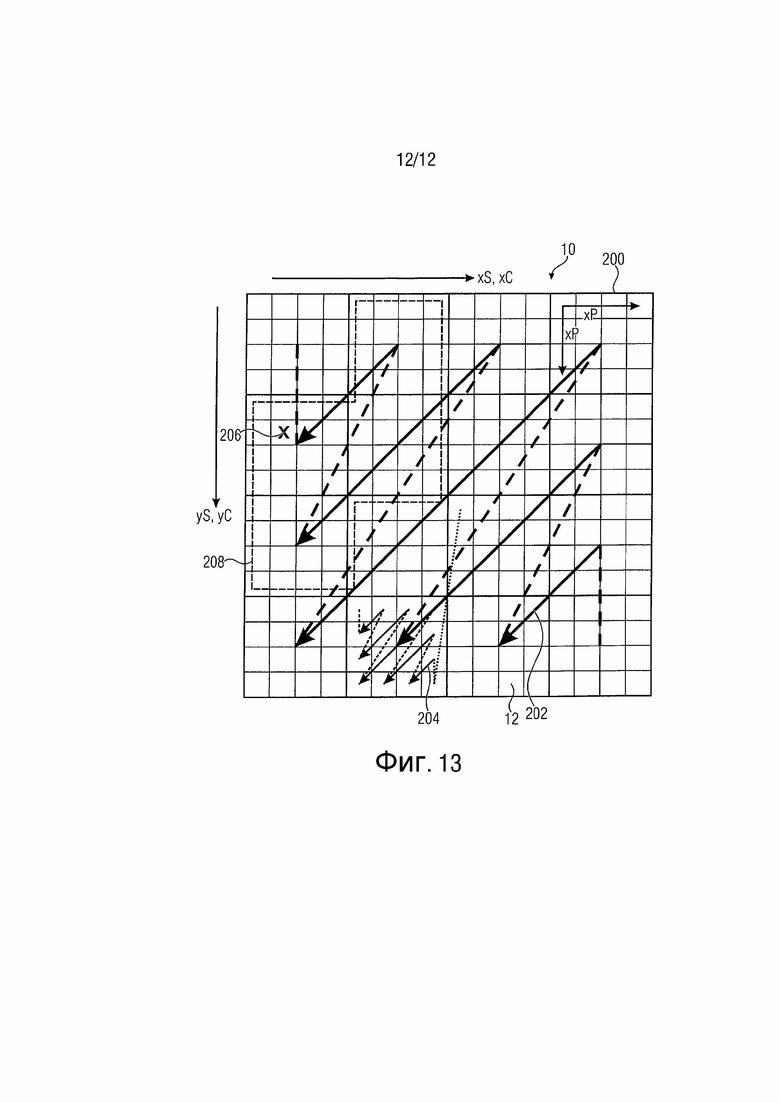
Изобретение относится к кодированию изображений. Технический результат - снижение сложности и повышение эффективности кодирования. Такой результат достигается за счет использования одной и той же функции для зависимости контекста и зависимости параметра символизации от ранее кодированных/декодированных коэффициентов преобразования. Использование одной и той же функции - с изменяющимся параметром функции - может использоваться в отношении разных размеров блока преобразования и/или частотных участков блоков преобразования в случае, если коэффициенты преобразования пространственно располагаются в блоках преобразования. Другой разновидностью данной идеи является использование одной и той же функции для зависимости параметра символизации от ранее кодированных/декодированных коэффициентов преобразования для разных размеров блока преобразования текущего коэффициента преобразования, разных типов информационной составляющей блока преобразования текущего коэффициента преобразования и/или разных частотных участков, на которых располагается текущий коэффициент преобразования в блоке преобразования. 3 н. и 23 з.п. ф-лы, 15 ил.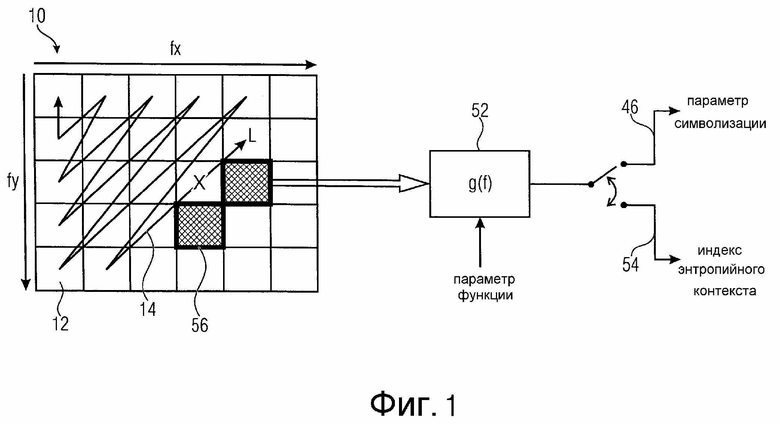
1. Декодер для декодирования потока данных, содержащего кодированное видео, включающее в себя информацию, связанную с множеством коэффициентов преобразования, ассоциированных с кодированным видео, причем декодер содержит:
контекстно-адаптивный энтропийный декодер, выполненный с возможностью, для текущего коэффициента преобразования, энтропийного декодирования, используя процессор, первого символа из потока данных с использованием контекста, при этом контекст определяется на основе операции, включающей в себя первый ранее декодированный коэффициент преобразования;
средство извлечения, выполненное с возможностью, используя процессор, если первый уровень коэффициента преобразования, ассоциированный с первым символом, по меньшей мере равен максимальному уровню, извлечения второго символа текущего коэффициента преобразования из потока данных;
десимволизатор, выполненный с возможностью, для текущего коэффициента преобразования, отображать, используя процессор, второй символ на второй уровень коэффициента преобразования на основе параметра символизации, при этом параметр символизации определяется на основе операции, включающей в себя второй ранее декодированный коэффициент преобразования и тип информационной составляющей блока преобразования текущего коэффициента преобразования; и
декодер изображений, выполненный с возможностью применения, используя процессор, кодирования с предсказанием на основе остаточного сигнала предсказания для восстановления блока изображения видео, при этом остаточный сигнал предсказания ассоциирован с энтропийно декодированным первым символом и вторым уровнем коэффициента преобразования,
при этом декодер выполнен с возможностью определения первого ранее декодированного коэффициента преобразования на основе относительного пространственного расположения текущего коэффициента преобразования относительно множества коэффициентов преобразования.
2. Декодер по п. 1, при этом декодер выполнен с возможностью извлечения из потока данных информации о положении последнего ненулевого коэффициента преобразования из числа коэффициентов преобразования блока коэффициентов преобразования вдоль предопределенного порядка сканирования, при этом множество коэффициентов преобразования охватывает коэффициенты преобразования блока коэффициентов преобразования от последнего ненулевого коэффициента преобразования по порядку сканирования до DC-коэффициента преобразования блока коэффициентов преобразования.
3. Декодер по п. 2, в котором десимволизатор выполнен с возможностью использования первой схемы символизации для отображения первого символа последнего ненулевого коэффициента преобразования на уровень, меньший или равный максимальному уровню, при этом нулевой уровень не применяется для последнего коэффициента преобразования.
4. Декодер по п. 2, в котором контекстно-адаптивный энтропийный декодер выполнен с возможностью энтропийного декодирования первого символа для последнего ненулевого коэффициента преобразования с использованием контекста, который отличается от контекста, используемого при энтропийном декодировании первого символа коэффициента преобразования, отличного от последнего ненулевого коэффициента преобразования.
5. Декодер по п. 2, в котором контекстно-адаптивный энтропийный декодер проходит по коэффициентам преобразования блока коэффициентов преобразования в порядке сканирования, начиная с последнего ненулевого коэффициента преобразования, до DC-коэффициента преобразования блока коэффициентов преобразования.
6. Декодер по п. 1, при этом декодер выполнен с возможностью декодирования множества коэффициентов преобразования из потока данных за два сканирования, при этом контекстно-адаптивный энтропийный декодер выполнен с возможностью энтропийного декодирования первого символа для коэффициентов преобразования из потока данных в порядке, соответствующем первому сканированию коэффициентов преобразования,
причем декодер содержит средство извлечения, выполненное с возможностью последовательного извлечения из потока данных вторых символов для коэффициентов преобразования, для которых первые символы отображены на максимальный уровень, в порядке, соответствующем второму сканированию коэффициентов преобразования.
7. Декодер по п. 1, при этом декодер выполнен с возможностью декодирования множества коэффициентов преобразования из потока данных последовательно за одно сканирование, при этом вторые символы располагаются в потоке данных между первыми символами коэффициентов преобразования, и при этом контекстно-адаптивный энтропийный декодер и средство извлечения выполнены с возможностью, для каждого коэффициента преобразования в порядке сканирования упомянутого одного сканирования, извлекать из потока данных вторые символы соответствующих коэффициентов преобразования, для которых первые символы отображены на максимальный уровень, непосредственно следом за энтропийным декодированием контекстно-адаптивным энтропийным декодером первых символов соответствующих коэффициентов преобразования, для которых первые символы отображены на максимальный уровень.
8. Декодер по п. 1, в котором средство извлечения выполнено с возможностью извлечения второго символа непосредственно из потока данных или с использованием энтропийного декодирования, использующего распределение фиксированной вероятности.
9. Декодер по п. 1, в котором десимволизатор выполнен с возможностью отображения первого символа на уровень коэффициента преобразования, меньший или равный максимальному уровню, ассоциированному с первым символом, на основе схемы усеченной унарной бинаризации.
10. Декодер по п. 1, в котором десимволизатор выполнен с возможностью отображения второго символа на основе кода Райса.
11. Кодер для кодирования в поток данных информации, связанной с множеством коэффициентов преобразования, ассоциированных с видео, причем кодер содержит:
кодер изображений, выполненный возможностью применения, используя процессор, кодирования с предсказанием к блоку изображения видео для получения остаточного сигнала предсказания, связанного с блоком;
контекстно-адаптивный энтропийный кодер, выполненный с возможностью, для текущего коэффициента преобразования, связанного с остаточным сигналом предсказания, энтропийного кодирования, используя процессор, первого символа в поток данных, используя контекст, при этом контекст определяется на основе операции, включающей в себя первый ранее кодированный коэффициент преобразования; и
символизатор, выполненный с возможностью отображения, используя процессор, первого уровня коэффициента преобразования текущего коэффициента преобразования на второй символ на основе параметра символизации, если первый уровень коэффициента преобразования по меньшей мере равен максимальному уровню, при этом параметр символизации определяется на основе операции, включающей в себя второй ранее кодированный коэффициент преобразования и тип информационной составляющей блока преобразования текущего коэффициента преобразования,
при этом кодер выполнен с возможностью определения первого ранее кодированного коэффициента преобразования на основе относительного пространственного расположения текущего коэффициента преобразования относительно множества коэффициентов преобразования.
12. Кодер по п. 11, при этом кодер выполнен с возможностью вставки в поток данных информации о положении последнего ненулевого коэффициента преобразования из числа коэффициентов преобразования блока коэффициентов преобразования вдоль предопределенного порядка сканирования, при этом множество коэффициентов преобразования охватывает коэффициенты преобразования блока коэффициентов преобразования от последнего ненулевого коэффициента преобразования по порядку сканирования до DC-коэффициента преобразования блока коэффициентов преобразования.
13. Кодер по п. 12, в котором символизатор выполнен с возможностью использования первой схемы символизации для отображения первого символа последнего ненулевого коэффициента преобразования на первый уровень коэффициента преобразования, при этом нулевой уровень не применяется для последнего коэффициента преобразования.
14. Кодер по п. 12, в котором контекстно-адаптивный энтропийный кодер выполнен с возможностью энтропийного кодирования первого символа для последнего ненулевого коэффициента преобразования с использованием контекста, который отличается от контекста, использованного при энтропийном декодировании первого символа коэффициента преобразования, отличного от последнего ненулевого коэффициента преобразования.
15. Кодер по п. 12, в котором контекстно-адаптивный энтропийный кодер проходит по коэффициентам преобразования блока коэффициентов преобразования в порядке сканирования, начиная с последнего ненулевого коэффициента преобразования, до DC-коэффициента преобразования блока коэффициентов преобразования.
16. Кодер по п. 11, при этом кодер выполнен с возможностью кодирования множества коэффициентов преобразования из потока данных за два сканирования, при этом контекстно-адаптивный энтропийный кодер выполнен с возможностью энтропийного кодирования первого символа для коэффициентов преобразования в поток данных в порядке, соответствующем первому сканированию коэффициентов преобразования,
причем кодер содержит средство вставки, выполненное с возможностью последовательной вставки в поток данных вторых символов для коэффициентов преобразования, для которых первые символы отображены на максимальный уровень, в порядке, соответствующем второму сканированию коэффициентов преобразования.
17. Кодер по п. 11, при этом кодер выполнен с возможностью кодирования множества коэффициентов преобразования в поток данных последовательно за одно сканирование, при этом вторые символы располагаются в потоке данных между первыми символами коэффициентов преобразования, и при этом контекстно-адаптивный энтропийный кодер и средство вставки кодера выполнены с возможностью, для каждого коэффициента преобразования в порядке сканирования упомянутого одного сканирования, вставлять в поток данных вторые символы соответствующих коэффициентов преобразования, для которых первые символы отображены на максимальный уровень, непосредственно следом за энтропийным кодированием контекстно-адаптивным энтропийным кодером первых символов соответствующих коэффициентов преобразования, для которых первые символы отображены на максимальный уровень.
18. Кодер по п. 11, дополнительно содержащий средство вставки, выполненное с возможностью вставки второго символа непосредственно в поток данных или с использованием энтропийного кодирования, использующего распределение фиксированной вероятности.
19. Кодер по п. 11, в котором символизатор выполнен с возможностью отображения первого символа на уровень коэффициента преобразования, меньший или равный максимальному уровню, на основе схемы усеченной унарной бинаризации.
20. Кодер по п. 11, в котором символизатор выполнен с возможностью отображения второго символа на основе кода Райса.
21. Способ для декодирования потока данных, содержащего кодированное видео, включающее в себя информацию, связанную с множеством коэффициентов преобразования, ассоциированных с кодированным видео, причем способ содержит:
энтропийное декодирование, для текущего коэффициента преобразования, первого символа из потока данных с использованием контекста, при этом контекст определяется на основе операции, включающей в себя первый ранее декодированный коэффициент преобразования;
если первый уровень коэффициента преобразования, ассоциированный с первым символом, по меньшей мере равен максимальному уровню, извлечение второго символа текущего коэффициента преобразования из потока данных;
отображение, для текущего коэффициента преобразования, второго символа на второй уровень коэффициента преобразования на основе параметра символизации, при этом параметр символизации определяется на основе операции, включающей в себя второй ранее декодированный коэффициент преобразования и тип информационной составляющей блока преобразования текущего коэффициента преобразования; и
применение кодирования с предсказанием на основе остаточного сигнала предсказания для восстановления блока изображения видео, при этом остаточный сигнал предсказания ассоциирован с энтропийно декодированным первым символом и вторым уровнем коэффициента преобразования,
при этом первый ранее декодированный коэффициент преобразования определяется на основе относительного пространственного расположения текущего коэффициента преобразования относительно множества коэффициентов преобразования.
22. Способ по п. 21, дополнительно содержащий извлечение из потока данных информации о положении последнего ненулевого коэффициента преобразования из числа коэффициентов преобразования блока коэффициентов преобразования вдоль предопределенного порядка сканирования, при этом множество коэффициентов преобразования охватывает коэффициенты преобразования блока коэффициентов преобразования от последнего ненулевого коэффициента преобразования по порядку сканирования до DC-коэффициента преобразования блока коэффициентов преобразования.
23. Способ по п. 21, дополнительно содержащий:
последовательное декодирование множества коэффициентов преобразования из потока данных за одно сканирование, при этом вторые символы располагаются в потоке данных между первыми символами коэффициентов преобразования, и
для каждого коэффициента преобразования в порядке сканирования одного сканирования, извлечение из потока данных вторых символов соответствующих коэффициентов преобразования, для которых первые символы отображены на максимальный уровень, непосредственно следом за энтропийным декодированием первых символов соответствующих коэффициентов преобразования, для которых первые символы отображены на максимальный уровень.
24. Способ по п. 21, дополнительно содержащий извлечение второго символа непосредственно из потока данных или с использованием энтропийного декодирования, использующего распределение фиксированной вероятности.
25. Способ по п. 21, дополнительно содержащий отображение первого символа на уровень коэффициента преобразования, меньший или равный максимальному уровню, на основе схемы усеченной унарной бинаризации.
26. Способ по п. 21, в котором отображение второго символа основано на коде Райса.
| TUNG NGUYEN et al.: "Reduced-complexity entropy coding of transform coefficient levels using truncated golomb-rice codes in video compression", IMAGE PROCESSING (ICIP), 2011 18TH IEEE 1-30 INTERNATIONAL CONFERENCE ON, IEEE, 11 September 2011 (2011-09-11), pages 753 - 756, XP032080600, ISBN: 978-1-4577-1304-0, DOI: 10.1109/ICIP.2011.6116664 | |||
| US |

