Перекрестные ссылки на связанные заявки
[0001] Настоящая заявка ссылается на приоритет предварительной заявки на патент США №63/003112, зарегистрированной 31 марта 2020 года, и заявки на патент США №17/087865, зарегистрированной 3 ноября 2020 года, при этом обе упомянутые заявки полностью включены в настоящий документ путем ссылки.
Область техники
[0002] Настоящее изобретение относится, в общем, к области обработки данных, а именно, к видеокодированию и видеодекодированию.
Предпосылки создания изобретения
[0003] Уже на протяжении десятилетий существуют методы видеокодирования и видеодекодирования с использованием внешнего предсказания изображений с компенсацией движения. Несжатое цифровое видео может содержать последовательность изображений, каждое из которых имеет заданный пространственный размер, например, 1920×1080 отсчетов яркости и соответствующих отсчетов цветности. Такая последовательность изображений может иметь фиксированную или переменную частоту смены изображений (неформально также называемую частотой смены кадров), равную, например, 60 изображениям в секунду, или 60 Гц. Несжатое видео предъявляет высокие требования к битовой скорости передачи данных (или битрейту). К примеру, видео формата 1080р60 4:2:0 с 8-битной глубиной отсчета (разрешение в 1920×1080 отсчетов яркости с частотной смены кадров 60 Гц) требует полосы пропускания около 1,5 Гб/с. Час такого видео требует более 600 ГБ памяти для хранения.
[0004] Одной из задач видеокодирования и видеодекодирования является снижение избыточности во входном видеосигнале за счет сжатия. Сжатие позволяет сократить требования к полосе пропускания или объему памяти для хранения в некоторых случаях до двух порядков величины или более. Может применяться как сжатие без потерь, так и с потерями, а также их комбинации. Под сжатием без потерь понимают методы, в которых из сжатого сигнала может быть восстановлена точная копия исходного сигнала. Когда используют сжатие с потерями восстановленный сигнал может не быть идентичным исходному, однако расхождение между исходным и восстановленным сигналами достаточно мало, чтобы восстановленный сигнал был пригоден для целевого применения. Сжатие с потерями широко применяется для видео. Величина допустимых искажений зависит от конкретного применения; например, пользователи коммерческих приложений потоковой передачи могут быть терпимее к искажениям, чем пользователи приложений телевещания. Степень сжатия подчиняется следующей закономерности: чем больше допустимые искажения, тем больше достижимая степень сжатия.
[0005] В видеокодере и видеодекодере может применяться ряд методов, относящихся к различным категориям, включая, например, компенсацию движения, преобразования, квантование и энтропийное кодирование, некоторые из которых будут рассмотрены ниже.
[0006] Исторически сложилось, что видеокодеры и видеодекодеры работали с заданным размером изображений, который в большинстве случаев был известен и оставался неизменным на протяжении всей кодированной видеопоследовательности (coded video sequence, CVS), группы изображений (Group of Pictures, GOP) или внутри аналогичных временных рамок, включающих множество изображений. К примеру, в стандарте MPEG-2 его структура позволяет изменять горизонтальное разрешение (и следовательно, размер изображения) в зависимости от определенных факторов, например, активности в видеосцене, однако только в 1-изображениях, а значит, как правило, только для группы GOP. В приложении Р Рекомендации Н.263 ITU-T (ITU-T Rec. Н.263 Annex Р) была определена передискретизация (ресэмплинг) опорных изображений для возможности использования различных разрешений внутри последовательности CVS. Однако в этом случае менялся лишь размер опорных изображений, а размер собственно изображений не менялся, что в результате давало возможность использовать лишь фрагменты всей поверхности изображения (при понижении разрешения, downsampling) или захватывать лишь часть сцены (при повышении разрешения, upsampling). Также, приложение Q Н.263 (Н.263 Annex Q) допускает повышающий и понижающий ресэмплинг отдельных макроблоков с коэффициентом, равным степени двойки (по любой оси). Однако снова, размер изображения остается неизменным. Размер макроблока в Н.263 фиксирован, и, следовательно, не должен сигнализироваться.
[0007] В современном видеокодировании изменения размера предсказываемых изображений встречаются более часто. К примеру, стандарт VP9 допускает ресэмплинг опорных изображений и изменение разрешения изображения в целом. Аналогично, были внесены соответствующие предложения для стандарта VVC (включая, например, документ Объединенной группы экспертов по видео JVET-M0135-v1, «Об адаптивном изменении разрешения (adaptive resolution change, ARC) для VVC, 9-19 января 2019 года, Hendry и соавт., полностью включенный в настоящий документ путем ссылки), допускающие ресэмплинг опорных изображений целиком, до отличающихся, повышенных или пониженных, разрешений. В упомянутом документе предлагается кодирование различных кандидатных разрешений в наборе параметров последовательности и осуществление ссылок на них в синтаксических элементах, для каждого изображения, в наборе параметров изображения.
Сущность изобретения
[0008] Варианты осуществления настоящего изобретения относятся к способу, системе и машиночитаемому носителю для кодирования видеоданных. В соответствии с одним из аспектов настоящего изобретения предложен способ кодирования видеоданных. Предложенный способ может включать прием видеоданных, включающих текущее изображение и одно или более других изображений. Проверяют первый флаг, соответствующий тому, ссылаются ли на текущее изображение одно или более других изображений в порядке декодирования. Проверяют второй флаг, соответствующий тому, является ли текущее изображение выводимым. Видеоданные декодируют на основе значений, соответствующих первому флагу и второму флагу.
[0009] В соответствии с еще одним из аспектов настоящего изобретения предложена компьютерная система для кодирования видеоданных. Компьютерная система может включать один или более процессоров, один или более блоков машиночитаемой памяти, один или более материальных машиночитаемых запоминающих устройств и программные инструкции, которые хранят по меньшей мере на одном из упомянутых одного или более запоминающих устройств, для исполнения по меньшей мере одним из упомянутых одного или более процессоров, с помощью по меньшей мере одного из упомянутых одного или более блоков памяти, при этом компьютерная система способно выполнять способ. Способ может включать прием видеоданных, включающих текущее изображение и одно или более других изображений. Проверяют первый флаг, соответствующий тому, ссылаются ли на текущее изображение одно или более других изображений в порядке декодирования. Проверяют второй флаг, соответствующий тому, является ли текущее изображение выводимым. Видеоданные декодируют на основе значений, соответствующих первому флагу и второму флагу.
[0010] В соответствии с еще одним из аспектов настоящего изобретения предложен машиночитаемый носитель для кодирования видеоданных. Машиночитаемый носитель может включать одно или более машиночитаемых запоминающих устройств и программные инструкции, которые хранят по меньшей мере на одном из упомянутых одного или более материальных запоминающих устройств, при этом программные инструкции исполняют при помощи процессора. Программные инструкции исполняют при помощи процессора для выполнения способа, который, соответственно, может включать прием видеоданных, включающих текущее изображение и одно или более других изображений. Проверяют первый флаг, соответствующий тому, ссылаются ли на текущее изображение одно или более других изображений в порядке декодирования. Проверяют второй флаг, соответствующий тому, является ли текущее изображение выводимым. Видеоданные декодируют на основе значений, соответствующих первому флагу и второму флагу.
Краткое описание чертежей
[0011] Описанные выше, а также другие цели, отличительные признаки и преимущества настоящего изобретения будут пояснены в дальнейшем подробном описании примеров осуществления настоящего изобретения, которое следует рассматривать вместе с приложенными чертежами. Элементы, показанные на чертежах, выполнены не в масштабе, поскольку иллюстрации служат исключительно для пояснения изобретения специалистам в данной области техники, вместе с приведенным подробным описанием. На чертежах:
[0012] на фиг. 1 эскизно показана упрощенная блок-схема системы связи, в соответствии с одним из вариантов осуществления настоящего изобретения;
[0013] на фиг. 2 эскизно показана упрощенная блок-схема системы связи, в соответствии с одним из вариантов осуществления настоящего изобретения;
[0014] на фиг. 3 эскизно показана упрощенная блок-схема декодера, в соответствии с одним из вариантов осуществления настоящего изобретения;
[0015] на фиг. 4 эскизно показана упрощенная блок-схема кодера, в соответствии с одним из вариантов осуществления настоящего изобретения;
[0016] фиг. 5 эскизно иллюстрируют варианты сигнализации параметров ARC в соответствии с существующим уровнем техники или одним из вариантов осуществления настоящего изобретения, как указано на чертеже;
[0017] на фиг. 6 показан пример синтаксической таблицы в соответствии с одним из вариантов осуществления настоящего изобретения;
[0018] на фиг. 7 эскизно проиллюстрирована компьютерная система в соответствии с одним из вариантов осуществления настоящего изобретения;
[0019] на фиг. 8 представлен пример структуры предсказания для масштабирования с адаптивным изменением разрешения;
[0020] на фиг. 9 показан пример синтаксической таблицы в соответствии с одним из вариантов осуществления настоящего изобретения;
[0021] на фиг. 10 эскизно показана упрощенная блок-схема анализа и декодирования цикла РОС для каждого блока доступа и каждого значения порядкового номера блока доступа;
[0022] на фиг. 11 эскизно проиллюстрирована структура битового потока видео, включающая многоуровневые субизображения;
[0023] на фиг. 12 эскизно проиллюстрировано отображение выбранного субизображения с повышенным разрешением;
[0024] на фиг. 13 показана блок-схема процедуры декодирования и отображения битового потока видео, включающего многоуровневые субизображения;
[0025] На фиг. 14 эскизно проиллюстрировано отображение 360-градус но го видео с уточняющим уровнем субизображения;
[0026] на фиг. 15 показан пример информации о компоновке субизображений и соответствующей ей структуры предсказания уровней и изображений в соответствии с одним из вариантов осуществления настоящего изобретения;
[0027] на фиг. 16 показан пример информации о компоновке субизображений и соответствующей ей структуры предсказания уровней и изображений, с возможностью пространственного масштабирования локальной области;
[0028] на фиг. 17 показаны пример синтаксической таблицы для информации о компоновке субизображений;
[0029] на фиг. 18 показан пример синтаксической таблицы сообщения SEI для информации о компоновке субизображений;
[0030] на фиг. 19 показан пример синтаксической таблицы для указания выходных уровней и информации о профиле/ярусе/уровне стандарта для каждого набора выходных уровней;
[0031] на фиг. 20 показан пример синтаксической таблицы для указания на режим выходного уровня для каждого набора выходных уровней;
[0032] на фиг. 21 показан пример синтаксической таблицы для указания на присутствие субизображения для каждого уровня, для каждого набора выходных уровней;
[0033] на фиг. 22 показан пример синтаксической таблицы для RBSP набора параметров видео;
[0034] на фиг. 23 показан пример синтаксической таблицы для указания на набор выходных уровней с режимом набора выходных уровней;
[0035] на фиг. 24 показан пример синтаксической таблицы заголовка изображения для указания информации о выводе изображения.
Подробное описание изобретения
[0036] В настоящем документе подробно описаны варианты осуществления заявленных структур и способов, однако при этом нужно понимать, что рассмотренные варианты осуществления настоящего изобретения являются исключительно иллюстрацией заявленных структур и способов, и они могут быть реализованы в различных формах. Предложенные структуры и способы, соответственно, могут быть реализованы в множестве различных форм и не должно считаться ограниченными изложенными здесь примерами осуществления. Напротив, примеры осуществления настоящего изобретения описаны для обеспечения всестороннего и полного понимания настоящего изобретения и для исчерпывающего разъяснения, специалистам в данной области техники, замысла настоящего изобретения на конкретных примерах его осуществления. В настоящем описании широко известные элементы и методы не будут описаны подробно, чтобы без необходимости не усложнять описание предложенных вариантов осуществления настоящего изобретения.
[0037] Как уже отмечалось, ранее видеокодеры и видеодекодеры работали с заданным размером изображений, который в большинстве случаев был известен и оставался неизменным на протяжении всей кодированной видеопоследовательности (coded video sequence, CVS), группы изображений (Group of Pictures, GOP) или внутри аналогичных временных рамок, включающих множество изображений. Однако на изображение могут как осуществляться ссылки из последующих изображений, для компенсации движения или предсказания иных параметров, так и не осуществляться. Каждое изображение может быть как выводимым (предназначенным для вывода), так и не выводимым. Соответственно, было бы желательно иметь возможность сигнализировать информацию о ссылках и информацию о выводе изображения в одном или более наборах параметров.
[0038] Аспекты настоящего изобретения описаны здесь на примере иллюстраций блок-схем алгоритмов и/или блок-схем способов, устройства (систем) и машиночитаемого носителя данных, в соответствии с различными вариантами осуществления настоящего изобретения. Следует понимать, что каждый блок упомянутых блок-схем и/или блок-схем алгоритмов, а также комбинации блоков на этих блок-схемах и/или блок-схемах алгоритмов могут быть реализованы с помощью машиночитаемых программных инструкций.
[0039] На фиг. 1 проиллюстрирована упрощенная блок-схема системы (100) связи в соответствии одним из примеров осуществления настоящего изобретения. Система (100) может включать по меньшей мере два терминала (110-120), связанных друг с другом сетью (150). При однонаправленной передаче данных первый терминал (110) может кодировать видеоданные локально для передачи во второй терминал (120) по сети (150). Второй терминал (120) может принимать кодированные видеоданные от первого терминала из сети (150), декодировать кодированные данные и отображать восстановленные видеоданные. Однонаправленная передача данных широко применяется в приложениях медиасервисов и аналогичных приложениях.
[0040] На фиг. 1 проиллюстрирована вторая пара терминалов (130, 140), сконфигурированных для поддержки двунаправленной передачи кодированного видео, которая может требоваться, например, при видеоконференцсвязи. При двунаправленной передаче данных оба терминала (130, 140) могут кодировать локально захватываемые видеоданные для передачи в другой терминал по сети (150). Оба терминала (130, 140) могут также принимать кодированные видеоданные, переданные другим терминалом, могут декодировать кодированные данные и отображать восстановленные видеоданные на локальном дисплейном устройстве.
[0041] В примере фиг. 1 терминалы (110-140) могут быть серверами, персональными компьютерами или смартфонами, однако без ограничения ими замысла настоящего изобретения. Варианты осуществления настоящего изобретения могут применяться в портативных компьютерах, планшетных компьютерах, медиаплеерах и/или специализированном оборудовании для видеоконференцсвязи. Сеть (150) может представлять собой любое количество сетей, передающих кодированные видеоданные между терминалами (110 140), включая, например, проводные и/или беспроводные сети связи. Сеть (150) связи может обеспечивать обмен данными по линиям связи с коммутацией каналов и/или коммутацией пакетов. Примерами таких сетей могут быть телекоммуникационные сети, локальные вычислительные сети, глобальные вычислительные сети и/или Интернет. В настоящем описании архитектура и топология сети (150) не играют никакой роли в функционировании предложенного изобретения, если на это явно не указано.
[0042] На фиг. 2 проиллюстрировано, в качестве примера применения настоящего изобретения, размещение видеокодера и декодера в окружении потоковой передачи. Предложенное изобретение может применяться с равной эффективностью и в других областях, где используется видео, включая, например, видеоконференцсвязь, цифровое телевидение, хранения сжатого видео на цифровых носителях, включая CD, DVD, карты памяти и т.п.
[0043] Система потоковой передачи может включать подсистему (213) захвата, которая может включать источник (201) видео, например, видеокамеру, которая формирует поток (202) несжатых отсчетов. Поток (202) отсчетов, показанный жирной линией, чтобы подчеркнуть больший объем данных по сравнению с кодированными видеопотоками, может обрабатываться кодером (203), связанным с камерой (201). Кодер (203) может включать аппаратное обеспечение, программное обеспечение, или их комбинацию, которые позволяют реализовать аспекты предложенного изобретения, в соответствии с последующим более подробным описанием. Битовый поток (204) кодированного видео, показанной тонкой линией, чтобы подчеркнуть меньший объем данных по сравнению с несжатым потоком видеоотсчетов, может сохраняться на сервере (205) потоковой передачи для последующего использования. Один или более клиентов (206, 208) потоковой передачи могут осуществлять доступ к серверу (205) потоковой передачи для получения копий (207, 209) битового потока (204) кодированного видео. Клиентское устройство (206) может включать видеодекодер (210), который декодирует принятую копию битового потока (207) кодированного видео и формировать выходной поток (211) видеотсчетов, который может отображаться на дисплее (212) или другом устройстве отображения (не показано на чертеже). В некоторых системах потоковой передачи битовые видеопотоки (204, 207, 209) могут быть кодированы в соответствии с заданными стандартами видеокодирования/видеосжатия. Примером таких стандартов может быть Рекомендация Н.265 ITU-T. В настоящее время ведется разработка стандарта видеокодирования, который неформально называют «универсальным видеокодированием» (Versatile Video Coding, VVC). Описанное в данном документе изобретение может применяться в контексте стандарта VVC.
[0044] Фиг. 3 является примером функциональной блок-схемы видеодекодера (210) соответствии с одним из вариантов осуществления настоящего изобретения.
[0045] Приемник (310) может принимать одну или более кодированных видеопоследовательностей для декодирования при помощи декодера (210). В этом же варианте осуществления или в альтернативных вариантах осуществления настоящего изобретения прием видеопоследовательностей может выполняться поочередно, при этом декодирование каждой из кодированных видеопоследовательностей не зависит от декодирования других видеопоследовательностей. Кодированная видеопоследовательность может быть принята из канала (312), который может представлять собой аппаратную и/или программную линию связи с запоминающим устройством, где хранят кодированные видеоданные. Приемник (310) может принимать кодированные видеоданные вместе с другими данными, например, кодированными аудиоданными и/или вспомогательными потоками данных, которые могут перенаправляться в соответствующие использующие их элементы (не показано на чертеже). Приемник (310) может отделять кодированную видеопоследовательность от остальных данных. Для борьбы с сетевым джиттером между приемником (310) и энтропийным декодером/анализатором (320) (далее, «анализатор») может быть установлена буферная память (315). Когда приемник (310) принимает данные из устройства хранения или передачи с достаточной полосой пропускания и управляемостью, или из сети с изосинхронной передачей, буфер (315) может не применяться или иметь малый объем. В случае применения пакетных сетей с негарантированной доставкой, таких как Интернет, буфер (315) необходим, может быть сравнительно объемным и, предпочтительно, иметь при этом адаптивный размер.
[0046] Видеодекодер (210) может иметь в своем составе анализатор (320) для восстановления символов (321) из энтропийно-кодированной видеопоследовательности. Типы этих символов могут включать, например, информацию, используемую для управления работой декодера (210), а также, возможно, информацию для управления устройством отображения, такого как дисплей (212), который может быть связан с декодером, но не являться его неотъемлемой частью, как это показано на фиг. 2. Управляющая информация для устройств отображения может, например, иметь форму сообщений дополнительной уточняющей информации (Supplementary Enhancement Information, SEI) или фрагментов наборов параметров информации об используемости видео (Video Usability Information, VUI) (не показано на чертеже). Анализатор (320) может выполнять анализ/энтропийное декодирование принятой кодированной видеопоследовательности. Кодированная видеопоследовательность может быть кодирована в соответствии с некоторой технологией или стандартом видеокодирования, и может следовать принципам, хорошо известным специалистам в данной области техники, включая кодирование с переменной длиной кодового слова, кодирование Хаффмана, контекстно-зависимое или контекстно-независимое арифметическое кодирование и т.п. Анализатор (320) может извлекать из кодированной видеопоследовательности набор параметров подгруппы по меньшей мере для одной подгруппы пикселей в видеодекодере, на основе по меньшей мере одного параметра, соответствующего группе. Подгруппы могут включать группы изображений (Groups of Pictures, GOP), изображения, тайлы, слайсы, макроблоки, кодовые пакеты (Coding Units, CU), блоки (blocks), пакеты преобразования (Transform Units, TU), пакеты предсказания (Prediction Units, PU) и т.п. Анализатор может также извлекать из кодированной видеопоследовательности такую информацию как коэффициенты преобразования, значения параметров квантователя, векторы движения и т.п.
[0047] Анализатор (320) может выполнять операции энтропийного декодирования/анализа над видеопоследовательностью, принятой из буфера (315), и формировать символы (321).
[0048] При восстановлении символов (321) могут использоваться различные блоки устройства, в зависимости от типа кодированных видеоизображений или их частей (например, внутренне и внешне предсказываемые изображения, внутренне и внешне предсказываемые блоки отсчетов), а также от других факторов. То, какие блоки устройства будут использованы, и каким образом, может определяться управляющей информацией подгруппы, извлеченной из кодированной видеопоследовательности анализатором (320). Для простоты поток такой управляющей информации подгруппы между анализатором (320) и множеством описанных ниже блоков устройства на чертеже не показан.
[0049] Помимо уже упомянутых функциональных блоков декодер 210 может быть концептуально подразбит на набор описанных ниже функциональных блоков. В практических реализациях, применяемых в коммерческих условиях, многие из этих блоков плотно взаимодействуют друг с другом и могут быть, по меньшей мере частично, взаимно интегрированы. Однако в целях описания предложенного изобретения подходит описанное ниже подразделение на функциональные блоки.
[0050] Первым из таких блоков может быть блок (351) масштабирования/обратного преобразования. Блок (351) масштабирования/обратного преобразования принимает квантованные коэффициенты преобразования, а также управляющую информацию, включая информацию о том, какое преобразование следует использовать, размер блока отсчетов, коэффициент квантования, масштабирующие матрицы квантования и т.п., в виде символов (321) из анализатора (320). Он выдает блоки отсчетов, включающие значения отсчетов, которые могут быть введены в агрегатор (355).
[0051] В некоторых случаях отсчеты на выходе из блока (351) масштабирования / обратного преобразования могут относиться к внутренне кодируемому блоку отсчетов, то есть: блоку отсчетов, для которого не используют информацию предсказания из ранее восстановленных изображений, но могут использовать информацию из ранее восстановленных частей текущего изображения. Такая информация предсказания может предоставляться блоком (352) внутреннего предсказания изображений. В некоторых случаях блок (352) внутреннего предсказания изображений может формировать блоки отсчетов тех же размеров и формы, что и восстанавливаемый блок отсчетов, с использованием уже восстановленной информации его окружения, полученной из текущего (частично восстановленного) изображения в памяти (356) текущих изображений. Агрегатор (355) может в некоторых случаях добавлять информацию предсказания, сформированную блоком (352) внутреннего предсказания, к выходной информации отсчетов, предоставляемой блоком (351) масштабирования/обратного преобразования, индивидуально для каждого отсчета.
[0052] В других случаях отсчеты на выходе блока (351) масштабирования/обратного преобразования могут относиться к блоку с внешним предсказанием, и возможно, с компенсацией движения. В таких случаях блок (353) предсказания с компенсацией движения может осуществлять доступ к памяти (357) опорных изображений и получать отсчеты, используемые для предсказания. После компенсации движения полученные отсчеты, в соответствии с символами (321), относящимися к этому блоку, могут быть добавлены агрегатором (355) к выходным данным блока масштабирования/обратного преобразования (в этом случае их называют разностными отсчетами или разностным сигналом), в результате чего формируют выходную информацию отсчетов. Адреса в памяти опорных изображений, по которым блок предсказания с компенсацией движения получает предсказанные отсчеты, могут определяться векторами движения, доступными для блока предсказания с компенсацией движения в форме символов (321), которые могут иметь, например, Х-компоненту, Y-компоненту и компоненту опорного изображения. Компенсация движения может также включать интерполяцию значений отсчетов, полученных из памяти (457) опорных изображений, когда применяют векторы движения, механизмы предсказания векторов движения и т.п., имеющие субпиксельную точность.
[0053] Отсчеты на выходе из агрегатора (355) могут обрабатываться при помощи различных методов контурной фильтрации в блоке (356) контурной фильтрации. Технологии сжатия видео могут включать технологии внутриконтурной фильтрации, которые управляются параметрами, содержащимися в кодированном битовом видеопотоке, и предоставляемыми в блок (356) контурной фильтрации в виде символов (321) из анализатора (320). Они могут также зависеть от метаинформации, полученной при декодировании предшествующих (в порядке декодирования) частей кодированного изображения или кодированной видеопоследовательности, а также - от ранее восстановленных и прошедших контурную фильтрацию значений отсчетов.
[0054] Выходными данными блока (356) контурной фильтрации может быть поток отсчетов, который подают в устройство (212) отображения, а также сохраняют в памяти (356) опорных изображений для использования при будущем внешнем предсказании изображений.
[0055] Отдельные кодированные изображения, после их полного восстановления могут использоваться в качестве опорных для будущего предсказания. После полного восстановления кодированного изображения, и, если оно было определено как опорное (например, анализатором (320)), текущее опорное изображение (356) может быть помещено в буфер (357) опорных изображений, и перед началом восстановления следующего кодированного изображения может быть выделена новая память текущих изображений.
[0056] Видеодекодер 320 может выполнять операции декодирования в соответствии с заранее заданной технологий сжатия видео, которая может быть задокументирована в стандарте, например, Рекомендации Н.265 ITU-T. Кодированная видеопоследовательность может удовлетворять синтаксису, заданному применяемой технологией или стандартом сжатия видео, в том смысле, что она удовлетворяет синтаксису, заданному в документе, или стандарте, технологии сжатия видео, и в частности, синтаксису специфицированных профилей стандарта. При этом, чтобы отвечать некоторым из технологий или стандартов сжатия видео, сложность кодированной видеопоследовательности должна быть в пределах ограничений, определяемых уровнем технологии или стандарта сжатия видео. В некоторых случаях уровни стандарта ограничивают максимальный размер изображения, максимальную частоту кадров, максимальную частоту восстановления отсчетов (измеряемую, например, в миллионах отсчетов за секунду), максимальный размер опорного изображения и т.п. Накладываемые уровнями ограничения в некоторых случаях могут быть дополнительно лимитированы при помощи спецификаций гипотетического эталонного декодера (Hypothetical Reference Decoder, HRD) и метаданных для управления буфером HRD-декодера, сигнализируемых в кодированной видеопоследовательности.
[0057] В одном из вариантов осуществления настоящего изобретения приемник (310) может вместе с кодированным видео принимать дополнительные (избыточные) данные. Эти дополнительные данные могут быть составной частью кодированной видеопоследовательности (или видеопоследовательностей). Дополнительные данные могут использоваться видеодекодером (320) для корректного декодирования данных и/или для более точного восстановления исходных видеоданных. Дополнительные данные могут иметь форму, например, уточняющих временных, пространственных или SNR уровней, избыточных слайсов, избыточных изображений, кодов упреждающей коррекции ошибок и т.п.
[0058] На фиг. 4 показана функциональная блок-схема видеокодера (203) в соответствии с одним из вариантов осуществления настоящего изобретения.
[0059] Кодер (203) может принимать видеоотсчеты от источника (201) видео (который не является частью кодера), захватывающего видеоизображения для кодирования при помощи кодера (203).
[0060] Источник (201) видео может подавать исходную видеопоследовательность для кодирования видеокодером (203) в форме цифрового потока видеоотсчетов, имеющих любую подходящую битовую глубину (например: 8 бит, 10 бит, 12 бит, …), любое цветовое пространство (например, ВТ.601 Y CrCB, RGB, ...) и любую подходящую структуру отчетов (например, Y CrCb 4:2:0, Y CrCb 4:4:4). В системе медиасервиса источник (201) видео может быть запоминающим устройством, на котором хранят заранее подготовленное видео. В системе видеоконференцсвязи источник (203) видео может быть видеокамерой, которая захватывает информацию изображений локально в форме видеопоследовательности. Видеоданные могут иметь форму множества отдельных изображений, которые передают ощущение движения при их последовательном просмотре. Сами изображения могут быть организованы в виде пространственной матрицы пикселей, где каждый пиксель может включать один или более отсчетов, в зависимости от применяемой структуры отсчетов, цветового пространства и т.п. Специалистам в данной области техники должно быть очевидна связь между пикселями и отсчетами. Далее в настоящем описании будут рассматриваться отсчеты.
[0061] В соответствии с одним из вариантов осуществления настоящего изобретения, видеокодер (203) может кодировать и сжимать изображения исходной видеопоследовательности в кодированную видеопоследовательность (443) в реальном времени, или в соответствии с другими временными ограничениями, накладываемыми практическим применением. Одной из функций контроллера (450) может быть обеспечение подходящей скорости кодирования. Контроллер управляет остальными функциональными блоками, описанными ниже, и быть функционально связан с этими блоками. Эта связь для простоты на чертеже не показана. Параметры, задаваемые контроллером, могут включать параметры, связанные с управлением скоростью (пропуск изображений, квантователь, значение X для методов оптимизации скорость-искажения, …), размером изображений, компоновкой групп изображений (GOP), максимальным диапазоном поиска векторов движения и т.п. Специалистам в данной области техники должны быть очевидны и другие функции контроллера (450), поскольку они могут соответствовать видеокодеру (203), оптимизированному для конструкции конкретной системы.
[0062] Некоторые из видеокодеров работают в конфигурации, которую специалисты в данной области техники называют «петлей кодирования». Крайне упрощенно, петля кодирования может состоять из подсистемы кодирования в кодере (430) (далее «кодер источника»), отвечающей за формирование символов на основе входных кодируемых изображений, а также опорных изображений, и (локального) декодера (433), встроенного в кодер (203) и восстанавливающего символы, с формированием данных отсчетов, которые бы идентичным образом формировал (удаленный) декодер (поскольку сжатие символов в кодированный битовый видеопоток является сжатием без потерь, в технологиях сжатия видео, рассматриваемых в настоящем изобретении). Этот восстановленный поток отсчетов вводят в память (434) опорных изображений. Поскольку декодирование потока символов дает результатом одинаковые с точностью до бита результаты, независимо от декодера (локального или удаленного), содержимое буфера опорных изображений также одинаково с точностью до бита в локальном кодере и удаленном кодере. Другими словами, подсистема предсказания в кодере «видит» в качестве отсчетов опорных изображений в точности те же значения отсчетов, которые «увидит» декодер, используя предсказание при декодировании. Этот фундаментальный принцип синхронности опорных изображений (и результирующий дрейф, если синхронность не может быть обеспечена, например, из-за ошибок в канале) должен быть хорошо известен специалистам в данной области техники.
[0063] Работа «локального» декодера (433) по существу идентична «удаленному» декодеру (210), которая уже была подробно описана выше в связи с фиг. 3. Однако, возвращаясь к фиг. 3, поскольку символы доступны, а кодирование/декодирование символов в кодированную видеопоследовательность энтропийным кодером (445) и анализатором (320) может выполняться без потерь, в локальном декодере (433) могут не быть в полной мере реализованы подсистемы энтропийного декодирования из состава декодера (210), включая канал (312), приемник (310), буфер (315) и анализатор (320).
[0064] Здесь можно заметить, что любая технология декодирования, помимо анализа/энтропийного декодирования, имеющаяся в декодере, должна присутствовать в по существу идентичной функциональной форме в соответствующем кодере. По этой причине описание настоящего изобретения сконцентрировано на работе декодера. Описание технологий кодирования может быть опущено, поскольку они могут быть обратными подробно описанным технологиям декодирования. Лишь в некоторых местах необходимо более подробное описание, и оно будет приведено ниже.
[0065] В числе своих операций кодер (430) источника может выполнять кодирование с предсказанием на основе компенсации движения, при котором входные кадры кодируют с предсказанием на основе одного или более ранее кодированных кадров видеопоследовательности, которые были помечены как «опорные кадры». Таким образом, подсистема (432) кодирования кодирует разности между блоками пикселей во входном кадре и блоками пикселей в опорном кадре (или кадрах), которые могут быть выбраны как опорные для предсказания входного кадра.
[0066] Локальный видеодекодер (433) может декодировать кодированные видеоданные кадров, помеченные как опорные, в зависимости от символов, формируемых кодером (430) источника. Операции подсистемы (432) кодирования, предпочтительно, являются обработкой данных с потерями. Когда кодированные видеоданные декодируют в видеодекодере (не показан на фиг. 4), восстановленная видеопоследовательность, как правило, является репликой исходной видеопоследовательности с некоторыми ошибками. Локальный видеодекодер (433) в точности воспроизводит процесс декодирования, который мог бы выполняться удаленным видеодекодером, над опорными кадрами и помещает восстановленные опорные кадры в кэш (434) опорных изображений. Таким образом, кодер (203) может локально хранить копии восстановленных опорных кадров, содержимое которых совпадает с восстановленными опорными кадрами, получаемыми удаленным видеодекодером (при отсутствии ошибок передачи).
[0067] Предиктор (435) может выполнять поиск предсказаний для подсистемы (432) кодирования. То есть, для нового кодируемого кадра предиктор (435) может выполнять поиск в памяти (434) опорных изображений, чтобы найти данные отсчетов (в качестве кандидатных опорных блоков пикселей), или метаданных, например, векторы движений опорных изображений, формы блоков и т.п., которые могут служить опорными для новых изображений. Предиктор (435), может находить подходящие опорные данные для каждого отдельного блока пикселей. В некоторых случаях, в зависимости от результатов поиска, полученных предиктором (435), опорные данные для предсказания входного изображения могут извлекаться из нескольких опорных изображений, хранимых в памяти (434) опорных изображений.
[0068] Контроллер (450) может управлять операциями кодирования в видеокодере (430), включая, например, задание параметров и параметров подгрупп, используемых для кодирования видеоданных.
[0069] Выходные данные всех описанных выше функциональных блоков могут подвергаться энтропийному кодированию в энтропийном кодере (445). Энтропийный кодер преобразует символы, формируемые различными функциональными блоками, в кодированную видеопоследовательность при помощи сжатия этих символов, без потерь, в соответствии с технологиями, известными специалистами в данной области техники, например, кодированием Хаффмана, кодированием с переменной длиной кодового слова, арифметическим кодированием и т.п.
[0070] Передатчик (440) может буферизовать кодированную видеопоследовательность (или видеопоследовательности), формируемую энтропийным кодером (445), чтобы подготовить ее к передаче по каналу (460), связи, который может представлять собой аппаратную и/или программную линию связи с запоминающим устройством, где хранят кодированные видеоданные. Передатчик (440) может объединять кодированные видеоданные из видеокодера (430) с другими передаваемыми данными, например, потоками кодированных аудиоданных и/или служебных данных (их источники не показаны на чертеже).
[0071] Контроллер (450) может управлять работой кодера (203). При кодировании контроллер (450) может присваивать каждому кодированному изображению некоторый тип кодированного изображения, который может влиять на применяемые к нему методы кодирования. Например, изображениям может быть присвоен один из описанных ниже типов кадров.
[0072] Внутренне предсказываемым изображением (I-изображением) может быть изображение, которое кодируют и декодируют без использования, в качестве источника для предсказания, каких-либо других кадров видеопоследовательности. Некоторые видеокодеки поддерживают различные типы внутренне предсказываемых изображений, например, изображения независимого обновления декодирования (Independent Decoder Refresh, IDR). Специалисты в данной области техники должны быть осведомлены о подобных вариантах I-изображений, а также об их свойствах и применимости.
[0073] Предсказываемое изображение (Р-изображение) - это изображение, которое может кодироваться и декодироваться при помощи внутреннего или внешнего предсказания с использованием максимум одного вектора движения и указателя на опорное изображение для предсказания значений отсчетов каждого блока отсчетов.
[0074] Двунаправленно предсказываемое изображение (В-изображение) - это изображение, которое может кодироваться и декодироваться при помощи внутреннего или внешнего предсказания с использованием максимум двух векторов движения и указателей на опорное изображение для предсказания значений отсчетов каждого блока отсчетов. Аналогично, в случае множественно предсказываемых изображений могут применяться более чем два опорных изображения и соответствующих метаданных, чтобы восстановить один блок отсчетов.
[0075] Исходные изображения обычно пространственно разбивают на множество блоков отсчетов (например, блоки размера 4×4, 8×8, 4×8 или 16×16 отсчетов в каждом) и кодируют поблочно. Блоки отсчетов могут кодироваться с предсказанием на основе других (уже кодированных) блоков, в зависимости от типов кодирования, назначенных соответствующим этим блоками изображениям. К примеру, блоки отсчетов в I-изображениях могут кодироваться без предсказания или с предсказанием на основе уже кодированных блоков того же изображения («пространственное предсказание» или «внутреннее предсказание»). Блоки пикселей в Р-изображениях могут кодироваться без предсказания, с помощью пространственного предсказания или с помощью временного предсказания на основе одного ранее кодированного опорного изображения. Блоки отсчетов в В-изображениях могут кодироваться без предсказания, с помощью пространственного предсказания или с помощью временного предсказания на основе одного или двух ранее кодированных опорных изображений.
[0076] Видеокодер (203) может выполнять операции кодирования в соответствии с заранее заданной технологией или стандартом видеокодирования, которые могут быть задокументированы в стандарте, например, в Рекомендации Н.265 ITU-T. При своем функционировании видеокодер (203) может выполнять различные операции сжатия, включая операции кодирования с предсказанием, использующие временную и пространственную избыточность во входной видеопоследовательности. Кодированные видеоданные, соответственно, могут удовлетворять синтаксису, заданному применяемой технологией или стандартом видеокодирования.
[0077] В одном из вариантов осуществления настоящего изобретения передатчик (440) может, совместно с кодированным видео, передавать дополнительные данные. Видеокодер (430), например, может предоставлять такие данные, как фрагмент кодированной видеопоследовательности. Дополнительные данные могут включать данные уточняющих временных, пространственных или SNR-уровней, избыточных изображений или слайсов, сообщений дополнительной уточняющей информации (SEI) или фрагментов наборов параметров информации об используемости видео (VUI) и т.п.
[0078] Перед тем, как аспекты настоящего изобретения будут рассмотрены более подробно, введем несколько терминов, используемых в остальной части данного описания.
[0079] Субизображение, в некоторых случаях, далее понимается как прямоугольная структура из отсчетов, блоков, макроблоков, пакетов кодирования, или аналогичных элементов, сгруппированных семантически, которые могут быть кодированы независимо с различным разрешением. Одно или более субизображений могут формировать изображение. Одно или более кодированных субизображений могут формировать кодированное изображение. Одно или более субизображений могут быть объединены в изображение, и при этом одно или более субизображений могут быть извлечены из изображения. В некоторых из вариантов осуществления настоящего изобретения одно или более субизображений могут быть объединены в сжатом виде, без перекодирования на уровне отсчетов, в единое кодированное изображение, и в этом случае, а также в других случаях, одно или более кодированных субизображений могут быть извлечены из кодированного изображения в сжатом виде.
[0080] Под адаптивным изменением разрешения (Adaptive Resolution Change, ARC) далее понимают механизм, который позволяет изменять разрешение изображения или субизображения внутри кодированной видеопоследовательности, например, при помощи ресэмплинга опорных изображений. Параметрами ARC далее будем называть управляющую информацию, необходимую для выполнения адаптивного изменения разрешения, которая может включать, например, параметры фильтрации, коэффициенты масштабирования, разрешения выводимых и/или опорных изображений, различные флаги управления и т.п.
[0081] Приведенное выше описание относится к кодированию и декодированию отдельных, семантически не зависимых видеоизображений. Перед описанием сущности кодирования/декодирования множества субизображений с независимыми параметрами ARC, и вносимыми ими дополнительными усложнениями, рассмотрим варианты сигнализации параметров ARC.
[0082] На примере фиг. 5 проиллюстрированы несколько новых вариантов осуществления сигнализации параметров ARC. Как отмечается в каждом из вариантов, они имеют свои преимущества и недостатки с точки зрения эффективности и сложности кодирования, а также с точки зрения архитектуры. В конкретном стандарте или технологии видеокодирования могут быть выбраны один или более из предложенных вариантов осуществления сигнализации ARC параметров, а также варианты, известные на существующем уровне техники. Эти варианты не обязательно взаимно исключают друг друга, и могут быть взаимозаменяемы в зависимости от требований конкретного применения, применяемых технологий и стандартов, а также выбора, выполняемого кодером.
[0083] Классы параметров ARC могут включать следующее:
[0084] - коэффициенты повышающего или понижающего ресэмплинга, отдельно по осям X и Y, или в комбинации;
[0085] - коэффициенты повышающего или понижающего ресэмплинга, с добавлением временного измерения, указывающего на постоянную скорость увеличения/уменьшения масштаба (зуммирования) для заданного количества изображений;
[0086] - любое из двух предыдущих может включать кодирование одного или более по возможности коротких синтаксических элементов, которые могут указывать на таблицу, содержащую упомянутые коэффициенты;
[0087] - разрешение, по оси X или Y, измеряемое в отсчетах, блоках, макроблоках, пакетах кодирования (CU), или с любой другой подходящей точностью, для входного изображения, выводимого изображения, опорного изображения, кодированного изображения, в комбинации, или по отдельности; Если присутствует более одного разрешения (например, одно для входного изображения и одно для опорного изображения), то в некоторых случаях один набор значений может определяться на основе другого набора значений. Это может управляться, например, при помощи специальных флагов. Более подробный пример будет рассмотрен ниже.
[0088] - координаты деформации (warping), подобные применяемым в приложении Р стандарта Н.263 (Н.263 Annex Р), снова, как упоминалось выше, с подходящей точностью. В приложении Р стандарта Н.263 определен один эффективный метод кодирования координат деформации, однако, потенциально можно предложить и более эффективные методы. К примеру, реверсивное кодирование, типа кодирования Хаффмана, с кодовым словом переменной длины, координат деформации в приложении Р может быть заменено на двоичное кодирование с кодовым словом соответствующей длины, которая, например, может вычисляться на основе максимального размера изображения, возможно, умноженного на коэффициент и смещенного на заданное значение, чтобы разрешить «деформацию» вне границ, заданных максимальным размером изображения.
[0089] - параметры фильтрации повышающего или понижающего ресэмплинга. В первом из рассмотренных случаев может присутствовать только один фильтр для повышающего и/или понижающего ресэмплинга. Однако в вариантах случаях может быть желательным обеспечить большую гибкость конструирования фильтров, а это может требовать сигнализации параметров фильтрации. Такие параметры могут выбираться с помощью указателя в списке возможных конструкций фильтра, фильтр может быть полностью определен (например, при помощи списка коэффициентов фильтрации, с использованием подходящих методов энтропийного кодирования), фильтр может быть неявно выбран при помощи коэффициентов повышающего или понижающего ресэмплинга, которые, в свою очередь сигнализируют в соответствии с описанными выше механизмами, и т.п.
[0090] В дальнейшем описании предполагается кодирование конечного набора коэффициентов повышающего или понижающего ресэмплинга (один и тот же коэффициент применяют для оси X и для оси Y), указываемого при помощи кодового слова. Такое кодовое слово, предпочтительно, может иметь переменную длину, например, с помощью экспоненциального кодирования Голомба (Ext-Golomb) для соответствующих синтаксических элементов, в таких стандартах видеокодирования, как Н.264 и Н.265. Одна из возможных таблиц соответствия значений коэффициентам повышающего или понижающего ресэмплинга проиллюстрирована в приведенной ниже таблице.

[0091] Могут быть предложены множество аналогичных таблиц соответствий, согласно требованиям применения и возможностям механизмов повышающего и понижающего ресэмплинга, доступных в стандарте или технологии видеокодирования. Таблица может быть расширена большим количеством значений. Значения могут быть также представлены и с помощью других механизмов кодирования, а не кодами Ext-Golomb, например, с помощью двоичного кодирования. Это может давать определенные преимущества, когда коэффициенты ресэмплинга используют вне собственно подсистем обработки видео (в первую очередь, в кодере и декодере), например, в MANE. Следует отметить, что в (предположительно) наиболее частом случае, когда изменения разрешения не требуется, может быть выбран короткий код Ext-Golomb, например, в показанной выше таблице, имеющий длину только в один бит.Это позволяет получить преимущество в эффективности кодирования, в общем случае, по сравнению с использованием двоичных кодов.
[0092] Количество записей в таблице, как и их семантика, могут быть конфигурируемыми, частично или полностью. К примеру, основной каркас таблицы может передаваться в наборе параметров высокого уровня, например, в наборе параметров последовательности или наборе параметров декодера. Альтернативно или в дополнение, в технологии или стандарте видеокодирования могут быть определены несколько подобных таблиц, выбор которых выполняют, например, при помощи набора параметров декодера или последовательности.
[0093] Ниже будет рассмотрено, каким образом коэффициенты повышающего или понижающего ресэмплинга (информация ARC), кодированные в соответствии с описанным выше, могут быть включены в синтаксис технологии или стандарта видеокодирования. Сходные рассуждения могут быть применимы для одного или нескольких кодовых слов, управляющих фильтрами повышающего или понижающего ресэмплинга. Случай, когда для фильтров или других структур данных необходимы сравнительно большие объемы данных, будет рассмотрен ниже.
[0094] Приложение Р спецификации Н.263 (Н.263 Annex Р) включает информацию 502 ARC в форме четырех координат деформации в заголовке 501 изображения, а именно, в расширении заголовка PLUSPTYPE 503 стандарта Н.263. Это представляется рациональным решением для случаев, когда а) заголовок изображения доступен, и b) ожидаются частные изменения информации ARC. Однако объем служебной информации при применении сигнализации типа, предложенного в Н.263, может быть довольно высок, при этом коэффициенты масштабирования между границами изображений могут быть несогласованными, поскольку заголовки изображений не обязательно хранят длительно.
[0095] Цитируемая выше спецификация JVCET-M135-v1 включает ссылочную информацию (505) ARC (индекс), расположенную в наборе (504) параметров изображения, которая указывает на таблицу (506), включающую целевые разрешения, которая, в свою очередь, расположена внутри набора (507) параметров последовательности. Помещение доступных разрешений в таблице (506) в наборе (507) параметров последовательности (507), по словам авторов, обусловлено применением набора SPS в качестве точки соглашения о совместимости при обмене информацией о возможностях. Разрешение может меняться в пределах, заданных значениями таблицы (506), от изображения к изображению, путем ссылки на подходящий набор (504) параметров изображения.
[0096] На фиг. 5 показаны также дополнительные возможные варианты передачи информации ARC в битовом потоке кодированного видео, описанные ниже. Каждый из этих вариантов обладает преимуществами по сравнению с описанным выше существующим уровнем техники. Предложенные варианты могут присутствовать в технологии или стандарте видеокодирования одновременно.
[0097] В одном из вариантов осуществления настоящего изобретения информация ARC (509), к примеру, коэффициент ресэмплинга (зуммирования), может присутствовать в заголовке слайса, заголовке GOB, заголовке тайла или заголовке группы тайлов (508) (далее - заголовок группы тайлов). Это может быть адекватным решением, если информация ARC имеет малый объем, например, одиночного значения ue(v) переменной длины или кодового слова фиксированной длины в несколько бит, как, например, это показано выше. Размещение информации ARC непосредственно в заголовке группы тайлов имеет то дополнительное преимущество, что информация ARC может применяться для субизображения, представленного, например, этой группой тайлов, а не только к целому изображению. Более подробно это будет описано ниже. Кроме того, даже если технология или стандарт видеокодирования подразумевают адаптивное изменение разрешения только для изображений в целом (в отличие, например, от адаптивного изменения разрешения на уровне группы тайлов), помещение информации ARC в заголовок группы тайлов, по сравнению с ее помещением в заголовок изображения, подобно Н.263, позволяет получить определенные преимущества с точки зрения устойчивости к ошибкам.
[0098] В этом же, или в других вариантах осуществления настоящего изобретения, например, информация (512) ARC может быть непосредственно представлена в соответствующем наборе (511) параметров, к примеру, в наборе параметров изображения, наборе параметров заголовка, наборе параметров тайла, наборе параметров адаптации (на чертеже показан набор параметров адаптации) и т.д. Область действия этого параметра наборов, предпочтительно, может быть не больше, чем изображение, например, группа тайлов. Использование информации ARC задают неявно, при помощи активации соответствующего набора параметров. К примеру, если в технологии или стандарте видеокодирования определено только ARC на уровне изображений, то подходящим может быть набор параметров изображения или эквивалентный набор.
[0099] В этом же, или в других вариантах осуществления настоящего изобретения, например, ссылочная информация (513) ARC может присутствовать с заголовке (514) группы тайлов или в аналогичной структуре данных. Такая ссылочная информация (513) может ссылаться на подмножество информации (515) ARC, доступной в наборе (516) параметров, с областью действия, превосходящей отдельное изображение, например, в наборе параметров последовательности или наборе параметров декодера.
[0100] Дополнительный уровень неявной активации набора PPS из заголовка группы тайлов, PPS, SPS, применяемой в JVET-M0135-v1 представляется излишним, поскольку наборы параметры изображений, как и наборы параметров последовательности, могут (и должны в некоторых стандартах, например, RFC3984) использоваться для соглашений, или объявлений, о совместимости. Однако если информация ARC должна также применяться к субизображению, например, представленному группой тайлов, лучшим выбором может быть набор параметров с областью действия, ограниченной группой тайлов, например, набор параметров адаптации или набор параметров заголовка. Также, если информация ARC имеет не пренебрежимо малый объем, например, содержит информацию управления фильтрацией, то есть, множество коэффициентов фильтрации, то с точки зрения эффективности кодирования набор параметров может быть лучшим решением, чем использование непосредственно заголовка (508), поскольку эти параметры могут использоваться повторно для будущих изображений или субизображений за счет ссылки на тот же набор параметров.
[0101] При использовании набора параметров последовательности или более высокоуровневых наборов параметров с областью действия, охватывающей множество изображений, могут быть актуальными соображения, описанные ниже.
[0102] 1. Набором параметров для хранения таблицы (516) с информацией ARC в некоторых случаях может быть набор параметров последовательности, однако в других случаях, предпочтительно, набор параметров декодера. Область действия набора параметров декодера может охватывать несколько CVS, а именно, кодированный видеопоток, т.е. все биты кодированного видео, от начала до завершения сеанса. Такая область действия может быть более подходящей, поскольку коэффициенты ARC могут быть запрограммированы в декодере, и возможно, реализованы аппаратно, поэтому аппаратные параметры в основном остаются постоянными в одной CVS (которая, по меньшей мере в некоторых мультимедийных системах, представляет собой группу изображений длиной в одну секунду или менее). При этом, помещение таблицы в набор параметров последовательности явно перечислено среди вариантов размещения, рассмотренных в настоящем документе, а именно, в связи с приведенным ниже пунктом 2.
[0103] 2. Ссылочная информация (513) ARC, предпочтительно, может быть помещена непосредственно в заголовок (514) изображения/слайса/тайла/GOB/ группы тайлов (далее, - в заголовок группы тайлов), вместо набора параметров изображения, как в JVCET-M0135-v1. Это предпочтительно по следующим причинам: когда кодеру необходимо изменить одно значение в наборе параметров изображения, например, ссылочную информацию ARC, ему нужно создать новый набор PPS и сослаться на этот новый набор PPS. Допустим, что изменяется только ссылочная информация ARC, а остальная информация, то есть, например, информация матрицы квантования, в наборе PPS остается неизменной. Эта информация может иметь значительный объем, и чтобы новый PPS был полным, ее нужно будет передать повторно. Поскольку ссылочная информация (513) ARC может быть одиночным кодовым словом, например, указателем на таблицу, и это единственное значение, которое меняется, то повторно передавать всю информацию матрицы квантования представляется неудобным и нерациональным. В такой мере, с точки зрения эффективности кодирования было бы значительно лучше исключить непрямое указание через набор PPS, предложенное в JVET-M0135-v1. Также, помещение ссылочной информации ARC в набор PPS имеет дополнительное неудобство, связанное с тем, что информация ARC, на которую ссылается ссылочная информация (513) ARC, необходимо будет применяться для всего изображения, а не для субизображений, поскольку областью действия набора параметров изображения является изображение в целом.
[0104] В этом же, или в альтернативном, варианте осуществления настоящего изобретения сигнализация параметров ARC может соответствовать подробному примеру, показанному на фиг. 6. На фиг. 6 показаны синтаксические деревья, в нотации, используемой в стандартах видеокодирования по меньшей мере с 1993 года. Такая нотация приблизительно соответствует языку программирования С. Выделенные жирным шрифтом строки указывают на синтаксические элементы, присутствующие в битовом потоке. Строки без выделения жирным в основном указывают на команды управления или на присвоение значений переменных.
[0105] Заголовок (601) группы тайлов, как пример синтаксической структуры заголовка, применимого для (возможно, прямоугольной) части изображения, может, кондиционально, содержать имеющий переменную длину и кодированный кодом Ехр-Golomb синтаксический элемент dec_pic_size_idx (602) (выделен жирным). Присутствие этого синтаксического элемента в заголовке группе тайлов может управляться в зависимости от использования адаптивного разрешения (603). В данном примере значение флага не выделено жирным, это означает, что флаг присутствует в битовом потоке на момент, когда он встречается в синтаксической диаграмме. Применяется ли адаптивное разрешение для данного изображения, или его части, может быть сигнализировано в любой высокоуровневой синтаксической структуре внутри или вне битового потока. В рассмотренном примере это сигнализировано в наборе параметров последовательности, как это будет показано ниже.
[0106] На фиг. 6В также показан фрагмент набора (610) параметров последовательности. Первый показанный синтаксический элемент это флаг (611) adaptive_pic_resolution_change_flag. Когда он имеет значение «ИСТИНА», флаг указывает на использование адаптивного разрешения, что, в свою очередь может требовать соответствующей информации управления. В данном примере такую информацию управления включают по условию, в зависимости от значения флага, с помощью выражения if() в наборе (612) параметров и в заголовке (601) группы тайлов.
[0107] Когда применяют адаптивное разрешение, в данном примере, кодируют выходное разрешение, измеряемое в отсчетах (613). Позиция 613 относится одновременно к output_pic_width_in_luma_samples и output_pic_width_in_luma_samples, которые совместно определяют разрешение выводимого изображения. В конкретной технологии или стандарте видеокодирования, в других местах, могут быть определены некоторые ограничения на любое из этих значений. К примеру, разрешение уровня стандарта может ограничивать общее количество выходных отсчетов, которое может быть равно произведению значений этих двух синтаксических элементов. Также, в конкретных технологиях или стандартах видеокодирования, или во внешних технологиях или стандартах, например, стандартах системы, может быть ограничен числовой диапазон (например, одно или оба измерения должны быть кратны степени двойки), или соотношение сторон (например, высота и ширина должны иметь заданное отношение, например, 4:3 или 16:9). Такие ограничения могут накладываться из-за аппаратной реализации, или по другим причинам, и должны быть известны специалистам в данной области техники.
[0108] В некоторых применениях желательно, чтобы кодер инструктировал декодер об использовании конкретного размера изображения, вместо неявного указания на размер выводимого изображения. В данном примере флаг reference_pic_size_presentflag (614) определяет кондициональное присутствие размеров (615) опорного изображения (снова, показанные обозначения относятся одновременно к ширине и к высоте).
[0109] Наконец, показана таблица возможных ширин и высот декодированного изображения. Такая таблица может быть указана, например, с помощью указателя (616) на таблицу, (num_dec_pic_size_in_luma_samples_minusl). "minus 1" может указывать на интерпретацию значения этого синтаксического элемента. К примеру, если кодированное значение равно нулю, присутствует только одна запись таблицы. Если значение равно пяти, имеются шесть записей таблицы. Для каждой «строки» таблицы ширину и высоту декодированного изображения затем включают в синтаксическую структуру (617).
[0110] На записи таблицы, обозначенные (617), может указывать синтаксический элемент (602) dec_pic_size_idx в заголовке группы тайлов, что позволяет иметь различные размеры декодированного изображения, то есть, по сути, эффект зуммирования, в каждой отдельной группе тайлов.
[0111] Некоторые технологии или стандарты видеокодирования, например, VP9, для обеспечения возможности пространственного масштабирования поддерживают пространственное масштабирование с выполнением некоторого вида ресэмплинга опорных изображений (соответствующая сигнализация значительно отличается от предложенной в настоящем изобретении) в комбинации с временным масштабированием. В частности, может выполняться повышающий ресэмплинг отдельных опорных изображений, с использованием методов типа ARC, до более высокого разрешения, в результате чего формируют основу пространственного уточняющего уровня. Изображения с повышенным разрешением могут уточняться с использованием стандартных механизмов предсказания в высоком разрешении, что позволяет повысить детализацию.
[0112] Предложенное изобретение может применяться в подобном окружении. В некоторых случаях, в этом же, или в альтернативном варианте осуществления настоящего изобретения, значение в заголовке пакета NAL, например, поле Temporal ID может использоваться для указания не только на временной, но и на пространственный уровень. Это позволяет получить ряд преимуществ в некоторых системах; к примеру, для окружений, где применяется масштабирование, могут, без изменений, применяться существующие выбираемые пакеты ретрансляции (Selected Forwarding Units, SFU), созданные и оптимизированные для избирательной ретрансляции временных уровней, в зависимости от значения Temporal ID в заголовке пакета NAL. Для возможности применения этой функциональности может быть необходимо соответствие между размером кодированного изображения и временным уровнем, на который ссылается поле Temporal ID в заголовке пакета NAL.
[0113] В некоторых технологиях видеокодирования пакет доступа (Access Unit, AU) может ссылаться на кодированные изображения, слайсы, тайлы, пакеты NAL и т.п., которые были захвачены и скомпонованы в соответствующий битовый поток изображений/слайсов/тайлов/пакетов NAL, в заданный момент времени. Таким моментом времени может быть, например, время композиции.
[0114] В стандарте HEVC и в некоторых других технологиях видеокодирования значение порядкового номера изображения (picture order count, РОС) может использоваться для указания на выбранное опорное изображение среди множества опорных изображений, хранимых в буфере декодированных изображений (DPB). Когда пакет доступа (AU) содержит одно или более изображений, слайсов или тайлов, то каждое изображение, слайс или тайл, принадлежащие одному пакету доступа, могут иметь одно и то же значение РОС, по которому может быть сделан вывод о том, что они были сформированы на основе контента с одинаковым временем композиции. Другими словами, в случае, когда два изображения/слайса/тайла содержат одно и то же заданное значение РОС, эти два изображения/слайса/тайла принадлежат одному пакету доступа, AU, и имеют одинаковое время композиции. И наоборот, два изображения/слайса/тайла с различными значениями РОС указывают на то, что эти изображения/слайсы/тайлы принадлежат разным пакетам доступа и имеют различные времена композиции.
[0115] В одном из вариантов осуществления настоящего изобретения это жесткое требование может быть ослаблено, то есть, пакет доступа может включать изображения, слайсы или тайлы с различными значениями РОС. За счет допущения различных значений РОС в одном пакете доступа можно использовать значение РОС для идентификации потенциальных независимо декодируемых изображений/слайсов/тайлов с одинаковым временем отображения. А это, в свою очередь, позволяет обеспечить поддержку множества уровней масштабирования без изменения сигнализации о выборе опорных изображений (например, сигнализации набора опорных изображений или списка опорных изображений), описанной более подробно ниже.
[0116] Однако все же желательно иметь возможность идентифицировать пакет доступа, к которому принадлежит изображение/слайс/тайл, среди остальных изображений/слайсов/тайлов с отличающимися значениями РОС, на основе исключительно значения РОС. Это может быть достигнуто в соответствии с приведенным ниже описанием.
[0117] В этом же, или в других вариантах осуществления настоящего изобретения, порядковый номер блока доступа (access unit count, AUC) может сигнализироваться в высокоуровневой синтаксической структуре, например, в заголовке пакета NAL, заголовке слайса, заголовке группы тайлов, в сообщении SEI, в наборе параметров или в разделителе пакетов доступа. Значение AUC может использоваться для определения, какие пакеты NAL, изображения, слайсы или тайлы принадлежат к заданному пакету доступа. Значение AUC может соответствовать конкретному моменту времени композиции. Значение AUC может быть кратно значению РОС. Значение AUC может вычисляться делением значения РОС на целочисленное значение. В некоторых вариантах реализации операции деления могут быть значительной нагрузкой для декодера. В таких случаях небольшое ограничение пространства номеров для значений AUC позволяет заменить операцию деления операцией сдвига. К примеру, значение AUC может быть равно значению старшего бита (Most Significant Bit, MSB) в диапазоне значений РОС.
[0118] В этом же варианте осуществления настоящего изобретения значения цикла РОС для блока доступа (рос_cycle_au) может сигнализироваться в синтаксической структуре верхнего уровня, например, в заголовке пакета NAL, заголовке слайса, заголовке группы тайлов, в сообщении SEI, в наборе параметров или в разделителе блока доступа. Значение poc_cycle_au может указывать, сколько последовательных отличающихся значений РОС могут быть связаны с одним пакетом доступа. Например, если значение poc_cycle_au равно 4, изображения, слайсы или тайлы со значением РОС, равным 0-3, включительно, относятся к пакету доступа со значением AUC, равным 0, а изображения, слайсы или тайлы со значением РОС, равным 4-7, включительно, относятся к пакету доступа со значением AUC, равным 1. Следовательно, значение AUC может быть вычислено делением значения РОС на значение poc_cycle_au.
[0119] В этом же, или в другом варианте осуществления настоящего изобретения, значение рос_cyle_au может быть вычислено на основе информации, располагающейся, например, в наборе параметров видео (VPS), которая определяет количество пространственных или SNR-уровней в кодированной видеопоследовательности. Один из примеров такого потенциального соответствия кратко описан ниже. Описанные выше вычисления позволяют сэкономить несколько бит в наборе VPS, и следовательно, повысить эффективность кодирования, однако может быть предпочтительным явное кодирование poc_cycle_au в соответствующей синтаксической структуре верхнего уровня, иерархически подчиненной набору параметров видео, что позволяет минимизировать poc_cycle_au для заданной малой части битового потока, например, для изображения. Такая оптимизация позволяет сэкономить больше бит, чем за счет описанной выше процедуры вычисления, поскольку значения РОС (и/или значения синтаксических элементов, опосредованно ссылающихся на РОС), могут кодироваться в синтаксических структурах нижнего уровня.
[0120] Описанные выше методы сигнализации параметров адаптивного разрешения могут быть реализованы в виде компьютерного программного обеспечения, где используются машиночитаемые инструкции, и которое физически хранят на одном или более машиночитаемых носителей. К примеру, на фиг. 7 показана компьютерная система 700 подходящая для реализации некоторых из вариантов осуществления настоящего изобретения.
[0121] Компьютерное программное обеспечение может быть кодировано с использованием любого подходящего машинного кода или языка программирования, который может обрабатываться при помощи ассемблирования, компиляции, линкования или аналогичных механизмов, в результате чего получают код, включающий инструкции, выполняемые непосредственно или при помощи интерпретации, исполнения микрокода и т.п., центральными процессорами компьютера (computer central processing units, CPUs), графическими процессорами (Graphics Processing Units, GPU) и т.п.
[0122] Инструкции могут выполняться на компьютерах, или компьютерных компонентах, различных типов, включая, например, персональные компьютеры, планшетные компьютеры, серверы, смартфоны, игровые устройства, устройства интернета вещей и т.п.
[0123] Компоненты компьютерной системы 700, показанные на фиг. 7, приведены исключительно для примера и не предполагают каких-либо ограничений на область применения или функциональность компьютерного обеспечения, реализующего варианты осуществления настоящего изобретения. Аналогично, показанная конфигурация компонентов также не должна интерпретироваться как имеющая какую-либо зависимость или требования, связанные с любым компонентом, проиллюстрированным в примере осуществления компьютерной системы 700, или комбинацией таких компонентов.
[0124] Компьютерная система 700 может включать устройства ввода из состава интерфейса пользователя. Устройства ввода в пользовательском интерфейсе могут реагировать на ввод от одного или более пользователей при помощи, к примеру, тактильного ввода (например, нажатий на клавиши, жестов скольжения пальцем по экрану, движений киберперчатки), аудиоввода (например, голоса, хлопков ладоней), визуального ввода (например, жестов), обонятельного ввода (не показано на чертеже). Устройства пользовательского интерфейса могут также применяться для захвата медиаданных различных типов, не обязательно связанных с сознательным вводом от человека, таких как аудио (например, голос, музыка, звуки окружающей среды), изображения (например, сканированные изображения, фотоизображения, полученные с фотокамеры), видео (например, двумерное видео, трехмерное видео, включая стереоскопическое видео).
[0125] Устройства пользовательского интерфейса могут включать одно или более из следующего (на чертеже показано только по одному устройству каждого типа): клавиатура 701, мышь 702, трекпад 703, сенсорный экран 710, кибер-перчатка 704, джойстик 705, микрофон 706, сканер 707, камера 708.
[0126] Компьютерная система 700 может также иметь в своем составе устройства вывода пользовательского интерфейса. Устройства вывода пользовательского интерфейса могут воздействовать на органы чувств одного или более пользователей, например, при помощи тактильного вывода, звука, света и/или запаха/вкуса. Устройства вывода пользовательского интерфейса могут включать устройства тактильного вывода (например, тактильная обратная связь от сенсорного экрана 710, киберперчатки 704 или джойстика 705, однако могут также присутствовать устройства тактильного вывода, не являющиеся при этом устройствами ввода). К примеру, подобными устройствами могут быть устройства аудиовывода (например, громкоговорители 709, наушники (не показаны на чертеже)), устройства визуального вывода (например, экраны 710, включая CRT-экраны, LCD-экраны, плазменные экраны, OLED-экраны, как сенсорные, так и без функций сенсорного ввода, как с функциями тактильно обратной связи, так и без них, - при этом некоторые из экранов могут быть способны выводить двумерную визуальную информацию или более чем трехмерную визуальною информацию, при помощи таки средств, как например, стереографический вывод; очки виртуальной реальности (не показаны на чертеже), голографические дисплеи, дым-машины, а также принтеры (не показаны на чертеже).
[0127] Компьютерная система 700 может также включать запоминающие устройства, доступные для пользователей, и связанные с ними носители данных, например, оптические носители, включая CD/DVD ROM/RW 720, с носителями 721 CD/DVD или аналогичными им, флэш-привод 722, съемный жесткий диск или твердотельный диск 723, применяемые ранее магнитные носители, например, ленты или гибкие диски (не показаны на чертеже), специализированные устройства на основе ROM/ASIC/PLD, например, аппаратные ключи (не показаны на чертеже), и т.п.
[0128] Специалисты в данной области техники должны при этом понимать, что выражение «машиночитаемый носитель данных», используемое в связи с настоящим изобретением, не включает в себя среды передачи данных, несущие волны или другие энергозависимые сигналы.
[0129] Компьютерная система 700 может также иметь интерфейс с одной или более сетями связи. Сети могут быть, например, беспроводными, проводными или оптическими. Сети также могут быть локальными, глобальными, городскими, размещаемыми на транспортных средствах или промышленных объектах, сетями реального времени, устойчивыми к задержкам и т.п. Примеры сетей включают такие локальные сети, как Ethernet, беспроводные LAN, сотовые сети, включая GSM, 3G, 4G, 5G, LTE и т.п., проводные или беспроводные глобальные сети цифрового телевещания, включая кабельное телевидение, спутниковое телевидение и сети эфирного вещания, сети транспортных средств и промышленных объектов, включая CANFJus, и т.п. Некоторые сети требуют наличия внешних адаптеров сетевых интерфейсов, подключаемых к портам данных или периферийным шинам (749) общего назначения (например, USB-портам компьютерной системы 700). Другие сети могут быть интегрированы во внутреннюю структуру компьютерной системы 700 за счет подключения к системной шине, в соответствии с приведенным ниже описанием (например, интерфейс Ethernet в системе персонального компьютера или интерфейс сети сотовой связи в компьютерной системе на базе смартфона). Применение любых из подобных сетей позволяет компьютерной системе 700 осуществлять связь с другими объектами. Такая связь может быть однонаправленной, только на прием (например, телевещание), однонаправленной, только на передачу (например, сеть CANbus в некоторые устройства CANbus) или двунаправленной, например, в другие компьютерные системы с использованием локальных или глобальных цифровых сетей. В любой из сетей и сетевых интерфейсов, описанных выше, могут применяться соответствующие протоколы и стеки протоколов.
[0130] Описанные выше устройства пользовательского интерфейса, доступные пользователям запоминающие устройства и сетевые интерфейсы могут быть подключены к базовой внутренней структуре 740 компьютерной системы 700.
[0131] Базовая внутренняя структура 740 может включать один или более центральных процессоров (Central Processing Units, CPU) 741, графических процессоров (Graphics Processing Units, GPU) 742, специализированных программируемых блоков обработки данных в форме электрически программируемых вентильных матриц (Field Programmable Gate Areas, FPGA) 743, аппаратных ускорителей 744 для определенных задач и т.п. Эти устройства, вместе с памятью 745 в режиме «только для чтения» (Readonly memory, ROM) 945, памятью 746 с произвольным доступом, внутренней памятью большой емкости, например, внутренними, недоступными пользователю жесткими дисками, SSD-дисками и аналогичной памятью 747, могут быть объединены системной шиной 748. В некоторых компьютерных системах к системной шине 748 может предоставляться доступ в виде одного или более физических разъемов, позволяющих расширять систему дополнительными CPU, GPU и т.п. Периферийные устройства могут подключаться либо непосредственно к базовой системной шине 748, либо к периферийной шине 749. Примерами архитектур периферийной шины могут служить шины PCI, USB и т.п.
[0132] CPU 741, GPU 742, FPGA 743 и ускорители 744 могут выполнять инструкции, которые, в совокупности, могут составлять описанный выше компьютерный код. Компьютерный код может храниться в памяти ROM 745 или RAM 746. Временные данные при этом могут храниться в RAM 746, тогда как постоянные данные могут храниться, например, во внутренней памяти 747 большой емкости. Высокая скорость сохранения данных в запоминающие устройства и извлечения данных из них может обеспечиваться за счет применения кэш-памяти, которая может быть тесно связан с одним или более CPU 741, GPU 742, памятью 747 большой емкости, ROM 745, RAM 746 и т.п.
[0133] Машиночитаемые носители данных могут хранить компьютерный код для выполнения различных машиноисполняемых операций. Такие носители и компьютерный код могут быть специально спроектированными и изготовленными для целей настоящего изобретения или могут быть широко распространенными и известными специалистам в области компьютерного программного обеспечения.
[0134] В качестве неограничивающего примера, компьютерная система с архитектурой 700, и в частности, базовой структурой 740, может предоставлять требуемую функциональность в результате исполнения, процессором (или процессорами) (включая CPU, GPU, FPGA, ускорители и т.п.), программного обеспечения, реализованного на одном или более материальных машиночитаемых носителях данных. Такие машиночитаемые носители данных могут быть носителями, связанными с описанными выше запоминающими устройствами большой емкости, которые доступны пользователям, или энергонезависимыми запоминающими устройствами в базовой структуре 740, например, встроенным запоминающим устройством 747 большой емкости или ROM 745. Программное обеспечение, которое реализует различные варианты осуществления настоящего изобретения, может храниться в подобных устройствах и исполняться внутренней структурой 740 компьютерной системы. Машиночитаемый носитель данных, в зависимости от конкретных требований, может включать одно или более запоминающих устройств или микросхем памяти. Программное обеспечение может обеспечивать выполнение, базовой структурой 740, и в частности, процессорами из его состава (включая CPU, GPU, FPGA и т.п.), необходимых процедуры, или частей необходимых процедур, описанных в данном документе, включая создание структур данных, хранимых в RAM 746, и модификацию этих структур данных в соответствии с процедурами, определенными программным обеспечением. В дополнение или альтернативно, компьютерная система может обеспечивать требуемую функциональность в результате работы логики, жестко запрограммированной или иным образом воплощенной в электрической схеме (например, ускорителе 744), которая может работать вместе с программным обеспечением, или вместо него, для выполнения требуемых процедур или частей требуемых процедур, описанных в данном документе. Упоминание программного обеспечения, там, где это уместно, может подразумевать такую логику и наоборот. Упоминание машиночитаемого носителя, там, где это уместно, может подразумевать электрическую схему (например, интегральную схему), на которой хранится исполняемое программное обеспечение, электрическую схему, реализующую исполняемую логику или оба эти случая одновременно. В объем настоящего изобретения входят все соответствующие комбинации из аппаратного и программного обеспечения.
[0135] На фиг. 8 показан пример структуры видеопоследовательности с комбинацией значений temporal_id, layer_id, РОС и AUC при адаптивном изменении разрешения. В данном примере изображение, слайс или тайл в первом пакете доступа с AUC=0 может иметь temporal_id=0, и layer_id=0 или 1, тогда как изображение, слайс или тайл во втором пакете доступа с AUC=1 может иметь temporal_id=1 и layer_id=0 или 1, соответственно. Значение РОС увеличивают на 1 в каждом изображении независимо от значений temporal_id и layer_id. В данном примере значение poc_cycle_au может быть равно 2. Предпочтительно, значение рос_cycle_au может быть задано равным количеству уровней (пространственного масштабирования). В данном примере, соответственно, значение РОС увеличивают на 2, тогда как значение AUC увеличивают на 1.
[0136] В рассмотренных выше вариантах осуществления настоящего изобретения может быть поддержана вся структура межуровневого предсказания и указания опорных изображений, или ее подмножество, с использованием существующей сигнализации набора опорных изображений (reference picture set, RPS) в HEVC или с использованием сигнализации списка опорных изображений (reference picture list, RPL). В RPS или RPL указание на выбранное опорное изображение выполняют за счет сигнализации значения РОС или значения разности РОС между текущим изображением и выбранным опорным изображением. В настоящем изобретении RPS и RPL могут использоваться для указания на структуру внешнего предсказания изображений или межуровневого предсказания без изменения сигнализации, однако с описанными ниже ограничениями. Если значение temporal_id опорного изображения больше, чем значение temporal_id текущего изображения, то для компенсации движения в текущем изображении, или иного предсказания, это опорное изображение использоваться не может. Если значение layer_id опорного изображения больше, чем значение layer_id текущего изображения, то для компенсации движения в текущем изображении, или иного предсказания, это опорное изображение использоваться не может.
[0137] В этом же, или в других вариантах осуществления настоящего изобретения, масштабирование векторов движения на основе разности РОС, для временного предсказания векторов движения, может быть запрещено между различными изображениями внутри блока доступа. Поэтому, несмотря на то, что каждое значение может иметь различные значения РОС внутри блока доступа, вектор движения не масштабируют и используют для временного предсказания векторов движения внутри блока доступа. Это необходимо, поскольку опорное изображение с отличающимся РОС в том же пакете доступа, рассматривают как опорное изображение, имеющее тот же момент времени. Соответственно, в данном варианте осуществления настоящего изобретения, функция масштабирования вектора движения может возвращать 1, когда опорное изображение принадлежит пакету доступа, к которому относится текущее изображение.
[0138] В этом же, или в других вариантах осуществления настоящего изобретения, масштабирование векторов движения на основе разности РОС, для временного предсказания векторов движения, может, опционально, деактивироваться на протяжении нескольких изображений, когда пространственное разрешение опорного изображения отличается от пространственного разрешения текущего изображения. Когда масштабирование векторов движения разрешено, его выполняют на основе одновременно разности РОС и соотношения пространственных разрешений между текущим изображением и опорным изображением.
[0139] В этом же, или в других вариантах осуществления настоящего изобретения, масштабирование вектора движения может выполняться на основе разности AUC, вместо разности РОС, для временного предсказания векторов движения, в частности, когда poc_cycle_au имеет неравномерные значения (когда vps_contant_poc_cycle_per_au=0). В противном случае (когда vps_contant_poc_cycle_per_au=1), масштабирование векторов движения на основе разности AUC может быть идентично масштабированию векторов движения на основе разности РОС.
[0140] В этом же, или в других вариантах осуществления настоящего изобретения, когда вектор движения масштабируют на основе разности AUC, опорный вектор движения в том же пакете доступа (с тем же значением AUC), что и текущее изображение, не масштабируют на основе разности AUC и используют для предсказания векторов движения без масштабирования или с масштабированием на основе отношения пространственного разрешения между текущим изображением и опорным изображением.
[0141] В этом же, или в других вариантах осуществления настоящего изобретения, значение AUC используют для определения границ блока доступа, а также для работы гипотетического опорного декодера (HRD), которому необходимы значения времен ввода и вывода с точностью до блока доступа. В большинстве случаев декодированное изображение в верхнем уровне в пакете доступа может выводиться для отображения. Значение AUC и значение layer_id могут использоваться для идентификации выводимого изображения.
[0142] В одном из вариантов осуществления настоящего изобретения изображение может состоять из одного или более субизображений. Каждое субизображение может покрывать локальную область или всю область изображения. Область, занимаемая субизображением может как перекрываться, так и не перекрываться с областями других изображений. Область, состоящая из одного или более субизображений может покрывать как всю область изображения, так и ее часть. Если изображение имеет субизображение, область, занимаемая субизображением, может быть идентична области, занимаемой изображением.
[0143] В том же варианте осуществления настоящего изобретения субизображение может кодироваться при помощи метода кодирования, аналогичного методу кодирования, используемому для кодированного изображения. Субизображение может кодироваться независимо или кодироваться в зависимости от другого субизображения, или кодированного изображения. Субизображение может быть как зависимым, в отношении его синтаксического анализа, от другого субизображения или кодированного изображения, так и независимым.
[0144] В этом же варианте осуществления настоящего изобретения кодированное субизображение может содержаться в одном или более уровнях. Кодированные субизображения в различных уровнях могут иметь различное пространственное разрешение. Может выполняться пространственный ресэмплинг исходного субизображения (повышающий или понижающий), оно может быть кодировано с использованием отличающихся параметров пространственного разрешения и включено в битовый поток, соответствующий одному из уровней.
[0145] В этом же, или в других вариантах осуществления настоящего изобретения, субизображение с параметрами (W, Н), где W - ширина изображения, а Н - высота субизображения, соответственно, может быть кодировано и включено в кодированный битовый поток, соответствующий уровню 0, тогда как субизображение с повышенным (или пониженным) разрешением, полученное на основе субизображения с исходным пространственным разрешением, с параметрами (W*Sw,k, Н*Sh,k), может быть кодировано и включено в кодированный битовый поток, соответствующий уровню k, где Sw,k, Sh,k - коэффициенты ресэмплинга по горизонтали и вертикали. Если значение Sw,k, Sh,k больше 1, ресэмплинг будет повышающим. Тогда как если значения Sw,k, Sh,k меньше 1, ресэмплинг будет понижающим.
[0146] В этом же, или в других вариантах осуществления настоящего изобретения, кодированное изображение в одном из уровней может иметь отличающееся визуальное качество от кодированного субизображения в другом уровне для того же субизображения или отличающегося субизображения. Например, субизображение i в уровне n может быть кодировано с параметром Qi,n квантования, тогда как субизображение j в уровне m может быть кодировано с параметром Qj,m квантования.
[0147] В этом же или в другом варианте осуществления настоящего изобретения кодированное субизображение в одном из уровней может быть декодировано независимо, без какой-либо зависимости анализа или декодирования от кодированных субизображений в других уровнях для той же локальной области. Уровень субизображения, который может быть независимо декодирован без ссылок на другие уровни субизображения той же локальной области, называют независимым уровнем субизображения. Кодированное субизображение в независимом уровне субизображения может как иметь, так и не иметь зависимости декодирования или анализа от ранее кодированных субизображений в том же уровне субизображения, однако кодированное субизображение не может иметь каких-либо зависимостей от кодированных изображений в другом уровне субизображения.
[0148] В этом же или в другом варианте осуществления настоящего изобретения кодированное субизображение в одном из уровней может быть декодировано зависимо, с любыми зависимостями, анализа или декодирования, от кодированных субизображений в других уровнях для той же локальной области. Уровень субизображения, который может быть декодирован зависимо, со ссылками на другие уровни субизображения той же локальной области, называют зависимым уровнем субизображения. Кодированное субизображение в зависимом уровне субизображения может ссылаться на кодированное субизображение, принадлежащее тому же субизображению, ранее кодированному субизображению в том же уровне субизображения, или на оба этих опорных субизображения.
[0149] В этом же или альтернативном варианте осуществления настоящего изобретения кодированное субизображение состоит из одного или более независимых уровней субизображения и одного или боле зависимых уровней субизображения. Однако по меньшей мере один независимый уровень субизображения должен присутствовать в каждом кодированном субизображении. Значение идентификатора уровня (layer_id), которое может находиться в заголовке пакета NAL или иной высокоуровневой синтаксической структуре, для независимого уровня субизображения может быть равно 0. Уровень субизображения с layer_id равным 0 может быть базовым уровнем субизображения.
[0150] В этом же или в альтернативном варианте осуществления настоящего изобретения изображение может состоять из одного или более субизображений заднего плана и одно субизображения переднего плана. Область, охватываемая субизображением заднего плана может быть равна области изображения. Область, занимаемая субизображением переднего плана может перекрываться с областью, охватываемой субизображением заднего плана. Субизображение заднего плана может быть базовым уровнем субизображения, тогда как субизображение переднего плана может быть небазовым (уточняющим) уровнем субизображения. Один или более небазовых уровней субизображения могут ссылаться на один и тот же базовый уровень для декодирования. Каждый небазовый уровень субизображения с layer_id, равным а, может ссылаться на небазовый уровень субизображения, с layer_id, равным b, где а больше b.
[0151] В этом же или в альтернативном варианте осуществления настоящего изобретения изображение может состоять из одного или более субизображений заднего плана, с субизображением переднего плана или без него. Каждое субизображение может иметь собственный базовый уровень субизображения и один или более небазовых (уточняющих) уровней. На каждый базовый уровень субизображения могут ссылаться один или более небазовых уровней субизображения. Каждый небазовый уровень субизображения с layer_id, равным а, может ссылаться на небазовый уровень субизображения, с layer_id, равным b, где а больше b.
[0152] В этом же или в альтернативном варианте осуществления настоящего изобретения изображение может состоять из одного или более субизображений заднего плана, с субизображением переднего плана или без него. На каждое кодированное субизображение в (базовом или небазовом) уровне субизображения могут ссылаться один или более небазовых уровней субизображения, принадлежащих к тому же субизображений, и один или более небазовых уровней субизображения, не принадлежащих к тому же субизображению.
[0153] В этом же или в альтернативном варианте осуществления настоящего изобретения изображение может состоять из одного или более субизображений заднего плана, с субизображением переднего плана или без него. Субизображение в одном из уровней может быть дополнительно разбито на множество субизображений в том же уровне. Одно или более кодированных субизображений в уровне b могут ссылаться на разбитое субизображение в уровне а.
[0154] В этом же или в альтернативном варианте осуществления настоящего изобретения кодированная видеопоследовательность (CVS) может представлять собой группу кодированных изображений. CVS может состоять из одной или более последовательностей кодированных субизображений (coded sub-picture sequences, CSPS), при этом CSPS может быть группой кодированных субизображений, охватывающих одну и ту же локальную область изображения. CSPS может иметь такое же временное разрешение, что и кодированная видеопоследовательность, или отличающееся от нее.
[0155] В этом же или в альтернативном варианте осуществления настоящего изобретения CSPS может быть кодирована и включена в один или более уровней. CSPS может состоять из одного или более уровней CSPS. Декодирование одного или более уровней CSPS, соответствующих CSPS, позволяет восстановить последовательность субизображений, соответствующих одной и той же локальной области.
[0156] В этом же или в альтернативном варианте осуществления настоящего изобретения количество уровней CSPS, соответствующих CSPS, может быть как равно количеству уровней CSPS, соответствующих другой CSPS, так и отличаться.
[0157] В этом же или в альтернативном варианте осуществления настоящего изобретения уровень CSPS может иметь временное разрешение (например, частоту смену кадров), отличающееся от другого уровня CSPS. Может выполняться временной ресэмплинг исходной (несжатой) последовательности субизображений (например, повышающий или понижающий), она может быть кодирована с использованием отличающихся параметров временного разрешения и включена в битовый поток, соответствующий одному из уровней.
[0158] В этом же или в альтернативном варианте осуществления настоящего изобретения последовательность субизображений с частотой F смены кадров может быть кодирована и включена в кодированный битовый поток, соответствующий уровню 0, тогда как последовательность субизображений с повышенным (или пониженным) временным разрешением, по сравнению с исходной последовательностью субизображений, с F*St,k, может быть кодирована и включена в кодированный битовый поток, соответствующий уровню k, где St,k - коэффициент временного ресэмплинга для уровня k. Если значение St,k больше 1, процедура временного ресэмплинга может быть преобразованием с повышением частоты смены кадров. Тогда как если значение St,k меньше 1, процедура временного ресэмплинга может быть преобразованием с понижением частоты смены кадров.
[0159] В этом же или в альтернативном варианте осуществления настоящего изобретения, когда на субизображение в уровне CSPS ссылается субизображение из уровня b, для компенсации движения или любого межуровневого предсказания, если пространственное разрешение этого уровня CSPS отличается от пространственного разрешения уровня b CSPS, то выполняют ресэмплинг декодированных пикселей в уровне CSPS и используют их в качестве опорных. В процедуре ресэмплинга может быть необходима фильтрация с повышающим или с понижающим ресэмплингом.
[0160] На фиг. 9, в соответствии с этим же или с альтернативным вариантом осуществления настоящего изобретения, показан пример синтаксических таблиц, для сигнализации синтаксического элемента vps_poc_cycle_au в наборе VPS (или SPS), в котором указывают рос_cycle_au, используемое для всех изображений/слайсов в кодированной видеопоследовательности, в заголовке слайса. Если значение РОС увеличивается в каждом пакете доступа равномерно, vps_contant_poc_cycle_per_au в наборе VPS может задают равным 1, a vps_poc_cycle_au сигнализируют в наборе VPS. В этом случае slice_poc_cycle_au не сигнализируют явно, а значение AUC для каждого блока доступа вычисляют делением значения РОС на vps_poc_cycle_au. Если значение РОС в каждом пакете доступа не увеличивается равномерно, то vps_contant_poc_cycle_per_au в наборе VPS может быть задано равным 0. В этом случае vps_access_unit_cnt не сигнализируют, тогда как slice_access_unit_cnt сигнализируют в заголовке слайса для каждого слайса или изображения. Каждый слайс или изображение может иметь отличающееся значение slice_access_unit_cnt. Значение AUC для каждого блока доступа вычисляют делением значения РОС на slice_poc_cycle_au. На фиг. 10 показана блок-схема, иллюстрирующая соответствующую последовательность операций.
[0161] В этом же или в других вариантах осуществления настоящего изобретения несмотря на то, что значения РОС в изображениях, слайсах или тайлах могут быть различными, эти изображения, слайсы или тайлы, соответствующие пакету доступа с одинаковыми значениями AUC, могут относиться к одному моменту времени декодирования или вывода. Следовательно, при отсутствии каких-либо зависимостей анализа иди декодирования между изображениями, слайсами или тайлами в одном пакете доступа, все изображения, слайсы или тайлы, относящиеся к одному пакету доступа, или их подмножество, могут декодироваться параллельно и могут выводиться в один момент времени.
[0162] В этом же или в других вариантах осуществления настоящего изобретения несмотря на то, что значения РОС в изображениях, слайсах или тайлах могут быть различными, эти изображения, слайсы или тайлы, соответствующие пакету доступа с одинаковыми значениями AUC, могут относиться к одному моменту времени композиции/отображения. Когда время композиции содержится в контейнерном формате, даже если изображения соответствуют различным пакетам доступа, но имеют одинаковое время композиции, эти изображения могут отображаться в один момент времени.
[0163] В этом же или в других вариантах осуществления настоящего изобретения каждое изображение, слайс или тайл могут иметь одинаковые временные идентификаторы (temporal_id) в одном пакете доступа. Все изображения, слайсы или тайлы, соответствующие одному моменту времени, или их подмножество, могут соответствовать одному временному подуровню. В этом же или в других вариантах осуществления настоящего изобретения все изображения, слайсы или тайлы могут иметь одинаковые или отличающиеся идентификаторы пространственного уровня (layer_id) в одном пакте доступа. Все изображения, слайсы или тайлы, соответствующие одному моменту времени, или их подмножество, могут соответствовать одному или различным пространственным уровням.
[0164] На фиг. 11 показан пример видеопотока, включающего CSPS видео заднего плана с layer_id, равным 0, и множеством уровней CSPS переднего плана. Тогда как кодированное субизображение может состоять из одного или более уровней CSPS, область заднего плана, которая не принадлежит ни одному из уровней CSPS переднего плана, может состоять из базового уровня. Базовый уровень может включать область заднего плана и области переднего плана, тогда как уточняющий уровень CSPS может включать область переднего плана. Уточняющий уровень CSPS может иметь более высокое визуальное качество, по сравнению с базовым уровнем, в той же области. Уточняющий уровень CSPS может ссылаться на восстановленные пиксели и на векторы движения базового уровня, соответствующего той же области.
[0165] В этом же или в альтернативном варианте осуществления настоящего изобретения битовый поток видео, соответствующий базовому уровню, содержится в одном треке, в видеофайле, тогда как уровни CSPS, соответствующие каждому субизображению, содержатся в отдельном треке.
[0166] В этом же или в альтернативном варианте осуществления настоящего изобретения битовый поток видео, соответствующий уровню, содержится в одном треке, тогда как уровни CSPS с тем же layer_id содержатся в отдельном треке. В данном примере трек, соответствующий уровню k, включает только уровни CSPS, соответствующие уровню k.
[0167] В этом же или в альтернативном варианте осуществления настоящего изобретения каждый уровень CSPS каждого субизображения хранят в отдельном треке. Каждый трек может как иметь, так и не иметь зависимость анализа или декодирования от одного или более других треков.
[0168] В этом же или в альтернативном варианте осуществления настоящего изобретения каждый трек может содержать битовые потоки, соответствующие уровням от i до j уровней CSPS всех субизображений, или их подмножества, где 0<i=<j=<k, а k - верхний уровень CSPS.
[0169] В этом же или в альтернативном варианте осуществления настоящего изобретения изображение состоит из соответствующих медиаданных, включая одно или более из следующего: карту глубины, карту значений альфа-канала, данные 3D-геометрии, карту занятости (occupancy тар) и т.п. Эти снабженные временными метками медиаданные могут быть разделены на один или более подпотоков данных, каждый из которых соответствует одному субизображению.
[0170] На фиг. 12, в соответствии с этим же или с альтернативным вариантом осуществления настоящего изобретения, показан пример видеоконференцсвязи на основе метода многоуровневых субизображений. В видеопотоке содержатся один битовый поток видео базового уровня, соответствующий изображению заднего плана, и один или более битовых потоков видео уточняющих уровней, соответствующих субизображениям переднего плана. Битовый поток видео каждого уточняющего уровня может соответствует уровню CSPS. На дисплее по умолчанию отображается изображение, соответствующее базовому уровню. Оно содержит изображения одного или более пользователей, помещенных внутри изображения, методом «картинка в картинке» (picture in a picture, PIP). Когда клиент осуществляет выбор конкретного пользователя, декодируют и отображают уточняющий уровень CSPS, соответствующий выбранному пользователю и имеющий повышенное качество или пространственное разрешение. На фиг. 13 показана блок-схема этой процедуры.
[0171] В этом же или в альтернативном варианте осуществления настоящего изобретения одном из примеров осуществления настоящего изобретения сетевое промежуточное оборудование (например, маршрутизатор) может выбирать подмножество уровней для передачи пользователю в зависимости от его полосы пропускания. Для адаптации к полосе пропускания может применяться разбиение изображений на субизображения. К примеру, если пользователю не хватает полосы пропускания, маршрутизатор может отбрасывать уровни или выбирать субизображения по их важности, или на основе применяемой конфигурации, причем это может выполняться динамически для адаптации к полосе пропускания.
[0172] На фиг. 14 показан сценарий применения, соответствующий 360-градусному видео. Когда сферическое 360-градусное изображение проецируют на плоское изображение, проекционное 360-градусное изображение может быть разбито на множество субизображений, в качестве базового уровня. Уточняющий уровень для конкретного субизображения, например, переднего субизображения, может быть кодирован и передан клиенту. Декодер может быть способен декодировать как базовый уровень, включающий все субизображения, так и уточняющий уровень выбранного субизображения. Когда текущий порт просмотра идентичен выбранному субизображению, отображаемое изображение может иметь более высокое качество, за счет декодированного субизображения в уточняющем уровне. В противном случае может быть отображено декодированное изображение базового уровня, с меньшим качеством.
[0173] В этом же или в альтернативном варианте осуществления настоящего изобретения информация о компоновке для отображения может присутствовать в файле в виде вспомогательной информации (например, сообщения SEI или метаданных). Одно или более декодированных субизображений могут быть перемещены и отображаться в зависимости от сигнализируемой информации о компоновке. Информация о компоновке может сигнализироваться сервером потоковой передачи, или вещательной станцией, или может формироваться повторно сетевым объектом или облачными сервером, или может определяться с использованием выбираемых пользователем настроек.
[0174] В одном из вариантов осуществления настоящего изобретения, когда входное изображение разбито на одну или более (прямоугольных) подобластей, каждая такая подобласть может быть кодирована в виде независимого уровня. Каждый независимый уровень, соответствующий локальной области, может иметь уникальное значение layer_id. Для каждого независимого уровня могут сигнализироваться размер субизображения и информация о местоположении субизображения. К примеру, размер изображения (ширина, высота), информация о смещении относительно верхнего левого угла (х_offset, у_offset). На фиг. 15 показан пример компоновки субизображений, соответствующей информации о размере и позиции субизображений, а также соответствующая структура предсказания изображений. Информация о компоновке, включающая размеры и позиции субизображений, может сигнализироваться в высокоуровневой синтаксической структуре, например, наборах параметров, заголовке слайса или группы тайлов, или в сообщении SEI.
[0175] В этом же варианте осуществления настоящего изобретения каждое субизображение, соответствующее независимому уровню, может иметь уникальное значение РОС внутри блока доступа. Когда на опорное изображение среди изображений, хранимых в буфере DPB, указывают с помощью синтаксического элемента (или элементов) в структуре RPS или RPL, может использоваться значение (или значения) РОС каждого субизображения, соответствующего одному из уровней.
[0176] В этом же или в альтернативном варианте осуществления настоящего изобретения для указания на структуру (межуровневого) предсказания, layer_id использоваться не может, а может использоваться значение (разности) РОС.
[0177] В этом же варианте осуществления настоящего изобретения субизображение со значением РОС, равным N, соответствующе уровню (или локальной области), может (но не обязательно) использоваться в качестве опорного изображения для субизображения с РОС, равным N+K, соответствующим тому же уровню (или той же локальной области), для предсказания с компенсацией движения. В большинстве случаев значение числа К может быть равно максимальному количеству (независимых) уровней, котором может совпадать с количеством подобластей.
[0178] На фиг. 16 рассмотрен расширенный случай фиг. 15, в соответствии с тем же или альтернативным вариантом осуществления настоящего изобретения. Когда входное изображение разделено на множество (например, четыре) подобластей, каждая локальная область может кодироваться с использованием одного или более уровней. В таком случае количество независимых уровней может быть равно количеству подобластей, и каждой подобласти будет соответствовать один или более уровней. Таким образом, каждая подобласть может быть кодирована с использованием одного или более независимых уровней и нуля или более зависимых уровней.
[0179] В этом же варианте осуществления настоящего изобретения, в соответствии с фиг. 16, входное изображение может быть разделено на четыре подобласти. Правая верхняя подобласть может быть кодирована в виде двух уровней, уровня 1 и уровня 4, тогда как правая нижняя подобласть может быть кодирована в виде двух уровней, уровня 3 и уровня 5. В таком случае уровень 4 может ссылаться на уровень 1 для предсказания с компенсацией движения, тогда как уровень 5 может ссылаться на уровень 3 для предсказания с компенсацией движения.
[0180] В этом же или в альтернативном варианте осуществления настоящего изобретения внутриконтурная фильтрация (например, деблокирующая фильтрация, адаптивная внутриконтурная фильтрация, изменение формы (reshaper), двусторонняя фильтрация или любая фильтрация на основе глубокого обучения) с пересечением границ уровней может быть (опционально) запрещена.
[0181] В этом же или в альтернативном варианте осуществления настоящего изобретения предсказание с компенсацией движения или внутреннее копирование блоков с пересечением границ блоков может быть (опционально) запрещено.
[0182] В этом же или в альтернативном варианте осуществления настоящего изобретения заполнение границы незначащей информацией (boundary padding) или внутриконтурная фильтрация на границах субизображений могут выполняться опционально. Флаг, указывающий, следует выполнять заполнение границы или нет, может сигнализироваться в высокоуровневой синтаксической структуре, например, наборе (или наборах) параметров (VPS, SPS, PPS или APS), заголовке слайса или группы тайлов или в сообщении SEI.
[0183] В этом же или в альтернативном варианте осуществления настоящего изобретения информация о компоновке подобластей (или субизображений) может сигнализироваться в наборе VPS или SPS. На фиг. 17 показаны примеры синтаксических элементов в наборах VPS и SPS. В данном примере в VPS сигнализируют флаг vps_sub_picture_dividing_flag. Этот флаг может указывать, разделено ли входное изображение (или изображения) на множество подобластей или нет. Когда значение флага vps_sub_picture_dividing_flag равно 0, входное изображение (или изображения) в кодированной видеопоследовательности (или последовательностях), соответствующей текущему набору VPS, не может быть разделено на множество подобластей. В этом случае размер входного изображения может быть равен размеру кодированного изображения, (pic_width_in_luma_samples, pic_height_in_luma_samples), которое сигнализируют в наборе SPS. Когда значение флага vps_sub_picture_dividing_flag равно 1, входное изображение (или изображения может быть разделено на множество подобластей. В этом случае синтаксические элементы vps_full_pic_width_in_luma_samples и vps_full_pic_height_in_luma_samples сигнализируют в наборе VPS. Значения vps_full_pic_width_in_luma_samples и vps_full_pic_height_in_luma_samples могут быть равны ширине и высоте входного изображения (или изображений) соответственно.
[0184] В этом же варианте осуществления настоящего изобретения значения vps_full_pic_width_in_luma_samples и vps_full_pic_height_in_luma_samples не могут использоваться для декодирования, однако могут использоваться для компоновки и отображения.
[0185] В этом же варианте осуществления настоящего изобретения, когда значение флага vps_sub_picture_dividing_flag равно 1, синтаксические элементы pic_offset_x и pic_offset_y могут сигнализироваться в наборе SPS, соответствующем конкретному уровню (или уровням). В этом случае размер кодированного изображения (pic_width_in_luma_samples, pic_height_in_luma_samples), сигнализируемый в SPS, может быть равен ширине и высоте подобласти, соответствующей заданному уровню. Также в SPS может сигнализироваться позиция (pic_offset_x, pic_offse_ty) левого верхнего угла подобласти.
[0186] В этом же варианте осуществления настоящего изобретения информация (pic_offset_х, pic_offset_у) о позиции левого верхнего угла подобласти не может использоваться для декодирования, однако может использоваться для компоновки и отображения.
[0187] В этом же варианте осуществления настоящего изобретения информация о компоновке (размере и позиции) всех подобластей или подмножества подобластей входного изображения (или изображений) и информация о зависимостях между уровнями может сигнализироваться в наборе параметров или в сообщении SEI. На фиг. 18 показаны примеры синтаксических элементов для указания информации о компоновке подобластей, о зависимостях между уровнями и о соотношении между подобластями и одним или более уровнями. В данном примере синтаксический элемент num_sub_region указывает на количество (прямоугольных) подобластей в текущей кодированной видеопоследовательности. Синтаксический элемент num_layers указывает на количество уровней в текущей кодированной видеопоследовательности. Значение num_layers моет быть больше или равно значению num_sub_region. Когда все подобласти кодируют в качестве одиночных уровней, значение num_layers может быть равно значению num_sub_region. Когда одну или более подобластей кодируют в виде множества уровней, значение num_layers должно быть больше значения num_sub_region. Синтаксический элемент direct_dependency_flag[i][j] указывает на зависимость i-го уровня от j-го уровня. Значение num_layers_for_region[i] указывает на количество уровней, относящихся к i-ой подобласти. Значение sub_region_layer_id[i][j] указывает layer_id j-го уровня, относящегося к i-ой подобласти. Значения sub_region_offset_x[i] и sub_region_offset_y[i] указывают на горизонтальное и вертикальное расположение левого верхнего угла i-ой подобласти соответственно. Значения sub_region_width[i] и sub_region_height[i] указывают на ширину и высоту i-ой подобласти соответственно.
[0188] В одном из вариантов осуществления настоящего изобретения один или более синтаксических элементов, которые определяют набор выходных уровней для указания на один или более уровней для вывода, с информацией об уровне, ярусе и профиле стандарта, или без такой информации, могут сигнализироваться в высокоуровневой синтаксической структуре, например, наборе VPS, DPS, SPS, PPS, APS или в сообщении SEI. В соответствии с иллюстрацией фиг. 19, синтаксический элемент num_output_layer_sets, указывающий на номер набора выходных уровней (output layer set, OLS) в кодированной видеопоследовательности, ссылающейся на набор VPS, может сигнализироваться в VPS. Для каждого набора выходных уровней может сигнализироваться флаг output_layer_flag, столько раз, сколько имеется выходных уровней.
[0189] В этом же варианте осуществления настоящего изобретения флаг output_Layer_flag[i], равный 1, определяет что i-й уровень должен быть выведен. Флаг vps_output_Layer_flag[i], равный 0, определяет что i-й уровень не должен быть выведен.
[0190] В этом же или в альтернативном варианте осуществления настоящего изобретения один или более синтаксических элементов, которые определяют информацию об уровне, ярусе и профиле стандарта для каждого набора выходных уровней, могут сигнализироваться в высокоуровневой синтаксической структуре, например, наборе VPS, DPS, SPS, PPS, APS или в сообщении SEI. Также, в соответствии с иллюстрацией фиг. 19, синтаксический элемент num_profile_tile_level, указывающий на номер информации об уровне, ярусе и профиле стандарта для каждого OLS в кодированной видеопоследовательности, ссылающейся на набор VPS, может сигнализироваться в VPS. Для каждого набора выходных уровней, может сигнализироваться (столько раз, сколько имеется выходных уровней) набор синтаксических элементов для информации об уровне, ярусе и профиле стандарта или указатель, указывающий на информацию об уровне, ярусе и профиле стандарта среди записей в информации об уровне, ярусе и профиле стандарта.
[0191] В этом же варианте осуществления настоящего изобретения значение profile_tier_level_idx[i][j] определяет указатель, в списке синтаксических структур profile_tier_level() в наборе VPS, на синтаксическую структуру profile_tier_level(), применимую для j-го уровня i-го набора OLS.
[0192] В этом же или в альтернативном варианте осуществления настоящего изобретения, в соответствии с иллюстрацией фиг. 20, синтаксический элемент num_profile_tile_level и/или num_output_layer_sets могут сигнализироваться когда максимальное количество уровней больше 1 (vps_max_layers_minusl>0).
[0193] В этом же или в альтернативном варианте осуществления настоящего изобретения, в соответствии с иллюстрацией фиг. 20, синтаксический элемент vps_output_layers_mode [i], указывающий на режим сигнализации выходного уровня для i-го выходного уровня, может присутствовать в наборе VPS.
[0194] В этом же варианте осуществления настоящего изобретения значение vps_output_layers_mode[i], равное 0, определяет, что выводят только верхний уровень с использованием i-го набора выходных уровней. Значение vps_output_layer_mode[i], равное 1, определяет, что выводят все уровни с использованием i-го набора выходных уровней. Значение vps_output_layer_mode[i], равное 2, определяет, что выходными уровнями являются уровни с флагом vps_output_layer_flag[i][j], равным 1, с использованием i-го набора выходных уровней. Может быть зарезервировано большее количество значений.
[0195] В этом же варианте осуществления настоящего изобретения output_layer_flag[i][j] может сигнализироваться или не сигнализироваться в зависимости от значения vps_output_layers_mode [i] для i-го набора выходных уровней.
[0196] В этом же или в альтернативном варианте осуществления настоящего изобретения, в соответствии с иллюстрацией фиг. 20, флаг vps_pt1_signal_flag [i] может присутствовать для i-го набора выходных уровней. В зависимости от значения vps_pt1_signal_flag[i] может сигнализироваться или не сигнализироваться информация об уровне, ярусе и профиле стандарта для i-го набора выходных уровней.
[0197] В этом же или в альтернативном варианте осуществления настоящего изобретения, в соответствии с иллюстрацией фиг. 21, количество субизображений, max_subpics_minus1, в текущей CVS может сигнализироваться в высокоуровневой синтаксической структуре, например, наборе VPS, DPS, SPS, PPS, APS или в сообщении SEI.
[0198] В этом же варианте осуществления настоящего изобретения, в соответствии с иллюстрацией фиг. 21, идентификатор субизображения, sub_pic_id[i], для i-го субизображения может сигнализироваться, когда количество субизображений больше 1 (max_subpics_minus1>0).
[0199] В этом же или в альтернативном варианте осуществления настоящего изобретения один или более синтаксических элементов, указывающих на идентификатор субизображения, принадлежащего каждому уровню каждого набора выходных уровней, может сигнализироваться в наборе VPS. В соответствии с иллюстрацией фиг. 22 и фиг. 23, значение sub_pic_id_layer[i][j][k] указывает на то, что k-е субизображение присутствует в j-м уровне i-го набора выходных уровней. С помощью этой информации декодер может распознавать, какое из субизображений может быть декодировано и выведено для каждого уровня заданного набора выходных уровней.
[0200] В одном из вариантов осуществления настоящего изобретения заголовок изображения (РН) является синтаксической структурой, которая содержит синтаксические элементы, применимые ко всем слайсам кодированного изображения. Пакет изображения (picture unit, PU) представляет собой набор пакетов NAL, которые связаны друг с другом согласно определенному правилу классификации, следуют друг за другом в порядке декодирования и содержат в точности одно кодированное изображение. Пакет изображения может содержать заголовок изображения (РН) и один или более пакетов NAL кодированных слайсов или пакетов NAL VCL, составляющих кодированное изображение.
[0201] В одном из вариантов осуществления настоящего изобретения набор SPS (RBSP) может быть доступен в процедуре декодирования до ссылки на него, он может быть включен в по меньшей мере один пакет доступа с Temporalid, равным 0, или предоставлен с помощью внешних средств.
[0202] В одном из вариантов осуществления настоящего изобретения набор SPS (RBSP) может быть доступен в процедуре декодирования до ссылки на него, он может быть включен по меньшей мере в один пакет доступа с Temporalid, равным 0, в CVS, которая содержит один или более наборов PPS, ссылающихся на этот SPS, или предоставлен с помощью внешних средств.
[0203] В одном из вариантов осуществления настоящего изобретения набор SPS (RBSP) может быть доступен в процедуре декодирования до ссылки на него в одном или более наборов PPS, он может быть включен по меньшей мере в один пакет изображения с nuh_layer_id, равным наименьшему значению nuh_layer_id среди пакетов NAL PPS, ссылающихся на пакет NAL SPS в CVS, которая содержит один или более наборов PPS, ссылающихся на этот SPS, или предоставлен с помощью внешних средств.
[0204] В одном из вариантов осуществления настоящего изобретения набор SPS (RBSP) может быть доступен в процедуре декодирования до ссылки на него в одном или более наборов PPS, он может быть включен по меньшей мере в один пакет изображения с Temporalid, равным 0, и nuh_layer_id, равным наименьшему значению nuh_layer_id среди пакетов NAL PPS, ссылающихся на пакет NAL SPS в CVS, которая содержит один или более наборов PPS, ссылающихся на этот SPS, или предоставлен с помощью внешних средств.
[0205] В одном из вариантов осуществления настоящего изобретения набор SPS (RBSP) может быть доступен в процедуре декодирования до ссылки на него в одном или более наборов PPS, он может быть включен по меньшей мере в один пакет изображения с Temporalid, равным 0, и с nuh_layer_id, равным наименьшему значению nuh_layer_id среди пакетов NAL PPS, ссылающихся на пакет NAL SPS в CVS, которая содержит один или более наборов PPS, ссылающихся на этот SPS, или предоставлен с помощью внешних средств.
[0206] В этом же или в альтернативном варианте осуществления настоящего изобретения значение pps_seq_parameter_set_id определяет значение sps_seq_parameter_set_id для набора SPS, на который ссылаются. Значение pps_seq_parameter_set_id может быть одинаковым во всех наборах PPS, на которые ссылаются кодированные изображения в CLVS.
[0207] В этом же или в альтернативном варианте осуществления настоящего изобретения все пакеты NAL SPS, имеющие одинаковое значение sps_seq_parameter_set_id в CVS, могут иметь одинаковый контент.
[0208] В этом же или в альтернативном варианте осуществления настоящего изобретения, независимо от значений nuh_layer_id, пакеты NALSPS могут иметь общее пространство значений sps_seq_parameter_set_id.
[0209] В этом же или в альтернативном варианте осуществления настоящего изобретения значение nuh_layer_id в пакете NAL SPS может быть равно наименьшему значению nuh_layer_id среди пакетов NAL PPS, который ссылается на данный пакет NAL SPS.
[0210] В одном из вариантов осуществления настоящего изобретения, когда на набор SPS с nuh_layer_id, равным m, ссылаются в одном или более наборов PPS с nuh_layer_id, равным n, уровень со значением nuh_layer_id, равным m, может быть тем же, что и уровень с nuh_layer_id, равным n, или (прямым или косвенным) опорным уровнем для уровня с nuh_layer_id, равным m.
[0211] В одном из вариантов осуществления настоящего изобретения набор PPS (RBSP) может быть доступен в процедуре декодирования до ссылки на него, он может быть включен по меньшей мере в один пакет доступа с Temporalid, равным Temporalid пакета NAL PPS, или предоставлен с помощью внешних средств.
[0212] В одном из вариантов осуществления настоящего изобретения набор PPS (RBSP) может быть доступен в процедуре декодирования до ссылки на него, он может быть включен по меньшей мере в один пакет доступа с Temporalid, равным Temporalid пакета NAL PPS в CVS, которая содержит один или более наборов заголовков изображения, РН (или пакетов NAL кодированных слайсов), ссылающихся на этот PPS, или предоставлен с помощью внешних средств.
[0213] В одном из вариантов осуществления настоящего изобретения набор PPS (RBSP) может быть доступен в процедуре декодирования до ссылки на него в одном или более заголовков изображения, РН (или пакетов NAL кодированных слайсов), он может быть включен по меньшей мере в один пакет изображения с nuh_layer_id, равным наименьшему значению nuh_layer_id среди пакетов NAL кодированных слайсов, ссылающихся на пакет NAL PPS в CVS, которая содержит один или более наборов заголовков изображения, РН (или пакетов NAL кодированных слайсов), ссылающихся на этот 3PS, или предоставлен с помощью внешних средств.
[0214] В одном из вариантов осуществления настоящего изобретения набор PPS (RBSP) может быть доступен в процедуре декодирования до ссылки на него в одном или более заголовков изображения, РН (или пакетов NAL кодированных слайсов), он может быть включен по меньшей мере в один пакет изображения с Temporalid, равным Temporalid пакета NAL PPS, и nuh_layer_id, равным наименьшему значению nuh_layer_id среди пакетов NAL кодированных слайсов, ссылающихся на пакет NAL PPS в CVS, которая содержит один или более наборов заголовков изображения, РН (или пакетов NAL кодированных слайсов), ссылающихся на этот PPS, или предоставлен с помощью внешних средств.
[0215] В этом же или в альтернативном варианте осуществления настоящего изобретения значение ph_pic_parameter_set_id в заголовке изображения, РН, определяет значение pps_pic_parameter_set_id для используемого PPS, на который ссылаются. Значение pps_seq_parameter_set_id может быть одинаковым во всех наборах PPS, на которые ссылаются кодированные изображения в CLVS.
[0216] В этом же или в альтернативном варианте осуществления настоящего изобретения все пакеты NAL PPS с одним значением pps_pic_parameter_set_id внутри пакета изображения должны иметь одинаковый контент.
[0217] В этом же или в альтернативном варианте осуществления настоящего изобретения, независимо от значений nuh_layer_id, пакеты NAL PPS могут иметь общее пространство значений pps_seq_parameter_set_id.
[0218] В этом же или в альтернативном варианте осуществления настоящего изобретения значение nuh_layer_id в пакете NAL SPS может быть равно наименьшему значению nuh_layer_id среди пакетов NAL кодированных слайсов, ссылающихся на данный пакет NAL PPS.
[0219] В одном из вариантов осуществления настоящего изобретения, когда на набор PPS с nuh_layer_id, равным m, ссылаются в одном или более пакетов NAL кодированных слайсов с nuh_layer_id, равным n, уровень со значением nuh_layer_id, равным m, может быть тем же, что и уровень с nuh_layer_id, равным n, или (прямым или косвенным) опорным уровнем для уровня с nuh_layer_id, равным m.
[0220] В одном из вариантов осуществления настоящего изобретения набор PPS (RBSP) может быть доступен в процедуре декодирования до ссылки на него, он может быть включен по меньшей мере в один пакет доступа с Temporalid, равным Temporalid пакета NAL PPS, или предоставлен с помощью внешних средств.
[0221] В одном из вариантов осуществления настоящего изобретения набор PPS (RBSP) может быть доступен в процедуре декодирования до ссылки на него, он может быть включен по меньшей мере в один пакет доступа с Temporalid, равным Temporalid пакета NAL PPS в CVS, которая содержит один или более наборов заголовков изображения, РН (или пакетов NAL кодированных слайсов), ссылающихся на этот PPS, или предоставлен с помощью внешних средств.
[0222] В одном из вариантов осуществления настоящего изобретения набор PPS (RBSP) может быть доступен в процедуре декодирования до ссылки на него в одном или более заголовков изображения, РН (или пакетов NAL кодированных слайсов), он может быть включен по меньшей мере в один пакет изображения с nuh_layer_id, равным наименьшему значению nuh_layer_id среди пакетов NAL кодированных слайсов, ссылающихся на пакет NAL PPS в CVS, которая содержит один или более наборов заголовков изображения, РН (или пакетов NAL кодированных слайсов), ссылающихся на этот 3PS, или предоставлен с помощью внешних средств.
[0223] В одном из вариантов осуществления настоящего изобретения набор PPS (RBSP) может быть доступен в процедуре декодирования до ссылки на него в одном или более заголовков изображения, РН (или пакетов NAL кодированных слайсов), он может быть включен по меньшей мере в один пакет изображения с Temporalid, равным Temporalid пакета NAL PPS, и nuh_layer_id, равным наименьшему значению nuh_layer_id среди пакетов NAL кодированных слайсов, ссылающихся на пакет NAL PPS в CVS, которая содержит один или более наборов заголовков изображения, РН (или пакетов NAL кодированных слайсов), ссылающихся на этот PPS, или предоставлен с помощью внешних средств.
[0224] В этом же или в альтернативном варианте осуществления настоящего изобретения значение ph_pic_parameter_set_id в заголовке изображения, РН, определяет значение pps_pic_parameter_set_id для используемого PPS, на который ссылаются. Значение pps_seq_parameter_set_id может быть одинаковым во всех наборах PPS, на которые ссылаются кодированные изображения в CLVS.
[0225] В этом же или в альтернативном варианте осуществления настоящего изобретения все пакеты NAL PPS с одним значением pps_pic_parameter_set_id внутри пакета изображения должны иметь одинаковый контент.
[0226] В этом же или в альтернативном варианте осуществления настоящего изобретения, независимо от значений nuh_layer_id, пакеты NAL PPS могут иметь общее пространство значений pps_seq_parameter_set_id.
[0227] В этом же или в альтернативном варианте осуществления настоящего изобретения значение nuh_layer_id в пакете NAL SPS может быть равно наименьшему значению nuh_layer_id среди пакетов NAL кодированных слайсов, ссылающихся на данный пакет NAL PPS.
[0228] В одном из вариантов осуществления настоящего изобретения, когда на набор PPS с nuh_layer_id, равным m, ссылаются в одном или более пакетов NAL кодированных слайсов с nuh_layer_id, равным n, уровень со значением nuh_layer_id, равным m, может быть тем же, что и уровень с nuh_layer_id, равным n, или (прямым или косвенным) опорным уровнем для уровня с nuh_layer_id, равным m.
[0229] Выходной уровень - это уровень из набора выходных уровней, который должен быть подан на выход. Набор выходных уровней (OLS) - это набор уровней, состоящий из уровней из одного или более заданных наборов уровней, при этом для одного или более уровней в этом наборе уровней указано, что они являются выходными уровнями. Указатель (индекс) уровня в наборе выходных уровней (OLS) - это указатель на уровень в списке уровней набора OLS.
[0230] Подуровень - это уровень временного масштабирования или битовый поток с временным масштабированием, состоящий из пакетов NAL VCL с конкретным значением переменной Temporalid, а также из соответствующих не-VLC пакетов NAL. Представление подуровня подмножество битового потока, состоящего из пакетов NAL конкретного подуровня и низлежащих подуровней.
[0231] RBSP-последовательность набора VPS может быть доступна в процедуре декодирования до ссылки на него, он может быть включен по меньшей мере в один пакет доступа с Temporalid, равным 0, или предоставлен с помощью внешних средств. Все NAL-пакеты VPS с заданным значением vps_video_parameter_set_id в CVS могут иметь одинаковый контент.
[0232] Значение vps_video_parameter_set_id содержит идентификатор VPS для ссылки из других синтаксических элементов. Значение vps_video_parameter_set_id может быть большим 0.
[0233] Значение vps_max_layers_minus1 плюс 1 определяет максимально допустимое количество уровней в каждой CVS, ссылающейся на данный набор VPS.
[0234] Значение vps_max_sublayers_minus1 плюс 1 определяет максимальное количество временных подуровней, которые могут содержаться в уровне в каждой CVS, ссылающейся на данный набор VPS. Значение vps_max_sublayers_minus1 может лежать в диапазоне от 0 до 6 включительно.
[0235] Флаг vps_all_layers_same_num_sublayers_flag, равный 1, указывает на то, что количество временных подуровней одинаково для всех уровней в каждой CVS, ссылающейся на данный набор VPS. Флаг vps_all_layers_same_num_sublayers_flag, равный 0, указывает на то, что уровни в каждой CVS, ссылающейся на данный набор VPS, не обязательно должны иметь одинаковое количество временных подуровней. Если этот флаг отсутствует, значение vps_all_layers_same_num_sublayers_flag определяют как равное 1.
[0236] Флаг vps_all_independent_layers_flag, равный 1, определяет, что все уровни в CVS кодируют независимо, без использования межуровневого предсказания. Флаг vps_all_independent_layers_flag, равный 0, определяет, что для одного или более уровней в CVS может использоваться межуровневое предсказание. Когда этот флаг отсутствует, значение vps_all_independent_layers_flag определяют как равное 1.
[0237] Значение vps_layer_id[i] определяет значение nuh_layer_id i-го уровня. Для любых двух неотрицательных значений тип, когда т меньше п, значение vps_layer_id[m] может быть меньше vps_layer_id [n].
[0238] Флаг, vps_independent_layer_flag[i], равный 1, определяет, что для уровня с индексом i не используют межуровневое предсказание. Флаг vps_independent_layer_flag[i], равный 0, определяет, что для уровня с индексом i может использоваться межуровневое предскзание и в наборе VPS присутствуют синтаксические элементы vps_direct_ref_layer_flag[i][j] для j в диапазоне от 0 до i-1 включительно. Если этот флаг отсутствует, значение vps_independent_layer_flag[i] определяют как равное 1.
[0239] Значение vps_direct_ref_layer_flag[i][j], равное 0, определяет, что уровень с порядковым номером j не является прямым опорным уровнем для уровня с порядковым номером i. Значение vps_direct_ref_layer_flag[i][j], равное 1, определяет, что уровень с порядковым номером j является прямым опорным уровнем для уровня с порядковым номером i. Когда значение vps_direct_ref_layer_flag[i][j] отсутствует для i и j в диапазоне от 0 до vps_max_layers_minus1 включительно, его значение определяют как равное 0. Когда флаг vps_independent_layer_flag[i] равен 0, может присутствовать по меньшей мере одно значение j в диапазоне от 0 до i-1 включительно, то есть, значение vps_direct_ref_layer_flag[i][j] равно 1.
[0240] Переменные NumDirectRefLayers[i], DirectRefLayerldx[i][d],
NumRefLayers[i], RefLayerIdx[i][r] и LayerUsedAsRefLayerFlag[j] вычисляют следующим образом:
for (i=0; i<=vps_max_layers_minus1; i++) {
for (j=0; j<=vps_max_layers_minus 1; j++) {
DependencyFlag[i][j]=vps_direct_ref_layer_flag[i][j]
for (k=0; k<i; k++)

[0241] Переменную GeneralLayerIdx[i], определяющую порядковый номер уровня с nuh_layer_id, равным vps_layer_id[i], вычисляют следующим образом:
for (i=0; i<=vps_max_layers_minus1; i++)
GeneralLayerIdx[vps_layer_id[i]]=i
[0242] Для любых двух различных значений i и j, обоих в диапазоне от 0 до vps_max_layers_minus1 включительно, когда DependencyFlagf[i][j] равен 1, это является требованием совместимости битового потока, гласящего, что значения chroma_format_idc и bit_depth_minus8, применимые к i-му уровню, могут быть равны значениям chroma_format_idc и bit_depth_minus8, соответственно, применимым к j-му уровню.
[0243] Значение max_tid_ref_present_flag[i], равное 1, определяет, что присутствует синтаксический элемент max_tid_il_ref_pics_plusl[i]. Значение max_tid_ref_present_flag[i], равное 0, определяет, что синтаксический элемент max_tid_il_ref_pics_plus1 [i] отсутствует.
[0244] Значение max_tid_il_ref_pics_plusl[i], равное 0, определяет, что для не-IRAP изображений i-го уровня не используют межуровневое предсказание. Значение max_tid_il_ref_pics_plus1 [i], большее 0, определяет, что для декодирования изображений i-го уровня в качестве ILRP не могут использоваться изображения с Temporalid больше max_tid_il_ref_pics_plusl[i] - 1. В случае его отсутствия значение max_tid_il_ref_pics_plus 1 [i] определяют как равное 7.
[0245] Флаг each_layer_is_an_ols_flag, равный 1, определяет, что каждый набор OLS содержит только один уровень, при этом каждый уровень в CVS, ссылающийся на данный набор VPS, является набором OLS с единственным содержащимся уровнем, являющимся единственным выходным уровнем. Флаг each_layer_is_an_ols_flag, равный 0, определяет, что набор OLS может содержать более одного уровня. Если vps_max_layers_minus1 равно 0, значение each_layer_is_an_ols_flag определяют как равное 1. В противном случае, когда vps_all_independent_layers_flag равен 0, значение each_layer_is_an_ols_flag определяют как равное 0.
[0246] Значение ols_mode_idc, равное 0, определяет, что общее количество наборов OLS, заданное набором VPS, равно vps_max_layers_minus1+1, при этом i-й набор OLS содержит уровни с порядковыми номерами от 0 до i включительно, и для каждого OLS только наивысший уровень в нем является выходным.
[0247] Значение ols_mode_idc, равное 1, определяет, что общее количество наборов OLS, заданное набором VPS, равно vps_max_layers_minus1+1, при этом i-й набор OLS содержит уровни с порядковыми номерами от 0 до i включительно, и для каждого OLS все уровни в нем являются выходными.
[0248] Значение ols_mode_idc, равное 2, определяет, что общее количество наборов OLS, заданных набором VPS, сигнализируют явно, и для каждого OLS выходные уровни сигнализируют явно, при этом остальные уровни являются прямыми или косвенными опорными уровнями для выходных уровней OLS.
[0249] Значение ols_mode_idc может лежать в диапазоне от 0 до 2 включительно. Значение ols_mode_idc, равное 3, зарезервировано ITU-T / ISO/IEC для будущего использования.
[0250] Когда флаг vps_all_independent_layers_flag равен 1, и флаг each_layer_is_an_ols_flag равен 0, значение ols_mode_idc определяют как равное 2.
[0251] Значение num_output_layer_sets_minus1 плюс 1 определяет общее количество наборов OLS, заданных набором VPS, когда ols_mode_idc равно 2.
[0252] Переменную TotalNumOlss, определяющую общее количество OLS, заданных набором VPS, вычисляют следующим образом:
if(vps_max_layers_minus1==0)
TotalNumOlss=1
else if (each_layer_is_an_ols_flag | | ols_mode_idc=0 | | ols_mode_idc=1)
TotalNumOlss=vps_max_layers_minus1+1 else_if(ols_mode_idc=2)
TotalNumOlss=num_output_layer_sets_minus1+1
[0253] Флаг ols_output_layer_flag[i][j], равный 1, определяет, что уровень с nuh_layer_id, равным vps_layer_id[j], является выходным уровнем i-го набора OLS, когда ols_mode_idc равно 2. Флаг ols_output_layer_flag[i][j], равный 0, определяет, что уровень с nuh_layer_id, равным vps_layer_id[j], не является выходным уровнем i-го набора OLS, когда ols_mode_idc равно 2.
[0254] Переменную NumOutputLayersInOls[i], определяющую количество выходных уровней в i-м наборе OLS, переменную NumSubLayersInLayerInOLS[i][j], определяющую количество подуровней в j-м уровне i-го набора OLS, переменную OutputLayerIdInOls[i][j], определяющую значение nuh_layer_id j-го выходного уровня в i-м OLS, и переменную LayerUsedAsOutputLayerFlag[k], определяющую, используют ли k-й уровень в качестве выходного хотя бы в одном наборе OLS, вычисляют следующим образом:




[0255] Для каждого значения i в диапазоне от 0 до vps_max_layers_minus1, включительно, значения LayerUsedAsRefLayerFlag[i] и LayerUsedAsOutputLayerFlag[i] могут быть одновременно равны 0. Другими словами, не может быть уровня, который не являлся бы ни выходным уровнем по меньшей мере одного OLS, ни опорным для какого-либо другого уровня.
[0256] Для каждого набора OLS может присутствовать по меньшей мере один уровень, который является выходным. Другими словами, для любого значения i в диапазоне от 0 до TotalNumOlss - 1 включительно значение NumOutputLayersInOls[i] может быть большим или равным 1.
[0257] Переменную NumLayersInOls[i], определяющую количество уровней в i-м наборе OLS, и переменную LayerldlnOls [i][j], определяющую значение nuh_layer_id j-го уровня в i-м наборе OLS, вычисляют следующим образом:


[0258] Переменную OlsLayerIdx[i][j], определяющую порядковый номер уровня OLS с nuh_layer_id, равным LayerIdInOls[i][j], вычисляют следующим образом:
for (i=0; i<TotalNumOlss; i++)
for j=0; j<NumLayersInOls[i]; j++)
OlsLayerIdx[i][LayerldlnOls[i][j]]=j
[0259] Самый нижний уровень в каждом наборе OLS может быть независимым уровнем. То есть, для каждого i в диапазоне от 0 до TotalNumOlss - 1 включительно значение vps_independent_layer_flag[General Layer Idx [LayerldlnOls[i][0]]] должно быть равно 1.
[0260] Каждый уровень должен входить в состав по меньше мере одного набора OLS, заданных набором VPS. Другими словами, для каждого уровня с конкретным значением nuh_layer_id, nuhLayerId, равным одному из vps_layer_id[k] для k в диапазоне от 0 до vps_max_layers_minus1 включительно может быть по меньшей мере одна пара значений i и j, где i лежит в диапазоне от 0 до TotalNumOlss - 1 влкючительно, a j лежит в диапазоне NumLayersInOls[i] - 1 включительно, такая что значение LayerIdInOlsf i][j] равно nuhLayerld.
[0261] В одном из вариантов осуществления настоящего изобретения процедуру декодирования текущего изображения CurrPic выполняют следующим образом:
- PictureOutputFlag задают следующим образом:
- если одно из приведенных ниже условий выполнено («истина»), флаг PictureOutputFlag устанавливают равным 0:
- текущее изображение является RASL-изображением, а флаг NoOutputBeforeRecoveryFlag для соответствующего IRAP-изображения равен 1.
- gdr_enabled_flag равен 1 и текущее изображение является GDR-изображением с флагом NoOutputBeforeRecoveryFlag, равным 1.
- gdr_enabled_flag равен 1, текущее изображение относится к GDR-изображению с флагом NoOutputBeforeRecoveryFlag, равным 1, и PicOrderCntVal текущего изображения меньше, чем RpPicOrderCntVal соответствующего GDR-изображения.
- sps_video_parameter_set_id равен 0, ols_mode_idc равен 0 и текущий пакет доступа, AU, содержит изображение picA, удовлетворяющему всем следующим условиям:
- PicA имеет PictureOutputFlag, равный 1. - PicA имеет nuh_layer_id, nuhLid, больший, чем у текущего изображения.
- PicA принадлежит выходному уровню из OLS (т.е. OutputLayerIdInOls[TargetOlsIdx][0] равен nuhLid).
- sps_video_parameter_set_id больше 0, olsmodeidc равен 2 и ols_output_layer_flag[TargetOlsIdx][GeneralLayerIdx[nuh_layer_id]] равен 0.
- В противном случае PictureOutputFlag устанавливают равным pic_output_flag.
[0262] После декодирования всех слайсов текущего изображения его помечают как «используемое в качестве краткосрочного опорного», и каждую запись ILRP в RefPicList[0] или RefPicList[1] помечают как «используемое в качестве краткосрочного опорного».
[0263] В этом же или в альтернативном варианте осуществления настоящего изобретения, когда каждый уровень является набором выходных уровней, PictureOutputFlag определяют равным pic_output_flag, независимо от значения ols_mode_idc.
[0264] В этом же или в альтернативном варианте осуществления настоящего изобретения PictureOutputFlag определяют равным 0, когда sps_video_parameter_set_id больше 0, each_layer_is_an_ols_flag равен 0, ols_mode_idc равен 0, и текущий пакет доступа, AU, содержит изображение picA, удовлетворяющее всем следующим условиям: PicA имеет PictureOutputFlag, равный 1, PicA имннт nuh_layer_id, nuhLid, больший, чем у текущего изображения, и PicA принадлежит выходному уровню из набора OLS (т.е. OutputLayerIdInOls[TargetOlsIdx][0] равно nuhLid).
[0265] В этом же или в альтернативном варианте осуществления настоящего изобретения, PictureOutputFlag определяют равным 0, когда sps_video_parameter_set_id больше 0, each_layer_is_an_ols_flag равен 0, ols_mode_idc равен 2, и ols_output_layer_flag[TargetOlsIdx][GeneralLayerIdx[nuh layer id]] равен 0.
[0266] Когда на изображение, для компенсации движения или предсказания иных параметров, могут как осуществляться ссылки из одного или более последующих изображений, так и не осуществляться, флаг, указывающий, ссылаются ли последующие изображения на текущее изображение или нет, может быть явно сигнализирован в заголовке изображения или в заголовке слайса.
[0267] К примеру, на фиг. 24 в заголовке изображения сигнализируют флаг non_reference_picture_flag. Флаг non_reference_picture_flag, равный 1, определяет, что изображение, относящееся к этому заголовку, никогда не используют в качестве опорного. Флаг non_reference_picture_flag, равный 0, определяет, что изображение, относящееся к этому заголовку, может как использоваться, так и не использоваться в качестве опорного.
[0268] Когда изображение может быть как обрезано и выведено для отображения, или в иных целях, так и не выводиться, флаг, указывающий, является ли текущее изображение обрезаемым и выводимым или нет, может быть явно сигнализирован в заголовке изображения или в заголовке слайса.
[0269] К примеру, на фиг. 24, в заголовке изображения сигнализируют pic_output_flag. Флаг pic_output_flag, равный 1, указывает на то, что текущее изображение может быть обрезано и выведено. Флаг pic_output_flag, равный 0, указывает на то, что текущее изображение не может быть обрезано и выведено.
[0270] Когда текущее изображение является неопорным, то есть, на него не могут ссылаться последующие в порядке декодирования изображения, и значение non_reference_picture_flag равно 1, значение pic_output_flag может быть равно 1, поскольку любые изображения, на которые не ссылаются последующие изображения и которые не выводят, не могут быть включены в битовый поток видео на стороне декодера.
[0271] В этом же или в альтернативном варианте осуществления настоящего изобретения, когда текущее изображение является неопорным (т.е. non_reference_picture_flag равен 1), pic_output_flag не сигнализируют явно, а определяют как равный 1.
[0272] На стороне кодера неопорное изображение, не являющееся выводимым, может не кодироваться в кодированный битовый поток.
[0273] В промежуточном элементе системы кодированные изображения с флагом non_reference_picture_flag, равным 1, и pic_output_flag, равным 0, могут отбрасываться из кодированного битового потока.
[0274] В данном документе были описаны несколько примеров осуществления настоящего изобретения, однако при этом возможны модификации, изменения и эквивалентные замены, которые попадают в объем настоящего изобретения. Соответственно, нужно понимать, что специалисты в данной области техники способны создать множество систем и способов, которые, хотя явно здесь и не описаны, реализуют замысел настоящего изобретения и соответственно, находятся в пределах его объема и сущности.


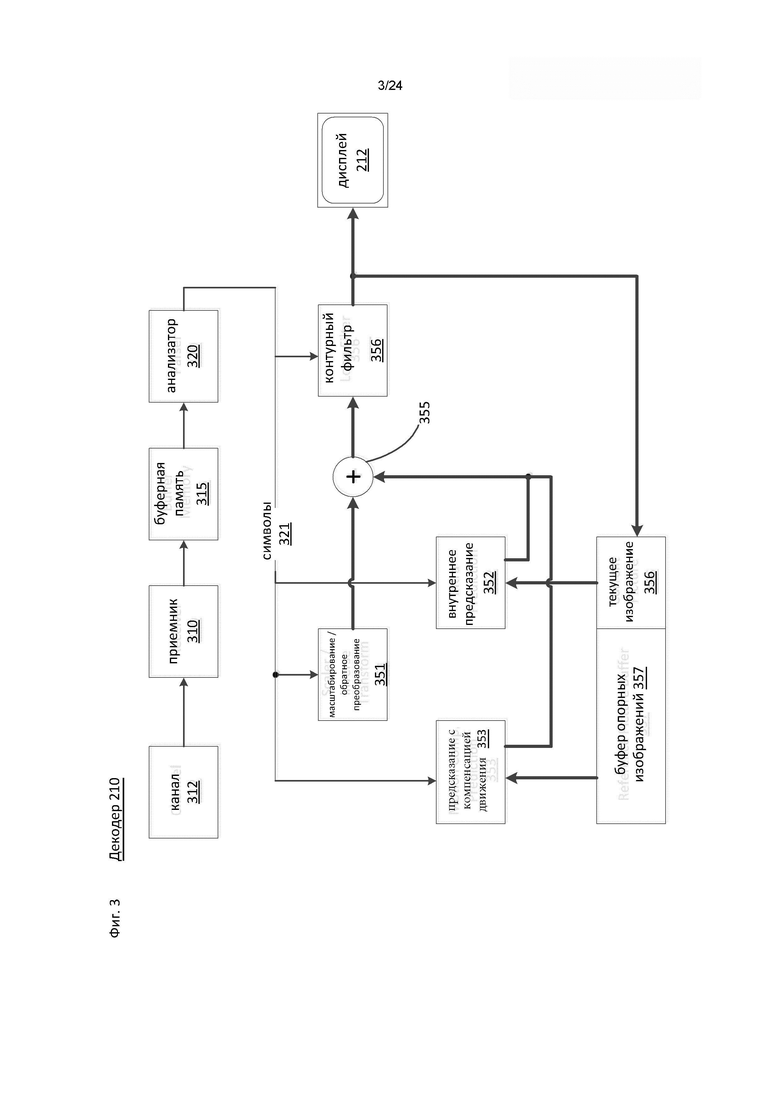






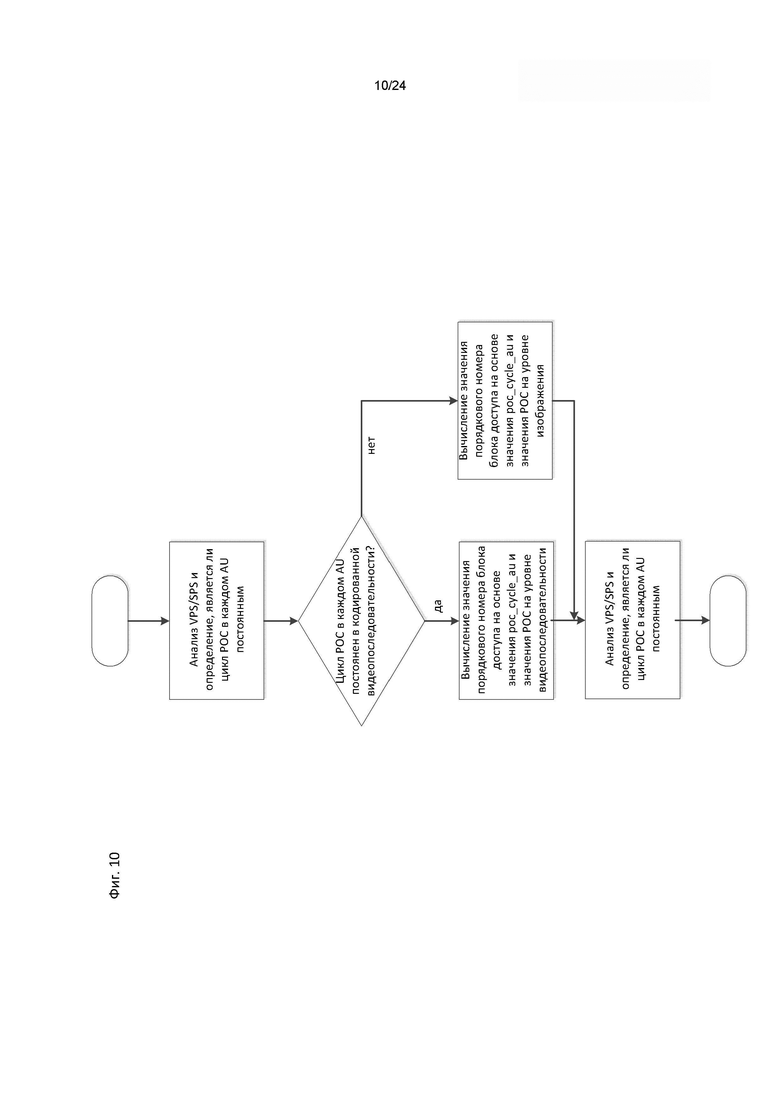



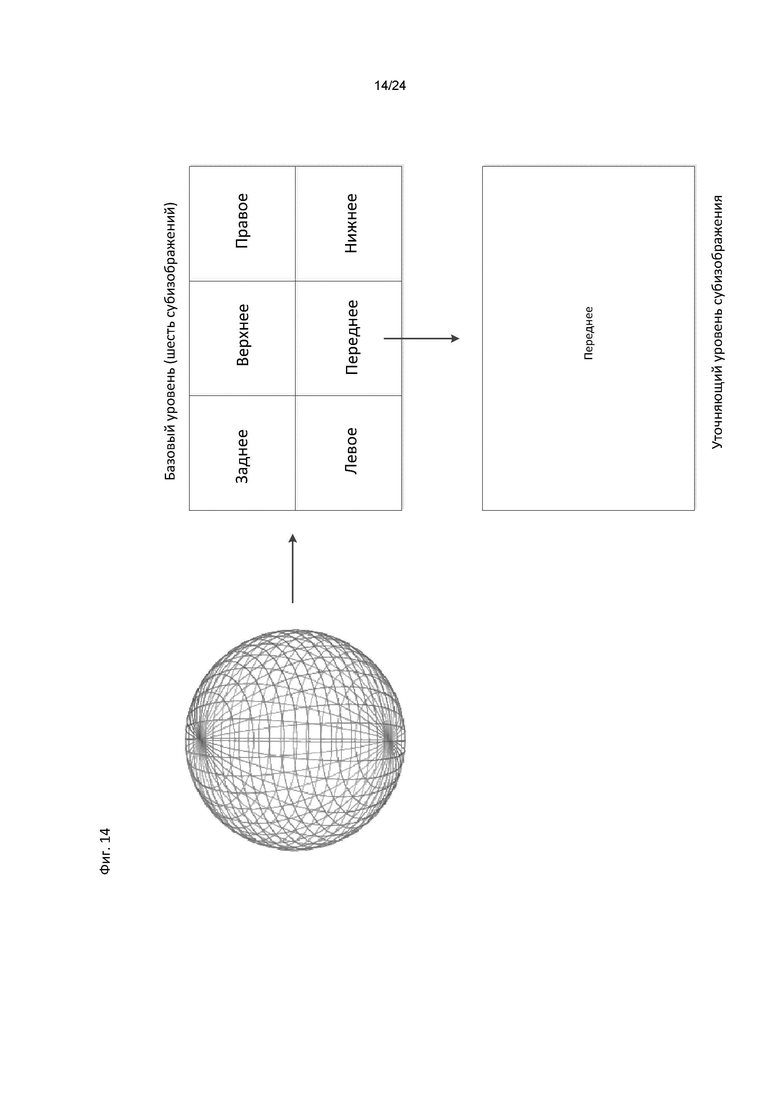
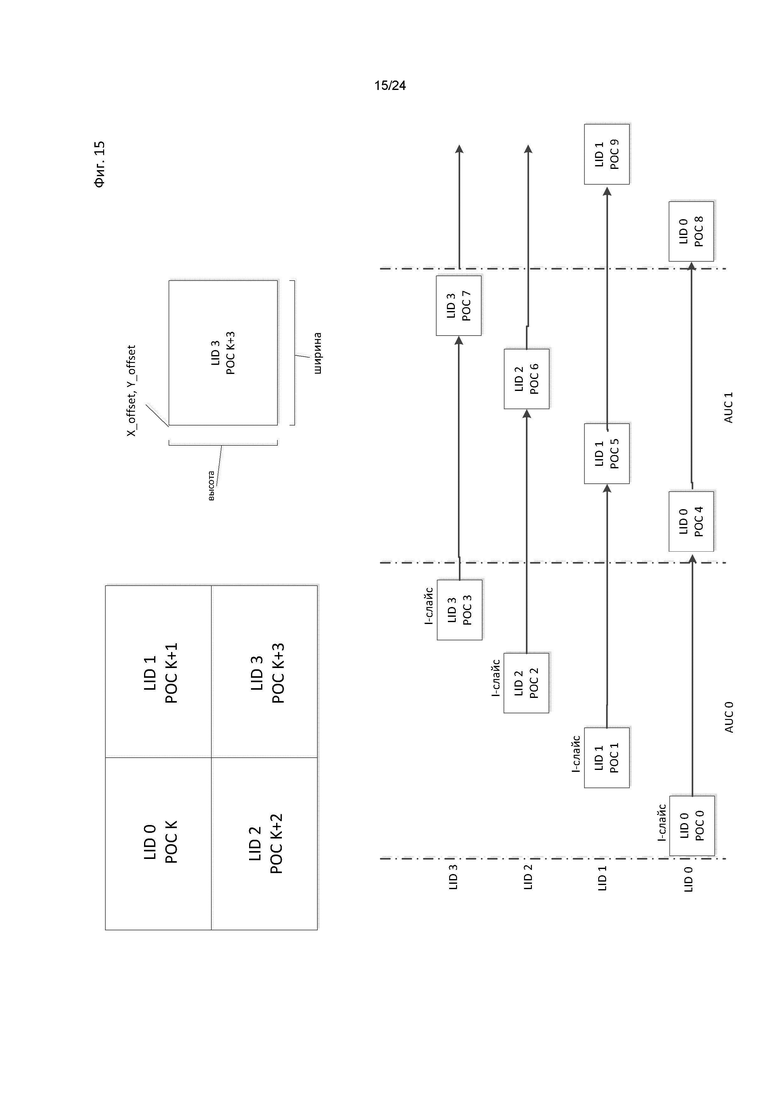



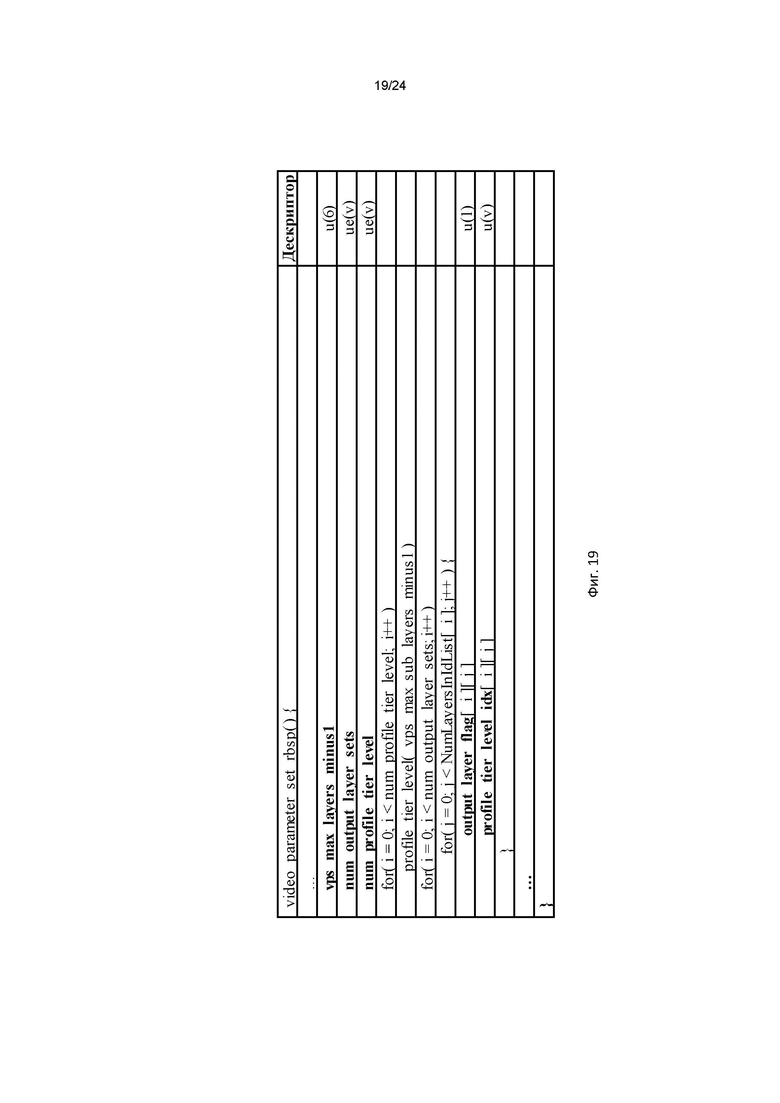





Группа изобретений относится к области обработки данных, а именно к видеокодированию и видеодекодированию. Техническим результатом является обеспечение сигнализации информации о ссылках и информации о выводе изображений в одном или более наборах параметров. Предложен способ декодирования видеоданных, исполняемый процессором. Способ содержит этап, на котором осуществляют прием видеоданных, включающих текущее изображение и одно или более последующих изображений. Далее, согласно способу, осуществляют проверку первого флага, указывающего, ссылаются ли на текущее изображение одно или более последующих изображений в порядке декодирования, проверку второго флага, указывающего, может ли текущее изображение быть выведено. А также осуществляют отбрасывание текущего изображения из видеоданных, если первый флаг указывает на отсутствие использования текущего изображения в качестве опорного изображения, а второй флаг указывает на неспособность текущего изображения быть выведенным. 3 н. и 14 з.п. ф-лы, 24 ил.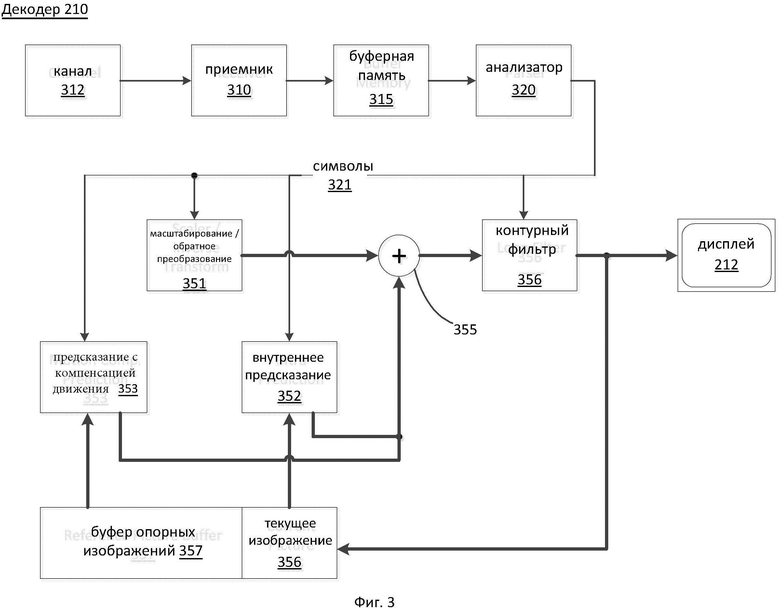
1. Способ декодирования видеоданных, исполняемый процессором и включающий:
прием видеоданных, включающих текущее изображение и одно или более последующих изображений;
проверку первого флага, указывающего, ссылаются ли на текущее изображение одно или более последующих изображений в порядке декодирования;
проверку второго флага, указывающего, может ли текущее изображение быть выведено; и
отбрасывание текущего изображения из видеоданных, если первый флаг указывает на отсутствие использования текущего изображения в качестве опорного изображения, а второй флаг указывает на неспособность текущего изображения быть выведенным.
2. Способ по п. 1, в котором первый флаг и второй флаг сигнализируют в заголовке изображения или в заголовке слайса, относящихся к упомянутым видеоданным.
3. Способ по п. 1, в котором первый флаг указывает, ссылаются ли на текущее изображение для компенсации движения или предсказания параметров.
4. Способ по п. 1, в котором второй флаг указывает, может ли текущее изображение быть обрезано и выведено для отображения или в других целях.
5. Способ по п. 1, в котором значение второго флага определяют во время декодирования на основе значения первого флага.
6. Способ по п. 1, в котором значение второго флага определяют во время кодирования на основе значения первого флага.
7. Компьютерная система для декодирования видеоданных, включающая:
один или более машиночитаемых носителей данных, сконфигурированных для хранения компьютерного программного кода: и
один или более компьютерных процессоров, сконфигурированных для доступа к упомянутому компьютерному программному коду и для выполнения операций согласно инструкциям упомянутого программного кода, при этом упомянутый компьютерный программный код включает:
код приема, сконфигурированный для обеспечения приема, одним или более компьютерными процессорами, видеоданных, содержащих текущее изображение и одно или более последующих изображений;
первый код проверки, сконфигурированный для обеспечения проверки, одним или более компьютерными процессорами, первого флага, указывающего, ссылаются ли на текущее изображение одно или более последующих изображений в порядке декодирования;
второй код проверки, сконфигурированный для обеспечения проверки, одним или более компьютерными процессорами, второго флага, указывающего, может ли текущее изображение быть выведено; и
код декодирования, сконфигурированный для обеспечения, одним или более компьютерными процессорами, отбрасывания текущего изображения из видеоданных, если первый флаг указывает на отсутствие использования текущего изображения в качестве опорного изображения, а второй флаг указывает на неспособность текущего изображения быть выведенным.
8. Компьютерная система по п. 7, в которой первый флаг и второй флаг сигнализируют в заголовке изображения или в заголовке слайса, относящихся к упомянутым видеоданным.
9. Компьютерная система по п. 7, в которой первый флаг указывает, ссылаются ли на текущее изображение для компенсации движения или предсказания параметров.
10. Компьютерная система по п. 7, в которой второй флаг указывает, может ли текущее изображение быть обрезано и выведено для отображения или в других целях.
11. Компьютерная система по п. 7, в которой значение второго флага определяют во время декодирования на основе значения первого флага.
12. Компьютерная система по п. 7, в которой значение второго флага определяют во время кодирования на основе значения первого флага.
13. Машиночитаемый носитель данных, имеющий хранимую на нем компьютерную программу для кодирования видеоданных, при этом компьютерная программа сконфигурирована для обеспечения выполнения, одним или более компьютерными процессорами, следующего:
прием видеоданных, включающих текущее изображение и одно или более последующих изображений;
проверка первого флага, указывающего, ссылаются ли на текущее изображение одно или более последующих изображений в порядке декодирования;
проверка второго флага, указывающего, может ли текущее изображение быть выведено; и
отбрасывание текущего изображения из видеоданных, если первый флаг указывает на отсутствие использования текущего изображения в качестве опорного изображения, а второй флаг указывает на неспособность текущего изображения быть выведенным.
14. Машиночитаемый носитель по п. 13, в котором первый флаг и второй флаг сигнализируют в заголовке изображения или в заголовке слайса, относящихся к упомянутым видеоданным.
15. Машиночитаемый носитель по п. 13, в котором первый флаг указывает, ссылаются ли на текущее изображение для компенсации движения или предсказания параметров.
16. Машиночитаемый носитель по п. 13, в котором второй флаг указывает, может ли текущее изображение быть обрезано и выведено для отображения или в других целях.
17. Машиночитаемый носитель по п. 13, в котором значение второго флага определяют во время декодирования на основе значения первого флага.
| US 20170134742 A1, 11.05.2017 | |||
| US 20190174144 A1, 06.06.2019 | |||
| US 20140301463 A1, 09.10.2014 | |||
| Система и способ предоставления указаний о выводе кадров при видеокодировании | 2014 |
|
RU2697741C2 |
| WO 2007148896 A1, 27.12.2007. | |||

