ВКЛЮЧЕНИЕ ПОСРЕДСТВОМ ССЫЛКИ
[0001] По настоящей заявке испрашивается приоритет согласно заявке на выдачу патента США №16/904,000 «Способ и устройство для уменьшения количества контекстных моделей для энтропийного кодирования флага значимости коэффициента преобразования», поданной 17 июня 2020 года, по которой испрашивался приоритет согласно предварительной заявке на выдачу патента США №62/863,742 «Способ уменьшения количества контекстных моделей для энтропийного кодирования флага значимости коэффициента преобразования», поданной 19 июня 2019 года, которые полностью включены в настоящий документ посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[0002] В настоящей заявке описаны варианты осуществления изобретения, в целом относящиеся к кодированию видеоданных.
УРОВЕНЬ ТЕХНИКИ
[0003] Описание уровня техники приведено здесь для представления в целом контекста изобретения. Работа авторов изобретения, в той мере, в какой она описана в этом разделе, а также аспекты описания, которые не могут квалифицироваться как уровень техники на момент подачи заявки, ни прямо, ни косвенно не признаются уровнем техники для настоящего изобретения.
[0004] Кодирование и декодирование видеоданных может осуществляться с использованием внешнего предсказания изображения с компенсацией движения. Цифровое видео без сжатия может включать последовательность изображений, каждое из которых имеет пространственный размер, например, 1920×1080 отсчетов яркости и связанных с ними отсчетов цветности. Последовательность изображений может иметь фиксированную или переменную частоту смены изображений (неформально также называемую частотой кадров), например, 60 изображений в секунду, или 60 Гц. Видео без сжатия предъявляет значительные требования к битовой скорости. Например, видео 1080р60 4:2:0 с 8 битами на отсчет (разрешение отсчетов яркости 1920×1080 при частоте кадров 60 Гц) требует полосы около 1,5 Гбит/с. Час такого видео требует объема памяти более 600 ГБ.
[0005] Одной целью кодирования и декодирования видеоданных может быть снижение избыточности во входном видеосигнале путем сжатия. Сжатие может способствовать смягчению вышеупомянутых требований к полосе или объему памяти, в ряде случаев на два порядка величины или более. Можно использовать как сжатие без потерь, так и сжатие с потерями, а также их комбинацию. Сжатие без потерь относится к методам реконструкции точной копии исходного сигнала из сжатого исходного сигнала. При использовании сжатия с потерями реконструированный сигнал может быть не идентичен исходному сигналу, но расхождение между исходным и реконструированным сигналами достаточно мало, так что реконструированный сигнал можно использовать для намеченного применения. Сжатие с потерями широко применяется для видеоданных. Допустимая степень искажения зависит от применения; например, пользователи некоторых заказных потоковых приложений могут мириться с более высокими искажениями, чем пользователи телевещательных приложений. Достижимая степень сжатия может отражать, что более высокое разрешенное/допустимое искажение может давать более высокую степень сжатия.
[0006] Кодер и декодер видеоданных могут использовать методы на основе нескольких широких категорий, включая, например, компенсацию движения, преобразование, квантование и энтропийное кодирование.
[0007] Технологии видеокодеков могут включать методы, известные как внутреннее кодирование. При внутреннем кодировании значения отсчетов представлены без ссылки на отсчеты или другие данные из ранее реконструированных опорных изображений. В некоторых видеокодеках изображение пространственно разбивается на блоки отсчетов. Когда все блоки отсчетов кодируются в режиме внутреннего кодирования, это изображение является изображением с внутренним кодированием. Изображения с внутренним кодированием и их производные, такие как изображения обновления независимого декодера, могут использоваться для сброса состояния декодера и, следовательно, могут использоваться в качестве первого изображения в кодированном битовом потоке видеоданных и видеосеансе или в качестве неподвижного изображения. Отсчеты блока с внутренним кодированием могут подвергаться преобразованию, а коэффициенты преобразования могут квантоваться перед энтропийным кодированием. Внутреннее предсказание может быть методом, который минимизирует значения отсчетов в области до преобразования. В некоторых случаях, чем меньше значение DC после преобразования и чем меньше коэффициенты АС, тем меньше битов требуется при заданном размере шага квантования для представления блока после энтропийного кодирования.
[0008] Традиционное внутреннее кодирование, например, известное из технологий кодирования поколения MPEG-2, не использует внутреннее предсказание. Однако некоторые новые технологии сжатия видеоданных включают методы, которые используют предсказание, например, из данных окружающих отсчетов и/или метаданных, полученных во время кодирования/декодирования пространственно соседних и предшествующих в порядке декодирования блоков данных. Такие методы в дальнейшем называются методами «внутреннего предсказания». Следует отметить, что по меньшей мере в некоторых случаях внутреннее предсказание использует только опорные данные из текущего реконструируемого изображения, а не из опорных изображений.
[0009] Существует много различных форм внутреннего предсказания. Когда в данной технологии кодирования видеоданных может использоваться более одного из таких методов, применяемый метод может использоваться в режиме внутреннего предсказания. В некоторых случаях режимы могут иметь подрежимы и/или параметры, которые могут кодироваться индивидуально или включаться в кодовое слово режима. Кодовое слово, используемое для данной комбинации режима/подрежима/параметра, может повлиять на повышение эффективности кодирования за счет внутреннего предсказания, как и технология энтропийного кодирования, используемая для преобразования кодовых слов в битовый поток.
[0010] Режим внутреннего предсказания был введен в Н.264, усовершенствован в Н.265 и дополнительно усовершенствован в новых технологиях кодирования, таких как совместная модель исследования  универсальное кодирование видеоданных
универсальное кодирование видеоданных  и набор эталонов
и набор эталонов 
 Блок предсказателя может быть сформирован с использованием значений соседних отсчетов, принадлежащих уже доступным отсчетам. Значения соседних отсчетов копируются в блок предсказания в соответствии с направлением. Ссылка на используемое направление может кодироваться в битовом потоке или сама может быть предсказана.
Блок предсказателя может быть сформирован с использованием значений соседних отсчетов, принадлежащих уже доступным отсчетам. Значения соседних отсчетов копируются в блок предсказания в соответствии с направлением. Ссылка на используемое направление может кодироваться в битовом потоке или сама может быть предсказана.
[0011] Компенсация движения может быть методом сжатия с потерями и может относиться к методам, в которых блок данных отсчетов из ранее реконструированного изображения или его части (опорного изображения) после пространственного сдвига в направлении, указанном вектором движения (MV, motion vector), используется для предсказания вновь реконструированного изображения или части изображения. В некоторых случаях опорное изображение может быть таким же, как реконструируемое в настоящий момент изображение. Векторы движения могут иметь два измерения X и Y или три измерения, при этом третье измерение указывает на используемое опорное изображение (последнее, косвенно, может быть измерением времени).
[0012] В некоторых методах сжатия видеоданных вектор движения, применимый к определенной области данных отсчетов, может быть предсказан на основе других векторов движения, например, на основе тех, которые связаны с другой областью данных отсчетов, соседней с реконструируемой областью, и предшествуют этому вектору движения в порядке декодирования. Это может существенно уменьшить объем данных, необходимых для кодирования вектора движения, что устраняет избыточность и увеличивает степень сжатия. Предсказание вектора движения может работать эффективно, например, потому что при кодировании входного видеосигнала, полученного от камеры (известного как естественное видео), существует статистическая вероятность того, что области, большие, чем область, к которой применим один вектор движения, перемещаются в сходном направлении и, следовательно, в некоторых случаях могут быть предсказаны с использованием сходного вектора движения, полученного из векторов движения соседней области. Это приводит к тому, что вектор движения, найденный для данной области, является сходным вектору движения, предсказанному на основе окружающих векторов движения, или совпадает с ним и, в свою очередь, может быть представлен после энтропийного кодирования меньшим количеством битов, чем в случае непосредственного кодирования вектора движения. В некоторых случаях предсказание вектора движения может быть примером сжатия без потерь сигнала (а именно, векторов движения), полученного из исходного сигнала (а именно, потока отсчетов). В других случаях само предсказание векторов движения может быть с потерями, например, из за ошибок округления при вычислении предсказателя на основе нескольких окружающих векторов движения.
[0013] Различные механизмы предсказания векторов движения описаны в стандарте H.265/HEVC (Рекомендация МСЭ-Т Н.265, «Высокоэффективное кодирование видеоданных», декабрь 2016 г.). Из множества механизмов предсказания векторов движения, которые предлагает стандарт Н.265, здесь описывается метод, далее называемый «пространственным слиянием».
[0014] Как показано на фиг. 1, текущий блок (101) содержит отсчеты, обнаруженные кодером в процессе поиска движения как предсказуемые на основе предыдущего блока того же размера, который пространственно сдвинут. Вместо непосредственного кодирования вектора движения, этот вектор движения может быть получен из метаданных, связанных с одним или несколькими опорными изображениями, например, на основе самого последнего (в порядке декодирования) опорного изображения с использованием вектора движения, связанного с любым из пяти окружающих отсчетов, обозначенных А0, А1 и В0, B1, В2 (от 102 до 106, соответственно). В стандарте Н.265 предсказание векторов движения может использовать предсказатели на основе того же опорного изображения, которое используется для соседнего блока.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0015] Согласно примеру осуществления изобретения способ декодирования видеоданных, выполняемый в видеодекодере, включает прием битового потока кодированных видеоданных, включающего текущее изображение и по меньшей мере один синтаксический элемент, который соответствует коэффициентам преобразования блока преобразования в текущем изображении. Способ также включает определение значения смещения на основе выходного значения монотонной неубывающей функции f(х), примененной к сумме (х) группы частично реконструированных коэффициентов преобразования. Способ также включает определение индекса контекстной модели на основе суммы упомянутого определенного значения смещения и базового значения Способ также включает выбор, по меньшей мере для одного синтаксиса текущего коэффициента преобразования, контекстной модели из множества контекстных моделей на основе упомянутого определенного индекса контекстной модели.
[0016] Согласно примеру осуществления изобретения способ декодирования видеоданных, выполняемый в видеодекодере, включает прием битового потока кодированных видеоданных, включающего текущее изображение и по меньшей мере один синтаксический элемент, который соответствует коэффициентам преобразования блока преобразования в текущем изображении. Способ также включает определение для каждой области контекстных моделей из множества областей контекстных моделей выходного значения монотонной неубывающей функции, примененной к сумме (х) группы частично реконструированных коэффициентов преобразования, и количества контекстных моделей, связанных с соответствующей областью контекстных моделей Способ также включает определение индекса контекстной модели на основе выходного значения монотонной неубывающей функции каждой области контекстных моделей Способ также включает выбор, по меньшей мере для одного синтаксиса текущего коэффициента преобразования, контекстной модели из множества контекстных моделей на основе упомянутого определенного индекса контекстной модели.
[0017] Согласно примеру осуществления изобретения видеодекодер для декодирования видеоданных включает схему обработки, сконфигурированную для приема битового потока кодированных видеоданных, включающего текущее изображение и по меньшей мере один синтаксический элемент, который соответствует коэффициентам преобразования блока преобразования в текущем изображении. Схема обработки также сконфигурирована для определения значения смещения на основе выходного значения монотонной неубывающей функции f(x), примененной к сумме (х) группы частично реконструированных коэффициентов преобразования. Схема обработки также сконфигурирована для определения индекса контекстной модели на основе суммы упомянутого определенного значения смещения и базового значения Схема обработки также сконфигурирована для выбора, по меньшей мере для одного синтаксиса текущего коэффициента преобразования, контекстной модели из множества контекстных моделей на основе упомянутого определенного индекса контекстной модели.
[0018] Согласно примеру осуществления изобретения видеодекодер для декодирования видеоданных включает схему обработки, сконфигурированную для приема битового потока кодированных видеоданных, включающего текущее изображение и по меньшей мере один синтаксический элемент, который соответствует коэффициентам преобразования блока преобразования в текущем изображении. Схема обработки также сконфигурирована для определения, для каждой области контекстных моделей из множества областей контекстных моделей, выходного значения монотонной неубывающей функции, примененной к сумме (х) группы частично реконструированных коэффициентов преобразования, и количества контекстных моделей, связанных с соответствующей областью контекстных моделей. Схема обработки также сконфигурирована для определения индекса контекстной модели на основе выходного значения монотонной неубывающей функции каждой области контекстных моделей. Схема обработки также сконфигурирована для выбора, по меньшей мере для одного синтаксиса текущего коэффициента преобразования, контекстной модели из множества контекстных моделей на основе упомянутого определенного индекса контекстной модели.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0019] Другие признаки, принципы и различные преимущества настоящего изобретения будут понятны из последующего подробного описания и прилагаемых чертежей.
[0020] Фиг. 1 схематическая иллюстрация текущего блока и окружающих его кандидатов для пространственного слияния в одном примере осуществления изобретения.
[0021] Фиг. 2 схематическая иллюстрация упрощенной структурной схемы системы связи в соответствии с вариантом осуществления изобретения.
[0022] Фиг. 3 - схематическая иллюстрация упрощенной структурной схемы системы связи в соответствии с вариантом осуществления изобретения.
[0023] Фиг. 4 - схематическая иллюстрация упрощенной структурной схемы декодера в соответствии с вариантом осуществления изобретения.
[0024] Фиг. 5 - схематическая иллюстрация упрощенной структурной схемы кодера в соответствии с вариантом осуществления изобретения.
0025] Фиг. 6 показывает структурную схему кодера в соответствии с другим вариантом осуществления изобретения.
[0026] Фиг. 7 показывает структурную схему декодера в соответствии с другим вариантом осуществления изобретения.
[0027] На фиг. 8А показан пример энтропийного кодера на основе контекстно адаптивного двоичного арифметического кодирования 
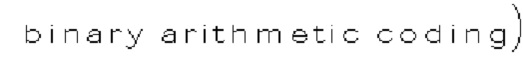 в соответствии с вариантом осуществления изобретения
в соответствии с вариантом осуществления изобретения
[0028] Фиг. 8 В показывает пример энтропийного декодера на основе CAB АС в соответствии с вариантом осуществления изобретения.
[0029] Фиг. 9 показывает пример порядка сканирования субблоков в соответствии с вариантом осуществления изобретения.
[0030] Фиг. 10 показывает пример способа сканирования субблоков, на основе которого формируют различные типы синтаксических элементов коэффициентов преобразования в соответствии с вариантом осуществления изобретения.
[0031] Фиг. 11 показывает пример локального шаблона, используемого для выбора контекста для текущих коэффициентов.
[0032] Фиг. 12 показывает диагональные позиции коэффициентов или уровней коэффициентов внутри блока коэффициентов.
[0033] Фиг. 13 иллюстрирует вычисление контекстного индекса для компонента яркости в соответствии с вариантом осуществления изобретения.
[0034] Фиг. 14 иллюстрирует вычисление контекстного индекса для компонента яркости в соответствии с вариантом осуществления изобретения.
[0035] Фиг. 15 иллюстрирует вычисление контекстного индекса для компонента яркости в соответствии с вариантом осуществления изобретения.
[0036] Фиг. 16 показывает блок-схему, описывающую способ энтропийного декодирования в соответствии с вариантом осуществления изобретения.
[0037] Фиг. 17 показывает блок-схему, описывающую способ энтропийного декодирования в соответствии с вариантом осуществления изобретения.
[0038] Фиг. 18 - схематическая иллюстрация компьютерной системы в соответствии с вариантом осуществления изобретения.
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
[0039] На фиг. 2 показана упрощенная структурная схема системы (200) связи согласно варианту осуществления настоящего изобретения. Система (200) связи включает в себя множество оконечных устройств, которые могут осуществлять связь друг с другом, например, через сеть (250). Например, система (200) связи включает в себя первую пару оконечных устройств (210) и (220), соединенных между собой через сеть (250). В примере, приведенном на фиг. 2, первая пара оконечных устройств (210) и (220) осуществляет однонаправленную передачу данных. Например, оконечное устройство (210) может кодировать видеоданные (например, поток видеоизображений, захваченных оконечным устройством (210)) для передачи в другое оконечное устройство (220) через сеть (250). Кодированные видеоданные могут передаваться в виде одного или более битовых потоков кодированных видеоданных. Оконечное устройство (220) может принимать кодированные видеоданные из сети (250), декодировать кодированные видеоданные для восстановления видеоизображений и их отображения согласно восстановленным видеоданным. Однонаправленная передача данных может быть свойственна приложениям служб массовой информации и т.п.
[0040] В другом примере, система (200) связи включает в себя вторую пару оконечных устройств (230) и (240), которые осуществляют двунаправленную передачу кодированных видеоданных, возникающих, например, в ходе видеоконференцсвязи. Для двунаправленной передачи данных, например, каждое оконечное устройство из оконечных устройств (230) и (240) может кодировать видеоданные (например, поток видеоизображений, захваченных оконечным устройством) для передачи в другое оконечное устройство из оконечных устройств (230) и (240) через сеть (250). Каждое оконечное устройство из оконечных устройств (230) и (240) также может принимать кодированные видеоданные, передаваемые другим оконечным устройством из оконечных устройств (230) и (240), и может декодировать кодированные видеоданные для восстановления видеоизображений и отображать видеоизображения на доступном устройстве отображения согласно восстановленным видеоданным.
[0041] В примере, приведенном на фиг. 2, оконечные устройства (210), (220), (230) и (240) могут быть проиллюстрированы как серверы, персональные компьютеры и смартфоны, но это не ограничивает принципы настоящего изобретения. Варианты осуществления настоящего изобретения находят применение для портативных компьютеров, планшетных компьютеров, медиаплееров и/или специального оборудования для видеоконференцсвязи. Сеть (250) представляет любое количество сетей, которые переносят кодированные видеоданные между оконечными устройствами (210), (220), (230) и (240), включая, например, проводные и/или беспроводные сети связи. Сеть (250) связи позволяет обмениваться данными в режиме канальной коммутации и/или пакетной коммутации. Примеры сетей включают телекоммуникационные сети, локальные сети, глобальные сети и/или интернет. Для настоящего рассмотрения архитектура и топология сети (250) могут не иметь отношения к настоящему изобретению, если конкретно не указаны ниже.
[0042] На фиг. 3 показано размещение видеокодера и видеодекодера в окружении потоковой передачи, в качестве примера применения настоящего изобретения. Настоящее изобретение может в равной степени использоваться и в других применениях обработки видеоданных, включая, например, видеоконференцсвязь, цифровое телевидение, хранение сжатого видео на цифровых носителях, в том числе CD, DVD, карте памяти и т.п.
[0043] Система потоковой передачи может содержать подсистему (313) захвата, которая может включать источник (301) видеоданных, например, цифровую камеру, создающую, например, поток (302) видеоизображений, не подвергнутых сжатию. Например, поток (302) видеоизображений включает отсчеты, полученные цифровой камерой. Поток (302) видеоизображений, показанный жирной линией, чтобы подчеркнуть большой объем данных по сравнению с кодированными видеоданными (304) (или битовыми потоками кодированных видеоданных), может обрабатываться электронным устройством (320), которое содержит видеокодер (303), подключенный к источнику (301) видеоданных. Видеокодер (303) может включать оборудование, программное обеспечение или их комбинацию для обеспечения или реализации аспектов настоящего изобретения, как более подробно описано ниже. Кодированные видеоданные (304) (или битовый поток (304) кодированных видеоданных), показанные тонкой линией, чтобы подчеркнуть меньший объем данных по сравнению с потоком (302) видеоизображений, могут храниться на потоковом сервере (305) для использования в будущем. Одна или более клиентских подсистем потоковой передачи, например клиентские подсистемы (306) и (308) на фиг. 3, могут осуществлять доступ к потоковому серверу (305) для извлечения копий (307) и (309) кодированных видеоданных (304). Клиентская подсистема (306) может содержать видеодекодер (310), например, в электронном устройстве (330). Видеодекодер (310) декодирует входящую копию (307) кодированных видеоданных и создает исходящий поток (311) видеоизображений, который может визуализироваться на дисплее (312) (например, отображающем экране) или другом устройстве визуализации (не показано). В некоторых системах потоковой передачи, кодированные видеоданные (304), (307) и (309) (например, битовые потоки видеоданных) могут кодироваться согласно тем или иным стандартам кодирования/сжатия видеоданных. Примеры этих стандартов включают Рекомендацию МСЭ-Т Н.265. Например, разрабатывается стандарт кодирования видеоданных под официальным названием «Универсальное кодирование видеоданных» (VVC, Versatile Video Coding). Настоящее изобретение может использоваться в контексте VVC.
[0044] Заметим, что электронные устройства (320) и (330) могут содержать другие компоненты (не показаны). Например, электронное устройство (320) может содержать видеодекодер (не показан), а электронное устройство (330) также может содержать видеокодер (не показан).
[0045] На фиг. 4 показана структурная схема видеодекодера (410) согласно варианту осуществления настоящего изобретения. Видеодекодер (410) может входить в состав электронного устройства (430). Электронное устройство (430) может содержать приемник (431) (например, приемные схемы). Видеодекодер (410) может использоваться вместо видеодекодера (310) в примере, приведенном на фиг. 3.
[0046] Приемник (431) может принимать одну или более кодированных видеопоследовательностей для декодирования видеодекодером (410), в том же или другом варианте осуществления изобретения, по одной кодированной видеопоследовательности за раз, причем декодирование каждой кодированной видеопоследовательности не зависит от других кодированных видеопоследовательностей. Кодированная видеопоследовательность может приниматься из канала (401), который может быть аппаратной/программной линией связи с запоминающим устройством, где хранятся кодированные видеоданные. Приемник (431) может принимать кодированные видеоданные с другими данными, например, кодированными аудиоданными и/или вспомогательными потоками данных, которые могут перенаправляться на соответствующие использующие их объекты (не показаны). Приемник (431) может отделять кодированную видеопоследовательность от других данных. Для борьбы с джиггером сети, между приемником (431) и энтропийным декодером/анализатором (420) (далее «анализатором (420)») может быть подключена буферная память (415). В некоторых вариантах применения буферная память (415) входит в состав видеодекодера (410). В других она может не входить в состав видеодекодера (410) (не показано). В прочих вариантах может иметься буферная память вне видеодекодера (410) (не показано), например, для борьбы с джиттером сети, помимо другой буферной памяти (415) в составе видеодекодера (410), например, для управления временем воспроизведения. Когда приемник (431) принимает данные от устройства хранения/перенаправления с достаточной полосой и управляемостью или из изосинхронной сети, буферная память (415) может быть не нужна или может быть мала. Для использования в пакетных сетях наилучшей попытки, например, в Интернете, буферная память (415) может потребоваться, может быть сравнительно большой, может иметь преимущественно адаптивный размер и по меньшей мере частично может быть реализована в операционной системе или аналогичных элементах (не показаны) вне видеодекодера (410).
[0047] Видеодекодер (410) может содержать анализатор (420) для реконструкции символов (421) из кодированной видеопоследовательности. Категории этих символов включают информацию, используемую для управления работой видеодекодера (410) и, возможно, информацию для управления устройством визуализации, например устройством (412) визуализации (например, отображающим экраном), которое не является неотъемлемой частью электронного устройства (430), но может быть подключено к электронному устройству (430), как показано на фиг. 4. Информация управления для устройств(а) визуализации может представлять собой сообщения дополнительной информации улучшения (SEI, Supplemental Enhancement Information) или фрагменты набора параметров информации о возможности использования видео (VUI, Video Usability Information) (не показаны). Анализатор (420) может анализировать / энтропийно декодировать принятую кодированную видеопоследовательность. Кодирование видеопоследовательности может осуществляться в соответствии с технологией или стандартом кодирования видеоданных и может следовать различным принципам, в том числе кодированию с переменной длиной серии, кодированию по Хаффману, арифметическому кодированию с контекстной чувствительностью или без нее и т.д. Анализатор (420) может извлекать из кодированной видеопоследовательности набор параметров подгруппы по меньшей мере для одной из подгрупп пикселей в видеодекодере на основе по меньшей мере одного параметра, соответствующего группе. Подгруппы могут включать группы изображений (GOP, Groups of Pictures), изображения, тайлы, слайсы, макроблоки, единицы кодирования (CU, Coding Units), блоки, единицы преобразования (TU, Transform Units), единицы предсказания (PU, Prediction Units) и т.д. Анализатор (420) также может извлекать из кодированной видеопоследовательности информацию, например, коэффициенты преобразования, значения параметров квантователя, векторы движения и т.д.
[0048] Анализатор (420) может осуществлять операцию энтропийного декодирования / анализа видеопоследовательности, принятой из буферной памяти (415), для создания символов (421).
[0049] Для реконструкции символов (421) могут использоваться несколько разных модулей в зависимости от типа кодированного видеоизображения или его частей (например: изображения с внутренним и внешним кодированием, блоки с внутренним и внешним кодированием) и других факторов. Какие модули и как используются, может определяться информацией управления подгруппами, полученной из кодированной видеопоследовательности анализатором (420). Поток такой информации управления подгруппами между анализатором (420) и модулями для простоты в дальнейшем не показан.
[0050] Помимо ранее упомянутых функциональных блоков, видеодекодер (410) может принципиально разделяться на несколько функциональных модулей, как описано ниже. В практической реализации в условиях коммерческих ограничений многие из этих модулей тесно взаимодействуют друг с другом и могут, по меньшей мере частично, встраиваться один в другой. Однако в целях описания настоящего изобретения уместно принципиальное разделение на перечисленные ниже функциональные модули.
[0051] Первым модулем является модуль (451) масштабирования / обратного преобразования. Модуль (451) масштабирования / обратного преобразования принимает квантованный коэффициент преобразования, а также информацию управления, включающую используемое преобразование, размер блока, коэффициент квантования, матрицы масштабирования квантования и т.д. в качестве символа(ов) (421) от анализатора (420). Модуль (451) масштабирования / обратного преобразования может выводить блоки, содержащие значения отсчетов, которые можно вводить в агрегатор (455).
[0052] В ряде случаев, выходные отсчеты блока (451) масштабирования / обратного преобразования могут относиться к блоку с внутренним кодированием; то есть к блоку, который не использует предсказанную информацию из ранее реконструированных изображений, но может использовать предсказанную информацию из ранее реконструированных частей текущего изображения. Такая предсказанная информация может обеспечиваться модулем (452) внутреннего предсказания изображения. В ряде случаев модуль (452) внутреннего предсказания изображения формирует блок такого же размера и формы, как у блока, подлежащего реконструкции, с использованием информации ранее реконструированного окружения, извлеченной из буфера (458) текущего изображения. Буфер (458) текущего изображения буферизует, например, частично реконструированное текущее изображение и/или полностью реконструированное текущее изображение. Агрегатор (455) в ряде случаев добавляет, для каждого отсчета, информацию предсказания, сформированную модулем (452) внутреннего предсказания, в информацию выходных отсчетов, предоставленную модулем (451) масштабирования / обратного преобразования.
[0053] В других случаях выходные отсчеты модуля (451) масштабирования / обратного преобразования могут относиться к блоку с внутренним кодированием, возможно, с компенсацией движения. В таком случае модуль (453) предсказания с компенсацией движения может осуществлять доступ к памяти (457) опорных изображений для извлечения отсчетов, используемых для предсказания. После применения компенсации движения к извлеченным отсчетам в соответствии с символами (421), относящимися к блоку, эти отсчеты могут добавляться агрегатором (455) к выходному сигналу модуля (451) масштабирования / обратного преобразования (в этом случае называемому отсчетами остатка или сигналом остатка) для генерации информации выходных отсчетов. Адреса в памяти (457) опорных изображений, откуда модуль (453) предсказания с компенсацией движения извлекает отсчеты для предсказания, могут управляться векторами движения, доступными модулю (453) предсказания с компенсацией движения, в форме символов (421), которые могут иметь, например, компоненты X, Y и компоненты опорного изображения. Компенсация движения также может включать интерполяцию значений отсчетов, извлеченных из памяти (457) опорных изображений, когда используются точные векторы движения подотсчетов, механизмы предсказания векторов движения и т.д.
[0054] К выходным отсчетам агрегатора (455) можно применять различные методы контурной фильтрации в модуле (456) контурного фильтра. Технологии сжатия видеоданных могут включать технологии контурного фильтра под управлением параметров, включенных в кодированную видеопоследовательность (также называемую битовым потоком кодированных видеоданных) и доступных модулю (456) контурного фильтра в качестве символов (421) от анализатора (420), но также могут реагировать на метаинформацию, полученную в ходе декодирования предыдущих (в порядке декодирования) частей кодированного изображения или кодированной видеопоследовательности, а также реагировать на ранее реконструированные и подвергнутые контурной фильтрации значения отсчетов.
[0055] Модуль (456) контурного фильтра может выдавать поток отсчетов, который может поступать на устройство (412) визуализации, а также сохраняться в памяти (457) опорных изображений для использования в будущем внешнем предсказании изображения.
[0056] Некоторые кодированные изображения, будучи полностью реконструированы, могут использоваться в качестве опорных изображений для будущего предсказания. Например, когда кодированное изображение, соответствующее текущему изображению, полностью реконструировано и идентифицировано как опорное изображение (например, анализатором (420)), буфер (458) текущего изображения может становиться частью памяти (457) опорных изображений, и может повторно выделяться свежий буфер текущего изображения до начала реконструкции следующего кодированного изображения.
[0057] Видеодекодер (410) может осуществлять операции декодирования согласно заранее заданной технологии сжатия видеоданных, например, по стандарту Рекомендации МСЭ Т Н.265. Кодированная видеопоследовательность может соответствовать синтаксису, заданному используемой технологией или используемым стандартом сжатия видеоданных, в том смысле, что кодированная видеопоследовательность может придерживаться как синтаксиса технологии или стандарта сжатия видеоданных, так и профилей, задокументированных в технологии или стандарте сжатия видеоданных. В частности, профиль может выбирать некоторые инструменты как инструменты, доступные для использования только под этим профилем, из всех инструментов, доступных в технологии или стандарте сжатия видеоданных. Также для согласованности может быть необходимо, чтобы сложность кодированной видеопоследовательности оставалась в границах, заданных уровнем технологии или стандарта сжатия видеоданных. В ряде случаев, уровни ограничивают максимальный размер изображения, максимальную частоту кадров, максимальную частоту отсчетов для реконструкции (измеряемую, например, в мегаотсчетах в секунду), максимальный размер опорного изображения и т.д. Пределы, установленные уровнями, в ряде случаев могут дополнительно ограничиваться спецификациями гипотетического эталонного декодера (HRD, Hypothetical Reference Decoder) и метаданными для управления буфером HRD, сигнализируемого в кодированной видеопоследовательности.
[0058] Согласно варианту осуществления изобретения, приемник (431) может принимать дополнительные (избыточные) данные с кодированными видеоданными. Дополнительные данные могут быть включены как часть кодированной(ых) видеопоследовательности(ей). Дополнительные данные могут использоваться видеодекодером (410) для правильного декодирования данных и/или более точной реконструкции исходных видеоданных. Дополнительные данные могут представлять собой, например, временные уровни улучшения, пространственные уровни улучшения или уровни улучшения отношения «сигнал/шум» (SNR, signal noise ratio), избыточные слайсы, избыточные изображения, коды прямой коррекции ошибок и т.д.
[0059] На фиг. 5 показана структурная схема видеокодера (503) согласно варианту осуществления настоящего изобретения. Видеокодер (503) входит в состав электронного устройства (520). Электронное устройство (520) содержит передатчик (540) (например, передающую схему). Видеокодер (503) может использоваться вместо видеокодера (303) в примере, приведенном на фиг. 3.
[0060] Видеокодер (503) может принимать отсчеты видеоданных от источника (501) видеоданных (который не входит в состав электронного устройства (520) в примере, показанном на фиг. 5), который может захватывать видеоизображение(я), подлежащее(ие) кодированию видеокодером (503). В другом примере источник (501) видеоданных входит в состав электронного устройства (520).
[0061] Источник (501) видеоданных может обеспечивать исходную видеопоследовательность, подлежащую кодированию видеокодером (503) в форме потока отсчетов цифровых видеоданных любой подходящей битовой глубины (например: 8 битов, 10 битов, 12 битов, …), любого цветового пространства (например, ВТ.601 Y CrCB, RGB, …) и любой подходящей структуры дискретизации (например, Y CrCb 4:2:0, Y CrCb 4:4:4). В системе службы массовой информации источником (501) видеоданных может быть запоминающее устройство, где хранится ранее подготовленное видео. В системе видеоконференцсвязи источником (501) видеоданных может быть камера, которая захватывает информацию локального изображения в виде видеопоследовательности. Видеоданные могут предоставляться как множество отдельных изображений, которые создают ощущение движения при наблюдении в последовательности. Сами изображения могут быть организованы как пространственный массив пикселей, где каждый пиксель может содержать один или более отсчетов в зависимости от используемой структуры дискретизации, цветового пространства и т.д. Специалисту в данной области техники нетрудно понять соотношение между пикселями и отсчетами. Последующее описание посвящено отсчетам.
[0062] Согласно варианту осуществления изобретения, видеокодер (503) может кодировать и сжимать изображения исходной видеопоследовательности в кодированную видеопоследовательность (543) в реальном времени или с учетом любых других временных ограничений, налагаемых применением. Установление надлежащей скорости кодирования является одной из функций контроллера (550). В некоторых вариантах осуществления изобретения контроллер (550) управляет другими функциональными модулями, как описано ниже, и функционально подключен к другим функциональным модулям. Подключение для простоты не показано. Параметры, установленные контроллером (550), могут включать параметры, связанные с регулировкой частоты (пропуск изображения, квантователь, значение лямбда, применяемое в методах оптимизации скорости искажения, и т.д.), размер изображения, организацию групп изображений (GOP, group of pictures), максимальную зону поиска вектора движения и т.д. Контроллер (550) может иметь другие подходящие функции, относящиеся к видеокодеру (503), оптимизированному для конкретной конструкции системы.
[0063] В некоторых вариантах осуществления изобретения видеокодер (503) выполнен с возможностью работать в контуре кодирования. В качестве очень упрощенного описания, например, контур кодирования может включать кодер (530) источника (например, отвечающий за создание символов, например, потока символов на основе входного изображения, подлежащего кодированию, и опорного(ых) изображения(ий)) и (локальный) декодер (533), встроенный в видеокодер (503). Декодер (533) реконструирует символы для создания данных отсчетов аналогично тому, как это делал бы (удаленный) декодер (поскольку любое сжатие между символами и битовым потоком кодированных видеоданных происходит без потерь в технологиях сжатия видеоданных, рассматриваемых в данном описании). Реконструированный поток отсчетов (данные отсчетов) поступают в память (534) опорных изображений. Поскольку декодирование потока символов приводит к результатам, с точностью до бита, которые не зависят от положения (локального или удаленного) декодера, содержимое памяти (534) опорных изображений также будет одинаковым с точностью до бита для локального кодера и удаленного кодера. Другими словами, часть предсказания кодера «видит» в качестве отсчетов опорного изображения точно такие же значения отсчетов, как «видел» бы декодер при использовании предсказания в ходе декодирования. Этот фундаментальный принцип синхронизма опорного изображения (и, в итоге, дрейф, если синхронизм не удается поддерживать, например, вследствие канальных ошибок) используется также в некоторых связанных областях техники.
[0064] «Локальный» декодер (533) может действовать таким же образом, как «удаленный» декодер, например, видеодекодер (410), подробно описанный выше со ссылкой на фиг. 4. Однако опять же, согласно фиг. 4, поскольку символы доступны, и кодирование/декодирование символов в кодированную видеопоследовательность энтропийным кодером (545) и анализатором (420) может осуществляться без потерь, части энтропийного декодирования видеодекодера (410), включающие буферную память (415) и анализатор (420), могут быть не полностью реализованы в локальном декодере (533).
[0065] При этом можно сделать вывод, что любая технология декодирования, присутствующая в декодере, за исключением анализа / энтропийного декодирования, также обязательно должна присутствовать по существу в идентичной функциональной форме в соответствующем кодере. По этой причине настоящее изобретение сконцентрировано на работе декодера. Описание технологий кодирования может быть сокращено, поскольку они являются обратными подробно описанным технологиям декодирования. Лишь в некоторых областях требуется более подробное описание, которое приведено ниже.
[0066] Согласно некоторым примерам, в ходе работы кодер (530) источника может осуществлять кодирование с предсказанием и компенсацией движения, при котором входное изображение кодируется с предсказанием на основе одного или более ранее кодированных изображений из видеопоследовательности, указанных как «опорные изображения». Таким образом, механизм (532) кодирования кодирует разности между блоками пикселей входного изображения и блоками пикселей опорного изображения(й), которое(ые) может(ут) выбираться в качестве ссылки(ок) предсказания на входное изображение.
[0067] Локальный видеодекодер (533) может декодировать кодированные видеоданные изображений, которые могут быть указаны как опорные изображения, на основе символов, созданных кодером (530) источника. Операции механизма (532) кодирования могут быть преимущественно процессами с потерями. Когда кодированные видеоданные могут декодироваться в видеодекодере (не показан на фиг. 5), реконструированная видеопоследовательность обычно может представлять собой копию исходной видеопоследовательности с некоторыми ошибками. Локальный видеодекодер (533) дублирует процессы декодирования, которые могут осуществляться видеодекодером на опорных изображениях, и может обеспечивать сохранение реконструированных опорных изображений в кэш памяти (534) опорных изображений. Таким образом, видеокодер (503) может локально сохранять копии реконструированных опорных изображений, имеющие такое же содержимое, как реконструированные опорные изображения, которые будут получены удаленным видеодекодером (в отсутствие ошибок передачи).
[0068] Предсказатель (535) может осуществлять поиски предсказания для механизма (532) кодирования. Таким образом, для нового изображения, подлежащего кодированию, предсказатель (535) может искать в памяти (534) опорных изображений данные отсчетов (в качестве кандидатов на роль опорных блоков пикселей) или конкретные метаданные, например, векторы движения опорного изображения, формы блоков и т.д., которые могут служить надлежащей ссылкой для предсказания новых изображений. Предсказатель (535) может работать на основе «блоки отсчетов × блоки пикселей» для нахождения надлежащих ссылок для предсказания. В ряде случаев, согласно результатам поиска, полученным предсказателем (535), входное изображение может иметь ссылки для предсказания, извлеченные из множества опорных изображений, хранящихся в памяти (534) опорных изображений.
[0069] Контроллер (550) может управлять операциями кодирования кодера (530) источника, включая, например, установление параметров, а также параметров подгруппы, используемых для кодирования видеоданных.
[0070] Выходной сигнал всех вышеупомянутых функциональных модулей может подвергаться энтропийному кодированию в энтропийном кодере (545). Энтропийный кодер (545) переводит символы, сформированные различными функциональными модулями, в кодированную видеопоследовательность путем сжатия символов без потерь согласно, например, технологиям кодирования по Хаффману, кодирования с переменной длиной серии, арифметического кодирования и т.д.
[0071] Передатчик (540) может буферизовать кодированную(ые) видеопоследовательность(и), созданную(ые) энтропийным кодером (545), для подготовки к передаче через канал (560) связи, который может быть аппаратной/программной линией связи с запоминающим устройством, где хранятся кодированные видеоданные. Передатчик (540) может объединять кодированные видеоданные от видеокодера (503) с другими данными, подлежащими передаче, например, с кодированными аудиоданными и/или вспомогательными потоками данных (источники не показаны).
[0072] Контроллер (550) может управлять работой видеокодера (503). В ходе кодирования контроллер (550) может назначать каждому кодированному изображению тот или иной тип кодированного изображения, который может определять методы кодирования, применимые к соответствующему изображению. Например, изображениям часто могут назначаться следующие типы изображения.
[0073] Изображение с внутренним кодированием (I-изображение), которое можно кодировать и декодировать без использования какого-либо другого изображения в последовательности в качестве источника для предсказания. Некоторые видеокодеки допускают разные типы изображений с внутренним кодированием, включая, например, изображения в формате независимого обновления декодера (IDR, Independent Decoder Refresh). Специалисту в данной области техники известны разновидности I-изображений и их соответствующие варианты применения и особенности.
[0074] Изображение с предсказанием (Р-изображение), которое можно кодировать и декодировать с использованием внутреннего предсказания или внешнего предсказания с использованием не более одного вектора движения и опорного индекса для предсказания значений отсчетов каждого блока.
[0075] Изображение с двунаправленным предсказанием (В-изображение), которое можно кодировать и декодировать с использованием внутреннего предсказания или внешнего предсказания с использованием не более двух векторов движения и опорных индексов для предсказания значений отсчетов каждого блока. Аналогично, изображения с множеством предсказаний могут использовать более двух опорных изображений и соответствующие метаданные для реконструкции одного блока.
[0076] Исходные изображения обычно допускают пространственное разделение на множество блоков отсчетов (например, блоки 4×4, 8×8, 4×8 или 16×16 отсчетов каждый) и кодирование на поблочной основе (блок за блоком). Блоки могут кодироваться с предсказанием со ссылкой на другие (ранее кодированные) блоки, определенные назначением кодирования, применяемым к соответствующим изображениям этих блоков. Например, блоки I-изображений могут кодироваться без предсказания или с предсказанием со ссылкой на ранее кодированные блоки того же изображения (с пространственным предсказанием или внутренним предсказанием). Блоки пикселей Р-изображений могут кодироваться с предсказанием, посредством пространственного предсказания или временного предсказания со ссылкой на одно ранее кодированное опорное изображение. Блоки В-изображений могут кодироваться с предсказанием, посредством пространственного предсказания или временного предсказания со ссылкой на одно или два ранее кодированных опорных изображения.
[0077] Видеокодер (503) может осуществлять операции кодирования согласно заранее заданной технологии или стандарту видеокодирования, например, Рекомендации МСЭ-Т Н.265. В своей работе видеокодер (503) может осуществлять различные операции сжатия, в том числе операции кодирования с предсказанием, которые используют временную и пространственную избыточность во входной видеопоследовательности. Поэтому кодированные видеоданные могут соответствовать синтаксису, заданному используемой технологией или стандартом кодирования видеоданных.
[0078] Согласно варианту осуществления изобретения, передатчик (540) может передавать дополнительные данные с кодированными видеоданными. Кодер (530) источника может включать такие данные как часть кодированной видеопоследовательности. Дополнительные данные могут содержать временные/пространственные/SNR уровни улучшения, другие формы избыточных данных, например, избыточные изображения и слайсы, сообщения SEI, фрагменты набора параметров VUI и т.д.
[0079] Видео может захватываться как множество исходных изображений (видеоизображений) во временной последовательности. Предсказание внутри изображения (часто сокращенно называемое внутренним предсказанием) использует пространственную корреляцию в данном изображении, а внешнее предсказание изображения использует (временную или иную) корреляцию между изображениями. Например, конкретное изображение, подлежащее кодированию/декодированию, которое называется текущим изображением, разбивается на блоки. Когда блок в текущем изображении аналогичен опорному блоку в ранее кодированном и все еще буферизованном опорном изображении в видео, блок в текущем изображении может кодироваться вектором, который называется вектором движения. Вектор движения указывает на опорный блок в опорном изображении и может иметь третье измерение, идентифицирующее опорное изображение, в случае использования множества опорных изображений.
[0080] В некоторых вариантах осуществления изобретения, может использоваться метод двойного предсказания в предсказании между изображениями. Согласно методу двойного предсказания, используются два опорных изображения, например, первое опорное изображение и второе опорное изображение, которые оба предшествуют в порядке декодирования текущему изображению в видео (но могут быть в прошлом и будущем, соответственно, в порядке отображения). Блок в текущем изображении может кодироваться первым вектором движения, который указывает на первый опорный блок в первом опорном изображении, и вторым вектором движения, который указывает на второй опорный блок во втором опорном изображении. Блок может предсказываться с помощью комбинации первого опорного блока и второго опорного блока.
[0081] Дополнительно, способ режима слияния может использоваться во внешнем предсказании изображения для повышения эффективности кодирования.
[0082] Согласно некоторым вариантам осуществления изобретения предсказания, например, внешнее предсказание изображения и внутреннее предсказание изображения осуществляются поблочно. Например, согласно стандарту HEVC, изображение в последовательности видеоизображений разбивается на единицы дерева кодирования (CTU, coding tree units) для сжатия, единицы CTU в изображении имеют одинаковый размер, например 64×64 пикселя, 32×32 пикселя или 16×16 пикселей. В общем случае единица CTU включает три блока дерева кодирования (СТВ, coding tree blocks), а именно, один блок СТВ яркости и два блока СТВ цветности. Каждая единица CTU может рекурсивно делиться на основе квадродерева на одну или несколько единиц кодирования (CU). Например, единица CTU размером 64×64 пикселя может делиться на одну единицу CU размером 64×64 пикселя или 4 единицы CU размером 32×32 пикселя или 16 единиц CU размером 16×16 пикселей. Например, каждая единица CU анализируется для определения типа предсказания для этой единицы CU, например, типа внешнего предсказания или типа внутреннего предсказания. Единица CU делится на одну или более единиц предсказания (PU) в зависимости от временной и/или пространственной предсказуемости. В целом, каждая единица PU включает блок предсказания (РВ, prediction block) яркости и два блока РВ предсказания цветности. Согласно варианту осуществления изобретения, операция предсказания при кодировании (кодировании/декодировании) осуществляется в единице блока предсказания. В качестве примера блока предсказания, блок предсказания яркости включает матрицу значений (например, значений яркости) для пикселей, например, 8×8 пикселей, 16×16 пикселей, 8×16 пикселей, 16×8 пикселей и т.п.
[0083] На фиг. 6 показана схема видеокодера (603) согласно другому варианту осуществления изобретения. Видеокодер (603) выполнен с возможностью приема блока обработки (например, блока предсказания) значений отсчетов в текущем видеоизображении в последовательности видеоизображений и кодирования блока обработки в кодированное изображение, которое составляет часть кодированной видеопоследовательности. Например, видеокодер (603) используется вместо видеокодера (303) в примере, приведенном на фиг. 3.
[0084] В примере HEVC видеокодер (603) принимает матрицу значений отсчетов для блока обработки, например, блока предсказания из 8×8 отсчетов и т.п. Видеокодер (603) определяет, наилучшим ли образом кодируется блок обработки в режиме внутреннего предсказания, режиме внешнего предсказания или режиме двойного предсказания с использованием, например, оптимизации «скорость искажения». Когда блок обработки подлежит кодированию в режиме внутреннего предсказания, видеокодер (603) может использовать метод внутреннего предсказания для кодирования блока обработки в кодированное изображение, а когда блок обработки подлежит кодированию в режиме внешнего предсказания или режиме двойного предсказания, видеокодер (603) может использовать метод внешнего предсказания или двойного предсказания, соответственно, для кодирования блока обработки в кодированное изображение. В некоторых технологиях видеокодирования режим слияния может быть подрежимом внешнего предсказания изображения, где вектор движения выводится из одного или более предсказателей вектора движения без привлечения кодированного компонента вектора движения вне предсказателей. В некоторых других технологиях видеокодирования может присутствовать компонент вектора движения, применимый к данному блоку. В порядке примера, видеокодер (603) содержит другие компоненты, например, модуль определения режима (не показан) для определения режима блоков обработки.
[0085] В примере, приведенном на фиг. 6, видеокодер (603) содержит кодер (630) внешнего кодирования, кодер (622) внутреннего кодирования, вычислитель (623) остатка, переключатель (626), кодер (624) остатка, общий контроллер (621) и энтропийный кодер (625), соединенные друг с другом так, как показано на фиг. 6.
[0086] Кодер (630) внешнего кодирования выполнен с возможностью приема отсчетов текущего блока (например, блока обработки), сравнения блока с одним или более опорными блоками в опорных изображениях (например, блоками в предыдущих изображениях и более поздних изображениях), создания информации внешнего предсказания (например, описания избыточной информации согласно методу внешнего кодирования, векторов движения, информации режима слияния) и вычисления результатов внешнего предсказания (например, блока предсказания) на основе информации внешнего предсказания с использованием любого подходящего метода. В некоторых примерах опорными изображениями являются декодированные опорные изображения, которые декодируются на основе информации кодированного видео.
[0087] Кодер (622) внутреннего кодирования выполнен с возможностью приема отсчетов текущего блока (например, блока обработки), в ряде случаев сравнения блока с блоками, ранее кодированными в том же изображении, формирования квантованных коэффициентов после преобразования и в ряде случаев также информации внутреннего предсказания (например, информации о направлении внутреннего предсказания согласно одному или более методам внутреннего кодирования). В порядке примера, кодер (622) внутреннего кодирования также вычисляет результаты внутреннего предсказания (например, блок предсказания) на основе информации внутреннего предсказания и опорных блоков в том же изображении.
[0088] Общий контроллер (621) выполнен с возможностью определения общих данных управления и управления другими компонентами видеокодера (603) на основе общих данных управления. Например, общий контроллер (621) определяет режим блока и выдает сигнал управления на переключатель (626) на основе режима. Например, когда режим является режимом внутреннего кодирования, общий контроллер (621) управляет переключателем (626) для выбора результата режима внутреннего кодирования для использования вычислителем (623) остатка и управляет энтропийным кодером (625) для выбора информации внутреннего предсказания и включения информации внутреннего предсказания в битовый поток, а когда режим является режимом внешнего кодирования, общий контроллер (621) управляет переключателем (626) для выбора результата внешнего предсказания для использования вычислителем (623) остатка и управляет энтропийным кодером (625) для выбора информации внешнего предсказания и включения информации внешнего предсказания в битовый поток.
[0089] Вычислитель (623) остатка выполнен с возможностью вычисления разности (данных остатка) между принятым блоком и результатами предсказания, выбранными из кодера (622) внутреннего кодирования или кодера (630) внешнего кодирования. Кодер (624) остатка выполнен с возможностью действовать на основе данных остатка для кодирования данных остатка для формирования коэффициентов преобразования. Например, кодер (624) остатка выполнен с возможностью преобразования данных остатка из пространственной области в частотную область и формирования коэффициентов преобразования. Затем коэффициенты преобразования подвергаются обработке квантования для получения квантованных коэффициентов преобразования. В различных вариантах осуществления изобретения видеокодер (603) также содержит декодер (628) остатка. Декодер (628) остатка выполнен с возможностью осуществления обратного преобразования и формирования декодированных данных остатка. Декодированные данные остатка могут надлежащим образом использоваться кодером (622) внутреннего кодирования и кодером (630) внешнего кодирования. Например, кодер (630) внешнего кодирования может формировать декодированные блоки на основе декодированных данных остатка и информации внешнего предсказания, а кодер (622) внутреннего кодирования может формировать декодированные блоки на основе декодированных данных остатка и информации внутреннего предсказания. Декодированные блоки надлежащим образом обрабатываются для формирования декодированных изображений, и декодированные изображения могут буферизоваться в схеме памяти (не показана) и в некоторых примерах использоваться в качестве опорных изображений.
[0090] Энтропийный кодер (625) выполнен с возможностью форматирования битового потока для включения кодированного блока. Энтропийный кодер (625) выполнен с возможностью включать различную информацию согласно подходящему стандарту, например, стандарту HEVC. Например, энтропийный кодер (625) выполнен с возможностью включать общие данные управления, выбранную информацию предсказания (например, информацию внутреннего предсказания или информацию внешнего предсказания), информацию остатка и другую подходящую информацию в битовый поток. Следует отметить, что, согласно изобретению, при кодировании блока в подрежиме слияния для любого из режима внешнего кодирования и режима двойного предсказания, информация остатка отсутствует.
[0091] На фиг. 7 показана схема видеодекодера (710) согласно другому варианту осуществления изобретения. Видеодекодер (710) выполнен с возможностью приема кодированных изображений, составляющих часть кодированной видеопоследовательности, и декодирования кодированных изображений для формирования реконструированных изображений. Например, видеодекодер (710) используется вместо видеодекодера (310) в примере, приведенном на фиг. 3
[0092] В примере, приведенном на фиг. 7, видеодекодер (710) содержит энтропийный декодер (771), декодер (780) внешнего декодирования, декодер (773) остатка, модуль (774) реконструкции и декодер (772) внутреннего декодирования, соединенные друг с другом так, как показано на фиг. 7.
[0093] Энтропийный декодер (771) может быть выполнен с возможностью реконструкции, из кодированного изображения, некоторых символов, которые представляют синтаксические элементы, образующие кодированное изображение. Такие символы могут включать, например, режим кодирования блока (например, режим внутреннего кодирования, режим внешнего кодирования, режим двойного предсказания, причем последние два в подрежиме слияния или другом подрежиме), информацию предсказания (например, информацию внутреннего предсказания или информацию внешнего предсказания), которая может идентифицировать определенный отсчет или метаданные, используемые для предсказания декодером (772) внутреннего декодирования или декодером (780) внешнего декодирования, соответственно, информацию остатка в виде, например, квантованных коэффициентов преобразования и т.п. Например, когда режим предсказания является режимом внутреннего или двойного предсказания, информация внешнего предсказания поступает на декодер (780) внешнего декодирования, а когда тип предсказания является типом внутреннего предсказания, информация внутреннего предсказания поступает на декодер (772) внутреннего декодирования. Информация остатка может подвергаться обратному квантованию и поступать на декодер (773) остатка.
[0094] Декодер (780) внешнего декодирования выполнен с возможностью приема информации внешнего предсказания и генерирования результатов внешнего предсказания на основе информации внешнего предсказания.
[0095] Декодер (772) внутреннего декодирования выполнен с возможностью приема информации внутреннего предсказания и генерирования результатов предсказания на основе информации внутреннего предсказания.
[0096] Декодер (773) остатка выполнен с возможностью осуществления обратного квантования для извлечения деквантованных коэффициентов преобразования и обработки деквантованных коэффициентов преобразования для преобразования остатка из частотной области в пространственную область. Декодер (773) остатка также может требовать некоторой информации управления (для включения параметра квантователя (QP, Quantizer Parameter)), и эта информация может обеспечиваться энтропийным декодером (771) (путь данных не показан, поскольку это может быть только информация управления малого объема).
[0097] Модуль (774) реконструкции выполнен с возможностью объединения, в пространственной области, остатка на выходе декодера (773) остатка и результатов предсказания (на выходе модулей внешнего или внутреннего предсказания, в зависимости от ситуации) для формирования реконструированного блока, который может входить в состав реконструированного изображения, которое, в свою очередь, может входить в состав реконструированного видео. Заметим, что могут осуществляться другие подходящие операции, например, операция устранения блочности и т.п., для повышения визуального качества.
[0098] Следует отметить, что видеокодеры (303), (503) и (603) и видеодекодеры (310), (410) и (710) могут быть реализованы с использованием любой подходящей технологии. Согласно варианту осуществления изобретения, видеокодеры (303), (503) и (603) и видеодекодеры (310), (410) и (710) могут быть реализованы с использованием одной или более интегральных схем. В другом варианте осуществления изобретения видеокодеры (303), (503) и (503) и видеодекодеры (310), (410) и (710) могут быть реализованы с использованием одного или более процессоров, которые исполняют программные инструкции.
[0099] Энтропийное кодирование может выполняться на последнем этапе кодирования видеоданных (или на первом этапе декодирования видеоданных) после сжатия видеосигнала до последовательности синтаксических элементов. Энтропийное кодирование может быть схемой сжатия без потерь, которая использует статистические свойства для сжатия данных, так что количество битов, используемых для представления данных, логарифмически пропорционально вероятности данных. Например, путем осуществления энтропийного кодирования набора синтаксических элементов, биты, представляющие синтаксические элементы (называемые бинами), могут быть преобразованы в меньшее количество битов (называемых кодированными битами) в битовом потоке. Контекстно адаптивное двоичное арифметическое кодирование  является одной из форм энтропийного кодирования. В САВАС контекстная модель, обеспечивающая оценку вероятности, может быть определена для каждого бина в последовательности бинов на основе контекста, связанного с соответствующим бином. Впоследствии процесс двоичного арифметического кодирования может выполняться с использованием оценок вероятности для кодирования последовательности бинов в кодированные биты в битовом потоке. Кроме того, контекстная модель обновляется с помощью новой оценки вероятности на основе кодированного бина.
является одной из форм энтропийного кодирования. В САВАС контекстная модель, обеспечивающая оценку вероятности, может быть определена для каждого бина в последовательности бинов на основе контекста, связанного с соответствующим бином. Впоследствии процесс двоичного арифметического кодирования может выполняться с использованием оценок вероятности для кодирования последовательности бинов в кодированные биты в битовом потоке. Кроме того, контекстная модель обновляется с помощью новой оценки вероятности на основе кодированного бина.
[0100] Фиг. 8А показывает пример энтропийного кодера (800А) на основе САВАС в соответствии с вариантом осуществления изобретения. Например, энтропийный кодер (800А) может быть реализован в энтропийном кодере (545) в примере на фиг. 5 или в энтропийном кодере (625) в примере на фиг. 6. Энтропийный кодер (800А) может включать модуль (810) контекстного моделирования и двоичный арифметический кодер (820). В примере различные типы синтаксических элементов предоставляются в качестве входных данных для энтропийного кодера (800А) Например, бин синтаксического элемента с двоичным значением может быть непосредственно введен в модуль (810) контекстного моделирования, в то время как синтаксический элемент с недвоичным значением может быть сначала преобразован в двоичную форму в строку бинов, а потом бины строки бинов будут введены в модуль (810) контекстного моделирования
[0101] В одном примере модуль (810) контекстного моделирования принимает бины синтаксических элементов и выполняет процесс контекстного моделирования, чтобы выбрать контекстную модель для каждого принятого бина. Например, принимается бин двоичного синтаксического элемента коэффициента преобразования в блоке преобразования. Соответственно, может быть определена контекстная модель для этого бина на основе, например, типа синтаксического элемента, типа цветового компонента коэффициента преобразования, местоположения коэффициента преобразования и ранее обработанных соседних коэффициентов преобразования и т.п. Контекстная модель может предоставлять оценку вероятности для этого бина
[0102] В примере для каждого типа синтаксических элементов может быть сконфигурирован набор контекстных моделей. Эти контекстные модели могут быть расположены в списке (802) контекстных моделей, который хранится в памяти (801), как показано на фиг. 8А. Каждая запись в списке (802) контекстных моделей может представлять контекстную модель. Каждой контекстной модели в списке может быть назначен индекс, называемый индексом контекстной модели или контекстным индексом. Кроме того, каждая контекстная модель может включать оценку вероятности или параметры, указывающие на оценку вероятности. Оценка вероятности может указывать на вероятность того, что бин равен 0 или 1. Например, во время контекстного моделирования модуль (810) контекстного моделирования может вычислить контекстный индекс для бина, и контекстная модель может быть выбрана в соответствии с контекстным индексом из списка (802) контекстных моделей и назначена бину
[0103] Кроме того, оценки вероятности в списке контекстных моделей могут быть инициализированы в начале работы энтропийного кодера (800А). После того как контекстная модель в списке (802) контекстных моделей назначена бину и используется для кодирования бина, контекстная модель впоследствии может быть обновлена в соответствии со значением бина с обновленной оценкой вероятности.
[0104] В примере двоичный арифметический кодер (820) принимает бины и контекстные модели (например, оценки вероятности), назначенные бинам, и, соответственно, выполняет процесс двоичного арифметического кодирования. В результате кодированные биты формируются и передаются в битовом потоке.
[0105] Фиг. 8 В показывает пример энтропийного декодера (800 В) на основе САВАС в соответствии с вариантом осуществления изобретения. Например, энтропийный декодер (800 В) может быть реализован в анализаторе (420) в примере на фиг. 4 или в энтропийном декодере (771) в примере на фиг. 7. Энтропийный декодер (800 В) может включать двоичный арифметический декодер (830) и модуль (840) контекстного моделирования. Двоичный арифметический декодер (830) принимает кодированные биты из битового потока и выполняет процесс двоичного арифметического декодирования для восстановления бинов из кодированных битов. Модуль (840) контекстного моделирования может работать аналогично модулю (810) контекстного моделирования. Например, модуль (840) контекстного моделирования может выбирать контекстные модели из списка (804) контекстных моделей, хранящегося в памяти (803), и предоставлять выбранные контекстные модели двоичному арифметическому декодеру (830). Однако модуль (840) контекстного моделирования определяет контекстные модели на основе восстановленных бинов из двоичного арифметического декодера (830). Например, на основе восстановленных бинов модуль (840) контекстного моделирования может знать тип синтаксического элемента следующего бина, который должен быть декодирован, и значения ранее декодированных синтаксических элементов. Эта информация используется для определения контекстной модели для следующего бина, который должен быть декодирован.
[0106] В варианте осуществления изобретения сигналы остатка блока преобразования сначала преобразуются из пространственной области в частотную область, что дает в результате блок коэффициентов преобразования. Затем выполняется квантование для квантования блока коэффициентов преобразования в блок уровней коэффициентов преобразования. В различных вариантах осуществления изобретения могут использоваться разные методы для преобразования сигналов остатка в уровни коэффициентов преобразования. Блок уровней коэффициентов преобразования далее обрабатывается для формирования синтаксических элементов, которые могут быть предоставлены энтропийному кодеру и кодированы в биты битового потока. В варианте осуществления изобретения процесс формирования синтаксических элементов из уровней коэффициентов преобразования может выполняться следующим образом.
[0107] Блок уровней коэффициентов преобразования может сначала быть разделен на субблоки, например, размером 4×4 позиций. Эти субблоки могут обрабатываться в соответствии с заранее заданным порядком сканирования. Фиг 9 показывает пример порядка сканирования субблоков, называемый обратным порядком диагонального сканирования. Как показано, блок (910) разделен на 16 субблоков (901). Субблок в правом нижнем углу обрабатывается первым, а субблок в верхнем левом углу обрабатывается последним. В примере субблок, в котором все уровни коэффициентов преобразования равны нулю, может быть пропущен без обработки.
[0108] Для субблоков, каждый из которых имеет по меньшей мере один ненулевой уровень коэффициентов преобразования, может выполняться четыре прохода сканирования в каждом субблоке. Во время каждого прохода могут сканироваться 16 позиций в соответствующем субблоке в обратном порядке диагонального сканирования. Фиг. 10 показывает пример способа (1000) сканирования субблока, на основе которого формируют различные типы синтаксических элементов коэффициентов преобразования.
[0109] Шестнадцать позиций (1010) коэффициентов внутри субблока показаны в одном измерении в нижней части фиг. 10. Позиции (1010) пронумерованы от 0 до 15, что отражает соответствующий порядок сканирования. Во время первого прохода сканируют позиции сканирования (1010), и могут быть сформированы три типа синтаксических элементов (1001-1003) в каждой позиции сканирования (1010):
(i) Первый тип двоичных синтаксических элементов (1001) (называемых флагами значимости и обозначаемых sig_coerr_nag), указывающих на то, равен ли абсолютный уровень коэффициента преобразования соответствующего коэффициента преобразования (обозначается absLevel) нулю или больше нуля.
(ii) Второй тип двоичных синтаксических элементов (1002) (называемых флагами четности и обозначаемых par_level_flag), указывающих на четность абсолютного уровня коэффициентов преобразования соответствующего коэффициента преобразования. Флаги четности формируют только тогда, когда абсолютный уровень коэффициента преобразования соответствующего коэффициента преобразования не равен нулю.
(iii) Третий тип двоичных синтаксических элементов (1003) (называемых флагами "больше 1" и обозначаемых rem_abs_gt1_nag), указывающих, больше ли (absLevel-1) >> 1, чем 0, для соответствующего коэффициента преобразования. Флаги "больше 1" формируют только тогда, когда абсолютный уровень коэффициента преобразования соответствующего коэффициента преобразования не равен нулю.
[0110] Во время второго прохода могут быть сформированы двоичные синтаксические элементы (1004) четвертого типа. Четвертый тип синтаксических элементов (1004) упоминается как флаги "больше 2" и обозначается rem_abs_gt2_flag. Четвертый тип синтаксических элементов (1004) указывает, больше ли абсолютный уровень коэффициента преобразования соответствующего коэффициента преобразования 4. Флаги "больше 2" формируют только тогда когда (absLevel-1)>>1 больше 0 для соответствующего коэффициента преобразования.
[0111] Во время третьего прохода может быть сформирован пятый тип недвоичных синтаксических элементов (1005). Пятый тип синтаксических элементов (1005) обозначается abs_remainder и указывает оставшееся значение абсолютного уровня коэффициента преобразования соответствующего коэффициента преобразования, которое больше 4. Синтаксические элементы (1005) пятого типа формируют только тогда, когда абсолютный уровень коэффициента преобразования для соответствующего коэффициента преобразования больше 4.
[0112] Во время четвертого прохода может быть сформирован шестой тип синтаксических элементов (1006) в каждой позиции (1010) сканирования с ненулевым уровнем коэффициента, указывающим знак уровня соответствующего коэффициента преобразования.
[0113] Вышеописанные различные типы синтаксических элементов (1001-1006) могут быть предоставлены энтропийному кодеру в соответствии с порядком проходов и порядком сканирования в каждом проходе. Могут использоваться различные схемы энтропийного кодирования для кодирования различных типов синтаксических элементов. Например, в варианте осуществления изобретения флаги значимости, флаги четности, флаги "больше 1" и флаги "больше 2" могут кодироваться энтропийным кодером на основе САВАС, таким как кодер, описанный в примере на фиг. 8А. Напротив, синтаксические элементы, сформированные во время третьего и четвертого проходов, могут кодироваться энтропийным кодером без использования САВАС (например, двоичным арифметическим кодером с фиксированными оценками вероятности для входных бинов).
[0114] Контекстное моделирование может выполняться для определения контекстных моделей для бинов некоторых типов синтаксических элементов коэффициентов преобразования. В варианте осуществления изобретения контекстные модели могут быть определены согласно локальному шаблону и диагональной позиции каждого текущего коэффициента (например, коэффициента, который в настоящее время обрабатывается), возможно, в сочетании с другими факторами.
[0115] Фиг. 11 показывает пример локального шаблона (1130), используемого для выбора контекста для текущих коэффициентов. Локальный шаблон (1130) может охватывать набор соседних позиций или коэффициентов текущего коэффициента (1120) в блоке (1110) коэффициентов. На фиг. 11 блок коэффициентов (1110) имеет размер 8×8 позиций и включает уровни коэффициентов в 64 позициях. Блок (1110) коэффициентов разделен на 4 субблока, каждый размером 4×4 позиции. На фиг. 11 локальный шаблон (1130) определяется как шаблон с 5 позициями, охватывающий 5 уровней коэффициентов в нижней правой части текущего коэффициента (1120). Когда обратный порядок диагонального сканирования используется для нескольких проходов по позициям сканирования в блоке коэффициентов (1110), соседние позиции в локальном шаблоне (1130) обрабатываются до текущего коэффициента (1120).
[0116] Во время контекстного моделирования информация об уровнях коэффициентов в локальном шаблоне (1130) может использоваться для определения контекстной модели. Для этого в некоторых вариантах осуществления изобретения определяется мера, называемая величиной шаблона, для измерения или указания величин коэффициентов преобразования или уровней коэффициентов преобразования в локальном шаблоне (1130). Величину шаблона затем можно использовать в качестве основы для выбора контекстной модели.
[0117] В одном примере величина шаблона определяется как сумма частично реконструированных абсолютных уровней коэффициентов преобразования внутри локального шаблона (1130) и обозначается sumAbsl. Частично реконструированный абсолютный уровень коэффициентов преобразования может быть определен согласно бинам синтаксических элементов  и rem_abs_gt1_flag соответствующего коэффициента преобразования. Эти три типа синтаксических элементов получаются после первого прохода по позициям сканирования субблока, выполняемого в энтропийном кодере или энтропийном декодере. В варианте осуществления изобретения частично реконструированный абсолютный уровень коэффициента преобразования в позиции (х, у) может быть определен согласно выражению
и rem_abs_gt1_flag соответствующего коэффициента преобразования. Эти три типа синтаксических элементов получаются после первого прохода по позициям сканирования субблока, выполняемого в энтропийном кодере или энтропийном декодере. В варианте осуществления изобретения частично реконструированный абсолютный уровень коэффициента преобразования в позиции (х, у) может быть определен согласно выражению
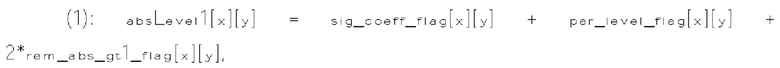
где х и у - координаты относительно верхнего левого угла блока (1110) коэффициентов, в то время как 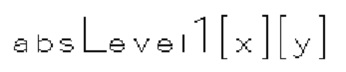 представляет частично реконструированный абсолютный уровень коэффициентов преобразования в позиции (x, y).
представляет частично реконструированный абсолютный уровень коэффициентов преобразования в позиции (x, y).
[0118] В другом примере величина шаблона определяется как разность, обозначенная tmplCpSuml, суммы частично реконструированных абсолютных уровней коэффициентов преобразования и количества, обозначенного numSig, ненулевых коэффициентов в локальном шаблоне (1130). Таким образом, указанную разность можно определить по формуле
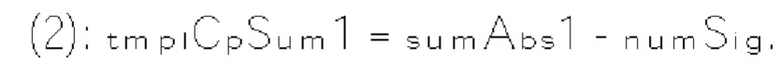
[0119] В других примерах величина шаблона может быть определена другими способами для указания величины коэффициентов преобразования или уровней коэффициентов преобразования.
[0120] В некоторых вариантах осуществления изобретения, чтобы использовать корреляцию между коэффициентами преобразования, ранее кодированные коэффициенты, охватываемые локальным шаблоном, показанным на фиг. 11, используются в выборе контекста для текущих коэффициентов, где позиция с квадратной штриховкой (1120) указывает текущую позицию коэффициента преобразования (х, у), а позиции с диагональной штриховкой указывают его пять соседей. Пусть 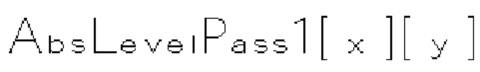 представляет частично реконструированные абсолютные уровни для коэффициента в позиции (х, у) после первого прохода, d представляет диагональную позицию текущего коэффициента (d=х+у), sumAbsl представляет собой сумму частично реконструированного абсолютного уровня
представляет частично реконструированные абсолютные уровни для коэффициента в позиции (х, у) после первого прохода, d представляет диагональную позицию текущего коэффициента (d=х+у), sumAbsl представляет собой сумму частично реконструированного абсолютного уровня 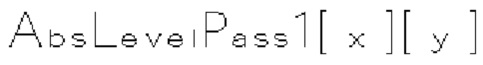 коэффициентов, охватываемых локальным шаблоном. Синтаксический элемент
коэффициентов, охватываемых локальным шаблоном. Синтаксический элемент 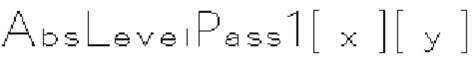 может быть вычислен из синтаксических элементов
может быть вычислен из синтаксических элементов 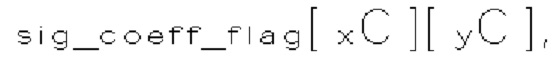
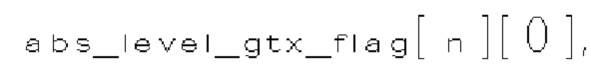
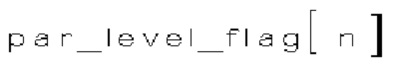 и
и 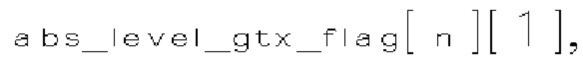 где
где 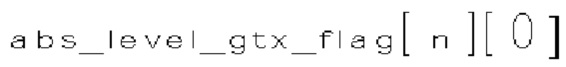 и
и 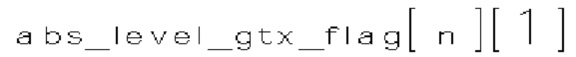 также известны соответственно как rem_abs_gt1_flag и rem_abs_gt2_flag для коэффициента в позиции n на фиг. 10.
также известны соответственно как rem_abs_gt1_flag и rem_abs_gt2_flag для коэффициента в позиции n на фиг. 10.
[0121] Фиг. 12 показывает диагональные позиции коэффициентов или уровней коэффициентов внутри блока (1210) коэффициентов. В варианте осуществления изобретения диагональную позицию для позиции 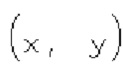 сканирования определяют согласно формуле
сканирования определяют согласно формуле
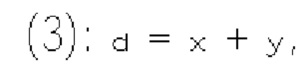
где d представляет диагональную позицию, а х и у - координаты соответствующей позиции. Диагональная позиция d каждого коэффициента может использоваться для определения различных частотных областей в блоке (1210) коэффициентов на основе одного или двух пороговых значений диагональной позиции. В качестве двух примеров, низкочастотная область (1220) определена с d<=3, в то время как высокочастотная область (1230) определена с d>=11, как показано на фиг. 12.
[0122] В некоторых вариантах осуществления изобретения, при кодировании 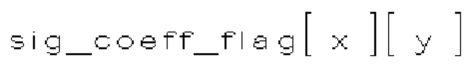 текущего коэффициента, индекс контекстной модели выбирается в зависимости от значения sumAbsl и диагональной позиции d. Более конкретно, как показано на фиг. 13, для компонента яркости индекс контекстной модели определяется в соответствии с формулами
текущего коэффициента, индекс контекстной модели выбирается в зависимости от значения sumAbsl и диагональной позиции d. Более конкретно, как показано на фиг. 13, для компонента яркости индекс контекстной модели определяется в соответствии с формулами

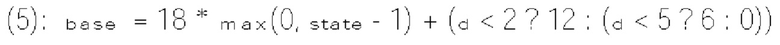
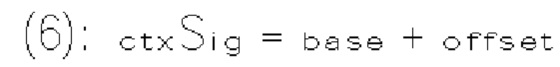
[0123] Для компонента цветности индекс контекстной модели определяется в соответствии с формулами
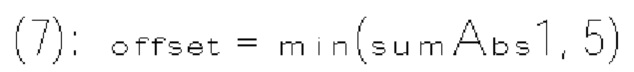
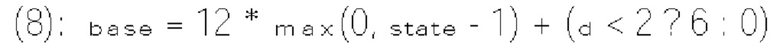
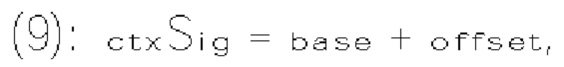
где состояние определяет используемый скалярный квантователь, а операторы ? и определены так, как в компьютерном языке С. Если зависимое квантование разрешено, состояние получают с использованием процесса перехода между состояниями. В противном случае зависимое квантование не разрешено, состояние равно 0.
[0124] В некоторых примерах количество контекстных моделей для кодирования 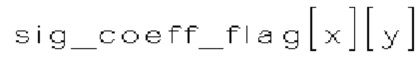 составляет 54 для яркости и 36 для цветности. Следовательно, общее количество контекстных моделей для кодирования
составляет 54 для яркости и 36 для цветности. Следовательно, общее количество контекстных моделей для кодирования 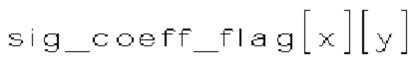 составляет 90, что составляет более 21% от 424 контекстных моделей в стандартизированных схемах контекстного моделирования, таких как VVC Draft 5.
составляет 90, что составляет более 21% от 424 контекстных моделей в стандартизированных схемах контекстного моделирования, таких как VVC Draft 5.
[0125] Таблица 1 иллюстрирует пример синтаксиса кодирования остатка. В таблице 1 хС соответствует координате х текущего коэффициента в блоке преобразования, а уС соответствует координате у текущего коэффициента в блоке преобразования.


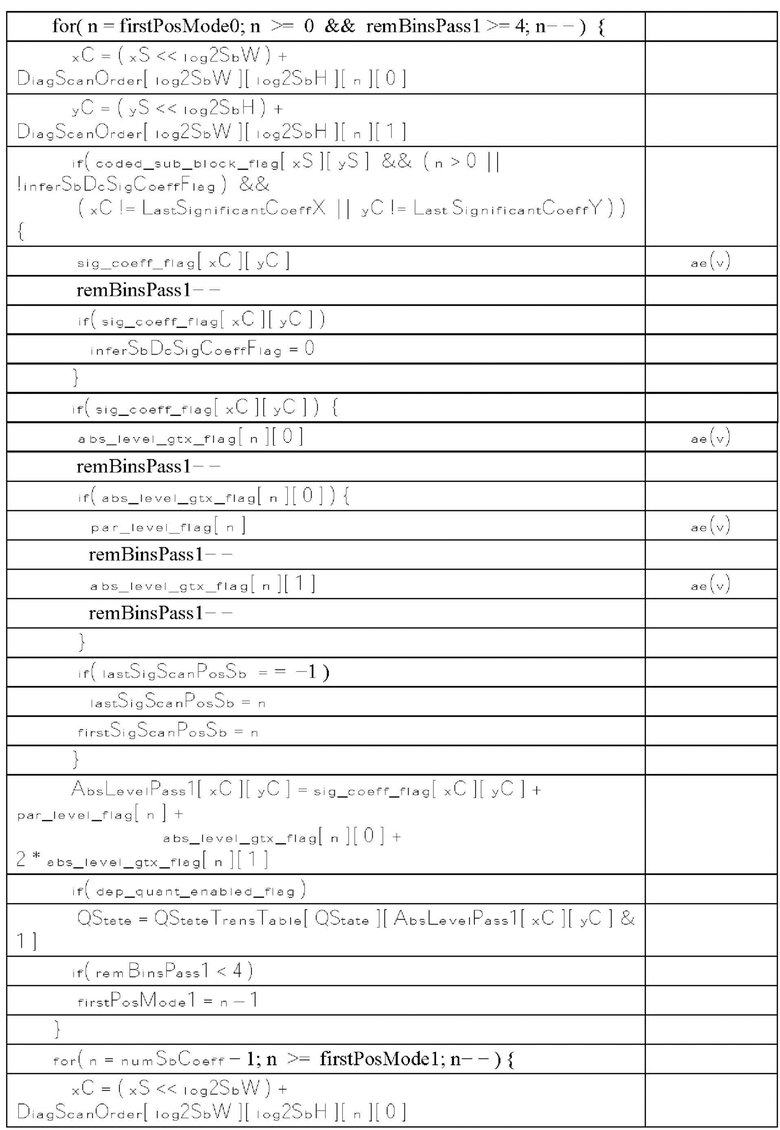


[0126] Когда количество контекстных моделей увеличивается, сложность аппаратного и программного обеспечения также увеличивается. Следовательно, желательно уменьшить количество контекстных моделей без ущерба для эффективности кодирования. В частности, желательно уменьшить количество контекстных моделей для кодирования значимости коэффициента преобразования, поскольку это более 21% из 424 контекстных моделей в стандартизированных схемах контекстного моделирования в VVC Draft 5.
[0127] Варианты осуществления настоящего изобретения могут использоваться по отдельности или совместно в любом порядке. Кроме того, любой из способов, кодер и декодер согласно вариантам осуществления настоящего изобретения могут быть реализованы посредством схемы обработки (например, посредством одного или более процессоров или одной или более интегральных схем). В одном примере один или более процессоров выполняют программу, которая хранится на машиночитаемом носителе. Согласно вариантам осуществления настоящего изобретения термин "блок" может пониматься как блок предсказания, блок кодирования или единица кодирования (то есть CU).
[0128] Согласно некоторым вариантам осуществления изобретения, область определяется как набор связанных позиций коэффициентов преобразования. Например, область представляет собой набор позиций (х, у) коэффициентов преобразования, таких, что 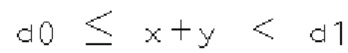 для некоторых неотрицательных целых чисел d0 и d1, называемых пороговыми значениями позиции. Варианты осуществления настоящего изобретения могут применяться к методам энтропийного кодирования флага значимости коэффициента преобразования
для некоторых неотрицательных целых чисел d0 и d1, называемых пороговыми значениями позиции. Варианты осуществления настоящего изобретения могут применяться к методам энтропийного кодирования флага значимости коэффициента преобразования 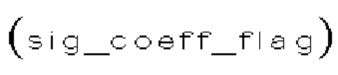 со следующими параметрами:
со следующими параметрами:
(i) N - количество контекстных моделей на область. В одном примере осуществления изобретения N равно 4. В другом примере осуществления изобретения N равно 5.
(ii) d0Y и d1Y - пороги диагональной позиции для областей яркости. В одном из примеров осуществления изобретения d0Y равно 2, a d1Y равно 5
(iii) d0C - порог диагональной позиции для областей цветности. В одном из примеров осуществления изобретения d0C равно 2.
(iv) f(х) монотонная неубывающая функция, которая отображает набор неотрицательных целых чисел в набор неотрицательных целых чисел.
(v) Когда N равно 5, функция f(х) определяется как
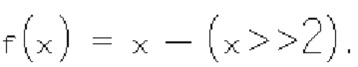
(vi) Когда N равно 4, функция f(x) определяется как
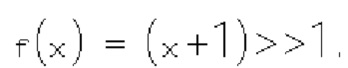
[0129] Согласно некоторым вариантам осуществления изобретения, при кодировании 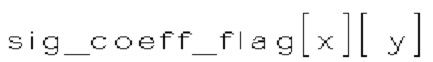 текущего коэффициента индекс контекстной модели выбирается в зависимости от значения
текущего коэффициента индекс контекстной модели выбирается в зависимости от значения  и диагональной позиции d. Более конкретно, как показано на фиг. 14, для компонента яркости индекс контекстной модели определяется в некоторых вариантах осуществления изобретения согласно формулам:
и диагональной позиции d. Более конкретно, как показано на фиг. 14, для компонента яркости индекс контекстной модели определяется в некоторых вариантах осуществления изобретения согласно формулам:
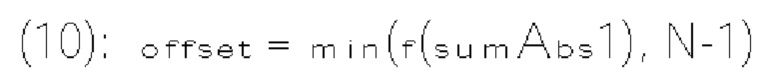
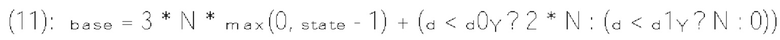
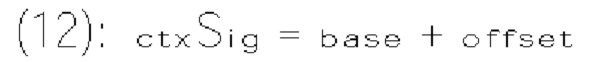
[0130] Для компонента цветности индекс контекстной модели определяется в соответствии с формулами
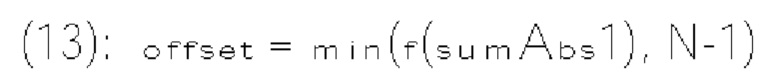
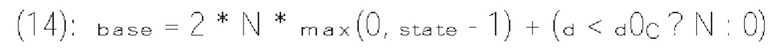
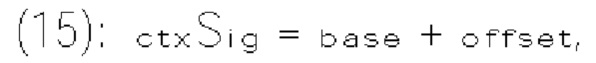
где состояние определяет скалярный квантователь, используемый, если зависимое квантование разрешено, и состояние выводится с использованием процесса перехода между состояниями. Если зависимое квантование не разрешено, в некоторых примерах состояние равно 0. Кроме того, в некоторых вариантах осуществления изобретения, как показано на фиг. 15, когда N равно 4 или 5, для обеспечения меньшей аппаратной сложности функция 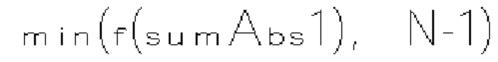 также может быть реализована как
также может быть реализована как 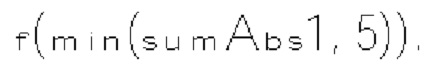
[0131] Стандартизированные схемы контекстного моделирования в VVC Draft 5 имеют 90 контекстных моделей для кодирования значимости коэффициентов преобразования. В вариантах осуществления настоящего изобретения, когда N равно 5, количество контекстных моделей уменьшается с 90 до 75, а когда N равно 4, количество контекстных моделей уменьшается с 90 до 60.
[0132] Согласно некоторым вариантам осуществления изобретения, монотонная неубывающая функция f(x) неотрицательного целого числа х может быть определена по формуле
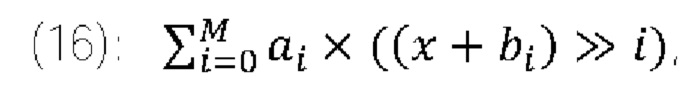
где 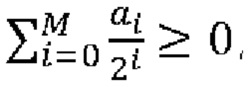 и bi - целочисленное значение. Кроме того, ai может быть 0, 1 или -1 для сокращения объема вычислений.
и bi - целочисленное значение. Кроме того, ai может быть 0, 1 или -1 для сокращения объема вычислений.
[0133] Согласно некоторым вариантам осуществления изобретения, контекстная область зависит от диагональной позиции d, так что количество контекстных моделей на область может зависеть от диагональной позиции d для дополнительного уменьшения количества контекстов. Например, количество контекстных моделей на область при  и
и 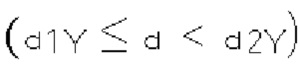 равно N1, N2 и N3, соответственно. В частности, количество контекстных моделей может изменяться в зависимости от значения d. В этом случае индекс контекстной модели может быть определен в соответствии с формулами
равно N1, N2 и N3, соответственно. В частности, количество контекстных моделей может изменяться в зависимости от значения d. В этом случае индекс контекстной модели может быть определен в соответствии с формулами
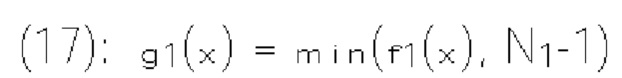


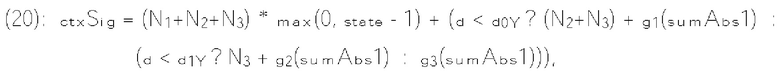
где f1(х), f2(х) и f3(x) - монотонные неубывающие функции неотрицательного целого числа х. Например, значения N1, N2 и N3 могут быть целыми числами от 1 до 16. Варианты осуществления изобретения, включающие уравнения (17)-(20), обеспечивают большую гибкость за счет уменьшения количества контекстов с одинаковой битовой скоростью
[0134] Альтернативный вариант осуществления настоящего изобретения может применяться к методам энтропийного кодирования флага значимости коэффициента преобразования со следующими параметрами:
(i) N - количество контекстных моделей на область. В этой реализации N равно 4,
(ii) d0Y - порог диагональной позиции для областей яркости. В этой реализации d0Y равно 5,
(iii) d0C - порог диагональной позиции для областей цветности. В этой реализации d0C равно 2,
(iv) Когда N равно 4, функция f(x) неотрицательного целого числа х определяется как f(х)=(х+1)>>1.
[0135] Согласно некоторым вариантам осуществления изобретения, при кодировании 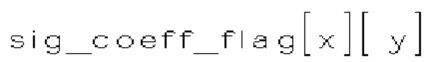 текущего коэффициента индекс контекстной модели выбирается в зависимости от
текущего коэффициента индекс контекстной модели выбирается в зависимости от 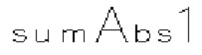 и диагональной позиции d, при этом для компонента яркости индекс контекстной модели определяется в соответствии с формулами:
и диагональной позиции d, при этом для компонента яркости индекс контекстной модели определяется в соответствии с формулами:
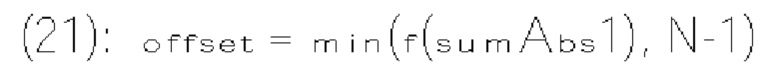
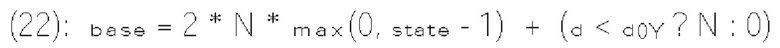
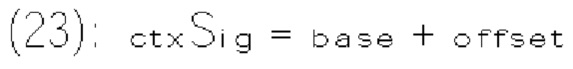
[0136] Для компонента цветности индекс контекстной модели определяется в соответствии с формулами
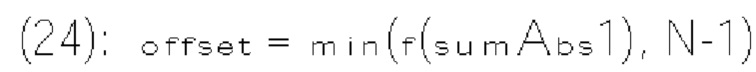
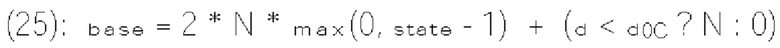
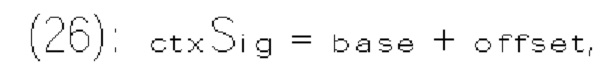
где состояние определяет скалярный квантователь, используемый, если зависимое квантование разрешено, и состояние выводится с использованием процесса перехода между состояниями. В противном случае зависимое квантование не разрешено, состояние равно 0.
[0137] В некоторых вариантах осуществления изобретения для обеспечения меньшей аппаратной сложности функция 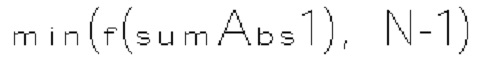 также может быть реализована как
также может быть реализована как 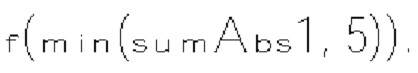
[0138] Стандартизированные схемы контекстных моделей в VVC Draft 5 имеют 90 контекстных моделей для кодирования значимости коэффициентов преобразования. В описанном выше альтернативном варианте осуществления изобретения (то есть в уравнениях (21)-(26)), когда N равно 4, количество контекстных моделей уменьшается с 90 до 48.
[0139] Фиг. 16 иллюстрирует вариант осуществления способа, выполняемого декодером, например видеодекодером (710). Способ может начинаться на этапе (S1600), на котором принимают битовый поток кодированных видеоданных, включающий текущее изображение и по меньшей мере один синтаксический элемент, который соответствует коэффициентам преобразования блока преобразования в текущем изображении. В качестве примера, по меньшей мере один синтаксис может представлять собой 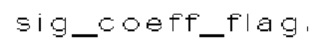 Способ переходит к этапу (S1602), на котором значение смещения определяют на основе выходного значения монотонной неубывающей функции f(x), примененной к сумме (х) группы частично реконструированных коэффициентов преобразования. Способ переходит к этапу (S1604), на котором индекс контекстной модели определяют на основе суммы упомянутого определенного значения смещения и базового значения. В качестве примера, индекс контекстной модели может быть определен в соответствии со способом, проиллюстрированным на фиг. 14 или 15 или описанным выше в альтернативном варианте осуществления изобретения (то есть с помощью уравнений (21)-(26)). Способ переходит к этапу (S1606), на котором по меньшей мере для одного синтаксиса текущего коэффициента преобразования выбирают контекстную модель из множества контекстных моделей на основе упомянутого определенного индекса контекстной модели.
Способ переходит к этапу (S1602), на котором значение смещения определяют на основе выходного значения монотонной неубывающей функции f(x), примененной к сумме (х) группы частично реконструированных коэффициентов преобразования. Способ переходит к этапу (S1604), на котором индекс контекстной модели определяют на основе суммы упомянутого определенного значения смещения и базового значения. В качестве примера, индекс контекстной модели может быть определен в соответствии со способом, проиллюстрированным на фиг. 14 или 15 или описанным выше в альтернативном варианте осуществления изобретения (то есть с помощью уравнений (21)-(26)). Способ переходит к этапу (S1606), на котором по меньшей мере для одного синтаксиса текущего коэффициента преобразования выбирают контекстную модель из множества контекстных моделей на основе упомянутого определенного индекса контекстной модели.
[0140] Фиг. 17 иллюстрирует вариант осуществления способа, выполняемого декодером, таким как видеодекодер (710). Способ может начинаться на этапе (S1700), на котором принимают битовый поток кодированных видеоданных, включающий текущее изображение и по меньшей мере один синтаксический элемент, который соответствует коэффициентам преобразования блока преобразования в текущем изображении. В качестве примера, по меньшей мере один синтаксис может представлять собой sig_coeff_flag. Способ переходит к этапу (S1702), где для каждой области контекстных моделей из множества областей контекстных моделей определяют выходное значение монотонной неубывающей функции, примененной к сумме (х) группы частично реконструированных коэффициентов преобразования, и количество контекстных моделей, связанных с соответствующей областью контекстных моделей. Например, функции g1(х)=min(f1(x), N1-1), g2(x)=min(f2(x), N2-1) и g3(х)=min(f3(x), N3-1), описанные выше, могут использоваться для соответствующей области контекстных моделей, где количество контекстных моделей на область (то есть N1, N2, N3) изменяется в зависимости от расстояния текущего коэффициента от верхнего левого угла блока преобразования. Способ переходит к этапу (S1 704), на котором индекс контекстной модели определяют на основе выходного значения монотонной неубывающей функции каждой области контекстных моделей. Способ переходит к этапу (S1706), где по меньшей мере для одного синтаксиса текущего коэффициента преобразования выбирают контекстную модель из множества контекстных моделей на основе упомянутого определенного индекса контекстной модели.
[0141] Вышеописанные способы могут быть реализованы в виде компьютерного программного обеспечения, использующего машиночитаемые инструкции и физически хранящегося на одном или более машиночитаемых носителях. Например, на фиг. 18 показана компьютерная система (1800), пригодная для осуществления некоторых вариантов осуществления изобретения.
[0142] Компьютерное программное обеспечение может кодироваться с использованием любого подходящего машинного кода или компьютерного языка, который может подвергаться ассемблированию, компиляции, редактированию связей или аналогичной обработке для создания кода, содержащего инструкции, которые могут выполняться напрямую или посредством интерпретации, выполнения микрокода и т.п., одним или более компьютерными центральными процессорами (CPU, central processing units), графическими процессорами (GPU, Graphics Processing Units) и т.п.
[0143] Инструкции могут выполняться на компьютерах различных типов или их компонентах, включая, например, персональные компьютеры, планшетные компьютеры, серверы, смартфоны, игровые устройства, устройства интернета вещей и т.п.
[0144] Компоненты компьютерной системы (1800), показанные на фиг. 18, носят иллюстративный характер и не призваны налагать какое либо ограничение на объем применения или функциональные возможности компьютерного программного обеспечения, реализующего варианты осуществления настоящего изобретения. Конфигурацию компонентов также не следует интерпретировать как имеющую какую-либо зависимость или требование в связи с любым компонентом или комбинацией компонентов, показанных в примере осуществления компьютерной системы (1800).
[0145] Компьютерная система (1800) может включать некоторые устройства ввода с человеко-машинным интерфейсом. Такое устройство ввода может отвечать за ввод одним или более пользователями посредством, например, тактильного ввода (например, нажатий на клавиши, махов, движений информационной перчатки), аудио-ввода (например, голосового, хлопков), визуального ввода (например, жестов), обонятельного ввода (не показан). Устройства интерфейса также могут использоваться для захвата некоторых информационных носителей, не обязательно напрямую связанных с осознанным вводом человеком, например звука (например, речи, музыки, внешнего звука), изображений (например, отсканированных изображений, фотографических изображений, полученных от камеры неподвижных изображений), видео (например, двумерного видео, трехмерного видео, включая стереоскопическое видео).
[0146] Входной человеко-машинный интерфейс устройства может включать одно или более из следующего (показано по одному): клавиатура (1801), мышь (1802), сенсорная панель (1803), сенсорный экран (1810), информационная перчатка (не показана), джойстик (1805), микрофон (1806), сканер (1807) и камера (1808).
[0147] Компьютерная система (1800) также может включать в себя некоторые устройства вывода с человеко-машинным интерфейсом. Такие устройства вывода могут стимулировать органы чувств одного или более пользователей посредством, например, тактильного вывода, звука, света и запаха/вкуса. Такие устройства вывода могут включать устройства тактильного вывода (например, тактильной обратной связи посредством сенсорного экрана (1810), информационной перчатки (не показана) или джойстика (1805), а также устройства тактильной обратной связи, которые не служат устройствами ввода), устройства вывода аудио (например: динамики (1809), наушники (не показаны)), устройства визуального вывода (например, экраны (1810), в том числе CRT-экраны, LCD-экраны, плазменные экраны, OLED-экраны, каждый с возможностями сенсорного экранного ввода или без них, каждый с возможностями тактильной обратной связи или без них, некоторые из них способны к двумерному визуальному выводу или более чем трехмерному выводу посредством, например, стереографическому выводу, очки виртуальной реальности (не показаны), голографические дисплеи, дымовые баки (не показаны) и принтеры (не показаны)
[0148] Компьютерная система (1800) также может включать доступные человеку запоминающие устройства и связанные с ними носители, например, оптические носители, включающие CD / DVD ROM / RW (1820) с носителями (1821) CD/DVD и т.п., карты (1822) флэш-памяти, сменный жесткий диск или твердотельный диск (1823), традиционные магнитные носители, например, ленту и магнитный диск (не показан), специализированные устройства на основе ROM/ASIC/PLD, например, защитные аппаратные ключи (не показаны) и т.п.
[0149] Специалисты в данной области техники также должны понимать, что термин «машиночитаемые носители», используемый в связи с настоящим изобретением, не охватывает среды передачи, несущие волны или другие временные сигналы.
[0150] Компьютерная система (1800) также может включать интерфейс (1854) к одной или более сетям (1855) связи. Сети могут быть, например, беспроводными, проводными, оптическими. Сети могут быть также локальными, глобальными, городскими, транспортными и промышленными, реального времени, допускающими задержку и т.д. Примеры сетей включают локальные сети, например, Ethernet, беспроводные сети LAN, сотовые сети, в том числе GSM, 3G, 4G, 5G, LTE и т.п., глобальные цифровые сети проводного или беспроводного телевидения, в том числе кабельное телевидение, спутниковое телевидение и наземное телевещание, транспортные и промышленные сети, включающие CANBus и т.д. Некоторые сети обычно требуют внешних адаптеров сетевого интерфейса, которые подключены к некоторым портам данных общего назначения или периферийным шинам (1849) (например, USB-порты компьютерной системы (1800)); другие обычно встраиваются в ядро компьютерной системы (1800) путем подключения к системной шине, как описано ниже (например, интерфейс Ethernet в компьютерную систему PC или интерфейс сотовой сети в компьютерную систему смартфона). Используя любую из этих сетей, компьютерная система (1800) может осуществлять связь с другими объектами. Такая связь может быть однонаправленной с возможностью только приема (например, телевещания), однонаправленной с возможностью только передачи (например, CANbus к некоторым устройствам CANbus) или двунаправленной, например, к другим компьютерным системам с использованием локальной или глобальной цифровой сети. Некоторые протоколы и стеки протоколов могут использоваться в каждой из этих сетей и вышеописанных сетевых интерфейсов.
[0151] Вышеупомянутые устройства человеко-машинного интерфейса, доступные человеку запоминающие устройства и сетевые интерфейсы могут подключаться к ядру (1840) компьютерной системы (1800)
[0152] Ядро (1840) может включать один или более центральных процессоров (CPU) (1841), графические процессоры (GPU) (1842), специализированные программируемые модули обработки в форме вентильных матриц, программируемых пользователем (FPGA, Field Programmable Gate Arrays) (1843), аппаратные ускорители (1844) для некоторых задач и т.д. Эти устройства, совместно с постоянной памятью (ROM) (1845), оперативной памятью (1846), внутренним хранилищем данных большой емкости, например, внутренними жесткими дисками, недоступными пользователю, SSD и т.п. (1847), могут соединяться посредством системной шины (1848). В некоторых компьютерных системах системная шина (1848) может быть доступна в форме одного или более физических разъемов для обеспечения расширений за счет дополнительных процессоров CPU, GPU и т.п. Периферийные устройства могут подключаться либо напрямую к системной шине (1848) ядра, либо через периферийную шину (1849). Архитектуры периферийной шины включают PCI, USB и т.п.
[0153] Устройства CPU (1841), GPU (1842), FPGA (1843) и ускорители (1844) могут выполнять некоторые инструкции, которые совместно могут составлять вышеупомянутый компьютерный код. Этот компьютерный код может храниться в памяти ROM (1845) или RAM (1846). Временные данные также могут храниться в памяти RAM (1846), тогда как постоянные данные могут храниться, например, во внутреннем хранилище (1847) данных большой емкости. Быстрое сохранение и извлечение из любого запоминающего устройства может обеспечиваться за счет использования кэш-памяти, которая может быть тесно связана с одним или более процессорами CPU (1841), GPU (1842), хранилищем (1847) данных большой емкости, памятью ROM (1845), RAM (1846) и т.п.
[0154] На машиночитаемых носителях может храниться компьютерный код для осуществления различных выполняемых компьютером операций. Носители и компьютерный код могут быть специально созданы в целях настоящего изобретения или могут относиться к хорошо известным и доступным специалистам в области компьютерного программного обеспечения.
[0155] В порядке примера, но не ограничения изобретения, компьютерная система, имеющая архитектуру (1800), и, в частности, ядро (1840) может обеспечивать функциональные возможности благодаря выполнению процессором(ами) (включающим(и) в себя CPU, GPU, FPGA, ускорители и т.п.) программного обеспечения, воплощенного в одном или более материальных машиночитаемых носителей. Такие машиночитаемые носители могут быть носителями, связанными с доступным пользователю хранилищем данных большой емкости, представленным выше, а также некоторым постоянным хранилищем ядра (1840), например, внутренним хранилищем (1847) данных большой емкости или ROM (1845). Программное обеспечение, реализующее различные варианты осуществления настоящего изобретения, может храниться в таких устройствах и выполняться ядром (1840) Машиночитаемый носитель может включать одно или более запоминающих устройств или микросхем, в соответствии с конкретными нуждами. Программное обеспечение может предписывать ядру (1840) и, в частности, его процессорам (включая CPU, GPU, FPGA и т.п.) выполнять конкретные способы или конкретные части описанных здесь конкретных способов, включая задание структур данных, хранящихся в памяти RAM (1846), и модификацию таких структур данных согласно способам, заданным программным обеспечением. Дополнительно или альтернативно, компьютерная система может обеспечивать функциональные возможности благодаря логике, зашитой или иным образом воплощенной в схеме (например, ускоритель (1844)), которая может действовать вместо программного обеспечения или совместно с программным обеспечением для выполнения конкретных способов или конкретных частей описанных здесь конкретных способов. Ссылка на программное обеспечение может охватывать логику, и наоборот, когда это уместно. Ссылка на машиночитаемые носители может охватывать схему (например, интегральную схему (1С, integrated circuit)), где хранится программное обеспечение для выполнения, схему, воплощающую логику для выполнения, или обе схемы, когда это уместно. Настоящее изобретение охватывает любую подходящую комбинацию аппаратного и программного обеспечения.
Приложение А: сокращения
JEM: модель совместного исследования
VVC: универсальное кодирование видеоданных
BMS: набор эталонов
MV: вектор движения
HEVC: высокопроизводительное кодирование видеоданных
SEI: дополнительная информация улучшения
VUI: информация о возможности использования видео
GOP: группа изображений
TU: единица преобразования
PU: единица предсказания
CTU: единица дерева кодирования
СТВ: блок дерева кодирования
РВ: блок предсказания
HRD: гипотетический эталонный декодер
SNR: отношение «сигнал/шум»
CPU: центральный процессор
CPU: графический процессор
CRT: кинескоп
LCD: жидкокристаллический дисплей
OLED: органический светодиод
CD: компакт-диск
DVD: цифровой видеодиск
ROM: постоянная память
RAM: оперативная память
ASIC: специализированная интегральная схема
PLD: программируемое логическое устройство
LAN: локальная сеть
GSM: глобальная система мобильной связи
LTE: проект долгосрочного развития систем связи
CANBus: шина контроллерной сети
USB: универсальная последовательная шина
PCI: соединение периферийных компонентов
FPGA: вентильная матрица, программируемая пользователем
SSD: твердотельный привод
IC: интегральная схема
CU: единица кодирования
[0156] Хотя здесь были описаны некоторые варианты осуществления изобретения, возможны изменения, перестановки и различные эквивалентные замены в пределах объема изобретения. Таким образом, специалисты в данной области техники могут предложить многочисленные системы и способы, которые, хотя в явном виде здесь не показаны и не описаны, воплощают принципы изобретения и, таким образом, соответствуют его сущности и объему.
[0157] (1) Способ декодирования видеоданных, выполняемый в видеодекодере и включающий прием битового потока кодированных видеоданных, включающего текущее изображение и по меньшей мере один синтаксический элемент, который соответствует коэффициентам преобразования блока преобразования в текущем изображении; определение значения смещения на основе выходного значения монотонной неубывающей функции f(x), примененной к сумме (х) группы частично реконструированных коэффициентов преобразования; определение индекса контекстной модели на основе суммы упомянутого определенного значения смещения и базового значения; выбор, по меньшей мере для одного синтаксиса текущего коэффициента преобразования, контекстной модели из множества контекстных моделей на основе упомянутого определенного индекса контекстной модели.
[0158] (2) Способ, описанный в (1), в котором базовое значение или значение смещения определяют на основе количества контекстных моделей, включенных в упомянутое множество контекстных моделей.
[0159] (3) Способ, описанный в (2), также включающий: определение, разрешено ли зависимое квантование для текущего коэффициента, и, если определено, что зависимое квантование разрешено для текущего коэффициента, базовое значение основано на состоянии квантователя.
[0160] (4) Способ, описанный в (3), в котором текущий коэффициент расположен в области яркости, а базовое значение основано на сравнении расстояния текущего коэффициента от верхнего левого угла блока преобразования с первым пороговым значением диагональной позиции
[0161] (5) Способ, описанный в (4), в котором базовое значение также основано на сравнении упомянутого расстояния со вторым пороговым значением диагональной позиции
[0162] (6) Способ, описанный в (3), в котором текущий коэффициент расположен в области цветности, а базовое значение основано на сравнении расстояния текущего коэффициента от верхнего левого угла блока преобразования с первым пороговым значением диагональной позиции
[0163] (7) Способ, описанный в (1)-(6), в котором монотонная неубывающая функция определена как х-(х>>2)
[0164] (8) Способ, описанный в (1)-(6), в котором монотонная неубывающая функция определена как (х+1)>>1.
[0165] (9) Способ, описанный в (1)-(8), в котором текущий коэффициент и группа частично реконструированных коэффициентов преобразования образуют шаблон, который составляет непрерывный набор коэффициентов преобразования.
[0166] (10) Способ, описанный в (1)-(9), в котором по меньшей мере один синтаксический элемент является флагом значимости коэффициента преобразования 
[0167] (11) Способ, описанный в (1)-(10), в котором битовый поток включает множество синтаксических элементов, которые включают упомянутый по меньшей мере один синтаксический элемент, при этом сумма (х) группы частично реконструированных коэффициентов преобразования основана на одном или более синтаксических элементах из множества синтаксических элементов.
[0168] (12) Способ декодирования видеоданных, выполняемый в видеодекодере и включающий: прием битового потока кодированных видеоданных, включающего текущее изображение и по меньшей мере один синтаксический элемент, который соответствует коэффициентам преобразования блока преобразования в текущем изображении; определение, для каждой области контекстных моделей из множества областей контекстных моделей, выходного значения монотонной неубывающей функции, примененной к сумме (х) группы частично реконструированных коэффициентов преобразования, и количества контекстных моделей, связанных с соответствующей областью контекстных моделей; определение индекса контекстной модели на основе выходного значения монотонной неубывающей функции каждой области контекстных моделей и выбор, по меньшей мере для одного синтаксиса текущего коэффициента преобразования, контекстной модели из множества контекстных моделей на основе упомянутого определенного индекса контекстной модели.
[0169] (13) Способ, описанный в (12), в котором определение индекса контекстной модели также основано на сравнении расстояния текущего коэффициента от верхнего левого угла блока преобразования с первым пороговым значением диагональной позиции и вторым пороговым значением диагональной позиции
[0170] (14) Способ, описанный в (12), в котором определение индекса контекстной модели также основано на сравнении расстояния текущего коэффициента от верхнего левого угла блока преобразования с первой диагональной позицией
[0171] (15) Видеодекодер для декодирования видеоданных, содержащий схему обработки, сконфигурированную для приема битового потока кодированных видеоданных, включающего текущее изображение и по меньшей мере один синтаксический элемент, который соответствует коэффициентам преобразования блока преобразования в текущем изображении, определения значения смещения на основе выходного значения монотонной неубывающей функции f(x), примененной к сумме (х) группы частично реконструированных коэффициентов преобразования, определения индекса контекстной модели на основе суммы упомянутого определенного значения смещения и базового значения и выбора, по меньшей мере для одного синтаксиса текущего коэффициента преобразования, контекстной модели из множества контекстных моделей на основе упомянутого определенного индекса контекстной модели.
[0172] (16) Видеодекодер, описанный в (15), в котором базовое значение или значение смещения определяется на основе количества контекстных моделей, включенных в упомянутое множество контекстных моделей.
[0173] (17) Видеодекодер, описанный в (16), в котором схема обработки также сконфигурирована для определения, разрешено ли зависимое квантование для текущего коэффициента, и, если определено, что зависимое квантование разрешено для текущего коэффициента, базовое значение основано на состоянии квантователя.
[0174] (18) Видеодекодер, описанный в (17), в котором текущий коэффициент расположен в области яркости, а базовое значение основано на сравнении расстояния текущего коэффициента от верхнего левого угла блока преобразования с первым пороговым значением диагональной позиции
[0175] (19) Видеодекодер, описанный в (18), в котором базовое значение также основано на сравнении упомянутого расстояния со вторым пороговым значением диагональной позиции
[0176] (20) Видеодекодер для декодирования видеоданных, содержащий схему обработки, сконфигурированную для приема битового потока кодированных видеоданных, включающего текущее изображение и по меньшей мере один синтаксический элемент, который соответствует коэффициентам преобразования блока преобразования в текущем изображении, определения, для каждой области контекстных моделей из множества областей контекстных моделей, выходного значения монотонной неубывающей функции, примененной к сумме (х) группы частично реконструированных коэффициентов преобразования, и количества контекстных моделей, связанных с соответствующей областью контекстных моделей, определения индекса контекстной модели на основе выходного значения монотонной неубывающей функции каждой области контекстных моделей и выбора, по меньшей мере для одного синтаксиса текущего коэффициента преобразования, контекстной модели из множества контекстных моделей на основе упомянутого определенного индекса контекстной модели.


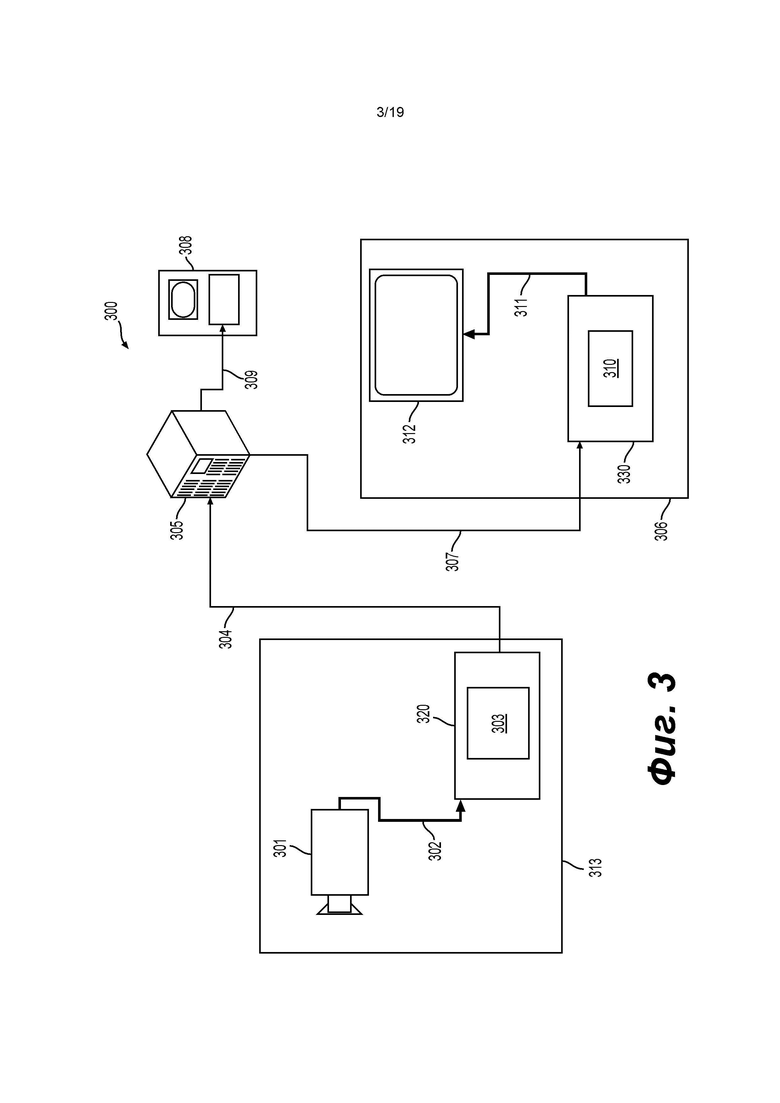
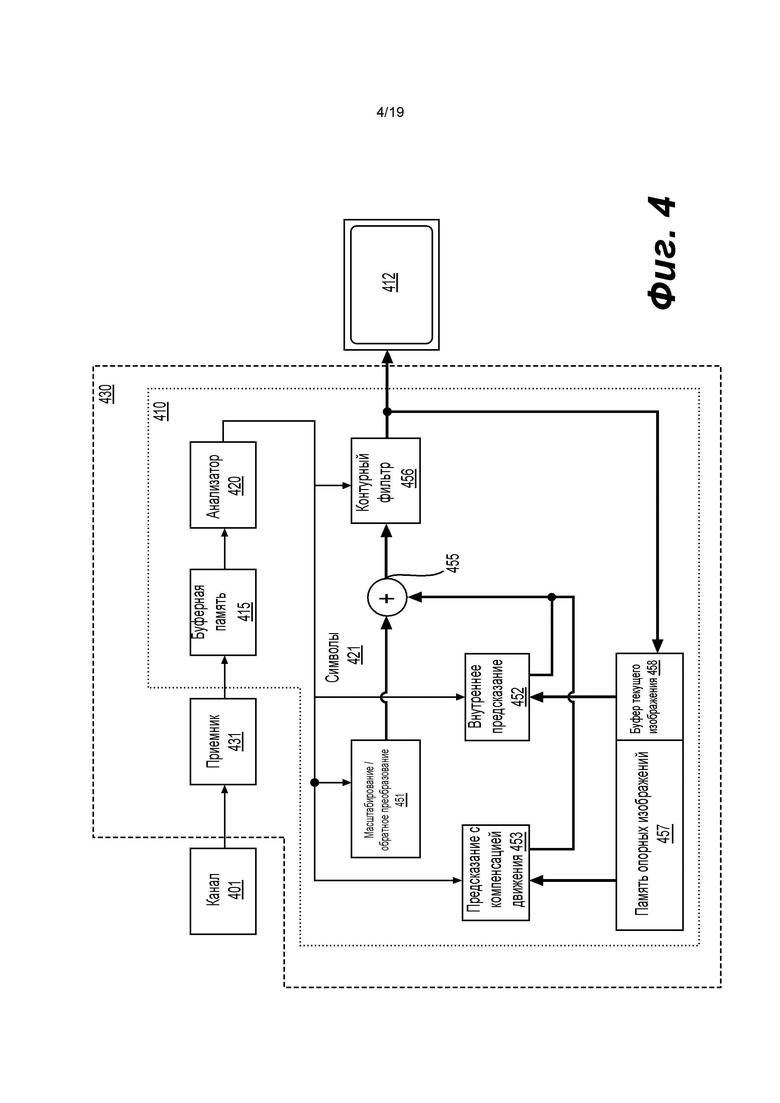
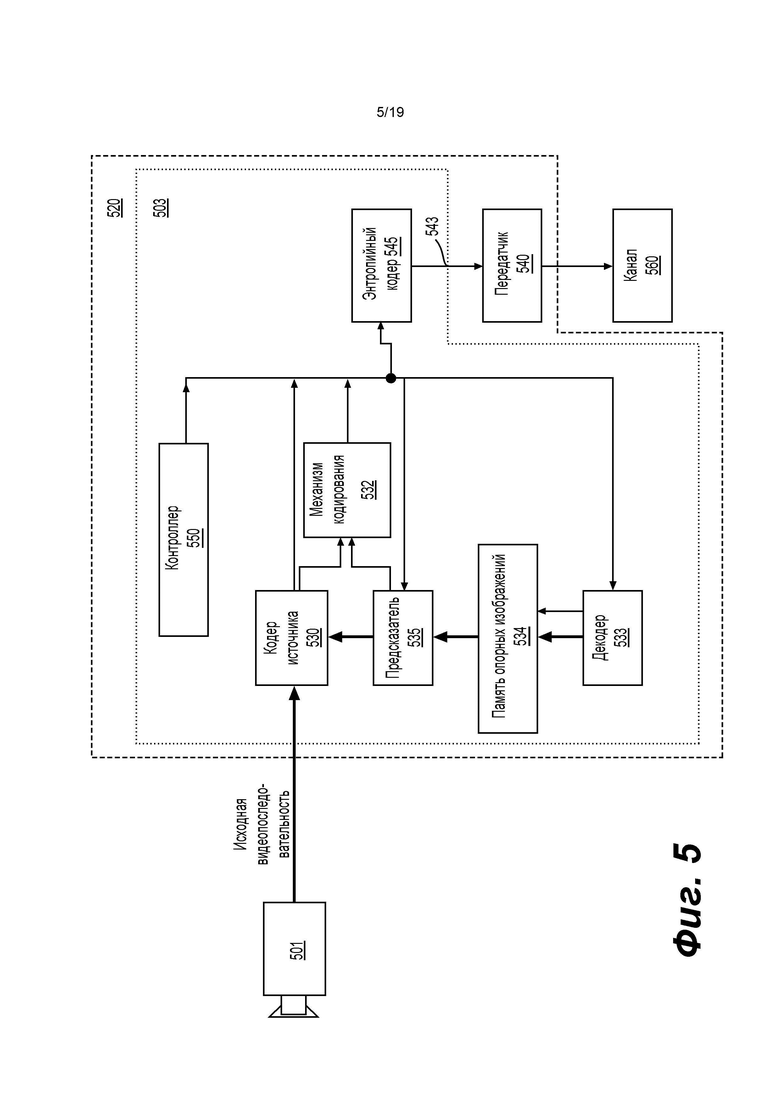
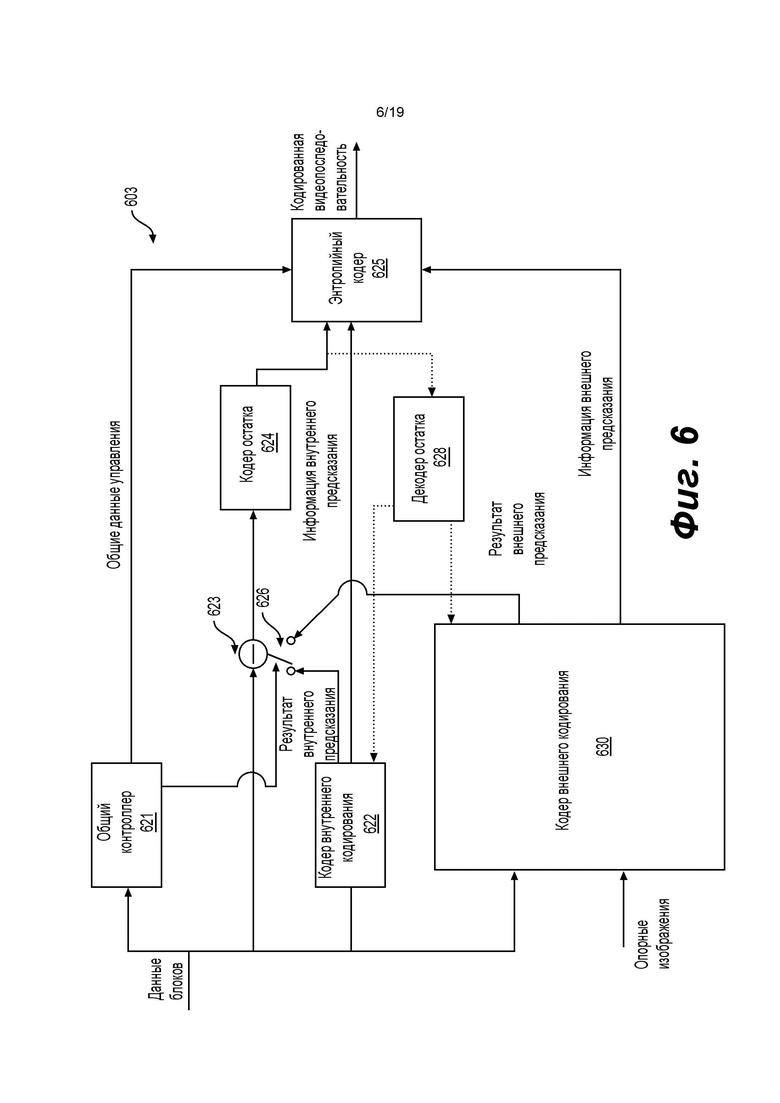

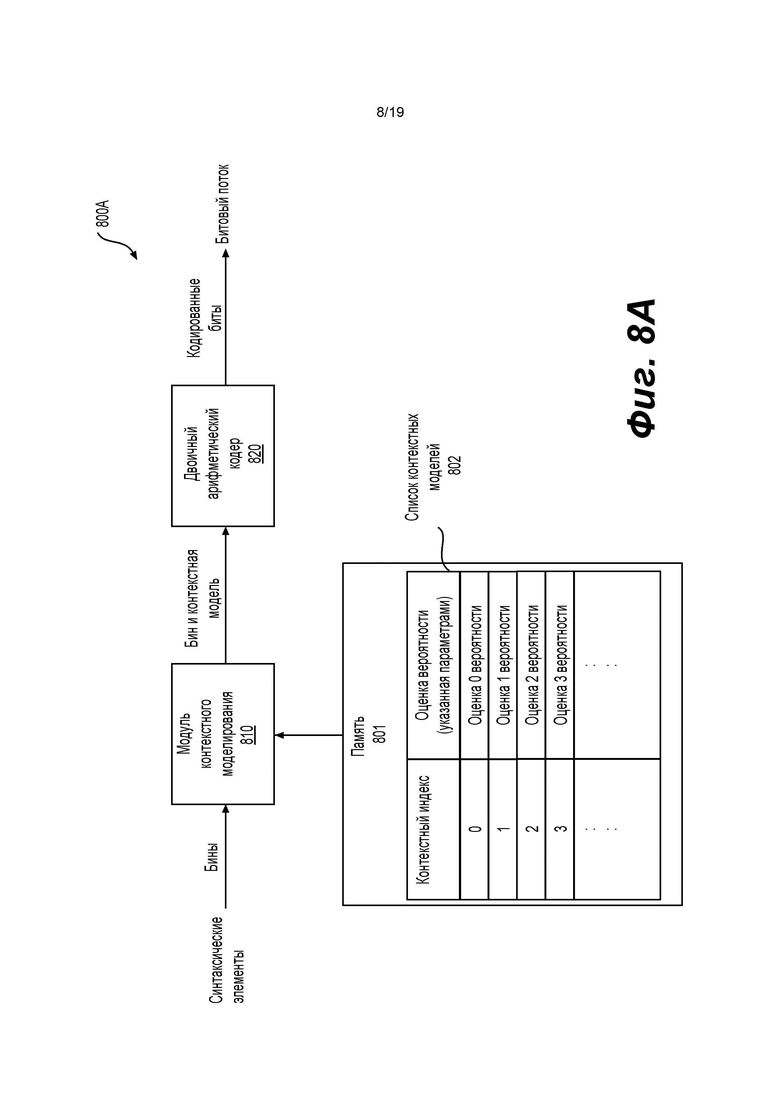
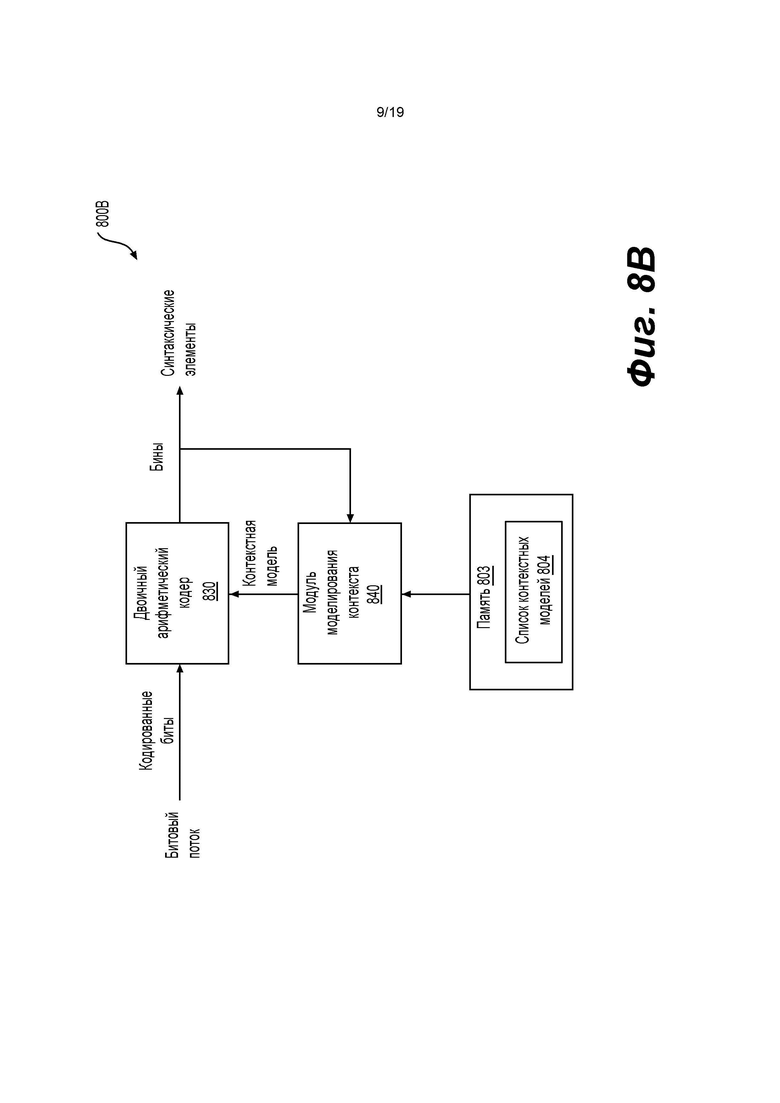
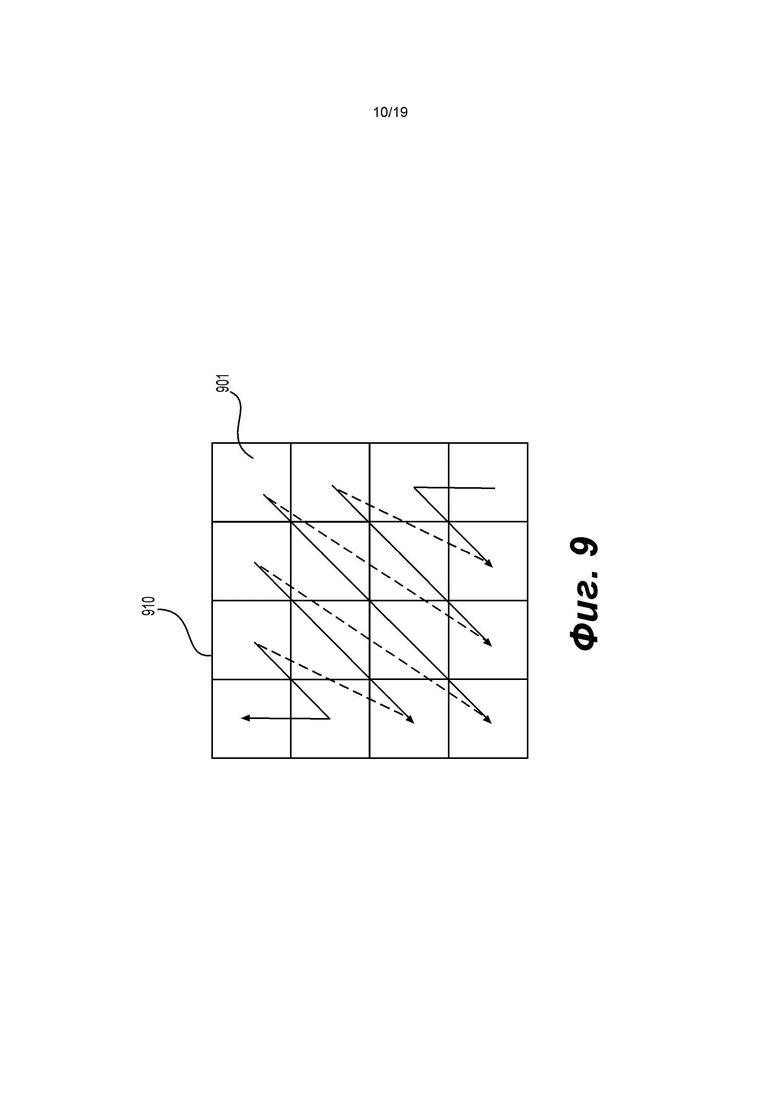

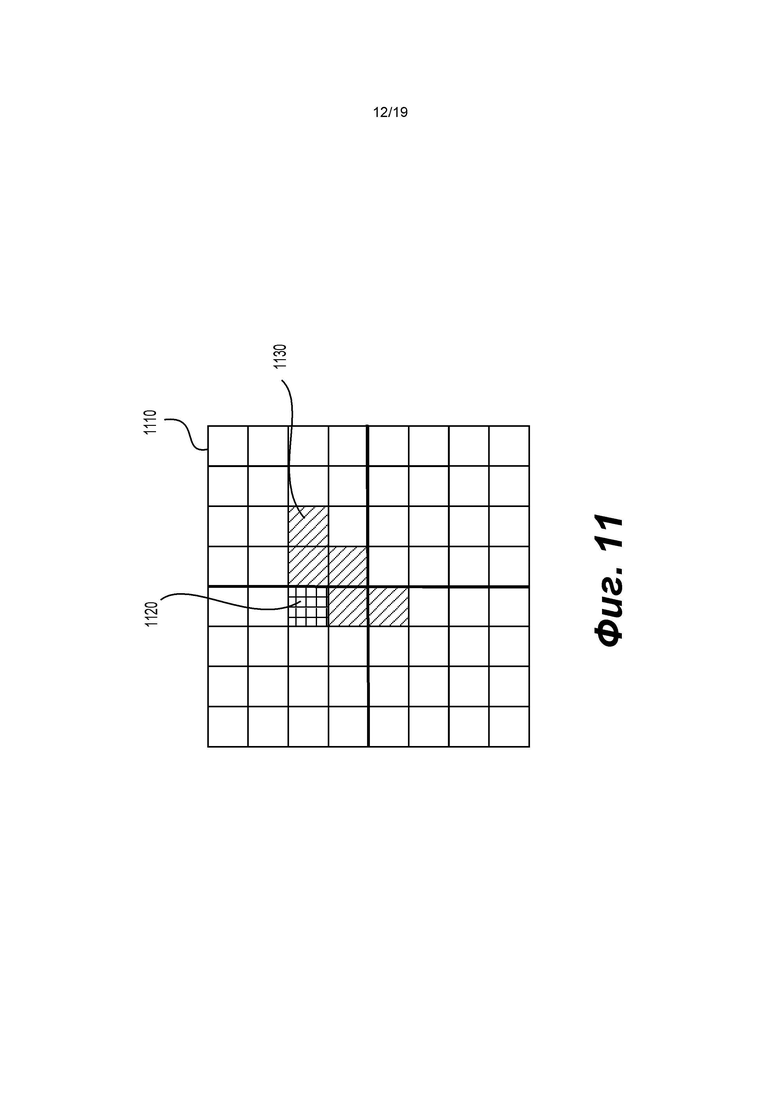
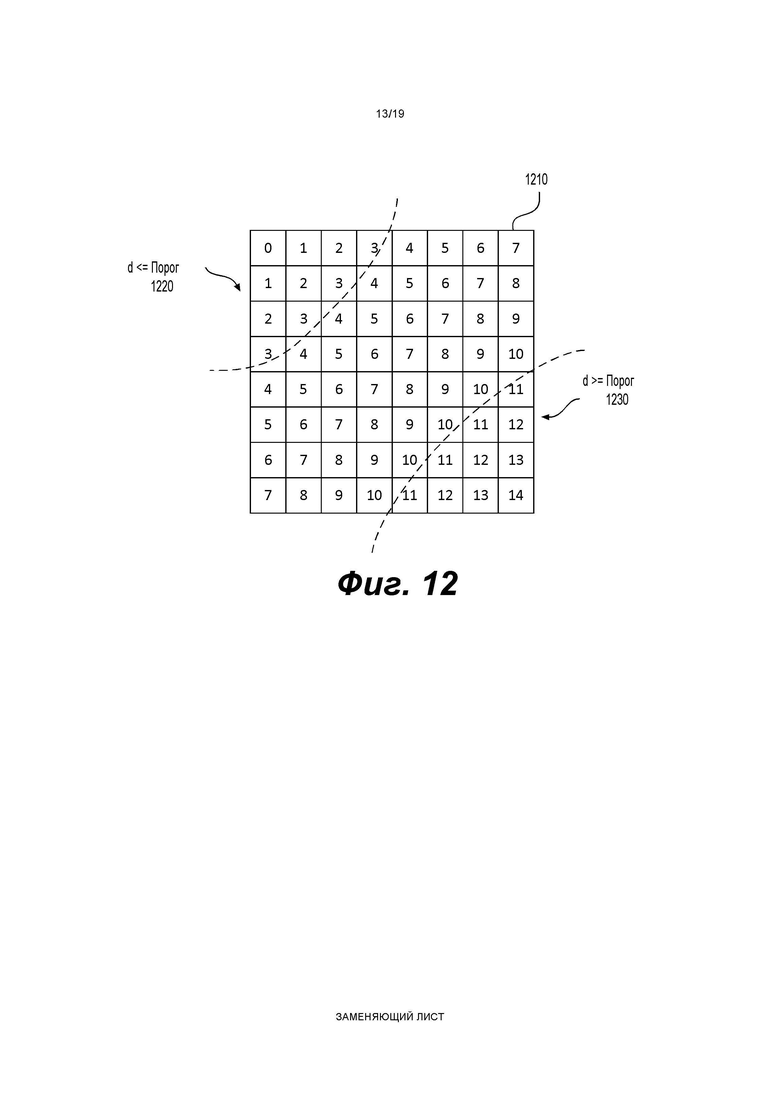
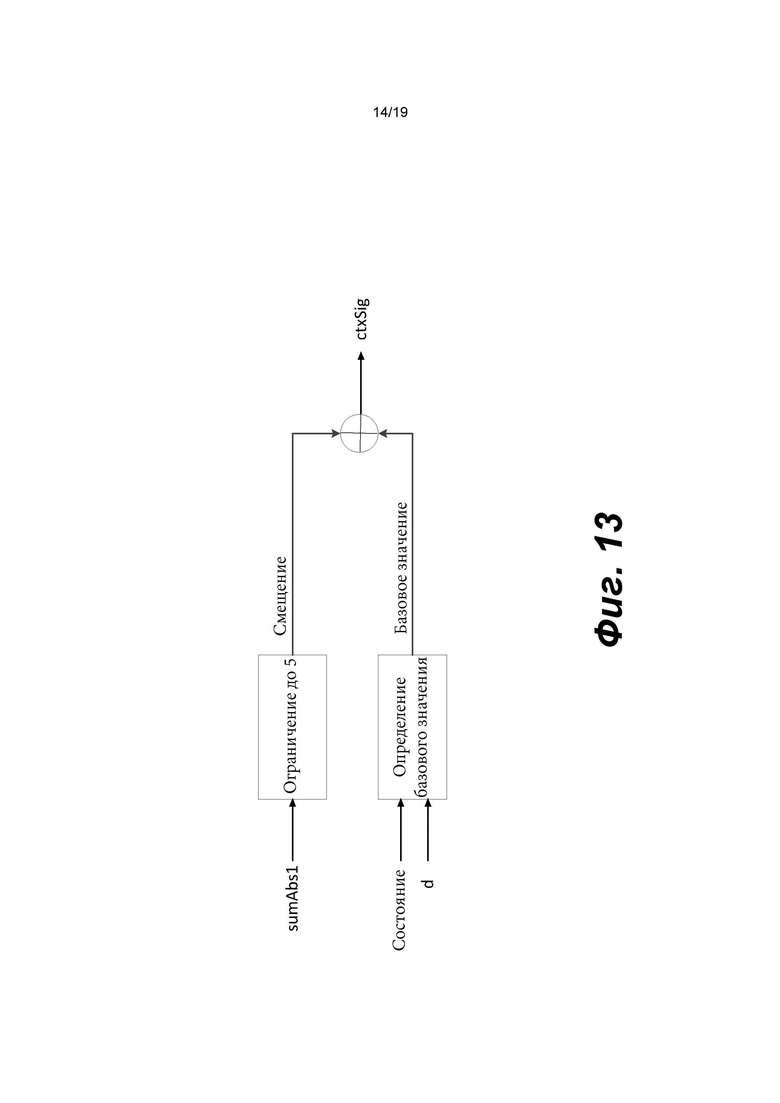
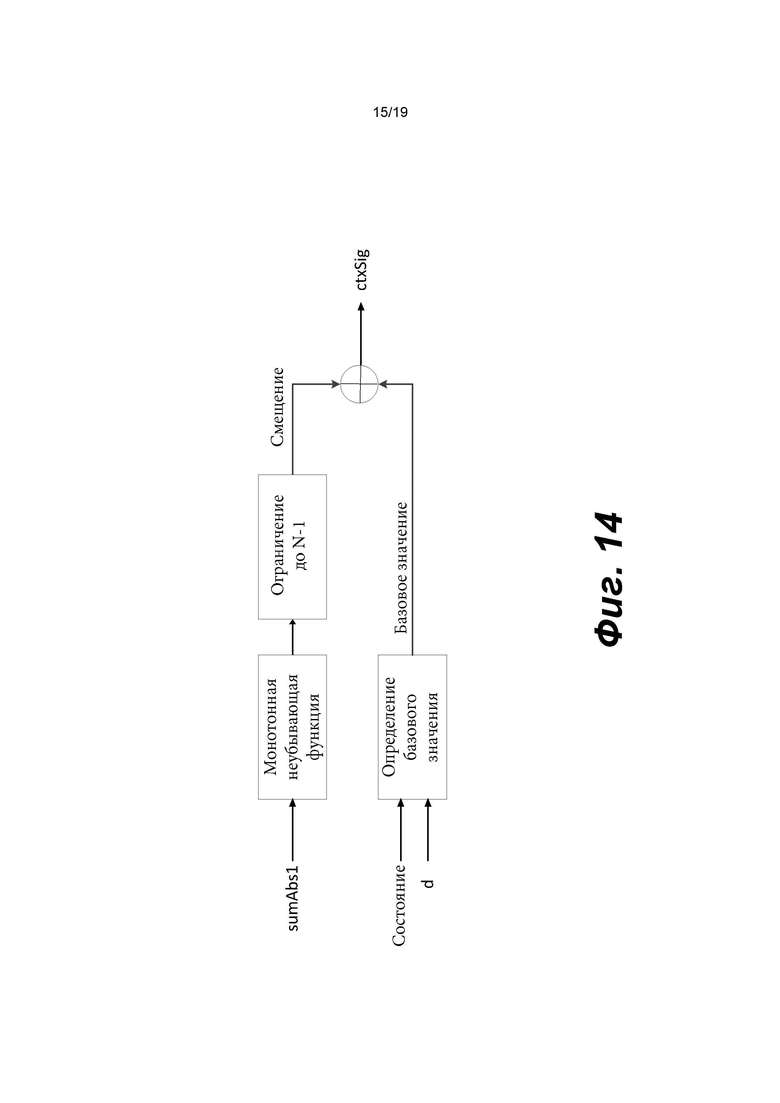
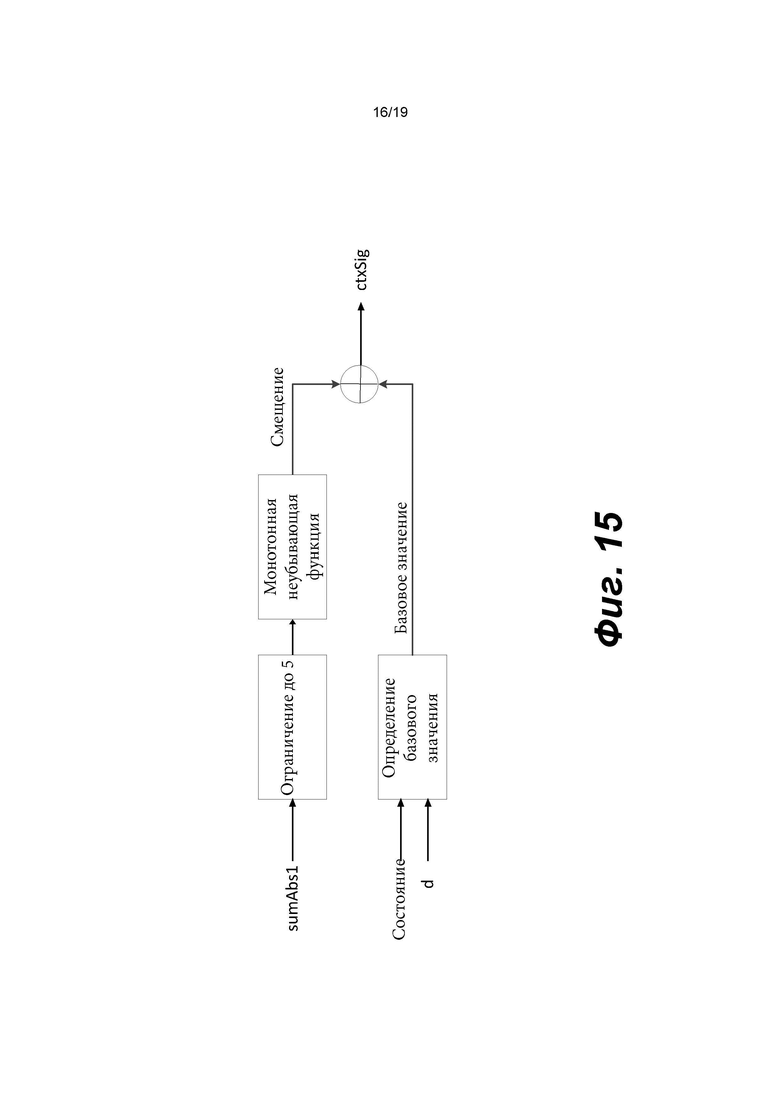
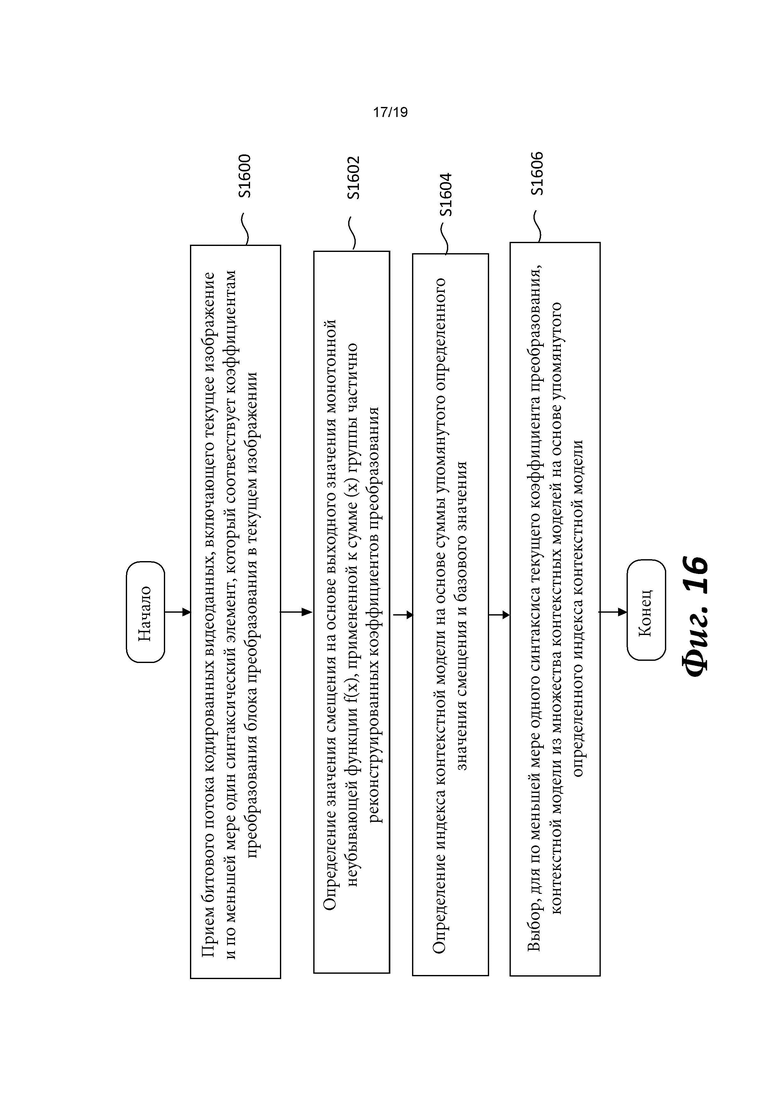
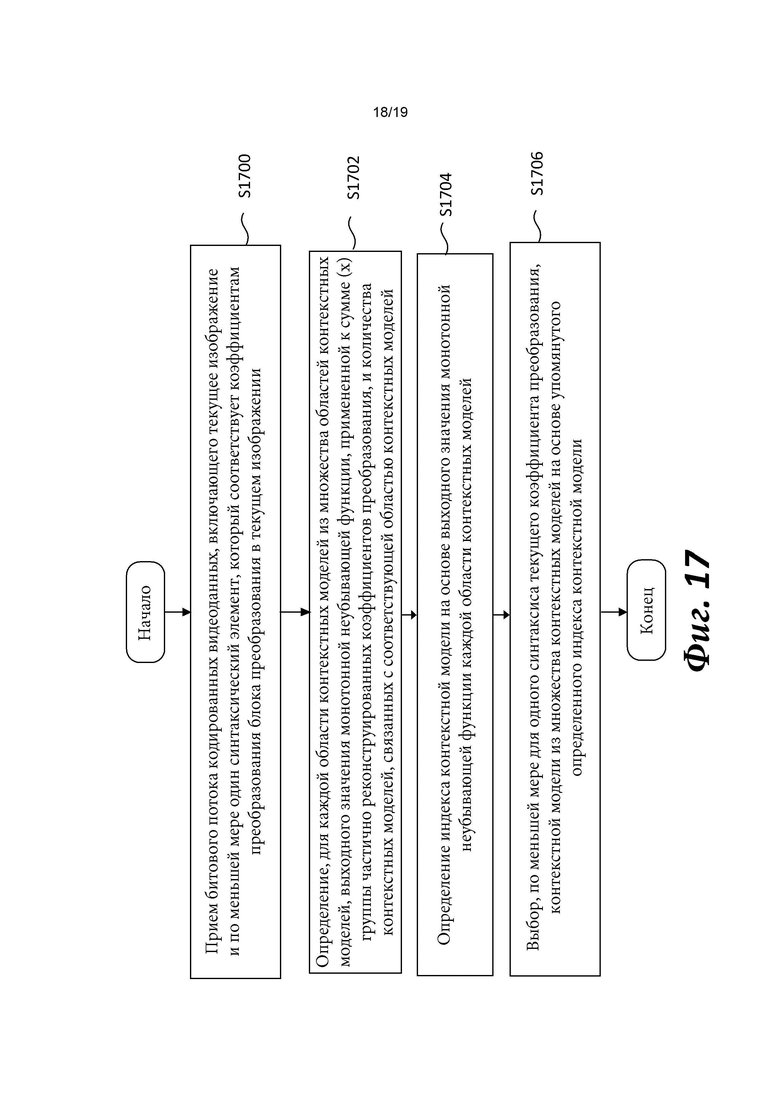
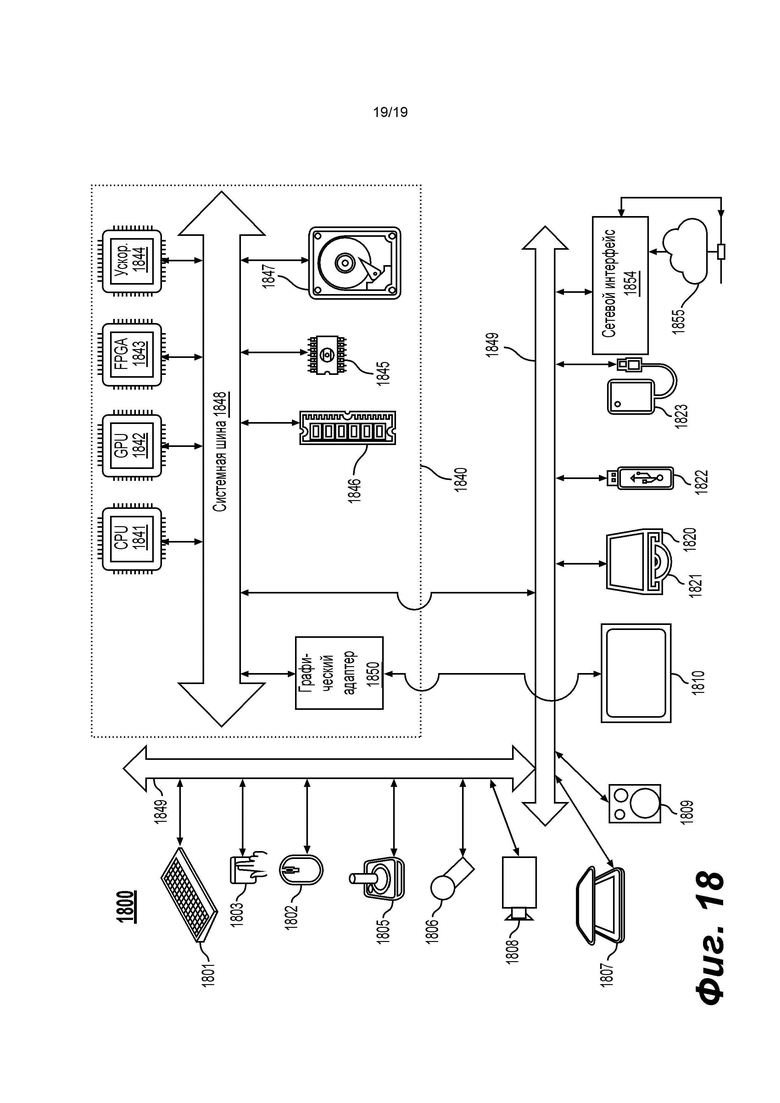
Группа изобретений относится к технологиям кодирования и декодирования видеоданных. Техническим результатом является повышение эффективности кодирования/декодирования видеоданных. Предложен способ декодирования видеоданных, выполняемый в видеодекодере. Видеодекодер содержит двоичный арифметический декодер, который принимает кодированные биты из битового потока и выполняет процесс двоичного арифметического декодирования для восстановления бинов из кодированных битов. Способ содержит этап, на котором осуществляют прием битового потока кодированных видеоданных, включающего текущее изображение и по меньшей мере один синтаксический элемент, который соответствует коэффициентам преобразования блока преобразования в текущем изображении. Далее осуществляют определение значения смещения на основе выходного значения монотонно неубывающей функции f(x), примененной к сумме (х) группы частично реконструированных коэффициентов преобразования. А также осуществляют определение индекса контекстной модели на основе суммы упомянутого определенного значения смещения и базового значения. 4 н. и 11 з.п. ф-лы, 19 ил., 1 табл.
1. Способ декодирования видеоданных, выполняемый в видеодекодере, причем видеодекодер содержит двоичный арифметический декодер, который принимает кодированные биты из битового потока и выполняет процесс двоичного арифметического декодирования для восстановления бинов из кодированных битов, и модуль контекстного моделирования, который определяет контекстные модели на основе упомянутых бинов из двоичного арифметического декодера, при этом способ включает:
прием битового потока кодированных видеоданных, включающего текущее изображение и по меньшей мере один синтаксический элемент, который соответствует коэффициентам преобразования блока преобразования в текущем изображении;
определение значения смещения на основе выходного значения монотонно неубывающей функции f(x), примененной к сумме (х) группы частично реконструированных коэффициентов преобразования;
определение индекса контекстной модели на основе суммы упомянутого определенного значения смещения и базового значения;
выбор, для по меньшей мере одного синтаксиса текущего коэффициента преобразования, контекстной модели из множества контекстных моделей на основе упомянутого определенного индекса контекстной модели; и
выполнение декодирования видеоданных с использованием выбранной контекстной модели,
при этом способ также включает:
определение, разрешено ли зависимое квантование для текущего коэффициента, и,
если определено, что зависимое квантование разрешено для текущего коэффициента, базовое значение основано на состоянии квантователя.
2. Способ по п. 1, в котором базовое значение или значение смещения определяют на основе количества контекстных моделей, включенных в упомянутое множество контекстных моделей.
3. Способ по п. 1, в котором текущий коэффициент расположен в области яркости, а базовое значение основано на сравнении расстояния текущего коэффициента от верхнего левого угла блока преобразования с первым пороговым значением диагональной позиции.
4. Способ по п. 3, в котором базовое значение также основано на сравнении упомянутого расстояния со вторым пороговым значением диагональной позиции.
5. Способ по п. 1, в котором текущий коэффициент расположен в области цветности, а базовое значение основано на сравнении расстояния текущего коэффициента от верхнего левого угла блока преобразования с первым пороговым значением диагональной позиции.
6. Способ по п. 1, в котором монотонно неубывающая функция определена как х-(х>>2).
7. Способ по п. 1, в котором монотонно неубывающая функция определена как (х+1)>>1.
8. Способ по п. 1, в котором текущий коэффициент и группа частично реконструированных коэффициентов преобразования образуют шаблон, который составляет непрерывный набор коэффициентов преобразования.
9. Способ по п. 1, в котором по меньшей мере один синтаксический элемент является флагом значимости коэффициента преобразования (sig_coeff_flag).
10. Способ по п. 1, в котором битовый поток включает множество синтаксических элементов, которые включают упомянутый по меньшей мере один синтаксический элемент, при этом сумма (х) группы частично реконструированных коэффициентов преобразования основана на одном или более синтаксических элементах из множества синтаксических элементов.
11. Способ декодирования видеоданных, выполняемый в видеодекодере, причем видеодекодер содержит двоичный арифметический декодер, который принимает кодированные биты из битового потока и выполняет процесс двоичного арифметического декодирования для восстановления бинов из кодированных битов, и модуль контекстного моделирования, который определяет контекстные модели на основе упомянутых бинов из двоичного арифметического декодера, при этом способ включает:
прием битового потока кодированных видеоданных, включающего текущее изображение и по меньшей мере один синтаксический элемент, который соответствует коэффициентам преобразования блока преобразования в текущем изображении;
определение, для каждой области контекстных моделей из множества областей контекстных моделей, выходного значения монотонно неубывающей функции, примененной к сумме (х) группы частично реконструированных коэффициентов преобразования, и количества контекстных моделей, связанных с соответствующей областью контекстных моделей;
определение индекса контекстной модели на основе выходного значения монотонно неубывающей функции каждой области контекстных моделей,
выбор, по меньшей мере для одного синтаксиса текущего коэффициента преобразования, контекстной модели из множества контекстных моделей на основе упомянутого определенного индекса контекстной модели и
выполнение декодирования видеоданных с использованием выбранной контекстной модели.
12. Способ по п. 11, в котором определение индекса контекстной модели также основано на сравнении расстояния текущего коэффициента от верхнего левого угла блока преобразования с первым пороговым значением диагональной позиции и вторым пороговым значением диагональной позиции.
13. Способ по п. 11, в котором определение индекса контекстной модели также основано на сравнении расстояния текущего коэффициента от верхнего левого угла блока преобразования с первой диагональной позицией.
14. Видеодекодер для декодирования видеоданных, содержащий:
схему обработки, сконфигурированную для выполнения способа по любому из пп. 1-10.
15. Видеодекодер для декодирования видеоданных, содержащий:
схему обработки, сконфигурированную для выполнения способа по любому из пп. 11-13.
| WO 2018149685 A1, 23.08.2018 | |||
| US 20170064336 A1, 02.03.2017 | |||
| US 20140003529 A1, 02.01.2014 | |||
| WO 2010091505 A1, 19.08.2010 | |||
| US 20190045226 A1, 07.02.2019 | |||
| ЭФФЕКТИВНОЕ ПО ИСПОЛЬЗОВАНИЮ ПАМЯТИ АДАПТИВНОЕ БЛОЧНОЕ КОДИРОВАНИЕ | 2007 |
|
RU2413360C1 |

